Embed Size (px)
Citation preview

1성균관대소프트웨어대학신동군
Computer Architecture
Chapter 4-3
The Processor:Enhancing Performance with Pipelining

2성균관대소프트웨어대학신동군
Data Hazards
Pipeline data hazards-Backward dep. lines
ReadWrite

3성균관대소프트웨어대학신동군
One Alternative Approach: Compiler Scheduling
Pipeline works but we do nothing useful during two nop cycles
--> Can compiler do some intelligent guess to replace nop’s?

4성균관대소프트웨어대학신동군
Hazard Detection
1a. EX/MEM.RegisterRd = ID/EX.RegisterRs1b. EX/MEM.RegisterRd = ID/EX.RegisterRt2a. MEM/WB.RegisterRd = ID/EX.RegisterRs2b. MEM/WB.RegisterRd = ID/EX.RegisterRt
sub $2, $1, $3
and $12, $2, $5 1a
or $13, $6, $2 2b
add $14, $2, $2 no
sw $15, 100($2) no
Q: Any Problem?
We can resolve hazards with forwarding- How do we detect when to forward?

5성균관대소프트웨어대학신동군
Detecting the Need to Forward
• Problems:
– Some instructions do not write registers
– $0 as destination (sll $0, $1, 2)
• do not forward nonzero result value
• But only if forwarding instruction will write to a register!
– EX/MEM.RegWrite, MEM/WB.RegWrite
• And only if Rd for that instruction is not $zero
– EX/MEM.RegisterRd ≠ 0,MEM/WB.RegisterRd ≠ 0

6성균관대소프트웨어대학신동군
Forwarding/Bypassing

7성균관대소프트웨어대학신동군
No Forwarding

8성균관대소프트웨어대학신동군
Forwarding

9성균관대소프트웨어대학신동군
Hazard Detection & Forwarding
1. EX Hazard
If (EX/MEM.RegWrite
and (EX/MEM.RegisterRd != 0)
and (EX/MEM.RegisterRd = ID/EX.RegisterRs))
ForwardA = 10 /* from prior ALU result */
If (EX/MEM.RegWrite
and (EX/MEM.RegisterRd != 0)
and (EX/MEM.RegisterRd = ID/EX.RegisterRt))
ForwardB = 10 /* from prior ALU result */

10성균관대소프트웨어대학신동군
Hazard Detection & Forwarding
2. MEM Hazard
If (MEM/WB.RegWrite
and (MEM/WB.RegisterRd != 0)
and (MEM/WB.RegisterRd = ID/EX.RegisterRs))
ForwardA = 01 /* from memory or earlier ALU result */
If (MEM/WB.RegWrite
and (MEM/WB.RegisterRd != 0)
and (MEM/WB.RegisterRd = ID/EX.RegisterRt))
ForwardB = 01 /* from memory or earlier ALU result */

11성균관대소프트웨어대학신동군
One Complication
add $1, $1, $2
add $1, $1, $3
add $1, $1, $4
If (MEM/WB.RegWrite
and (MEM/WB.RegisterRd != 0)
and (EX/MEM.RegisterRd != ID/EX.RegisterRs)
and (MEM/WB.RegisterRd = ID/EX.RegisterRs))
ForwardA = 01
Result in MEM stage is more recent!

12성균관대소프트웨어대학신동군
Forwarding Example
sub $2, $1, $3
and $4, $2, $5
or $4, $4, $2
add $9, $4, $2

13성균관대소프트웨어대학신동군
Clock 3

14성균관대소프트웨어대학신동군
Clock 4

15성균관대소프트웨어대학신동군
Clock 5

16성균관대소프트웨어대학신동군
Clock 6

17성균관대소프트웨어대학신동군
Load-Use Data Hazard
Need to stall
for one cycle

18성균관대소프트웨어대학신동군
Hazard Detection Logic
If (ID/EX.MemRead
and ((ID/EX.RegisterRt = IF/ID.RegisterRs) or
(ID/EX.RegisterRt = IF/ID.RegisterRt)))
Stall the pipeline

19성균관대소프트웨어대학신동군
How to Stall
• If instruction in the ID stage stall
– instruction in the IF stage must be stalled as well
• Stalling means preventing any progress
– Prevent PC and IF/ID from changing
– Keep the old values (that is, keep washing the same clothes)
• Insert nop in the EX stage
– Set the EX, MEM and WB control fields to 0
– The minimum is to deassert RegWrite and MemWrite (i.e,. No State Change)

20성균관대소프트웨어대학신동군
Stall Example

21성균관대소프트웨어대학신동군
Pipelined Control with Hazard Detection Unit

22성균관대소프트웨어대학신동군
Stall & Forwarding Example
lw $2, 20 ($1)
and $4, $2, $5
or $4, $4, $2
add $9, $4, $2

23성균관대소프트웨어대학신동군
Clock 2
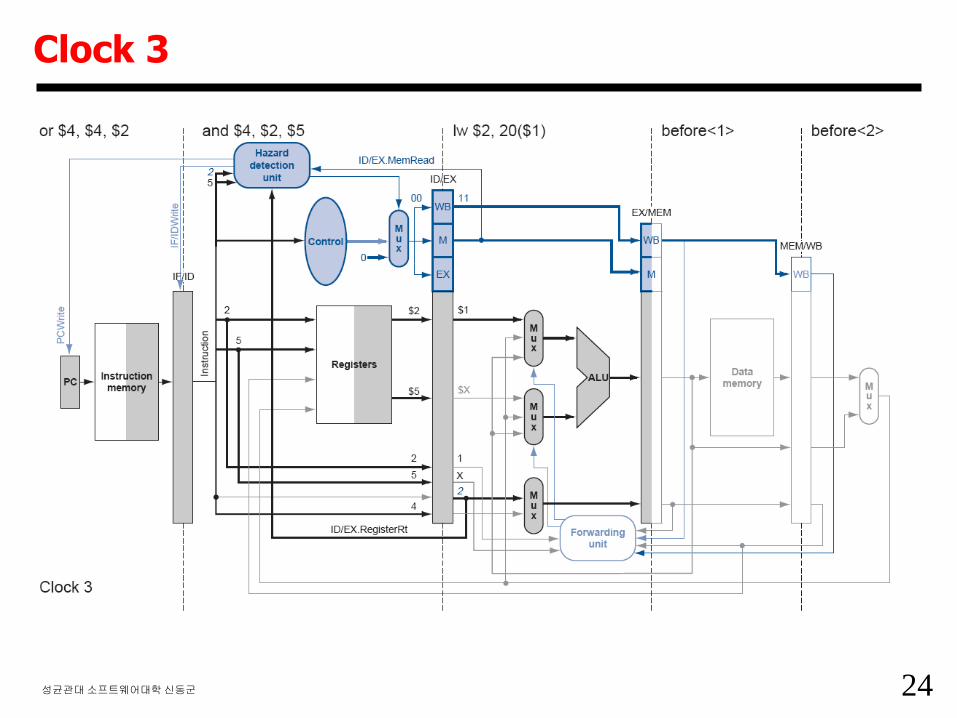
24성균관대소프트웨어대학신동군
Clock 3

25성균관대소프트웨어대학신동군
Clock 4

26성균관대소프트웨어대학신동군
Clock 5
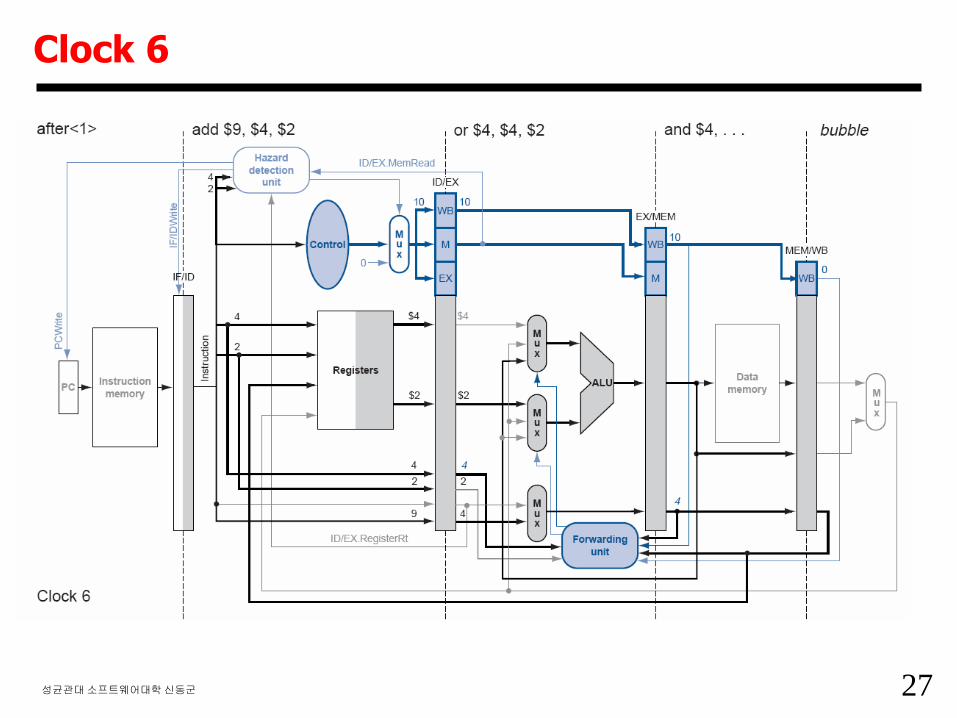
27성균관대소프트웨어대학신동군
Clock 6

28성균관대소프트웨어대학신동군
Clock 7

29성균관대소프트웨어대학신동군
Stalls and Performance
• Stalls reduce performance
– But are required to get correct results
• Compiler can arrange code to avoid hazards and stalls
– Requires knowledge of the pipeline structure

30성균관대소프트웨어대학신동군
Branch Hazards
• If branch outcome determined in MEM
PC
Flush these
instructions
(Set control
values to 0)
Stall three cycles

31성균관대소프트웨어대학신동군
Static Prediction: Branch Not Taken
• Alternative to simple stalling
• Assume that branches will not be taken:
– If really not taken, we are fine.
– If taken, discard/flush instructions in IF, ID and EX stages
• Make them nop’s.
• Q: How can we improve the performance further?

32성균관대소프트웨어대학신동군
Taken-Branch Penalty
• Taken-branch penalty = 3 cycles
– 3 instructions to flush
• How to improve?
1. Compute the branch target address EARLIER
2. Make a branch decision EARLIER
• How early? IF? ID? EXE?
ID Stage
1. branch target address calculation
Move a branch adder from MEM to ID
2. branch decision
Exclusive ORing two registers then ORing all bits
➔ if two registers are equal, the result is 0
How about forwarding and stalling?add $1, $2, $3beq $1, $5, 10
A B AB
0 0 0
0 1 1
1 0 1
1 1 0
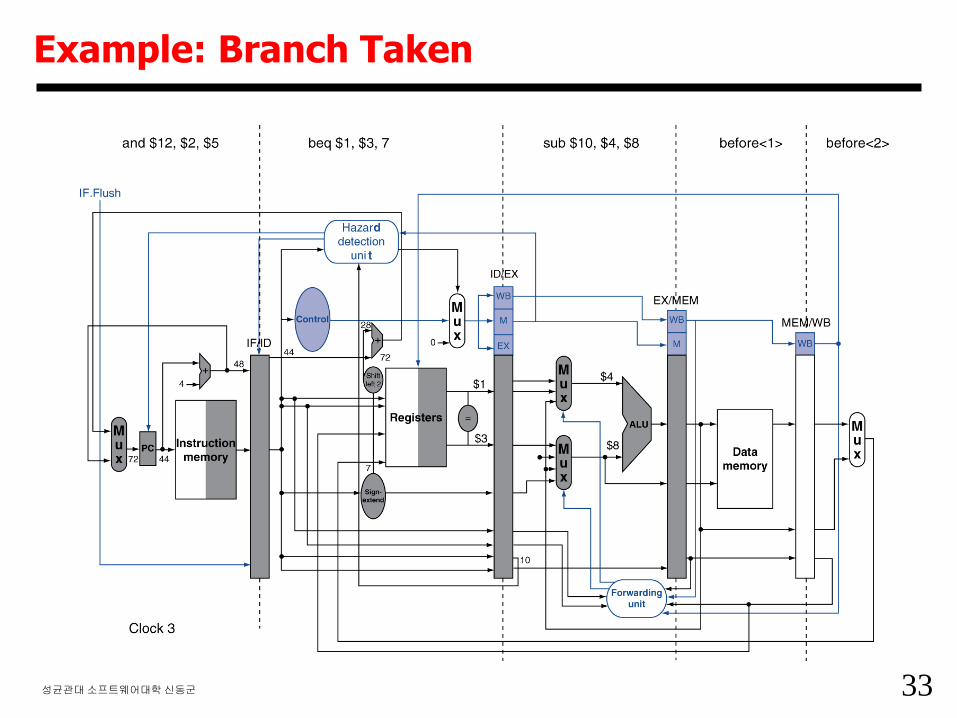
33성균관대소프트웨어대학신동군
Example: Branch Taken

34성균관대소프트웨어대학신동군
Example: Branch Taken

35성균관대소프트웨어대학신동군
Data Hazards for Branches
• If a comparison register is a destination of 2nd or 3rd
preceding ALU instruction
…
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
add $4, $5, $6
add $1, $2, $3
beq $1, $4, target
Can resolve using forwarding

36성균관대소프트웨어대학신동군
Data Hazards for Branches
• If a comparison register is a destination of preceding ALU instruction or 2nd preceding load instruction
– Need 1 stall cycle
beq stalled
IF ID EX MEM WB
IF ID EX MEM WB
IF ID
ID EX MEM WB
add $4, $5, $6
lw $1, addr
beq $1, $4, target

37성균관대소프트웨어대학신동군
Data Hazards for Branches
• If a comparison register is a destination of immediately preceding load instruction
– Need 2 stall cycles
beq stalled
IF ID EX MEM WB
IF ID
ID
ID EX MEM WB
beq stalled
lw $1, addr
beq $1, $0, target

38성균관대소프트웨어대학신동군
Dynamic Branch Prediction
• In deeper and superscalar pipelines, branch penalty is more significant
• Use dynamic prediction
– Predict the future branch behavior by the recent past
– Branch prediction buffer (aka branch history table)
– Indexed by recent branch instruction addresses
– Stores outcome (taken/not taken)
• To execute a branch
– Check table, expect the same outcome
– Start fetching from fall-through or target
– If wrong, flush pipeline and flip prediction

39성균관대소프트웨어대학신동군
1-bit Predictor
• For loop branch, mispredict twice instead of once
– Mispredict on the first iteration
– Mispredict on the last iteration
outer: ……
inner: ……beq …, …, inner…beq …, …, outer
40성균관대소프트웨어대학신동군
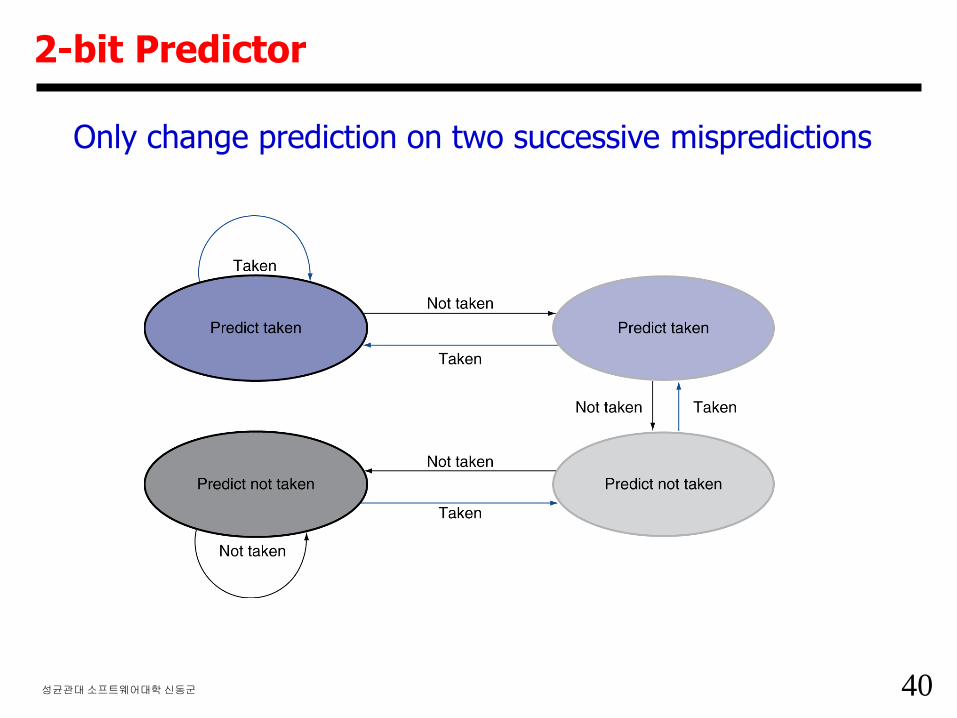
2-bit Predictor
Only change prediction on two successive mispredictions

41성균관대소프트웨어대학신동군
Calculating the Branch Target
• Even with predictor, still need to calculate the target address
– 1-cycle penalty for a taken branch
• Branch target buffer
– Cache of target addresses
– Indexed by PC when instruction fetched
• If hit and instruction is branch predicted taken, can fetch target immediately

42성균관대소프트웨어대학신동군
Exceptions
• Exception = unprogrammed control transfer
– system takes action to handle the exception• must record the address of the offending instruction
– returns control to user
– must save & restore user state
User program
_________________________________________________
System Exception Handler
___________________________________return fromexception
normal control flow:sequential, jumps, branches, calls, returns

43성균관대소프트웨어대학신동군
Two Types of Exceptions
• Interrupts
– caused by external events
– asynchronous to program execution
– may be handled between instructions
– simply suspend and resume user program
• Traps
– caused by internal events
• exceptional conditions (overflow)
• errors (parity)
• faults (non-resident page)
– synchronous to program execution
– condition must be remedied by the handler

44성균관대소프트웨어대학신동군
MIPS Convention
• Exception
– means any unexpected change in control flow, without distinguishing internal or external
• Interrupt
– only when the event is externally caused.
Type of event From where? MIPS terminology
I/O device request External Interrupt
Invoke OS from user program Internal Exception
Arithmetic overflow Internal Exception
Using an undefined instruction Internal Exception
Hardware malfunctions Either Exception or Interrupt

45성균관대소프트웨어대학신동군
MIPS Exception Handling
• How does MIPS handle exceptions?
– Saves PC in the dedicated register EPC
• cannot overwrite $ra because its value is needed to complete executing the interrupted program
– Records the reason for the exception in the Cause register
– Loads special value into PC, the exception handler’s address (PC 0x80000180)
• cf. vectored interrupt
– the exception handler’s address is determined by the cause of the exception
– undef: PC 0x8000000, overflow: PC 0x80000180
– The instruction RFE restores the PC from EPC
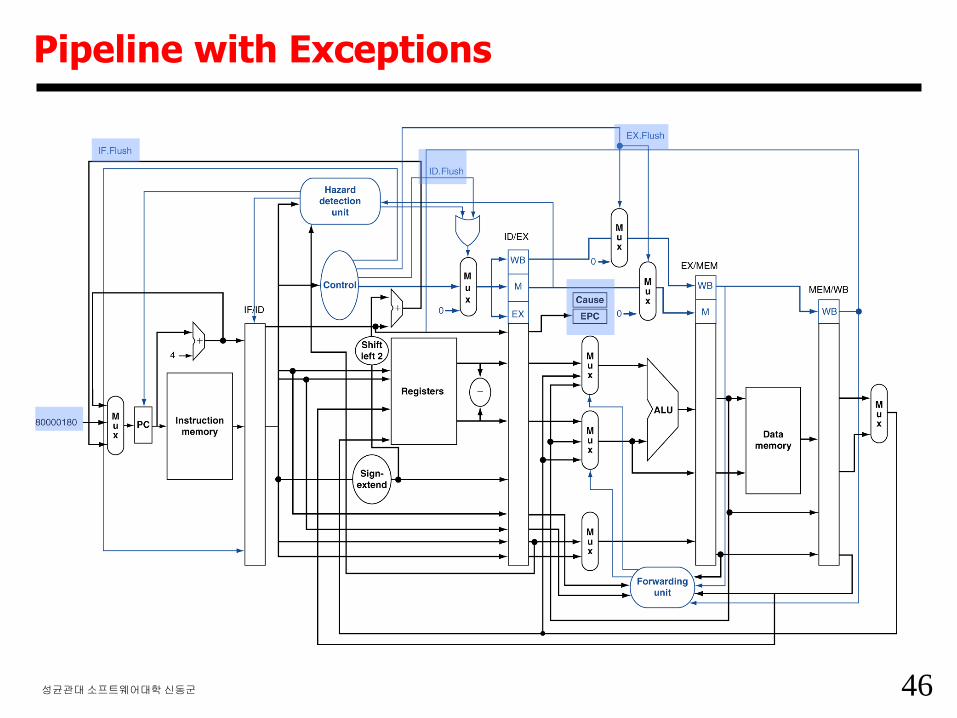
46성균관대소프트웨어대학신동군
Pipeline with Exceptions

47성균관대소프트웨어대학신동군
Exception Example
40: sub $11, $2, $4
44: and $12, $2, $5
48: or $13, $2, $6
4C: add $1, $2, $1 overflow exception
50: slt $15, $6, $7
54: lw $16, 50($7)
Exception Handler:
80000180: sw $25, 1000($0)
80000184: sw $26, 1004($0)

48성균관대소프트웨어대학신동군
Exception Example

49성균관대소프트웨어대학신동군
Exception Example

50성균관대소프트웨어대학신동군
Multiple Exceptions in Same Cycle
• IF: Memory Fault
• ID: Undefined Instruction
• EXE: Arithmetic Overflow, O/S Calls
• MEM: Memory Fault
• WB: None
• Q: How to detect which instruction(s) caused interrupt(s)?
– In MIPS, collected in Cause register
– Guess based on the types of exceptions for each stages
• Q: How to prioritize multiple exceptions?
– In MIPS, the earliest instruction first
– Flush subsequent instructions
– “Precise” exceptions

51성균관대소프트웨어대학신동군
Imprecise Interrupts
• In complex pipelines
– Multiple instructions issued per cycle
– Out-of-order completion
– Maintaining precise exceptions is difficult!
• Imprecise Exception
– Just stop pipeline and save state
– Including exception cause(s)
– Let the handler work out
• Which instruction(s) had exceptions
• Which to complete or flush
• May require “manual” completion
– Simplifies hardware, but more complex handler software
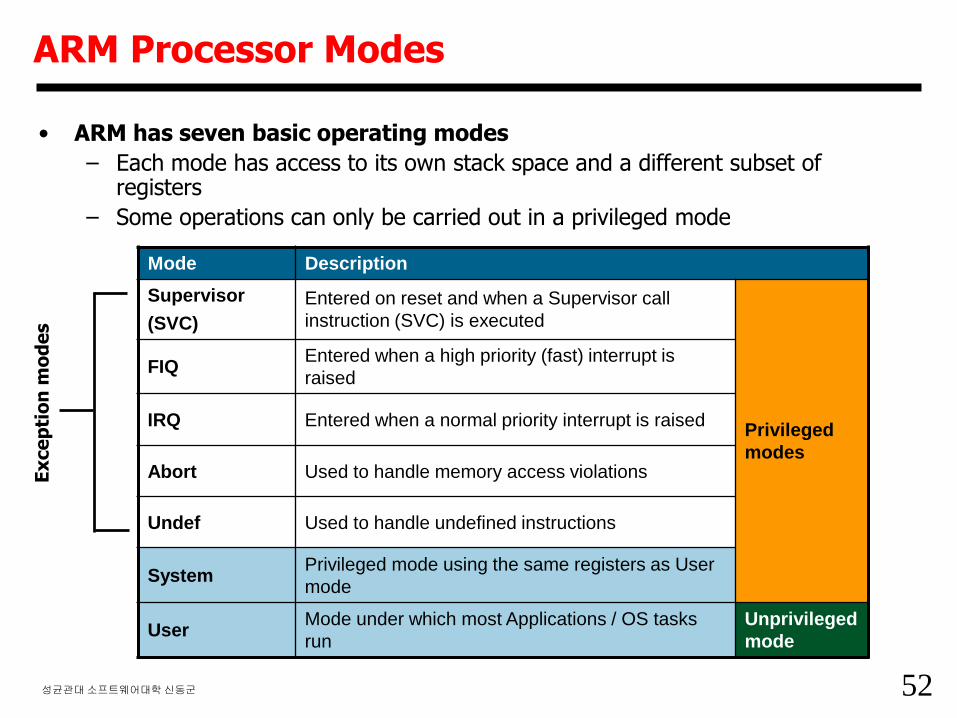
52성균관대소프트웨어대학신동군
• ARM has seven basic operating modes
– Each mode has access to its own stack space and a different subset of registers
– Some operations can only be carried out in a privileged mode
ARM Processor Modes
Mode Description
Supervisor
(SVC)
Entered on reset and when a Supervisor call
instruction (SVC) is executed
Privileged
modes
FIQEntered when a high priority (fast) interrupt is
raised
IRQ Entered when a normal priority interrupt is raised
Abort Used to handle memory access violations
Undef Used to handle undefined instructions
SystemPrivileged mode using the same registers as User
mode
UserMode under which most Applications / OS tasks
run
Unprivileged
mode
Ex
ce
pti
on
mo
de
s
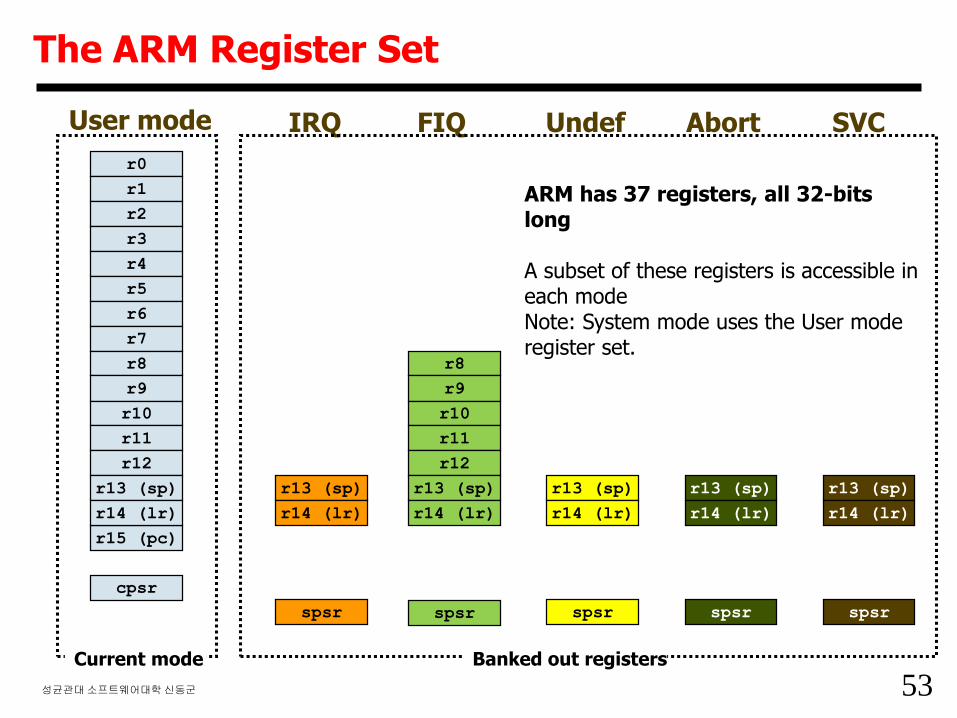
53성균관대소프트웨어대학신동군
The ARM Register Set
r0
r1
r2
r3
r4
r5
r6
r7
r8
r9
r10
r11
r12
r15 (pc)
cpsr
r13 (sp)
r14 (lr)
User mode
spsr
r13 (sp)
r14 (lr)
IRQ FIQ
r8
r9
r10
r11
r12
r13 (sp)
r14 (lr)
spsr spsr
r13 (sp)
r14 (lr)
Undef
spsr
r13 (sp)
r14 (lr)
Abort
spsr
r13 (sp)
r14 (lr)
SVC
Current mode Banked out registers
ARM has 37 registers, all 32-bits long
A subset of these registers is accessible in each modeNote: System mode uses the User mode register set.

54성균관대소프트웨어대학신동군
The ARM Register Set
User
mode
r0-r7,
r15,
and
cpsr
r8
r9
r10
r11
r12
r13 (sp)
r14 (lr)
spsr
FIQ
r8
r9
r10
r11
r12
r13 (sp)
r14 (lr)
r15 (pc)
cpsr
r0
r1
r2
r3
r4
r5
r6
r7
User
r13 (sp)
r14 (lr)
spsr
IRQ
User
mode
r0-r12,
r15,
and
cpsr
r13 (sp)
r14 (lr)
spsr
Undef
User
mode
r0-r12,
r15,
and
cpsr
r13 (sp)
r14 (lr)
spsr
SVC
User
mode
r0-r12,
r15,
and
cpsr
r13 (sp)
r14 (lr)
spsr
Abort
User
mode
r0-r12,
r15,
and
cpsr
Thumb state
Low registers
Thumb state
High registers
Note: System mode uses the User mode register set

55성균관대소프트웨어대학신동군
Vector Table
Exception Handling
• When an exception occurs, the core…– Copies CPSR into SPSR_<mode>– Sets appropriate CPSR bits
• Change to ARM state (if appropriate)• Change to exception mode • Disable interrupts (if appropriate)
– Stores the return address in LR_<mode>– Sets PC to vector address
• To return, exception handler needs to…– Restore CPSR from SPSR_<mode>– Restore PC from LR_<mode>
• Cores can enter ARM state or Thumb state when taking an exception– Controlled through settings in CP15
• Note that v7-M and v6-M exception model is different
FIQ
IRQ
(Reserved)
Data Abort
Prefetch Abort
Supervisor Call
Undefined Instruction
Reset
0x1C
0x18
0x14
0x10
0x0C
0x08
0x04
0x00

56성균관대소프트웨어대학신동군
Advanced Topics
• To increase ILP
– Deeper pipeline
• Less work per stage ➔ shorter clock cycle
– Multi Issue
• Multiple instructions per stage
• CPI < 1 or IPC (Instructions Per Clock Cycle) > 1
• Static Multiple Issue: VLIW
• Dynamic Multiple Issue: Superscalar

57성균관대소프트웨어대학신동군
Speculation
• “Guess” what to do with an instruction
– Start operation as soon as possible
– Check whether guess was right
• If so, complete the operation
• If not, roll-back and do the right thing
• Common to static and dynamic multiple issue
• Examples
– Speculate on branch outcome
• Roll back if path taken is different
– Speculate on load
• Roll back if location is updated
sw $5, $4(5)…lw $2, $3(10)
$4+5 ≠ $3+10

58성균관대소프트웨어대학신동군
Compiler/Hardware Speculation
• Compiler can reorder instructions
– e.g., move an instruction across a branch
– or a load across a store
– Can include “fix-up” instructions to recover from incorrect guess
• Hardware can look ahead for instructions to execute
– Buffer results until it determines they are actually needed
– Flush buffers on incorrect speculation
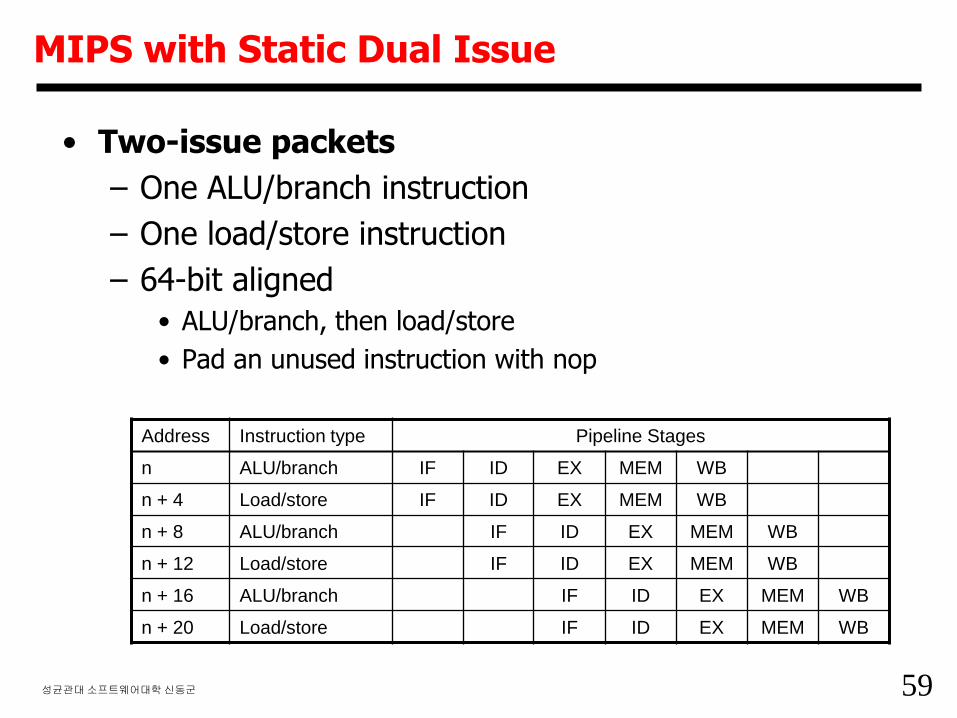
59성균관대소프트웨어대학신동군
MIPS with Static Dual Issue
• Two-issue packets
– One ALU/branch instruction
– One load/store instruction
– 64-bit aligned
• ALU/branch, then load/store
• Pad an unused instruction with nop
Address Instruction type Pipeline Stages
n ALU/branch IF ID EX MEM WB
n + 4 Load/store IF ID EX MEM WB
n + 8 ALU/branch IF ID EX MEM WB
n + 12 Load/store IF ID EX MEM WB
n + 16 ALU/branch IF ID EX MEM WB
n + 20 Load/store IF ID EX MEM WB

60성균관대소프트웨어대학신동군
Static Two-Issue Datapath

61성균관대소프트웨어대학신동군
Scheduling Example
• Schedule this for dual-issue MIPS
Loop: lw $t0, 0($s1) # $t0=array elementaddu $t0, $t0, $s2 # add scalar in $s2sw $t0, 0($s1) # store resultaddi $s1, $s1,–4 # decrement pointerbne $s1, $zero, Loop # branch $s1!=0
ALU/branch Load/store cycle
Loop: nop lw $t0, 0($s1) 1
addi $s1, $s1,–4 nop 2
addu $t0, $t0, $s2 nop 3
bne $s1, $zero, Loop sw $t0, 4($s1) 4
IPC = 5/4 = 1.25 (c.f. peak IPC = 2)

62성균관대소프트웨어대학신동군
Loop Unrolling
• Replicate loop body to expose more parallelism
– Reduces loop-control overhead
• Use different registers per replication
– Called “register renaming”
– Avoid loop-carried “anti-dependencies”
• Store followed by a load of the same register
• Aka “name dependence”
– Reuse of a register name

63성균관대소프트웨어대학신동군
Loop Unrolling Example
• IPC = 14/8 = 1.75
– Closer to 2, but at cost of registers and code size
ALU/branch Load/store cycle
Loop: addi $s1, $s1,–16 lw $t0, 0($s1) 1
nop lw $t1, 12($s1) 2
addu $t0, $t0, $s2 lw $t2, 8($s1) 3
addu $t1, $t1, $s2 lw $t3, 4($s1) 4
addu $t2, $t2, $s2 sw $t0, 16($s1) 5
addu $t3, $t3, $s2 sw $t1, 12($s1) 6
nop sw $t2, 8($s1) 7
bne $s1, $zero, Loop sw $t3, 4($s1) 8

64성균관대소프트웨어대학신동군
Dynamic Pipeline Scheduling
• Allow the CPU to execute instructions out of order to avoid stalls
– But commit result to registers in order
• Example
lw $t0, 20($s2)addu $t1, $t0, $t2sub $s4, $s4, $t3slti $t5, $s4, 20
– Can start sub while addu is waiting for lw

65성균관대소프트웨어대학신동군
Dynamically Scheduled CPU
Results also sent
to any waiting
reservation stations
Reorders buffer for
register writesCan supply
operands for
issued instructions
Preserves
dependencies
Hold pending
operands

66성균관대소프트웨어대학신동군
Register Renaming
• Reservation stations and reorder buffer effectively provide register renaming
• On instruction issue to reservation station
– If operand is available in register file or reorder buffer• Copied to reservation station
• No longer required in the register; can be overwritten
– If operand is not yet available• It will be provided to the reservation station by a function unit
• Register update may not be required
mult $t1, $s0, $t2sub $s4, $t1, $t3slti $s0, $s2, 20

67성균관대소프트웨어대학신동군
Speculation
• Predict branch and continue issuing
– Don’t commit until branch outcome determined
• Load speculation
– Avoid load and cache miss delay
• Predict the effective address
• Predict loaded value
• Load before completing outstanding stores
• Bypass stored values to load unit
– Don’t commit load until speculation cleared

68성균관대소프트웨어대학신동군
Why Do Dynamic Scheduling?
• Why not just let the compiler schedule code?
• Not all stalls are predicable
– e.g., cache misses
• Can’t always schedule around branches
– Branch outcome is dynamically determined
• Different implementations of an ISA have different latencies and hazards

69성균관대소프트웨어대학신동군
Does Multiple Issue Work?
• Yes, but not as much as we’d like
• Programs have real dependencies that limit ILP
• Some dependencies are hard to eliminate– e.g., pointer aliasing
• Some parallelism is hard to expose– Limited window size during instruction issue
• Memory delays and limited bandwidth– Hard to keep pipelines full
• Speculation can help if done well

70성균관대소프트웨어대학신동군
Power Efficiency
• Complexity of dynamic scheduling and speculations requires power
• Multiple simpler cores may be better
Microprocessor Year Clock Rate Pipeline
Stages
Issue
width
Out-of-order/
Speculation
Cores Power
i486 1989 25MHz 5 1 No 1 5W
Pentium 1993 66MHz 5 2 No 1 10W
Pentium Pro 1997 200MHz 10 3 Yes 1 29W
P4 Willamette 2001 2000MHz 22 3 Yes 1 75W
P4 Prescott 2004 3600MHz 31 3 Yes 1 103W
Core 2006 2930MHz 14 4 Yes 2 75W
UltraSparc III 2003 1950MHz 14 4 No 1 90W
UltraSparc T1 2005 1200MHz 6 1 No 8 70W

71성균관대소프트웨어대학신동군
Cortex A8 and Intel i7
Processor ARM A8 Intel Core i7 920
Market Personal Mobile Device Server, cloud
Thermal design power 2 Watts 130 Watts
Clock rate 1 GHz 2.66 GHz
Cores/Chip 1 4
Floating point? No Yes
Multiple issue? Dynamic Dynamic
Peak instructions/clock cycle 2 4
Pipeline stages 14 14
Pipeline schedule Static in-order Dynamic out-of-order withspeculation
Branch prediction 2-level 2-level
1st level caches/core 32 KiB I, 32 KiB D 32 KiB I, 32 KiB D
2nd level caches/core 128-1024 KiB 256 KiB
3rd level caches (shared) - 2- 8 MB

72성균관대소프트웨어대학신동군
ARM Cortex-A8 Pipeline

73성균관대소프트웨어대학신동군
ARM Cortex-A8 Performance

74성균관대소프트웨어대학신동군
Core i7 Pipeline

75성균관대소프트웨어대학신동군
Core i7 Performance

76성균관대소프트웨어대학신동군
Performance Impact
Advanced Vector Extensions(subword parallelism)

77성균관대소프트웨어대학신동군
Pitfalls
• Poor ISA design can make pipelining harder
– e.g., complex instruction sets (VAX, IA-32)
• Significant overhead to make pipelining work
• IA-32 micro-op approach
– e.g., complex addressing modes
• Register update side effects, memory indirection
– e.g., delayed branches
• Advanced pipelines have long delay slots

78성균관대소프트웨어대학신동군
Concluding Remarks
• ISA influences design of datapath and control
• Datapath and control influence design of ISA
• Pipelining improves instruction throughputusing parallelism
– More instructions completed per second
– Latency for each instruction not reduced
• Hazards: structural, data, control
• Multiple issue and dynamic scheduling (ILP)
– Dependencies limit achievable parallelism
– Complexity leads to the power wall





























