Embed Size (px)
Citation preview

CENTRO UNIVERSITÁRIO UNIVATES
CENTRO DE CIÊNCIAS EXATAS E TECNOLÓGICAS
CURSO DE ENGENHARIA DE CONTROLE E AUTOMAÇÃO
AUGUSTO LIMBERGER LENZ
COMPUTAÇÃO PARALELA COM ARQUITETURA DE PROCESSAMENTO GRÁFICO CUDA APLICADA A UM
CODIFICADOR DE VÍDEO H.264
Lajeado
2012

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
AUGUSTO LIMBERGER LENZ
COMPUTAÇÃO PARALELA COM ARQUITETURA DE PROCESSAMENTO GRÁFICO CUDA APLICADA A UM
CODIFICADOR DE VÍDEO H.264
Trabalho de Conclusão de Curso apresentado ao Centro de Ciências Exatas e Tecnológicas do Centro Universitário UNIVATES, como parte dos requisitos para a obtenção do título de bacharel em Engenharia de Controle e Automação.Área de concentração: Computação paralela
ORIENTADOR: Ronaldo Hüsemann
Lajeado
2012

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
AUGUSTO LIMBERGER LENZ
COMPUTAÇÃO PARALELA COM ARQUITETURA DE PROCESSAMENTO GRÁFICO CUDA APLICADA A UM
CODIFICADOR DE VÍDEO H.264
Este trabalho foi julgado adequado para a obtenção do título de bacharel em Engenharia de Controle e Automação do CETEC e aprovado em sua forma final pelo Orientador e pela Banca Examinadora.
Orientador: ____________________________________
Prof. Ronaldo Hüsemann, UNIVATES
Doutor pelo PPGEE/UFRGS – Porto Alegre, Brasil
Banca Examinadora:
Prof. Marcelo de Gomensoro Malheiros, UNIVATES
Mestre pela FEEC/UNICAMP – Campinas, Brasil
Prof. Maglan Cristiano Diemer, UNIVATES
Mestre pelo PPGCA/UNISINOS – São Leopoldo, Brasil
Coordenador do curso de Engenharia de Controle e Automação
_______________________________
Prof. Rodrigo Wolff Porto
Lajeado, Junho de 2012.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
Dedico este trabalho ao meu pai, Edu, e a minha mãe, Ivone, por acreditarem na
importância da educação.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
AGRADECIMENTOS
À minha família, pelo apoio, incentivo e compreensão nos momentos difíceis, no
transcorrer da realização desse trabalho e demais atividades da graduação.
Ao professor Ronaldo Hüsemann, pela sua orientação, pelas oportunidades de
trabalhar em projetos de pesquisa e pela amizade cultivada ao longo desse período.
Aos colegas do Laboratório de Engenharia Aplicada: Anderson Giacomolli, Diego
Schwingel e Marco Gobbi pelas contribuições no desenvolvimento desse trabalho.
Aos colegas de curso, pela amizade e companhia durante o decorrer desta jornada.
À Luisa por todo o amor, carinho e compreensão.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
RESUMO
Este trabalho investiga a utilização de processadores gráficos (GPUs) como coprocessadores em arquiteturas de computadores no contexto da codificação de vídeo. O objetivo específico é implementar módulos do codificador H.264 em tecnologia CUDA, presente nas placas de vídeo da empresa NVIDIA. Dessa forma, algoritmos paralelizáveis são executados na GPU de forma a acelerar a codificação e aliviar a carga da CPU principal. O primeiro estudo de caso foi a implementação do módulo computacional, situado no codificador intraquadro, que foi integrado ao software de referência para validação e testes. Os resultados obtidos apontam um ganho de cerca de 3,9 vezes no tempo de execução deste módulo para vídeos de alta definição. No segundo estudo de caso foi abordado o codificador interquadros através da estimação de movimento. Um algoritmo de busca adequado à arquitetura paralela em questão foi proposto e implementado, além da implementação do cálculo de SAD. Os resultados obtidos na estimação de movimento apontam para um aumento na velocidade de execução em torno de 5,7 vezes para vídeos de alta definição.
Palavras-chaves: Codificação de Vídeo, Computação Paralela, GPGPU, CUDA.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
ABSTRACT
This work investigates the use of graphical processing units (GPUs) as co-processors for computer architectures in the context of video encoding. The specific goal is to implement modules of the H.264 encoder in CUDA, present in NVIDIA video cards. Thus, parallelizable algorithms have been implemented on the GPU to accelerate the encoding and reduce the load of the main CPU. The first case study was the implementation of computational module, situated in the intra-frame encoder, that was integrated into the reference software for validation and testing. The results show a speedup of 3.9 times in the execution of computational module for high-definition video. In the second case study, the inter-frame encoder was approached through motion estimation. A search algorithm suitable for parallel architecture was proposed and implemented, in addition to the SAD calculation. The results show a speedup of 5.7 times in the execution for high-definition videos.
Keywords: Video Coding, Parallel Computing, GPGPU, CUDA.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
SUMÁRIO
1 INTRODUÇÃO...................................................................................................................152 UNIDADE DE PROCESSAMENTO GRÁFICO............................................................19
2.1 Histórico das GPUs......................................................................................................192.1.1 Primeira geração...................................................................................................202.1.2 Segunda geração....................................................................................................202.1.3 Terceira Geração...................................................................................................212.1.4 Quarta geração......................................................................................................212.1.5 Quinta geração......................................................................................................22
2.2 Pipeline gráfico tradicional.........................................................................................222.3 Processamento de propósito geral em GPU...............................................................232.4 Visão Geral da CUDA..................................................................................................232.5 Arquitetura de hardware............................................................................................252.6 Modelo de programação..............................................................................................27
2.6.1 Função Kernel.......................................................................................................272.6.2 Hierarquia de threads...........................................................................................282.6.3 Hierarquia de memória........................................................................................29
2.7 Detalhamento dos espaços de memória......................................................................312.7.1 Registradores e memória local.............................................................................312.7.2 Memória compartilhada.......................................................................................312.7.3 Memória global.....................................................................................................322.7.4 Memória de textura e superfície..........................................................................332.7.5 Memória de constantes.........................................................................................34
3 CODIFICAÇÃO DE VÍDEO.............................................................................................353.1 Vídeo digital..................................................................................................................353.2 Compressão de vídeo...................................................................................................363.3 Introdução ao H.264....................................................................................................373.4 Descrição do codec H.264............................................................................................37
3.4.1 Predição intraquadro............................................................................................383.4.2 Transformadas diretas e inversas........................................................................403.4.2.1 Transformada discreta de cossenos..................................................................413.4.2.2 Transformada de Hadamard............................................................................443.4.3 Quantização...........................................................................................................453.4.4 Estimativa de movimento.....................................................................................483.4.4.1 Algoritmos de busca...........................................................................................503.4.4.2 Critérios de similaridade...................................................................................533.4.5 Compensação de movimento................................................................................543.5 Trabalhos relacionados............................................................................................54
4 DESCRIÇÃO DO SISTEMA DESENVOLVIDO...........................................................564.1 Codificação intraquadro..........................................................................................57
4.2 Algoritmos de computação intra................................................................................574.2.1 Implementação da DCT direta e inversa............................................................594.2.2 Implementação da Transformada de Hadamard..............................................594.2.3 Implementação da Quantização..........................................................................60

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
4.3 Codificação interquadros........................................................................................614.3.1 Algorítimo de busca proposto..............................................................................614.3.2 Implementação da estimação de movimento......................................................62
5 RESULTADOS PRÁTICOS..............................................................................................665.1 Integração com o software de referência...................................................................665.2 Avaliação dos resultados no módulo computacional intra.......................................675.3 Avaliação do algoritmo de busca proposto................................................................695.4 Avaliação dos resultados da estimativa de movimento em GPU.............................715.5 GPU profiling...............................................................................................................75
6 CONCLUSÃO.....................................................................................................................77

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
LISTA DE FIGURAS
Figura 1 Shader tradicional x shader unificado, adaptado de (IKEDA, 2011).................24Figura 2 Escalabilidade da arquitetura CUDA, adaptada de (NVIDIA, 2011a)..............25Figura 3 Cenários comuns de branch divergence, adaptada de (HAN;
ABDELRAHMAN , 2011).....................................................................................26Figura 4 Organização das threads, adaptada de (NVIDIA, 2011a)...................................29Figura 5 Fluxo típico de uma aplicação CUDA....................................................................30Figura 6 Padrões de acesso coalescido (CONRAD, 2010)...................................................32Figura 7 Acesso não coalescido (CONRAD, 2010)...............................................................33Figura 8 Estrutura do codificador H.264 (REDIESS, 2006)...............................................38Figura 9 Modos de predição para blocos 16x16 de luminância. (AGOSTINI, 2007).......39Figura 10 Modos de predição para blocos 4x4 de luminância (AGOSTINI, 2007)..........40Figura 11 Bloco de entrada (a) e resultado da DCT (b) (RICHARDSON, 2003).............42Figura 12 Macroblocos de crominância e luminância com componentes DC destacados
(MAJOLO, 2010)....................................................................................................44Figura 13 Quadros consecutivos de vídeo (RICHARDSON, 2003)....................................49Figura 14 Na esquerda, o resíduo sem estimativa de movimento. Na direita, o resíduo
com estimativa de movimento (RICHARDSON, 2003)......................................49Figura 15 Predição interquadro (DINIZ, 2009)...................................................................50Figura 16 Algoritmo de busca completa (PORTO, 2012)...................................................51Figura 17 Large Diamond Search (LDS) e Small Diamond Search (SDS) (PORTO, 2008)
..................................................................................................................................52Figura 18 Algoritmo de busca logarítmica (RICHARDSON, 2002)..................................52Figura 19 Processo de codificação intraquadro, adaptada de (DINIZ, 2009)...................57Figura 20 Etapas do módulo computacional........................................................................58Figura 21 Arquitetura proposta para módulo computacional usando GPUs NVIDIA
(HUSEMANN et al., 2011b). ................................................................................58Figura 22 Relacionamento das threads com os componentes DC......................................60Figura 23 Padrão de busca do algoritmo proposto..............................................................62Figura 24 Procedimento de redução usado no cálculo de SAD, adaptado de (NVIDIA,
2012).........................................................................................................................64Figura 25 Distribuição do tempo entre as etapas.................................................................76

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
LISTA DE CÓDIGOS
Listagem 1 Declaração e chamada de um kernel.................................................................28Listagem 2 Protótipo da função intrínseca usad..................................................................63Listagem 3 Primeira etapa da redução.................................................................................64

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
LISTA DE TABELAS
Tabela 1 Evolução da distribuição dos estágios entre CPU e GPU....................................23Tabela 2 Características dos espaços de memória na arquitetura CUDA séries G80 e
G200.........................................................................................................................30Tabela 3 Passos de quantização.............................................................................................46Tabela 4 Valores de PF para cada posição...........................................................................47Tabela 5 Fator de multiplicação............................................................................................47Tabela 6 Complexidade dos módulos do codificador H.264...............................................56Tabela 7 Principais características das duas placas utilizadas...........................................66Tabela 8 Comparação dos tempos de processamento para vídeos 4CIF...........................68Tabela 9 Comparação dos tempos de processamento vídeo HD........................................68Tabela 10 Avaliação do algoritmo de busca proposto para 3 Mbps..................................70Tabela 11 Avaliação do algoritmo de busca proposto para 4 Mbps..................................70Tabela 12 Avaliação do algoritmo de busca proposto para 5 Mbps..................................71Tabela 13 Comparação dos desempenho em QCIF.............................................................72Tabela 14 Comparação dos desempenho em CIF................................................................73Tabela 15 Comparação dos desempenho em 4CIF..............................................................73Tabela 16 Comparação dos desempenho em 720p...............................................................74Tabela 17 Comparação dos desempenho em 1080p.............................................................75

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
LISTA DE ABREVIATURAS
AMD Advanced Micro Devices
ANSI American National Standards Institute
API Application Programming Interface
AVC Advanced Video Coding
CAD Computer Aided Design
CIF Common Intermediate Format
CPU Central Unit Processing
CUDA Compute Unified Device Architecture
DC Direct Current
DCT Discrete Cosine Transform
DSP Digital Signal Processor
DVD Digital Versatile Disc
FS Full Search
GLSL OpenGL Shading Language
GPU Graphics Processing Unit
GPGPU General Purpose GPU
HD High Definition
HLSL High Level Shader Language
IBM International Business Machines
IEC International Electro-technical Commission
ISO International Organization for Standardization
ITU-T International Telecommunication Union – Telecommunication
Standardization Sector
JSVM Joint Scalable Video Model
JVT Joint Video Team
LDS Large Diamond Search
LS Logarithmic Search
MAE Mean Square Error
MSE Mean Square Error

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
MC Compensação de movimento
ME Estimativa de movimento
MF Multiplication Factor
MPEG Motion Picture Experts Group
PC Personal Computer
PCIe Peripheral Component Interconnect Express
PF Post-Scaling Factor
PGC Professional Graphics Controller
QP Quantization Parameter
RAM Random Access Memory
RGB Red Green Blue
SAD Sum of Absolute Differences
SD Standard Definition
SDS Small Diamond Search
SGI Silicon Graphics International
SIMD Single Instruction, Multiple Data
SIMT Single-Instruction, Multiple-Thread
SLI Scalable Link Interface
SM Streaming Multiprocessor
SP Scalar Processors
SSE Streaming SIMD Extensions
SVC Scalable Video Coding
VRAM Video Random Access Memory

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
15
1 INTRODUÇÃO
A capacidade de armazenar e transportar vídeo em formato digital tornou as aplicações
que fazem uso desta tecnologia parte do cotidiano das pessoas. Atualmente, o vídeo digital
está presente em televisores, Digital Versatile Discs (DVDs), videoconferência e sistemas de
telemedicina (FUJITSU, 2010).
A codificação de vídeo é a técnica essencial que possibilita a utilização de vídeos de
forma eficiente. Essa técnica permite a transformação do sinal de vídeo em uma representação
comprimida, onde são eliminadas redundâncias, e, com isso reduzir a largura de banda
necessária para transportar o vídeo ou o espaço em disco necessário para armazená-lo. O
processo de decodificação recupera o sinal de vídeo original ou uma aproximação deste, de
forma que possa ser visualizado em sua forma original (RICHARDSON, 2003).
A necessidade por técnicas de compressão de vídeo pode ser ilustrada pelo seguinte
cenário. Considerando-se, por exemplo, um vídeo com standard definition (SD), que possui
720 x 480 pixeis, e utilizando o sistema de três cores primárias red green blue (RGB), com 8
bits de representação para cada cor e 30 quadros por segundo, seriam necessários
aproximadamente 30 MB para armazenar apenas um segundo de vídeo.
Dada esta necessidade, surgiram diversas formas de realizar a codificação. Pode-se
dizer que a base das técnicas empregadas na maioria dos codificadores atuais foi estabelecida
na norma H.261 da International Telecommunication Union – Telecommunication
Standardization Sector (ITU-T) definida em 1989, da qual pode-se destacar como algoritmos
principais a estimativa de movimento, transformada discreta de cosseno (DCT), quantização
linear e codificação de entropia (GHANBARI, 2003).
Posteriormente, foi desenvolvido o padrão MPEG-2 pelo Motion Picture Experts
Group (MPEG) e também adotado pela ITU-T, como uma norma conjunta das duas entidades
e passando a ser chamado H.262/MPEG-2, que tornou-se extremamente popular. O MPEG-2
foi empregado, por exemplo, nos DVDs e em diversos sistemas de televisão digital
(MAJOLO, 2010). Este padrão continuou popular ao longo dos anos, sendo largamente
empregado ainda nos dias de hoje.
A criação de técnicas inovadoras, como a codificação de cenas sintéticas e naturais em
um modelo de codificação baseado em objetos independentes e a possibilidade de codificação
realizada sobre objetos não necessariamente retangulares, resultou no padrão MPEG-4
(RICHARDSON, 2003).

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
16
As entidades MPEG e ITU-T uniram novamente esforços para desenvolver um novo
padrão de codificação. Este grupo de trabalho é conhecido como Joint Video Team (JVT).
Como resultado surgiu o padrão chamado de Advanced Video Coding (AVC), publicado
como a recomendação H.264 da ITU-T e como a parte dez do MPEG-4 (AGOSTINI, 2007).
A elaboração do codec H.264 foi feita com o aumento da eficiência da compressão
sendo o principal objetivo, resultando em aumentos significativos nas taxas de compressão.
No entanto, esta evolução levou inevitavelmente ao aumento dos requisitos de processamento
para os dispositivos codificadores e decodificadores (RICHARDSON, 2003).
Os algoritmos empregados para codificação de vídeo requerem computação intensa,
tornando necessárias técnicas computacionais sofisticadas e o uso de arquiteturas dedicadas
que tornem possível a execução destes algoritmos em tempo real. Dentre as soluções que vêm
sendo adotadas pode-se destacar a utilização de arquiteturas do tipo Single Instruction,
Multiple Data (SIMD), Digital Signal Processor (DSP) e o desenvolvimento de
coprocessadores dedicados em hardware (GREENE; TULJAPURKAR, 2007).
Uma alternativa recentemente explorada para aumento de desempenho de algoritmos é
a utilização de unidades de processamento gráfico, ou Graphics Processing Unit (GPU), como
plataformas para processamento de propósito geral. Este conceito, que é conhecido como
General Purpose GPU (GPGPU), torna possível explorar o poder de processamento das placas
aceleradoras de vídeo em aplicações que não necessariamente façam uso de recursos gráficos
(CHEUNG et al., 2010).
As GPUs possuem uma arquitetura altamente paralela, capaz de executar a mesma
operação em um grande número de elementos ao mesmo tempo. Esta forma de organização é
apropriada ao seu objetivo original - processamento de gráficos em três dimensões (3D), mas
também pode ser empregada na implementação de algoritmos úteis em diversos outros
campos (IKEDA, 2011).
Nos últimos anos, foram criadas tecnologias para adequar a GPU ao processamento de
propósito geral e facilitar o desenvolvimento de programas que possam fazer uso deste
recurso. Um exemplo notável é a arquitetura de computação paralela da NVIDIA denominada
Compute Unified Device Architecture (CUDA) (NVIDIA, 2011d). Outros exemplos são:
Advanced Micro Devices (AMD) Stream (AMD, 2011), o framework OpenCL (KHRONOS,
2011) e a application programming interface (API) Microsoft Direct Compute
(MICROSOFT, 2009).
Acredita-se que a utilização de placas de vídeo como ferramenta de auxílio na tarefa
de codificação de vídeo seja de grande interesse, dada a variedade de aplicações com vídeo

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
17
digital e a grande disseminação destes dispositivos em computadores pessoais. Portanto, este
trabalho se propõe a investigar a utilização de GPUs, presentes nas placas de vídeo
compatíveis com a tecnologia NVIDIA CUDA, como coprocessadores da Central Unit
Processing (CPU) no contexto da codificação de vídeo. Mais especificamente, o objetivo é
implementar módulos do codificador H.264 que possuam algoritmos paralelizáveis na GPU,
de forma a acelerar a codificação e aliviar a carga da CPU principal.
Desta forma, foi explorada a implementação de referência do codificador H.264 de
forma a identificar pontos onde a utilização da arquitetura CUDA seja vantajosa. A partir
dessa análise e da revisão da literatura, foram definidos dois módulos do codificador a serem
trabalhados como estudos de caso: módulo computacional e módulo de estimação de
movimento.
O primeiro estudo de caso aborda o codificador intraquadros através da
implementação dos algoritmos do módulo computacional: transformada discreta de cossenos
direta e inversa, transformada de Hadamard direta e inversa, quantização e quantização
inversa. Já o segundo estudo de caso aborda a codificação interquadros através da
implementação de algoritmos da estimação de movimento: algoritmo de busca e cálculo de
similaridade.
Para tornar possível a validação e a avaliação dos módulos desenvolvidos foi realizada
a integração com o codificador de referência do padrão H.264. Dessa forma, o software de
referência serviu como base de comparação em termos do desempenho alcançado e a
validação dos resultados será obtida através da comparação dos vídeos comprimidos gerados
pelo software original com os vídeos obtidos pela versão paralela.
A fim de embasar o desenvolvimento deste trabalho foram pesquisados trabalhos
relacionados. Sprandlin et al. (2009) por exemplo analisou a viabilidade de implementar um
codificador MPEG-2 na arquitetura CUDA. Chan et al. (2009), Cheung et al. (2010) e Huang,
Shen e Wu (2009) por sua vez exploraram diferentes abordagens para acelerar a execução dos
algoritmos de estimativa de movimento também utilizando CUDA. Monteiro et al. (2011)
realizaram a implementação do algoritmo de busca completa em CUDA, obtendo ganhos de
velocidade de 600 vezes. Os trabalhos estudados apontam que a utilização da tecnologia
CUDA pode trazer avanços à área de codificação de vídeo, de forma a tornar viável a
execução em tempo real de complexas técnicas de codificação em vídeos de alta resolução.
O texto desta monografia foi organizado da seguinte forma. O capítulo 2 apresenta
uma revisão de literatura acerca da evolução da arquitetura das GPUs que culminou no
conceito de GPGPU. O capítulo 3 define os conceitos relacionados à codificação de vídeo, as

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
18
características básicas do padrão H.264 e uma descrição dos trabalhos relacionados estudados.
O capítulo 4 formaliza a proposta de trabalho que guiou a execução das atividades. O capítulo
5 apresenta os estudos de caso realizados. Por fim, o capítulo 6 apresenta as conclusões
obtidas e aponta possíveis trabalhos futuros.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
19
2 UNIDADE DE PROCESSAMENTO GRÁFICO
A Unidade de Processamento Gráfico é um processador dedicado à aceleração de
aplicações gráficas. A arquitetura das GPUs difere substancialmente das tradicionais CPUs,
pois direcionam-se a necessidades específicas, como processamento de dados 3D com ponto
flutuante. Sua organização interna torna possível uma intensidade aritmética muito maior,
através da execução de diversas operações iguais em dados independentes (OWNEW et al.,
2005).
Essas características surgiram da necessidade de processar um grande número de
pixeis para gerar uma imagem a ser exibida. Como cada pixel é independente dos demais é
possível calcular os valores de vários pixeis simultaneamente. Esta arquitetura paralela
possibilita portanto a execução de um grande número de operações por unidade de tempo.
2.1 Histórico das GPUs
A ideia de se utilizar processadores especificamente para as tarefas relacionadas a
vídeo remonta ao ano de 1984 quando a International Business Machines (IBM) lançou a
primeira placa de vídeo com microprocessador próprio (Intel 8088) de forma a amenizar a
carga da CPU principal. Nesta época, o processador era empregado apenas para gerar os
sinais de vídeo, a fim de possibilitar melhores taxas de atualização da tela. Essa solução,
conhecida como Professional Graphics Controller (PGC), era destinada a custosos sistemas de
Computer Aided Design (CAD) e não se disseminou para o mercado de massa (DUKE;
WALL, 1985).
Em 1986, a Texas Instruments lançou o processador TMS34010. Este chip, além de
possuir uma memória dedicada para vídeo, chamada de Video Random Access Memory
(VRAM) e suporte a display, foi um dos primeiros a apresentar um conjunto de instruções
voltado ao processamento gráfico (GUTTAG et al., 1988).
Entretanto, no final dos anos 80 surgiram as primeiras placas de vídeo compatíveis
com a arquitetura IBM-PC (Personal Computer), que possuíam implementações em hardware
das primitivas gráficas de duas dimensões (2D) e, por isso, tornaram-se conhecidas como
placas aceleradoras 2D (CROW, 2004).
No início dos anos 90, a Silicon Graphics International (SGI), que era líder no
mercado de gráficos 3D, criou a API OpenGL, que posteriormente tornou-se um padrão
mantido por diversas entidades. O surgimento da OpenGL trouxe uma forma uniforme de
acesso às diferentes placas gráficas e deixou aos fabricantes a responsabilidade de

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
20
desenvolver device drivers para os seus produtos. Posteriormente, a empresa Microsoft lançou
o conjunto de APIs DirectX, que inclui a API Direct3D que tornou-se grande competidora da
OpenGL.
A possibilidade de escrever software utilizando uma API de alto nível compatível com
uma grande diversidade de placas de vídeo teve um forte impacto no mercado para aplicativos
gráficos (CROW, 2004).
No início da década de 90 começavam a se tornar comuns aplicativos com gráficos 3D
que faziam uso do poder de processamento da CPU, criando uma demanda crescente por
aceleração 3D em hardware. Por volta de 1995, surgiram os primeiros produtos a implementar
essa ideia: S3 ViRGE, ATI Rage, Matrox Mystique e 3dfx Voodoo. O passo seguinte à
aceleração 3D foi o surgimento das GPUs, que ocorreu por volta de 1998, acrescentando
processamento gráfico 3D ao hardware. No entanto, nesse período o processamento gráfico
ainda era realizado por funções fixas definidas no projeto da GPU. A partir desse ponto, a
evolução pode ser definida em cinco gerações (IKEDA, 2011).
2.1.1 Primeira geração
No final da década de 90, haviam três grandes empresas no segmento: NVIDIA, ATI e
3Dfx (com seus respectivos produtos, RIVA TNT2 - NV5, Rage 128 e Voodoo3). Nos
dispositivos dessa geração não havia processamento na placa além da rasterização,
texturização e geração dos sinais para o monitor. A rasterização consiste na conversão de
representações vetoriais de objetos 3D em uma representação matricial, também conhecida
como raster. Já a texturização é responsável pela aplicação de uma textura às faces de um
objeto tridimensional. A imagem 3D é sintetizada por um conjunto de polígonos (comumente
triângulos), resultantes da projeção para um espaço bidimensional (AZEVEDO, 2003).
2.1.2 Segunda geração
Em 1999, o lançamento da GeForce 256 (NV10) pela empresa NVIDIA, destacou-se
pela introdução do pipeline gráfico, tornando a GPU responsável pela transformação e
iluminação dos polígonos, especificados em coordenadas de mundo. Neste período a ATI
lançou a família de produtos Radeon R100 com a tecnologia HyperZ, que permitia evitar
cálculos desnecessários em pixeis não visíveis na projeção final.
O pipeline gráfico é um modelo conceitual composto por estágios que aplicam uma
série de algoritmos aos dados processados por uma GPU. Os dados de entrada são um

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
21
conjunto de vértices e os respectivos atributos. Após a execução de todos os estágios do
pipeline, obtém-se a representação de uma imagem a ser exibida na tela. A adoção dessa
arquitetura possibilitou um grande avanço nos jogos e aplicações gráficas em tempo real, pois
boa parte das tarefas que antes eram feitas pela CPU foram levadas para o hardware da GPU.
Esta arquitetura permitia uma certa flexibilidade ao desenvolvedor, que podia configurar os
módulos da GPU (IKEDA, 2011).
A empresa 3DFX, por sua vez, lançou a tecnologia Scalable Link Interface (SLI), que
permitia a conexão e utilização em paralelo de duas placas de vídeo. Posteriormente, a 3DFX
foi adquirida pela NVIDIA, que passou a utilizar esta tecnologia em sua linha de produtos.
Neste mesmo período, ATI e NVIDIA tinham produtos com características semelhantes
dando início a uma concorrência acirrada (IKEDA, 2011).
2.1.3 Terceira Geração
Em 2001, a NVIDIA lançou a primeira GPU programável – GeForce 3 (NV20), que
competiu diretamente com a Radeon 8500 (R200) lançada pela ATI. A introdução das
técnicas de pixel shading e vertex shading foi a grande evolução desta geração (VIANA,
2009).
O pixel shading torna possível desenvolver programas capazes de manipular os pixeis
após a rasterização, de forma a criar efeitos na imagem, como por exemplo, rugosidade ou
desfoque. Já vertex shading possibilita a criação de programas capazes de manipular a
estrutura dos vértices do modelo tridimensional (ou seja, antes de rasterização), para otimizar
os modelos 3D ou alterar o modelo dinamicamente. Os programas desenvolvidos com essas
duas técnicas são conhecidos como shaders. Ambas as técnicas são utilizadas a fim de obter
maior realismo nas imagens sem sobrecarregar a CPU principal, pois os shaders são
executados inteiramente pela GPU (ST-LAURENT, 2004).
A capacidade de processamento desta geração era limitada, sendo necessário utilizar a
linguagem de montagem (assembly) da GPU. Entretanto, a partir desta fase a GPU começou a
ser encarada com um hardware vetorial programável (VIANA, 2009).
2.1.4 Quarta geração
A quarta geração introduziu o tratamento de variáveis de ponto flutuante e uma maior
flexibilidade na utilização de dados de textura. Nesse período, com início por volta de 2003, a

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
22
concorrência foi intensa com o lançamento da série FX (NV30) e GeForce 6 pela NVIDIA e
da série R300 e X1 pela ATI.
Este foi um momento importante na evolução das placas de vídeo, devido a ser a
primeira vez na história em que foi possível desenvolver, ainda que precariamente, aplicativos
de propósito geral sobre tecnologias de GPU (NVIDIA, 2009).
2.1.5 Quinta geração
O ponto marcante das placas dessa geração são as arquiteturas elaboradas para
explorar a computação paralela de propósito geral em GPUs. Pode-se dizer, portanto, que
somente a partir de meados de 2006 que a computação paralela em hardware gráfico tornou-
se de grande interesse no mercado, indo além da comunidade científica (IKEDA, 2011). O
conceito de desenvolvimento de programas de propósito geral para GPUs é um dos focos
deste trabalho e, portanto, será detalhado a partir da Subseção 2.3.
2.2 Pipeline gráfico tradicional
O processo executado por todo o pipeline pode ser dividido em duas etapas principais:
processamento de geometria e renderização. A primeira etapa transforma as coordenadas dos
objetos de três dimensões em representações de duas dimensões, apropriadas à exibição. A
segunda etapa preenche a área entre as coordenadas 2D com pixeis que representam a
superfície dos objetos. O estágio de geometria ainda pode ser subdividido em: transformações
e iluminação (CROW, 2004).
Inicialmente, apenas a renderização era implementada em hardware, por ser uma
operação simples e repetitiva, e as outras operações eram executadas pela CPU. Com a
evolução no desenvolvimento das GPUs, cada vez mais tarefas foram alocadas às placas de
vídeo, a fim de diminuir a carga da CPU (NVIDIA, 1999).
A ideia do pipeline é fazer com que cada um desses módulos opere em paralelo, ao
invés de tratar um pixel de cada vez. Nas placas de vídeo modernas, o pipeline completo é
replicado diversas vezes, de forma a obter maior vazão no processamento. Ao longo dos anos,
mais etapas do pipeline foram sendo trazidas da CPU para a GPU, chegando ao cenário atual,
onde apenas a lógica da aplicação e as computações da cena são executadas pela CPU
principal. A Tabela 1 lista os estágios do pipeline gráfico e a evolução da distribuição dos
mesmos entre CPU e GPU.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
23
As características do pipeline delinearam a arquitetura das GPUs. O fato de todos os
pixeis necessitarem passar pelos mesmos módulos de execução levou as GPUs a adotarem
arquiteturas paralelas.
Tabela 1 Evolução da distribuição dos estágios entre CPU e GPU.
Estágio 1996 1997 1998 1999
Lógica da aplicação CPU CPU CPU CPU
Computações da cena CPU CPU CPU CPU
Transformações CPU CPU CPU GPU
Iluminação CPU CPU CPU GPU
Criação dos triângulos CPU Processador gráfico Processador gráfico GPU
Renderização Processador gráfico Processador gráfico Processador gráfico GPUFonte: NVIDIA, 1999.
2.3 Processamento de propósito geral em GPU
O uso da GPU para processamento de propósito geral começou com a utilização de
linguagens de shading, como Direct3D High Level Shader Language (HLSL) e OpenGL
Shading Language (GLSL). Dessa forma, aplicações em diversas áreas foram aceleradas, no
entanto exigindo que todos os algoritmos fossem adaptados para trabalhar com dados
expressos em termos de vértices e texturas. Nas primeiras soluções, haviam outras limitações,
como a impossibilidade de leituras e escritas em posições aleatórias da memória (NVIDIA,
2009).
O uso de chips e APIs gráficas neste contexto revelou um grande potencial na
aceleração de algoritmos que possuam uma estrutura passível de paralelização, fazendo uso de
hardware padrão presente em um grande número de computadores. O surgimento deste novo
segmento resultou na criação de arquiteturas que tornam as GPUs mais apropriadas ao
processamento geral e ao desvinculamento de seus ambientes de desenvolvimento das APIs
gráficas tradicionais. A primeira arquitetura de GPGPU, também chamada de computação
para GPU, foi criada pela empresa NVIDIA e será detalhada a seguir.
2.4 Visão Geral da CUDA
CUDA é a arquitetura de computação paralela de propósito geral que faz uso da
capacidade de processamento presente nas GPUs da NVIDIA. A arquitetura CUDA provê um
modelo de programação escalável baseado em três conceitos centrais: uma hierarquia de
grupos de threads, memória compartilhada entre as threads e barreiras de sincronização.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
24
Esses conceitos são expostos ao desenvolvedor como um conjunto de extensões à linguagem
C (NVIDIA, 2011a).
A arquitetura CUDA definiu duas alterações principais na organização das GPUs: a
unificação dos shaders (vertex e pixel shaders) e a criação de memória compartilhada. O
componente resultante da união dos shaders é chamado stream processor (SP). Essas
alterações transformaram as GPUs em dispositivos adequados ao processamento de propósito
geral (HUANG; SHEN; WU, 2009).
A Figura 1 ilustra a arquitetura unificada dos shaders em contraste aos shaders
tradicionais. A unificação dos shaders transformou as unidades especializadas em
processamento de vértices ou pixeis, por exemplo, em unidades de computação genérica
interconectadas por um escalonador dinâmico que divide a carga de processamento entre as
diversas unidades que compõe a GPU. Dessa forma, a utilização dos recursos de hardware foi
flexibilizada.
Figura 1 Shader tradicional x shader unificado, adaptado de (IKEDA, 2011).
Os grupos de threads são escalonados para execução em um dos núcleos,
sequencialmente ou simultaneamente, sem que seja necessário explicitar em qual núcleo o
bloco será alocado. Desta forma, um mesmo programa poderá ser executado em GPUs com
diferentes quantidade de núcleos e, ainda assim, fará uso de todo o poder de computação
disponível.
A Figura 2 ilustra a execução de um mesmo programa em duas placas de vídeo, a da
esquerda possui uma GPU com dois núcleos e a da direita com quatro núcleos. O programa
em questão foi parametrizado para execução com oito blocos de threads. No primeiro caso,
cada núcleo fica responsável pela execução de quatro blocos. Já no segundo caso, os oito

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
25
blocos são divididos entre os quatro núcleos disponíveis. Esse escalonamento é realizado
internamente pela GPU e não é determinado pelo código da aplicação. Dessa forma, a
arquitetura provê um ambiente escalável para a execução dos programas.
Figura 2 Escalabilidade da arquitetura CUDA, adaptada de (NVIDIA, 2011a).
A arquitetura CUDA já sofreu algumas alterações desde a sua concepção inicial.
Algumas características foram sendo implementadas ao longo do tempo, a fim de aprimorar o
desempenho das GPUs. Portanto, diferentes placas podem conter um conjunto de
características diferentes. A fim de identificar as características presentes em um determinado
dispositivo, todas as placas são categorizadas em compute capabilities identificados por um
versionamento numérico. Os manuais da NVIDIA apresentam as características do hardware
de acordo com essa numeração. Por exemplo, um determinada funcionalidade pode estar
presente apenas nos dispositivos de compute capability 1.2. Se a funcionalidade for descrita
para o compute capability 2.x, significa que todos as placas com versão 2 suportam-na,
independentemente do outro algarismo.
2.5 Arquitetura de hardware
As placas de vídeo compatíveis com a tecnologia CUDA possuem um conjunto
escalável de multiprocessadores, que são chamados streaming multiprocessors (SMs). Os
SMs são compostos por uma série de processadores escalares (scalar processors – SP), uma
unidade de instrução multi thread e memória compartilhada. Os blocos de threads criados

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
26
pelo kernel são escalonados para execução em SMs com capacidade ociosa. As threads dentro
de um mesmo bloco são executadas concorrentemente, pois cada thread é mapeada em um
SP, com seus próprios registradores. A NVIDIA chamou essa arquitetura de Single-
Instruction, Multiple-Thread (SIMT) (NVIDIA, 2011a).
O escalonador de threads separa-as em grupos, chamados warps. A cada ciclo de
instrução um warp é selecionado para execução, então a mesma instrução é executada em
todas as threads ativas neste warp (NVIDIA, 2011c). Apesar de todas as threads começaram
a execução no mesmo ponto do código, há a possibilidade de que haja ramificação na
execução. Neste caso, nem todas as threads estarão ativas no mesmo momento, resultando na
serialização da execução. Portanto, para que seja alcançada eficiência máxima na execução
paralela das threads é necessário que não hajam ramificações no fluxo de execução (branch
divergence) dentro de um mesmo warp (HAN; ABDELRAHMAN , 2011).
A Figura 3 apresenta três casos típicos onde ocorre a divergência no fluxo de
execução. Na situação (a), o incremento executado dentro do bloco condicional faz com que
os SPs destinados às threads que não executam o incremento fiquem inativos por alguns
ciclos. O cenário (b) pode ser interpretado como duas instruções condicionais na sequência,
com as mesmas implicações do exemplo anterior. No terceiro caso, o número de iterações
executadas no laço pode diferir para cada thread. A diferença no número de iterações do laço
para cada thread resultará que os SPs alocados para as threads com menor número de
iterações ficarão inativos, enquanto os outros SPs executam as últimas iterações para as outras
threads do mesmo warp (HAN; ABDELRAHMAN , 2011).
Figura 3 Cenários comuns de branch divergence, adaptada de (HAN; ABDELRAHMAN , 2011).
Esta arquitetura criada pela NVIDIA é similar às arquiteturas SIMD presentes em
diversas CPUs, no entanto, existem diferenças importantes (REN et al. 2010). Nas
arquiteturas SIMD, diversos elementos de dados são salvos em um registrador. A largura dos

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
27
registradores, que determina o nível de paralelismo em nível de instrução, é exposta ao
software. Na arquitetura SIMT, por outro lado, o paralelismo se dá pela execução de diversas
threads que podem executar trechos de código distintos (NVIDIA, 2011c).
O comportamento específico da arquitetura SIMT pode ser ignorado pelo programador
a fim de obter-se uma implementação meramente funcional de determinado algoritmo, mas
através da adequação da implementação às características próprias do hardware (GPU) é
possível obter maiores ganhos de desempenho. Analogamente, nas arquiteturas tradicionais é
possível ignorar a largura das linhas de cache e, ainda assim, obter implementações
funcionais. No entanto, quando almeja-se obter picos de desempenho essa informação precisa
ser considerada (NVIDIA, 2011c).
2.6 Modelo de programação
O modelo de programação do CUDA permite que o programador crie um grande
número de threads que executarão código escalar, ou seja, cada thread analisada isoladamente
contém código que será executado sequencialmente, sem nenhum nível de paralelismo. O
modelo de programação criado pela NVIDIA possibilita aos desenvolvedores criar aplicações
paralelas com certo grau de facilidade, mesmo aqueles que não possuem grande familiaridade
com arquiteturas paralelas (BAKHODA et al., 2009).
As características do modelo de programação são expostas ao programador através de
uma extensão da linguagem de programação ANSI C (American National Standards
Institute). Os três conceitos chave desse modelo são descritos nas subseções seguintes: kernel,
hierarquia de threads e hierarquia de memória.
2.6.1 Função Kernel
A extensão da linguagem C criada pela NVIDIA possibilita a criação de funções que
serão executadas na GPU. Para tanto, existem três palavras-chave: __global__, __device__ e
__host__. A primeira delas específica uma função que será executada na GPU, mas será
chamada da CPU. Uma função com esta característica é chamada de kernel e cabe ao
programador especificar quantas vezes esta função deve ser executada paralelamente. Para
tanto, na chamada do kernel é definido o tamanho do grid, ou seja, a quantidade de blocos de
threads (NVIDIA, 2011). Na Listagem 1, a linha um contém o protótipo com a declaração de
um kernel e a linha dois a chamada do kernel, com a especificação dos parâmetros de
execução.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
28
1 __global__ kernel_function(char *buffer);
2 kernel_function<<<dimGrid,dimBlock,0,stream>>>(buffer);
Listagem 1 Declaração e chamada de um kernel.
A palavra-chave __device__, por outro lado, declara uma função que será executada
pela GPU e poderá ser invocada somente por código executado na própria GPU. Já a palavra-
chave __host__ declara funções convencionais, ou seja, que são chamadas e executadas pela
CPU. __host__ é o qualificador padrão na declaração de funções, portanto, não precisa estar
explícito no protótipo da função.
2.6.2 Hierarquia de threads
A organização das threads se dá na forma de blocos com uma, duas ou três dimensões.
Esse arranjo torna simples a execução de cálculos em elementos de vetores, matrizes ou
volumes. A identificação da thread que está sendo executada é possível através dos índices
que identificam a posição da thread dentro do bloco. Os índices são disponibilizados ao
programador através da variável tridimensional threadIdx que contém três campos de inteiros
sem sinal: x, y, z.
Os blocos contém grupos de threads que são organizados em um grid, que também
pode ter até três dimensões. O tamanho do grid é determinado a partir da quantidade de dados
a serem manipulados ou pela quantidade de processadores.
Os blocos são identificados dentro do grid de mesma forma que as threads dentro de
um bloco. Para tanto, existe a variável blockIdx, do tipo uint3. Já o tamanho dos blocos, ou
seja, a quantidade de threads pode ser obtido através da variável blockDim.
As variáveis threadIdx, blockIdx e blockDim são chamadas built-in, ou seja, elas são
automaticamente acessíveis dentro do kernel, mesmo sem terem sido explicitamente
declaradas.
A execução dos blocos de threads poderá ocorrer em qualquer ordem, serialmente ou
paralelamente. Portanto, a operação executada em um bloco não pode depender de resultados
obtidos em outros blocos. Essa característica possibilita a escalabilidade do código, de forma
a utilizar diferentes quantidades de núcleos de processamento disponíveis (NVIDIA, 2011a).
As threads que residem no mesmo bloco são executadas no mesmo SM podendo
cooperar entre si através do compartilhamento de dados (pela memória compartilhada) e
sincronização da execução com funções intrínsecas que servem como barreiras na execução,

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
29
de forma que a execução prossiga apenas quando todas as threads tenham finalizado a
execução de uma determinada sequência de instruções.
AFigura 4 ilustra a forma de organização hierárquica das threads.
Figura 4 Organização das threads, adaptada de (NVIDIA, 2011a)
2.6.3 Hierarquia de memória
CUDA expõe seu modelo de memória, que é composto por diferentes espaços de
memória, tornando necessário ao desenvolvedor conhecer a arquitetura e definir onde cada
conjunto de dados da aplicação deve residir. A correta utilização das diferentes memórias
presentes na placa de vídeo, geralmente, tem implicação direta no desempenho do aplicativo.
A Tabela 2 apresenta um visão geral das memórias disponíveis na arquitetura CUDA.
Pode-se observar que as memórias mais abundantes possuem uma latência elevada por
estarem localizadas fora do chip. A quinta coluna da tabela define que as memórias de
constantes e de texturas possuem acesso somente de leitura, ou seja, é possível escrever nestas
memórias apenas através de código executado na CPU. A subseção seguinte apresenta um
detalhamento de cada uma dessas memórias.
O fluxo dos dados na aplicação geralmente segue o seguinte padrão: inicialmente os
dados são copiados da memória RAM (random access memory) do computador (host) para a
memória global da GPU (device), através do barramento Peripheral Component Interconnect
Express (PCIe). Após essa cópia os dados já estão acessíveis às threads, no entanto, é comum
realizar a transferência da memória global para a memória compartilhada de um SM, de forma
a minimizar a quantidade de acessos à memória global. Dessa forma, a memória
compartilhada é utilizada como um cache entre a memória global e o aplicativo, para reduzir
os efeitos da alta latência no acesso a memória global.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
30
Tabela 2 Características dos espaços de memória na arquitetura CUDA séries G80 e G200.
Memória Localização Tamanho LatênciaSomente leitura
Escopo
Registradores SMaté 64 kB por
SM ~ 0 ciclos não thread
LocalPlaca de
vídeodepende da
global400 – 600
ciclosnão thread
Compartilhada SM1 16 kB por SM >= 4 ciclos nãoTodas as
threads em um bloco
GlobalPlaca de
vídeoaté 1024 MB
400 – 600 ciclos
nãoTodas as
threads + host
ConstantePlaca de vídeo2 64 kB 0 – 600 ciclos sim
Todas as threads + host
TexturaPlaca de vídeo3
depende da global
0 – 600 ciclos simTodas as
threads + hostFonte: Adaptado de NVIDIA, 2011b e Conrad, 2010.
Após esta etapa, as threads manipulam os dados que estão na memória compartilhada,
utilizando os registradores para armazenar variáveis de controle e resultados intermediários.
Ao final do processamento, cada thread escreve o resultado da sua execução na memória
global, a fim de tornar acessível ao host os resultados obtidos. Por fim, o host copia os
resultados que estão na memória global de volta para a memória do computador.
Figura 5 Fluxo típico de uma aplicação CUDA.
1Esta memória possui cache nos dispositivos 2.x.2Esta memória possui cache em todos os dispositivos.3Esta memória possui cache em todos os dispositivos.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
31
2.7 Detalhamento dos espaços de memória
A seguir serão apresentados os detalhes relevantes de cada memória.
2.7.1 Registradores e memória local
Os registradores são utilizados para armazenar as variáveis automáticas (também
chamadas de variáveis locais). Se não houver espaço suficiente, o compilador alocará as
variáveis na memória local. Dessa forma, estruturas ou vetores (automáticos) grandes
possivelmente serão alocados na memória local. Como a memória local está localizada fora
do chip e não possui cache (em dispositivos 1.x), apresenta tempo acesso elevado (NVIDIA,
2011b). A memória local é apenas uma abstração sobre a memória global, com escopo
limitado a cada thread (IKEDA, 2011). Portanto, a quantidade e o tamanho das variáveis
automáticas podem influenciar diretamente o desempenho do aplicativo.
2.7.2 Memória compartilhada
A memória compartilhada está localizada dentro de cada multiprocessador, por isso,
possui latência cerca de cem vezes menor do que a memória global ou local, porém o tamanho
total desta memória é reduzido (NVIDIA, 2011b). A memória compartilhada pode ser
utilizada como uma memória cache explicitamente gerenciada, ou seja, cabe ao programador
utilizar esse recurso para minimizar a quantidade de acessos a memória global.
A memória compartilhada é organizada em bancos, ou seja, módulos que podem ser
acessados simultaneamente, a fim de obter uma alta largura de banda. Essa arquitetura
permite que diversas requisições, que acessem endereços localizados em diferentes bancos,
possam ser atendidas ao mesmo tempo. Por outro lado, se uma requisição de acesso a
memória contiver acessos em endereços localizados no mesmo banco haverá um conflito de
acesso. Nessa situação, os acessos serão separados em requisições consecutivas separadas
para que não contenham nenhum conflito (NVIDIA, 2011a).
A ocorrência de conflitos se dá quando mais de uma thread pertencente ao mesmo
half-warp4 solicitam acesso a posições de memória que localizam-se em um mesmo banco.
Há uma exceção no caso de todas as threads de um half-warp executarem uma leitura no
mesmo endereço, neste caso o conteúdo lido é disponibilizado para todas as threads através
de um broadcast. Em dispositivos com compute capability 2.x há também a possibilidade de
4 Half-warp é um grupo de threads, com metade do tamanho de um warp. Em dispositivos com compute capability 1.x, o half-warp é menor unidade escalonada pelo SM. Já em dispositivos com compute capability 2.x a menor unidade escalonada é o próprio warp.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
32
multicast, onde o conteúdo lido é disponibilizado para um grupo de threads, mas não
necessariamente para todas (NVIDIA, 2011b).
2.7.3 Memória global
A memória global está localizada na placa de vídeo, no entanto, não sendo integrada
ao chip da GPU, possui alta latência no acesso. Esta memória pode ser acessada através de
transações de 32, 64 ou 128 bytes, alinhadas. Isto é, o endereço do primeiro elemento
manipulado precisa ser um múltiplo do tamanho do segmento (NVIDIA, 2011a).
As requisições de acesso à memória global efetuadas por um half-warp (em
dispositivos com compute capability 1.x) ou por um warp (em dispositivos com compute
capability 2.x) são combinadas resultando na menor quantidade de transações possível, que
obedeça as regras de alinhamento impostas pela arquitetura de hardware (NVIDIA, 2011b).
As regras que definem o agrupamento dos acessos à memória global em transações
variam entre dispositivos com diferentes compute capabilities. Inicialmente, a arquitetura da
GPU impunha restrições mais severas no padrão de acesso que resultava na combinação de
vários acessos em uma transação. Entretanto, as placas de vídeo mais recentes, que possuem
compute capability 2.x, apresentam avanços nesse quesito.
A Figura 6 ilustra padrões de acesso que permitem o acesso coalescido, ou seja, o
acesso a várias posições de memória em apenas uma transação. Desta forma, os efeitos da
latência de acesso são diluídos. A figura (a) exemplifica o acesso coalescido a variáveis float
de quatro bytes. A figura (b) ilustra o acesso coalescido por um warp divergente, ou seja,
neste caso nem todas as threads acessam as respectivas variáveis.
Figura 6 Padrões de acesso coalescido (CONRAD, 2010).
A Figura 7, por outro lado, exemplifica padrões de acesso que não possibilitam o
acesso coalescido. A figura (a) possui um padrão de acesso não sequencial, ou seja, as

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
33
threads não acessam as suas respectivas posições. Já a figura (b) apresenta um padrão de
acesso sequencial. No entanto, o acesso é desalinhado o que impossibilita o coalescing.
Figura 7 Acesso não coalescido (CONRAD, 2010).
Uma característica dos dispositivos com compute capability 2.x que pode amenizar o
impacto da alta latência no acesso a memória global é a presença de dois níveis de cache
(cache L1 e L2) entre o SM e a memória global.
O cache L1 é composto de linhas de 128 bytes que mapeiam segmentos alinhados na
memória global. Já o cache L2 é composto por linhas de 32 bytes. O tamanho das linhas
determinam o tamanho da transação que será usada para acessar os dados através do cache.
Em certas circunstâncias pode ser vantajoso utilizar apenas o cache L2, por exemplo,
quando os acessos são dispersos na memória a utilização de cache com linhas mais estreitas
resulta numa menor quantidade de leituras ou escritas desnecessárias. Por esse motivo, o
compilador possui um parâmetro que permite definir se os acessos a memória global
utilizarão os caches L1 e L2 ou apenas o L2 (NVIDIA, 2011a).
2.7.4 Memória de textura e superfície
A memória de textura ou superfície está localizada na memória da placa de vídeo e
possui cache otimizado para acesso a dados que apresentem localidade espacial em duas
dimensões, ou seja, dados localizados em posições próximas. Além disso, esse espaço de
memória é projetado de forma a obter fluxos de leitura com latência constante. Dessa forma,
uma leitura do cache reduz a largura de banda demandada, mas a latência se mantém
constante (NVIDIA, 2011a).

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
34
Quando um warp necessita de um dado que está presente no cache há um ganho
significativo no tempo de leitura, caso o dado não esteja disponível no cache o tempo de
acesso será o mesmo de uma leitura na memória global convencional.
A memória de textura pode ser escrita a partir do host, mas do ponto de vista da GPU
é uma memória somente de leitura.
2.7.5 Memória de constantes
A memória de constantes está localizada no dispositivo e possui memória cache.
Possui acesso somente de leitura pela GPU. Além de ser usada explicitamente, em
dispositivos com compute capability 2.x esta memória pode ser utilizada pelo compilador
através de instruções específicas (NVIDIA, 2011a).

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
35
3 CODIFICAÇÃO DE VÍDEO
Um codificador de vídeo transforma o vídeo de sua forma original em uma
representação comprimida, de forma a permitir uma utilização mais eficiente de recursos
como largura de banda (nos sistemas de comunicação) e espaço (nos sistemas de
armazenamento). A utilização do vídeo codificado requer um decodificador, que é o sistema
capaz de realizar a conversão inversa, a fim de obter o vídeo na sua forma natural. O par
codificador/decodificador é o que se chama codec (RICHARDSON, 2010).
3.1 Vídeo digital
O vídeo digital baseia-se na utilização de dados amostrados temporalmente e
espacialmente. A partir da amostragem, obtém-se uma matriz retangular com valores que
representam a informação visual que é composta por três componentes, devido às
características fisiológicas do sistema visual humano (GONZALEZ, 2000).
A forma de representação das três componentes é chamado espaço de cores. Existem
diversos espaços empregados em diferentes aplicações. Os monitores de vídeo utilizam o
RGB, baseado nas componentes vermelha, verde e azul. Já os sistemas de televisão e os
codificadores de vídeo utilizam o YCbCr, que define a luminância (Y), a crominância azul
(Cb) e a crominância vermelha (Cr) (SHI; SUN, 2008).
A utilização do espaço de cores YCbCr associado com a subamostragem das
crominâncias é realizada através de padrões de amostragem bem estabelecidos, como 4:4:4,
4:2:2 e 4:2:0. Na amostragem 4:4:4 as crominâncias são mantidas intactas, portanto, todos os
pixeis possuem uma amostra de cada componente (Y, Cb e Cr). No caso 4:2:2, a amostragem
das crominâncias possui a metade da resolução no sentido horizontal, ou seja, para cada
quatro amostras de luminância existem duas amostras de cada crominância. Por fim, o
formato 4:2:0 reduz a resolução tanto horizontalmente quanto verticalmente, ou seja, para
cada quatro amostras de luminância é utilizada apenas uma amostra de cada crominância,
obtendo 50% menos bits na representação, se comparado com o formato 4:4:4
(RICHARDSON, 2003).
A subamostragem é amplamente utilizada nos codificadores atuais, devido à redução
do espaço de informação ocupado por esta técnica. Por exemplo, um vídeo em formato
YCbCr 4:2:0 obtém uma taxa de compressão de 50% em relação a um vídeo em RGB ou
YCbCr 4:4:4 com perdas de qualidade pouco significativas (AGOSTINI, 2007).

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
36
3.2 Compressão de vídeo
As técnicas de compressão com perdas são amplamente utilizadas nos codificadores
de vídeo atuais, de forma a explorar as limitações do sistema de visão humano. Além disso, o
olho humano possui sensibilidade diferenciada em relação a diferentes componentes ou
características da imagem (GONZALEZ, 2000).
Entretanto, a representação digital de vídeos apresenta uma enorme quantidade de
dados redundantes que possibilita a utilização de técnicas de codificação preditiva sem perdas.
Os altos níveis de compactação obtidos pelos codecs atuais são possíveis com a combinação
destas técnicas (com e sem perdas) (DINIZ, 2009).
Um codificador de vídeo, de forma geral, é composto por três partes principais:
módulo temporal, módulo espacial e codificador de entropia. Cada um desses módulos é
responsável por remover um tipo de redundância presente no vídeo (AGOSTINI, 2007):
a) Redundância Espacial: devida à correlação existente entre os pixeis ao longo de
um quadro (por isso, chamada intraquadro). A remoção dessa redundância é
realizada no domínio espacial e no domínio das frequências, pela predição
intraquadro e quantização, respectivamente. A quantização é uma operação
irreversível, pois gera perdas na codificação. No entanto, as perdas tendem a ser
pouco significativas na qualidade visual da imagem.
b) Redundância Temporal: se deve à correlação existente entre os diversos quadros
(por isso, chamada interquadro) temporalmente adjacentes. Essas redundância
pode ser visualizada como uma dimensão adicional da redundância espacial
(GONZALEZ, 2000). Esta correlação temporal é tratada pelo módulos de
estimativa e compensação de movimento.
c) Redundância Entrópica: relaciona-se com a probabilidade de ocorrência de
determinados símbolos, sendo que quanto maior a probabilidade de ocorrência
de um determinado símbolo, menos informação estará sendo codificada através
dele. A codificação de entropia utiliza algoritmos de compressão sem perdas
objetivando a codificação da maior quantidade de informação possível por
símbolo. A entropia é a medida da quantidade média de informação codificada
por símbolo (SHI; SUN, 2007).

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
37
3.3 Introdução ao H.264
H.264 é um padrão internacional de codificação de vídeo para a indústria. É composto
por um documento publicado pela ITU-T e ISO/IEC (como sendo a parte 10 do MPEG-4) que
possui instruções que definem o formato do vídeo codificado. Além disso, é definido, em
detalhes, o funcionamento de um decodificador capaz de decodificar o formato especificado
(ITU-T, 2003).
Assim como em outros padrões de codificação, não são especificados os detalhes do
codificador. A única restrição imposta na implementação do codificador, é que ele precisa
gerar um bitstream (fluxo de vídeo codificado) conforme a especificação, de forma que possa
ser decodificado corretamente por qualquer implementação do decodificador
(RICHARDSON, 2003). O H.264 define um conjunto de técnicas e ferramentas de
compressão, o codificador pode optar por qual desses itens irá fazer uso.
O padrão H.264 foi originalmente publicado em 2003 e sofreu diversas revisões e
atualizações desde então. Os conceitos básicos deste codec são os mesmos presentes no
MPEG-2 e MPEG-4 Visual, no entanto, os avanços sugeridos proporcionam um aumento
potencial na eficiência, qualidade e flexibilidade da compressão (RICHARDSON, 2010).
3.4 Descrição do codec H.264
O codificador possui dois caminhos por onde os dados fluem: o caminho direto,
através do qual é gerado a sequência de bytes que representa o vídeo codificado e o caminho
de reconstrução do vídeo, através do qual o codificador monta os quadros decodificados a
serem usados como referência.
Inicialmente, cada macrobloco5 do quadro original a ser codificado é subtraído de um
macrobloco de referência obtido pela predição intraquadro ou pela compensação/estimativa
de movimento. Os macroblocos de referência utilizados são oriundos de quadros
reconstruídos pelo caminho de reconstrução, que executa as operações identicamente a um
decodificador (RICHARDSON, 2003).
Os macroblocos de diferenças (geralmente chamados de macroblocos de resíduos) são
processados pelos módulos de transformadas e quantização. Os coeficientes quantizados e as
informações de controle, que indicam as decisões tomadas pelo codificador, são repassadas ao
codificador de entropia que irá reduzir o nível de redundância entrópica do fluxo de bits de
saída (bitstream). Por fim, o vídeo codificado será colocado dentro de “pacotes”
5Macrobloco é um bloco de 16x16 pixeis.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
38
padronizados, referenciados como NAL (Network Abstraction Layer) (RICHARDSON,
2003).
As técnicas de compressão baseadas em predição de blocos da imagem fazem uso de
blocos da vizinhança (temporal ou espacial) que foram codificados anteriormente ao bloco
atual. Tanto o codificador quanto o decodificador executam o procedimento de compensação,
de forma que o codificador utilize como quadro de referência o mesmo resultado que será
obtido pelo decodificador.
Portanto, o resultado quantizado será processado pelo bloco de quantização inversa e
transformadas inversas. O resultado desta etapa será somado ao resultado da predição
intraquadro ou interquadro e filtrado (para diminuir os efeitos do particionamento da imagem
em blocos) e então formará a próxima imagem de referência, ou seja, uma versão
decodificada do bloco original (RICHARDSON, 2003).
A Figura 8 apresenta os blocos constituintes do codificador H.264.
Figura 8 Estrutura do codificador H.264 (REDIESS, 2006).
3.4.1 Predição intraquadro
A predição intraquadro tem por objetivo diminuir a redundância espacial dentro um
quadro. Sua característica principal é permitir a compressão de dados de cada quadro de
forma auto contida, ou seja, cada quadro da sequência de vídeo pode ser processado de forma
independente de todos os demais. Este procedimento é aplicado a todos elementos dos
macroblocos no domínio espacial (AGOSTINI, 2007).
O padrão H.264 define a aplicação da predição intraquadro nos componentes de
luminância e crominância dos macroblocos I (Intra), resultando em macroblocos preditos com
base em amostras reconstruídas, ou seja, que já percorreram todo o caminho de reconstrução

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
39
do codificador. O resultado desta predição é subtraído do macrobloco original a fim de gerar
um macrobloco de resíduos a serem codificados.
Segundo a norma H.264, existem dois tipos de blocos I: de tamanho 4x4 e 16x16. No
primeiro caso o conjunto de 16x16 amostras é processado separadamente em blocos de 4x4.
Já no segundo caso, o macrobloco é tratado sem divisões. Para cara tipo de macrobloco I,
existem vários modos de predição que visam atacar determinados padrões espaciais no quadro
de vídeo. Por exemplo, as Figuras 9 e 10, apresentam os quatro modos de predição para
macroblocos I 16x16 e os nove modos de predição para macroblocos I 4x4, respectivamente
(RICHARDSON, 2003).
Figura 9 Modos de predição para blocos 16x16 de luminância. (AGOSTINI, 2007)
As crominâncias são processadas em blocos 8x8 e existem quatro modos de predição
possíveis. No entanto, as duas crominâncias sempre utilizam o mesmo modo
(RICHARDSON, 2003).
A decisão de qual modo de predição será empregado em cada macrobloco fica a cargo
do codificador. Existem duas abordagens para a tomada desta decisão: algoritmos de busca
completa (que calculam todos os modos possíveis a fim de encontrar qual fornece a melhor
eficiência na compressão) e algoritmos rápidos (que baseiam-se em alguma heurística, usando
informação do vídeo a ser codificado, de forma a diminuir a complexidade da decisão)
(AGOSTINI, 2007).

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
40
Figura 10 Modos de predição para blocos 4x4 de luminância (AGOSTINI, 2007).
3.4.2 Transformadas diretas e inversas
A codificação por transformadas é uma técnica de compressão que explora a
correlação entre os pixeis de uma imagem, sendo empregada tanto em codificação de imagens
quanto codificação de vídeo. Este estágio do codificador converte blocos da imagem de
entrada ou de resíduos da predição em outro domínio. O domínio para o qual os dados de
entrada são convertidos deve conter a informação original separada em componentes
descorrelacionadas e com a maior parte da energia do sinal concentrada em um pequeno
número de componentes. Além disso, é necessário que a transformada seja reversível, de
forma que seja possível voltar à representação original. A transformada adotada na maior
parte dos codecs é a DCT bidimensional (SHI; SUN, 2008).
O padrão H.264 define a utilização de duas transformadas: DCT e Transformada de
Hadamard. O codificador H.264 transforma e quantiza os blocos de coeficientes residuais. A
transformada utilizada é uma versão aproximada da DCT, chamada core transform. Após esta
etapa, em certos casos, é empregada a Transformada de Hadamard aos coeficientes DC6
obtidos na etapa anterior (RICHARDSON, 2003). As seções seguintes apresentarão os
detalhes de cada uma dessas transformadas.
6Coeficientes DC são aqueles que possuem frequência zero.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
41
3.4.2.1 Transformada discreta de cossenos
A DCT é uma transformada derivada da Transformada de Fourier cujo objetivo é
converter um bloco de dados de entrada para o domínio das frequências. A equação 1 define a
DCT (RICHARDSON, 2003).
Y =A · X · AT (1)
Onde
Y é a matriz de saída
X é a matriz de entrada
A é a matriz de coeficientes da transformada
AT é a matriz A transposta
A matriz A é definida pela Equação 2.
Aij=C i ·cos 2j1· i ·
2n (2)
Onde
C i=0= 1n (3)
C i≠0= 2n (4)
Onde i e j representam a posição do elemento na matriz (linha e coluna,
respectivamente) e n representa o número de linhas ou colunas do bloco.
A partir das Equações 2, 3 e 4 obtém-se a seguinte matriz de coeficientes para aplicar
a transformada em blocos 4x4:
A=[12
·cos 012
·cos 012
·cos 012
·cos 0
12·cos
8 12 ·cos
3·
8 12 ·cos
5·8 1
2 ·cos
7 ·
8
12 ·cos2 ·
8 12 ·cos
6 ·
8 12 ·cos
10 ·
8 12 ·cos
14 ·
8
12·cos
3·8 1
2 ·cos
9 ·
8 12 ·cos
15·8 1
2 ·cos
21 ·
8
] (5)
A Figura 11 exemplifica o funcionamento desta transformada. É possível notar que o
bloco resultante (b) possui as componentes mais significativas concentradas na parte superior
esquerda do bloco.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
42
Figura 11 Bloco de entrada (a) e resultado da DCT (b) (RICHARDSON, 2003).
Como pode-se observar, implementações dessa transformada requerem o uso de
aproximações de fatores irracionais. Se forem adotadas diferentes aproximações no
codificador e no decodificador, pode haver uma certa discrepância entre predições usadas
como referência, resultando distorção na saída do processo de decodificação.
Padronizações anteriores, como o MPEG-2 ou MPEG-4 adotaram diferentes medidas
para minimizar o impacto dessas aproximações. No entanto, o H.264 (e outros codecs
recentes) abordaram esse problema definindo um algoritmo adequado à implementação com
aritmética inteira com precisão limitada, de forma a eliminar a necessidade da utilização de
valores aproximados. Além disso, a implementação das transformadas em aritmética inteira
contribui para a diminuição do custo computacional das transformações (HUSEMANN et al.,
2010).
A matriz da transformada definida em 5 pode ser reescrita da seguinte forma:
A=[a a a ab c −c −ba −a −a ac −b b −c
] (6)
Onde
a=12
(7)
b= 12·cos
8 (8)
c= 12·cos
3·8
(9)
Considerando-se as definições 1, 6, 7, 8 e 9 obtém-se:

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
43
Y =A · X · AT=[
a a a ab c −c −ba −a −a ac −b b −c
] · X · [a b a ca c −a −ba −c −a ba −b a −c
] (10)
que pode ser fatorada em:
Y =A · X · AT=C · X · CT
⊙E (11)
Y =[1 1 1 12 1 −1 −21 −1 −1 11 −2 2 −1
] ·[1 2 1 11 1 −1 −21 −1 −1 21 −2 1 −1
]⊙[a2 ab
2a2 ab
2ab
2b2
4ab
2b²4
a2 ab2
a²ab
2ab
2b²4
ab2
b²4
] (12)
Onde ⊙ significa que cada elemento da matriz C · X · CT é multiplicado pelo
elemento correspondente na matriz E. Essa multiplicação ponto-a-ponto não é efetivamente
calculada na implementação da DCT, no entanto, estes fatores de escala são compensados
durante a quantização.
Os fatores a e b da matriz E são aproximados para simplificar a implementação.
a=12
(13)
b=25 (14)
A DCT inversa é necessária para transformar os dados para o seu domínio original,
tanto no decodificador quanto no laço de realimentação do codificador. A DCT inversa é
definida pela Equação 15.
X =AT · Y · A (15)
Onde
X é a matriz recuperada
Y é a matriz transformada
A é a matriz de coeficientes da transformada
AT é a matriz A transposta

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
44
As mesmas considerações feitas na transformada direta são aplicadas à transformada
inversa, de forma a obter a operação inversa equivalente, resultando na Equação 16. A
multiplicação ponto-a-ponto, analogamente, será compensada na quantização inversa.
X =AT · X · A=[1 1 1
12
112
−1 −1
1 −12 −1 1
1 −1 1 −12] · X ·[
1 1 1 1
112
−12 −1
1 −1 −1 112
−1 1 −12] (16)
3.4.2.2 Transformada de Hadamard
O padrão H.264 define a aplicação da transformada de Hadamard aos coeficientes DC
dos blocos após o cálculo da DCT, de forma aumentar a compressão em áreas homogêneas
(RICHARDSON, 2003). Por exemplo, um macrobloco de luminâncias (16 blocos de 4x4
amostras) resulta em um bloco 4x4 de componentes DC a serem processadas pela
transformada de Hadamard. No caso de um macrobloco de crominâncias, o bloco de
componentes DC é 2x2, devido à utilização de subamostragem nas crominâncias. A Figura 12
destaca os componentes DC dentro dos macroblocos de crominância (a) e luminância (b).
Figura 12 Macroblocos de crominância e luminância com componentes DC destacados (MAJOLO, 2010).
A definição matricial da transformada de Hadamard, aplicada às amostras de
luminância, é apresentada na Equação 17.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
45
Y L=12·[
1 1 1 11 1 −1 −11 −1 −1 11 −1 1 −1
] · X L ·[1 1 1 11 1 −1 −11 −1 −1 11 −1 1 −1
] (17)
Onde
XL é matriz 4x4 dos coeficientes DC resultantes da execução da DCT em um
bloco de 16x16 luminâncias;
YL é a matriz com os resultados obtidos pela transformada de Hadamard.
Quando aplicada às amostras de crominâncias, a transformada é definida pela Equação
18.
Y L=[1 11 −1] · X C ·[1 1
1 −1] (18)
Onde
XC é a matriz com os valores DC resultantes da DCT aplicada às crominâncias
YL é a matriz que contém o resultado da transformada.
A equação da transformada inversa de Hadamard (para blocos 4x4 de luminâncias) é
obtida através da manipulação da Equação 17, resultando em:
X L=18 ·[
1 1 1 11 1 −1 −11 −1 −1 11 −1 1 −1
] ·Y L · [1 1 1 11 1 −1 −11 −1 −1 11 −1 1 −1
] (19)
A divisão por oito na Equação 19 não é realizada no cálculo da Hadamard inversa, no
entanto, é compensado durante a quantização inversa.
O mesmo procedimento aplicado à Equação 18 resulta na equação para transformada
inversa de Hadamard aplicada aos blocos 2x2 de crominâncias.
X C=[1 11 −1] ·Y C ·[1 1
1 −1] (20)
3.4.3 Quantização
O padrão H.264 conta com um módulo quantizador escalar. A quantização dos
coeficientes obtidos pelas transformadas resulta na redução da informação e,
consequentemente, na compressão dos dados.
A quantização consiste, basicamente, de uma divisão por valor inteiro, de maneira a
reduzir a faixa dos valores (RICHARDSON, 2003).

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
46
A equação básica que define a quantização é:
FQij=round X ij
Qstep (21)
Onde
FQ é o resultado da quantização;
X é o valor a ser quantizado;
Qstep é o passo de quantização;
round é uma função que aproxima o valor para o inteiro mais próximo.
O parâmetro Qstep determina a intensidade da quantização, ou seja, quanto maior o
Qstep maior a compressão atingida e, consequentemente, maior a perda de informação gerada
no arredondamento. A determinação do valor do Qstep é um passo importante na
configuração do codificador (MAJOLO, 2010).
A determinação do Qstep é realizada indiretamente através de uma tabela com 52
valores que podem ser assumidos pelo Qstep, que são indexados pelo Quantization
Parameter (QP). A relação entre o Qstep e QP é a seguinte: para cada incremento de seis
unidades do QP, o Qstep é multiplicado por dois.
Essa relação é apresentada na Tabela 3. A utilização desta tabela foi adotada a fim de
evitar a necessidade de operações custosas como, cálculos com ponto flutuante e divisões
(RICHARDSON, 2003).
Tabela 3 Passos de quantização.
QP 0 1 2 3 4 5 6 7 8 9 10 11 12 ...Qstep 0,625 0,6875 0,8125 0,875 1 1,125 1,25 1,37
51,62
51,75 2 2,25 2,5
QP ... 18 ... 24 ... 30 ... 36 ... 42 ... 48 ... 51Qstep 5 10 20 40 80 160 224
Fonte: RICHARDSON, 2003
Como foi mencionado na subseção sobre a transformada DCT, uma multiplicação
escalar oriunda daquela transformada não é implementada, precisando ser compensada
durante a quantização. Essa compensação é feita através da variável Post-Scaling Factor (PF),
definida pela Tabela 4, resultando na Equação 22. As variáveis a e b são definidas nas
Equações 13 e 14.
FQij=round X ij ·PF
Qstep (22)

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
47
Tabela 4 Valores de PF para cada posição.
Posição (i, j) PF(0,0), (2,0), (0,2) e (2,2) a²(1,1), (1,3), (3,1) e (3,3) b²/4
Outras ab/2 Fonte: RICHARDSON, 2003.
Para fins de substituir divisões por deslocamento de bits, o termo PF / Qstep na
Equação 22 pode ser substituído por:
PFQstep
=MF
2qbits (23)
Onde
MF é o fator de multiplicação definido na Tabela 5;
qbits é definido por
qbits=15 floor QP6
(24)
sendo floor a função que realiza o arredondamento para baixo.
A equação final, em aritmética inteira, é expressa por:
∣FQij ∣=∣X ij ∣· MF f ≫qbits (25)
signFQij =signX ij (26)
Onde
f é 2qbits/3 para blocos da predição intra e 2qbits/6 para blocos da predição inter;
>> é o descolocamento binário para direita;
sign é a função que acessa o sinal do número.
Tabela 5 Fator de multiplicação.
Posições Posições
QP (0,0), (2,0), (2,2) e (0,2) (1,1), (1,3), (3,1) e (3,3) Outras posições0 13107 5243 80661 11916 4660 74902 10082 4194 65543 9362 3647 58254 8192 3355 52435 7282 2893 4559
Fonte: RICHARDSON, 2003.
Por fim, apresenta-se a definição da quantização inversa, que serve para recuperar o
valor anterior. Como a quantização é um procedimento que causa perdas, o valor recuperado é
uma aproximação do valor original, que depende do parâmetro QP. Este parâmetro terá o

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
48
mesmo valor na quantização direta e inversa. A equação da quantização inversa para os
componentes AC7 de luminâncias é definida em 27.
X ' ij=FQ ij · V ij ·2QP /6 (27)
Onde
X'ij é o valor recuperado;
FQij é o valor quantizado;
Vij é uma constante definida em 28;
QP é o parâmetro de quantização.
V ij=Qstep · PF ij ·64 (28)
A quantização inversa para os componentes DC é expressa pela equação 29.
X ' ij=FQ ij · V 0,0 ·2 floor QP /6 para QP >= 12
X ' ij=[FQij · V 0,0 · 21− floor QP /6 ]≫QP /6 para QP < 12
(29)
Onde
floor é operação que arredonda o número para baixo;
>> é deslocamento binário para direita.
3.4.4 Estimativa de movimento
A estimação de movimento trabalha no modelo temporal do vídeo com o objetivo de
encontrar e remover dados redundantes em quadros temporalmente adjacentes, algo
relativamente comuns em sequências de vídeo naturais. A partir do modelo temporal,
aproveitam-se as similaridades entres os quadros baseando-se em dados previamente
processados a fim de obter um quadro estimado (RICHARDSON, 2002).
A Figura 13 apresenta dois quadros temporalmente consecutivos no vídeo. Já a Figura
14a ilustra a similaridade entre os dois quadros através da codificação diferencial, ou seja, o
quadro é obtido através da simples subtração entre os dois quadros originais.
Nas figuras, o tom acinzentado predominante indica as regiões em que não há
diferença entre os dois quadros, o que pode ser explorado para reduzir a quantidade de dados
realmente necessários para construir a segunda imagem a partir da primeira.
A utilização das técnicas de estimação de movimento possibilitam reduzir os resíduos
obtidos pela codificação diferencial. A Figura 14b ilustra o resíduo obtido após a realização
da estimação de movimento.
7Coeficientes AC são aqueles que possuem frequência diferente de zero.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
49
(a) (b)
Figura 13 Quadros consecutivos de vídeo (RICHARDSON, 2003).
(a) (b)
Figura 14 Na esquerda, o resíduo sem estimativa de movimento. Na direita, o resíduo com estimativa de movimento (RICHARDSON, 2003).
A obtenção da estimativa de movimento se dá pela determinação de qual bloco dos
quadros de referência mais se assemelha ao macrobloco que está sendo processado, a fim de
que possa-se codificar apenas a diferença entre o bloco atual e o bloco selecionado e um vetor
de movimento que define a posição da região usada na predição. Este vetor é incluído no
bitstream de forma a permitir ao decodificador a realização do processo inverso
(compensação de movimento) (PORTO, 2008).
A estimação de movimento baseia-se em algoritmos de busca, que visam encontrar o
bloco que possui a maior similaridade com o bloco atual (melhor casamento), e em critérios
de similaridade que serão detalhados nas subseções seguintes.
A Figura 15 ilustra o procedimento de estimativa de movimento, que em conjunto com
a compensação de movimento constitui a predição interquadro. Segundo (PURI; CHEN;
LUTHRA, 2004) o codificador interquadros é o módulo que contém a maior complexidade
computacional em um codificador de vídeo.
O padrão H.264/AVC inovou na predição interquadro ao inserir a possibilidade de
blocos de tamanho variável, interpolação de valores intermediários (atingindo resolução de

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
50
meio ou quarto de pixel) e utilização de múltiplos quadros de referência (incluindo quadros
futuros) (RICHARDSON, 2003).
Figura 15 Predição interquadro (DINIZ, 2009).
3.4.4.1 Algoritmos de busca
Os algoritmos de busca especificam como a busca pelo bloco com maior similaridade
será realizada dentro de uma área de tamanho pré-definido chamada janela de busca. Em
geral, os algoritmos mais utilizados são os baseados em blocos de pixeis (em oposição aos
baseados em objetos). A escolha de um algoritmo de busca é extremamente importante, pois
tem impacto significativo, tanto na eficiência da compressão, quanto na complexidade
computacional do codificador (PORTO, 2012).
Os algoritmos de busca podem ser divididos em algoritmos ótimos e rápidos: os
algoritmos ótimos obtém o vetor de movimento correspondente ao bloco com maior
similaridade em relação ao bloco atual através da análise de todos os possíveis candidatos. Por
outro lado, os algoritmos rápidos obtém uma diminuição do tempo de busca através de
heurísticas que diminuem a quantidade de candidatos a serem analisados, ao custo de obterem
um vetor de movimento subótimo (PORTO, 2008).
O algoritmo Full Search (FS) é um algoritmo ótimo, pois compara a similaridade de
todos os possíveis blocos dentro da janela de busca. A iteração sobre todos os candidatos pode
ser de diversas formas, começando no canto superior esquerdo e finalizando no canto inferior
direito ou realizando uma busca em formato de espiral ao redor de uma posição central, por

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
51
exemplo. Os diferentes blocos candidatos são obtidos através do deslocamento da borda do
bloco em uma amostra, conforme ilustrado na Figura 16.
Figura 16 Algoritmo de busca completa (PORTO, 2012)
O algoritmo FS dificilmente é empregado em aplicações práticas que requerem
codificação em tempo real de altas resoluções, a menos que seja utilizada uma arquitetura
desenvolvida especialmente para este fim. Este algoritmo não possui dependência de dados,
portanto, é possível explorar um grande nível de paralelismo (SOARES, 2007).
Os algoritmos rápidos tentam obter bons vetores de movimentos mesmo sem fazer
uma busca exaustiva, ou seja, sem testar todos os possíveis blocos. Dentre as diversas formas
de realizar a busca propostas na literatura, a seguir serão abordados dois algoritmos de
interesse no contexto deste trabalho: Diamond Search (DS) e Logarithmic Search (LS).
O algoritmo DS é um algoritmo rápido que realiza a busca em um formato de
diamante. Este formato determina a posição dos blocos considerados candidatos dentro da
janela de busca. Usualmente, esse algoritmo emprega dois padrões de busca: Large Diamond
Search (LDS) e Small Diamond Search (SDS) (ZHU; MA, 2000).
Inicialmente a LDS compara as similaridades entre o bloco atual e nove blocos
candidatos ao redor da posição central da janela de busca. Se o bloco que resultar no menor
resíduo não estiver no centro do diamante, esta etapa será repetida com base em uma nova
posição central localizada no melhor bloco encontrado. Este procedimento se repete até que o
bloco de maior similaridade esteja na posição central. Num segundo momento, a SDS realiza
um refinamento ao redor da posição determinada na etapa anterior. Para tanto, é realizada a
comparação entre a similaridade da posição central e de quatro blocos vizinhos. A Figura 17

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
52
ilustra este procedimento. As posições “L” fazem parte do diamante grande e “S” do diamante
pequeno.
Figura 17 Large Diamond Search (LDS) e Small Diamond Search (SDS) (PORTO, 2008)
O algoritmo LS, inicialmente, compara o bloco atual com cinco blocos candidatos: a
posição (0, 0) e quatro blocos a S pixeis da origem na horizontal e na vertical, onde S é o
valor do passo inicial. Na etapa seguinte, a origem é posicionada no melhor bloco encontrado
na etapa anterior e o procedimento é repetido nessa nova posição. Quando o melhor
casamento ocorrer na posição central o valor do passo é dividido por dois, até que o passo
chegue ao valor um. Na sequência, as oito posições ao redor do bloco anteriormente
selecionado são testadas. O bloco com menor similaridade nesta etapa resulta no vetor de
movimento para a realização da predição.
A Figura 18 ilustra o funcionamento do algoritmo LS com o passo S valendo dois
inicialmente. No exemplo dado, para cada iteração da busca o bloco com maior similaridade é
destacado em negrito.
Figura 18 Algoritmo de busca logarítmica (RICHARDSON, 2002).
A quantidade de iterações executadas na LDS depende do vídeo em questão, o que
dificulta a análise do desempenho. Entretanto, o algoritmo DS diminui, em média, cerca de
150 vezes o número de blocos candidatos a terem a similaridade calculada e comparada, em
relação ao algoritmo de busca completa (PORTO, 2012). No padrão de busca LS ocorre a

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
53
mesma situação: o número de comparações necessárias depende da quantidade de iterações
efetuadas e varia em cada caso.
Uma técnica muitas vezes empregada conjuntamente a algoritmos de busca rápidos
como DS e LS é a determinação de uma posição inicial para a busca diferente de (0, 0) através
de vetores de movimento previamente obtidos (TOURAPIS, 2001). Por exemplo, pode-se
determinar a posição inicial da busca baseando-se nos vetores de movimento encontrados nos
blocos adjacentes do quadro atual. Essa ideia explora a localidade espacial, ou seja, o fato de
que blocos vizinhos tendem a ter movimentação semelhante. No entanto, dessa forma cria-se
uma dependência de dados entre os blocos de um mesmo quadro, o que dificulta a utilização
de paralelismo em nível de bloco. Uma outra alternativa é escolher a posição inicial de busca
a partir de dados proveniente de quadros previamente processados, ou seja, a exploração da
localidade temporal. Essa ideia baseia-se na premissa de que o mesmo bloco em quadros
temporalmente adjacentes possuam movimentação semelhante. Essa abordagem cria uma
dependência de dados entre os quadros, mas, possibilita o paralelismos em nível de blocos
dentro de um mesmo quadro.
3.4.4.2 Critérios de similaridade
Os critérios de similaridade são usados para determinar o grau de semelhança entre
dois blocos de pixeis. Diversos critérios foram propostos na literatura: Mean Square Error
(MSE), Mean Absolute Error (MAE), Sum of Absolute Differences (SAD) entre outros
(RICHARDSON, 2002).
A Equação 30 define o cálculo do SAD, que é usualmente empregado na estimativa de
movimento devido a sua simplicidade e em resultar em uma boa aproximação da energia do
bloco (PORTO, 2012).
SAD=∑i=0
N−1
∑j=0
N−1
∣C ij−Rij ∣ (30)
Onde
N é o tamanho do bloco
Cij é o pixel na posição (i,j) do bloco atual
Rij é o pixel na posição (i,j) do bloco de referência

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
54
3.4.5 Compensação de movimento
A compensação de movimento tem por objetivo encontrar, a partir do vetor de
movimento obtido pela estimação de movimento, os blocos mais semelhantes com o atual
dentre os blocos previamente codificados para obter o bloco predito. Para tanto, a
compensação de movimento necessita obter os parâmetros gerados pela estimação de
movimento (AZEVEDO, 2006).
O vídeo será, inicialmente, reconstruído com base no quadro predito. Em seguida,
serão corrigidas as diferenças entre o quadro original e o quadro estimado, utilizando o quadro
residual.
3.5 Trabalhos relacionados
Sprandlin et al. (2009) avaliaram a viabilidade de paralelizar a implementação de
referência do codificador MPEG-2, utilizando a tecnologia CUDA, e obtiveram significativos
ganhos de velocidade em partes específicas da implementação. No entanto, esses resultados
são severamente diluídos se analisado o aplicativo como um todo. Foi destacada a
importância de minimizar as transferências de dados entre a CPU e a placa de vídeo, pois a
alta latência e a pequena largura de banda do barramento PCIe foram apontadas como fatores
que limitaram os resultados.
Chan et al. (2009) demonstraram a viabilidade de implementar o algoritmo piramidal
de estimação de movimento do padrão H.264 utilizando CUDA. O resultado obtido foi uma
diminuição de 56 vezes no tempo gasto na execução do algoritmo, no entanto, foi utilizada
uma aproximação do vetor predito a fim de eliminar interdependências que diminuiriam o
nível de paralelismo alcançável.
Ren et al. (2010) propuseram duas implementações do módulo de predição-intra do
codificador H.264 em GPU. Na primeira implementação, foram eliminados dois modos de
predição a fim de alcançar um maior paralelismo em nível de blocos 4x4. A outra alternativa
explora o paralelismo em nível de macrobloco. No entanto, para eliminar as dependências
entre macroblocos vizinhos é necessária uma alteração no algoritmo (com consequências
insignificantes na qualidade em vídeos de alta definição). Os ganhos obtidos nas duas
implementações propostas ficaram em torno de cinco vezes em relação à implementação de
referência.
Huang, Shen e Wu (2009) estudaram a utilização de CPUs multi núcleo em conjunto
com GPUs, atuando como coprocessadores, para a implementação de um codificador de vídeo

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
55
H.264/SVC (extensão do H.264/AVC com técnicas de codificação escalável). Foi estudada a
divisão das tarefas entre as duas arquiteturas (CPUs e GPUs) e a transição de dados entre elas.
Os resultados obtidos apontaram que a execução do algoritmo de busca completa na
estimativa de movimento na GPU resultou em melhor desempenho se comparado à
implementação utilizando CPU multi núcleo.
Cheung et al. (2010) investigaram o uso de GPUs para codificação e decodificação de
vídeo. Este trabalho faz uma revisão da literatura acerca da estruturação e particionamento
dos módulos entre CPU e GPU. Por fim, é implementada a estimativa de movimento do
H.264 na GPU, através da qual é explorado o trade-off entre os ganhos de velocidade e a
qualidade obtida. Os experimentos levam a resultados de execução cerca de três vezes mais
rápida com a utilização da GPU e foi destacada a importância de expor o máximo paralelismo
de dados possível à GPU.
Monteiro et al. (2011) exploraram o uso da arquitetura CUDA no contexto da
estimativa de movimento, obtendo um ganho de velocidade de 600 vezes na implementação
do algoritmo de busca completa.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
56
4 DESCRIÇÃO DO SISTEMA DESENVOLVIDO
O aumento na complexidade computacional no padrão H.264 em relação aos padrões
anteriores é significante. Essa característica torna desafiadora a implementação de um sistema
capaz de executar a codificação em tempo real, especialmente para vídeos de alta resolução
(DINIZ, 2009). Inserido nesse contexto, o presente trabalho consiste na investigação da
utilização de GPUs, presentes nas placas de vídeo da NVIDIA, como coprocessadores no
contexto da codificação de vídeo. Para tanto, utilizou-se a tecnologia NVIDIA CUDA,
apresentada no segundo capítulo deste trabalho.
Um ponto importante foi a identificação dos algoritmos de codificação de vídeo que
são apropriados à implementação em arquiteturas paralelas. Por isso, faz-se necessária a
revisão de literatura apresentada previamente e o estudo da implementação de referência do
codificador H.264.
A complexidade computacional dos diversos módulos do codificador H.264 foi
analisada em diversos trabalhos encontrados na literatura. Em geral, as análises consideram o
tempo de processamento necessário por cada módulo, o que equivale aproximadamente ao
número de operações executadas (HOROWITZ, 2003). A Tabela 6 apresenta o percentual da
complexidade computacional dos principais módulos do H.264, segundo a avaliação de Zhang
et al. (2005).
Tabela 6 Complexidade dos módulos do codificador H.264.
Módulo Complexidade %ME / MC 81,78
T / Q / T-1 / Q-1 5,49Predição intraquadro 5,29
Filtro 0,82Outros 6,62
Fonte: ZHANG et al., 2003.
Pode-se notar claramente que a parcela mais significativa localiza-se na estimativa e
compensação de movimento. Essas técnicas situam-se na predição interquadro, ou seja,
exploram as redundâncias temporais do vídeo. Por outro lado, na exploração das redundâncias
espaciais dentro de um quadro do vídeo, destacam-se as transformadas e quantização diretas e
inversas (que juntas compõe o que pode ser chamado de módulo computacional) e a própria
predição intraquadro. O desenvolvimento deste trabalho foi dividido em duas etapas: o estudo
dos algoritmos relacionados à codificação intraquadro e codificação interquadro.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
57
4.1 Codificação intraquadro
A arquitetura do codificador intra é apresentada pela Figura 19, que também ilustra a
relação do módulo computacional com as demais etapas do processo.
Figura 19 Processo de codificação intraquadro, adaptada de (DINIZ, 2009).
O módulo computacional está localizado no laço de codificação intra. A predição-intra
depende dos dados oriundos dos estágios T/Q/T-1/Q-1, o que inviabiliza a implementação de
um pipeline entre estas etapas. Por este motivo o módulo computacional adiciona uma
latência ao codificador intraquadro. Uma alternativa para diminuir essa latência é a
exploração do paralelismo encontrado nos algoritmos de computação intra (AGOSTINI,
2007). Portanto, no contexto deste trabalho, optou-se por explorar, dentre os estágios da
codificação intraquadro, o paralelismo no módulo computacional.
4.2 Algoritmos de computação intra
Os blocos de transformadas e quantização diretas e inversas em conjunto compõe o
módulo computacional. Este módulo é uma das ferramentas de codificação que explora as
redundâncias espaciais dentro de um quadro do vídeo.
No contexto deste estudo de caso, foi implementada uma função kernel responsável
por processar os 16 blocos 4x4 que compõe um macrobloco de luminâncias. A Figura 20
apresenta as etapas que são executadas sequencialmente por esta função.
As três primeiras etapas fazem parte do processo de codificação e resultam na matriz
de coeficientes que é fornecida ao codificador de entropia. Já as três últimas etapas fazem
parte do laço de realimentação, fornecendo os macroblocos de referência a serem utilizados
pela predição intra.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
58
Figura 20 Etapas do módulo computacional.
A solução proposta explora dois tipos de paralelismo. O primeiro deles se deve à
paralelização das operações executadas dentro de cada algoritmo. Isto é possível devido à
independência de cada posição da matriz em relação as demais. Já o segundo tipo de
paralelismo refere-se a diferentes tarefas dentro do laço de codificação, mais especificamente
o fornecimento de um macrobloco quantizado ao codificador de entropia enquanto o módulo
computacional já está processando os próximos macroblocos.
A implementação proposta organiza a execução do kernel em blocos com 16x16x1
threads, ou seja, os blocos tridimensionais da arquitetura CUDA foram diretamente mapeados
para os macroblocos da imagem. Já as dimensões do grid, que definem a quantidade de
blocos, são calculadas de acordo com o tamanho do vídeo que estiver sendo codificado. A
Figura 21 apresenta uma visão geral do funcionamento do kernel proposto.
Figura 21 Arquitetura proposta para módulo computacional usando GPUs NVIDIA (HUSEMANN et al., 2011b).
Um ponto importante é a minimização da quantidade de acessos à memória global
devido à alta latência deste acessos. Por este motivo, a memória compartilhada, que possui
acesso mais veloz, foi utilizada como uma espécie de cache. Dessa forma, cada bloco de
threads quando alocado para execução em um SM copia um macrobloco da memória global.
Como cada thread copia o seu respectivo elemento do macrobloco, essas cópias podem ser
combinadas em um menor número de transações de acesso à memória global. Após isto, a
memória global só é acessada novamente para disponibilizar os dados de saída.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
59
Um outro ponto crítico na utilização da arquitetura CUDA é a transferência de dados
entre CPU e GPU, devido ao gargalo criado pelo barramento PCIe (HUANG; SHEN; WU,
2009). Portanto, a arquitetura proposta realiza todas as seis etapas listadas anteriormente em
um único kernel, realizando apenas três transferências através do barramento PCIe: a cópia
dos dados de entrada para a placa de vídeo e as duas transferências com os resultados
calculados pela GPU (saída do processo de quantização e saída da DCT inversa).
Nas seções seguintes serão feitas considerações a respeito da implementação de cada
uma das etapas constituintes do módulo computacional na arquitetura CUDA.
4.2.1 Implementação da DCT direta e inversa
A implementação da DCT é realizada através de duas multiplicações matriciais, como
definido na Equação 1 apresentada na Subseção 3.4.2.1. A matriz de coeficientes, obtida
através da definição da transformada, foi armazenada em memória. A primeira multiplicação
faz uso direto dessa matriz, no entanto, a segunda multiplicação requer o resultado da
transposição dessa matriz. A fim de diminuir o número de operações necessárias, o resultado
da transposição também foi armazenado em memória.
O local escolhido para armazenar essas matrizes foi a memória de constantes. Essa
escolha se deve ao fato de que essa memória possui acesso com cache, o que pode diminuir a
latência de acesso, e possui capacidade suficiente para armazenar todas as tabelas necessárias
nesta abordagem. Embora a DCT seja calculada para blocos 4x4 no H.264, as matrizes
definidas na memória de constantes possuem dimensões 16x16. A matriz 4x4 da DCT foi
replicada quatro vezes em cada dimensão, a fim de que os 16 blocos 4x4 do quadro, que são
processados simultaneamente, acessem posições distintas da memória. Isto, evita que diversas
threads conflitem na tentativa de acessar a mesma posição na memória.
A implementação da DCT inversa é idêntica à DCT direta, com exceção das matrizes
que definem a transformada, que possuem valores distintos.
4.2.2 Implementação da Transformada de Hadamard
A Transformada de Hadamard também pode ser expressa em termos matriciais, como
apresentado na Equação 17, definida na Subseção 3.4.2.2. A abordagem adotada nessa etapa é
similar àquela utilizada na DCT, pois também são calculadas multiplicações de matrizes e as
matrizes que definem a transformada também foram armazenadas na memória de constantes.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
60
Uma particularidade da implementação da Transformada de Hadamard é a maneira
como as threads foram relacionadas aos elementos do macrobloco. Como esta transformada
opera sobre os coeficientes DC do resultado obtido pela DCT, as matrizes envolvidas nesta
transformada possuem dimensões 4x4. Entretanto, o bloco de threads foi definido com 16x16,
levando ao fato de que nem todas as threads estarão envolvidas na execução deste algoritmo.
A Figura 22 ilustra a relação entre o número da thread e a posição do componente DC
processado. As posições vazias não são utilizadas no cálculo de Hadamard.
Figura 22 Relacionamento das threads com os componentes DC.
Devido ao tamanho reduzido das matrizes nessa etapa do processamento, a eficiência
da utilização do SM é reduzida, pois cada thread que não foi utilizada nessa etapa equivale a
um SP ocioso. No entanto, a operação é ainda vantajosa nessas circunstâncias devido a esta
etapa estar inserida entre outras operações custosas.
4.2.3 Implementação da Quantização
O código de implementação da quantização direta baseia-se nas Equações 25 e 26 e
nas constantes definidas nas Tabelas 3, 4 e 5, todas apresentadas na Subseção 3.4.3. As
tabelas com os fatores de multiplicação, fatores de escala e definição do parâmetro Qstep
foram armazenadas na memória de constantes.
Cada uma das threads do bloco é responsável por quantizar um elemento do
macrobloco. Como a quantização trata os componentes DC de cada bloco 4x4 de forma
diferenciada, o código executado não é igual para todas as threads. As threads cujos índices
são divisíveis por quatro são aquelas que processam os componentes DC e, portanto,
executam uma rotina levemente diferente das demais.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
61
Esta condição que determina a execução de diferentes trechos de código baseada no
índice da thread leva a ocorrência da divergência no fluxo de execução (branch divergence),
quando as threads que divergem encontram-se no mesmo warp.
A quantização inversa baseia-se nas Equações 27 e 29 e é implementada da mesma
forma que a quantização direta.
4.3 Codificação interquadros
O principal módulo dentro do codificador interquadros é o bloco responsável por obter
a estimativa de movimento, ou seja, obter os vetores de movimento que determinam os blocos
a serem utilizados na predição interquadros. Este módulo executa o algoritmo de busca e
necessita realizar uma quantidade significativa de cálculos de similaridade (PORTO, 2012).
A fim de acelerar o codificação de vídeos com auxílio da GPU foram estudados os
algoritmos envolvidos para identificar procedimentos paralelizáveis. Esse estudo levou à
implementação do cálculo de SAD em tecnologia CUDA. Além disso, foi proposto um
algoritmo de busca adequado à arquitetura em questão. As próximas seções apresentam o
algoritmo proposto e os detalhes de implementação.
Diversos trabalhos encontrados na literatura, propuseram diferentes formas de
implementar a estimação de movimento em GPU. Uma abordagem consiste, simplesmente,
em implementar algum algoritmo já conhecido utilizando a tecnologia CUDA. Outra
alternativa, consiste na exploração de diferentes algoritmos que sejam mais apropriados à
arquitetura em questão. No presente trabalho, o algoritmo de busca utilizado baseia-se em um
algoritmo tradicional, no entanto, foram realizadas algumas adaptações a fim de tornar a sua
execução eficiente em uma GPU.
4.3.1 Algorítimo de busca proposto
O algoritmo de busca proposto é semelhante ao DS, porém, emprega apenas a busca
SDS. Além disso, a posição inicial da busca é determinada pelo vetor de movimento obtido
para o bloco em questão no quadro anterior, de forma a explorar a localidade temporal da
movimentação.
Portanto, o algoritmo proposto consiste nos seguintes procedimentos:
• definição da posição central da busca como sendo a posição indicada pelo vetor de
movimento encontrado para o bloco atual no quadro anterior;

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
62
• cálculo do SAD na posição central e em quatro posições ao redor da posição central,
segundo o padrão de busca SDS, conforme ilustrado na Figura 23;
• se o menor SAD estiver na posição central, a busca chegou ao fim, caso contrário, a
busca é executada novamente em torno da posição que apresentou o menor SAD.
Este algoritmo permite a exploração de dois níveis de paralelismo através da
arquitetura CUDA. O primeiro é o paralelismo em nível de bloco, explorado no algoritmo de
busca, e o segundo é o paralelismo em nível de pixel, explorado na implementação do cálculo
de SAD.
Figura 23 Padrão de busca do algoritmo proposto.
4.3.2 Implementação da estimação de movimento
O algoritmo de busca proposto foi implementado em uma função __kernel__ e o
cálculo de SAD foi implementado em uma função __device__, de forma a poder ser invocada
a partir de outras funções executadas na GPU. A execução foi organizada em blocos de (16,
8x1) threads, de forma que o cálculo de SAD utilize 128 threads simultâneas. O tamanho da
grade de blocos é calculado dinamicamente em função da resolução do vídeo que está sendo
codificado. Com base nessa organização, cada bloco do vídeo é tratado por um SM da GPU.
A implementação realizada considera blocos de 16x16 pixeis, não tendo sido implementada a
possibilidade de obter vetores de movimento para sub-blocos do macrobloco, prevista no
H.264.
A arquitetura escalável da GPU permite que vários blocos de threads sejam
executados simultaneamente, ou seja, a quantidade de multiprocessadores presentes na GPU
utilizada determinará a quantidade de macroblocos tratados paralelamente. Essa situação é
possível graças a independência de um macrobloco em relação aos demais (em um mesmo
quadro do vídeo) alcançada com o algoritmo de busca proposto.
Além do algoritmo de busca é executado o cálculo do SAD, que é composto por duas
operações consecutivas: (i) obtenção da diferença absoluta para cada pixel analisado e (ii)

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
63
somatório dos resultados da operação anterior. Para implementar essa operação foi utilizada a
instrução de baixo nível usad que recebe três argumentos e calcula a soma da diferença
absoluta dos dois primeiros argumentos com o terceiro. A implementação dessas operações
em linguagem C seria traduzida em um maior números de instruções. Portanto, a instrução
usad executa as duas operações conjuntamente de maneira mais veloz.
1 __device__ unsigned int
2 __usad( unsigned int x, unsigned int y, unsigned int z );
Listagem 2 Protótipo da função intrínseca usad.
A Listagem 2 exibe o protótipo da função usad que executa o cálculo definido na
Equação 31.
usad=∣ x− y∣z (31)Onde
x é o pixel do bloco atual
y é o pixel do bloco de referência
z é o valor a ser acumulado
Por exemplo, considerando-se macroblocos do padrão H.264 (16x16 pixeis):
inicialmente são calculadas as diferenças absoluta dos 128 últimos pixeis do bloco, a seguir,
são calculadas as diferenças absolutas dos 128 primeiros pixeis do bloco e, na mesma
operação, soma-se o resultado com as diferenças obtidas na etapa anterior. Ao final dessas
duas etapas, tem-se um vetor com 128 valores que precisam ser somados. Esse somatório é
implementado através de um procedimento de redução (na verdade, o vetor tem 128 posições
ao invés de 256, que é o tamanho do bloco, por que o primeiro estágio da redução já foi
realizado pela instrução usad, conforme ilustrado pela Listagem 3). Portanto, o primeiro
estágio da redução opera com 128 threads ativas, o segundo opera com 64 threads e o terceiro
com 32 threads e assim por diante. Entre os estágios é necessário sincronizar a execução das
threads. Entretanto, quando o número de threads ativas é 32 ou menos (últimas etapas da
redução) a chamada à função de sincronização é desnecessária visto que todas as threads
ativas estão no mesmo warp, permitindo que todas sejam executadas simultaneamente. O
procedimento de redução é ilustrado na Figura 24.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
64
1 absDiff[idx + 128] = __usad(cur[idx + 128],
2 ref[idx + 128],
3 0);
4 absDiff[idx] = __usad(cur[idx],
5 ref[idx],
6 absDiff[idx + 128]);
7 __syncthreads();
Listagem 3 Primeira etapa da redução
Figura 24 Procedimento de redução usado no cálculo de SAD, adaptado de (NVIDIA, 2012).
Além da implementação do cálculo de similaridade foi realizada a implementação da
lógica do algoritmo de busca proposto. As comparações necessárias para determinar qual a
posição que possui o menor SAD calculado e os testes para verificar os limites do quadro e da
janela de busca são executadas apenas pela thread (0,0), devido a serem operações
sequenciais.
A implementação realizada fez uso de diferentes memórias presentes na arquitetura
CUDA. O quadro de referência e o quadro a ser codificado foram armazenados na memória
de texturas, que possui estrutura de cache otimizada para acesso a dados com localidade 2D.
Essa característica é particularmente apropriada devido à natureza do acesso aos pixeis do
quadro de referência, onde threads vizinhas acessam posições adjacentes da memória e, a cada
iteração do algoritmo de busca, a posição acessada será deslocada em uma posição.
As variáveis de controle, índices e resultados intermediários foram colocadas na
memória compartilhada. Dessa forma, essas variáveis podem ser acessadas por threads
participantes de um mesmo bloco além de diminuir a quantidade de acessos a memória global.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
65
As transferências de dados entre o PC e a placa de vídeo ocorrem em pacotes que
comportam os múltiplos macroblocos H.264 (16x16 pixeis) de forma a reduzir a latência de
comunicação entre a CPU e a GPU.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
66
5 RESULTADOS PRÁTICOS
A experimentação realizada fez uso do software de referência JSVM (Joint Scalable
Video Model) que implementa o codificador H.264/SVC (ITU, 2010). O padrão Scalable
Video Coding (SVC) é um anexo à norma H.264/AVC, que trata da codificação de vídeo
escalável (HUSEMANN et. al. 2010). No entanto, no presente trabalho não foram explorados
os conceitos de escalabilidade da codificação.
O software JSVM é desenvolvido pela JVT, servindo de complemento aos
documentos que compõe a especificação da norma. Esse software é disponibilizado aos
pesquisadores e serve de base para estudar os detalhes do padrão, novos algoritmos ou para
comparação com diferentes implementações. O JSVM é escrito na linguagem C++ (ITU,
2010).
O ambiente utilizado no desenvolvimento e experimentação é composto por um
computador com processador Intel Core 2 Quad, 2 GB de memória RAM e duas placas de
vídeo: NVIDIA 8500 GT e GTX 560 Ti. Foi utilizado sistema operacional GNU/Linux
(distribuição Ubuntu) e o CUDA toolkit, que contém o compilador e demais ferramentas
necessárias ao desenvolvimento de programas que utilizem a GPU.
A Tabela 7 apresenta uma comparação das principais especificações das duas placas
utilizadas na experimentação.
Tabela 7 Principais características das duas placas utilizadas.
Modelo da placa 8500 GT GTX 560 Ti
Compute Capability 1.1 2.1Núcleos CUDA (unidades) 16 384Clock dos núcleos (MHz) 900 1645Largura de banda da memória (GB/s) 12,8 128Largura do barramento (bits) 128 256
5.1 Integração com o software de referência
A implementação dos algoritmos em arquitetura CUDA foi integrada ao JSVM versão
9.19.9, sendo possível, em tempo de compilação, ativar a aceleração destes algoritmos através
da GPU. Desta forma, foi possível validar o funcionamento da solução proposta e avaliar os
resultados obtidos, em termos do desempenho alcançado no módulo em questão.
O software JSVM precisou ser adaptado para tornar possível expor à GPU um
conjunto de dados suficientemente grande para que se possa fazer uso eficiente da arquitetura
paralela. Na implementação de referência, os módulos do codificador recebem um

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
67
macrobloco, processam e devolvem os resultados. As alterações realizadas fizeram com que
os módulos em questão pudessem acessar a um quadro inteiro, de forma a entregar à placa de
vídeo um conjunto de macroblocos a serem codificados. No entanto, a interface foi mantida
de forma que as funções continuassem fornecendo os resultados em um macrobloco por vez
para os outros estágios da codificação.
Um outro ponto que necessitou de adaptação foi o tipo de dados usado pra representar
os pixeis. No software JSVM são utilizadas variáveis de 16 bits, no entanto, nos trechos do
codificador que foram abordados os pixeis assumem apenas valores de 0 a 255 (8 bits). Sendo
que os quadros precisam ser copiados para a memória da placa de vídeo, o uso de variáveis de
16 bits significa que metade dos bytes transferidos pelo barramento PCIe seriam
desnecessários. Portanto, optou-se por transformar o quadro de vídeo para variáveis de 8 bits
antes do envio para a placa de vídeo. Embora essa alteração diminua o tempo das
transferência pelo barramento, o tempo necessário pra fazer essa transformação é
considerável. A fim de diminuir o tempo gasto nessa operação, a cópia foi implementada em
linguagem assembly fazendo uso da tecnologia Streaming SIMD Extensions Version 2
(SSE2). A implementação otimizada resultou em uma diminuição de aproximadamente 3,5
vezes no tempo necessário para transformar um quadro de alta resolução. Esse ponto não vai
ser detalhado neste trabalho, por estar além do escopo, tendo sido citado apenas por ser uma
técnica utilizada para realizar a integração da implementação na GPU com o software JSVM.
5.2 Avaliação dos resultados no módulo computacional intra
A validação do funcionamento das implementações foi efetuada da seguinte forma:
um mesmo arquivo de vídeo sem compressão foi codificado através do JSVM original e da
versão implementada fazendo uso da tecnologia CUDA. Ao final do processo de compressão,
os arquivos foram submetidos a uma comparação byte a byte.
A análise do desempenho alcançado pela implementação proposta foi realizada através
da comparação do tempo médio por quadro na execução do módulo computacional na CPU
(implementação original do JSVM) e na GPU (através da implementação em CUDA).
Dois cenários foram avaliados, o primeiro considerando-se vídeos em resolução 4CIF
(Common Intermediate Format) (704x576) e o segundo considerando HD (High Definition)
(1920x1080 pixeis). Os testes foram executados em duas placas de vídeo para fins de
comparação.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
68
As tabelas a seguir resumem os resultados de tempos médios por quadro em unidades
de milissegundos.
Tabela 8 Comparação dos tempos de processamento para vídeos 4CIF.
Configuração
CPU 8500 GT GTX 560 TiTempo de execução 40,99 ms 70,75 ms 11,27 ms
Ganho obtido 1 0,58 3,63
Tabela 9 Comparação dos tempos de processamento vídeo HD.
Configuração
CPU 8500 GT GTX 560 TiTempo de execução 208,71 ms 303,57 ms 53,89 ms
Ganho obtido 1 0,81 3,87
As tabelas 8 e 9 sintetizam os resultados obtidos. Com a utilização da placa de vídeo
GTX 560 Ti, a compressão de vídeos 4CIF foi acelerada em cerca de 3,6 vezes, enquanto que
para vídeos HD a aceleração foi de cerca de 3,9 vezes. Já com a placa 8500 GT a execução
ficou mais lenta para ambas resoluções.
As diferenças de desempenho se justificam, pois a placa 8500 GT possui apenas 16
núcleos de execução com frequência de operação de 900 MHz, enquanto a GTX 560 Ti
possui 384 núcleos, operando a 1645 MHz. Além disso, a largura de banda da memória da
placa mais recente é dez vezes maior. Portanto, além de a placa 8500 GT fornecer um nível
muito menor de paralelismo, o gargalo no acesso a memória é muito acentuado, o que explica
os resultados inferiores.
Os resultados apresentados levam em consideração o tempo de execução na GPU, as
transferências pelo barramento PCIe e as cópias entre os espaços de memória na placa de
vídeo. Além disso, é considerado o tempo necessário em rotinas que adaptam o formato dos
dados entre o formato esperado pela JSVM e o formato utilizado no código escrito para a
GPU. Dessa forma, os resultados foram obtidos em um ambiente que considera os detalhes de
implementação e integração com o software original.
A medição do desempenho que resultou nos tempos de processamento apresentados
foi realizada através da instrução RDTSC. Essa instrução retorna o valor atual do contador de
ciclos (ticks) da CPU. O valor do contador foi lido antes e depois da chamada da função a ter
o tempo de execução medido. A diferença entre as duas leituras é o número de ciclos

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
69
transcorridos durante a execução da função. Por fim, a partir do número de ticks e da
frequência do processador pode-se determinar o tempo transcorrido.
5.3 Avaliação do algoritmo de busca proposto
A seguir é apresentada uma avaliação do algoritmo de busca proposto no capítulo
anterior. Para tornar possível a avaliação da qualidade do algoritmo proposto foi realizada
uma implementação em linguagem C++, que foi comparada com outros dois algoritmos, que
fazem parte da implementação de referência utilizada. Ressalta-se que nessa etapa do
desenvolvimento do trabalho, não há a utilização da GPU, pois o objetivo é apenas verificar
se os resultados produzidos pelo algorítimo são adequados.
A avaliação foi feita através da codificação de um conjunto de três vídeos, utilizando
diferentes configurações: foram experimentados três diferentes algoritmos em três diferentes
bit rates. Neste experimento foram utilizados vídeos com uma resolução intermediária:
704x576 (4CIF). Os três vídeos utilizados são brevemente descritos a seguir (Xiph, 2012).
• Harbour: um personagem conversa com a câmera e em determinado momento,
aponta para uma construção ao lado e posteriormente a câmera se desloca nessa
direção;
• City: visão panorâmica ao redor da torre do prédio Empire State;
• Crew: tripulação de um ônibus espacial se dirigindo para o veículo.
Os dois algoritmos comparados com o algoritmo proposto são chamados: log search e
fast search. O log search foi apresentado na revisão de literatura e o fast search é basicamente
a mesma coisa, com exceção de que recebe uma lista de possíveis blocos candidatos a serem
utilizados como ponto de partida para a busca. Essa lista de candidatos é montada
previamente com base nos vetores de movimento dos blocos anteriores, fazendo com isso que
o tempo para computar o vetor de movimento seja reduzido.
A tabelas 10, 11 e 12 apresentam os resultados para as configurações de 3 Mbps, 4
Mbps e 5 Mbps, respectivamente. A terceira coluna apresenta o tempo consumido pela
execução do algoritmo analisado (em ticks de CPU). As colunas quatro, cinco e seis
apresentam o PSNR (que é a medida objetiva da qualidade do vídeo resultante) para cada
componente da imagem.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
70
Tabela 10 Avaliação do algoritmo de busca proposto para 3 Mbps.
Vídeo Algoritmo Tempo (ticks)PSNR
Y (dB) U (dB) V (dB)
Harbourlog search 9958597952 30,3415 39,5439 41,1279
fast search 6750188752 30,3693 39,5665 41,1435
proposto 3733243384 30,2710 39,5181 41,1026
Citylog search 10107549840 32,7228 41,0294 43,0708
fast search 6974555600 32,7933 41,0663 43,1187
proposto 4012906120 32,6770 41,0214 43,0427
Crewlog search 11635612904 36,1829 40,4985 40,6504
fast search 8719348688 36,2318 40,5369 40,7081
proposto 11380719656 35,8747 40,2853 40,3455
Tabela 11 Avaliação do algoritmo de busca proposto para 4 Mbps.
Vídeo Algoritmo Tempo (ticks)PSNR
Y (dB) U (dB) V (dB)
Harbourlog search 9992114448 31,2119 39,8495 41,4876
fast search 6769695912 31,2273 39,8481 41,4766
proposto 3684888104 31,1224 39,7872 41,3755
Citylog search 10225264624 33,3200 41,3341 43,3772
fast search 7085572472 33,3960 41,3954 43,4468
proposto 3871233064 33,3176 41,3311 43,3781
Crewlog search 11851405480 37,0798 41,0895 41,4683
fast search 8987651528 37,1329 41,1184 41,5146
proposto 11229536160 36,8556 40,9264 41,2279
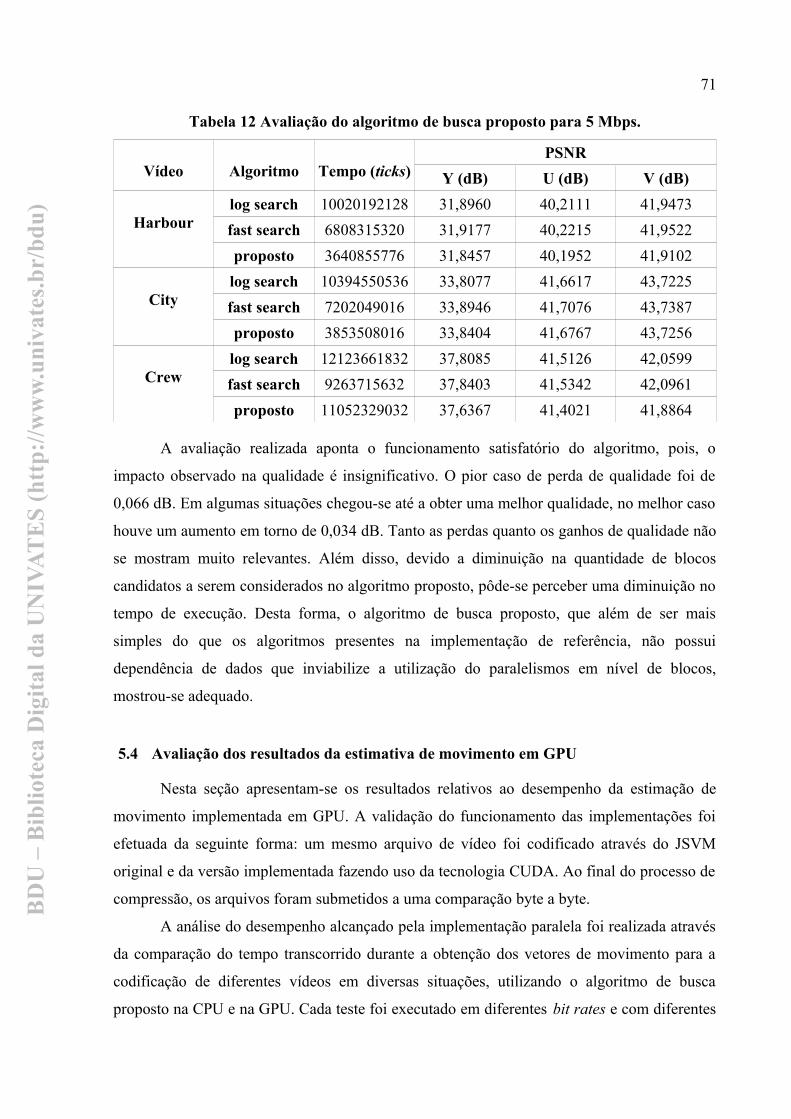
BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
71
Tabela 12 Avaliação do algoritmo de busca proposto para 5 Mbps.
Vídeo Algoritmo Tempo (ticks)PSNR
Y (dB) U (dB) V (dB)
Harbourlog search 10020192128 31,8960 40,2111 41,9473
fast search 6808315320 31,9177 40,2215 41,9522
proposto 3640855776 31,8457 40,1952 41,9102
Citylog search 10394550536 33,8077 41,6617 43,7225
fast search 7202049016 33,8946 41,7076 43,7387
proposto 3853508016 33,8404 41,6767 43,7256
Crewlog search 12123661832 37,8085 41,5126 42,0599
fast search 9263715632 37,8403 41,5342 42,0961
proposto 11052329032 37,6367 41,4021 41,8864
A avaliação realizada aponta o funcionamento satisfatório do algoritmo, pois, o
impacto observado na qualidade é insignificativo. O pior caso de perda de qualidade foi de
0,066 dB. Em algumas situações chegou-se até a obter uma melhor qualidade, no melhor caso
houve um aumento em torno de 0,034 dB. Tanto as perdas quanto os ganhos de qualidade não
se mostram muito relevantes. Além disso, devido a diminuição na quantidade de blocos
candidatos a serem considerados no algoritmo proposto, pôde-se perceber uma diminuição no
tempo de execução. Desta forma, o algoritmo de busca proposto, que além de ser mais
simples do que os algoritmos presentes na implementação de referência, não possui
dependência de dados que inviabilize a utilização do paralelismos em nível de blocos,
mostrou-se adequado.
5.4 Avaliação dos resultados da estimativa de movimento em GPU
Nesta seção apresentam-se os resultados relativos ao desempenho da estimação de
movimento implementada em GPU. A validação do funcionamento das implementações foi
efetuada da seguinte forma: um mesmo arquivo de vídeo foi codificado através do JSVM
original e da versão implementada fazendo uso da tecnologia CUDA. Ao final do processo de
compressão, os arquivos foram submetidos a uma comparação byte a byte.
A análise do desempenho alcançado pela implementação paralela foi realizada através
da comparação do tempo transcorrido durante a obtenção dos vetores de movimento para a
codificação de diferentes vídeos em diversas situações, utilizando o algoritmo de busca
proposto na CPU e na GPU. Cada teste foi executado em diferentes bit rates e com diferentes

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
72
vídeos, de forma a apurar os efeitos de diferentes movimentações e taxas no desempenho da
solução implementada.
Nos experimentos com resoluções QCIF, CIF e 4CIF foram utilizados os vídeos:
Harbour, City e Crew descritos anteriormente.
A Tabela 13 mostra os resultados em resolução QCIF (176x144). São exibidos os
tempos medidos em ticks e o ganho de desempenho obtido na codificação de 150 quadros.
Tabela 13 Comparação dos desempenho em QCIF.
Bit Rate (Mbps) VídeoTempo (Ticks)
GanhoCPU GPU
1,0
Harbour 66479736 41946336 1,58
City 79241240 43974032 1,80
Crew 180118504 73542064 2,45
1,5
Harbour 66220912 41451504 1,60
City 79218536 42030080 1,88
Crew 176833432 72193760 2,45
2,0
Harbour 66362752 41451264 1,60
City 79181200 41844328 1,89
Crew 177143624 72008496 2,46
O resultado obtido nesse experimento foi a execução da estimativa cerca de 2 vezes
mais rápido, em média.
A seguir são apresentados nas tabelas 14 e 15 os resultados obtidos na codificação de
300 quadros para as resoluções CIF (352x288) e 4CIF (704x576), respectivamente. O ganho
médio para vídeos CIF ficou em 3,2 vezes. Já para vídeo 4CIF o ganho médio foi 4,4 vezes.
Pode-se observar que o vídeo Crew se destaca por proporcionar ganhos mais
significativos. Isso se deve ao fato de que esse vídeo possui uma movimentação mais
irregular, fazendo com o número de iterações executadas no algoritmo de busca seja maior.
Na GPU, em virtude do paralelismo, esse maior número de iterações não acarreta num tempo
de execução tão elevado, fazendo com que os ganho sejam mais significativos.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
73
Tabela 14 Comparação dos desempenho em CIF.
Bit Rate (Mbps) VídeoTempo (Ticks)
GanhoCPU GPU
1,5
Harbour 608962368 242260808 2,51
City 644581448 256862120 2,51
Crew 1850875744 410079816 4,51
2,0
Harbour 600011024 241781616 2,48
City 636971624 244448744 2,61
Crew 1790051832 405597264 4,41
2,5
Harbour 599781040 241923208 2,48
City 637199392 243116504 2,62
Crew 1764680864 404803688 4,36
Tabela 15 Comparação dos desempenho em 4CIF.
Bit Rate (Mbps) VídeoTempo (Ticks)
GanhoCPU GPU
3
Harbour 3698837480 1101751384 3,36
City 3987186552 1071361776 3,72
Crew 11321692552 1722507296 6,57
4
Harbour 3670192632 1072984904 3,42
City 3879998576 1103117032 3,52
Crew 11186873208 1722076480 6,50
5
Harbour 3604432704 1131506144 3,19
City 3834388056 1118375600 3,43
Crew 10984781680 1777918352 6,18
Pode-se perceber que para cada caso obteve-se diferentes ganhos de velocidade. Isso
se deve às diferentes movimentações contidas em cada cena. Nos vídeo que necessitam
executar mais iterações do algoritmo de busca para encontrar o vetor de movimento, o ganho
obtido com a implementação paralela é maior devido a maior quantidade de operações que
acaba sendo executada em paralelo. Essa mesma situação ocorre em todas as resoluções.
Os testes realizados para a resolução de 720p usaram os seguintes vídeos (Xiph,
2012):
• Park Run: um homem com um guarda-chuva correndo em um parque, com
bastante detalhes de árvores, neve e água ao fundo.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
74
• Shields: homem com barba e uma jaqueta manchada andando na frente de uma
parede de cheia de escudos.
• Stockholm: vista panorâmica sobre a cidade de Estocolmo com detalhes de casas,
água e carros em movimento.
A Tabela 16 apresenta os resultados obtidos na codificação de 300 quadros na
resolução 720p (1280x720). O ganho médio obtido ficou em torno de 3,5 vezes.
Tabela 16 Comparação dos desempenho em 720p.
Bit Rate (Mbps) VídeoTempo (Ticks)
GanhoCPU GPU
5
Park Run 6967414440 2039930968 3,42
Shields 7854453352 2080444688 3,78
Stockholm 7214870912 2015496392 3,58
6
Park Run 6991465496 2232668848 3,14
Shields 7692344128 2094760952 3,67
Stockholm 7115970144 2002541160 3,55
7
Park Run 6985800840 2015903552 3,47
Shields 7454606568 2043065824 3,65
Stockholm 7053992600 2058054824 3,43
Nos testes em resolução 1080p foram utilizados os seguintes vídeos (Xiph, 2012):
• Pedestrian Area: imagem de pedestres e ciclistas se andando em uma esquina
movimentada;
• Rush Hour: cena uma avenida urbana movimentada, com movimentação de
veículos e pessoas.
• Station 2: vista de trilhos de trem com a câmera em movimento.
• Tractor: vídeo de um trator trabalhando no campo com a câmera acompanhando o
movimento do trator.
A Tabela 17 apresenta os resultados obtidos para a resolução 1080p (1920x1080),
realizando a codificação de 300 quadros. O ganho de velocidade obtido foi em torno de 5,7
vezes, em média.
Todos os resultados apresentados foram obtidos em um ambiente real que considera os
tempos de transferência entre a memória RAM e a memória da placa de vídeo e os detalhes de
integração com o software JSVM. O único tempo que foi desconsiderado na análise que
resultou nas tabelas apresentadas foi o tempo de inicialização da memória de texturas. Essa

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
75
operação ocorre apenas no tratamento do primeiro quadro. Portanto, se o programa for
utilizado para codificar um número suficientemente grande de quadros essa demora inicial
será diluída. Por exemplo, em uma aplicação que continuamente codifica quadros oriundos de
uma câmera esse atraso devido a memória de texturas não será relevante.
Tabela 17 Comparação dos desempenho em 1080p.
Bit Rate (Mbps) VídeoTempo (Ticks)
GanhoCPU GPU
10
Pedestrian Area 61756846624 8217576568 7,52
Rush Hour 34157617704 6056045560 5,64
Station 2 15342743488 4535798208 3,38
Tractor 42607764448 6656709832 6,40
12
Pedestrian Area 61834028200 8183602400 7,56
Rush Hour 33590761832 5999540512 5,60
Station 2 15278702952 4631230432 3,30
Tractor 41746334120 6589026472 6,34
14
Pedestrian Area 61162550536 8175085368 7,48
Rush Hour 33467682088 5967215752 5,61
Station 2 15365570400 4542242944 3,38
Tractor 41325355408 6575557472 6,28
5.5 GPU profiling
Nesta seção é apresentada uma breve análise de profiling obtida através do aplicativo
NVIDIA Visual Profiler (nvvp), a fim de determinar a fração de tempo gasta na comunicação
entre a CPU e placa de vídeo, em relação ao tempo total de execução. O experimento foi
realizado codificando 300 quadros de vídeo na resolução 720p, com os mesmos três vídeos
utilizados nos experimentos anteriores. Para cada vídeo obtém-se diferentes tempos de
execução da função kernel devido ao fato de que o algoritmo de busca efetuará um número
diferente de iterações de acordo com as características de movimentação presentes na cena.
Os dados apresentados na Figura 25 são o resultado médio obtido nos três vídeos.
Os resultados deste experimento mostram que para vídeos 720p o tempo de execução
do kernel (na cor amarela) é aproximadamente o mesmo tempo gasto na transferência dos
quadros para a memória da placa de vídeo (em azul). A cópia dos resultados da placa para a
memória RAM (em cor laranja) consome pouco tempo visto que é necessário apenas obter os
vetores de movimento e os SADs correspondentes.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
76
A quantidade de dados que precisam ser movidos para a placa de vídeo depende da
resolução utilizada. As cópias ocorrem a cada novo quadro, sendo necessário transferir o
quadro atual e o quadro de referência previamente obtido.
Figura 25 Distribuição do tempo entre as etapas.
A medida que se analise resoluções maiores o tempo de transferência se mostra menos
significativo em relação ao total.
CPU -> GPUCPU <- GPUkernel

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
77
6 CONCLUSÃO
O presente trabalho apresentou uma investigação a cerca da utilização da GPU como
coprocessador para aceleração da codificação de vídeo, de acordo com o padrão H.264. Essa
proposta vai ao encontro do aumento da complexidade computacional dos codificadores
atuais, com vistas a tornar possível a codificação de vídeos de alta resolução em tempo real. O
uso da GPU nesse contexto é uma ideia que vem sendo explorada como alternativa a
utilização de outras tecnologias como instruções SIMD, coprocessadores em hardware
dedicado entre outras.
A revisão de literatura apresentou os fundamentos da compressão de vídeos e da
arquitetura de computação paralela CUDA. Foram realizados dois estudos de caso para
verificar na prática a viabilidade da proposta. No contexto da codificação intraquadros foi
realizada a implementação do módulo computacional, composto pelas transformadas e
quantização. Já no codificador interquadros, foram implementados um algoritmo de busca e o
cálculo de similaridade presentes na estimação de movimento.
Os experimentos no módulo computacional mostraram um ganho de cerca de 3,9
vezes no tempo de execução para vídeos HD. Os testes com a estimativa de movimento
resultaram em um ganho de cerca de 6 vezes, devido a maior quantidade de operações
realizadas nesse módulo do codificador.
Os resultados obtidos mostram que a ideia de utilizar a arquitetura CUDA para a
aceleração de codificadores é viável. Cabe ressaltar que a obtenção de bons resultados requer
o estudo da arquitetura CUDA em detalhes, pois a simples adaptação da implementação em C
para utilizar CUDA pode não explorar o potencial da GPU. Dessa forma, é preciso estudar os
algoritmos a fim de identificar onde o paralelismo é possível e expressar o algoritmo de forma
a encaixá-lo no modelo de execução da GPU. Em alguns casos, pode ser interessante a
proposição de novos algoritmos que possuam um maior paralelismo.
Como oportunidades de continuação desse trabalho de pesquisa, cita-se a possibilidade
de melhorias na implementação da estimativa de movimento. Uma alternativa é a exploração
do paralelismo no cálculo de SAD executado no algoritmo de busca. Visto que a cada iteração
da busca é necessário calcular o SAD de alguns blocos (no pior caso, são cinco blocos a
serem tratados), pode-se pensar em alguma forma de obter os SADs paralelamente. Outra
possibilidade de obter ganhos melhores na estimação de movimento é utilizar o paralelismo
entre a CPU principal e a GPU, através da utilização de chamadas assíncronas. Até o

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
78
momento, esse conceito foi usado apenas no módulo computacional, entretanto, empregá-lo
na estimativa de movimento não requer grande esforço de programação.
Há ainda a possibilidade de fazer uma implementação mais abrangente da estimativa
de movimento considerando outras funcionalidades possíveis no H.264. Por exemplo, pode-se
explorar a capacidade do H.264 de tratar partições do macrobloco separadamente, gerando um
vetor de movimento para cada sub-bloco. Outra possibilidade é explorar a estimativa de
movimento com resolução de meio pixel ou um quarto de pixel. Além disso, pode-se estudar
outros módulos que também possam ser paralelizados, como filtro antiblocagem,
compensação de movimento e predição intraquadros.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
79
REFERÊNCIAS
AGOSTINI, L. V. Desenvolvimento de Arquiteturas de Alta Performance Dedicadas à Compressão de Vídeo Segundo o Padrão H.264. 2007. 173 p. Tese (Doutorado em Computação) – Programa de Pós-Graduação em Computação (PPGC), Universidade Federal do Rio Grande do Sul, Porto Alegre, 2007.
AMD. ATI Stream Technology. 2011. Disponível em: http://www.amd.com/US/PRODUCTS/TECHNOLOGIES/STREAM-TECHNOLOGY/Pages/stream-technology.aspx . Acesso em 13 de novembro. 2011.
AZEVEDO, A. MoCHA: Arquitetura Dedicada para a Compensação de Movimento em Decodificadores de Vídeo de Alta Definição, Seguindo o Padrão H.264. 2006. 120 p. Dissertação (Mestrado em Ciência da Computação) – Programa de Pós-Graduação em Computação (PPGC), Universidade Federal do Rio Grande do Sul, Porto Alegre, 2006.
AZEVEDO, Eduardo; CONCI, Aura. Computação grafica: teoria e pratica. Rio de Janeiro: Elsevier, 2003.
BAKHODA, A.; et al. Analyzing CUDA workloads using a detailed GPU simulator. IEEE International Symposium on Performance Analysis of Systems and Software, [S.l.], p. 163-174, April 2009.
CHAN, L.; et al. Paralellizing H.264 Motion Estimation Algorithm using CUDA. MIT IAP 2009, Final Project . 2009
CHEUNG, N.; et. al. Video Coding on Multicore Graphics Processors . IEEE Signal Processing Magazine, [S.l.], v. 27, n. 2, p. 79-89, March 2010.
CONRAD, D. F. Análise da Hierarquia de Memórias em GPGPUs. 2010. 43 p. Trabalho de Conclusão (Graduação em Ciência da Computação) – Instituto de Informática, Universidade Federal do Rio Grande do Sul, Porto Alegre, 2010.
CROW, T. S. Evolution of the Graphical Processing Unit. 2004. 59 p. Professional Paper (Master of Science), Department of Computer Science and Engineering, University of Nevada, Reno, 2004.
DINIZ, C. M. Arquitetura de Hardware Dedicada para Predição Intra-Quadro em Codificadores do Padrão H.264/AVC de Compressão de Vídeo. 2009. 96 p. Dissertação (Mestrado em Ciência da Computação) – Programa de Pós-Graduação em Computação (PPGC), Universidade Federal do Rio Grande do Sul, Porto Alegre, 2009.
DUKE, K. A; WALL, W. A. A professional graphics controller. IBM Systems Jounal. Volume 24, 1985.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
80
FUJITSU. Emerging Markets for H.264 Video Encoding: Leveraging High Definition and Efficient IP Networking . 2010 . 6 p. Disponível em: http://www.fujitsu.com/emea/services/microelectronics/mpeg/. Acesso em: 13 de novembro. 2011.
GHANBARI, M. Standard Codecs: Image Compression to Advanced Video Coding. United Kingdom: The Institution of Electrical Engineers, 2003.
GONZALEZ, R. C.; WOODS, R. E.; CESAE JUNIOR, R. M. Processamento de imagens digitias. São Paulo: Edgard Blucher, 2000.
GREENE P.; TULJAPURKAR S. The basics of HD H.264 and next-generation encoding. EE Times Magazine, Julho, 2007. Disponível em: http://www.eetimes.com/design/signal-processing-dsp/4013356/The-basics-of-HD-H-264-and-next-generation-encoding?pageNumber=0 . Acesso em: 15 de outubro. 2011.
GUTTAG et al. The TMS34010: An Embedded Microprocessor. Proceedings... [S.l.]: IEEE, 1988. v. 8, n. 3, p. 39-52.
HAN, T. D.; ABDELRAHMAN, T. S. Reducing Branch Divergence in GPU programs. Proceedings of the Fourth Workshop on General Purpose Processing on Graphics Processing Units [S.l.]: 2011.
HOROWITZ, M. et al, H.264/AVC Baseline Profile Decoder Complexity Analysis. IEEE Transactions on Circuits and Systems for Video Technology, [S.l.], v. 13, n. 7, p. 704-716, July 2003.
HUANG, Y.; SHEN, Y.; WU, J. Scalable computation for spatially scalable video coding using NVIDIA CUDA and multi-core CPU. Proceedings of the 17th ACM International Conference on Multimedia. [S.l.]: 2009.
HUSEMANN, R. et al. Aumento de Desempenho de Codificação Intra H.264 Usando Arquitetura de GPU NVIDIA CUDA. In: Simpósio Brasileiro de Sistemas Multimídia e Web, 2011, Florianópolis. Anais . . . Florianópolis, 2011.
HUSEMANN, R. et al. Proposta de Solução de HW/SW Co-Design para o Módulo Computacional de um Codificador H.264/SVC. In XVI Simpósio Brasileiro de Sistemas Multimídia e WEB, 2010, Belo Horizonte. Anais . . . Belo Horizonte, BH. 2010.
IKEDA, P. A. Um estudo do uso eficiente de programas em placas gráficas. 2011. 80 p. Dissertação (Mestrado em Ciências) – Programa de Pós-Graduação em Ciência da Computação, Universidade de Sâo Paulo, São Paulo, 2011.
ITU - INTERNATIONAL TELECOMMUNICATION UNION. ITU-T Recommendation H.264/AVC (05/03): advanced video coding for generic audiovisual services. 2003.
ITU, H.264/SVC Reference Software for H.264 advanced video coding (JSVM version 9.19.9), 2010. Disponível em <http://ip.hhi.de/imagecom_G1/savce/downloads/SVC-Reference-Software.htm> Acesso em: 1º agosto de 2011.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
81
KHRONOS Group. OpenCL: The open standard for parallel programming of heterogeneous systems. 2011. Disponível em: http://www.khronos.org/opencl/ . Acesso em 13 de novembro. 2011.
MAJOLO, M. Arquitetura dos Módulos de Transformadas e de Quantização de um Codificador de Vídeo H.264. 2010. 71 p. Projeto de Diplomação (Graduação em Engenharia Elétrica) – Departamento de Engenharia Elétrica, Universidade Federal do Rio Grande do Sul, Porto Alegre, 2010.
MICROSOFT. Direct Compute PDC HOL. 2009. Disponível em: http://archive.msdn.microsoft.com/directcomputehol . Acesso em 13/11/2011.
NVIDIA. Technical Brief: Transform and Lighting. 1999. 13 p. Disponível em: http://developer.nvidia.com/system/files/akamai/gamedev/docs/TransformAndLighting.pdf. Acesso em: 13 de novembro. 2011.
NVIDIA. NVIDIA’s Next Generation CUDA Compute Architecture: Fermi . 2009. 22 p. Disponível em: http://www.nvidia.com/content/PDF/fermi_white_papers/NVIDIA_Fermi_Compute_Architecture_Whitepaper.pdf. Acesso em: 1 de outubro. 2011.
NVIDIA. NVIDIA CUDA C Programming Guide. 2011. 187 p. Disponível em: http://developer.download.nvidia.com/compute/cuda/4_0/toolkit/docs/CUDA_C_Programming_Guide.pdf. Acesso em: 5 de agosto. 2011a.
NVIDIA. NVIDIA CUDA CUDA C Best Practices Guide. 2011. 76 p. Disponível em: http://developer.download.nvidia.com/compute/cuda/4_0/toolkit/docs/CUDA_C_Programming_Guide.pdf. Acesso em: 5 de agosto. 2011b.
NVIDIA. PTX: Parallel Thread Execution. ISA Version 2.3. 2011. 76 p. Disponível em: http://developer.download.nvidia.com/compute/DevZone/docs/html/C/doc/ptx_isa_2.3.pdf. Acesso em: 5 de agosto. 2011c.
NVIDIA. CUDA: Parallel Programming Made Easy. 2011. Disponível em: http://www.nvidia.com/object/cuda_home_new.html . Acesso em 13 de novembro. 2011d.
NVIDIA. Optimizing Parallel Reduction in CUDA. 2012. Disponível em: http://developer.download.nvidia.com/compute/cuda/1.1-Beta/x86_website/projects/reduction/doc/reduction.pdf. Acesso em 25 de junho. 2012.
OWNEW, J. D; et al. A Survey of General-Purpose Computation on Graphics Hardware. Computer Graphics Forum. v. 26, n. 1, p. 80-113. March 2007.
PORTO, R. E. C. Desenvolvimento Arquitetural para Estimação de Movimento de Blocos de Tamanhos Variáveis Segundo o Padrão H.264/AVC de Compressão de Vídeo Digital. 2008. 96 p. Dissertação (Mestrado em Ciência da Computação) – Programa de Pós-Graduação em Computação (PPGC), Universidade Federal do Rio Grande do Sul, Porto Alegre, 2008.
PORTO, M. S. Desenvolvimento Algorítimico e Arquitetural para a Estimação de Movimento na Compressão de Vídeo de Alta Definição. 2012. 166p. Tese (Doutorado Em

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
82
Ciência da Computação) - Programa de Pós-Graduação em Computação (PPGC), Universidade Federal do Rio Grande do Sul, Porto Alegre, 2012.
PURI, A.; CHEN, X.; LUTHRA, A. Video coding using the H.264/MPEG-4 AVC compression standard . Signal Processing: Image Communication. v. 19, p. 793-849, 2004.
REDIESS, F.; et al. Projeto de Hardware para a Compensação de Movimento do Padrão H.264/AVC de Compressão de Vídeo. Hífen, Uruguaiana, 2006.
REN, J.; et al. Parallel Streaming Intra Prediction for Full HD H.264 Encoding. 5th
International Conference on Embedded and Multimedia Computing (EMC). p. 1-6, August 2010.
RICHARDSON, I. Video Codec Design: Developing Image and Video Compression Systems. Chichester: John Wiley and Sons, 2002.
RICHARDSON, I. H.264/AVC and MPEG-4 Video Compression – Video Coding for Next-Generation Multimedia. Chichester: John Wiley and Sons, 2003.
RICHARDSON, I. The H.264 Advanced Video Compression Standard. Chichester: John Wiley and Sons, 2010.
SHI, Y. Q; SUN, H. Image and Video Compreesion – Multimedia Engineering. Boca Raton: CRC Press, 2008.
SOARES, A. B. Exploração do Paralelismo em Arquiteturas para Processamento de Imagens e Vídeo. 2007. 143p. Tese (Doutorado Em Ciência da Computação) - Programa de Pós-Graduação em Computação (PPGC), Universidade Federal do Rio Grande do Sul, Porto Alegre, 2007.
SPRANDLIN, M; et al. Parallelizing MPEG-2 with CUDA: Feasibility of Porting Existing Applications to a GPGPU. CS315a - Parallel Computer Architecture and Programming, Final Project . Standford, 2009.
ST-LAURENT, S. Shader for the Game Programmers and Artists. Boston: Thomson Course Technology PTR, 2004.
TOURAPIS, A. M.; AU, O. C.; LIOU, M. L. Predictive motion vector field adaptive search technique (PMVFAST) – enhancing block based motion estimation. In: IEEE VISUAL COMMUNICATIONS AND IMAGE PROCESSING, 2001, San Jose. Proceedings... San Jose: IEEE Circuits and Systems Society, 2001. p. 883-892.
VIANA, J. R. M. Programação em GPU: Passado, Presente e Futuro. Escola Regional de Computação Ceará, Maranhão e Piauí - ERCEMAPI 2009, Parnaíba: 2009 v. 1. p. 1-25, 2009.
XIPH. Xiph.org Test Media. Disponível em: http://media.xiph.org/video/derf/. Acesso em: 11 de julho. 2012.
ZHANG, J. et al. Performance and Complexity Joint Optimization for H.264/AVC Video Coding. In: IEEE INTERNATIONAL SYMPOSIUM ON CIRCUITS AND SYSTEMS, ISCAS, 2003. Proceedings... [S.l.]: IEEE, 2003. v. 2, p. II888-II891.

BD
U –
Bib
liote
ca D
igita
l da
UN
IVAT
ES
(htt
p://w
ww
.uni
vate
s.br/
bdu)
83
ZHU, S.; MA, K. A New Diamond Search Algorithm for Fast Block-Matching Motion Estimation. IEEE Transactions on Image Processing, [S.l.], v. 9, n. 2, p. 287-290, Fev. 2000.]





























