Embed Size (px)
Citation preview

Deep Learningの前提知識
2017年11月16日

今回の内容
• Deep Learningについての前提知識の紹介。
• 細かい部分は、プロジェクトのページの輪読の資料を参考にする。
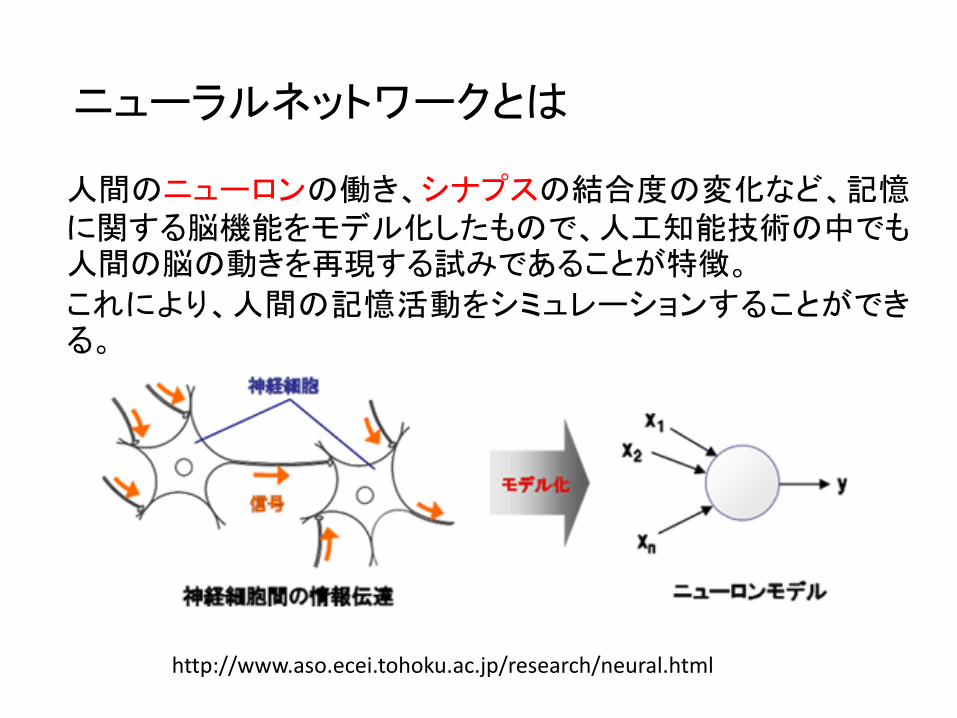
ニューラルネットワークとは
人間のニューロンの働き、シナプスの結合度の変化など、記憶に関する脳機能をモデル化したもので、人工知能技術の中でも人間の脳の動きを再現する試みであることが特徴。
これにより、人間の記憶活動をシミュレーションすることができる。
http://www.aso.ecei.tohoku.ac.jp/research/neural.html

ニューラルネットの活用例
多次元のデータから、認識問題、好み等の類推、パターン認識、行動制御、データマイニングなどが可能で、幅広い分野で使用することができる。最近流行りのDeep Learningもニューラルネットを発展させたものです。
https://wirelesswire.jp/2016/03/51084/
https://codeiq.jp/magazine/2015/09/28068/

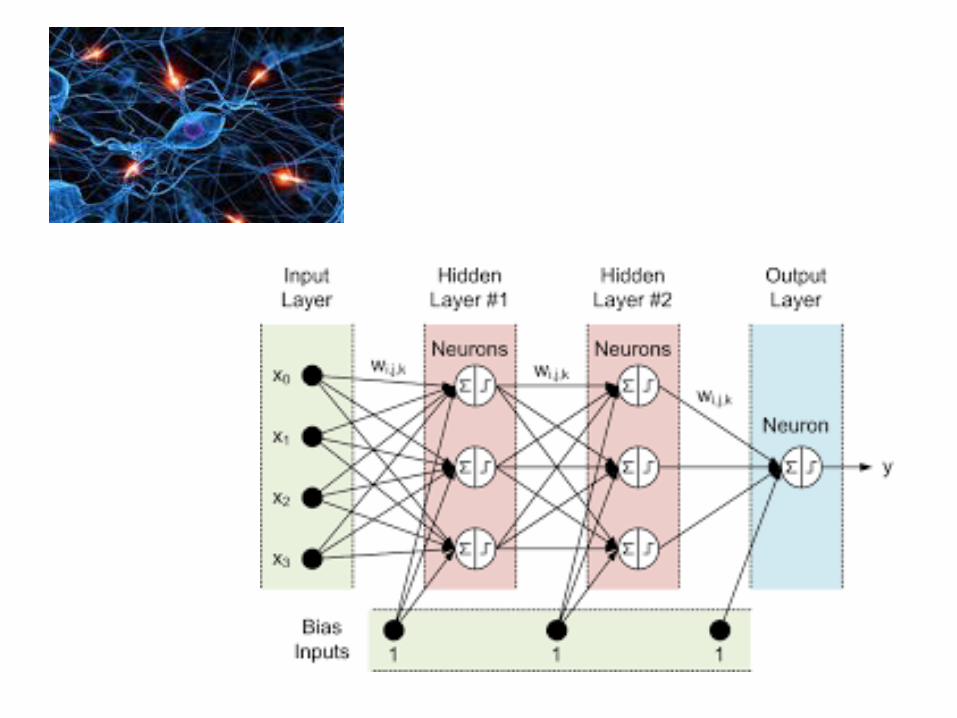
Deep Learningへの発展
• 従来のニューラルネットワークでは、層の数を多くすると学習が困難であった。しかし、誤差逆伝播法を使用することにより、層を多くしても学習が可能となった。
• 層を多くすると学習時間が長くなる問題点があったが、それは近年のコンピュータの発展やGPUにより解消できるようになった。
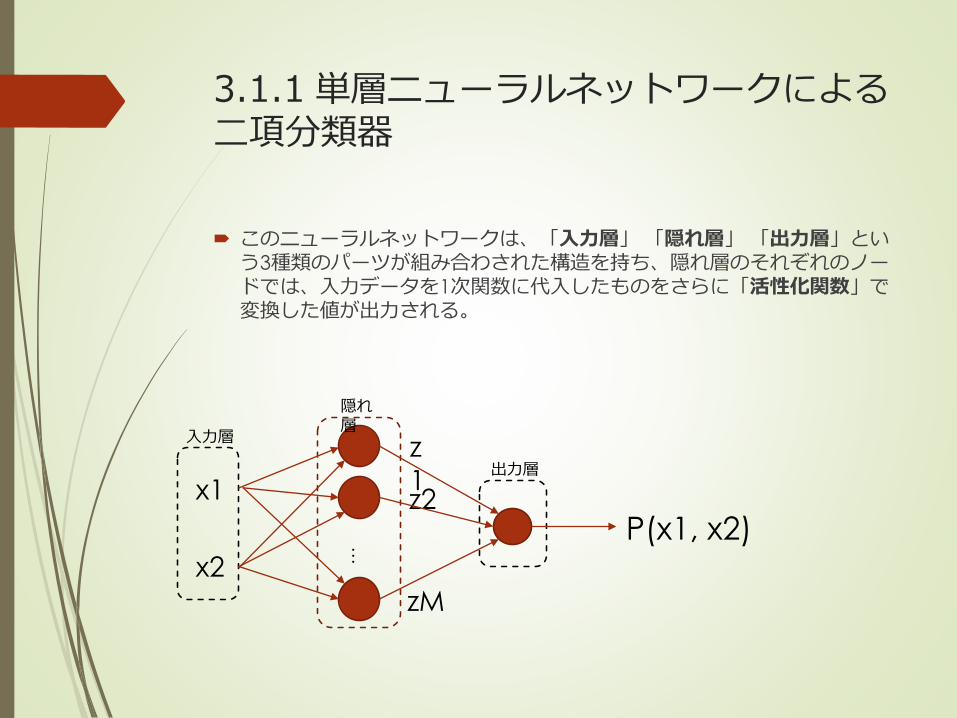
3.1.1 単層ニューラルネットワークによる二項分類器
このニューラルネットワークは、「入力層」 「隠れ層」 「出力層」という3種類のパーツが組み合わされた構造を持ち、隠れ層のそれぞれのノードでは、入力データを1次関数に代入したものをさらに「活性化関数」で変換した値が出力される。
x1
x2…
z
1z2
zM
入力層
隠れ層
出力層
P(x1, x2)

3.1.1 単層ニューラルネットワークによる二項分類器
具体的に言うと、隠れ層には全部でM個のノードがあるとして、それぞれの出力は、次の式で与えられる。
(活性化関数h(x)の中身については後述)
z1 = h(w11x1 + w21x2 + b1)
z2 = h(w12x1 + w22x2 + b2)
:
z1 = h(w1Mx1 + w2Mx2 + bM)

3.1.1 単層ニューラルネットワークによる二項分類器
さらに、最後の出力層では、これらの値を1次関数に代入したものをシグモイド関数で 0 ~ 1 の確率の値に変換する。
2つの値からなるデータ(x1, x2)が、隠れ層を通ることで、M個の値の
データ(z1, … , zM)に拡張されていると考えることができる。
z = σ(w1z1 + w2z2 + … + wMzM + b)

3.1.1 単層ニューラルネットワークによる二項分類器
今までは人間の脳を構成する神経細胞である「ニューロン」の反応を模式化したものを考えていたため、活性化関数にシグモイド関数を用いていた。
しかし今回は作成するのは機械学習のモデルであるから、現実のニューロンの動きを忠実に再現する必要はない。
よって実際の活性化関数としては、シグモイド関数の他に、ハイパボリックタンジェントtanh x や、ReLU(Rectified Linear Unit / 正規化線形関数)などの関数を適宜用いることになる。
本節では、理論的な分析が実施しやすいという理由から、主にハイパボリックタンジェントを用いた例で解説を進める。
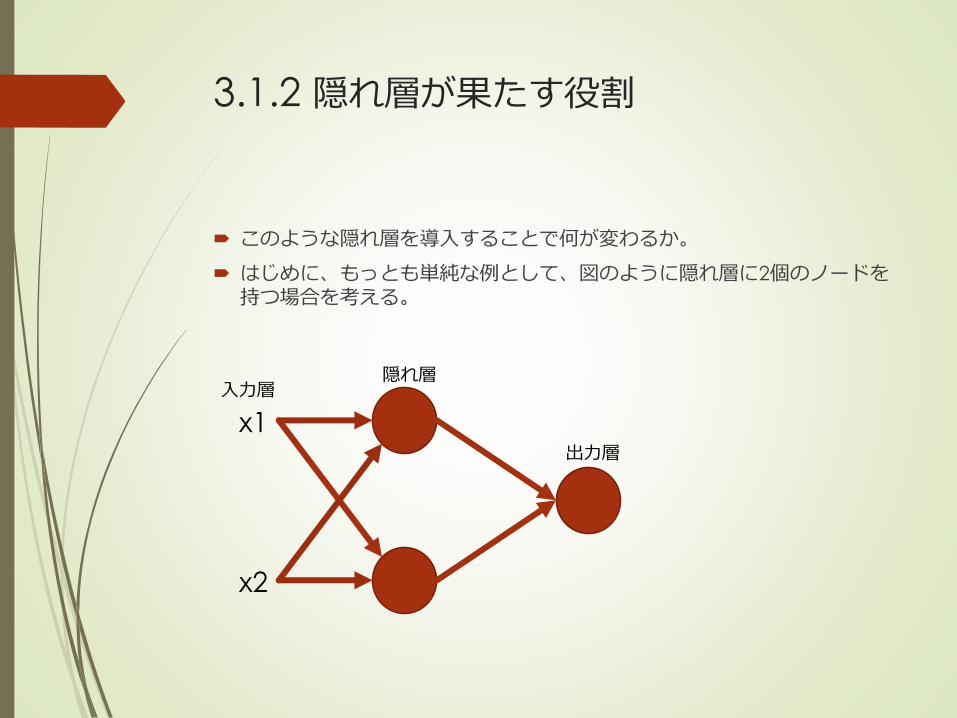
3.1.2 隠れ層が果たす役割
このような隠れ層を導入することで何が変わるか。
はじめに、もっとも単純な例として、図のように隠れ層に2個のノードを持つ場合を考える。
x1
x2
入力層隠れ層
出力層
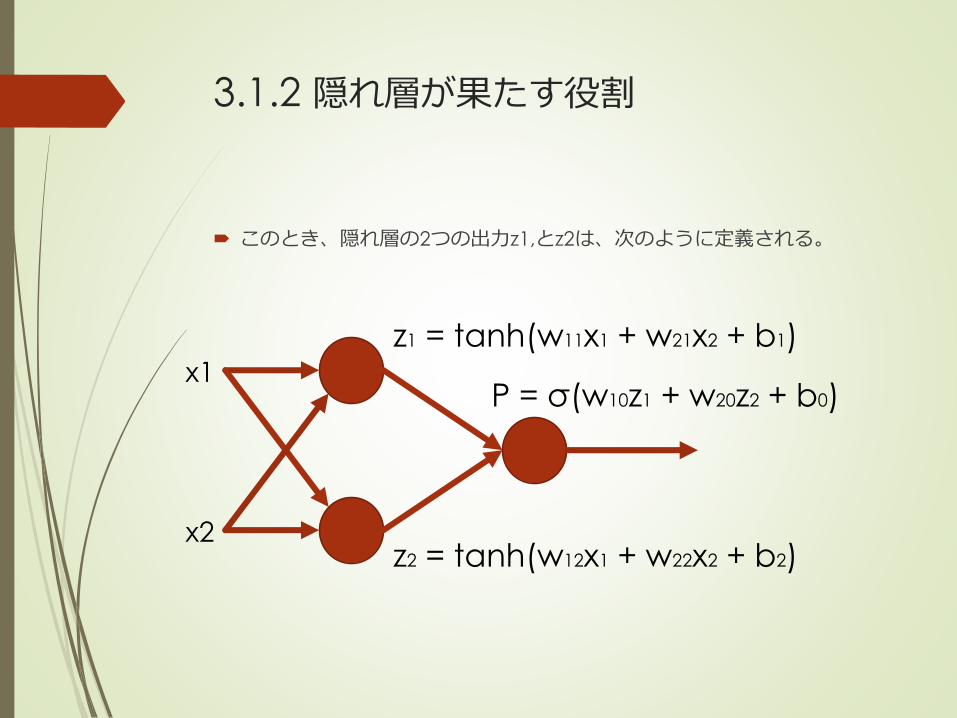
3.1.2 隠れ層が果たす役割
このとき、隠れ層の2つの出力z1,とz2は、次のように定義される。
x1
x2
z1 = tanh(w11x1 + w21x2 + b1)
z2 = tanh(w12x1 + w22x2 + b2)
P = σ(w10z1 + w20z2 + b0)
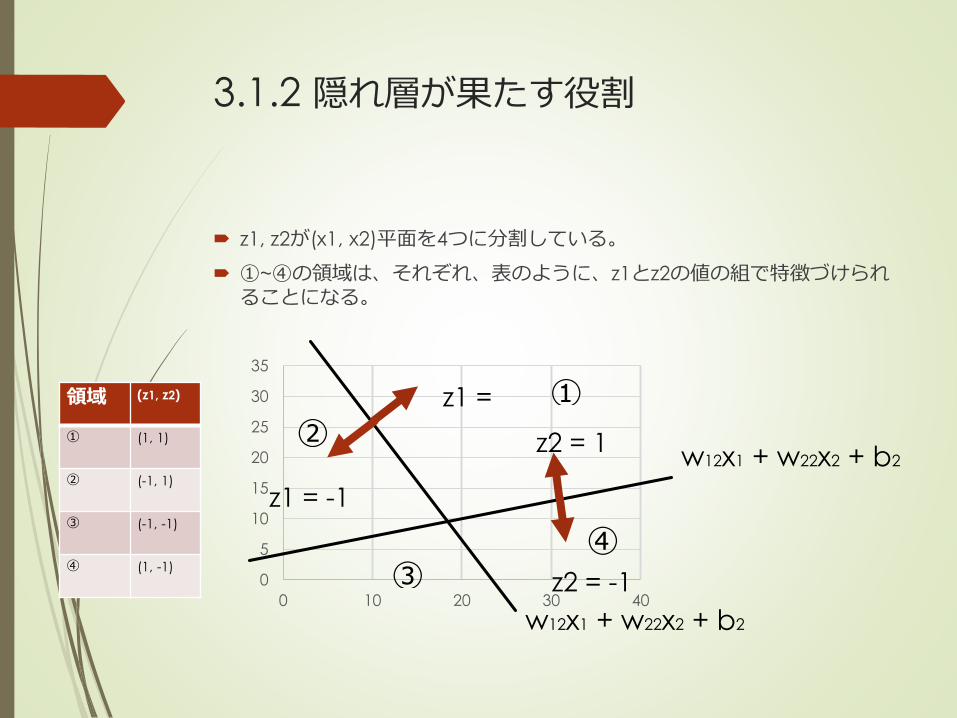
3.1.2 隠れ層が果たす役割
z1, z2が(x1, x2)平面を4つに分割している。
①~④の領域は、それぞれ、表のように、z1とz2の値の組で特徴づけられることになる。
0
5
10
15
20
25
30
35
0 10 20 30 40
z1 =
z2 = 1
z1 = -1
z2 = -1
①
②
③④
w12x1 + w22x2 + b2
w12x1 + w22x2 + b2
領域 (z1, z2)
① (1, 1)
② (-1, 1)
③ (-1, -1)
④ (1, -1)

3.1.2 隠れ層が果たす役割
このようにして決まった(z1, z2)の値を出力層のシグモイド関数に代入することで、最終的な確率Pの値が計算される。
具体的には以下の関係式になる。
P = σ(w10z1 + w20z2 + b0)

3.1.2 隠れ層が果たす役割
今回の場合、(z1, z2)は、前項図に示した4つの領域でそれぞれ決まった値を取るので、結局、4つの領域それぞれに異なる確率P(z1, z2)が割り当てられることになる。
隠れ層を持たない、出力層だけを用いたロジスティック回帰の場合は、(以前の発表で見たように)、(x1, x2)平面を直線で2つに分割する結果が得られた。今回はちょうどそれを4つの領域に拡張したような結果だ。
それでは、本当にこのような結果になるかどうか、TensorFlowのコードを用いて、次ページより確認してみる。

3.1.3 ノード数の変更と活性化関数の変更による効果
単層ニューラルネットワークにおいて、隠れ層のノード数を増やした場合と、活性化関数を変更した場合について考える
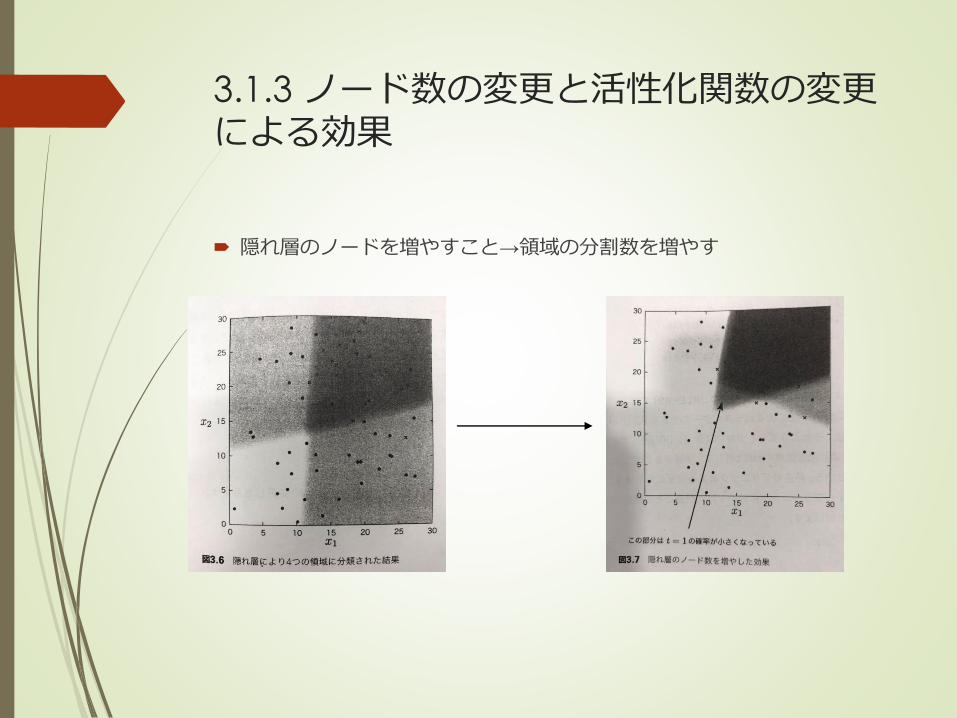
3.1.3 ノード数の変更と活性化関数の変更による効果
隠れ層のノードを増やすこと→領域の分割数を増やす
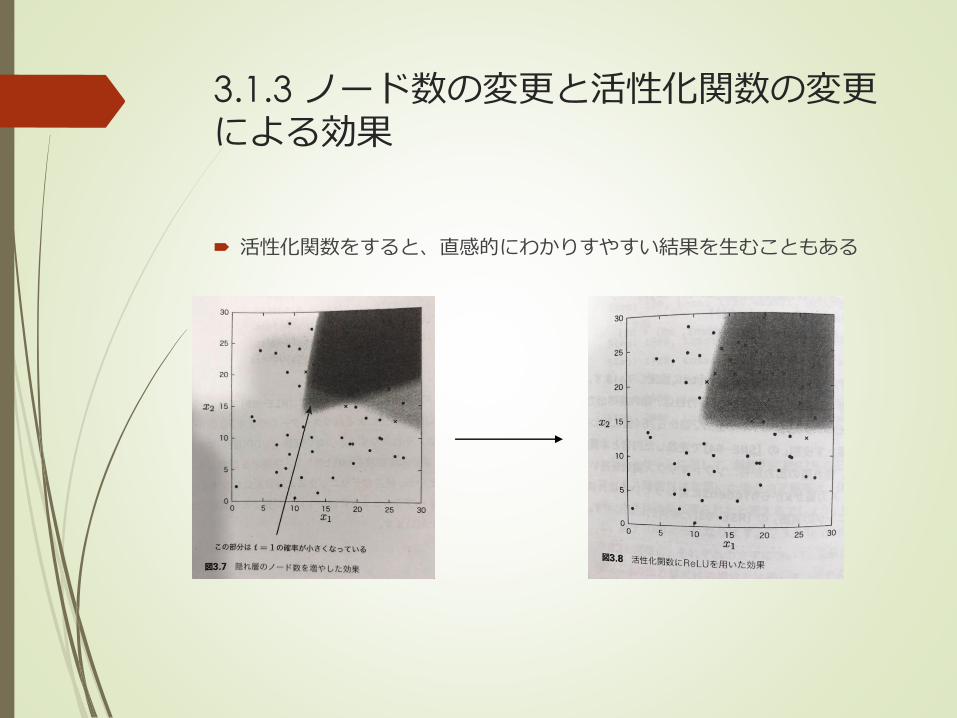
3.1.3 ノード数の変更と活性化関数の変更による効果
活性化関数をすると、直感的にわかりすやすい結果を生むこともある
4
ミニバッチと確率的勾配降下法 の おさらい
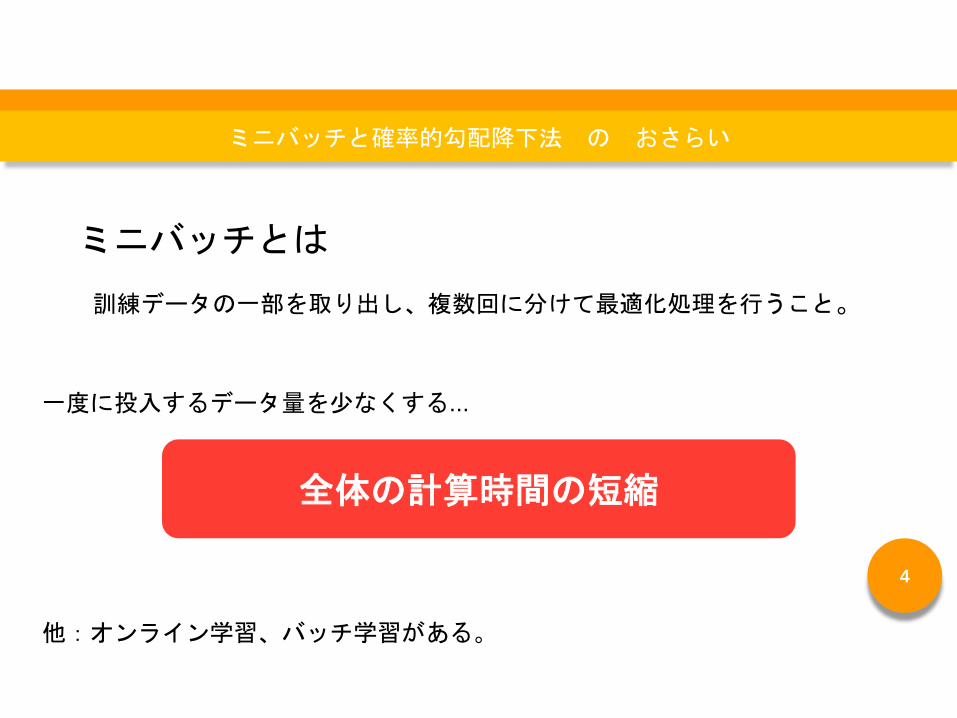
ミニバッチとは
訓練データの一部を取り出し、複数回に分けて最適化処理を行うこと。
全体の計算時間の短縮
一度に投入するデータ量を少なくする...
他:オンライン学習、バッチ学習がある。
5
ミニバッチと確率的勾配降下法 の おさらい
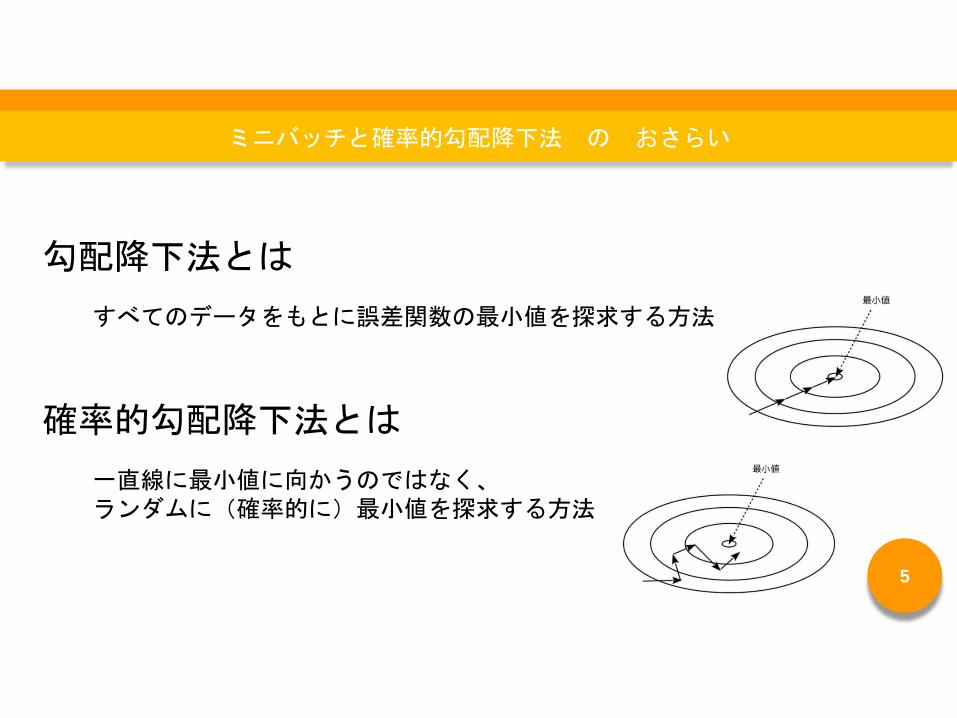
勾配降下法とは
すべてのデータをもとに誤差関数の最小値を探求する方法
確率的勾配降下法とは
一直線に最小値に向かうのではなく、ランダムに(確率的に)最小値を探求する方法

6
ミニバッチと確率的勾配降下法 の おさらい
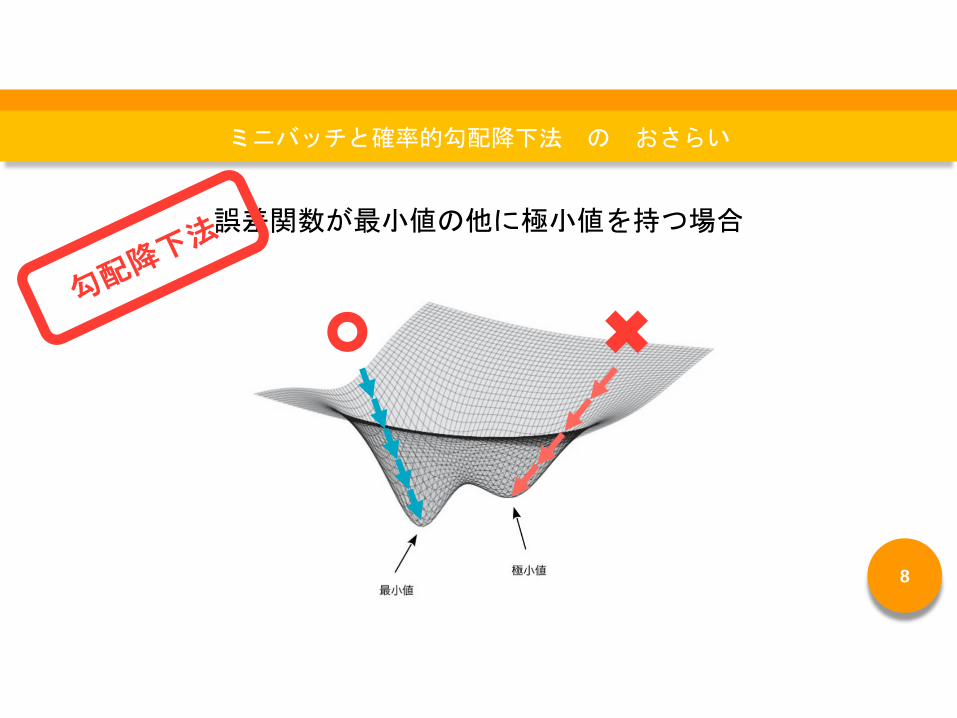
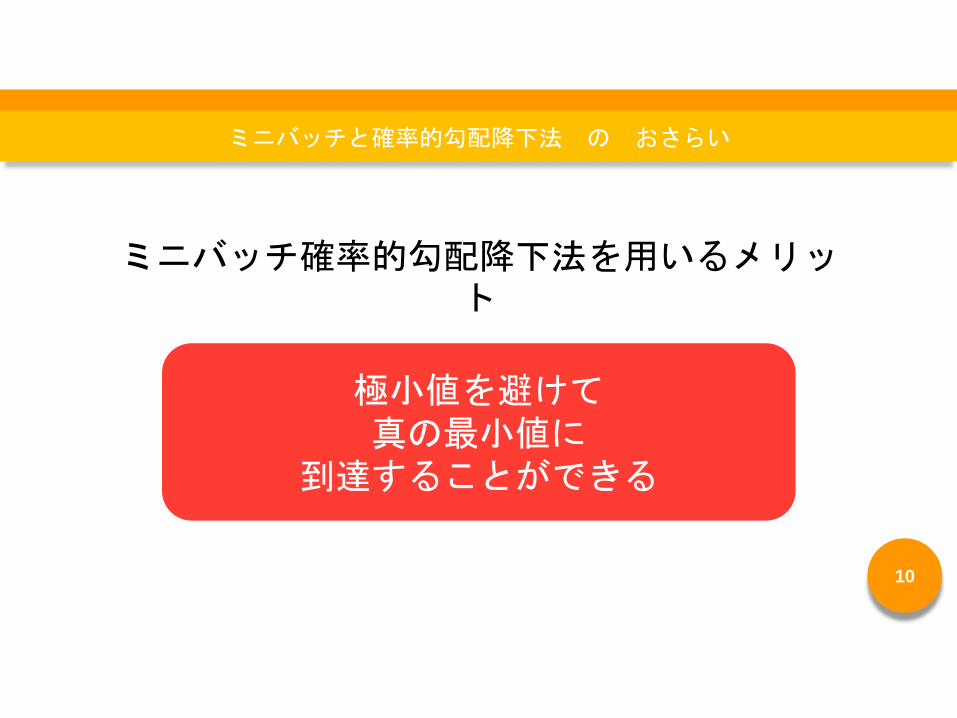
ミニバッチ確率的勾配降下法を用いるメリット
極小値を避けて真の最小値に
到達することができる
7
ミニバッチと確率的勾配降下法 の おさらい
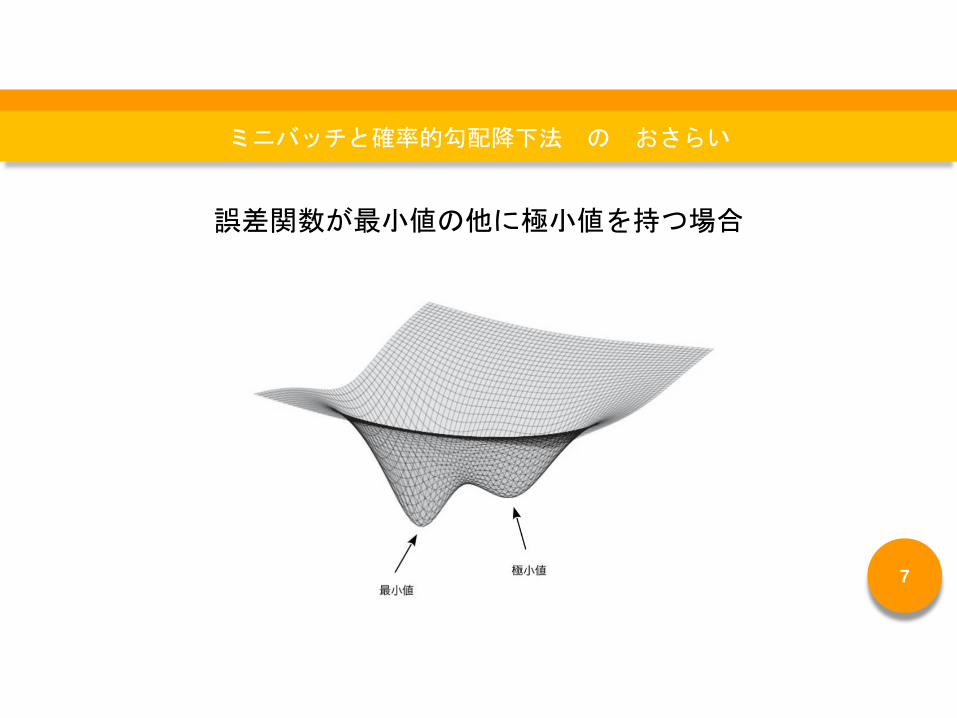
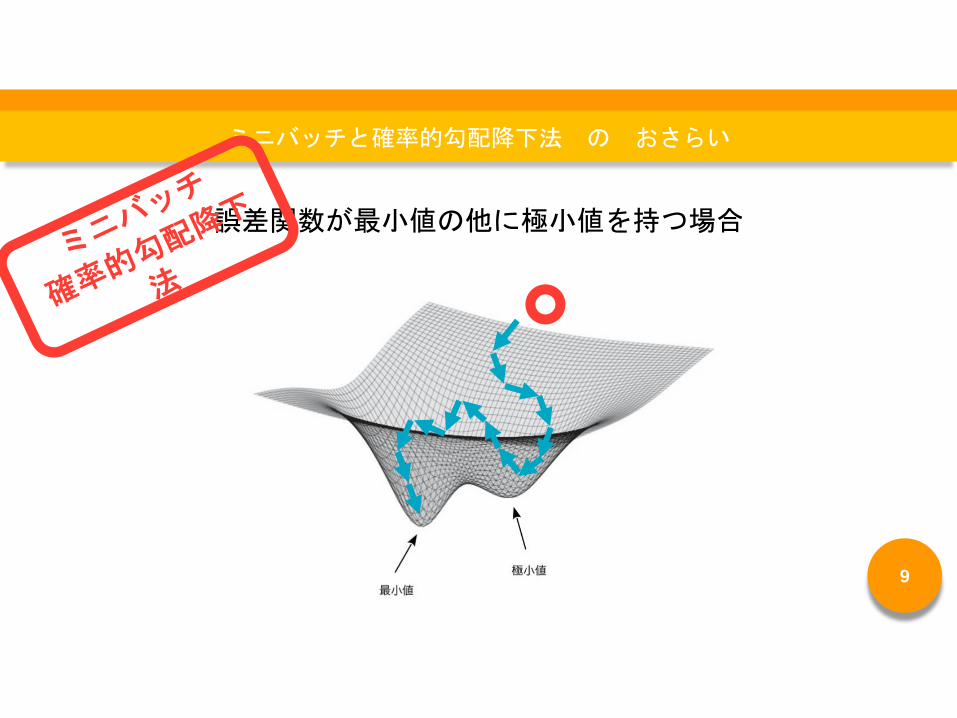
誤差関数が最小値の他に極小値を持つ場合
8
ミニバッチと確率的勾配降下法 の おさらい
誤差関数が最小値の他に極小値を持つ場合
9
ミニバッチと確率的勾配降下法 の おさらい
誤差関数が最小値の他に極小値を持つ場合
10
ミニバッチと確率的勾配降下法 の おさらい
ミニバッチ確率的勾配降下法を用いるメリット
極小値を避けて真の最小値に
到達することができる

11
第3章 3.3.3 補足:パラメータが極小値に収束する例
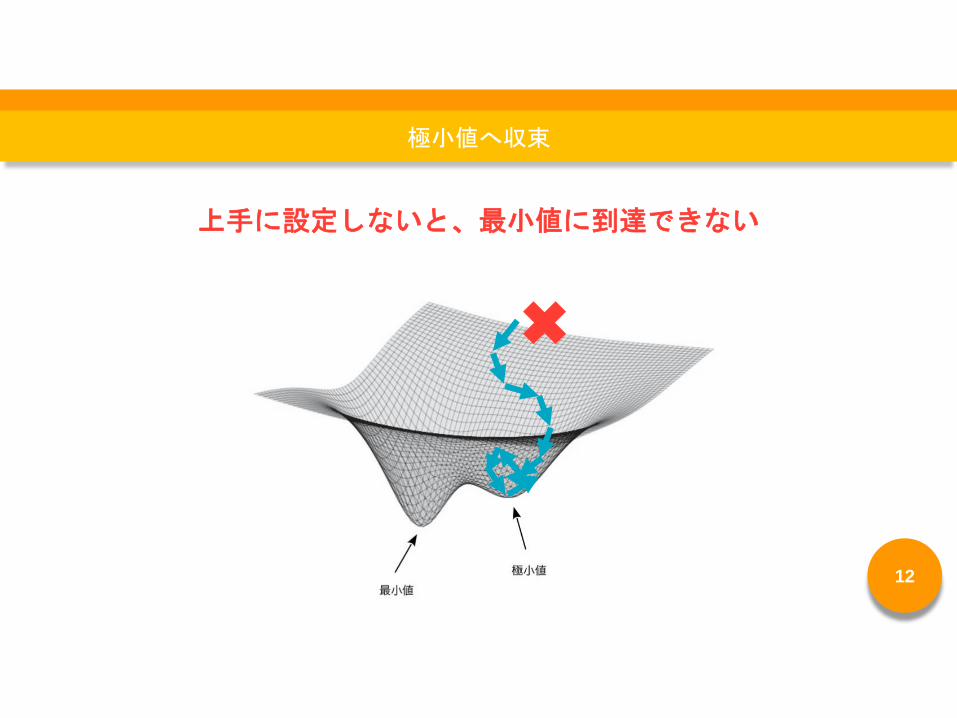
極小値へ収束
12
極小値へ収束
上手に設定しないと、最小値に到達できない

13
極小値へ収束
学習率

14
極小値へ収束
学習率とは
パラメータ更新の幅のこと。(パラメータをどのくらい動かすか)
(学習率) ≤ 1
15
極小値へ収束
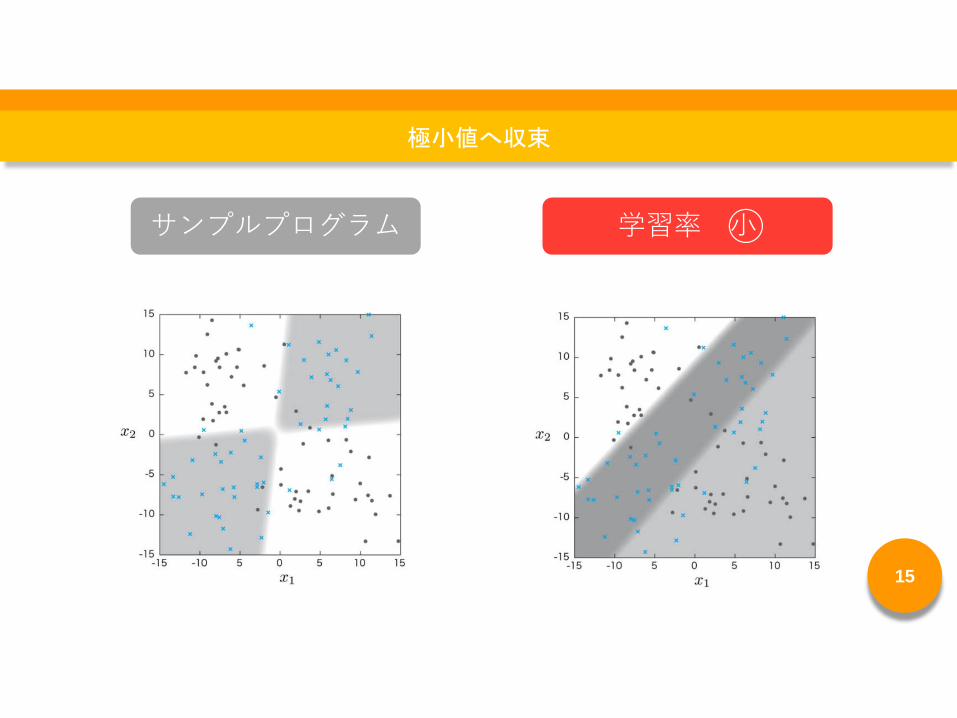
サンプルプログラム 学習率 小◯
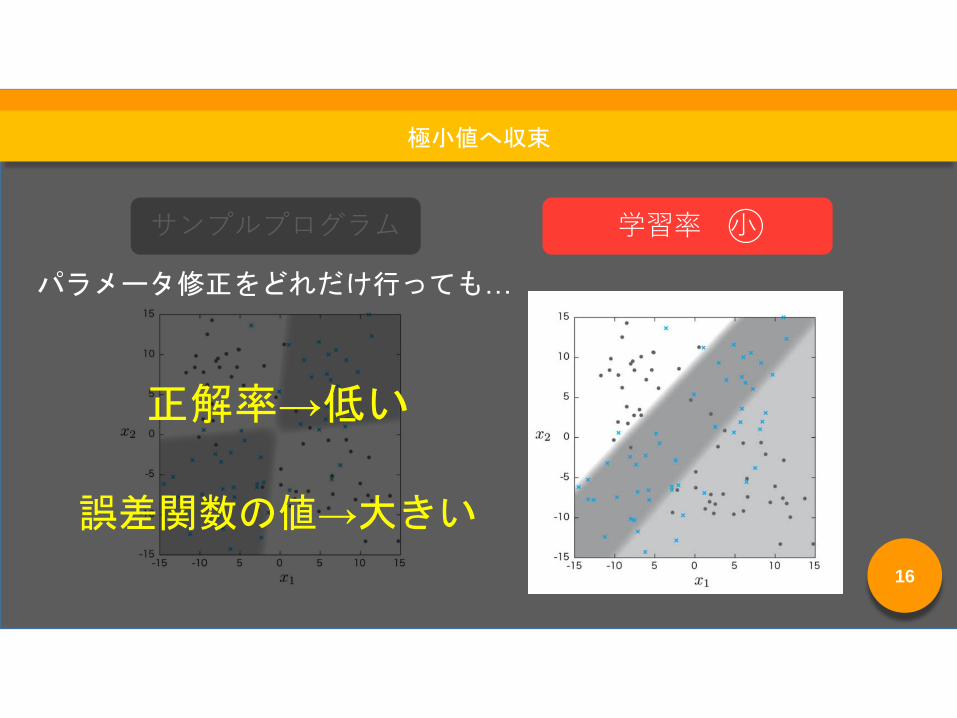
サンプルプログラム
16
極小値へ収束
学習率 小◯
正解率→低い
誤差関数の値→大きい
パラメータ修正をどれだけ行っても…
17
極小値へ収束
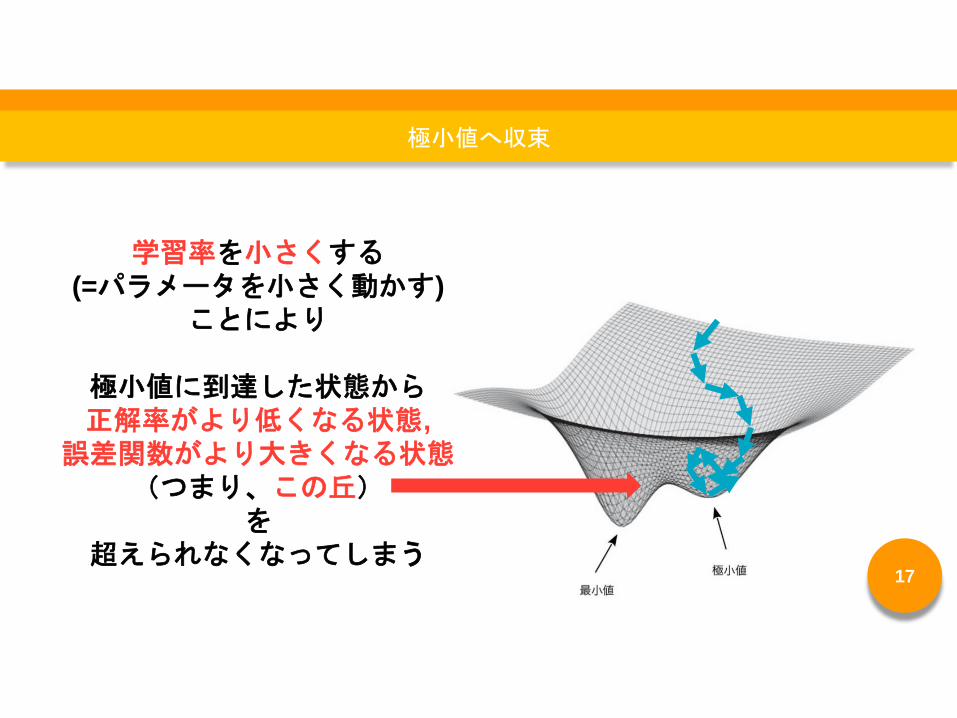
学習率を小さくする(=パラメータを小さく動かす)
ことにより
極小値に到達した状態から正解率がより低くなる状態,
誤差関数がより大きくなる状態(つまり、この丘)
を超えられなくなってしまう

19
まとめ
ミニバッチ確率的勾配降下法を使用すれば最小値へ到達できるかもしれない
大きすぎる→いつまで経っても収束しない小さすぎる→極小値から抜け出せない丁度いい →最小値に行くかも?
学習率が

オーバーフィッティング
先ほどのサンプルコードでは「正解率」の変化を確認し、約94%の正解率を達成している
しかし、機械学習においてトレーニングセットに対する正解率を計算することはあまり意味がない
むしろ、パラメーター最適化の結果に対して誤った理解を与える危険性がある
機械学習で重要なのは、未知のデータに対する予測の精度を上げることで
与えられたデータを正確に予測することではない
特に多数のパラメーターを含むモデルを使用する場合、トレーニングセットのデータだけが持つ
特徴に対して過剰な最適化が行われ、トレーニングセットに対する正解率は非常に高くても、
未知のデータに対する予測精度はよくないという結果になる → オーバーフィッティング(過学習)

テストセットの使用
オーバーフィッティングを避けるために、一部のデータをテスト用に取り分けておくことで、トレー
ニングに使用しないデータに対する正解率は、未知のデータに対する正解率に相当するものと
期待する
厳密には、現在手元にあるデータとこれから得られる未知のデータが同じ性質を持っているとい
う保証はないが、トレーニングセットそのものの正解率を見るよりは良い方法と考えられる
例として80%のデータでトレーニングを行いながら、残り20%のデータに対する正解率の変化を
見られるようにコードを修正する

L2正則化
• ユークリッド距離。
• 重みが発散しないようにする。

簡単な分類器のサンプル
• SVMについて少し触れてみる。
• プロジェクトページのサンプルを使ってみる。
• コードはここを参考にした。https://qiita.com/yasunori/items/8720c85e75b4679cae47

Deep Learningのサンプル
• サンプルの文字認識について触れてみる。
• Jupyterのノートブックのセルで以下のコマンドを打ち込む。
• !git clone https://github.com/enakai00/jupyter_tfbook
• これで手に入れた中で、Chapter3~4のものを動かしてみる。

多次元配列によるモデルの表現
• TensorFlowでは、計算に使用するデータは多次元配列として表現します。
• 例えば、n月の予測気温𝑦𝑛は行列を用いて以下のように表せます。
𝑦𝑛= 𝑛0, 𝑛1, 𝑛2, 𝑛3, 𝑛4
𝑤0
𝑤1
𝑤2
𝑤3
𝑤4

・12か月分のデータを1つの計算式にまとめると、𝑦 = 𝑋𝑤 (1.1)
𝑦 =
𝑦1
𝑦2
⋮𝑦11
𝑦12
, 𝑋 =
10 11
20
⋮120
21
121
12 13
22
122
23
123
14
24
124
, 𝑤 =
𝑤0
𝑤1
𝑤2
𝑤3
𝑤4
1.) Xはトレーニングセットとして与えられたデータから構成されます。このような変数を「Placeholder」と呼びます。2.) wはこれから最適化を実施するパラメータです。このような変数を「Variable」と呼びます。
パラメータの最適化を実施するには二乗誤差を求める必要があります。これは先程定義した予測値yと、トレーニングセットtから計算できます。次にtを定義していきます。

𝑡 =𝑡1𝑡2⋮𝑡12
n月の実際の平均気温を縦に並べたベクトルtを定義します。ここで、新しい演算を2つ定義します。どちらもTensorFlowを利用する際には関数として用意されていますが、まずはデータの関係を学んでいくために定義していきます。
ベクトル 𝑣 =𝑣1𝑣2⋮𝑣𝑁
に対して、
𝑠𝑞𝑢𝑎𝑟𝑒 𝑣 =
𝑣12
𝑣22
⋮𝑣𝑁2

𝑟𝑒𝑑𝑢𝑐𝑒_𝑠𝑢𝑚 𝑣 = 𝑖=1𝑁 𝑣𝑖
squareはベクトルの各成分を二乗し、reduce_sumはベクトルの各成分の和を計算します。これらの関数を用いて、二乗誤差は
𝐸 =1
2𝑟𝑒𝑑𝑢𝑐𝑒_𝑠𝑢𝑚 𝑠𝑞𝑢𝑎𝑟𝑒 𝑦 − 𝑡 (1.2)
と表せます。これで平均気温を予測する関数と、そこに含まれるパラメータを最適化する基準となる誤差関数を行列形式で表すことができました。ここからTensorFlowのコードに置き換えていきます。

TensorFlowのコードによる表現
• 今回は簡単化のため、定義式などをJupyterのノートブックに直接書き下していきます。

・まず始めに必要なモジュールをインポートしていきます。
import tensorflow as tfimport numpy as npimport matplotlib.pyplot as plt
数値計算ライブラリのNumPyと、グラフ描画ライブラリのmatplotlibをインポートします。

・(1.1)のXに相当する変数を定義する。Xは「Placeholder」と呼ばれるものと紹介しました。TensorFlowで定義されている
placeholderクラスを使います。
x = tf.placeholder(tf.float32, [None, 5])
1.) float32 … 行列の要素となる数値のデータ型を指定しています。(float32は32ビット浮動小数点)2.) [None, 5] … 行列のサイズを指定してします。(1.1)では12×5の行列でしたが、12という部分はユーザが使用するデータ数によって変わります。そういう場合、Noneと指定することによってプログラムが任意のデータ数を受け取ることができるようになります。

・(1.1)のwに相当する変数を定義する。
w = tf.Variable(tf.zeros([5,1]))
wは最適化の対象となる「Variable」に対応しています。なので、クラスVariableを使います。
1.) tf.zeros([5,1]) … 引数の部分で変数に初期値を与えています。この場合、すべての要素が0の5×1行列を生成しています。0以外の定数や、乱数を用いることも可能です。

・(1.1)の式を表してみる
y = tf.matmul(x, w)
tf.mutmulは、行列の掛け算を行う関数です。(1.1)をそのまま表現できていることがわかります。
この時点ではまだxに具体的な値が入っていません。実際の計算処理はこのあとやっていきます。

・誤差関数(1.2)を表現する。(1.2)の右辺には、先ほど表現したyに加えて、実際に観測された気温tが使われていま
す。これはXと同様に、「クラスplaceholder」を用います。
t = tf.placeholder(tf.float32, [None, 1])

・誤差関数を表現する(続き)ここまでで誤差関数に必要なものは定義してきたので、表現してみましょう。
loss = tf.reduce_sum(tf.square(y - t))
1.) tf.reduce_sumとtf.squareはそれぞれ先ほど勝手に定義した関数です。
2.) (1.2)では右辺の先頭に1
2がついていましたが、誤差関数が最小になるようにパラ
メータを設定するという意味では、先頭の1
2はあっても無くても変わらないので省略され
ています。

・二乗誤差を最小にするパラメータ次に、二乗誤差を最小にするパラメータを決定する処理を書いていきます。TesorFlow
では最適化を行うとき、勾配降下法によるパラメータ最適化のアルゴリズムを利用しています。まずは、最適化に使用するアルゴリズム(トレーニングアルゴリズム)を選択します。
train_step = tf.train.AdamOptimizer().minimize(loss)
1.) tf.train.AdamOptimizer()はTensorFlowが提供するトレーニングアルゴリズムの1つです。与えられたトレーニングセットのデータから誤差関数を計算して、その勾配ベクトルの反対方向にパラメータを修正します。
2.) 比較的性能が良いです。学習率εが自動的に調節されるため、ディープラーニングでよく利用される。3.) 一番後ろのminimize(loss)は、lossを誤差関数として、これを最小化するようになって
います。
学習率がよく分かるサイト : http://qiita.com/isaac-otao/items/6d44fdc0cfc8fed53657

・ここからここまでで機械学習を実行する準備が整いました。次から実際に、トレーニングアルゴリズムを実行して、誤差関数を最小にするパラメー
タの値を決定します。

・セッションによるトレーニングの実行TensorFlowではトレーニングアルゴリズムの実行環境となる「セッション」を用意して、
その中でパラメータ(Variable)に相当する変数の値を計算します。まずは新しいセッションを用意して、Variableを初期化します。
sess = tf.Session()sess.run(tf.initialize_all_variables())
1.) セッションを変数sessに格納しています。2.) tf.initialize_all_variable()でセッション内のVariableの値が初期化されます。3.)一般には複数のセッションを定義して、それぞれのセッションごとに計算することが
可能です。次のスライドで紹介します。
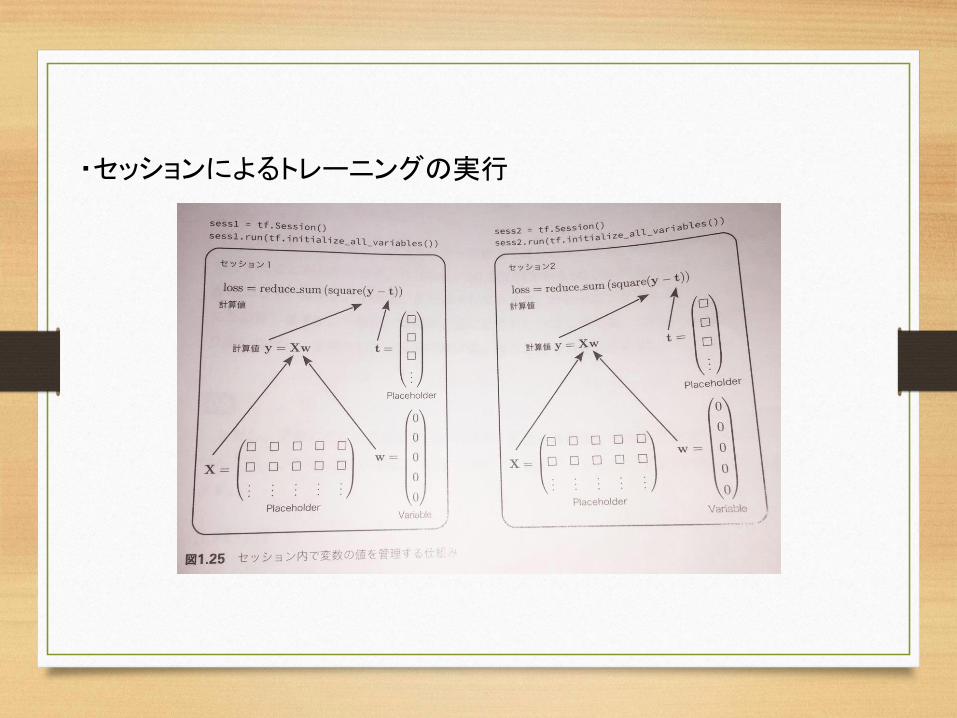
・セッションによるトレーニングの実行

・トレーニングアルゴリズムの実行トレーニングアルゴリズムの実行もセッション内で行います。この際、Placeholderにト
レーニングセットのデータを代入する必要があるので以下のデータを用意します。
1.) tとXをそれぞれ初期化しています。reshape()で12×1行列に直しています。Xはまず0で12×5行列に初期化したあと、値を代入しています。
train_t = np.array([5.2, 5.7, 8.6, 14.9, 18.2, 20.4, 25.5, 26.4, 22.8, 17.5, 11.1, 6.6])train_t = train_t.reshape([12,1])
train_x = np.zeros([12,5])for row, month in enumerate(range(1,13)):
for col, n in enumerate(range(0,5)):train_x[row][col] = month**n

・勾配降下法によるパラメータの最適化
1.)4行目:トレーニングアルゴリズムを実行することでVariable(ここではw)の値を修正しています。feed_dictでは、Placeholderに辞書形式で具体的な値をセットしています。
2.)6行目:セッション内で計算値lossを評価しており、その時点の値を取り出す効果があります。この場合、その時点でのVariableの値を用いて計算した結果を返しています。
実行結果を確認してみます。
i = 0for _ in range(100000):i += 1sess.run(train_step, feed_dict = {x:train_x, t:train_t})if i % = 10000 == 0:loss_val = sess.run(loss, feed_dict = {x:train_x, t:train_t})print(‘Step: %d, Loss: %f’ % (i, loss_val))

・実行結果
実行結果を見ると、パラメータ(w)の修正を繰り返すことで誤差関数が減少していることがわかります。
50000回目から60000回目増加していますが、このような変動を繰り返しながらも全体として、誤差関数が減少していきます
Step: 10000, Loss: 31.014391Step: 20000, Loss: 29.295158Step: 30000, Loss: 28.033054Step: 40000, Loss: 26.855808Step: 50000, Loss: 25.771938Step: 60000, Loss: 26.711918Step: 70000, Loss: 24.436256Step: 80000, Loss: 22.975143Step: 90000, Loss: 22.194229Step: 100000, Loss: 21.434664

・どこまで減少すれば十分か?
どこまでやればいいかを見極めるのは簡単ではないので、さらに100,000回繰り返してみると最後に値の増加が現れます。そこでトレーニングを打ち切り、パラメータの値を確認します。
1行目で、セッション内でVariable wを評価することで保持されている値を取り出しています。このときPlaceholderの値は影響しないので、feed_dictの指定はいりません。
wの値はNumPyのarrayオブジェクトとして取り出され、print文で表示すると行列形式に整形されて表示されます。
w_val = sess.run(w)print w_val

・予測気温の計算ここまでの結果を用いて、予測気温を次式で計算する関数を用意します。
𝑦 𝑥 = 𝑤0 +𝑤1𝑥 + 𝑤2𝑥2 + 𝑤3𝑥
3 +𝑤4𝑥4 =
𝑚=0
4
𝑤𝑚𝑥𝑚
def predict(x):result = 0.0for n in range(0,5):
result += w_val[n][0] * x**nreturn result
・この関数をグラフに表示する
1行目: 図形領域を示すオブジェクトを取得する2行目: その中にグラフを描く領域を取得(次で詳しく)3行目: x軸の表示範囲の設定(この場合、単位は月)4行目: トレーニングセットのデータを散布図にプロット
fig = plt.figure()subplot = fig.add_subplot(1,1,1)subplot.set_xlim(1,12)subplot.scatter(range(1,13), train_t)
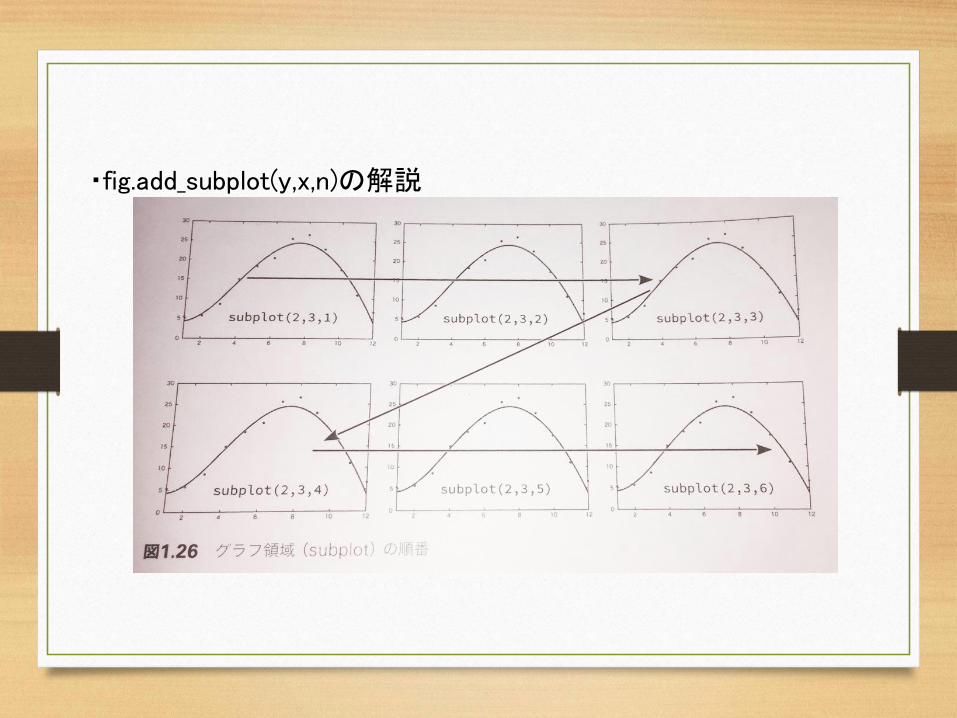
・fig.add_subplot(y,x,n)の解説

・関数をグラフに表示する(つづき)
1行目: np.linespace()は、1~12の範囲を等間隔に分けた100個の値のリストを返します。2行目: NumPyのarrayオブジェクトには、本来引数にスカラーを取る関数にarrayオブジェクト
を渡した場合、それぞれの要素を引数に渡した結果返ってきた値を格納したarrayオブジェクトを返してくれる、という性質があります(このような関数をユニバーサル関数と呼ぶ)。この場合、linexの各要素を引数に渡した結果が配列として返ってきます。
3行目: 一般的にpyplotモジュールでグラフを描画する場合は、「x軸方向のデータリスト」と「y軸方向のデータリスト」を引数として渡します。今回もそのようにしてグラフを描画しています。
linex = np.linspace(1,12,100)liney = predict(linex)subplot.plot(linex, liney)
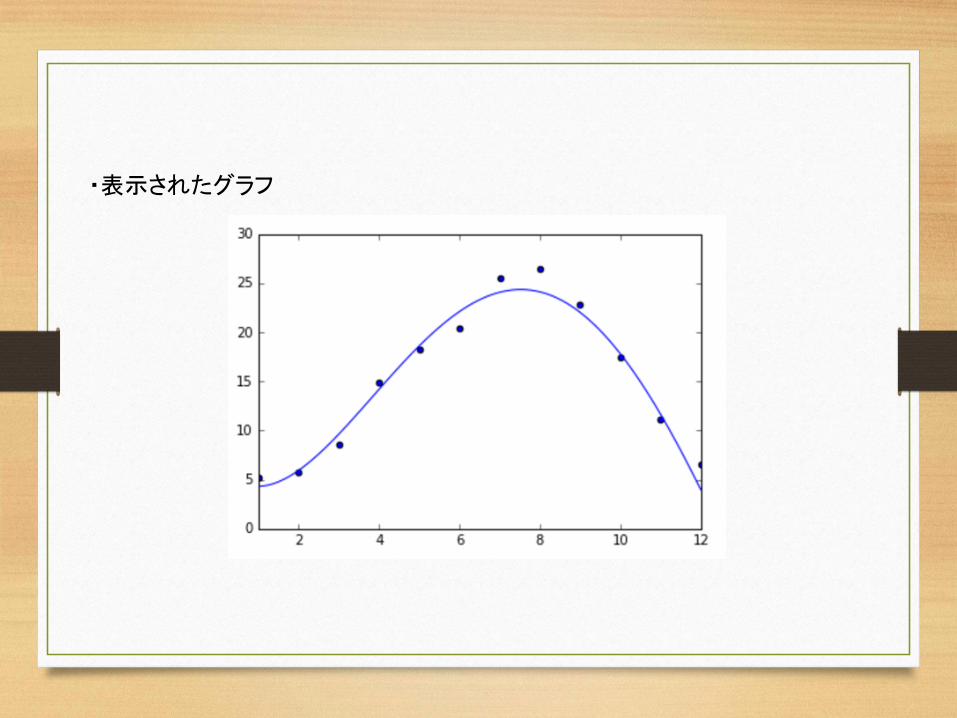
・表示されたグラフ

2.3.1 MNISTデータセットの利用方法
webで公開されているデータセットで、そこから上の手書き数字のサンプルを取り出すことができる。
TensorFlowにはMNISTのデータセットをダウンロードして、NumPyの配列として格納するモジュールが用意されている。
このデータセットのサンプルは全体として、トレーニング用の55,000個、テスト用の10,000個、検証用の5,000個のデータがある。
MNIST ……

2.3.1 MNISTデータセットの利用方法
MNISTのデータセットをダウンロードして、imagesには画像データの配列
を、labelsには画像が何の数字かを表す配列を格納している。それぞれ10個分の画像データを取り出している。

2.3.1 MNISTデータセットの利用方法
取り出した画像データ(グレースケール)の、28×28=784個のピクセルについて、それぞれの濃度を表す数値(0~1の浮動小数)を並べたNumPyの一次元配列になっている。画像は一部を取り出したもの。
上の例では、(先頭を0として)8番目の要素が1になっているので、画像が「8」の数字であることを示している。このような表し方を「1-of-Kベクトル」を用いたラベル付けと呼ぶ。

2.3.1 MNISTデータセットの利用方法
取り出した10個の画像を表示した。画像の上の数字はラベルから取得
した値で正解となる数字を表している。
崩した書き方の文字やノイズが混入した画像が含まれているのがわかる。これらの数字をラベル通りに判定することが目標となる。
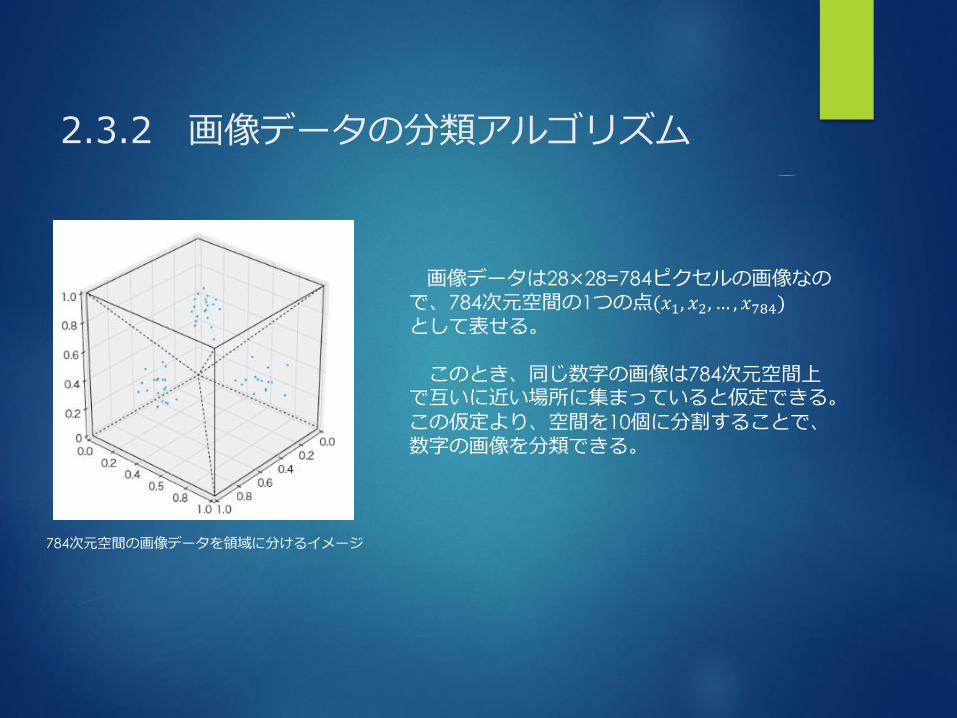
2.3.2 画像データの分類アルゴリズム
画像データは28×28=784ピクセルの画像なので、784次元空間の1つの点(𝑥1, 𝑥2, … , 𝑥784)として表せる。
このとき、同じ数字の画像は784次元空間上で互いに近い場所に集まっていると仮定できる。この仮定より、空間を10個に分割することで、数字の画像を分類できる。
784次元空間の画像データを領域に分けるイメージ

次回
• Deep Learning挑戦。





























