Embed Size (px)
Citation preview

1. IBM Infosphere Data stage content
Contents Introduction about Data stage Difference between server jobs and Parallel jobs Pipeline parallelism and Partition Parallelism Partition Techniques Configuration file Processing Environment Data Stage Client and Server Components
Data stage Designer Introduction about Data stage Designer Repository Palatte Types of Links
File Stages Sequential file Data set File set Lookup file set
Database Stages Oracle Enterprise ODBC Enterprise Dynamic RDBMS
Processing Stages Aggregator Change Apply Change Capture Compare Compress Copy Decode Difference Encode Expand Filter Funnel Generic Join Look up Merge Modify Pivote Remove Duplicate External Filter

Sort Surrogate Key Generator Switch Transformer
Debugging Stages Column Generator Head Peek Row Generator Sample Tail
Datastage Manager Introduction about Data stage Manager Importing the Jobs Exporting the Jobs
2. IBM Infosphere Information Analyzer content
Information Analyzer Overview
Overview about Information Analyzer Tabs Home Overview Investigate Data Quality Operate
Types of Analysis in IA
Column Analysis Overview Frequency distribution Domain and completeness Data Class Analysis Format Analysis
Base Line Analysis
Foreign Key and Cross Domain Analysis

Primary Key Analysis
Single Column Analysis Multi Column Analysis
Data rules creation process
Defining Data rule Defintion Setting Bench Marks Data Rule Logic Validation Deriving Data rule from rule definition
Rule Sets Creation Process
Create List of Data rules Defining Rule set Definition Adding Data rules to rule set
Creating IA Projects
Importing Meta Data Adding Data Source to IA project Adding users to IA project Adding Groups to IA project
Information Analyzer Projects Roles
Bussiness Analyst Data Steward Data Operator Drill Down user
Virtual Column Creation Process
Different Types of Reports in IA Column Domain Report Column Frequency Report Data Rule Exception Report

Project Summary Report======================================================
3. IBM Info sphere Quality Stage Content:
Introduction about Data Quality
Data Quality Issues
Rule Set Files
Classification Table Dictionary File Pattern Action File Reference Tables Override Tables
User Define Rule sets Creation process
Investigate Stage
Character Discrete:
Investigate Character Discrete with C Mask Character Discrete with T Mask Character Discrete with X Mask
Character Concatenate:
Word Investigate:
Word Investigate for Full Name Word Investigate for Address Word Investigate for Area
Standardize Stage
Standardize Country Standardize Domain Preprocessing Standardize Name Standardize Address Standardize Area

Match Frequency Stage
Data Rules stage
AVI (Address Verification Interface Stage)

DATAWAREHOUSE:-------------------------------
Data ware house is nothing but collection of transactional data and historical data and can be maintained in dwh for analysis purpose.They are 3 types of tools should be maintained on any data warehousing project1. ETL Tools2. OLAP Tools (or) Reporting Tools3. Modeling Tool
ETL TOOL:ETL is nothing but Extraction, Transformation, and Loading. a ETL Developer(those who are expertise in dwh extracts data from heterogeneous databases(or)Flat files, Transform data from source to target(dwh) while transforming needs to apply transformation rules and finally load data into dwh.There are several ETL Tools available in the market those are1. Data stage2. Informatica3. Abinitio4. Oracle Warehouse Builder5. Bodi (Business Objects Data Integration)6. MSIS (Microsoft Integration Services)
OLAP:OLAP is nothing but Online Analytical Processing and these tools are called as reporting Tools AlsoA OLAP Developer analyses the data ware house and generate reports based on selection criteria.There are several OLAP Tools are available1. Business Objects2. Cognos3. Report Net4. SAS

5. Micro Strategy6. Hyperion7. MSAS (Microsoft Analysis Services)
MODELING TOOL:Those who are working with ERWIN Tool called data modeler .A data modeler can design data base of DWH with the help of fallowing toolsA ETL Developer can extract data from source databases (or) flat files(.txt,csv,.xls etc) and populates into DWH .While populating data into DWH they are some staging areas can be maintained between source and target .these staging areas are called staging area1 and staging area2.
STAGING AREA:Staging Area is nothing but is temporary place which is used for cleansing unnecessary data (or) unwanted data (or) inconsistency data.
Note: A Data Modeler can design DWH in two ways1. ER Modeling2. Dimensional Modeling
ER Modeling:
ER Modeling is nothing but entity relationship modeling. in this model always call table as entities and it may be second normal form (or) 3rd normal form (or) in between 2nd and 3rd normal form
Dimensional Modeling:In this model tables called as dimensions (or) fact tables. It can be subdivided into three schemas.
1. Star Schema2. Snow Flake Schema3. Multi Star Schema (or) Hybrid (or) Galaxy
Star Schema:A fact table surrounded by dimensions is called start schema. it looks like startIn a start schema if there is only one fact table then it is called simple start schema.In a start schema if there are more than one fact table then it is called complex start schema

Sales Fact table:Sale_idCustomer_idProduct_idAccount_idTime_idPromotion_idSales_per_dayProfit_per_day
Account Dimension:Account_idAccount_typeAccount_holder_nameAccount_open_dateAccount_nomineeAccount_open_balence
Pramotion:Promotion_idPromotion_typePromotion_datePramotion_designationPramotion_Area
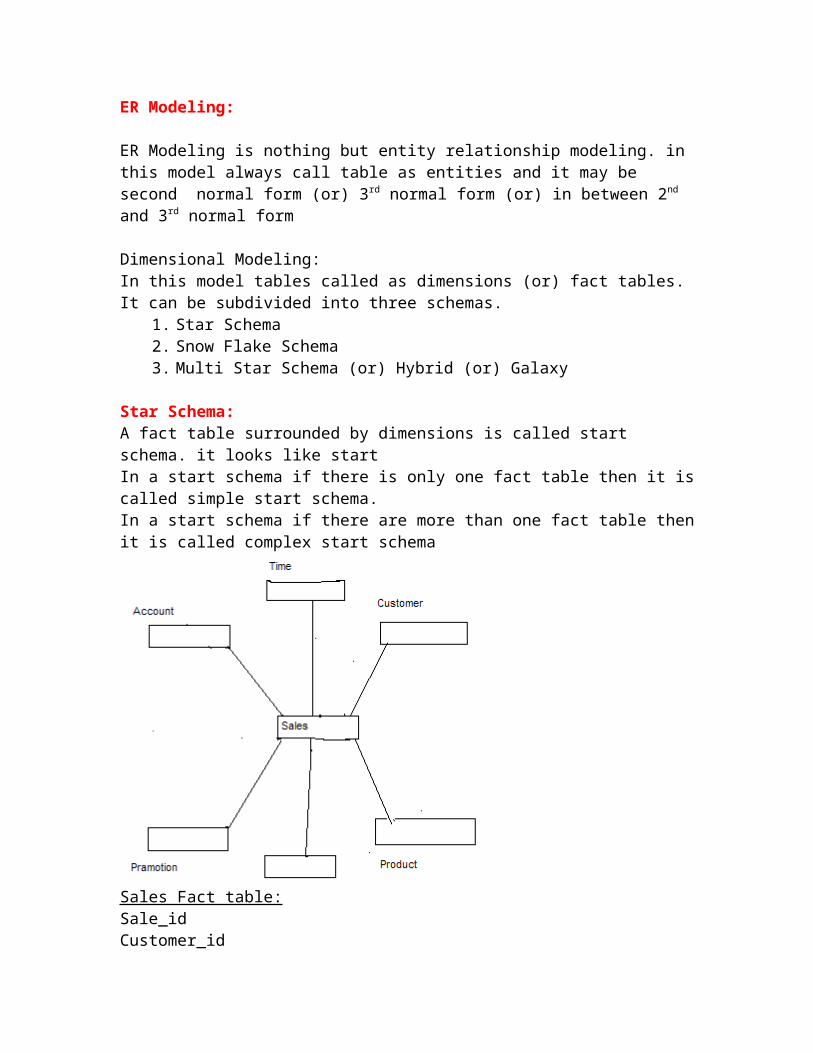
Product:Product_idProduct_nameProduct_typeProduct_descProduct_versionProduct_stratdateProduct_expdateProduct_maxpriceProduct_wholeprice
Customer:Cust_idCust_nameCust_typeCust_addressCust_phoneCust_nationalityCust_genderCust_father_nameCust_middle_name
Time:Time_idTime_zoneTime_formatMonth_dayWeek_dayYear_dayWeek_Yeat
DIMENSION TABLE: If a table contains primary keys and provides detail information about the table (or) master information of the table then called dimension table.
FACT TABLE: If a table contains more foreign keys and it’s having transactions, provides summarized information such a table called fact table.

DIMENSION TYPES:There are several dimension types are available
CONFORMED DIMENSION:
If a dimension table shared with more than one fact table (or) having foreign key more than one fact table. Then that dimension table is called confirmed dimension.
DEGENERATED DIMENSION:If a fact table act as dimension and it’s shared with another fact table (or) maintains foreign key in another fact table .such a table called degenerated dimension.
JUNK DIMENSION:A junk dimension contains text values, genders,(male/female),flag values(True/false) and which is not use full to generate reports. Such dimensions is called junk dimension.
DIRTY DIMENSION: If a record occurs more than one time in a table by the difference of non key attribute such a table is called dirty dimension
FACT TABLE TYPES:There are 3 types of fact s are available in fact table1. Additive facts2. Semi additive facts 3. Non additive facts
ADDITIVE FACTS:If there is a possibility to add some value to the existing fact in the fact table .that facts we called as additive fact.
SEMI ADDITIVE FACT:
If there is possibility to add some value to the existing fact up to some extent in the fact table is we called as semi additive fact.
NON ADDITIVE FACT:If there is not possibility to add some value to the existing fact in the fact table is we called as Non additive fact.
SNOW FLAKE SCHEMA: Snow Flake schema maintains in dimension table normalized data .in this schema some dimension tables are not directly maintained relation ship with fact table and those are maintained relation ship with another dimension

DIFFERENCE BETWEEN STAR SCHEMA AND SNOW FLAKE SCHEMA:
Star schema Snow flake schemaIt maintains demoralized data in the dimension table
It maintains normalized data in the dimension table
Performance will be increased when joining fact table to dimension table when
compared with snow flake
Performance will be decreases when joining fact table to dimension table to shrunken dimension table because it require more inner joins when compared with snow flake
All dimension table should maintain ed relation ship directly with fact table
Some dimension tables are not directly maintained relationship with fact table
INTRODUCTION ABOUT DATA STAGE:
1. Data stage:Data stage is a comprehensive ETL tool Or we can say Data stage is an data Integration and transformation tool which enables collection and consolidation of data from several sources,its transformation and delivery into one or multiple target systems
ETL stands for Extarction,Transformation ,LoadEExtraction from any sourceTTransformation(rich set of transformation capabilities)LLoading in to any target
There are several ETL Tools available in the market those are1. Data stage2. Informatica3. Abinitio4. Oracle Warehouse Builder5. Bodi (Business Objects Data Integration)6. MSIS (Microsoft Integration Services)

History of Data stage:
History Begins in 1997 the first version of data stage released by VMRAK company it’s a US based company Mr Lee scheffner is the father of data stageThose days data stage we callaed as Data integrator
In 1997 Data integrator acquired by company called TORRENTAgain in 1999 INFORMIX company has acquired this Data integrator from TORRENT companyIn 2000 ASCENTIAL company aquired this Data Integrator and after that Ascentaial Data stage server EditionFrom 6.0 to 7.5.1 versions they supports only Unix flavor environmentBecause server configured on only Unix plot form environmentIn 2004, a version 7.5.x2 is released that support server configuration for windows flatform also.In 2004, December the version 7.5.x2 were having ASCENTIAL suite componentsProfile stage, Quality stage, Audit stage, Meta stage, DataStage Px, DataStage Tx, DataStage MUS,These are all Individual toolsIn 2005, February the IBM acquired all the ASCENTIAL suite components and theIBM released IBM DS EE i.e., enterprise edition.In 2006, the IBM has made some changes to the IBM DS EE and the changes are theintegrated the profiling stage and audit stage into one, quality stage, Meta stage, andDataStage Px.IBM WEBSPHERE DS & QS 8.0In 2009, IBM has released another version that “IBM INFOSPHERE DS & QS 8.1”
Features Of Data stage:There are 5 important features of DataStage, they are- Any to Any,- Plat form Independent,- Node configuration,- Partition parallelism, and- Pipe line parallelism.

Any to Any:
Data stages can extract data from any source and can load data in to any target
Platform Independent:A job can run in any processor is called platform independentData stage jobs can run on 3 types of processorsThree types of processor are there, they are1. UNI Processor2. Symmetric Multi Processor (SMP), and3. Massively Multi Processor (MMP).
Node Configuration:Node is a logical CPU ie.instance of physical CPUThe process of creating virtual CPU’s is called Node configurationExample:ETL job requires executing 1000 recordsIn Uni processor it takes 10 mins to execute 1000 recordsBut in same thing SMP processor takes 2.5 mins to execute 1000 records
Difference between server jobs and Parallel jobs:Parallel jobs:1. Datastage parallel jobs can run in parallel on multiple nodes2. Parallel jobs support partition parallelism (Round robin Hash modulus etc.3. The transformer in Parallel jobs compiles in C++4. Parallel jobs run on more than one node5. Parallel jobs run on UNIX platform6. Major difference in job architecture level Parallel jobs process in parallel. It uses the configuration file to know the number of CPU's defined to process parallely
Server jobs:1. Datastage server jobs do not run on multiple nodes2. Data stage server jobs don't support the parallelism (Round robin Hash modulus etc.3. The transformer in server jobs compiles in Basic language4. Data stage server jobs run on only one node5. Data stage server jobs run on unix platform6. Major difference in job architecture level Server jobs process in sequence one stage after other

Configuration File:
What is configuration file? What is the use of this in data stage?
It is normal text file. it is having the information about the processing and storage resources that are available for usage during parallel job execution.
The default configuration file is having like
Node: - it is logical processing unit which performs all ETL operations.
Pools: - it is a collection of nodes.
Fast Name: it is server name. by using this name it was executed our ETL jobs.
Resource disk:- it is permanent memory area which stores all Repository components.
Resource Scratch disk:-it is temporary memory area where the staging operation will be performed.
Configuration file: Example: {
node "node1"{
fastname "abc"pools ""resource disk "/opt/IBM/InformationServer/Server/Datasets" {pools ""}resource scratchdisk "/opt/IBM/InformationServer/Server/Scratch" {pools
""}}node "node2"{
fastname "abc"pools ""resource disk "/opt/IBM/InformationServer/Server/Datasets" {pools ""}resource scratchdisk "/opt/IBM/InformationServer/Server/Scratch" {pools
""}}
}

Note:In a configuration file No node names has same nameDefault Node pool is “ “ At least one node must belong to the default node pool, which has a name of "" (zero-length string).
Pipeline parallelism:Pipe:Pipe is a channel through which data moves from one stage to another stage
Pipeline parallelism: It’s a technique of simultaneously processing Extraction, Transformation and, Loading
Partition Parallelism:Partitioning:Partioning is a technique of dividing the data into chunksData stage supports 8 types of partitionsPartioning plays a important role in data stageEvery stage in Data stage associated with default partitioning techniqueDefualt partinining technique is Hash
Note:Selection of portioning techniques is based on 1 .Data(Volume ,Type2 .Stage3. No of key Columns5.Key column data type
Partitioning techniques are grouped in to two categories 1.Key Based2.Key Less
Key Based Partitiong techniques:1.Hash2.Modulo3.Range4.DB2
Key Less Partioning techniques:1.Random2.Round robin3.Entire4.Same

Data stage Architecture:Data stage is a client server technology so that it has server comopents and client components
Servercompoents (Unix) Client components(Windows)PX Engine Data stage AdministratorData stage Repository Data stage ManagerPackage Installer Data stage Director Data stage Designer
Data stage Server:The server components again classified in to
Data stage server: It is the heart of data stage and its contain the archestrate Engine usually this engine picks up requirement from the client component and according to the request it performs the operation and respond to the client components ,if it requires it get the information from data stage repository
Data stage Repository:The repository conatins jobs,table definations,file definations,routines,shared containers etcPackage Instaler:It is used to install the softwares and gives compatability to the other softwares
Client Components:The client component again classified intoData stage AdministartorData stage ManagerData stage DirectorData stage Designer
Data stage Administrator:Ds admin can create projects and delete the projects Can give permissions to the usersCan define global parameters
Data stage Manager:Datastage Manager can import and export the jobscan create routinesCan configure configuration file
Data stage Director:

Da ta stage Director can validate ajobsCan run the jobsCan monitor a jobCan schedule ajobCan view the job logs
Data stage Designer:Through Data stage Designer a developer can design a jobs and compile and run a jobs
Differences between 7.5.x2 & 8.0.1
7.5X2:1. Four client components (Ds Designer,Ds Director,Ds Manager,Ds Administrator)2. Architecture Components( Server Components,Client Component3. Two tier architecture4.Os dependent with respect to users5. Capable of Phase3, Phase46.No web based Administration7.File Based Repository
8.0.:1. Five client components (Ds Designer,Ds Director,Information Analyzer,Ds Administrator, Web console)2. Architecture Components Common User Interface Common Repository Common Engine Common Connectivity Common Shared services3. N- tier architecture4. Os Independent with respect to users but one time dependent5. Capable of All Phases6.Web based Administration through web console7.Data base Based Repository

Data stage 7.5x2 Client Components:
In 7.5x2 we have 4 client components
Data stage Designer:it is to create jobs, compile, run and multiple job compile.It can handle four type of jobs1.Server Jobs2. Parallel jobs3. Job Sequencing4. Main frame Jobs
Data stage DirectorUsing data stage DirectorCan schedule the jobs,run the jobsCan Monitor the jobs,Unlock the jobs,Batch jobsCan View (job, Status, logs)Message Handling
Data stage ManagerCan Import and Export the repository componentsNode Configuration
Data stage AdministratorCan create the projectsCan delete the projectsOrganize the projects
Server Components:We have 3 server components
1. PX Engine: it is executing DataStage jobs and it automatically selects the partitiontechnique.
2. Repository: It contains the repository components
3.Package Installer:Package Instaler has packs and Plug Ins

Data stage 8.0.1 Client Components:
In 8.0.1 we have 5 client componentsData stage Designer:it is to create jobs, compile, run and multiple job compile.It can handle four type of jobs1.Server Jobs2. Parallel jobs3. Job Sequencing4. Main frame Jobs5.Data Qulaity jobs
Data stage DirectorUsing data stage DirectorCan schedule the jobs,run the jobsCan Monitor the jobs,Unlock the jobs,Batch jobsCan View (job, Status, logs)Message Handling
Data stage AdministratorCan create the projectsCan delete the projectsOrganize the projects
Web Console:Through administrator components can perform the below tasks1.Security services2.Scheduling services3.Logging services4.Reporting services5.Domian Management5.Session Management
Information Analyzer:It is also console for IBM infosphere Information Server consoleIt performs All activities of Phase11.Column Analysis2.BaseLine Analysis3.Primary Key Analysis4.foriegn Key Analysis5.Cross Domian Analysis

Data stage 8.0.1 Architecture:
1. Common User Interface Unified user is called a Common user interface1. Web console2. Information Analyzer3. Data stage Designer4. Data stage Director5. Data stage Administrator
2. Common Respository Common Repository devided in to two types1. Global Repository: It is used for data stage jobs files would store here2. Local Repository: for storing induvidual files
Common repository we called as a Meta data server
3. Comon Engine:It is responsible for the following Data Profiling AnalysisData Data Quality AnalysisData Transmission Analysis
4. Common ConnectivityIt provides the common connections to the Common Repository

Stages Enhancements and Newly Introduced stages Comparison from 7.5x2 And 8.0.1:
Stage Category Type Stage Name
Available Stage version 7.5X2 Avilable Stage in Version 8.0.1
Processing StageSCD(Slowly Change Dimension) Not Available Available
Processing Stage FTP(File Transfer Protocal) Not Available AvailableProcessing Stage WTX(Webshere Transfer) Not Available AvailableProcessing Stage Surrogate Key Available Available (Enhance ment done)
Processing Stage Look up
Available(Normal Lookup,Sprase Lookup)
Available( Range Lookup,Caseless Lookup)
Data Base Stage IWAY Not Available AvailableData Base Stage Classic Federation Not Available AvailableData Base Stage ODBC Connector Not Available AvailableData Base Stage Netteza Not Available Available
Data Base Stage Sql builder Not Available
Available(All Stages Technqs used wrto SQL Builder)
Note: Data base stages and Processing stage has Enhancements has done
Datastage Designer Window:
Its has Title BarIBM Infosphere Datastage and Quality stage Designer
Menu bar File,Edit,View,Repository,Diagram,Import,Export,Tools,Window,Help
Tool BarTool Options like Jobproperties,Compile,Run
RepositoryRepository which contains Repository components

File Stages:----------------
Sequential file stage:===============Sequential file stage is a file stage which is used to read the data sequentially or Parallely. If it is 1 file - It reads the data sequentially If it is N files - It reads the data Parallely Sequential file supports 1 Input link |1 Output Link | 1 reject link. To read the data, we have read methods. Read methods are a) Specific files b) File Patterns Specific File is for particular file And File Pattern is used for Wild cards. And in Error Mode. It has Continue Fail and Output If you select Continue - If any data type mismatch it will send the rest of the data to the target. If you Select Fail- Job Abort or Any Data type mismatch Output- It will send the mismatch data to Rejected data file. Error data we get are Data type Mismatch Format Mismatch Condition Mismatch and we have the option like Missing File Mode: In this Option we have three sub options like Depends Error Ok (That means How to handle, if any file is missed)
Different Options usage in Sequential file:-----------------------------------------------------
Read Method=Specific file Then execute in sequencial modeRead Method=File patternThen execute in file pattern Note :If we choose Read method =Specific file then it asks input file path If we select Read method=File Pattern then it asks ask pattern

Example for file pattern:Emp1.txtEmp2.txtTo read the data of above two files then file pattern should be like Emp?.txt?--> for one character match*--> for one or more character match
Example jobs for Lab Hand out:1. Read Method =Specific files Rejectmode=Continue,Fail,Output Note:If Reject Mode=Output then you must provide the output reject link for rejected records other wise it gives error
2. Read Method=File PatternRejectmode=Continue,Fail,OutputNote:If Reject Mode=Output then you must provide the output reject link for rejected records other wise it gives error
3. Read Method =Specific files Rejectmode=Continue,Fail,Output FileNameColumn=InputRecordFilepath
Note1:If Reject Mode=Output then you must provide the output reject link for rejected records other wise it gives errorNote2: If FileNameColumn=InputRecordFilepathHere FileNameColumn is an Option if we select this option then we have to create one more extra column in extended column properties then in output file you will get the InputRecordFilepathColumn extra at output
4. Read Method =Specific files Rejectmode=Continue,Fail,Output RowNumberColumn=InputRowNumberColumn
Note1:If Reject Mode=Output then you must provide the output reject link for rejected records other wise it gives errorNote2: RowNumberColumn=InputRowNumberColumnHere RowNumberColumn is an Option if we select this option then we have to create one more extra column in extended column properties then in output file you will get the InputRowNumberColumn extra at output

Sequencialfile Options:
FilterFileNameColumnRowNumcolumnRead FirstrowsNullFieldvalue
1.Filter OptionsSed command:--------------------
Sed: is a stream Editor for filtering and transforming text from standard input to standard output
Sed ‘5q’It displays first 5 linesSed ‘2p’It displays all lines but 2nd line will displayed twiceSed ‘1d’it displays all records except first recordSed ‘1d,2d’ it displays all lines except the first and second recordSed –n ‘2,4p’ here it prints only from record 2 to 4 onlySed –n –e ‘2p’ –e ‘3p’It displays only 2 nd 3rd lineSed ‘$d’ it is for deleting the trailer recordSed ‘i\’ it insert the blank line after each line
Grep commands:-----------------------
1) grep “string” Ex: grep “bhaskar”2) grep –v “string” Ex: grep – v “bhaskar”3) grep –i “String” Ex: grep - i “bhaskar”




![HomeKONCEPT · w]tmeprme qs w]tmeprme qs wepsr ^ neheprm » qs wtm ( qs oyglrme qs [mexvs et qs keve ( qs e^miroe qs osx s[rme](https://img.pdfslide.tips/doc/110x75/5b7823787f8b9aee298e7ba6/homekoncept-wtmeprme-qs-wtmeprme-qs-wepsr-neheprm-qs-wtm-qs-oyglrme.jpg)
























