Embed Size (px)
Citation preview

Conceitos Avançados de Conceitos Avançados de Arquitetura de ComputadoresArquitetura de Computadores
Arquiteturas RISC Arquiteturas RISCArquiteturas Superpipeline e Arquiteturas Superpipeline e SuperescalaresSuperescalares

Melhorando a performanceMelhorando a performance
• Como melhorar a performance de máquinas implementadas como pipeline?– Aumentar o número de estágios do pipeline
• Superpipeline
– Replicar recursos para executar instruções em paralelo• SuperescalarSuperescalar

superpipeline
superescalar
Melhorando a performanceMelhorando a performance pipeline

Melhorando a performanceMelhorando a performance
SuperpipelineSuperpipeline
• Limitações no tamanho do pipeline:1) Hazards de dados:
pipeline maior => mais paradas2) Hazards de controle:
pipeline maior => saltos mais lentos3) Tempo dos registradores do pipeline:
Limita o tempo mínimo por estágio (clock)
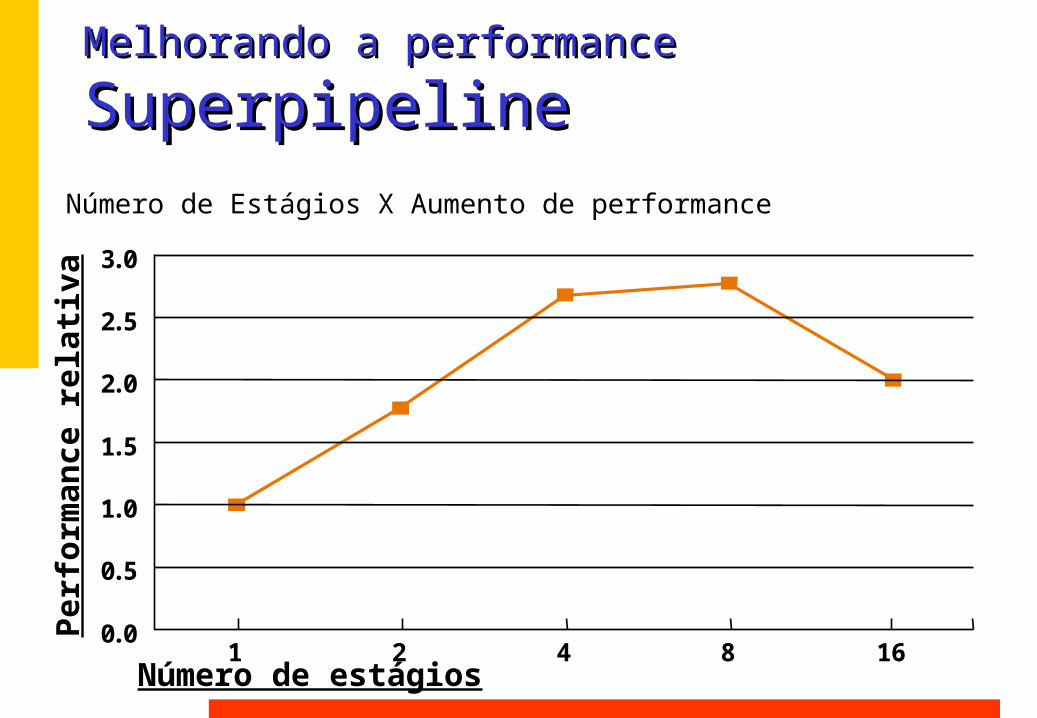
Melhorando a performanceMelhorando a performance
SuperpipelineSuperpipelineNúmero de Estágios X Aumento de performance
1 2 4 8 160.0
0.5
1.0
1.5
2.0
2.5
3.0
Número de estágios
Perf
orm
ance
rel
ativ
a

Processador superescalarProcessador superescalar
• Execução simultânea de instruções:– aritméticas, loads, stores, etc
• Aplicável a máquinas RISC e CISC– RISC: melhor uso efetivo– CISC: implementação mais difícil
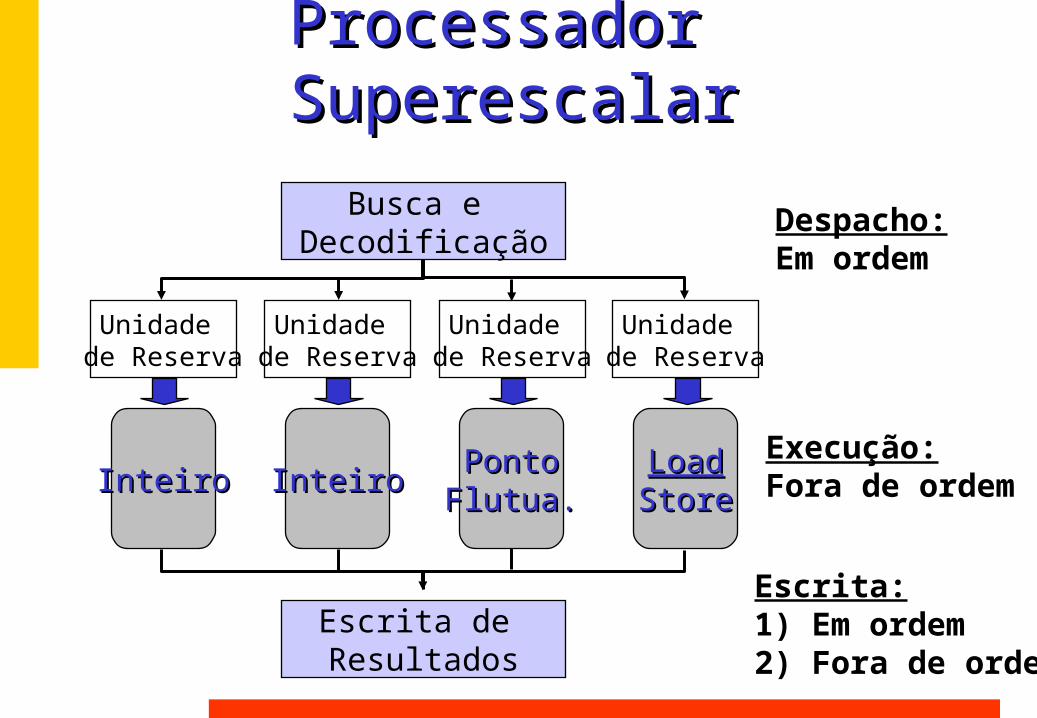
Processador SuperescalarProcessador SuperescalarBusca e
Decodificação
Unidade de Reserva
InteiroInteiro
Escrita de Resultados
InteiroInteiro LoadLoadStoreStore
PontoPontoFlutua.Flutua.
Unidade de Reserva
Unidade de Reserva
Unidade de Reserva
Despacho:Em ordem
Execução:Fora de ordem
Escrita:1) Em ordem2) Fora de ordem
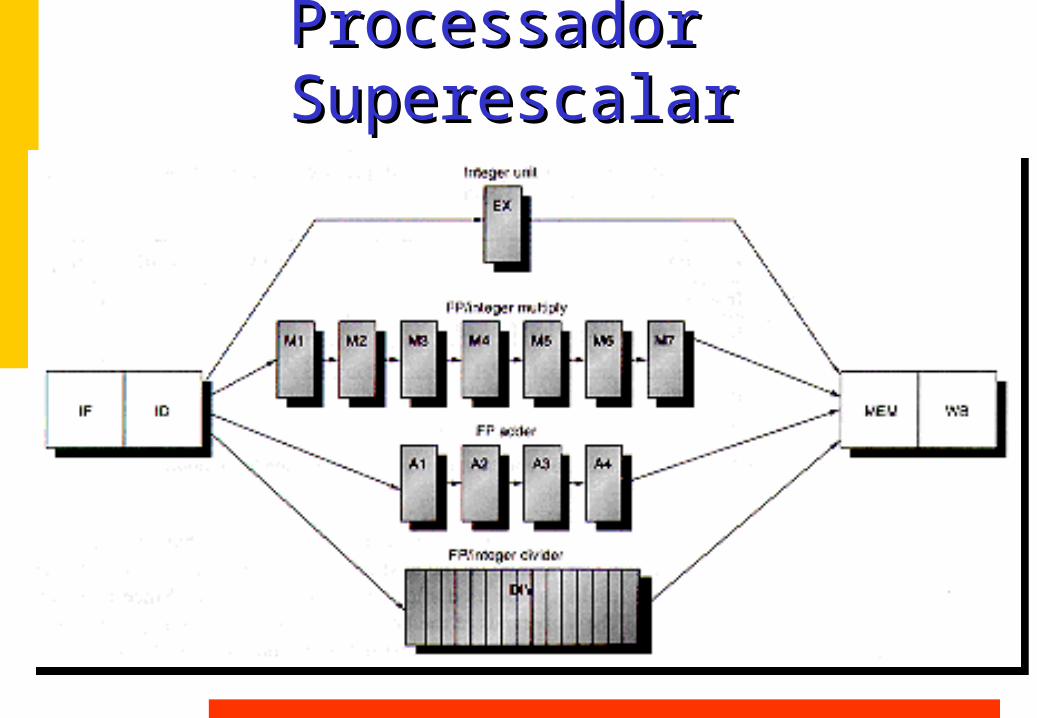
Processador SuperescalarProcessador Superescalar

Superescalar:Superescalar:
Revisando Dependências de DadosRevisando Dependências de Dados
- Dependência Verdadeira: Read-after-Write (RAW)
- - Dependência de Saída:Dependência de Saída:Write-after-Write (WAW)Write-after-Write (WAW)
- - Antidependência:Antidependência:Write-after-Read (WAR)Write-after-Read (WAR)

Superescalar:Superescalar:
Dependências WAR e WAWDependências WAR e WAW
As CPUs comuns não apresentam estas dependências porque apenas um estágio do pipeline altera o estado da máquina (os registradores) na ordem em que as instruções são iniciadas.
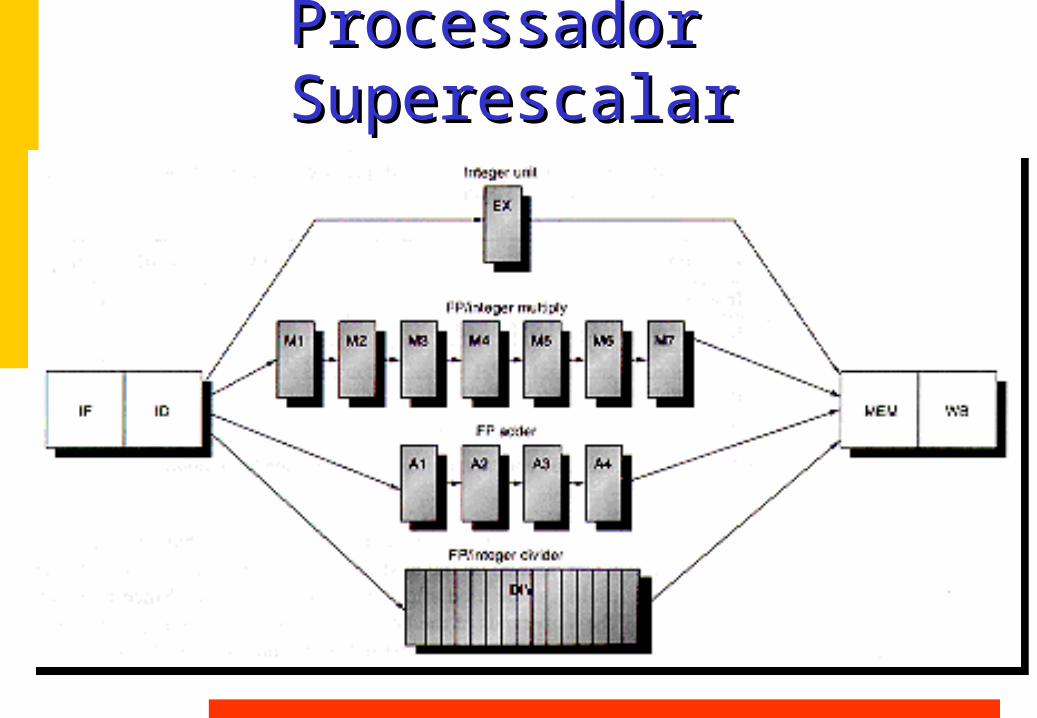
Processador SuperescalarProcessador Superescalar

Superescalar:Superescalar:Dependências de DadosDependências de Dados
r3:= r0 + r5 (I1)r4:= r3 + 1 (I2) r3:= r5 + 1 (I3) r7:= r3 - r4 (I4)
• Dependência Verdadeira: (RAW)I2 e I1, I4 e I3, I4 e I2
• Antidependência: (WAR)I3 não pode terminar antes de I2 iniciar
• Dependências de Saída: (WAW)I3 não pode terminar antes de I1

Dependências de Dados WAR e WAW:Dependências de Dados WAR e WAW:
Como tratá-lasComo tratá-las
1) Inserir NOPs ou bolhas (igual RAW)
2) Inserir instruções independentes (igual RAW)
3) Renomeação de registradores3) Renomeação de registradores

Superescalar:Superescalar:
Renomeação de RegistradoresRenomeação de Registradores
r3 := r3 + r5 r3b:= r3a + r5ar4:= r3 + 1 r4b:= r3b + 1
r3:= r5 +1 r3c:= r5a + 1r7:= r3 - r4 r7a:= r3c - r4b
Unidade deUnidade derenomeaçãorenomeação
RegsFísicos
RegsVirtuais

VLIW (EPIC)VLIW (EPIC)
Very Long Instruction Word
O compilador descobre as instruções que podem ser executadas em paralelo e agrupa-as formando uma longa instruçãoque será despachada para a máquina

SuperescalarSuperescalar x x VLIWVLIWdetecção de paralelismo
hardware compiladortempo disponível para realizar a detecção
pouco muitorelógio
mais lento mais rápidoarquitetura
CISC CISC RISCRISC

Crusoe: www.transmeta.comCrusoe: www.transmeta.com
• Projetado para sistemas portáteis:– Gerenciamento eficiente da potência
• (LongRun Power Management)
– Fornece o necessário de poder computacional
• Code Morphing Technology– Compatibilidade com x86– Máquina VLIW

CrusoeCrusoeLongRun Power ManagemenLongRun Power Managementt• Controle da Frequência e voltagem
Potência=(Capacitância x Frequência x Voltagem2) /2

CrusoeCrusoeCode Morphing TechnologyCode Morphing Technology

CrusoeCrusoe
Code Morphing TechnologyCode Morphing Technology• Código do Code Morphing fica em ROM na CPU
(inacessível para instruções x86)• Traduz dinamicamente (interpreta) instruções
x86 para VLIW do µP• Acumula estatísticas de uso de sequências de
instruções• Traduz as sequências mais usadas para
CrusoeCrusoe
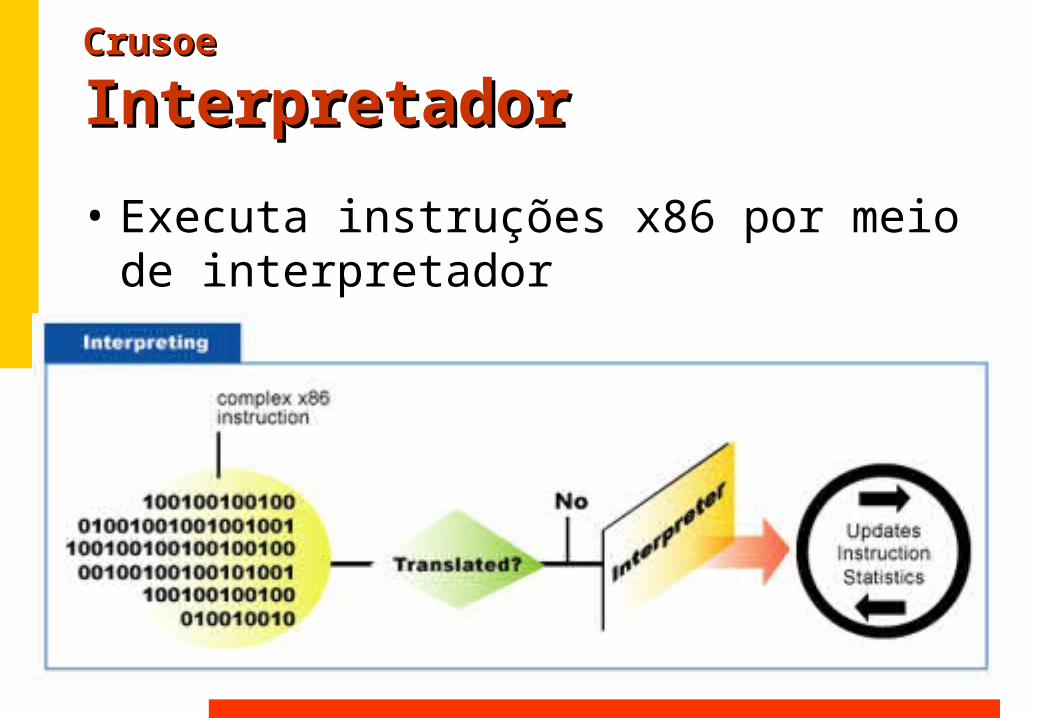
InterpretadorInterpretador• Executa instruções x86 por meio de
interpretador
CrusoeCrusoe
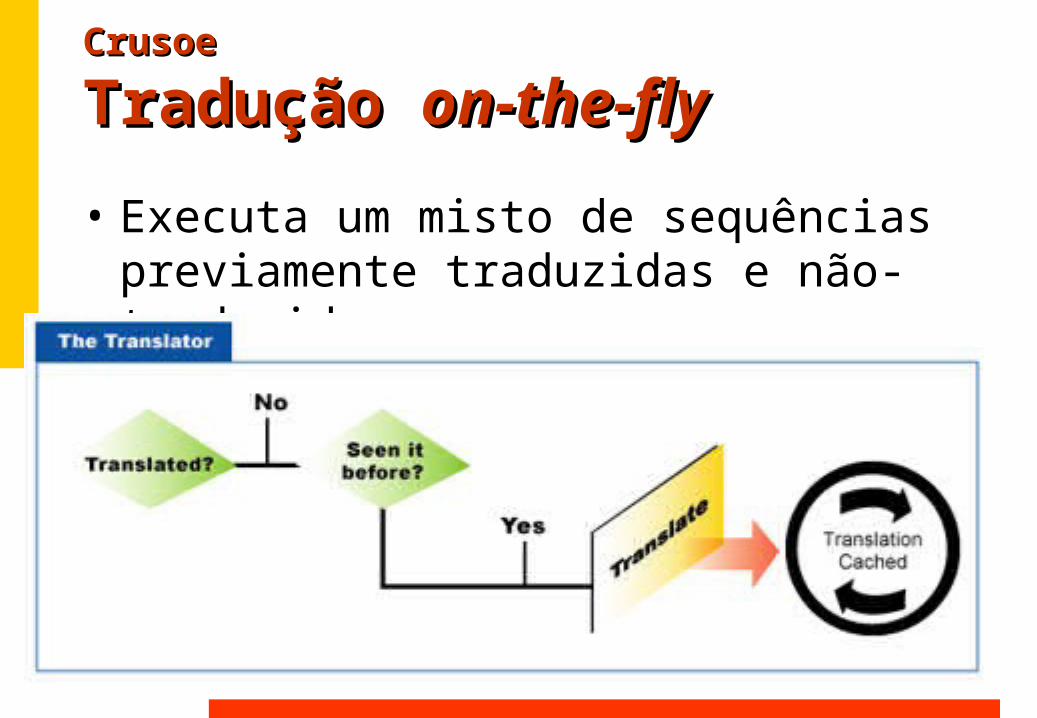
Tradução Tradução on-the-flyon-the-fly• Executa um misto de sequências
previamente traduzidas e não-traduzidas
CrusoeCrusoe
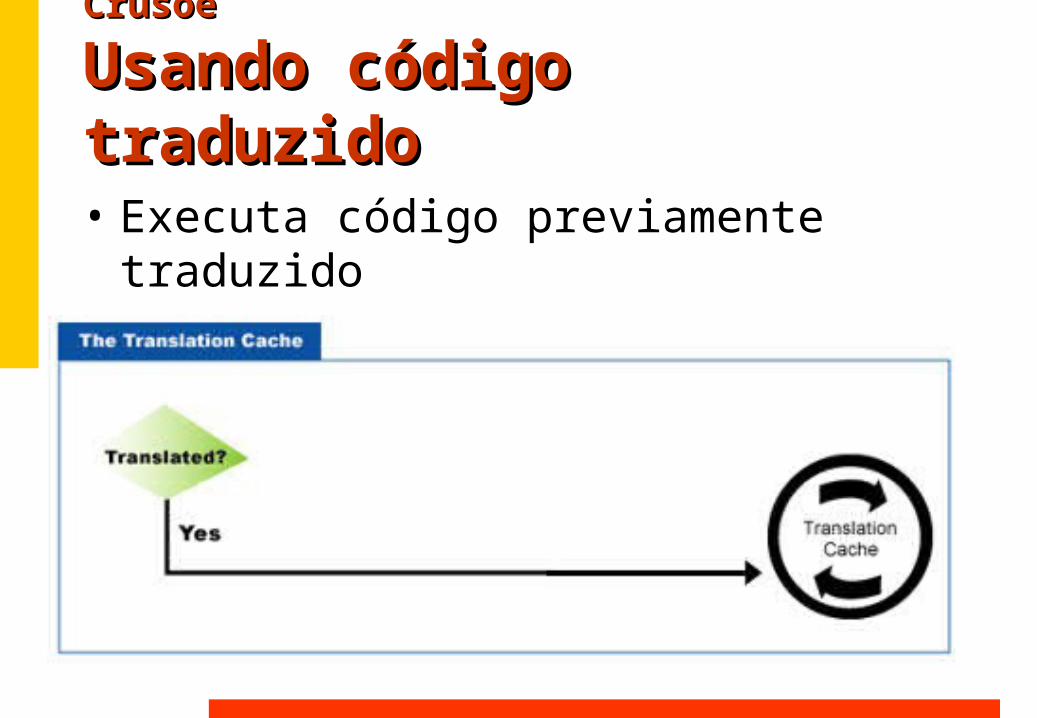
Usando código traduzidoUsando código traduzido• Executa código previamente traduzido

CPUs com pipelineCPUs com pipeline
• 80862 estágios• 286 4 estágios• 386 6 estágios• 486 8 estágios
• 68000 3 estágios• 68020 5 estágios• Alpha 21264
– 9 estágios– 6 inst/clk– out-of-order exec.– 600MHz (1997)– 15 milhões trans.
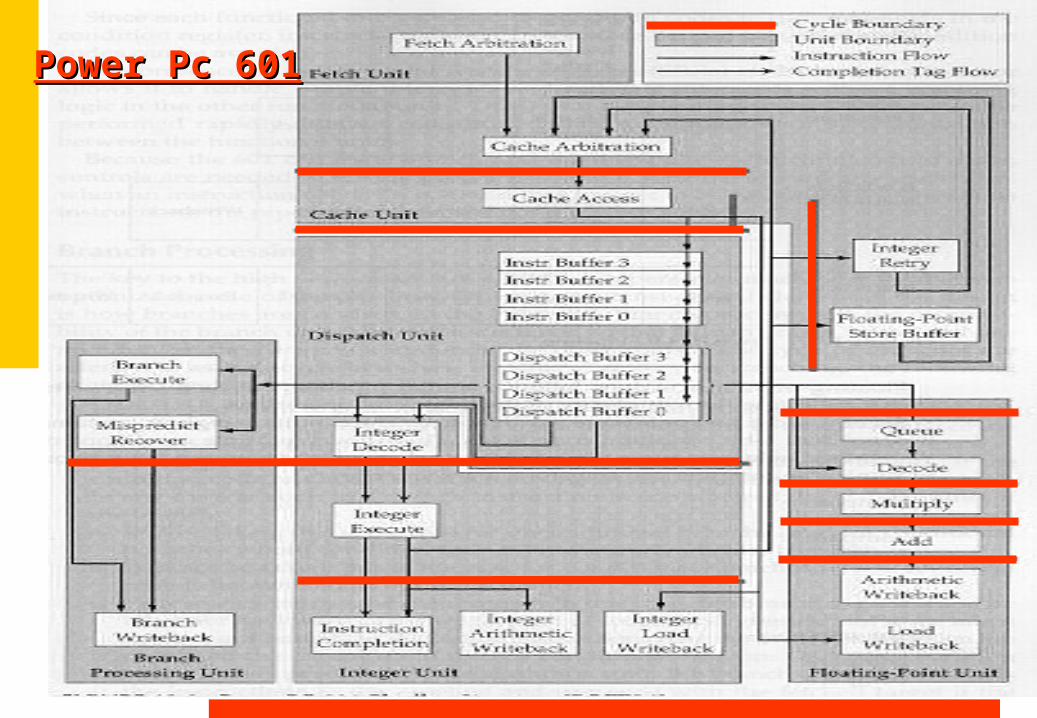
Power Pc 601Power Pc 601
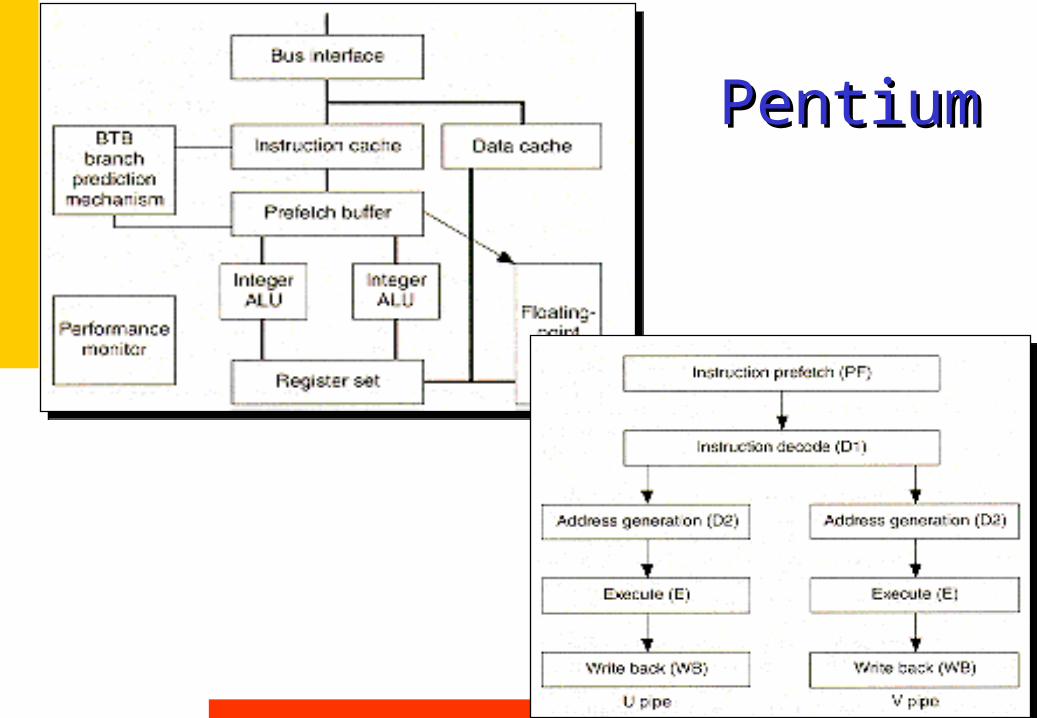
PentiumPentium





























