Embed Size (px)
Citation preview

370
Covert communication of speech signals based on Collatz encoding
Comunicación encubierta de señales de voz utilizando la codificación de Collatz
Sebastián Mendoza1, Diego Renza2, Dora M. Ballesteros L.3 [email protected], [email protected], [email protected]
Universidad Militar Nueva Granada Bogotá, Colombia
Artículo de Investigación
Abstract
It is presented a method for speech encoding based on the Collatz conjecture. The objective is to conceal the secret information of a speech message through mathematical operations based on variable length encoding (analog-to-digital), randomization and digital-to-analog encoding. The main characteristics of our proposal are: the encoded signal is not of a fixed length; the encoded signal is always longer than the original speech signal; the scrambling degree of the encoded signal is very close to 100%; entropy of the encoded signal is significantly higher than that of the original speech signal. With our method, it is expected an encoded signal without trace of the original content, and then, if the encoded signal is intercepted by a non-authorized user, the data secrecy is preserved. This is the main strength of our proposal.
Keywords: encoding, covert communication, Collatz conjecture, scrambling degree, compression/expansion rate. Resumen
Se presenta un método para la codificación del habla basado en la conjetura de Collatz. El objetivo es ocultar la información secreta de un mensaje de voz a través de operaciones matemáticas basadas en codificación de longitud variable, aleatorización y codificación digital a análoga. Las principales características de nuestra propuesta son: la señal codificada no es de longitud fija; la señal codificada es siempre de mayor duración que la duración de la señal de voz original; el grado de aleatorización de la señal codificada es muy cercano al 100%; la entropía de la señal codificada es significativamente mayor que la de la señal de voz original. Con nuestro método, se espera que la señal codificada no tenga rastro del contenido original y, por consiguiente, si la señal codificada es interceptada por un usuario no autorizado, se preserva el secreto de los datos. Esta es la principal aplicación de nuestro método.
Palabras clave: codificación, comunicación encubierta, conjetura de Collatz, nivel de aleatorización.
© 2017. IAI All rights reserved
Actas de Ingeniería Volumen 3, pp. 370-376, 2017
http://fundacioniai.org/actas

371
1. Introducción Con el avance del tiempo y la tecnología, el volumen
de información que se procesa a diario ha crecido exponencialmente, siendo la seguridad de estos datos en la mayoría de los casos, irrelevante. Sin embargo, en algunas situaciones, la privacidad de la información puede ser significativa, por lo cual la seguridad de la misma se ha convertido en una necesidad cuando se transmiten datos confidenciales. En los últimos años se han propuesto métodos orientados a brindar un nivel de seguridad sobre los datos por parte de usuarios no autorizados. La finalidad de dichos métodos consiste en mantener un nivel de seguridad alto y confiable sobre la información que se está transmitiendo (por ejemplo, señales de audio, imagen o video), garantizando que los datos estén protegidos contra el acceso y manipulación de terceros; adicionalmente, es necesario garantizar la calidad del mensaje en el proceso de recuperación, asegurando así que solamente el destinatario conozca el contenido de la información [1].
En la literatura se han propuesto diferentes técnicas orientadas a la protección de la información en sistemas de comunicación. El enfoque puede estar orientado en dos líneas: utilizando técnicas de ocultamiento de información o modificando el contenido original. En el primer caso (data hiding), los métodos buscan mantener la existencia de la información en secreto con un alto grado de imperceptibilidad [15] sobre una señal huésped [5]. Algunas alternativas como la estenografía han estado orientadas principalmente a imágenes, aunque también se encuentran aplicaciones orientadas también a audio [12,13]. En el segundo caso, se tiene dos grupos de opciones: la aleatorización de los datos (scrambling), y el cifrado (encriptación). Ambas se complementan, dado que en el scrambling se modifica la posición de los datos (en el dominio del tiempo, frecuencia o tiempo-frecuencia) [1], mientras que en el cifrado se cambia la representación binaria de los mismos [14].
En las comunicaciones actuales, se considera el cifrado de datos como un proceso para volver indescifrable la información del mensaje, relacionando los aspectos de seguridad, confidencialidad e integridad [9]. De forma general, las técnicas que utilizan cifrado están basadas en algoritmos que utilizan una o más llaves orientadas a la protección de la información. Para este tipo de métodos, los autores en [2] clasifican dichas técnicas en dos categorías: simétrico y asimétrico. El cifrado simétrico maneja una clave principal tanto para el proceso de cifrado como para el descifrado, lo que implica que tanto el transmisor como el receptor deben tener conocimiento de dicha clave. En el cifrado asimétrico, se establecen dos llaves: una pública para el proceso de cifrado, y una privada para el proceso de descifrado. Esto se considera más funcional, dado que no es necesario que el transmisor y receptor definan una clave secreta [2].
Dentro de los métodos propuestos para los algoritmos de cifrado de datos, se tienen los métodos DES (Data Encryption Standard), Blowfish, AES (Advanced Encryption Standard) y RSA (Rivest, Shamir y Adleman). DES es un algoritmo de cifrado algorítmico de bloques simétricos, es decir, utiliza una misma clave privada de
56 bits (en el proceso de cifrado como descifrado), agrupando los datos en bloques de 64 bits. Blowfish por su parte es un algoritmo que se basa en el cifrado de bloques, utilizando una clave de longitud variable entre 32 y 448 bits. Este algoritmo es vulnerable a ataques diferenciales y de fuerza bruta, además de esto, su funcionamiento incluye dos bloques principales: expansión de la llave y cifrado de datos [10]. Otro método bien conocido es el AES, algoritmo que utiliza una clave variable de hasta 256 bits, que además puede cifrar los datos en bloques de 128 bits, manteniendo la seguridad en los mismos. Por otro lado, el algoritmo de cifrado simétrico RSA utiliza la llave pública del receptor para realizar el cifrado de los datos, y una privada para el descifrado de los mismos [16].
En el contexto de audio, algunos autores proponen metodologías de aplicación al cifrado de señales, entre ellos el algoritmo RSA que se utiliza para el cifrado en las bandas de menor frecuencia de la señal, de tal manera que proporciona seguridad en los datos cifrando los componentes de mayor energía de la señal [10].
Específicamente, en este documento se propone un nuevo método orientado al enmascaramiento (encubrimiento) de una señal de audio. En este caso, se desea encubrir el contenido original de una señal de audio (de 8 bits por muestra), a través de la codificación de las muestras y la posterior representación de las mismas en palabras de 16 bits. Para el proceso de codificación, se utilizan vectores binarios generados a través de la conjetura de Collatz, cuya principal característica es la longitud variable. Lo anterior implica que la representación de las nuevas muestras no presenta correlación con las muestras originales, por lo cual su contenido no presenta rastros de la señal original. Para ofrecer un mayor nivel de seguridad e incertidumbre a la señal de salida, los códigos de Collatz son aleatorizados a partir de un valor semilla, dado por una clave que puede ingresar el usuario.
2. Método propuesto
En la Figura 1 se presenta el enmascaramiento de una
señal de audio utilizando la codificación y binarización de las muestras de audio a través de la conjetura de Collatz. Cada uno de los bloques mostrados se explicará con detalle en las siguientes secciones.
Figura 1. Diagrama de bloques del método propuesto
2.1 Ajuste de la señal
La entrada de este bloque corresponde a una señal de
audio denominada x(t), cuyos parámetros son ajustados a conveniencia para el procesamiento de la misma, en los bloques posteriores. El primer parámetro ajustado es la frecuencia de muestreo (Fs), el cual se establece en 8 kHz. El objetivo de este ajuste es representar el contenido

372
sensible de la señal, utilizando la frecuencia de muestreo mínima para señales de voz, de acuerdo con el teorema de Nyquist. El segundo ajuste corresponde al número de bits por muestra (Q), el cual se establece en 8 bits por muestra. Este número de bits permite mantener un equilibrio entre una buena cuantización de la señal y un bajo tamaño para el almacenamiento de la señal codificada. Dado que la representación de las muestras a través de la conjetura de Collatz implica una expansión en la tasa de bit de la señal, los anteriores ajustes evitan que el tamaño de la señal de salida se expanda considerablemente.
2.2 Reducción por conjetura de Collatz
Para la representación binaria de las muestras de la
señal utilizando la conjetura de Collatz, cada muestra (en valor decimal) se reemplazará por el respectivo código binario dado por la aplicación de la conjetura de Collatz en dicho valor decimal. Para una fácil implementación de este bloque, se generan 256 códigos binarios diferentes y de longitud variable. Estos 256 códigos corresponden uno a uno a los 256 valores que pueden tomar las muestras de la señal de audio (8 bits). Una vez generado este conjunto de códigos, se intercambia o representa cada muestra por medio de su código binario.
La conjetura de Collatz expresa que todo número entero mayor a uno puede reducirse a la unidad aplicando de forma iterativa dos operaciones que dependen de si la entrada corresponde a un número par o impar. Si el número de entrada es par, se divide entre dos (L/2), de lo contrario, si este valor es impar debe multiplicarse por 3 y adicionarle 1 (3L+1). Al resultado de esta operación se le aplica de nuevo la regla, hasta que el número se reduce a 1.
Como ejemplo, la aplicación de la conjetura al número 13, implica como primera operación 3*(13) + 1= 40; ya que este resultado es par se divide entre dos 40 / 2 = 20, y así sucesivamente, obteniendo la secuencia (13, 40, 20, 10, 5, 16, 8, 4, 2, 1). Como se puede observar en la secuencia anterior, se necesitan nueve iteraciones para reducir el número de entrada a 1. Sin embargo, el número de iteraciones para reducir cada entero es variable. Es de precisar aquí, que, aunque el planteamiento de la conjetura de Collatz no ha sido demostrada aún para todos los números enteros, es fácilmente comprobable para enteros en el rango 1<L≤257, que corresponde al rango de valores que se utiliza para el método propuesto.
Para la generación de los códigos binarios a partir de la conjetura de Collatz, cada iteración del proceso anterior agrega un bit al código binario de salida. En este caso, cuando la operación aplicada es L/2, se agrega un bit “0”, en caso contrario se agrega un bit “1”. Cuando el número se ha reducido a 1, se agregan los bits “11” como cabecera del vector. Esta cabecera es necesaria para facilitar la posterior separación de los códigos, dado que la longitud del vector resultante es variable. La selección del valor de esta cabecera obedece a las reglas de la conjetura de Collatz, debido que no existen dos números impares consecutivos en el proceso iterativo. Es decir, en el código binario obtenido mediante la aplicación de la conjetura de Collatz nunca se obtienen dos bits 1 seguidos, excepto para la cabecera de cada código. La
Figura 2 resume el proceso de generación del vector binario a partir de la conjetura de Collatz.
Figura 2. Proceso de generación de vector binario
2.3 Aleatorización
Posterior a la obtención de los 256 códigos de longitud variable generados en el proceso de binarización mediante la conjetura de Collatz, en este bloque se ejecuta la aleatorización de los datos. Este proceso se realiza utilizando como base una clave secreta escogida por el usuario (utilizada en el proceso de enmascaramiento y recuperación de los datos), la cual genera un valor aleatorio de semilla que permite designar un patrón de aleatorización a los datos de entrada y, de esta manera, facilitar el proceso de recuperación. La salida de este bloque es un vector que contiene los 256 códigos aleatorizados en diferentes posiciones. Esta salida se toma como referencia para reemplazar cada una de las muestras de la señal original por su respectivo código, es decir a cada muestra de la señal original le corresponde un código del vector de aleatorización. Por último, se concatenan cada uno de los códigos en un solo vector. La cabecera (11) permite identificar el inicio (y fin) de cada uno de los códigos.
2.4 Byte a Word
El objetivo de este bloque es agrupar los bits del
vector dado en la etapa anterior, en grupos de 16 bits. De esta forma, los datos se representan por palabras (de 16 bits), que determinarán las muestras de la señal de salida. Teniendo en cuenta que la longitud del vector binario no necesariamente es múltiplo de 16, se realiza un previo procesamiento de la señal. Primero se identifica la cantidad de datos del vector que contiene los códigos de las muestras originales, se determina si es múltiplo de 16, y en caso negativo, se agregan la cantidad de ceros necesarios para que el número de bits sea igual al múltiplo de 16 inmediatamente superior.
2.5 DAC
En esta fase el valor binario de cada muestra en 16
bits se convierte a un valor análogo, cuyo rango dinámico será similar al de la señal original. La frecuencia de muestreo es la misma que la de la señal original. Es importante aclarar que la señal modificada contiene la información de la señal original, con la salvedad que esta información está enmascarada. El objetivo es brindar un nivel extra de seguridad y fiabilidad a los usuarios. Esta señal enmascarada será la que se transmita y la que recibe el usuario final, que precisará de un algoritmo de recuperación para la extracción de los datos ocultos en la señal modificada. En la Figura 3 se representa por medio de bloques, un resumen del proceso de recuperación de la señal, implementado en el receptor de los datos.

373
Figura 3. Proceso de recuperación de la señal ADC 16 bits
La señal recibida corresponde a la señal modificada
resultante del proceso de enmascaramiento de la señal, descrito anteriormente. Esta señal será la entrada de este bloque, donde se realiza el proceso de conversión de cada muestra análoga [x’(t)] a un valor digital de 16 bits. De esta forma, la salida de este bloque es un vector binario que concatena cada uno de los códigos de Collatz que se utilizaron para la representación de las muestras de la señal original. Como se ha comentado hasta aquí, aunque las muestras de la señal modificada se representen en 16 bits, la longitud de los códigos de Collatz es variable, por lo cual es necesaria una correcta separación, la cual se realiza en el siguiente bloque.
2.6 Separación de códigos
Los datos binarios recibidos de la conversión ADC son
utilizados para realizar la separación de los códigos, debido a que éstos vienen concatenados en un solo vector y cada uno de ellos tiene una longitud variable (n). Para una efectiva implementación de esta tarea, el proceso de codificación original incluyó la inserción de la cabecera 11, por lo cual, solamente se precisa detectar este separador, para identificar el bit de inicio y fin de cada código o muestra. Así mismo, es posible obtener la posición de cada uno de los códigos, que será utilizada para su extracción y posterior comparación con el conjunto global de códigos de Collatz.
Para esta comparación, es preciso generar de nuevo en el receptor los 256 códigos de Collatz, y la aleatorización de forma similar a la explicada en las secciones 2.2 y 2.3. Para la aleatorización de estos códigos se precisa de la clave utilizada en el proceso de enmascaramiento, lo que provee un nivel de seguridad de los datos, dado que, si no se tiene conocimiento de esta clave, el ordenamiento de los códigos será incierto, y como consecuencia el valor de las muestras obtenidas diferirá completamente respecto a la señal original. Este nivel de incertidumbre está asociado al número de permutaciones que se pueden realizar sobre un conjunto de L elementos, en este caso de 256 códigos. Esto equivale a un número posible de combinaciones de ¡256!, donde el símbolo! representa el operador factorial. En el caso de aplicar el algoritmo propuesto con datos de 16 bits, la complejidad se incrementa, llegando a un número de permutaciones de ¡65536!
2.7 Comparación
El proceso de comparación de cada código extraído se
realiza contra el conjunto completo de los 256 códigos de Collatz, proceso en el cual se selecciona el código con la similitud más alta respecto al código evaluado. Sin embargo, y teniendo en cuenta que la longitud de los códigos es variable, primero se filtran solamente los
códigos cuya longitud sea igual a la del código evaluado. Esto reduce significativamente el costo computacional del proceso de recuperación de la señal. Una vez obtenidos los códigos de la misma longitud, se realiza una operación de correlación entre los códigos y se selecciona la posición del código con la correlación más alta. Esta posición corresponde al valor de la muestra de la señal. Este procedimiento se realiza hasta evaluar la totalidad de códigos extraídos de la señal transmitida.
La salida de este bloque corresponde a los valores de las muestras de la señal original, bajo las mismas condiciones que se hayan impuesto en el bloque de preprocesamiento, es decir una frecuencia de muestreo de 8 kHz y una codificación de 8 bits.
2.8 Normalización
La normalización es utilizada especialmente para
ajustar los datos de la señal recuperada, para que el rango dinámico sea el mismo de la señal original. El objetivo es representar la señal que recuperada que inicialmente se encuentra entre 0 y 255 en un rango dinámico comprendido entre -1 y 1. Para esto, basta con restar 128 a cada uno de los datos y dividir el resultado obtenido entre 2bits-1, donde bits es igual a 8. De esta forma, la señal recuperada tendrá el mismo volumen (o muy similar) al de la señal original.
3. Implementación y evaluación del método
Para evaluar el funcionamiento y validar el método
propuesto se realizaron pruebas orientadas a medir el nivel de desorden y el factor de expansión de la señal enmascarada respecto a la señal original. El nivel de desorden se estimó calculando tanto la entropía como el nivel de aleatorización (SD) de las dos señales. Estos dos parámetros permitieron determinar el grado de incertidumbre para las dos señales y compararlos entre sí. Para el cálculo del grado de desorden se utilizan las Ecuaciones (1) a (4) [11].
𝐷(𝑖) = 1
4 ∑ {4 ∗ 𝑆(𝑖) − (𝑆(𝑖 − 1) + 𝑆(𝑖 − 2) +𝑁−2
𝑖=3
𝑆(𝑖 + 1) + 𝑆(𝑖 + 2)) } (1)
Donde S(i) corresponde a la i-ésima muestra del audio, N es el número total de muestras de dicha señal y D es un vector que contiene M – 4 valores; de tal forma que 𝐷1 corresponde a la señal original y 𝐷2 a la señal modificada. Con la diferencia y suma de estos resultados, se obtienen los valores B y A de las siguientes ecuaciones (2) y (3).
𝐵 = 𝐷2 − 𝐷1 (2) 𝐴 = 𝐷2 + 𝐷1 (3)
Finalmente, el nivel de aleatorización (SD) se calcula de acuerdo con la ecuación (4).
𝑆𝐷 = 𝐵
𝐴 (4)
SD representa el grado de desorden de la señal modificada en comparación con la señal original. Este valor se encuentra en un rango entre -1 y 1, donde los valores más altos representan un mejor encubrimiento de los datos, es decir el contenido original de la señal de audio ha sido completamente alterado en el proceso de
374
codificación [13]. Así mismo, también se evalúa la tasa de compresión y/o ensanchamiento de la señal modificada con respecto a la original. Es decir, se identifica la relación entre el número de muestras de la señal modificada y el número de muestras de la señal original.
Para la evaluación del método, se utilizaron 50 señales de audio en formato wav, cada una con una duración de 5 segundos y una frecuencia de muestreo de 8kHz. El contenido de las señales de voz incluye hablantes masculinos y femeninos en idioma español. En total se realizaron 250 pruebas, que implicaron la utilización de cinco claves diferentes: una solamente numérica, una alfanumérica, y tres una con solo letras y de diferentes longitudes. Se utilizaron diferentes clases de claves con el fin de evaluar la dependencia de los resultados respecto a la clave dada por el usuario en el proceso de enmascaramiento de los datos. Las 5 claves utilizadas en las pruebas realizadas son:
1. Numérica: 060312.
2. Alfanumérica: Sebas9706.
3. Texto 1: Shannon.
4. Texto 2: Telecomunicaciones.
5. Texto 3: Mom.
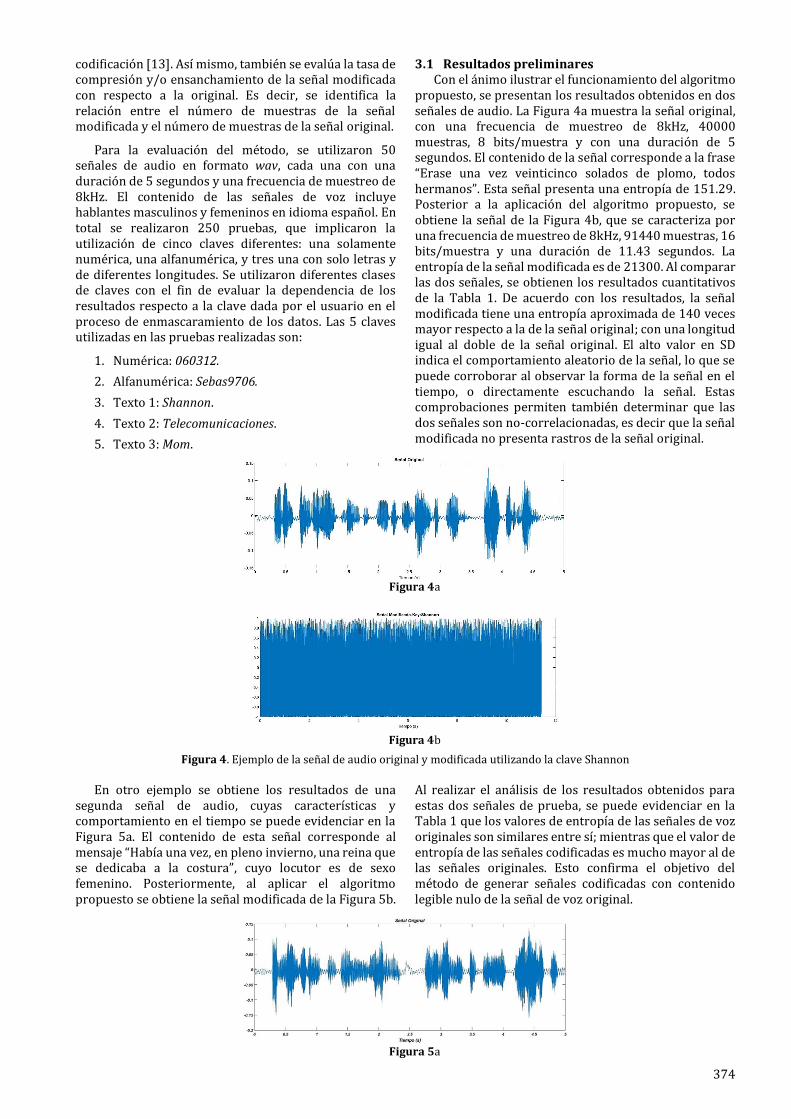
3.1 Resultados preliminares Con el ánimo ilustrar el funcionamiento del algoritmo
propuesto, se presentan los resultados obtenidos en dos señales de audio. La Figura 4a muestra la señal original, con una frecuencia de muestreo de 8kHz, 40000 muestras, 8 bits/muestra y con una duración de 5 segundos. El contenido de la señal corresponde a la frase “Erase una vez veinticinco solados de plomo, todos hermanos”. Esta señal presenta una entropía de 151.29. Posterior a la aplicación del algoritmo propuesto, se obtiene la señal de la Figura 4b, que se caracteriza por una frecuencia de muestreo de 8kHz, 91440 muestras, 16 bits/muestra y una duración de 11.43 segundos. La entropía de la señal modificada es de 21300. Al comparar las dos señales, se obtienen los resultados cuantitativos de la Tabla 1. De acuerdo con los resultados, la señal modificada tiene una entropía aproximada de 140 veces mayor respecto a la de la señal original; con una longitud igual al doble de la señal original. El alto valor en SD indica el comportamiento aleatorio de la señal, lo que se puede corroborar al observar la forma de la señal en el tiempo, o directamente escuchando la señal. Estas comprobaciones permiten también determinar que las dos señales son no-correlacionadas, es decir que la señal modificada no presenta rastros de la señal original.
Figura 4a
Figura 4b
Figura 4. Ejemplo de la señal de audio original y modificada utilizando la clave Shannon
En otro ejemplo se obtiene los resultados de una
segunda señal de audio, cuyas características y comportamiento en el tiempo se puede evidenciar en la Figura 5a. El contenido de esta señal corresponde al mensaje “Había una vez, en pleno invierno, una reina que se dedicaba a la costura”, cuyo locutor es de sexo femenino. Posteriormente, al aplicar el algoritmo propuesto se obtiene la señal modificada de la Figura 5b.
Al realizar el análisis de los resultados obtenidos para estas dos señales de prueba, se puede evidenciar en la Tabla 1 que los valores de entropía de las señales de voz originales son similares entre sí; mientras que el valor de entropía de las señales codificadas es mucho mayor al de las señales originales. Esto confirma el objetivo del método de generar señales codificadas con contenido legible nulo de la señal de voz original.
Figura 5a

375
Figura 5b
Figura 5. Señal de prueba con: a) frecuencia de 8kHz, 4000 muestras, voz femenina, 8 bits y duración de 5 s; b) frecuencia de 8kHz, 92253 muestras, 16 bits y duración de 11.53 s
Tabla 1. Aplicación de la función resumen para una señal con voz masculina
Entropía Original
Entropía Modificada
Tasa comprensión y/o ensanchamiento
Nivel de aleatorización
Audio Prueba 1 151.29 21300 2.2860 0.9973 Audio Prueba 2 156.90 19800 2.4283 0.9969
3.2 Resultados consolidados
Se realizaron pruebas utilizando 50 señales de audio, y cinco claves diferentes, para un total de 250 pruebas. Con el ánimo de consolidar los resultados para las cuatro métricas utilizadas (entropía de la señal original, entropía de la señal modificada, tasa de compresión y/o ensanchamiento, y nivel de aleatorización) se utilizaron gráficas con intervalos de confianza al 95% que permiten determinar dónde se concentran los resultados, y cuál es su rango dinámico (mínimo y máximo). Desde la Figura 6 hasta la Figura 10 se presentan los resultados consolidados para cada métrica, utilizando una clave diferente. Cada Figura corresponde a los resultados de 50 pruebas. La Figura 11 resume los resultados de las 250 pruebas, con las 5 claves diferentes.
Figura 6. Intervalos de confianza utilizando Shannon: a) entropía original, b) entropía señal modificada, c) tasa de
compresión o ensanchamiento, d) SD
Figura 7. Intervalos de confianza utilizando Sebas9706: a) entropía original, b) entropía señal modificada, c) tasa de
compresión o ensanchamiento, d) SD
De acuerdo con los resultados de la Figura 6, los
valores de entropía de las señales codificadas son mucho más altos que los de las señales de voz originales.
Adicionalmente, en todos los casos, la señal codificada es de mayor longitud a la de la señal original (entre 2 y 3 veces) y el valor de aleatorización es casi igual al 100% (como mínimo el 99.4%). Los resultados obtenidos en las Figuras 7 a 10 son similares a los de la Figura 6. De nuevo, la entropía de la señal codificada es mucho mayor a la de la señal original; la tasa de expansión es mayor a 1 y el valor de aleatorización cercano al 100%.
Figura 8. Intervalos de confianza utilizando Telecomunicaciones: a) entropía original, b) entropía señal modificada, c) Tasa de compresión o ensanchamiento, d) SD
Figura 9. Intervalos de confianza utilizando 060312: a) entropía original, b) entropía señal modificada, c) Tasa de
compresión o ensanchamiento, d) SD
Figura 10. Intervalos de confianza utilizando la clave “Mom”: a) entropía original, b) entropía señal modificada, c) Tasa de
compresión o ensanchamiento, d) SD

376
Figura 11. Consolidado de las 250 pruebas: a) entropía original, b) entropía señal modificada, c) Tasa de compresión o
ensanchamiento, d) SD De acuerdo con los resultados de la Figura 11, la señal
codificada tiene una longitud mayor a la de la señal original, sin importar la clave utilizada. El valor esperado de expansión es de aproximadamente 2.8 (donde se concentra el 95% de los resultados). Por otra parte, en todos los casos la entropía de la señal codificada es mucho mayor a la de la señal original, lo que significa que el contenido original deja de ser legible. Esto se ratifica con el parámetro de nivel de desorden de los datos, que es muy cercano al 100%.
4. Conclusiones
En este documento se propuso un método orientado a la protección de datos, especialmente los datos de las señales de audio. El método utiliza un nivel de seguridad que se basa en una clave, la cual genera una aleatorización específica a los datos codificados mediante la conjetura de Collatz. Los datos obtenidos en las pruebas permiten afirmar que los datos que conforman la señal modificada no tienen ningún rastro o similitud con los datos de la señal original, y que esta afirmación es válida para cualquier tipo de clave (numérica, alfanumérica) utilizada en el proceso de enmascaramiento y recuperación de los datos.
En términos de seguridad de la información, se pudo observar en la validación del algoritmo, el alto nivel de desorden (SD) que presentan las señales obtenidas a la salida del proceso de enmascaramiento de la señal (señal modificada), esto implica que el contenido de la señal original ha sido alterado por completo en el proceso de codificación de los datos.
Agradecimientos
Este trabajo hace parte del proyecto IMP-ING-2136 de 2016, financiado por la Vicerrectoría de Investigaciones de la Universidad Militar Nueva Granada.
Referencias [1] Ballesteros, L., Camacho, S. & Renza, D. (2016). An
unconditionally secure speech scrambling scheme based on an imitation process to a gaussian noise signal. J. Inf. Hiding Multimedia Sig. Process, 7(2), pp. 233-242.
[2] Rajanarayanan, S. & Pushparaghavan, A. (2012). Recent developments in signal encryption–a critical survey. International Journal of Scientific and Research Publications, 2(6), pp.1-7.
[3] Dhanya, G. & Jayakumari, J. (2014). Optimal speech scrambling technique for OFDM based system. International Journal of Applied Engineering Research, 9(24), pp. 28871-28878.
[4] Carvajal, B., Gallegos, F. & López, J. (2009). Esteganografía para Imágenes RGB: Factor de Escalamiento. Journal of Vectorial Relativity, 4(3), pp. 66-77.
[5] Rocha, A. (2003). Camaleão: um software para segurança
digital utilizando esteganografia. [6] Velásquez, G., Molina, L. & Briones, Í. (2017). Analysis of
steganography techniques applied in audio and image files. Pol. Con. 2(1), pp. 51-67.
[7] Lara, L. & Tipantuña, C. (2015). Revisión del Estado del Arte de los Estándares de Codificación y Compresión de Audio MPEG y sus Aplicaciones. Revista Politécnica, 35(1), 21.
[8] Hernández, E. (2016). Cifrado de audio por medio del algoritmo Triple-DES-96.
[9] Kaur, M. & Kaur, M. (2014). Survey of Various Encryption Techniques for Audio Data. Int. J. Adv. Res. Comput. Sci. Softw. Eng, 4(5).
[10] Madain, A. et al. (2014). Audio scrambling technique based on cellular automata. Multimedia tools and applications, 71(3), 1803-1822.
[11] Dutta, P., Bhattacharyya, D. & Kim, T. (2009). Data hiding in audio signal: A review. International journal of database theory and application, 2(2), pp. 1-8.
[12] Jayaram, P., Ranganatha, H. & Anupama, H. (2011). Information hiding using audio steganography–a survey. The International Journal of Multimedia & Its Applications (IJMA) Vol, 3, pp. 86-96.
[13] Ballesteros L., Renza, D. & Camacho, S. (2016) High Scrambling Degree in Audio Through Imitation of an Unintelligible Signal. In Martínez, J. et al. (Eds), Pattern Recognition. MCPR 2016. Lecture Notes in Computer Science, 9703. Springer, Cham.
[14] Lin, Y. & Abdulla, W. (2015). Audio Watermark - A Comprehensive Foundation Using MATLAB. Berlin: Springer.
[15] Zhou, X. & Tang, X. (2011, August). Research and implementation of RSA algorithm for encryption and decryption. 2011 6th International Forum on Strategic Technology (IFOST), (Vol. 2, pp. 1118-1121).





























