Embed Size (px)
Citation preview


Daftar Isi 1. Belajar dari Data
2. Python
3. Pandas
4. Linear Regression
5. Logistic Regression
6. Naive Bayes
7. Decision Tree (and Random Forest)
8. Neural Network
9. K-Means
10. Market Basket Analysis
11. Computer Vision
12. Python dan Big Data

Pengantar
Buku ini pertama kali dimulai oleh penulis sebagai sebuah proyek pribadi untuk
mempersiapkan suatu materi pengenalan umum Machine Learning yang kebetulan memang
menjadi salah satu bidang profesi penulis. Tujuannya adalah agar semakin banyak orang
Indonesia yang bisa mendapat akses ke ilmu ini, yang dalam beberapa tahun terakhir ini
mendapat banyak perhatian khususnya di kalangan praktisi teknologi informasi.
Machine Learning hampir selalu dikaitkan dengan Artificial Intelligence (kecerdasan buatan),
sehingga ketika Anda mendengar tentang teknologi ini, barangkali pikiran Anda akan
melayang ke robot humanoid (berwujud seperti manusia) yang bisa berbicara, beraksi dan
berperilaku seperti manusia. Ini bisa jadi adalah akibat pengaruh media massa dan industri
hiburan yang sering memberikan gambaran keliru tentang teknologi ini. Pada kenyataannya,
penerapan Machine Learning kebanyakan bukan bertujuan membuat robot humanoid.
Machine Learning saat ini lebih banyak dipergunakan untuk kepentingan bisnis, misalnya
mendorong peningkatan penjualan atau membangun layanan digital yang memudahkan
pelanggan.
Machine learning adalah bidang ilmu yang masih sangat muda (dibandingkan dengan
misalnya ilmu kedokteran). Hingga dua puluh tahun lalu pun belum banyak orang yang
paham tentang ilmu ini. Adapun begitu, sekarang perkembangannya sangat pesat. Revolusi
Industri Keempat disebut-sebut sangat dipengaruhi oleh teknologi Artificial Intelligence dan
Machine Learning. Sebuah riset yang dilaksanakan Gartner[1] menyatakan bahwa di tahun
2022 teknologi Artificial Intelligence dan Machine Learning akan memberikan potensi bisnis
senilai 3.900 milyar dolar dalam berbagai bidang industri di seluruh dunia, sebuah potensi
yang luar biasa besar. Ini akan berakibat semakin banyak tenaga ahli di bidang ini yang akan
dicari untuk dipekerjakan di industri.
Banyak orang yang memiliki kekhawatiran bahwa Artificial Intelligence dan Machine
Learning akan terlalu banyak mengambil alih peran manusia sehingga banyak orang akan
kehilangan pekerjaan, bahkan akan menjadi “musuh” bagi umat manusia. Suatu kekhawatiran
yang tidak perlu, karena hingga kini sebenarnya para ahli masih belum paham benar
bagaimana otak biologis manusia bekerja, apalagi menirunya ke dalam bentuk mesin.
Teknologi Artificial Intelligence masih jauh dari bisa menghasilkan mesin dengan kecerdasan
setingkat manusia, apalagi sampai mengancam umat manusia. Jadi jangan khawatir, robot
pembunuh seperti di film “Terminator” masih tetap akan jadi fiksi untuk waktu yang lama.
Kita tidak akan membahas tentang pro-kontra tentang Machine Learning di dalam buku ini.
Tujuan kita di sini adalah mempelajari berbagai algoritma Machine Learning yang bisa
dipakai untuk mempermudah kehidupan kita.
Untuk Siapa Buku Ini
Buku ini memperkenalkan kepada pembaca konsep-konsep dasar tentang Machine Learning.
Pembaca akan bisa membaca sekilas tentang landasan teori, kemudian langsung diberikan
panduan praktek dengan contoh-contoh agar pembaca dapat langsung memperoleh
pengalaman pertama dengan dunia Machine Learning.
Karena Machine Learning adalah bidang ilmu yang luas, buku ini difokuskan untuk
mencakup pembahasan hal-hal praktis yang umum dipergunakan di dunia industri, bukan
pada pembahasan akademis. Buku ini bukan berisi teori matematika, namun berisi penerapan

praktis. Pembahasan di dalam buku ini dibuat sedemikian rupa agar mudah untuk diikuti,
ditulis dengan bahasa yang sejelas mungkin, menghindarkan kompleksitas dan teori
matematika yang rumit. Tujuannya agar buku ini dapat diikuti oleh pembaca dari beragam
latar belakang pendidikan, terutama para profesional di dunia industri dan praktisi teknologi
informasi.
Sebagai sebuah materi pengenalan, buku ini dirancang sebagai pintu pertama bagi para
peminat bidang baru yang mengasyikkan ini, sehingga selanjutnya bisa membaca referensi
lain yang lebih detail. Dengan demikian, buku ini memang tidak diperuntukkan bagi para ahli
matematika atau para Data Scientist yang ingin mempelajari hal-hal tingkat lanjut.
Agar dapat mengerti dan mengikuti isi buku ini, pembaca perlu memiliki pengetahuan dasar
mengenai bahasa pemrograman. Bab 2 akan mengajarkan dasar-dasar bahasa Python, namun
pembahasannya tidak cocok bagi mereka yang belum pernah memahami konsep
pemrograman. Apabila pembaca belum memiliki pengalaman pemrograman sama sekali,
penulis menyarankan pembaca untuk membaca tutorial terkait dasar pemrograman sebelum
membaca buku ini. Beberapa bab dalam buku ini juga mendemonstrasikan penerapan di
sistem operasi Linux, sehingga pembaca diharapkan setidak memiliki pengetahuan dasar
tentang sistem operasi ini.
Di dalam buku ini, istilah-istilah dalam Bahasa Inggris sebanyak mungkin tetap
dipertahankan dan tidak diganti dengan terjemahan Bahasa Indonesia, dengan maksud agar
ketika pembaca terjun ke dunia nyata di lingkungan industri atau ilmiah, pembaca tidak perlu
kaget lagi dengan istilah-istilah yang biasanya hampir selalu dikomunikasikan dalam Bahasa
Inggris.
Bagaimana Cara Memakai Buku ini
Buku ini dirancang untuk dibaca dari bab pertama hingga bab akhir secara berurutan,
terutama Bab 1 hingga Bab 3 dengan tujuan pembaca dapat memiliki pemahaman awal
tentang Machine Learning, Python dan modul pendukungnya. Pembaca yang diharapkan
dapat membaca satu bab hingga selesai sebelum melanjutkan ke bab berikutnya.
Bab 4 hingga akhir adalah berbagai contoh kasus penerapan Machine Learning yang
sebaiknya dibaca bila pembaca sudah selesai memahami Bab 1 hingga Bab 3. Adapun begitu,
bab-bab selanjutnya tentang contoh kasus bisa diikuti secara berurutan maupun tidak,
tergantung pada minat pembaca.
Pembaca disarankan langsung mempraktekkan contoh-contoh program yang disediakan.
Dengan langsung terjun ke coding (menulis kode program), pembaca akan mendapat
pemahaman yang lebih baik. Kode program yang ditampilkan dalam buku ini disajikan
secara bertahap, agar pembaca dapat memahami setiap bagian sebelum melangkah ke bagian
selanjutnya. Ada beberapa bagian kode program yang dicetak tebal, untuk memudahkan
pembaca melihat bagian-bagian dalam program yang menjadi perhatian dan pembahasan.
Dalam buku ini, terminologi penting, istilah asing dan kode program akan dicetak sesuai
konsensus berikut:
• Terminologi penting akan dicetak dengan font tebal (bold).
• Istilah Bahasa Asing akan dicetak dengan font miring (italics).
• Kode program, variabel dan perintah akan dicetak dengan font Courier.

Untuk dapat mengikuti seluruh contoh di buku ini, Anda hanya memerlukan sebuah laptop
atau komputer PC/Mac yang telah terpasang Python (disarankan versi terbaru). Cara
mengunduh dan memasang Python dapat dilihat di Lampiran 1. Tidak ada spesifikasi khusus
untuk komputer yang diperlukan untuk mengikuti seluruh contoh di buku ini, semua PC/Mac
produksi di atas tahun 2010 secara umum bisa dipakai, adapun begitu disarankan setidaknya
memiliki RAM 8GB.
Tidak perlu khawatir dengan banyaknya istilah baru yang mungkin akan Anda temukan
sepanjang buku ini. Asalkan Anda senang bereksperimen, tidak takut menulis kode program,
maka dijamin Anda akan menyukai bidang ini. Sudah siap? Mari kita mulai!
Dios Kurniawan
http://dioskurn.com

BAB 1 Belajar dari Data Sadarkah kita bahwa di masa kini, setiap langkah manusia modern dalam kesehariannya
selalu meninggalkan digital footprint (jejak digital) di mana-mana? Di dunia yang serba
digital saat ini, banyak aspek kehidupan kita dalam aktivitas sehari-hari yang telah direkam
ke dalam sistem komputer. Bank menyimpan data transaksi perbankan Anda, toko-toko
online menyimpan sejarah belanja Anda, jaringan telepon selular mencatat kemana saja Anda
pergi, media sosial mencatat interaksi Anda dengan teman Anda, apa yang Anda bicarakan
dan Anda sukai, layanan music streaming mencatat jenis lagu selera Anda, ojek online
mencatat perjalanan dan pesanan makanan Anda, dan seterusnya. Suka tidak suka, data
tentang kehidupan Anda berceceran di mana-mana.
Salah satu yang menjadi pencetus begitu banyaknya data yang dihasilkan manusia adalah
ponsel pintar. Dengan semakin luasnya penggunaan ponsel pintar yang selalu tersambung ke
internet, semakin tinggi pula intensitas manusia dalam menghasilkan data. Sebuah laporan
riset yang dikeluarkan oleh DOMO[2] menyebutkan bahwa di tahun 2020 rata-rata setiap
manusia di bumi menghasilkan data sebesar 1,7 MB per detik. Kelihatannya kecil, tapi jangan
lupa, ada 86,400 detik dalam sehari dan ada tujuh milyar lebih manusia di bumi!
Tidak hanya dihasilkan oleh aktivitas manusia, data juga dihasilkan oleh mesin-mesin,
sensor-sensor, dan peralatan-peralatan elektronik lainnya. MGD (machine-generated data,
data yang dihasilkan oleh mesin) memiliki potensi manfaat yang tinggi karena tidak
mendapat pengaruh campur tangan manusia (emosi, subyektivitas, dan sebagainya). MGD
yang dihasilkan di dunia cenderung semakin besar dari hari ke hari. Menurut hasil riset yang
dilakukan IDC[3], pada tahun 2025, 30% data yang ada di dunia akan dihasilkan oleh mesin,
bukan oleh manusia.
Singkatnya, dunia kita akan dibanjiri oleh data yang tersimpan di beragam macam sistem
komputer. Itu sebabnya Big Data, yaitu data dalam skala yang amat besar, sudah menjadi
istilah yang sering disebut sejak awal dekade ini.
Data yang banyak ini harus kita apakan? Meskipun kita memiliki sangat banyak data, semua
tidak akan bermanfaat kecuali kita bisa menggali nilai-nilai yang terkandung di dalamnya.
Data yang tidak dimanfaatkan hanya akan menumpuk di dalam sistem komputer,
menghabiskan media penyimpan tanpa guna. Di sinilah perlunya ilmu Data Science untuk
membantu mendapatkan manfaat dari data.
Dalam bahasa yang paling sederhana, Data Science adalah ilmu multidisipliner yang
mempelajari tentang upaya mendapatkan pemahaman yang lebih dari berbagai macam data.
Tujuannya agar didapatkan kesimpulan dari informasi yang terkandung di dalam data,
sehingga orang dapat mengambil keputusan - dan tindakan - yang tepat.
Ada pula yang menyebut ilmu ini dengan istilah Data Analytics, di mana batas pemisahnya
memang tidak terdefinisi dengan jelas. Adapun demikian, di dalam buku ini kita menganggap
Data Science memiliki lingkup yang lebih luas dari Data Analytics. Data Analytics lebih
difokuskan pada memecahkan permasalahan atau menjawab pertanyaan tertentu yang
spesifik. Data Analytics berusaha memberikan kesimpulan dari apa yang sudah diketahui
sebelumnya. Berbeda dengan Data Science yang berupaya menghasilkan pemahaman lebih
luas, yaitu menemukan hal-hal penting apa saja yang terkandung di dalam data, dan hal-hal
yang potensial bisa dijadikan pertanyaan lebih lanjut.

Mungkin Anda bertanya, apa manfaat Data Science sebenarnya dalam kehidupan kita sehari-
hari? Jawabannya bisa beragam. Data Science telah umum dipergunakan secara sistematis
oleh dunia industri khususnya perusahaan besar untuk berbagai kepentingan misalnya untuk
kegiatan pemasaran digital, merancang produk baru, atau meningkatkan kualitas layanan
kepada pelanggan. Data Science juga banyak dipergunakan oleh banyak organisasi di bidang
kesehatan, bidang ilmiah dan bidang penyusunan kebijakan publik. Adapun demikian,
motivasi utama Data Science lebih sering adalah untuk monetisasi (mendapatkan keuntungan
finansial), karena informasi yang bernilai tinggi dapat menghasilkan banyak uang. Data bisa
dieksploitasi untuk menghasilkan keuntungan bisnis, dan bahkan sering menjadi produk
bisnis itu sendiri – ada banyak perusahaan yang penghasilan terbesarnya justru dari menjual
data.
Apakah hanya organisasi atau perusahaan besar saja yang bisa mempraktekkan Data
Science? Tentu tidak. Usaha kecil dan menengah pun bisa jadi memiliki cukup banyak data
yang berpotensi nilai tinggi. Transaksi penjualan toko, penjualan obat di apotik, atau
penjualan restoran adalah contoh-contoh data yang meskipun tidak termasuk Big Data namun
tetap bisa sangat berguna untuk upaya peningkatan usaha.
Di masa kini telah tersedia banyak pilihan perangkat lunak yang telah dikembangkan untuk
membantu pekerjaan mereka yang bergelut di bidang Data Science. Kita dapat memilih
apakah hendak mempergunakan perangkat lunak komersial (yang berbayar) atau perangkat
lunak open-source (sumber terbuka), dengan kelebihan dan kekurangan masing-masing.
Dengan relatif murahnya perangkat keras dan perangkat lunak serta begitu banyaknya materi
belajar di internet, saat ini ilmu Data Science telah menjadi bidang yang democratized
(dimiliki masyarakat umum), artinya Data Science bukan ilmu yang eksklusif dan bisa
diakses oleh orang kebanyakan. Pendeknya, tanpa memperhatikan latar belakang pendidikan,
siapapun yang memiliki laptop dan kemauan untuk belajar yang tinggi, sekarang bisa
mencoba algoritma Data Science canggih tanpa kesulitan berarti. Dengan upaya yang lebih
serius, setiap orang bisa menerapkan model-model praktis untuk memecahkan problematika
bisnis maupun ilmiah, tanpa perlu gelar di bidang matematika atau ilmu komputer.
Adapun demikian tetap diperlukan orang-orang profesional yang memang fokus di bidang
Data Science. Data Scientist adalah profesi bagi mereka yang memiliki latar belakang
pendidikan matematika, statistik atau ilmu komputer, memiliki pengetahuan mendalam
tentang pemrograman (umumnya dengan Python, R, Java atau Scala), serta memiliki
pemahaman mendalam akan bidang industri yang digeluti (disebut juga domain expertise).
Tidak jarang Data Scientist profesional adalah mereka yang sudah mengenyam jenjang
pendidikan master atau doktor.
Data Scientist memang profesi yang relatif masih muda usianya (sepuluh tahun lalu pun
orang masih belum banyak mengenal profesi ini), namun saat ini sudah menjadi suatu peran
yang sangat dibutuhkan dan berbayaran tinggi. Menurut laporan LinkedIn[4], Data Science
merupakan keahlian yang memiliki masa depan paling menjanjikan. Dunia industri bersedia
membayar banyak untuk mendapatkan Data Scientist yang berpengalaman untuk
memecahkan masalah big data mereka yang semakin hari semakin kompleks. Data Science
adalah pilihan karir yang menarik. Pasti Anda pun setuju dengan hal ini, karena bila tidak,
Anda tidak akan membaca buku ini bukan?
Meniru Cara Belajar Manusia

Manusia secara alamiah mempergunakan panca indera yaitu mata, telinga, hidung, lidah dan
saraf kulit untuk menangkap hal-hal yang ada di sekitarnya dan kemudian “data mentah” ini
dikirimkan ke otak untuk diterjemahkan menjadi konsep-konsep yang sudah dikenal misalnya
barang, orang, udara dingin, bau harum, rasa sedap makanan, dan sebagainya. Dengan
teknologi, cara kerja manusia inilah yang dalam beberapa hal ingin dicoba ditiru agar bisa
diterapkan dalam komputer untuk memudahkan pekerjaan manusia.
Machine learning adalah ilmu yang mempelajari tentang algoritma komputer yang bisa
mengenali pola-pola di dalam data, dengan tujuan untuk mengubah beragam macam data
menjadi suatu tindakan yang nyata dengan sesedikit mungkin campur tangan manusia.
Dengan Machine Learning, kita dapat menciptakan mesin (komputer) yang “belajar” dari
data yang ada, selanjutnya dia bisa membuat keputusan secara mandiri tanpa perlu diprogram
lagi. Secara umum Machine Learning berada di bawah payung AI (artificial intelligence,
kecerdasan buatan), yang batasannya pun sebenarnya belum disepakati semua orang.
Walaupun teknologi kecerdasan buatan terus berkembang pesat, mesin yang benar-benar bisa
belajar dan “lebih cerdas” dari manusia masih jauh dari kenyataan. Sebenarnya mesin hanya
mencari pola dari sejumlah data yang diberikan kepadanya, kemudian mengubah program di
dalam dirinya agar mengikuti pola yang telah ditemukan. Bila pola-polanya terkumpul cukup
banyak, maka program akan bisa membuat prediksi matematis terhadap apa yang akan
datang. Jadi, mesin masih sebatas melakukan pattern matching (pencocokan pola).
Kita bisa beragumentasi bahwa komputer memiliki memori dan kemampuan proses
matematis yang jauh lebih cepat dari manusia, namun kecepatan bukanlah kecerdasan. Salah
satu perbedaan utama manusia dengan mesin adalah hingga hari ini, belum ada mesin yang
bisa mengajari mesin yang lain, seperti halnya manusia bisa mengajari ilmu baru kepada
manusia lain.
Lalu apa bedanya Machine Learning dengan Data Science? Sebenarnya tidak ada definisi
baku tentang ini, dan setiap orang bisa membuat batasan sendiri. Keduanya tidak sama,
namun banyak kemiripan dan irisan antara kedua bidang ilmu ini. Adapun untuk mudahnya,
kita bisa melihat Machine Learning sebagai bidang yang saling melengkapi dengan ilmu
Data Science. Data Science memanfaatkan Machine Learning untuk mencapai tujuannya.
Para profesional yang bekerja dengan Machine Learning di dunia industri sering disebut
sebagai Machine Learning Engineer. Pekerjaan mereka lebih berfokus pada rekayasa
perangkat lunak untuk menerapkan algoritma Machine Learning pada lingkungan produksi.
Ini sedikit berbeda dengan Data Scientist yang tugasnya lebih condong pada pekerjaan
analisis statistik dan matematis. Adapun demikian, dalam buku ini kita akan mempergunakan
istilah Data Scientist saja untuk mengacu pada para profesional di kedua bidang Data Science
dan Machine Learning, karena kedua bidang ini memang banyak beririsan.
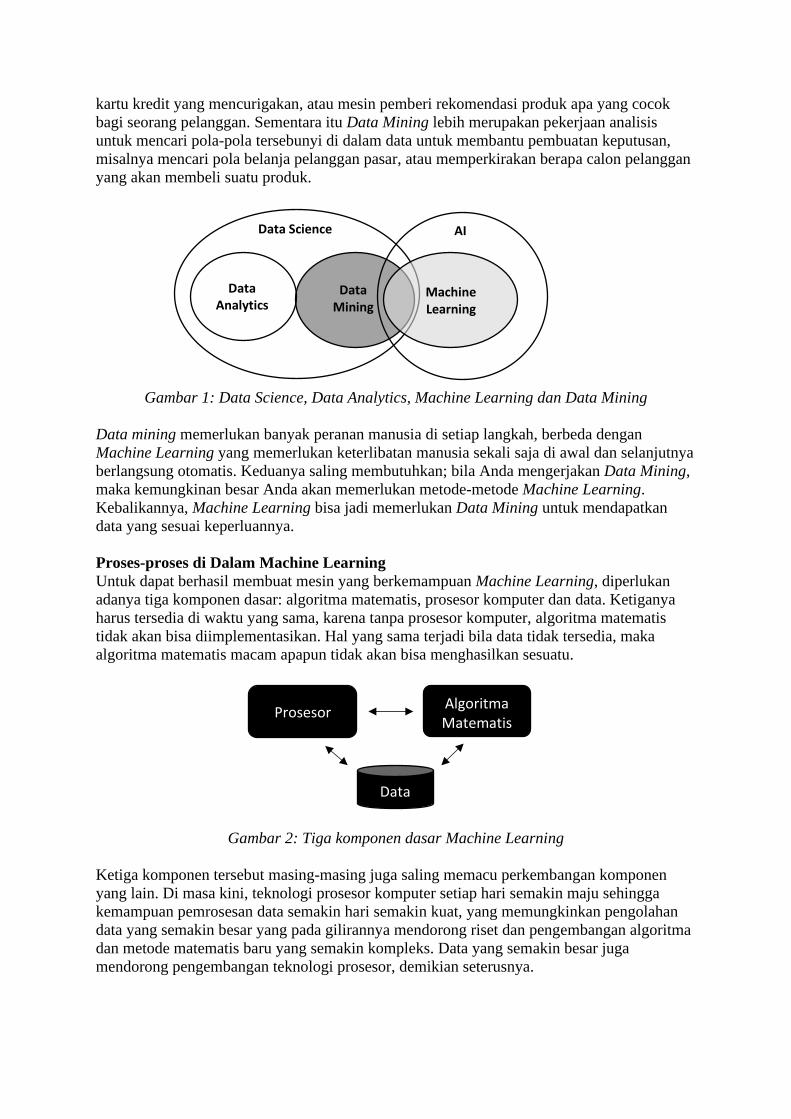
Selain itu, ada pula disiplin ilmu serupa yaitu Data Mining yang mempelajari tentang metode
untuk menghasilkan pengetahuan dengan mengenali pola-pola dari data yang berjumlah
besar, yang bila mempergunakan mata manusia belaka akan sukar dilakukan.
Meskipun mirip, Data Mining tidak sama dengan Machine Learning. Ada irisan antara
keduanya yang masih belum terlalu jelas, namun untuk mudah diingat, Machine Learning
lebih bertujuan untuk membangun sistem yang melakukan pekerjaan-pekerjaan spesifik
secara otomatis, misalnya mesin untuk mengenali gambar, mesin untuk pendeteksi transaksi
Data Science AI
kartu kredit yang mencurigakan, atau mesin pemberi rekomendasi produk apa yang cocok
bagi seorang pelanggan. Sementara itu Data Mining lebih merupakan pekerjaan analisis
untuk mencari pola-pola tersebunyi di dalam data untuk membantu pembuatan keputusan,
misalnya mencari pola belanja pelanggan pasar, atau memperkirakan berapa calon pelanggan
yang akan membeli suatu produk.
Gambar 1: Data Science, Data Analytics, Machine Learning dan Data Mining
Data mining memerlukan banyak peranan manusia di setiap langkah, berbeda dengan
Machine Learning yang memerlukan keterlibatan manusia sekali saja di awal dan selanjutnya
berlangsung otomatis. Keduanya saling membutuhkan; bila Anda mengerjakan Data Mining,
maka kemungkinan besar Anda akan memerlukan metode-metode Machine Learning.
Kebalikannya, Machine Learning bisa jadi memerlukan Data Mining untuk mendapatkan
data yang sesuai keperluannya.
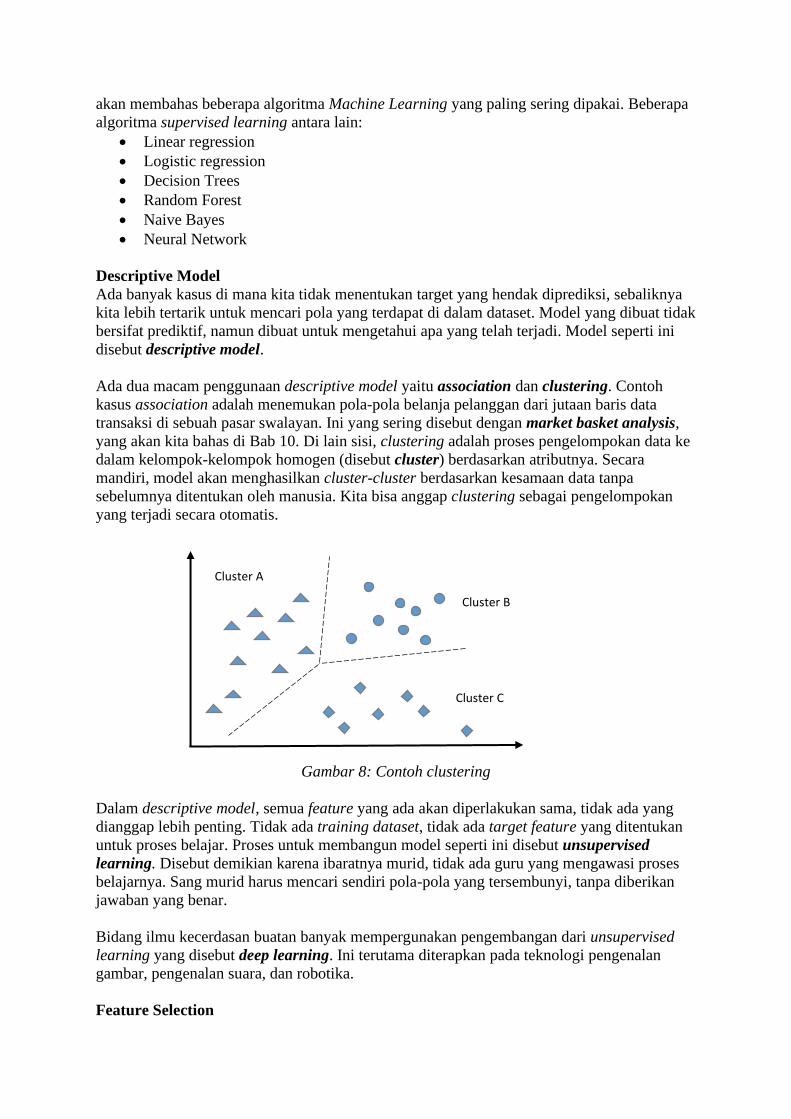
Proses-proses di Dalam Machine Learning
Untuk dapat berhasil membuat mesin yang berkemampuan Machine Learning, diperlukan
adanya tiga komponen dasar: algoritma matematis, prosesor komputer dan data. Ketiganya
harus tersedia di waktu yang sama, karena tanpa prosesor komputer, algoritma matematis
tidak akan bisa diimplementasikan. Hal yang sama terjadi bila data tidak tersedia, maka
algoritma matematis macam apapun tidak akan bisa menghasilkan sesuatu.
Gambar 2: Tiga komponen dasar Machine Learning
Ketiga komponen tersebut masing-masing juga saling memacu perkembangan komponen
yang lain. Di masa kini, teknologi prosesor komputer setiap hari semakin maju sehingga
kemampuan pemrosesan data semakin hari semakin kuat, yang memungkinkan pengolahan
data yang semakin besar yang pada gilirannya mendorong riset dan pengembangan algoritma
dan metode matematis baru yang semakin kompleks. Data yang semakin besar juga
mendorong pengembangan teknologi prosesor, demikian seterusnya.
Prosesor Algoritma Matematis
Data
Data Mining
Data Analytics
Machine Learning

Suatu mesin dapat dikatakan “belajar” apabila mesin tersebut dapat menggunakan data yang
diberikan kepadanya untuk meningkatkan kualitas keluaran mesin secara bertahap. Ini mirip
dengan cara belajar manusia, yaitu mempergunakan pengalaman di masa lalu untuk
memperbaiki cara kerjanya sehingga bila menjumpai situasi serupa di masa depan, reaksi
manusia akan lebih baik. Manusia (umumnya) bisa belajar dari pengalaman buruk agar tidak
ingin jatuh ke lubang yang sama. Bila Anda sudah tahu dari pengalaman bahwa mengendarai
mobil pribadi di Jalan Raya Jenderal Sudirman pada saat jam sibuk hari Jumat sore ternyata
membuat Anda terjebak kemacetan parah, maka secara alamiah Anda akan memilih jalur lain
yang lebih lancar atau naik kendaraan umum di hari Jumat minggu berikutnya. Otomatis otak
kita membuat “algoritma” sendiri.
Ada banyak algoritma Machine Learning yang sudah diciptakan untuk keperluan yang
berbeda-beda, namun semuanya mengikuti prinsip yang sama yaitu meniru (atau berusaha
meniru) cara manusia belajar. Secara umum, ada tiga langkah penting dalam proses belajar:
1. Pengumpulan Data, misalnya data hasil pengukuran dari transaksi, sensor-sensor,
catatan-catatan, tulisan, angka, gambar, suara dan sebagainya. Dalam terminologi
komputer, dataset adalah sekelompok data yang memiliki keterkaitan satu sama lain
yang dapat dimanipulasi oleh komputer sebagai satu kesatuan.
2. Abstraksi, yaitu proses yang menterjemahkan data-data menjadi suatu model yang
lebih umum (mengenai apa definisi model akan dibahas di bawah ini).
3. Generalisasi, yaitu proses yang mempergunakan model hasil abstraksi sebagai dasar
pembuatan keputusan atau kesimpulan.
Gambar 3: Proses belajar
Sebagai contoh yang lebih mudah dipahami, ketika Anda hendak melakukan perjalanan dari
suatu tempat ke tempat yang lain dengan kendaraan, Anda tidak mencoba mengingat pada
detik atau menit ke berapa Anda berbelok ke kiri, kemudian pada detik atau menit ke sekian
berbelok ke kanan, dan seterusnya.
Cara yang lebih masuk akal adalah Anda mempergunakan tanda-tanda yang ada di jalanan
untuk diingat sebagai tanda kapan harus berbelok kanan, kapan berjalan lurus, kapan
berbelok kiri dan seterusnya. Otak Anda mencoba mempergunakan data-data dari indera
mata Anda ke dalam suatu konsep umum yang lebih mudah dipahami dan diingat. Inilah
proses abstraksi.
Kemudian Anda melakukan generalisasi, yaitu mempergunakan ingatan itu pada saat Anda
harus menjalani lagi tugas yang serupa. Jadi ketika Anda harus melakukan perjalanan menuju
tempat yang sama, Anda kemungkinan besar tetap bisa sampai di tujuan meskipun berangkat
dari tempat yang berbeda, atau berjalan kaki, bukan naik kendaraan.
Contoh lain adalah ketika Anda di jalan raya melihat sebuah mobil bermerk baru yang belum
pernah Anda lihat sebelumnya. Meskipun ini adalah pertama kalinya Anda melihat mobil
tersebut, Anda sudah dapat menyimpulkan bahwa barang tersebut adalah sebuah mobil,
dikarenakan Anda sudah memiliki ingatan di dalam otak Anda sebagai hasil proses abstraksi
Data Abstraksi Generalisasi

di masa lalu terhadap beragam obyek yang pernah Anda lihat. Bila ada barang beroda empat,
memiliki pintu-pintu dan jendela kaca, dengan sepasang lampu depan-belakang, maka barang
itu memenuhi syarat sebagai sebuah mobil sehingga Anda pun akan mempercayai bahwa
yang Anda lihat adalah sebuah mobil. Anda tidak memasukkan data-data yang tidak relevan
misalnya warna cat mobil atau warna kaca mobil ke dalam memori Anda.
Gambar 4: Contoh proses abstraksi dari data yang terkumpul
Di sini lah muncul konsep yaitu model. Dalam contoh di atas, otak Anda telah membuat
model untuk benda bernama mobil, dan model itu diterapkan pada panca indera Anda saat
melihat obyek baru. Rangsangan visual akan dicocokkan dengan beragam model di otak
Anda, sehingga Anda dapat membuat kesimpulan mengenai obyek yang sedang Anda lihat.
Contoh lain: bila Anda sudah pernah menikmati hidangan ayam goreng, berarti lidah dan
hidung Anda sudah pernah pula memberikan data-data ke memori otak Anda mengenai
citarasa dan aroma ayam goreng. Data-data ini sudah disimpan di dalam otak Anda sebagai
model bernama “ayam goreng”. Jadi meskipun seandainya mata Anda ditutup, tidak melihat
ke makanan yang sedang disantap, data dari lidah dan hidung Anda beserta model di memori
otak Anda sudah cukup untuk mengetahui makanan apa yang sedang Anda makan. Kalau
berbau seperti ayam dan rasanya seperti ayam, kemungkinan besar Anda memang sedang
makan ayam. Proses abstraksi dan generalisasi ini berlangsung dengan sendirinya di bawah
kesadaran Anda.
Adapun tidak demikian untuk sebuah komputer. Semua proses harus diprogram secara jelas.
Komputer sendiri tidak bisa membuat dan memilih model apa yang akan dipakai. Komputer
harus “diajari” untuk menyimpulkan data-data mentah menjadi suatu model. Inilah yang
disebut proses training, yaitu proses “pelatihan” membentuk suatu model berdasarkan suatu
dataset (yang disebut training dataset).
Kita melatih model dengan tujuan agar model dapat menghasilkan kesimpulan baru
berdasarkan data-data baru yang nantinya akan muncul. Dengan algoritma matematis, model
dibuat fit (cocok) dengan training dataset. Semakin bagus kualitas training dataset ini,
semakin bagus model yang dibangun.
“Mobil yang pernah saya lihat” (data)
“Sebuah Mobil” (abstraksi)

Di dalam Machine Learning, model bisa berupa persamaan matematis, atau berupa aturan
logis (misalnya “if-then-else”), bisa juga berupa diagram alur berbentuk tree (pohon).
Algoritma yang dipergunakan untuk membangun model tentunya tetap harus ditentukan oleh
manusia. Bisa kita umpamakan manusia adalah guru, dan mesin adalah murid. Murid hanya
memodelkan struktur yang disediakan guru.
Saat model sudah dibangun dan dilatih, data sudah diubah menjadi bentuk abstrak yang
merangkum semua informasi aslinya. Dengan bentuk yang abstrak, beragam hubungan di
antara data menjadi bisa ditemukan, yang sebelumnya tidak terlihat.
Adapun demikian, proses belajar belum tuntas bilamana hasil proses abstraksi tidak
dipergunakan untuk membuat tindakan. Di sinilah proses generalisasi terjadi. Model harus
beradaptasi dengan data baru yang belum pernah diterima sebelumnya. Data-data baru yang
diterima oleh mesin akan dicocokkan dengan pengetahuan abstrak yang sudah dimiliki untuk
kemudian dijadikan suatu kesimpulan. Misalnya program pendeteksi transaksi ilegal di
sebuah bank, program sudah memiliki model yang menggeneralisasi transaksi-transaksi jahat,
dan membuat prediksi berupa peringatan ketika pola di data baru ada yang cocok dengan
model itu.
Training Dataset
Agar algoritma Machine Learning dapat menjalankan proses belajar, kita perlu
mempersiapkan training dataset sesuai dengan kasus yang ingin kita pecahkan. Ada beberapa
macam data yang bisa dijadikan training dataset:
• Structured data, yaitu data yang terstruktur dengan tipe data yang konsisten dan dapat
disimpan dalam tabel berupa baris-baris dan kolom (oleh sebab itu biasa disebut data
tabular).
• Unstructured data yang tidak memiliki struktur tetap, misalnya teks, gambar, suara
dan video.
Dalam buku ini, kita akan lebih fokus ke kasus yang mempergunakan structured data.
Adapun begitu tanpa memandang macam datanya, secara umum training dataset harus
berisikan tiga macam input (masukan) yaitu:
1. Example, yaitu rekaman yang menggambarkan satu obyek yang sedang diamati. Sebagai
contoh, data transaksi penjualan di sebuah toserba adalah sekumpulan example. Dalam
structured data, satu baris dalam tabel mewakili satu example, jadi satu transaksi
pembelian adalah satu example.
2. Feature, yaitu karakteristik atau atribut dari suatu example. Misalnya jenis, ukuran,
warna, usia, dan beragam macam hasil pengukuran yang terkait dengan obyek yang
sedang diamati.
Merk Mobil Model Tahun Warna Mesin Transmisi
1 Toyota Kijang 2008 Hitam 2000 manual
2 Toyota Corolla 2003 Putih 1800 otomatis
3 Honda Accord 2005 Hitam 2400 otomatis
4 Daihatsu Taft 2010 Hijau 2700 manual
5 Chevrolet Captiva 2012 Abu-abu 2400 otomatis
6 VW Polo 2013 Putih 1400 otomatis
7 Suzuki Carry 2007 Biru 1500 manual
example
feature

Gambar 5: Contoh structured data
Feature bisa berupa elemen data yang bersifat continuous yaitu nilai numerik misalnya
angka penjualan dan jumlah pelanggan. Feature bisa juga elemen data dalam bentuk
sekumpulan kategori, misalnya jenis kelamin, kategori produk, kelompok penyakit, dan
sebagainya. Feature yang berupa kategori seperti ini sering disebut dengan data-data
nominal. Lebih khusus lagi, kategori berupa daftar yang berbentuk urutan tertentu
(misalnya ukuran kecil/sedang/besar, atau usia anak/remaja/dewasa) disebut sebagai data
ordinal. Sementara itu, feature yang berisi elemen data yang hanya memiliki dua
kemungkinan nilai (misal ‘Ya’ atau ‘Tidak’) disebut binary feature.
3. Target Feature (atau disebut juga label) yaitu feature yang ingin diketahui atau
diprediksi nilainya dengan bantuan model Machine Learning. Target feature harus
terdefinisi dengan baik karena algoritma Machine Learning memerlukannya untuk belajar
membuat fungsi matematis yang memetakan hubungan antara feature yang ada dengan
target yang ingin diprediksi. Contoh target feature yang umum:
• Angka penjualan perusahaan
• Angka pertumbuhan ekonomi dan angka inflasi
• Jenis kelamin laki-laki atau perempuan
• Kelompok usia penduduk (anak-anak, remaja, dewasa, tua)
• Transaksi ilegal atau legal
• Calon pembeli produk atau bukan calon pembeli produk
• Pesan e-mail biasa atau e-mail sampah
• Sentimen percakapan positif atau negatif
• Transaksi kartu kredit yang jahat atau normal
Hal yang penting diperhatikan dalam adalah training dataset harus mencakup seluruh
jangkauan nilai yang nanti akan diprediksi. Sebagai contoh, bila kita ingin memprediksi
berapa suhu esok hari di suatu daerah, maka training dataset harus memiliki example yang
mencakup seluruh jangkauan suhu yang pernah tercatat di daerah itu, misalnya dari 10C
hingga 35C. Kita tidak bisa memprediksi sesuatu yang ada di luar jangkauan training
dataset, misalnya 42C atau -2C.
Mengukur Kinerja Model
Setelah kita membangun model, kita tentu tidak bisa langsung memakainya. Kita harus tahu
apakah model sudah baik atau belum, yaitu melakukan apa yang disebut dengan proses
evaluasi atau validasi model. Bagaimana mengukur baik atau tidaknya sebuah model?
Setelah suatu model dilatih dengan training dataset, model harus diuji dengan dataset baru
(disebut test dataset) yang dipergunakan untuk mengukur kinerjanya. Ini yang disebut dengan
proses scoring.
Ukuran terpenting baik-buruk sebuah model adalah seberapa akurat model tersebut bila
dihadapkan dengan data baru. Dalam contoh model pendeteksi transaksi perbankan ilegal,
harus diukur berapa banyak transaksi yang oleh model dikategorikan sebagai jahat memang
benar-benar terbukti sebagai transaksi jahat. Bila model mendeteksi 100 transaksi jahat
namun ternyata hanya 50 saja yang benar-benar transaksi jahat, jadi hanya separuh saja
prediksi yang benar, maka model ini memiliki akurasi yang buruk karena tidak ada bedanya
dengan deteksi acak atau asal-asalan belaka, seperti melempar koin ke udara dan melihat sisi
mana yang menghadap ke atas ketika koin mendarat di tanah.

Dari mana kita bisa mendapatkan test dataset? Praktek yang biasa dilakukan adalah membagi
dataset yang tersedia menjadi dua, yaitu training dataset dan test dataset. Test dataset
jumlahnya lebih sedikit dari training dataset, umumnya sekitar 20% dari total seluruh
example. Meskipun lebih sedikit, dalam pemilihan test dataset ini harus dipastikan bahwa
isinya dipilih secara acak, jumlahnya cukup besar serta bisa mewakili keseluruhan populasi
dataset.
Gambar 6: Training dan Test Dataset
Perlu diingat bahwa tidak ada model yang selalu sukses melakukan generalisasi semua data
dengan tingkat akurasi yang selalu tinggi. Setiap macam algoritma Machine Learning
memiliki kelebihan dan kelemahan masing-masing.
Salah satu penyebab mengapa model tidak selalu akurat adalah karena adanya noise, yaitu
data yang bervariasi di luar kewajaran bila dibandingkan dengan data lain di dalam dataset
yang sama. Terkadang noise diakibatkan oleh hal-hal yang tidak bisa dijelaskan secara pasti,
namun lebih sering noise diakibatkan oleh kesalahan dalam pengukuran (misalnya alat ukur
yang belum dikalibrasi), atau data yang tidak terekam dengan baik misalnya elemen data
hilang, terpotong, atau null (kosong). Bisa juga noise dihasilkan oleh manusia, misalnya
dalam suatu survei, responden yang mengisi survei tidak memberikan jawaban yang tepat
(karena salah membaca, terburu-buru, atau kelelahan) sehingga hasilnya menjadi tidak masuk
akal ketika dibandingkan dengan hasil survei dari responden lain.
Bila kita melatih model dengan terlalu banyak noise di dalam training dataset, kita akan
menemukan masalah yang disebut overfitting. Karena noise adalah fenomena yang acak dan
tidak bisa dijelaskan secara pasti, noise akan membuat pola sesungguhnya di dalam data
menjadi kabur dan tidak jelas. Model yang overfit akan nampak bagus dalam proses training
namun ketika diuji dengan test dataset kinerjanya akan merosot. Itu sebabnya kita harus
sebisa mungkin menghilangkan noise dari training dataset sebelum membuat model.
Predictive Model
Dalam bahasa ilmiah, prediction (prediksi) yaitu perkiraaan apa yang akan terjadi di masa
depan (tentunya dilakukan secara matematis, bukan dengan ilmu gaib). Prediksi bisa didapat
berdasarkan pengetahuan dan pengalaman di masa lalu. Sebagai contoh bila kita ingin
memprediksi bagaimana cuaca esok hari di sebuah kota maka kita perlu terlebih dahulu
mendapatkan data iklim dan pola cuaca di daerah itu untuk tahun-tahun sebelumnya. Bila kita
ingin memperkirakan berapa laba perusahaan bulan depan, maka kita memerlukan data-data
penjualan dan pengeluaran perusahaan di masa sebelumnya. Karena dipakai sebagai dasar
membuat prediksi, data-data ini disebut predictor.
Hampir mirip dengan prediksi, bila kita ingin membuat perkiraan terhadap apa yang telah
terjadi, maka yang kita lakukan adalah membuat estimasi. Contohnya adalah membuat
Training Dataset Test Dataset
Keseluruhan dataset

estimasi berapa tinggi badan seseorang, atau membuat estimasi berapa jarak yang telah
ditempuh sebuah kendaraan.
Predictive model, seperti namanya, dipergunakan untuk memecahkan persoalan-persoalan
yang memerlukan prediksi dan estimasi. Algoritma Machine Learning akan mencoba
mencari hubungan antara target feature (yang ingin diprediksi) dan feature yang lain yang
tersedia di dalam dataset. Perlu dipahami bahwa perbedaan antara prediksi dan estimasi
secara matematis sebenarnya tidak ada, sehingga bisa kita pergunakan model yang sama.
Selain dipergunakan untuk membuat prediksi nilai-nilai numerik, predictive model bisa
dipergunakan juga untuk melakukan kategorisasi, artinya menentukan suatu example masuk
ke dalam kategori yang mana (dalam bidang Machine Learning, kategori disebut juga dengan
istilah class). Prediksi seperti ini disebut dengan classification (klasifikasi), dan modelnya
disebut classification model. Contoh classification antara lain:
• Cuaca diperkirakan cerah, berawan, hujan, atau hujan badai
• Pelanggan dikelompokkan ke golongan pelanggan baru, pelanggan biasa, atau
pelanggan setia
• Pasien dinilai beresiko rendah atau tinggi mendapat serangan jantung
• E-mail dipisahkan antara spam (berisi pesan sampah) dan yang bukan.
Agar dapat membuat prediksi, predictive model harus diberi petunjuk yang jelas tentang apa
yang harus diprediksi, juga bagaimana caranya belajar agar modelnya bisa terbentuk. Ibarat
seorang murid yang perlu bimbingan dan pengawasan, proses training seperti ini disebut
supervised learning. Pengawasan di sini tidak berarti harfiah diawasi oleh manusia, namun
artinya manusia harus mempersiapkan apa yang disebut ground truth, yaitu data lengkap
hasil pengamatan di dunia nyata yang akan dijadikan masukan bagi dasar proses belajar. Data
lengkap ini berisi feature-feature dan target feature. Tugas mesin adalah menemukan fungsi
matematis yang paling bisa menggambarkan hubungan antara feature dan target feature-nya.
Gambar 7: Supervised Learning
Hasil keluaran model juga harus dievaluasi oleh manusia agar kemudian dapat dilakukan
langkah-langkah untuk membuat model menjadi lebih baik lagi, dengan melihat feature yang
mana saja yang paling berpengaruh terhadap unjuk kerja model.
Ada banyak macam algoritma Machine Learning untuk membuat predictive model. Jenis
target feature, jumlah feature dan jenis data yang bisa dijadikan predictor akan menentukan
algoritma yang cocok untuk memecahkan kasus yang sedang dihadapi. Di dalam buku ini kita
Training Dataset
Features
Target / Label
Algoritma
Dataset Baru (tanpa label)
Model Data Baru + Label
akan membahas beberapa algoritma Machine Learning yang paling sering dipakai. Beberapa
algoritma supervised learning antara lain:
• Linear regression
• Logistic regression
• Decision Trees
• Random Forest
• Naive Bayes
• Neural Network
Descriptive Model
Ada banyak kasus di mana kita tidak menentukan target yang hendak diprediksi, sebaliknya
kita lebih tertarik untuk mencari pola yang terdapat di dalam dataset. Model yang dibuat tidak
bersifat prediktif, namun dibuat untuk mengetahui apa yang telah terjadi. Model seperti ini
disebut descriptive model.
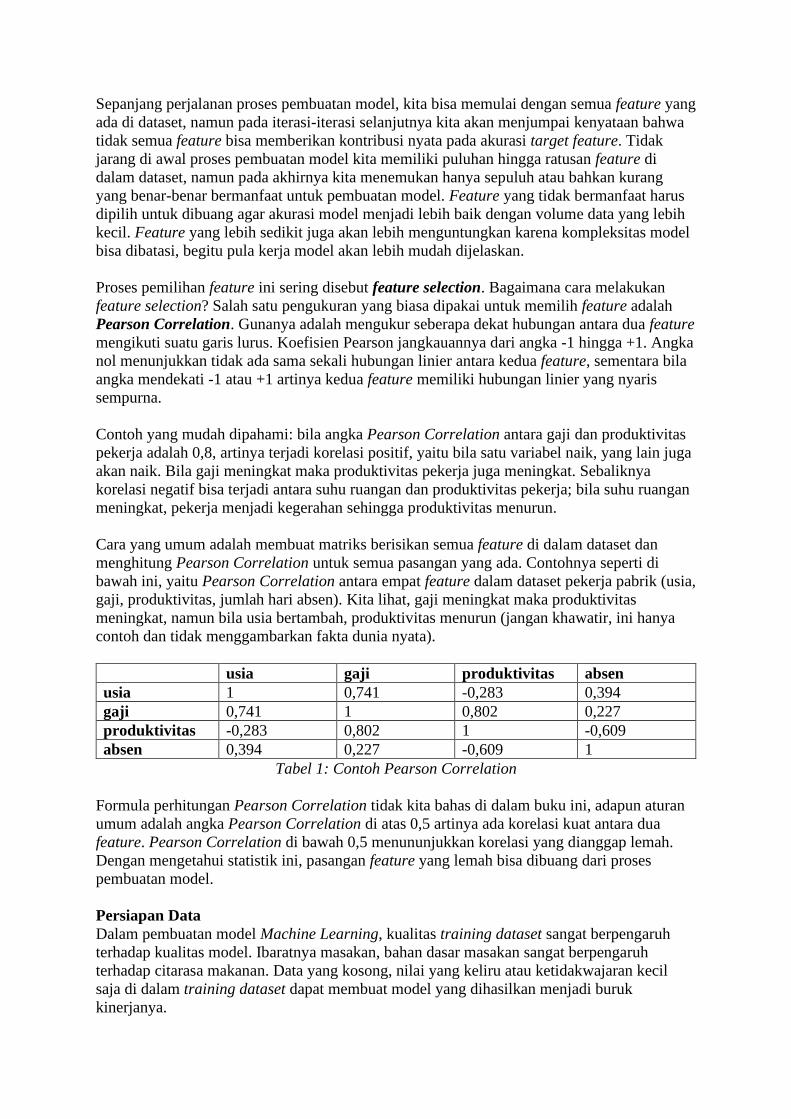
Ada dua macam penggunaan descriptive model yaitu association dan clustering. Contoh
kasus association adalah menemukan pola-pola belanja pelanggan dari jutaan baris data
transaksi di sebuah pasar swalayan. Ini yang sering disebut dengan market basket analysis,
yang akan kita bahas di Bab 10. Di lain sisi, clustering adalah proses pengelompokan data ke
dalam kelompok-kelompok homogen (disebut cluster) berdasarkan atributnya. Secara
mandiri, model akan menghasilkan cluster-cluster berdasarkan kesamaan data tanpa
sebelumnya ditentukan oleh manusia. Kita bisa anggap clustering sebagai pengelompokan
yang terjadi secara otomatis.
Gambar 8: Contoh clustering
Dalam descriptive model, semua feature yang ada akan diperlakukan sama, tidak ada yang
dianggap lebih penting. Tidak ada training dataset, tidak ada target feature yang ditentukan
untuk proses belajar. Proses untuk membangun model seperti ini disebut unsupervised
learning. Disebut demikian karena ibaratnya murid, tidak ada guru yang mengawasi proses
belajarnya. Sang murid harus mencari sendiri pola-pola yang tersembunyi, tanpa diberikan
jawaban yang benar.
Bidang ilmu kecerdasan buatan banyak mempergunakan pengembangan dari unsupervised
learning yang disebut deep learning. Ini terutama diterapkan pada teknologi pengenalan
gambar, pengenalan suara, dan robotika.
Feature Selection
Cluster A
Cluster B
Cluster C
Sepanjang perjalanan proses pembuatan model, kita bisa memulai dengan semua feature yang
ada di dataset, namun pada iterasi-iterasi selanjutnya kita akan menjumpai kenyataan bahwa
tidak semua feature bisa memberikan kontribusi nyata pada akurasi target feature. Tidak
jarang di awal proses pembuatan model kita memiliki puluhan hingga ratusan feature di
dalam dataset, namun pada akhirnya kita menemukan hanya sepuluh atau bahkan kurang
yang benar-benar bermanfaat untuk pembuatan model. Feature yang tidak bermanfaat harus
dipilih untuk dibuang agar akurasi model menjadi lebih baik dengan volume data yang lebih
kecil. Feature yang lebih sedikit juga akan lebih menguntungkan karena kompleksitas model
bisa dibatasi, begitu pula kerja model akan lebih mudah dijelaskan.
Proses pemilihan feature ini sering disebut feature selection. Bagaimana cara melakukan
feature selection? Salah satu pengukuran yang biasa dipakai untuk memilih feature adalah
Pearson Correlation. Gunanya adalah mengukur seberapa dekat hubungan antara dua feature
mengikuti suatu garis lurus. Koefisien Pearson jangkauannya dari angka -1 hingga +1. Angka
nol menunjukkan tidak ada sama sekali hubungan linier antara kedua feature, sementara bila
angka mendekati -1 atau +1 artinya kedua feature memiliki hubungan linier yang nyaris
sempurna.
Contoh yang mudah dipahami: bila angka Pearson Correlation antara gaji dan produktivitas
pekerja adalah 0,8, artinya terjadi korelasi positif, yaitu bila satu variabel naik, yang lain juga
akan naik. Bila gaji meningkat maka produktivitas pekerja juga meningkat. Sebaliknya
korelasi negatif bisa terjadi antara suhu ruangan dan produktivitas pekerja; bila suhu ruangan
meningkat, pekerja menjadi kegerahan sehingga produktivitas menurun.
Cara yang umum adalah membuat matriks berisikan semua feature di dalam dataset dan
menghitung Pearson Correlation untuk semua pasangan yang ada. Contohnya seperti di
bawah ini, yaitu Pearson Correlation antara empat feature dalam dataset pekerja pabrik (usia,
gaji, produktivitas, jumlah hari absen). Kita lihat, gaji meningkat maka produktivitas
meningkat, namun bila usia bertambah, produktivitas menurun (jangan khawatir, ini hanya
contoh dan tidak menggambarkan fakta dunia nyata).
usia gaji produktivitas absen
usia 1 0,741 -0,283 0,394
gaji 0,741 1 0,802 0,227
produktivitas -0,283 0,802 1 -0,609
absen 0,394 0,227 -0,609 1
Tabel 1: Contoh Pearson Correlation
Formula perhitungan Pearson Correlation tidak kita bahas di dalam buku ini, adapun aturan
umum adalah angka Pearson Correlation di atas 0,5 artinya ada korelasi kuat antara dua
feature. Pearson Correlation di bawah 0,5 menununjukkan korelasi yang dianggap lemah.
Dengan mengetahui statistik ini, pasangan feature yang lemah bisa dibuang dari proses
pembuatan model.
Persiapan Data
Dalam pembuatan model Machine Learning, kualitas training dataset sangat berpengaruh
terhadap kualitas model. Ibaratnya masakan, bahan dasar masakan sangat berpengaruh
terhadap citarasa makanan. Data yang kosong, nilai yang keliru atau ketidakwajaran kecil
saja di dalam training dataset dapat membuat model yang dihasilkan menjadi buruk
kinerjanya.

Untuk mendapatkan data yang berkualitas tinggi bukanlah hal yang sederhana. Tantangan
pertama bagi data scientist adalah mendapatkan data yang diperlukan dari sumbernya,
biasanya berupa sistem transaksional yang isi datanya tidak bersih. Selain itu data yang
diperlukan belum tentu tersedia di sumbernya, dan kalaupun tersedia, umumnya terpencar-
pencar di banyak lokasi dan lebih rumit lagi, tersimpan dalam berbagai macam format (SQL
database, file text, dan sebagainya). Diperlukan mekanisme khusus untuk pengumpulan dan
persiapan data agar bisa dipakai untuk keperluan Machine Learning. Di beberapa penerapan,
data yang sudah dipersiapkan untuk proses Data Analytics dan Machine Learning disebut
dengan Analytical Base Table.
Data collection adalah proses pengumpulan dan pengambilan data dari sumber-sumber data
yang bisa dilakukan secara berkala (per hari, per jam, atau per sekian menit) atau secara real-
time. Tidak semua data perlu diambil, hanya informasi yang sekiranya diperlukan untuk
proses analisis saja yang dipilih. Setelah terkumpul, hampir selalu diperlukan upaya untuk
mengkonversi, membersihkan, menghilangkan elemen-elemen data yang duplikat, tidak
konsisten, atau isinya bermasalah. Setelah itu, data yang ada harus diubah strukturnya agar
sesuai dengan bentuk dan ukuran yang dibutuhkan oleh algoritma Machine Learning yang
dituju. Pekerjaan biasanya dikerjakan oleh para Data Engineer, yaitu spesialis yang mengerti
bagaimana metode transformasi data ke bentuk yang bisa dipakai oleh para Data Scientist.
Contoh transformasi data antara lain:
1. Membuang data duplikat/ganda
2. Membuang data yang kosong
3. Membuang data yang keliru
4. Menggabungkan semua data ke dalam satu tabel
5. Membuat data-data turunan hasil perhitungan (“calculated fields”)
6. Mentransformasi format dan struktur tabel
7. Melihat profil data secara keseluruhan dengan cara visual
Kasus yang sangat sering terjadi dalam praktek adalah banyaknya nilai hilang atau kosong di
dalam dataset. Kebanyakan algoritma Machine Learning tidak dapat menerima data yang
kosong, sehingga dataset harus dimanipulasi terlebih dahulu sebelum masuk ke proses
pembuatan model.
Beberapa pendekatan yang umum untuk menangani nilai kosong adalah impute yang artinya
mengganti nilai yang hilang dengan nilai yang lain seperti angka rata-rata atau angka default.
Pendekatan lain adalah dengan menghapus seluruh example yang memiliki feature berisi nilai
kosong bila diketahui informasi yang hilang memiliki hubungan kuat terhadap target feature
(dan sebaliknya, example tetap dibiarkan saja bilamana informasi yang hilang setelah melalui
pengujian statistik terbukti tidak memiliki hubungan yang kuat dengan target feature).
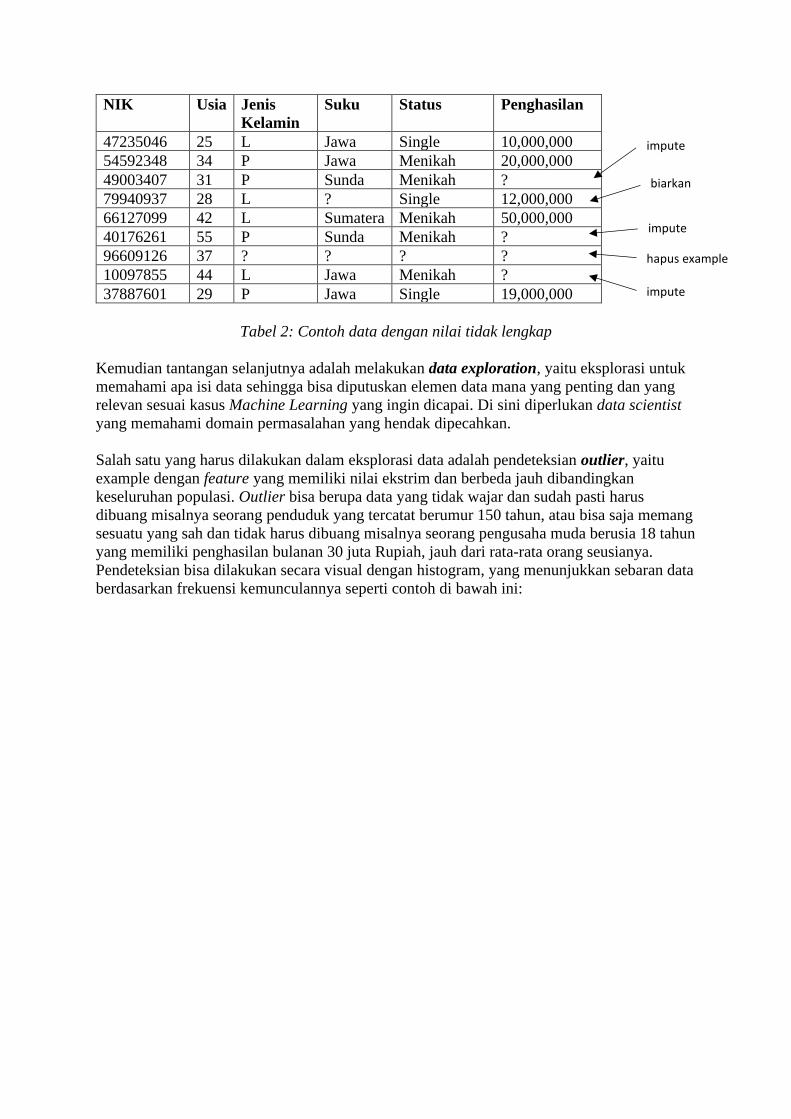
NIK Usia Jenis
Kelamin
Suku Status Penghasilan
47235046 25 L Jawa Single 10,000,000
54592348 34 P Jawa Menikah 20,000,000
49003407 31 P Sunda Menikah ?
79940937 28 L ? Single 12,000,000
66127099 42 L Sumatera Menikah 50,000,000
40176261 55 P Sunda Menikah ?
96609126 37 ? ? ? ?
10097855 44 L Jawa Menikah ?
37887601 29 P Jawa Single 19,000,000
Tabel 2: Contoh data dengan nilai tidak lengkap
Kemudian tantangan selanjutnya adalah melakukan data exploration, yaitu eksplorasi untuk
memahami apa isi data sehingga bisa diputuskan elemen data mana yang penting dan yang
relevan sesuai kasus Machine Learning yang ingin dicapai. Di sini diperlukan data scientist
yang memahami domain permasalahan yang hendak dipecahkan.
Salah satu yang harus dilakukan dalam eksplorasi data adalah pendeteksian outlier, yaitu
example dengan feature yang memiliki nilai ekstrim dan berbeda jauh dibandingkan
keseluruhan populasi. Outlier bisa berupa data yang tidak wajar dan sudah pasti harus
dibuang misalnya seorang penduduk yang tercatat berumur 150 tahun, atau bisa saja memang
sesuatu yang sah dan tidak harus dibuang misalnya seorang pengusaha muda berusia 18 tahun
yang memiliki penghasilan bulanan 30 juta Rupiah, jauh dari rata-rata orang seusianya.
Pendeteksian bisa dilakukan secara visual dengan histogram, yang menunjukkan sebaran data
berdasarkan frekuensi kemunculannya seperti contoh di bawah ini:
impute
hapus example
impute
impute
biarkan
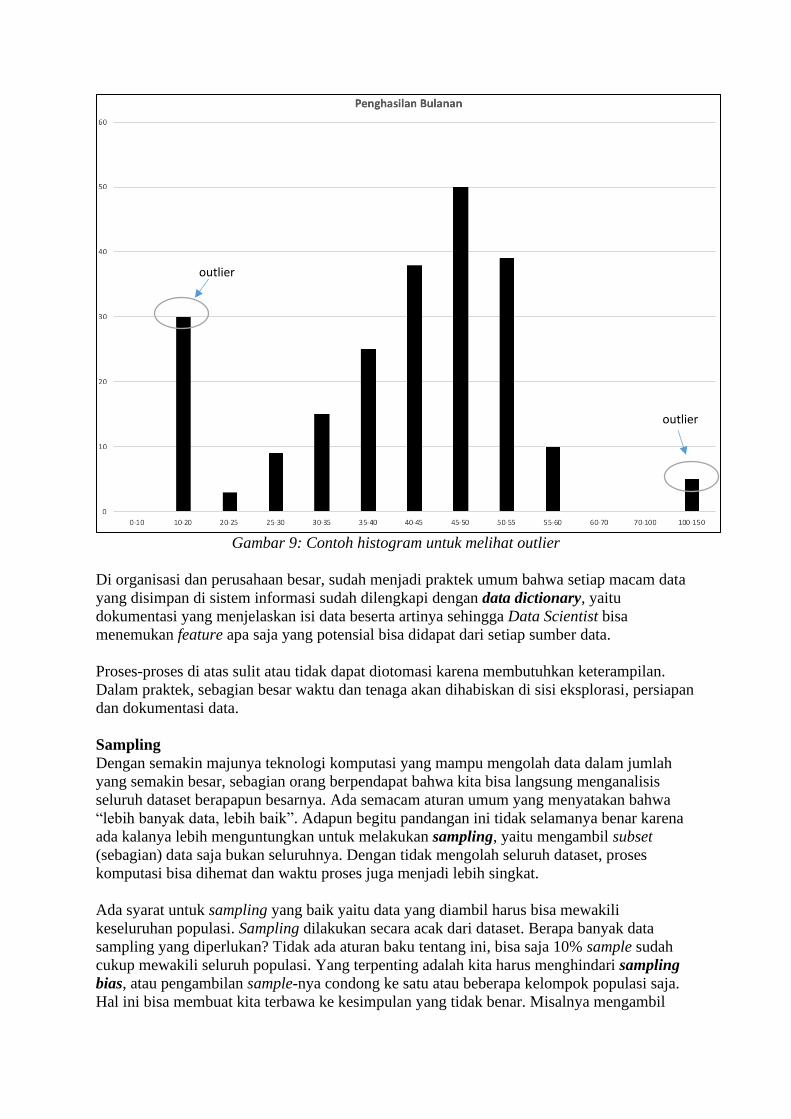
Gambar 9: Contoh histogram untuk melihat outlier
Di organisasi dan perusahaan besar, sudah menjadi praktek umum bahwa setiap macam data
yang disimpan di sistem informasi sudah dilengkapi dengan data dictionary, yaitu
dokumentasi yang menjelaskan isi data beserta artinya sehingga Data Scientist bisa
menemukan feature apa saja yang potensial bisa didapat dari setiap sumber data.
Proses-proses di atas sulit atau tidak dapat diotomasi karena membutuhkan keterampilan.
Dalam praktek, sebagian besar waktu dan tenaga akan dihabiskan di sisi eksplorasi, persiapan
dan dokumentasi data.
Sampling
Dengan semakin majunya teknologi komputasi yang mampu mengolah data dalam jumlah
yang semakin besar, sebagian orang berpendapat bahwa kita bisa langsung menganalisis
seluruh dataset berapapun besarnya. Ada semacam aturan umum yang menyatakan bahwa
“lebih banyak data, lebih baik”. Adapun begitu pandangan ini tidak selamanya benar karena
ada kalanya lebih menguntungkan untuk melakukan sampling, yaitu mengambil subset
(sebagian) data saja bukan seluruhnya. Dengan tidak mengolah seluruh dataset, proses
komputasi bisa dihemat dan waktu proses juga menjadi lebih singkat.
Ada syarat untuk sampling yang baik yaitu data yang diambil harus bisa mewakili
keseluruhan populasi. Sampling dilakukan secara acak dari dataset. Berapa banyak data
sampling yang diperlukan? Tidak ada aturan baku tentang ini, bisa saja 10% sample sudah
cukup mewakili seluruh populasi. Yang terpenting adalah kita harus menghindari sampling
bias, atau pengambilan sample-nya condong ke satu atau beberapa kelompok populasi saja.
Hal ini bisa membuat kita terbawa ke kesimpulan yang tidak benar. Misalnya mengambil
outlier
outlier
sampling data satu hari transaksi saja sementara ada hari-hari lain yang memiliki pola
transaksi berbeda. Pola belanja pelanggan di hari Senin bisa sangat berbeda dengan di hari
Sabtu.
Sampling bisa dilakukan dengan pengambilan acak sederhana, atau bisa dengan metode yang
disebut stratified sampling, yaitu memisahkan populasi ke dalam segmen-segmen kecil
terlebih dahulu sebelum dilakukan pengambilan acak. Tujuannya agar bisa mengambil
sample yang merata untuk seluruh elemen data. Misalnya data penduduk dipecah ke dalam
strata berdasarkan jenis kelamin, usia, suku, dan sebagainya sebelum dilakukan pengambilan
acak.
Standarisasi Data
Ketika kita akan membangun model Machine Learning, penting untuk memastikan setiap
feature berada di dalam jangkauan nilai yang sama. Kita tidak ingin ada feature yang
jangkauan angkanya tinggi (misalnya dalam order ribuan atau jutaan) mendominasi feature
yang jangkauan angkanya jauh di bawahnya (misalnya puluhan atau ratusan). Sebagai
contoh, adalah hal yang lumrah bila suatu transaksi dengan mata uang Rupiah bernilai dalam
orde juta atau milyar, namun orde yang sama tidak wajar untuk transaksi dengan mata uang
Dolar Amerika.
Beberapa algoritma Machine Learning tidak bisa bekerja baik bila hal seperti ini dibiarkan.
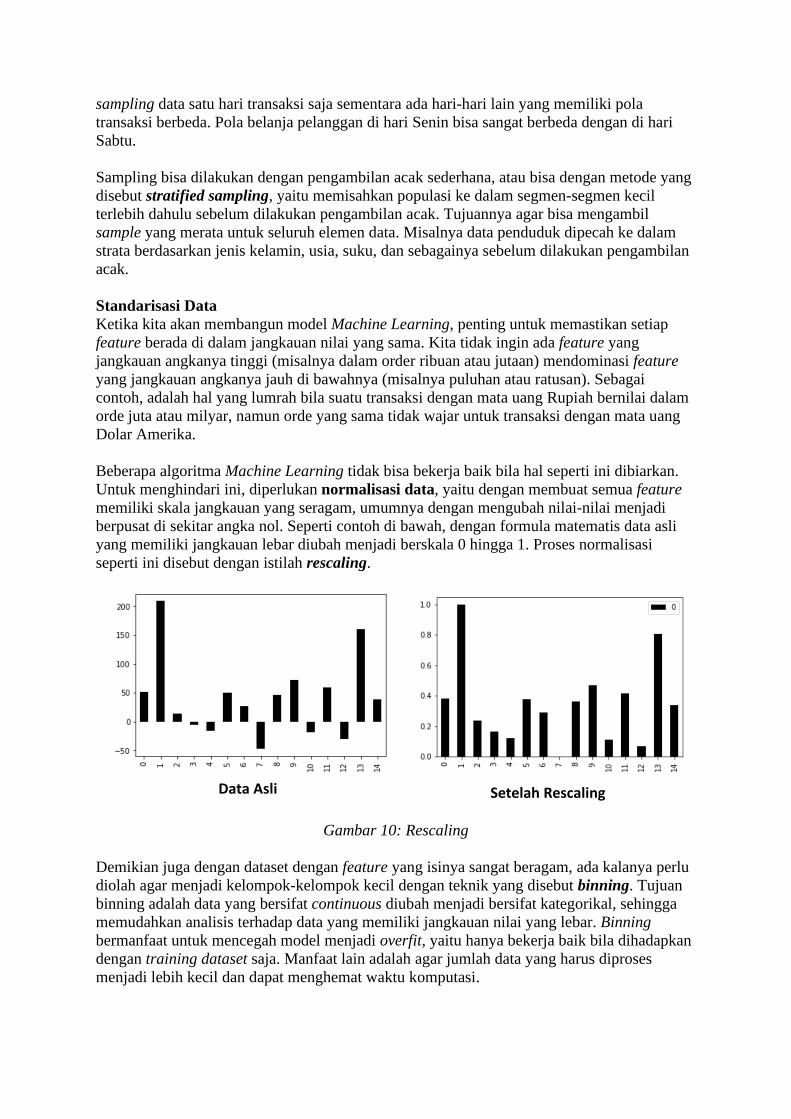
Untuk menghindari ini, diperlukan normalisasi data, yaitu dengan membuat semua feature
memiliki skala jangkauan yang seragam, umumnya dengan mengubah nilai-nilai menjadi
berpusat di sekitar angka nol. Seperti contoh di bawah, dengan formula matematis data asli
yang memiliki jangkauan lebar diubah menjadi berskala 0 hingga 1. Proses normalisasi
seperti ini disebut dengan istilah rescaling.
Data Asli
Setelah Rescaling
Gambar 10: Rescaling
Demikian juga dengan dataset dengan feature yang isinya sangat beragam, ada kalanya perlu
diolah agar menjadi kelompok-kelompok kecil dengan teknik yang disebut binning. Tujuan
binning adalah data yang bersifat continuous diubah menjadi bersifat kategorikal, sehingga
memudahkan analisis terhadap data yang memiliki jangkauan nilai yang lebar. Binning
bermanfaat untuk mencegah model menjadi overfit, yaitu hanya bekerja baik bila dihadapkan
dengan training dataset saja. Manfaat lain adalah agar jumlah data yang harus diproses
menjadi lebih kecil dan dapat menghemat waktu komputasi.

Contoh binning adalah data penghasilan rumah tangga penduduk di suatu wilayah yang
bernilai di atas sepuluh juta Rupiah dikelompokkan menjadi tingkat penghasilan tinggi, di
bawah tiga juta Rupiah sebagai tingkat penghasilan rendah, dan seterusnya. Binning juga
umumnya dipergunakan untuk pengolahan gambar digital dengan cara mengkombinasikan
banyak pixel (elemen terkecil gambar) yang berdekatan menjadi satu pixel saja.
Mendapatkan Dataset
Di lingkungan nyata, data yang akan diolah biasanya berasal dari dalam sistem informasi
transaksional di perusahaan atau organisasi yang bersangkutan. Data bisa berupa transaksi
penjualan, database pelanggan, hasil survei atau data lain yang dihasilkan kegiatan nyata.
Semua organisasi memiliki kebijakan masing-masing mengenai kerahasiaan informasi,
termasuk juga adanya undang-undang yang melindungi privasi pelanggan. Oleh karena itu
biasanya data akan dijaga ketat dan tidak dapat dibawa keluar dari organisasi.
Bagi kita yang sedang belajar, kita juga memerlukan dataset untuk berlatih, namun biasanya
kita menemui kesulitan untuk mendapatkan dataset yang sesuai karena kita tidak memiliki
akses ke data asli seperti mereka yang bekerja di organisasi-organisasi besar. Alternatifnya,
ada beberapa situs di internet yang menyediakan contoh-contoh dataset yang bebas untuk
dipergunakan. UCI Machine Learning Repository yang berada di University of California
di Amerika Serikat adalah salah satu situs yang paling populer untuk mendapatkan contoh
dataset bagi proses latihan dan belajar. Situs ini menyediakan banyak dataset yang berasal
dari kasus-kasus nyata di berbagai bidang, baik bidang ilmiah maupun sektor bisnis. Setiap
dataset sudah dilengkapi dengan deskripsi yang mendetail tentang dataset tersebut.
Sebagai alat bantu pembelajaran, di buku ini kita akan mempergunakan beragam dataset
untuk latihan. Beberapa dataset berupa data hasil rekayasa, namun beberapa lagi merupakan
dataset yang berasal dari kasus nyata di lapangan. Lampiran 2 buku ini akan menunjukkan di
mana Anda bisa mengunduh dataset yang diperlukan.
Di bab selanjutnya kita akan memperkenalkan Python, dengan fokus pada fasilitas yang
disediakan oleh bahasa pemrograman ini untuk keperluan Machine Learning.

BAB 2 Python untuk Machine Learning Hingga kini, Python masih merupakan bahasa pemrograman yang termasuk paling populer di
dunia[5], pertumbuhan jumlah penggunanya selalu positif sejak diperkenalkan awal 1990-an.
Sebagai bahasa yang serba guna, beragam macam program dapat dibuat dengan Python,
mulai dari program sederhana untuk sekolah, program komputasi ilmiah, aplikasi bisnis
hingga Machine Learning. Banyak perusahaan dan organisasi besar yang memanfaatkan
software yang ditulis dengan Python. Jadi bila Anda memiliki keahlian di bahasa
pemrograman ini, Anda seharusnya tidak akan kesulitan mencari pekerjaan. Begitu juga bila
menjadi technopreneur adalah jalan hidup Anda, memiliki pengetahuan tentang Python akan
bisa membantu bisnis Anda. Pokoknya, Anda tidak akan rugi belajar Python!
Sehebat apa sebenarnya Python, dibandingkan dengan bahasa-bahasa lain yang tidak kalah
populer, misalnya Java, JavaScript, C/C++ dan sebagainya? Tentunya Python bukan jawaban
bagi semua permasalahan. Python memiliki keterbatasan dan kekurangan, salah satunya
adalah kurang cocok untuk aplikasi yang bekerja sangat berat, membutuhkan respons ekstra
cepat, atau program yang melakukan operasi panjang yang memakan banyak CPU (central
processing unit) komputer. Python juga bukan bahasa yang cocok (walaupun bukan berarti
tidak bisa) untuk membuat aplikasi yang memiliki tampilan grafis yang kompleks, tidak
seperti Java yang biasa dipakai untuk membuat aplikasi desktop dan aplikasi ponsel Android.
Python adalah bahasa scripting (bisa dieksekusi tanpa perlu compiler). Hal inilah yang
membuat Python dipilih banyak pengembang perangkat lunak untuk membuat program yang
pendek dengan cepat, atau untuk membuat tugas-tugas yang perlu dijalankan berkala secara
otomatis. Python sering diposisikan sebagai fasilitas untuk membuat program yang langsung
bisa menyelesaikan masalah-masalah umum tanpa perlu banyak kerepotan.
Pada awalnya dahulu, Python banyak dipergunakan oleh programmer karena kemampuannya
untuk memanipulasi data bertipe string (misalnya teks) dengan mudah. Sejalan dengan
waktu, Python juga masuk ke wilayah pengolahan data untuk analisis. Python memiliki daya
tarik tersendiri karena tersedia banyak library tambahan untuk manipulasi dan visualisasi
data. Banyak Data Scientist yang kini memakai Python, di samping bahasa-bahasa populer
lain seperti R atau MATLAB.
Kabar baik lainnya, Python termasuk mudah dipelajari. Para pemula atau mereka yang sudah
biasa memakai bahasa pemrograman lain tidak akan kesulitan untuk mengerti konsep-konsep
di dalam Python, dan dengan waktu yang tidak lama akan bisa memakai Python untuk
keperluan yang produktif.
Python untuk Machine Learning
Sesuai survey yang dilakukan oleh Kaggle[6] (sebuah komunitas Data Science yang dimiliki
oleh Google), Python adalah bahasa nomor satu paling populer dipergunakan untuk Machine
Learning dan artificial intelligence. Popularitas Python ini salah satunya adalah karena
tersedianya banyak library (modul-modul siap pakai) yang mendukung kegiatan Data
Analytics dan Machine Learning, misalnya Matplotlib, Numpy, Pandas, Scikit-learn, dan
library tambahan Python lainnya. Berkat beragam library ini, tidak perlu lagi kita membeli
perangkat lunak mahal untuk membangun kemampuan Machine Learning. Itu pula alasan
utama mengapa buku ini dibuat: semua orang bisa mempelajari Python tanpa hambatan
biaya.

Di banyak organisasi dan industri, untuk kegiatan riset atau ujicoba ide-ide baru, kebanyakan
orang mempergunakan perangkat lunak analisis data dan data mining komersial seperti SAS
atau SPSS. Setelah ide-ide teruji dengan cukup, biasanya program akan dipindahkan ke
lingkungan produksi untuk dipergunakan langsung di kegiatan operasional organisasi atau
perusahaan. Dahulu, program semacam itu biasanya harus ditulis ulang di bahasa lain seperti
Java atau C++ agar dapat bekerja dengan lebih efisien.
Sekarang, dengan semakin lengkapnya Python untuk bisa dipergunakan baik untuk keperluan
eksperimental, ujicoba maupun untuk langsung diterapkan di lingkungan produksi, semakin
banyak pula orang yang meninggalkan cara membuat program dua kali seperti dahulu kala.
Tim yang bekerja di bagian riset atau analisis bisa mempergunakan bahasa yang sama dengan
pengembang dan programmer. Ini tentunya membuat peningkatan produktivitas karena hasil
kerja bisa segera diterapkan untuk keuntungan organisasi atau perusahaan.
Dasar-dasar Python
Buku ini menganggap pembaca sudah memiliki pengetahuan dasar tentang pemrograman
dengan bahasa apapun, tidak harus dengan Python. Pembaca diharapkan sudah mengerti
konsep-konsep umum seperti variabel, array, loop, dan sebagainya. Dalam bab ini akan
dijelaskan kembali mengenai dasar-dasar Python terutama yang akan berguna untuk
mengikuti contoh-contoh dalam bab-bab selanjutnya dalam buku ini. Perlu diperhatikan
bahwa buku ini tidak mencoba menjadi acuan lengkap Python. Pembaca dapat mengacu ke
referensi lain yang lebih lengkap.
Python adalah interpreted language, artinya source code (kode sumber) program yang Anda
tulis akan dijalankan baris-per-baris oleh Python interpreter. Berbeda dengan bahasa lain
misalnya C/C++ atau Java yang mengharuskan Anda mempergunakan compiler untuk
mengubah source code menjadi executable (program yang bisa dieksekusi). Tentu ada
kelebihan dan kekurangan masing-masing.
Untuk cara-cara memasang Python di komputer Anda, silakan lihat Lampiran 1 buku ini.
Setelah terpasang, Python interpreter bisa dibuka dengan command prompt atau terminal di
komputer Anda dan ketikkan “Python”:
Gambar 11: screenshot Python interpreter
Cara lain menjalankan program Python adalah dengan menulis kode program Anda di dalam
sebuah file text biasa (biasanya disimpan dengan extension “.py”), kemudian eksekusi file
tersebut dengan perintah:

python <nama file.py>
Ada pula Python interpreter yang dibuat oleh IPython Project, yang bertujuan membuat
pekerjaan programmer lebih mudah dibanding bila mempergunakan Python interpreter
standar. IPython mempercepat proses coding dan debugging (mencari kesalahan) program.
Informasi lebih lengkap tentang IPython Project dapat dilihat di situsnya https://ipython.org.
Jupyter Notebook
IPython project juga menyediakan fasilitas yaitu Jupyter Notebook, di sini kita bisa menulis
program Python, menjalankannya seperti kita memakai IPython dan kemudian menyimpan
hasil keluarannya, sekaligus menulis komentar yang diperlukan. Fasilitas ini berbasis web,
jadi kita bisa melakukan semuanya melalui web browser. Source code bisa disimpan di
server, tidak disimpan di disk komputer lagi. Keluaran hasil program pun disajikan di web
browser.
Dengan alasan kemudahan-kemudahan Jupyter Notebook, di dalam bab-bab berikutnya buku
ini kita akan mempergunakan fasilitas ini. Jupyter Notebook dapat diunduh dan dipergunakan
secara cuma-cuma. Cara instalasi Jupyter Notebook dapat dilihat di Lampiran 1.
Program Pertama
Mari kita coba membuat program pertama kita, yang dalam Jupyter Notebook disebut
“Notebook”. Sebagai awal, Anda bisa buka Notebook baru dengan klik menu New-> Python3 (atau Python 2 bila versi ini yang terpasang) seperti gambar di bawah:
Gambar 12: Tampilan Jupyter Notebook
Notebook baru sudah siap, sehingga kita bisa mulai membuat program Python pertama kita
yang mencetak ke layar tulisan “halo dunia!” dengan fungsi print(). Ketik perintah berikut
dan kemudian klik tombol “Run”:
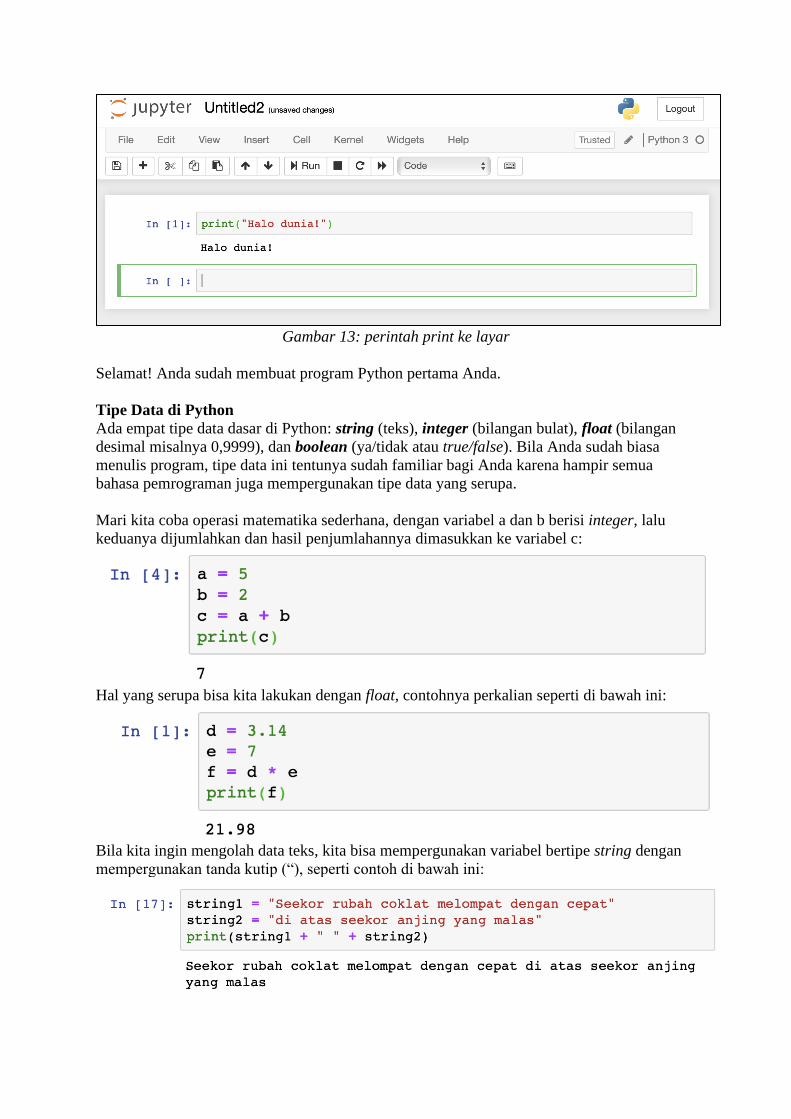
Gambar 13: perintah print ke layar
Selamat! Anda sudah membuat program Python pertama Anda.
Tipe Data di Python
Ada empat tipe data dasar di Python: string (teks), integer (bilangan bulat), float (bilangan
desimal misalnya 0,9999), dan boolean (ya/tidak atau true/false). Bila Anda sudah biasa
menulis program, tipe data ini tentunya sudah familiar bagi Anda karena hampir semua
bahasa pemrograman juga mempergunakan tipe data yang serupa.
Mari kita coba operasi matematika sederhana, dengan variabel a dan b berisi integer, lalu
keduanya dijumlahkan dan hasil penjumlahannya dimasukkan ke variabel c:
Hal yang serupa bisa kita lakukan dengan float, contohnya perkalian seperti di bawah ini:
Bila kita ingin mengolah data teks, kita bisa mempergunakan variabel bertipe string dengan
mempergunakan tanda kutip (“), seperti contoh di bawah ini:

Branching dan Loop
Salah satu kemampuan yang hampir pasti ada di setiap bahasa pemrograman adalah
conditional branching, yaitu ketika eksekusi program harus memilih ke salah satu cabang
berdasarkan syarat suatu nilai boolean bernilai true atau false. Dalam Python, perintah yang
dipergunakan adalah if dan else seperti contoh di bawah ini:
if a > 5: print('Lebih besar dari 5') else: print('Lebih kecil dari atau sama dengan 5')
Contoh di atas mempergunakan operator perbandingan > (lebih besar dari) untuk menguji
apakah variabel a lebih besar dari angka 5. Bila syarat terpenuhi (true) maka blok di
bawahnya dieksekusi, bila tidak (false) maka blok di bawah else yang akan dieksekusi.
Selain operator >, berikut beberapa operator perbandingan yang lain yang umum dipakai:
== sama dengan
!= tidak sama dengan
>= lebih besar dari atau sama dengan
< lebih kecil dari
<= lebih kecil dari atau sama dengan
Perlu diingat bahwa kita harus menambahkan indentasi (spasi) pada blok program di bawah
if (dan else) karena Python tidak mengenal tanda awal dan akhir blok seperti di bahasa lain
seperti Java yang mempergunakan simbol kurung kurawal.
Selain branching, konsep dasar lain adalah loop yang dipakai ketika kita ingin ada suatu blok
program dieksekusi secara berulang-ulang sampai suatu syarat terpenuhi. Python memiliki
dua pilihan untuk loop, yaitu dengan perintah while atau dengan for. Contoh di bawah
akan mengulang eksekusi blok program selama variabel a masih di bawah 5 dengan perintah
while:
a = 1 while a < 5: print(a) a = a + 1 Serupa dengan itu, perintah for kita pergunakan untuk mengulang eksekusi suatu blok
program sebanyak yang kita tentukan. Perbedaannya, for umumnya bisa dipergunakan
untuk mengakses isi dari suatu struktur data yang berisi banyak elemen seperti string, juga
List dan Tuple (keduanya akan dibicarakan di bagian lain di bab ini). Sebagai contoh kita
ingin mengeluarkan seluruh isi suatu variabel string:
for x in "halo": print(x) h
a
l
o

Loop akan berguna dalam Machine Learning dan kita akan mempergunakannya juga di bab-
bab selanjutnya dalam buku ini.
Function
Seperti di hampir semua bahasa pemrograman, Python juga mengenal konsep function
(fungsi), yaitu suatu blok kode program yang menerima input (masukan), memprosesnya dan
kemudian menghasilkan suatu output (keluaran). Function hanya bekerja bilamana dipanggil
dan dapat dipanggil berulang-ulang. Bila Anda punya serangkaian tugas yang akan dipanggil
lebih dari satu kali di dalam program, maka Anda sebaiknya membuat sebuah function dan
menuliskan tugas-tugas itu di dalamnya.
Cara memanggil function adalah dengan memberikan tanda kurung buka dan kurung tutup di
belakang nama function. Di antara kedua tanda kurung kita bisa memasukan satu atau lebih
parameter sebagai masukan bagi function. Contohnya adalah print() yang baru saja kita
pergunakan di atas. Function ini merupakan built-in function, yaitu fungsi yang sudah
tertanam di dalam Python dan bisa selalu dipanggil. Beberapa contoh built-in function
lainnya:
len() Menghitung panjang karakter dari suatu object
hash() Menghasilkan kode hash berupa integer berukuran tetap
round() Membulatkan integer atau float
hex() Mengubah dari integer ke heksadesimal
int() Mengubah dari string atau float ke integer
float() Mengubah dari string atau integer ke float
chr() Mengubah dari kode Unicode ke string
tuple() Menghasilkan sebuah Tuple (lihat bagian lain dari bab ini)
Contoh penggunaan function hex() untuk mengubah integer bernilai 1234 menjadi
heksadesimal :
a = hex(1234) print(a) 0x4d2
Perlu diketahui bahwa sebuah function bisa saja tidak memerlukan parameter apapun, atau
tidak mengeluarkan keluaran apapun. Function seperti ini dipakai untuk mengeksekusi
serangkaian perintah dan kita tidak ingin tahu hasilnya.
Kita dapat juga membuat function kita sendiri, misalnya sebuah function f(x) untuk
menghasilkan keliling sebuah lingkaran. Anda tentu masih ingat rumus keliling lingkaran
yang kita semua sudah pelajari sewaktu di sekolah dasar yaitu 3,14 dikalikan dua kali jari-jari
lingkaran. Sebuah function dideklarasikan (dibuat) dengan mempergunakan kata kunci def,
dan keluarannya dengan kata kunci return.
def f(x): return 3.14 * x * 2 Fungsi ini kemudian kita panggil dengan:
x = 7 y = f(x) print(y)

43.96
Method
Python adalah bahasa yang object-oriented (berorientasi obyek), jadi segala hal yang ada di
Pyton baik berupa integer, float, string dan boolean akan diperlakukan sebagai object. Setiap
object bisa memiliki banyak function sendiri di dalamnya yang disebut method. Kita
memanggil method persis seperti memanggil function, dengan menambahkan nama object
dan tanda titik di depannya:
object.method() Misalnya kita memilki sebuah object bernama penjualan dan di dalamnya adalah method
bernama cetak_laporan() maka kita memanggilnya dengan cara:
penjualan.cetak_laporan() Import
Dalam Python, kita bisa memasukkan (“mengimpor”) modul baru ke dalam program kita
sehingga bisa kita pergunakan sesuai keperluan. Modul bisa berupa modul standar Python,
atau modul yang Anda buat sendiri (atau orang lain). Ini kita lakukan dengan
mempergunakan perintah import, contohnya kita impor modul math yang ada di dalam
Python 3 untuk mengerjakan beragam operasi matematika:
import math as m Kata kunci as di atas dipakai untuk menyebutkan nama alias bagi modul yang baru saja
diimpor. Selanjutnya kita nama alias ini yang kita pergunakan saat memanggil salah satu
function yang ada di dalam modul. Sebagai contoh kita panggil function sqrt() untuk
menghitung akar kuadrat sebuah integer:
y = m.sqrt(49) print(y) 7.0
Dalam bab-bab selanjutnya kita akan banyak mengimpor modul dari library tambahan seperti
Pandas, Scikit-learn, matplotlib dan sebagainya. Kita akan bahas tentang berbagai library ini
di bab-bab selanjutnya.
List dan Tuples
Selain empat tipe data dasar Python yang sudah kita diskusikan di atas, struktur data yang
juga penting untuk dipahami dalam Python adalah Tuple dan List. Tuple adalah tempat untuk
menyimpan lebih dari satu object dalam suatu urutan. Contohnya, kita masukkan enam buah
elemen berupa angka ke dalam sebuah Tuple bernama t:
t = (1,3,5,7,11,13) print(t) (1, 3, 5, 7, 11, 13)

Contoh lain, kita bisa memasukkan string “qwerty” ke dalam sebuah Tuple bernama q, yang
isinya adalah elemen-elemen karakter dari string itu. Ini dilakukan dengan fungsi tuple():
q = tuple(‘qwerty’) print(q) (‘q’, ‘w’, ‘e’, ‘r’, ‘t’, ‘y’)
Setelah diisi dengan nilai, elemen-elemen di dalam Tuple bisa diakses dengan
mempergunakan tanda bracket []. Penomorannya diawali dari angka nol, bukan 1. Bila Anda
sudah biasa mempergunakan bahasa-bahasa lain seperti Java, ini akan terlihat mirip.
Misalnya kita ingin mengambil elemen nomor 4 dari Tuple q di atas, maka kita taruh angka 3
ke dalamnya:
r = q[3] print(r) ‘r’
Yang menarik, kita bisa melakukan beragam macam operasi terhadap sebuah Tuple.
Misalnya bila kita kalikan suatu Tuple dengan suatu angka, maka hasilnya adalah semua
elemen di dalam Tuple akan digandakan sebanyak angka tersebut, dan hasilnya adalah sebuah
Tuple baru hasil gabungan proses penggandaan:
q * 3
(‘q’, ‘w’, ‘e’, ‘r’, ‘t’, ‘y’, ‘q’, ‘w’, ‘e’, ‘r’, ‘t’, ‘y’, ‘q’, ‘w’, ‘e’, ‘r’, ‘t’, ‘y’)
Perlu diingat bahwa tuple bersifat immutable, artinya setelah dibuat dia tidak dapat diubah
lagi. Kita buktikan dengan mencoba mengubah salah satu elemen di dalam Tuple, maka
hasilnya adalah pesan error:
q[3] = ‘a’ TypeError: 'tuple' object does not support item assignment
Untuk melakukan operasi terhadap isi dari setiap elemen di dalam Tuple satu per satu, kita
bisa mempergunakan loop dan fungsi enumerate() seperti contoh berikut:
x = tuple('halo') for a, b in enumerate(x): print('Isi elemen ' + str(a) + ' adalah ' + b)
Isi elemen 0 adalah h
Isi elemen 1 adalah a
Isi elemen 2 adalah l
Isi elemen 3 adalah o
Fungsi enumerate() pada contoh di atas akan memasukkan index (angka urutan dari angka
nol) ke dalam variabel a, dan isi elemen ke dalam variabel b. Seluruh Tuple akan dibaca dari
awal hingga akhir.
List, di lain hal, serupa dengan tuple namun bersifat mutable, yang berarti isinya dapat
diubah-ubah setelah dibuat. Jumlah elemen dalam List pun dapat ditambah atau dikurangi.
Cara membuat List mirip dengan cara membuat Tuple, bedanya kita pergunakan tanda
bracket [] bukan tanda kurung ():

list1 = [1, 3, 5, 7, 11] [1, 3, 5, 7, 11] Bisa juga kita membuat sebuah List dengan fungsi list() seperti contoh:
list2 = list(‘abcdefg’) print(list2) ['a', 'b', 'c', 'd', 'e', 'f', 'g']
Tidak seperti Tuple, kita bisa menambahkan jumlah elemen ke dalam List, dengan perintah
append() untuk menambah elemen ke bagian paling belakang, atau dengan perintah
insert() untuk memasukkan elemen di tengah-tengah List. Contohnya kita akan
menambah sebuah elemen tambahan :
list2.append(‘i’) print(list2) ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'i']
Elemen baru telah ditambahkan ke bagian akhir List. Sekarang kita akan memasukkan
elemen baru di antara ‘g’ dan ‘I’, yaitu posisi ke-8 (ingatlah bahwa penomoran diawali dari
angka nol):
list2.insert(7, ‘h’) print(list2) ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i']
Kebalikannya, bila kita ingin menghapus suatu elemen dari List, perintah pop() bisa
dipergunakan dengan menyertakan nomor urutan yang dikehendaki. Contoh, kita akan
menghapus elemen berisi karakter ‘d’ dari contoh di atas, yaitu elemen nomor 4:
list2.pop(3) print(list2) ['a', 'b', 'c', 'e', 'f', 'g', 'h', 'i']
Cara di atas berlaku bila kita tahu nomor urutan elemen yang hendak kita hapus. Bagaimana
bila kita tidak punya informasi nomor urutan tersebut? Kita bisa mempergunakan perintah
remove() yang akan mencari elemen pertama di dalam List yang berisi nilai tertentu.
Contohnya kita ingin membuang elemen dari List yang berisi nilai ‘f’:
list2.remove(‘f’) print(list2) ['a', 'b', 'c', 'e', 'g', 'h', 'i']
Salah satu pekerjaan yang paling sering dikerjakan dalam bidang analisis data adalah sorting
(mengurutkan) data. Dengan List, hal ini mudah sekali dilakukan, yaitu dengan cara
memanggil perintah sort(). Contoh berikut memasukkan serangkaian elemen berisi angka
tidak berurutan, kemudian mengurutkannya:
list3 = [9, 1, 7, 3, 6, 5, 4, 2, 8] list3.sort() [1, 2, 3, 4, 5, 6, 7, 8, 9]

Bisa juga kita tambahkan parameter reverse=true untuk mengurutkan secara terbalik:
list3.sort(reverse=true) [9, 8, 7, 6, 5, 4, 3, 2, 1]
Untuk tipe data string, mengurutkan elemen-elemen List berdasarkan suatu kunci, misalnya
panjang string di dalam tiap elemen:
list4 = ['abc', 'de', 'f', 'ghi', 'jklmn', 'op'] list4.sort(key=len) ['f', 'de', 'op', 'abc', 'ghi', 'jklmn']
Parameter key=len (dari kata ‘length’) di contoh di atas dipergunakan oleh fungsi sort()
untuk mengurutkan berdasarkan panjang / jumlah huruf elemen. Kita bisa mempergunakan
fungsi-fungsi lain di parameter ini.
Salah satu hal penting yang sering dilakukan terhadap data adalah mengambil subset
(sebagian) dari data. Untuk ini kita pergunakan notasi slicing (pemotongan) yaitu
[start:stop] di samping List. Contoh, kita ingin mengambil sebagian dari elemen
pertama (0) sebanyak empat elemen:
list5 = ['a', 'b', 'c', 'd', 'e', 'f', 'g'] list5[0:4] ['a', 'b', 'c', 'd']
Apabila [start] dikosongkan, yang secara otomatis Python akan menganggap awal adalah
nol, atau artinya operasi dilakukan dari awal List. Dalam contoh di atas, [0:4] bisa cukup
ditulis dengan [:4] saja dan hasilnya akan sama:
list5[:4] ['a', 'b', 'c', 'd']
Serupa dengan itu, bila stop dikosongkan, maka Python akan menganggap operasi dilakukan
hingga akhir List.
list5[2:] ['c', 'd', 'e', 'f', 'g']
Suatu List juga bisa berisi banyak List. Contoh di bawah ini sebuah listList berisi tiga buah
list,List, masing-masing berisi tiga elemen:
list6 = [[1,2,3], [4,5,6], [7, 8, 9]] [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
Untuk mengakses seluruh isi suatu List berisi banyak List seperti di atas, bisa
mempergunakan for-loop seperti contoh di bawah ini:
n = 0 for arr in list6: n = n + 1

print("list", n, "=", arr) list 1 = [1, 2, 3]
list 2 = [4, 5, 6]
list 3 = [7, 8, 9]
Pada dasarnya sebuah List akan berguna saat Anda memerlukan tempat untuk menyimpan
serangkaian nilai yang bisa diubah-ubah saat program bekerja. Adapun demikian perlu
diperhatikan bahwa proses modifikasi terhadap suatu List adalah proses yang berat dan
memakan cukup banyak sumber daya komputer. Bila ada banyak elemen di dalam List,
misalnya ribuan atau puluhan ribu, maka perintah insert() atau remove() bisa menjadi
proses yang tidak efisien karena Python harus menggeser semua elemen untuk memberi
ruang bagi elemen baru yang masuk, atau mengisi posisi elemen yang terhapus.
Melihat penjelasan di atas, List dan Tuple nampak serupa, perbedaannya Tuple bersifat
immutable sementara List bersifat mutable. Lalu, mengapa tidak kita selalu memakai List saja
dan kita lupakan Tuple? Alasannya adalah karena Tuple secara komputasional lebih hemat
memori. Jadi bila Anda ingin membuat urutan data yang tidak akan berubah, pergunakan saja
Tuple.
Dictionary
Struktur data yang lain juga penting untuk kita pelajari adalah Dict, dari kata dictionary.
Mirip seperti List, Dict juga mutable, bedanya adalah Dict dipergunakan untuk menyimpan
pasangan key-value (kunci dan nilai isinya).
Untuk membuat Dict, kita pergunakan tanda kurung kurawal {}:
pelajaran = {"senin": "matematika, bahasa indonesia", "selasa": "fisika, biologi", "rabu": "agama, kimia"} Contoh di atas menunjukkan kita memasukkan tiga kunci yaitu “senin”, “selasa” dan “rabu”,
kemudian memasukkan nama-nama pelajaran sebagai nilai-nilai yang terkait dengan masing-
masing kunci tadi. Untuk melihat isi seluruh Dict, dan hasilnya setiap pasangan kunci-nilai
disimpan dalam sebuah Tuple, kita pergunakan fungsi items():
pelajaran.items() dict_items([('senin', 'matematika, bahasa indonesia'), ('selasa', 'fisi
ka, biologi'), ('rabu', 'agama, kimia')])
Setelah dibuat, kita bisa mengambil isi Dict dengan mempergunakan kunci yang kita
kehendaki, misalnya kita ingin tahu pelajaran apa di hari Rabu:
pelajaran['rabu'] 'agama, kimia'
Bila kunci yang dicari tidak ditemukan, akan ada pesan kesalahan yang muncul. Bila ini
terjadi saat program sedang berjalan, secara sendirinya keseluruhan program akan terhenti.
Tentunya bukan ini yang kita inginkan, jadi kita memerlukan suatu cara yang lebih baik
untuk menangani situasi ketika kunci yang kita cari tidak ditemukan namun program tetap
bisa berjalan normal. Untuk ini kita pakai fungsi get():

pelajaran.get('kamis', 'tidak ada pelajaran') Parameter pertama adalah kunci yang kita cari, dan parameter kedua adalah nilai yang
dikeluarkan apabila kunci tersebut tidak ditemukan. Dengan demikian, program tidak akan
berhenti di luar rencana.
Kunci bisa berupa obyek Python apa saja, namun biasanya yang dipergunakan adalah tipe
data skalar (integer, float, atau string).
Lambda Function
Kita bisa juga membuat function yang tidak memiliki nama, yaitu suatu fungsi pendek yang
isinya hanya satu statement saja. Misalnya fungsi sederhana yang singkat saja dan hanya
dipakai satu kali. Untuk ini Python menyediakan kata kunci Lambda, yang artinya adalah
fungsi anonim, tanpa nama. Contoh fungsi sederhana yang mengkalikan suatu parameter
angka dengan angka 10:
def fungsi_singkat(a): return a * 10
Karena sangat singkat, penulisan fungsi di atas bisa digantikan dengan fungsi tanpa nama,
dengan cara mempergunakan kata kunci lambda seperti berikut:
lambda a: a * 10 Mengapa kita perlu fungsi lambda seperti ini? Jawabannya adalah karena banyak fungsi-
fungsi dalam Python yang menerima fungsi juga sebagai parameternya. Sebagai gambaran,
berikut contoh sebuah fungsi yang menerima fungsi lain sebagai salah satu parameter:
def tampilkan_pelanggan(daftar_pelanggan, fungsi): for nama in daftar_pelanggan: nama_lengkap = fungsi(nama) print(nama_lengkap) Kita lihat bahwa fungsi di atas selain menerima sebuah List daftar_pelanggan, juga
menerima fungsi sebagai parameternya. Fungsi tersebut akan melakukan sesuatu pada
setiap nama di dalam List daftar_pelanggan. Setelah itu hasilnya akan ditampilkan ke
layar.
Sekarang kita akan mencoba membuat sebuah List daftar pelanggan:
daftar_pelanggan = [‘andi’, ‘budi’, ‘cica, ‘dedi’, ‘eksi’] Kemudian kita siapkan sebuah fungsi pendek bernama ubah() yang akan mengganti huruf
depan nama ke huruf kapital dan menambahkan string di depan setiap nama:
def ubah(nama): return ‘Bapak/Ibu ’ + nama.capitalize() Kita lemparkan kedua parameter ini ke fungsi tampilkan_pelanggan(), dan yang seperti
kita harapkan, setiap nama di dalam List akan diubah sesuai fungsi pendek yang kita buat:

tampilkan_pelanggan(daftar_pelanggan, ubah) Bapak/Ibu Andi
Bapak/Ibu Budi
Bapak/Ibu Cica
Bapak/Ibu Dedi
Bapak/Ibu Eksi
Hasil yang sama bisa kita peroleh dengan lebih singkat, kita tiadakan fungsi ubah() dan
menggantinya dengan fungsi lambda:
tampilkan_pelanggan(daftar_pelanggan, lambda a: ‘Bapak/Ibu’ + a.capitalize()) Seperti kita lihat, fungsi lambda bisa dipakai bila kita hendak mengirimkan fungsi pendek
sebagai parameter bagi fungsi lainnya. Banyak fungsi manipulasi data dalam Python yang
bisa memanfaatkan fungsi lambda seperti ini. Kita akan lihat dalam contoh-contoh di bab-bab
selanjutnya.
NumPy
Meskipun Python sudah memiliki kemampuan mengolah data dalam List dan Tuple seperti
dijelaskan di atas, sering dirasakan oleh orang-orang yang banyak bekerja di bidang analisis
data bahwa Python masih kurang cepat untuk melakukan pengolahan data dalam
multidimension array (array yang berdimensi banyak) dibandingkan dengan bila dibuat di
bahasa lain seperti C atau Java.
Kekurangan ini yang mendorong dibuatnya library tambahan yaitu NumPy, kependekan dari
“Numerical Python”, yang memungkinkan pengolahan array dengan lebih efisien dan cepat.
Numpy memiliki struktur array tersendiri yang berbeda dengan standar Python.
Array dalam NumPy sebenarnya mirip dengan List atau Tuple, hanya bedanya setiap elemen
dalam array harus bertipe data sama. Array satu dimensi bisa dianggap sebagai satu baris
variabel yang sama jenisnya, sementara array dua dimensi bisa dilihat seperti tabel dengan
banyak baris dan banyak kolom. Array tiga dimensi, meski tidak terlalu sering dipakai, bisa
dianggap seperti kubus dengan panjang, tinggi dan lebar. Istilah rank dipakai dalam NumPy
untuk menggantikan istilah dimensi.
Sebelum bisa mempergunakan NumPy, Anda perlu unduh library ini dengan cara cukup
mudah. Di command prompt komputer, jalankan perintah:
conda install numpy Setelah instalasi selesai, kita bisa mempergunakan NumPy dengan perintah import. Contoh
untuk membuat array dengan NumPy:
import numpy as np x = np.array( [1, 3, 5, 7, 9, 11, 13, 17, 23, 29] )

Baris pertama memasukkan NumPy dengan diwakili variabel bernama np. Selanjutnya,
variabel x akan diciptakan sebagai array NumPy, dengan berisikan sederatan angka dalam
sebuah List.
print(x) [ 1 3 5 7 9 11 13 17 23 29 ]
Terlihat di atas bahwa variabel x yang merupakan array memiliki ukuran yaitu 10 elemen:
print(x.size) 10
Mengambil elemen dalam array caranya mirip dengan List. Misalnya kita ingin mengambil
elemen ke-4 sampai dengan ke-8:
x[4:8] array([ 9, 11, 13, 17])
Mengubah elemen juga bisa dilakukan dengan cara serupa, misalnya kita hendak mengganti
elemen ke-8 dengan angka nol:
x[7] = 0 print(x) [ 1 3 5 7 9 11 13 0 23 29 ]
Seperti disebutkan sebelumnya, dengan NumPy kita bisa membuat array multidimensi yang
berguna bila Anda perlu melakukan komputasi numeris dengan matriks yang kompleks.
Untuk membuat array 2-dimensi dalam NumPy, contohnya sebagai berikut:
y = np.array([[1, 2, 3], [4, 5, 6]]) print(y)
Untuk melihat wujud array yang baru saja kita buat, perintah shape di bawah ini akan
menunjukkan bahwa ada dua dimensi dengan masing-masing berukuran tiga elemen:
print(y.shape) (2, 3)
Barangkali Anda bertanya, mengapa kita harus memakai NumPy dan apa saja yang bisa
dilakukan dengannya? Salah satu alasannya adalah NumPy lebih efisien dalam pengelolaan
memori komputer dibandingkan List. Perbedaan kecepatan untuk pengolahan data yang besar
bisa sangat signifikan bila dikerjakan dengan NumPy, yang dalam beberapa kasus, bisa
mencapai 10 kali lebih cepat. Bila kita harus mengolah data dalam jumlah sangat banyak,
perbedaan ini akan sangat terasa.
NumPy juga menjadi dasar library lain seperti Scikit-learn. Dalam buku ini akan kita
demonstrasikan kemampuan NumPy yang sering dipergunakan untuk keperluan analisis data
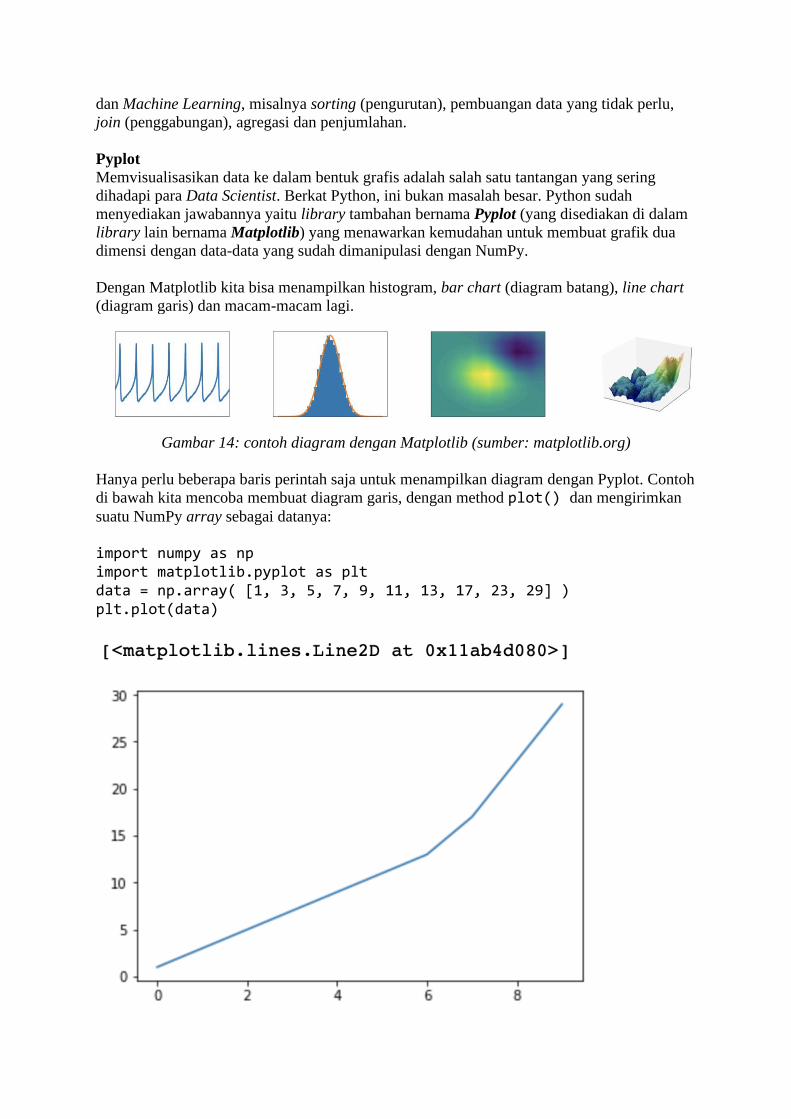
dan Machine Learning, misalnya sorting (pengurutan), pembuangan data yang tidak perlu,
join (penggabungan), agregasi dan penjumlahan.
Pyplot
Memvisualisasikan data ke dalam bentuk grafis adalah salah satu tantangan yang sering
dihadapi para Data Scientist. Berkat Python, ini bukan masalah besar. Python sudah
menyediakan jawabannya yaitu library tambahan bernama Pyplot (yang disediakan di dalam
library lain bernama Matplotlib) yang menawarkan kemudahan untuk membuat grafik dua
dimensi dengan data-data yang sudah dimanipulasi dengan NumPy.
Dengan Matplotlib kita bisa menampilkan histogram, bar chart (diagram batang), line chart
(diagram garis) dan macam-macam lagi.
Gambar 14: contoh diagram dengan Matplotlib (sumber: matplotlib.org)
Hanya perlu beberapa baris perintah saja untuk menampilkan diagram dengan Pyplot. Contoh
di bawah kita mencoba membuat diagram garis, dengan method plot() dan mengirimkan
suatu NumPy array sebagai datanya:
import numpy as np import matplotlib.pyplot as plt data = np.array( [1, 3, 5, 7, 9, 11, 13, 17, 23, 29] ) plt.plot(data)
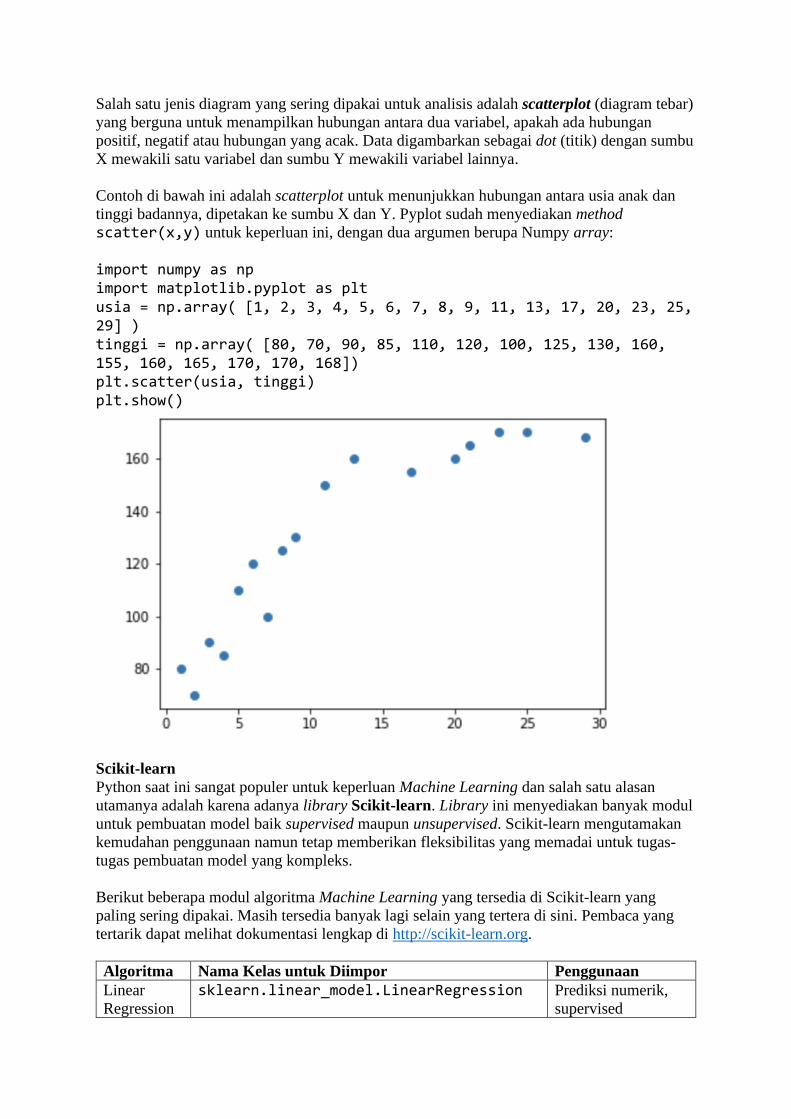
Salah satu jenis diagram yang sering dipakai untuk analisis adalah scatterplot (diagram tebar)
yang berguna untuk menampilkan hubungan antara dua variabel, apakah ada hubungan
positif, negatif atau hubungan yang acak. Data digambarkan sebagai dot (titik) dengan sumbu
X mewakili satu variabel dan sumbu Y mewakili variabel lainnya.
Contoh di bawah ini adalah scatterplot untuk menunjukkan hubungan antara usia anak dan
tinggi badannya, dipetakan ke sumbu X dan Y. Pyplot sudah menyediakan method
scatter(x,y) untuk keperluan ini, dengan dua argumen berupa Numpy array:
import numpy as np import matplotlib.pyplot as plt usia = np.array( [1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 13, 17, 20, 23, 25, 29] ) tinggi = np.array( [80, 70, 90, 85, 110, 120, 100, 125, 130, 160, 155, 160, 165, 170, 170, 168]) plt.scatter(usia, tinggi) plt.show()
Scikit-learn
Python saat ini sangat populer untuk keperluan Machine Learning dan salah satu alasan
utamanya adalah karena adanya library Scikit-learn. Library ini menyediakan banyak modul
untuk pembuatan model baik supervised maupun unsupervised. Scikit-learn mengutamakan
kemudahan penggunaan namun tetap memberikan fleksibilitas yang memadai untuk tugas-
tugas pembuatan model yang kompleks.
Berikut beberapa modul algoritma Machine Learning yang tersedia di Scikit-learn yang
paling sering dipakai. Masih tersedia banyak lagi selain yang tertera di sini. Pembaca yang
tertarik dapat melihat dokumentasi lengkap di http://scikit-learn.org.
Algoritma Nama Kelas untuk Diimpor Penggunaan
Linear
Regression
sklearn.linear_model.LinearRegression Prediksi numerik,
supervised
Logistic
Regression
sklearn.linear_model.LogisticRegression Classification,
supervised
Decision
Trees
sklearn.tree.DecisionTreeClassifier Classification,
supervised
Random
Forest
sklearn.ensemble.RandomForestClassifier Classification,
supervised
Naive
Bayes
sklearn.naive_bayes Classification,
supervised
K-means sklearn.cluster.KMeans Clustering,
unsupervised
Neural
Network
sklearn.neural_network Regression dan
classification,
supervised
SVM sklearn.svm Regression dan
classification,
supervised
Selain itu scikit-learn juga menyediakan banyak fasilitas untuk melakukan manipulasi data,
beberapa di antaranya yang akan kita pergunakan di buku ini yaitu:
sklearn.model_selection Untuk memilih training dan test dataset
sklearn.metrics Untuk melakukan pengukuran terhadap berbagai
kinerja model
sklearn.preprocessing Untuk melakukan berbagai transformasi terhadap data
mentah
sklearn.feature_extraction Untuk mengambil feature dari text dan gambar
SciPy
Tidak berhenti di situ, ada pula satu lagi library yang bisa membantu penerapan komputasi
ilmiah yang melibatkan kalkulasi matematis, misalnya aljabar linier, pemrosesan sinyal dan
statistik. Dalam buku ini kita tidak banyak mempergunakan library ini. Pembaca yang
tertarik dapat membuka dokumentasinya di https://www.scipy.org.
MLXtend
Algoritma Machine Learning sangatlah banyak, dan tidak semua tersedia di dalam satu
library saja. Sebagai contoh di Bab 9 kita akan mempergunakan library MLXtend untuk bisa
membuat model dengan Association Rules, yang kebetulan belum tersedia di Scikit-learn.
Keras
Library Python yang masih cukup baru adalah Keras. Library ini menyediakan beragam
fungsi untuk Neural Network (jaringan saraf) yang berguna untuk keperluan deep learning.
Keras dipergunakan bersama TensorFlow, sebuah kumpulan perangkat lunak yang
dikembangkan oleh Google. Di buku ini kita tidak membahas khusus tentang deep learning,
pembaca yang tertarik dapat membuka dokumentasi Keras di https://keras.io/.

BAB 3 Pandas Proses persiapan data adalah sangat penting karena tanpa dataset yang sesuai, proses
pembuatan model tidak akan bisa dilakukan dengan baik. Secara umum di hampir semua
kasus, proses persiapan data bisa menghabiskan lebih dari separuh waktu dan energi seorang
Data Scientist. Beberapa orang bahkan menyebutkan bahwa tidaklah mengherankan bila
persiapan data bisa memakan 70% tenaga dan waktu mereka.
Dengan alasan ini, sekelompok orang di komunitas pengembang Python di tahun 2008
memulai sebuah proyek open source bernama Pandas (permainan kata dari “Python for Data
Analysis”, jadi tidak ada hubungannya dengan hewan serupa beruang di daratan Cina), yang
tujuannya membuat library Python khusus untuk memudahkan proses persiapan data yang
umum seperti:
1. Membersihkan data, misalnya mendeteksi nilai yang kosong dan menghapus atau
menggantinya dengan nilai lain;
2. Memanipulasi data, misalnya membuang kolom tertentu, membalik urutan kolom,
mencari nilai tertentu di dalam tabel, atau membuat pivot table;
3. Mendapatkan statistik cepat dari data, misalnya nilai rata-rata, median, maksimum
dan minimum dari suatu kolom.
Pandas menyediakan struktur data tingkat tinggi dan fungsi-fungsi yang dibuat untuk
mempermudah manipulasi data dalam tabel, misalnya mengubah bentuk tabel, melakukan
agregasi, mengambil subset data tertentu, dan sebagainya. Ini sangat cocok untuk proses
persiapan data. Pekerjaan Data Scientist menjadi lebih ringan, dan bisa menjadi lebih
produktif memecahkan masalah-masalah Data Science dan Machine Learning dan tidak
terlalu menghabiskan waktu banyak lagi untuk pekerjaan persiapan data.
Karena kemudahan penggunaannya, Pandas sangat populer dan banyak orang menganggap
Pandas sebagai solusi penolong di banyak kerumitan pengolahan data yang sebelumnya sukar
dipecahkan dengan Python standar. Kita akan banyak mempergunakan Pandas di dalam buku
ini.
Apa bedanya Pandas dengan Numpy? Pandas sebenarnya mengambil banyak gaya
pemrograman Numpy yang memanfaatkan array, adapun perbedaan utamanya adalah Numpy
dirancang untuk menyimpan data numerik sementara Pandas lebih dirancang untuk
menyimpan data yang heterogen serupa tabel dalam database. Pandas juga tidak banyak
memakai perintah for - loop untuk mengakses isi array.
Pandas dapat diunduh dengan cuma-cuma, bahkan sudah terpasang secara otomatis ketika
kita memasang Anaconda. Lampiran 1 menunjukkan cara mengunduh dan memasang Pandas.
Bab ini akan memberikan pembaca pengenalan dasar tentang Pandas. Adapun demikian,
pembahasan hanya dibatasi pada kemampuan Pandas yang penting saja, sekedar agar
pembaca dapat mengikuti bab-bab berikutnya buku ini.
Dasar-dasar Pandas
Untuk mempergunakan Pandas, kita harus mengimpor library ini di awal program Python
seperti ini:
import pandas as pd

Selanjutnya pd bisa kita pakai untuk mengakses fungsi-fungsi Pandas di program kita.
Namun sebelum sampai ke sana, kita bahas dahulu konsep-konsep dasarnya.
Pandas mempergunakan konsep penyimpanan data yang disebut Series dan DataFrame. Kita
bisa anggap Series adalah kolom, sementara DataFrame adalah sebuah tabel yang berisi
sekumpulan Series. Keduanya memiliki index yang mengidentifikasi setiap baris isinya,
dimulai dari angka nol. Di contoh di bawah ini, kita punya dua Series yaitu “apel” dan
“jeruk”, yang bila digabungkan akan menjadi sebuah DataFrame, seperti terlihat di gambar
berikut:
apel
0 5
1 2
2 0
3 1
jeruk
0 0
1 3
2 8
3 2
apel jeruk
0 5 0
1 2 3
2 0 8
3 1 2
Gambar 15: contoh Series dan DataFrame
Series pada dasarnya adalah array satu dimensi. Contoh membuat sebuah Series dengan
empat elemen (seperti “apel” di gambar di atas):
apel = pd.Series([5,2,0,1]) Bila kita tidak menyertakan index, Pandas akan otomatis membuatkan index untuk Series
kita, berawal dari angka nol. Perlu diingat bahwa index tidak harus unik, artinya bisa ada nilai
sama di dalam index. Kita juga bisa membuat index sendiri:
jeruk = pd.Series([0,3,8,2], index=[1,2,3,4]) Index tidaklah harus berupa angka numerik. Bisa kita ganti index dengan string:
jeruk.index=['a','b','c','d']) Setelah Series terbentuk, kita bisa mengakses salah satu isi Series yang kita kehendaki
dengan mempergunakan index-nya:
apel[1] 2
jeruk['b'] 3
Sementara itu, DataFrame sebetulnya tidak berbeda jauh dengan array NumPy seperti yang
sudah kita pelajari di bab sebelumnya, yaitu serupa tabel dua dimensi dengan baris dan
kolom. Karena lebih familiar bagi kita yang biasa mengolah data terstruktur, DataFrame
akan lebih sering dipergunakan dalam pekerjaan Machine Learning.
Cara membuat sebuah DataFrame yang paling mudah adalah seperti di bawah ini:
Series DataFrame

df1 = pd.DataFrame([3,2,0,1], columns=['apel'], index=[1,2,3,4])
Perintah di atas akan membuat sebuah DataFrame bernama df1 dengan kolom tunggal
bernama ‘apel’, dengan isi (3,2,0,1) dan index yang telah ditentukan (1,2,3,4).
Bagaimana bila kita hendak membuat DataFrame dengan dua kolom? Kita buat dulu sebuah
Dict (mengenai Dict sudah dibahas di bab sebelumnya) yang kemudian kita jadikan
parameter untuk membuat DataFrame:
dict1 = { 'apel': [5, 2, 0, 1], 'jeruk': [0, 3, 8, 2] } df1 = pd.DataFrame(dict1) Variabel dict1 adalah sebuah Dict berisi dua List yaitu apel dan jeruk, masing-masing
dengan empat isi datanya. Kemudian dict1 dimasukkan sebagai parameter untuk membuat
DataFrame bernama df1. Seperti Series, bila kita tidak menentukan index, maka sebuah
index otomatis akan dibuat dimulai dari angka nol. Bila kita lihat isi df1, akan muncul
seperti ini:
Setelah DataFrame terbentuk, kita bebas melakukan manipulasi terhadapnya. DataFrame
sederhana ini akan kita pakai untuk contoh-contoh selanjutnya di bab ini.
Pertama, kita coba menghitung jumlah data di dalam DataFrame dengan fungsi count(),
dan juga menghitung jumlah keseluruhan semua nilai yang ada di dalam setiap kolom dengan
fungsi sum():
df1.count()

df1.sum()
Pandas menyediakan function describe() yang dapat menampilkan statistik singkat
tentang dataset, seperti jumlah data, angka rata-rata (mean), angka minimal, angka
maksimum, standard deviation dan sebagainya. Ini berguna untuk mendapatkan gambaran
cepat mengenai data yang hendak diproses, terutama untuk DataFrame berukuran besar:
df1.describe()
Mengambil Subset dari DataFrame
Salah satu kekuatan Pandas adalah kemampuannya untuk memanipulasi data, termasuk
mengakses subset (sebagian) dari dataset untuk diproses lebih lanjut. Sebagai contoh kita bisa
membaca satu kolom saja dari DataFrame untuk dimasukkan ke sebuah Series:
apel = df1.apel Hasil yang sama bisa didapat dengan cara seperti ini:
apel = df1['apel'] Bisa juga kita ambil kolom lebih dari satu, dengan urutan yang kita tentukan sendiri:

jeruk_apel = df1['jeruk', 'apel'] Untuk mengambil beberapa baris saja dari DataFrame, kita bisa memakai cara slicing
(potong data) yang sama seperti dengan Numpy. Contoh di bawah ini akan mengambil baris
0 hingga 2:
df1[0:2]
Serupa dengan di atas, contoh di bawah akan mengambil baris ke-2 hingga yang paling akhir:
df1[2:]
Memilih baris-baris tertentu dari suatu DataFrame berdasarkan suatu perbandingan juga
dapat dilakukan. Contoh di bawah akan menentukan baris-baris mana yang memiliki nilai
lebih besar daripada 2 di kolom ‘jeruk’, dengan True bila memenuhi syarat, False bila
tidak:
df1['jeruk']>2
Setelah itu kita bisa menampilkan hanya baris-baris yang memenuhi syarat (True) ke layar:
df1[df1['jeruk']>2]

Ada kalanya kita hanya ingin melihat sekilas isi sebuah DataFrame. Fungsi head() dipakai
untuk membaca beberapa baris pertama saja. Contoh di bawah ini akan menampilkan dua
baris:
df1.head(2)
Untuk melakukan transpose yaitu menukar posisi baris dengan kolom, bisa dilakukan dengan
mudah seperti di bawah ini. Perlu diingat ini hanya untuk keperluan tampilan ke layar saja,
struktur DataFrame yang asli tidak diubah.
df1.T
Mempergunakan Index
Seperti yang sudah dibahas di awal, semua DataFrame memiliki index. Sebenarnya ada dua
index yaitu index baris dan index kolom. Index bermanfaat untuk membantu kita memilih
subset data yang di perlukan dari sebuah DataFrame. Ada dua cara untuk mengakses index,
yaitu operator iloc (dengan integer) dan loc (dengan nama index). Contoh pertama dengan
iloc kita ambil subset data dengan index=3:
df1.iloc[3]
Subset data di atas muncul karena ada hanya ada satu baris dalam DataFrame yang
berindex=3. Contoh berikut menampilkan subset data dengan index=1 dan index=3 yang
menghasilkan dua baris:
df1.iloc[[1,3]]
Slicing juga bisa kita lakukan seperti sebelumnya. Contoh berikut akan mengambil semua
baris dari baris ke-2 dan seterusnya hingga akhir DataFrame (ingat bahwa penomoran
diawali dari angka nol):
df1[1:]

Contoh di bawah akan mengambil semua baris dari awal DataFrame sebanyak 2 baris :
df1[:2]
Kita bisa juga menentukan kolom mana saja yang akan ditampilkan, dengan urutan yang kita
tentukan juga. Contoh di bawah akan menampilkan subset data berindex=3, kolom 1 dan
kolom 0:
df1.iloc[3, [1,0]]
Cara lain adalah dengan mengacu pada index yang bukan integer. Kita buat DataFrame baru
dengan index berupa alfanumerik (a,b,c,d):
dict1 = { 'apel': [5, 2, 0, 1], 'jeruk': [0, 3, 8, 2] } df2 = pd.DataFrame(dict1, index=['a','b','c','d'])

Kemudian isi DataFrame bisa kita akses index dengan operator loc. Contoh di bawah akan
mengambil baris dengan index = ‘c’ (baris ke-3):
df2.loc['c']
Index juga bisa kita pakai untuk menghapus baris-baris atau kolom-kolom yang kita tentukan.
Fungsi drop() seperti contoh di bawah ini yang akan menghapus baris dengan index = ‘b’, dengan asumsi kita menghapus baris (bukan kolom):
df3 = df2.drop('b')
Perlu diperhatikan bahwa kita menampung hasil operasi drop() di atas ke sebuah
DataFrame baru bernama df3. DataFrame aslinya sendiri tidak disentuh, artinya df2 tidak
akan diubah meskipun operasi drop() dieksekusi berkali-kali. Bilamana bukan ini yang kita
inginkan, kita bisa menambahkan opsi inplace=True agar operasi drop() terhadap
DataFrame langsung mengubah isi DataFrame aslinya:
df2.drop('b', inplace=True) Selain itu, dengan index kita bisa juga menghapus seluruh isi sebuah kolom. Caranya sama
dengan menghapus baris, bedanya kita tambahkan opsi axis=1. Angka 1 menunjukkan
kolom, sementara angka 0 menunjukkan baris (namun 0 adalah default value jadi tidak perlu
dituliskan). Contoh di bawah akan menghilangkan kolom ‘jeruk’ dari DataFrame:
df2.drop('jeruk', axis=1, inplace=True)
Membuang Data Duplikat dan Data Kosong

Salah satu permasalahan klasik yang dihadapi dalam proses persiapan data adalah mencari
dan membuang data ganda atau duplikat, yaitu data yang muncul lebih dari sekali.
Tergantung pada permasalahan yang hendak dipecahkan dan algoritma yang dipergunakan,
data duplikat bisa membawa dampak negatif terhadap proses pembuatan model bila
dipergunakan sebagai training dataset. Umumnya, data duplikat harus dibuang.
Pandas menyediakan beberapa kemudahan untuk mencari dan menghilangkan data yang
terduplikasi. Untuk memberikan ilustrasi, contoh di bawah ini memperlihatkan sebuah
DataFrame dengan beberapa nilai yang berulang.
df1 = pd.DataFrame([1, 2, 2, 3, 4, 5, 5, 6, 7], columns=['nilai'])
Fungsi duplicated() yang disediakan Pandas bisa sangat membantu untuk mencari data-
data yang muncul lebih dari sekali di DataFrame. Fungsi akan mengembalikan True bila
data dideteksi sebagai duplikat, False bila tidak. Bila kita coba dengan contoh DataFrame di
atas di mana angka 2 dan 5 muncul dua kali, maka hasil fungsi adalah seperti di bawah ini:
df1.duplicated()
Seperti terlihat, semua baris yang isinya sudah pernah muncul di baris sebelumnya akan
ditandai dengan True. Setelah bisa dideteksi, kita bisa memutuskan apakah data duplikat

perlu dihapus dari DataFrame atau tidak. Untuk menghapus data duplikat, fungsi
drop_duplicates() dapat dipergunakan seperti contoh di bawah ini:
df2 = df1.drop_duplicates(keep='first')
Penting diketahui bahwa fungsi drop_duplicates() tidak mengubah DataFrame aslinya,
sehingga hasil penghapusan duplikat harus disimpan di sebuah DataFrame baru.
Bila kita lihat, opsi keep='first' yang ditambahkan dalam panggilan fungsi
drop_duplicates() seperti contoh di atas dipergunakan untuk memberitahu Pandas
bahwa data duplikat yang harus dihapus adalah semua data duplikat selain yang paling awal
ditemukan di dalam DataFrame. Jadi misalnya ditemukan ada sepuluh baris berisi duplikat,
maka baris pertama akan dibiarkan sedangkan sembilan baris lainnya dibuang. Bila opsi ini
diganti menjadi keep='last', maka sebaliknya Pandas akan menghapus semua baris
duplikat selain baris yang terakhir ditemukan. Ini menarik bila kasus data duplikat yang kita
ingin pecahkan memiliki banyak kolom lain yang mungkin tidak terduplikasi.
Adapun begitu, perlu dipahami bahwa semua kolom yang ada di dalam DataFrame akan
diperiksa apakah ada data terduplikasi atau tidak. Untuk lebih spesifik bahwa kita hanya ingin
membuang duplikat dari satu kolom tertentu (bila DataFrame memiliki banyak kolom), maka
nama kolom harus disebutkan, misalnya:
df1.drop_duplicates(['nilai'], keep='first')
Pandas juga memudahkan kita untuk mencari data yang kosong atau hilang di dalam
DataFrame atau Series. Sebagai contoh kita memiliki sebuah DataFrame dengan enam nilai
numerik, di mana dua di antaranya adalah data kosong. Python memiliki terminologi standar
untuk menyebut data kosong yaitu ‘None’:
df1 = pd.DataFrame([1, 2, None, 4, 5, None], columns=['nilai'])

Terlihat bahwa data yang kosong ditampilkan sebagai NaN (“not a number”). Selanjutnya bila
kita ingin membuang data yang kosong ini, kita bisa mempergunakan fungsi dropna()
seperti contoh di bawah ini. Perhatikan bahwa hasilnya harus dimasukkan ke sebuah
DataFrame baru (dalam hal ini df2) karena DataFrame aslinya tidak akan diubah:
df2 = df1.dropna()
Semua data yang kosong bisa juga diganti dengan suatu angka tertentu. Untuk operasi
semacam ini kita bisa mempergunakan fungsi fillna(). Contoh di bawah akan mengisi
semua data yang kosong dengan angka 999:
df3 = df1.fillna(999)

Membuat Nilai Baru dalam DataFrame
Ada kalanya kita perlu menjalankan fungsi kondisional seperti if-then di dalam
DataFrame, misalnya bila suatu nilai dalam suatu kolom memenuhi syarat tertentu maka
dibuatlah suatu nilai baru. Fungsi loc() bisa dipergunakan untuk keperluan ini. Contoh di
bawah akan menentukan rapor seorang murid bila nilainya lebih rendah dari lima maka yang
bersangkutan tidak lulus:
df1 = pd.DataFrame([1, 2, 3, 4, 5, 6, 7, 8], columns=['nilai']) df1.loc[df1['nilai'] >= 5, 'kelulusan'] = 'Lulus' df1.loc[df1['nilai'] < 5, 'kelulusan'] = 'Gagal'
Membaca File
Pada kenyataan sehari-hari, hal yang pertama biasanya harus Anda lakukan sebelum
mengerjakan tugas-tugas data analisis adalah membaca dan memuat data ke dalam program,
misalnya data yang berasal dari sebuah file text yang kolom-kolomnya dipisahkan dengan
tanda koma (comma-separated values, CSV). Dengan Pandas hal ini mudah sekali. Cukup
satu baris saja dan seluruh isi file CSV akan diimpor ke dalam suatu DataFrame:
df = pd.read_csv('C:\\nama_file.csv') Lokasi fisik file di contoh di atas adalah untuk sistem operasi Microsoft Windows. Untuk
sistem operasi Untuk MacOS atau Linux, lokasi fisik file ditulis seperti di bawah ini:
df = pd.read_csv('/Users/diosk/nama_file.csv') Ketika perintah di atas dieksekusi, file CSV akan dimuat ke dalam memori dan DataFrame
df akan menyimpan isinya. Jumlah kolom di dalam file akan dikenali secara otomatis, sesuai
jumlah tanda koma di dalam tiap baris.

Ada kalanya kita ingin menentukan sendiri jumlah kolom, ini bisa dilakukan dengan
menambahkan parameter usecols seperti contoh di bawah ini yang akan meminta Pandas
untuk memuat lima kolom saja:
df = pd.read_csv('/Users/diosk/nama_file.csv', usecols=range(5))
Baris pertama di dalam file akan secara otomatis dianggap sebagai header dan dijadikan
nama kolom. Bila bukan itu yang dikehendaki, kita bisa meminta Pandas untuk tidak
menganggap baris pertama sebagai kolom, namun sebagai data biasa (Pandas akan
memberikan nama kolom berupa urutan angka mulai dari nol):
df = pd.read_csv('nama_file.csv', header=None) Ada kalanya kita ingin menentukan sendiri nama kolom-kolom dalam DataFrame, kita
pergunakan atribut names seperti di bawah ini:
df = pd.read_csv('nama_file.csv', names=['a', 'b', 'c']) Pandas akan menempelkan index ke DataFrame secara otomatis. Bilamana kita ingin
mempergunakan salah satu kolom di dalam DataFrame sebagai index, kita pergunakan
atribut index_col seperti di bawah ini:
df = pd.read_csv('nama_file.csv', names=['a', 'b', 'c'], index_col='a')
Sering kali kita menemui file yang isinya tidak konsisten, misalnya ada satu baris yang
jumlah kolomnya tidak sama dengan baris-baris lainnya. Pandas secara otomatis akan
berhenti membaca file bila menemui satu saja baris seperti ini. Untuk mencegah hal ini, bisa
ditambahkan dengan parameter error_bad_lines='False' yang akan membuat baris-
baris yang bermasalah dilewati saja:
df = pd.read_csv('nama_file.csv', error_bad_lines='False')
Apabila Anda mengetahui file CSV yang hendak dibuka sangat besar, misalnya dalam orde
ratusan megabyte atau bahkan gigabyte, maka untuk mencegah proses pembacaan file yang
terlalu panjang atau tidak cukup masuk ke memori komputer yang tersedia, kita bisa batasi
berapa banyak baris yang akan dibaca. Dengan menentukan nilai atribut nrows seperti
contoh di bawah, maksimal seribu baris pertama saja yang akan dibaca:
df = pd.read_csv('nama_file.csv', nrows=1000) Selain membaca dari file CSV, Anda juga bisa membaca dari format data yang lain misalnya
Microsoft Excel, JSON, HTML, database SQL bahkan dari web API. Sebagai contoh
membuka file Microsoft Excel:
fileXL = pd.ExcelFile('nama_file.xlsx') df = pd.read_excel(fileXL, 'sheet1') Mungkin Anda bertanya, berapa besar ukuran maksimal file yang dapat dibuka dengan
Pandas? Pada dasarnya ini tergantung kepada besarnya memori komputer yang dipergunakan.

Bila Anda mempergunakan sebuah laptop dengan memori 8 GB, maka secara teoritis ukuran
maksimal file yang bisa dibaca dan dimuat ke dalam DataFrame harus lebih kecil dari itu. Di
banyak kasus, kita harus berhadapan dengan data yang volumenya sangat besar dalam orde
puluhan bahkan ratusan GB, yang melebihi kapasitas komputer biasa. Kita akan
membicarakan tentang solusinya di Bab 12.
Join
Bila pembaca yang terbiasa mempergunakan database dan SQL, maka pasti sudah akrab
dengan konsep table join (penggabungan tabel). Dengan SQL, kita bisa menggabungkan
lebih dari satu tabel mempergunakan suatu key yang sama, dan setiap key tersebut ada di
dalam semua tabel. Cara yang umum adalah dengan join dengan tanda sama dengan (=):
SELECT nama_kolom FROM tabel1 a, tabel2 WHERE a.key = b.key Contoh di atas menggabungkan tabel1 dan tabel2 dengan mempergunakan kolom ‘key’
yang ada di kedua tabel. Hasilnya, isi tabel1 dan tabel2 akan ditampilkan seluruhnya,
dengan syarat isi kolom ‘key’ di kedua tabel dapat saling dipertemukan.
Gambar 16: Operasi join dua tabel
Pandas juga memungkinkan kita melakukan join dua DataFrame, dengan cara yang mirip
dengan SQL. Cara pertama adalah dengan menjumlahkan dua DataFrame dengan
mempergunakan index sebagai acuannya. Mari kita lihat contoh di bawah ini, terdapat dua
buah DataFrame yaitu df1 dan df2 yang dijumlahkan sehingga menghasilkan df3:
df1 = pd.DataFrame([4,2,5,1], columns=['nanas'], index=[1,2,3,4]) df2 = pd.DataFrame([1,3,9,6], columns=['nanas'], index=[2,3,4,5]) df3 = df1 + df2 print(df3)
Terlihat baris-baris di kedua DataFrame dengan index yang beririsan adalah 2, 3 dan 4.
Dengan demikian baris-baris tersebut kemudian dijumlahkan isinya. Adapun baris-baris yang
indexnya tidak ada di kedua DataFrame (yaitu 1 dan 3) akan ditampilkan sebagai ‘NaN’
(“not a number”) karena tidak dapat digabungkan.
tabel1 tabel2 Data dalam irisan : tabel1.key = tabel2.key

Cara lain yang lebih fleksibel untuk menggabungkan dua DataFrame adalah mempergunakan
fungsi merge() yang dapat melakukan join dengan mempergunakan suatu kolom sebagai
kuncinya. Sebagai contoh untuk menjelaskan fungsi ini, kali ini kita buat dua buah
DataFrame yaitu ‘kategori’ dan ‘menu’. Sebagai contoh kita pakai sebuah file CSV sebagai
sumbernya, berisi empat baris kategori makanan dan minuman sebagai berikut:
df_kategori = pd.read_csv('kategori.csv', names=['kategori_id','kategori'], index_col=['kategori_id'])
DataFrame kedua berisi sepuluh baris produk makanan dan minuman, bersama dengan kode
kategorinya sebagai berikut:
df_menu = pd.read_csv('menu.csv', names=['produk','kategori_id'])
Selanjutnya kita lakukan operasi join terhadap dua DataFrame ini, dengan mempergunakan
kolom “kategori_id” sebagai kunci. Ini seperti layaknya kita lakukan join dalam database
SQL. Hasil operasi ini adalah DataFrame baru berupa gabungan dari kedua DataFrame:

df1 = pd.merge(df_menu, df_kategori, on='kategori_id')
Operasi join yang kita lihat di atas termasuk inner join, yaitu hanya baris-baris yang
memiliki kunci yang beririsan saja yang ditampilkan, mirip seperti di inner join di SQL.
Lawannya adalah outer join, yaitu ketika semua baris akan ditampilkan meskipun tidak ada
pasangannya. Dalam contoh di atas kategori ‘kudapan’ juga ditampilkan:
df1 = pd.merge(df_menu, df_kategori, on='kategori_id', how='outer')

Mengurutkan Data
Operasi sorting (pengurutan) adalah salah satu operasi yang sangat sering dilakukan dalam
proses analisis data. Dalam database SQL, perintah yang dipakai adalah SORT BY. Dalam
Pandas, kita pergunakan fungsi sort_values dan sort_index.
Melanjutkan contoh dari sebelumnya, kita mencoba mengurutkan DataFrame df_menu
berdasarkan nama produk, secara alfabetik (dari A ke Z):
df_menu.sort_values(by='produk')

Urutan di atas adalah urutan dari bawah ke atas yaitu dari A ke Z. Bisa juga urutan kita balik
dari Z ke A, dengan opsi ascending=False :
df_menu.sort_values(by='produk', ascending=False)

Index juga bisa dipergunakan sebagai dasar untuk operasi pengurutan. Contoh di bawah akan
mengurutkan DataFrame berdasarkan index yang sudah ditentukan, dari nilai yang terbesar
ke yang terkecil:
df_menu.sort_index(ascending=False) Satu fungsi lain yang juga menarik adalah menentukan ranking isi nilai di dalam data.
Contohnya kita buat sebuah DataFrame dengan enam buah nilai acak, kemudian kita masing-
masing tentukan rankingnya dengan ranking=1 bagi nilai yang tertinggi hingga
ranking=6 bagi nilai terendah:
df1 = pd.DataFrame( [4, 5, 2, 7, 1, 8], columns=['nilai'] ) df1.rank()
Binning
Di bab 1 kita sudah menyinggung mengenai teknik binning, yaitu memecah dataset ke dalam
kelompok-kelompok kecil (“bin”) untuk memudahkan proses analisis. Sebagai gambaran,
misalnya kita memiliki sebuah dataset berupa sejumlah orang yang menjadi sasaran survei.
Kita ingin membagi dataset ini menjadi tiga kelompok usia yaitu remaja, dewasa dan lanjut
usia. Kelompok pertama diperuntukkan bagi orang-orang dengan usia 15-20 tahun, kelompok
kedua 21-55 tahun, dan kelompok terakhir berusia di atas 55 tahun.
Gambar 17: contoh dataset yang dipecah dengan binning
Ini bisa kita lakukan dengan mudah di Pandas. Fungsi cut() akan membagi dataset ke dalam
bin yang sesuai. Pertama kita definisikan terlebih dahulu kelompok usia yang kita kehendaki
dalam sebuah array, disertai dengan label nama kelompoknya:
kelompok_usia = [15, 20, 55, 100] kelompok_usia_label = ['remaja', 'dewasa', 'lanjut usia']
Sasaran Survei
Lansia (bin 3) Dewasa (bin 2) Remaja (bin 1)

Selanjutnya kita buat array berupa usia 25 orang responden survei, yang kemudian
dimasukkan sebagai parameter untuk fungsi cut():
responden = [17,18,19,21,68,16,72,23,55,27,28,30,32,33,34,47,38,40,42,48,50,55,61,66,76] binning = pd.cut(responden, kelompok_usia, labels=kelompok_usia_label) print(binning)
Semua responden sudah dimasukkan ke dalam tiga kelompok berdasarkan usianya. Kita bisa
pergunakan fungsi value_counts() untuk menghitung isi masing-masing kelompok usia:
pd.value_counts(binning)
Bila kita perhatikan, semua operasi di atas mempergunakan array. Agar bisa melihat hasil
binning dengan lebih mudah, kita buat sebuah DataFrame yang berisikan seluruh responden
beserta kode kelompok usianya masing-masing dengan membaca atribut codes (kelompok
pertama dikodekan dengan angka nol, kelompok kedua dengan angka 1, dan seterusnya):
codes = binning.codes dict1 = { 'usia': usia, 'kelompok': codes } df1 = pd.DataFrame(dict1, columns=['usia','kelompok']) df1.head(5)

Penggunaan lain fungsi cut() adalah ketika kita ingin melakukan binning terhadap suatu
DataFrame, maka kita bisa menambahkan satu kolom baru yang berisikan label kategorinya
(‘kelompok’ dalam contoh di bawah):
kelompok_usia = [15, 20, 55, 100] kelompok_usia_label = ['remaja', 'dewasa', 'lanjut usia'] binning = pd.cut(df1['usia'], kelompok_usia, labels=kelompok_usia_label) df1['kelompok'] = binning
Membuat Agregat
Salah satu alasan mengapa SQL dipergunakan secara luas untuk manipulasi database adalah
kemampuannya untuk menggabungkan dan membuat agregasi data dengan mudah. Operasi
group by yang biasa dilakukan di SQL juga bisa dilakukan di Pandas.
Sebagai contoh kita memiliki dataset sederhana berupa daftar penerbangan berisi tanggal,
nomor penerbangan, kota asal, kota tujuan, jumlah penumpang dan durasi penerbangan dalam
menit (contoh data ini dapat diunduh berupa file CSV dari lokasi yang disebutkan di
Lampiran 2 buku ini):
df1 = pd.read_csv('penerbangan.csv', names=['tanggal', 'flight', 'asal', 'tujuan', 'penumpang', 'durasi']) df1.head(5)
Misalnya kita ingin melihat berapa jumlah total penumpang yang terangkut setiap hari, maka
kita akan melakukan agregasi terhadap kolom ‘tanggal’ dan menjumlahkan kolom
‘penumpang’ dan ‘durasi’. Bila Anda sudah familiar dengan SQL, maka hal ini mudah saja
dilakukan dengan SQL sebagai berikut:
SELECT tanggal, SUM(penumpang), SUM{durasi) FROM penerbangan GROUP BY tanggal Di Pandas, kita bisa mendapatkan hasil yang sama dengan cara memanggil fungsi
groupby() seperti ini:
perhari = df1.groupby('tanggal')
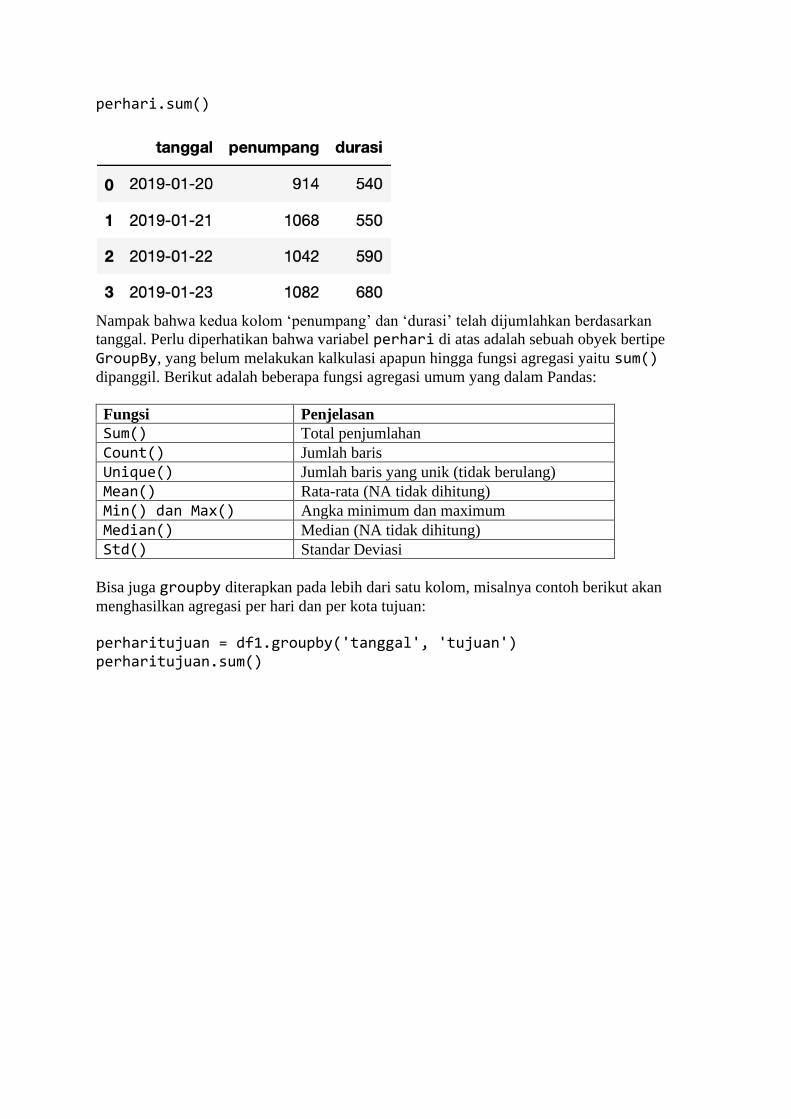
perhari.sum()
Nampak bahwa kedua kolom ‘penumpang’ dan ‘durasi’ telah dijumlahkan berdasarkan
tanggal. Perlu diperhatikan bahwa variabel perhari di atas adalah sebuah obyek bertipe
GroupBy, yang belum melakukan kalkulasi apapun hingga fungsi agregasi yaitu sum()
dipanggil. Berikut adalah beberapa fungsi agregasi umum yang dalam Pandas:
Fungsi Penjelasan
Sum() Total penjumlahan
Count() Jumlah baris
Unique() Jumlah baris yang unik (tidak berulang)
Mean() Rata-rata (NA tidak dihitung)
Min() dan Max() Angka minimum dan maximum
Median() Median (NA tidak dihitung)
Std() Standar Deviasi
Bisa juga groupby diterapkan pada lebih dari satu kolom, misalnya contoh berikut akan
menghasilkan agregasi per hari dan per kota tujuan:
perharitujuan = df1.groupby('tanggal', 'tujuan') perharitujuan.sum()

Perlu kita pahami bahwa proses agregasi seperti di atas bisa memakan banyak sumber daya
komputer terutama untuk dataset berukuran besar. Bila kita tidak menginginkan semua kolom
numerik untuk dihitung dalam proses agregasi, maka kita harus menentukan nama kolom
yang dijadikan kunci. Contoh di bawah adalah bila kita hanya ingin melihat berapa jumlah
total penumpang berdasarkan kota asal (keluarannya bukan berupa DataFrame, namun
berupa Series):
perkota = df1['penumpang'].groupby(df1['asal']) perkota.sum()
Pivot Table
Dataset daftar penerbangan di atas adalah satu contoh data yang disusun dengan format yang
disebut stacked format (bertumpuk). Disebut demikian karena setiap observasi (dalam hal ini
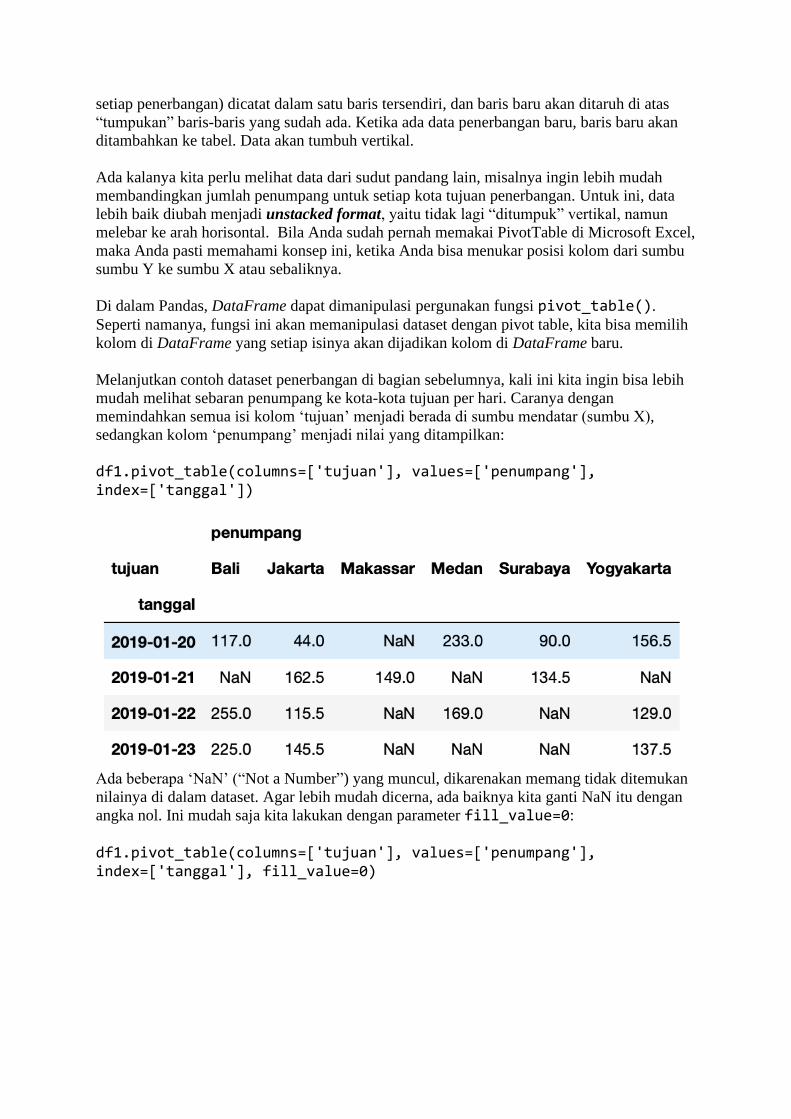
setiap penerbangan) dicatat dalam satu baris tersendiri, dan baris baru akan ditaruh di atas
“tumpukan” baris-baris yang sudah ada. Ketika ada data penerbangan baru, baris baru akan
ditambahkan ke tabel. Data akan tumbuh vertikal.
Ada kalanya kita perlu melihat data dari sudut pandang lain, misalnya ingin lebih mudah
membandingkan jumlah penumpang untuk setiap kota tujuan penerbangan. Untuk ini, data
lebih baik diubah menjadi unstacked format, yaitu tidak lagi “ditumpuk” vertikal, namun
melebar ke arah horisontal. Bila Anda sudah pernah memakai PivotTable di Microsoft Excel,
maka Anda pasti memahami konsep ini, ketika Anda bisa menukar posisi kolom dari sumbu
sumbu Y ke sumbu X atau sebaliknya.
Di dalam Pandas, DataFrame dapat dimanipulasi pergunakan fungsi pivot_table().
Seperti namanya, fungsi ini akan memanipulasi dataset dengan pivot table, kita bisa memilih
kolom di DataFrame yang setiap isinya akan dijadikan kolom di DataFrame baru.
Melanjutkan contoh dataset penerbangan di bagian sebelumnya, kali ini kita ingin bisa lebih
mudah melihat sebaran penumpang ke kota-kota tujuan per hari. Caranya dengan
memindahkan semua isi kolom ‘tujuan’ menjadi berada di sumbu mendatar (sumbu X),
sedangkan kolom ‘penumpang’ menjadi nilai yang ditampilkan:
df1.pivot_table(columns=['tujuan'], values=['penumpang'], index=['tanggal'])
Ada beberapa ‘NaN’ (“Not a Number”) yang muncul, dikarenakan memang tidak ditemukan
nilainya di dalam dataset. Agar lebih mudah dicerna, ada baiknya kita ganti NaN itu dengan
angka nol. Ini mudah saja kita lakukan dengan parameter fill_value=0:
df1.pivot_table(columns=['tujuan'], values=['penumpang'], index=['tanggal'], fill_value=0)

Fungsi agregasi yang dipakai di atas adalah nilai rata-rata (mean). Kita bisa ganti itu dengan
fungsi agregasi lainnya, misalnya menghitung nilai penjumlahan total (sum). Ini ditentukan
oleh parameter aggfunc, seperti contoh berikut:
df1.pivot_table(columns=['tujuan'], values=['penumpang'], index=['tanggal'], fill_value=0, aggfunc='sum')
Mengakses Database
Dalam banyak penggunaan di lingkungan organisasi besar atau di industri, data hampir selalu
tersimpan di dalam suatu database relasional berbasis SQL, misalnya Oracle, Microsoft SQL
Server, MySQL dan sejenisnya.
SQLAlchemy adalah sebuah modul pembantu yang tersedia untuk Python, tujuannya
menyediakan kemudahan akses ke beragam macam database SQL. Untuk mendapatkan
SQLAlchemy, kita perlu mengunduhnya mempergunakan Anaconda. Kita lakukan dengan
membuka console di komputer kita lalu memerintahkan conda install seperti berikut ini:
conda install -c anaconda sqlalchemy Setelah SQLAlchemy terpasang, dan selanjutnya kita impor modul ini ke dalam program
Python kita, dan kita buka koneksi ke SQL database dengan menyediakan informasi tipe

database, alamat IP server database beserta username dan passwordnya. Contoh di bawah ini
akan mengakses data yang ada di dalam sebuah database MySQL:
import pandas as pd from sqlalchemy import create_engine from sqlalchemy.engine.url import URL engine = create_engine(URL( drivername="mysql", username="user", password="password", host="192.168.0.1", database="database1" )) conn = engine.connect() query = 'SELECT * FROM tabel1' df1 = pd.read_sql(sql=query, con=conn, chunksize=10000) Hasil dari program di atas adalah DataFrame df1 yang berisi data dari SQL query ditentukan
di variabel query. DataFrame ini selanjutnya bisa kita pergunakan seperti biasa dalam
proses selanjutnya.
Kesimpulan
Bab ini hanya membahas fungsi-fungsi Pandas yang penting yang diperlukan untuk
melanjutkan pembahasan di buku ini. Masih sangat banyak kemampuan Pandas yang belum
dibahas. Pembaca dapat mengeksplorasi sendiri dengan membaca dokumentasi Pandas yang
tersedia online. Dokumentasi lengkap Pandas dapat diperoleh di https://pandas.pydata.org

BAB 4 Membuat Ramalan dengan Linear Regression Judul bab ini mungkin dapat memberi salah pengertian, seolah-olah kita sedang membuat
mesin untuk meramal masa depan – Machine Learning bukan dibuat untuk menjadi peramal.
Istilah yang tepat adalah membuat prediksi atau dalam bahasa Inggris, forecast.
Kalau kita perhatikan, banyak hal di dunia ini yang sebenarnya saling terkait dan dapat
dijelaskan secara matematis. Contoh yang paling sederhana, kita bisa membuat prediksi
berapa kilometer sebuah mobil bisa berjalan bila kita isi sejumlah bahan bakar. Bila kita isi
bensin 20 liter, maka kita bisa memperkirakan mobil akan membawa kita menempuh jarak
100 kilometer, tentunya mempertimbangkan faktor yang mempengaruhi seperti kecepatan
rata-rata, putaran mesin, beban yang diangkut, usia mobil, dan sebagainya.
Contoh lain, kita bisa membuat prediksi berapa banyak pengeluaran bulanan seorang kepala
keluarga bila kita tahu berapa penghasilannya. Kita juga bisa tahu berapa kira-kira nilai ujian
akhir seorang mahasiswa bila kita tahu berapa jam yang ia telah habiskan untuk belajar dan
mengerjakan latihan soal. Kita bisa memperkirakan berapa kenaikan PDB (Produk Domestik
Bruto) sebuah negara tahun depan bila angka kemiskinan diturunkan sekian persen dan
pertumbuhan investasi ditingkatkan sekian juta dolar. Masih banyak lagi contoh hubungan
matematis antara satu variabel dengan variabel lain yang bisa kita dapatkan dari kehidupan
sehari-hari.
Bila kita lihat contoh di atas, jumlah bensin adalah suatu angka numerik yang bisa kita pakai
sebagai landasan membuat prediksi (maka disebut juga sebagai predictor). Secara ilmiah,
predictor adalah variabel yang tidak bergantung pada variabel lain, sehingga disebut
independent variable.
Sementara itu, semakin banyak bensin, semakin jauh angka kilometer yang dapat ditempuh
oleh mobil. Karena bergantung kepada variabel lain, maka angka ini disebut dependent
variable. Dependent variable inilah angka yang ingin kita prediksi, atau disebut juga target.
Perlu diingat bahwa dependent variable jumlahnya hanya satu, namun independent variable
jumlahnya bisa lebih dari satu. Dalam ilmu statistik, teknik untuk mencari perkiraan
hubungan antara variabel-variabel numerik ini disebut metode regression analysis. Ada
banyak algoritma yang sudah diciptakan di bawah naungan regression analysis, namun di
buku ini kita akan ambil yang paling sederhana untuk kita coba dengan Python.
Memprediksi Nilai Numerik
Apabila kita ingat kembali pelajaran matematika di sekolah, kita tahu cara menghitung suatu
persamaan garis lurus y = mx + c, di mana y dan x adalah koordinat titik pada bidang
kartesius, m adalah gradien yang menentukan kemiringan garis (dalam bahasa Inggris:
slope), dan c adalah konstanta intercept, yang menentukan di mana y ketika x = 0.
Gambar 18: persamaan garis lurus
(0,0) x
y m
intercept

Metode linear regression mempergunakan prinsip yang serupa. Kita membuat model yang
bisa menghasilkan perkiraan nilai y (sebagai dependent variable) dari nilai x (sebagai
independent variable) dengan menarik garis lurus imajiner dengan nilai slope dan nilai
intercept tertentu.
Algoritma Machine Learning akan mencari nilai slope dan intercept sedemikian rupa hingga
garis lurus imajiner yang terbentuk dapat sedekat mungkin mendefinisikan hubungan antara x
dan y. Ini didapatkan dari proses training (pelatihan) model seperti yang sudah kita bahas di
Bab 1. Hasilnya, kita akan memiliki model yang bisa kita pakai untuk membuat perkiraan
suatu angka numerik yang tidak kita ketahui berdasarkan data-data numerik lainnya yang
sudah diketahui.
Metode ini umumnya dipakai untuk melakukan prediksi sesuatu yang mungkin terjadi di
masa depan berdasarkan suatu dataset dari sejarah masa lalu. Contoh penerapan misalnya
untuk bidang keuangan, bidang ekonomi, ramalan cuaca, perancangan mesin, riset pemasaran
bisnis dan contoh yang lebih menarik misalnya untuk memprediksi hasil pemilihan umum.
Mempersiapkan Data
Tanpa terlalu banyak melihat ke dalam teori matematikanya, kita langsung saja
mempraktekkan scikit-learn untuk melakukan linear regression sederhana. Agar bisa
mempergunakan contoh dalam kehidupan sehari-hari, kita akan melanjutkan contoh kasus di
atas yaitu memprediksi jumlah bensin yang dikonsumsi sebuah mobil untuk menempuh suatu
perjalanan. Sebagai sumber data, kita pakai data sejarah pengisian bensin dan jarak yang
ditempuh untuk beberapa puluh kali pengisian. File contoh data ini berupa file CSV (comma-
separated values) dan bisa diunduh dari alamat yang ditunjukkan di Lampiran 2 buku ini.
Setelah file diunduh ke dalam komputer, kita buka file CSV tersebut dengan Pandas:
import pandas as pd df1 = pd.read_csv('C:\Bensin.csv') df1

Kita lihat dari data di atas bahwa ada dua informasi penting; jumlah liter bensin yang diisikan
ke dalam tangki mobil, dan jumlah kilometer yang berhasil ditempuh. Berbekal data hasil
pengukuran di masa lalu ini, kita ingin membuat model yang bisa memprediksi apabila kita
mengisi lagi tangki bensin hari ini dengan jumlah tertentu, berapa kilometer yang akan bisa
ditempuh sebelum kita harus mengisi bensin lagi. Secara nalar umum, semakin banyak
bensin, semakin jauh jarak yang bisa ditempuh, artinya ada hubungan linier antara kedua
variabel.
Dengan linear regression, pada prinsipnya kita dapat membuat perkiraan untuk masa depan
berdasarkan data yang dikumpulkan di masa lalu sebagai training dataset. Jumlah bensin
berperan sebagai independent variable alias predictor karena angka ini lah yang diketahui
terlebih dahulu ketika bensin diisikan ke dalam tangki. Sementara seberapa jauh mobil dapat
berjalan barulah bisa diketahui kemudian setelah semua bahan bakar dikonsumsi, sehingga
peranannya adalah sebagai dependent variable (atau target). Karena hanya ada satu
independent variable, maka yang kita akan coba kerjakan di sini disebut sebagai simple
linear regression (kita akan membahas juga tentang multiple regression setelahnya).
Sebelum melangkah lebih lanjut, kita harus mengenal terlebih dahulu tentang statistik penting
dari data yang ada di file kita, misalnya angka minimum, maksimum dan rata-rata (mean). Ini
bisa dilakukan dengan fungsi describe():
df1.describe()

Nampak di angka count (hitung jumlah baris) bahwa kita memiliki 65 baris data di dalam file
ini. Kita sudah pelajari di Bab 1 bahwa untuk menguji suatu model kita perlu membagi data
yang tersedia ini menjadi training dataset dan test dataset. Aturan sederhana yang biasa
dipakai adalah kita ambil 80% data yang ada untuk training dataset, dan sisanya 20% untuk
test dataset. Aturan ini tidaklah baku, bisa saja Anda memilih 70%-30% atau berapapun,
dengan syarat data harus diambil secara acak.
Satu hal penting yang harus diingat adalah training dataset harus memiliki predictor yang
nilai minimum dan maksimumnya mencakup seluruh jangkauan target variable yang nanti
akan diprediksi. Model tidak akan bisa memprediksi target variable dengan akurat apabila
belum pernah dilatih dengan training data yang sesuai, misalnya bila kita ingin memprediksi
100 liter bahan bakar, sementara training data kita hanya memiliki predictor dengan nilai
maksimal 45 liter.
Memisahkan Training Data dan Test Data
Untuk memisahkan data, scikit-learn sudah menyiapkan fungsi train_test_split()
untuk memisahkan training dataset dengan test dataset secara acak. Ini kita lakukan dengan
mengimpor modul model_selection dari scikit-learn. Mari kita coba langsung, dengan
kode yang ditambahkan ditandai dengan huruf tebal di bawah ini:
import pandas as pd import numpy as np import sklearn.model_selection as ms df1 = pd.read_csv('C:\Bensin.csv') liter = df1[['Liter']] kilometer = df1[['Kilometer']] X_train, X_test, y_train, y_test = ms.train_test_split(liter, kilometer, test_size=0.2, random_state=0) print(X_train.size, X_test.size)
45 20
Dalam program di atas, kita import scikit-learn ke dalam program Python dan kemudian
disimpan dalam suatu variabel yaitu ms. Dari sini kita panggil fungsi train_test_split

untuk memisahkan training dataset dan test dataset. Untuk itu kita sebelumnya perlu
membuat dua NumPy array untuk mengambil isi kolom Liter dan isi kolom kilometer dari
DataFrame df1. Kedua NumPy array ini kita kemudian masukkan ke dalam fungsi
train_test_split() yang akan menghasilkan empat buah NumPy array: dua untuk
training dataset, dua lagi untuk test dataset. Kita pakai parameter test_size = 0.2 yang
artinya 20% dari seluruh isi DataFrame df1 akan dijadikan test dataset.
Ada semacam persetujuan di bidang Data Science untuk mempergunakan huruf X (huruf
besar) untuk mewakili feature, dan huruf y (huruf kecil) untuk mewakili target. Jadi features
di training dataset diwakili oleh X_train, sementara features di test dataset diwakili
X_test. Demikian juga y_train dan y_test mewakili target untuk training dataset dan
test dataset.
Setelah kita pisahkan, nampak bahwa NumPy array X_train (dan pasangannya y_train)
berisikan 45 baris data atau 80% dari total data yang ada, dan sekarang ini yang kita anggap
sebagai training dataset. Sisanya 20 baris berada di NumPy array X_test (dan pasangannya
y_test), yang sementara tidak kita sentuh dahulu sampai proses pengujian model.
Visualisasi
Agar mudah kita lihat sebaran training data, scatterplot biasanya menjadi pilihan untuk
visualisasi data. Seperti yang sudah kita pelajari di Bab 3, kita akan mempergunakan
matplotlib untuk membuat scatterplot terhadap training dataset. Fungsi scatter()
memerlukan data berbentuk Pandas Series atau NumPy array untuk sumbu X dan sumbu Y.
Kita sudah punya training data dalam X_train dan y_train, jadi kita bisa langsung
mempergunakannya tanpa perlu perubahan apapun.
Kode kita ubah lagi (ditandai dengan huruf tebal). Agar scatterplot lebih lengkap, kita
berikan label nama sumbu X dan sumbu Y, begitu pula judul (title) yang dipampangkan di
atas grafik.
import pandas as pd import numpy as np import sklearn.model_selection as ms import matplotlib.pyplot as plt df1 = pd.read_csv('C:\Bensin.csv') liter=df1[['Liter']] kilometer=df1[['Kilometer']] X_train, X_test, y_train, y_test = ms.train_test_split(liter, kilometer, test_size=0.2, random_state=0) plt.scatter(X_train, y_train, edgecolors='r') plt.xlabel('Liter') plt.ylabel('Kilometer') plt.title('Konsumsi Bahan Bakar') plt.show()
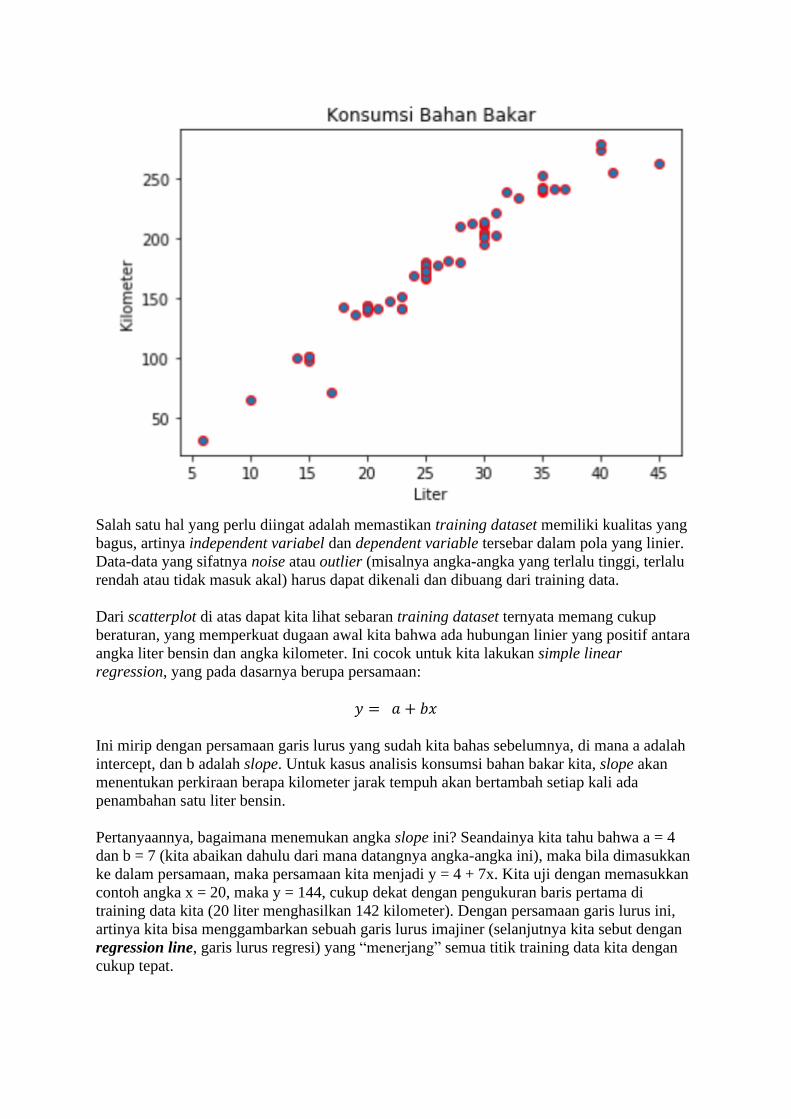
Salah satu hal yang perlu diingat adalah memastikan training dataset memiliki kualitas yang
bagus, artinya independent variabel dan dependent variable tersebar dalam pola yang linier.
Data-data yang sifatnya noise atau outlier (misalnya angka-angka yang terlalu tinggi, terlalu
rendah atau tidak masuk akal) harus dapat dikenali dan dibuang dari training data.
Dari scatterplot di atas dapat kita lihat sebaran training dataset ternyata memang cukup
beraturan, yang memperkuat dugaan awal kita bahwa ada hubungan linier yang positif antara
angka liter bensin dan angka kilometer. Ini cocok untuk kita lakukan simple linear
regression, yang pada dasarnya berupa persamaan:
𝑦 = 𝑎 + 𝑏𝑥
Ini mirip dengan persamaan garis lurus yang sudah kita bahas sebelumnya, di mana a adalah
intercept, dan b adalah slope. Untuk kasus analisis konsumsi bahan bakar kita, slope akan
menentukan perkiraan berapa kilometer jarak tempuh akan bertambah setiap kali ada
penambahan satu liter bensin.
Pertanyaannya, bagaimana menemukan angka slope ini? Seandainya kita tahu bahwa a = 4
dan b = 7 (kita abaikan dahulu dari mana datangnya angka-angka ini), maka bila dimasukkan
ke dalam persamaan, maka persamaan kita menjadi y = 4 + 7x. Kita uji dengan memasukkan
contoh angka x = 20, maka y = 144, cukup dekat dengan pengukuran baris pertama di
training data kita (20 liter menghasilkan 142 kilometer). Dengan persamaan garis lurus ini,
artinya kita bisa menggambarkan sebuah garis lurus imajiner (selanjutnya kita sebut dengan
regression line, garis lurus regresi) yang “menerjang” semua titik training data kita dengan
cukup tepat.
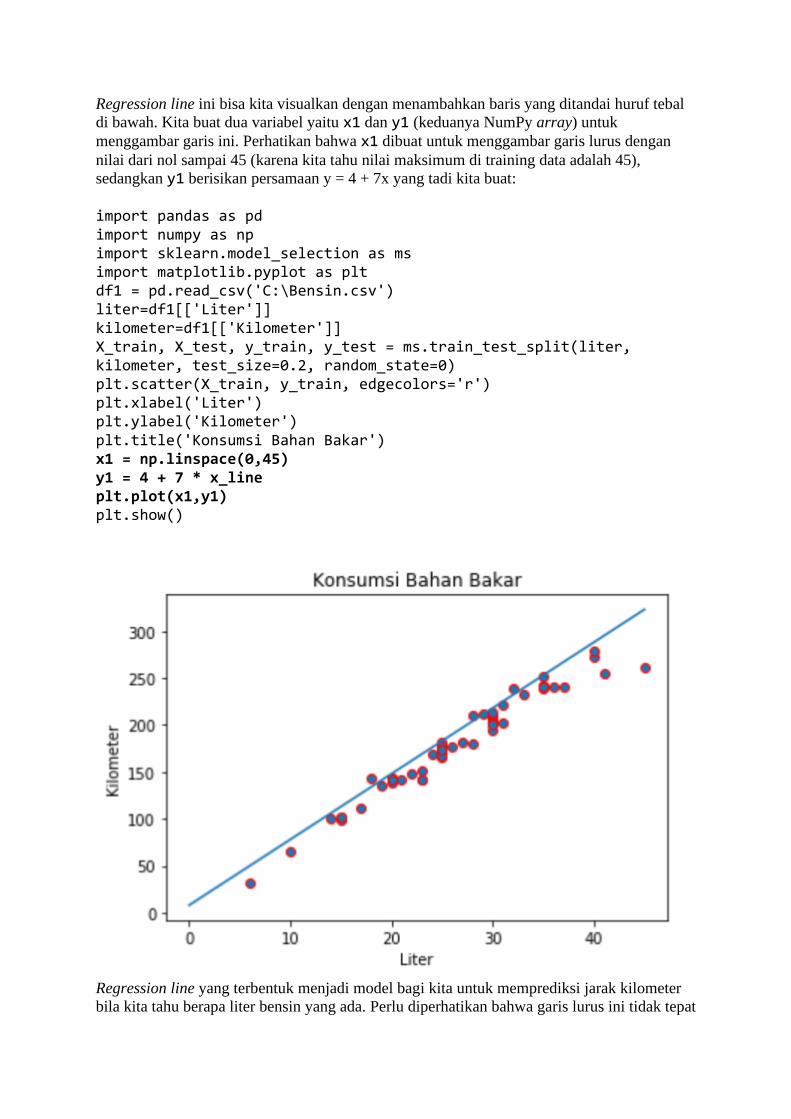
Regression line ini bisa kita visualkan dengan menambahkan baris yang ditandai huruf tebal
di bawah. Kita buat dua variabel yaitu x1 dan y1 (keduanya NumPy array) untuk
menggambar garis ini. Perhatikan bahwa x1 dibuat untuk menggambar garis lurus dengan
nilai dari nol sampai 45 (karena kita tahu nilai maksimum di training data adalah 45),
sedangkan y1 berisikan persamaan y = 4 + 7x yang tadi kita buat:
import pandas as pd import numpy as np import sklearn.model_selection as ms import matplotlib.pyplot as plt df1 = pd.read_csv('C:\Bensin.csv') liter=df1[['Liter']] kilometer=df1[['Kilometer']] X_train, X_test, y_train, y_test = ms.train_test_split(liter, kilometer, test_size=0.2, random_state=0) plt.scatter(X_train, y_train, edgecolors='r') plt.xlabel('Liter') plt.ylabel('Kilometer') plt.title('Konsumsi Bahan Bakar') x1 = np.linspace(0,45) y1 = 4 + 7 * x_line plt.plot(x1,y1) plt.show()
Regression line yang terbentuk menjadi model bagi kita untuk memprediksi jarak kilometer
bila kita tahu berapa liter bensin yang ada. Perlu diperhatikan bahwa garis lurus ini tidak tepat
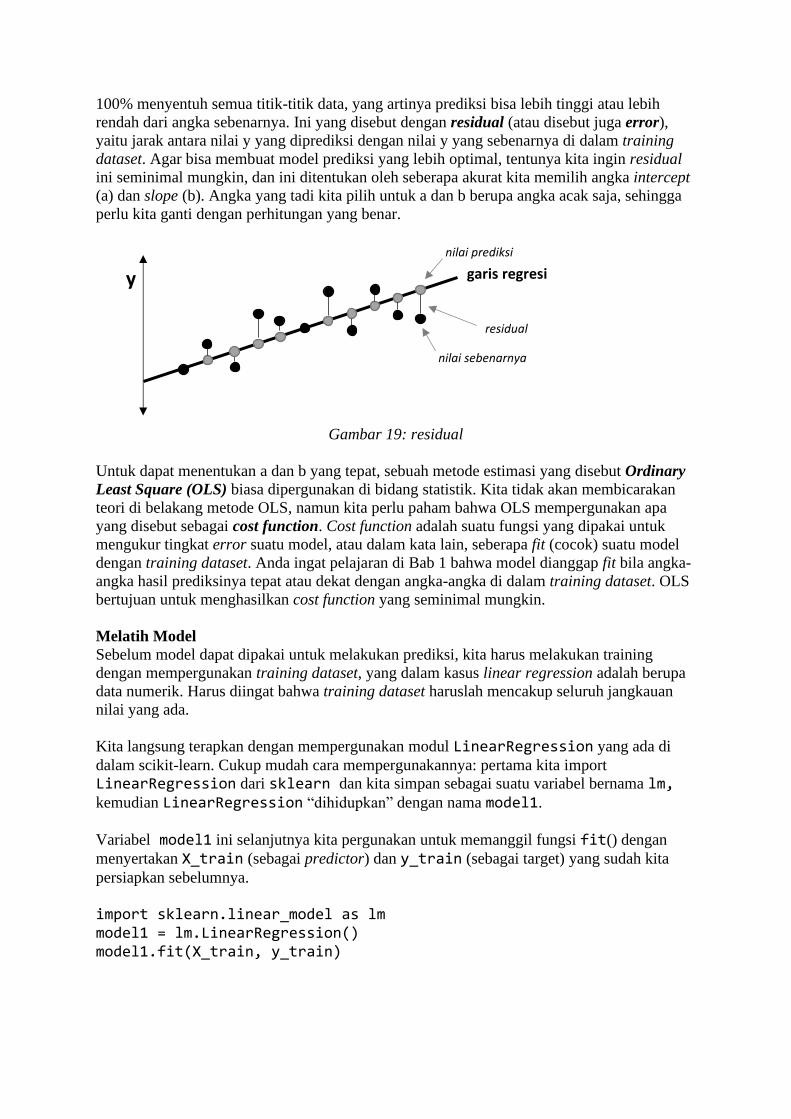
100% menyentuh semua titik-titik data, yang artinya prediksi bisa lebih tinggi atau lebih
rendah dari angka sebenarnya. Ini yang disebut dengan residual (atau disebut juga error),
yaitu jarak antara nilai y yang diprediksi dengan nilai y yang sebenarnya di dalam training
dataset. Agar bisa membuat model prediksi yang lebih optimal, tentunya kita ingin residual
ini seminimal mungkin, dan ini ditentukan oleh seberapa akurat kita memilih angka intercept
(a) dan slope (b). Angka yang tadi kita pilih untuk a dan b berupa angka acak saja, sehingga
perlu kita ganti dengan perhitungan yang benar.
Gambar 19: residual
Untuk dapat menentukan a dan b yang tepat, sebuah metode estimasi yang disebut Ordinary
Least Square (OLS) biasa dipergunakan di bidang statistik. Kita tidak akan membicarakan
teori di belakang metode OLS, namun kita perlu paham bahwa OLS mempergunakan apa
yang disebut sebagai cost function. Cost function adalah suatu fungsi yang dipakai untuk
mengukur tingkat error suatu model, atau dalam kata lain, seberapa fit (cocok) suatu model
dengan training dataset. Anda ingat pelajaran di Bab 1 bahwa model dianggap fit bila angka-
angka hasil prediksinya tepat atau dekat dengan angka-angka di dalam training dataset. OLS
bertujuan untuk menghasilkan cost function yang seminimal mungkin.
Melatih Model
Sebelum model dapat dipakai untuk melakukan prediksi, kita harus melakukan training
dengan mempergunakan training dataset, yang dalam kasus linear regression adalah berupa
data numerik. Harus diingat bahwa training dataset haruslah mencakup seluruh jangkauan
nilai yang ada.
Kita langsung terapkan dengan mempergunakan modul LinearRegression yang ada di
dalam scikit-learn. Cukup mudah cara mempergunakannya: pertama kita import
LinearRegression dari sklearn dan kita simpan sebagai suatu variabel bernama lm,
kemudian LinearRegression “dihidupkan” dengan nama model1.
Variabel model1 ini selanjutnya kita pergunakan untuk memanggil fungsi fit() dengan
menyertakan X_train (sebagai predictor) dan y_train (sebagai target) yang sudah kita
persiapkan sebelumnya.
import sklearn.linear_model as lm model1 = lm.LinearRegression() model1.fit(X_train, y_train)
residual
y garis regresi
nilai sebenarnya
nilai prediksi

Setelah program di atas dijalankan, maka berarti model1 sudah di-training dengan metode
OLS terhadap training dataset kita. Kita coba keluarkan nilai slope yang berhasil dihitung,
dengan melihat atribut coef_:
model1.coef_ array([[6.67233259]])
Terlihat di atas bahwa nilai slope adalah sekitar 6,672. Harus dipahami apabila Anda
mencoba hal ini di komputer Anda, bisa jadi hasilnya sedikit berbeda karena training data
yang Anda pakai dipilih secara acak pada saat proses pemilahan test dataset dan training
dataset, yang pasti berbeda di setiap komputer.
Selanjutnya, kita lihat nilai intercept-nya juga:
model1.intercept_ array([3.94246568]) Slope hasil perhitungan adalah sekitar 3,942. Sekarang kita sudah mengetahui slope dan
intercept, sehingga persamaan garis lurus yang kita miliki menjadi y = 3,942 + 6,672x. Inilah
model yang kita akan pergunakan untuk melakukan prediksi selanjutnya. Kita visualkan
dengan diagram garis, caranya dengan memasukkan angka-angka ini untuk formula variabel
y1:
import pandas as pd import numpy as np import sklearn.model_selection as ms import matplotlib.pyplot as plt df1 = pd.read_csv('C:\Bensin.csv') liter=df1[['Liter']] kilometer=df1[['Kilometer']] X_train, X_test, y_train, y_test = ms.train_test_split(liter, kilometer, test_size=0.2, random_state=0) plt.scatter(X_train, y_train, edgecolors='r') plt.xlabel('Liter') plt.ylabel('Kilometer') plt.title('Konsumsi Bahan Bakar') x1 = np.linspace(0,45) y1 = 3.94 + 6.67 * x_line plt.plot(x1,y1) plt.show()
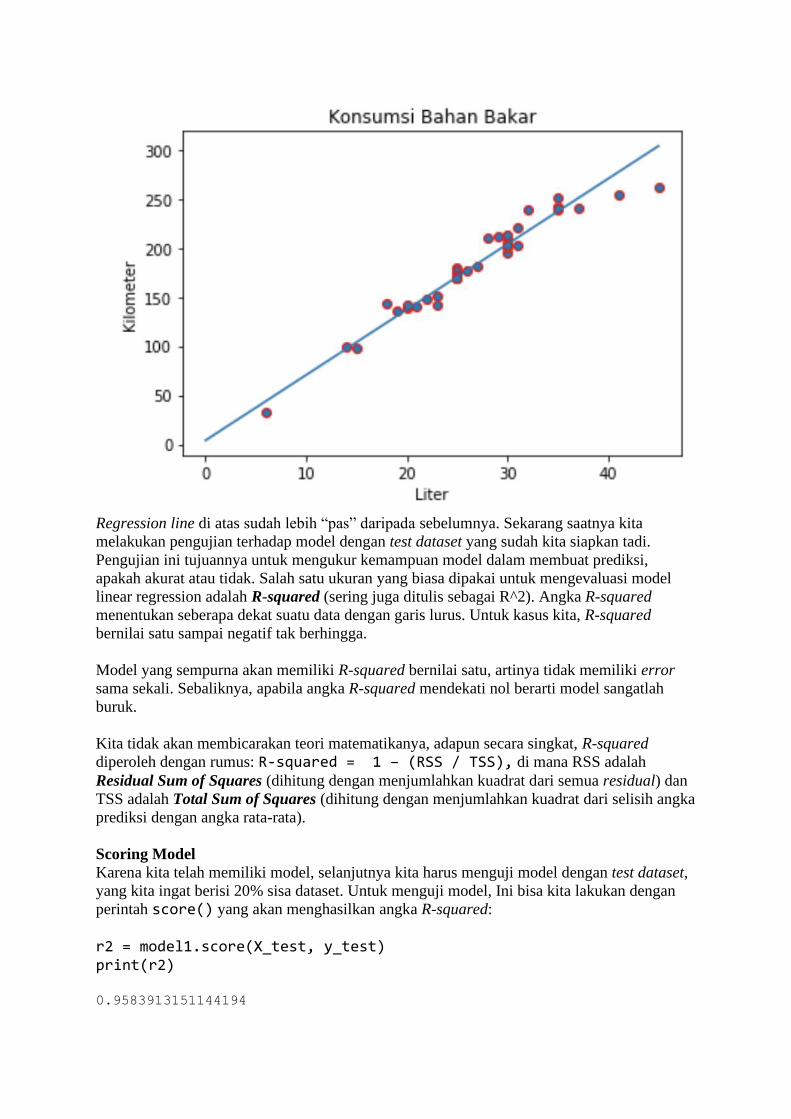
Regression line di atas sudah lebih “pas” daripada sebelumnya. Sekarang saatnya kita
melakukan pengujian terhadap model dengan test dataset yang sudah kita siapkan tadi.
Pengujian ini tujuannya untuk mengukur kemampuan model dalam membuat prediksi,
apakah akurat atau tidak. Salah satu ukuran yang biasa dipakai untuk mengevaluasi model
linear regression adalah R-squared (sering juga ditulis sebagai R^2). Angka R-squared
menentukan seberapa dekat suatu data dengan garis lurus. Untuk kasus kita, R-squared
bernilai satu sampai negatif tak berhingga.
Model yang sempurna akan memiliki R-squared bernilai satu, artinya tidak memiliki error
sama sekali. Sebaliknya, apabila angka R-squared mendekati nol berarti model sangatlah
buruk.
Kita tidak akan membicarakan teori matematikanya, adapun secara singkat, R-squared
diperoleh dengan rumus: R-squared = 1 – (RSS / TSS), di mana RSS adalah
Residual Sum of Squares (dihitung dengan menjumlahkan kuadrat dari semua residual) dan
TSS adalah Total Sum of Squares (dihitung dengan menjumlahkan kuadrat dari selisih angka
prediksi dengan angka rata-rata).
Scoring Model
Karena kita telah memiliki model, selanjutnya kita harus menguji model dengan test dataset,
yang kita ingat berisi 20% sisa dataset. Untuk menguji model, Ini bisa kita lakukan dengan
perintah score() yang akan menghasilkan angka R-squared:
r2 = model1.score(X_test, y_test) print(r2) 0.9583913151144194

Hasil dari R-squared adalah di atas 0,958, mendekati angka satu yang artinya model kita
sudah cukup bagus. Bersenjatakan model yang sudah kita anggap akurat, kita dapat
memakainya untuk melakukan prediksi terhadap dataset baru. Fungsi predict() dipakai
untuk keperluan ini. Misalnya kita ingin memperkirakan berapa kilometer yang bisa
ditempuh dengan 60 liter bensin:
jarak = model1.predict(60) print(jarak) [[404.28242138]]
Jadi dengan 60 liter bensin, kita bisa menempuh 404,28 kilometer. Sekarang kita coba
hasilkan angka prediksi dari semua isi test dataset:
prediksi = model1.predict(X_test) print(prediksi) [[107.51566118]
[172.0986203 ]
[172.0986203 ]
[159.18202848]
[139.80714074]
[268.97305898]
[204.39009986]
[236.68157942]
[ 75.22418162]
[243.13987534]
[172.0986203 ]
[139.80714074]
[191.47350804]]
Kita bandingkan dengan angka kilometer yang ada di test dataset (sudah kita simpan di
dalam variabel y_test):
print(y_test) Kilometer
45 102.0
29 167.0
43 177.0
62 142.0
34 144.0
33 278.0
31 211.0
40 241.0
26 65.0
63 241.0
22 166.2
2 144.0
11 180.0
Terlihat dari perbandingan baris-per-baris, model kita sudah berhasil membuat prediksi
dengan ketepatan yang cukup baik. Model dapat terus diperbaiki dengan training dataset

yang lebih lengkap agar model menjadi tetap akurat dalam menghadapi dataset baru, atau
dalam istilah Data Science, model yang lebih robust (kokoh) .
Multiple Linear Regression
Contoh di atas kita membuat model untuk memprediksi dengan satu variabel predictor saja.
Bagaimana bila kita memiliki banyak predictor? Dalam praktek di dunia nyata, biasanya kita
memang akan dihadapkan dengan banyak variabel, bisa puluhan bahkan ratusan variabel.
Variabel inilah yang menjadi feature bagi proses training model.
Semua variabel harus kita asumsikan akan mempengaruhi prediksi, walaupun kita belum tahu
seberapa besar pengaruhnya. Sebagai contoh, selain jumlah bahan bakar yang diisikan ke
dalam tangki, jarak yang bisa ditempuh mobil juga akan dipengaruhi oleh beban muatan,
kecepatan rata-rata, putaran mesin dan sebagainya. Semua variabel mempunyai pengaruh
dengan bobot yang berbeda-beda. Dari sinilah kita perlu mengenal multiple linear
regression, yaitu regresi linear yang melibatkan lebih dari satu variabel.
Kita bisa anggap multiple linear regression sama saja seperti simple linear regression,
tujuannya sama yaitu mencari nilai koefisien slope dan intercept yang menghasilkan tingkat
error sekecil mungkin.
Setiap predictor akan memiliki koefisien slope masing-masing, sehingga masing-masing
predictor akan memiliki “bobot” sendiri-sendiri terhadap hasil akhir prediksi. Dalam simple
linear regression, kita mengikuti persamaan y = a + bx. Dalam multiple linear regression,
persamaannya menjadi y = a + bx + bx + bx + …. bx. Kita lihat bahwa tidak hanya satu,
sekarang kita memiliki banyak variabel predictor. Lebih tepatnya, setiap predictor diberi
nama berbeda x1, x2 dan seterusnya hingga xn, lebih jelasnya sebagai berikut:
𝑦 = 𝑎 + 𝑏1𝑥1 + 𝑏2𝑥2 + ⋯ + 𝑏𝑛𝑥𝑛
Tugas Machine Learning adalah menemukan nilai a, b1, b2 dan seterusnya agar garis regresi
yang terbentuk bisa memprediksi nilai y bila kita sudah mengetahui nilai-nilai x1, x2, dan
seterusnya. Perlu diingat bahwa sebaik apapun model prediksi, tidak akan 100% sempurna
dan akurat. Pasti akan ada residual seperti yang sudah kita bicarakan sebelumnya.
Untuk mempraktekkan multiple linear regression, kita akan melanjutkan contoh kasus
konsumsi bahan bakar dengan mempergunakan training dataset yang telah diperkaya oleh
banyak variabel. File dapat diunduh di lokasi yang disebutkan di Lampiran 2. Isi file
memiliki lima variabel tambahan, yaitu jumlah penumpang, beban muatan bagasi, kecepatan
rata-rata, putaran mesin rata-rata dan suhu luar. Faktor-faktor ini kita pahami dapat
mempengaruhi konsumsi bahan bakar.
import pandas as pd df2 = pd.read_csv('C:\Bensin2.csv') df2

Korelasi Antar Data
Sebelum kita melangkah dengan pembuatan model, kita perlu melihat apakah benar ada
keterkaitan antara variabel-variabel baru yang ada di dalam training data. Kita boleh memiliki
asumsi dari awal, namun agar upaya pembuatan model kita tidak sia-sia, semua asumsi harus
dibuktikan kebenarannya.
Kita ingat di Bab 1 telah dibahas mengenai Pearson Correlation yang dapat memberikan
ukuran seberapa dekat hubungan antara dua variabel dalam mengikuti suatu garis lurus.
Korelasi ini bernilai dari positif 1 hingga negatif 1, di mana angka 1 (baik positif maupun
negatif) berarti terjadi hubungan sempurna yang linier antara kedua variabel. Misalnya angka
korelasi positif, artinya kedua variabel bergerak ke arah yang sama; bila satu variabel naik
nilainya, maka nilai variabel lainnya akan ikut naik juga. Sebaliknya bila angka korelasi
negatif, artinya kedua variabel bergerak ke arah yang berlawanan; bila satu variabel naik
nilainya, maka nilai variabel lain menurun. Angka korelasi nol berarti tidak ada sama sekali
hubungan linier antara kedua variabel.
Dalam kasus kita, kita perlu memahami seberapa besar pengaruh variabel jumlah penumpang
dengan konsumsi bahan bakar, begitu juga variabel-variabel lainnya. Variabel-variabel yang
tidak memiliki korelasi memadai dapat kita buang dari pembuatan model.
Menghitung Pearson Correlation dengan Python sangat mudah, karena library Numpy telah
menyediakan fungsi corr() yang siap pakai untuk ini. Mari kita coba buat program baru:
import pandas as pd df2 = pd.read_csv('C:\Bensin2.csv') df2.corr(method='pearson')

Perhatikan kolom paling kanan dalam matrix korelasi di atas: nampak bahwa “Suhu” adalah
variabel yang nilainya paling rendah mendekati nol, artinya naik-turunnya suhu udara nyaris
tidak memiliki hubungan dengan jarak “Kilometer” yang ditempuh. “Suhu” bukan variabel
yang signifikan sehingga bisa kita abaikan, tidak perlu kita sertakan dalam proses pembuatan
model. Variabel-variabel lain, meski dengan bobot berbeda-beda, masih menunjukkan
korelasi dengan “Kilometer” sehingga akan tetap kita masukkan ke dalam proses pembuatan
model. Total ada empat variabel (atau feature) yang akan kita pergunakan.
Pemodelan
Persis seperti simple linear regression, cara yang sama kita lakukan untuk melatih model.
Kali ini untuk test dataset kita cukup ambil 10% saja agar lebih banyak data untuk training.
Kita masukkan semua variabel predictor (dalam kasus kita, ada empat) ke dalam satu
DataFrame, dan kemudian kita lakukan training dengan memanggil fungsi fit():
import pandas as pd import numpy as np df2 = pd.read_csv('/Users/dioskurn/Bensin2.csv') X = df2[['Liter','Penumpang','Bagasi','Kecepatan']] y = df2[['Kilometer']] X_train, X_test, y_train, y_test = ms.train_test_split(X, y, test_size=0.1, random_state=0) model1.fit(X_train, y_train)
Pada titik ini, model sudah dibuat “fit” dengan training dataset dan koefisien intercept dan
slope sudah berhasil ditemukan. Mari kita lihat hasilnya:
print('intercept=', model1.intercept_) print('slope=', model1.coef_) intercept= [101.81520098]
slope= [[ 6.6224162 1.76939958 -0.49140941 -2.23887916]]
Karena kita telah tahu berapa nilai koefisien intercept dan slope, maka persamaan regresi
menjadi sebagai berikut (dibulatkan 3 angka di belakang koma):
𝑦 = 101.815 + 6.622 𝑥1 + 1.769 𝑥2 + (−0.491) 𝑥3 + (−2.238)𝑥4

Nah, model kita sudah jadi. Kita coba uji dengan suatu angka acak, misalnya 30 liter bensin,
2 penumpang, 10 kg bagasi dan kecepatan rata-rata 50 km/h. Keempat predictor ini kita
masukkan ke dalam sebuah NumPy array seperti biasa, kemudian dimasukkan ke fungsi
predict() :
data1= np.array([[30, 2, 10, 50]]) hasil = model1.predict(data1) print(hasil) [[187.16843425]]
Hasilnya bila kita masukkan ke dalam persamaan regresi di atas, menjadi: y = 101,815 +
198,66 + 3,538 + (-4,91) + (-111,9) = 187,2. Hasilnya cukup dekat dengan harapan kita.
Adapun bagus tidaknya akurasi model ini dalam melakukan prediksi dapat dilihat dengan
melihat R-squared hasil scoring terhadap test data. Anda bisa mencobanya sendiri.
Kesimpulan
Linear regression adalah metode untuk membuat model prediksi yang memerlukan training
dataset berupa nilai-nilai numerik, yang biasanya adalah hasil pengukuran di masa lalu.
Model dibangun dengan formula matematis untuk menemukan koefisien intercept dan slope
yang paling sesuai agar garis lurus imajiner dapat melalui titik-titik dalam training data.
Harus diingat selalu bahwa tidak semua kasus cocok dengan model linear regression. Model
prediksi memerlukan hubungan yang linier antara independent variable dan dependent
variable. Data yang tersebar secara acak tanpa pola linier tidak akan bisa dibuat modelnya.
Agar model dapat membuat prediksi yang akurat, training dataset haruslah berkualitas bagus.
Anda harus melakukan pengamatan yang cukup seksama dengan data profiling terhadap data
sebelum melangkah ke proses pembuatan model. Salah satu cara yang umum untuk
melakukan profiling adalah mempergunakan scatterplot seperti contoh di bab ini. Kualitas
model sangat ditentukan oleh kualitas training dataset yang tersedia, sehingga proses
eksplorasi terhadap data, pemilihan feature mana saja yang dianggap berguna untuk
pembuatan model, dan demikian juga proses pembersihan data menjadi aktivitas yang perlu
mendapatkan fokus lebih.
Setelah model kita bangun, tentunya kita harus menerapkannya ke lingkungan yang nyata.
Kita bisa menerapkan linear regression pada kegiatan-kegiatan ilmiah, analisis bisnis, atau
aplikasi teknis yang bersifat real-time di sektor industri. Misalnya melanjutkan contoh di bab
ini, model prediksi konsumsi bahan bakar dapat diterapkan dalam sistem komputer di
kendaraan untuk menghitung secara langsung perkiraan jarak yang dapat ditempuh dengan
memanfaatkan sensor-sensor di kendaraan. Anda dapat membuat program yang membaca
sensor tangki bensin, speedometer, tachometer atau sensor-sensor lain untuk menghitung
beban muatan, dan sebagainya. Program kemudian melakukan scoring mempergunakan
model yang sudah Anda latih sebelumnya untuk seketika dapat melakukan perhitungan
prediksi dan hasilnya ditampilkan di layar di dashboard pengemudi.

Gambar 20: Contoh penerapan prediction model
Salah satu perbedaan metode regression dengan metode lainnya adalah metode ini
menyerahkan sepenuhnya pemilihan feature atau variabel predictor kepada manusia. Di sini
diperlukan peran seorang domain expert (ahli di bidang tertentu) yang memiliki pemahaman
dan pengalaman terhadap bidang yang sedang dianalisis, misalnya diperlukan seorang ahli
ekonomi untuk mencari feature yang terkait dengan analisis ekonomi, atau seorang dokter
untuk mencari variabel predictor bagi model-model di bidang kesehatan.
Dashboard
Scoring Pengumpul
Data
Model Sensor

Bab 5 Logistic Regression Di bab sebelumnya kita menjalankan suatu kasus yang melibatkan prediksi terhadap nilai-
nilai numerik dengan linear regression. Adapun dalam sebagian besar kasus penggunaan
Machine Learning adalah untuk melakukan klasifikasi (classification), yaitu
mengelompokkan data-data hasil observasi ke dalam kategori yang sesuai. Misalnya
mengkelompokkan seluruh pelanggan sebuah toko online ke kategori A, B atau C dengan
mempergunakan data-data transaksi penjualan di masa lalu.
Ini yang sering disebut dengan classification prediction modelling, yaitu upaya
pengembangan model berupa sebuah fungsi yang secara matematis dapat memetakan dengan
sedekat mungkin suatu variabel input (X) ke suatu variabel output (Y) yang sudah ditentukan.
Variabel output (disebut juga target) ini berupa sekelompok kategori (disebut juga kelas).
Model dikembangkan dengan mempergunakan data-data observasi beserta dengan label
kategorinya masing-masing sebagai target. Dengan model ini, data baru yang berisi hasil
observasi (yang tidak ada label kategorinya) nantinya bisa diprediksi masuk ke kategori yang
mana.
Lebih spesifik lagi, kasus yang serupa adalah binary classification, yaitu membuat prediksi
yang sifatnya menghasilkan jawaban ya/tidak, misalnya membuat prediksi terhadap sesuatu
hal, apakah akan terjadi atau tidak terjadi:
• Apakah hari ini akan turun hujan?
• Apakah seorang pelanggan akan membeli produk kita?
• Apakah seorang nasabah pinjaman kredit akan gagal bayar?
Seperti yang kita pelajari di Bab 1, ada beberapa metode untuk classification, misalnya
Decision Tree dan Neural Networks. Adapun di bab ini kita akan melanjutkan pembahasan
bab sebelumnya, yaitu kita mempergunakan algoritma Logistic Regression. Kita bisa anggap
algoritma ini sebagai bentuk lain Linear Regression, bedanya Linear Regression
dipergunakan untuk memprediksi nilai-nilai numerik, sementara Logistic Regression
dipergunakan untuk memprediksi kategori biner (“0” atau “1”).
Dengan hanya ada dua kemungkinan, kita bisa mempergunakan keluaran Logistic Regression
sebagai prediksi “ya” atau “tidak”, “sukses” atau “gagal”, “pria” atau “wanita” dan
sebagainya. Prediksi ini dibuat berdasarkan satu atau lebih feature yang menjadi predictor.
Setiap feature akan diberikan bobot masing-masing.
Gambar 21: Prinsip dasar Logistic Regression dengan feature dan bobotnya (b)
Kita ingat dari bab sebelumnya bahwa dalam Linear Regression dipergunakan metode
Ordinary Least Square (OLS) untuk membuat pendekatan garis lurus. Dalam Logistic
bn
b2
b1
Predictor
Logistic Regression
feature 1
feature 2
feature n
“ya”
“tidak”
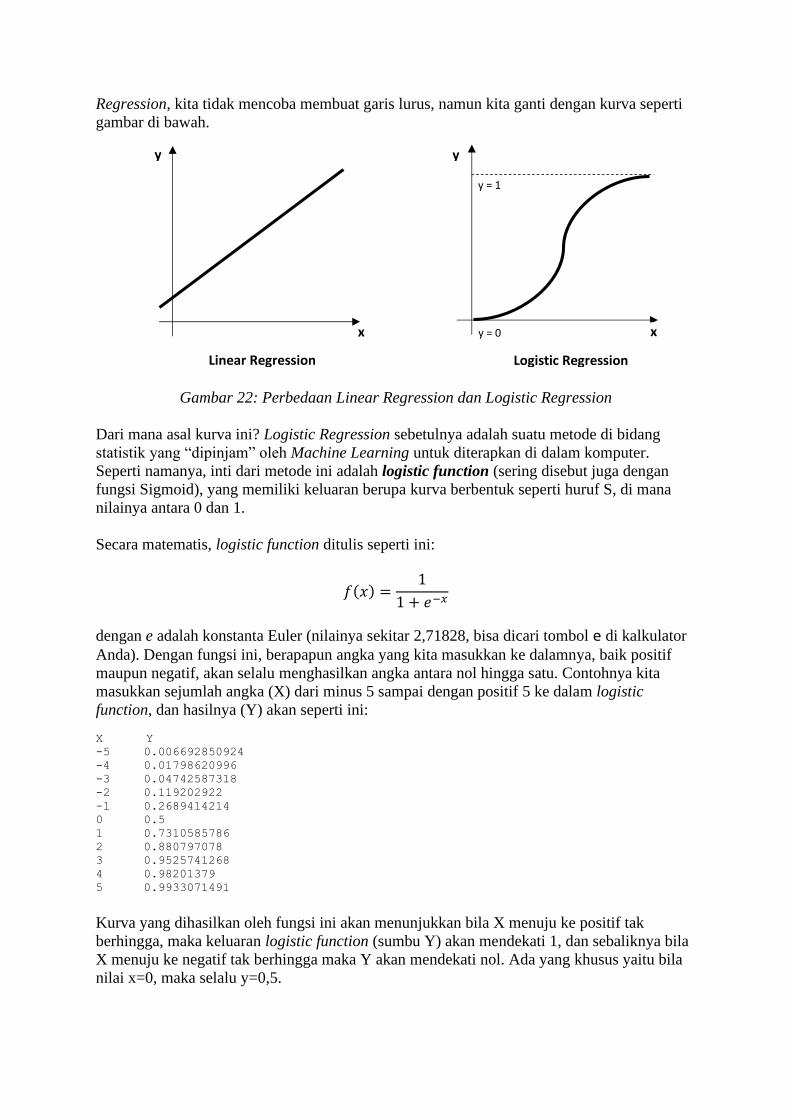
Regression, kita tidak mencoba membuat garis lurus, namun kita ganti dengan kurva seperti
gambar di bawah.
Gambar 22: Perbedaan Linear Regression dan Logistic Regression
Dari mana asal kurva ini? Logistic Regression sebetulnya adalah suatu metode di bidang
statistik yang “dipinjam” oleh Machine Learning untuk diterapkan di dalam komputer.
Seperti namanya, inti dari metode ini adalah logistic function (sering disebut juga dengan
fungsi Sigmoid), yang memiliki keluaran berupa kurva berbentuk seperti huruf S, di mana
nilainya antara 0 dan 1.
Secara matematis, logistic function ditulis seperti ini:
𝑓(𝑥) =1
1 + 𝑒−𝑥
dengan e adalah konstanta Euler (nilainya sekitar 2,71828, bisa dicari tombol e di kalkulator
Anda). Dengan fungsi ini, berapapun angka yang kita masukkan ke dalamnya, baik positif
maupun negatif, akan selalu menghasilkan angka antara nol hingga satu. Contohnya kita
masukkan sejumlah angka (X) dari minus 5 sampai dengan positif 5 ke dalam logistic
function, dan hasilnya (Y) akan seperti ini:
X Y
-5 0.006692850924
-4 0.01798620996
-3 0.04742587318
-2 0.119202922
-1 0.2689414214
0 0.5
1 0.7310585786
2 0.880797078
3 0.9525741268
4 0.98201379
5 0.9933071491
Kurva yang dihasilkan oleh fungsi ini akan menunjukkan bila X menuju ke positif tak
berhingga, maka keluaran logistic function (sumbu Y) akan mendekati 1, dan sebaliknya bila
X menuju ke negatif tak berhingga maka Y akan mendekati nol. Ada yang khusus yaitu bila
nilai x=0, maka selalu y=0,5.
y y
x x
y = 1
y = 0
Linear Regression Logistic Regression

Gambar 23: keluaran fungsi Sigmoid
Tidak seperti Linear Regression yang memprediksi keluaran numerik yang bersifat
kuantitatif, model Logistic Regression dipergunakan untuk membuat prediksi kualitatif.
Lebih jelasnya, Logistic Regression memodelkan probabilitas (kemungkinan) apakah suatu
nilai input masuk ke kategori pertama (disebut class 0), atau kebalikannya masuk ke kategori
kedua (disebut class 1).
Bila keluaran model menunjukkan probabilitas lebih besar dari 0,5 maka dapat dianggap
bahwa nilai input yang dimasukkan ke dalam model akan dikategorikan ke dalam class 0.
Sebaliknya bila angka probabilitas lebih rendah dari 0,5 maka nilai input akan dikategorikan
ke class 1.
Kita tahu bahwa Logistic Regression memerlukan satu atau lebih feature sebagai predictor.
Bila ada sebanyak n feature (diwakili huruf x), maka untuk mendapatkan suatu output
(keluaran) akan diperlukan n + 1 koefisien (diwakili huruf b) seperti berikut:
𝑜𝑢𝑡𝑝𝑢𝑡 = 𝑏0 + 𝑏1𝑥1 + 𝑏2𝑥2 + … + 𝑏𝑛𝑥𝑛
Mirip dengan linear regression (yang mencari nilai slope dan intercept yang tepat), dalam
Logistic Regression tugas algoritma Machine Learning adalah mencari nilai terbaik untuk
koefisien b0, b1, b2 dan bn berdasarkan perhitungan mempergunakan training dataset yang
tersedia. Ada beberapa metode optimisasi yang bisa dipergunakan, salah satunya disebut
gradient descent. Kita tidak akan mendiskusikan tentang teori di belakang metode ini, namun
dapat dapat digambarkan bahwa metode ini memerlukan banyak iterasi untuk akhirnya
mendapatkan nilai koefisien yang paling tepat.
Output di atas akan kemudian diterapkan menjadi angka probabilitas dengan bantuan logistic
function:
𝑝(𝑐𝑙𝑎𝑠𝑠 0) =1
(1 + 𝑒−𝑜𝑢𝑡𝑝𝑢𝑡)
Fungsi di atas akan menunjukkan probabilitas suatu nilai input akan dikategorikan ke class 0.
Contohnya, kita hendak memprediksi probabilitas seorang mahasiswa akan lulus ujian, yang
secara matematis ditulis: p(lulus_ujian) yang bisa bernilai antara 0 dan 1. Misalnya hasil
keluaran fungsi adalah 0,8 maka dapat dinyatakan bahwa ada 80% kemungkinan pelajar
tersebut akan masuk kelompok pelajar yang lulus ujian. Demikian juga apabila keluarannya
0,2 maka kemungkinan besar pelajar tersebut akan masuk kelompok yang tidak lulus ujian.
Dengan bantuan training dataset, kita akan meminta komputer untuk mencari nilai yang tepat
untuk koefisien-koefisien di atas agar formula kita lengkap. Setelah formula didapatkan, kita
bisa menerapkannya sebagai model untuk melakukan scoring terhadap dataset baru yang
tidak diketahui target kategorinya.
Sama seperti Linear Regression, kita harus memastikan bahwa dataset baru yang hendak di-
scoring harus memiliki angka-angka yang dalam cakupan yang sama dengan training dataset.
Tanpa hal ini, hasil prediksi menjadi tidak dapat memiliki akurasi yang tinggi.
Logistic Regression dengan Scikit-learn
Untuk menunjukkan penggunaan Logistic Regression dengan Scikit-learn, kita akan
mengambil contoh kasus yaitu penjualan mobil. Kita memiliki sebuah dataset berisi daftar
orang yang pernah menjadi sasaran marketing, yaitu orang-orang yang sudah pernah diberi
tawaran membeli mobil di tahun-tahun sebelumnya. Dataset sudah memiliki data orang-orang
mana saja yang akhirnya membeli mobil. Inilah target dari model kita.
Selanjutnya dari dataset ini kita mencoba membuat model prediksi terhadap data-data calon
pembeli baru, siapa saja yang memiliki kemungkinan tinggi untuk membeli mobil. Contoh
dataset dapat diunduh dari situs yang disebutkan di Lampiran 2.
Dataset berisi sekitar 200 baris yang setiap baris mewakili satu calon pembeli mobil (nama
calon pembeli dihilangkan, digantikan dengan ID numerik), beserta dengan informasi usia,
status pernikahan, penghasilan bulanan, berapa jumlah mobil yang sudah dimiliki, dan
informasi apakah akhirnya calon pembeli tersebut benar-benar membeli mobil (diwakili oleh
nilai 0 atau 1 di kolom Target). Kelima informasi inilah yang akan menjadi feature di dalam
training data kita. Berikut contohnya:
ID Usia
(tahun)
Status
(0=single,
1=menikah,
2=menikah dengan
anak, 3=duda/janda
Kelamin
(0=pria,
1=wanita)
Memiliki
Mobil
(jumlah)
Penghasilan
(x100 Juta
Rupiah per
tahun)
[Target]
Beli
Mobil
(0=tidak,
1=ya)
1 32 1 0 0 240 1
2 49 2 1 1 100 0
3 52 1 0 2 250 1
4 26 2 1 1 130 0
5 45 3 0 2 237 1
Kita akan melatih model mempergunakan dataset ini dengan tujuan pada saat kita memiliki
dataset baru berisi calon pembeli lain, kita bisa memprediksi apakah masing-masing calon
pembeli akan masuk ke kategori 0 (akan membeli mobil) atau 1 (tidak akan membeli mobil).
Mempersiapkan Training Dataset
Setelah Anda unduh file dataset berupa file CSV (comma separated values), langkah pertama
adalah mempersiapkannya sebagai training dataset. Dengan bantuan Pandas, kita muat file
tersebut, kemudian kita lihat statistik pentingnya:
import pandas as pd df1 = pd.read_csv("C:\calonpembelimobil.csv") df1.describe()

Terlihat ada 250 baris di dalam dataset kita, artinya ada 250 orang calon pembeli. Ada lima
feature dan kita lihat usia rata-rata adalah 38,87 tahun, penghasilan minimal adalah 95 dan
maksimal 490 (dalam ratus juta Rupiah). Status pernikahan dan jenis kelamin juga ada di
dalam jangkauan sesuai yang diharapkan.
Tapi tunggu dulu! Nilai maksimal usia calon pembeli terbaca 164 tahun. Ini tidak masuk akal,
bisa dipastikan ini adalah data yang keliru. Data seperti ini adalah noise yang harus kita
buang dari training dataset. Dengan mempergunakan logika umum, calon pembeli yang
usianya > 100 tahun sebaiknya kita hapus dari dataset. Untungnya, dengan Pandas,
menghapus data seperti ini mudah saja kita lakukan:
df1 = df1[df1['Usia'] <= 100]
Sebagai suatu yang “wajib” kita lakukan terhadap sembarang dataset yang akan kita
pergunakan, kita perlu melihat apakah ada data yang kosong (null) di dalamnya:
df1.isnull().sum() ID 0
Usia 0
Status 0
Kelamin 0
Memiliki_Mobil 3
Penghasilan 0
Beli_Mobil 0
dtype: int64
Ternyata ada tiga baris data yang berisi null. Artinya ketiga baris ini harus dibuang data
dataset kita, karena apabila kita biarkan, akan membuat model tidak akurat. Pandas bisa
membantu kita lagi:
df1.dropna()
Mari kita lihat dari seluruh calon pembeli, berapa banyak calon pembeli yang akhirnya
membeli mobil (kolom “Beli_Mobil” = 1):

df1['Beli_Mobil'].value_counts()
Ternyata statistik di atas menunjukkan bahwa ada 114 orang yang akhirnya membeli mobil.
Jumlahnya kurang lebih separuh dari dataset kita. Nampaknya dataset kita sudah cukup baik.
Tidak ada data yang perlu dibersihkan atau diubah lagi.
Seperti di bab sebelumnya, kita akan mempergunakan sebagian besar (80%) dari dataset yang
tersedia sebagai training dataset, dan sisanya (20%) sebagai test dataset. Training dataset
dipergunakan untuk membentuk model, kemudian test dataset dipergunakan untuk menguji
model tersebut dan mengevaluasi akurasinya.
Kita ingat dari bab sebelumnya bahwa ada semacam konsensus untuk mempergunakan huruf
X (huruf besar) untuk mewakili semua feature, dan huruf y (huruf kecil) untuk mewakili
target. Dalam training dataset kita, feature akan kita simpan di DataFrame bernama
X_train sementara targetnya disimpan di y_train. Demikian pula dalam test dataset,
feature akan disimpan di DataFrame bermana X_test dan targetnya disimpan di y_test.
Gambar 24: Pembagian dataset ke dalam training dataset dan test dataset
Untuk keperluan training, kita akan mempergunakan seluruh feature yang ada (usia, status
perkawinan, jenis kelamin, jumlah mobil yang sudah dimiliki, dan penghasilan tahunan).
Kolom “ID” tidak diperlukan, jadi kita buang dari training data dan test data.
Training dan test dataset harus dipilih secara acak. Seperti yang sudah kita lihat di bab
sebelumnya, kita tidak perlu repot karena Pandas akan melakukan ini untuk kita. Fungsi
train_test_split() dapat dipanggil dengan memasukkan ukuran test data (di contoh di
bawah 0,2 = 20%):
import sklearn.model_selection as ms X=df1[['Usia', 'Status', 'Kelamin', 'Memiliki_Mobil', 'Penghasilan']] y=df1.Beli_Mobil
X_train
y_train
Training Dataset (80%) Dataset
X_test
y_test
Model
Scoring
Test Dataset (20%)
y_prediksi
Evaluasi

X_train,X_test,y_train,y_test = ms.train_test_split(X,y,test_size=0.2,random_state=0)
Sebagai pengingat, aturan yang umum adalah kita perlu memastikan bahwa angka-angka di
test dataset harus berada di dalam jangkauan angka-angka di training dataset. Angka usia
minimum dan maksimum di dalam test dataset tidak boleh berada di luar angka usia
minimum dan maksimum di dalam training dataset, demikian juga jumlah penghasilan, dan
lain-lain. Model prediksi tidak akan akurat bekerja apabila harus memprediksi dataset yang
jangkauannya belum pernah dilatih dengan training dataset.
Pembuatan Model
Kita akan mempergunakan scikit-learn untuk membuat model Logistic Regression, yang
sudah menyediakan semuanya dengan lengkap. Tentu pertama-tama kita harus impor terlebih
dahulu paket yang diperlukan, yaitu LogisticRegression di dalam
sklearn.linear_model. Kemudian untuk melatih model, fungsi fit() kita panggil
dengan memasukkan training dataset yang sudah kita siapkan di atas:
import sklearn.linear_model as lm model = lm.LogisticRegression(solver='lbfgs') model.fit(X_train, y_train) Di titik ini, Machine Learning sudah berhasil menemukan koefisien untuk masing-masing
dari kelima feature di training data. Mari kita tengok apa isinya:
print(model.coef_) [[-0.04068644 0.14132231 -3.23475728 -0.1061514 0.03912208]]
Kita akan membicarakan tentang cara mengukur kinerja model di bagian berikutnya.
Sekarang kita pakai model ini untuk mengeluarkan seluruh hasil prediksi terhadap test data,
kita ingat kita sudah siapkan X_test yang berisi 40 baris data, jadi akan ada 40 baris hasil
prediksi (dalam angka nol dan satu):
y_prediksi = model.predict(X_test) print(y_prediksi) [0 0 0 0 0 1 1 0 0 1 0 0 0 1 1 0 1 0 0 1 1 0 0 1 0 1 1 1 0 0 1 1 1 1 0 0 1
1 1 1]
Model sudah berhasil membuat prediksi apakah seorang calon pembeli akan membeli mobil
atau tidak. Sebagai contoh, kita lihat lima calon pembeli pertama dari test data:
X_test.head()

Di baris pertama, ada calon pelanggan no.993, seorang pria usia 25 tahun, menikah dan
memiliki anak, penghasilan 208 juta Rupiah per tahun dan belum pernah memiliki mobil.
Model memprediksi dia tidak akan membeli mobil (Beli_Mobil=0). Benarkah prediksi ini
bila dibandingkan dengan target aslinya di DataFrame y_test? Mari kita lihat:
y_test.head(1)
Ternyata benar bahwa calon pelanggan tersebut tidak membeli mobil (Beli_Mobil = 0).
Pemeriksaan secara acak seperti ini dapat memberikan gambaran, namun kita perlu mengukur
dengan lebih seksama seberapa baik kinerja model yang sudah kita buat ini.
Mengukur Kinerja Model
Ada beberapa cara untuk mengukur kinerja suatu model yang menghasilkan binary
classification seperti yang sedang kita buat. Kita akan bahas satu-per-satu, namun
sebelumnya kita harus memahami terlebih dahulu konsep true positive (TP), true negative
(TN), false positive (FP) dan false negative (FN). Untuk lebih mudah, kita lihat tabel
“prediksi vs kenyataan” di bawah ini:
Kenyataan
Positif Negatif
Prediksi Positif TP FP
Negatif FN TN
Tabel X: Confusion Matrix
Tabel ini sering juga disebut confusion matrix karena istilah yang dipergunakan bisa
membuat kebingungan bagi orang yang membacanya. Adapun secara singkat bisa kita ingat
bahwa:
• TP : model memprediksi positif (“ya”), dan benar karena kenyataannya memang
positif (“ya”)
• TN : model memprediksi negatif (“tidak”), dan benar karena kenyataannya memang
negatif (“tidak”)
• FP : model memprediksi positif (“ya”), namun salah karena kenyataannya negatif
(“tidak”)
• FN : model memprediksi negatif (“ya”), namun salah karena kenyataannya positif
(“ya”)
Contoh sebuah confusion matrix:

Kenyataan
Positif Negatif
Prediksi Positif 50 10
Negatif 5 100
Angka TP=50 dan FP=10 artinya model memprediksi 50 kasus positif yang tepat, dan 10
kasus positif yang tidak tepat. Demikian pula FN=5 dan TN=100 berarti model memprediksi
5 kasus negatif yang tepat, dan 100 kasus negatif yang keliru.
Tentunya kita ingin model kita selalu menghasilkan TP dn TN yang maksimal, artinya
prediksi tepat 100%. Namun skenario ideal seperti ini hampir tidak mungkin dicapai, dan
model yang kita buat hampir selalu akan menghasilkan salah satu atau kedua macam error
(kesalahan) yaitu FP dan FN.
Ramalan cuaca: “hari ini tidak hujan”
(False Negative/FN)
Ramalan cuaca: “hari ini hujan”
(False Positive/FP)
Gambar 25: ilustrasi False Negative dan False Positive
Setelah kita paham konsep di atas, mari kita coba keluarkan statistik kinerja model kita
dengan melihat confusion matrix-nya. Kita bisa impor terlebih dahulu paket metrics di
scikit-learn, dan kita masukkan test data:
import sklearn.metrics as met confusionmatrix = met.confusion_matrix(y_test, y_prediksi) [[17 0]
[ 3 20]]
Kita lihat dari confusion matrix bahwa model kita menghasilkan TP = 17, FP = 0, FN=3 dan
TN=20. Bagaimana kita mempergunakan angka-angka ini? Kita bisa pergunakan untuk
mengukur accuracy (akurasi) model. Rumusnya adalah jumlah prediksi yang benar dibagi
dengan total seluruh prediksi:
𝑎𝑐𝑐𝑢𝑟𝑎𝑐𝑦 =𝑇𝑃 + 𝑇𝑁
𝑇𝑃 + 𝑇𝑁 + 𝐹𝑃 + 𝐹𝑁

Dengan rumus ini, kita hitung secara manual, model kita memiliki akurasi yaitu 17+20 dibagi
17+20+0+3 = 0.925. Bila tidak ingin menghitung manual, lebih mudahnya kita panggil saja
fungsi score() untuk menghitungnya:
score = model.score(X_test, y_test) print(score) 0.925
Artinya, akurasi model kita bernilai 92,5% yang berarti sudah sangat baik. Secara umum di
bidang Data Science, model dengan akurasi di atas 70% sudah bisa digolongkan sebagai
model yang berkinerja baik.
Angka di atas mengukur keseluruhan akurasi model, tanpa membedakan error FP maupun
FN. Ini kurang informatif terutama pada penerapan model yang lebih difokuskan pada
mendeteksi false positive atau false negative saja. Misalnya di industri perbankan, model
untuk mendeteksi transaksi mencurigakan di dalam sebuah bank akan lebih sensitif terhadap
false negative. Karena bank umumnya lebih mengutamakan keamanan nasabah, manajemen
bank tidak ingin mengambil resiko gagal mendeteksi transaksi mencurigakan dibandingkan
mengeluarkan biaya untuk memeriksa semua transaksi yang dianggap mencurigakan
meskipun akhirnya ternyata terbukti tidak bermasalah. Untuk mengukur kinerja model
semacam ini, melihat angka akurasi saja tidaklah cukup.
Untuk itu ada saatnya kita perlu mengukur jumlah data yang sukses diprediksi sebagai positif,
dibandingkan dengan seluruh data yang diprediksi positif baik yang kenyataannya benar
maupun tidak benar. Ini disebut dengan precision (ketepatan), yang rumusnya:
𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 =𝑇𝑃
𝑇𝑃 + 𝐹𝑃
Precision memberi petunjuk seberapa baik model dapat “menangkap” prediksi yang positif.
Model kita memiliki angka precision yaitu 17 dibagi 17+0 = 1, atau 100%, yang artinya
semua prediksi positif berhasil “ditangkap”. Lebih mudahnya, scikit-learn bisa kita minta
mengeluarkan angka precision:
precision = met.precision_score(y_test, y_prediksi) print(precision) 0.9837389
Dengan definisi precision seperti di atas, semakin banyak FP, atau model sering salah
memprediksi data sebagai positif, maka angka precision akan semakin rendah.
Sementara itu sensitivity (atau disebut juga recall) mengukur banyaknya data yang sukses
diprediksi sebagai positif dibandingkan dengan seluruh data yang pada kenyataannya positif.
Sensitivity memberi kita petunjuk seberapa banyak model telah “luput” dalam menangkap
kasus-kasus yang seharusnya diprediksi positif. Rumusnya:
𝑠𝑒𝑛𝑠𝑖𝑡𝑖𝑣𝑖𝑡𝑦 =𝑇𝑃
𝑇𝑃 + 𝐹𝑁
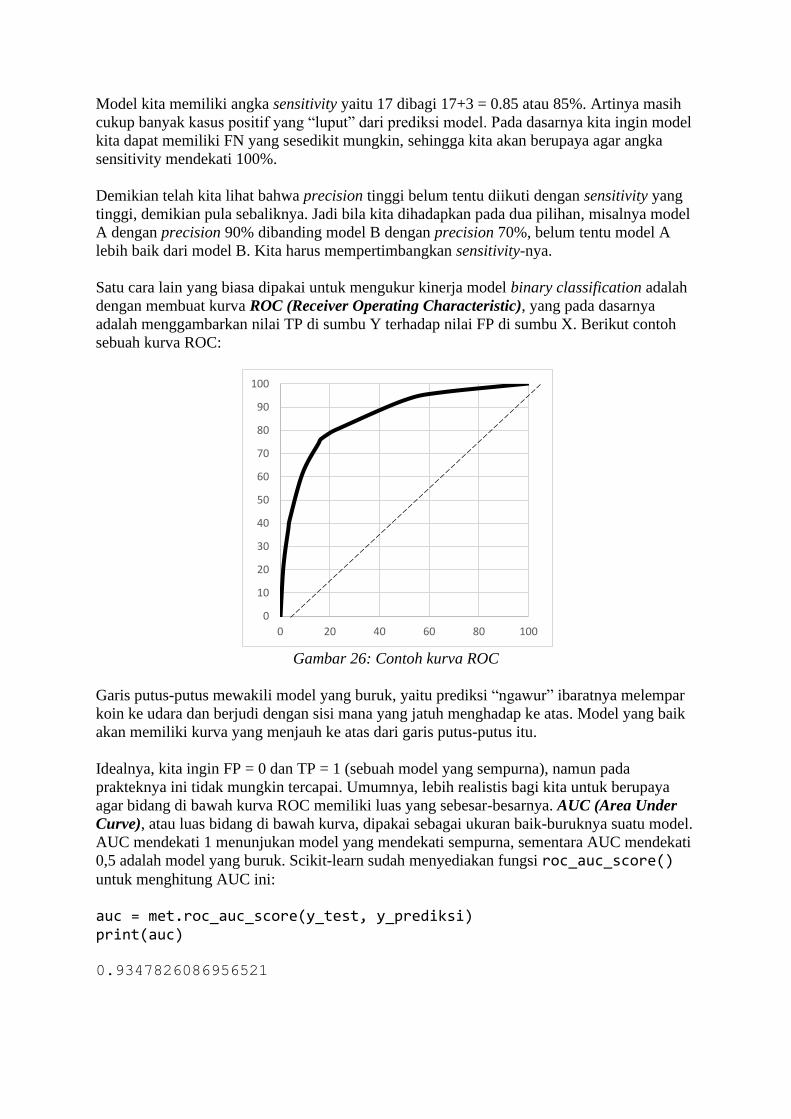
Model kita memiliki angka sensitivity yaitu 17 dibagi 17+3 = 0.85 atau 85%. Artinya masih
cukup banyak kasus positif yang “luput” dari prediksi model. Pada dasarnya kita ingin model
kita dapat memiliki FN yang sesedikit mungkin, sehingga kita akan berupaya agar angka
sensitivity mendekati 100%.
Demikian telah kita lihat bahwa precision tinggi belum tentu diikuti dengan sensitivity yang
tinggi, demikian pula sebaliknya. Jadi bila kita dihadapkan pada dua pilihan, misalnya model
A dengan precision 90% dibanding model B dengan precision 70%, belum tentu model A
lebih baik dari model B. Kita harus mempertimbangkan sensitivity-nya.
Satu cara lain yang biasa dipakai untuk mengukur kinerja model binary classification adalah
dengan membuat kurva ROC (Receiver Operating Characteristic), yang pada dasarnya
adalah menggambarkan nilai TP di sumbu Y terhadap nilai FP di sumbu X. Berikut contoh
sebuah kurva ROC:
Gambar 26: Contoh kurva ROC
Garis putus-putus mewakili model yang buruk, yaitu prediksi “ngawur” ibaratnya melempar
koin ke udara dan berjudi dengan sisi mana yang jatuh menghadap ke atas. Model yang baik
akan memiliki kurva yang menjauh ke atas dari garis putus-putus itu.
Idealnya, kita ingin FP = 0 dan TP = 1 (sebuah model yang sempurna), namun pada
prakteknya ini tidak mungkin tercapai. Umumnya, lebih realistis bagi kita untuk berupaya
agar bidang di bawah kurva ROC memiliki luas yang sebesar-besarnya. AUC (Area Under
Curve), atau luas bidang di bawah kurva, dipakai sebagai ukuran baik-buruknya suatu model.
AUC mendekati 1 menunjukan model yang mendekati sempurna, sementara AUC mendekati
0,5 adalah model yang buruk. Scikit-learn sudah menyediakan fungsi roc_auc_score()
untuk menghitung AUC ini:
auc = met.roc_auc_score(y_test, y_prediksi) print(auc)
0.9347826086956521
0
10
20
30
40
50
60
70
80
90
100
0 20 40 60 80 100
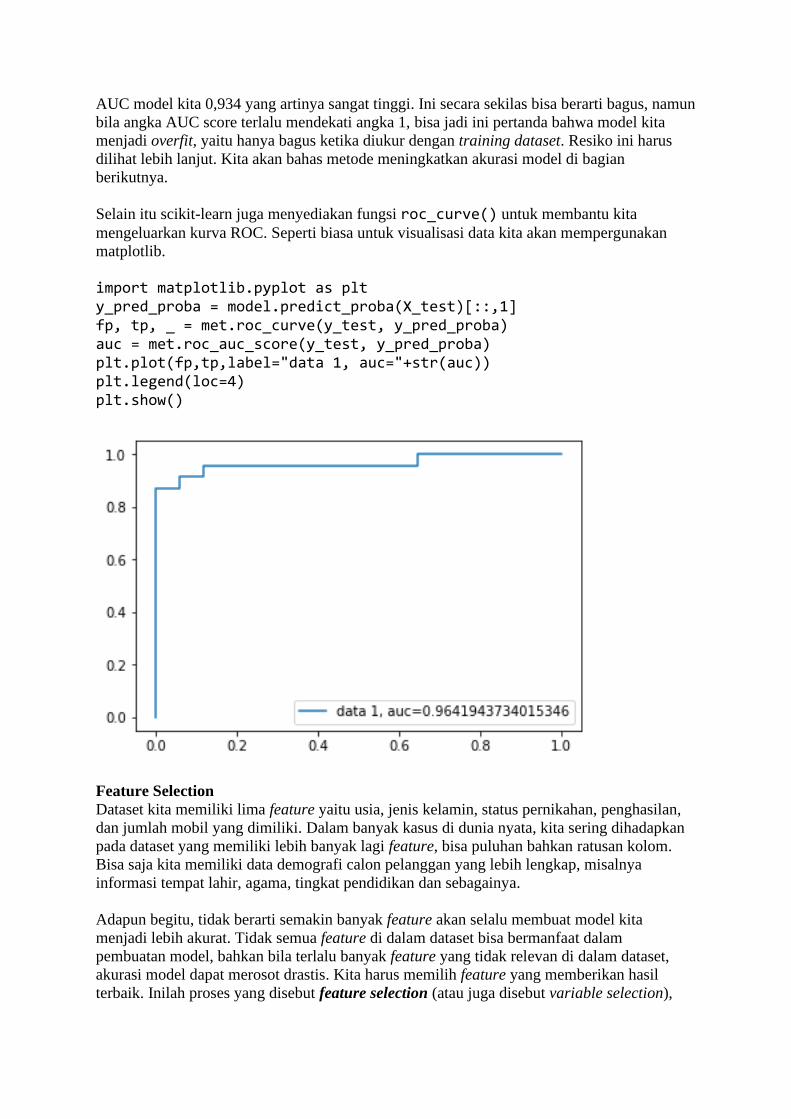
AUC model kita 0,934 yang artinya sangat tinggi. Ini secara sekilas bisa berarti bagus, namun
bila angka AUC score terlalu mendekati angka 1, bisa jadi ini pertanda bahwa model kita
menjadi overfit, yaitu hanya bagus ketika diukur dengan training dataset. Resiko ini harus
dilihat lebih lanjut. Kita akan bahas metode meningkatkan akurasi model di bagian
berikutnya.
Selain itu scikit-learn juga menyediakan fungsi roc_curve() untuk membantu kita
mengeluarkan kurva ROC. Seperti biasa untuk visualisasi data kita akan mempergunakan
matplotlib.
import matplotlib.pyplot as plt y_pred_proba = model.predict_proba(X_test)[::,1] fp, tp, _ = met.roc_curve(y_test, y_pred_proba) auc = met.roc_auc_score(y_test, y_pred_proba) plt.plot(fp,tp,label="data 1, auc="+str(auc)) plt.legend(loc=4) plt.show()
Feature Selection
Dataset kita memiliki lima feature yaitu usia, jenis kelamin, status pernikahan, penghasilan,
dan jumlah mobil yang dimiliki. Dalam banyak kasus di dunia nyata, kita sering dihadapkan
pada dataset yang memiliki lebih banyak lagi feature, bisa puluhan bahkan ratusan kolom.
Bisa saja kita memiliki data demografi calon pelanggan yang lebih lengkap, misalnya
informasi tempat lahir, agama, tingkat pendidikan dan sebagainya.
Adapun begitu, tidak berarti semakin banyak feature akan selalu membuat model kita
menjadi lebih akurat. Tidak semua feature di dalam dataset bisa bermanfaat dalam
pembuatan model, bahkan bila terlalu banyak feature yang tidak relevan di dalam dataset,
akurasi model dapat merosot drastis. Kita harus memilih feature yang memberikan hasil
terbaik. Inilah proses yang disebut feature selection (atau juga disebut variable selection),

yaitu pemilihan feature atau atribut data yang memberikan kontribusi paling besar terhadap
keluaran prediksi model yang kita harapkan.
Selain bertujuan untuk meningkatkan akurasi model yang kita kembangkan, feature selection
juga dapat bermanfaat untuk:
1. Mengurangi overfitting. Ingat di Bab 1 kita sudah membahas tentang overfitting ini
yaitu melatih model dengan banyak noise sehingga model menjadi tidak akurat bila
dihadapkan dengan dataset baru. Semakin sedikit feature, kemungkinan kita
menemukan noise di dalam dataset menjadi berkurang.
2. Mengurangi beban komputasi. Dengan membuang feature yang tidak perlu, volume
data yang harus diproses untuk training menjadi lebih sedikit, dan beban kerja
komputer (dan waktu proses) dapat dikurangi.
Bilamana model kita memiliki akurasi yang kurang baik, yang pertama harus dilakukan
adalah menjalankan feature selection. Kita buang feature yang tidak berguna, yang membuat
akurasi model menjadi rendah. Metode Recursive Feature Elimination (RFE) dapat dipakai
untuk memilih feature yang terbaik untuk pembuatan model. Cara kerjanya adalah dengan
menghilangkan feature satu-per-satu dan secara berulang-ulang (rekursif) membangun
model, lalu mengevaluasi keluaran model berdasarkan feature yang tersisa. Dengan cara
melihat akurasi model, akhirnya dapat ditemukan feature mana saja (atau kombinasi feature
mana saja) yang memberikan kontribusi maksimal terhadap proses prediksi.
Scikit-learn sudah menyediakan fungsi RFE ini, sehingga kita tidak perlu repot lagi
melakukan proses manual. Sebagai contoh, kita ingin mengidentifikasi tiga feature yang
paling tinggi pengaruhnya terhadap akurasi model. Kita impor modul feature_selection
dan kita panggil fungsi RFE dengan menyertakan model yang sudah dilatih dan angka 3
(artinya tiga feature yang kita inginkan):
import sklearn.feature_selection as fs rfe = fs.RFE(model, 3) rfe = rfe.fit(X_train, y_train) print('Support=', rfe.support_) print('Ranking=', rfe.ranking_) Support= [False True True True False]
Ranking= [3 1 1 1 2]
Terlihat bahwa metode RFE menunjukkan feature no.2, 3, dan 4 yang paling tinggi
rangkingnya (ditandai dengan angka 1 dan “true” pada support). Ketiga feature yang paling
berpengaruh adalah Status Perkawinan, Jenis Kelamin dan Memiliki Mobil, baru kemudian
diikuti Penghasilan dan Usia. Ini dapat kita artikan bahwa ketiga feature yang paling
berpengaruh tersebut sudah cukup untuk membuat model dengan akurasi yang tinggi,
sehingga apabila kedua feature lainnya diabaikan maka model tetap dapat memberikan
prediksi yang cukup baik.
Pada prakteknya, proses feature selection adalah salah satu aktivitas yang paling penting
dilakukan dalam membangun model, dan seringkali harus dilakukan secara berulang-ulang
karena di dunia industri, jumlah feature bisa puluhan hingga ratusan. Akurasi model
ditentukan oleh pemilihan feature yang tepat, karena aturan “garbage in, garbage out”

(memasukkan sampah akan menghasilkan sampah pula) berlaku di sini. Dalam konteks Data
Science, “sampah” adalah noise di dalam data.
Feature juga bisa ditambah jumlahnya dengan cara mempergunakan data turunan, data
gabungan atau data hasil kalkulasi. Proses ini disebut feature creation, yaitu membuat
feature-feature baru dari data-data yang sudah ada. Contohya Di sini diperlukan pemahaman
terhadap domain permasalahan yang sedang dipecahkan (jenis industri, proses bisnis, dan
sebagainya).
Kesimpulan
Di bab ini kita telah mencoba membuat model binary classification. Logistic Regression
adalah metode yang banyak dipergunakan karena relatif mudah dipahami dan mudah
diterapkan untuk keperluan binary classification. Ada banyak contoh penerapan Logistic
Regression di bidang medis (prediksi pasien akan menderita suatu penyakit atau tidak),
bidang keuangan (prediksi seorang kreditor akan gagal bayar atau tidak), bidang marketing
(prediksi seorang pelanggan akan membeli produk atau tidak), dan di bidang lainnya.
Tidak hanya untuk binary classification, sebenarnya kita bisa juga mempergunakan Logistic
Regression untuk kasus-kasus prediksi yang bersifat multinomial atau ordinal, misalnya
mengklasifikasikan penduduk suatu wilayah ke dalam kategori-kategori tertentu.
Sayangnya, Logistic Regression tidak mampu menangani dataset dengan banyak feature.
Logistic regression juga lebih rentan terhadap overfitting. Ini sebabnya proses feature
selection menjadi perlu mendapat perhatian lebih sebelum melakukan training.

BAB 6 Decision Tree Dalam kehidupan kita sebagai manusia, setiap hari kita dihadapkan pada proses pembuatan
keputusan yang tanpa kita sadari kita mempergunakan suatu pola tersendiri untuk mendukung
proses tersebut. Sebagai contoh, misalnya suatu hari ada seseorang yang menelepon Anda
dan meminta bantuan pinjaman sejumlah uang. Tentunya sebelum Anda menjawab apakah
akan memenuhi permintaannya atau tidak, secara naluriah akan muncul proses pembuatan
keputusan di pikiran Anda berdasarkan berbagai faktor seperti berikut:
1. Apakah orang ini saudara atau kawan dekat Anda, ataukah seseorang yang belum
lama dikenal? Bila bukan kawan atau saudara, Anda akan langsung memutuskan
untuk menolak permintaannya. Namun jika orang ini adalah saudara atau kawan
Anda, maka pikiran Anda akan menuju ke langkah selanjutnya.
2. Apakah pernah ada sejarah buruk tentang orang ini, misalnya suka berhutang dan
tidak mengembalikan? Bila jawabannya ya, maka keputusan Anda adalah menolak
permintaan pinjaman. Bila tidak ada sejarah yang tidak baik tentang orang ini, maka
proses pembuatan keputusan dilanjutkan ke langkah selanjutnya.
3. Apakah jumlah uang yang diminta melebihi kemampuan Anda untuk memberi
pinjaman, misalnya di bawah sepuluh juta Rupiah? Bila iya, maka Anda akan
memberitahu orang tersebut bahwa Anda tidak bisa meminjamkan uang. Bila
jumlahnya masih dalam jangkauan Anda, maka Anda akan memenuhi permintaan
pinjaman orang tersebut.
Bila proses pembuatan keputusan di atas kita gambarkan dalam suatu diagram alur, maka
akan muncul diagram seperti di bawah ini:
Gambar 27: contoh proses pembuatan keputusan
Proses bercabang seperti pohon seperti inilah yang dicoba ditiru ke dalam algoritma
komputer yang disebut Decision Tree. Seperti kita lihat di diagram di atas, kotak di puncak
pohon (disebut root node) memiliki dua “anak” di bawahnya (disebut node). Di setiap kotak
ada proses pembuatan keputusan yang menghasilkan dua cabang, ke kiri dan ke kanan.
Pembuatan keputusan dilakukan dengan menguji suatu variabel, misalnya apakah nilai
variabel melebihi suatu ambang batas tertentu. Bila jawabannya “ya”, maka proses berlanjut
Tidak
Tidak
Tidak Ya
Ya
Ya
Saudara atau kawan dekat?
Ada sejarah buruk? Tolak
Meminjam >10 juta? Tolak
Tolak Setuju
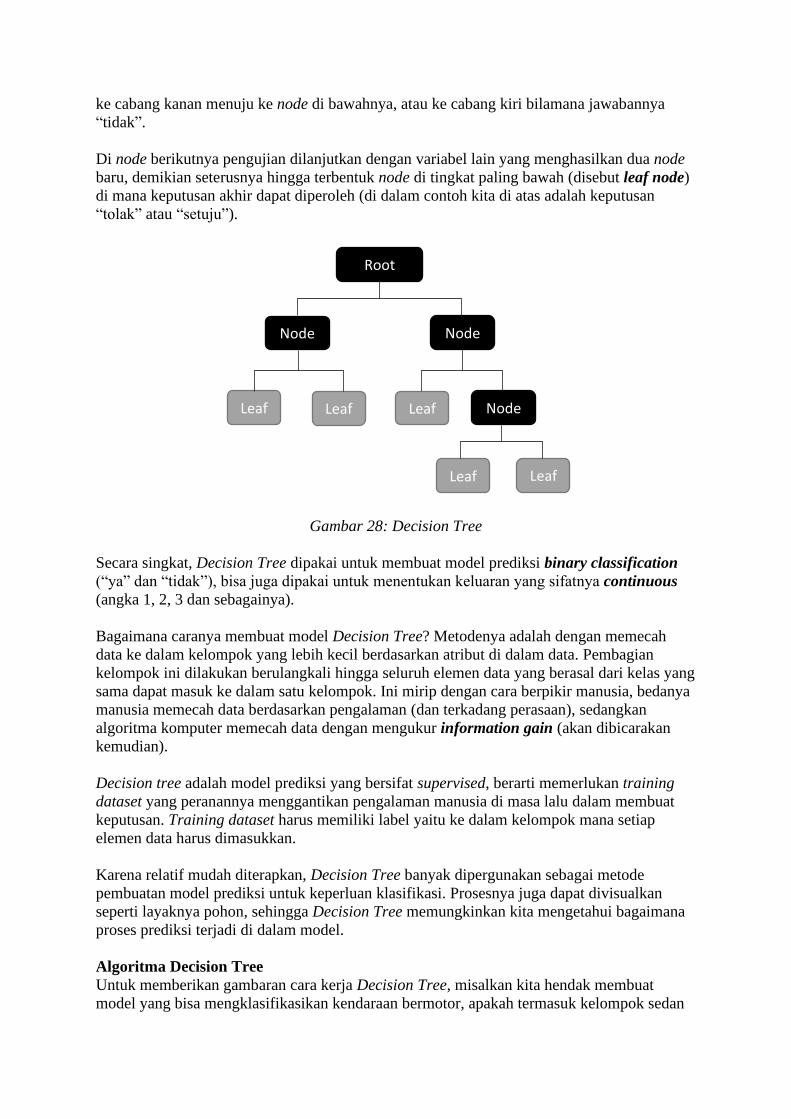
ke cabang kanan menuju ke node di bawahnya, atau ke cabang kiri bilamana jawabannya
“tidak”.
Di node berikutnya pengujian dilanjutkan dengan variabel lain yang menghasilkan dua node
baru, demikian seterusnya hingga terbentuk node di tingkat paling bawah (disebut leaf node)
di mana keputusan akhir dapat diperoleh (di dalam contoh kita di atas adalah keputusan
“tolak” atau “setuju”).
Gambar 28: Decision Tree
Secara singkat, Decision Tree dipakai untuk membuat model prediksi binary classification
(“ya” dan “tidak”), bisa juga dipakai untuk menentukan keluaran yang sifatnya continuous
(angka 1, 2, 3 dan sebagainya).
Bagaimana caranya membuat model Decision Tree? Metodenya adalah dengan memecah
data ke dalam kelompok yang lebih kecil berdasarkan atribut di dalam data. Pembagian
kelompok ini dilakukan berulangkali hingga seluruh elemen data yang berasal dari kelas yang
sama dapat masuk ke dalam satu kelompok. Ini mirip dengan cara berpikir manusia, bedanya
manusia memecah data berdasarkan pengalaman (dan terkadang perasaan), sedangkan
algoritma komputer memecah data dengan mengukur information gain (akan dibicarakan
kemudian).
Decision tree adalah model prediksi yang bersifat supervised, berarti memerlukan training
dataset yang peranannya menggantikan pengalaman manusia di masa lalu dalam membuat
keputusan. Training dataset harus memiliki label yaitu ke dalam kelompok mana setiap
elemen data harus dimasukkan.
Karena relatif mudah diterapkan, Decision Tree banyak dipergunakan sebagai metode
pembuatan model prediksi untuk keperluan klasifikasi. Prosesnya juga dapat divisualkan
seperti layaknya pohon, sehingga Decision Tree memungkinkan kita mengetahui bagaimana
proses prediksi terjadi di dalam model.
Algoritma Decision Tree
Untuk memberikan gambaran cara kerja Decision Tree, misalkan kita hendak membuat
model yang bisa mengklasifikasikan kendaraan bermotor, apakah termasuk kelompok sedan
Root
Node Node
Node Leaf
Leaf Leaf
Leaf Leaf
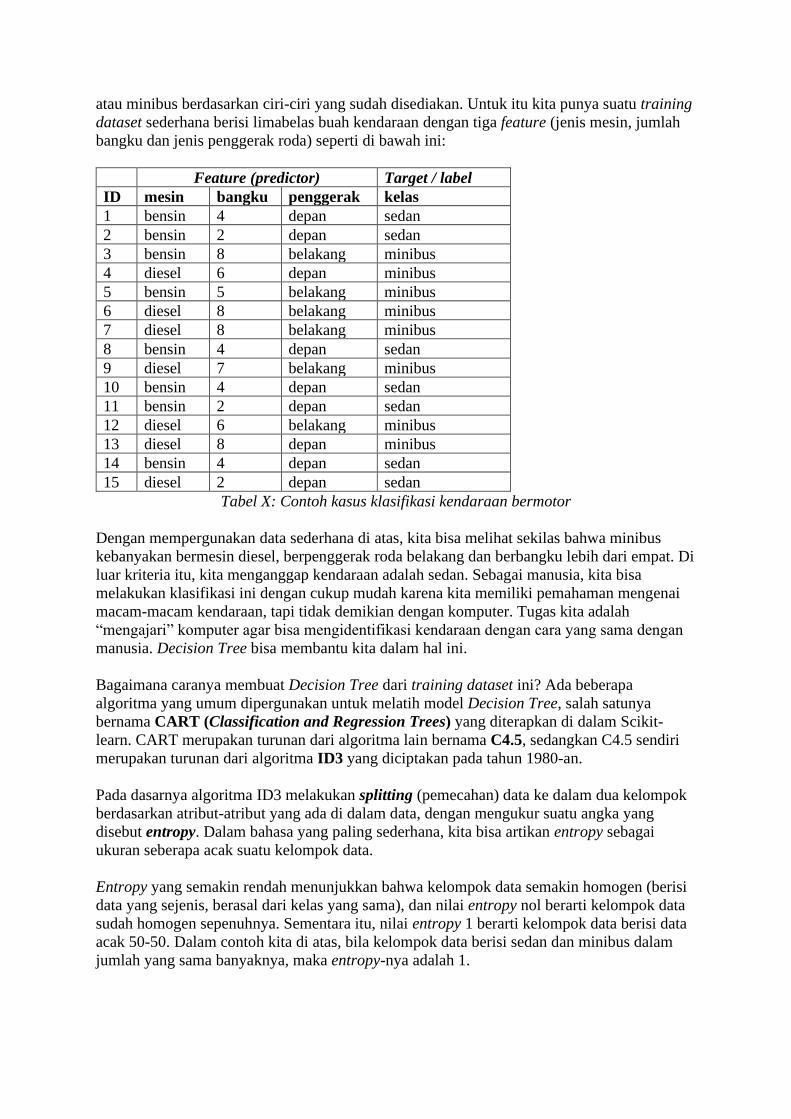
atau minibus berdasarkan ciri-ciri yang sudah disediakan. Untuk itu kita punya suatu training
dataset sederhana berisi limabelas buah kendaraan dengan tiga feature (jenis mesin, jumlah
bangku dan jenis penggerak roda) seperti di bawah ini:
Feature (predictor) Target / label
ID mesin bangku penggerak kelas
1 bensin 4 depan sedan
2 bensin 2 depan sedan
3 bensin 8 belakang minibus
4 diesel 6 depan minibus
5 bensin 5 belakang minibus
6 diesel 8 belakang minibus
7 diesel 8 belakang minibus
8 bensin 4 depan sedan
9 diesel 7 belakang minibus
10 bensin 4 depan sedan
11 bensin 2 depan sedan
12 diesel 6 belakang minibus
13 diesel 8 depan minibus
14 bensin 4 depan sedan
15 diesel 2 depan sedan
Tabel X: Contoh kasus klasifikasi kendaraan bermotor
Dengan mempergunakan data sederhana di atas, kita bisa melihat sekilas bahwa minibus
kebanyakan bermesin diesel, berpenggerak roda belakang dan berbangku lebih dari empat. Di
luar kriteria itu, kita menganggap kendaraan adalah sedan. Sebagai manusia, kita bisa
melakukan klasifikasi ini dengan cukup mudah karena kita memiliki pemahaman mengenai
macam-macam kendaraan, tapi tidak demikian dengan komputer. Tugas kita adalah
“mengajari” komputer agar bisa mengidentifikasi kendaraan dengan cara yang sama dengan
manusia. Decision Tree bisa membantu kita dalam hal ini.
Bagaimana caranya membuat Decision Tree dari training dataset ini? Ada beberapa
algoritma yang umum dipergunakan untuk melatih model Decision Tree, salah satunya
bernama CART (Classification and Regression Trees) yang diterapkan di dalam Scikit-
learn. CART merupakan turunan dari algoritma lain bernama C4.5, sedangkan C4.5 sendiri
merupakan turunan dari algoritma ID3 yang diciptakan pada tahun 1980-an.
Pada dasarnya algoritma ID3 melakukan splitting (pemecahan) data ke dalam dua kelompok
berdasarkan atribut-atribut yang ada di dalam data, dengan mengukur suatu angka yang
disebut entropy. Dalam bahasa yang paling sederhana, kita bisa artikan entropy sebagai
ukuran seberapa acak suatu kelompok data.
Entropy yang semakin rendah menunjukkan bahwa kelompok data semakin homogen (berisi
data yang sejenis, berasal dari kelas yang sama), dan nilai entropy nol berarti kelompok data
sudah homogen sepenuhnya. Sementara itu, nilai entropy 1 berarti kelompok data berisi data
acak 50-50. Dalam contoh kita di atas, bila kelompok data berisi sedan dan minibus dalam
jumlah yang sama banyaknya, maka entropy-nya adalah 1.

Proses splitting dilakukan bertingkat dari atas ke bawah, menghasilkan kelompok data yang
semakin kecil. Setiap kelompok data dibuat sedemikian rupa agar entropy-nya serendah
mungkin; dalam contoh kita di atas, sedan semua masuk ke dalam kelompok sedan, minibus
semua masuk ke dalam kelompok minibus.
Di setiap tingkatan, semua feature, yaitu atribut data yang ada, diuji untuk untuk
mendapatkan entropy yang serendah mungkin. Semakin banyak tingkatan dalam Decision
Tree, artinya pohon semakin “tinggi” dan proses splitting semakin kompleks, model akan
menjadi lebih fit. Adapun begitu, untuk mencegah Decision Tree menjadi terlalu panjang
yang dapat mengakibatkan overfitting (model nampak bagus pada saat training namun tidak
bisa bekerja baik saat dipakai dengan data baru), suatu proses yang disebut pruning
(pemangkasan) perlu dilakukan. Cabang-cabang yang terlalu panjang dipangkas, dan node-
node di tingkat atas dijadikan leaf node.
Dengan mengesampingkan terlebih dahulu bagaimana formula menghitung entropy, kita coba
membuat Decision Tree dengan training dataset yang ada. Dimulai dari root node, kita
masukkan seluruh training dataset berisi 15 kendaraan (7 sedan dan 8 minibus), kemudian
kita menguji salah satu feature yaitu apakah kendaraan bermesin bensin atau bukan:
Gambar 29: Decision Tree dengan feature jenis mesin
Di root node, nilai entropy mendekati angka 1 karena training dataset belum disentuh dan
kebetulan berisi sedan dan minibus dalam jumlah yang hampir sama (7 vs 8). Kemudian
setelah proses splitting, di node paling kiri, kelompok data diisi oleh semua kendaraan
bermesin bensin (6 sedan dan 2 minibus). Masih masih ada campuran kedua macam
kendaraan, itu sebabnya nilai entropy kelompok ini masih tinggi. Di cabang kanan, node
berisikan kendaraan bermesin diesel yaitu 6 minibus dan 1 sedan. Meskipun angka entropy-
nya jauh lebih rendah, kelompok ini masih belum homogen.
Sekarang kita coba proses splitting dengan feature yang lain, yaitu melihat kendaraan
berdasarkan penggerak roda apakah penggerak roda depan atau bukan. Hasilnya lebih baik,
karena menghasilkan dua “anak” dengan kelompok data yang entropy-nya lebih rendah,
bahkan entropy nol untuk cabang kanan:
Ya Tidak
Entropy = 0.996
Isi = 7 sedan, 8 minibus
feature: mesin bensin?
Entropy = 0.811
Isi = 6 sedan + 2 minibus
Entropy = 0.591
Isi = 6 minibus + 1 sedan
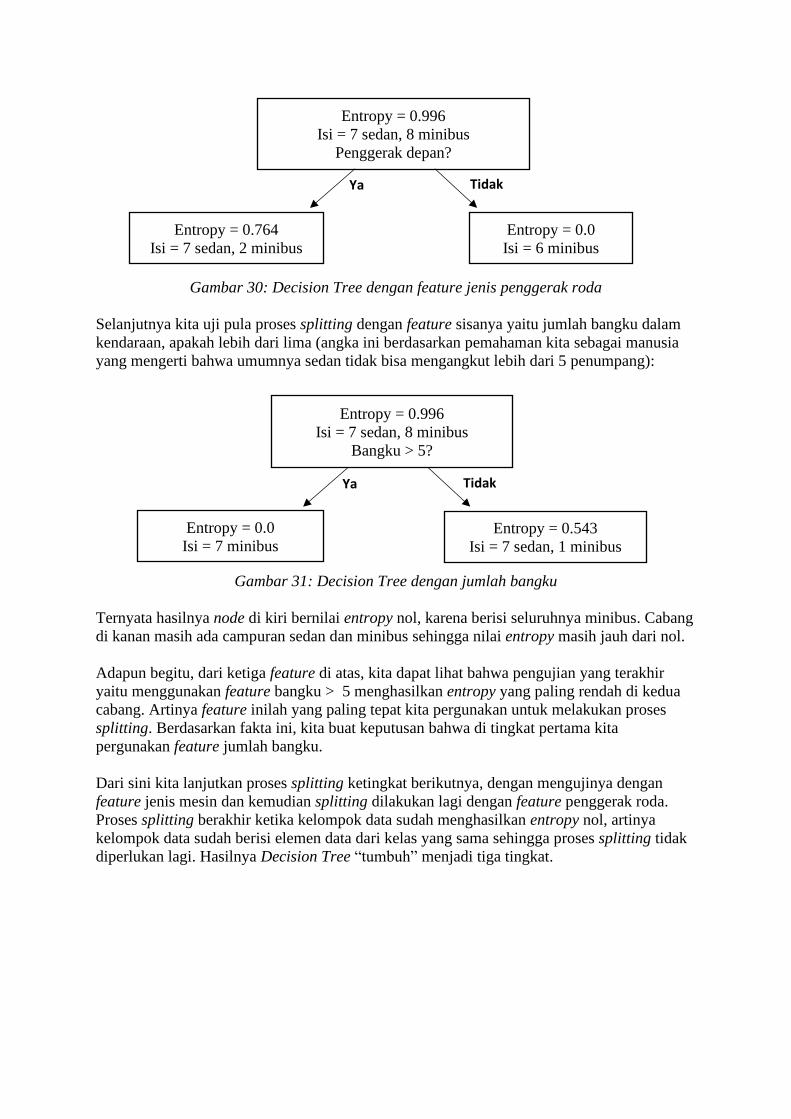
Gambar 30: Decision Tree dengan feature jenis penggerak roda
Selanjutnya kita uji pula proses splitting dengan feature sisanya yaitu jumlah bangku dalam
kendaraan, apakah lebih dari lima (angka ini berdasarkan pemahaman kita sebagai manusia
yang mengerti bahwa umumnya sedan tidak bisa mengangkut lebih dari 5 penumpang):
Gambar 31: Decision Tree dengan jumlah bangku
Ternyata hasilnya node di kiri bernilai entropy nol, karena berisi seluruhnya minibus. Cabang
di kanan masih ada campuran sedan dan minibus sehingga nilai entropy masih jauh dari nol.
Adapun begitu, dari ketiga feature di atas, kita dapat lihat bahwa pengujian yang terakhir
yaitu menggunakan feature bangku > 5 menghasilkan entropy yang paling rendah di kedua
cabang. Artinya feature inilah yang paling tepat kita pergunakan untuk melakukan proses
splitting. Berdasarkan fakta ini, kita buat keputusan bahwa di tingkat pertama kita
pergunakan feature jumlah bangku.
Dari sini kita lanjutkan proses splitting ketingkat berikutnya, dengan mengujinya dengan
feature jenis mesin dan kemudian splitting dilakukan lagi dengan feature penggerak roda.
Proses splitting berakhir ketika kelompok data sudah menghasilkan entropy nol, artinya
kelompok data sudah berisi elemen data dari kelas yang sama sehingga proses splitting tidak
diperlukan lagi. Hasilnya Decision Tree “tumbuh” menjadi tiga tingkat.
Entropy = 0.0
Isi = 7 minibus Entropy = 0.543
Isi = 7 sedan, 1 minibus
Entropy = 0.996
Isi = 7 sedan, 8 minibus
Bangku > 5?
Entropy = 0.996
Isi = 7 sedan, 8 minibus
Penggerak depan?
Entropy = 0.764
Isi = 7 sedan, 2 minibus
Entropy = 0.0
Isi = 6 minibus
Ya Tidak
Ya Tidak
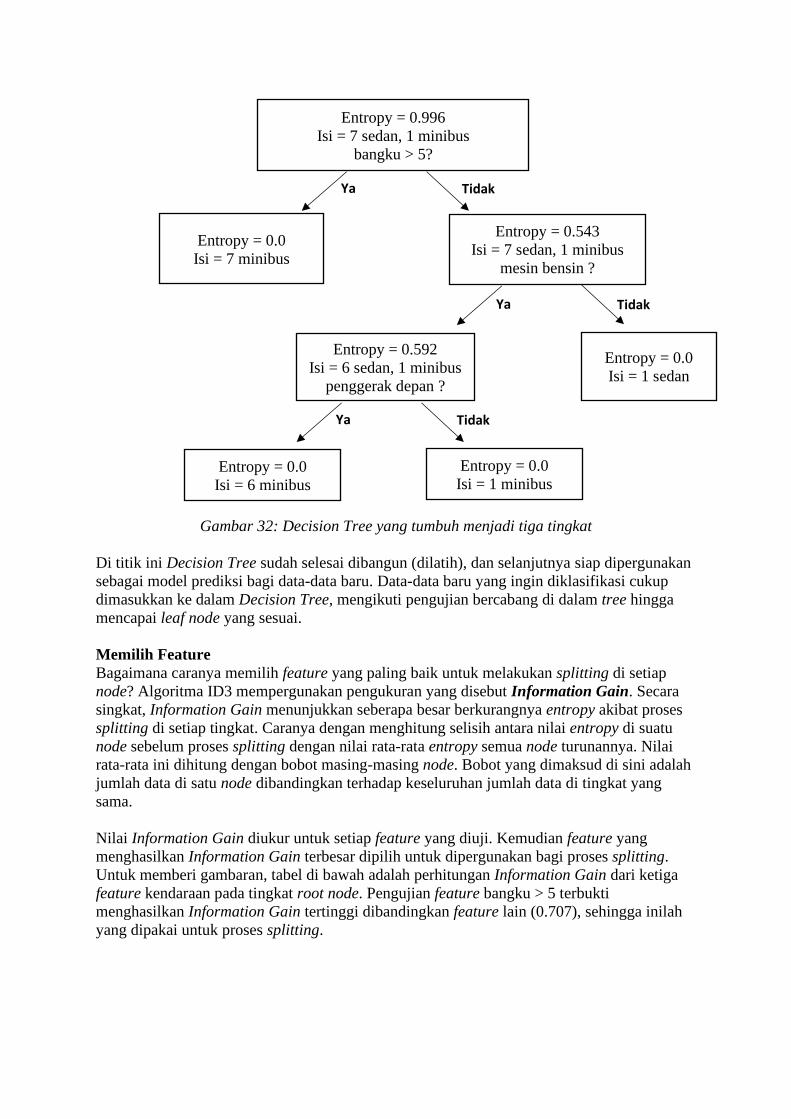
Gambar 32: Decision Tree yang tumbuh menjadi tiga tingkat
Di titik ini Decision Tree sudah selesai dibangun (dilatih), dan selanjutnya siap dipergunakan
sebagai model prediksi bagi data-data baru. Data-data baru yang ingin diklasifikasi cukup
dimasukkan ke dalam Decision Tree, mengikuti pengujian bercabang di dalam tree hingga
mencapai leaf node yang sesuai.
Memilih Feature
Bagaimana caranya memilih feature yang paling baik untuk melakukan splitting di setiap
node? Algoritma ID3 mempergunakan pengukuran yang disebut Information Gain. Secara
singkat, Information Gain menunjukkan seberapa besar berkurangnya entropy akibat proses
splitting di setiap tingkat. Caranya dengan menghitung selisih antara nilai entropy di suatu
node sebelum proses splitting dengan nilai rata-rata entropy semua node turunannya. Nilai
rata-rata ini dihitung dengan bobot masing-masing node. Bobot yang dimaksud di sini adalah
jumlah data di satu node dibandingkan terhadap keseluruhan jumlah data di tingkat yang
sama.
Nilai Information Gain diukur untuk setiap feature yang diuji. Kemudian feature yang
menghasilkan Information Gain terbesar dipilih untuk dipergunakan bagi proses splitting.
Untuk memberi gambaran, tabel di bawah adalah perhitungan Information Gain dari ketiga
feature kendaraan pada tingkat root node. Pengujian feature bangku > 5 terbukti
menghasilkan Information Gain tertinggi dibandingkan feature lain (0.707), sehingga inilah
yang dipakai untuk proses splitting.
Entropy = 0.0
Isi = 7 minibus
Entropy = 0.543
Isi = 7 sedan, 1 minibus
mesin bensin ?
Entropy = 0.996
Isi = 7 sedan, 1 minibus
bangku > 5?
Entropy = 0.592
Isi = 6 sedan, 1 minibus
penggerak depan ?
Entropy = 0.0
Isi = 1 sedan
Entropy = 0.0
Isi = 1 minibus Entropy = 0.0
Isi = 6 minibus
Ya Tidak
Ya Tidak
Ya Tidak
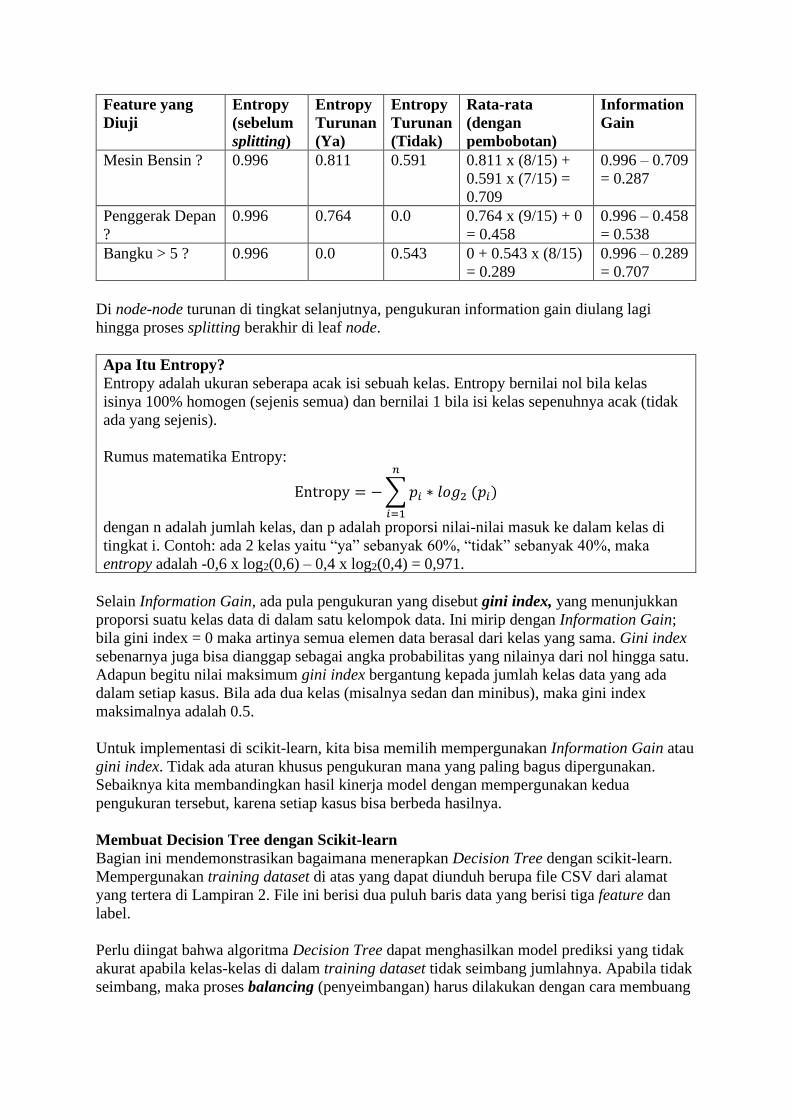
Feature yang
Diuji
Entropy
(sebelum
splitting)
Entropy
Turunan
(Ya)
Entropy
Turunan
(Tidak)
Rata-rata
(dengan
pembobotan)
Information
Gain
Mesin Bensin ? 0.996 0.811 0.591 0.811 x (8/15) +
0.591 x (7/15) =
0.709
0.996 – 0.709
= 0.287
Penggerak Depan
?
0.996 0.764 0.0 0.764 x (9/15) + 0
= 0.458
0.996 – 0.458
= 0.538
Bangku > 5 ? 0.996 0.0 0.543 0 + 0.543 x (8/15)
= 0.289
0.996 – 0.289
= 0.707
Di node-node turunan di tingkat selanjutnya, pengukuran information gain diulang lagi
hingga proses splitting berakhir di leaf node.
Apa Itu Entropy?
Entropy adalah ukuran seberapa acak isi sebuah kelas. Entropy bernilai nol bila kelas
isinya 100% homogen (sejenis semua) dan bernilai 1 bila isi kelas sepenuhnya acak (tidak
ada yang sejenis).
Rumus matematika Entropy:
Entropy = − ∑ 𝑝𝑖 ∗ 𝑙𝑜𝑔2 (𝑝𝑖)
𝑛
𝑖=1
dengan n adalah jumlah kelas, dan p adalah proporsi nilai-nilai masuk ke dalam kelas di
tingkat i. Contoh: ada 2 kelas yaitu “ya” sebanyak 60%, “tidak” sebanyak 40%, maka
entropy adalah -0,6 x log2(0,6) – 0,4 x log2(0,4) = 0,971.
Selain Information Gain, ada pula pengukuran yang disebut gini index, yang menunjukkan
proporsi suatu kelas data di dalam satu kelompok data. Ini mirip dengan Information Gain;
bila gini index = 0 maka artinya semua elemen data berasal dari kelas yang sama. Gini index
sebenarnya juga bisa dianggap sebagai angka probabilitas yang nilainya dari nol hingga satu.
Adapun begitu nilai maksimum gini index bergantung kepada jumlah kelas data yang ada
dalam setiap kasus. Bila ada dua kelas (misalnya sedan dan minibus), maka gini index
maksimalnya adalah 0.5.
Untuk implementasi di scikit-learn, kita bisa memilih mempergunakan Information Gain atau
gini index. Tidak ada aturan khusus pengukuran mana yang paling bagus dipergunakan.
Sebaiknya kita membandingkan hasil kinerja model dengan mempergunakan kedua
pengukuran tersebut, karena setiap kasus bisa berbeda hasilnya.
Membuat Decision Tree dengan Scikit-learn
Bagian ini mendemonstrasikan bagaimana menerapkan Decision Tree dengan scikit-learn.
Mempergunakan training dataset di atas yang dapat diunduh berupa file CSV dari alamat
yang tertera di Lampiran 2. File ini berisi dua puluh baris data yang berisi tiga feature dan
label.
Perlu diingat bahwa algoritma Decision Tree dapat menghasilkan model prediksi yang tidak
akurat apabila kelas-kelas di dalam training dataset tidak seimbang jumlahnya. Apabila tidak
seimbang, maka proses balancing (penyeimbangan) harus dilakukan dengan cara membuang

sebagian data (atau menambah data) dari salah satu kelas. Untungnya, training dataset kita
berisikan dua kelas (sedan dan minibus) yang besarnya hampir sama.
Mari langsung kita coba dengan program baru, tentunya terlebih dahulu kita impor library
andalan kita yaitu pandas, kemudian kita buka file CSV:
import pandas as pd df1 = pd.read_csv("C:\\decisiontree1.csv") encoding = {"mesin": {"bensin": 0, "diesel": 1}, "penggerak": {"depan": 0, "belakang": 1}} df1.replace(encoding, inplace=True)
Di dalam file, oleh karena isi feature masih ada yang berupa nilai alfanumerik (“bensin”,
“diesel”, “depan” dan “belakang”) maka kita perlu melakukan transformasi berupa encoding
(pengkodean) ke angka 0 dan 1 agar scikit-learn bisa membacanya nanti. Untuk keperluan ini
kita pakai fungsi replace() yang ada di dalam DataFrame. “Mesin bensin” dikodekan
dengan angka 0, “mesin diesel” dengan angka 1. Demikian juga dengan penggerak roda
“depan” dan “belakang” menjadi 0 dan 1. Parameter inplace=True artinya DataFrame
langsung diubah secara permanen.
Setelah program dijalankan, DataFrame df1 akan berisi training dataset yang sudah hampir
siap. Kita coba lihat hasilnya:
print(df1)

Ketiga feature (mesin, bangku dan penggerak) akan kita simpan dalam satu dataset terpisah
dengan labelnya. Seperti sudah dibahas di bab-bab sebelumnya, features disimpan dalam
variabel bernama X (huruf besar), dan labelnya dalam variabel bernama y (huruf kecil).
Kolom ID tidak kita perlukan sehingga perlu kita buang dari training dataset dengan fungsi
drop(), begitu juga dengan label (yang harus ditaruh di variabel y).
Selanjutnya, seperti contoh di bab-bab sebelumnya pula, kita akan ambil 20% dari training
dataset ini sebagai test data untuk menguji akurasi model kita nanti. Kita impor paket
sklearn.model_selection agar kita bisa memakai fungsi train_test_split() untuk
keperluan ini. Hasilnya training dataset akan ditaruh di variabel X_train dan y_train,
sementara test dataset di X_test dan y_test. Karena dataset kita kecil, 20% artinya akan
ada empat baris saja.
import sklearn.model_selection as ms X = df1.drop(['ID','label'], axis=1) y = df1['label'] X_train, X_test, y_train, y_test = ms.train_test_split(X,y, test_size=0.2) Scikit-learn sudah mempersiapkan implementasi Decision Tree yaitu
DecisionTreeClassifier yang ada di dalam paket skelarn.tree. Sebagai ujicoba
pertama, kita akan melatih model dengan pergunakan entropy sebagai kriteria pengukuran
proses splitting. Untuk ujicoba berikutnya nanti kita akan mencoba mempergunakan gini
index dan akan kita bandingkan hasilnya. Kita juga bisa menentukan jumlah maksimal
kedalaman tree, dalam hal ini kita batasi 5 tingkat saja (max_depth=5).
import sklearn.tree as tree model1 = tree.DecisionTreeClassifier(criterion='entropy', max_depth=5) model1.fit(X_train, y_train)
Sampai di titik ini, model sudah terbangun dan bisa diuji dengan test dataset. Mari kita uji
dengan memasukkan test dataset kita yang sudah kita siapkan sebagai variabel X_test, dan
hasil prediksinya dimasukkan dalam variabel y_prediksi :
y_prediksi = model1.predict(X_test) Untuk memastikan apakah keluaran model prediksi sudah sesuai harapan, kita lihat variabel
y_prediksi ini:
print(y_prediksi)
['sedan' 'minibus' 'minibus' 'minibus' 'minibus' 'minibus' 'minibus'
'sedan']
Kita hanya memiliki delapan test data, maka muncul hanya delapan pula hasil prediksi. Hasil
ini perlu kita bandingkan dengan label yang sebenarnya di dalam test data, apakah akurat atau
tidak (perlu diperhatikan bahwa di komputer Anda mungkin akan muncul hasil yang berbeda,
karena training dan test dataset yang berbeda):

import sklearn.metrics as met print(met.accuracy_score(y_test, y_prediksi)) 0.875
Akurasi model kita 87.5%, yang artinya sudah cukup baik dibandingkan dengan sekedar
menebak secara acak (50/50), namun masih bisakah akurasi ini kita tingkatkan? Kita bisa
mencoba untuk mengganti kriteria splitting dari entropy menjadi gini index, dan kita ulang
proses di atas untuk membandingkan hasilnya (kode yang diubah dicetak tebal di bawah ini):
import sklearn.tree as tree import sklearn.metrics as met model1 = tree.DecisionTreeClassifier(criterion='gini', max_depth=5) model1.fit(X_train, y_train) y_prediksi = model1.predict(X_test) print(y_prediksi) print(met.accuracy_score(y_test, y_prediksi))
['minibus' 'minibus' 'minibus' 'sedan']
0.75
Ternyata akurasinya justru lebih rendah. Artinya gini index bukan metode yang tepat untuk
penggunaan di kasus kita kali ini.
Visualisasi
Salah satu keunggulan Decision Tree adalah algoritma ini transparan dalam proses
trainingnya sehingga memungkinkan kita mempelajari bagaimana tree dapat terbentuk.
Cara yang terbaik untuk melihat Decision Tree adalah dengan menampilkannya secara visual.
Untuk ini kita perlu bantuan Graphviz, sebuah open source library untuk visualisasi
berbagai macam keperluan. Selain itu kita perlu juga library pydotplus yang menjadi
penghubung Python dengan Graphviz yang mempergunakan format khusus yaitu DOT
language.
Untuk mengunduh dan install kedua modul ini, pastikan komputer Anda terhubung ke
internet dan kemudian jalankan Conda:
conda install -c anaconda graphviz conda install -c conda-forge pydotplus Setelah keduanya terpasang, untuk menggambarkan Decision Tree cukup mudah saja, yaitu
dengan cara memanggil fungsi export_graphviz() dengan memasukkan model1 yang
sudah kita buat tadi sebagai salah satu parameternya. Parameter lainnya adalah labels, yaitu
nama semua features yang ada. Keluaran dari fungsi ini adalah dot_data, berisi data
berformat khusus DOT yang dipakai oleh Graphviz. Dengan bantuan pydotplus kita buat
graph data dari dot_data ini, agar selanjutnya dapat dibuat visualisasinya oleh Graphviz.
Hasil visualisasi bisa dituliskan dengan fungsi write_png() ke dalam sebuah file image
(berformat PNG) di folder lokal komputer kita. Kita beri nama file ini decisiontree.png.

import pydotplus as pp labels = ['mesin','bangku','penggerak'] dot_data = tree.export_graphviz(model1, out_file=None, feature_names=labels, filled = True, rounded = True) graph = pp.graph_from_dot_data(dot_data) graph.write_png('decisiontree.png')
Bila kita buka file PNG tersebut, akan muncul visualisasi Decision Tree seperti ini:
Gambar 33: Decision Tree hasil GraphViz
Diagram di atas memberikan pemahaman yang lebih baik kepada kita, bagaimana algoritma
Decision Tree membangun model yang kita sudah latih. Informasi disajikan mencakup
feature yang diuji di setiap node, nilai entropy, jumlah data di node tersebut (“sample”) dan
juga jumlah elemen data di setiap kelas data (misalnya [18, 14] di root node artinya ada 18
sedan dan 14 minibus).
Terlihat bahwa di root node, feature yang dipilih oleh algoritma untuk diuji adalah jumlah
bangku apakah di bawah 5 (algoritma menuliskan angka 4.5, namun ini sama saja artinya).
Proses splitting pertama menghasilkan kelompok “true” di kiri berisi 17 sample, kelompok
“false” berisi 15 sample. Di tingkat bawahnya, proses splitting diulang lagi, dan feature yang
dipilih adalah tipe mesin apakah bensin (“0”) atau diesel (“1”). Demikian seterusnya
sehingga leaf node tercapai.
Decision Trees untuk Membuat Regression Model
Selain untuk keperluan klasifikasi seperti contoh di atas, algoritma Decision Tree juga dapat
dimanfaatkan untuk membuat model Regression Trees, yang gunanya memprediksi target
yang sifatnya kategorikal misalnya “tinggi”, “sedang”, “rendah” dan sebagainya.
Prinsipnya sama dengan model klasifikasi, adapun proses splitting menjadi sedikit lebih
kompleks karena metrik evaluasinya berbeda. Scikit-learn sudah mempersiapkan paket

DecisionTreeRegressor untuk keperluan ini. Adapun demikian pembahasan tentang
Regression Trees tidak termasuk dalam cakupan buku ini, pembaca disarankan membaca
dokumentasi scikit-learn bila ingin mencobanya.
Pengembangan Decision Trees
Dalam contoh sedan dan minibus di atas kita hanya mempergunakan tiga feature sederhana
sehingga proses pembuatan Decision Tree menjadi mudah. Bagaimana bila kita memiliki
banyak feature, belasan sampai puluhan? Di sinilah kelemahan Decision Tree akan nampak,
karena bila kita memasukkan banyak variabel yang tidak memiliki hubungan jelas, Decision
Tree akan kesulitan membuat model yang kokoh.
Untuk mencegahnya, kita harus memastikan training dataset sudah terlebih dahulu kita
lakukan profiling, yaitu sudah kita pelajari isi dan korelasi antar variabelnya. Variabel yang
dirasa tidak relevan harus dibuang.
Decision Tree memiliki kelemahan lain yaitu cenderung membuat model yang overfit.
Apabila tree yang dibangun menjadi terlalu kompleks, maka jumlah tingkatan menjadi terlalu
panjang mengikuti training dataset yang efek buruknya adalah menjadi tidak akurat ketika
dihadapkan dengan data baru yang lain. Ini bisa sedikit banyak diatasi dengan menentukan
kedalaman (“depth”) dari tree, yang memerlukan eksperimen iteratif.
Decision Tree juga termasuk algoritma Machine Learning yang unstable (tidak stabil),
artinya perubahan kecil saja terhadap data akan membuat model berubah cukup drastis.
Random Forest
Kombinasi instrumen musik yang dimainkan bersama akan bisa menghasilkan alunan lagu
yang lebih indah, barangkali adalah analogi yang cocok untuk menggambarkan metode yang
disebut Ensemble. Metode ini memungkinkan kita menggabungkan beberapa model untuk
mendapatkan hasil yang lebih baik daripada manjalankan setiap model sendiri-sendiri.
Gambar 34: Pembuatan model dengan metode ensemble
Untuk mengatasi kelemahan Decision Tree, metode ensemble yang disebut Random Forest
banyak dimanfaatkan untuk mencapai hasil akurasi yang lebih baik. Disebut forest (hutan)
karena berisikan banyak trees (pohon). Prinsipnya adalah membangun beberapa model
Decision Tree dan kemudian menggabungkan hasilnya. Seperti politik devide et impera
(pecah belah dan taklukkan), training dataset yang besar jumlahnya dipecah-pecah dan setiap
model mendapat subset dari training data secara acak. Setiap model akan menghasilkan
keluaran yang berbeda-beda pula. Dengan membangun banyak model dan menggabungkan
semua keluarannya, diharapkan terbentuk sebuah model baru yang lebih robust (kokoh) dan
lebih akurat.
Training
Dataset
Model 1
Model 2 2122
Model 3 2122
Model Ensemble
Fungsi Penggabungan

Bagaimana caranya agar hasil dari banyak model dapat digabungkan? Untuk ini diperlukan
suatu fungsi penggabungan yang menyatukan atau memilih hasil dari model terbaik. Karena
Decision Tree seringkali dimanfaatkan untuk membangun classification model, fungsi
penggabungan ini berupa mekanisme voting (penentuan dengan suara terbanyak) yang
menjadi penentu keluaran mana yang akan dipakai. Setiap tree akan memberikan hak
suaranya, dan kelas yang paling populer yang akan dimenangkan sebagai hasil akhir.
Analoginya adalah ketika ada sebuah kontes dengan banyak juri, maka kontestan yang
mendapat nilai paling banyak dari semua juri akan menjadi pemenang. Dalam konteks
Random Forest, mekanisme voting dilaksanakan dengan memanfaatkan test dataset ketika
proses validasi terjadi.
Scikit-learn menyediakan modul sklearn.ensemble yang di dalamnya terdapat
RandomForestClassifier untuk keperluan membuat Random Forest. Contoh dibawah
ini akan membuat model dengan 100 buah Decision Tree (“estimator”):
import sklearn.ensemble as ens rf = ens.RandomForestClassifier(n_estimators=100) Terlihat di kode program di atas, Random Forest sudah kita siapkan dalam variabel rf. Dari
sini kita kemudian memuat training dan test dataset dengan pandas seperti biasa. Kita pakai
file yang sama dengan contoh sebelumnya:
import pandas as pd import sklearn.model_selection as ms df1 = pd.read_csv("C:\\decisiontree1.csv") encoding = {"mesin": {"bensin": 0, "diesel": 1}, "penggerak": {"depan": 0, "belakang": 1} } df1.replace(encoding, inplace=True) print(df1) X = df1.drop(['ID','label'], axis=1) y = df1['label'] X_train, X_test, y_train, y_test = ms.train_test_split(X,y, test_size=0.2)
Selanjutnya kita latih model dengan fit() seperti biasa :
rf.fit(X_train, y_train) Di titik ini model telah terbentuk. Bila kita lihat parameter apa saja yang dipakai oleh model,
akan terlihat seperti di bawah ini:
print(rf)

Salah satu parameter menarik adalah bootstrap = true yang artinya setiap tree akan
mendapatkan dataset yang diambil dengan metode yang disebut bootstrap sampling. Tujuan
metode ini adalah membuat setiap tree mendapatkan training dataset yang berbeda. Bila
parameter bootstrap ini bernilai false, artinya setiap tree akan mendapat seluruh training
dataset yang sama.
Selanjutnya kita bisa langsung memakai model dengan test dataset untuk scoring dan
mendapatkan hasil prediksi:
y_prediksi = rf.predict(X_test) Kita ukur seberapa akurat hasil prediksi model ini, dengan cara membandingkan hasil
prediksi dengan test dataset:
import sklearn.metrics as met akurasi = met.accuracy_score(y_test, y_prediksi) print(akurasi) 0.875
Kita bisa bereksperimen dengan berbagai parameter di atas, memilih feature yang paling pent
ing dan mengulang lagi training model untuk mendapat hasil yang berbeda. Bagaimana cara m
engetahui feature apa saja yang paling berkontribusi terhadap hasil prediksi? Ini penting agar
di iterasi berikutnya kita dapat langsung menghilangkan feature yang tidak memiliki pengaru
h tinggi. Di bawah ini kita bisa melihat bahwa feature kedua adalah feature yang paling penti
ng dengan score paling tinggi:
score = rf.feature_importances_ print(score) [0.20483358 0.47741512 0.3177513 ]
Feature yang paling rendah score-nya bisa dibuang dari training dataset. Dengan berbagai
ujicoba, kita bisa mendapatkan hasil yang lebih baik dengan Random Forest dibanding bila
kita hanya mempergunakan model Decision Tree tunggal.
Random Forest dengan Dataset yang Lebih Besar
Dalam contoh kasus di atas kita mempergunakan dataset sederhana. Untuk membuat
demonstrasi yang lebih menarik dengan data nyata, kita akan mencoba mempergunakan
dataset dari UCI Machine Learning yang berjudul “Adult Data”. Dataset ini berisi sejumlah
kecil data sensus penduduk tahun 1994 di Amerika Serikat, yang bisa dipakai untuk membuat
classification model yang tujuannya memprediksi apakah seseorang memiliki penghasilan

tahunan di atas lima puluh ribu dolar atau di bawah itu, berdasarkan data-data sensus yang
ada.
Dataset ini memiliki tidak kurang dari 48 ribu baris data dengan lima belas feature hasil
sensus penduduk yang tertera di daftar di bawah ini:
No Nama Feature Macam Nilai Penjelasan
1 age Continuous Umur, dalam tahun
2 workclass Nominal Kelas pekerjaan
3 fnlwft Continuous Bobot akhir
4 education Nominal Tingkat pendidikan
5 education_num Continuous Lama pendidikan, dalam tahun
6 marital_status Nominal Status perkawinan
7 occupation Nominal Pekerjaan
8 protective_serv Nominal Wajib militer
9 relationship Nominal Hubungan
10 race Nominal Suku/ras
11 sex Nominal Jenis kelamin
12 capital gain Continuous Pendapatan dari hasil investasi
13 capital loss Continuous Kerugian dari hasil investasi
14 hours-per-week Continuous Jam kerja dalam seminggu
15 native_country Nominal Negara asal
Dataset ini dapat diunduh dengan bebas dari alamat yang disebutkan di dalam Lampiran 2
buku ini. Dalam contoh kita, file yang telah kita unduh kita beri nama adult_data.csv.
Dengan program di bawah, kita muat file ini ke dalam sebuah DataFrame bernama df1 :
import pandas as pd import numpy as np import sklearn.tree as tree import sklearn.model_selection as ms import sklearn.ensemble as ens import sklearn.metrics as met rf = ens.RandomForestClassifier(n_estimators=100) df1 = pd.read_csv("/Users/dioskurn/adult_data.csv") df1.head(10)
Sebelum melangkah lebih lanjut, sebagai upaya untuk memastikan training dataset kita bebas
dari data yang kosong (null), kita panggil fungsi dropna() yang akan membersihkan
DataFrame df1 dari data yang kosong:

df1.dropna(inplace=True)
Semua feature akan kita pergunakan kecuali bobot akhir (“fnwgt”). Adapun kita lihat bahwa
banyak feature yang berupa nilai nominal (berupa kategori), sehingga kita perlu membuatnya
menjadi nilai-nilai continuous berupa kode angka agar model bisa bekerja baik.
Ada beberapa cara untuk melakukan ini, yang termudah adalah mempergunakan fungsi
LabelEncoder di modul preprocessing yang disediakan oleh scikit-learn. Kita mulai
dari jenis kelamin (“sex”) yang dikodekan menjadi 0 dan 1 dan ditaruh di kolom baru
bernama “sex code”:
import sklearn.preprocessing as prep gender = prep.LabelEncoder() gender.fit(df1['sex']) df1['sex_code'] = gender.transform(df1['sex']) df1[['sex','sex_code']].head(5)
Semua feature nominal lainnya yaitu “education”, “race”, “workclass”, “occupation”,
“relationship” dan “native” kita perlakukan sama:
education = prep.LabelEncoder() education.fit(df1['education']) df1['education_code'] = education.transform(df1['education']) race = prep.LabelEncoder() race.fit(df1['race']) df1['race_code'] = race.transform(df1['race']) workclass = prep.LabelEncoder() workclass.fit(df1['workclass']) df1['workclass_code'] = workclass.transform(df1['workclass']) occupation = prep.LabelEncoder() occupation.fit(df1['occupation']) df1['occupation_code'] = occupation.transform(df1['occupation'])

relationship = prep.LabelEncoder() relationship.fit(df1['relationship']) df1['relationship_code'] = relationship.transform(df1['relationship']) native = prep.LabelEncoder() native.fit(df1['native']) df1['native_code'] = native.transform(df1['native'])
Kemudian, karena semua predictor sudah kita ganti dengan nilai numerik, maka kita bisa
buang semua feature aslinya dan kita masukkan ke DataFrame baru bernama X. Sementara
itu labelnya disimpan dalam DataFrame bernama y:
X = df1.drop(['fnlwgt','workclass','education','marital-status','occupation','relationship','race','sex','native','label'], axis=1) y = df1['label']
Pada titik ini, dataset sudah siap untuk dipakai sebagai training dataset. Namun jangan lupa,
kita perlu test dataset, oleh sebab itu kita akan ambil 20% untuk test dataset:
X_train, X_test, y_train, y_test = ms.train_test_split(X,y, test_size=0.2)
Selanjutnya proses training dan scoring bisa kita lakukan seperti biasa:
rf.fit(X_train, y_train) y_prediksi = rf.predict(X_test) print('akurasi = ', met.accuracy_score(y_test, y_prediksi)) print(met.classification_report(y_test, y_prediksi)) print(rf.feature_importances_)
Dari statistik di atas, nampak bahwa akurasi model adalah 0,8486, tidak terlalu buruk namun
masih bisa ditingkatkan lagi. Caranya dengan melakukan analisis lebih lanjut terhadap
training dataset karena kita belum benar-benar membersihkannya dari data yang tidak bersih.

Kita bisa juga melakukan binning terhadap beberapa feature misalnya “capital_gain” dan
“capital_loss” karena di dalamnya masih banyak angka nol.
Satu hal yang perlu diingat juga adalah angka akurasi bukanlah ukuran unjuk kerja yang
terpenting. Perlu juga dilihat angka precision dan sensitivity model yang kita buat, dengan
mempergunakan fungsi precision_score() seperti yang sudah kita coba di bab
sebelumnya. Dengan menjalankan fungsi tersebut, terlihat juga bahwa feature yang
memberikan kontribusi tertinggi (22%) adalah feature pertama yaitu “education_num”.
Feature yang tidak memberikan kontribusi bisa dicoba dibuang dari dataset. Dengan berbagai
eksperimen, kita bisa mendapatkan akurasi model yang lebih tinggi.
Kesimpulan
Kekuatan utama Decision Tree adalah implementasinya yang tidak sulit. Juga karena
prosesnya transparan, hasil model mudah dijelaskan secara visual sehingga hasil analisis data
mudah dijelaskan kepada pihak lain, misalnya klien bisnis. Secara umum, Decision Tree
adalah algoritma yang biasanya dicoba pertama kali sebelum mencoba strategi Machine
Learning lainnya bilamana ternyata hasilnya kurang memuaskan.
Metode Random Forest diciptakan untuk membangun model yang lebih kokoh dengan
memanfaatkan banyak model Decision Tree. Metode semacam ini disebut juga dengan istilah
bagging (bootstrap aggregation). Random Forest bisa lebih efektif mengatasi masalah
overfitting, karena ada banyak hasil prediksi yang bisa diambil dan menghilangkan bias yang
mungkin ada.
Adapun begitu karena banyak model yang harus dibangun, biaya komputasi Random Forest
akan berlipat kali lebih tinggi dan memerlukan waktu lebih lama. Selain itu Random Forest
juga menghilangkan transparansi proses, tidak seperti Decision Tree di mana tree bisa
divisualisasikan dengan jelas.
Ada metode ensemble lain yang disebut dengan boosting, di mana proses prediksi dilakukan
secara bertingkat dan berurutan untuk mendapatkan hasil yang lebih baik. Ini berbeda dengan
Random Forest yang membangun banyak model dan dieksekusi secara paralel kemudian
menggabungkan hasil-hasilnya. AdaBoost, Gradient Descent dan XGBoost adalah tiga
algoritma boosting yang populer dipakai. Scikit-learn menyediakan juga beberapa penerapan
alogritma boosting di atas, pembaca yang tertarik dapat membuka dokumentasi scikit-learn
untuk informasi lebih lanjut.

BAB 7 Naive Bayes Ketika Anda membuka aplikasi ramalan cuaca di ponsel, maka Anda bisa jadi akan melihat
suatu angka misalnya “80%” di samping gambar awan dan hujan. Angka ini menunjukkan
probability (kemungkinan) hujan akan terjadi. Bila angka ini tinggi, maka kemungkinannya
lebih tinggi pula bahwa akan turun hujan di hari itu. Mengapa perlu ada angka probability?
Jawabannya adalah karena kita membutuhkan suatu metode matematis untuk mengatasi
ketidakpastian dalam berbagai fenomena di sekitar kehidupan manusia. Hujan adalah suatu
yang tidak pasti, namun kita memerlukan suatu metode yang membantu kita menentukan
apakah harus membawa payung atau tidak sebelum bepergian (keputusan ‘ya’ atau ‘tidak’)
Dalam bidang peramalan cuaca, untuk mengukur kemungkinan turunnya hujan para ahli
meteorologi mempergunakan data pengukuran terkait atmosfir bumi (tekanan udara, suhu,
kecepatan angin, gumpalan awan dan sebagainya) saat terjadi hujan di masa lalu. Probability
80% artinya hujan terbukti turun di suatu wilayah dalam 8 dari 10 kasus di masa lalu, yaitu di
saat angka-angka pengukuran atmosfirnya serupa.
Algoritma Naive Bayes adalah metode yang mempergunakan prinsip probability seperti di
atas untuk membuat model prediksi klasifikasi. Dengan memanfaatkan data tentang kejadian
di masa lalu, model bisa membuat perkiraan apa yang akan terjadi di masa depan. Metode ini
menghitung probability suatu kejadian, dan bisa berubah bila ada informasi pendukung
tambahan yang disediakan.
Keunggulan Naive Bayes adalah sifatnya yang efektif dan cepat untuk mengolah data
berjumlah besar. Karena kelebihannya itu, Naive Bayes biasa dipergunakan di aplikasi seperti
spam filtering (pendeteksi pesan sampah) dan deteksi anomali di jaringan komputer.
Algoritma Naive Bayes bahkan dianggap sebagai standar de facto untuk penerapan klasifikasi
teks misalnya sentiment analysis (menentukan apakah penulis suatu komentar bernada
positif, negatif atau netral).
Bagaimana Naive Bayes Bekerja
Naive Bayes (NB) adalah sekumpulan (bukan hanya satu) algoritma klasifikasi yang
dibangun berdasarkan Teori Bayes (diambil dari nama Thomas Bayes, seorang ahli
matematika dari Inggris di abad ke-18). Semua algoritma di bawah payung NB pada
prinsipnya menghitung seberapa tinggi kemungkinan suatu example masuk ke suatu
kelompok / kelas. Model klasifikasi yang memakai metode Bayes memanfaatkan training
dataset untuk menghitung kemungkinan setiap kelas berdasarkan nilai-nilai featurenya.
Ketika model kemudian dihadapkan pada data baru, feature baru akan dipakai untuk
menghitung kelas mana yang kemungkinannya tertinggi.
Dalam ilmu statistik, Teori Bayes dipakai untuk menjelaskan apa yang disebut conditional
probability, yaitu kemungkinan munculnya suatu kejadian A bila suatu kejadian B muncul.
Karena kejadian A bergantung kepada kejadian B, itu sebabnya disebut conditional
(bersyarat).

Formula Conditional Probability
Secara matematis, kemungkinan bersyarat (P) ini ditulis sebagai berikut:
𝑃(𝐴|𝐵) =𝑃(𝐵|𝐴) 𝑃(𝐴)
𝑃(𝐵)=
𝑃(𝐴 ∩ 𝐵)
𝑃(𝐵)
Notasi P(A) menunjukkan kemungkinan A terjadi, P(A | B) menunjukkan kemungkinan A
terjadi bila B terjadi, sementara P (A ∩ 𝐵) menunjukkan kemungkinan P(A) dan P(B)
terjadi bersamaan.
Sebagai contoh untuk menjelaskan teori ini di dunia nyata, katakanlah kita hendak membuat
model prediksi yang menentukan apakah sebuah pesan SMS termasuk pesan sampah atau
bukan. Sebagai data yang sudah kita miliki dari pengamatan sebelumnya, pesan sampah
kebanyakan berisi kata “kredit” (pesan sampah memang kebanyakan mengirimkan tawaran
kartu kredit atau pinjaman tanpa agunan), yang katakanlah jumlahnya 10% dari seluruh pesan
SMS, lalu kita tulis sebagai P(“kredit”) = 0,1. Demikian juga dari pengamatan sebelumnya,
diperoleh statistik bahwa misalnya 32% dari seluruh pesan SMS adalah pesan sampah,
sehingga kita tulis P(sampah) = 0,2. Kita tentu harus berasumsi bahwa tidak semua pesan
SMS yang berisi kata “kredit” adalah pesan sampah, katakanlah hanya 40% saja, sehingga
ditulis P(“kredit”|sampah) = 0,4.
Dengan menerapkan Teori Bayes, kita dapat menghitung apa yang disebut dengan posterior
probability, yang menunjukkan kemungkinan sebuah pesan SMS dianggap sebagai pesan
sampah bila di dalamnya ditemukan kata “kredit”. Secara matematis hal ini ditulis sebagai
berikut:
𝑃(sampah|"kredit") = 𝑃("kredit"|sampah) 𝑃(sampah)
𝑃("𝑘𝑟𝑒𝑑𝑖𝑡")
Model prediksi dibangun dengan melihat apabila posterior probability melampaui suatu
ambang batas tertentu (misalnya 50%), maka dibuat keputusan bahwa pesan SMS tersebut
adalah sebuah pesan sampah.
Mengapa disebut “naive” (naif) karena semua feature di dalam data dianggap setara
pentingnya dan dan tidak punya ketergantungan satu sama lain. Meskipun prinsipnya
sederhana, Naive Bayes bisa menjadi algoritma yang menghasilkan model prediksi yang
cukup efektif dan bisa jadi mengalahkan algoritma lain yang lebih rumit.
Scikit-learn menyediakan tiga pilihan modul di bawah payung Naive Bayes yaitu Gaussian
NB, Bernoulli NB dan Multinominal NB. Gaussian NB dipergunakan untuk kasus dengan
feature berupa angka numerik (bersifat continuous), Bernoulli NB lebih cocok untuk feature
yang bersifat binary, sedangkan Multinominal NB diperuntukkan bagi kasus dengan feature
yang bersifat nominal.
Bencana Kapal Titanic
Sebagai contoh kasus untuk mendemonstrasikan algoritma Naive Bayes, kita akan mencoba
membangun sebuah model klasifikasi sederhana dengan mempergunakan dataset yang sangat
populer dipakai untuk latihan yaitu “Titanic Dataset”. Dataset ini berisi data penumpang

kapal RMS Titanic yang menjadi legenda sejak tenggelam dalam pelayaran perdananya tahun
1912. Kapal ini mengangkut lebih dari 2.200 penumpang, yang ketika kecelakaan terjadi
lebih dari separuhnya tidak tertolong. Berdasarkan informasi yang terdapat di dalam dataset
ini, kita akan mencoba membuat model prediksi apakah seorang penumpang kapal Titanic
akan selamat atau tidak dalam kecelakaan tragis ini.
Selain nama penumpang, dataset berisi informasi mengenai masing-masing penumpang
(usia, jenis kelamin, jumlah rombongan, harga tiket yang dibeli dan lain-lain) beserta label
keterangan apakah penumpang yang bersangkutan selamat atau tidak.
Dataset ini dapat diunduh dengan bebas dan dengan bantuan mesin pencari seperti Google
dataset ini akan sangat mudah ditemukan di banyak situs. Ukuran file ini tidak besar, hanya
sekitar 61KB. Silakan buka Lampiran 2 buku ini untuk informasi cara mengunduh dataset
Titanic. Seperti biasa file training dataset tersedia dalam format CSV, dan kita beri nama
titanic_train.csv.
Mari kita langsung coba buka file training ini dan kita lihat isinya:
import pandas as pd df_train = pd.read_csv("/Users/diosk/titanic_train.csv") df_train.head(10)
Terlihat bahwa dataset ini memiliki 12 kolom, yang penjelasannya adalah sebagai berikut: PasengerID – Nomor urut penumpang Name – Nama penumpang Pclass – Tiket kelas kabin yang dibeli penumpang (kelas 1,2 atau 3) Sex – Jenis kelamin penumpang Age – Usia penumpang saat kecelakaan terjadi SibSp – Jumlah kerabat atau pasangan yang ikut serta ParCh – Jumlah orang tua atau anak yang ikut serta Ticket – Nomor tiket penumpang Fare – Harga tiket yang dibeli penumpang Cabin – Nomor kabin penumpang Embarked – Nama kota pelabuhan asal (C = Cherbourg; Q = Queenstown; S = Southampton) Survived – Selamat (1) atau Tidak Selamat (0)
Karena kita akan mencoba membuat model prediksi apakah seseorang akan selamat atau
tidak, maka kolom “Survived” akan kita jadikan label atau target feature dalam training
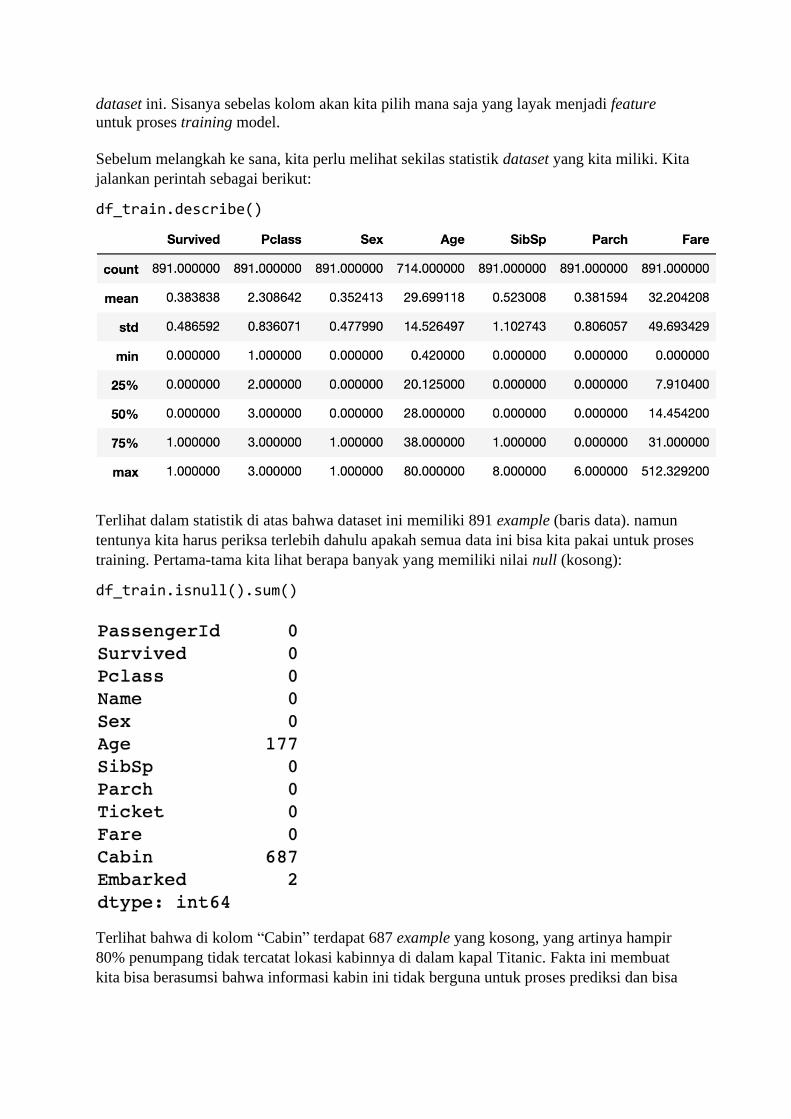
dataset ini. Sisanya sebelas kolom akan kita pilih mana saja yang layak menjadi feature
untuk proses training model.
Sebelum melangkah ke sana, kita perlu melihat sekilas statistik dataset yang kita miliki. Kita
jalankan perintah sebagai berikut:
df_train.describe()
Terlihat dalam statistik di atas bahwa dataset ini memiliki 891 example (baris data). namun
tentunya kita harus periksa terlebih dahulu apakah semua data ini bisa kita pakai untuk proses
training. Pertama-tama kita lihat berapa banyak yang memiliki nilai null (kosong):
df_train.isnull().sum()
Terlihat bahwa di kolom “Cabin” terdapat 687 example yang kosong, yang artinya hampir
80% penumpang tidak tercatat lokasi kabinnya di dalam kapal Titanic. Fakta ini membuat
kita bisa berasumsi bahwa informasi kabin ini tidak berguna untuk proses prediksi dan bisa

kita buang dari dataset. Kita pergunakan fungsi drop() dengan parameter inplace=True
agar kolom ini dibuang permanen langsung dari dataset:
df_train.drop(['Cabin'], axis=1, inplace=True) Tidak demikian dengan kolom “Embarked” yang hanya ada dua saja yang kosong. Apakah
kita hapus dua example ini? Karena jumlahnya sedikit, pilihan yang lebih tepat adalah kita
lakukan impute, yaitu kita isi example yang kosong dengan nilai yang paling banyak terdapat
di dalam dataset.
Dengan perintah value_counts() di bawah ini, kita dapatkan fakta bahwa mayoritas
penumpang RMS Titanic berangkat dari Pelabuhan “Southampton” (S), sehingga kita bisa isi
example yang kosong dengan nilai “S”. Pandas menyediakan fungsi fillna() yang sangat
bermanfaat untuk tugas seperti ini:
df_train['Embarked'].value_counts()
df_train['Embarked'].fillna('S', inplace=True) Satu hal yang perlu diingat adalah algoritma Naive Bayes yang akan dipergunakan dalam
contoh kasus kita kali ini mengharuskan semua feature disimpan dalam bentuk numerik, jadi
semua nama pelabuhan (“S”, “C” dan ”Q”) harus dikodekan dengan angka 0, 1 dan 2.
Dengan Pandas, ini mudah sekali dilakukan:
embarked = {"Embarked": {"S": 0, "C": 1, "Q": 2}} df_train.replace(embarked, inplace=True)
Selanjutnya kita perhatikan kolom “Age” yang ternyata juga memiliki cukup banyak
informasi kosong (sebanyak 177 example). Sebenarnya tidaklah bijak bila kita buang
informasi usia penumpang, namun untuk sementara ini hal itulah yang akan kita lakukan.
Kita hapus saja seluruh 177 example yang kosong. Perintah berikut akan menghapus semua
example yang memiliki nilai null:
df_train.dropna(inplace=True, how='any')
Perlu diperhatikan pula bahwa usia penumpang dan informasi “Fare” (harga tiket) disimpan
sebagai angka desimal. Nilai yang terlalu beragam dengan banyak angka di belakang nol
tidak menguntungkan untuk proses pembuatan model. Jadi kita perlu ubah tipe data keduanya
menjadi integer:
df_train['Fare'] = df_train['Fare'].astype(int) df_train['Age'] = df_train['Age'].astype(int) Informasi “Name”, “PassengerID” dan “Ticket” yang ada di dalam dataset dapat kita
asumsikan bahwa ketiganya tidak akan menjadi feature yang berguna bagi model prediksi.
Mengapa? Karena nama seseorang atau nomor tiketnya tidak bisa dijadikan dasar bahwa

orang yang bersangkutan akan selamat dari kecelakaan atau tidak (kecuali kita percaya
tahyul). Ketiga kolom ini bisa langsung kita buang dari training dataset:
df_train = df_train.drop(['PassengerId','Name','Ticket'], axis=1) Melangkah ke kolom selanjutnya yaitu kolom “Sex” (jenis kelamin). Kita bisa lihat bahwa
feature ini berupa data kategorikal berisi ‘male’ (pria) dan ‘female’ (wanita). Ini perlu kita
ubah menjadi kode numerik berupa 0 dan 1:
sex = {"Sex": {"male": 0, "female": 1}} df_train.replace(sex, inplace=True) Sekarang training dataset kita sudah siap, mari kita periksa sekali lagi sebelum melangkah ke
proses training:
df_train.head(10)
Dataset sudah siap. Berikutnya kita langsung coba melatih model Naive Bayes. Seperti yang
kita lakukan di bab sebelumnya, kita pecah dahulu dataset ini menjadi training dataset dan
test dataset, dengan persentase 75% untuk training dan sisanya 25% untuk test dataset.
Semua feature untuk training dataset disimpan dalam variabel X_train, sedangkan labelnya
di dalam variabel y_train. Hal yang sama dengan test dataset yang disimpan di dalam
variabel X_test dan labelnya di y_test:
import sklearn.model_selection as ms features = df_train[['Pclass','Embarked','Sex','Age','Fare','SibSp','Parch']]

label = df_train['Survived'] X_train, X_test, y_train, y_test = ms.train_test_split(features, label, test_size=0.25, random_state=0) Untuk kasus kita yang featurenya bersifat continuous, kita akan mempergunakan modul
Gaussian NB yang disediakan oleh scikit-learn. Kita import modul GaussianNB dan kita
panggil fit() untuk menjalankan proses training:
import sklearn.naive_bayes as nb import sklearn.metrics as met gnb = nb.GaussianNB() gnb.fit(X_train, y_train) Di titik ini, model kita sudah jadi dan siap untuk kita uji dengan test dataset. Kita ukur
accuracy dan precision-nya dengan bantuan modul sklearn.metrics (mengenai
perbedaan accuracy dan precision, silakan buka kembali pembahasan di bab sebelumnya):
y_prediksi = gnb.predict(X_test) accuracy = met.accuracy_score(y_test, y_prediksi) precision = met.precision_score(y_test, y_prediksi) print('Accuracy=', accuracy, 'Precision=', precision)
Accuracy= 0.7415730337078652 Precision= 0.6891891891891891
Seperti di bab sebelumnya, kita coba mengukur AUC dengan membuat visualisasi ROC
curve dengan bantuan matplotlib:
import matplotlib.pyplot as plt y_pred_proba = gnb.predict_proba(X_test)[::,1] fp, tp, _ = met.roc_curve(y_test, y_pred_proba) auc = met.roc_auc_score(y_test, y_pred_proba) plt.plot(fp,tp,label="data 1, auc="+str(auc)) plt.legend(loc=4) plt.show()
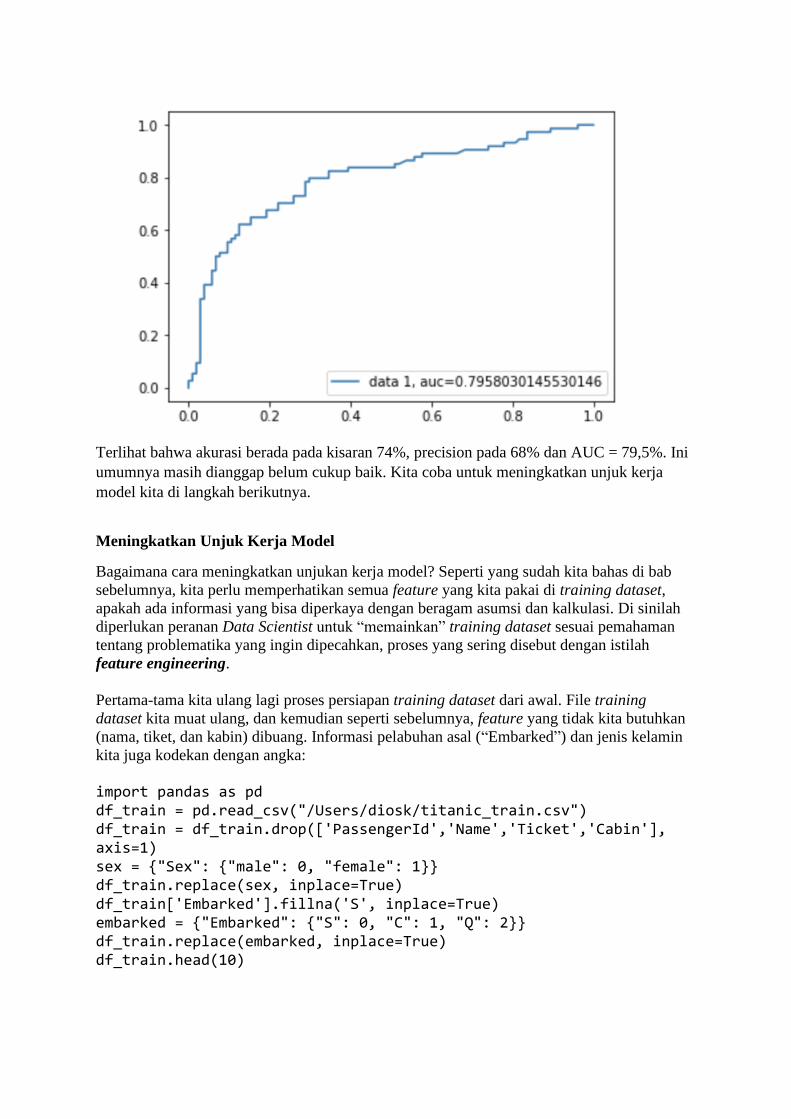
Terlihat bahwa akurasi berada pada kisaran 74%, precision pada 68% dan AUC = 79,5%. Ini
umumnya masih dianggap belum cukup baik. Kita coba untuk meningkatkan unjuk kerja
model kita di langkah berikutnya.
Meningkatkan Unjuk Kerja Model
Bagaimana cara meningkatkan unjukan kerja model? Seperti yang sudah kita bahas di bab
sebelumnya, kita perlu memperhatikan semua feature yang kita pakai di training dataset,
apakah ada informasi yang bisa diperkaya dengan beragam asumsi dan kalkulasi. Di sinilah
diperlukan peranan Data Scientist untuk “memainkan” training dataset sesuai pemahaman
tentang problematika yang ingin dipecahkan, proses yang sering disebut dengan istilah
feature engineering.
Pertama-tama kita ulang lagi proses persiapan training dataset dari awal. File training
dataset kita muat ulang, dan kemudian seperti sebelumnya, feature yang tidak kita butuhkan
(nama, tiket, dan kabin) dibuang. Informasi pelabuhan asal (“Embarked”) dan jenis kelamin
kita juga kodekan dengan angka:
import pandas as pd df_train = pd.read_csv("/Users/diosk/titanic_train.csv") df_train = df_train.drop(['PassengerId','Name','Ticket','Cabin'], axis=1) sex = {"Sex": {"male": 0, "female": 1}} df_train.replace(sex, inplace=True) df_train['Embarked'].fillna('S', inplace=True) embarked = {"Embarked": {"S": 0, "C": 1, "Q": 2}} df_train.replace(embarked, inplace=True) df_train.head(10)

Kolom “Age” nampak masih memiliki ‘NaN’ (nilai kosong) yang bila diperiksa lebih dalam
cukup banyak jumlahnya (177 example). Meskipun tidak sedikit, persentasenya masih di
bawah 20% dari seluruh dataset sehingga kita seharusnya tidak begitu saja membuang
informasi ini. Dengan mempergunakan nalar umum, informasi usia penumpang barangkali
berguna bagi proses pembuatan model: kita bisa berasumsi bahwa orang yang lebih muda
fisiknya lebih kuat dibandingkan mereka yang sudah tua sehingga kemungkinan untuk bisa
menyelamatkan diri menjadi lebih tinggi. Atas dasar inilah kita sebaiknya melakukan impute,
kita ganti ‘NaN’ dengan angka yang bermakna. Dalam praktek, biasanya hal seperti ini diisi
dengan angka rata-rata.
Berapa nilai rata-rata usia penumpang? Bukan sesuatu yang mengherankan bila kita punya
asumsi bahwa usia rata-rata untuk pria dan wanita tidaklah sama. Kita buktikan dengan
fungsi mean(), dan hasilnya ternyata benar berbeda antara pria dan wanita:
pria = df_train['Age'].loc[df_train['Sex'] == 0].mean() wanita = df_train['Age'].loc[df_train['Sex'] == 1].mean() print('Pria=', pria, 'Wanita=', wanita) Pria= 30.7252166377816 Wanita= 27.914745222929923
Dengan demikian sekarang kita bisa mengisi example yang nilai usianya masih kosong
dengan kedua angka rata-rata di atas:
df_train['Age'].loc[(df_train['Sex'] ==0) & (df_train['Age'].isnull() == True)] = 30.725 df_train['Age'].loc[(df_train['Sex'] ==1) & (df_train['Age'].isnull() == True)] = 27.914
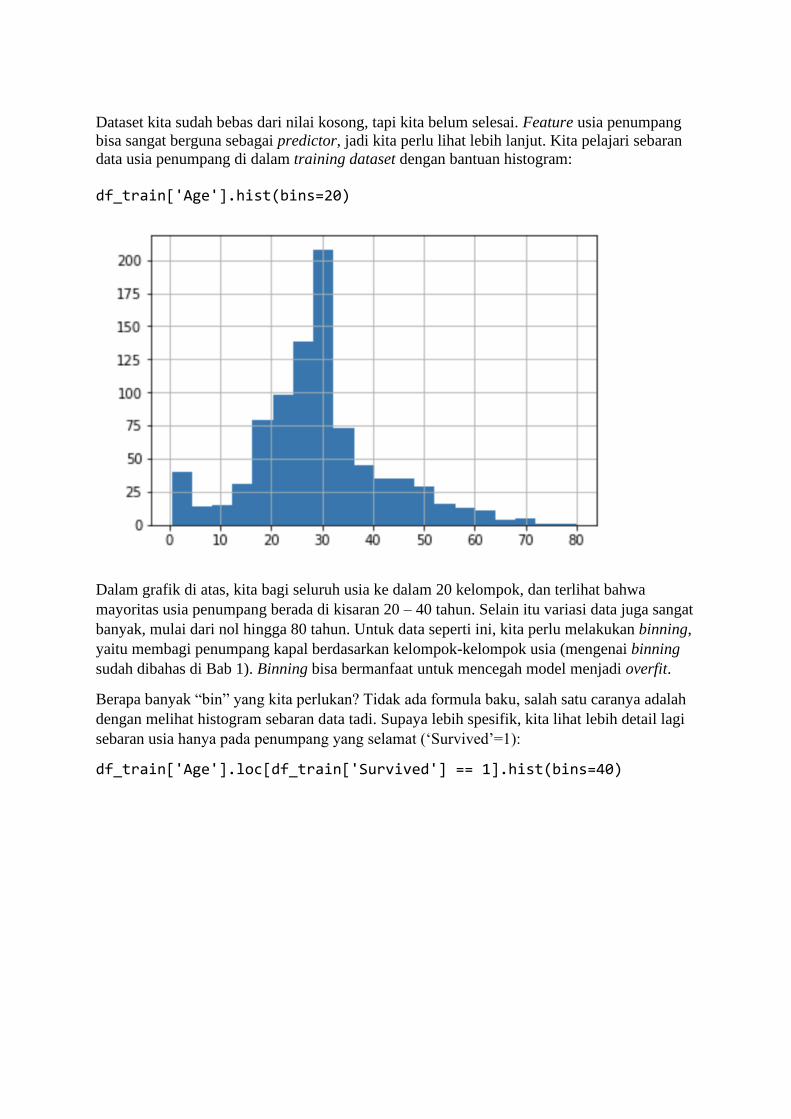
Dataset kita sudah bebas dari nilai kosong, tapi kita belum selesai. Feature usia penumpang
bisa sangat berguna sebagai predictor, jadi kita perlu lihat lebih lanjut. Kita pelajari sebaran
data usia penumpang di dalam training dataset dengan bantuan histogram:
df_train['Age'].hist(bins=20)
Dalam grafik di atas, kita bagi seluruh usia ke dalam 20 kelompok, dan terlihat bahwa
mayoritas usia penumpang berada di kisaran 20 – 40 tahun. Selain itu variasi data juga sangat
banyak, mulai dari nol hingga 80 tahun. Untuk data seperti ini, kita perlu melakukan binning,
yaitu membagi penumpang kapal berdasarkan kelompok-kelompok usia (mengenai binning
sudah dibahas di Bab 1). Binning bisa bermanfaat untuk mencegah model menjadi overfit.
Berapa banyak “bin” yang kita perlukan? Tidak ada formula baku, salah satu caranya adalah
dengan melihat histogram sebaran data tadi. Supaya lebih spesifik, kita lihat lebih detail lagi
sebaran usia hanya pada penumpang yang selamat (‘Survived’=1):
df_train['Age'].loc[df_train['Survived'] == 1].hist(bins=40)
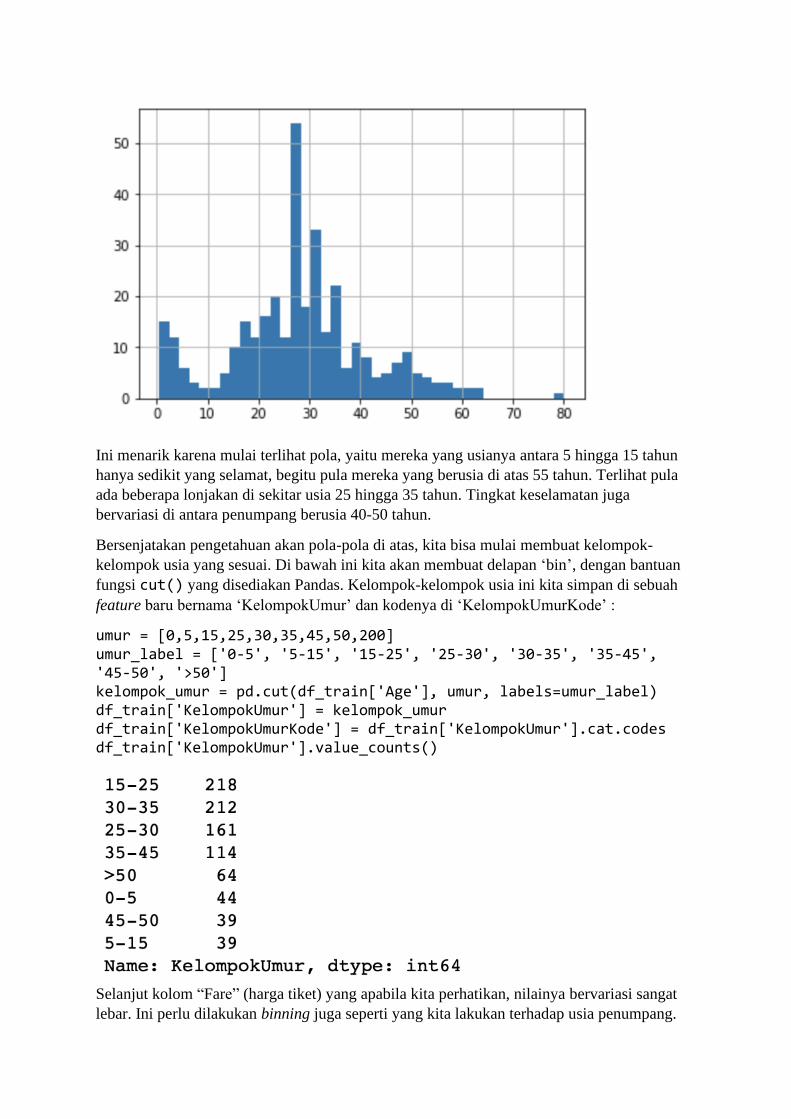
Ini menarik karena mulai terlihat pola, yaitu mereka yang usianya antara 5 hingga 15 tahun
hanya sedikit yang selamat, begitu pula mereka yang berusia di atas 55 tahun. Terlihat pula
ada beberapa lonjakan di sekitar usia 25 hingga 35 tahun. Tingkat keselamatan juga
bervariasi di antara penumpang berusia 40-50 tahun.
Bersenjatakan pengetahuan akan pola-pola di atas, kita bisa mulai membuat kelompok-
kelompok usia yang sesuai. Di bawah ini kita akan membuat delapan ‘bin’, dengan bantuan
fungsi cut() yang disediakan Pandas. Kelompok-kelompok usia ini kita simpan di sebuah
feature baru bernama ‘KelompokUmur’ dan kodenya di ‘KelompokUmurKode’ :
umur = [0,5,15,25,30,35,45,50,200] umur_label = ['0-5', '5-15', '15-25', '25-30', '30-35', '35-45', '45-50', '>50'] kelompok_umur = pd.cut(df_train['Age'], umur, labels=umur_label) df_train['KelompokUmur'] = kelompok_umur df_train['KelompokUmurKode'] = df_train['KelompokUmur'].cat.codes df_train['KelompokUmur'].value_counts()
Selanjut kolom “Fare” (harga tiket) yang apabila kita perhatikan, nilainya bervariasi sangat
lebar. Ini perlu dilakukan binning juga seperti yang kita lakukan terhadap usia penumpang.
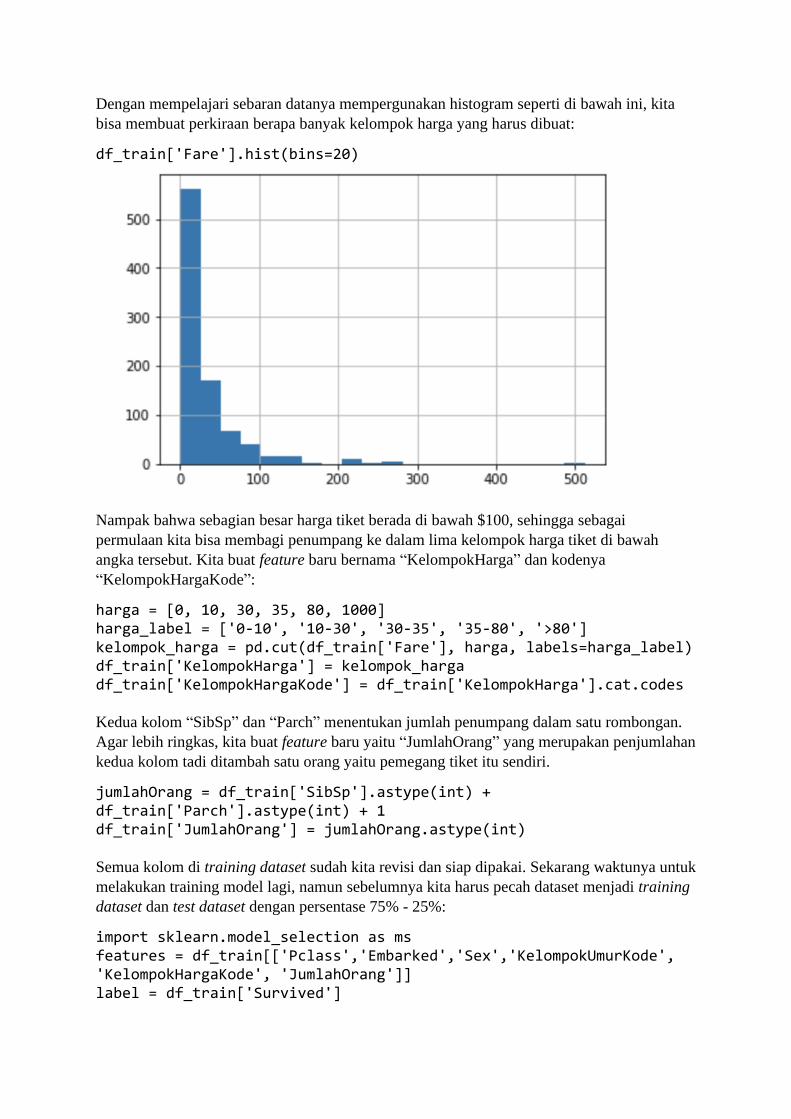
Dengan mempelajari sebaran datanya mempergunakan histogram seperti di bawah ini, kita
bisa membuat perkiraan berapa banyak kelompok harga yang harus dibuat:
df_train['Fare'].hist(bins=20)
Nampak bahwa sebagian besar harga tiket berada di bawah $100, sehingga sebagai
permulaan kita bisa membagi penumpang ke dalam lima kelompok harga tiket di bawah
angka tersebut. Kita buat feature baru bernama “KelompokHarga” dan kodenya
“KelompokHargaKode”:
harga = [0, 10, 30, 35, 80, 1000] harga_label = ['0-10', '10-30', '30-35', '35-80', '>80'] kelompok_harga = pd.cut(df_train['Fare'], harga, labels=harga_label) df_train['KelompokHarga'] = kelompok_harga df_train['KelompokHargaKode'] = df_train['KelompokHarga'].cat.codes Kedua kolom “SibSp” dan “Parch” menentukan jumlah penumpang dalam satu rombongan.
Agar lebih ringkas, kita buat feature baru yaitu “JumlahOrang” yang merupakan penjumlahan
kedua kolom tadi ditambah satu orang yaitu pemegang tiket itu sendiri.
jumlahOrang = df_train['SibSp'].astype(int) + df_train['Parch'].astype(int) + 1 df_train['JumlahOrang'] = jumlahOrang.astype(int) Semua kolom di training dataset sudah kita revisi dan siap dipakai. Sekarang waktunya untuk
melakukan training model lagi, namun sebelumnya kita harus pecah dataset menjadi training
dataset dan test dataset dengan persentase 75% - 25%:
import sklearn.model_selection as ms features = df_train[['Pclass','Embarked','Sex','KelompokUmurKode', 'KelompokHargaKode', 'JumlahOrang']] label = df_train['Survived']
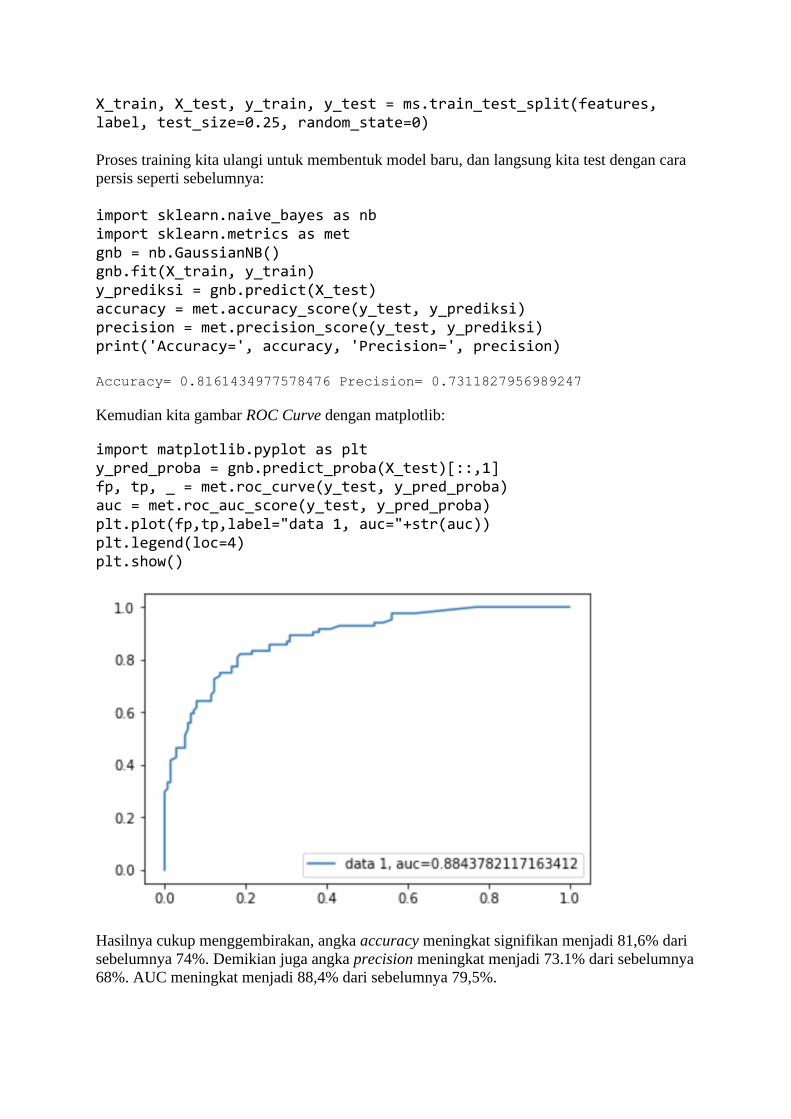
X_train, X_test, y_train, y_test = ms.train_test_split(features, label, test_size=0.25, random_state=0) Proses training kita ulangi untuk membentuk model baru, dan langsung kita test dengan cara
persis seperti sebelumnya:
import sklearn.naive_bayes as nb import sklearn.metrics as met gnb = nb.GaussianNB() gnb.fit(X_train, y_train) y_prediksi = gnb.predict(X_test) accuracy = met.accuracy_score(y_test, y_prediksi) precision = met.precision_score(y_test, y_prediksi) print('Accuracy=', accuracy, 'Precision=', precision) Accuracy= 0.8161434977578476 Precision= 0.7311827956989247
Kemudian kita gambar ROC Curve dengan matplotlib:
import matplotlib.pyplot as plt y_pred_proba = gnb.predict_proba(X_test)[::,1] fp, tp, _ = met.roc_curve(y_test, y_pred_proba) auc = met.roc_auc_score(y_test, y_pred_proba) plt.plot(fp,tp,label="data 1, auc="+str(auc)) plt.legend(loc=4) plt.show()
Hasilnya cukup menggembirakan, angka accuracy meningkat signifikan menjadi 81,6% dari
sebelumnya 74%. Demikian juga angka precision meningkat menjadi 73.1% dari sebelumnya
68%. AUC meningkat menjadi 88,4% dari sebelumnya 79,5%.

Kita sudah melihat bahwa dengan melakukan sedikit perubahan pada training dataset kita
bisa memperoleh model yang berkemampuan lebih baik dalam membuat prediksi. Model ini
pun sebetulnya masih berpotensi untuk ditingkatkan lagi unjuk kerjanya. Semuanya kembali
kepada peranan Data Scientist dalam melakukan proses feature engineering.
Kesimpulan
Algoritma Naive Bayes pada dasarnya cukup sederhana dan efektif untuk dijadikan model
prediksi. Naive Bayes juga tidak terlalu sensitif bila kehilangan data. Naive Bayes cocok
untuk penerapan di mana banyak atribut dalam informasi yang harus dianalisis secara
bersamaan waktunya.
Adapun begitu sering tidak memberikan unjuk kerja yang tinggi dibandingkan dengan model
yang lebih rumit. Sering kali Naive Bayes adalah pilihan pertama algoritma yang diterapkan
untuk kebanyakan problem klasifikasi, dan bila hasilnya belum memenuhi harapan, baru
kemudian dibandingkan dengan algoritma lain. Dalam banyak kasus klasifikasi, sering kali
Data Scientist akan membandingkan unjuk kerja Naive Bayes dibandingkan dengan Logistic
Regression. Salah satu ciri pekerjaan data science adalah memang melakukan tugas-tugas
yang bersifat eksperimental, jadi jangan takut untuk mengulang pekerjaan seperti ini!

BAB 8 Neural Network Otak manusia memiliki kemampuan untuk mengenali pola di dalam informasi yang berasal
dari panca indera dengan akurasi yang sangat tinggi. Seperti yang telah dijelaskan di Bab 1,
kemampuan pengenalan pola ini diperoleh melalui proses belajar yang kompleks. Artificial
Neural Network (selanjutnya disingkat ANN) yaitu jaringan syaraf tiruan, adalah metode
untuk mencoba mengikuti cara belajar manusia dengan meniru arsitektur sistem syaraf otak
dan kemudian menerapkannya ke dalam perangkat lunak komputer.
ANN adalah metode yang bersifat black box (kotak hitam), dalam arti apa yang terjadi di
dalam proses tidak dapat terlihat dengan jelas dari luar. Data masuk ke dalam kotak dan
kemudian hasilnya keluar tanpa kita bisa tahu apa persis proses yang membuatnya demikian.
Model dibentuk berdasarkan kalkulasi matematis yang rumit, sehingga keluarannya akan
sukar dipahami. Adapun begitu, itu tidak menghalangi implementasi Neural Network untuk
banyak kegiatan praktis di dunia industri maupun ilmiah.
Beberapa contoh penggunaan ANN misalnya untuk pengenalan suara, pengenalan tulisan
tangan dan pengenalan gambar. Di bidang ilmiah banyak pula penerapannya misalnya untuk
analisis ekonomi dan peramalan cuaca. Kita juga sudah sering mendengar tentang mobil
cerdas yang bisa berjalan sendiri tanpa pengemudi, yang cara kerjanya pun berdasarkan
jaringan syaraf tiruan.
ANN memang rumit dan membutuhkan pemahaman mendalam tentang ilmu matematika,
namun beruntung bagi kita yang tidak punya gelar akademik di bidang itu: scikit-learn sudah
menyediakan modul Neural Network sehingga kita bisa mempergunakannya untuk
pembuatan model dengan beberapa baris program saja.
Dasar Neural Network
Otak manusia terdiri dari milyaran sel yang disebut neuron. Neuron-neuron ini bekerja sama
menerima rangsangan dari panca indera, memproses informasinya dan kemudian menentukan
reaksi apa yang harus dilakukan. Menurut sejumlah penelitian, otak manusia berisi hampir
100 milyar neuron, berkali lipat dibandingkan mahluk hidup lainnya. Sebagai perbandingan,
yang paling dekat adalah simpanse dan gorilla yang memiliki sekitar 3 milyar neuron,
sementara seekor tikus rata-rata hanya memiliki 70 juta neuron [6]. Dengan jaringan syaraf
yang begitu kompleks, otak manusia mampu menyimpan informasi dan pengetahuan yang
sangat besar dalam skala yang hingga kini masih belum bisa diukur dengan tepat oleh para
ahli.
Masing-masing neuron berisikan tiga komponen penting yaitu dendrit, nukleus dan akson.
Dendrit menerima rangsangan berupa sinyal-sinyal dari luar dan dikirimkan ke inti sel yaitu
nukleus untuk diolah. Nukleus akan mendapatkan sinyal dalam jumlah yang banyak yang
akan terus terakumulasi hingga suatu ambang batas tercapai. Pada saat itu nukleus akan
menghasilkan sinyal keluaran yang mengalir melalui akson hingga ujungnya. Di ujung akson,
sinyal diproses secara kimiawi agar dapat mencapai neuron selanjutnya. Demikian seterusnya
sinyal akan berlanjut mengalir ke neuron-neuron lain di dalam jaringan syaraf.
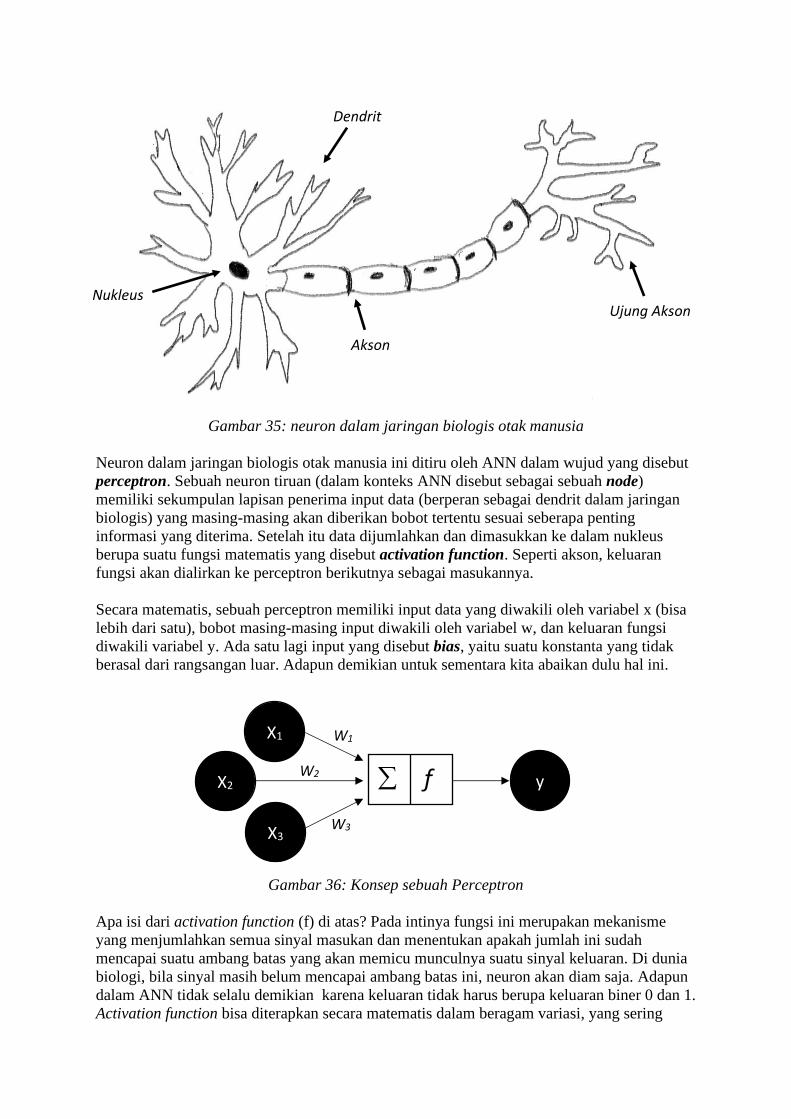
Gambar 35: neuron dalam jaringan biologis otak manusia
Neuron dalam jaringan biologis otak manusia ini ditiru oleh ANN dalam wujud yang disebut
perceptron. Sebuah neuron tiruan (dalam konteks ANN disebut sebagai sebuah node)
memiliki sekumpulan lapisan penerima input data (berperan sebagai dendrit dalam jaringan
biologis) yang masing-masing akan diberikan bobot tertentu sesuai seberapa penting
informasi yang diterima. Setelah itu data dijumlahkan dan dimasukkan ke dalam nukleus
berupa suatu fungsi matematis yang disebut activation function. Seperti akson, keluaran
fungsi akan dialirkan ke perceptron berikutnya sebagai masukannya.
Secara matematis, sebuah perceptron memiliki input data yang diwakili oleh variabel x (bisa
lebih dari satu), bobot masing-masing input diwakili oleh variabel w, dan keluaran fungsi
diwakili variabel y. Ada satu lagi input yang disebut bias, yaitu suatu konstanta yang tidak
berasal dari rangsangan luar. Adapun demikian untuk sementara kita abaikan dulu hal ini.
Gambar 36: Konsep sebuah Perceptron
Apa isi dari activation function (f) di atas? Pada intinya fungsi ini merupakan mekanisme
yang menjumlahkan semua sinyal masukan dan menentukan apakah jumlah ini sudah
mencapai suatu ambang batas yang akan memicu munculnya suatu sinyal keluaran. Di dunia
biologi, bila sinyal masih belum mencapai ambang batas ini, neuron akan diam saja. Adapun
dalam ANN tidak selalu demikian karena keluaran tidak harus berupa keluaran biner 0 dan 1.
Activation function bisa diterapkan secara matematis dalam beragam variasi, yang sering
W2 X2
W1 X1
W3 X3
f
y
Dendrit
Akson
Nukleus Ujung Akson

dipakai adalah fungsi Logistic Sigmoid, Tanh dan Rectified Linear Unit. Pemilihan
activation function ini bergantung kepada permasalahan yang ingin dipecahkan.
Beberapa Formula Activation Function
Logistic Sigmoid: input berupa sembarang angka dan keluarannya berupa angka antara 0
hingga 1.
𝑓(𝑥) =1
1 + 𝑒−𝑥
Tanh: input berupa sembarang angka dan keluarannya berupa angka antara -1 dan 1.
𝑓(𝑥) = 2𝜎(2𝑥) − 1
ReLU (Rectified Linear Unit): input berupa sembarang angka dan keluarannya berupa
angka dari input kecuali angka negatif diganti menjadi nol.
𝑓(𝑥) = max (0, 𝑥)
Yang harus diingat adalah apapun activation function yang kita pakai, sinyal masukan harus
dibatasi berada dalam suatu jangkauan yang tidak terlalu lebar. Contohnya fungsi sigmoid
hanya menerima nilai masukan berjangkauan positif 5 hingga negatif 5. Bila data yang kita
masukkan ada dalam jangkauan yang terlalu lebar, model akan menghasilkan keluaran yang
tidak akurat. Ibaratnya memutar lagu dengan volume terlalu keras akan terdengar pecah
suaranya karena sirkuit elektronik tidak sanggup mereproduksi seluruh gelombang suara,
sehingga ujung atas dan ujung bawahnya dipangkas.
Solusi menghindari ini adalah dengan mengubah semua nilai input ke angka-angka yang
tidak jauh dari angka nol. Proses ini dilakukan dengan metode normalisasi feature seperti
yang dijelaskan di Bab 1.
Seberapa banyak node yang bisa dibuat dalam sebuah jaringan syaraf tiruan? Untuk
memecahkan masalah yang kompleks, model ANN bisa dibangun dengan memiliki banyak
node namun jumlahnya tidak akan sampai milyaran seperti di dalam otak manusia. Hingga
kini penerapan ANN yang paling canggih hanya ratusan atau ribuan saja. Tentu saja dengan
semakin majunya teknologi komputasi, tidak menutup kemungkinan di masa depan nanti
jumlahnya menjadi jutaan node dan komputer bisa menjadi semakin cerdas mendekati
mahluk hidup.
Multi Layer Perceptron
Karena jumlahnya banyak, semua node dalam jaringan harus diatur mengikuti suatu struktur
khusus, yang paling umum adalah Multi Layer Perceptron (MLP), yaitu perceptron dengan
banyak lapisan. Satu lapisan berisi beberapa node yang memiliki fungsi serupa. Secara
umum, ada tiga macam lapisan yaitu input layer untuk menerima masukan sinyal dari dunia
luar, output layer yang menghasilkan prediksi akhir dan satu atau lebih hidden layer yang
melakukan proses di antara keduanya.

Gambar 37: Multi Layer Perceptron
Yang menarik untuk diperhatikan adalah setiap node di dalam satu lapisan akan tersambung
secara penuh ke semua node di lapisan berikutnya. Ini bukan suatu keharusan tapi umumnya
demikian, bergantung kepada jenis model yang hendak dibangun. Hubungan antara node juga
akan diberikan angka bobot masing-masing yang menentukan seberapa penting feature yang
bersangkutan. Informasi mengalir dalam satu arah yaitu dari kiri ke kanan, sehingga disebut
dengan jaringan feedforward.
Jumlah node di input layer disesuaikan dengan jumlah feature yang hendak dipergunakan
sebagai masukan untuk pembuatan model. Bila ada sepuluh feature, maka akan ada sepuluh
input node pula. Demikian juga dengan output node, jumlahnya disesuaikan dengan keluaran
yang diharapkan dari model.
Adapun untuk hidden layer tidak ada aturan khusus, jumlahnya bergantung kepada seberapa
kompleks proses pembelajaran yang dikehendaki. Semakin kompleks membutuhkan semakin
banyak node di dalam hidden layer. Tentunya semakin banyak node, proses komputasi juga
akan menjadi semakin berat. Suatu metode Machine Learning yang saat ini menjadi
pembahasan hangat adalah deep learning yang memanfaatkan hidden layer dalam jumlah
sangat banyak.
Bagaimana cara membangun model dengan MLP? MLP adalah metode supervised learning,
oleh sebab itu membutuhkan label di training dataset. Seperti seorang bayi yang baru lahir,
jaringan syaraf masih seperti lembaran kosong yang harus dilatih dengan diberikan
pengalaman-pengalaman baru. Semakin banyak rangsangan yang diterima, koneksi antara
neuron akan menguat dan sang bayi akan mulai mengenali barang dan mahluk di
sekelilingnya.
Langkah berikutnya adalah melakukan training itu sendiri, dengan mekanisme iterarif yang
disebut backpropagation. Backpropagation bisa dianalogikan dengan proses belajar dari
kesalahan. Pertama-tama ditentukan bobot berupa angka acak untuk setiap koneksi antar
neuron. Selanjutnya di setiap iterasi, angka bobot untuk setiap koneksi disesuaikan.
Input Layer
Output Layer
X2
X1
y
X3
H1
Hidden Layer
H2
Data

Penyesuaian angka bobot dilakukan dengan mengirim umpan balik ke input node. Keluaran
dari output node dibandingkan dengan label yang ada di training data, sehingga tingkat
kesalahan dapat diukur. Sejalan dengan pengulangan berkali-kali dengan teknik yang disebut
gradient descent, tingkat kesalahan dapat diturunkan sehingga tercapai suatu nilai yang
dianggap cukup.
Contoh Penggunaan MLP
MLP sebenarnya adalah metode yang cukup serbaguna, dapat dipergunakan untuk prediksi
numerik, pengenalan pola dan juga membuat klasifikasi seperti Logistic Regression dan
Decision Trees. MLP sering dianggap sebagai metode yang paling bisa memberikan akurasi
maksimal dibanding metode lain.
Kekurangannya adalah MLP membutuhkan proses komputasi yang lebih intensif, serta
memiliki resiko tinggi menghasilkan model yang overfit (tidak bagus ketika dihadapkan
dengan dataset yang berbeda dengan training dataset). Selain itu tidak seperti Decision Trees
yang transparan, hasil akhir MLP lebih sulit untuk dijelaskan.
Scikit-learn sudah menyediakan modul sklearn.neural_network yang termasuk di
dalamnya MLPClassifier untuk pekerjaan klasifikasi yang akan kita coba demonstrasikan
di bawah ini.
Untuk contoh kasus kali ini, kita akan mencoba membuat model binary classification berupa
pendeteksi okupansi ruang perkantoran berdasarkan suhu ruangan, kelembaban udara, cahaya
dan tingkat kandungan CO2. Dengan sensor-sensor yang mengukur keempat parameter
tersebut, kita bisa menentukan apakah di ruang kantor yang diamati sedang ada orang yang
bekerja atau tidak, sehingga sistem pendingin udara dapat dihidupkan atau dimatikan secara
otomatis.
Kita akan mempergunakan dataset dalam jumlah yang cukup besar karena memang pada
dasarnya ANN membutuhkan training dataset dalam jumlah yang besar. Kita akan
mempergunakan contoh dataset dari UCI Machine Learning Repository berjudul “Occupancy
Detection Dataset”. Cara mengunduh dataset ini dapat ditemukan di Lampiran 2 buku ini.
Dataset ini berisi tidak kurang dari 8,000 pengukuran yang masing-masing berisi nomor urut
(id), date (tanggal dan waktu pengukuran), temperature (suhu), humidity (kelembaban), light
(cahaya), CO2, dan humidity ratio (rasio kelembaban). Kita akan pergunakan pengukuran ini
sebagai feature untuk proses training. Ini ditambah occupancy sebagai label yaitu apakah
ruangan terisi orang atau tidak. Nilai 1 berarti ruang kantor berisi orang, nilai nol berarti
kosong.
Berikut contoh beberapa baris dataset ini:

Mari kita langsung buat program Python baru, dan kita impor semua modul yang kita
perlukan yaitu Pandas, Neural Network dan model_selection, kemudian file dataset kita
buka dengan Pandas:
import pandas as pd import sklearn.neural_network as ann import sklearn.model_selection as ms occupancy = pd.read_csv('occupancy.csv', names = ["id", "date","Temperature","Humidity","Light","CO2","HumidityRatio","Occupancy"]) File dataset kita buka dengan menentukan delapan kolom yang ada di dalam file. Karena id
dan date bukan feature yang bisa kita pergunakan untuk proses training, kita buang kedua
kolom tersebut, menyisakan lima feature untuk kita olah lebih lanjut. Dari sini kita pisahkan
feature dan labelnya. Ingat bahwa ada konsensus tidak tertulis yang mempergunakan variabel
bernama X untuk feature, dan y untuk label.
X = occupancy.drop(['id','date'],axis=1) y = occupancy['Occupancy']
Selanjutnya, kita lakukan profiling singkat dari kelima feature ini. Kita ingin tahu statistik
pentingnya:
X.describe()

Hasilnya kita lihat ada 8,143 baris data, dengan jangkauan angka yang beragam untuk
masing-masing feature. Misalnya suhu berada dalam jangkauan (min dan max) dari 19
hingga 23, sementara cahaya memiliki jangkauan dari nol hingga 1546. Perbedaan jangkauan
ini terlalu lebar, sedangkan MLP tidak akan bekerja baik dengan kondisi seperti ini (lain
halnya dengan algoritma Decision Trees atau Naive Bayes yang tidak akan terpengaruh
dengan feature dengan jangkauan angka yang berbeda-beda). Dengan kenyataan ini, kita
harus melakukan proses normalisasi data agar jangkauan semua feature berada dalam kisaran
yang sama. Kita akan lakukan hal ini kemudian.
Seperti biasa, sebelum proses training kita akan pecah dataset ini menjadi dua, yaitu training
dataset dan test dataset, dengan proporsi 80:20. Hasilnya kita taruh dua pasang variabel
(X_train dan y_train, serta X_test dan y_test). Ada tak kurang 39 ribu baris data
untuk training:
X_train, X_test, y_train, y_test = ms.train_test_split(X, y, test_size = 0.2) X_train.size
39084
Selanjutnya adalah proses normalisasi data seperti yang dibicarakan sebelumnya. Scikit-learn
menyediakan sklearn.preprocessing untuk melakukan normalisasi data atau disebut
juga feature scaling. Dengan metode matematis tertentu, semua feature akan “dipadatkan”
agar menjadi seragam jangkauannya, berkisar di sekitar angka nol. Caranya sangat mudah,
kita pergunakan StandardScaler dan kemudian fungsi fit() dan transform():
import sklearn.preprocessing as pp scl = pp.StandardScaler(copy=True, with_mean=True, with_std=True) scl.fit(X_train) X_train = scl.transform(X_train) X_test = scl.transform(X_test)

Perlu diperhatikan bahwa normalisasi ini harus dilakukan baik untuk training dataset maupun
test dataset. Bila kita tilik sedikit, training dataset sekarang jangkauan angkanya hanya dari
sekitar negatif 2 hingga positif 7:
print(X_train.min()) print(X_train.max()) -1.6373640478400397
7.331926073661455
Dataset sudah siap untuk proses training. MLPClassifier memerlukan dua parameter
penting yaitu jumlah hidden layer dan jumlah maksimal iterasi. Tidak ada formula khusus
untuk menentukan keduanya, jadi kita awali dengan angka acak yaitu lima node di hidden
layer dan sepuluh kali iterasi maksimal:
mlp = ann.MLPClassifier(hidden_layer_sizes=(5),max_iter=10) mlp.fit(X_train, y_train)
Di titik ini, model sudah terbentuk dan bisa diuji dengan test dataset. Hasil prediksi disimpan
di variabel y_prediksi.
y_prediksi = mlp.predict(X_test) Kita lihat bagaimana unjuk kerja model MLP yang sudah kita bangun. Seperti di bab
sebelumnya, kita akan memakai modul sklearn.metrics untuk mengeluarkan statistik
penting model yang sudah kita buat:
import sklearn.metrics as met print(met.classification_report(y_test, y_prediksi))
Nampak bahwa angka precision untuk ruang kantor kosong (class 0) dan ruang kantor terisi
orang (class 1) bernilai 0,8 dan 0,52. Ini. Masih belum cukup bagus, jadi kita akan ulang lagi
pembuatan model dengan parameter yang berbeda. Perlu dipahami bahwa angka precision di
atas bisa berbeda bila dijalankan di saat yang berbeda.
Kita ulang lagi proses training, kali ini dengan jumlah maksimal iterasi ditingkatkan menjadi
20:
mlp = nn.MLPClassifier(hidden_layer_sizes=(5),max_iter=20) mlp.fit(X_train, y_train)

y_prediksi = mlp.predict(X_test) print(met.classification_report(y_test, y_prediksi))
Hasilnya sudah jauh lebih baik daripada sebelumnya, dengan angka precision sudah sama
dengan atau mendekati angka 1. Hasil yang lebih baik lagi bisa dicapai dengan
bereksperimen di jumlah node di hidden layer.
Kita bisa juga mengubah jenis activation function pada saat memanggil MLPClassifier
untuk mendapatkan hasil yang berbeda. Ada beberapa pilihan activation function, yaitu
logistic (untuk fungsi logistic sigmoid), relu (rectified linear unit) dan tanh (tangen
hyperbolik). Contohnya sebagai berikut:
mlp = nn.MLPClassifier(hidden_layer_sizes=(5),max_iter=10, activation='logistic')
Untuk mengeluarkan semua angka-angka bobot di setiap node, kita bisa membaca atribut
coefs_ seperti di bawah ini:
print(plp.coefs_) [array([[ 0.2728909 , -0.49508115, 0.39527455, 0.23867167, 0.3682964
7],
[ 0.25346443, 0.05448436, 0.16278709, -0.2846937 , -0.0443805
8],
[ 1.12616029, 0.98355342, -1.06127054, -0.58540627, -0.7307054
5],
[ 1.09534797, 0.41827501, -0.70202245, -0.79817261, -0.5399819
3],
[-0.23546237, -0.03731758, 0.02988376, 0.55348229, 0.1555783
8],
[ 0.84130517, 2.28932092, -1.56754411, -1.95371694, -2.0063443
3]]),
array([[ 1.56042234],
[ 1.89073178],
[-1.50195338],
[-1.47025094],
[-1.51384612]])]
Kesimpulan
Artificial Neural Network adalah metode yang mencoba mensimulasikan pendekatan otak
manusia yang bisa diterapkan untuk beragam keperluan: klasifikasi, prediksi numerik dan

juga pengenalan pola. Seperti jaringan otak biologis yang memanfaatkan sel-sel neuron,
ANN mempergunakan perceptron untuk mendapatkan proses belajar.
Mempergunakan ANN di scikit-learn cukup mudah, hanya dengan sedikit baris program kita
sudah bisa mendapatkan hasil yang memadai untuk ekseperimen awal. Tingkat akurasi yang
tinggi juga bisa didapat dengan sedikit eksperimen. Selain MLPClassifier yang kita
pergunakan dalam contoh kasus di atas, Scikit-learn juga menyediakan MLPRegressor
untuk penerapan regression, memprediksi keluaran numerik.
Adapun demikian, kekurangan ANN adalah sifatnya yang seperti black box (kotak hitam),
membuat kita sulit melihat apa yang sebenarnya terjadi di dalam proses pembuatan model
dan menterjemahkan model itu sendiri. Kita tidak mudah menemukan feature apa yang
penting bagi akurasi model. Kekurangan ini bisa membuat ANN menjadi sesuatu yang
“haram” diterapkan di beberapa bidang yang membutuhkan transaparansi misalnya
penegakan hukum atau analisis medis. Model yang sulit dijelaskan cara bekerjanya akan
menjadi sesuatu yang ilegal atau bahkan membahayakan nyawa manusia.
ANN lebih tepat dimanfaatkan untuk memecahkan problematika yang melibatkan data di
mana input dan outputnya sudah dipahami dengan cukup baik. Seperti contoh kasus di atas di
mana suhu, cahaya dan kelembaban udara adalah konsep yang cukup mudah ditebak
hubungannya satu sama lain.

BAB 9A Churn Prediction
Dalam dunia bisnis, pelanggan bukan sekedar raja, namun pelanggan adalah segalanya.
Pelanggan adalah sumber pemasukan yang menghidupi perusahaan. Sebagus apapun produk
dan layanan yang dijual, apabila tidak ada pelanggan yang membeli, maka bisnis tidak akan
bertahan. Itu sebabnya mendapatkan pelanggan dan mempertahankan pelanggan sudah pasti
menjadi fokus utama setiap perusahaan, apapun bidang industrinya.
Dalam bab ini kita akan membahas tentang solusi Machine Learning untuk suatu
permasalahan nyata di industri telekomunikasi yaitu persaingan memperebutkan pelanggan.
Industri telekomunikasi di masa kini adalah medan persaingan yang sangat ketat, karena
pelanggan memiliki banyak pilihan. Pelanggan dapat dengan mudahnya berpindah
berlangganan dari satu perusahaan ke perusahaan yang lain. Pelanggan cukup membeli kartu
perdana baru, memasukkannya ke dalam ponsel, dan membuang kartu yang lama. Perusahaan
telekomunikasi yang bisa memberikan pelayananan yang terbaik dan harga yang paling
kompetitif akan menjadi pilihan pelanggan.
Banyak para praktisi pemasaran di industri telekomunikasi yang berupaya keras agar
pelanggan tidak berpindah menjadi pelanggan perusahaan pesaing. Mengapa demikian?
Karena mendapatkan pelanggan baru biayanya jauh lebih mahal daripada mempertahankan
pelanggan setia yang sudah ada. Untuk menarik calon pelanggan baru, perusahaan harus
mengeluarkan biaya iklan dan biaya promosi yang tidak sedikit. Itu pun belum menjamin
keberhasilan mendapatkan pelanggan “berkualitas”, yaitu pelanggan yang setia dan
menyumbangkan pemasukan bagi perusahaan. Jadi, mempertahankan pelanggan yang sudah
ada menjadi prioritas dibandingkan mencari pelanggan baru.
Adapun begitu, mempertahankan pelanggan juga bukan perkara yang mudah. Cara yang
umum adalah dengan memberikan paket penawaran harga khusus atau bonus kepada
pelanggan agar tidak tergoda berpaling ke perusahaan pesaing. Adapun cara seperti ini bila
diberikan kepada semua pelanggan yang ada, akan menjadi mahal biayanya karena pelanggan
yang memiliki kecenderungan untuk berhenti berlangganan (dalam bahasa industri disebut
dengan istilah churn) jumlahnya bisa jadi hanya sedikit. Tidak ada urgensi untuk
memberikan penawaran khusus atau bonus kepada pelanggan yang memang sudah setia,
karena tanpa itu pun mereka tetap akan menjadi pelanggan.
Cara terbaik adalah memastikan penawaran khusus atau bonus diberikan hanya kepada
pelanggan-pelanggan tertentu yang diketahui memang memiliki kecenderungan untuk churn,
yaitu mereka yang berencana berhenti berlangganan. Karena khusus ditujukan kepada
pelanggan-pelanggan tertentu, biaya yang harus dikeluarkan untuk memberikan promosi
menjadi lebih rendah.
Churn prediction adalah salah satu model prediktif yang cukup luas dipergunakan di industri
untuk keperluan pencegahan churn seperti ini. Tujuannya mencari dan mengenali pelanggan
mana saja yang kemungkinan besar akan berhenti berlangganan, sekaligus mengetahui tanda-
tanda apa saja yang membuat mereka demikian. Dengan memperhatikan tanda-tanda ini,
pelanggan yang memiliki kemungkinan tinggi untuk berhenti berlangganan layanan dapat
dihubungi untuk selanjutnya diberikan paket penawaran harga khusus untuk mencegah
mereka benar-benar berhenti berlangganan.

Dalam contoh kasus di bab ini, kita akan mencoba membuat model churn prediction untuk
sebuah perusahaan telekomunikasi fiktif bernama “MobiTel” yang menjual layanan internet
dengan kartu prabayar. Tidak sedikit pelanggan MobiTel yang telah berpindah langganan ke
perusahaan pesaing akibat tawaran harga dan layanan yang lebih menarik. Pihak manajemen
MobiTel menyadari masalah ini dan berencana meluncurkan program-program promosi
untuk menahan laju churn.
Secara teknis, persoalan menebak pelanggan yang akan churn ini dikerjakan dengan
algoritma binary classification seperti Logistic Regression, Decision Tree atau Random
Forest yang sudah kita pelajari di bab-bab sebelumnya.
Pada akhirnya, model prediktif ini akan menghasilkan churn score kepada masing-masing
pelanggan, berupa angka 0 (”tidak”) dan 1 (“ya”), yaitu indikator yang menunjukkan apakah
pelanggan yang bersangkutan diprediksi akan berhenti berlangganan atau tidak.
Pada akhirnya, hasil model ini akan dipergunakan oleh Divisi Marketing MobiTel untuk
menawarkan paket-paket khusus kepada pelanggan yang churn score-nya bernilai “ya”,
dengan tujuan mencegah mereka pindah berlangganan ke perusahaan pesaing.
Mempersiapkan Dataset
Sebagai training dataset, kita mempergunakan daftar pelanggan yang mempergunakan jasa
MobiTel. Dataset berisi lima ribu example, berisikan nomor pelanggan, usia, berapa lama
pelanggan tersebut telah menjadi pelanggan MobiTel, dan informasi lain tentang pembelian
pulsa isi ulang dan pemakaian internetnya.
Daftar pelanggan yang di dalamnya termasuk pelanggan-pelanggan yang telah churn di masa
lalu. Pelanggan yang telah churn akan ditandai tersendiri, dengan demikian kita bisa
membuat model yang melihat tanda-data yang ditunjukkan oleh kelompok pelanggan ini.
Dataset ini bisa diunduh berupa file CSV dari situs yang ditunjukkan di Lampiran 2 buku ini.
Dataset berisi beberapa features seperti terlihat di tabel di bawah ini:

BAB 9 Clustering Dalam industri retail, salah satu yang sering dilakukan para analis bisnis adalah pembuatan
customer segmentation (segmentasi pelanggan atau sering juga disebut segmentasi pasar)
yang pada dasarnya adalah memilah pelanggan ke dalam kelompok-kelompok yang memiliki
kesamaan tersendiri. Kelompok bisa dibentuk berdasarkan demografi, pola pembelian,
geografis dan sebagainya.
Secara logis, orang-orang yang memiliki kesamaan perilaku akan kita golongkan ke dalam
kelompok yang sama pula. Pria yang berpakaian formal berada di kawasan perkantoran di
hari kerja akan berbeda perilakunya dengan anak muda yang memakai celana jeans dan kaos
di kampus sekolah. Begitu juga seorang wanita dewasa yang membawa anaknya di pasar
swalayan pada pagi hari akan kita golongkan ke segmen ibu rumah tangga.
Dengan dibuatnya kelompok-kelompok (segmen) pelanggan, proses pemasaran dapat lebih
terarah dan menyasar ke segmen pelanggan yang tepat. Contohnya sebuah perusahaan alat
kecantikan dapat memasang iklan khusus ke segmen pelanggan wanita usia tertentu saja,
sehingga tidak perlu mengeluarkan biaya iklan untuk segmen pria yang sudah hampir pasti
tidak akan menjadi pelanggannya.
Seperti yang sudah kita pelajari di Bab 1, machine learning bisa membantu kita untuk
memecahkan problematika di atas dengan bantuan algoritma matematis untuk mencari pola
di dalam data. Algoritma yang sering dipakai adalah K-Means Clustering yang akan kita
coba pelajari dalam bab ini. Adapun demikian sebelum kita ke sana, kita bahas dulu apa yang
dimaksud dengan clustering.
Clustering adalah proses yang membagi data ke dalam beberapa cluster (yaitu kelompok
yang isinya mirip) dengan melihat kesamaan antar data. Bisa kita anggap clustering adalah
metode untuk menemukan kelompok-kelompok data secara otomatis.
Kita tidak tahu dari awal bagaimana dan berapa banyak cluster yang nantinya akan terbentuk
melalui proses clustering. Dengan melakukan clustering, kita mendapatkan pengetahuan baru
tentang kelompok-kelompok yang terbentuk secara alamiah. Clustering sifatnya bukan
prediksi (memperkirakan masa depan), namun lebih bersifat knowledge discovery, yaitu
melihat apa yang telah terjadi.
Analoginya adalah dalam suatu acara pertemuan masal (misalnya pesta pernikahan, seminar,
pertandingan olah raga, atau kampanye politik), orang-orang yang memiliki banyak
kesamaan dari sisi usia, jenis kelamin, suku atau bidang pekerjaan akan cenderung duduk
berkumpul dan mengobrol bersama. Machine learning bertugas menemukan kumpulan-
kumpulan ini, meskipun di awal acara pertemuan kita tidak memiliki informasi siapa saja
yang akan hadir dalam acara ini.
Clustering berbeda dengan supervised learning seperti klasifikasi dan prediksi yang
memerlukan training data dengan label. Metode Decision Tree seperti yang kita pelajari di
bab sebelumnya memerlukan data training untuk dapat membentuk kelompok-kelompok
data. Sebaliknya, clustering tidak memerlukan training dataset. Clustering justru akan
menciptakan data baru yang kemudian dapat dipergunakan untuk memperkaya data yang ada.
Bagaimana caranya algoritma Machine Learning bisa mencari cluster? Kelompokkan data
sehingga elemen yang serupa atau saling terkait ditempatkan di cluster yang sama.
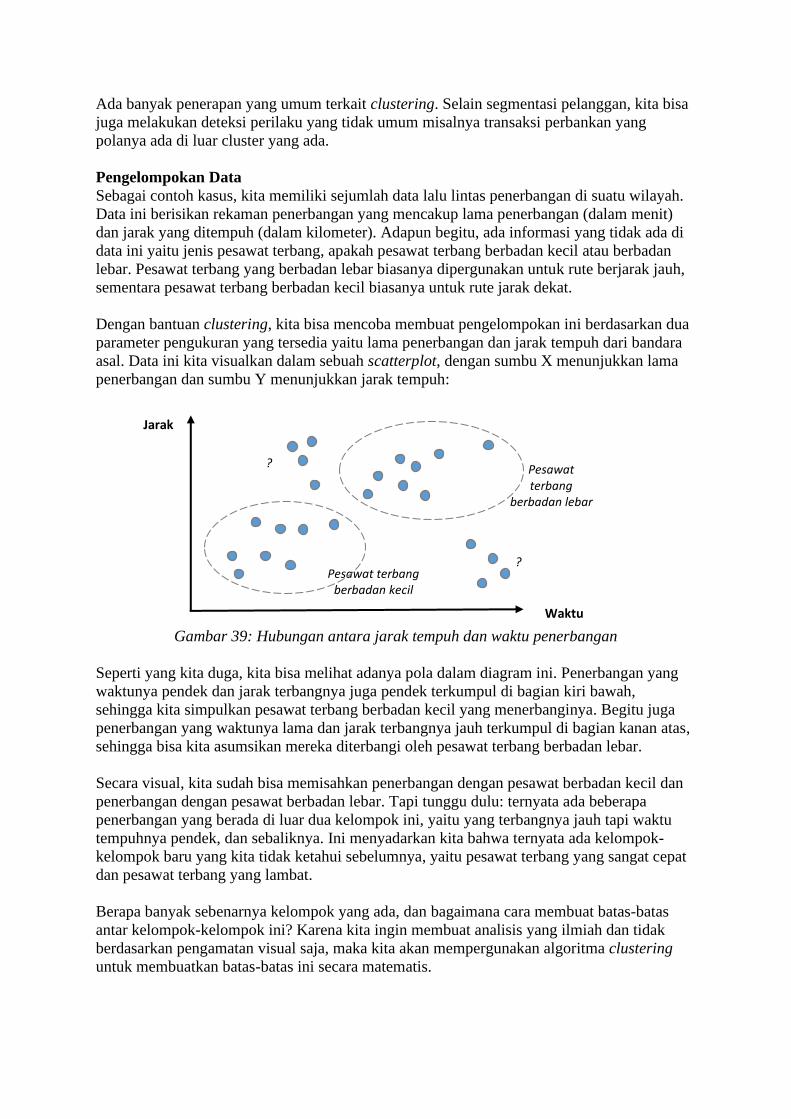
Ada banyak penerapan yang umum terkait clustering. Selain segmentasi pelanggan, kita bisa
juga melakukan deteksi perilaku yang tidak umum misalnya transaksi perbankan yang
polanya ada di luar cluster yang ada.
Pengelompokan Data
Sebagai contoh kasus, kita memiliki sejumlah data lalu lintas penerbangan di suatu wilayah.
Data ini berisikan rekaman penerbangan yang mencakup lama penerbangan (dalam menit)
dan jarak yang ditempuh (dalam kilometer). Adapun begitu, ada informasi yang tidak ada di
data ini yaitu jenis pesawat terbang, apakah pesawat terbang berbadan kecil atau berbadan
lebar. Pesawat terbang yang berbadan lebar biasanya dipergunakan untuk rute berjarak jauh,
sementara pesawat terbang berbadan kecil biasanya untuk rute jarak dekat.
Dengan bantuan clustering, kita bisa mencoba membuat pengelompokan ini berdasarkan dua
parameter pengukuran yang tersedia yaitu lama penerbangan dan jarak tempuh dari bandara
asal. Data ini kita visualkan dalam sebuah scatterplot, dengan sumbu X menunjukkan lama
penerbangan dan sumbu Y menunjukkan jarak tempuh:
Gambar 39: Hubungan antara jarak tempuh dan waktu penerbangan
Seperti yang kita duga, kita bisa melihat adanya pola dalam diagram ini. Penerbangan yang
waktunya pendek dan jarak terbangnya juga pendek terkumpul di bagian kiri bawah,
sehingga kita simpulkan pesawat terbang berbadan kecil yang menerbanginya. Begitu juga
penerbangan yang waktunya lama dan jarak terbangnya jauh terkumpul di bagian kanan atas,
sehingga bisa kita asumsikan mereka diterbangi oleh pesawat terbang berbadan lebar.
Secara visual, kita sudah bisa memisahkan penerbangan dengan pesawat berbadan kecil dan
penerbangan dengan pesawat berbadan lebar. Tapi tunggu dulu: ternyata ada beberapa
penerbangan yang berada di luar dua kelompok ini, yaitu yang terbangnya jauh tapi waktu
tempuhnya pendek, dan sebaliknya. Ini menyadarkan kita bahwa ternyata ada kelompok-
kelompok baru yang kita tidak ketahui sebelumnya, yaitu pesawat terbang yang sangat cepat
dan pesawat terbang yang lambat.
Berapa banyak sebenarnya kelompok yang ada, dan bagaimana cara membuat batas-batas
antar kelompok-kelompok ini? Karena kita ingin membuat analisis yang ilmiah dan tidak
berdasarkan pengamatan visual saja, maka kita akan mempergunakan algoritma clustering
untuk membuatkan batas-batas ini secara matematis.
?
? Pesawat terbang
berbadan lebar
Pesawat terbang berbadan kecil
Jarak
Waktu

Berbeda dengan kasus classification mempergunakan Decision Trees di bab sebelumnya di
mana kita memiliki training dataset lengkap dengan labelnya, di kasus kali ini kita tidak
memiliki data seperti itu. Kita tidak punya data nyata yang menunjukkan jenis pesawat
terbang sehingga kita tidak bisa melakukan training. Inilah alasannya mengapa clustering
termasuk metode unsupervised learning.
Cluster-cluster yang ingin kita buat harus berisikan elemen data yang homogen, sehingga
algoritma clustering harus memanfaatkan suatu metode pengukuran untuk melihat seberapa
dekat elemen-elemen data saling berhubungan.
Algoritma K-Means
Metode clustering dengan algoritma K-Means sebenarnya bukan hal baru dan sudah dikenal
sejak tahun 1960-an untuk berbagai penerapan ilmiah. K-Means banyak dipergunakan karena
sifatnya yang cukup sederhana dan mudah dipahami bahkan bagi mereka yang tidak memiliki
latar belakang ilmu statistik, namun efektif bisa menemukan cluster di dalam data secara
cepat.
Prinsip dasar dari k-Means adalah melakukan proses iteratif (berulang) untuk menggeser
centroid, yaitu suatu titik imajiner di dalam setiap cluster agar letaknya tepat ada di titik
tengah cluster. Di “titik tengah” dalam konteks clustering artinya adalah angka yang secara
aritmetis menunjukkan jarak rata-rata dari centroid ke seluruh titik data yang ada di dalam
cluster bernilai sama. Titik-titik data kemudian dipasangkan dengan centroid terdekat. Kita
bisa bayangkan centroid sebagai pusat cluster yang mengikat anggota-anggota di dalamnya,
seperti di gambar di bawah. Proses penggeseran centroid diulangi berkali-kali hingga
diperoleh posisi centroid yang stabil, dan kemudian kita anggap pembentukan cluster pun
selesai.
Gambar 40: Centroid di setiap cluster
K-means bertujuan agar kita mendapatkan sejumlah cluster yang isinya sebisa mungkin
homogen (seragam). Sejalan dengan itu, kita ingin mendapatkan sekumpulan cluster yang
sejauh mungkin berbeda satu sama lain, sehingga batas antar cluster juga menjadi lebih jelas.
Mengapa disebut k-Means? K adalah suatu konstanta yang menentukan jumlah centroid,
yang berarti juga sama dengan jumlah cluster yang akan dibentuk. Kita bisa memilih berapa
saja angka k, asalkan tidak lebih banyak dari jumlah datanya sendiri. Umumnya, semakin
banyak cluster yang dibentuk, maka masing-masing cluster akan semakin homogen, adapun
begitu pada saat yang sama ini akan meningkatkan resiko model menjadi overfit, yaitu tidak
bisa membuat prediksi yang akurat ketika dihadapkan dengan data-data baru.
centroid centroid

Menentukan angka k yang terlalu tinggi juga memiliki konsekuensi yaitu proses komputasi
yang menjadi terlalu berat dan memakan waktu lama. Tidak ada rumus baku untuk
menentukan berapa angka yang tepat untuk menentukan angka k, umumnya ini ditentukan
berdasarkan konteks permasalahan yang dihadapi. Seringkali jumlah cluster ditentukan oleh
tuntutan dan kebutuhan bisnis. Sebagai contoh, bila suatu perusahaan sudah memiliki
pemahaman awal tentang segmen pelanggan yang ingin dibentuk, misalnya ada tiga yaitu
segmen anak muda, segmen dewasa dan segmen orang tua, maka bisa ditentukan k = 3.
Lebih jelasnya, berikut langkah-langkah algoritma k-Means:
1. Buat centroid sebanyak k dan tentukan posisi awal secara acak.
2. Tentukan cluster yang sesuai untuk setiap titik data dengan cara menghitung centroid yang
jaraknya terdekat (cara menghitung jarak dijelaskan di dalam boks di bawah).
3. Geser centroid ke posisi baru dengan menghitung jarak rata-rata setiap titik di dalam
cluster.
4. Hitung ulang jarak tiap titik data ke semua centroid, dan masukkan titik data ke cluster
baru bilamana perlu.
5. Ulangi langkah 3 sampai 5 hingga suatu kriteria terpenuhi dan posisi centroid sudah bisa
dianggap stabil.
Bagaimana cara menghitung jarak?
Formula yang paling umum untuk menghitung jarak antara dua titik adalah Euclidean
distance. Ibaratnya mempergunakan penggaris dan pensil untuk menarik garis lurus antara
dua titik, jarak yang dihitung adalah jarak yang paling dekat. Ada juga formula lain yang
disebut Manhattan distance, yang menghitung jarak dengan mempertimbangkan rute
berbelok-belok seperti orang berjalan di jalanan kota. Algoritma K-Means bisa
mempergunakan beragam formula jarak, namun di buku ini kita mempergunakan
Euclidean distance.
Euclidean Distance = √(𝑋1 − 𝑋2)2 + (𝑌1 − 𝑌2)2
(X1, Y1) adalah koordinat titik awal dan (X2, Y2) adalah koordinat titik tujuan.
Penentuan angka k ini sendiri sebenarnya merupakan satu proses eksperimental yang bisa
membawa kita menemukan pola-pola baru yang menarik. Dengan “memainkan” angka k, kita
bisa mengamati bagaimana batas-batas cluster ikut berubah. Cluster yang sudah homogen akan
sedikit saja berubah meskipun angka k dinaikkan, sementara cluster yang karakteristiknya
tidak (atau kurang) homogen akan berubah lebih banyak.
Ada metode khusus untuk memperkirakan angka k yang optimal yang disebut elbow method.
Pada prinsipnya metode ini mengukur seberapa homogen masing-masing cluster ketika angka
k dinaikkan, kemudian menemukan titik di mana peningkatan angka k tidak lagi menghasilkan
cluster yang lebih homogen secara signifikan dibanding sebelumnya. Titik yang dicari ini
disebut elbow point karena bila kurvanya digambar di sebuah grafik, titik ini akan nampak
seperti siku tangan manusia.
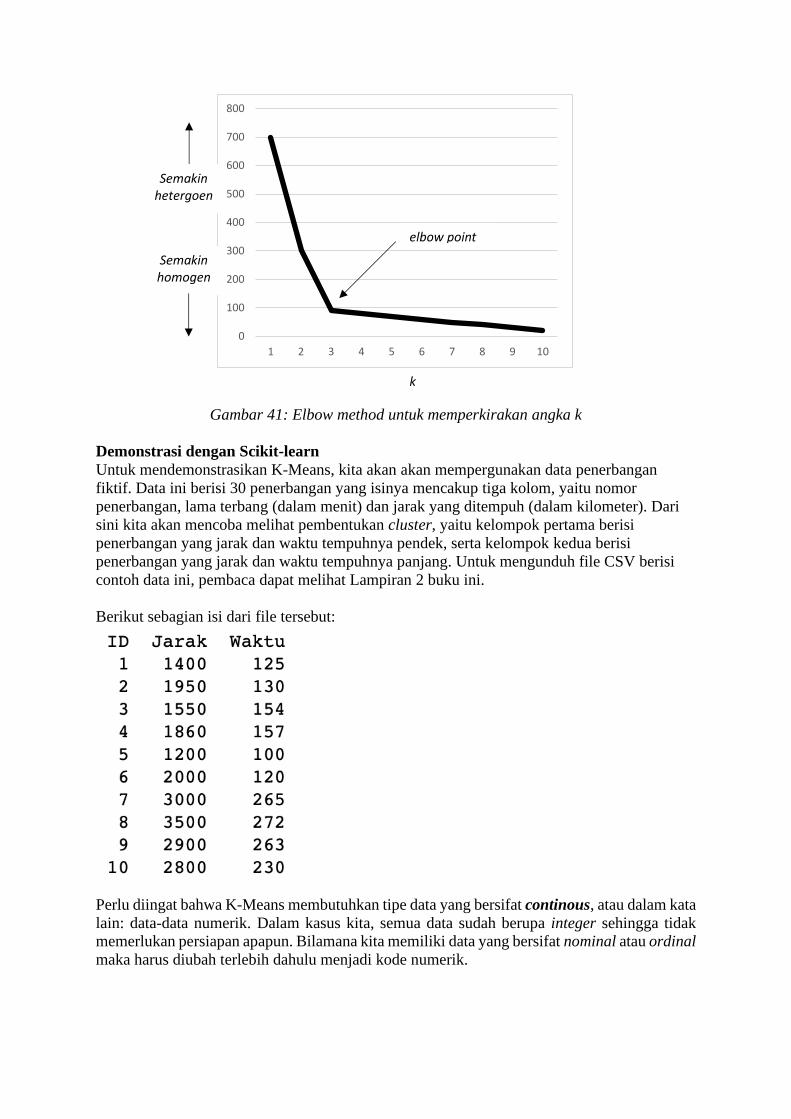
k
Gambar 41: Elbow method untuk memperkirakan angka k
Demonstrasi dengan Scikit-learn
Untuk mendemonstrasikan K-Means, kita akan akan mempergunakan data penerbangan
fiktif. Data ini berisi 30 penerbangan yang isinya mencakup tiga kolom, yaitu nomor
penerbangan, lama terbang (dalam menit) dan jarak yang ditempuh (dalam kilometer). Dari
sini kita akan mencoba melihat pembentukan cluster, yaitu kelompok pertama berisi
penerbangan yang jarak dan waktu tempuhnya pendek, serta kelompok kedua berisi
penerbangan yang jarak dan waktu tempuhnya panjang. Untuk mengunduh file CSV berisi
contoh data ini, pembaca dapat melihat Lampiran 2 buku ini.
Berikut sebagian isi dari file tersebut:
Perlu diingat bahwa K-Means membutuhkan tipe data yang bersifat continous, atau dalam kata
lain: data-data numerik. Dalam kasus kita, semua data sudah berupa integer sehingga tidak
memerlukan persiapan apapun. Bilamana kita memiliki data yang bersifat nominal atau ordinal
maka harus diubah terlebih dahulu menjadi kode numerik.
0
100
200
300
400
500
600
700
800
1 2 3 4 5 6 7 8 9 10
elbow point
Semakin hetergoen
Semakin homogen
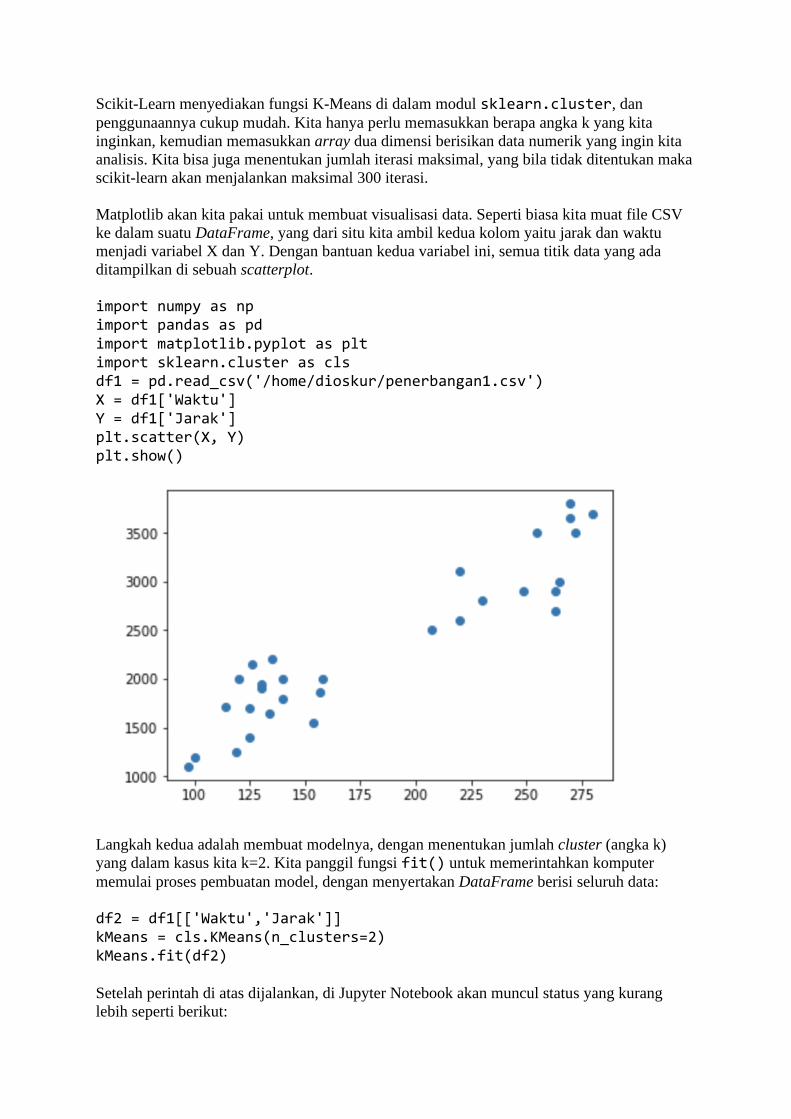
Scikit-Learn menyediakan fungsi K-Means di dalam modul sklearn.cluster, dan
penggunaannya cukup mudah. Kita hanya perlu memasukkan berapa angka k yang kita
inginkan, kemudian memasukkan array dua dimensi berisikan data numerik yang ingin kita
analisis. Kita bisa juga menentukan jumlah iterasi maksimal, yang bila tidak ditentukan maka
scikit-learn akan menjalankan maksimal 300 iterasi.
Matplotlib akan kita pakai untuk membuat visualisasi data. Seperti biasa kita muat file CSV
ke dalam suatu DataFrame, yang dari situ kita ambil kedua kolom yaitu jarak dan waktu
menjadi variabel X dan Y. Dengan bantuan kedua variabel ini, semua titik data yang ada
ditampilkan di sebuah scatterplot.
import numpy as np import pandas as pd import matplotlib.pyplot as plt import sklearn.cluster as cls df1 = pd.read_csv('/home/dioskur/penerbangan1.csv') X = df1['Waktu'] Y = df1['Jarak'] plt.scatter(X, Y) plt.show()
Langkah kedua adalah membuat modelnya, dengan menentukan jumlah cluster (angka k)
yang dalam kasus kita k=2. Kita panggil fungsi fit() untuk memerintahkan komputer
memulai proses pembuatan model, dengan menyertakan DataFrame berisi seluruh data:
df2 = df1[['Waktu','Jarak']] kMeans = cls.KMeans(n_clusters=2) kMeans.fit(df2) Setelah perintah di atas dijalankan, di Jupyter Notebook akan muncul status yang kurang
lebih seperti berikut:

KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
n_clusters=2, n_init=10, n_jobs=None, precompute_distances='auto',
random_state=None, tol=0.0001, verbose=0)
Ada yang menarik dari status di atas, yaitu max_iter = 300 yang artinya algoritma k-
Means akan dibatasi dan berhenti setelah maksimal 300 iterasi. Ini bisa kita ubah saat
kMeans diinisialisasi, kita bisa bereksperimen dengan angka ini bila kita merasa kurang puas
dengan hasil model.
Kita tentu ingin tahu di mana centroid yang sudah berhasil diidentifikasi oleh model. Caranya
dengan membaca variabel cluster_centers_ yang isinya adalah array berisi koordinat
semua centroid (karena nilai k=2, maka ada dua centroid; baris pertama adalah centroid
pertama, baris kedua adalah centroid kedua):
centroids = kMeans.cluster_centers_ print(centroids) [[ 129.64705882 1730.82352941]
[ 251.07692308 3126.92307692]]
Agar mudah kita pahami, kita akan visualkan kedua centroid ini di dalam scatterplot. Kita
pergunakan satu variabel (bernama centroid_X) untuk menampung posisi-posisi centroid
di sumbu X, dan satu variabel lain (bernama centroid_Y) untuk menampung posisi-posisi
centroid di sumbu Y. Agar tampil berbeda di scatterplot, kita tentukan simbol ‘X’ berwarna
hitam dengan ukuran besar untuk mewakili semua centroid.
centroid_X = centroids[:,0] centroid_Y = centroids[:,1] plt.scatter(centroid_X, centroid_Y, color='black', marker='X', s=200) plt.show() Hasilnya akan muncul scatterplot sebagai berikut:
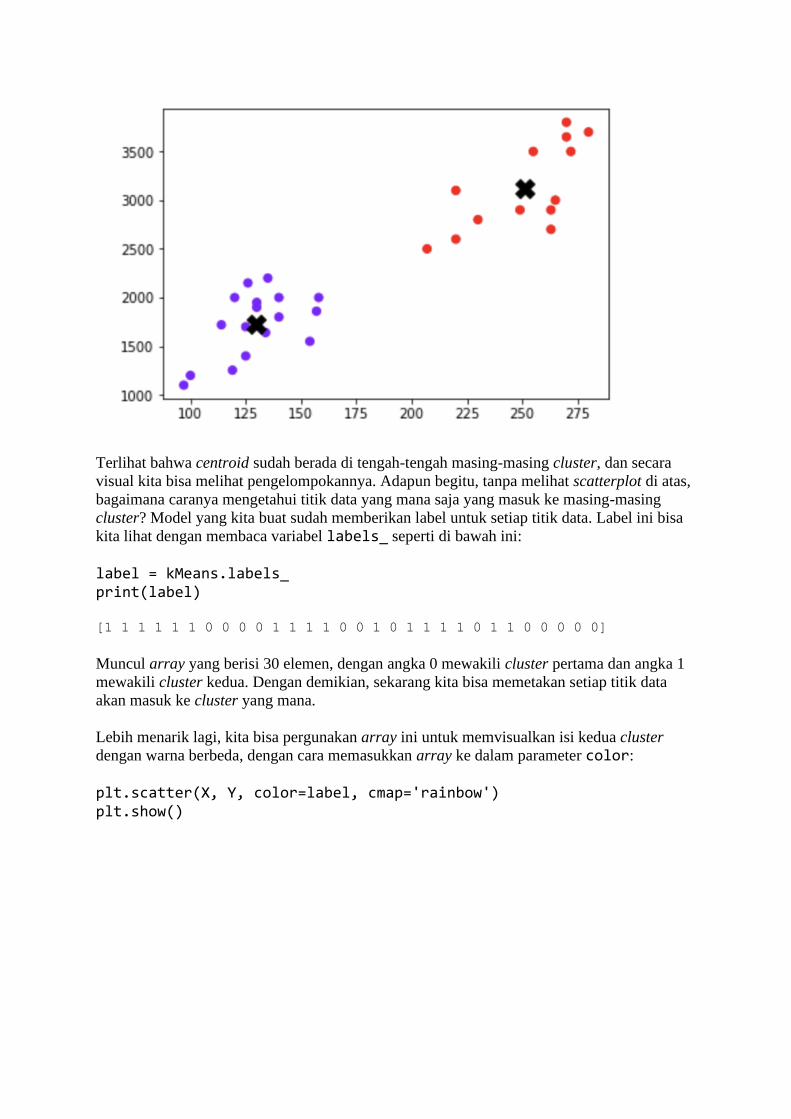
Terlihat bahwa centroid sudah berada di tengah-tengah masing-masing cluster, dan secara
visual kita bisa melihat pengelompokannya. Adapun begitu, tanpa melihat scatterplot di atas,
bagaimana caranya mengetahui titik data yang mana saja yang masuk ke masing-masing
cluster? Model yang kita buat sudah memberikan label untuk setiap titik data. Label ini bisa
kita lihat dengan membaca variabel labels_ seperti di bawah ini:
label = kMeans.labels_ print(label) [1 1 1 1 1 1 0 0 0 0 1 1 1 1 0 0 1 0 1 1 1 1 0 1 1 0 0 0 0 0]
Muncul array yang berisi 30 elemen, dengan angka 0 mewakili cluster pertama dan angka 1
mewakili cluster kedua. Dengan demikian, sekarang kita bisa memetakan setiap titik data
akan masuk ke cluster yang mana.
Lebih menarik lagi, kita bisa pergunakan array ini untuk memvisualkan isi kedua cluster
dengan warna berbeda, dengan cara memasukkan array ke dalam parameter color:
plt.scatter(X, Y, color=label, cmap='rainbow') plt.show()
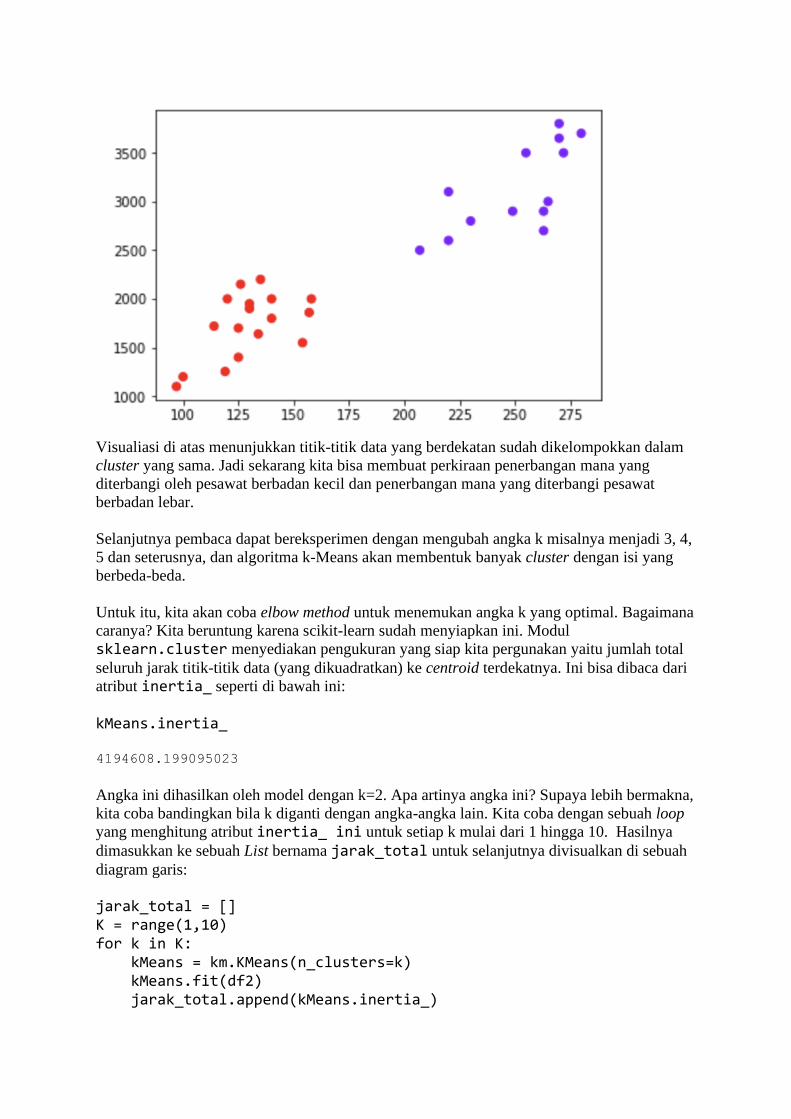
Visualiasi di atas menunjukkan titik-titik data yang berdekatan sudah dikelompokkan dalam
cluster yang sama. Jadi sekarang kita bisa membuat perkiraan penerbangan mana yang
diterbangi oleh pesawat berbadan kecil dan penerbangan mana yang diterbangi pesawat
berbadan lebar.
Selanjutnya pembaca dapat bereksperimen dengan mengubah angka k misalnya menjadi 3, 4,
5 dan seterusnya, dan algoritma k-Means akan membentuk banyak cluster dengan isi yang
berbeda-beda.
Untuk itu, kita akan coba elbow method untuk menemukan angka k yang optimal. Bagaimana
caranya? Kita beruntung karena scikit-learn sudah menyiapkan ini. Modul
sklearn.cluster menyediakan pengukuran yang siap kita pergunakan yaitu jumlah total
seluruh jarak titik-titik data (yang dikuadratkan) ke centroid terdekatnya. Ini bisa dibaca dari
atribut inertia_ seperti di bawah ini:
kMeans.inertia_ 4194608.199095023
Angka ini dihasilkan oleh model dengan k=2. Apa artinya angka ini? Supaya lebih bermakna,
kita coba bandingkan bila k diganti dengan angka-angka lain. Kita coba dengan sebuah loop
yang menghitung atribut inertia_ ini untuk setiap k mulai dari 1 hingga 10. Hasilnya
dimasukkan ke sebuah List bernama jarak_total untuk selanjutnya divisualkan di sebuah
diagram garis:
jarak_total = [] K = range(1,10) for k in K: kMeans = km.KMeans(n_clusters=k) kMeans.fit(df2) jarak_total.append(kMeans.inertia_)
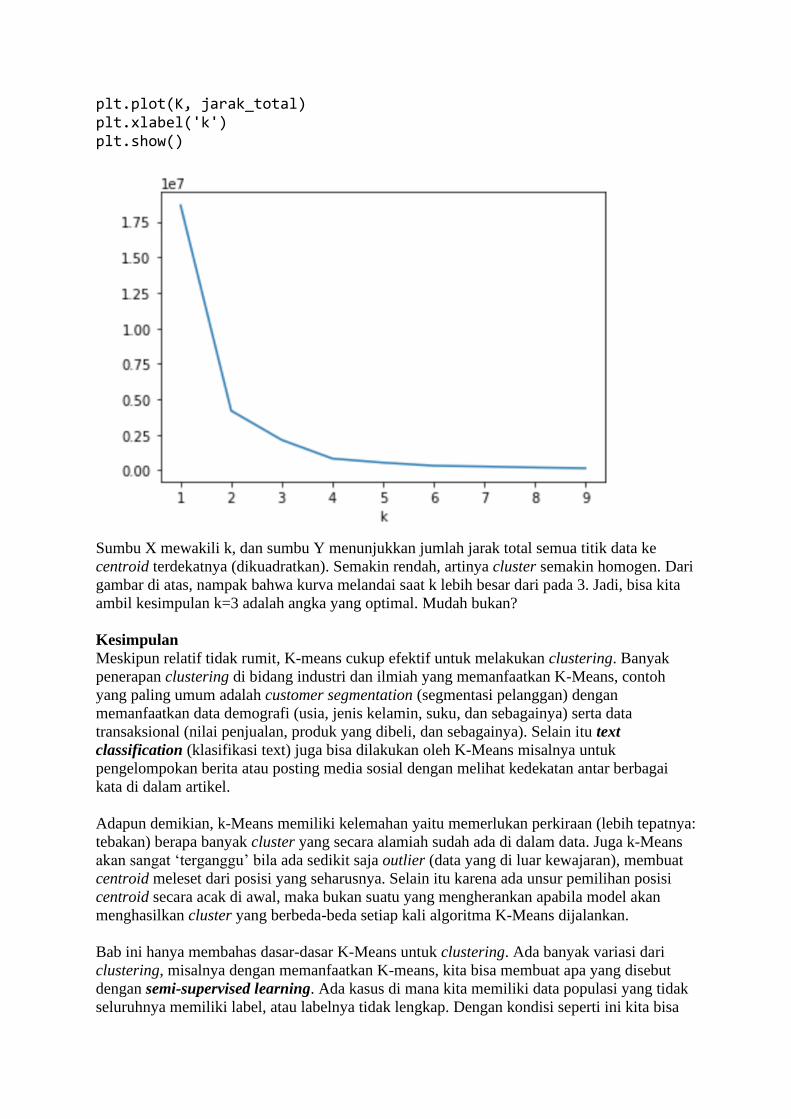
plt.plot(K, jarak_total) plt.xlabel('k') plt.show()
Sumbu X mewakili k, dan sumbu Y menunjukkan jumlah jarak total semua titik data ke
centroid terdekatnya (dikuadratkan). Semakin rendah, artinya cluster semakin homogen. Dari
gambar di atas, nampak bahwa kurva melandai saat k lebih besar dari pada 3. Jadi, bisa kita
ambil kesimpulan k=3 adalah angka yang optimal. Mudah bukan?
Kesimpulan
Meskipun relatif tidak rumit, K-means cukup efektif untuk melakukan clustering. Banyak
penerapan clustering di bidang industri dan ilmiah yang memanfaatkan K-Means, contoh
yang paling umum adalah customer segmentation (segmentasi pelanggan) dengan
memanfaatkan data demografi (usia, jenis kelamin, suku, dan sebagainya) serta data
transaksional (nilai penjualan, produk yang dibeli, dan sebagainya). Selain itu text
classification (klasifikasi text) juga bisa dilakukan oleh K-Means misalnya untuk
pengelompokan berita atau posting media sosial dengan melihat kedekatan antar berbagai
kata di dalam artikel.
Adapun demikian, k-Means memiliki kelemahan yaitu memerlukan perkiraan (lebih tepatnya:
tebakan) berapa banyak cluster yang secara alamiah sudah ada di dalam data. Juga k-Means
akan sangat ‘terganggu’ bila ada sedikit saja outlier (data yang di luar kewajaran), membuat
centroid meleset dari posisi yang seharusnya. Selain itu karena ada unsur pemilihan posisi
centroid secara acak di awal, maka bukan suatu yang mengherankan apabila model akan
menghasilkan cluster yang berbeda-beda setiap kali algoritma K-Means dijalankan.
Bab ini hanya membahas dasar-dasar K-Means untuk clustering. Ada banyak variasi dari
clustering, misalnya dengan memanfaatkan K-means, kita bisa membuat apa yang disebut
dengan semi-supervised learning. Ada kasus di mana kita memiliki data populasi yang tidak
seluruhnya memiliki label, atau labelnya tidak lengkap. Dengan kondisi seperti ini kita bisa

lakukan clustering untuk menghasilkan label, kemudian dari situ kita terapkan supervised
learning misalnya Decision Trees untuk menemukan variabel-variabel yang paling penting
untuk setiap kelas.
Oleh karena K-Means adalah metode belajar yang unsupervised, maka hasil model hanya
akan menunjukkan manfaatnya bila kita bisa menemukan pemahaman baru dari cluster-
cluster yang terbentuk. Tidak ada ground truth yang dapat dibandingkan dengan hasil model.
Mesin hanya bertugas menemukan pola, dan selanjutnya terserah Anda!

Bab 10 Market Basket Analysis Bayangkanlah Anda datang ke sebuah toko swalayan, dengan pikiran hendak membeli satu-
dua barang bagi keperluan rumah. Ketika Anda sudah menemukan apa yang dicari, di rak
sebelahnya Anda melihat barang lain yang menarik hati Anda, dan tanpa pikir panjang Anda
mengambilnya juga. Ini yang sering disebut impulsive buying, membeli tanpa rencana.
Pengusaha toko swalayan paham ini, dan mereka meletakkan barang-barang yang sering
dibeli pelanggan secara bersamaan, misalnya roti tawar dengan mentega, di rak yang
berdekatan. Ini akan meningkatkan penjualan sekaligus memudahkan pelanggan.
Bagaimana cara menemukan produk-produk yang cocok diletakkan berdekatan? Di sinilah
suatu metode yang disebut Market Basket Analysis (analisis keranjang belanja) banyak
dipergunakan di industri retail. Disebut “market basket” karena metode ini mengamati dan
mencari pola dari barang-barang apa saja yang ada di dalam keranjang belanja pelanggan.
Metode ini termasuk ke dalam kategori unsupervised learning karena berupaya menggali
pola-pola dari data tanpa terlebih dahulu memiliki pemahaman akan pola seperti apa yang
kita harapkan.
Hal yang sama dilakukan di toko-toko online. Di saat Anda berbelanja online, barang-barang
yang menarik hati Anda biasanya sudah muncul di layar, bahkan sebelum Anda memilih
apapun. Bahkan terkadang toko online menyajikan juga pilihan barang-barang yang secara
umum tidak ada hubungannya. Recommendation system, yaitu sistem yang bisa
memperkirakan barang apa yang menarik untuk pelanggan, memilihkan barang-barang ini
berdasarkan pola belanja Anda sebelumnya, atau pola belanja pelanggan-pelanggan lain yang
dianggap memiliki ketertarikan serupa dengan Anda. Situs streaming musik dan video pun
mempergunakan sistem yang serupa untuk menyajikan konten music atau film yang
kemungkinan besar Anda suka. Recommendation System adalah salah satu penerapan
Machine Learning di dunia bisnis yang sudah luas dipergunakan.
Dalam bab ini, kita akan mencoba metode market basket analysis yang memanfaatkan data
transaksi di sebuah gerai restoran. Kita akan mencari produk-produk makanan dan minuman
yang sering dibeli bersama oleh pelanggan, sehingga pemilik restoran bisa merancang paket-
paket makanan dan minuman yang kemungkinan besar akan laku. Dengan paket, pelanggan
menjadi mudah memilih dan mendorongnya untuk kembali berkunjung di waktu berikutnya.
Association Rules
Market Basket Analysis bertujuan menemukan pola-pola hubungan yang sering muncul di
dalam data, misalnya data transaksi penjualan. Pola yang kita cari disebut association rule,
atau bisa diterjemahkan bebas sebagai hubungan (asosiasi) antara kombinasi beberapa item
(barang, orang, produk, atau apapun yang diwakili oleh kata benda) yang sering muncul
bersamaan.
Apabila suatu hubungan sedemikian seringnya muncul di dalam data, maka hubungan ini
kemudian dianggap sebagai suatu keharusan, atau “aturan” (rule) yang wajib dipenuhi. Dari
sinilah istilah association rule (selanjutnya cukup kita sebut rule) punya arti yaitu aturan yang
menentukan hubungan antar item di dalam data.
Dalam notasi matematis, sebuah association rule memiliki antecedent (hal yang mengawali)
yang ditulis di kiri tanda panah, dan sebuah consequent (efek atau akibat) di sebelah kanan
anak panah.
{ antecedent } → { consequent }

Nilai-nilai yang ada di dalam tanda kurung kurawal {} disebut itemset, bisa terdiri dari satu
item atau lebih.
Dengan contoh yang lebih mudah dipahami, kita coba melihat kasus klasik yaitu hubungan
antara barang belanjaan berupa roti, mentega dan selai. Contoh sebuah rule yang bisa
dihasilkan dari tiga barang tersebut:
{ roti } → { mentega } Rule di atas menunjukkan bahwa bilamana roti dibeli, maka mentega juga (kemungkinan
besar) akan dibeli. Secara teoritis artinya telah terbentuk aturan yaitu kemunculan roti
mengakibatkan kemunculan mentega. Adapun demikian harus diperhatikan bahwa rule ini
berlaku satu arah, artinya ketika mentega dibeli, maka roti belum tentu akan dibeli - bisa jadi
seorang pelanggan membeli mentega untuk memasak kue, bukan untuk dioleskan di roti.
Lebih lanjut lagi, ketika roti dan mentega dibeli bersamaan, maka bisa jadi akan muncul rule
baru, yaitu selai coklat akan sangat mungkin dibeli juga:
{ roti, mentega } → { selai coklat } Rule di atas menunjukkan itemset berisi roti dan mentega akan mengakibatkan itemset berisi
selai coklat muncul pula di dalam data. Sekali lagi, rule ini tidak berlaku sebaliknya, artinya
selai coklat tidak mengakibatkan roti dan mentega muncul di dalam data.
Sukses tidaknya market basket analysis ditentukan dengan kualitas rule yang berhasil
ditemukan. Bisa jadi bila data yang kita masukkan tidak memuat pola-pola yang cukup
banyak, atau dengan kata lain kualitasnya tidak baik, maka rule yang muncul juga tidak akan
memberikan pengetahuan baru pada kita. Itu sebabnya untuk mempergunakan association
rule, kita harus mempersiapkan data yang berjumlah banyak, dan berpotensi memiliki banyak
pola-pola hubungan di dalamnya. Bila dalam data transaksi penjualan hanya memiliki sedikit
misalnya hanya empat atau lima macam produk, maka association rule tidak akan
menghasilkan rule yang menarik karena pelanggan hanya membeli barang yang itu-itu saja.
Kita ingat di Bab 1 bahwa unsupervised learning tidak memerlukan training karena yang kita
inginkan bukanlah membuat prediksi, namun kita ingin mendapatkan pemahaman dari pola-
pola hubungan di dalam data yang sudah ada. Bisa kita anggap bahwa kita memiliki sebuah
mesin, data besar yang kita miliki kita masukkan ke dalamnya, kemudian kita bisa melihat
hasil keluaran dari mesin ini sambil memperhatikan adakah sesuatu pola menarik yang bisa
kita dapatkan. Di sini perlu proses iterasi, pengulangan beberapa kali hingga diperoleh hasil
kualitatif yang dikehendaki, dan bisa berbeda-beda untuk setiap macam data.
Hubungan-hubungan menarik antara banyak variabel dalam data hanya dapat ditemukan
dengan bantuan komputer bila sudah melibatkan data yang besar. Seandainya manusia hanya
mengandalkan tangan dan mata, bisa juga menemukan pola-pola ini bilamana ukuran data
hanya beberapa puluh baris, atau paling besar beberapa ratus baris. Ketika dihadapkan
dengan data dengan ribuan bahkan jutaan baris bersama dengan ratusan variabel, ibarat
mencari jarum dalam jerami, manusia tidak akan sanggup seberapapun hebat staminanya.
Association rule tidak hanya bisa dimanfaatkan untuk Market Basket Analysis. Banyak
implementasi lain di industri keuangan misalnya untuk menemukan transaksi kartu kredit

yang tidak wajar atau di bidang penelitian ilmiah misalnya untuk mencari pola dalam DNA
manusia.
Memisahkan Data yang Tidak Diperlukan
Sebelum kita bisa menemukan pola-pola hubungan antar itemset dalam data, kita perlu
terlebih dahulu membuang itemset yang kita tahu tidak akan pernah berhubungan satu sama
lain. Contoh sederhana adalah hubungan antara produk untuk pria dengan produk untuk
wanita, yang dengan logika umum adalah produk-produk yang tidak dibeli secara bersamaan
oleh satu pelanggan yang sama. Misalnya rule { sepatu pria, lipstik } adalah rule yang
tidak akan terjadi, atau amat jarang terjadi.
Produk-produk seperti di atas tidak akan memberikan kontribusi pada proses analisis, jadi
perlu dikeluarkan dari dataset untuk mencegah komputer menangani data yang terlalu besar.
Bila sebuah toko memiliki 10 macam produk, maka diperlukan 210 = 1024 kombinasi itemset,
suatu angka yang masih masuk akal. Namun bila jumlah produk menjadi 100, maka akan
diperlukan 2100 atau milyaran kombinasi, suatu jumlah yang sangat berat bahkan untuk
komputer tercanggih pun.
Salah satu algoritma yang populer untuk memilih data bagi keperluan market basket analysis
adalah Apriori. Prinsip dasar apriori adalah meyakini bahwa semua subset (sebagian) dari
sebuah itemset yang frekuensi kemunculannya tinggi haruslah memiliki frekuensi
kemunculan yang tinggi pula. Untuk memahami maksud dari prinsip ini, kita ambil contoh
sepatu pria dan lipstik di atas. Sesuai prinsip apriori, itemset { sepatu pria, lipstik } hanya
akan sering muncul (frekuensi kemunculannya tinggi) apabila subsetnya yaitu { sepatu pria
} dan { lipstik } keduanya juga sering muncul. Satu saja subset tersebut tidak sering muncul
(frekuensi kemunculannya rendah), maka tidak perlu lagi menghitung kemungkinan rule
yang melibatkan sepatu pria dan lipstik. Kombinasi ini bisa langsung diabaikan.
Apriori bisa berguna untuk mengidentifikasi itemset yang frekuensi kemunculannya tinggi.
Agar lebih jelas lagi, mari kita pergunakan contoh data transaksi penjualan makanan dan
minuman di sebuah restoran seperti berikut:
ID_Trans Makanan & Minuman
1 Soto, nasi putih, es teh
2 Perkedel, soto, kopi susu, bakso
3 Nasi putih, bakso, soto
4 Perkedel, kopi susu, es teh
5 Soto, nasi putih, es teh
Seorang tamu restoran biasanya memesan makanan bersama dengan minuman. Dari contoh
pola pemesanan di atas, kita bisa melihat bahwa soto hampir selalu dipesan bersama nasi
putih. Begitu juga tamu yang memesan perkedel selalu memesan kopi susu untuk menemani
kudapannya. Kombinasi-kombinasi itu mudah kita lihat karena kita semua sudah familiar
dengan konsep makanan dan minuman, tidak memerlukan keterampilan khusus untuk melihat
pola dan hubungannya. Adapun demikian, komputer tidak memiliki pemahaman yang sama
akan makanan dan minuman seperti manusia, sehingga diperlukan pengukuran matematis
untuk menentukan kombinasi yang perlu diikutkan dalam proses analisis dan kombinasi yang
tidak perlu.

Dua konsep pengukuran yang penting dalam association rules adalah support dan
confidence.
Support menentukan seberapa sering suatu itemset muncul dalam data, diukur dalam skala
nol hingga satu. Nol artinya tidak pernah muncul dalam data, sementara angka satu berarti
itemset tersebut selalu muncul. Cara menghitungnya sederhana saja, yaitu dengan
menghitung seluruh pemunculan suatu itemset atau rule dan kemudian dibagi jumlah data:
𝑆𝑢𝑝𝑝𝑜𝑟𝑡(𝑎 → 𝑏) =𝑗𝑢𝑚𝑙𝑎ℎ 𝑡𝑟𝑎𝑛𝑠𝑎𝑘𝑠𝑖 𝑦𝑎𝑛𝑔 𝑚𝑒𝑙𝑖𝑏𝑎𝑡𝑘𝑎𝑛 (𝑎 → 𝑏)
𝑗𝑢𝑚𝑙𝑎ℎ 𝑡𝑜𝑡𝑎𝑙 𝑡𝑟𝑎𝑛𝑠𝑎𝑘𝑠𝑖
“Jumlah transaksi yang melibatkan (a -> b)” dihitung dari berapa kali rule { a } -> { b }
muncul di dalam dataset. Dari contoh lima transaksi pesanan makanan dan minuman di atas,
angka support untuk rule { perkedel } -> { kopi susu } karena muncul di dua transaksi
maka menjadi 2 / 5 = 0,4. Begitu pula { soto } -> { nasi putih } memiliki angka support
0,6 (karena ada tiga transaksi). Support juga bisa dihitung untuk itemset yang berisi satu item
saja misalnya { soto } dengan angka support 4 / 5 = 0,8.
Perlu dipahami bahwa contoh di atas dengan hanya lima transaksi sebenarnya sangatlah kecil.
Dalam praktek lazimnya kita akan berhadapan dengan ribuan atau bahkan jutaan transaksi,
sehingga bisa jadi ada angka support yang kecil sekali misalnya 0,0001 yaitu jika itemset
tersebut hanya ditemukan sedikit saja di dalam transaksi.
Confidence dipakai untuk menentukan akurasi suatu rule, atau bisa juga dianggap sebagai
ukuran seberapa yakin (confident) kita terhadap suatu rule. Sama seperti support, angka
confidence adalah dari nol hingga satu, di mana angka satu berarti kita sangat yakin dan
sebaliknya angka nol berarti tidak ada keyakinan terhadap rule yang dimaksud. Confidence
ditentukan oleh seberapa sering suatu item Y muncul dalam transaksi yang melibatkan X.
Misalnya suatu angka confidence 0,8 artinya bilamana suatu barang X dibeli pelanggan, maka
80% dari transaksi itu akan menunjukkan bahwa pelanggan juga membeli barang Y.
Secara matematis, confidence dihitung sebagai berikut:
𝐶𝑜𝑛𝑓𝑖𝑑𝑒𝑛𝑐𝑒(𝑎 → 𝑏) =𝑆𝑢𝑝𝑝𝑜𝑟𝑡(𝑎 → 𝑏)
𝑆𝑢𝑝𝑝𝑜𝑟𝑡(𝑎)
Sesuai contoh transaksi pesanan makanan di atas, angka confidence untuk rule { soto } -> {
nasi putih } adalah hasil pembagian support (soto -> nasi putih) dengan support
(soto), yaitu 0,6 / 0,8 = 0,75. Artinya, kita memiliki keyakinan bahwa 75% pelanggan akan
memesan nasi putih bilamana dia memesan soto. Suatu angka yang cukup tinggi, cukup
untuk meyakini bahwa ada hubungan yang khusus antara kedua produk ini.
Namun kita belum selesai sampai di situ. Bagaimana kalau sekarang kita melihat rule
sebaliknya, yaitu { nasi putih } -> { soto }? Kita hitung bahwa angka support untuk nasi
putih saja adalah 3/5 = 0,6, berarti angka confidence untuk rule ini adalah 0,6 / 0,6 = 1.
Artinya, keyakinan kita adalah 100% bahwa setiap kali orang memesan nasi putih, dia juga
akan memesan soto.
Dengan demikian, bila kita pergunakan perkiraan matematis ini, maka kita punya keyakinan
bahwa ketika seorang pelanggan ditawari untuk memesan nasi putih, maka kemungkinan dia

juga akan memesan seporsi soto. Keyakinan kita akan lebih tinggi dibandingkan bila
pelanggan tadi datang dan ditawari untuk memesan soto saja. Tentu saja ini sekedar contoh
belaka, juga kita berasumsi bahwa pelanggan tidak alergi nasi.
Dalam kasus di mana itemset berisi lebih dari satu item, misalnya ada tiga { nasi putih,
soto } -> { es teh }, angka confidence harus dihitung dari persentase kedua kombinasi
barang yaitu nasi putih dan soto ditemukan bersama es teh.
Menghitung angka support dan confidence ini penting sebelum melangkah lebih lanjut. Kita
bisa menentukan ambang minimal untuk support dan confidence, dan kemudian menerapkan
algoritma apriori untuk mengurangi secara drastis jumlah data yang harus diproses.
Memilih Rule yang Kuat
Rule { soto } -> { nasi putih } bisa dianggap rule yang “kuat” karena angka support dan
confidence yang cukup tinggi. Rule yang kuat seperti ini yang kita cari dengan cara
menghitung semua kombinasi item yang ada di dalam data. Ketika ada ratusan produk dan
ribuan transaksi, yang secara logis akan menghasilkan sangat banyak rule.
Dengan menetapkan ambang minimal yang tepat untuk support dan confidence, kita bisa
mengurangi jumlah rule yang layak mendapat perhatian kita. Kedua angka ini harus
“dimainkan” ambang batasnya agar rule yang kuat saja yang muncul.
Kembali ke contoh transaksi di atas, bila kita tetapkan angka minimal confidence = 0,7, maka
rule { soto } -> { nasi putih } akan lolos dari ambang batas ini karena angka confidence-
nya 75%. Adapun rule lain misalnya { bakso } -> { perkedel } tidak akan lolos karena
angka confidence-nya hanya 0,5. Kembali harus diingat prinsip apriori: seluruh subset dari
suatu itemset yang sering muncul, harus sering muncul juga. Karena bakso kita anggap tidak
lewat ambang batas, artinya tidak sering muncul, maka kita bisa buang rule yang melibatkan
bakso dan perkedel dari analisis kita.
Agar bisa menemukan rule-rule baru, ada dua langkah di dalam algoritma Apriori yang harus
dijalani. Langkah pertama adalah mengambil semua itemset yang angka support-nya
melampaui ambang batas minimal tertentu, dan membuang sisanya. Kemudian hasil langkah
pertama ini dimasukkan ke langkah kedua yaitu menemukan association rule yang angka
confidence-nya mencapai suatu ambang batas minimal. Rule yang tidak memenuhi ambang
batas akan dibuang.
Buku ini tidak akan membicarakan mengenai cara kerja algoritma Apriori. Kita hanya akan
mempelajari cara mempergunakannya untuk memecahkan masalah kita. Satu hal yang perlu
dipahami adalah algoritma Apriori hanya bisa bekerja baik bila kita memiliki data transaksi
yang besar jumlahnya. Bila dipergunakan di dataset yang kecil, apriori bisa jadi akan
memberikan pola-pola acak yang kurang bermanfaat.
Persiapan Data
Seperti biasa, sebelum proses analisis bisa kita mulai, kita harus mengerjakan proses
persiapan data agar data transaksi yang kita dapatkan bisa cocok dengan algoritma yang akan
kita pergunakan. Dalam bab ini kita akan memanfaatkan file contoh data transaksi dari
sebuah restoran fiktif yang bisa diunduh dari situs yang tertera di bagian Lampiran 2 buku ini,
berformat CSV (comma-separated values). File bernama bab10_semua_transaksi.csv.
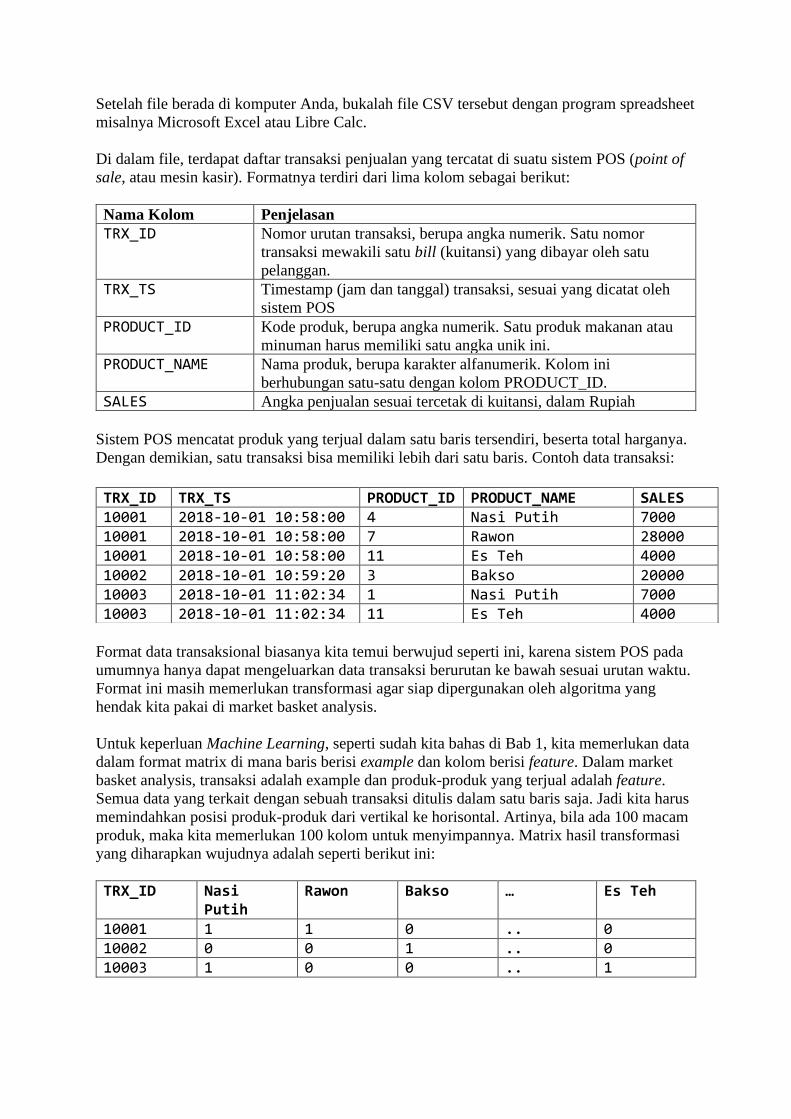
Setelah file berada di komputer Anda, bukalah file CSV tersebut dengan program spreadsheet
misalnya Microsoft Excel atau Libre Calc.
Di dalam file, terdapat daftar transaksi penjualan yang tercatat di suatu sistem POS (point of
sale, atau mesin kasir). Formatnya terdiri dari lima kolom sebagai berikut:
Nama Kolom Penjelasan
TRX_ID Nomor urutan transaksi, berupa angka numerik. Satu nomor
transaksi mewakili satu bill (kuitansi) yang dibayar oleh satu
pelanggan.
TRX_TS Timestamp (jam dan tanggal) transaksi, sesuai yang dicatat oleh
sistem POS
PRODUCT_ID Kode produk, berupa angka numerik. Satu produk makanan atau
minuman harus memiliki satu angka unik ini.
PRODUCT_NAME Nama produk, berupa karakter alfanumerik. Kolom ini
berhubungan satu-satu dengan kolom PRODUCT_ID.
SALES Angka penjualan sesuai tercetak di kuitansi, dalam Rupiah
Sistem POS mencatat produk yang terjual dalam satu baris tersendiri, beserta total harganya.
Dengan demikian, satu transaksi bisa memiliki lebih dari satu baris. Contoh data transaksi:
Format data transaksional biasanya kita temui berwujud seperti ini, karena sistem POS pada
umumnya hanya dapat mengeluarkan data transaksi berurutan ke bawah sesuai urutan waktu.
Format ini masih memerlukan transformasi agar siap dipergunakan oleh algoritma yang
hendak kita pakai di market basket analysis.
Untuk keperluan Machine Learning, seperti sudah kita bahas di Bab 1, kita memerlukan data
dalam format matrix di mana baris berisi example dan kolom berisi feature. Dalam market
basket analysis, transaksi adalah example dan produk-produk yang terjual adalah feature.
Semua data yang terkait dengan sebuah transaksi ditulis dalam satu baris saja. Jadi kita harus
memindahkan posisi produk-produk dari vertikal ke horisontal. Artinya, bila ada 100 macam
produk, maka kita memerlukan 100 kolom untuk menyimpannya. Matrix hasil transformasi
yang diharapkan wujudnya adalah seperti berikut ini:
TRX_ID Nasi Putih
Rawon Bakso … Es Teh
10001 1 1 0 .. 0 10002 0 0 1 .. 0 10003 1 0 0 .. 1
TRX_ID TRX_TS PRODUCT_ID PRODUCT_NAME SALES 10001 2018-10-01 10:58:00 4 Nasi Putih 7000 10001 2018-10-01 10:58:00 7 Rawon 28000 10001 2018-10-01 10:58:00 11 Es Teh 4000 10002 2018-10-01 10:59:20 3 Bakso 20000 10003 2018-10-01 11:02:34 1 Nasi Putih 7000 10003 2018-10-01 11:02:34 11 Es Teh 4000

Ingat, dalam market basket analysis kita hanya ingin menemukan hubungan antar produk-
produk. Karena itu kolom waktu transaksi (TRX_TS) dan angka Rupiah penjualan (SALES)
bukanlah informasi yang diperlukan untuk menemukan rule, jadi keduanya bisa kita buang
dari dataset.
Dalam matrix ini, kotak-kotak (disebut sel) akan berisi nilai numerik 0 dan 1, yang mewakili
“tidak ada” dan “ada” di dalam setiap transaksi. Misalnya transaksi dengan nomor TRX_ID = 10001 berisi dua pesanan berupa nasi putih dan rawon, maka sel di kolom yang bersangkutan
diisi dengan angka 1, sedangkan sel lainnya dibiarkan berisi angka nol. Ini memerlukan
teknik transformasi yang sering disebut sebagai one-hot encoding, yaitu proses yang
mengubah variabel kategori menjadi bentuk nol dan satu.
Untuk proses persiapan data, seperti biasa kita akan gunakan andalan kita yaitu Pandas. Mari
kita langsung buat program baru yang membaca file berisi dataset transaksi:
import pandas as pd df1 = pd.read_csv('bab10_semua_transaksi.csv', parse_dates=['TRX_TS'], index_col=[‘TRX_ID’])
Kita muat semua data transaksi ke dalam satu DataFrame yang kita namai df1 dengan
kolom TRX_ID sebagai index dengan parameter index_col. Kolom TRX_TS karena berisi
tanggal dan jam transaksi, kita masukkan sebagai data bertipe date. File ini berisi tak kurang
30,000 baris.
Untuk memastikan data sudah masuk sesuai harapan kita, mari kita lihat isi Dataframe:
df1.head(10)
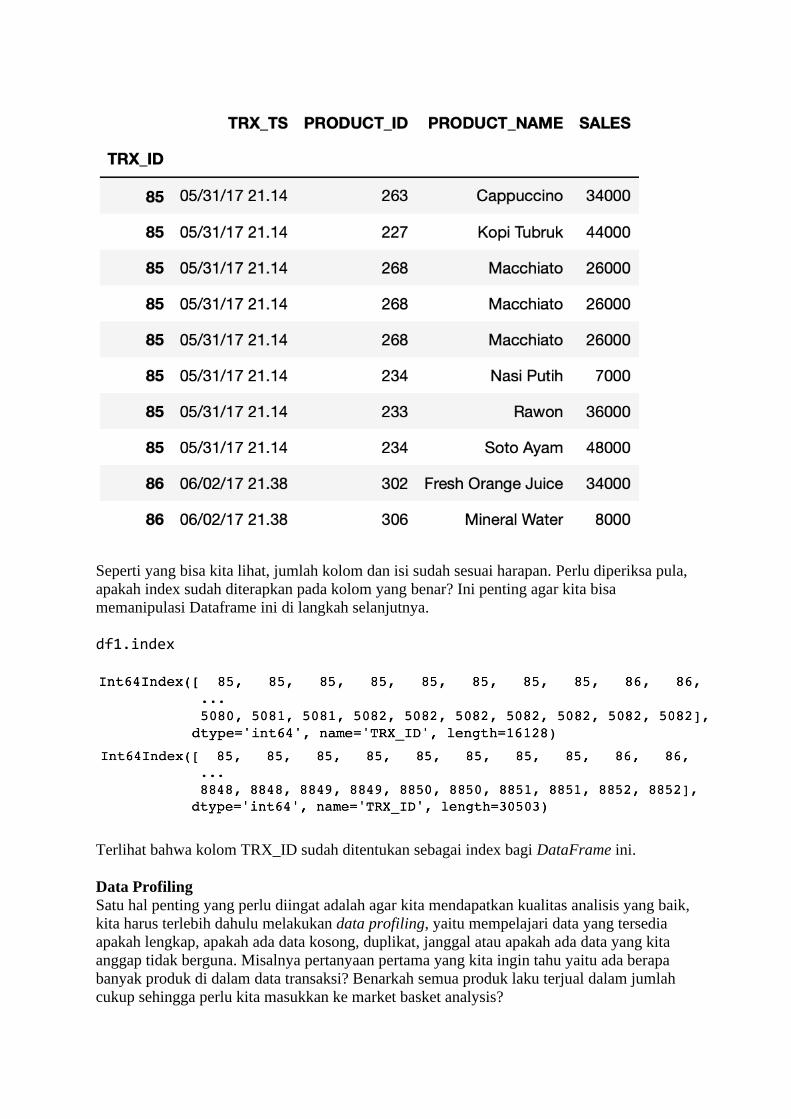
Seperti yang bisa kita lihat, jumlah kolom dan isi sudah sesuai harapan. Perlu diperiksa pula,
apakah index sudah diterapkan pada kolom yang benar? Ini penting agar kita bisa
memanipulasi Dataframe ini di langkah selanjutnya.
df1.index
Terlihat bahwa kolom TRX_ID sudah ditentukan sebagai index bagi DataFrame ini.
Data Profiling
Satu hal penting yang perlu diingat adalah agar kita mendapatkan kualitas analisis yang baik,
kita harus terlebih dahulu melakukan data profiling, yaitu mempelajari data yang tersedia
apakah lengkap, apakah ada data kosong, duplikat, janggal atau apakah ada data yang kita
anggap tidak berguna. Misalnya pertanyaan pertama yang kita ingin tahu yaitu ada berapa
banyak produk di dalam data transaksi? Benarkah semua produk laku terjual dalam jumlah
cukup sehingga perlu kita masukkan ke market basket analysis?

Untuk menjawabnya kita pergunakan fungsi value_counts() yang gunanya untuk
menghitung jumlah kemunculan setiap nilai yang unik. Sebelumnya kita harus memilih
kolom PRODUCT_NAME saja, karena fungsi value_counts() hanya menerima data berupa
Series.
df1['PRODUCT_NAME'].value_counts().sort_values(ascending=False)
Daftar di atas menunjukkan semua nama produk (ada 55 produk) beserta jumlah
kemunculanny., diurutkan dari yang terbesar ke yang terkecil. Cukup memberi gambaran,
namun statistik di atas hanya melihat jumlah penjualan, bukan total penjualan dalam Rupiah.
Bagi dunia usaha, lebih penting melihat produk berdasarkan kontribusinya terhadap
pendapatan. Untuk itu, kita akan mencoba melihat total penjualan dalam Rupiah untuk tiap
produk. Ini bisa kita lakukan dengan fungsi groupby() dan sum() seperti yang sudah kita
bahas di Bab 3, dengan terlebih dahulu membuang PRODUCT_ID karena kita tidak ingin
kolom ini ikut dijumlahkan. Kita buat sebuah DataFrame baru yaitu df2 untuk menampung
hasilnya.
df2 = df1.drop(['PRODUCT_ID'], axis=1).groupby('PRODUCT_NAME').sum()
Kita tertarik untuk melihat produk mana saja yang paling laku, maka DataFrame df2
kemudian kita urutkan dengan fungsi sort_values() berdasarkan Rupiah penjualan
(kolom SALES), diurutkan dari nilai tertinggi ke terendah (ascending=False). Karena ada
banyak produk, kita ambil saja 30 produk yang paling laku untuk kita lihat dalam bentuk
visual berupa bar chart:
df2.sort_values(by=['SALES'], ascending=False).head(30).plot(kind='bar')
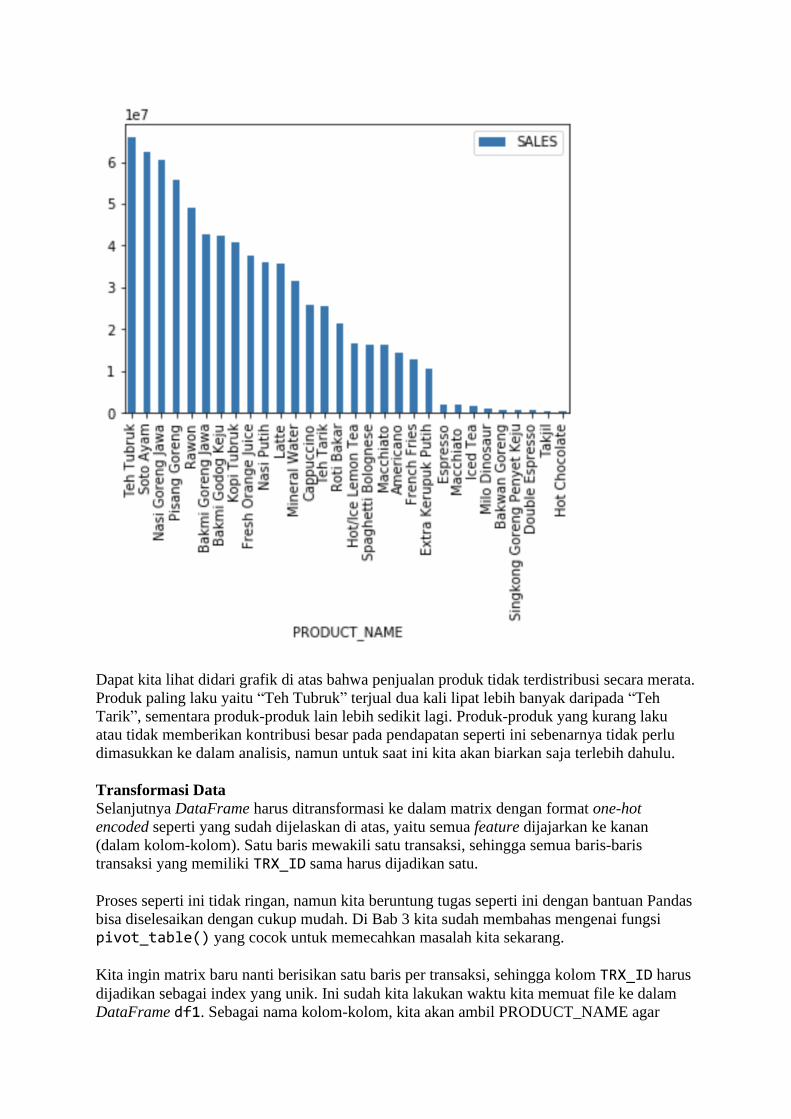
Dapat kita lihat didari grafik di atas bahwa penjualan produk tidak terdistribusi secara merata.
Produk paling laku yaitu “Teh Tubruk” terjual dua kali lipat lebih banyak daripada “Teh
Tarik”, sementara produk-produk lain lebih sedikit lagi. Produk-produk yang kurang laku
atau tidak memberikan kontribusi besar pada pendapatan seperti ini sebenarnya tidak perlu
dimasukkan ke dalam analisis, namun untuk saat ini kita akan biarkan saja terlebih dahulu.
Transformasi Data
Selanjutnya DataFrame harus ditransformasi ke dalam matrix dengan format one-hot
encoded seperti yang sudah dijelaskan di atas, yaitu semua feature dijajarkan ke kanan
(dalam kolom-kolom). Satu baris mewakili satu transaksi, sehingga semua baris-baris
transaksi yang memiliki TRX_ID sama harus dijadikan satu.
Proses seperti ini tidak ringan, namun kita beruntung tugas seperti ini dengan bantuan Pandas
bisa diselesaikan dengan cukup mudah. Di Bab 3 kita sudah membahas mengenai fungsi
pivot_table() yang cocok untuk memecahkan masalah kita sekarang.
Kita ingin matrix baru nanti berisikan satu baris per transaksi, sehingga kolom TRX_ID harus
dijadikan sebagai index yang unik. Ini sudah kita lakukan waktu kita memuat file ke dalam
DataFrame df1. Sebagai nama kolom-kolom, kita akan ambil PRODUCT_NAME agar
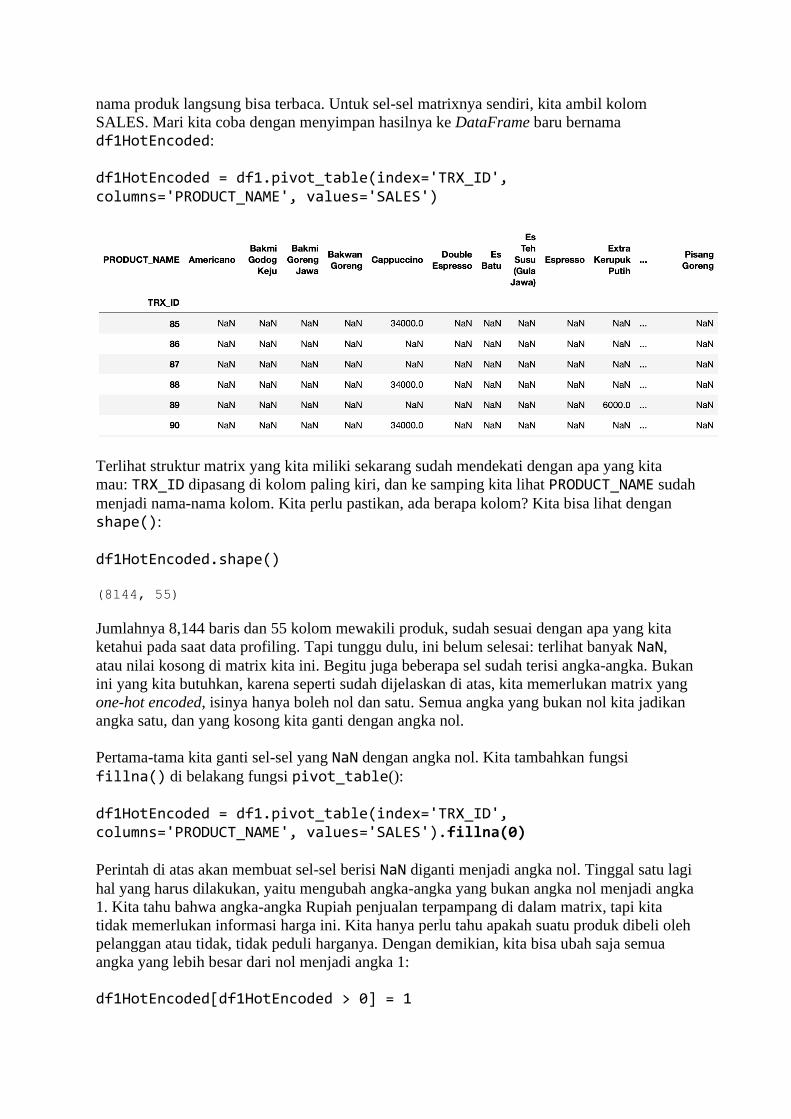
nama produk langsung bisa terbaca. Untuk sel-sel matrixnya sendiri, kita ambil kolom
SALES. Mari kita coba dengan menyimpan hasilnya ke DataFrame baru bernama
df1HotEncoded:
df1HotEncoded = df1.pivot_table(index='TRX_ID', columns='PRODUCT_NAME', values='SALES')
Terlihat struktur matrix yang kita miliki sekarang sudah mendekati dengan apa yang kita
mau: TRX_ID dipasang di kolom paling kiri, dan ke samping kita lihat PRODUCT_NAME sudah
menjadi nama-nama kolom. Kita perlu pastikan, ada berapa kolom? Kita bisa lihat dengan
shape():
df1HotEncoded.shape() (8144, 55)
Jumlahnya 8,144 baris dan 55 kolom mewakili produk, sudah sesuai dengan apa yang kita
ketahui pada saat data profiling. Tapi tunggu dulu, ini belum selesai: terlihat banyak NaN,
atau nilai kosong di matrix kita ini. Begitu juga beberapa sel sudah terisi angka-angka. Bukan
ini yang kita butuhkan, karena seperti sudah dijelaskan di atas, kita memerlukan matrix yang
one-hot encoded, isinya hanya boleh nol dan satu. Semua angka yang bukan nol kita jadikan
angka satu, dan yang kosong kita ganti dengan angka nol.
Pertama-tama kita ganti sel-sel yang NaN dengan angka nol. Kita tambahkan fungsi
fillna() di belakang fungsi pivot_table():
df1HotEncoded = df1.pivot_table(index='TRX_ID', columns='PRODUCT_NAME', values='SALES').fillna(0) Perintah di atas akan membuat sel-sel berisi NaN diganti menjadi angka nol. Tinggal satu lagi
hal yang harus dilakukan, yaitu mengubah angka-angka yang bukan angka nol menjadi angka
1. Kita tahu bahwa angka-angka Rupiah penjualan terpampang di dalam matrix, tapi kita
tidak memerlukan informasi harga ini. Kita hanya perlu tahu apakah suatu produk dibeli oleh
pelanggan atau tidak, tidak peduli harganya. Dengan demikian, kita bisa ubah saja semua
angka yang lebih besar dari nol menjadi angka 1:
df1HotEncoded[df1HotEncoded > 0] = 1
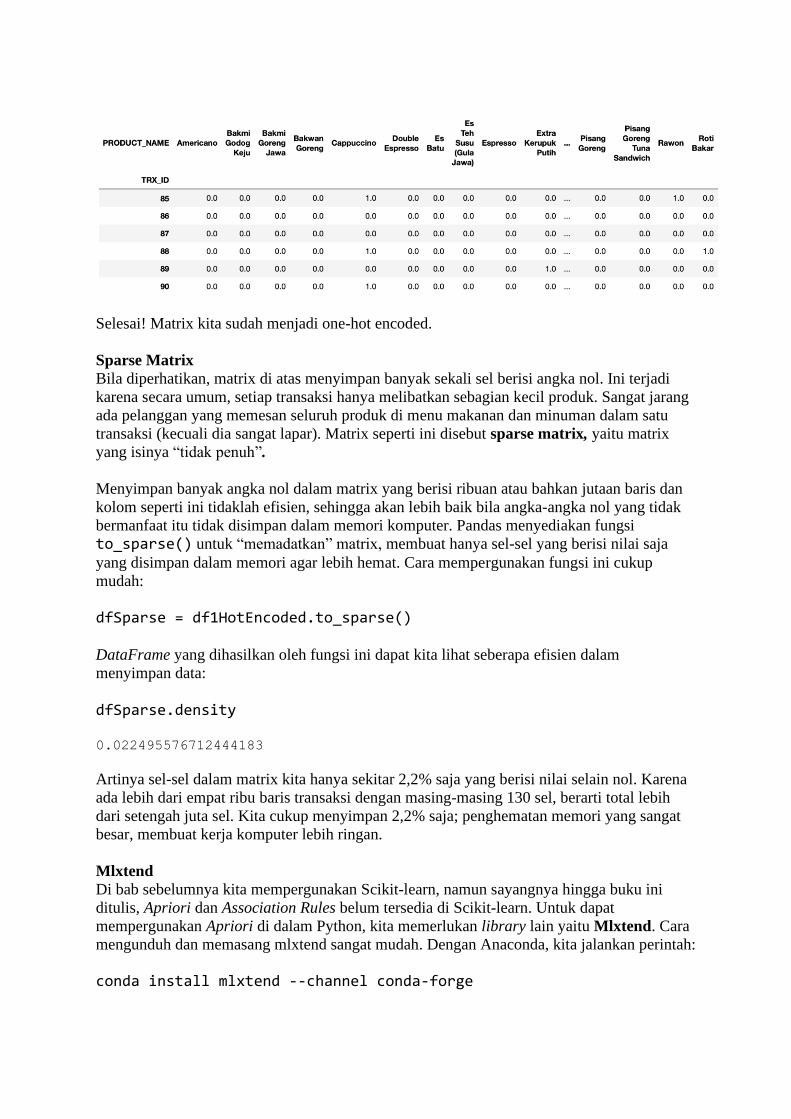
Selesai! Matrix kita sudah menjadi one-hot encoded.
Sparse Matrix
Bila diperhatikan, matrix di atas menyimpan banyak sekali sel berisi angka nol. Ini terjadi
karena secara umum, setiap transaksi hanya melibatkan sebagian kecil produk. Sangat jarang
ada pelanggan yang memesan seluruh produk di menu makanan dan minuman dalam satu
transaksi (kecuali dia sangat lapar). Matrix seperti ini disebut sparse matrix, yaitu matrix
yang isinya “tidak penuh”.
Menyimpan banyak angka nol dalam matrix yang berisi ribuan atau bahkan jutaan baris dan
kolom seperti ini tidaklah efisien, sehingga akan lebih baik bila angka-angka nol yang tidak
bermanfaat itu tidak disimpan dalam memori komputer. Pandas menyediakan fungsi
to_sparse() untuk “memadatkan” matrix, membuat hanya sel-sel yang berisi nilai saja
yang disimpan dalam memori agar lebih hemat. Cara mempergunakan fungsi ini cukup
mudah:
dfSparse = df1HotEncoded.to_sparse()
DataFrame yang dihasilkan oleh fungsi ini dapat kita lihat seberapa efisien dalam
menyimpan data:
dfSparse.density 0.022495576712444183
Artinya sel-sel dalam matrix kita hanya sekitar 2,2% saja yang berisi nilai selain nol. Karena
ada lebih dari empat ribu baris transaksi dengan masing-masing 130 sel, berarti total lebih
dari setengah juta sel. Kita cukup menyimpan 2,2% saja; penghematan memori yang sangat
besar, membuat kerja komputer lebih ringan.
Mlxtend
Di bab sebelumnya kita mempergunakan Scikit-learn, namun sayangnya hingga buku ini
ditulis, Apriori dan Association Rules belum tersedia di Scikit-learn. Untuk dapat
mempergunakan Apriori di dalam Python, kita memerlukan library lain yaitu Mlxtend. Cara
mengunduh dan memasang mlxtend sangat mudah. Dengan Anaconda, kita jalankan perintah:
conda install mlxtend --channel conda-forge

Setelah terpasang, langkah pertama adalah mengimpor fungsi
frequent_patterns.apriori dari Mlxtend untuk menyaring data yang frekuensinya
tinggi, yaitu yang sering muncul sesuai prinsip Apriori. Suatu itemset akan dianggap sering
muncul apabila angka support-nya melampaui suatu ambang batas minimal (threshold) yang
kita tentukan sebagai parameter untuk fungsi apriori. Misalnya kita tentukan ambang batas
0,5, maka itemset yang muncul adalah yang terdapat di dalam setidaknya 50% isi data.
Ambang batas ini kita masukkan sebagai parameter bernama min_support. Berikut
contohnya:
import mlxtend.frequent_patterns.apriori as apriori df3 = apriori(dfSparse, min_support=0.5, use_colnames=True) Parameter use_colnames=True menunjukkan kita ingin nama produk ditampilkan seperti
apa adanya. Hasil keluaran fungsi apriori() disimpan dalam DataFrame df3. Namun
DataFrame ini ternyata kosong. Mengapa demikian? Jawabannya karena ambang batas yang
kita pasang terlalu tinggi.
Menemukan angka min_support ini memerlukan ujicoba beberapa kali hingga dapat
menghasilkan jumlah rule yang layak untuk bisa kita pelajari lebih lanjut. Bila angka
min_support terlalu tinggi, bisa jadi tidak ada rule yang dihasilkan. Sebaliknya, bila terlalu
rendah, maka jumlah rule yang muncul akan menjadi terlalu banyak, menyulitkan kita
mendapatkan kesimpulan.
Untuk awal, kita mulai dengan angka min_support = 0.5, dan ternyata tidak
menghasilkan rule apapun. Data transaksi yang kita miliki rupanya tidak terlalu banyak
menyimpan pasangan-pasangan produk yang terjual bersama-sama. Kita perlu perluas
pencarian kita, dengan cara kita turunkan menjadi min_support = 0.1, dan barulah
beberapa rule muncul.

Kalau kita lihat lebih dalam, angka min_support = 0.1 artinya suatu itemset harus ada
setidaknya di 10% dari total transaksi, yaitu 10% x 4,565 = 457 transaksi. Tidak terlalu
banyak produk yang terjual hingga angka ini. Ketika min_support diturunkan lagi, semakin
banyak rule muncul dan semakin banyak pasangan produk yang menarik untuk kita
perhatikan.
Dengan proses di atas, sekarang kita sudah bisa menyaring data dengan itemset yang
memiliki frekuensi kemunculan yang tinggi. Prasyarat ini penting kita penuhi agar kita bisa
mendapatkan pola-pola menarik di dalam data transaksi. Setelah dataset sudah dihilangkan
dari transaksi-transaksi yang kita tahu tidak lolos ambang batas, selanjutnya kita bisa
menggali association rule dari dataset.
Mencari Association Rule
Selain support dan confidence, ada satu lagi hasil pengukuran penting yaitu lift. Secara
sederhana, lift adalah petunjuk apakah ada hubungan antara dua itemset ketika keduanya

muncul bersamaan, ataukah keduanya muncul bersamaan hanya karena kebetulan saja. Lift
bisa bernilai positif atau negatif. Lift = 1 artinya tidak ada hubungan apa-apa antara kedua
itemset, jadi kalaupun mereka muncul bersamaan, itu adalah sesuatu yang murni random
(acak) saja.
Nilai lift > 1 artinya ada hubungan positif antara kedua itemset dan keduanya muncul bukan
sekedar karena kebetulan belaka. Sementara bila lift < 1 maka hubungan kedua itemset terlalu
lemah sehingga tidak perlu kita perhatikan. Secara umum, kita akan mencari rule yang lift-
nya positif dan tinggi, di atas angka satu.
Secara matematis, cara menghitung lift adalah:
𝐿𝑖𝑓𝑡 (𝑎 → 𝑏) =𝐶𝑜𝑛𝑓𝑖𝑑𝑒𝑛𝑐𝑒 (𝑎 → 𝑏)
𝑆𝑢𝑝𝑝𝑜𝑟𝑡 (𝑎)
Tidak seperti confidence, lift berlaku sama untuk dua arah, baik { a -> b } maupun { b -> a }. Untungnya Mlxtend juga sudah menyediakan fungsi untuk menghitung lift, kita
tidak perlu menghitung sendiri. Untuk ini kita akan mempergunakan fungsi
frequent_patterns.association_rules. Kali ini disertakan tiga parameter penting
yaitu sumber data berupa DataFrame yang sudah disaring dengan Apriori, kemudian metrik
yang kita kehendaki (dalam hal ini “lift”) dan angka ambang batas minimum untuk lift = 1:
import mlxtend.frequent_patterns.association_rules as association_rules df4 = association_rules(df3, metric='lift', min_threshold=1)
Dapat kita lihat semua angka support, confidence dan lift yang penting bagi kita untuk
menentukan rule manakah yang akan bermanfaat untuk diperhatikan lebih lanjut. Secara
umum, market basket analysis seperti yang kita lakukan ini tujuannya adalah untuk
menemukan rule-rule yang confidence dan lift-nya tinggi. Untuk itu kita perlu mengurutkan
hasil keluaran Association Rules dengan ketiga kolom tersebut, dengan mempergunakan
fungsi sort_values() yang tersedia di Pandas seperti sudah kita bicarakan di bab
sebelumnya:
df4.sort_values(by=['support','confidence','lift'], ascending=False)
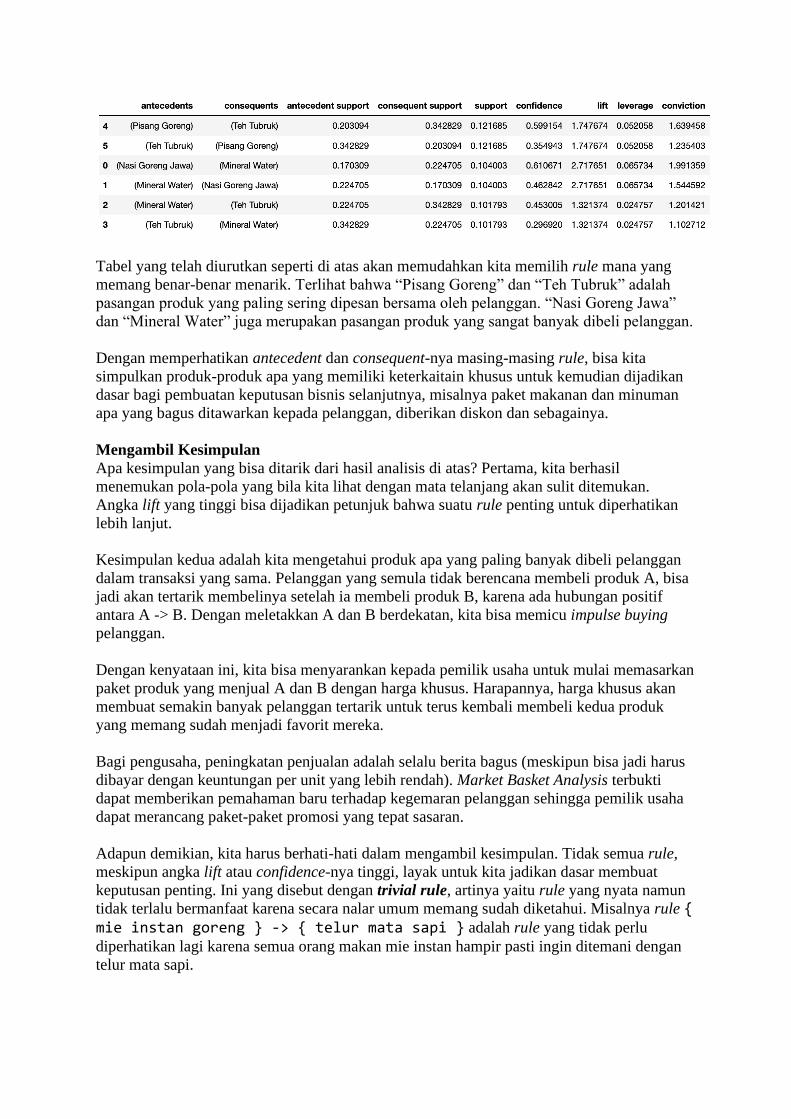
Tabel yang telah diurutkan seperti di atas akan memudahkan kita memilih rule mana yang
memang benar-benar menarik. Terlihat bahwa “Pisang Goreng” dan “Teh Tubruk” adalah
pasangan produk yang paling sering dipesan bersama oleh pelanggan. “Nasi Goreng Jawa”
dan “Mineral Water” juga merupakan pasangan produk yang sangat banyak dibeli pelanggan.
Dengan memperhatikan antecedent dan consequent-nya masing-masing rule, bisa kita
simpulkan produk-produk apa yang memiliki keterkaitain khusus untuk kemudian dijadikan
dasar bagi pembuatan keputusan bisnis selanjutnya, misalnya paket makanan dan minuman
apa yang bagus ditawarkan kepada pelanggan, diberikan diskon dan sebagainya.
Mengambil Kesimpulan
Apa kesimpulan yang bisa ditarik dari hasil analisis di atas? Pertama, kita berhasil
menemukan pola-pola yang bila kita lihat dengan mata telanjang akan sulit ditemukan.
Angka lift yang tinggi bisa dijadikan petunjuk bahwa suatu rule penting untuk diperhatikan
lebih lanjut.
Kesimpulan kedua adalah kita mengetahui produk apa yang paling banyak dibeli pelanggan
dalam transaksi yang sama. Pelanggan yang semula tidak berencana membeli produk A, bisa
jadi akan tertarik membelinya setelah ia membeli produk B, karena ada hubungan positif
antara A -> B. Dengan meletakkan A dan B berdekatan, kita bisa memicu impulse buying
pelanggan.
Dengan kenyataan ini, kita bisa menyarankan kepada pemilik usaha untuk mulai memasarkan
paket produk yang menjual A dan B dengan harga khusus. Harapannya, harga khusus akan
membuat semakin banyak pelanggan tertarik untuk terus kembali membeli kedua produk
yang memang sudah menjadi favorit mereka.
Bagi pengusaha, peningkatan penjualan adalah selalu berita bagus (meskipun bisa jadi harus
dibayar dengan keuntungan per unit yang lebih rendah). Market Basket Analysis terbukti
dapat memberikan pemahaman baru terhadap kegemaran pelanggan sehingga pemilik usaha
dapat merancang paket-paket promosi yang tepat sasaran.
Adapun demikian, kita harus berhati-hati dalam mengambil kesimpulan. Tidak semua rule,
meskipun angka lift atau confidence-nya tinggi, layak untuk kita jadikan dasar membuat
keputusan penting. Ini yang disebut dengan trivial rule, artinya yaitu rule yang nyata namun
tidak terlalu bermanfaat karena secara nalar umum memang sudah diketahui. Misalnya rule { mie instan goreng } -> { telur mata sapi } adalah rule yang tidak perlu
diperhatikan lagi karena semua orang makan mie instan hampir pasti ingin ditemani dengan
telur mata sapi.

Rule yang kita harapkan ada rule yang actionable, yaitu rule yang bisa memberikan
pengetahuan baru yang berguna untuk bisa diterapkan dalam kegiatan nyata. Di sinilah
tantangan seorang Data Scientist, yaitu memiliki pemahaman tentang proses bisnis sehingga
bisa melihat rule-rule yang sudah umum dan bisa disingkirkan dari analisis.

BAB 11 Computer Vision Di jaman sekarang, gambar dan video digital ada di mana-mana. Ponsel yang ada di tangan
hampir setiap orang modern saat ini bisa dengan mudahnya bisa mengambil foto dan sekejap
mengirimkannya melalui jaringan nirkabel ke mana pun di dunia, termasuk melalui media
sosial. Begitu juga dengan video digital yang saat ini bisa dibuat oleh siapapun bahkan oleh
anak-anak, diunggah dan diunduh dengan bebas di platform video seperti Youtube. Kamera
CCTV juga dengan rajin 24 jam sehari merekam aktivitas orang-orang di hampir semua
tempat publik. Dunia telah dibanjiri oleh gambar digital.
Kita tahu bahwa perangkat lunak komputer pada umumnya tidak akan kesulitan untuk
membuat index pencarian dokumen teks dalam jumlah yang besar sekalipun, namun untuk
gambar digital tidak demikian. Agar dapat membuat index untuk pencarian gambar,
perangkat lunak harus dapat terlebih dahulu “melihat” isi dokumen gambar dan menemukan
obyek-obyek di dalamnya. Bagi manusia, hal ini adalah hal yang bisa dilakukan secara
naluriah dengan cepat. Kita tidak perlu waktu lama untuk bisa mengenali benda-benda yang
ada dalam sebuah foto, atau wajah-wajah orang di dalam suatu video. Tidak demikian dengan
komputer. Salah satu tantangan terberat membuat perangkat lunak komputer yang bisa
mengenali obyek di dalam gambar adalah fakta bahwa hingga kini kita masih belum benar-
benar bisa memahami (apalagi menirukan) bagaimana sesungguhnya cara kerja manusia
mengenali obyek yang diterima oleh indera matanya.
Walaupun kemampuan manusia mengenali obyek masih menjadi misteri, sejak beberapa
dekade terakhir berbagai metode pendekatan telah ditemukan dan teknologi untuk pengenalan
obyek dalam gambar digital juga masih terus berkembang. Bila kita tertarik untuk menggeluti
bidang ini, maka hampir pasti kita harus mempelajari suatu yaitu cabang ilmu yang disebut
Computer Vision (CV). CV adalah upaya manusia membuat perangkat lunak komputer yang
bisa mengenali obyek di dalam gambar digital. Ini berbeda dengan metode image processing
(pengolahan citra) yang biasa dimanfaatkan untuk memanipulasi gambar digital, namun tidak
bertujuan memahami isi gambar.
Sebagai sebuah cabang ilmu, CV banyak beririsan dengan Machine Learning. Beragam
algoritma Machine Learning yang sudah kita bahas di buku ini juga tidak sedikit
dipergunakan di dalam CV. Serupa dengan metode supervised learning lainnya, CV dalam
penggunaan praktis juga memerlukan proses training.
OpenCV
Dalam bab ini, kita akan mencoba membuat penerapan praktis CV untuk mengambil
informasi dari gambar diam dan gambar bergerak atau video. Untuk itu kita akan
memanfaatkan OpenCV, sebuah library open source yang menyediakan banyak fungsi CV
yang menarik untuk dieksplorasi. OpenCV dapat dipakai dengan beragam bahasa
pemrograman seperti C++, Java, Perl dan tentu saja bahasa favorit kita yaitu Python.
OpenCV dapat diunduh dengan bebas dari situs https://opencv.org. Instruksi untuk instalasi
tersedia di sana. Bila Anda mempergunakan Anaconda, prosesnya instalasinya juga mudah.
Caranya dengan menjalankan perintah di bawah ini di sebuah terminal (pastikan Anda
tersambung ke internet):
conda create -name ComputerVision python=3.7
conda install -c menpo opencv source activate ComputerVision

Perhatikan bahwa contoh di atas mempergunakan Python versi 3.7, gantilah dengan versi
Python yang terpasang di komputer Anda apabila berbeda.
Setelah itu kita bisa memakai OpenCV di program python kita dengan mengimpornya:
import cv2 Bila tidak ada pesan error, artinya Anda sudah siap untuk mengikuti pembahasan
selanjutnya, yaitu pendeteksian obyek dalam gambar digital yang akan kita coba bangun
sebagai sebuah contoh kasus.
Pendeteksian Wajah
Anda pasti pernah mengalami ketika Anda mengunggah foto di platform media sosial
misalnya Facebook, secara otomatis Facebook akan membuat tanda gambar kotak di wajah-
wajah orang yang muncul di foto tersebut dan menawarkan kepada Anda untuk men-tag-nya
sebagai teman-teman Anda. Ini adalah contoh penerapan nyata Machine Learning untuk
facial detection (pendeteksian wajah). Lebih jauh lagi, Facebook juga menerapkan facial
recognition (pengenalan wajah) sehingga bisa menampilkan nama-nama teman-teman Anda
yang ada di dalam sebuah foto.
Di bab ini kita akan mencoba untuk membuat sebuah program untuk memecahkan tantangan
yang pertama yaitu pendeteksian wajah. Sebuah file gambar (dalam format JPEG atau PNG)
akan dibaca oleh program dan kemudian semua wajah yang muncul di gambar akan ditandai
dengan simbol kotak. Untuk program kedua kita akan mempergunakan video sebagai input
program.
Program kita bertujuan melakukan pendeteksian - bukan pengenalan - sehingga kita belum
mempedulikan siapa pemilik wajah yang ada di dalam gambar. Proses deteksi akan
menghasilkan lokasi koordinat tempat wajah (atau wajah-wajah) yang berhasil dideteksi.
Seterusnya terserah kita untuk melakukan proses lebih lanjut, misalnya untuk dilakukan
pengenalan siapa individu yang wajahnya muncul di gambar.
Ada beberapa metode untuk pengenalan obyek di dalam gambar, salah satunya adalah
algoritma pengenalan obyek berbasis Haar Cascade (diambil dari nama ahli matematika dari
Hongaria, Alfred Haar). Algoritma Haar Cascade akan dipergunakan dalam contoh program
kita sebagai classifier, yaitu suatu bentuk khusus dari predictive model untuk klasifikasi.
Tidak hanya untuk wajah, obyek yang dicoba dikenali bisa berupa anggota tubuh lain (misal
hidung, mata, mulut) atau benda apapun asalkan kita bisa menyediakan training dataset-nya.
Pembahasan detail mengenai teori dan cara kerja algoritma pendeteksian obyek berbasis Haar
Cascade berada di luar lingkup buku ini, namun secara singkat perlu dipahami bahwa
algoritma memerlukan training dataset berupa sampel positif (gambar obyek yang ingin
dideteksi, dalam kasus kita adalah wajah orang) dan sampel negatif (tidak berisi gambar
obyek yang ingin dideteksi).
OpenCV menyediakan fasilitas untuk memuat file dalam format JPG atau PNG beserta label
lokasi obyek di dalam gambar untuk dijadikan training dataset. Agar algoritma dapat bekerja
efektif, sampel positif dan negatif untuk training dataset harus tersedia dalam jumlah yang
besar, ratusan bahkan ribuan gambar. Adapun begitu, untuk keperluan pendeteksian wajah,

kabar baiknya adalah kita tidak harus membuat training dataset sendiri, karena OpenCV
sudah menyediakan training dataset yang bisa langsung dipakai. Kita akan bahas ini
kemudian.
Bagaimana caranya agar komputer bisa mengenali gambar? Kita tentu sudah memahami
bahwa gambar digital sebenarnya adalah sekumpulan titik yang disebut pixel. Satu file
gambar digital bisa memiliki jutaan pixel yang disusun dalam baris dan kolom layaknya
sebuah tabel. Sebuah gambar yang dihasilkan oleh sebuah kamera digital dengan resolusi
standar 1920 x 1080 memiliki lebih dari dua juta pixel. Gambar dengan resolusi yang sangat
tinggi bisa memiliki sampai 30 juta pixel.
Karena komputer hanya bisa bekerja dengan angka, maka setiap pixel harus diwakili oleh
sebuah angka. Angka ini menunjukkan intensitas cahaya yang biasanya berada dalam
jangkauan nol hingga 255, dengan angka nol berarti gelap total atau hitam. Untuk gambar
berwarna, ada tiga angka seperti ini untuk setiap pixel, masing-masing mewakili komponen
warna merah, hijau dan biru (sering disebut RGB, red-green-blue). Adapun begitu, algoritma
pengenalan obyek tidak memerlukan informasi warna, sehingga kita kesampingkan dulu hal
ini. Gambar berwarna justru harus terlebih dahulu diubah menjadi gambar tanpa warna
(sering disebut grayscale).
Tentunya tidak efisien bila jutaan pixel harus diolah secara satu per satu. Itu sebabnya cara
kerja algoritma pengenalan obyek adalah dengan mengolah sekumpulan pixel yang
membentuk elemen gambar seperti garis, sudut-sudut, atau bentuk-bentuk lain. Inilah yang
dijadikan feature bagi proses training.
Bila kita perhatikan sebuah gambar wajah, wilayah di sekitar mata nampak lebih gelap
dibanding wilayah sekitar pipi. Begitu juga batang hidung nampak lebih cerah dibandingkan
wilayah sekitar mata. Angka-angka intensitas cahaya dalam gabungan beberapa pixel bila
dikumpulkan dengan ciri lainnya bisa dipakai sebagai feature untuk pengenalan wajah (lihat
penjelasan di boks).
Bagaimana Algoritma Pengenalan Obyek berbasis Haar Cascade Bekerja
Algoritma ini ditemukan oleh dua orang periset bernama Paul Viola dan Michael Jones
yang dituangkan dalam paper ilmiah mereka di tahun 2001, sehingga seringkali algoritma
ini disebut juga dengan algoritma Viola-Jones. Mereka memberikan ide yang bertujuan
untuk menghasilkan metode pendeteksian obyek yang cepat sehingga cocok untuk
penggunaan secara real-time. Algoritma ini bisa dipakai untuk mengenali beragam obyek,
namun face detection memang merupakan fokus utamanya.
Ada dua langkah yang perlu dijalankan di dalam algoritma Viola-Jones[8]:
1. Haar Features
Keseluruhan gambar dipecah ke dalam bagian-bagian kecil berbentuk segi empat. Di
setiap bagian kecil ini, wilayah dalam gambar yang cerah dan gelap dijumlahkan.
Kemudian empat macam feature yang disebut Haar feature seperti di bawah
dipergunakan untuk mendeteksi batas-batas wilayah gelap dan terang (feature nomor 1
dan 2), juga untuk mendeteksi garis (feature nomor 3) dan garis diagonal (feature
nomor 4). Bila kita terapkan ini pada misalnya wilayah mata, maka akan muncul suatu
nilai positif pada feature nomor 2, sedangkan sebaliknya bila diterapkan pada sebuah
gambar tembok yang polos dan kosong, maka nilai semua feature akan nyaris nol.

Karena wilayah yang harus diukur bisa jadi sangat banyak, maka untuk mengurangi
beban komputasi dibuatlah tabel penjumlahan yang disebut integral image. Intinya ini
dipergunakan agar perhitungan perbedaan antar wilayah kotak menjadi lebih sederhana.
2. AdaBoost dan Cascading Classifier
Selanjutnya setiap Haar feature diatas digabungkan agar bisa ditentukan apakah suatu
wilayah dianggap bagian dari wajah. Metode ensemble AdaBoost dipergunakan untuk
secepatnya membuang feature yang tidak relevan dan memilih feature yang dapat
meningkatkan akurasi klasifikasi wajah atau bukan wajah. Algoritma ini
memungkinkan wilayah yang jelas bukan bagian dari wajah dapat segera dilewati
untuk penghematan proses komputasi. Ini penting karena mayoritas bagian gambar
tidaklah berisi obyek yang ingin dideteksi.
Memproses File Gambar
Di bagian ini kita akan membuat program demonstrasi deteksi wajah dengan masukan sebuah
file gambar dalam format JPEG atau PNG. Langkah pertama adalah impor modul OpenCV
(versi yang digunakan buku ini adalah versi 2.4).
Selanjutnya kita buka sebuah file JPEG atau PNG dengan perintah imread() dari OpenCV.
Anda bisa mempergunakan gambar apa saja yang berisi setidaknya satu gambar wajah
seseorang. Untuk contoh kali ini, kita pergunakan foto almarhum Presiden Soeharto yang
diperoleh dari Wikipedia. Foto ini harus diubah menjadi grayscale dengan fungsi
cvtColor() karena seperti sudah disinggung sebelumnya, algoritma pengenalan obyek
tidak memerlukan informasi warna:
import cv2 as cv foto = cv.imread('/Users/diosk/presiden1.jpg') foto_gray = cv.cvtColor(foto, cv.COLOR_BGR2GRAY) Sebelum melangkah lebih jauh, kita uji terlebih dahulu dengan menampilkan foto grayscale
ini ke layar. Ini dilakukan dengan perintah imshow(). Fungsi waitKey() perlu
ditambahkan untuk membuat program menunggu pengguna komputer menekan sembarang
tombol keyboard agar program tidak langsung berakhir. Fungsi destroyAllWindows()
dipanggil untuk mengakhiri program dan membersihkan layar dari semua window di layar.
cv.imshow("Foto", foto_gray) cv.waitKey(0) cv.destroyAllWindows()

Gambar 42: foto wajah yang sudah diubah ke grayscale
Setelah foto siap, langkah berikutnya adalah kita aktifkan class pendeteksi obyek, yang di
dalam OpenCV diberi nama CascadeClassifier. Seperti kita ketahui, pendeteksian wajah
memerlukan training dataset berupa sebuah file XML. Untungnya, di dalam paket OpenCV
telah tersedia training dataset standar yang berisikan ribuan sampel-sampel wajah yang bisa
kita pakai. Ini cukup untuk eksperimen pertama kita di sini, adapun demikian training dataset
ini tidak sepenuhnya lengkap dan tidak selalu berhasil mendeteksi wajah orang misalnya dari
ras atau suku tertentu yang belum ada sampelnya. Dalam kasus seperti itu, kita harus
membuat training dataset sendiri. Ini akan kita bicarakan di bagian lain bab ini.
Training dataset standar yang disediakan OpenCV berada di file bernama
haarcascade_frontalface_alt.xml. Lokasi file XML ini ada di folder
/data/haarcascades/ di tempat Anda memasang OpenCV di komputer Anda (bila tidak
bisa ditemukan, file XML ini juga bisa diunduh dari situs OpenCV). Perintah berikut akan
memuat CascadeClassifier ke dalam variabel cc_wajah dengan menyertakan file XML
yang disebut di atas:
cc_wajah = cv.CascadeClassifier('/data/haarcascade_frontalface_alt.xml') if cc_wajah.empty(): raise IOError('File XML tidak ditemukan!') Pastikan bahwa file XML bisa sudah ada dan bisa diakses, sebab bilamana tidak, program
akan berhenti dengan pesan error file tidak bisa ditemukan. Pada titik ini kita sudah siap
untuk menjalankan pendeteksian wajah. Kita panggil method/fungsi detectMultiScale
dengan memasukkan foto grayscale yang sudah kita persiapkan sebelumnya:
hasil = cc_wajah.detectMultiScale(foto_gray, scaleFactor=1.1, minNeighbor=5) Apa arti parameter scaleFactor=1.1 di atas? Ini adalah konstanta yang bila kita ubah,
apabila semakin tinggi angkanya maka proses deteksi akan lebih cepat namun demikian
melemahkan kehandalannya (semakin kecil kemungkinan deteksi berhasil). Secara umum,
Anda bisa bereksperimen dengan mengubah-ubah angka ini dari 1,0 hingga 3,0 dan
perhatikan efeknya terhadap akurasi dan kecepatan proses deteksi.

Parameter kedua yaitu minNeighbor=5 juga menentukan akurasi deteksi. Semakin rendah
nilai ini, semakin besar kemungkinan obyek yang bukan wajah dideteksi sebagai wajah (false
positive yang tinggi), sebaliknya bila nilainya tinggi, semakin besar kemungkinan ada wajah
lolos dari deteksi (false negative yang tinggi). Anda bisa bereksperimen dengan angka ini
untuk mendapatkan akurasi yang sesuai.
Setelah perintah di atas dijalankan, akan terbentuk sebuah List (variabel hasil) yang berisi
kumpulan wajah yang berhasil terdeteksi di dalam gambar. Bila program tidak berhasil
mendeteksi adanya waja, variabel hasil akan kosong. Mari kita lihat isinya, apakah kosong
atau berisi nilai:
print(hasil) [[137 106 177 177]]
Terlihat bahwa proses deteksi wajah berhasil dan tidak kosong. Karena variabel hasil
adalah sebuah List, dari sini kita bisa menghitung ada berapa orang yang wajahnya terdeteksi
di dalam gambar dengan menampilkan jumlah elemen dalam List:
jumlah_wajah = len(hasil) print("Terdeteksi", jumlah_wajah, "orang di dalam gambar") Terdeteksi 1 orang di dalam gambar
Untuk setiap obyek (wajah) yang terdeteksi, akan diwakili oleh empat angka (posisi sumbu x,
posisi sumbu y, lebar dan tinggi) yang membentuk wilayah berupa persegi panjang di dalam
gambar. Keempat angka ini bisa kita ambil dari List sebagai variabel x,y, w dan h, kemudian
kita visualkan berupa persegi panjang dengan bantuan fungsi rectangle() yang disediakan
OpenCV.
x =(hasil[0][0]) y =(hasil[0][1]) w =(hasil[0][2]) h =(hasil[0][3]) cv.rectangle(foto, (x,y), (x+w,y+h), color=(0,255,0), thickness=6)
Hasil deteksi wajah selain ditampilkan ke layar dengan fungsi imshow() juga disimpan ke
sebuah file dengan fungsi imwrite(). Agar program tidak langsung berakhir, fungsi
waitKey() dipergunakan untuk menunggu pengguna komputer menekan sembarang tombol
di keyboard sebelum program berlanjut ke perintah selanjutnya. Fungsi
destroyAllWindows() membersihkan memori layar dengan menutup semua window. Bila
program berikut dijalankan, hasilnya akan muncul di layar:
cv.imshow("Foto", foto) cv.imwrite('/Users/diosk/hasil_deteksi.jpg', foto) cv.waitKey(0) cv.destroyAllWindows()

Gambar 43: Pendeteksian wajah tunggal
Program kita sukses mendeteksi wajah Presiden Soeharto. Perhatikan bahwa parameter
thickness=6 menentukan tebal garis (bila Anda rasa garis kotak terlalu tebal, angka ini
bisa dikurangi). Parameter color=(0,255,0) menghasilkan kotak berwarna hijau karena
ketiga angka tersebut mewakili nilai warna RGB dengan R (red) = 0, G (green) = 255 dan B
(blue) = 0. Anda bisa ubah warna ini misalnya menjadi warna merah dengan membuat
R=255, G=0 dan B=0.
Contoh gambar di atas hanya berisikan wajah satu orang saja. Bagaimana bila ada lebih dari
satu orang di dalam gambar? Seperti sudah dijelaskan sebelumnya, variabel hasil adalah
sebuah List yang berisi seluruh wajah yang berhasil dideteksi. Agar lebih jelas, kita ganti file
gambar dengan gambar berisi lebih dari satu orang. Kita ambil foto lain sebagai contoh yang
berisikan tokoh-tokoh penting (foto dapat diunduh dari lokasi yang disebutkan di Lampiran 2
buku ini).
Sebelum kita lanjutkan, program harus diubah dengan mempergunakan for-loop untuk
mengakses semua informasi wajah dari List yang dihasilkan oleh proses deteksi, kemudian
masing-masing ditandai dengan gambar kotak:
import cv2 as cv cc_wajah = cv.CascadeClassifier('/Users/diosk/haarcascade_frontalface_alt.xml') if cc_wajah.empty(): raise IOError('File XML tidak bisa ditemukan!') foto = cv.imread('/Users/diosk/tokoh1.jpg') foto_gray = cv.cvtColor(foto, cv.COLOR_BGR2GRAY) hasil = cc_wajah.detectMultiScale(foto_gray, scaleFactor=1.2, minNeighbors=5) print("Terdeteksi ", len(face_rects), " orang di dalam gambar:") for (x,y,w,h) in hasil: cv.rectangle(foto, (x,y), (x+w,y+h), color=(0,255,0), thickness=5) cv.imshow('Deteksi Wajah', foto) cv.imwrite('/Users/diosk/hasil_deteksi.jpg', foto) cv.waitKey(0)

cv.destroyAllWindows() Hasilnya akan muncul sebagai berikut: Terdeteksi 22 orang di dalam gambar:
Gambar 44: Pendeteksian banyak wajah
Video
Agar lebih menarik lagi, kita akan mencoba membuat program yang melakukan proses
deteksi wajah dengan masukan berupa video, sehingga proses deteksi berjalan terus tanpa
henti. Untuk mudahnya, kita akan mempergunakan webcam yang hampir selalu ada di setiap
laptop. OpenCV menyediakan class untuk menangkap video yaitu VideoCapture().
Webcam diwakili oleh angka nol sebagai parameter saat mengaktifkan kelas ini.
Secara garis besar tidak ada perubahan pada program Python yang sudah kita buat, hanya kita
ganti masukan gambar dari pembacaan file menjadi pembacaan video yang dilaksanakan oleh
fungsi read() di dalam suatu while loop yang menangkap satu frame di setiap iterasi dan
diulang terus. Agar program dapat kita hentikan, user bisa menekan tombol ESC (kode 27)
untuk membuat program keluar dari while loop tersebut.
Satu catatan penting adalah untuk menulis dan menjalankan program ini disarankan tidak
mempergunakan Jupyter Notebook, namun mempergunakan Python interpreter seperti
IPython karena fungsi video sulit ditampilkan di Jupyter Notebook.
import cv2 as cv cc_wajah = cv.CascadeClassifier('/Users/dioskurn/haarcascade_frontalface_alt.xml') if cc_wajah.empty(): raise IOError('File XML tidak bisa ditemukan!') webcam1 = cv.VideoCapture(0) while True:

ret, frame = webcam1.read() frame = cv.resize(frame, None, fx=0.8, fy=0.8, interpolation=cv.INTER_AREA) frame_gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY) hasil = cc_wajah.detectMultiScale(frame_gray, 1.1, 5) for (x,y,w,h) in hasil: cv.rectangle(frame, (x,y), (x+w,y+h), (0,255,0), 5) cv.imshow('Face Detection', frame) tombol = cv.waitKey(1) if tombol == 27: break webcam1.release() cv.destroyAllWindows() Perhatikan bahwa kita menambahkan fungsi resize() dengan tujuan memperkecil ukuran
gambar video menjadi 80% saja. Anda bisa ubah nilai ini sesuai kebutuhan.
Anda juga bisa mengganti webcam dengan file video, atau bisa juga dengan kamera IP /
CCTV sebagai sumber video. Syaratnya, kamera tersebut mendukung protokol streaming
RSTP atau HTTP. Dalam buku ini penulis mempergunakan kamer IP merk TP-Link yang
bisa diakses melalui HTTP. Untuk itu kita ganti panggilan ke VideoCapture() dengan
alamat IP dari kamera yang ingin kita akses, seperti contoh di bawah ini:
webcam1 = cv.VideoCapture('http://admin:[email protected]/?action=stream') Melatih Pengenalan Obyek
Tidak terbatas pada pendeteksian wajah, kita bisa melatih CascadeClassifier dengan
obyek-obyek lain, misalnya logo, mobil, hewan dan sebagainya. Syaratnya, kita harus
menyiapkan training dataset berupa sebanyak-banyaknya sampel positif berupa gambar
obyek yang ingin kita deteksi dan juga sebanyak-banyaknya sampel negatif.
Untuk keperluan training, OpenCV menyediakan dua program yaitu
opencv_createsamples dan opencv_traincascade. Keduanya ada di folder tempat
OpenCV dipasang di disk Langkah pertama dalam proses training adalah memanfaatkan
program opencv_createsamples untuk menghasilkan sampel positif berbentuk file
berekstensi .vec yang kemudian dipergunakan untuk training oleh program
opencv_traincascade.
Sampel positif yang diperlukan harus mencakup berbagai variasi posisi, sudut kemiringan,
atau variasi latar belakang. Ini diperlukan untuk memperkuat kemungkinan pendeteksian
berhasil.
Kita ingat bahwa algoritma berbasis Haar Cascade memanfaatkan perbedaan intensitas
cahaya di dalam gambar sebagai dasar penentuan feature. Oleh karena itu gambar sampel
obyek yang kita persiapkan haruslah obyek yang memang memiliki banyak sudut atau
lekukan yang kontras perbedaan intensitas terang-gelapnya. Gambar yang sedikit garis
kontrasnya, terlalu terang atau terlalu gelap akan kurang baik dijadikan sampel.
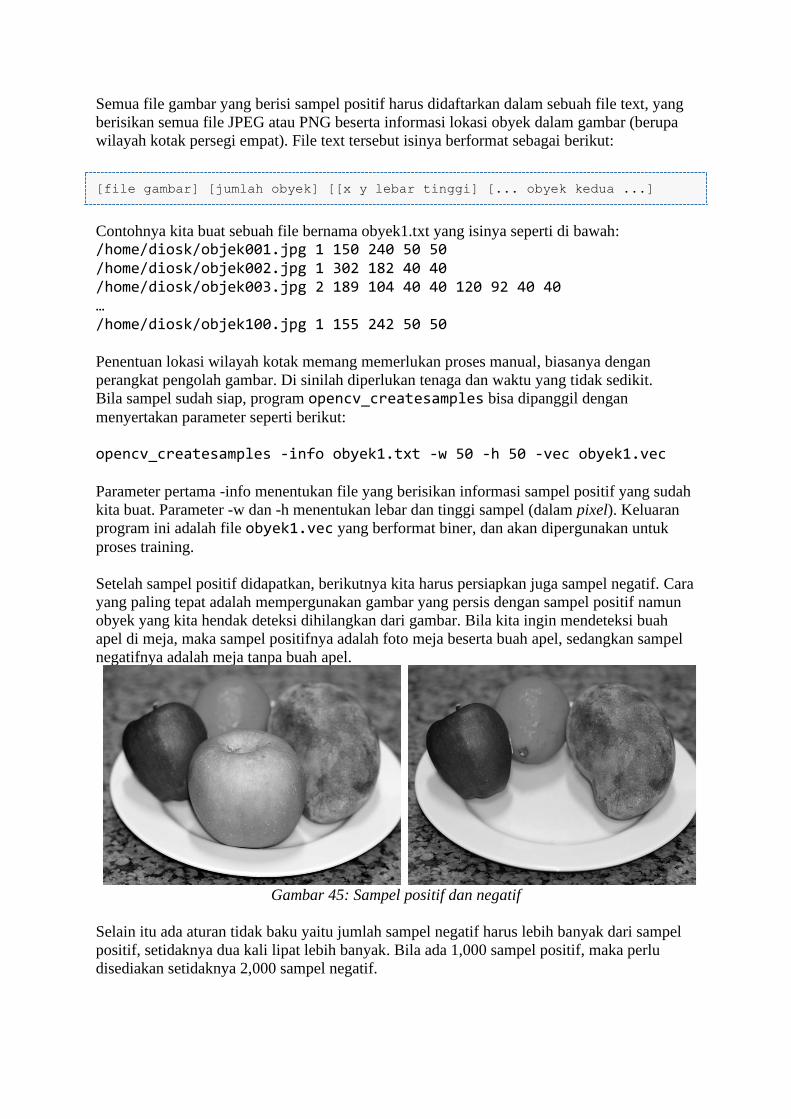
Semua file gambar yang berisi sampel positif harus didaftarkan dalam sebuah file text, yang
berisikan semua file JPEG atau PNG beserta informasi lokasi obyek dalam gambar (berupa
wilayah kotak persegi empat). File text tersebut isinya berformat sebagai berikut:
[file gambar] [jumlah obyek] [[x y lebar tinggi] [... obyek kedua ...]
Contohnya kita buat sebuah file bernama obyek1.txt yang isinya seperti di bawah:
/home/diosk/objek001.jpg 1 150 240 50 50 /home/diosk/objek002.jpg 1 302 182 40 40 /home/diosk/objek003.jpg 2 189 104 40 40 120 92 40 40 … /home/diosk/objek100.jpg 1 155 242 50 50 Penentuan lokasi wilayah kotak memang memerlukan proses manual, biasanya dengan
perangkat pengolah gambar. Di sinilah diperlukan tenaga dan waktu yang tidak sedikit.
Bila sampel sudah siap, program opencv_createsamples bisa dipanggil dengan
menyertakan parameter seperti berikut:
opencv_createsamples -info obyek1.txt -w 50 -h 50 -vec obyek1.vec Parameter pertama -info menentukan file yang berisikan informasi sampel positif yang sudah
kita buat. Parameter -w dan -h menentukan lebar dan tinggi sampel (dalam pixel). Keluaran
program ini adalah file obyek1.vec yang berformat biner, dan akan dipergunakan untuk
proses training.
Setelah sampel positif didapatkan, berikutnya kita harus persiapkan juga sampel negatif. Cara
yang paling tepat adalah mempergunakan gambar yang persis dengan sampel positif namun
obyek yang kita hendak deteksi dihilangkan dari gambar. Bila kita ingin mendeteksi buah
apel di meja, maka sampel positifnya adalah foto meja beserta buah apel, sedangkan sampel
negatifnya adalah meja tanpa buah apel.
Gambar 45: Sampel positif dan negatif
Selain itu ada aturan tidak baku yaitu jumlah sampel negatif harus lebih banyak dari sampel
positif, setidaknya dua kali lipat lebih banyak. Bila ada 1,000 sampel positif, maka perlu
disediakan setidaknya 2,000 sampel negatif.
Semua file gambar sampel negatif harus diletakkan di satu folder terpisah, dan nama-
namanya didaftarkan dalam sebuah file text. Karena tidak ada obyek yang perlu dikenali,
maka kita tidak perlu menentukan wilayah persegi empat seperti di sampel positif.
Proses training dilakukan dengan memanggil program opencv_traincascade, dengan
parameter seperti berikut ini:
opencv_traincascade -data /home/diosk/samples -vec obyek1.vec -bg neg-filepaths.txt -precalcValBufSize 2048 -precalcIdxBufSize 2048 -numPos 100 -numNeg 1000 -nstages 20 -minhitrate 0.999 -maxfalsealarm 0.5 -w 20 -h 20 -nonsym -baseFormatSave
Parameter -data menentukan folder tempat file sampel berada. Parameter -numPos adalah
jumlah sampel positif (dalam contoh ini ada 100) dan -numNeg adalah jumlah sampel negatif
(dalam contoh ini ada 1000). Parameter lainnya dapat diubah-ubah dengan eksperimen untuk
mendapatkan hasil terbaik. Hasil keluaran program ini adalah sebuah file bernama
cascade.XML yang kemudian bisa dipakai untuk program pendeteksian.
Membuat training dataset memang sebuah proses yang tidak ringan, karena umumnya
diperlukan ratusan hingga ribuan sampel positif dan negatif. Mengerjakannya dengan tangan
satu-per-satu akan memerlukan waktu sangat lama. Ada trik sederhana yaitu mempergunakan
kamera video untuk merekam obyek yang sama dari berbagai sudut dan pencahayaan,
kemudian dengan perangkat lunak video editor kita ambil frame yang diperlukan. Dengan
cara ini, kita bisa mendapat puluhan bahkan ratusan sampel positif dalam sekali pengambilan
gambar.
Kesimpulan
Computer Vision adalah cabang ilmu yang masih terus berkembang dan sangat menarik
untuk dipelajari. Selain Haar Cascade, ada classifier lain yang cukup sering dipergunakan
yaitu Local Binary Pattern (LBP). Berikut adalah perbandingan keunggulan dan kelemahan
masing classifier:
Algoritma Kelebihan Kekurangan
Haar • Akurasi cukup tinggi
• Tingkat kekeliruan
rendah, hampir selalu bisa
mendeteksi wajah
• Perlu data training yang banyak
• Relatif kompleks dan
memerlukan sumberdaya
komputasi yang besar
• Tidak bisa mendeteksi wajah
yang gelap
LBP • Kompleksitas lebih rendah
dibanding Haar
• Training bisa lebih singkat
• Tidak seakurat Haar
• Tingkat kekeliruan tinggi, sering
gagal mendeteksi wajah
Teknologi pendeteksian dan pengenalan wajah meskipun terus berkembang, penerapannya di
dunia nyata sering mendapat sorotan tajam karena rentan disalahgunakan. Tidak seperti
teknologi pengenalan biometrik lain misalnya sidik jari, pengenalan wajah bisa dilakukan
dari jauh tanpa kontak fisik, tanpa seijin orang yang sedang diidentifikasi.
Bayangkan bila wajah Anda ditangkap kamera di jalanan dan perusahaan periklanan tertentu
memanfaatkan identitas Anda untuk mengirimkan iklan tanpa ijin Anda. Kepolisian bisa

menangkap seorang warga atas tuduhan kriminal berdasarkan pengenalan wajah yang
dihasilkan komputer, yang kita tahu belum 100% akurat. Dalam kasus yang lebih ekstrim,
Pemerintah China dikabarkan mepergunakan teknologi ini untuk keperluan politis, misalnya
mengawasi etnik minoritas tertentu di wilayahnya. Itu sebabnya Microsoft di bulan Juni 2019
menghapus jutaan file wajah dari databasenya yang bernama MS-Celeb atas dasar kurangnya
regulasi pemerintah yang mengatur penggunaan teknologi facial recognition.
Computer Vision memang bidang yang menarik untuk didalami, adapun begitu kita harus
memanfaatkannya dengan penuh kehati-hatian. Pastikan kita tidak mengganggu privacy
orang lain ketika kita memanfaatkan identitasnya untuk keperluan pembuatan model Machine
Learning.

Bab 12 Python dan Big Data Dalam pelajaran kita di bab-bab sebelumnya, kita sudah melihat bagaimana Python (bersama
dengan Pandas, Numpy, Scikit-learn dan library lainnya) manipulasi data. Tidak
mengherankan Python menjadi sangat populer dan menjadi pilihan banyak Data Scientist.
Adapun demikian, bisa kita lihat dalam contoh-contoh kasus di bab-bab sebelumnya, ukuran
data yang kita pergunakan masih berupa file berukuran kecil, hanya ratusan baris atau
maksimal ribuan baris data. Ukurannya pun hanya beberapa megabyte. Apakah artinya kita
tidak bisa mempergunakan file berukuran lebih besar? Tentu bisa. Anda bisa saja mengolah
data dengan Pandas sampai jutaan baris tanpa masalah. Secara teoritis, selama ukuran data
masih lebih kecil dari ukuran memori komputer Anda, maka data pasti masih bisa diolah.
Bila kapasitas hard disk dan RAM (random access memory, memori utama) komputer Anda
masih lebih besar dari ukuran dataset yang diolah Python, maka semua akan baik-baik saja
(asal Anda bersedia bersabar menunggu proses yang menjadi lebih lama untuk data yang
besar).
Nah, bagaimana bila kita dihadapkan pada data yang bahkan lebih besar lagi? Di era digital
masa kini di mana Big Data menjadi problematika umum karena volume dan
kompleksitasnya, bukan sesuatu yang mengejutkan bila kita harus mengolah data berukuran
ratusan juta bahkan milyaran baris data. Ukuran data di masa kini sudah lumrah bila
mencapai orde ratusan gigabyte atau bahkan terabyte. Apakah Python masih mampu untuk
mengelola data sebesar itu?
Meskipun tidak dituliskan secara jelas di dokumentasimya, ada beberapa pendapat yang
mengatakan bahwa Python dan Pandas masih sanggup menangani data hingga berukuran
100GB. Jadi apabila data yang harus kita olah berukuran besar, kita bisa memindahkan
program Python kita ke komputer berspesifikasi tinggi dengan RAM yang besar kapasitasnya
(kita bisa membeli komputer dengan RAM 128GB atau lebih besar lagi).
Tapi itu juga belum pasti bisa menyelesaikan masalah. Bagaimana bilamana pada suatu titik
dataset yang harus kita proses berukuran maha besar dan tidak dapat diolah di satu mesin
saja? Solusinya adalah mempekerjakan banyak prosesor yang melaksanakan tugas secara
paralel, suatu teknik yang disebut parallel processing.
Analoginya adalah ketika kita punya kereta kuda yang bebannya semakin berat, kita bisa saja
mengganti kuda yang lama dengan kuda yang lebih besar dan kuat, namun tetap saja ada
batasan kekuatan seekor kuda. Pada suatu titik beban maksimal, kuda sekuat apapun tidak
akan kuat menarik kereta. Pilihan yang logis untuk masalah ini adalah kita tambah jumlah
kudanya.
Satu Mesin
Banyak Mesin
Gambar 46: Ilustrasi parallel processing

Prosesor komputer jaman sekarang biasanya memiliki banyak core (inti), yang
memungkinkan parallel processing di dalam satu komputer yang sama. Kebanyakan PC dan
laptop saat ini juga telah dilengkapi dengan prosesor dengan 2 core, 4 core bahkan lebih.
Sebagai contoh, prosesor Intel i7 generasi ke-9 memiliki 6 core.
Adapun demikian, kenyataan yang harus kita terima adalah: Python sejak lahir dirancang
untuk dijalankan di sebuah komputer dengan satu core tunggal saja. Memproses data di
dalam banyak prosesor paralel bukanlah “bakat alami” Python. Program Python yang kita
buat hanya akan dijalankan oleh Python intepreter di satu core saja, meskipun komputer kita
memiliki prosesor dengan banyak core.
Tanpa parallel processing, bila seorang Data Scientist tetap ingin mempergunakan Python
dan library pendukungnya, maka dia harus membuat kompromi dengan mengurangi jumlah
data agar cukup dimuat ke dalam satu core prosesor. Ini biasanya dilakukan dengan
mengambil sejumlah sampel data, misalnya ribuan atau ratusan ribu baris saja dari jutaan atau
milyaran baris data yang sebenarnya tersedia untuk dilakukan analisis. Jumlah kolom juga
bisa saja diambil yang benar-benar perlu, sebelum dimuat ke dalam DataFrame. Tapi tentu
saja cara ini ada batasnya dan tidak memecahkan masalah ketika data yang harus diolah
benar-benar tidak cukup lagi masuk ke dalam satu mesin.
Permasalahan ini yang kemudian mendorong orang mengembangkan teknik yang disebut
dengan out-of-core processing, yaitu metode untuk membuat pemrosesan data yang tidak
cukup dimasukkan ke dalam memori utama komputer. .
Tidak terbatas di satu mesin, kita bisa juga membuat distributed processing yang artinya kita
menyiapkan banyak mesin dengan banyak prosesor yang digabung dalam satu jaringan
komputer, membentuk suatu computing cluster (kelompok komputer). Di dalam kelompok
komputer ini, masing-masing mengerjakan bagian kecil dari data, dan kemudian hasilnya
digabungkan untuk dijadikan hasil akhir. Apabila data yang harus diolah menjadi semakin
besar, jumlah mesin bisa ditambah lagi. Cara ini cukup fleksibel untuk mengatasi semakin
bertumbuhnya ukuran data yang harus diolah oleh suatu organisasi. Itu sebabnya solusi
permasalahan Big Data banyak mempergunakan metode semacam ini.
Apache Spark
Salah satu solusi untuk parallel processing dan distributed processing yang populer saat ini
adalah dengan mempergunakan Apache Spark, yang berawal dari riset di laboratorium
AMPLab di University of California, Berkeley. Apache Spark adalah sebuah ekosistem
lengkap yang dirancang untuk memecahkan berbagai permasalahan Big Data. Konsep
dasarnya adalah menyusun suatu lingkungan komputasi yang terdiri dari banyak mesin
(dalam Spark, istilahnya adalah “node”) yang disebut Master dan Worker. Seperti Namanya,
Worker Node bertugas mengerjakan proses komputasi terhadap data, sedangkan Master Node
bertugas menjadi menjadi pengelola keseluruhan cluster. Jumlah Worker Node bisa ditambah
sesuai kebutuhan, dari minimal dua buah hingga ribuan.
Apache Spark dirancang dengan pemikiran dasar bahwa komputasi harus dibawa sedekat
mungkin dengan data, tujuannya untuk meminimalkan pergerakan data. Data ditaruh tersebar
di seluruh Worker Node, yang masing-masing akan mengerjakan porsinya sendiri. Lebih
hebat lagi, semua dilakukan di memori utama (bukan di disk) sehingga proses menjadi sangat
cepat dan efisien.

Apache Spark juga mengenal konsep DataFrame serupa dengan Pandas, namun tidak ada
kemiripan di antara keduanya (selain namanya) karena implementasinya berbeda sekali.
Segala macam data di dalam Apache Spark disimpan dalam suatu struktur yang disebut
dengan RDD (resilient distributed dataset) yang sifatnya immutable (tidak bisa diubah
setelah dibuat).
Untuk Machine Learning, terdapat library Spark MLlib yang memang dari awal sudah
dirancang untuk membangun model yang memanfaatkan kemampuan distributed processing.
Seperti Scikit-learn, MLLib menyediakan banyak algoritma untuk klasifikasi, clustering dan
regression.
Program untuk Apache Spark bisa dibuat dengan beberapa pilihan bahasa, yaitu Java, Python,
R dan Scala. Untuk bahasa Python, Apache Spark mempergunakan jembatan penghubung
yang disebut PySpark.
Alasan utama mengapa Apache Spark menjadi populer adalah karena Apache Spark
membuat pengolahan data dalam skala besar menjadi relatif mudah. Segala kerumitan yang
menjadi masalah di distributed processing sudah “dibungkus” dengan rapi oleh Apache
Spark. Model pemrogramannya relatif mudah untuk dipahami, tidak memerlukan keahlian
khusus yang mendalam akan pemrograman di komputasi parallel dan sistem terdistribusi
yang pada masa terdahulu harus dilakukan dengan bahasa C/C++ yang rumit. Di masa lalu,
membuat program distributed processing memerlukan energi yang luar biasa.
Kekurangannya adalah kita tidak bisa lagi mempergunakan program Python yang sudah kita
buat dengan Pandas dan Scikit-learn. Kita harus menulis ulang semuanya di PySpark. Karena
memiliki model komputasi dan pemrograman yang berbeda sekali, pembahasan Apache
Spark berada di luar lingkup buku ini.
Dask
Jalan keluar apabila kita ingin menjadikan program Python dijalankan di banyak prosesor
secara paralel namun tidak ingin mempergunakan Apache Spark adalah Dask. Dask
merupakan sekumpulan library yang gunanya memungkinkan program Python yang telah
kita buat (menggunakan Pandas, Numpy dan Scikit-learn) bisa lebih cepat kerjanya karena
dapat memanfaatkan banyak core prosesor yang tersedia. Keterbatasan Python interpreter
yang hanya bisa bekerja di satu core prosesor menjadi terpecahkan.
Daya tarik utama Dask adalah kita tetap bisa mempergunakan program Python yang sudah
kita buat dengan hanya sedikit penyesuaian, tidak seperti bila kita mempergunakan Apache
Spark yang mengharuskan kita menulis ulang semua program. Tentu hal ini menarik sekali
bagi Data Scientist yang sudah terbiasa dengan Pandas, Numpy dan Scikit-learn.
Berbeda dengan Apache Spark yang bisa dipergunakan dengan beberapa bahasa
pemrograman (Scala, Java dan Python), Dask merupakan bagian dari ekosistem Python
sehingga tidak mendukung bahasa pemrogaman yang lain. Pendeknya, hampir semua yang
sudah kita pelajari di dalam buku ini dapat dijalankan pula di Dask.
Bila di Pandas kita mengenal DataFrame, maka Dask menyediakan padanannya yaitu Dask
DataFrame, yang cara penggunaannya kurang lebih meniru Pandas. Walaupun Apache Spark
juga memiliki konsep DataFrame, namun cara penggunaannya berbeda dan mengharuskan
kita mempelajari pemrograman API (application programming interface) baru. Berikut

contoh singkat penggunaan Dask DataFrame, yang bila kita perhatikan, hampir tidak ada
bedanya dengan Pandas:
import dask.dataframe as dd df1 = dd.read_csv('file.csv') df1.groupby(df.account_id).balance.sum()
Untuk Machine Learning, Dask menyediakan Dask-ML, yang bisa berinteroperasi dengan
Scikit-learn dan cara penggunaannya pun mirip. Dask-ML memungkinkan proses training
bisa dilaksanakan di banyak core prosesor sehingga secara teoritis bisa mengakodomasi
dataset yang jauh lebih besar dibandingkan bila hanya ada satu core prosesor.
Serupa dengan Apache Spark, Dask juga bisa menerapkan penggunaan distributed processing
untuk pengolahan data sangat besar. Ini bisa dicapai dengan membangun suatu computing
cluster yang berisi banyak mesin yang disebut Worker (“pekerja”) dan satu mesin yang
disebut Scheduler yang akan mengelola keseluruhan proses. Scheduler akan membagi tugas
komputasi pada setiap worker untuk diproses secara independen. Secara teoritis, Dask dapat
memanfaatkan ratusan hingga ribuan core prosesor. Untuk melakukan distributed processing
seperti ini, kita harus mempergunakan library Dask Distributed, yang akan kita coba
demonstrasikan di bagian selanjutnya.
Memasang Dask
Untuk mengunduh dan memasang Dask, sangat mudah bila Anda sudah mempergunakan
Anaconda Distribution. Perintahnya seperti berikut:
conda install dask Untuk memasang Dask Distributed dan Dask-ML, perintahnya:
conda install dask distributed -c conda-forge conda install -c conda-forge dask-ml
Untuk memperagakan konsep parallel processing dengan Dask, kita perlu memerlukan
beberapa mesin komputer. Sebagai contoh di buku ini, kita akan mempersiapkan empat buah
mesin yang tersambung dalam sebuah jaringan lokal, satu sebagai Scheduler, tiga sebagai
Worker. Semua mempergunakan sistem operasi Linux. Anaconda Distribution dan Dask juga
telah terpasang di keempat mesin ini (cara memasang Andaconda dapat dilihat di Lampiran 1
buku ini). Diagram di bawah menunjukkan keempat mesin tersebut:
Gambar 47: Contoh empat mesin dalam sebuah cluster Dask
Scheduler (192.168.100.106)
Worker 3 (192.168.100.109)
Worker 2 (192.168.100.108)
Worker 1 (192.168.100.107)

Langkah pertama adalah mempersiapkan Scheduler. Dengan asumsi Anaconda telah
terpasang di home directory, maka kita panggil program dask-scheduler dari directory
tersebut:
cd \home\dioskurn\Anaconda\bin dask-scheduler
Layar akan menunjukkan bahwa Scheduler sudah bekerja dan siap menunggu koneksi dari
Worker. Selanjutnya, di ketiga mesin Worker, kita aktifkan program dask-worker dengan
mengeksekusi perintah berikut:
dask-worker tcp://192.168.100.106:8786
IP address yang tercantum di atas (192.168.100.106) adalah alamat mesin Scheduler. Semua
Worker akan mencantumkan alamat yang sama, karena memang hanya ada satu Scheduler.
Dask berkomunikasi melalui jaringan dengan protokol TCP di port 8786, jadi kita harus
memastikan port tersebut tidak dihalangi oleh firewall di jaringan lokal yang mungkin aktif.
Bila hubungan telah terjalin, di layar Scheduler akan muncul indikasi bahwa sudah ada tiga
Worker yang tersambung:
Gambar 48: Dask Scheduler
Untuk memudahkan pemantauan cluster, Dask menyediakan aplikasi web bernama Bokeh,
yang memungkinkan kita melihat status masing-masing Worker, berapa besar sumber daya
komputasi yaitu CPU (central processing unit) dan memori yang dikonsumsi. Bokeh bisa
diakses di port 8787 seperti di bawah ini:
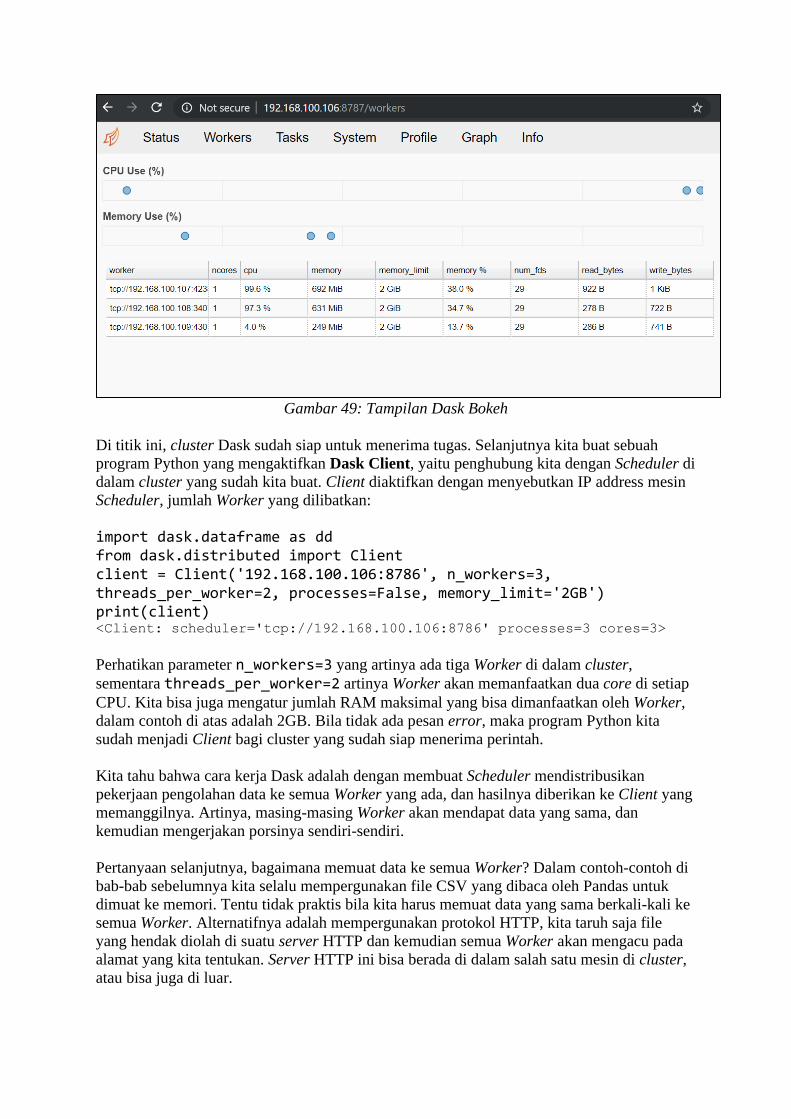
Gambar 49: Tampilan Dask Bokeh
Di titik ini, cluster Dask sudah siap untuk menerima tugas. Selanjutnya kita buat sebuah
program Python yang mengaktifkan Dask Client, yaitu penghubung kita dengan Scheduler di
dalam cluster yang sudah kita buat. Client diaktifkan dengan menyebutkan IP address mesin
Scheduler, jumlah Worker yang dilibatkan:
import dask.dataframe as dd from dask.distributed import Client client = Client('192.168.100.106:8786', n_workers=3, threads_per_worker=2, processes=False, memory_limit='2GB') print(client) <Client: scheduler='tcp://192.168.100.106:8786' processes=3 cores=3>
Perhatikan parameter n_workers=3 yang artinya ada tiga Worker di dalam cluster,
sementara threads_per_worker=2 artinya Worker akan memanfaatkan dua core di setiap
CPU. Kita bisa juga mengatur jumlah RAM maksimal yang bisa dimanfaatkan oleh Worker,
dalam contoh di atas adalah 2GB. Bila tidak ada pesan error, maka program Python kita
sudah menjadi Client bagi cluster yang sudah siap menerima perintah.
Kita tahu bahwa cara kerja Dask adalah dengan membuat Scheduler mendistribusikan
pekerjaan pengolahan data ke semua Worker yang ada, dan hasilnya diberikan ke Client yang
memanggilnya. Artinya, masing-masing Worker akan mendapat data yang sama, dan
kemudian mengerjakan porsinya sendiri-sendiri.
Pertanyaan selanjutnya, bagaimana memuat data ke semua Worker? Dalam contoh-contoh di
bab-bab sebelumnya kita selalu mempergunakan file CSV yang dibaca oleh Pandas untuk
dimuat ke memori. Tentu tidak praktis bila kita harus memuat data yang sama berkali-kali ke
semua Worker. Alternatifnya adalah mempergunakan protokol HTTP, kita taruh saja file
yang hendak diolah di suatu server HTTP dan kemudian semua Worker akan mengacu pada
alamat yang kita tentukan. Server HTTP ini bisa berada di dalam salah satu mesin di cluster,
atau bisa juga di luar.

File yang dicoba dibuka untuk contoh kita kali ini adalah sebuah file CSV, berisi data fiktif
pelacakan perangkat GPS (Global Positioning System) yang dipasang pada kendaraan
bergerak. File CSV yang kita proses berukuran cukup besar, berisi sekitar 1 juta baris. Ada 10
informasi dalam file ini yaitu timestamp (waktu pelacakan), IMEI (nomor identitas
perangkat), informasi pelacakan yaitu koordinat, kekuatan sinyal, kode jaringan selular,
identitas menara selular dan identitas pelanggan. Kita akan pakai informasi waktu pelacakan
sebagai index. Fungsi read_csv() di Dask dibuat mirip dengan di Pandas, seperti di bawah
ini:
df1 = dd.read_csv('http://192.168.100.101/download/rawdata.csv', names=['timestamp','imei','lat','long','signal','lac','cid','mcc','mnc','imsi'], usecols=range(10), parse_dates=['timestamp'], error_bad_lines='False', sep=',\s*', engine='python', skipinitialspace='True').set_index('timestamp') df1.head(10)
Karena ukuran file yang cukup besar (200MB), proses pembacaan file akan memerlukan
waktu beberapa lama (tergantung kekuatan prosesor dan kecepatan jaringan). Setelah proses
selesai, DataFrame bisa dipergunakan seperti biasa.
Sebelum kita melakukan sesuatu terhadap DataFrame, kita perlu memastikan DataFrame ini
tetap berada di memori. Mengapa? Karena hasil komputasi secara aktif akan dihapus dari
memori Worker untuk memberi ruang bagi proses komputasi selanjutnya. Untuk mencegah
Dask membaca ulang lagi data dari file, karena kita masih perlu isi DataFrame ini untuk
proses selanjutnya, maka kita panggil fungsi persist() yang gunanya untuk menjaga agar
DataFrame tetap disimpan di memori dan tidak dihapus:
df1 = df1.persist() Selanjutnya kita mencoba suatu proses komputasi yang cukup berat untuk menguji kerja
Dask. Misalnya kita ingin tahu berapa banyak data pelacakan yang tercatat untuk setiap
perangkat GPS. Untuk ini kita lakukan fungsi agregasi groupby() dan count(). Perlu
diperhatikan bahwa Dask DataFrame sedikit berbeda dengan Pandas: Dask Dataframe
sifatnya lazy (malas), artinya Dask belum akan bertindak apa-apa terhadap DataFrame bila
belum mendapat instruksi dengan perintah compute().

df1.groupby('imei').long.count().compute()
Proses agregasi seperti ini akan cukup banyak menyita sumber daya komputasi, dan bisa
memerlukan waktu cukup panjang tergantung kepada kekuatan prosesor di Worker. Selama
proses berlangsung, kita dapat melihat perkembangannya melalui Bokeh, di mana kita bisa
melihat penggunaan CPU dan memori yang meningkat di semua Worker. Angka yang wajar
adalah di atas 90% yang artinya seluruh sumber daya yang ada dimanfaatkan dengan
maksimal.
Dask-ML
Setelah melihat demonstrasi dengan Dask DataFrame di atas, selanjutnya kita akan mencoba
membuat model Machine Learning dengan library Dask-ML. Dalam kasus kali ini kita akan
melakukan clustering dengan algoritma K-means, mirip seperti yang sudah kita bahas di Bab
10. Bedanya, kali ini kita akan melihat sebaran lokasi perangkat GPS berdasarkan
koordinatnya.
Informasi latitude (garis lintang) dan longitude (garis bujur) yang ada di dalam data bisa kita
pergunakan untuk keperluan clustering ini. Dengan Dask-ML, kita bisa impor langsung
modul dask_ml.cluster dan menentukan jumlah cluster yang kita inginkan (dalam contoh
ini, sepuluh cluster):

import dask_ml.datasets import dask_ml.cluster df2 = df1[['lat','long']] km = dask_ml.cluster.KMeans(n_clusters=10, init_max_iter=2, oversampling_factor=10) km.fit(df2) centroids = km.cluster_centers_ print(centroids)
Hasilnya adalah sepuluh cluster yang centroid-nya nampak sebagai berikut:
Angka-angka di atas adalah koordinat-koordinat lokasi geografis yang mungkin agak sulit
kita pahami bila tidak dilihat secara visual. Untuk ini, kita coba pergunakan scatterplot untuk
menggambarkan kesepuluh titik centroid di atas. Sebagai referensi, kota Jakarta berada di
sekitar 106 Bujur Timur dan 6 Lintang Selatan (wilayah di selatan khatulistiwa diwakili
dengan angka negatif).
import matplotlib.pyplot as plt Y = centroids[:,0] X = centroids[:,1] fig, ax = plt.subplots() ax.scatter(X,Y)
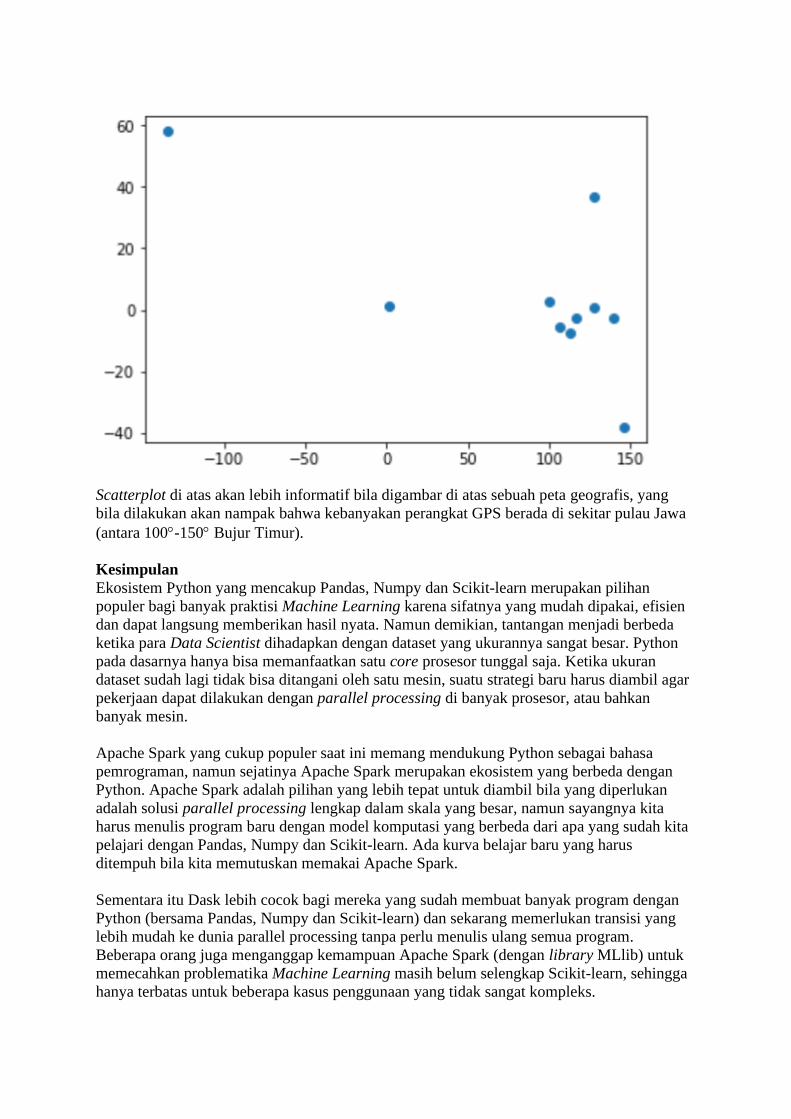
Scatterplot di atas akan lebih informatif bila digambar di atas sebuah peta geografis, yang
bila dilakukan akan nampak bahwa kebanyakan perangkat GPS berada di sekitar pulau Jawa
(antara 100-150 Bujur Timur).
Kesimpulan
Ekosistem Python yang mencakup Pandas, Numpy dan Scikit-learn merupakan pilihan
populer bagi banyak praktisi Machine Learning karena sifatnya yang mudah dipakai, efisien
dan dapat langsung memberikan hasil nyata. Namun demikian, tantangan menjadi berbeda
ketika para Data Scientist dihadapkan dengan dataset yang ukurannya sangat besar. Python
pada dasarnya hanya bisa memanfaatkan satu core prosesor tunggal saja. Ketika ukuran
dataset sudah lagi tidak bisa ditangani oleh satu mesin, suatu strategi baru harus diambil agar
pekerjaan dapat dilakukan dengan parallel processing di banyak prosesor, atau bahkan
banyak mesin.
Apache Spark yang cukup populer saat ini memang mendukung Python sebagai bahasa
pemrograman, namun sejatinya Apache Spark merupakan ekosistem yang berbeda dengan
Python. Apache Spark adalah pilihan yang lebih tepat untuk diambil bila yang diperlukan
adalah solusi parallel processing lengkap dalam skala yang besar, namun sayangnya kita
harus menulis program baru dengan model komputasi yang berbeda dari apa yang sudah kita
pelajari dengan Pandas, Numpy dan Scikit-learn. Ada kurva belajar baru yang harus
ditempuh bila kita memutuskan memakai Apache Spark.
Sementara itu Dask lebih cocok bagi mereka yang sudah membuat banyak program dengan
Python (bersama Pandas, Numpy dan Scikit-learn) dan sekarang memerlukan transisi yang
lebih mudah ke dunia parallel processing tanpa perlu menulis ulang semua program.
Beberapa orang juga menganggap kemampuan Apache Spark (dengan library MLlib) untuk
memecahkan problematika Machine Learning masih belum selengkap Scikit-learn, sehingga
hanya terbatas untuk beberapa kasus penggunaan yang tidak sangat kompleks.

Adapun Dask merupakan library yang berusia muda (pada saat buku ini ditulis versi terakhir
Dask adalah Release 2.0), sehingga masih belum sangat stabil. Di sisi lain, Apache Spark
sudah lebih matang karena lahir beberapa tahun lebih awal. Popularitas Dask di kalangan
praktisi Big Data juga belum seluas Apache Spark, namun demikian Dask terus
dikembangkan secara aktif didukung oleh Anaconda Inc (perusahaan yang mengembangkan
Anaconda Distribution) dan nampaknya memiliki masa depan yang cukup cerah.
Apache Spark dan Dask adalah solusi Big Data yang dengan segala kelebihan dan
kekurangannya, memungkinkan kita menikmati kemudahan membangun solusi parallel
processing untuk data dalam ukuran sangat besar. Di masa lalu, mengolah data yang
berukuran besar tidak mungkin dilakukan dikarenakan belum tersedianya teknologi
komputasi yang memadai. Saat ini situasinya berbeda. Sumber daya komputasi saat ini relatif
murah, dengan biaya media penyimpanan yang selalu turun (bila dihitung per-byte). Begitu
juga telah banyak perangkat lunak open-source yang tersedia untuk dipergunakan oleh semua
orang untuk keperluan Data Science dan Machine Learning. Dokumentasi dan informasi juga
tersedia online, sebagian besar tanpa biaya.
Ibaratnya, sekarang semua orang dapat membangun sistem komputer yang di masa lalu hanya
bisa dilakukan oleh organisasi-organisasi besar yang mempekerjakan banyak ahli dan
memiliki dana besar. Sekarang kita bisa membangun “super computer” kita sendiri dengan
perangkat lunak open-source yang nyaris tak berbayar, dijalankan di atas komputer-komputer
biasa yang bisa kita beli dengan harga relatif murah dari produsen manapun. Kita bahkan
tidak harus membeli sendiri perangkat keras dan perangkat lunaknya karena saat ini banyak
pilihan layanan cloud computing yang memungkinkan kita mendapatkan akses ke sumber
daya komputasi sesuai kebutuhan dalam hitungan menit, dengan sewa harian, mingguan atau
bulanan bermodalkan kartu kredit saja.
Sungguh, jaman telah berubah.
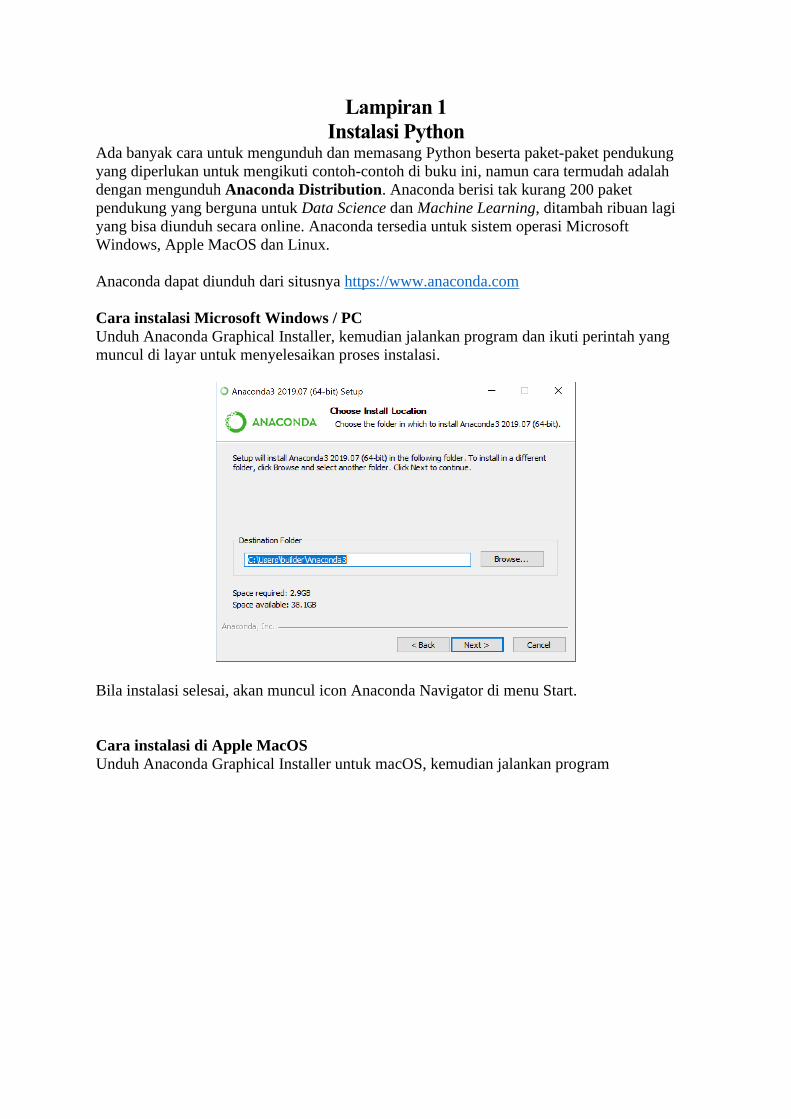
Lampiran 1
Instalasi Python Ada banyak cara untuk mengunduh dan memasang Python beserta paket-paket pendukung
yang diperlukan untuk mengikuti contoh-contoh di buku ini, namun cara termudah adalah
dengan mengunduh Anaconda Distribution. Anaconda berisi tak kurang 200 paket
pendukung yang berguna untuk Data Science dan Machine Learning, ditambah ribuan lagi
yang bisa diunduh secara online. Anaconda tersedia untuk sistem operasi Microsoft
Windows, Apple MacOS dan Linux.
Anaconda dapat diunduh dari situsnya https://www.anaconda.com
Cara instalasi Microsoft Windows / PC
Unduh Anaconda Graphical Installer, kemudian jalankan program dan ikuti perintah yang
muncul di layar untuk menyelesaikan proses instalasi.
Bila instalasi selesai, akan muncul icon Anaconda Navigator di menu Start.
Cara instalasi di Apple MacOS
Unduh Anaconda Graphical Installer untuk macOS, kemudian jalankan program

Bila instalasi selesai, akan muncul icon Anaconda Navigator di menu Launchpad.
Cara instalasi di Linux
Anaconda bisa diinstall menggunakan graphical interface atau menggunakan command line
di terminal. Di bawah ini adalah cara mengunduh dan melakukan instalasi dengan command
line:
curl -O https://repo.continuum.io/archive/Anaconda3-2019.03-Linux-x86_64.sh
Perhatikan versi Anaconda yang tepat. Pada saat buku ini ditulis, Anaconda yang tersedia
adalah versi 3. Setelah file selesai diunduh, kemudian jalankan file script instalasi dan ikuti
instruksi yang muncul:
bash Anaconda3-2019.03.0-Linux-x86_64.sh
Sebagai catatan, perhatikan apakah Linux yang terpasang di komputer Anda sudah memiliki
Bunzip2, sebuah program untuk membuka kompresi. Bunzip2 biasanya memang tidak
terpasang di beberapa paket distribusi Linux. Bila demikian situasinya, fungsi Bunzip2 harus
diganti dengan membuat file baru seperti ini:
#!/usr/bin/env python import bz2, sys print bz2.BZ2File(sys.argv[2]).read()
Simpan file ini sebagai bunzip2 di directory /usr/bin di komputer Anda. Pastikan file ini
bisa dieksekusi.
Instalasi Pandas dan Scikit-learn
Pandas dan Scikit-learn sebenarnya sudah terpasang secara otomatis ketika kita memasang
Anaconda. Adapun bila perlu memasang sendiri, untuk mengunduh dan memasang Pandas
serta Scikit-learn, pergunakan perintah:
conda install pandas conda install scikit-learn

Perlu diingat bahwa Pandas dan Scikit-learn memerlukan NumPy agar bisa bekerja.
Anaconda sudah memasukkan NumPy ini ke dalam paket wajibnya, adapun demikian harus
diperiksa apakah NumPy telah terpasang di komputer Anda.
Instalasi Jupyter Notebook
Jupyter Notebook bisa diunduh dengan Anaconda seperti paket-paket Python lainnya.
Caranya dengan menjalankan perintah berikut:
conda install -c conda-forge jupyterlab
Setelah terpasang, akan muncul icon Jupyter Notebook di aplikasi Anaconda Navigator.
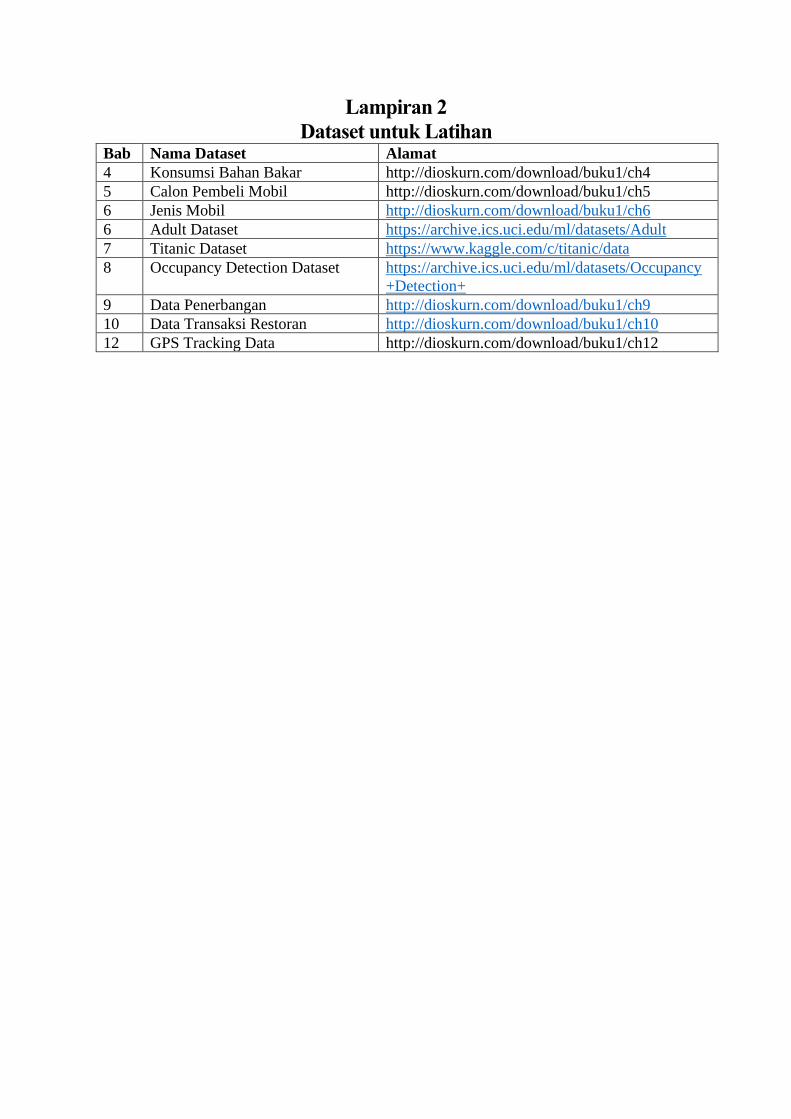
Lampiran 2
Dataset untuk Latihan Bab Nama Dataset Alamat
4 Konsumsi Bahan Bakar http://dioskurn.com/download/buku1/ch4
5 Calon Pembeli Mobil http://dioskurn.com/download/buku1/ch5
6 Jenis Mobil http://dioskurn.com/download/buku1/ch6
6 Adult Dataset https://archive.ics.uci.edu/ml/datasets/Adult
7 Titanic Dataset https://www.kaggle.com/c/titanic/data
8 Occupancy Detection Dataset https://archive.ics.uci.edu/ml/datasets/Occupancy
+Detection+
9 Data Penerbangan http://dioskurn.com/download/buku1/ch9
10 Data Transaksi Restoran http://dioskurn.com/download/buku1/ch10
12 GPS Tracking Data http://dioskurn.com/download/buku1/ch12

Referensi [1] Gartner Release “Global AI Business Value”,
https://www.gartner.com/en/newsroom/press-releases/2018-04-25-gartner-says-global-
artificial-intelligence-business-value-to-reach-1-point-2-trillion-in-2018
[2] DOMO Report “Data Never Sleeps” https://www.domo.com/news/press/data-never-sleeps-
7
[3] IDC Report https://www.seagate.com/id/id/our-story/data-age-2025/
[4] IBM Report https://www.forbes.com/sites/louiscolumbus/2017/05/13/ibm-predicts-
demand-for-data-scientists-will-soar-28-by-2020/#136df227e3bd
[5] Kaggle survey https://www.kaggle.com/sudhirnl7/data-science-survey-2018
[6] Tiobe Index 2019 https://www.tiobe.com/tiobe-index/
[7] Jumlah Neuron Otak Binatang
https://en.wikipedia.org/wiki/List_of_animals_by_number_of_neurons
[8] Robust Real-time Object Detection, Viola-Jones https://www.slideshare.net/wolf/avihu-
efrats-viola-and-jones-face-detection-slides/
[9] Fast Algorithms for Mining Association Rules, Rakesh Agrawal and Ramakrishnan Srikant
http://www.vldb.org/conf/1994/P487.PDF

Bibliografi
• Analytics in A Big Data World, Bart Baesens, John Wiley & Sons, ISBN:
9781118892718
• The Art of Statistics Learning from Data, David Spiegelhalter, Penguin Books, ISBN:
9780241258750
• Python for Data Analysis, Wes McKinney, O’Reilly Media Inc,
ISBN:9781491957660
• Python AI Projects for Beginners, Joshua Eckworth, Packt Publishing, ISBN:
9781789539462
• Introducing Python, Bill Lubanovic, O’Reilly Media Inc, ISBN: 9781449359362
• Big Data at Work, Thomas H. Davenport, Harvard Business Review Press, Global
Text ISBN: 9781422168165
• Data Mining for The Masses, Dr. Matthew North, Global Text Project, ISBN:
9780615684376
• Python Documentation, https://docs.python.org
• Scikit-learn Documentation, https://scikit-learn.org
• Pandas Documentation, https://pandas.pydata.org
• Dask Documentation, https://dask.org
• Apache Spark Documentation, https://spark.apache.org





























