Embed Size (px)
Citation preview

Carsten Herbe
DOAG Konferenz – November 2014
Data Mart Offload nach Hadoop
Star Schema in HDFS anstatt RDBMS

©
Wir fokussieren mit unseren Services die Herausforderungen des Marktes und verbinden
Mensch und IT.
11.11.2014 Data Mart Offload nach Hadoop Seite 2
Über metafinanz
metafinanz gehört seit fast 25 Jahren zu den
erfahrensten Software- und Beratungshäusern mit
Fokus auf die Versicherungsbranche.
Mit einem Jahresumsatz von 270 Mio. EUR und über
450 Mitarbeitern entwickeln wir für unsere Kunden
intelligente zukunftsorientierte Lösungen für
komplexe Herausforderungen
Business Intelligence
Insurance
Reporting
Standard & Adhoc
Reporting
Dashboarding
BI Office Integration
Mobile BI & In-memory
SAS Trainings for
Business Analysts
Analytics
Predictive Models,
Data Mining
& Statistics
Social Media
Analytics
Customer Intelligence
Scorecarding
Fraud & AML
Risk
Solvency II
(Standard & internal
Model)
Regulatory Reporting
Compliance
Risk Management
Enterprise DWH
Data Modeling &
Integration & ETL
Architecture: DWH
& Data Marts
Hadoop & Columnar
DBs
Data Quality &
Data Masking
Themenbereiche
BI & Risk
Ihr Kontakt : Carsten Herbe
Head of Data Warehousing
Mehr als 10 Jahre DWH-Erfahrung
Oracle & OWB Expertise
Certified Hadoop Developer
mail [email protected]
phone +49 89 360531 5039

©
Agenda
1
Schema Design 4
Motivation
2 Exkurs Hadoop
3 Architektur
5 Hive Metadaten & SQL Engine
11.11.2014 Seite 3
6
Fazit 9
Anbindung BI Tool
7 Offload Prozess
8 Performance-Analyse
Data Mart Offload nach Hadoop

©
1. Motivation
©
Platzt Ihr DWH aus
allen Nähten?
11.11.2014 Seite 5 Data Mart Offload nach Hadoop

©
Warten Ihre
BI-Nutzer ewig?
Data Mart Offload nach Hadoop 11.11.2014 Seite 6

©
Obwohl Sie im DWH
alles richtig gemacht
haben?
11.11.2014 Seite 7 Data Mart Offload nach Hadoop

©
Sie suchen dringend
eine Lösung die dem
Kostendruck
standhält?
11.11.2014 Seite 8 Data Mart Offload nach Hadoop

©
2. Exkurs Hadoop
©
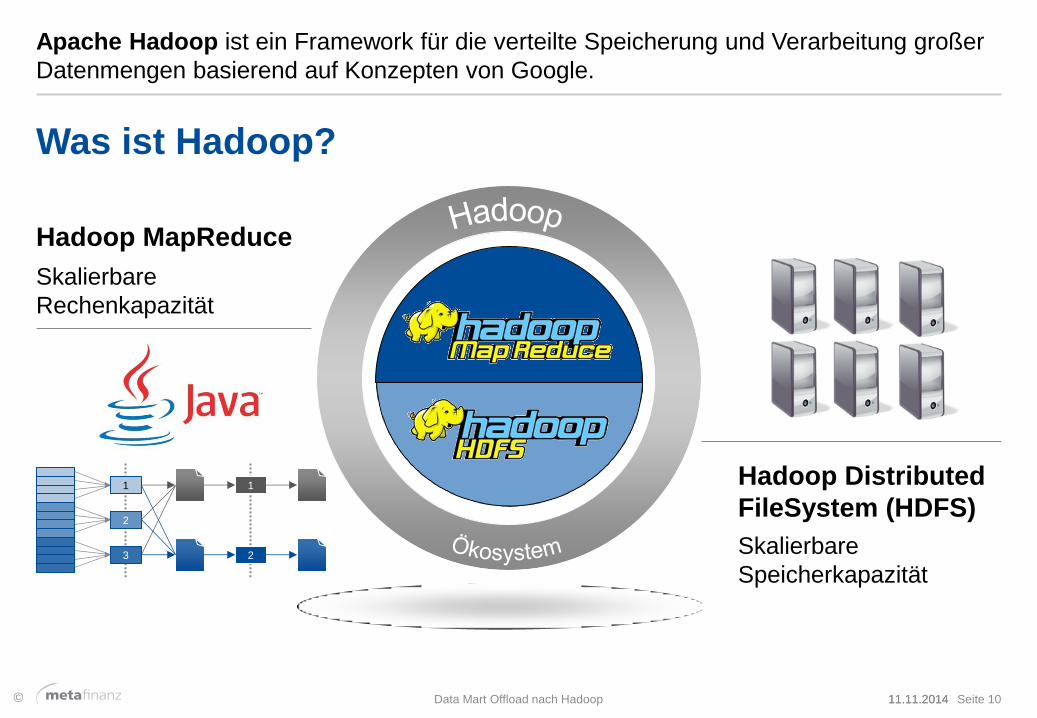
Apache Hadoop ist ein Framework für die verteilte Speicherung und Verarbeitung großer
Datenmengen basierend auf Konzepten von Google.
Data Mart Offload nach Hadoop Seite 10 11.11.2014
Hadoop Distributed
FileSystem (HDFS)
Skalierbare
Speicherkapazität
Skalierbare
Rechenkapazität
Hadoop MapReduce
1
2
1
2
3
Was ist Hadoop?
11.11.2014

©
Das Hadoop-Ökosystem besteht aus einer Vielzahl von Tools und Frameworks und wird
ständig durch neue Projekte erweitert.
11.11.2014 Data Mart Offload nach Hadoop Seite 11
HttpFS
Cascalog
FuseDFS
SequenceFiles Big Data Connectors
Big SQL
Crunch
Kafaka
Oryx
ORCFiles
©
Hadoop
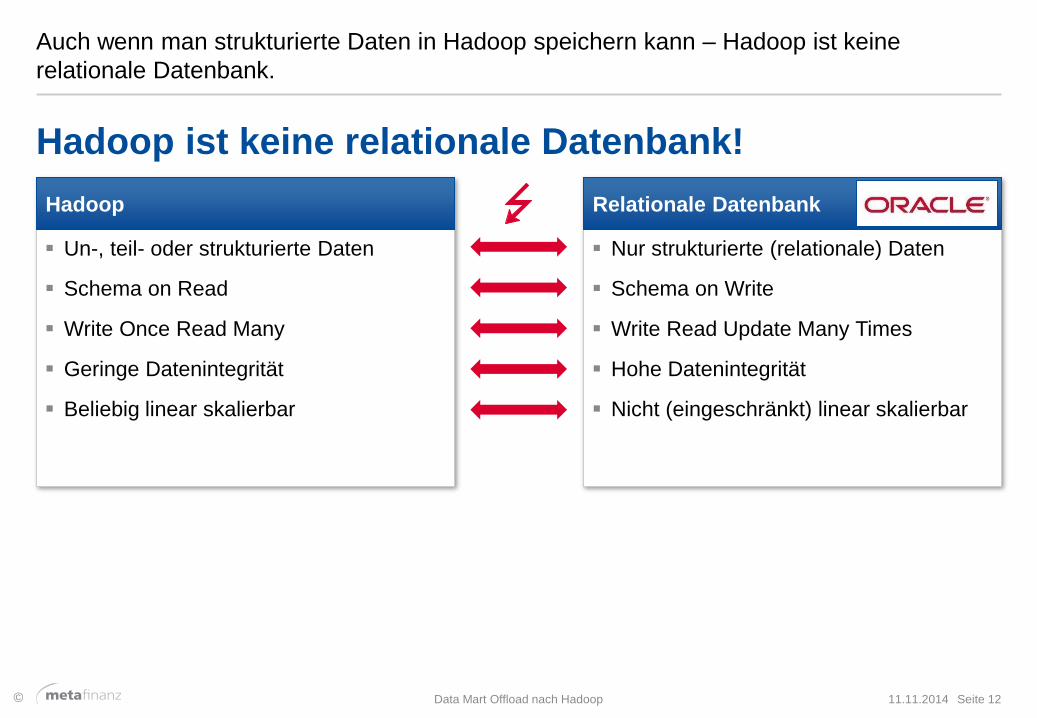
Un-, teil- oder strukturierte Daten
Schema on Read
Write Once Read Many
Geringe Datenintegrität
Beliebig linear skalierbar
Auch wenn man strukturierte Daten in Hadoop speichern kann – Hadoop ist keine
relationale Datenbank.
11.11.2014 Data Mart Offload nach Hadoop Seite 12
Hadoop ist keine relationale Datenbank!
Relationale Datenbank
Nur strukturierte (relationale) Daten
Schema on Write
Write Read Update Many Times
Hohe Datenintegrität
Nicht (eingeschränkt) linear skalierbar

©
3. Architektur
©
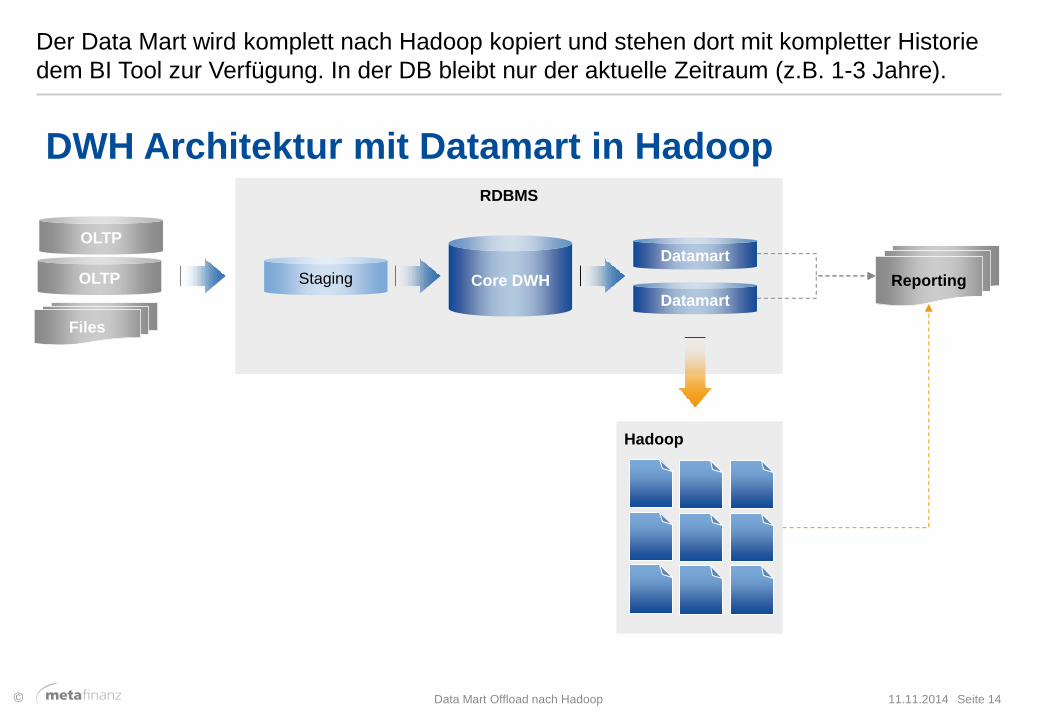
RDBMS
Der Data Mart wird komplett nach Hadoop kopiert und stehen dort mit kompletter Historie
dem BI Tool zur Verfügung. In der DB bleibt nur der aktuelle Zeitraum (z.B. 1-3 Jahre).
11.11.2014 Data Mart Offload nach Hadoop Seite 14
OLTP
Core DWH
DWH Architektur mit Datamart in Hadoop
Datamart
Datamart
Staging
Files
Reporting OLTP
Hadoop

©
Anbindung BI Tool
Bereitstellung Metadaten (Tabellen, Spalten, …)
Auswahl Hadoop SQL Engine (Hive, Impala, …)
Anbindung Hadoop als Datenquelle an das BI Tool
Hadoop Infrastruktur
Aufbau Hadoop Cluster
Konfiguration SQL Engine/Security
Backup
Aufbau Betrieb
Design, Prozesse und Anbindung an das BI Tool werden in diesem Vortrag beschrieben.
Eine Beschreibung des Aufbaus einer Hadoop Infrastruktur würde den Rahmen sprengen.
11.11.2014 Data Mart Offload nach Hadoop Seite 15
Was ist zu tun?
Schema Design in HDFS
Logisches Daten/Datei-Modell
Partitionierung (für ETL und Abfragen)
Physikalische Speicherung (File Format, Komprimierung)
Offload Prozess
Hinzufügen/„Replacement“ bestehender Daten
Einbindung ETL Prozess
Verfügbarkeit für das Reporting
©
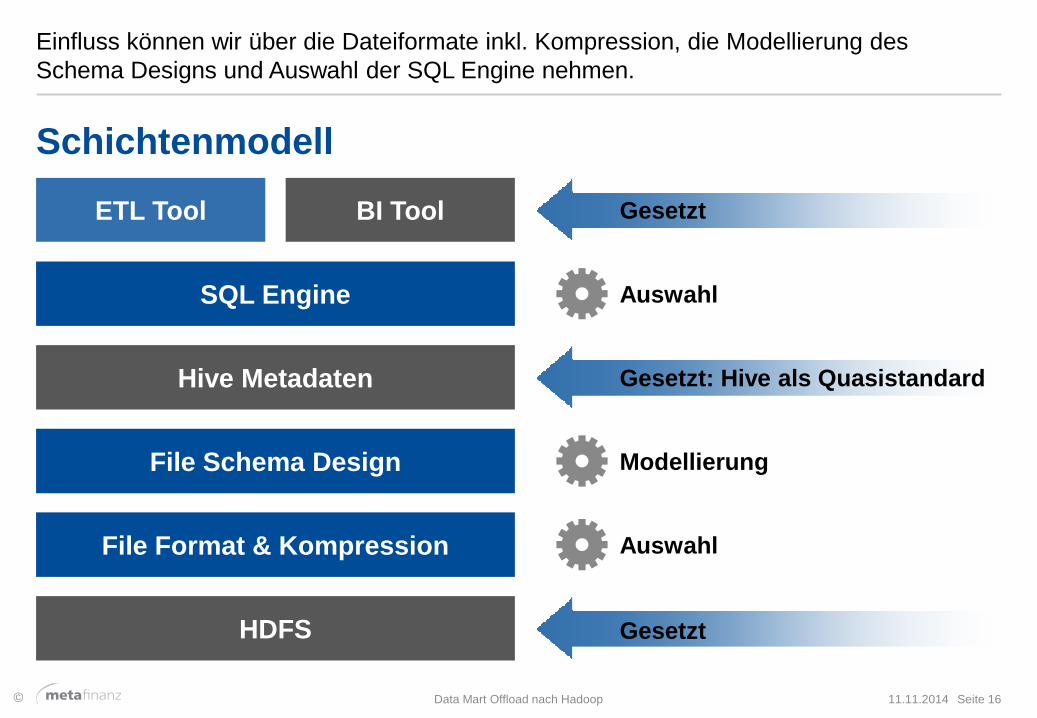
Einfluss können wir über die Dateiformate inkl. Kompression, die Modellierung des
Schema Designs und Auswahl der SQL Engine nehmen.
11.11.2014 Data Mart Offload nach Hadoop Seite 16
Schichtenmodell
Gesetzt HDFS
Gesetzt: Hive als Quasistandard Hive Metadaten
Gesetzt BI Tool ETL Tool
Auswahl SQL Engine
Modellierung File Schema Design
Auswahl File Format & Kompression

©
4. Schema Design
HDFS
File Format & Kompression
File Schema Design
Hive Metadaten
SQL Engine
BI Tool ETL Tool
©
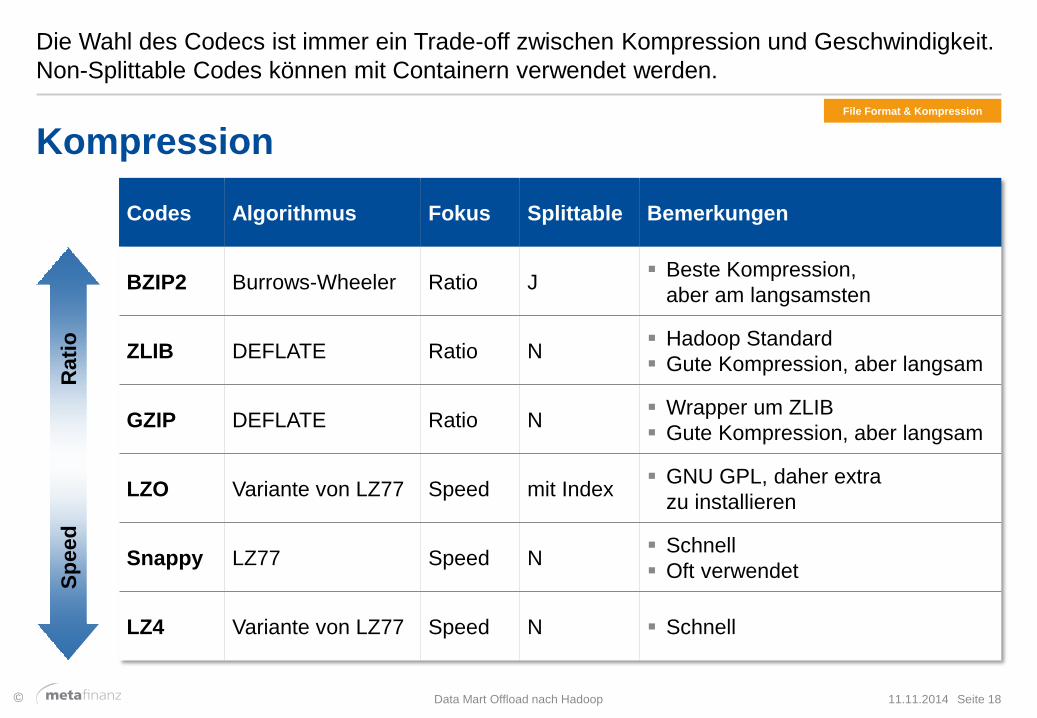
Die Wahl des Codecs ist immer ein Trade-off zwischen Kompression und Geschwindigkeit.
Non-Splittable Codes können mit Containern verwendet werden.
11.11.2014 Data Mart Offload nach Hadoop Seite 18
Kompression
Codes Algorithmus Fokus Splittable Bemerkungen
BZIP2 Burrows-Wheeler Ratio J Beste Kompression,
aber am langsamsten
ZLIB DEFLATE Ratio N Hadoop Standard
Gute Kompression, aber langsam
GZIP DEFLATE Ratio N Wrapper um ZLIB
Gute Kompression, aber langsam
LZO Variante von LZ77 Speed mit Index GNU GPL, daher extra
zu installieren
Snappy LZ77 Speed N Schnell
Oft verwendet
LZ4 Variante von LZ77 Speed N Schnell
Rati
o
Sp
eed
File Format & Kompression

©
Dateiformate beinhalten teilweise selbstbeschreibende Metadaten und sind auch
komprimiert splittable. Die Toolunterstützung ist aber unterschiedlich.
11.11.2014 Data Mart Offload nach Hadoop Seite 19
Dateiformate
Zeilenorientiert
Textformat
(TSV/CSV)
Sequence Files
AVRO
…
Spaltenorientiert
RCFile
(row columnar)
ORC
(optimized row columnar)
Parquet
File Format & Kompression

©
Beim Schema Design in HDFS kann man das Star Schema übernehmen oder es in ein
denormalisiertes Result Set transformieren.
11.11.2014 Data Mart Offload nach Hadoop Seite 20
Schema Design: Star Schema vs Result Set
Einfach umsetzbar Performance-orientiert
Star Schema
1:1 Übernahme des relationalen
Datenmodells aus der DB.
Keine Anpassung der Zugriffsschicht
im BI Tool.
Viele Joins bei Abfragen.
Kleine Dimensionen kleine Dateien.
Result Set
Transformation notwendig:
Denormalisierung des Star Schemas.
Anpassung der Zugriffsschicht im BI Tool.
Keine Joins bei Abfragen.
Höherer Speicherbedarf.
File Schema Design

©
Die Partitionierung muss ein einfaches Aktualisieren („Replacement“) neuer Daten
ermöglichen und idealerweise für eine gute Abfrageperformance sorgen.
11.11.2014 Data Mart Offload nach Hadoop Seite 21
Partitionierung: Laden & Abfragen
Fakten
Partitionierung nach (fachlichen) Zeitscheiben
Beim Load:
Aktuelle Partition löschen & neu laden (Korrekturen)
Oder anhängen der neuen Daten (keine Korrekturen)
Dimensionen Partitionierung nach fachlichen Kriterien (z.B. Mandant)
Beim Load: i.d.R. Komplett-Load
Partitions-/Datei-Größen beachten:
Nicht zu klein im Vergleich zur HDFS-Blockgröße (128 MB)!
Load Frequenz nach Use Case (e.g. Historische Daten)
File Schema Design
©
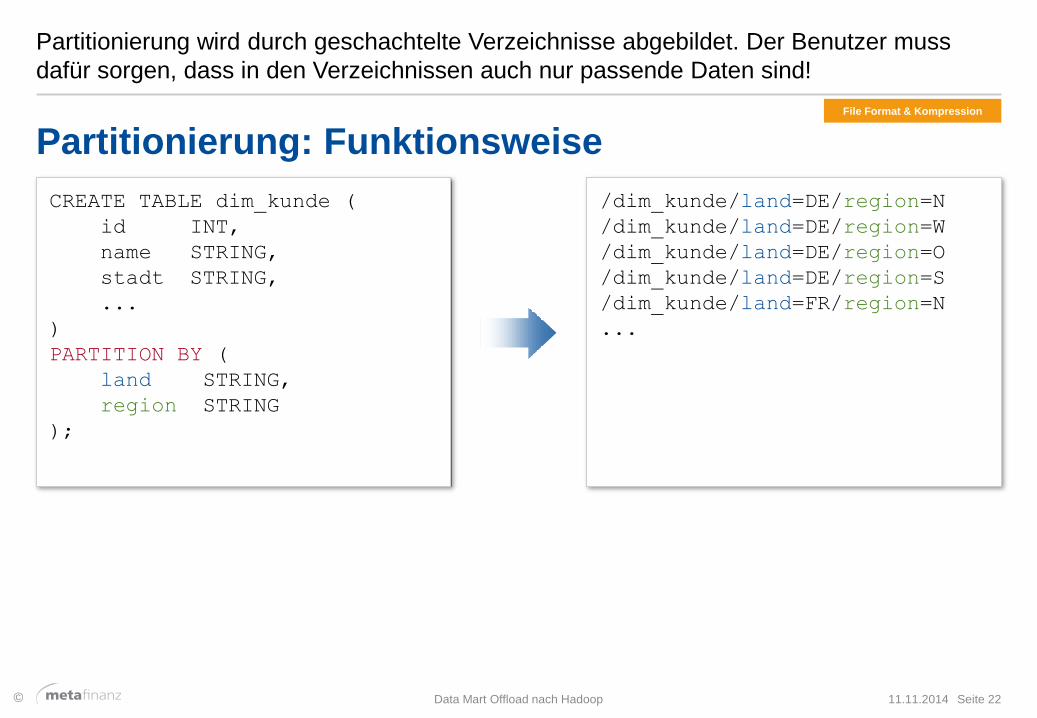
Partitionierung wird durch geschachtelte Verzeichnisse abgebildet. Der Benutzer muss
dafür sorgen, dass in den Verzeichnissen auch nur passende Daten sind!
11.11.2014 Data Mart Offload nach Hadoop Seite 22
Partitionierung: Funktionsweise
CREATE TABLE dim_kunde (
id INT,
name STRING,
stadt STRING,
...
)
PARTITION BY (
land STRING,
region STRING
);
/dim_kunde/land=DE/region=N
/dim_kunde/land=DE/region=W
/dim_kunde/land=DE/region=O
/dim_kunde/land=DE/region=S
/dim_kunde/land=FR/region=N
...
File Format & Kompression

©
5. Hive Metadaten & SQL Engine
HDFS
File Format & Kompression
File Schema Design
Hive Metadaten
SQL Engine
BI Tool ETL Tool
©
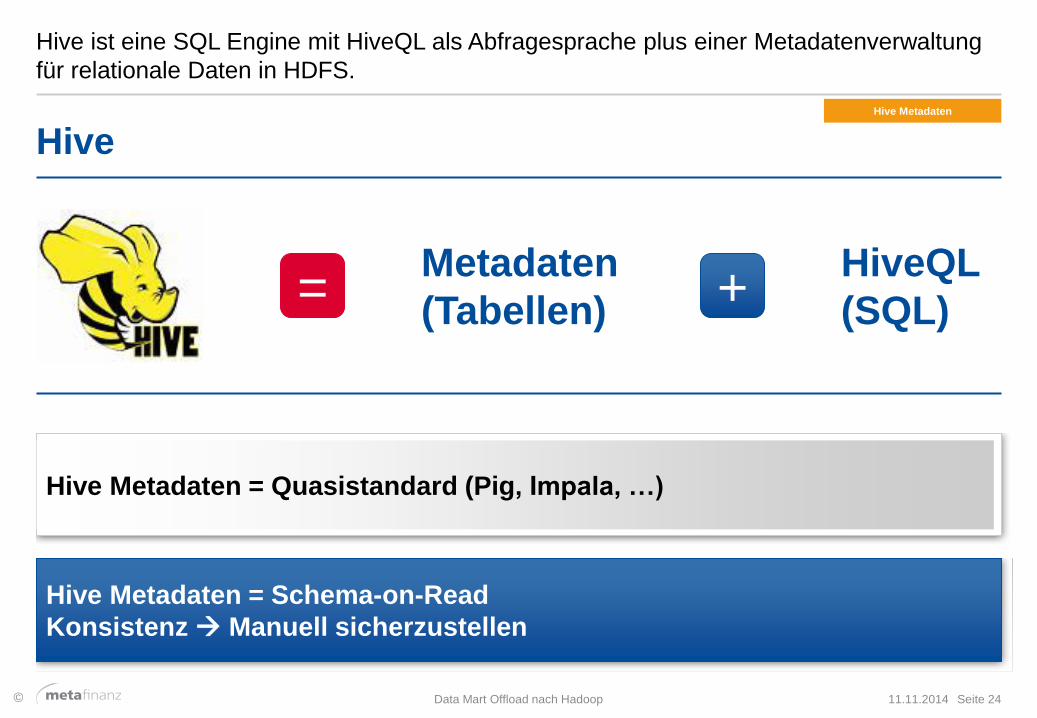
Hive ist eine SQL Engine mit HiveQL als Abfragesprache plus einer Metadatenverwaltung
für relationale Daten in HDFS.
11.11.2014 Data Mart Offload nach Hadoop Seite 24
Hive
Metadaten
(Tabellen)
Hive Metadaten = Schema-on-Read
Konsistenz Manuell sicherzustellen
Hive Metadaten = Quasistandard (Pig, Impala, …)
= HiveQL
(SQL) +
Hive Metadaten

©
Metadaten können für bestehende Dateien definiert werden. INSERT und SELECT
funktionieren wie gewohnt, UPDATE und DELETE gibt es nicht.
11.11.2014 Data Mart Offload nach Hadoop Seite 25
Hive Beispiele
CREATE TABLE dim_kunde (
id INT,
name STRING,
stadt STRING,
alter INT,
...
)
PARTITION BY (
land STRING,
region STRING
);
INSERT INTO TABLE dim_kunde
SELECT ... FROM stg_kunde;
SELECT
region,
avg(alter)
FROM dim_kunde
WHERE land = ‘DE’
GROUP BY region
;
SQL Engine
©
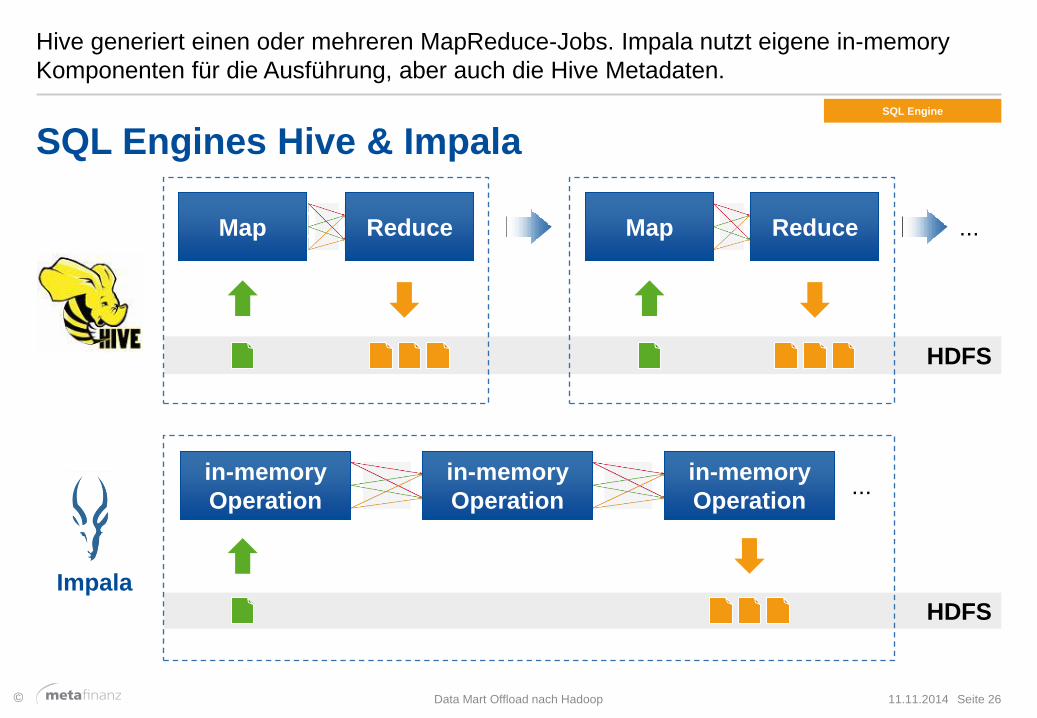
Hive generiert einen oder mehreren MapReduce-Jobs. Impala nutzt eigene in-memory
Komponenten für die Ausführung, aber auch die Hive Metadaten.
11.11.2014 Data Mart Offload nach Hadoop Seite 26
SQL Engines Hive & Impala
HDFS
Map Reduce ... Map Reduce
HDFS
...
Impala
in-memory
Operation
in-memory
Operation
in-memory
Operation
SQL Engine
©
6. Anbindung BI Tool
HDFS
File Format & Kompression
File Schema Design
Hive Metadaten
SQL Engine
BI Tool ETL Tool
©
BI Tool
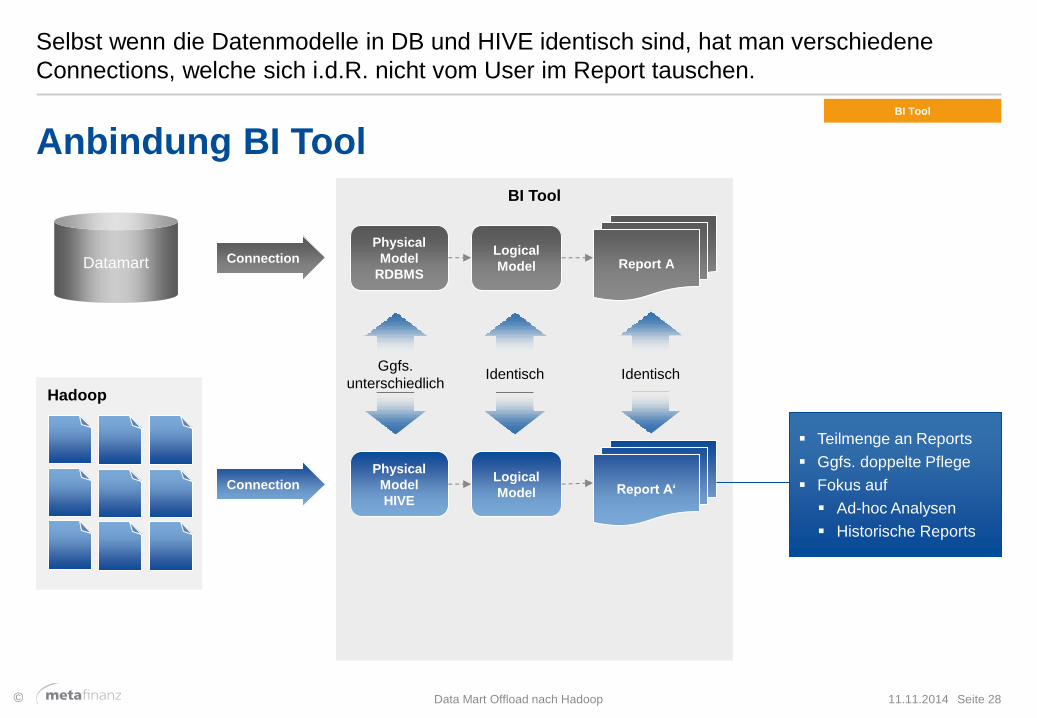
Selbst wenn die Datenmodelle in DB und HIVE identisch sind, hat man verschiedene
Connections, welche sich i.d.R. nicht vom User im Report tauschen.
11.11.2014 Data Mart Offload nach Hadoop Seite 28
Anbindung BI Tool
Datamart Connection Report A Logical
Model
Physical
Model
RDBMS
Teilmenge an Reports
Ggfs. doppelte Pflege
Fokus auf
Ad-hoc Analysen
Historische Reports
Hadoop
Connection Report A‘ Logical
Model
Physical
Model
HIVE
Ggfs.
unterschiedlich Identisch Identisch
BI Tool

©
7. Offload Prozess
HDFS
File Format & Kompression
File Schema Design
Hive Metadaten
SQL Engine
BI Tool ETL Tool
©
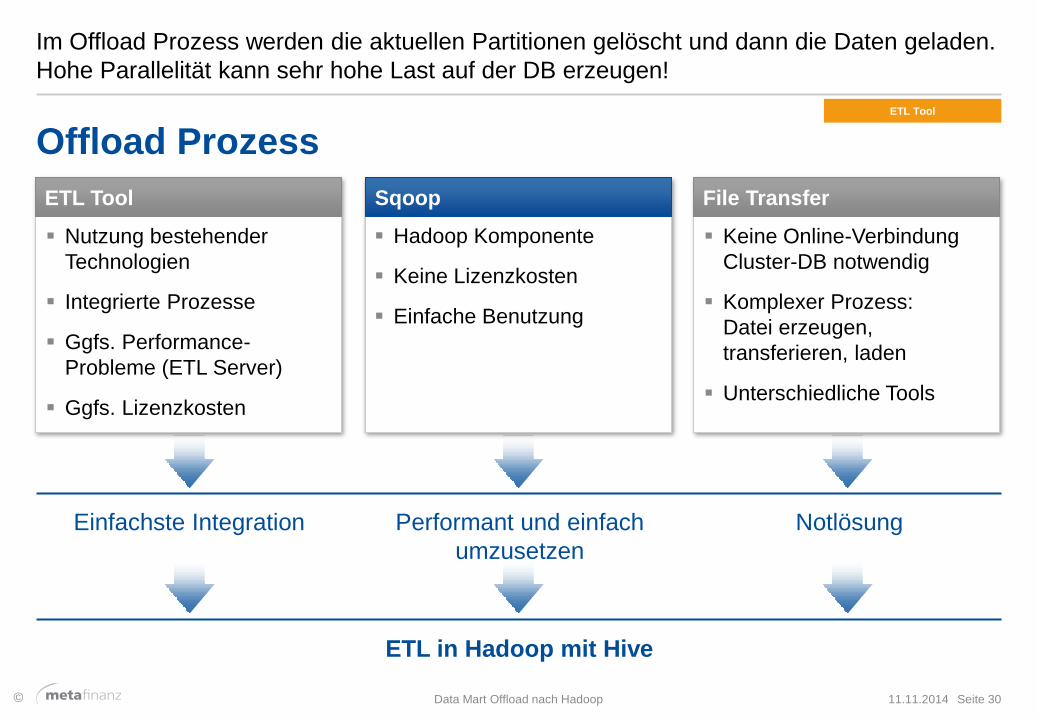
Im Offload Prozess werden die aktuellen Partitionen gelöscht und dann die Daten geladen.
Hohe Parallelität kann sehr hohe Last auf der DB erzeugen!
11.11.2014 Data Mart Offload nach Hadoop Seite 30
Offload Prozess
Sqoop
Hadoop Komponente
Keine Lizenzkosten
Einfache Benutzung
File Transfer
Keine Online-Verbindung
Cluster-DB notwendig
Komplexer Prozess:
Datei erzeugen,
transferieren, laden
Unterschiedliche Tools
ETL Tool
Nutzung bestehender
Technologien
Integrierte Prozesse
Ggfs. Performance-
Probleme (ETL Server)
Ggfs. Lizenzkosten
ETL in Hadoop mit Hive
Einfachste Integration Performant und einfach
umzusetzen
Notlösung
ETL Tool
©
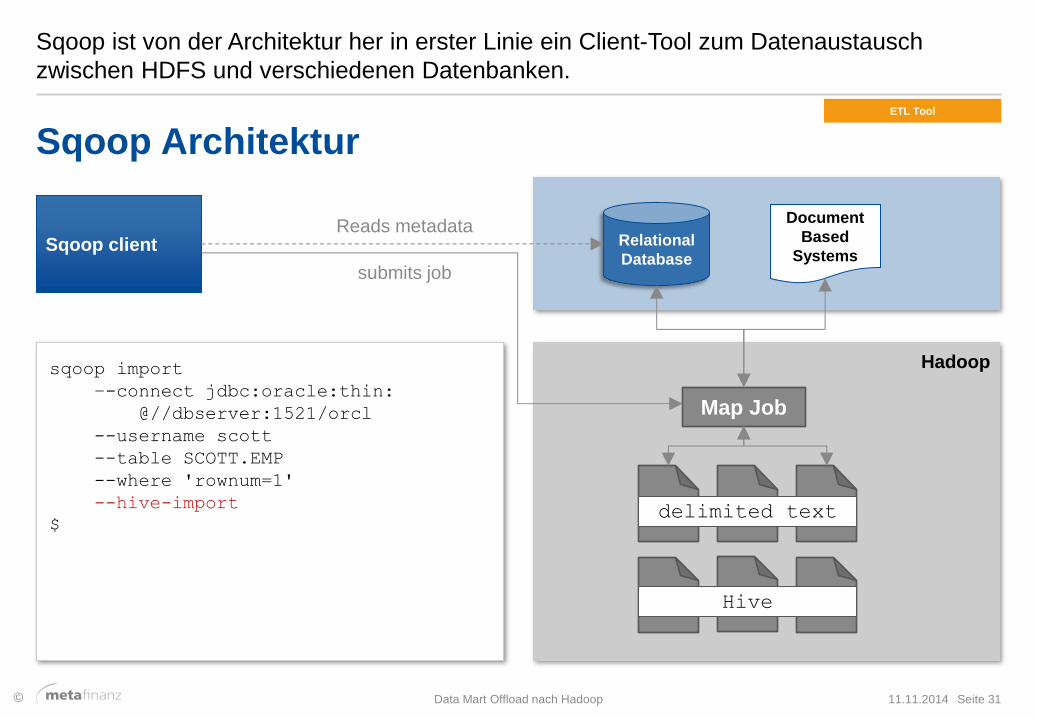
Sqoop ist von der Architektur her in erster Linie ein Client-Tool zum Datenaustausch
zwischen HDFS und verschiedenen Datenbanken.
11.11.2014 Data Mart Offload nach Hadoop Seite 31
Sqoop Architektur
Hadoop
Relational
Database
Document
Based
Systems
Hive
delimited text
Sqoop client Reads metadata
sqoop import
–-connect jdbc:oracle:thin:
@//dbserver:1521/orcl
--username scott
--table SCOTT.EMP
--where 'rownum=1'
--hive-import
$
Map Job
submits job
ETL Tool

©
8. Performance-Analyse
©
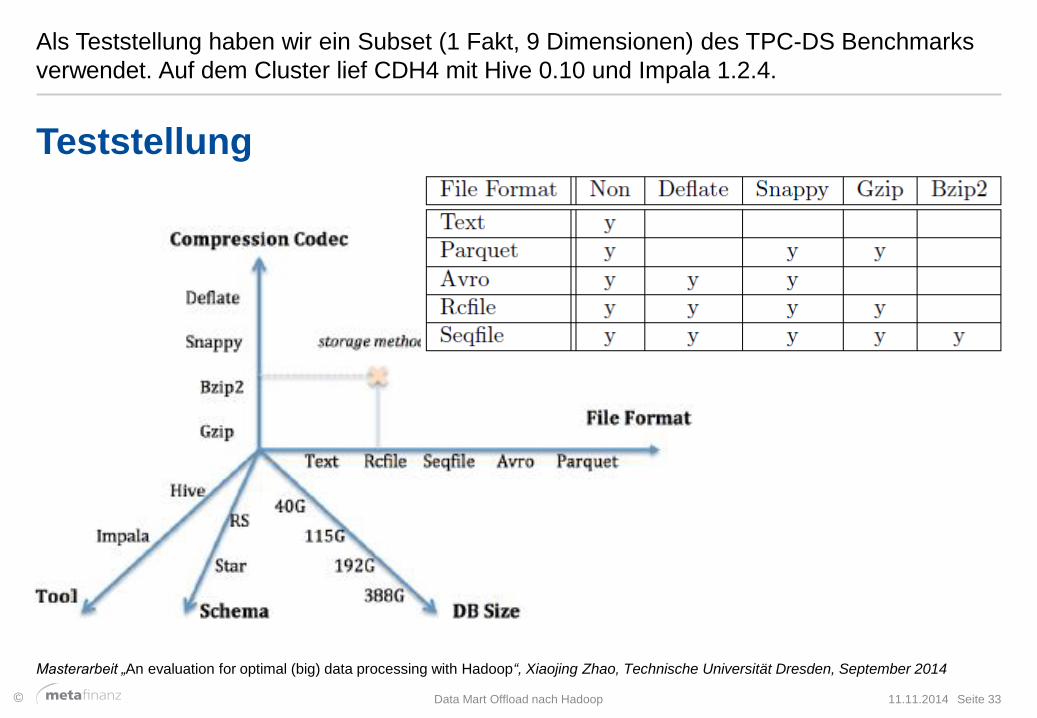
Als Teststellung haben wir ein Subset (1 Fakt, 9 Dimensionen) des TPC-DS Benchmarks
verwendet. Auf dem Cluster lief CDH4 mit Hive 0.10 und Impala 1.2.4.
11.11.2014 Data Mart Offload nach Hadoop Seite 33
Teststellung
Masterarbeit „An evaluation for optimal (big) data processing with Hadoop“, Xiaojing Zhao, Technische Universität Dresden, September 2014

©
Alle Test-Kombinationen und weitere Fragestellungen wurden im Rahmen einer
Masterarbeit detailliert untersucht.
11.11.2014 Data Mart Offload nach Hadoop Seite 34
Masterarbeit „Real-time SQL on Hadoop“
Download bald unter
hadoop.metafinanz.de
©
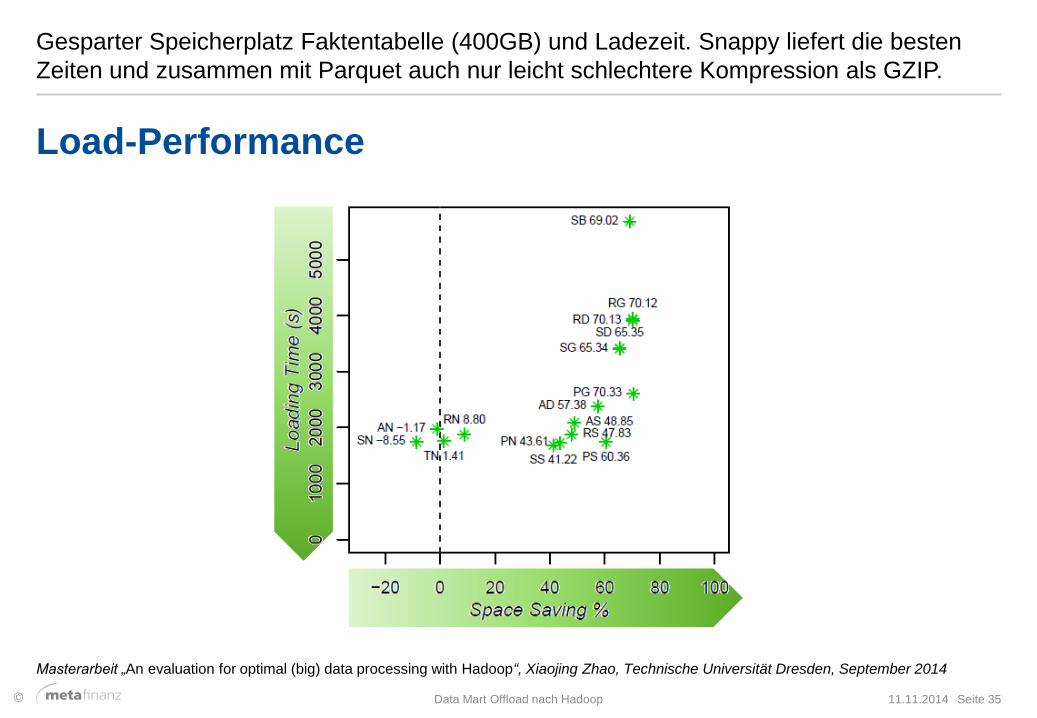
Gesparter Speicherplatz Faktentabelle (400GB) und Ladezeit. Snappy liefert die besten
Zeiten und zusammen mit Parquet auch nur leicht schlechtere Kompression als GZIP.
11.11.2014 Data Mart Offload nach Hadoop Seite 35
Load-Performance
Masterarbeit „An evaluation for optimal (big) data processing with Hadoop“, Xiaojing Zhao, Technische Universität Dresden, September 2014
©
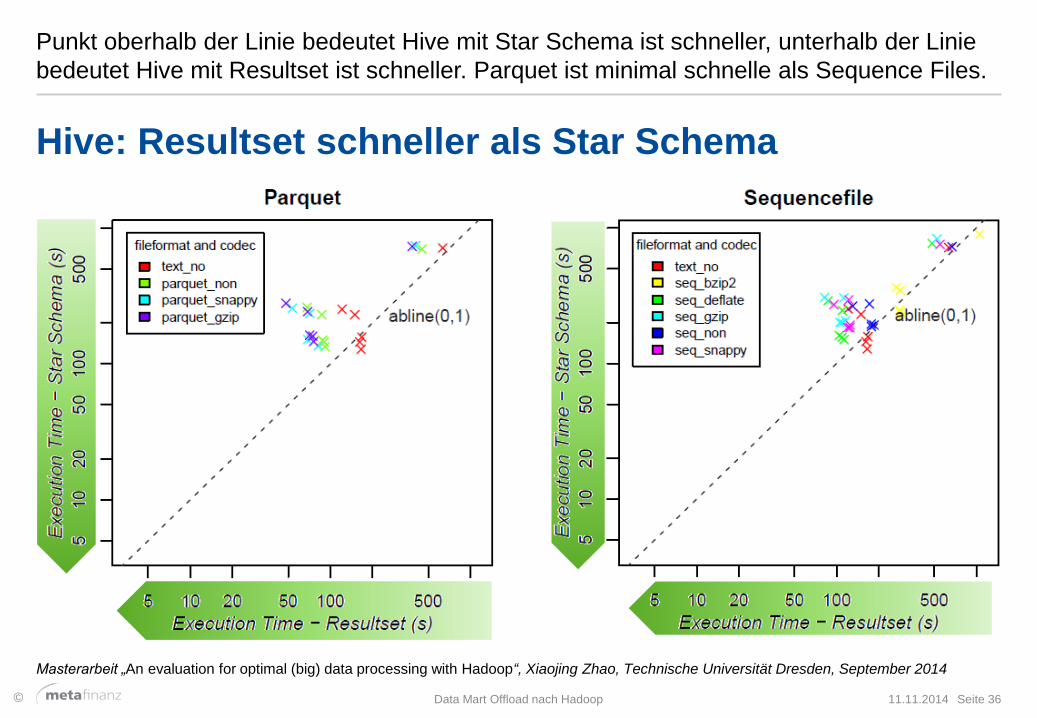
Punkt oberhalb der Linie bedeutet Hive mit Star Schema ist schneller, unterhalb der Linie
bedeutet Hive mit Resultset ist schneller. Parquet ist minimal schnelle als Sequence Files.
11.11.2014 Data Mart Offload nach Hadoop Seite 36
Hive: Resultset schneller als Star Schema
Masterarbeit „An evaluation for optimal (big) data processing with Hadoop“, Xiaojing Zhao, Technische Universität Dresden, September 2014
©
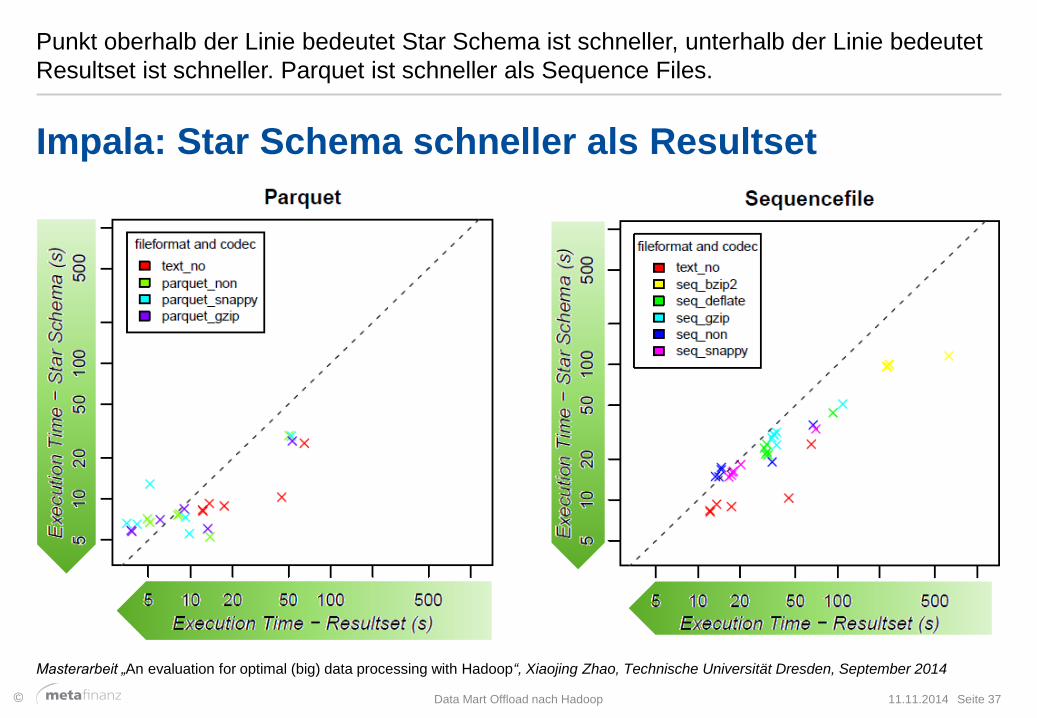
Punkt oberhalb der Linie bedeutet Star Schema ist schneller, unterhalb der Linie bedeutet
Resultset ist schneller. Parquet ist schneller als Sequence Files.
11.11.2014 Data Mart Offload nach Hadoop Seite 37
Impala: Star Schema schneller als Resultset
Masterarbeit „An evaluation for optimal (big) data processing with Hadoop“, Xiaojing Zhao, Technische Universität Dresden, September 2014

©
Parquet ist zwar etwas CPU intensiver als die meisten anderen Formate, verbraucht dafür
aber deutlich weniger Speicher.
11.11.2014 Data Mart Offload nach Hadoop Seite 38
Impala: CPU vs. Memory Trade-off
Masterarbeit „An evaluation for optimal (big) data processing with Hadoop“, Xiaojing Zhao, Technische Universität Dresden, September 2014
©
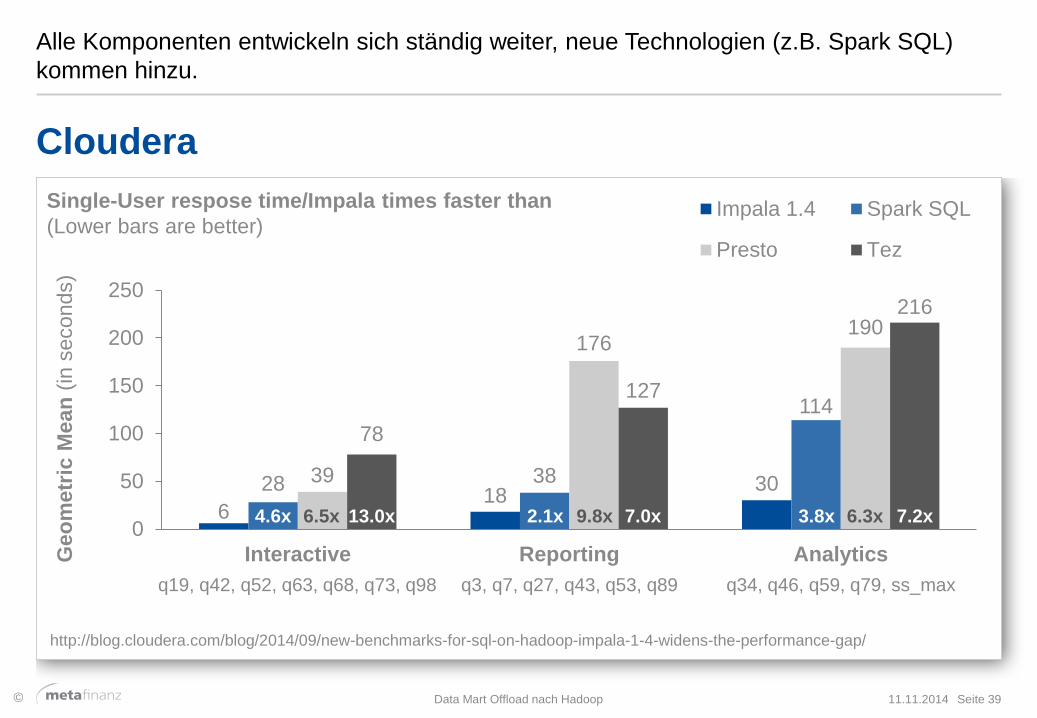
Alle Komponenten entwickeln sich ständig weiter, neue Technologien (z.B. Spark SQL)
kommen hinzu.
11.11.2014 Data Mart Offload nach Hadoop Seite 39
Cloudera
http://blog.cloudera.com/blog/2014/09/new-benchmarks-for-sql-on-hadoop-impala-1-4-widens-the-performance-gap/
6 18
30 28 38
114
39
176 190
78
127
216
0
50
100
150
200
250
Interactive Reporting Analytics
Impala 1.4 Spark SQL
Presto Tez
Single-User respose time/Impala times faster than
(Lower bars are better)
Geo
metr
ic M
ean
(in
seconds)
q19, q42, q52, q63, q68, q73, q98 q3, q7, q27, q43, q53, q89 q34, q46, q59, q79, ss_max
4.6x 2.1x 6.5x 13.0x 9.8x 7.0x 3.8x 7.2x 6.3x

©
9. Fazit
©
RDBMS
Hadoop
OLTP
Core DWH
Datamart
Datamart
Staging
Files
Reporting
OLTP
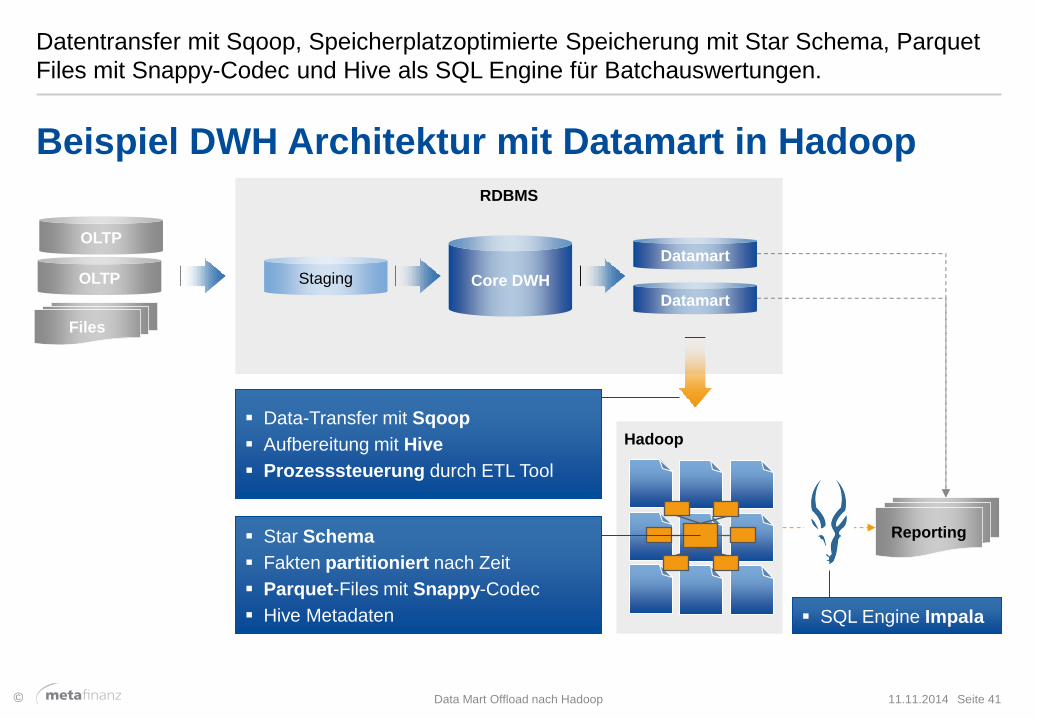
Datentransfer mit Sqoop, Speicherplatzoptimierte Speicherung mit Star Schema, Parquet
Files mit Snappy-Codec und Hive als SQL Engine für Batchauswertungen.
11.11.2014 Data Mart Offload nach Hadoop Seite 41
Beispiel DWH Architektur mit Datamart in Hadoop
Data-Transfer mit Sqoop
Aufbereitung mit Hive
Prozesssteuerung durch ETL Tool
Star Schema
Fakten partitioniert nach Zeit
Parquet-Files mit Snappy-Codec
Hive Metadaten SQL Engine Impala
©
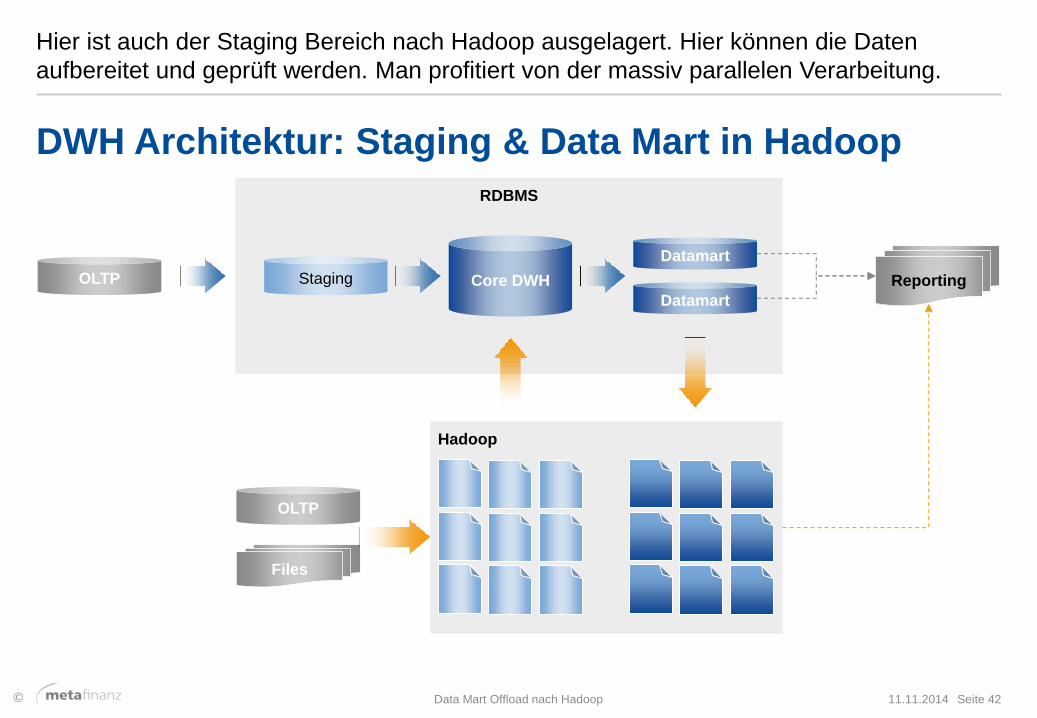
Hier ist auch der Staging Bereich nach Hadoop ausgelagert. Hier können die Daten
aufbereitet und geprüft werden. Man profitiert von der massiv parallelen Verarbeitung.
11.11.2014 Data Mart Offload nach Hadoop Seite 42
DWH Architektur: Staging & Data Mart in Hadoop
RDBMS
Hadoop
Core DWH
Datamart
Datamart
Reporting Staging OLTP
OLTP
Files

©
metafinanz unterstützt Ihre Kunden bei Einführung von Hadoop end-to-end:
Von Entscheidung und Konzeption bis hin zu Einführung und Optimierung.
metafinanz ist herstellerunabhängig, erfahren, kompetent, zuverlässig und lieferfähig
BUILD DECIDE PLAN OPTIMIZE
metafinanz Consulting Leistungen rund um Data Warehouse und Enterprise Information Management
Businessanalyse, Systemauswahl und Integrationskonzept
Gesamtheitliche IT Architektur Strategie und Designkonzeption (IT Strategie)
Customizing von Big Data Lösungen für Ihre besonderen Business Anforderungen (Zukunftsfähigkeit)
DWH Configuration & Optimierung für mehr Leistungsfähigkeit (Effizienzpotential)
Vorstudie
Hadoop-Strategie
Identifikation Use Cases
Tool-/Distributor-Auswahl & Architektur
Projekt- und Betriebs-Setup
11.11.2014 Seite 43 DWH-Metadaten, wie und wozu
DWH Cost Savings
Data Mart Offload (hist. Daten)
ETL-Offload: Staging
Calculation Offload
Dokumentenverarbeitung
Dokumentenarchivierung
Volltextsuche
Textanalyse
Log-File-Analysen Click-Stream-Analyse Web-Anwendungen
Security Analytics (Server-Logs, Firewall-Logs, …)

©
Treffen Sie uns an unserem Stand
… und gewinnen ein iPad Mini!
Interesse? Austausch? Livedemo des Datenfluss-Datamart?
Herzlichen Dank!
metafinanz Informationssysteme GmbH
Leopoldstr. 146
Phone: +49 89 360531-0
Fax: +49 89 350531-5015
Email: [email protected]
www.metafinanz.de
Mehr zu Data Warehousing & Hadoop
http://dwh.metafinanz.de
Besuchen Sie uns auch auf:

![BIG DATA ÉS GÉPI TANULÁS KÖRNYEZET AZ MTA Cloud.pdf · Cloud Public IP VM[1] HDFS DATA –TEXT FILES VM[2] HDFS VM[10] HDFS VM[1] SPARK WORKER VM[2] SPARK WORKER VM[10] SPARK](https://img.pdfslide.tips/doc/110x75/5ed40e2b8d46b66d22635e6c/big-data-s-gpi-tanuls-krnyezet-az-mta-cloudpdf-cloud-public-ip-vm1.jpg)



























