Embed Size (px)
Citation preview

Der Clusterkonfigurator
Die optimale Ausstattung definieren Die Leistung eines HPC-Clusters mathematisch zu beschreiben und vorherzusagen, ist bislang kaum versucht worden. Ein präziser Algorithmus würde die Optimierung im Alltag deutlich vereinfachen. Im Rahmen eines Forschungsprojekts wurden die hierfür notwendigen Grundlagen erarbeitet.
von Leonardo Lapeira, transtec AG

Der ClusterkonfiguratorLEONARDO LAPEIRAtranstec AG, Tübingen
Copyright 2003 - 2007©Dieses Werk ist geistiges Eigentum der transtec AG.www.transtec.de
Es darf ohne Zustimmung des Autors und der transtec AG weder kopiert noch auszugsweise abgedruckt oder in einer anderen Form vervielfältigt werden.
Alle in diesem Buch enthaltenen Informationen wurden mit größter Sorgfalt zusammengestellt. Dennoch können fehlerhafte Angaben nicht völlig ausgeschlossen werden. Die transtec AG und der Autor haften nicht für etwaige Fehler und deren Folgen.
Die in diesem Buch verwendeten Soft- und Hardwarebezeichnungen sind häufig eingetragene Warenzeichen. Sie werden in diesem Buch ohne Gewährleistung der freien Verwendbarkeit genutzt. Das Abdrucken von Waren- und Handelsnamen auf den folgenden Seiten berechtigt nicht zu der Annahme, diese Namen als frei im Sinne der Markenschutzgesetzgebung zu betrachten.
Autor: Leonardo LapeiraRedaktion: Dr. Andreas Koch, Bernd Zell, Johannes WiedmannGrafiken: Leonardo Lapeira, Johannes Wiedmann
- 2 -

Inhaltsverzeichnis
KAPITEL 1 - Einführung 5
KAPITEL 2 - Die Aufgabestellung 7
KAPITEL 3 - Erste theoretische Grundlagen 9
3.1Rechnerarchitekturen 9
3.1.1 SISD Rechner 9
3.1.2 MIMD Rechner 10
3.2SharedMemory–DistributedMemory 10
3.2.1 Shared Memory Systeme 10
3.2.2 Distributed Memory Systeme 11
3.3VerteilteRechensysteme 11
3.4DieClusterhardware 12
3.4.1 CPU 13
3.4.2 Die CPU Register 13
3.4.3 Level 1 – Cache oder First Level Cache 14
3.4.4 Level 2 – Cache oder Second Level Cache 14
3.4.5 RAM 14
3.4.6 Bus Mastering und Direct Memory Access (DMA) 14
3.4.7 Das Verbindungsnetzwerk 15
KAPITEL 4 - Performancebestimmung verteilter Rechensysteme 16
4.1Parallelisierungsgrad 16
4.2SpeedupundEffizienz 16
4.3Faktoren,diedenSpeedupaufApplikationsebenelimitieren 18
4.4DasGesetzvonAmdahl 18
4.5LatenzundBandbreite 20
4.6EineinfachesPerformancemodell 21
KAPITEL 5 - Performancebestimmung in der Praxis 23
5.1PerformancebestimmungnachderMethodedessequentiellenAnteils 23
5.2TheoretischePeakperformance 23
5.3RechenleistungbeieinerspezifischenApplikation 12
5.4Gesamtrechenzeit 24
5.5Effizienz 24
5.6DerLinpackBenchmark 24
5.7BestimmungderLatenzundBandbreiteeinzelnenKomponenten 25
5.7.1 nbench 25
5.7.2 Cachebench 26
5.7.3 ping / fping 28
5.7.4 bing 29
KAPITEL 6 - Bottlenecks 31
6.1SuperlineareSpeedups 31
6.2ApplikationseigenschaftenundHardwareBottlenecks 32
6.3DualCPUSysteme 33
6.4Netzwerkflaschenhals 34
6.5Input/Output 35
KAPITEL 7 - Mathematische Grundlagen zum Optimierungsverfahren 37
7.1LineareOptimierung 37
7.2Problemstellung 37
- 3 -

7.3GeometrischeDeutung:Maximum-undMinimum-OptimierungimR² 38
7.4DerSimplex-AlgorithmusunddieBildungdesSimplextableaus 39
7.5SchrittezurBerechnungdesSimplexes 41
7.6KünstlicheVariablen 80
KAPITEL 8 - Das Konfigurationsproblem 45
8.1DieDefinitioneinerZielfunktion 45
8.2DieRandbedingungen 46
8.3ProblemabhängigeRandbedingungen:EineBeispielkonfiguration. 49
8.4DerClusterkonfigurator 51
8.5EineBeispielberechnungmitHilfedesClusterkonfigurators 55
KAPITEL 9 - Schlussfolgerungen und Ausblick 62
Anhang A: Einrichtung eines Linux-Clusters 64
A.1Hardware 64
A.2Systemsoftware 64
A.2.1 Der Masterknoten: Betriebssysteminstallation 65
A.2.1.1 Namensauflösung 67
A.2.1.2 PXE fähiges DHCP 68
A.2.1.3 TFTP Server 69
A.2.1.4 NIS (Network Information Service) 69
A.2.1.5 NFS (Network File System) 71
A.2.1.6 rsh/ssh 72
A.2.1.7 Zeitausgleich durch einen XNTP Server 73
A.2.1.8 Batch Queuing System 74
A.2.1.9 Automatisierung durch Skripte 77
A.2.1.10 Sicherheitsaspekte 78
- 4 -

KAPITEL 1 - Einführung
Supercomputer kommen zum Einsatz wenn es um die Simulation realer Vorgänge geht, deren hohe Komplexität die Nutzung von herkömmlichen Rechenarchitekturen unmöglich macht. Oft sind diese Simulationen selbst auf den modernsten Einzelprozessorre-chenanlagen nicht innerhalb einer befriedigenden Zeitspanne zu bewältigen. Hat man zufällig mit Berechnungen zu tun, die we-gen einer sehr feinen Diskretisierung mit sehr großen Datenmengen arbeiten müssen, so ist die Ausführung der Simulation sogar auf der schnellsten Einprozessormaschine nicht mehr möglich. Die technisch maximal einsetzbare Speichergröße auf Einzelprozes-sormaschinen stellt hierbei eine unüberwindbare Hürde dar.
Supercomputer stellen praktisch ohne Ausnahme den einzigen Weg zur Verbesserung unseres Verständnisses über die Funktions-weise vielschichtiger Systeme dar. In der Tat ist für fast jeden Forscher, der sich mit solchen Aufgaben beschäftigt, ein Supercom-puter das ideale Werkzeug wertvolle Erkenntnisse so schnell wie möglich zu erhalten. Die Problemstellungen, die nach Rechen-power auf Supercomputerniveau verlangen, erstrecken sich somit von der Hochenergiephysik bis hin zur Erstellung von „Special Effects“ für Kinofilme. Wenn man noch dazu betrachtet, dass Wirtschaft und Industrie ebenfalls sinnvolle Nutzungsmöglichkeiten für solche Systeme gefunden haben, kann man durchaus verstehen, warum High Performance Computing ein aktuelles Thema bleibt.
So beliebt wie High Performance Computing (HPC) in den verschiedenen akademischen und industriellen Kreisen auch ist, bleibt die Anschaffung eines Supercomputers meistens aus. Die finanziellen Mittel die zur Verfügung stehen reichen nur selten, den hohen Preis eines solchen Systems begleichen zu können. Diese hohen Kosten waren eben einer der wichtigsten Gründe, warum Anfang der 90er Jahre Thomas Sterling und Don Backer, damalige Mitarbeiter einer Forschungsgruppe bei der amerikanischen Luft- und Raumfahrt Behörde (NASA) sich mit der Entwicklung von Rechenarchitekturen beschäftigten, die deutlich kostengünsti-ger werden sollten als es das traditionelle Supercomputing bis dato war.
Das Ergebnis, eine Ansammlung von 16 Prozessoren des Typs Intel 80486, welche über channel bonding1) Ethernet miteinander kommunizierten und unter dem Namen Beowulf2) im Sommer 1994 bekannt gegeben wurde. Die Sache war von Anfang an ein Erfolg. Sofort wurden in zahlreichen Universitäten überall auf der Welt ähnliche Systeme gebaut. Diese gewannen dermaßen an Bedeutung, dass schließlich auch die Industrie darauf aufmerksam wurde und für den eigenen Bedarf ähnliche Systeme einsetzte. Beowulf-Cluster oder auch Computing Cluster (die Bezeichnung Beowulf ist seitdem etwas in Vergessenheit geraten) stellen also die wirtschaftlichste Realisierung eines Supercomputers dar. Cluster sind im Prinzip Ansammlungen von Computern, deren Hard-warekomponenten größtenteils aus handelsüblichen PC-Komponenten bestehen und durch eine bestimmte Netzwerktechnologie miteinander kommunizieren. Hinzu kommt eine besondere Softwarekonfiguration, die diese vernetzten Maschinen aus der Sicht des Anwenders wie ein einziges und einheitliches System erscheinen lassen.
Durch die steigende Nachfrage an Rechenleistung in Form von Clustern ist ein Markt entstanden, in welchem nun auch großen Fir-men wie Sun, SGI, HP, IBM, etc. Platz gefunden haben. Die meisten Anbieter konzentrierten sich auf die Entwicklung von adminis-trativen Softwarewerkzeugen, die dem Anwender die Arbeit mit dem System erleichtern sollen. Es gibt also zahlreiche Clustertools, auch wenn diese in den meisten Fällen nur zusammen mit der entsprechenden hauseigenen Hardware bzw. dem Betriebsystem richtig arbeiten und/oder deren Nutzung durch Software-Lizenzen geregelt wird.
Was für uns auffällig war ist die absolute Abwesenheit von Studien, Softwaretools o. ä., die sich mit den Möglichkeiten auseinan-dersetzen, solche HPC-Systeme noch wirtschaftlicher zu machen. Cluster stellen sicherlich die billigste Hochleistungscomputerar-chitektur dar, die man zurzeit kaufen kann. Dies heißt aber noch lange nicht, dass sie schon alle ihre Vorteile ausgespielt hat.
Das Hauptziel des hier vorgestellten Projekts ist es deswegen, mit Hilfe wissenschaftlicher Methoden die Durchführung einer genauen Analyse. Falls realisierbar, soll ein Softwaretool entwickelt werden, ein so genannter Clusterkonfigurator, welcher uns in die Lage versetzen soll, maßgeschneiderte Hardwarekonfigurationen solcher Cluster sowohl für unseren Kunden als auch für unser Unternehmen wirtschaftlicher zu gestalten. Wirtschaftlich heißt also, dass durch die Ergebnisse des Clusterkonfigurators eine Anzahl von Aussagen getroffen werden soll, die sowohl unsere Angebotserstellung als auch die Kaufentscheidung des Kunden optimal beeinflussen sollte.
In diesem Sinne wird es notwendig sein, zuerst die Aufgabestellung so genau wie möglich zu definieren. Erst dann werden wir den entsprechenden theoretischen und praktischen Rahmen aufbauen können, in dem wir uns zu der gewünschten Lösung, dem Clusterkonfigurator, bewegen werden.
Viele haben mir in der einen oder anderen Weise geholfen, diese Arbeit fertig zu schreiben; ihnen allen schulde ich Dank. Insbe-
1) Der Begriff channel bonding bezeichnet eine besondere Netzwerkkonfiguration, in der zwei oder mehrere Netzwerkkarten zu einem einzigen Kommu-nikationskanal gebündelt werden. Während sich für den Benutzer nichts an der Funktionalität des Netzes ändert, steigert sich jedoch die Netzwerkperfor-mance durch das additive Verhalten des Datendurchsatzes.
2) Beowulf, eine epische Erzählung über die Abenteuer eines großen skandinavischen Kriegers aus dem sechsten Jahrhundert, wurde in einer alten Form der englischen Sprache aus der zehnten Jahrhundert geschrieben. Dass die Maschine von Sterling und Becker mit diesem Namen benannt wurde, hat eher mit den literarischen Vorlieben der Architekturdesigner zu tun.
- 5 -

sondere möchte ich Herrn Dpl. Phys. Martin Konold wegen seiner wertvollen Beiträge und Anregungen erwähnen; diese haben die Entwicklung des Projektes maßgeblich beeinflusst. Andere Leute haben verschiedene Teilabschnitte früherer Textversionen durch-gelesen und zahlreiche hilfreiche Verbesserungsvorschläge gemacht: Herrn Dr. Andreas Koch, Herrn Bernd Zell und Herrn Johannes Wiedmann. Herrn Wiedmann möchte ich auch für seine Hilfe in Sachen JavaScript und wegen der Verbesserung mehrerer Bilder meinen Dank aussprechen.
- 6 -

KAPITEL 2 - Die Aufgabenstellung
Die Leistung traditioneller Supercomputer basiert auf stark spezialisierten Hardwarekomponenten. Die meist an die vorgegebene Aufgabe angepassten Recheneinheiten greifen auf einen gemeinsamen Speicherbestand zu. Die Interkommunikation zwischen den verschiedenen Systemkomponenten erfolgt über Kommunikationskanäle, deren Architektur vom Maschinenhersteller selbst entworfen wurde. Der größte Vorteil eines Clustersystems gegenüber anderen Supercomputerklassen ist ein deutlich besseres Preisleistungsverhältnis. Dieses wird, wie oben bereits erwähnt, insbesondere durch den Einsatz von handelsüblichen Hardware-komponenten erreicht. Jedes Mal wenn die Leistung einer im Clusterbau eingesetzten PC-Komponente steigt und/oder deren Preis sinkt, sind wir in der Lage ein besseres System anzubieten.
So viel Flexibilität und relative Simplizität auf der Hardwareebene hat jedoch ihren Preis. Wir werden etwas später deutlich er-kennen können, warum sich die Supercomputerklasse zu der Computercluster gehören, als einfach zu bauen aber schwierig zu programmieren charakterisieren lässt. Damit ist gemeint, dass eine gute Portion an Optimierungsmöglichkeiten in der Codeopti-mierung liegt und somit letztendlich beim Anwender. Das Grundprinzip der Clusterarchitektur, die zum Erfolg des Modells führt, entpuppt sich somit für uns ebenfalls als wichtiges Hindernis für ein einfaches Erreichen der optimalen Clusterkonfiguration. Denn genau der Aspekt der Softwareoptimierung ist der Teil, auf den wir am wenigsten Einfluss nehmen können.
Wir sind uns gleich von vorneherein darüber im Klaren, dass eine theoretische Lösung für das Problem der Optimierung einer Clusterkonfiguration das Thema für eine Dissertation im Fachgebiet der Informatik werden kann. Die Umsetzung lässt sich beliebig kompliziert gestalten. Damit wir auf konkrete Ergebnisse überhaupt kommen, müssen wir unsere Ziele entsprechend beschränken.
Aus dem Grund verstehen wir unsere Aufgabe als die methodische Suche nach einer möglichen Lösung für folgendes Problem: Wie kann man die höchste Performance für eine möglichst breite Palette von rechenleistungshungrigen Anwendungen erzielen, bei einer innerhalb einer gegebenen Zeitspanne der im PC-Bereich zur Verfügung stehenden Hardware und einem meist vom Kun-den fest vorgegebenen Budget? Wir werden im Laufe der vorliegenden Arbeit dieses Problem als Konfigurationsproblem bezeich-nen, auch wenn wir es später ein wenig anders formulieren werden.
Als erster allgemeiner Lösungsansatz für das Konfigurationsproblem wollen wir folgenden Weg einschlagen: Wir werden erstmals versuchen die wichtigsten Merkmale zu erkennen, die für die Beschreibung eines Clusters nach dem Supercomputermodell gelten. Wir sind der Überzeugung, dass aus diesem Prozess sich ausreichend grundlegende Erkenntnisse gewinnen lassen, die später durch eine geeignete Interpretation in Form eines mathematischen Modells festgehalten werden können. Die Lösung des in dem Modell implizit enthaltenen mathematischen Problems werden wir anschließend als Ergebnis des Clusterkonfigurators darstellen. Auf diese Weise wird der Clusterkonfigurator als Referenzpunkt im Bezug auf die Zusammenstellung einer optimalen Clusterkonfi-guration und das entsprechende optimale Kundenangebot dienen.
Um die Übersichtlichkeit der Darstellung so effektiv wie möglich zu gestalten, haben wir dieses Dokument in sieben weitere Kapitel gegliedert: Im Kapitel 3 setzen wir uns mit den ersten nötigen theoretischen Grundlagen auseinander, die wir für die Definition und Entwicklung unseres mathematischen Modells für nötig halten. Wir beschreiben zuerst einige parallele Architekturen. Insbe-sondere betrachten wir das Modell, welches die theoretische Informatik für die sog. Distributed Memory Computer standardmäßig definiert (Cluster gehören eindeutig zu dieser Supercomputerklasse). Zum Abschluss dieses Kapitels betrachten wir kurz die Hard-warekomponenten, die diesen Architekturtyp eindeutig charakterisieren.
Kapitel 4 beschäftigt sich mit grundlegenden Begriffen, die ebenfalls aus der theoretischen Informatik stammen (Speedup, Effizi-enz, Amdahl’sches Gesetz, usw.), so dass wir erstmals über eine Quantifizierung der Systemleistung sprechen können. Mit Hilfe zweier grundlegender Kennzahlen, nämlich der Latenz und der Bandbreite, wird ein Performancemodell aufgestellt, das für den Rest des Weges als Referenz für die Bestimmung der Clusterperformance gelten soll.
In Kapitel 5 behandeln wir einige Standardmethoden zur praktischen Bestimmung der Rechenleistung eines Clusters. Dabei wer-den Methoden betrachtet, die es uns erlauben die gesamte Performance eines Clusters zu ermitteln. Wir werden jedoch einige weitere Benchmarks betrachten, die uns Informationen über die Leistung spezifischer Hardwarekomponenten liefern können. Wir versuchen dadurch unser Clustermodell zu verfeinern und weitere Aspekte des Konfigurationsproblems besser zu verstehen.
Mit Bottlenecks beschäftigt sich Kapitel 6. Dort betrachten wir in ausführlicher Form die wichtigsten Leistungsbremser eines Clus-tersystems und versuchen zu verstehen wo diese entstehen, wie man sie charakterisieren kann und ihre negativen Auswirkungen in das Modell sinnvoll einzubauen hat.
Kapitel 7 stellt thematisch den sogenannten Simplex-Algorithmus in den Mittelpunkt, ein Lösungsverfahren, das wir für die Lösung eines linearen Optimierungsproblems benötigen. Wir wollen damit den Weg für die Aufstellung eines einfachen mathematischen Modells zur Beschreibung des Konfigurationsproblems im nächsten Kapitel möglich machen.
In Kapitel 8 versuchen wir durch eine praktische Umsetzung aller Begriffe, die in den Kapiteln 3 bis 7 beleuchtet wurden, die Imp-lementierung eines ersten funktionalen Lösungsverfahrens für das Konfigurationsproblem abzugeben. Es wird z. B. die mathema-tische Darstellung des Modells betrachtet und erste Versuche zur Generierung einer “optimale Lösung“ vorgestellt. Anschließend
- 7 -

werden die Ergebnisse dieser Untersuchungen in Form eines Computerprogramms zusammengefasst und mit den theoretischen Vorhersagen verglichen. Die Struktur des Clusterkonfigurators und einige, durch seinen Einsatz gewonnene Ergebnisse stehen hier im Mittelpunkt.
Kapitel 9 beschreibt schließlich unsere gesamten Ergebnisse und kann als zusammenfassende Analyse der Vorteile, Anwendungs-möglichkeiten und potentiellen weiteren Entwicklung der vorliegenden Studie und ihrer Softwareumsetzung verstanden werden.
Als Abschluss und Ergänzung dieser Arbeit liefern wir im Anhang A eine ausführliche Beschreibung der Arbeitschritte, die für die Installation und Inbetriebnahme eines Clusters notwendig sind. Damit wollen wir dem interessierten Leser die Gelegenheit bieten, das Thema Cluster aus einer praktischen Perspektive kennen zu lernen.
- 8 -

KAPITEL 3 - Erste theoretische Grundlagen
Wie oben bereits angedeutet, haben wir in diesem Kapitel hauptsächlich mit Grundbegriffen zu tun, welche die theoretische Informatik für die Charakterisierung der Eigenschaften von Parallelrechnern entwickelt hat. Wir werden hier besonders auf Perfor-manceanalyse und Verfahren zur Performancemessung solcher Parallelerechner etwas detaillierter eingehen. Dabei werden wir versuchen nicht nur die Menge an theoretischen Grundlagen, die den Rahmen unseres Lösungsansatzes bilden, sinnvoll einzu-schränken, sondern uns von vorneherein ein Bild von der Komplexität des Problems zu verschaffen.
3.1Rechnerarchitekturen
Hochleistungsrechnen bedeutet meistens paralleles Rechnen. Während bei traditionellen, sequentiellen Berechnungen (auf Ein-prozessorsystemen) ein Befehl nach dem anderen abgearbeitet wird, werden bei der parallelen Bearbeitung des gleichen Problems mehrere Befehle gleichzeitig ausgeführt, indem mehrere Prozessoren gleichzeitig eingesetzt werden und die Rechenlast auf diese verteilt wird. Die Arbeit jedes Rechners, egal ob er über einen einzigen oder mehrere Prozessoren verfügt, ist jedoch stets die gleiche:
• Ein Instruktionsset (das Programm) steuert die vom Rechner auszuführenden Aktionen.• Ein Datenset (Data Stream) wird vom Programm überarbeitet und modifiziert.
Aus dieser Beziehung zwischen einem gegebenen Instruktionsset und seinem zu bearbeitenden Datenset hat Flynn 1966 ein Sche-ma zur Klassifizierung von Rechnerarchitekturen eingeführt, das sich bis dato als sehr hilfreich erwiesen hat.
SISD Single Instruction, Single Data
Das sind herkömmliche Einzelprozessorsysteme
SIMD Single Instruction, Multiple Data
„Massiv Parallele“ Rechner und Vektor Rechner lassen sich hier klassifizieren.
MISD Multiple Instruction, Single Data
Nicht in kommerzieller Form auf dem Markt vorhanden
MIMD Multiple Instruction, Multiple Data
Die meisten Parallelrechner lassen sich hier unterbringen
Tabelle3.1: Klassifizierungsschema nach Flynn.
Tabelle 3.1. listet die Rechenarchitekturen nach diesem Schema. Unter den vier Architekturtypen nach Flynn sind für uns tatsäch-lich nur zwei von Interesse: SISD und MIMD, deswegen wollen wir Sie etwas ausführlicher betrachten.
3.1.1 SISD Rechner
SISD Rechner sind Rechnersysteme wie konventionelle PCs oder Workstations. Ein einziger Prozessor arbeitet mit einem einzigen Instruktionsset und operiert auf ein einziges Datenset. Das Instruktionsset wird in sequenzieller Form durchgeführt (Abb. 3.1).
Abbildung3.1: SISD Rechner schematisch.
Man spricht also von einem Befehl pro CPU Rechenzyklus und per Datenelement. Heutzutage besitzen Mainframes mehr als eine CPU, diese CPUs führen jedoch unabhängige Programme durch. In dem Sinne sind solche Systeme ebenfalls als SISD Maschinen zu betrachten, die auf unabhängige Datensets operieren. Beispiele von den eben genanten SISD Maschinen findet man in den Workstations von DEC, HP, Sun usw.
Obwohl diese Rechenarchitektur nichts mit Parallelismus zu tun hat, wollen wir sie näher betrachten, denn einige Performanceei-genschaften von Clustern lassen sich innerhalb des Einprozessormodells einfacher verstehen.
- 9 -
Kontroll-Einheit Instruktionsset Prozessor Datenset Speicher

3.1.2 MIMD Rechner
Die zweite für uns wichtige Rechnerarchitektur ist die nach Flynn benannte MIMD Architektur (s. Tab 3.1).
Bei MIMD-Maschinen arbeiten die Recheneinheiten nach dem Programm, das von der eigenen Kontrolleinheit des Prozessors durchgeführt wird. Die Gesamtheit der Prozessoren ist also nicht nur in der Lage mehrere unterschiedliche Instruktionssets gleich-zeitig auszuführen, sondern auch auf unterschiedlichen Datensets zu operieren. Im Gegensatz zu den oben erwähnten Multi-Pro-zessor SISD Maschinen sind bei MIMD Instruktions- und Datensets untereinander abhängig. Beide stellen unterschiedliche Teile der gleichen Rechenaufgabe dar. Auf diese Weise können MIMD Maschinen die gleichzeitige Ausführung mehrerer kleiner Jobs un-terstützen und dadurch die gesamte Ausführungszeit des Hauptjobs deutlich verkürzen. Es gibt zahlreiche Beispiele solcher MIMD basierten Rechensystemen, angefangen bei einem herkömmlichen Dualprozessorsystem bis hin zu der SGI/Cray T3E mit tausenden von Prozessoren.
3.2 SharedMemory–DistributedMemory
Das Klassifizierungs-Schema von Flynn reicht leider nicht aus, um die Hauptmerkmale von Supercomputern vollständig zu definie-ren. Ein weiteres grundlegendes Unterscheidungsmerkmal, das uns bei der Analyse von HPC-Systemen unterstützen kann, ist die Struktur des Datenzugriffs seitens der einzelnen Prozessoren. Prozessoren müssen auf Datenbestände operieren, die sich im Allge-meinen im Hauptspeicher des Computers befinden. Die Art und Weise,in der die Prozessoren mit den Daten interagieren,hängt mit der Speicherarchitektur zusammen. Die zwei wichtigsten Speicherarchitekturen sind unter folgenden Namen bekannt:
• Shared Memory• Distributed Memory
3.2.1 Shared Memory Systeme
Shared Memory Systeme besitzen mehrere CPUs und alle teilen sich einen gemeinsamen Speicher-Adressraum (Abb. 3.3).
Abbildung3.2: Es gibt N Prozessoren, N Instruktionssets und N Datensets.
Abbildung3.3: Parallelrechner mit gemeinsamem Speicher (Shared Memory). Die Prozessoren P1 bis Pn greifen auf einem ge-meinsamen Speicher zu.
- 10 -

Die CPU-Speicherzugriffe erfolgen mit der gleichen Priorität, so dass zu einem gegebe-nen Zeitpunkt nur eine bestimmte Speicher-adresse von einem einzigen Prozessor benutzt werden darf. Shared Memory Systeme sind sowohl bei den SIMD als auch bei den MIMD Rechenarchitekturen zu finden, so dass sie kurz auch als SM-SIMD und SM-MIMD bezeichnet werden.ezeichnet werden.
3.2.2 Distributed Memory Systeme
Bei Rechnern mit verteiltem Speicher (distributed memory) hat jeder Prozessor Pi, (i = 1,…, n,) einen eigenen lokalen Speicher, auf den nur er zugreifen kann (Abb. 3.4).
Abbildung3.4:Parallelrechner mit verteiltem Speicher (Distributed Memory).
Die Prozessoren kommunizieren miteinander über ein bestimmtes Netzwerk, so dass je-der Prozessor in der Lage ist, Daten aus seinem eigenen Speicher mit anderen Prozesso-ren auszutauschen. Ähnlich wie im Fall von Shared Memory Systemen findet man Distri-buted Memory Systeme sowohl unter den Single Instruction Multiple Data Maschinen (DM-SIMD) als auch unter den Multip-le Instruction Multiple Data Systemen (DM-MIMD).
3.3 VerteilteRechensysteme
Mit den SM-MIMD und DM-MIMD Architekturtypen haben wir alle Rechnerklassenbehandelt, die in der Welt der Hochleistungscomputer von Bedeutung sind. Wir können nun versuchen clusterartige Hochper-formancesysteme innerhalb einer der oben definier-ten Klassen einzustufen. Die Abbildung 3.5 zeigt zuerst eine schematische Darstellung der Standard Hardware Hauptkomponenten in einer typischen Clusterkonfiguration.
Abbildung3.5:Schematische Darstellung einer Standard Clusterkonfiguration
- 11 -
Netzwerk
P1 P2 Pn
M1 M2 Mn
Switch 100/1000 Mbit
MasterKnoten
CPUSpeicherFestplatte
eth0 eth1
node1
CPUSpeicherFestplatte
eth0
node2
CPUSpeicherFestplatte
eth0
node32
CPUSpeicherFestplatte
eth0
Internet
..............

Man erkennt an diesem Bild zunächst einmal die Struktur eines Distributed Memory Systems wieder (jede CPU besitzt eigenen Speicher). Die Prozessoren, die bei den üblichen Clusterkonfigurationen eingesetzt werden, sind ausnahmslos vollwertige RISC-Pro-zessoren (sie verfügen über eigene Kontrolleinheiten). Es ließe sich auch behaupten, dass Cluster in die Klasse der MIMD Maschi-nen einzustufen sind3).
Wenn wir diese Gedankenlinie verfolgen, können wir Cluster insgesamt als ein gut gelungenes Beispiel der DM-MIMD Architektur ansehen. Es gibt leider zwei wichtige Tatsachen, welche die Allgemeingültigkeit einer solchen Behauptung in Frage stellen: Die Rechenknoten eines Clusters kommunizieren durch (Gigabit) Ethernet (im besten Fall über SCI oder Myrinet Netzwerkkomponen-ten) und arbeiten gleichzeitig an verschiedenen Teilen eines gegebenen Programms. Im Prinzip unterscheidet sich das nicht vom Konzept der DM-MIMD Architektur, da aber die Kommunikationsgeschwindigkeit zwischen den Prozessoren bei Clustersystemen um einige Größenordnungen langsamer ist als die von dedizierten DM-MIMD Maschinen, kann man nicht von echtem Parallelis-mus sprechen. Man bezeichnet deswegen Clustersysteme besser als verteilteRechensysteme (Distributed Processing Systems oder Multicomputers), damit man eben diesem wichtigen Unterschied Rechnung trägt.
Der zweite Punkt der unsere Analyse noch zu verkomplizieren vermag, hat mit der Tatsache zu tun, dass bei der Hardwarekonfigu-ration von Standard Clustern der Einsatz von Dualprozessorfähigen Maschinen als Rechenknoten bevorzugt wird. SMP 4) Rechner (Dual Athlon, Pentium III oder Xeon Systeme) sind aber nicht anderes als SM-MIMD Maschinen, deren zwei Prozessoren auf einen gemeinsamen Hauptspeicher zugreifen. Als erste Zusammenfassung lässt sich also sagen: Cluster sind verteilte Rechensysteme (die dem Konzept von DM-MIMD Systemen ähneln), deren einzelne Bestandteile sich jedoch häufig besser als SM-MIMD beschreiben lassen.
Als direkte Konsequenz dieser Erkenntnis haben wir es bei einem Cluster mit einem System zu tun, das mit den Vorteilen aber auch mit den Nachteilen beider Systemarchitekturen behaftet ist. So sind die Rechenknoten eines Clusters in der Lage, mehrere Teile eines Jobs gleichzeitig auszuführen, was die Gesamtausführungszeit des Hauptjobs deutlich verkürzen kann. Die Synchronisa-tionsaufgaben, die für die Koordination der Prozessoren am Ende des parallelen Anteils eines Jobs notwendig sind, können jedoch stark zunehmen. Das könnte den Zeitgewinn bei der Parallelausführung des Programms im Endeffekt zunichte machen.
Andererseits bringen die Distributed Memory Eigenschaften eines Clusters z.B. als Vorteil mit, dass die Speichergröße direkt mit der Anzahl der CPUs steigt. Eine größere Anzahl von Prozessoren lässt also die Speichergröße und die Bandbreite steigen, der Benut-zer ist aber für das Senden und Empfangen von Daten zwischen den Unterprozessen verantwortlich. Die meisten Daten werden zwar nur zwischen Prozessor und lokalem Speicher wie bei einem sequentiellen Rechner transportiert, dies ist aber für die prakti-sche Programmierung ein wesentlicher Nachteil: Wenn Daten von anderen Prozessoren benötigt werden, sind diese durch spezielle Befehle zum Versenden über das Netzwerk zu transportieren. Es ist also eine besondere Softwareschnittstelle (auch Parallelbiblio-thek5) genannt) notwendig, um diese Form der Rechenprozessverteilung zu ermöglichen. Die Leistung einer bestimmten parallelen Anwendung hängt somit nicht nur mit der Leistung der im Cluster eingesetzten Hardware zusammen, sondern auch stark mit der intrinsischen Leistung der implementierten Parallelbibliotheken.
Letzteres führt uns zu der Erkenntnis, dass das Erreichen der optimalen Leistung eines clusterartigen Hochleistungscomputers sowie die Programmierung geeigneter Anwendungen, die diese potentielle Leistung sinnvoll ausnutzen, keinesfalls einfach sind. Glücklicherweise stehen die Anschaffungskosten sowie der Zeitaufwand für den Zusammenbau eines Clusters im positiven Verhält-nis zu den oben genannten Nachteilen.
3.4 DieClusterhardware Wir haben oft genug erwähnt, dass Cluster sich von anderen High Performance Rechensystemen unterscheiden, weil man für ihre technische Realisierung auf handelsübliche Hardwarekomponenten zurückgreift. Die einzelnen Rechenknoten eines Clusters sind also genau genommen normaler PCs6). In der Abbildung 3.6 geben wir eine neue schematische Darstellung eines verteilten
3) RISC steht für Reduced Instruction Set Computer, und entspricht einer Prozessorarchitektur, die für die Ausführung einer beschränkten Anzahl von Instruktionstypen konzipiert worden ist. Die dahinter liegende Idee ist die Menge an Transistoren und Schaltkreisen, die für die Ausführung jedes neuen Instruktionssets notwendig sind, so niedrig wie möglich zu halten und auf diese Weise die Komplexität der Funktionsweise eines Mikroprozessors stark zu reduzieren.
4) SMP (Symmetric Multi Processing) bezeichnet die Rechenarchitektur, die die Zusammenarbeit von zwei oder mehr CPUs innerhalb desselben Computers möglich macht. Symmetrisch heißt hier: gleichwertige Prozessoren mit gleichen Speicherzugriffsrechten.
5) Die wohl bekanntesten Beispiele solcher Parallelbibliotheken sind PVM (Parallel Virtual Machine) und MPI (Message Passing Interface). Sie unterscheiden sich zwar in vielen Details, basieren aber auf dem gleichen Konzept: Man erstellt - wie bei den üblichen sequenziellen Programmen- ein Programm, das dann auf mehreren Computern ausgeführt wird. Die einzelnen Kopien des Programms differenzieren sich nach dem Start nur durch eine Zahl, den sog. Rang, der von 0 bis zur Anzahl der Kopien minus eins läuft. Aufgrund des Rangs können die Programmkopien dann unterschiedliche Teile des Programms lösen. Die hohe Akzeptanz, von der Cluster seit einigen Jahren profitieren, ist nicht zuletzt auf die starke Verbreitung dieses Programmierungsschemas zurückzuführen.
6) In den meisten Fällen verfügen jedoch die Rechenknoten über keine Aus- und Eingabegeräte wie Graphikkarte, Maus oder Tastatur. Weniger üblich ist die Abwesenheit von Festplatten in den Knoten.
- 12 -

Rechensystems wieder. Es sind im Vergleich zum Schema auf Abbildung 3.5 zu dem Rechenknoten einige Komponenten dazu gekommen, die bei einer genauen Analyse der Faktoren die zu der gesamten Rechenleistung eines Clusters beitragen, unbedingt beachtet werden müssen. Wir geben hier nur eine kurze Beschreibung dieser Hardwarekomponenten (die allgemeine Funktion dieser Bestandteile innerhalb eines Computers sind meistens gut bekannt) und konzentrieren uns später im Kapitel 6 auf ihre Rolle im Bezug auf die tatsächlich erreichbare Leistung eines verteilten Rechensystems
Abbildung3.6:Schematische Darstellung eines Clusters aus der Hardwaresicht.
3.4.1 CPU
Der Hauptprozessor (Central Processing Unit, kurz CPU) stellt das Kernstück eines PCs dar. Die CPU steuert, regelt und kontrolliert Arbeitsprozesse. Sie steht in ständigem Signalaustausch mit Bausteinen des Motherboards. Die CPU besteht, wie fast jeder Mikroprozessor, aus integrierten Schaltungen, welche die unterschiedlichen Funktionseinheiten des Prozessors beinhalten. CPUs weisen in der Regel zwei solche Funktionseinheiten auf: Zum einen, die sog. Verarbeitungseinheit EU (Execution Unit) und zum anderen die Busverbindungseinheit BIU (Bus Interface Unit). Die EU ist zuständig für die Ausführung der Maschinenbefehle und die Dekodierung derselben. Hauptaufgabe der BIU ist das Ausführen sämtlicher Busoperationen für die EU. Zu diesen Einheiten gehören weitere wichtige Subelemente wie die Control Unit (CU), der Coprozessor, die Adress- und Datenbusse oder die Arithmetic Logic Unit (ALU). Diese Komponenten lassen sich jedoch einheitlich in Verbindung mit einer bestimmten CPU Architektur bringen, so dass wir uns nicht im Einzelnen um sie kümmern werden.
Im Allgemeinen wird die Geschwindigkeit eines Computersystems durch die Taktfrequenz seiner CPU definiert. Diese Frequenz wird durch einen Oszillator, bestehend aus einem Quarz in einem kleinen Zinnbehälter, vorgegeben. Wird Spannung angelegt, beginnt dieser mit einer gleichmäßigen Frequenz zu schwingen. Jede Anweisung, die der Prozessor ausführt, dauert eine bestimmte Anzahl von Taktimpulsen. Wie viel Taktimpulse pro Sekunde der Taktgeber gibt, wird in Hertz angegeben (1 Megahertz = 1 Millon Taktimpulse pro Sekunde).
3.4.2 Die CPU Register
Um auf wichtige Daten während der Ausführung eines Jobs schnell zugreifen zu können verfügt die Control Unit der CPU über mehrere Speicherplätze innerhalb des Prozessors, die so genannten Register. Es gibt Befehlsregister, Register für Operanden und Ergebnisse, Spezialregister, die z.B. für die Hauptspeicheradressierung zuständig sind oder ein Statusregister, mit dessen Hilfe bestimmte Zustände nach Ausführung von Befehlen abgefragt werden können.
- 13 -
NODE 1
DMA DMA
PIO PIO
RAM
Level 2 Cache
Level 2 Cache
Level 1 CacheCPU
Register
CPU0
Level 1 CacheCPU
Register
CPU0
HDD PCI Bus/Daten Bus
eth0 eth1 myri-net
Infini-band
NODE n
DMA DMA
PIO PIO
RAM
Level 2 Cache
Level 2 Cache
Level 1 CacheCPU
Register
CPU0
Level 1 CacheCPU
Register
CPU0
HDD PCI Bus/Daten Bus
eth0 eth1 myri-net
Infini-band
.....................
SWITCHED NETWORK
MYRINET
INFINIBAND

3.4.3 Level 1 – Cache oder First Level Cache
Im Cache eines Prozessors werden Daten gespeichert, auf die der Prozessor wiederholt zugreifen muss. Diese Daten können entweder richtige Daten sein, oder auch Programmcode, der abgearbeitet werden muss. Aufgrund dieser Trennung wird der Level 1 - Cache meistens in zwei Bereiche aufgeteilt: Ein Cache für Daten und ein Cache für Programmcode. Der Level 1 – Cache wird mit vollem Core Takt betrieben und seine typische Große rangiert zwischen 32 KB und 1 MB7).
3.4.4 Level 2 – Cache oder Second Level Cache
Der Level 2 – Cache ist die zweite Stufe des Cachespeichers. Er ist zwar langsamer als der L1 – Cache, aber immer noch schneller als der Hauptspeicher. Er ist wesentlich größer als der L1 – Cache (zwischen 256 KB und 2 MB). Auch dort werden häufig benötigte Daten zwischengespeichert. Der L2 – Cache wird abhängig vom Prozessor mit halben oder vollem Core Takt betrieben.
3.4.5 RAM
Random Access Memory. Das RAM ist der Arbeitspeicher (Hauptspeicher) eines Rechners, also der physikalische Ort, an dem das Hauptsteuerprogramm (das Betriebssystem) eines Computers sowie der Ausführungscode und die Daten aller aktiven Applikationen geladen und der CPU zur Verfügung gestellt werden. Da die Zugriffszeit für alle Speicherzellen sowohl beim Lesen als auch beim Schreiben in etwa gleich ist, bezeichnet man das RAM als Speicher mit wahlfreiem Zugriff (daher “Random Access“).
Zurzeit werden hauptsächlich die sog. Double Data Rate RAM (DDR - RAM) Hauptspeichermodule im PC Bereich eingesetzt, eine Speicherarchitektur die nicht nur doppelt so viele Daten pro Bustakt überträgt (verglichen mit der vorherigen SD-RAM Hauptspei-cherarchitektur), sondern auch höhere Bustaktfrequenzen unterstützt. So kann z.B. DDR266 mit 133 MHz, DDR333 mit bis zu 166 MHz arbeiten. In Zusammenhang mit der Intel Xeon CPU Architektur besteht die Möglichkeit, so genannten RAMBUS Speicher einzusetzen (auch RDRAM genannt), welcher einen Bustakt von mehr als 400MHz verträgt.
3.4.6 Bus Mastering und Direct Memory Access (DMA)
Während der Ausführung einer bestimmten Aufgabe findet am Computer eine beachtliche Menge an Kommunikationsaktivitäten zwischen den Hardwarekomponenten statt. Für unsere Zwecke ist die Art und Weise, wie diese Kommunikation zwischen CPU, Speicher, PCI Bus und Festplatte erfolgt, von großer Bedeutung. Aufgrund dessen beschäftigen wir uns kurz mit dem aktuellen Kommunikationsmodell zwischen CPU und Hardwareperipherie.
Durch die schnellen Datenbusse (PCI, AGP, etc.) fließen pro Sekunde große Datenmengen. Über eine lange Zeit war es die Aufgabe der CPU, den Transfer dieser Informationen zu kontrollieren. Der Prozessor agiert praktisch als Vermittler zwischen dem Betriebsys-tem und den spezifischen Hardwarekomponenten8). Um die CPU von diesen Aufgaben zu befreien und dabei die Multitasking Fä-higkeiten der CPUs allgemein zu verbessern wurde das Konzept von Bus Mastering eingeführt. Die neuen Hardwarekomponenten, die sog. Bus Masters, sind in der Lage, die Kontrolle über den Datenbus zu übernehmen und ihre spezifischen Aufgaben selbst zu erledigen. Die notwendigen Kontrollfähigkeiten sind in den Chipsatz eingebaut, so dass die verschiedenen Anfragen zur Kontroll-übernahme des Datenbusses problemlos erfolgen. Zurzeit ist Bus Mastering in der PC Welt meistens bei den Geräten für den PCI Bus zu finden (Soundkarten, Netzwerkkarten, etc.), sowie bei IDE/ATA Devices (Festplatten, DVD Laufwerke, etc).
Im Fall der IDE/ATA Devices ist die Bus Mastering Fähigkeit solcher Laufwerke eher unter den Namen Ultra DMA bekannt. DMA steht für Direct Memory Access und bezeichnet das Datentransferprotokoll, bei dem das beteiligte Gerät seine Informationen direkt in den Hauptspeicher schreibt bzw. aus dem Speicher liest, ohne jegliche Beteiligung vom Prozessor. Ultra DMA ist eine Form von Bus Mastering, denn während diese DMA Transfers stattfinden übernimmt das Laufwerk die Kontrolle über den IDE-Datenbus. Verschiedene DMA Modi sind der IDE/ATA Schnittstelle bekannt, standardmäßig beherrschen jedoch heutige Festplatten mindestens den so genannten UDMA/100 Modus.
7) Während der Bustakt (der Takt des Motherboards, mit dem die CPU auf den Speicher zugreifen kann) zurzeit bei mindestens 133 MHz liegt, arbeiten CPUs mit einem Vielfachen dieses Taktes. Der Multiplikator, mit dem der Bustakt vervielfacht wird, ist entweder in der CPU fest eingestellt oder lässt sich auf dem Motherboard manuell einstellen.
8) Bis zur Mitte der 90er Jahre war das sog. Programmed I/O (PIO) Protokoll die einzige Methode um Daten zwischen der CPU und anderen Peripheriegeräten zu transportieren. Dies ist eine Technik, bei der sich die CPU direkt um die Kontrolle des Datentransfers zwischen den Hardwarekomponenten kümmert. Diese Technik funktioniert sehr gut bei langsamen Geräten wie Tastaturen, Diskettenlaufwerken oder Modems, nicht aber bei Komponenten wie Festplatten oder CD-ROM Laufwerken, die auf hohe Datentransferleistungen angewiesen sind. PIO provoziert eine starke Ausbremsung der Systemperformance, denn die CPU wird von ihren spezifischen Aufgaben abgelenkt wenn Lese-Schreibereignisse auf solche schnellen Komponenten erfolgen. PIO ist nicht in der Lage, mit der Leistung der heutigen Festplatten mitzuhalten. Trotzdem werden die PIO Modes von den meisten PC Systemen nicht nur aus Kompatibilitätsgründen mit alter Hardware weiter unterstützt, sondern auch weil PIO als letzte Grundlage gilt, wenn Treiberprobleme oder Softwarefehler Schwierigkeiten bei Ultra DMA Zugriffen verursachen.
- 14 -

3.4.7 Das Verbindungsnetzwerk
Das Verbinden mehrerer Computer zu einem Clustersystem verlangt die Anwesenheit von mindestens einer Netzwerkschnittstelle NIC9) pro PC und einem bzw. mehreren Netzwerkswitches um den Informationsaustausch zwischen den PCs zu beschleunigen. Obwohl es natürlich andere Möglichkeiten für die Realisierung der Kommunikation zwischen den Knoten gibt, hat sich diese Switched Netzwerktopologie in der Clusterwelt als Standard durchgesetzt, vor allem wegen ihrer hohen Skalierbarkeit (zusätzliche Knoten lassen sich vergleichsweise sehr einfach in eine vorhandene Clusterstruktur einbinden).
Je mehr Rechenknoten man an einen Cluster einbinden will, desto wichtiger wird auch das Verbindungsnetzwerk. Oft steckt in diesem die Hälfte der Gesamtkosten eines Systems, da man sich als Ziel gesetzt hat, die Prozessorleistung optimal auszunutzen. Bei einer falschen Wahl der Netzwerktechnik würden die schnellen Prozessoren die meiste Zeit nur auf Daten von Ihren Nachbarprozessoren warten, anstatt zu rechnen. Wie wir später sehen werden (s. §4.6) gibt es zwei Größen, die bei der Leistungsbestimmung sämtlicher Hardwarekomponenten, nicht nur der Netze, ausschlaggebend sind: Der Durchsatz, meist in Bit pro Sekunde gemessen, und die Latenzzeit, in Mikrosekunden (µs) gemessen.
Der Begriff Durchsatz, auch Bandbreite genannt, bezieht sich hier auf die Menge an Daten, die das Netz zwischen zwei Netzwerkknoten in der Sekunde transportieren kann. Die Latenzzeit gibt die Zeit an, die vom Aufruf der Sendefunktion bis zur Rückkehr der Empfangsoperation für eine kurze Nachricht vergeht. Während gewöhnliche Netze wie Ethernet oder Fast-Ethernet mit einem theoretischen Durchsatz von 10 bzw. 100 Mbits/s und einer Latenzzeit von etwa 250 bis 150 µs die meist benutzten Netzwerkschnittellen sind, findet man spezielle Netzwerktechnologien wie SCI oder MYRINET, die für die Bearbeitung paralleler Applikationen genau abgestimmt sind. Diese zeichnen sich durch einen ausgesprochen hohen Durchsatz von bis zu 4 Gbits/s (Gigabits pro Sekunde) und eine niedrige Latenzzeit von weniger als 10 µs aus.
Solch gewaltige Unterschiede sind teils in der Hardware zu suchen, teils aber auch in der Software. Da für paralleles Rechnen nur geringe Distanzen überbrückt werden müssen (alle Rechner stehen normalerweise in einem Raum), lässt sich die Hardware zu diesem Zweck optimieren, was sich zu Gunsten der höheren Bandbreite entwickelt. Die Unterschiede in der Latenzzeit lassen sich eher auf der Softwareebene verstehen: Auf Ethernet setzt praktisch immer TCP/IP als Protokollstack auf. Die Abarbeitung des gesamten Stacks verbunden mit betriebssystembedingten Aktivitäten und Interrupt-Behandlung kostet dabei viel CPU-Zeit. Eine Lösung dieses Problems besteht darin, TCP/IP und das Betriebssystem zu umgehen. Es ist dazu notwendig, Teile der Hardware für Anwendungen (und Bibliotheken) direkt in den Benutzeradressraum einzubetten. Die wohl bekanntesten Netze, die diese Technik anwenden, sind die oben erwähnten SCI (Scalable Coherent Interface) und MYRINET. SCI ist durch IEEE 1596 standardisiert, während MYRINET dem ANSI/VITA 26-1998 Standard entspricht. Sowohl für SCI als auch für MYRINET gibt es momentan jeweils nur einen Anbieter. Die Schwedische Firma Dolphin für SCI und die US-Amerikanische Firma MYRICOM für MYRINET. Genau diese fehlende Konkurrenz zusammen mit den geringen Stückzahlen, die im Vergleich mit Standardnetzwerktechnologien verkauft werden, haben leider sehr hohe Preise zur Folge. Eine wichtige Alternative zu diesen Netzwerktechnologien wird in die Zukunft die sog. INFINIBAND NetzwerkStandard darstellen, welcher nicht nur einen offenen Standard ist sondern einen besseren Preis-/Leistung Verhältnis im Vergleich zu SCI und MYRINETaufweist. Zurzeit wird die INFINIBAND Hardwaremarkt von der US-Unternehmen MELLANOX dominiert.
9) Die Bezeichnung NIC (Network Interface Card) wird regelmäßig eingesetzt um Netzwerkschnittstellen / Netzwerkarten in kompakter Form zu benennen.
- 15 -

KAPITEL 4 - Performancebestimmung verteilter Rechensysteme
Eine der ersten Fragen, mit denen man sich während des Entwurfs und Aufbaus eines Clusters beschäftig, ist natürlich die nach der Rechenleistung, welche sich bei dem System erwarten lässt. Performance ist in den meisten Fällen die Hauptmotivation für die Anschaffung eines Clusters, und aus diesem Grund ist die Messung der Rechenleistung und der Vergleich zwischen verschiedenen einsetzbaren Architekturen und Clusterkonfigurationen von relevanter Bedeutung.
Um das Problem der Bestimmung der Rechenleistung von Parallelrechnern richtig verstehen zu können müssen wir weiterhin auf grundlegende Begriffe der theoretischen Informatik zurückgreifen. Erst dann können einige wichtige Messmethoden sinnvoll erläutert werden und die entsprechenden quantitativen Aussagen über die Systemperformance eines gegebenen Systems liefern.
4.1 Parallelisierungsgrad
Ein Paralleler Algorithmus kontrolliert die Durchführung eines Programms, welches seinerseits die simultane Ausführung von zwei oder mehr Prozessen auf zwei oder mehr CPUs steuert. Drei wichtige Parameter, die die Qualität eines parallelen Algorithmus bestimmen sind der Parallelisierungsgrad, der Speedup und die Effizienz:
Der Parallelisierungsgrad eines Algorithmus ist die Anzahl P der theoretisch maximal, parallel ausführbaren Operationen. Beispielsweise hat die Addition zweier n – komponentiger Vektoren den Parallelisierungsgrad P=n, da die n Additionen unabhängig voneinander und somit zeitgleich ausgeführt werden können.
4.2 SpeedupundEffizienz
Zur Charakterisierung der Leistungsfähigkeit eines parallelen Programms wird meist der Speedups verwendet. Um diesen Begriff besser zu verstehen betrachten wir die Zeit TP die man benötigt, um die Lösung eines gegebenen Problems mit dem schnellsten bekannten seriellen Algorithmus auf einem Prozessor zu erhalten und mit TP die Zeit, die man zur Lösung des gleichen Problems auf dtem Parallelrechner mit N solcher Prozessoren benötigt. Der Speedup eines parallelen Algorithmus ist
P
S
TT
S = (4.1)
Ein Wort müssen wir noch zu der genauen Bedeutung von Ts sagen, also der Zeit die benötigt wird, um den schnellsten bekannten seriellen Algorithmus auf einem Prozessor durchzuführen. Man kann hier einen Prozessor aus dem parallelen Computer nehmen oder wir können die schnellste sequenzielle Maschine benutzen, die zu dem Zeitpunkt des Vergleichs auf dem Markt existiert. Letzteres wäre in der Tat das genaueste Verfahren um die Leistung des parallelen Algorithmus zu messen, ist jedoch in der Praxis nicht ohne weiteres machbar. Der schnellste Prozessor auf dem Markt steht nicht jedem zur Verfügung, so dass eine Messung unter diesen Bedingungen in der Regel nicht durchführbar ist.
Eine leicht modifizierte Definition des Speedups ist folgende: Die von dem parallelen Algorithmus benötigte Laufzeit auf einem Prozessor T1 geteilt durch die Laufzeit TP desselben Algorithmus auf N Prozessoren:
PTTS 1=
(4.2)Gewöhnlich gilt T1 ≠ TS meistens ist T1 ≥ TS
Eng verknüpft mit der Definition des Speedup ist die Effizienz eines parallelen Programms. Die Effizienz eines parallelen Algorithmus bei einer Berechnung mit N Prozessoren ist
(4.3) wobei S durch die Beziehung (4.1) gegeben ist und für e Definitionsgemäß e ≤1gilt.
Die Effizienz lässt sich folgendermaßen interpretieren: Ist e nahe bei 1, so ist der Parallelrechner durch den verwendeten Algorithmus gut genutzt. Im Idealfall ist ein Algorithmus vollständig parallelisierbar. Dann gilt e=1 und man hat die ideale Beschleunigung im Vergleich zur seriellen Berechnung, d.h. S=P. Das Problem kann somit durch den Algorithmus in der Zeit gelöst werden10).
10) Applikationen mit solch hohem Effizienzgrad werden EPC Applikationen genannt (EPC steht für „Embarrassingly Parallel Computations“). Diese Applikationen weisen einen sehr hohen Parallelisierungsgrad n auf, so dass ihre absolute Effizienz von Rechensystem unabhängig ist.
11 TP⋅
- 16 -
NSe =

In aller Regel ist aber e < 1, da nicht 100% eines Algorithmus parallelisierbar ist und im Allgemeinen Daten zwischen den Prozessoren auszutauschen sind, so dass wegen der entstehenden Kommunikation auch Zeit benötigt wird.
Ein kleines numerisches Beispiel zeigt deutlich die Beziehung zwischen den beiden Größen: Wenn der schnellsten bekannten serielle Algorithmus z.B. 8 Sekunden für die Berechnung braucht, also TS = 8, der parallele Algorithmus jedoch 2 Sekunden auf 5 Prozessoren für die gleiche Berechnung benötigt, dann gilt:
S = TS /Tp = 8/2 = 4e=S/N = 4/5 = 0.8 = 80%
und der parallele Algorithmus weißt einen Speedup von 4 bei der Verwendung von 5 Prozessoren auf, sowie eine Effizienz von 80%.
In Abbildung 4.1 haben wir die theoretische Laufzeit für ein Parallelprogramm, das auf mehreren Prozessoren durchgeführt wird, gegen die Anzahl der eingesetzten CPUs aufgetragen. Die helle Kurve wird aus den theoretischen, die dunkle Kurve aus der tatsächlich gemessenen Laufzeitwerten gewonnen.
Abbildung4.1: Theoretische gegen gemessene Laufzeitwerte für ein typisches Parallelprogramm.
Wie die Abbildung zeigt befindet sich ein Punkt auf der Effizienzkurve, ab dem die Addition von weiteren Prozessoren keine Reduzierung der Laufzeit mehr mit sich bringt. Sehr oft ist sogar auf der Effizienzkurve einen Punkt zu finden, ab dem der Einsatz zusätzlicher CPUs eine langsamere Ausführungszeit zur Folge hat.
Oft ist aufgrund der Problemgröße eine sequentielle Berechnung nicht mehr möglich, sodass Ts oder T1 nicht vorliegen. In solchen Fällen macht der inkrementelle Speedup
(4.4)
eine entsprechende Aussage über die Qualität des parallelen Verfahrens (etwas mehr dazu ist im Kapitel 5 unter Superlineare Speedups zu finden)
- 17 -
ozessorenPaufLaufzeitozessorenaufLaufzeit
NSP
i PrPr
)( 2=
real
theoretisch
Lauf
zeit
CPU Anzahl
0 2 4 6 8 10 12
1,2
1
0,8
0,6
0,4
0,2
0

4.3 Faktoren,diedenSpeedupaufApplikationsebenelimitieren
Unter den Hauptfaktoren, die das Erreichen eines höheren Speedups stark beeinträchtigen, finden wir den sog. SoftwareOverhead.Mit dem Begriff will man der Tatsache Rechnung tragen, dass im Allgemeinen die Anzahl der zu bearbeitenden Programminstruktionen bei Parallelprogrammen höher ist als die des sequentiellen Pendants.
Der Speedup wird ebenfalls durch die Performance der langsamsten Komponente, die an der Berechnung teilnimmt, entscheidend beeinflusst. Man spricht in diesem Zusammenhang vonLoadBalancing und versucht dann zu gewährleisten, dass die Gesamtlast auf alle Recheneinheiten gleichmäßig verteilt wird.
In dem ungünstigen Fall, dass die Kommunikationsvorgänge zwischen Prozessen und den rein rechnerischen Aufgaben eines Parallelprogramms sich nicht überlappen, braucht man extra Zeit, um die direkte Kommunikation zwischen den Prozessoren zu ermöglichen, also den Anschluss zu finden. Diese zusätzliche Zeitspanne, bei der die Prozessoren tatsächlich nichts rechnen, wird negative Auswirkungen auf den Speedup haben. Ziel des Programmierers beim Entwurf eines parallelen Algorithmus soll also sein, die relative Menge an Rechenarbeit, die zwischen Kommunikationsakten bzw. Synchronisationsprozessen erfolgt, so groß wie möglich zu machen. Man nennt diese Eigenschaft die Granularitätsgröße11) eines Algorithmus.
4.4 DasGesetzvonAmdahl
Die Idee, eine Computerberechnung durch die Implementierung eines parallelen Algorithmus zu beschleunigen, ist alles andere als neu. Zu Beginn der Ära der Digitalcomputer gab es bereits Anwendungen, die nach hoher Rechenleistung verlangten. IBM hatte damals als Lösungsansatz gleich die Nutzung eines Parallelenrechners für dieses Problem in Erwägung gezogen. Die Forscher bei IBM fanden jedoch ziemlich rasch heraus, dass die Geschwindigkeit bei der Ausführung einer Parallelapplikation durch den Einsatz zusätzlicher Prozessoren nicht ohne weiteres steigen kann. Diese Beobachtungen wurden durch das sog. Gesetz von Amdahl festgehalten (Gene AMDAHL 1967).
Um auf die explizite Form des Gesetzes von Amdahl zu kommen müssen wir zuerst eine Definition der Geschwindigkeit eines Programms geben. Aus der Physik kennen wir die Definition der Durchschnittsgeschwindigkeit als der Länge der durchgefahrenen Strecke geteilt durch die gesamte Zeit, die für die Fahrt benötigt wurde. Bei Computern führt man eine Arbeit durch, anstatt eine Distanz zu überbrücken, so dass die Geschwindigkeit eines Algorithmus sich sinnvoll als der Quotient der verrichteten Arbeit W und der dafür verwendeten Zeit T definieren lässt: (4.5)
R bezeichnet man als die Geschwindigkeit oder Geschwindigkeitsrate der Applikationsausführung.
Sei nun TS die Zeit, die der Prozessor benötigt um den seriellen Anteil eines Programms durchzuführen (die Teile des Programms, die sich ausschließlich eines nach dem anderen bearbeiten lassen) und TP die entsprechende Zeit, die der gleiche Prozessor braucht für die Ausführung von Programmteilen, die parallel durchgeführt werden können. Dann ist die Gesamtdurchführungszeit eines Programms wie folgt gegeben:
(4.6)
und (4.5) lässt sich wie folgt umschreiben.
(4.7)
Die (1) verweist auf die Anzahl von Prozessoren, die an dem Problem rechnen. Definieren wir α als die Mindestzeit für die Ausführung des sequenziellen Anteils eines Programms und (1 - α) als den verbleibenden parallelisierbaren Anteil dieses Programms, dann gilt
(4.8)und aus dieser Beziehung ebenfalls
11) Ein Programm ist dann stark oder besser gesagt grob granular, wenn die notwendige Zeit für Kommunikationsakte zwischen Prozessen sehr klein ist im Vergleich mit der Zeit, welche die Prozessoren für Berechnungen aufwenden. Der negative Effekt der Interprozesskommunikation auf den Speedup wird also reduziert wenn die Größe der Granularität steigt.
- 18 -
TWR =
PS TTT +=
PS TTWR+
=)1(
TT
TTT S
PS
S =+
=α

(4.9)
Wenn N Prozessoren für die Durchführung des parallelen Anteils eingesetzt werden, erhalten wir für die Geschwindigkeitsrate des Programms im idealen Fall:
(4.10)
Der Geschwindigkeitsgewinn oder Speedup S der Applikation durch den Einsatz von N Prozessoren lässt sich also durch den Quotienten R(N)/R(1) ausdrücken (Gl.(4.7) und (4.10)):
Wir eliminieren W und benutzen Gleichung (4.6) um die obige Gleichung etwas umzuformen
(4.11)
Aus (4.6) folgt TS = T - TS und wegen (4.8) gilt α * T = TS, so dass sich TP in TP = T - α * T = T (1 - α) umschreiben lässt. Wir setzen diese zwei Beziehungen in (4.11) und erhalten
(4.12)
Die Gleichungen (4.11) und (4.12) stellen zwei unterschiedliche mathematische Ausdrücke des berühmten Gesetzes von Amdahl dar, wobei die Form bei (4.12) in der Literatur häufiger vorkommt.
Um die Bedeutung dieser Beziehungen besser zu verstehen stellen wir uns folgende Situation vor: Wir haben ein Programm, das aus 100 Instruktionen besteht. Jede Instruktion braucht zur Durchführung immer die gleiche Zeit. Wenn 80 dieser Instruktionen sich parallel ausführen lassen (TP = 80) und 20 Instruktionen sequentiell durchgeführt werden müssen (TS = 20), dann ergibt sich beim Einsatz von 80 Prozessoren (N = 80) aus (4.11)
S (80) = 100 / (20 + 80/80) = 100 / 21 < 5 d.h. ein Speedup von nur 5 ist für dieses Problem zu erreichen, unabhängig davon wie viele Prozessoren für diese Berechnung eingesetzt werden.
In der Form (4.12) lässt sich aus dem Amdahl Gesetz noch mehr Information herausholen. Stellen wir uns jetzt vor, dass wir einen Algorithmus haben dessen sequentieller Anteil nur α = 0.01 beträgt. Damit ist mit 10 Prozessoren nach (4.12) höchstens ein Speedup
erreichbar. Mit 100 Prozessoren kann aber höchstens noch
erzielt werden. Für große Prozessorenzahl N wird eine Sättigung erreicht (Abbildung 4.1), denn es gilt
( )T
TTTT SS −
=−=− 11 α
( )N
αα −+
=11
25.500199.01
≈=S
17.9109.01
≈=S
( ) ααα1
/11limlim =−+
=∞→∞→ N
SPN
- 19 -
( )NTTWNR
PS +=)(
( )( )PS
PS
TTWNTTW
RNRS
++
==)1()(
NTT
T
NTT
TTS
PS
PS
pS
+=
+
+=
( ) ( )
−
+=
−+⋅
=
NT
T
NTT
TNSαα
αα 11)(

- 20 -
Für den Extremfall α = 0, d.h. ein Programm ohne sequentiellen Anteil, wäre S(N) = N, also der Idealfall. Ist dagegen α = 1, d.h. das Programm weist überhaupt keinen Parallelismus auf, so ist S(N) = 1, unabhängig davon wie viele Prozessoren eingesetzt werden. All diese Tatsachen lassen uns begreifen was das Gesetz von Amdahl tatsächlich ausdrücken will:
Unabhängig von der Anzahl der Prozessoren, die an der Ausführung eines parallelen Algorithmus gleichzeitig arbeiten, wird der erreichbaren Speedup S(N) durch die Anzahl der Programminstruktionen, die sequentiell abgearbeitet werden müssen, effektiv eingeschränkt.
Da fast jedes Parallelprogramm etwas sequentiellen Code enthält, könnte man ja zu dem traurigen Schluss kommen, dass es in keinem Fall eine sinnvolle Investition ist, Parallelcomputer mit einer hohen Anzahl von Prozessoren zu bauen, da diese nie einen brauchbaren Speedup erreichen werden. Glücklicherweise gibt es zahlreiche wichtige Anwendungen, die parallelisiert werden können (oder müssen) und eine sehr kleine sequenzielle Fraktion aufweisen (α < 0.001). Einige davon fallen sogar in der Kategorie derr EPC Applikationen (s. 4.2).
4.5 LatenzundBandbreite
Die ersten Erkenntnisse, die wir aus der Diskussion des Gesetzes von Amdahl gewonnen haben, lassen uns zu Recht vermuten, dass für uns das Problem der Performancebestimmung eines Clustersystems von entscheidender Relevanz ist. Ein für uns geeignetes Performancemodell muss in der Lage sein, etwas kompliziertere Systemzusammenhänge zu beschreiben, als es das schlichte Gesetz von Amdahl tatsächlich kann. Aus praktischen Gründen darf es aber nicht den Komplexitätsgrad eines wissenschaftlichen Modells aus der theoretischen Informatik erreichen.
Um das Problem der Performancebestimmung erstmals angreifen zu können, müssen wir zwei sehr wichtige Begriffe klar definieren: Latenz und Bandbreite. Diese haben wir im Zusammenhang mit dem Kommunikationsnetzwerk bereits im Kapitel 3 angedeutet, wir möchten sie hier aber etwas allgemeiner betrachten.
Stellen wir uns also vor, dass eine beliebige Hardwarekomponente bestimmte Information von einer zweiten Komponente benötigt, damit sie an einem laufenden Job weiter arbeiten kann bzw. diesen starten kann. Die erste Komponente sendet dementsprechend ein Signal über den Kommunikationskanal zwischen den beiden Komponenten, welches die zweite Komponente über die Art des Datentransfers informiert. Die zweite Komponente stellt dann die verlangten Daten der ersten Komponente bereit.
Die minimal mögliche Zeitspanne tL zwischen dem Senden des Signals und dem Moment, in dem die Daten tatsächlich zur Verfügung stehen, wird als Latenzzeitbezeichnet. Die Bandbreite B bezeichnet hingegen die maximale Datenmenge, die in einer Sekunde über den Kommunikationskanal transferiert werden kann,gemessen ab dem Zeitpunkt, an dem der Informationstransfer
Speedup150
100
50
50 100 150P
α=0
α=0.01
Abbildung4.2: Maximal erreichbarer Speedup nach dem Gesetz von Amdahl

tatsächlich angefangen hat. Die Latenzzeit wird in Zeiteinheiten gemessen (typisch Sekunden bis Mikrosekunden), während die Bandbreite in Megabyte bzw. Gigabyte pro Sekunde angegeben wird.
Eine sehr wichtige Eigenschaft dieser zwei Größen ist es, dass sie eine ausreichende Charakterisierung der Leistung beliebiger Hardwaresubsysteme ermöglichen. Wir wollen daher während des nächsten Abschnitts ausschließlich diese beiden Größen als Basis für die Entwicklung eines Modells benutzen, bei dem die relevanten Züge der Clusterarchitektur erhalten bleiben und nebenbei die Bestimmung der Performance von solchen Clustersystemen vereinfacht wird. Dieses Vorgehen wird eine klare Rechtfertigung später finden, wenn wir uns mit der Erstellung des mathematischen Modells für das Konfigurationsproblem beschäftigen werden.
4.6 EineinfachesPerformancemodell
Als Ausgangspunkt bei der Entwicklung eines solchen Performancemodells wollen wir die Ausführungszeit T einer Applikation definieren und diese als zu bestimmende Größe betrachten. T wird also in diesem Zusammenhang eine Funktion der Latenzzeit tL und der Bandbreite B sein. Somit lässt sich eine erste Beziehung, die das Problem beschreibt, in allgemeiner Form schreiben als
T = f ( tL, B) (4.13)
Als nächstes definieren wir die gesamte Ausführungszeit eines parallelen Programms auf einer Multiprozessormaschine als die Zeitspanne, die zwischen dem Starten der ersten Programminstruktion auf dem ersten Prozessor bis zum Ausführen der letzten Programminstruktion auf dem letzten Prozessor vergeht. Während der Programmausführung ist jeder Prozessor eines Clusters entweder am Rechnen, versucht mit einem anderen Prozessor zu kommunizieren oder befindet sich im Leerlauf. Wir bezeichnen diese Intervalle entsprechend als i
Kommi
ch TT ,Re und ileerT .
Die Rechenzeit ( ichTRe ) ist die Zeit, in der das parallele Programm ausschließlich CPU Aktivität generiert. Wenn (4.13) gelten soll,
hängt die Dauer der Zeit in erste Linie von tL und B12) ab. Die Latenzzeit einer CPU lässt sich mit der minimalen Zeit verknüpfen die notwendig ist, um eine einzige CPU-Instruktion durch die EU- und BIU-Einheiten der CPU zu evaluieren und mit ihrer Durchführung zu starten (s. 3.4.1).
Die erreichbare Bandbreite steht hingegen mit der Kommunikation zwischen der CPU und dem Memory Subsystem in Verbindung, sie hängt also direkt von der Geschwindigkeit ab, mit der die Daten von First-, Second Level Cache und Hauptspeicher zur CPU transportiert werden können und umgekehrt.
Die Kommunikationszeit eines Algorithmus iKommT bezeichnet die Zeitspanne, in welcher der Algorithmus sich mit Sende- und
Empfangsoperationen von Daten beschäftigt. Wir müssen zwischen zwei Typen von Kommunikationsvorgängen in einem Cluster unterscheiden: Interprozessorkommunikation und Intraprozessorkommunikation. Bei der Interprozessorkommunikation lokalisieren sich die Sende- und Empfangakte auf unterschiedliche Prozessoren. Diese Art der Kommunikation wird immer dann auftreten, wenn der parallele Algorithmus einen Job pro Prozessor startet. Bei der Intraprozessorkommunikation finden zwei Kommunikationsvorgänge innerhalb desselben Prozessors statt (Kommunikationsakte zwischen den zwei Prozessoren eines Dual Prozessorssystems können auf Grund der schnellen Busverbindung ebenfalls als Intraprozessorkommunikation behandelt werden). In Clusterumgebungen, wo die Rechenknoten unter normalen Umständen über Ethernet kommunizieren, ist natürlich die Intrapro-zessorkommunikation viel schneller als die Interprozessorkommunikation.
Wie bereits im Abschnitt 3.4.7 angedeutet, kann die Netzwerkkommunikation zwischen zwei Prozessoren ebenfalls durch die Latenzzeit tL und die Bandbreite der vorhandenen Netzwerkinfrastruktur, welche die zwei Prozessoren verbindet, in ausreichender Form beschrieben werden, so dass die Funktion (4.13) hier ebenfalls Gültigkeit findet.
Die letztere der oben erwähnten Zeitspannen, nämlich die Leerlaufzeit (TLeer) ist in ihrer Bedeutung leicht nachvollziehbar, jedoch in der Regel schwierig zu bestimmen, weil sie mit zahlreichen Faktoren verknüpft ist. Ein Prozessor kann sich im Leerlauf befinden weil er zu dem gegebenen Zeitpunkt keine Instruktionen oder keine Daten zur Bearbeitung bekommen hat. Diese Situationen sind entweder softwarebedingt (die Anordnung der Programminstruktionen kann die Länge der Leerlaufzeitspanne entscheidend beeinflussen), oder entstehen durch die begrenzte Leistung von bestimmten Hardwarekomponenten (mehr dazu im Kapitel 6).
Wir können jetzt die gesamte Ausführungszeit T auf zwei Arten definieren: Als die Summe der Rechen-, Kommunikations- und Leerlaufzeiten bei einem bestimmten Prozessor j, also
J
leerj
Kommj
ch TTTT ++= Re
12) Andere Faktoren wie die Problemgrösse, also die Anzahl von Instruktionen, die einen Algorithmus bilden, sowie der Anzahl von Jobs bzw. Unterprozessen, die gestartet werden müssen, spielen sicherlich dabei keine so unbedeutende Rolle. Wir werden jedoch diese Faktoren nicht in ihre tiefe Bedeutung berücksichtigen, denn ansonsten würden wir auf keinen Fall auf ein einfaches Modell stoßen können.
- 21 -

oder als die Summe dieser drei Zeitspannen über alle Prozessoren geteilt durch die Anzahl P der vorhandenen Prozessoren:
Die letzte Definition ist etwas nützlicher, denn es ist natürlich einfacher, die gesamte Rechen- und Kommunikationszeit eines parallelen Algorithmus zu bestimmen, als die Zeiten für Rechen- und Kommunikationstätigkeiten auf einzelnen Prozessoren zu messen. Aus dem oben Gesagten lässt sich deutlich erkennen, dass das Performanceproblem sich als ein Kommunikationsproblem interpretieren lässt, bei dem die Geschwindigkeit des Informationsaustausches eine wesentliche Rolle spielt. Der Vorteil bei einer solchen Interpretation ist, dass wir in der Lage sind, ein sehr einfaches Kommunikationsmodell zu bilden, das mit nur zwei Parametern für die Beschreibung des Problems auskommt: Die uns bereits bekannte Latenzzeit tL, also die notwendige Zeit, um die Kommunikation zwischen zwei Prozesse erstmals starten zu können, und die sog. Transferzeit pro Wort tW (typisch vier Byte Länge), welche durch die Bandbreite des Kommunikationskanals, der die zwei Prozesse verbindet, bestimmt wird. Somit schreiben wir die Funktion (4.13) wie folgt um:
(4.14)
Die Zeitfunktion T hat nun tatsächlich zwei Komponenten und ihre Form kann auf einfache Weise bestimmt werden.
Abbildung4.3: Einfaches Modell für Kommunikationszeit. Man hat hier die Zeit gegen die Größe der gesendeten Nachrichten in Bytes aufgetragen. Die Steigung der Geraden entspricht der Transferzeit pro Wort und der y-Achsenabschnitt stellt die Latenzzeit
dar.
In der Abbildung 4.3 lässt sich ablesen, dass die benötigte Zeit um ein Signal der Länge L zu schicken durch die folgende Beziehung gegeben ist:
(4.13)
Diese einfache Beziehung eignet sich für die Bestimmung von ichTRe und i
KommT in zahlreichen Hardwarekonfigurationen und deswegen wird sie uns bald wieder begegnen.
Die Tabelle 4.1 auf der nächsten Seite zeigt noch eine Liste von den auf verschiedenen Architekturen gemessenen Werten für tL und tW. Aufgrund der kontinuierlichen Entwicklung und Verbesserung von Hardwarekomponenten lassen sich diese Werte natürlich nur mit Vorsicht genießen. Man kann trotzdem dabei erkennen wie stark die Schwankungen in den Werten für tL und tW sind. Wie erwartet, weisen verschiedene Systeme deutlich unterschiedliche Performanceeigenschaften auf.
Tabelle4.1:Näherungswerte für die Parameter tL und tW auf einigen Parallelenmaschinen, gegeben in Mikrosekunden (µsec).
Maschine tL tL
IBM SP2 40 0.11
Intel DELTA 77 0.54
Intel Paragon 121 0.54
Meiko CS-2 87 0.08
nCUBE-2 154 2.4
Thinking Maschines CM-5 82 0.44
Workstations über Ethernet 1500 5.0
+= ∑ ∑ ∑
−
=
−
=
−
=
1
0
1
0
1
0Re
1 P
i
P
i
P
i
ileer
iKomm
ich TTT
PT
( )leerKommch TTTP
T ++= Re1
- 22 -
}
}
tL = Latenz
tW = Transferzeit pro Word
L = Nachrichtengröße
T = Zeit
( )WL ttfT ,=
LttT wL +=

KAPITEL 5 - Performancebestimmung in der Praxis
In den letzten Abschnitten haben wir wichtige Hintergrundinformationen behandelt, so dass wir jetzt in der Lage sind einige der oft eingesetzten Performance Messmethoden zu besprechen. Die beschriebenen Methoden sind teilweise direkt aus theoretischen Ergebnissen abgeleitet worden, andere dagegen folgen einem vollkommen praktischen Ansatz.
5.1 PerformancebestimmungnachderMethodedessequentiellenAnteils
Die Gleichung (4.12) lässt sich nach α auflösen, somit ergibt sich
(5.1)
Der so erhaltene Wert von α ist nützlich weil die Gleichung (4.11) für den Speedup einen stark idealisierten Fall beschreibt, nämlich dass alle Prozessoren a priori genau gleich viel rechnen, also ein perfektes „Load Balancing“ vorliegt. Aus diesem Grund lassen sich eventuell vorhandene Probleme auf Software- bzw. Hardwareebene nicht unmittelbar aus dem Speedup bzw. aus der Effizienz identifizieren. Betrachten wir die Ergebnisse auf Tabelle 5.1.Hätten wir die Werte für α nicht mittabelliert, könnten wir praktisch nicht ausmachen wie gut oder schlecht die Ergebnisse für S und e sind. Warum z.B. sinkt die Effizienz ständig? Da α fast konstant bleibt, können wir schließen, dass dieses Verhalten sehr wahrscheinlich auf eine beschränkte Parallelisierbarkeit der Applikation zurückzuführen ist. Würden dagegen die erhaltenen α Werte ständig und stetig wachsen, erhielten wir dann ein Zeichen dafür, dass die Granularitätsgröße der Applikation zu klein ist.
Tabelle5.1: Werte für S(N), e und α in Abhängigkeit von N:
5.2 TheoretischePeakperformance
Dieser Performancewert wird einfach durch die Summe der maximalen Leistung, die eine bestimmte Systemkomponente rein theoretisch erreichen kann, definiert. Zum Beispiel, für den Fall wissenschaftlicher Applikationen, in der die CPU Leistung eine wesentliche Rolle spielt, kann dies durch die folgende Beziehung ausdruckt werden:
P = N * C * F * R (5.2)
P ist hier die addierte CPU Performance, N die Anzahl von Knoten, C die Anzahl von CPUs pro Knoten, F die Anzahl von Floatingpointoperationen per Clock Takt, und R die Clock Rate (gemessen in Zyklen pro Sekunde). P wird typischerweise in Millionen von Floatingpointoperationen pro Sekunde (MFlop/s) oder in Milliarden von Floatingpointoperationen pro Sekunde (GFlop/s). Für Applikationen nichtwissenschaftlicher Natur werden Integeroperationen pro Sekunde statt Floatingpointoperationen benutzt, so dass die Leistung in Mip/s (Millionen Instruktionen pro Sekunde) oder Gips (Milliarden Instruktionen pro Sekunde) gemessen werden.
Der Vorteil dieser Methode ist, dass sie relativ einfach zu berechnen ist und noch dazu sehr viele Messungen dieser Art ständig publiziert werden, so dass ein Leistungsvergleich ebenfalls unkompliziert durchzuführen ist. Der größte Nachteil liegt natürlich darin, dass diese Leistung für echte Benutzerapplikationen unmöglich zu erreichen ist. Dieser Wert wird trotzdem benutzt um die Effizienz einer Anwendung zu ermitteln, also der Quotient zwischen der theoretischen maximalen Leistung und der tatsächlich erreichten Performance (mehr dazu später).
5.3 RechenleistungbeieinerspezifischenApplikation
Dieser Wert (P) wird uns durch die Anzahl von durchgeführten Operationen während der Ausführung einer spezifischen Anwendung (W), geteilt durch die gesamte Ausführungszeit (T) gegeben:
(5.3)
N Speedup (S(N)) Effizienz (e) α2 1.95 97 0.024
3 2.88 96 0.021
4 3.76 94 0.021
8 6.96 87 0.021
TWP =
NNNS
111)(1
−−
=α
- 23 -

Ähnlich wie bei der theoretischen Peakperformance, wird P hier in MFlop/s, GFlop/s, Mip/s oder Gips angegeben. Dieser Wert ist als Aussage für die zu erwartende Leistung des Systems offensichtlich bedeutungsvoller als der Wert aus der theoretischen Peakperformance, seine Bestimmung kann jedoch schwieriger zu erreichen sein. Selbst wenn die Anwendung die Parallelumgebung bereits ausnutzen kann (die Anwendung wurde parallelisiert), muss trotzdem die Anzahl der von der Anwendung ausgeführten Floatingpoint- bzw. Integer-Operationen genau ermittelt werden. Trotzdem lassen sich sehr nützliche Informationen gewinnen, wenn man diese Methode richtig einsetzt.
5.4 Gesamtrechenzeit
Wählt man eine spezifische Testapplikation mit einer vorgegebenen Problemgröße und misst man die exakte CPU-Zeit die benötigt wird, um diese Berechnung durchzuführen, kann man diese Zeitangabe als Maß der Performance eines Parallelrechners benutzen. Das Verfahren ist denkbar einfach und als zusätzlicher Vorteil kommt hinzu, dass die Ermittlung der genauen Anzahl der Rechenoperationen entfällt, die z.B. bei der Angabe der Rechenleistung nach 5.2 notwendig ist. Hinsichtlich der gesamten Systemperformance eines parallelen Rechners liefert diese Methode eine absolute Aussage über die tatsächliche Leistung des Systems. Man muss sich aber im Klaren sein, dass dieses Ergebnis nur von Bedeutung ist, wenn man es mit der erhaltenen Zeitmessungen derselben Testberechnung auf anderen Parallelrechnersystemen vergleichen kann.
5.5 Effizienz
Wenn wir die Rechenleistung eines Systems bei der Berechnung einer bestimmten Applikation messen, und diesen Wert mit dem theoretisch zu erwartenden maximalen Leistungswert für dieselbe Applikation vergleichen, erhalten wir eine Aussage über die prozentuale Nutzung der maximale Systemleistung für die spezifische Anwendung. Diese Methode ist natürlich sinnvoll wenn man wissen will, in wieweit eine Applikation die zur Verfügung stehende Rechenleistung des Systems wirklich benutzt. Ein viel zu niedriger Prozentualenwert würde z.B. bedeuten, dass eine vorhandene Clusterkonfiguration bzw. die Anwendung selbst stark anpassungsbedürftig ist. Ein viel zu hoher Wert würde andererseits andeuten, dass es sich bei der ausgewählten Applikation möglicherweise um eine EPC Applikation handelt, welche zum einen fast auf jeder Clusterarchitektur eine ähnliche hohe prozentuale Performanceleistung erreichen würde, zum anderen keine sinnvolle Information über die tatsächliche Rechenleistung der spezifischen Hardwarekonfiguration liefert.
5.6 DerLinpackBenchmark
Man erkennt anhand des oben Gesagten, dass es keine absolute Performancemessmethode gibt, die einerseits einfach einzusetzen ist und andererseits uns eine vollständige Beschreibung der Rechenleistung einer Clusterkonfiguration liefert. Diese variieren sehr stark in ihrer Bedeutung und der Art und Weise, mit der sich die relevanten Werte gewinnen lassen. Man kann dazu tendieren, die am einfachsten einsetzbare Methode zu favorisieren, nämlich die Messung der Ausführungszeit für die Applikation auf dem spezifischen System. Es gibt allerdings die Schwierigkeit, dass die jeweiligen Messungen nur ausgeführt werden können, wenn man das System bereits aufgebaut hat. Damit sind nachträgliche Änderungen der Systemkonfiguration entsprechen schwierig und teuer. Selbst wenn man Zugriff auf die gewünschte Konfiguration hätte und die Leistungsmessungen durchführen könnte, müsste man zunächst klären wie die Ergebnisse zu interpretieren sind. Ebenfalls zu überprüfen ist, wie man die erhaltenen Leistungswerte mit anderen Resultaten sinnvoll vergleichen kann, damit ein konkretes Bild der Systemperformance entsteht.
All diese Schwierigkeiten hat die Benutzergemeinde von Parallelcomputern und Clustern dazu bewegt, ihre Performancemessungen durch einige wenige Standard Benchmark Programme durchzuführen. Auf diese Weise lässt sich leichter bestimmen, ob eine gegebene Konfiguration effektiver als eine andere ist (als direktes Ergebnis der Benchmark-Tests). Die Relevanz solcher Vergleiche im Bezug auf eine spezifische Applikation kann man prinzipiell in Frage stellen. Aber die Erfahrung zeigt, dass es relativ gut dokumentierte Benchmarks gibt, welche uns eine sinnvolle Korrelation mit der entsprechenden eigenen Applikation aufbauen lassen.
Das berühmteste Beispiel dafür ist der Linpack Benchmark. Der Linpack Benchmark wurde 1975 von Jack Dongarra ins Leben gerufen als er mit der Ansammlung von Messergebnissen begann, die sich auf die Geschwindigkeit eines Systems bei der Lösung eines 100 x 100 großen linearen Gleichungssystem bezogen haben. Während die Größe dieser Aufgabe schon lange nicht mehr eine Herausforderung für einen Supercomputer ist, kann sie trotzdem gut verwenden, um die Rechenperformance eines Computers zu bestimmen. Insbesondere kann man auf diese Weise die Performance der einzelnen Rechenknoten in einem Cluster bestimmen.
1988 wurde der so genannte „Scalable Linpack Benchmark“, auch als „Parallel Linpack Benchmark“ bekannt, von Dongarra freigegeben. Dieser Benchmark wurde für die Messung der Rechenleistung mittelgroßer bis großer paralleler und verteilter Rechensystem entwickelt und lief bisher auf zahlreichen Computersystemen. Im Gegensatz zum ersten Linpack Benchmark wird bei der parallelen Version die Größe der Matrix nicht vorgegeben. Stattdessen wird dem Benutzer die Freiheit gegeben, das größte lineare Gleichungssystem, das mit den vorhandenen Speicherressourcen optimal berechnet werden kann, zu lösen. Ferner wird der Benutzer nicht verpflichtet, einen vorgegebenen Programmcode zu benutzen, wie es beim Standard Linpack Benchmark
- 24 -

der Fall war. Es besteht somit die Möglichkeit, jede denkbare Programmiersprache und Parallelbibliothek zu benutzen (sogar Assemblercode Bibliotheken sind erlaubt).
Seit 12 Jahren pflegen Dongarra und Strohmaier eine Liste mit den 500 schnellsten Computersystemen der Welt, die den parallelen Linpack Benchmark als Maßstab verwendet. Die aktuelle Liste lässt sich auf der Webseite www.top500.org betrachten. Die Linpack Benchmarks sind denkbar einfach einzusetzen. Die Umrechnungen für die Performancebestimmung erfolgen mühelos wenn man die Zeitmessungen durchgeführt hat. Der Hauptvorteil liegt jedoch in der Tatsache, dass es eine sehr große Menge an Ergebnissen gibt, mit denen man sehr leicht die eigene Konfiguration mit ähnlichen Hardwarekonfigurationen vergleichen kann.
Es gibt natürlich auch Nachteile bei der Nutzung von beiden Linpack Benchmarks (Single Prozessor und parallele Version): Beide liefern ein etwas verzerrtes Bild der echten Systemperformance. Dies liegt in der Tatsache begründet, dass die Benchmark Algorithmen aus Matrizenberechnungen bestehen, welche auf Hardwareebene eine sehr hohe Datenlokalisierbarkeit aufweisen (mehr dazu im Kapitel 6). Aus dem Benchmark abgeleitete Effizienzwerte von über 50% sind keine Seltenheit. Echte wissenschaftliche Applikationen erreichen hingegen nur selten Effizienzwerte über 20% auf parallelen Rechnern (vgl. gleich. 4.3).
5.7 BestimmungderLatenzundBandbreiteeinzelnenKomponenten
Man kann natürlich andere Methoden zur Messung der Performancecharakteristika eines Clusters einsetzen. Diese konzentrieren sich jedoch meistens auf ganz bestimmte Eigenschaften der Systemkomponenten wie Latenz und Bandbreite, oder sie versuchen die Auslastung systemspezifischer Ressourcen (I/O, Speicher, Netzwerkleistung, etc.) in Erfahrung zu bringen. Diese Tatsache macht diese Methoden weniger geeignet wenn es darum geht, eine allgemeingültige Aussage über die Gesamtleistung eines parallelen Rechners zu ermitteln, sie können uns jedoch bei der Aufgabe helfen, das von uns im §4.6 dargestellte Performancemodell zu überprüfen und zu verfeinern.
Wir beschreiben im Folgenden einige Linux Betriebssystemtools sowie Standard Open Source Benchmarks, welche entweder Teil der Linux Systemtools sind oder sehr leicht im Internet zu finden sind. Wir werden uns dabei auf die Messung von CPU- und Speicherperformance konzentrieren. I/O Performance lassen wir vorerst unbetrachtet.
5.7.1 nbench
nbench-byte ist eine verbesserte und aktualisierte Version von der BYTEmark Benchmark Suite, welche ursprünglich von Rick Grehan mit der Unterstützung der Computer Fachzeitschrift BYTE entwickelt worden ist. Die Aufgabe der Linux/UNIX Portierung wurde von Uwe F. Mayer übernommen und er selbst ist zurzeit für die Pflege und die weitere Entwicklung des Benchmarkcodes zuständig.
nbench-byte 2.2.1 benutzt 10 unterschiedliche Algorithmen, die repräsentativ für CPU intensive Aufgaben gewählt worden sind und generiert damit drei so genannte „Index figures“: Ein Integer Index, ein Floatingpoint Index und ein Memory Index. Der Memory Index trägt der Tatsache Rechnung, dass bei den meisten CPUs das Memory Subsystem den größten Leistungsbremser darstellt (mehr dazu im nächsten Kapitel).
Eine der auffälligsten Eigenschaften von nbench-byte ist, dass er die Messergebnisse selbst kalibriert, d.h. die so erhaltenen Werten werden anschließend mit denen aus einem AMD K6/233 CPU System verglichen, das mit 32 MB Hauptspeicher und 256KB L2-Cache ausgestattet ist. Ferner führt das Benchmark Programm bei jedem der zu startenden Tests die Bestimmung der minimalen Schrittanzahl durch, die für eine genaue Messung der Durchführungszeit notwendig ist. Dann wird diese Routine fünfmal nacheinander gestartet und anschließend eine statistische Analyse der jeweiligen Ergebnisse durchgeführt, um die Konsistenz der Ergebnisse zu überprüfen13).
Ist das nicht der Fall, dann wird nbench-byte diese Tests bis zu 25 Mal erneut durchfahren und die statistische Konsistenz dabei stets überprüfen. Wird die minimal nötigte Konsistenz trotzdem nicht erreicht, liefert nbench eine Warnung zusammen mit den entsprechenden Ergebnissen.
Wir vermissen allerdings eine wichtige Eigenschaft bei nbench-byte. nbench ist kein multi-threaded Benchmark, er kann also nicht den Speedup bestimmen, der durch den Einsatz von Multiprozessor Hardware entstehen sollte. Die Datei 5.1 zeigt am Beispiel des AMD Athlon MP 2000+ Prozessors wie die Standardausgabe von nbench-byte aussieht:
13) Die statistische Überprüfungsroutine verifiziert, ob wenigstens 95% der Ergebnisse eine Maximalabweichung von 5% bezüglich des Mittelwertes aller Messungen aufweist.
- 25 -

BYTEmark* Native Mode Benchmark ver. 2 (10/95)
Index-split by Andrew D. Balsa (11/97) Linux/Unix* port by Uwe F. Mayer (12/96,11/97)
TEST : Iterations/sec. : Old Index : New Index : : Pentium 90* : AMD K6/233* -----------------:------------------:-------------:------------ NUMERIC SORT : 947.84 : 24.31 : 7.98 STRING SORT : 128.49 : 57.41 : 8.89 BITFIELD : 3.3458e+08 : 57.39 : 11.99 FP EMULATION : 81.175 : 38.95 : 8.99 FOURIER : 17480 : 19.88 : 11.17 ASSIGNMENT : 17.256 : 65.66 : 17.03 IDEA : 2429.2 : 37.15 : 11.03 HUFFMAN : 1173.4 : 32.54 : 10.39 NEURAL NET : 22.382 : 35.96 : 15.12 LU DECOMPOSITION : 770.16 : 39.90 : 28.81 =================ORIGINAL BYTEMARK RESULTS====================
INTEGER INDEX : 42.432 FLOATING-POINT INDEX: 30.551
Baseline(MSDOS*) :Pentium* 90, 256 KB L2-cache, Watcom*compiler 10.0
====================LINUX DATA BELOW========================== CPU : Dual AuthenticAMD AMD Athlon(tm)Processor 667MHz
L2 Cache : 256 KB OS : Linux 2.4.20-64GB-SMP
C compiler : gcc version 3.3 20030226 (prerelease)(SuSE Linux) libc : ld-2.3.2.so MEMORY INDEX : 12.197 INTEGER INDEX : 9.523
FLOATING-POINT INDEX: 16.945 Baseline (LINUX): AMD K6/233*,512 KB L2-cache, gcc 2.7.2.3,
libc-5.4.38 * Trademarks are property of their respective holder.
Datei5.1: Ausgabe von nbench-byte auf dem AMD Athlon MP 2000+.
Anhand dieses Ergebnisses können wir zum Beispiel leicht erkennen, dass die Floating Point Leistung eines einzelnen AMD Athlon MP 2000+ etwa 17 Mal höher ist als die der Standard Benchmark CPU (AMD K6/233).
5.7.2 Cachebench
Cachebench ist ein Benchmark, der für die Performanceevaluierung sämtlicher eventuell vorhandener Levels (L1- L2, Hauptspeicher) in der Speicherhierarchie eines Computers konzipiert worden ist. Das Programm wurde von Philip J. Mucci geschrieben und liegt derzeit in der Version 2.0 vor14).
Wie im Abschnitt 3.4 erwähnt sind Caches grundsätzlich sehr kleine und schnelle Speicherausführungen, die für die Beschleunigung von Berechnungen ausgelegt sind, die mit regelmäßig auftretenden Datensets arbeiten. Durch den Einsatz von Cachebench will man also erfahren, wie effizient eine Speicherhierarchie unter der Wirkung einer sehr hohen Floatingpointauslastung arbeiten kann.
Cachebench besteht zurzeit aus acht verschiedenen Testroutinen. Jede Routine führt wiederholte Zugriffe auf unterschiedlich großen Datensets durch. Die Zugriffszeiten für jede Datensetgröße über eine bestimmte Anzahl von Iterationen werden festgehalten. Wenn man die Anzahl von Iterationen mit der jeweiligen Datengröße multipliziert bekommt man die genaue Anzahl von Bytes, auf die zugegriffen worden ist. Diese Zahl wird durch die gesamte Zugriffszeit dividiert, so dass man einen Wert in Megabyte pro Sekunde bekommt. Neben diesem Durchsatzwert werden auch die Zugriffszeiten für die entsprechenden Datensets geliefert.
14) Sowohl Cachebench als auch nbench-byte stehen per FTP oder HTTP auf dem Server des „Linux Benchmarking Project“ zum Download bereit, und zwar im Verzeichnis www.tux.org/pub/bench.
- 26 -

Die verschiedenen Testroutinen sind:
• Cache Read• Cache Write• Cache Read/Modify/Write• Hand Tuned Cache Read• Hand Tuned Cache Write• memset() Aus der C Standardbibliothek• memcpy() Aus der C Standardbibliothek
Auf diese Weise werden 8 Kurven generiert, die das Verhalten von den Speichersubsystemen ziemlich detailliert wiedergeben.
Abbildung5.1: Ergebnisse von Cachebench auf einen Single AMD Athlon MP 2000+.
Die Abbildung 5.1 zeigt die Ergebnisse des Benchmarks auf dem AMD Athlon MP 2000+. Man kann leicht erkennen, wie die Bandbreite der Kommunikation zwischen CPU und L1, L2 oder Hauptspeicher von der Problemgröße abhängt. Wenn die Größe des Registervektors kleiner als die Cachegröße ist, kommen alle angeforderten Dateien direkt aus dem L1-Cache und die Bandbreite erreicht ihren höchsten Wert.
Beim Übertreffen der L1-Cache Größe (im vorliegenden Fall 64 KByte), können die Daten noch in den L2-Cache passen, so dass die Bandbreite auf die vom den L2-Cache zu erwartende Leistung sinkt. Der letzte Leistungssprung nach unten ist zu beobachten, wenn die Größe der aufgeforderten Daten regelmäßig die L2-Cache Größe übertrifft (hier 256 KByte). Dann können wir höchsten den charakteristischen Datendurchsatz für den Hauptspeicher erreichen.
18000
16000
14000
12000
10000
8000
6000
4000
2000
0
64 256 1024 4096 16384 65536 262144 1.04858e+061.1943e+06 1.67772e+07
ReadWriteRMWTuned ReadTuned WriteTuned RMWmemset()memcpy()
x*
Cache Performance of AMD Athlon MP 2000+
Vector Length
MB/
Sec
- 27 -
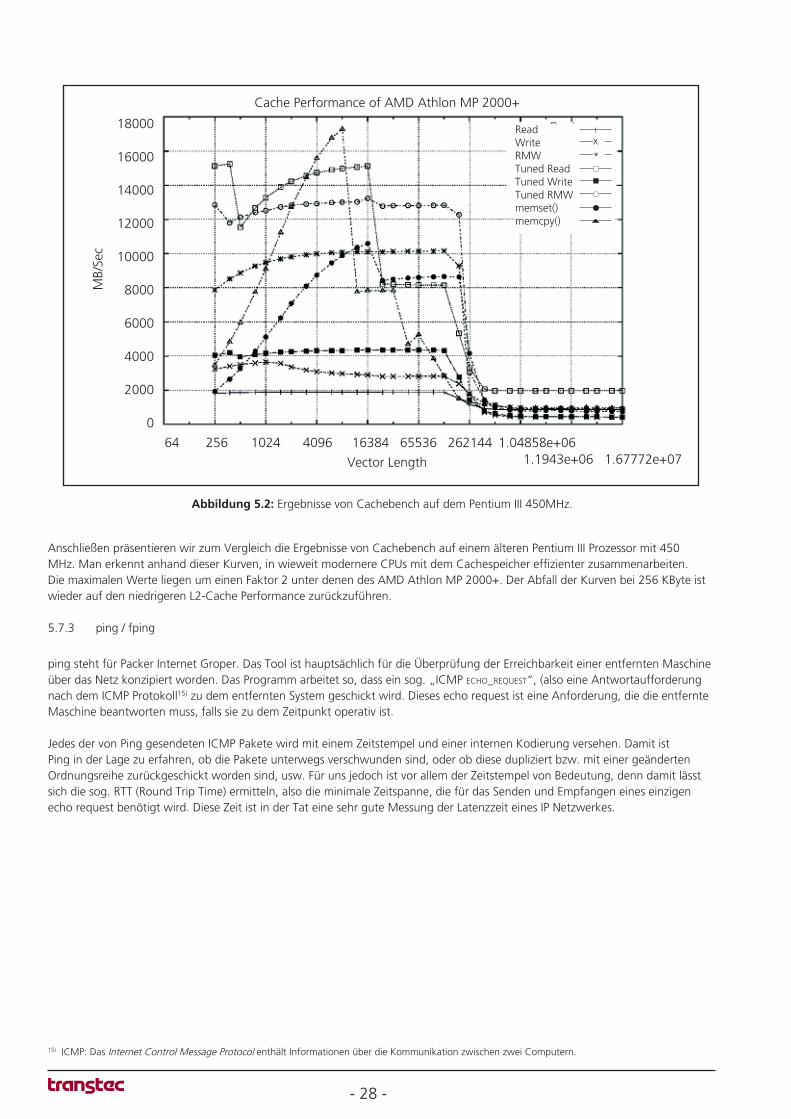
Abbildung5.2: Ergebnisse von Cachebench auf dem Pentium III 450MHz.
Anschließen präsentieren wir zum Vergleich die Ergebnisse von Cachebench auf einem älteren Pentium III Prozessor mit 450 MHz. Man erkennt anhand dieser Kurven, in wieweit modernere CPUs mit dem Cachespeicher effizienter zusammenarbeiten. Die maximalen Werte liegen um einen Faktor 2 unter denen des AMD Athlon MP 2000+. Der Abfall der Kurven bei 256 KByte ist wieder auf den niedrigeren L2-Cache Performance zurückzuführen.
5.7.3 ping / fping
ping steht für Packer Internet Groper. Das Tool ist hauptsächlich für die Überprüfung der Erreichbarkeit einer entfernten Maschine über das Netz konzipiert worden. Das Programm arbeitet so, dass ein sog. „ICMP ECHO_REqUEST“, (also eine Antwortaufforderung nach dem ICMP Protokoll15) zu dem entfernten System geschickt wird. Dieses echo request ist eine Anforderung, die die entfernte Maschine beantworten muss, falls sie zu dem Zeitpunkt operativ ist.
Jedes der von Ping gesendeten ICMP Pakete wird mit einem Zeitstempel und einer internen Kodierung versehen. Damit ist Ping in der Lage zu erfahren, ob die Pakete unterwegs verschwunden sind, oder ob diese dupliziert bzw. mit einer geänderten Ordnungsreihe zurückgeschickt worden sind, usw. Für uns jedoch ist vor allem der Zeitstempel von Bedeutung, denn damit lässt sich die sog. RTT (Round Trip Time) ermitteln, also die minimale Zeitspanne, die für das Senden und Empfangen eines einzigen echo request benötigt wird. Diese Zeit ist in der Tat eine sehr gute Messung der Latenzzeit eines IP Netzwerkes.
15) ICMP: Das Internet Control Message Protocol enthält Informationen über die Kommunikation zwischen zwei Computern.
18000
16000
14000
12000
10000
8000
6000
4000
2000
0
64 256 1024 4096 16384 65536 262144 1.04858e+061.1943e+06 1.67772e+07
ReadWriteRMWTuned ReadTuned WriteTuned RMWmemset()memcpy()
x*
Cache Performance of AMD Athlon MP 2000+
Vector Length
MB/
Sec
- 28 -

fantasma:/# ping www.host.de PING 153.94.0.82 (153.94.0.82) 56(84) bytes of data. 64 bytes from 153.94.0.82: icmp_seq=1 ttl=128 time=1.50 ms 64 bytes from 153.94.0.82: icmp_seq=2 ttl=128 time=0.306 ms 64 bytes from 153.94.0.82: icmp_seq=3 ttl=128 time=0.313 ms 64 bytes from 153.94.0.82: icmp_seq=4 ttl=128 time=0.302 ms 64 bytes from 153.94.0.82: icmp_seq=5 ttl=128 time=0.301 ms 64 bytes from 153.94.0.82: icmp_seq=6 ttl=128 time=0.298 ms 64 bytes from 153.94.0.82: icmp_seq=7 ttl=128 time=0.323 ms 64 bytes from 153.94.0.82: icmp_seq=8 ttl=128 time=0.346 ms 64 bytes from 153.94.0.82: icmp_seq=9 ttl=128 time=0.320 ms 64 bytes from 153.94.0.82: icmp_seq=10 ttl=128 time=0.295 ms
--- 153.94.0.82 ping statistics --- 10 packets transmitted,10 received, 0% packet loss,time 9006ms rtt min/avg/max/mdev = 0.295/0.431/1.508/0.359 ms
Datei5.2: Ausgabe des ping Befehls ohne Parameter.
Unter den Informationen, die die Ausgabe von ping liefert, steht die IP Adresse des entfernten Systems, die ICMP Sequenzzahlen und die Round Trip Zeiten in Millisekunden. Eine Zusammenfassung der Informationen ist in der letzten Zeile zu finden. Dort sind die Anzahl von gesendeten, empfangenen und verloren gegangenen Paketen, sowie die Statistiken über gesamte Laufzeit der Kommunikation zu finden, und ebenso eine statistische Auswertung für RTT.
fpingist ein ping ähnliches Programm, das genauso auf der Nutzung des ICMP Protokolls aufbaut um die Aktivität eines entfernten Systems zu registrieren. fping unterscheidet sich von ping, weil bei fping die Möglichkeit besteht, nicht nur eine Zielmaschine auf der Kommandozeile für die Rückmeldung zu definieren besteht. Man hat ebenfalls die Möglichkeit, eine Datei mit den Namen bzw. IP Adressen der zu überprüfenden Hosts zu erstellen. fping wird dann der Reihe nach ein einziges „echo request“ Paket zu den Systemen auf der Liste verschicken.
Die Defaulteinstellungen von fping bewirken, dass bei der Antwort einer Zielmaschine diese sofort aus der Liste der Zielmaschinen ausgetragen wird und als „alive“ gemeldet wird. Antwortet die Maschine nach einer gewissen Zeit bzw. nach einer bestimmten Anzahl von erneuten Versuchen nicht, wird die betroffene Maschine als unerreichbar („unreachable“) gemeldet. Die Datei 5.3 enthält ein einfaches Beispiel der Standardausgabe von fping:
Datei5.3:Die Standardausgabe des fpings Befehls
Interessant für eine schnelle Messung der Latenzzeit eines Netzes ist der Einsatz von fping zusammen mit den Optionen –C und -q. Die Datei 5.4 zeigt eben die Ausgabe von fping –C 4 -q:
- fantasma:~ # fping –C 4 –q 192.168.0.30 - 192.168.0.30 : 1.7 0.7 0.7 0.7
Datei5.4:Ausgabe des fpings Befehls mit den –C und –q Parameter
Wir sehen, dass nur die Antwortzeit in Millisekunden auf jedes der vier ICMP ECHO_REqUEST Pakete ausgegeben wird, was uns eine schnelle Abschätzung der Latenzzeit einer Verbindung erlaubt. Die Messung der Latenzzeiten mit Hilfe von ping/fping lassen sich nicht nur bei Fast Ethernetverbindungen durchführen, die Latenz von Gigabit Ethernet und Myrinet Netzen können ebenso unproblematisch in Erfahrung gebracht werden.
- fantasma:~ # fping 192.168.0.38 192.168.0.39 192.168.0.40 - 192.168.0.38 is alive - 192.168.0.39 is alive - 192.168.0.40 is unreachable
Die Datei 5.2 zeigt uns ein Beispiel von dem Einsatz des ping Befehls:
- 29 -

5.7.4 bing
bing ist ein Netzwerktool, das die Bandbreite einer point-to-point Netzwerkverbindung bestimmen kann, und zwar durch das Senden von ICMP ECHO_REqUEST Pakete und die darauf folgende Messung der RTT für die von Programm automatisch wechselnden Paketgroßen an jeder Seite der Verbindung.
Wenn sich der gemessene Wert von RTT bei der Übertragung einer bestimmten Paketgröße ändert, wird der neue Durchsatz angegeben, sonst werden diese Informationen defaultmäßig von bing unterdrückt.
fantasma:~ # bing 192.168.0.10 192.168.0.1 BING 192.168.0.10 (192.168.0.10) and 192.168.0.1 (192.168.0.1) 44 and 108 data bytes 1024 bits in 0.000ms 1024 bits in 0.014ms: 73142857bps, 0.000014ms per bit 1024 bits in 0.015ms: 68266667bps, 0.000015ms per bit 1024 bits in 0.014ms: 73142857bps, 0.000014ms per bit 1024 bits in 0.015ms: 68266667bps, 0.000015ms per bit 1024 bits in 0.014ms: 73142857bps, 0.000014ms per bit 1024 bits in 0.013ms: 78769231bps, 0.000013ms per bit 1024 bits in 0.014ms: 73142857bps, 0.000014ms per bit 1024 bits in 0.013ms: 78769231bps, 0.000013ms per bit 1024 bits in 0.014ms: 73142857bps, 0.000014ms per bit 1024 bits in 0.013ms: 78769231bps, 0.000013ms per bit
--- 192.168.0.10 statistics --- bytes out in dup loss rtt (ms): min avg max 4435035283503528 0% 0.008 0.009 89.851 10835035283503528 0% 0.008 0.009 90.168
--- 192.168.0.1 statistics --- bytes out in dup loss rtt (ms): min avg max 4435035283503528 0% 0.061 0.064 93.252 10835035283503527 0% 0.074 0.077 94.628 --- estimated link characteristics --- estimated throughput 78769231bps minimum delay per packet 0.044ms (3471 bits) average statistics (experimental) : packet loss: small 0%, big 0%, total 0% warning: rtt big host1 0.009ms < rtt small host2 0.009ms average throughput 78769231bps average delay per packet 0.046ms (3597 bits) weighted average throughput 78769220bps
Datei5.5: Standardausgabe des bings Befehls
Wird das Programm mit den richtigen Parametern aufgerufen, dann arbeitet bing so lange, bis eine maximale Anzahl von Iterationen erreicht wird, oder das Programm durch ein SIGINT Signal (Stgr + C) unterbrochen wird. Gleichzeitig wird eine kurze Zusammenfassung der Aktivitäten abgegeben. Die Datei 5.5 oben zeigt eine Beispielausgabe von bing. Eine einfache Rechnung zeigt uns anschließend, dass der Link aus dem Beispiel 5.5 einen Durchsatz von ca. 9.85MB/s aufweist, was die Leistung einer 100MBit Ethernet Anbindung entspricht.
- 30 -

KAPITEL 6 - Bottlenecks
Rechner bestehen aus zahlreichen Hardwarekomponenten. Diese wechselwirken in der Regel auf komplizierte Weise. Die Arbeiten, die diese Komponenten für die CPU verrichten, erfolgen mit stark unterschiedlicher Geschwindigkeit. Gelegentlich muss die CPU warten bis die spezifischen Jobs von diesen Hardwaresubsystemen erledigt werden, manchmal sind die Rechnerkomponenten diejenigen, die auf die CPU warten müssen. Man tendiert dazu, die CPU als die schnellste Komponente im System zu identifizieren. Auch wenn sie in den meisten Fällen diejenige Komponente ist, welche die größte Leerlaufzeit besitzt, müssen wir als wichtigste Tatsache festhalten, dass die Rechenleistung des Systems leidet, wenn es häufig die beschriebenen Warte- und Leerlaufzeiten gibt.
Versuchen wir eine bestimmte Anzahl von miteinander kommunizierenden Maschinen in einen einzigen Computer zu verwandeln, so erreichen solche Performanceprobleme einen noch höheren Komplexitätsgrad. Ein einziger im Leerlauf befindlicher Prozessor kann durch das Warten auf bestimmte Operationen bzw. Ergebnisse dermaßen abgebremst werden, dass die auf allen Rechenknoten verteilte Berechnung entscheidend verlangsamt wird.
Wenn es zwei oder mehr wechselwirkende Ressourcen eines Computersystems gibt und davon eine oder mehrere ihre maximale Leistung deutlich früher als die restlichen Ressourcen erreichen, so spricht man von einem Bottleneck(zu Deutsch: Flaschenhals).
Wir sind natürlich daran interessiert, so viel wie möglich über solche Leistungsbremser zu lernen, da sie eine grundlegende Rolle in unserem Verständnis über die Performance von Parallelrechnern spielen. Wir werden jedoch nur die klassischen Bottlenecks betrachten, die bei den meisten Computerberechnungen von Bedeutung sind: Der CPU Cache (Größe und Geschwindigkeit), der CPU-Speicherbus, das Kommunikationsnetzwerk und die Schreib/Leseoperationen der Festplatte.
6.1 SuperlineareSpeedups
Um jetzt ein besseres Bild über die Motivationen dieses Kapitels zu geben, wollen wir folgendes Beispiel betrachten: Angenommen, wir verfügen über einen Cluster, der aus Rechenknoten ohne Festplatten besteht und 128 MB Hauptspeicher pro Knoten aufweist. Wir haben weiterhin eine Applikation, welche insgesamt 128 MB Hauptspeicher während der Ausführung benötigt, andererseits jedoch eine Aufteilung der gesamten Problemgröße zulässt. Man kann also die Applikation bequem in 32 MB große Speichersegmente aufteilen, so dass sie z.B. auf 4 Knoten parallel auf dem Cluster laufen könnte.
Würden wir zuerst diese Applikation auf einem einzigen Rechenknoten ausführen, müsste der Job ständig auf Swapspeicher zugreifen. In unserem Fall ist die einzige Möglichkeit Swapspeicher zu benutzen der Zugriff über das Netzwerk auf die Festplatte eines entfernten Fileservers. Swapping ist jedoch sehr nachteilig, was die Performance einer Applikation angeht. Festplatten sind 2 bis 3 Zehnerpotenzen langsamer als der direkte Hauptspeicherzugriff, und Swapping über das Netzwerk macht dies noch schlimmer. Werden ständig Zugriffe auf die entfernte Festplatte benötigt, um die Speicherinhalte zu laden bzw. zu entladen, so kann die Zeit zur Ausführung der Applikation stark ansteigen.
Diese negativen Auswirkungen können so weit gehen, dass selbst der Sequentiellanteil des Programms viel langsamer ausgeführt wird. Die Ursache dafür liegt in der Tatsache, dass sowohl der Parallel- als auch der Sequentiellanteil regelmäßig aus dem Speicher ausgelagert und wieder geladen werden müssen, abhängig vom berechneten Programmteil.
Wenn dieselbe Applikation hingegen auf 4 Knoten des Clusters läuft, muss man sicherlich mit Zeitverlusten rechnen, die auf die notwendigen Kommunikationsvorgängen zwischen den Prozessen zurückzuführen sind. Die Jobs auf den Knoten müssen jetzt aber nicht mehr auf Swapspeicher schreiben. Diese verteilten Jobs passen in den Hauptspeicher der Knoten und es bleibt noch Speicherplatz übrig für das Laden des Betriebsystems, Programmbibliotheken, Buffers, etc. Durch die geeignete Verteilung der Jobs auf dem Cluster kann es sogar vorkommen, dass der dadurch erreichte Speedup sehr groß wird und eine Verletzung des Gesetzes von Amdahl möglich ist16).
Dieses Ergebnis kann etwas überraschend wirken, lässt sich aber beim näheren Hinsehen relativ leicht erklären. In der Tat hat das im Kapitel 4 abgeleitete Gesetz von Amdahl eine gewisse Stetigkeit vorausgesetzt bezüglich des durch den Parallel- und Sequentiellanteil definierten Zeitquotienten (s. Gleichung 4.11). Insbesondere haben wir vorausgesetzt, dass die Zeiten TS und TP sich bei der Aufteilung der N parallelen Jobs nicht großartig unterscheiden. Es ist also kein außergewöhnliches Beispiel notwendig gewesen um zu zeigen, dass diese Annahme in der Welt der echten Computerapplikationen nicht mehr gilt, da reale Systeme über begrenzte Ressourcen verfügen oder weil nicht alle vorhandenen Ressourcen innerhalb der gleichen Zeitskala miteinander kommunizieren können.
Speedups, die das einfache Gesetz von Amdahl verletzen, werden als superlineareSpeedups bezeichnet und werden in zahlreichen Fachpublikationen detailliert behandelt. Im Grunde genommen entsteht ein superlinearer Speedup, wenn der erreichte Speedup
16) Man kann sich eine noch extremere Situation vorstellen und sich fragen, welchen Speedup man erreichen würde wenn diese Rechenknoten überhaupt keine Möglichkeit zum Swapping hätten (z.B. wenn keine entfernten Festplatten für die Auslagerung vorhanden sind). In diesem Fall würde der Job auf einem einzigen Knoten nicht laufen können und man hätte eine unendliche Ausführungszeit für diese Applikation zur Folge. Mit dem Einsatz von vier Knoten bei der Berechnung der Applikation würde man aber eine endliche Ausführungszeit bekommen und somit einen unendlichen Speedup erreichen, was die oben gemeinte Verletzung des Gesetzes von Amdahl deutlich darstellt.
- 31 -

nach der Parallelisierung einer Applikation viel schneller skaliert als N. In den meisten praktischen Fällen lässt sich dieses Verhalten des Speedups auf die breite Palette der in einem Computersystem existierenden Hardwarezugriffszeiten zurückführen.
6.2 ApplikationseigenschaftenundHardwareBottlenecks
Werfen wir nun einen Blick auf die wichtigsten Bottlenecks, die die Performance von parallelen Applikationen bedeutend beeinträchtigen können. Wir beginnen mit einer einfachen Tabelle, welche die unterschiedlichen Bottlenecks zeigt, sowie die Leistungswerte, die diese Bottlenecks charakterisieren.
Tabelle6.1: Typische Leistungswerte für wichtige Bottlenecks.
Man erkennt gleich beim ersten Blick auf die Tabelle, dass die eingetragenen Zeiteinheiten für die verschiedene Hardware-komponenten sich zwischen sieben oder mehr Zehnerpotenzen unterscheiden. Vergleichen wir die Latenzzeit eines CPU Taktzyklus beim Zugriff auf eine bestimmte Speicheradresse innerhalb des L1 – Cache, welche weniger als eine Nanosekunde beträgt, mit der Latenzzeit von 5 oder mehr Millisekunden, die für den Zugriff auf eine bestimmte Adresse auf der Festplatte nötig ist.Ähnlich dramatisch fällt der Vergleich zwischen Bandbreiten im Bereich von einem Megabyte pro Sekunde bei Datentransfers über Standardethernet mit den Durchsatzraten im Bereich von Gigabyte pro Sekunde im Fall des L1- Caches aus.
Noch ein weiterer interessanter Aspekt, der sich aus der Tabelle entnehmen lässt, hat mit der Hierarchie der im System vorhandenen Speicherelemente zu tun. Die großen Unterschiede in den Latenz- und Zugriffszeiten bei den verschiedenen Speicherarten machen sie für eine Performanceanalyse schwierig zu handhaben. Man kann aber diese Unterschiede hinter einer Durchschnittslatenz verstecken und dadurch die Performanceanalyse für spezifische Applikationen vereinfachen. Dieser Durchschnittswert wird einfach durch die Anzahl von Zugriffen, die auf den verschiedenen Speicherarten erfolgen, bestimmt (dabei lassen sich Festplatten und Datentransfers über das Netzwerk ebenfalls als Speicherelemente behandeln).
Was wir haben ist, mathematisch ausgedrückt, eine Wahrscheinlichkeitsverteilung. Nehmen wir an, Pi ist die Wahrscheinlichkeit, die von der gegebenen Applikation unmittelbar benötigte Datei bzw. den Programmcode innerhalb der i-ten Speicherart zu finden und Li ist die entsprechende Latenzzeit für diesen Speicher (die Speicherarten entsprechen den auf der Tabelle 5.1 bereits erwähnten). Auf diese Weise ist die durchschnittliche Zeit , die das System warten muss, bis die Daten oder die Programmbefehle erstmals verfügbar sind (gesamte Latenzzeit) durch folgende Beziehung gegeben
(6.1)
Beispiel: Wenn wir die folgenden Zugriffswahrscheinlichkeitswerte PLI = 0.05, PL2 = 0.9 und PL2 = 0.05 für eine Berechnung hätten, die vollständig innerhalb des Hauptspeichers passt, erhält man aus (6.1)
(6.2)
in Nanosekunden. Die Abschätzung der Gesamtlatenzzeit für das System wäre natürlich noch komplizierter, wenn wir jede Hardwarekomponente betrachten würden. Die wirklich relevante Tatsache ist hier jedoch eine andere: Solange die Speicherhierarchie des vorliegenden Systems bei einer durchschnittlichen Latenzzeit und Bandbreite bleibt, deren Wert vernünftig nah an den Standardwerten von L1 und/oder L2 Cache für die gegebene Applikation liegt, gibt es keinen guten Grund mehr Geld in eine noch teurere Speicherhierarchie zu investieren.
Bottleneck Beschreibung Latenz Bandbreite
L1 CacheLesen/Schreiben von CPU auf L1
Cache0.4 - 5 ns
(1 CPU Takt)Bis zu 20 GB/s
L2 CacheLesen/Schreiben von
L1 auf L2 Cache4 – 10 ns 400-1000 MB/s
HauptspeicherLesen/Schreiben von
L2 Cache auf Speicher40 – 80 ns 100-400 MB/s
Festplatte (lokal)Lesen/Schreiben von CPU auf
Festplatte5 - 15 ms 1-80 MB/s
Festplatte (NFS)Lesen/Schreiben von CPU auf
NFS Dateisystem5 - 20 ms 0.5-70 MB/s
Netzwerk Schreiben von CPU zu CPU 5 - 50 µs 0.5-100 MB/s
- 32 -
L
∑ ⋅=i
ii LpL
75.950*05.08*9.01*05.0 =++=L

Es ist natürlich üblich, dass die Vorteile eines großen L2 Cache z.B. von den CPU Herstellern überdimensioniert dargestellt werden, denn sie sind logischerweise daran interessiert, noch teurere (und rentablere) CPUs zu verkaufen. Die Erfahrung zeigt jedoch, dass es eine breite Palette von parallelen Applikationen gibt, die von der Nutzung größerer Cachespeicher nicht richtig profitieren können. Noch dazu kommt der Preisunterschied, der sich zwischen CPUs mit kleinem bzw. großem Cache bis zum Faktor 10 bewegt. Für solche Algorithmen beispielsweise, könnte man sicherlich besser beraten sein, wenn man statt einem einzigen Xeon System mit 2 MB Cachegröße gleich 3 komplette Celeron Systeme kauft.
Natürlich gibt es eine andere Klasse von Anwendungen die sich dadurch auszeichnet, dass ganze Instruktionssets bzw. Datenbestände in den Cachespeicher passen. Solche Anwendungen sind aufgrund dessen deutlich schneller als normale Anwendungen, welche auf den Hauptspeicher zugreifen müssen17). Die Ursache für solche hohe Leistungen liegt in der Tatsache begründet, dass diese Algorithmen eine relativ kleine Anzahl von Programmschleifen durchführen, die aus sequentiellen Instruktionen bestehen. Diese Struktur lässt das Laden ganzer Datenblöcke aus dem Hauptspeicher in den Cache zu und diese Datenbestände reichen für lange Berechnungsphasen vollständig aus. Im günstigen Fall kann der Algorithmus ständig im L1 Cache „leben“ und somit über lange Zeit mit der vollen CPU Geschwindigkeit abgearbeitet werden. Die Bedingung hierfür lautet PL1 + PL2 >> PM , so dass die CPU häufig bereits im Cachespeicher die für die Berechnung notwendigen Daten findet, ohne auf den langsamen Hauptspeicher zugreifen zu müssen. Solche Applikationen nutzen die verfügbare CPU Leistung sehr effizient aus.
Was passiert nun, wenn ein Algorithmus die Addition von beliebig positionierten Datenbytes aus einem 1 MB großen Datenbereich regelmäßig durchführt? Dann wird die Wahrscheinlichkeit für das Programm, die unmittelbar benötigten Daten innerhalb des Caches zu finden, deutlich geringer. Mit einem 128 KB großen L2-Cache könnte diese Wahrscheinlichkeit nicht größer als 1/10 sein, so dass 90% der Zeit etwa 60 ns benötigt werden um das nächste zu addierende Byte aus dem Hauptspeicher zu holen, während die restlichen 10% der Zeit nur 10 ns (oder weniger) für diese Aufgabe gebraucht werden. Man erhält also einen Durchschnittswert von einem Byte pro 55 ns (plus ein CPU Takt für die eigentliche Additionsaufgabe).
Mit einem 512 KB großen L2 Cache steigt die Wahrscheinlichkeit, die unmittelbar benötigte Datei im Cache zu finden auf das Doppelte und die durchschnittliche Latenzzeit reduziert sich auf 35 ns. Mit einem 1 GB L2 großen Cache befinden sich die Daten ständig im Cache und wir kommen auf eine Latenzzeit von ungefähr 10 ns, also einen Faktor 6 schneller als mit dem 128 KB großen Cache. Solche Applikationen wie die hier beschriebene weisen eine stark „nicht lokalisierte“ Speicherzugriffsstruktur auf und profitieren daher am meisten von größeren Caches.
Beim näheren Hinschauen kann man auch sogar behaupten, dass Applikationen dieser Klasse - bei geeigneter Parallelisierung - sehr gute Chancen haben, einen superlinearen Speedup zu erreichen. In der Tat, wenn wir den oben erwähnten 1 MB großen Datenbereich in 10 Datensektoren jeweils mit einer Größe von 100 KB aufteilen, dann würden die 10 so verteilten Jobs im Cache eines kleineren Prozessors (z.B. Celeron mit 128 KB Cache) mit ungefähr der sechsfachen Geschwindigkeit laufen. Dazu kommt ein Faktor 10 auf Grund der parallelen Ausführung der Additionen. Diese Bedingungen zusammen mit der Wahl einer geeigneten Granularitätsgröße können der Applikation zu einer noch höheren Effizienz verhelfen. Im Endeffekt bekommen wir eine Parallelumgebung, die für den betroffenen Algorithmus einen noch höheren Speedup aufweisen kann als es von einem einfachen 10 Knoten-Cluster zu erwarten wäre, bei dem man den Cacheflaschenhals ignoriert hat.
6.3 DualCPUSysteme
Es gibt eine Fülle von Programmen bzw. Benutzerapplikationen, deren Berechnungszeit (sei es auf einer parallelen oder einer sequentiellen Maschine) sehr stark von der Geschwindigkeit abhängt, mit der die Daten oder die Programminstruktionen aus dem Hauptspeicher geholt werden können. Die CPU Leistung spielt dabei eine etwas untergeordnete Rolle. Unter diesen sog. Memory Bound Applikationen findet man Programme, die sehr große Matrizen multiplizieren oder viele sequentielle Operationen mit Daten aus großen Datenblöcken ausführen. Während der Programmsausführung werden ständig neue Datenblöcke aus dem Hauptspeicher geholt und in den Cachespeicher abgelegt (und umgekehrt), so dass der Speicherbus kontinuierlich unter starker Belastung steht. Unter diesen Umständen taucht ein weiterer wichtiger potentieller Bottleneck bei Clusterkonfigurationen auf.
Es hat sich innerhalb der Clusterwelt die Routine etabliert, mehr CPU Rechenleistung in Form von Dual SMP Systemen (auch einfach Dual Prozessorsysteme genannt) zu erreichen. Dual CPU Motherboards sind nur wenig teurer als die Single CPU Pendants. Die CPUs teilen sich jedoch dabei alle anderen Hardwarekomponenten wie Speicher, Gehäuse, Festplatten, Netzteil, etc. untereinander. Auf diese Weise erhofft man sich durch eine relativ kleine zusätzliche Investition eine höhere Rechenleistung pro Knoten. Falls der erreichbare Speedup für eine bestimmte Applikation sehr stark von der CPU Leistung abhängt, stellen SMP Systeme die optimale Hardwarebasis für diese Applikation dar. Im Falle einer sehr starken CPU-Abhängigkeit des Algorithmus kann
17) Hierzu ist das ebenfalls von J. Dongarra initiierte ATLAS Projekt (Automatically Tuned Linear Algebra System) zu erwähnen. Dieses Projekt versucht, die Generierung von optimierten Algorithmen für lineare Algebra Berechnungen zu automatisieren, so dass die notwendigen Programmschleifen und Speicherblockgrößen an die Cachegröße des Computers angepasst werden. Dadurch wird der Speedup für die jeweilige Applikation um den Faktor 2 bis 3 beschleunigt.
- 33 -

man es sogar mit einer EPC Applikation zu tun haben, denn die Zahl der verarbeiteten Instruktionen ist proportional zur Anzahl der CPUs. Handelt es sich hingegen bei dem spezifischen Job um einen speicherbedingten Job, so stellt man schnell fest, dass durch den Einsatz von Dual Prozessor Systemen der Speicherbus stärker belastet wird. Wenn zwei CPUs gleichzeitig Daten aus dem Speicher zu holen versuchen - und zwar so schnell wie sie es können - muss in der Regel einer von beiden Prozessoren warten, bis der Datenbus wieder frei wird. Dieses Verhalten kann also in der Tat die Leistung solcher speichergebundenen Jobs auf SMP Systemen so stark beeinträchtigen, dass wir in der Regel nur 140-160% Leistungszuwachs beobachten werden, statt der durch den Einsatz zweier CPUs zu erwarteten 200%. Die unmittelbare Schlussfolgerung lautet also, dass speichergebundene Applikationen im Allgemeinen auf Einzelprozessor Systemen bessere Chancen haben, eine höhere Effizienz zu erreichen.
6.4 Netzwerkflaschenhals
Außer Speicherbedingten und CPU - bedingten Applikationen gibt es auch solche, die sehr stark von der Leistung der Kommunikationsschnittstelle zwischen den Prozessoren abhängen. Diese sind innerhalb des Clustermodells als netzwerkbedingte Applikationen einzustufen. Es gibt leider zahlreiche Aspekte die man in Betracht ziehen muss, wenn man es mit netzwerkbedingten Applikationen zu tun hat: Ist es sinnvoll zwei NICs pro Rechenknoten zu verwenden um den Datendurchsatz zu erhöhen? Ist der Job etwa auch speicherleistungsabhängig, (die Netzwerkarten werden eben über den Speicherbus angesprochen), oder will man doch noch SMP Systeme benutzen? Diese können nämlich unter Umständen eine viel effizientere Nutzung der Netzwerkressourcen ermöglichen, denn die Übertragung von Daten über das Netz dauert deutlich länger, wenn der Zielprozessor während der Kommunikation mit der Durchführung anderer Tätigkeiten beschäftigt ist (eine zweite CPU kann da Abhilfe schaffen). Wir können aus diesem Grund keine allgemeingültige Regel aufstellen, die uns eine einfache Entscheidung über die bessere Hardwarearchitektur für netzwerkbedingte Applikationen ermöglicht. Wir betrachten jedoch kurz den wichtigsten Aspekt, der mit der Performance einer netzwerkbedingten Applikation verbunden ist, nämlich die Konkurrenz für die Bandbreite und schildern dabei, wie das Netzwerk zum Flaschenhals werden kann.
Stellen wir uns die Frage was passiert, wenn zwei Prozessoren zum gleichen Zeitpunkt versuchen, Daten über dieselbe Leitung zu schicken. Unter normalen Umständen erfolgt ein einziger Transfer über die Datenleitung, der zweite Transfer muss darum auf eine Warteschleife gestellt werden oder er wird zurückgewiesen. Statt sich auf die Aktivität der einzelnen Prozessoren zu konzentrieren erweist es sich in der Praxis als vorteilhafter, den ganzen Prozess so zu modellieren, als ob die beiden Prozessoren sich die zur Verfügung stehende Bandbreite teilen müssten. Bei dem Kommunikationsterm im Performancemodell aus Abschnitt 4.6 bedeutet dies, dass der Term tw L für das Volumen des Datentransfers geeicht werden soll und zwar durch die Anzahl n der Prozessoren, die miteinander bei dem Senden auf der gleichen Datenleitung konkurrieren. Die Gleichung 4.13 wird entsprechend umgeformt zu
(6.3)
Der Eichfaktor n trägt nun der Tatsache Rechnung, dass die effektive Bandbreite für jeden Prozessor nur den Bruchteil 1/n der echten Bandbreite beträgt. Die negative Auswirkung der Konkurrenz auf die Bandbreite zeigt sich im Prinzip sehr deutlich, wenn die Granularitätsgroße der Applikation zu klein ist (s. §4.3) und zahlreiche Kommunikationsprozesse generiert werden, so dass entsprechend viele Daten über die Netzwerkleitung geschickt werden. Ebenfalls sind sog. synchrone Algorithmen anfällig, also Algorithmen, die das gleichzeitige Senden und Empfangen von Prozessordaten erlauben (oder Algorithmen, bei denen die Prozessoren während des Wartens auf weitere Prozessdaten im Leerlauf bleiben).
Asynchrone Algorithmen können im Gegensatz dazu während des Wartens auf nötige Daten andere Jobs für die CPUs starten und sind somit vom Problem der Konkurrenz für die Bandbreite nur bedingt betroffen.
Anschließend müssen wir noch bemerken, dass bei der Gleichung 6.3 eine wichtige Tatsache unberücksichtigt bleibt. Bei den Kollisionen von Daten, die gleichzeitig auf derselben Leitung gesendet werden, kommt es zu neuen Kommunikationsvorgängen beim Datensender und das wiederum kostet nochmals wertvolle Zeit. Im Clusterumfeld arbeitet man jedoch fast ausnahmslos mit Switched Netzwerken, und genau deswegen erlauben wir uns, die negativen Auswirkungen dieses zeitraubenden Faktors außer acht zu lassen18).
18) Die meisten Kommunikationsnetzwerke bei Clusterkonfigurationen benutzen weniger als N² Datenleitungen um N Prozessoren zu verbinden. Es müssen also Netzwerk Switches benutzt werden, um die Daten aus einem Quellprozessor optimal ins Ziel zu transportieren. Die Aufgabe des Switches ist es, die Daten anzuhalten oder umzuleiten wenn mehrere Zugriffe gleichzeitig auf demselben Netzwerkkanal stattfinden. Die Anzahl von Switches die kontaktiert werden müssen, um Daten aus dem Sendeprozessor bis zum Zielprozessor zu schicken, wird als Abstand zwischen den Prozessoren bezeichnet. Der Abstand zwischen zwei Prozessoren und die Länge des benötigten Kabels sind in der Regel nicht von Bedeutung, wenn es um die Bestimmung der Netzwerkperformance eines Systems geht. Man darf aber nicht vergessen, dass der Einsatz besonders langer Kommunikationskabel und mehrerer Switches gerade bei hochwertigen Netzwerkinterfaces wie Myrinet, die Hardwareanschaffungskosten eines Clusters in die Höhe treiben können.
- 34 -
LnttT WLBegrenzKomm ⋅+=

6.5 Input/Output
Ein letzter noch zu berücksichtigender, relevanter Faktor bei der Bestimmung der Performance einiger paralleler Applikationen ist die Zeit welche benötigt wird, um Daten aus dem Hauptspeicher in die sekundären Speicher zu transportieren, also die Zeit für Standard Schreib/Leseoperationen auf der Festplatte. Unter den Applikationen, die einen starken I/O Charakter aufweisen, erkennen wir folgende:
• Checkpoints: Es gibt bestimmte Applikationen mit beträchtlich großer Laufzeitspanne. Eine periodische Sicherung des Berechnungszustands zu einem gegebenen Zeitpunkt mit Hilfe des sog. Checkpointings, ist in diesem Fall von großer Bedeutung, damit man die Risiken und Folgen von Systemausfällen sinnvoll minimieren kann. Die Zustandssicherung großer Berechnungen kann viele Gigabytes in Anspruch nehmen.
• Simulationen: Applikationen aus der Wissenschaft und der Technik verfolgen die Entwicklung physikalischer Systeme im Laufe der Zeit und ermöglichen auf diese Weise die Visualisierung und Analyse des betrachteten Systems. Solche Simulationen können erstaunlich große Datenmengen erzeugen (hunderte von Gigabytes pro Laufzeitperiode)
• Virtual Memory Berechnungen: Einige Applikationen arbeiten mit Datenstrukturen, die größer sind als der im System zur Verfügung stehende Hauptspeicher. Im Prinzip kann ein virtuelles Speichersystem (Swapbereich) die notwendigen Datentransfers zwischen Speicher und Harddisk realisieren (auch wenn diese deutlich langsamer sind als reine Speicherzugriffe). Das Problem dabei ist, dass nicht jede Clusterkonfiguration einen virtuellen Speicher zur Verfügung stellt. Selbst wenn virtueller Speicher vorhanden ist, so ist die Leistung der Applikation trotzdem durch eine optimierte Gestaltung der Datentransfers über das I/O System deutlich steigerbar.
• Datenanalyse: Andere parallele Applikationen sind für die Analyse sehr großer Datenbestände konzipiert, zum Beispiel für die Ergebnisse von Klimasimulationen. Die aus Wetterstationen gesammelten Daten können nach extremen Werten durchsucht werden (z.B. wo liegen die höchsten Temperatur- oder Luftfeuchtigkeitswerte, etc). Eine Videodatenbank lässt sich nach spezifischen Bildern durchsuchen oder eine Datenbank mit Informationen über Kreditkarten wird nach bestimmten Merkmalen durchsucht, die trügerische Transaktionen charakterisieren. Solche Applikationen für Datenanalysen sind aus der Sicht des I/O Systems sehr belastend, da zahlreiche kleine Rechenaufgaben auf Daten erfolgen, die ständig von der Festplatte geholt werden müssen.
Wir können in der Regel unsere Erkenntnisse aus dem Bereich Interprozesskommunikation direkt auf den Bereich I/O übertragen und dadurch wichtige Rückschlüsse über dessen Auswirkung auf die Systemperformance ziehen. Man betrachtet hierfür die Schreib-Leseoperationen als eine Art Interprozessorkommunikation, in denen die Festplatten eine Sonderrolle spielen. Die Struktur eine Schreib/Lese Operation auf Festplatte lässt sich wie beim Netzwerk durch eine Latenzzeit und eine Zeit pro Nachrichtentransfer (Durchsatz) verstehen. Wir können somit die gleiche Beziehung benutzen
(6.4)
(T = Kommunikationszeit, tL = Latenzzeit, tW = Transferzeit pro Wort, L = Größe der gesendeten Nachricht). Wir müssen dabei nur berücksichtigen, dass die Latenzzeit typischerweise viel größer ist als im Falle des Netzwerks. In gleicher Form wie bei der Interprozesskommunikation ist der Schlüssel zu höherer Leistung die Maximierung der Nutzung der verfügbaren Kommunikationskanäle bei gleichzeitiger Minimierung der Kommunikationsprozesse.
Wenn ein Computersystem nur eine Festplatte hat, oder wenn mehrere Platten mit einem einzigen Prozessor verbunden sind, kann man sehr wenig für die Optimierung der I/O Leistung einer parallelen Anwendung erreichen. In der Praxis sind aber die meisten Clusterkonfigurationen mit mehreren I/O Kommunikationsleitungen versehen, entweder durch die Anwesenheit von speziellen I/O Knoten (Plattenarrays), oder weil auf jedem Rechenknoten eine Festplatte vorhanden ist. Von Architekturen dieser Art profitieren hauptsächlich Anwendungen, die so programmiert sind, dass die Prozessoren konkurrierende Schreib/Lese Operationen asynchron starten können.
- 35 -
LttT WL +=

Abbildung6.1:I/O Architektur eines Clusters. P Prozessoren sind durch mehrere I/O Kanäle mit D Festplatten verbunden.
Wir wollen diesen Abschnitt mit der Bemerkung abschließen, dass uns die Eins zu Eins Übertragung des Netzwerkkommu-nikationsmodells auf das Problem der Disk-Prozessor Interkommunikation ebenfalls auf eine Granularitätsgröße bei Schreib/-Lese Operationen sprechen lässt. Es gibt also eine gewisse Anzahl von unterschiedlichen Schreib/Lese Operationen, die für den Datentransfer zwischen Platte und Hauptspeicher (und umgekehrt) notwendig sind. Je weniger solcher Operationen pro Rechenzyklus generiert werden, desto niedriger ist die Auswirkung der I/O Leistung auf die gesamte Performance des Systems und der darauf laufenden Applikationen.
PProzessoren
I/O Pfade
FFestplatten
- 36 -

KAPITEL 7 - Mathematische Grundlagen zum Optimierungsverfahren
Unser Ziel ist, wie wir es im Kapitel 2 bereits angedeutet haben, ein mathematisches Modell zu entwickeln, das uns den Prozess der Konfiguration und Angeboterstellung eines HPC Clusters (oder kurz: Das Konfigurationsproblem) optimieren lässt. Diese Optimierung verstehen wir als die vereinfachte Suche nach einem Gleichgewicht zwischen Rechenleistung und Wirtschaftlichkeit eines Systems. Wenn wir als Unternehmen das allgemeine Problem der Erstellung eines Angebots für ein Clustersystem näher betrachten erkennen wir die Existenz von zwei Standardsituationen, die sich nur leicht voneinander unterscheiden: Es gibt Kunden mit einem fest vorgegebenen Budget, diese wollen die beste Rechenleistung für das zur Verfügung stehende Geld bekommen. Das Gegenteil ist auch möglich (obwohl etwas seltener zu sehen): Der Kunde legt eine vorgegebene minimale Rechenleistung fest und will den besten Preis für diese Systemperformance bekommen. Beides Mal erkennen wir die Existenz eines Optimierungsproblems, dessen erfolgreiche Lösung sowohl von technischen als auch von wirtschaftlichen Faktoren abhängt.
Wir haben in den letzten drei Kapiteln viele Aspekte behandelt die uns erst in die Lage versetzen, die Hardwarestruktur eines Clusters sowie die Wechselwirkung dieser Hardware mit spezifischen Eigenschaften paralleler Applikationen zu verstehen. Der nächste Schritt in die oben genannte Richtung besteht natürlich darin, eine solide Verbindung zwischen diesen technisch orientierten Informationen und denjenigen Aspekten, die mit der Kostenoptimierung zu tun haben, aufzubauen.
Schon seit Anfang der vierziger Jahre versucht man, optimierte Lösungen für diverse Problemstellungen durch den Einsatz der so genannten Simplexmethode zu erreichen, einem mathematischen Verfahren, das aus dem Gebiet der linearen Optimierung bekannt ist. Wir wollen in diesem Kapitel das Verfahren genauer vorstellen, denn wir möchten dieses später als Ansatzpunkt für die Lösung des Konfigurationsproblems benutzen. Dabei werden wir so viel vom Thema linearer Optimierung bzw. Simplex-Verfahren in diesem Kapitel behandelt, wie es für die Analyse des Problems und die Erstellung eines mathematischen Modells notwendig sein wird.
7.1 LineareOptimierung
Im Jahre 1947 wurde von George B. Dantzing das Thema „lineare Optimierung“ mathematisch begründet. Dieses damals ausschließlich für die Optimierung militärischer Einsätze konzipierte Verfahren wurde jedoch in den darauf folgenden Jahren als Standardverfahren für die Optimierung verschiedener Probleme aus der Wirtschaft eingesetzt, einem Gebiet, in dem auch heute noch ihre hauptsächliche Anwendung liegt.
Als eine ihrer bekanntesten Anwendungen ist sicherlich das Rundreiseproblem (engl. travelling salesman) zu nennen: Man sucht nach der kürzesten Reiseroute zwischen n verschiedenen Orten, die alle Orte genau einmal besucht und am Ende wieder zum Ausgangspunkt zurückkehrt. Auch das Transportproblem oder das Reihenfolgeproblem sind bekannte Anwendungsgebiete der linearen Optimierung19). Kurz gesagt, es existieren in der Praxis zahlreiche unterschiedliche Optimierungsprobleme, die mit dem Lösungsverfahren der linearen Optimierung, der Simplexmethode, gelöst werden können. Wir sind der Ansicht, dass sich das Konfigurationsproblem mit dem wir uns hier befassen, unter bestimmte Voraussetzungen auf diese Weise lösen lässt. Daher wird im Folgenden eine allgemeine Beschreibung des Verfahrens geliefert.
7.2 Problemstellung
In der Mathematik spricht man von einem Optimierungsproblem, wenn man die Bestimmung des Optimalen Wertes (Maximum oder Minimum) einer sogenannten Zielfunktion zu erreichen versucht. Der Zielfunktion unterliegt einer bestimmten Anzahl von Nebenbedingungen (auch Restriktionen genannt), welche die Funktionsbildenden Variablen direkt beeinflussen. Es gibt zahlreiche Methoden, die für die Lösung solcher Probleme in der Mathematik eingesetzt werden können. Welche davon in der Tat benutzt wird, hängt einzig und allein von der Form der Zielfunktion ab.
Lineare Optimierung20) ist das Verfahren, welches für die Lösung eines Optimierungsproblems angewendet wird, wenn die Zielfunktion eine lineare Funktion ist und die Nebenbedingungen ebenfalls lineare Gleichungen bzw. lineare Ungleichungen sind. Ein lineares Optimierungsproblem lässt sich letztlich stets in folgende Form bringen:
19) Das Transportproblem versucht die Transportkosten eines bestimmten Produktes zu minimieren, welche in n verschiedene Fabriken hergestellt wird. Die Abnehmer des Produktes befinden sich an verschiedenen Orten und benötigen im Allgemeinen unterschiedliche Mengen des Produktes, so dass die Kosten für den Transport je nach Entfernung der Fabriken und der Abnehmer unterschiedlich hoch sind. Das Reihenfolgeproblem versucht seinerseits die kürzeste Gesamtlauf zu finden, die die Herstellung von n Produkten auf m Maschinen ermöglichen soll.
20) Früher auch als „lineare Programmierung“ bezeichnet. Programmierung bedeutete damals noch in ihrem eigenen Sinn eine Planung, also das Aufstellen eines Arbeitsplanes und wurde erst später mit dem wachsenden Einfluss des Computers mit dem Erstellen eines Computerprogramms in Zusammenhang gebracht.
- 37 -

Gesucht sind solche Werte der n reellen Variablen x1 , x2 , K, xn für welche die Zielfunktion
P(x) = p1x1 + p2x2 + K + pnxn (7.1)
ihren Minimalwert annimmt, wenn alle Punkte betrachtet werden, deren Koordinaten die Nebenbedingungen
a11x1 + a12x2 + K + a1nxn = b1
a21x1 + a22x2 + K + a2nxn = b2
........................................... (7.2) am1x1 + am2x2 + K + amnxn = bm
a11x1 + a12x2 + K + a1nxn = b1
erfüllen. Die Koeffizienten aij , bi , pj (i = 1.2, K , m, j = 1,2,K, n) sind dabei reelle Zahlen.
Ein Übergang von P(x) zu P(x) + const ändert nichts bezüglich der Minimalstelle. In Matrizenschreibweise mit x
nR∈ , der (m,n)-Matrix A= (aij), p= (p1 , p2 , K, pn )T,
b = o21) lässt sich die lineare Optimierungsaufgabe so formulieren:
Ax = b x ≥ 0 P(x) = pTx = Min!.
Ist das Maximum einer Zielfunktion gesucht, so ist dieses gleichbedeutend mit
P(x) = - P(x) = (- p1)x1 + K + (-pn)xn = Min!
Treten Ungleichungen als Nebenbedingungen auf, z.B. ai1x1 + K + ainxn ≤ bi , so kann man durch Definition einer neuen Variablen w, einer sogenannten Schlupfvariablen, zur Gleichung ai1x1 + K + ainxn + w = bi übergehen. Auch für die neue Variable w gilt w ≥ 0. In der Zielfunktion ordnen wir der Schlupfvariablen den Koeffizienten 0 zu.
Ein x = (x1, …,xn)T, das allen Nebenbedingungen genügt, heißt zulässiger Punkt. Die Menge aller zulässigen Punkte heißt zulässiger
Bereich. Ändert sich durch das Weglassen einer Nebenbedingung der zulässige Bereich nicht, so heißt diese Nebenbedingung überflüssig.
7.3 GeometrischeDeutung:Maximum-undMinimum-OptimierungimR²
Bei Problemen mit zwei Variablen kann man darauf verzichten, von Ungleichungen durch Einführen einer Schlupfvariablen zu Gleichungen überzugehen. Eine lineare Ungleichung a1x1 + a2x2 ≤ b lässt sich unmittelbar geometrisch interpretieren: Alle Punkte, die dieser Ungleichung genügen, liegen auf der Geraden a1x1 + a2x2 = b und in einer der Halbebenen, in die diese Gerade die Ebene teilt. So lassen sich im R ² die Nebenbedingungen durch lineare Ungleichungen mit zwei Variablen sowie durch die Nichtnegativitätsbestimmungen der beiden Variablen darstellen. Dadurch wird ein begrenztes oder auch offenes Gebiet, eine konvexe Menge, festgelegt22).
Diese konvexe Menge kann entweder beschränkt (Abb. 6.1 a und b) oder unbeschränkt (Abb. 6.1 c) sein: eine solche beschränkte konvexe Menge nennt man auch ein Simplex.
21) x ≥ o heißt also x1 ≥ 0, K ,xn ≥ 0
22) Eine Menge S in einem n-dimensionalen Raum wird als konvexe Menge bezeichnet, wenn jedes Segment, das zwei beliebige Punkte innerhalb der Menge verbindet, sich vollständig innerhalb von S befindet.
Abbildung7.1: Verschiedene Arten zulässiger Bereiche für Maximum-Optimierung
a) b) c)x1 x1 x1
x2x2x2
- 38 -
( ) ≥Tmbb ,,1 K

Alle Elemente, die eine zulässige Lösung für das Problem darstellen, müssen folglich auch Elemente dieser konvexen Menge sein. Da sämtliche Ungleichungen aus „≤“-Zeichen bestehen, gehören auch die Rand- und Eckpunkte zu dieser Menge. Von diesen verschiedenen zulässigen Lösungen gilt es nun, denjenigen Wert zu finden, für den die Zielfunktion ihr absolutes Maximum oder auch Minimum annimmt. Je nach Art der Zielfunktion und der dazugehörigen Lösungsmenge gibt es natürlich auch unterschiedliche Lösungsmöglichkeiten: Beim ersten Beispiel von Abb. 7.1 gibt es genau einen Punkt, für den die Zielfunktion einen maximalen Wert annimmt: diesen Punkt nennt man auch Lösung der Maximum Optimierung.
Anders beim Beispiel b) in der Abb. 7.1; hier existiert eine ganze Strecke als Lösung, die von zwei Eckpunkten beschränkt wird. Einen solchen Fall nennt man eine mehrdeutige Lösung: Es gibt mehrere Optimalpunkte, mit denen jeweils derselbe optimale Wert erreicht wird; in der Praxis erfolgt in einem solchen Fall die Auswahl aus den verschiedenen Lösungen nach anderen Gesichtspunkten, wie z.B. Flexibilität, Skalierbarkeit, etc. Ist die Menge der zulässigen Lösungen unbeschränkt, wie in c), so kann man kein absolutes Maximum und somit auch keine Lösung finden. In diesen beiden letzten Fällen treten bei der rechnerischen Lösung Unstimmigkeiten auf, aus denen man die Art der Lösung leicht erkennen und dann passende Maßnahmen ergreifen kann. Ebenfalls möglich ist der Fall, dass überhaupt kein Bereich von zulässigen Elementen existiert, es also z.B. keinen Punkt gibt, der zwei Ungleichungen gleichzeitig erfüllt. In diesem Fall kann natürlich auch keine optimale Lösung gefunden werden.
Bei einer Minimum Optimierung treten Unterschiede genau diesbezüglich auf (Abb. 7.2):
Abbildung7.2: Verschiede Arten zulässiger Bereiche für Maximum Optimierung
Es lässt sich aus der Abbildung 7.2 sofort entnehmen, dass hier eine unbeschränkte konvexe Menge nicht unbedingt bedeuten muss, dass keine Lösung gefunden werden kann.
Ganz im Gegenteil gibt es bei einer Minimum Optimierung immer mindestens eine Lösung: entweder ein Eckpunkt, wie bei dem Fall in a), eine Strecke als Lösung in b) oder gar, wie beim letzten Fall, den Ursprung (0,0) als absolutes Minimum. Da die Nichtnegativitätsbedingungen notwendigerweise ein Teil jeder Optimierungsaufgabe sind, sollte diese Tatsache eigentlich nicht sehr verwundern. Dies bedeutet einfach, dass auf jeden Fall ein Minimum gefunden werden kann, unabhängig davon, ob die Menge der zulässigen Lösungen unbeschränkt ist oder nicht.
Speziell in kleineren Dimensionen kann die rechnerische Lösung (wie wir sie im kommenden Abschnitt behandeln werden) zu aufwändig im Vergleich zu der graphischen Lösung sein. Dieses graphische Verfahren findet nur in zwei, höchstens drei Dimensionen eine vernünftige Anwendung. In größeren Dimensionen kann man Optimierungsaufgaben nicht mehr auf einfache Weise graphisch darstellen. Solche mehrdimensionalen Aufgaben werden ausschließlich durch Computerberechnungen gelöst. Wir haben das graphische Lösungsverfahren trotzdem hier mitbehandelt, weil wir dadurch einige wichtige Aspekte der linearen Optimierung übersichtlicher darstellen können.
7.4 DerSimplex-AlgorithmusunddieBildungdesSimplextableaus
Der erste Schritt beim Simplex-Algorithmus besteht darin, alle Nebenbedingungen eines Linearen Optimierungsproblems (LOP) so umzuschreiben, dass sie einen positiven konstanten Wert auf der rechten Seite der Ungleichungen aufweisen. Dann wandeln wir alle Ungleichungen in Gleichungen, durch die Einführung der oben genannten Schlupfvariablen, um.
Zum Beispiel lassen sich die Ungleichungen –x + 2y ≤ 6 und 5x + 4y ≤ 40 entsprechend als –x + 2y + w1 = 6 und 5x + 4y + w2 = 40 umschreiben, wobei w1 und w2 Variablen sind, die positive Werte (oder den Wert Null) annehmen können und 1 als Koeffizient aufweisen. Diese neuen Variablen werden benötigt, um eine Justierung der linken Seite der Gleichungen bezüglich der konstanten Terme auf der rechten Seite zu ermöglichen. Betrachten wir folgendes Beispiel.
Das Maximum der Zielfunktion P(x,y) = x + 4y wird gesucht. P(x) unterliegt folgenden Restriktionen: –x + 2y ≤ 6 und 5x + 4y ≤ 40. Da ständig x, y ≤ 0 schreiben wir die Nebenbedingungen wie oben erläutert
- 39 -
a) b) c)x1 x1 x1
x2x2x2

–x + 2y + w1 = 6 5x + 4y + w2 = 40 (7.3)und die Zielfunktion
P – x – 4y = 0
Ein LOP, das in der oben genannten Form vorliegt, befindet sich in der kanonischen Form. Ein LOP in kanonischer Form kann in einer Tabelle folgender Art gespeichert werden: Wir konstruieren zuerst eine Variablen Identifizierungszeile wie unten abgebildet (der Einfachheit halber benutzen wir hierfür das Beispiel oben)
Als nächstes tragen wir die Koeffizienten der Problemvariablen sowie die von der Schlupfvariablen in der Tabelle ein. Ebenso werden die Konstanten (6, 40) auf der rechten Seite von (6.3) in der Spalte b aufgeschrieben. Wir erhalten
Die letzte Spalte „Verif“ auf der rechten Seite der Tabelle wird eingeführt um die Verifizierung der Zwischenergebnisse von der Berechnung zu vereinfachen. Wir tragen dort die Summe der Koeffizienten jeder Zeile ein, wobei der Term auf der Spalte b mitberücksichtig wird. Dies liefert
Ein kurzer Blick auf die Tabelle zeigt uns, dass die zwei vorhandenen Nebenbedingungen (n=2) nun vier Variablen aufweisen (m = 4). Wir tragen die Basisvariablen in eine separate Spalte auf der linken Seite der Tabelle ein. Ferner merken wir, dass die Spalten mit den Koeffizienten der Schlupfvariablen eine Einheitsmatrix bilden.
Als letztes betrachten wir die Zielfunktion P = x + 4y. Wir schreiben sie wie folgt um: P - x + 4y = 0, und tragen ihre Koeffizienten in der letzten Zeile, der sog. Indexzeile unten im Tableau ein, also:
Somit haben wir ein so genanntes Simplextableau für das LOP in (7.3) vervollständigt und wir können uns der Lösung desselben widmen.
- 40 -
x y w1 w2 b Verif
x y w1 w2 b Verif
-1 2 1 0 6
5 4 0 1 40
Basis x y w1 w2 b Verif
w1 -1 2 1 0 6 8
w2 5 4 0 1 40 50
Problem- Variablen
Schlupf- Variablen Konstanten
Kern Einheitsmatrix
Basis x y w1 w2 b Verif
w1 -1 2 1 0 6 8
w2 5 4 0 1 40 50
P -1 -4 0 0 0 -5

7.5 SchrittezurBerechnungdesSimplexes
i) Wir selektieren die Spalte mit dem größten negativen Koeffizienten auf der Indexzeile, in unserem Fall -4. Diese Spalte wird als Pivotspalte bezeichnet. Wir markieren sie hier mit einem Kästchen.
ii) Bei jeder Zeile dividieren wir den Wert in der Spalte b jeweils durch die positiven Koeffizienten aus der Pivotspalte. Der kleinste Quotient bestimmt nun die sog. Pivotzeile. Für die Zeile 1 (w1), r = 3
26= , für die Zeile 2 (w2), r = 10
440
= . Die Zeile 1 wird also unsere Pivotzeile. Wir markieren sie ebenfalls mit einem Kasten:
Das Tabellenelement bei dem sich Pivotzeile und Pivotspalte treffen ist das Pivotelement: Hier die Zahl 2.
iii) Als nächstes dividieren wir alle Einträge in der Pivotzeile durch das Pivotelement um diese in eine 1 umzuwandeln. In dem unten stehenden Simplextableau haben wir dieses Element mit einem Kreis markiert. Die neue so entstehende Zeile wird als Hauptzeile bezeichnet. Die restlichen Elemente des Tableaus bleiben unverändert, so dass wir folgendes erhalten
iv) Nun benutzen wir die Hauptzeile um auf den anderen Zeilen des Tableaus zu operieren (einschließlich der Indexzeile). Somit lassen sich die anderen Koeffizienten in der Pivotspalte auf Null reduzieren. Die Hauptzeile bleibt dabei unverändert. Die neuen Einträge in den restlichen Positionen auf dem Tableau, inklusive der in der b Spalte und der Verifizierungsspalte, lassen sich wie folgt bestimmen:
Neuer Wert = Alter Wert – Produkt der entsprechenden Einträge auf der Pivotzeile und der Pivotspalte
Zum Beispiel in der zweiten Zeile (w2): 5 wird durch 5 – (–½) · (4) = 5 + 2 = 7 ersetzt 4 wird durch 4 – (1) · (4) = 4 – 4 = 0 ersetzt 0 wird durch 0 – (½) · (4) = 0 – 2 = –2 ersetzt 50 wird durch 50 – (4) · (4) = 50 –16 = 34 ersetzt, etc.
Basis x y w1 w2 b Verif
w1 -1 2 1 0 6 8
w2 5 4 0 1 40 50
P -1 -4 0 0 0 -5
Pivotspalte
Basis x y w1 w2 b Verif
w1 -1 2 1 0 6 8
w2 5 4 0 1 40 50
P -1 -4 0 0 0 -5
Pivotelement
Pivotzeile
Basis x y w1 w2 b Verif
w1 -½ 1 ½ 0 3 4
w2 5 4 0 1 40 50
P -1 -4 0 0 0 -5
Einheitspivot
Pivotspalte
Hauptzeile
Indexzeile
1 A
B K
K wird durch
K - (A X B) ersetzt
Hauptzeile
- 41 -

Und für die Indexzeile:
–1 wird durch –1 – (–½) · (–4) = –1 – 2 = –3, etc.
Wenn wir auf diese Weise weitermachen und die Operationen für die Zeile (P) vervollständigen, erhalten wir23)
23) Hier können wir die Rolle der Verifizierungsspalte deutlich erkennen. Wenn die erhaltenen Werte in dieser Spalte nicht mit den Summen der Elemente auf den entsprechenden Zeilen übereinstimmen, ist mit Sicherheit einen Fehler während der Berechnung unterlaufen.
v) Änderung der Basisvariablen: In ihrer Endform besteht die Pivotspalte aus einer einzigen Eins und sonst Nullen. Die 1 taucht in der Spalte y auf, das bedeutet, dass die Variable w1 auf der Basisspalte sich durch y ersetzen lässt.
Es gibt nun zwei Spalten, die aus einer 1 und sonst nur Nullen bestehen. Diese sind y und w2, welche ab jetzt die Basisvariablen auf der linken Spalte darstellen. Wenn wir die Werte auf der b Spalte ablesen, können wir eine neue Basis angeben, nämlich y = 3 und w2= 28. Jede andere Variable, die auf der Basisspalte nicht auftaucht, hat nun den Wert Null. Eine LOP Lösung in diesen Moment würde lauten x = 0, y = 3, w2 = 28. Wir sind jedoch noch nicht fertig. Die Indexzeile (P) enthält noch einen negativen Eintrag, so dass wir das obige Verfahren wiederholen müssen.
Jetzt dividieren wir die Pivotzeile durch das Pivotelement (7) um dieses auf 1 zu reduzieren. Somit erhalten wir:
- 42 -
Basis x y w1 w2 b Verif
w1 -½ 1 ½ 0 3 4
w2 7 0 -2 1 28 34
P -3 0 2 0 12 11
Basis x y w1 w2 b Verif
w1 -½ 1 ½ 0 3 4
w2 7 0 -2 1 28 34
P -3 0 2 0 12 11
y
Basis x y w1 w2 b Verif
y -½ 1 ½ 0 3 4
w2 7 0 -2 1 28 34
P -3 0 2 0 12 11
Pivotzeile
Pivotspalte
Basis x y w1 w2 b Verif
w1 -½ 1 ½ 0 3 4
w2 1 0 -2/7 1/7 4 34/7
P -3 0 2 0 12 11
Pivotzeile

Wir benutzen die Hauptzeile erneut, um auf die anderen Zeilen des Tableaus zu operieren und dadurch die in der Pivotspalte enthaltenen Einträge auf Null zu reduzieren:
Wir merken nun, dass w2 in der Basisspalte sich durch x substituieren lässt. x war eben der Name der Spalte, die das letzte Pivotelement enthalten hat. Wir bekommen schließlich:
Eine neue Basis besteht jetzt aus x = 4 und y = 5. Ferner, da wir keine negativen Einträge mehr in der Indexspalte finden, sind wir auf die optimale Lösung für das LOP Problem (7.3) gekommen. Der optimale Wert von P ist aus der b Spalte abzulesen: Pmax = 24.
Wir haben hier eine mehr oder weniger detaillierte Darstellung des Simplexalgorithmus abgeliefert, wenn auch nur in zwei Variablen. Obwohl das Konfigurationsproblem sicherlich mehr als zwei Variable enthalten wird, können wir erkennen, dass das soeben ausführlich beschriebene Simplex-Verfahren grundsätzlich gleich bleibt, auch wenn wir es auf Probleme mit mehr als zwei Variablen einsetzen möchten.
Die Tatsache, dass es sich bei dem Simplex-Verfahren um einen Iterationsprozess handelt, welcher so oft wiederholt werden muss, bis die Indexseile keine negativen Einträge mehr aufweisen, macht es leicht durch den Einsatz eines Computerprogramms Lösungen für LOP Probleme mit mehreren Variablen zu finden. Eine Lösung des Konfigurationsproblems in Softwareform wird uns daher später nahe gelegt.
7.6 KünstlicheVariablen
Bevor wir unseren Ausflug in die mathematischen Grundlagen der Optimierung abschließen, müssen wir noch eine Methode betrachten, die das Simplex-Verfahren in seiner Anwendbarkeit kräftig erweitert. Dazu nehmen wir folgendes Beispiel: Wir wollen die Funktion P = 7x + 4y maximieren, die mit den Restriktionen: 2 x + y ≤ 150, 4 x + 3 y ≤ 350 und x + y ≥ 80 (x, y ≥ 0) versehen ist. Wenn wir diese Ungleichungen durch die Einführung von Schlupfvariablen in Gleichungen umwandeln, bekommen wir:
2 x + y + w 1 = 150 4 x + 3 y + w 2 = 350 (6.4) x + y - w 3 = 80 und die Zielfunktion lautet: P - 7x - 4y = 0. Die dritte Restriktion ist eine „Größer als“ Bedingung, so dass man die positive Schlumpfvariable (w3) subtrahieren muss, um die Gleichung zu erhalten. Wir bilden unser erstes Tableau
- 43 -
Basis x y w1 w2 b Verif
y 0 1 5/14 1/14 5 45/7
w2 1 0 -2/7 1/7 4 34/7
P 0 0 8/7 3/7 24 179/7
Basis x y w1 w2 b Verif
y 0 1 5/14 1/14 5 45/7
x 1 0 -2/7 1/7 4 34/7
P 0 0 8/7 3/7 24 179/7
Basis x y w1 w2 w3 b Verif
w1 2 1 1 0 0 150 152
w2 4 3 0 1 0 350 358
w3 1 1 0 0 -1 80 81
P -7 -4 0 0 0 0 -11

Wir stehen jetzt vor einem Problem, denn wir haben keine Einheitsmatrix im Tableau, mit der wir nach dem Simplex-Verfahren vorgehen können. Die Spalte w3 enthält das Element -1 und somit ist es für uns unmöglich, durch irgendeine arithmetischen Operation gleichzeitig eine positive 1 in der Spalte w3 zu bekommen und alle Elemente in der Spalte (b) der Konstanten noch positiv zu halten (die Konstanten in b sind per Definition positiv). Die Ursache des Problems liegt eigentlich in der Anwesenheit eines negativen Terms bei der Schlumpfvariablen in (6.3). Wir können trotzdem die Situation lösen, und zwar durch die Einführung einer neuen kleinen positiven Variablen (w4), so dass w1, w2 und w4 einer Einheitsmatrix bilden und die Anwendung des Simplex-Verfahren wieder möglich wird. Selbstverständlich ist w4 von fiktivem Charakter und muss daher verschwindend klein gewählt werden. Sie darf ebenfalls beim Endergebnis nicht mehr auftauchen.
Um all diese Bedingungen zu erfüllen, führen wir in die Zielfunktion den neuen Term -Mw4 ein, wobei M ein sehr großer, positiver Koeffizient ist. Dies garantiert uns letztendlich, dass w4 aus dem Endergebnis verschwinden wird. Wir schreiben dann: P = 7x + 4y – Mw4. Die neue Variable w4 wird künstliche Variable genannt. Die dritte Nebenbedingung in 6.4 wird zu
x + y - w 3 + w4 = 80
Wir schreiben das System (6.4) erneut um:
2x + y + w 1 = 150 4x + 3y + w 2 = 350 (6.5) x + y - w 3 + w4 = 80 P - 7x - 4y + Mw4 = 0
Als nächstes wird das Simplextableau wie üblich gebildet:
Merken wir uns:i) Die Spalten w1, w2 und w4 bilden nun eine Einheitsmatrixii) Es gibt jetzt 6 Variable und 3 Nebenbedingungen, das heißt, n = 6 und m = 3, so dass aus (n – m), 6 -3 = 3. Es
müssen also 3 Variablen gleich Null gestellt werden. Wir starten mit x, y und w3 als Null. w1, w2 und w 4 bilden die erste Basislösung mit den Koeffizienten in der b Spalte.
Wir verfahren nun wie im Abschnitt 6.5 bereits beschrieben und arbeiten nach dem Verfahren so lange an dem Tableau, bis kein weiterer negativer Eintrag in der Indexzeile zu finden ist. Wir wollen auf die nötigen Zwischenberechnungen verzichten und eher das Tableau bis zu diesem Punkt gleich angeben:
Die optimale Lösung für das Problem (6.4) bzw. (6.5) lautet am Ende:
Pmax = 500 mit x = 50, y = 50
- 44 -
Basis x y w1 w2 w3 w4 b Verif
w1 2 1 1 0 0 0 150 152
w2 4 3 0 1 0 0 350 358
w4 1 1 0 0 -1 1 80 81
P -7 -4 0 0 0 M 0 M-11
Basis x y w1 w2 w3 w4 b Verif
x 1 0 3/2 -½ 0 0 50 52
w3 0 0 -½ ½ 1 -1 20 20
y 0 1 -2 1 0 0 50 50
P 0 0 5/2 -½ 0 M 550 M-553

KAPITEL 8 - Das Konfigurationsproblem
Nachdem wir in Kapitel 7 die mathematischen Grundlagen zur Lösung von allgemeinen linearen Optimierungsproblemen nach dem Simplex-Verfahren diskutiert haben, können wir nun zum ersten Mal versuchen eine quantitative Aussage über das Konfigurationsproblem zu liefern. Dafür müssen wir in der Lage sein, dieses Problem in algebraischer Form umzuschreiben und zwar in Form einer linearen Funktion. Die entsprechenden Restriktionen denen die Funktion unterliegt, müssen ebenfalls eine Gruppe von linearen Gleichungen bzw. Ungleichungen bilden, wenn das Simplex-Verfahren hier Anwendung finden soll.
An dieser Stelle müssen wir uns im Klaren sein, dass es sich bei dem hier dargestellten Lösungsansatz um einen ersten Versuch handelt, der uns zu einem besseren Verständnis der Zusammenhänge verhelfen soll. Es ist durchaus möglich, dass auf Grund der komplexeren Natur des Konfigurationsproblems die Anwendung anderer mathematischer Methoden bzw. Optimierungsverfahren notwendig sein wird, um praxistaugliche Ergebnisse durch den Einsatz des Clusterkonfigurators zu erreichen. Wir würden jedoch ohne diese erste Evaluierung nicht tiefer in die Analyse des Konfigurationsproblems gehen können.
8.1 DieDefinitioneinerZielfunktion
Die Entwicklung eines mathematischen Modells, das die Gegebenheiten eines konkreten Problems so akkurat wie möglich wiedergeben soll, verfolgt immer ein ähnliches Muster. Die Hauptmerkmale, die das Problem charakterisieren, müssen als mathematische Variablen dargestellt werden und die Art und Weise wie diese Problemcharakteristika untereinander Wechselwirken, muss in Form von mathematischen Funktionen ausgedrückt werden. Diese Funktionen können ebenfalls wichtige limitierende Faktoren innerhalb des Problems in algebraische Form ausdrücken. Wir werden dieses Schema verfolgen. Es müssen aber dazu noch einige vernünftige, vereinfachende Annahmen gemacht werden, um unsere erste Annäherung zu der algebraischen Form des Konfigurationsproblems nicht unnötig zu erschweren.
Wir wissen, z.B. dass das Konfigurationsproblem zwei grundlegende, wenn auch leicht unterschiedliche Ziele, verfolgen kann: Man will die Leistung einer bestimmten Clusterkonfiguration bei einen vorgegebenen Preis optimieren, also
Leistung = max!
Preis = const. (8.1)
oder man hat als Vorgabe eine bestimmte Leistung zu erreichen und will für derer Anschaffung so wenig wie möglich bezahlen:
Leistung = max!
Preis = min! (8.2)
Wir werden ansatzweise das Konfigurationsproblem in der Form (8.2) in Angriff nehmen, wir hätten jedoch genauso gut mit der Form (8.1) starten können. Von zentraler Bedeutung für die geeignete mathematische Deutung des Problems, ist das Aufstellen einer linearen Funktion, die sowohl als Zielfunktion im mathematischen Sinne fungieren muss und die Gegebenheiten des Problems in guter Annäherung wiedergeben kann.
In Übereinstimmung mit der Gleichung (6.1) definieren wir zunächst einen sog. Preisvektor P, dessen Komponenten, den auf dem Markt zum gegebenen Zeitpunkt geltenden Hardwarepreisen entsprechen.
}
}
123 (8.3)456
pi stellt den Preis für die i-te Hardwarekomponente dar. Die pi sind also reine skalare Größen und die Variable i ( i = 1, 2, K , N ) zählt die relevanten Hardwarekomponente durch, welche am Aufbau des Clusters beteiligt sind (also CPU, RAM, NIC, usw.).
Nun definieren wir einen zweiten Vektor, nämlich der Stückzahlvektor N, dessen Komponenten nun die auftretenden Mengen des i-ten Hardwareteils angeben, z. B. 32 Netzwerkkarten, 64 CPUs, etc:
123 (8.4)456
- 45 -

Durch die Bildung des Skalarproduktes dieser zweier Vektoren lässt sich eine lineare Funktion bilden, die wir als Kostenfunktion K(p) bezeichnen werden. Also
K = N T · p (8.5)
Formal ausgedrückt bekommen wir für (8.4) 24)
K = wobei die Koeffizienten jiδ wie folgt definiert sind:
=≠
=jifallsjifalls
ji 10
δ . Die obere Beziehung ist jedoch nichts anderes als eine lineare Funktion der Form (v. Gl. (6.1):
K (p) = N1p1 + N2p2 + K + Nnpn (8.6)
Diese einfache Funktion wollen wir als Zielfunktion für das Konfigurationsproblem betrachten und wie aus der Formulierung (8.2) zu entnehmen ist, muss sie eben minimiert werden:
K (p) = NT p = min !. (8.7)
8.2 DieRandbedingungen
Der nächste Schritt zur mathematischen Formulierung des Problems besteht darin, die in Betracht kommenden Randbedingungen im Sinne von Gl. (6.2) zu definieren. Abhängig von der Form des Konfigurationsproblems unterliegt der Funktion (8.6) eine variable Anzahl solcher Bedingungen. Einige davon sind sicherlich allgemeiner Natur, so dass sie unter Umständen innerhalb jedes Konfigurationsproblems, welches wir in der Form (8.2) formulieren können, Gültigkeit finden. Es gibt jedoch andere Anfangsbedingungen, deren Form sehr stark von den Besonderheiten einer spezifischen Konfiguration abhängt. Im Folgenden behandeln wir die allgemeingültigen Anfangsbedingungen. Die Diskussion über die problemabhängigen Randbedingungen verschieben wir auf den nächsten Abschnitt. Dort werden wir uns mit einer Beispielkonfiguration ausführlich beschäftigen und anschließend einen ersten Einsatz des Clusterkonfigurators versuchen.
Obwohl die erste Randbedingung mit der wir uns hier beschäftigen ziemlich trivial wirkt, muss sie bei der Mathematik des Problems unbedingt betrachtet werden. Sie lautet:
N1 ≥ 0, N2 ≥ 0, NN ≥ 0 (8.8)
Diese Beziehungen entsprechen der logischen Vorstellung, dass jede Hardwarekomponente mindestens einmal bei der Clusterkonfiguration vorkommt. Bei der Lösung des Konfigurationsproblems (8.2) kann jedoch häufiger die Bedingung auftreten.
N1 ≥ m, N2 ≥ m, K, NN ≥ m (8.9)
Diese Beziehung, im Gegenteil zu (8.7), fixiert die Mindestanzahl von Knoten im Cluster auf den Wert m. Daraus lässt sich gleichfalls entnehmen, dass jede relevante Hardwarekomponente mindestens einmal pro Knoten vorkommen muss.
Man könnte hierzu einwenden, dass die Zahl m der Knoten eigentlich nicht vorgegeben sein sollte, also erst durch den Einsatz des Clusterkonfigurators in Erfahrung gebracht werden müsste. Die Praxis zeigt uns jedoch, dass dieses Vorgehen in der Tat notwendig ist, denn es gibt ja bekanntlich verschiedene technische Grenzen, welche die Festlegung einer unteren Grenze bei der Knotenzahl erzwingen25). Wir müssen dabei beachten, dass die Zahl m keineswegs die endgültige Knotenzahl für die gegebene Clusterkonfiguration darstellt. Sie ist nur dazu da, um uns bei der Aufgabe zu helfen, deutlich plausiblere Ergebnisse zu erzielen.
Die zweite Randbedingung mit einem allgemeingültigen Charakter besagt, dass eine geforderte Gesamtperformance erreicht werden muss. Diesem entspricht die Aussage Leistung = const. aus (8.2). Da wir nach dem Simplex-Verfahren vorgehen wollen, haben wir also nach einer linearen Beziehung zu suchen, die in der Tat einiges gewährleisten muss. Zum einen muss sie Änderungen an der Hardwarekonfiguration zulassen und die unterschiedliche Leistungswerte für die jeweiligen Komponenten zum Ausdruck bringen. Zum anderen muss die Funktion in der Lage sein, den Einfluss von einer gegebenen Applikation auf die gesamte Performance zu berücksichtigen. Diese Beziehung bzw. Funktion wird anschließend dem konstanten, vorgegebenen Wert für die Performance gleichgestellt.
24) Zur Erinnerung: Aus einer gegebenen n X m-Matrix A lässt sich durch Spiegelung der Elemente an der Hauptdiagonalen (gebildet durch die Elemente
a11, a22, a33, K ...) die sog. transponierte m x n-Matrix AT bilden. Also AT = jiTij aa = Vektoren sind Matrizen mit einer einzigen Spalte.
25) Die theoretische maximale Leistung heutiger CPUs liegt nur knapp über der 3 GFlop/s Grenze, so dass eine Leistung von z.B. 100 Gflop/s prinzipiell erst ab 40 CPUs erreicht werden kann.
( ) ( ) j
N
jiijij
Ti pNpN ⋅=⋅ ∑
=1,δ
- 46 -

Um die Form einer solchen Funktion zu bestimmen haben wir zwei wichtige Richtlinien zu verfolgen: Einerseits muss die Funktion, wie oben gesagt, eine lineare Form aufweisen, andererseits muss sie die Leistung der jeweiligen Hardwarekomponenten bzw. Subsysteme durch zwei Kennzahlen beschreiben, nämlich die Latenzzeit und die Bandbreite (s. 4.6). Auf dieser Weise können wir erwarten, die durch den Einsatz des Clusterkonfigurators stark von einander abweichenden Clusterkonfigurationen beschreiben zu können.
Wir führen hierzu einen Performancevektor s wie folgt ein
s =
(8.10)
dessen Komponenten sich durch die jeweiligen Leistungswerte der performancerelevanten Hardwarebestandteile ausdrücken lassen. In Abschnitt 4.6 haben wir allerdings das Performanceproblem in ein Kommunikationsproblem uminterpretiert. Dabei sind wir zu dem Schluss gekommen, dass wir die Leistung sämtlicher Hardwarekomponenten mit Hilfe ihrer charakteristischen Werte für die Latenzzeit und die Bandbreite bei der Interprozesskommunikation bestimmen können.
Wir bringen gerade dies zum Ausdruck, indem wir die Komponenten si des Vektors s mit der Interprozesseskommunikationszeit t identifizieren, so wie sie durch die Beziehung (4.13) im Abschnitt 4.6 definiert wurde: t = tL + tW L (tL = Latenzzeit, tW = Transferzeit, L = Größe der übertragenen Nachricht). Für den Netzwerkkommunikationsanteil nehmen wir statt (4.13) natürlich die Beziehung (6.3): t = tL + tW n L, welche zusätzlich die Konkurrenz für die Bandbreite zwischen n kommunizierenden Prozessoren berücksichtig. Wir machen außerdem von der Tatsache gebraucht, dass B≡ tW L und schreiben die Komponenten des Vektors (8.10) in ausführlicher Form wie folgt:
s
(8.11)
wobei wir die Komponente j mit dem Netzwerkanteil identifiziert haben, n die Anzahl von Prozessoren ist und k < N 26).
Laut (8.11) hängt die Leistung des Systems von der Anzahl der performancerelevanten Komponenten und ihrer entsprechenden Interprozesskommunikationsleistung ab. Wir haben dabei dennoch die Auswirkungen der Applikationseigenschaften auf der gesamten Leistung des Clusters noch nicht betrachtet. Um diesem wichtigen Faktor ins Modell einfließen zu lassen, führen wir eine sog. Gewichtungsmatrix G mit der Form
G =
(8.12)
ein, deren Elemente gij sog. Gewichtungsfaktoren sind. Diese Elemente erlauben uns den Aufbau einer Beziehung zwischen einer Applikation und den spezifischen Hardwareressourcen, die von dieser Applikation beansprucht werden. Die Matrix G ist auf 1 normiert, also gilt | G | = 1. Dieses heißt in der Praxis, dass jede Komponente gij einen Wert zwischen 0 und 1 annimmt, so dass folgende Beziehung gilt
(8.13)
26) Der Unterschied zwischen den Zahlen N und k der Komponenten lässt sich am besten verstehen wenn man bedenkt, dass der Vektor N solche Hardwarekomponenten wie Hauptplatine, Gehäuse, Netzteile, usw. berücksichtigen muss. Diese sind hinsichtlich der Performancebestimmung mehr oder weniger unbedeutsam.
- 47 -
=
N
i
s
ss
sM
r 2
1
( )( )
( )
( )
+
+
++
==
kL
jL
L
L
i
Bt
nBt
BtBt
s
M
Mr2
1
kkg
gg
KOM
MK
0
000
22
11
122111,
=+++=∑=
nnii
n
jiij gggg Lδ

wobei die Koeffizienten ijδ wieder die Bedingungen
=≠
=jifallsjifalls
ji 10
δ erfüllen. Die durch die Beziehung
s´ = G s (8.14)
definierte Transformation des Performancevektor s liefert uns den Vektor s´, den wir hier Gewichtetenperformancevektor nennen. Die Komponenten von s´ sehen wie folgt aus
s´ =
Das ist
s´
(8.15)
Um auf die Gesamtperformance zu kommen, brauchen wir nur noch einen neuen Stückzahlvektor M, der sich aber vom Stückzahlvektor (8.4) unterscheidet, indem er, ähnlich wie die Vektoren s und s´, nur die performancerelevanten Komponenten durchzählt.
M =
Wir bilden schließlich das Skalarprodukt zwischen den zwei Vektoren s´ und Nk um die von uns gesuchte lineare Funktion Performance = const zu erhalten. Wir bekommen wie üblich
S = M T · s´ (8.16)
Formal ausgedrückt bekommen wir für (8.16)
S = also S (s´) = Die von uns gesuchte zweite Randbedingung, lautet nun einfach:
= const (8.17)oder mit Hilfe von (8.15)
= const (8.18)
- 48 -
kkg
gg
KOM
MK
0
000
22
11
( )( )
( )
( )
+
+
++
kL
jL
L
L
Bt
nBt
BtBt
M
M2
1
( )( )
( )
( )
+
+
++
=′=
kLkk
jLjj
L
L
Btg
nBtg
BtgBtg
s
M
Mr222
111
=
k
j
M
MM
MM
r 2
1
kk sMsMsM ′++′+′ K2211
( ) ( ) j
k
jiijij
Ti sMsM ′⋅=′⋅ ∑
=1,δ
nn sMsMsM ′++′+′ K2211
( ) ( ) ( ) ( )kLkkkjLjjjLL BtgMnBtgMBtgMBtgM +++++++++ KL11111111

Für eine erste Annäherung zu der Form der Leistungsfunktion soll uns Gleichung (8.18) genügen, ansonsten würde der Komplexitätsgrad des Modells deutlich über die Maßen steigen.
8.3 ProblemabhängigeRandbedingungen:EineBeispielkonfiguration.
Bisher haben wir die Form von zwei allgemeingültigen Randbedingungen betrachtet, die bei der Analyse eines beliebigen Konfigurationsproblems eine gesonderte Rolle spielen. Die Gemeinsamkeiten unter den verschiedenen Konfigurationsproblemen hören jedoch an dieser Stelle gleich auf. Von einfachen Tatsachen ausgehend, wie die Anzahl von Rechenknoten oder die Technologie des Kommunikationsnetzwerkes bis hin zu der parallelen Applikationen selbst die Vielfältigkeit der Faktoren, die bei der Konfiguration eines Clusters eine Rolle spielen ist einfach enorm. Aus diesem Grund glauben wir, dass eine verständliche Darstellung des Verfahrens mit dem wir das Konfigurationsproblem zu lösen versuchen am besten erreicht ist, wenn wir gleich zu einem konkreten Beispiel Bezug nehmen.
Gesucht ist die optimale Konfiguration für einen Cluster, auf dem eine stark CPU belastende Parallelapplikation laufen wird und eine Rechenleistung von mindestens 80 GFlop/s erreicht werden soll. Abhängig von der Leistung der gewählten CPUs sollte diesem die Rechenleistung von einem mit mindestens 20 Knoten ausgestatteten Cluster entsprechen. Wir werden im Folgenden die notwendigen Schritten beschreiben, die hier als Vorbereitung für den Einsatz des Clusterkonfigurators dienen.
Die Untersuchung beginn mit folgenden Definitionen: Seien NCPU die Anzahl von CPUs (in Stück), die für den Aufbau eines Clusters benötigt werden, NRAM die über den Knoten dieses Clusters verteilter Hauptspeicherkapazität (in GB), NNIC die gesamte Anzahl von eingebauten NICs (in Stück) und NGsys die dazu notwendige Anzahl von Grundsystemen27), (ebenfalls in Stück). Aufgrund der Performanceeigenschaften der Beispielapplikation, die wir auf dem Cluster laufen lassen werden, setzen wir ebenfalls voraus, dass eine Dualprozessorarchitektur für die Knoten, wie auch dem Masterknoten, die bessere Wahl darstellt.
Rein theoretisch kann eine moderne CPU ca. eine Instruktion pro Taktzyklus durchführen. Wenn wir eine CPU nehmen, die mit einer Taktfrequenz von 3 GHz arbeitet, würde das bedeuten, dass wir eine theoretische Maximalleistung von 3 GFlop/s aus dieser CPU erwarten könnten. Aus verschiedenen Gründen, die wir bereits relativ ausführlich im Kapitel 4 betrachten haben, können wir leider diese theoretische CPU Leistung nicht als gültigen Wert für die effektive Rechenleistung eines Systems nehmen. Wir berücksichtigen diese Tatsache und benutzen nur 60% der theoretischen Maximalleistung als effektive CPU-Leistung für die Rechnerknoten. Die eingesetzten CPUs liefern somit eine Peak Leistung von ca. 1,8 GFlop/s.
Nach einer einfachen Rechnung 80/1.8 = 44,4 kommen wir zu dem Schluss, dass wir mindestens 44 solcher 3 GHz CPUs benötigen würden, um die Performancevorgabe zu erreichen. Dies ist wiederum mit dem Einsatz von mindestens 22 Knoten auf Dual Prozessor Basis verbunden. Formal ausgedrückt heißt das also m ≥ 22.
Mittels Gl (8.3) bilden wir als nächstes den Preisvektor mit beispielhaften Komponentenpreisen wie folgt:
• Einzelpreis einer CPU: =CPUp 300 € • Preis eines Gigabytes Hauptspeichers: =RAMp 100 € • Netzwerkkartenpreis =NICp 60 € 28) • Grundsystempreis =Gsysp 350 €
Also p = (300, 100, 60, 350)
Durch die Angabe der Komponenten des Preisvektors haben wir automatisch die relevanten Hardwarekomponenten benannt, die von der Preisfunktion mitberücksichtigt werden. Da es eine direkte Beziehung zwischen dem Preis von Hardwareteilen und ihrer entsprechenden Leistung besteht, lassen sich ebenfalls über den Preisvektor (und die damit verbundene Zielfunktion) Unterschiede bei der zu erwartende Hardwareleistung des Systems leicht in Erwägung ziehen. Besteht z.B. der Preisvektor aus Komponenten pi , die überall niedrige Werte aufweisen, können wir sofort daran erkennen, dass es sich um Hardwareteile handelt, die keine überdurchschnittliche Leistung liefern können.
Unter der Komponente, die wir für unsere erste Analyse gewählt haben, vermissen wir insbesondere die Abwesenheit von 1st- und 2nd Level Cache als Komponenten des Preisvektors. Die Erklärung hierfür ist jedoch leicht zu ersehen, denn es liegen keine Preisinformationen für L1- bzw. L2 vor, die in irgendeine Form eine Trennung vom CPU Preis ermöglichen könnten. Während unseres ersten Versuchs werden wir ebenfalls auf die Betrachtung von I/O Subsystemen verzichten.
27) Ein Grundsystem bezeichnet hier die Ansammlung der restlichen Hardwarekomponenten wie Hauptplatine, Gehäuse, Netzteil, etc, die nach unserem Modell keine bedeutende Rolle bei der Performancebestimmung spielen sollten, jedoch für die Bestimmung des Endpreises unbedingt berücksichtigt werden müssen.28) Die Kosten der Netzwerkinfrastruktur (Switches, Netzverkabelung, etc.) werden bei den Netzwerkkartenstückpreisen miteinbezogen.
- 49 -

In unserer Beispielkonfiguration nimmt die Kostenfunktion (also die Zielfunktion) (8.6) die spezifische Form
K(p) = GsysNICRAMCPU NNNN 35060100300 +++ = min ! (8.19)
ein. Die Preisfunktion muss unter folgenden Randbedingungen (RB) minimiert werden:
• Jede Komponente muss nach (8.9) mindestens einmal verbaut werden. 2 CPUs und mindestens 2 GB Hauptspeicher sollten jedem Knoten zugeteilt werden. Da m ≥ 22 gilt also: RB_1. .
• Die geforderte Gesamtperformance von 80 GFlop/s muss mindestens erreicht werden: RB_2. NICNICRAMRAMCPUCPU sMsMsM ′+′+′ = 80.
Spätestens in diesem Augenblick werden wir ernsthaft mit dem Problem konfrontiert, auf welche Weise die Rechenleistung is′ = ( )iLii Btg + der einzelnen performancerelevanten Hardwarekomponenten zu bestimmen ist damit die Messergebnisse in die Performanceformel sinnvoll eingebettet werden können. Genauer gesagt müssen wir Methoden definieren, mit denen sich diese Performanceergebnisse sinnvollerweise in reinen MFlop/s bzw. GFlop/s Zahlen ausdrücken lassen. Es ist offensichtlich so, dass die Bestimmung dieser für uns geeigneten Form der Performanceformel einen Schritt von entscheidender Bedeutung darstellt. Wir können hier jedoch nicht dem Anspruch gerecht werden, diese komplexe Aufgabe im Rahmen der vorliegenden Arbeit zu lösen. Dazu gehören unzählige Stunden von intensiven Performancemessungen und Ergebnisanalysen, welche eigentlich das Thema eines separaten Forschungsprojekts werden können29).
Unsere Absicht an der Stelle ist vielmehr zu überprüfen, ob unsere ursprüngliche Idee, nämlich das Problem der Konfiguration eines Clusters mit Hilfe eines mathematischen Modells zu lösen, praktikabel ist oder nicht. In diesem Sinne wollen wir vorerst nur eine plausible Beziehung für die Performanceformel liefern, so wie die nötigen Randbedingungen angeben, die sich aus dem Beispielproblem in logischer Form herleiten lassen.
Ein wichtiger Aspekt, den wir hierfür unbedingt berücksichtigen müssen, ist dass die Gesamtperformance von der Applikation abhängig ist. Nehmen wir mal an, dass unsere Parallelapplikation die Systemressourcen folgendermaßen belastet: 60% CPU, 30% Speicher, 10% Netzwerk. Damit sieht die Matrix G wie folgt aus
G =
Die lineare Beziehung für die Performanceformel, also RB_2, könnte wie folgt aussehen
(8.20)
Unter der Beziehung (8.20) verbergen sich einige vereinfachende Annahmen, zum Beispiel, dass die Speicherperformance prozentual bzw. linear in die Performance eingeht oder dass die Gesamtperformance von der Zahl der Netzwerkkarten unabhängig ist, solange mindestens eine Netzkarte pro Knoten verbaut wird. Weitere wichtige Randbedingungen sind:
• RB_3: 0≥− GsysCPU NM . Wir haben mindestens so viele Knoten wie CPUs• RB_4: 02 ≤− GsysCPU NM . Die maximale Anzahl von CPUs pro Knoten ist 2• RB_5: 0≥− GsysNIC NM . Wir haben mindestens eine Netzwerkkarten pro Knoten• RB_6: 02 ≤− GsysNIC NM . Es dürfen nicht mehr als 2 Netzwerkkarten pro Knoten eingesetzt werden.• RB_7: 0≥− GsysRAM NM . Es muss mindestens 1 GB Hauptspeicher pro Knoten verbaut werden.• RB_8: 04 ≤− GsysRAM NM . Wir wollen ein Maximum von 4 GB Hauptspeicher pro Knoten zulassen30).
29) Um nur ein Gefühl zu bekommen, mit welcher Art von Problem wir es hier zu tun haben, betrachten wir kurz die Komponente CPUs′ . Die Gesamtperformance der CPUs ergibt sich aus der theoretischen Einzelperformance s
CPU multipliziert mit der Anzahl der CPUs (M) und diskontiert um den
Performanceverlust durch den sequentiellen Anteil α (vgl. Amdahl’sches Gesetz, Abschnitt 4.4). Nehmen wir für unser Testproblem α = 0.1% an. Es gilt also nach Gl. (4.12): S = 1 / α – (1 – α)/ M = 1 / 0.1 + 0.9M . Damit ist CPUs′ = S M = (1 / 0.1 + 0.9M ) M. Diese Beziehung ist bereits nicht mehr linear in der Variable M, so dass wir sie in eine sog. Taylorreihe (Annäherung an eine Funktion durch Polynome) entwickeln müssen, um eine lineare Approximation für CPUs′ zu bekommen (Linearitätsbedingung). Das Ergebnis dieser Taylorentwicklung lautet: = M – M(M-1)α + M(M-1)² α² + M²(M-1)³ α³ +…. Wenn wir nur den Linearanteil der Entwicklung nehmen, kommen wir zu dem Ergebnis = M. Man stellt also fest, dass hier die Linearisierung den Sachverhalt zu sehr vereinfacht und es darf deshalb nicht linear gerechnet werden. Nichtlineare Optimierungsverfahren sind jedoch um einiges komplizierter als sein lineares Pendant, so dass wir hier auf eine Behandlung des Problems in nichtlinearer Form verzichten müssen.30) Die tatsächlich erreichbare Hauptspeicherkapazität eines Computers ist durch das Produkt der maximalen Größe der auf dem Markt verfügbaren Speichermodule mal der Anzahl von Speicherbänken, die die eingesetzte Hauptplatine aufweist, obwohl 8 GB Hauptspeicher zur Zeit möglich sind, wollen wir bei der 4 GB Grenze bleiben, damit die gegebenen Motherboards für den INTEL Xeon oder AMD Athlon MP Prozessor, welche maximal 4 GB Hauptspeicher annehmen, hier mitberücksichtigt werden können.
- 50 -
22,22,44,44 ≥≥≥≥ GsysNICRAMCPU NNNN
1.00003.00006.0
801.03.06.0 ≥++ NICRAMCPU MMM

8.4 DerClusterkonfigurator
Wir hatten bereits in Abschnitt 7 angedeutet, dass aufgrund des iterativen Charakters des Simplex-Verfahrens die Nutzung eines Computeralgorithmus zur effizienten Lösung des Konfigurationsproblems sich als eine vorteilhafte Möglichkeit erweisen kann. Die dahinter liegende Idee besteht einfach darin, ein Computerprogramm zu erstellen, das die Formulierung des zu optimierenden Problems als Eingabe zulässt und eine Lösung, ohne weiteren Einfluss eines externen Benutzers, nach dem Simplex-Verfahren liefern kann.
Wir wollen hier natürlich weder eine erneute Analyse des Simplex-Verfahrens durchführen, noch die Struktur des Codes für den Clusterkonfigurator in allen Einzelheiten beschreiben (Der Quellcode zum Programm lässt sich mit Hilfe eines Internet Browsers anschauen, indem man z.B. das Pulldown-Menü Ansicht öffnet und die Option Quelltext anzeigen wählt). Stattdessen versuchen wir die Struktur des Verfahrens in Form eines Kontrollflussdiagramms zusammenfassend darzustellen, so dass man sich dabei einen schnellen Überblick über die interne logische Struktur des Clusterkonfigurators als Programm verschaffen kann (s. Abbildung 8.1 auf S. 98). Zur Erinnerung können wir noch das lineare Optimierungsproblem (7.2) in der folgenden kompakten Form schreiben:
rsrs bxa = , wobei die folgende Terminologie beachtet werden muss (s. Kapitel 7):
s : Pivotspaltexs : Problemvariablenr : Anzahl von Spalten in der Matrixαrs : Koeffizienten der Matrix A in Gleichungssystem (s. Gl. 7.2)br : Summenelemente
- 51 -

Abbildung8.1: Kontrollflussdiagramm für den Simplex-Algorithmus
Start
Gibt es ein s,
so dass xs das richtige Vorzei-
chen hat und eine Verbesserung
zulässt
Eine optimale Lösung wurde gefunden. Das Ergebnis wird ausgegeben.
HALT
Ein solches xs wird ausgewählt.
Gibt es ein r, so dass ars>0.
Es gibt keine optimale Lösung für das Problem.
HALT
Es wird r so gewählt um den Quotienten br / ars zu minimieren,
mit ars>0.
Es wird ars pivotiert um ein neues Tableau mit x zu bilden, die alte
Basisvariable wird ersetzt.
Nein
Nein
Ja
Ja
- 52 -

Sind Aufgabenstellung und Ziel des Programms vom Programmierer eindeutig verstanden worden, geht es als nächstes um die Wahl der Computersprache, die eingesetzt wird, um die Umsetzung des Problems in eine für die Maschine verständliche Sprache zu ermöglichen. Die Wahl der Computersprache, in die der Algorithmus letztendlich implementiert wird, hängt zum größten Teil vom Programmierer, aber auch von der Natur des zu lösenden Problems ab.
Das Programm, welches das Konfigurationsproblem für uns lösen soll, hat einige wichtige Vorgaben zu erfüllen. Außer den logischen Aufgaben, die das Programm zu meistern hat, wie z.B. das Empfangen und Interpretieren von Benutzereingaben, die Durchführung der Lösungsberechnung nach dem Simplex-Verfahren, das Abfangen von fehlerhaften Eingaben, etc. wäre es natürlich wünschenswert, wenn sich das Tool sehr einfach benutzen ließe.
Um diese Vorgaben zu erfüllen haben wir uns zuerst für die Nutzung der Programmiersprache C entschieden, denn C lässt bekanntlich die Erstellung von höchsteffizientem Code zu und genießt außerdem im Linux Umfeld sehr große Beliebtheit. Gleich zu Beginn der Softwareentwicklungsphase waren wir uns im Klaren, dass wir das Rad nicht neu erfinden wollten. Aufgrund des breiten Anwendungsspektrums, bei welchem der Einsatz von linearen Optimierungsverfahren möglich wird, konnte erwartetet werden, dass einige öffentliche, per Internet zugängliche Programme existieren, die das Simplex-Verfahren implementieren. Unsere Aufgabe beschränkte sich somit auf die Durchführung der nötigen, an unsere Gegebenheiten angepassten Codemodifikationen und die anschließende Erstellung einer hierfür geeigneten Benutzerschnittstelle. Diese sollte für die korrekte Eingabe der Daten und die geeignete Darstellung der Programmergebnisse sorgen.
Während unserer Internetrecherche sind wir jedoch auf einem Tool gestoßen, das 1998 von S. Waner und S.R. Costenoble an der Fakultät für Mathematik der Hofstra Universität, New York, entwickelt wurde. Das Simplex-Method Tool entsprach in vielen Punkten unserer Vorstellung. Dass es in JavaScript implementiert war erwies sich schnell als ein Vorteil, denn JavaScript ist für seine hervorragende Portierbarkeit (auf Architektur und Betriebssystemebene) bekannt.
Wie bei allen anderen Scriptsprachen besteht ein JavaScript Programm aus einer Ansammlung von direkten Anweisungen (sog. Funktionen), die mit einander kommunizieren um ein bestimmtes Ziel zu erreichen. Die Komponenten der Sprache, sog. grammatikale Elemente wie z.B. Ausdrücke und Operatoren, lassen sich auf einfache Weise kombinieren und auch wenn sie die Mächtigkeit einer höhere Sprache wie C nicht erreichen können, führen sie in zahlreichen Fällen zur schnellen Erstellung völlig funktioneller Programme31).
JavaScript ist eine Programmiersprache „für das Web“ und wurde dementsprechend an die spezifischen Bedürfnissen von Web Entwickler angepasst. Die unterschiedlichen Sprachmodule spiegeln also die Eigenschaften vom allgemeinen Webdesign wieder, so dass JavaScript dazu fähig ist, Webseiten dynamisch zu ändern, zu manipulieren und auf interaktive Änderungen zu reagieren.
Ausschlaggebend für die Entscheidung, den JavaScript Code gegenüber dem C Code zu favorisieren, war also die Tatsache, dass sich in dieser Form der Clusterkonfigurator mit Hilfe eines beliebigen Webbrowsers denkbar einfach aufrufen und von dort aus direkt bedienen ließe. Die plattformunabhängige Nutzung des Programms wäre somit bestens gewährleistet.
Die Abbildung 8.2 auf der nächsten Seite zeigt die interaktive Schnittstelle des Clusterkonfigurators, die mit Hilfe eines Browsers (Internet Explorer, Netscape, Opera, etc.), geladen wird. Wie man hier sieht präsentiert sich das Programm mit zwei Hauptsektionen: Die erste Sektion gibt einige wichtige Informationen zur Bedienung des Tools. Die Bemerkungen beschreiben etwas detaillierter, was man zum Beispiel bei der Eingabe von großen Zahlen oder Dezimalziffern beachten muss und was die Wahl des Ausgabetyps unten „Typ“ im Arbeitsfenster bei der Darstellung der Ergebnisse bewirkt.
31) Es gibt unterschiedliche JavaScript Versionen, die von bestimmten Browsern unterstützt werden. Dies kann leider nicht nur zur Verwirrung, sondern auch zu erheblichen Inkompatibilitäten führen. Einige Zeit später, nachdem Netscape die Unterstützung von JavaScript eingeführt hatte, versuchte Microsoft ähnliches beim Internet Explorer in Form von sog. „JScript“. Die Microsoft Implementierung des JavaScripts war jedoch sehr instabil und verursachte zahlreiche Schwierigkeiten. Ein wichtiger Schritt zur Standardisierung der Sprache ist durch die Freigabe der offiziellen Version von EMACScript language Specification für die JavaScript Sprache gemacht worden.
- 53 -

Abbildung8.2: Die Startmaske des Clusterkonfigurators
- 54 -

Die zweite Sektion, das eigentliche Arbeitsfenster, enthält verschiedene Buttons, deren Funktion eigentlich nach einem kurzen Blick auf die Seite leicht zu verstehen sein sollte. Wenn wir auf den „Beispiel“ Knopf darauf drücken erscheint im oberen Feld ein Beispielproblem, das zum Aufklärung der richtigen Formateingabe des Problems in das Eingabefenster dienen soll und natürlich durch Betätigung des „Lösung“ Knopfs gelöst werden kann. Genauso interessant sind die Zusatzinformationen, die gleichzeitig am unteren Fenster erscheinen. Diese erklären in noch ausführlicherer Form wie ein Konfigurationsproblem eingegeben werden muss, damit es vom Tool fehlerfrei gelöst werden kann. In der Abbildung 8.3 können wir die Ausgabemaske betrachten, die nach der Betätigung des „Beispiel“ Knopfs angezeigt wird.
Abbildung8.3: Ausgabemaske nach einem Klick auf den „Beispiel“ Knopf
Ganz am Ende der Seite ist noch eine Warnung angebracht, die dem Benutzer über eventuelle Risiken bei der Nutzung von rechenintensiven JavaScript Tools informieren soll (s. Abbildung 8.2). Als letzte wichtige Anweisung zur Bedienung des Tools müssen wir erwähnen, dass während des Eintippens der Problemdefinitionen im Eingabefeld keine leeren Zeilen entstehen dürfen, auch nicht am Ende der Eingabe. Das Tool will sonst diese leere Zeilen als Ungleichungen auswerten und meldet sofort einen Fehler, was für den unerfahrenen Benutzer verwirrend wirken kann.
8.5 EineBeispielberechnungmitHilfedesClusterkonfigurators
Da der Clusterkonfigurator bei der Eingabe von Variablen momentan nur einzelne Buchstaben unterstützt, müssen wir das Konfigurationsproblem aus Abschnitt 8.3 in einer noch kompakteren Form ausdrücken, so dass die Eingabe der nötigen Beziehungen vom Programm erstmals abgearbeitet werden können. Folgende Definitionen werden hierfür verwendet:
x : Anzahl CPUs in Stücky : Anzahl von GB (RAM)z : Anzahl NICs in Stückw : Anzahl Grundsysteme in Stück (Gehäuse, Hauptplatine, usw.)
Beispiel Preisvektor in €: p = ( )gsysnicramcpu pppp ,,, = (300, 100, 60, 350)
- 55 -

Preisformel oder Zielfunktion: Summe über Teilsummen von Anzahl mal Preis der Komponenten
min!35060100300 =+++=+++ wzyxwpzpypxp gsysnicramcpu
Die Randbedingungen RB_1 bis RB_8 lauten nun:
• RB_1: 22,22,44,44 ≥≥≥≥ wzyx• RB_2: 801.03.06,0 ≥++ zyx Performanceformel• RB_3: 0≥− wx• RB_4: 02 ≤− wx• RB_5: 0≥− wz • RB_6: 02 ≤− wz• RB_7: 0≥− wy• RB_8: 04 ≤− wy
Wir geben diese Beziehungen im Eingabefeld ein und bevor wir auf den „Lösung“ Knopf drücken, setzen wir die Anzahl von signifikanten Ziffern bei „Rundung“ auf 2 zurück, denn ein Ergebnis in Dezimal- bzw. Bruchdarstellung würde in unserem Fall eher weniger Sinn machen. Die Ergebnismaske für dieses Konfigurationsproblem ist auf Abbildung 8.4 unten zu sehen.
Abbildung8.4: Ausgabemaske des Clusterkonfigurators für das Konfigurationsproblem aus Abschnitt 8.3.
- 56 -

Während auf dem Lösungsfeld nun das Ergebnis für das angegebene Problem erscheint, zeigt uns das untere Feld wie erwartet sämtliche Tableaus, also alle Zwischenberechnungen bis zum Erhalten der Endlösung. Für das oben stehende Problem werden 11 Tableaus generiert und 10 Zwischenberechnungen durchgeführt um das Ergebnis zu bekommen. Der Lösungsvektor, der auf dem Lösungsfeld erscheint lautet:
Optimale Lösung: p = 45000; x = 64, y = 130, z = 32, w = 32
Die Interpretation des Lösungsvektors ist denkbar einfach. Das Tool schlägt zuerst den Einsatz von 32 Knoten vor, so dass wir insgesamt 64 CPUs für die Konfiguration benutzen müssen und eine theoretische Peakperformance von ca. 115,2 GFlop/s erhalten. 130 GByte RAM sind unter den Knoten zu verteilen, so dass jeder der Knoten 4 GByte Hauptspeicher bekommen soll. Im Bereich des Kommunikationsnetzwerks, muss eine Netzwerkkarte pro Knoten eingebaut werden. Der Clusterkonfigurator berechnet einen minimalen Preis für diese optimale Konfiguration, der im vorliegenden Fall 45.000 € beträgt. Die einzelnen Werte und die Lösung sind soweit schlüssig. Wir können trotzdem keine weiteren Rückschlüsse über die Tauglichkeit des Clusterkonfigurators ziehen, solange wir keine weitere Situationen und mögliche Konfigurationen mit Hilfe des Tools analysieren. In diesem Sinne wollen wir eine kurze Reihe von Gedankenexperimenten durchführen, die uns mit den nötigen Informationen zur Evaluierung der Aussagekraft dieses Algorithmus versehen sollen. Fragen wir uns zum Beispiel, was würde passieren wenn wir unsere Leistungsvorgabe verdoppeln, also 160 statt 80 GFlop/s erreichen müssten. Die Problemformulierung würde wie folgt aussehen:
Minimize p = 300x + 100y + 60z + 350w subject to0.6x + 0.3y + 0.1z >= 160x >= 44, y >= 44, z >= 22, w >= 22x - w >= 0x - 2w <= 0z - w >= 0z - 2w <= 0y - w >= 0y - 4w <= 0
wobei wir hier sehr stark von der Annahme Gebrauch gemacht haben, dass aufgrund der hohen CPU Abhängigkeit unserer Beispielapplikation die Leistung derselben nahezu linear mit dem Einsatz zusätzlicher CPUs skaliert. Die Mindestanzahl von CPUs muss also rein theoretisch verdoppelt werden und somit auch die minimale Systemspeichergröße. Der Clusterkonfigurator liefert für dieses Problem folgenden Lösungsvektor (Abb. 8.5):
Optimale Lösung: p = 90000; x = 130, y = 260, z = 64, w = 64
Alle Werte, bis auf die Anzahl der CPUs, haben sich wie erwartet verdoppelt, so dass die nötige interne Konsistenz der Programmlösungen vorhanden zu sein scheint.
- 57 -

Abbildung8.5: Ausgabemaske des Clusterkonfigurators für den Fall einer verdoppelten Leistungsvorgabe.
Obwohl der Lösungsvektor erneut einen fundierten Eindruck macht, ist uns hier der Wert für die Anzahl der CPUs ein wenig zu hoch. Auch wenn wir bedenken, dass 2 CPUs weniger zu nehmen sind (64 Knoten auf Dualbasis benötigen 128 und nicht 130 Prozessoren). Unseren Abschätzungen nach würden wir mit der effektiven Prozessorleistung von 128 CPUs auf eine theoretische Rechenkapazität von etwa 230 GFlop/s kommen, einen Wert, der bereits 37,5% über der Leistungsvorgabe liegt. Hier könnte man sogar 10 Knoten weniger nehmen, so dass wir immer noch eine Leistung von 194 GFlop/s anbieten können und 8100 € einsparen würden.
Eine Erklärung hierfür ist sicherlich auf die Tatsache zurückzuführen, dass wir durch die extrem lineare Annäherung, die zur Analyse des Sachverhalts verfolgt haben, wichtige Informationen auf dem Weg zur Lösung verlieren und dies sich wiederum in der Form unserer Lösungsvektoren widerspiegelt. Betrachten wir aber einige weitere exemplarische Situationen.
Der nächste wichtige Test besteht daran, Änderungen an den Komponentenpreisen einzuführen um zu beobachten, inwieweit diese sich in dem Lösungsvektor widerspiegeln. Nehmen wir zum Beispiel an, dass sich der Preis für ein Grundsystem um 20% reduziert hat, also dass 280=gsysp = 280 €. Das Konfigurationsproblem lautet nun:
Minimize p = 300x + 100y + 60z + 280w subject to0.6x + 0.3y + 0.1z >= 80x >= 44, y >= 44, z >= 22, w >= 22x - w >= 0x - 2w <= 0z - w >= 0z - 2w <= 0y - w >= 0y - 4w <= 0
Der Lösungsvektor wird vom Programm berechnet zu (Abb. 8.6)Optimale Lösung: p = 43000; x = 64, y = 130, z = 32, w = 32
- 58 -

Abbildung8.6:Die Berechnung für den Fall, dass der Grundsystempreis um 20% sinkt
Dieses Ergebnis entspricht in der Tat unseren Erwartungen. Dass die Werte für die Komponenten des Lösungsvektors, die mit den performancerelevanten Hardwarekomponenten verknüpft sind, sich nicht ändern wenn keine großen Änderungen an der Grundsystempreis-Komponente gsysp des Preisvektors auftritt, wurde erwartet. Nur der Endpreis hat sich logischerweise geändert und ist um 2000 € gesunken.
Nun berücksichtigen wir eben den Fall, dass sich der Preis einer leistungsrelevanten Komponente sehr deutlich ändert. Sagen wir zum Beispiel, dass der Preis pro Gigabyte Hauptspeicher, der erfahrungsgemäß sehr stark schwanken kann, zum Zeitpunkt der Angebotserstellung um beachtliche 50% sinkt. Somit hätten wir 50=ramp = 50 €. Aus der Zielfunktion
p = 300x + 50y + 60z + 350w
erhalten wir vom Clusterkonfigurator folgenden Lösungsvektor:
Optimale Lösung: p = 38000; x = 44, y = 160, z = 41, w = 41
Hier ist etwas durchaus Interessantes geschehen. Angesichts des stark verbilligten Speicherpreises gibt der Clusterkonfigurator sogar die Dualprozessor- zu Gunsten einer Einzelprozessorarchitektur auf. Dafür wird die Anzahl der Knoten natürlich erhöht und aufgrund der neuen CPU Anzahl eine Rechenleistung von 1.8x44 = 79.2 GFlop/s angeboten. Man kann hier vielleicht noch Protest erheben, denn immerhin stimmt beim Lösungsvektor die Anzahl von Knoten nicht mit der von CPUs überein. Wichtiger ist jedoch die Aussage zu erkennen, dass unter den neuen Preisbedingungen die tatsächlich wirtschaftlichere Konfiguration seitens der Einzelprozessorarchitektur liegen könnte. Genauer betrachtet erkennen wir jedoch zwei wichtige Argumente, die dagegen sprechen würden.
Zum einen müssten wir zusätzliche 3 Knoten nehmen, um von den vorgeschlagenen 41 auf 44 Knoten zu kommen. Nur auf diese Weise liegen wir wirklich nah an der Performancevorgabe von 80 GFlop/s. Der Betrag für die 3 Knoten errechnet sich leicht zu 3x(300 + 50 + 60 + 350) = 2280 €. Mit 38000 + 2280 = 40280 € liegen wir natürlich 4720 € unter dem Preis, den der Kunde für die Dualprozessorkonfiguration hätte zahlen müssen. Die Höhe dieses Betrages könnte zwar unter Umständen die Entscheidung des Kunden zu Gunsten der Einzelprozessorkonfiguration wenden, es gibt aber auch eine schlechte Nachricht: Der Kunde
- 59 -

bekommt 68,7% weniger Leistungspotential bei einer solchen Konfiguration. Das hier ist also ein erstes deutliches Beispiel einer Situation an welchem wir leicht erkennen können, dass unser mathematisches Modell für den Clusterkonfigurator noch verbesserungsbedürftig ist.
Noch ein letztes Konfigurationsproblem wollen wir analysieren, bevor wir zu einer zusammenfassenden Diskussion unserer bisherigen Ergebnisse übergehen. Eine in der Tat nicht ganz triviale Frage lautet, wie ändern sich die Verhältnisse wenn wir eine Applikation betrachten würden, die durch andere Terme gii in der Matrix G gekennzeichnet wäre? Betrachten wir hierzu eine Applikation, deren G Matrix wie folgt gegeben ist
G =
so dass die Performancefunktion in Korrespondenz mit unserer ersten Definition in (8.20) folgende Gestalt einnimmt: 0.5x + 0.2y + 0.3z ≥ 80. Es handelt sich hier um eine Applikation, welche die Systemressourcen im Netzwerkbereich stärker in Anspruch nimmt (20% mehr im Vergleich zu der ursprünglichen Applikation) dafür CPU- und Hauptspeicherressourcen insgesamt um 10% weniger. Die zu diesem Konfigurationsproblem passenden Angaben für den Clusterkonfigurator lassen sich folgendermaßen aufschreiben:
Minimize 300x + 100y + 60z + 350w subject to0.5x + 0.2y + 0.3z >= 80x >= 44, y >= 44, z >= 22, w >= 22x - w >= 0x - 2w <= 0z - w >= 0z - 2w <= 0y - w >= 0y - 4w <= 0
Der entsprechende Lösungsvektor ergibt sich nach dem Einsatz des Clusterkonfigurators zu:
Optimale Lösung: p = 49000; x = 67, y = 130, z = 67, w = 33
Die stärkere Belastung der Netzwerkressourcen wird von dem Lösungsvektor deutlich wiedergegeben. Außer der Tatsache, dass diese letzte Applikation eine etwas teuerere Hardwarekonfiguration erfordert, kann man noch zu der Lösung sagen, dass z.B. unsere anfängliche Standardvorgabe, die den Einsatz einer Dualprozessorarchitektur vorzieht, weiterhin verfolgt wird. Genauso werden, wie bisher gemacht, 4 GByte RAM pro Maschine zugeteilt (die gesamte Anzahl von CPUs und GB Speicher muss etwas nach unten korrigiert werden, denn hier sind 32 Knoten statt 33 sinnvoll, so dass x = 64, y = 128 und z = 64). Was wir aufgrund der neuen Gestalt der Leistungsfunktion erwartet haben und tatsächlich aufgetreten ist, ist die Erhöhung der vom Algorithmus berechneten Anzahl von NICs in dem Lösungsvektor. Man kann dies natürlich als einen kleinen Erfolg des Modells betrachten, denn auch wenn wir nicht über eine exakte Beziehung für die Leistungsfunktion verfügen, ist das Modell durchaus in der Lage auf solchen Veränderungen zu reagieren.
Eine noch gründlichere Analyse der Lösung lässt uns aber zusätzliche Faktoren erkennen, die unbedingt mitberücksichtig werden müssen. Mit dem Einsatz von 64 Netzwerkarten haben wir deutlich die magische Grenze von 48 überstiegen, die aufgrund des Einsatzes von Netzwerkswitches zwangsläufig beachtet werden muss. Standardmäßig weist ein Netzwerkswitch nur bis zu 32 Knoten auf, so dass wir durch die zusätzlichen 32 NICs dazu automatisch gezwungen werden, mehr Geld in das Kommunikationsnetzwerk zu investieren32).
Wenn wir eine realistischere Preisangabe überhaupt erreichen wollen, müssen diese nachvollziehbaren Zusatzkosten, die von der Erhöhung der Netzwerkartenanzahl verursacht wurden, zusammen mit der Preisjustierung aufgrund der nicht benötigten Komponenten zusammen betrachtet werden. Die Komponenten, die nicht eingesetzt werden (1 Grundsystem weniger, 3 CPUs weniger, etc), ergeben zusammen einen Betrag von 2090 €, während für den extra Netzwerkswitch sich bis zu 600 € einberechnen sind. Wir kommen somit auf eine Summe von ca. 1500 €, die vom Clusterkonfigurator Endpreis abgezogen werden muss. Der korrigierte Preis für das System lautet im Endeffekt etwa 47000€, also doch noch rund 2000 € teurer als die Startkonfiguration.
32) Es gibt Netzwerkswitches mit bis zu 72 Ports auf dem Markt, diese sind aber um einiges teuerer als die Standard 24 oder 32 Port Switches.
3.00002.00005.0
- 60 -

Aus diesem Ergebnis könnten wir vielleicht zu dem Schluss kommen, dass netzwerkbelastende Applikationen zu kostspieligeren Konfigurationen führen. Die Bestätigung einer solchen Aussage würde natürlich die Analyse weiterer ähnlicher Konfigurationsprobleme erfordern. Ein letztes Beispiel und die Praxis ganz im Allgemeinen sagen uns jedoch, dass dies tatsächlich der Realität entspricht.
Eine Frage zu der oben erhaltenen Lösung ist jedoch berechtigt, nämlich ob das Problem der Netzwerkbelastung auf Applikationsebene ständig vom Clusterkonfigurator durch den mehr oder weniger simplen Einsatz mehrerer Netzwerkkarten gelöst wird. Die Antwort wird wohl momentan ja lauten, weil wir einfach noch keine dedizierte Kontrollstrukturen im Programm eingebaut haben, die z.B. dem Programm selbständige Entscheidungen zwischen existierenden Netzwerktechnologien ermöglichen können, welche für das gegebene Konfigurationsproblem am besten geeignet sind.
Wir können jedoch wie gesagt durch das Preis-Leistung Verhältnis der Hardwarekomponenten auf indirekter Weise die Performancewerte einer Komponente beeinflussen. Als leichtes Beispiel hierfür lässt sich für die Netzwerkkomponente nicp ein Preis definieren, sagen wir 500 €, der fast so hoch ist wie der Geldwert eines ganzen Knoten. Diese Verhältnisse kennen wir bereits aus dem Einsatz von hochleistungsfähigen Netzwerkkomponenten wie Myrinet, SCI oder ähnlichem. Unter diesen Umständen gilt für die Preisfunktion
300x + 100y + 500z + 350w = min!
Mit der Performanceformel 0.5x + 0.2y + 0.3z >= 80 und den üblichen Randbedingungen erhalten wir für den Lösungsvektor in dieser Situation
Optimale Lösung: p = 70000; x = 76, y = 150, z = 38, w = 38
Es wird also wieder eine einzige Netzwerkschnittsstelle pro Knoten eingesetzt, wobei der Endpreis für die Konfiguration, wie erwartet, durch die Nutzung von solchen speziellen Netzwerklösungen ganz deutlich in die Höhe geht.
- 61 -

KAPITEL 9 - Schlussfolgerungen und Ausblick
Ganz nach unserer Erwartungen entfaltete sich die Lösung des Konfigurationsproblems zu einem recht komplexen Unterfangen. Wir haben mit relativer Ausführlichkeit die Schritte überarbeitet, die zum einen die nötigen Grundlagen zum Verständnis des Problems vermitteln und zum anderen das Erstellen eines mathematischen Modells für die Beschreibung desselben ermöglichen. Die im Hintergrund stehende Zielsetzung, nämlich aus dieser mathematischen Darstellung und ihrer entsprechenden Lösung ein Softwarealgorithmus zu entwickeln lag somit in greifbarer Nähe.
Im Großen und Ganzen hat sich dieses Vorgehen als adäquat erwiesen. Die Ergebnisse des Clusterkonfigurators am Ende des letzten Kapitels spiegeln in sehr guter Näherung die Realität wieder. Dieses Tool besitzt ein großes Potential, nicht nur weil es bereits brauchbare Resultate liefert, sondern weil sich das Konzept um den Clusterkonfigurator als sehr ausbauungswürdig erweist. Der alles entscheidende Fortschritt wäre natürlich vor allen Dingen die Bestimmung einer viel effizienteren und realistischeren Performancefunktion. Aber auch sehr interessante Erweiterungen lassen sich in Zukunft implementieren, welche zum Beispiel in Verbindung mit spezifischen, weit verbreiten Kundenapplikationen stehen (LSDYNA, Gaussian, Fluid, etc.).
Wie momentan gesehen sind wir nur in der Lage, ein Konfigurationsproblem zu analysieren, das mathematisch ausgedrückt ausschließlich in linearer Form vorliegt. Wenn wir die Wechselwirkung unter den verschiedenen performancerelevanten Hardwarekomponenten besser verstehen würden, könnten wir eine weitaus mächtigere mathematische Darstellung des Sachtverhalts erreichen und somit auch die Aussagekraft des Clusterkonfigurators deutlich steigern. Dies bedeutet natürlich, dass andere mathematische Methoden zur Lösung des Problems eingesetzt werden müssen. Durch die vorliegende Arbeit wurde jedoch deutlich bewiesen, dass unser im Kapitel 2 formuliertes Konfigurationsproblem eine mathematische und eine darauf basierte Softwarelösung zulässt.
Wir haben mit der Gleichung (8.18) im Prinzip gezeigt, dass wir allein mit Hilfe von zweier Kennzahlen, der Latenzzeit und der Bandbreite, das Leistungsprofil von performancerelevanten Hardwarekomponenten wiedergeben können. Dies hat eine echte Simplifizierung der Zusammenhänge bezüglich des Konfigurationsproblems zur Folge. Wir gehen ebenfalls davon aus, dass die aus einem nichtlinearen mathematischen Modell hergeleitete Performanceformel ziemlich anders als in (8.18) aussehen wird, die charakteristischen Größen tL und B, aber auf jeden Fall in der endgültigen Form derselben erhalten bleiben werden. Mehr als die Schwierigkeiten bei der Messung von tL und B geht es uns eher um eine andere Problematik: Wie lassen sich diese Messgrößen in Form von reinen Performancezahlen (MFlop/s, GFlop/s, etc.) angeben, so dass wir hier trotzdem ein nicht lineares mathematisches Lösungsverfahren erfolgreich einsetzen können. Wir müssen also eine sinnvolle Methode finden um diese „Übersetzung“ zu realisieren.
Als nächstes erwarten wir, dass ein für die Lösung nichtlinearer Konfigurationsprobleme geeignetes mathematisches Verfahren nicht nur eine komplexere Mathematik beinhaltet, sondern nicht-lineare Lösungsverfahren in der Regel auch schwieriger zu programmieren und mit einem höheren Rechenaufwand verbunden sind. Hier können wir also eine Stelle mit Entwicklungspotential erkennen, im Falle dass man sich für eine Fortführung in der Entwicklung des Clusterkonfigurators entscheidet.
Die Aufgaben, die nach dem Abschluss dieses Projekts noch offen stehen sind also nicht wenige. Wir wollen sie zusammenfassend in zwei Hauptgruppen unterteilen. Zum einen haben wir Aufgaben grundlegender Natur:
• Entwicklung eines realistischeren mathematischen Modells für die Beschreibung des Konfigurationsproblems. • Herleiten einer besseren Performancefunktion aus dem neuen Modell • Festlegung eines hierzu geeigneten mathematischen Lösungsverfahrens • Implementierung der notwendigen Softwareanpassungen, die aufgrund der Verbesserungen in dem mathematischen
Modell entstehen werden.
Die zweite Gruppe enthält hingegen Verbesserungen, die eher mit der Benutzungsfreundlichkeit und der besseren Funktionalität des Tools verbunden sind:
• Automatische Überprüfung der Definition für die technisch bedingten Hardwareparameter. Nicht realisierbare Clusterkonfigurationen sollten gleich bei der Eingabe abgelehnt und die Ursachen hierfür dem Benutzer deutlich bekannt gegeben werden.
• Einführung von Kontrollstrukturen im Programm, die spezifische Architekturänderungen an einer Clusterkonfiguration durch programmeigenständige Entscheidungen zulassen.
• Das Eingabefeld muss noch benutzerfreundlicher werden. Statt der bisher verwendeten algebraischen Notation sollten wir die Dateneingabe eines Konfigurationsproblems für den Benutzer noch intuitiver gestalten. Das Programm sollte die Benutzereingabe im Hintergrund auf die notwendige algebraische Form bringen.
Während die ersten 4 aufgelisteten Aufgaben, wie oben kurz geschildert, erhebliche Schwierigkeiten aufbereiten können, sind die letzten 3 verhältnismäßig leicht zu bewerkstelligen. In diesem Zusammenhang dürfte klar sein, dass eine eventuelle Überarbeitung des Tools weiterhin mit Hilfe von JavaScript implementiert wird, da JavaScript aufgrund seiner Portierbarkeit und Simplizität hierfür
- 62 -

sehr gut geeignet ist.
Wir möchten an der Stelle noch deutlich zum Ausdruck bringen, welche entscheidende Rolle der Entwurf eines Softwaretools zur Konfigurationsoptimierung von Clustersystemen in der ständigen Verbesserung der Qualität der HPC Produkte der Firma Dr. Koch Computertechnik AG gespielt hat. In der Tat konnten mit der Durchführung des Projekts die Kenntnisse im Umgang mit hoch optimierten Clustern erheblich gesteigert werden. Auch die zusätzlichen Aktivitäten, die im Zusammenhang mit der Förderung für ein Projekt dieser Art Unterstützung fanden, wie zum Beispiel der Besuch von spezialisierten Schulungen und Messeveranstaltungen, stellten sich als eine echte Bereicherung für die Dr. Koch Computertechnik AG heraus.
Im diesem Sinne ist einer der Wünsche der Firma transtec AG nach der Übernahme von der Firma Dr. Koch Computertechnik AG, von all diesen positiven Erfahrungen gezielt zu profitieren. Die transtec AG hat sich aus diesem Gründen dafür entschieden, die weitere Entwicklung des Clusterkonfigurators zu unterstützen, sofern dies von der Förderung für sinnvoll gehalten wird. Es sei jedoch wohlgemerkt, dass andere förderungswürdige Projektgebiete der transtec AG ebenfalls in Frage kämen.
Welches Projekt auch immer am Schluss Unterstützung finden sollte, stehen grundsätzlich die positiven Konsequenzen einer solchen Projektausführung im Vordergrund, wie zum Beispiel die Verbesserungen in der Qualität der transtec Produkte und Dienste im HPC Umfeld und die damit verbundene Steigerung der Beständigkeit und Konkurrenzfähigkeit des Unternehmens. In einer so stark umkämpften Branche der Computerdienstleistungen, wie sich derzeit die HPC Branche darstellt, kann zweifellos die Differenzierung, die sich durch die Forschung in speziellen technologischen Gebieten erreichen lässt, die mittel- und langfristige Konsolidierung eines jeden Unternehmens entscheidend beeinflussen.
AnhangA: EinrichtungeinesLinux-Clusters
Bisher sind Linux HPC Cluster mehr oder weniger das Hauptthema durch unsere gesamte Arbeit gewesen. Wir halten deswegen für sinnvoll, die von uns über die gesamte Projektzeit gesammelten Erfahrungen mit Clustereinrichtungen zu dem Hauptdokument als Anhang in zusammenfassender Form hinzuaddieren. Im folgendem werden also die Standard Arbeitschritte, von der Hardwareauswahl über die Vermittlung der nötigen Kenntnisse zum Betriebsystem und zur Systemverwaltung bis hin zum Einsatz von parallelen Programmbibliotheken und paralleler Software, beschrieben.
A.1 Hardware
Als ersten Schritt beim Aufbau eines Clusters wollen wir die Auswahl der dafür benötigten Hardware betrachten33). Das Charakteristische bei Cluster ist deren Aufbau aus Einzelrechnern und das Verbinden dieser sog. Knoten über ein Netzwerk. Damit hören die Gemeinsamkeiten unter Clustern aber auch schon auf. Sowohl bei der Auswahl der Hardware für die Knoten als auch für das Netzwerk stehen sehr viele Möglichkeiten offen. Aus diesem Grund kann hier keine komplette Beschreibung gegeben werden, sondern es soll stattdessen exemplarisch an der hier verwendeten Hardwarekonfiguration gezeigt werden, wie ein solches System aussehen kann und worauf man achten sollte.
Die Abbildung A.1 zeigt das schematische Bild eines 32 Knoten großen Clusters und seiner Verbindungsstruktur.
33) Wir gehen davon aus, dass man vor der Hardwareanschaffung geeignete Untersuchungen durchgeführt hat um die Leistungsmerkmale der auf den Cluster zu fahrenden Applikationen genauer zu verstehen. Auf dieser Weise lässt sich die Auswahl der Clusterhardware optimal gestalten.
- 63 -

AbbildungA1:Vernetzungsstruktur und Komponentenkonfiguration für den geplanten Linux Cluster (Masterknoten + 32 Rechenknoten)
Der Masterknoten besitzt im Gegensatz zu den Knoten zwei Netzwerkkarten, eine für die interne Kommunikation mit den anderen Knoten und eine für die Integration des Rechners (und somit auch vom Cluster selbst) an eine vorhandene Netzwerkinfrastruktur bzw. das Internet. Der Masterknoten weist jedoch zusätzliche Komponenten auf, die ihn von den Rechenknoten unterscheiden:
Die Betriebssysteminstallation auf dem Masterknoten ist, wie wir sehen werden, viel aufwändiger und komplexer als die von den Rechenknoten. Von daher wird sie durch den Einsatz eines IDE-RAID Controllers und zweier gleich großer, im RAID 1 Modus gespiegelte Festplatten, gesichert (Kapazität ~ 40 GB. Ferner wird an dem Masterknoten wegen der zentralen Verwaltung und Lagerung der Benutzerkonten und Daten ein externes SCSI to IDE Festplattensystem angeschlossen (typisch im RAID 5 Modus, gelegentlich auch im RAID 10 Modus konfiguriert), deren Kapazitätsgröße von der zu verwaltenden Datenmenge direkt abhängt.
Der Masterknoten verfügt ebenfalls über zusätzlichen I/O Geräte wie z.B. CD-ROM bzw. DVD und Floppy Laufwerke. Nicht ganz untypisch sind Komponenten wie Tape-Streamer und CD- oder DVD-Brenner bei der Hardwarekonfiguration des Masterknotens, welche als Backup Subsystem fungieren. Die Größe des Hauptspeichers ist bei allen Maschinen gleich (2 GB DDRAM). Die Verbindung der Knoten unter sich erfolgt über einen 100 MBit/s Ethernet Switch. Für die einzelnen Knoten (einschließlich der Masterknoten) wurden wegen des besseren Preis-Leistungs-Verhältnisses Dual Prozessor Systeme gewählt. Dies hat zur Folge, dass die beiden Prozessoren sich die Netzwerkbandbreite teilen müssen, aber intern direkt über einen schnellen Bus miteinander kommunizieren können.
Als besonderes Merkmal bei der vorliegenden Hardwarekonfiguration erkennen wir die Anwesenheit von Myrinet Netzwerkkomponenten, welche aufgrund ihrer hohe Bandbreite und sehr niedriger Latenzzeiten eine optimale Umgebung für den Einsatz paralleler Applikationen anbieten (s. §3.4.7). Wie man hier sehen kann, ist es nicht unbedingt erforderlich, den Masterknoten mit einer Myrinet Netzwerkschnittstelle zu versehen. Schließlich will man nicht, dass der Masterknoten, der ja eher mit zahlreichen Koordinationsaufgaben beschäftig ist, mit Ressourcenaufwändigen Berechnungen noch zusätzlich belastet wird. Sind die Hardwarekomponenten endgültig ausgewählt, dann ist der erste Schritt zum Aufbau eines Clusters vollzogen.
A.2 Systemsoftware
Um auf die Hardwareressourcen, die im letzten Abschnitt ausgesucht und physikalisch miteinander verbunden wurden, zugreifen zu können, benötigt man ein geeignetes Betriebsystem. Für die Prozessorarchitektur, die sich auf dem Mark durchgesetzt hat (die sog. X86-Prozessorarchitektur), kämmen dabei eine Vielzahl von Variationen in Frage. Einige wie etwa Windows 2000 von Microsoft, Solaris von Sun Microsystems, BeOS von Be Inc, sind kommerzielle Produkte, während anderen wie Linux und FreeBSD sog. Open Source Betriebsysteme sind. Aus den folgenden Gründen ist für die Einrichtung des
Switch 100/1000 Mbit
Myrinet Switch
MasterKnoten2 CPUs2GB HauptspeicherVGA Karte2 HDD (RAID s)CD-ROM/DVD)FloppyStreamer/CD-Brenner
eth0 eth1
node12 CPUs2GB HauptspeicherHDD (Swap/Scratch)
eth0 myri0
node22 CPUs2GB HauptspeicherHDD (Swap/Scratch)
eth0 myri0
node322 CPUs2GB HauptspeicherHDD (Swap/Scratch)
eth0 myri0
Internet/Lokale- Netzwerkinfrastruktur
IP:129.13.114.105Netmask:255.255.0.0
IP:192.168.0.254Netmask:255.255.255.0
IP:192.168.0.1Netmask:255.255.255.0
IP:10.0.0.1Netmask:255.0.0.0
IP:192.168.0.32Netmask:255.255.255.0
IP:10.0.0.32Netmask:255.0.0.0
Externes Disk Array (~1,2 TB RAID 5)
..............
- 64 -

Clusters die Wahl auf Linux gefallen34):
• Linux ist freie Software, wodurch nur geringe Kosten bei der Beschaffung des Betriebsystems anfallen. Bei einem Cluster, bestehend aus 32 Knoten, wären Beispielweise bei einem kommerziellen System 32-mal Lizenzgebühren zu entrichten. Bei Linux hingegen ist nur der einmalige Anschaffungspreis zu bezahlen (oder sogar gar keinen, wenn man bedenkt, dass die meisten Linux Distributionen für den Download kostenlos zur Verfügung stehen). Außerdem sind bei kommerziellen Systemen Programmentwicklungswerkzeuge, die bei Linux meistens zum Lieferumfang dazu gehören, oftmals noch separat zu kaufen.
• Linux ist ein Multiuser/Multitasking Betriebsystem. Daher können mehrere Benutzer auf einem Rechner gleichzeitig arbeiten, ohne sich gegenseitig zu behindern.
• Linux bietet eine stabile und sichere Netzwerkumgebung. Dies ist einerseits wichtig bei der Verbindung der einzelnen Knoten des Clusters miteinander, aber vor allem beim Zugriff auf dem Cluster von außerhalb.
• Linux unterstützt Symmetric Multi Processing (SMP). In einem Rechner können dabei mehrere Prozessoren an unterschiedlichen Aufgaben arbeiten, Linux Cluster können somit als eine Art MIMD Rechner betrieben werden (s. Kap. 3).
• Unter Linux stehen diverse Standardbibliotheken zur parallelen Programmierung zur Verfügung (PVM, MPI, LAM), was die Portierbarkeit von parallelen Applikationen enorm steigert.
Nicht verschweigen sollte man dabei auch, dass Linux einige Nachteile mit sich bringt:
• Linux bietet keinen Support, der mit dem Produkt miterworben wird. Wird professionelle Unterstützung benötigt, so ist diese separat zu kaufen (allerdings muss man sagen, dass dies bei kommerziellen Betriebsysteme nicht viel anders wäre).
• Linux gibt keine Garantie für das Funktionieren von Betriebsystemteilen. Durch eine ständige Weiterentwicklung sind viele Werkzeuge noch in der Entwicklungsphase und es ist möglich, dass bestimmte nicht zufrieden stellend funktionieren. Aber selbst bei fertig gestellten Programmen übernimmt kein Entwickler eine Funktionsgarantie. Die Programme werden zumeist von freiwilligen Programmierern in deren Freizeit erstellt. Damit ist es verständlich, dass diese keine Garantie geben, für ein Produkt an dem sie nichts verdienen.
• Linux ist immer noch ein System, das wegen fehlender graphischer Werkzeuge schwierig administrierbar zu sein scheint (hinsichtlich dazu hat sich in letzter Zeit jedoch sehr viel getan). Einige Programme sind nicht so dokumentiert, wie man sich das vielleicht wünschen würde. Darum ist ein gewisses Eigenengagement und Wissen nötig, um komplexere Dinge, wie den Aufbau eines Clusters zu verwirklichen.
Bevor nun auf die Installation des Betriebsystems im Einzelnen eingegangen wird, seien noch ein paar allgemeine Dinge erwähnt. Der Masterknoten und die Rechenknoten werden unterschiedlich eingerichtet. Dabei ist zu beachten, dass auf allen Rechenknoten die gleiche Softwarekonfiguration eingespielt wird, um Inkompatibilitäten durch unterschiedliche Programmversionen oder fehlende Betriebsystemkomponenten zu verhindern. Der Masterknoten benötigt neben den Client-Programmen für bestimmte Netzwerkdienste und Protokolle zusätzlich noch die Server-Programme. Weiterhin ist die Installation von Applikationen, Bibliotheken, Compilern und ein Batch Queuing System zu erledigen (dazu später mehr), so dass der Masterknoten mehr oder weniger als Referenzpunkt für alle Clustertätigkeiten dienen kann. Als die einzige Maschine im Cluster, die mit der Außenwelt kommunizieren darf, ist ebenfalls eine sinnvolle Absicherung dieses Rechners durch einige Firewallregeln zu unternehmen.
Die Konfiguration eines Linux Clusters erfordert spezifische Vorkenntnisse über das Betriebsystem, die den Rahmen der vorliegenden Einführung sehr leicht sprengen würden. Daher werden wir uns also nur an den Stellen aufhalten, wo die spezifischen Themen zur Clusterkonfiguration behandelt werden müssen, betriebsystemspezifische Begriffe werden hingegen ohne all zu große Ausführlichkeit angesprochen.
A.2.1 DerMasterknoten:Betriebssysteminstallation
Im Folgenden soll die Installation der Linux Distribution auf dem Masterknoten beschrieben werden. Doch bevor wir die Einzelheiten hierfür behandeln, müssen wir noch ein paar Worte über die Linux Distribution sprechen, die für unsere Zwecke am besten passt. Obwohl es zahlreiche Linux Distributionen auf dem Mark gibt, haben sich in Europa vorwiegend die Distributoren Red Hat, SuSE und Debian deutlich etabliert.
Red Hat ist die meist eingesetzte Linux Distribution weltweit, was natürlich die Kompatibilität der Installation mit einer beiteren Palette an Softwaretools am besten garantieren kann. Für SuSE spricht die Tatsache, dass die Distribution über sehr anwenderfreundliche Installation- und Konfigurationstools verfügt, die viele Systemadministratoren zu schätzen wissen. Debian GNU/Linux ist eine Distribution, die sehr viel Wert auf Stabilität legt und wird wegen ihrer längeren Versionszyklen in speziellen
34) Die Argumente, die für den Einsatz von Linux sprechen, gelten meistens genauso für FreeBSD. Obwohl FreeBSD eine ähnliche Leistung und Stabilität wie Linux aufweisen kann, muss man als entscheidenden Vorteil von Linux sagen, dass die Unterstützung von neuer Hardware unter Linux viel schnellere Fortschritte macht als unter FreeBSD. Nicht zuletzt spielt ein Know-how Faktor eine Rolle, denn es ist viel einfacher, Leute mit fundierten Linux-Kenntnissen zu finden, als das unter FreeBSD der Fall ist.
- 65 -

Kreisen bevorzugt. Welche Distribution auf das Festplattensystem des Masterknoten schließlich installiert wird hat nicht zuletzt mit den persönlichen Vorlieben und Gewohnheiten desjenigen zu tun, der sich mit der Aufgabe der Clusterkonfiguration in der Praxis beschäftig.
Für unsere Beispielinstallation werden wir die SuSE Distribution in der Version 8.2 einsetzen. Das Vorgehen zur Installation einer anderen Distribution wird im Einzelnen von dem hier beschriebenen abweichen, insgesamt gesehen sind die Installationsroutinen jedoch ähnlich.
Zunächst wird von der ersten CD-ROM bzw. von der ersten DVD gebootet. Das SuSE Linux Installationsprogramm wird dann vom Medium geladen und die Vorinstallationsphase beginnt. Der Startbildschirm zeigt mehrere Auswahlmöglichkeiten für den weiteren Verlauf der Installation. Da wir ein komplett neues System einrichten wollen, wählen wir die Option Installation mit den Pfeil-Tasten aus. Die Installationsroutine lädt nun ein minimales Linux System, das den weiteren Installationsvorgang kontrolliert. Zum Abschluss des Ladevorgangs wird das Installationsprogramm YaST gestartet und nach wenigen Sekunden sehen wir die graphische Oberfläche, die uns durch die Installation führen wird.
Die Installationsroutine beginnt mit der Auswahl der Sprache und den entsprechenden Tastaturlayouts. Eine Standardzeitzone wird ebenfalls definiert. Nach dem der Menüpunkt Neuinstallation ausgewählt wird, startet die Installationsroutine mit der Erkennung der vorhandenen Hardware. Einige Voreinstellungen zur Installation und Konfiguration des Systems werden ebenfalls angezeigt. An dieser Maske kann man vieles an den Standardinstallationseinstellungen ändern bzw. justieren. Im Normalfall ist der Partitionierungsvorschlag von YaST sinnvoll, für einen Masterknoten sind aber wichtige Besonderheiten zu beachten. Während die Linux Standardpartitionen auf die zwei im RAID 1 Modus konfigurierten Systemfestplatten wie üblich eingerichtet werden, muss man beachten, dass die /home Partition, wo die ganzen Benutzerdaten in Zukunft gespeichert werden, auf das externe Festplatten RAID gelegt wird35). Mit 40 GB Festplattenplatz für die Installation des Betriebssystem und die Applikationen steht uns da reichlich Platz zur Verfügung. Wir Partitionieren das RAID 1 System wie folgt:
35) Da die Partitionen in einem laufenden System nur mit relativ großem Aufwand geändert werden können, sollte man bei der Partitionierung und der darauffolgenden Definition der Dateisysteme eines Masterknotens immer die Vorteile der Einrichtung eines Logical Volume Manager (LVM) nutzen. Ein so angelegtes Dateisystem lässt sich nicht nur im laufenden Betrieb vergrößern oder verlagern, sondern erlaubt auch die konsistente Durchführung von Backups während des laufenden Betriebs. Anleitung und wichtige Informationen des „Logical Volume Manager“ befinden sich an erste Stelle im offiziellen LVM Howto. Die Einrichtung eines LVMs unter SuSE wird ausführlich im SuSE Administrationshandbuch beschrieben.
/boot 100 MB Linux Native (ext2) swap 1 GB Linux Swap / Rest Linux Native(reiserfs)
DateiA.1: Partitionierungsvorschlag für das RAID 1 auf dem Masterknoten
Durch die Zuweisung des restlichen freien Speicherplatzes auf der Festplatte zum Root Dateisystem „/“ hängen automatisch alle Linux Verzeichnisse (/usr, /var, /bin, etc) direkt an /. Somit können sie relativ problemlos nach Bedarf wachsen.Wir nehmen zuerst als Basis für die Softwarekonfiguration des Masterknotens den SuSE Standard Vorschlag an, dann selektieren wir per Hand diejenige Pakete zur Installation, die für unsere Zwecke notwendig sind und nicht automatisch markiert wurden. Dabei wird es auch wichtig sein, während dieser Selektierungsphase gleich nach Softwarepaketen Ausschau zu halten, die in einer Clusterumgebung keine Nutzung finden um diese zu deselektieren. Auf diese Weise erhalten wir ein viel schlankeres und effizienteres System. Hierfür klicken wir in der Maske Installationseinstellungen auf Software und dann auf Standard-System. Darauf folgend klicken wir auf Erweiterte Auswahl.
Die Hauptgruppen, die zu der Standard Softwareauswahl gehören sind mit einem Haken markiert und man kann als erstes den Haken bei der Gruppe Büroanwendungen entfernen, denn der Masterknoten sollte nicht unter normalen Umständen für die Ausführung solche Aufgaben wie Textbearbeitung oder ähnliches vorgesehen sein. Damit bleiben die Selektionen Graphisches Grundsystem, KDE Desktop Umgebung, Dokumentation zu Hilfe und Support und C/C++ Compiler und Werkzeuge bestehen. Als nächstes gehen wir in dieser Maske auf Filter und klicken dort auf den Eintrag Paketgruppen.
Es werden zahlreiche Möglichkeiten angezeigt. Unter diesen sind für uns die Subgruppen Languages, Libraries, Sources, Clustering und Networking hauptsächlich von Interesse (eventuell kann auch Scientific mitberücksichtig werden). Wir listen jetzt die Softwarepakete auf, die für unsere Zwecke installiert werden müssen:
- 66 -

• Languages: cpp, gcc, gcc-c++, gcc-f77, perl.• Libraries: mpich, eventuell auch pvm• Sources: kernel-source• Clustering: eventuell OpenPBS36), xpvm, xmpi• Networking: dhcp-server, dhcp-tools, xinetd oder inetd, nfs-utils oder nfs-server, rsh-server, rsync, tftp, xntp, ypbind und
yptools.• Scientific: blas,lapack.
Nachdem wir mit der Auswahl der Software zufrieden sind und die letzten Installationseinstellungen zur Sprache und Zeitzone sowie für den Bootmanager überprüft haben, kann man mit einem Klick auf Weiter den Vorschlag mit all den eben durchgeführten Änderungen annehmen. Wir bekommen einen grünen Bestätigungsdialog zu sehen und klicken auf ja, um mit der eigentliche Installation zu beginnen. Je nach Rechnerleistung und Softwareauswahl dauert das Kopieren der Pakete meist zwischen 15 und 30 Minute. Sind das System und die ausgewählte Software fertig installiert sind, müssen wir noch ein Passwort für den Systemadministrator (Benutzer Root) festlegen. Anschließend bekommen wir die Gelegenheit, während der Installation einen Internet-Zugang und eine Netzwerkverbindung zu konfigurieren. Auf diese Weise ist es möglich, im Rahmen der Installation Softwareupdates für SuSE Linux einzuspielen und ggf. Namensdienste für die zentrale Verwaltung der Benutzer in einer vorhandenen Netzwerk Infrastruktur einzurichten. In unseren Beispiel nehmen wir jedoch an, dass keine Namensdienstbasierte Benutzerauthentifizierung im lokalen Netz vorhanden ist, so dass wir dieses auf dem Masterknoten einrichten müssen (s. A.2.1.3 weiter unten).
Zum Abschluss der Installation präsentiert YaST noch einen Dialog, in dem wir die Möglichkeit haben, die Graphikkarte sowie verschiedene am System angeschlossene Komponenten einzurichten. Wir stellen die Graphikkarte auf die von uns gewünschten Werte ein und klicken schließlich auf Installation abschließen.
Nach einem letzten Reboot ist SuSE Linux installiert und wir können uns an das Systemanmelden. Der Masterknoten steht nun zum Arbeiten zur Verfügung. Was noch fehlt, um den Rechner für seine administrativen Aufgaben vorzubereiten, ist die Einrichtung der Netzwerkdienste und der Programmbibliotheken zur Ausführung paralleler Applikationen. Das dazu notwendige Vorgehen wird nachfolgend beschrieben.
A.2.1.1 Namensauflösung
Ein weit verbreiteter Gebrauch im Umgang mit Computersystemen, die über Netzwerke miteinander kommunizieren, ist die Umsetzung von IP-Adressen (z.B. 127.0.0.1) in eingängigen, gut zu behaltenden Namen und umgekehrt.
Für Rechner, die mit dem Internet verbunden sind, wird diese Umsetzung normalerweise durch einen DNS-Server vorgenommen37). Von Rechnern, die nur mit dem internen Netzwerk des Linux Clusters verbunden sind, ist aber das Internet nicht direkt erreichbar. Außerdem wurden für die einzelnen Knoten IP-Adressen aus einem privaten Bereich verwendet, die nicht in DNS-Tabellen eingetragen werden. Deswegen muss auf die Möglichkeit zurückgegriffen werden, solche Namenseintragungen auf jedem einzelnen Knoten in der Datei /etc/hosts vorzunehmen. Die folgende Beispieldatei zeigt das Vorgehen hierfür:
36) Wir nennen Open PBS hier, weil dieses Batch Queuing System sehr weit verbreitet ist. Wir werden jedoch bei der Wahl der Ressourcen-Verwaltungssoftware auf das Grid Engine System von Sun setzen (mehr dazu später). 37) Das Domain Name System (DNS) ist eine verteilte Datenbank, die Informationen über Rechner im Inter-/Intranet enthält. Die gespeicherten Daten enthalten im allgemeinen Rechnernamen, IP-Adressen und Mail-Routing-Informationen.
#/etc/hosts # 127.0.0.1localhost 192.168.0.254 master.cluster.de master 192.168.0.1 node1.cluster.de node1 192.168.0.2 node2.cluster.de node2 192.168.0.3 node3.cluster.de node3 .... .... 192.168.0.32 node32.cluster.de node32
DateiA.2: /etc/hosts: Namensauflösung für den Cluster
In die erste Spalte schreibt man die IP-Adresse, in die zweite den so genannten Full-Qualified-Hostname, das sind der Rechnername plus der Domainname, und in die dritte Spalte trägt man den Rechnernamen ein. Zum Einloggen auf Knoten 1 kann es nun wesentlich kürzer ssh node1 anstelle von ssh 192.168.0.1 verwendet werden.
- 67 -

A.2.1.2 PXEfähigesDHCP
Das so genannte Dynamic Host Configuration Protocol dient dazu, Einstellungen in einem Netzwerk zentral von einem Server aus zu vergeben, statt diese dezentral an einzelnen Arbeitsstationen oder wie bei uns hier, an jedem einzelnen Rechenknoten vorzunehmen. Ein mit DHCP konfigurierter Client verfügt selbst nicht über statische Adressen, sondern konfiguriert sich nach den Vorgaben des DHCP-Servers. Um den Masterknoten als DHCP-Server einzuschalten müssen wir unter SuSE Linux folgenden Befehl eingeben:
# insserv /etc/init.d/dhcpd /etc/init.d/rc5.d
Letztes bewirkt, dass der DHCP-Server beim jeden Start des Betriebssystems im Run Level 5 (dem graphischen Modus) automatisch zur Verfügung steht38). Unsere Netzwerkkonfiguration (s. Abb. A.1) setzt voraus, dass das interne Netz mit der zweiten Netzwerkkarte auf dem Masterknoten bedient wird (Device eth1). Damit diese Netzwerkschnittstelle auch die DHCP Anfragen bekommt bzw. bearbeiten kann, müssen wir in der Datei /etc/sysconfig/dhcpd, die Variable DHCP_INTERFACE gleich „eth1“ setzen.
Anschließend muss die zentrale Konfigurationsdatei /etc/dhcpd.conf eingestellt werden und zwar so, dass der DHCP-Server die sog. PXE Erweiterungen benutzen kann39). Nur so ist der Server in der Lage, das Boot Loader Programm an den Knoten zu übertragen. Die Datei A.3 auf der darauf folgenden Seite zeigt eine Beispieldatei dhcpd.conf, die genau das macht.
Aus den in der Datei enthaltenen Einstellungen lässt sich entnehmen, dass wir eine statische IP Konfiguration für die Rechenknoten benutzen wollen, denn jeden Knoten bekommt immer die gleiche IP Adresse vom DHCP Server zugewiesen. Diese Vorgehens- Weise ist für die Cluster Konfiguration erforderlich, damit die verschiedenen Automatisierungsscripte sowie bestimmten Applikationen korrekt funktionieren.
38) Bootet man lieber in den Textmodus (Run Level 3 unter SuSE) würde der Befehl nur leicht vom oberen abweichen: # insserv /etc/init.d/dhcpd /etc/init.d/rc3.d39) PXE ist ein offener, industrieller Standard, der von zahlreichen Software- und Hardwareherstellern entwickelt wurde. Von der Firma Intel ins Leben gerufen, wurde PXE sehr schnell von anderen Unternehmen wie 3Com, HP, Dell, Compaq etc, weiter unterstützt. PXE arbeitet zusammen mit einer Netzwerkkarte (NIC) im PC und lässt diese als Boot Device agieren.
# DHCP Service configuration, version 3.0 ISC
ddns-update-style none; option domain-name „cluster.de“; option domain-name-servers 192.168.0.254; use-host-decl-names on; default-lease-time 86400; max-lease-time 86400;
# Specific options for the PXE protocol
option space PXE; option PXE.mtftp-ip code 1 = ip-address; option PXE.mtftp-cport code 2 = unsigned integer 16; option PXE.mtftp-sport code 3 = unsigned integer 16; option PXE.mtftp-tmount code 4 = unsigned integer 8; option PXE.mtftp-delay code 5 = unsigned integer 8; option PXE.discovery-control code 6 = unsigned integer 8; option PXE.discovery-mcast-addr code 7 = ip-address;
subnet 192.168.0.0 netmask 255.255.255.0 { class „pxeclients“ {
match if substring (option vendor-class-identifier, 0, 9)=“PXE Cli- ent“; option vendor-class-identifier „PXEClient“; vendor-option-space PXE; option PXE.mtftp-ip 0.0.0.0; filename „pxelinux.0“; next-server 192.168.0.254;
}host node01 { hardware ethernet 00:04:76:1b:35:4f; fixed-address 192.168.0.1; }
- 68 -

} host node02 { hardware ethernet 00:04:76:eb:f1:e3; fixed-address 192.168.0.2; } host node03 { hardware ethernet 00:04:76:22:17:43; fixed-address 192.168.0.3; } M host node32 { hardware ethernet 00:01:02:a8:2b:1d; fixed-address 192.168.0.32; } }
DateiA.3: /etc/dhcpd.conf auf master.
A.2.1.3 TFTPServer
Wie wir in Kurze sehen werden, ist pxelinux das Ladeprogramm, welches wir für das Hochfahren der Rechenknoten über das Netzwerk benötigen (s. §A.2.2.4). Pxelinux erfordert seinerseits die Anwesenheit eines TFTP Servers41) im Netz (in der Regel wird das DHCP-Server System diese Rolle ebenfalls übernehmen), der die sog. TSIZE (transfer size) Option verstehen kann. Diese Option ist im Grunde genommen ein Mechanismus, mit dem pxelinux in der Lage versetzt wird, die Größe einer Datei zu Bestimmen bevor sie übertragen wird.
tftp-hpa, eine modifizierte Version des Standard BSD TFTP Servers, funktioniert hierfür ausgezeichnet (der Suffix „-hpa“ steht für H. Peter Anvin, Autor dieser tftp Version und von dem oben genannten pxelinux Programm). Ein wichtiger Punkt bei der Konfiguration des TFTP Servers ist, dass der TFTP Dämon „in.tftpd“ immer von einem so genannten Meta-Dämon, wie inetd oder xinetd, gesteuert wird. Man muss sich also vergewissern, dass der aktive Meta-Dämon die richtige Konfiguration für TFTP enthält. Die relevanten Dateien hierzu sind /etc/inetd.conf für inetd oder /etc/xinetd.d/tftp für xinetd42). Will man inetd verwenden, muss man einfach das „#“ Zeichen aus der Zeile:
tftp dgram udp wait root /usr/sbin/in.tftpd in.tftpd –s /tftpboot
in der Datei /etc/inetd.conf entfernen. Beim xinetd editieren wir die Datei/etc/xinetd.d/tftp so, dass die Variable disable auf „no“ gesetzt wird. Der Parameter –s informiert den Dämon in.tftpd über die Position der Dateien, die die TFTP Clients herunterladen können. In unserem Fall ist dies das Verzeichnis /tftpboot.
Schließlich müssen wir einen automatischen Start des Meta-Dämons beim Booten ver-anlassen. Der Befehl würde im allgemeinen Fall so aussehen:
# insserv /etc/init.d/<meta-dämon> /etc/init.d/rc5.d
wobei <meta-dämon> für inetd oder xinetd steht.
A.2.1.4 NIS(NetworkInformationService)
NIS ermöglicht es, alle Benutzer des Clusters zentral auf dem Masterknoten einzurichten und dann diese Benutzerinformationen über den ganzen Cluster zu verteilen43).
41) TFTP steht für Trivial File Transfer Protocol und ist eine vereinfachte Form des wohl bekanntesten FTP Protokoll. TFTP benutzt den UDP (User Datagram Protocol) als Übertragungsfundament und, anders als FTP, arbeitet es ohne Sicherheitsvorkehrungen. Er wird ausschließlich für die Übertragung von Startdateien verwendet, die das Booten von X-Terminals, Routers, Disklessclients, etc. ermöglichen und auf hohe Sicherheit nicht angewiesen sind.42) Der Meta-Dämon inetd ist standardmäßig durch xinetd in praktisch jeder modernen Linux Distribution abgelöst worden. SuSE Linux bietet inetd jedoch noch als Option zu xinetd für diejenigen, die mit der alten inetd Konfiguration besser vertraut sind. 43) Der heute mit NIS bezeichnete Network Information Service hieß zuerst yellow pages. Da dieser Name aber durch die Firma Britisch Telecom geschützt war, wurde das Programm in NIS umbenannt. Dennoch heißen die Pakete, die die Software für NIS zur Verfügung stellen, bei den meisten Linux Distributionen nach wie vor ypclient und ypserv.
- 69 -

Der Administrator spart damit Arbeit, sich auf allen Knoten einzuloggen und alle Benutzer auf jedem einzelnen einzurichten. Der Masterknoten soll ebenfalls die Aufgabe des Servers übernehmen und alle anderen Knoten inklusive der Masterknotens selbst sollen ihre Informationen als Clients von diesem bekommen.
Auf der Knotenseite ist nicht viel zu tun, um auf den NIS Server zugreifen zu können. Im Wesentlichen muss nur das RPM Paket ypclient eingespielt werden und in der Datei /etc/yp.conf die IP-Adresse (Achtung: Generischer Name funktioniert nicht!) des Servers bekannt gegeben werden:
# /etc/yp.conf # ypserver 192.168.0.254
Datei A.3: Die Datei /etc/yp.conf
Welche Informationen über NIS bezogen werden und welche lokal verfügbar sind, wird in der Datei /etc/nsswitch.conf (Name Service Switch) festgelegt. Diese Datei ist im Paket ypclient enthalten und kann für die hier benötigten Standardaufgaben unverändert verwendet werden. Wir müssen ferner /etc/init.d/ypclient zu den Startscripten auf allen Knoten hinzufügen (auch auf den Masterknoten), so dass ypbind ebenfalls gleich nach dem Start gestartet wird und eine Verbindung zum NIS Server auf dem Master herstellt:
# insserv /etc/init.d/ypclient /etc/init.d/rc3.dMöchte ein Benutzer in einer NIS Umgebung sein Passwort ändern, so kann er nicht den Befehl passwd verwenden, sondern muss stattdessen mit dem Befehl yppasswd die Passwortänderung dem Masterknoten bekannt geben, damit dieser sie dann über das ganze Netzwerk verteilen kann. Damit ein Benutzer nicht versehentlich sein Passwort nur lokal ändert, sollte der Administrator dafür sorgen, dass passwd nicht verfügbar ist, indem er passwd umbenennt oder löscht.
Auf der Server-Seite, also auf dem Masterknoten, muss das RPM-Paket ypserv installiert werden. Danach müssen die Informationen, die über NIS verteilt werden sollen, zuerst einmal in so genannten Maps abgelegt werden. Diese Maps kann man einfach durch das Ausführen des Befehl make im Verzeichnis /var/yp erzeugen lassen.
Sind nun die Informationen in den entsprechenden Maps gespeichert, so muss noch bestimmt werden, welche Informationen überhaupt über NIS verteilt werden. In der Datei /etc/ypserv.conf auf dem Masterknoten können Optionen und Zugriffsberechtigungen für den NIS Server festgelegt werden. Optionen werden in der Form: option: [yes|no] angegeben. Zugriffsberechtigungen haben die Syntax:
host:map:security:mangle[:field]
In der Beispielkonfigurationsdatei weiter unten bedeutet beispielsweise die Option dns: no, dass der Server, wenn Anfragen von Clients kommen, die nicht in der Hosts-Map verzeichnet sind, keine Anfrage an einen DNS Server stellt. Dies ist für den Linux- Cluster sinnvoll, da alle Knoten IP Adressen aus einem privaten Bereich haben und somit nicht im DNS Server eingetragen werden.
Bei der ersten Zugriffsberechtigung steht im Feld host ein Stern als Wildcard für alle Rechner, die auf den Server zugreifen. Die Map, für die Berechtigungen festgelegt werden sollen, ist shadow.byname. Die Angabe port im security Feld erlaubt nur Anfragen von Ports mit Nummern niedriger als 1024. Dies sind so genannte privilegierte Portnummern, die den Benutzern nicht zur Verfügung stehen, sondern exklusiv für das System reserviert sind. Die Angabe yes im mangle Feld besagt, das bei Anfragen, die nicht von privilegierten Ports kommen, ein x als Ergebnis zurückgeliefert wird.
# /etc/ypserv.conf # dns: no * : shadow.byname : port : yes * : passwd.adjunct.byname : port : yes * : * : port : yes
DateiA.4: /etc/ypserv.conf
Auch der Start des NIS Serverdienstes erfolgt wie schon der der Knoten Dienste während des Bootvorgangs durch Startup Scripte. Hierfür geben wir ein:
# insserv /etc/init.d/ypserv # insserv /etc/init.d/yppasswdd
- 70 -

Das Script /etc/init.d/ypserv startet den NIS-Server ypserv und das Script /etc/init.d/yppasswd startet das Programm rpc.yppasswdd, das dem Benutzer das Ändern seines Passwortes erlaubt.
A.2.1.5 NFS(NetworkFileSystem)
Im letzten Abschnitt ist beschrieben worden, wie es möglich ist, die Benutzer des Parallelrechners zentral zu verwalten. Hier soll es nun darum gehen, wie man diesen Benutzern, die sich auf jedem Knoten des Parallelrechners einloggen können, überall die gleiche Arbeitsumgebung zur Verfügung stellt, und wie man ihnen den Zugriff auf die Dateien aus ihrem Home-Verzeichnis ermöglichen kann. Dabei soll nicht auf allen Festplatten der einzelnen Knoten für den Benutzer ein Home Verzeichnis vorhanden sein, sondern die Arbeitsverzeichnisse sollen von einem zentralen Rechner bezogen werden. Damit verhindert man unnötiges Hin- und Herkopieren zwischen den einzelnen Knoten und erreicht gleichzeitig, dass der Benutzer immer mit der aktuellen Datei arbeitet.
Das Network File System (NFS), das 1984 von der Firma Sun Microsystems entwickelt wurde, ist der geeignete Weg zur Realisierung dieser Wünsche. NFS ist ein Server-Client System, bei dem der Server die Anfragen (in diesem Fall Lese-Schreibzugriffe auf eine Festplatte) der Clients bedient.
Üblicherweise wird man den NFS Server auf dem Masterknoten aufsetzen und in unserer Beispielkonfiguration hatten wir ein externes RAID (SCSI to IDE) System für die zentrale Datenspeicherung vorgesehen (s. Abb. A.1). Man installiert dazu das Paket nfs-utils oder das Paket nfs-server. Die Entscheidung zwischen den Paketen nfs-utils und nfs-server fällz fast immer zu Gunsten von nfs-utils, denn dieser Server ist direkt im Linux Kernel eingebettet und weist dadurch höhere Performance auf. Es gibt aber Situationen, bei denen der Einsatz von den sog. User Space NFS Servern dem Vorzug gegeben wird (Paket nfs-server). Dies ist vor allem dann der Fall, wenn man z.B. ein NFS Dateisystem aus dem lokalen Netz zum master exportieren muss und dieses vom Masterknoten den Rechenknoten ebenfalls per NFS zur Verfügung gestellt werden soll (sog. NFS reexport). Diese Reexport Option wird vom Paket nfs-utils nicht unterstützt.
Auf einem NFS Server müssen die folgenden Netzwerkserver gestartet werden:
• RPC Portmapper (portmap)• RPC Mount Dämon (rpc.mount)• RPC NFS Dämon (rpc.nfsd)
Diese Programme werden beim Hochfahren des Systems von den Scripten /etc/init.d/portmap und /etc/init.d/nfsserver gestartet. Wie bei den anderen bisher betrachteten Netzwerkdiensten, müssen auch diese Dienste beim Hochfahren des Masterknotens automatisch gestartet werden. Hierzu verwendet man unter SuSE Linux:
# insserv /etc/init.d/portmap# insserv /etc/init.d/nfsserver
Neben dem Start dieser Dämonen muss noch festgelegt werden, welche Dateisysteme an welche Rechner exportiert werden sollen. Dies geschieht in der Datei /etc/exports:
# /etc/exports # /usr 192.168.0.254/24(ro,no_root_squash) /home 192.168.0.254/24(rw,sync,no_wdelay,no_root_squash) /opt 192.168.0.254/24(rw,sync,no_wdelay,no_root_squash)
DateiA.5: Die Datei /etc/exports wird von mountd und nfs gelesen.
Je Verzeichnis, welches exportiert werden soll, wird eine Zeile benötigt, in der festgehalten ist, welche Rechner wie darauf zugreifen dürfen. Alle Unterverzeichnisse eines exportierten Verzeichnisses werden automatisch ebenfalls exportiert. Die berechtigten Rechner werden üblicherweise mit ihren Namen (inklusive Domainname) angegeben, es ist aber auch möglich, mit den Jokerzeichnen `*´ und `?´ zu arbeiten, die die aus bash bekannte Funktion haben, oder durch Angabe einer bestimmten IP Adresse bzw. eines Adressenbereichs. Werden keine Angaben gemacht, so hat jeder Rechner mit Netzverbindung zu master die Erlaubnis, auf dieses Verzeichnis (mit den angegebenen Rechten) zuzugreifen.
Die Rechte, mit denen das Verzeichnis exportiert wird, werden in einer von Klammern umgebenen Liste nach dem Rechnernamen angegeben. Die Berechtigung rw steht zum Beispiel für Lese- und Schreibberechtigung. root_squash bewirkt, dass die dem Benutzer `root´ auf dem Clientrechner zustehenden Sonderrechte auch für das importierte Verzeichnis gewährt werden, obwohl er auf einem anderen Rechner seine `home´ Verzeichnis hat. In der vorhergehenden Beispielkonfigurationsdatei werden z.B. allen
- 71 -

Rechner in der Subnetzmaske 192.168.0.0 die Verzeichnisse /home und /opt zum Lesen und Schreiben zur Verfügung gestellt. Das Verzeichnis /usr wird hingegen nur zum Lesen bereitgestellt, der Benutzer `root´ behält aber in jedem Fall seine Sonderrechte. Weitere wichtige Optionen für die NFS Zugriffsrechte lassen sich aus dem NFS Howto entnehmen.
Auf der Knotenseite können beim Start des Rechners alle über NFS zu beziehenden Verzeichnisse automatisch gemountet werden, indem man zuerst den Prozess nfs in den geeigneten Runlevel einträgt, z.B:
# insserv /etc/init.d/nfs /etc/init.d/rc3.d
(wir werden später genauer betrachten, wie man auf den Knoten die nötigen Dienste einträgt). Um mount mitzuteilen, welche Verzeichnisse aus dem Masterknoten über NFS zu beziehen sind, dient die Datei /etc/fstab:
# /etcfstab # /dev/ram0 / ext2 defaults 1 1 /dev/hda1 swap swap pri=42 0 0 /dev/hda2 /scratch reiserfs defaults 0 0 master:/usr /usr nfs ro,timeo=7,acregmin=10,acregmax=120 0 0 master:/opt /opt nfs rw,timeo=7,acregmin=10,acregmax=120 0 0 master:/home /home nfs rw 0 0 devpts /dev/pts devpts mode=0620,gid=5 0 0 proc /proc proc defaults 0 0
DateiA.6: /etc/fstab: Definition der Optionen für den mount Befehl.
Hier werden die NFS Verzeichnisse aus master genauso wie lokale Verzeichnisse eingetragen. Anstelle des Device (z.B. /dev/hda1) schreibt man nun den Namen des NFS Servers und den dortigen Verzeichnisnamen. Als Dateisystemtyp verwendet man nfs. Der Mountpoint wird, wie bei lokalen Verzeichnissen, in die zweite Spalte eingetragen und auch die anderen mount Parameter (z.B. ro, rw, etc.) haben die gleiche Bedeutung wie bei lokalen Verzeichnisse.
A.2.1.6 rsh/ssh
Nachdem nun die Benutzer auf allen Knoten des Clusters einen Account besitzen undnach dem Einloggen dort auch ihr Homeverzeichnis vorfinden, müssen wir noch das Einloggen von einem Knoten des Clusters auf einen anderen Knoten ohne Passwortabfrage ermöglichen. Dies ist insbesondere dann sinnvoll, wenn von master aus auf jedem Knoten ein Programm gestartet werden soll. In diesem Fall wäre nämlich ansonsten für jeden einzelnen Knoten jeweils eine Passwortabfrage nötig.
Sowohl das Programm rsh als auch das Programm ssh ermöglichen ein solches Einloggen ohne Passwortanfrage, weshalb auch beide hier kurz besprochen werden sollen. Bei rsh (Remote Shell) kann jeder Benutzer in seinem Homeverzeichnis eine Datei ~/.rhosts anlegen, in die die Namen aller Rechner eingetragen werden, von denen aus ein Einloggen ohne Passwortabfrage erfolgen darf. Wenn man also eine Datei mit dem folgenden oder ähnlichen Inhalt erzeugt, so wird diese in das Bootimage für den Knoten angelegt (dazu natürlich später mehr) und ein passwortfreies Einloggen auf allen Rechnern ist verwirklicht.
# ~/.rhosts master node01 node02 node32
DateiA.7: Die Datei ~/.rshosts: Remotezugriff ohne Passwort.
Um dem einzelnen Benutzer die Arbeit, sich eine Datei .rhosts zu erzeugen, abzunehmen, legt der Administrator entweder eine globale Datei /etc/hosts.equiv an, die dann für alle Benutzer gilt und nur von root verändert werden kann, oder er legt eine Datei /etc/skel/.rhosts an, die beim Einrichten eines neuen Benutzers automatisch in dessen Homeverzeichnis kopiert wird und von ihm dort unverändert benutzt oder modifiziert werden kann. Als letzte Hürde für das passwortfreie Einloggen steht die Datei /etc/securetty, welche mit den Einträgen für rlogin und rexec versehen werden muss.
Das Starten des Programms rsh wird allerdings ähnlich wie TFTP von einem Meta Dämon gesteuert. Falls wir hierzu inetd benutzen, müssen wir das Zeichen `#´ aus den folgenden Zeilen entfernen:
- 72 -

shell stream tcp nowait root /usr/sbin/tcpd in.rshd -Lshell stream tcp nowait root /usr/sbin/tcpd in.rshd –aLlogin stream tcp nowait root /usr/sbin/tcpd in.rlogindlogin stream tcp nowait root /usr/sbin/tcpd in.rlogind -aexec stream tcp nowait root /usr/sbin/tcpd in.rexecd
Falls xinetd hingegen der aktive Meta Dämon ist, dann müssen wir nur die Dateien rexec, rlogin und rsh im Verzeichnis /etc/xinetd.d editieren, und zwar jedes Mal die Variable disable einfach auf „no“ setzen. Da wir bereits einen Meta Dämon beim Hochfahren von master automatisch starten (s. TFTP Server §A.2.1.3), brauchen wir uns an der Stelle nicht weiter über das automatische Starten der rsh Server zu kümmern.
Für das Programm ssh (Secure Shell) ist das Vorgehen, um sich passwortfrei einloggen zu können ein wenig anders. Zuerst erzeugt sich jeder Benutzer mit dem Befehl ssh-keygen einen so genannten privaten- und einen öffentlichen Schlüssel. Nach Ausführen des Programms findet man dann in Verzeichnis ~/.ssh den öffentlichen Schlüssel identit.pub und den privaten Schlüssel identity vor. Alle Rechner, auf denen der öffentlichen Schüssel in der Datei authorized_keys eingetragen ist, erlauben nun ein einloggen ohne Abfrage des Passwortes. Kopiert man also die Datei identity.pub in die Datei authorized_keys um und kopiert man diese automatisch an der geeigneten Stelle beim Hochfahren des Knoten, so kann man passwortfrei zwischen den einzelnen Knoten wechseln.
Beim ersten Einloggen auf den Knoten von master aus, sind diese Rechner für das Programm ssh unbekannt. Deswegen wird die Meldung erscheinen:
Host key not found from the list of known hosts.Are you sure you want to continue connecting (yes/no)?
Die Frage ist mit yes zu beantworten. Bei weiteren Einloggvorgängen sind die Knoten dann in der Datei know_hosts eingetragen und es findet keine weitere Abfrage mehr statt. Der ssh Server ist per Default in der SuSE Distribution automatisch beim Start aktiv und daher sind während der Masterknoten-Konfiguration keine sonderlichen Einstellungen hierzu erforderlich.
A.2.1.7 ZeitausgleichdurcheinenXNTPServer
Der NTP Server (Network Time Protocol) wird eingesetzt, wenn eine Zeitsynchronisierung zwischen einer oder mehreren Maschinen und einer Referenzzeitquelle stattfinden soll. Das ist insbesondere auf Clustersystemen sinnvoll, denn viele Applikationen, die unterschiedliche Prozesse auf mehreren Knoten starten, überprüfen die Zeitstempel einiger Dateien um die Entstehung von korrupten Daten zu verhindern.
Nach der Installation des Pakets xntp legt SuSE die Konfigurationsdatei xntpd.conf wie üblich im Verzeichnis /etc an. Für den Masterknoten kann die relevante Sektion dieser Datei wie auf die darauf folgende Seite aussehen. Man sieht aus der unterstehenden Datei, dass master über das Internet mit mehreren Zeitservern eine Verbindung aufbauen kann, welche ihrerseits Atomuhren als Zeitquelle verwenden. Dadurch ist man in der Lage, eine Genauigkeit beim Zeitabgleich im Bereich von Millisekunden zu erreichen. Wir veranlassen einen automatischen Start des Zeitservers auf master durch den Befehl:
- 73 -

# insserv /etc/init.d/xntpd # /etc/ntp.conf # # Sample NTP configuration file. # See package ‚xntp-doc‘ for documentation, Mini-HOWTO and FAQ.
## ## Outside source of synchronized time ## ## server xx.xx.xx.xx # IP address of server # time server eingeben hus 08 05 2003 # server ntp.rz.uni-ulm.de. version 3
server ntp.physik.uni-ulm.de. version 3 server ntp.mathematik.uni-ulm.de. version 3 ##
DateiA.8:Ausschnitt aus der Datei /etc/xntpd.conf für master
Auf der Seite der Rechenknoten soll das Programm xntpd ebenfalls automatisch beim Hochfahren aktiviert werden, allerdings benutzen diese Maschinen den Masterknoten als Zeitserver. Der relevante Abschnitt bei der Datei /etc/xntpd.conf entspricht dem in der Datei A.9 dargestellten.
# /etc/ntp.conf # ## ## Outside source of synchronized time ## ## server xx.xx.xx.xx # IP address of server # time server eingeben hus 08 05 2003 server 192.168.0.254
DateiA.9: Ausschnitt aus der Datei /etc/xntpd.conf für die Rechenknoten
A.2.1.8 BatchQueuingSystem
Die potentiell hohe Leistung eines Clusters kann nur mit größter Effektivität ausgenutzt werden, wenn die anfallende Arbeit intelligent auf alle Ressourcen verteilt ist. Die Aufgabe von der so genannter Batch Queuing System oder auch Jobverwaltungssysteme (JVS) besteht eben daran, eine möglichst hohe Systemauslastung aufrecht zu erhalten. JVS erfüllen weiterhin andere wichtige Aufgaben: Sie werden eingesetzt, wenn mehrere Benutzer um dieselben Betriebsmittel konkurrieren und dabei Anwendungen einsetzen, die sich in Art und Umfang ihres Ressourcenverbrauchs stark unterscheiden können. Dabei handelt es sich sowohl um Batch Anwendungen als auch um interaktive Applikationen. Da die Kapazitäten begrenzt sind, können in der Regel nicht alle Benutzer zur gleichen Zeit bedient werden.
Das zentrale Konzept von JVS ist daher die Queue, in der Aufträge (Jobs) gesammelt werden, die dann bei passender Gelegenheit zur Ausführung kommen. Die Schwierigkeit besteht darin, zu entscheiden, nach welchen Kriterien die Aufträge abzuarbeiten sind. Außer das Erreichen einer optimalen Lastverteilung, spielen hier andere Faktoren eine Rolle, zum Beispiel, eine möglichst große Fairness, eine möglichst kurze Abarbeitung der Jobs (so bald sie erst zur Ausführung kommen) oder eine intelligente Ausnutzung von begrenzten Mittel wie CPU Zeit oder Speicher. Diese Ziele stehen teilweise in Widerspruch zu einander. Man muss also Prioritäten setzen, die das Systemverhalten in die eine oder andere Richtung lenkt.
Um ein Beowulf Cluster mit der Funktionalität eines JVS zu versehen, gibt es sowohl kommerzielle als auch frei verfügbare, auf Open Source Software basierende Lösungen, die die oben geschilderten Anförderungen erfüllen können. Das bekannteste Beispiel davon ist das Open Portable Batch System, häufig Open PBS genannt, das bis von Kurzen das JVM im Clusterumfeld schlechthin darstellte. Wir werden unserer Aufmerksamkeit hier jedoch einer vergleichsweise neu JVM-Software schenken, die innerhalb der Open Source Gemeinde unter den Namen Sun Grid Engine bekannt ist und nach unsere Meinung auf den guten Weg ist Open PBS als Standard abzulösen.
- 74 -

Durch die Übernahme der Firma Gridware und des Produkts Codine im Jahre 2000 hatte sich die Firma Sun Microsystems für einen schnellen Einstieg in die Welt des Cluster-Computings entschieden. Codine ist dabei eine kommerzielle Weiterentwicklung des freien DQS (Distributed Queuing System), das am Supercomputer Computations Research Institute der Florida State University entwickelt wurde. Sun nannte Codine in Grid Engine um, unterwarf es einiger Simplifizierungen, fügte noch einige sinnvolle Features hinzu und gab den Sourcecode im Juli 2001 frei.
Die Architektur von Grid Engine ähnelt der des PBS: Es gibt einen eigenen Master- und Scheduler-Prozess, und ein Exec-Dämon ist für die Ausführung der Jobs und das Ressourcen-Management verantwortlich. Für die Kommunikation zwischen den Prozessen sorgt ein spezieller Kommando-Dämon. Von Vorteil ist, dass zu dem Master-Prozess „sge_qmaster“ zusätzlich Shadow-Server definiert werden können, die bei einem Ausfall des Master-Dämons die Arbeit übernehmen.
Für die Konfiguration bietet Grid Engine ein komfortables und vollständiges grafisches Interface an. Mit dem Kommando „qmon“ können jedoch alle Funktionen der Oberfläche genauso effektiv bedient werden. Jede vorgenommene Änderung, sei es per GUI oder per Kommandoseile, wirkt sich sofort auf das System aus; Dämonen müssen nicht neu gestartet werden.
Beim Queuing-System verfolgt Grid Engine ein grundsätzlich anderes Konzept als die meisten JVM-Systeme (Open PBS, PBS Pro, LFS, etc). Hier gibt es keine Netzwerkqueues, Queues sind stattdessen immer einem Host zugeordnet. Daher wird jeder Job nach dem Abschicken zunächst in eine globale Holding Area gestellt, von wo aus der Scheduler den Job erst dann in eine Queue stellt, wenn ein geeigneter Platz frei wird.
Die SuSE Linux Distribution liefert die Sun Grid Engine (SGE) Software in rpm Format schon von werk aus. Die Installation und Konfiguration sind also denkbar einfach. Installiert man ein frisches System, dann wählt man das Paket grindengine-5.3-125.i586.rpm zur Installation. Auf ein bereits installiertes System kann man, nach dem mounten des CD-Rom Laufwerks mit folgendem Befehl die Installation von Grid Engine nachholen:
# rpm –ivh /media/cdrom/grindengine-5.3-125.i586.rpm
SuSE Linux installiert SGE per Default im Verzeichnis /opt. Um den SGE Master zu konfigurieren, wechseln wir in dem Verzeichnis /opt/gridengine. Es gibt einzig und allein zwei Stellen wo wir selber tätig werden müssen bevor wir mit der Konfiguration eines SGE Masters unter SuSE 8.2 starten wollen. SuSE legt während der Installation von der SGE Software eine Datei namens „configuration“ in das Verzeichnis /opt/gridengine/default/common. Diese enthält Pfade für die Lokalisierung wichtiger SGE Komponenten, die nicht mit den Defaultwerte der Installationsroutine von Sun kompatible sind. Dieses Problem, dass zum Abbruch der Installation führt, lässt sich am einfachsten vermeiden in dem man mit der Installation erst anfängt, wenn man die Datei configuration gelöscht hat. Der zweite Schritt zur reibungslosen Installation der SGE Software muss nicht unbedingt durchgeführt werden, kann uns aber schon bei Installationen ab 16 Knoten viel Zeit sparen. Hierzu wird die Erstellung eine Datei empfohlen, die sämtliche Namen alle Knoten enthält. Bei unserer Beispielkonfiguration heißen die Knoten einfach node1 bis node32. Mit dem Bash Befehl
# for i in `seq 1 32`; do echo node$i >> nodelist; done
erstellen wir eine Textdatei namens nodelist, die eine Liste der Clusterknoten enthält. Diese Namen müssen allerdings in der Datei /etc/hosts, wie im Abschnitt A.2.1.1 (Namensauflösung) angetragen sein.
Dann wechseln wir ins Verzeichnis /opt/gridengine und rufen wir von dort einfach das Script install_qmaster auf:
/opt/gridengine #./install_qmaster
Welcome to the Grid Engine installation---------------------------------------
Grid Engine qmaster host installation-------------------------------------
Before you continue with the installation please read these hints:
- Your terminal window should have a size of at least 80x24 characters
- The INTR character is often bound to the key Ctrl-C. The term >Ctrl-C< is used during the installation if you have the possibility to abort the installation
- 75 -

The qmaster installation procedure will take approximately 5-10 minutes.
Hit <RETURN> to continue >>
Ab diesem Punkt kann man ohne bedenken die Defaultwerte der Installationsroutine annehmen. Diese reichen für die ersten Erfahrungen mit SGE vollkommen aus. Auf die Frage:
Adding Grid Engine hosts------------------------
Please now add the list of hosts, where you will later install your executiondaemons. These hosts will be also added as valid submit hosts.
Please enter a blank separated list of your execution hosts. You maypress <RETURN> if the line is getting too long. Once you are finishedsimply press <RETURN> without entering a name.
You also may prepare a file with the hostnames of the machines where you planto install Grid Engine. This may be convenient if you are installing GridEngine on many hosts.
Do you want to use a file which contains the list of hosts (y/n) [n] >> ybeantworten wir mit y und geben wir den Pfad zu der oben erstellten Datei /root/nodelist an. Somit wird die automatische Einrichtung der Hostqueues gestartet:Adding admin and submit hosts from file---------------------------------------
Please enter the file name which contains the host list: /root/nodelistnode1.cluster.de added to administrative host listnode1.cluster.de added to submit host listnode2.cluster.de added to administrative host listnode2.cluster.de added to submit host listnode3.cluster.de added to administrative host listnode3.cluster.de added to submit host list node32.cluster.de added to administrative host listnode32.cluster.de added to submit host listFinished adding hosts. Hit <RETURN> to continue >>
Auf dem SGE Master ist damit die Arbeit getan. Auf der Knoten Seite erfolgt die SGE Konfiguration noch unproblematischer. Das Verzeichnis /opt auf dem Master wird dem Knoten per NFS zur Verfügung gestellt, so dass wir nach dem Einloggen einfach ins Verzeichnis /opt/gridengine wechseln und das Kommando:
node1#./install_exec
ausführen. Wir werden folgenden Dialog zu sehen bekommen:
Welcome to the Grid Engine execution host installationIf you haven’t installed the Grid Engine qmaster host yet, you must execute this step (with >install_qmaster<) prior the execution host installation. For a sucessfull installation you need a running Grid Engine qmaster. It is also neccesary that this host is an administrative host. You can verify your current list of administrative hosts with the command:
# qconf -sh
You can add an administrative host with the command:
# qconf -ah <hostname>
The execution host installation will take approximately 5 minutes
Hit <RETURN> to continue >>
- 76 -

Nach der einen Konfiguration für den Rechenknoten auf dem Server angelegt wird, wird der notwendigen Prozess auf dem Knoten „sge_qexecd“ gestartet und die Konfigurationsroutine abgeschlossen:
Grid Engine execution daemon startupStarting execution daemon. Please wait ... done Ist der sge_execd Programm auf jedem Rechenknoten gestartet, kann man nun anfangen Jobs an das JVM-System zur Bearbeitung zu schicken. Im Verzeichnis /opt/gridengine/examples findet man sehr nützliche Beispiele, die für die Erstellung eigener Jobscripte von großer Hilfe sein können.
A.2.1.9 AutomatisierungdurchSkripte
Viele Aufgaben, die auf einem Cluster zu erledigen sind, betreffen nicht nur einen einzelnen Knoten, sondern müssen auf eine bestimmte Anzahl von Knoten bzw. auf allen Knoten durchgeführt werden. Um ein manuelles Einloggen auf jedem Rechner des Clusters und dann die manuelle Durchführung der Aufgabe auf dem entsprechenden Rechner zu vermeiden, kann man Skripte zur Automatisierung verwenden.
Sinnvolle Skripte wären beispielsweise ein Skript namens cps, das alle laufenden Prozesse auf allen Knoten des Clusters ausgibt, ckill, das alle Prozesse eines bestimmten Namens auf dem ganzen Cluster beendet, creboot oder chalt, die den Cluster neu starten oder herunterfahren. Beispielhaft soll hier das Skript chalt vorgestellt werden:
#!/bin/bash ################################## # Halt all nodes of the cluster # ##################################
BASENAME=“node“ LASTNODE=0 NUM=32 NAME=$BASENAME$NUM ERROR=“ok“
until [ $BASENAME$LASTNODE = $NAME ] do echo $NAME if ping -c 1 -i 1 $NAME >/dev/null 2>&1 ; then ssh $NAME /sbin/halt -n else echo $NAME „ not responding“ ERROR=“not_responding“ fi NUM=$[$NUM - 1] NAME=$BASENAME$NUM done if [ $ERROR = „not_responding“ ] ; then echo „Halt not successfull!!!“ else echo „Halt successfull“ /sbin/halt -n fi
DateiA.10: Skript chalt zum Herunterfahren allen Rechenknoten eines Clusters
Dieses Skript ist auf master zu starten und sollte deswegen auch nur dort installiert sein. Außerdem sollte nur root die Berechtigung dazu haben, dieses Skript auszuführen.
Wenn auf master das Skript gestartet wird, so wird beginnend bei node32 bis zu node1 durch die until-Schleife immer wieder die gleiche Aufgabe erledigt. Zuerst wird mittels des Kommandos ping geprüft, ob der Rechner erreichbar ist. Falls ja, wird ihm mittels des Kommandos halt mitgeteilt, er solle sich herunterfahren. Ist er nicht erreichbar, so wird eine Fehlermeldung ausgegeben
- 77 -

und ein Flag gesetzt. Waren nun alle Rechner erreichbar, so kann sich der Masterknoten nach Beendigung der Schleife selbst herunterfahren. War aber mindestens einer der Rechner nicht erreichbar, so wird eine Fehlermeldung ausgegeben und master nicht heruntergefahren, um root die Möglichkeit zu geben, manuelle Maßnahmen zu ergreifen, um den nicht antwortenden Rechner herunterzufahren.
Auf ganz ähnliche Weise kann man auch die oben vorgeschlagenen Skripte ckill, creboot usw. verwirklichen, indem man einfach das Kommando halt gegen ein entsprechendes Kommando austauscht. Noch besser wäre es natürlich ein einziges Skripttool zur Hand haben, das alle wichtigen administrativen Aufgaben im Cluster durch die Eingabe von Steuerparameter erledigen könnte. Die Entwicklung eines solchen Tools erfordert jedoch etwas mehr Erfahrung in der Bash-Programmierung. Einheitliche Tools wie die eben beschriebene gehören in aller Regel zu dem Lieferumfang beim kommerziellen Clusteranbieter.
A.2.1.10Sicherheitsaspekte
Das passwortfreie Wechseln zwischen den einzelnen Knoten bedingt eine gewisse zusätzliche Gefahr für Clusterkonfigurationen, die Statusinformationen, oder sogar das ganze Betriebsystem lokal auf der Festplatte gespeichert haben. Gelingt es einem Hacker, auf dem Masterknoten einzudringen, so hat er auch Zugang zu allen anderen Knoten des Clusters. Richtet er auf den einzelnen Knoten Schäden an, die eine Neuinstallation notwendig machen, so ist nicht ein Rechner, sondern es sind alle Rechner des Clusters neu zu installieren, was einen enormen Arbeitsaufwand bedeutet. Deswegen kommt dem Schutz von dem Masterknoten, als Zugangsrechner für den Cluster, eine besondere Bedeutung zu. Obwohl diese Gefahr beim Clusterkonfigurationen, die RAM-Disk Images verwenden, nicht so extrem ist, die Schaden, die durch einen Hackereinbruch im System entstehen können, sollten auf keinen Fall unterschätzt werden.
Jeder Benutzer sollte sich aus diesem Grund von außen auf dem Cluster nur per ssh einloggen, welches die Authentifizierungs- und Sessions-Daten in verschlüsselter Form überträgt. Das Programm rsh sollte auf keinen Fall zum externen Einloggen verwendet werden, da es alle Daten in unverschlüsselter Form ans Netz gibt und ein Hacker, der an diesem Netz lauscht, so die Passwörter im Klartext mitlesen kann. Bei Einloggvorgängen innerhalb des Clusters ist eine Verschlüsselung, wenn man den eigenen Benutzern vertraut, nicht notwendig, da jemand der das interne Netz abhören will, Zugang zu mindestens einem Knoten des Clusters haben muss.
Um niemanden in die Versuchung zu führen, sich unverschlüsselt bei dem Masterknoten anzumelden, sollte der Administrator Zugänge über rsh generell, auch im internen Netzwerk, verbieten. Dazu ist der rsh-Dienst in der Datei /etc/inetd.conf auszukommentieren. Das Programm ssh bietet als weiteren Vorteil gegenüber rsh automatisches X11-Forwarding, d. h. die Ausgabe von X11-basierten Programmen wird automatisch an den richtigen Bildschirm weitergeleitet.
Auch das Programm ftp überträgt übrigens die Passwörter im Klartext und sollte daher vermieden werden. Als Ersatz hierfür kann das Programm scp (secure copy) zum Einsatz kommen, das im gleichen Paket wie das Programm ssh enthalten ist.
- 78 -