Embed Size (px)
Citation preview

Datenarchivierung von Energiedaten (DAvE)
Projektdokumentation
Themensteller: Prof. Dr.-Ing. Jorge Marx Gómez
Betreuer: Dr.-Ing. Andreas SolsbachM. Eng. & Tech. Viktor DmitriyevM. Sc. Jad Asswad
Abgabetermin: 31.03.2018


Abstract
Die Digitalisierung der Energiebranche stellt diese vor neuen Herausforderungen. Um Datenvon Smart Metern im Kontext von Big Data zu verarbeiten, existieren bereits Ansätze.Die Archivierung von diesen und die Analyse mit passenden Werkzeugen können neueMehrwerte generieren.
In diesem Projekt wurde ein prototypisches System (DAvE) entwickelt, um riesige Da-tenmengen zu archivieren und daraus mithilfe von Machine Learning Algorithmen Vor-hersagemodelle zu generieren. Die genutzte Machine Learning Bibliothek ist scikit-learn.Um einen entkoppelten bidirektionalen Datenstrom zu garantieren, wird Apache Kafka alsMessaging System implementiert. Für den Datentransport zwischen den einzelnen Subsys-temen des DAvE-Systems und zu externen Messaging Systemen wird Apache NiFi genutzt.Als zuverlässiges und skalierbares Datenbankmanagementsystem wird Apache Cassandraverwendet.
Das Ergebnis ist ein prototypisches System, welches Smart Meter Daten und Wetterda-ten archivieren und bereitstellen kann. Ebenfalls stellt das DAvE-System eine Plattformzur Wissensgenerierung dar. Erzeugte Vorhersagemodelle können per PMML ausgetauschtwerden.


Inhaltsverzeichnis Inhaltsverzeichnis
Inhaltsverzeichnis
Abbildungsverzeichnis VI
Tabellenverzeichnis VII
Listingverzeichnis X
Abkürzungsverzeichnis XI
1. Einleitung 11.1. Zielsetzung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.2. Projekteinbettung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.3. Aufbau der Projektdokumentation . . . . . . . . . . . . . . . . . . . . . . . 3
2. Projektorganisation 52.1. Mitglieder der Projektgruppe DAvE . . . . . . . . . . . . . . . . . . . . . . 52.2. Stakeholder . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.3. Projektvorgehen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3.1. Kleingruppen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.3.2. Vorgehensmodell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.3.3. Kommunikation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.4. Projektphasen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.4.1. Erste Phase - Seminararbeiten & Konzeption . . . . . . . . . . . . . 92.4.2. Zweite Phase - Entwicklung . . . . . . . . . . . . . . . . . . . . . . . 92.4.3. Dritte Phase - Testen, Korrekturen, Dokumentation . . . . . . . . . 10
3. Konzept 113.1. Use Cases . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.1.1. Daten archivieren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113.1.2. Anfragenbearbeitung von Daten . . . . . . . . . . . . . . . . . . . . . 123.1.3. Modellerzeugung für das Power Forecasting . . . . . . . . . . . . . . 133.1.4. Modellerzeugung für das Load Forecasting . . . . . . . . . . . . . . . 14
3.2. Anforderungen (Technische und Funktionale Anforderungen) . . . . . . . . . 153.2.1. Anforderungen Datenanalyse . . . . . . . . . . . . . . . . . . . . . . 153.2.2. Anforderungen Datenarchivierung . . . . . . . . . . . . . . . . . . . 163.2.3. Anforderungen Datenimport . . . . . . . . . . . . . . . . . . . . . . . 163.2.4. Anforderungen Schnittstelle . . . . . . . . . . . . . . . . . . . . . . . 17
3.3. Systemarchitektur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
4. Technologieauswahl 234.1. Archivierung: Datenbank . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
4.1.1. Anforderungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 254.1.2. Beschreibung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
I

Inhaltsverzeichnis Inhaltsverzeichnis
4.2. Archivierung: Data�ow Management . . . . . . . . . . . . . . . . . . . . . . 274.2.1. Anforderungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 284.2.2. Beschreibung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.3. Messaging System . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 324.3.1. Anforderung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 334.3.2. Beschreibung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
4.4. Data Science . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 374.4.1. Anforderungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 374.4.2. Beschreibung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.5. Data Engineering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 434.5.1. Anforderungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 434.5.2. Beschreibung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5. Installation 49
5.1. Infrastruktur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 495.2. Archivierung: Datenbank . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 505.3. Archivierung: Data�ow Management . . . . . . . . . . . . . . . . . . . . . . 525.4. Kommunikationskomponente . . . . . . . . . . . . . . . . . . . . . . . . . . 53
5.4.1. Apache Kafka . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 545.4.2. RabbitMQ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 555.4.3. Apache Tomcat und Docker . . . . . . . . . . . . . . . . . . . . . . . 56
5.5. Data Science . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
6. Realisierung 59
6.1. Datenquellen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 596.1.1. Wetterdaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 596.1.2. Winddaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 606.1.3. Sonnendaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 606.1.4. Qualitätsniveau der Aufzeichnungen . . . . . . . . . . . . . . . . . . 616.1.5. Smart-Meter-Daten . . . . . . . . . . . . . . . . . . . . . . . . . . . . 616.1.6. SMARD-Daten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
6.2. Archivierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 626.2.1. Schema-De�nition . . . . . . . . . . . . . . . . . . . . . . . . . . . . 626.2.2. Datenimport . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 666.2.3. Datenexport . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
6.3. Kommunikationskomponente . . . . . . . . . . . . . . . . . . . . . . . . . . 856.3.1. Konzept . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 856.3.2. Umsetzung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
6.4. Data Science . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 986.4.1. Steuerung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 986.4.2. Modellierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
7. Gesamtarchitektur 109
II

Inhaltsverzeichnis Inhaltsverzeichnis
8. Test und Evaluation 1118.1. Testumgebung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
8.1.1. Installation LV-Simulator . . . . . . . . . . . . . . . . . . . . . . . . 1118.1.2. Erweiterungsprogrammierung LV-Simulator . . . . . . . . . . . . . . 1128.1.3. Inbetriebnahme LV-Simulator . . . . . . . . . . . . . . . . . . . . . . 113
8.2. Evaluationskonzept . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1158.3. Komponententest . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1158.4. Integrationstests . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1218.5. Systemtests . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
9. Fazit und Ausblick 1259.1. Fazit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1259.2. Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
Literaturverzeichnis 131
A. Anhang 133A.1. Tabelle Auswahl Datenbanken . . . . . . . . . . . . . . . . . . . . . . . . . . 133A.2. Paper . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
A.2.1. Data Archive 2.0 - Adaptation of ICT Solutions for the Future En-ergy Sector Transformation . . . . . . . . . . . . . . . . . . . . . . . 136
A.2.2. Datenarchivierung von Energiedaten und Generierung von Vorher-sagemodellen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138
A.2.3. BUIS Paper DAvE . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141A.3. Seminararbeiten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153
A.3.1. Maged Ahmad - Hadoop ecosystem components: Ambari, HDFS andMapReduce . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153
A.3.2. Julian Brunner - Methoden von Data Mining und Machine Learning 172A.3.3. Alexander Eguchi - Vorstellung von bestehenden Big Data Architek-
turen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194A.3.4. Jens Feldhaus - Soft Skills für Software Entwicklungsteams: Klassi-
sche vs. Agile Softwareentwicklung . . . . . . . . . . . . . . . . . . . 209A.3.5. Nils Meyer - Portability of Data Mining Machine Learning models
using PMML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 227A.3.6. Jakob Möller - Catalog of use cases and case studies of data-driven
models in the energy domain . . . . . . . . . . . . . . . . . . . . . . 244A.3.7. Miriam Müller - Best practices in data archiving . . . . . . . . . . . 262A.3.8. Yasin Oguz - Vergleich von Odysseus mit weiteren Open Source CEP
Plattformen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 287A.3.9. Henning Schlotmann - Die Rolle von Data Science und Data Engi-
neering in Unternehmen . . . . . . . . . . . . . . . . . . . . . . . . . 312A.3.10.Martin Sonntag - KDD-Prozess und CRISP-DM . . . . . . . . . . . 336A.3.11.Helge Wendtland - Testing von Software . . . . . . . . . . . . . . . . 359
III


Abbildungsverzeichnis Abbildungsverzeichnis
Abbildungsverzeichnis
1. NDS Projektübersicht . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32. Use Case 1: Daten archivieren . . . . . . . . . . . . . . . . . . . . . . . . . . 123. Use Case 2: Anfragenbearbeitung von Daten . . . . . . . . . . . . . . . . . . 134. Use Case 3: Modellerzeugung für das Power Forecasting . . . . . . . . . . . 145. Use Case 4: Modellerzeugung für das Load Forecasting . . . . . . . . . . . . 156. Übersicht der Komponenten in DAvE . . . . . . . . . . . . . . . . . . . . . . 197. NiFi Data�ow Beispiel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 308. NiFi Prozessor Kon�guration Beispiel . . . . . . . . . . . . . . . . . . . . . 329. Allgemeine Funktionsweise von Messaging Systemen . . . . . . . . . . . . . 3310. Ein Schema für ein Kafka Architektur . . . . . . . . . . . . . . . . . . . . . 3611. Cassandra Cluster . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5212. Einstellungen ListFTP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6613. Einstellung RouteOnAttribute . . . . . . . . . . . . . . . . . . . . . . . . . . 6714. 1. Teil DWD-Import . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6715. Einstellung Entfernen der Metadaten . . . . . . . . . . . . . . . . . . . . . . 6816. Einstellung ConvertRecord . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6817. 2.Teil DWD-Import . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6918. Einstellung EvaluateJsonPath . . . . . . . . . . . . . . . . . . . . . . . . . . 6919. Anpassung Messdatum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7020. 3.Teil DWD-Import . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7121. Startzeitpunkt Sonnendaten . . . . . . . . . . . . . . . . . . . . . . . . . . . 7322. Kon�guration GetFile-Prozessor . . . . . . . . . . . . . . . . . . . . . . . . . 7423. Kon�guration EvaluateJsonPath Verbrauch . . . . . . . . . . . . . . . . . . 7524. Kon�guration EvaluateJsonPath Erzeugung . . . . . . . . . . . . . . . . . . 7525. Anpassen des Datums bei SMARD-Daten . . . . . . . . . . . . . . . . . . . 7526. Data�ow: Import der Smart-Meter-Daten . . . . . . . . . . . . . . . . . . . 7727. Import der Smart-Meter-Daten: ConsumeKafka Kon�guration . . . . . . . . 7828. Import der Smart-Meter-Daten: ExecuteScript Kon�guration . . . . . . . . 7929. Import der Smart-Meter-Daten: EvaluateJsonPath Kon�guration . . . . . . 8030. Import der Smart-Meter-Daten: PutCassandraQL Kon�guration . . . . . . . 8131. Data�ow: Datenexport im JSON-Format . . . . . . . . . . . . . . . . . . . . 8232. Datenexport im JSON-Format: QueryCassandra Kon�guration . . . . . . . 8333. Datenexport im JSON-Format: SplitJson Kon�guration . . . . . . . . . . . 8334. Data�ow: Datenexport im COSEM-Format . . . . . . . . . . . . . . . . . . 8435. schematische Darstellung zur Beantwortung einer Anfrage . . . . . . . . . . 8536. Schematische Darstellung der Anfrageverarbeitung einer Data Mining Anfrage 8737. Package-Struktur der Kommunikationskomponente . . . . . . . . . . . . . . 9238. Prozessablauf zur Abfrage von PMML-Modellen . . . . . . . . . . . . . . . . 9339. Prozessablauf zur Abfrage von Smart Metern . . . . . . . . . . . . . . . . . 9440. Ni�-Con�g: Work�ow . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9541. Ni�-Steuerung: Work�ow . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
V

Abbildungsverzeichnis Abbildungsverzeichnis
42. Ni�-Steuerung: Klassen Struktur . . . . . . . . . . . . . . . . . . . . . . . . 9743. Konzept des PMML Prozesses . . . . . . . . . . . . . . . . . . . . . . . . . . 9944. Beispiel neuronales Netz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10745. Gesamarchitektur DAvE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
VI

Tabellenverzeichnis Tabellenverzeichnis
Tabellenverzeichnis
1. Betreuer und Projektgruppenmitglieder . . . . . . . . . . . . . . . . . . . . 52. Meilensteinplan, April 2017 . . . . . . . . . . . . . . . . . . . . . . . . . . . 93. Meilensteinplan, Dezember 2017 . . . . . . . . . . . . . . . . . . . . . . . . . 104. Anforderung Datenanalyse . . . . . . . . . . . . . . . . . . . . . . . . . . . . 165. Anforderungen Datenarchivierung . . . . . . . . . . . . . . . . . . . . . . . . 176. Anforderungen Datenimport . . . . . . . . . . . . . . . . . . . . . . . . . . . 207. Anforderungen Schnittstelle . . . . . . . . . . . . . . . . . . . . . . . . . . . 218. Anforderungen Data Science Framework . . . . . . . . . . . . . . . . . . . . 389. Kriterienkatalog für Machine Learning Frameworks Teil I . . . . . . . . . . 4010. Kriterienkatalog für Machine Learning Frameworks Teil II . . . . . . . . . . 4111. Systeminfrastruktur des DAvE-Cluster . . . . . . . . . . . . . . . . . . . . . 5012. Komponententests I . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11613. Komponententests II . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11714. Komponententests III . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11815. Komponententests IV . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11916. Komponententests V . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12017. Integrationstests . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12218. Systemtests . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
VII


Listingverzeichnis Listingverzeichnis
Listingverzeichnis
1. Fehlermeldung Spark MLlib . . . . . . . . . . . . . . . . . . . . . . . . . . . 422. Beispieldatensatz LV-Simulator, JSON-Format . . . . . . . . . . . . . . . . 463. Beispieldatensatz LV-Simulator, COSEM-XML-Format . . . . . . . . . . . . 474. Download und Installation von Apache Cassandra . . . . . . . . . . . . . . . 505. Anpassungen master cassandra.yaml . . . . . . . . . . . . . . . . . . . . . . 516. Anpassungen cassandra-topology.properties . . . . . . . . . . . . . . . . . . 517. Überprüfung cassandra-rackdc.properties . . . . . . . . . . . . . . . . . . . . 528. Start von Apache Cassandra . . . . . . . . . . . . . . . . . . . . . . . . . . . 529. Download und Installation von Apache NiFi . . . . . . . . . . . . . . . . . . 5310. Kon�guration des Ports von Apache NiFi . . . . . . . . . . . . . . . . . . . 5311. Kon�guration der JVM memory settings . . . . . . . . . . . . . . . . . . . . 5312. Start-Skript . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5513. Befehle für Kafka . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5514. Installation von RabbitMQ auf Ubuntu . . . . . . . . . . . . . . . . . . . . . 5515. Installation RabbitMQ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5616. Kon�guration RabbitMQ . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5617. Start-Skript . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5718. Installieren der Data Science Komponenten . . . . . . . . . . . . . . . . . . 5819. Erzeugung des Keyspaces . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6320. Erstellung der Tabellen für DWD-Daten . . . . . . . . . . . . . . . . . . . . 6421. Erstellung der Tabellen für SMARD-Daten . . . . . . . . . . . . . . . . . . 6522. Erstellung der Tabelle für LV-Daten . . . . . . . . . . . . . . . . . . . . . . 6523. Pfade für den FTP-Server historische Daten . . . . . . . . . . . . . . . . . . 6724. Zeitstempel Klimadaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7025. CQL INSERT Statements . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7126. Pfade für den FTP-Server aktuelle Daten . . . . . . . . . . . . . . . . . . . 7227. Filtern des Messdatums nach bestimmten Datum . . . . . . . . . . . . . . . 7328. CQL INSERT Statements SMARD . . . . . . . . . . . . . . . . . . . . . . . 7629. ExecuteScript, Framework . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7930. NiFi, Insert XML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8031. CQL DDL zur Erzeugung der Report-Tabelle . . . . . . . . . . . . . . . . . 8832. Antwort, Station . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8933. asynchrone Antwort . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8934. Antwort, Wetter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8935. Antwort, Modelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9136. Base64 kodiertes PMML-Model . . . . . . . . . . . . . . . . . . . . . . . . . 9137. Erstellen der Tabelle model_jobs und model_list . . . . . . . . . . . . . . . 9838. Cronjobs zur Steuerung der Data Science Funktionen . . . . . . . . . . . . . 10039. Lesen der noch nicht bearbeiteten Anfragen . . . . . . . . . . . . . . . . . . 10040. Parsen der PMML Datei . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10141. Extrahieren von Wochentag und Uhrzeit aus dem timestamp . . . . . . . . 103
IX

Listingverzeichnis Listingverzeichnis
42. Extrahierung Input-Daten SVM . . . . . . . . . . . . . . . . . . . . . . . . . 10443. Auszug Entwicklung SVM-Modell . . . . . . . . . . . . . . . . . . . . . . . . 10444. Lernen des SVM-Modells . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10545. Preprocessing Random Forest . . . . . . . . . . . . . . . . . . . . . . . . . . 10546. Trainieren des Random Forests . . . . . . . . . . . . . . . . . . . . . . . . . 10647. Skalierung der Daten für das neuronale Netz . . . . . . . . . . . . . . . . . . 10748. Au�ösen Versionsprobleme des Pakets networkx . . . . . . . . . . . . . . . . 11249. Installation LV-Simulator . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11250. Auszug Kafka-Output Klasse, LV-Simulator . . . . . . . . . . . . . . . . . . 11451. Auszug Kon�guration, LV-Simulator . . . . . . . . . . . . . . . . . . . . . . 114
X

Abkürzungsverzeichnis Abkürzungsverzeichnis
Abkürzungzverzeichnis
AMQP Advanced Message Queuing Protocol
AXT Agent for XML Transportation
CAP Consistency, Availability und Partition tolerance
CLI Command Line Interface
COSEM Companion Speci�cation for Energy Metering
CQL Continuous Query Language
CSV Comma Separated Values
DASH Data AnalyticS with Hadoop
DAvE Datenarchvierung von Energiedaten
DLMS Device Language Message Speci�cation
DMM Data Mining Modelle
DWD Deutscher Wetterdienst
ELT Extract, Load und Transform
FIFO first in �rst out
FTP File Transfer Protocol
HDFS Hadoop Distributed File System
ID Identi�kation
JSON JavaScript Object Notation
JVM Java Virtual Machine
KDD Knowledge Discovery in Databases
LV Low Voltage
MB Message Broker
MLP Multi Layer Perceptron
MQ Message Queue
NiFi NiagaraFiles
OAS OpenAPI Speci�kation
PMML Predictive Model Markup Language
PV Photovoltaikanlage
QL Query Language
QN Qualitätsniveau
REST Representational State Transfer
SMARD Strommarktdaten
SVM Support Vector Machine
UUID Universally Unique Identi�er
VM Virtuelle Maschine
XML Extensible Markup Language
XI

Abkürzungsverzeichnis Abkürzungsverzeichnis
XII

1 EINLEITUNG
1. Einleitung
Durch die Einführung des Gesetztes zur Digitalisierung der Energiewende, wurde das Start-signal für eine digitale Infrastruktur mit Smart Grids inklusive Smart Metern in Deutsch-land gesetzt. Dies führt zum Austausch aller herkömmlichen Ferraris-Zähler durch intelli-gente Messsysteme bis zum Jahr 2032.
Der Ausgleich zwischen Stromangebot und -nachfrage stellt eine zentrale Herausforderungdabei dar, wodurch die Digitalisierung der Energiewende anhand der Vielfalt von Dateneine Schlüsselfunktion zur Lösung dieser Aufgabe beitragen kann. Anhand der e�zientenNutzung der Energie können Stromnetze stabilisiert werden und Leistungsengpässe verrin-gert werden, sodass die Steuerung und Regelung mit digitalen Technologien weiter in dasZentrum des zukünftigen Energiesystems treten.[Bun16a]
Diese Einführung konfrontiert die Netzbetreiber mit der Bewältigung riesiger Datenmen-gen. Durch einen umfassenden Einsatz von Informations- und Kommunikationstechnologienkönnen aus der Herausforderung neue Chancen generiert werden. Es ist möglich aus denDatenmengen umfassende Mehrwerte für die beteiligten Akteure zu gewinnen, damit An-gebot und Nachfrage zeitnah erfasst und besser aufeinander abgestimmt werden können.Die anfallenden Daten können nicht nur archiviert werden, sondern bieten weitläu�ge Po-tentiale zu Datenanalyse für eine Stabilisierung des Stromnetzes und die Bildung variablerVersorgungstarife. Darüber hinaus können in der neuen Energiewelt zukunftsfähige Ge-schäftsmodelle entstehen, die neben der Optimierungsprozesse des Energiesystems weitereVorteile für Erzeuger und Verbraucher bieten.[Ger16]
In dem Kontext der Energiewende mit der Einführung von intelligenten Messsystemengilt es eine Architektur zu entwickeln, die Daten persistent über Jahrzehnte archivierenkann. Mit geeigneten Analysewerkzeugen sollen neue Mehrwerte durch die Auswertungdieser Daten generiert werden. Die Architektur zur Archivierung und Analyse von groÿenDatenmengen sollen in unterschiedlichen Branchen angewendet werden. Zunächst wirdsie prototypisch im Energiesektor umgesetzt. Zusätzlich sollen geeignete Analysewerkzeu-ge implementiert werden, um Muster aus den archivierten Daten zu erkennen. Es mussmöglich sein, Stromerzeuger und -anbieter in die Lage zu versetzen, Vorhersagen überEnergieverbräuche und Stromerzeugung zu bilden und nutzen zu können. Anhand von ge-nerierten Vorhersagemodellen können dazu Auskünfte in unterschiedlichen Zeitperiodengetro�en werden. Durch den Datenzuwachs ist es möglich, die Vorhersagemodelle stetigzu optimieren und somit immer bessere Prognosen zu erhalten. Dies ermöglicht es denStromerzeugern, den Energieverbrauch zu prognostizieren und somit die bereitzustellendeMenge an Strom besser kalkulieren zu können.
Die Umsetzung dieses Vorhabens wird im Rahmen der Projektgruppe DAvE an der Carlvon Ossietzky Universität Oldenburg realisiert. Das zugehörige Konzept und dessen Um-setzung werden im Folgenden erläutert.
1

1.1 Zielsetzung 1 EINLEITUNG
1.1. Zielsetzung
Das Projekt beschäftigt sich mit der Leitfrage, wie ein datengetriebener Energiemarkt inder Zukunft aussehen kann. Dabei gilt es eine Kombination aus Netz, Daten und Analysezu scha�en und anhand dieser Erkenntnisse neue Geschäftsmodelle aufzeigen zu können.Es muss die Möglichkeit gescha�en werden, die anfallenden Daten aus Smart Metern ar-chivieren zu können. Dazu wird eine Infrastruktur gescha�en, mit Hilfe dieser die Datenentgegengenommen und in einem Archiv abgelegt werden. Zusätzlich können die archivier-ten Daten zur Wissensgenerierung, z. B. zur Vorhersage des Energieverbrauchs, ausgewertetwerden. Die generierten Vorhersagemodelle werden zur Verfügung gestellt und dadurch fürDritte nutzbar gemacht.
Neben der primären Datenquellen, einem Niederspannungsnetz, sollen zusätzlich externeDatenquellen eingebunden werden. Dazu gehören Wetterdaten vom Deutschen Wetter-dienst. Dazu werden die stündlich bereitgestellten Daten angefragt und archiviert. Diesebeinhalten u. a. Informationen zu Windgeschwindigkeiten und Sonnenstunden und ermög-lichen Prognosen für die potentielle Energieerzeugung mit Wind- und Solarkraft. Zusätzlichist es möglich, die Daten auch aufgrund ihrer geographischen Informationen auszuwerten.
Das System muss dabei durch das hohe Datenaufkommen den gestiegenen Anforderungenan sehr groÿe Datenmengen gerecht werden. Durch den Einsatz von Big Data Technologienund Data Science Verfahren werden Anfragen bezüglich Last- und Vermarktungsprogno-sen auf hochaufgelösten und umfangreichen Langzeitdaten ermöglicht, welche beteiligtenAkteuren zukünftig Mehrwerte in den Prozessen ihrer Leistungserstellung ermöglichen kön-nen. Damit Anfragen an das Archiv gestellt werden können, ist eine Schnittstelle zu diesemnotwendig. Mit der Schnittstelle sollen archivierte Daten angefragt und Prognosemodelleangefordert werden.
1.2. Projekteinbettung
Die Projektgruppe DAvE wird in der Abteilung VLBA unter der Leitung von Prof. Dr.-Ing.Jorge Marx-Gómez betreut. Die Umsetzung erfolgt als Teil des Projekts NetzDatenStrom(NDS) am OFFIS in Oldenburg unter der Leitung von Dr.-Ing.Sven Rosinger. Das ProjektNetzDatenStrom dient der Erforschung einer standardkonformen Integration von quellof-fenen Big Data Lösungen in existierende Netzleitsysteme. Das Projekt hat zum Ziel dieDe�nition von o�enen und standardisierten Schnittstellen sowie einer Referenzarchitekturfür Netzleitsysteme. Darüber hinaus soll ein Datenaustausch über einen zentralen Enter-prise Service Bus geregelt werden. Eine Erweiterung von vorhandenen Archiv- und Da-tenbankstrukturen von Leitsystemlösungen durch Big Data Komponenten ist vorgesehen,sodass die Speicherung und Verarbeitung von groÿen Datenmengen ermöglicht wird. Dar-über hinaus soll eine Auswertung und Verarbeitung von Mess- und Sensordaten in Echtzeitsowie die Anbindung externer und Integration heterogener Daten ermöglicht werden. Die
2
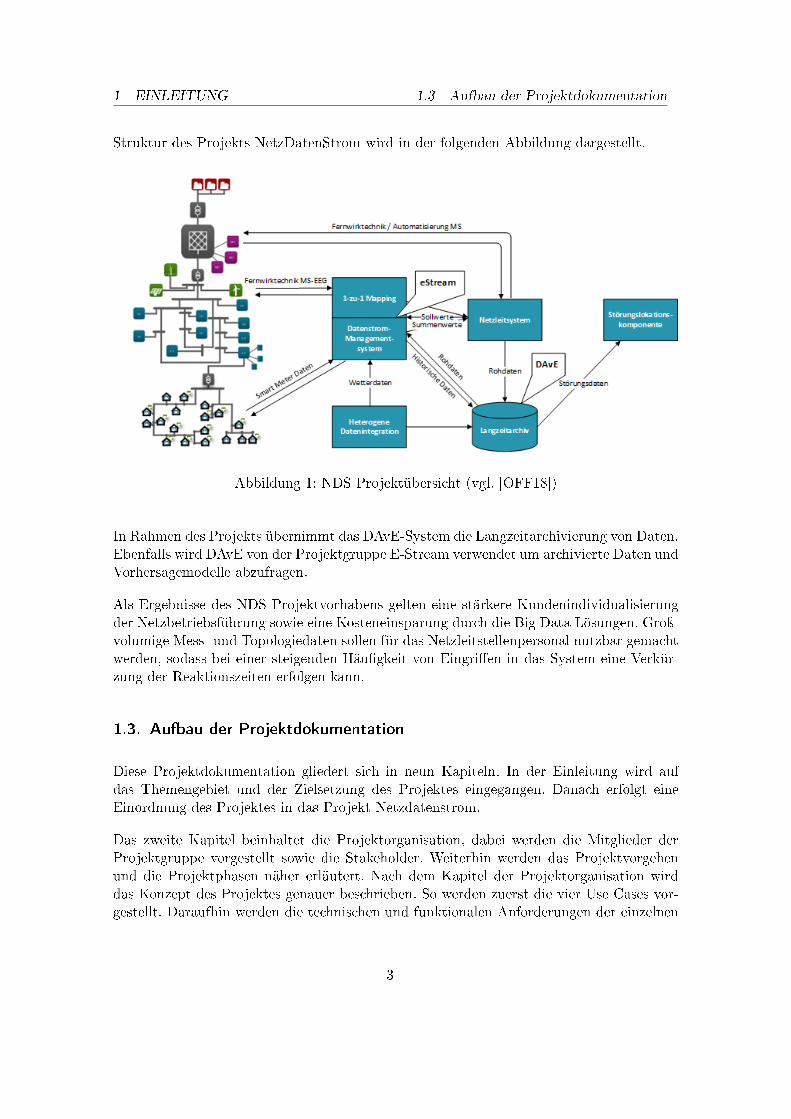
1 EINLEITUNG 1.3 Aufbau der Projektdokumentation
Struktur des Projekts NetzDatenStrom wird in der folgenden Abbildung dargestellt.
Abbildung 1: NDS Projektübersicht (vgl. [OFF18])
In Rahmen des Projekts übernimmt das DAvE-System die Langzeitarchivierung von Daten.Ebenfalls wird DAvE von der Projektgruppe E-Stream verwendet um archivierte Daten undVorhersagemodelle abzufragen.
Als Ergebnisse des NDS Projektvorhabens gelten eine stärkere Kundenindividualisierungder Netzbetriebsführung sowie eine Kosteneinsparung durch die Big Data Lösungen. Groÿ-volumige Mess- und Topologiedaten sollen für das Netzleitstellenpersonal nutzbar gemachtwerden, sodass bei einer steigenden Häu�gkeit von Eingri�en in das System eine Verkür-zung der Reaktionszeiten erfolgen kann.
1.3. Aufbau der Projektdokumentation
Diese Projektdokumentation gliedert sich in neun Kapiteln. In der Einleitung wird aufdas Themengebiet und der Zielsetzung des Projektes eingegangen. Danach erfolgt eineEinordnung des Projektes in das Projekt Netzdatenstrom.
Das zweite Kapitel beinhaltet die Projektorganisation, dabei werden die Mitglieder derProjektgruppe vorgestellt sowie die Stakeholder. Weiterhin werden das Projektvorgehenund die Projektphasen näher erläutert. Nach dem Kapitel der Projektorganisation wirddas Konzept des Projektes genauer beschrieben. So werden zuerst die vier Use Cases vor-gestellt. Daraufhin werden die technischen und funktionalen Anforderungen der einzelnen
3

1.3 Aufbau der Projektdokumentation 1 EINLEITUNG
Komponenten des Projektes erörtert. Abschlieÿend erfolgt eine Beschreibung der System-architektur. Die darauf folgende Technologieauswahl wird in Kapitel 4 erläutert. Es werdenAnforderungen für die Technologieauswahl in den jeweiligen Bereichen aufgestellt. Darauf-hin erfolgt eine Beschreibung der untersuchten Technologien sowie eine kurze Auswertung,die zeigt, welche Technologien verwendet werden. Das fünfte Kapitel behandelt die Instal-lation der einzelnen Komponenten, welche im vorherigen Kapitel ausgewählt wurden.
Nach der Installation wird im sechsten Kapitel die Realisierung näher beschrieben. Sowerden zuallererst die ausgewählte Datenquellen vorgestellt. Daraufhin wird die Imple-mentierung der jeweiligen Komponenten im Einzelnen geschildert.
In dem siebten Kapitel wird die Gesamtarchitektur des Systems der Projektgruppe vorge-stellt und beschrieben, wie die einzelnen Komponenten miteinander verbunden sind.
Im Anschluss folgt das Kapitel Test und Evaluation. Es wird auf die Testumgebung ein-gegangen sowie das Evaluationskonzept, die Komponententests, die Integrationstest unddie Systemtests näher erläutert. Abschlieÿend wird ein Fazit und ein Ausblick über dasgesamte Projekt gegeben. Dabei werden die Erfahrungen der PG beschrieben und in Aus-sicht gestellt, in wie weit das entwickelte System nach dem Abschluss noch weiterentwickeltwerden könnte.
4

2 PROJEKTORGANISATION
2. Projektorganisation
In diesem Kapitel wird Organisation des Projektes dargestellt und erläutert. Zunächst wer-den die Mitglieder der Projektgruppe sowie die vergebenen Rollen und Aufgaben innerhalbder Projektgruppe gennant. Darauf folgt die Vorstellung des Vorgehens innerhalb des Pro-jekts in 2.3: Projektvorgehen. Geschlossen wird dieses Kaptitel mit einer Übersicht überdie Projektphasen in 2.4: Projektphasen.
2.1. Mitglieder der Projektgruppe DAvE
Die Projektgruppe umfasst drei Betreuer und elf Projektgruppenmitglieder. Im Folgendensind alle beteiligten Personen in der Tabelle 1: Betreuer und Projektgruppenmitgliederalphabetisch aufgeführt.
Betreuer PG-Mitglieder
M.Sc Jad Asswad Maged AhmadM. Eng. & Tech. Viktor Dimitryev Julian BrunnerDr,-Ing. Andreas Solsbach Alexander Eguchi
Jens FeldhausNils MeyerJakob MöllerMiriam MüllerYasin OguzHenning SchlotmannMartin SonntagHelge Wendtland
Tabelle 1: Betreuer und Projektgruppenmitglieder
Zu Beginn der Projektgruppe wurden einige Sonderrollen vergeben, welche durch einzelneProjektgruppenmitglieder wahrgenommen wurden. Die Rollen umfassen folgende:
Projektmanager Aufgabe des Projektmanagers ist es, die Koordination der Gruppe si-cherzustellen. Dazu ist es notwendig, dass der Projektmanager einen Teil seiner wöchentli-chen Arbeitszeit dafür aufwendet, den aktuellen Stand des Projektes zusammenzutragen.Der Projektmanager koordiniert darüber hinaus Termine mit den Betreuern und der Pro-jektgruppe E-Stream.
Dokumentationsbeauftragter Der Dokumentationsbeauftragte ist dafür zuständig, Vor-lagen für alle Dokumente vorzubereiten und die Einhaltung der Vorlage sicherzustellen.
5

2.2 Stakeholder 2 PROJEKTORGANISATION
Dokumente in diesem Kontext sind u. a. die Seminararbeiten und die Abschlussdokumen-tation des Projektes. Das Ziel des Dokumentationsbeauftragten ist es, ein einheitlichesAussehen und einen einheitlichen Aufbau aller Dokumente zu gewährleisten.
Blogbeauftragter Die Aufgabe des Blogbeauftragten ist es, während der Laufzeit derProjektgruppe Ereignisse und Events zu dokumentieren. Diese werden auf einem Blog aufder Webseite der Abteilung VLBA verö�entlicht.
Serveradministrator Der Serveradministrator hat den Auftrag, die Funktionalität der In-frastruktur sicherzustellen. Ein Ausfall der Infrastruktur hätte eine negative Auswirkungauf den Projektfortschritt zur Folge und würde die Weiterarbeit behindern. Um die Verfüg-barkeit des Administrators zu gewährleisten wurden zwei Stellvertreter zusätzlich benannt.
Testbeauftragter Der Testbeauftragte ist dafür zuständig, dass die Projektergebnissegetestet werden. Der Träger dieser Rolle stellt sicher, dass ein Testkonzept erarbeitet wirdund das Konventionen für das Testen aufgestellt werden. Weiterhin werden Testphasengeplant, dessen Einhaltung gewährleistet. Das Testen übernehmen jedoch alle Mitgliederin der Projektgruppe.
Scrum Master Da zwischenzeitlich ein agiles Vorgehen angelehnt an Scrum verwendetwurde, wurde für diesen Zeitraum ein ScrumMaster bestimmt, der den Prozess koordinierteund evaluierte.
2.2. Stakeholder
Stakeholder, die ein Interesse an der Realisierung des Projektes haben waren sowohl dieProjektbetreuer als auch die Projektgruppe E-Stream.
Projektbetreuer Die Projektbetreuer Dr,-Ing. Andreas Solsbach, M. Eng. & Tech. ViktorDimitryev und M. Sc. Jad Asswad unterstützen die Projektgruppe als erste Ansprechpart-ner bei inhaltlichen und organisatorischen Fragen rund um das Projekt. Auÿerdem wurdenalle Projektmeilensteine und -fortschritte ihnen vorgestellt und re�ektiert.
Projektgruppe E-Stream Über das Projekt NetzDatenStrom besteht eine Kooperationmit der parallel verlaufenen Projektgruppe E-Stream. Über die Schnittstelle des DAvE-Systems greift die Projektgruppe auf archivierte Daten und generierte Vorhersagemodellezu.
6

2 PROJEKTORGANISATION 2.3 Projektvorgehen
2.3. Projektvorgehen
Im folgenden Abschnitt wird das Vorgehen der Projektgruppe vorgestellt. Dazu wird dieHerangehensweise an Aufgaben und die Kommunikation innerhalb der Gruppe beschrie-ben. Zuerst wird die Projektgruppenorganisation im Unterabschnitt 2.3.1: Kleingruppenvorgestellt. Im Anschluss daran wird das Vorgehensmodell in 2.3.2: Vorgehensmodell be-schrieben. Abschlieÿend werden die verwendeten Kommunikationskanäle genannt.
2.3.1. Kleingruppen
Das Projektteam wurde in Kleingruppen aufgeteilt. Die Aufteilung in Kleingruppen hattedie Motivation die Abarbeitung von Aufgabenpaketen zu parallelisieren. Auÿerdem hat-te es die Auswirkung, dass diese Gruppen sich auf Subsysteme spezialisieren konnten.Die Kleingruppen hatten dabei unterschiedliche Aufgabenschwerpunkte. Insgesamt wur-den fünf Kleingruppen gebildet:
• Archivierung
• Schnittstelle E-Stream
• Data Science
• Date Engineering
• Evaluation
Die Bildung der Kleingruppen ist ein Vorgri� auf die Konzeption des DAvE-Systems imKapitel 3: Konzept und repräsentiert die darin enthaltenen einzelnen Subsysteme. Im Ver-lauf des Projektes wurde die Gruppe Data Engineering aufgelöst, da die Aufgaben derGruppe abgeschlossen wurden. Die Gruppe Evaluation wurde zum Ende der Projektgrup-pe gebildet, um das Testvorgehen für den Prototypen zu planen.
Ebenfalls zu bemerken ist, dass sich die Zusammenstellung der Kleingruppen während desProjektes geändert hat. Gründe waren neben dem Au�ösen, bzw. Bilden von Gruppenauch die Umverteilung von Projektgruppenmitgliedern. Damit die Gruppen ihre Aufga-benpakete bewältigen konnten, war das Umverteilen von Ressourcen notwendig.
2.3.2. Vorgehensmodell
Während des Projekts hat sich ein agiles Projektvorgehen etabliert. Aufgrund der Kom-plexität der Aufgabenstellung und Gröÿe der Projektgruppe war ein iteratives Vorgehenerforderlich. Des Weiteren konnte die Terminierung von Projektabschnitten gemäÿ derMeilensteinplanung nicht in allen Fällen fristgerecht eingehalten werden.
7

2.4 Projektphasen 2 PROJEKTORGANISATION
Wie bereits im vorherigen Unterabschnitt 2.3.1: Kleingruppen erläutert, hatte jede Klein-gruppe dabei unterschiedliche Themenschwerpunkte und darauf zugeschnittene Aufgaben-pakete. Der Fortschritt der Aufgabenpakete wurde in einem wöchentlichen Gruppentre�envon den Kleingruppen vorgestellt. Dieses Vorgehensmodell erwies sich gerade in den frü-hen Projektphasen als sinnvoll, da der tatsächliche Umfang der Aufgabenpakete, aufgrundvon fehlendem Fachwissen, nur schwer festzustellen war. Die neuen Arbeitspakete wurdenjeweils auf den Ergebnissen der vorherigen Woche aufgebaut.
Im späteren Projektverlauf wurde das agile Vorgehen stärker strukturiert, angelehnt amVorgehensmodell Scrum. Begründet war diese Anpassung dadurch dass der Technologie-auswahlprozess arbeitsintensiver war. Zur Unterstützung dieses Vorgehens wurde die Pro-jektmanagement Software Jira genutzt. Alle erfassbaren Aufgabenpakete wurden in dasSystem übernommen. Der Planungsvorgang erfolgte alle zwei Wochen, dadurch waren dieAufgabenpakete besser strukturiert. Darüber hinaus ermöglichte Jira eine wesentlich bes-sere Dokumentation des Projektfortschritts. Zudem wurden Verantwortliche für die Aufga-benpakete benannt, welche die Qualität des Ergebnisses und des Prozesses sicherstellten.
Nach knapp zwei Monaten wurde jedoch die Verwendung von Jira zu aufwendig. Die ein-gesetzte Zeit zur Organisation der Aufgaben in Jira hat keinen angemessenen Mehrwertfür die Projektgruppe. Darüber hinaus waren viele Aufgabenpakete, welche sich aufgrundneuer verwendeter Technologien ergeben haben, nicht so gut einzuschätzen wie zunächstgedacht, was dazu führte das viele Aufgabenpakete nicht in der dafür vorgesehenen Zeitbearbeitet werden konnten. Durch die gute Zusammenarbeit und die o�ene Kommunikati-on innerhalb der Projektgruppe war es möglich, auch ohne die präzisen Strukturen, welcheJira ermöglicht, schnell und nachvollziehbar Ergebnisse zu erzielen. Durch das Wegfallendes Aufwands zur Organisation der Aufgaben in Jira wurde eine Menge Zeit eingespart.
2.3.3. Kommunikation
Die Kommunikation innerhalb der Projektgruppe wurde über zwei Kanäle gesteuert. Alsprimärer Kommunikationskanal wurde E-Mail verwendet. Für eine unmittelbarer Kom-munikation, insbesondere innerhalb der Projektgruppe, wurden die Messaging DiensteWhatsApp und Slack genutzt. Die Kommunikation mit der Projektgruppe E-Stream wurdezunächst via Slack geführt, jedoch führte dies nicht zu den gewünschten kurzen Kommu-nikationswegen. Im späteren Verlauf der Projektgruppe wurde verstärkt E-Mail genutzt.
2.4. Projektphasen
Der Projektverlauf lässt sich in drei Phasen einteilen. Diese werden im folgenden dargestelltund erläutert. Ebenfalls werden die in den Phasen erstellen Meilensteinpläne gezeigt.
8

2 PROJEKTORGANISATION 2.4 Projektphasen
2.4.1. Erste Phase - Seminararbeiten & Konzeption
Um einen Überblick über die Thematik des Projektrahmens und -ziels zu erhalten, wurdezunächst eine Seminararbeitsphase durchgeführt. Darin hat sich jedes Projektgruppenmit-glied in einen relevanten Bereich der Projektdomäne eingearbeitet und die Erkenntnissein einer Seminararbeit festgehalten und der gesamten Gruppe vorgestellt. Die Bearbei-tungszeit dafür war auf einen Monat begrenzt. Die Präsentationen schlossen sich daran an.Währenddessen konnten Fragen geklärt werden, die im Zusammenhang mit dem Themen-bereich aufgetreten sind. Die erste Phase bot die Möglichkeit Speziallisten für bestimmteProjektbereiche zu �nden. Eine weitere Aufgabe in der ersten Phase war das Projektzieleindeutig zu formulieren und die Projektmitglieder in Kleingruppen aufzuteilen.
Während der gesamten ersten Projektphase wurdenWorkshops und kleinere Ideen�ndungs-seminare abgehalten. Diese Workshops dienten dazu, das Projektziel genauer zu bestimmenund einordnen zu können. Dieses Vorgehen war notwendig, da zum Projektstart keine ein-deutige Zielformulierung, Anforderungen oder genaue Beschreibung der Projektumgebungde�niert war. In dieser Phase konnten die unspezi�schen Vorgaben an die Projektgruppekonstruktiv erarbeitet und de�niert werden.
Als Ergebnis wurde u. a. ein grober Meilensteinplan erstellt. Dieser ist der folgenden Tabellezu entnehmen.
Meilenstein Datum
Entwurf - Architektur 19.04.2017Entwurf - Big Data Archive 31.05.2017Prototyp testen 17.07.2017Prototyp präsentieren 31.07.2017Produkt vorstellen 04.12.2017Abschluss der Nachbearbeitung 12.02.2018Abschluss der Dokumentation 23.02.2018Abschlusspräsentation 09.04.2018
Tabelle 2: Meilensteinplan, April 2017
2.4.2. Zweite Phase - Entwicklung
In der zweiten Projektphase erfolgte die Aufteilung der Projektgruppenmitglieder in dieKleingruppen. Wie im Unterabschnitt 2.3.1: Kleingruppen beschrieben, hatte jede Klein-gruppe dabei eine eigene Zielsetzung die erfüllt werden sollte. Die Aufgaben der Gruppenwurden von ihr selbst de�niert. In wöchentlichen Tre�en wurden die Fortschritte präsen-tiert und besprochen sowie die Aufgabenpakete der nächsten Woche vorgestellt.
Ebenfalls wurden Workshops zusammen mit der Projektgruppe E-Stream veranstaltet, um
9

2.4 Projektphasen 2 PROJEKTORGANISATION
die Schnittstelle des DAvE-Systems zu de�nieren. Dies geschah auf Grundlage von gemein-sam de�nierten Anwendungsfällen, welche eine Schnittmenge mit den Anwendungsfällendieser Projektgruppe ist (siehe hierzu auch 3.1: Use Cases).
Zum Ende dieser Projektphase konnte ein aktualisierter Meilensteinplan erstellt werden.Dieser ist in Tabelle 3: Meilensteinplan, Dezember 2017 dargestellt.
Meilenstein Datum
De�nition Architekturkonzept 20.06.2017De�nition Use Cases PG E-Stram 18.10.2017Fertigstellung Prototyp 08.12.2017Präsentation Prototyp 11.12.2017Umsetzung Use-Cases 31.01.2018Fertigstellung Dokumentation 31.03.2018
Tabelle 3: Meilensteinplan, Dezember 2017
2.4.3. Dritte Phase - Testen, Korrekturen, Dokumentation
In der letzten Phase des Projektes wurde der Prototyp getestet. Der Test erfolgte anhandstrukturierter Komponenten- und Integrationstests. Etwaige Fehler konnten dadurch iden-ti�ziert und behoben werden. In einem abschlieÿenden Workshop mit der ProjektgruppeE-Stream wurde die Schnittstelle �nalisiert und von beiden Projektgruppen abgenommen.
Darüber hinaus stand die Dokumentation der Projektergebnisse im Zentrum der Projekt-arbeit. Daneben wurden für die ECDA-Konferenz ein Abstract der Projektergebnisse ein-gereicht und ein Full Paper für die BUIS-Tage 2018, welche von der Abteilung VLBAveranstaltet wird, verfasst.
10

3 KONZEPT
3. Konzept
Das folgende Kapitel beschreibt das Konzept der Projektgruppe. Zuerst werden in dem Ab-schnitt 3.1: Use Cases die Anwendungsfälle beschrieben. Danach werden die Anforderungenauf Grundlage der Anwendungsfälle im 3.2: Anforderungen (Technische und FunktionaleAnforderungen) de�niert. Das Kapitel wird mit der vorläu�ge Systemarchitektur im Ab-schnitt 3.3: Systemarchitektur abgeschlossen.
3.1. Use Cases
Bei der Entwicklung der Use Cases lag der Fokus darauf, realistische Anwendungsfälle zude�nieren. Aus diesem Grund wurde der Fokus auf die gesamtsystem-notwendigen Funktio-nen gelegt. Das primäre Ziel der Projektgruppe ist es, die nachfolgenden Use Cases umzu-setzen. Die Use Cases konnten zu jederzeit erweitert werden � zusätzliche Funktionalitätenwurden nicht von der Implementierung ausgeschlossen. Es wurden von der Projektgruppevier Use Cases entworfen.
1. Daten archivieren
2. Anfragenbearbeitung von Daten (spez. COSEM-Format)
3. Modellerzeugung für das Power-Forecasting
4. Modellerzeugung für das Load-Forecasting
Im Folgenden sind die vier Use Cases beschrieben und die dazugehörigen Use Case Dia-gramme skizziert.
3.1.1. Daten archivieren
Der Use Case soll die Archivierung der Daten realisieren. Es werden heterogene Daten-quellen angeschlossen, bspw. Wetterdienste. Alle Datenquellen werden auf die selbe Artund Weise angeschlossen. Der Archivierungsprozess besteht ggfs. aus der Erweiterung derRohdaten mit zusätzlichen Metadaten für die Datenarchivierung. Die eingehenden Da-ten werden strukturiert in der Datenbank abgelegt. Des Weiteren werden unterschiedlicheLogging-Methoden durchgeführt. Die Daten werden persistent archiviert. Die Rohdatenwerden unverändert archiviert, die Metadaten werden lediglich zu den Rohdaten hinzuge-fügt. Stromerzeuger und Kunden stellen Rohdaten bereit. Diese werden in DAvE archiviert.
Essentielle Schritte:
1. Datenquellen beschreiben
11

3.1 Use Cases 3 KONZEPT
2. Datenströme entgegennehmen
3. Metadaten zu Rohdaten hinzufügen
4. Daten archivieren
5. Logging durchführen
Abbildung 2: Use Case 1: Daten archivieren
3.1.2. Anfragenbearbeitung von Daten
Der Use Case soll die Bearbeitung von Anfragen an das System realisieren. Die Anfragenan das System werden vom System zunächst empfangen. Nachdem eine Anfrage empfangenwurde, wird diese geprüft. Bei einer validen Anfrage wird diese ausgeführt. Es können Da-tensätze angefragt werden. Die Daten werden je nach Anfrage selektiert und im Anschlussversendet.
Essentielle Schritte:
1. Anfrage überprüfen
2. Anfrage übersetzen
3. Übersetzte Anfrage ausführen
4. Daten versenden
12

3 KONZEPT 3.1 Use Cases
Abbildung 3: Use Case 2: Anfragenbearbeitung von Daten
3.1.3. Modellerzeugung für das Power Forecasting
Der Use Case soll die Erstellung von Power Forecasting Modellen für Windkraft und PV-Anlagen realisieren. Innerhalb eines KDD-Prozesses werden Vorhersagemodelle entwickeltund Data Mining Modelle (DMM) werden innerhalb von DAvE ausgeführt. DMM werdenauf selektierte archivierte Datensätze angewendet. Das Modell wird im Anschluss expor-tiert.
Essentielle Schritte:
1. Auswahl der Datenquelle
2. Datenset erstellen
3. Daten integrieren
4. Daten vorverarbeiten - ETL, Datenset bereinigen
5. Auswahl der DMM
6. Anwendung DMM - Ergebnis ist ein Modell
7. Evaluieren des Modells
8. Versenden des Vorhersagemodells
13

3.1 Use Cases 3 KONZEPT
Abbildung 4: Use Case 3: Modellerzeugung für das Power Forecasting
3.1.4. Modellerzeugung für das Load Forecasting
Der Use Case soll die Erstellung von Load Forecasting Modellen realisieren. Innerhalbeines KDD-Prozesses werden Vorhersagemodelle entwickelt und DMM werden innerhalbvon DAvE ausgeführt. DMM werden auf selektierte archivierte Datensätze angewendet.Das Modell wird im Anschluss exportiert.
Essentielle Schritte:
1. Datenset erstellen
2. Daten integrieren
3. Daten vorverarbeiten - ETL, Datenset bereinigen
4. Auswahl der DMM
5. Anwendung DMM - Ergebnis ist ein Modell
6. Evaluieren des Modells
7. Versenden des Vorhersagemodells
14

3 KONZEPT 3.2 Anforderungen (Technische und Funktionale Anforderungen)
Abbildung 5: Use Case 4: Modellerzeugung für das Load Forecasting
3.2. Anforderungen (Technische und Funktionale Anforderungen)
Zur Umsetzung des Datenarchivs und seiner Komponenten ist es notwendig, dass im Vorfeldgenaue Anforderungen an das System de�niert werden. Diese beschreiben detailliert, wasdas System leisten muss. Die Anforderungen zeigen die Kompetenzen des Systems auf.
Es wurden zum Projektbeginn Anforderungen de�niert, die während der Entwicklung um-zusetzen sind. Diese Anforderungen wurden dabei allerdings im Projektverlauf durch Än-derungen der Rahmenbedingungen für das System angepasst. Solche werden in funktionale,nichtfunktionale sowie Anforderungen für das Verhalten im Fehlerfall gegliedert. Ziel ist eskeine Lösungsvorgaben zu tre�en, sondern lediglich zu de�nieren, welche Vorgaben durcheine Lösung erfüllt werden müssen. Diese werden in den folgenden Tabellen dargestellt.
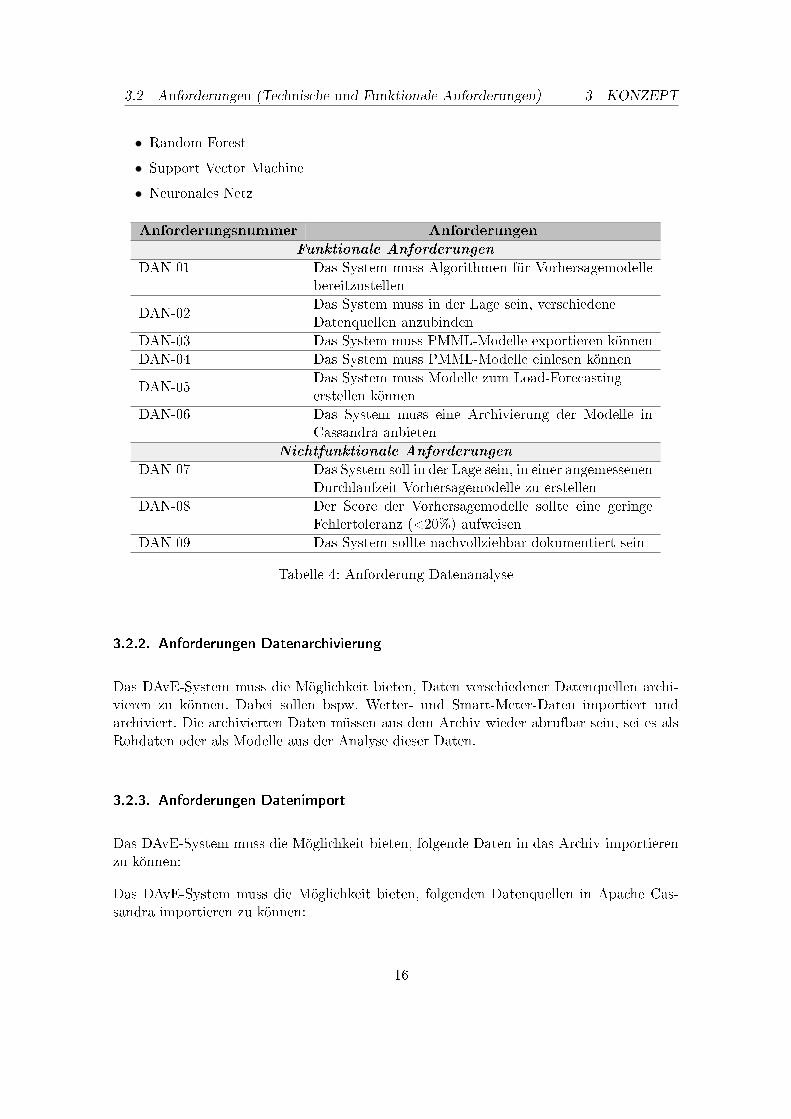
3.2.1. Anforderungen Datenanalyse
Das DAvE-System muss die Möglichkeit bieten, anhand der importierten Daten Vorhersa-gemodelle erstellen zu können. Dabei sollen folgende Modelle unterstützt werden:
• Lineare Regression
15
3.2 Anforderungen (Technische und Funktionale Anforderungen) 3 KONZEPT
• Random Forest
• Support Vector Machine
• Neuronales Netz
Anforderungsnummer Anforderungen
Funktionale Anforderungen
DAN-01 Das System muss Algorithmen für Vorhersagemodellebereitzustellen
DAN-02Das System muss in der Lage sein, verschiedeneDatenquellen anzubinden
DAN-03 Das System muss PMML-Modelle exportieren könnenDAN-04 Das System muss PMML-Modelle einlesen können
DAN-05Das System muss Modelle zum Load-Forecastingerstellen können
DAN-06 Das System muss eine Archivierung der Modelle inCassandra anbieten
Nichtfunktionale Anforderungen
DAN-07 Das System soll in der Lage sein, in einer angemessenenDurchlaufzeit Vorhersagemodelle zu erstellen
DAN-08 Der Score der Vorhersagemodelle sollte eine geringeFehlertoleranz (<20%) aufweisen
DAN-09 Das System sollte nachvollziehbar dokumentiert sein
Tabelle 4: Anforderung Datenanalyse
3.2.2. Anforderungen Datenarchivierung
Das DAvE-System muss die Möglichkeit bieten, Daten verschiedener Datenquellen archi-vieren zu können. Dabei sollen bspw. Wetter- und Smart-Meter-Daten importiert undarchiviert. Die archivierten Daten müssen aus dem Archiv wieder abrufbar sein, sei es alsRohdaten oder als Modelle aus der Analyse dieser Daten.
3.2.3. Anforderungen Datenimport
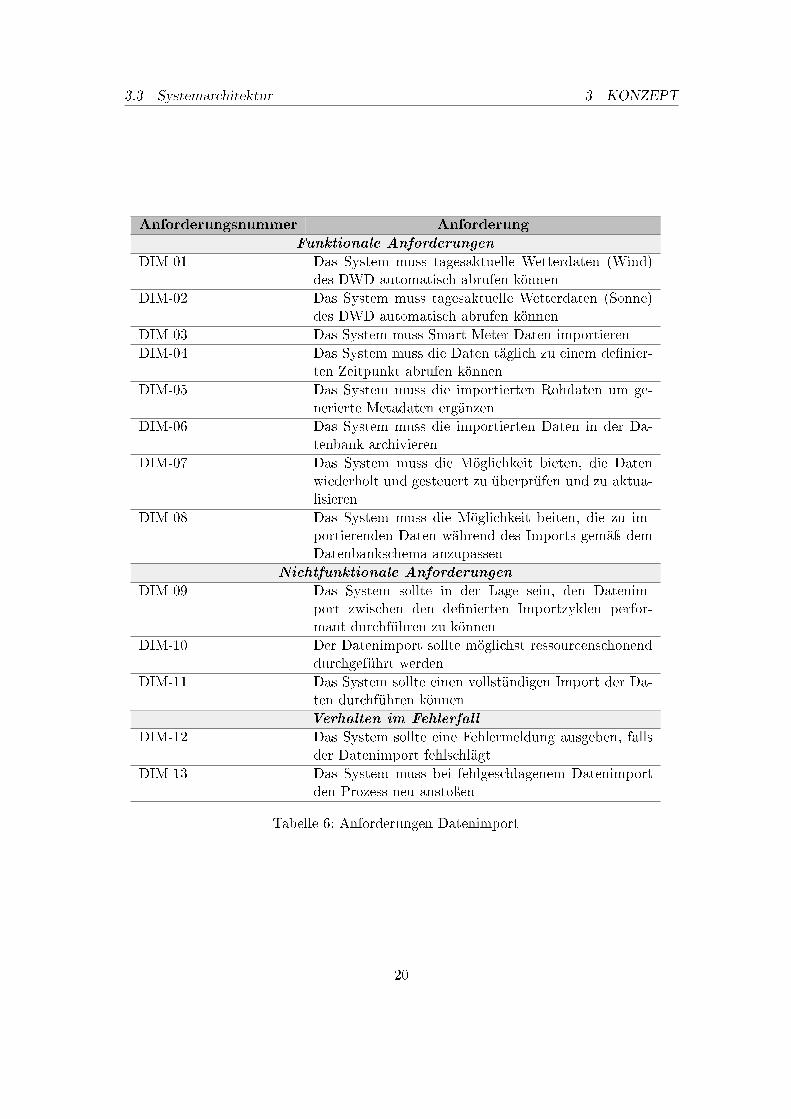
Das DAvE-System muss die Möglichkeit bieten, folgende Daten in das Archiv importierenzu können:
Das DAvE-System muss die Möglichkeit bieten, folgenden Datenquellen in Apache Cas-sandra importieren zu können:
16
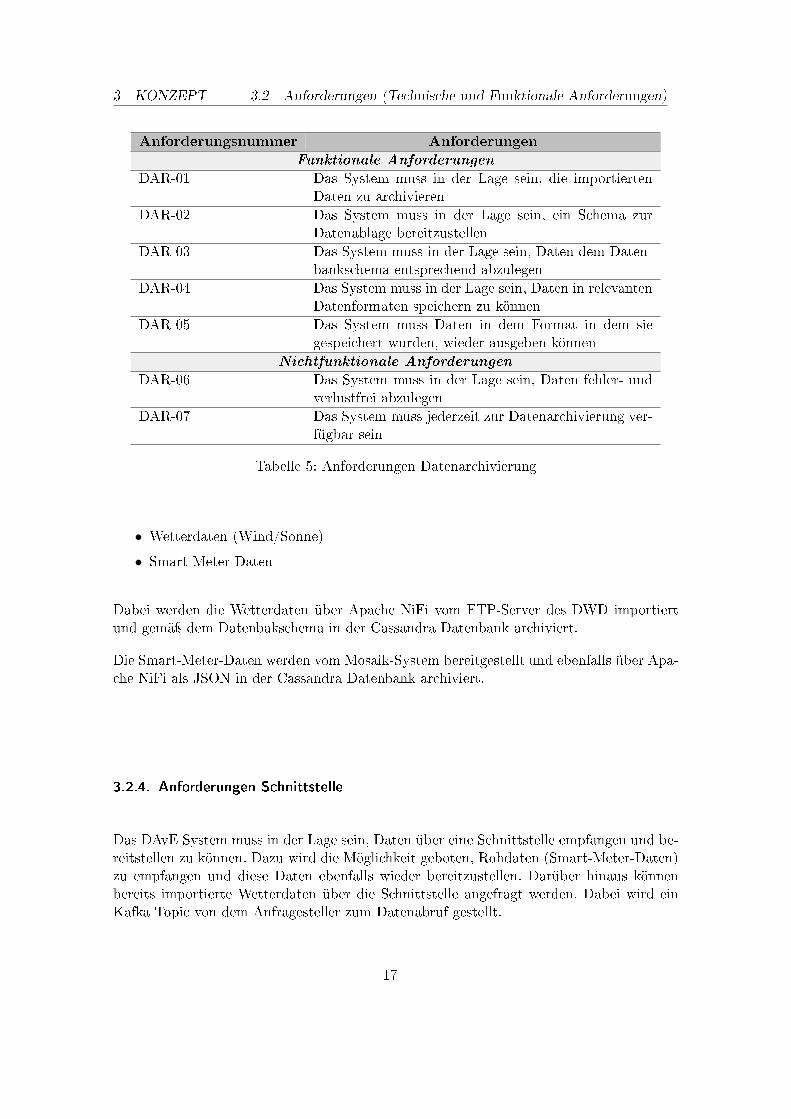
3 KONZEPT 3.2 Anforderungen (Technische und Funktionale Anforderungen)
Anforderungsnummer Anforderungen
Funktionale Anforderungen
DAR-01 Das System muss in der Lage sein, die importiertenDaten zu archivieren
DAR-02 Das System muss in der Lage sein, ein Schema zurDatenablage bereitzustellen
DAR-03 Das System muss in der Lage sein, Daten dem Daten-bankschema entsprechend abzulegen
DAR-04 Das System muss in der Lage sein, Daten in relevantenDatenformaten speichern zu können
DAR-05 Das System muss Daten in dem Format in dem siegespeichert wurden, wieder ausgeben können
Nichtfunktionale Anforderungen
DAR-06 Das System muss in der Lage sein, Daten fehler- undverlustfrei abzulegen
DAR-07 Das System muss jederzeit zur Datenarchivierung ver-fügbar sein
Tabelle 5: Anforderungen Datenarchivierung
• Wetterdaten (Wind/Sonne)
• Smart-Meter-Daten
Dabei werden die Wetterdaten über Apache NiFi vom FTP-Server des DWD importiertund gemäÿ dem Datenbakschema in der Cassandra Datenbank archiviert.
Die Smart-Meter-Daten werden vom Mosaik-System bereitgestellt und ebenfalls über Apa-che NiFi als JSON in der Cassandra Datenbank archiviert.
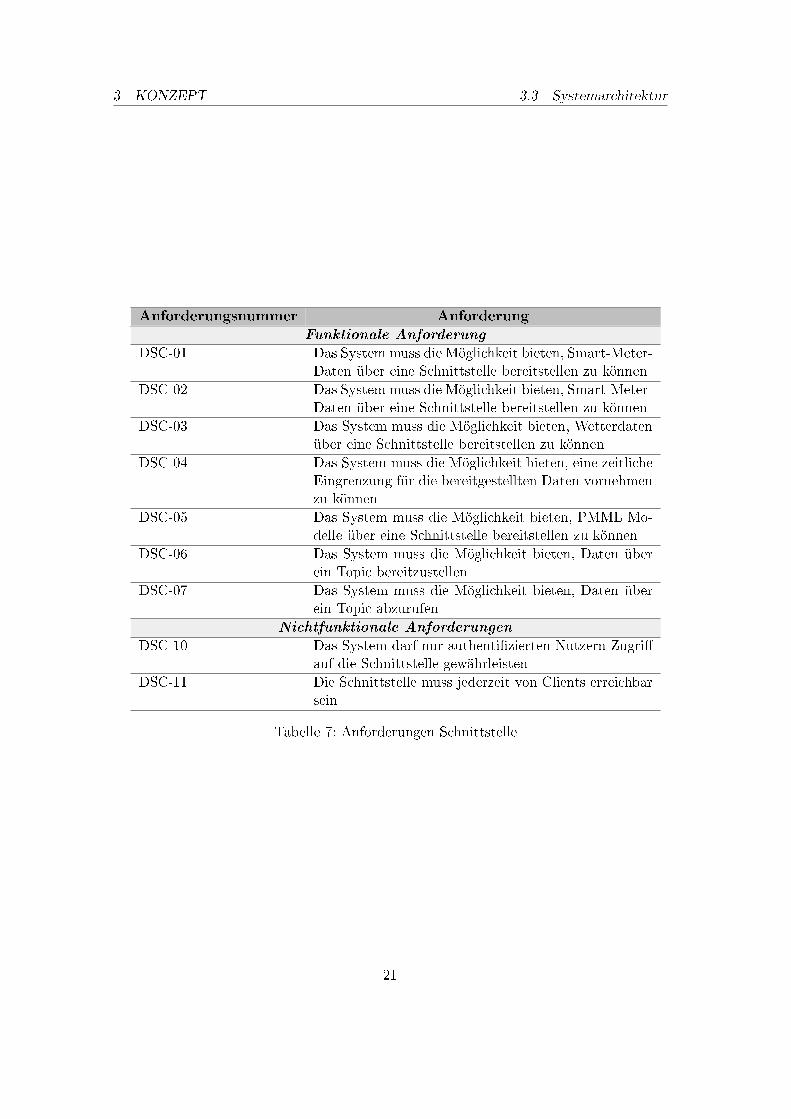
3.2.4. Anforderungen Schnittstelle
Das DAvE System muss in der Lage sein, Daten über eine Schnittstelle empfangen und be-reitstellen zu können. Dazu wird die Möglichkeit geboten, Rohdaten (Smart-Meter-Daten)zu empfangen und diese Daten ebenfalls wieder bereitzustellen. Darüber hinaus könnenbereits importierte Wetterdaten über die Schnittstelle angefragt werden. Dabei wird einKafka Topic von dem Anfragesteller zum Datenabruf gestellt.
17

3.3 Systemarchitektur 3 KONZEPT
3.3. Systemarchitektur
In diesem Abschnitt wird die konzeptionelle Architektur des DAvE Systems dargestellt underläutert. Der Entwurf der konzeptionellen Architektur ist das Ergebnis der dokumentierenAnforderungen (siehe 3.2: Anforderungen (Technische und Funktionale Anforderungen))und den entworfenen Use Cases (siehe 3.1: Use Cases).
Um den primären Anwendungsfall, das Archivieren von Smart-Meter-Daten, zu adressie-ren, ist eine Archivierungsebene innerhalb der Architektur des DAvE-Systems notwendig.Innerhalb dieser sind Datenbanksysteme dafür zuständig, alle zu archivierenden Daten per-sistent zu speichern. Um den Anforderungen von Big Data gerecht zu werden, ist daraufzu achten dass die Archivierungsebene mit ihren Systemen skalierbar ist um auch riesigeMengen von Daten speichern zu können. Um die archivierten Daten Konsumenten zur Ver-fügung zu stellen oder auf ihnen Modelle für verschiedene Vorhersagezwecke zu erstellen,ist es ebenfalls essentiell dass die Daten abgefragt werden können.
Als weitere konzeptionelle Schicht in der Architektur ist die Data-Mining-Schicht zu planen.Darin enthaltene Komponenten müssen in der Lage sein Vorhersagemodelle basierend aufden archivierten Smart-Meter-Daten zu generieren. Da das DAvE-System die Generierungdieser Modelle beherrscht, diese jedoch nicht im Kontext von DAvE eingesetzt (deployed)werden sollen, ist bereits in den Anforderungen spezi�ziert dass die generierten Modellemit der standardisierten Datei-Schnittstelle für Data-Mining-Modelle PMML exportiertwerden können.
Um externen Konsumenten die Funktionen des DAvE-Systems zur Verfügung zu stellen undum die Daten externer Datenquellen in die Archivierungsebene zu überführen, ist letztlicheine Kommunikationsebene notwendig. Zum einen beinhaltet diese eine Schnittstelle umdas Bereitstellen von archivierten Daten und generierten Modellen zu ermöglichen, undzum anderen steuert diese den Daten�uss externer Datenquellen, z. B. Smart-Meter-Datenoder Wetterdaten, in die Archivierungsebene.
Um eine o�ene Architektur zu scha�en, wird die Auswahl von Technologien welche diekonzeptionelle Architektur realisieren, auf standardisierte, freie und quello�ene Technolo-gien, Software und Systeme beschränkt. Die eben beschriebenen Komponenten werden in6: Übersicht der Komponenten in DAvE abgebildet.
18
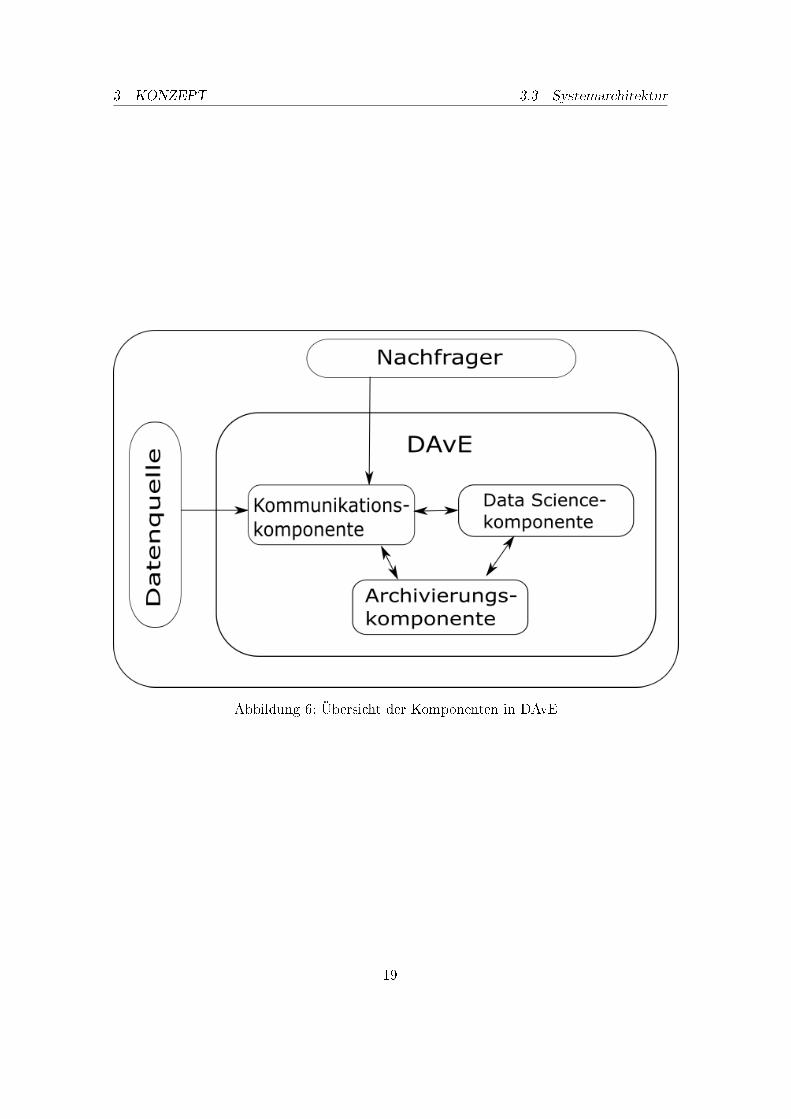
3 KONZEPT 3.3 Systemarchitektur
Abbildung 6: Übersicht der Komponenten in DAvE
19
3.3 Systemarchitektur 3 KONZEPT
Anforderungsnummer Anforderung
Funktionale Anforderungen
DIM-01 Das System muss tagesaktuelle Wetterdaten (Wind)des DWD automatisch abrufen können
DIM-02 Das System muss tagesaktuelle Wetterdaten (Sonne)des DWD automatisch abrufen können
DIM-03 Das System muss Smart-Meter-Daten importierenDIM-04 Das System muss die Daten täglich zu einem de�nier-
ten Zeitpunkt abrufen könnenDIM-05 Das System muss die importierten Rohdaten um ge-
nerierte Metadaten ergänzenDIM-06 Das System muss die importierten Daten in der Da-
tenbank archivierenDIM-07 Das System muss die Möglichkeit bieten, die Daten
wiederholt und gesteuert zu überprüfen und zu aktua-lisieren
DIM-08 Das System muss die Möglichkeit beiten, die zu im-portierenden Daten während des Imports gemäÿ demDatenbankschema anzupassen
Nichtfunktionale Anforderungen
DIM-09 Das System sollte in der Lage sein, den Datenim-port zwischen den de�nierten Importzyklen perfor-mant durchführen zu können
DIM-10 Der Datenimport sollte möglichst ressourcenschonenddurchgeführt werden
DIM-11 Das System sollte einen vollständigen Import der Da-ten durchführen könnenVerhalten im Fehlerfall
DIM-12 Das System sollte eine Fehlermeldung ausgeben, fallsder Datenimport fehlschlägt
DIM-13 Das System muss bei fehlgeschlagenem Datenimportden Prozess neu anstoÿen
Tabelle 6: Anforderungen Datenimport
20
3 KONZEPT 3.3 Systemarchitektur
Anforderungsnummer Anforderung
Funktionale Anforderung
DSC-01 Das System muss die Möglichkeit bieten, Smart-Meter-Daten über eine Schnittstelle bereitstellen zu können
DSC-02 Das System muss die Möglichkeit bieten, Smart-Meter-Daten über eine Schnittstelle bereitstellen zu können
DSC-03 Das System muss die Möglichkeit bieten, Wetterdatenüber eine Schnittstelle bereitstellen zu können
DSC-04 Das System muss die Möglichkeit bieten, eine zeitlicheEingrenzung für die bereitgestellten Daten vornehmenzu können
DSC-05 Das System muss die Möglichkeit bieten, PMML Mo-delle über eine Schnittstelle bereitstellen zu können
DSC-06 Das System muss die Möglichkeit bieten, Daten überein Topic bereitzustellen
DSC-07 Das System muss die Möglichkeit bieten, Daten überein Topic abzurufen
Nichtfunktionale Anforderungen
DSC-10 Das System darf nur authenti�zierten Nutzern Zugri�auf die Schnittstelle gewährleisten
DSC-11 Die Schnittstelle muss jederzeit von Clients erreichbarsein
Tabelle 7: Anforderungen Schnittstelle
21


4 TECHNOLOGIEAUSWAHL
4. Technologieauswahl
In diesem Kapitel wird die durchgeführte Technologieauswahl vorgestellt und begründet.Zunächst erfolgt die Beschreibung des Technologieauswahlprozesses im Bereich der Ar-chivierung für ein Datenbanksystem und ein Data�ow Management-System in den Ab-schnitten 4.1: Archivierung: Datenbank und 4.2: Archivierung: Data�ow Management. DieAuswahl für Systeme zur Kommunikation wird im Abschnitt 4.3: Messaging System be-gründet. Im Abschnitt 4.4: Data Science werden ausgewählte Komponenten für den BereichData Science im DAvE-System beschrieben. Im letzten Abschnitt 4.5: Data Engineeringwird das Kapitel der Technologieauswahl durch die Auswahl im Bereich Data Engineeringabgeschlossen.
4.1. Archivierung: Datenbank
Eine entscheidende Komponente für ein Archiv stellt die Datenbank dar, in welcher dieDaten persistent gespeichert und bei Bedarf abgerufen werden können. Auf dem Marktexistiert eine Vielzahl an Datenbanksystemen, so galt es für die DAvE Architektur einpassendes System zu wählen. Im Folgenden wird das Vorgehen bei der Wahl der Datenbankbeschrieben.
Aus der zum Projektbeginn einhergehenden Seminarphase erschloss sich, dass relationaleDatenbanken für die Herausforderungen von Big Data nicht geeignet sind. Relationale Da-tenbanken sind der Vielzahl an Daten und verschiedenen Datenquellen nicht gewachsen.So konnte die verfügbare Auswahl in einem ersten Schritt auf NoSQL-Datenbanken be-schränkt werden, da diese für die Herausforderungen im Big Data Kontext ausgelegt sind(vgl. [Har15], S. 30).
DB1 Die Datenbank muss einem nicht relationalen Ansatz verfolgen (NoSQL).
In einem nächsten Schritt wurde ein Überblick über den Markt an NoSQL-Datenbankengescha�en. Die Auswahl an NoSQL-Datenbanken fällt im Vergleich zur relationalen Da-tenbanken noch relativ gering aus, da diese einhergehend mit Big Data erst in den letztenzehn Jahren an Bedeutung gewonnen haben (vgl. [Har15], S. 30). In der aktuellen Auswahlan Systemen stellten sich die folgenden Datenbanken als eine der etabliertesten NoSQL-Datenbanksysteme heraus (vgl. [Sol18]):
• Apache Cassandra
• Apache HBase
• MongoDB
Diese drei Systeme sind in der Literatur mit am häu�gsten vorzu�nden und werden vielfach
23

4.1 Archivierung: Datenbank 4 TECHNOLOGIEAUSWAHL
miteinander verglichen, daher beschränkte sich die weitere Recherche auf diese Systeme(vgl. [Sol18, OBALB15, MH13]).
Die Datenbanken wurden auf ihre Eigenschaften hin untersucht und es wurde eine Tabelleaufgestellt (siehe A.1: Tabelle Auswahl Datenbanken), welche das technische Datenblatt derSysteme vergleicht. Eine der Angaben in dieser Tabelle ist der Typ des Datenbanksystems.
Der Typ des Systemes stellt ein entscheidendes Kriterium, für die Wahl des Datenbank-systems dar. Dieser Typ gibt an, auf welche Weise und in welchem Format die Datenabgespeichert werden, auÿerdem werden einige Operationen durch diesen Typ limitiert(vgl. [Sul15], S. 332f.). Apache Cassandra und Apache HBase sind den Collumn FamilyDatabases zugehörig und MongoDB dagegen den Document Databases. Collumn FamilyDatabases eignen sich für Anwendungen, welche jederzeit Daten in die Datenbank schrei-ben müssen, verteilt sind auf mehrere Datenzentren, und hohe Datenmengen im Bereichvon mehreren hundert Terabyte aufkommen lassen können.todozu langer Satz, kürzer Auÿerdem wird dieser Typ bereits erfolgreich für Analysen imAktienmarkt genutzt, also einem Markt bei dem schnell reagiert werden muss und es unteranderem gilt Prognosen aufzustellen, wie es auch bei Energiedaten der Fall ist (vgl. [Sul15],S. 334 f.). Somit entspricht der Typ der Collumn Family Databases dem Anwendungszweckunseres Archives am ehesten.
DB2 Die Datenbank muss dem Typ der Collumn Family Databases zugehörig sein.
Mit Bestimmung des für unseren Anwendungszweck geeigneten Types der Datenbank konn-te das System MongoDB ausgeschlossen werden. Die Wahl zwischen Apache Hbase undApache Cassandra verlief äuÿerst wechselhaft. Die Datenblätter der beiden Systeme un-terscheiden sich nur an wenigen Punkten, dies erschwerte die Wahl und erforderte weitereAspekte in Betracht zu ziehen. Die DAvE Architektur sollte ursprünglich mit dem HadoopEco-System umgesetzt werden, somit war Apache Hbase, welches eine Komponente diesesSystem ist, eine favorisierte Wahl. Dies sollte allerdings kein primäres Argument für dieWahl des Datenbanksystemes sein.
Um eine Wahl festigen zu können, strebten wir einen Praxisversuch der Systeme an. Dazunutzten wir Virtuelle Maschinen auf einigen der Rechnern der PG-Mitglieder in Verbin-dung mit der Software Vagrant (vgl. [Has18]). So konnte die Installation der beiden Daten-banksysteme erprobt werden. Der produktive Praxisbetrieb hingegen erwies sich als nichtdurchführbar, da die Leistung der genutzten Rechner nicht ausreichte. Als Anforderungfür die Installation der Datenbank ergab sich zunächst, dass die Installation erfolgreich er-probt werden konnte. Somit konnten wir sicherstellen, dass die Installation auf dem Servermöglich sein dürfte.
DB3 Die Installation der Datenbank muss auf den Testsystemen der PG-Nutzer erfolgreichdurchgeführt werden können.
24

4 TECHNOLOGIEAUSWAHL 4.1 Archivierung: Datenbank
Des Weiteren betrachteten wir für die Wahl das CAP Theorem. Das CAP Theorem be-sagt, dass eine verteilte Datenbank zur selben Zeit nur zwei der folgenden Eigenschaftenabdecken kann:
• Consistency: Die Consistency beschreibt die Eigenschaft, dass jeder Nutzer derDatenbank in jeder Instanz (Kopien der Daten auf unterschiedlichen Server-Clustern)eine identische Ansicht der Daten hat.
• Availability: Die Availability beschreibt die Eigenschaft, dass bei dem Ereignis einesFehlers, die Datenbank operational verfügbar bleibt. Alle Anfragen werden beantwor-tet.
• Partition tolerance: Die Partition tolerance beschreibt die Eigenschaft, dass dieDatenbank auch bei Netzwerkfehlern, einzelner Netzknoten oder Partition des Netzesweiter arbeitet.
Demnach muss sich bei der Wahl eines verteilten Datenbanksystems für zwei dieser Ei-genschaften entschieden bzw. priorisiert werden (vgl. [Har15], S. 43 f.). Wir favorisierenhierbei die Verfügbarkeit gegenüber der Konsistenz der Daten und somit die CAP Theo-rem Kombination AP.
DB4 Die Datenbank muss nach dem CAP Theorem eine Kombination aus Availability undPartition tolerance bieten.
4.1.1. Anforderungen
In diesem Abschnitt werden die Anforderungen, welche in Abschnitt 4.1: Archivierung:Datenbank aufgestellt wurden zusammenfassend aufgelistet, damit sie im Abschnitt 4.1.2:Beschreibung für den Vergleich der Datenbank und die Auswahl hinzugezogen werdenkönnen.
DB1 Die Datenbank muss einem nicht relationalen Ansatz verfolgen (NoSQL).
DB2 Die Datenbank muss dem Typ der Collumn Family Databases zugehörig sein.
DB3 Die Installation der Datenbank muss auf den Testsystemen der PG-Nutzer erfolgreichdurchgeführt werden können.
DB4 Die Datenbank muss nach dem CAP Theorem eine Kombination aus Availability undPartition tolerance bieten.
25

4.1 Archivierung: Datenbank 4 TECHNOLOGIEAUSWAHL
4.1.2. Beschreibung
In diesem Abschnitt werden die, aus der in Abschnitt 4.1: Archivierung: Datenbank an-gesprochenen Marktanalyse resultierenden Datenbanksysteme Apache Hbase und Apa-che Cassandra in Kurzform beschrieben und auf die Anforderungen in Abschnitt 4.1.1:Anforderungen untersucht. Die Datenbank MongoDB wurde in Abschnitt 4.1: Archivie-rung: Datenbank bereits aus der Auswahl ausgeschlossen.
Apache Hbase Bei Apache Hbase handelt es sich um die verteilte, skalierbare NoSQLDatenbank des Apache Hadoop Eco-Systems und dient hierbei als Big Data Speicher. DieseDatenbank eignet sich nach Herstellerangaben, wenn ein stichprobenartiger Echtzeitzugri�auf die Massendaten notwendig erscheint. Ziel dieses Open Source Projektes ist es sehrgroÿe Tabellen zu hosten, was Millionen von Reihen und Spalten beinhaltet. Apache HBaseist nach dem Vorbild von Google's Bigtable entstanden. Statt wie Google's Bigtable aufdas Google File System zu setzen, setzt Apache HBase auf Hadoop und HDFS auf. EinigeFunktionen dieser Datenbank sind (vgl. [The18a]):
• Lineare und modulare Skalierbarkeit
• Konsistente Schreib- und Lesezugri�e
• Automatisch und kon�gurierbares sharding von Tabellen
• Eine einfach zu nutzende Java API für den Client-Zugri�
Weitere Information zum Hadoop System sind der Seminararbeit Hadoop Ecosystem Com-ponents: Ambari, HDFS and MapReduce (siehe Anhang) zu entnehmen.
Apache Hbase ist somit ganz nach Anforderung DB1: Anforderungen eine NoSQL Da-tenbank, auÿerdem zählt sie zu den Column Family Databases (s. Anforderung DB2:Anforderungen)(vgl. [Sul15], S. 334 f.). Die Installation dieser Datenbank ist relativ auf-wendig, da sie eine Komponente des Hadoop Ecosystems darstellt und somit ist sie ab-hängig von dessen Komponenten und setzt diese voraus. Die Installation verlief erfolgreichmithilfe von Apache Ambari (Abschnitt xyz) (s.AnforderungDB3: Anforderungen). Hbasedeckt nach dem CAP Theorem die Eigenschaften Consistency und Partition tolerance ab,dies widerspricht der Anforderung DB4: Anforderungen (vgl. [Sah15]).
Apache Cassandra Die Apache Cassandra Datenbank ist eine skalierbare NoSQL Daten-bank mit hoher Avaibility ohne dabei auf Performance verzichten zu müssen. Lineare Ska-lierbarkeit und scalability sowie bewiesene Fehlertoleranz verhelfen kritische Daten sicherzu speichern. Apache Cassandra ermöglicht Replikationen der Daten zwischen verschiede-nen Datenzentren und gehört in diesem Gebiet laut Herstellerangaben zu den Besten. DieseFähigkeit verscha�t den Nutzern geringere Latenzzeiten und löst das Problem regionalerGrenzen. Die Eigenschaften mit denen der Hersteller sich auszeichnet sind (vgl. [The16]):
26

4 TECHNOLOGIEAUSWAHL 4.2 Archivierung: Data�ow Management
• Fehlertoleranz, die Daten werden automatisch auf verschiedene Nodes repliziert
• Performanz, so schlägt Apache Cassandra die Konkurrenz mehrfach in PerformanceVergleichen
• Dezentralisierung, es gibt keinen Single Point of Failure und keine Netzwerk Fla-schenhalse, da jeder Node im Cluster identisch ist
Apache Cassandra ist ganz nach Anforderung DB1: Anforderungen eine NoSQL Da-tenbank, auÿerdem zählt sie zu den Collumn Family Databases (s. Anforderung DB2:Anforderungen) (vgl. [Sul15], S. 334 f.). Die Installation dieser Datenbank ist im Ver-gleich zur Installation von Apache Hbase unkompliziert, da keine zusätzlichen Kompo-nenten vorausgesetzt werden. Die Installation verlief erfolgreich, somit wird die Anfor-derung DB3: Anforderungen erfüllt. Apache Cassandra deckt nach dem CAP Theoremdie Eigenschaften Availability und Partition tolerance ab und erfüllt damit die Anforde-rung DB4: Anforderungen (vgl. [Sah15]).
Ergebnis Nach den aufgestellten Anforderungen setzt sich in diesem Vergleich ApacheCassandra durch. Die Installation erwies sich als simpel und setzte keine weiteren Kompo-nenten voraus, womit sich diese Datenbank im Vergleich zu Apache Hbase um einiges �exi-bler erweist. Auÿerdem erfüllt Apache Cassandra die Anforderung DB4: Anforderungen,nach dem CAP Theorem die Eigenschaften Availability und Partition tolerance zu verei-nen. Weiterhin bietet Apache Cassandra die Kon�gurationsmöglichkeit für jede Tabelle einso genanntes consistency level zu kon�gurieren, womit je Tabelle eingestellt werden kann,ob mehr zur Availability oder zur Consistency tendiert wird (vgl. [Dat18]). Dies machtApache Cassandra dahingehend �exibel, ob die Präferenzen nach dem CAP Theorem eherzur Availability oder zur Consistency tendieren.
4.2. Archivierung: Data�ow Management
Für ein Archiv stellt neben dem Sichern von Daten, das Abrufen der gesicherten Daten ei-ne bedeutende Funktion dar. Nach dem Abruf der Daten innerhalb der DAvE-Architektursteht die Übermittlung dieser Daten an die Nutzer aus. Für diesen Zweck wurde der Mes-sage Broker Apache Kafka gewählt, mit jenem Datenströme verwaltet werden können undso das Abrufen und Versenden von Daten ermöglicht wird (Querverweis Kapitel Kafka,Usecases).
Um Daten aus der Datenbank an Apache Kafka zu übermitteln galt es, die Datenbank(in diesem Fall Apache Cassandra) mit Apache Kafka zu verbinden und den Daten�usszwischen diesen Komponenten zu managen. Es wurde eine Recherche eingeleitet, um diesemZweck dienliche, mögliche Technologien aus�ndig zu machen. Als Ergebnis dieser Rechercheergaben sich folgende Kandidaten:
27

4.2 Archivierung: Data�ow Management 4 TECHNOLOGIEAUSWAHL
• Kafka Connect
• Apache NiFi
Unseren Use Cases entsprechend muss es ermöglicht werden, Daten aus der Datenbank inApache Kafka zu übermitteln.
DFM1 Die Data�ow Management Lösung muss den Daten�uss von der Datenbank, hinzu Apache Kafka ermöglichen.
Weiterhin sollten Daten aus Apache Kafka in die Datenbank übertragen werden können.
DFM2 Die Data�ow Management Lösung muss den Daten�uss von Apache Kafka, zu derDatenbank ermöglichen.
Die Übertragung sollte möglichst automatisiert statt�nden können.
DFM3 Die Data�ow Management Lösung sollte den Daten�uss automatisiert managenkönnen.
Um eine Wahl festigen zu können, wurden die Testkandidaten auf virtuellen Maschinen aufeinigen der Rechnern der PG-Mitglieder installiert. Im Anschluss wurden diese Lösungenerprobt. Als Anforderung für die Installation der Datenbank ergab sich zunächst, dass dieInstallation erfolgreich erprobt werden konnte. Somit konnten wir sicherstellen, dass dieInstallation auf dem Server möglich sein dürfte.
DFM4 Die Installation der Data�ow Management Lösung muss auf den Testsystemen derPG-Nutzer erfolgreich durchgeführt werden können.
Eine weitere Anforderung ist, dass die Nutzung der Technologie für die angedachten Zwecke(Verbindung von Apache Kafka und Cassandra) erfolgreich auf den Testsystemen durch-geführt werden kann. Auf diese Weise kann ein erfolgreicher Betrieb gewährleistet werden.Auÿerdem kann so sichergestellt werden, dass die gewählte Lösung den nötigen Funktions-umfang abdeckt.
DFM5 Die Data�ow Management Lösung muss in einem Praxistest erfolgreich den Da-tenstrom zwischen Apache Kafka und Cassandra managen.
4.2.1. Anforderungen
In diesem Abschnitt werden die Anforderungen, welche in Abschnitt 4.1: Archivierung:Datenbank aufgestellt wurden zusammenfassend aufgelistet, damit diese im Abschnitt 4.1.2:
28

4 TECHNOLOGIEAUSWAHL 4.2 Archivierung: Data�ow Management
Beschreibung für den Vergleich der Datenbank und die Auswahl hinzugezogen werden kön-nen.
DFM1 Die Data�ow Management Lösung muss den Daten�uss von der Datenbank, hinzu Apache Kafka ermöglichen.
DFM2 Die Data�ow Management Lösung muss den Daten�uss von Apache Kafka, zu derDatenbank ermöglichen.
DFM3 Die Data�ow Management Lösung sollte den Daten�uss automatisiert managenkönnen.
DFM4 Die Installation der Data�ow Management Lösung muss auf den Testsystemen derPG-Nutzer erfolgreich durchgeführt werden können.
DFM5 Die Data�ow Management Lösung muss in einem Praxistest erfolgreich den Da-tenstrom zwischen Apache Kafka und Cassandra (Datenbank) managen.
4.2.2. Beschreibung
In diesem Abschnitt werden die aus der in Abschnitt 4.2: Archivierung: Data�owManagementangesprochenen Recherche resultierenden Data�ow Management Lösungen Kafka Connectund Apache NiFi, in Kurzform beschrieben und auf die Anforderungen in Abschnitt 4.2.1:Anforderungen untersucht.
Kafka Connect Kafka Connect ist ein Tool, dass Daten zwischen Apache Kafka und ande-ren Systemen zuverlässig sowie skaliert überträgt. Es ermöglicht auf einfache und schnelleWeise Konnektoren zu de�nieren, welche Datenmengen in und aus Apache Kafka bewe-gen. Kafka Connect kann komplette Datenbanken oder Metriken von den Applikationeneines Servers, in einen Kafka Topic aufnehmen und die Daten für das Stream Processingverwenden (vgl. [The18b]).
Kafka Connect enthält folgende Funktionen (vgl. [The18b]):
• Ein Framework für Kafka Konnektoren - Kafka Connect ermöglicht eine standardi-sierte Integration von anderen Dateisystemen mit Apache Kafka
• REST-Schnittstelle - Management von Konnektoren über eine einfach zu bedienendeREST-Schnittstelle
• Streaming/batch Integration - Kafka Connect nutzt die vorhandenen Fähigkeiten vonApache Kafka und ist damit eine ideale Lösung für die Überbrückung von Streaming-und Batch-Datensystemen
Kafka Connect erfüllt die zuvor aufgestellten funktionalen Anforderungen. Die Installation
29

4.2 Archivierung: Data�ow Management 4 TECHNOLOGIEAUSWAHL
und Bedienung erwies sich allerdings als problematisch. Die Dokumentation und einschlägi-gen Tutorials sind mangelhaft und teils veraltet. Während der Installation und Bedienungtraten vermehrt Fehlermeldungen und Probleme auf, sodass die praktische Nutzung sichals nicht durchführbar erwies.
Apache NiFi Apache NiFi unterstützt das Nutzen skalierbarer gerichteter Graphen fürden Transport und das Transformieren von Daten. Dies wurde entwickelt, um Daten�üs-se zwischen verschiedenen Systemen zu automatisieren. Daten�uss ist in diesem Kontextder automatisierte und gesteuerte Fluss von Informationen zwischen Systemen. Solch eineLösung erweist sich als notwendig, seit dem Unternehmen mehr als ein System betreiben.Die Systeme erstellen eigens Daten und konsumieren Daten anderer Systeme. Apache NiFiermöglicht diesen Datentransport zu kon�gurieren und zu steuern (vgl. [The18c]).
Einige der Features sind (vgl. [The18c]:
• Ein Web-based User Interface
• Hochgradig Kon�gurierbar
• Daten�üsse können zur Laufzeit modi�ziert werden
• Das Erstellen eigener Prozessoren ist möglich
Apache NiFi erfüllt die funktionalen Anforderungen, welche an eine Data�ow ManagementLösung gesetzt wurden. Die Installation erwies sich als unkompliziert, von der Hersteller-seite wird ein Paket heruntergeladen, entpackt und der NiFi Prozess muss dann nur nochgestartet werden. Die Bedienung wird durch das Web-Interface erleichtert. Apache Kafkamit einer Datenbank zu verbinden erfolgt problemlos. Apache NiFi ermöglicht es einemData�ows zu erstellen, in welchen Prozessoren mit gerichteten Graphen miteinander ver-bunden werden. Die Prozessoren ermöglichen Funktionalitäten, wie das Empfangen, Mani-pulieren und Senden von FlowFiles. FlowFiles beinhalten einen Datensatz sowie zugehörigeAttribute. So gibt es Eingangsprozessoren, wie z. B. QueryCassandra mit dem Daten ausCassandra per CQL-Abfrage entnommen werden können, mit weiteren Prozessoren wer-den diese Daten manipuliert und letzten Endes z. B. mit einem Ausgangsprozessor in einereinem Kafka Topic hinterlegt.
Ein Beispiel für solch einen Data�ow ist in Abbildung 7: NiFi Data�ow Beispiel zu sehen.
Abbildung 7: NiFi Data�ow Beispiel
30

4 TECHNOLOGIEAUSWAHL 4.2 Archivierung: Data�ow Management
Die einzelnen Komponenten des dargestellten Data�ows sollen im Folgenden beschriebenwerden, hierzu wird auf die in roter Schrift markierten Punkte 1. bis 4. eingegangen.
1. Prozessoren: Dies sind die NiFi Komponenten welche genutzt werden, um eintre�endeDaten abzufangen, Daten aus externen Quellen zu beziehen und Daten an externeQuellen zu übermitteln. Weiterhin werden Prozessoren genutzt um Informationen auseinzelnen Daten weiterzuleiten, zu transformieren oder zu extrahieren (vgl. [The18c]).Prozessoren bzw. auch ganze Data�ows können zur weiteren Strukturierung in einerProzessorgruppe gruppiert werden.
a) Prozessortyp: Bezeichnet den verwendeten Prozessor (die Prozessorklasse).
b) Prozessorname: Ein individuell anpassbarer Prozessorname.
c) Prozessormonitoring: Hier werden unter anderem eintre�ende Daten (In)und ausgehende Daten (Out) erfasst.
d) Prozessorstatus: Beschreibt den Status des Prozessors, es wird unterschiedenzwischen Probleme liegen vor dargestellt mit einemWarndreieck, Gestartet sym-bolisiert durch eine grüne Pfeilspitze und dem Status Gestoppt, welcher mittelseines roten Quadrates repräsentiert.
2. Konnektor: Sobald Prozessoren und andere Komponenten dem NiFi Canvas (Ar-beits�äche) hinzugefügt und kon�guriert wurden, ist der nächste Schritt die Kompo-nenten miteinander zu verbinden, um den Daten�uss zu de�nieren ([The18c]). BeimVerknüpfen der Komponenten wird eine Beziehung gewählt.
a) Konnektor-Beziehung: Die Konnektor-Beziehung gibt ähnlich wie in UMLKlassendiagrammen an, in welcher Beziehung die einzelnen Komponenten ste-hen. So kann z. B. der weitere Fluss der Daten, welche erfolgreich (succes) durcheinen Prozessor bearbeitet wurden bestimmt werden und wie die Daten behan-delt werden sollen, bei denen Fehler vorkamen.
3. Label: Diese Komponente wird genutzt um einzelne Teile eines Data�ows zu doku-mentieren (vgl. [The18c]).
4. Canvas: Hierbei handelt es sich um die Arbeits�äche, auf der Komponenten in Apa-che NiFi platziert werden.
Solche Data�ows können in einem Template gesichert und als Vorlage weitergenutzt wer-den. Diese Templates können auch im XML-Format heruntergeladen, weitergegeben undin Apache NiFi hochgeladen werden.
Der Dialog für die Kon�guration der Prozessoren wird in der folgenden Abbildung 8: NiFiProzessor Kon�guration Beispiel veranschaulicht. Hier können die einzelnen Eigenschaften(properties) eingestellt werden.
31

4.3 Messaging System 4 TECHNOLOGIEAUSWAHL
Abbildung 8: NiFi Prozessor Kon�guration Beispiel
Ergebnis Kafka Connect ist durch die schlechte Handhabung mit häu�gen Fehlermeldun-gen ausgeschieden, das verbinden von Apache Kafka mit anderen Systemen erwies sich inder Praxis, nicht als problemlos durchführbar. Apache NiFi erfüllt den angestrebten Zweckund durch das Web-Interface ist die Bedienung leichter. Apache NiFi bietet eine Vielzahlvon Prozessoren, welche den Umgang mit den verschiedensten Systemen ermöglichen. Wei-terhin können bei Bedarf auch eigene Prozessoren erstellt werden. Durch die Vielzahl anProzessoren kann Apache NiFi nicht nur die angestrebte Verbindung von Apache Kafkamit einer Datenbank ermöglichen, es kann auch für andere Zwecke genutzt werden. Eskönnen z. B. Daten von FTP-Servern automatisiert heruntergeladen und direkt in einerDatenbank abgelegt werden. So kann Apache NiFi in DAvE dazu genutzt werden, um dasArchiv mit Wetterdaten zu erweitern. Dieses Werkzeug erweist sich als vielseitig einsetzbarund mächtig im Umgang mit Daten.
4.3. Messaging System
In diesem Abschnitt werden die Anforderungen für die Datenbereitstellung hergeleitet undbenannt. Im Anschluss werden die zwei ausgewählten Messaging Systeme vorgestellt underläutert. Der Abschnitt wird durch eine kurze Zusammenfassung mit einem Abgleich derAnforderung abgeschlossen.
32

4 TECHNOLOGIEAUSWAHL 4.3 Messaging System
Abbildung 9: Allgemeine Funktionsweise von Messaging Systemen
4.3.1. Anforderung
Die Teilanforderungen für die Kommunikation und Transport der Daten, konnten aufGrund momentanen Stillstand nur schwer de�niert werden. Anhand der Use Case Archivie-rung von Rohdaten aus dem Niederspannungsnetz und der voraussichtlichen gesetzlichensowie normierten Rahmenbedingungen wurden die anfallenden Datenmengen abgeschätzt.Eine Herausforderung ist die Bewältigung der kontinuierlich-ankommenden Daten aus demNiederspannungsnetz [Bun16b]. Um den Datenstrom von dem System zu Entkoppeln wur-de entschieden eine Messaging System zu nutzen. Die grundlegende Funktionsweise einesMessaging System wird in der Abbildung 9: Allgemeine Funktionsweise von MessagingSystemen dargestellt.
Nach einer Recherche über das Format, den Inhalt und der Lieferung der Smart-Meter-Daten aus dem Niederspannungsnetz mussten noch die Randbedingungen de�niert wer-den. Im Gesetz zur Digitalisierung von Energiedaten wurde festgelegt, dass in periodischenZeitabständen die Informationen versandt werden sollen und dies mehrmals am Tag, dermomentane Zyklus liegt bei 15 Minuten. Somit ergab sich, dass es entweder einen konti-nuierlichen Datenstrom oder eine Bulk Lieferung von Daten erwartet werden konnte.
Der genaue Umfang und die Gröÿe der erwarteten Smart-Meter-Daten steht momentannoch aus. Mit dieser Ungewissheit und der vermuteten Lieferung der Smart-Meter-Daten,wurde entschieden, dass ein Werkzeug genutzt werden muss, um die Annahme der Smart-Meter-Daten vom Rest des System zu entkoppeln. Wie bereits erwähnt ist eine Leitlinie indiesem Porjekt, ein Open-Source System zu entwickeln. Daher beschränkte sich die Suchezuallererst auf Werkzeuge mit einer Open-Source Lizenz.
Damit ergab sich zum einen die Anforderung eines hohen Durchsatzes und die AllgemeineAnforderung nach einer Open-Source Software.
Anhand der vorliegenden Informationen, wurden erste Anforderungen formuliert. Zur Aus-wahl standen unterschiedliche Messaging System. Im erste Schritt wurden die Messaging
33

4.3 Messaging System 4 TECHNOLOGIEAUSWAHL
Systeme genauer auf die Merkmale, Systemanforderungen, Vor- und Nachteile untersucht.Dazu wurde eine Literatur-Recherche durchgeführt. Innerhalb der Literatur-Recherchewurde sowohl die Dokumentation der Werkzeuge also auch nach wissenschaftlichen Be-wertungen gesucht.
Unter anderem wurden die Arbeiten von [Ion15] und [JL17] angesehen. In der Arbeit von[Ion15] wurde RabbitMQ mit ActiveMQ verglichen. Dabei wurde festgestellt, dass Rabbit-MQ schneller Daten an Clients sendet als ActiveMQ, obwohl im selben Test ActiveMQ dieDaten schneller empfangen kann.[Ion15] Die Arbeit von [JL17] verglich unterschiedlicheMessage Broker und Message Queues miteinander. Untersuchungsgegenstand war ApacheKafka und AMQP (advanced message queue protocol). Das Ziel war den Durchsatz unddie Zuverlässigkeit zu überprüfen. Daraus resultierte, das Apache Kafka im Vergleich mitAMQP einen besseren Durchsatz hat. Liegt allerdings der Fokus auf einer hohen Zuverläs-sigkeit so ist Apache Kafka ungeeignet. Mit diesen Informationen haben wir die Auswahlauf zwei Message Broker reduziert. Zur engeren Auswahl standen Apache Kafka und Rab-bitMQ.
Im zweiten Schritt wurden die Messaging Systeme auf ihre Tauglichkeit untersucht. Da-zu wurde ein Testsystem vorbereitet und die Messaging System prototypisch eingerichtet.Die Untersuchung umfasste zwei Etappen. Zuerst wurde ein Single-Node Cluster kon�-guriert. In der nächsten Kon�guration wurde das Cluster um zwei Nodes erweitert. DasTestsystem hatte die selben Kon�guration, wie die zu diesem Zeitpunkt geplante Gesamt-architektur. Das primäre Ziel war hierbei, die Einrichtung und der Betrieb der beidenMessaging Systeme. Die Installation und Kon�guration des Cluster verlief ohne groÿeSchwierigkeiten. Auch bei dem Betrieb wurden zwischen der Single-Node Kon�gurationund der Multicluster-Kon�guration keine Unterschiede festgestellt. Es wurden erste kleineProgramme geschrieben, um das Erzeugen und konsumieren von Daten zu testen.
Während der ersten Sondierungen konnten noch foglende Anforderungen festgestellt wer-den:
• Das Messaging Systeme muss zuverlässig arbeiten. D. h. es dürfen keine Nachrichtenverloren gehen. Dazu zählt auch bei einem unerwartet Ausfall der Server.
• Das Messaging Systeme muss zuverlässig arbeiten. D. h. es dürfen keine Nachrichtenverloren gehen. Dazu zählt auch bei einem unerwartet Ausfall der Server.
• Das Messaging System muss skalierbar sein. Es müssen weiter Knoten einem Clusterwährend des Betriebs hinzufügbar sein.
• Die Nachrichten sollten nicht während der Übertagung zerlegt werden.
34

4 TECHNOLOGIEAUSWAHL 4.3 Messaging System
4.3.2. Beschreibung
In diesem Abschnitt werden die beiden Streaming Plattformen Apache Kafka und Rab-bitMQ vorgestellt. Dabei wird zuerst auf die allgemeine Architektur eingegangen und imAnschluss auf die Arbeitsweise.
Kafka Architektur Apache Kafka ist eine verteilte Streaming Plattform. Dabei werdenNachrichten (Messages) durch sog. Abonnenten (Subscriber) konsumiert und durch sog.Produzenten (Producer) erzeugt. Die erzeugten Daten werden auf einem Server gespeichert.Die Messages können in Apache Kafka sog. Topics kategorisiert werden.
Eine Kafka Topic besteht aus mehreren Bestandteilen. Ein Producer kann auf diversen Par-titionen Messages senden. Jede Partition wird protokolliert. Eine Message innerhalb einesTopics besteht aus der Nachricht und einem o�set. Ein o�set ist ein einzigartige Identi-�kation innerhalb einer Partition. Der o�set kann dazu genutzt werden einen Startpunktbeim abonnieren zu setzen.
Des Weiteren bietet Apache Kafka diverse andere Vorteile: eine hohe Skalierbarkeit, Per-sistenz und Zuverlässigkeit. Weiterhin können Empfangsbestätigungen von Apache Kaf-ka bereitgestellt werden, welche durch einen Parameter aktiviert werden. Apache Kafkaschreibt die Messages auf die Festplate und repliziert diese, daraus erfolgt eine gute Feh-lertoleranz. Auÿerdem wird eine Empfangsbestätigung an den Producer gesendet, solangehält der Producer die Message vor. Es können weitere Knoten während des Betriebs hinzu-gefügt werden. Zusätzlich können Multi-Broker auf einem Single-Node-Cluster betriebenwerden. Ein Broker ist der Kafka Service der über einen Port angesprochen werden kann.Die Replikation bzw. das Loggen auf der Festplatte führt zu einer Dauerhaftigkeit derMessages. Die Abbildung 10: Ein Schema für ein Kafka Architektur zeigt schematisch dieArchitektur eines Kafka Cluster. Es zeigt mehrere Producer und Consumer sowie die KafkaUmgebung. Ein Kafka Cluster besteht aus mehreren Brokern, welche durch ein ZookeeperService verwaltet werden vgl. [Tut18] und [The18b].
RabbitMQ Architektur RabbitMQ zählt ebenfalls zu den Messaging Systemen. Die Ar-beitsweise entspricht dabei mehr der Message Queue (MQ). Eine Queue ist eine Sammlungvon Messages. Die Queue hat einen eindeutigen systemweiten Namen und die Messageswerden in RabbitMQ nach First in First out (FIFO) sortiert. Für eine Queue können di-verse Einstellungen gesetzt werden, bspw. aktiviert Auto-delete das Löschen einer Queuenachdem der letzte Consumer sich abgemeldet hat. Die Messages werden persistent aufder Festplatte gesichert. Daher existieren nicht nur die Queues, sondern auch die Messagesnach einem Neustart der Broker.
Ein Broker ist hier ebenfalls ein Node der die Prozesse verwaltet und verarbeitet. In einemCluster können zwei Typen von Broker eingestellt werden. So kann ein Broker als RAM
35

4.3 Messaging System 4 TECHNOLOGIEAUSWAHL
Abbildung 10: Ein Schema für ein Kafka Architektur (vgl.[Tut18])
Node fungieren. Die RAM Nodes speichern die Nachrichten ausschlieÿlich im RAM. Wo-hingegen eine Disk Node auch die Messages auf der Festplatte speichert. Die Verwaltungeines Clusters wird über das Advanced Message Queuing Protocol gesteuert.
Das AMQP ist in Erlang entwickelt worden. Erlang ist eine Programmiersprache. AMQPist ein open standard für die Übermittlung von Informationen von und zu Organisationenund Anwendungen. RabbitMQ nutzt das AMQP, um die einzelnen Nodes innerhablb einesClusters zu verbinden.
RabbitMQ besteht aus mehreren miteinander interagierender Komponenten. Ein Producersendet eine Message an den Broker. Die Message wird an die Queue weitergeleitet und kanndann von einem Consumer abonniert werden. Die Weiterleitung einer Message zu einerQueue kann unterschiedlich eingestellt werden. Die Message kann direkt auf eine Queueweitergeleitet werden. Messages können auf eine Anzahl unterschiedliche Queues verteiltwerden oder Anhand eines Muster auf unterschiedliche Queues sortiert werden.
Ergebnis Die Einrichtung sowie die Wartung von Apache Kafka ist relativ unkompliziert.Weiterhin kann Kafka durch diverse Erneuerungen sehr zuverlässig arbeiten und bietet einehohe Fehlertoleranz. Das Hinzufügen von weiteren Knoten ist ebenfalls sehr einfach, da dieVerwaltung nicht von Kafka sondern von Zookeeper übernommen wird.
Bei RabbitMQ konnten dieselben Eigenschaften festgestellt werden. Es ist ein verteiltesMessaging System und höchst zuverlässig aufgrund einer Empfangsbestätigung. DiesesVorgehen verursacht aber ein geringen Durchsatz. Die Einrichtung ist ein wenig aufwen-
36

4 TECHNOLOGIEAUSWAHL 4.4 Data Science
diger als bei Kafka. Die Skalierbarkeit wird durch das AMQP sichergestellt. Die Wartungkann über eine Command Line Interface (CLI) durchgeführt werden. Es zeigte sich, dasskeine Entscheidung getro�en werden kann, ohne die Messaging Systeme im Prototypen zutesten. Daher emp�ehlt es sich beide Messaging Systeme in der Gesamtarchitektur zu im-plementieren. Für die Kooperation mit der Projektgruppe E-Stream wurde Apache Kafkaeine höhere Priorität zugewiesen als RabbitMQ.
4.4. Data Science
Im folgenden werden die Anforderungen an die Data Science Komponente hergeleitet undbetrachtete Frameworks beschrieben und evaluiert.
4.4.1. Anforderungen
Für die Auswahl des Data Science Frameworks wurden sieben Anforderungen formuliert,welche im Folgenden näher erläutert werden und in Tabelle 8: Anforderungen Data ScienceFramework nochmals zusammengefasst:
Hadoop/Cassandra Grundlage der Vorhersagemodelle sind die, in der Datenbank gespei-cherten, historischen Daten. Daher ist es notwendig, dass eine Schnittstelle zur verwendetenDatenbank bereit gestellt wird. Zuerst sollte das Framework eine Schnittstelle zu Apache
Hadoop unterstützen. Allerdings hat sich die Projektgruppe im späteren Verlauf auf ApacheCassandra geeinigt, sodass eine Unterstützung von Hadoop nicht mehr notwendig war.Wichtigkeit: hoch
Programmiersprache Bei dieser Anforderung soll das Framework wenn möglich die Pro-grammiersprache Python unterstützen. Einige Gründe, warum Python zur Datenanalyseverwendet werden sollte, sind im gleichnamigen Abschnitt erläutert. Darüber hinaus wirdPython von vielen Machine Learning Frameworks unterstützt, was die Möglichkeiten zurDatenanalyse erheblich erweitert.Wichtigkeit: mittel
PMML Für das Versenden bzw. den Austausch von Modellen bietet der Standard PMML
die optimale Lösung. Zudem wurde sich mit der Projektgruppe E-Stream auf diesen Stan-dard geeinigt. Daraus ergibt sich die Anforderung, dass das Framework in der Lage seinsollte PMML zu unterstützen.Wichtigkeit: hoch
37

4.4 Data Science 4 TECHNOLOGIEAUSWAHL
Open/Close Source Das Framework sollte Open Source sein, da die Projektgruppe be-schlossen hat, nur mit Open Source Software zu arbeiten.Wichtigkeit: hoch
Aktualität-Updates Das Framework sollte in einem regelmäÿigen Abstand vom Entwick-ler aktualisiert werden, in dem mögliche Fehler beseitigt und neue Funktionalitäten hin-zugefügt werden. Zudem sollte das Framework möglichst aktuell sein, um den heutigenStandards zu entsprechen.Wichtigkeit: mittel
Erscheinungsdatum Das Erscheinungsdatum ist ein leichtes Indiz für die Entwicklungs-phase und die Reife einer Software. So kann auÿerdem davon ausgegangen werden, dass äl-tere Software eine geringere Fehleranfälligkeit aufweist und es eine umfangreichere (Fehler-)Dokumentation vorliegt.Wichtigkeit: gering
Algorithmen Die Kernaufgabe des Bereichs Data Science ist es Modelle bzw. Prognosenzu erstellen. Für die Erstellung dieser Prognosen ist die Verfügbarkeit eines umfangreichenPools an Algorithmen essentiell. Daher sollte das Framework eine groÿe Vielfalt an Me-thoden bereit stellen, damit verschiedene Modelle hinsichtlich ihrer Prognosen betrachtetwerden können.Wichtigkeit: hoch
Anforderungsnummer Anforderung
DSF-01 Das Framework muss eine Schnittstelle zu Apache Ha-doop und Apache Cassandra bieten
DSF-02 Das Framework muss die Sprache Python unterstützenDSF-03 Das Framework muss den PMML Standard unterstüt-
zenDSF-04 Das Framework muss ein Open-Source Projekt seinDSF-05 Das Framework muss stetig aktualisiert werdenDSF-06 Das Framework muss sich in einer ausreichenden Rei-
fephase be�ndenDSF-07 Das Framework muss eine ausreichende Anzahl an Ma-
chine Learning Algorithmen bieten
Tabelle 8: Anforderungen Data Science Framework
38

4 TECHNOLOGIEAUSWAHL 4.4 Data Science
4.4.2. Beschreibung
Im Folgenden werden mehrere Frameworks, die für die Datenanalysen in DAvE in Fragekamen, gegenüber gestellt. Da viele Frameworks auf Eignung überprüft wurden, wird nichtauf alle im Detail eingegangen. Tabelle 9: Kriterienkatalog für Machine Learning Frame-works Teil I und Tabelle 10: Kriterienkatalog für Machine Learning Frameworks Teil IIstellen die einzelnen Frameworks in Zusammenhang mit den Anforderungen, die im letztenKapitel erläutert wurden, übersichtlich dar. Installiert und umfangreich getestet wurdennur die Frameworks, die alle wichtigen Anforderungen erfüllten.
Deeplearning4j kann zwei wichtige Anforderungen nicht erfüllen. Zum einen werden nichtgenügend Algorithmen zur Analyse bereit gestellt, zum anderen wird der PMML-Standardnicht unterstützt. Letzteres wird ebenfalls von den beiden Tools WEKA und mlpy nichtunterstützt, weshalb diese als Analysewerkzeuge nicht in Frage kamen. Zum Zeitpunktder Evaluation war noch nicht entschieden, ob Hadoop oder Cassandra als Datenbankverwendet wird. Deshalb wurde KNIME auch nicht weiter betrachtet, da hier ein kosten-p�ichtiger Big Data Connector notwendig gewesen wäre. Bezüglich TensorFlow war imVorfeld nicht ersichtlich, ob eine Schnittstelle zu Cassandra bereit gestellt wird. Somit�elen scitkit-learn, Spark MLlib und R Studio, die alle wichtigen Anforderungen er-füllen, in die engere Auswahl. Installiert und getestet wurden zunächst Spark MLlib undscitkit-learn, da beide Python als Programmiersprache unterstützen.
scikit-learn scikit-learn ist ein Open-Source Projekt für maschinelles Lernen in Py-thon. Es wird stetig weiterentwickelt und verbessert und besitzt eine groÿe Nutzergemeinde,wodurch viele Tutorials und Lösungsvorschläge für diverse Problemstellungen existieren.Daneben wird eine umfangreiche Dokumentation1 bereitgestellt, die zu vielen Algorithmenzusätzlich ausführliche Code-Beispiele liefert (vgl. [MGR17], S. 6).
scikit-learn basiert auf den Python-Bibliotheken NumPy und SciPy. NumPy ist ein grund-legendes Paket für wissenschaftliche Berechnungen in Python, welches die die Funktionali-tät für mehrdimensionale Arrays und mathematische Funktionen, wie z. B. lineare Algebraenthält. Das NumPy-Array ist in scikit-learn die fundamentale Datenstruktur. JeglicheDaten werden in Form von NumPy-Arrays verarbeitet, bzw. müssen in solche umgewandeltwerden. SciPy ist eine Sammlung von Funktionen zum wissenschaftlichen Rechnen in Py-thon, die u.a. Routinen für fortgeschrittene lineare Algebra, Optimierung mathematischerFunktionen und statistische Verteilung enthält. scikit-learn verwendet Funktionen ausdieser Sammlung, um seine Algorithmen zu implementieren (vgl. [MGR17], S. 8).
Spark MLlib Apache Spark ist ein Framework für Cluster Computing, das unter einerOpen-Source-Lizenz ö�entlich verfügbar ist. Spark kann sowohl Standalone als auch mit
1siehe http://scikit-learn.org/stable/documentation.html
39
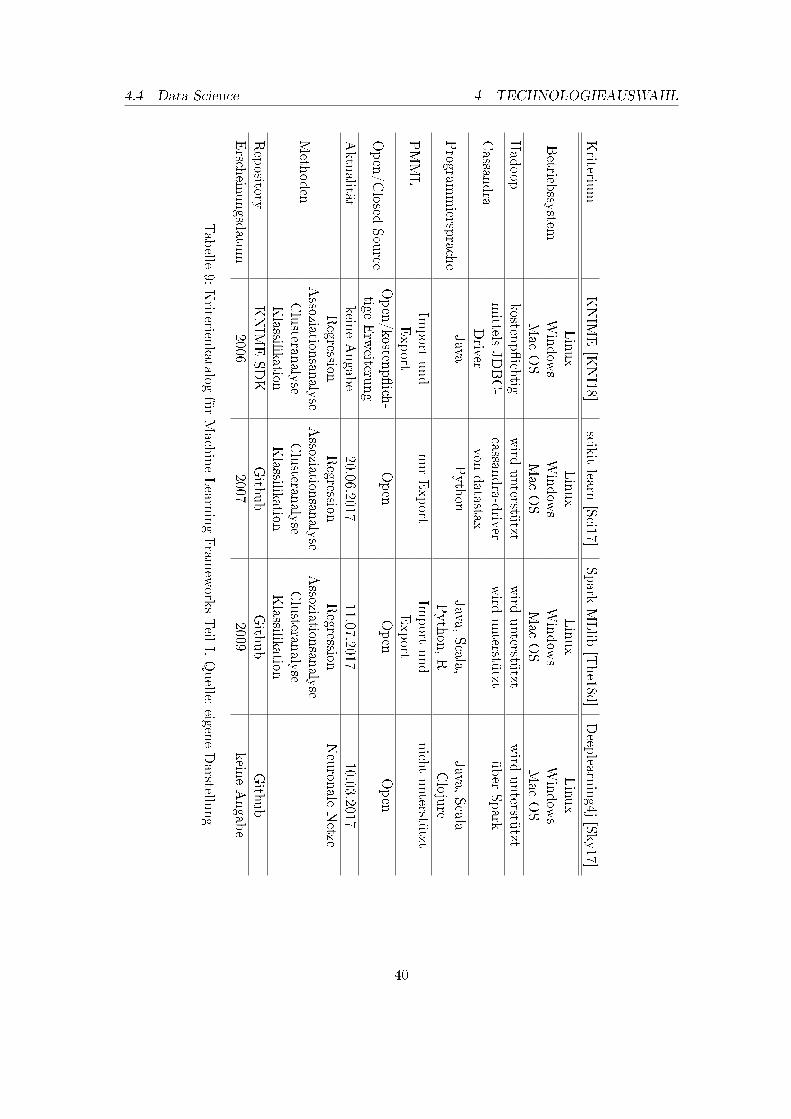
4.4 Data Science 4 TECHNOLOGIEAUSWAHL
Kriterium
KNIM
E[KNI18]
scikit-learn[Sci17]
SparkMLlib
[The18d]
Deeplearning4j
[Sky17]
Betriebssystem
Linux
Linux
Linux
Linux
Window
sWindow
sWindow
sWindow
sMac
OS
Mac
OS
Mac
OS
Mac
OS
Hadoop
kostenp�ichtigwird
unterstütztwird
unterstütztwird
unterstützt
Cassandra
mittels
JDBC-
cassandra-driverwird
unterstütztüb
erSpark
Driver
vondatastax
Program
miersprache
JavaPython
Java,Scala,
Java,Scala
Python,
RClojure
PMML
Import
undnur
Export
Import
undnicht
unterstütztExport
Export
Open/C
losedSource
Open/kostenp�ich-
Open
Open
Open
tigeErweiterung
Aktualität
keineAngab
e20.06.2017
11.07.201710.03.2017
Methoden
Regression
Regression
Regression
Neuronale
Netze
Assoziationsanalyse
Assoziationsanalyse
Assoziationsanalyse
Clusteranalyse
Clusteranalyse
Clusteranalyse
Klassi�kation
Klassi�kation
Klassi�kation
Repository
KNIM
ESD
KGithub
Github
Github
Erscheinungsdatum
20062007
2009keine
Angab
e
Tabelle
9:Kriterienkatalog
fürMachine
Learning
Fram
eworks
Teil
I.Quelle:
eigeneDarstellung
40
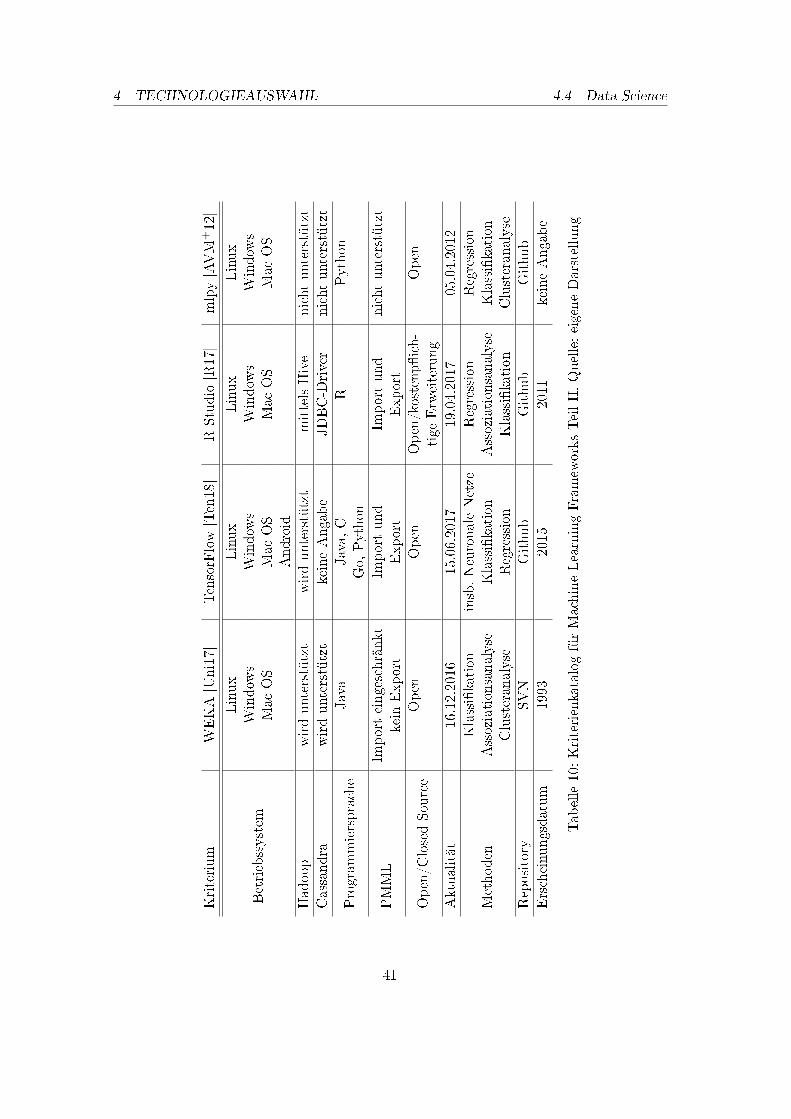
4 TECHNOLOGIEAUSWAHL 4.4 Data Science
Kriterium
WEKA[Uni17]
TensorFlow[Ten18]
RStudio[R17]
mlpy[AVM
+12]
Betriebssystem
Linux
Linux
Linux
Linux
Windows
Windows
Windows
Windows
Mac
OS
Mac
OS
Mac
OS
Mac
OS
Android
Hadoop
wirdunterstützt
wirdunterstützt
mittelsHive
nichtunterstützt
Cassandra
wirdunterstützt
keineAngabe
JDBC-Driver
nichtunterstützt
Program
miersprache
Java
Java,C
RPython
Go,Python
PMML
Importeingeschränkt
Importund
Importund
nichtunterstützt
kein
Export
Export
Export
Open/C
losedSource
Open
Open
Open/kostenp�ich-
Open
tige
Erweiterung
Aktualität
16.12.2016
15.06.2017
19.04.2017
05.04.2012
Methoden
Klassi�kation
insb.NeuronaleNetze
Regression
Regression
Assoziationsanalyse
Klassi�kation
Assoziationsanalyse
Klassi�kation
Clusteranalyse
Regression
Klassi�kation
Clusteranalyse
Repository
SVN
Github
Github
Github
Erscheinungsdatum
1993
2015
2011
keineAngabe
Tabelle10:KriterienkatalogfürMachine
LearningFramew
orks
TeilII.Quelle:eigene
Darstellung
41

4.4 Data Science 4 TECHNOLOGIEAUSWAHL
1 # The RDD materialization time is unpredicable , ifwe set a timeout for socket reading operation ,it will very possibly fail. See SPARK -18281.
2 Exception: could not open socket
Listing 1: Fehlermeldung Spark MLlib
YARN oder Mesos betrieben werden und besteht aus den Komponenten Spark Core, SparkSQL, Spark Streaming , Machine Learning Library (MLlib) und GraphX. Für den BereichData Science in DAvE ist insbesondere die Komponente MLlib interessant, in der alle gän-gigen Machine Learning Methoden implementiert sind. Spark-Core bildet die Grundlagedes gesamten Systems und stellt grundlegende Infrastruktur-Funktionalitäten bereit. DieDatenstruktur für alle Operationen wird als Resilent Distributet Dataset (RDD) bezeich-net, das einen logischen (Teil-)Bestand von Daten darstellt. Mithilfe von Spark SQL könnendiese RDD's in DataFrames umgewandelt werden. Zudem bietet Spark eine Schnittstelleum auf HDFS oder HBase zugreifen zu können. Des weiteren werden die Programmier-sprachen Java, Scala und Python unterstützt (siehe [The18d])
Beim Testen der Spark MLlib wurden einige Fehler identi�ziert, die beim Darstellen vonDataFrames im Jupyter Notebook auftraten. Folgende Fehlermeldung trat sowohl beimAnzeigen der DataFrames, als auch beim Umwandeln in ein pandas-DataFrame auf:
In der Fehlerdokumentation von Spark wurde zu diesem Fehler auch keine passende Lösungbereit gestellt.
Beim Testen von scikit-learn wurden hingegen keine Fehlerfälle identi�ziert. Da einefehlerfreie Anzeige von Daten, insbesondere während der Entwicklung von Modellen, es-sentiell ist, wurde scikit-learn als engültiges Machine Learning Tool ausgewählt.
In den folgenden Abschnitten werden weitere Komponenten, die zur Entwicklung der Ma-chine Learning Modelle benötigt werden, eingehend beschrieben.
Python Pyhton ist für viele Anwendungen aus dem Bereich Data Science zu einer derbeliebtesten Programmiersprachen geworden. Python kombiniert die Ausdruckskraft allge-mein nutzbarer Programmiersprachen mit der einfachen Benutzbarkeit einer domänenspe-zi�schen Skriptsprache. Insbesondere im Rahmen von Datenanalysen existieren für Pythoneine Vielzahl von Bibliotheken, wie z. B. zum Laden von Daten, Visualisieren, Berechnenvon Statistiken oder Methoden für das maschinelle Lernen. Dies gibt Data Scientists einensehr umfangreichen Werkzeugkasten für jegliche Einsatzgebiete. Ein Hauptvorteil von Py-thon ist die Möglichkeit direkt mit dem Code zu interagieren, sei es in einer Konsole oderin einer anderen Umgebung wie dem Jupyter Notebook (vgl. [MGR17], S. 5f.).
42

4 TECHNOLOGIEAUSWAHL 4.5 Data Engineering
pandas pandas ist eine Python-Bibliothek zur Datenaufbereitung und Analyse, die umdie Datenstruktur DataFrame herum aufgebaut ist. Ein DataFrame kann als eine Art Ta-belle verstanden werden. Vorteil gegenüber NumPy-Arrays ist, dass pandas in jeder Spalteunterschiedliche Datentypen zulässt. pandas enthält eine groÿes Spektrum an Methodenzum Modi�zieren und Verarbeiten dieser DataFrames. Insbesondere sind SQL-artige Such-anfragen möglich (vgl. [MGR17], S. 10). Im Rahmen dieses Projektes wird pandas ver-wendet, um Daten von Cassandra in Python auslesen zu können. Zudem wird durch diebereitgestellten Methoden eine e�ziente Vorverarbeitung möglich, um beispielsweise Roh-daten in die benötigten Datentypen umzuwandeln.
matplotlib matplotlib ist eine Python-Bibliothek zum wissenschaftlichen Plotten, dieumfangreiche Funktionen zum Erstellen von Diagrammen, wie z. B. Liniendiagramme,Histogramme oder Streudiagramme, enthält. Die Daten und unterschiedliche Aspekte die-ser Daten zu visualisieren, kann wichtige Erkenntnisse liefern und wurde im Rahmen desTeilbereichs Data Science für sämtliche Visualisierungsaufgaben eingesetzt. Im JupyterNotebook können Diagramme über den Befehl %matplotlib inline direkt im Browserdargestellt werden (siehe [MGR17], S. 10).
4.5. Data Engineering
Aufgabe der Gruppe Data Engineering ist die Identi�zierung von möglichen Datenquellenund die Analyse der Daten für einen Einsatz im Projekt. Zusätzlich müssen Möglichkeitenzur Einbindung dieser Datenquellen in das Gesamtsystem aufgezeigt werden. Aus die-sem Grund wurden an dieser Stelle alle Daten untersucht, die mit dem Projektszenarioin Verbindung stehen. Im Anschluss werden die geeigneten Datenquellen selektiert undMöglichkeiten eines Imports in das System sowie die Eignung zur Einbindung in die Ge-samtarchitektur untersucht.
4.5.1. Anforderungen
Die Anforderung an die Technologien und die Datenquellen ist die einwandfreie, automa-tisierte Importmöglichkeit in das Gesamtsystem, da ein manueller Datenimport für denspäteren Betrieb nicht in Frage kommt. Zur Umsetzung der Use-Cases sind Wetterdatenund Smart-Meter-Daten nötig. Die Wetterdaten werden vom Deutschen Wetterdienst ge-liefert und können vom eigenen FTP-Server abgerufen werden. Diese Wetterdaten gilt esdirekt vom FTP Abzufragen und in das System einzubinden. Zusätzlich werden Daten fürSmart-Meter-Daten mittels des LV-Sim erstellt und bereitgestellt. Mithilfe der ausgewähl-ten Technologie musste es möglich sein, die Daten aus den verschiedenen Quellen, zu jederbeliebigen Zeit automatisch abzurufen und in der Datenbank speichern zu können.
43

4.5 Data Engineering 4 TECHNOLOGIEAUSWAHL
4.5.2. Beschreibung
Die erste Hürde bei dem Import der Datenquellen bestand in der Importmöglichkeit fürSmart-Meter-Daten. Da kaum Datensätze für Smart-Meter-Daten zur Verfügung standen,musste eine Alternative Möglichkeit des Datenimports gescha�en werden.
An dieser Stelle kam das Python Tool mosaik mit der Netzdatenstrom-Simulation des O�ceEnergie zum Einsatz. Mit diesem Toolset ist es möglich, in gewisser Weise Echtzeitdatenzu erzeugen. Das Toll wird im folgenden genauer beschrieben.
Für den Import von Wetterdaten wurden verschiedene Möglichkeiten getestet, welche imfolgenden beschrieben sind. Der Teilbereich des Data-Engineerings fokussiert sich auf denImport der beschriebenen Datenquellen in das DAvE-System. Dabei soll konkret eine Mög-lichkeit gefunden werden, Wetterdaten, Smart-Meter-Daten und Daten über Energieerzeu-gung und -verbrauch im System zu archivieren. Dazu wird eine Technologie benötigt, dieeinen automatisierten Import dieser Daten in die Cassandra Datenbank, in regelmäÿigenAbständen, oder im Bedarfsfall gewährleistet. Zur Implementierung einer solchen Techno-logie, haben wir folgende Lösungen in Betracht gezogen:
Eigenentwicklung in Java Zunächst wurde sich für eine Eigenentwicklung auf Java Basisentschieden. Während der Entwicklung kam es zu Problemen mit der für den FTP Importnotwendigen Java Bibliothek Apache Commons Net. Da das Problem nicht vollständigidenti�zierbar war, wurde sich dazu entschlossen, andere Möglichkeiten des Datenimportesin Betracht zu ziehen, weshalb die Eigenentwicklung auf der Basis von Java an dieser Stelleabgebrochen wurde.
PyFTPToHDFS Ein weiterer Ansatz basierte auf der Nutzung eines Python Skripteszum automatischen Import der Wetterdaten. Der Projektgruppe wurde ein fertiges Skriptzur Verfügung gestellt, welches lediglich hätte angepasst werden müssen. Das Skript erstellteinen Pfad zum FTP-Server der Wetterdaten und importiert diese Daten in HDFS. Auf-grund der Einstellung einer Nutzung von HDFS und mangelnder Erfahrung in der Nutzungvon Python, wurde diese Option jedoch zunächst hinten angestellt.
AXT Zum Import von Daten wurde zusätzlich eine Eigenentwicklung der vorherigen Pro-jektgruppe DASH herangezogen. Dabei handelt es sich um das Java-basierte ProgrammAXT. Dies ermöglicht den Datenimport von einer Quelle und überträgt diese Daten inHDFS. Zusätzlich bietet es die Möglichkeit, Dateien mit Meta-Informationen wie Dateina-men oder Dateigröÿe anreichern zu können. Das Programm bietet somit den Einstiegspunktfür einen ELT-Prozess, sodass nachgelagerte Programme auf die von AXT vorbereitetenund übertragenen Daten zugreifen können. Dabei werden die Informationen aus den Datei-en extrahiert oder es werden bereits im System vorhandene Dateien angepasst. AXT kommt
44

4 TECHNOLOGIEAUSWAHL 4.5 Data Engineering
für die Anwendungsfälle von DAvE deswegen in Frage, weil es sich auf einen Datenimportvon einem FTP-Server und deren Extraktion in HDFS bezieht, sodass der Work�ow zurArchivierung von Wetterdaten abgebildet werden kann. Dabei bietet sich vor allem derVorteil, dass gröÿere Datenmengen e�zient und in kurzer Zeit übertragen werden können.Die Besonderheit dabei liegt allerdings darin, dass in dem Anwendungsfall von AXT eingesondertes Datenformat vorliegt. Dabei handelt es um ZML-Daten, die in XML-Datenkonvertiert werden und als solche archiviert werden.Für die Anwendungsfälle von DAvE wäre deshalb eine umfangreichere Anpassung desQuellcodes notwendig gewesen. Darüber hinaus wird für die Archivierung von DAvE ei-ne Cassandra Datenbank anstatt von HDFS herangezogen. Aufgrund dieser Anpassungenund der Architektur wurde der Ansatz von AXT verworfen, um eine den Anforderungenentsprechende Lösung zu �nden.
Apache NiFi Letztendlich wurde sich für das Tool Apache NiFi entschieden, welchesbereits in anderen Bereichen des Projektes zur Anwendung gekommen ist. Apache NiFiermöglicht einen zeitgesteuerten vollautomatischen Import der Wetterdaten von dem FTPServer des deutschen Wetterdienstes.
Low Voltage Simulator Als Teil des Projekts NetzDatenStrom des OFFIS existiert dieSimulationssoftware Low Voltage Simulator (LV-Sim) für Niederspannungsnetze, welcheSmartmeter(gateway)-Daten zu den simulierten Netzen erzeugt. Die Simulationssoftware(:LV-Simulator) basiert auf dem Simulationsframework mosaik2 des OFFIS und ist in derProgrammiersprache Python geschrieben. Während der gesamten Laufzeit dieser Projekt-gruppe befand sich der LV-Simulator in der Entwicklung. Diese und alle weiteren Informa-tionen sind der nur für Projektmitglieder zugänglichen Onlinedokumentation des LV-Simsowie E-Mail-Kommunikationen und persönlichen Gesprächen mit den Programmierernentnommen (siehe [OFF18]).
Um den Anwendungsfall des Archivierens von Smart-Meter-Daten des Prototypen desDAvE-Systems testen und durchführen zu können, ist es notwendig Smart-Meter-Dateneines externen Produzenten erstellen zu lassen und über die de�nierten Schnittstellen zuarchivieren. Da sich diese Projektgruppe und das DAvE-System in das Projekt NetzDa-tenStrom eingliedert, wird der LV-Simu zu diesem Zweck verwendet. Dieses Programm si-muliert diesen externen Produzenten eines Datenstroms von Smart-Meter-Daten. Dadurchentfällt der Auswahlprozess für ein geeignetes Softwaresystem, welches diese Aufgabe über-nehmen soll.
Der LV-Sim erzeugt Smart-Meter-Daten im JSON-Format, diese können jedoch auch op-tional im COSEM-XML-Format ausgegeben werden. Jeweils ein Beispieldatensatz für dasJSON-Format und das COSEM-XML-Format ist den Abbildungen 2: Beispieldatensatz LV-
2siehe https://mosaik.offis.de/
45

4.5 Data Engineering 4 TECHNOLOGIEAUSWAHL
1 {2 "ldevs": [3 {4 "ldev_id ": "sm_38e3e715 -0e70 -4585 -8bc8 -bfa9a82e32f7",5 "objects ": [6 {7 "value": 40064.60324999999 ,8 "capture_time ": 314664 ,9 "status ": "000",
10 "scaler ": -3,11 "logical_name ": "TODO: OBIS -ID",12 "unit": 3013 }14 ]15 },16 {17 "ldev_id ": "sm_5fdf2caf -c2dd -4981 -8e71 -a6f87393f108",18 "objects ": [19 {20 "value": 57028.70040000003 ,21 "capture_time ": 314664 ,22 "status ": "000",23 "scaler ": -3,24 "logical_name ": "TODO: OBIS -ID",25 "unit": 3026 }27 ]28 }29 ],30 "logical_name ": "smgw_eb868bb1 -b5c0 -4400 -abd2 -097 d86b21239
"31 }
Listing 2: Beispieldatensatz LV-Simulator, JSON-Format
Simulator, JSON-Format und 3: Beispieldatensatz LV-Simulator, COSEM-XML-Format zuentnehmen.
COSEM steht für Companion Speci�cation for Energy Metering und ist ein standardisiertesFormat zum Austausch von Smart-Meter-Daten. Dieser Standard wird von der DLMS UserAssociation verwaltet. DLMS ist wiederum eine Abkürzung für Device Language Messagespeci�cation. Der COSEM-Standard steht als XML Schema De�niton zur Verfügung, da-durch können Daten mit der COSEM-Struktur in Form einer XML-Datei als COSEM-XMLausgetauscht werden (vgl. [DLM18]).
Die Generierung der Smart-Meter-Daten kann vielfältig kon�guriert werden, z. B. ist esmöglich unterschiedliche Output-Klassen dynamisch in den Programmablauf zu integrie-ren, um die erzeugten Daten auf verschiedene Arten auszugeben und weiterzuverarbeiten.Dazu gehören u. a. die Möglichkeiten der Ausgabe auf der Console oder das Schreiben in
46

4 TECHNOLOGIEAUSWAHL 4.5 Data Engineering
1 <cosem >2 <ldevs count ="1">3 <ldev id=" sm_ebba2e0d -8530 -4933 -a504 -76 b162ed0fb3">4 <objects count ="1">5 <object class -id="4" id="TODO: OBIS -ID" version ="0">6 <attributes count ="6">7 <attribute id="1">8 <value >9 <string >TODO: OBIS -ID </string >
10 </value >11 </attribute >12 <attribute id="2">13 <value >14 <float64 >8735.074424999999 </ float64 >15 </value >16 </attribute >17 <attribute id="3">18 <value >19 <integer >-3</integer >20 <enum >30</enum >21 </value >22 </attribute >23 <attribute id="4">24 <value >25 <enum >000</enum >26 </value >27 </attribute >28 <attribute id="5">29 <value >30 <double -long -unsigned >55342 </ double -long -
unsigned >31 </value >32 </attribute >33 </attributes >34 </object >35 </objects >36 </ldev >37 </ldevs >38 </cosem >
Listing 3: Beispieldatensatz LV-Simulator, COSEM-XML-Format
47

4.5 Data Engineering 4 TECHNOLOGIEAUSWAHL
eine Output-Datei.
Des Weiteren ist der LV-Sim mit einer Topologie zu kon�gurieren. Dies ist eine Struktur derzu simulierenden Smart Meter. Die Topologie kann mit einigen Parametern zufallsgeneriertoder per JSON-Datei dem Simulator vorgegeben werden.
48

5 INSTALLATION
5. Installation
In diesem Kapitel werden die ausgewählten Technologien, die im Kapitel 4: Technologieauswahlvorgestellt wurden, installiert. Dazu wird zuerst die Infrastruktur der Systemumgebung imAbschnitt 5.1: Infrastruktur eingegangen. Die Abschnitte 5.2: Archivierung: Datenbankund 5.3: Archivierung: Data�ow Management umfassen die gesamte Installation des Ar-chivs. Es wird seperate auf die Datenbank und danach auf das Data�ow Managementeingegangen. Der Abschnitt 5.4: Kommunikationskomponente umfasst die Installation derMessaging Systeme und des Webservers. Abgeschlossen wird dieses Kapitel mit dem Ab-schnitt 5.5: Data Science. Dabei wird die Installation der Subsysteme der Data ScienceKomponente erläutert.
5.1. Infrastruktur
In der Systemumgebung be�ndet sich ein Cluster von Virtuelle Maschinen (folgend :DAvE-Cluster). Die Virtuellen Maschinen (:VMs) des DAvE-Clusters mit ihren Aufgaben undDiensten sind in 11: Systeminfrastruktur des DAvE-Cluster aufgeführt. Innerhalb dieserTabelle sind bereits Entscheidungen aus dem Kapitel 4: Technologieauswahl sowie teilweiseAbschnitte aus den Kapiteln 5: Installation und 6: Realisierung vorgegri�en und sie stelltdie �nale Infrastruktur dar. Auf allen VMs ist das Betriebssystem Ubuntu in der Version14.04 LTS installiert.
Die VM master beinhaltet die meisten Dienste. Das endgültige Big Data ArchivsystemDAvE läuft innerhalb eines Webservers auf dieser VM und greift auf die anderen Dienstedieser und der anderen VMs zu. Ebenfalls ist diese VM der Host für einen Kafka Broker,welcher verwendet wird um Daten aus dem Archiv den externen Anfragestellern zur Ver-fügung zu stellen. Die Data Mining Komponente des DAvE-Systems be�ndet sich ebenfallsauf der VM master. Dafür ist eine Python3-Umgebung eingerichtet. Damit diese VM inder Entwicklungsphase von allen Projektgruppenmitgliedern genutzt werden kann hat je-des Mitglied einen eigenen Benutzer auf dem System. Administrative Zugänge sind denSystemadministratoren vorbehalten.
Die VMs slave1 - slave5 dienen als reine Cassandra Nodes. Auf ihnen werden die zuarchivierenden Daten aufgeteilt und gespeichert. Da dies der einzige Zweck der VMs ist,ist der Zugang zu diesen nur von den Systemadministratoren möglich.
Um die Interaktionen mit anderen System zu simulieren wird die VM mosaik-vm ver-wendet. Darauf be�ndet sich der LV-Simulator sowie eine zum Betrieb dessen notwendigePython3-Umgebung. Um das Importieren von Daten von externen Kafka Brokern zu tes-ten, be�ndet sich ebenfalls eine weitere Kafka Broker auf dieser VM.
49
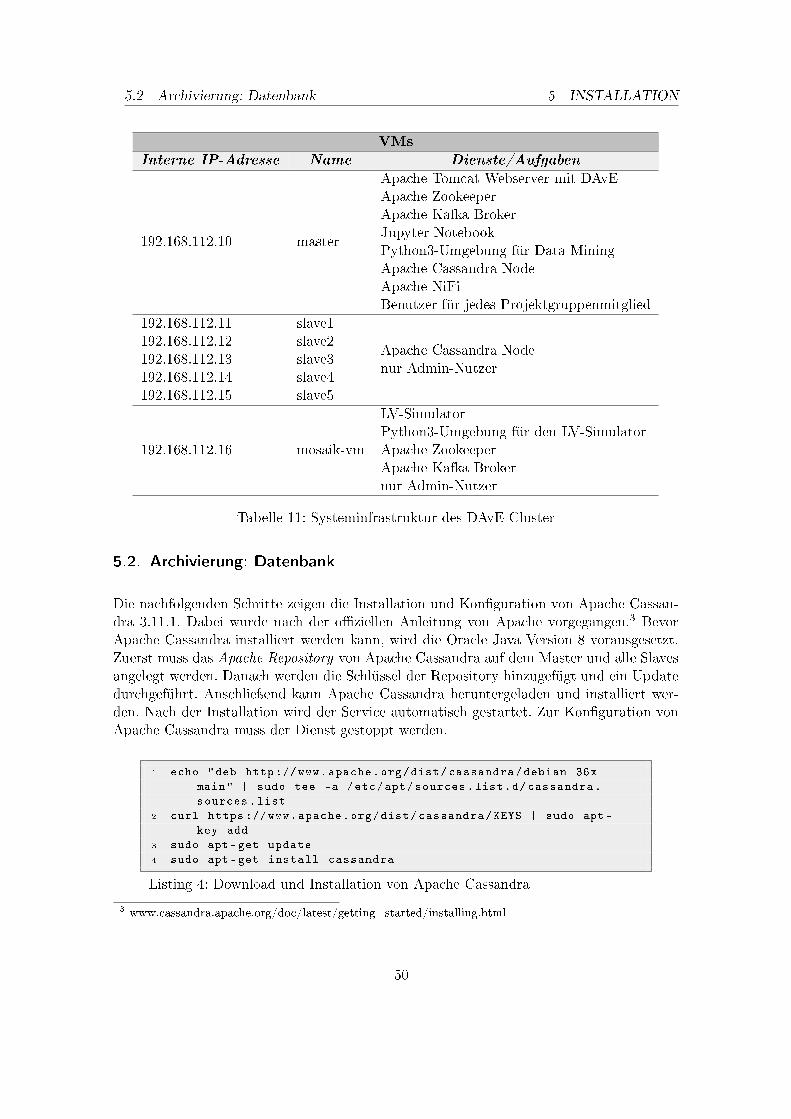
5.2 Archivierung: Datenbank 5 INSTALLATION
VMs
Interne IP-Adresse Name Dienste/Aufgaben
192.168.112.10 master
Apache Tomcat Webserver mit DAvEApache ZookeeperApache Kafka BrokerJupyter NotebookPython3-Umgebung für Data MiningApache Cassandra NodeApache NiFiBenutzer für jedes Projektgruppenmitglied
192.168.112.11 slave1
Apache Cassandra Nodenur Admin-Nutzer
192.168.112.12 slave2192.168.112.13 slave3192.168.112.14 slave4192.168.112.15 slave5
192.168.112.16 mosaik-vm
LV-SimulatorPython3-Umgebung für den LV-SimulatorApache ZookeeperApache Kafka Brokernur Admin-Nutzer
Tabelle 11: Systeminfrastruktur des DAvE-Cluster
5.2. Archivierung: Datenbank
Die nachfolgenden Schritte zeigen die Installation und Kon�guration von Apache Cassan-dra 3.11.1. Dabei wurde nach der o�ziellen Anleitung von Apache vorgegangen.3 BevorApache Cassandra installiert werden kann, wird die Oracle Java Version 8 vorausgesetzt.Zuerst muss das Apache Repository von Apache Cassandra auf dem Master und alle Slavesangelegt werden. Danach werden die Schlüssel der Repository hinzugefügt und ein Updatedurchgeführt. Anschlieÿend kann Apache Cassandra heruntergeladen und installiert wer-den. Nach der Installation wird der Service automatisch gestartet. Zur Kon�guration vonApache Cassandra muss der Dienst gestoppt werden.
1 echo "deb http :// www.apache.org/dist/cassandra/debian 36xmain" | sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list
2 curl https ://www.apache.org/dist/cassandra/KEYS | sudo apt -key add -
3 sudo apt -get update4 sudo apt -get install cassandra
Listing 4: Download und Installation von Apache Cassandra
3 www.cassandra.apache.org/doc/latest/getting_started/installing.html
50

5 INSTALLATION 5.2 Archivierung: Datenbank
Damit alle Knotenpunkte auf dem selben Rack sind und miteinander kommunizierenkönnen, müssen verschiedene Eigenschaften in den Dateien cassandra.yaml, cassandra-topology.properties, cassandra-rackdc.properties angepasst werden. Die Dateien sind unterdem Pfad �:/etc/cassandra/� zu �nden. Auf allen Knoten müssen in der Datei cassan-dra.yaml die Seeds und listen_adress individuell verändert werden. Für den Master sehendie Anpassungen folgendermaÿen aus:
1 Seeds: "master.local" #auf allen Nodes2 listen_adress:master.local #z. B. für Slave1: listen_adress:
slave1.local
Listing 5: Anpassungen master cassandra.yaml
Des Weiteren muss auf allen Nodes in der Datei cassandra-topology.properties folgende Zei-len auskommentiert und die darunterliegenden Zeilen hinzugefügt werden.
1 #192.168.1.100= DC1:RAC12 #192.168.2.200= DC2:RAC23
4 #10.0.0.10= DC1:RAC15 #10.0.0.11= DC1:RAC16 #10.0.0.12= DC1:RAC27
8 #10.20.114.10= DC2:RAC19 #10.20.114.11= DC2:RAC1
10
11 #10.21.119.13= DC3:RAC112 #10.21.119.10= DC3:RAC113
14 #10.0.0.13= DC1:RAC215 #10.21.119.14= DC3:RAC216 #10.20.114.15= DC2:RAC217
18 192.168.112.10= DC1:RAC119 192.168.112.11= DC1:RAC120 192.168.112.12= DC1:RAC121 192.168.112.13= DC1:RAC122 192.168.112.14= DC1:RAC123 192.168.112.15= DC1:RAC1
Listing 6: Anpassungen cassandra-topology.properties
In der cassandra-rackdc.properties sollte noch überprüft werden, ob die folgenden Zeilenvorhanden sind. Ansonsten müssten diese noch dazugeschrieben werden.
51

5.3 Archivierung: Data�ow Management 5 INSTALLATION
1 dc=DC12 rack=RAC1
Listing 7: Überprüfung cassandra-rackdc.properties
Zudem musste noch in der Datei cqlshrc die Zeitzone auf die Mitteleuropäische Zeit (CET)geändert werden. Nach den Anpassungen wird Apache Cassandra gestartet und es wirdüberprüft, ob sich alle Knoten im selben Rack be�nden.
1 sudo service cassandra start2 nodetool status
Listing 8: Start von Apache Cassandra
Abbildung 11: Cassandra Cluster
5.3. Archivierung: Data�ow Management
Nachfolgend wird die Installation und Kon�guration von Apache NiFi gezeigt. Als Vorlagedient hier die o�zielle Anleitung von Apache. 4 Voraussetzung der Installation von ApacheNiFi ist die Oracle Java Version 8. Bevor Apache NiFi installiert werden kann, laden wirunsere gewünschte Version von der o�ziellen Downloadseite herunter. 5 Da wir Ubuntubenutzen und die aktuellste Version 1.4.0 ist, benötigen wir die Binaries mit der Endung�.tar.gz�. Diese werden, wenn möglich, direkt in das gewünschte Verzeichnis heruntergeladenund dort entpackt. Um Apache NiFi nun starten zu können, muss im Terminal in dasInstallationsverzeichnis von NiFi navigiert werden. Es gibt nun zwei Startmöglichkeiten,aber auch die Möglichkeit den Dienst wieder zu stoppen oder den Status einzusehen:
4https://ni�.apache.org/docs/ni�-docs/html/getting-started.html5http://ni�.apache.org/download.html
52

5 INSTALLATION 5.4 Kommunikationskomponente
1 # im Vordergrund starten2 bin/nifi.sh run3 # im Hintergrund starten4 bin/nifi.sh start5 # NiFi stoppen6 bin/nifi.sh stop7 # Status einsehen8 bin/nifi.sh status
Listing 9: Download und Installation von Apache NiFi
In unserem Fall müssen vorerst aber noch einige Kon�gurationen angepasst werden, um auf-tretenden Problemen vorzubeugen. Voraussetzung dafür ist, dass Apache NiFi gestoppt ist.Erst nach der Änderung kann Apache NiFi wieder gestartet werden. Zum Einen haben wirden Standardport ändern müssen, da dieser bei der Erstinstallation bereits vergeben war.Die Einstellungen können in dem Unterordner für Kon�gurationsdateien im ursprünglichentpackten NiFi-Ordner geändert werden. Für das Verändern des Ports wird nun folgendeseingegeben:
1 cd /opt/nifi -1.4.0/ conf2 sudo nano nifi.properties3 # Abändern des Ports4 # web properties #5 nifi.weg.http.port =1904
Listing 10: Kon�guration des Ports von Apache NiFi
Des Weiteren reichen die JVM memory settings nicht aus, um die Datenmengen fehlerlosübermitteln zu können. Deswegen wird die Gröÿe des JVM memories angepasst:
1 cd /opt/nifi -1.4.0/ conf2 sudo nano bootstrap.conf3 # Ändern der JVM memory settings4 java.arg.2= Xms16g5 java.arg.3= Xms16g
Listing 11: Kon�guration der JVM memory settings
Nach der erfolgreichen Installation und Kon�guration von NiFi kann die Benutzerober�ächein einem beliebigen Browser über die Adresse �localhost:1904/ni�� angesteuert werden.
5.4. Kommunikationskomponente
In diesem Abschnitt wird die Installation von Apache Kafka und RabbitMQ eingegan-gen. Dabei wird Schritt für Schritt der gesamte Installation erläutert. Im Abschnitt 5.4.3:
53

5.4 Kommunikationskomponente 5 INSTALLATION
Apache Tomcat und Docker wird auf die Installation von Tomcat und Docker eingegangen.
5.4.1. Apache Kafka
In diesem Abschnitt wird auf die Einrichtung, sowie auf die Kon�guration des Kafka Clusterfür DAvE eingegangen. Dazu werden zuerst die Installationsschritte beschrieben. Der zweiteSchritt ist die Kon�guration die durchgeführt wurden.
Es wurde Apache Kafka 1.0.0 für den Prototyp verwendet. Bei der Einrichtung wurde dieDokumentation der Apache Kafka herangezogen (vgl. [The18b]). Für die Verwaltung derTopics muss vorher noch ein Apache Zookeeper Service gestartet werden. Der ZookeeperService wird mit der Installation von Apache Kafka mitgeliefert. Es ist auch möglich dasApache Projekt direkt von der eigenen Website zu erhalten. Für den Prototyp wurde dieProjektversion 3.4 genutzt.
Die Wurzelverzeichnis von Zookeeper und Kafka be�nden sich innerhalb des /opt-Verzeichnissesin Ubuntu. In dem bin-Ordner innerhalb der Kafka Verzeichnis sind alle notwendigenBefehl-Skripte, unter anderem die Start und Stopp-Skripte, hinterlegt. Im Con�g-Ordnerbe�nden sich die Kon�gurationsdateien. Der Aufbau bei Zookeeper ähnelt dem von Kafka.Die Start- und Stopp-Skripte be�nden sich ebenfalls im /bin-Verzeichnis. Die Kofniguratio-nen be�nden sich im /conf -Verzeichnis. Die Kafkakon�guration durchlief eine Entwicklung.
In der ersten Version wurde die server.properties in /Kafka/conf/ angepasst. Aufgrund derNetzwerkarchitektur musste die Einstellung advertised.host.name musste aktiviert werden.Der Wert für diese Einstellung war die Hostname des Master-Server auf dem der ApacheKafka Service läuft. Des Weiteren musste auch die advertised.port Einstellung aktiviert undvergeben werden. In der zookeeper.properties mussten weitere Einstellung überprüft wer-den. Dazu zählen die tickTime, dataDir und clientPort Einstellung. Die tickTime gibt dieminimale Verzögerung an bis eine Verbindung zum Zookeeper Service geschlossen wird. DieEinstellung im Prototyp wurde auf 2000 millisekunden festgelegt. Die Einstellung dataDirgibt den Pfad zu den Log-Dateien an. Die clientPort-Einstellung wurde auf dem Standard-wert belassen. Der Zookeeper Service ist unter dem Port 2181 auf dem master.local -Servererreichbar.
In der �nalen Version der Kon�guration konnten die Grundeinstellung aller Services genutztwerden. Dafür wurde die hosts-Datei auf Fehler überprüft und korrigiert. Die Befehl-Skripteumfassen Start- und Stopp-Befehle, sowie Monitoring Skripte. Für den Prototyp wurdendie Start- und Stopp-Befehle, das Topic-Skript und Erzeuger/Verbraucher Skripte genutzt.Die Befehle zum Starten der Services werden im Listing 12: Start-Skript gezeigt. DieseBefehle lassen die Services im Hintergrund starten.
Zum Überprüfen der Einstellung wurden die Befehle im Listing 13: Befehle für Kafkagenutzt. Der erste Befehl erzeugt ein Topic Hello Kafka. Dazu wurden die Parameter
54

5 INSTALLATION 5.4 Kommunikationskomponente
1 bin/zkServer.sh config/zoo.cfg2 bin/kafka -server -start.sh -daemon config/server.properties
Listing 12: Start-Skript
1 bin/kafka -topics.sh --create --zookeeper localhost :2181 --replication -factor 1 --partitions 1 --topic HelloKafka
2 bin/kafka -topics.sh --list --zookeeper localhost :21813 bin/kafka -console -producer.sh --broker -list localhost :9092
--topic HelloKafka4 bin/kafka -console -consumer.sh --bootstrap -server localhost
:9092 --topic HelloKafka --from -beginning
Listing 13: Befehle für Kafka
übergeben, wo der Zookeeper Services angesprochen werden kann. Des Weiteren werdendie Replikationsfaktoren und die Partition angegeben. Der Parameter �create erzeugt dasTopic. Der zweite Befehl gibt listet die alle vorhanden Topics auf. Dabei muss das TopicHelloKafka auftauchen. Die letzten beiden Befehle dienen zur Nachrichtenerzeugung unddas Abrufen des Topics HelloKafka.
5.4.2. RabbitMQ
Die Installation eines RabbitMQ Server wurde für den Prototyp folgendermaÿen durchge-führt. Die Version der RabbitMQ Software ist die Release 3.6 und die Erlang Bibliothek20.1 für RabbitMQ muss ebenfalls installiert sein. RabbitMQ wurde auf den Server mas-ter.local, slave1 und slave2 installiert. Das Listing 14: Installation von RabbitMQ aufUbuntu zeigt die verwendeten Befehle um Erlang zu installieren. Dazu muss das ErlangRepository auf Ubuntu hinzugefügt werden und dann kann Erlang heruntergeladen undinstalliert werden (vlg. [Piv18]).
Der nächste Schritt ist RabbitMQ zu installieren. Dazu muss zuerst der das RabbitMQRepository hinzugefügt werden. Im Anschluss muss auch der Public Key hinzugefügt wer-den. Dann kann RabbitMQ installiert werden. Das Listing 15: Installation RabbitMQ zeigtdie verwendeten Befehle (vlg. [Piv18]).
1 wget https :// packages.erlang -solutions.com/erlang -solutions_1 .0_all.deb
2 sudo dpkg -i erlang -solutions_1 .0_all.deb3 sudo apt -get update4 sudo apt -get install erlang erlang -nox
Listing 14: Installation von RabbitMQ auf Ubuntu
55

5.4 Kommunikationskomponente 5 INSTALLATION
1 echo 'deb http :// www.rabbitmq.com/debian/ testing main ' |sudo tee /etc/apt/sources.list.d/rabbitmq.list
2 wget -O- https :// www.rabbitmq.com/rabbitmq -release -signing -key.asc | sudo apt -key add -
3 sudo apt -get update4 sudo apt -get install rabbitmq -server
Listing 15: Installation RabbitMQ
1 sudo update -rc.d rabbitmq -server defaults2 sudo systemctl enable rabbitmq -server3 sudo service rabbitmq -server start4 #Add Admin5 sudo rabbitmqctl add_user admin password6 sudo rabbitmqctl set_user_tags admin administrator7 sudo rabbitmqctl set_permissions -p / admin ".*" ".*" ".*"8 #Einrichtung der Weboberfläche9 sudo rabbitmq -plugins enable rabbitmq_management
Listing 16: Kon�guration RabbitMQ
Das Starten und die Kon�guration der RabbitMQ Services werden im Listing 16: Kon�gu-ration RabbitMQ gezeigt. Zuerst wird der Dienst eingerichtet. Mit dem Befehl in Zeile 2wird die RabbitMQ Systemctl aktiviert. Damit lässt sich RabbitMQ über eine CLI steuern.Der Befehl in Zeile 3 startet dann den Services. Als nächstes wird ein Admin eingerichtet.Der letzte Befehl aktiviert die Webober�äche für RabbitMQ. Damit kann unter anderemder Zustand anhand eines Monitors beobachtet werden (vlg. [Piv18]).
Zum Abschluss muss noch das Cluster erzeugt werden. Aufgrund der Hochverfügbarkeitund Zuverlässigkeit wurde ein Cluster mit einer Abbild des master.local erstellt. Dazu be-�ndet sich im Verzeichnis /var/lib/rabbitmq/ eine Datei .erlang.cookie. Diese Datei enthälteine eindeutige Iden�kationsnummer. Diese Datei oder der Inhalt muss kopiert und auf demzweiten Server hinterlegt werden. Damit werden wird ein Abbild erzeugt (vlg. [Piv18]).
5.4.3. Apache Tomcat und Docker
Im folgenden wird auf die Erreichbarkeit des System via REST eingegangen. Der TomcatService wird innerhalb eines Dockercontainers betrieben. Dazu wurde eine Docker Instal-lation genutzt und ein Tomcat Image. Für die Docker Installation wurde die Version 17.0.4ausgewählt. Der Apache Tomcat Container wurde vom o�cial Repository mit der Versi-on 8.0.50 genutzt. Die Installation wurde auch wieder nach der o�ziellen Dokumentationdurchgeführt. Da der einzige erreichbare Server der master.local ist, wurde auch nur aufdiesem der Tomcat Container erzeugt. Der Port 9090 wurde für die Erreichbarkeit derSchnittstelle ausgewählt. Der Port 9090 muss in der server.xml in der Tomcat/conf geän-
56

5 INSTALLATION 5.5 Data Science
1
2 FROM tomcat :8.0.20 - jre83
4 COPY /conf/server.xml /usr/local/tomcat/conf/server.xml5
6 COPY /dave_server/dave_server.war /usr/local/tomcat/webapps/dave_server.war
Listing 17: Start-Skript
dert werden. Dazu muss das Attribute Port im Connector -Tag von 8080 auf 9090 geändertwerden. Eine alternative Einstellung des Ports in der server.xml ist die Einstellung in derweb.xml im war -Verzeichnis von DAvE.
Die DAvE Docker�le beinhaltet eine Referenz auf die o�zielle Tomcat Docker�le und denDocker-Befehl zum kopieren einer Datei. Das Listing 17: Start-Skript zeigt den Inhalt dieserDocker�le.
5.5. Data Science
Um die Data Science Funktionalitäten anzubieten, wurden mehrere Komponenten auf derVM installiert. Python wurde bereits mit dem auf der VM installierten Betriebssystemmitgeliefert. Um weitere Python Pakete zu installieren, wurde zunächst pip installiert (Lis-ting 18: Installieren der Data Science Komponenten, Zeile 1) Im Anschluss daran wurdedie Entwicklungsumgebung Jupyter installiert (Listing 18: Installieren der Data ScienceKomponenten, Zeile 3). Diese wurde zum Untersuchen der Daten und zum Entwickeln derModelle genutzt. Im folgenden wurden die für die Anwendung der Data Science Methodenund das Erstelllen von Modellen relevanten Pakete installiert (Listing 18: Installieren derData Science Komponenten, Zeile 5-8). Zum Export der erstellten Modelle in das PMMLFormat wurde weiterhin das Paket sklearn2pmml installiert (Listing 18: Installieren derData Science Komponenten, Zeile 10). Zum anschlieÿenden Parsen der PMML Dateienwar das Paket lxml erforderlich (Listing 18: Installieren der Data Science Komponenten,Zeile 12). Für die Anbindung an die Cassandra Datenbank wurde der von Datastax ent-wickelte Treiber verwendet (Listing 18: Installieren der Data Science Komponenten, Zeile13).
57

5.5 Data Science 5 INSTALLATION
1 sudp apt -get install python3 -pip2
3 sudo pip3 install jupyter4
5 sudo pip3 install numpy6 sudo pip3 install scipy7 sudo pip3 install scikit -learn8 sudo pip3 install pandas9
10 sudo pip3 install git+https :// github.com/jpmml/sklearn2pmml.git
11
12 sudo pip3 install lxml13
14 sudo pip3 install cassandra -driver
Listing 18: Installieren der Data Science Komponenten
58

6 REALISIERUNG
6. Realisierung
Das Ziel dieses Kapitels ist die Erläuterung der Realisierung des Prototyps. Dabei wirdzuerst im Abschnitt 6.1: Datenquellen auf die Datenquellen eingegangen. Dort werdendiese beschrieben und näher erläutert. Der Abschnitt 6.2: Archivierung umfasst unter an-derem die Beschreibung des Datenbankschemas sowie den Datenimport und -export. Au-ÿerdem wird auf die erarbeiteten Prozesse in Apache NiFi eingegangen. Im Abschnitt 6.3:Kommunikationskomponente wird auf die Umsetzung der Schnittstelle eingegangen undwie die Messaging System eingebunden wurden. Des Weiteren wird der Prozess für dieVerarbeitung der Anfragen beschrieben. Abschlieÿend wir im Abschnitt 6.4: Data Scienceauf die PMML-Modellerstellung eingegangen. Es wird zwischen der Steuerung und derModellierung des Prozesses di�erenziert.
6.1. Datenquellen
In dem Big Data-Archiv müssen diverse Datenquellen zur Speicherung und Abfrage vonDaten bereitliegen. Für die Auswertung werden aktuelle und historische Wetterdaten zumPower-Forecast genutzt und anhand von Smart-Meter Daten des Stromnetzes Lastprogno-sen ermöglicht. Zusätzlich werden Daten des statistischen Bundesamtes (SMARD-Daten)über realisierte und prognostizierte Energieverbräuche und -erzeugung herangezogen
6.1.1. Wetterdaten
Anhand von aktuellen und historischen Wetterdaten können Prognosen für die Strom-erzeugung ermöglicht werden. Dazu dienen in erster Linie Sonnen- und Wind-Daten, umaufgrund dieser Basis Prognosen für Wind- und Solarenergie aufstellen zu können. DieseDaten werden vom Deutschen Wetterdienst bereitgestellt und sind über einen FTP-Server6
abrufbar. Die Daten werden deutschlandweit an diversen Wetterstationen erfasst. Dabeiwird die Möglichkeit geboten, zwischen jährlichen, monatlichen, täglichen und stündlichenWerten auszuwählen. In diesem Anwendungsfall werden stündliche Werte herangezogen.Die Daten auf dem FTP-Server werden somit stündlich aktualisiert. Dazu werden Zip-Files hochgeladen, die Textdateien mit den relevanten Werten enthalten. Zusätzlich sinddie Zip-Files mit Metadaten angereichert. Es gibt pro Zip-File eine Produkt-Textdateimit den Messwerten sowie weitere Text-Dateien, die Stationsmetadaten enthalten. Aucheine Parameterbeschreibung ist dort gegeben. Die Parameterbeschreibungen enthalten Be-schreibungen der erfassten Werte sowie Beschreibungen zu den Metadaten der Stationen.Im Datenarchiv werden die Zip-Dateien mit stündlichen Werten zu Windgeschwindigkeitenund Sonnenstunden benötigt, um anschlieÿend die Auswertung der Daten zu ermöglichen.
6ftp://ftp-cdc.dwd.de/pub/CDC/observations_germany/climate/
59

6.1 Datenquellen 6 REALISIERUNG
6.1.2. Winddaten
Die Wind-Daten des Deutschen Wetterdienstes werden deutschlandweit an diversen Wet-terstationen erfasst. Relevant sind dabei vor allem die Produkt-Textdateien, die für dieAuswertung relevante Informationen erhalten. Die Datei enthält dabei jeweils folgendeParameter:
• STATIONS_ID - Stationsidenti�kationsnummer
• MESS_DATUM_ENDE - Intervallende im Format YYYYMMDDHH
• QN_3 - Qualitätsniveau
• F - mittlere Windgeschwindigkeit in m/s
• D - mittlere Windrichtung in Grad
• eor - Ende data record
Fehlerwerte sind mit -999 gekennzeichnet. Das Qualitätsniveau ist per default auf QN_3gesetzt und bedeutet älte automatische Prüfung und Korrektur. Im Laufe der Zeit wird dasQualitätsniveau der Messungen überarbeitet, welches allerdings für diesen Anwendungsfallnicht relevant ist. Wichtig sind dabei die Stationsidenti�kationsnummer zur geogra�schenZuordnung, das Datum und die Uhrzeit sowie die Windgeschwindigkeit und die Richtung.
6.1.3. Sonnendaten
Die Sonnen-Daten des Deutschen Wetterdienstes liegen ähnlich wie der Wind-Daten aufdem FTP-Server in Zip-Dateien vor. Diese Dateien enthalten die Stationsbeobachtungenals Produkt-Textdatei sowie die zugehörigen Metadaten. Dabei ist jedoch lediglich dieProdukt-Textdatei relevant, da diese die zur Station gehörigen Beobachtungen den Son-nenstunden beinhaltet. Die Datei enthält die folgenden Parameter:
• STATIONS_ID - Stationsidenti�kationsnummer
• MESS_DATUM - Messdatum im Format YYYYMMDDHH
• QN_7 - Qualitätsniveau
• SD_SO - Stündliche Sonnenscheindauer
• eor - End data record
Ähnlich wie bei den Winddaten sind die Fehlerwerte mit -999 gekennzeichnet. Das Quali-tätsniveau ist bei diesem Beispiel auf 7 gesetzt, was bedeutet, dass die Aufzeichnung diezweite Prüfung durchlaufen hat und der Wert noch korrigiert werden könnte.
60

6 REALISIERUNG 6.1 Datenquellen
6.1.4. Qualitätsniveau der Aufzeichnungen
In den Produkt-Textdateien steht in den Parametern jeweils der Indikator für das Quali-tätsniveau (QN). Dieser kann je nach Aufzeichnung einen unterschiedlichen Wert haben.In den zuvor genannten Beispielen hat das Qualitätsniveau den Wert QN_3 bzw. QN_7.Die vollständige Au�istung des Qualitätsniveaus sieht folgendermaÿen aus:
• 1 - nur formale Prüfung
• 2 - nach individuellen Kriterien geprüft
• 3 - alte automatische Prüfung und Korrektur
• 5 - historische, subjektive Verfahren
• 7 - 2. Prüfung durchlaufen, vor Korrektur
• 8 - Qualitätssicherung auÿerhalb Routine
• 9 - nicht alle Parameter korrigiert
• 10 - Qualitätsprüfung abgeschlossen, Korrekturen beendet
Wie in der Au�istung zu erkennen ist, können die Werte diverse Prüfungen durchlaufen,um als vollständig korrekt anerkannt zu werden. Das Qualitätsniveau von 1-10 ist also stei-gend, sodass Werte mit QN_10 die beste Qualität haben. Somit werden die erfassten Wertenach dem Upload auf den FTP ggf. noch geändert und das Qualitätsniveau angepasst. DieÄnderung benötigt allerdings eine gewisse Zeit, sodass dafür keine Berücksichtigung statt-�nden kann und die täglich erfassten Werte unabhängig vom Qualitätsniveau importiertwerden müssen.
6.1.5. Smart-Meter-Daten
Als Smart-Meter Daten werden Daten aus einer Niederspannungs-Simulation herangezo-gen, die selbst über ein Simulations-Framework erstellt werden und darüber hinaus durchdie Kooperation mit eStream über eine Schnittstelle im System abgelegt werden. Die Si-mulation ist Teil des Mosaik-Frameworks zur Generierung von Smart-Meter-Daten in ei-nem Smart-Grid bestehend aus Smart-Meter-Gateways und Smart-Metern. Dabei wirddie automatische Erstellung einer Smart-Grid Simulation für verschiedenste Szenarien er-möglicht, die sich beliebig komplex gestalten lassen. Der Fokus dabei wird auf die gene-rierten Messdaten gelegt, die in der Ausgabe der Simulation die Energieverbräuche derHaushalte in einem Grid darstellen. Diese Daten sind für spätere Analysezwecke für Aus-sagen über prognostizierte Energieverbäuche notwendig. Die erzeugten Ausgaben wurdeneingangs im JSON-Format ausgegeben und sind nach einer Umstellung des System alsCOSEM-formatierte XML-Dateien abrufbar. Topologisch werden die einzelnen Messwerte
61

6.2 Archivierung 6 REALISIERUNG
der Haushalte mit IDs in dem Format den Smart-Metern zugeordnet, welche wiederumden Smart-Meter-Gateways zugeordnet sind. Somit wird in den Ausgaben jeweils die Zu-ordnung der Messwerte im jeweiligen Smart-Grid erkenntlich gemacht.
6.1.6. SMARD-Daten
SMARD stellt Strommarktdaten für Deutschland und Europa in Echtzeit zur Verfügung.Dabei werden Daten wie Erzeugung, Verbrauch, Import und Export und Daten zur Regel-energie für unterschiedliche Zeiträume in gra�scher und tabellarischer Form bereitgestellt.Für die Anwendungszwecke der Datenanalyse werden die Daten zur Energieerzeugung undfür den Verbrauch herangezogen. Dabei kann sowohl auf realisierte, als auch auf prognos-tizierte Daten zurückgegri�en werden. Vor allem die realisierten Daten stehen für Ver-gleichszwecke bei der Datenanalyse im Fokus. Dazu werden in 15-minütigen Abständendie jeweiligen Daten in MWh aufgelistet. Die Daten veranschaulichen einerseits den ge-samten Energieverbrauch sowie die gesamte Energieerzeugung, lassen aber auch bei derErzeugung eine Klassi�zierung nach den jeweiligen Energieressourcen zu. So lassen sich zuVergleichszwecken Werte über Wind- und Sonnenenergie heranziehen, die im DAvE-Systemabgelegt werden.
6.2. Archivierung
In diesem Abschnitt wird die Umsetzung der Archivierungskomponente dargestellt. Da-bei wird zuerst auf die Schemade�nition eingegangen. Danach folgt der Datenimport undDatenexport, in dem gezeigt wird, wie die Daten der verschiedenen Datenquellen durchApache NiFi in Apache Cassandra abgespeichert bzw. abgerufen werden.
6.2.1. Schema-De�nition
Wie in den vorherigen Kapiteln erwähnt, ist Cassandra die ausgewählte Datenbank, inder die Daten aus den Datenquellen gespeichert werden sollen. Zuerst wird in Cassandraein Keyspace erstellt, sozusagen der äuÿerste Container, in denen sämtliche Tabellen mitInhalten gespeichert werden können. Es werden bei der Ausführung ein beliebiger Name,eine class und ein replication factor benötigt. Der Name des Keyspaces ist dave, hat alsclass simple strategy und einen replication factor von 3. Simple strategy wird verwendet,wenn lediglich ein Datencenter benutzt wird. Bei mehreren Datencentern würde man eineNetworkTopologyStrategy anwenden. Der replication factor ist standardmäÿig auf 3 einge-stellt, welches für unsere Zwecke ausreicht. Dies dient zur Absicherung der Daten, um einenVerlust vorzubeugen. Die Zahl drei bedeutet in diesem Fall eine dreifache Speicherung desjeweiligen Dateninhalts. Ist der Keyspace erstellt, können die benötigten Tabellen erzeugt
62

6 REALISIERUNG 6.2 Archivierung
werden. Für jede Datenquelle wird dazu eine individuelle Tabelle dem Keyspace hinzuge-fügt. Danach kann mit der Erstellung von Tabellen für die Dateninhalte begonnen werden.
1 CREATE KEYSPACE dave2 WITH REPLICATION = { 'class ' : 'SimpleStrategy ', '
replication_factor ' : 3 };
Listing 19: Erzeugung des Keyspaces
DWD-Daten Die für uns relevanten Daten des deutschen Wetterdienstes sind aufgeteiltin Klimadaten, Sonnendaten und Winddaten, die jeweils eine eigene Tabelle erhalten. Indiesen Tabellen sollen die zur Verfügung gestellten historischen und aktuellen Daten zusam-mengeführt werden. Damit die Wetterstationen der DWD-Daten lokalisiert werden können,muss zusätzlich noch eine Tabelle mit den gegebenen Informationen zur Beschreibung die-ser erstellt werden. Es muss zudem der Primary Key der Tabelle vorher gut ausgewähltsein, um die Tabellen später übersichtlicher zu halten. Dazu haben wir für jede Tabelleeinen Partition Key, der zur Datenverteilung über die Nodes hinweg verantwortlich ist,und einen Clustering Key, um die Daten sortieren zu können, ausgesucht. In diesem Fallwird die Stations ID als Partition Key und das dazugehörige Messdatum als ClusteringKey verwendet. Dies dient dazu, um nach der Stations ID abfragen und dem Messdatumsortieren zu können. Auch der Tabellenname wird vorher bewusst gewählt, um diese späterbesser zu identi�zieren.
63

6.2 Archivierung 6 REALISIERUNG
1 # Klimadaten2 CREATE TABLE dwd_climate_ger_daily(MESS_DATUM date ,
STATIONS_ID text , QN_3 text , FX text , FM text , QN_4 text, RSK text , RSKF text , SDK text , SHK_TAG text , NM text ,VPM text , PM text , TMK text , UPM text , TXK text , TNKtext , TGK text , eor text , PRIMARY KEY (STATIONS_ID ,MESS_DATUM)) WITH CLUSTERING ORDER BY (MESS_DATUM DESC);
3
4 # Sonnendaten5
6 CREATE TABLE dwd_sun_ger_hourly(STATIONS_ID text , MESS_DATUMtimestamp , QN_7 text , SD_SO text , eor text , PRIMARY KEY(STATIONS_ID , MESS_DATUM)) WITH CLUSTERING ORDER BY (
MESS_DATUM DESC);7
8 # Winddaten9
10 CREATE TABLE dwd_wind_ger_hourly(STATIONS_ID text ,MESS_DATUM timestamp , QN_3 text , F text , D text , eortext , PRIMARY KEY (STATIONS_ID , MESS_DATUM)) WITHCLUSTERING ORDER BY (MESS_DATUM DESC);
11
12 # Stationsbeschreibung13
14 CREATE TABLE stations_ger_description(stations_id text ,stationshoehe text , geobreite text , geolaenge text ,stationsname text , bundesland text , PRIMARY KEY (bundesland , stations_id , stationsname , geobreite ,geolaenge , stationshoehe)) WITH CLUSTERING ORDER BY (stations_id ASC , stationsname ASC , geobreite asc ,geolaenge asc , stationshoehe asc);
Listing 20: Erstellung der Tabellen für DWD-Daten
SMARD-Daten Bei den SMARD-Daten wurde ähnlich wie bei den DWD-Daten vor-gegangen. Hier werden zwei Tabellen für die Stromerzeugung und den Stromverbraucherstellt. Der Primary Key ist in diesem Fall das Datum und die Uhrzeit.
64

6 REALISIERUNG 6.2 Archivierung
1 CREATE TABLE dave.smard_stromerzeugung_quarter (2 datum date ,3 uhrzeit text ,4 biomasse text ,5 braunkohle text ,6 erdgas text ,7 kernenergie text ,8 photovoltaik text ,9 pumpspeicher text ,
10 sonstige_erneuerbare text ,11 sonstige_konventionelle text ,12 steinkohle text ,13 wasserkraft text ,14 wind_offshore text ,15 wind_onshore text ,16 PRIMARY KEY (datum , uhrzeit)17 ) WITH CLUSTERING ORDER BY (uhrzeit ASC)18
19 CREATE TABLE dave.smard_stromverbrauch_quarter (20 datum date ,21 uhrzeit text ,22 verbrauch text ,23 PRIMARY KEY (datum , uhrzeit)24 ) WITH CLUSTERING ORDER BY (uhrzeit ASC)
Listing 21: Erstellung der Tabellen für SMARD-Daten
LV-Daten Die Simulationsdaten des Projekts Netzdatenstrom werden ebenfalls in Cas-sandra abgespeichert. Hierfür wurde eine Tabelle erzeugt. Der Primary Key ist in diesemFall die Spalte smartmeter und timestamp.
1 CREATE TABLE dave.nds_sim_XML (2 smartmeter text ,3 timestamp bigint ,4 scaler text ,5 status text ,6 unit text ,7 value text ,8 logical_name text ,9 PRIMARY KEY (smartmeter , timestamp)
10 ) WITH CLUSTERING ORDER BY (timestamp DESC);
Listing 22: Erstellung der Tabelle für LV-Daten
65

6.2 Archivierung 6 REALISIERUNG
6.2.2. Datenimport
Im Folgenden werden nun die einzelnen Schritte erläutert, die in Apache NiFi für denDatenimport getätigt wurden. Um in NiFi Daten importieren zu können, müssen unter-schiedliche Prozessoren sowie die erstellten Tabellen aus Cassandra genutzt werden. Zuerstwird der Prozess des Imports von DWD-Daten erläutert. An diesem wird genauer gezeigt,welche Prozessoren genutzt wurden und welche Kon�gurationen durchgeführt werden muss-ten. Danach folgen noch die Kon�gurationen des Imports der SMARD- und DWD-Daten.Dabei werden nicht mehr die kompletten Prozesse gezeigt, sondern die wichtigsten Einstel-lungen und individuellen Änderungen der einzelnen Prozessoren.
DWD-Daten-Import Da der deutsche Wetterdienst die Wetterdaten in historische undneueste Daten aufgeteilt hat, wurde auch der Import danach gegliedert. So wurden zu-allererst die historischen Daten importiert. Dadurch mussten für die Sonnen-, Wind undKlimadaten Prozesse in Apache NiFi erstellt werden.
DWD-Daten Historisch Wir zeigen nun den kompletten Prozess des Imports der histori-schen Sonnendaten und geben ergänzend � falls Unterschiede vorhanden � die Einstellungenfür die Wind- und Klimadaten an. Per Drag&Drop können die einzelnen Prozessoren aufdie Arbeits�äche abgelegt werden. Für das Herunterladen der Daten auf unseren Serverwerden drei Prozessoren genutzt. Der erste Prozessor ist der ListFTP Prozessor, der ver-wendet wird, um auf den FTP-Server des deutschen Wetterdienstes zuzugreifen und damiteine Liste, der dort sich be�ndenden Dateien, erstellt wird. In diesem wurden bei den Pro-perties der Hostname, Port, Username und der Remote Path angepasst (siehe Abbildung).
Abbildung 12: Einstellungen ListFTP
Für die Wind- und Klimadaten werden jeweils andere Pfade des FTP-Servers angegeben,die folgendermaÿen aussehen:
66

6 REALISIERUNG 6.2 Archivierung
1 # Winddaten2 /pub/CDC/observations_germany/climate/hourly/wind/historical
/3 # Klimadaten4 /pub/CDC/observations_germany/climate/daily/kl/historical/
Listing 23: Pfade für den FTP-Server historische Daten
Da wir nicht alle Dateien des angegebenen Pfades importieren wollen, wird der RouteOnAt-tribute Prozessor verwendet. In diesem Prozessor muss eine Property hinzugefügt werden,damit nach bestimmten Dateien ge�ltert werden kann. In diesem Fall wurde die selbster-nannte Eigenschaft �letofetch hinzugefügt, damit nur die ZIP-Dateien mit den relevantenDaten heruntergeladen werden.
Abbildung 13: Einstellung RouteOnAttribute
Für die Winddaten bleibt diese Einstellung gleich. Die Klimadaten hingegen müssen nachtageswerte_KL ge�ltert werden. Der RouteOnAttribute Prozessor wird mit dem FetchFTPProzessor verbunden, damit die vorher angelegte Liste mit den ausgewählten Daten gefülltwerden können. Dazu werden bei den Properties wieder der Hostname, Port, Usernameund der Remote File angegeben. Beim Remote File wird dazu lediglich $path/$�lenameeingegeben. Falls es in diesem Prozessor zu einem fehlerhaften FlowFile kommt, soll dieserein weiteres Mal den Prozessor durchlaufen. Dies wird mit einem selbstgerichteten Pfeilauf dem Prozessor gelöst. Der erste Teil des Datenimports sieht nun folgendermaÿen aus:
Abbildung 14: 1. Teil DWD-Import
67

6.2 Archivierung 6 REALISIERUNG
Nachdem die Dateien auf dem Server sind, werden diese nun im UnpackContent Prozes-sor entpackt. Hier muss ausgewählt werden, welche Formate entpackt werden müssen. Inunserem Fall gibt es nur ZIP-Dateien. Danach gilt es die nicht benötigten Dateien mittelseines RouteOnAttribute Prozessors rauszu�ltern. In den entpackten Ordnern be�nden sichDateien mit Metadaten, die für die Archivierung nicht mehr benötigt werden. Dazu muss inden Properties eine Eigenschaft hinzugefügt werden. Diese Eigenschaft haben wir �lenamebenannt und besagt, dass jeder Dateiname mit dem Inhalt Metadaten nicht weitergeleitetwerden soll.
Abbildung 15: Einstellung Entfernen der Metadaten
Im nächsten Schritt wird die herausge�lterte CSV-Datei in ein JSON-Format umgewan-delt. Dazu benötigen wir den ConvertRecord Prozessor. Dieser beinhaltet in den Proper-ties einen Record Reader und einen Record Writer. Für den Value dieser Property mussein Service erstellt werden (siehe Abbildung). Für den Record Reader haben wir als TypeCSV-Reader ausgewählt, in dem eingestellt wird, wie das Schema der CSV-Datei aussehensoll. Hier wird beispielsweise eingestellt, welches Trennzeichen innerhalb des Dokumentesgelten und dass die erste Zeile als Header angezeigt werden soll. In unserem Fall wurde einSemikolon als Trennzeichen und Treat First Line as Header auf true gesetzt. Dieser Servicewurde HistoricalCSVReader_without_schema genannt. Zudem wurde noch ein RecordWri-ter erstellt, dessen Typ JsonRecordSetWriter ist. Hier wird lediglich in den Properties dieSchema Write Strategy in set 'avro.schema' Attribute geändert. Diesen RecordWriter habenwir HistoricalJsonRecordSetWriter_without_schema genannt.
Abbildung 16: Einstellung ConvertRecord
68

6 REALISIERUNG 6.2 Archivierung
Danach wird ein SplitJson Prozessor angebunden, der das FlowFile in einzelne Zeilen split-ten soll, damit diese später problemlos in Cassandra gespeichert werden können. Hierzumuss in den Properties die JsonPath Expression in $.* geändert werden, da der Inhalt desFiles eine einfache Struktur aufweist und nicht geschachtelt ist. Da im FlowFile noch Zellensind, die als Wert -999 aufweisen, wird in einem ReplaceText Prozessor der Inhalt in Nullgeändert. Dafür muss zusätzlich der Wert Literal Replace bei der Replacement Strategyausgewählt werden. Der zweite Teil des Datenimports ist in der folgenden Abbildung zusehen.
Abbildung 17: 2.Teil DWD-Import
Für den letzten Teil müssen die Daten für den Import in Cassandra vorbereitet werden.Dazu benötigen wir den EvaluateJsonPath Prozessor, damit wir den Inhalt der FlowFilesbestimmten Attributen zuordnen können. In den Properties wird der Wert bei der Einstel-lung der Destination auf FlowFile-attribute gesetzt, damit Apache NiFi neue Attributeerstellen kann. Hierzu können die JsonPath-Ausdrücke verwendet werden, um die Wertedes FlowFiles zu extrahieren. Wenn dieser Prozessor durchlaufen wurde, hat das FlowFiledie angelegten Attribute hinzugefügt. Die folgende Abbildung zeigt die fünf Attribute derSonnendaten. Für die Wind- und Klimadaten werden die Attribute entsprechend erstellt.Auch hierbei werden die Spaltennamen der Ausgangstabelle genommen, um an die Wertedes FlowFiles zu kommen.
Abbildung 18: Einstellung EvaluateJsonPath
69

6.2 Archivierung 6 REALISIERUNG
Als nächstes wird das Messdatum einem gewünschten Format angepasst. In einem Up-dateAttribute Prozessor fügen wir den Properties einen weiteren Eigenschaft hinzu undnennen diesen date. Der Wert dazu ändert das Format für die Sonnen- und Winddatennach unseren Wünschen um (siehe Abb. 20).
Abbildung 19: Anpassung Messdatum
Da die Klimadaten nur täglich aktualisiert werden, benötigen wir bei der Formatierungdes Zeitstempels keine Stundenangabe. Deswegen muss die Angabe bei den Klimadatenfolgendermaÿen aussehen:
1 # Klimadaten2 date: ${mess_datum:toDate (" yyyyMMdd "):format ("yyyy -MM-dd")}
Listing 24: Zeitstempel Klimadaten
Nach diesem Prozessor ist das FlowFile soweit, dass es in Cassandra eingespeichert werdenkann. Dazu benötigen wir zuerst den ReplaceText Prozessor, um ein CQL INSERT State-ment zu erstellen, und den PutCassandraQL Prozessor für die Verbindung zu Cassandra.Das hinzugefügte CQL-Statement sieht je nach Datensatz folgendermaÿen aus:
70

6 REALISIERUNG 6.2 Archivierung
1 # Sonnendaten2 insert into dwd_sun_ger_hourly(STATIONS_ID , MESS_DATUM , QN_7
, SD_SO , eor ) values ('${stations_id}', '${date}', '${qn_7}', '${sd_so}', '${eor}' )
3
4 # Winddaten5 insert into dwd_wind_ger_hourly(STATIONS_ID , MESS_DATUM ,
QN_3 , F, D, eor ) values ('${stations_id}', '${date}', '${qn_3}', '${f}', '${d}', '${eor}' )
6
7 # Klimadaten8 insert into dwd_climate_ger_daily(STATIONS_ID , MESS_DATUM ,
QN_3 , FX , FM ,QN_4 , RSK ,RSKF , SDK ,SHK_TAG , NM , VPM ,PM , TMK , UPM , TXK , TNK , TGK ,eor ) values ('${stations_id}', '${date}', '${qn_3}', '${fx}', '${fm}', '${qn_4}', '${rsk}', '${rskf}', '${sdk}', '${shk_tag}', '${nm}', '${vpm}', '${pm}', '${tmk}', '${upm}', '${txk}', '${tnk}','${tgk}', '${eor}')
Listing 25: CQL INSERT Statements
In dem PutCassandraQL Prozessor werden lediglich der Username cassandra, das Pass-wort cassandra, der keyspace dave und die Cassandra Contact Points (127.0.0.1:9042)eingestellt. Zur Fehlervermeidung lassen wir fehlerhafte FlowFiles mittels eines selbstge-richteten Pfeiles noch einmal den Prozessor durchlaufen. Sind alle Prozessoren miteinanderverbunden, kann der gesamte Prozess mit dem Startbutton ausgeführt werden. Es ist zu-dem möglich, diesen jederzeit zu stoppen, den Status einzusehen und gegebenenfalls in dieeinzelnen FlowFiles zu schauen. Der dritte Teil des Datenimports sieht nun folgendermaÿenaus:
Abbildung 20: 3.Teil DWD-Import
Aktuelle DWD-Daten Nachdem die historischen Daten gespeichert wurden, werden nundie aktuellen Wetterdaten der Tabelle hinzugefügt. Dazu wurde der gleiche Prozess wie vor-hin beschrieben, für die Sonnen-, Wind-, und Klimadaten genutzt. Der einzige Unterschiedzwischen den Prozessen ist der Pfad, von wo die Daten abgerufen werden sollen. Da aber
71

6.2 Archivierung 6 REALISIERUNG
auch die Daten des Deutschen Wetterdienstes täglich aktualisiert werden und diese in un-serer Datenbank ebenfalls aktuell gehalten werden sollen, benötigen wir zusätzlich zu demeinmaligen Import der historischen und der aktuellen Daten einen immer wiederkehrendenImport der neuen Daten. Dieser Prozess ist nahezu identisch zu dem oben beschriebenenhistorischen Datenimport. Der wesentliche Unterschied besteht darin, dass aufgrund desFilterns ein zusätzlicher Prozessor hinzugefügt wird, einige Einstellung geändert werdenmüssen und der gesamte Prozess so eingestellt wird, dass dieser zu einer bestimmten Uhr-zeit täglich neu aktiviert wird. Wie diese tägliche Aktivierung genau funktioniert wird imletzten Abschnitt erläutert.
Für die genaue Kon�guration des Prozesses emp�ehlt sich den oberen Abschnitt zu denhistorischen Datenimport begleitend mit der nachfolgenden Beschreibung anzusehen. Da-mit dieser für die aktuellen Daten komplettiert werden kann, sind dazu noch einige kleineÄnderungen vorzunehmen. Zur genaueren Einordnung wird der Prozess nochmals kurzbeschrieben.
Wie bei der oberen Beschreibung teilen wir den Gesamtprozess wieder in drei Teilprozesseund erklären anhand dessen die zu den Sonnen-, Wind- und Klimadaten verschiedenenEinstellungen. Zu Beginn des Prozesses ist die einzige Änderung zu dem Import der his-torischen Daten die Datenquelle der aktuellen Daten. Da die DWD-Daten, wie oben be-schrieben, in historische und aktuelle Daten aufgeteilt werden müssen, benötigen wir einenanderen Pfad in den Properties des ListFTP Prozessors. Dieser ist sowohl für die Sonnen-,Wind- als auch Klimadaten unterschiedlich.
1 # Sonnendaten2 /pub/CDC/observations_germany/climate/hourly/sun/recent/3 # Winddaten4 /pub/CDC/observations_germany/climate/hourly/wind/recent/5 # Klimadaten6 /pub/CDC/observations_germany/climate/daily/kl/recent/
Listing 26: Pfade für den FTP-Server aktuelle Daten
Die Kon�guration der anderen Prozessoren im ersten Teil bleiben identisch, sodass nachAbschluss des FetchFTP Prozessors die gewünschten Daten erfolgreich auf dem Servergespeichert wurden, um dann damit weiterarbeiten zu können.
Im zweiten Teil sind die Prozesse und auch die Einstellungen je nach Datenart wie bei demhistorischen Datenimport. Hier geht es darum, dass die Daten, nachdem sie entpackt wur-den, in das JSON Format gewandelt werden, um diese dann in einzelne Zeilen zu splitten,damit sie später problemlos in unsere Tabelle in Cassandra eingefügt werden können. Nachdem Teilen in einzelne Zeilen müssen noch wiederkehrende Werte, die Nullwerte aussagen(hier: -999) durch Null ersetzt werden. Im letzten Teil muss nun ein Prozessor hinzuge-fügt werden, der dafür sorgt, dass die Zeile mit dem Datum eines davorliegenden Tagesimportiert wird. Da die Klimadaten täglich, die Sonnen- und Winddaten stündlich aufge-
72

6 REALISIERUNG 6.2 Archivierung
nommen und täglich auf dem FTP-Server des DWD hochgeladen werden, wollen wir diesein unserer Datenbank aktuell halten. Dazu benötigen wir zwischen dem EvaluateJsonPathProzessor und dem Konvertieren des Zeitstempels einen Prozessor, der ein Attribut hin-zufügt, mit dem sich der Datensatz nach einem bestimmten Datum �ltern lässt. DieserProzessor bewirkt, dass das FlowFile nur die Daten weiterschickt, die als Messdatum einenvorherigen Tag aufweisen. Da auf dem FTP-Server die Daten des davorliegenden Tagestäglich zur Mittagszeit hochgeladen werden, wir aber bereits in der Nacht aktualisieren,benötigen wir zwei Tage vor der Systemzeit, welches durch das Subtrahieren von 172800000Sekunden von der Systemzeit realisiert wird. Da wir die aktuellen Datensätze den bereitsimportierten historischen Daten hinzufügen, verläuft das Einfügen der Daten in Cassandradann wieder identisch zu den historischen Daten, weshalb die letzten beiden Prozessorengleich kon�guriert bleiben können. Nachdem die Prozessoren nun so eingestellt sind, dassdie einzelne Zeile des vorherigen Tages in die Datenbank gespeichert wird, benötigen wirnoch die Einstellung, dass die Prozessoren täglich aktiviert werden. Dazu gibt es in jedemProzessor die Möglichkeit eine bestimmte Startzeit einzustellen. Standardmäÿig wird jederProzessor auf eingehende Flow�les reagieren. Es reicht in unserem Fall also aus, wenn nurder erste Prozessor (hier: ListFTP) aktiviert wird, der dann beginnt, das Flow�le an dennächsten Prozessor zu schicken. Ab da wird der ganze Prozess automatisch durchlaufen,bis die gesamte Datenmenge gespeichert ist. Unter dem Reiter Scheduling im ListFTP-Prozessor kann mittels der Funktion CRON dem Prozessor ein Startzeitpunkt angegebenwerden. CRON ist eine zeitbasierte Ausführung von Prozessen in Unix und unixbasiertenBetriebssystemen und dient genau für unsere Zwecke. Der Prozess der Klimadaten startetum 0 Uhr, die Sonnendaten um 2 Uhr (siehe folgende Abb.) und die Winddaten um 4 Uhr.Der gewählte Zeitraum ist aufgrund der Vermeidung von Engpässen auf dem Server für diejeweiligen Sonnen, Wind und Klimadaten über die Nacht verteilt. Damit diese Funktion inNiFi aber auch greifen kann, müssen alle Prozessoren im gesamten Prozess bereits gestartetsein und durchgängig laufen.
1 ${mess_datum:contains ("${now():toNumber ():minus (172800000):format('yyyyMMdd ')}")}
Listing 27: Filtern des Messdatums nach bestimmten Datum
Abbildung 21: Scheduling Strategy
73

6.2 Archivierung 6 REALISIERUNG
SMARD-Daten Der Import der SMARD-Daten ist ähnlich aufgebaut wie die Prozesseder DWD-Daten. Da aber die Webseite der Bundesnetzagentur7 keinen FTP-Server besitzt,werden die beiden Dateien manuell auf den Server heruntergeladen. Es wurden hier zweiProzesse erstellt, die die selben Prozessoren verwenden. So wurden die letzten zwei Jah-re (01.01.2016 - 01.01.2018) des realisierten Stromverbrauchs und der Stromerzeugung inDeutschland in Cassandra abgespeichert. Damit die Daten in Cassandra archiviert werdenkönnen, muss von NiFi die CSV-Datei abgerufen werden. Dies geschieht durch den GetFileProzessor. In diesem kann der Pfad des Servers sowie der Dateiname angegeben werden.Die folgende Abbildung zeigt die Kon�guration des Prozessors für den Stromverbrauch.Für den Prozess der Stromerzeugungsdaten wurde nur der File Filter abgeändert, um andie andere CSV-Datei zu gelangen.
Abbildung 22: Kon�guration GetFile Prozessor
Da die Daten nicht entpackt werden müssen, folgt nach dem GetFile Prozessor direkt dieUmwandlung der Datei von JSON zu CSV und anschlieÿend das Splitten in einzelne Zei-len. Hier sind die Prozessoren und Einstellungen die gleichen wie beim DWD-Datenimport.Die restlichen Schritte wie die Vorbereitung der Daten, das Umwandeln des Zeitstempels,die Erstellung des CQL-Statements und das Verbinden zur Datenbank benutzten auch diegleichen Prozessoren wie beim Import der Wetterdaten, allerdings müssen diese anderskon�guriert werden. Die folgende Abbildung zeigt die Kon�guration für den EvaluateJson-Path Prozessor. Für die Daten der Erzeugung müssen in diesem Prozessor andere Attributeangegeben werden.
7 https://www.smard.de/blueprint/servlet/page/home/downloadcenter/download_marktdaten/
74

6 REALISIERUNG 6.2 Archivierung
Abbildung 23: Kon�guration EvaluateJsonPath Verbrauch
Abbildung 24: Kon�guration EvaluateJsonPath Erzeugung
Das Anpassen des Messdatums wird auch hier durch ein UpdateAttribute Prozessor durch-geführt. Die Kon�guration ist bei den beiden Prozessen gleich.
Abbildung 25: Anpassen des Datums bei SMARD-Daten
Die Kon�guration des folgenden ReplaceText Prozessor, der das CQL-Statement beinhal-tet, ist wiederum unterschiedlich, da für den Stromverbrauch und der Stromerzeugung
75

6.2 Archivierung 6 REALISIERUNG
jeweils eine Tabelle erstellt wurde und diese unterschiedliche Attribute besitzen.
1 # Verbrauch2 insert into smard_stromverbrauch_quarter(Datum , Uhrzeit ,
Verbrauch) values ('${date}', '${uhrzeit}', '${verbrauch}')
3
4 # Erzeugung5 insert into smard_stromerzeugung_quarter(Datum , Uhrzeit ,
Biomasse , Wasserkraft , Wind_Offshore , Wind_Onshore ,Photovoltaik , Sonstige_Erneuerbare , Kernenergie ,Braunkohle , Steinkohle , Erdgas , Pumpspeicher ,Sonstige_Konventionelle) values ('${date}', '${uhrzeit}', '${biomasse}', '${wasserkraft}','${windoffshore}','${windonshore}','${photovoltaik}','${sonstige_erneuerbare}','${kernenergie}','${braunkohle}','${steinkohle}','${erdgas}','${pumpspeicher}', '${sonstige_konventionelle}')
Listing 28: CQL INSERT Statements SMARD
Zum Abschluss wird beiden Prozessoren wieder der PutCassandraQL Prozessor verwendet,um eine Verbindung zu Datenbank herzustellen. Diese besitzt die selben Einstellungen wiebeim DWD-Datenimport.
76

6 REALISIERUNG 6.2 Archivierung
Smart-Meter-Daten Import Der in Abbildung 26: Data�ow: Import der Smart-Meter-Daten Data�ow zeigt den Import von Smart-Meter-Daten in Cassandra auf.
Abbildung 26: Data�ow: Import der Smart-Meter-Daten
Zuerst werden die Daten, welche in einem Kafka Topic hinterlegt sind abgerufen. Fürden Abruf der Daten aus einem Kafka Topic wird der Prozessor ConsumeKafka_0_11verwendet. Folgende Prozessor Eigenschaften (properties) sind anzupassen:
• Kafka Brokers:Die URI zu den abzurufenden Kafka Brokern z. B. 134.106.56.15:29092(Kafka Broker der Partnergruppe E-Stream)
• Topic Name(s): Die Namen der abzurufenden Kafka Topics
• Group ID: Diese werden genutzt, um die Kafka Consumer zu identi�zieren
Der entsprechende Kon�gurationsdialog ist in Abbildung 27: Import der Smart-Meter-Daten: ConsumeKafka Kon�guration dargestellt.
77

6.2 Archivierung 6 REALISIERUNG
Abbildung 27: Import der Smart-Meter-Daten: ConsumeKafka Kon�guration
Smart-Meter-Daten werden in einer COSEM Struktur, welches eine XML Struktur vor-weist, übermittelt. So werden die Daten aus dem ConsumeKafka_0_11 Prozessor an einenSplitXML Prozzesor übergeben und dort die einzelnen Datensätze in sperate XML Dateien(FlowFiles) geteilt. Die einzige Property, welche in diesem Prozessor zu kon�gurieren istlautet:
• Split Depth: Angabe der Stelle in der XML Struktur, an welcher die Datei geteiltwerden soll. Der Wert 1 bedeutet, dass die XML im Wurzel Element geteilt wird.
In diesem Fall ist der Wert der Split Depth auf 1 gesetzt. Im Anschluss werden die, ausdem SplitXML Prozessor resultierenden FlowFiles, in das JSON-Format konvertiert. Hierzuwird der ExecuteScript Prozessor eingesetzt. Dieser Prozessor führt ein in der Program-miersprache Groovy geschriebenes Skript aus.
Ein wichtiger Teil des Skriptes, um es für den ExecuteScript Prozessor lau�ähig zu machenist der Befehl in Zeile 1 des Listings 29: ExecuteScript, Framework. Dieser Befehl ermöglichtes auf die FlowFiles innerhalb einer NiFi Session zuzugreifen. Die nachfolgenden Codezeilen
78

6 REALISIERUNG 6.2 Archivierung
1 flowFile = session.get()2 if (! flowFile) return def text = 'Hello world!'; // Cast a
closure with an inputStream and outputStream parameterto StreamCallback
3 flowFile = session.write(flowFile , { inputStream ,outputStream ->
4 text = IOUtils.toString(inputStream , StandardCharsets.UTF_8) outputStream.write(toJsonBuilder(text).toPrettyString().getBytes(StandardCharsets.UTF_8))
5 }as StreamCallback)6 session.transfer(flowFile , REL_SUCCESS)
Listing 29: ExecuteScript, Framework
binden den Input Stream ein transformieren diesen und geben ihn als Output Streamaus ,welcher im JSON Format ist. Hierzu wird die Methode toJsonBuilder, welche innerhalbdieses Skipts de�niert ist.
In Abbildung 28: Import der Smart-Meter-Daten: ExecuteScript Kon�guration wird dieentsprechende Kon�guration des ExecuteScript Prozessor innerhalb dieses Data�ows ver-bildlicht.
Abbildung 28: Import der Smart-Meter-Daten: ExecuteScript Kon�guration
79

6.2 Archivierung 6 REALISIERUNG
1 insert into nds_sim_XML(smartmeter , timestamp , scaler ,status , unit , value , logical_name) values ( '${sm}', ${time}, '${scaler}', '${status}', '${unit}', '${value}','${logical_name }')
Listing 30: NiFi, Insert XML
Im nächsten Schritt werden die Arrays innerhalb der resultierenden FlowFiles in einzelneJSON Fragmente geteilt. Zu diesem Zweck wird der SplitJson Prozessor gebraucht, wieauch bereits in den vorherigen Data�ows des Imports beschrieben wurde. Die PropertyJsonPath Expression wurde in diesem Fall auf $.* gesetzt.
Die resultierenden FlowFiles des SplitJson Prozessor werden an einen EvaluateJsonPathweitergeleitet. Dieser Prozessor wurde bereits in den vorangegangen Data�ows beschrieben.In Abbildung 29: Import der Smart-Meter-Daten: EvaluateJsonPath Kon�guration werdendie gesetzten Attribute aufgezeigt.
Abbildung 29: Import der Smart-Meter-Daten: EvaluateJsonPath Kon�guration
Diese Attribute werden im Folgenden Replace Text Prozessor eingesetzt. Jener Prozessorwird an dieser Stelle genutzt, um das CQL Query zu de�nieren, mit welchem die einzelnenDatensätze in eine Cassandra Tabelle eingefügt werden. Die kon�gurierte Porperty ist indiesem Fall Replacement Value und der Wert (value) wird mit dem zu nutzendem CQLQuery gesetzt. Das genutzte Query ist in 30: NiFi, Insert XML zu sehen.
Der Data�ow endet mit einem PutCassandraQL Prozessor, welcher ein CQL Query erwar-
80

6 REALISIERUNG 6.2 Archivierung
tet. Das CQL Query wird wie beschrieben vom Replace Text Prozessor geliefert. Hier wirdkon�guriert wie der PutCassandraQL Prozessor eine Verbindung zu Cassandra aufbaut.Entscheidende Properties für diesen Fall sind:
• Cassandra Contact Points: Eine Liste der Kontaktpunkte, der anzusprechendenCassandra Nodes
• Keyspace: Der anzusprechende Cassandra Keyspace• Client Auth: Einstellung, wie die Client Authenti�zierung der anzusprechendenCassandra Nodes gesetzt ist
• Username: Nutzername für den Zugri� auf das Cassandra Cluster
• Password: Passwort für den Zugri� auf das Cassandra Cluster
• Consistency Level: Das in den anzusprechenden Tabellen gesetzte ConsistencyLevel
In der Abbildung 30: Import der Smart-Meter-Daten: PutCassandraQL Kon�guration istdie Kon�guration der Cassandra Datenbank innerhalb der DAvE Architektur dargestellt.
Abbildung 30: Import der Smart-Meter-Daten: PutCassandraQL Kon�guration
81

6.2 Archivierung 6 REALISIERUNG
6.2.3. Datenexport
In diesem Abschnitt wird der Export der in DAvE be�ndlichen Daten erläutert. Für den Da-tenexport wird wie auch beim Import Apache Ni� genutzt. Um in NiFi Daten exportierenzu können, müssen unterschiedliche Prozessoren sowie die erstellten Tabellen aus ApacheCassandra genutzt werden. Es wird zunächst der Data�ow für den Export der DWD-Datenerläutert. An diesem wird genauer gezeigt, welche Prozessoren genutzt werden und welcheKon�gurationen durchgeführt wurden. Anschlieÿend folgt die Erläuterung des Data�owfür den Export der Smart-Meter-Daten. Dabei werden nicht mehr die kompletten Prozessegezeigt, sondern die wichtigsten Einstellungen und individuelle Änderungen der einzelnenProzessoren.
Datenexport im JSON-Format In diesem Abschnitt wird der Datenexport, welcher imJSON-Format übermittelt wird, erläutert. Die Use Cases der DAvE-Architektur beinhal-ten die Abfrage von historischen Wetterdaten, das Ergebnis solch einer Abfrage kann überden folgenden Data�ow eingeholt und übermittelt werden. Mit dem in Abbilung 31: Da-ta�ow: Datenexport im JSON-Format dargestellten Data�ow können jedoch alle Dateninnerhalb des DAvE-Systems abgefragt werden, sofern die Ausgabe im JSON-Format vomSystem vorgesehen ist. So kann der Data�ow auch bei möglicher Erweiterung mit anderenDatenquellen für den Export genutzt werden.
Abbildung 31: Data�ow: Datenexport im JSON-Format
Der dargestellte Data�ow beginnt mit einem QueryCassandra Prozessor, dieser dient derAbfrage von Daten innerhalb einer Cassandra Datenbank mittels eines CQL Querys. DiePropertys dieses Prozessors gleichen im weitesten den Propertys des PutCassandraQL Pro-zessors. Folgende Propertys unterscheiden sich:
• CQL select query: Angabe der zu tätigenden CQL Abfrage
• Output Format: Angabe des Ausgabe Formats des Resultats. Es stehen das JSON-Format und das Avro-Format zur Auswahl
In Abbildung 32: Datenexport im JSON-Format: QueryCassandra Kon�guration werdendie in DAvE genutzten Einstellungen dargestellt, die CQL Query Property ist auftragsspe-zi�sch und wird somit dynamisch kon�guriert.
82

6 REALISIERUNG 6.2 Archivierung
Abbildung 32: Datenexport im JSON-Format: QueryCassandra Kon�guration
Das Ergebnis aus der CQL Select Anfrage ist in diesem Fall im JSON-Format und ein ein-zelnes JSON-Array, welches alle Datensätze beinhaltet. Damit jeder Datensatz als einzelneKafka Message übermittelt werden kann, wird ein SplitJson Prozessor genutzt, welcher be-reits Abschnitt 6.2.2: Datenimport erläutert wird. Die für diesen Data�ow entscheidendeProperty ist die JsonPath Expression. Das JSON-Array, welches mit diesem Prozessorgeteilt werden soll wird mit result indiziert, daher ist der Wert der Property $.results .In Abbildung 33: Datenexport im JSON-Format: SplitJson Kon�guration ist die gewählteKon�guration aufgezeigt.
Abbildung 33: Datenexport im JSON-Format: SplitJson Kon�guration
Abschlieÿend werden die aus dem SplitJson Prozessor resultierenden FlowFiles an einenPublishKafka Prozessor weitergeleitet. Dieser Prozessor dient dem Senden von Messages,welche den Inhalt von FlowFiles beinhalten, an Apache Kafka. Die Propertys dieses Prozes-sors decken die nötigen Informationen für die Verbindung mit einem oder mehreren KafkaBrokern:
• Kafka Brokers: URI der anzusprechenden Kafka Broker
83

6.2 Archivierung 6 REALISIERUNG
• Topic Name: Topic Namen der anzusprechenden Kafka Broker
Diese Propertys sind auftragsspezi�sch und werden dementsprechend dynamisch angepasst.
Datenexport im COSEM-Format In diesem Abschnitt wird der Datenexport, welcherim COSEM-Format übermittelt wird, erläutert. Die Use Cases der DAvE-Architektur be-inhalten die Abfrage von historischen Smart-Meter-Daten, das Ergebnis solch einer Abfragekann über den folgenden Data�ow eingeholt und übermittelt werden. In Abbilung 34: Da-ta�ow: Datenexport im COSEM-Format ist der hierfür genutzte Data�ow dargestellt.
Abbildung 34: Data�ow: Datenexport im COSEM-Format
Dieser Data�ow unterscheidet sich nur an wenigen Stellen vom Data�ow, welcher für denDatenexport im JSON-Format genutzt und in Abschnitt 6.2.3: Datenexport im JSON-Format beschrieben wird. Die beiden Data�ows sind grundlegend identisch, auÿer der Kon-vertierung der Daten vom JSON-Format in das COSEM-Format. Die Konvertierung in dasCOSEM-Format ist notwendig, da dieses Format der Standard für die Kommunikation überSmart-Meter-Daten, ist. Es werden im Folgenden lediglich die abweichenden Prozessorenerläutert. Der Data�ow beginnt mit einem QueryCassandra Prozessor gefolgt von einemSplitJson Prozessor. Die FlowFiles aus dem SplitJson Prozessor werden an einen JoltTrans-formJSON Prozessor weitergeleitet. Dieser Prozessor wird an dieser Stelle genutzt, um daseingehende �ache JSON-Array in ein verschachteltes JSON-Array zu transformieren. Aufdiese Weise wird das JSON-Array für die Konvertierung in das COSEM-Format vorbe-reitet. Hierzu wurde die Property Jolt Speci�cation kon�guriert, in dieser wird ein Skripteingestellt, welches die vorzunehmende Transformation de�niert.
Nach der Transformierung des JSON Arrays werden die resultierenden FlowFiles an einenExecuteScript Prozessor übergeben. Dieser Prozessor wird in diesem Data�ow genutzt, um
84

6 REALISIERUNG 6.3 Kommunikationskomponente
ein Python-Skript auszuführen, welches die FlowFiles vom JSON-Format in das COSEM-Format überführt.
Abschlieÿend werden die FlowFiles als Message an einen oder mehrere Kafka Broker mit-tels eines PublishKafka Prozessors gesendet. Die Kon�guration und Beschreibung diesesProzessors ist im Abschnitt 6.2.3: Datenexport im JSON-Format beschrieben.
6.3. Kommunikationskomponente
In diesem Abschnitt wird auf die Umsetzung der Kommunikationskomponente eingegan-gen, dazu wird zuerst das PMML-Auftragskonzept vorgestellt. Während dessen wird dieKomponente zu den anderen abgegrenzt. Im Anschluss wird die RESTful API vorgestelltund uum Schluss wird die Struktur und das Verhalten näher beschrieben.
6.3.1. Konzept
Für die Kommunikation mit externen Systemen wurde für DAvE eine RESTful Schnittstellede�niert. Diese beinhaltet Funktionen um diverse Prozesse zu starten. Für das Konzeptmussten die Use Cases weiter ausformuliert werden. Das Ergebnis sind zwei unterschiedlicheProzesstypen.
Abbildung 35: schematische Darstellung zur Beantwortung einer Anfrage
Die Abbildung 35: schematische Darstellung zur Beantwortung einer Anfrage zeigt sche-matisch das zugrunde-liegende Konzept zur Beantwortung einer Anfrage. Eine Anfragemarkiert ein Start-Ereignis. Die Anfrage wird immer sofort beantwortet. Dabei wird zwi-schen einem synchron und einem asynchronen Prozess unterschieden. Beide Prozesstypenerwidern unverzüglich die Anfrage. Im Falle eines synchron Prozesses wird eine Anfragedirekt mit einem validen Ergebnis beantwortet. Die Verarbeitung geschieht sequenziell. Diesynchronen Prozesse sind:
• Die Abfrage nach allen Wetterstationen innerhalb Deutschlands.
• Die Anfrage nach dem Prozess-Status einer asynchronen Anfrage.
85

6.3 Kommunikationskomponente 6 REALISIERUNG
• Die Anfrage von angebotenen PMML-Modellen.
• Die Anfrage nach einem speziellen PMML-Modell durch die modelId.
Bei den asynchronen Prozessen verläuft die Erwiderung der Anfrage und die Verarbeitungdieser parallel. Die Antwort für einen asynchronen Prozess beinhaltet immer eine Uni�edResource Identi�cation (URI) und eine Topic-Bezeichnung. Die Topic-Bezeichnung ist imgesamten System eindeutig und einzigartig. Die asynchronen Prozesse sind:
• Die Anfrage nach historischen Daten.
• Die Anfrage nach der aktuellstem PMML-Modell anhand der PMML-Struktur
• Der Auftrag nach einem neu-berechneten PMML-Modell.
Die Antwort einer Anfrage umfasst zwei Teile. Es wird eine URI und eine Topic-Bezeichnungerzeugt. Die URI setzt sich aus dem Host und einem Port zusammen. Der Port wird durchden ausgewählten Messaging System de�niert. Der Topic ist eine UUID. Anhand dieser In-formationen kann das PMML-Modell oder die Ergebnismenge über einen Broker abonniertwerden.
Die Topic-Bezeichnung ist gleichzeitig ein interner einzigartiger Schlüssel. Es werden alleasynchronen Prozesse protokolliert, um den Verarbeitungsfortschritt festzustellen und beibedarf diese neu zu starten. Anhand des Protokolls kann der Verarbeitungszustand abge-fragt werden. Für die Verarbeitung einer Data Mining Anfrage sind die Status abfragenessentiell.
Das Konzept zur Verarbeitung einer Data Mining Anfrage wird in der Abbildung 36:Schematische Darstellung der Anfrageverarbeitung einer Data Mining Anfrage schematischdargestellt. Die Steuerung wird im Abschnitt 6.4.1: Steuerung näher erläutert. Im erstenSchritte wird die Anfrage entgegengenommen. Eine Anfrage besteht aus einer Broker-Angabe und einem PMML-Modell. Das PMML-Modell muss als Base64 kodiert sein, damitwird der Anfrageprozess angestoÿen. Der nächste Schritt ist die Protokollierung und daserzeugen eines Topics auf einem MB. Dann wird eine Antwort mit den Informationen, wodas Ergebnis hinterlegt sein wird, zurückgeschickt. Als nächstes �ndet die Protokollierungstatt. Im Anschluss wird der Auftrag in eine Auftragstabelle gespeichert. Das Starten einerperiodischen Abfrage über den Status des Auftrags ist der Abschluss dieses Prozessteils.
Der zweite Teil beginnt mit einer Statusänderung des Auftrags. Der Status wird durchein Long-Datentyp repräsentiert. Dabei entsprechen negative Zahlen einem Fehlercode.Positive Werte werden als EPOCH interpretiert und damit geben sie den Zeitpunkt derFertigstellung an. Bei einer erfolgreichen Beendigung wird das PMML-Modell als Base64kodiert und übertragen.
86
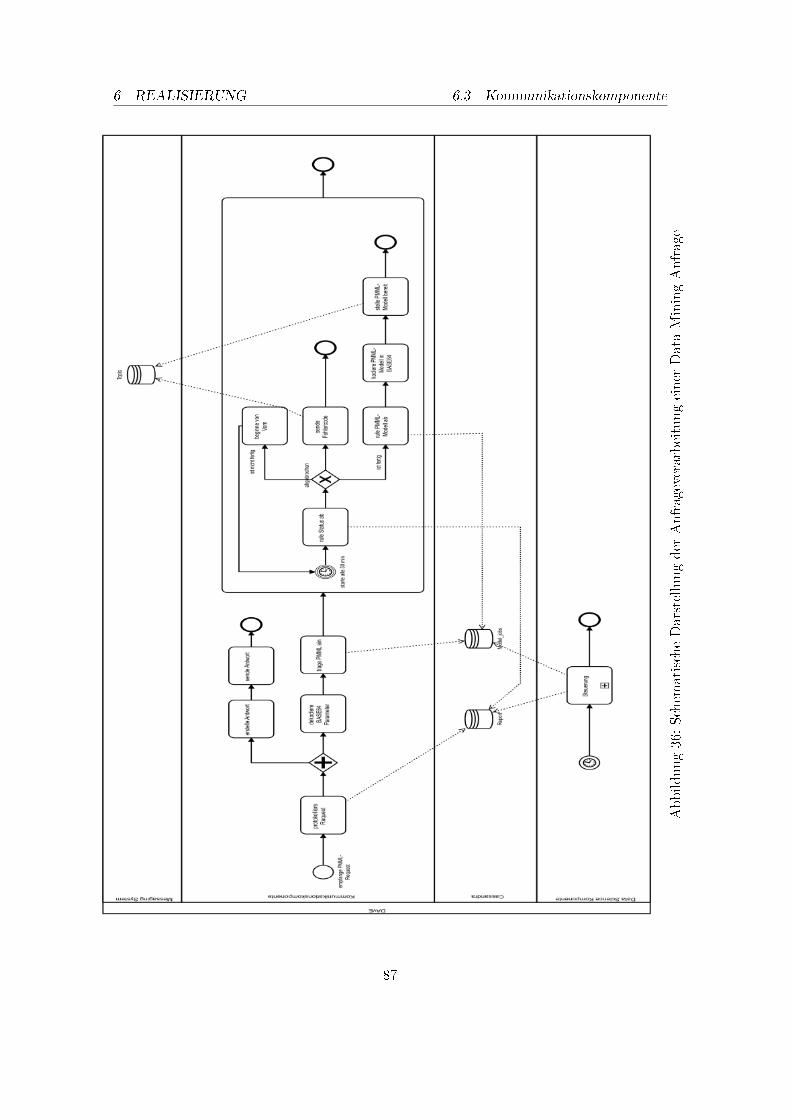
6 REALISIERUNG 6.3 Kommunikationskomponente
Abbildung36:SchematischeDarstellung
derAnfrageverarbeitung
einerDataMiningAnfrage
87

6.3 Kommunikationskomponente 6 REALISIERUNG
1 Create Table if not exists report (jobid uuid primary key ,startTime bigint , finishTime bigint , parameter text ,endpoint text , error text);
Listing 31: CQL DDL zur Erzeugung der Report-Tabelle
6.3.2. Umsetzung
Die Umsetzung beinhaltet die Struktur sowie das Verhalten der Kommunikationskompo-nente. Begonnen wird mit einer Erläuterung der RESTful Schnittstelle. Im Anschluss wirddie Struktur dargelegt. Die Kommunikationskomponente beinhaltet die Message Brokerund die RESTful Schnittstelle. Für die Beschreibung der Schnittstelle wurde das ToolSwagger genutzt.
Swagger ist ein Online Editor für die textuelle Beschreibung einer OpenAPI Spezi�kation(OAS) in JSON oder Yaml. Aus dieser textuellen Beschreibung kann, in unterschiedlichenSprachen, testbarer Quellcode generiert werden. Des Weiteren lässt sich eine Schnittstelledarin weiterentwickeln.
RESTful Schnittstelle Die RESTful Schnittstelle kategorisiert die Endpunkte in zweiGruppen. Die erste Gruppe historicData beinhaltet sämtliche Endpunkte bezüglich his-torischer Daten. Die zweite Gruppe DataMining umfasst die Daten Analyse Funktionen.Die De�nition wurde Anhand der Use Cases abgeleitet. Die Schnittstelle ist nicht durcheine Authenti�zierung geschützt. Die Endpunkten erwarten immer ein JSON-String. DasJSON-Format wurde als Übertragungsformat ausgewählt.
Für die Protokollierung der asynchronen Prozesse wurde eine Tabelle erstellt. Das Listing31: CQL DDL zur Erzeugung der Report-Tabelle zeigt den dazugehörige CQL DDL Befehl.Die jobid -Attribut ist in der Tabelle der primary key.
Die Gruppe historicData umfasst acht Endpunkte mit drei Get-Methoden und fünf POST-Methoden. Die Endpunkte .../data/weather/topic und .../data/smgw/topic erwarten eineTopic-Bezeichnung. Die Antwort ist eine Zustandsbeschreibung über den Fortschritt einesAuftrags. Der Endpunkt .../data/weather/weatherStations/ liefert eine Liste mit allen zurVerfügung stehenden Wetterstationen innerhalb Deutschlands. Der Endpunkt ../data/s-mgws/ bietet die Möglichkeit archivierte Smart-Meter-Daten anzufragen. Die Endpunk-te für Informationen über Wetterdaten sind erreichbar unter .../data/weather/climate/,.../data/weather/sun/ und .../data/weather/wind/. Die Endpunkte für Wetterinformatio-nen erwarten eine Koordinate. Als Antwort wird eine Adresse des MB auf dem die Datenhinterlegt sind und die nächste Wetterstation zurückgeliefert.
Das Listing 32: Antwort, Station zeigt das Antwortschema für die Anfrage aller zurver-fügungstehenden Wetterstationen. Es wird eine Liste erstellt. Elemente dieser Liste sind
88

6 REALISIERUNG 6.3 Kommunikationskomponente
1 [2 {3 "stationId ": "string",4 "name": "string",5 "coor": {6 "lon": 53.14118 ,7 "lat": 8.214678 },9 "alt": 0,
10 "state": "string"11 }12 ]
Listing 32: Antwort, Station
1 "URI":" localhost :9092" ,2 "Topic ":"9 bd2380a -1b30 -4d89 -85b1 -139322 bec43e"
Listing 33: asynchrone Antwort
1 "URI":" localhost :9092" ,2 "Topic ":"9 bd2380a -1b30 -4d89 -85b1 -139322 bec43e",3 {4 "stationId ": "string",5 "name": "string",6 "coor": {7 "lon": 53.14118 ,8 "lat": 8.214679 },
10 "alt": 0,11 "state": "string"12 }
Listing 34: Antwort, Wetter
89

6.3 Kommunikationskomponente 6 REALISIERUNG
die Wetterstationen mit der Stationsidenti�kationnummer, Namen, Koordinaten und demBundesland. Das Listing 33: asynchrone Antwort zeigt das Antwortschema einer Asynchro-nen Anfrage. Wie bereits beschrieben enthält dies eine URI und eine Topic-Bezeichnung.Das Listing 34: Antwort, Wetter zeigt das Antwortschema für die Anfrage nach Wetterin-formationen, es zeigt zu der gewöhnlichen asynchronen Antwort noch zusätzlich die nächsteWetterstation.
Die DataMining Kategorie umfasst fünf Endpunkte. Diese beinhaltet drei GET-Methodenund zwei POST-Methoden. Die Post-Methoden starten asynchrone Prozesse. Als Inputwird ein PMML-Modell übergeben. Der Endpunkt ../datamining/submission/ wird ge-nutzt, um ein übergebenes PMML-Modell neu zu berechnen. Der Endpunkt .../dataminin-g/latests/ erwartet ebenfalls ein PMML-Modell, dabei werden die vorhandenen PMML-Modelle abgeglichen und dasselbe PMML-Modell mit der aktuellsten Version zurückge-liefert. Für den asynchronen Prozess ../datamining/submission/ wird wiederum ein End-punkt bereitgestellt, um den Fortschritt abzufragen.
Die Endpunkten emph.../datamining/models/ und .../datamining/latests/modelid gehö-ren zu einem zweistu�gen Anfrageprozess. Dabei wird zuerst eine Liste mit allen angebo-tenen PMML-Modellen angefragt. Diese Liste ist im Listing 35: Antwort, Modelle gezeigt.Die Listenelemente enthalten Informationen über die Modell-Id., ein Name sowie eine Be-schreibung und den Zeitpunkt der letzten Aktualisierung. Die zweite Stufe ist die konkreteAnfrage eines Modells via Modell-Id. Dieser synchrone Prozesse erzeugt die Antwort wie inListing 36: Base64 kodiertes PMML-Model. Das Objekte ist wie bereits erwähnt in einemJSON-Format und beendet damit die Anfrage.
Struktur und Verhalten der Kommunikationskomponente Die Schnittstelle umfasst un-terschiedliche Bestandteile. Der Source Folder gen enthält Klassen die durch das Tool Swag-ger CodeGenerate erzeugt wurden. Dieser besteht aus den Packages io.swagger.api undio.swagger.model. Das Package io.swagger.api beinhaltet wiederum die gesamte Schnitt-stelle und Endpunkte. Das Package io.swagger.model beinhaltet die Datenobjekte, dieüber die Schnittstelle übertragen werden. Der SourceFolder src/main/java enthält diegesamte Geschäftslogik für die Verarbeitung der Anfragen. Das Package io.swagger ent-hält ebenfalls Swagger generierten Code. Die Verarbeitungslogik be�ndet sich im Packagede.uniol.vlba.dave. Die notwendigen Kon�gurationsdateien be�nden sich im Source Foldersrc/main/resources. Die Testklassen sowie notwendige Kon�gurationen für den Testumbe-gung be�nden sich in den Source Folder src/test.
90

6 REALISIERUNG 6.3 Kommunikationskomponente
1 [2 {3 "modelId ": 1,4 "name": "linear regression on nds data",5 "discription ": "regression",6 "lastbuild ": 15219504177 },8
9 {10 "modelId ": 2,11 "name": "SVR on smard data",12 "discription ": "regression",13 "lastbuild ": 152195292614 },15 ...16 ,17 {18 "modelId ": 6,19 "name": "linear regression on nds data for estream",20 "discription ": "regression",21 "lastbuild ": 152195301722 }23 ]
Listing 35: Antwort, Modelle
1 {2 "pmml": "PD94bWwgdmVyc2lvb ... BNTUw+Cg=="3 }
Listing 36: Base64 kodiertes PMML-Model
91

6.3 Kommunikationskomponente 6 REALISIERUNG
Abbildung 37: Package-Struktur der Kommunikationskomponente
Im Folgenden wird das Verhalten exemplarisch für ein asynchron und einen synchronen Pro-zess aufgezeigt. Der synchrone Prozessablauf wird beispielhaft an dem Prozess zur Abfrageder PMML-Modelle gezeigt. Das Diagramm 38: Prozessablauf zur Abfrage von PMML-Modellen zeigt der Vorgang zur Anfrageverarbeitung. Ein Nachfrager ruft den Endpunkt.../datamining/latests/modelid auf. Dann wird eine Datenbankverbindung zu Cassandraerzeugt. Die vorher erzeugte CQL-Query wird gesendet. Aus der Ergebnismenge wird eineAntwort erzeugt. Diese wird dann an den Nachfrager weitergeleitet.
Das Diagramm39: Prozessablauf zur Abfrage von Smart Metern zeigt das Verhalten beieiner asynchronen Verarbeitung. Dort wird die Anfrage nach Smart Meter exemplarischvorgeführt. Auch hier wird der Prozess durch eine Nachfrage angestoÿen. Während derErzeungung der Antwort parallelisiert sich der Verarbeitungprozess. Der Status kann wäh-rend und nach der Prozess abgefragt werden, damit ist diese Abfrage beendet. Das abrufendes Topics kann nun zu jeden Zeitpunkt erfolgen.
Im nachfolgenden Abschnitt wird die Anfragebearbeitung mittels Apache NiFi beschrieben.
Anfragebearbeitung in Apache NiFi Wie bereits in der Technologieauswahl in Ab-schnitt 4.2 beschrieben wurde, wird das Data�ow Management in DAvE über ApacheNi� betrieben. Aufträge, welche über DAvE's RESTful-Schnittstelle eingehen, müssen au-tomatisiert in Apache NiFi bearbeitet werden. Apache NiFi bietet für den Zugri� und dieSteuerung neben der Web UI auch eine REST API8 an. In diesem Abschnitt wird die
8https://ni�.apache.org/docs/ni�-docs/rest-api/index.html
92
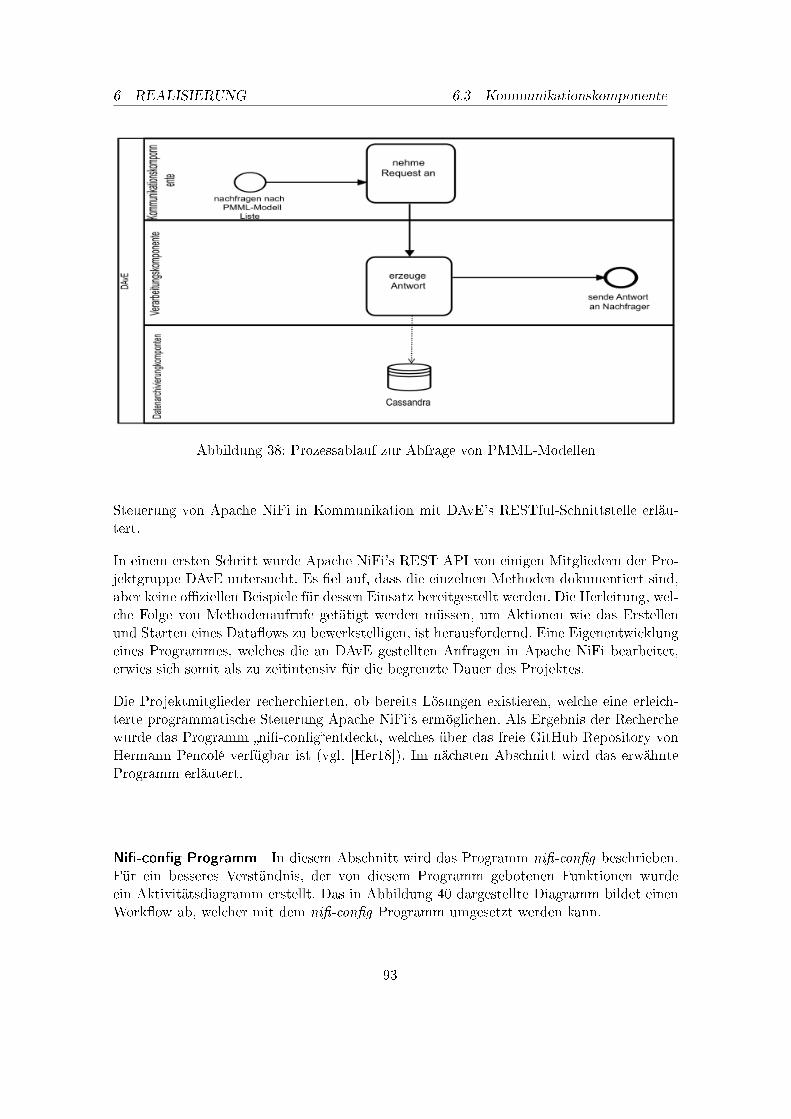
6 REALISIERUNG 6.3 Kommunikationskomponente
Abbildung 38: Prozessablauf zur Abfrage von PMML-Modellen
Steuerung von Apache NiFi in Kommunikation mit DAvE's RESTful-Schnittstelle erläu-tert.
In einem ersten Schritt wurde Apache NiFi's REST API von einigen Mitgliedern der Pro-jektgruppe DAvE untersucht. Es �el auf, dass die einzelnen Methoden dokumentiert sind,aber keine o�ziellen Beispiele für dessen Einsatz bereitgestellt werden. Die Herleitung, wel-che Folge von Methodenaufrufe getätigt werden müssen, um Aktionen wie das Erstellenund Starten eines Data�ows zu bewerkstelligen, ist herausfordernd. Eine Eigenentwicklungeines Programmes, welches die an DAvE gestellten Anfragen in Apache NiFi bearbeitet,erwies sich somit als zu zeitintensiv für die begrenzte Dauer des Projektes.
Die Projektmitglieder recherchierten, ob bereits Lösungen existieren, welche eine erleich-terte programmatische Steuerung Apache NiFi's ermöglichen. Als Ergebnis der Recherchewurde das Programm �ni�-con�g�entdeckt, welches über das freie GitHub Repository vonHermann Pencolé verfügbar ist (vgl. [Her18]). Im nächsten Abschnitt wird das erwähnteProgramm erläutert.
Ni�-con�g Programm In diesem Abschnitt wird das Programm ni�-con�g beschrieben.Für ein besseres Verständnis, der von diesem Programm gebotenen Funktionen wurdeein Aktivitätsdiagramm erstellt. Das in Abbildung 40 dargestellte Diagramm bildet einenWork�ow ab, welcher mit dem ni�-con�g Programm umgesetzt werden kann.
93
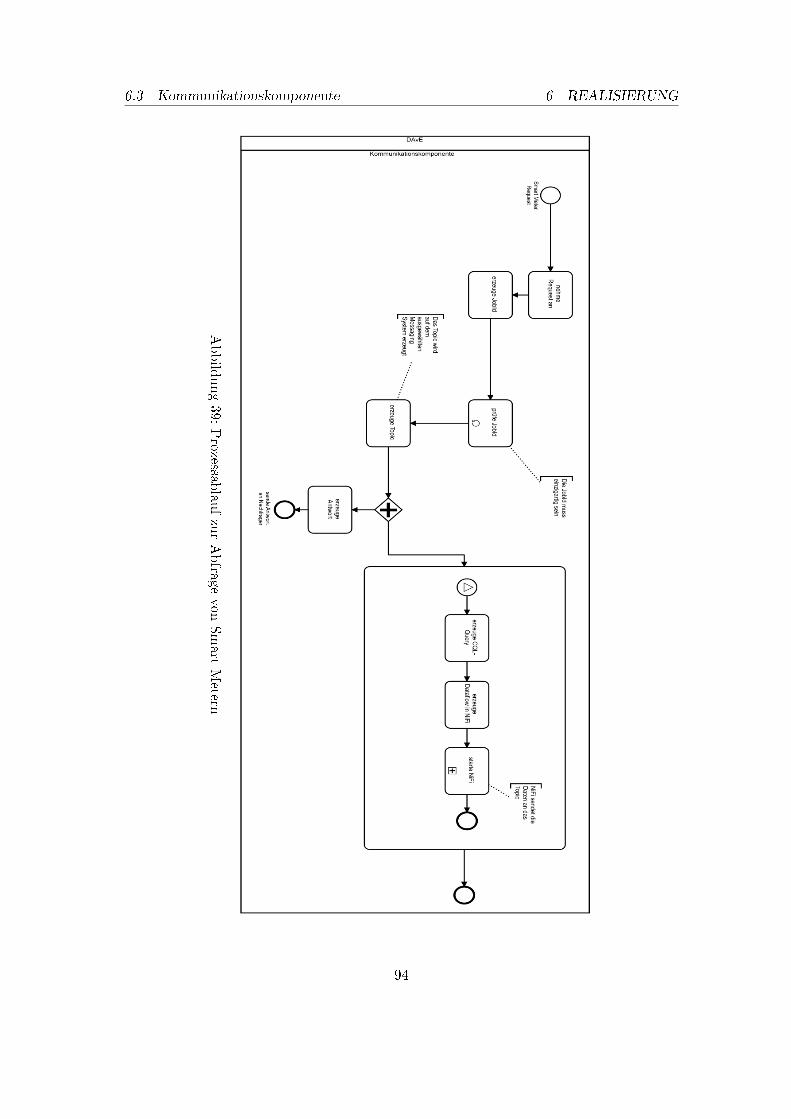
6.3 Kommunikationskomponente 6 REALISIERUNG
Abbildung
39:Prozessablauf
zurAbfrage
vonSm
artMetern
94

6 REALISIERUNG 6.3 Kommunikationskomponente
Abbildung 40: Ni�-Con�g: Work�ow
Das ni�-con�g Programm bietet die Möglichkeit bestehende Templates auf das NiFi Canvaszu platzieren (deployen), auÿerdem kann eine Kon�gurationsdatei aus Data�ows extrahiertwerden. Diese Kon�gurationsdateien werden im JSON-Format abgelegt und bieten dieMöglichkeit, Einstellungen eines jeden Processors innerhalb des Data�ows zu bearbeiten.
Hat man die Kon�gurationsdatei seinen Anforderungen entsprechen angepasst, kann manmit dem ni�-con�g Programm diese Kon�gurationsdatei nutzen, um den entsprechendenData�ow im Betrieb, zu kon�gurieren. Die Anpassungen werden vorgenommen und dieStandardeinstellung des Programmes sieht vor, dass der kon�gurierte Data�ow im An-schluss gestartet wird. Auÿerdem können mit dem Programm Data�ows vom Ni� Canvasentfernt werden (undeployed). Die Steuerung von Apache NiFi mittels dieses Programmessetzt voraus, dass die genutzten Data�ows und darin be�ndlichen Prozessoren eindeutigbenannt sind (vgl. [Her18]).
Die Funktionalitäten des vorgestellten Programmes sind ausreichend für die in DAvE ange-strebten Zwecke, da DAvE feste Use Cases erfüllt. Jeder Use Case wird durch einen festenData�ow abgedeckt. Einzig einige Einstellungen in bestimmten Prozessor Kon�guratio-nen unterscheiden sich je Anfrage. Dementsprechend genügt es, wenn vorher festgelegteTemplates genutzt werden, welche die Use Cases abdecken. Und die Data�ows dann auf-tragsspezi�sch kon�guriert werden.
Das Bedienen des ni�-con�g Programmes und das Kon�gurieren der extrahierten Kon�gu-rationsdateien sollte automatisiert ablaufen. Zu diesem Zweck wurde in Eigenentwicklungein Programm in Java geschrieben, welches im nächsten Abschnitt beschrieben wird.
95

6.3 Kommunikationskomponente 6 REALISIERUNG
Eigentwicklung: DAvE NiFi-Steuerung In diesem Abschnitt wird ein Programm erläu-tert, welches das im vorherigen Abschnitt 6.3.2 beschriebene Programm ni�-con�g automa-tisiert bedient und nötige Vorverarbeitungen vornimmt. Das Programm wird im Folgendenals Ni�-Strg beannt und ist in DAvE's Schnittstelle im Paket de/uniol/vlba/dave/nifiimplementiert.
Für ein besseres Verständnis, der von diesem Programm Ni�-Strg gebotenen Funktionen,wurde ein Aktivitätsdiagramm erstellt, welches in Abbildung 41 zu sehen ist.
Abbildung 41: Ni�-Steuerung: Work�ow
Der abgebildete Work�ow fasst die Arbeitsschritte des Programmes zusammen. Über DA-vE's RESTful-Schnittstelle werden Anfragen an DAvE übermittelt. Für die Bearbeitungdieser Anfragen innerhalb Apache NiFi's wird das Programm Ni�-Strg angesprochen undder Auftrag mit den nötigen Parametern übergeben. Im Anschluss wird eine Vorverar-beitung unternommen, in dieser werden die übergebenen Parameter z. B. genutzt, um einCQL Query zu bilden oder Zeitangaben in ein passendes Datumsformat konvertiert.
Jede Anfrage wird mittels einer UUID eindeutig unterschieden. Die Anfragen beziehen
96

6 REALISIERUNG 6.3 Kommunikationskomponente
sich auf einen der Use Cases von DAvE. Für diese Use Cases sind jeweils vorgefertigte NiFiTemplates hinterlegt. Die UUID wird in Ni�-Strg genutzt, um das Template und darinde�nierte Prozessoren mit eindeutigen Bezeichnern zu versehen. Hierzu wird mittels einesXML-Parsers an die ursprünglichen Bezeichner, die UUID angehangen.
Mit diesem Schritt wird gewährleistet, dass eindeutige Bezeichner genutzt werden, welcheseine Voraussetzung für die Nutzung des Programmes ni�-con�g ist (siehe Abschnitt 6.3.2).In einem nächsten Schritt wird eine Funktion des Programmes ni�-con�g angesprochen,mit dieser wird das Template, welches den abgezielten Use Case abbildet, auf das NiFiCanvas deployed.
Danach wird aus dem platzierten Template bzw. dem darin enthaltenen Data�ow eine Kon-�gurationsdatei im JSON-Format extrahiert. Mittels eines JSON-Parsers werden die in derAnfrage übermittelten Parameter in den entsprechenden Prozessoren übernommen. Dar-auf folgend wird eine weitere Funktion des Programmes ni�-con�g angesprochen, um mitder angepassten Kon�gurationsdatei den Data�ow zu modi�zieren und mit den gesetzenEinstellungen zu starten.
Wenn Fehler innerhalb dieser Folge von Aktivitäten aufgetreten sind, werden diese in ei-nem Log festgehalten und mit DAvE's RESTful-Schnittstelle wird dem Anfragesteller eineFehlermeldung übermitteln, andernfalls wird eine Erfolgsmeldung übermittelt.
Nachfolgend wird auf die Struktur der verwendeten Klassen des Programmes Ni�-Strgeingegangen. Die Struktur ist in Abbildung 42 veranschaulicht.
Abbildung 42: Ni�-Steuerung: Klassen Struktur
Die Klasse NifiUtils enthält alle Methoden, welche für die Vorverarbeitung der Datenund das Steuern des Programmes ni�-con�g genutzt werden.
Die Klasse NifiMain stellt die Hauptklasse dar, diese wird innerhalb DAvE's RESTful
97

6.4 Data Science 6 REALISIERUNG
1 session.execute("CREATE TABLE if not exists dave.model_list(model_id int , description text , features set <text >,target text ,method text ,script_name text , tables set <text >, model text , model_type text , generation_datebigint , PRIMARY KEY (model_id));")
2
3
4 session.execute('CREATE TABLE if not exists dave.model_jobs(job_id uuid , input_pmml text , output_pmml text , methodtext , features set <text >, target text , start_time bigint, end_time bigint ,model_type text , model_id int , PRIMARYKEY (job_id , start_time));')
Listing 37: Erstellen der Tabelle model_jobs und model_list
Schnittstelle angesprochen. Innerhalb dieser Klasse wird die Vorverarbeitung vorgenom-men, die beinhaltet z. B. das generieren eines CQL Queries aus den in der Anfrage gelie-ferten Information. Hierfür werden Methoden aus der NifiUtils Klasse verwendet. DieKlasse NifiScenario setzt den in Abbildung 41 dagestellten Work�ow, ab dem SchrittTemplate und Prozessoren mit eigenständigen Namen versehen um. Hierzu werden dieentsprechenden Methoden aus der NifiUtils Klasse, in der richtigen Folge aufgerufen.Die Klasse NifiMain setzt diesen Ablauf nach der Vorverarbeitung in Gang.
Ein Löschen der Data�ows ist im aktuellen Entwicklungsstand nicht möglich, da ApacheNiFi nicht für das einmalige Ausführen von Data�ows vorgesehen ist. Aus diesem Grundist eine Abfrage, ob ein Durchlauf im Data�ow terminiert ist, erschwert. Das Löschen einesData�ows ohne solch eine Abfrage stellt die Gefahr dar, das Data�ows vorzeitig entferntwerden und somit die Daten noch nicht vor dem Löschen erfolgreich verarbeitet wurden.
6.4. Data Science
Zur Umsetzung der spezi�zierten Data Science Use Cases wurde eine Konzept für die Um-setzung der hierfür erforderlichen Komponenten entwickelt. Dieses wird in der Abbildung43: Konzept des PMML Prozesses ausführlich dargestellt.
6.4.1. Steuerung
Um die Generierung von neuen Modellen zu steuern wurde ein aus mehreren Python Skrip-ten bestehendes Steuerungssystem entwickelt. Zur Speicherung der Zwischenstände undDaten werden die Tabellen model_list und model_jobs genutzt. Die Erstellung von die-sen wird im Listing 37: Erstellen der Tabelle model_jobs und model_list dargestellt.
Zu Beginne wird zunächst die Tabelle model_list mit allen angebotenen Modellen gefüllt,
98
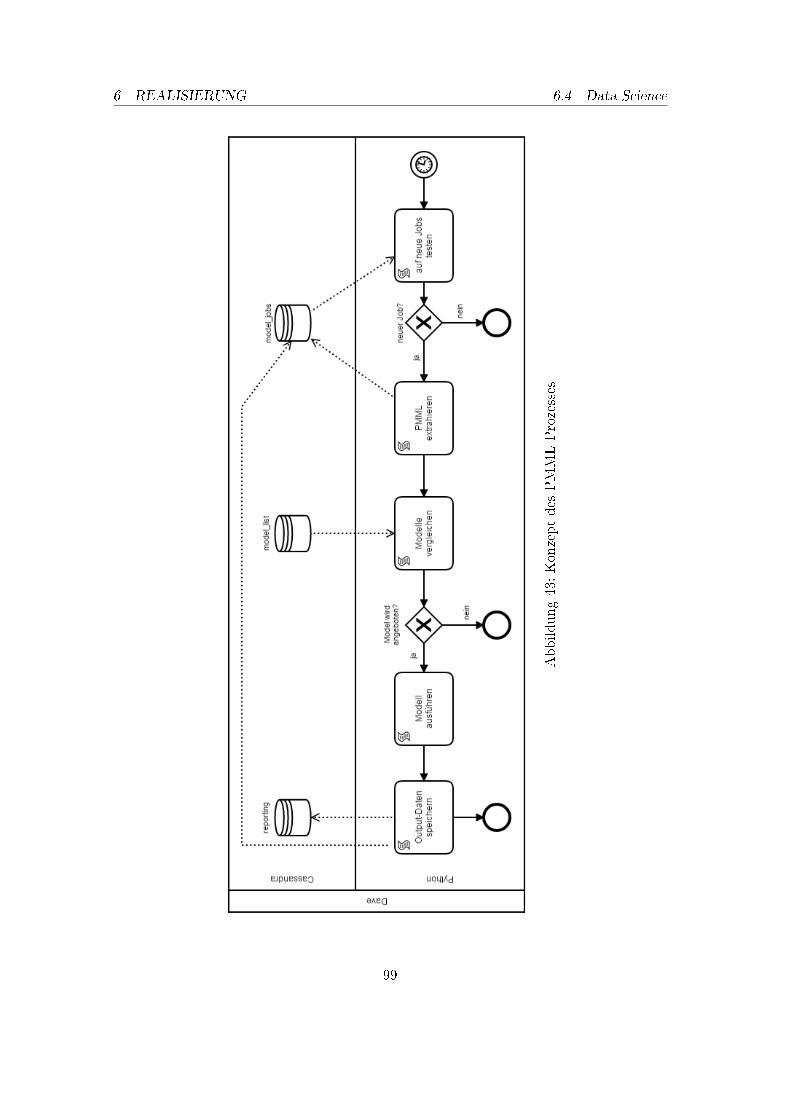
6 REALISIERUNG 6.4 Data Science
Abbildung43:Konzept
desPMMLProzesses
99

6.4 Data Science 6 REALISIERUNG
1
2 */1 * * * * sudo -H python3 /home/hduser/models/pmml_script_launcher.py
3
4 0 6 * * Sun sudo -H python3 /home/hduser/models/update_models_in_model_list.py
Listing 38: Cronjobs zur Steuerung der Data Science Funktionen
1 def latest_jobs(session , latesttime):2 rows = session.execute(3 "SELECT * FROM dave.model_jobs WHERE start_time > " + str(
latesttime) + " allow filtering ")4 jobs = pd.DataFrame(list(rows))5 return jobs6
7 def load_latest_job_time ():8 try:9 latesttime = pickle.load(open("time.pickle", "rb"))
10 except (OSError , IOError) as e:11 latesttime = 012 pickle.dump(latesttime , open("time.pickle", "wb"))13 return latesttime
Listing 39: Lesen der noch nicht bearbeiteten Anfragen
dies erfolgt über das Python-Skript initialize_model_list. Um zu prüfen, ob neue Mo-delle angefragt wurden wird dabei jede Minute mithilfe eines Cronjobs (siehe 38: Cronjobszur Steuerung der Data Science Funktionen) das Python-Skript pmml_skript_launcher
gestartet. In diesem wird zunächst eine Session zur Verbindung mit der Cassandra Daten-bank erzeugt. Anschlieÿend prüft das Skript mit den in einem pickle File gespeichertenStartzeiten der vorherigen Modelle, ob es in der Tabelle model_jobs Modellanfragen gibtdie noch nicht bearbeitet wurden. Falls dies der Fall ist wird die letzte Startzeit dieserModelle wieder in das pickle File geschrieben und die Verarbeitung der Anfrage gestartet.Der Ablauf ist im Listing 39: Lesen der noch nicht bearbeiteten Anfragen dargestellt.
Bei der Verarbeitung werden zunächst aus den in der Tabelle model_jobs be�ndlichenPMML Dateien die zur Unterscheidung relevanten Werte extrahiert. Da es in scikit-learnkeine Funktionalität gibt, um PMML Modelle zur importieren und zu parsen wurde dafüreine Methode entwickelt, die die Bibliothek lxml in Kombination mit regulären Ausdrückennutzt. Der Code zur Extraktion wird im Listing 40: Parsen der PMML Datei) dargestellt.Damit erfüllt das System die Anforderung DAN-04.
Die extrahierten Werte sind die Methode, der Modeltyp, die Feature Felder und das TargetFeld. Diese Werte werden um die Anfragen zu protokollieren in der Tabelle model_jobs
gespeichert. Nach dem Extrahieren der Werte werden diese genutzt, um zu prüfen, ob die
100

6 REALISIERUNG 6.4 Data Science
1 def pmml_extractor(pmml):2
3 pmml_xml = ElementTree.fromstring(4 pmml , parser=ElementTree.XMLParser(encoding='utf -8'))5 # read method6 method = ''7 modeltag = pmml_xml.xpath ( './*[re:match(local -name(), "\w*[m
,M]odel|NeuralNetwork ")]',8 namespaces ={'re ': "http :// exslt.org/regular -expressions "})9
10 model_type = re.sub(r '\{[^) ]*\}', '', modeltag [0]. tag)11 for datafield in modeltag:12 method = datafield.attrib['functionName ']13 # read target and feature columns14 fields = []15 target = ''16 features = []17 for datafield in pmml_xml.iter ('{*} MiningField '):18 fields.append(datafield.attrib['name '])19 if 'usageType ' in datafield.attrib and datafield.attrib['
usageType '] in [" predicted", "target "]:20 target = datafield.attrib['name ']21 else:22 features.append(datafield.attrib['name '])23
24 return method , target , features , model_type
Listing 40: Parsen der PMML Datei
101

6.4 Data Science 6 REALISIERUNG
angefragten Modelle angeboten werden, also in der Tabelle model_list vorhanden sind.Die angebotenen Modelle sind in der aktuellen Version Lineare Regression, Support VectorRegression, Random Forest Regression und Neuronale Netzwerke. Falls das Modell nichtvorhanden ist, wird in der Tabelle report zu dem Job der Zeitstempel -2 gesetzt. Falls dasentsprechende Modell angeboten wird, wird dessen Ausführung gestartet. Alle Modellge-nerierungen sind in dem separatem Python-Skript ML_Script de�niert. Hier werden dieModelle generiert und danach als Ausgabe PMML in der Tabelle model_jobs gespeichert.Dadurch erfüllt das System die Anforderung DAN-03 und DAN-07. Zusätzlich wird alsIndikator, dass die Aufgabe abgeschlossen ein Endzeitstempel in der Tabelle model_jobs
und in der Tabelle report gespeichert.
Neben dem Anfragen von Modellen über das Senden von PMML Modellen besteht auchdie Möglichkeit Modelle über Ihre ID anzufragen. Dazu werden in der Tabelle model_listPMML Modelle vorgehalten. Diese werden durch das über einen Cronjob wöchentlich aus-geführte Skript update_models_in_model_list aktuell gehalten.
6.4.2. Modellierung
In diesem Abschnitt werden die entwickelten Modelle und die zugrundeliegenden Methodenvorgestellt. Im Rahmen des Projektes wurden verschiedene Modelle entwickelt und getestet.In die �nale Version wurden insgesamt sechs Modelle integriert. Diese basieren sowohl aufhistorischen Energiedaten, als auch auf Smart-Meter-Daten aus Mosaik. Damit erfüllt dasSystem die Anforderungen DAN-05 und DAN-06. Zudem wird durch die Implementierungvon verschiedenen Algorithmen Anforderung DAN-01 ebenfalls erfüllt.
Lineare Regression Die lineare Regression geht von einem linearen Zusammenhang zwi-schen den Eingabewerten und den resultierenden vorhergesagten Werten aus. Lineare Mo-delle sind einfach und verständlich und bieten häu�g eine adäquate Beschreibung des Ein-�usses der Eingabewerte auf den Ausgabewert. Für Vorhersagen können sie manchmalbessere Ergebnisse liefern als elaborierte, nicht-lineare Modelle (vgl. [HTF09], S. 43). Dieallgemeine Formel für die lineare Regression ist die folgende:
�y = w[0] * x[0] + w[1] * x[1] + ... + w[p] * x[p] + b
Dabei bezeichnen x[0] bis x[p] die Features (in diesem Fall existieren p Features), w und bsind gelernte Parameter des Modells und �y ist die Vorhersage, die das Modell macht (vgl.[Mü16], S. 45).
Insgesamt wurden zwei Modelle mithilfe des linearen Regression umgesetzt. Für die Erzeu-gung beider Modell wurden die Netzdatenstromdaten aus der Tabelle nds_sim1 genutzt.
Im ersten Modell wurden zunächst die Felder timestamp und value in numerische Werte
102

6 REALISIERUNG 6.4 Data Science
1 df[['timestamp ','value ']] = df[['timestamp ','value ']]. apply(pd.to_numeric)
2 df['timestamp '] = pd.to_datetime(df['timestamp '],unit='s')3 df['dummy_time '] =pd.to_numeric(df.timestamp.map(lambda x: x
.strftime('%H%M')))4 df['dummy_day '] = df['timestamp '].dt.dayofweek
Listing 41: Extrahieren von Wochentag und Uhrzeit aus dem timestamp
konvertiert. Daraufhin werden die Daten auf ein einzelnes Smart-Meter beschränkt. ImAnschluss wir ein scikit-learn LinearRegression Modell initialisiert. Dieses wird mit demtimestamp als Feature und dem value als Target trainiert. Im Anschluss wird das Mo-dell unter Zuhilfenahme der sklearn2pmml Bibliothek als PMML exportiert und in derDatenbank gespeichert. Dieses Modell ist sehr einfach, bietet dafür aber auch keine guteVorhersagegenauigkeit.
Im zweiten Modell, welches mit der linearen Regression umgesetzt wurde, wurden aus demtimestamp der Wochentag und die Uhrzeit als einzelne Features extrahiert (siehe 41: Ex-trahieren von Wochentag und Uhrzeit aus dem timestamp). Diese werden anschlieÿend zurVorhersage genutzt. Dadurch bietet das Modell eine deutlich bessere Vorhersagegenauigkeitals das rein mit dem timestamp arbeitende.
Support Vektor Machine Support Vektor Machines (SVM) sind eine Erweiterung vonlinearen Modellen, bei der komplexere Modelle möglich sind. Ein lineares Modell lässtsich durch das Hinzufügen weiterer Merkmale �exibler machen, beispielsweise durch dieQuadrierung eines Merkmals. Allerdings bedeutet das Hinzufügen neuer Merkmale einenerhöhten Rechenaufwand. Daher implementiert eine SVM den sogenannten Kernel-Trick,mit dem man das Modelle in einem höher dimensionalen Raum trainieren kann, ohne dieneue Repräsentation explizit zu berechnen (vgl. [MGR17], S. 88�.).
In DAvE wird die Regressionsfunktion der SVM auf dem SMARD-Datensatz9 angewendet.Die zu vorhersagende Gröÿe ist die Stromerzeugung durch Photovoltaik. Aus dem Datumund der Uhrzeit der Rohdaten werden die Merkmale 'minute', 'hour', 'month' und 'day'extrahiert, um die Anzahl der Merkmale zu erweitern (siehe Listing 42: Extrahierung Input-Daten SVM).
Die SVM wurde mithilfe der Klasse GridSearchCV entwickelt und optimiert, die im Mo-dul model_selection implementiert ist. Diese Klasse kombiniert die Gittersuche mit derKreuzvalidierung. Bei der Kreuzvalidierung werden die Daten wiederholt aufgeteilt, um dieAuswertung der Verallgemeinerung stabiler zu machen. So werden bspw. bei der 3-fachenKreuzvalidierung die Daten in drei gleich gröÿe Teile (Folds) aufgeteilt. Anschlieÿen werdenmehrere Modelle erstellt. Beim ersten Modell stellt der erste Fold den Testdatensatz und
9Detailliert beschrieben wird der SMARD-Datensatz unter dem Kapitel 6.1.6: SMARD-Daten
103

6.4 Data Science 6 REALISIERUNG
1 # extract input data2 data['minute '] = data['uhrzeit '].dt.minute3 data['hour '] = data['uhrzeit '].dt.hour4 data['month '] = data['datum '].dt.month5 data['day '] = data['datum '].dt.day6
7 # create feature and target set8 X = data[['minute ', 'hour ', 'month ', 'day ']]9 y = data['photovoltaik ']
Listing 42: Extrahierung Input-Daten SVM
1 # parameters to be tested2 # for development only3 param_grid = {'C': [0.001 , 0.01, 0.1, 1, 10, 100], 'gamma ':
[0.001 , 0.01, 0.1, 1, 10, 100]}4
5 # train models6 from sklearn.svm import SVR7 from sklearn.model_selection import GridSearchCV8 grid_search = GridSearchCV(SVR(kernel='rbf '), param_grid , cv
=3, verbose =3)9 grid_search.fit(X_train , y_train)
10
11 # display results of GirdSearchCV12 results = pd.DataFrame(grid_search.cv_results_)13 display(results.head (120))
Listing 43: Auszug Entwicklung SVM-Modell
die übrigen Folds den Trainingsdatensatz dar. Für jedes Modell wird anschlieÿend die Ge-nauigkeit berechnet, woraus am Ende ein Durchschnittswert gebildet wird (vgl. [MGR17],S. 236). Mithilfe der Gittersuche ist es möglich die optimalen Parameter eines Modellszu ermitteln. Hierbei wird für jede Kombinationen der Parameter ein Modell erstellt (vgl.[MGR17], S. 246f.). Das Listing 43: Auszug Entwicklung SVM-Modell zeigt die Parameter,für die - in jeder möglichen Kombination - ein Modell erstellt erstellt wurde. Die Ergeb-nisse des der GridSearchCV werden in dem Attribut cv_results_ gespeichert. Für jedeKombination der Parameter werden umfangreiche Informationen gespeichert, wie z.B. diedurchschnittliche Genauigkeit (Score) auf den Test- und Trainingsdaten. Um die bestenParameter bzw. den besten Score zu ermitteln, können die Attribute best_params_ bzw.best_score_ ausgelesen werden. In unserem Fall sind die besten Parameter C=100 undgamma=0.1, mit einem Score von 85.5% auf den Testdaten. In dem Prototypen wird dieGittersuche mit Kreuzvalidierung nicht mit jeder Anfrage gestartet, da die Berechnung al-ler Kombinationen viel Zeit in Anspruch nimmt. Daher wird das SVM-Modell mit den obengenannten besten Parametern verwendet, wie es in Listing 44: Lernen des SVM-Modellsdargestellt ist.
104

6 REALISIERUNG 6.4 Data Science
1 # use model with best score2 from sklearn2pmml import PMMLPipeline3 model = SVR(C=100, gamma =0.1)4 pipeline = PMMLPipeline ([(" SVR", model)])5 pipeline.fit(X_train , y_train)
Listing 44: Lernen des SVM-Modells
1 # aggregate input data2 sum_per_hour = data2.groupby(['datum ', 'hour ', 'month ', 'day
', 'year '], as_index=False).aggregate(sum)3
4 # create feature and target set5 X = sum_per_hour [['hour ', 'month ', 'day ', 'year ']]6 y = sum_per_hour['photovoltaik ']
Listing 45: Preprocessing Random Forest
Random Forest Random Forests sind im Wesentlichen eine Menge von Entscheidungs-bäumen10, wobei sich jeder Baum in gewissem Maÿe von den übrigen unterscheidet. Da-durch wird das Hauptproblem des Over�ttings von Entscheidungsbäumen umgangen. DieIdee eines Random Forest ist es, dass jeder Baum eine gute Vorhersage tre�en kann, abervoraussichtlich einen Teil der Daten over�ttet. Bei der Konstruktion mehrerer Bäume kanndurch Mitteln der Ergebnisse das Over�tting reduziert werden. Die Unterschiedlichkeit dereinzelnen Bäume wird dadurch erreicht, dass beim Aufbauen der Bäume ein Zufallselementverwendet wird. Variieren kann hierbei die Auswahl der Datenpunkte und die Auswahl derzu testenden Merkmale bei jeder Teilung (vgl. [MGR17], S. 80).
In DAvE wird der Random Forest ebenfalls auf den SMARD-Daten, zur Vorhersage derStromerzeugung durch Photovoltaik, angewendet. Anders als bei der SVM, wird die Strom-erzeugung für jede Stunde summiert betrachtet. Diese Aggregation ist notwendig, da diePMML-Datei sonst eine Gröÿe erreichen würde, in der sie als String nicht in Apache Cas-sandra speicherbar wäre. Stattdessen wird das Jahr als zusätzliches Merkmal heran gezogen(siehe Listing 45: Preprocessing Random Forest).
Der Random Forest ist in der Klasse RandomForestRegressor im Modul ensemble imple-mentiert. Der Parameter n_estimators gibt an, wie viele unterschiedliche Bäume erzeugtwerden. Je höher dieser Wert ist, desto robuster wird das Modell. Allerdings wird auchmehr Speicher und Rechenzeit benötigt (vgl. [MGR17], S. 85). Während der Entwick-lungsphase hat sich gezeigt, dass n_estimators=10 bereits sehr gute Ergebnisse liefert.Eine Erhöhung dieses Wertes verbessert die Genauigkeit nur sehr geringfügig. Zudem wirddadurch die Gröÿe der späteren PMML-Datei gering gehalten. Der Parameter max_depth
10Auf das Prinzip der Entscheidungsbäume wird in der angehängten Seminararbeit Methoden von Data
Mining und Machine Learning näher eingegangen
105

6.4 Data Science 6 REALISIERUNG
1 # fit model2 from sklearn.ensemble import RandomForestRegressor3 from sklearn2pmml import PMMLPipeline4 forest = RandomForestRegressor(n_estimators =10, max_depth
=20, random_state =2)5 pipeline = PMMLPipeline ([(" RandomForest", forest)])6 pipeline.fit(X_train , y_train)
Listing 46: Trainieren des Random Forests
gibt die Tiefe eines Baumes an. Bäume ohne Begrenzung der Tiefe sind sehr anfällig fürOver�tting und können schlechter auf neue Daten verallgemeinern (vgl. [MGR17], S. 72f.).Daher werden die in Listing 46: Trainieren des Random Forests dargestellten Parameterfür das Trainieren des Random Forests verwendet. Der Score auf den Testdaten beträgtca. 94,6%.
Neuronales Netz scikit-learn verwendet als neuronales Netz u.a. die Methode desmehrschichtigen Perzeptrons (englisch multilayer perceptron, MLP). MLPs lassen sich alsVerallgemeinerung von linearen Modellen ansehen, wobei mehrere Verarbeitungsschritte zueiner Entscheidung führen. Die Vorhersage �y einer linearen Regression errechnet sich, wieim vorherigen Abschnitt beschrieben, durch die gewichtete Summe der Eingabemerkmalex[0] bis x[p] mit den Koe�zienten w[0] bis w[p] als Gewichte. Bei einem MLP wird dasBerechnen einer gewichteten Summe nun mehrfach wiederholt. Abbildung 44: Beispiel neu-ronales Netz zeigt beispielhaft ein neuronales Netz mit einer verborgenen Schicht. JederKnoten (Neuron) auf der linken Seite steht für ein Merkmal der Eingabe und die Ver-bindungslinien geben die erlernten Koe�zienten als Gewichtung eines jeden Merkmals an.Die verborgene Schicht kann als Zwischenschritt betrachtet werden, wo an jedem Neurondieser Schicht eine gewichtete Summe der Eingabewerte berechnet wird. Der Knoten aufder rechten Seite stellt die Ausgabe dar und berechnet sich wiederum durch die gewichteteSumme der verborgenen Schicht (vgl. [MGR17], S. 99f.).
In DAvE wird das neuronale Netz auf zwei unterschiedliche Datensätze angewendet. Zumeinen - wie die beiden Modelle zuvor auch - auf dem SMARD-Datensatz zur Vorhersageder Stromerzeugung aus Photovoltaik, zum anderen auf den simulierten Smartmeter-Daten.Beim Letzteren wurde im Voraus prototypisch ein Smartmeter festgelegt. Bei beiden Mo-dellen war im Preprocessing eine Skalierung der Daten notwendig, denn neuronale Netzeerwarten, dass alle Merkmale der Eingabe in ähnlicher Weise variieren (vgl. [MGR17], S.108). Realisiert wurde dies mithilfe des StandardScaler von scikit-learn, was in Lis-ting 47: Skalierung der Daten für das neuronale Netz abgebildet ist. Der StandardScalerstellt sicher, dass jedes Merkmal den Mittelwert 0 und die Varianz 1 aufweisen. Dadurchwird sichergestellt, dass alle Merkmale in der gleichen Gröÿenordnung liegen (vgl. [MGR17],S.125).Auf den SMARD-Daten wird ein neuronales Netz mit zwei verborgenen Schichten mit je-
106
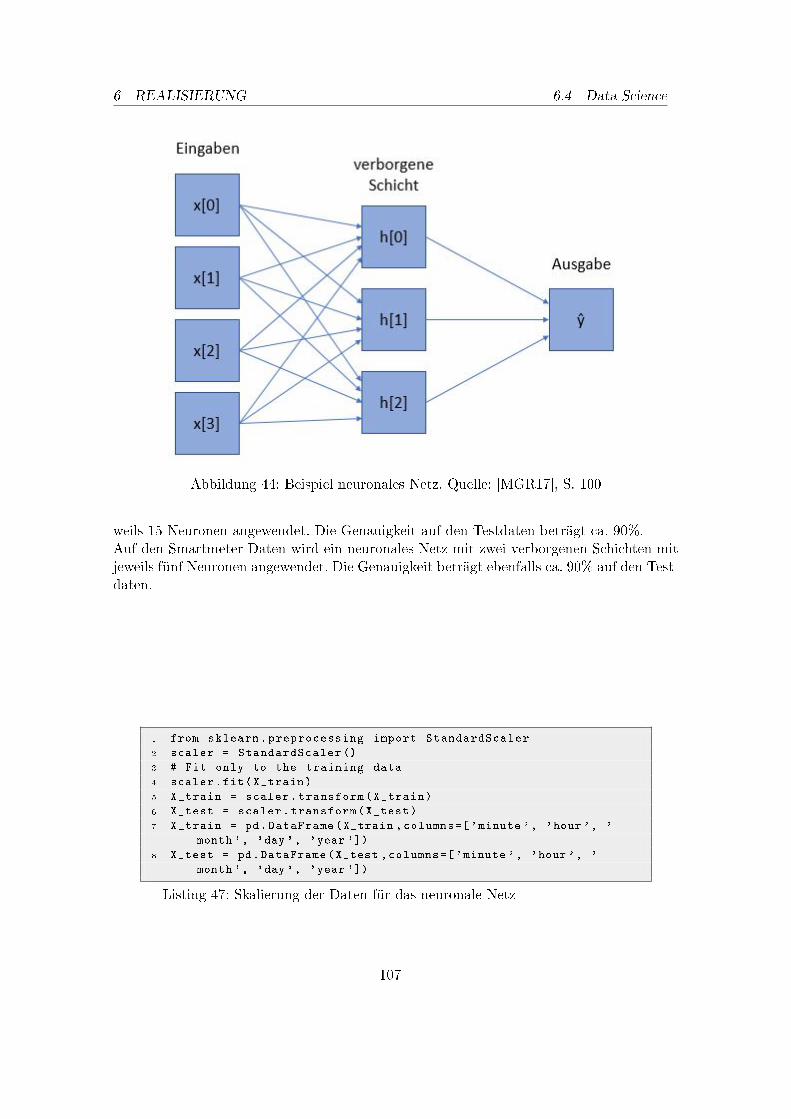
6 REALISIERUNG 6.4 Data Science
Abbildung 44: Beispiel neuronales Netz. Quelle: [MGR17], S. 100
weils 15 Neuronen angewendet. Die Genauigkeit auf den Testdaten beträgt ca. 90%.Auf den Smartmeter-Daten wird ein neuronales Netz mit zwei verborgenen Schichten mitjeweils fünf Neuronen angewendet. Die Genauigkeit beträgt ebenfalls ca. 90% auf den Test-daten.
1 from sklearn.preprocessing import StandardScaler2 scaler = StandardScaler ()3 # Fit only to the training data4 scaler.fit(X_train)5 X_train = scaler.transform(X_train)6 X_test = scaler.transform(X_test)7 X_train = pd.DataFrame(X_train ,columns=['minute ', 'hour ', '
month ', 'day ', 'year '])8 X_test = pd.DataFrame(X_test ,columns=['minute ', 'hour ', '
month ', 'day ', 'year '])
Listing 47: Skalierung der Daten für das neuronale Netz
107


7 GESAMTARCHITEKTUR
Abbildung 45: Gesamarchitektur DAvE
7. Gesamtarchitektur
In diesem Abschnitt wird abschlieÿend zur Realisierung die Gesamtarchitektur visualisiertund erläutert. Dazu gehört dass alle ausgewählten Software-Dienste und -Systeme verortetwerden sowie die Interaktion dieser Komponenten untereinander beschrieben wird. DieGesamtarchitektur ergibt durch den Zusammenschluss dieser ausgewählten Subsysteme.
In Abbildung 45: Gesamarchitektur DAvE ist das Gesamtsystem visualisiert. Wichtigist, dass das System DAvE als ein Zusammenschluss von diversen Subsystemen verstan-den wird. Die Systemgrenzen des Systems DAvE sind der Abbildung zu entnehmen. AlsArchivierungs-, bzw. Datenbanksystem wird Apache Cassandra eingesetzt. Innerhalb des-sen werden jegliche zu archivierenden Daten persistent gespeichert. Das Subsystem istgeclustert, sodass es auf die Gesamtmenge und den Durchsatz der Archivdaten angepasstwerden kann.
Bei dem Subsystem des Bereichs Data Science handelt es sich um eine Python3-Umgebungmit der Machine Learning Bibliothek scikit-learn.
Das Bereitstellen von Daten aus dem Datenbanksystem wird mit dem Message BrokerSystem Apache Kafka realisiert. Wie das Apache Cassandra auch das Kafka Subsystemgeclustert werden, um den Ansprüchen von Big Data gerecht zu werden.
109

7 GESAMTARCHITEKTUR
Ein essentielle Aufgabe übernimmt das System Apache NiFi. Dieses Data�ow Manage-ment Subsystem ist dafür zuständig dass Importe und Exporte sowie Transformation derArchivdaten asynchron durchgeführt werden. Im Falle des Imports wird das Topic einesexternen Datenerzeugers abonniert und alle neuen Inhalten in das interne Zielformat desDatenbanksystems überführt und in dieses archiviert. Werden diese archivierten Inhalteangefragt und externen Konsumenten zur Verfügung gestellt werden, werden die Datendurch einen Export-Prozess in Apache NiFi in das ursprüngliche Format überführt undauf einen Kafka Topic im DAvE-System exportiert.
Um entsprechende Anfragen an das DAvE-System zu stellen, wird eine RESTful-Schnittstelleeingesetzt. Darüber können z.B. die archivierten Smart Meter Daten für einen bestimm-ten Zeitraum angefragt werden. Bei der Plattform der Webserver-Komponente handelt essich um einen Apache Tomcat Webserver, ein Subsystem. Die RESTful-Schnittstelle ist alsJava Servlet auf dem Webserver realisiert. Dabei handelt es sich um eine Eigenentwick-lung basierend auf dem Swagger-Framework, genauer den Werkzeugen Swagger Editor undSwagger Codegen (siehe hierfür den Unterabschnitt 6.3.2: Umsetzung).
Im Kontext der Gesamtarchitektur sind darüber hinaus ebenfalls Datenquellen und Konsu-menten zu nennen. Zu den Datenquellen gehört z.B. das Topic eines Message Broker einesexternen Datenerzeugers welcher dort die Daten hinterlegt oder auch der FTP-Server desDeutschen Wetterdiensts. Wie bereits in diesem Abschnitt erwähnt, extrahiert DAvE mitdem Subsystem NiFi aus diesen Quellen Daten und archiviert diese.
Konsumenten können Anfragen über die bereits beschriebene RESTful-Schnittstelle stellen.Bei den Anfragen kann es sich zum einen um das Bereitstellen von archivierten Daten oderzum anderen um das Erzeugen eines Machine Learning Modells handeln. Die Ergebnissedieser Anfragen werden in der Regel ebenfalls per Apache NiFi asynchron auf das MessageBroker Subsystem Kafka innerhalb des DAvE-Systems bereitgestellt und können dort vonden Konsumenten abgefragt werden.
110

8 TEST UND EVALUATION
8. Test und Evaluation
Das Ziel der Projektgruppe bestand darin, ein möglichst fehlerfreien Prototypen zu ent-wickeln. Aus diesem Grund wurde sich frühzeitig dazu entschieden ausführlich zu testen.Es wurde beschlossen, alle selbst entwickelten Komponenten mittels Komponententests aufkorrekte Implementierung zu überprüfen. Darüber hinaus wurde ein Testkonzept zur Über-prüfung der logischen Funktionalität der einzelnen Komponenten und des Gesamtsystemsentwickelt.
8.1. Testumgebung
Um das Archivieren von Smartmeterdaten im COSEM-XML-Format testen zu können,war es notwendig den LV-Simulator auf dem Clustersystem auf der dafür vorgesehenenVM mosaik-VM zu installieren, zu erweitern und in Betrieb zu nehmen. Im Folgendemwerden die notwendigen Schritte zur Installation, die Erweiterungsprogrammierung unddie Inbetriebnahme inklusive der zugrundeliegenden Kon�guration erläutert.
8.1.1. Installation LV-Simulator
Um die Softwaresimulationssoftware (siehe 4.5.2: Low Voltage Simulator) in der System-umgebung auf der VM mosaik-vm (siehe 11: Systeminfrastruktur des DAvE-Cluster) inBetrieb zu nehmen, waren diverse Installationsschritte und nachträgliche Programmer-weiterungen notwendig (diese werden in 8.1.2: Erweiterungsprogrammierung LV-Simulatorbeschrieben). Die notwendigen Installationsschritte werden in diesem Abschnitt vorgestellt.
Bei der Installation traten unvorhersehbare Schwierigkeiten auf. Der Dokumentation aufder Projektwebseite folgend (siehe [OFF18], Menüpunkt Wiki→ Installation) kam es beimTesten des LV-Simulators, auch ohne selbstgeschriebene Erweiterungen, zu Laufzeitfeh-lern. Diese konnten darauf zurückgeführt werden, dass bei der Installation des abhängigenPython-Paktes mosaik das darin benötigte und automatisch mitinstallierte Paket networkxmit einer falschen Version geladen worden ist. Der dokumentierten Installation mussten al-so noch weitere Schritte folgen. Diese sind im Listing 48: Au�ösen Versionsprobleme desPakets networkx zu sehen. Mit der Zeile 1 wird das Paket mosaik inkl. des Paktes networkxin einer falschen Version installiert. Darau�olgend muss dieses wieder deinstalliert werden.Mit dem dritten Befehl wird dann networkx mit expliziter Angabe der zu installierendenVersion geladen.
Die vollständige Installation, bzw. die notwendigen Schritte zur Installation sind im Lis-ting 49: Installation LV-Simulator angegeben. Als Voraussetzung sei angemerkt, dass diePython-Pakete pip und virtualenv bereits auf der VM installiert worden sind. Beginnendmit der Zeile 1 wird zunächst ein neues Verzeichnis /opt/nds erzeugt. Mit dem Befehl in
111

8.1 Testumgebung 8 TEST UND EVALUATION
1 pip install mosaik2 pip uninstall networkx3 pip install networkx ==1.11
Listing 48: Au�ösen Versionsprobleme des Pakets networkx
1 sudo mkdir /opt/nds2 cd /opt/nds3 sudo sudo chwon -c benutzer:gruppe nds4 git clone link_zum_nds_repo netzdatenstrom_dave5 virtualenv -p /usr/bin/python3 .4 .virtualenvs/lv6 source .virtualenvs/lv/bin/activate7 pip install xlrd8 pip install numpy9 pip install requests
10 pip install mosaik11 pip uninstall networkx12 pip install networkx ==1.1113 cd netzdatenstrom_dave/LV-Simulation/lv_simulation/14 python src/simulation_main.py ../ simulation_scenarios/DAvE/
scenario_config_simple_consoleoutput.json
Listing 49: Installation LV-Simulator
Zeile 3 wird der Verzeichniseigentümer auf den Benutzer geändert, welcher alle weiterenSchritte vornimmt und den Simulator startet. Dabei steht benuter und gruppe stellvertre-tend für den entsprechenden Benutzer und die dazugehörige Benutzergruppe. Der nächsteBefehl klont das git-Repository des LV-Simulators und legt es im Verzeichnis netzdaten-strom_dave an. Wie auf der Projektwebseite des LV-Simulators empfohlen wird (siehe[OFF18], Menüpunkt Wiki → Installation), wird mit dem Befehl der Zeile 6 eine virtuellePython-Umgebung mit der Python-Version 3.4 eingerichtet. Nachdem in diese mit demnächsten Befehl gewechselt worden ist, können dann die benötigten Python-Pakete in dievirtuelle Python-Umgebung lv installiert werden. Die Probleme mit der Versionsnummerdes Pakets networkx wurden in diesem Abschnitt bereits erläutert. Mit dem Befehl derZeile 14 wird der LV-Simulator mit einer einfachen Kon�guration und Ausgabe auf demTerminal gestartet.
8.1.2. Erweiterungsprogrammierung LV-Simulator
Da die Projektgruppe einen direkten Zugri� auf das Entwicklungsrepository hatte und derLV-Simulator laufend erweitert worden ist, haben wir uns dazu entschieden dieses auf eineigenes Repository manuell zu spiegeln. Dies hat die Vorteile, dass zum einen die Hoheit desRepositorys bei der Projektgruppe liegt und somit Zugri�sschwierigkeiten darauf vermie-
112

8 TEST UND EVALUATION 8.1 Testumgebung
den werden und zum anderen, dass Programmerweiterung und das Fixieren11 von Entwick-lungsständen möglich sind ohne sich mit den Verantwortlichen des Original-Repositorysabsprechen zu müssen. Diese Anpassungen können dennoch bei Bedarf problemlos in dasOriginal-Repository überführt werden.
Durch die Anforderung bzw. der Schnittstellende�nition, dass von DAvE zu archivierendeDaten auf einem Messaging System vorliegen müssen, musste der LV-Simulator dahinge-hend erweitert werden sodass dieser die erzeugten simulierten Smartmeterdaten auf einenzu kon�gurierenden Messaging System, in diesem Fall Apache Kafka, weiterleitet.
Dafür war es notwendig eine neue Output-Klasse zu schreiben, welche mit Hilfe der Kaf-ka API12 für Python die generierten Datensätze auf einen Kafka Topic schreibt. Nebendem Schreiben dieser Klasse und der Einbindung dieser in den bestehenden Quellcode,war es ebenfalls notwendig eine neue Kon�gurationsdatei inklusive neuer Kon�gurations-parameter zu erstellen. Diese enthält zusätzlich die Informationen der Adresse des KafkaBrokers inklusive des Ports sowie den Namen des Ziel-Topics. Darüber hinaus ist in derneue Output-Klasse anhand eines Parameters zu steuern ob die Smartmeterdaten im JSON-oder COSEM-XML-Format erzeugt werden sollen. Ein Auszug der beschriebenen Erwei-terung ist in 50: Auszug Kafka-Output Klasse, LV-Simulator zu sehen.
In Zeile 7 wird ein Produzent für Nachrichten des kon�gurierbaren Kafka Brokers bootstrap-serverserzeugt. Der Ziel-Kafka Topic wird aus dem Parameter topic übernommen. Ebenfalls wirdin Zeile 9 der Parameter output_type gelesen, welche dazu führt dass die Smart-Meter-Daten im JSON- oder COSEM-XML-Format an das Kafka Topic gesendet werden. DieseFallunterscheidung und das Senden der Nachrichten ist den Zeilen 15 bis 19 zu entnehmen.
8.1.3. Inbetriebnahme LV-Simulator
Nachdem die Installation und die Erweiterungsprogrammierung durchgeführt wurde, konn-te der LV-Simulator zu Testzwecken in Betrieb genommen werden. Da es für die Tests derArchivierung keine Bedeutung hat ob und welche Struktur der Generierung der Smart-meterdaten zu Grunde liegt, wurde eine simple Kon�guration des Simulators verwendet.Wie bereits im Abschnitt 8.1.2: Erweiterungsprogrammierung LV-Simulator erwähnt, wa-ren zusätzliche Kon�gurationsparameter anzugeben, damit die Ausgabe des Simulators imCOSEM-XML-Format auf ein spezi�zierten Kafka Broker erfolgt. Die dafür notwendigenZeilen in der Kon�guration sind im Listing 51: Auszug Kon�guration, LV-Simulator zusehen.
Beim Ausführen des LV-Simulators ist darauf zu achten dass, wie im Listing 49: InstallationLV-Simulator in Zeile 14 sichtbar, das Ausführungsverzeichnis /LV-Simulation/lv_simulationist, da die Kon�guration auf weitere Dateien im relativen Pfad data/ verweist.
11gemeint ist das Setzen von tags im git-Repository12siehe https://pypi.python.org/pypi/kafka-python
113

8.1 Testumgebung 8 TEST UND EVALUATION
1 class Kafka(Simulator):2 def init(self , sid , output_options , start_difference):3 self.step_size = output_options['step_size ']4 self.start_difference = start_difference5 if start_difference == 0:6 self.first_step = False7 self.producer = KafkaProducer(bootstrap_servers=
output_options["bootstrap_servers"])8 self.topic = output_options["topic"]9 self.output_type = output_options["output_type"]
10 return self.meta11
12 def step(self , time , inputs):13 for console_id , smgw in inputs.items():14 for smgw_id , smgw_cosem in smgw['message '].items
():15 if self.output_type.upper () == "JSON":16 self.producer.send(self.topic , json.
dumps(smgw_cosem).encode ())17 elif self.output_type.upper () == "XML":18 cosem_xml_message = cosem_xml.
convert_json_to_xml(smgw_cosem)19 self.producer.send(self.topic ,
cosem_xml_message)20
21 if self.first_step:22 self.first_step = False23 return time + self.start_difference24 return time + self.step_size
Listing 50: Auszug Kafka-Output Klasse, LV-Simulator
1 "output ": "Kafka",2 "output_options ":3 {4 "step_size ": 900,5 "bootstrap_servers ": "master.local :9092" ,6 "topic": "LV_SIM_XML",7 "output_type ": "xml"8 },
Listing 51: Auszug Kon�guration, LV-Simulator
114

8 TEST UND EVALUATION 8.2 Evaluationskonzept
8.2. Evaluationskonzept
Für die Abnahme des System ist es notwendig, dass die de�nierten Anforderungen erfülltwerden und eine fehlerfreie Nutzung gewährleistet wird. Dazu wurde ein Testplan mit unter-schiedlichen Testarten de�niert, was die Überprüfung der Funktionen unterstützt, wodurchmögliche Fehler identi�ziert werden können. Mit den Tests sollen zum einen die Anforde-rungen an das System geprüft werden, darüber hinaus werden die abgebildeten Anwen-dungsfälle des Systems für einen fehlerfreien Durchlauf erprobt. Die gewählten Testartenwerden im Folgenden kurz dargestellt:
• Komponententest Es werden alle Komponenten des Systems getestet. Dazu werdenDatenimport, Archivierung, Datenanalyse und Schnittstellen separat voneinander be-trachtet und auf die jeweiligen Funktionen geprüft, sodass mögliche Fehler spezi�schzur Komponente identi�ziert werden können.
• Integrationstest Nach der Prüfung der einzelnen Komponenten muss das Zusam-menspiel der Komponenten geprüft werden. Es gilt das Zusammenspiel und die Funk-tionen an Schnittstellen und Übergabepunkten auf Fehler zu prüfen.
• Systemtest Nachdem die einzelnen Komponenten sowie deren Zusammenspiel ge-prüft wurden ist es notwendig, einen Test des gesamten Systems durchzuführen. Zielist es Grundfunktionalitäten des Systems zu überprüfen. Es geht hier nicht um eineinhaltliche Überprüfung des System, sondern darum festzustellen, ob die Infrastruk-tur für das Gesamtsystem ausreichend konzipiert ist.
In den nachfolgenden Tabellen werden die entsprechenden Tests inklusive der entsprechen-den Ergebnisse zusammengefasst. Die Tabellen geben einen Überblick über die durchge-führten Tests der Projektgruppe.
8.3. Komponententest
In diesem Abschnitt werden die de�nienerten Komponententests vorgestellt. Diese be�n-den sich in den Tabellen 12: Komponententests I und dieser folgenden. Die Tests werdendurch ein Code, eine Zugehörigkeit und eine Beschreibung de�niert. Zusätzlich wird einerwartetes Ergebnis de�niert, dass anhand der Anforderungen formuliert wurden. Das tat-sächliche Ergebnis beschreibt formal das Ergebnis des Systems. Es wurden insgesamt 31Komponententests durchgeführt.
115
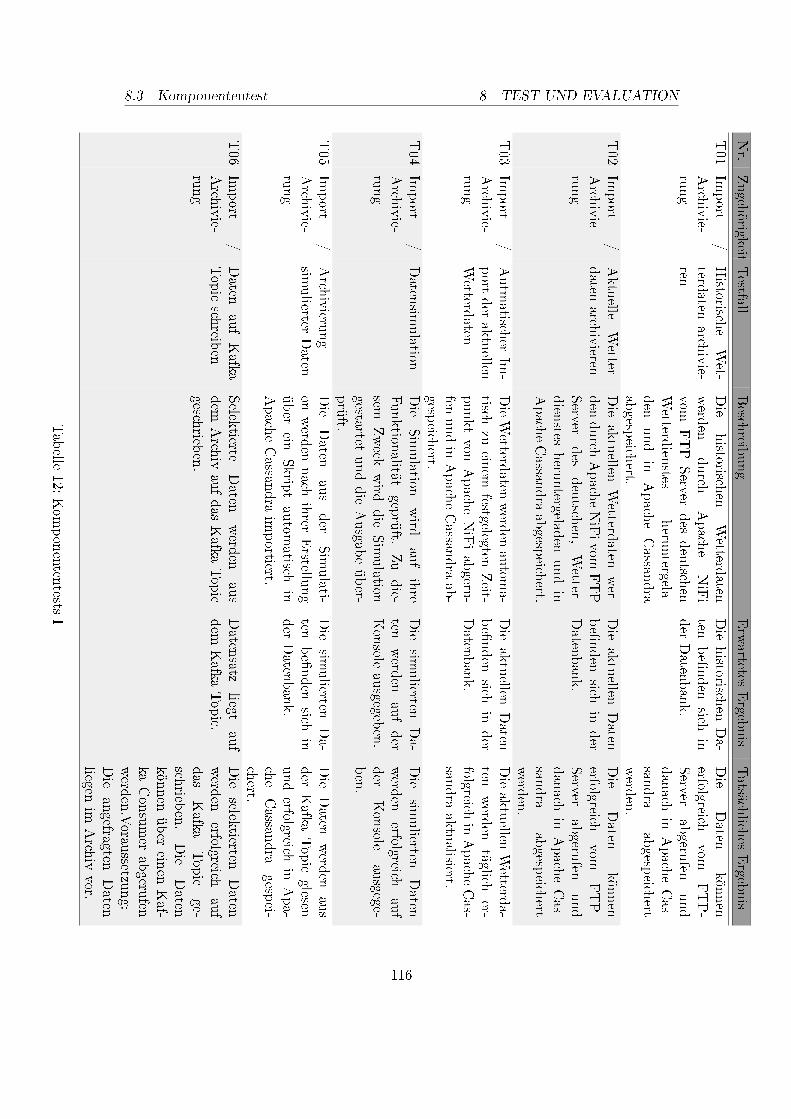
8.3 Komponententest 8 TEST UND EVALUATION
Nr.
Zugehörigkeit
Testfall
Beschreibung
Erwartetes
Ergebnis
Tatsächliches
Ergebnis
T01
Import
/Archivie-
rung
Historische
Wet-
terdatenarchivie-
ren
Die
historischenWetterdaten
werden
durchApache
NiFi
vomFTP
Serverdes
deutschenWetterdienstes
heruntergela-den
undin
Apache
Cassandra
abgespeichert.
Die
historischenDa-
tenbe�nden
sichin
derDatenbank.
Die
Daten
könnenerfolgreich
vomFTP-
Serverabgerufen
unddanach
inApache
Cas-
sandraabgesp
eichertwerden.
T02
Import
/Archivie-
rung
Aktuelle
Wetter-
datenarchivieren
Die
aktuellenWetterdaten
wer-
dendurch
Apache
NiFivom
FTP
Serverdes
deutschen,Wetter-
dienstesheruntergeladen
undin
Apache
Cassandra
abgespeichert.
Die
aktuellenDaten
be�nden
sichin
derDatenbank.
Die
Daten
könnenerfolgreich
vomFTP-
Serverabgerufen
unddanach
inApache
Cas-
sandraabgesp
eichertwerden.
T03
Import
/Archivie-
rung
Autm
atischerIm
-port
deraktuellen
Wetterdaten
DieWetterdaten
werden
automa-
tischzu
einemfestgelegten
Zeit-
punktvon
Apache
NiFiabgeru-
fenund
inApache
Cassandra
ab-gesp
eichert.
Die
aktuellenDaten
be�nden
sichin
derDatenbank.
Dieaktuellen
Wetterda-
tenwerden
täglicher-
folgreichinApache
Cas-
sandraaktualisiert.
T04
Import
/Archivie-
rung
Datensim
ulationDie
Simulation
wird
aufihre
Funktionalität
geprüft.Zu
die-sem
Zweck
wird
dieSim
ulationgestartet
unddie
Ausgab
eüb
er-prüft.
Die
simulierten
Da-
tenwerden
aufder
Konsole
ausgegeben.
Die
simulierten
Daten
werden
erfolgreichauf
derKonsole
ausgege-ben.
T05
Import
/Archivie-
rung
Archivierung
simulierter
Daten
Die
Daten
ausder
Simulati-
onwerden
nachihrer
Erstellung
über
einSkript
automatisch
inApache
Cassandra
importiert.
Die
simulierten
Da-
tenbe�nden
sichin
derDatenbank.
Die
Daten
werden
ausder
Kafka
Topic
glesenund
erfolgreichin
Apa-
cheCassandra
gespei-
chert.T06
Import
/Archivie-
rung
Daten
aufKafka
Topic
schreiben
SelektierteDaten
werden
ausdem
Archiv
aufdas
Kafka
Topic
geschrieben.
Datensatz
liegtauf
demKafka
Topic.
Die
selektiertenDaten
werden
erfolgreichauf
dasKafka
Topic
ge-schrieb
en.Die
Daten
könnenüb
ereinen
Kaf-
kaConsum
erabgerufen
werden.V
oraussetzung:Die
angefragtenDaten
liegenim
Archiv
vor.
Tabelle
12:Kom
ponententests
I
116
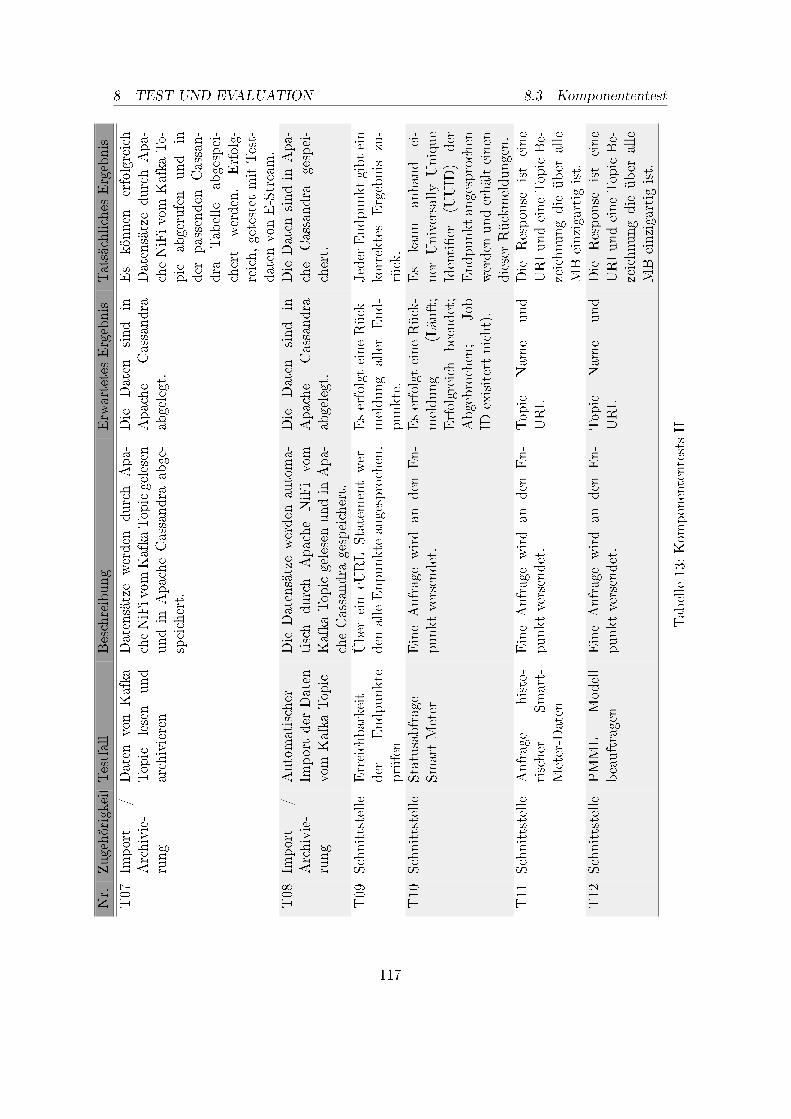
8 TEST UND EVALUATION 8.3 KomponententestNr.
ZugehörigkeitTestfall
Beschreibung
ErwartetesErgebnis
TatsächlichesErgebnis
T07
Import
/Archivie-
rung
Daten
vonKafka
Topic
lesen
und
archivieren
Datensätzewerden
durch
Apa-
cheNiFivom
Kafka
Topicgelesen
undin
ApacheCassandra
abge-
speichert.
Die
Daten
sind
inApache
Cassandra
abgelegt.
Es
können
erfolgreich
DatensätzedurchApa-
cheNiFivom
Kafka
To-
pic
abgerufen
und
inderpassenden
Cassan-
dra
Tabelle
abgespei-
chert
werden.
Erfolg-
reich,
getestet
mitTest-
datenvonE-Stream.
T08
Import
/Archivie-
rung
Autom
atischer
ImportderDaten
vom
Kafka
Topic
Die
Datensätzewerdenautoma-
tisch
durch
Apache
NiFivom
Kafka
Topicgelesenundin
Apa-
cheCassandra
gespeichert.
Die
Daten
sind
inApache
Cassandra
abgelegt.
DieDaten
sind
inApa-
che
Cassandra
gespei-
chert.
T09
Schnittstelle
Erreichbarkeit
der
Endpunkte
prüfen
Über
eincU
RL
Statem
entwer-
denalleEnpunkteangesprochen.
Eserfolgteine
Rück-
meldung
allerEnd-
punkte.
JederEndpunktgibt
ein
korrektesErgebniszu-
rück.
T10
Schnittstelle
Statusabfrage
SmartMeter
EineAnfrage
wird
anden
En-
punktversendet.
Eserfolgteine
Rück-
meldung
(Läuft;
Erfolgreich
beendet;
Abgebrochen;
Job
IDexisitertnicht).
Es
kann
anhand
ei-
nerUniversally
Unique
Identi�er
(UUID
)der
Endpunktangesprochen
werdenunderhälteinen
dieser
Rückm
eldungen.
T11
Schnittstelle
Anfrage
histo-
rischer
Smart-
Meter-Daten
EineAnfrage
wird
anden
En-
punktversendet.
Topic
Nam
eund
URI.
Die
Response
isteine
URIundeine
TopicBe-
zeichnungdieüb
eralle
MBeinzigartigist.
T12
Schnittstelle
PMML
Modell
beauftragen
EineAnfrage
wird
anden
En-
punktversendet.
Topic
Nam
eund
URI.
Die
Response
isteine
URIundeine
TopicBe-
zeichnungdieüb
eralle
MBeinzigartigist.
Tabelle13:Kom
ponententestsII
117
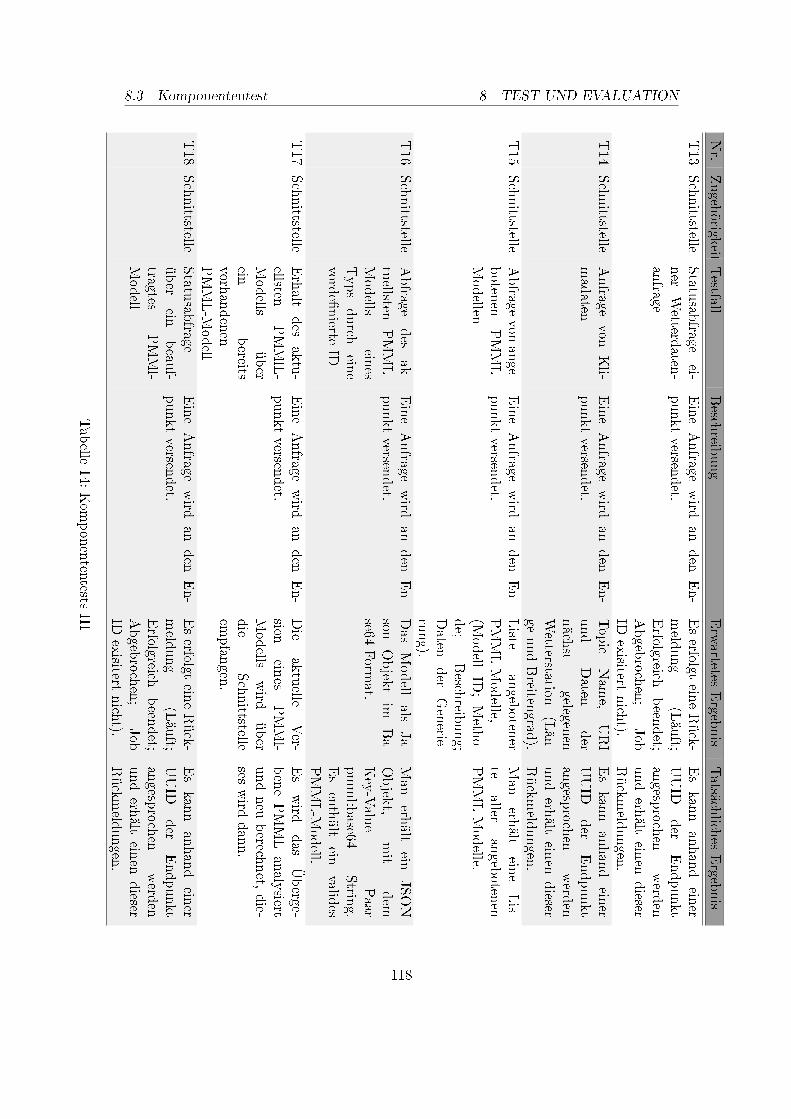
8.3 Komponententest 8 TEST UND EVALUATION
Nr.
Zugehörigkeit
Testfall
Beschreibung
Erwartetes
Ergebnis
Tatsächliches
Ergebnis
T13
SchnittstelleStatusabfrage
ei-ner
Wetterdaten-
anfrage
Eine
Anfrage
wird
anden
En-
punktversendet.
Eserfolgt
eineRück-
meldung
(Läuft;
Erfolgreich
beendet;
Abgebrochen;
JobID
exisitertnicht).
Eskann
anhandeiner
UUID
derEndpunkt
angesprochenwerden
underhält
einendieser
Rückm
eldungen.T14
SchnittstelleAnfrage
vonKli-
madaten
Eine
Anfrage
wird
anden
En-
punktversendet.
Topic
Nam
e,URI
undDaten
dernächst
gelegenenWetterstation
(Län-
geund
Breitengrad).
Eskann
anhandeiner
UUID
derEndpunkt
angesprochenwerden
underhält
einendieser
Rückm
eldungen.T15
SchnittstelleAbfrage
vonange-
botenen
PMML-
Modellen
Eine
Anfrage
wird
anden
En-
punktversendet.
Liste
angebotener
PMML-M
odelle,(M
odellID
;Metho-
de;Beschreibung;
Daten
derGenerie-
rung).
Man
erhälteine
Lis-
tealler
angebotenen
PMML-M
odelle.
T16
SchnittstelleAbfrage
desak-
tuellstenPMML-
Modells
einesTyps
durcheine
vorde�nierteID
Eine
Anfrage
wird
anden
En-
punktversendet.
Das
Modell
alsJa-
sonObjekt
imBa-
se64Form
at.
Man
erhältein
JSON
Objekt,
mit
demKey-V
aluePaar
pmml:base64
String.Esenthält
einvalides
PMML-M
odell.T17
SchnittstelleErhalt
desaktu-
ellstenPMMlL-
Modells
über
einbereits
vorhandenenPMML-M
odell
Eine
Anfrage
wird
anden
En-
punktversendet.
Die
aktuelleVer-
sioneines
PMMl-
Modells
wird
über
dieSchnittstelle
empfangen.
Es
wird
dasÜberge-
bene
PMML
analysiertund
neuberechnet,
die-ses
wird
dann.
T18
SchnittstelleStatusabfrageüb
erein
beauf-
tragtesPMMl-
Modell
Eine
Anfrage
wird
anden
En-
punktversendet.
Eserfolgt
eineRück-
meldung
(Läuft;
Erfolgreich
beendet;
Abgebrochen;
JobID
exisitertnicht).
Eskann
anhandeiner
UUID
derEndpunkt
angesprochenwerden
underhält
einendieser
Rückm
eldungen.
Tabelle
14:Kom
ponententests
III
118
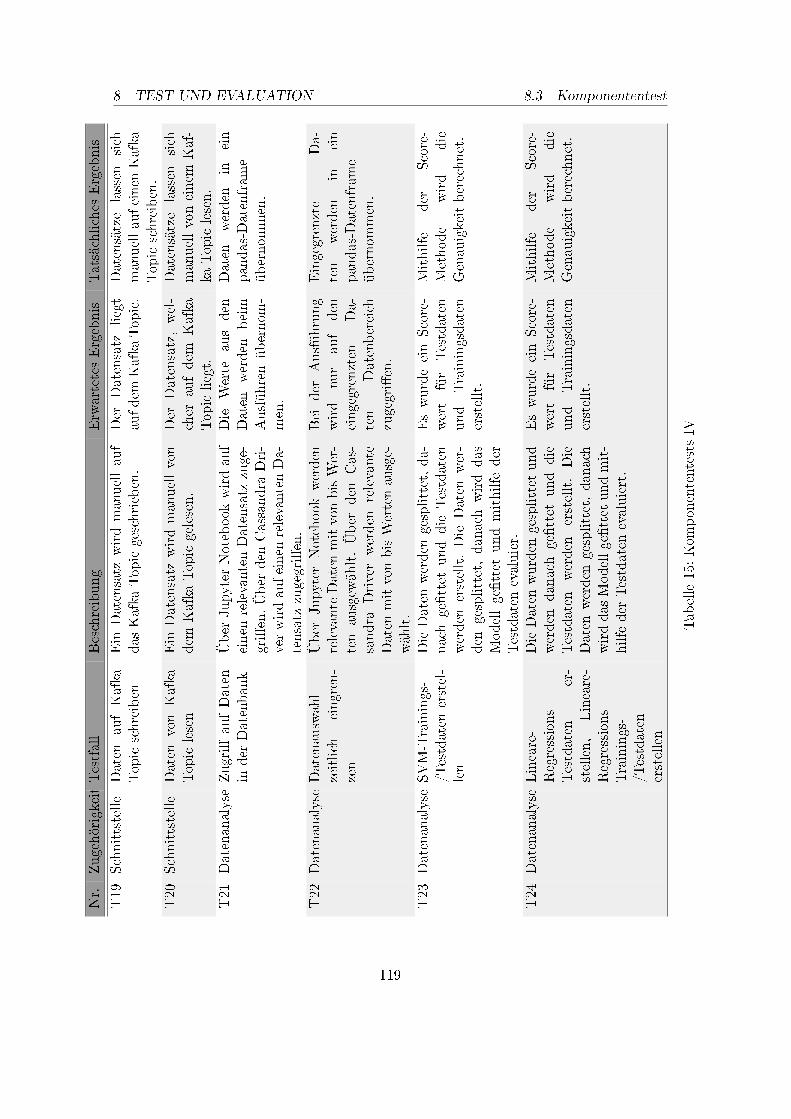
8 TEST UND EVALUATION 8.3 KomponententestNr.
ZugehörigkeitTestfall
Beschreibung
ErwartetesErgebnis
TatsächlichesErgebnis
T19
Schnittstelle
Daten
aufKafka
Topicschreiben
Ein
Datensatz
wirdmanuellauf
dasKafka
Topicgeschrieben.
Der
Datensatz
liegt
aufdem
Kafka
Topic.
Datensätze
lassen
sich
manuellaufeinenKafka
Topicschreiben.
T20
Schnittstelle
Daten
vonKafka
Topiclesen
Ein
Datensatz
wirdmanuellvon
dem
Kafka
Topicgelesen.
Der
Datensatz,wel-
cher
aufdem
Kafka
Topicliegt.
Datensätze
lassen
sich
manuellvoneinem
Kaf-
kaTopiclesen.
T21
DatenanalyseZugri�aufDaten
inderDatenbank
Über
JupyterNotebookwirdauf
einenrelevanten
Datensatz
zuge-
gri�en.Über
denCassandra
Dri-
verwirdaufeinenrelevanten
Da-
tensatzzugegri�en.
Die
Werte
ausden
Daten
werden
beim
Ausführen
übernom-
men.
Daten
werden
inein
pandas-Datenfram
eüb
ernommen.
T22
DatenanalyseDatenauswahl
zeitlich
eingren-
zen
Über
JupyterNotebookwerden
relevanteDaten
mitvonbisWer-
tenausgew
ählt.Über
denCas-
sandra
Driverwerden
relevante
Daten
mitvonbisWertenausge-
wählt.
Bei
derAusführung
wird
nur
auf
den
eingegrenzten
Da-
ten
Datenbereich
zugegri�en.
Eingegrenzte
Da-
ten
werden
inein
pandas-Datenfram
eüb
ernommen.
T23
DatenanalyseSV
M-Trainings-
/Testdaten
erstel-
len
DieDaten
werdengesplittet,da-
nach
ge�ttetunddieTestdaten
werdenerstellt.Die
Daten
wer-
dengesplittet,
danach
wirddas
Modellge�ttetundmithilfeder
Testdaten
evaluier.
Eswurde
einScore-
wert
für
Testdaten
und
Trainingsdaten
erstellt.
Mithilfe
der
Score-
Methode
wird
die
Genauigkeitberechnet.
T24
DatenanalyseLineare-
Regressions
Testdaten
er-
stellen,
Lineare-
Regressions
Trainings-
/Testdaten
erstellen
DieDaten
wurdengesplittetund
werdendanach
ge�ttetunddie
Testdaten
werden
erstellt.Die
Daten
werdengesplittet,danach
wirddasModellge�ttetundmit-
hilfederTestdaten
evaluiert.
Eswurde
einScore-
wert
für
Testdaten
und
Trainingsdaten
erstellt.
Mithilfe
der
Score-
Methode
wird
die
Genauigkeitberechnet.
Tabelle15:Kom
ponententestsIV
119
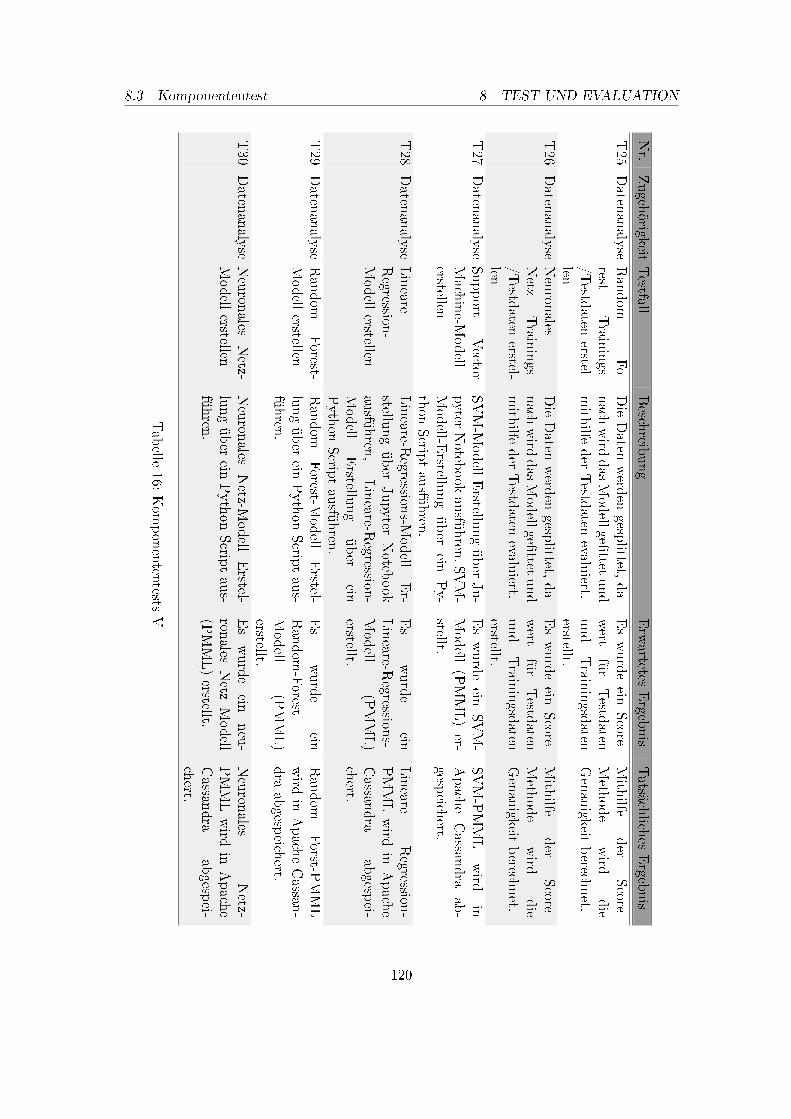
8.3 Komponententest 8 TEST UND EVALUATION
Nr.
Zugehörigkeit
Testfall
Beschreibung
Erwartetes
Ergebnis
Tatsächliches
Ergebnis
T25
Datenanalyse
Random
Fo-
restTrainings-
/Testdaten
erstel-len
DieDaten
werden
gesplittet,da-
nachwird
dasModellge�ttet
undmithilfe
derTestdaten
evaluiert.
Eswurde
einScore-
wert
fürTestdaten
undTrainingsdaten
erstellt.
Mithilfe
derScore-
Methode
wird
dieGenauigkeit
berechnet.
T26
Datenanalyse
Neuronales
Netz
Trainings-
/Testdaten
erstel-len
DieDaten
werden
gesplittet,da-
nachwird
dasModellge�ttet
undmithilfe
derTestdaten
evaluiert.
Eswurde
einScore-
wert
fürTestdaten
undTrainingsdaten
erstellt.
Mithilfe
derScore-
Methode
wird
dieGenauigkeit
berechnet.
T27
Datenanalyse
Support
Vector
Machine-M
odellerstellen
SVM-M
odellErstellung
über
Ju-pyter
Noteb
ookausführen.SV
M-
Modell-E
rstellungüb
erein
Py-
thonScript
ausführen.
Eswurde
einSV
M-
Modell
(PMML)er-
stellt.
SVM-PMML
wird
inApache
Cassandra
ab-gesp
eichert.
T28
Datenanalyse
Lineare
Regression-
Modell
erstellen
Lineare-R
egressions-Modell
Er-
stellungüb
erJupyter
Noteb
ookausführen,
Lineare-R
egression-Modell
Erstellung
über
einPython
Scriptausführen.
Es
wurde
einLineare-R
egressions-Modell
(PMML)
erstellt.
Lineare
Regression-
PMMLwird
inApache
Cassandra
abgespei-
chert.
T29
Datenanalyse
Random
Forest-
Modell
erstellenRandom
Forest-M
odellErstel-
lungüb
erein
Python
Scriptaus-
führen.
Es
wurde
einRandom
-Forest
Modell
(PMML)
erstellt.
Random
Forst-P
MML
wird
inApache
Cassan-
draabgesp
eichert.
T30
Datenanalyse
Neuronales
Netz-
Modell
erstellenNeuronales
Netz-M
odellErstel-
lungüb
erein
Python
Scriptaus-
führen.
Es
wurde
einneu-
ronalesNetz
Modell
(PMML)erstellt.
Neuronales
Netz-
PMMLwird
inApache
Cassandra
abgespei-
chert.
Tabelle
16:Kom
ponententests
V
120

8 TEST UND EVALUATION 8.4 Integrationstests
8.4. Integrationstests
Die Integrationstests umfassen werden in diesem Abschnitt vorgestellt. Dazu wurde eben-falls eine Tabellenstruktur genutzt. Auch hier umfasst die Tabelle einen Testcode, den Test-fall, eine Zugehörigkeit und eine Beschreibung. Die erwarteten Ergebnisse werden dann mitden tatsächlichen Ergebnissen verglichen. Das System wird hier als Blackbox betrachtet.Die Tabelle 17: Integrationstests zeigt die Ergebnisse.
8.5. Systemtests
Im folgenden Abschnitt wird auf die Systemtests eingegangen. Diese umfassen 5 Tests ummehrere Bereiche und Merkmale des Gesamtsystems zu prüfen. Die Tabelle 18: Systemtestszeigt die unterschiedlichen Testfälle. Die Beschreibung werden die Testfälle mit dem Er-gebnis beschrieben. Teilweise können keine Ergebnisse der Tests vorgestellt werden.
121
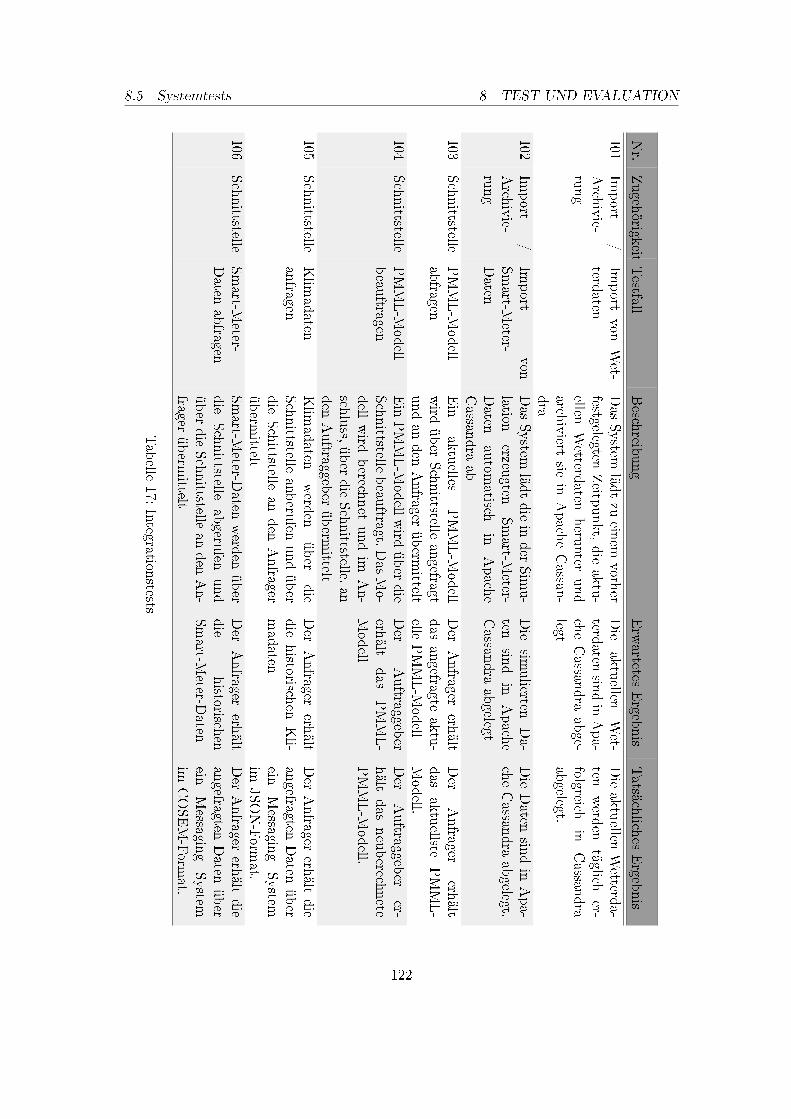
8.5 Systemtests 8 TEST UND EVALUATION
Nr.
Zugehörigkeit
Testfall
Beschreibung
Erwartetes
Ergebnis
Tatsächliches
Ergebnis
I01Im
port
/Archivie-
rung
Import
vonWet-
terdatenDas
Systemlädt
zueinem
vorherfestgelegten
Zeitpunkt,
dieaktu-
ellenWetterdaten
herunterund
archiviertsie
inApache
Cassan-
dra
Die
aktuellenWet-
terdatensind
inApa-
cheCassandra
abge-legt
Dieaktuellen
Wetterda-
tenwerden
täglicher-
folgreichin
Cassandra
abgelegt.
I02Im
port
/Archivie-
rung
Import
vonSm
art-Meter-
Daten
Das
Systemlädt
diein
derSim
u-lation
erzeugtenSm
art-Meter-
Daten
automatisch
inApache
Cassandra
ab
Die
simulierten
Da-
tensind
inApache
Cassandra
abgelegt
DieDaten
sindin
Apa-
cheCassandra
abgelegt.
I03Schnittstelle
PMML-M
odellabfragen
Ein
aktuellesPMML-M
odellwird
über
Schnittstelleangefragt
undan
denAnfrager
überm
ittelt
Der
Anfrager
erhältdas
angefragteaktu-
ellePMML-M
odell
Der
Anfrager
erhältdas
aktuellstePMML-
Modell.
I04Schnittstelle
PMML-M
odellbeauftragen
Ein
PMML-M
odellwird
über
dieSchnittstelle
beauftragt.D
asMo-
dellwird
berechnet
undim
An-
schluss,üb
erdie
Schnittstelle,an
denAuftraggeb
erüb
ermittelt
Der
Auftraggeb
ererhält
dasPMML-
Modell
Der
Auftraggeb
erer-
hältdas
neuberechnete
PMML-M
odell.
I05Schnittstelle
Klim
adatenanfragen
Klim
adatenwerden
über
dieSchnittstelle
anberufen
undüb
erdie
Schittstellean
denAnfrager
überm
ittelt
Der
Anfrager
erhältdie
historischenKli-
madaten
Der
Anfrager
erhältdie
angefragtenDaten
über
einMessaging
Systemim
JSON-Form
at.I06
SchnittstelleSm
art-Meter-
Daten
abfragenSm
art-Meter-D
atenwerden
über
dieSchnittstelle
abgerufenund
über
dieSchnittstelle
anden
An-
fragerüb
ermittelt
Der
Anfrager
erhältdie
historischenSm
art-Meter-D
aten
Der
Anfrager
erhältdie
angefragtenDaten
über
einMessaging
Systemim
COSE
M-Form
at.
Tabelle
17:Integrationstests
122

8 TEST UND EVALUATION 8.5 Systemtests
Nr. Testfall Beschreibung
S1 Performance Verschiedene Funktionalitäten des System wer-den mehrmals hintereinander ausgeführt. DiePerformance muss dabei gleichbleibend sein.
S2 Erreichbarkeit Da sich das System in einer Testumgebung be�n-det, ist die Erreichbarkeit unter Realbedingungnicht testbar.
S3 Korrektheit Die Korrektheit des Systems wird durch dasmehrmalige einspielen der gleichen Datensätzeüberprüft.
S4 Skalierbarkeit Da sich das System in einer Testumgebung be-�ndet, ist die Skalierbarkeit nicht überprüfbar.Durch den Einsatz einer verteilten Datenbankist es theoretisch jedoch möglich das System aufeine beliebige Gröÿe zu skalieren.
S5 Sicherheit Da sich das System in einer Testumgebung be�n-det, ist die Sicherheit nicht überprüfbar. Bei derEntwicklung eigener Komponenten wurde daraufgeachtet, dass Daten durch die Ausführung die-ser Komponenten nicht verändert werden kön-nen. Bei der Sicherheit eingesetzter Komponen-ten wie Apache Kafka oder Apache Cassandrakann die Sicherheit von Seiten der Projektgrup-pe nicht gewährleistet werden.
Tabelle 18: Systemtests
123


9 FAZIT UND AUSBLICK
9. Fazit und Ausblick
In diesem abschlieÿenden Kapitel werden im Abschnitt 9.1: Fazit die Erfahrungen derProjektgruppe zusammengefasst und bewertet. Dabei wird auf unterschiedliche Aspektedes Projektes eingegangen. Im nachfolgenden Abschnitt wird ein Ausblick über möglicheFunktionserweiterungen und Verbesserungen für DAvE gegeben. Dabei werden die unter-schiedlichen Bereiche von DAvE betrachtet.
9.1. Fazit
Ablauf des Projekts Der Projektablauf gliederte sich in drei Phasen. Diese waren dieSeminarphase, die Entwicklungsphase und die Testphase. Im Nachhinein stellte sich heraus,dass einige in der Seminarphase behandelte Themen für die weitere Projektarbeit nichtrelevant waren. Zudem erstreckte sich die Seminarphase über einen zu groÿen Anteil desProjektzeitraumes. Im ersten Abschnitt der Entwicklung �el die Konzepterstellung undTechnologieauswahl sehr zeitintensiv aus. Ursache für diese Verzögerung war die fehlendeErfahrung im Bereich Big Data und den dazugehörenden Technologien. Beim Versuchdie ursprünglich ausgewählten Technologien zum Einsatz zu bringen, traten verschiedeneProbleme auf, die die Auswahl anderer Technologien notwendig machten. Aufgrund dessenverzögerte sich die weitere Projektarbeit deutlich. Ein weiterer Verzögerungsfaktor war,dass zu Beginn der Technologieauswahl kein einheitliches Testsystem zur Verfügung stand.Aufgrund der gesamten Verzögerung ging viel Implementierungs- und Testzeit verloren,sodass eine neue Meilensteinplanung durchgeführt werden musste. Das agile Vorgehen hatsich im Laufe des Projekts als sinnvolles Vorgehensmodell etabliert. Das VorgehensmodellScrum wäre mit einem zu hohen Koordinationsaufwand verbunden gewesen.
Kooperation E-Stream Die Kooperation mit der PG E-Stream hatte positive und her-ausfordernde Aspekte. Zu den Herausforderungen zählte die Kommunikation. Diese verliefzeitweise stockend. Für die schnelle Kommunikation wurde ein Instant-Messaging Dienstausgewählt. Dieser wurde im Laufe des Projekts durch E-Mail-Kommunikation abgelöst.Behindert wurde die Kooperation vor allem durch einen unterschiedlichen Projektfort-schritt. Zur Verbesserung wäre eine synchronisierte Seminarphase vorteilhaft gewesen. Auf-grund dessen konnten keine gemeinsamen Entscheidungen getro�en werden, stattdessenkonnte nur noch auf Entscheidungen der anderen PG reagiert werden. Befruchtend ander Zusammenarbeit, war der andere Blickwinkel auf die gleiche Thematik. Ein Zusam-menarbeit der Projektgruppen ist aus unserer Sicht sinnvoll, erfordert jedoch eine genauePlanung und ständige Abstimmung.
Werkzeuge für die Projektorganisation Die Verwaltung der im Projektverlauf entstan-denen Dokumente wurde mit dem Organisationswerkzeug Con�uence realisiert, zu diesen
125

9.1 Fazit 9 FAZIT UND AUSBLICK
zählen unter anderem die Sitzungsprotokolle. Um einen Gesamtüberblick über alle Auf-gabenpakete zu erhalten, sollte im weiteren Projektfortschritt Jira genutzt werden. Diesstellte sich jedoch als zu groÿer Organisationsaufwand heraus. Der Mehrwert rechtfertigtenicht den Mehraufwand.
Für die Versionierung wurde einer von der Universität bereitgestellter Git Dienst genutzt.Dieser wurde nicht nur für den Quellcode genutzt, sondern auch für die Zusammenarbeitbei der Erstellung der Dokumentation.
Technologien Im Rahmen der Data Science Komponente war die scikit-learn Bibliothekein zentrales Werkzeug. Diese bietet eine Vielzahl von Modellen. Dadurch lieÿen sich neueModelle ohne groÿen Zeitaufwand implementieren und anwenden. Die Dokumentation warsehr gut gep�egt und beschrieben. Es gibt eine sehr aktive Online-Community, von der vieleFragestellung bereits beantwortet wurden. Dies unterstützt ein sehr e�zientes Arbeit mitder Bibliothek. Ein Nachteil ist die fehlende Import-Funktion für PMML-Dateien. Diesehat sich im Projektverlauf als relevant herausgestellt, da diese zur Umsetzung eines UseCases der PG E-Stream erforderlich gewesen wäre.
Im Rahmen des Datenimports hat sich Apache NiFi als ein mächtiges Werkzeug her-ausgestellt. Der gesamte Prozess wird über Apache NiFi gesteuert. So konnte bspw. derproblematische Datenimport mittels Java von einem FTP-Server durch Apache NiFi er-setzt werden. Apache NiFi bietet unter anderem eine Vielzahl von Funktionen um Datenzu manipulieren. Es ist möglich den Data�ow visuell darzustellen. Die Benutzerober�ächehalf bei der Erstellung von Prozessen und der Kon�guration dieser. Die Vielzahl von vorde-�nierten Prozessoren ermöglichen einen vielseitigen Einsatz sowie die Integration weitererModule. So ist es auch möglich die Anfrage der historischen Daten mit Apache NiFi zubearbeiten.
Mit dem DAvE-System wird ein beispielhafter Ansatz gescha�en, die gestiegenen Anforde-rungen an das Datenaufkommen durch intelligente Messsysteme zu bewerkstelligen. Fernerwird durch die Verarbeitung der Messwerte aus der Niederspannungsebene eine Möglich-keit gescha�en, aus den Daten Mehrwerte und datengetriebene Geschäftsmodelle zu ent-wickeln. Primär bieten die Big Data Technologien und Data Science Verfahren Lösungenzur Anfrage- und Vermarktungsprognosen oder eine Integration von externen Daten indie Netzbetriebsführung. Dies ermöglicht neben möglichen Kosteneinsparungen eine stär-kere Kundenindividualisierung bei der Netzbetriebsführung. Die Daten können für dasNetzleitstellenpersonal zusätzlich für neue Netzplanungen oder neue Mehrwertdienste fürIndustriekunden nutzbar gemacht werden. Darüber hinaus können Reaktionszeiten beigleichzeitiger Steigerung der Häu�gkeit und Komplexität von Eingri�en verkürzt werden.
126

9 FAZIT UND AUSBLICK 9.2 Ausblick
9.2. Ausblick
Im Laufe der Umsetzung des DAvE-Systems war vor allem die Koordination der verschie-denen Komponenten und Subsystemen im Cluster des Prototypen eine groÿe Herausforde-rung. Zudem wurden einige Subsysteme installiert, kon�guriert und in Betrieb genommen,jedoch zu einem späteren Zeitpunkt wieder aus Gesamtsystem entfernt. Der Zeitaufwandund die fachliche Herausforderung für diese Aufgaben war signi�kant.
Um Probleme in diesem Kontext in Zukunft zu vermeiden emp�ehlt es sich Subsystememit Hilfe von Containerdiensten zur Verfügung zu stellen. Die VirtualisierungssoftwareDocker bietet sich insbesondere an um z. B. den Message Broker oder das Datenbanksys-tem in einem geclusterten System zu virtualisieren. Dadurch lieÿe sich Zeit zur Installa-tion der Subsysteme sparen. Allein eine entsprechende Kon�guration der, in Containernbereitgestellten Subsysteme, wäre noch notwendig. Darüber hinaus würde diese Art derBereitstellung eines komplexen Systems die Portabilität und Stabilität dessen verbessern.
Im Rahmen der Data Science Komponente lieÿe sich Auswertung über angefragte Mo-delle die noch nicht angeboten werden erstellen. Auf Basis dieser Auswertungen könntendann neue Modelle erstellt werden. Zudem wird bisher noch nicht der Score der Modellemitgeliefert, dieser lieÿe sich zur Bewertung der Qualität durch den Anwender mit überge-ben. Für gröÿere Datensätze bei der Modellerzeugung würde die Möglichkeit bestehen dasTrainieren auf mehrere Knoten parallel durchzuführen.
Bei der Benutzung von Apache NiFi ist die Protokollierungsfunktion bisher ungenutzt.Es ist uns zurzeit nicht möglich, automatisch auf Fehlermeldungen oder auf erfolgreichemDatenimporten hingewiesen zu werden. So muss manuell täglich überprüft werden, ob dieDaten erfolgreich importiert worden sind oder ob Fehler aufgetreten sind.
Neben den aufgezeigten Anwendungsfällen besteht die Möglichkeit, weitere Nutzen aus denDaten der Energiewende zu scha�en. Durch die Digitalisierung der Stromzähler entstehtauch auf Konsumentenseite der Bedarf, über die verbrauchten Energiemengen informiertzu werden. Die Daten können somit aus dem Archiv abgefragt werden und beispielsweiseüber ein Letztverbraucher-Portal zur Verfügung gestellt werden.
127


Literatur Literatur
Literatur
[AVM+12] Albanese, Davide ; Visintainer, Roberto ; Merler, Stefano ; Ricca-donna, Samantha ; Jurman, Giuseppe ; Furlanello, Cesare: mlpy: Ma-chine Learning Python Projekt Homepage. http://mlpy.sourceforge.net/.Version: 2012. � [Online; Stand 31. März 2018]
[Bun16a] Bundesministerium für Wirtschaft und Energie: Die Digitalisie-rung der Energiewende. https://www.bmwi.de/Redaktion/DE/Artikel/
Energie/digitalisierung-der-energiewende.html. Version: 2016. � [On-line; Stand: 28. März 2016]
[Bun16b] Bundestag: Gesetz zur Digitalisierung der Energiewende. August 2016. ��60 Nr.3
[Dat18] DataStax, Inc.: CONSISTENCY|CQL for Apache Cassandra3.0. https://docs.datastax.com/en/cql/3.3/cql/cql_reference/
cqlshConsistency.html, 2018. � [Online; Stand 15. Februar 2018]
[DLM18] DLMS User Association: DLMS User Association Homepage. https:
//www.dlms.com/index2.php. Version: 2018. � [Online; Stand 31. März 2018]
[Ger16] German Watch: Sechs Thesen zur Digitalisierung der Energiewende: Chan-cen, Risiken und Entwicklungen. https://germanwatch.org/de/download/
15649.pdf. Version: 2016. � [Online; Stand: 28. März 2016]
[Har15] Harrison, G.: Next generation databases: NoSQL, NewSQL, and Big Data :what every professional needs to know about the future of databases in a worldof NoSQL and Big Data. New York : Apress (IOUG), 2015 (The expert'svoice in Oracle)
[Has18] HashiCorp: HashiCorp Vagrant Homepage. https://www.vagrantup.com/,2018. � [Online; Stand 15. Februar 2018]
[Her18] Hermann, Pencolé: ni�-con�g Github Repository. https://github.com/
hermannpencole/nifi-config, 2018. � [Online; Stand 15. Februar 2018]
[HTF09] Hastie, Trevor ; Tibshirani, Robert ; Friedman, Jerome: The Elements ofStatistical Learning. Springer New York, 2009. http://dx.doi.org/10.1007/978-0-387-84858-7. http://dx.doi.org/10.1007/978-0-387-84858-7
[Ion15] Ionescu, V. M.: The analysis of the performance of RabbitMQ and Ac-tiveMQ. In: 2015 14th RoEduNet International Conference - Networking inEducation and Research (RoEduNet NER), 2015. � ISSN 2068�1038, S. 132�137
129

Literatur Literatur
[JL17] John, V. ; Liu, X.: A Survey of Distributed Message Broker Queues. In:ArXiv e-prints (2017), April
[Jup18] Jupyter Notebook: What is the Jupyter Notebook? http:
//jupyter-notebook-beginner-guide.readthedocs.io/en/latest/
what_is_jupyter.html. Version: 2018. � [Online; Stand 17. Februar 2018]
[KNI18] KNIME AG: KNIME Homepage. https://www.knime.com/. Version: 2018.� [Online; Stand 31. März 2018]
[Mü16] Müller, Andreas C.: Introduction to machine learning with Python: a guidefor data scientists. First edition. Beijing ; Boston : O'Reilly Media, Inc, 2016.� ISBN 978�1�4493�6941�5
[MGR17] Müller, Andreas C. ; Guido, Sarah ; Rother, Kristian: Einführung in Ma-chine Learning mit Python: Praxiswissen Data Science. Heidelberg : O'Reilly,2017
[MH13] Moniruzzaman, A. B. M. ; Hossain, Syed A.: NoSQL Database: New Eraof Databases for Big data Analytics - Classi�cation, Characteristics and Com-parison. 2013
[OAS18] OASIS: AMQP is the Internet Protocol for Business Messaging. https:
//www.amqp.org/about/what. Version: 2018. � [Online; Stand 20. März 2018]
[OBALB15] Oussous, Ahmed ; Benjelloun, Fatima-Zahra ; Ait Lahcen, Ayoub ;Belfkih, Samir: Comparison and Classi�cation of NoSQL Databases forBig Data. 2015
[OFF18] OFFIS e. V.: NetzDatenStrom Projektseite. https://eprojects.offis.
de/redmine/projects/netzdatenstrom. Version: 2018. � [Online; Stand: 1.Januar 2018]
[Piv18] Pivotal Software: RabbitMQ Documentation. http://www.rabbitmq.
com. Version: 2018. � [Online; Stand 31. März 2018]
[R17] RTools Technology Inc: RStudio. https://www.rstudio.com/.Version: 2017. � [Online; Stand 20. März 2018]
[Sah15] Sahu, B. K.: A Real Comparison Of NoSQL Databases HBa-se, Cassandra & MongoDB. https://www.linkedin.com/pulse/
real-comparison-nosql-databases-hbase-cassandra-mongodb-sahu/,2015. � [Online; Stand 15. Februar 2018]
[Sci17] Scikit-learn developers: Online Documentation. http:
//scikit-learn.org/stable/. Version: 2017. � [Online; Stand 31.
130

Literatur Literatur
März 2018]
[Sky17] Skymind: What is Eclipse Deeplearning4j? https://deeplearning4j.org/.Version: 2017. � [Online; Stand: 20. März 2018]
[Sol18] Solid IT gmbh: DB-Engines Ranking - die Rangliste der populärsten Da-tenbankmanagementsysteme. https://db-engines.com/de/ranking, 2018. �[Online; Stand 15. Februar 2018]
[Sul15] Sullivan, D.: NoSQL for mere mortals. Upper Saddle River, NJ : PearsonEducation, 2015 (For mere mortals series)
[Ten18] Tensorflow developers: Projekt Homepage. https://www.tensorflow.org/. Version: 2018. � [Online; Stand 31. März 2018]
[The16] The Apache Software Foundation: Apache Cassandra Projekt Home-page. http://cassandra.apache.org/, 2016. � [Online; Stand 31. März2018]
[The18a] The Apache Software Foundation: Apache HBase Homepage. https:
//hbase.apache.org/, 2018. � [Online; Stand 15. Februar 2018]
[The18b] The Apache Software Foundation: Apache Kafka Documentation.https://kafka.apache.org/documentation/. Version: 2018. � [Online;Stand 31. März 2018]
[The18c] The Apache Software Foundation: Apache NiFi Online Dokumentation.https://nifi.apache.org/docs.html, 2018. � [Online; Stand 15. Februar2018]
[The18d] The Apache Software Foundation: Apache Spark Projekt Homepage.http://spark.apache.org/. Version: 2018. � [Online; Stand 29. März 2018]
[Tut18] Tutorials Point Pvt. Ltd.: Apache Kafka Online Tutorium. https://
www.tutorialspoint.com/apache_kafka/index.htm. Version: 2018. � [On-line; Stand 31. März 2018]
[Uni17] University of Waikato: WEKA. https://www.cs.waikato.ac.nz/ml/
weka/. Version: 2017. � [Online; Stand: 20. März 2018]
131


A ANHANG
A. Anhang
A.1. Tabelle Auswahl Datenbanken
133
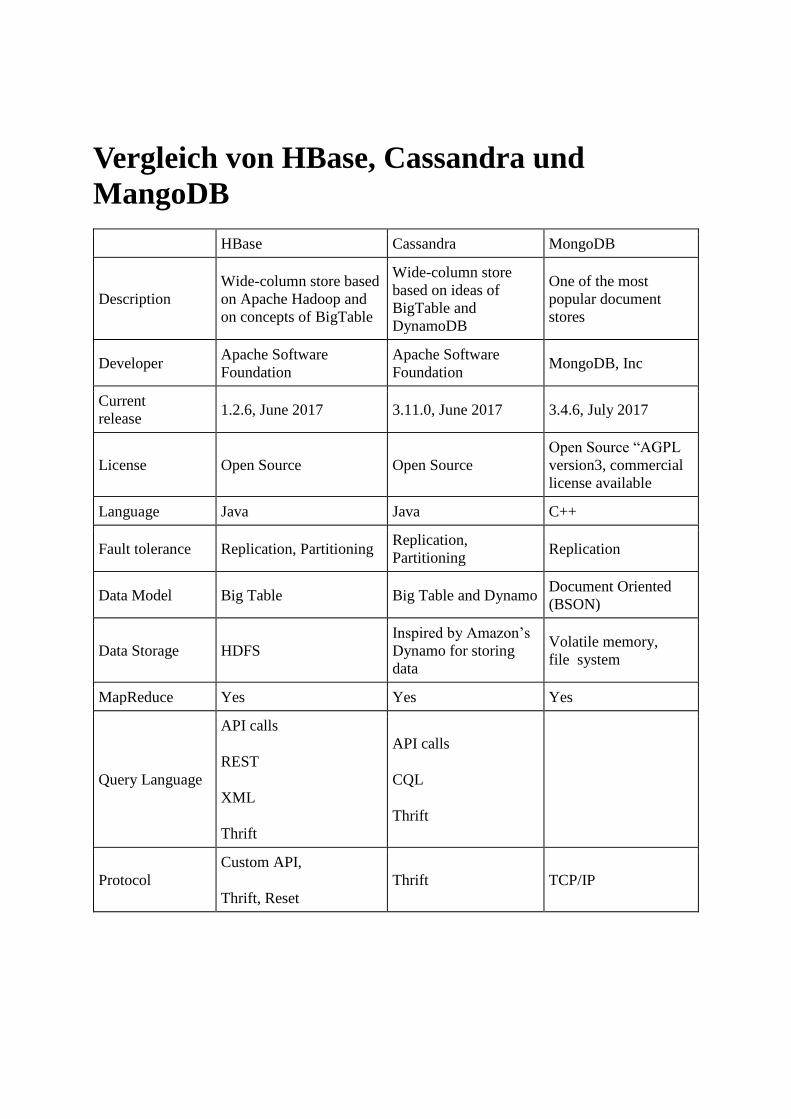
Vergleich von HBase, Cassandra und
MangoDB
HBase Cassandra MongoDB
Description
Wide-column store based
on Apache Hadoop and
on concepts of BigTable
Wide-column store
based on ideas of
BigTable and
DynamoDB
One of the most
popular document
stores
Developer Apache Software
Foundation
Apache Software
Foundation MongoDB, Inc
Current
release 1.2.6, June 2017 3.11.0, June 2017 3.4.6, July 2017
License Open Source Open Source
Open Source “AGPL
version3, commercial
license available
Language Java Java C++
Fault tolerance Replication, Partitioning Replication,
Partitioning Replication
Data Model Big Table Big Table and Dynamo Document Oriented
(BSON)
Data Storage HDFS
Inspired by Amazon’s
Dynamo for storing
data
Volatile memory,
file system
MapReduce Yes Yes Yes
Query Language
API calls
REST
XML
Thrift
API calls
CQL
Thrift
Protocol
Custom API,
Thrift, Reset
Thrift TCP/IP
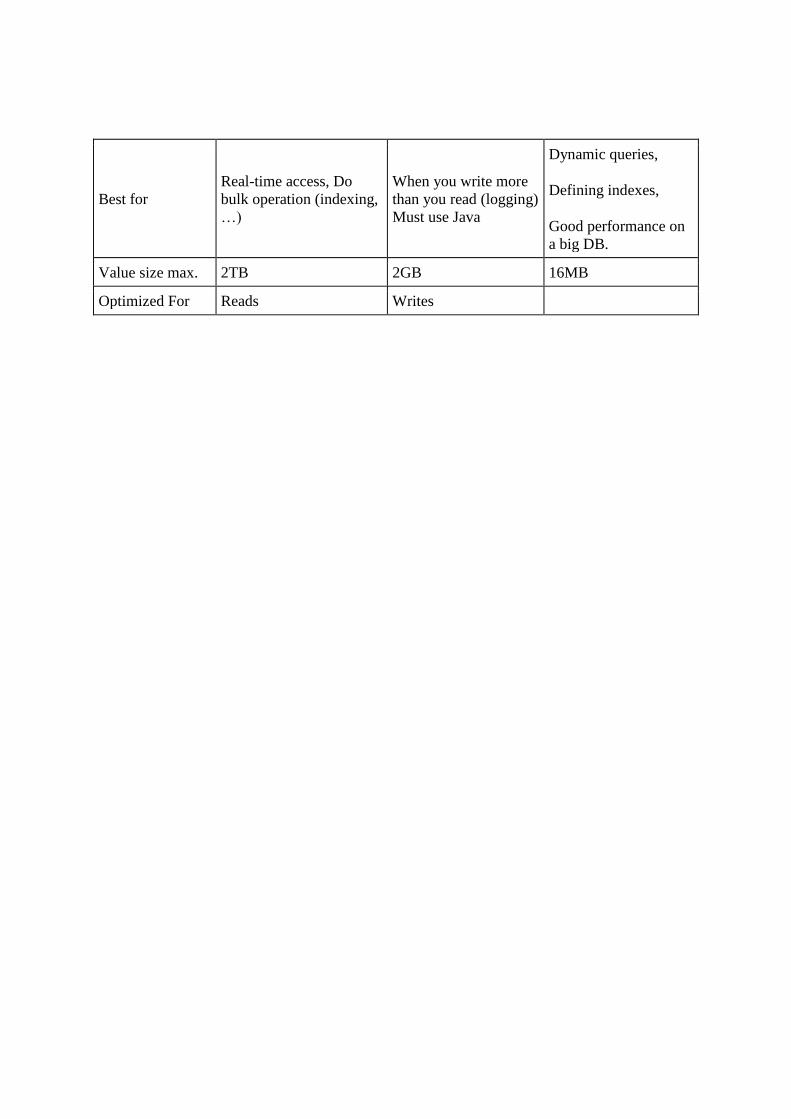
Best for
Real-time access, Do
bulk operation (indexing,
…)
When you write more
than you read (logging)
Must use Java
Dynamic queries,
Defining indexes,
Good performance on
a big DB.
Value size max. 2TB 2GB 16MB
Optimized For Reads Writes

A.2 Paper A ANHANG
A.2. Paper
A.2.1. Data Archive 2.0 - Adaptation of ICT Solutions for the Future Energy SectorTransformation
136

Data Archive 2.0 - Adaptation of ICT Solutions for the Future Energy SectorTransformation
Keywords: data archive, smart grid, data mining
The ongoing transformation of the energy sector (in German ”Energiewende”) provides major challenges for energyproducers, grid operators and other energy market players, such as field-device manufacturers. One of these challengesis the growing amount of data that is generated by measuring devices, which are going to be the standard for dealingwith the energy consumption and production of a single household, such as smart meters. In such a world, a numberof new information technologies are emerging with the aim of exploiting the growing amount of data and approachingbalance between supply and demand possibilities. In order to address the aforementioned challenge, a conceptualarchitecture was developed and tested. The architecture supports the generation of prediction models, which are ableto make forecasts about energy supply and demand on different levels, through the use of the different methods ofmachine learning. The architecture consists of three core components:
• Data Archive: a central database for storing all data received and send by the system including the data frommultiple heterogeneous external sources as well as models generated by the data mining component.
• Data Mining Component: used to generate various predictions and forecasts based on the data received by thesystem. This includes forecasts of the future load derived from smart meter data and power generation forecastsfrom renewable energy sources such as wind and photovoltaic. These models are to be send and received usingthe Predictive Model Markup Language (PMML), the industry standard for prediction models [1].
• Communication Component: manages the internal and external communication of the system. It processes thedata flows between the individual components of the systems and towards external information suppliers andinformation consumers. It enables the system to receive and process the standard message format for devicescommunication in smart grids, COmpanion Specification for Energy Metering (COSEM) [2].
In order to prove the feasibility of the architecture a prototypical implementation took place. The proposed architec-ture stack mainly consists of open source software. For the data archiving component the database system ApacheCassandra has been used. The data mining component has been implemented using Python and the scikit-learn li-brary. The communication component consists of two sub components: Apache Kafka (a message broker) and ApacheNifi (a data flow management system). Following the implementation, the system was tested and the integration ofthe components was successful. Further tests regarding the performance of the system are necessary.
References
[1] Alex Guazzelli, Michael Zeller, Wen-Ching Lin, Graham Williams, et al. PMML: An open standard for sharingmodels. The R Journal, 1(1):60–65, 2009.
[2] Stefan Feuerhahn, Michael Zillgith, Christof Wittwer, and Christian Wietfeld. Comparison of the communicationprotocols DLMS/COSEM, SML and IEC 61850 for smart metering applications. In Smart Grid Communications(SmartGridComm), 2011 IEEE International Conference on, pages 410–415. IEEE, 2011.

A.2 Paper A ANHANG
A.2.2. Datenarchivierung von Energiedaten und Generierung vonVorhersagemodellen
138

Datenarchivierung von Energiedaten und Generierung von
Vorhersagemodellen
Abstract Die Energiewende stellt die Energiebranche vor Herausforderungen. Um die Daten von Smart Metern
zu verarbeiten existieren bereits Ansätze. Die Archivierung und die passenden Analysewerkzeuge
können neue Mehrwerte aus diesen Daten generieren. Es soll eine Architektur entwickelt werden,
um riesige Datenmengen zu archivieren und daraus mit den passenden Analysewerkzeugen
Vorhersagemodelle zu generieren. Das Ergebnis sind Vorhersagemodelle, um bspw. die Erzeugung
von Strom besser handzuhaben.
Einleitung
Bis zum Jahr 2032 sollen alle Ferraris-Zähler durch intelligente Messsysteme (Smart Meter) ersetzt
werden. Das hat der Bundestag in einem Gesetzesentwurf zur Digitalisierung der Energiewende1
beschlossen. Die Netzbetreiber sind somit mit der Bewältigung riesiger Datenmengen konfrontiert.
Es existieren bereits Ansätze, um riesige Datenmengen zu verarbeiten, z.B. MapReduce (Rauber &
Runger, 2013). Diese Datenmengen können nach der Verarbeitung archiviert und analysiert werden.
Dazu soll eine Architektur entwickelt werden, um die Daten persistent über Jahrzehnte zu archivieren
und mit geeigneten Analysewerkzeugen neue Mehrwerte zu generieren. Hierzu sollen erste
Vorschläge erarbeitet werden, um die Schnittstellen zwischen den Stromerzeugern, Stromanbietern
und Konsumenten zu beschreiben und zu standardisieren. Zusätzlich soll durch die Nutzung
geeigneter Analysewerkzeuge Stromerzeuger und -anbieter in die Lage versetzt werden, geeignete
Vorhersagemodelle zu erzeugen und zu nutzen.
Solche Vorhersagemodelle geben Auskünfte über den Energieverbrauch oder die Stromerzeugung
von unterschiedlichen Zeitperioden. Dabei wird der Energieverbrauch der Haushalte analysiert und
einem Verhaltensmuster zugeordnet. Daraus lässt sich eine Nachfragemodell erzeugen, um die
erforderliche Menge Strom bereitzustellen. Die Einordnung der Haushalte in Verhaltensmuster muss
durch historische Daten trainiert und kontinuierlich verbessert werden. Somit ist die Archivierung ein
essenzieller Schritt, um neue Verhaltensmuster zu erzeugen und bestehende zu verbessern.
Die Architektur zur Archivierung und Analyse von großen Datenmengen soll in unterschiedlichen
Branchen einsetzbar sein. Die Architektur soll prototypisch im Energiesektor umgesetzt werden und
es sollen erste Analysewerkzeuge implementiert werden. Dazu werden unter anderem die Lambda-
Architektur, und andere Referenzarchitekturen, bspw. eine Architektur für eine Langzeitarchivierung
untersucht und bewertet. Mögliche Analysewerkzeuge sind neuronale Netze, Random Forest,
Support vector machine und weitere Algorithmen aus dem maschinellem Lernen. Bei der
Konzipierung des Prototyps wird auf getesteten Techniken zurückgegriffen, wie bspw. dem Hadoop
Distributed Filesystem (HDFS) und NoSQL Datenbanken (Jiang, 2016). Das Ziel ist, den Prototyp in
einem Testverfahren zu erproben und zu bewerten.
1 „Entwurf eines Gesetzes zur Digitalisierung der Energiewende“, Drucksache 18/7555, 17.02.2016

Literaturverzeichnis Dean, J., & Ghemawat, S. (2004). MapReduce: Simplified Data Processing on Large Clusters. Sixth
Symposium on Operating System Design and Implementation. San Francisco.
Jiang, H. W. (2016). Energy big data: A survey. Access, IEEE, 4, (S. 3844-3861).
Rauber, T. R., & Runger, G. (2013). Parallele Programmierung (3. Aufl. 2013. ed., EXamen.press).
Berlin Heidelberg: : Springer.
Viana, P., & Sato, L. (2014). A Proposal for a Reference Architecture for Long-Term Archiving,
Preservation, and Retrieval of Big Data. 2014 IEEE 13th International Conference on Trust,
Security and Privacy in Computing and Communications, (S. 622-629).

A ANHANG A.2 Paper
A.2.3. BUIS Paper DAvE
141

Seite 1 von 10
BUIS-Tage 2018: Projektgruppe DAvE
1 Data-Science zur Energiewende
Durch Datenanalysen Mehrwerte aus der Datenflut der Energiewende generieren.
Zusammenfassung
Das Gesetz der Digitalisierung der Energiewende führt zur Einführung von Smart Metern in Deutschland und zum
Aufbau einer digitalen Infrastruktur zwischen Stromerzeugern und -verbrauchern. Hauptaugenmerk liegt auf der
Instandsetzung von intelligenten Messsystemen, welche als Kommunikationsplattform mehr Sicherheit
gewährleisten können als herkömmliche Lösungen. Dies führt allerdings zu einem erhöhten Datenaustausch,
welcher durch die Energiebranche bewältigt werden muss. Das Zusammenwirken von Archivierung und
Analysewerkzeugen führt zur einer Handhabung der Datenmengen und ermöglicht zugleich die Generierung von
Mehrwerten. Diese Mehrwerte können durch die von DAvE entwickelte Architektur bewerkstelligt werden. Durch
Vorhersagemodelle aus den archivierten Daten entsteht die Möglichkeit, dass beteiligte Akteure die Erzeugung
und Verbräuche besser kalkulieren und Potentiale für neue Geschäftsmodelle entdecken können.
1.1 Einleitung
Die Digitalisierung der Energiewende führt zum Austausch aller herkömmlichen Ferraris-Zähler durch
intelligente Messsysteme bis zum Jahr 2032. Diese Einführung konfrontiert die Netzbetreiber mit der
Bewältigung riesiger Datenmengen. Doch die Datenmengen bringen auch neue Chancen für die
beteiligten Akteure mit sich. Denn die anfallenden Daten können nicht nur archiviert werden, sondern
bieten weitläufige Potentiale zu Datenanalyse. Dazu gilt es eine Architektur zu entwickeln, die Daten
persistent über Jahrzehnte archivieren kann und mit geeigneten Analysewerkzeugen neue Mehrwerte
durch die Auswertung dieser Daten generieren kann.
Die Architektur zur Archivierung und Analyse von großen Datenmengen wird in unterschiedlichen
Branchen einsetzbar sein. Zunächst wird sie prototypisch im Energiesektor umgesetzt und es werden
Analysewerkzeuge zur Ableitung von Verhaltensmustern aus den Daten der Haushalte implementiert.
Es muss möglich sein, Stromerzeuger und -anbieter in die Lage zu versetzen, Vorhersagen über
Energieverbräuche und Stromerzeugung zu treffen und nutzen zu können. Anhand von generierten
Vorhersagemodellen können dazu Auskünfte in unterschiedlichen Zeitperioden getroffen werden.
Durch den Datenzuwachs ist es möglich, die Vorhersagemodelle stetig zu optimieren und somit immer
bessere Prognosen ableiten zu können. Dies ermöglicht es den Stromerzeugern, die Nachfrage durch
Konsumenten zu prognostizieren und somit die bereitzustellende Menge an Strom besser kalkulieren
zu können.
Die Umsetzung dieses Vorhabens wird im Rahmen der Projektgruppe DAvE an der Carl von Ossietzky
Universität Oldenburg realisiert. Das zugehörige Konzept und dessen Umsetzung werden im
Folgenden erläutert.
1.2 Projektgruppenvorstellung
Im Rahmen der Projektgruppe DAvE (Datenarchivierung von Energiedaten) in der Abteilung Very
Large Business Applications (VLBA) unter der Leitung von Prof. Dr. Ing Marx Gómez, widmen sich
zwölf Masterstudierende aus den Bereichen Informatik und Wirtschaftsinformatik der Konzeption und
Entwicklung eines Big Data-Archivs. Im Zeitraum vom 1. April 2017 bis 31. März 2018 wird von der
Projektgruppe eine Architektur zur Speicherung und Auswertung von Energiedaten konzipiert und
entwickelt, die für Stromerzeuger und –anbieter entscheidende Mehrwerte generieren kann. Dabei
steht die Analyse von Netz und Daten im Vordergrund, sodass basierend auf den Erkenntnissen
mögliche datengetriebene Geschäftsmodelle aufgezeigt werden können. Die Aufgaben werden von

Seite 2 von 10
Teilgruppen mit den Kernkompetenzen Datenbereitstellung und –Import, Datenarchivierung,
Datenanalyse und der Erstellung einer Schnittstelle zum Senden und Empfangen von Smart Meter-
und Wetterdaten sowie der Bereitstellung von Vorhersagemodellen realisiert. Zusätzlich wurde in der
Entwicklungsphase ein Testmanagement eingeführt, welches die Umsetzung während der Entwicklung
anhand von Testdrehbüchern prüft. Die Organisation der Projektgruppe wird in Abbildung 1.1
dargestellt.
Diese Teilgruppen werden durch Andreas Solsbach, Viktor Dmitriyev und Jad Asswad betreut. Dabei
wird durch wöchentliche Abstimmungen der Projektfortschritt kommuniziert und Änderungs- und
Optimierungswünsche werden zügig in den Entwicklungsfortschritt eingebunden. Die Arbeitspakete
werden anschließend in SCRUM-ähnlichen Iterationen umgesetzt.
1.3 Zielsetzung des Projektes
Das Projekt beschäftigt sich mit der Leitfrage, wie ein datengetriebener Energiemarkt in der Zukunft
aussehen kann. Dabei gilt es eine Kombination aus Netz, Daten und Analyse zu schaffen und anhand
dieser Erkenntnisse neue Geschäftsmodelle aufzeigen zu können. Es muss die Möglichkeit geschaffen
werden, die anfallenden Daten aus Smart Metern und Smart Meter Gateways speichern und
archivieren zu können. Dazu wird eine Infrastruktur geschaffen, über die Daten aus Datenquellen
entgegengenommen und in einem Archiv abgelegt werden. Bei diesen Daten handelt es sich primär
um Datenströme aus einer Niederspannungssimulation von Haushalten. Anschließend muss es
ermöglicht werden, die archivierten Daten zur Wissensgenerierung über das Konsumentenverhalten
auswerten zu können. Das generierte Wissen wird folglich durch Vorhersagemodelle zur Verfügung
gestellt und für Dritte nutzbar gemacht.
Zusätzlich sollen externe Datenquellen in Form von Wetterdaten archiviert werden. Dazu stellt der
Deutsche Wetterdienst stündlich Werte bereit, die vom System angefragt und archiviert werden. Diese
Daten werden bezüglich Windgeschwindigkeiten und Sonnenstunden ausgewertet und ermöglichen
somit eine Prognose für potentielle Energieerzeugung über Wind- und Solarkraft. Zusätzlich ist es
möglich, die Daten auch aufgrund ihrer geographischen Informationen auszuwerten, um Hinweise
über Standorte zu geben.
Das System muss dabei durch das hohe Datenaufkommen den gestiegenen Anforderungen an die
Datenhandhabung und an die Notwendigkeit des schnellen Zugriffs gerecht werden. Durch den
Einsatz von Big Data-Technologien und Data Science-Verfahren werden somit Anfragen bezüglich
Last- und Vermarktungsprognosen auf hochaufgelösten und umfangreichen Langzeitdaten
gewährleistet, die beteiligten Akteuren zukünftig Mehrwerte in den Prozessen ihrer Leistungserstellung
ermöglichen können.
Drüber hinaus muss es möglich sein, eine offene und standardisierte Schnittstellenarchitektur zu
schaffen, über die ein Datenaustausch zur Archivierung und zur Abfrage von Vorhersagemodellen
realisiert wird. Somit ist es Dritten möglich, Daten in das System einzuspeisen und Anfragen zur
Auswertung dieser Daten zu stellen. Nach der Auswertung der Daten durch Analysewerkzeuge müssen
die erstellten Modelle wieder über die Schnittstelle an jene Anfrager zur Verfügung gestellt werden.
Abb. 1.1: Projektorganisation DAvE

Seite 3 von 10
1.4 Definition der Anwendungsfälle
Zur Umsetzung der genannten Ziele ist die Definition von Anwendungsfällen (Use Cases) notwendig,
um genau zu definieren welche Funktionen das zu erstellende System erfüllen muss. Dabei wurde sich
auf vier Kernfunktionalitäten festgelegt, die im Folgenden erläutert werden.
1.4.1 Use Case: Daten archivieren
Das erste Use Case, welches in Abbildung 1.2 dargestellt wird, behandelt die Datenarchivierung des
DAvE-Systems. Für dieses Use Case werden die drei Akteure Wetterdienst, Stromerzeuger und
Stromanbieter benötigt. Zu Beginn werden unterschiedliche Datenquellen an das System angebunden.
Solche Daten wären zum Beispiel Klimadaten vom Deutschen Wetterdienst. Die angekommenen
Datenströme werden entgegengenommen und persistent sowie unverändert archiviert. Weiterhin
werden die Daten auf Fehler überprüft und sollten Fehler vorhanden sein, sendet das DAvE-System
eine Fehlermeldung.
Es kann bei diesem Use Case auch zu Ausnahmenfällen kommen. Solche Ausnahmefälle wären
beispielsweise Datendefekte, Kapazitätsauslastungen bei der Verarbeitung oder Speicherauslastungen.
1.4.2 Use Case: Anfragebearbeitung von Daten
In dem zweiten Use Case, welches in Abbildung 1.3 zu sehen ist, wird die Anfragebearbeitung von
Daten verarbeitet. Zuerst stellt der Anfrager eine Anfrage, welche verarbeitet und anschließend
geprüft wird. Danach werden gleichzeitig die Rohdaten und Funktionen für die Anfrage vorbereitet.
Der nächste Schritt besteht darin, dass die Anfrage ausgeführt wird, sodass im Anschluss daran das
Versenden der Daten erfolgen kann.
Zusätzlich zu der allgemeinen Anfrage der Datensätze können auch spezifische Anfragen über diese
Datensätze getätigt werden. Ausnahmefälle bei diesem Use Case wären, dass Anfragen nicht valide
oder Ergebnismengen zu groß sind, sodass das System dem Nutzer eine Rückmeldung geben muss.
Abb. 1.2: Use Case: Daten archivieren

Seite 4 von 10
1.4.3 Use Case: Modellerzeugung für das Power-Forecasting
Abbildung 1.4 zeigt das dritte Use Case, welches die Modellerzeugung für das Power Forecasting für
Windkraft und Photovoltaikanlagen behandelt. Es werden für dieses Use Case die Akteure
Stromerzeuger, Stromanbieter sowie Netzbetreiber benötigt. Im ersten Schritt erfolgt die Anfrage der
Daten, worauf Daten für das Datenset abgerufen werden. Anschließend wird das Datenset erstellt und
eine Energiequelle ausgewählt. Daraufhin findet die Vorverarbeitung des Datensets statt. Auf dieses
Datenset erfolgt die Anwendung der Mining-Methode und das daraus entstehende Datenmodell wird
evaluiert. Zum Schluss besteht die Möglichkeit das Datenmodell einzusetzen.
Dieses Use Case hat im Vergleich zu den anderen Use Cases auch Ausnahmefälle, denn hierbei kann
ein Under- oder Overfitting zu einem Ausfall führen.
Abb. 1.3: Use Case: Anfragebearbeitung von Daten
Abb. 1.4: Use Case: Modellerzeugung für das Power-Forecasting
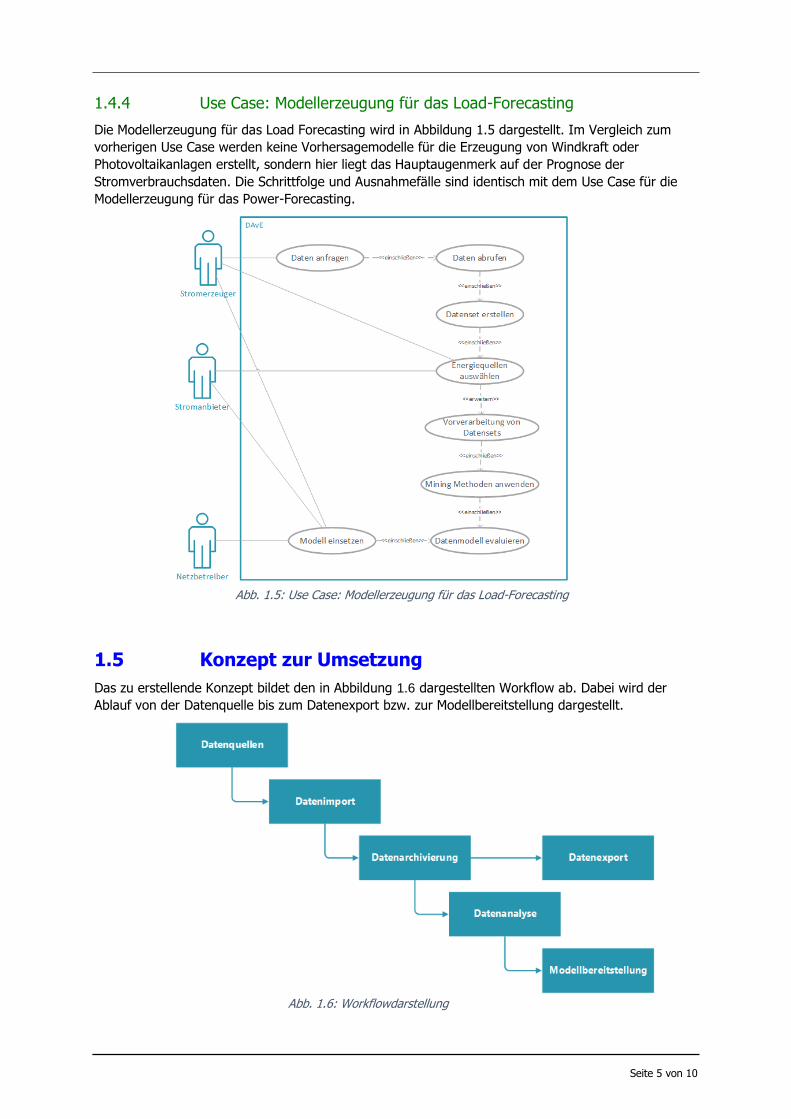
Seite 5 von 10
1.4.4 Use Case: Modellerzeugung für das Load-Forecasting
Die Modellerzeugung für das Load Forecasting wird in Abbildung 1.5 dargestellt. Im Vergleich zum
vorherigen Use Case werden keine Vorhersagemodelle für die Erzeugung von Windkraft oder
Photovoltaikanlagen erstellt, sondern hier liegt das Hauptaugenmerk auf der Prognose der
Stromverbrauchsdaten. Die Schrittfolge und Ausnahmefälle sind identisch mit dem Use Case für die
Modellerzeugung für das Power-Forecasting.
1.5 Konzept zur Umsetzung
Das zu erstellende Konzept bildet den in Abbildung 1.6 dargestellten Workflow ab. Dabei wird der
Ablauf von der Datenquelle bis zum Datenexport bzw. zur Modellbereitstellung dargestellt.
Abb. 1.5: Use Case: Modellerzeugung für das Load-Forecasting
Abb. 1.6: Workflowdarstellung

Seite 6 von 10
- Datenquellen
Das System muss bestehende Datenquellen verarbeiten können. Als Datenquellen dienen die
Wetterdaten des Deutschen Wetterdienstes und die Verbrauchsdaten von Haushalten aus der
Niederspannungssimulation. Die Daten dienen im weiteren Verlauf als Grundlage für die
Modellerzeugung.
- Datenimport
Die Daten werden über einen automatisierten Prozess aus den bestehenden Datenquellen
importiert. Dazu muss zu einem definierten Zeitpunkt der Import von sich täglich erneuernden
Daten in das Archiv durchgeführt werden.
- Datenarchivierung
Die importierten Daten aus den jeweiligen Datenquellen werden im Archiv abgelegt. Dazu wird in
Tabellen ein Datensatz erzeugt, der mit neuen Daten aktualisiert wird, ohne die bereits
bestehenden Daten zu überschreiben. Die Daten werden dabei nach dem jeweiligen Datum
sortiert.
- Datenexport
Nach der Datenarchivierung besteht die Möglichkeit, die sortierten Daten als solche wieder ohne
Bearbeitung für einen Datenexport bereitzustellen. Dies gewährleistet für Dritte, Daten im Archiv
abzulegen und anschließend wieder auslesen zu können.
- Datenanalyse
Die in das Archiv importierten Daten können im Anschluss für eine Datenanalyse genutzt werden.
Dazu lassen sich Analysealgorithmen auf die Datensätze anwenden, die Vorhersagemodelle
erzeugen. Diese Modelle können anschließend zu Prognosezwecken verwendet werden.
- Modellbereitstellung
Die erzeugten Modelle können anschließend für Anfragesteller bereitgestellt werden. Dazu ist es
möglich, auf die zur Archivierung gesendeten Daten eine Anfrage zur Modellerstellung zu stellen.
Diese Anfrage wird im Anschluss bearbeitet und das Modelle wird dem Benutzer zur Verfügung
gestellt.
1.5.1 Architektur zur Technologieauswahl
In Abbildung 1.7 wird die DAvE-Architektur dargestellt, welche aus zwei Ebenen besteht. Die unterste
Ebene ist die Archivierungsebene, welche die Datenbank enthält. Als Datenbank wird Apache
Cassandra verwendet. Auf der obersten Ebene befindet sich die Verarbeitungsebene, welche den
Message Broker, das Datenflow Management und das maschinelle Lernen umfasst. Apache Kafka stellt
in der DAvE-Architektur den Message Broker dar. Für das Datenflow- Management wird Apache NiFi
eingesetzt und für das maschinelle Lernen Scikit-Learn wird Scikit-Learn verwendet. Außerhalb der
DAvE-Architektur befinden sich die Datenquellen. Es werden Klimadaten vom Deutschen Wetterdienst
sowie die Daten vom Low-Voltage Simulator (LVS) genutzt. Mit dem LVS werden Smart Meter-Daten
generiert, welche für die DAvE-Architektur verwendet werden.

Seite 7 von 10
Der automatisierte Datenimport des DAvE-Systems wird von NiFi gesteuert. Des Weiteren lädt NiFi die
temporären Klimadaten vom Deutschen Wetterdienst über deren FTP-Server herunter und archiviert
täglich die aktuellsten Werte in Cassandra. Die Daten vom LVS werden vor der Archivierung in einem
eigenen Kafka Broker geschrieben. Dieser wird dann von der NiFi Komponente angenommen, sodass
die Daten bzw. Messages, welche sich im Kafka Broker befinden, in Cassandra archiviert werden.
Weiterhin steuert NiFi die Datenübermittlung zwischen Cassandra und Kafka.
Bei einer Datenanfrage wird der NiFi-Prozess gestartet, indem die bestimmten Daten, welche
angefragt wurden, abgerufen und verarbeitet werden. Danach werden diese in einem Kafka Topic
abgelegt. Der Datenanfrager kann somit auf das Topic zugreifen, um an die Daten zu gelangen.
Das maschinelle Lernen wird eingesetzt, um Modelle zu erzeugen. Dabei werden die archivierten
Daten aus Cassandra für die Verwendung der Modelle genutzt. Die erstellen Modelle werden
anschließend in ein Predicitive Model Markup Language (PMML)-Modell umgewandelt. Diese werden
danach in Cassandra archiviert und können abgerufen werden.
1.5.2 Systemkomponenten
- Mosaik ist ein Open Source Framework für die automatische Erstellung von großflächigen Smart
Grid Simulationen für unterschiedliche Szenarien. Dabei werden Verbrauchsdaten in einem Netz
aus Smart Metern und Smart Meter Gateways generiert. Die Daten werden als COSEM-formatierte
XML-Dateien empfangen und archiviert.[1]
Abb. 1.7: Architektur der Systemkomponenten

Seite 8 von 10
- Apache NiFi ist ein Framework, mit dem komplexe Datenworkflows umgesetzt werden können.
Dazu werden Importmechanismen von Daten aus unterschiedlichen Datenquellen zur Verfügung
gestellt und darüber hinaus Transformationsmöglichkeiten bereitgestellt. Über ein User-Interface
können die Dataflows durch eine Verknüpfung von Prozessoren konfiguriert, gestartet und
überwacht werden.[2]
- Apache Kafka ist ein Open Source Projekt für die Verarbeitung von Datenströmen. Dazu wurden
Mechanismen zu Speicherung und Verarbeitung von Datenströmen entwickelt und es wird eine
Schnittstelle zum Laden und Exportieren von Datenströmen zu Drittsystemen bereitgestellt. Kafka
ist ein verteiltes System, welches durch Skalierbarkeit und Fehlertoleranz ausgezeichnet wird und
sich deshalb überwiegend für Big-Data-Anwendungen eignet.[3]
- Scikit Learn ist eine freie Bibliothek für maschinelles Lernen, die Algorithmen für
Klassifizierungen, Regressionen und Clustering bereitgestellt. Es stellt einfache und effiziente
Tools für Data-Mining und Data-Analyse zur Verfügung, sodass verschiedene Vorhersagemodelle
aus Support-Vector-Machines, Random Forest, Neuronalen Netzen oder der Linearen Regression
erstellt werden können.[4]
- Apache Cassandra ist ein einfaches, verteiltes Datenbankverwaltungssystem für große und
strukturierte Datenbanken. Es zeichnet sich durch eine hohe Skalierbarkeit und Ausfallsicherheit
bei verteilten Systemen aus. Cassandra ist darüber hinaus die am meisten verbreitete
spaltenorientierte NoSQL-Datenbank. In einer Cassandra Datenbank werden die einzelnen
Datensätze in multidimensionalen Hashtables abgelegt, sodass jede Zeile eines Hashtables
beliebig viele Spalten haben kann.[5]
1.6 Mehrwerte durch den Einsatz von DAvE
Es wurden schon frühzeitig die Potentiale von Datenanalysen für Unternehmen erkannt. So können
vor allem die Prozesse zur Leistungserstellung optimiert werden und somit langfristig kosteneffizienter
gestaltet werden. Dadurch werden einerseits Gewinne maximiert und andererseits die
Wettbewerbsfähigkeit und der Unternehmenserfolg zunehmend beeinflusst.
Darüber hinaus können Unternehmen durch prognostiziertes Verhaltensweisen bessere
Entscheidungen treffen. Vor allem für den Energiesektor können spezifische Mehrwerte generiert
werden, von denen Energieerzeuger und -anbieter profitieren können:
- Bedarfsplanung der Ressourcen
Durch die Analyse der Verbraucher und deren Verhaltensweisen kann nahezu genau prognostiziert
werden, welcher Haushalt zu einer bestimmten Tageszeit wieviel Energie benötigt. Die
historischen Daten lassen sich angereichert mit Erfahrungswerten soweit auswerten, dass ein
Verbrauchsmuster erkennbar ist und somit den Bedarf für jede Netzregion spezifisch vorhergesagt
werden kann.
- Effektivitätssteigerung
Anhand der analysierten Wetterdaten ist es möglich, nahezu genau vorherzusagen, wann die
Windgeschwindigkeiten und Sonnenstunden für eine Stromerzeugung geeignet sind. Dadurch
können Stromerzeuger erkennen, zu welchen Tages- und Jahreszeiten mit einer Einspeisung
dieser regenerativen Energieträger zu rechnen ist. Darüber hinaus werden durch die Auswertung
der geografischen Lage dieser Datenquellen Hinweise auf mögliche neue Standorte zur
Energiegewinnung gegeben.

Seite 9 von 10
- Effizienzsteigerung
Energieerzeuger und -anbieter können exakt auslesen, zu welchen Tageszeiten in welchem Netz
Energie verbraucht wird. Dadurch wird es ermöglicht, die Energieerzeugung genauer steuern zu
können und somit auch nur die Energie einzuspeisen, die laut Prognose von den Haushalten
verbraucht wird. Dadurch soll eine Überproduktion von Energie vermieden werden.
- Erstellung von Prognosen
Es werden Prognosen erstellt, die über Energieverbräuche von Haushalten informieren und
Verhaltensmuster aufzeigen. Zusätzlich dazu werden Auskünfte über erwartete Wetterverhältnisse
gegeben, aus denen Prognosen über mögliche Energieerzeugung erstellt werden können. Darüber
hinaus können die Prognosen für Markt- und Verhaltensforschung genutzt werden.
- Transparenz für beteiligte Akteure
Durch die Nutzung der anfallenden Daten ist es möglich, für alle beteiligten Akteure mehr
Transparenz zu schaffen. Somit wissen Energieerzeuger und -anbieter nahezu genau über das
Konsumentenverhalten Bescheid, können sich abstimmen und somit besser auf Bedarfe und
Maxima im Verbrauch reagieren.
- Schnittstellenoffenheit
Das System wurde so konzipiert, dass es möglich ist, externe Daten zu archivieren. Aus den
archivierten Daten können anschließend Analysemodelle erstellt werden, die über diese
Schnittstelle wieder abrufbar sind. Dies wurde bereits in der Praxis erprobt, sodass externe
Datenströme mit Verbrauchsdaten von Haushalten archiviert und ausgewertet wurden.
1.7 Ausblick
Mit dem DAvE-System wird ein Ansatz geschaffen, die gestiegenen Anforderungen an das
Datenaufkommen durch intelligente Messsysteme zu bewerkstelligen. Ferner wird durch die
Verarbeitung der Messwerte aus der Niederspannungsebene eine Möglichkeit geschaffen, aus den
Daten Mehrwerte oder gar datengetriebene Geschäftsmodelle zu entwickeln. Zudem ist es immer
wichtiger, die Daten nicht nur einfach zu speichern, sondern auch ein Nutzen daraus ziehen zu
können. So besteht durch die Digitalisierung der Stromzähler auch auf Konsumentenseite der Bedarf,
über die verbrauchten Energiemengen informiert zu werden. Die Daten können somit aus dem Archiv
abgefragt werden und beispielsweise über ein Letztverbraucherportal zur Verfügung gestellt werden.
Primär bieten die Big Data-Technologien und Data Science-Verfahren Lösungen zur Anfrage- und
Vermarktungsprognosen oder gar eine Integration von externen Daten in die Netzbetriebsführung.
Dies ermöglicht neben möglichen Kosteneinsparungen eine stärkere Kundenindividualisierung bei der
Netzbetriebsführung. Die Daten können für das Netzleitstellenpersonal zusätzlich für neue
Netzplanungen oder neue Mehrwertdienste für Industriekunden nutzbar gemacht werden. Darüber
hinaus können Reaktionszeiten bei gleichzeitiger Steigerung der Häufigkeit und Komplexität von
Eingriffen verkürzt werden. Da das DAvE-System derzeit nur mit simulierten Messdaten arbeitet, bleibt
es spannend zu sehen, wie es sich in Zukunft eine Änderung im Echtbetrieb auswirkt.

Seite 10 von 10
1.8 Literatur
[1] OFFIS. Modulare Simulation aktiver Komponenten im Smart Grid [Online]. Available:
https://www.offis.de/offis/projekt/mosaik.html
[2] Apache Software Foundation. Apache NiFi [Online]. Available: https://nifi.apache.org
[3] L. Berle. (2017, October 17). Apache Kafka – eine Schlüsselplattform für hochskalierbare Systeme [Online]. Available:
https://www.informatik-aktuell.de/betrieb/verfuegbarkeit/apache-kafka-eine-schluesselplattform-fuer-hochskalierbare-
systeme.html
[4] D. Cournapeau. Scikit-learn – Machine Learning in Python [Online]. Available: http://scikit-learn.org/stable/index.html#
[5] M.Jensing, P. Ghadir. (2015, June 17). Apache Cassandra – Für Daten ohne Grenzen [Online]. Available:
https://www.innoq.com/de/articles/2015/06/apache-cassandra/


A ANHANG A.3 Seminararbeiten
A.3. Seminararbeiten
A.3.1. Maged Ahmad - Hadoop ecosystem components: Ambari, HDFS andMapReduce
153

Hadoop ecosystem components:Ambari, HDFS and MapReduce
Seminararbeit im Rahmen der Projectgruppe Big Data Archive
Themensteller: Prof. Dr.-Ing. Jorge Marx GomezBetreuer: M. Eng. & Tech. Viktor Dmitriyev
Dr.-Ing. Andreas SolsbachJad Asswad, M.Sc.
Vorgelegt von: Maged [email protected]
Abgabetermin: 21. Mai 2017

Contents Contents
Contents
List of Figures 3
1 Big Data 4
2 HADOOP 52.1 Hadoop Distributed File System . . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.1 HDFS architecture components . . . . . . . . . . . . . . . . . . . . . 62.2 MapReduce . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.1 MapReduce components . . . . . . . . . . . . . . . . . . . . . . . . . 102.2.2 MapReduce 2.0 (MR v2) . . . . . . . . . . . . . . . . . . . . . . . . 12
2.3 Ambari . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.3.1 Ambari Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.3.2 Hadoop Components Supported by Apache Ambari . . . . . . . . . 15
3 CONCLUSION 16
References 17
2

List of Figures List of Figures
List of Figures
1 Diya Soubra’s multidimensional 3V diagram showing big data’s expansionover time (vgl.[Fra14],S.2.f.) . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 Hadoop ecosystem (vgl.[LKRH15],S.6.f.) . . . . . . . . . . . . . . . . . . . . 63 Block replication (vgl.[B+08],S.7.f.) . . . . . . . . . . . . . . . . . . . . . . . 84 HDFS Archeticture (vgl.[KK14],S.83.f.) . . . . . . . . . . . . . . . . . . . . 85 MapReduce model (vgl.[WSV14],S.13.f.) . . . . . . . . . . . . . . . . . . . . 96 Job submission process (vgl.[WSV14],S.23.f.) . . . . . . . . . . . . . . . . . 117 YARN architecture (vgl.[WSV14],S.25.f.) . . . . . . . . . . . . . . . . . . . 138 Ambari architecture (vgl.[WSV14],S.214.f.) . . . . . . . . . . . . . . . . . . 14
3

1 BIG DATA
1 Big Data
The term ,big data’ is usually overused and misunderstood, because there is no commonly
agreed-upon definition of this term. But ,the big data Problem’ in another meaning the
description of the challenges it represents would be a widely accepted explanations. In
2001, Laney in his Article ,3D data management: controlling data volume, velocity and
variety’ represented the 3’V dimension. These dimensions Volume, Velocity and Variety
are described as follows:(vgl.[LKRH15],S.3.f.)
• Volume: Volume refers to amount of data.
• Velocity: Velocity refers to the speed of data processing.
• Variety: Different types of data and sources of data, for example: unstructured text,
audio, video, images, sensors and etc.(vgl.[LKRH15],S.3.f.)
Figure 1: Diya Soubra’s multidimensional 3V diagram showing big data’s expansion overtime (vgl.[Fra14],S.2.f.)
According to Cox and Ellsworth, which were the first authors to discuss big data in the
context of modern computing, the big data Problem consists of two issues: (vgl.[LKRH15],S.4.f.)
4

2 HADOOP
Big data collections are set of various data, which are independently manageable, but
they are too big to suit on disk, those usually come from various origins, they are in dif-
ferent formats and they are stored in different repositories.(vgl.[LKRH15],S.4.f.)
The difference between the big data objects and collections, the big data objects usually
come from one source, but they are too large individual data, which cannot be processed
on available hardware using standard algorithms. (vgl.[LKRH15],S.4.f.)
Distributed storage system give us a solution to big data collections problem(vgl.[LKRH15],S.4.f.)
To manage this distributed storage system we need a tool, which is wealthy in function-
ality, this tool shall be able to move huge amount of data into the system without los-
ing any piece of data. One of the tools which provides lot of big data requirements is
Hadoop.(vgl.[Fra14],S.3.f.) in this search I will try to clarify what is hadoop ecosystem
and some of his components.
2 HADOOP
Hadoop is a Programming framework used to support the processing of large data sets
in a distributed computing environment. Hadoop was developed by Google’s MapReduce
that is a software framework where an application break down into various parts. The
Current Apache Hadoop ecosystem consists of the Hadoop Kernel, MapReduce, HDFS and
numbers of various components like Apache Hive, Base and Zookeeper. (vgl.[Fra14],S.4.f.)
Doug Cutting hadoop project designer, His son, has a toy called Hadoop, he found that
children are creators by naming things, therefore he call his project as the name of the
toy ,Hadoop’ (vgl.[Whi12],S9.f.)
The project made up of more than one module like Hadoop distributed file system (HDFS),
MapReduce and Yet another Resource Negotiator (YARN).
The Hadoop ecosystem consists of very large collection of projects bank on these module,
the common design of this ecosystem could be characterized in three layers, which are:
Storage layer, processing layer and management layer. Because the ecosystem consists of
very large number of projects, therefore we decided to show some of them not all of them
as shown in Figure 2.(vgl.[LKRH15],S.6.f.)
The Storage layer exist at the bottom layer, HDFS is involved in this layer, and in this
research we will talk more about HDFS.(vgl.[LKRH15],S.6.f.)
The processing layer exists over the storage layer the base of this layer is YARN, in
this layer would the actual analysis happen.(vgl.[LKRH15],S.7.f.)
The management layer exists over the storage layer and consists of various tools for
user interaction, monitoring like Ambari is included in this Layer.(vgl.[LKRH15],S.7.f.)
5

2.1 Hadoop Distributed File System 2 HADOOP
Figure 2: Hadoop ecosystem (vgl.[LKRH15],S.6.f.)
In this research we will speak in more detailed about HDFS, MapReduce and Ambari.
2.1 Hadoop Distributed File System
Hadoop Distributed File System known as HDFS is a file system created to store huge
amount of Data through numerous of nodes, the architecture of the HDFS is master-slave.
The huge amount of data is would be splitted, duplicated and distributed on more than
one device. Duplicating data helps to compute the data quickly efficiently. therefore
HDFS named as ,self-healing’ distributed file system, that’s mean, if a certain amount of
data is got lost or crashed, or by other meaning the DataNode where the data was saved
is down, the Duplicated data would be used instead of the lost one, this way will help to
continue the work without any problem. (vgl.[LKRH15],S.5.f.) (vgl.[KK14],S.82.f.)
2.1.1 HDFS architecture components
NameNode and DataNodes: As mentioned above HDFS has a master/slave architec-
ture. A HDFS cluster include a simple NameNode, a master server control a namespace
which is a file system and organize approaching file form the clients. There are also many
DataNode, normally one DataNode for every node in the cluster, which control the storage
on this nodes. HDFS display a file system called namespace, which admit the user data to
be saved in files. In inside, a file would be divided into one or more block, which would be
saved in the DataNodes. The NameNode implement namespace procedures for example
6

2.1 Hadoop Distributed File System 2 HADOOP
opening, closing and renaming files and directories. It is also responsible for determining
the mapping of blocks for every DataNodes. DataNodes responsibilities are serving the
requests from the file system’s clients like read and write, they also create, delete und du-
plicate blocks depending on NameNode commands.(vgl.[Whi12],S.48.f.) (vgl.[B+08],S.4.f.)
The NameNode and DataNode are parts of a software created to work on goods devices.
These devices usually use a GNU/Linux as operating system. HDFS created in java to suit
any devices which supports java, these devices can run the NameNode or the DataNode
software. Using Java means that HDFS can be used on various number of devices, usually
in the cluster would one NameNode software on one device, other devices would deploy
DataNode software, the architecture does not prevent deploying more than one DataNode
software, but it is seldom to use in real.(vgl.[B+08],S.5.f.)
Actually using one NameNode in the cluster, make the architecture of the system easy.
The NameNode is the warehouse for all HDFS metadata, the system is made thus the
user data wouldn’t flood through the NameNode.(vgl.[B+08],S.5.f.)
The File System Namespace: A traditional hierarchical file organization would be sup-
ported by HDFS, directories and store files inside them could be created from a user or
application, this hierarchy is like to nearly all other current file systems, one file system
namespace can do the following: create, remove, move a file or rename file, the HDFS
architecture prevent implementing features like hard link or soft link, even though HDFS
does not support them.(vgl.[B+08],S.5.f.)
The NameNode is responsible for the file system namespace, in NameNode the file system
namespace would be managed, all the changes in it would be stored by the NameNode.
Also the number of duplicated files that should be managed by HDFS could be determined
by an application. The NameNode saved the number of copies of a file and this named as
replication factor of that file.(vgl.[B+08],S.6.f.)
Data replication: The main purpose of designing HDFS is to save reliably big file in
different devices belong to a large cluster. It saves every single file as a series of blocks,
except the last block all the block in the file are the same size, these blocks are duplicated,
because of the failure problem, for every file the replication factor and the block size
could be configured, determining the number of duplicating of a file by an application, file
creation time could be determined by the replication factor and could be changed later, the
file in HDFS have the feature, that it have one writer and are write-once.(vgl.[B+08],S.6.f.)
All decisions concerning the replication of blocks would be made by the NameNode, it get
regularly Heartbeat and a Blockreport from every DataNode in the cluster, the Blockreport
7
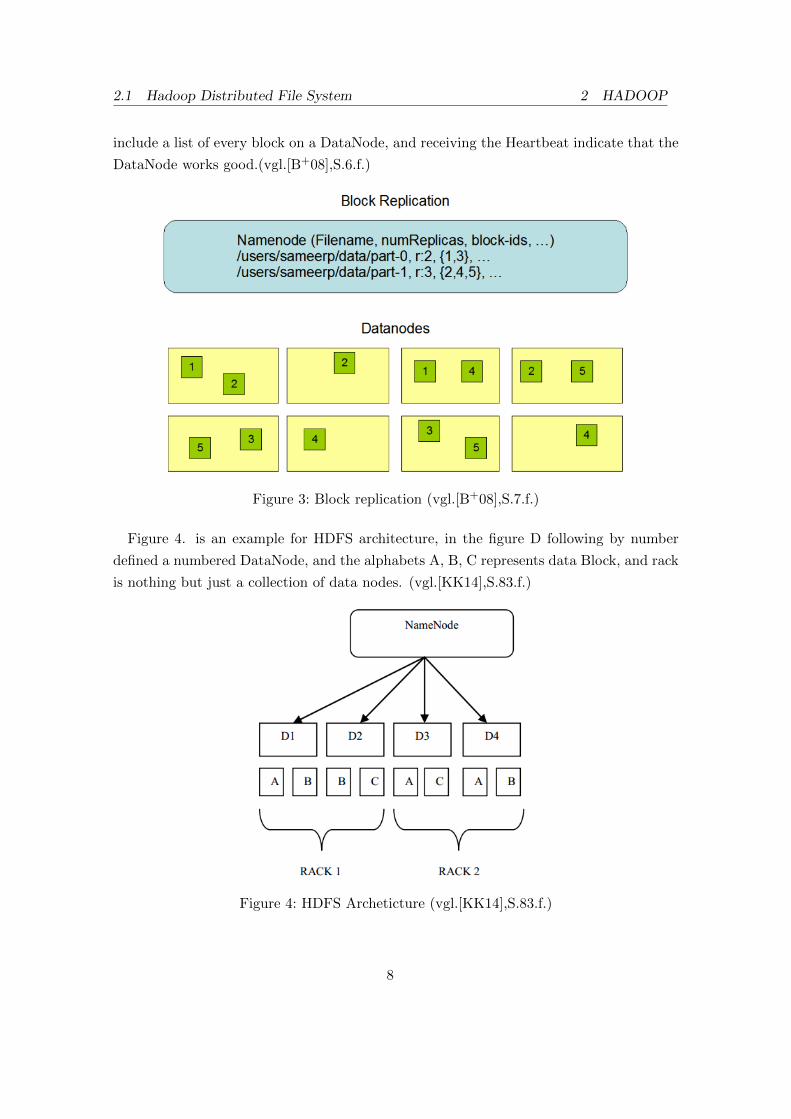
2.1 Hadoop Distributed File System 2 HADOOP
include a list of every block on a DataNode, and receiving the Heartbeat indicate that the
DataNode works good.(vgl.[B+08],S.6.f.)
Figure 3: Block replication (vgl.[B+08],S.7.f.)
Figure 4. is an example for HDFS architecture, in the figure D following by number
defined a numbered DataNode, and the alphabets A, B, C represents data Block, and rack
is nothing but just a collection of data nodes. (vgl.[KK14],S.83.f.)
Figure 4: HDFS Archeticture (vgl.[KK14],S.83.f.)
8

2.2 MapReduce 2 HADOOP
2.2 MapReduce
MapReduce model is supported by Hadoop, this model was brought in by Google to solve
big clusters problems in the devices. This model depends on two functions:(vgl.[WSV14],S.12.f.)
• Map: the function takes key/value pairs as input and generates an intermediate set
of key/value pairs.(vgl.[WSV14],S.12.f.)
• Reduce: the function which merges all the intermediate values associated with the
same intermediate key.(vgl.[WSV14],S.12.f.)
In Hadoop the main idea of MapReduce, that is the data can be split into logical
blocks, and at first every one can be handled by map task, the result can be divided
physically into specific sets, which are saved afterwords, and each one is passed to reduce
task.(vgl.[WSV14],S.12.f.)
Figure 5: MapReduce model (vgl.[WSV14],S.13.f.)
A map task can keep running on any register node on the cluster, and various map tasks
can keep running in parallel over the cluster, the map task is responsible for changing
the input record into key/value sets. The output of the considerable number of maps
9

2.2 MapReduce 2 HADOOP
will be parceled, and each segment will be saved. There will be one parcel for each
reduce task. Each segment’s sorted keys and the values related with the keys are then
prepared by the reduce task. It would be numerous reduce task running in parallel on the
cluster.(vgl.[WSV14],S.13.f.)
Normally, there is four classes would be provided to Hadoop framework, class which will
read the input record and change them into key/value combine per record, mapper class,
reducer class, and the class which will change the key/value combine which are the result
of the reduce task into output records.(vgl.[WSV14],S.13.f.)
2.2.1 MapReduce components
TaskTracker: Runs on individual DataNodes and is in charge of beginning and oversee-
ing singular Map/Reduce tasks. Which would be communicated with the JobTracker. The
TaskTracker, which keeps running on each process node of the Hadoop group, acknowl-
edges demands for individual tasks, for example, Map, Reduce, and Shuffle operations.
Each TaskTracker is arranged with an arrangement of channels that is typically set up
as the aggregate number of cores accessible on the device. At the point when a de-
mand is gotten (from the JobTracker) to dispatch a task, the TaskTracker starts another
JVM for the task. JVM reuse is conceivable, yet real utilization cases of this element
are difficult to find. Most clients of the Hadoop stage essentially turn it off. The Task-
Tracker is doled out a task relying upon what number of free slots it has (add up to
number of tasks= genuine tasks running).The TaskTracker is in charge of sending pulse
messages to the JobTracker. Aside from telling the JobTracker that it is sound, these
messages additionally educate the JobTracker concerning the quantity of accessible free
slots.(vgl.[WSV14],S.17.f.)(vgl.[WSV14],S.23.f.)
JobTracker: One of the master segments, it is in charge of dealing with the general
execution of work. It performs capacities, for example, planning child tasks (singular
Mapper and Reducer) to individual nodes, monitoring the soundness of each task and node,
it also reschedule the break down task. As we will soon illustrate, similar to the NameNode,
the Job Tracker turns into a bottleneck with regards to scaling Hadoop to very big clusters.
At the point when a user presents work to the Hadoop framework, the grouping of steps
appeared in Figure 6. is started.(vgl.[WSV14],S.17.f.)(vgl.[WSV14],S.23.f.)
The procedure is nitty gritty in the accompanying strides:(vgl.[WSV14],S.23.f.)
1. The job demand is gotten by the Job Tracker.(vgl.[WSV14],S.23.f.)
10

2.2 MapReduce 2 HADOOP
Figure 6: Job submission process (vgl.[WSV14],S.23.f.)
2. Most MapReduce jobs require at least one input directories. The Job Tracker asks
for the NameNode for a rundown of DataNodes facilitating the pieces for the records
contained in the rundown of input directories.(vgl.[WSV14],S.23.f.)
3. The JobTracker now gets ready for the job execution. Amid this progression, the
JobTracker decides the quantity of tasks (Map tasks and Reduce tasks) expected to
execute the job. It additionally endeavors to plan the tasks as near the information
blocks as would be possible.(vgl.[WSV14],S.24.f.)
4. The JobTracker presents the tasks to every TaskTracker node for execution. The
TaskTracker node are observed for their wellbeing. They send pulse messages to
the JobTracker node at predefined interims. On the off chance that pulse mes-
sages are not gotten for a predefined length of time, the TaskTracker node is re-
garded to have failed, and the task is rescheduled to keep running on a different
node.(vgl.[WSV14],S.24.f.)
5. When every one of the tasks have finished, the JobTracker refreshes the status of
the job as successful. On the off chance that a specific number of tasks fail more
than once (the correct number is determined through design in the Hadoop setup
11

2.2 MapReduce 2 HADOOP
records), the JobTracker declares a job as failed.(vgl.[WSV14],S.24.f.)
6. Users survey the JobTracker for updates about the Job advance.(vgl.[WSV14],S.24.f.)
The talk so far on Hadoop 1.x components ought to have made it clear that even the
JobTracker is a solitary purpose of failure. On the off chance that the JobTracker goes
down, so does the whole cluster with the running jobs. Additionally there is just a solitary
JobTracker, which builds the heap on a solitary JobTracker in a situation of various jobs
running all the while.(vgl.[WSV14],S.24.f.)
2.2.2 MapReduce 2.0 (MR v2)
MapReduce has experienced a total redesign. The outcome is Hadoop 2.0, which is once
in a while called MapReduce 2.0 (MR v2) or YARN.(vgl.[WSV14],S.24.f.)
MR v2 is application programming interface (API)–compatiblewith MR v1, with only a
recompile step. Be that as it may, the fundamental design has been redesigned totally. In
Hadoop 1.x, the JobScheduler has two noteworthy functions: Resource management and
Job scheduling/job monitoring.(vgl.[WSV14],S.24.f.)
YARN intends to isolate these functions into discrete daemons. The thought is to have
a worldwide Resource Manager and a per–application Application Master. Note, we said
application, not job. In the new Hadoop 2.x, an application can either be a solitary job in
the feeling of the traditional MapReduce work or a Directed Acyclic Graph (DAG) of jobs.
A DAG is a diagram whose nodes are associated so that no cycles are conceivable. That
is, paying little respect to how you navigate a chart, you can’t achieve a node again during
the time spent traversal. In plain English, a DAG of jobs suggests jobs with progressive
connections between each other.(vgl.[WSV14],S.24.f.)
MapReduce v2 or YARN as it is called, have different architecture of the MapReduce v1,
the new components are: Global Resource Manager, Node Manager, Application-specific
Application Master, Scheduler and Container.(vgl.[WSV14],S.24.f.)
A container incorporates a subset of the aggregate number of CPU cores and size of
the principle memory. An application will keep running in set of containers. An Ap-
plication Master example will ask for assets from the Global Resource Manager. The
Scheduler will assign the assets (containers) through the per-node Node Manager. The
Node Manager will then report the utilization of the individual containers to the Resource
Manager.(vgl.[WSV14],S.25.f.)
The Global Resource Manager and the per-node Node Manager shape the administration
framework for the new MapReduce system. The Resource Manager is a definitive expert
for assigning assets. Every application sort has an Application Master. (For instance,
12

2.3 Ambari 2 HADOOP
MapReduce is a sort, and each MapReduce job is an occasion of the MapReduce sort, like
the class and question relationship in object oriented programming). For every utilization
of the application sort, an Application Master example is instantiated. The Application
Master case consults with the Resource Manager for containers to execute the jobs. The
Resource Manager uses the scheduler (worldwide part) working together with the per-node
Node Manager to apportion these assets. From a framework point of view, the Application
Master additionally keeps running in a container.(vgl.[WSV14],S.25.f.)
Figure 7: YARN architecture (vgl.[WSV14],S.25.f.)
2.3 Ambari
A web-based tool for provisioning, managing, and monitoring Apache Hadoop clusters
which includes support for Hadoop HDFS, Hadoop MapReduce, Hive, HCatalog, HBase,
ZooKeeper, Oozie, Pig and Sqoop. Ambari also provides a dashboard for viewing cluster
health such as heatmaps and ability to view MapReduce, Pig and Hive applications vi-
sually along with features to diagnose their performance characteristics in a user-friendly
manner.(vgl.[WSV14],S.214.f.)(vgl.[WSV14],S.399.f.)
13

2.3 Ambari 2 HADOOP
2.3.1 Ambari Architecture
Figure 8: Ambari architecture (vgl.[WSV14],S.214.f.)
Ambari agents, Ambari server and Ambari web are major components of Ambari.(vgl.[WSV14],S.215.f.)
Ambari agents are the Ganglia screens (gmond) which runs on separate hosts that
gather measurements.(vgl.[WSV14],S.215.f.)
Ambari server is in charge of gathering data gotten from each host through the Ganglia
monitors which runs on them. The Ambari server has the accompanying parts:(vgl.[WSV14],S.215.f.)
Postgres RDBMS which saves the cluster setup.(vgl.[WSV14],S.215.f.)
Authorization provider which could be integrated with an organizational authenti-
cation/authorization provider like the LDAP service.(vgl.[WSV14],S.215.f.)
Optional Nagios service which would support alerts and notifications.(vgl.[WSV14],S.215.f.)
REST API would be integrated with the web front-end Ambari Web. The REST
API can likewise be utilized by custom applications.(vgl.[WSV14],S.215.f.)
14

2.3 Ambari 2 HADOOP
Ambari Web is the online interface for the clients.(vgl.[WSV14],S.215.f.)
2.3.2 Hadoop Components Supported by Apache Ambari
Ambari supports various number of Hadoop components some of them:
HDFS: NameNodes, secondary NameNodes and DataNodes would be allowed to be
administered by Ambari(vgl.[WSV14],S.399.f.).
MapReduce: Ambari deals with the default settings for MapReduce. Review that in
YARN, MapReduce jobs are controlled by a MapReduce Application Master that is be-
gun for each employment. This Application Master utilizes these default settings when it
begins a job unless they are abrogated by the job submitter.(vgl.[WSV14],S.399.f.)
Some other Hadoop components which supports Ambari: Hive, Pig, HCatalog, HBase and
etc.(vgl.[WSV14],S.399.f.)
Installing Apache Ambari: 64-bit versions of the following systems is supported by
Ambari: Redhat Enterprise Linux (RHEL) 5 and 6, CentOS 5 and 6, Oracle Enterprise
Linux (OEL) 5 and 6 and SuSE Linux Enterprise Server (SLES) 11.(vgl.[WSV14],S.401.f.)
Ambari does not support windows operating systems, therefore you should install VM to
try out Ambari which is provided by Hortonworks. The following steps explain how to
install Ambari using VMs:(vgl.[WSV14],S.401.f.)
1. Download and install VirtualBox.
2. Download the Hortonworks Sandbox, which is the VM that comes installed with the
Hortonworks distribution of Hadoop 2.x.
3. Import and start the Hortonworks Sandbox through your VirtualBox.
4. Go to http://localhost:8888 and complete the registration process.
5. Click Enable Ambari.
6. Go to http://localhost:8080 and enter the default username/password as admin/
admin. You are now inside the Ambari UI.
7. Ambari monitors the Hadoop 2.x instance running in the sandbox.
(vgl.[WSV14],S.401.f.)
15

3 CONCLUSION
3 CONCLUSION
The paper starts with introduction about Big Data , which bring a lot of benefits to
business, then in this paper we talk about Hadoop, which is one of the solutions for Big
Data problem, then we talk about Hadoop ecosystem like HDFS , MapReduce, MapReduce
v2 (YARN) and lastly about Ambari and how could we use it and install it to our systems.
16

References References
References
[B+08] Dhruba Borthakur et al. HDFS architecture guide. Hadoop Apache Project,
53, 2008.
[Fra14] Michael Frampton. Big Data made easy: A working guide to the complete
Hadoop toolset. Apress, 2014.
[KK14] Amogh Pramod Kulkarni and Mahesh Khandewal. Survey on Hadoop and
Introduction to YARN. International Journal of Emerging Technology and
Advanced Engineering, 4(5):82–87, 2014.
[LKRH15] Sara Landset, Taghi M Khoshgoftaar, Aaron N Richter, and Tawfiq Hasanin.
A survey of open source tools for machine learning with big data in the Hadoop
ecosystem. Journal of Big Data, 2(1):24, 2015.
[Whi12] Tom White. Hadoop: The definitive guide. ” O’Reilly Media, Inc.”, 2012.
[WSV14] Sameer Wadkar, Madhu Siddalingaiah, and Jason Venner. Pro Apache Hadoop.
Apress, 2014.
17

References References
Abschließende Erklarung
Ich versichere hiermit, dass ich meine Diplomarbeit / Individuelle Projekt ...(Titel der
Arbeit)... selbstandig und ohne fremde Hilfe angefertigt habe, und dass ich alle von
anderen Autoren wortlich ubernommenen Stellen wie auch die sich an die Gedankengange
anderer Autoren eng anlegenden Ausfuhrungen meiner Arbeit besonders gekennzeichnet
und die Quellen zitiert habe.
Oldenburg, den May 21, 2017 Maged Ahmad
18

A.3 Seminararbeiten A ANHANG
A.3.2. Julian Brunner - Methoden von Data Mining und Machine Learning
172

Methoden von Data Mining undMachine Learning
Seminararbeit im Rahmen der Projektgruppe Big Data Archive
Themensteller: Prof. Dr.-Ing. Jorge Marx GomezBetreuer: M. Eng. & Tech. Viktor Dmitriyev
Dr.-Ing. Andreas SolsbachJad Asswad, M.Sc.
Vorgelegt von: Julian BrunnerWesterdeich 5828197 [email protected]
Abgabetermin: 21. Mai 2017

Inhaltsverzeichnis Inhaltsverzeichnis
Inhaltsverzeichnis
Abbildungsverzeichnis III
1 Einleitung 1
2 Einfuhrung 22.1 Definitionen und Begriffsabgrenzungen . . . . . . . . . . . . . . . . . . . . . 22.2 Ablauf einer Datenanalyse . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
3 Methoden und Algorithmen 43.1 Klassifikation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
3.1.1 k-Nearest Neighbour . . . . . . . . . . . . . . . . . . . . . . . . . . . 53.1.2 Entscheidungsbaume . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
3.2 Cluster-Analyse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93.2.1 Partitionierende Clusterbildung . . . . . . . . . . . . . . . . . . . . . 93.2.2 Dichtebasiertes Clustern . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.3 Assoziationsanalyse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133.3.1 A-Priori-Algorithmus . . . . . . . . . . . . . . . . . . . . . . . . . . 13
4 Fazit 15
Literaturverzeichnis IV
II

Abbildungsverzeichnis Abbildungsverzeichnis
Abbildungsverzeichnis
1 k-Nearest Neigbour . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52 k-Nearest Neighbour (Ausgangswerte) . . . . . . . . . . . . . . . . . . . . . 63 k-Nearest Neigbour (Zielwerte) . . . . . . . . . . . . . . . . . . . . . . . . . 74 k-Nearest Neighbour (nominale Werte) . . . . . . . . . . . . . . . . . . . . . 75 Dichtebasiertes Clustern . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
III

1 EINLEITUNG
1 Einleitung
Die Menge an Informationen und Daten ist in den letzten Jahren stetig gestiegen. Laut
Runkler (vgl. [Run15], S. V) verdoppeln sich die Informationen in der Welt etwa alle 20
Monate. Jede Sekunde werden Millionen von Daten gemessen, erhoben und gespeichert.
Der Grund der Datensammlung besteht nicht zuletzt darin, dass die Speicherung dieser
Daten durch den zunehmenden technologischen Fortschritt stetig gunstiger wird. Zum
anderen wird selbstverstandlich auch ein Nutzen erwartet, wodurch bestenalls ein Wett-
bewerbsvorteil generiert werden soll. Sowohl in unserem beruflichen als auch im privaten
Umfeld werden Daten gesammelt. Hierzu zahlen beispielsweise Unternehmensdaten, Fi-
nanztransaktionsdaten, Daten zur Steuerung von Prozessen, sowie Verbraucherdaten. Um
daraus den o.g. Nutzen erzielen zu konnen, sind Datenanalysen und -auswertungen not-
wendig. Ziel von Datenanalysen ist es, Daten zu nutzen, um relevante Informationen zu
finden, diese zu strukturieren, neue Erkenntnisse zu gewinnen, Ursachen und Wirkungen
zu erkennen, sowie Forecasts zu entwickeln und entsprechend optimale Entscheidungen zu
treffen. Sowohl fur die Datenanalyse als auch zur Sammlung, Vorbereitung und Nutzung
der Daten werden viele unterschiedliche Modelle und Algorithmen aus Bereichen wie z.B.
Statistik, maschinelles Lernen, Musterkennung oder kunstlicher Intelligenz herangezogen.
Wird nun die zunehmende Wichtigkeit von Datenanalysen fur die Entscheidungsfindung
berucksichtigt, ist es nicht verwunderlich, dass die Anzahl der Unternehmen, die sich mit
der Erhebung und Auswertung von Daten beschaftigen, stetig steigt. Die Daten und daraus
ableitbaren Informationen sind mittlerweile zu einer Handelsware und einem Produktions-
faktor geworden (vgl. [CL16], S. V; vgl. [Run15], S. V).
Angesichts des Themas unserer Projektgruppe (”Big Data Archive: Data Science zu
Energiewende“) ist auch eine Einordnung in den Energiesektor notwendig. Denn hier
spielen genaue Vorhersagen sowohl fur die Energieverbrauche als auch fur schwanken-
de Einspeisungen aus erneuerbaren Energien eine wichtige Rolle fur die optimale Pla-
nung und Durchfuhrung des Ressourceneinsatzes. Auf Grundlage dieser Prognosen werden
die Energie und Leistung ermittelt und breitgestellt, die zur Deckung des nachgefragten
Bedarfs benotigt werden. Aufgrund des wachsenden Anteils von erneuerbaren Energien
und der damit verbundenen flukturierender Einspeisung aus dezentralen Erzeugungsan-
lagen (z.B. aus Windkraft und Photovoltaik) steigen die technischen Herausforderungen
fur Energieversorgungssysteme. In Anbetracht der kontinuierlichen Weiterentwicklung von
Informations- und Kommunikationstechnologien, sind detailliertere Informationen uber die
zeitlichen und raumlichen Aspekte zu Verbrauch und Erzeugung (z.B. Industrie und Haus-
halt) und uber exogene Einflussgroßen (z.B. Windgeschwindigkeit und Sonneneinstrah-
1

2 EINFUHRUNG
lung) verfugbar. Diese erhohte Verfugbarkeit von detaillierteren Informationen ermoglicht
es neue Prognose- und Optimierungsverfahren zu gestalten. Durch die individuellen Ver-
brauchsverhalten entstehen verschiedene Verbrauchsmuster mit speziellen charakteristi-
schen Eigenschaften, wodurch passende Prognosemethoden abgeleitet werden konnen. An
diesem Punkt spielen besonders Big-Data-Anwendungen und Data Mining-Methoden eine
entscheidende Rolle, denn die Basis einer optimalen Prognose ist eine vorab durchzufuhren-
de und umfassende Datenanalyse um die genannten charakteristischen Eigenschaften zu
identifizieren (vgl. [Ins17]).
2 Einfuhrung
2.1 Definitionen und Begriffsabgrenzungen
Durch die großen Mengen an Daten reicht heutzutage eine manuelle Auswertung in der
Regel nicht mehr aus. Selbst die Statistik stoßt haufig an ihre Grenzen. Deshalb werden
weitere Datenanalyse-Techniken benotigt, mit denen in Daten nach Mustern und Zusam-
menhangen gesucht wird. Diese Vorgehensweise ist Gegenstand des Data Minings (vgl.
[CL16], S. 2). Der Begriff Data Mining hat als Ziel, Wissen aus Daten zu extrahieren (vgl.
[FPSS96], S. 1). Wissen definiert sich in diesem Zusammenhang als interessante Muster,
die allgemein gultig, nicht trivial, neu, nutzlich und verstandlich sind (vgl. [Run15], S.
2). Aus diesem Grund ist die direkte Ubersetzung”Abbau von Daten“ etwas irrefuhrend,
denn es geht beim Data Mining nicht um die Generierung von Daten selbst, sondern um
die Generierung von Wissen aus bereits vorhandenen Daten (vgl. [HK00], S.5).
Data Mining beinhaltet Techniken aus vielen Forschungsgebieten. Letzten Endes ba-
sieren alle Analyse-Verfahren des Data Minings auf der Mathematik, insbesondere die
Statistik steuert viele Ansatze zur Datenanalyse bei. Die Kunstliche Intelligenz stellt in
erster Linie Techniken fur die Darstellung der Ergebnisse bereit, wie beispielsweise die
Reprasentation von Wissen als logische Formeln und Regeln. Eine andere Art der Ergeb-
nisdarstellung ist die Visualisierung als Grundlage zur Nutzung oder Bewertung. Nicht
zuletzt stellt das Gebiet der Datenbanken eine weitere Disziplin des Data Minings dar,
denn dadurch wird erst die Verwaltung von großen Datenmengen ermoglicht (vgl. [CL16],
S. 11f.).
Oftmals wird Data-Mining auch mit dem Begriff Business Intelligence (BI) in Verbin-
dung gebracht. Unter BI wird der effektive und effiziente Umgang mit dem in einem Unter-
nehmen verfugbaren Wissen verstanden, mit dessen Hilfe man versucht Wettbewerbsvor-
teile zu erreichen. Die Aufgaben umfassen dabei Wissensgewinnung, Wissensverwaltung
2

2.2 Ablauf einer Datenanalyse 2 EINFUHRUNG
und Wissensverarbeitung. BI im engeren Sinne wird durch Kernapplikationen definiert,
die eine Entscheidungsfindung direkt unterstutzen, wie z.B. Online Analytical Processing
(OLAP), Management Information Systems (MIS) und Executive Information Systems
(EIS). Im weiteren Sinne umschließt das BI alle Anwendungen mit denen Analysen durch-
gefuhrt oder vorbereitet werden, wozu u.a. auch das Data Mining zahlt (vgl. [CL16], S.3f.).
Somit kann Business Intelligence als Oberbegriff des Data Minings angesehen werden (vgl.
[Cha16]).
Ebenfalls eng verwandt ist das Thema Maschinelle Lernen. Im Gegensatz zum Data
Mining liegt der Fokus weniger auf dem Erkennen neuer Muster in Daten als vielmehr
auf die Entwicklung geeigneter Modelle zur Entdeckung bekannter Muster in neuen Da-
ten. Dennoch sind die verwendeten Methoden in beiden Fallen stark deckungsgleich (vgl.
[CFZ09], S.1). Das maschinelle Lernen ist nicht nur im Datenbankbereich relevant, sondern
auch im Gebiet der kunstlichen Intelligenz, was insbesondere den Lernaspekt anspricht.
Dies lasst sich anhand des Beispiels der Gesichtserkennung verdeutlichen: Menschen erken-
nen ihnen bekannte Personen anhand ihrer Gesichter. Dies geschieht allerdings unbewusst
ohne dabei erklaren zu konnen, wie man es tut. Somit ist es unmoglich den Ablauf in
Worte zu fassen und ein Programm dafur zu schreiben. Allerdings ist bekannt, dass ein
Gesicht eine gewisse Struktur aufweist. Augen, Mund und Nase an bestimmten Stellen
im Gesicht ergeben ein Muster, welches sich aus unterschiedlichen Kombinationen dieser
Bestandteile zusammensetzt. Werden nun Beispielbilder eines Gesichtes analysiert, erfasst
ein Lernprogramm das fur diese Person spezifische Muster und erkennt die Person anhand
eines gegebenen Bildes nach genau diesem Muster. Maschinelles Lernen bedeutet also,
Modelle mit bestimmten Parametern zu optimieren. Lernen heißt in diesem Kontext, ein
Programm auszufuhren, um die Parameter unter Verwendung von Trainingsdaten oder
Erfahrungswerten zu optimieren (vgl. [Alp08], S. 2f.).
2.2 Ablauf einer Datenanalyse
Nach Fayyad et al. [FPSS96] ist Data Mining Teil eines ubergeordneten Prozesses, der als
Knowledge Discovery in Databases (KDD) bezeichnet wird. Beide Begriffe werden haufig
synonym verwendet, wobei genau genommen Data Mining lediglich den Teil des gesam-
ten KDD-Prozesses darstellt, in dem die eigentliche Mustererkennung erfolgt (Piatetsky-
Shapiro 2007). In der ersten Phase des KDD-Prozesses (Selektion) erfolgt die Auswahl
des Datenbestandes, der fur die gewahlte Aufgabenstellung relevant ist. In der Phase
der Vorverarbeitung wird dieser Zieldatenbestand nun bereinigt. Um etwaige Datenqua-
litatsmangel zu beseitigen, werden fehlerhafte oder fehlende Werte werden notfalls entfernt
3

3 METHODEN UND ALGORITHMEN
oder ersetzt. Des weiterem kann der Datenbestand durch weitere Attribute angereichert
werden, sofern es die Aufgabenstellung verlangt. In der dritten Phase, der Transforma-
tion, werden die Daten in Abhangigkeit von dem gewahlten Analyseverfahren benotigte
Form uberfuhrt. Hierzu zahlt bspw. die Gruppierung von metrischen Werten in Interval-
le. Anschließend geschieht das eigentliche Data Mining, in dem geeignete mathematische
Verfahren angewendet werden, um die im Datenbestand vorhandenen und bislang un-
bekannten Muster zu erkennen. Erst in der letzten Phase wird durch Interpretation der
gefundenen Muster Wissen generiert, das auf Verwendbarkeit hin zu evaluieren ist. Sollte
die Aufgabenstellung nicht ausreichend gelost werden konnen, ist ein Rucksprung in eine
der vorherigen Phasen moglich (vgl. [FPSS96], S. 6).
3 Methoden und Algorithmen
Die Verfahren im Data Mining werden anhand ihrer Ziele unterschieden. So konnen die ver-
schiedenen Ansatze in Klassifikation, Regression, Clustering, Generalisierung und Assozia-
tionsanalyse unterteilt werden (vgl. [Gee14], S.10). Beim maschinellen Lernen wird meist
nur zwischen uberwachten Lernen, wobei die Ausgabewerte bekannt sind, und unuber-
wachten Lernen, mit nicht bekannten Ausgabewerten, unterschieden. Die Klassifikation
und die Assoziationsanalyse fallen dabei unter die Kategorie uberwachtes Lernverfahren.
Das Clustering hingegen wird als unuberwachtes Lernverfahren eingeordnet (vgl. [Bis09],
S. 2; vgl. [HCXY07], S. 56).
3.1 Klassifikation
Das Ziel der Klassifikation ist die Einteilung der Daten in Klassen anhand von Klassifika-
tionsmerkmalen. Auf Grundlage von einer vorgegebenen Trainingsmenge an Datensatzen,
bei denen das Klassifikationsmerkmal bekannt ist, wird durch Klassifikationsalgorithmen
ein Modell entwickelt. Modelle konnen z.B. Klassifikationsregeln oder Entscheidungsbaume
sein. Dieses Modell wird anschließend an Testdaten, bei denen ebenfalls die Klassifikation
bekannt ist, gepruft und gegebenenfalls korrigiert, bis es fur die Testdaten nur noch eine
geringe Fehlerquote aufweist. Man spricht hierbei von einem uberwachten Lernverfahren,
da fur den Lernprozess sowohl die Klassen als auch die Zugehorigkeit der Trainings- und
Testobjekte vorher bekannt ist. In der Anwendungsphase kann das Klassifikationsmodell
nun neue Datensatze, fur die noch keine Klassenzugehorigkeit vorliegt, in Klassen ein-
ordnen. Die Wichtigkeit des Lernprozesses besteht darin zu erkennen, inwiefern die gege-
benen Eigenschaften die Klassenzuordnung beeinflussen. Eindeutige Klassenzuordnungen
4

3.1 Klassifikation 3 METHODEN UND ALGORITHMEN
mussen nicht zwangslaufig gewunscht sein. So ist auch oftmals die Wahrscheinlichkeit fur
die Zugehorigkeit von Interesse, wodurch ein Objekt unter Umstanden zu mehreren Klas-
sen zugeordnet werden kann (mit unterschiedlichen Wahrscheinlichkeiten) (vgl. [CL16],
S.59ff.).
Bei der Klassifikation gibt es zwei unterschiedliche Vorgehensweisen. Die instanzenba-
sierten Verfahren ermitteln die Klassifikation anhand des ahnlichsten Objekts aus der Trai-
ningsmenge. Der zweite Ansatz berechnet anhand der Trainingsdatensatze ein Modell, mit
dessen Hilfe neue Datensatze klassifiziert werden. Die Trainingsdatensatze werden danach
nicht weiter benotigt (vgl. [CL16], S.83).
3.1.1 k-Nearest Neighbour
Ein Beispiel fur instanzenbasierte Verfahren ist das k-Nearest Neighbour-Verfahren. Vor-
erst werden alle Beispielobjekte gespeichert. Die neuen Objekte werden klassifiziert, indem
die Ahnlichkeit zu den Beispielobjekten berechnet wird (Abstands- und Ahnlichkeitsma-
ße). Ausschlaggebend sind die k Objekte, die zu dem neuen Objekt am ahnlichsten sind.
Anschließend wird ermittelt welche Klasse bei diesen k Nachbarn am haufigsten vorkommt.
In Abbildung 1 soll fur das Objekt ◦ die Klasse bestimmt werden (⊕ oder •). Fur k = 1
gilt, klasse(◦) = •, fur k = 5 gilt, klasse(◦) = ⊕ (vgl. [CL16], S.83).
Abbildung 1: k-Nearest NeigbourQuelle: vgl. [CL16], S. 84
Entscheidend fur das Ergebnis ist somit die Wahl von k, was vor allem bei Ausreißern
problematisch ist (vgl. [HKP12], S. 327). Daher ist es von Vorteil mehrere Varianten mit
unterschiedlichen k zu berechnen und die vorhergesagten Klassen zu vergleichen (vgl.
[CL16], S.83).
5

3.1 Klassifikation 3 METHODEN UND ALGORITHMEN
Algorithmus
1. Lernschritt: Sei f(x) die zu erlernende Funktion, speichere jedes Trainingsbeispiel
(x, f(x)) in einer Liste Trainingsbeispiele.
Fur die unterschiedlichen Arten von Datentypen gibt es nun unterschiedliche Klassifikati-
onsschritte. Fur diskrete Funktionen gilt folgender Klassifikationsschritt:
2. Klassifikationsschritt: Sei V = v1, v2, ..., vm die endliche Menge der Werte, die das
Zielattribut annehmen kann und y das zu klassifizierende Beispiel.
a) Fur alle xi aus der Menge der Trainingsbeispiele berechne die Ahnlichkeit zu y.
b) Wahle die k Beispiele aus, die zu y am ahnlichsten sind.
c) Die Klasse fur y berechnet sich aus:
klasse(y) = maxv∈V
k∑
p=1
δ(v, f(xp)
Die Funktion klasse berechnet die Klasse, die unter den k ahnlichsten Beispielen am
haufigsten vorkommt und ordnet sie dem Objekt y zu (vgl. [CL16], S.85).
Im folgenden Beispiel soll der neue Datensatz in die Einkommensklasse: hoch, mittel oder
gering klassifiziert werden. Zuerst wird zu jedem Beispieldatensatz die Distanz bestimmt.
Fur dieses Beispiel eignet sich die euklidische Distanz:
distE(v, w) =
√∑
i
(vi − wi)2
Abbildung 2: k-Nearest Neighbour (Ausgangswerte)Quelle: vgl. [CL16], S.86
6
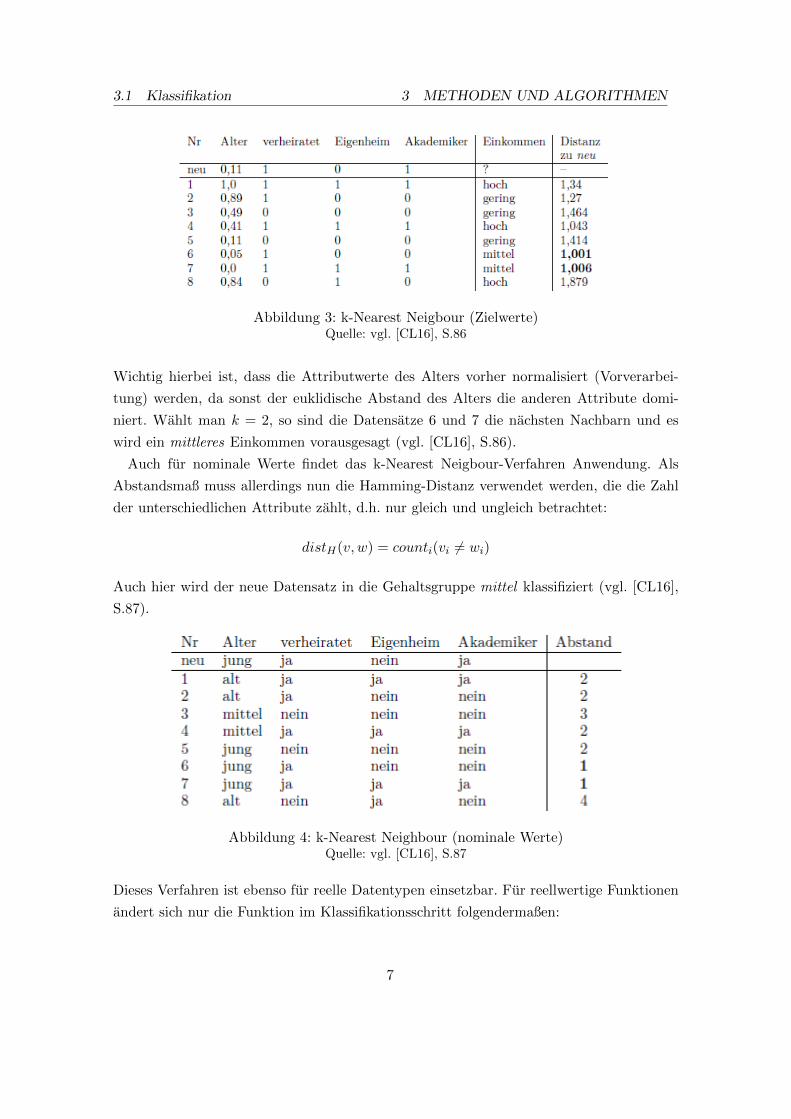
3.1 Klassifikation 3 METHODEN UND ALGORITHMEN
Abbildung 3: k-Nearest Neigbour (Zielwerte)Quelle: vgl. [CL16], S.86
Wichtig hierbei ist, dass die Attributwerte des Alters vorher normalisiert (Vorverarbei-
tung) werden, da sonst der euklidische Abstand des Alters die anderen Attribute domi-
niert. Wahlt man k = 2, so sind die Datensatze 6 und 7 die nachsten Nachbarn und es
wird ein mittleres Einkommen vorausgesagt (vgl. [CL16], S.86).
Auch fur nominale Werte findet das k-Nearest Neigbour-Verfahren Anwendung. Als
Abstandsmaß muss allerdings nun die Hamming-Distanz verwendet werden, die die Zahl
der unterschiedlichen Attribute zahlt, d.h. nur gleich und ungleich betrachtet:
distH(v, w) = counti(vi 6= wi)
Auch hier wird der neue Datensatz in die Gehaltsgruppe mittel klassifiziert (vgl. [CL16],
S.87).
Abbildung 4: k-Nearest Neighbour (nominale Werte)Quelle: vgl. [CL16], S.87
Dieses Verfahren ist ebenso fur reelle Datentypen einsetzbar. Fur reellwertige Funktionen
andert sich nur die Funktion im Klassifikationsschritt folgendermaßen:
7

3.1 Klassifikation 3 METHODEN UND ALGORITHMEN
2. Klassifikationsschritt:
c) Der Zielattributwert fur y ergibt sich aus:
f ′(y) =
∑kp=1 f(xp)
k
Der Zielwert fur y berechnet sich demnach aus dem Mittelwert der k nachsten Nachbarn.
Zu beachten ist, dass hierbei keine Zuordnung in eine Klasse stattfindet, sondern ein
numerischer Wert berechnet wird. Deshalb handelt es sich um keine Klassifikation mehr,
sondern um eine numerische Vorhersage (vgl. [CL16], S.87f.).
3.1.2 Entscheidungsbaume
Entscheidungsbaume ordnen sich in die Klasse der modellbasierten Klassifikationsverfah-
ren ein (vgl. [CL16], S.83). Als Basis werden Trainingsdatensatze mit bekannter Klassen-
zugehorigkeit benotigt. Der Baum wir derart gestaltet, dass in jedem Knoten ein Attri-
but abgefragt und eine Entscheidung getroffen wird, bis ein Blatt erreicht wird. An den
Blattern kann schließlich die Klassifikation abgelesen werden. Schwierigkeit dieses Ver-
fahrens ist, dass auf jeder Ebene des Baumes entschieden werden muss, welches Attribut
zugewiesen wird (vgl. [Ulr01], 27f.).
ID3-Algorithmus
An der Fragestellung des Auswahlproblems knupft der ID3-Algorithmus (Induction of De-
cision Trees) an. Dieser basiert auf einem Maß fur den Informationsgehalt eines Attributs.
Der Informationsgehalt berechnet sich wiederum durch die Entropie (Maß fur Unordnung).
Eine niedrige Entropie entspricht dabei einem hohen Informationsgehalt des Baumes. Fur
das Auswahlproblem wird in jedem Schritt die Entropie aller Attribute errechnet. Anhand
des Attributs mit der niedrigsten Entropie wird der Baum anschließend geteilt und fur
jede mogliche Auspragung ein Ast gebildet. Dieses Verfahren endet, wenn es sich bei allen
Knoten um homogene Knoten handelt. Homogene Knoten sind Blatter, dessen Beispiel-
datensatze identische Attributwerte haben (vgl. [Ulr01], S. 28f.).
Falls numerische Werte verwendet werden, mussen die Werte anhand von Schwellenwer-
ten in Klassen eingeteilt werden. Dies hat den Grund, dass zu viele Auspragungen den
Baum sehr stark anwachsen lassen, was die Ubersichtlichkeit stark beeintrachtigt (vgl.
[Ulr01], S. 29.). Anhand von Entscheidungsbaumen lassen sich leicht Klassifikationsregeln
ableiten, welche in der Regel folgende Form haben: WENN Bedingung UND Bedingung
DANN Folgerung (vgl. [CL16], S. 72).
8

3.2 Cluster-Analyse 3 METHODEN UND ALGORITHMEN
3.2 Cluster-Analyse
Wie der Name bereits vermuten lasst, ist das Ziel der Clusteranalyse eine Menge an Da-
ten in Cluster (Teilmengen) zu zerlegen. Dabei sollen die Objekte innerhalb eines Cluster
moglichst ahnlich zueinander sein und Objekte verschiedener Cluster zueinander moglichst
unahnlich. Fur die Clusterbildung werden, wie schon bei der Klassifikation, Abstandsmaße
zur Berechnung der Ahnlichkeit verwendet (vgl. [CL16], S. 57). Das Clustering wird ohne
vorheriges Training direkt auf die zu verarbeitenden Daten angewandt. Deshalb wird auch
von einem unuberwachten Lernverfahren gesprochen (vgl. [HKP12], S. 444). Neben dem
Clustering existiert außerdem der Ansatz der Generalisierung, der zum Ziel hat, die Merk-
male von Daten auf wenige aussagekraftige Merkmale zu reduzieren. Oftmals wird dieser
Ansatz zur Vorverarbeitung genutzt, um numerische Datentypen nominal abzubilden. Fur
das Cluster-Verfahren gibt es mehrere Kategorisierungen. Zum einen die partitionierende
Clusterbildung, welche den Abstand zwischen Daten und Mittelpunkt bzw. eines reprasen-
tativen Punkts in der Mitte minimiert und anhand dessen die Cluster bildet. Eine zweite
Variante ist die dichtebasierte Clusterbildung, die neben der Distanz auch die Dichte der
Daten berucksichtigt Zudem existieren die Varianten der hierarchischen Clusterbildung
(vgl. [Gee14], S. 11f.). Diese beschranken sich jedoch auf wenige tausend Elemente (vgl.
[CL16], S. 137). Daher wird, durch die hohe Anzahl an Daten in unserem Projekt, nicht
weiter auf die hierarchische Clusterbildung eingegangen.
3.2.1 Partitionierende Clusterbildung
Bei der partitionierenden Clusterbildung wird eine (beliebige) Anfangspartitionierung von
k Clustern gewahlt. Daraus werden die Objekte schrittweise zwischen den Clustern um-
geordnet, sodass sich die Qualitat der Gruppierung stetig verbessert. Je nach Wahl des
Verfahrens wird dazu in jedem Rechendurchlauf fur jedes Cluster der Centroid (Mittelwert
der Objekte) oder der Medoid (typischer Vertreter des Clusters) berechnet. Im Anschluss
werden alle Objekte dem Cluster zugeordnet, welches sie am nachsten sind. Das Verfahren
ist abgeschlossen, wenn die Qualitat der Partitionierung nicht weiter verbessert werden
kann, d.h. kein Objekt mehr einem anderen Cluster zugeordnet wird. Wichtig ist, dass
jedes Cluster aus mindestens einem Objekt besteht, wobei jedes Objekt hochstens einem
Cluster zugeordnet sein darf (vgl. [CL16], S. 135f.). Die Qualitat eines Clusters kann uber
eine Kostenfunktion beschrieben werden:
Kosten(Ci =∑
x∈Ci
dist(x, x)
9

3.2 Cluster-Analyse 3 METHODEN UND ALGORITHMEN
k-Means-Algorithmus
Bei diesem Algorithmus wird der Centroid fur jedes Cluster berechnet, also der Mittelwert
aller enthaltenen Objekte. Im Prinzip sieht der Algorithmus folgendermaßen aus:
PROCEDURE k-Means
Erzeuge (zufallig) k Anfangscluster Ci
DO
Bestimme Centroide x1, x2, . . . , xk der Cluster
Berechne neue Zuordnung aller x aus Eingabedaten zu Clustern Ci
IF (|x− xi| < |x− xj |) // Es existiert ein x, welches naher zu einem anderen
Mittelpunkt xi als zum aktuellen Cluster Cj(xj) ist
Ordne x Ci zu
tauschErfolgt = true
ELSE
tauschErfolgt = false
WHILE (tauschErfolgt = true)
END k-Means
Vorteile des k-Means ist, dass es leicht zu implementieren ist, da es prinzipiell nur aus Ab-
standsberechnungen und Neuzuordnungen besteht. Entgegen der Vermutungen, dass viele
Iterationen fur die optimale Partitionierung gebraucht werden, zeigt die Praxis, dass die
Anzahl der Iterationen vergleichsweise klein ist. Nachteile liegen in dem hohen Rechenauf-
wand, da bei jedem Schritt alle Distanzen neu berechnet werden mussen. Zudem hangt die
Anzahl der Iterationen stark von den gewahlten Initialclustern ab. Ein weiteres Problem
liefern Ausreißer, da jedes Objekt in die Berechnung des Centroiden einfließt (vgl. [CL16],
S.141).
k-Medoid-Algorithmus
Dieser Algorithmus ist dem k-Means-Algorithmus sehr ahnlich. Der Unterschied besteht
darin, dass anstelle des Mittelwertes ein Element der Eingabedatenmenge als Reprasen-
tant eines Clusters dient. Dies hat zum Vorteil, dass dieses Verfahren unempfindlicher
gegen Ausreißer ist. Um die optimale Partitionierung zu finden, werden stetig die Me-
doide getauscht um die Qualitat der Cluster zu erhohen (vgl. [CL16], S. 148). Stellt sich
nun die Frage inwiefern die”besten“ Medoide gefunden werden konnen. Einer der ersten
Algorithmen war der PAM-Algorithmus (Partitioning Around Medoids). PAM fuhrt eine
vollstandige Suche nach den besten Medoiden durch, indem er eine komplette Matrix mit
den Distanzen zwischen den Objekten berechnet. Dadurch lassen sich zwar gute Cluster
finden, jedoch steigt der Aufwand mit hohen Datenmengen stark an (vgl. [KR05], S. 123).
10

3.2 Cluster-Analyse 3 METHODEN UND ALGORITHMEN
Deshalb kann dieser Algorithmus fur unser Projekt als eher ungeeignet angesehen werden.
Ein anderes Verfahren ist der CLARANS-Algorithmus (Clustering Large Applications
based on RANdomized Search), der die kompletten Daten durchsucht, sondern zufallsba-
siert nur eine Teilmenge berucksichtigt. Dafur mussen zwei Parameter festgelegt werden.
Zum einen muss festgelegt werden, wie oft nach einer guten Cluster-Bildung gesucht wird.
Zum anderen wie viele Versuche des Vertauschens eines Medoids mit einem Nichtmedi-
od maximal erlaubt sind, ohne dass eine Verbesserung eintritt. Das CLARANS-Verfahren
verzichtet auf eine Vollstandigkeit, wodurch schneller ein Ergebnis erzielt werden kann
(vgl. [NH94], S. 145).
Zu den partitionierenden Verfahren gehoren ebenso diejenigen, die Daten anhand von
Wahrscheinlichkeiten zu einen oder auch mehreren Clustern zuordnen. Jedoch nimmt man
bei diesen Verfahren an, dass die Daten aus einem Zufallsexperiment entstanden sind. Da
dies nicht auf die zu bearbeitenden Daten in unserem Projekt zutrifft, konnen solche
Verfahren vernachlassigt werden (vgl. [CL16], S. 153).
3.2.2 Dichtebasiertes Clustern
Die bisher betrachteten Verfahren konnen Cluster, wie sie in Abbildung 5 dargestellt sind,
nur schlecht erkennen. Diese Daten weisen raumlich stark unterschiedliche Strukturen auf.
Wie der Name schon sagt, werden bei dichtebasierten Clusterverfahren neben dem Abstand
auch die Menge an Daten, die innerhalb eines bestimmten Radius liegen, berucksichtigt.
Der Radius ε und die Mindestanzahl an Nachbarobjekten muss vorher festgelegt werden
(vgl. [CL16], S. 160).
Abbildung 5: Dichtebasiertes ClusternQuelle: vgl. [CL16], S. 138
11

3.2 Cluster-Analyse 3 METHODEN UND ALGORITHMEN
DBScan-Algorithmus
Ein klassischer Algorithmus ist der DBScan-Algorithmus [EKSX96], der folgendermaßen
aufgebaut ist:
PROCEDURE DBSCAN(DB, ε, MinimumPunkte)
clusterId = 0
Kennzeichne alle x ∈ DB als unklassifiziert
FORALL x ∈ DB
IF x unklassifiziert
IF expandiere(DB, x, clusterId, MinimumPunkte)
clusterId++
END DBScan
PROCEDURE expandiere(DB, x, clusterId, MinimumPunkte, ε)
Set = {y ∈ DB|dist(x, y) ≤ ε}IF (Set.size < MinimumPunkte)
Kennzeichne x als noise
RETURN false
FORALL y ε Set
Kennzeichne y mit clusterId
Losche x aus Set
FORALL z ε Set
Set2 = {y ∈ DB|dist(z, y) ≤ ε}IF (Set2.size ≥ MinimumPunkte)
FORALL s ε Set2
IF s gehort zu keinem Cluster (unklassifiziert oder noise)
IF s unklassifiziert
Fuge s in Set ein
Markiere s mit clusterid
Losche z aus Set
RETURNtrue
END expandiere
Zu Beginn werden alle Objekt als unklassifiziert gekennzeichnet. Es wird mit einem belie-
bigen Objekt begonnen und die Objekte, die in der ε-Umgebung liegen, in Set eingefugt.
Falls die Anzahl der Nachbarobjekte zu gering ist, wird das Objekt als”noise“ gekenn-
zeichnet. Andernfalls entsteht ein neues Cluster. Als nachstes wird fur alle Nachbarobjekte
(Objekte aus Set) gepruft, ob diese auch genugend Nachbarobjekte besitzen (Set2 ). Dieser
12

3.3 Assoziationsanalyse 3 METHODEN UND ALGORITHMEN
Algorithmus setzt sich solange fort, bis alle Objekte klassifiziert sind. Bei dem DBScan
konnen drei verschiedene Arten von Punkten erkannt werden:
1. Objekte, die in ihrer Umgebung die Mindestanzahl an Nachbarobjekte besitzen,
werden Kernobjekte genannt.
2. Objekte, die von einem Kernobjekt erreicht werden, aber selber nicht die Mindestan-
zahl an Nachbarobjekten erreichen. Diese Objekte bilden den Rand des Clusters.
3. Rauschpunkte (noise), die weder von Kernobjekten erreicht werden, noch selber
genugend Nachbarobjekte besitzen.
Vorteile von dichtebasierten Verfahren ist die automatische Berechnung der Clusteranzahl.
Außerdem konnen Cluster erkannt werden, die raumlich starke Unterschiede aufweisen.
Problematisch wird es bei der optimalen Wahl der Parameter, da diese die Bildung der
Cluster stark beeinflussen (vgl. [CL16], S.160ff.).
3.3 Assoziationsanalyse
Ziel einer Assoziationsanalyse ist das Finden von Regeln, die zwischen mehreren Elemen-
ten gelten. Assoziationsregeln sind den Regeln aus der Klassifikation ahnlich, wobei sich
die Vorhersagen nicht auf das Zielattribut beschrankt, sondern Zusammenhange zwischen
beliebigen Attributen gesucht werden. Die Assoziationsanalyse fallt unter die Kategorie
uberwachtes Lernverfahren, da Regeln anhand von Beispieldaten abgeleitet werden. For-
mal wird eine Datenmenge von Transaktionen betrachtet, wobei jede Transaktion aus einer
Menge einzelner Elemente besteht. Eines der wichtigsten Verfahren zur Erzeugung von As-
soziationsregeln ist der A-Priori-Algorithmus [AS94], auf dem auch andere Algorithmen
aufbauen (vgl. [Gee14], S. 18; vgl. [CL16], S. 176).
3.3.1 A-Priori-Algorithmus
Ziel dieses Algorithmus ist es, Frequent Itemsets zu finden. Unter Items konnen beliebige
Objekte verstanden werden. Frequent Itemsets sind somit Mengen von Objekten, dessen
relative Haufigkeit (Support) einen vorher festgelegten minimalen Schwellwert uberschrei-
ten. Der Support ist die Anzahl der Transaktionen, die das Item bzw. Itemset als Teilmenge
enthalten, im Verhaltnis zur Gesamtzahl der Transaktionen. Beispielsweise ist die Menge
{Brot, Butter, Wasser}, bei einem minimalen Support von 5% ein Frequent Itemset, wenn
diese Dreier-Kombination in mindestens 5% aller Einkaufe vorkommt. Der Algorithmus
kann in zwei Schritte aufgeteilt werden:
13

3.3 Assoziationsanalyse 3 METHODEN UND ALGORITHMEN
1. Das Finden von Frequent Itemsets mit ausrechendem Support
2. Die Erzeugung von Assoziationsregeln aus allen Frequent Itemsets
Begonnen wird im ersten Schritt mit dem Finden von einelementigen Frequent Intemsets
und der Berechnung des jeweiligen Supports. Ist der Support kleiner als der Schwell-
wert, wird der Kandidat verworfen. Im zweiten Durchlauf werden aus den einelementigen
Frequent Itemsets zweielementige und im dritten dreielementige Itemsets gebildet. Diese
Iteration (Join-Phase) wird solange fortgefuhrt, bis keine Frequent Itemsets mehr gefun-
den werden, die den Schwellwert ubersteigen. Der Algorithmus verbindet alle (k − 1)-
elementigen Itemsets, die sich nur in einem Element unterscheiden, miteinander, sodass
k-elemtige Itemsets entstehen. In der Pruning-Phase wird fur jeden k-elementigen Kandi-
daten gepruft, ob jede (k − 1)-elementige Teilmenge auch ein Frequent-Itemset war. Falls
nicht, wird der k-elementige Kandidat entfernt. Um das Laufzeitverhalten zu verbessern,
wird die Monotonieeigenschaft der Itemsets verwendet: A ⊂ B → supp(A) ≥ supp(B).
Sie besagt, dass der Support nicht kleiner werden kann, wenn aus einem Frequent Itemset
ein Item herausgenommen wird. Erfullt also ein einelementiges Itemset den geforderten
Support nicht, so kann ein Set, das dieses Item enthalt, den Support auch nicht erfullen.
Hat man z.B. die zwei Frequent Itemsets {A,B,C} und {A,C,D} so konnte daraus das
Frequent Itemset {A,B,C,D} gebildet werden. Allerdings ist bekannt, dass {B,C,D} kein
Dreier-Frequent-Set war, so kann {A,B,C,D} wegen der Monotonie auch kein Frequent
Itemset sein. Folgender Ablauf verdeutlicht den Algorithmus zur Generierung der Fre-
quent Itemsets (FIS):
PROCEDURE GenerateFIS(minSupp, setOfItems)
FIS1 = {{x} | supp({x}) ≥ minSupp} // Berechne alle FIS der Große 1
k=1
WHILE FISk 6= ∅k++
Berechne FISk = {a ∪ b | a, b ∈ FISk−1, | a ∪ b |= k} // Join-Phase
FORALL c ∈ FISk // Pruning-Phase
IF (x ⊂ c existiert mit | x |= k − 1 und x /∈ FISk−1)losche c in FISk
FORALL c ∈ FISk // Support erfullt?
IF (supp{c} < minSupp)
losche c in FISk
RETURN⋃
i FISi
END GenerateFIS
14

4 FAZIT
Im zweiten Schritt werden aus den Frequent Itemsets Regeln erzeugt. Dazu wird jedes Fre-
quent Itemset X in zwei nichtleere Teilemengen A und X \A zerlegt. Zum Beispiel konnte
fur das Set X = {a, b, c, d} die Regel (a, b) → (c, d) abgeleitet werden. Fur jede Regel
muss anschließend gepruft werden, ob sie die minimale Konfidenz erfullt. Die Konfidenz
misst, wie oft die Regel zutrifft, in Relation zur Anzahl, wie oft sie hatte zutreffen mussen.
Sie berechnet also die Sicherheit einer Regel. Wie sicher eine Regel mindestens sein soll,
muss vor der Analyse festgelegt werden (vgl. [CL16], S. 176ff.).
Interessant fur unser Projekt konnte moglicherweise auch die zeitliche Abhangigkeit von
Transaktionen sein. Dafur werden die einzelnen Elemente der Transaktionen lediglich als
binare Variablen gespeichert, da fur Sequenzmuster quantitative Werte unbedeutend sind.
Lediglich der zeitliche Aspekt ist fur die Analyse von Interesse (vgl. [Got], S. 51).
4 Fazit
Es existieren eine Vielzahl vom moglichen Methoden und Algorithmen, mit denen sich ei-
ne erfolgreiche Datenanalyse durchfuhren lasst. Berucksichtigt man die hohen Datenmen-
gen mit denen wir im Zuge unseres Projektes arbeiten werden, lassen sich diesbezuglich
bereits einige Algorithmen ausschließen. Verfahren wie der PAM-Algorithmus oder die
hierarchische Clusterbildung konnen demnach bereits vernachlassigt werden, da diese sich
auf eine geringe Anzahl von Datensatzen beschranken. Auch Entscheidungsbaume konnen
sehr schnell unubersichtlich werden, wenn Daten eine hohe Attributmenge mit vielen un-
terschiedlichen Auspragungen besitzen. Ein entscheidender Faktor fur eine erfolgreiche
Datenanalyse ist eine gute Vorverarbeitung der Daten. Fur die meisten Verfahren ist es
zwingend erforderlich, dass die Daten in einer bestimmten Form vorliegen. Wird die Vor-
verarbeitung der Daten vernachlassigt, kann dies starke Auswirkungen auf die Ergebnisse
der Analyse haben. Auch auf die richtige Auswahl der Paramater der einzelnen Methoden
muss geachtet werden. Neben Qualitatsverlusten kann die falsche Wahl der Parameter
auch die Laufzeit der Verfahren stark beeinflussen. Des weiteren weisen alle Methoden
gewissen Starken und Schwachen auf. Daher variieren die geeigneten Verfahren je nach
Aufgabenstellung und vorliegenden Daten.
Neben den Verfahren, die in dieser Ausarbeitung vorgestellt wurden, gibt es naturlich
noch eine große Menge weiterer Ansatze, wie z.B. neuronale Netze. Allerdings ginge eine
Betrachtung weiterer Ansatze uber den Umfang dieser Ausarbeitung hinaus. Betrachtet
wurden deshalb Ansatze, die grundlegend fur das Verstandnis weiterer Verfahren sind.
15

Literatur Literatur
Literatur
[Alp08] Ethem Alpaydin. Maschinelles Lernen. Oldenbourg, Muenchen, 2008.
[AS94] Rakesh Agrawal and Ramakrishnan Srikant. Fast algorithms for mining asso-
ciation rules in large databases. Proceedings of the 20th International Confe-
rence on Very Large Data Bases, pages 487–499, 1994.
[Bis09] Christopher M. Bishop. Pattern recognition and machine learning. Springer,
New York, NY, corrected at 8. printing 2009 edition, 2009.
[CFZ09] Bertrand Clarke, Ernest Fokoue, and Hao Helen Zhang. Principles and theo-
ry for data mining and machine learning. Springer, Dordrecht; Heidelberg;
London; New York, 2009.
[Cha16] Peter Chamoni. Data mining, 2016.
[CL16] Juergen Cleve and Uwe Laemmel. Data Mining. De Gruyter, Berlin, 2nd ed.
edition, 2016.
[EKSX96] Martin Ester, Hans-Peter Kriegel, Joerg Sander, and Xiaowei Xu. A density-
based algorithm for discovering clusters in large spatial databases with noise.
Proceedings of the Second International Conference on Knowledge Discovery
and Data Mining, pages 226–231, 1996.
[FPSS96] Usama M. Fayyad, Gregory Piatetsky-Shapiro, and Padhraic Smyth. From
data mining to knowledge discovery: an overview. In Gregory; Smyth Padhraic
Fayyad, Usama M.; Piatetsky-Shapiro, editor, Advances in knowledge discovery
and data mining, pages 1–34. AAAI Press, Menlo Park, Calif., 1996.
[Gee14] Dennis Geesen. Maschinelles Lernen in Datenstrommanagementsystemen, vo-
lume 27. OlWIR Oldenburger Verl. fuer Wirtschaft Informatik und Recht,
Edewecht, 2014.
[Got] Christian Gottermeier.
[HCXY07] Jiawei Han, Hong Cheng, Dong Xin, and Xifeng Yan. Frequent pattern mining:
Current status and future directions. Journal of Data Mining and Knowledge
Discovery, 15(1):55–86, 2007.
[HK00] Jiawei Han and Micheline Kamber. Data mining: Concepts and techniques.
Morgan Kaufmann, San Francisco, [nachdr.] edition, 2000.
IV

Literatur Literatur
[HKP12] Jiawei Han, Micheline Kamber, and Jian Pei. Data mining: Concepts and
techniques. Elsevier/Morgan Kaufmann, Amsterdam, 3. ed. edition, 2012.
[Ins17] Fraunhofer Institut. Zeitreihenanalyse und prognosen fuer den energiemarkt,
2017.
[KR05] Leonard Kaufman and Peter J. Rousseeuw. Finding groups in data: An intro-
duction to cluster analysis. Wiley-Interscience, Hoboken, NJ, 2005.
[NH94] Raymond T. Ng and Jiawei Han. Efficient and effective clustering methods
for spatial data mining. Proceedings 20th Int. Conf. Very Large Data, pages
144–155, 1994.
[Run15] Thomas A. Runkler. Data Mining: Modelle und Algorithmen intelligenter Da-
tenanalyse. Springer Vieweg, Wiesbaden, 2., aktualisierte auflage edition, 2015.
[Ulr01] Christian Ulrich. Grundbegriffe des Data Mining aufbereitet fur eine
Datenbank-Vorlesung. 2001.
V

Literatur Literatur
Abschließende Erklarung
Ich versichere hiermit, dass ich meine Seminararbeit selbstandig und ohne fremde Hilfe
angefertigt habe, und dass ich alle von anderen Autoren wortlich ubernommenen Stellen
wie auch die sich an die Gedankengange anderer Autoren eng anlegenden Ausfuhrungen
meiner Arbeit besonders gekennzeichnet und die Quellen zitiert habe.
Oldenburg, den 15. Januar 2018 Julian Brunner
VI

A.3 Seminararbeiten A ANHANG
A.3.3. Alexander Eguchi - Vorstellung von bestehenden Big Data Architekturen
194

Vorstellung von bestehenden BigData Architekturen
Seminararbeit im Rahmen der Projektgruppe Big Data Archive
Themensteller: Prof. Dr.-Ing. Jorge Marx GomezBetreuer: M. Eng. & Tech. Viktor Dmitriyev
Dr.-Ing. Andreas SolsbachJad Asswad, M.Sc.
Vorgelegt von: Alexander EguchiSemesteranschriftWohnort: 26127 OldenburgTelefonnummer: 0174/[email protected]
Abgabetermin: 22. Mai 2017

Abbildungsverzeichnis Abbildungsverzeichnis
Abbildungsverzeichnis
1. Lambda-Architektur nach [MW15] . . . . . . . . . . . . . . . . . . . . . . . 62. Das Drei-Stufen-Architektur nach [JWW+16] . . . . . . . . . . . . . . . . . 83. Referenzarchitektur nach ([VS14]) fur die Langzeitarchivierung . . . . . . . 10
2

A EINLEITUNG
A. Einleitung
Big Data ist nicht nur ein Modewort der Informatik oder Wirtschaftsinformatik. Big Data
beschreibt die Moglichkeit aus allen internetfahigen Geraten, aus Sensoren oder aus dem
Konsumverhalten von Kunden einen mogliches Vorhersagemodell uber das Verhalten von
Objekten zu erzeugen. Der beispielhafter Mehrwert fur Unternehmen als auch fur Indus-
trien liegt dabei auf einer besseren Planung von Ressourcen und Arbeitsprozessen. Dazu
mussen die richtigen Daten gesammelt und mit gute Funktionen ausgewertet werden, um
die Daten korrekt zu interpretieren. Mit diesem Hintergrund soll die Projektgruppe”Big
Data Archive“ im gleichnamigen Modul an der Carl von Ossietzky Universitat Oldenburg
eine Archivierungsarchitektur entwickeln und implementieren, um auf historische Daten
zugreifen zu konnen, damit die Funktionen fur Vorhersagen verbessert werden konnen.
Genauer sollen erste mogliche Szenarien beschrieben werden, um auf die historische Daten
zuruck zugreifen und mogliche Handlungsempfehlungen zu formulieren. Außerdem sollen
die historischen Daten an weitere Anwendungen zur Analyse geliefert werden.
A.1. Ziel dieser Arbeit
Innerhalb der Projektgruppe”Big Data Archive“ soll mit dieser Seminararbeit ein Uber-
blick uber bestehende Archivierungsarchitekturen im Big Data Kontext gegeben werden,
um Daten zu archivieren, zu analysieren und zu visualisieren. Des Weiteren soll mit die-
ser Arbeit ein moglicher Ansatz fur die weitere konzeptionelle Entwicklung innerhalb der
Projektgruppe aufgezeigt werden.
A.2. Aufbau
Im folgenden Abschnitt wird die Struktur dieser Arbeit vorgestellt. Diese Seminararbeit
setzt sich aus insgesamt drei Kapiteln zusammen. Im Kapitel”Grundlagen“ werden not-
wendige Sachverhalte im Bereich von Big Data erlautert. Das Kapitel”Architekturen “
befasst sich mit unterschiedlichen Architekturen zur Archivierung und allgemein mit Ar-
chitekturen im Big Data Kontext. Die Seminararbeit wird durch ein Fazit und ein Ausblick
abgeschlossen.
3

B GRUNDLAGEN
B. Grundlagen
Dieses Kapitel erklart einige grundlegende Sachverhalte. Dazu wird im Abschnitt B.1 zu-
erst allgemein auf das Thema Big Data eingegangen. Im Anschluss wird Big Data zu den
traditionellen relationalen Datenbanken abgegrenzt. Der Abschnitt B.2 erlautert nicht-
relationalen Datenbanken und NoSQL Datenbanken. Dabei wird das CAP-Theorem vor-
gestellt und ebenfalls erlautert.
B.1. Big Data
Heutzutage konnen Datenquellen die unterschiedlichsten Formen annehmen. Die Daten
werden nicht nur durch Sensoren und menschliche Aktivitaten produziert, Datenbanken
konnen als Datenquellen verwendet werden (vgl.[WU12], S. 7ff). Diese zwei Aspekte wer-
den im Big Data Kontext beschrieben und sind Bestandteil der Abgrenzung von Big Data
zu traditionellen Datenbanksystemen. Im Big Data Kontext sind die Datensatze sehr groß
und/oder heterogen. Sie konnen als strukturierte oder unstrukturierte Daten vorkommen.
Das fuhrt dazu, dass traditionelle Datenbankwerkzeuge nicht mehr mit den Datensatze
umgehen konnen. Zusatzlich mussen die Informationen teilweise in Echtzeit oder nahe
Echtzeit verarbeitet und die Ergebnisse prasentiert werden konnen (vgl. [Fra15], S. 3ff ).
Die 3V ’s wurden, in ihrer ursprunglichen Form genutzt, um Big Data einzugrenzen und
zu der traditionellen Datenbanksystemen abzugrenzen. Die 3V’s beschreiben:
Velocity beschreibt die Geschwindigkeit mit der Daten gesendet werden. Die Geschwin-
digkeit kann sich zwischen den genutzten Datenquellen unterscheiden.
Variety beschreibt die Datenvielfalt der ankommenden unstrukturierten und strukturier-
ten Daten.
Volume beschreibt die Menge der gesendeten Daten.
Die 3V’s ermoglichen eine Abgrenzung von Big Data zu traditionellen Datenbankma-
nagementsystem (DBMS), zusatzlich zu den 3V’s schließt Big Data unter anderem auch
die Verarbeitung, Speicherung, Analyse der Datensatze mit ein (vgl. [Fra15], S. 3ff ). Zu
der ursprunglichen Form der 3V’s sind zwei Kriterien, die Veracity (Richtigkeit) und
Value (Wert) hinzugekommen (vlg.[DLM14], S. 104). Veracity umfasst die Qualitat von
Datenquellen und der Datensatze verstanden. Value beschreibt den Wert der gesammelten
Daten im Zusammenhang mit der Nutzung der Daten. Wie bereits erwahnt wird Big Data
nicht nur durch die 5V’s beschrieben.
4

B.2 Nicht relationale Datenbanken und NoSQL B GRUNDLAGEN
Weiterhin umfasst Big Data nach [DLM14] auch 1. neue Datenmodelle, 2. neue Daten-
analysemethoden, 3. neue Infrastrukturen und Werkzeuge, sowie 4. die Quellen und Ziele
der Rohdaten und 5. Datenstrome.
B.2. Nicht relationale Datenbanken und NoSQL
Der Paradigmenwechsel von traditionellen relationalen DBMS zu verteilten Datenbanken
forderte neue Konsistenzmodelle und Datenbankarchitekturen. Der Umgang von immer
großer werdenden Datenmengen konnte nach [Gra15] nicht mehr von einem einzigen Sys-
tem bewaltigt werden. Große Datenmengen mussen weiterhin in einer annehmbaren Zeit
verarbeitet werden, auf Grund dessen wurden die Daten auf mehrere Systeme verteilt und
auch gespeichert . Die Verteilung der Arbeit hatte zur folge das nicht mehr den AKID
(ACID)-Eigenschaften befolgt werden konnten(vgl. [Gra15]).
In verteilten Datenbanksystemen ein Konsistenz-Eigenschaften einzusetzen, wurde das
CAP-Theorem formuliert. Das Prinzip, das mit dem CAP-Theorem verfolgt wird, ist eine
eventuelle Konsistenz der Datenbanken herzustellen (vgl. [Kle15], 2ff). Die Eigenschaften
des CAP-Theorem sind:
C: Konsistenz (Consistency) beschreibt die Eigenschaft das jeder Nutzer die selben Sicht
auf die Daten hat (vgl. [Kle15], 3f).
A: Verfugbarkeit (Availability) beschreibt die kontinuierliche Verbindung der Datenban-
ken innerhalb der Infrastruktur und wie Ausfallsicher die Verbindungen sind (vgl.
[Kle15], 2f).
P: Ausfalltoleranz (Partition tolerance) beschreibt den Kommunikationsausfall uber
einzelne Knoten in einer Infrastruktur, wenn ein Knoten in einem Netzwerk ausfallt
und das Gesamtsystem in zwei disjunkte Teile zerfallt (vgl. [Kle15], 4f).
Diese Eigenschaften kann eine sog. eventuelle Konsistenz hergestellt werden. Eine even-
tuelle Kosistenz beschreibt die Erreichung von zwei dieser Eigenschaften bei der Auswahl
von verteilten Datenbanksystemen (vgl. [Kle15], 5f).
B.3. Zusammenfassung
In diesem Kapitel wurde auf den Begriff Big Data eingegangen und zu relationalen DBMS
abgegrenzt. Im Anschluss wurde auf nicht-relationale Datenbanken erlautert. Im Verlauf
wurde das CAP-Theorem vorgestellt.
5

C ARCHITEKTUREN
C. Architekturen
Im folgenden Abschnitt werden unterschiedliche Big Data Architekturen vorgestellt. Zu-
erst wird im Abschnitt C.1 die Lambda-Architektur nach [MW15] vorgestellt. Aufbauend
darauf wird im Abschnitt C.2 auf eine Agent-basierte Variante der Lambda-Architektur
eingegangen. Im Abschnitt C.3 wird die Drei-Stufen-Architektur betrachtet, die bereits
als analytisches Big Data Framework im Energiesektor akzeptiert wurde. Am Ende dieses
Kapitels wird eine Referenzarchitektur fur die Langzeitarchivierung vorgestellt.
C.1. Lambda Architektur
Es existieren einige sehr unterschiedliche Ansatze die Daten zu speichern, zu analysieren
und zu visualisieren. Die Lambda-Architektur erfullt weitestgehend Eigenschaften die von
Big Data Architekturen erwunscht werden (vgl. [MW15], S 7ff). Nach [MW15] umfasst die
Lambda-Architektur drei Ebenen. Die erste Ebene ist der Batch-Layer, gefolgt von dem
Serving-Layer und der Speed-Layer. Die Layer bieten Dienste an die nachfolgenden Layer
an. Der Serving-Layer und Speed-Layer konnen Dienste fur Anwendungen bereitstellen.
Abbildung 1: Lambda-Architektur nach [MW15]Quelle: vgl. [MW15], S. 19
Die Abbildung 1 illustriert die grundlegende Architektur nach [MW15]. Der Daten-
strom ausgehend von aktiven und passiven Datenquellen wird dupliziert und parallel an
6

C.2 Multi-Agenten-basierte Lambda-Architektur C ARCHITEKTUREN
den Batch-Layer und an den Speed-Layer ubermittelt. Die Aufgabe des Speed-Layer ist
es die ankommenden Daten unverzuglich bereitzustellen. Der Batch-Layer archiviert die
ankommenden Daten in einem Datenbanksystem. Der Serving-Layer speichert die Daten
von oft genutzten Queries sog. Views und bietet diese als Ergebnis den nachfolgenden An-
wendungen an (vgl. [MW15], S 16f). Der Serving-Layer greift direkt auf die Rohdaten im
Batch-Layer zu. Mit der Lambda-Architektur wird ein Konzept bereitgestellt, um Daten
aus unterschiedlichen Quellen, mit unterschiedlichen Geschwindigkeiten bereitzustellen, zu
archivieren und zu analysieren. Die Umsetzung der einzelnen Layer ist unabhangig von
den genutzten Techniken. So kann bspw. ein Hadoop Distributed File System zur Spei-
cherung der Daten im Batch-Layer genutzt werden und fur den Speed-Layer kann ein
Datenstrommanagementsystem verwendet werden (vgl. [MW15], S 21f).
C.2. Multi-Agenten-basierte Lambda-Architektur
Im folgenden wird eine Architektur vorgestellt, die als Grundlage die Lambda-Architektur
nutzt. Die einzelnen Layer werden durch Agenten reprasentiert (vgl. [TR14], S. 335). Be-
ginnend wird durch ein Empfangs-Agenten. Dieser Agent nimmt diverse Datenstrome und
Ereignisse entgegen und fuhrt die Vor-Verarbeitung aus. Die Vor-Verarbeitung umfasst die
Filterung, Formatanderung, die Veroffentlichung von Datenobjekten, etc. Der Empfangs-
Agent dupliziert den Datenstrom und leitet diesen an einen Archivar-Agenten und einen
Datenstrom-Verarbeitungs-Agenten weiter. Der Archivar-Agent wird dem Batch-Layer zu-
geordnet. Der Datenstrom-Verarbeitungs-Agenten wird dem Speed-Layer zugeordnet. Die
Aufgabe des Archivar-Agenten umfasst das Empfangen und das Speichern des Daten-
stroms. Die Datenbank kann bspw. nach [TR14] ein Hadoop Distributed File System
(HDFS) sein. Die Datenbank sollte nach [TR14] die Eigenschaften haben, jedes Ereignis
und Datum zu speichern, es muss außerdem große Datensatze verarbeiten konnen. Im
nachfolgenden Schritt werden die Batch-Verarbeitungen durchgefuhrt. Die Batch-Driver-
Agenten und die Batch-Worker-Agenten fuhren die Verarbeitung durch und werden als
Batch-Verarbeitung als logische Einheit zusammengefasst. Die Verarbeitung wird durch
ein Master-Slave-Verhaltnis ausgefuhrt, d.h. die Erzeugung eines Auftrags und die Koordi-
nation wird durch den Batch-Driver-Agenten ausgefuhrt. Der Batch-Worker-Agenten uber-
nimmt im Anschluss den Auftrag und fuhrt diesen aus. Das Ergebnis eines Batch-Worker-
Agenten ist eine View nach der Lambda-Architektur (vgl. [TR14], S. 335). Die Batch-
Verarbeitung kann nach [TR14] durch eine verteilte Verarbeitung mit YARN oder Mesos
durchgefuhrt werden. Der Speed-Layer wird ebenfalls durch zwei Agenten reprasentiert.
Der Datenstrom-Verarbeitungs-Agent nimmt den Datenstrom vom Empfangs-Agenten
7

C.3 Drei-Stufen-Framework C ARCHITEKTUREN
Abbildung 2: Das Drei-Stufen-Architektur nach [JWW+16]Quelle: vgl. [JWW+16], S. 3847
entgegen, leitet diese dann an einen Echtzeit-Verarbeitungs-Agenten weiter. Auch im
Speed-Layer wird ein Master-Slave-Verhaltnis zur Verarbeitung angewendete und als lo-
gische Einheit zusammengefasst. Die Ergebnisse werden im Arbeitsspeicher festgehalten,
um einen schnellen Zugriff auf die Ergebnisse zu gewahrleisten. Die beiden Views vom
Echtzeit-Verarbeitungs-Agenten und von der Batch-Verarbeitung werden im Serving-Layer
durch drei weitere Agenten bereitgestellt. Der Batch-Aggregator-Agent und der Echtzeit-
Aggregator-Agenten stellen dann die unterschiedlichen Views zusammen. Durch einen de-
dizierten Service-Agenten kann dann durch eine Anwendung auf die Views zugegriffen
werden (vgl. [TR14], S. 335). Die technische Umsetzung erfolgte fur den Batch-Layer
durch ein Hadoop System. Die Batch-Verarbeitung wird durch YARN und SPARk durch-
gefuhrt. Die Verwaltung von Driver- und Worker-Agenten wird durch Akka actor System
Framework realisiert. Die gesamte Kommunikation wird uber JSON geregelt.
C.3. Drei-Stufen-Framework
Im folgenden wird eine Architektur betrachtet, die bereits in einem Smart Grid eingesetzt
wurde. Die Abbildung 2 zeigt die Drei-Stufen-Architektur nach [JWW+16]. Der innere
Kern besteht aus einer Data Mining Plattform. Der mittlere Bereich ist die Verbindung
8

C.4 Referenzarchitektur fur die Langzeitarchivierung C ARCHITEKTUREN
zwischen dem inneren und außeren Bereich. Der außere Bereich dient als Vor-Verarbeitung
(vgl. [JWW+16], S. 3846f). Der innere Kreis ist verantwortlich fur die Mining-Bearbeitung
der Daten und den Zugang auf diese. Das Wachstum des Datenvolumens, die Verteilung
der Daten auf die Speichercluster mussen wahrend der Verarbeitung berucksichtigt wer-
den. Diese Anforderung wird in der Drei-Stufen-Architektur durch die Parallelisierung
von Rechenknoten im inneren Kern erreicht, dazu muss die Datenanalyse und die Aufga-
benbearbeitung verteilt werden. In der mittleren Schicht werden datenbezogene Aufgaben
durchgefuhrt. Dazu werden Informationen verteilt und Wissen aus den Bereichen und
Anwendungen genutzt. Die Informationsverteilung sollte ein Ziel fur den gesamten Ver-
arbeitungsprozess sein (vgl. [JWW+16], S. 3847). In der außersten Schicht werden durch
Datenfusionstechnologien die heterogenen, unsicheren, unvollstandigen Daten und Daten
aus unterschiedlichen Quellen vorbereitet. Damit im weiteren Verlauf durch Data Mining
und local learning ein Wissen uber das Smart Grid generiert werden kann. Zur Verbesse-
rung der Ergebnisse durchlauft das Modell und die Parameter einen Kreislauf, wobei das
Ergebnisse fur die erneute Betrachtung berucksichtigt wird (vgl. [JWW+16], S. 3846f).
Diese Architektur wurde nach [JWW+16] in eine Smart Grid integriert, um ein bestehen-
des Smart Grid zu verbessern. Dazu wurden Cloud Technologien, Big Data Analysen und
die Drei-Stufen-Architektur genutzt. Die Archivierung der Daten wird durch ein Cloud-
basierte Cassandra Datenbank (Cassandra DB) und HDFS erreicht. Das HDFS verteilte
die Speichermedien zu Knoten um diese auf Racks zu verteilen. Die gesammelten Daten
umfassen das Konsumentenverhalten, Detaillierte Informationen zu den Erzeugern und
Nachfragern und historische Wetterdaten und werden durch die Cassandra DB gespei-
chert. Abgerufen werden diese Daten zur Schatzung des Strombedarfs (vgl. [JWW+16], S.
3847).
C.4. Referenzarchitektur fur die Langzeitarchivierung
Die im folgenden Abschnitt beschriebene Referenzarchitektur von (vgl. [VS14]) dient zur
Archivierung, Erhaltung und zur Wiederverwendung von Daten in Big Data. Die un-
und strukturierten Daten sollen in dieser Architektur archiviert werden. Fur die Refe-
renzarchitektur wurden sieben Anforderungen formuliert: 1. Es sollte ermoglicht werden
Datenobjekte abzugeben, wiederzuverwenden und loschen, 2. die Architektur sollte mit
Arhivierungstrategien arbeiten, 3. es sollte moglich sein die archivierten Daten verwalten
zu konnen, 4. die Datenintegritat sollte durch ein Protokoll bewiesen werden, 5. die Daten
sollten vertraulich behandelt, 6. es sollte den Datentransfer von einem Service zu einem
anderen protokolliert werden und 7. es sollen operationen auf Gruppen von Datenobjekten
9
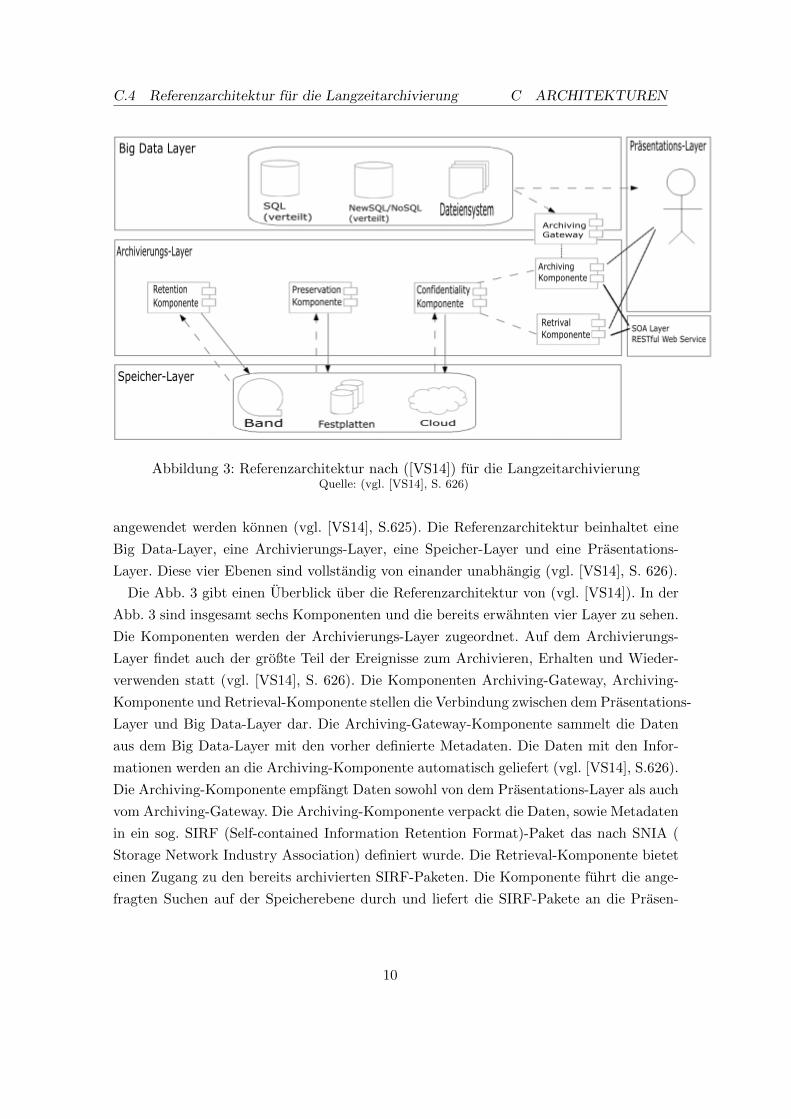
C.4 Referenzarchitektur fur die Langzeitarchivierung C ARCHITEKTUREN
Abbildung 3: Referenzarchitektur nach ([VS14]) fur die LangzeitarchivierungQuelle: (vgl. [VS14], S. 626)
angewendet werden konnen (vgl. [VS14], S.625). Die Referenzarchitektur beinhaltet eine
Big Data-Layer, eine Archivierungs-Layer, eine Speicher-Layer und eine Prasentations-
Layer. Diese vier Ebenen sind vollstandig von einander unabhangig (vgl. [VS14], S. 626).
Die Abb. 3 gibt einen Uberblick uber die Referenzarchitektur von (vgl. [VS14]). In der
Abb. 3 sind insgesamt sechs Komponenten und die bereits erwahnten vier Layer zu sehen.
Die Komponenten werden der Archivierungs-Layer zugeordnet. Auf dem Archivierungs-
Layer findet auch der großte Teil der Ereignisse zum Archivieren, Erhalten und Wieder-
verwenden statt (vgl. [VS14], S. 626). Die Komponenten Archiving-Gateway, Archiving-
Komponente und Retrieval-Komponente stellen die Verbindung zwischen dem Prasentations-
Layer und Big Data-Layer dar. Die Archiving-Gateway-Komponente sammelt die Daten
aus dem Big Data-Layer mit den vorher definierte Metadaten. Die Daten mit den Infor-
mationen werden an die Archiving-Komponente automatisch geliefert (vgl. [VS14], S.626).
Die Archiving-Komponente empfangt Daten sowohl von dem Prasentations-Layer als auch
vom Archiving-Gateway. Die Archiving-Komponente verpackt die Daten, sowie Metadaten
in ein sog. SIRF (Self-contained Information Retention Format)-Paket das nach SNIA (
Storage Network Industry Association) definiert wurde. Die Retrieval-Komponente bietet
einen Zugang zu den bereits archivierten SIRF-Paketen. Die Komponente fuhrt die ange-
fragten Suchen auf der Speicherebene durch und liefert die SIRF-Pakete an die Prasen-
10

C.5 Zusammenfassung C ARCHITEKTUREN
tationsebene zuruck (vgl. [VS14], S.626). Die Confidentiality-Komponente garantiert den
Zugriffsschutz auf die Speicherebene. Es pruft durch Authentifizierung der Daten und stellt
somit eine Zugangskontrolle vor dem Schreiben der Datenelementen dar (vgl. [VS14], S.
626). Die Retention-Komponente und die Preservation-Komponente sorgen fur die Schutz
der SIRF-Pakete. Dabei ubernimmt die Retention-Komponente den physikalische Siche-
rung, also das Loschen von redundanten Daten und die Migration auf andere Speicher-
medien. Die Preseravtion-Komponente ubernimmt Sicherung des logischen Teil der Daten
und der Metadaten Verwaltung (vgl. [VS14], S. 626).
In dem Big Data-Layer befinden sich die Daten, die spater archiviert werden sollen. Die
Daten in dem Big Data-Layer befindet sich im Informationslebenszyklus in den Bereichen
der Erzeugung, Auswertung. Im weiteren Verlauf des Zyklus werden die Daten kaum noch
genutzt und fur gewohnlich geloscht oder archiviert (vgl. [VS14], S. 623 u. S. 627). In
dem Big Data-Layer konnen die unstrukturierten Daten bspw. aus einem MapReduce-
Arbeitsprozess oder direkt aus einer HDFS stammen, sie konenn auch aus einer relatio-
nalen Datenbank als strukturierte Daten extrahiert werden (vgl. [VS14], S.627). Auf dem
Speichere-Layer werden die physikalischen Daten hinterlegt. Die physikalische Umsetzung
der Speichermedien ist unabhangig von der Referenzarchitektur, folglich konnen die Da-
ten auf verteilten Datenbanken, Cloud-basierten Speichercluster oder auf Magnetbandern
archiviert werden (vgl. [VS14], S. 627). In der Arbeit von [VS14] wurde angefangen die Re-
ferenzarchitektur prototypisch umzusetzen. Fur die Archivierung wurden unterschiedliche
Speicherlosungen implementiert und fur ein Benchmark mit Daten befullt. Es wurde eine
HDFS, DB2, MongoDB und eine einfache Verteilte Dateisystem umgesetzt (vgl. [VS14],
S. 628).
C.5. Zusammenfassung
In diesem Abschnitt wurden vier unterschiedliche Architekturen im Big Data Kontext zur
Archivierung und Analyse vorgestellt. Es wurde zuerst auf die Lambda-Architektur einge-
gangen. Die Vorteile der Lambda-Architekturen ist die parallele Verarbeitung von Daten-
stromen und archivierten Daten. Die Multi-Agenten-Architektur bietet die selben Vorteile,
wie die Lambda-Architektur. Die technische Umsetzung der Multi-Agenten-Architektur
wurde erlautert. Die Drei-Stufen-Architektur beschreibt eine andere Architektur. Zum
Schluss wurde eine Referenzarchitektur fur die Langzeitarchivierung beschrieben.
11

D FAZIT UND AUSBLICK
D. Fazit und Ausblick
In diesem Kapitel wird zuerst ein Fazit gezogen. Im Anschluss des Fazits wird ein Ausblick
fur die Projektgruppe auf weitere Aufgaben und Workshops gegeben.
D.1. Fazit
Diese Arbeit beschrieb die Lambda-Architektur, eine Multi-Agenten Architektur als prak-
tische Umsetzung der Lambda-Architektur, die Drei-Stufen-Architektur und eine Lang-
zeitarchivierungs-Architektur. Die Architekturen wurden kurz erlautert. Es wurde die ein-
zelnen Komponenten beschrieben. Die Beschreibung beinhaltet die Aufgabenbeschreibung
und teilweise eine technische Umsetzungsbeschreibung. Die vorgestellten Architekturen in
dieser Arbeit forderten keine besondere technische Umsetzung. Die Architekturen beschrei-
ben modulare Komponenten die eine unterschiedliche technische Umsetzungen zulassen.
D.2. Ausblick
Fur die konzeptionelle Entwicklung einer Architektur fur datengetrieben Geschaftmodelle,
Archivierung und Auswertung von Daten im Big Data Kontext muss die Projektgrup-
pe”Big Data Archive“ weitere Workshops in den Bereich der technischen Umsetzung
durchfuhren. Die Workshops sollten sich dabei auf die Themen Speicherlosungen, Daten-
strommanagementsysteme, Datenauswertung und Daten-schutz und -sicherheit fokussie-
ren.
12

Literatur Literatur
Literatur
[DLM14] Demchenko, Y. ; Laat, C. de ; Membrey, P.: Defining architecture com-
ponents of the Big Data Ecosystem. In: 2014 International Conference on
Collaboration Technologies and Systems (CTS), 2014, S. 104–112
[Fra15] Frampton, Michael: Big Data made easy - A Working Guideto the Complete
Hadoop Toolset. 2015
[Gra15] Grawunder, Dr. M.: Vorlesung: Informationssysteme III. 2015
[JWW+16] Jiang, H. ; Wang, K. ; Wang, Y. ; Gao, M. ; Zhang, Y.: Ener-
gy big data: A survey. In: IEEE Access 4 (2016), S. 3844–3861.
http://dx.doi.org/10.1109/ACCESS.2016.2580581. – DOI 10.1109/AC-
CESS.2016.2580581. – ISSN 2169–3536
[Kle15] Kleppmann, Martin: A Critique of the CAP Theorem. In: CoRR ab-
s/1509.05393 (2015). http://arxiv.org/abs/1509.05393
[MW15] Marz, Nathan ; Warren, James: Big Data: Principles and Best Practices
of Scalable Realtime Data Systems. 1st. Greenwich, CT, USA : Manning
Publications Co., 2015. – ISBN 1617290343, 9781617290343
[TR14] Twardowski, B. ; Ryzko, D.: Multi-agent Architecture for Real-Time Big
Data Processing. In: 2014 IEEE/WIC/ACM International Joint Conferences
on Web Intelligence (WI) and Intelligent Agent Technologies (IAT) Bd. 3,
2014, S. 333–337
[VS14] Viana, P. ; Sato, L.: A Proposal for a Reference Architecture for Long-
Term Archiving, Preservation, and Retrieval of Big Data. In: 2014 IEEE 13th
International Conference on Trust, Security and Privacy in Computing and
Communications, 2014. – ISSN 2324–898X, S. 622–629
[WU12] Weber, Dr. M. ; Urbanski, Jurgen: Big Data im Praxiseinsatz - Szenarien,
Beispiele, Effekte. 2012
13

Literatur Literatur
Abschließende Erklarung
Ich versichere hiermit, dass ich meine Seminararbeit”Vorstellung von bestehenden Big Da-
ta Architekturen“ selbstandig und ohne fremde Hilfe angefertigt habe und dass ich alle von
anderen Autoren wortlich ubernommenen Stellen wie auch die sich an die Gedankengange
anderer Autoren eng anlegenden Ausfuhrungen meiner Arbeit besonders gekennzeichnet
und die Quellen zitiert habe.
Oldenburg, den 26. Mai 2017 NAME
14

A ANHANG A.3 Seminararbeiten
A.3.4. Jens Feldhaus - Soft Skills für Software Entwicklungsteams: Klassische vs.Agile Softwareentwicklung
209

Soft Skills furSoftware Entwicklungsteams:
Klassische vs. AgileSoftwareentwicklung
Seminararbeit im Rahmen der Projektgruppe Big Data Archive
Themensteller: Prof. Dr.-Ing. Jorge Marx GomezBetreuer: M. Eng. & Tech. Viktor Dmitriyev
Dr.-Ing. Andreas SolsbachJad Asswad, M.Sc.
Vorgelegt von: Name: Jens FeldhausSemesteranschrift: Nobelstraße 3PLZ Wohnort: 26129 [email protected]
Abgabetermin: 21.05.2017

Inhaltsverzeichnis Inhaltsverzeichnis
Inhaltsverzeichnis
Abbildungsverzeichnis 3
1 Einleitung 4
2 Motivation 4
3 Grundlagen 53.1 Klassische Methoden . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
3.1.1 Wasserfallmodell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53.1.2 Spiralmodell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
3.2 Agile Methoden . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103.2.1 SCRUM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
4 Soft Skills in der Softwareentwicklung 14
5 Schluss 15
Literaturverzeichnis 16
2

Abbildungsverzeichnis Abbildungsverzeichnis
Abbildungsverzeichnis
1 Wasserfallmodell nach Royce . . . . . . . . . . . . . . . . . . . . . . . . . . 72 Das Spiralmodell der Softwareentwicklung . . . . . . . . . . . . . . . . . . . 93 Scrum - auf einer Seite erklart . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3

2 MOTIVATION
1 Einleitung
Ein Softwareprojekt in einem Unternehmen wird nie von nur einer Person erledigt. Es ist
immer eine Gruppe an einem bestimmten, großeren Projektziel interessiert. Um ein Soft-
wareprojekt erfolgreich abzuschließen, braucht man aber nicht nur fachmannisches Wissen,
sondern auch kommunikative Fahigkeiten (soft skills). Denn oftmals scheitern Softwarepro-
jekte nicht aus technischen Grunden, sondern aufgrund von mangelnder Kommunikation.
Deswegen ist es heutzutage enorm wichtig, dass man als Arbeitnehmer nicht nur tech-
nisches know-how, sondern auch soziale und kommunikative Fahigkeiten, die einem das
Arbeiten in der Gruppe voranbringt. Es ist aber nicht nur die Kommunikation innerhalb
der Gruppe, sondern speziell auch die Kommunikation mit externen Projektbeteiligten,
die sehr wichtig ist. Es kommt in jedem Fall auf eine effektive und klare Kommunikation
untereinander an.
Geht es um die Softwareentwicklung selbst, stellt man sich meist eine Frage. Welche
Methode soll verwendet werden? Agile und klassische Methoden sind in der Softwareent-
wicklung ein wichtiges Themengebiet. Wahrend klassische Methoden sich auf den forma-
lisierten Prozess konzentrieren, legen die agilen Methoden wert auf die Entwicklung und
die Kommunikation zwischen der Entwickler und den Kunden. (vgl. [Wei04], S.3ff)
Da sowohl klassische, als auch agile Methoden Vor- und Nachteil mit sich bringen,
lasst sich keine generelle Aussage daruber treffen, welche Vorgehensweise geeigneter ist.
Vielmehr muss im Einzelfall unter Berucksichtigung der Projektbedingungen abgewagt
werden, welche der beiden Richtungen tendenziell zielfuhrender ist.
2 Motivation
Soft Skills haben in einer Gruppenarbeit einen hohen Stellenwert. Es ist wichtig, dass man
sich in einer Projektgruppe gewisse Gedanken daruber macht, inwieweit man Soft Skills
in einem Software- Entwicklungsteam braucht und wie man diese anwenden kann. Diese
Seminararbeit soll einem die Rolle der Soft Skills innerhalb eines Software Entwicklungs-
teams mit Blick auf die klassische und die agile Softwareentwicklung darstellen. Dabei
werden zuerst die Grundladen der klassischen und der agilen Softwareentwicklung darge-
stellt, um danach die Thematik der Soft Skills aufzugreifen. Ziel ist es, sowohl klassische
als auch agile Projektmanagementmethoden kennen zu lernen und inwieweit Soft Skills
einen Teil dazu beitragen.
4

3 GRUNDLAGEN
3 Grundlagen
Um einen Einblick uber die moglichen Projektmanagementmethoden zu bekommen, wer-
den nachfolgend sowohl klassische als auch agile Methoden anhand von einiger Vertretern
vorgestellt.
3.1 Klassische Methoden
Unter klassischen Methoden versteht man Modelle zur Realisierung von Softwareproduk-
ten, die sowohl gegenwartige als auch gangige Verfahren der Softwareentwicklung beinhal-
ten. Diese klassischen Methoden der Softwareentwicklung (heavyweight methods) ubert-
ragen ingenieurswissenschaftliche Ansatze der Projektdurchfuhrung auf Softwareprojekte
mit dem Blick auf den Prozess an sich. Klassisch bedeutet in diesem Sinne, dass die Auftei-
lung des gesamten Entwicklungsprozesses in klar uberschaubare, zeitlich meist abgegrenzte
Phasen mit jeweils unterschiedlichen Aktivitaten gegliedert wird. Ziel dabei ist es, dass
die Effizienz bezuglich der Steuerung der Softwareentwicklung verbessert und gleichzeitig
die Komplexitat minimiert wird. Mittels der klassischen Modellen lasst sich so die Im-
plementierung des Codes weitestgehend sicher verwalten und beherrschen. Als Beispiele
werden im Folgenden das Wasserfallmodell und das Spiralmodell naher beschrieben.(vgl.
[eT], [Wei04], S.3ff)
3.1.1 Wasserfallmodell
Das Wasserfallmodell (engl.: waterfall model) von Winston Royce ist das wohl alteste und
auch der bekannteste Vertreter der Projektmanagementmethoden. Er beschrieb bereits
1970 in einem Aufsatz ein in Phasen strukturiertes Modell, um die Entwicklung großer
Softwareprojekte voranzutreiben. Es gibt neben dem Modell von Royce auch noch andere
Auspragungen. Ein weiteres Modell ware das Phasenmodell nach Boehm 1981, welches eine
ahnliche Grundstruktur besitzt, aber minimale Abweichungen in der Ausgestaltungstiefe
aufweist. (vgl. [Chr92])
Das Wasserfallmodel beschreibt eine lineare und sequentielle Entwicklungsmethode mit
der grundlegenden Idee anhand der Entwicklungstatigkeiten das gesamte Projekt in Pha-
sen zu unterteilen. (vgl. [onp])
Dieses Modell basiert auf eine top-down Verfahrensweise, die jeweils durch ein Weitergeben
von Fach-Dokumenten zwischen den jeweiligen Phasen verbunden ist. Wichtig ist dabei,
dass die Verbindung zweier Phasen lediglich den Austausch untereinander ermoglicht. Es
ist somit nicht moglich, dass eine Phase ubersprungen wird. Des Weiteren gilt darauf zu
5

3.1 Klassische Methoden 3 GRUNDLAGEN
achten, dass jede Phase unterschiedliche Aufgaben und Ziele definiert, die erst erfullt wer-
den mussen, damit mit der nachsten Phase vorangeschritten werden kann. Die Gesamtheit
der Phasen ergibt schlussendlich den Lebenszyklus der Softwareentwicklung.
Im Grunde besteht das ursprungliche Wasserfallmodell (nach Royce 1970) aus den sie-
ben folgenden Phasen:
Systemanforderungen (System Requirements):
Die erste Phase beschreibt die Anforderungen, die sich nicht mit dem digitalen Pro-
dukt, sondern mit den geschaftsrelevanten Aspekten (Preis, Verfugbarkeit) befassen. Hier
werden u.a. die Dokumentation und Sicherheitsaspekte naher bestimmt. Man spricht auch
von den nicht-funktionalen Anforderungen.
Softwareanforderung (Software Requirements)
In der zweiten Phase wird die Frage beantwortet, welche funktionalen Anforderungen
die fertiggestellte Software haben muss. Diese werden in einem Lastenheft prazisiert, wel-
ches dann als Ergebnisse der Phase dient.
Anforderungsanalyse (Analysis)
Bei der Anforderungsanalyse werden die Funktionen der Software gegliedert und struk-
turiert, um so Funktionselemente und Funktionseinheiten besser zu trennen. Das Ergebnis
dieser Phase ist ein Pflichtenheft, in welchem die zu entwickelnden Anforderungen um-
fasst. Diese Phase soll die Funktionen auf ihre Machbarkeit und Wichtigkeit untersuchen.
Programmdesign (Program design)
Aufbauend auf das Lasten- und Pflichtenheft wird nun das technische Design versucht
umzusetzen. U.a. wird in dieser Phase uber die Informationsarchitektur und die einge-
setzten Technologien entschieden (Programmiersprache, Klassenbibliotheken, Programma-
blaufe).
Implementierung (Coding)
Die Implementierung dient zur Realisierung der Strukturen und Ablaufe unter der
Berucksichtigung der Rahmenbedingungen und Ziele. Ziel ist es beim Beenden dieser Pha-
se eine bereits lauffahige Software vorlegen zu konnen (Betaversion).
6

3.1 Klassische Methoden 3 GRUNDLAGEN
Testing (Testing, Integration)
Nach der Implementierung ist das Testen der Softwarekomponenten, der Module und
des gesamten Systems vonnoten. Hier gilt es Fehler ausfindig zu machen, die es umgehend
zu beheben gilt, um die Kosten bestmoglich gering zu halten. Außerdem sollte die Inte-
gration auf bestimmte Betriebssysteme uberpruft werden.
Einfuhrung (Operations)
In der Einfuhrung geht es um die Abnahme des Auftraggebers. Gegebenenfalls wird hier
ein Service angeboten, der sich um Updates und Wartungsarbeiten kummert, bevor das
Produkt dann an den Kunden ausgeliefert werden kann.
Jeder dieser Phasen wird von verschiedenen Teams bearbeitet. Bis die Entwickler bei
der Implementierung anfangen konnen, mussen sich erst der Auftraggeber, das Projektma-
nagement und die Senior-Entwickler zusammensetzen, um das Wunschprodukt zu bespre-
chen. Auch das Testing wird dann meist separat von einem Team bearbeitet. Des Weiteren
konnen u.a. noch Marketingexperten bei der Einfuhrung teilnehmen.(vgl. [onp])
Abbildung 1: Wasserfallmodell nach Royce vgl.[Kuh12]
7

3.1 Klassische Methoden 3 GRUNDLAGEN
Dank der simplen, sequentiellen Anordnung und die klar gegliederten Phasen, ist die Or-
ganisationsstruktur von Projekten meist sehr einfach gehalten. Problematisch ist jedoch,
dass die Auftraggeber nur zu Beginn der Entwicklung mit einbezogen sind, was dazu fuhren
kann, dass gewunschte Anforderungen wahrend einer Entwicklung nahezu nicht verandert
werden konnen. Das große Problem ist also, dass Veranderungen durch die logische Abfolge
nicht vorgesehen sind. Des Weiteren sind Fehler, die erst in spateren Phasen auftauchen,
oftmals schwer zuruckzufuhren und lassen sich nur muhevoll beheben. Dieses Modell sollte
deswegen moglichst bei bekannten und risikoarmen Verfahren benutzt werden.
3.1.2 Spiralmodell
Ein weiteres Modell ist das Spiralmodell, welches 1988 von Barry W. Boehm veroffentlicht
wurde. Es beschreibt den Softwareprozess nicht als eine Sequenz von Aktivitaten, sondern
als Spirale, die als iterativer Zyklus mit wiederkehrenden Schritten angewendet wird. Das
hat den Vorteil, dass die Zyklen so lange durchlaufen werden konnen bis alle vorhandenen
Probleme gelost sind, da nicht zuruckgeschaut werden muss, sondern man neu aufkom-
mende Probleme jederzeit behandeln kann. Dabei wird darauf geachtet, dass die Risiken
wahrend der Projektabwicklung moglichst gering gehalten werden, um so steigende Ge-
samtkosten, Mehraufwand und ein verspateten Release zu verhindern. Vorgesehen ist das
ganze Modell insbesondere zur Planung von großen, risikoreichen Softwareprojekten. (vgl.
[Bau13], [Wei04], S.5ff)
In diesem Modell werden in jedem Zyklus vier Phasen durchschritten:
Ziel- und Alternativbestimmung:
Mit dem Auftraggeber werden gemeinsam Ziele, mogliche Alternativen und die Rahmen-
bedingungen (Programmiersprache, Betriebssysteme, Umgebungen) festgelegt.
Risikoanalyse- und Evaluierung:
In der nachsten Phase werden mogliche Risiken identifiziert und bewertet. Es werden Pro-
totypen, Simulationen und Analysesoftware zur Ermittlung von Risiken benutzt, um so
diese bewerten und gegebenenfalls reduzieren zu konnen.
Entwicklung und Testen:
8

3.1 Klassische Methoden 3 GRUNDLAGEN
Bei der Entwicklung werden die Prototypen weiter ausgebaut und um die gewunschten
Funktionalitaten erweitert. Der Code wird mehrmals geschrieben, getestet und auf einer
Test-Umgebung migriert, bis die Software schlussendlich auf eine Produktivumgebung im-
plementiert werden kann.
Planung des nachsten Zyklus:
In der letzten Phase wird der nachste Zyklus geplant. Hier wird entschieden, inwiefern
Fehler aufgetreten sind, wie man diese beheben kann und ob es womoglich eine bessere
Alternative gibt, die im nachsten Zyklus bevorzugt werden sollte.
Es gilt im gesamten Prozess darauf zu achten, dass die Prioritaten bei der Risikoana-
lyse hoch gesetzt werden. In dieser Phase gilt es namlich samtliche Fehler aufzudecken,
anzusprechen und zu behandeln. Erst wenn keine Risiken mehr vorhanden sind, ist das
Projekt abgeschlossen. Das wird insofern gelost, dass in jedem weiteren Durchlauf des Zy-
klus Risiken gelost werden, die schlussendlich ein risikofreies Produkt ergeben. (vgl [Boe],
S.7ff.)
Abbildung 2: Das Spiralmodell der Softwareentwicklung [eT]
9

3.2 Agile Methoden 3 GRUNDLAGEN
Das Spiralmodell ist besonders fur große Projekte geeignet. In diesen sind die Kosten ein
entscheidender Faktor, der durch das Losen der immer wiederkehrenden Risiken stark redu-
ziert werden konnen. Des Weiteren konnen Konflikte fruhzeitig und schnellstmoglich gelost
werden. Auch fur das Behandeln von Feedback kann sich schnellstmoglich gekummert wer-
den. Es gibt aber auch die Gefahr, dass man in eine Schleife gerat, die die Projektdauer
verlandern, wenn falsche Entscheidungen getroffen wurden. (vgl. [bib], S.7ff.)
3.2 Agile Methoden
Die agilen Projektmanagement-Methoden sind das Resultat der kritischen Betrachtung
der bis dahin eingesetzten, klassischen Methoden. Es bezeichnet Ansatze im Softwareent-
wicklungsprozess, die einen erhohten wert auf Transparenz und Flexibilitat legen. Mittels
einem schnelleren Einsatz der entwickelten Systeme lassen sich so Risiken im Entwick-
lungsprozess minimieren. Die Idee ist, Teilprozesse einfach und beweglich zu halten. Im
Zuge dessen entstand 2001 das sogenannte Manifest fur agile Softwareentwicklung, welches
auf den folgenden vier Werten besteht:
- Individuen und Interaktion sind wichtiger als Prozesse und Werkzeuge.
- Lauffahige Software ist wichtiger als umfangreiche Dokumentation.
- Die Zusammenarbeit mit dem Kunden ist wichtiger als Vertragsverhandlungen.
- Auf Anderungen reagieren ist wichtiger als einem Plan zu folgen. (vgl. [MCD], S.3ff.)
Diese besagen, dass fur eine erfolgreiche Entwicklung von Programmen zwar formale
Grundlagen wie standardisierte Prozesse, Dokumentation sowie vorgegebene Rahmen und
Handlungsanweisungen durch Vertrage notwendig sind, weiche Kriterien wie Kommuni-
kation, Rucksichtnahme auf Beteiligte und flexibles Agieren jedoch mindestens ebenso
wichtig sind. Um diese Werte zu berucksichtigen, wurden deshalb die zwolf Prinzipien
formuliert, die bei der agilen Softwareentwicklung befolgt werden sollen.
- Unsere hochste Prioritat ist es, den Kunden durch fruhe und kontinuierliche Auslieferung
wertvoller Software zufrieden zu stellen.
- Heiße Anforderungsanderungen selbst spat in der Entwicklung willkommen. Agile Pro-
zesse nutzen Veranderungen zum Wettbewerbsvorteil des Kunden.
- Liefere funktionierende Software regelmaßig innerhalb weniger Wochen oder Monate und
bevorzuge dabei die kurzere Zeitspanne.
- Fachexperten und Entwickler mussen wahrend des Projektes taglich zusammenarbeiten.
- Errichte Projekte rund um motivierte Individuen. Gib ihnen das Umfeld und die Un-
10

3.2 Agile Methoden 3 GRUNDLAGEN
terstutzung, die sie benotigen und vertraue darauf, dass sie die Aufgabe erledigen.
- Die effizienteste und effektivste Methode, Informationen an und innerhalb eines Entwick-
lungsteam zu ubermitteln, ist im Gesprach von Angesicht zu Angesicht.
- Funktionierende Software ist das wichtigste Fortschrittsmaß.
- Agile Prozesse fordern nachhaltige Entwicklung. Die Auftraggeber, Entwickler und Be-
nutzer sollten ein gleichmaßiges Tempo auf unbegrenzte Zeit halten konnen.
- Standiges Augenmerk auf technische Exzellenz und gutes Design fordert Agilitat.
- Einfachheit - die Kunst, die Menge nicht getaner Arbeit zu maximieren - ist essenziell.
- Die besten Architekturen, Anforderungen und Entwurfe entstehen durch selbstorgani-
sierte Teams.
- In regelmaßigen Abstanden reflektiert das Team, wie es effektiver werden kann und passt
sein Verhalten entsprechend an.(vgl. [Sie])
3.2.1 SCRUM
Als ein Beispiel fur agile Projektmanagementmethoden wird im Folgenden SCRUM be-
schrieben:
Der Begriff”SCRUM“ stammt aus dem Rugby und bezeichnet das
”organisierte Ge-
drange“. Die Projektmanagement-Methode SCRUM ist inspiriert durch das Konzept des
”Lean Managements“, dessen Entwicklung maßgeblich durch Toyotas
”Lean Production“
vorangetrieben wurde. Es stamm von Ken Schwaber und wurde erstmals 1999 aufgegrif-
fen.(vgl. [3m5])
”Das Ziel von Scrum ist, auf Anderungen schnell, unkompliziert und dennoch angemessen
zu reagieren, anstatt Zeit und Energie auf die Erstellung, Durchsetzung und Nachfuhrung
veralteter Plane zu verschwenden.“ (vgl. [bib])
Beim Scrum gibt es drei Rollen, die am Prozess direkt beteiligt sind: Den Product Owner
(stellt fachliche Anforderungen und priorisiert sie), den Scrum Master (Verantwortlicher
fur das Managen des Prozesses) und das Team (Entwickler).
11

3.2 Agile Methoden 3 GRUNDLAGEN
Die folgenden Projektmanagementinstrumente sind beim Scrum von besonderer Wich-
tigkeit:
Kurze Iteration:
Beim Scrum gibt es die sogenannten Sprints, die eine bestimmte kurze Iteration vorgibt,
in der bestimmte Aufgaben erledigt und ein bestimmtes Ziel erreicht werden sollen. Die
Idee dahinter ist, dass sich in kurzeren Zeitraumen, kleiner gesteckte Ziele leichter erfullen
lassen.
Product Backlog:
Das Product Backlog ist ein Log, welches vom Product Owner wahrend des gesamten
Projektes gepflegt, erweitert und priorisiert wird. In diesem stehen alle bekannten An-
forderungen und Arbeitsergebnisse, die fur das Projekt vonnoten sind. Es entwickelt sich
wahrend des gesamten Projektes weiter, so konnen gewisse Anforderungen gestrichen, an-
ders priorisiert oder neu aufgenommen werden. Das soll das Planen einfacher machen, da
alles, was das Planen fehlertrachtig macht, vermieden wird.
Sprint Backlog:
Aus dem Product Backlog lassen sich kleinere Arbeitspakete entnehmen, die in den einzel-
nen Sprints bearbeitet werden sollen. Diese Arbeitspakete lassen sich innerhalb des Sprints
noch einmal herunterbrechen auf noch kleinere Arbeitspakete, die von einzelnen Bearbei-
tern oder Kleingruppen innerhalb des Sprintzeitraumes bearbeitet werden mussen. Diese
werden in dem Sprint Backlog festgehalten. Wichtig ist es, dass alle Aufgaben, die das
Team fur das Abschließen des Sprints fur notig halten, auch bearbeitet werden. Es gilt
diesbezuglich Kriterien aufzustellen, die versichern, dass das gewunschte Sprintziel erreicht
werden konnte.
Timeboxing:
Beim Timeboxing geht es darum, dass man Prioritaten beim Erfullen der Aufgaben setzt,
sodass diese in dem geplanten, zeitlichen Rahmen erfullt werden konnen. Es gilt der Grund-
satz, am Stichtag ’auslieferbar’ geht vor ’Funktionsumfang’. Es ist wichtig, dass lediglich
Aufgaben aufgestellt werden, die zum Gesamtprodukt beitragen und die zusatzlich auch
realisierbar sind. Das benotigt zum Sprintbeginn eine gut durchdachte Aufgabenerstellung
und Zuteilung. Deshalb ist die gesamte Gruppe dazu aufgefordert, mittels verschiedener
Methoden eine passende Aufwandsschatzung zu errechnen.
12

3.2 Agile Methoden 3 GRUNDLAGEN
Transparenz:
Die Transparenz ist das wohl machtigste Werkzeug in Scrum. Auf einem Whiteboard wird
das Sprint Backlog gefuhrt, um so den Inhalt und den Fortschritt fur alle Beteiligten
darzustellen. Dadurch, dass Jeder einsehen kann, welche Aufgaben wie weit erledigt wur-
den, weiß jede beteiligte Person, was um einen herum passiert. Des Weiteren wird durch
diese Transparenz ein gewisser Erfolgsdruck geschurt, weil jederzeit direkt auf Probleme
hingewiesen werden kann. Es gibt außerdem sogenannte Daily Scrums, in denen in jedem
Meeting von jeder Person dargestellt wird, was derjenige bereits erledigt hat und was noch
ansteht. Am Ende eines Sprints gibt es einen Sprint Review, der alle Arbeitspakete ab-
schließt und Probleme anspricht, die aufgekommen sind. (vgl. [bib])
Abbildung 3: Scrum - auf einer Seite erklart [3m5]
Sozusagen basiert Scrum also auf einer inkrementellen Vorgehensweise, die durch trans-
parentes Abarbeiten von Aufgaben setzt mit dem Grundsatz, dass ein funktionierendes
Produkt wichtiger ist als eine Spezifikation.
13

4 SOFT SKILLS IN DER SOFTWAREENTWICKLUNG
4 Soft Skills in der Softwareentwicklung
Unter Soft Skills versteht man soziale Kompetenzen, die viele Eigenschaften einer Personlich-
keit abdecken. Im allgemeinen sind es Fahigkeiten, wie z. B. Menschenkenntnis, Durchsetzungs-
und Einfuhlungsvermogen. Sie basieren auf unserer Personlichkeit mit ihren Faktoren wie
Empathie, Durchsetzung, Sensibilitat, Flexibilitat. Einige dieser sind im beruflichen All-
tag von enormer Relevanz. Dort geht es beispielsweise um Kommunikations-, Konflikt-
und Teamfahigkeit, womit man in Gruppenarbeiten taglich konfrontiert wird. Sind die-
se Fahigkeiten nur geringfugig ausgepragt, kann man schnell verzweifeln oder sogar den
Anschluss verlieren bzw. gegebenenfalls nicht den Erfolg verzeichnen, den man trotz sei-
ner technischen Fahigkeiten erreichen konnte. Es gilt deshalb fur jede Partei, sich diesen
Fahigkeiten bei einem selbst bewusst zu machen und diese regelmaßig zu hinterfragen. Es
sollte nie der Status eintreten, dass die Fahigkeiten nicht mehr verbessert werden sollten.
Die Kommunikation lasst sich stetig verbessern.
Das wohl großte Problem innerhalb der Kommunikation sind Missverstandnisse. Ein Soft-
wareentwickler muss sich mit verschiedenen Parteien auseinandersetzen, weshalb es oft-
mals dazu kommt, dass alle beteiligten Parteien einen unterschiedlichen Kenntnisstand zur
Thematik aufweisen. Ziel sollte es sein, dass jede Partei die andere Partei so versteht, dass
keine Missverstandnisse auftreten. Oftmals ist es aber so, dass man diese Missverstand-
nisse nicht einmal verhindern kann, selbst wenn beide Parteien das Gefuhl haben, alles
verstanden zu haben. Das bedeutet namlich nicht, dass dem auch so ist. Es ist nicht nur
der mangelnde Kenntnisstand zwischen zweier Parteien, sondern auch die andere Art und
Weise zu Denken, die Missverstandnisse entstehen lassen konnen. Es spielen viele Faktoren
eine Rolle, die den Menschen pragen. So sind z.B. die Gene, die durch Sozialisation entwi-
ckelten, unterschiedlichen Bedurfnisse, Werte und Charakterzuge wichtige Bausteine, die
einen Menschen zu dem machen, was er ist. An diesen Faktoren gilt es zu arbeiten, sei es
durch Weiterbildung oder aber durch regelmaßiges Feedback bei der taglichen Arbeit.
Im Hinblick auf die Methoden der Softwareentwicklung kann man nur geringfugig diffe-
renzieren. Das Grundlegende, die Gruppenarbeit an sich, ist in allen Methoden Hauptbe-
standteil fur eine erfolgreiche Zielerfullung. Und in jeder Gruppenarbeit sind soft skills von
enormer Bedeutung. Es macht lediglich den Unterschied, ob im Projekt klassische oder
agile Methoden angewendet werden, wenn man auf die Intensivitat der Kommunikation
schaut. Bei agilen Softwareprojekten ist der Austausch untereinander viel ofter gegeben,
wenn man einen immer wiederkehrenden iterativen Ablauf hat, der auf regelmaßiges Feed-
back setzt. Durch den regelmaßig erzwungenen Austausch kann man besser Problematiken
aufgreifen und diese auch losen. Bei klassischen Projektmethoden ist die Kommunikati-
14

5 SCHLUSS
on dahingehend eingeschrankter, aber bei weitem nicht zu vernachlassigen. Beispielsweise
kommt ein Softwareentwickler nur unregelmaßig mit den Stakeholdern in Kontakt. Da-
durch ist die Kommunikation beeintrachtigt, aber da ist es umso wichtiger, dass man
richtig kommuniziert und gewisse Probleme schon fruhzeitig erkennt und beseitigt.
5 Schluss
Wie in der Seminararbeit behandelt, gibt es mehrere Moglichkeiten, wie man ein Projekt
anhand verschiedener Methoden durchfuhren kann. Sowohl in der klassischen als auch in
der agilen Softwareentwicklung findet man Methoden, die zu verschiedenen Projektergeb-
nissen fuhren konnen. Dabei sind innerhalb von Projekten die Soft Skills von enormer
Wichtigkeit. Wenn ein Mitarbeiter bzw. die gesamte Gruppe die Fahigkeit besitzt, sich
kommunikativ einzubringen, kann es in einem wesentlich positiveren Ergebnis resultieren.
Dabei sollte jede Partei sich selbst hinterfragen und nie aufhoren nach Verbesserungen
dieser Fahigkeiten zu streben.
15

Literatur Literatur
Literatur
[3m5] Flexibilitat hat einen namen: Scrum.
[Bau13] Roman Bauer. Hard- und Software im Entwicklungsprozeß integrierter Produk-
te: Die Anwendung des Just-in-Time-Konzeptes in Forschung und Entwicklung.
Springer-Verlag, 2013.
[bib] Agile und klassische vorgehensmodelle.
[Boe] Barry W. Boehm. A spiral model of software development and enhancement.
[Chr92] Gerhard Chroust. Modelle der Softwareentwicklung. Oldenbourg, 1992.
[eT] eLancer Team. Klassische modelle der softwareentwicklung.
[Kuh12] Dr. Marco Kuhrmann. Wasserfallmodell, 2012.
[MCD] Natali Brozmann Marie Claire Dzukou.
[onp] Wasserfallmodell.
[Sie] Dr. Markus Siepermann.
[Wei04] Tan Weiss. Klassische vs. agile methoden der softwareentwicklung, 2004.
16

Literatur Literatur
Abschließende Erklarung
Ich versichere hiermit, dass ich meine Seminararbeit ’Soft Skills fur Software Entwick-
lungsteams: Klassische vs. Agile Softwareentwicklung’ selbstandig und ohne fremde Hilfe
angefertigt habe, und dass ich alle von anderen Autoren wortlich ubernommenen Stellen
wie auch die sich an die Gedankengange anderer Autoren eng anlegenden Ausfuhrungen
meiner Arbeit besonders gekennzeichnet und die Quellen zitiert habe.
Oldenburg, den 27. Marz 2018 Jens Feldhaus
17

A ANHANG A.3 Seminararbeiten
A.3.5. Nils Meyer - Portability of Data Mining Machine Learning models usingPMML
227

Portability of Data Mining/MachineLearning models using PMML
Case of various programming languages
Seminararbeit
Themensteller: M. Eng. & Tech. Viktor Dmitriyev
Vorgelegt von: Nils MeyerFeldstraße 2726127 Oldenburg0441 [email protected]
Abgabetermin: 21. Mai 2017

Contents Contents
Contents
1 Proposal 3
2 Introduction 42.1 Knowledge Discovery in Databases, Data Mining and Machine Learning . . 42.2 Predictive Model Markup Language . . . . . . . . . . . . . . . . . . . . . . 5
3 Developing and Deploying a Model 9
4 JPMML 12
5 Conclusion 14
References 15
2

1 PROPOSAL
1 Proposal
Knowledge Discovery in Databases is an abstract and wide term which describes the pro-
cess of discovering and extracting novel knowledge out of generally masses of data. The
KDD process includes the sub-step of Data Mining (:DM). Acknowledging DM as an iso-
lated process, it applies actual strategies for discovering and exposing knowledge with
algorithms on data with partially enormous volumes which is considered Big Data.
As a result of Data Mining, or in the broader sense Knowledge Discovery in Databases,
a model could be developed representing novel knowledge such as the internal dependen-
cies of the data domain it was build for. The resulting predictive model can then be
deployed into an environment where it is used to score data which is not familiar to the
model yet. The process of developing and deploying a model could be time consuming,
costly and the quality assurance is disputable when the environments and applications
are changing alongside this process. As a solution to this challenge, the Predictive Model
Markup Language (:PMML) is introduced to function as an interface for predictive models.
First, in this term paper an introduction for the most important terms in the context of
PMML is provided. Following PMML is also introduced. Then the integration of PMML
in the process of model development and deployment is shown. Furthermore, an example
of how a model can be developed and deployed using PMML and open source software is
given. For this purpose the JPMML free software library will be briefly described. Lastly,
a brief conclusion is given.
3

2 INTRODUCTION
2 Introduction
This section addresses the definitions of Knowledge Discovery in Databases, Data Mining
and Machine Learning and their distinction from each other. On top of that predictive
modelling is put into context of these terms. Lastly, the Predictive Model Markup Lan-
guage is described.
2.1 Knowledge Discovery in Databases, Data Mining and Machine Learning
Knowledge Discovery in Databases (:KDD), Data Mining (:DM) and Machine Learning,
etc. are broad terms which are to some extent used synonymously. Especially the se-
mantic meaning of the terms KDD and DM can be mixed up. Fayyad et al. presented a
distinction which will be shortly summarised.
KDD addresses the whole process of transforming low-level data into knowledge which
can come in different forms like a compact report, an approximation or a predictive model
(see [FPS96], p.37). DM is considered a sub-process embedded in the abstract holistic
process of KDD. The mining of data consists of ”[...] the application of specific algorithms
for extracting patterns from data.”(source [FPS96], p.39) Among others, essential steps to
enable DM with valid extracted patterns including generated knowledge are data prepa-
ration, data cleaning and data selection and are again part of KDD.
Subsuming, Fayyad et al. defined KDD as:
”KDD is the nontrivial process of identifying valid, novel, potentially useful,
and ultimately understandable patterns in data.” (source [FPS96], p.40f)
and subsequent DM as:
”Data mining is a step in the KDD process that consists of applying data anal-
ysis and discovery algorithms that, under acceptable computational efficiency
limitations, produce a particular enumeration of patterns (or models) over the
data.” (source [FPS96], p.41)
Machine Learning, a term often used in conjunction with DM, is roughly summarised
as the research field of automating processes to learn from data and applying knowledge
to it. Especially of importance in this context are the methods, strategies and techniques
of Machine Learning because they are used as approaches for DM (see [Kan02], p.4).
4

2.2 Predictive Model Markup Language 2 INTRODUCTION
One possible goal of KDD and therefore of DM can be categorised as the discovery of
predictive patterns and models. These models can be used to predict the specifications of
newly domain specific data for which the model was discovered by processing the deployed
model. A predictive model could be e.g. a classification or regression model (see [FPS96],
p.43).
2.2 Predictive Model Markup Language
The Predictive Model Markup Language (:PMML) is a XML-based open format used to
enable interoperability with predictive models in the context of DM. To be more specific,
PMML is used to represent those models. It was first initiated by the Data Mining Group
(:DMG) in 1999 as version 1.0 for the purpose of creating a portable solution for predictive
models for both the developer and the consumer.
The DMG was founded in 1998 to develop standards for DM and is a vendor lead con-
sortium which advances and maintains PMML up to the present day (see [GHM02], p.59f).
Besides PMML the DMG also specified the complimentary standard Portable Format for
Analytics (PFA). As of today, PMML is released as version 4.31.
When KDD and DM became prominent applications in business and scientific orientated
fields, the lack of standardisation in DM modelling made this process time consuming and
technical difficult when models were developed and deployed across vendors and their in-
dividual solutions and applications (see [AGH+07], p.22f). PMML offers a resolution to
this issue by forming an open standard which is vendor and technical independent and
contains a multitude of features necessary to represent a model. Using PMML, a model
can be developed, then exported to this interface format and successively deployed into
an environment where the model is put to work.
Due to the fact that PMML is based on XML, the general structure is described by a
XML Schema Definition (XSD). According to that a PMML file contains the following
elements:
• Header
• Mining Build Task
• Data Dictionary
1Version 4.3 was released August 2016.
5

2.2 Predictive Model Markup Language 2 INTRODUCTION
• Transformation Dictionary
• Model
• Extension
The following brief overview of theses elements is provided with reference to Pechter (see
[Pec09], p.20f) and the online documentation of PMML available at the online presence
of the DMG (see [Gro17]).
Header The mandatory header holds meta informations about the application that
generated the PMML file, the version of this application or the time stamp of generation.
Also a description for the file can be stored in the header.
Mining Build Task This element is optional and serves as a container for information
about how the model was build or rather generated. The DMG directly recommends to
use this element to store ”[...] task specifications as defined by other mining standards,
e.g., in SQL or Java.” (source [Gro17], description MiningBuildTask) Information included
in this element do not target the PMML consumer as the receiver, but the producer for
the purpose of documentation.
Data Dictionary Within this element all data fields further used by the model are in-
troduced and described. Not only limited to the data dictionary, the naming conventions
should be obeyed, e.g. the name of elements should start with an upper-case character,
the attribute names with a lower-case and the character ”-” should not be used.
Each data field is represented by a data field -element. Data fields consist of their field
name, data type and their data type category. The data type category could either be
categorical, ordinary or continuous. Also a multitude of optional descriptions can be
submitted in the data dictionary. An interval for continuous numeric data fields can be
defined, within it the data field values are considered valid. A hierarchy for categorical
data fields can be introduced by specifying a taxonomy. PMML supports well known data
types like string, integer, float, double, boolean and some variations of datetime types.
The data dictionary does not distinguish between training or scoring datasets but in-
troduces the structure of data used by the model.
6

2.2 Predictive Model Markup Language 2 INTRODUCTION
Transformation Dictionary This dictionary contains transformation rules which are
used to map data fields from the data dictionary to transformed data. These so called
derived fields are declared by using a transformation rule with a data field from the data
dictionary. For example, a transformation rule could be a normalisation of continuous or
discrete values, an aggregation or a mapping of values based on value pairs. A derived
field addresses the need of transforming the raw data to data which is valid and meet the
requirements of the model it is used for. Another essential aspect of the data transfor-
mation is the treatment of missing and invalid data. Hence a derived field can optionally
implement methods for how missing or invalid data should be treated.
Model The model element contains the actual model. A wide variety of models is
supported. Each model has an individual set of defining elements, but they all share some
common ones. Within the mining schema all data fields must be listed which take part in
the model, or to put it another way, are required to pass to the model. Optional output
fields can be introduced with the output element. Here, information like the probability,
predicted value, standard error or other model specific features can be introduced as out-
put delivered by the model.
Next, the model statistics element serves a similar purpose but delivers statistics de-
rived from the model building task which can be univariate or multivariate statistics. For
the quality representation of a model the model explanation can be used. It can include
numeric figures for graphs or classification numbers for the specific model e.g. the number
of records used to build the model or the corresponding mean error. With the optional
element targets a unified structure for outcomes of the model can be specified. Outcome
values can be further transformed or a default value can be predetermined should the
model not deliver a computed value for an outcome. The local transformation element
works exactly like the transformation dictionary with the limitation that the included de-
rived fields are only applicable in the scope of the corresponding model.
To address the essential need to verify a model, the model verification element can be
supplied by the model producer. Basically this element contains a set of training data and
the outputs the model generated in the environment of the model producer. A consumer
of this model can then perform a functioning test and verify this model in his environment.
Besides other model specific elements the model itself is embedded within the model part
of the PMML file. Because of the fact that the supported models together feature a wide
variety of model types, only a brief overview of the available models is given. To name a
7

2.2 Predictive Model Markup Language 2 INTRODUCTION
few, PMML features models like an association, clustering, regression and tree model or
a network or scorecard. Also a meta mining model to link multiple models e.g. to form a
sequence within the PMML file is included.
Extension Extensions can be implemented at almost every other element in a PMML
file. Extensions offer the possibility of expanding PMML files with vendor specific ele-
ments, structures etc. For example, another data type could be introduced with exten-
sions and used in the data dictionary. With the use of extensions, producers of predictive
models do not have to limit their features of a model represented by PMML should a
specific feature not be included in the standard PMML.
8

3 DEVELOPING AND DEPLOYING A MODEL
3 Developing and Deploying a Model
As mentioned earlier in the section Predictive Model Markup Language the purpose of
PMML is to enable the interoperability of predictive models. PMML addresses especially
those use cases where a model is developed by a producer and then deployed in a diverse
environment of the consumer. This use case is particularly complex when the environ-
ment of the consumer differs from the producers in terms of different software systems,
applications, vendor specifications and implementations of algorithms used for DM and
development of models (see [AGH+07], p.22).
Figure 1: The sub-steps of the KDD process (source [FPS96], p.41)
As explained further by Fayyad et al. and Anand et al. the process of developing a
model does follow a standardisation on an abstract level. Starting with KDD, this pro-
cess does contain sub-steps shown in the figure The sub-steps of the KDD process. Here,
certain analogies between KDD and PMML can be observed. The sub-step of selection
in KDD could be mapped to the data dictionary in PMML which introduces the raw
data to the model. Next, the steps of preprocessing and transforming data are also cov-
ered by PMML given the ability to handle missing and invalid data and also to represent
transformations. These can range from trivial transformations like applying a scale to
data values to more sophisticated methods like converting values using user defined func-
tions or aggregating the raw data. The actual DM embedded in KDD would be achieved
9

3 DEVELOPING AND DEPLOYING A MODEL
with PMML by deploying the exported model into an environment where it can be scored.
Since PMML offers rich features to document model quality, statistics describing it and
the possibility to include data to verify the deployment of the model, the interpretation and
evaluation tasks are leveraged by PMML. The iterative nature of such a KDD process is
supported by PMML serving as an exchangeable format operating standardised interfaces.
The Cross-Industry Standard Process for Data Mining (:CRISP-DM) is a process model
which standardises DM and extends KDD by subdividing and describing the whole pro-
cess similar to KDD. Here again, similarities between the CRISP-DM tasks and elements
included in PMML can be observed. Due to the fact that CRISP-DM is another approach
to KDD, this follows a logical conclusion. The abstract CRISP-DM process model is
graphically represented by the figure The process model of CRISP-DM.
Figure 2: The process model of CRISP-DM (source [AGH+07], p.24)
10

3 DEVELOPING AND DEPLOYING A MODEL
CRISP-DM is an iterative process model like KDD. Especially the data preparation,
modelling and evaluation tasks follow corresponding sub-steps within KKD and therefore
are covered by PMML. The business and data understanding tasks are essential to this
process model to form a common understanding and interpretation of the data and in-
formation domain. Finally, the deployment task of CRIPS-DM resembles the process of
importing a PMML file and installing the containing model.
11

4 JPMML
4 JPMML
Apart from the vendors listing their mostly proprietary applications and solutions on the
website of the DMG as reference, the Java PMML API (:JPMML) open source repository
can be found. Villu Ruusmann offers several Java libraries, as well as some Python and
R libraries, to work with PMML. Following some selected libraries and their purpose
will be described. These informations are collected from the JPMML repository and its
documentation files (see [Ruu17]).
JPMML Evaluator The arguably richest library in the context of JPMML features
an evaluator for Java which can be used to deploy and score PMML models. The projects
website states:
”JPMML-Evaluator is de facto the reference implementation of the PMML
specification versions 3.0, 3.1, 3.2, 4.0, 4.1, 4.2 and 4.3 for the Java platform
[...]” (source [Ruu17] JPMML-Evaluator, features)
Its core capacities are pre-processing the input field, evaluating the model, post-processing
targets and outputs as well as performing a verification following the model verification op-
tional specified in the PMML file. The evaluator supports a wide variety of PMML features
and models, nevertheless limitations exists. Models like the Baseline, Sequence and Time
series as well as the Gaussian Process model are not supported. Also some elements like
the standard error within the output fields or the lag function at a derived field are missing.
By using this library and its functions offered, Java programmes can be upgraded to
handle the raw data delivered to the model as well as transforming it, following the specifi-
cations within a PMML file. Also the model can be scored ”[...] fast and memory efficient.”
(source [Ruu17] JPMML-Evaluator, Features) using this transformed data. Considering
the other features JPMML is bundling, the whole PMML file is functional utilisable.
JPMML Model The other core library besides the evaluator is the model library.
This library can be used contrary to the evaluator and targets the producer of a PMML
model. With it, PMML files can be managed by representing the PMML entirely as a
Java object. This means, PMML structures can be build and exported starting from
scratch. Also existing PMML files can be imported, manipulated or upgraded from an
older PMML version and then again exported. This library also features a validator to
verify the shapeliness of PMML files.
12

4 JPMML
Converting Libraries As stated before, alongside the evaluator and model library other
smaller exists inside the JPMML repository. These are mainly for the purpose of convert-
ing models from another file format to PMML e.g. Scikit-Learn pipelines, Apache Spark
ML pipelines or R models. Also evaluators for platforms other then Java can be found
like evaluators for Apache Spark, Apache Storm, Apache Hive or the PostgreSQL database.
For the purpose of testing the core libraries of JPMML the example applications pro-
vided directly by the projects website were executed using an example PMML file and
corresponding data sets from the website of the DMG. In fact, the examples were working
as expected and the JPMML libraries appear elaborate and simply put, work as promised.
All these libraries are released under the AGPL-3.02 free software licence and therefore
can be considered open source. This means, all the libraries can be downloaded, freely
modified and used with other projects as long as the license specifics are maintained.
2GNU Affero General Public License v3.0
13

5 CONCLUSION
5 Conclusion
KDD, DM and Machine Learning are fields which overlap each other but all feature the
similarity that they handle masses of data by processing it to turn the raw data to novel
knowledge. Business and scientific predictive models are built within a KDD process us-
ing DM methods which in turn partially apply algorithms from the Machine Learning field.
PMML is an open standard to enable interoperability when working with predictive
models. It particularly offers the possibility to exchange models between producers and
consumers regardless of specific environments and applications and serves as a universal
interface. The process of building and deploying models is somewhat standardised with
KDD and CRISP-DM.
Apart of commercial applications implementing PMML as a interface, JPMML is a
collection of mostly Java libraries forwarding the use of PMML with Java. The open
source repository includes functionalities for producers and consumers of PMML plus
some libraries to convert other data formats to PMML. Also, proved with the existence
of libraries which interconnect JPMML with other software systems and environments,
JPMML can be used not only in the context of the Java JVM.
14

References References
References
[AGH+07] Sarabjot Singh Anand, Marko Grobelnik, Frank Herrmann, Mark Hornick,
Christoph Lingenfelder, Niall Rooney, and Dietrich Wettschereck. Knowledge
discovery standards. Artificial Intelligence Review, 27(1):21–56, 2007.
[FPS96] Usama Fayyad, Gregory Piatetsky-Shapiro, and Padhraic Smyth. From data
mining to knowledge discovery in databases. AI Magazine, 17(3):37–54, 1996.
[GHM02] Robert L. Grossman, Mark F. Hornick, and Gregor Meyer. Data mining stan-
dards inititaves. Communications of the ACM, 45(8):59 – 61, 2002.
[Gro17] Data Mining Group. Online documentation of PMML version 4.3.
http://dmg.org/pmml/v4-3/GeneralStructure.html, 05 2017.
[Kan02] Mehmed Kantardzic. Data Mining: Concepts, Models, Methods and Algo-
rithms. John Wiley & Sons, Inc., New York, NY, USA, 2002.
[Pec09] Rick Pechter. What’s PMML and What’s New in PMML 4.0? SIGKDD
Explor. Newsl., 11(1):19–25, November 2009.
[Ruu17] Villu Ruusmann. Online repository for the JPMML library.
https://github.com/jpmml, 05 2017.
15

References References
Abschließende Erklarung
Ich versichere hiermit, dass ich meine Seminararbeit Portability of Data Mining/Machine
Learning models using PMML - Case of various programming languages selbstandig und
ohne fremde Hilfe angefertigt habe, und dass ich alle von anderen Autoren wortlich
ubernommenen Stellen wie auch die sich an die Gedankengange anderer Autoren eng
anlegenden Ausfuhrungen meiner Arbeit besonders gekennzeichnet und die Quellen zitiert
habe.
Oldenburg, den 20. Mai 2017 Nils Meyer
16

A.3 Seminararbeiten A ANHANG
A.3.6. Jakob Möller - Catalog of use cases and case studies of data-driven models inthe energy domain
244

Catalog of use cases and case studiesof data-driven models in the energy
domainSeminararbeit
Themensteller: Jad Asswad, M.Sc.Betreuer: Jad Asswad, M.Sc.
Vorgelegt von: Jakob MollerBloherfelder Str. 1626129 Oldenburg0441/[email protected]
Abgabetermin: 21. Mai 2017

Contents Contents
Contents
1 Introduction 3
2 Data-Driven Models in the Energy Domain 32.1 Big Data and Data-Driven Models . . . . . . . . . . . . . . . . . . . . . . . 3
2.1.1 Big Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32.1.2 Data-Driven Models . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.2 Current Situation in the Energy Domain . . . . . . . . . . . . . . . . . . . . 42.2.1 Smart Grids . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42.2.2 Renewable Energy . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.3 Use Cases and Case Studies . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.3.1 Generation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.3.2 Distribution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.3.3 Utilization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
3 Conlusion and Outlook 14
References 15
2

2 DATA-DRIVEN MODELS
1 Introduction
In this work an overview of existing data-driven models in the energy domain is provided.
For this overview the literature has been searched for the most prevalent trends and
developments of data-driven models in the energy domain. The resulting overview can be
used as a foundation and inspiration for the models the project group “Big Data Archive:
Data Science fur die Energiewende” is going to develop. The focus of this work is hereby
not on the details of the data models themselves, but rather on their possible applications.
The work is structured as follows. First important terms in regards to Big Data and the
energy domain will be explained. After that, the most prevalent use cases and case studies
for data-driven models in the energy domain will be presented in a categorized manner.
Finally a conclusion and an outlook for the potential usage of the approaches and models
in the project group are given.
2 Data-Driven Models in the Energy Domain
In this chapter important terms for the understanding of the use cases and case studies
are presented. First terms in regards to data processing will be defined. In the second
part terms from the energy domain and the current situation in it will be described.
2.1 Big Data and Data-Driven Models
This chapter defines the terms Big Data and data-driven Models, which are important for
the presentation of the use cases and case studies.
2.1.1 Big Data
The term Big Data was used to label data with different characteristics over the last years.
Multiple definitions of Big Data have been proposed over the last decade. A common theme
for all definitions is, that Big Data has certain attributes which causes different challenges
while working with it. The attributes which Big Data possesses are referred to as the
3 or even 4 Vs. These are: Volume (amount of data), Velocity (speed of data), Variety
(range of data types / sources ) and Veracity (quality of data). These Vs of Big Data
make new forms of data processing necessary to enable decision-making, insight discovery
and process optimization. (cf. [CCW16], p. 30)
3

2.2 Current Situation in the Energy Domain 2 DATA-DRIVEN MODELS
2.1.2 Data-Driven Models
Modern science and engineering mainly use so-called first-principle models. These models
are derived from basic scientific models like Newton’s law. These basic models have been
verified using experimental data. Various applications are then build on top of these
basic models. In many domains the development of first-principle models poses a problem
because the first principles are either not known or the studied systems are to complex to
model. In the abscence of first-principle models, models directly derived from analyzing
data can be used. These are the so-called data-driven models. (cf. [Kan11], pp. 1-2)
Data-driven models are not directly derived from physical processes. Instead they are
created by analyzing data about a system. The focus of the analysis is on finding con-
nections between the system state variables like input and output. Data-driven modeling
works without exact knowledge of the physical behavior of the system. (cf. [SSA09], pp.
17-18)
It is thereby focused on methods that can be used for building models which replace
or complement physically based models. The methods used are derived from different
fields like artificial intelligence, machine learning, data mining and knowledge discovery in
databases. Different algorithms from these fields can be used to determine the relationship
between a systems input and output. For capturing the relationship between input and
output a training data set, which contains most of the behavior found in the system, is
used. Afterwards the generated model can be tested using an independent data set to
determine how well it can generalize to before unknown data.(cf. [SSA09], p. 18)
2.2 Current Situation in the Energy Domain
Smart grids can produce an immense amount of data through measuring devices such
as smart meters. Therefore, classic approaches to analyzing this data are not sufficient
anymore. For this reason Big Data models are used for working with data in the energy
domain. (cf. [JWW+16], pp. 3844-3845)
2.2.1 Smart Grids
Smart grids are next generation power grids in which the electricity distribution is up-
graded by incorporating two-way communication between consumers and providers and
computing capabilities for improved control, efficiency, reliability and safety. They are
expected to be a modernization of the legacy electricity network. The smart grid controls
appliances at consumers’ homes to save energy, reduce costs and increase reliability and
4

2.3 Use Cases and Case Studies 2 DATA-DRIVEN MODELS
efficiency. These benefits are achieved by the balancing of supply and demand in the en-
ergy network. The smart grid covers the whole infrastructure from power generation by
classic and renewable sources through transmission and distribution and the utilization
at the consumers’. For this infrastructure, the smart grid provides monitoring, automatic
protection and optimization. (cf. [YQST13], p. 1)
Smart grids use various measuring devices. These devices generate a huge amount of
data, which has to be processed in order to make for example the balancing of supply and
demand possible (cf. [JWW+16], p. 3856). The amount of data is in fact so overwhelming,
that it can only be processed by using Big Data technologies.(cf. [JWW+16], p. 3844)
2.2.2 Renewable Energy
Renewable energy sources are for the most part characterized by their variable- and inter-
mittentness. Unlike traditional sources they do not provide a controllable, steady stream of
power. Integrating renewable energy sources into the electricity network therefore usually
requires extensive backup generation or energy storage capacity to counter the variable
and intermittent nature of such sources (cf. [KGA+11], p. 1).
To meet national energy policy objectives, such as the ones of the German “Energiewende”,
the integration of renewable energy sources into the electrical network is necessary (cf.
[CCW16], p. 232). Because of its nature renewable energy requires optimization on mul-
tiple fronts, such as the grid, the market, utilization and storage. Renewable energy also
increases the dependability of electrification on weather and weather forecasts. Big data
models can be used for optimization on all these fronts (cf. [Ali13], p. 159).
2.3 Use Cases and Case Studies
Due to the presented challenges and opportunities, the use of data-driven models in the
energy domain is highly sensible. A diverse set of case studies has been conducted for data-
driven models. Some data-driven models are already in use. Hereinafter exemplary use
cases and case studies are presented in a categorized manner. The categories generation,
transmission and distribution and utilization are used as proposed by Ali et al.(cf. [Ali13],
p. 159).
2.3.1 Generation
Diverse use cases for generation exist because of the diversity of energy sources. The use
of data-driven models in the generation of power is especially important for renewable
5

2.3 Use Cases and Case Studies 2 DATA-DRIVEN MODELS
sources (cf. [CCW16], p. 232). This is due to the fact that these sources possess an often
variable and hard to predict nature. (cf. [KGA+11], p. 1) (cf. [Ali13], pp. 59-60)
Wind Power Forecasting
Motivation On of the use cases of data-driven models in energy generation is wind
power forecasting (cf. [KZ10]). Wind power forecasting is important for the reliability of
the electricity system and for handling the volatility of the generated power. The volatile
nature of the wind makes modeling its behavior challenging. Factors such as past states
of wind speed, temperature, humidity, latitude, terrain topography and air pressure all
impact wind speed. Since the generated power is dependent on the wind speed, the quality
of the wind power prediction is highly dependent on an accurate wind speed prediction.
(cf. [KZ10], p. 1112) Forasmuch as wind speed is highly variable, wind power generation
is too. Therefore it is difficult to guarantee that load and generation remain balanced.
This uncertainty of wind power impacts various factor such as reliability and operational
efficency of the power grid. Accurate forecasts are consequently a prerequisite for the
integration of wind power into a smart grid.cf. [MZV12], p. 1)
Data Data for wind power prediction can come from various sources. The data Kusiak
and Zhang used for their data-driven model was collected by Supervisory Control and Data
Acquisition systems. The dataset was collected over a period of four weeks and contains
over 120 parameters. From the parameters, only the ones relevant to the wind speed
prediction were selected. One challenge Kusiak and Zhang were faced with was, that the
dataset contained multiple errors. Data which contained errors were excluded from further
analysis. (cf. [KZ10], p. 1112) In a paper by Murugesan et al. which also tries to solve
the problem of wind power prediction, data from an actual wind farm in the western USA
has been used. (cf. [MZV12], p. 2)
Method Kusiak and Zhang discuss a data-driven approach to the short-term forecast-
ing of wind power, which is especially relevant for the control of wind turbines and online
monitoring. (cf. [KZ10], p. 1112). For the short-term forecasting, they used exponential
smoothing and multiple data-mining algorithms for wind speed and power prediction. In
their approach, they first developed multiple models for wind speed prediction. They then
introduced three data-driven models for power forecasting in which the best model for
wind prediction is used. Finally they determine the best model for power forecasting by
comparative analysis. (cf. [KZ10], p. 1112)
6

2.3 Use Cases and Case Studies 2 DATA-DRIVEN MODELS
For the wind speed prediction model five different data-mining algorithms were used.
These are neural networks, boosting tree, random forest, support vector machine and k-
nearest neighbor (cf. [KZ10], p. 1114). A total of 80000 (cf. [KZ10], p. 1114) data points
exists in the used data set. 60000 data points (cf. [KZ10], p. 1115) were used as a training
dataset for generating the models. Afterwards the other 20000 data points (cf. [KZ10], p.
1115) were taken as a test dataset for comparing the models. The result of the comparison
was, that the neural network predicted the wind speed most accurately.(cf. [KZ10], pp.
1115-1116)
Consequently, the neural network model was utilized as an input for the development
of the wind power prediction models (cf. [KZ10], p. 1117). For the wind power prediction
models the same five algorithms, as in the development of the wind speed model were used
(cf. [KZ10], p. 1116). The three developed models for wind power were for the most part
directly derived from the existing data. Some of the models used additional controllable
variables like the blade angle (cf. [KZ10], p. 111-118).
Results The developed power prediction models allow for an accurate prediction of
power produced by wind turbines. By this they enable the control of wind turbines, early
discovery of faults and the easy integration of wind turbines into a smart grid. (cf. [KZ10],
p. 1121)
2.3.2 Distribution
Load Forecasting
Motivation Load forecasting is the predecition of the demand load on the grid. It is
an instrument for system planning, operation and control. (cf. [SLW09], p. 1460) Better
forecasting of the actual power consumption is important to enhance operation, energy
management and planning of electrical power systems. On the one hand overestimation
of the required load can lead to startup of too many generation units or excessive energy
purchase. Underestimation on the other hand can lead to risky operation, which is vulner-
able to disturbance. The better forecasting accuracy could therefore bring benefits worth
millions of dollars. (cf. [SLW09], p. 1460) Utilizing smart meter data is one way of making
these improved load forecasts possible (cf. [QLH+15], p. 1). Many energy providers are
deploying smart meters as a first step towards smart grids. These smart meters generate
data at such a rate and volume that traditional systems cannot handle it. Therefore, a
big part of the data is collected but not analyzed.(cf. [QLH+15]) The usage of this data
beyond its main purpose, billing, is a crucial challenge for energy providers. It can lead to
7

2.3 Use Cases and Case Studies 2 DATA-DRIVEN MODELS
new opportunities for consumers and energy providers. One of these is the improved load
forecasting.(cf. [QLH+15], p. 1) Usually load forecasting is performed by using system
level data. Due to the previously small amount of smart meters, forecasting using smart
meter data is still limited. Since smart meters collect data at the endpoint, the data can
be aggregated on different levels. They could for example be grouped by the geographical
location or by the substations they are connected to. This could be used for clustering
and the discovery of patterns in load consumption, which then lead to better forecasting.
(cf. [QLH+15], p. 1)
Data The data used by Quilumba et al. was real-world smart meter data from Ireland
and the United States. Prior to usage the data was preprocessed. Missing data records
were completed, corrected or eliminated. Furthermore weather data for the corresponding
regions has been used. (cf. [QLH+15], p. 3) In a similar effort to enable better load
forecasting Fan et al. used load data by a midwest US energy provider. They furthermore
used temperature data from multiple weather services, which they combined for better
forecasting results. (cf. [SLW09], p. 1461)
Method Quilumba et al. show how smart meter data can be used to improve the
accuracy of intraday load forecasting. In the process presented by Quilumba et al. the
customers were grouped based on similar consumption patterns. Then load forecasting has
been conducted for each group. Finally the individual forecasting results were aggregated
to obtain a system level forecast. (cf. [QLH+15], p. 1) For better prediction the data was
summarized and clustered. The clustering worked by grouping customers based on their
consumption behavior (cf. [QLH+15], pp. 3-5). After the clustering neural networks were
used to generate forecasts for the different clusters. These then were aggregated to de-
termine the system level load. Different clustering combinations were tested to determine
the clustering combination that resulted in the most accurate forecast (cf. [QLH+15], p.
5). In general, clustering prior to forecasting lead to more accurate system load forecasts
(cf. [QLH+15], p. 6-7). Fan et al. also used neural networks in their approach to load
forecasting (cf. [SLW09], p. 1463). For this they first trained the neural networks with
one dataset and then verified the models with another dataset (cf. [SLW09], p. 1464).
Result These more accurate load forecasts help energy providers in planning and can
enable better energy management. This better energy management can in turn lead to
improved customer experience, utility operations and power management(cf. [QLH+15],
p. 7)
8

2.3 Use Cases and Case Studies 2 DATA-DRIVEN MODELS
Demand and Price Forecasting
Motivation In modern smart grids, consumers will have the possibility to react to
changing electricity prices(cf. [MZR12], p. 664). This allows the energy providers to
reduce peak loads and customers to take part in energy-saving programs (cf. [CTW+12],
p. 70). The customers reaction to prices can lead to a shifted demand which in turn can
lead to different prices than initially forecasted. (cf. [MZR12], pp. 664)
So far, price forecasts were mostly build on a unidirectional relationship between price
and demand. It was assumed that the available demand forecasts were mostly accurate.
These demand forecast were then used as an input for price forecasting. The main problem
with these models was, that they did not take into account the potential reaction of
consumers’ to the predicted prices. The customers reaction can influence the demand
which then also influences the predicted prices again. Therefore the existing models fail
to capture price-demand dynamics.(cf. [MZR12], pp. 664)
The unidirectional models for price and demand forecasting are still in use because
in the past electricity demand has shown little elasticity to electricity prices. However,
with the development of smart grids, consumers will have the possibility to manage their
consumption for economic, reliability or environmental reasons. Smart meters will enable
the introduction of new electricity tariffs and dynamic pricing. Furthermore new consumer
behavior modification initiatives are expected to emerge. Consumers who embrace new
technologies will be enabled to shift their consumption to low cost hours. Therefore the
electricity demand is likely to switch from an inelastic behavior to a more price-responsive
environment.(cf. [MZR12], pp. 664)
Because of this, the price and demand forecasting is so valuable. Especially since in
energy markets small changes in demand can lead to steep price changes. These steep
price changes occur due to the behavior of expensive marginal generation technologies.
(cf. [MZR12], pp. 664-665)
Data Motamedia et al. evaluated their price forecasting model using real-life electric-
ity market data from New South Wales in Australia and the Connecticut Zone in New
England. (cf. [MZR12], p.672)
Method Motamedia et al. present a forecasting framework that enables the combined
forecasting of both price and demand. Their framework uses data association mining to
9

2.3 Use Cases and Case Studies 2 DATA-DRIVEN MODELS
extract patterns in consumers’ reaction to price forecasts. These patterns are then used
to improve the initial price and demand forecasts.(cf. [MZR12], p. 664) The forecasting
model works in three steps. First initial price and demand forecasts are generated using
a multi-input multi-output forecasting engine. In this case a neural network has been
used as the forecasting engine. In the next step demand-price interaction patterns were
extracted from the data using data association mining. Data association mining algorithms
are unsupervised algorithms which discover frequent relationships between the variables
in Big Datasets. In the third step the extracted patterns were then applied to the initial
forecast to generate a modified demand and price forecast.(cf. [MZR12], p. 667-669)
Results The framework was able to considerably improve the forecasting accuracy of
the initial price and demand forecasts. The extracted price and demand patterns can fur-
thermore be used to design new demand-response products and incentives. (cf. [MZR12],
p. 672)
Comparison The two approaches by Quilumba et al. and Motamedia et al. focus on
different aspects. The model by Quilumba et al. focuses only on demand forecast based
on historic data. It works well, when it is used in a market with fixed prices. Motamedia
et al. take the forecasting one step further by anticipating customers reaction to price
forecast, which in turn rely on initial demand forcasts. Their model is useful when flexible
pricing for the consumers is available and can help in the advancement of demand response
products.
2.3.3 Utilization
Building Energy Consumption Forecasting
Motivation Multiple forecasting models for building energy consumption exist. Older
approaches to forecasting building energy consumption relied heavily on detailed informa-
tion about the physical properties of a building. As an alternative researches have been
exploring data-driven approaches, which forgo the need for information on the buildings
physical properties (cf. [JDK14], pp. 1675 - 1676) Accurate prediction is important for
energy providers to determine the future energy supply and prevent shortages. Since the
operation of modern society and individual life depends on technologies that constantly
consume energy, it is critical to secure a reliable and sufficient supply of energy. To make
10

2.3 Use Cases and Case Studies 2 DATA-DRIVEN MODELS
this possible, the ability to estimate and predict power demand is necessary. Since build-
ings account for 20-40% of the energy consumption they are an important factor in the
prediction of energy consumption. (cf. [NR13], p.1) The forecasting of building energy
consumption is also important to improve energy efficeny and overall sustainability (cf.
[JDK14], p. 1675).
Data Smart Meters are an important data source for the forecasting of building en-
ergy consumption. They enable the collection of energy consumption data in a very fine
resolution. Nonetheless there are different challenges in the processing of this data. These
challenges are for example improperly calibrated meters or missing values. Therefore, the
data needs to be cleared before it can be used with the forecasting algorithms. (cf. [NR13],
p.2) In their paper Noh and Rajagopal use data from a building on the Stanford Univer-
sity campus. The building contains over 2370 measurement points for heating, ventilation,
and air conditioning which collect data every minute. The main focus is thereby on power
and energy consumption measurements such as lighting, plug loads, heating and cooling
loads. For the purpose of forecasting the energy data points were aggregated to 15 minute
intervals and the heating and cooling data points were aggregated to hourly intervals. (cf.
[NR13], p.4) The forecasting approach by Jain et al. used the consumption data of a
multi-family residential building on the Columbia University campus in New York City
(cf. [JDK14], pp. 1678). In addition it used temperature data from the National Oceanic
and Atmosphere Association and information on weekends and holidays for the university.
(cf. [JDK14], p. 1679)
Method Noh and Rajagopal presented two data-driven forecasting algorithms for
building energy consumption (cf. [NR13]). The two presented forecasting algorithms
used smart meter data and weather data to predict the building energy consumption.
One of the algorithm can be used for short term forecasting in the ranges of hours. The
other algorithm can be used for the forecasting of longer ranges like day-ahead forecasting.
(cf. [NR13], p.2) For the short-term forecasting an autoregressive model was used. For
the long-term forecasting gaussian process regression was used. The models were build by
the usage of the mentioned data. (cf. [NR13], p.2)
Results The short term forecasting model allowed for forecasting with a low prediction
error. The day-ahead forecasting allowed for equally accurate predictions. (cf. [NR13],
pp. 5-6) The forecasting of the building energy consumption can be used for different
functions. It enables energy providers to plan ahead and secure enough energy supply.
11

2.3 Use Cases and Case Studies 2 DATA-DRIVEN MODELS
Especially the accurate prediction of peak demands can help to reduce energy cost by
avoiding the last-minute use of expensive energy generators. It also allows for diagnosis of
the buildings energy system performance by the comparsion of forecasted values with ac-
tual measurements. Strong deviations from the predictions could indicate malfunction in
the system. Finally, because the model show the relation between predictors like weather
variables, human behavior, etc. and the resulting energy consumption, control schemes to
improve energy efficency can be developed. Incentives could be created to alter the input
variable in such a way that the energy consumption will decrease.(cf. [NR13], p. 6-7)
Non Intrusive Load Monitoring
Motivation Another approach to make load prediction more reliable is non-intrusive
load monitoring. Accurate predictions benefit from a determination of which and how
household electrical devices are used. (cf. [YNAK00], p. 183)
Monitoring of the usage of appliances by the energy provides is not done very broadly
so far. The main reason for this is the huge amount of residential customers and that the
available monitoring tools are not cost-effective. Because of this, an easy not to expensive
monitoring system is needed for this purpose. The Information gathered by this easy
monitoring system could then be used for energy management and general advancement
of energy conversation and efficiency.(cf. [YNAK00], p. 183)
A non-intrusive appliance load monitoring systems is such a system, that could be used
for residential customers. It determines the individual loads of each device from the total
electric load of a house. (cf. [YNAK00], p. 183)
Data For developing a data-driven non-intrusive load monitoring model load informa-
tion from electrical meters can be used (cf. [YNAK00], pp. 184-185). For some approaches
load signatures of each device are required, before non-intrusive load monitoring is possible
(cf. [WeDW13], pp. 74 - 76)
Method There are two different types of monitoring systems; the intrusive and the
non-intrusive. The first one measures consumption by using power meters on each device
in the house. Since this system requires entering the house it is called intrusive. The data
can be very accurate but comes with high cost and the hassle of setting up the system in
the house.(cf. [YNAK00], pp. 184-185)
12

2.3 Use Cases and Case Studies 2 DATA-DRIVEN MODELS
In contrast to this, the non-intrusive system does not require entering the house or an
extensive setup. It can determine the load of the individual devices from information
only gathered at the energy meter. Therefore it has advantages to the intrusive load
monitoring.(cf. [YNAK00], pp. 184-185)
The non-intrusive load monitoring system proposed by Yoshimoto et al. uses a neural
network to determine the state of each device. It allows for the detection of which devices
are switched on or off. It is also able to recognize inverter-driven devices who can have a
changing energy consumption over time like for example air conditioning. (cf. [YNAK00],
p. 185) More methods for non-intrusive load monitoring are discussed by Wong et al.
(cf. [WeDW13]). These are for example support vector machines, naive bayse classifier,
k-nearest neighbour and clustering(cf. [WeDW13], p.77).
The neural network for non-intrusive appliance load monitoring has the load curve data
as an input and the state of the different appliances as an output. The neural network
was trained using a dataset in which it was known, which devices where switched on or
off. After the training the neural network has been tested with a before unknown test
dataset.(cf. [YNAK00], pp. 189-192)
Results The results showed that the neural network was able to determine the oper-
ating states of each device. It could also determine the individual loads of each device
from the total household load. The proposed system enables the determination of which
and how consumer electrical devices are used in the residential sector. (cf. [YNAK00], pp.
192-193)
Comparison Building energy consumption forecasting allows for the accurate predic-
tion of the energy consumption of a building. In the case of Noh and Rajagopal it required
many different measurement points inside the building. These many measurements points
enable the model to show the relation between different input variables and the resulting
energy consumption. With this knowledge of the relations between the variables detailed
incentive schemes to lower energy consumptions could be developed. Non-intrusive load
monitoring also allows for the prediction of a customers energy consumption. For this
it does only require one measurement point. A consequence of this is, that the resulting
model will not show the relations between the variables as detailed as the building energy
consumption forecasting model.
13

3 CONLUSION AND OUTLOOK
3 Conlusion and Outlook
The presented exemplary use cases and case studies show the possibilities of data-driven
models in the energy domain. It is described how they can enable the development of
better forecasting models. By improving forecasting various new use cases like dynamic
pricing can be enabled. It also makes the better integration of renewable energy sources
into the smart grid possible and enables better energy management.
From the different presented use cases and case studies a common approach to the de-
velopment of data-driven models in the energy domain can be extracted. The main input
for the development of the models is measurement data from diverse sources. These are
for example weather data sets or data sets from energy providers or government initia-
tives. For the most part this data requires some amount of prior processing. Unnecessary
parameters have to be omitted and erroneous data points have to be excluded. After
that the data set has to be separated into two parts. One part for the generation of the
data-driven model and one part for the testing of the model. A diverse set of techniques
and algorithms can then be used to develop the model. In the presented use cases and
case studies neural networks were the most prevalent technique.
The extracted approach could be beneficial for the usage in the project group ”Big Data
Archive: Data Science fur die Energiewende”. The mentioned algorithms and techniques
can be an inspiration for potential usage. The work gives a comprehensive overview over
the most prevalent use cases and cases for data-driven models in the energy domain.
Nevertheless more use cases and case studies do exist which might be worth researching
for the project group. Finally the presented use cases and case studies can give hints in
which areas of the energy domain the development of business models with Big Data is
possible.
14

References References
References
[Ali13] A B M Shawkat Ali, editor. Smart Grids. Green Energy and Technology.
Springer London, London, 2013. DOI: 10.1007/978-1-4471-5210-1.
[CCW16] Jose Marıa Cavanillas, Edward Curry, and Wolfgang Wahlster, editors. New
Horizons for a Data-Driven Economy. Springer International Publishing,
Cham, 2016. DOI: 10.1007/978-3-319-21569-3.
[CTW+12] S.C. Chan, K.M. Tsui, H.C. Wu, Yunhe Hou, Yik-Chung Wu, and Felix Wu.
Load/Price Forecasting and Managing Demand Response for Smart Grids:
Methodologies and Challenges. IEEE Signal Processing Magazine, 29(5):68–
85, September 2012.
[JDK14] R. K. Jain, T. Damoulas, and C. E. Kontokosta. Towards Data-Driven Energy
Consumption Forecasting of Multi-Family Residential Buildings: Feature Se-
lection via The Lasso. In Computing in Civil and Building Engineering (2014),
pages 1675–1682. 2014.
[JWW+16] Hui Jiang, Kun Wang, Yihui Wang, Min Gao, and Yan Zhang. Energy big
data: A survey. IEEE Access, 4:3844–3861, 2016.
[Kan11] Mehmed Kantardzic. Data mining: concepts, models, methods, and algo-
rithms. John Wiley : IEEE Press, Hoboken, N.J, 2nd ed edition, 2011. OCLC:
ocn700735391.
[KGA+11] Andrew Krioukov, Christoph Goebel, Sara Alspaugh, Yanpei Chen, David E.
Culler, and Randy H. Katz. Integrating renewable energy using data analytics
systems: Challenges and opportunities. IEEE Data Eng. Bull., 34(1):3–11,
2011.
[KZ10] Andrew Kusiak and Zijun Zhang. Short-Horizon Prediction of Wind
Power: A Data-Driven Approach. IEEE Transactions on Energy Conversion,
25(4):1112–1122, December 2010.
[MZR12] Amir Motamedi, Hamidreza Zareipour, and William D. Rosehart. Electricity
Price and Demand Forecasting in Smart Grids. IEEE Transactions on Smart
Grid, 3(2):664–674, June 2012.
15

References References
[MZV12] Sugumar Murugesan, Junshan Zhang, and Vijay Vittal. Finite state Markov
chain model for wind generation forecast: A data-driven spatiotemporal ap-
proach. pages 1–8. IEEE, January 2012.
[NR13] Hae Young Noh and Ram Rajagopal. Data-driven forecasting algorithms for
building energy consumption. page 86920T, April 2013.
[QLH+15] Franklin L. Quilumba, Wei-Jen Lee, Heng Huang, David Y. Wang, and
Robert L. Szabados. Using Smart Meter Data to Improve the Accuracy of
Intraday Load Forecasting Considering Customer Behavior Similarities. IEEE
Transactions on Smart Grid, 6(2):911–918, March 2015.
[SLW09] Shu Fan, Luonan Chen, and Wei-Jen Lee. Short-Term Load Forecasting Us-
ing Comprehensive Combination Based on Multimeteorological Information.
IEEE Transactions on Industry Applications, 45(4):1460–1466, July 2009.
[SSA09] D. Solomatine, Linda M. See, and R. J. Abrahart. Data-driven modelling:
concepts, approaches and experiences. In Practical hydroinformatics, pages
17–30. Springer, 2009.
[WeDW13] Yung Fei Wong, Y. Ahmet Sekercioglu, Tom Drummond, and Voon Siong
Wong. Recent approaches to non-intrusive load monitoring techniques in res-
idential settings. In Computational Intelligence Applications In Smart Grid
(CIASG), 2013 IEEE Symposium on, pages 73–79. IEEE, 2013.
[YNAK00] K. Yoshimoto, Y. Nakano, Y. Amano, and B. Kermanshahi. Non-intrusive ap-
pliances load monitoring system using neural networks. 2000 ACEEE Summer
Study on Energy Efficiency in Buildings - Proceedings, 2:183–194, 2000.
[YQST13] Ye Yan, Yi Qian, Hamid Sharif, and David Tipper. A Survey on Smart Grid
Communication Infrastructures: Motivations, Requirements and Challenges.
IEEE Communications Surveys & Tutorials, 15(1):5–20, 2013.
16

References References
Abschließende Erklarung
Ich versichere hiermit, dass ich meine Seminararbeit “Catalog of use cases and case studies
of data-driven models in the energy domain” selbstandig und ohne fremde Hilfe angefertigt
habe, und dass ich alle von anderen Autoren wortlich ubernommenen Stellen wie auch die
sich an die Gedankengange anderer Autoren eng anlegenden Ausfuhrungen meiner Arbeit
besonders gekennzeichnet und die Quellen zitiert habe.
Oldenburg, den 21. Mai 2017 Jakob Moller
17

A.3 Seminararbeiten A ANHANG
A.3.7. Miriam Müller - Best practices in data archiving
262

Best practices in data archivingSeminararbeit im Rahmen der Projektgruppe Big Data Archive
Themensteller: Prof. Dr.-Ing. Jorge Marx GomezBetreuer: M. Eng. & Tech. Viktor Dmitriyev
Dr.-Ing. Andreas SolsbachJad Asswad, M.Sc.
Vorgelegt von: Miriam MullerBlumenstraße. 2226121 Oldenburg:Telefonnummer:[email protected]
Abgabetermin: 21. Mai 2017

Inhaltsverzeichnis Inhaltsverzeichnis
Inhaltsverzeichnis
Abkurzungsverzeichnis 3
Abbildungsverzeichnis 4
Tabellenverzeichnis 4
1 Einleitung 51.1 Zielsetzung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.2 Aufbau der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2 Grundlagen 72.1 Archiv . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.2 Elektronische Langzeitarchivierung . . . . . . . . . . . . . . . . . . . . . . . 72.3 Revisionssichere elektronische Archivierung . . . . . . . . . . . . . . . . . . 72.4 Datenarchivierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
3 Technologie Datenarchivierung 93.1 Optische Speichermedien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93.2 Bandbasierte Archivierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93.3 Festplattenbasierte Archivierung . . . . . . . . . . . . . . . . . . . . . . . . 103.4 Cloud . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
4 Benchmarking 124.1 Google Cloud Storage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124.2 Amazon Web Service . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134.3 Anforderungen Datenarchivierung . . . . . . . . . . . . . . . . . . . . . . . 154.4 Vergleich Amazon Glacier, Google Nearline und Coldline . . . . . . . . . . . 16
5 Fazit 19
Literaturverzeichnis 20
2

Abkurzungsverzeichnis Abkurzungsverzeichnis
Abkurzungsverzeichnis
WORM Write Once, Read Multiple Times
SaaS Service as a Service
PaaS Plattform as a Service
IaaS Infrastructure as a Service
TB Terabyte
GB Gigabyte
PB Petabyte
3

Abbildungsverzeichnis Tabellenverzeichnis
Abbildungsverzeichnis
1 Coldline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122 Nearline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133 Glacier . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
Tabellenverzeichnis
1 Produktvergleich . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4

1 EINLEITUNG
1 Einleitung
Seit dem Beginn der Antike1 und der Entstehung von Amtern sowie die Weiterentwick-
lung des politischen Systems, bewahrten die Menschen Dokumente auf. So wurde bereits
im antiken Athen Duplikate von Rechnungen und Vertragen angefertigt, welche fur die
Archivierung bestimmt waren. Die Archivierung diente der Forderung von Arbeitsprozes-
sen in den Bereichen Verwaltung und Forschung. Beispielsweise wurden archivierte Daten
fur den Vergleich von Gerichtsprozesse herangezogen (vgl. [VD13]).
Im Laufe der Epochen entwickelte sich die Menschheit durch den technischen Fortschritt
weiter. Zu diesem Fortschritt zahlt auch die Weiterentwicklung der Archivierung, welche
bis heute anhalt und langst nicht abgeschlossen ist.
Mit Ende des 20. Jahrhunderts begann das Zeitalter der Digitalisierung, seitdem ist die
Archivierung, hier Datenarchivierung genannt, ein fester Bestandteil vieler Unternehmen.
Durch die Digitalisierung kommt es zu einem rapiden Anstieg von Datenmengen, welche
komplex und oft unstrukturiert sein konnen. Diese Datenmengen werden auch Big Data
genannt (vgl. [Neu17]). Big Data kann dazu fuhren, dass das Volumen einer Datenbank
aufschwillt, sodass hohe Kosten fur ein Unternehmen entstehen konnen. Damit dies nicht
geschieht ist der Einsatz einer gezielten Datenarchivierung notwendig, welche relevante
Daten strukturiert ablegt und andere Daten gezielt vernichtet (vgl. [Gmb16]).
1.1 Zielsetzung
In der heutigen Zeit gibt es viele Anbieter auf dem Markt, welche Produkte zur Da-
tenarchivierung mittels Cloud Computings anbieten. Dazu zahlen etwa IBM, Microsoft
Azure, Google Cloud Storage oder Amazon Web Services. Das Ziel dieser Seminararbeit
ist ein Benchmarking fur solche Produkte, der Datenarchivierung, durchzufuhren. Die-
ser Vergleich wird anhand von unterschiedlichen Kriterien durchgefuhrt und ausgewertet.
Des Weiteren wird das Ziel verfolgt Begri↵e von einander abzugrenzen wie z. B. elek-
tronische Langzeitarchivierung und revisionssichere elektronische Archivierung. Daruber
hinaus werden einzelne Technologien der Datenarchivierung vorgestellt sowie ihre Vor-
und Nachteile.
1Die Epoche, der Antike dauerte von ca. 800 v. Chr. bis ca. 600 n. Chr..
5

1.2 Aufbau der Arbeit 1 EINLEITUNG
1.2 Aufbau der Arbeit
Diese Seminararbeit ist in funf Kapitel gegliedert. Das erste Kapitel umfasst die Einlei-
tung, welche eine Einfuhrung in die Thematik gibt. Danach folgt die Zielsetzung sowie
der Aufbau der Arbeit. Im zweiten Kapitel werden die grundlegenden Begri↵e wie Ar-
chiv, elektronische Langzeitarchivierung, revisionssichere elektronische Archivierung und
Datenarchivierung erlautert.
Das dritte Kapitel beinhaltet die einzelnen Technologien der Datenarchivierung sowie ihre
Vor- und Nachteile. In dem vierten Kapitel werden zuerst die Produkte Google Cloud Sto-
rage Coldline, Nearline und Amazon Glacier vorgestellt. Daraufhin erfolgt eine Definition,
der Anforderungen, an die Datenarchivierung. Danach findet der Vergleich zwischen drei
Produkten statt, unter der Berucksichtigung der definierten Anforderungen. Ebenso wird
der Vergleich in diesem Kapitel ausgewertet. Zum Schluss erfolgt im funften Kapitel das
Fazit.
6

2 GRUNDLAGEN
2 Grundlagen
Zu Beginn dieses Kapitels wird der Begri↵ Archiv naher erlautert. Danach erfolgt eine
Abgrenzung der Begri↵e elektronische Langzeitarchivierung, revisionssichere elektronische
Archivierung und Datenarchivierung.
2.1 Archiv
Archive dienen der Aufbewahrung, Sicherung und Ordnung von Unikaten oder gesammel-
ten Datensatze, wie z. B. Urkunden, welche einen rechtlichen, historischen oder politischen
Hintergrund besitzen (vgl. [Dud16]). Diese wurden von juristischen oder naturlichen Per-
sonen sowie von Verwaltungsstellen oder Intuitionen niedergeschrieben und werden nach
bestimmten Richtlinien zur Verfugung gestellt (vgl. [Pol14], S. 6).
Im Laufe der Jahrzehnte hat sich das Archiv weiterentwickelt, zu einem digitalen Ar-
chiv. Das digitale Archiv ist ein Informationssystem, welches verschiedene digitale Daten
aufbewahrt und diese fur bestimmte Benutzer zur Verfugung zu stellt.
2.2 Elektronische Langzeitarchivierung
Auch bei der elektronischen Langzeitarchivierung sollen die Informationen gesichert, ge-
ordnet und zuganglich gemacht werden. Der Zustand der archivierten Informationen bleibt
unveranderbar (vgl. [Rei09], S. 282). Je nach Branche gelten fur die elektronische Lang-
zeitarchivierung verschiedene Aufbewahrungsfristen. Beispielsweise betragt der Zeitraum
in der Automobilindustrie 15 Jahre (vgl. [dA08]).
Die Langzeitarchivierung bringt Probleme mit sich, z. B. konnen Daten, welche auf Spei-
chermedien hinterlegt wurden, nur noch schwer identifiziert werden. Grund dafur ist der
rasante Fortschritt in der Technologie. Dies fuhrt dazu, dass in den nachsten Jahren, die
Haltbarkeit der Speichermedien nicht gewahrleistet werden kann. Das hat wiederum zur
Folge, dass die darauf liegenden Daten nur noch schwer lesbar sind (vgl. [Sto15]). Bei-
spielsweise die Verdrangung der Floppy Disk als Speichermedium.
2.3 Revisionssichere elektronische Archivierung
Die revisionssichere elektronische Archivierung beinhaltet ebenfalls die gleichen Ziele, wie
die elektronische Langzeitarchivierung, nur mit dem Unterschied, dass diese den Forderun-
gen des Handelsgesetzbuches § 239, § 257 HGB, der Abgabeordnung § 146, § 147, § 200 und
der Grundsatze ordnungsmaßiger DV-geschutzter Buchfuhrungssysteme nachgeht. Damit
die oben genannten Paragrafen eingehalten werden, hat der Verband Organisations- und
7

2.4 Datenarchivierung 2 GRUNDLAGEN
Informationssysteme e. V. 10 Merksatze definiert, welche als Leitfaden dienen. Beispiels-
weise beinhaltet ein Merkmal die Aussage, dass Dokumente nicht verandert werden konnen
(vgl. [Pfu12]).
2.4 Datenarchivierung
Die Datenarchivierung kann als Prozess definiert werden, welcher dafur zustandig ist Daten
zu speichern, die nicht mehr aktiv genutzt werden. Diese Daten konnen aber fur zukunf-
tige Vorhaben verwendet werden. Beispielsweise konnen sie fur den Vergleich mit aktiven
Daten herangezogen werden. Die Aufbewahrung, der nicht aktiven Daten, findet auf einem
abgesonderten Storage-Gerat statt.
Haufig wird der Begri↵ Datenarchivierung mit Datenbackup gleichgesetzt. Jedoch sind
diese beiden Begri↵e von einander abzugrenzen. Ein Datenbackup ist fur eine kurzfristige
Speicherung zustandig, wobei einen Datenarchiv, Daten langfristig absichert. Weiterhin
wird es dafur genutzt, um verlorene Daten wiederherzustellen. Das heißt, es wird eine
Kopie, der Datei erstellt, damit diese fur die Wiederherstellung verwendet werden kann.
Im Gegensatz zu einem Datenbackup werden bei einem Datenarchiv Orginaldaten abge-
speichert (vgl. [Rou10]).
8

3 TECHNOLOGIE DATENARCHIVIERUNG
3 Technologie Datenarchivierung
Zu Beginn der Datenarchivierung wurden optische Speichermedien genutzt wie z. B. Dis-
ketten. Im Laufe der Jahre sind Alternativen, wie bandbasierte Archivierung, festplatten-
basierte Archivierung und die Cloud entstanden. Der Grund fur die Entwicklung dieser
Speichermedien ist der schnelle Wachstum, der Datenmengen. Denn dieser steigt heutzu-
tage innerhalb von Sekunden an.
In den folgenden Abschnitten werden die einzelnen Speichermedien vorgestellt, welche fur
die Datenarchivierung genutzt werden konnen. Ebenso werden ihre Vor- und Nachteile
aufgezeigt.
3.1 Optische Speichermedien
Zu den optischen Speichermedien zahlen beispielsweise CDs, DVDs oder Blu-ray Discs.
Diese Art der Speichermedien ist eine der ersten Alternativen in der Datenarchivierung
und wird auch als Write Once, Read Multiple Times (WORM) bezeichnet. Die Entstehung
dieser Bezeichnung basiert darauf, dass solch ein Speichermedium nur einmal beschrieben
werden kann und ist somit gegen Anderungen geschutzt (vgl. [MKD17]). Optische Spei-
chermedien werden auch weiterhin entwickelt. So hat z. B. Sony im Jahre 2016 die zweite
Generation des Optical Disc Archive vorgestellt. Dies ist in der Lage bis zu 3,3 Terabyte
(TB) zu speichern und kann jede Multi-Layer-Disc bearbeiten (vgl. [Gu16]). Optische
Speichermedien haben den Vorteil einer langen Lebensdauer. So hat eine Blu-ray Disk
eine Lebensdauer von 50-100 Jahren. Unter der Voraussetzung, dass diese entsprechend
gegen Einflussfaktoren wie z. B. Licht gelagert wird (vgl. [Sch17]). Weiterhin konnen mit
dem Einsatz von optischen Speichermedien Energiekosten eingespart werden, da diese
nicht die ganze Zeit bestromt werden mussen. Nachteilig an diesen Speichermedien ist,
dass sie eine geringe Leseleistung sowie Schreibleistung aufweisen (vgl. [Dor10]).
3.2 Bandbasierte Archivierung
Bei der bandbasierten Archivierung werden die digitalen Daten auf Magnetbander abge-
speichert. Fur eine langfristige Aufbewahrung werden die Magnetbander an eine Einrich-
tung versendet, sodass diese nicht mehr im Unternehmen vorhanden sind.
Vor einigen Jahren wurde prognostiziert, dass das Magnetband aussterben wurde. Dieser
Fall ist jedoch nicht eingetreten, sondern der entgegengesetzte Fall. Viele Unternehmen ver-
wenden heutzutage immer noch Magnetbander fur ihre Datenarchivierung (vgl. [Nun14]).
Ebenso wird diese Technologie immer noch weiterentwickelt. Beispielsweise haben im Jah-
9

3.3 Festplattenbasierte Archivierung 3 TECHNOLOGIE DATENARCHIVIERUNG
re 2015 IBM und Fujifilm das Magnetband soweit einwickeln konnen, dass ein einziges
Magnetband bis zu 220 TB aufnehmen kann (vgl. [Far15]).
Vorteil dieser Archivierung ist, dass die Daten, welche auf den Magnetbandern abgespei-
chert werden, nicht verandert werden konnen. Dies geht nur mit einer geeigneten Kombi-
nation von Soft- und Hardware (vgl. [Nun14]). Weiterhin kann die Speicherkapazitat der
Magnetbander erweitert werden, indem neue Magnetbander hinzugefugt werden. Durch
diese Erweiterung ist es moglich eine großere Menge an Daten zu speichern (vgl. [Ort09]).
Bander haben eine lange Lebensdauer von ca. 30 Jahren, wenn diese richtig gelagert wer-
den (vgl. [Som16]). Daruber hinaus konnen mit dem Einsatz von Magnetbandern Kosten
eingespart werden, in Bezug auf die Datenarchivierung. So konnen beispielsweise im Be-
reich Energie Kosten reduziert werden. Grund dafur ist, dass Magnetbander nicht die
ganze Zeit mit Strom versorgt werden mussen (vgl. [Nun14]). Nachteilig an der bandba-
sierten Archivierung ist, dass die Daten, wenn sie benotigt werden, nicht sofort vorhanden
sind. Durch die externe Auslagerung mussen diese erst geholt werden (vgl. [Ort09]). Ein
weiterer Nachteil kann bei der Entschlusselung der Daten entstehen. Durch den techni-
schen Fortschritt werden Softwares weiterentwickelt. Dies kann dazu fuhren, dass altere
Softwares uberschrieben werden, sodass die Daten nicht mehr entschlusselt werden konnen
(vgl. [Eng14]).
3.3 Festplattenbasierte Archivierung
Die festplattenbasierte Archivierung kann zum Einsatz kommen, wenn ein Unternehmen
z. B. mehrere Standorte hat. Durch diese Art der Archivierung konnen Mitarbeiter von
verschiedenen Standorten auf die Festplatte zugreifen. Die Festplatte kann ausgelagert
werden oder im Unternehmen bleiben.
Vorteil dieser Archivierung ist ein schneller Zugri↵ auf die archivierten Daten. Im Vergleich
zur bandbasierte Archivierung, ist die Lebensdauer der festplattenbasierten Archivierung
eher gering, diese betragt ca. 5 Jahre. Ursache dafur ist, dass diese z. B. anfalliger sind fur
Eruptionen (vgl. [Som16]). Weiterhin fallen mit der Verwendung, der festplattenbasierten
Archivierung hohere Kosten an. Beispielsweise steigen dadurch die Energiekosten, da die
Festplatte immer an das Netz angeschlossen ist (vgl. [Ort09]).
3.4 Cloud
Die Cloud hat in den letzten Jahren an Interesse gewonnen, da diese zum einen kostenguns-
tig ist und zum anderen den Anforderungen des schnellen Wachstums der Datenarchivie-
rung entspricht (vgl. [BK16], S. 1). So kann beispielsweise die Speicherkapazitat je nach
10

3.4 Cloud 3 TECHNOLOGIE DATENARCHIVIERUNG
belieben immer wieder erweitert werden (vgl. [Ort09]). Fur die Nutzung einer Cloud, ste-
hen drei Arten zur Verfugung Software as a Service (SaaS), Platform as a Service (PaaS)
und Infrastructure as a Service (IaaS) (vgl. [Tez16]).
Bei SaaS wird dem Kunden online eine Software zur Verfugung gestellt. Diese Dienstleis-
tung wird von einem externen Anbieter angeboten und gepflegt. Fur die Nutzung dieser
Dienstleistung muss der Kunde ein Entgeld bezahlen und benotigt fur den Zugang einen
Webbrowser (vgl. [Tez16]). Vorteil ist, dass der Kunde Kosten einspart, beispielsweise in
den Bereichen Verwaltung und Wartung. Weiterhin hat der Kunde die Moglichkeit von
jedem Standort auf die Software zuzugreifen, da diese sich nicht lokal auf einem Rech-
ner befindet. Updates werden vom Anbieter durchgefuhrt, sodass sich der Kunde auf das
Kerngeschaft konzentrieren kann. Ohne großen Aufwand kann dieses Modell ebenso in die
Unternehmensstruktur ubernommen werden. Grund dafur ist, dass durch die Nutzung der
Cloud, andere Systeme nicht beeintrachtigt werden. Diese Modell kann aber auch Nachtei-
le zum Vorscheinen bringen. Durch die Sicherung der Daten, bei dem externen Anbieter,
ist der Kunde abhangig von den Datenschutzbedingungen (vgl. [Ort09]).
Die zweite Art ist PaaS. Dieses ermoglicht dem Kunden in der Cloud eigene Programme zu
entwickeln, wie beispielsweise ein Datenarchivierungssystem. In Form einer Dienstleistung
stellt der Anbieter eine Umgebung fur die Entwicklung zur Verfugung, welche wiederum
aus verschiedenen Frameworks besteht, wie z. B. Hadoop (vgl. [Tez16]).
Dadurch, dass dem Kunden die Moglichkeit geboten wird, mit den Frameworks vom An-
bieter zu arbeiten, konnen so Kosten reduziert werden. Ebenso ubernimmt der Anbieter
die Verwaltung der darunterliegenden Hardware, so kann sich der Kunde auf die Anwen-
dungsentwicklung fokussieren. Nachteilig ist, dass der Kunde eine gewisse Abhangigkeit
vom Anbieter hat. Zum Beispiel konnte es schwierig werden, wenn der Kunde zu einem
anderen Anbieter wechseln mochte. Grund dafur konnte sein, dass der Anbieter nicht die
gleiche Entwicklungsumgebung verwendet, sodass die Gefahr entstehen konnte, dass der
komplette Prozess der Archivierung still gelegt wird. Dies hatte wiederum zur Folge, dass
der Kunde hohe Kosten tragen musste (vgl. [Bri17b]).
Zum Schluss gibt es noch IaaS, hierbei handelt es sich um die Anmietung einer Hardware
bzw. Teils einer Hardware. Der Kunde muss eigenstandig die Hardware verwalten und
diese ebenso warten. Die Aufgaben des Anbieters beinhaltet, zu einen, die Bereitstellung
der Hardware und zum anderen sollte der Server fehlerfrei laufen (vgl. [Bri17a]). Vorteilgig
ist, dass auch hier, der Kunde wieder Kosten einsparen kann, durch die Anmietung der
Hardware. Trotzdem weißt dieses Modell einen Nachteil auf. Verfugt der Kunde uber keine
Kenntnisse in den Bereichen Wartung und Konfigurationen, kann dies zu Fehlern fuhren,
welche wiederum schwerwiegend fur das Unternehmen sein konnen (vgl. [ITW17]).
11

4 BENCHMARKING
4 Benchmarking
In diesem Kapitel werden aktuelle Produkte, welche den Service der Datenarchivierung in
der Cloud anbieten, naher erlautert und miteinander verglichen. Unter anderem werden die
Vor- und Nachteile dieser Produkte aufgezeigt. Grund dafur ist das wachsende Interesse
an Cloud Diensten und dessen nutzen (vgl. [PV17], S.5 ). Dadurch steigt auch wiederum
das Interesse an Datenarchivierungssystemen, die sich in einer Cloud befinden.
Die folgenden Produkte Google Cloud Storage Coldline, Nearline und Amazon Glacier
werden in den nachsten Abschnitten vorgestellt.
4.1 Google Cloud Storage
Seit dem Jahr 2016 gibt es auf dem Markt, dass Produkt Coldline. Dieses gehort mit zu
der Familie der Google Cloud Storage, welche aus vier Optionen besteht und ist die vierte,
dieser Optionen2. Coldline ist ausgerichtet auf die Langzeitarchivierung von Daten, welche
einmal im Jahr benotigt werden. Es ist unter anderem das gunstigste Preismodell der vier
Optionen von Google Cloud Storage. Die Preise, Datenzugri↵szeit sowie Mindestspeicher-
zeit werden in der folgenden Abbildung dargestellt:
Abbildung 1: Coldline (vgl. [Rou17a] & vgl. [Pla17])
Aus der Abbildung 1 ist zu erkennen, dass der Speicherpreis pro Gigabyte (GB) monatlich
0,7 Cent betragt und fur den Datenabruf pro GB werden nochmals 0,5 Cent erhoben. Die
Zugri↵szeit betragt nur wenige Millisekunden und die vorgeschriebene Speicherzeit liegt
bei mindestens 90 Tagen (vgl. [Rou17a] & vgl. [Pla17]). Unter anderem wird mit den Ser-
vice Level Agreement3 festgelegt, dass die Daten zu 99 % zur Verfugung stehen, wenn der
Kunde diese benotigt (vgl. [Pla17]). Das abrufen der archivierten Daten erfolgt entweder
uber Google APIs oder uber die Google Cloud Platform Console. Im Bereich Datensicher-
heit wirbt Google mit der gleichen Infrastruktur, welche sie selbst nutzen. Daruber hinaus
ist Coldline kompatibel mit anderen Google Diensten wie z. B. Google Compute Engine
und Google App Engine (vgl. [Rou17a]).
2Die anderen drei Optionen sind Nearline, Multi- Regional Storage und Regional Storage.3Service Level Agreement ist eine Vereinbarung zwischen dem Kunden und dem Anbieter.
12

4.2 Amazon Web Service 4 BENCHMARKING
Google Cloud Storage bietet weiterhin eine zweite Option fur die Datenarchivierung, wel-
che unter dem Namen Nearline bekannt ist und ist die dritte Option. Das Konzept von
Nearline ist fur archivierte Daten gedacht, die einmal im Monat vom Kunden abgerufen
werden. In der folgenden Abbildung werden die Preise, Datenzugri↵szeit und Mindestspei-
cherzeit von Nearline dargestellt:
Abbildung 2: Nearline (vgl. [Pla17] & vgl. [Rou17b])
Die Abbildung 2 zeigt, dass sich die Speicherkosten pro GB monatlich auf 0,1 Cent be-
laufen und fur den Datenabruf pro GB werden 0,1 Cent genommen. Die Datenzugri↵szeit
findet bei dieser Option innerhalb von 3 Sekunden statt. Ebenso wie bei Coldline wird eine
Mindestspeicherzeit vorgeschrieben von 30 Tagen (vgl. [Pla17] & vgl. [Rou17b]). Bei Near-
line konnen die archivierten Daten genauso abgerufen werden, wie bei Coldline und es wird
ebenso die Moglichkeit angeboten mit anderen Google Diensten zusammenzuarbeiten (vgl.
[Pla17]). Die Vorteile von Coldline und Nearline sind einerseits unbegrenzte Speicherka-
pazitat und andererseits kostengunstige Preismodelle. Zwei weitere Vorteile sind, dass die
Daten verschlusselt werden und das die Zugri↵skontrolle beim Kunden liegt (vgl. [Rou17b]
& vgl. [Rou17a]). Des Weiteren betragt die Datenzugri↵szeit wenige Millisekunden bzw.
Sekunden, so muss der Kunde nicht lange auf seine angeforderten Daten warten. Ein Nach-
teil konnte entstehen, wenn der Kunde die archivierten Daten mehrfach benotigt oder die
Daten vor der Mindestablaufzeit loscht. Dies kann zu unerwunschten Kosten fuhren.
4.2 Amazon Web Service
Amazon Glacier gehort mit zum Amazon Web Service und ist ein Produkt, welches fur
die langfristige Datenarchivierung genutzt wird. Dieses Produkt bietet die Moglichkeit
nicht nur vereinzelte Daten hochzuladen, sondern auch komplette Archive (vgl. [Ser17c]).
Ebenso konnen beliebige Datentypen hochgeladen werden und es wird eine unbegrenzte
Speicherkapazitat angeboten. Die Speicherzeit betragt mindestens 90 Tage. Wenn Daten
innerhalb der 90 Tage entfernt werden, muss der Kunde eine entsprechende Gebuhr bezah-
len. Des Weiteren stehen dem Kunden zu 99 % die archivierten Daten zur Verfugung. Der
Preis fur die Nutzung in Deutschland betragt 0,0045 $ pro GB monatlich. Weiterhin gibt
13

4.2 Amazon Web Service 4 BENCHMARKING
es drei Kategorien, welche Amazon Glacier anbietet, wobei bis zu 10 GB Amazon Glacier
Daten jeden Monat kostenlos abgerufen werden konnen. Aus der folgenden Abbildung,
konnen die drei Kategorien entnommen werden:
Abbildung 3: Produktkategorien (vgl. [Ser17b])
In der Abbildung 3 ist zu erkennen, dass die Datenzugri↵szeit, Datenabrufe und Abrufan-
forderungen je nach Kategorie unterteilt werden. Die kostengunstige Kategorie ist Bulk,
wobei die Datenzugri↵szeit 5 bis 12 Stunden betragen kann. Als nachstes folgt dann Kate-
gorie Standard mit einer Datenzugri↵szeit von 3 bis 5 Stunden. Die teuerste Kategorie ist
Expedited, welche aber wiederum die schnellste Zugri↵szeit vorweist, mit einer Geschwin-
digkeit von 1 bis 5 Minuten (vgl. [Ser17b]).
Die Ubertragungspreise sind in allen drei Kategorien gleich. Fur Daten, welche in Ama-
zon Glacier hochgeladen werden wird nichts eingenommen. Bei ausgehenden Daten aus
Amazon Glacier in anderen Andere Amazon Web Service Bereichen wird eine Gebuhr von
0,020 $ pro GB erhoben. Geht es um die Ubertragung von Daten, die aus Amazon Glacier
in das Internet hochgeladen werden, so Sta↵eln sich die Preise je nach GB pro Monat, TB
pro Monat und Petabyte (PB) pro Monat. Beispielsweise kostet das ausgehen von Daten
bis zu 10 TB pro Monat 0,090 $, bei den darauf folgenden 40 TB wurden es dann 0,085 $
pro GB betragen (vgl. [Ser17b]).
Im Bereich Datensicherheit wirbt Amazon Glacier bei der Datenubertragung mit Trans-
port Layer Security4, welche auch unter den Namen Secure Sockets Layer bekannt ist.
Des Weiteren werden die Daten verschlusselt und die Zugri↵skontrolle liegt beim Kun-
den (vgl. [Ser17c]). Daruber hinaus werden rechtliche und geschaftliche Vorgaben bei der
Speicherung der Daten berucksichtigt. Dies geschieht durch die entsprechende Auswahl
4Verschlusselungsprotokoll fur eine sicher Informationsubertragung.
14

4.3 Anforderungen Datenarchivierung 4 BENCHMARKING
der Amazon Web Services Region (vgl. [Ser17a]). Fur die Speicherung der Archive werden
Container genutzt. Diese bestehen wiederum aus einem Datenspeicher, welche vom Kun-
den verwaltet werden kann. (vgl.[Ser17c]). Als Speichersysteme dienen Commodity Hard-
wares, welche aus einer hohen Anzahl von Arrays bestehen. Diese setzten sich wiederum
aus einer Menge von relativ preiswerten Festplatten zusammen (vgl. [Bu12]). Außerdem
ist eine Integration mit Amazon Simple Storage Service moglich, indem Daten verschoben
werden konnen.
Amazon Glacier bringt sowohl Vorteile als auch Nachteile mit sich. Zu den Vorteilen von
Amazon Glacier zahlen zum einen die niedrigen Preise, welche durch die verschiedenen
Produktkategorien gescha↵en werden. Zum anderen werden rechtliche und geschaftliche
Vorgaben beachtet, sodass der Kunde sein Hauptaugenmerk auf das Kerngeschaft richten
kann. Daruber hinaus steht eine unbegrenzte Speicherkapazitat zur Verfugung. Dies hat
den Vorteil, dass der Kunde eine uneingeschrankte Anzahl an Datenmengen archivieren
kann (vgl. [Ser17a]).
Der einzige Nachteil an Amazon Glacier ist die Datenzugri↵szeit. Diese kann etwa mehrere
Minuten oder Stunden betragen, je nach Auswahl des Produktes.
4.3 Anforderungen Datenarchivierung
Bevor die einzelnen Produkte verglichen werden, sollten Anforderungen definiert werden,
welche bei der Auswahl des richtigen Datenarchivierungssystems helfen. In diesem Ver-
gleich der Seminararbeit Best practices in data archiving werden folgende Anforderungen
definiert, welche aus Sicht eines Unternehmens von Bedeutung sein konnten:
Kosten: Die Kosten eines Datenarchivierungssystems sollten nicht allzu hoch sein. Es
sollte z. B. darauf geachtet werden wie hoch der Verbrauch bei den Energiekosten ist oder
wie viel eingenommen wird fur einen Speicherpreis pro GB im Monat.
Datensicherheit : Im voraus sollte geklart werden, ob der Anbieter eine sichere Datenubert-
ragung anbietet, wie z. B. Transport Layer Security. Daruber hinaus sollte gewahrleistet
werden, dass die archivierten Daten verschlusselt werden, sodass niemand diese lesen bzw.
verandern kann.
Zugri↵srechte: Eine weitere wichtige Anforderung ist die Zugri↵skontrolle. Die Kontrolle
sollte beim Unternehmen liegen.
15

4.4 Vergleich Amazon Glacier, Google Nearline und Coldline 4 BENCHMARKING
Abrufzeiten: Es sollte darauf geachtet werden, wie lange die einzelnen Produkte benotigen,
um die archivierten Daten zu laden. Hierbei sollte das Hauptaugenmerk auf das Speicher-
medium besonders gelegt werden, denn die Geschwindigkeit ist von diesem abhangig. Bei-
spielsweise versprechen Cloud Produkte Abrufzeiten von Millisekunden (vgl. [Pla17]). Bei
einer Nutzung eines Magnetbandes kann es schon mehrere Stunden betragen (vgl. [Ort09]).
Integration: Das Archivierungssystem sollte ohne großen Aufwand in die Infrastruktur des
Unternehmens eingebunden werden konnen. Beispielsweise konnen Cloud Produkt ohne
Probleme in die Infrastruktur eines Unternehmens integriert werden. Dafur muss namlich
kein extra System installiert werden, denn die Nutzung erfolgt uber einen Webbrowser
(vgl. [Ort09]).
Speicherkapazitat : Bei der Auswahl der Produkte sollte darauf geachtet werden, dass die
Speicherkapazitat, der Anwendung entsprechend ausreicht. Denn in Zeiten von Big Data,
wachst die Datenmenge stetig, sodass Produkte in ihrer Speicherkapazitat erweitert wer-
den konnen.
Lebensdauer : Fur eine lange Datenarchivierung sollte berucksichtigt werden, wie lange
die Daten auf einem Speichermedium existieren konnen. Zum Beispiel konnen Daten nur
in einer Cloud fur immer existieren, sofern es den Anbieter noch gibt und dieser die Daten
spiegelt und sichert. Magnetbander konnen z. B. bei der richtigen Lagerung bis zu 30 Jahre
halten (vgl. [Red13]).
4.4 Vergleich Amazon Glacier, Google Nearline und Coldline
Der Produktvergleich wird in einer Tabelle dargestellt. In der ersten Zeile befinden sich die
einzelnen Produkte und die Spalten beinhalten verschiedene Kategorien, mit denen Google
Cloud Storage Coldline, Nearline und Amazon Glacier untereinander verglichen werden.
Danach erfolgt der Vergleich von Amazon Glacier und Google Cloud Storage Nearline.
Im Anschluss werden Amazon Glacier und Google Cloud Storage Coldline miteinander
verglichen.
16

4.4 Vergleich Amazon Glacier, Google Nearline und Coldline 4 BENCHMARKING
Glacier Nearline Coldline
Speicherpreis pro GB im Monat 0,0045 $ 0,1 Cent 0,7 Cent
Datenabruf pro GB 0,003 $ - 0,0036 $ 0,1 Cent 0,5 Cent
Mindestspeicherzeit 90 Tage 30 Tage 90 Tage
Loschkosten pro GB 0,01 $ - 0,03 $ 0,01 Cent 0,01 Cent
Datenzugri↵szeit Min. - Std. 3 Sekunden Millisekunden
Speicherkapazitat unbegrenzt unbegrenzt unbegrenzt
Dauerhaftigkeit 99 % 99 % 99 %
Zugri↵skontrolle Kunde Kunde Kunde
Verschlusselung Vorhanden Vorhanden Vorhanden
Schnittstellen zu anderen Produkten Moglich Moglich Moglich
Tabelle 1: Produktvergleich
Zuerst werden die Produkte Amazon Glacier und Google Cloud Storage Nearline mitein-
ander vergleichen. Wie aus der Tabelle 1 ersichtlich wird, ist Nearline in der Kategorie
Speicherpreis pro GB im Monat mit einem Preis von 0,1 Cent gunstiger als Glacier. Eben-
so ist der Datenabruf pro GB mit Nearline preiswerter, als mit Glacier. Dennoch muss
beachtet werden, dass Glacier pro Monat einen kostenlosen Abruf von 10 GB anbietet.
Bei beiden Produkten wird eine Mindestspeicherzeit vorgeschrieben. Jedoch ist diese bei
Nearline geringer, als bei Glacier. Die Loschkosten pro GB sind bei Nearline ebenfalls
vorteilhafter, als bei Glacier, da bei Glacier eine Preispanne von 0,01 $ bis 0,03 $ existiert.
In der Kategorie Datenzugri↵szeit ist Nearline mit einer Geschwindigkeit von 3 Sekunden
schneller, als Glacier, welches Minuten bis Stunden benotigt, je nach Wahl des Preismo-
dells. Die Kategorien Speicherkapazitat, Dauerhaftigkeit, Zugri↵skontrolle, Verschlusse-
lung und Schnittstellen zu anderen Produkten sind bei Glacier und Nearline identisch.
Der Vergleich dieser beiden Produkte zeigt, dass Nearline in den Gebieten Speicherpreis
pro GB im Monat, Datenabruf pro GB und Loschkosten pro GB wesentlich preiswerter ist
17

4.4 Vergleich Amazon Glacier, Google Nearline und Coldline 4 BENCHMARKING
als Glacier. Zusatzlich betragt die Mindestspeicherzeit 30 Tage und die Datenzugri↵szeit
belauft sich auf 3 Sekunden. Aus diesem Grunde ist Nearline die bessere Wahl.
Als nachstes werden Amazon Glacier und Google Cloud Storage Coldline verglichen. Aus
der Tabelle 1 ist zu entnehmen, dass Coldline in dem Bereich Speicherpreis pro GB im Mo-
nat kostspieliger mit 0,7 Cent ist anstatt Glacier. Des Weiteren ist Glacier im Gegensatz
zu Coldline preiswerter bei dem Abruf der Daten pro GB. Die Speicherzeit betragt bei
beiden Produkten jeweils 90 Tage und die Loschkosten belaufen sich bei Coldline auf 0,01
Cent und bei Glacier auf 0,001 $ bis 0,003 $. In der Kategorie Datenzugri↵szeit benotigt
Coldline nur Millisekunden im Kontrast zu Glacier. Ahnlich wie bei dem Vergleich mit
Nearline sind die Produkte in den Bereichen Speicherkapazitat, Dauerhaftigkeit, Zugri↵s-
kontrolle, Verschlusselung und Schnittstellen zu anderen Produkten ubereinstimmend.
Durch den Vergleich von Glacier und Coldline wird deutlich, dass Glacier das preiswer-
tere Produkt in den Bereichen Speicherpreis pro GB im Monat und Datenabruf pro GB
ist. In der Kategorie Datenzugri↵szeit ist Coldline allerdings Glacier uberlegen, auch die
Loschkosten sind geringer bei Coldline. Jedoch sind sowohl Coldline als such Glacier emp-
fehlenswerte Produkte.
18

5 FAZIT
5 Fazit
In dieser Seminararbeit wurden Produkte zur Datenarchivierung verglichen, dabei wurde
detailliert auf die Produkte Google Cloud Storage Nearline, Coldline und Amazon Glacier
eingegangen. Der Vergleich zwischen Amazon Glacier und Google Cloud Storage Nearline
zeigt, unter der Berucksichtigung, der definierten Kriterien, welche fur den Vergleich ver-
wendet wurden, dass Nearline die bessere Wahl ist.
Der zweite Vergleich zwischen Amazon Glacier und Google Cloud Storage Coldline hat
ergeben, dass beide Produkte eine gute Wahl sind.
Die verglichenen Produkte, sowie die Wahl der Anforderungen bzw. Kriterien sind nicht fur
jedes Unternehmen optimal, da es unterschiedliche Unternehmen gibt und diese wiederum
auch verschiedene Anforderungen an ein Datenarchivierungssystem haben. Bei der Wahl
des Produktes sollte das Hauptaugenmerk auf die Definition der Anforderungen gerichtet
sein, denn es gibt kein Produkt, welches das Beste von allen ist. Daruber hinaus sollte bei
der Wahl der Anforderung, darauf geachtet werden, welche Plane fur die Zukunft mit den
archivierten Daten verfolgt werden.
Im Bereich Technologie der Datenarchivierung existieren verschiedene Speichermedien,
welche verwendet werden konnen. Auch hier kann nicht gesagt werden, welches Produkt
das Beste von allen ist. Dies ist ebenso abhangig von der Definition der Anforderungen
und Weiterverwendung der archivierten Daten.
19

Literatur Literatur
Literatur
[BK16] Jason Bu�ngton and Monya Keane. Why You Should Add Cloud Sto-
rage to Your Data Protection Strategy. https://www.ancoris.com/wp-
content/uploads/2016/11/ ESG-Solution-Showcase-Goole-Cloud-Data-
Protection-Aug-2016.pdf, 2016. [Online; Stand 12. Mai 2017].
[Bri17a] Profit Bricks. Was ist Infrastructure as a Service (IaaS)?
https://www.profitbricks.de/de/cloud-lexikon/iaas/#, 2017. [Online; Stand
12. Mai 2017].
[Bri17b] Profit Bricks. Was ist Platform as a Service (PaaS)?
https://www.profitbricks.de/de/cloud-lexikon/paas/, 2017. [Online; Stand 15.
Mai 2017].
[Bu12] Rene Bust. Amazon Web Services prasentiert Amazon Glacier: Gunstiger Cloud
Storage fur das Langzeit-Backup. https://www.crisp-research.com/amazon-
web-services- prasentieren-amazon-glacier-gunstiger-cloud-storage-fur-das-
langzeit-backup/, 2012. [Online; Stand 16. Mai 2017].
[dA08] Verband der Automobilindustrie. Qualitatsmanagement in der Automobilin-
dustire 1, 2008.
[Dor10] Pierre Dorion. Data archiving techniques: Choosing the best archive me-
dia. http://searchdatabackup.techtarget.com/tip/Data-archiving- techniques-
Choosing-the-best-archive-media, 2010. [Online; Stand 19. Mai 2017].
[Dud16] Online-Worterbuch Duden. Die deutsche Rechtschreibung.
http://www.duden.de/rechtschreibung/Archiv, 2016. [Online; Stand 10.
Mai 2017].
[Eng14] Holger Engelland. Langzeitarchivierung von Unternehmensdaten Magnetband,
Festplatte oder Cloud? http://www.lanline.de/magnetband-festplatte-oder-
cloud-html/, 2014. [Online; Stand 11. Mai 2017].
[Far15] Parwez Farsan. Datenarchivierung: IBM und Fujifilm entwickeln Magnetband
mit 220 TB. https://www.computerbase.de/2015-04/datenarchivierung-ibm-
und- fujifilm-entwickeln-magnetband-mit-220-tb/, 2015. [Online; Stand 19. Mai
2017].
20

Literatur Literatur
[Gmb16] PBS Software GmbH. Digitale Archivierung von Unternehmensdaten im Zeital-
ter von Big Data. http://businessreporter.biz/portfolio/pbs-software-digitale-
archivierung-von-unternehmensdaten-im-zeitalter-von-big-data/, 2016. [Online;
Stand 15. Mai 2017].
[Gu16] Michael Gunsch. Optical Disc Archive: Sonys Archivspeicher fasst nun
3,3 TByte. https://www.computerbase.de/2016-04/optical-disc- archive-sonys-
archivspeicher-fasst-nun-3.3-tbyte/, 2016. [Online; Stand 19. Mai 2017].
[ITW17] ITWissen. IaaS (infrastructure as a service). http://www.itwissen.info/IaaS-
infrastructure-as-a-service- Infrastructure-as-a-Service.html, 2017. [Online;
Stand 12. Mai 2017].
[MKD17] MKDiscPress. Herstellung, Aufbau und Funktion optischer Speichermedien.
http://www.mkdiscpress.de/ratgeber/ optische-speichermedien/, 2017. [Online;
Stand 19. Mai 2017].
[Neu17] Hannah Neureiter. Big Data – groß, komplex, schnelllebig. https://www.kern-
partner.at/blog/detail/ big-data-gross-komplex-schnelllebig.html, 2017. [Onli-
ne; Stand 21. Mai 2017].
[Nun14] Michael Nuncic. Magnetbander bieten mehr Sicherheit bei der Archivierung als
Festplatten oder Cloud-Storage. http://blog.krollontrack.de/magnetbaender-
bieten-mehr- sicherheit-bei-der-archivierung-als-festplatten-oder-cloud-
storage/1601, 2014. [Online; Stand 11. Mai 2017].
[Ort09] Joseph Ortiz. The Evolution of Data Archiving.
http://www.storage-switzerland.com/Articles/Entries/2009/4/6 The
Evolution of Data Archiving.html, 2009. [Online; Stand 11. Mai 2017].
[Pfu12] Andreas Pfund. Revisionssichere Elektronische Archivierung.
http://www.andreas-pfund.de/archivierung/elektronische archivierung/ re-
visionssicherheit.php, 2012. [Online; Stand 19. Mai 2017].
[Pla17] Google Cloud Platform. Archival Cloud Storage: Nearline and Coldline. htt-
ps://cloud.google.com/storage/archival/, 2017. [Online; Stand 16. Mai 2017].
[Pol14] Christopher Pollin. Prinzipien digitaler Datenarchivie-
rung. https://www.researchgate.net/publication/269401833
Prinzipien digitaler Datenarchivierung Bachelorthesis, 2014. [Online; Stand
15. Mai 2017].
21

Literatur Literatur
[PV17] Dr. Axel Pols and Marko Vogel. Cloud Monitor 2017.
https://www.bitkom.org/Presse/Anhaenge-an-PIs/2017/03-Maerz/Bitkom-
KPMG-Charts-PK-Cloud-Monitor-14032017.pdf, 2017. [Online; Stand 19. Mai
2017].
[Red13] Bernd Reder. Ratgeber Langzeitarchivierung: Dateiformate und Speicher-
medien. https://www.computerbase.de/2016-04/optical-disc- archive-sonys-
archivspeicher-fasst-nun-3.3-tbyte/, 2013. [Online; Stand 19. Mai 2017].
[Rei09] Georg Reiss, Georg und Reis. Praxisbuch IT- Dokumentation. Addison-Wesley
Verlag, 2009.
[Rou10] Margaret Rouse. Datenarchivierung. http://www.searchstorage.de/definition/
Datenarchivierung, 2010. [Online; Stand 11. Mai 2017].
[Rou17a] Margaret Rouse. Google Cloud Storage Coldline.
http://searchcloudcomputing.techtarget.com/definition/ Google-Cloud-
Storage-Coldline, 2017. [Online; Stand 16. Mai 2017].
[Rou17b] Margaret Rouse. Google Cloud Storage Nearline.
http://searchcloudcomputing.techtarget.com/definition/ Google-Cloud-
Storage-Nearline, 2017. [Online; Stand 16. Mai 2017].
[Sch17] Ste↵an Schasche. Lebensdauer von Festplatten, DVDs, CDs, und Co. im
Uberblick. http://www.pc-magazin.de/ratgeber/speichermedien- lebensdauer-
dvd-festplatte-usb-stick-floppy-disk-1485976.html, 2017. [Online; Stand 19. Mai
2017].
[Ser17a] Amazon Web Services. Amazon Glacier. https://aws.amazon.com/de/glacier/,
2017. [Online; Stand 16. Mai 2017].
[Ser17b] Amazon Web Services. Amazon Glacier Preise. htt-
ps://aws.amazon.com/de/glacier/pricing/, 2017. [Online; Stand 16. Mai
2017].
[Ser17c] Amazon Web Services. Amazon Glacier Produktdetails. htt-
ps://aws.amazon.com/de/glacier/details/#security, 2017. [Online; Stand
16. Mai 2017].
22

Literatur Literatur
[Som16] Lea Sommerhauser. Diese Storage-Systeme werden uberleben. http://www.it-
zoom.de/it-director/e/diese-storage-systeme-werden- ueberleben-14933/, 2016.
[Online; Stand 19. Mai 2017].
[Sto15] Doc Storage. Haltbarkeit von digitalen Speichern.
https://www.speicherguide.de/wissen/doc-storage/haltbarkeit-von- digitalen-
speichern-20903.aspx, 2015. [Online; Stand 09. Mai 2017].
[Tez16] Tino Tezel. Cloud Computing: SaaS, PaaS and IaaS einfach er-
klart. https://www.datenschutzbeauftragter-info.de/ die-cloud-saas-paas-und-
iaas-einfach-erklaert/, 2016. [Online; Stand 12. Mai 2017].
[VD13] Peter Van Dam. Archive in den Niederlanden.
https://www.uni-muenster.de/NiederlandeNet/nl-wissen/ bildungfor-
schung/vertiefung/archive/geschichte.html, 2013. [Online; Stand 15. Mai
2017].
23

Literatur Literatur
Abschließende Erklarung
Ich versichere hiermit, dass ich meine Seminararbeit Best practices in data archiving
selbstandig und ohne fremde Hilfe angefertigt habe, und dass ich alle von anderen Autoren
wortlich ubernommenen Stellen wie auch die sich an die Gedankengange anderer Autoren
eng anlegenden Ausfuhrungen meiner Arbeit besonders gekennzeichnet und die Quellen
zitiert habe.
Oldenburg, den 21. Mai 2017 NAME
24

A ANHANG A.3 Seminararbeiten
A.3.8. Yasin Oguz - Vergleich von Odysseus mit weiteren Open Source CEPPlattformen
287

Vergleich von Odysseus mit weiterenOpen Source CEP Plattformen
Seminararbeitim Rahmen der Projektgruppe Big Data Archive
Themensteller: Prof. Dr.-Ing. Jorge Marx GomezBetreuer: M. Eng. & Tech. Viktor Dmitriyev
Dr.-Ing. Andreas SolsbachJad Asswad, M.Sc.
Vorgelegt von: Yasin [email protected]
Abgabetermin: 21. Mai 2017

Inhaltsverzeichnis Inhaltsverzeichnis
Inhaltsverzeichnis
Glossar 3
Symbolverzeichnis 3
Abbildungsverzeichnis 4
Tabellenverzeichnis 4
1. Einleitung 51.1. Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.2. Problemstellung und Zielsetzung . . . . . . . . . . . . . . . . . . . . . . . . 5
2. Grundlagen 62.1. Complex Event Processing Einfuhrung . . . . . . . . . . . . . . . . . . . . . 6
2.1.1. Ereignisse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.1.2. Complex Event Processing . . . . . . . . . . . . . . . . . . . . . . . 72.1.3. Ereignisregeln und EPL . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2. Complex Event Processing Platform . . . . . . . . . . . . . . . . . . . . . . 92.2.1. CEP Plattform: Odysseus . . . . . . . . . . . . . . . . . . . . . . . . 92.2.2. Andere Plattformen . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.3. Open Source . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3. Vergleichskriterien 143.1. Betriebssystem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143.2. Sprachtyp . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143.3. Dokumentation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143.4. Integrierte Entwicklungsumgebung . . . . . . . . . . . . . . . . . . . . . . . 153.5. Debugging . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153.6. Visualisierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153.7. Weitere Features . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
4. Vergleich der Plattformen 164.1. Vergleich . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
5. Fazit und Ausblick 185.1. Fazit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185.2. Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
A. Anhang 20
Literaturverzeichnis 21
2

Inhaltsverzeichnis Inhaltsverzeichnis
Glossar
Symbolverzeichnis
3

Abbildungsverzeichnis Tabellenverzeichnis
Abbildungsverzeichnis
1. Odysseus Ausschnitt: Empfangen von Ereignissen . . . . . . . . . . . . . . . 12
Tabellenverzeichnis
1. Vergleich der CEP Plattformen . . . . . . . . . . . . . . . . . . . . . . . . . 16
4

1 EINLEITUNG
1. Einleitung
1.1. Motivation
In der heutigen Zeit, der weltweiten Vernetzung und der Erhebung von Daten in vielfacher
Form, werden große Datenmengen in verschiedensten Weisen, in kurzester Zeit ubermittelt.
Dieser Umstand wird mit dem Begriff Big Data zusammengefasst. Grundlegend fur Big
Data ist, dass irgendwo, in diskreten Zeitpunkten Daten wie z. B. Temperaturen erfasst
werden und in einem Netzwerk ubermittelt. Im Laufe der Zeit verandern sich diese Daten
zu diesen diskreten Zeitpunkten der Messung. Als Grund solch einer Zustandsanderungen
lasst sich ein zeitlich genau erfassbares Geschehnis festhalten, das als Ereignis (engl. event)
bezeichnet wird. Diese große Datenmengen erfordern neue Losungen zur Datenanalyse. Es
wird eine Software vorausgesetzt die durchgehend im Betrieb ist und Umweltereignisse
erfasst und auf diese eingeht. Eine zeitnahe Identifikation von Beziehungen zwischen den
gegenwartigen und in der Vergangenheit aufgefassten Ereignissen wird vorausgesetzt, um
schnell passende Reaktionen zu veranlassen. Complex Event Processing (CEP) ist die
softwareseitige Losung fur diese Analysen und Ausarbeitung von Reaktionen (vgl. [?], S. 1 f.).
Eine Complex Event Processing Plattform ist eine Anwendung, welche es ermoglicht, eben
dieses beschriebene CEP anzuwenden (vgl. [?]).
1.2. Problemstellung und Zielsetzung
Die Projektgruppe Big Data Archive der Universitat Oldenburg sieht es fur ihr Projekt vor,
eine Big Data Archive Plattform zu realisieren. Ein vorgesehener Bestandteil der Big Data
Archive Architektur ist eine CEP Plattform. Ein angestrebtes Ziel ist die Nutzung einer
Open Source Losung. Die Projektgruppe steht vor der Wahl einer geeigneten Plattform,
eine naheliegende Wahl bietet sich mit der Losung der Abteilung Informationssysteme des
Department fur Informatik ihrer Universitat (Oldenburg). Nichtsdestotrotz sollen weitere
Open Source Anwendungen in Betracht gezogen werden und mit Odysseus verglichen
werden, um alle Moglichkeiten die der Markt anbietet zu berucksichtigen und eine passende
Wahl zu treffen.
Entsprechend der Problemstellung lassen sich fur diese Arbeit folgende Ziele benennen:
1. Das Recherchieren und Vorstellen der aktuellen Open Source Plattformen mit Fokus
auf Odysseus
2. Das Aufstellen eines Vergleiches der vorgestellten Plattformen.
Im nachsten Kapitel folgt die Darstellung der Grundlagen fur diese Arbeit.
5

2 GRUNDLAGEN
2. Grundlagen
In diesem Kapitel werden die fachlichen Grundlagen, der in dieser Seminararbeit behandelten
Thematik zum Complex Event Processing erlautert. Zu diesem Zweck werden im Abschnitt 2.1
zunachst die Grundlagen des Complex Event Processing verdeutlicht, da laut Problemstellung
eine passende Plattform fur diese Technologie zu finden ist. Daraufhin wird im Abschnitt 2.2
der Begriff Complex Event Processing Platform definiert und es werden die zu vergleichenden
Plattformen vorgestellt. Im Abschnitt 2.3 wird der Begriff Open Source erlautert, da die
gesuchte Plattform eine solche Lizenz vorzuweisen hat.
2.1. Complex Event Processing Einfuhrung
Das Complex Event Processing (CEP) befasst sich mit dem Umgang von Ereignissen.
Daher ist ein genauer Blick darauf, was Ereignisse genau umfassen, notwendig.
2.1.1. Ereignisse
Eingehend wird der Begriff eines Ereignisses in dem Zusammenhang des Themas dieser
Arbeit zunachst grundlegend definiert und im Anschluss folgt eine Erlauterung von Auspragungen
des Ereignisbegriffs.
Nach Luckham und Schulte ist ein Ereignis (engl. event) all jenes was geschieht, oder von
dem erwartet wird, dass es geschieht. Dies konnen z. B. Aktivitaten wie ein finanzieller
Handel, Vorgange wie das Landen eines Flugzeuges oder Entscheidungen sein (vgl. [?]).
Nach Bruns bezieht sich ein Ereignis verallgemeinert auf den Wechsel eines Zustands, also
in der Regel auf die Anderung des Wertes eines Attributes eines realen oder virtuellen
Objekts wie z. B. eines Datenbankeintrages (vgl. [?], S. 9).
Des Weiteren werden mit Ereignissen im Idealfall Ereignisdaten mitgefuhrt, ohne diese
ist die weitere Verarbeitung der Ereignisse unmoglich. Die Ereignisdaten beinhalten den
Kontext in dem das Ereignis stattgefunden hat. Ereignisdaten lassen sich in zwei Arten
unterteilen. Zum einen existierenallgemeine Metadaten, dazu zahlen die Ereignis-ID, zur
eindeutigen Unterscheidung der Ereignisse und der Zeitstempel (engl. timestamp), welcher
den Zeitpunkt des Auftretens des Ereignisses festhalt. Außerdem konnen die Quelle und der
Typ des Ereignisses in den Metadaten enthalten sein. Die weitere Art von Ereignisdaten
sind spezifische Kontextdaten, diese beschreiben den Sachverhalt, in jenem das Ereignis
auftrat. Ein Ereignis, welches durch einen Stromzahler ausgelost wurde enthalt z. B. den
gemessenen Wert des Stromverbrauches (vgl. [?], S. 10).
Neben den bereits beschriebenen einfachen, atomaren Ereignissen gibt es auch sogenannte
6

2.1 Complex Event Processing Einfuhrung 2 GRUNDLAGEN
komplexe Ereignisse. Komplexe Ereignisse sind eine Zusammensetzung mehrerer fur sich
allein stehender Ereignisse, welche miteinander in Beziehung stehen. Die Beziehung unter
den einzelnen Ereignissen passt zu einem vorgegebenen Muster (vgl. [?], S. 14).
Komplexe Ereignisse sind somit eine Zusammensetzung mehrerer Ereignisse. Neben der
Betrachtung einer Zusammensetzung von Ereignissen ist auch der Ereignisstrom, welcher
eine linear geordnete Folge von kontinuierlich eintreffenden atomaren Ereignissen darstellt,
fur das CEP entscheidend (vgl. [?], S. 21) (vgl. [?], S. 10). Die Ereignisse in diesem Strom
konnen unterschiedlichen Typs sein oder auch verschiedene Quellen aufweisen (vgl. [?], S. 21).
Nach dem der Begriff Ereignis geklart wurde, als auch die komplexen Ereignisse und
Ereignisstrome behandelt wurden, wird im nachsten Abschnitt das Complex Event Processing
naher definiert.
2.1.2. Complex Event Processing
In diesem Abschnitt wird das Complex Event Processing definiert.
Complex Event Processing (CEP) ist eine Softwaretechnologie, welche eine dynamische
Analyse von massiven Daten- bzw. Ereignisstromen in Echtzeit gewahrleistet. Es konnen
kausale, temporale, raumliche und andere Beziehungen zwischen Ereignissen mit dieser
Technik beschrieben werden. Diese Beziehungen definieren Muster, auf jene die Ereignismenge
gepruft wird (event pattern matching) (vgl. [?], S. 10).
Die Untersuchung auf das Auftreten von spezifischen Ereignismustern ermoglicht Relationen
zwischen Ereignissen in massiven Ereignisstromen zu identifizieren. Die Suche erfolgt uber
eine langere Zeitspanne auf dem selben Ereignisstrom (vgl. [?], S. 11).
Die Machtigkeit der Operatoren bestimmt die Art der Mustererkennung, es wird zwischen
drei Arten unterschieden (vgl. [?], S. 11):
• Erkennen einfacher Ereignismuster : Es werden atomare Ereignisse oder boolesche
Verbindungen von Ereignissen in einer Ereignismenge erkannt. Ein einfache Muster
ware hierbei z. B. (A and B and not (C)) (vgl. [?], S. 11).
• Erkennen komplexer Ereignismuster : Wenn einfache Muster nicht genugen muss
mehr als ein Operator fur die Spezifikation von komplexeren Mustern hinzugezogen
werden (vgl. [?], S. 21), (vgl. [?], S. 11). Operatoren, zur Analyse der Reihenfolge
von Ereignissen oder um Zeitfenster fur das Eintreten fur Ereignisse zu definieren,
sind hierbei ausschlaggebend (vgl. [?], S. 11).
• Abstraktion von Ereignismustern: Wird in einem Ereignisstrom ein Muster erkannt,
so kann ein komplexes Ereignis auf einer hoheren Abstraktionsebene gebildet werden.
7

2.1 Complex Event Processing Einfuhrung 2 GRUNDLAGEN
Diese Abstraktion von Ereignismustern vereinfacht das Verstandnis komplexer Situationen
und reduziert die Quantitat der relevanten Ereignisse. Ubliche Operationen hierfur
sind das Bilden von Summen oder Durchschnittswerten (vgl. [?], S. 11).
Wurden Ereignismuster erkannt kann eine vordefinierte Reaktion auf dieses Ereignis folgen,
im nachsten Kapitel wird dies erlautert.
2.1.3. Ereignisregeln und EPL
In diesem Abschnitt wird in kurze auf die Ereignisregeln und die in damit in Verbindung
stehende Event Pattern Language eingegangen.
Eine Ereignisregel (event processing rule) definiert eine spezifische Reaktion, die beim
Auffinden eines Musters ausgelost werden soll. Die Regeln sind nach Bruns (vgl. [?], S. 11)
in Bedingungs- und Aktionsteil zu gliedern :
• Der Bedingungsteil enthalt ein oder mehrere miteinander verknupften Muster, auf
jene der Ereignisstrom uberpruft wird. Tritt im Ereignisstrom das Muster auf, so
ist die definierte Bedingung erfullt bzw. sie matched, und der Aktionsteil der Regel
wird daraufhin ausgefuhrt (vgl. [?], S. 12).
• Der Aktionsteil definiert eine Reaktion oder Aktion (action), welche ausgefuhrt
wird, sobald das Muster im Ereignisstrom erkannt wurde. Solche Aktionen konnen
das Erzeugen eines neuen Ereignisses oder das Anstoßen eines Dienstes in einem
Anwendungssystem sein (vgl. [?], S. 12).
Diese Regeln werden in speziellen Sprachen, den sogenannten Event Processing Languages
formuliert. Diese Sprachen ermoglichen deklarativ zu beschreiben, was geschehen soll
(Reaktion) bei Eintritt bestimmter Ereignismuster, welche ebenfalls mithilfe der EPL
vordefiniert werden konnen (vgl. [?], S. 12). Bisher liegt kein Standard fur Event Processing
Languages vor, die CEP Produkte nutzen eigens gewahlte Sprachen (vgl. [?], S. 13). Die
EPL’s lassen sich in drei Arten kategorisieren (vgl. [?], S. 63):
• Datenstrom-basierte Sprachen sind an Datenbankanfragesprachen angelehnt. Oft
basieren diese Sprachen auf der Datenbankabfragesprache SQL und erweitern diese
mit Sprachkonstrukten, welche den Zugriff auf den Datenstrom ermoglichen. Sie
enthalten die Operatoren zum Bilden komplexer Ereignisse (siehe Abschnitt 2.1.2)
(vgl. [?], S. 63).
• Kompositionsoperator-basierte Sprachen sind imperativ ausgelegte Sciptsprachen,
welche eigens fur das Complex Event Processing entwickelt worden (vgl. [?], S. 63).
8

2.2 Complex Event Processing Platform 2 GRUNDLAGEN
• Logik-basierte Sprachen liegen Systemen des Business Rule Management zugrunde
und arbeiten daher auch regelbasiert. Das Prinzip nach dem gearbeitet lasst sich wie
folgt beschreiben, ein vordefiniertes Ereignis stoßt die Ausfuhrung einer Regel an,
welche bei einer erfullten Bedingung eine festgelegte Aktion auslost (vgl. [?], S. 12).
Die Zuordnung der Sprachen zu den jeweiligen Kategorien ist nicht exakt festlegbar, da
die Sprachen haufig Eigenschaften mehrerer Kategorien vorweisen (vgl. [?], S. 63).
In den bisherigen Abschnitten wurden einige Grundlagen des Complex Event Processing
geklart, die Complex Event Processing Plattform, welche Hauptbestandteil des Seminarthemas
ist wurde bisher nicht definiert, dieser Schritt folgt im nachsten Abschnitt.
2.2. Complex Event Processing Platform
CEP Plattformen oder auch Engines sind Softwaresysteme, welche die Anwendung von
CEP ermoglichen (vgl. [?]). Wie Schulte anmerkt existieren im Event Processing viele
Begriffe, die uneindeutig voneinander abgegrenzt werden und oft als Synonyme verwendet
werden (vgl. [?]). So beschreibt Bruns die Event Processing Engine wie folgt (vgl. [?], S. 14):
Die Enigine ubernimmt die Musterkennung in den Ereignisstromen. Die Engine gleicht
fortlaufend den Datenstrom mit den Mustern in den Bedingungsteilen der Regeln ab. Wenn
eines der Muster in im Strom erkannt wird, wird die verknupfte Regel abgearbeitet. Die
Ereignisse werden in einem gewissen Zeit- oder Langenfenster gepruft, da die Ereignismengen
ublicherweise zu groß sind, um vollstandig gespeichert zu werden. Neue Ereignisse werden
beim Eintreffen dem dem Fenster erganzt, alte Ereignisse fallen schließlich heraus (vgl. [?], S. 14).
Die Engine ist somit als Kernstuck fur die CEP Verarbeitung in einer CEP Anwendung zu
verstehen, sie wird im Zusammenhang mit Event Processing Agents genannt (vgl. [?], S. 14).
Die Plattform ist nach Bruns dementsprechend die eigentliche Anwendungssoftware, welche
zu bedienen ist um das CEP anzuwenden (vgl. [?], S. 46).
Im Folgenden werden die in dieser Arbeit zu betrachtenden CEP Plattformen vorgestellt.
Zunachst wird im nachsten Abschnitt auf Odysseus eingegangen, welches mit den im
darauffolgenden Abschnitt beschriebenen Plattformen in Kapitel 4 verglichen wird.
2.2.1. CEP Plattform: Odysseus
Im Jahr 2007 entstand aus Forschungsprojekt der Abteilung Informationssysteme am
Department fur Informatik der Universitat Oldenburg das Oldenburger DynaQuest Datastream
Query System (Odysseus)[?], im folgenden wird auf dieses System naher eingegangen. Der
Grundgedanke hinter dieser Software war die Schaffung eines anpassungsfahigen Frameworks
zur effizienten Verarbeitung von Datenstromen, welches universell einsetzbar ist. Odysseus
9

2.2 Complex Event Processing Platform 2 GRUNDLAGEN
verfugt uber einen weiteren Funktionsumfang als Systeme, welche ausschließlich Complex
Event Processing verarbeiten, da es zudem als Datenstrommanagementsystem fungiert.
Die Verarbeitung von eingehenden Daten verschiedener Typen erfolgt uber Anfragen,
hierzu muss zunachst die Einbindung der Datenstromquellen erfolgt sein. Die aus der
Verarbeitung ermittelten Ergebnisse, werden anschließend kontinuierlich an die spezifizierte
Anwendung weitergeleitet. Odysseus bietet fur die Anfragen Definition Datenstrom-basierte
Sprachen (siehe Abschnitt 2.1.3) wie Procedural Query Language (PQL) oder StreamSQL,
ein Beispiel fur PQL folgt (vgl. [?]).
//PQL: Abfrage von Attributen
out = PROJECT({ATTRIBUTES=[’id’,’String’]}, s:data)
Odysseus bietet die Integration neuer Operatoren (siehe Abschnitt 2.1.2). Bei der Verarbeitung
von Anfragen werden Ressourcen gespart, indem gleiche Verarbeitungsschritte verschiedener
Anfragen zusammengefasst werden. Solche Optimierungen nimmt Odysseus eigenstandig
vor. Die unterstutzte Mehrbenutzerfahigkeit ist ein weiteres Mittel zur Ressourceneinsparung,
die Odysseus anbietet. Die Mehrbenutzerfahigkeit ermoglicht es, einen Odysseus Server fur
mehrere verschiedener Anwendungen parallel zu gebrauchen. Uber ein installierbares Plug-
in ist bei Bedarf auch die Verteilung der Anfragen auf mehrere Instanzen im Netzwerk
moglich. Solche Plug-ins ermoglichen es dem Nutzer, Odysseus dem Anwendungsgebiet
mit verschiedensten Features anzupassen. So wird der Funktionsumfang erweitert oder
bestehende Standardkomponenten ersetzt. Es existieren z. B. Plug-ins, welche Odysseus
eine Erweiterungen fur zusatzliche Datentypen, Zugriffsprotokolle und komplexe Mustererkennung,
aber auch Test- und Auswertungstools zur Stabilisierung der Systemlast bieten. Das
Einbinden der Datenquellen wird durch eine Auswahl an bereits implementierten Adapter-
Schnittstellen erleichtert. Das System kann auch frei selbst um Features erweitert werden,
wenn z. B. noch weitere Protokolle oder Ubertragungsmechanismen benotigt werden, um
bisher nicht unterstutzte Sensoren zu nutzen, konnen diese selbst in Java programmiert
und nachtraglich eingebunden werden. Der Zugriff auf Odysseus ist auf mehrere Arten
moglich, so kann dieser per Webservice, Konsole oder Java erfolgen. Die Steuerung und
Ausfuhrung von Odysseus wird mit der eigenen Sprache namens Odysseus Script abgehandelt
(vgl. [?]). Odysseus wurde in einer Client-Server-Architektur umgesetzt. So ist das System
zusammengesetzt aus den Hauptkomponenten: Odysseus Server - der Kernkomponente des
Systems, welche die Verarbeitungsmechanismen, Anfrageschnittstellen und Benutzerverwaltung
ubernimmt und Odysseus Studio - der Plattform, welche die Administration des Servers,
das Spezifizieren von Datenstromquellen und das Stellen von Anfragen bereitstellt (vgl. [?]).
Odysseus Server ist so modular aufgebaut, dass ein Erweitern, Anpassen oder Austauschen
10

2.2 Complex Event Processing Platform 2 GRUNDLAGEN
von Schritten (wie translate oder schedule) bis hin zu einzelnen Operatoren problemlos
moglich ist. Auf diese Weise kann auch das standardmaßig genutzte Datenformat von
relationalen Tupeln ersetzt werden, diese gewahrleistet eine Verarbeitung von RDF, XML
oder JSON-Objekten. Weiterhin ist Odysseus eine OSGi-basierte Architektur, welche aus
mehr als 200 Komponenten besteht, die logisch gruppiert abgeschlossene Features bilden.
Diese Features sind leicht zu aktualisieren als auch nachinstallierbar (vgl. [?]). Das Odysseus
Studio stellt eine graphische Oberflache dar, welche dem Nutzer verschiedene Interaktionsmoglichkeiten
mit dem Odysseus Server bietet. Dem Entwickler wird uber die auf auf dem Eclipse-
Framework basierende Entwicklungsumgebung eine schnelle und einfache Weise geboten,
Anfragen zu stellen. Die Anwendung ist zudem plattformunabhangig einsetzbar. Nicht nur
der Server lasst sich uber Plug-ins erweitern, auch der Odyseuss Studio Anwendung ist
diese offen. Odyseuss Studio basiert auf Eclipse RCP, dies hat den Vorteil, dass eine breite
Auswahl vorhandener Eclipse-Plug-ins, wie Git zur Versionskontrolle oder Mylyn fur eine
Aufgabenverwaltung, den Funktionsumfang erweitern. Weitere Features von Odysseues
Studio sind das Syntaxhighlighting und die Autovervollstandigung des Editors. Hinzukommt,
die gebotene Debugging Moglichkeit, die Visualisierung von Zwischenergebnissen und der
graphische Editor, mit diesem lassen sich Anfragen uber Drag’n’Drop definieren (vgl. [?]).
Es folgt in Abbildung 1 ein Beispiel der Anwendung Odysseus. Es wird der Empfang
von Temperaturdaten dargestellt. Ein PQL-Query zur Definition der Datenquelle wird im
unteren Fenster dargestellt und direkt uber diesem, die empfangenen Daten.
11

2.2 Complex Event Processing Platform 2 GRUNDLAGEN
Abbildung 1: Odysseus Ausschnitt: Empfangen von Ereignissen
2.2.2. Andere Plattformen
In diesem Abschnitt sollen die Plattformen in Kurze vorgestellt werden, welche sich im
Rahmen der Recherche fur diese Arbeit als Vergleichsobjekte ermittelt wurden. Es konnten
sich drei Produkte neben Odysseus heraus kristallisieren. Dabei fiel auf, dass es einige
weitere Produkte im Laufe der Zeit gab, aber diese Projekte nach einer gewissen Zeitspanne
eingestellt wurden, wie z. B. Open ESB, welches zunachst von Sun Microsystems and
Seebeyond entwickelt wurde, dann fur eine gewisse Zeit von einer freien Community weiter
in Stand gehalten wurde (vgl. [?]). Seit 2015 folgten hier dennoch keine neuen Releases
und der Login, welcher fur den Download benotigt wird ist nicht mehr moglich (vgl. [?]).
Die Produkte, welche schließlich fur den Vergleich hinzugezogen werden sind folgende:
Esper Espertech Inc. bietet neben ihrer kommerziellen Losung namens Esper Enterprise
Edition, bereits seit 2006 eine Open Source Losung an, welche Esper heißt (vgl. [?]). Esper
ist eine Engine zur Anaylse von Ereignisserien als auch zur Korrelation von Ereignissen
(vgl. [?]). Das Produkt ist in Java als Esper als auch fur .NET als NEsper verfugbar
und weist eine eigene EPL auf, fur die eine Online Applikation zum Testen und Erlernen
angeboten wird (vgl. [?]).
12

2.3 Open Source 2 GRUNDLAGEN
Drools Fusion Die Plattform Drools von der JBoss Community beinhaltet ein Modul
namens Drools Fusion, welches die CEP Features ubernimmt (vgl. [?]). Ziele von Drools
Fusion sind unter anderem die Unterstutzung von Ereignissen, dies beinhaltet die Erkennung,
Korrelation, Aggregation und Komposition dieser. Ein weiteres Ziel ist die Bereitstellung
einer Moglichkeit zur Modellierung von zeitlichen Beziehung zwischen den Ereignissen.
Drools basiert auf Java und bietet eine auf Eclipse basierende Entwicklungsumgebung
(vgl. [?]).
WSO2 Complex Event Processor WSO2 CEP von WSO2 ermoglicht das Erkennen und
den Umgang mit Ereignissen und Mustern von mehreren Datenquellen. WSO2 wirbt das
Produkt als hochst performant, sehr skalierbar und es schone Zeit und Kosten des Nutzers
(vgl. [?]).
Die zu vergleichenden Plattformen in dieser Arbeit sollen fur das CEP geeignet sein,
das Complex Event Processing wurde in den vorangegangenen Abschnitten erlautert. Ein
weiteres Merkmal der Plattformen ist, dass es sich um Open Source Anwendungen handelt.
Wie Open Source Software spezifiziert ist, wird im nachsten Abschnitt aufgezeigt.
2.3. Open Source
Die zu vergleichenden Anwendungen in dieser Seminararbeit sind Open Source Anwendungen,
diese sind wie folgt spezifiziert. Der Quellcode, aus dem die Anwendung hervorgeht, ist
bei Open Source Anwendungen generell offenzulegen. Der Code muss dementsprechend
frei verfugbar sein und ist gewohnlich auch kostenfrei, z. B. durch ein Downloadangebot
der Anwendung im Internet. Einige Merkmale, welche Open Source Software genauer
kennzeichnen sind (vgl. [?], S. 7 f.):
• Ein offener Quellcode.
• Integritatsschutz des Originals.
• Verbreitung der Lizenzvorschriften
• Neutralitatsgebot gegenuber anderen Technologien
• Verbot der Beschrankung auf ein bestimmtes Produkt
Dementsprechend bedeutet Open Source nicht zwangslaufig, dass die Nutzung Software
auch immer kostenlos angeboten werden muss (vgl. [?], S. 7 f.).
13

3 VERGLEICHSKRITERIEN
3. Vergleichskriterien
Die in Abschnitt 2.2 vorgestellten Open Source Plattformen sollen in einem nachsten
Schritt unter Berucksichtigung von bestimmten Kriterien verglichen werden. Jene Kriterien
werden in diesem Kapitel vorgestellt. Es wird der Titel des Kriteriums genannt gefolgt von
einer Definition. Abschließend wird eine Erlauterung gegeben, weshalb dieses Kriterium
hinzugezogen wird. Die gewahlten Kriterien sind moglichst so gewahlt, das lediglich objektive
Angaben gewahrleistet werden. Kriterien wie die Benutzerfreundlichkeit werden nicht
hinzugezogen, da diese subjektiv zu bewerten sind. Die hier gewahlten Kriterien sind
angelehnt an die Kriterien der Arbeit aus dem Jahr 2010 von Vidackovic et al. (vgl. [?], S. 16 ff.).
In der Arbeit von Vidackovic et al. wurde eine Marktubersicht von Real-Time Monitoring
Produkten aufgestellt, welche ebenfalls CEP Funktionen beinhalten.
3.1. Betriebssystem
• Definition: Die von der Plattform unterstutzten Betriebssysteme.
• Erlauterung: Damit die Plattform unter der eigenen Hardware- und Software-
Konfiguration eingesetzt werden kann, muss die Plattform das jeweilige Betriebssystem
unterstutzen. Es werden die unterstutzten Betriebssysteme aufgezahlt.
3.2. Sprachtyp
• Definition: Der Sprachtyp der Event Processing Language (EPL). Es wird unterschieden
in Datenstrom-basierte Sprachen, Kompositionsoperator-basierte Sprachen und Logik-
basierte Sprachen (siehe Abschnitt 2.1.3).
• Erlauterung: Der Sprachtyp der EPL kann ein Auswahlkriterium darstellen, da
bereits vorhandene Kenntnisse in dem gebotenem Typ, sich als Vorteil bei der Arbeit
mit der Plattform heraus stellen konnen. So konnten Kenntnisse uber SQL z. B. den
Umgang mit, das Erlernen einer Datenstrom-basierten EPL erleichtern.
3.3. Dokumentation
• Definition: Die Art der gebotenen Dokumentation.
• Erlauterung: Die Plattform sollte damit sie effizient genutzt werden kann, uber
eine Dokumentation verfugen. Es wird verglichen inwiefern eine Dokumentation
besteht und ob auch Anwendungsbeispiele geboten werden. Neben der Betrachtung
14

3.4 Integrierte Entwicklungsumgebung 3 VERGLEICHSKRITERIEN
der Informationen von Herstellerseite, wird auch Literatur, Beispiele oder ahnliches
aus externen Quellen in Betracht gezogen.
3.4. Integrierte Entwicklungsumgebung
• Definition: Beinhalten einer Entwicklungsumgebung, zum Definieren von Abfragen
oder Regeln in einer EPL.
• Erlauterung: Eine Entwicklung kann dem Entwickler eine wesentlich schnellere und
effiziente Umsetzung seiner Anfragen oder Regeln ermoglichen (vgl. [?]).
3.5. Debugging
• Definition: Bieten einer Moglichkeit zum Debugging.
• Erlauterung: Es muss mindestens die Moglichkeit vorhanden sein, EPL Code in
der IDE zu debuggen und/oder Testanfragen an die Event Processing Engine zu
ubermitteln. Debugging Funktionen erleichtern das aufspuren moglicher Fehler im
formulierten Code (vgl. [?])
3.6. Visualisierung
• Definition: Beinhalten einer Moglichkeit zur graphischen Visualisierung der Events.
• Erlauterung: Eine Visualisierung kann die Analyse von Ereignissen und das prasentieren
dieser verbessern. Wenn ein solche Visualisierungsfunktion vorhanden ist, werden die
Moglichkeiten wie Diagrammtypen aufgefasst.
3.7. Weitere Features
• Definition: Zusatzliche Komponenten, die reine Eventverarbeitungen ubersteigen.
• Erlauterung: Das beinhalten von Komponenten, welche uber die Eventverarbeitung
hinaus gehen, konnen ein Vorteil darstellen. Komplettlosungen konnen unter anderem
eine reibungslose Kommunikation und Zusammenarbeit unter den einzelnen Komponenten
gewahrleisten, wie man es von ERP Systemen gewohnt ist.
15

4 VERGLEICH DER PLATTFORMEN
4. Vergleich der Plattformen
In diesem Kapitel werden die im Kapitel 2 im Abschnitt 2.2 vorgestellte Auswahl an Open
Source Complex Event Processing Plattformen verglichen. In den vorangegangen Kapiteln
wurde auf den hier stattfindenden Vergleich der CEP Plattformen hingearbeitet. Zunachst
wurde eine weitere Literaturrecherche getatigt, dabei wurde auf Referenzen gepruft, mit
denen auf die im Kapitel 3 aufgestellten Kriterien die Produkte gepruft werden konnten.
Es folgt im nachsten Abschnitt die Prasentation des Vergleiches.
4.1. Vergleich
In diesem Abschnitt sollen die Ergebnisse aus der Recherche fur den Vergleich der CEP
Plattformen prasentiert und ausgewertet werden. Der Vergleich wird in der folgenden
Tabelle 1 dargestellt. In der Kopfzeile sind die vier in Abschnitt 2.2 vorgestellten Plattformen
angeordnet. In der ersten Spalte sind die in Kapitel 3 definierten sieben Kriterien wiederzufinden.
Jede Plattform wird auf Erfullen der Kriterien gepruft, mit Vermerk in welcher Weise das
Kriterium erfullt wurde und Verweis auf eine Referenz.
Kriterium / Plattform Odysseus Esper Drools Fusion WSO2 CEP
Betriebssystem
SprachtypDatenstrom-basiert
(vgl. [Teac])
Datenstrom-basierte Sprache
SiddhiQL (vgl. [WSOa])
Dokumentation
Wiki, Beispiele und
Tutorials enthalten und
Forum (vgl. [Teaa], [Teae])
Dokumentation, Beispiele
und Tutorials. Außerdem
eine EPL Learning
Applikation und Literatur
(vgl. [Incb ], [Incc], [BD15],
[Hed17] )
Dokumentation, Beispiele
und Tutorials. Außerdem
wird ein Forum angeboten
(vgl. [Comb], [Comc])
Dokumentation,
Videotutorials und Beispiele.
Außerdem werden
kostenpflichtige Trainings
und Zertifikate angeboten.
(vgl. [WSOa], [WSOe],
[WSOf])
EntwicklungsumgebungIntegriert, basiert auf Eclipse
(vgl. [Tead]) Nicht vorhanden
Integriert, basiert auf Eclipse
(vgl. [Comc])
Integriert als Weboberfläche
(vgl. [WSOa], [WSOd])
DebuggingMöglichkeit in Odysseus
Studio (vgl. [Tead])Nicht vorhanden
Möglichkeit vorhanden
(vgl. [Comc])
Mehrere Möglichkeiten z. B.
über "Siddhi Try It" Queries
prüfbar
(vgl. [WSOc], [WSOd])
Visualisierung Nicht vorhanden nicht vorhanden
Vielfache Möglichkeiten zur
Visualisierung zur
Erleichterung des
Monitorings (vgl. [WSOa])
Weitere FeaturesDatenstrom-management
(vgl. [Teab])Nicht vorhanden
Drools Expert als rule engine
(vgl. [Coma])Nicht vorhanden
Plattformunabhängig, Alle
mit Java Runtime
(vgl. [Tead])
Zwischenergebnisse
visualisierbar
(vgl. [Tead])
Datenstrom-basiert, eigene
Sprache (vgl. [Incc])
Plattformunabhängig, Alle
mit Java Runtime
(vgl. [Incc])
Plattformunabhängig, Alle
mit Java Runtime
(vgl. [Coma])
Kompositionsoperator-
basiert (vgl. [Coma])
Plattformunabhängig, Alle
mit Java Runtime
(vgl. [WSOb])
Tabelle 1: Vergleich der CEP Plattformen
Der in Tabelle 1 prasentierte Vergleich lasst sich wie folgt auswerten: Alle Vergleichsobjekte
sind unter jedem Betriebssystem verfugbar, welches Java Runtime unterstutzt. Bis auf
16

4.1 Vergleich 4 VERGLEICH DER PLATTFORMEN
Drools Fusion, mit einer Kompositionsoperator-basierten Sprache, bedienen sich alle weiteren
Plattformen einer Datenstrom-basierten Event Processing Language. Alle Plattformen
bieten von Herstellerseite aus eine Dokumentation oder ein Wiki an, welches Tutorials
und Beispiele enthalt. Odysseus und Drools Fusion verfugen zudem uber ein Forum. Esper
weißt dafur eine Web Applikation auf, mit der man die genutzte EPL erlernen kann und es
existiert Literatur zu dieser Plattform. WSO2 CEP hat statt nur textbasierten Tutorials
auch Videotutorials im Angebot, außerdem kann man kostenpflichtig an Trainings mit
Zertifikaten teilnehmen. Bis auf Esper weisen alle Plattformen eine Entwicklungsumgebung,
zum Definieren von Anfragen oder Regeln in einer EPL, als auch Debugging Moglichkeiten,
auf. WSO2 CEP bietet hierbei mehrere Moglichkeiten zum Debugging, so ist mit Siddhi
Try It beispielsweise das Prufen der Queries moglich. Lediglich Odysseus und WSO2 CEP
konnen Ergebnisse und Ereignisse visualisieren, WSO2 CEP wirbt hierbei mit einer breiten
Auswahl an Visualisierungsmoglichkeiten. Features, welche uber die reine Ereignisverarbeitung
hinaus gehen, weisen die Plattformen Odysseus, mit der Moglichkeit zum Datenstrommanagment
und Drools Fusion mit der enthaltenen rule engine Komponente Drools Expert, auf. Abschließend
lasst sich zusammenfassen, dass die Plattformen im Funktionsumfang viele Gemeinsamkeiten
aufweisen und der Ereignisverarbeitung nach eigenen Angaben genugen. Esper erfullt
einige Kriterien nicht, welche von den anderen Plattformen erfullt werden, daher konnte
man die anderen Plattformen Esper vorziehen. Odysseus erfullt als einziges Produkt
alle Plattformen, damit konnte man dieses Produkt bevorzugt wahlen. Welche Plattform
letzten Endes fur das eigene Projekt zu nutzen ist, muss selbst entschieden werden.
Alle Plattformen weisen in gewisser Weise Vorzuge gegenuber den anderen auf, dieser
funktionale Vergleich soll lediglich als ein Anhaltspunkt fur eine Entscheidung dienen.
17

5 FAZIT UND AUSBLICK
5. Fazit und Ausblick
In diesem Kapitel werden die Ergebnisse dieser Arbeit in einem Fazit resumiert und
gepruft. Anschließend folgt ein Ausblick der Perspektiven, die eine weitere Bearbeitung
des betrachteten Themas bietet.
5.1. Fazit
In diesem Kapitel wird eine abschließende Betrachtung vorgenommen und ausgewertet,
inwieweit die Fragestellungen dieser Seminararbeit beantwortet werden konnten. Dazu
werden im Folgenden die in Abschnitt 1.3 aufgefuhrten Hauptziele dieser Arbeit auf ihre
Erfullung gepruft.
Im Abschnitt 2.2 wurde das erste Hauptziel erfullt, es wurden neben Odysseus drei weitere
Open Source CEP Plattformen identifiziert und vorgestellt, wobei die Vorstellung von
Odysseus umfangreicher ausfiel. Es wurde festgestellt, dass der Open Source Markt fur
CEP Plattformen noch sehr ubersichtlich ausfallt. Nur wenige Open Source Produkte sind
in den letzten Jahren auf den Markt gekommen und von Diesen sind einige Projekte im
Laufe der Zeit eingestellt worden.
In Kapitel 4 wurde der Vergleich der Plattformen, anhand des in Kapitel 3 aufgestellten
Kriterienkataloges, vorgenommen. So ist auch das zweite Hauptziel erfullt. Bei der Auswertung
des Vergleiches ergab sich, dass alle Plattformen ihre Gewissen Vorteile bieten. Esper
von Esptech Inc. konnte Vergleichweise wenig Kriterien erfullen. Odysseus ist die einzige
Plattform, welche jedes Kriterium erfullt. Es ist eine Vergleich von vier Open Source
CEP Plattformen entstanden. Dieser ermoglicht, sich nach eigenen Bedurfnissen fur eine
passende Plattform zu entscheiden.
Es lasst sich eine personliche Empfehlung zur Nutzung der Plattform Odysseus fur Projekt
der Projektgruppe Big Data Archive aussprechen. Die Plattform erwies sich als einziges
Produkt, welches alle Kriterien erfullen konnte. Bei der Betrachtung der Dokumentation
dieser Plattform fiel auf, dass diese an einigen Punkten nicht aktualisiert wurde und
teilweise als unubersichtlich schien. Allerdings kann durch die von der Universitat gebotene
Nahe und der Kontakt zu den Entwicklern diesen Punkt ausgleichen. So konnten bei Fragen
Verantwortliche des Entwicklungsteams personlich kontaktiert werden. Das Produkt wurde
mit dem Anspruch entwickelt, anpassungsfahig und universell einsetzbar zu sein. So konnen
uber Plug-ins neue Funktionen nachinstalliert werden und es wird von Herstellerseite die
eigene Entwicklung von neuen Features als unkompliziert beworben, außerdem konnen
18

5.2 Ausblick 5 FAZIT UND AUSBLICK
eigene Operatoren frei definiert werden. Diese Erweiterbarkeit der Plattform konnte im
Rahmen der Projektarbeit notig sein, um die Ziele der zu entwickelnden Losung zu erreichen.
So kann die Plattform, in dem fur die Projektgruppe vorgesehenen Kontext erweitert
und angepasst werden. Die integrierte Funktionalitat als Datenstrommanagementsystem
konnte sich ebenfalls als ein Vorteil herausstellen.
Im Folgenden folgt ein Ausblick auf Moglichkeiten, die eine weitere Arbeit im Themengebiet
dieser Ausarbeitung bieten konnte.
5.2. Ausblick
Die im Rahmen dieser Abschlussarbeit durchgefuhrten Untersuchungen fuhrten zu einem
Vergleich von Open Source CEP Plattformen. Dieser Vergleich kann bereits als eine
Anhaltspunkt fur eine Auswahl der, fur das eigene Projekt geeigneten Plattform dienen.
Bei einer weiteren Bearbeitung dieses Themengebietes ware die Betrachtung weiterer
Plattformen moglich, sofern neue Open Source Losungen auf dem Markt erscheinen.
So kann die Auswahl und der Vergleich erweitert werden. Auch eine Uberarbeitung des
Kriterienkatalog konnte sich als sinnvoll erweisen, so konnte dieser mit neuen Kriterien
erweitert werden. Die praktische Anwendung jeder Plattform anhand eines einheitlichen
Szenarios ist ebenfalls vorstellbar. Das hier behandelte Thema bietet somit noch einige
Perspektiven fur eine Fortsetzung der Arbeit.
19

A ANHANG
A. Anhang
20

Literatur Literatur
Das Literaturverzeichnis ist Bestandteil jeder wissenschaftlichen Arbeit. Prazise und aussagekraftige
Angaben erleichtern die Recherche fur spatere Leser. Die Verwendung von Zitaten oder
Ideen aus anderen Arbeiten oder aus sonstigen Quellen ohne deutlichen Hinweis auf deren
Ursprung stellt eines der schwersten akademischen Vergehen dar. Eine wissenschaftliche
Arbeit, in der dieser Fehler wiederholt gemacht wird, wird zu Recht als Plagiat bezeichnet.[?]
Literatur
[Ban10] G. Bandel. Open Source Software: Fordert oder hemmt diese Art der
Softwareentwicklung den Wettbewerb? Diplomica Verlag GmbH, Hamburg, 1.
auflage edition, 2010.
[BD15] R. Bruns and J. Dunkel. Complex Event Processing: Komplexe Analyse von
massiven Datenstromen mit CEP. Essentials. Springer Vieweg, Wiesbaden, 2015.
[BG08] A. Bolles and M. Grawunder. Implementierung einer rdf-datenstromverarbeitung
mit SPARQL. In Grundlagen von Datenbanken, volume 01/2008 of Technical
Report, pages 36–40. School of Information Technology, International University
in Germany, 2008.
[Coma] JBoss Community. Drools Documentation. http://docs.jboss.org/drools/
release/6.1.0.Final/drools-docs/html_single/index.html. [Online; Stand
20. Mai 2017].
[Comb] JBoss Community. Drools Forum. http://drools.org/community/forum.html.
[Online; Stand 20. Mai 2017].
[Comc] JBoss Community. Drools Fusion - JBoss Community. http://drools.jboss.
org/drools-fusion.html. [Online; Stand 20. Mai 2017].
[Comd] OpenESB Community. Home. http://www.open-esb.net/. [Online; Stand 20.
Mai 2017].
[Come] OpenESB Community. News. http://www.open-esb.net/index.php?option=
com_content&view=category&layout=blog&id=84&Itemid=472. [Online; Stand
20. Mai 2017].
[Hed17] U. Hedtstuck. Complex Event Processing: Verarbeitung von Ereignismustern in
Datenstromen. eXamen.press. Springer Vieweg, Berlin, 2017.
21

Literatur Literatur
[Inca] EsperTech Inc. EsperTech - Company. http://www.espertech.com/company/
index.php. [Online; Stand 20. Mai 2017].
[Incb] EsperTech Inc. EsperTech - Esper. http://www.espertech.com/esper/. [Online;
Stand 20. Mai 2017].
[Incc] EsperTech Inc. EsperTech - Esper. http://www.espertech.com/esper/
release-5.3.0/esper-reference/html/index.html. [Online; Stand 20. Mai
2017].
[Incd] EsperTech Inc. EsperTech - Products - Esper. http://www.espertech.com/
products/esper.php. [Online; Stand 20. Mai 2017].
[Luc10] Luckham, D. and Schulte, W. S. Event processing glossary – version
2.0. http://www.complexevents.com/wp-content/uploads/2011/08/EPTS_
Event_Processing_Glossary_v2.pdf, 2010. [Online; Stand 20. Mai 2017].
[Sch15] R. Schulte. Cep technology: Epps, dscps and other product categories, 2015.
[Teaa] Odysseus Team. Odysseus - Index page. http://forum.odysseus.informatik.
uni-oldenburg.de/. [Online; Stand 20. Mai 2017].
[Teab] Odysseus Team. Odysseus Data Stream Management and Complex Event
Processing. http://odysseus.informatik.uni-oldenburg.de/index.php?id=
77. [Online; Stand 20. Mai 2017].
[Teac] Odysseus Team. Odysseus Data Stream Management and Complex Event
Processing: Odysseus Server - Der Kern. http://odysseus.informatik.
uni-oldenburg.de/index.php?id=84. [Online; Stand 20. Mai 2017].
[Tead] Odysseus Team. Odysseus Data Stream Management and Complex Event
Processing: Odysseus Server - Die Benutzeroberflache. http://odysseus.
informatik.uni-oldenburg.de/index.php?id=85. [Online; Stand 20. Mai
2017].
[Teae] Odysseus Team. Odysseus Home - Odysseus - Odysseus wiki. https:
//wiki.odysseus.informatik.uni-oldenburg.de/display/ODYSSEUS/
Odysseus+Home. [Online; Stand 20. Mai 2017].
[VR10] K. Vidackovic and S. Renner, T.and Rex. Marktubersicht Real-Time Monitoring
Software: Event Processing Tools im Uberblick ; [Forschungsprojekt] iC RFID -
intelligent catering. Fraunhofer Verl., Stuttgart, 2010.
22

Literatur Literatur
[WSOa] WSO2. Complex Event Processor. http://wso2.com/products/
complex-event-processor/. [Online; Stand 20. Mai 2017].
[WSOb] WSO2. Installation Prerequisites - Complex Event Processor 4.2.0 - WSO2
Documentation. https://docs.wso2.com/display/CEP420/Installation+
Prerequisites. [Online; Stand 20. Mai 2017].
[WSOc] WSO2. Monitoring and Debugging - Complex Event Processor 4.2.0 - WSO2
Documentation. https://docs.wso2.com/display/CEP420/Monitoring+and+
Debugging. [Online; Stand 20. Mai 2017].
[WSOd] WSO2. Siddhi Try It Tool - Complex Event Processor 4.2.0 - WSO2
Documentation. https://docs.wso2.com/display/CEP420/Siddhi+Try+It+
Tool. [Online; Stand 20. Mai 2017].
[WSOe] WSO2. WSO2 Complex Event Processor Documentation - Complex Event
Processor 4.2.0 - WSO2 Documentation. https://docs.wso2.com/display/
CEP420/WSO2+Complex+Event+Processor+Documentation. [Online; Stand 20.
Mai 2017].
[WSOf] WSO2. WSO2 Training and Certification. http://wso2.com/training/.
[Online; Stand 20. Mai 2017].
23

Literatur Literatur
Abschließende Erklarung
Ich versichere hiermit, dass ich meine Seminararbeit Vergleich von Odysseus mit weiteren
Open Source CEP Plattformen selbstandig und ohne fremde Hilfe angefertigt habe, und
dass ich alle von anderen Autoren wortlich ubernommenen Stellen wie auch die sich an die
Gedankengange anderer Autoren eng anlegenden Ausfuhrungen meiner Arbeit besonders
gekennzeichnet und die Quellen zitiert habe.
Oldenburg, den 15. Januar 2018 Yasin Oguz
24

A.3 Seminararbeiten A ANHANG
A.3.9. Henning Schlotmann - Die Rolle von Data Science und Data Engineering inUnternehmen
312

Die Rolle von Data Science und DataEngineering in Unternehmen
Seminararbeit im Rahmen der Projektgruppe Big Data Archive
Themensteller: Prof. Dr.-Ing. Jorge Marx GomezBetreuer: M. Eng. & Tech. Viktor Dmitriyev
Dr.-Ing. Andreas SolsbachJad Asswad, M.Sc.
Vorgelegt von: Henning SchlotmannBloherfelderstr. 132a26129 [email protected]
Abgabetermin: 21. Mai 2017

Inhaltsverzeichnis Inhaltsverzeichnis
Inhaltsverzeichnis
Abbildungsverzeichnis 3
1 Einleitung 4
2 Big Data 52.1 Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.2 Datenmengen in Unternehmen . . . . . . . . . . . . . . . . . . . . . . . . . 6
3 Data Science und Data Engineering 73.1 Data Science . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73.2 Data Engineering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83.3 Data Product . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
4 Das Data-Science Unternehmenskonzept 9
5 Data Science fur Branchen 105.1 Industrie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105.2 Handel und Konsumguter . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105.3 Energiewirtschaft . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115.4 Technologie und Medien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115.5 Transport und Logistik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115.6 Finanzdienstleistungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
6 Einsatzgebiete von Data Science 136.1 Potentiale der Einsatzbereiche . . . . . . . . . . . . . . . . . . . . . . . . . . 136.2 Data Science Anwendungsfalle . . . . . . . . . . . . . . . . . . . . . . . . . 15
6.2.1 Experimente und Analysen in Echtzeit . . . . . . . . . . . . . . . . . 156.2.2 Personalisierung von Produkten, Services und Marketing . . . . . . . 156.2.3 Innovation von Produkten und Services . . . . . . . . . . . . . . . . 16
6.3 Umsetzung von Geschaftszielen . . . . . . . . . . . . . . . . . . . . . . . . . 17
7 Mehrwerte durch Data Science 18
8 Fazit und Ausblick 20
Literaturverzeichnis 22
2

Abbildungsverzeichnis Abbildungsverzeichnis
Abbildungsverzeichnis
1 Analytische Potentiale in Funktionen . . . . . . . . . . . . . . . . . . . . . . 132 Analytische Potentiale in Prozessen . . . . . . . . . . . . . . . . . . . . . . . 143 Wertschopfung durch Produktinnovation . . . . . . . . . . . . . . . . . . . . 16
3

1 EINLEITUNG
1 Einleitung
Daten werden heutzutage als das neue Gold bezeichnet. Deshalb gilt es fur Unternehmen
danach zu suchen, um neue Unternehmenswerte zu generieren. Vor allem durch die Anfor-
derungen der hochvernetzten und digitalen Gesellschaft wird diese Herausforderung immer
großer (vgl. [Shm16] S. XXI).
Die Informationen der Welt verdoppeln sich etwa alle 20 Monate. Das McKinsey Glo-
bal Institute hat unter anderem erforscht, dass die meisten amerikanischen Unternehmen
mit mehr als 1000 Angestellten durchschnittlich 200 Terrabytes an gespeicherten Daten
verwalten. Daruber hinaus wird prognostiziert, dass die generierten Daten weltweit um 40
Prozent ansteigen werden. Daraus konnen sich fur Unternehmen profitable Moglichkeiten
ergeben, um die Daten zu Kostenreduktion zu nutzen und daruber hinaus den Gewinn zu
steigern. Dies wird uberwiegend durch die gesteigerte Effizienz sowie die hohere Qualitat
der Prozesse gewahrleistet (vgl.[Lar14] S. 1).
Zu den wichtigsten Datenquellen gehoren geschaftliche und industrielle Prozesse. Das
Ziel ist es, diese Daten durch Datenanalysen nutzbar zu machen und relevante Informa-
tionen zu finden, neue Erkenntnisse zu gewinnen, Ursachen und Wirkungen zu erkennen,
Entwicklungen vorherzusagen und optimale Entscheidungen zu treffen (vgl. [Run15] S.
48).
Bei den großen generierten Datenmengen ist die Sprache von Bid Data, welches fur
Unternehmen derzeit an großer Relevanz gewinnt. Es wird davon ausgegangen, dass der
weltweite Umsatz mit Big Data-Losungen bis zum Jahr 2025 auf mehr als 85 Milliarden
Euro ansteigen wird. Durch die intelligente Aufbereitung und Nutzung der steigenden Da-
tenmengen, werden das wirtschaftliche und gesellschaftliche Leben grundlegend verandert.
Dabei stellt sich die Frage, welche Rolle die Daten in Betrieben spielen und wie diese stra-
tegisch genutzt werden. Daruber hinaus muss beachtet werden, welcher Mehrwert dadurch
erzielt werden kann und welche Hurden und Herausforderungen es dabei gibt. Derzeit wird
der Fokus vor allem darauf gelegt, dass Unternehmen Big Data nutzen, um neue Produk-
te oder Dienstleistungen auf Basis von Daten zu entwickeln oder bestehende Prozesse zu
verbessern. Dabei ruckt das Generieren von Wissen aus den Daten immer mehr in den
Mittelpunkt der Wertschopfungskette (vgl. [Dat15] S. 4).
Die Disziplinen zur Wissensgenerierung werden als Data Engineering und Data Science
bezeichnet. Im Folgenden gilt es darzustellen, welche Bedeutung diesen fur die Unter-
nehmen beigemessen wird, welche Anwendungsfalle daraus generiert werden konnen und
welchen Mehrwert es dadurch gibt.
4

2 BIG DATA
2 Big Data
2.1 Definition
Allgemein wird Big Data nach Dumbill als”Daten, welche die Prozesskapazitat von kon-
ventionellen Datenbanksystemen aufgrund der Menge, Schnelllebigkeit oder inkompatiblen
Struktur uberschreiben“, definiert. Dabei zeichnet sich Big Data vor allem durch folgende
Charakteristika aus:
1. Umfang (Volume): Eine große Menge an Daten, die aufgenommen, analysiert und
gemanagt werden muss. Der Umfang an Daten wachst mit steigender Anzahl von
Datenquellen oder einer hoheren Datentiefe.
2. Varietat (Variety): Die Struktur der Daten variiert stark, da diese zunehmend aus
neuen Quellen innerhalb und außerhalb der Organisation stammen. Dabei konnen
auch bisher unbekannte Strukturierungsformen auftreten.
3. Schnelllebigkeit (Velocity): Dies beschreibt die Geschwindigkeit, mit der Daten pro-
duziert und verandert werden mussen. Dazu wird eine schnelle Analyse und Entschei-
dungsfindung verlangt. Die Schnelllebigkeit wird von der Anzahl an Datenquellen
und der gesteigerten Rechenleistung der datengetriebenen Gerate beeinflusst.
4. Richtigkeit (Veracity): Die Qualitat und Quelle der rezipierten Daten. Die Qualitat
wird dabei durch Inkonsistenz, Unvollstandigkeit und Ambiguitaten beeinflusst. Fur
datenbasierte Entscheidungen wird eine gewisse Nachvollziehbarkeit und Begrund-
barkeit verlangt (vgl. [Kin14] S. 34f).
5. Datenquellen (Reach): Die Datenherkunft ist ein zentraler Aspekt von Big Data.
Dazu gilt es zu analysieren, welche Daten im Unternehmen vorhanden sind und
wie die genutzt werden oder ob sie genutzt werden konnen. Deshalb kann es auch
sinnvoll sein, externe Daten einzubeziehen oder interne Daten neu zu erheben. Dabei
gilt es zu klaren, welche Daten zur Entscheidungsunterstutzung zu erheben sind (vgl.
[Pri13] S. 10).
Die Daten konnen strukturiert, semistrukturiert oder unstrukturiert vorliegen. Struk-
turierte Daten werden in herkommlichen Datenbankstrukturen gespeichert. Semi- bzw.
unstrukturierte Daten konnen allerdings von standardisierten Instrumenten nicht verar-
beitet werden und erfordern dazu komplexere Verfahren (vgl. [Kin14] S. 34f).
5

2.2 Datenmengen in Unternehmen 2 BIG DATA
2.2 Datenmengen in Unternehmen
Die zu verarbeitenden Daten konnen sehr vielfaltig sein. Dazu gehoren unter anderem
Prozessdaten, die zur Automatisierung und Steuerung von Prozessen Daten erfasst, ge-
speichert und verarbeitet werden. Dies wird durch die Informationstechnik mit Sensoren,
Steuerungs- und Regelungssignalen, Bedienungs- und Beobachtungsdaten sowie Planungs-
daten und Kennzahlen vorangetrieben. Auf diesen Ebenen lassen sich Data Mining Poten-
tiale zur Prozessoptimierung und der Steigerung der Wettbewerbsfahigkeit erschließen. Des
Weiteren gibt es Daten aus Geschaftsprozessen, die analysiert werden, um diese Prozesse
besser zu verstehen und zu optimieren. In den Prozessen fallen Daten zu Kunden, Portfolio,
Vertriebs- und Marketingprozessen, Service, Preisbildung, Finanzen, Risiken oder Com-
pliance an. Dazu wird unter anderem Cross-Selling analysiert, um Produkte zukunftig
optimal zu platzieren oder die Preisgestaltung zu optimieren. Auch gezielte Kundenan-
gebote und Werbemaßnahmen konnen anhand solcher Daten abgeleitet werden. Daruber
hinaus gibt es auch Textdaten und strukturierte Daten. Dazu gehoren Textdokumente und
elektronische Nachrichten (Email, Nachrichten in Social Media), Web-Dokumente oder
vernetzte Datenbanken. Die Informationen in den Daten werden gefiltert und durchsucht,
extrahiert und strukturiert. Die strukturierten Daten konnen nach definierten Ordnungs-
kriterien gesammelt und angelegt werden. Auch Bild und Videodaten werden durch die
steigende Verfugbarkeit von Kameras (Smartphones) oder satellitenbasierte Bildquellen
immer relevanter. Dadurch stehen große Mengen an Bild- und Videodaten zur Verfugung,
in denen mit Data Mining-Methoden Objekte gesucht werden, die mit anderen Informa-
tionen in Beziehung gesetzt werden konnen (vgl. [Run15] S. 1f).
Anhand dieser Daten konnen Entscheidungen, die bisher auf Spekulationen beruhten,
gezielt getroffen werden. Anhand von Big Data konnen viele Aspekte einer modernen
Gesellschaft gesteuert werden, die Handel, Produktion oder Finanzen betreffen. Es kann
die Wertschopfung von Unternehmen verandern, beeinflusst, wie Markte definiert werden
und wie Unternehmen Informationen uber ihre Aktivitaten nutzen. Dazu mussen die Daten
nicht nur gesammelt, sondern auch ausgewertet und entsprechend eingesetzt werden (vgl.
[Kin14] S. 37).
6

3 DATA SCIENCE UND DATA ENGINEERING
3 Data Science und Data Engineering
Fur die in Unternehmen umfangreich gesammelten Informationen bedarf es einer gezielten
Auswertung. Dazu verzeichnen Unternehmen im Bereich Big Data einen zunehmenden
Bedarf an Data Scientists und Data Engineers. Diese Disziplinen stehen dabei im direkten
Zusammenhang zueinander. Kurzgefasst ist die Aufgabe des Data Scientist, die richtigen
Fragen auf einen beliebigen Datenbestand anzuwenden. Der Data Engineer hingegen ist
dafur verantwortlich, dass die Scientists ihren Job effizienter ausfuhren konnen und stellt
die Daten bereit (vgl. [Dat14]).
3.1 Data Science
Daten sind nicht nutzbar, solange daraus kein Wissen generiert werden kann. Unterneh-
men werden deshalb immer mehr datengesteuert und nutzen die Einblicke in Daten fur
Geschaftsentscheidungen. Die Methode mit der diese Einblicke in Daten geschaffen werden,
wird als Data Science bezeichnet. Data Science ist multidisziplinar und eine Kombinati-
on aus statistischen Analysen, Programmierung und einer Expertise der Domanen. Dazu
werden uberwiegend Tools angewandt, um einzelne Analysen durchfuhren zu konnen (vgl.
[Pat14] S. 1f).
Die Aufgabe der Data Science liegt vor allem in der Vorbereitung der Analyse. Dort
geht um das Suchen, Zusammenstellen und Integrieren von moglicherweise heterogenen
Datenquellen zur Informationsfindung. Die Analyseergebnisse mussen zudem mit Maßen
uber die Korrektheit, Vollstandigkeit und Anwendbarkeit ausgestattet werden. Data Scien-
tists in Unternehmen mussen eine Kreativitat und wissenschaftliche Denkweise vereinen,
um neuartige Erkenntnisse zu fordern. Dazu ist ein unternehmerisches Denken mit einem
klaren Ziel notwendig. Ziel ist es, ausgehend von einer Fragestellung ein Data Product
zu entwickeln, welches eine neue Information oder einen neuen Service zur Wertschopfung
aus der Analyse bestehender Daten generiert. Die Unternehmen verfolgen damit allgemein
die Erzeugung eines betrieblichen Mehrwerts aus Daten. Dabei ist zu beachten, dass Data
Sciene leicht zu Data Mining abgegrenzt wird, da nun nicht mehr explorativ sondern ge-
zielt nach Mehrwerten fur eine Organisation gesucht wird. Allerdings werden dazu auch
Data Mining Tools eingesetzt (vgl. [Fas16] S. 60ff.).
7

3.2 Data Engineering 3 DATA SCIENCE UND DATA ENGINEERING
3.2 Data Engineering
Durch Data Engineering wird die Daten-Infrastruktur bzw. Daten-Architektur zur Verfugung
gestellt. Der Data Engineer sammelt und erfasst die Daten, speichert diese, fuhrt Batch-
und Realtime-Processing darauf durch und stellt die Daten dem Data Scientist uber eine
Schnittstelle zur Verfugung. Dieser kann die Daten dann uber die Schnittstelle anfordern.
Diese Schritte konnen einerseits durch Big Data-Tools vorgenommen werden, allerdings
ist dies fur die Zielsetzung meist nicht ausreichend. Haufig reicht ein Tool nicht fur die
Anforderung und muss angepasst oder verbessert werden. Daruber hinaus braucht ein
Data Engineer tiefgrundige Einsichten in die Datenbanken sowie in Best Practices. Dazu
muss er das Wissen uber die Datenbank-Administration und deren Wartung sowie uber
Data-Cleaning fur eine deterministische Datenzufuhr besitzen.
Diese Disziplin kann sich teilweise mit der Data Science uberschneiden, da dieselben Ziele
verfolgt werden. Wahrend ein Data Scientist beispielsweise eine Hadoop System nutzt,
um Anworten fur eine bestimmte Zielsetzung zu finden, wurde der Data Engineer einen
iterativen Machine Learning Algorithmus programmieren, um diesen beispielsweise auf ein
Cluster anzuwenden. Deswegen bevorzugen einige Unternehmen es, wenn Mitarbeiter mit
beiden Thematiken vertraut sind, sodass auch ein Wechsel zwischen den Rollen moglich
ist (vgl.[Dat14]).
3.3 Data Product
Der Data Scientist plant gezielt Data Products, die seinem Unternehmen zu einem Mehr-
wert verschaffen konnten. Dies ist das Ergebnis, einer wertgetriebenen Analyse und kann
dabei zur Entscheidungsanalyse fur Endkunden oder interne Stakeholder dienen. Dabei
wird ein Mehrwert aus der Analyse der Daten geschopft und realisiert, welcher den Be-
reichen Service Engineering und der klassischen Produktentwicklung dient. Zu Beginn
der Analyse fur ein Produkt, wird sich mit dem realisierbaren Wert des Produkts fur
den Kunden beschaftigt, um anschließend zu identifizieren, wie das Ziel erreicht werden
kann. Daraufhin werden die notwendigen Datenquellen betrachtet, die sowohl aus unter-
nehmensinternen als auch aus externen Daten bestehen konnen. Haufig ergibt sich aus der
Kombination dieser Daten der Schlussel zur Beantwortung der Fragestellung. Schließlich
werden analytische Modelle gesucht, die auf die Daten angewandt werden konnen (vgl.
[Fas16] S. 65f).
8

4 DAS DATA-SCIENCE UNTERNEHMENSKONZEPT
4 Das Data-Science Unternehmenskonzept
Fur den Einsatz von Big Data wird ein unternehmensweites Konzept benotigt und die
Bereitschaft aller beteiligten Personen, damit umzugehen. Dies verbreitet sich vom Chief
Information Officer, uber Fuhrungskrafte bis hin zum CEO. Der CIO treibt dabei die
Big-Data Projekte an und identifiziert Geschaftschancen und Anforderungen. Im weiteren
Verlauf der Projekte liegt die Verantwortung bei den Fuhrungskraften. Diese sind vor
allem dafur zustandig zu prufen, ob die Projekte erfolgreich sein konnen. Die Umsetzung
liegt schließlich in den Handen der Fuhrungskrafte und des CEO, sodass Business Cases
und Roadmaps erstellt werden. Diese Roadmap muss anschließend durch den CIO und die
IT-Abteilung umgesetzt werden.
Data Science als unternehmensweites Konzept erfordert Vision, Strategie und Anfor-
derungen an eine Big-Data Losung. Dies ist fur ein gemeinsames Verstandnis fur den
Einsatz im Unternehmen notwendig und um die Geschaftsziele zu erreichen. Das Kon-
zept definiert die wichtigsten geschaftlichen Herausforderungen und die Anforderungen an
Geschaftsprozesse zur Umsetzung von Big Data sowie an die IT-Architektur. Durch das
Konzept wird die Basis fur eine schrittweise Implementierung im Unternehmen gelegt, so-
dass ein nachhaltiger geschaftlicher Nutzen daraus gezogen werden kann. Die Effektivitat
ist allerdings abhangig von den Daten, den Tools und Experten in der Materie. Deswegen
ist es erforderlich zuvor die notwendigen Investitionen zu leisten. Dabei erweist es sich als
sinnvoll, Mitarbeiter in den Prozess zu involvieren und weiterzubilden, die bereits mit den
Geschaftsprozessen und Herausforderungen im Unternehmen vertraut sind.
Fur die Umsetzung bedarf es einer Strategie und einer Roadmap, die Business Cases
enthalt. Dazu ist es notwendig, messbare Ergebnisse zu definieren. Die Business Cases
werden im Laufe dieser Seminararbeit genauer erlautert (vgl. [IBM12] S. 14f).
9

5 DATA SCIENCE FUR BRANCHEN
5 Data Science fur Branchen
Der Anwendungsbereich von Data Science ist sehr breit gefachert. Aktuell wird ein großes
Potenzial in der Industrie gesehen, aber auch Dienstleistungen und Handel verweisen gu-
te Chancen fur einen erfolgreichen Einsatz von Big Data-Losungen. Nachfolgend werden
relevante Branchen und Anwendungsfelder dafur dargestellt.
5.1 Industrie
In der industriellen Produktion wird durch die neuen Analysen die Moglichkeit gebo-
ten, Fertigungsprozesse maßgeblich zu optimieren. Dazu konnen Maschinen und Anlagen
und die an der Fertigung beteiligten Mitarbeiter optimiert werden. Daruber hinaus lassen
sich Variablen wie Energiekosten, Lastprofile, Revisions- und Wartungsarbeiten zu einer
optimalen Auslastung beeinflussen. Auch komplexe Produktionsablaufe konnen simuliert
werden, um Schwachstellen oder Fehler zu erkennen. Weiter konnen die Produktionskos-
ten und die Qualitat neuer Waren durch vorhandene Variablen prazise angegeben wer-
den. Auch mogliche Ausfalle durch Storungen konnen vorhergesagt werden und praventiv
behandelt werden, damit keine Kosten durch Produktionsstillstande entstehen. Dadurch
konnen unter anderem Wartungsarbeiten nach einem kalkulierten Bedarf durchgefuhrt
werden, wodurch wiederum Kosten eingespart werden konnen. Auch Lagerkosten konnen
durch automatische Dispositionsprozesse und Bestandssteuerung gesenkt werden, da diese
die Materialplanung vereinfachen und optimieren konnen (vgl. [Pri13] S.26).
5.2 Handel und Konsumguter
Fur den Handel und Konsumguter konnen ganzheitliche Kundenanalysen durch die Aus-
wertung relevanter Daten durchgefuhrt werden. Dabei kann vor allem die Kundenbindung
im Onlinehandel verbessert werden, wenn sich das Produktportfolio an die Bedurfnisse und
Vorlieben des Kunden anpassen und optimieren lasst. So konnen gezielte Angebote genau
dann, wenn die Nachfrage am großten ist, preissensitiv auf bestimmte Kundengruppen
zugeschnitten und prasentiert werden. Daruber hinaus ist vor allem fur den Onlinehan-
del eine Verbesserung der Retourevorgange oder eine Reduktion der Anzahl an Retouren
moglich. Diese kann durch die Verknupfung von unterschiedlichen Daten erreicht werden,
wenn die Ursachen der Rucksendungen aufgedeckt und behoben werden. So konnen durch
die Berechnung uber die Wahrscheinlichkeit einer Rucksendung bestimmte kundenspezifi-
sche Vorkehrungen getroffen werden, um praventiv darauf zu reagieren.
Allgemein kann der Einsatz den Unternehmen dazu verhelfen, seine Kunden und Kun-
10

5.3 Energiewirtschaft 5 DATA SCIENCE FUR BRANCHEN
dengruppen sowie deren Gewohnheiten besser zu verstehen und dadurch beispielswei-
se kundenorientierte Werbung zu schalten oder individuelle Angebote zu unterbreiten.
Zusatzlich besteht die Moglichkeit, detaillierte Analysen uber Lieferanten durchzufuhren,
um darauf spezifische Einstufungen wie Zuverlassigkeit oder Qualitat vornehmen zu konnen.
Auch intern konnen anhand von intelligenter Absatzplanung die Lager bzw. Lagerbestande
und Bestellungen optimiert werden (vgl. [Pri13] S. 25).
5.3 Energiewirtschaft
Die Energiewirtschaft wird immer wichtiger. Deswegen gibt es in diesem Bereich Anwen-
dungsfalle fur spezifische Analysen. So kann durch die Analyse der Kundenstruktur eine
Kundensegmentierung vorgenommen werden, in der Kunden nach ihrer Profitabilitat ein-
geordnet werden konnen. Auch weitreichende Modelle wie ein Scoring Modell fur Kunden
ließe sich dadurch ableiten. Anhand des Wissens von Kunden und Kundengruppen uber
deren Verhalten sind Clusteranalysen nach gewunschten und benotigten Tarifen moglich.
Daruber hinaus sind durch Analysen von Ablaufen der Energieverteilung Optimierungspo-
tenziale zu identifizieren, wodurch gunstigere Tarife angeboten werden konnen und somit
Neukunden gewonnen werden konnten (vgl. [Pri13] S. 25).
5.4 Technologie und Medien
Ahnlich zur Energiewirtschaft lasst sich auch hier fur Unternehmen eine Analyse der Kun-
denstruktur durchfuhren, anhand der eine Segmentierung der Kundengruppen vorgenom-
men werden kann. Dadurch werden beispielsweise in der Telekommunikation Optimie-
rungsmoglichkeiten fur Tarifarten und -strukturen erkannt, sodass attraktive Tarife fur
die Kundenbindung und -gewinnung nutzbar gemacht werden. Dabei konnen beispiels-
weise Anpassungen in Abhangigkeit der Tageszeit, von geografischen Daten sowie von
Gruppentarifen getatigt werden. Andererseits sind auch Analysen uber die Abwanderung
von Kunden moglich. Anhand dieser konnen unzufriedene Kunde besser identifiziert und
kundenseitigen Kundigungen vorgebeugt werden. Daruber hinaus konnen Schwachstellen
des Unternehmens aufgedeckt werden (vgl. [Pri13] S. 25).
5.5 Transport und Logistik
Die bereits beschriebene Optimierung der Retourevorgange im Handel kann sich auch
positiv auf die Logistik auswirken. Daruber hinaus konnen Risiken durch ganzheitliche
Analysen effizient bewertet werden, sodass vor alle komplexen Investitionen oder Projek-
te unterstutzt werden konnen. Andererseits konne auch bereits bestehende Prozesse oder
11

5.6 Finanzdienstleistungen 5 DATA SCIENCE FUR BRANCHEN
Prozessablaufe analysiert, simuliert und optimiert werden. Dabei kann auf Faktoren wie
den Personaleinsatz oder die Kapazitatsplanung Einfluss genommen werden. Zusatzlich
kann eine Track-and-Trace Anwendung implementiert werden, wodurch logistische Pro-
zesse dargestellt werden und eine Echtzeituberwachung gewahrleistet wird (vgl. [Pri13] S.
26).
5.6 Finanzdienstleistungen
In Banken und Versicherungen herrscht ein großes Wissen uber die Kunden. Dazu konnen
durch eingehende Kundenanalysen aus internen und externen Daten, personliche und ab-
strakte Informationen gesammelt und verwendet werden. Dadurch konnen Angebote ge-
zielt auf die Lebenssituation des Kunden angepasst werden, sodass das Angebotsportfolio
auf dem Lebenszyklus des Kunden abgebildet wird. Durch diese Angebote besteht die
Moglichkeit, eine lebenslange Kundenbindung durch die Services zu erzielen. Dafur konnen
Risiken individuell prognostiziert und Risikozuschlage flexibel definiert werden. So konnen
Banken Kreditausfallrisiken gezielt prognostizieren. Auch Beratungsangebote konnen ver-
bessert werden, indem flexible Reaktionen und Angebote an die Lebensumstande des Kun-
den angepasst werden. Daruber hinaus konnen auch Marketingangebote effektiver gestal-
tet werden und auf die Bedurfnisse von besonders profitablen Kundengruppen fokussiert
werden (vgl. [Pri13] S. 26).
12

6 EINSATZGEBIETE VON DATA SCIENCE
6 Einsatzgebiete von Data Science
Data Science kann vielseitig in Unternehmen eingesetzt werden. Dabei kann nahezu jedes
Einsatzgebiet durch den Einsatz unterstutzt werden. Nachfolgend werden die Bereiche
aufgezeigt und die die Bedeutung fur den jeweiligen Bereich verdeutlicht.
6.1 Potentiale der Einsatzbereiche
Data Science kann in allen Unternehmensbereichen eingesetzt werden. Vor allem aber
in den Bereichen Marketing, Betrugsermittlung, Produktinnovation und Service-Effizienz.
Ein Großteil der Unternehmen setzt zudem auf Analysen im Controlling Bereich (vgl.
[Kin14] S. 62). Daruber hinaus hilft Big Data bei der Entwicklung neuer Geschaftsmodel-
le, Produktideen und Dienstleistungen. Innerhalb eines Unternehmens werden vielseitige
Potentiale in Funktionen wie Unternehmenssteuerung, Vertrieb sowie Fertigung und Ent-
wicklung geschaffen. In der folgenden Ubersicht werden Analytische Potentiale in Unter-
nehmensfunktionen dargestellt. Dabei wird die Auspragung der Funktionen gemessen.
Abbildung 1: Analytische Potentiale in Funktionen
(vgl. [Fas16] S.40)
Wie man in der Darstellung erkennen kann, werden vor allem Management, Unterneh-
13
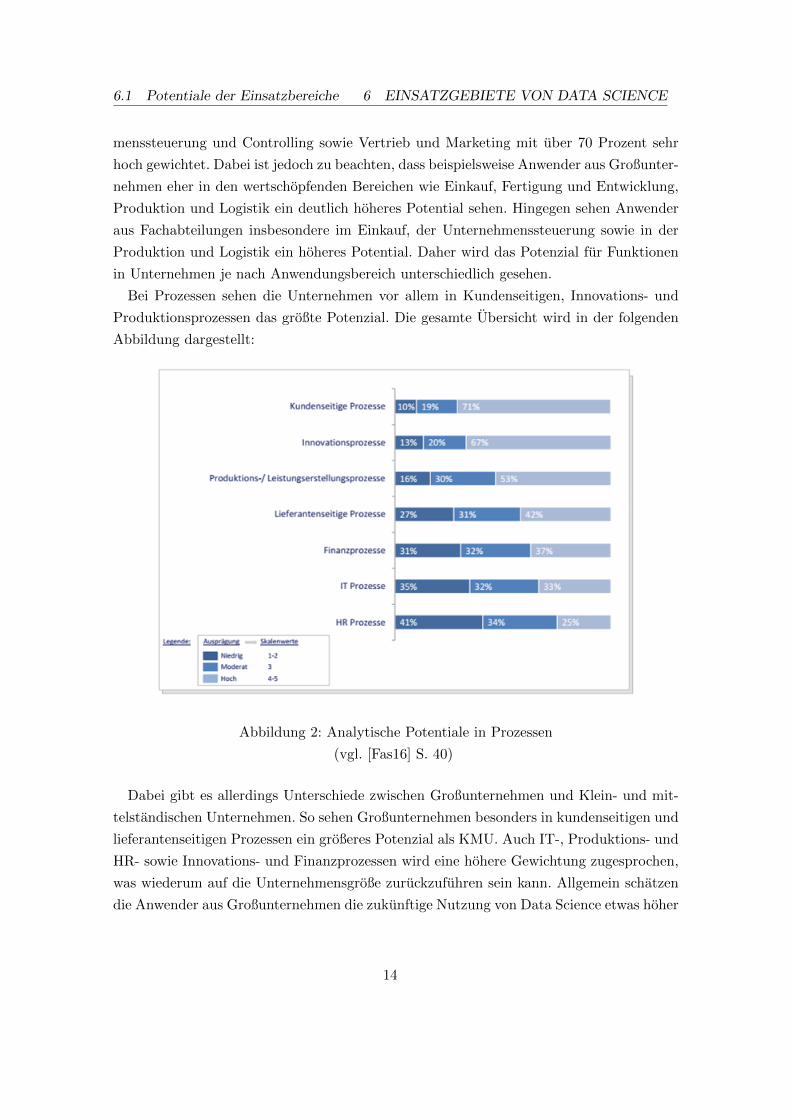
6.1 Potentiale der Einsatzbereiche 6 EINSATZGEBIETE VON DATA SCIENCE
menssteuerung und Controlling sowie Vertrieb und Marketing mit uber 70 Prozent sehr
hoch gewichtet. Dabei ist jedoch zu beachten, dass beispielsweise Anwender aus Großunter-
nehmen eher in den wertschopfenden Bereichen wie Einkauf, Fertigung und Entwicklung,
Produktion und Logistik ein deutlich hoheres Potential sehen. Hingegen sehen Anwender
aus Fachabteilungen insbesondere im Einkauf, der Unternehmenssteuerung sowie in der
Produktion und Logistik ein hoheres Potential. Daher wird das Potenzial fur Funktionen
in Unternehmen je nach Anwendungsbereich unterschiedlich gesehen.
Bei Prozessen sehen die Unternehmen vor allem in Kundenseitigen, Innovations- und
Produktionsprozessen das großte Potenzial. Die gesamte Ubersicht wird in der folgenden
Abbildung dargestellt:
Abbildung 2: Analytische Potentiale in Prozessen
(vgl. [Fas16] S. 40)
Dabei gibt es allerdings Unterschiede zwischen Großunternehmen und Klein- und mit-
telstandischen Unternehmen. So sehen Großunternehmen besonders in kundenseitigen und
lieferantenseitigen Prozessen ein großeres Potenzial als KMU. Auch IT-, Produktions- und
HR- sowie Innovations- und Finanzprozessen wird eine hohere Gewichtung zugesprochen,
was wiederum auf die Unternehmensgroße zuruckzufuhren sein kann. Allgemein schatzen
die Anwender aus Großunternehmen die zukunftige Nutzung von Data Science etwas hoher
14

6.2 Data Science Anwendungsfalle 6 EINSATZGEBIETE VON DATA SCIENCE
ein als KMU. Dabei fallen vor allem die Datenflut und die zunehmende Wettbewerbsinten-
sitat ins Gewicht. Dennoch wird durch den Einsatz ein hoher Zielerreichungsgrad gesehen
(vgl. [Fas16] S. 45f.).
6.2 Data Science Anwendungsfalle
Es gibt branchenspezifische als auch -ubergreifende Einsatzgebiete von Big Data. Nach-
folgend werden die am haufigsten auftretenden Einsatzgebiete genannt.
6.2.1 Experimente und Analysen in Echtzeit
Es ist moglich, umfangreiche Variationen von Produkten und Services auf ihre Auswir-
kungen von Veranderungen auf die Kosten, Durchlaufzeit und Lieferung zu prufen. Dies
ermoglicht, Prozesse effizienter zu gestalten. Webseiten werden vielfach in Echtzeit perso-
nalisiert und an ihre Kunden angepasst. Dies ermoglicht es, Empfehlungs- oder Reputati-
onssysteme zu erzeugen und anhand von Informationen zu Marktbedurfnissen, Nachfrage
und Konsumenten die Produkte und Dienstleistungen auf Individuen anzupassen. Die
Unternehmen generieren dadurch rund 20 Prozent mehr Umsatz. Auch interne Prozesse
konnen durch die Analyse von Datenflussen in der Wertschopfungskette effizient gesteigert
werden. Die Analyse fuhrt zu einer hoheren Service-Verfugbarkeit, es kann schneller auf
Probleme reagiert werden und durch Echtzeitdaten konnen bessere Handlungsentschei-
dungen getroffen werden und somit Gewinne maximiert werden (vgl. [Kin14] S. 63).
6.2.2 Personalisierung von Produkten, Services und Marketing
Konsumentenanalysen sind fur viele Unternehmen das großte Ziel im Bereich Big Data.
Dadurch konnen personliche Attribute, Lebensereignisse, Beziehungen, Gefuhle, Produk-
tinteressen und Kaufabsichten von Kunden miteinander verbunden werden, um ein Ge-
samtbild zu erstellen. Daruber soll ein umfangreiches Verstandnis uber die Kunden erlangt
werden, um Verhaltensweisen zu Produkten erkennen zu konnen und entsprechend dar-
auf reagieren zu konnen. Es sollen Bedurfnisse und Trends aufgezeigt werden, anhand der
ein zielgerichtetes Marketing stattfinden kann. Dazu werden Werbekampagnen optimiert,
Cross- und Up-Selling verbessert und die Abwanderung der Kunden minimiert.
Zusatzlich kann die Nachfrageprognose optimiert werden, sodass ein Wettbewerbsvor-
teil erlangt wird. Dabei kann auch der jeweilige Standort identifiziert werden und Vorrate
und Engpasse berechnet werden. Des Weiteren kann durch eine Echtzeitanalyse von Kun-
dennachfrage, von Konkurrenzverhalten und des Lagerbestands der Preis analysiert wer-
den und eine dynamische Preisbildung umgesetzt werden. Vor allem Social Media spielt
15

6.2 Data Science Anwendungsfalle 6 EINSATZGEBIETE VON DATA SCIENCE
eine wichtige Rolle bei der Personalisierung von Angeboten. Die Daten aus diversen
Kanalen oder aus dem Internetverhalten helfen personalisierte Angebote auf die bevor-
zugten Kanale umzusetzen (vgl. [Kin14] S. 64 f.).
6.2.3 Innovation von Produkten und Services
Innovationen und Weiterentwicklung von Produkten und Services von Unternehmen wer-
den durch Big Data Analysen unterstutzt. Dadurch konnen zeitnah Angebote erstellt wer-
den, die den Wunschen und Bedurfnissen der Zielgruppen entsprechen. Produktinnovation
ist dabei einer der wichtigsten Erfolgsfaktoren von Unternehmen. Durch die Analysen wird
eine Prufung von Szenarios und die Antizipation des Erfolgs von neuen Produkten und
Services gestaltet. Weiterhin konnen neue Markttrends erkannt werden und Kundenfeed-
back fur die Entwicklung neuer Produkte und Services genutzt werden. Dadurch wird die
Wertschopfungskette umgewandelt, da die Bedurfnisse der Kunden bereits in dem Innova-
tionsprozess integriert werden. Die umgewandelte Wertschopfungskette wird in folgender
Darstellung veranschaulicht.
Abbildung 3: Wertschopfung durch Produktinnovation(vgl. [Kin14] S. 67)
Dadurch konnen individualisierte Produkte und Dienstleistungen entstehen, die eine
16

6.3 Umsetzung von Geschaftszielen 6 EINSATZGEBIETE VON DATA SCIENCE
hohere Erfolgswahrscheinlichkeit am Markt erreichen konnen. Daruber hinaus konnen
schneller neue Geschaftsfelder erkannt und eroffnet werden (vgl. [Kin14] S. 66ff).
6.3 Umsetzung von Geschaftszielen
Fur die Unternehmen gibt es Geschaftsziele, die es durch einen Data Science Ansatz zu
erreichen gilt. Diese werden so kategorisiert, dass es gilt das Geschaft zu verstehen, Ent-
scheidungen zu verbessern und die Geschwindigkeit zu erhohen. Dabei werden die Infor-
mationen als ein Produkt angesehen, welches zum Erreichen der Ziele verwendet wird. Um
das Geschaft zu identifizieren sollen Chancen im Geschaftsfeld identifiziert werden, um ei-
nerseits Umsatzsteigerungspotentiale zu erkennen und andererseits auch Kostensenkungs-
potentiale aufzudecken. Daruber hinaus soll mehr Transparenz geschaffen werden, um
Erfolge und Misserfolge sowie Ursachen-Wirkungsbeziehungen nachvollziehen zu konnen.
Daruber hinaus sollen auch Risiken erkannt werden. Um Entscheidungen zu verbessern,
soll eine gewisse Prognosefahigkeit geschaffen werden, was sowohl Entscheidungsqualitat
als auch -geschwindigkeit erhoht und den Entscheidungsprozess weniger komplex gestaltet.
Die Geschwindigkeit eines Unternehmens kann erhoht werden, indem die Reaktionsfahig-
keit verbessert wird, um auf aktuelle Trend und Kundenbedurfnisse eingehen zu konnen.
Durch die Analyse von Daten kann zudem das Vertrauen in die Richtigkeit der Zahlen
geschaffen werden, sodass beispielsweise Kennzahlen effektiver genutzt werden konnen.
Wenn eine Information außerdem als Data Produkt vorliegt, kann diesen Produkt durch
Aufbereitung und Verkauf zur Monetarisierung fuhren. Somit kann Data Science eine wich-
tige Saule fur die Umsetzung der Geschaftsziele sein und die Geschaftsprozesse vielseitig
unterstutzuen und optimieren (vgl. [Fas16] S. 47f.).
17

7 MEHRWERTE DURCH DATA SCIENCE
7 Mehrwerte durch Data Science
Information wird als handlungsbestimmendes Wissen gekennzeichnet. Sie kann wirtschaft-
liches Handeln beeinflussen und leistet einen Beitrag zur Erfullung betrieblicher Aufgaben
zum Erreichen unternehmerischer Ziele. Somit nimmt Data Science eine wichtige Rolle fur
die Prozesse zur Leistungserstellung ein (vgl. [Run15] S. 6).
Big Data entwickelt sich fur Unternehmen zu einem Vermogensgegenstand. So wird
nachweislich besagt, dass Unternehmen mit einem effektiven Einsatz von Big Data mit
einer Produktivitatssteigerung von durchschnittlich 6 Prozent profitieren. Daruber hinaus
zeigt eine Studie von IBM, dass Unternehmen mit einer Integration von Big Data in ihre
Prozesse eine Umsatzsteigerung von 10,8 Prozent (2012) mit steigender Tendenz verzeich-
nen konnten. Auch der Gewinn vor Steuern und Zinsen steigt und Aktienkurse konnen
aufgewertet werden. Es wird dabei auch von dem Begriff”Data Monetization“ gesprochen,
welcher gleichbedeutend mit der Maximierung des Umsatzpotentials von verfugbaren Da-
ten durch die Institutionalisierung der Erfassung, Speicherung, Analyse und effektiven
Verbreitung der Daten ist. Durch die Erkenntnisse ist es beispielsweise moglich, Prozesse
kosteneffizienter durchzufuhren.
Durch interne Analytik kann die Wettbewerbsfahigkeit und der Unternehmenserfolg zu-
nehmend beeinflusst werden. So konnen sich branchengleiche Unternehmen primar durch
die Nutzung von Unternehmensinformationen und Analytik diversifizieren. Diese werden
auf moglichst viele Entscheidungen, strategische Ziele oder die Ausfuhrung operativer
Aufgaben innerhalb des Unternehmens angewandt. Dadurch konnen Wachstum, die Leis-
tungsfahigkeit sowie die Wettbewerbsfahigkeit von Unternehmen positiv beeinflusst wer-
den. Dabei konnen nicht nur interne Daten eine wichtige Rolle spielen, sondern sind es auch
zunehmend externe Daten, die eine teils eingeschrankte Perspektive erweitern konnen.
So konnen beispielsweise Informationen aus Beziehungen zwischen Kunden und konkur-
rierenden Unternehmen von Relevanz fur eine mogliche Effizienzsteigerung der eigenen
Wertschopfungskette sein. Da unternehmenseigene Daten haufig vergangenheitsorientiert
sind, bieten diese haufig nur begrenzt Potential fur zukunftsorientierte Strategien und
Maßnahmen. Diese betreffen uberwiegend Bestandskunden, die bereits mehrere Produkte
eines Unternehmens kaufen. Dabei sind vor allem sogenannte”Ein-Produkt-Kunden in-
teressant, weil diese zusatzlichen Absatz in anderen Produktsparten generieren konnen.
Dazu bietet es sich an, neue externe Daten aus Internetanalysen anzureichern. Das großte
Potential dabei stellt die Weiterentwicklung von existierenden Umsatzstromen durch vollig
neue Umsatzquellen dar.
So kann einerseits ein hoherer Umsatz durch den Einsatz von Big Data generiert werden,
18

7 MEHRWERTE DURCH DATA SCIENCE
andererseits konnen aber auch bessere Entscheidungen getroffen werden. Diese betreffen
uberwiegend unternehmerische Entscheidungen. Weitere Ziele sind die Verbesserung des
Kundenerlebnisses, Verkaufssteigerungen, Risikoreduktion, Produktinnovation sowie effizi-
ente Betriebsprozesse und Qualitatssteigerungen von Produkten und Services (vgl [Kin14]
S. 60f.).
19

8 FAZIT UND AUSBLICK
8 Fazit und Ausblick
Data-Science und -Engineering gewinnen zunehmend an Bedeutung. Anhand der aufge-
zeigten Mehrwerte lasst sich erkennen, dass Unternehmen zukunftig einen starken Fokus
auf die Wissensgenerierung aus Daten legen mussen. Durch die starke Zunahme der Daten
es es zwingend notwendig, diese nicht nur zu speichern, sondern auch auszuwerten. Vor
allem durch die starke Relevanz von Social Media werden diese Daten immer wichtiger,
um Trends fur neue Produkte zu erkennen und Angebote auf Kunden zuschneiden zu
konnen. Daruber hinaus sind nicht nur die Produkte von Unternehmen von Bedeutung,
sondern vielmehr die internen Prozesse, die es zu untersuchen und zu optimieren gilt. Dies
bietet die Chance zur Nutzung neuer Daten, Technologien und Analysemethoden, die bis
zu einem gewissen Grad und nahezu jeder Branche Anwendung finden konnen. Dadurch
konnen Entscheidungen gelenkt werden, Vorhersagen getatigt werden und vor allem Kos-
teneinsparungspotentiale aufgedeckt werden. Durch den Einsatz von Analysen kann ein
wichtiger Wettbewerbsfaktor geschaffen werden, der langfristig zum Unternehmenserfolg
beitragen kann. Vor allem ergibt sich dadurch die Moglichkeit, sich auf Markten von der
Konkurrenz abzuheben.
Aktuell und in Zukunft wird eine erhebliche Zunahme der Nutzung von Big Data ver-
zeichnet. Dies liegt stark an dem starken kompetitiven Wettbewerbsumfeld. Vor allem in
Großunternehmen wird eine starke zukunftige Entwicklung gesehen. Dabei gibt es diverse
Treiber fur eine starke Nutzung, wie neue technologische Entwicklungen durch In Me-
mory, Cloud Computing, oder die steigende Datenflut auf Unternehmen. Dabei mussen
sich die Unternehmen der zunehmenden Wettbewerbsitensitat und steigende Komplexitat
und Dynamik des Marktumfeldes stellen (vgl. [Fas16] S. 47f.). Vielfach ergibt sich dabei
die Herausforderung dazu einen Business Case zu erstellen, gepaart mit einer geringen
Bereitschaft in neue Technologien zu investieren, ohne messbare Erfolge garantiert zu be-
kommen. Allerdings ist es notwendig, ein umfassendes Verstandnis der Markte, Kunden,
Produkte, Vorschriften, Wettbewerber, Lieferanten und Mitarbeiter zu haben, um Wett-
bewerbsvorteile erzielen zu konnen. Dies erfordert die effektive Nutzung von Daten und
deren Analyse. Deswegen werden Daten als die wertvollste Ressource zum Erlangen von
Differenzierungsmoglichkeiten angesehen. Somit werden neue Wege entdeckt, um sich er-
folgreich vom Wettbewerb abzusetzen. Es werden zudem umfassend die Leistungsfindung
und Leistungsfahigkeit des Unternehmens verbessert (vgl. [IBM12] S. 16f.).
Aktuell gibt es fur zahlreiche Unternehmen allerdings noch Probleme bei der Umset-
zung. Konzepte sind nicht klar definiert und Prozesse wie Datensammlung und -validierung
werden haufig manuell ausgefuhrt und bieten dadurch nicht ausreichende Ausgangsbedin-
20

8 FAZIT UND AUSBLICK
gungen. In den Unternehmen fehlt es zusatzlich an strukturierten Konzepten und der
Verantwortung gegenuber Data Science und Data Engineering. Auch Potentiale bezuglich
der Wirksamkeit werden haufig nicht vollends ausgeschopft. Wenn diese Barrieren besei-
tigt werden, wird die Rolle zunehmend wichtiger (vgl. [Fas16] S. 49f.). Viele Unternehmen
verzeichnen bereits große Erfolge durch die Einsatz von Data Science, sodass eine An-
wendung in Zukunft zur Sicherstellung der Wettbewerbsfahigkeit nahezu unausweichlich
wird.
21

Literatur Literatur
Literatur
[Dat14] Insight Data. Data Science vs. Data Engineering. 2014. Online; Stand 20.05.2017.
[Dat15] Smart Data. Big Data Business - 10 Thesen zur Nutzung von Bid Data im
deutschsprachigen Raum. 2015. Online; Stand 21.05.2017.
[Fas16] Daniel Fasel. Big Data - Grundlagen, Systeme und Nutzungspotenziale. Springer
Vieweg, Wiesbaden, 2016.
[IBM12] IBM. Analytics: Big Data in der Praxis. 2012. Online; Stand 20.05.2017.
[Kin14] Stefanie King. Big Data - Potential und Barrieren der Nutzung im Unterneh-
menskontext. Springer VS, Wiesbaden, 2014.
[Lar14] Daniel T. Larose. Discovering knowledge in Data - An Introduction to Data
Mining. Wiley, New Jersey, 2014.
[Pat14] Manas A. Pathak. Beginning Data Science with R. Springer, Heidelberg, 2014.
[Pri13] PricewaterhouseCoopers. Big Data - Bedeutung, Nutzen, Mehrwehrt. 2013. On-
line; Stand 18.05.2017.
[Run15] Thomas A. Runkler. Data Mining - Modelle und Algorithmen intelligenter Da-
tenanalyse. Springer VS, Wiesbaden, 2015.
[Shm16] Galit Shmueli. Data Mining For Business Analytics. Wiley, New Jersey, 2016.
22

Literatur Literatur
Abschließende Erklarung
Ich versichere hiermit, dass ich meine Seminararbeit ”Die Rolle von Data Science und Data
Engineering in Unternehmenßelbstandig und ohne fremde Hilfe angefertigt habe, und dass
ich alle von anderen Autoren wortlich ubernommenen Stellen wie auch die sich an die
Gedankengange anderer Autoren eng anlegenden Ausfuhrungen meiner Arbeit besonders
gekennzeichnet und die Quellen zitiert habe.
Oldenburg, den 21. Mai 2017 Henning Schlotmann
23

A.3 Seminararbeiten A ANHANG
A.3.10. Martin Sonntag - KDD-Prozess und CRISP-DM
336

KDD-Prozess und CRISP-DMSeminararbeit im Rahmen der Projektgruppe Big Data Archive
Themensteller: Prof. Dr.-Ing. Jorge Marx GomezBetreuer: M. Eng. & Tech. Viktor Dmitriyev
Dr.-Ing. Andreas SolsbachJad Asswad, M.Sc.
Vorgelegt von: Martin SonntagRigaer Str. 1149377 Vechta04441/[email protected]
Abgabetermin: 21. Mai 2017

Inhaltsverzeichnis Inhaltsverzeichnis
Inhaltsverzeichnis
Abbildungsverzeichnis 3
Abkurzungsverzeichnis 4
1 Einleitung 51.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.2 Ziel der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.3 Aufbau der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2 Grundlagen 72.1 Definitionen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.2 Einsatzgebiete von KDD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2.1 Investment und Finanzen . . . . . . . . . . . . . . . . . . . . . . . . 82.2.2 Gesundheitswesen und Medizin . . . . . . . . . . . . . . . . . . . . . 92.2.3 Handel und Marketing . . . . . . . . . . . . . . . . . . . . . . . . . . 92.2.4 Astronomie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3 Vorgehensmodelle des KDDM 103.1 KDD-Prozess . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123.2 CRISP-DM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.2.1 CRISP-DM Referenzmodell . . . . . . . . . . . . . . . . . . . . . . . 153.3 Vergleich von KDD-Prozess und CRISP-DM . . . . . . . . . . . . . . . . . . 17
4 Fazit 19
Literaturverzeichnis 20
2

Abbildungsverzeichnis Abbildungsverzeichnis
Abbildungsverzeichnis
1 Relativer Aufwand fur spezifische Schritte im KDD-Prozess . . . . . . . . . 112 Evolution der KDDM-Prozessmodelle . . . . . . . . . . . . . . . . . . . . . 113 Uberblick uber die Schritte des KDD-Prozesses . . . . . . . . . . . . . . . . 124 Die vier Ebenen der CRISP-DM Methodik . . . . . . . . . . . . . . . . . . . 155 Phasen des CRISP-DM Referenzmodells . . . . . . . . . . . . . . . . . . . . 156 Generische Tasks und Outputs vom CRISP-DM Referenzmodell . . . . . . . 177 Vergleich der Prozessschritte von KDD-Prozess und CRISP-DM . . . . . . . 18
3

Abkurzungsverzeichnis Abkurzungsverzeichnis
Abkurzungsverzeichnis
CRISP-DM Cross-Industry Standard Process for Data Mining
DBMS Datenbank-Management-System
DM Data-Mining
KD Knowledge Discovery
KDD Knowledge Discovery Databases
KDDM Knowledge Discovery und Data-Mining
SKICAT Sky Image Cataloging and Analysis Tool
TB Terabyte
4

1 EINLEITUNG
1 Einleitung
1.1 Motivation
In der heutigen Zeit steigt die Anzahl der gespeicherten Daten immer weiter an. Dies
betrifft viele verschiedene Unternehmensbereiche, wie beispielsweise die Fertigung, Finan-
zen, Marketing oder auch den Einzelhandel. Dabei ist es wichtig, einen Uberblick uber
große Datenmengen zu behalten und Wissen sowie Erkenntnisse aus diesen zu erlangen.
So konnte ein Unternehmen von Verbrauchsgutern bspw. durch gewonnenes Wissen aus
Daten, wie den Verkaufen von bestimmten Waren durch verschiedene Altersgruppen, her-
ausfinden, welche Marketingstrategie als nachstes eingesetzt werden sollte. Somit konnen
große Datenbanken viel Potenzial bieten, aus denen Nutzen erzielt werden kann. Meis-
tens besteht diese Gewinnung von Wissen nur aus statistischen und manuellen Analysen
(vgl. [FPsS96b], S. 27 f.), welche jedoch bei sehr großen Datenmengen recht kostspielig
und zeitintensiv sind. Aufgrund dessen wird der Einsatz von rechnergestutzten Methoden
zum Erhalt von neuen und wichtigen Informationen immer essenzieller. Der Einsatz sol-
cher Methoden gehort zum Gebiet der Knowledge Discovery in Databases (KDD) (vgl.
[Sha12], S. 51). Der Begriff KDD wurde erstmals in den fruhen 90er-Jahren von den Wis-
senschaftlern Gregory Piatetsky-Shapiro und William J. Frawley erwahnt. In dieser Zeit
gab es den Drang viele Data-Mining-Algorithmen zu entwickeln, die in der Lage waren,
nach Wissen in verschiedenen Daten zu suchen. In den letzten Jahren ist die Anzahl an
Knowledge Discovery- und Data-Mining-Projekten stark angestiegen. Diese wurden jedoch
immer komplexer, sodass einige Probleme wie Verzogerungen in der Projektplanung oder
auch eine geringere Produktivitat, auftraten. Zudem kann es auch heute noch vorkommen,
dass nicht alle Projektergebnisse nutzlich sind oder die Vorhaben generell scheitern. Die
Rate der gescheiterten Projekte liegt heutzutage bei uber 50 %. Deshalb wird es immer
wichtiger, dass Methoden und Standards entwickelt bzw. eingesetzt werden, um mit den
neuen Projekttypen, Anwendungen und Domanen zurechtzukommen und diese bewaltigen
zu konnen (vgl. [MMS09], S.1).
1.2 Ziel der Arbeit
Diese Ausarbeitung wird im Zuge der Projektgruppe”Big Data Archive“ erstellt. Die
Projektgruppe hat das Ziel ein Datenarchiv aufzubauen, in dem eine große Menge an
Daten gespeichert wird. Aus diesen Daten sollen dann durch Anwendung von Data-Mining
Wissen oder Erkenntnisse bezogen werden. Das Ziel dieser Arbeit ist es deshalb, einen
Uberblick uber bestehende KDD-Methoden zu schaffen, den KDD-Prozess und CRISP-
5

1.3 Aufbau der Arbeit 1 EINLEITUNG
DM naher zu erlautern und der Frage nachzugehen, ob sich eine dieser beiden Methoden
fur die Projektgruppe eignet.
1.3 Aufbau der Arbeit
Die vorliegende Arbeit lasst sich in drei Abschnitte einteilen. Der Einleitung folgend wer-
den Grundlagen zu den wichtigsten Begriffen des KDD geschaffen. Hierbei werden bspw.
Begriffe wie Knowledge Discovery in Databases und Data-Mining definiert und unterschie-
den. Zudem erfolgt eine kurze Einfuhrung daruber, in welchen Bereichen KDD eingesetzt
werden kann. An die Grundlagen anschließend werden die Vorgehensmodelle des KDD vor-
gestellt. Dabei werden im Besonderen der KDD-Prozess nach dem Datenwissenschaftler
Usama M. Fayyad und CRISP-DM naher vorgestellt und danach miteinander verglichen.
Abschließend werden die Ergebnisse zusammengefasst und ein Fazit gezogen.
6

2 GRUNDLAGEN
2 Grundlagen
In diesem Kapitel wird erlautert, was der Begriff Knowledge Discovery in Databases genau
bedeutet. Dafur werden im Folgenden weitere wichtige Begriffe wie bspw. Data-Mining
(DM) erklart, um Missverstandnisse zu verhindern. Zudem wird beschrieben, in welchen
Einsatzgebieten KDD-Technologien eingesetzt werden konnen.
2.1 Definitionen
Wenn es um die Techniken und Werkzeuge zur Gewinnung von Wissen aus großen Da-
tenbestanden geht, fallen immer wieder Begriffe wie Knowledge Discovery in Databases,
Knowledge Discovery (KD) und Data-Mining (vgl. [MMF10], S. 137). Deshalb ist es sinn-
voll zunachst die Begriffe KD und KDD zu unterscheiden. Knowledge Discovery wird als
Prozess der Wissenssuche uber einen bestimmten Anwendungsbereich aufgefasst. KDD
hingegen beinhaltet den Prozess der Knowledge Discovery, aber angewandt auf Datenban-
ken (vgl. [KM06], S. 2). Eine genauere Definition liefert Fayyad et al.:
”KDD ist ein nichttrivialer Prozess zur Identifikation gultiger, neuartiger, po-
tentiell nutzlicher und verstandlicher Muster in Daten“([FPsS96a], ubersetzt
S. 40 f.).
Die Definition zeigt, dass KDD ein nichttrivialer Prozess aus mehreren Teilschritten wie
der Datenvorbereitung oder der Suche nach Mustern ist. Diese und weitere Teilschritte
werden im spateren Verlauf noch naher erlautert. Nichttrivial meint, dass der Vorgang
nicht nur eine einfache Berechnung von vordefinierten Mengen durchfuhren kann, son-
dern auch besondere Muster (engl. Pattern), Beziehungen oder Strukturen erkennt (vgl.
[FPsS96b], S. 30). Daten sind in diesem Kontext Sachverhalte. Muster sind eine Teilmen-
ge dieser Daten oder ein Modell passend zu dieser Teilmenge. Mit Gultigkeit der Muster
ist gemeint, dass entdeckte Abhangigkeiten auch mit einer bestimmten Sicherheit in den
neuen Daten zu finden sein mussen. Außerdem sollen die Muster oder auch die neuen Er-
kenntnisse fur das System und dem Nutzer neuartig sein und im besten Fall auch nutzlich
fur die gestellte Aufgabe. Zusatzlich sollen die Abhangigkeiten und Muster verstandlich
sein. Dabei mussen sie nicht beim ersten Durchlauf verstanden werden, dies kann auch
erst bei der Nachbereitung geschehen (vgl. [MMF10], S. 142). Ein Pattern, welches nach
Ansicht des Nutzers interessant und sicher ist, wird auch als Wissen (engl. Knowledge)
bezeichnet. Die Ausgabe eines Programms, das einen gewissen Sachverhalt in einer Da-
tenbank uberpruft und dabei Muster zu diesem erzeugt, wird entdecktes Wissen (engl.
discovered Knowledge) genannt (vgl. [FPSM92], S. 58).
7

2.2 Einsatzgebiete von KDD 2 GRUNDLAGEN
Das Knowledge Discovery in Databases ist aber immer noch eine relativ neue Forschungs-
disziplin und ein interdisziplinares Fachgebiet. Es befasst sich mit den Praktiken und
Werkzeugen aus verschiedenen und angrenzenden Fachbereichen, bspw. dem Wissensma-
nagement, das maschinelle Lernen, kunstliche Intelligenz oder auch der Statistik und Wahr-
scheinlichkeitsrechnung (vgl. [Sha12], S. 52).
Der Begriff Data-Mining wird in der Literatur haufig als Synonym zum KDD-Prozess be-
trachtet und somit als ein gesamter Prozess zur Entdeckung von Wissen verstanden. Im
KDD-Prozess wird er allerdings als ein Teilschritt dessen angesehen (vgl. [Lin16], S. 143).
Data-Mining ist dabei die Anwendung von speziellen Algorithmen zur Analyse von Daten,
um relevante Muster, Verbindungen oder Anomalien zu erkennen. Viele Wissenschaftler
sehen den Schritt des Data-Minings als den wichtigsten Bestandteil des KDD-Prozesses
(vgl. [ZZW04], S. 31 f.).
Der letzte hierzu erwahnende Begriff Knowledge Discovery und Data-Mining (KDDM)
beinhaltet den KD-Prozess angewandt auf alle Datenquellen und unterstutzt zusatzlich
das Erforschen und Analysieren des Anwendungsbereichs (vgl. [KM06], S. 2).
2.2 Einsatzgebiete von KDD
Der Einsatz von KDD kann theoretisch in jedem industriellen, wissenschaftlichen oder
geschaftlichen Sektor potenziell nutzlich sein, wo bspw. große Mengen an Daten in Daten-
banken gespeichert werden (vgl. [ZZW04], S. 34). KDD-Technologien spielen in unserem
Alltag in vielen Bereichen eine wichtige Rolle. Ein Beispiel ware der Besuch eines Online-
Shops, wo dem Nutzer durch den Einsatz verschiedenster Analysemethoden Produkte
vorgeschlagen werden, die ihn interessieren konnten. Die Forschung im KDD-Bereich ist
großtenteils anwendungsabhangig, da viele Methoden oder Technologien entwickelt wur-
den, als sie in ihrem jeweiligem Anwendungsbereich gefragt waren (vgl. [Xu14], S. (19-10)).
Im Folgenden werden nun einige Einsatzgebiete des KDD vorgestellt.
2.2.1 Investment und Finanzen
Ein Gebiet, in dem KDD-Technologien eingesetzt werden, sind die Finanzen. Sie un-
terstutzen verschiedenste Anwendungen wie die Betrugserkennung, um kriminelle Trans-
aktionen zu erkennen, Vorhersagen fur den Borsenmarkt oder auch das Portfoliomanage-
ment (vgl. [Xu14], S. (19-10)). Ein konkreter Anwendungsfall ist das von Daiwa Securities
entwickelte Portfolio-Management-System. Dieses untersucht eine große Anzahl an Akti-
enkursen, um daraufhin ein Portfolio zu erstellen, welches das Risiko der jeweiligen Aktie
und die erwunschte Rendite betrachtet (vgl. [ES00], S. 7 f.).
8

2.2 Einsatzgebiete von KDD 2 GRUNDLAGEN
2.2.2 Gesundheitswesen und Medizin
Im Gesundheitswesen wird der Einsatz von KDD immer wichtiger. Die große Menge an
Daten im Bereich des Gesundheitswesens ist immer schwieriger mit Hilfe von traditionellen
Methoden zu analysieren. Mit Unterstutzung von Data-Mining-Methoden kann jedoch
bspw. ausgewertet werden, wie effektiv eine Behandlung angeschlagen hat. Dabei werden
Ursachen, Symptome und der Verlauf der Behandlung gegenubergestellt und verglichen
(vgl. [KT05], S. 64 ff.). Weitere Einsatzmoglichkeiten sind das Entdecken von infektiosen
Erkrankungen oder auch das Diagnostizieren von Krankheiten (vgl. [Xu14], S. (19-12)).
2.2.3 Handel und Marketing
Auch im Bereich des Geschaftsbetriebs ist der Einsatz KDD ein sehr wichtiger Fak-
tor geworden, da auch hier sehr viele Daten gesammelt und analysiert werden konnen.
Fast in jedem Sektor wird Data-Mining eingesetzt, bspw. beim Customer-Relationship-
Management, Supply-Chain-Management, Wissensmanagement, Bestandskontrolle oder
auch Marketing (vgl. [GS06], S. 79). Gerade im Bereich des Marketings und E-Commerce
ist es nun moglich, die Kundendatenbanken zu untersuchen. Im Online-Shop mussen die
Kunden sich beim Betreiber anmelden und somit ihre Daten angeben. Dadurch ist es
moglich sie besser zu identifizieren und so unterschiedliche Kundengruppen zu entdecken
oder auch Vorhersagen zum Kundenverhalten zu machen (vgl. [ES00], S. 7 ff.).
2.2.4 Astronomie
Durch den Einsatz von verschiedenen Teleskopen werden in der Astronomie große Mengen
an Daten gesammelt. Beispielsweise wurden bei der Durchfuhrung des Projektes”Palo-
mar Observatory Sky Survey“ ca. 3 TB Bilddaten gespeichert. Eine solch große Menge an
Daten lasst sich unmoglich manuell auswerten und somit ist der Einsatz von Technologi-
en notwendig. Ein konkretes Beispiel ist das SKICAT-System. Dieses fuhrt eine Bildseg-
mentierung durch und weist dann fur jedes gefundene Objekt, z. B. Sterne oder Galaxi-
en, unterschiedliche Attributwerte zu. Mit der Unterstutzung eines Entscheidungsbaum-
Klassifikator werden dann die Objekte von selbst klassifiziert. Dadurch ist es moglich wei-
tere - auch manuelle - Analysen durchzufuhren. Durch den Einsatz dieses Systems konnen
die Klassifikationen wesentlich schneller durchgefuhrt und auch weit entfernte Objekte
konnen nun eingeordnet werden, was vorher nicht moglich war (vgl. [ES00], S. 6 f.).
9

3 VORGEHENSMODELLE DES KDDM
3 Vorgehensmodelle des KDDM
Nachfolgend wird ein Uberblick uber die verschiedenen Vorgehensweisen und Prozesse des
KDDM gegeben. Alle KDDM-Prozessmodelle bestehen im Allgemeinen aus einer Menge
von Prozessschritten, die Wiederholungen oder Iterationen beinhalten. (vgl. [KM06], S. 4).
Dabei lassen sich fur die gangigen Modelle vier Prozessschritte zusammenfassen ([Sha12],
S.57):
1. (Daten-)Vorbereitung
2. Datenvorverarbeitung
3. Methodenanwendung
4. Ergebnisinterpretation
Bei der Datenvorbereitung wird die Anbindung an eine Datenquelle durchgefuhrt und die
Daten werden selektiert. Der zweite Schritt beinhaltet die Vorverarbeitung von Daten. Da-
bei werden diese bereinigt und in entsprechend nutzbare Formate umgewandelt. Dadurch
konnen nun ergebnisbringende Methoden eingesetzt werden, die zu neuen Ergebnissen
fuhren. Im letzten Prozessschritt werden diese dann gemeinsam mit Experten des An-
wendungsbereichs interpretiert. Allerdings mussen in den vorkommenden Prozessschritten
verschiedene Aufwande erbracht werden. Hierzu hat die Wissenschaft in unterschiedlichen
Projekten Schatzungen zur Verfugung gestellt. Diese wurden durch Kurgan und Musilek
in einer Grafik (s. Abb. 1) naher dargestellt. Die Ergebnisse zeigen, dass fast alle Prozesse
den gleichen relativen Aufwand besitzen. Nur der Prozess der Datenvorbereitung benotigt
einen deutlich hoheren Einsatz mit ungefahr 50 % (vgl. [Sha12], S. 57 ff.). Grunde fur
diesen hohen Aufwand sind z. B., dass die Unternehmen oft nicht alle notwendigen Daten
gesammelt haben, die gesammelten Daten Fehlerraten von bis zu 5 % enthalten oder diese
redundant und inkonsistent sein konnen (vgl. [Red98], S.80).
10
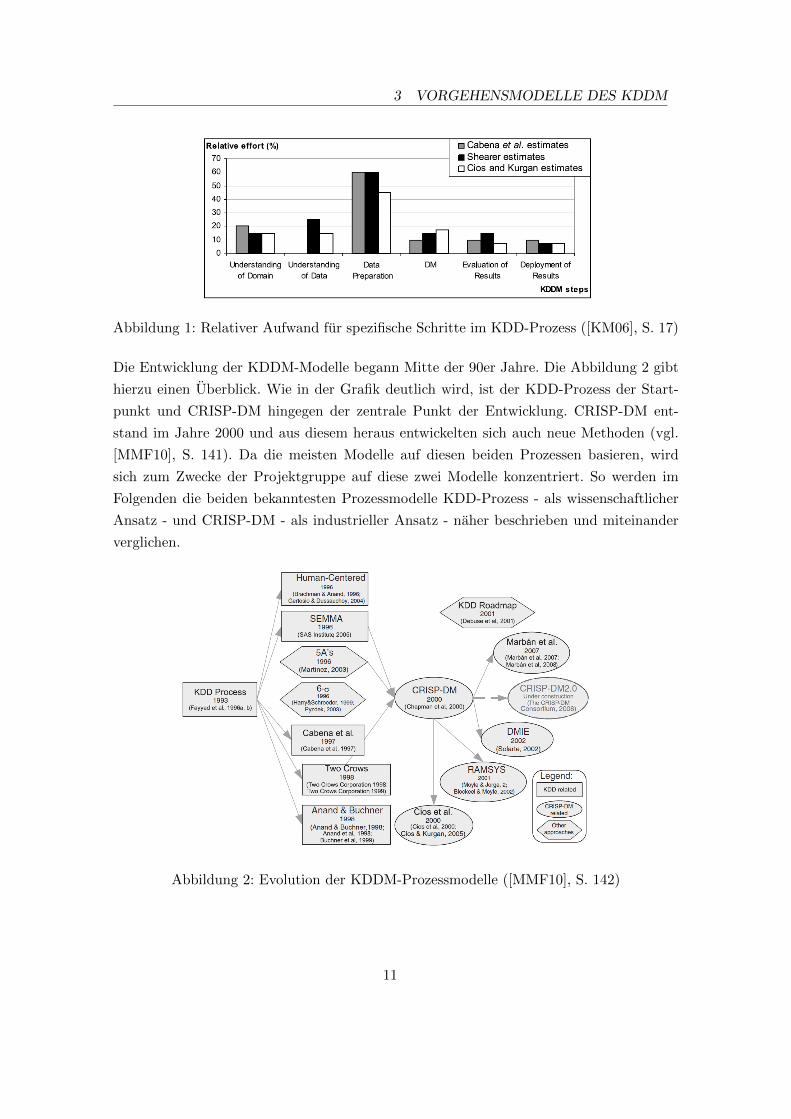
3 VORGEHENSMODELLE DES KDDM
Abbildung 1: Relativer Aufwand fur spezifische Schritte im KDD-Prozess ([KM06], S. 17)
Die Entwicklung der KDDM-Modelle begann Mitte der 90er Jahre. Die Abbildung 2 gibt
hierzu einen Uberblick. Wie in der Grafik deutlich wird, ist der KDD-Prozess der Start-
punkt und CRISP-DM hingegen der zentrale Punkt der Entwicklung. CRISP-DM ent-
stand im Jahre 2000 und aus diesem heraus entwickelten sich auch neue Methoden (vgl.
[MMF10], S. 141). Da die meisten Modelle auf diesen beiden Prozessen basieren, wird
sich zum Zwecke der Projektgruppe auf diese zwei Modelle konzentriert. So werden im
Folgenden die beiden bekanntesten Prozessmodelle KDD-Prozess - als wissenschaftlicher
Ansatz - und CRISP-DM - als industrieller Ansatz - naher beschrieben und miteinander
verglichen.
Abbildung 2: Evolution der KDDM-Prozessmodelle ([MMF10], S. 142)
11

3.1 KDD-Prozess 3 VORGEHENSMODELLE DES KDDM
3.1 KDD-Prozess
Das bekannteste Vorgehensmodell wurde von Usama Fayyad, Gregory Piatetsky-Shapiro
und Padhraic Smyth entwickelt und 1996 zum ersten Mal vorgestellt. Wie vorher schon
beschrieben, ist das Ziel des Prozesses der Gewinn von nutzlichem Wissen aus den vor-
handenen Daten (vgl. [Sha12], S. 60). Die folgende Abbildung zeigt den KDD-Prozess.
Dieser besteht aus mehreren Prozessschritten und ist interaktiv sowie iterativ. Es ist bspw.
moglich, dass der Prozess Wiederholungsschleifen zwischen zwei Phasen besitzt. Das Mo-
dell beinhaltet die Schritte Domanenverstandnis, Datenselektion, Datenvorbereitung und
-bereinigung, Datenreduktion und -projektion, Auswahl der Aufgabe des Data-Minings,
Auswahl des DM-Algorithmus, Data-Mining, Interpretation sowie die Verwendung des
entdeckten Wissens (vgl. [FPsS96a], S. 42).
Abbildung 3: Uberblick uber die Schritte des KDD-Prozesses ([MMF10], S. 143)
Die neun erwahnten Schritte vom Vorgehensmodell von Fayyad et al. (1996) werden hier
nun noch einmal naher beschrieben:
1. Learning the application domain: Als erstes ist es wichtig, dass die Anwen-
der ein Verstandnis der Anwendungsdomane erlangen. Zudem sollten die Ziele der
Untersuchung definiert werden (vgl. [FPsS96a], S. 42).
2. Creating a target data set: Ausgehend vom ersten Schritt werden die fur die Un-
tersuchung notwendigen Daten ausgewahlt. Es ist zudem moglich, dass Domanenex-
perten Angaben zur Datenverwendbarkeit machen. Dadurch konnen z. B. abgelegte
Daten durch geeignete Abfragen selektiert und fur die weitere Untersuchung im ge-
eigneten Format abgespeichert werden (vgl. [Sha12], S. 62).
3. Data cleaning and pre-processing: Sehr oft besitzen Datenbanken und die dort
abgelegten Informationen Fehler und Inkonsistenzen. Das zum Schluss entdeckte
Wissen konnte somit verfalscht werden, falls diese Fehler nicht vorher behandelt
12

3.1 KDD-Prozess 3 VORGEHENSMODELLE DES KDDM
werden (vgl. [Sha12], S. 62). Deshalb beinhaltet dieser Schritt grundlegende Tatig-
keiten wie das Entfernen von Rauschen sowie den richtigen Umgang mit Ausreißern
und DBMS-Problemen wie Datentypen oder fehlende und unbekannte Werte (vgl.
[FPsS96b], S. 30).
4. Data reduction and projection: Der vierte Schritt enthalt abhangig der Zielde-
finition die Auswahl von Funktionen zur Darstellung der Daten. Außerdem werden
Tranformationsmethoden angewendet sowie die Datendimensionen reduziert, um da-
durch die effektive Anzahl an Variablen zu reduzieren (vgl. [FPsS96b], S. 30).
5. Choosing the function of data mining: Diese Phase beinhaltet das Uberein-
stimmen der Ziele des KDD-Prozesses aus dem ersten Schritt mit der jeweiligen
DM-Methode wie z. B. Summarization, Classification, Regression und Clustering
(vgl. [FPsS96a], S. 42).
6. Choosing the data mining Algorithm: Hier werden die Methoden ausgewahlt,
die fur die Suche nach Mustern in den Daten zustandig sein sollen. Zudem wird
entschieden, welche Modelle und Parameter fur die angewendeten Methoden geeignet
sind (vgl. [FPsS96a], S. 42).
7. Data mining: In diesem Schritt wird das eigentliche Data-Mining durchgefuhrt. Es
wird nach interessanten Mustern in ihrer jeweilig dargestellten Form gesucht. Dies
beinhaltet Klassifikationsregeln oder -baume, Regressionsmodelle oder auch Cluste-
ring (vgl. [FPsS96b], S. 31).
8. Interpretation: In der achten Phase werden die gefundenen Muster interpretiert.
Zudem besteht, wenn es notig ist, die Moglichkeit noch zu den vorherigen Schrit-
ten zuruckzugehen. Auch beinhaltet dieser Schritt die Visualisierung der entdeckten
Muster oder das Entfernen von redundanten und unwichtigen Mustern. Außerdem
sollten die nutzlichen Muster so dargestellt werden, dass sie verstandlich sind (vgl.
[FPsS96b], S. 31).
9. Using discovered knowledge: Im letzten Schritt soll das neue Wissen direkt ge-
nutzt werden. Dies kann das Einbeziehen des Wissens in andere Systeme fur weitere
Handlungen sein oder auch das einfache Dokumentieren dieser bedeuten. Eine wei-
tere Maßnahme ist das Abgleichen des gefundenen Wissens mit dem vorher vorhan-
denen Kenntnissen (vgl. [FPsS96a], S. 42).
13

3.2 CRISP-DM 3 VORGEHENSMODELLE DES KDDM
3.2 CRISP-DM
Der Begriff CRISP-DM steht fur Cross-Industry Standard Process for Data-Mining. Die-
ses Vorgehensmodell ist aus der industriellen Praxis entstanden und deckt alle wichtigen
Punkte eines Data-Mining-Projekts ab (vgl. [Sha12], S. 64 f.). Es wurde durch Daimler
Chrysler, SPSS und NCR im Jahr 1999 entwickelt und die Version 1.01 wurde komplett
dokumentiert und veroffentlicht (vgl. [SQ14], S. 219). CRISP-DM ist herstellerunabhangig
und wird als nicht offizieller Standard fur das Entwickeln von KDDM-Projekten angese-
hen (vgl. [MMS09], S. 5). So zeigt auch eine von KDnuggets - eine fuhrende Website
zum Thema Big Data und Data-Mining - im Jahr 2014 durchgefuhrte Umfrage mit 200
Teilnehmern, dass CRISP-DM mit 43 % immer noch die am meisten genutzte Methodik
bei der Durchfuhrung von Data-Mining-Projekten ist und das, obwohl diese noch nicht
fur neue Herausforderungen, wie bspw. Big Data, angepasst wurde. Da es ein Mangel
an neuen Vorgehensmodellen gibt, verwendet auch 27 % der Teilnehmer ihre eigene Me-
thodik. Der KDD-Prozess wird noch von etwa 7,5 % genutzt (vgl. [Pia14]). Außerdem
deckt CRISP-DM nur relativ wenige Aufgaben zu Projekt- und Qualitatsmanagement ab.
Dies wird aber immer wichtiger, da die Projekte immer weiter an Komplexitat zunehmen
(vgl. [MMF10], S. 162 f.).
Die Methodik von CRISP-DM wird veranschaulicht im Sinne eines hierarchischen Modells
(s. Abb. 4). Dieses besteht aus einer Menge von Aufgaben, die auf vier unterschiedlichen
Ebenen beschrieben werden. Die Ebenen bestehen dabei aus der Phase, der generischen
Aufgabe, dem spezialisierten Task und schließlich der Prozessinstanz (vgl. [Sha12], S. 65).
Auf der obersten Ebene ist der Data-Mining-Prozess in mehrere Phasen gegliedert, wobei
jede aus einigen generischen Aufgaben aus der zweiten Ebenen besteht. Fur die generi-
schen Tasks aus der zweiten Ebene wird angestrebt, dass sie so komplett und stabil wie
moglich sind. Dies bedeutet, dass sie den ganzen Prozess des Data-Minings abdecken und
das Modell auch vor unerwarteten neuen Entwicklungen gultig ist. Die dritte Ebene, die
spezialisierten Tasks, stellt dar, wie die Handlungen in den generischen Aufgaben durch-
gefuhrt werden sollten in verschiedenen Situationen. Es wird somit gezeigt, wie sich eine
Aufgabe in unterschiedlichen Lagen andert. Zudem ist es in der Praxis haufig moglich, die
Tasks in unterschiedlichen Reihenfolgen durchzufuhren und es kann z. B. notwendig sein,
zu vorherigen Aufgaben zuruckzugehen und einige Aktionen zu wiederholen. Die letzte
und vierte Ebene, die Prozessinstanz, beinhaltet die Aufzeichnung der Handlungen, Ent-
scheidungen und Ergebnisse des Data-Mining-Vorhabens. Eine Prozessinstanz stellt dabei
klar, was bei einer einzelnen Beschaftigung genau geschieht (vgl. [CCK+00], S. 6).
1[CCK+00]
14

3.2 CRISP-DM 3 VORGEHENSMODELLE DES KDDM
Abbildung 4: Die vier Ebenen der CRISP-DM Methodik ([CCK+00], S. 6)
3.2.1 CRISP-DM Referenzmodell
Das CRISP-DM Referenzmodell (s. Abb. 5) besteht aus sechs Phasen, deren Abfolge
nicht starr ist. Zudem ist es, falls erforderlich, moglich zwischen einzelnen Schritten Vor-
und Rucksprunge durchzufuhren. Die Pfeile zeigen die wichtigsten und regelmaßigsten
Abhangigkeiten zwischen den Phasen. Der außere Kreis symbolisiert die zyklische Natur
von Data-Mining, da der Prozess des Data-Minings nicht endet, wenn eine Losung entwi-
ckelt wurde. Denn durch die gewonnen Lehren bei der Prozessdurchfuhrung konnen neue
wichtige Business-Fragen entstanden sein (vgl. [CCK+00], S. 10).
Abbildung 5: Phasen des CRISP-DM Referenzmodells ([CCK+00], S.10)
15

3.2 CRISP-DM 3 VORGEHENSMODELLE DES KDDM
Im Folgenden werden die einzelnen Phasen des Referenzmodells naher erlautert und im
Anschluss gibt die Abbildung 6 Auskunft uber die generischen Aufgaben (fett) sowie die
Outputs (kursiv) der jeweiligen Schritte:
1. Business Understanding: In der ersten Phase sollen die Ziele und Anforderungen
ermittelt und das Anwendungsszenario verstanden werden. Wichtige Fragen waren
dabei, warum das Projekt wichtig fur das Unternehmen ist und wie die gewonnenen
Ergebnisse spater eingesetzt werden konnten (vgl. [LM15], S. 70). Das erlangte Wis-
sen soll dafur genutzt werden, um eine Problemstellung fur das Data-Mining-Projekt
zu definieren und einen ersten Plan zur Zielerreichung zu entwickeln (vgl. [CCK+00],
S. 10).
2. Data Understanding: In der zweiten Phase wird eine Datensammlung vollzogen.
Mit dieser Sammlung werden verschiedene Handlungen durchgefuhrt, um mit den
Daten vertrauter zu werden. Außerdem sollen Datenqualitatsprobleme sowie inter-
essante Teilmengen erkannt werden, uber die Hypothesen von versteckten Informa-
tionen aufgestellt werden konnen (vgl. [CCK+00], S. 10).
3. Data Preparation: In der Phase der Data Preparation wird die ausgesuchte Da-
tensammlung fur die weitere Behandlung zusammengesetzt. Es werden dabei un-
terschiedliche Aufgaben durchgefuhrt. Dazu zahlt die Auswahl von Attributen, die
Transformation sowie die Bereinigung der Daten. Dadurch soll ein Datensatz in ei-
nem Format entstehen, das fur die kommenden eingesetzten Methoden in der nachs-
ten Phase geeignet ist. Die Aufgaben dieser Phase konnen dabei ofters und ohne
bestimmte Reihenfolge ausgefuhrt werden (vgl. [Sha12], S. 66).
4. Modeling: Hier werden unterschiedliche Modellierungsverfahren ausgewahlt und
eingesetzt sowie die Algorithmen und die zugehorigen Parameter festgelegt. Fur glei-
che und ahnliche DM-Probleme gibt es verschiedene Techniken und Methoden, die
eingesetzt werden konnen. Allerdings besitzen manche Techniken bestimmte Anfor-
derungen an die Daten, sodass ein Ruckschritt zur Data Preparation haufig notwen-
dig ist (vgl. [CCK+00], S.11).
5. Evaluation: Im funften Schritt wird das entwickelte Modell auf seine Qualitat un-
tersucht und ob die erstellten Ziele aus der ersten Phase mit ihm erreicht werden
konnen (vgl. [Sha12], S. 67). Es ist somit wichtig, noch einmal die vorherigen Schritte
des Erstellungsprozesses zu uberprufen und am Ende eine Entscheidung zu treffen,
wo die Ergebnisse des Data-Minings verwendet werden sollen (vgl. [CCK+00], S.11).
16

3.3 Vergleich von KDD-Prozess und CRISP-DM 3 VORGEHENSMODELLE
6. Deployment: Die Erstellung des Modells ist nicht das Ende des Prozesses. Denn
auch wenn das Hauptziel dieses Verfahrens ist, Wissen aus Daten zu gewinnen, so
wird im letzten Schritt das erzielte Wissen geordnet und derart prasentiert, dass die
Stakeholder es nutzen konnen. Je nach Anforderung unterscheidet sich die Komple-
xitat dieser Phase. So kann es eine einfache Erstellung eines Berichts sein oder auch
eine komplexe Implementierung von wiederholbaren DM-Prozessen im gesamten Un-
ternehmen (vgl. [CCK+00], S.11).
Abbildung 6: Generische Tasks (fett) und Outputs (kursiv) vom CRISP-DM Referenzmo-dell ([CCK+00], S. 12)
3.3 Vergleich von KDD-Prozess und CRISP-DM
Bei dem Vergleich dieser beiden Modelle fallt zuallererst auf, dass der KDD-Prozess neun
und CRISP-DM sechs Phasen besitzt. Doch bei genauerer Betrachtung sind die genannten
Prozesse doch recht aquivalent und beinhalten ahnliche Aufgaben. So ist der Schritt der
Datenvorbereitung beim KDD-Prozess in zwei Schritte aufgeteilt, namlich in Data Clea-
ning und Data Reduction. Außerdem ist auch die Phase Modeling von CRISP-DM beim
KDD-Prozess in drei einzelne Schritte aufgesplittet. Der KDD-Prozess stellt diese Phase
durch die Schritte Data Mining Function, Choosing the DM algorithm und Data Mining
spezifischer dar. Die folgende Abbildung gibt daruber einen Uberblick (vgl. [MMF10] S. 155).
17
3 VORGEHENSMODELLE
Abbildung 7: Vergleich der Prozessschritte von KDD-Prozess und CRISP-DM(Eigene Darstellung, angelehnt an [MMF10] S. 155)
Ein weiterer Unterschied bzw. Vorteil von CRISP-DM ist, dass es eine sehr ausfuhrli-
che Dokumentation besitzt, wo hingegen beim KDD-Prozess nach Fayyad, die einzel-
nen Schritte nicht so detailliert beschrieben werden. So unterteilt sich die CRISP-DM-
Dokumentation in Referenzmodell und Benutzerhandbuch. Beim Referenzmodell wird ein
schneller Uberblick uber die Phasen, Aufgaben und Outputs gegeben und beschrieben, was
zu tun ist. Beim Teil des Benutzerhandbuchs werden Hinweise fur jede Phase und Aufga-
be zur Verfugung gestellt. Es wird dabei geschildert, wie etwas zu tun ist (vgl. [MMF10],
S.146). Insgesamt unterscheiden sich diese beiden Methoden aber nur marginal, was auch
damit zu tun hat, dass der KDD-Prozess das Ursprungsmodell ist, auf denen sich die
nachfolgenden Methoden bezogen haben. So besitzen die beiden Prozesse ahnliche Phasen
und lassen außerdem Vor- oder Rucksprunge zwischen diesen zu.
18

4 FAZIT
4 Fazit
Im Rahmen dieser Seminararbeit wurde zur Einordnung dieses Themas zuallererst ein
Grundverstandnis uber den Begriff Knowledge Discovery in Databases geschaffen und zu
anderen Begriffen abgegrenzt. Zudem wurde gezeigt, dass KDD in vielen Bereichen, wie
bspw. im Marketing oder Investment, eingesetzt wird und nutzliche Erkenntnisse bringen
kann. Weiter ist eine Vielzahl an KDDM-Methoden vorhanden, doch die am Haufigsten
in der Literatur genannten, sind der KDD-Prozess von Fayyad et al. und CRISP-DM. Die
Vorstellung und der Vergleich dieser beiden Methoden haben gezeigt, dass diese sich sehr
ahneln und sich keine großen Unterschiede ergeben. Sie besitzen zwar eine unterschied-
liche Anzahl an Phasen, aber der wesentliche Grundgedanke ist gleich. Im Rahmen der
Projektgruppe jedoch ist die Methode CRISP-DM besser geeignet, da der Prozess durch
die Dokumentation spezifischer erlautert wird, was fur Anfanger in diesem Gebiet den
Einstieg erleichtert. CRISP-DM zeigt, was fur allgemeine Aufgaben und Outputs anfal-
len konnen. Zudem wird diese Methode immer noch am haufigsten verwendet und als
nicht offizieller Standard deklariert. Allerdings deckt CRISP-DM nicht sehr viele Projekt-
und Qualitatsmanagementaufgaben ab. So sind in einem KDD-Projekt nicht nur die Da-
ten wichtig, sondern auch das managen der Personen und Aufgaben in diesem Projekt.
Deshalb konnte es sinnvoll sein, den Prozess ein wenig zu uberarbeiten und auf die Pro-
jektgruppe abzustimmen.
19

Literatur Literatur
Literatur
[CCK+00] Pete Chapman, Julian Clinton, Randy Kerber, Thomas Khabaza, Thomas
Reinartz, Colin Shearer, and Rudiger Wirth. CRISP-DM 1.0 Step-by-step data
mining guide. Technical report, The CRISP-DM consortium, August 2000.
[ES00] Martin Ester and Jorg Sander. Knowledge Discovery in Databases: Techniken
und Anwendungen. Springer Verlag, 2000.
[FPSM92] William J. Frawley, Gregory Piatetsky-Shapiro, and Cristopher J. Matheus.
Knowledge Discovery in Databases - An Overview. Ai Magazine, 13:57–70,
1992.
[FPsS96a] Usama Fayyad, Gregory Piatetsky-shapiro, and Padhraic Smyth. From Data
Mining to Knowledge Discovery in Databases. AI Magazine, 17:37–54, 1996.
[FPsS96b] Usama Fayyad, Gregory Piatetsky-shapiro, and Padhraic Smyth. The KDD
Process for Extracting Useful Knowledge from Volumes of Data. Communica-
tions of the ACM, 39:27–34, 1996.
[GS06] Rayid Ghani and Carlos Soares. Data Mining for Business Applications: KDD-
2006 Workshop. SIGKDD Explor. Newsl., 8(2):79–81, 2006.
[KM06] Lukasz A. Kurgan and Petr Musilek. A survey of Knowledge Discovery and
Data Mining Process Models. Knowl. Eng. Rev., 21(1):1–24, 2006.
[KT05] Hian Chye Koh and Gerald Tan. Data Mining Applications in Healthcare.
Journal of Healthcare Information Management, 19(2):64–72, 2005.
[Lin16] Markus Linden. Geschaftsmodellbasierte Unternehmenssteuerung mit
Business-Intelligence-Technologien. Springer Fachmedien, 2016.
[LM15] Carsten Lanquillon and Hauke Mallow. Advanced Analytics mit Big Data.
In Joachim Dorschel, editor, Praxishandbuch Big Data: Wirtschaft – Recht –
Technik, pages 55–89. Springer Gabler, 2015.
[MMF10] Gonzalo Mariscal, Oscar Marban, and Covadonga Fernandez. A survey of
data mining and knowledge discovery process models and methodologies. The
Knowledge Engineering Review, 25(2):137–166, 2010.
20

Literatur Literatur
[MMS09] Oscar Marban, Gonzalo Mariscal, and Javier Segovia. A Data Mining & Know-
ledge Discovery Process Model. In Julio Ponce and Adem Karahoca, editors,
Data Mining and Knowledge Discovery in Real Life Applications, pages 1–16.
Intech, 2009.
[Pia14] Gregory Piatetsky. CRISP-DM, still the top methodology for analytics, data
mining, or data science projects. http://www.kdnuggets.com/2014/10/crisp-
dm-top-methodology-analytics-data-mining-data-science-projects.html, 2014.
[Online; Stand 16. Mai 2017].
[Red98] Thomas C. Redman. The Impact of Poor Data Quality on the Typical Enter-
prise. Commun. ACM, 41(2):79–82, 1998.
[Sha12] Armin Sharafi. Knowledge Discovery in Databases. Eine Analyse des Ande-
rungsmanagements in der Produktentwicklung. Springer Fachmedien, 2012.
[SQ14] Umair Shafique and Haseeb Qaiser. A Comparative Study of Data Mining
Process Models (KDD, CRISP-DM and SEMMA). International Journal of
Innovation and Scientific Research, 12(1):217–222, 2014.
[Xu14] Jennifer Jie Xu. Knowledge Discovery and Data Mining. In Heikki Topi and Al-
len Tucker, editors, Computing Handbook, Third Edition: Information Systems
and Information Technology, pages (19–1)–(19–15). Chapman & Hall/CRC
Press, 3rd edition, 2014.
[ZZW04] Shichao Zhang, Chengqi Zhang, and Xindong Wu. Knowledge Discovery in
Multiple Databases. Springer Verlag, 2004.
21

Abschließende Erklarung
Ich versichere hiermit, dass ich meine Seminararbeit selbstandig und ohne fremde Hilfe
angefertigt habe, und dass ich alle von anderen Autoren wortlich ubernommenen Stellen
wie auch die sich an die Gedankengange anderer Autoren eng anlegenden Ausfuhrungen
meiner Arbeit besonders gekennzeichnet und die Quellen zitiert habe.
Oldenburg, den 8. Januar 2018 Martin Sonntag

A ANHANG A.3 Seminararbeiten
A.3.11. Helge Wendtland - Testing von Software
359

Testing von SoftwareSeminararbeit im Rahmen der Projektgruppe Big Data Archive
Themensteller: Prof. Dr.-Ing. Jorge Marx GomezBetreuer: M. Eng. & Tech. Viktor Dmitriyev
Dr.-Ing. Andreas SolsbachJad Asswad, M.Sc.
Vorgelegt von: Helge WendtlandReiherstieg 22421244 Buchholz0176 [email protected]
Abgabetermin: 21. Mai 2017

Inhaltsverzeichnis Inhaltsverzeichnis
Inhaltsverzeichnis
1 Einleitung 3
2 Grundsatze fur Softwaretests 42.1 Testabdeckung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42.2 Vollstandigkeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42.3 Planung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42.4 Flexibilitat . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.5 Programmierer 6= Tester . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.6 Dokumentation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.7 Testnutzen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
3 Der Testprozess 63.1 Testplanung und -steuerung . . . . . . . . . . . . . . . . . . . . . . . . . . . 63.2 Testanalyse und -design . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73.3 Testrealisierung und -durchfuhrung . . . . . . . . . . . . . . . . . . . . . . . 73.4 Testauswertung und -bericht . . . . . . . . . . . . . . . . . . . . . . . . . . 73.5 Abschluss der Testaktivitaten . . . . . . . . . . . . . . . . . . . . . . . . . . 8
4 Testen in agilen Projekten 94.1 Agiles Testmanagement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
5 Testautomatisierung 115.1 JUnit Tests . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115.2 Was spricht gegen Unit Tests . . . . . . . . . . . . . . . . . . . . . . . . . . 12
6 Qualitat von Anforderungen 136.1 Qualitatskriterien fur Anforderungen . . . . . . . . . . . . . . . . . . . . . . 136.2 Testen von Anforderungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
7 Fazit 16
Literaturverzeichnis 17
2

1 EINLEITUNG
1 Einleitung
In dieser Arbeit geht es um die Qualitatssicherung in der Softwareentwicklung mittels
Softwaretests. Der Nutzen von Softwaretests wird von Spillner und Linz folgendermaßen
beschrieben:
Das Testen von Software dient durch die Identifizierung von Defekten und deren anschlie-
ßender Beseitigung zur Steigerung der → Softwarequalitat. Die Testfalle sollen so gewahlt
werden, dass sie weitgehend der spateren Benutzung der Software entsprechen. Die nach-
gewiesene Qualitat des Programms wahrend der Tests entspricht dann der zu erwartenden
Qualitat wahrend der spateren Benutzung ([SL12], S.11).
Das Ziel des Testens besteht also darin, Fehler in der Software zu ermitteln, um diese zu
beheben und ein moglichst fehlerfreies Produkt zu entwickeln. Das oberste Ziel ist es also,
eine moglichst hohe Qualitat in dem Endprodukt zu erreichen. Dabei gibt es in der Praxis
gravierende Unterschiede, wie das Testen in verschiedenen Softwareprojekten umgesetzt
wird. Diese Arbeit behandelt Themen, die fur die Projektgruppe im Entwicklungsprozess
relevant sein konnen. Da im Rahmen dieser Ausarbeitung unmoglich alle Verfahren und
Werkzeuge erlautert werden konnen, die zur Qualitatssicherung von Software eingesetzt
werden konnen, werden Annahmen getroffen, wie der Softwareentwicklungsprozess in der
Projektgruppe verlaufen konnte, damit der Fokus auf einige Kernthemen gelegt werden
kann. Zunachst einmal wird davon ausgegangen, dass ein agiles und iteratives Vorgehen
zum Einsatz kommt. Des Weiteren wird angenommen, dass es in jedem Fall Ziel der
Projektgruppe ist, einen moglichst hohen Qualitatsstandard im Entwicklungsprozess zu
erreichen.
Zunachst werden die Grundsatze fur Softwaretests beschrieben. Diese sind allgemein
gultig und sollten bei jeder Art von Testverfahren beachtet werden. Im Anschluss erfolgt
die Betrachtung eines typischen Testprozesses und darauf aufbauend die Besonderheiten,
die sich bei der agilen Entwicklung ergeben. Im Anschluss wird die Automatisierung von
Softwaretests beschrieben. Am Ende der Arbeit erfolgt ein Ubergang in die Anforderungs-
erhebung und damit verbunden die Fragestellung, wie bereits bei der Anforderungserhe-
bung die Qualitat des Endproduktes sichergestellt werden kann.
Die zentrale Fragestellung der Arbeit lautet:
Welche Maßnahmen konnen ergriffen werden, um die Qualitat von Software
wahrend des Entwicklungsprozesses zu verbessern?
3

2 GRUNDSATZE FUR SOFTWARETESTS
2 Grundsatze fur Softwaretests
Beim Testen von Software gibt es einige Grundsatze die von vornherein beachtet werden
sollten. Diese Grundsatze gelten fur alle Testprojekte egal welcher Große. Sie definieren
grobe Richtlinien an die die Tester sich halten sollte (vgl. [Wit16], S.11).
2.1 Testabdeckung
Tests zeigen die Anwesenheit von Fehlern. Je hoher die Testabdeckung ist, desto wahr-
scheinlicher ist es demnach auch, dass die getestete Software keine Fehler mehr enthalt.
Eine hohe Testabdeckung ist jedoch kein Beweis dafur, dass die Software fehlerfrei ist.
Es ist trotz Tests nicht ausgeschlossen, dass auch nach dem Rollout noch Fehler in der
Software vorhanden sind (vgl. [Wit16], S.11).
2.2 Vollstandigkeit
Es ist so gut wie unmoglich eine 100% Testabdeckung zu erreichen. Es wird immer Ein-
gabeparameter geben, welche nicht getestet werden, da sie in der Praxis kaum relevant
sind, oder sich kaum von den getesteten Parametern unterscheiden. Somit kann es weiter-
hin bestimmte Parameter geben, welche aus bestimmten Grunden zu falschen Ergebnissen
fuhren (vgl. [Wit16], S.11f). Ein fehlerfreies Softwaresystem gibt es derzeit nicht und wird
es wahrscheinlich auch niemals geben. Sobald ein Softwaresystem einen gewissen Kom-
plexitatsgrad erreicht hat, ist es nicht mehr moglich, alle Parameter zu beachten. Die
Erstellung einer großen und komplexen fehlerfreien Software ist somit nicht moglich (vgl.
[SL12], S.10).
2.3 Planung
Testen ist ein begleitender Prozess. Es sollte bereits fruhzeitig in die Tests investiert wer-
den. Schon bevor die ersten Programmzeilen geschrieben wurden, konnen die Anforde-
rungen getestet werden und Testkonzepte fur spatere Tests ausgearbeitet werden. Gene-
rell gilt, dass Fehler billiger behoben werden konnen, je fruher sie entdeckt werden (vgl.
[Wit16], S.12.). Daruber hinaus ist es fur den Projektaufwand wichtig zu wissen, wie viel
Zeit fur Tests investiert werden muss. Der Testaufwand sollte moglichst prazise aus den
vorhandenen Informationen abgeleitet werden. Zusatzlich sollte das Testumfeld beruck-
sichtigt werden. Die Tester sollten sich immer vor Augen halten, wer das System am Ende
bedient. Trotz praziser Planung ist es dennoch wichtig, eine gewisse Flexibilitat beizube-
halten. Wahrend des Projekts konnen Ereignisse eintreten, die ein Umdenken beim Testen
4

2.4 Flexibilitat 2 GRUNDSATZE FUR SOFTWARETESTS
erforderlich machen (vgl. [Wit16], S.13f.).
2.4 Flexibilitat
Fehler treten in den meisten Fallen nicht alleine auf. Wird ein Fehler in einer Komponente
gefunden, ist es wahrscheinlich, dass weitere Fehler in der Komponente stecken. Fur den
Tester ist es wichtig auf solche Situationen zu reagieren. Der Tester muss sich an dieser
Stelle in einen Nutzer hinein versetzen konnen, welcher die Software nicht kennt und die
Software eventuell ganz anders bedient, als von den Entwicklern vorgesehen (vgl. [Wit16],
S.12f). Wenn die Anforderungen an der Realitat vorbeigehen oder die Bedienung des
Systems zu umstandlich ist, wird die Software nach dem Release keine Nutzerakzeptanz
finden (vgl. [Wit16], S.15).
2.5 Programmierer 6= Tester
Ein Programmierer der seine eigene Software testet findet in der Regel weniger Fehler
als ein unabhangiger Tester. Ein Programmierer versucht beim Testen eher zu beweisen,
dass seine eigene Software funktioniert. Ein unabhangiger Tester kann zudem eher Miss-
verstandnisse bei der Anforderungserhebung aufdecken als der Entwickler (vgl. [Wit16],
S.14).
2.6 Dokumentation
Es mussen die Eingangsdaten, die erwarteten Ergebnisse und die erhaltenen Daten do-
kumentiert werden. Tests mussen reproduzierbar sein. Bei gleichen Parametern muss ein
Test auch immer die gleichen Ergebnisse liefern (vgl. [Wit16], S.14).
2.7 Testnutzen
Testen soll zwei Zwecke wahrend der Softwareentwicklung erfullen. Zum einen soll die An-
zahl der Fehler wahrend der Entwicklung moglichst gering gehalten werden, zum anderen
dient das Testen der Abnahme durch den Auftraggeber, da die Funktionalitat der Software
sichergestellt werden kann (vgl. [Wit16], S.17).
5

3 DER TESTPROZESS
3 Der Testprozess
Es gibt eine ganze Reihe von Softwareentwicklungsmodellen, wie beispielsweise das V-
Modell, das Wasserfallmodell, das Spiralmodell, aber auch agile Modelle wie beispielsweise
Scrum. In jedem dieser Modelle gehort das Testen zum Entwicklungsprozess. Die Bedeu-
tung der Tests unterscheidet sich jedoch von Modell zu Modell, besonders im Bezug auf
den Umfang des Testprozesses (vgl. [SL12], S.19). Trotz der unterschiedlichen Modelle lasst
sich ein allgemeiner Testprozess ableiten. Dieser Prozess besteht aus folgenden Phasen:
• Testplanung und -steuerung
• Testanalyse und -design
• Testrealisierung und -durchfuhrung
• Testauswertung und -bericht
• Abschluss der Testaktivitaten
Diese Phasen mussen nicht zwangslaufig streng nacheinander abgearbeitet werden, die
Phasen konnen sich ebenfalls uberschneiden (vgl. [SRWL06], S.11).
3.1 Testplanung und -steuerung
Da es sich beim Testen um eine sehr umfangreiche Aufgabe handelt, sollte die Planung
bereits zum Projektbeginn durchgefuhrt werden. Die Ziele des Tests mussen festgelegt
werden, genau wie die benotigten Ressourcen. Hierzu mussen die zur Durchfuhrung noti-
gen Mitarbeiter, sowie deren Aufgaben, die zu veranschlagende Zeit und die Werkzeuge
festgelegt werden. Die Ergebnisse sind in einem Testkonzept zu dokumentieren. Die Test-
planung muss ggf. wahrend der Entwicklung angepasst werden. Da ein vollstandiger Test
nicht moglich ist, mussen bei der Teststrategie Prioritaten gesetzt werden. Es kann auch
vorkommen, dass mehrere Testverfahren notwendig sind, um ein moglichst solides Test-
ergebnis zu erlangen. Kritische Systemkomponenten mussen besonders intensiv getestet
werden, um Fehler an relevanten Stellen, welche auch andere Systemkomponenten betref-
fen konnten, zu vermeiden. In der Planungsphase werden zudem Testendkriterien definiert,
welche festlegen, wann der Test als abgeschlossen gilt. Auch diese Testendkriterien konnen
sich innerhalb eines Projekts fur verschiedene Tests unterscheiden. Die Planungsphase soll-
te grundlich durchgefuhrt werden, um die Ressourcen, welche fur den Test zur Verfugung
stehen optimal zu verteilen. Zudem geraten Softwareprojekte gerne unter Zeitdruck. Auch
6

3.2 Testanalyse und -design 3 DER TESTPROZESS
dieser Umstand muss bei der Planung berucksichtigt werden. Eine Priorisierung bewirkt,
dass die kritischen Systemkomponenten zuerst getestet werden. Sollte beim Testen die
Zeit zu knapp werden, kann der Fokus so auf die wichtigsten Komponenten gelegt werden.
(vgl. [SRWL06], S.11ff.).
3.2 Testanalyse und -design
In der Analysephase ist zunachst zu klaren, ob die verwendeten Dokumente prazise genug
sind, um daraus Testverfahren und Testfalle abzuleiten. Gibt es Mangel, muss ggf. nach-
gebessert werden. Wahrend des Testdesigns werden dann die Testverfahren und Testfalle
abgeleitet. Dokumentiert werden die Ergebnisse in der Testspezifikation. Der Testplan
bestimmt schließlich die zeitliche Reihenfolge der Testdurchfuhrung und die Zuordnung
der Tester. Es werden logische Testfalle definiert, welche im nachsten Schritt konkretisiert
werden. Die Testfalle konnen als Blackbox oder Whitebox Tests spezifiziert werden. Die
Spezifizierung der Testfalle ist ein andauernder Prozess und kann auch noch wahrend der
Entwicklung stattfinden. Die Testfalle mussen zunachst Vorbedingungen, Randbedingun-
gen fur den Test, Nachbedingungen und das Erwartete Ergebnis bzw. das Erwartete Ver-
halten beschreiben. Der Sollzustand wird zusatzlich dokumentiert (vgl. [SRWL06], S.13f.).
Je nach Umfang des Projekts kann diese Phase auch parallel zur Testplanung starten (vgl.
[Wit16], S.3).
3.3 Testrealisierung und -durchfuhrung
Bei der Realisierung werden konkrete Testfalle aus den logischen Testfallen abgeleitet.
Vor der Testdurchfuhrung mussen alle notigen Vorbereitungen getroffen werden (Installa-
tion der Testumgebung, etc.). Im Rahmen der Komponenten- und Integrationstests kann
eine werkzeuggestutzte Durchfuhrung sinnvoll werden. Danach werden die Tests durch-
gefuhrt und die Ergebnisse dokumentiert. Es ist sinnvoll zuerst Basisfunktionalitaten zu
testen. Sollten hier bereits Fehler auftreten ist ein tieferer Einstieg nicht sinnvoll. Alle
Fehler mussen analysiert werden, sodass die Ursache klar dokumentiert werden kann. Ein
festgestellter Fehler kann im Zweifel auch auf einen fehlerhaften Test zuruckgefuhrt wer-
den. Die Priorisierung der Tests ist bewirkt an dieser Stelle, dass Fehler, welche schwere
Auswirkungen auf das System haben, fruh erkannt werden (vgl. [SRWL06], S.15f.).
3.4 Testauswertung und -bericht
Nach der Testdurchfuhrung ist zu kontrollieren, ob die festgelegten Testendkriterien erfullt
wurden. Diese Uberprufung kann dazu fuhren, dass der Test als beendet gilt. Es kann sich
7

3.5 Abschluss der Testaktivitaten 3 DER TESTPROZESS
aber auch herausstellen, dass bestimmte Tests nicht durchgefuhrt werden konnten, oder
weitere Tests erforderlich sind. Sind weitere Tests erforderlich, ist zu ermitteln, an welcher
Stelle des Testprozesses wieder eingestiegen werden muss. Durch diese erweiterten Tests
entstehen Zyklen, welche von vornherein eingeplant werden mussen. Wird zu Beginn der
Planung von nur einem Zyklus ausgegangen kann dies spater zu Verzogerungen fuhren.
Wie viele Testzyklen letztendlich notwendig sind, ist nur schwer abzuschatzen. Hier konnen
Vergleichsdaten aus ahnlichen Projekten nutzlich sein. in der Praxis bestimmen oftmals die
noch vorhandenen Ressourcen wann die Testphase beendet wird. Am Ende der Testphase
ist ein Bericht fur alle Entscheidungstrager zu erstellen (vgl. [SRWL06], S.16.).
3.5 Abschluss der Testaktivitaten
Nach der Beendigung der Testphase sollten die gesammelten Erfahrungen dokumentiert
werden. Die Daten konnen bei weiteren Projekten helfen, die Testphase zu verbessern.
Dazu sollten alle Erkenntnisse, sowie positive und negative Erfahrungen innerhalb der
Testphase dokumentiert werden. Wird dieser letzte Schritt in jedem Projekt durchgefuhrt,
entsteht ein kontinuierlicher Verbesserungsprozess, welcher sich positiv auf kunftige Pro-
jekte auswirkt. Auch andere Projektteams konnen von dieser abschließenden Dokumenta-
tion profitieren und ihren Testprozess anhand der Ergebnisse verbessern. (vgl. [SRWL06],
S.17.).
8

4 TESTEN IN AGILEN PROJEKTEN
4 Testen in agilen Projekten
Die agile Softwareentwicklung stellt ein Problem fur das traditionelle Testen von Softwa-
re dar. Bei der agilen Softwareentwicklung andern sich die Anforderungen im Laufe des
Projekts immer wieder. In jedem Entwicklungszyklus konnen neue oder veranderte Anfor-
derungen auftreten. Ziel dieses agilen iterativen Entwicklungsprozesses ist es, immer einen
genauen Uberblick uber den aktuellen Entwicklungsstand zu haben. Zusatzlich erlaubt
das agile Vorgehen eine Anpassung an Sachverhalte, welche zu Projektbeginn noch nicht
bekannt waren. Es ist zwar problemlos moglich einzelne Komponenten mit Unittests zu
uberprufen, Integrations- oder Systemtests gestalten sich jedoch schwieriger. Neue Kom-
ponenten werden teilweise in einem zwei Wochen Zyklus ausgeliefert, der Testprozess muss
sich an diesen Umstand anpassen. Agiles Testen muss deshalb so gestaltet sein, dass die
Ziele der agilen Softwareentwicklung optimal unterstutzt werden. Beim agilen Testen sollte
der Fokus deshalb auf folgenden Punkten liegen:
• Hohe Kundenzufriedenheit, die durch die bessere Kommunikation zwischen Entwick-
lerteam und Kunde entsteht.
• Hohe Produktqualitat, da die Entwicklungsaktivitat von Anfang an auf der Auffin-
dung und Vermeidung von Fehlern ausgerichtet ist.
• Hohe Entwicklungsgeschwindigkeit, die durch die Reduktion von Dokumentationen
und unnotigen Fehlerkorrekturen bewirkt wird.
• Schnelle Reaktion auf Anderungen, die durch die kurzen Zyklen und Iterationen
ermoglicht wird.
• Hohe Teammotivation, die durch Selbstmotivation und ein dauerhaft einhaltbares
Arbeitstempo unterstutzt wird (vgl. [Wit16], S.259f.).
Dabei mussen jedoch weiterhin Punkte aus den klassischen Testverfahren beachtet wer-
den:
• Gute Planbarkeit, Verfolgbarkeit und Nachweisbarkeit der Testaktivitaten.
• Hohe Systematik des Testentwurfs, daraus resultierend eine hohe und reproduzier-
bare Testabdeckung (vgl. [Wit16], S.260).
Der großte Unterschied zwischen agiler und klassischer Softwareentwicklung besteht in
der Veranderung der Anforderungen wahrend des Projekts. Das fuhrt zu einer verhalt-
nismaßig hohen Effizienz von automatisierten Tests, da die einzelnen Komponenten viel
9

4.1 Agiles Testmanagement 4 TESTEN IN AGILEN PROJEKTEN
ofter getestet werden mussen. Die Tests werden dabei in Test Tasks aufgegliedert. Jeder
Task kann dabei einen von funf Zustanden haben.
• Offen
• In Bearbeitung (Testfall und Testprozedur werden geschrieben)
• Test durchgefuhrt
• Fehler gemeldet
• Abgeschlossen
Im Idealfall haben am Ende eines jeden Iterationszyklus alle Test Tasks den Zustand ab-
geschlossen, was bedeutet, dass alle umgesetzten Komponenten aus der Iteration getestet
wurden (vgl. [Wit16], S.260).
4.1 Agiles Testmanagement
Bei agilen Projekten hat der Product Owner bzw. der Kunde auch im Testmanagement ein
gewisses Mitspracherecht. Der Kunde muss jederzeit zur Verfugung stehen und Auskunft
uber die Relevanz einzelner Anforderungen geben sowie Missverstandnisse aufklaren. Der
Fokus beim agilen Testen liegt folglich viel starker auf der Validierung als bei klassischen
Projekten. Der Tester wird außerdem viel starker mit in das Projekt einbezogen und ist
nicht nur dafur zustandig festzustellen, ob die entwickelten Komponenten lauffahig sind.
Viel mehr bringt der Tester fruhzeitig seine Gedanken und Vorschlage mit ins Projekt
ein. Zudem betrachtet er eventuell auftretende Risiken gegebenenfalls von einem anderen
Standpunkt aus. Im Gegensatz zu klassischen Tests verschiebt sich der Aufwand beim
Testen stark. Das ableiten der Tests aus den Anforderungen, das Umsetzen und Automa-
tisieren der Tests, sowie die Bewertung der Ergebnisse erfolgen relativ zeitgleich bei jeder
Iteration. In klassischen Projekten werden diese Punkte im Idealfall einmalig nacheinander
durchgefuhrt. Testen wird also als ganzheitliche Aufgabe verstanden. Durch die Nahe zum
Entwicklerteam und die stark ausgepragte Kommunikationsstruktur in agilen Projekten
konnen Tester sehr schnell auf auftretende Probleme mit entsprechenden Tests reagieren
(vgl. [Wit16], S.261).
10

5 TESTAUTOMATISIERUNG
5 Testautomatisierung
Manuelles Testen kann durch Benutzung der Software uber die Benutzeroberflache durch-
gefuhrt werden. Fur Teile der Implementierung, die auf diese weise nicht getestet werden
konnen, kann der Debugger benutzt werden, um um den Code Schritt fur Schritt zu
uberprufen. Diese Art des Testens ist meist nicht sonderlich effektiv und nicht effizient.
Automatisierte Test hingegen mussen erst geschrieben werden und sind dementsprechend
zunachst teurer. Automatisiertes Testen ist deshalb nicht immer der richtige Weg. Ein
geubter Tester kann das Wissen uber die Funktionalitat des Endproduktes nutzen, um
gezielt Szenarios zu testen, die mit automatisierten Tests nur schwer nachzustellen sind.
Sobald eine Komponente jedoch sehr oft getestet werden muss, ist der automatisierte Test
wesentlich kostengunstiger (vgl. [Bin00], S.804).
Testautomatisierung ist eine Moglichkeit einen Test immer wieder mit einer sehr kurzen
Ausfuhrungszeit durchzufuhren. Der Nachteil der Testmethode sind die hohen Anfangskos-
ten, um die automatisierten Tests zu erstellen. Um das Vorgehen zu rechtfertigen, mussen
also zunachst die Erstellungskosten gegen die gesparte Ausfuhrungszeit aufgerechnet wer-
den. Angenommen das Programmieren und Dokumentieren eines Tests dauert zehn mal
so lange wie die manuelle Ausfuhrung des Tests, dann lohnt sich das automatisierte Vorge-
hen, sobald wir wissen, dass wir den Tests mindestens zehn mal ausfuhren werden. Diese
Annahme ist naturlich sehr hypothetisch und berucksichtigt nicht, dass einige Tests sich
wahrend der Entwicklung andern, oder nicht mehr benotigt werden. Es macht nur wenig
Sinn eine komplette Software uber alle Ebenen hinweg zu testen, da der Entwicklungsauf-
wand in keinem Verhaltnis zum Nutzen steht (vgl. [Lin05], S.17f.).
Es gibt Tools, um Systeme automatisiert unter hoher Last zu testen, Tools zum Testen
von Benutzeroberflachen und noch viele mehr. Aufgrund der Anforderungen an die Pro-
jektgruppe wird sich hier auf das automatisierte Testen von objektorientierten Unit Tests
beschrankt. Ein solcher Test besteht in der Regel darin, dass ein oder mehrere Objekte
erzeugt werden. Diese werden in einen bestimmten Ausgangszustand gebracht und dann
mit Nachrichten gefuttert. Dann werden die Veranderungen des Objektes sowie die Aus-
wirkungen auf die Umgebung beobachtet. Es werden also Testtreiber erstellt (vgl. [Lin05],
S.18f.).
5.1 JUnit Tests
Mit Unit-Frameworks konnen automatisierte Tests fur verschiedene Programmiersprachen
geschrieben werden. Im Falle von Java heißt das Werkzeug JUnit. Der große Vorteil fur
die Entwickler ist, dass die Tests direkt in Java programmiert werden konnen. Es konnen
11

5.2 Was spricht gegen Unit Tests 5 TESTAUTOMATISIERUNG
zu allen Komponenten Test erstellt werden, um das Verhalten der Komponente zu testen.
Bei dem Erstellen automatisierter JUnit Tests muss darauf geachtet werden, die Tests
vernunftig zu strukturieren, um die Ubersicht zu behalten und auch große Mengen an
Tests verwalten zu konnen. Zu einer einzelnen Komponente konnen eine große Anzahl
Tests anfallen, um das Verhalten auf unterschiedliche Art und Weise zu testen. Es gibt
zwei typische Herangehensweisen, wo die JUnit Tests angelegt werden. Die eine Moglichkeit
ist es, die Testklassen in dem gleichen Paket wie die zu testenden Klassen anzulegen. Der
Vorteil hierbei ist, dass die Verknupfung direkt sichtbar wird. Die andere Moglichkeit ist,
die Testklassen separat zu speichern, um Test-Code und Produkt-Code zu trennen. Hierzu
kann die Paketstruktur der Codes dupliziert werden, damit die Tests strukturiert abgelegt
und leicht wiedergefunden werden konnen (vgl. [Kle12], S.45.).
5.2 Was spricht gegen Unit Tests
Es gibt einige negative Argumente, die in Verbindung mit Unit Tests immer wieder genannt
werden. Im folgenden werden einige Argumente aufgefuhrt, die gerne gegen Unit Tests
angefuhrt werden. Der erste Punkt ist der große Aufwand, der mit der Erstellung von Unit
Tests einher geht. bei Unit Tests ist der Aufwand umso hoher, je weiter die Entwicklung
bereits vorangeschritten ist. Es kann dazu kommen, dass man gar nicht mehr weiß wo
man anfangen soll, wenn man erst in einem spaten Entwicklungsstudium damit beginnt
die Tests zu schreiben. Anstatt am Anfang der Entwicklung zu argumentieren, dass die
Entwicklung von Unit Tests zu aufwendig ist, sollte sich eher die Frage gestellt werden,
wie viel Zeit ansonsten fur die Fehlersuche und manuellen Nachbearbeitung benotigt wird
(vgl. [HT05], S.9ff.).
Ein weiterer Punkt ist die lange Ausfuhrungszeit von Unit Tests. Eigentlich konnen
mehrere 100 Unit Tests pro Sekunde ausgefuhrt werden. Sollte es vorkommen ,dass einige
Tests zu langsam sind, sollten diese wenigen langsamen Tests von den anderen getrennt
werden, um sie seltener separat auszufuhren (vgl. [HT05], S.11.).
Einige Programmierer argumentieren, dass sie nicht wissen, wie sich das Programm
eigentlich verhalten soll. An dieser Stelle sollte die Software noch nicht programmiert
werden, da die Software nicht entwickelt werden kann ,wenn noch nicht bekannt ist, was
sie eigentlich machen soll (vgl. [HT05], S.12).
Das Argument”es kompiliert doch“ wird gerne als Argument gegen Unit Tests genutzt.
Unit Tests kontrollieren jedoch nicht, ob der Code kompiliert, sondern, wie er sich verhalt
(vgl. [HT05], S.12).
12

6 QUALITAT VON ANFORDERUNGEN
6 Qualitat von Anforderungen
Um Qualitativ hochwertige Software zu entwickeln, mussen zunachst Qualitativ hochwer-
tige Anforderungen formuliert werden. Dabei gibt es eine Reihe von Qualitatskriterien, die
Anforderungen erfullen sollten, damit ein qualitativ hochwertiges Softwareprodukt entwi-
ckelt werden kann.
6.1 Qualitatskriterien fur Anforderungen
• Vollstandig
Jede Anforderung muss die geforderte und zu liefernde Qualitat exakt beschreiben.
Das bedeutet auch, dass die Anforderung messbar sein muss, damit eine Uberprufung
moglich ist. Unvollstandige Anforderungen sollten markiert und spater erganzt wer-
den.
• Notwendig
jede Anforderung sollte eine Leistung, Eigenschaft oder ein Qualitatsmerkmal be-
schreiben, welche bzw. welches der Kunde auch wirklich braucht. Eine Anforderung
gilt nur dann als notwendig, wenn sie zur Erfullung des Systemziels dient.
• Atomar
Jeder Anforderungssatz enthalt genau eine Anforderung. Die strikte Trennung der
Anforderungen dient der Ubersicht und dem Verstandnis. Die Anforderungen soll
dadurch simpel gehalten werden, damit sie leicht verstandlich sind.
• Verfolgbar
Jede Anforderung muss zu ihrem Ursprung hin zuruck verfolgbar sein. Die Quelle der
Anforderung muss immer deutlich erkennbar sein, damit eine gewisse Transparenz
entsteht und auch voneinander abgeleitete Anforderungen nachvollziehbar sind.
• Technisch losungsneutral
Anforderungen mussen immer losungsneutral formuliert werden und durfen keine
Einschrankungen hinsichtlich der Entwicklung oder der Architektur machen. Die
Anforderungen beschreiben lediglich was das fertige System konnen muss.
• Realisierbar
Anforderungen mussen innerhalb der Systemgrenzen umsetzbar sein. Es durfen keine
grundlegenden technischen Neuerungen durch Anforderungen gefordert werden.
13

6.2 Testen von Anforderungen 6 QUALITAT VON ANFORDERUNGEN
• Konsistent
Anforderungen mussen gegenuber allen anderen Anforderungen widerspruchsfrei for-
muliert sein.
• Eindeutig
Jede Anforderung darf nur auf eine Art und Weise verstanden werden und sollte
zusatzlich einfach formuliert und leicht verstandlich sein.
• Prufbar
Jede Anforderung muss so beschreiben sein, dass die geforderte Funktionalitat durch
einen Test oder eine Messung nachzuweisen ist.
Daruber hinaus existieren ahnliche Anforderungskriterien im Hinblick auf Vollstandig-
keit und Konsistenz fur die Anforderungsspezifikation (vgl. [Rup14], S.26f.).
6.2 Testen von Anforderungen
Genau wie fertig gestellte Komponenten konnen auch Anforderungen durch einen Qua-
litatssicherungsprozess getestet werden. Zum Testen von Anforderungen gibt es Techniken,
welche je nach Prufkriterium angewendet werden konnen.
• Reviews
• Prototypen
• Testfalle
• Analysemodelle (z.B UML-Diagramme)
• Metriken (mathematische Herangehensweise)
Diese Methodiken sollten in einem Plan-Do-Check-Act orientierten Verfahren angewen-
det werden. Durch diese”iterative“Herangehensweise an die Qualitatssicherung konnen die
Anforderungen in jedem Zyklus weiter verbessert werden. Grundlage dieser Qualitatssiche-
rungsmaßnahmen ist ein Qualitatssicherungsleitfaden, welcher vorweg entwickelt werden
muss. In diesem Leitfaden werden die Qualitatsziele festgelegt, die Qualitatssicherungs-
methoden ausgewahlt, die Zeitpunkte der Prufung definiert und die Prufer ernannt (vgl.
[Rup14], S.306ff.).
Plan
Sind alle Vorbereitungen getroffen, kann der eigentliche Testprozess beginnen. Zunachst
14

6.2 Testen von Anforderungen 6 QUALITAT VON ANFORDERUNGEN
wird das Vorgehen geplant, die Prufbarkeit der Anforderungen wird sichergestellt und
Prufungsgegenstand definiert. Es wichtig festzustellen, ob das Anforderungsdokument fur
den Test ausreicht. Ein Kriterium fur dafur konnte eine Mindestanzahl an Tests sein, die
vor der Prufung vorhanden sein muss. Es ist nicht immer sinnvoll alle Anforderungen zu
testen, da der Aufwand dafur sehr hoch sein kann. Welche Anforderungen getestet werden,
sollte von den Testern anhand von sinnvoll festgelegten Kriterien selbst entschieden wer-
den. Im Anschluss mussen die Ergebnisse dieser Phase dokumentiert werden (vgl. [Rup14],
S.312f.).
Do
Sind die Vorbereitungen abgeschlossen, wird das Spezifikationselement untersucht und
ein Prufbericht verfasst. Die Prufung erfolgt anhand einer einheitlichen Prufvorlage und
eines einheitlichen Qualitatssicherungsleitfadens. Der Prufer uberpruft jede Anforderung
anhand des Qualitatssicherungsleitfaden (vgl. [Rup14], S.313f.).
Check
Nach der Durchfuhrung der Prufung werden die Ergebnisse beurteilt und mit den festge-
legten Qualitatszielen verglichen. Bei dieser Prufung ist ein genaues hinsehen gefragt. Es
muss beurteilt werden, ob die Prufung zufriedenstellend durchgefuhrt wurde und ob der
abschließende Prufbericht zufriedenstellend ist. Schlecht definierte Anforderungen, oder
Fehler im Prufprozes sollten an dieser Stelle ermittelt werden (vgl. [Rup14], S.314f.).
Act
vorausgesetzt die Qualitatskriterien wurden nicht erfullt, sind im Anschluss Maßnahmen
einzuleiten, um eine Verbesserung herbei zu fuhren. Gerade sprachliche Mangel sollten in
dem Prozess bereits erkannt worden sein und hier angepasst werden. Die Uberarbeitung
der Anforderungen kann schnell zu neuen Mangeln fuhren, weshalb eine erneute Uber-
prufung zu empfehlen ist. Im Idealfall wurde bereits bei der Einfuhrung des Qualitats-
sicherungsprozesses uberlegt, wie mit Problemen, welche wahrend der Prufung sichtbar
werden umgegangen wird (vgl. [Rup14], S.315f.).
15

7 FAZIT
7 Fazit
In der Arbeit werden einige Verfahren und Werkzeuge vorgestellt, um die Qualitat bei der
Softwareentwicklung zu verbessern. Von den Grundlagen bis hin zu JUnit Tests gibt es
fur Entwicklerteams vielseitige Moglichkeiten, um eine qualitativ hochwertige und funk-
tionierende Software zu erstellen. Der Aufwand fur die Etablierung eines Testverfahrens
wirkt zwar zunachst sehr hoch, der Gesamtaufwand fur den Testprozess wird dadurch aber
berechenbar. Ohne Testverfahren kann ein Projekt schnell bei der Fehlersuche aus dem
Ruder laufen, weil der Aufwand zu groß wird.
Fur die Projektgruppe lassen sich aus dieser Arbeit einige Herangehensweisen an die
Entwicklung der Software ableiten. Zunachst sollten sich die Vorteile von gut uberleg-
ten Testverfahren klar gemacht werden. Dann sollte die Projektgruppe bereits bei der
Anforderungserhebung qualitatssichernde Maßnahmen einsetzen und direkt im Anschluss
damit beginnen, ein Testverfahren fur den Entwicklungsprozess zu entwickeln. Bei der
Entwicklung eines Testverfahrens sollte sich an dem etablierten Testprozess aus Kapitel
drei orientiert werden, da diese Grobstruktur fur alle Entwicklungsverfahren gultig ist. Da
ein Agiles Entwicklungsverfahren fur das Projekt angemessen scheint und die Anforderun-
gen zum aktuellen Zeitpunkt noch uberhaupt nicht abgeschatzt werden konnen, ist ein
automatisiertes Testverfahren zumindest in Teilen empfehlenswert. Grundlegende Anfor-
derungen, welche fruhzeitig feststehen sollten durch automatisierte Tests gepruft werden,
da diese Test im spateren Entwicklungsverlauf immer wieder durchgefuhrt werden mussen.
Bei Komponenten, welche erst zu einem spateren Zeitpunkt Entwickelt werden, weil bei-
spielsweise die Anforderungen zunachst nicht vorhanden waren, muss dann abgeschatzt
werden, ob sich der Aufwand der Testautomatisierung lohnt.
Wenn die hier genannten Maßnahmen von der Projektgruppe eingesetzt werden, erhoht
das in jedem Fall die Qualitat des zu entwickelnden Endproduktes.
16

Literatur Literatur
Literatur
[Bin00] Robert V. Binder. Testing Object-Oriented Systems - Models, Patterns, and
Tools. Addison-Wesley, 2000.
[HT05] Andrew Hunt and David Thomas. Pragmatisch Programmieren - Unit Tests
mit JUnit. Hanser, 2005.
[Kle12] Stephan Kleuker. Qualitatssicherung durch Softwaretests - Vorgehensweisen
und Werkzeuge zum Test von Java-Programmen. Springer, 2012.
[Lin05] Johannes Link. Softwaretests mit JUnit - Techniken der testgetreibenen Ent-
wicklung. dpunkt, 2005.
[Rup14] Chris Rupp. Requirements-Engineering und -Management - aus der praxis von
klassisch bis agil. Hanser, 2014.
[SL12] Andreas Spillner and Tilo Linz. Basiswissen Softwaretest - Aus- und Weiter-
bildung zum Certified Tester. dpunkt, 2012.
[SRWL06] Andreas Spillner, Thomas Roßner, Mario Winter, and Tilo Linz. Praxiswissen
Softwaretest - Testmanagement. dpunkt, 2006.
[Wit16] Frank Witte. Testmanagement und Softwaretest - Theoretische Grundlagen
und praktische Umsetzung. Springer Vieweg, 2016.
17

Literatur Literatur
Abschließende Erklarung
Ich versichere hiermit, dass ich meine Seminararbeit Testing von Software selbstandig
und ohne fremde Hilfe angefertigt habe, und dass ich alle von anderen Autoren wortlich
ubernommenen Stellen wie auch die sich an die Gedankengange anderer Autoren eng
anlegenden Ausfuhrungen meiner Arbeit besonders gekennzeichnet und die Quellen zitiert
habe.
Oldenburg, den 21. Mai 2017 Helge Wendtland
18




























