Embed Size (px)
Citation preview

DAS PIPELINE-OPERATIONSPRINZIP
Patrick Quicker
29.07.2015
1

Gliederung
1) Motivation und Idee 2) Wie funktioniert Pipelining? 3) Analyse des Prinzips 4) Data Flow Dependencies 5) Control Flow Dependencies
2

1) Motivation und Idee
Beschleunigung von CPUs Mehr Instruktionen pro Zeit abarbeiten
⇒Wie?
3

1) Motivation und Idee 4
Henry Ford
Quelle: Wikipedia

1) Motivation und Idee
Übertragung des Fließbandprinzips auf Computer C. V. Ramamoorthy & H. F. Li
Maximale Ausnutzung der Recheneinheit Erhöhung des Durchsatzes
=> Minimierung von CPI
5

(Am Beispiel einer DLX Pipeline)
2) Wie funktioniert Pipelining?

2) Wie funktioniert Pipelining?
Ohne Pipeline: Instruktionen in einem Schritt ausgeführt
Mit Pipeline: Instruktionen werden aufgeteilt Teilschritte werden hintereinander ausgeführt
=> Mehrere Instruktionen gleichzeitig
7

2) Wie funktioniert Pipelining?
Annahmen für Pipelining: 1. Instruktion lässt sich aufteilen 2. Teilschritte dauern gleich lang 3. Instruktionen sind unabhängig von einander
4. Teilschritte dauern länger als Registerzugriff
8

2) Wie funktioniert Pipelining?
Pipeline-Stages für DLX: Instruction Fetch (IF) Instruction Decode (ID) Register-File-Read (RFR) Execution (EX) Write-Back (WB)
9
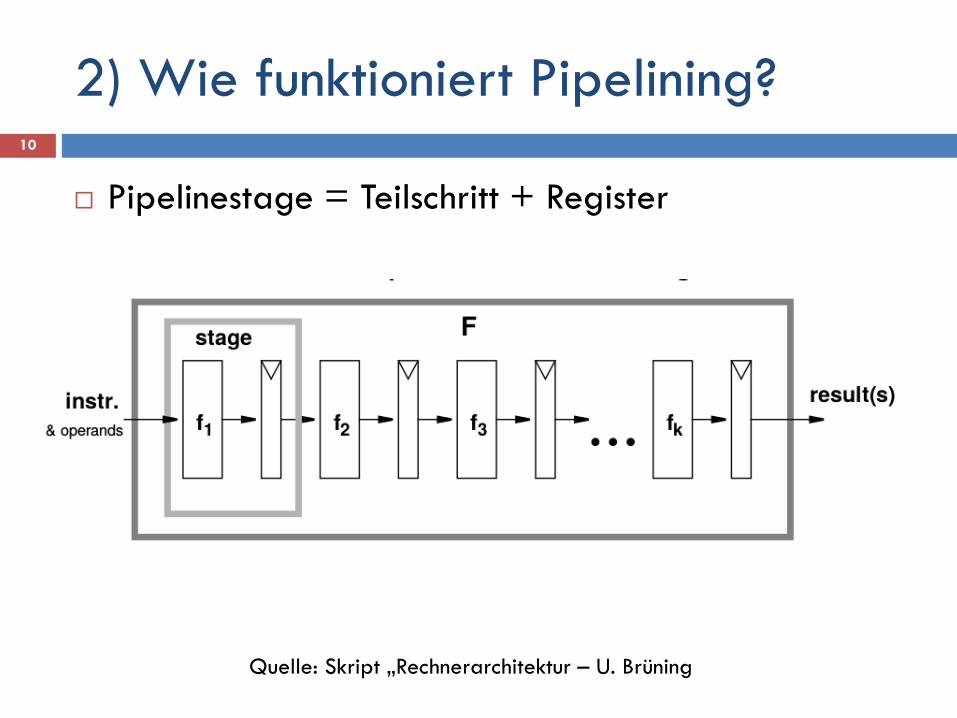
2) Wie funktioniert Pipelining?
Pipelinestage = Teilschritt + Register
10
Quelle: Skript „Rechnerarchitektur – U. Brüning
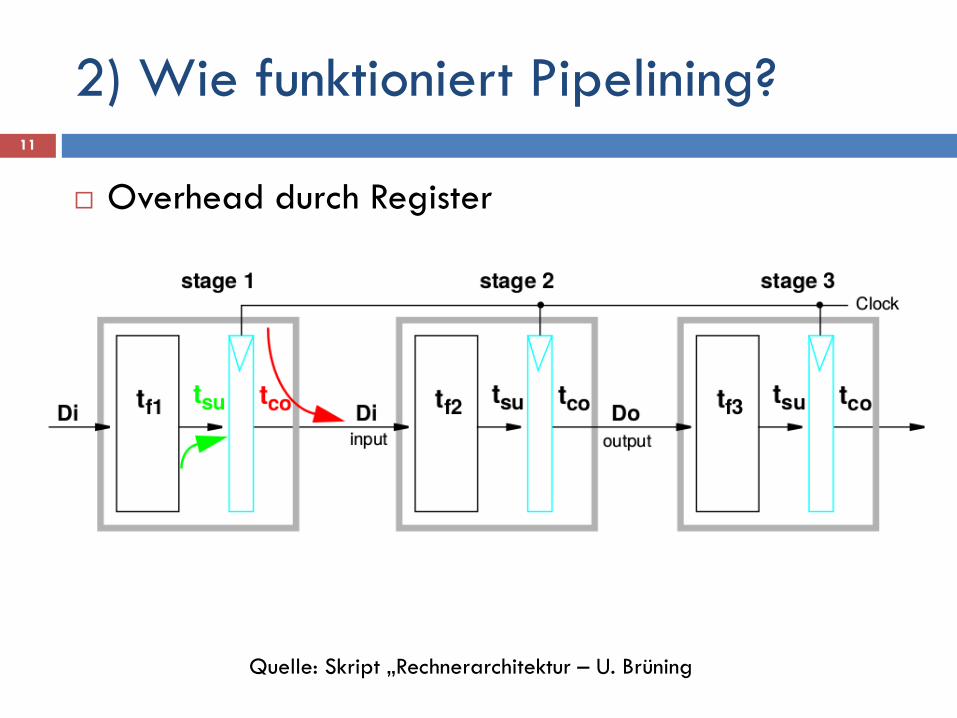
2) Wie funktioniert Pipelining? 11
Quelle: Skript „Rechnerarchitektur – U. Brüning
Overhead durch Register
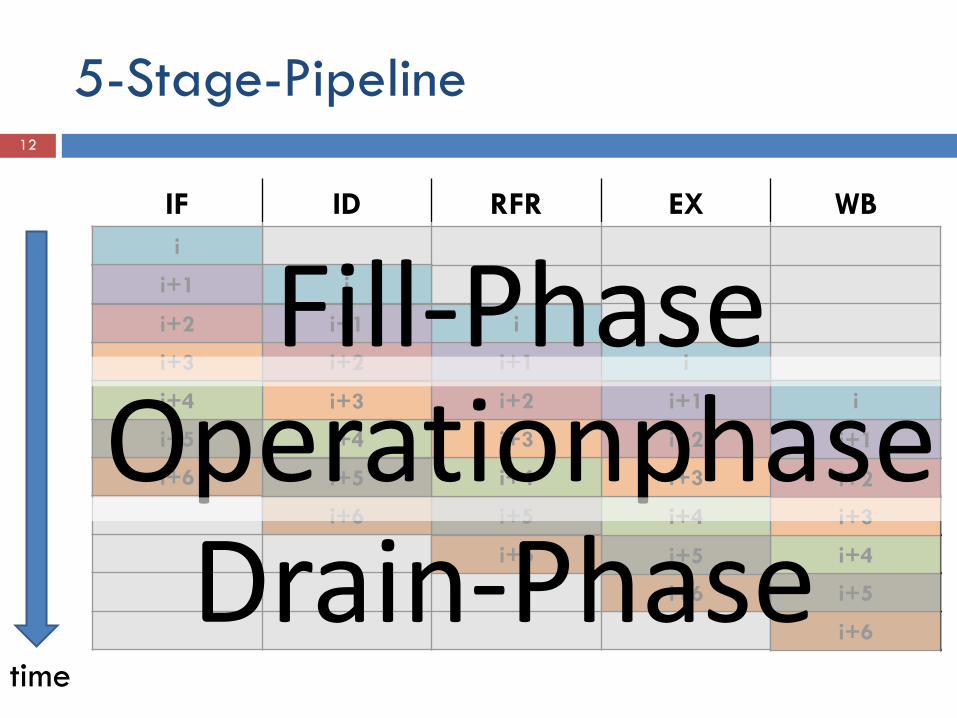
5-Stage-Pipeline
IF ID RFR EX WB
time i+6
i+5 i+6
i+4 i+5 i+6
i+3 i+4 i+5 i+6
i+2 i+3 i+4 i+5 i+6
i+1 i+2 i+3 i+4 i+5
i i+1 i+2 i+3 i+4
i i+1 i+2 i+3
i i+2 i+1
i i+1
i
12
Fill-Phase Operationphase
Drain-Phase
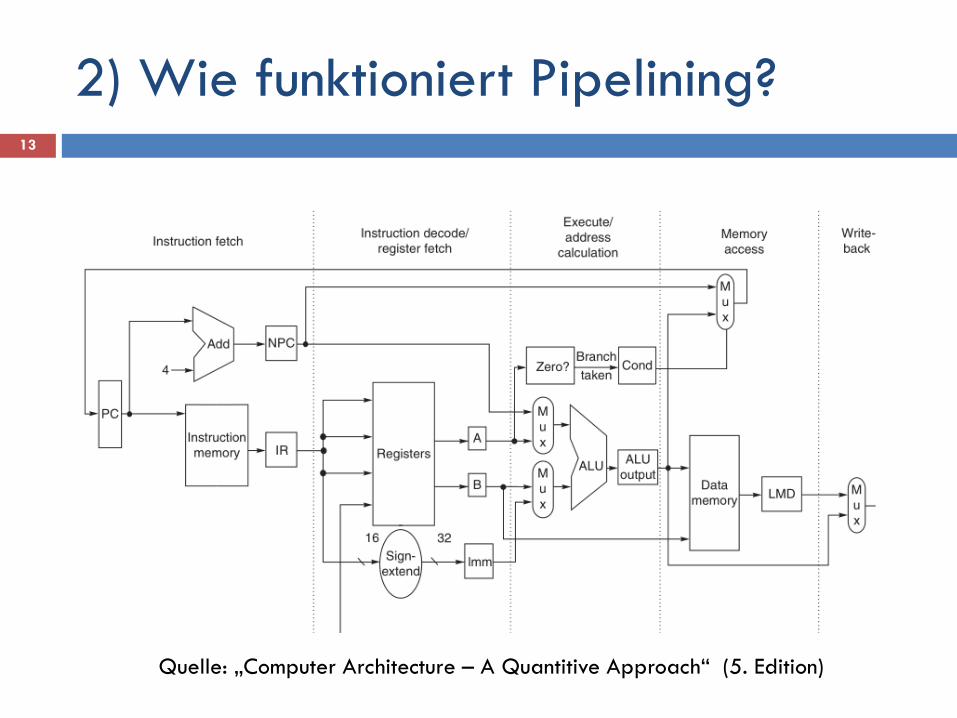
2) Wie funktioniert Pipelining? 13
Quelle: „Computer Architecture – A Quantitive Approach“ (5. Edition)

3) Analyse des Prinzips

3) Analyse des Prinzips 15
Alle Teile der CPU ausgenutzt Fertige Instruktionen pro Takt gleich.. .. Aber höhere Taktfrequenz Troughput größer d.h. mehr fertige Instruktionen pro Zeit ..theoretisch k-mal besser

3) Analyse des Prinzips 16
Bearbeitungszeit: t(n,k) = k + (n-1) Troughput:
TP(n,k) = 𝑛𝑡(𝑛,𝑘)
= 𝑛𝑘+(𝑛−1)

3) Analyse des Prinzips 17
Gewinn:
G(n,k) = 𝑍𝑍𝑍𝑡 𝑛𝑍𝑛𝑛𝑡 𝑔𝑍𝑔𝑍𝑔𝑍𝑔𝑍𝑛𝑍𝑔𝑍𝑍𝑍𝑡 𝑔𝑍𝑔𝑍𝑔𝑍𝑔𝑍𝑛𝑍𝑔
= 𝑛∗𝑘𝑘+(𝑛−1)
lim𝑛→∞
𝑆 → 𝑘
Je mehr Stages desto besser?

3) Analyse des Prinzips 18
Effizienz sinkt Latenz der Instruktionen steigt Initialisierung der Pipeline dauert Unterschiedliche Instruktionen
Je kleiner die Teilschritte, desto höher die Taktfrequenz
Taktfrequenz hängt vom längsten Teilschritt ab

3) Analyse des Prinzips
Annahmen für Pipelining: 1. Instruktion lässt sich aufteilen 2. Teilschritte dauern gleich lang 3. Instruktionen sind unabhängig von einander
4. Teilschritte dauern länger als Registerzugriff
19

3) Analyse des Prinzips 20
Ziel des Pipelinedesigns: Balancieren der Länge von Pipelinestages Balancieren der Anzahl von Pipelinestages

4) Data Flow Dependencies

4) Data Flow Dependencies 22
Instruktionen können abhängig von einander sein: Beispiel: i+1: Y ← A + B i+2: X ← Y + C => i+2 muss auf i+1 warten

4) Data Flow Dependencies
IF ID RFR EX WB
i+2
time
i+3
i+2 i+3
i+1 i+2 i+3
i i+1 i+2 i+3
i i+1 i+2 i+3
i i+2 i+1
i i+1
i
23

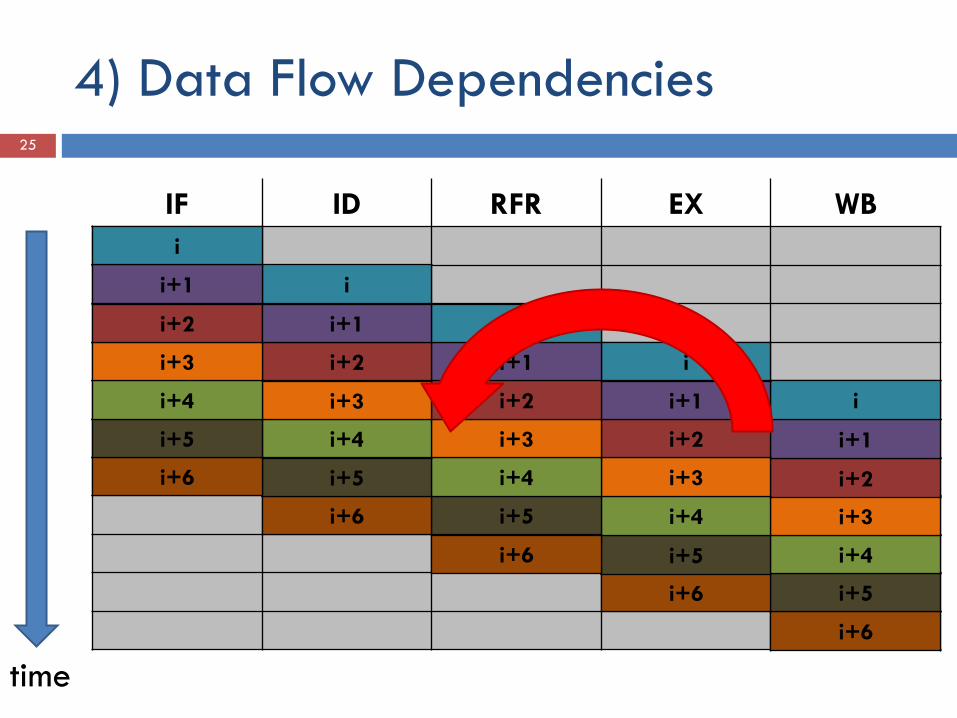
4) Data Flow Dependencies 24
Read after write (RAW) Einfügen von Bubbles durch:
Hardware interlocks Compiler
=> Verzögerung Lösung:
Forwarding Compiler ordnet Instruktionen
4) Data Flow Dependencies
IF ID RFR EX WB
time i+6
i+5 i+6
i+4 i+5 i+6
i+3 i+4 i+5 i+6
i+2 i+3 i+4 i+5 i+6
i+1 i+2 i+3 i+4 i+5
i i+1 i+2 i+3 i+4
i i+1 i+2 i+3
i i+2 i+1
i i+1
i
25
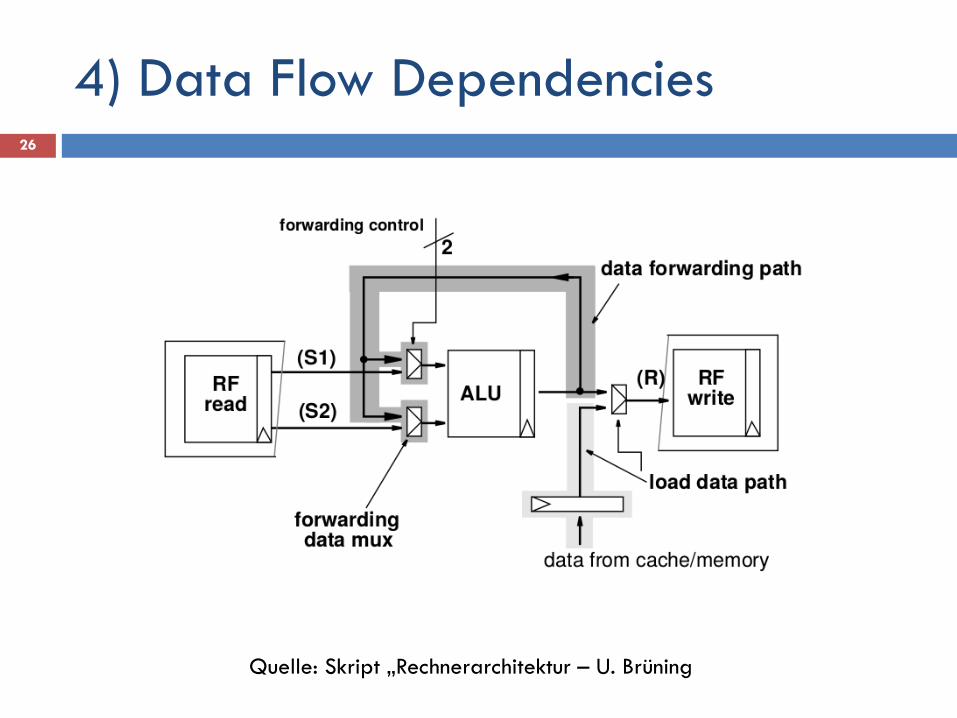
4) Data Flow Dependencies 26
Quelle: Skript „Rechnerarchitektur – U. Brüning

4) Data Flow Dependencies 27
Write after write (WAW):
i: Y ← A / B i+1: Y ← C + D i+1 schreibt früher, weil schneller Auftreten, wenn Schreiben in mehreren Stages möglich
ist

4) Data Flow Dependencies 28
Write after read (WAR):
i: X ← Y + B i+1: Y ← A + C Wichtig, wenn Compiler Reihenfolge der Ins. ändert Irrelevant bei sequentieller Abfolge

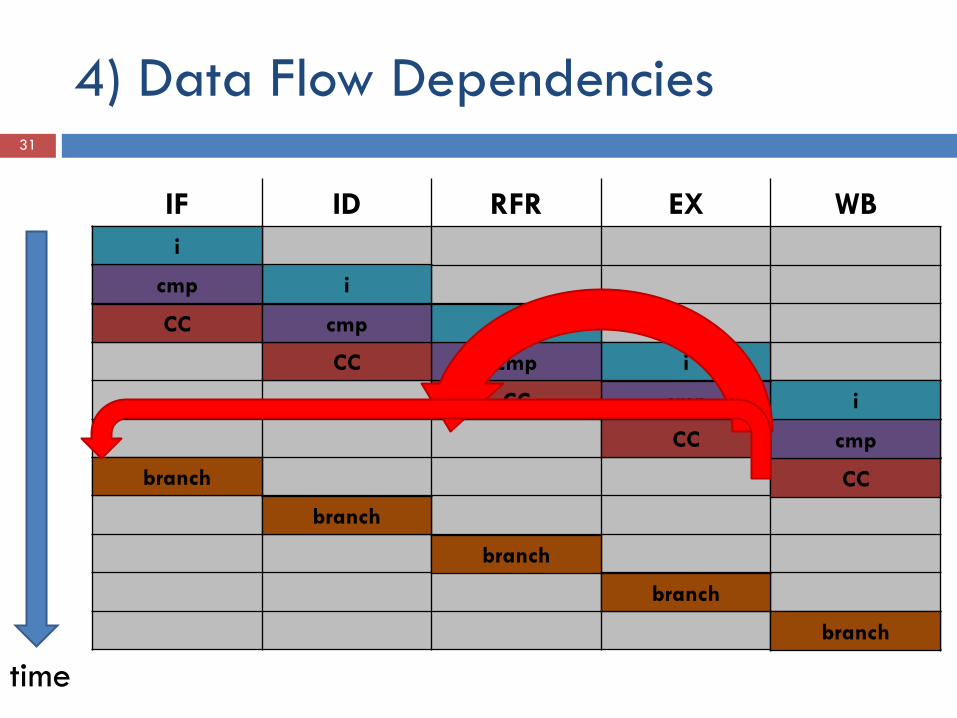
5) Control Flow Dependencies

5) Control Flow Dependencies 30
Bedingte Verzweigung (if-Abfrage) Jumpinstruction Jump to subroutine Return from subroutine
4) Data Flow Dependencies
IF ID RFR EX WB
time branch
branch
branch
branch
CC branch
cmp CC
i cmp CC
i cmp CC
i CC cmp
i cmp
i
31
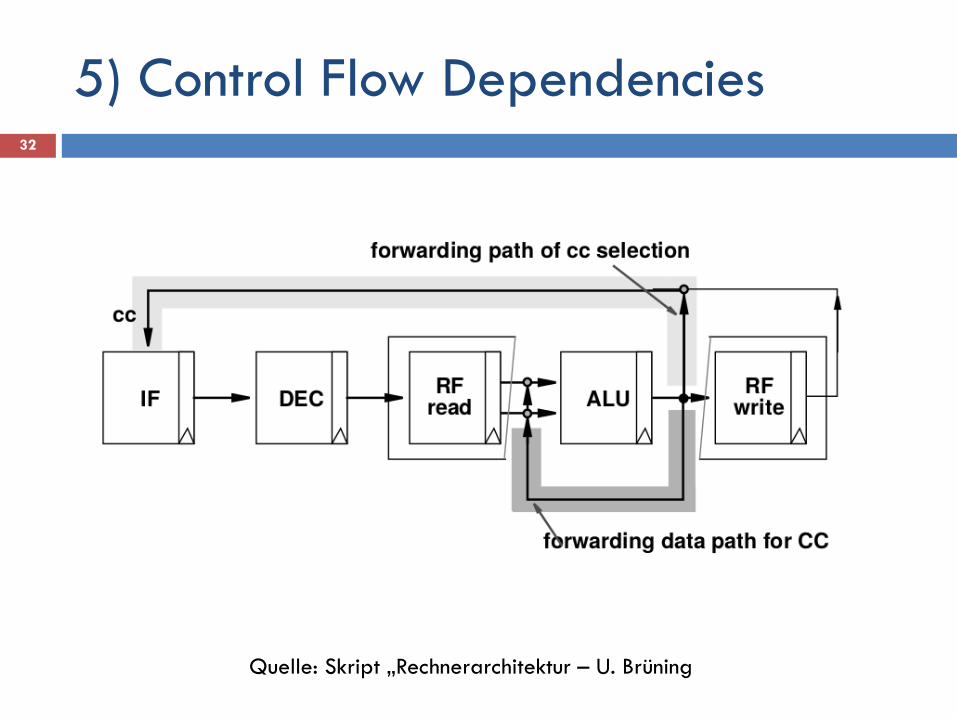
5) Control Flow Dependencies 32
Quelle: Skript „Rechnerarchitektur – U. Brüning
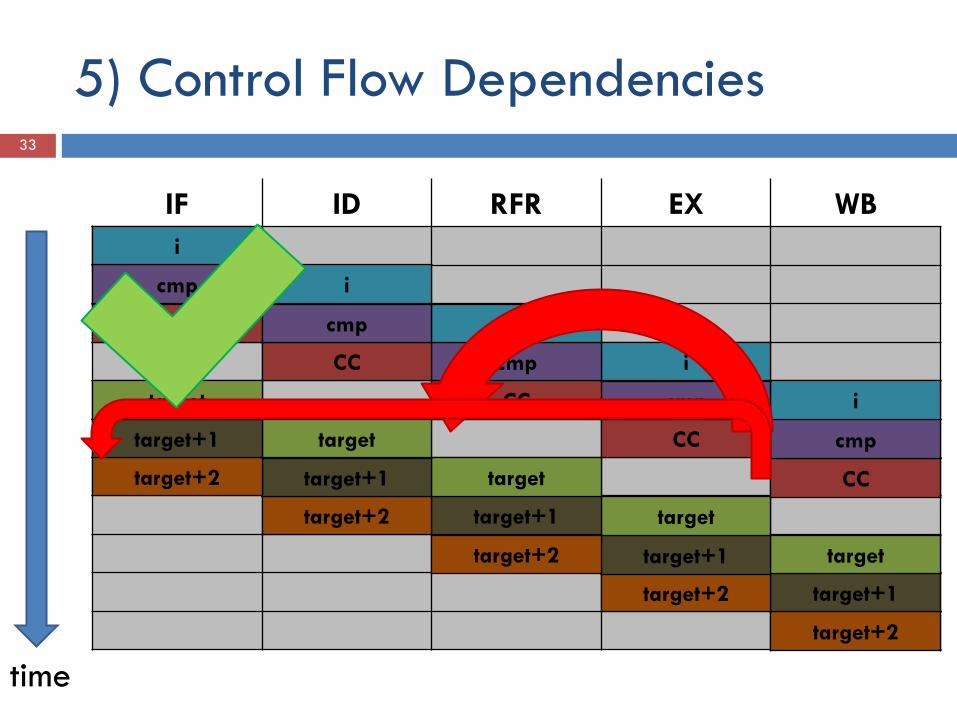
5) Control Flow Dependencies
IF ID RFR EX WB
time target+2
target+1 target+2
target target+1 target+2
target target+1 target+2
CC target target+1 target+2
cmp CC target target+1
i cmp CC target
i cmp CC
i CC cmp
i cmp
i
33
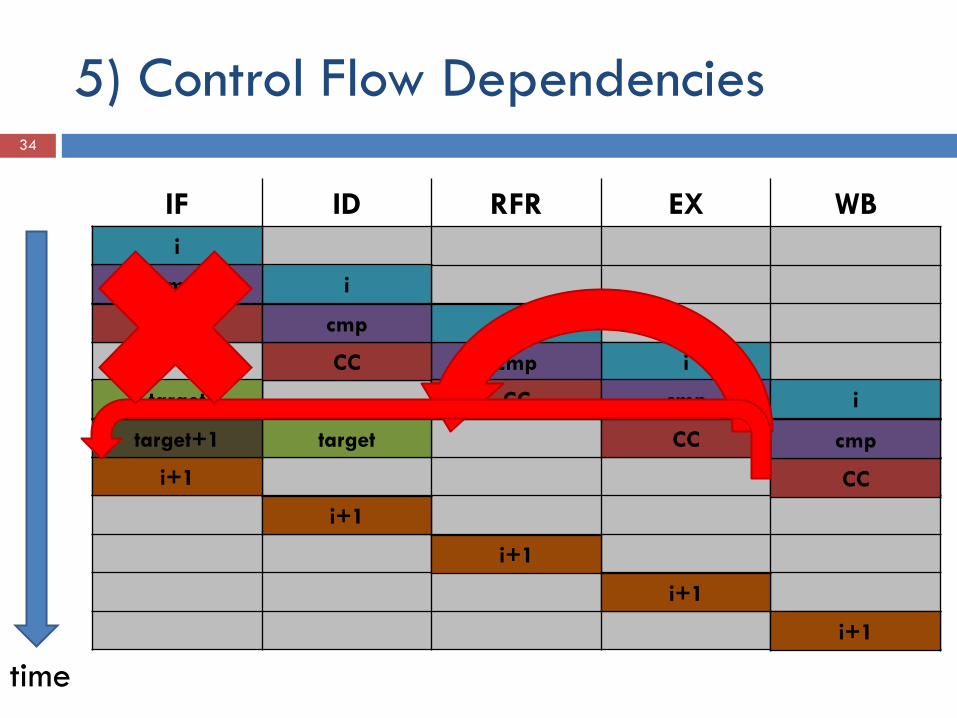
5) Control Flow Dependencies
IF ID RFR EX WB
time i+1
i+1
i+1
i+1
CC i+1
cmp CC target target+1
i cmp CC target
i cmp CC
i CC cmp
i cmp
i
target CC cmp i
34

Zusammenfassung 35
Pipelining… …ermöglicht maximale Ausnutzung der Ressourcen …beschleunigt den Prozess …ist komplizierter als gedacht …erhöht Hardwareaufwand …wird heute standartmäßig in Rechnern genutzt

Quellen 36
„Computer Architecture – A Quantitive Approach“ (2. Edition) John L. Hennessy & David A. Patterson [1996]
„Pipeline Architecture“ C. V. Ramamoorthy & H. F. Li [1977]
Skript „Rechnerarchitektur“ U. Brüning
Wikipedia





























