Embed Size (px)
Citation preview

Data mining
資料探勘
資料探勘( Data Mining )是一種專門的程序,可在大量存放的資料中,找出先前並不知道,但最後可有效理解的資訊,並可利用這些找出的資訊建立一個預測或分類的模型,或識別不同資料庫之相似性,產生的資訊可協助決策者進行更週延的決策。

資料探勘的方法
資料探勘的工具是利用資料以建立一些模擬真實世界的模式( Model ),利用這些模式描述資料中的特徵及關係。這些模式有兩種用處:( 1 )瞭解資料的特徵與關係可以提供決策時所需要的資訊,例如關聯模式( Association Model )可以幫助超市或百貨商場規畫貨品擺設;
( 2 )資料的特徵可做預測,例如從郵寄名單中預測出那些客戶最可能對你的推銷做回應,你可以只對特定的對象做推銷,增加行銷。

資料探勘的方法
區分為五種模式: 分類( Classification )、 趨勢分析( Trend Analysis )、 分群( Clustering )、 關聯( Association ) 循序特徵( Sequence Pattern )

分類
是根據一些變數的數值做計算,再依照結果作分類。從歷史性已分類的資料中部份取樣,經由實際的運作測試,研究資料分類的特徵及規則,然後再根據這些特徵建立模式,對其他未經分類或是新的資料做預測。
例如醫院從病人診斷記錄中,找出疾病特徵,建立分類模式,這分類模式便能依據新病人的資料(年齡、性別、體重、體溫、血壓 ...... )推論出其所患的疾病。

趨勢分析
用現有的數值來預測未來的數值,其所分析的數值與時間皆有相關,一般用於預測與事件改變的比對。
例如公司依據去年的在收益及成長率,來評估今年的收益,或將去年的收益表與今年收益作比較,找出差異分析其原因。

分群
是將資料分組,其目的是找出各組之間的差異及同組中成員的相似性,使群內差異小,群外差異大。
例如銀行將客戶依其年齡、收入、居住地點 ...等的相似性分群,這樣分群能讓銀行瞭解最佳的客戶群及提供最合適的產品及服務給適當的客戶。

關聯
是要在同一個交易中找出隱含其它項目之存在的項目。
例如:零售商店店長發現顧客買碳酸飲料時會和洋芋片一起選購。故店長將兩類商品貨架放在一起,並只針對其中一種商品進行折扣促銷,連帶另一項未促銷的商品,同樣獲得青睞,達到商場銷售的目的。

循序特徵
與關聯關係很密切,所不同的是序列特徵中相關的項目( Item )是以時間來區分,找出某段時間內的可預期行為特徵。
例如:發現在申請 ATM 卡的新活期存款用戶中,有 42%會在 90 天內申請定期付款。
資料探勘的技術
Pieter 與 Dolf 認為資料探勘不是一種新技術,而是結合多項專業技術的研究,它包括機器學習、統計方法、資料庫、專家系統及資料視覺化的領域。
而 Curt也認為資料探勘的技術至少包括資料視覺化、機器學習技術、統計技術及資料庫四種技術。
統計方法( Statistical Approaches )
資料探勘使用許多統計工具,包括 Bayesian 網路、迴歸分析、相關分析及分群分析( Cluster Analysis ),通常統計模式是經由訓練資料集( Training Data Sets )來建立,然後從模式中尋求規則及特徵。

機器學習方法( Machine Learning Approaches ) 像統計方法一樣,機器學習方法尋求一個最佳模式來符合測試資料( Testing Data )。不同之處在於大多數機器學習方法利用資料自動化學習過程,自動歸納出分類規則及建立模組。
資料探勘最常使用的機器學習方法包括決策樹歸納( Decision Tree Induction )及概念式分群( ConceptualClustering )。

資料庫導向方法( Database-oriented Approaches ) 資料庫導向方法不像前兩個技術在尋找最佳模式,轉而著重在處理現有的資料,是一種屬性導向歸納( Attribute-oriented Induction ),反覆從大量的資料中找出共同的規則及模式。

視覺探索( Visual Exploration ) 將多維度的資料轉換成視覺化物件,如點、線及區域,讓使用者可以動態檢視及探索有興趣的部分,進而分析出資料的模式。
其他方法
如類神經網路( Neural Network )運用於資料的分類及預測,約略集合( Rough Set )運用於分類及分群。
這些技術可以互相整合來處理複雜的問題及提供替代方案,如統計方法可以結合視覺探索技術,用以輔助系統處理資料模式及趨勢分析。
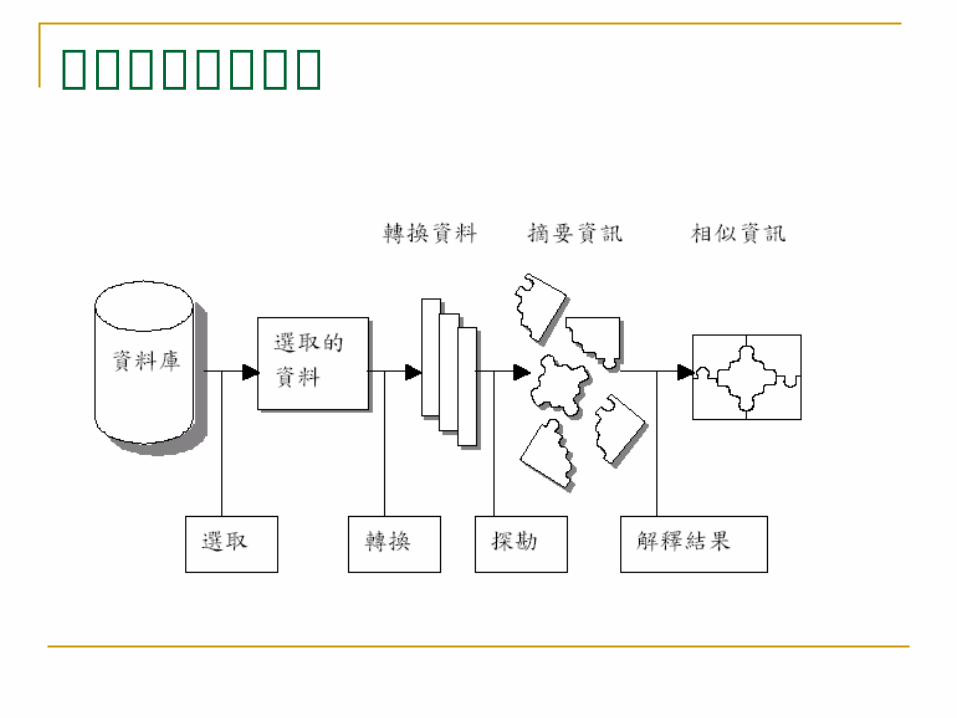
資料探勘執行流程

資料探勘執行流程 選取輸入資料:資料探勘的第一步驟,是指定要探勘和分析的資
料,資料來源不一定是特定資料庫中的所有資料,探勘的資料可能從一個或多個資料庫中,取得表格、概略表或記錄文字檔。
轉換資料:為降低資料量,首先將收集的資料作整理、清除重複或無效的資料記錄,並且確保消費者資料的完整。
資料探勘:使用資料探勘方法如分類、趨勢分析、分群、關聯及循序特徵等,從轉換後的資料中發掘存在的多種特徵及資訊。
解釋結果:經過資料探勘後,一般以文字及圖形來顯示結果。

發掘關聯式規則 發掘關聯式規則( Mining Association Rule )在給定的一個銷售
資料庫中,每一筆交易可能含有一項或多項商品以構成該次交易,想從交易商品項目中發現重要關聯性,也就是相同交易中,某些商品項目產生連帶其它商品項目出現。
Agrawal 等學者提出一個數學模式,用以說明發掘關聯式規則的問題,令 I={i1, i2, … , in} , I 即是所欲討論的項目( Items )所組成的集合,在此 I 可想像成百貨店或超市內所有商品組成的集合,D 是一個交易的集合,亦可視為一特定資料庫,其中每一個交易T 是項目的集合,像 T I ,注意,每筆交易中商品項目購買的數量是不考量的,另外每筆交易皆有一個交易序號 TID 作為識別。
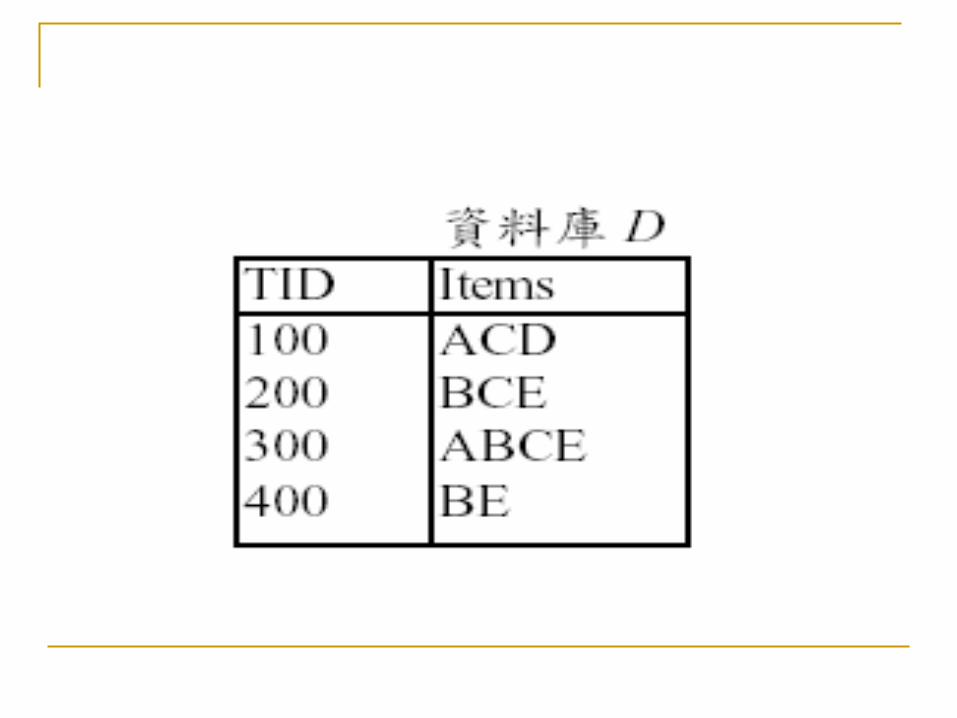



發掘關聯規則的工作可分為兩個階段:( 1 )在資料庫中找出所有符合限制的頻繁項目集與
( 2 )使用前述方法所找出的頻繁項目集,找出資料庫中隱含的關聯規則。
關聯式法則的定義及相關名詞介紹 假設一商品物項集合 (itemset) I 包含了所有可能的商品物項 {i1 ,
i2 ,… im} ,並設 D 為一群商品交易紀錄的集合,且每一筆交易紀錄 (transaction) T 所包含的就是一群物項的集合,所以所有的T 出現的物項都是可以被 I 所涵蓋的,而不管該物項的數量。一個關聯式法則的形成為前提物項集合 (antecedent itemset) 結果物項集合 (consequent itemset) ,前後兩種物項集合都是 I 的子集合,且兩者的交集為空集合,對於一個關聯式法則為 XY , X 、Y 為兩個包含於 I 的非空集合,則支持度是 D 中包含了 XY 的交易所佔百分比。信賴度 (confidence) 是 D 中同時包含 XY 之交易數和包含 X 之交易數的比值。 ( 支持度與信賴度都是介於 0 與1 之間 )


一個有效的關聯式法則,必須滿足”信賴度大於等於使用者預設最小信賴度 C 且支持度大於等於使用者預設最小支持度 S 的關聯式法則” 。而對於一個物項集,我們定義其支持度為包含該物項集合的交易個數。高頻物項集合 (frequent itemset 或 large itemset) 為支持度大於等於使用者預設最小支持度 S 乘以交易總數 D 的物項集合。例 : 若{XY} 是一個高頻物項集合且 {XY} 的支持度除以{X} 的支持度 C 則 XY 是一個有效的關聯式法則。最後產生有效的關聯式法則,是由高頻物項集合推導而來。
Apriori 演算法
(1) 首先訂定過濾規則強度的門檻值─最小支持度及最小信賴度。(2) Apriori 演算法使用了候選物項集合 (Candidate Itemset) 的觀
念,首先產生出物項集合,稱為候選物項集合,若候選物項集合的支持度大於或等於
最小支持度minisup ,則該候選物項集合為高頻物項集合 (Large Itemset) 。(3) 在 Apriori 演算法的過程中,首先由資料庫讀入所有的交易,
得出候選單物項集合 (Candidate 1- itemset) 的支持度,再找出高頻單物項集合 (Lar
ge 1- itemset) ,並利用這些高頻單物項集合的結合,產生候選 2 物項集合 (Candidate
2- itemset) 。

(4) 再掃描資料庫,得出候選 2 物項集合的支持度以後,再找出高頻 2 物項集合,並利用這些高頻 2 物項集合的結合,產生候選 3 物項集合。
(5) 重覆掃描資料庫、與最小支持度比較,產生高頻物項集合,再結合產生下一級候選物項集合,直到不再結合產生出新的候選物項集合為止。

存在 k 種物項的物項集合稱之為 k- 物項集合 (k-itemset) 令C k 表示有 k 個物項的候選物項集合 ( 或稱為候選 k- 物項集合 ) 所組成的集合, L k 表示有 k 個物項的高頻物項集合 ( 或稱為高頻 k- 物項集合 ) 所組成的集合,則用遞回方式產生候選物項。
集合的過程可以表示為:
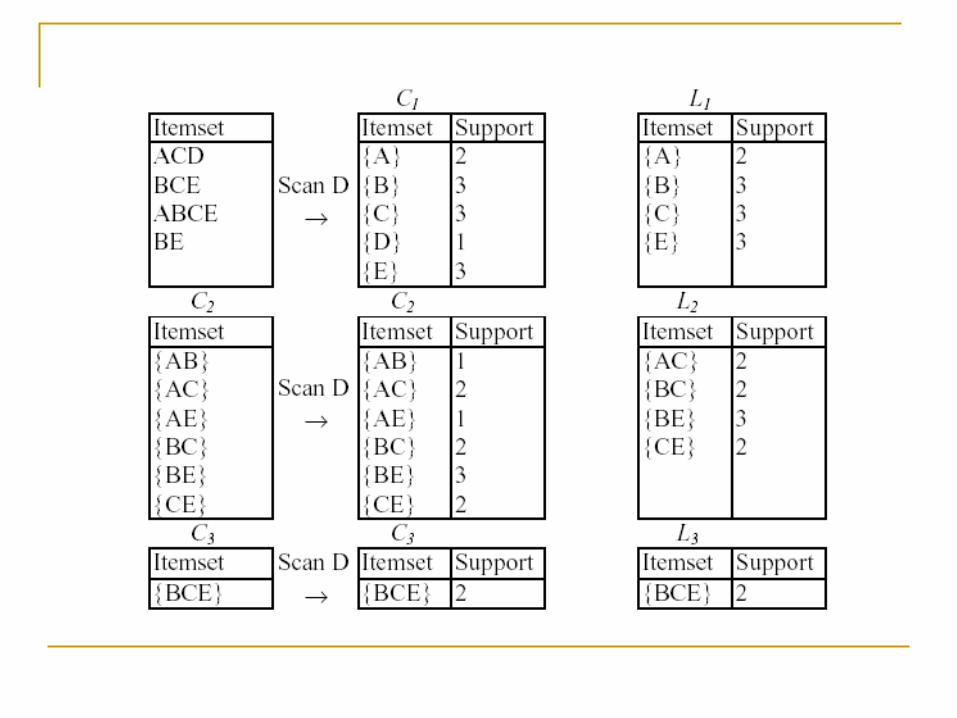

上述的關聯式規則架構發展至今,不管是本身架構上或是應用面上的使用仍有諸多不適, 需要予以調整, 如( 1 ) Piatesky-Shapiro 曾經指出項目集間的獨立關係,如果 support ( X =>Y ) support ( X ) * support ( Y ) ,則在規則中的項目將趨近於獨立的關係。( 2 )在關聯規則的架構下並沒有辦法討論項目間關聯的方向是否一致、關聯程度的大小、興趣程度等;以一個例子說明此類問題,以早餐店為例,若只討論兩個項目商品,牛奶及麵包,此兩項目在 500 筆的交易記錄,其銷售狀況如下表所示:
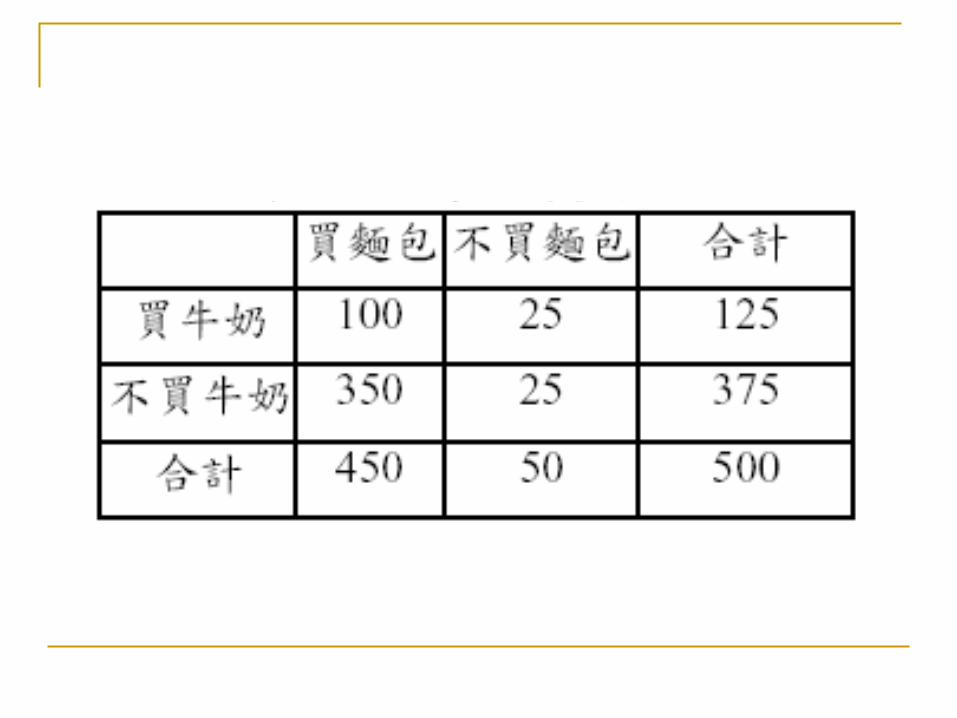
若是利用關聯規則 Support-Confidence 的架構,可得出較佳的法則是“買牛奶 _ 買麵包”,其 Confidence 高達 80% ,但“不買牛奶 _ 買麵包”,其 Confidence 高達 93.3% ,很明顯“買牛奶 _買麵包”不是一個最佳的規則,若針對買牛奶的人來促銷買麵包,應該不是一個很好的行銷策略。除了以上兩點外,尚還有執行時效的考量,而這些問題正是影響關聯規則是否正確的關鍵因素。
DHP 演算法
Chen et al. 於 1995 年提出了 DHP(Direct Hashing and Pruning) 演算法,主要利用了刪減不必要候選物項集合的概念來改善以往在關聯式法則挖掘時的效率, DHP 演算法是以 Apriori 演算法為基礎,另外再加入了 hash table 的架構,使其效能進一步的有效提昇。
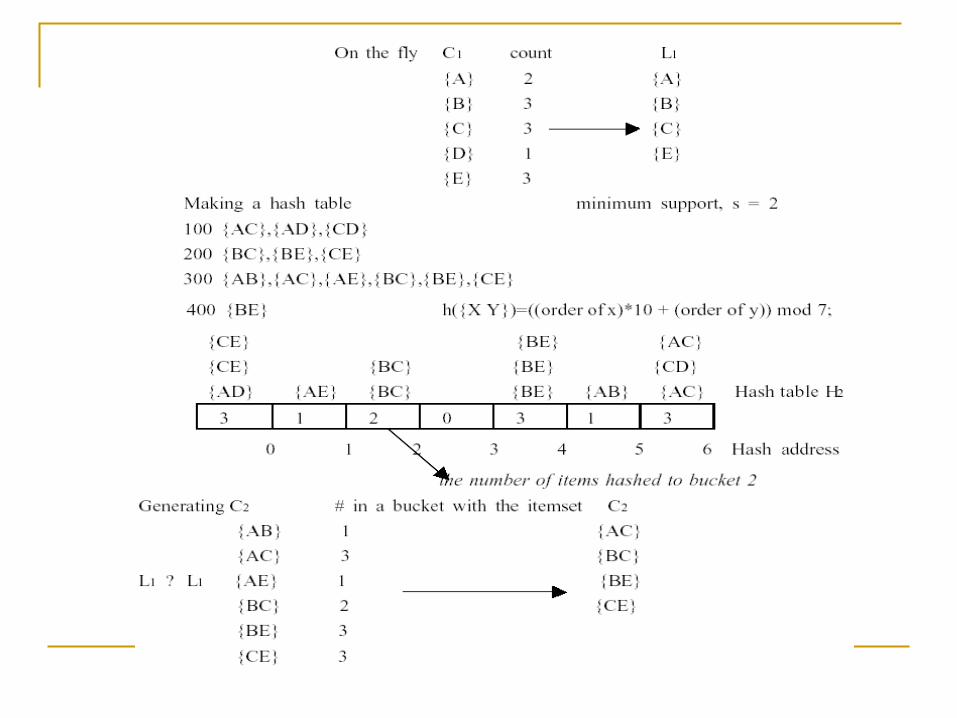
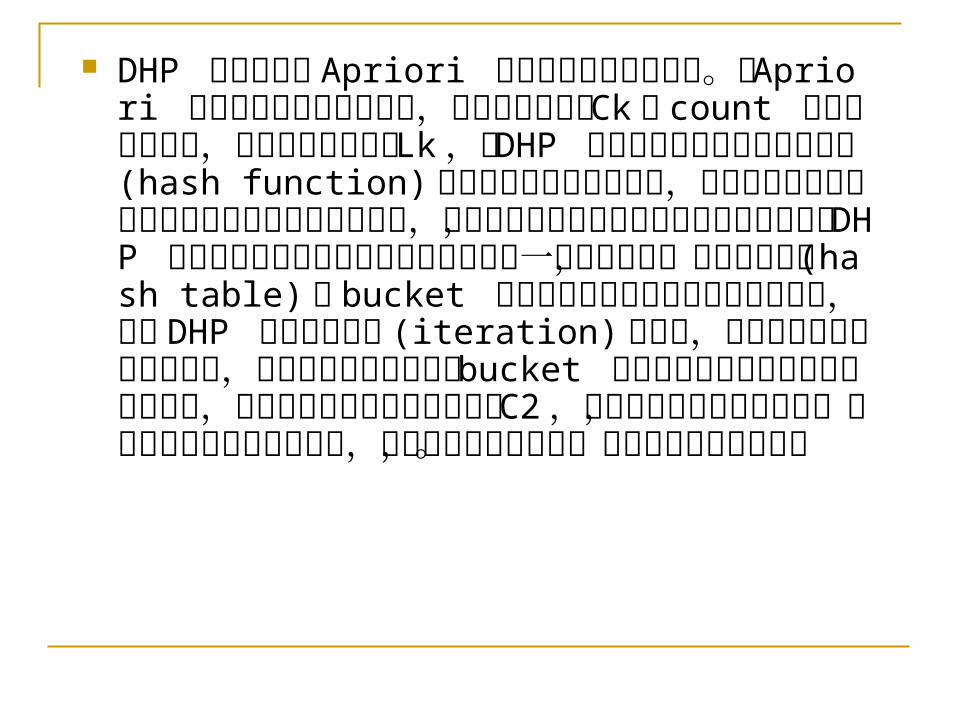
DHP 演算法是以 Apriori 演算法為基礎而於改善。在 Apriori 演算法做重覆資料庫掃描,計算候選項集合 Ck 的 count 與支持度做比較,產生高頻物項集合 Lk ,而 DHP 主要的貢獻在於利用雜湊函數(hash function) 過濾非高頻候選物項集合,然後再掃描資料庫計算未過濾的高頻候選物項集合,以減少候選物項集合的數目來掃描資料庫, DHP 演算法過濾非高頻候選物項集合是使用一種雜湊函數,並根據雜湊表 (hash table) 中 bucket 的數值去刪除不必要的候選物項集合,同時 DHP 會隨著回合數 (iteration) 的增加,而需要掃描的資料量會變小,其優點在於以雜湊表中 bucket 的數值當作刪除候選物項集合的上限,在第二回合時候可以大幅縮小 C2 ,因為要不斷計算雜湊函數,刪除不需要之候選物項集合,要掃描的資料量減少,因而提高執行的效率。
Partition 演算法
Savasere et al. 於 1995 年提出 Partition 演算法 [25] 其主要的概念是由 Apriori 演算法延伸而來,在搜尋高頻物項集合及導出關聯式法則等方面,其作法仍與 Apriori 演算法雷同,而 Paritition 演算法提出主要是改善資料庫的掃描次數,提升挖掘的效率。

Partition 演算法是將資料庫分成許多的區段,讓每個區段的大小都能容納於主記憶體中,利用分割區段的特性, Partition 演算法可以減少資料庫掃描的次數,而且最多只需要掃描 2 次資料庫。在找出高頻物項集合時,其需經 2 個步驟:
(1) 個別計算各區段中各物項集合的支持度,以找出各區段中的所有高頻物項集合。
(2) 將各區段中所有的高頻物項集合集合起來後,再掃描資料庫找出真正的高頻物項集合。

Partition 演算法的缺點
Partition 演算法只要經過 2 次的資料庫掃描,以減少 I/O 的次數,但其缺點如下:
(1) 由於各區段中產生高頻物項集合,並不表示在整個資料庫中亦為高頻物項集合,因此會產生過多的高頻物項集合,導致第二次掃描資料庫 I/O 次數頻繁效能不佳。
(2) 為了減少在不同區段中重覆產生高頻物項集合,而且為了能利用估計的方式提早結束挖掘,在系統做挖掘前必須先將資料庫作排序。
(3) 由於分段對各區段資料庫做挖掘,因此計算量會比Apriori 演算法更大。









