Embed Size (px)
Citation preview

Deep Learning For Embedded Security Evaluation
Deep Learning For Embedded Security EvaluationEmmanuel PROUFF
Joint work with Ryad Benadjila, Eleonora Cagli (CEA LETI), Cecile Dumas (CEA
LETI), Houssem Maghrebi (UL), Loic Masure (CEA LETI), Thibault Portigliatti (ex
SAFRAN), Remi Strullu and Adrian Thillard
ANSSI (French Network and Information Security Agency)
June 17, 2019
June 2019, Summer School, Sibenik, Croatia| E. Prouff| 0/18

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Illustration| Template Attacks|
Probability distribution function (pdf) of Electromagnetic Emanations
Cryptographic Processing with a secret k = 1.
1/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Illustration| Template Attacks|
Probability distribution function (pdf) of Electromagnetic Emanations
Cryptographic Processing with a secret k = 1.
1/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Illustration| Template Attacks|
Probability distribution function (pdf) of Electromagnetic Emanations
Cryptographic Processing with a secret k = 2.
1/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Illustration| Template Attacks|
Probability distribution function (pdf) of Electromagnetic Emanations
Cryptographic Processing with a secret k = 3.
1/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Illustration| Template Attacks|
Probability distribution function (pdf) of Electromagnetic Emanations
Cryptographic Processing with a secret k = 4.
1/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Illustration| Template Attacks|
Context:
Target Device Clone Device
[On Clone Device] For every k estimate the pdf of−→X | K = k.
k = 4k = 1 k = 2 k = 3
[On Target Device] Estimate the pdf of−→X.
k = ?
[Key-recovery] Compare the pdf estimations.
2/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Illustration| Template Attacks|
Context:
Target Device Clone Device
[On Clone Device] For every k estimate the pdf of−→X | K = k.
k = 4k = 1 k = 2 k = 3
[On Target Device] Estimate the pdf of−→X.
k = ?
[Key-recovery] Compare the pdf estimations.
2/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Illustration| Template Attacks|
Context:
Target Device Clone Device
[On Clone Device] For every k estimate the pdf of−→X | K = k.
k = 4k = 1 k = 2 k = 3
[On Target Device] Estimate the pdf of−→X.
k = ?
[Key-recovery] Compare the pdf estimations.
2/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Illustration| Template Attacks|
Context:
Target Device Clone Device
[On Clone Device] For every k estimate the pdf of−→X | K = k.
k = 4k = 1 k = 2 k = 3
[On Target Device] Estimate the pdf of−→X.
k = ?
[Key-recovery] Compare the pdf estimations.
2/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Illustration| Template Attacks|
Context:
Target Device Clone Device
[On Clone Device] For every k estimate the pdf of−→X | K = k.
k = 4k = 1 k = 2 k = 3
[On Target Device] Estimate the pdf of−→X.
k = ?
[Key-recovery] Compare the pdf estimations.2/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Illustration| Template Attacks|
Side Channel Attacks (Classical Approach)
Notations
~X observation of the device behaviour
P public input of the processing
Z target (a cryptographic sensitive variable Z = f(P,K))
Goal: make inference over Z, observing ~X
Pr[Z|~X]
Template Attacks
Profiling phase (using profiling traces under known Z)
I manage de-synchronization problemI mandatory dimensionality reductionI estimate for each value of z
Attack phase (N attack traces ~xi, e.g. with known plaintexts pi)Log-likelihood score for each key hypothesis k
dk =
N∑i=1
log Pr[~X = ~xi|Z = f(pi, k)]
3/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Illustration| Template Attacks|
Side Channel Attacks (Classical Approach)
Notations
~X observation of the device behaviour
P public input of the processing
Z target (a cryptographic sensitive variable Z = f(P,K))
Goal: make inference over Z, observing ~X Pr[Z|~X]
Template Attacks
Profiling phase (using profiling traces under known Z)
I manage de-synchronization problemI mandatory dimensionality reductionI estimate for each value of z
Attack phase (N attack traces ~xi, e.g. with known plaintexts pi)Log-likelihood score for each key hypothesis k
dk =
N∑i=1
log Pr[~X = ~xi|Z = f(pi, k)]
3/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Illustration| Template Attacks|
Side Channel Attacks (Classical Approach)
Notations
~X observation of the device behaviour
P public input of the processing
Z target (a cryptographic sensitive variable Z = f(P,K))
Goal: make inference over Z, observing ~X Pr[Z|~X]
Template Attacks
Profiling phase (using profiling traces under known Z)
I manage de-synchronization problemI mandatory dimensionality reductionI estimate for each value of z
Attack phase (N attack traces ~xi, e.g. with known plaintexts pi)Log-likelihood score for each key hypothesis k
dk =N∑i=1
log Pr[~X = ~xi|Z = f(pi, k)]
3/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Illustration| Template Attacks|
Side Channel Attacks (Classical Approach)
Notations
~X observation of the device behaviour
P public input of the processing
Z target (a cryptographic sensitive variable Z = f(P,K))
Goal: make inference over Z, observing ~X Pr[Z|~X]
Template Attacks
Profiling phase (using profiling traces under known Z)
I manage de-synchronization problemI mandatory dimensionality reduction
I estimate Pr[~X|Z = z] by simple distributions for each value of z
Attack phase (N attack traces ~xi, e.g. with known plaintexts pi)Log-likelihood score for each key hypothesis k
dk =N∑i=1
log Pr[~X = ~xi|Z = f(pi, k)]
3/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Illustration| Template Attacks|
Side Channel Attacks (Classical Approach)
Notations
~X observation of the device behaviour
P public input of the processing
Z target (a cryptographic sensitive variable Z = f(P,K))
Goal: make inference over Z, observing ~X Pr[Z|~X]
Template Attacks
Profiling phase (using profiling traces under known Z)
I manage de-synchronization problemI mandatory dimensionality reduction
I estimate Pr[~X|Z = z] for each value of z
Attack phase (N attack traces ~xi, e.g. with known plaintexts pi)I Log-likelihood score for each key hypothesis k
dk =N∑i=1
log Pr[~X = ~xi|Z = f(pi, k)]
3/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Illustration| Template Attacks|
Side Channel Attacks (Classical Approach)
Notations
~X observation of the device behaviour
P public input of the processing
Z target (a cryptographic sensitive variable Z = f(P,K))
Goal: make inference over Z, observing ~X Pr[Z|~X]
Template Attacks
Profiling phase (using profiling traces under known Z)
I manage de-synchronization problem
I mandatory dimensionality reductionI estimate Pr[~X|Z = z] for each value of z
Attack phase (N attack traces ~xi, e.g. with known plaintexts pi)I Log-likelihood score for each key hypothesis k
dk =N∑i=1
log Pr[~X = ~xi|Z = f(pi, k)]
3/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Illustration| Template Attacks|
Side Channel Attacks (Classical Approach)
Notations
~X observation of the device behaviour
P public input of the processing
Z target (a cryptographic sensitive variable Z = f(P,K))
Goal: make inference over Z, observing ~X Pr[Z|~X]
Template Attacks
Profiling phase (using profiling traces under known Z)I manage de-synchronization problemI mandatory dimensionality reductionI estimate Pr[ε(X)|Z = z] for each value of z
Attack phase (N attack traces ~xi, e.g. with known plaintexts pi)I Log-likelihood score for each key hypothesis k
dk =N∑i=1
log Pr[ε(X) = ε(xi)|Z = f(pi, k)]
3/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Defensive Mechanisms
+
Misaligning Countermeasures
Random Delays, Clock Jittering, ...
In theory: assume to be insufficient to provide security
In practice: one of the main issues for evaluators
=⇒ Need for efficient resynchronization techniques
Masking Countermeasure
Each key-dependent internal state element is randomly split into 2 shares
The crypto algorithm is adapted to always manipulate shares at 6= times
The adversary needs to recover information on the two shares to recover K
=⇒ Need for efficient Methods to recover tuple of leakage samplesthat jointly depend on the target secret
4/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Defensive Mechanisms
+
Misaligning Countermeasures
Random Delays, Clock Jittering, ...
In theory: assume to be insufficient to provide security
In practice: one of the main issues for evaluators
=⇒ Need for efficient resynchronization techniques
Masking Countermeasure
Each key-dependent internal state element is randomly split into 2 shares
The crypto algorithm is adapted to always manipulate shares at 6= times
The adversary needs to recover information on the two shares to recover K
=⇒ Need for efficient Methods to recover tuple of leakage samplesthat jointly depend on the target secret
4/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Motivating Conclusions
Now:
preprocessing to prepare dataI Traces resynchronisationI Selection of PoIs
make strong hypotheses on thestatistical dependencyI e.g. Gaussian approximation
characterization to extractinformationI e.g. Maximum Likelihood
The proposed perspective:
preprocessing to prepare dataI Traces resynchronisationI Selection of PoIs
make strong hypotheses on thestatistical dependencyI e.g. Gaussian approximation
Train algorithms to directlyextract information
5/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Motivating Conclusions
Now:
preprocessing to prepare dataI Traces resynchronisationI Selection of PoIs
make strong hypotheses on thestatistical dependencyI e.g. Gaussian approximation
characterization to extractinformationI e.g. Maximum Likelihood
The proposed perspective:
preprocessing to prepare dataI Traces resynchronisationI Selection of PoIs
make strong hypotheses on thestatistical dependencyI e.g. Gaussian approximation
Train algorithms to directlyextract information
5/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Side Channel Attacks
Notations
~X side channel trace
Z target (a cryptographic sensitive variable Z = f(P,K))
Goal: make inference over Z, observing ~X Pr[Z|~X]
Template Attacks Machine Learning Side Channel Attacks
Profiling phase (using profiling traces under known Z)I manage de-synchronization problemI mandatory dimensionality reductionI estimate Pr[~X|Z = z] for each value of z
Attack phase (N attack traces, e.g. with known plaintexts pi)I Log-likelihood score for each key hypothesis k
dk =N∑i=1
log Pr[~X = ~xi|Z = f(pi, k)]
6/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Side Channel Attacks with a Classifier
Notations
~X side channel trace
Z target (a cryptographic sensitive variable Z = f(P,K))
Goal: make inference over Z, observing ~X Pr[Z|~X]
Template Attacks Machine Learning Side Channel Attacks
Profiling phase (using profiling traces under known Z)I manage de-synchronization problemI mandatory dimensionality reductionI estimate Pr[~X|Z = z] for each value of z
Attack phase (N attack traces, e.g. with known plaintexts pi)I Log-likelihood score for each key hypothesis k
dk =N∑i=1
log Pr[~X = ~xi|Z = f(pi, k)]
6/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Side Channel Attacks with a Classifier
Notations
~X side channel trace
Z target (a cryptographic sensitive variable Z = f(P,K))
Goal: make inference over Z, observing ~X Pr[Z|~X]
Template Attacks Machine Learning Side Channel Attacks
Training phase (using training traces under known Z)I manage de-synchronization problemI mandatory dimensionality reductionI estimate Pr[~X|Z = z] for each value of z
Attack phase (N attack traces, e.g. with known plaintexts pi)I Log-likelihood score for each key hypothesis k
dk =N∑i=1
log Pr[~X = ~xi|Z = f(pi, k)]
6/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Side Channel Attacks with a Classifier
Notations
~X side channel trace
Z target (a cryptographic sensitive variable Z = f(P,K))
Goal: make inference over Z, observing ~X Pr[Z|~X]
Template Attacks Machine Learning Side Channel Attacks
Training phase (using training traces under known Z)I manage de-synchronization problemI mandatory dimensionality reductionI construct a classifier F s.t. F (~x)[z] = y ≈ Pr[Z = z|~X = ~x]
Attack phase (N attack traces, e.g. with known plaintexts pi)I Log-likelihood score for each key hypothesis k
dk =N∑i=1
log Pr[~X = ~xi|Z = f(pi, k)]
6/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Side Channel Attacks with a Classifier
Notations
~X side channel trace
Z target (a cryptographic sensitive variable Z = f(P,K))
Goal: make inference over Z, observing ~X Pr[Z|~X]
Template Attacks Machine Learning Side Channel Attacks
Training phase (using training traces under known Z)I manage de-synchronization problemI mandatory dimensionality reductionI construct a classifier F s.t. F (~x)[z] = y ≈ Pr[Z = z|~X = ~x]
Attack phase (N attack traces, e.g. with known plaintexts pi)I Log-likelihood score for each key hypothesis k
dk =N∑i=1
logF (~xi)[f(pi, k)]
6/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Side Channel Attacks with a Classifier
Notations
~X side channel trace
Z target (a cryptographic sensitive variable Z = f(P,K))
Goal: make inference over Z, observing ~X Pr[Z|~X]
Template Attacks Machine Learning Side Channel Attacks
Training phase (using training traces under known Z)Integrated approach
I manage de-synchronization problemI mandatory dimensionality reductionI construct a classifier F s.t.
F (~x)[z] = y ≈ Pr[Z = z|~X = ~x]
Attack phase (N attack traces, e.g. with known plaintexts pi)I Log-likelihood score for each key hypothesis k
dk =N∑i=1
logF (~xi)[f(pi, k)]
6/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Machine Learning Approach
Overview of Machine Learning Methodology
Human effort:
choose a class of algorithms
Neural Networks
choose a model to fit +tune hyper-parameters
MLP, ConvNet
Automatic training:
automatic tuning oftrainable parametersto fit data
Stochastic Gradient Descent
aaa
7/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Machine Learning Approach
Overview of Machine Learning Methodology
Human effort:
choose a class of algorithmsNeural Networks
choose a model to fit +tune hyper-parameters
MLP, ConvNet
Automatic training:
automatic tuning oftrainable parametersto fit dataStochastic Gradient Descent
aaa
7/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Machine Learning Approach
Overview of Machine Learning Methodology
Human effort:
choose a class of algorithmsNeural Networks
choose a model to fit +tune hyper-parametersMLP, ConvNet
Automatic training:
automatic tuning oftrainable parametersto fit dataStochastic Gradient Descent
aaa
7/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Machine Learning Approach
Overview of Machine Learning Methodology
Human effort:
choose a class of algorithmsNeural Networks
choose a model to fit +tune hyper-parametersMLP, ConvNet
Automatic training:
automatic tuning oftrainable parametersto fit dataStochastic Gradient Descent
aaa
7/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018
Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
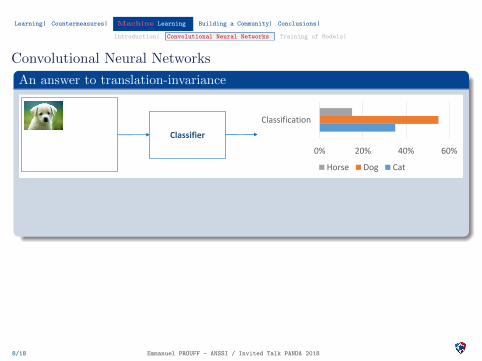
Convolutional Neural Networks
An answer to translation-invariance
0% 20% 40% 60%
Classification
Horse Dog Cat
Classifier
It is important to explicit the data translation-invarianceConvolutional Neural Networks: share weights across space
8/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Convolutional Neural Networks
An answer to translation-invariance
0% 20% 40% 60%
Classification
Horse Dog Cat
Classifier
It is important to explicit the data translation-invarianceConvolutional Neural Networks: share weights across space
8/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018
Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Convolutional Neural Networks
An answer to translation-invariance
0% 20% 40% 60%
Classification
Horse Dog Cat
Classifier
It is important to explicit the data translation-invarianceConvolutional Neural Networks: share weights across space
8/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Convolutional Neural Networks
An answer to translation-invariance
0% 20% 40% 60%
Classification
Horse Dog Cat
Classifier
It is important to explicit the data translation-invariance
Convolutional Neural Networks: share weights across space
8/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
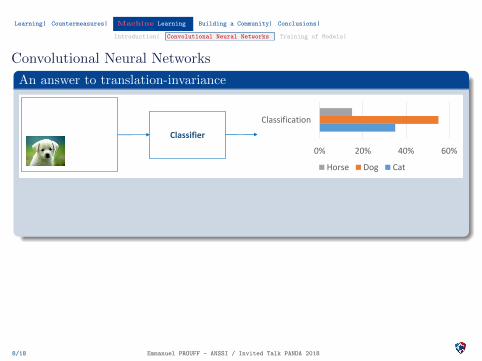
Convolutional Neural Networks
An answer to translation-invariance
0% 10% 20% 30% 40% 50%
Classification
Horse Dog Cat
Classifier? ? ?
It is important to explicit the data translation-invariance
Convolutional Neural Networks: share weights across space
8/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018
Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
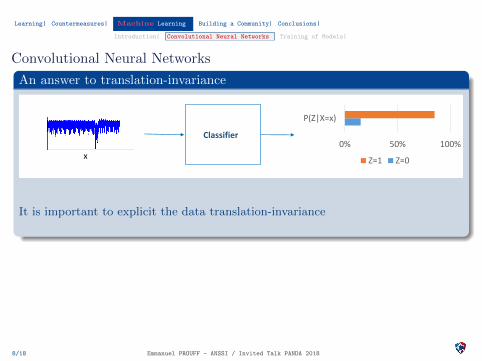
Convolutional Neural Networks
An answer to translation-invariance
Classifier0% 50% 100%
P(Z|X=x)
Z=1 Z=0x
It is important to explicit the data translation-invariance
Convolutional Neural Networks: share weights across space
8/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Convolutional Neural Networks
An answer to translation-invariance
Classifier0% 50% 100%
P(Z|X=x)
Z=1 Z=0x
It is important to explicit the data translation-invariance
Convolutional Neural Networks: share weights across space
8/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Convolutional Neural Networks
An answer to translation-invariance
Classifier0% 50% 100%
P(Z|X=x)
Z=1 Z=0x
It is important to explicit the data translation-invariance
Convolutional Neural Networks: share weights across space
8/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Convolutional Neural Networks
An answer to translation-invariance
Classifier0% 50% 100%
P(Z|X=x)
Z=1 Z=0x
It is important to explicit the data translation-invarianceConvolutional Neural Networks: share weights across space
8/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Convolutional Neural Networks
An answer to translation-invariance
Classifier0% 50% 100%
P(Z|X=x)
Z=1 Z=0x
It is important to explicit the data translation-invarianceConvolutional Neural Networks: share weights across space
8/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Basic Example
Figure: Convolutional filtering: W = 2, nfilter = 4, stride = 1, padding = same. Maxpooling layer: W = stride = 3.
9/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Example: masked manipulation of a sensitive datum Z
Figure: Deep Learning Behaviour Against Masked Datum
10/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Example: masked manipulation of a sensitive datum Z
Figure: Deep Learning Behaviour Against Masked Datum
11/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018
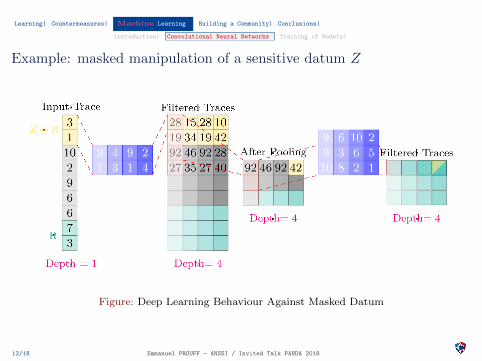
Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Example: masked manipulation of a sensitive datum Z
Figure: Deep Learning Behaviour Against Masked Datum
12/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Training of Neural NetworksTrading Side-Channel Expertise for Deep Learning Expertise .... or huge computational power!
Training
Aims at finding the parameters of the function modelling for thedependency btw the target value and the leakage.
The search is done by solving a minimization problem with respect to somemetric (aka loss function)
The training algorithm has itself some training hyper-parameters:the number of iterations (aka epochs) of the minimization procedure,the number of input traces (aka batch) treated during a single iteration.
The trained model has architecture hyper-parameters:the size of the layers, the nature of the layers, the number of layers, etc.
Tricky Points
Find sound hyper-parameters is the main issue in Deep Learning: this can bedone thanks to a good understanding of the underlying structure of thedata and/or access to important computational power.
13/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Training of Neural NetworksTrading Side-Channel Expertise for Deep Learning Expertise .... or huge computational power!
Training
Aims at finding the parameters of the function modelling for thedependency btw the target value and the leakage.
The search is done by solving a minimization problem with respect to somemetric (aka loss function)
The training algorithm has itself some training hyper-parameters:the number of iterations (aka epochs) of the minimization procedure,the number of input traces (aka batch) treated during a single iteration.
The trained model has architecture hyper-parameters:the size of the layers, the nature of the layers, the number of layers, etc.
Tricky Points
Find sound hyper-parameters is the main issue in Deep Learning: this can bedone thanks to a good understanding of the underlying structure of thedata and/or access to important computational power.
13/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Training of Neural NetworksTrading Side-Channel Expertise for Deep Learning Expertise .... or huge computational power!
Training
Aims at finding the parameters of the function modelling for thedependency btw the target value and the leakage.
The search is done by solving a minimization problem with respect to somemetric (aka loss function)
The training algorithm has itself some training hyper-parameters:the number of iterations (aka epochs) of the minimization procedure,the number of input traces (aka batch) treated during a single iteration.
The trained model has architecture hyper-parameters:the size of the layers, the nature of the layers, the number of layers, etc.
Tricky Points
Find sound hyper-parameters is the main issue in Deep Learning: this can bedone thanks to a good understanding of the underlying structure of thedata and/or access to important computational power.
13/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Training of Neural NetworksTrading Side-Channel Expertise for Deep Learning Expertise .... or huge computational power!
Training
Aims at finding the parameters of the function modelling for thedependency btw the target value and the leakage.
The search is done by solving a minimization problem with respect to somemetric (aka loss function)
The training algorithm has itself some training hyper-parameters:the number of iterations (aka epochs) of the minimization procedure,the number of input traces (aka batch) treated during a single iteration.
The trained model has architecture hyper-parameters:the size of the layers, the nature of the layers, the number of layers, etc.
Tricky Points
Find sound hyper-parameters is the main issue in Deep Learning: this can bedone thanks to a good understanding of the underlying structure of thedata and/or access to important computational power.
13/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Training of Neural NetworksTrading Side-Channel Expertise for Deep Learning Expertise .... or huge computational power!
Training
Aims at finding the parameters of the function modelling for thedependency btw the target value and the leakage.
The search is done by solving a minimization problem with respect to somemetric (aka loss function)
The training algorithm has itself some training hyper-parameters:the number of iterations (aka epochs) of the minimization procedure,the number of input traces (aka batch) treated during a single iteration.
The trained model has architecture hyper-parameters:the size of the layers, the nature of the layers, the number of layers, etc.
Tricky Points
Find sound hyper-parameters is the main issue in Deep Learning: this can bedone thanks to a good understanding of the underlying structure of thedata and/or access to important computational power.
13/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Introduction| Convolutional Neural Networks| Training of Models|
Training of Neural NetworksTrading Side-Channel Expertise for Deep Learning Expertise .... or huge computational power!
Training
Aims at finding the parameters of the function modelling for thedependency btw the target value and the leakage.
The search is done by solving a minimization problem with respect to somemetric (aka loss function)
The training algorithm has itself some training hyper-parameters:the number of iterations (aka epochs) of the minimization procedure,the number of input traces (aka batch) treated during a single iteration.
The trained model has architecture hyper-parameters:the size of the layers, the nature of the layers, the number of layers, etc.
Tricky Points
Find sound hyper-parameters is the main issue in Deep Learning: this can bedone thanks to a good understanding of the underlying structure of thedata and/or access to important computational power.
13/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
ASCAD Open Data-Base| Results|
Creation of an open database for Training and Testing
ANSSI recently publishes
source codes of secure implementations of AES128 for public 8-bitarchitectures (https://github.com/ANSSI-FR/secAES-ATmega8515)I first version: 10-masking + processing in random orderI second version: affine masking + processing in random order (plus other
minor tricks)
data-bases of electromagnetic leakages(https://github.com/ANSSI-FR/ASCAD)
example scripts for the training and testing of models in SCA contexts
Goal
Enable fair and easy benchmarking
Initiate discussions and exchanges on the application of DL to SCA
Create a community of contributors on this subject
14/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
ASCAD Open Data-Base| Results|
Comparisons with State-Of-the-Art Methods
15/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
ASCAD Open Data-Base| Results|
Feedbacks & Open Issues
Feedbacks
The number of epochs for the training is between 100 and 1000
Model architectures are relatively complex (more than 10 layers)
Data-bases for the training must be large
Require important processing capacities (several GPUs, RAM memory, etc.)
Importance of cross-validation
Open Issues
Models are trained to recover manipulated values (e.g. sbox outputs) but notthe key itself
Current loss functions measure the accuracy of pdf estimations but not theefficiency of the resulting attack
Adaptation to get (very) efficient key enumeration algorithms
16/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
ASCAD Open Data-Base| Results|
Feedbacks & Open Issues
Feedbacks
The number of epochs for the training is between 100 and 1000
Model architectures are relatively complex (more than 10 layers)
Data-bases for the training must be large
Require important processing capacities (several GPUs, RAM memory, etc.)
Importance of cross-validation
Open Issues
Models are trained to recover manipulated values (e.g. sbox outputs) but notthe key itself
Current loss functions measure the accuracy of pdf estimations but not theefficiency of the resulting attack
Adaptation to get (very) efficient key enumeration algorithms
16/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
ASCAD Open Data-Base| Results|
Feedbacks & Open Issues
Feedbacks
The number of epochs for the training is between 100 and 1000
Model architectures are relatively complex (more than 10 layers)
Data-bases for the training must be large
Require important processing capacities (several GPUs, RAM memory, etc.)
Importance of cross-validation
Open Issues
Models are trained to recover manipulated values (e.g. sbox outputs) but notthe key itself
Current loss functions measure the accuracy of pdf estimations but not theefficiency of the resulting attack
Adaptation to get (very) efficient key enumeration algorithms
16/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
ASCAD Open Data-Base| Results|
Feedbacks & Open Issues
Feedbacks
The number of epochs for the training is between 100 and 1000
Model architectures are relatively complex (more than 10 layers)
Data-bases for the training must be large
Require important processing capacities (several GPUs, RAM memory, etc.)
Importance of cross-validation
Open Issues
Models are trained to recover manipulated values (e.g. sbox outputs) but notthe key itself
Current loss functions measure the accuracy of pdf estimations but not theefficiency of the resulting attack
Adaptation to get (very) efficient key enumeration algorithms
16/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
ASCAD Open Data-Base| Results|
Feedbacks & Open Issues
Feedbacks
The number of epochs for the training is between 100 and 1000
Model architectures are relatively complex (more than 10 layers)
Data-bases for the training must be large
Require important processing capacities (several GPUs, RAM memory, etc.)
Importance of cross-validation
Open Issues
Models are trained to recover manipulated values (e.g. sbox outputs) but notthe key itself
Current loss functions measure the accuracy of pdf estimations but not theefficiency of the resulting attack
Adaptation to get (very) efficient key enumeration algorithms
16/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
ASCAD Open Data-Base| Results|
Feedbacks & Open Issues
Feedbacks
The number of epochs for the training is between 100 and 1000
Model architectures are relatively complex (more than 10 layers)
Data-bases for the training must be large
Require important processing capacities (several GPUs, RAM memory, etc.)
Importance of cross-validation
Open Issues
Models are trained to recover manipulated values (e.g. sbox outputs) but notthe key itself
Current loss functions measure the accuracy of pdf estimations but not theefficiency of the resulting attack
Adaptation to get (very) efficient key enumeration algorithms
16/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
ASCAD Open Data-Base| Results|
Feedbacks & Open Issues
Feedbacks
The number of epochs for the training is between 100 and 1000
Model architectures are relatively complex (more than 10 layers)
Data-bases for the training must be large
Require important processing capacities (several GPUs, RAM memory, etc.)
Importance of cross-validation
Open Issues
Models are trained to recover manipulated values (e.g. sbox outputs) but notthe key itself
Current loss functions measure the accuracy of pdf estimations but not theefficiency of the resulting attack
Adaptation to get (very) efficient key enumeration algorithms
16/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
ASCAD Open Data-Base| Results|
Feedbacks & Open Issues
Feedbacks
The number of epochs for the training is between 100 and 1000
Model architectures are relatively complex (more than 10 layers)
Data-bases for the training must be large
Require important processing capacities (several GPUs, RAM memory, etc.)
Importance of cross-validation
Open Issues
Models are trained to recover manipulated values (e.g. sbox outputs) but notthe key itself
Current loss functions measure the accuracy of pdf estimations but not theefficiency of the resulting attack
Adaptation to get (very) efficient key enumeration algorithms
16/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
ASCAD Open Data-Base| Results|
Feedbacks & Open Issues
Feedbacks
The number of epochs for the training is between 100 and 1000
Model architectures are relatively complex (more than 10 layers)
Data-bases for the training must be large
Require important processing capacities (several GPUs, RAM memory, etc.)
Importance of cross-validation
Open Issues
Models are trained to recover manipulated values (e.g. sbox outputs) but notthe key itself
Current loss functions measure the accuracy of pdf estimations but not theefficiency of the resulting attack
Adaptation to get (very) efficient key enumeration algorithms
16/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
ASCAD Open Data-Base| Results|
Feedbacks & Open Issues
Feedbacks
The number of epochs for the training is between 100 and 1000
Model architectures are relatively complex (more than 10 layers)
Data-bases for the training must be large
Require important processing capacities (several GPUs, RAM memory, etc.)
Importance of cross-validation
Open Issues
Models are trained to recover manipulated values (e.g. sbox outputs) but notthe key itself
Current loss functions measure the accuracy of pdf estimations but not theefficiency of the resulting attack
Adaptation to get (very) efficient key enumeration algorithms
16/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Recent Results|
Recent Results on DL for SCA Evaluation
DL for leakage identification after successful attack: HettwerGehrerGuneysu2019,
PerinEgeWoudenberg,MasureDumasProuff2019
Application to asymmetric cryptography running on defensive hardware:CarboneConinCornelieDassanceDufresneDumasProuffVenelli2019
Various studies to explain the behaviour of deep learning analysis (and/or toimprove it) in the context of side-channel attacks:PicekHeuserJovicBhasinRegazzoni19, KimPicekHeuserBhasinHanjalic19, etc.
17/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Recent Results|
Conclusions
State-of-the-Art Template Attack separates resynchronization/dimensionalityreduction from characterization
Deep Learning provides an integrated approach to directly extractinformation from rough data (no preprocessing)
Many recent results validate the practical interest of the Machine Learningapproach
We are in the very beginning and we are still discovering how much DeepLearning is efficient
New needs:I big data-bases for the training,I platforms to enable comparisons and benchmarking,I create an open community ”ML for Embedded Security Analysis”,I encourage exchanges with the Machine Learning community,I understand the efficiency of the current countermeasures
Thank You! Questions?
18/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Recent Results|
Conclusions
State-of-the-Art Template Attack separates resynchronization/dimensionalityreduction from characterization
Deep Learning provides an integrated approach to directly extractinformation from rough data (no preprocessing)
Many recent results validate the practical interest of the Machine Learningapproach
We are in the very beginning and we are still discovering how much DeepLearning is efficient
New needs:I big data-bases for the training,I platforms to enable comparisons and benchmarking,I create an open community ”ML for Embedded Security Analysis”,I encourage exchanges with the Machine Learning community,I understand the efficiency of the current countermeasures
Thank You! Questions?
18/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Recent Results|
Conclusions
State-of-the-Art Template Attack separates resynchronization/dimensionalityreduction from characterization
Deep Learning provides an integrated approach to directly extractinformation from rough data (no preprocessing)
Many recent results validate the practical interest of the Machine Learningapproach
We are in the very beginning and we are still discovering how much DeepLearning is efficient
New needs:I big data-bases for the training,I platforms to enable comparisons and benchmarking,I create an open community ”ML for Embedded Security Analysis”,I encourage exchanges with the Machine Learning community,I understand the efficiency of the current countermeasures
Thank You! Questions?
18/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Recent Results|
Conclusions
State-of-the-Art Template Attack separates resynchronization/dimensionalityreduction from characterization
Deep Learning provides an integrated approach to directly extractinformation from rough data (no preprocessing)
Many recent results validate the practical interest of the Machine Learningapproach
We are in the very beginning and we are still discovering how much DeepLearning is efficient
New needs:I big data-bases for the training,I platforms to enable comparisons and benchmarking,I create an open community ”ML for Embedded Security Analysis”,I encourage exchanges with the Machine Learning community,I understand the efficiency of the current countermeasures
Thank You! Questions?
18/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Recent Results|
Conclusions
State-of-the-Art Template Attack separates resynchronization/dimensionalityreduction from characterization
Deep Learning provides an integrated approach to directly extractinformation from rough data (no preprocessing)
Many recent results validate the practical interest of the Machine Learningapproach
We are in the very beginning and we are still discovering how much DeepLearning is efficient
New needs:I big data-bases for the training,I platforms to enable comparisons and benchmarking,I create an open community ”ML for Embedded Security Analysis”,I encourage exchanges with the Machine Learning community,I understand the efficiency of the current countermeasures
Thank You! Questions?
18/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018

Learning| Countermeasures| Machine Learning| Building a Community| Conclusions|
Recent Results|
Conclusions
State-of-the-Art Template Attack separates resynchronization/dimensionalityreduction from characterization
Deep Learning provides an integrated approach to directly extractinformation from rough data (no preprocessing)
Many recent results validate the practical interest of the Machine Learningapproach
We are in the very beginning and we are still discovering how much DeepLearning is efficient
New needs:I big data-bases for the training,I platforms to enable comparisons and benchmarking,I create an open community ”ML for Embedded Security Analysis”,I encourage exchanges with the Machine Learning community,I understand the efficiency of the current countermeasures
Thank You! Questions?18/18 Emmanuel PROUFF - ANSSI / Invited Talk PANDA 2018