Embed Size (px)
Citation preview

Seminararbeit
Aktuelle Entwicklungen im Bereich Visual Computing
Prof. Dr. T. Jung, Prof. Dr. P. Hufnagl
CUDA
René Schimmelpfennig (530698)
Angewandte Informatik
Berlin, 8. Februar 2011

Inhaltsverzeichnis
I
1 GESCHICHTE DER GRAFIKKARTEN 1
2 LEISTUNG DER GPUS 3
3 GPGPU 6
3.1 GESCHICHTLICHES 6
3.2 OPENCL 7
4 CUDA 8
4.1 HARDWARESEITIG 8
4.2 SOFTWARESEITIG 10
5 BEISPIEL – MATRIZENMULTIPLIKATION 12
5.1 VARIANTE 1: SEQUENTIELLER ABLAUF 12
5.2 VARIANTE 2: PARALLEL DURCHFÜHRUNG MIT CUDA 13
5.3 VARIANTE 3: OPTIMIERTER CUDA-ALGORITHMUS 13
6 ANWENDUNG 15
6.1 NVIDIA PHYSX 15
6.2 FOLDING@HOME 15
6.3 ADOBE CREATIVE SUITE 15
7 QUELLEN 17

Kapitel 1 – Geschichte der Grafikkarten
1
1 Geschichte der Grafikkarten
Wir blicken zurück in das Jahr 1977: Der Apple II kam auf dem Markt. Es war
möglich ihn mit Steckkarten aufzurüsten. Unter anderem um die Grafikausgabe
zu erweitern: Dies war sozusagen die erste Grafikkarte. Sie schaffte eine
Auflösung von bis zu 280*192 Pixel mit 6 Farben, was für damalige Verhältnisse
schon eine Revolution war.
Abbildung 1.1: Apple II
Der erste IBM PC („5150“) erschien 1981 und brachte ebenfalls eine eigene
Platine mit, welche für die Grafikausgabe zuständig war. Jedoch konnte sie nur
einfarbigen Text darstellen (Monochrome Display Adapter, kurz MDA). Der
amerikanische Hersteller „Hercules“ bot 1982 spezielle Grafikkarten für diese PC-
Baureihe an, mit der neben der Text- auch die Grafikausgabe mit bis zu 720*348
Pixeln ermöglicht wurde. Ab 1989 sind Grafikkarten mit Farbausgabe Standard.
Bis Anfang der 1990er konnten die Entwickler jedoch nur den Textmodus nutzen,
sowie im Grafikmodus einzelne Pixel setzen. Die Hauptaufgabe der Grafikkarten
bestand bis zu diesen Zeitpunkt darin, die Daten in ein geeignetes
Ausgangssignal für den Monitor umzuwandeln.
Erst im Jahre 1991 kamen die ersten Grafikkarten auf den Markt, die einen
speziellen Prozessor integriert haben, die GPU (Graphics Processing Unit). Nun
war es für die Entwickler möglich Befehle zum Zeichnen von Linien und Füllen
von Flächen zu nutzen, die dann – ohne Belastung der CPU – direkt von der
Grafikkarte ausgeführt wurden. Dies kam vor allem dem Betriebssystemen mit
einer grafischen Oberfläche zugute.
Das Computerspiel „Doom“ löste 1993 einen 3D-Spiele-Boom aus, da die
Menschen von den neuartigen Entwicklungen in der Computerspiele-Industrie
begeistert waren: Jeder wollte bei sich zu Hause selber in virtuelle Spielwelten
abtauchen. Der Hersteller „3Dfx“ nutzte die Gunst der Stunde und brachte Mitte
der 1990er den 3D-Beschleuniger-Chip „Voodoo“ hervor, der auf einer extra
Erweiterungskarte (zusätzlich zur Grafikkarte) die Berechnungen für die 3D-
Ausgabe übernahm. Dadurch wurden auf der CPU wieder Ressourcen für andere
Aufgaben frei und es waren grafisch noch beeindruckende Spiele möglich.

Kapitel 1 – Geschichte der Grafikkarten
2
Abbildung 1.2: PC-Spiel "Doom"
Mit dem Ende der 1990er Jahre übernahmen die Grafikkarten die Dekodierung
von komprimierten Videos (z.B. MPEG). Um die Leistung der Grafikkarte noch
weiter zu steigern, kamen Hersteller wie „3Dfx“ auf die Idee mehrere Grafikchips
zu nutzen.
Dem – bis dahin noch kleinen und unbekannten – Hersteller „Nvidia“ gelang 1999
mit der „Riva 128“ der Durchbruch da sie die erste Grafikkarte war, die GPU und
Grafikbeschleuniger auf einer Karte vereinte.
Kapitel 2 – Leistung der GPUs
3
2 Leistung der GPUs
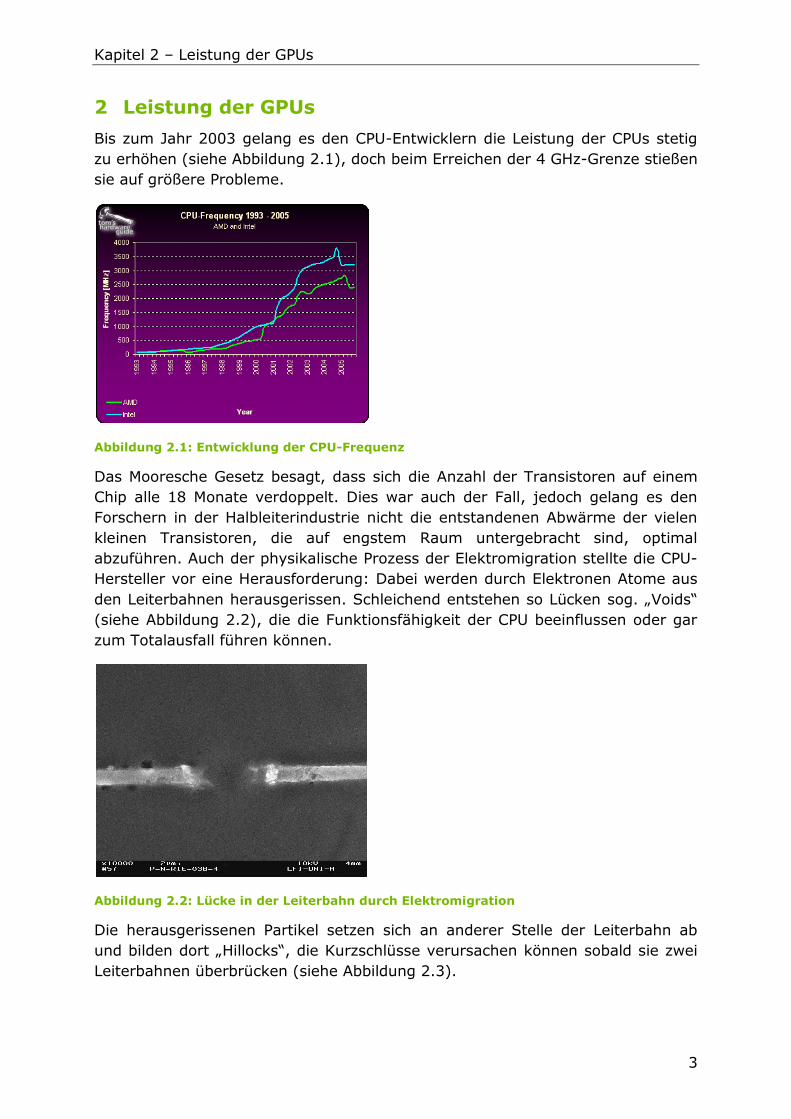
Bis zum Jahr 2003 gelang es den CPU-Entwicklern die Leistung der CPUs stetig
zu erhöhen (siehe Abbildung 2.1), doch beim Erreichen der 4 GHz-Grenze stießen
sie auf größere Probleme.
Abbildung 2.1: Entwicklung der CPU-Frequenz
Das Mooresche Gesetz besagt, dass sich die Anzahl der Transistoren auf einem
Chip alle 18 Monate verdoppelt. Dies war auch der Fall, jedoch gelang es den
Forschern in der Halbleiterindustrie nicht die entstandenen Abwärme der vielen
kleinen Transistoren, die auf engstem Raum untergebracht sind, optimal
abzuführen. Auch der physikalische Prozess der Elektromigration stellte die CPU-
Hersteller vor eine Herausforderung: Dabei werden durch Elektronen Atome aus
den Leiterbahnen herausgerissen. Schleichend entstehen so Lücken sog. „Voids“
(siehe Abbildung 2.2), die die Funktionsfähigkeit der CPU beeinflussen oder gar
zum Totalausfall führen können.
Abbildung 2.2: Lücke in der Leiterbahn durch Elektromigration
Die herausgerissenen Partikel setzen sich an anderer Stelle der Leiterbahn ab
und bilden dort „Hillocks“, die Kurzschlüsse verursachen können sobald sie zwei
Leiterbahnen überbrücken (siehe Abbildung 2.3).

Kapitel 2 – Leistung der GPUs
4
Abbildung 2.3: Durch Elektromigration ausgelöste Ablagerungen
Die Elektromigration wird durch das Hitzeproblem noch verstärkt und führt
unweigerlich zur Zerstörung der CPU.
Da all diese Probleme nicht ohne weiteres lösbar waren, verabschiedeten sich die
CPU-Hersteller im Jahr 2005 von dem Ziel, die Frequenz der CPU immer weiter
erhöhen zu wollen, und setzen ganz auf Mehrkernprozessoren.
Die Hersteller von Grafikchips hatten diese Probleme nicht, da sie eine andere
Architektur benutzen. Zudem verschafft diese den GPUs eine wesentlich höhere
Rechenleistung (bis zu 20mal mehr als CPUs; siehe Abbildung 2.4).
Abbildung 2.4: Potential der GPU im Vergleich zur CPU
Eine CPU ist für universelle Befehle ausgelegt: Sie muss mit willkürlichen
Speicherzugriffen, mit Verzweigungen und einer ganzen Reihe von
unterschiedlichen Datentypen zurechtkommen. Befehle werden von ihr
sequentiell ausgeführt.

Kapitel 2 – Leistung der GPUs
5
Wenn man den Aufbau in Abbildung 2.5 betrachtet erkennt man, dass ein großer
Teil des Chips vom Cache und dem Controller eingenommen werden. Die
Recheneinheiten (Arithmetic Logic Unit, kurz ALU) müssen im Gegensatz dazu
mit sehr wenig Platz auskommen: Dies sei in der universellen Einsetzbarkeit von
CPUs geschuldet.
Abbildung 2.5: Architektur einer CPU
GPUs wurden von Anfang an auf Grafikberechnungen ausgelegt (siehe Abbildung
2.6). Ihre Aufgabe besteht darin Polygone zu laden und daraus die
entsprechenden Pixel zu berechnen. Der Grafikchip arbeitet nach dem SIMD-
Prinzip (Single Instruction, Multiple Data) und führt somit Befehle parallel aus,
wodurch die ALUs besser ausgenutzt werden können. Da die Pixel im Speicher
nebeneinander liegen, wird nur ein kleiner Cache benötigt und die Zugriffszeiten
fallen gering aus.
Abbildung 2.6: Architektur einer GPU

Kapitel 3 – GPGPU
6
3 GPGPU
Angetrieben durch die Wissenschaft, die immer auf der Suche nach
Leistungsstärkeren Computer für ihre Berechnungen ist, kam man auf den
Gedanken, den Grafikkarten-Chip als mathematischen Co-Prozessor für
allgemeine Berechnungen zu verwenden. Dieses Verfahren wird als General
Purpose Computation on Graphics Processing Unit (kurz GPGPU) bezeichnet.
Mit Hilfe von GPGPU würde man zudem noch sehr viel Geld einsparen: CPU-
Systeme in dieser Leistungsklasse kosten einige Tausend Euro, ein paar
Grafikkarten aber nur einen Bruchteil davon.
Dabei ist zu beachten, dass Grafikchips ihren Geschwindigkeitsvorteil gegenüber
den CPUs nur ausspielen können wenn sie einen Algorithmus auf eine ganze
Menge von Daten anwenden sollen. Dazu muss sich die Berechnung in viele
parallel ausführbare Teile zerlegen lassen.
Man sollte allerding folgende Punkte beachten, die beim Einsatz von GPGPU
anfallen:
Die GPUs verschiedener Hersteller unterscheiden sich stark. Hier muss
eine einheitliche Schnittstelle geschaffen werden, die es erlaubt den
Grafik-Prozessor zur Berechnung von allgemeinen mathematischen
Aufgaben einzusetzen (vgl. „OpenCL“).
Für die parallele Programmierung sind spezielle Konzepte notwendig.
Grafikkarten besitzen meist wenig Speicher.
Der Speicher ist manchmal meist von minderer Qualität als der, der bei
CPUs eingesetzt wird. Es muss also eine gewisse Fehleranfälligkeit
berücksichtigt werden.
Da es die PC-Architektur nicht erlaubt Programme direkt auf der GPU
auszuführen, ist GPGPU weiterhin auf die CPU angewiesen.
3.1 Geschichtliches
Im Jahr 2000 erschienen die ersten Grafikkarten, bei denen es möglich war die
GPU zu programmieren (GeForce 3 und ATI R200). Man konnte eigene Shader
programmieren um neuartige Grafikeffekte zu erzeugen. Nvidia stellte dazu die
Programmiersprache „Cg“ („C for Graphics“) bereit, welche stark an C angelehnt
ist. Anfänglich war die Shader-Programmierung auf 10 Instruktionen pro
Programm begrenzt. Zudem musste man sich mit exotischen Datentypen mit 9
oder 12 Bit Festkomma anfreunden.
Die nächste Generation an Grafikchips brachte im Jahr 2003 auf diesem Gebiet
Verbesserungen: Mit der GeForce FX (Chipsatz NV30) wurden regulär 32 Bit
Gleitkommaberechnungen auf der GPU unterstützt. Auch war es nun möglich
mehr als 1000 Befehle auf der GPU auszuführen. Dies machte die GPUs zum
Lösen von mathematischen Berechnungen (z.B. Matrizenmultiplikationen)
interessant. Doch leider war die Programmierung sehr kompliziert: Man benötigte

Kapitel 3 – GPGPU
7
Wissen über die Grafik-Programmierung, da beim Zugriff auf die GPU kein Weg
an DirectX oder OpenGL vorbeiführte.
Dieser Sachverhalt wurde durch ein paar Studenten der Standford-Uni
grundlegend geändert: Mit Ihrem Studentenprojekt „BrookGPU“ erschufen sie im
Jahr 2004 eine einheitliche API um GPGPU plattformübergreifend zu ermöglichen.
Die Programme konnten in C geschrieben werden, was vielen Entwicklern
entgegen kam. Der daraus erzeugte Algorithmus konnte auf hunderten
Shaderprozessoren der Grafikkarte ausgeführt werden. Ein Datenstrom wurde
anschließend durch diese Shader geschleust, weshalb man dieses Verfahren auch
als „Stream Computing“ bezeichnet.
Da „BrookGPU“ ohne Unterstützung der Chiphersteller auskommen musste,
waren nach dem Erscheinen einer neuen Treiberversion Anpassungen notwendig.
Die Industrie verzichtete deshalb auf den Einsatz: Für sie waren Systemausfälle
mit einem zu hohem finanziellen Risiko verbunden, denn es war nicht
gewährleistet, dass das Studenten-Team fortlaufend die Bibliothek aktualisiert.
Doch bei Wissenschaftlern und Hobby-Programmierern stieß „BrookGPU“ mit
seinen Möglichkeiten auf zunehmendes Interesse.
Bald erweckte die Technologie die Aufmerksamkeit der beiden größten
Grafikchip-Hersteller AMD und Nvidia: Sie sahen ein, dass sie mit GPGPU die Tür
zu einem weiteren Markt aufstoßen können: Hauptabnehmer ihrer Produkte sind
bisher größtenteils PC-/Konsolen-Spieler und Multimedia-Enthusiasten. Mit
GPGPU könnten sie ihre Grafikchips zusätzlich für die Wissenschaft und
Forschung interessant machen.
So bekamen die Entwickler von „BrookGPU“ ein Übernahmeangebot: Die Hälfte
wechselte daraufhin zu AMD, der andere Teil zu Nvidia. Bei AMD wurde die API
weiter verbessert und in „Brook+“ umbenannt. Auf Seiten Nvidias entstand
daraus „CUDA“.
3.2 OpenCL
Mit „OpenCL“ (Open Computing Language) existiert eine, ursprünglich von Apple
entwickelte, API für plattformunabhängiges Rechnen auf diversen Arten von
Prozessoren (z.B. CPU und GPU). Zum erstem Mal wurde sie im Mac-
Betriebssystem „Snow Leopard“ (Mac OS X v10.6) implementiert um eine
spürbare Beschleunigung des Systems zu erzielen. Im Jahre 2008 wurde
„OpenCL“ durch die Khronos Group - zu der neben Apple auch Intel, Nvidia, AMD
und viel weitere Unternehmen angehören und die unteranderem auch für
„OpenGL“ zuständig ist - standardisiert.

Kapitel 4 – CUDA
8
4 CUDA
Bei CUDA (Compute Unified Device Architecture) handelt es sich um eine, im
Jahr 2006 eingeführte, GPGPU-Technologie von Nvidia. Seit der GeForce 8
(Chipsatz G80) ist es möglich CUDA einzusetzen. Die Technik ist Hard- und
Softwareseitig implementiert: So erfordert jede neue CUDA-Version eine neue
Hardware. Als Programmiersprache wird auf C zurückgegriffen, welches von
Nvidia um zusätzliche Schlüsselwörter für die parallele Programmausführung
erweitert wurde. Ab der Chip-Architektur „Fermi“ ist die Nutzung von C++
möglich. Daneben existieren mittlerweile für eine ganze Reihe von
Programmiersprachen Wrapper (z.B. Python, Java, .Net).
Mit „Tesla“ wendet sich Nvidia auch gezielt an Firmen und
Forschungseinrichtung, die CUDA professionell Einsetzen wollen: Die Karten
dienen als reine Stream-Prozessoren und sind deswegen mit keiner Schnittstelle
für Monitore ausgestattet.
CUAD bietet diverse Möglichkeiten an um GPGPU-Programme zu implementieren
(siehe Abbildung 4.1). So kann, wie bereits angesprochen, der von Nvidia
bevorzugte Weg mittels C beschritten werden. Daneben lässt sich auch Fortran,
das vor allem bei Wissenschaftlern populär ist, als Programmiersprache
einsetzen. Alternativ können über „OpenCL“ oder „DirectCompute“, das von
Microsoft entwickelt wurde und Bestandteil von DirectX 11 ist, Berechnungen auf
der Grafikkarte vorgenommen werden.
Abbildung 4.1: Architektur von CUDA
4.1 Hardwareseitig
Ein CUDA-Programm wird auf der Hardware von mehreren Threads ausgeführt.
Sie sind direkter Bestandteil der Hardware, wodurch sie leichtgewichtiger sind als
die Threads einer CPU. Jeder Thread ist über eine eindeutige ID identifizierbar.
Wie in Abbildung 4.2 ersichtlich ist, können Threads über den Shared Memory
miteinander kommunizieren. Zwischen 64 und 512 Threads fasst man in einem
Blöck zusammen. Bei der Initialisierung von CUDA kann die genaue
Threadanzahl angegeben werden: Hier können bestimmte Werte dem

Kapitel 4 – CUDA
9
Algorithmus zu einem extremen Performancevorteil verhelfen. Es wird garantiert,
dass alle Threads eines Blocks vom selben Multiprozessor ausgeführt werden.
Abhängig vom Grafikchip lassen sich bis zu 8 Blöcke einem Multiprozessor
zuordnen. Jeder Block erhält eine ID und ist darüber eindeutig identifizierbar. Die
Kommunikation von Threads unterschiedlicher Blöcke kann nur über den Global
Memory erfolgen, welcher deutlich langsamer arbeitet als der Shared Memory.
Blöcke wiederum werden zu einem Grid zusammengefasst. Alle Blöcke und somit
auch Threads führen ein und denselben Algorithmus aus.
Abbildung 4.2: Grid-Modell von CUDA
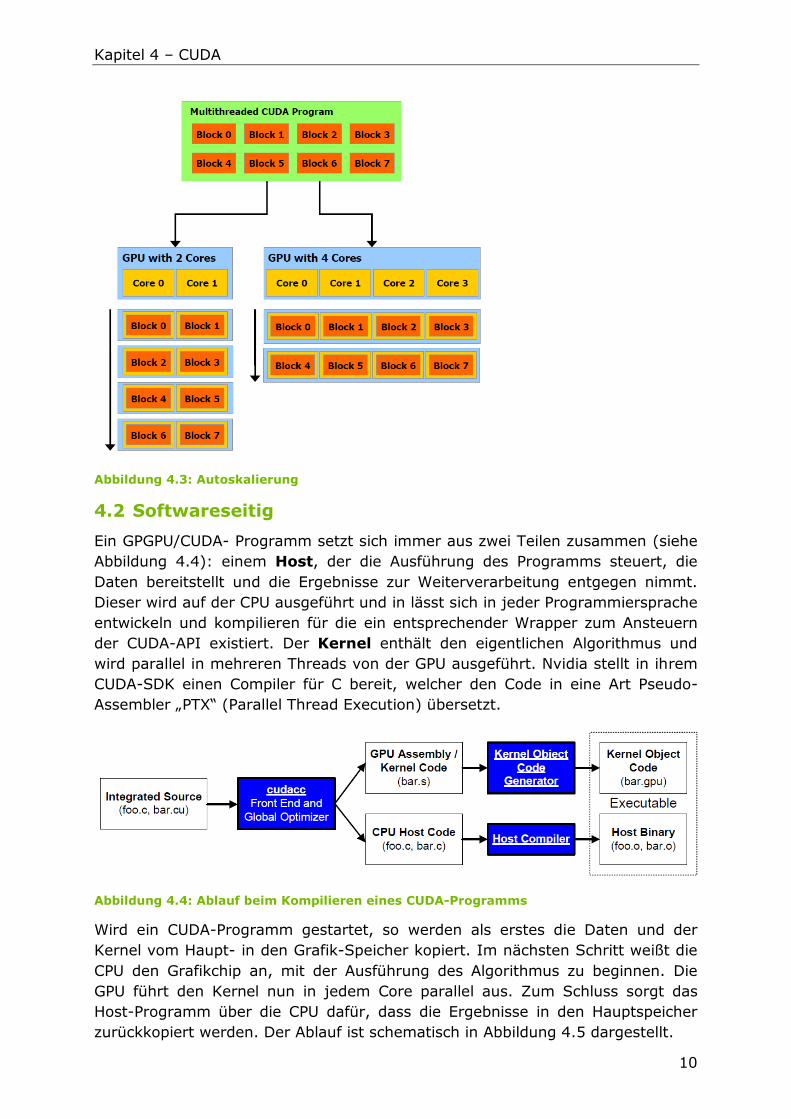
Das CUDA-Framework sorgt selbständig dafür, dass die Blöcke gleichmäßig auf
die jeweilige Anzahl an GPU-Kernen der Grafikkarte aufgeteilt werden (siehe
Abbildung 4.3). Dies wird als Autoskalierung bezeichnet.
Kapitel 4 – CUDA
10
Abbildung 4.3: Autoskalierung
4.2 Softwareseitig
Ein GPGPU/CUDA- Programm setzt sich immer aus zwei Teilen zusammen (siehe
Abbildung 4.4): einem Host, der die Ausführung des Programms steuert, die
Daten bereitstellt und die Ergebnisse zur Weiterverarbeitung entgegen nimmt.
Dieser wird auf der CPU ausgeführt und in lässt sich in jeder Programmiersprache
entwickeln und kompilieren für die ein entsprechender Wrapper zum Ansteuern
der CUDA-API existiert. Der Kernel enthält den eigentlichen Algorithmus und
wird parallel in mehreren Threads von der GPU ausgeführt. Nvidia stellt in ihrem
CUDA-SDK einen Compiler für C bereit, welcher den Code in eine Art Pseudo-
Assembler „PTX“ (Parallel Thread Execution) übersetzt.
Abbildung 4.4: Ablauf beim Kompilieren eines CUDA-Programms
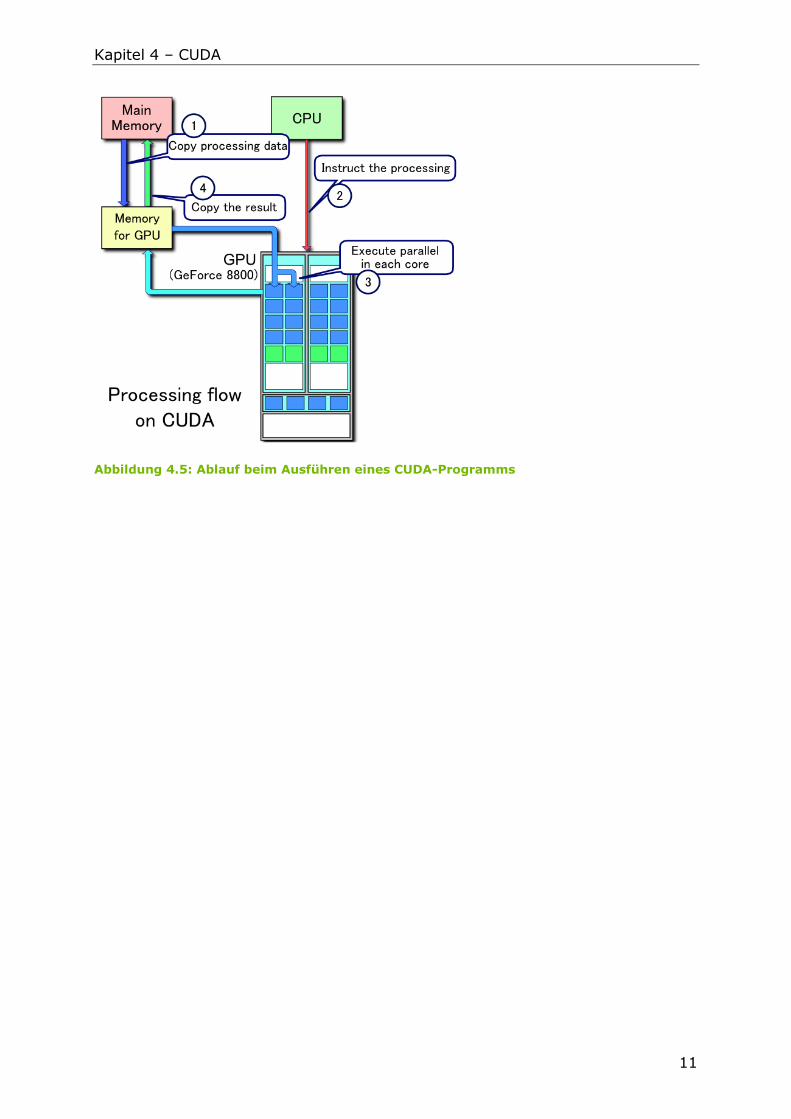
Wird ein CUDA-Programm gestartet, so werden als erstes die Daten und der
Kernel vom Haupt- in den Grafik-Speicher kopiert. Im nächsten Schritt weißt die
CPU den Grafikchip an, mit der Ausführung des Algorithmus zu beginnen. Die
GPU führt den Kernel nun in jedem Core parallel aus. Zum Schluss sorgt das
Host-Programm über die CPU dafür, dass die Ergebnisse in den Hauptspeicher
zurückkopiert werden. Der Ablauf ist schematisch in Abbildung 4.5 dargestellt.
Kapitel 4 – CUDA
11
Abbildung 4.5: Ablauf beim Ausführen eines CUDA-Programms

Kapitel 5 – Beispiel – Matrizenmultiplikation
12
5 Beispiel – Matrizenmultiplikation
Als anschauliches und einfach nachvollziehbares Beispiel für den Einsatz von
GPGPU wird in Dokumentationen häufig die Multiplikation zweier Matrizen
angeführt. Die Matrizen-Multiplikation findet vor allem für die Transformationen
und Rotation geometrischer Objekte Anwendung. Sie stellt ein Schlüsselkonzept
der linearen Algebra da.
Um zwei Matrizen miteinander zu Multiplizieren, werden sie zunächst in ein
Falkschema eingetragen und anschließend wird die eine Matrix in Zeilen- („M“)
und die andere in Spalten-Vektoren („N“) zerlegt. An der Stelle, wo sich die
Vektoren kreuzen wird das Skalarprodukt in die Ergebnismatrix („P“) eingesetzt.
Dieser Vorgang ist in Abbildung 5.1 schematisch dargestellt.
Abbildung 5.1: Ablauf Matrixmultiplikation
5.1 Variante 1: Sequentieller Ablauf
Auf der CPU kann der Algorithmus sequentiell so umgesetzt werden:
Listing 5.1: Matrixmultiplikation mittels CPU
Wie in Listing 5.1 entnommen werden kann, werden drei ineinander
verschachtelte Schleifen benötigt. Dadurch ergibt sich eine Komplexität von
O(n³), wobei „n“ die Größe der Matrix angibt. Je höher die Dimensionen der
Matrizen, umso länger benötigt der Algorithmus für die Ausführung.

Kapitel 5 – Beispiel – Matrizenmultiplikation
13
5.2 Variante 2: parallel Durchführung mit CUDA
Der oben gezeigte sequentielle Algorithmus lässt sich nun gut zur parallelen
Abarbeitung durch CUDA anpassen: Dazu werden die beiden Matrizen im Global
Memory der Grafikkarte abgelegt und die Berechnung für jedes Element der
Ergebnismatrix wird durch einen eigenem Thread vorgenommen:
Listing 5.2: Matrixmultiplikation mit CUDA
Wie in Listing 5.2 zu sehen ist, wird ein CUDA-Programm in C geschrieben. In der
ersten Zeile taucht das CUDA-spezifische Schlüsselwort „__global__“ auf,
welches immer einen Kernel kennzeichnet.
Der Algorithmus kann nun deutlich schneller abgearbeitet werden als der in
Variante 1 beschriebene. Jedoch ergeben sich eine Reihe von Nachteile: So wird
der Kernel nur von einem einzigen Block durchgeführt. Da hier die maximale
Anzahl an Threads auf 512 begrenzt ist, können keine allzu großen Matrizen
miteinander multipliziert werden. Auch ist es Nachteilig, dass nur der langsame
Global Memory verwendet wird.
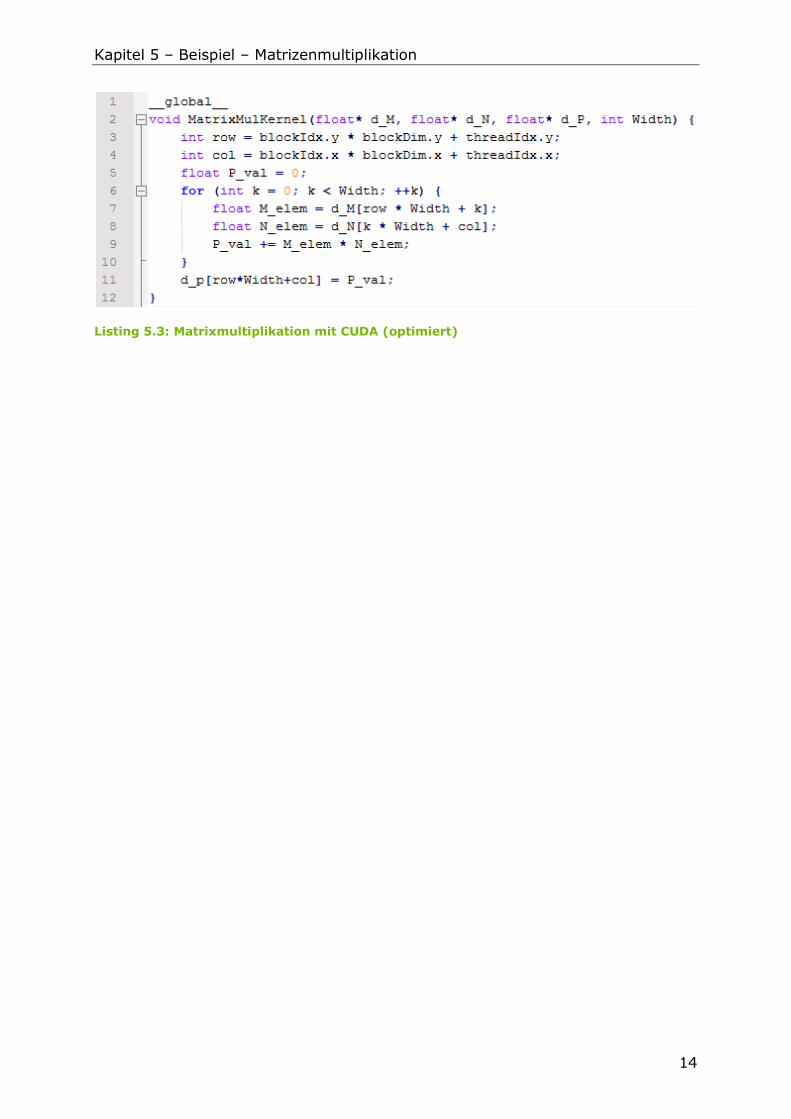
5.3 Variante 3: optimierter CUDA-Algorithmus
Variante 2 wurde dahingehend optimieren, dass die Matrizen in gleichgroße Teile
zerlegt werden. Jeder Teil wird von einem Block und somit von bis zu 512
Threads abgearbeitet. Die Daten werden in kleine Portionen zerlegt und vom
Global Memory in den effizienteren Shared Memory kopiert. Der CUDA-Quellcode
kann dem Listing 5.3 entnommen werden.
Kapitel 5 – Beispiel – Matrizenmultiplikation
14
Listing 5.3: Matrixmultiplikation mit CUDA (optimiert)

Kapitel 6 – Anwendung
15
6 Anwendung
Die Einsatzgebiete von CUDA sind vielfältig:
Simulation von physikalischen Vorgängen (Strömungen, Gravitation,
Temperatur und Crash-Tests)
Wettervorhersage
der Daten- und Finanzanalyse
Verarbeitung von akustischen und elektrischen Signalen
CT- und Ultraschall-Bildrekonstruktion
Kryptographie (z.B. MD5-Brute-Force)
6.1 Nvidia PhysX
Da in Computerspielen verstärkt Physiksimulation eingesetzt wird um das
Erscheinungsbild möglichst realistisch darzustellen, diese Berechnung die CPU
allerding sehr stark beansprucht, hat Anfang der 2000er Jahre der amerikanische
Halbleiterhersteller Ageia Technologies separate Physikbeschleuniger-Karten
(PPU) entwickelt und auf den Markt gebracht. Durch sie war eine detailreichere
und weitreichendere Simulation möglich. Einige große Hersteller setzten die
Technologie in ihren Spielen ein. Bei Spielern ohne Physikbeschleunigerkarte
wurden die entsprechenden Effekte dann nicht dargestellt, was jedoch für den
Spielverlauf keine negativen Folgen hatte. Im Jahre 2008 übernahm Nvidia das
Unternehmen und integrierte deren Physik-Engine „PhysX“ in CUDA. So ist es
heutzutage möglich, eine entsprechende CUDA-fähige Grafikkarte vorausgesetzt,
sehr detailreiche physikalische Simulationseffekte ohne entsprechende
Erweiterungskarten zu erleben. Die Berechnung übernimmt in dem Fall direkt die
GPU. Sollte diese schon mit der reinen Grafikberechnung ausgelastet sein, so
kann „PhysX“ auch auf eine zweite Grafikkarte ausgelagert werden.
6.2 Folding@home
Bei „Folding@home“ handelt es sich um ein Projekt der Stanford Universität.
Dabei wird die Faltung von Proteinen simuliert, was zur Erforschung von
Alzheimer, BSE und Krebs von großem Nutzen ist. Um bei dem Projekt
mitzumachen, lädt man sich einen Client herunter. Dieser bezieht dann Daten
vom Server der Universität und führt im Hintergrund Berechnungen mit ihnen
durch. Die Ergebnisse werden letztendlich wieder an den zentralen Server
geleitet. So ergibt sich ein weltweites Netzwerk, welches im Ganzen einen
Supercomputer darstellt (Distributed Computing). In neueren Client-Versionen
kann die GPU mittels CUDA die anfallenden Simulationen durchführen.
Ursprünglich war das Projekt ganz auf den Einsatz auf einer CPU konzipiert.
6.3 Adobe Creative Suite
Auch die Design- und Grafikprogramme von Adobe setzen seit Version 4 CUDA
ein. Besonders beim Rendern von Videos ergibt sich ein enormer
Geschwindigkeitsvorteil, so dass Effektvorschauen größtenteils in Echtzeit
ablaufen können. Ebenso werden aufwändige Transformationen (z.B. Drehen,

Kapitel 6 – Anwendung
16
Skalieren) und der Einsatz von Filtern und Effekten in „Photoshop“ und
„Illustrator“ auf die Grafikkarte verlagert, wodurch ein flüssigeres Arbeiten
ermöglicht werden soll.

Kapitel 7 – Quellen
17
7 Quellen
• http://www.nvidia.de/object/cuda_home_new_de.html
• http://www.nvidia.com/object/what_is_cuda_new.html
• http://developer.download.nvidia.com/compute/cuda/3_2/toolkit/docs/CU
DA_C_Programming_Guide.pdf
• http://www.nvidia.com/content/CUDA-ptx_isa_1.4.pdf
• http://ambermd.org/gpus/benchmarks.htm
• http://www.tomshardware.de/CUDA-Nvidia-CPU-GPU,testberichte-
240065.html
• http://en.wikipedia.org/wiki/CUDA
• http://de.wikipedia.org/wiki/Grafikkarte
• http://de.wikipedia.org/wiki/Apple_II
• http://en.wikipedia.org/wiki/OpenCL
• http://www.informatik.uni-hamburg.de/WSV/teaching/sonstiges/EwA-
Folien/Mueller-Paper.pdf
• http://www.cis.udel.edu/~cavazos/cisc879/papers/ppopp-08-ryoo.pdf
• http://www.cse.shirazu.ac.ir/~azimi/gpu89/lectures/07-MatMult-Basic.pdf
• c‘t 11/2009, „Parallel-Werkzeuge“, Seite 142ff, Manfred Bertuch





























