Embed Size (px)
Citation preview

77
Ćwiczenie nr 10:
ANALIZA GŁÓWNYCH SKŁADOWYCH
Celem przedostatniego ćwiczenia laboratoryjnego jest wykonanie analizy podobieństwa
cech i obiektów metodą o największym ciężarze gatunkowym, jaką jest analiza głównych
składowych (ang. Principle Component Analysis, PCA). Realizacja tego celu gwarantuje masę
zabawy i niezapomnianych wrażeń.
I. PRZYGOTOWANIE DANYCH DO PROGRAMU PCA.EXE.
Należy przygotować dwa pliki danych wejściowych do programu PCA.EXE. Pierwszy
plik, o przykładowej nazwie dane.nzw (wymagane jest rozszerzenie *.nzw26), powinien
zawierać nazwy wszystkich obiektów, umieszczone w kolumnie. Długość nazwy obiektu nie
może przekraczać ośmiu znaków. Drugi plik, o przykładowej nazwie dane.txt (nazwa
pierwszego pliku musi pokrywać się z nazwą drugiego - powinny różnić się jedynie
rozszerzeniami!) powinien zawierać wartości z tabeli danych autoskalowanych – bez nazw
zmiennych oraz obliczonych wartości średnich i odchyleń standardowych. Koniecznie trzeba
pamiętać, aby w pliku dane.txt zamienić przecinki na kropki!
II. WYKONANIE OBLICZEŃ.
Po przygotowaniu dwóch plików z danymi wejściowymi, należy umieścić je w tym
samym folderze, w którym znajduje się PCA.EXE, a następnie uruchomić program. W wyniku
tych działań wywiąże się kolejna, pełna wzajemnego szacunku dyskusja pomiędzy Studentem a
programem PCA.EXE.
PCA: ANALIZA CZYNNIKÓW!
STUDENT: <zadowolony, naciska dwa razy Enter>
PCA: Ilosc zmiennych…
STUDENT: <wpisuje liczbę swoich zmiennych, Enter>
PCA: Liczba obiektow…
STUDENT: <wpisuje liczbę swoich obiektów, Enter>
PCA: Zapis wynikow?
STUDENT: <wpisuje> t <i naciska Enter>
PCA: Nazwa pliku wynikowego:
STUDENT: <tworzy unikalną w skali świata nazwę pliku
wynikowego, złożoną z maksymalnie 8 znaków, wpisuje
ją i naciska Enter>
26 Częstym problemem, który pojawia się w trakcie zajęć, a który nadzwyczaj skutecznie zniechęca
program PCA.EXE do działania, jest przygotowywanie pliku o nazwie dane.nzw.txt, zamiast
dane.nzw. Aby przygotować plik z rozszerzeniem *.nzw, należy otworzyć Notatnik, umieścić w oknie
wymaganą zawartość, a następnie wybrać opcję Zapisz jako…, zaś typ pliku ustawić na Wszystkie
pliki (*.*). Dopiero przy takich ustawieniach podanie nazwy pliku jako dane.nzw zaowocuje
utworzeniem pliku o pożądanym rozszerzeniu.

78
PCA: WCZYTANIE DANYCH.
Nazwa zestawu obiektow…
STUDENT: <podaje nazwę swojego zestawu danych bez
rozszerzenia, np.> dane <i naciska Enter>
PCA: Nazwa zmiennej 1:
STUDENT: <podaje nazwę zmiennej, która w macierzy danych
autoskalowanych stanowi pierwszą kolumnę od lewej i
naciska Enter>
PCA: <pyta kolejno o nazwy wszystkich zmiennych>
STUDENT: <uprzejmie odpowiada>
PCA: <pokazuje macierz korelacji i pyta:> drukujemy?
STUDENT: <odpowiada:> t <i naciska Enter trzy razy>
PCA: <podaje parametry pierwsze składowej i pyta:> Liczymy
dalej?
STUDENT: t <Enter>
PCA: <podaje parametry kolejnych składowych, a student na
pytanie:> Liczymy dalej? <odpowiada> t <tak długo, aż
PCA wyświetli następujący komunikat:>
n-ta27 skladowa
n-ta wartosc wlasna: 0.0000
wyjasnia 0.0% zmiennosci
dotychczasowe składowe: 100%
Odchylenie resztowe: 0.00
Liczymy dalej?
STUDENT: <odpowiada> n <i naciska Enter>
PCA: <wyświetla podejrzaną tabelę i pyta:> Ile składowych
uznajesz za istotne?
STUDENT: <obserwuje pierwszy i trzeci wiersz podejrzanej
tabeli, tj. wartości wlasne oraz sumaryczny % , a
następnie podejmuje decyzję:>
1) <jeżeli tylko jedna lub dwie wartości własne są
większe od 1 oraz druga od lewej wartość w
wierszu sumaryczny % jest bliska 90, odpowiada:>
2
2) <jeżeli więcej niż dwie wartości własne są
większe od 1, i/lub druga od lewej wartość w
wierszu sumaryczny % jest na poziomie 60-70 –
odpowiada:> 3
3) <w przeciwnym razie odpowiada:> 4
PCA: <wyświetla tabelę ładunków oraz długości składowych i
pyta> drukujemy?
STUDENT: t <i naciska Enter trzy razy>
PCA: Wykonac Varimax?
STUDENT: t <Enter>
PCA: <wyświetla tabelę ładunków oraz długości składowych
po rotacji VARIMAX>
27 Jeżeli wszystko zostało wykonane poprawnie, w miejscu n pojawi się wartość o jeden większa, niźli
liczba zmiennych. Oznacza to, że liczba składowych, które wyjaśniają więcej, niźli 0,0% zmienności, jest
dokładnie taka, jak liczba zmiennych.

79
STUDENT: <naciska Enter trzy razy>
PCA: Drukowac?
STUDENT: t <Enter>
PCA: UZYSKANE CZYNNIKI:
<tabela>
Drukujemy?
STUDENT: t <Enter>
PCA: NOWY ZESTAW?
STUDENT: n <Enter>
PCA: <kończy pracę>
STUDENT: <urządza sobie 5 minut przerwy>
PROWADZĄCY: <przygotowuje się psychicznie na grad pytań>
III. WYKRES ZMIENNYCH W PRZESTRZENI VARIWEKTORÓW I MAPA
LINIOWA OBIEKTÓW.
Wyniki wykonanych w sekcji II obliczeń zostały umieszczone w pliku wynikowym o
rozszerzeniu *.OUT.
Przykład:
Zestaw MIECZE, który zawiera 7 zmiennych i 20 obiektów, poddaliśmy
analizie głównych składowych. Po wykonaniu obliczeń i uwzględnieniu
dwóch pierwszych składowych jako istotnych, otrzymaliśmy następujące
wyniki:
G L O W N E S K L A D O W E
Odchylenie ogolne = 0.97
wartosci wlasne: 4.7770 0.8973 0.4589 0.2813
% informacji 71.84 13.49 6.90 4.23
sumaryczny % 71.84 85.33 92.23 96.46
resztowe od.sta. 0.5587 0.4417 0.3594 0.2800
Za istotne uznano 2 skladowe !
Po udzieleniu pozytywnej odpowiedzi na propozycje wykonania
rotacji VARIMAX otrzymaliśmy następujące wyniki końcowe:
Ladunki skladowych Dlugosc skladowych
(DC*) 0.9431 0.1077 0.9493
(DG*) 0.8947 0.1244 0.9033
(DR) 0.7540 0.1157 0.7629
(M) 0.9361 0.0104 0.9362

80
(SM) 0.8455 -0.1693 0.8623
(T) 0.9053 0.0658 0.9077
(CR*) 0.2357 0.9359 0.9652
W Y L I C Z O N E C Z Y N N I K I :
czyn 1 czyn 2
AER 0.280 1.193
AND 7.024 -1.922
AZU -4.121 -0.356
BAL -3.552 -1.104
DUR -2.434 -0.742
EXC 1.878 0.545
GLA 1.604 0.224
GOL -2.613 1.517
GRA -1.066 -0.711
GUR 0.447 -0.014
GWY -3.005 0.152
HER -4.276 -1.028
HUR -3.536 -0.360
JOY -2.483 -1.090
LOD -1.884 -0.565
ORK 2.526 0.627
SIH 1.691 0.119
UMB 12.580 1.996
URI 8.649 2.100
ZAD -7.709 -0.581
Na końcu pliku wynikowego programu PCA.EXE znajdują się dwie tabele.
Kolejne wiersze pierwszej z nich odpowiadają kolejnym zmiennym w przestrzeni
dwóch lub trzech pierwszych variwektorów. Zmienne te są reprezentowane przez wektory o
składowych równych obliczonym ładunkom (po rotacji VARIMAX) i mogą nadawać
znaczenia (interpretacje) poszczególnym variwektorom.
Aby wykonać wykres zmiennych w przestrzeni variwektorów, należy nanieść te
wektory na układ współrzędnych, którego osie reprezentują dwa lub trzy pierwsze
variwektory28
.
Przykład, c.d.:
Wykonujemy wykres zmiennych zestawu MIECZE w przestrzeni dwóch
pierwszych variwektorów:
28 Istnieje uzasadnione niebezpieczeństwo, że za istotne zostaną uznane trzy pierwsze główne składowe.
Będzie to wiązało się z koniecznością wykonania wykresów trójwymiarowych (XYZ). Instrukcja
stworzenia ich w Excelu (a dokładniej: ich iluzji) znajduje się w Dodatku E na końcu niniejszej instrukcji.
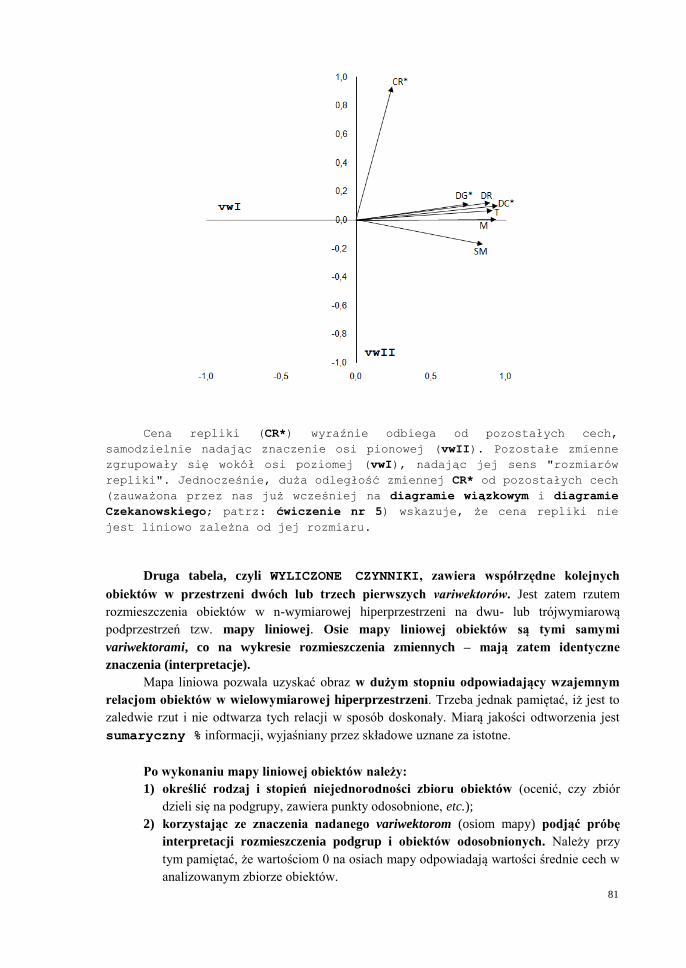
81
Cena repliki (CR*) wyraźnie odbiega od pozostałych cech,
samodzielnie nadając znaczenie osi pionowej (vwII). Pozostałe zmienne
zgrupowały się wokół osi poziomej (vwI), nadając jej sens "rozmiarów
repliki". Jednocześnie, duża odległość zmiennej CR* od pozostałych cech
(zauważona przez nas już wcześniej na diagramie wiązkowym i diagramie
Czekanowskiego; patrz: ćwiczenie nr 5) wskazuje, że cena repliki nie
jest liniowo zależna od jej rozmiaru.
Druga tabela, czyli WYLICZONE CZYNNIKI, zawiera współrzędne kolejnych
obiektów w przestrzeni dwóch lub trzech pierwszych variwektorów. Jest zatem rzutem
rozmieszczenia obiektów w n-wymiarowej hiperprzestrzeni na dwu- lub trójwymiarową
podprzestrzeń tzw. mapy liniowej. Osie mapy liniowej obiektów są tymi samymi
variwektorami, co na wykresie rozmieszczenia zmiennych – mają zatem identyczne
znaczenia (interpretacje).
Mapa liniowa pozwala uzyskać obraz w dużym stopniu odpowiadający wzajemnym
relacjom obiektów w wielowymiarowej hiperprzestrzeni. Trzeba jednak pamiętać, iż jest to
zaledwie rzut i nie odtwarza tych relacji w sposób doskonały. Miarą jakości odtworzenia jest
sumaryczny % informacji, wyjaśniany przez składowe uznane za istotne.
Po wykonaniu mapy liniowej obiektów należy:
1) określić rodzaj i stopień niejednorodności zbioru obiektów (ocenić, czy zbiór
dzieli się na podgrupy, zawiera punkty odosobnione, etc.);
2) korzystając ze znaczenia nadanego variwektorom (osiom mapy) podjąć próbę
interpretacji rozmieszczenia podgrup i obiektów odosobnionych. Należy przy
tym pamiętać, że wartościom 0 na osiach mapy odpowiadają wartości średnie cech w
analizowanym zbiorze obiektów.

82
Przykład, c.d.:
Wykonujemy mapę liniową obiektów zestawu MIECZE w przestrzeni
dwóch pierwszych variwektorów:
Na mapie liniowej dostrzegamy dwa zwarte skupienia obiektów
(wewnątrz szarych elips) i kilka mniej lub bardziej rozrzuconych
obiektów odosobnionych.
Uzyskana mapa pozwala na scharakteryzowanie poszczególnych podgrup
obiektów, zgodnie ze znaczeniem osi: oś pozioma = rozmiar repliki, oś
pionowa = cena repliki.
I tak:
1) obiekt AND jest repliką o znacznych rozmiarach, a przy tym
zdecydowanie najtańszą;
2) obiekty URI i UMB są replikami największymi i najdroższymi;
3) grupę obiektów {EXC, GLA, GUR, ORK, SIH} charakteryzują
rozmiary i ceny lekko powyżej przeciętnych;
4) grupę obiektów {AZU, BAL, DUR, GRA, HER, HUR, JOY, LOD}
charakteryzują rozmiary i ceny lekko poniżej przeciętnych;

83
5) obiekt ZAD jest najmniejszy, lecz jego cena plasuje się
zaledwie lekko poniżej średniej (drogie materiały? kunszt
kowala?);
6) obiekty AER i GOL mają przeciętne rozmiary, lecz są dość
drogie;
7) obiekt GWY ma prawie identyczne rozmiary, jak obiekt GOL, lecz
jest od niego o wiele tańszy (konkurencja rynkowa!).
Skonfrontujmy powyższe wnioski z wejściową tabelą danych (patrz:
ćwiczenie nr 2). Teraz dopiero jesteśmy w stanie zauważyć niektóre
prawidłowości, istniejące w danych od początku, lecz ujawnione dopiero
po zastosowaniu analizy głównych składowych. Rzeczywiście: ZAD jest
repliką najmniejszą, AND najtańszą, zaś UMB i URI są największe i
jednocześnie najdroższe. Jednakże wypowiedzenie się o cechach
pozostałych replik na podstawie samej li tylko tabeli danych jest
praktycznie niemożliwe.
IV. SPRAWOZDANIE.
W sprawozdaniu należy umieścić wykres zmiennych oraz mapę liniową obiektów w
przestrzeni odpowiedniej liczby variwektorów, wraz z komentarzem. Prosimy również o
dołączenie pliku wynikowego z programu PCA.EXE.

84
Dodatek E:
Tworzenie iluzji wykresu trójwymiarowego w Excelu.
Zgodnie ze stanem wiedzy Autorów tego opracowania, Excel nie posiada "przyrodzonej"
zdolności do tworzenia wykresów punktowych w trójwymiarowym układzie współrzędnych.
Ergo, w celu stworzenia takiego wykresu w Excelu, należy posłużyć się odpowiednim trikiem
matematycznym. Jeżeli Czytelnik zetknął się w swojej karierze z rysunkiem technicznym,
powinien znać ten trik - zamiast zatem tłumaczyć jego ideę, przejdziemy od razu do praktyki.
Przykład:
20 modeli myśliwskich celowników optycznych opisano 7 cechami. Po
wykonaniu analizy PCA za istotne uznaliśmy trzy pierwsze główne
składowe. Po rotacji VARIMAX uzyskaliśmy następujące ładunki:
Ladunki skladowych
0.8663 0.1944 -0.0288
0.2647 0.8354 0.0780
0.8157 -0.3052 0.1775
0.8830 0.2552 0.0906
0.1394 0.8587 0.1618
-0.4623 0.7732 0.1410
0.0354 0.1633 0.9771
Musimy teraz wykonać wykres 3D, obrazujący rozmieszczenie wektorów
siedmiu zmiennych (opisanych przez zaprezentowane powyżej ładunki) w
przestrzeni trzech ortogonalnych variwektorów; a w praktyce – w
układzie współrzędnych XYZ.
Załóżmy, że oś pozioma układu współrzędnych będzie odpowiadała variwektorowi I
(vwI; ładunki w kolumnie lewej), oś pionowa – variwektorowi II (vwII; ładunki w kolumnie
środkowej), zaś oś skierowana w stronę Czytelnika – variwektorowi III (vwIII; ładunki w
kolumnie prawej).

85
Iluzję wykresu 3D można zatem uzyskać, przy pomocy Excela, w następujący sposób:
1) Najpierw, należy odpowiednio zmodyfikować wartości ładunków dwóch
pierwszych variwektorów za pomocą wartości ładunków trzeciego variwektora (dla
wszystkich zmiennych), zgodnie z wzorami:
xJ’ = xJ – 0,5∙zJ
yJ’ = yJ – 0,5∙zJ
gdzie:
xJ – wartość ładunku variwektora I J-tej zmiennej;
yJ – wartość ładunku variwektora II J-tej zmiennej;
zJ – wartość ładunku variwektora III J-tej zmiennej.
Otrzymuje się w ten sposób współrzędne wektorów zmiennych, [x’,y’].
2) Następnie, należy obliczyć współrzędne rzutów prostokątnych końców tych
wektorów na płaszczyznę, wyznaczoną przez vwI i vwIII [x",y"]; zgodnie z
wzorami:
xJ" = xJ'
yJ" = –0,5∙zJ
Punkty te mają za zadanie ułatwić określenie, w której części przestrzeni znajdują
się końce wektorów "oryginalnych" zmiennych.
3) Ostatecznie, należy wykonać w Excelu wykres punktowy (X,Y) z wartości x’ i y’
(pierwsza seria danych) oraz x" i y" (druga seria danych); zaś oś skierowaną w
stronę Czytelnika dorysować… ręcznie, za pomocą narzędzia Autokształty.
Korzystając z tego samego narzędzia, należy również dorysować wektory

86
zmiennych (połączyć początek układu współrzędnych z końcem wektora) i linie
rzutowania (połączyć koniec wektora z jego rzutem na płaszczyznę).
Przykład, c.d.:
Tabelę zawierającą obliczone współrzędne wektorów (oraz ich rzutów
na płaszczyznę), a także wykonaną iluzję wykresu 3D dla powyższych
danych zaprezentowaliśmy poniżej.
x y z x' y' x" y"
0,866 0,194 -0,029 0,881 0,209 0,881 0,014
0,265 0,835 0,078 0,226 0,796 0,226 -0,039
0,816 -0,305 0,178 0,727 -0,394 0,727 -0,089
0,883 0,255 0,091 0,838 0,210 0,838 -0,045
0,139 0,859 0,162 0,059 0,778 0,059 -0,081
-0,462 0,773 0,141 -0,533 0,703 -0,533 -0,071
0,035 0,163 0,977 -0,453 -0,325 -0,453 -0,489

87
Ćwiczenie nr 11:
ANALIZA SKUPIEŃ
Efektem wykonania analizy podobieństwa obiektów jest otrzymanie obrazu
rozmieszczenia obiektów w wielowymiarowej przestrzeni cech. Obraz ten może mieć postać
diagramu Czekanowskiego, dendrytu lub diagramu wiązkowego. Często jednak, w
przypadku niejednorodnego zbioru obiektów, nie jest oczywiste, na ile podzbiorów (i o jakim
charakterze) można go sensownie podzielić. Pewnych sugestii w tym zakresie może dostarczyć
analiza głównych składowych, a zwłaszcza mapa liniowa obiektów. Przy pomocy mapy
liniowej możliwe jest podjęcie próby dokonania podziału zbioru obiektów metodą najstarszą,
subiektywną, ale niekiedy zadziwiająco skuteczną, tj. "na oko".
Reguły sztuki domagają się jednak zastosowania możliwie obiektywnej metody podziału
zestawu obiektów na podzbiory. Metody takie oferuje dział chemometrii zwany analizą
skupień; należą do nich, m.in., naturalny podział diagramu wiązkowego oraz naturalny
podział dendrytu. Ponieważ w trakcie ćwiczenia nr 6 został wykonany dendryt obiektów,
poniżej opiszemy zastosowanie naturalnego podziału dendrytu.
I. NATURALNY PODZIAŁ DENDRYTU.
W celu zobrazowania poszczególnych kroków tej metody, posłużymy się dendrytem
wykonanym dla zestawu MIECZE. Do dzieła!
1) Podział dendrytu rozpoczyna się od umieszczenia go w zasięgu ręki.
Kopiujemy dendryt dla zestawu MIECZE w miejsce łatwo dostępne:
2) Następnie, należy wypisać wiązadła pomiędzy obiektami w dendrycie. W
wykonaniu zadania bardzo pomocna jest tabela sporządzona zgodnie z poleceniami

88
zawartymi w punkcie 2) sekcji III instrukcji do ćwiczenia nr 6, zawierająca spis
wiązadeł pomiędzy obiektami w obrębie skupień pierwotnych. Wystarczy zatem
skopiować ww. tabelę do używanego obecnie arkusza i uzupełnić ją o brakujące
połączenia między skupieniami pierwotnymi.
Interesująca nas tabela została wcześniej opisana jako tabela
VI.1. Kopiujemy ją zatem do nowego arkusza i uzupełniamy
informacjami o połączeniach AZU-BAL, GRA-GUR oraz ORK-URI,
uzyskanymi dzięki tabelom VI.3., VI.4. oraz VI.5.
Obiekt: Sąsiad: Odległość:
GWY AZU 1,332
ZAD AZU 2,033
GRA DUR 0,907
GLA EXC 0,930
GUR EXC 1,006
SIH GLA 1,048
LOD GRA 1,064
GOL GWY 2,397
AZU HUR 0,899
HER HUR 0,879
BAL JOY 0,596
DUR JOY 0,423
AND ORK 4,237
EXC ORK 0,512
AER SIH 1,653
UMB URI 2,619
AZU BAL 1,054
GRA GUR 1,576
ORK URI 3,116
3) Kolejnym krokiem jest posortowanie tabeli względem kolumny Odległość od
wartości największej do najmniejszej.
Obiekt: Sąsiad: Odległość:
AND ORK 4,237
ORK URI 3,116
UMB URI 2,619
GOL GWY 2,397
ZAD AZU 2,033
AER SIH 1,653
GRA GUR 1,576
GWY AZU 1,332
LOD GRA 1,064
AZU BAL 1,054
SIH GLA 1,048
GUR EXC 1,006
GLA EXC 0,930
GRA DUR 0,907
AZU HUR 0,899
HER HUR 0,879
BAL JOY 0,596
EXC ORK 0,512
DUR JOY 0,423

89
4) Następnie, należy dodać do tabeli kolumnę Ilorazy. Umieszcza się w niej
wartości ilorazów dwóch sąsiednich odległości (górna/dolna) na poziomie
odległości dolnej.
Wypełnienie nowej kolumny "Ilorazy" rozpoczynamy w drugim
wierszu od góry, definiując iloraz odległości obiektów AND-ORK
i ORK-URI, a następnie formułę tę przeciągamy w dół, do końca
tabeli.
Obiekt: Sąsiad: Odległość: Ilorazy:
AND ORK 4,237
ORK URI 3,116 1,360
UMB URI 2,619 1,190
GOL GWY 2,397 1,093
ZAD AZU 2,033 1,179
AER SIH 1,653 1,230
GRA GUR 1,576 1,049
GWY AZU 1,332 1,183
LOD GRA 1,064 1,252
AZU BAL 1,054 1,009
SIH GLA 1,048 1,006
GUR EXC 1,006 1,042
GLA EXC 0,930 1,082
GRA DUR 0,907 1,025
AZU HUR 0,899 1,009
HER HUR 0,879 1,023
BAL JOY 0,596 1,475
EXC ORK 0,512 1,164
DUR JOY 0,423 1,210
W tak przygotowanej tabeli poszukuje się dostatecznie dużych wartości lokalnie
największych ilorazów (LNI). Przez pojęcie "lokalnie największego ilorazu"
rozumiemy wartość w kolumnie Ilorazy, która: i) jest większa, niż jej sąsiedzi
(górny i dolny); ii) nie jest ostatnia w tabeli (ale może być pierwsza, pomimo braku
sąsiada "od góry"). Do dalszej analizy używa się jednak tylko tych LNI, które
spełniają kolejne kryteria: i) ich wartość jest większa od pewnej wartości krytycznej,
zwykle równej 1,2; ii) nie znajdują się zbyt blisko dolnego końca tabeli. Użycie LNI
znajdujących się w dolnych rejonach tabeli doprowadziłoby bowiem do rozpadu
dendrytu na niemal wyłącznie pojedyncze obiekty, a przez to do utraty informacji o
wewnętrznej strukturze zbioru obiektów.
Podane powyżej kryteria spełniają wartości LNI wyróżnione w
poniższej tabeli ciemnym tłem:
Obiekt: Sąsiad: Odległość: Ilorazy:
AND ORK 4,237
ORK URI 3,116 1,360
UMB URI 2,619 1,190
GOL GWY 2,397 1,093
ZAD AZU 2,033 1,179
AER SIH 1,653 1,230
GRA GUR 1,576 1,049
GWY AZU 1,332 1,183

90
LOD GRA 1,064 1,252
AZU BAL 1,054 1,009
SIH GLA 1,048 1,006
GUR EXC 1,006 1,042
GLA EXC 0,930 1,082
GRA DUR 0,907 1,025
AZU HUR 0,899 1,009
HER HUR 0,879 1,023
BAL JOY 0,596 1,475
EXC ORK 0,512 1,164
DUR JOY 0,423 1,210
Ilorazy 1,475 oraz 1,210 nie spełniają ww. kryteriów z uwagi na
swe położenie w tabeli.
5) Kolejnym krokiem jest ustalenie wersji podziału dendrytu. Wyboru dokonuje się
pomiędzy dwiema wersjami podziału: jednoznaczną i hierarchiczną. Wersja
jednoznaczna zakłada jednoetapowy podział dendrytu, zaś wersja hierarchiczna –
stopniowy.
Podział jednoetapowy wymaga odnalezienia największej z wartości LNI, a
następnie usunięcia z dendrytu wszystkich połączeń znajdujących się w
wierszach powyżej odnalezionego maximum maximorum.
Dla zestawu MIECZE, największa wartość LNI znajduje się w
drugim wierszu tabeli i wynosi 1,360. Zastosowanie wersji
jednoznacznej sprowadza się zatem do usunięcia połączenia AND-
ORK, co prowadzi do wyodrębnienia punktu odbiegającego AND.
W tym przypadku, wersja jednoznaczna nie ujawniła żadnych
nowych informacji dotyczących wewnętrznej struktury zbioru
danych. Oddzielenie się obiektu AND jako punktu odbiegającego

91
było doskonale widoczne już w trakcie analizy głównych
składowych, zatem do stwierdzenia wyjątkowości ww. obiektu
wykonanie analizy skupień nie było konieczne.
Wersja hierarchiczna zakłada stopniowy, hierarchiczny podział dendrytu w celu
uzyskania dokładniejszych informacji o wewnętrznej strukturze zbioru danych.
Podział ten przeprowadza się, usuwając stopniowo z dendrytu połączenia znajdujące
się w wierszach powyżej kolejnych LNI.
Podział hierarchiczny dendrytu, wykonanego dla zestawu MIECZE,
rozpoczynamy od usunięcia połączeń znajdujących się w wierszach
powyżej wartości pierwszego LNI (równej 1,360), a zatem od
usunięcia połączenia AND-ORK (połączenie to usunęliśmy
całkowicie z poniższej wizualizacji dendrytu).
Następnie, usuwamy połączenia znajdujące się w wierszach
powyżej wartości drugiego LNI (równej 1,230), czyli połączenia:
ORK-URI, UMB-URI, GOL-GWY oraz AZU-ZAD (połączenia te
przedstawiliśmy w postaci szarych linii przerywanych).
Na końcu, usuwamy połączenia znajdujące się w wierszach powyżej
wartości trzeciego (i ostatniego) LNI (równej 1,252), czyli
połączenia: AER-SIH, GRA-GUR oraz AZU-GWY (połączenia te
przedstawiliśmy w postaci linii przerywanych).
W tym konkretnym przypadku, pierwszy etap podziału
hierarchicznego doprowadził do takiego samego obrazu, jak
podział jednoznaczny. Takie zjawisko nie jest regułą.
Drugi etap podziału wyodrębnił pojedyncze obiekty, stanowiące
punkty odbiegające drugiego rzędu, czyli: GOL, UMB, URI oraz
ZAD.

92
Ostatni etap podziału ujawnił istnienie dwóch jednorodnych
podzbiorów, złożonych z obiektów: {AZU, BAL, DUR, GRA, LOD,
HER, HUR, JOY} oraz {EXC, GLA, GUR, ORK, SIH}. Pojawiły się
również punkty odbiegające trzeciego rzędu, czyli AER oraz ZAD.
Naturę uzyskanych podzbiorów można w pełni określić dopiero po konfrontacji
uzyskanego obrazu z tabelą danych wejściowych oraz z wynikami analizy głównych
składowych. Radość tę pozostawimy sobie jednak na sam koniec – doświadczą jej w pełni
jedynie ci, którzy wybrali dla swoich danych problem analizy skupień. Tych, którzy wybrali
jeden z dwóch pozostałych problemów, zapraszamy do prześledzenia przykładu,
zaprezentowanego w sekcji IV instrukcji do sprawozdania końcowego.
II. SPRAWOZDANIE.
W sprawozdaniu Student powinien umieścić tabelę zaprezentowaną w punkcie 4) sekcji
I, a także dokonać podziału dendrytu metodą jednoznaczną lub hierarchiczną (jeżeli wersja
jednoznaczna nie ujawni wewnętrznej struktury zbioru, należy zastosować wersję
hierarchiczną). Mile widziana będzie próba dokonania wstępnej interpretacji natury
otrzymanych podzbiorów.

93
Zadanie domowe:
SPRAWOZDANIE KOŃCOWE
W instrukcji do ćwiczenia nr 1 sformułowaliśmy propozycje problemów, które są
możliwe do rozwiązania w trakcie zajęć laboratoryjnych z chemometrii, a które miały dotyczyć
przygotowanych przez Studentów zestawów danych. Propozycje te prezentowały się
następująco:
1. Modelowanie zależności wybranej cechy od pozostałych zmiennych
(nazywanych wówczas zmiennymi objaśniającymi).
2. Analiza podobieństwa zmiennych i obiektów (poznanie wewnętrznej struktury
zbioru danych).
3. Analiza skupień pozwalająca na obiektywny podział niejednorodnego zbioru
obiektów na jednorodne podgrupy.
Niniejsza, ostatnia już instrukcja ma na celu pomóc Studentowi w przygotowaniu
sprawozdania końcowego, którego treść ma stanowić możliwie jednoznaczne rozwiązanie
problemu, wybranego dla Jego zestawu danych.
Jeżeli Student skorzystał z sugestii podanej we wprowadzeniu do niniejszego skryptu,
tj. gromadził wszystkie wyniki w jednym pliku (zawierającym obliczenia dla każdego z
ćwiczeń w osobnym arkuszu) - sprawozdanie końcowe może przyjąć postać kolejnego
arkusza kalkulacyjnego, do którego zostaną przeniesione (skopiowane) wyniki cząstkowe
z odpowiednich arkuszy, wraz z ewentualnymi uzupełnieniami. Jeżeli jednak Student
odczuwa potrzebę bardziej "literackiej" prezentacji wyników, możliwe jest oczywiście
przygotowanie sprawozdania w całości w postaci pliku tekstowego.
Ponieważ sposób przygotowania wszystkich składników sprawozdania końcowego
został już podany w poprzednich instrukcjach, poniżej nie będziemy powtarzali ich opisu.
Mimo tego prosimy, aby Student nie odwdzięczał się nam tym samym – w sprawozdaniu
końcowym należy umieścić wymagane obliczenia, wykresy, opisy i wnioski w jednym
miejscu i w podanym poniżej porządku.
Do przeprowadzenia przykładowej dyskusji końcowej wykorzystamy wyniki uzyskane
dla bardzo dobrze znanego już Czytelnikowi zestawu MIECZE.
I. CZĘŚĆ WSPÓLNA.
Niezależnie od natury postawionego problemu, początkowa część sprawozdania
powinna zawierać następujące elementy:
przygotowaną do dalszych analiz tabelę danych wejściowych, zawierającą: źródło
danych, datę utworzenia i modyfikacji, imię i nazwisko Studenta, definicję problemu
oraz objaśnienia skrótów;

94
wszystkie elementy sprawozdania z ćwiczenia nr 3 ("Kontrola pojedynczych
zmiennych");
wszystkie elementy sprawozdania z ćwiczenia nr 4 ("Korelacje pomiędzy
zmiennymi");
wszystkie elementy sprawozdania z ćwiczenia nr 5 ("Analiza podobieństwa
cech").
Wszystkie wymienione wyżej elementy, wykonane dla zestawu MIECZE,
znajdują się w instrukcjach do odpowiednich ćwiczeń.
II. MODELOWANIE ZALEŻNOŚCI WYBRANEJ CECHY OD POZOSTAŁYCH
ZMIENNYCH.
W przypadku, gdy celem Studenta jest skonstruowanie liniowego modelu zależności
zmiennej zależnej od pozostałych zmiennych, należy zwrócić szczególną uwagę na postać
zależności pomiędzy zmienną zależną i pozostałymi zmiennymi. Warto wykorzystać w tym
celu odpowiednie wykresy korelacyjne, wykonane w trakcie ćwiczenia nr 4. Jeżeli okaże się,
że występują wyraźne zależności nieliniowe, należy podjąć próbę ich linearyzacji (patrz:
ćwiczenie nr 9). Jeżeli zakończy się ona powodzeniem, radykalnie wzrosną szanse na
uzyskanie eleganckiego i istotnego modelu liniowego. W takim przypadku, niestety trzeba
będzie powtórzyć analizę transformowanej zmiennej (ćwiczenie nr 3), analizę
podobieństwa cech (ćwiczenie nr 5) oraz analizę głównych składowych (ćwiczenie nr 10)
dla nowego, zlinearyzowanego zestawu zmiennych.
W sprawozdaniu końcowym należy umieścić ponadto:
informacje o (ewentualnie) użytych funkcjach linearyzujących;
tabelę danych autoskalowanych (jeżeli zastosowano funkcje linearyzujące –
autoskalowanie należy wykonać ponownie, wykorzystując dane po linearyzacji!);
wykres rozmieszczenia zmiennych w przestrzeni istotnych variwektorów:
jeżeli nie dokonano linearyzacji zmiennych – należy użyć elementów
sprawozdania z ćwiczenia nr 10 ("Analiza głównych składowych");
w przeciwnym wypadku – należy wykonać obliczenia i wykres od nowa (dla
danych po linearyzacji);
wnioski dotyczące relacji pomiędzy zmiennymi:
czy wybrana zmienna zależna jest skorelowana z pozostałymi zmiennymi?;
czy zmienne objaśniające są skorelowane pomiędzy sobą?;
decyzję, wraz z uzasadnieniem, o podjęciu próby stworzenia modelu zależności
lub o rezygnacji z niej;
w przypadku podjęcia próby stworzenia modelu zależności: wszystkie etapy
tworzenia modelu przez program MEOD.EXE oraz ocenę jakości ostatecznego
modelu.
Przykład:

95
Dla zestawu MIECZE, najbardziej naturalną cechą, której wartości
chcielibyśmy modelować w oparciu o wartości pozostałych zmiennych, jest
cena repliki, CR*.
Wartości współczynniki korelacji liniowej oraz determinacji
(ćwiczenie nr 4, sekcja I) wskazują na kompletny brak liniowych
zależności zmiennej CR* od pozostałych zmiennych. Wykresy korelacyjne
zmiennej CR* (nieumieszczone w instrukcjach) nie wskazują również na
istnienie jakichkolwiek zależności nieliniowych.
Analiza wiązkowa zmiennych (ćwiczenie nr 5, sekcja II) oraz
diagram Czekanowskiego dla cech (ćwiczenie nr 5, sekcja III) wyraźnie
wskazują, iż spośród wszystkich cech zmienna CR* jest najmniej
skorelowana z pozostałymi. W rzeczywistości możemy mówić o braku
korelacji.
Wykres zmiennych w przestrzeni dwóch pierwszych variwektorów
(ćwiczenie nr 10, sekcja III) potwierdza, iż zmienna CR* jest prawie
ortogonalna do zmiennych objaśniających. Z kolei same zmienne
objaśniające są na tyle do siebie podobne, że w praktyce opisują tylko
jedną cechę replik - ich wielkość.
Wszystkie powyższe obserwacje skłaniają nas ku wnioskowi, iż
podejmowanie próby stworzenia liniowego modelu zależności zmiennej CR*
od pozostałych zmiennych jest pozbawione sensu.
Odpowiedź na postawiony problem jest zatem następująca:
niemożliwie jest modelowanie ceny repliki w oparciu o wartości
pozostałych cech.
Wykazaliśmy tym samym, że cena repliki nie zależy od jej
rozmiarów, lecz od innych parametrów, takich jak: i) rodzaju materiału,
z którego ją wykonano; ii) kunsztu kowala oraz iii) ewentualnych
zdobień. Tego typu parametry trudno jest wyrazić w postaci liczbowej,
przez co nie znalazły się one w tabeli danych wejściowych.
III. ANALIZA PODOBIEŃSTWA ZMIENNYCH I OBIEKTÓW.
Jeżeli celem Studenta jest poznanie wewnętrznej struktury zbioru danych, w
sprawozdaniu końcowym powinien umieścić (prócz elementów opisanych w sekcji I):
wszystkie elementy sprawozdania z ćwiczenia nr 6 ("Analiza podobieństwa
obiektów");
wszystkie elementy sprawozdania z ćwiczenia nr 10 ("Analiza głównych
składowych");
zestawienie wniosków dotyczących analizy podobieństwa zmiennych, tj. wnioski
z ćwiczeń nr 4, 5 i 10;
zestawienie wniosków dotyczących analizy podobieństwa obiektów, tj. wnioski z
ćwiczeń nr 6 i 10;
podsumowanie, zawierające określenie wewnętrznej struktury zbioru danych, tj.
odpowiedzi na pytania: i) czy wszystkie zmienne pochodzą z jednej populacji
generalnej?; oraz ii) czy wszystkie obiekty pochodzą z jednej populacji generalnej?.

96
Przykład:
Ponieważ większość z podanych wyżej elementów znajduje się w
przykładach zawartych w instrukcjach do odpowiednich ćwiczeń, nie
będziemy prezentowali ich ponownie (o czym lojalnie uprzedziliśmy).
Odpowiedź na pytanie i) (dotyczące zmiennych) została w dużej
części sformułowana w przykładzie zaprezentowanym w sekcji II. W tym
miejscu wypada nam ją tylko powtórzyć w następującej postaci: wszystkie
zmienne, poza CR*, należą do jednej populacji generalnej. Zmienna CR*,
wyraźnie "odstająca" od pozostałych, należy do innej populacji
generalnej.
Wnioski, zebrane z ćwiczeń nr 6 i 10 pozwalają na sformułowanie
odpowiedzi na pytanie ii). Dendryt obiektów (ćwiczenie 6, sekcja III),
diagram Czekanowskiego dla obiektów (ćwiczenie 6, sekcja IV) oraz mapa
liniowa obiektów w przestrzeni dwóch pierwszych variwektorów (ćwiczenie
10, sekcja III) wyraźnie sugerują niejednorodność zbioru obiektów,
ergo: obiekty z zestawu MIECZE nie pochodzą z jednej populacji
generalnej.
Mapa liniowa obiektów pozwoliła nam również na oszacowanie
charakteru niejednorodności zbioru. Zawiera on szereg punktów
odbiegających oraz prawdopodobnie dwa, w miarę jednorodne podzbiory.
Charakterystykę przypuszczalnych podzbiorów i punktów
odbiegających opisaliśmy w przykładzie, zawartym w sekcji III ćwiczenia
nr 10. Wykorzystaliśmy w tym celu interpretacje nadane dwóm pierwszym
variwektorom.
IV. ANALIZA SKUPIEŃ, POZWALAJĄCA NA OBIEKTYWNY PODZIAŁ
NIEJEDNORODNEGO ZBIORU OBIEKTÓW NA JEDNORODNE PODGRUPY.
Jeżeli celem Studenta jest podzielenie niejednorodnego zbioru danych na wewnętrznie
jednorodne podzbiory, w sprawozdaniu końcowym powinien umieścić (prócz elementów
opisanych w sekcji I):
wszystkie elementy sprawozdania z ćwiczenia nr 6 ("Analiza podobieństwa
obiektów");
wszystkie elementy sprawozdania z ćwiczenia nr 10 ("Analiza głównych
składowych");
wszystkie elementy sprawozdania z ćwiczenia nr 11 ("Analiza skupień");
zestawienie wniosków dotyczących analizy podobieństwa obiektów, tj. wnioski z
ćwiczeń nr 6, 10 i 11;
w przypadku uprzedniej znajomości liczby i charakteru podzbiorów: podsumowanie
zawierające potwierdzenie (lub brak potwierdzenia) podziału obiektów na
znane wcześniej podzbiory, na podstawie wniosków z ćwiczeń nr 10 i 11;
97
w przypadku nieznajomości liczby i charakteru podzbiorów (ale przy uzasadnionym
podejrzeniu niejednorodności zestawu obiektów): podsumowanie zawierające
podział obiektów na nieznane wcześniej podzbiory oraz próbę określenia ich
charakteru (natury), na podstawie wniosków z ćwiczeń nr 10 i 11.
Przykład:
Elementy podane w pierwszych czterech punktach znajdują się w
przykładach zawartych w instrukcjach do odpowiednich ćwiczeń. W drodze
wyjątku, w tej sekcji niektóre z nich zaprezentujemy ponownie:
1) tabela surowych danych wejściowych:
Obiekt\Zmienna DC DG DR M SM T CR
AER 119 92 15 1900 5 1,5 500
AND 152 100 32 2500 12 2 260
AZU 88 71 14 1200 7 1 380
BAL 95 75 13 1400 7 1 320
DUR 102 81 14 1400 8 1 342
EXC 120 90 18 1800 10 1,5 450
GLA 120 95 12 1900 10 1,5 419
GOL 100 69 26 1100 6 1 600
GRA 106 83 15 1600 10 1 350
GUR 104 81 15 1800 10 1,5 406
GWY 103 81 15 1450 5 1 400
HER 85 60 14 1500 8 1 340
HUR 90 65 16 1600 7 1 380
JOY 100 80 14 1500 8 1 320
LOD 92 80 10 1800 10 1 375
ORK 130 97 18 1800 10 1,5 450
SIH 123 95 14 2200 8 1,5 390
UMB 180 125 40 3200 15 2 600
URI 160 120 25 2700 12 2 650
ZAD 68 54 13 800 5 1 375
2) mapa liniowa obiektów w przestrzeni istotnych variwektorów:

98
3) wynik analizy skupień uzyskany metodą naturalnego podziału
dendrytu (wersja hierarchiczna):
W trakcie kompletowania danych do zestawu MIECZE nie posiadaliśmy
żadnych informacji, dotyczących ewentualnej niejednorodności zbioru

99
danych. Surowa tabela danych oczywiście również nie dostarczyła żadnych
sugestii w tym zakresie.
Dendryt obiektów, wykonany w trakcie ćwiczenia nr 6, ujawnił
tendencję obiektów do formowania grup oraz istnienie punktów
odbiegających. Mapa liniowa obiektów, wykonana w trakcie ćwiczenia nr
10, potwierdziła informacje ujawnione przez dendryt. Co więcej,
pozwoliła na subiektywne oszacowanie liczby i składu utworzonych
podzbiorów oraz na ich charakterystykę w oparciu o interpretację
variwektorów.
Subiektywnie utworzoną ośmioelementową grupę #1, {AZU, BAL, DUR,
GRA, LOD, HER, HUR, JOY}, możemy opisać jako "repliki o cenach i
rozmiarach lekko poniżej przeciętnej", natomiast pięcioelementową grupę
#2, {EXC, GLA, GUR, ORK, SIH}, jako "repliki o cenach i rozmiarach
lekko powyżej przeciętnej". Nie są to opisy wyczerpujące. Pozostałe
punkty, nienależące do żadnej grupy, czyli obiekty AER, AND, GOL, GWY,
UMB, URI oraz ZAD, zostały opisane adekwatnie do pozycji zajmowanych na
mapie liniowej.
Punktem odbiegającym jest obiekt AND. Kontrola pojedynczych
zmiennych nie wykazała istnienia punktu odbiegającego – okazało się
jednak, iż wyjątkowość obiektu AND objawia się dopiero po uwzględnieniu
większej liczby zmiennych.
Naturalny podział dendrytu, który jest metodą dalece bardziej
obiektywną, niźli subiektywne odczytanie mapy liniowej, doprowadził do
identycznych wniosków. Grupy, widoczne na powyższym dendrycie, mają, w
porównaniu do grup utworzonych na podstawie mapy liniowej, identyczny
skład. Wygląda na to, iż zaproponowany podział możemy uznać za
ostateczny i "obowiązujący".
Pojawia się jednak pytanie: czy jesteśmy w stanie nieco poszerzyć
charakterystykę utworzonych grup i uzasadnić ich jednorodność?
Odpowiedzi na to pytanie udziela konfrontacja składu uzyskanych
grup z tabelą danych wejściowych. Okazuje się bowiem, iż wszystkie
repliki należące do grupy #1 są mieczami jednoręcznymi, co tłumaczy ich
"rozmiary lekko poniżej przeciętnej", ponieważ średnia arytmetyczna
wartości zmiennej T wynosi 1,30. Z kolei grupa #2 zawiera wszystkie
miecze półtoraręczne obecne w zestawie danych, co tłumaczy ich
"rozmiary lekko powyżej przeciętnej". Trzy wyraźnie odstające od reszty
obiekty, tj. AND, UMB i URI, są replikami mieczy dwuręcznych o
skrajnych cenach.
Na koniec, chcielibyśmy odwołać się do dwóch uwag, zawartych w instrukcji do
ćwiczenia nr 2.
Po pierwsze, ostrzegaliśmy przed uwzględnianiem w danych zmiennych nieciągłych,
takich jak zmienna T, z uwagi na ich potencjalnie wysoki wpływ na wynik analizy
podobieństwa obiektów oraz analizy skupień. Jak się okazało – niebezpodstawnie.

100
Po drugie, wykonanie analiz chemometrycznych i przedstawienie ich wyników w formie
graficznej (dendryt, diagram wiązkowy, mapa liniowa obiektów, etc.) rzeczywiście
umożliwia odnajdywanie prawidłowości, których oko, w chemometryczne narzędzia
nieuzbrojone, nie jest w stanie dostrzec.
***
I taki był cel tych ćwiczeń. Mamy nadzieję, że dostarczyły one Studentom odrobiny
satysfakcji (i radości) z zabawy metodami chemometrycznymi. Na pierwszy rzut oka zdają
się one być trudne i nieprzystępne; zyskują jednak przy bliższym poznaniu. Iucundi acti
labores.29
Mamy nadzieję, że przekonaliśmy Czytelnika, iż nawet z pozoru chaotyczne zbiory
liczb mogą zawierać użyteczną informację i być atrakcyjnym obiektem dociekań.
29 "Miłe są trudy zakończone" - Cyceron.





























