Embed Size (px)
DESCRIPTION
bases de l'optimisation non linéaire
Citation preview

Optimisation L2-MASS 2013-2014
Pierre Puiseux
20 février 2014

2

TABLE DES MATIÈRES 3
Table des matières
1 Introduction et rappels 51.1 Représentation graphique . . . . . . . . . . . . . . . . . . . . . 5
1.2 Formules de Taylor . . . . . . . . . . . . . . . . . . . . . . . . 6
1.3 Convexité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.4 Applications quadratiques . . . . . . . . . . . . . . . . . . . . 9
2 Optimisation sans contrainte 112.1 Extrema libres . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.2 Dérivée directionnelle, profil . . . . . . . . . . . . . . . . . . . 12
2.3 Condition nécessaire d’optimalité . . . . . . . . . . . . . . . . 14
2.4 Condition suffisante d’optimalité . . . . . . . . . . . . . . . . . 14
2.5 Algorithmes de gradient . . . . . . . . . . . . . . . . . . . . . 16
2.5.1 Gradient à pas fixe . . . . . . . . . . . . . . . . . . . . 17
2.5.2 Gradient à pas optimal . . . . . . . . . . . . . . . . . . 18
3 Contraintes égalité, multiplicateurs de Lagrange 213.1 Définitions et notations . . . . . . . . . . . . . . . . . . . . . . 21
3.2 Quelques exemples . . . . . . . . . . . . . . . . . . . . . . . . 22
3.3 Deux variables et une seule contrainte égalité . . . . . . . . . . 23
3.4 Cas général . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.5 En résumé . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4 Contrainte inégalité 314.1 Définition et exemples . . . . . . . . . . . . . . . . . . . . . . 31
4.2 Conditions nécessaires (KKT) . . . . . . . . . . . . . . . . . . 33
4.3 Conditions suffisantes (KKT) . . . . . . . . . . . . . . . . . . . 33
cc le mercredi 5/03
Correction lundi 10/03
Exam mercredi 12/03
Pierre Puiseux

4 TABLE DES MATIÈRES
Avertissement
ce ne sont que des notes de cours, en perpétuelle évolution, dans lesquelles subsistent certainement denombreuses erreurs et approximations !
Notations
R : R ∪ {−∞,+∞}
C : C ∪ {−∞,+∞}
K : R ou C et K : R ou C.
χA : fonction caractéristique de l’ensemble A.
L (E,F ) : applications linéaires de E dans F (E et F espaces vectoriels).
Lc (E,F ) : applications linéaires continues de E dans F (E et F espaces vectoriels normés).
|||Φ||| : norme de l’application linéaire Φ.
(f |g) produit scalaire.
C (A,B) = C0 (A,B) fonctions continues de A dans B.
Cp : fonctions de classe Cp
(u|v) : produit scalaire.
x, y, z, . . . des nombres réels
x, y, z, . . . des vecteurs de Rn
∇f (x) ou f ′ (x) : le gradient de f au point x.
∇2f (x) ou f ′′ (x) ou Hf (x) : la matrice hessienne de f au point x.

5
Chapitre 1
Introduction et rappels
L’optimisation est l’étude des fonctions f : Rn → R, pour lesquelles on cherche un point a =(a1, a2, . . . an) ∈ C ⊂ Rn en lequel f atteint un maximum ou un minimum.
Le point a est recherché dans un ensemble C qui prend en compte certaines contraintes du problème.
Un problème d’optimisation (minimisation) s’écrira :
(P)
{Minf (x)x ∈ C
On se restreint le plus souvent ici à des fonctions de deux ou trois variables (n = 2).
La fonction à optimiser est appelée fonction coût ou fonction objectif.
1.1 Représentation graphique
On considèrera une fonction f d’un ouvert D à valeurs dans R, où D est de la forme D = ]α1, β1[×]α2, β2[ si n = 2 et plus généralement D = ]α1, β1[× ]α2, β2[× · · · × ]αn, βn[ dans Rn .
On sait représenter graphiquement une fonction f : R2 → R et traçant dans R3 l’ensemble des pointsde coordonnées (x, y, z) avec z = f (x, y).
On peut également tracer les courbes de niveau ou isovaleurs (comme sur une carte IGN).
Pour n > 2 c’est plus délicat, on n’a pas de mode de visualisation directe de f comme dans R2. Lesisovaleurs sont des surfaces dans Rn−1 , difficiles à représenter graphiquement.
Pierre Puiseux
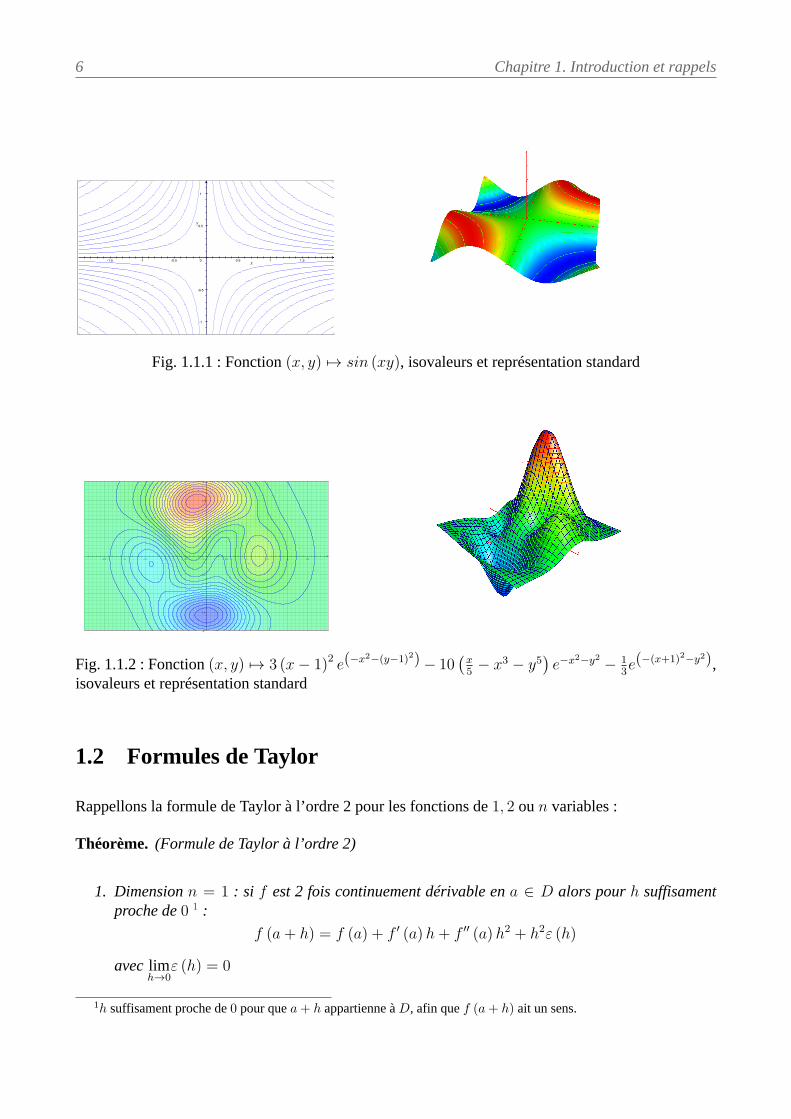
6 Chapitre 1. Introduction et rappels
-1.5 -1 -0.5 0 0.5 1 1.5
-1
-0.5
0.5
1
Fig. 1.1.1 : Fonction (x, y) 7→ sin (xy), isovaleurs et représentation standard
-2,5 -2 -1,5 -1 -0,5 0 0,5 1 1,5 2 2,5
-2
-1,5
-1
-0,5
0,5
1
1,5
2
Fig. 1.1.2 : Fonction (x, y) 7→ 3 (x− 1)2 e(−x2−(y−1)2)− 10(x5− x3 − y5
)e−x2−y2 − 1
3e(−(x+1)2−y2),
isovaleurs et représentation standard
1.2 Formules de Taylor
Rappellons la formule de Taylor à l’ordre 2 pour les fonctions de 1, 2 ou n variables :
Théorème. (Formule de Taylor à l’ordre 2)
1. Dimension n = 1 : si f est 2 fois continuement dérivable en a ∈ D alors pour h suffisamentproche de 0 1 :
f (a+ h) = f (a) + f ′ (a)h+ f ′′ (a)h2 + h2ε (h)
avec limh→0
ε (h) = 0
1h suffisament proche de 0 pour que a+ h appartienne à D, afin que f (a+ h) ait un sens.

1.3 Convexité 7
2. Dimension n = 2 : si f est 2 fois continuement dérivable en (a, b) ∈ D alors pour (h, k)suffisament proche de (0, 0) :
f (a+ h, b+ k) = f (a, b)+∂f
∂x(a, b)h+
∂f
∂y(a, b) k+
∂2f
∂x2h2+2
∂2f
∂x∂y(a, b)hk+
∂2f
∂y2k2(h2 + k2
)ε (h, k)
avec lim(h,k)→(0,0)
ε (h, k) = 0
3. Dimension n : si f est 2 fois continuement dérivable en a ∈ D alors pour h ∈ Rn suffisamentproche de 0Rn :
f (a+ h) = f (a) +∇f (a) .h+∇2f (a) (h, h) + ∥h∥22 ε (h)
avec limh→0Rn
ε (h) = 0
Remarque. Dans cette écriture, ∇f (a) ∈ Rn est le vecteur gradient de f en a, ∇2f (a) ∈ Rn,n est lamatrice hessienne de f en a et∇2f (a) (h, h) désigne le produit matriciel h×∇2f (a)× ht.
(h1 h2 . . . hn
)×
∂2f∂x2
1(a) ∂2f
∂x1∂x2(a) . . . ∂2f
∂x1∂xn(a)
∂2f∂x1∂x2
(a) . . . . . . ...... . . . . . . ∂2f
∂xn−1∂xn(a)
∂2f∂x1∂xn
(a) . . . ∂2f∂xn−1∂xn
(a) ∂2f∂x2
n(a)
×
h1
h2...hn
1.3 Convexité
Un résumé très rapide des propriétés de positivité des matrices.
Proposition 1.1. Soit n un entier et A ∈ Rn,n une matrice carrée.
– On appelle valeurs propres de A les racines du polynôme de degré n
pA (λ) = det (A− λIn)
– Si la matriceA est symétrique, alors elle admet n valeurs propres réelles λi, i ∈ J1, nK, certainesde ces valeurs pouvant être multiples, c’est à dire des racines multiples de pA.
– Si ∀i ∈ J1, nK, λi ≥ 0 alors la matrice est positive, et on a
∀x ∈ Rn, xt.A.x ≥ 0
– Si ∀i ∈ J1, nK, λi > 0 alors la matrice est définie positive, et on a
∀x ∈ Rn, x ̸= 0 ⇒ xt.A.x > 0
Dans ce cas, A est également inversible.

8 Chapitre 1. Introduction et rappels
Définition 1.1. Une partie de C ⊂ Rn est dite convexe si et seulement si
∀a, b ∈ C ,∀ω ∈ [0, 1] , (1− ω) a+ ωb ∈ C
En d’autre termes, tout segment qui relie deux points de C est entièrement dans C .
Exemple.
– Un ballon de rugby, de foot, sont convexes, un freezebee n’est pas convexe, un gruyère nonplus.
– le carré C = [0, 1]2 est strictement convexe : si a,b ∈ C et ω ∈ [0, 1] alors (1− ω) a + ωb =((1− ω) xa + ωxb(1− ω) ya + ωyb
). Or {
0 ≤ xa ≤ 1 et0 ≤ xb ≤ 1
comme ω et 1− ω sont positifs, on en déduit :{0 ≤ (1− ω)xa ≤ 1− ω et0 ≤ ωxb ≤ ω
et en additionnant :0 ≤ (1− ω)xa + ωxb ≤ 1
de manière analogue la deuxième coordonnée de (1− ω) a+ ωb vérifie :
0 ≤ (1− ω) ya + ωyb ≤ 1
et finalement on a bien(1− ω) a+ ωb ∈ C
Définition 1.2. Soit D un ouvert de Rn et f : D → R. On dit que f est
1. convexe si
∀x, y ∈ D, ∀ω ∈ [0, 1] , f ((1− ω) x+ ωy) ≤ (1− ω) f (x) + ωf (y)
2. strictement convexe si l’inégalité précédente est stricte :
∀x, y ∈ D, x ̸= y, ∀ω ∈ [0, 1] , f ((1− ω) x+ ωy) < (1− ω) f (x) + ωf (y)
3. f est (strictement) concave si −f est (strictement) convexe.
Autrement dit f est convexe signifie que la représentation graphique de f est en dessous du segmentqui joint le point (x, f (x)) au point (y, f (y)).
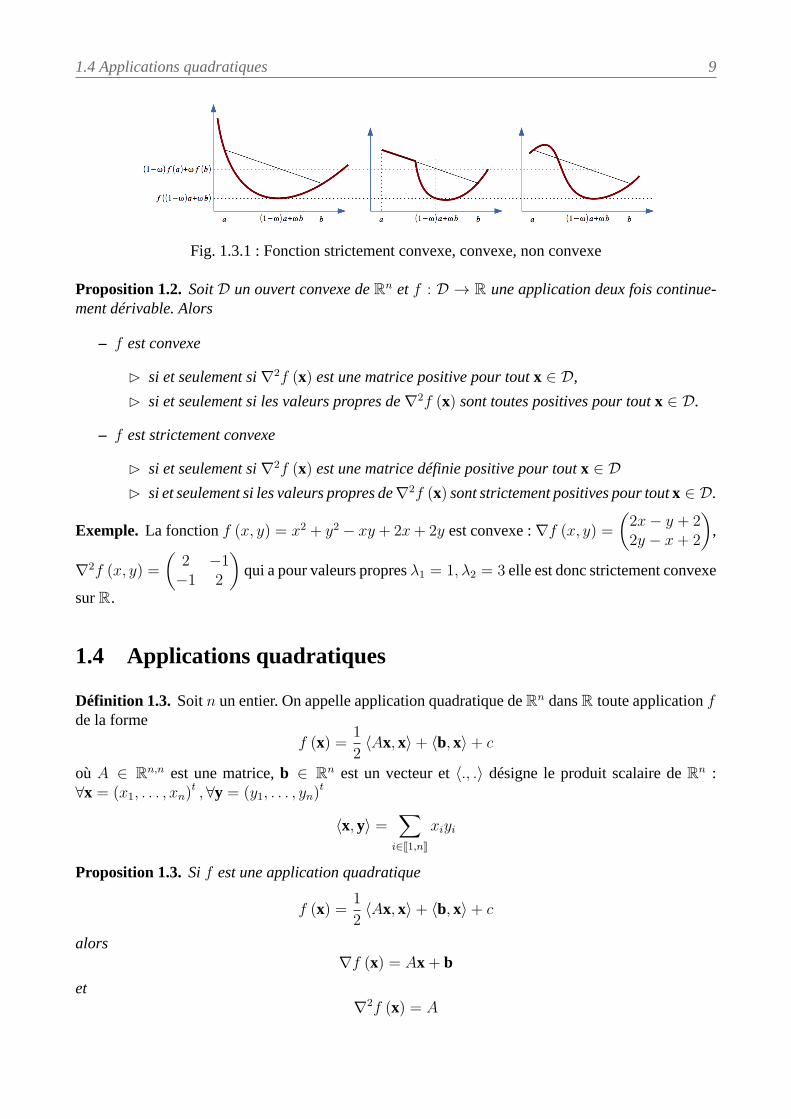
1.4 Applications quadratiques 9
Fig. 1.3.1 : Fonction strictement convexe, convexe, non convexe
Proposition 1.2. Soit D un ouvert convexe de Rn et f : D → R une application deux fois continue-ment dérivable. Alors
– f est convexe
◃ si et seulement si ∇2f (x) est une matrice positive pour tout x ∈ D,◃ si et seulement si les valeurs propres de ∇2f (x) sont toutes positives pour tout x ∈ D.
– f est strictement convexe
◃ si et seulement si ∇2f (x) est une matrice définie positive pour tout x ∈ D◃ si et seulement si les valeurs propres de∇2f (x) sont strictement positives pour tout x ∈ D.
Exemple. La fonction f (x, y) = x2 + y2 − xy + 2x+ 2y est convexe :∇f (x, y) =
(2x− y + 22y − x+ 2
),
∇2f (x, y) =
(2 −1−1 2
)qui a pour valeurs propres λ1 = 1, λ2 = 3 elle est donc strictement convexe
sur R.
1.4 Applications quadratiques
Définition 1.3. Soit n un entier. On appelle application quadratique de Rn dans R toute application fde la forme
f (x) =1
2⟨Ax, x⟩+ ⟨b, x⟩+ c
où A ∈ Rn,n est une matrice, b ∈ Rn est un vecteur et ⟨., .⟩ désigne le produit scalaire de Rn :∀x = (x1, . . . , xn)
t ,∀y = (y1, . . . , yn)t
⟨x, y⟩ =∑
i∈J1,nKxiyi
Proposition 1.3. Si f est une application quadratique
f (x) =1
2⟨Ax, x⟩+ ⟨b, x⟩+ c
alors∇f (x) = Ax+ b
et∇2f (x) = A

10 Chapitre 1. Introduction et rappels
Exemple 1.1. (x, y) 7→ x2 + y2 + xy− 2x+3 est une application quadratique dont les éléments sontdonnés par :
∇f (x) =(2x+ y − 22y + x
)∇2f (x) =
(2 11 2
)Donc f (x) = 1
2⟨Ax, x⟩+ ⟨b, x⟩+ c avec A =
(2 11 2
),b =
(−20
)et c = 3.

11
Chapitre 2
Optimisation sans contrainte
2.1 Extrema libres
Définition. Soit (a, b) un point de D. On dit que
1. f admet un maximum local en (a, b) s’il existe un ε > 0 tel que f (a, b) ≥ f (x, y) pour tout(x, y) tel que |x− a| < ε et |y − b| < ε ;
2. f admet un minimum local en (a, b) s’il existe un ε > 0 tel que f (a, b) ≤ f (x, y) pour tout(x, y) tel que |x− a| < ε et |y − b| < ε ;
3. f admet un maximum global en (a, b) si f (a, b) ≥ f (x, y) pour tout (x, y) ∈ D ;
4. f admet un minimum global en (a, b) si f (a, b) ≤ f (x, y) pour tout (x, y) ∈ D.
– Dessin en 2d, en 3d
– extremum = max ou min
Remarque. On notera que trouver un minimum pour la fonction f équivaut à trouver un maximumpour la fonction -f
rappel extremum 1dThéorème 2.1. Soit I un intervalle ouvert de R, non vide, et f : I → R une fonction deux foiscontinuement dérivable en a ∈ I , telle que f ′ (a) = 0. Alors :
– si f ′′ (a) < 0, f admet un maximum local en a
– si f ′′ (a) > 0 alors f admet un minimum local en a
– si f ′′ (a) = 0 on ne peut pas conclure.
Pour le 3-ème cas, penser aux deux fonctions x 7→ x2 et x 7→ x3 en a = 0, dont l’une est minimum,l’autre ne l’est pas.Ce comportement de f au voisinage de a se lit directement dans son développement limité à l’ordre2, (h positif ou négatif ) :
f (a+ h)− f (a) = h2 (f ′′ (a) + ε (h))
avec limh→0 ε (h) = 0. Donc si f ′′ (a) > 0, alors f (a+ h) > f (a), autrement dit f est minimum ena.
Pierre Puiseux
12 Chapitre 2. Optimisation sans contrainte
2.2 Dérivée directionnelle, profil
Définition. On suppose f continuement dérivable sur D. Soit A = (a, b) ∈ D et une directiond = (u, v) donnée.
– On appelle dérivée directionnelle de f en (a, b) dans la direction (u, v) la quantité
∂f
∂x(a, b)u+
∂f
∂y(a, b) v
– on appelle coupe ou profil de f le long de la droite A, d la fonction
γ (t) = f (A+ td)
= f (a+ tu, b+ tv)
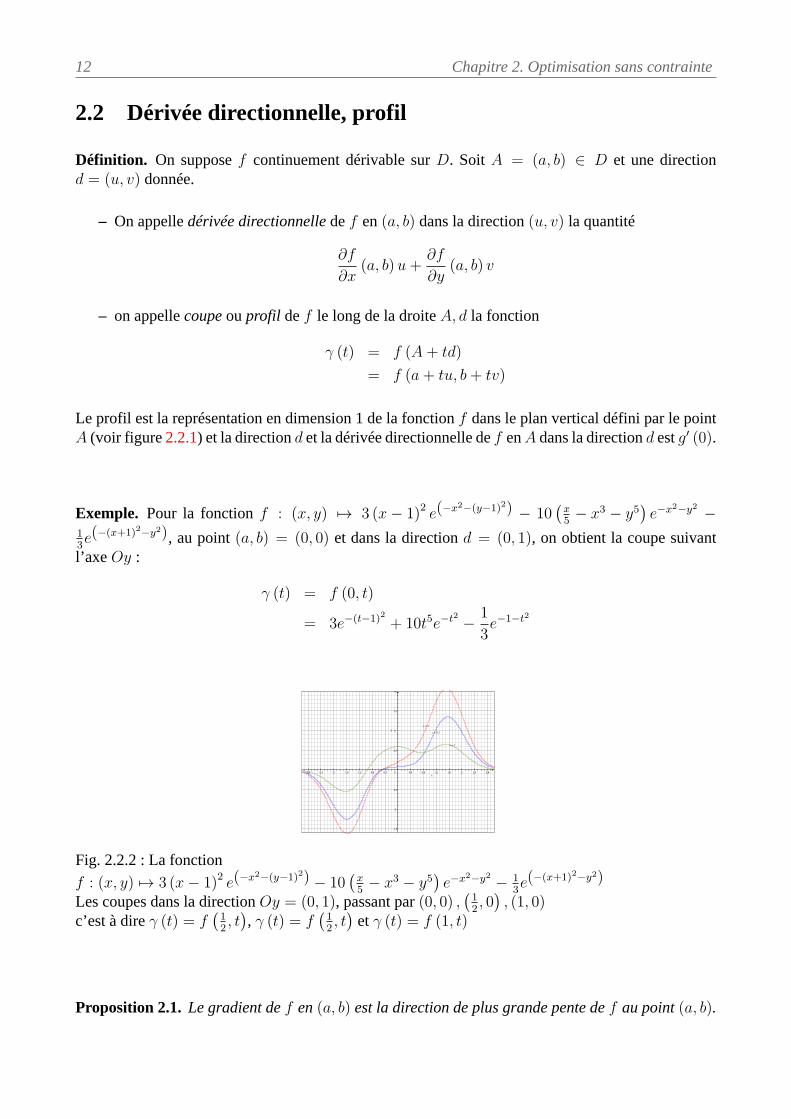
Le profil est la représentation en dimension 1 de la fonction f dans le plan vertical défini par le pointA (voir figure 2.2.1) et la direction d et la dérivée directionnelle de f enA dans la direction d est g′ (0).
Exemple. Pour la fonction f : (x, y) 7→ 3 (x− 1)2 e(−x2−(y−1)2) − 10(x5− x3 − y5
)e−x2−y2 −
13e(−(x+1)2−y2), au point (a, b) = (0, 0) et dans la direction d = (0, 1), on obtient la coupe suivantl’axe Oy :
γ (t) = f (0, t)
= 3e−(t−1)2 + 10t5e−t2 − 1
3e−1−t2
-2,8 -2,4 -2 -1,6 -1,2 -0,8 -0,4 0 0,4 0,8 1,2 1,6 2 2,4 2,8
-7,5
-5
-2,5
2,5
5
7,5
10
x = 0
x = 0.5
x = 1
Fig. 2.2.2 : La fonctionf : (x, y) 7→ 3 (x− 1)2 e(−x2−(y−1)2) − 10
(x5− x3 − y5
)e−x2−y2 − 1
3e(−(x+1)2−y2)
Les coupes dans la direction Oy = (0, 1), passant par (0, 0) ,(12, 0), (1, 0)
c’est à dire γ (t) = f(12, t), γ (t) = f
(12, t)et γ (t) = f (1, t)
Proposition 2.1. Le gradient de f en (a, b) est la direction de plus grande pente de f au point (a, b).
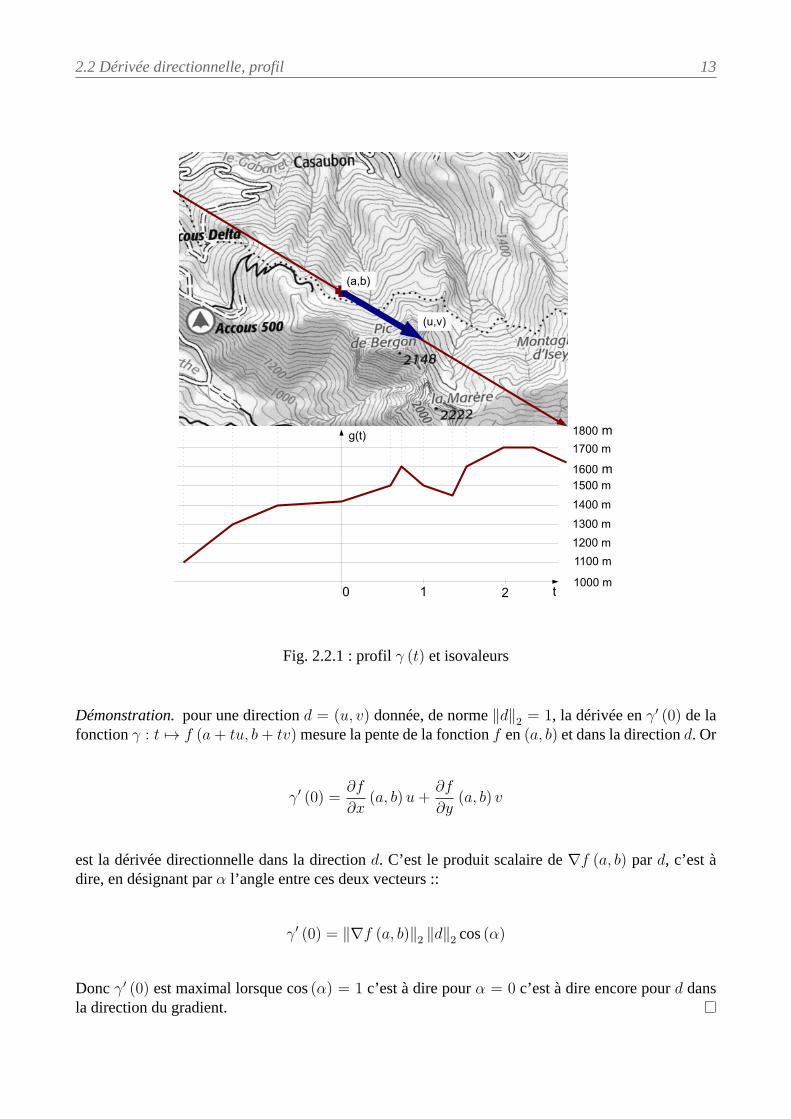
2.2 Dérivée directionnelle, profil 13
1000 m
1100 m
1200 m
1300 m
1400 m
1500 m1600 m
1700 m
1800 m
t0 1
(u,v)
2
g(t)
(a,b)
Fig. 2.2.1 : profil γ (t) et isovaleurs
Démonstration. pour une direction d = (u, v) donnée, de norme ∥d∥2 = 1, la dérivée en γ′ (0) de lafonction γ : t 7→ f (a+ tu, b+ tv)mesure la pente de la fonction f en (a, b) et dans la direction d. Or
γ′ (0) =∂f
∂x(a, b)u+
∂f
∂y(a, b) v
est la dérivée directionnelle dans la direction d. C’est le produit scalaire de ∇f (a, b) par d, c’est àdire, en désignant par α l’angle entre ces deux vecteurs ::
γ′ (0) = ∥∇f (a, b)∥2 ∥d∥2 cos (α)
Donc γ′ (0) est maximal lorsque cos (α) = 1 c’est à dire pour α = 0 c’est à dire encore pour d dansla direction du gradient.

14 Chapitre 2. Optimisation sans contrainte
2.3 Condition nécessaire d’optimalité
Théorème. (condition nécessaire, ordre 1) si f est continuement dérivable sur D, si (a, b) ∈ D estun extremum, alors le gradient de f en (a, b) est nul :
∂f
∂x(a, b) =
∂f
∂y(a, b) = 0
La nullité du gradient en (a, b) est une condition nécessaire, mais insuffisante, pour que f admette unextremum en (a, b). Les points ou le gradient s’annule sont appelés points critiques.
Exemple. f (x, y) = xy a pour point critique (0, 0) et f (0, 0) = 0 n’est ni un minimum ni un maxi-mum car f prend des valeurs positives et négatives sur tout voisinage de (0, 0) puisque f (x, x) > 0et f (x,−x) < 0.
2.4 Condition suffisante d’optimalité
Cherchons maintenant une condition suffisante d’optimalité.
Une condition suffisante pour que la fonction f soit maximum au point (a, b) est que la coupe γsoit maximum en 0 pour toutes les directions (u, v). Ce qui revient à dire que γ′ (0) = 0 et γ′′ (0) < 0pour toutes les directions (u, v), ou encore :
– ∂f∂x
(a, b)u+ ∂f∂y
(a, b) v est nul pour toute direction (u, v) et
– γ′′ (0) = ∂2f∂x2 (a, b)u
2 + 2uv ∂2f∂x∂y
(a, b) + ∂2f∂y2
(a, b) v2 est négatif pour toute direction (u, v)
La première condition est la nullité du gradient de f en (a, b).
Définition. On appelle hessienne de f en (a, b) la matrice
(∂2f∂x2 (a, b)
∂2f∂x∂y
(a, b)∂2f∂x∂y
(a, b) ∂2f∂y2
(a, b)
), parfois notée
D2f (a, b) ou Hf (a, b) ou même simplement f ′′ (a, b).
Les valeurs propres d’une matrice A sont les racines du polynôme P (λ) = det (A− λI).
On appelle vecteur propre associé à la valeur propre λ tout vecteur U non nul vérifiant AU = λU .
On remarque que γ′′ (0) =(u v
)D2f (a, b)
(uv
), la théorie des formes bilinéaires s’applique : pour
que γ′′ (0) > 0 dans toutes les directions (u, v), il suffit que la hessienne soit une matrice définiepositive, c’est à dire que ses valeurs propres soient strictement positives.
On peut retenir le théorème :

2.4 Condition suffisante d’optimalité 15
Théorème 2.2. Soit D un domaine ouvert de R2, f une fonction deux fois continûment différentiablesur D et (a, b) un point de D. Notons ∇ le gradient et H la matrice hessienne de f au point (a, b).
1. Si∇ = 0 et siH a toutes ses valeurs propres strictement négatives, alors (a, b) est un maximumlocal pour f .
2. Si ∇ = 0 et si H a toutes ses valeurs propres strictement positives, alors (a, b) est un minimumlocal pour f .
3. Si ∇ = 0 et si H a certaines de ses valeurs propres strictement positives, toutes les autresstrictement négatives, alors (a, b) est un point selle pour f .
4. Si ∇ = 0 et si certaines valeurs propres de H sont nulles, alors on ne peut pas conclure.
x
y
z
(a,b)
Dx
y
z
(a,b)
D
x
y
z
(a,b)
D
Fig. 2.4.1 : Maximum, minimum et point col en dimension 2
Exemple. (dimension 2) f (x, y) = xy2+2x2+y2. Au point (x, y), le gradient et la matrice hessiennesont :
∇f (x, y) =
(y2 + 4x2xy + 2y
);H =
(4 2y2y 2 (x+ 1)
)

16 Chapitre 2. Optimisation sans contrainte
– CN : les points critiques sont (−1, 2) , (−1,−2) et (0, 0).
– CS :
◃ (a, b) = (−1, 2) H =
(4 44 0
)la hessienne a pour valeurs propres λ = 2 + 2
√5 > 0,
µ = 2− 2√5 < 0 c’est un point selle.
◃ (a, b) = (−1,−2)H =
(4 −4−4 0
)la hessienne a pour valeurs propres λ = 2+2
√5 > 0,
µ = 2− 2√5 < 0 c’est un point selle.
◃ (a, b) = (0, 0)H =
(4 00 2
)la hessienne a pour valeurs propres λ = 4, µ = 2 toutes deux
positives, c’est un minimum.
Lorsque la fonction f est à deux variables (x, y), cette analyse par valeurs propres se simplifie, et iln’est pas nécessaire de calculer les valeurs propres :
γ′′ (0) = ∂2f∂x2 (a, b)u
2+2uv ∂2f∂x∂y
(a, b)+ ∂2f∂y2
(a, b) v2 est un polynôme du second degré en u, la condi-tion γ′′ (0) < 0 (suffisante pour avoir un maximum) est de la forme αu2 + 2βu + γ < 0 pour tout
(u, v). Le discriminant réduit de ce polynôme est ∆′ = v2((
∂2f∂x∂y
(a, b))2
− ∂2f∂x2 (a, b)
∂2f∂y2
(a, b)
)=
−v2 detH (x, y). On en déduit :
Théorème 2.3. (spécifique à la dimension 2)
– si detH (a, b) > 0 alors γ′′ (0) est de signe constant : le signe de ∂2f∂x2 (a, b) ;
◃ si ∂2f∂x2 (a, b) < 0 , alors f admet un maximum en (a, b) ;
◃ si ∂2f∂x2 (a, b) > 0 , alors f admet un minimum en (a, b) ;
– si detH (a, b) < 0 alors γ′′ (0) change de signe (a, b) est un point selle ;
– si detH (a, b) = 0 on ne peut pas conclure.
2.5 Algorithmes de gradient
Pour calculer le minimum d’une fonction f : Rn → R dont on connaît le gradient∇f : Rn → Rn
On rappelle que le gradient de f en (a, b) est un vecteur de Rn qui indique la plus grande pente en(a, b).
L’idée pour minimiser une fonction (si le problème est de trouver un maximum pour+f , on minimise−f ) , est de partir d’un point donné, x(0) et de suivre la plus grande pente (en descendant) pour aboutirà un point x(1), puis de recommencer jusqu’à aboutir à un point critique (où le gradient est nul).

2.5 Algorithmes de gradient 17
2.5.1 Gradient à pas fixe
Pour deux vecteurs u, v ∈ Rn, on définit le produit scalaire :
u.v =∑
1≤k≤n
ukvk
et la norme euclidienne de u par∥u∥2 =
√u.u
L’algorithme du gradient consiste à partir d’une approximation initiale x(0) = (x0, y0), à se déplacerdans la direction de la plus grande pente, donc du gradient, d’un pas t. Si t > 0, le déplacement se faitdans la direction f croissante, si t < 0, on se déplace dans la direction f décroissante.
On stoppe les itérations lorsque f(x(k))ou bien x(k) est stationnaire. Ici, on a choisi la stationnarité
de f(x(k)).
Algorithme 2.1 Algorithme du gradient à pas fixe pour minimiser une fonction fx(0), ε, f,∇f, t sont donnés, k = 0répéter :
– x(k+1) = x(k) − t∇f(x(k))
– k = k + 1
jusqu’à∣∣f (x(k)
)− f
(x(k−1)
)∣∣ < ε
Exemple. Le programme Python qui suit implémente l’algorithme du gradient à pas fixe, pour lafonction (x, y) 7→ x2 + y2 − xy. Le test d’arrêt des itérations se fait sur la norme du gradient : c’est àdire sur
∥∥∇f(x(k))∥∥2
2< ε2, ce qui équivaut à
∥∥x(k+1) − x(k)∥∥2< ε. Afin d’interdire une boucle infini,
(en cas de non convergence), on limite également le nombre d’itérations avec le paramètre itmax
#!/usr/local/bin/python2.7
# -*- coding : utf-8 -*-
''' Optimisation : gradient à pas fixe'''
def f(x,y) :
return x*x + y*y - x*y
def gradf(x,y) :
return [2*x - y, 2*y - x]
def gradient(X0=[1.0,1.0], f=f, gradf=gradf, eps=1.e-5, itmax=100, t=1.0) :
'''Gradient à pas fixe'''
X = [X0]
x,y = X0
F = [f(x,y)]
it = 1
while 1 :
dx, dy = gradf(x, y)
18 Chapitre 2. Optimisation sans contrainte
dx, dy = t*dx, t*dy
if (dx*dx+dy*dy)< eps*eps or it >= itmax :
break
else :
it += 1
x -= dx
y -= dy
F.append(f(x,y))
X.append([x,y])
return (it, X, F)
if __name__ == '__main__' :
import numpy as np
import matplotlib.pyplot as plt
it, X, F = gradient(X0=[1.0,0.0], f=f,
gradf=gradf, eps=1.e-6,
itmax=50, t=0.667)
print it, len(F)
print F
plt.plot(range(it), F)
plt.show()
0 5 10 15 20 250.0
0.2
0.4
0.6
0.8
1.0
Fig. 2.5.1 : Valeur de la fonction objectif en fonction du numéro d’itération, algorithme du gradient
2.5.2 Gradient à pas optimal
Ici, on demande à l’algorithme de déplacer x(k), toujours dans la direction du gradient, mais cette foisjusqu’au minimum de f , c’est à dire de minimiser la coupe
t ∈ R 7→ γk (t) = f(x(k) + t.∇f
(x(k)))
En général, on ne dispose pas d’une expression analytique de la coupe γk. La minimisation de cettefonction (appelée recherche linéaire) peut être assez difficile à mener. Il existe des algorithmes (règlesde Wolfe, d’Armijo, ...) qui approchent ce minimum.

2.5 Algorithmes de gradient 19
Algorithme 2.2 Algorithme du gradient à pas optimalx(0), ε, f,∇f sont donnésk = 0répéter :
– calcul de ∇f(x(k))
– trouver tk qui minimise la coupe γk : t ∈ R 7→ f(x(k) + t∇f
(x(k)))
– x(k+1) = x(k) − tk∇f(x(k))
– k = k + 1
jusqu’à∣∣f (x(k)
)− f
(x(k−1)
)∣∣ < ε

20 Chapitre 2. Optimisation sans contrainte

21
Chapitre 3
Contraintes égalité, multiplicateurs deLagrange
3.1 Définitions et notations
En toute généralité, nous posons le problème d’optimisation sous contraintes égalité ainsi :
SoitD un ouvert non vide deRn, et soit f : D → R la fonction coût ou fonction objectif, continuementdifférentiable.
Les contraintes g1, . . . , gp sont p applications continuement différentiables et
C = {x ∈ D, gi (x) = 0, ∀i ∈ J1, pK}Le problème de minimisation à résoudre est :
(P)
{Minf (x)x ∈ C
Définition 3.1. On appelle lagrangien du problème (P) la fonction
L (x, λ) = L (x1, x2, . . . , xn, λ1, . . . , λm)
= f (x) +∑
i∈J1,pKλigi (x)
Notation. On note (observez l’indice x)
∇xL (x, λ) = ∇f (x) +∑
i∈J1,pKλi∇gi (x)
et∇2
xL (x, λ) = ∇2f (x) +∑
i∈J1,pKλi∇2gi (x)
On voit facilement
Pierre Puiseux

22 Chapitre 3. Contraintes égalité, multiplicateurs de Lagrange
– que∇xL (x, λ) est le vecteur constitué des n premières composantes de∇L (x, λ) et
– que∇2xL (x, λ) est la sous matrice constituée des n première lignes et n premières colonnes
de∇2L (x, λ)
∇2xL (x, λ) =
∂2L∂x2
1
∂2L∂x1∂x2
. . . ∂2L∂x1∂xn
∂2L∂x1∂x2
. . . . . . ...... . . . . . . ∂2L
∂xn−1∂xn
∂2L∂x1∂xn
. . . ∂2L∂xn−1∂xn
∂2L∂x2
n
(x, λ)
3.2 Quelques exemples
Exemple 3.1. Minimiser la fonction f : x 7→ x2 sous la contrainte x = 1 à pour unique solutionévidente x = 1. Mais x = 1 n’est pas point critique de f puisque f ′ (1) = 2 ̸= 0. Il est donc clair quela méthode d’optimisation sans contrainte du chapitre précédent ne peut pas s’appliquer telle qu’elleau problème contraint.
Exemple 3.2. Minimiser ou maximiser
f (x, y) = x3y − x2 + 3x+ y2 + 2y
sous la contrainteg (x, y) = 2x+ y − 1 = 0
La contrainte fournit y = 1 − 2x que l’on reporte dans f (x, y) qui devient une fonction à une seulevariable
h (x) = f (x, 1− 2x)
= −2x4 + x3 + 3x2 − 5x+ 3
= −(x− 1)(2x3 + x2 − 2x+ 3)
-2 -1,5 -1 -0,5 0 0,5 1 1,5 2
-5
-2,5
2,5
5
7,5
10
Fig. 3.2.1 : h (x) = −2x4 + x3 + 3x2 − 5x+ 3
Remarque. g (x, y) = 0 est l’équation de la droite passant par A = (0, 1) et dirigée par le vecteurd = (1,−2). Minimiser la fonction f sous la contrainte g (x, y) = 0 équivaut donc à minimiser lacoupe de f sur cette droite. Cette coupe est précisément la fonction γ : t 7→ f (A+ td).
on trouve facilement que γ est maximum en x = −1, avec γ (−1) = 8.

3.3 Deux variables et une seule contrainte égalité 23
Les contraintes ne sont pas nécessairement linéaires comme g (x, y) dans l’exemple précédent.
Exemple 3.3. (contrainte non linéaire) : parmi les parallélépipèdes de surface S0 fixée, lequel a le vo-lume maximal ? x, y désignant les longueurs des cotés du parallélépipède, la surface est S (x, y, z) =2 (xy + yz + zx) et son volume est V (x, y, z) = xyz. Le problème consiste donc à trouver le maxi-mum de V (x, y, z) sous la contrainte 2 (xy + yz + zx) = S0. On peut calculer z :
z =S0
2− xy
x+ y
et maximiser
VS0 (x, y) = xyS0
2− xy
x+ y
On trouve alors la maximum par la technique usuelle :
x = y =
√S0
6
puis z = x = y, ce qui montre que le cube est la solution cherchée.
Remarque. dans le cas d’un problème d’optimisation à n variables le nombre de contraintes « indé-pendantes » (dans un sens à préciser) doit être inférieur à n car sinon, pour p = n contraintes, lescontraintes forment un système de n équations à n inconnues. Dans les bons cas, il n’y a qu’une seulesolution, indépendante de la fonction à optimiser. Pour p > n il peut n’y avoir aucune solution.
Exemple 3.4. Le problème suivant : trouver le minimum de la fonction f (x, y) = xy sous lescontraintes x + y = 1 et x − y = 1 a pour unique solution (x, y) = (1, 0), qui est le seul pointde R2 satisfaisant les deux contraintes. Cette solution est obtenue sans tenir aucun compte de la fonc-tion à optimiser. Les contraintes dans ce cas sont deux équations de droites, la solution est l’uniqueintersection de ces deux droites, sauf cas particulier (droites parallèles ou confondues).
3.3 Deux variables et une seule contrainte égalité
On se place en dimension n = 2 (f est une fonction a deux variables) avec une seule contrainte égalitég. L’ensemble des contraintes est
C = {(x, y) ∈ D, g (x, y) = 0}
Le lagrangien du problème est donc
L (x, y, λ) = f (x, y) + λg (x, y)
Le théorème suivant donne une condition nécessaire d’existence d’un minimum contraint :
Théorème 3.1. (condition nécessaire, ordre 1) SoitD un domaine ouvert de R2, f et g deux applica-tions continuement dérivables de D dans R. On note
C = {(x, y) ∈ D, g (x, y) = 0}

24 Chapitre 3. Contraintes égalité, multiplicateurs de Lagrange
Si f restreinte à C présente un extrémum en (a, b) ∈ C et si la contrainte est qualifiée :
∇g (a, b) ̸= 0R2
alors le lagrangien admet un point critique (a, b, λ∗) et λ∗ est appelé multiplicateur de Lagrange :
∇L (a, b, λ∗) = 0R3
Remarque.
1. Si (a, b, λ∗) et un point critique du lagrangien, alors (a, b) ∈ A car ∂L∂λ
(a, b, λ∗) = g (a, b) = 0.
2. Si la contrainte n’est pas qualifiée en (a, b), il se peut que f restreinte àA présente un extrémumen (a, b) ∈ A mais que le multiplicateur de Lagrange λ∗ n’existe pas.
3. Si la contrainte est le cercle unité x2 + y2 = 1 on a une interprétation simple du multiplicateurde Lagrange : minimiser f (x, y) sous la contrainte x2 + y2 = 1 revient à minimiser φ (θ) =f (cos (θ) , sin (θ)) pour θ ∈ R, c’est un problème en 1 dimension, sans contrainte. La conditionnécessaire d’optimalité s’écrit : φ′ (θ) = 0 soit
− sin (θ)∂f
∂x(cos (θ) , sin (θ)) + cos (θ)
∂f
∂y(cos (θ) , sin (θ))
ce qui peut s’interpréter ainsi : les deux vecteurs∇f (cos (θ) , sin (θ)) et u = (cos (θ) , sin (θ))t
sont colinéaires. Or u n’est autre que ∇g (cos (θ) , sin (θ)) avec g (x, y) = x2 + y2 − 1 donc ilexiste un réel λ∗ tel que ∇f (cos (θ) , sin (θ)) = λ∗∇g (cos (θ) , sin (θ))
Définition 3.2. (Hessienne bordée) La matrice hessienne du lagrangien est aussi appelée la matricehessienne bordée de f
∇2L (x, y, λ) =
∂2L∂x2 (x, y, λ)
∂2L∂y∂x
(x, y, λ) ∂g∂x
(x, y)∂2L∂x∂y
(x, y, λ) ∂2L∂y2
(x, y, λ) ∂g∂y
(x, y)∂g∂x
(x, y) ∂g∂y
(x, y) 0
Théorème 3.2. (Condition suffisante, ordre 2) Soit D un domaine ouvert de R2, f et g deux applica-tions deux fois continuement dérivables de D dans R. Soit (a, b, λ∗) un point critique du lagrangien
L (x, y, λ) = f (x, y) + λg (x, y)
alors
– si le déterminant de la hessienne bordée ∇2L (a, b, λ∗) est strictement négatif, (a, b) est unminimum local du problème contraint ;
– si le déterminant de la hessienne bordée∇2L (a, b, λ∗) est strictement positif, (a, b) est un maxi-mum local du problème contraint.
ATTENTION : Le théorème précédent est valide uniquement pour deux variables (x, y)

3.3 Deux variables et une seule contrainte égalité 25
Exemple 3.5. Optimimiser
f (x, y) = x3y − x2 + 3x+ y2 + 2y
sous la contrainteg (x, y) = 2x+ y − 1 = 0
Le lagrangien du problème est
L (x, y, λ) = x3y − x2 + 3x+ y2 + 2y + λ (2x+ y − 1)
1. Gradient et hessienne bordée :
∇L (x, y, λ) =
3x2y − 2x+ 3 + 2λx3 + 2y + 2 + λ
2x+ y − 1
et
∇2L (x, y, λ) =
6xy − 2 3x2 23x2 2 12 1 0
2. un seul point critique de L : (−1, 3, 7)∇2L (−1, 3, 7) =
−20 3 23 2 12 1 0
et
3. La contrainte est qualifiée au point (−1, 3) car∇g (−1, 3) =
(21
)̸= 0R2
4. det (∇2L (−1, 3, 7)) = 24 > 0 donc f présente un maximum contraint en (−1, 3) : f (−1, 3) =8
5. figures
Fig. 3.3.1 : f (x, y) = x3y − x2 + 3x+ y2 + 2y et la contrainte 2x+ y − 1 = 0

26 Chapitre 3. Contraintes égalité, multiplicateurs de Lagrange
3.4 Cas général
La fonction à optimiser est f : D ⊂ Rn → R où D est un ouvert de Rn.
Les p contraintes égalité sont gi (x) = 0, 1 ≤ i ≤ p où gi sont p fonctions de D dans R.
L’ensemble contraint est donc
C = {x ∈ D, ∀i, 1 ≤ i ≤ p, gi (x) = 0}
et le problème de minimisation est :
(P)
{Minf (x)x ∈ C
Définition 3.3. On dit que les contraintes sont qualifiées au point x∗ si et seulement si la famille
{∇gi (x∗) , 1 ≤ i ≤ p}
est une famille libre.
On commence par des conditions nécessaires :
Théorème 3.3. (condition nécessaire, ordre 1) On suppose que f et gi, 1 ≤ i ≤ p sont continuementdérivables sur D.
– Si f restreinte à C présente un extremum en x∗ ∈ C et
– si les contraintes sont qualifiées
alors le lagrangien admet un point critique (x∗, λ∗) avec λ∗ =(λ∗1, λ
∗2, . . . , λ
∗p
):
∇L (x∗, λ∗) = 0R3
les λ∗i sont appelés multiplicateurs de Lagrange.
Remarque.
1. Si (x∗, λ∗) et un point critique du lagrangien, alors x∗ ∈ C car ∂L∂λj
(x∗, λ∗) = gj (x∗) = 0.
2. Si la contrainte n’est pas qualifiée en x∗, il se peut que f restreinte à C présente un extremumen x∗ ∈ C mais que les multiplicateurs de Lagrange λ∗ n’existent pas.
La version « faible » pour les conditions suffisantes :
Théorème 3.4. (Condition suffisante d’ordre 2) On suppose que f et gj, 1 ≤ j ≤ p sont deux foiscontinuement dérivables sur D et que
– (x∗, λ∗) est un point critique du lagrangien,
– les contraintes en x∗ sont qualifiées,
– la matrice ∇2xL (x∗, λ∗) est définie positive,

3.4 Cas général 27
alors x∗ est un minimum du problème contraint.
Exemple 3.6. Dans l’exemple (3.5), ∇2xL (−1, 3, 7) =
(−20 33 2
)a une valeur propre négative,
l’autre positive. Ce théorème ne permet pas de conclure.
Dans l’exemple suivant, le théorème permet de conclure :
Exemple 3.7. Minimiser f (x, y, z) = x+ y + z sous la contrainte g (x, y, z) = x2 + y2 + z2 − r2
1. Le Lagrangien est
L (x, y, z, λ) = x+ y + z + λ(x2 + y2 + z2 − r2
)le gradient :
∇L (x, y, z, λ) =
1 + 2λx1 + 2λy1 + 2λz
x2 + y2 + z2 − r2
la hessienne :
∇2L (x, y, z, λ) =
2λ 0 0 2x0 2λ 0 2y0 0 2λ 2z2x 2y 2z 0
et son déterminant :
det(∇2L (x, y, z, λ)
)= −16λ2
(x2 + y2 + z2
)< 0
2. Points critiques : x = y = z = − 12λ
et la contrainte donne 3x2 = r2 donc les points critiquessont :
A = (x∗, λ∗) =
(√3
3r,
√3
3r,
√3
3r,−
√3
2r
)et B = −A.
Vérifions que la contrainte est qualifiée pour chacun de ces points :
∇g (x, y, z) =
2x2y2z
donc ∇g (x∗) ̸= 0 et ∇g (−x∗) ̸= 0 ces deux points critiques sont donc candidats à être desextrema contraints.
3. De l’égalité∇2
xL (x, y, z, λ) = 2λId3
on déduit, en utilisant le théorème précédent :
– au point A on a ∇2xL (A) a donc pour valeurs propres λ1 = λ2 = λ3 = −
√3r
< 0 on adonc un maximum.

28 Chapitre 3. Contraintes égalité, multiplicateurs de Lagrange
– au pointB = −A les valeurs propres∇2xL (B) de sont λ1 = λ2 = λ3 =
√3r
> 0 on a doncun minimum.
Voici une version plus raffinée de ce théorème :
Théorème 3.5. (Condition suffisante d’ordre 2) On suppose que f et g1, g2, . . . , gp sont deux foiscontinuement dérivables sur D et que
1. (x∗, λ∗) est un point critique du lagrangien, et
2. les contraintes en x∗ sont qualifiées,
3. pour tout h ∈ Rn tel que ∀i ∈ J1, pK,∇gi (x∗) .h = 0
ht.∇2xL (x∗, λ∗) .h > 0
alors x∗ est un minimum du problème contraint.
Si on remplace la troisième condition par
ht.∇2xL (x∗, λ∗) .h < 0
alors x∗est un maximum
Remarque. La différence avec le théorème précédent tient à la condition 3 : on demande ici que lamatrice ∇2
xL (x∗, λ∗) soit définie positive seulement pour les vecteurs h qui sont orthogonaux à tousles gradients des contraintes.
Proposition 3.1. (règle pratique) La troisième condition du théorème précédent est équivalente à :toutes les racines du polynôme
p (λ) = det(A− λIn D
Dt 0
)sont positives, où In la matrice identité de Rn,n,
A = ∇2xL (x∗, λ∗) ∈ Rn,n
etD = (∇gj (x∗))1≤j≤p ∈ Rn,p
(D est la matrice dont les p colonnes sont les gradients des contraintes).
Exemple 3.8. Dans l’exemple (3.5),
∇2L (−1, 3, 7) =
−20 3 −23 2 −1−2 −1 0
et
p (λ) =
∣∣∣∣∣∣−20− λ 3 −2
3 2− λ −1−2 −1 0
∣∣∣∣∣∣ = 24 + 5λ
a pour racine λ = −245< 0, on a donc un maximum en f (−1, 3) = 8.

3.5 En résumé 29
3.5 En résumé
Pour une ou plusieurs contraintes égalité, on utilisera la méthodologie suivante :
Contraintes égalités
1. Déterminer les points critiques du lagrangien, et
2. pour chaque point critique (x∗, λ∗) :
(a) vérifier que les contraintes en x∗ sont qualifiées,(b) trouver les racines du polynôme
p (t) = det(A− tIn D
Dt 0
)i. si les racines sont toutes strictement positives, on a un minimum en f (x∗) ;ii. si les racines sont toutes strictement négatives, on a un maximum en f (x∗) ;iii. sinon on ne peut pas conclure.

30 Chapitre 3. Contraintes égalité, multiplicateurs de Lagrange

31
Chapitre 4
Contrainte inégalité
4.1 Définition et exemples
En toute généralité, nous posons le problème d’optimisation sous contraintes (égalité et inégalité)ainsi :
SoitD un ouvert non vide deRn, et soit f : D → R la fonction coût ou fonction objectif, continuementdifférentiable.
Les contraintes g1, . . . , gp et h1, . . . , hq sont p+ q applications continuement différentiables et
C = { x ∈ D, gi (x) = 0, ∀i ∈ J1, pK︸ ︷︷ ︸contraintes égalité
et hj (x) ≤ 0,∀j ∈ J1, qK︸ ︷︷ ︸ }contraintes inégalité
Le problème de minimisation à résoudre est :
(P)
{Minf (x)x ∈ C
Définition 4.1. Soit x ∈ D.
– On dit que la contrainte inégalité hj est active ou saturée en x si et seulement si
hj (x) = 0
– On dit que les contraintes g1, . . . , gp et h1, . . . , hq sont qualifiées en x si et seulement si
(QC)x :{∇g1 (x) , . . . ,∇gp (x)}
∪{∇hj (x) |hj saturée}
est une famille libre
– On appelle Lagrangien du problème (P) la fonction :
L (x, λ, µ) = f (x) +∑
i∈J1,pKλigi (x) +∑
j∈J1,qKµjhj (x)
Pierre Puiseux

32 Chapitre 4. Contrainte inégalité
– On note∇xL (x, λ, µ) = ∇f (x) +
∑i∈J1,pKλi∇gi (x) +
∑j∈J1,qKµj∇hj (x)
et∇2
xL (x, λ, µ) = ∇2f (x) +∑
i∈J1,pKλi∇2gi (x) +∑
j∈J1,qKµj∇2hj (x)
Remarque. On voit facilement
– que∇xL (x, λ, µ) est le vecteur constitué des n premières composantes de∇L (x, λ, µ) et
– que ∇2xL (x, λ, µ) est la sous matrice constituée des n première lignes et n premières colonnes
de∇2L (x, λ, µ)
∇2xL (x, λ, µ) =
∂2L∂x2
1
∂2L∂x1∂x2
. . . ∂2L∂x1∂xn
∂2L∂x1∂x2
. . . . . . ...... . . . . . . ∂2L
∂xn−1∂xn
∂2L∂x1∂xn
. . . ∂2L∂xn−1∂xn
∂2L∂x2
n
(x, λ, µ)
Exemple 4.1.
On considère un bien B, de quantité 100 à répartir entre 5 consommateurs. Chaque consommateurreçoit une quantité xi du bien B. Il doit en recevoir une quantité minimale qi et en espère la quantitépi avec
i qi pi
1 10 202 15 253 20 404 15 405 25 40
Formalisons ce problème sous forme d’un minimum à calculer.
La fonction coût :f (x) =
∑1≤i≤5
(xi − pi)2
les contraintes : ∑1≤i≤5
xi = 100
etxi ≥ qi, 1 ≤ i ≤ 5

4.2 Conditions nécessaires (KKT) 33
4.2 Conditions nécessaires (KKT)
Théorème 4.1. (conditions nécessaires, Karush-Kuhn-Tucker.)Si x∗ ∈ C est un minimum local de f sur C et si (QC)x∗ est vérifiée, alors il existe λ∗ = (λ1, . . . , λp)et µ∗ = (µ1, . . . , µq) tels que :
1. (x∗, λ∗, µ∗) vérifie :∇xL (x∗, λ∗, µ∗) = 0
2. et les multiplicateurs µj, j ∈ J1, qK vérifient :
∀j ∈ J1, qK,{µj > 0 si la contrainte est saturée en x∗
µj = 0 sinon
ou de manière équivalente :
∀j ∈ J1, qK,{µj ≥ 0 etµjhj (x∗) = 0
Remarque.
1. Pour un problème de maximisation, il suffit de remplacer ∀j ∈ J1, qK, µj ≥ 0 par ∀j ∈J1, qK, µj ≤ 0.
2. Si la contrainte hj n’est pas saturée, alors µj = 0 et la contrainte n’intervient plus dans lelagrangien, c’est comme si elle était absente du problème initial.
4.3 Conditions suffisantes (KKT)
Définition 4.2. On dit que (P) est un problème de programmation convexe si :
– D est un ouvert convexe (c’est le cas notamment si D = Rn) ;
– f est convexe ;
– les contraintes égalité gi, i ∈ J1, pK sont des applications affines ;– les contraintes inégalité hj, j ∈ J1, qK sont des applications convexes.
Théorème 4.2. (conditions suffisantes, Karush-Kuhn-Tucker.) Si (P) est un problème de program-mation convexe, et si (QC)x∗ est vérifiée, alors les deux conditions KKT en x∗ ∈ C sont suffisantespour que x∗ soit un minimum global de f .
Exemple 4.2. La fonction objectif :
f (x, y, z) = x2 + y2 + z2
les contraintes : {g (x, y, z) = x+ y + z − 3 = 0
h (x, y, z) = 2x− y + z − 5 ≤ 0
Consiste à déterminer dans R3 la distance à l’origine du demi-plan défini par les contraintes.

34 Chapitre 4. Contrainte inégalité
Les conditions KKT s’écrivent :
∇f (x) + λ∇g (x) + µ∇h (x) = 0
(ii) µ (2x− y + z − 5) = 0
(iii) µ ≥ 0
soit
(i)
2x+ λ+ 2µ = 0
2y + λ− µ = 0
2z + λ+ µ = 0
(ii) µ (2x− y + z − 5) = 0
(iii) µ ≥ 0
Supposons µ ̸= 0, alors
(iν) 2x− y + z − 5 = 0
et
(i) ⇒
x = (−λ− 2µ)/2
y = (−λ+ µ)/2
z = (−λ− µ)/2
La contrainte égalité implique 3λ+ 2µ = −6 et avec (iν) : λ+ 3µ = −5 d’où µ = −97< 0 ce qui
est incompatible avec (iii).
Donc µ = 0 puis λ = −2 et x = y = z = 1. Il s’agit d’un minimum global de f sur C car C est unconvexe, f est convexe, ainsi que les contraintes.
Exemple 4.3. On reprend l’exemple donné en introduction et on le simplifie : La fonction objectifest :
f (x) =∑
i∈J1,5K (xi − pi)2
les contraintes :
g (x) =∑
i∈J1,5Kxi − 100 = 0
hi (x) = qi − xi ≤ 0, i ∈ J1, 5KLe lagrangien
L (x, λ, µ) = f (x) + λg (x) +∑
i∈J1,5Kµihi (x)
La première condition KKT s’écrit :
∇f (x) + λ∇g (x) +∑
i∈J1,5Kµi∇hi (x) = 0

4.3 Conditions suffisantes (KKT) 35
et avec la seconde condition KKT :
(i)
2 (xi − pi) + λ− µi = 0
µi (xi − qi) = 0
µi ≥ 0
i ∈ J1, nK∑
xi = 100
TODO
Exercices
Sans contrainte
Exercice 4.1. Pour chacune des fonctions de R2 dans R suivantes :
f1(x, y) = x3 + 3xy2 − 15x− 12y
f2(x, y) = x2 + y2 − xy
f3(x, y) = x2 − y2 − xy
f4(x, y) = x3 + y3 − x2y2
f5(x, y) = 4x2 + 4y2 − (x+ y)4
1. Calculer le gradient de f .
2. Déterminer les points critiques de f .
3. Calculer la matrice hessienne de f .
4. Pour chacun des points critiques de f , donner les conclusions tirées de l’examen de la matricehessienne.
5. Pour chacun des points critiques de f , dire s’il s’agit ou non d’un extremum global de f .
Exercice 4.2. Pour chacune des fonctions de R2 dans R suivantes :
f1 (x, y, z) = x2 + 2y2 + 3z2
f2 (x, y, z) = x2 + 2y2 − 3z2
f3 (x, y, z) = x4 + y2 + z2−4x−2y−2z + 4
f4 (x, y, z) = x4−2x2y + 2y2 + 2z2 + 2yz−2y−2z + 2
f5 (x, y, z) = 3(x2 + y2 + z2)−2(x+ y + z)4
1. Calculer le gradient de f et la matrice hessienne de f .
2. Déterminer les points critiques de f .
3. Pour chacun des points critiques de f , donner les conclusions tirées de l’examen de la matricehessienne.

36 Chapitre 4. Contrainte inégalité
Contraintes égalité
Exercice 4.3. Optimiser f (x, y) = x2y sous la contrainte 4x+ y = 30 en utilisant deux méthodes :
1. en se ramenant à un problème à une variable
2. en utilisant les techniques de lagrangien.
Exercice 4.4. Chercher les extrema de la fonction f (x, y) = x2y sous la contrainte 12x+2y−180 = 0
Exercice 4.5. Chercher les extrema de la fonction f (x, y) = x (1 + y) sous la contrainte 5x+10y−5 = 0
Exercice 4.6. Chercher les extrema de la fonction f (x, y, z) = x+ y+ z sous la contrainte x2+ y2+z2 = 1
Exercice 4.7. Chercher les extrema de la fonction f (x, y) = x+ y sous la contrainte x2 + y2 = 1
Exercice 4.8. Optimiser f (x, y) = xy
1. sous la contrainte x+ y = 6
2. sous la contrainte x2 + y2 = 2
Exercice 4.9. On veut maximiser la fonction
f (x, y, z) = x2yz
sous la contrainte2x+ 4y + z − 64 = 0
Montrer que ce problème se ramène à un problème d’optimisation sans contrainte et résoudre ce pro-blème.
Exercice 4.10.
On note C le cercle unité de R2 :
C ={(x, y) ∈ R2, x2 + y2 = 1
}On considère les fonctions
f (x, y) = x+ y f (x, y) = x+ y − xy f (x, y) = x2 − yf (x, y) = x2 + y2 − xy f (x, y) = x2 + y2 − x2y2
1. Utiliser les conditions nécessaires d’ordre 1 pour déterminer les candidats à être des extremapour la restriction de f à C.
2. Pour chacun de ces points, dire s’il s’agit ou non d’un extremum pour la restriction de f à C
Exercice 4.11. Optimiser f (x, y, z) = x2 + y2 + z2

4.3 Conditions suffisantes (KKT) 37
sous la contrainte x+ 2y = 2 et x2 + 2y2 + 2z2 = 2
Exercice 4.12. Optimiser f (x, y, z) = xyz difficile
sous la contrainte
x+ y + z − 1 = 0
x2 + y2 + z2 − 1 = 0
Indication : il y a 6 points critiques pour le lagrangien. On pourra vérifier que les points(23, 23,−1
3,−2
9, 13
)et (1, 0, 0, 0, 0) en font partie, et on en déduira les autres avec des arguments de symétrie.
Contraintes inégalités
Exercice 4.13. (Problème deKepler.) Inscrire dans l’ellipsoïdeE ={(x, y, z) ∈ R3, x
2
a2+ y2
b2+ z2
c2= 1}
le parallèlépipède de volume maximal, sont les cotés sont parallèles aux axes.
Exercice 4.14. Soit f (x, y) = 2x− y
1. Justifier l’existence d’un extrema sur le domaine
C ={(x, y) ∈ R2, x2 + y2 = 1
}2. Justifier l’existence d’un extrema sur le domaine
C1 ={(x, y) ∈ R2, x2 + y2 ≤ 1
}Exercice 4.15. Maximiser x sous la contrainte y ≥ x2 et x+ y ≤ 1.
Exercice 4.16. Minimiser x sous la contrainte y ≥ 0 et y ≤ (1 + x)3.
Exercice 4.17. Optimiser f (x, y) = ex2+y2 + y2 − 1 pour (x, y) ∈ C = {(x, y) ∈ R2; x2 + y2 ≤ 9}
Exercice 4.18. Minimiser f (x, y) = x2 pour (x, y) ∈ C = {(x, y) ∈ R2;x2 + y2 ≤ 2 et x = y}
Exercice 4.19. Résoudre :
(P)
max
(− (x− 4)2 − (y − 4)2
)x+ y ≤ 4
x+ 3y ≤ 9
Exercice 4.20. Les fonctions suivantes sont elles convexes ?
1. (x, y) 7→ x2 + y2 + 4xy
2. (x, y) 7→ 2x2 − 2y2 − 6z2 + 3xy − 4xz + 7yz
3. (x, y) 7→ ex + ey
4. (x, y) 7→ exey

38 INDEX
Index
Ccontraintes qualifiées, 26courbes de niveau, 5
FFormule de Taylor, 6
Iisovaleurs, 5
LLagrangien, 31lagrangien, 21
Mmultiplicateurs de Lagrange, 21
Pprogrammation convexe, 33
Pierre Puiseux

BIBLIOGRAPHIE 39
Bibliographie
[1]
Pierre Puiseux





























