Embed Size (px)
Citation preview

DataminingDatamining
Ing. Edwin Ramos Velásquez
1
Ing. Edwin Ramos Velásquez

¿Qué es minería de datos?
Es el proceso de extraer conocimiento útil y comprensible, previamentedesconocido, desde grandes volúmenes de datos almacenados en distintosformatos. Es decir, la tarea fundamental de la minería de datos es encontrarmodelos inteligibles a partir de los datos, para que este proceso sea efectivodebería ser automático o semiautomático (asistido) y el uso de los patronesdescubiertos debería ayudar a tomar decisiones más seguras que reporten, portanto, algún beneficio a la organización.
Es el proceso de extraer conocimiento útil y comprensible, previamentedesconocido, desde grandes volúmenes de datos almacenados en distintosformatos. Es decir, la tarea fundamental de la minería de datos es encontrarmodelos inteligibles a partir de los datos, para que este proceso sea efectivodebería ser automático o semiautomático (asistido) y el uso de los patronesdescubiertos debería ayudar a tomar decisiones más seguras que reporten, portanto, algún beneficio a la organización.
Mineríade
Datos
Deudas
Empleados tardones
VentasCompras
ArticulosCONOCIMIENTODATOS¿Cuántos productos compraré?¿A qué empleados debo despedir?¿Cuánto venderé este mes?¿A quién debo comprar más?¿Qué deuda debo pagar primero?
a) Minería dedatos en unabodega
b) Minería dedatos en unhospital
2
Mineríade
Datos
Deudas
Empleados tardones
VentasCompras
ArticulosCONOCIMIENTODATOS¿Cuántos productos compraré?¿A qué empleados debo despedir?¿Cuánto venderé este mes?¿A quién debo comprar más?¿Qué deuda debo pagar primero?
Mineríade
Datos
Pacientes
MedicinasConsultorios
Camas Enfermeros
AmbulanciasCONOCIMIENTODATOS
¿Qué medicinas compraré?¿Cuantas camas proveer?¿A qué enfermeros contratar?¿Qué enfermedad será epidemia?¿Qué consultorio tiene máspacientes?
a) Minería dedatos en unabodega
b) Minería dedatos en unhospital
el objetivo de la minería de datos es convertir datos en conocimiento.

Ejemplo 1: Análisis de créditos bancarios
El primer ejemplo pertenece al ámbito de la banca. Un banco por Internet desea obtener reglaspara predecir qué personas de las que solicitan un crédito no lo devuelven. La entidad bancariacuenta con los datos correspondientes a los créditos concedidos con anterioridad a sus clientes(cuantía del crédito, duración en años, etc.) y otros datos personales como el salario del cliente,si posee casa propia, etc. Algunos registros de clientes de esta base de datos se muestran acontinuación:
A partir de éstos, las técnicas de minería de datos podrían sintetizar algunas reglas, como porejemplo:
El banco podría entonces utilizar estas reglas para determinar las acciones a realizar en eltrámite de los créditos: si se concede o no el crédito solicitado, si es necesario pedir avalesespeciales, etc.
El primer ejemplo pertenece al ámbito de la banca. Un banco por Internet desea obtener reglaspara predecir qué personas de las que solicitan un crédito no lo devuelven. La entidad bancariacuenta con los datos correspondientes a los créditos concedidos con anterioridad a sus clientes(cuantía del crédito, duración en años, etc.) y otros datos personales como el salario del cliente,si posee casa propia, etc. Algunos registros de clientes de esta base de datos se muestran acontinuación:
A partir de éstos, las técnicas de minería de datos podrían sintetizar algunas reglas, como porejemplo:
El banco podría entonces utilizar estas reglas para determinar las acciones a realizar en eltrámite de los créditos: si se concede o no el crédito solicitado, si es necesario pedir avalesespeciales, etc.
IDCD-Crédito
(Años)D-Crédito
(US)Salario
(Dolares)Casa
propiaCuentasmorosas …
Devuelvecrédito
101 15 60,000 2,200 SI 2 … NO102 2 30,000 3,500 SI 0 … SI103 9 9,000 1,700 SI 1 … NO104 15 18,000 1,900 NO 0 … SI105 10 24,000 2,100 NO 0 … NO
Datos para análisisde riesgo encréditos bancarios
Regla 1:SI
Cuentas_morosas < 0ENTONCES
Devuelve_crédito = NO
Regla 2:SI
( Cuentas_morosas = 0 ) Y( (Salario>2,500)O (D-crédito>10) )
ENTONCESDevuelve_crédito = SI
3
El primer ejemplo pertenece al ámbito de la banca. Un banco por Internet desea obtener reglaspara predecir qué personas de las que solicitan un crédito no lo devuelven. La entidad bancariacuenta con los datos correspondientes a los créditos concedidos con anterioridad a sus clientes(cuantía del crédito, duración en años, etc.) y otros datos personales como el salario del cliente,si posee casa propia, etc. Algunos registros de clientes de esta base de datos se muestran acontinuación:
A partir de éstos, las técnicas de minería de datos podrían sintetizar algunas reglas, como porejemplo:
El banco podría entonces utilizar estas reglas para determinar las acciones a realizar en eltrámite de los créditos: si se concede o no el crédito solicitado, si es necesario pedir avalesespeciales, etc.
Regla 1:SI
Cuentas_morosas < 0ENTONCES
Devuelve_crédito = NO
Regla 2:SI
( Cuentas_morosas = 0 ) Y( (Salario>2,500)O (D-crédito>10) )
ENTONCESDevuelve_crédito = SI

Este es uno de los ejemplos más típicos de minería de datos, un supermercado quiere obtenerinformación sobre el comportamiento de compra de sus clientes. Piensa que de esta forma puede mejorarel servicio que les ofrece:
Reubicación de los productos que se suelen comprar juntos, Localizar el emplazamiento idóneo para nuevos productos, etc.
Para ello dispone de la información de los productos que se adquieren en cada una de las compras ocestas. Un fragmento de la base de datos se muestra en la tabla siguiente:
Analizando estos datos del supermercado, podría encontrar, por ejemplo que: El 100 por ciento de las veces que se compran pañales, también se compra leche, El 50 por ciento de las veces que se compran huevos también se compra aceite, o El 33 por ciento de las veces que se compra vino y salmón, entonces se compran lechugas.
También se puede analizar cuáles de estas asociaciones son frecuentes, porque una asociación muyestrecha entre los productos puede ser poco frecuente y, por tanto, poco útil.
Ejemplo 2: Análisis de la cesta de la compra
Este es uno de los ejemplos más típicos de minería de datos, un supermercado quiere obtenerinformación sobre el comportamiento de compra de sus clientes. Piensa que de esta forma puede mejorarel servicio que les ofrece:
Reubicación de los productos que se suelen comprar juntos, Localizar el emplazamiento idóneo para nuevos productos, etc.
Para ello dispone de la información de los productos que se adquieren en cada una de las compras ocestas. Un fragmento de la base de datos se muestra en la tabla siguiente:
Analizando estos datos del supermercado, podría encontrar, por ejemplo que: El 100 por ciento de las veces que se compran pañales, también se compra leche, El 50 por ciento de las veces que se compran huevos también se compra aceite, o El 33 por ciento de las veces que se compra vino y salmón, entonces se compran lechugas.
También se puede analizar cuáles de estas asociaciones son frecuentes, porque una asociación muyestrecha entre los productos puede ser poco frecuente y, por tanto, poco útil.
idCesta Huevos Aceite Pañales Vino Leche Mantequilla Salmón Lechugas1 SI NO NO SI NO SI SI SI2 NO SI NO NO SI NO NO SI3 NO NO SI NO SI NO NO NO4 NO SI SI NO SI NO NO NO5 SI SI NO NO NO SI NO SI6 SI NO NO SI SI SI SI NO7 NO NO NO NO NO NO NO NO8 SI SI SI SI SI SI SI NO
Datos de lacesta decompra
4
Este es uno de los ejemplos más típicos de minería de datos, un supermercado quiere obtenerinformación sobre el comportamiento de compra de sus clientes. Piensa que de esta forma puede mejorarel servicio que les ofrece:
Reubicación de los productos que se suelen comprar juntos, Localizar el emplazamiento idóneo para nuevos productos, etc.
Para ello dispone de la información de los productos que se adquieren en cada una de las compras ocestas. Un fragmento de la base de datos se muestra en la tabla siguiente:
Analizando estos datos del supermercado, podría encontrar, por ejemplo que: El 100 por ciento de las veces que se compran pañales, también se compra leche, El 50 por ciento de las veces que se compran huevos también se compra aceite, o El 33 por ciento de las veces que se compra vino y salmón, entonces se compran lechugas.
También se puede analizar cuáles de estas asociaciones son frecuentes, porque una asociación muyestrecha entre los productos puede ser poco frecuente y, por tanto, poco útil.
idCesta Huevos Aceite Pañales Vino Leche Mantequilla Salmón Lechugas1 SI NO NO SI NO SI SI SI2 NO SI NO NO SI NO NO SI3 NO NO SI NO SI NO NO NO4 NO SI SI NO SI NO NO NO5 SI SI NO NO NO SI NO SI6 SI NO NO SI SI SI SI NO7 NO NO NO NO NO NO NO NO8 SI SI SI SI SI SI SI NO

Tareas de la minería dedatosTareas de la minería dedatos
5
Tareas de la minería de datos
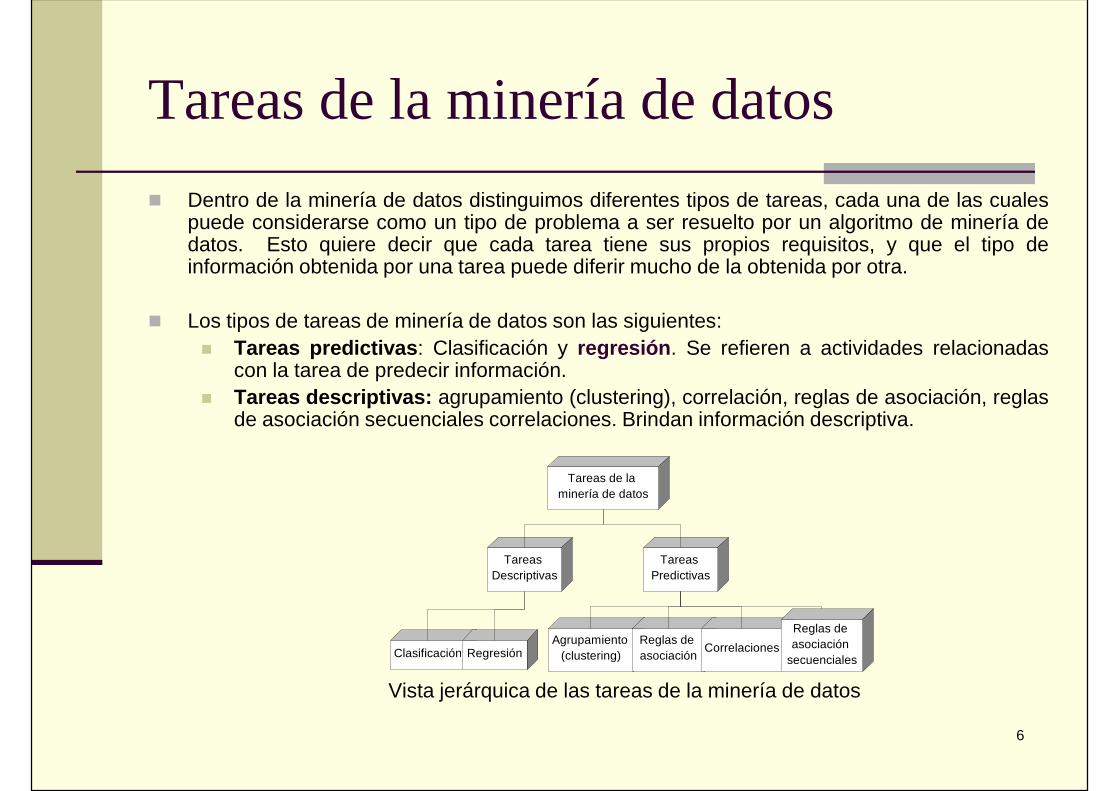
Dentro de la minería de datos distinguimos diferentes tipos de tareas, cada una de las cualespuede considerarse como un tipo de problema a ser resuelto por un algoritmo de minería dedatos. Esto quiere decir que cada tarea tiene sus propios requisitos, y que el tipo deinformación obtenida por una tarea puede diferir mucho de la obtenida por otra.
Los tipos de tareas de minería de datos son las siguientes: Tareas predictivas: Clasificación y regresión. Se refieren a actividades relacionadas
con la tarea de predecir información. Tareas descriptivas: agrupamiento (clustering), correlación, reglas de asociación, reglas
de asociación secuenciales correlaciones. Brindan información descriptiva.
Vista jerárquica de las tareas de la minería de datos
Dentro de la minería de datos distinguimos diferentes tipos de tareas, cada una de las cualespuede considerarse como un tipo de problema a ser resuelto por un algoritmo de minería dedatos. Esto quiere decir que cada tarea tiene sus propios requisitos, y que el tipo deinformación obtenida por una tarea puede diferir mucho de la obtenida por otra.
Los tipos de tareas de minería de datos son las siguientes: Tareas predictivas: Clasificación y regresión. Se refieren a actividades relacionadas
con la tarea de predecir información. Tareas descriptivas: agrupamiento (clustering), correlación, reglas de asociación, reglas
de asociación secuenciales correlaciones. Brindan información descriptiva.
Vista jerárquica de las tareas de la minería de datos
Clasificación
TareasDescriptivas
RegresiónAgrupamiento
(clustering)
Tareas de laminería de datos
TareasPredictivas
Reglas deasociación Correlaciones
Reglas deasociación
secuenciales
6
Dentro de la minería de datos distinguimos diferentes tipos de tareas, cada una de las cualespuede considerarse como un tipo de problema a ser resuelto por un algoritmo de minería dedatos. Esto quiere decir que cada tarea tiene sus propios requisitos, y que el tipo deinformación obtenida por una tarea puede diferir mucho de la obtenida por otra.
Los tipos de tareas de minería de datos son las siguientes: Tareas predictivas: Clasificación y regresión. Se refieren a actividades relacionadas
con la tarea de predecir información. Tareas descriptivas: agrupamiento (clustering), correlación, reglas de asociación, reglas
de asociación secuenciales correlaciones. Brindan información descriptiva.
Vista jerárquica de las tareas de la minería de datos
Clasificación
TareasDescriptivas
RegresiónAgrupamiento
(clustering)
Tareas de laminería de datos
TareasPredictivas
Reglas deasociación Correlaciones
Reglas deasociación
secuenciales

Tareas de la minería de datos
Tareas de la minería de datos:A) Clasificación. Cada instancia de (o registro de la BD) pertenece a una clase,
la cual se indica mediante el valor de un atributo que llamamos la clase de lainstancia. Este atributo puede tomar diferentes valores discretos, cada uno delos cuales corresponde a una clase. El objetivo es recogidos los datos deinterés, un explorador puede decidir qué tipo de patrón quiere descubrir.
Ejemplo: Un oftalmólogo desea disponer de un sistema que le sirva paradeterminar la conveniencia o no de recomendar la cirugía ocular a suspacientes. Para ello dispone de una BD de sus antiguos pacientesclasificados en operados satisfactoriamente o no operadossatisfactoriamente, en función del tipo de problema que padecían (miopía ysu grado, o astigmatismo) y de su edad. El modelo encontrado se utiliza paraclasificar nuevos pacientes, es decir, para decidir si es conveniente operarlos ono.
Tareas de la minería de datos:A) Clasificación. Cada instancia de (o registro de la BD) pertenece a una clase,
la cual se indica mediante el valor de un atributo que llamamos la clase de lainstancia. Este atributo puede tomar diferentes valores discretos, cada uno delos cuales corresponde a una clase. El objetivo es recogidos los datos deinterés, un explorador puede decidir qué tipo de patrón quiere descubrir.
Ejemplo: Un oftalmólogo desea disponer de un sistema que le sirva paradeterminar la conveniencia o no de recomendar la cirugía ocular a suspacientes. Para ello dispone de una BD de sus antiguos pacientesclasificados en operados satisfactoriamente o no operadossatisfactoriamente, en función del tipo de problema que padecían (miopía ysu grado, o astigmatismo) y de su edad. El modelo encontrado se utiliza paraclasificar nuevos pacientes, es decir, para decidir si es conveniente operarlos ono.
7
Tareas de la minería de datos:A) Clasificación. Cada instancia de (o registro de la BD) pertenece a una clase,
la cual se indica mediante el valor de un atributo que llamamos la clase de lainstancia. Este atributo puede tomar diferentes valores discretos, cada uno delos cuales corresponde a una clase. El objetivo es recogidos los datos deinterés, un explorador puede decidir qué tipo de patrón quiere descubrir.
Ejemplo: Un oftalmólogo desea disponer de un sistema que le sirva paradeterminar la conveniencia o no de recomendar la cirugía ocular a suspacientes. Para ello dispone de una BD de sus antiguos pacientesclasificados en operados satisfactoriamente o no operadossatisfactoriamente, en función del tipo de problema que padecían (miopía ysu grado, o astigmatismo) y de su edad. El modelo encontrado se utiliza paraclasificar nuevos pacientes, es decir, para decidir si es conveniente operarlos ono.
Operados satisfactoriamente No Operados satisfactoriamente
Condiciones
Tareas de la minería de datos
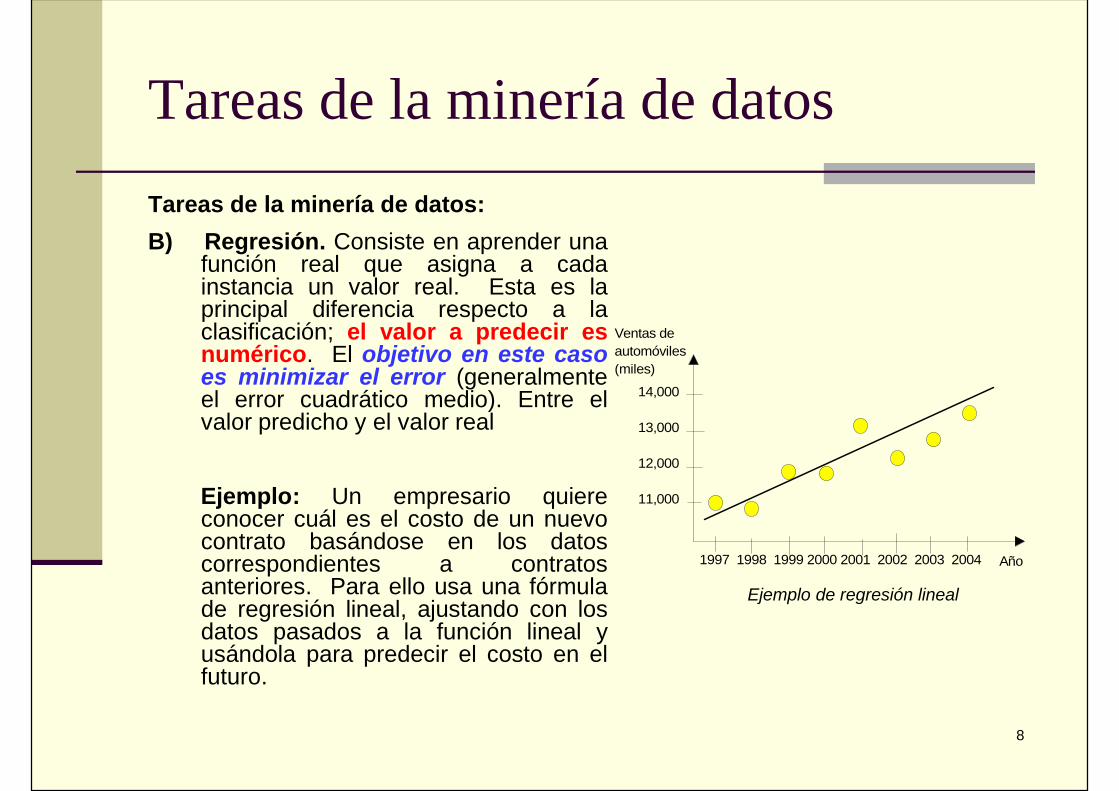
Tareas de la minería de datos:B) Regresión. Consiste en aprender una
función real que asigna a cadainstancia un valor real. Esta es laprincipal diferencia respecto a laclasificación; el valor a predecir esnumérico. El objetivo en este casoes minimizar el error (generalmenteel error cuadrático medio). Entre elvalor predicho y el valor real
Ejemplo: Un empresario quiereconocer cuál es el costo de un nuevocontrato basándose en los datoscorrespondientes a contratosanteriores. Para ello usa una fórmulade regresión lineal, ajustando con losdatos pasados a la función lineal yusándola para predecir el costo en elfuturo.
Tareas de la minería de datos:B) Regresión. Consiste en aprender una
función real que asigna a cadainstancia un valor real. Esta es laprincipal diferencia respecto a laclasificación; el valor a predecir esnumérico. El objetivo en este casoes minimizar el error (generalmenteel error cuadrático medio). Entre elvalor predicho y el valor real
Ejemplo: Un empresario quiereconocer cuál es el costo de un nuevocontrato basándose en los datoscorrespondientes a contratosanteriores. Para ello usa una fórmulade regresión lineal, ajustando con losdatos pasados a la función lineal yusándola para predecir el costo en elfuturo.
Ventas deautomóviles(miles)
Año
14,000
13,000
12,000
11,000
1997 1998 1999 2000 2001 2002 2003 2004
8
Tareas de la minería de datos:B) Regresión. Consiste en aprender una
función real que asigna a cadainstancia un valor real. Esta es laprincipal diferencia respecto a laclasificación; el valor a predecir esnumérico. El objetivo en este casoes minimizar el error (generalmenteel error cuadrático medio). Entre elvalor predicho y el valor real
Ejemplo: Un empresario quiereconocer cuál es el costo de un nuevocontrato basándose en los datoscorrespondientes a contratosanteriores. Para ello usa una fórmulade regresión lineal, ajustando con losdatos pasados a la función lineal yusándola para predecir el costo en elfuturo.
Ventas deautomóviles(miles)
Año
14,000
13,000
12,000
11,000
1997 1998 1999 2000 2001 2002 2003 2004
Ejemplo de regresión lineal
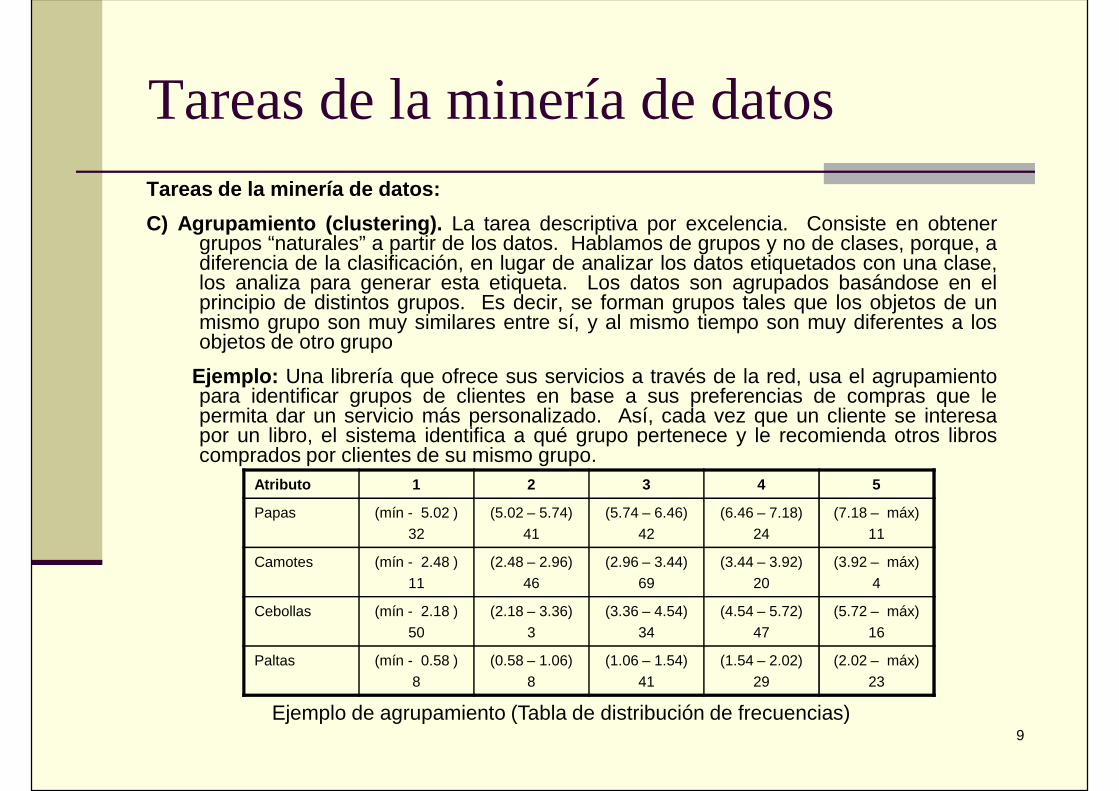
Tareas de la minería de datosTareas de la minería de datos:C) Agrupamiento (clustering). La tarea descriptiva por excelencia. Consiste en obtener
grupos “naturales” a partir de los datos. Hablamos de grupos y no de clases, porque, adiferencia de la clasificación, en lugar de analizar los datos etiquetados con una clase,los analiza para generar esta etiqueta. Los datos son agrupados basándose en elprincipio de distintos grupos. Es decir, se forman grupos tales que los objetos de unmismo grupo son muy similares entre sí, y al mismo tiempo son muy diferentes a losobjetos de otro grupo
Ejemplo: Una librería que ofrece sus servicios a través de la red, usa el agrupamientopara identificar grupos de clientes en base a sus preferencias de compras que lepermita dar un servicio más personalizado. Así, cada vez que un cliente se interesapor un libro, el sistema identifica a qué grupo pertenece y le recomienda otros libroscomprados por clientes de su mismo grupo.
Tareas de la minería de datos:C) Agrupamiento (clustering). La tarea descriptiva por excelencia. Consiste en obtener
grupos “naturales” a partir de los datos. Hablamos de grupos y no de clases, porque, adiferencia de la clasificación, en lugar de analizar los datos etiquetados con una clase,los analiza para generar esta etiqueta. Los datos son agrupados basándose en elprincipio de distintos grupos. Es decir, se forman grupos tales que los objetos de unmismo grupo son muy similares entre sí, y al mismo tiempo son muy diferentes a losobjetos de otro grupo
Ejemplo: Una librería que ofrece sus servicios a través de la red, usa el agrupamientopara identificar grupos de clientes en base a sus preferencias de compras que lepermita dar un servicio más personalizado. Así, cada vez que un cliente se interesapor un libro, el sistema identifica a qué grupo pertenece y le recomienda otros libroscomprados por clientes de su mismo grupo.
Atributo 1 2 3 4 5
Papas (mín - 5.02 )32
(5.02 – 5.74)41
(5.74 – 6.46)42
(6.46 – 7.18)24
(7.18 – máx)11
9
(mín - 5.02 )32
(5.02 – 5.74)41
(5.74 – 6.46)42
(6.46 – 7.18)24
(7.18 – máx)11
Camotes (mín - 2.48 )11
(2.48 – 2.96)46
(2.96 – 3.44)69
(3.44 – 3.92)20
(3.92 – máx)4
Cebollas (mín - 2.18 )50
(2.18 – 3.36)3
(3.36 – 4.54)34
(4.54 – 5.72)47
(5.72 – máx)16
Paltas (mín - 0.58 )8
(0.58 – 1.06)8
(1.06 – 1.54)41
(1.54 – 2.02)29
(2.02 – máx)23
Ejemplo de agrupamiento (Tabla de distribución de frecuencias)
Tareas de la minería de datos
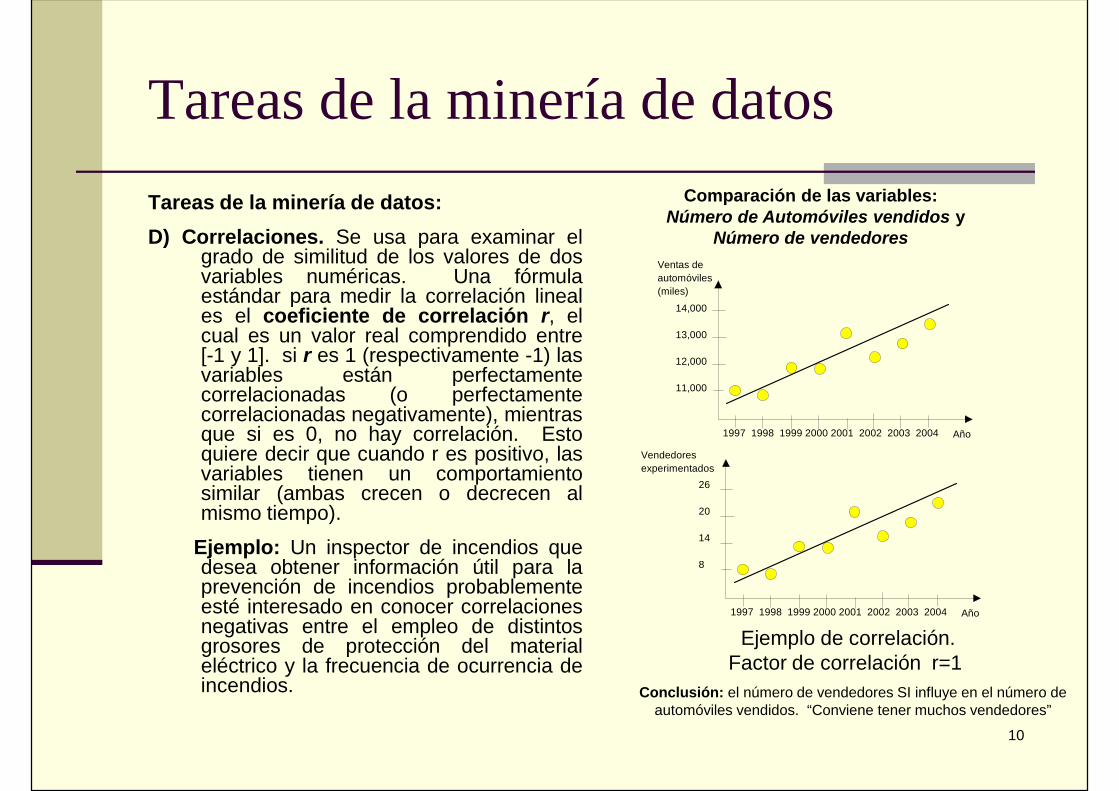
Tareas de la minería de datos:D) Correlaciones. Se usa para examinar el
grado de similitud de los valores de dosvariables numéricas. Una fórmulaestándar para medir la correlación lineales el coeficiente de correlación r, elcual es un valor real comprendido entre[-1 y 1]. si r es 1 (respectivamente -1) lasvariables están perfectamentecorrelacionadas (o perfectamentecorrelacionadas negativamente), mientrasque si es 0, no hay correlación. Estoquiere decir que cuando r es positivo, lasvariables tienen un comportamientosimilar (ambas crecen o decrecen almismo tiempo).
Ejemplo: Un inspector de incendios quedesea obtener información útil para laprevención de incendios probablementeesté interesado en conocer correlacionesnegativas entre el empleo de distintosgrosores de protección del materialeléctrico y la frecuencia de ocurrencia deincendios.
Ventas deautomóviles(miles)
Año
14,000
13,000
12,000
11,000
1997 1998 1999 2000 2001 2002 2003 2004
Comparación de las variables:Número de Automóviles vendidos y
Número de vendedores
Tareas de la minería de datos:D) Correlaciones. Se usa para examinar el
grado de similitud de los valores de dosvariables numéricas. Una fórmulaestándar para medir la correlación lineales el coeficiente de correlación r, elcual es un valor real comprendido entre[-1 y 1]. si r es 1 (respectivamente -1) lasvariables están perfectamentecorrelacionadas (o perfectamentecorrelacionadas negativamente), mientrasque si es 0, no hay correlación. Estoquiere decir que cuando r es positivo, lasvariables tienen un comportamientosimilar (ambas crecen o decrecen almismo tiempo).
Ejemplo: Un inspector de incendios quedesea obtener información útil para laprevención de incendios probablementeesté interesado en conocer correlacionesnegativas entre el empleo de distintosgrosores de protección del materialeléctrico y la frecuencia de ocurrencia deincendios.
Ventas deautomóviles(miles)
Año
14,000
13,000
12,000
11,000
1997 1998 1999 2000 2001 2002 2003 2004
Vendedoresexperimentados
Año
26
20
14
8
1997 1998 1999 2000 2001 2002 2003 2004
10
Tareas de la minería de datos:D) Correlaciones. Se usa para examinar el
grado de similitud de los valores de dosvariables numéricas. Una fórmulaestándar para medir la correlación lineales el coeficiente de correlación r, elcual es un valor real comprendido entre[-1 y 1]. si r es 1 (respectivamente -1) lasvariables están perfectamentecorrelacionadas (o perfectamentecorrelacionadas negativamente), mientrasque si es 0, no hay correlación. Estoquiere decir que cuando r es positivo, lasvariables tienen un comportamientosimilar (ambas crecen o decrecen almismo tiempo).
Ejemplo: Un inspector de incendios quedesea obtener información útil para laprevención de incendios probablementeesté interesado en conocer correlacionesnegativas entre el empleo de distintosgrosores de protección del materialeléctrico y la frecuencia de ocurrencia deincendios.
Vendedoresexperimentados
Año
26
20
14
8
1997 1998 1999 2000 2001 2002 2003 2004
Ejemplo de correlación.Factor de correlación r=1
Conclusión: el número de vendedores SI influye en el número deautomóviles vendidos. “Conviene tener muchos vendedores”
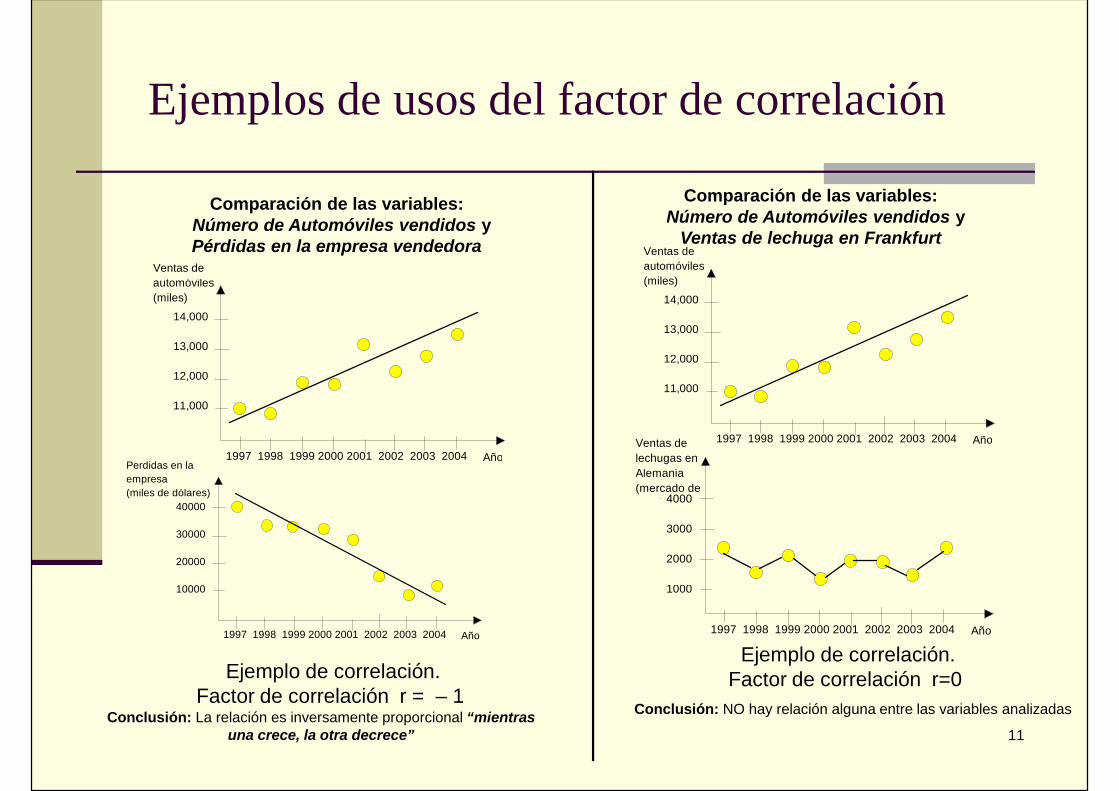
Ejemplos de usos del factor de correlación
Ventas deautomóviles(miles)
Año
14,000
13,000
12,000
11,000
1997 1998 1999 2000 2001 2002 2003 2004
Comparación de las variables:Número de Automóviles vendidos y
Ventas de lechuga en FrankfurtVentas deautomóviles(miles)
Año
14,000
13,000
12,000
11,000
1997 1998 1999 2000 2001 2002 2003 2004
Comparación de las variables:Número de Automóviles vendidos yPérdidas en la empresa vendedora Ventas de
automóviles(miles)
Año
14,000
13,000
12,000
11,000
1997 1998 1999 2000 2001 2002 2003 2004Ventas delechugas enAlemania(mercado deFrankfurt)
Año
4000
3000
2000
1000
1997 1998 1999 2000 2001 2002 2003 2004
Perdidas en laempresa(miles de dólares)
Año1997 1998 1999 2000 2001 2002 2003 2004
40000
30000
20000
10000
Ventas deautomóviles(miles)
Año
14,000
13,000
12,000
11,000
1997 1998 1999 2000 2001 2002 2003 2004
11
Ventas delechugas enAlemania(mercado deFrankfurt)
Año
4000
3000
2000
1000
1997 1998 1999 2000 2001 2002 2003 2004
Ejemplo de correlación.Factor de correlación r=0
Conclusión: NO hay relación alguna entre las variables analizadas
Perdidas en laempresa(miles de dólares)
Año1997 1998 1999 2000 2001 2002 2003 2004
40000
30000
20000
10000
Ejemplo de correlación.Factor de correlación r = – 1
Conclusión: La relación es inversamente proporcional “mientrasuna crece, la otra decrece”

Tareas de la minería de datos
Tareas de minería de datos E) Reglas de asociación. Muy similar a las correlaciones. Tiene como objetivo identificar
relaciones no explícitas entre atributos categóricos. Pueden ser de muchas formas, aunquela formulación más común es del estilo: “si el atributo X toma el valor d, entonces el atributoY toma el valor b”. Las reglas de asociación no implican una relación causa-efecto, esdecir, puede no existir una causa para que los datos estén asociados. Este tipo de tarea seusa frecuentemente en el análisis de la cesta de la compra, para identificar productos queson frecuentemente comprados juntos.
Ejemplo 1: Una compañía sanitaria desea analizar las peticiones de servicios médicossolicitados por sus asegurados. Cada petición contiene información sobre las pruebasmédicas que fueron realizadas al paciente durante una visita. Toda esta información sealmacena en una base de datos en la que cada petición es un registro cuyos atributosexpresan si se realiza o no cada una de las posibles pruebas médicas que pueden serrealizadas a un paciente. Mediante reglas de asociación, un sistema encontraría aquellaspruebas médicas que frecuentemente se realizan juntas, por ejemplo un 70 % de las vecesque se pide un análisis de orina también se solicita uno de sangre, y esto ocurre en dos decada diez pacientes. La precisión de esta regla es del 70% y el soporte del 20%.Ejemplo 2: Los clientes que compran pañales también compran jabón para niños, en el80% de los casos.
Tareas de minería de datos E) Reglas de asociación. Muy similar a las correlaciones. Tiene como objetivo identificar
relaciones no explícitas entre atributos categóricos. Pueden ser de muchas formas, aunquela formulación más común es del estilo: “si el atributo X toma el valor d, entonces el atributoY toma el valor b”. Las reglas de asociación no implican una relación causa-efecto, esdecir, puede no existir una causa para que los datos estén asociados. Este tipo de tarea seusa frecuentemente en el análisis de la cesta de la compra, para identificar productos queson frecuentemente comprados juntos.
Ejemplo 1: Una compañía sanitaria desea analizar las peticiones de servicios médicossolicitados por sus asegurados. Cada petición contiene información sobre las pruebasmédicas que fueron realizadas al paciente durante una visita. Toda esta información sealmacena en una base de datos en la que cada petición es un registro cuyos atributosexpresan si se realiza o no cada una de las posibles pruebas médicas que pueden serrealizadas a un paciente. Mediante reglas de asociación, un sistema encontraría aquellaspruebas médicas que frecuentemente se realizan juntas, por ejemplo un 70 % de las vecesque se pide un análisis de orina también se solicita uno de sangre, y esto ocurre en dos decada diez pacientes. La precisión de esta regla es del 70% y el soporte del 20%.Ejemplo 2: Los clientes que compran pañales también compran jabón para niños, en el80% de los casos.
12
Tareas de minería de datos E) Reglas de asociación. Muy similar a las correlaciones. Tiene como objetivo identificar
relaciones no explícitas entre atributos categóricos. Pueden ser de muchas formas, aunquela formulación más común es del estilo: “si el atributo X toma el valor d, entonces el atributoY toma el valor b”. Las reglas de asociación no implican una relación causa-efecto, esdecir, puede no existir una causa para que los datos estén asociados. Este tipo de tarea seusa frecuentemente en el análisis de la cesta de la compra, para identificar productos queson frecuentemente comprados juntos.
Ejemplo 1: Una compañía sanitaria desea analizar las peticiones de servicios médicossolicitados por sus asegurados. Cada petición contiene información sobre las pruebasmédicas que fueron realizadas al paciente durante una visita. Toda esta información sealmacena en una base de datos en la que cada petición es un registro cuyos atributosexpresan si se realiza o no cada una de las posibles pruebas médicas que pueden serrealizadas a un paciente. Mediante reglas de asociación, un sistema encontraría aquellaspruebas médicas que frecuentemente se realizan juntas, por ejemplo un 70 % de las vecesque se pide un análisis de orina también se solicita uno de sangre, y esto ocurre en dos decada diez pacientes. La precisión de esta regla es del 70% y el soporte del 20%.Ejemplo 2: Los clientes que compran pañales también compran jabón para niños, en el80% de los casos.

Tareas de la minería de datos
Tareas de minería de datosReglas de asociación secuenciales Son un caso especial de reglas de asociación. Se usa para determinar patrones
secuenciales en los datos. Estos patrones se basan en secuencias temporales de acciones ydifieren de las reglas de asociación en que las relaciones entre los datos se basan en eltiempo.
Ejemplo: Una tienda de electrodomésticos y equipos de audio analiza las ventas que haefectuado usando análisis secuencial y descubre que el 30% de los clientes que compraronun televisor hace seis meses, luego, compraron un DVD en los siguientes dos meses.
Tareas de minería de datosReglas de asociación secuenciales Son un caso especial de reglas de asociación. Se usa para determinar patrones
secuenciales en los datos. Estos patrones se basan en secuencias temporales de acciones ydifieren de las reglas de asociación en que las relaciones entre los datos se basan en eltiempo.
Ejemplo: Una tienda de electrodomésticos y equipos de audio analiza las ventas que haefectuado usando análisis secuencial y descubre que el 30% de los clientes que compraronun televisor hace seis meses, luego, compraron un DVD en los siguientes dos meses.
Compra cunapara bebes
Compratelevisor
Comprapañales
CompraDVD
Compra cajaspara DVD
Compra juguetesde niño ¿ ... ?
¿ ... ?
Tiempo
1 2 3 4 5 6 ...
Secuencia 2
Secuencia 1
mes mes mes mes mes mes ...
13
Tareas de minería de datosReglas de asociación secuenciales Son un caso especial de reglas de asociación. Se usa para determinar patrones
secuenciales en los datos. Estos patrones se basan en secuencias temporales de acciones ydifieren de las reglas de asociación en que las relaciones entre los datos se basan en eltiempo.
Ejemplo: Una tienda de electrodomésticos y equipos de audio analiza las ventas que haefectuado usando análisis secuencial y descubre que el 30% de los clientes que compraronun televisor hace seis meses, luego, compraron un DVD en los siguientes dos meses.
Compra cunapara bebes
Compratelevisor
Comprapañales
CompraDVD
Compra cajaspara DVD
Compra juguetesde niño ¿ ... ?
¿ ... ?
Tiempo
1 2 3 4 5 6 ...
Secuencia 2
Secuencia 1
mes mes mes mes mes mes ...

Patrones a descubrir:
• Una vez recogidos los datos de interés, un explorador puede decidir quétipo de patrón quiere descubrir.
• El tipo de conocimiento que se desea extraer va a marcar claramente latécnica de minería de datos a utilizar.
• Según como sea la búsqueda del conocimiento se puede distinguir entre:
• Directed data mining: se sabe claramente lo que se busca,generalmente predecir unos ciertos datos o clases.
• Undirected data mining: no se sabe lo que se busca, se trabaja conlos datos (¡hasta que confiesen!).
• En el primer caso, algunos sistemas de minería de datos se encargangeneralmente de elegir el algoritmo más idóneo entre los disponiblespara un determinado tipo de patrón a buscar.
Tareas de la minería de datosPatrones a descubrir:
• Una vez recogidos los datos de interés, un explorador puede decidir quétipo de patrón quiere descubrir.
• El tipo de conocimiento que se desea extraer va a marcar claramente latécnica de minería de datos a utilizar.
• Según como sea la búsqueda del conocimiento se puede distinguir entre:
• Directed data mining: se sabe claramente lo que se busca,generalmente predecir unos ciertos datos o clases.
• Undirected data mining: no se sabe lo que se busca, se trabaja conlos datos (¡hasta que confiesen!).
• En el primer caso, algunos sistemas de minería de datos se encargangeneralmente de elegir el algoritmo más idóneo entre los disponiblespara un determinado tipo de patrón a buscar.
14
Patrones a descubrir:
• Una vez recogidos los datos de interés, un explorador puede decidir quétipo de patrón quiere descubrir.
• El tipo de conocimiento que se desea extraer va a marcar claramente latécnica de minería de datos a utilizar.
• Según como sea la búsqueda del conocimiento se puede distinguir entre:
• Directed data mining: se sabe claramente lo que se busca,generalmente predecir unos ciertos datos o clases.
• Undirected data mining: no se sabe lo que se busca, se trabaja conlos datos (¡hasta que confiesen!).
• En el primer caso, algunos sistemas de minería de datos se encargangeneralmente de elegir el algoritmo más idóneo entre los disponiblespara un determinado tipo de patrón a buscar.

A) Ejemplos de Modelo Predictivo:
Queremos saber si se podrá jugar o no jugar esta tarde al tenis. Hemos recogido datos de experiencias anteriores:
Ejemplo Cielo Temperatura Humedad Físico JugarTennis1 Soleado Calor Alta Débil NO2 Soleado Calor Alta Muy bien NO3 Nublado Calor Alta Débil SI4 Lluvioso Templado Alta Débil SI5 Lluvioso Frío Normal Débil SI6 Lluvioso Frío Normal Muy bien NO7 Nublado Frío Normal Muy bien SI8 Soleado Templado Alta Débil No9 Soleado Frío Normal Débil SI10 Lluvioso Templado Normal Débil SI11 Soleado Templado Normal Muy bien SI12 Nublado Templado Alta Muy bien SI13 Nublado Calor Normal Débil SI14 Lluvioso Templado Alta Muy bien NO
Datos Seleccionados Data Agregada
Queremos saber si se podrá jugar o no jugar esta tarde al tenis. Hemos recogido datos de experiencias anteriores:
Ejemplo Cielo Temperatura Humedad Físico JugarTennis1 Soleado Calor Alta Débil NO2 Soleado Calor Alta Muy bien NO3 Nublado Calor Alta Débil SI4 Lluvioso Templado Alta Débil SI5 Lluvioso Frío Normal Débil SI6 Lluvioso Frío Normal Muy bien NO7 Nublado Frío Normal Muy bien SI8 Soleado Templado Alta Débil No9 Soleado Frío Normal Débil SI10 Lluvioso Templado Normal Débil SI11 Soleado Templado Normal Muy bien SI12 Nublado Templado Alta Muy bien SI13 Nublado Calor Normal Débil SI14 Lluvioso Templado Alta Muy bien NO
Datos Seleccionados Data Agregada
15
Ejemplo Cielo Temperatura Humedad Físico JugarTennis1 Soleado Calor Alta Débil NO2 Soleado Calor Alta Muy bien NO3 Nublado Calor Alta Débil SI4 Lluvioso Templado Alta Débil SI5 Lluvioso Frío Normal Débil SI6 Lluvioso Frío Normal Muy bien NO7 Nublado Frío Normal Muy bien SI8 Soleado Templado Alta Débil No9 Soleado Frío Normal Débil SI10 Lluvioso Templado Normal Débil SI11 Soleado Templado Normal Muy bien SI12 Nublado Templado Alta Muy bien SI13 Nublado Calor Normal Débil SI14 Lluvioso Templado Alta Muy bien NO
Datos Seleccionados Data Agregada
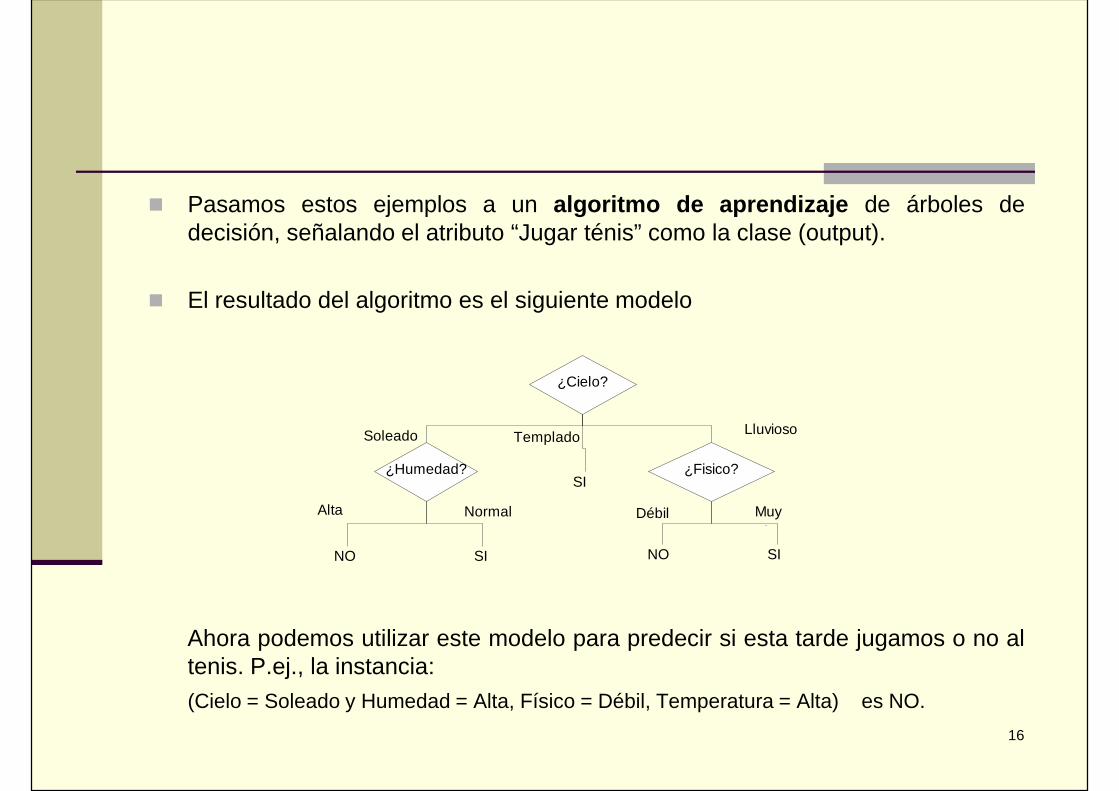
Pasamos estos ejemplos a un algoritmo de aprendizaje de árboles dedecisión, señalando el atributo “Jugar ténis” como la clase (output).
El resultado del algoritmo es el siguiente modelo
Ahora podemos utilizar este modelo para predecir si esta tarde jugamos o no altenis. P.ej., la instancia:(Cielo = Soleado y Humedad = Alta, Físico = Débil, Temperatura = Alta) es NO.
Pasamos estos ejemplos a un algoritmo de aprendizaje de árboles dedecisión, señalando el atributo “Jugar ténis” como la clase (output).
El resultado del algoritmo es el siguiente modelo
Ahora podemos utilizar este modelo para predecir si esta tarde jugamos o no altenis. P.ej., la instancia:(Cielo = Soleado y Humedad = Alta, Físico = Débil, Temperatura = Alta) es NO.
¿Humedad?
¿Cielo?
¿Fisico?SI
Soleado LluviosoTemplado
NO SI NO SI
Alta Normal Débil MuyBien
16
Pasamos estos ejemplos a un algoritmo de aprendizaje de árboles dedecisión, señalando el atributo “Jugar ténis” como la clase (output).
El resultado del algoritmo es el siguiente modelo
Ahora podemos utilizar este modelo para predecir si esta tarde jugamos o no altenis. P.ej., la instancia:(Cielo = Soleado y Humedad = Alta, Físico = Débil, Temperatura = Alta) es NO.
¿Humedad?
¿Cielo?
¿Fisico?SI
Soleado LluviosoTemplado
NO SI NO SI
Alta Normal Débil MuyBien

Regresión, comparación dedos variables usando elStatGraphics Plus 5.1
Regresión, comparación dedos variables usando elStatGraphics Plus 5.1
17
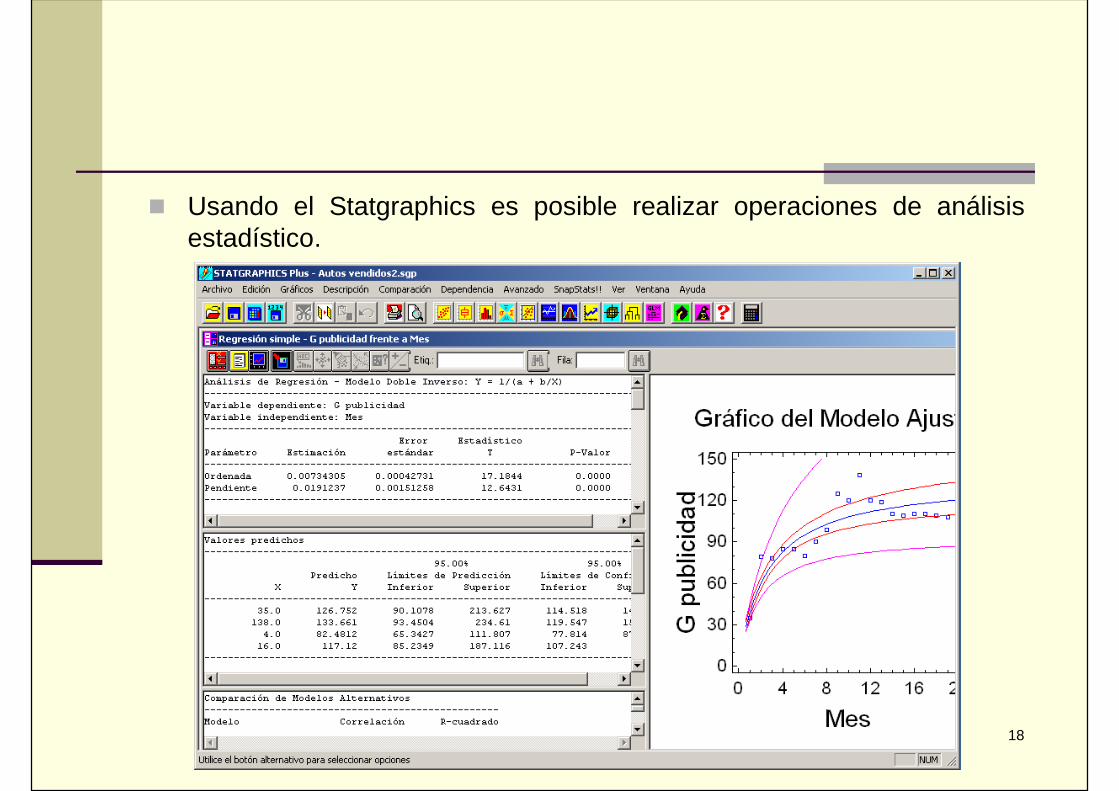
Usando el Statgraphics es posible realizar operaciones de análisisestadístico.
18

EJERCICIO DEMINERIA DE DATOSEJERCICIO DEMINERIA DE DATOS
19

Paso 1: Titulo del análisisMontos óptimos de inversión en publicidad en la empresa “Imports Junior S.A.”
Paso 2: Formulación del problemaEl gerente de la empresa “Imports Junior S.A.” desea promover un plan de
marketing, y está profundamente interesado en conocer los montos quedebieran invertirse en publicidad.
El problema es el siguiente:
Paso 1: Titulo del análisisMontos óptimos de inversión en publicidad en la empresa “Imports Junior S.A.”
Paso 2: Formulación del problemaEl gerente de la empresa “Imports Junior S.A.” desea promover un plan de
marketing, y está profundamente interesado en conocer los montos quedebieran invertirse en publicidad.
El problema es el siguiente:
¿Qué monto debo invertir en publicidad para maximizar mis ganancias?
20

Paso 3: MetodologíaSe realizarán dos contrastaciones por regresión: En una primera oportunidad se contrastarán las variables
“Ganancias” y “Mes”, para identificar en qué meses se producenlas mayores ganancias.
A continuación se contrastarán las variables “Gastos en publicidad”y “Mes” y se obtendrá la media de los meses en los cuales seobtuvieron mayores ganancias. Esta media obtenida es el valorque dará respuesta a la pregunta inicialmente formulada.
Paso 4: Temática de los datos de la muestra.Los datos de la muestra son el informe de ventas, ganancias y gastosen publicidad realizados por la empresa “Imports Junior S.A.” durantelos primeros N meses del año 2005.
Paso 3: MetodologíaSe realizarán dos contrastaciones por regresión: En una primera oportunidad se contrastarán las variables
“Ganancias” y “Mes”, para identificar en qué meses se producenlas mayores ganancias.
A continuación se contrastarán las variables “Gastos en publicidad”y “Mes” y se obtendrá la media de los meses en los cuales seobtuvieron mayores ganancias. Esta media obtenida es el valorque dará respuesta a la pregunta inicialmente formulada.
Paso 4: Temática de los datos de la muestra.Los datos de la muestra son el informe de ventas, ganancias y gastosen publicidad realizados por la empresa “Imports Junior S.A.” durantelos primeros N meses del año 2005.
21
Paso 3: MetodologíaSe realizarán dos contrastaciones por regresión: En una primera oportunidad se contrastarán las variables
“Ganancias” y “Mes”, para identificar en qué meses se producenlas mayores ganancias.
A continuación se contrastarán las variables “Gastos en publicidad”y “Mes” y se obtendrá la media de los meses en los cuales seobtuvieron mayores ganancias. Esta media obtenida es el valorque dará respuesta a la pregunta inicialmente formulada.
Paso 4: Temática de los datos de la muestra.Los datos de la muestra son el informe de ventas, ganancias y gastosen publicidad realizados por la empresa “Imports Junior S.A.” durantelos primeros N meses del año 2005.
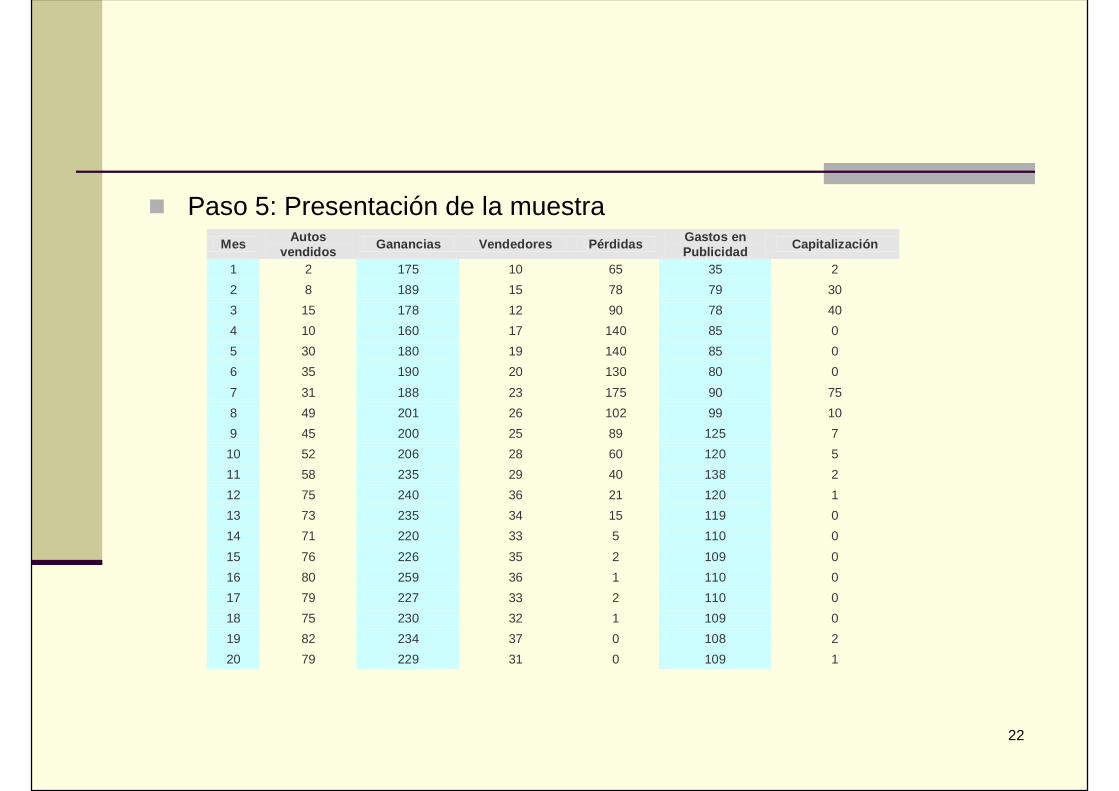
Paso 5: Presentación de la muestraMes Autos
vendidos Ganancias Vendedores Pérdidas Gastos enPublicidad Capitalización
1 2 175 10 65 35 22 8 189 15 78 79 303 15 178 12 90 78 404 10 160 17 140 85 05 30 180 19 140 85 06 35 190 20 130 80 07 31 188 23 175 90 758 49 201 26 102 99 109 45 200 25 89 125 710 52 206 28 60 120 511 58 235 29 40 138 212 75 240 36 21 120 113 73 235 34 15 119 014 71 220 33 5 110 015 76 226 35 2 109 016 80 259 36 1 110 017 79 227 33 2 110 018 75 230 32 1 109 019 82 234 37 0 108 220 79 229 31 0 109 1
Paso 5: Presentación de la muestraMes Autos
vendidos Ganancias Vendedores Pérdidas Gastos enPublicidad Capitalización
1 2 175 10 65 35 22 8 189 15 78 79 303 15 178 12 90 78 404 10 160 17 140 85 05 30 180 19 140 85 06 35 190 20 130 80 07 31 188 23 175 90 758 49 201 26 102 99 109 45 200 25 89 125 710 52 206 28 60 120 511 58 235 29 40 138 212 75 240 36 21 120 113 73 235 34 15 119 014 71 220 33 5 110 015 76 226 35 2 109 016 80 259 36 1 110 017 79 227 33 2 110 018 75 230 32 1 109 019 82 234 37 0 108 220 79 229 31 0 109 1
22
Mes Autosvendidos Ganancias Vendedores Pérdidas Gastos en
Publicidad Capitalización
1 2 175 10 65 35 22 8 189 15 78 79 303 15 178 12 90 78 404 10 160 17 140 85 05 30 180 19 140 85 06 35 190 20 130 80 07 31 188 23 175 90 758 49 201 26 102 99 109 45 200 25 89 125 710 52 206 28 60 120 511 58 235 29 40 138 212 75 240 36 21 120 113 73 235 34 15 119 014 71 220 33 5 110 015 76 226 35 2 109 016 80 259 36 1 110 017 79 227 33 2 110 018 75 230 32 1 109 019 82 234 37 0 108 220 79 229 31 0 109 1
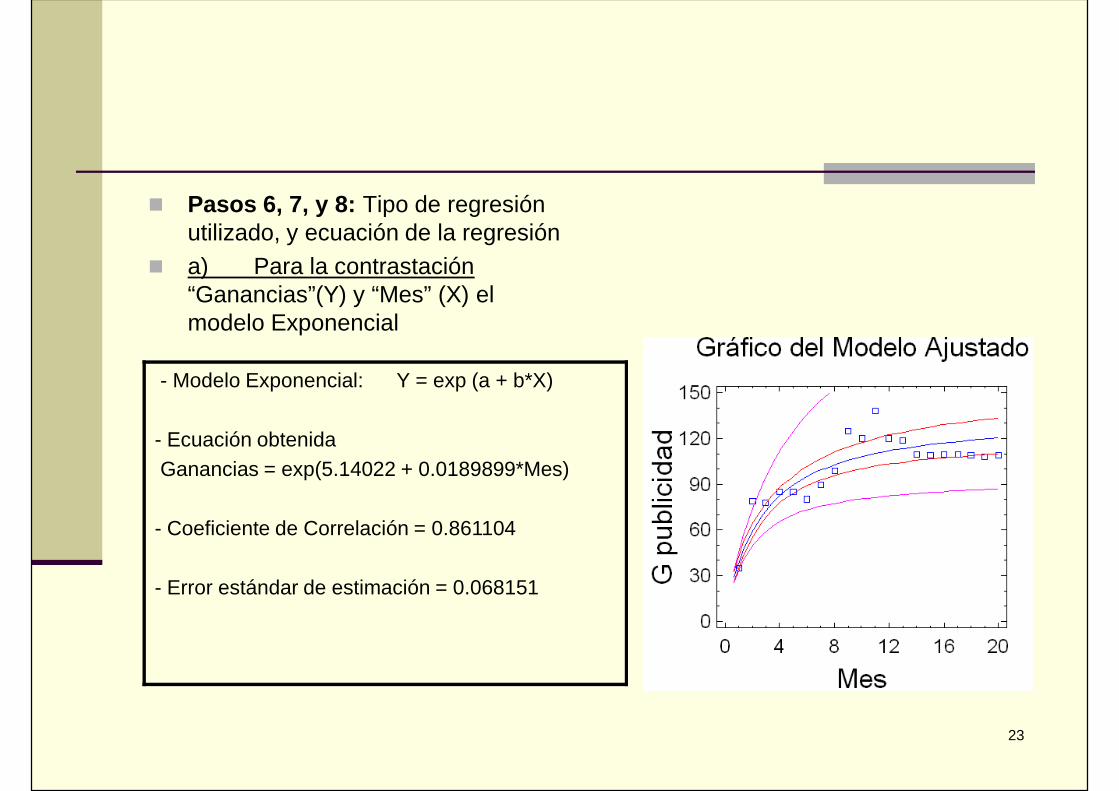
Pasos 6, 7, y 8: Tipo de regresiónutilizado, y ecuación de la regresión
a) Para la contrastación“Ganancias”(Y) y “Mes” (X) elmodelo Exponencial
Pasos 6, 7, y 8: Tipo de regresiónutilizado, y ecuación de la regresión
a) Para la contrastación“Ganancias”(Y) y “Mes” (X) elmodelo Exponencial
- Modelo Exponencial: Y = exp (a + b*X)
- Ecuación obtenidaGanancias = exp(5.14022 + 0.0189899*Mes)
- Coeficiente de Correlación = 0.861104
- Error estándar de estimación = 0.068151
23
- Modelo Exponencial: Y = exp (a + b*X)
- Ecuación obtenidaGanancias = exp(5.14022 + 0.0189899*Mes)
- Coeficiente de Correlación = 0.861104
- Error estándar de estimación = 0.068151
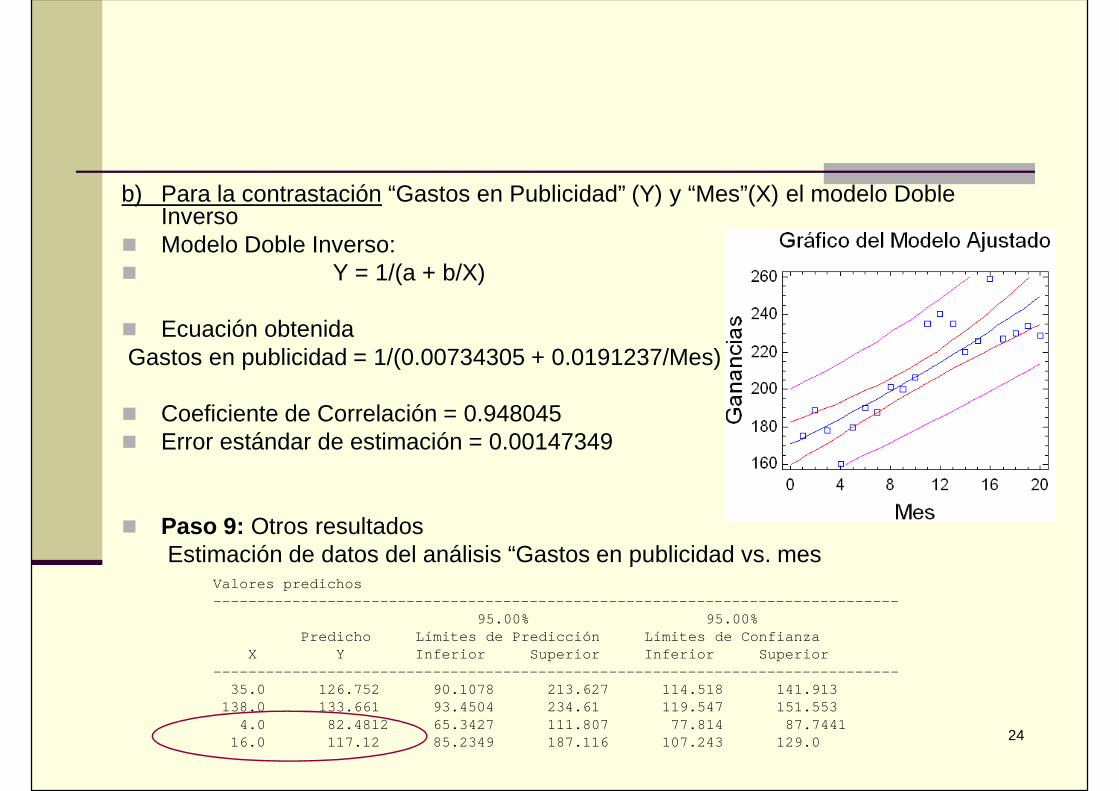
b) Para la contrastación “Gastos en Publicidad” (Y) y “Mes”(X) el modelo DobleInverso
Modelo Doble Inverso: Y = 1/(a + b/X)
Ecuación obtenidaGastos en publicidad = 1/(0.00734305 + 0.0191237/Mes)
Coeficiente de Correlación = 0.948045 Error estándar de estimación = 0.00147349
Paso 9: Otros resultadosEstimación de datos del análisis “Gastos en publicidad vs. mes
b) Para la contrastación “Gastos en Publicidad” (Y) y “Mes”(X) el modelo DobleInverso
Modelo Doble Inverso: Y = 1/(a + b/X)
Ecuación obtenidaGastos en publicidad = 1/(0.00734305 + 0.0191237/Mes)
Coeficiente de Correlación = 0.948045 Error estándar de estimación = 0.00147349
Paso 9: Otros resultadosEstimación de datos del análisis “Gastos en publicidad vs. mes
24
b) Para la contrastación “Gastos en Publicidad” (Y) y “Mes”(X) el modelo DobleInverso
Modelo Doble Inverso: Y = 1/(a + b/X)
Ecuación obtenidaGastos en publicidad = 1/(0.00734305 + 0.0191237/Mes)
Coeficiente de Correlación = 0.948045 Error estándar de estimación = 0.00147349
Paso 9: Otros resultadosEstimación de datos del análisis “Gastos en publicidad vs. mes
Valores predichos------------------------------------------------------------------------------
95.00% 95.00%Predicho Límites de Predicción Límites de Confianza
X Y Inferior Superior Inferior Superior------------------------------------------------------------------------------35.0 126.752 90.1078 213.627 114.518 141.913138.0 133.661 93.4504 234.61 119.547 151.553
4.0 82.4812 65.3427 111.807 77.814 87.744116.0 117.12 85.2349 187.116 107.243 129.0

Paso 10: Presentación del nuevo conocimientoA la luz del primer análisis detectamos que entre los meses 12 y 20 se producen lasmayores ganancias, luego, en el segundo gráfico, observamos que en este intervalo losmontos de gastos en publicidad se han estabilizado. Al parecer se ha entrado a unasegunda fase de marketing y se esta invirtiendo un monto estabilizado en publicidad.
El monto estimado para un período intermedio, es 117.12, sin embargo, debeconsiderarse que este monto es óptimo temporalmente es decir, a la larga, según lorecomendaría un especialista en marketing, el monto puede bajarse aún más hasta unmonto piso, debajo del cual no debería bajar más el monto de lo invertido en publicidad.
Paso 11: Técnicas utilizadasRegresión
Paso 12: ConclusionesLa técnica de regresión puede ser perfectamente utilizadas en actividades de minería dedatos en las cuales se deseare estimar o predecir valores.
Paso 13: BibliografíaManual de StatGraphicsOtros Libros
Paso 10: Presentación del nuevo conocimientoA la luz del primer análisis detectamos que entre los meses 12 y 20 se producen lasmayores ganancias, luego, en el segundo gráfico, observamos que en este intervalo losmontos de gastos en publicidad se han estabilizado. Al parecer se ha entrado a unasegunda fase de marketing y se esta invirtiendo un monto estabilizado en publicidad.
El monto estimado para un período intermedio, es 117.12, sin embargo, debeconsiderarse que este monto es óptimo temporalmente es decir, a la larga, según lorecomendaría un especialista en marketing, el monto puede bajarse aún más hasta unmonto piso, debajo del cual no debería bajar más el monto de lo invertido en publicidad.
Paso 11: Técnicas utilizadasRegresión
Paso 12: ConclusionesLa técnica de regresión puede ser perfectamente utilizadas en actividades de minería dedatos en las cuales se deseare estimar o predecir valores.
Paso 13: BibliografíaManual de StatGraphicsOtros Libros
El monto estimado para un período intermedio, es 117.12
25
Paso 10: Presentación del nuevo conocimientoA la luz del primer análisis detectamos que entre los meses 12 y 20 se producen lasmayores ganancias, luego, en el segundo gráfico, observamos que en este intervalo losmontos de gastos en publicidad se han estabilizado. Al parecer se ha entrado a unasegunda fase de marketing y se esta invirtiendo un monto estabilizado en publicidad.
El monto estimado para un período intermedio, es 117.12, sin embargo, debeconsiderarse que este monto es óptimo temporalmente es decir, a la larga, según lorecomendaría un especialista en marketing, el monto puede bajarse aún más hasta unmonto piso, debajo del cual no debería bajar más el monto de lo invertido en publicidad.
Paso 11: Técnicas utilizadasRegresión
Paso 12: ConclusionesLa técnica de regresión puede ser perfectamente utilizadas en actividades de minería dedatos en las cuales se deseare estimar o predecir valores.
Paso 13: BibliografíaManual de StatGraphicsOtros Libros

Tarea adesarrollar
Hacer el análisis deregresión de lasventas de unaempresa (porejemplo,distribuidora degaseosas, bodega,usuario deZofraTacna) ypresentar losresultados en dela siguiente forma
ITEM DEL INFORME DESCRIPCION1. Título del Análisis Título de su análisis.2. Formulación del problema Pregunta central a la cual se pretende dar
respuesta con el análisis3. Metodología Descripción genérica de la estrategia a aplicar.4. Temática de los datos seleccionados: Describa el lugar de donde fue extraída la
muestra de datos que utilizará en su ejercicio deanálisis de datos.
5. Presentación de la muestra Especifique los datos utilizados en el presentetrabajo de análisis de datos.
6. Tipo de Regresión: Describa el método de regresión utilizado.(Lineal, exponencial, multiplicativo, inversa de X,inversa de Y, etc)
7. Ecuación de regresión La ecuación aplicada para la estimación(Ejemplo de regresión lineal : y = 12 x + 15 )
8. Resultados generalesFactor de correlación
Error estándar de estimación Tablas comparativas
Presentación de los resultados decontrastaciones y/o análisis de datos.
9. Otros Resultados Tablas y/o gráficos de resultados que seránutilizadas en la obtención de nuevo conocimiento
10. Presentación del nuevo conocimientoa) ……..b) ………..c) …….. …….
Describa las conclusiones (nuevo conocimiento)que usted ha podido obtener del análisis dedatos. Realice una adecuada sustentación dedescripción de sus razones.
11. Técnicas de análisis aplicadasa) Regresiónb) Método 1c) Método 2d) …….
Mencione las técnicas de minería de datos queha utilizado en el presente análisis de datos yjustifique su utilización.
12. Conclusiones Conclusiones del presente trabajo13. Bibliografía Descripción de los libros y/o páginas de Internet
utilizadas.
Hacer el análisis deregresión de lasventas de unaempresa (porejemplo,distribuidora degaseosas, bodega,usuario deZofraTacna) ypresentar losresultados en dela siguiente forma
ITEM DEL INFORME DESCRIPCION1. Título del Análisis Título de su análisis.2. Formulación del problema Pregunta central a la cual se pretende dar
respuesta con el análisis3. Metodología Descripción genérica de la estrategia a aplicar.4. Temática de los datos seleccionados: Describa el lugar de donde fue extraída la
muestra de datos que utilizará en su ejercicio deanálisis de datos.
5. Presentación de la muestra Especifique los datos utilizados en el presentetrabajo de análisis de datos.
6. Tipo de Regresión: Describa el método de regresión utilizado.(Lineal, exponencial, multiplicativo, inversa de X,inversa de Y, etc)
7. Ecuación de regresión La ecuación aplicada para la estimación(Ejemplo de regresión lineal : y = 12 x + 15 )
8. Resultados generalesFactor de correlación
Error estándar de estimación Tablas comparativas
Presentación de los resultados decontrastaciones y/o análisis de datos.
9. Otros Resultados Tablas y/o gráficos de resultados que seránutilizadas en la obtención de nuevo conocimiento
10. Presentación del nuevo conocimientoa) ……..b) ………..c) …….. …….
Describa las conclusiones (nuevo conocimiento)que usted ha podido obtener del análisis dedatos. Realice una adecuada sustentación dedescripción de sus razones.
11. Técnicas de análisis aplicadasa) Regresiónb) Método 1c) Método 2d) …….
Mencione las técnicas de minería de datos queha utilizado en el presente análisis de datos yjustifique su utilización.
12. Conclusiones Conclusiones del presente trabajo13. Bibliografía Descripción de los libros y/o páginas de Internet
utilizadas.
26
Hacer el análisis deregresión de lasventas de unaempresa (porejemplo,distribuidora degaseosas, bodega,usuario deZofraTacna) ypresentar losresultados en dela siguiente forma
ITEM DEL INFORME DESCRIPCION1. Título del Análisis Título de su análisis.2. Formulación del problema Pregunta central a la cual se pretende dar
respuesta con el análisis3. Metodología Descripción genérica de la estrategia a aplicar.4. Temática de los datos seleccionados: Describa el lugar de donde fue extraída la
muestra de datos que utilizará en su ejercicio deanálisis de datos.
5. Presentación de la muestra Especifique los datos utilizados en el presentetrabajo de análisis de datos.
6. Tipo de Regresión: Describa el método de regresión utilizado.(Lineal, exponencial, multiplicativo, inversa de X,inversa de Y, etc)
7. Ecuación de regresión La ecuación aplicada para la estimación(Ejemplo de regresión lineal : y = 12 x + 15 )
8. Resultados generalesFactor de correlación
Error estándar de estimación Tablas comparativas
Presentación de los resultados decontrastaciones y/o análisis de datos.
9. Otros Resultados Tablas y/o gráficos de resultados que seránutilizadas en la obtención de nuevo conocimiento
10. Presentación del nuevo conocimientoa) ……..b) ………..c) …….. …….
Describa las conclusiones (nuevo conocimiento)que usted ha podido obtener del análisis dedatos. Realice una adecuada sustentación dedescripción de sus razones.
11. Técnicas de análisis aplicadasa) Regresiónb) Método 1c) Método 2d) …….
Mencione las técnicas de minería de datos queha utilizado en el presente análisis de datos yjustifique su utilización.
12. Conclusiones Conclusiones del presente trabajo13. Bibliografía Descripción de los libros y/o páginas de Internet
utilizadas.

FIN
27





























