Embed Size (px)
Citation preview

SVEUCILIŠTE U ZAGREBUFAKULTET ELEKTROTEHNIKE I RACUNARSTVA
SEMINAR
Duboke neuronske mrežeFlorijan Stamenkovic
Voditelj: Marko Cupic
Zagreb, ožujak 2015.

SADRŽAJ
1. Uvod 1
2. Hopfieldove mreže 32.1. Definicija . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.2. Energija . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.3. Konvergencija . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.4. Podešavanje težina . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.5. Adresiranje memorije putem sadržaja . . . . . . . . . . . . . . . . . 6
3. Boltzmannov stroj 83.1. Notacija . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
3.2. Stohasticki neuroni . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3.3. Simulirano kaljenje . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.4. Generativni probabilisticki model . . . . . . . . . . . . . . . . . . . 12
3.5. Termalna ravnoteža . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.6. Ucenje . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.6.1. Motivacija . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.6.2. Modeliranje distribucije vjerojatnosti . . . . . . . . . . . . . 15
3.6.3. Izglednost . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.6.4. Procjena najvece izglednosti parametara Boltzmannovog stroja 17
3.6.5. Složenost ucenja . . . . . . . . . . . . . . . . . . . . . . . . 20
3.6.6. Ucenje Monte Carlo metodom . . . . . . . . . . . . . . . . . 20
3.6.7. Primjer ucenja MCMC metodom . . . . . . . . . . . . . . . 21
3.7. Skriveni neuroni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4. Ograniceni Boltzmannov stroj 274.1. Definicija . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4.2. Produkt strucnjaka . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
ii

4.3. Skriveni neuroni kao znacajke . . . . . . . . . . . . . . . . . . . . . 32
4.4. Ucenje . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.4.1. Kontrastna divergencija . . . . . . . . . . . . . . . . . . . . . 33
4.4.2. Kontrastna divergencija, algoritamska implementacija . . . . 36
4.4.3. Dodatni parametri ucenja . . . . . . . . . . . . . . . . . . . . 40
4.4.4. Perzistentna kontrastna divergencija . . . . . . . . . . . . . . 43
4.5. Primjer ucenja ogranicenog Boltzmanovog stroja . . . . . . . . . . . 45
5. Duboka probabilisticka mreža 515.1. Definicija . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
5.2. Generativni probabilisticki model . . . . . . . . . . . . . . . . . . . 52
5.3. Diskriminativni model . . . . . . . . . . . . . . . . . . . . . . . . . 54
5.4. Treniranje . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
5.4.1. Pohlepno predtreniranje slojeva . . . . . . . . . . . . . . . . 57
5.4.2. Fino podešavanje . . . . . . . . . . . . . . . . . . . . . . . . 58
6. Primjer korištenja 616.1. Definicija problema . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
6.2. Skup za treniranje . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
6.3. Korišten model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
6.4. Nacin evaluiranja . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
6.5. Obavljeni pokusi, najbolja mreža . . . . . . . . . . . . . . . . . . . . 63
6.6. Rezultati . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
6.7. Prag pouzdanosti klasifikacije . . . . . . . . . . . . . . . . . . . . . 65
7. Zakljucak 67
8. Literatura 68
9. Sažetak 70
iii

1. Uvod
Umjetne neuronske mreže su se pokazale kao dobar alat za rješavanje klasifikacijskih
i regresijskih problema u podrucju mekog racunarstva. Njihova snaga primarno leži
u slojevitom (odnosno slijednom) kombiniranju jednostavnih nelinearnih elemenata,
neurona. Nažalost, unatoc obecavajucim rezultatima u primjeni na manjim i srednje
teškim problemima, pokazalo se da je velike neuronske mreže iznimno teško trenirati
za rješavanje specificnog zadatka. Algoritmi koji se baziraju na optimizaciji mreže
gradijentnim metodama skloni su pronalasku lokalnih optimuma (kojih u kompleksnim
mrežama ima previše da bi ih se izbjeglo). Pošto se pri propagaciji unatrag iznos
gradijenta umanjuje otprilike za red velicine po sloju, treniranje mreža s više od pet
ili šest slojeva je presporo da bi bilo od koristi (engl. vanishing gradient problem).
Nadalje, iole kompleksne mreže su u pravilu vrlo teško interpretabilne. Cak i ako se
postignu dobre performanse, mreža je u biti "crna kutija", skoro je nemoguce analizom
postici uvid zašto dobro rade.
U zadnjih desetak godina slojevitim umjetnim neuronskim mrežama pristupa se
na novi nacin. Radi se s nekoliko tehnika koji imaju par zajednickih aspekata. Slo-
jevi mreža treniraju se jedan po jedan. Time se omogucava korištenje dubljih mreža
s dobro utreniranim svim slojevima. Pri oblikovanju svakog sloja cesto se postiže
visok stupanj interpretabilnosti. Treniranjem slojeva pojedinacno poboljšava se pre-
traga parametarskog prostora mreže: bolje se izbjegavaju lokalni optimumi. Moguce
je efikasno trenirati više slojeva koji sadrže veci broj neurona, što omogucava stvaranje
puno kompleksnijih mreža koje se dobro nose s težim zadatcima. Niži slojevi mogu
se trenirati sa neoznacenim podatcima (polu-nadzirano ucenje). Konacno, nakon treni-
ranja pojedinih slojeva postojece gradijentne tehnike se mogu primjeniti na rezultira-
jucu višeslojnu mrežu u svrhu dodatnog rafiniranja interakcije slojeva i poboljšanja
rezultata.
Kao zajednicko ime za više tehnika koje na ovaj nacin pristupaju treniranju um-
jetne neuronske mreže koristi se termin "duboka neuronska mreža". Duboke neuronske
mreže na tipicnim klasifikacijskim problemima postižu rezultate koji su medu pona-
1

jboljima ikad postignutim.
Ovaj seminar razmatra oblikovanje "dubokog stroja vjerovanja" (engl. deep belief
net). Radi se o dubokoj neuronskoj mreži u kojoj je svaki sloj treniran kao ograniceni
Boltzmannov stroj odnosno RBM (engl. restricted Boltzmann machine). Pri tome
se za svaki korak oblikovanja mreže pomno razmatra matematicka podloga, kao i
znacenje dobivenih rezultata. Cilj rada je oblikovati tekst koji ce zainteresiranom ci-
tatelju omoguciti jednostavan i sustavan ulazak u podrucje dubokih mreža. Pri tome se
od citatelja ocekuje poznavanje elementarne algebre i teorije vjerojatnosti. Od koristi
može biti i upoznatost s tipicnim problemima i terminologijom strojnog ucenja, kao i
umjetnim neuronskim mrežama opcenito.
2

2. Hopfieldove mreže
Kako bi što lakše objasnili Boltzmannov stroj, a potom i njegovu primjenu u dubokim
neuronskim mrežama, prvo cemo promotriti Hopfieldovu mrežu, koju je definirao J.J.
Hopfield 1982. godine u [7].
2.1. Definicija
Hopfieldova mreža je oblik umjetne neuronske mreže s povratnim vezama. Mreža
ima proizvoljan broj elemenata (neurona). Pojedini neuron si nalazi se u jednom od
dva moguca stanja si ∈ {−1, 1}.1 Stanje svih neurona mreže oznacavamo vektorom
s. Neuroni su spojeni težinskim vezama, gdje je wij težina (engl. weight) veze medu
neuronima si i sj . Postoje dva ogranicenja na težinske veze:
1. wij = wji,∀i, ∀j (simetricnost)
2. wii = 0,∀i (neuron nema vezu sam sa sobom)
Mreža se kroz vrijeme mjenja, u smislu promjene stanja neurona. Ne postoji defini-
ran redoslijed kojim neuroni mjenjaju stanje, u pravilu se biraju nasumicno. Moguce
je i paralelno mjenjanje stanja neurona, ali ono mora biti asinkrono jer u suprotnom
može doci do oscilacije mreže. Nacin promjene stanja neurona opisan je u nastavku.
2.2. Energija
Hopfieldova mreža može se promatrati kao energetski model. Za stanje s energija
mreže E(s) je definirana kao:
E(s) = −∑i
∑j>i
wijsisj −∑i
bisi (2.1)
1Ponekad se kao stanja neurona koriste i vrijednosti 0 i 1. Funkcionalnost mreže se time ne mjenja,
ali su primjeri manje ilustrativni. Stoga u ovom radu za Hopfieldovu mrežu koristimo stanja −1 i 1.
3

gdje bi predstavlja pristranost (engl. bias) neurona si, koje možemo postaviti u 0
bez utjecaja na funkcionalnost mreže.2
Iz definicije energije možemo izracunati utjecaj neurona sk na energiju mreže.
Definirajmo prvo energiju mreže za vektor stanje u kojem nam je poznato samo stanje
neurona sk, oznacimo to stanje s ε:
E(sk = ε) = −∑i
∑j>i
wijsisj −∑i
bisi
= −∑i 6=k
∑j 6=kj>i
wijsisj −∑i 6=k
bisi −∑j 6=k
wkjεsj − bkε
= −∑i 6=k
∑j 6=kj>i
wijsisj −∑i 6=k
bisi − ε
(∑j 6=k
wkjsj + bk
)(2.2)
Pojasnimo dobiveni izraz. U izrazu za cjelokupnu energiju (2.1) sumiramo po svim
parovima neurona (uzimajuci u obzir težinsku vezu medu njima) i pristranostima po-
jedinih neurona. Kako bismo izdvojili doprinos neurona sk energiji mreže, izuzimamo
ga iz obje sume. Sada možemo definirati utjecaj neurona sk na energiju mreže kao
razliku energije kada je sk = −1 i energije kada je sk = 1. Naprosto cemo u izraz
(2.2) uvrstiti konkretne vrijednosti (−1 i 1) te izracunati razliku:
∆Ek =E(sk = −1)− E(sk = 1)
=−∑i 6=k
∑j 6=kj>i
wijsisj −∑i 6=k
bisi − (−1)
(∑j 6=k
wkjsj + bk
)
+∑i 6=k
∑j 6=kj>i
wijsisj +∑i 6=k
bisi + (+1)
(∑j 6=k
wkjsj + bk
)
=2∑j 6=k
wkjsj + 2bk (2.3)
Vidimo da su se pokratili svi energetski doprinosi osim onih na koje neuron sk ima
izravan utjecaj. Ovo ima smisla s obzirom na to da tražimo razliku energija mreža cija
se stanja razlikuju samo u stanju neurona sk. Naglasimo još jednom da u Hopfieldovoj
mreži ne postoje težinske veze neurona samog sa sobom: wii = 0, ∀i. Stoga vrijedi:2Vrijedi kada se koriste stanja si ∈ {−1, 1}. Kada se koriste stanja si ∈ {0, 1}, pristranosti su bitne
za funkcioniranje mreže te se mogu promatrati kao težinske veze s posebnim neuronom cije je stanje
uvijek 1.
4

∆Ek = 2∑j 6=k
wkjsj + 2bk = 2∑j
wkjsj + 2bk
Obje oznake su u kontekstu Hopfieldovih mreža (a kasnije i Boltzmannovog stroja)
vrijedece.
2.3. Konvergencija
Energetski modeli teže ka stanjima niske energije, analogno fizikalnim sustavima.
Stoga neuroni Hopfieldove mreže postavljaju svoje stanje u skladu s pravilom: 3
si =
1, ako ∆Ei = 2∑
j wijsj + 2bi ≥ 0
−1, inace(2.4)
Vidimo da ce neuron si nakon evaluacije biti u stanju 1 iskljucivo ako je E(si =
−1) vece ili jednako odE(si = 1). Kada je ∆Ei negativan, što znaci da jeE(si = −1)
manje od E(si = 1), neuron si ce nakon evaluacije biti u stanju −1.
Dakle, neuroni pri evaluaciji poprimaju ono stanje koje daje manju energiju mreže.
Ovo se dešava sve dok ona ne konvergira u lokalni energetski minimum. U tom
trenutku neuroni više ne mjenjaju stanje.
Možemo u ovom trenutku primjetiti da je pretraživanje energetskog krajolika mreže
stohasticno s obzirom na redosljed kojim neuroni evaluiraju svoje stanje. Lokalni min-
imum energije u koji ce mreža konvergirati ponekad ovisi tom redosljedu. Nadalje,
primjetimo da mreža nema mogucnosti izlaska iz lokalnog optimuma (niti energetske
"doline") u kojoj se nalazi.
2.4. Podešavanje težina
Postavlja se pitanje kako kontrolirati u koji energetski minimum ce mreža konvergirati.
Konvergencija primarno ovisi o težinama veza medu neuronima i pocetnom stanju
mreže. U manjoj mjeri ovisi o redosljedu kojim neuroni evaluiraju stanja. Pocetna
stanja mreže ovise o problemu koji se rješava i uglavnom su dijelom nasumicna. Jasno
je stoga da kada mrežu "treniramo", to cinimo podešavanjem težina veza medu neu-
ronima.3Ovu dobro poznatu vrstu neurona u literaturi cesto nalazimo pod nazivom BTU (engl. binary thresh-
old unit).
5

Za zadani vektor stanja s promatramo stanja neurona si i sj . Ako su oni u istom
stanju (oba su u stanju −1 ili su oba u stanju 1), energija mreže ce biti minimalna ako
je je wij = 1. Ovo je vidljivo iz izraza (2.1). U drugu ruku, ako je jedan od neurona
u stanju 1, a drugi u −1, energija mreže ce biti minimalna ako je wij = −1. Iz ovog
opažanja proizlazi jednostavno pravilo podešavanja težina:
wij = sisj (2.5)
Ako koristimo pristranosti, bi se racuna kao težinska veza neurona i dodatnog neu-
rona koji je uvijek u stanju 1. Stoga vrijedi:
bi = si
Promotrimo treniranje mreže na jednostavnom primjeru. Pretpostavimo da želimo
da mreža od cetiri neurona konvergira u s =[111− 1
]. Težine izracunate u skladu s
izrazom (2.5) prikazane su na slici 2.1 (pristranosti zanemarujemo).
s1 s2
s3 s4
-1-1
-1
11
1
Slika 2.1: Izracunate težine za s = [111− 1]
Pretpostavimo sada da mrežu dovedemo u vektor stanje s′ =[−111− 1
]. Možemo
zamisliti da je to stanje posljedica utjecaja šuma na stanje s. Potom evaluiramo stanja
neurona nasumicnim redosljedom, dok mreža ne konvergira. Jedini neuron koji mi-
jenja stanje je s1, nakon cega je mreža došla u vektor stanje s koje je energetski mini-
mum. Vidimo da je mreža sposobna iz djelomicno tocnog vektor stanja rekonstruirati
zapamceno.
2.5. Adresiranje memorije putem sadržaja
Navedena sposobnost Hopfieldove mreže da na temelju djelomicng binarnog vektora
rekonstruira onaj vektor kojim smo ju trenirali zove se "adresiranje memorije putem
sadržaja" (engl. content adressable memory).
6

Mreža može imati više lokalnih energetskih minimuma. Stoga je moguce utrenirati
ju da "zapamti" i rekonstruira n binarnih vektora. Tada pravila podešavanja težina i
pristranosti glase:
wij =∑k=1
nski skj
bi =n∑k=1
ski
gdje je ski i-ti neuron vektor stanja sk. Ponekad se parametri normaliziraju faktorom
1/n, ali to nema utjecaja na rad mreže.
Broj vektora koji mreža može zapamtiti (njen kapacitet) ovisi o njenom broju neu-
rona. Pitanje kapaciteta Hopfieldove mreže je istraživano u dubinu, ali nije relevantno
za temu ovog seminara.
7

3. Boltzmannov stroj
Geoffrey E. Hinton 1983. godine opisao je ideju da se Hopfieldova mreža može koris-
titi ne samo za pohranu binarnih vektora vec i kao "racunalni proces u kojem se visoko
vjerojatna kombinacija odabire iz velikog skupa meduzavisnih hipoteza" [2]. U ovom
poglavlju ce ta ideja biti opisana.
Boltzmannov stroj je oblik Hopfieldove mreže te dosadašnja razmatranja tog mod-
ela vecinom i dalje vrijede. Kljucna razlika je da se stanja neurona evaluiraju sto-
hasticki, što ce biti opisano u nastavku.
3.1. Notacija
Oznake korištene u opisu Hopfieldove mreže i dalje vrijede, sažeti podsjetnik naveden
je u tablici 3.1.
Tablica 3.1: Oznake korištene u poglavlju o Boltzmannovom stroju
s Binarni vektor koji definira stanje svih neurona u mreži
si Stanje i-tog neurona mreže
wij Težina (engl. weight) veze medu neuronima si i sjbi Pristranost (engl. bias) neurona siE(s) Energija mreže za vektor stanje s
E(si = 1) Energija mreže kada je si u stanju 1, pri cemu su stanja drugih neu-
rona fiksirana na proizvoljnu vrijednost
∆Ei Razlika izmedu energija mreže s obzirom na stanje neurona si, pri
cemu su stanja drugih neurona fiksirana na proizvoljnu vrijednost
Kao oznake stanja pojedinih neurona koristiti cemo si ∈ {0, 1}, što je uobicajena
konvencija za Boltzmannov stroj. Izraz za energiju mreže nije se promjenio, i dalje
vrijedi:
8

E(s) = −∑i
∑j>i
wijsisj −∑i
bisi (3.1)
S obzirom na oznake stanja {0, 1}, iz izraza za energiju mreže vidimo da je utjecaj
neurona si na energiju sada:
∆Ei = E(si = 0)− E(si = 1) =∑j 6=i
wijsj + bi =∑j
wijsj + bi (3.2)
Detalji skoro identicnog izvoda koji je proveden uz pretpostavku da neuroni popri-
maju stanja {−1, 1} mogu se vidjeti za izraz (2.3) u poglavlju o Hopfieldovoj mreži.
Ako neuroni poprimaju stanja {0, 1}, kroz izvod za ∆E se ne generira konstanta 2 te
dobivamo (3.2).
3.2. Stohasticki neuroni
Razmotrimo sada ideju da neuroni ne mjenjaju stanje deterministicki, vec u skladu
s nekom vjerojatnošcu (stohasticki). U statistickoj mehanici Boltzmannova distribu-
cija govori da je vjerojatnost stanja nekog sustava proporcionalna njegovoj energiji na
sljedeci nacin:
P (s) ∝ e−E(s)kT
gdje je P (s) vjerojatnost da se sustav nade u stanju s, T temperatura i k Boltz-
mannova konstanta. Radi lakšeg zapisa možemo u ovom trenutku pretpostaviti da je
kT = 1, što nece utjecati na naše razmatranje. Time dobivamo:
P (s) ∝ e−E(s)
Kako bismo proporcionalnost u Boltzmannovim jednadžbama pretvorili u jednakosti
i dobili ispravan vjerojatnosni prostor, moramo normalizirati distribuciju:
P (s) =e−E(s)∑s′ e−E(s′)
=e−E(s)
Z(3.3)
gdje s′ oznacava jedno od svih mogucih stanja u kojem se Boltzmannov stroj može
naci. Z se naziva particijska funkcija (engl. partition function) te je uobicajena oznaka
za funkciju koja osigurava ispravnost vjerojatnosne distribucije.1
1Particijska funkcija se oznacava simbolom Z zbog njemacke rijeci zustandssumme, koja znaci
"suma po stanjima".
9

Razmotrimo kakve implikacije ovo ima za proizvoljni neuron si. Mreža je u stanju
s, razmatramo vjerojatnost da ce neuron si biti u stanju ε ako su svi ostali neuroni
mreže u fiksiranom stanju. Uvodimo oznaku P (s1, s2, ..., si−1, si = ε, si+1, ..., sn−1, sn),
što krace pišemo P (si = ε). Prisjetimo se, energiju mreže kada je neuron si = ε
(dok su ostali neuroni fiksirani na prozivoljne vrijednosti) oznacavali smo analogno s
E(si = ε). Neuron si može poprimiti stanja {0, 1}, svi ostali neuroni su fiksirani, pa
su moguca dva stanja s pripadnim vjerojatnostima P (si = 0) i P (si = 1). Iz Boltz-
mannove distribucije poznato je da je odnos vjerojatnosti dva stanja jednaka odnosu
njihovih eksponenciranih energija:
P (si = 0)
P (si = 1)=e−E(si=0)
e−E(si=1)= e−(E(si=0)−E(si=1)) = e−∆Ei (3.4)
S obzirom da neuron si može poprimiti samo stanja 0 i 1, a svi drugi neuroni mreže
su trenutacno fiksiranih vrijednosti, znamo da vrijedi P (si = 0) + P (si = 1) = 1.
Iskoristimo to kako bismo eliminirali jednu nepoznanicu iz izraza (3.4):
e−∆Ei =P (si = 0)
P (si = 1)=
1− P (si = 1)
P (si = 1)=
1
P (si = 1)− 1
na temelju cega jednostavno pronalazimo izraz za vjerojatnost da neuron si bude u
stanju 1:
P (si = 1) =1
1 + e−∆Ei= σ(∆Ei) (3.5)
gdje je σ(x) uobicajena notacija za cesto korištenu sigmoidalnu funkciju. Vjero-
jatnost stanja možemo zapisati izravno putem težina i pristranosti:
P (si = 1) =1
1 + e−(∑
j wijsj+bi)= σ(
∑j
wijsj + bi) (3.6)
Dakle, ovime smo izrekli vjerojatnost da je neuron si u stanju 1, kada su svi drugi
neuroni fiksirani na proizvoljne vrijednosti. Ta vjerojatnost ne ovisi o trenutnoj vrijed-
nosti si (prisjetimo se: neuroni u Boltzmannovom stroju nemaju vezu sami sa sobom,
dakle u izrazu (3.6) je wii = 0). Ako sada i dalje držimo sve neurone sj, j 6= i fiksir-
ane i uzorkujemo novo stanje neurona si, jasno je da ce neuron poprimiti vrijednost 1
s vjerojatnošcu P (si = 1).
10
3.3. Simulirano kaljenje
Algoritam simuliranog kaljenja (engl. simulated annealing) genericka je optimizaci-
jska metaheuristika kojoj je svrha pronalazak što boljeg rješenja (nadamo se globalnog
optimuma). Algoritam ne igra presudnu ulogu u Boltzmannovim strojevima (može i
ne mora se koristiti), ali dobro pojašnjava razliku izmedu Hopfieldove mreže i Boltz-
mannovog stroja.
Pri izvodu vjerojatnosti stanja stohastickog neurona postavili smo da je kT = 1,
gdje je k Boltzmannova konstanta a T temperatura sustava. Pretpostavimo sada da je
k = 1, ali da je temperatura T promjenjivi parametar. Time dobivamo vjerojatnost:
P (si = 1) =1
1 + e−∆EiT
= σ(−∆EiT
)
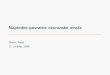
Graf 3.1 prikazuje vjerojatnost P (si = 1) s obzirom na ∆Ei za tri razlicite vrijed-
nosti parametra T . Vidimo da pri temperaturi T = 1 vjerojatnost poprima vrijednosti
blizu 1 vec pri energiji ∆Ei = 5, odnosno blizu 0 pri energiji ∆Ei = −5. Pri višoj
temperaturi (T = 5) vjerojatnost se sporije priklanja granicnim vrijednostima, dok se
pri temperaturi T = 50 na rasponu ∆Ei ∈ [−20, 20] vjerojatnost krece izmedu 0.4 i
0.6.
0
0.2
0.4
0.6
0.8
1
-20 -15 -10 -5 0 5 10 15 20
T = 1
T = 5
T = 50
Slika 3.1: P (si = 1) s obzirom na ∆E za razlicite vrijednosti parametra T
Iz grafa možemo zakljuciti što se s vjerojatnošcu dogada i pri ekstremnim temper-
aturama. Pri T = 0 vjerojatnost ce biti 0 za sve vrijednosti ∆Ei < 0, odnosno 1 za sve
11

∆Ei > 0. Pri temperaturi T =∞ vjerojatnost ce biti 0.5 za sve vrijednosti ∆Ei.
Sada možemo zakljuciti kakav utjecaj ovo ima na Boltzmannov stroj. Ako evaluiramo
stanja neurona pri vrlo visokim temperaturama sustava, vjerojatnost da ce oni poprim-
iti stanje 0 odnosno 1 je približno jednaka. Cijela mreža ce stoga prelaziti u razlicita
vektor stanja nasumicno. Postupnim snižavanjem temperature vjerojatnost stanja neu-
rona sve više ovisi o energetskoj razlici tih stanja, odnosno o težinama i pristranostima
mreže. Cijela mreža ce težiti prema stanjima koja imaju nisku energiju, ali mogucnost
prelaska u stanje više energije postoji. Ako postavimo temperaturu sustava na T = 0,
stanja neurona deterministicki postaju 0 ili 1 ovisno o ∆Ei, kao u Hopfieldovoj mreži.
U Boltzmannovom stroju temperatura se uglavnom fiksira na T = 1. U tom smislu
se simulirano kaljenje ne koristi izravno, ali dobro ilustrira razliku izmedu determinis-
tickog i stohastickog neurona. Boltzmannov stroj pretražuje šire podrucje energetskog
krajolika, jer može prelaziti u stanja više energije. Ovo svojstvo omogucava pronalazak
boljih energetskih minimuma.
3.4. Generativni probabilisticki model
Boltzmannov stroj je generativni probabilisticki model. Pojasnimo to na primjeru
stroja koji se sastoji od tri neurona. Težine medu neuronima su definirane kao na
slici 3.2. Pristranosti su postavljene na vrijednost 0.
s1 s2
s3
4-2
1
Slika 3.2: Boltzmannov stroj s definiranim težinama, pristranosti su 0
Boltzmannov stroj za n neurona može se naci u 2n stanja. U našem primjeru to
je 8 razlicitih stanja. Svako od tih stanja ima tocno definiranu energiju. Na temelju
energije u skladu s izrazom (3.3) racunamo vjerojatnost stanja. Dobiveni rezultati su
vidljivi u tablici 3.2.
Primjetimo da su vjerojatnosti izracunate za temperaturu sustava T = 1. Ako
bismo temperaturu sustava postavili u T = ∞, vjerojatnost svakog stanja bi bila 1/8.
12

Tablica 3.2: Distribucija vjerojatnosti Boltzmannovog stroja sa slike 3.2
s E(s) e−E(s) P (s)
0 0 0 0 1 0.01
0 0 1 0 1 0.01
0 1 0 0 1 0.01
0 1 1 -4 54.59 0.67
1 0 0 0 1 0.01
1 0 1 2 0.13 0.00
1 1 0 -1 2.71 0.03
1 1 1 -3 20.08 0.25
Z = 81.54
Kako temperatura teži u T = 0, izraz e−E(s)T eksponencijalno raste te vjerojatnost stanja
s najnižom energijom teži u 1.
Vidimo da razlicita stanja stroja imaju jasno definiranu vjerojatnost. Stoga je Boltz-
mannov stroj probabilisticki model. Isto tako znamo da je stroj u stanju prelaziti iz
jednog stanja u drugo u skladu s tim vjerojatnostima, što možemo promatrati kao pro-
ces u kojem stroj generira izlaz. Stoga kažemo da je generativni model.
3.5. Termalna ravnoteža
Promotrimo sada dinamicko ponašanje Boltzmannovog stroja. Neuroni se evaluiraju
nasumicnim redosljedom, kao i u Hopfieldovoj mreži. Postavlja se pitanje: ako smo
krenuli iz nasumicno odabranog pocetnog stanja stroja, što možemo ocekivati od mreže
u buducnosti?
Promjene stanja Boltzmannovog stroja možemo promatrati kao Markovljev lanac.
To znaci da za stanje mreže st u trenutku t možemo definirati vjerojatnost prelaska u
stanje st+1 za sva moguca stanja. Predocimo ovo primjerom.
Pretpostavimo da radimo s mrežom od pet neurona. Stanje mreže oznacavamo
sa s =[s1s2s3s4s5
]. U trenutku t ona se nalazi u stanju st =
[00011
]. Evalu-
acijom neurona s2 mreža prelazi u stanje st+1, koje može biti[01011
]ili[00011
].
Koje su vjerojatnosti da mreža u trenutku t + 1 bude u nekom od ova dva stanja? U
obzir moramo uzeti vjerojatnost evaluacije baš neurona s2 i vjerojatnost da taj neuron
poprimi odredeno stanje, recimo 1. Pošto se neuroni evaluiraju nasumicnim redoslje-
dom, vjerojatnost da se neuron s2 odabere za evaluaciju je 0.2. Stoga vrijedi:
13

P (st+1 =[01011
]|st =
[00011
]) = 0.2P (st+1,2 = 1|st =
[01011
])
= 0.2σ(−∑j
w2jst,j − b2)
= 0.2σ(−w24 − w25 − b2)
gdje st+1,2 oznacava stanje neurona s2 u trenutku t+ 1. Ovaj izraz sam po sebi nije
bitan, ali prikazuje da je vjerojatnost prelaska iz svakog stanja u svako drugo stanje
definirana te ovisi samo o trenutnom stanju te težinama i pristranostima mreže. Neo-
visnost o stanju mreže u svim trenutcima koji prethode trenutnom nazivamo odsutnost
pamcenja ili Markovljevo svojstvo.
Za sve temperature T > 0 moguce je u konacnom broju koraka iz svakog stanja
stroja doci u svako drugo stanje (promjenom stanja neurona koji su u ta dva stanja ra-
zliciti). Time je ispunjen uvjet ergodicnosti Markovljevog lanca pa on ima stacionarnu
distribuciju, identicnu distribuciji Boltzmannovog stroja izracunatoj putem energija.
Vjerojatnost nekog stanja u stacionarnoj distribuciji može se promatrati kao udio
vremena koji stroj provodi u tom stanju, kada broj promjena stanja (evaluacija neurona)
teži u beskonacnost. Stacionarna distribucija ovisi o temperaturi na kojoj se neuroni
evaluiraju, što je pokazano u prethodnom poglavlju. Jednom kada je stroj radio na
nekoj konstantnoj temperaturi dovoljno dugo da mijenja stanja u skladu (okvirno) sa
stacionarnom distribucijom, kažemo da je postigao termalnu ravnotežu (engl. thermal
equilibrium).
Simulirano kaljenje se može koristiti kao pomocni alat za smanjenje vremena potrebnog
da se postigne termalna ravnoteža. Pocevši s visokim temperaturama te postupnim
smanjenjem temperature, manja je mogucnost zaglavljenja u lokalnim energetskim
dolinama koje nisu visoko vjerojatne u stacionarnoj distribuciji.
3.6. Ucenje
3.6.1. Motivacija
Vidjeli smo kako Boltzmannov stroj može modelirati vjerojatnosnu distribuciju bi-
narnih vektora. Nadalje, prisjetimo se svojstva Hopfieldove mreže koju smo nazvali
"adresiranje memorije putem sadržaja". Boltzmannov stroj, kao generalizirani model
Hopfieldove mreže, posjeduje i to svojstvo. Navedimo par primjera gdje ovakav model
može biti od prakticne koristi.
14

Detekcija anomalija
Zamislimo da ponašanje korisnika unutar nekog sigurnosnog sustava predstavimo bi-
narnim vektorom. Tada je moguce izgraditi Boltzmannov stroj koji modelira distribu-
ciju uobicajenih ponašanja. Potom promatramo ponašanje sustavu dosad nevidenog
korisnika. Binarni vektor tog ponašanja zabilježimo i postavimo kao stanje Boltzman-
novog stroja. Za neko neuobicajeno, malo vjerojatno ponašanje, energija stroja ce
biti sukladno visoka. Na taj nacin možemo detektirati anomalije cak i ako nam nije
unaprijed poznato kojeg su oblika.
Eliminacija šuma
Ovakva primjena oslanja se na mogucnost stroja da adresira memoriju putem pamcenja.
Realna je situacija da primimo prouku koja je zbog buke u komunikacijskom kanalu
djelomicno iskvarena. Ako je poznata distribucija ocekivanih poruka, te posjedujemo
Boltzmannov stroj koji modelira tu distribuciju, poruku možemo procistiti tako da ju
postavimo kao pocetno stanje stroja te mu potom dozvolimo konvergira prema ener-
getskom minimumu. Stroj ce eliminirati šum i predociti nam cistu poruku, baš onu
koja je najvjerojatnija s obzirom na primljenu iskvarenu.
Modeliranje uvjetne vjerojatnosti, klasifikacija
Klasifikacija podataka tipicna je primjena neuronskih mreža i mnogih drugih algori-
tama. Rješenje takvih problema možemo potražiti i primjenom Boltzmannovog stroja.
Detaljan opis takvog sustava biti ce predocen kroz ovaj rad, stoga ovdje samo navodimo
mogucnost takve primjene.
3.6.2. Modeliranje distribucije vjerojatnosti
Rekli smo da je Boltzmannov stroj generativni probabilisticki model. Povežimo to s
realnim primjerom. Zamislimo da želimo nauciti stroj da generira slikovni zapis tri
razlicita slova, predocena na slici 3.3.
Sva tri slova mogu se predociti kao binarni vektor od 7∗5 = 35 bita. Trebali bismo
biti u stanju nauciti Boltzmannov stroj da s odredenom vjerojatnošcu generira neko od
ta tri slova. Ovakav stroj imao bi izravnu primjenu pri eliminaciji šuma u komunikaciji.
Jasno je da moramo podesiti težine i pristranosti mreže na nacin da binarni vektori koji
odgovaraju slovima imaju niske energetske vrijednosti. Kako to uciniti?
15

Slika 3.3: Slikovni zapis slova A, B i C
3.6.3. Izglednost
U podrucju strojnog ucenja cesto se koristi procjena parametara putem maksimalne
izglednosti. Slijedi sažeti opis te metode, za detalje treba pogledati neki od mnogih
dostupnih materijala o osnovama strojnog ucenja.
Želimo izgraditi Boltzmannov stroj koji modelira distribuciju vjerojatnosti. Kako
bismo to ucinili, koristimo primjere (binarne vektore) distribucije koju želimo. Oz-
naka x predstavlja jedan primjer za ucenje. Skup svih primjer za ucenje koje imamo,
cija brojnost je N , oznacavamo s D. Primjetimo da skup D predstavlja vjerojatnosnu
distribuciju, gdje je pojavljivanje pojedinog primjera ima vjerojatnost 1/N.
Želimo da naš Boltzmannov stroj modelira vjerojatnosnu distribuciju primjera iz
skupaD. Kako bi to postigli, potrebno je podesiti težine i pristranosti mreže. Uvodimo
oznaku θ, koja oznacava skup svih parametara modela (težine i pristranosti). Koris-
teci tu notaciju, možemo reci da modeliramo vjerojatnost primjera uvjetovanu skupom
parametara:
P (x|θ)
Pošto nam je vec poznata distribucija primjera D, a zanimaju nas parametri θ,
uvodimo termin izglednost (engl. likelihood), koju cemo oznaciti simbolom L. Iz-
glednost parametara uvjetovana primjerom jednaka je vjerojatnosti tog primjera uvje-
tovanoj parametrima:
L(θ|x) = P (x|θ)
Razmotrimo znacenje predocenog izraza. Poanta nije u procjeni tocne vjerojat-
nosti, vec u ideji da ako mjenjamo parametre θ tako da oni povecavaju vjerojatnost
pojavljivanja primjera x (desna strana izraza), tada time istovremeno povecavamo iz-
glednost da su parametri θ baš oni koje tražimo (lijeva strana).
16

Ista ideja primjenjiva je na cijeli skup primjera za ucenje D. Pretpostavimo da su
primjeri za ucenje uzorkovani iz samo jedne distribucije (to znaci da nismo u distribu-
ciju dnevnih temperatura zraka unijeli mjerenja temperature mora). Pretpostavimo
nadalje da su uzorci medusobno nezavisni (to znaci primjerice da smo mjerili svaki
dan tocno jednom). Tada govorimo o podatcima koji su nezavisni i identicno dis-
tribuirani, za što se u literaturi cesto koristi akronim iid (engl. independent, identically
distributed). Ako je zadovoljen iid uvjet, možemo definirati vjerojatnost cijelog skupa
za ucenje D:
P (D)iid=∏x∈D
P (x)
Iz dobivene vjerojatnosti P (D), možemo definirati izglednost parametara s obzirom
na cijeli skup za ucenje D:
L(θ|D) = P (D|θ) iid=∏x∈D
P (x|θ) (3.7)
Pošto u pravilu znamo za vjerojatnost P (x|θ), promjenom parametara θ možemo
mjenjati vjerojatnost P (D|θ). Tražimo skup parametara koji doticnu vjerojatnost mak-
simizira. Za Boltzmannov stroj to bi znacilo da smo pronašli težine i pristranosti koje
dobro modeliraju skup primjera D. Za pronalazak maksimuma vjerojatnosti P (D|θ)koristimo gradijentni uspon.
Još nam preostaje objasniti cesto korišteni trik koji ce i nama biti od pomoci. Raz-
motrimo logaritamsku funkciju lnx. Ona je rastuca na cijeloj domeni: povecanjem
argumenta x, povecava se vrijednost funkcije lnx. Pošto se racunica izglednosti odvija
na intervalu P (x) ∈ [0, 1], unutar domene logaritamske funkcije (izuzevši rubnu vri-
jednost 0, što nije problem), znamo da povecanjem P (x) raste i lnP (x). Stoga umjesto
maksimizacije izglednosti možemo koristiti maksimizaciju log-izglednosti:
lnL(θ|D) = lnP (D|θ) iid= ln
∏x∈D
P (x|θ) =∑x∈D
lnP (x|θ) (3.8)
Maksimizacijom log-izglednosti pronalazimo isti skup parametara θ kao i mak-
simizacijom obicne izglednosti, ali matematicki izracun cesto bude jednostavniji.
3.6.4. Procjena najvece izglednosti parametara Boltzmannovog stroja
Primjenimo procjenitelj najvece izglednosti parametara na model Boltzmannovog stroja.
Potrebno je pronaci gradijent funkcije log-izglednosti po težinama i pristranostima
17

mreže. Koristimo log-izglednost jer pojednostavljuje racun. Krenimo s uvrštavanjem
izraza za vjerojatnost stanja P (x) u izraz za log-izglednost:
lnL(θ|D) =∑x∈D
lnP (x|θ) =∑x∈D
lne−E(x,θ)
Z(θ)
=∑x∈D
(ln e−E(x,θ) − lnZ(θ)
)=∑x∈D
(−E(x, θ)− lnZ(θ))
Uveli smo novu oznaku E(x, θ) koja oznacava energiju mreže za vektor stanje x
uz trenutne parametre mreže θ. Izvedimo sada gradijent dobivenog izraza s obzirom
na težinu veze wij:
∂
∂wijlnL(θ|D) =
∑x∈D
(−∂E(x, θ)
∂wij− ∂ lnZ(θ)
∂wij
)
=∑x∈D
(−∂E(x, θ)
∂wij− 1
Z(θ)
∂Z(θ)
∂wij
)Izvedimo ukratko potrebne parcijalne derivacije:
∂E(x, θ)
∂wij=
∂
∂wij
(−∑k
∑l>k
wklxkxl −∑k
bkxk
)
= −xixj
∂Z(θ)
∂wij=
∂
∂wij
∑t
e−E(t,θ) =∑t
∂e−E(t,θ)
∂wij
=∑t
−e−E(t,θ)∂E(t, θ)
∂wij
=∑t
−e−E(t,θ) ∂
∂wij
(−∑k
∑l>k
wkltktl −∑k
bktk
)
=∑t
−e−E(t,θ) · (−1) · titj
18

=∑t
e−E(t,θ)titj
pri cemu xi oznacava i-tu komponentu vektor stanja x, a ti i-tu komponentu vektor
stanja t. Oznaka t i dalje predstavlja jedno od svih mogucih vektor stanja stroja.
Uvrstimo dobivene parcijalne derivacije u izraz za log-izglednost:
∂
∂wijlnL(θ|D) =
∑x∈D
(−∂E(x, θ)
∂wij− 1
Z(θ)
∂Z(θ)
∂wij
)
=∑x∈D
(xixj −
1
Z(θ)
∑t
e−E(t,θ)titj
)
Primjetimo da se primjer x koristi samo u pocetku izraza. Stoga možemo pojed-
nostaviti izraz:
∂
∂wijlnL(θ|D) =
(∑x∈D
xixj
)−N
∑t
e−E(t,θ)
Z(θ)titj
Sada postaje vidljivo da je dio izraza unutar sumacije po stanjima t upravo vjero-
jatnost stanja t u skladu s izrazom (3.3), pa nadalje pojednostavljujemo:
∂
∂wijlnL(θ|D) =
(∑x∈D
xixj
)−N
∑t
P (t|θ)titj
Konacno, možemo dobiveni izraz još malo urediti tako da obje strane podjelimo s
brojem primjera za ucenje N . To možemo uciniti jer nam je za optimizaciju gradijent-
nim spustom bitan smjer gradijenta, a ne njegov iznos. Dobivamo:
1
N
∂
∂wijlnL(θ|D) =
∑x∈D
1
Nxixj −
∑t
P (t|θ)titj
Pošto pretpostavljamo da su primjeri iz skupa za ucenje podjednako vjerojatni,
vjerojatnost pojavljivanja pojedinog primjera je tocno 1/N. Tu vjerojatnost možemo
oznaciti kao Pdata(s):
1
N
∂
∂wijlnL(θ|D) =
∑x∈D
Pdata(x)xixj −∑t
P (t|θ)titj
= Edata [sisj]− Emodel [sisj] (3.9)
19

Rezultirajuci gradijent vrlo je jednostavnog oblika, pojasnimo što tocno znaci. Oz-
naka Edata [·] predstavlja vjerojatnosno ocekivanje s obzirom na skup za ucenje D. Oz-
naka Emodel [·] predstavlja vjerojatnosno ocekivanje po svim mogucim stanjima modela.
Dakle, ako želimo povecati vjerojatnost da stroj generira primjere za ucenje D,
moramo težinewij povecavati u smjeru Edata [sisj], odnosno smanjivati u smjeru Emodel [sisj].
Uzevši u obzir izraz za energiju mreže (3.1) , efekt takve korekcije težina biti ce sman-
jenje energije stroja za stanja iz skupa D, uz povecanje energije za sva moguca stanja.
Izravna posljedica toga je povecanje vjerojatnosti stanja iz skupa D, što smo željelji
postici.
Na isti nacin se izvodi izraz za gradijent logaritamske izglednosti u ovisnosti o
pristranosti bi, konacni rezultat tog izvoda glasi:
1
N
∂
∂bilnL(θ|D) = Edata [si]− Emodel [si]
3.6.5. Složenost ucenja
Izraz gradijenta log-izglednosti (3.9) je elegantan i lako se tumaci, ali nažalost nije od
velike koristi. Problem je u clanu Emodel [·]. Da bi se taj clan izracunao, potrebno je
znati vjerojatnost svih mogucih stanja stroja. Kako broj stanja eksponencijalno raste s
brojem neurona u stroju, tako raste i racunalna složenost ucenja. Za realne zadatke u
kojima bi stroj sadržavao nekoliko tisuca neurona ili više, procjena parametara putem
maksimalne izglednosti nije izvediva.
3.6.6. Ucenje Monte Carlo metodom
Problem ucenja Boltzmannovog stroja maksimizacijom izglednosti proizlazi iz ekspo-
nencijalne složenosti izracuna vjerojatnosti svih mogucih stanja stroja. Ta stanja su
nam potrebna za izracun ocekivanja Emodel [·]. Pogledajmo alternativni pristup treni-
ranju stroja u kojem se doticno ocekivanje ne racuna egzaktno nego aproksimira. Radi
se o "Markovljev lanac Monte Carlo" metodi (engl. Markov chain Monte Carlo). Cesto
se u literaturi koristi akronim MCMC.
U poglavlju 3.5 objašnjeno je kako je dinamika promjena stanja Boltzmannovog
stroja zapravo Markovljev lanac. Nadalje, rekli smo da je stacionarna distribucija
tog lanca jednaka vjerojatnosnoj distribuciji stroja izracunatoj putem energije. Sta-
cionarnu distribuciju Markovljevog lanca možemo aproksimirati pamteci stanja lanca
kroz konacni broj koraka. U kontekstu Boltzmannovog stroja to se može uciniti na
sljedeci nacin. Stroj se dovede u termalnu ravnotežu za temperaturu T = 1 (simulirano
20

kaljenje se može koristiti kako bi se ubrzalo uravnotežavanje). Ovo traje odredeni broj
promjena stanja stroja, koja ne bilježimo. Kada je ravnoteža postignuta, nasumicna
evaluacija neurona se nastavlja te stroj mjenja stanja. Sada bilježimo (uzorkujemo)
stanje stroja nalazi nakon svake evaluacije neurona. Ovo se naziva Gibbsovo uzorko-
vanje (engl. Gibbs sampling). Bilježimo naravno i broj puta koliko se stroj našao
u istom stanju. Kada bismo ovo cinili u beskonacnost, statistika posjecenosti stanja
koju smo sakupili bila bi stacionarna distribucija lanca, jednaka energetskoj distribuciji
stroja. Korištenjem konacnog broja uzoraka dobivamo aproksimaciju distribucije koju
možemo koristiti za treniranje. Naprosto ocekivanje Emodel [·] u metodi maksimalne
izglednosti zamjenimo ocekivanjem koje proizlazi iz sakupljene statistike posjecenosti
stanja.
Treniranje Boltzmannovog stroja s velikim brojem neurona MCMC metodom puno
je brže od izravnog racunanja vjerojatnosti stanja, ali je i dalje presporo da bi omogucavalo
izradu dovoljno složenih modela. Nadalje, postavlja se pitanje koliko dugo je potrebno
cekati da stroj postigne termalnu ravnotežu te koliko je uzoraka potrebno sakupiti kako
bismo dobro aproksimirali stacionarnu distribuciju. Egzaktnih odgovora na ova pitanja
nema, ona ovise o kompleksnosti stroja i distribuciji koju modeliramo, što je dodatna
prepreka ucinkovitom korištenju MCMC pristupa.
3.6.7. Primjer ucenja MCMC metodom
Promotrimo ucenje Boltzmannovog stroja Markovljev lanac Monte Carlo metodom na
primjeru. Razmatramo stroj sa 16 neurona, odnosno 216 = 65536 mogucih stanja.
Stroj ne modelira neku unaprijed definiranu distribuciju vjerojatnosti, parametre mu
generiramo nasumicno. Težine i pristranosti su inicijalizirane slucajnim odabirom iz
normalne distribucije sa srednjom vrijednošcu 0 i varijancom 1, N (0, 1).
Gibbsovim uzorkovanjem uzimamo 2 · 106 uzoraka. Uzorak uzimamo tako da na-
sumicno odaberemo neuron mreže, postavimo ga u stanje 0 ili 1 u skladu s pripadnom
vjerojatnošcu te potom zapamtimo stanje cijele mreže. Prvu cetvrtinu uzoraka odbacu-
jemo pretpostavljajuci da je to vrijeme potrebno da stroj dode do termalne ravnoteže.
Ne koristimo simulirano kaljenje. Po završetku uzorkovanja, na temelju uzetih uzoraka
možemo definirati vjerojatnosnu distribuciju stanja. Vjerojatnost stanja je definirana
kao broj uzoraka jednakih tom stanju, podjeljeno s ukupnim brojem uzoraka.
Neovisno o sakupljenim uzorcima racunamo pravu distribuciju vjerojatnosti stroja,
definiranu putem energije. Ovo je moguce pošto radimo sa strojem koji ima samo 16
neurona, u prakticnim primjenama gdje mreža može imati više tisuca neurona racu-
21

nanje vjerojatnosti putem energije bilo bi vrlo neprakticno.
Potom možemo usporediti pravu vjerojatnosnu distribuciju stanja (izracunatu putem
energije) i distribuciju aproksimiranu uzorkovanjem (MCMC metodom). Želimo vid-
jeti koliko dobro možemo aproksimirati pravu distribuciju uzorkovanjem.
Tablica 3.3 sadrži vjerojatnosti za najvjerojatnija stanja (po pravoj distribuciji).
Stupci tablice slijedom sadrže:
– vektor stanje stroja,
– pravu vjerojatnost s obzirom na energiju tog stanja,
– vjerojatnost aproksimiranu s prvih 200 tisuca neodbacenih uzoraka,
– vjerojatnost aproksimiranu sa svih 1.5 milijun neodbacenih uzoraka,
– odnos prave vjerojatnosti i aproksimacije s 200 tisuca uzoraka,
– odnos prave vjerojatnosti i aproksimacije s 1.5 milijun uzoraka.
Tablica 3.3: Primjer MCMC aproksimacije najvjerojatnijih stanja Boltzmannovog stroja
s P (s) P200k(s) P1500k(s)P (s)
P200k(s)P (s)
P1500k(s)
1111111101001110 0.26202 0.25124 0.26238 1.043 0.999
1111111111001110 0.16258 0.16701 0.16191 0.973 1.004
1111111111101110 0.13333 0.13295 0.13155 1.003 1.014
1111111101000110 0.05405 0.04923 0.05434 1.098 0.995
1011111111101110 0.02749 0.03120 0.02735 0.881 1.005
Vidimo da su aproksimacije dobivene vecim brojem uzoraka u pravilu bliže pravoj
distribuciji. Isto tako možemo primjetiti da su sve uzorkovane vjerojatnosti vrlo blizu
pravim vjerojatnostima. Ovo je posljedica toga što promatramo aproksimacije najv-
jerojatnijih stanja. Za njih MCMC metode najbrže konvergiraju prema stacionarnim
vjerojatnostima. Drukciju sliku o kvaliteti aproksimirane distribucije daje tablica 3.4.
Ona sadrži stanja koja su u poretku po pravoj vjerojatnosti na mjestima od 1500 do
1505 (od sveukupno 65536).
Vidimo da su aproksimacije za manje vjerojatna stanja osjetno lošije, u smislu pro-
porcije prave vjerojatnosti i aproksimirane. Ovo je posebno naglašeno kada se aproksi-
macija radi s manjim brojem uzoraka. Bez da prikazujemo konkretne vrijednosti, lako
je zakljuciti da su za još manje vjerojatna stanja MCMC aproksimacije proporcionalno
lošije. Da bi se njih iole kvalitetno aproksimiralo potreban je iznimno velik broj uzo-
raka.
22
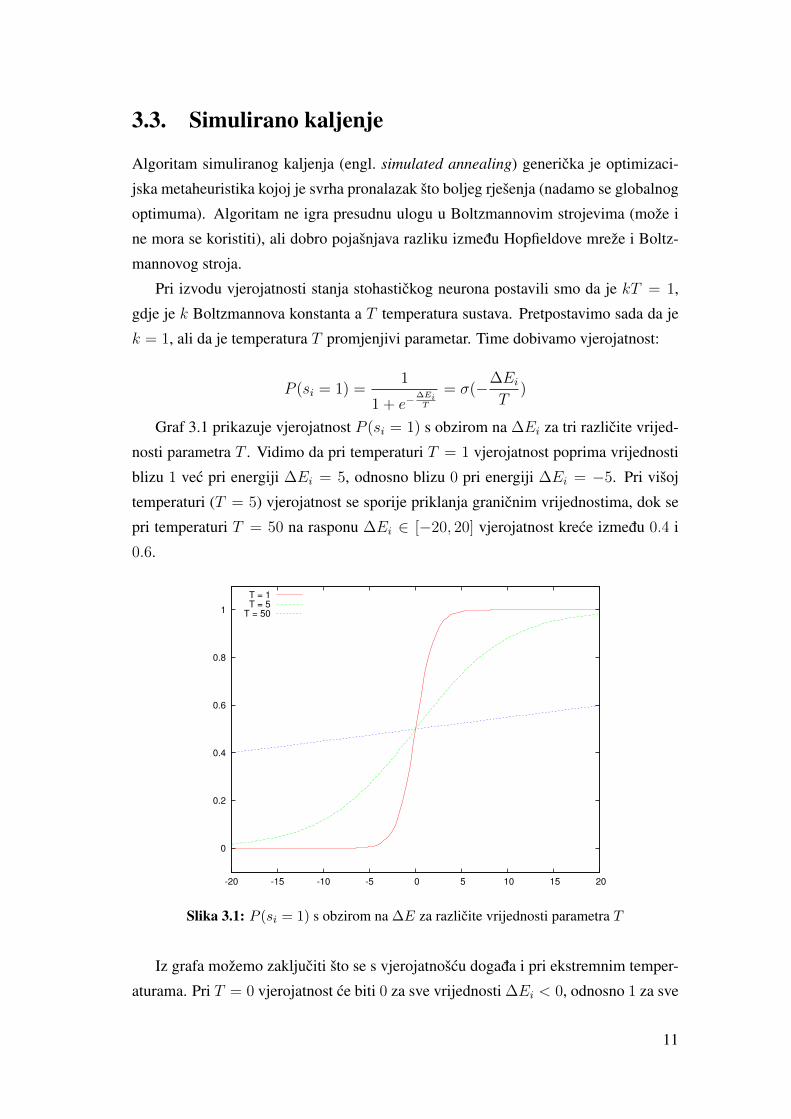
Tablica 3.4: Primjer MCMC aproksimacije manje vjerojatnih stanja Boltzmannovog stroja
s P (s) P200k(s) P1500k(s)P (s)
P200k(s)P (s)
P1500k(s)
1111110010010010 1.18 · 10−06 1.50 · 10−05 2.00 · 10−06 0.079 0.592
0011110110111110 1.18 · 10−06 0 2.67 · 10−06 ∞ 0.444
0111110110001010 1.18 · 10−06 0 0 ∞ ∞1011111110111100 1.18 · 10−06 0 2.67 · 10−06 ∞ 0.442
1011111110001100 1.18 · 10−06 0 2.67 · 10−06 ∞ 0.441
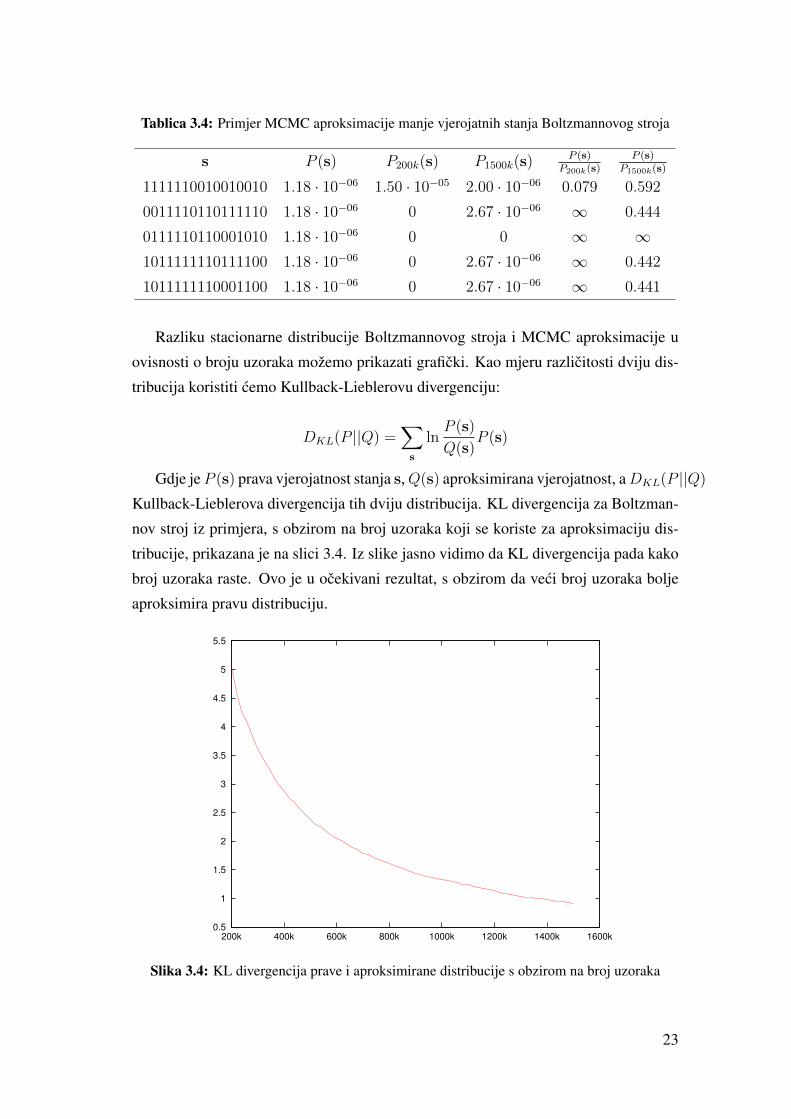
Razliku stacionarne distribucije Boltzmannovog stroja i MCMC aproksimacije u
ovisnosti o broju uzoraka možemo prikazati graficki. Kao mjeru razlicitosti dviju dis-
tribucija koristiti cemo Kullback-Lieblerovu divergenciju:
DKL(P ||Q) =∑s
lnP (s)
Q(s)P (s)
Gdje je P (s) prava vjerojatnost stanja s,Q(s) aproksimirana vjerojatnost, aDKL(P ||Q)
Kullback-Lieblerova divergencija tih dviju distribucija. KL divergencija za Boltzman-
nov stroj iz primjera, s obzirom na broj uzoraka koji se koriste za aproksimaciju dis-
tribucije, prikazana je na slici 3.4. Iz slike jasno vidimo da KL divergencija pada kako
broj uzoraka raste. Ovo je u ocekivani rezultat, s obzirom da veci broj uzoraka bolje
aproksimira pravu distribuciju.
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
5.5
200k 400k 600k 800k 1000k 1200k 1400k 1600k
Slika 3.4: KL divergencija prave i aproksimirane distribucije s obzirom na broj uzoraka
23

Što možemo zakljuciti iz ovog primjera? Iako se radi o Boltzmannovom stroju sa
samo 16 neurona, potreban je vrlo velik broj uzoraka da bi se kvalitetno aproksimi-
ralo njegovu distribuciju. Ta aproksimacija je u pravilu bolja za visoko vjerojatna
nego za nisko vjerojatna stanja. Nadalje, sakupljanje velikog broja uzoraka je mem-
orijski zahtjevno. Memorijska složenost dodatno raste s brojem neurona u stroju (u
svakom uzorku pamtimo stanje svakog neurona mreže). Ocigledno je da za kom-
pleksne Boltzmannove strojeve, koji mogu sadržavati stotine tisuca neurona, MCMC
metoda ne rješava problem pronalaska prave vjerojatnosne distribucije stanja, vec samo
omogucava pronalazak relativno grubih aproksimacija.
Iako su grube aproksimacije cesto dovoljno dobre za treniranje stroja (u pravilu
modeliramo stanja visokih vjerojatnosti, koje MCMC bolje procjenjuje), kolicina uzo-
raka potrebnih za aproksimaciju je i dalje problem. Osim toga, broj potrebnih uzoraka i
vrijeme dolaska stroja u termalnu ravnotežu uvelike ovise o distribuciji koju stroj treba
modelirati, ne postoje univerzalna pravila koja bi ih odredila. Prikladne vrijednosti se
odreduju eksperimentalno, što dodatno otežava i produljuje proces ucenja.
3.7. Skriveni neuroni
U mnogim slucajevima nije dovoljno imati samo neurone vidljivih varijabli, vec je
mrežu potrebno proširiti skupom neurona cije vrijednosti nisu poznate u primjerima za
ucenje. Svrha toga može biti potreba za modeliranjem varijabli za koje znamo da pos-
toje, ali cije vrijednosti nam nisu poznate (latentne varijable) ili za opcenitim proširen-
jem ekspresivnosti modela (kompleksniji model može modelirati kompleksnije dis-
tribucije).
Vektor stanje Boltzmannovog stroja sa skrivenim neuronima tada postaje unija vek-
tor stanja vidljivih i skrivenih jedinica: s = {v,h}. Oznaka v dolazi od engleske rijeci
visible, a oznaka h od hidden. Nas u pravilu zanima distribucija vidljivih jedinica.
Samo njih možemo usporediti s postojecim primjerima. Njihova distribucija doduše
ovisi o svim jedinicama stroja:
P (v) =∑h
P (v,h)
Dakle, vjerojatnost da se vidljivi neuroni stroja nadu u stanju v jednaka je sumi
vjerojatnosti da su vidljivi neuroni u tom stanju, a skriveni neuroni h u jednom od svih
mogucih stanja. Ako energiju stroja za neko stanje E(s) zapišemo pomocu oznaka za
vidljivi i skriveni dio tog istog stanja E(v,h), možemo nastaviti s izvodom:
24

P (v) =∑h
e−E(v,h)∑v′,h′ e−E(v′,h′)
=∑h
e−E(v,h)
Z
Pogledajmo kakav ucinak uvodenje skrivenih jedinica ima na procjenu parametara
mreže pomocu maksimalne izglednosti. Moramo uzeti u obzir da primjeri iz skupa za
ucenje D sadrže vrijednosti samo vidljivih jedinica. Stoga u izraz (3.8) uvrštavamo
dobivenu vjerojatnost P (v):
lnL(θ|D) =∑v∈D
(ln∑h
e−E(v,h,θ) − lnZ(θ)
)
=
(∑v∈D
ln∑h
e−E(v,h,θ)
)−N lnZ(θ)
Za dobivenu log-izglednost potrebno je naci gradijent u ovisnosti o nekom konkret-
nom parametru, primjerice wij .
∂
∂wijlnL(θ|D) =
∑v∈D
∂
∂wijln∑h
e−E(v,h,θ) −N ∂
∂wijlnZ(θ)
Gradijent drugog logaritma (lnZ(θ)) vec je izveden i necemo ga ponavljati. Pogleda-
jmo samo gradijent prvog logaritma:
∂
∂wijln∑h
e−E(v,h,θ) =1∑
h e−E(v,h,θ)
∂
∂wij
∑h
e−E(v,h,θ)
=1∑
h e−E(v,h,θ)
∑h
−e−E(v,h,θ) ∂
∂wijE(v,h, θ)
=
∑h
(e−E(v,h,θ)sisj
)∑h e−E(v,h,θ)
Neka ne zbunjuje pojavljivanje oznaka si i sj u konacnom rezultatu izvoda, iako
smo koristili vektore v i h u prethodnim koracima. Oznake si i sj oznacavaju da
se može raditi o bilo kojim neuronima, vidljivim ili skrivenim. Izvedeni gradijent
u ovisnosti o parametru wij vrijedi neovisno o kojim neuronima se radi. Dobiveni
gradijent možemo urediti na sljedeci nacin:
25

∂
∂wijln∑h
e−E(v,h,θ) =
∑h
(e−E(v,h,θ)sisj
)Z(θ)∑
h e−E(v,h,θ)
Z(θ)
=
∑h (P (v,h|θ)sisj)∑
h P (v,h|θ)
Razmotrimo znacenje dobivenog izraza. Radi se o težinskom usrednjavanju um-
noška sisj s obzirom na vjerojatnost P (v,h|θ), po svim mogucim stanjima skrivenih
neurona mreže. Izracun cijelog izraza stoga ima eksponencijalnu racunalnu složenost
s obzirom na broj skrivenih neurona.
Konacno, uvrstimo dobivenu parcijalnu derivaciju u gradijent log-izglednosti. Is-
tovremeno cemo obje strane izraza podijeliti s N , brojem primjera za ucenje D:
1
N
∂
∂wijlnL(θ|D) =
1
N
∑v∈D
∂
∂wijln∑h
e−E(v,h,θ) − ∂
∂wijlnZ(θ)
=1
N
∑v∈D
∑h (P (v,h|θ)sisj)∑
h P (v,h|θ)− Emodel [sisj]
= Edata
[∑h (P (v,h|θ)sisj)∑
h P (v,h|θ)
]− Emodel [sisj]
Složenost clana Emodel [·] i dalje je eksponencijalna, ali je broj neurona o kojima ona
ovisi povecan za broj skrivenih neurona. Vidimo da su problemi treniranja modela sa
skrivenim jedinicama uvecani za faktor koji eksponencijalno raste s njihovim brojem.
26

4. Ograniceni Boltzmannov stroj
Boltzmannov stroj je potpuno povezan, sadrži težinske veze izmedu svaka dva neurona
mreže. Kao takav, vrlo je ekspresivan, sposoban izraziti korelaciju izmedu bilo koje
dvije varijable, vidljive ili latentne. S druge strane, pokazali smo kako je ucenje Boltz-
mannovog stroja izrazito složeno, cesto cak i prakticno nemoguce. Kako bi omogucili
efikasno ucenje, potrebno je pojednostaviti model. Jedno takvo pojednostavljenje
je ograniceni Boltzmannov stroj, koji se cesto imenuje akronimom RBM (engl. Re-
stricted Boltzmann Machine).
4.1. Definicija
U ogranicenom Boltzmannovom stroju postoje vidljivi i skriveni neuroni. Prisjetimo
se, stanja vidljivih neurona oznacavaju varijable ciju distribuciju modeliramo i koje
su sadržane u primjerima za ucenje. Stanja skrivenih neurona oznacavaju neke nama
nepoznate, latentne varijable. Njihove vrijednosti nisu sadržane u primjerima za ucenje,
a koristimo ih kako bi povecali izražajnu snagu modela.
Ogranicenje koje uvodimo je da ne postoje veze izmedu vidljivih neurona, kao ni
veze izmedu skrivenih neurona. Postoje veze iskljucivo izmedu vidljivih i skrivenih
neurona. Ogranicenja pristranosti ne postoje. Primjer ogranicenog Boltzmannovog
stroja prikazan je na slici 4.1.
v1 v2
h1
v3 v4
h2 h3
Slika 4.1: Ograniceni Boltzmannov stroj s 4 vidljiva i 3 skrivena neurona
27

Vidljivi neuroni su u donjem dijelu slike, oznaceni s v1, v2, v3 i v4. Vektor stanja
svih vidljivih neurona oznacavamo s v. U gornjem dijelu slike nalaze se skriveni
neuroni, oznaceni s h1, h2 i h3. Vektor stanja skrivenih neurona oznacavamo s h.
Prikazane su i sve težinske veze u modelu (težine nisu oznacene radi jasnoce). Ovakav
prikaz mreže cest je u literaturi. Neuroni su u njemu grupirani u dva sloja pa se stoga
i govori o "vidljivom sloju" odnosno "skrivenom sloju". U daljnjem tekstu se koristi
ova konvencija.
Definirani model prvi puta je predložen 1986. pod nazivom "harmonium", kao
matematicki opis biološkog procesiranja perceptivnih podražaja [11]. U kontekstu um-
jetnih neuronskih mreža Geoffrey Hinton mu je dao naziv "ograniceni Boltzmannov
stroj".
Energija RBM-a definirana je jednako kao i u Boltzmannovom stroju, ali je zbog
uvedenog ogranicenja izraz malo drukciji. Ako je skup svih neurona stroja s unija
vidljivih i skrivenih neurona, s = v ∪ h, tada vrijedi:
E(v,h) = E(s) = −∑i
∑j>i
wijsisj −∑i
bisi
= −∑vk∈v
∑hl∈h
wklvkhl −∑vk∈v
bkvk −∑hl∈h
blhl (4.1)
izraz nije izveden korak po korak jer bi indeksacija bila zbunjujuca, stoga oprav-
dajmo dobiveno logicki. U prvoj liniji izraza definirana je energija Boltzmannovog
stroja na opcenit nacin, koji vrijedi i za RBM. Ta energija se sastoji od težinskih veza
neurona "svaki sa svakim" te pristranosti pojedinih neurona. U RBM-u težinske veze
postoje samo medu neuronima razlicitih slojeva. Stoga umnožak "svaki sa svakim"
možemo izraziti kao "svaki vidljiv sa svakim skrivenim". Pristranosti svih neurona
možemo izraziti zbrojem pristranosti neurona vidljivog i skrivenog sloja. Upravo ovo
je zapisano u konacnom izrazu energije ogranicenog Boltzmannovog stroja (4.1).
Razmotrimo nadalje posljedice uvedenih ogranicenja na vjerojatnosne izraze. Neu-
roni unutar istog sloja su neovisni jedni o drugima, uz uvjet da je suprotni sloj fiksiran
na neko stanje. Na primjeru dva neurona vidljivog sloja:
P (vi, vj|h) = P (vi|h)P (vj|h)
Zajednicka vjerojatnost stanja dva vidljiva neurona jednaka je umnošku pojedinih
vjerojatnosti, uz fiksirane vrijednosti skrivenog sloja. Istovremeno, ne možemo reci da
su neuroni opcenito nekorelirani:
28

P (vi, vj) 6= P (vi)P (vj)
Korelacija postoji, ali je izražena preko skrivenog sloja, a ne izravnim težinskim
vezama. Ovo možemo poopciti. Recimo da mreža ima n neurona vidljivog sloja i m
neurona skrivenog sloja. Tada vrijedi:
P (v|h) = P (v1, v2, ..., vn|h) =∏vi∈v
P (vi|h) (4.2)
Isto tako možemo izraziti uvjetnu vjerojatnost skrivenog sloja:
P (h|v) = P (h1, h2, ..., hm|v) =∏hi∈h
P (hi|v) (4.3)
Iz ovakvog probabilistickog opisa teško je razviti dobru intuiciju o ogranicenom
Boltzmannovom stroju. Promotrimo ga stoga iz druge perspektive.
4.2. Produkt strucnjaka
Postoji više nacina da se kombiniranjem razlicitih distribucija definira neka nova.
Cesto korišten pristup su primjerice mješavine (engl. mixtures), koje se baziraju na
sumiranju i normalizaciji više distribucija. Alternativan pristup je kombiniranje dis-
tribucija množenjem. Ako kažemo da je svaka od elementarnih distribucija svojevrsni
strucnjak (engl. expert), tada njihov normalizirani umnožak nazivamo produktom strucn-
jaka (engl. Product of Experts) [3].
Za n diskretnih distribucija P1(x), P2(x), ..., Pn(x) nad domenom D, za svaki x ∈D definiramo njihov produkt:
P ′(x) =n∏i=1
Pi(x)
Kako bi taj umnožak bio ispravno definirana distribucija vjerojatnosti, potrebno
je osigurati da je suma vjerojatnosti svih x iz domene D jednaka jedan. Dobivamo
normalizirani produkt, odnosno ispravno definiran produkt strucnjaka:
P (x) =P ′(x)∑
x′∈D P′(x′)
=
∏ni=1 Pi(x)∑
x′∈D∏n
i=1 Pi(x′)
=
∏ni=1 Pi(x)
Z(4.4)
Gdje Z(x) kao i obicno oznacava particijsku funkciju koja normalizira vjerojat-
nosnu distribuciju. Specificnost ovakvog kombiniranja distribucija najlakše je pre-
29
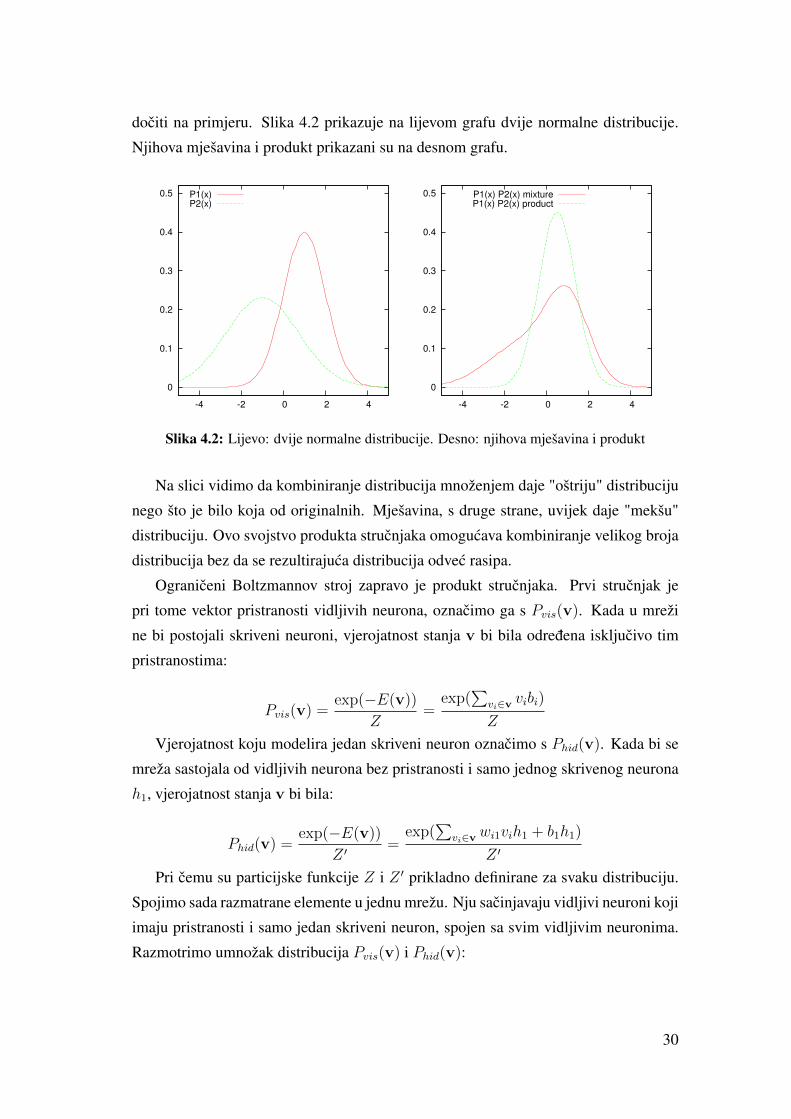
dociti na primjeru. Slika 4.2 prikazuje na lijevom grafu dvije normalne distribucije.
Njihova mješavina i produkt prikazani su na desnom grafu.
0
0.1
0.2
0.3
0.4
0.5
-4 -2 0 2 4
P1(x)P2(x)
0
0.1
0.2
0.3
0.4
0.5
-4 -2 0 2 4
P1(x) P2(x) mixtureP1(x) P2(x) product
Slika 4.2: Lijevo: dvije normalne distribucije. Desno: njihova mješavina i produkt
Na slici vidimo da kombiniranje distribucija množenjem daje "oštriju" distribuciju
nego što je bilo koja od originalnih. Mješavina, s druge strane, uvijek daje "mekšu"
distribuciju. Ovo svojstvo produkta strucnjaka omogucava kombiniranje velikog broja
distribucija bez da se rezultirajuca distribucija odvec rasipa.
Ograniceni Boltzmannov stroj zapravo je produkt strucnjaka. Prvi strucnjak je
pri tome vektor pristranosti vidljivih neurona, oznacimo ga s Pvis(v). Kada u mreži
ne bi postojali skriveni neuroni, vjerojatnost stanja v bi bila odredena iskljucivo tim
pristranostima:
Pvis(v) =exp(−E(v))
Z=
exp(∑
vi∈v vibi)
Z
Vjerojatnost koju modelira jedan skriveni neuron oznacimo s Phid(v). Kada bi se
mreža sastojala od vidljivih neurona bez pristranosti i samo jednog skrivenog neurona
h1, vjerojatnost stanja v bi bila:
Phid(v) =exp(−E(v))
Z ′=
exp(∑
vi∈v wi1vih1 + b1h1)
Z ′
Pri cemu su particijske funkcije Z i Z ′ prikladno definirane za svaku distribuciju.
Spojimo sada razmatrane elemente u jednu mrežu. Nju sacinjavaju vidljivi neuroni koji
imaju pristranosti i samo jedan skriveni neuron, spojen sa svim vidljivim neuronima.
Razmotrimo umnožak distribucija Pvis(v) i Phid(v):
30

Pvis(v)Phid(v) =exp(
∑vi∈v vibi)
Z
exp(∑
vi∈v wi1vih1 + b1h1)
Z ′
=exp(
∑vi∈v vibi +
∑vi∈v wi1vih1 + b1h1)
ZZ ′
Prisjetimo se da particijske funkcije ne ovise o stanju za koje se racuna vjerojat-
nost, one su konstante koje osiguravaju da je suma vjerojatnosti svih elemenata domene
jednaka jedan. Stoga ih možemo "namještati" kako god je potrebno da se postigne is-
pravna distribucija. Normaliziramo li dobiveni produkt nekom particijskom funkcijomZZ′/Z′′, dobivamo produkt dvaju strucnjaka (strucnjak pristranosti vidljivih neurona
i strucnjak jednog skrivenog neurona). Istovremeno cemo jedini skriveni neuron h1
uvrstiti u vektor h:
Pvis(v)Phid(v)ZZ ′
Z ′′=
exp(∑
vi∈v vibi +∑
vi∈v wi1vih1 + b1h1)
ZZ ′ZZ ′
Z ′′
=exp(
∑vi∈v vibi +
∑vi∈v
∑hj∈hwijvihj +
∑hj∈h bjhj)
Z ′′
=e−E(v)
Z ′′
Vidimo da smo dobili ništa drugo nego vjerojatnost stanja v u ogranicenom Boltz-
mannovom stroju. Na istovjetan nacin možemo nastaviti dodavati skrivene neurone.
Svaki skriveni neuron svojom pristranošcu i težinskim vezama prema vidljivim neu-
ronima modelira distribuciju vidljivih neurona. Množenjem te distribucije s posto-
jecim RBM-om i normalizacijom dobivamo RBM s jednim skrivenim neuronom više.
Vidimo stoga da je RBM produkt strucnjaka.
Sada ponovo možemo razmotriti ograniceni Boltzmannov stroj, ovaj put kao pro-
dukt strucnjaka. Semantika stroja može se lakše objasniti. Pristranosti vidljivih neu-
rona modeliraju njihovu distribuciju. Nadalje, svaki skriveni neuron modelira dis-
tribuciju stanja vidljivog sloja. Ukupna distribucija RBM-a je produkt strucnjaka svih
skrivenih neurona i distribucije definirane pristranošcu vidljivih. U takvoj distribuciji
najvjerojatnija su ona stanja za koja se najveci broj strucnjaka slaže da su vjerojatna.
Stanja za koja malo strucnjaka kaže da su vjerojatna u konacnoj su distribuciji vrlo
malo vjerojatna. Time se produkt strucnjaka razlikuje od mješavine distribucija un-
utar koje stanje može biti vjerojatno cak i ako je u u vecini komponenti mješavine
malo vjerojatno. Izražajna moc modela raste s brojem skrivenih neurona. "Oštrina"
31

distribucije vjerojatnosti može rasti s brojem strucnjaka. Stoga je koristeci veliki broj
skrivenih neurona moguce modelirati vrlo izražena i uska podrucja visoke vjerojat-
nosti.
4.3. Skriveni neuroni kao znacajke
Pri treniranju ogranicenog Boltzmannovog stroja u pravilu želimo da se svaki skriveni
neuron RBM-a specijalizira na neko usko podrucje ulaznog prostora. Ovo je u skladu
s promatranjem RBM-a kao produkta strucnjaka. Tada svaki skriveni neuron modelira
jednu "znacajku". Pojasnimo što se time misli i koje su implikacije.
Promotrimo jedan skriveni neuron hi. On je spojen sa svim vidljivim neuronima
težinskim vezama (pozitivnim ili negativnim). Razmotrimo prvo utjecaj vidljivog neu-
rona vj na hi kada je vj = 1. Pozitivna veza medu njima (wij > 0) povecava vjerojat-
nost da je hi isto tako u stanju 1. Negativna veza (wij < 0) cini suprotno, ona povecava
vjerojatnost da je hi u stanju 0. Veza težine blizu nuli (wij ≈ 0) znaci da vidljivi neuron
vj nema utjecaja na skriveni hi.
S druge strane, vidljivi neuron vj u stanju 0 ne utjece na vjerojatnost stanja skrivenog
neurona hi. Na prvi pogled ovo može implicirati da je težina veze nebitna. To nije do-
bra intuicija iz dva razloga. Prvi razlog je cinjenica da je za neko drugo stanje cijelog
stroja vidljivi neuron vj u stanju 1. Drugi razlog je to što su veze obostrane. Pris-
jetimo se, RBM je generativni model, on može generirati stanja vidljivog sloja. Ako
je poželjno da vidljivi neuron vj bude pretežno u stanju 0, tada ce težinske veze od
skrivenog sloja prema njemu biti pretežno negativne ili blizu nuli (ako je pristranost
tog vidljivog neurona negativna).
Dakle, vidimo da pozitivna težinska veza modelira korelaciju medu stanjima neu-
rona, dok negativna težinska veza modelira antikorelaciju. Težinske veze velikog ap-
solutnog iznosa modeliraju snažnu korelaciju odnosno antikorelaciju. Težinske veze
koje su blizu nuli modeliraju nepostojanje korelacije.
Razmotrimo sada koncept specijalizacije skrivenog neurona. Specijalizacija skrivenog
neurona hi na usko podrucje ulaznog prostora znaci da je za vecinu veza s vidljivim
slojem težina veze blizu nuli. Tako povezani neuroni vidljivog sloja nemaju bitan ut-
jecaj na stanje neurona hi. Vrijedi i obrnuto, skriveni neuron hi nema utjecaja na te
neurone vidljivog sloja. Samo dio težina izmedu hi i vidljivog sloja znatno odstupa od
nule. Ako su ti neuroni vidljivog sloja "podudarni" s težinama veza s hi, onda ce hivrlo vjerojatno biti u stanju 1. Pod "podudarni" mislimo na to da su vidljivi neuroni u
stanju 0 gdje su težine vezanja negativne, odnosno u stanju 1 gdje su težine veznja poz-
32

itivne. U generativnom smjeru (kada RBM generira stanja vidljivog sloja na temelju
nekog stanja skrivenog sloja) vrijedi sljedece. Ako je specijalizirani skriveni neuron
hi u stanju 1, tada ce on vršiti utjecaj na vidljivi sloj u skladu sa svojim težinama u
podrucju specijalizacije. Negativne težine ce vidljive neurone tjerati u stanje 0, dok ce
ih pozitivne težine tjerati u stanje 1. Ako je hi u stanju 0, nece vršiti nikakav utjecaj na
cijeli vidljivi sloj.
Specijalizirani skriveni neuron može detektirati "znacajku" u vidljivom sloju: situaciju
kada su vidljivi neuroni unutar njegovog podrucja specijalizacije vrlo uskladeni s težin-
skim vezama prema njima. Ako je znacajka prisutna, skriveni neuron koji ju pred-
stavlja biti ce s velikom vjerojatnošcu u stanju 1. Pošto je RBM model koji na temelju
pojedinih znacajki modelira distribuciju primjera za ucenje, njegovo treniranje dovodi
do izlucivanja kvalitetnih rekonstrukcijskih znacajki. Takve znacajke su iznimno ko-
risne za klasifikacijske i generalizacijske zadatke nad podatcima. Nadalje, ako je broj
znacajki manji od dimenzionalnosti ulaznog prostora, možemo govoriti i o redukciji
dimenzionalnosti odnosno kompresiji.
4.4. Ucenje
Ucenju RBMa može se pristupiti na isti nacin kao i ucenju neogranicenog Boltzman-
novog stroja. Iako je zbog ogranicenja RBMa broj parametara (težinskih veza) nešto
manji nego u Boltzmannovom stroju istog broja neurona, racunalna složenost mak-
simizacije izglednosti i MCMC pristupa je i dalje ekponencijalna s obzirom na broj
neurona. Pogledajmo stoga alternativni pristup treniranju, koji je prakticno izvediv.
4.4.1. Kontrastna divergencija
Razmotrimo RBM kao Markovljev lanac, kao što je opisano u poglavlju 3.5. Uzimat
cemo u obzir ponajprije stanja vidljivog sloja v. Možemo reci da stroj evaluacijom
neurona mjenja stanja vidljivog sloja što cini Markovljev lanac:
v0 → v1 → v2 → ...
Pri tome svaka promjena oblika vn → vn+1 znaci evaluaciju svih neurona vidljivog
sloja. Prisjetimo se, stanje vidljivog sloja RMBa uvjetovano je stanjem skrivenog sloja
h u skladu s izrazom (4.2). Vrijedi i obrnuto, stanje skrivenog sloja uvjetovano je
vidljivim slojem, u skladu s izrazom (4.3). Prisjetimo se da je za svaki neuron vidljivog
sloja vjerojatnost poprimanja konkretne vrijednosti (0 ili 1) u RBMu neovisna o drugim
33

neuronima vidljivog sloja, ako je zadano stanje vidljivog sloja: P (vi|v,h) = P (vi|h).
Stoga je preciznije reci da RBM mjenja stanja na sljedeci nacin:
v0 → h0 → v1 → h1 → v2 → h2 → ...
Vrativši se na razmatranje RBMa kao Markovljevog lanca, mi cemo jednim "ko-
rakom" u lancu smatrati promjenu stanja oba sloja vn → hn → vn+1 → hn+1.
Za svaki korak tako definiranog Markovljevog lanca definirana je distribucija vjero-
jatnosti Pn stanja RBMa, odnosno vjerojatnost Pn(v) da je nakon n koraka RBM
u stanju v. Primjetimo da je P0 (distribucija stanja nakon nula koraka) definirana
iskljucivo skupom podataka za ucenje. U toj distribuciji RBM još nije uopce djelovao
na ulazne podatke. Analogno je distribucija P∞ distribucija stanja RBMa koja više ne
ovisi o podatcima jer stacionarna distribucija Markovljevog lanca ne ovisi o pocetnom
stanju.
Vratimo se sada na ucenje Boltzmannovog stroja procjenom najvece izglednosti,
kao što je opisano u poglavlju 3.6.4. Konacni izraz (3.9) za taj pristup ucenju Boltz-
mannovog stroja glasi:
1
N
∂
∂wijlnL(θ|D) = Edata [sisj]− Emodel [sisj]
Primjetimo da taj izraz uzima u obzir dvije distribucije, odnosno ocekivanja param-
etara za te distribucije Edata [·] i Emodel [·]. Distribucije stanja na kojima se ta oceki-
vanja baziraju možemo oznaciti s Pdata i Pmodel, pri cemu je zapravo Pdata = P0, a
Pmodel = P∞. Gradijent izglednosti postaje nula kada je distribucija modela jednaka
distribuciji podataka. Tada je cilj ucenja ostvaren: stroj idealno modelira podatke
za ucenje. U tom smislu ucenje modela možemo predociti i kao minimizaciju raz-
like (divergencije) tih dviju distribucija. Za formalni zapis iskoristiti cemo Kullback-
Lieblerovu divergenciju pa funkcija koju želimo minimizirati postaje:
DKL(P0||P∞) =∑s
P0(s) ln
(P0(s)
P∞(s)
)Nažalost, ovakva nam formulacija problema ucenja nije pomogla. Racunalna složenost
optimizacije KL divergencije jednaka je složenosti optimizacije izglednosti. Još uvi-
jek nam je potreban efikasniji nacin ucenja modela. Nastavimo stoga s razmatranjem
RBMa kao Markovljevog lanca.
Dokazano je da se KL divergencija Markovljevog lanca u odnosu na stacionarnu
distribuciju nikada ne povecava kako broj koraka raste [8]:
34

DKL(Pn||P∞) ≥ DKL(Pn+1||P∞)
Ovo intuitivno ima smisla, što je stroj dulje djelovao na podatke, to je njegova
distribucija stanja bliže stacionarnoj.
Nadalje, za svaku distribuciju Pn u n-tom koraku lanca i distribuciju Pn+1 u sljedecem
koraku vrijedi da njihova jednakost povlaci njihovu stacionarnost: Pn = Pn+1 =⇒Pn = P∞. Intuitivno receno: ako se distribucija stanja radom stroja ne mjenja, tada je
stroj zasigurno u podrucju stacionarne distribucije. Na temelju tih znacajki KL diver-
gencije Markovljevog lanca, funkciju gubitka možemo definirati kao razliku dviju KL
divergencija koje su udaljene svega nekoliko koraka:
DKL(P0||P∞)−DKL(Pn||P∞) (4.5)
Tako definirana funkcija gubitka naziva se "kontrastna divergencija" [4]. Na temelju
prethodno izloženog znamo da je navedena razlika divergencija uvijek pozitivna, a
nulu postiže u trenutku kada je Pn = P∞. Dakle, smanjivanjem navedene razlike
divergencija postižemo da distribucija modela P∞ teži ka distribuciji podataka P0.
Kljucna dobrobit ovako definiranog problema ucenja jest da je gradijent funkcije
gubitka po parametrima modela θ lako racunljiv:
− ∂
∂θ(DKL(P0||P∞)−DKL(Pn||P∞)) ≈ −EP0
[∂
∂θE(θ)
]+ EPn
[∂
∂θE(θ)
](4.6)
Puni izvod dobivenog izraza preskacemo zbog njegove duljine (zainteresiranog ci-
tatelja upucujemo na rad [1]) , ali je potrebno razjasniti nekoliko detalja. Racunamo
negativni gradijent zato jer je kontrastna divergencija definirana kao funkcija gubitka
koju trebamo minimizirati (za razliku od maksimizacije izglednosti). Stoga se u param-
etarskom prostoru krecemo u smjeru negativnog gradijenta. Gradijent je definiran kao
aproksimacija jer je ignoriran clan za koji se pokazalo da u praksi ne mjenja njegov
smjer, a nije lako racunljiv (vidjeti [4]). Funkcija E(θ) unutar izraza ocekivanja na
desnoj strani je uobicajena funkcija energije Boltzmannovog stroja (odnosno RBMa),
definirana u izrazu (3.1).
Pogledajmo sada gradijente funkcije kontrastne divergencije, u ovisnosti o teži-
nama i pristranostima mreže:
35

− ∂
∂wij(DKL(P0||P∞)−DKL(Pn||P∞)) ≈ EP0 [sisj]− EPn [sisj] (4.7)
− ∂
∂bi(DKL(P0||P∞)−DKL(Pn||P∞)) ≈ EP0 [bi]− EPn [bi] (4.8)
Razmotrimo znacenje tih izraza. Možemo primjetiti da su nalik izrazu (3.9) ucenja
Boltzmannovog stroja maksimizacijom izglednosti. Krucijalna razlika je što se pri
ucenju maksimizacijom izglednosti koristi ocekivanje distribucije modela Emodel [·] (što
možemo oznaciti i s EP∞ [·]), dok se pri ucenju kontrastnom divergecijom koristi
EPn [·]. Konceptualno, jasno je kako korištenje ocekivanja EP∞ [·] opravdanije u smislu
približavanja stacionarne distribucije P∞ podatcima, što je cilj ucenja. Isto tako je
jasno da je ocekivanje EPn [·] za male vrijednosti n puno lakše aproksimirati uzorko-
vanjem. Cjelokupni izraz gradijenta implicira promjenu parametara mreže na nacin
da RBM nakon n koraka rekonstrukcije vidljivog sloja što manje "odluta" od pocetne
distribucije podataka P0.
Može se postaviti pitanje koliko je ucenje kontrastnom divergencijom efikasno.
Testiranje vršeno u [4] je pokazalo kako se tim pristupom može efektivno uciti RBM,
cak i kada je broj koraka n samo 1. Ovaj oblik kontrastne divergencije oznacit cemo s
CD1. Naravno, moguce je koristiti i rekonstrukcije nakon veceg broja koraka. Cest je
pristup koji kombinira obje tehnike: u pocetnim fazama ucenja primjenjuje se CD1, a
kako gradijent od CD1 postaje sve manji, povecava se broj koraka.
4.4.2. Kontrastna divergencija, algoritamska implementacija
Razmotrimo sada konkretni algoritam jednokoracne kontrastne divergencije, oznacene
s CD1. Funkcija gubitka koju želimo minimizirati je:
DKL(P0||P∞)−DKL(P1||P∞)
Pri tome je P1 distribucija stanja RBMa nakon što je evaluirao skriveni sloj v0 →h0, potom vidljivi sloj h0 → v1 te na kraju opet skriveni v1 → h1. P1 je dakle
distribucija jednokoracne rekonstrukcije oba sloja. Bitno je primjetiti da je za tocno
odredivanje P1 potrebno beskonacno puno uzoraka, jer je svaka evaluacija v0 → h0 →v1 → h1 nedeterministicka: moguca su brojna rezultirajuca stanja h0, v1 i h1 za
svaki pocetni v0. U praksi se ovaj problem ignorira, te se P1 aproksimira sa samo
jednom rekonstrukcijom svakog vektora v0 iz podataka za ucenje. Ova aproksimacija
je statisticki opravdana jer ce rekonstrukcije biti baš one najvjerojatnije, koje najviše
36

utjecu na ocekivanje. Nadalje, s obzirom da skup primjera za ucenje tipicno sadrži
mnoge slicne primjere, te da se ucenje obavlja velikim brojem prolazaka kroz cijeli
skup, tako ce se za neke slicne v0 zapravo izracunati i u aproksimaciju P1 ubrojiti
mnogi razliciti h0, v1 i h1.
Što se tice samih evaluacija neurona oba sloja bitno je primjetiti nekoliko stvari.
Uvjetna nezavisnost neurona istog sloja (primjerice za vidljivi sloj P (vi|v,h) = P (vi|h))
omogucava da se svi neuroni istog sloja evaluiraju istovremeno. Ovo pogoduje par-
alelizaciji izracuna korištenjem više procesora, jezgri ili grafickih kartica. Što se tice
sakupljanja uzoraka, objasnimo proces na dijelu v0 → h0. Racunamo prvo vjerojat-
nost P (hi|v0) = 1 postavljanja neurona hi u stanje 1. Potom je potrebno postaviti
stanje neurona hi u stanje 0 ili 1 u skladu s vjerojatnošcu P (hi|v0) = 1. Tek tada, kada
smo dobili binarni vektor h0 stanja neurona skrivenog sloja, krecemo s evaluacijama
neurona vidljivog sloja. Ovaj proces je naravno identican i pri evaluaciji h0 → v1 i
tako dalje.
U skladu s izrazom (4.7) za gradijentnu optimizaciju kontrastne divergencije CD1
potrebna su nam ocekivanja težinskih veza EP1 [sisj] i pristranosti EP1 [bi]. Naveli
smo da cemo distribuciju P1 aproksimirati jednokoracnim rekonstrukcijama primjera
za ucenje. Stoga bismo navedena ocekivanja mogli izracunati na sljedeci nacin:
EP1 [sisj] =∑v∈D
P (v)sisi =∑v∈D
1
|D|sisi =
1
|D|∑v∈D
sisi
EP1 [si] =∑v∈D
P (v)si =1
|D|∑v∈D
si
Pri cemu je D skup primjera za ucenje, a vjerojatnost pojavljivanja svakog prim-
jera 1/|D|. Stanja neurona si i sj su uzeta iz mreže nakon što je korak rekonstrukcije
obavljen.
Iako je navedeni postupak ispravan, možemo ga poboljšati. Razmotrimo prvo
ocekivanje stanja jednog neurona E [si]. Raspisat cemo ga po definiciji ocekivanja:
E [si] =∑
a∈{0,1}
P (si = a)a
=P (si = 0) · 0 + P (si = 1) · 1
=P (si = 1)
37

Vidimo da je ocekivanje stanja neurona koji prima vrijednosti iz 0, 1 jednako vjero-
jatnosti da se on nade u stanju 1. Razmotrimo nadalje ocekivanje umnoška stanja dvaju
neurona E [sisj]:
E [sisj] =∑
a,b∈{0,1}
P (si = a, sj = b)ab
=P (si = 0, sj = 0) · 0 · 0 + P (si = 0, sj = 1) · 0 · 1+
P (si = 1, sj = 0) · 1 · 0 + P (si = 1, sj = 1) · 1 · 1
=P (si = 1, sj = 1)
=P (si = 1)P (sj = 1|si = 1)
S obzirom da u RBMu težinske veze imamo samo medu neuronima nasuprotnih
slojeva, bez gubitka opcenitosti možemo pisati:
E [vihj] =P (vi = 1)P (hj = 1|vi = 1)
U tom smislu nam uvjetna vjerojatnost P (hj = 1|vi = 1) ne predstavlja problem
jer smo upravo nju izracunali.
Dobivene rezultate možemo iskoristiti u algoritmu za CD1. Umjesto da ocekivanja
stanja neurona racunamo na temelju binarnih stanja 0 i 1, možemo iskoristiti vjero-
jatnosti. Pri tome je važno istaknuti dvije stvari. Prvo je da korištenjem vjerojatnosti
bolje aproksimiramo ocekivanje nego kada na temelju vjerojatnosti evaluiramo binarna
stanja te ih potom usrednjavamo. Drugo je da moramo biti pažljivi da vjerojatnosti ko-
ristimo samo za izracun ocekivanja, odnosno gradijenata. Pri racunanju vjerojatnosti
stanja neurona moramo koristiti binarne vrijednosti neurona nasuprotnog sloja, a ne
vjerojatnosti.
Jednom kada smo izracunali gradijente kontrastne divergencije s obzirom na težine
i pristranosti mreže, vršimo gradijentnu minimizaciju funkcije gubitka. Tema gradi-
jentne optimizacije široko je podrucje te izlazi izvan okvira ovog rada. Postoje i vari-
jante specijalno razvijene u kontekstu treniranja RBMa, odnosno dubokih neuronskih
mreža, ali kvalitetna konvergencija može se postici i korištenjem najjednostavnijih al-
goritama gradijentnog spusta.
38

Na nacin slican opisanom se koristi i kontrastna divergencija s više koraka. Jedina
razlika je da se rekonstrukcija vidljivog i skrivenog sloja slijedno cini više puta, te
se tek u posljednjem koraku racunaju gradijenti odnosno ocekivanja kao i kod CD1.
Razlozi za korištenje višekoracne kontrastne divergencije su ociti: bolje aproksimira
ucenje maksimizacijom izglednosti, pri tome povecavajuci racunsku kompleksnost. U
praksi se cesto krece s CD1, da bi se broj koraka divergencije povecavao u kasnijim
fazama ucenja.
Pokažimo na kraju vrlo okvirno algoritam treniranja RBMa. Parametre mreže
mjenjat cemo na temelju gradijenata izracunati iz pojedinacnih primjera, iako se to u
praksi ne radi (vidi poglavlje "mini-serije" u 4.4.3). Za detaljnu diskusiju o pojedinim
koracima (primjerice o tome kako inicijalizirati parametre RBMa) citatelja upucujemo
na [5].
Algorithm 1 Treniranje RBMa1: D = skup podataka za ucenje
2: ε = stopa ucenja
3: θ = parametri RBMa
4: n = broj koraka kontrastne divergencije
5: inicijaliziraj θ nasumicnim vrijednostima
6: while treniranje nije gotovo do7: for v0 ∈ D do8: h0 = vjerojatnosti i aktivacije skrivenog sloja
9: E[v0] = ocekivanja stanja vidljivog sloja
10: E[h0] = ocekivanja stanja skrivenog sloja
11: E[v0 × h0] = ocekivanja umnožaka stanja skrivenog i vidljivog sloja
12: for i = 0 to n do13: korak kontrastne divergencije
14: end for15: E[vn], E[hn], E[vn × hn]
16: ∇CDn← E[·0]− E[·n] = gradijenti po parametrima
17: θ ← θ + ε · ∇CDn18: end for19: end while
39

4.4.3. Dodatni parametri ucenja
Uz opisan algoritam kontrastne divergencije pri treniranju RBMa cesto se koriste još
neke tehnike. Osvrnimo se ukratko na najbitnije.
Rijetkost aktivacije skrivenih neurona
"Rijetkost" (engl. sparsity) u kontekstu RBM-a znaci da se svaki skriveni neuron ak-
tivira (poprima stanje 1) tek mali dio vremena. Pri treniranju modela uvodi se dodatni
hiperparametar rijetkosti, nazovimo ga r, koji definira udio vremena koji je poželjno
da svaki skriveni neuron bude aktivan. Rijetkost nije neophodna pri treniranju RBM-a
koji služi za modeliranje distribucije vjerojatnosti, ali se pokazala korisnom pri treni-
ranju diskriminativnih (klasifikacijskih) modela [9]. Dobro podešen hiperparametar ri-
jetkosti dovodi do kvalitetne specijalizacije skrivenih neurona, odnosno do izlucivanja
kvalitetnih znacajki.
Uvedimo sada oznaku shj za stvarni udio vremena aktivacije neurona hj:
shj =1
N
N∑n=1
Pn(hj = 1) = Edata [P (hj = 1)]
Nacin na koji osiguravamo da za skriveni neuron hj udio vremena aktivacije shjbude blizu hiperparametra rijetkosti r je sljedeci. U funkciju gubitka se uvodi dodatni
clan koji kažnjava odstupanje aktivacije skrivenog neurona od željene. Nazvati cemo
taj clan Espars:
Espars =∑hj∈h
−r log (shj)− (1− r) log (1− shj) (4.9)
Ovako definiranu dodatnu grešku RBMa nazivamo greškom unakrsne entropije.
Njenu minimizaciju možemo ukljuciti u postojece treniranje RBMa gradijentnom op-
timizacijom. Graf 4.3 prikazuje doprinos jednog skrivenog neurona grešci. Prim-
jecujemo da iscrtana funkcija ima globalni minimum kada je r = s te da je glatka
(derivabilna) u svim tockama domene (0, 1).
Gradijent ovako definirane kazne odstupanja od poželjne rijetkosti je lako racunljiv:
40
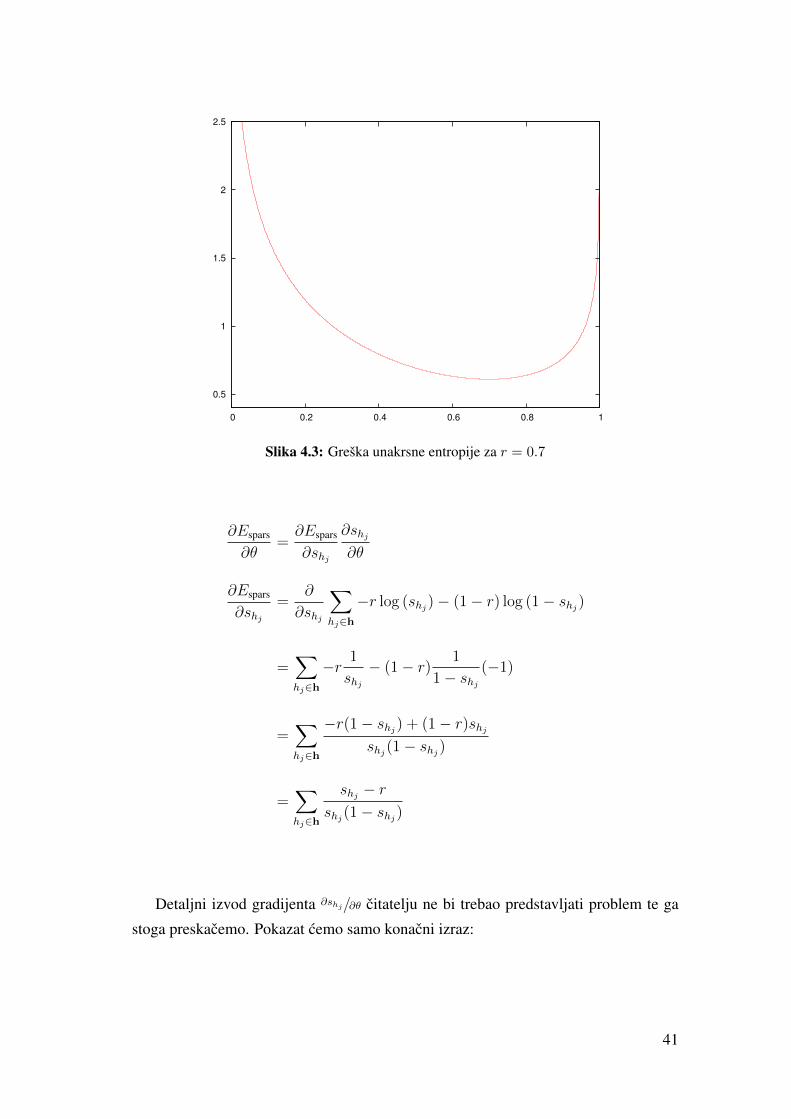
0.5
1
1.5
2
2.5
0 0.2 0.4 0.6 0.8 1
Slika 4.3: Greška unakrsne entropije za r = 0.7
∂Espars
∂θ=∂Espars
∂shj
∂shj∂θ
∂Espars
∂shj=
∂
∂shj
∑hj∈h
−r log (shj)− (1− r) log (1− shj)
=∑hj∈h
−r 1
shj− (1− r) 1
1− shj(−1)
=∑hj∈h
−r(1− shj) + (1− r)shjshj(1− shj)
=∑hj∈h
shj − rshj(1− shj)
Detaljni izvod gradijenta ∂shj/∂θ citatelju ne bi trebao predstavljati problem te ga
stoga preskacemo. Pokazat cemo samo konacni izraz:
41

∂shj∂θ
=∂
∂θEdata [P (hj = 1)]
= Edata
[P (hj = 1) (1− P (hj = 1))
∂
∂θ
(∑vi∈v
wijvi + bhj
)]
Pokažimo sada iznos cjelokupnog gradijenta kazne odstupanja od poželjne rijetkosti
ovisno o konkretnom parametru, primjerice težini veze dvaju neurona wij:
∂Espars
∂wij=∂Espars
∂shj
∂shj∂wij
=shj − r
shj(1− shj)Edata [P (hj = 1) (1− P (hj = 1)) vi]
= (shj − r)Edata
[P (hj = 1) (1− P (hj = 1))
shj(1− shj)vi
]Primjetimo razlomak unutar ocekivanja Edata [·]. Brojnik i nazivnik imaju istu
formu a(1 − a) gdje je u brojniku a vjerojatnost P (hi = 1) aktivacije neurona hiza neki primjer, dok je u nazivniku a ocekivanje te iste vjerojatnosti shi . Možemo pret-
postaviti da je vjerojatnost P (hi = 1) generalno bliska njenom ocekivanju shi te cijeli
razlomak izjednaciti s 1 (iako nemamo matematicko opravdanje za uciniti to), cime
dobivamo jednostavniji izraz:
∂Espars
∂wij≈ (shj − r)Edata [vi]
Dobiveni rezultat vrlo je jednostavan za dodati postojecem ucenju RBMa, pri cemu
se greška odstupanja od poželjne rijetkosti i njen gradijent množe faktorom "troška
rijetkosti", oznacenim cs, kako bi se rijetkost više ili manje naglasila. U slucaju da
radimo minimizaciju (KL divergencije u algoritmu kontrastne divergencije), u funkciju
koju minimiziramo gradijentnim spustom dodajemo clan:
csEspars
Primjetimo kako smo pri uvodenju rijetkosti u RBM modelu dodali dva hiper-
parametra treniranja: rijetkost s te trošak rijetkosti cs. Pronalazak vrijednosti tih hiper-
parametara koji ce rezultirati izlucivanjem kvalitetnih znacajki iziskuje odredeni trud i
produljuje trajanje treniranja RBMa.
42

Kažnjavanje velikih težina (regularizacija)
"Regularizacija" je u podrucju strojnog ucenja naziv za razlicite mehanizme cija svrha
je sprecavanje prenaucenosti modela. Prenaucenost modela zapravo znaci da se model
previše prilagodio podatcima iz skupa za ucenje, cime gubi sposobnost generalizacije.
Posljedice prenaucenosti su loše performanse na nevidenim primjerima.
Primjerice, ako treniramo model za koji želimo da klasificira rukom pisana slova,
naša želja je da model tocno klasificira i dosad nevideno slovo na temelju njegove
slicnosti videnim primjerima. Model je prenaucen ako nije u stanju tocno klasificirati
slovo koje nije sasvim podudarno nekom primjeru iz skupa za ucenje.
Regularizacija se u raznim modelima strojnog ucenja vrši na razlicite nacine. U
kontekstu RBMa, vrši se "kažnjavanjem težina" (engl. weight decay). Kažnjavanje
težina znaci da se vrijednostima težinskih veza medu neuronima ne dopušta prevelik
rast, po apsolutnom iznosu. Ideja je da težine veza nikad ne bi trebale postati toliko
velike da samostalno dominiraju nad ostalim vezama. Bitan je generalni kontekst i
generalna podudarnost znacajki.
Za opširniji opis regularizacije i kažnjavanja težina citatelj može konzultirati neke
od brojnih materijala i udžbenika iz podrucja strojnog ucenja.
Mini-serije
Tipicno se u diskusiji o treniranju unaprijednih neuronskih mreža backpropagation
spominju dva krajnja pristupa. Stohasticki pristup parametre mreže podešava nakon
evaluacije svakog pojedinog primjera za ucenje (izracuna gradijenata za taj primjer).
Batch pristup u drugu ruku racuna gradijente za sve primjere, te potom koristi njihovu
aritmeticku sredinu za podešavanje parametara mreže.
Pri treniranju RBMa preporuca se korištenje "mini-serija" (engl. mini-batches) [5].
Mini-serije su podskupovi skupa za ucenje koji tipicno dobro predstavljaju cijeli skup
(npr. sadrže barem nekoliko primjera iz svake klase), ali su puno manji. U tom smislu
je varijanca izmedu gradijenata mini-serija puno manja nego izmedu pojedinih prim-
jera, ali je broj primjera potreban da se izracuna svaki gradijent relativno malen.
4.4.4. Perzistentna kontrastna divergencija
Postoje odredene slicnosti izmedu korištenja kontrastne divergencije i maksimizacije
izglednosti pri treniranju RBMa. Uocimo te slicnosti kako bismo uvidjeli da one im-
pliciraju mnogobrojne varijante algoritma ucenja. Prisjetimo se gradijenta funkcije
43

maksimizacije izglednosti:
1
N
∂
∂wijlnL(θ|D) = Edata [sisj]− Emodel [sisj]
Prvi dio desne strane izraza (Edata [sisj]) cesto se naziva "pozitivnom" fazom ucenja,
jer se njegovim dodavanjem (zbrajanjem) vrijednostima parametara krecemo ka cilju
ucenja. Drugi dio desne strane izraza (Emodel [sisj]) se naziva "negativnom" fazom jer
se njegovim oduzimanjem od vrijednosti parametara krecemo ka cilju ucenja. Primje-
timo kako je pozitivni dio jednak bez obzira koristimo li maksimizaciju izglednosti ili
kontrastnu divergenciju, on ovisi samo o distribuciji podataka za ucenje Pdata. Nega-
tivni dio se razlikuje, radi se o distribuciji koju modelira stroj (pri maksimizaciji izgled-
nost), odnosno o distribuciji n-koracnih rekonstrukcija (pri kontrastnoj divergenciji).
Pri tome znamo da kontrastna divergencija aproksimira distribuciju modela Pdata jer je
njen egzaktan izracun racunski odvec složen. Postavlja se pitanje postoji li neki bolji
nacin da se aproksimira Pmodel.
Perzistentna kontrastna divergencija (PCD) naziv je za pristup prvi puta opisan
u [12]. Radi se o metodi koja negativnu fazu ucenja racuna na temelju odredenog
broja negativnih "cestica". Negativna cestica je zapravo RBM koji prolazi kroz ra-
zlicita stanja vn → hn → vn+1 → hn+1 → .... Svaka negativna cestica je po
pitanju težina i pristranosti identicna RBMu koji treniramo, ali prolazi kroz stanja
kao sasvim nezavisan stroj. Stanja kroz koja negativne cestice prolaze koristimo za
aproksimaciju distribucije Pmodel. Ideja je da kao i kod kontrastne divergencije ces-
ticu inicijaliziramo primjerom za ucenje v0 (postavimo primjer za ucenje kao stanje
vidljivog sloja RBMa). Potom svaka cestica napravi jedan ili više koraka promjene
stanja, nakon cega racunamo gradijente na nacin vec pokazan. U tom trenutku slicnost
s kontrastnom divergencijom prestaje. Nakon promjene parametara modela potrebno
je ponovno izracunati gradijente. Pri kontrastnoj divergenciji negativne cestice nastavl-
jaju s promjenom stanja bez da ih "vracamo" u stanje odredeno primjerom za ucenje.
One se stoga sve više i više udaljavaju od pocetnog primjera s kojim smo ih inicijal-
izirali. Time se postiže da negativne cestice uz istu racunsku složenost bolje modeliraju
distribuciju Pmodel. Primjetimo razliku naspram obicne kontrastne divergencije, gdje se
negativna faza gradijenta racuna na temelju stanja RBMa udaljenog od primjera za
ucenje svega nekoliko koraka.
Postavlja se pitanje koji je dobar broj negativnih cestica i da li je možda još bolji
pristup da svaka cestica obavi nekoliko koraka prije racunanja gradijenta. Testiranja u
[12] pokazala su da je prikladno uzeti broj negativnih cestica jednak broju primjera u
44

mini-seriji te da pri svakoj primjeni gradijenta cestice trebaju obaviti tocno jedan korak
Markovljevog lanca.
Usporedba perzistentne kontrastne divergencije s CD1 i CD10 algoritmima pokazala
je da PCD cesto daje bolje rezultate [12], pogotovo kako trajanje treniranja raste. Even-
tualni nedostatak PCD pristupa je povecana osjetljivost algoritma na stope ucenja pri
gradijentnom spustu, ali ta osjetljivost generalno ne predstavlja veliki problem.
4.5. Primjer ucenja ogranicenog Boltzmanovog stroja
Pokažimo sada ucenje RBM-a na primjeru. Radit cemo ekstrakciju znacajki iz digi-
talnih slika rukom pisanih kapitaliziranih slova. Oblikovanje ovakvog RBM-a je tip-
ican prvi korak pri izradi klasifikatora rukom pisanih slova. Osim za klasifikacijski
zadatak, dobiveni RBM se može koristiti za generiranje primjera klasa s kojima je
treniran. Nadalje, takav model može prepoznati uzorke koji jako odstupaju od prim-
jera za ucenje. Energija mreže za slovo slicno onima iz skupa za ucenje biti ce niska.
Energija mreže za neko drugo slovo biti ce visoka što može biti korisna indikacija o
nepoznatosti.
Skup podataka za treniranje sastoji se od po 9537 primjera svakog slova. Svaka
slika je dimenzija 24 × 32, dakle sadrži 768 piksela. Slike su procesirane tako da je
svaki piksel crne ili bijele boje, ne koriste se tonovi sive, kao ni boje. Nekoliko slika iz
skupa za ucenje prikazani su na slici 4.4.
Slika 4.4: Nekoliko slika iz skupa za ucenje RBM-a
Broj vidljivih neurona ogranicenog Boltzmannovog stroja koji treniramo je 768,
gdje svaki neuron predstavlja po jedan piksel slike. Zadatak RBM-a ce biti izluciti
najbolje rekonstrukcijske znacajke na temelju primjera za ucenje. Stroj treniramo al-
goritmom kontrastne divergencije CD1 s uvjetom rijetkosti i regularizacijom.
Pri treniranju RBM-a potrebno je odrediti stope ucenja, trajanje treniranja (broj
epoha odnosno prolazaka kroz cijeli skup za ucenje) i nekoliko hiperparametara mod-
45

ela. Hiperparametri modela utjecu na proces treniranja i konacne parametre (težine i
pristranosti RBM-a) modela. U našem slucaju hiperparametri su broj skrivenih neu-
rona, rijetkost te faktori kažnjavanja rijetkosti i kažnjavanja težina. Stope ucenja odreduju
koliko se težine i pristranosti modela modificiraju svakim korakom ucenja. Broj skrivenih
neurona (izlucenih znacajki) odreduje i sveukupni broj parametara modela, odnosno
njegovu složenosti.
Opcenita diskusija o optimizaciji hiperparametara RBM-a izlazi izvan okvira ovog
teksta. U našem primjeru, vrijednosti hiperparametara su utvrdene empirijski. Okvirne
vrijednosti su odredene i proces optimizacije provoden u skladu s [5]. Pri tome se
primarno optimizirala kvaliteta izlucenih znacajki u smislu lokalne specijaliziranosti
skrivenih neurona. Zbog jednostavnosti se preferiralo modele s manjim brojem neu-
rona u skrivenom sloju. Jednostavniji modeli se brže uce i (opcenito govoreci) imaju
dobru sposobnost procjene nevidenih primjera. Naravno, prejednostavan model nije
sposoban izluciti dobre znacajke iz skupa za ucenje.
Znacajke RBM-a mogu se jednostavno vizualizirati. Prisjetimo se, u RBM-u svaki
skriveni neuron predstavlja znacajku. Parametri skrivenog neurona su njegova pristra-
nost i težine veza s vidljivim slojem. Stoga znacajku prikazujemo kao sliku u kojoj je
svaka težina veze s neuronom vidljivog sloja prikazana jednim pikselom (pristranosti
ne vizualiziramo jer ih po potrebi lako pregledamo u numerickom obliku). Poredak
piksela je isti kao i poredak neurona vidljivog sloja s obzirom na piksele iz primjera za
ucenje. Ideja je prikazana na slici 4.5. U lijevom dijelu slike imamo primjer za ucenje
koji ima 2 × 3 piksela. Srednji dio slike prikazuje taj primjer za ucenje pohranjen u
vidljivi sloj RBM-a, spojen s jednim skrivenim neuronom. Desni dio slike prikazuje
kako se težine spajanja skrivenog neurona prikazuju vizualno.
v1 v2
v3 v4
v5 v6
hi
wi1
wi5
wi2
wi6
wi4
wi3
wi1 wi2
wi3 wi4
wi5 wi6
Slika 4.5: Nacin vizualizacije znacajke (skrivenog neurona)
Na ovaj nacin dobivene znacajke možemo jednostavno interpretirati. Bijeli pikseli
u primjerima za ucenje oznacavaju neuron u stanju 1, a crni pikseli neuron u stanju
0. Svijetli pikseli na slici znacajke oznacavaju pozitivne težine vezanja. Tamni pik-
46

seli oznacavaju negativne težine veza. Na temelju diskusije o znacajkama u poglavlju
4.3 zakljucujemo da podudarnost svijelih i tamnih dijelova izmedu slike znacajke i
primjera za ucenje govori o njihovoj koreliranosti. Za neko stanje vidljivog sloja, u
skrivenom sloju ce se aktivirati one znacajke s podudarnim težinama.
Pogledajmo konacno primjere izlucenih znacajki, prvo na vrlo jednostavnom RBM-
u. Razmotrimo stroj treniran samo nad primjerima kapitaliziranog slova A. Koristili
smo 120 skrivenih neurona s parametrom rijetkosti od 0.15 (velicina mreže i parametri
su pronadeni eksperimentalno). Treniranje kroz 50 epoha je trajalo oko 3 minute.
Izlucene znacajke prikazane su na slici 4.6.
Slika 4.6: Znacajke izlucene za kapitalizirano slovo A
Vidimo da vecina znacajki predstavlja neku od sastavnih linija slova A. Isto tako
možemo primijetiti da postoje blage varijacije medu znacajkama koje predstavljaju
istu liniju slova. Ovo omogucava da se velik broj razlicitih slova A rekonstruira ko-
rištenjem malog podskupa znacajki. Nadalje, primjetimo da korištenjem 120 znacajki
možemo s velikom preciznošcu rekonstruirati slike koje imaju 768 piksela. Time smo
efektivno ostvarili kompresiju podataka posebno prilagodenu slikama slicnim primjer-
ima za ucenje.
Pogledajmo ilustracije radi kakve znacajke možemo izluciti ako RBM treniramo
bez uvjeta rijetkosti. Treniramo RBM nad istim slikama kao i u prethodnom primjeru.
47

Svi hiperparametri osim rijetkosti ostali su nepromjenjeni. Trajanje treniranja nije se
promijenilo. Rezultati su prikazani na slici 4.7.
Slika 4.7: Znacajke izlucene za kapitalizirano slovo A bez uvjeta rijetkosti
Možemo vidjeti da su izlucene znacajke osjetno drukcije. Iako neke znacajke pred-
stavljaju jednu od linija slova A, mnogo ih ne možemo tako interpretirati. Štoviše, za
vecinu znacajki je vrlo teško ponuditi ikakvu interpretaciju. Bez obzira na otežanu
interpretaciju znacajki, RBM treniran bez uvjeta rijetkosti u pravilu bolje modelira
distribuciju primjera za ucenje. Kao što je vec spomenuto, pokazano je da za klasi-
fikacijske zadatke RBM s uvjetom rijetkosti uglavnom daje bolje rezultate.
Pogledajmo sada znacajke izlucene za malo kompleksniji RBM. Stroj treniramo
nad primjerima kapitaliziranih slova A, B i C (svaka klasa je zastupljena s 9537 slika).
Pošto modeliramo osjetno složeniju distribuciju, potrebno nam je više skrivenih neu-
rona. Empirijski se pokazalo da korištenje oko 300 skrivenih neurona daje dobre
rekonstrukcije uz izlucene dobre znacajke. Koristimo 276 skrivenih neurona (broj blizu
300 koji se lijepo prikaže u 23 × 12 mreži). Hiperparametar rijetkosti je postavljen na
0.07. Smisleno je da ako koristimo veci broj skrivenih neurona, svaki od njih u pros-
jeku treba biti rjede aktivan. Stroj se trenira kroz 150 epoha, ukupno trajanje treniranja
je približno 40 minuta. Izlucene znacajke su prikazane na slici 4.8.
Vidimo da su uspješno izlucene lokalne znacajke, skriveni neuroni su se specijal-
48

Slika 4.8: Znacajke izlucene za kapitalizirana slova A, B i C
izirali. Mnoge znacajke su specificne za neko od slova A, B ili C, neke znacajke su
zajednicke za sve klase. Ovako izlucene znacajke mogu poslužiti za rekonstrukciju
slike slova (modeliranje distribucije skupa za ucenje) i kao oblik kompresije, isto kao
i znacajke RBM-a treniranog samo sa slovom A. Nadalje, RBM za slova A, B i C
može poslužiti kao osnova za klasifikator. Ako vidljive neurone postavimo u stanje
koje odgovara nekom od slova A, B ili C, aktivirat ce se skriveni neuroni sa znaca-
jkama koje su velikim dijelom specijalizirane za baš tu klasu slova. Stoga klasifikator
možemo trenirati nad neuronima skrivenog sloja (aktivacijama znacajki), umjesto nad
neuronima vidljivog sloja (pikselima slike). Upravo ova ideja je u pozadini obliko-
vanja dubokih neuronskih mreža baziranih na RBM-u te ce biti detaljnije razradena u
sljedecim poglavljima.
Zanimljivo je pogledati i znacajke koje izlucuje RBM za slova A, B i C, ali bez
korištenja rijetkosti. Ponovno treniramo RBM, sve postavke osim rijetkosti su ne-
promjenjene. Znacajke su prikazane na slici 4.9.
Kao i u primjeru jednostavnijeg RBM-a, vidimo da mnoge znacajke nisu lokalno
specijalizirane. I dalje vrijedi da ovako izlucene znacajke nešto bolje modeliraju dis-
tribuciju primjera za ucenje te cine manju rekonstrukcijsku grešku, ali su lošija osnova
za izgradnju klasifikatora.
49

Slika 4.9: Znacajke izlucene za kapitalizirana slova A, B i C bez rijetkosti
50

5. Duboka probabilisticka mreža
5.1. Definicija
Duboka probabilisticka mreža (engl. deep belief network, DBN) je generativni graficki
model. Termin DBN se prvi puta pojavio u [6], iako su mreže bazirane na stohastickim
sigmoidalnim neuronima poznate od prije pod sigmoid belief net [10]. Grafickim mod-
elima se u statistici i vjerojatnosti nazivaju modeli u kojima su slucajne varijable pred-
stavljene cvorovima grafa, a zavisnosti varijabli lukovima. Usmjerenost lukova oz-
nacava smjer zavisnosti, što cemo objasniti na primjeru DBNa. Za opširniju diskusiju
o grafickim modelima citatelja upucujemo na materijale iz podrucja vjerojatnosti.
U kontekstu neuronskih mreža, slucajne varijable (odnosno covorove grafa) nazi-
vamo neuronima. Tu konvenciju smo koristili dosad kroz ovaj rad pa cemo se nje i
držati. Neka citatelja ne zbunjuje meduzamjenjivost ovih termina u literaturi.
DBN se sastoji od neurona organiziranih u slojeve, slicno kao i RBM, ali se DBN
tipicno sastoji od više od dva sloja. Pri tome prvi (najniži) sloj u pravilu sadrži
"vidljive" neurone, one cije vrijednosti za neki primjer znamo. Stoga cemo taj sloj
oznacavati s v (engl. visible). Ostali slojevi sadrže skrivevene neurone koje cemo oz-
nacavati s h0, ...,hn, pri cemu je sloj h0 susjedan sloju v. Ovakva arhitektura tipicna
je u podrucju unaprijednih neuronskih mreža. Primjer je cesto korištena slojevita feed-
forward mreža koju treniramo algoritmom backpropagation. Važno je odmah u startu
shvatiti da je formulacija duboke probabilisticke mreže bitno drukcija od feed-forward
mreže. DBN je generativna probabilisticka mreža, što znaci da modelira distribuciju
stanja neurona vidljivog sloja. Kao što cemo detaljno razjasniti, to znaci da se signali
po vezama krecu od udaljenih skrivenih slojeva mreže prema vidljivom sloju, kako
bi se u njemu generirao neki primjer. Pri tome želimo da je distribucija generiranih
primjera što slicnija distribuciji primjera za ucenje.
Za veze medu neuronima DBNa vrijedi sljedece. Prvo, veze medu neuronima is-
tog sloja ne postoje, kao i kod RBMa. Nadalje, veze postoje samo medu neuronima
susjednih slojeva, izmedu slojeva v i h0, odnosno slojeva hi i hi+1. Konacno, veze
51

izmedu najvišeg (najudaljenijeg od v) i njemu susjednog sloja nisu usmjerene, dok su
sve ostale veze usmjerene prema nižem sloju. Znacenje usmjerenosti ce biti objašn-
jeno u poglavlju 5.2, zasad je najbitnije steci dojam o arhitekturi mreže. U tu svrhu je
jednostavan DBN predocen na slici 5.1. Arhitektura mreže u primjeru je ilustrativna te
ne govori ništa opcenito o broju slojeva i neurona DBNa.
v1 v2
h01
v3 v4
h02 h03
v
h0
h11 h12 h13
h21 h22 h23
h1
h2
Slika 5.1: Primjer jednostavne DBN mreže.
Neuroni u DBN mreži isti su kao i neuroni koje smo razmatrali u Boltzmannovim
strojevima (i RBMu). Radi se dakle o neuronima koji mogu biti u dva stanja, oznacena
0 i 1. Stanje u kojem se neuron nalazi odredeno je stohasticki s obzirom na "ulaze" u
neuron, odnosno težinske veze s drugim neuronima. Detaljan izvod vjerojatnosti stanja
ovakvog neurona obraden je u poglavlju 3. Prisjetimo se samo konacnog rezultata
(izveden u formuli 3.6)
P (si = 1) =1
1 + e−(∑
j wijsj+bi)= σ(
∑j
wijsj + bi)
5.2. Generativni probabilisticki model
U definiciji DBN mreže rekli smo da su sve veze osim onih medu dva najviša sloja
usmjerene prema dolje, odnosno u konacnici prema vidljivom sloju. Umjerenost veze
znaci da neuron od kojeg veza krece utjece na neuron u koji ulazi, ali ne i obrnuto.
Razmotrimo ovaj koncept na jednostavnom primjeru:
52

A B
Slika 5.2: Usmjerenost u grafickom probabilistickom modelu, primjer 1.
Slika 5.2 prikazuje neurone A i B. Veza medu njima usmjerena je od neurona
A prema neuronu B. Znacenje takvog usmjerenja je da neuron A utjece na neu-
ron B, ali ne i obrnuto. U probabilistickim grafickim modelima, kao što je DBN,
svaki cvor grafa (neuron) predstavlja slucajnu varijabu. U našem primjeru dvije sluca-
jne varijable imaju vjerojatnosne distribucije P (A) i P (B). Za zadano usmjerenje
vrijedi da je P (A|B) = P (A), odnosno da neuron A ne ovisi o B. Suprotno nije
istina, P (B|A) 6= P (B). Bitno je primjetiti kako su implicirane nezavisnosti neurona
uvjetne. Razmotrimo primjer od tri varijable prikazan na slici 5.3.
A B C
Slika 5.3: Usmjerenost u grafickom probabilistickom modelu, primjer 2.
U primjeru s neuronima A, B i C ne možemo reci da je neuron C generalno neza-
visan o A: P (C|A) 6= P (C), ali možemo reci da je C uvjetno nezavisan o A ako je
zadan B: P (C|A,B) = P (C|B). Ovo je lako iscitati iz slike. Vidimo da A utjece na
B, logicno je stoga da A indirektno utjece i na C, ali ako vec znamo u kojem stanju je
B, za razmatranje neurona C više nam nije bitan A.
Vratimo se sada na razmatranje DBN mreže. Slika 5.1 prikazuje generalnu arhitek-
turu DBNa. Vidimo da dva najviša sloja mreže (h2 i h1) cine bipartitan graf bez
usmjerenja na vezama. Ovo je arhitektura identicna vec razmatranom ogranicenom
Boltzmannovom stroju. Dva najviša sloja utjecu medusobno jedan na drugi, ali su
neuroni istog sloja uvjetno neovisni jedni o drugima, ako je zadano stanje suprotnog
sloja. Razmotrimo sada niže slojeve. Vidimo da su veze od h1 prema h0 usmjerene.
Sloj h1 utjece na sloj h0. Istovremeno vidimo da je sloj h0 uvjetno nezavisan o svim
drugim neuronima, ako je h1 zadan. Analogno je v uvjetno nezavisan o slojevima h2
i h1 ako je zadan h0.
Koje je znacenje ovakve arhitekture? Dva najviša sloja mreže, u našem primjeru
h2 i h1, cine RBM koji ne ovisi o drugim varijablama. Taj RBM modelira distribu-
ciju vjerojatnosti P (h1,h2) stanja neurona slojeva h1 i h2. Ta distribucija uvjetuje
distribuciju P (h0) sloja h0, koja nadalje uvjetuje distribuciju P (v) sloja v. Vidimo
53

dakle da smo u konacnici došli do distribucije stanja vidljivog sloja, tojest podataka
koji su nam od interesa. Prirodno se može postaviti pitanje cemu svi ti slojevi, kada
smo distribuciju P (v) mogli modelirati obicnim RBMom (samo dva sloja neurona),
kao što smo vec cinili. Odgovor na to pitanje je: ekspresivnost. Svaki dodatni sloj
u mreži povecava ekspresivnost modela u smislu sposobnosti modeliranja složenije
distribucije stanja vidljivog sloja.
5.3. Diskriminativni model
U praksi se neuronske mreže, graficki modeli i opcenito algoritmi strojnog ucenja
vrlo cesto koriste za klasifikaciju podataka. Klasifikacija je odredivanje pripadnosti
nekog primjera jednoj (ili više, ovisno o zadatku) od konacnog broja "klasa" odnosno
"razreda". Pri tome svaka klasa obuhvaca primjere koji su po nekom kriteriju medu-
sobno slicni, odnosno razliciti od primjera drugih klasa. Tipicne primjene klasifikacije
su detekcija neželjene pošte (engl. spam detection), prepoznavanje lica na fotografi-
jama, raspoznavanje rukom pisanih slova itd.
Pokažimo kako se duboka probabilisticka mreža može koristiti kao diskriminativni
model. Razmotrimo klasifikacijski problem gdje svaki primjer pripada tocno jednoj od
K razlicitih klasa. Pri tome cemo za primjer x klasu kojoj on pripada oznacavati s y,
pri cemu je y ∈ [1, K]. Kada treniramo klasifikacijski model potrebni su nam primjeri
za ucenje koji su oznaceni. To znaci da moramo znati klasu kojoj svaki primjer za
ucenje pripada. Skup za ucenje D stoga se sastoji od N parova znacajki primjera x i
labela y, odnosno D = {x(i), y(i)}Ni=1.
Prisjetimo se da radimo s neuronskom mrežom u kojoj neuroni poprimaju vrijed-
nosti iz {0, 1}. Možemo pretpostaviti da smo primjere za ucenje vec predocili kao
binarne vektore, preostaje još da isto ucinimo i s oznakama klasa. U problemu s K
klasa prakticno je pripadnost pojedinoj klasi predociti zasebnim neuronom. Tada se
svaka oznaka y(i) iz skupa za ucenje, koja je cijeli broj iz raspona [1, K], može pre-
dociti binarnim vektorom od K elemenata. Primjerice, oznaku y(i) = 4 u problemu s
K = 5 klasa oznacavamo binarnim vektorom y(i) = [0, 0, 0, 1, 0]. Ovakav nacin kodi-
ranja labela naziva se one-hot encoding. Koristeci one-hot kodiranje skup za ucenje D
prikazan je iskljucivo binarnim vektorima primjera i oznaka: D = {x(i),y(i)}Ni=1.
Spojimo sada primjer za ucenje x(i) i pripadni binarni vektor labela y(i) u jedan
binarni vektor i oznacimo ga v(i) = [x(i),y(i)], pošto se radi o varijablama koje su u
dubokoj mreži predstavljene vidljivim slojem. Modeliranjem distribucije vjerojatnosti
P (v) zapravo modeliramo zajednicku distribuciju (engl. joint-probability distribution)
54

primjera i labela P (x,y).
Generativni probabilisticki modeli opcenito modeliraju distribuciju vjerojatnosti
P (v) vidljih varijabli v, odnosno P (x,y). Ustanovili smo da to cini i duboka proba-
bilisticka mreža. Kako tu sposobnost modeliranja zajednicke distribucije iskoristiti za
klasifikaciju?
Iz probabilisticke perspektive problem klasifikacije možemo razmatrati kao pitanje
uvjetne vjerojatnosti P (y|x). Razmatranje klasifikacije na taj nacin dovodi do razla-
ganja zajednicke vjerojatnosti na faktore i uvjetne vjerojatnosti, no u radu s dubokom
probabilistickom mrežom to ne bi bilo od pomoci. Razlog tomu je što pri radu s
dubokom mrežom nikada ne racunamo konkretne vjerojatnosti (uvjetne ili zajednicke)
pošto one ovise o prevelikom broju neurona (prisjetimo se diskusije o složenosti iz
poglavlja 3.6.5). Umjesto toga, razmotrimo što se dešava s dubokom probabilistickom
mrežom, treniranom da modelira zajednicku distribuciju P (x,y), iz perspektive akti-
vacije neurona.
Zadatak mreže je da za dosad nevideni primjera x generira prikladne labele y,
odnosno da klasificira x. Mreža modelira distribuciju stanja vidljivog sloja na sljedeci
nacin. Dva najdublja sloja modeliraju distribuciju svojih stanja. Potom se ta distribu-
cija propagira do vidljivog sloja v, pri cemu postaje sve kompleksnija i izražajnija.
Pošto vidljivi sloj v predstavlja znacajke x i labele y, pitanje klasifikacije je zapravo
sljedece: u kojem stanju trebaju biti dva najdublja sloja mreže kako bi se u vidljivom
sloju generirao primjer x? Tada ce po definiciji u vidljivom sloju istovremeno biti
generirane prikladne labele labele y. Dakle, potrebno je da za primjer x pronademo
prikladno stanje najdubljih slojeva mreže te potom na temelju tog stanja generiramo
odgovarajuci y.
Time smo pojasnili osnovnu ideju toga kako se duboga probabilisticka mreža, kao
generativni model, može koristiti za klasifikacijski zadatak. Prakticna primjena kao i
objašnjenje nacina treniranja slijedi u nastavku.
5.4. Treniranje
Treniranje dubokog grafickog modela, poput duboke probabilisticke mreže, velikim je
dijelom problem odredivanja prikladnog stanja skrivenih neurona (engl. hidden vari-
able inference) na temelju stanja vidljih neurona. Pojasnimo zašto.
Pretpostavimo prvo da unaprijed znamo prikladna stanja skrivenih neurona za svaki
primjer iz skupa za ucenje postavljen u vidljivi sloj v. Tada se treniranje mreže svodi na
podešavanje težina veza i pristranosti neurona tako da poznata stanja skrivenih neurona
55

h cine vrlo vjerojatnim generiranje poznatog stanja vidljivog sloja v. Ovakav model
je zapravo model bez skrivenih varijabli. Postupak treniranja može biti vremenski
zahtjevan, ali je jednostavan i za smislene distribucije v i h konvergira bez problema.
U realnosti naravno ne znamo unaprijed prikladna stanja skrivenih neurona h za
svaki primjer za ucenje v. Istovremeno je potrebno utvrditi prikladna stanja skrivenih
neurona i podesiti parametre mreže tako da budu u skladu da distribucijom (v,h).
Jasno je da se radi o puno kompleksnijem zadatku nego kada su sva stanja poznata.
Razmotrimo kako se može utvrditi stanje skrivenih varijabli. Koristeci teoriju
vjerojatnosti možemo, uz proizvoljno postavljene težine veznja i pristranosti, izracu-
nati uvjetnu vjerojatnost stanja skrivenih neurona. Primjerice, ako su neuroni vi i hjpovezani snažnom pozitivnom vezom, aktivno stanje vidljivog neurona vi implicira s
velikom vjerojatnošcu da je njegovu aktivaciju prouzrocio upravo hj . Na taj se nacin
može utvrditi koji skriveni neuroni su uzrocnici aktivacije vidljivih neurona. Jednom
kada znamo stanja svih neurona, parametri se lako korigiraju kako bi se cijela mreža
što bolje prilagodila skupu za ucenje.
Nažalost, objašnjeni proces ispravnog utvrdivanja stanja skrivenih neurona je uve-
like otežan fenomenom "otklona uzroka" (engl. explaining-away). Promotrimo o cemu
se radi. Jednostavan primjer od tri neurona (jedan vidljiv i dva skrivena) prikazan je
na slici 5.4. Znamo pristranosti i težine vezanja, dakle znamo tocno koju distribuciju
stanja neuroni modeliraju.
h1 h2
v1-20
-20-20
40 40
Slika 5.4: Primjer fenomena "otklona uzroka"
Vidimo da svi neuroni (h1, h2 i v1) imaju veliku negativnu pristranost, dakle sami
po sebi imaju vrlo malu vjerojatnost aktivacije. Istovremeno, skriveni neuroni h1 i h2
još vecom pozitivnom vezom utjecu na v1. Stoga, ako se bilo koji od skrivenih neurona
aktivira, vjerojatnost aktivacije vidljivog v1 postaje vrlo visoka. Pitanje koje nas zan-
ima jest kako na temelju poznatog stanja vidljivog neurona dokuciti stanja skrivenih?
Kada je neuron v1 aktiviran, uvjetna vjerojatnosti P (h1 = 1|v1 = 1) postaje vrlo
visoka, upravo zato što znamo da je nešto moralo potaknuti v1 na aktivaciju. Isto
možemo reci i za vjerojatnost P (h2 = 1|v1 = 1). Upravo ovdje dolazi do komp-
56

likacije. Znamo da sva tri neurona imaju vrlo malu vjerojatnost aktivacije s obzirom
na njihove pristranosti. Vidjevši da je neuron v1 aktiviran, mi možemo izracunati vi-
soku posteriornu vjerojatnost da su h1 i h2 aktivni, ali za aktivaciju v1 dostatno je da
samo jedan od njih bude aktivan. Odnosno, ako znamo da je h1 aktivan, uz v1, tada je
vjerojatnost P (h2 = 1|v1 = 1, h1 = 1) zapravo iznimno mala1. Upravo ovo se naziva
"otklonom uzroka". Iz perspektive neurona h2, poznata aktivacija h1 objasnila je ak-
tivaciju neurona v1, otklonivši potrebu za aktivacijom h2. Može se reci da su neuroni
h1 i h2 vrlo snažno antikorelirani, kada je v1 aktivan. Nažalost, u grafickom modelu
sa slike ta antikorelacija nije definirana jer ne postoji veza izmedu h1 i h2. Isto vri-
jedi i za duboke probabilisticke mreže jer u njima neuroni istog sloja nisu povezani.
Stoga se pri izracunu aktivacije skrivenih varijabli h1 i h2 na temelju aktivacije v1 u
pravilu aktiviraju oba, iako to zapravo nije u skladu s pravim vjerojatnostima tog istog
grafickog modela. Ova nesposobnost pravilnog odredivanja stanja skrivenih varijabli
uvelike otežava treniranje grafickih modela, pogotovo u slucajevima kada je skrivenih
neurona dovoljan broj da iscrpne ili MCMC metode presporo konvergiraju.
5.4.1. Pohlepno predtreniranje slojeva
Kompleksnost treniranja višeslojnih grafickih modela opcenito izlazi izvan okvira ovog
rada, dovoljno je reci da do sredine 2000-ih nisu postojale efikasne metode za ucenje
prakticno primjenjivih modela. Situacija se mjenja radom [6] u kojem Hinton i Osin-
dero predlažu predtreniranje dubokih mreža sloj po sloj. Necemo ulaziti u detaljnu
analizu probabilisticke opravdanosti predloženog pristupa, vec se fokusirati na prak-
ticnu primjenu.
Kljucna ideja je da se cijela mreža ne trenira odjednom, jer takvo treniranje vrlo
sporo konvergira i ima tendenciju zaglavljivanja u bliskim lokalnim optimuma. Um-
jesto toga, mreža se trenira sloj po sloj. Prvo se treniraju neuroni najpliceg skrivenog
sloja, onog spojenog na vidljivi sloj. Podešavaju se pristranosti tog sloja i težine
vezanja na vidljivi sloj. Nakon ogranicene kolicine treniranja dobiveni parametri se
"zamrzavaju". Njihova trenutna vrijednost u narednim se koracima ne mjenja. Potom
se trenira sljedeci skriveni sloj. Ulazne vrijednosti u taj sloj su aktivacije prethodnog
skrivenog sloja, dobivene na temelju primjera za ucenje i zamrznutih parametara prethodnog
sloja. Treniranje drugog skrivenog sloja u tom smislu mjenja samo pristranosti drugog
sloja i težine vezanja na prethodni. Nakon završetka treniranja drugog sloja, zam-
1Citatelju preporucamo da raspiše tocne vjerojatnosti svih mogucih kombinacija stanja (samo ih je
8) na nacin opisan u poglavlju 3.4. Time ce se razjasniti opisano ponašanje uvjetnih vjerojatnosti.
57

rzavaju se tako podešeni parametri mreže te se prelazi na sljedeci skriveni sloj. Ovaj
postupak se ponavlja sve dok se ne ne istreniraju svi slojevi mreže. Opisani algoritam
prikazan je u ispisu 2.
Navedeni algoritam naziva se pohlepnim zato jer se slojevi treniraju slijedno, jedan
po jedan, pri cemu se vec podešeni parametri (prethodno istrenirani slojevi) ne mjen-
jaju. "Pohlepnost" ovog algoritma implicira odredenu suboptimalnost treniranja. Ovako
istrenirana mreža nece davati najbolje moguce rezultate, ali to niti nije bio cilj. Radi
se uistinu o predtreniranju. Mrežu smo htjeli dovesti u parametarski prostor u kojem
ce daljnje treniranje brže konvergirati prema boljem optimumu nego da nismo proveli
postupak predtreniranja.
Objasnili smo okvirno kako predtreniranje iterira kroz slojeve mreže. Potrebno je
još razjasniti kako se pojedini slojevi treniraju. U kontekstu duboke probabilisticke
mreže, svaki sloj (spojen na prethodni) izgleda poput ogranicenog Boltzmannovog
stroja. Neuroni su organizirani u dva sloja, medusobno potpuno spojena, bez veza
unutar istog sloja. Uistinu, ovo je definicija RBMa. U tom smislu su svi algoritmi
treniranja RBMova prikladni, u praksi je smisleno koristiti jednokoracnu prezistentnu
kontrastnu divergenciju, kao poznato efikasnu opciju.
Algorithm 2 Pohlepno predtreniranje po slojevima1: D = skup podataka za ucenje
2: n = broj skrivenih slojeva mreže
3: for i = 1 to n do4: RBMi = ograniceni boltzmannov stroj za trenutni sloj
5: if i = 1 then6: Di = D
7: else8: Di = RBMi−1(Di−1)
9: end if10: treniraj RBMi koristeci Di
11: end for
5.4.2. Fino podešavanje
Pohlepno predtreniranje slojeva mrežu dovodi u podrucje parametarskog prostora u
kojem možemo ocekivati daljnju konvergenciju prema kvalitetnom optimumu. Težine
i pristranosti mreže nakon predtreniranja kvalitetno modeliraju distribuciju skupa za
58

ucenje, ali proces treniranja nije završen. Rezultati mnogih eksperimenata pokazuju
da mreža nakon predtreniranja ima prostora za poboljšanje. Stoga mrežu nastavljamo
trenirati algoritmima koji rade odjednom s citavom mrežom, umjesto s pojedinim slo-
jevima, kao što je obicaj s konvencionalnim unaprijednim neuronskim mrežama. Ovaj
proces se tipicno naziva fino podešavanje (engl. fine-tuning) parametara.
Razmatrali smo primjene mreže u svrhu modeliranja distribucije vjerojatnosti i u
svrhu diskriminacije (klasifikacije) nevidenih uzoraka u poznate klase. Fino podeša-
vanje parametara mreže se razlikuje ovisno o njenoj konacnoj primjeni. Dobro su
poznata dva algoritma finog podešavanja koje opisujemo u nastavku.
Algoritam "gore-dolje"
Algoritam "gore-dolje" (engl. up-down algorithm) predložen je u [6] kao efikasan
nacin finog-podešavanja težina u dubokoj vjerojatnosnoj mreži. Konceptualno je al-
goritam slican kontrastnoj divergenciji. Na temelju primjera za ucenje se generiraju
stanja svih skrivenih neurona (prema "gore"). Potom se rekreira stanje vidljivog sloja
(prema "dolje") pocevši od najvišeg skrivenog te se minimizira odstupanje rekonstruk-
cije od originalnog primjera. Od kontrastne divergencije se algoritam razlikuje jer
ona generira stanje samo jednog skrivenog sloja, dok je pri treniranju duboke mreže
potrebno generirati više njih. Generiranje stanja skrivenih slojeva do najdubljeg te
slijedno generiranje prema dolje racunalno je zahtjevno i ima visoku varijancu stanja
(prisjetimo se, stanje svakog neurona odreduje se stohasticki). Zbog toga je za nje-
govo korištenje presudno kvalitetno predtreniranje slojeva. Bez predtreniranja algori-
tam presporo konvergira da bi bio prakticno koristan.
Algoritam "gore-dolje" optimizira rekonstrukciju primjera za ucenje. U razma-
tranju kontrastne divergencije vec je utvrdeno da takva optimizacija dobro aproksimira
modeliranje distribucije vjerojatnosti primjera za ucenje.
Konkretnu implementaciju ovog algoritma necemo opisivati zbog relativno visoke
kompleksnosti i male primjenjivosti. Naime, duboke vjerojatnosne mreže koriste se
najcešce za diskriminativne zadatke (opcenito za nadzirano ucenje), puno rjede je
potrebno u konacnici izgraditi iskljucivo generativni model. Za fino podešavanje duboke
mreže za diskriminativni zadatak postoji brži i jednostavniji algoritam. Stoga se algori-
tam "gore-dolje" u praksi rijetko koristi. Citatelja kojeg zanima algoritam "gore-dolje"
upucujemo na rad [6] u kojem su teorijska podloga i implementacija detaljno objašn-
jeni.
59

Algoritam Backpropagation
Algoritam backpropagation poznat je nacin treniranja unaprijednih neuronskih mreža.
Literatura u kojoj je detaljno objašnjen je lako dostupna, eventualno neupucenom ci-
tatelju predlažemo [13].
Backpropagation se u kontekstu dubokih probabilistickih koristi primarno za nadzi-
rano ucenje, odnosno klasifikaciju. Ovo je posljedica toga što backpropagation min-
imizira grešku izlaznog sloja mreže, pri cemu je izlazni sloj tipicno oznaka razreda
(jedan neuron po razredu).
Fino podešavanje duboke probabilisticke mreže backpropagation algoritmom za-
htjeva promjenu definicije mreže. Backpropagation radi s neuronskim mrežama koje
imaju realne aktivacije neurona (naspram diskretnih {0, 1} aktivacija) koje se odreduju
deterministicki (naspram stohasticnog odredivanja). Moguce su razlicite aktivacijske
funkcije mreže, tipicno se koriste sigmoidalna funkcija i tangens hiperbolni. U kontek-
stu finog podešavanja duboke probabilisticke mreže prikladna je sigmoidalna funkcija
jer je njen izlaz unutar intervala [0, 1]. Dakle, probabilisticku mrežu s diskretnim ak-
tivacijama cemo koristiti kao deterministicku mrežu s realnim aktivacijama. Pri tome
parametri mreže (težine i pristranosti) ostaju isti. Za ovakav pristup finom podeša-
vanju ne postoji matematicko opravdanje. Efektivno se odricemo definicije mreže kao
generativnog probabilistickog modela i koristimo ju kao unaprijednu višeslojnu mrežu.
Izlazni (najdublji) sloj mreže sadrži neurone od kojih svaki predstavlja jedan razred.
Primjer za koji su izracunate aktivacije izlaznog sloja svrstava se u razred neurona koji
je imao najvecu aktivaciju. Ako se pri tome aktivacije svih neurona izlaznog sloja
podijele sa sumom tih aktivacija (time njihova suma postaje 1), govorimo o softmax
klasifikaciji. Takve aktivacije možemo tumaciti kao pouzdanost klasifikacije.
Mnoga testiranja, ukljucujuci testiranja provedena u originalnom radu o dubokim
probabilistickim mrežama [6], su pokazala da ovaj pristup daje najbolje rezultate na
diskriminativnom zadatku. Backpropagation algoritam vrlo efikasno trenira mrežu.
Prisjetimo se, kljucni problemi tog algoritma su tendencija zaglavljivanja u lokalnom
optimumu i smanjenje efikasnosti treniranja kako dubina mreže raste. Korištenjem
pohlepnog predtreniranja po slojevima zapravo smanjujemo utjecaj tih problema.
60

6. Primjer korištenja
6.1. Definicija problema
U sklopu automatskog ocjenjivanja ispitnih obrazaca na fakultetu potrebno je prepoz-
nati rukom pisano slovo upisano u za to predvideno mjesto. Slovo indicira odabrani
odgovor na pitanje u ispitu. U pravilu nema više od šest ponudenih mogucnosti, stoga
je potrebno prepoznati slova iz skupa {A, B, C, D, E, F} (koriste se samo kapital-
izirana slova). Uz mogucnosti odabira odgovora na obrascu je dopušteno koristiti još
dva znaka s posebnim znacenjem: slovo "X" i povlaku "-". Sustav treba moci prepoz-
nati i kada na odredenoj lokaciji nije upisano ništa, odnosno znak praznine. Radi se
dakle o diskriminacijskom zadatku od devet razreda.
6.2. Skup za treniranje
Skup podataka za treniranje sakupljen je na Fakultetu Elektrotehnike i Racunarstva u
Zagrebu 2014. godine. Za svaki od devet razreda sadrži 9537 primjera (sveukupno
85833 primjera).
Svaki primjer je procesiran tako da je minimalno pravokutno podrucje unutar kojeg
postoje ne-bijeli slikovni elementi izrezano i skalirano u 4:3 omjer. Potom je rezultat
smanjen na rezoluciju (32, 24) i pretovren u sliku sivih tonova. Konacno, primjeri su
binarizirani, tako da sadrže samo crnu i bijelu boju, usporedbom s fiksnim pragom od
50% intenziteta. Tako procesirani nasumicno odabrani primjeri prikazani su na slici
6.1.
6.3. Korišten model
Za zadani diskriminacijski zadatak trenirali smo umjetnu neuronsku mrežu. Predtreni-
ranje je provedeno po definiciji duboke probabilisticke mreže: pohlepnim treniran-
61

Slika 6.1: Nasumicno odabrani primjeri iz skupa za ucenje, nakon procesiranja. Po jedan redak
za svaki od razreda {A, B, C, D, E, F, X, , -}.
jem stoga ogranicenih Boltzmannovih strojeva sloj po sloj. Fino podešavanje param-
etara mreže obavljeno je backpropagation algoritom, mreža je dakle u tom trenutku
pretvorena u deterministicku mrežu s realnim aktivacijama i izlaznim softmax slojem.
6.4. Nacin evaluiranja
U prvoj fazi treniranja mreže potrebno je pronaci arhitekturu i hiperparametre koji
daju najbolje rezultate. Iscrpno pretraživanje mogucnosti je nemoguce jer ih je prak-
ticki beskonacno. Kako bi se maksimizirao broj pokusa koji se mogu izvršiti na dos-
tupnom hardveru u zadanom vremenu, pokusi su u ovoj fazi bili evaluirani koristeci
jednostavnu holdout metodu. Fiksni broj primjera za ucenje, jednoliko rasporedenih
po razredima, izuzima se iz skupa za treniranje. Po završetku treniranja se performanse
mreže evaluiraju koristeci izuzete primjere. Naš skup za evaluaciju (primjeri izuzeti iz
skupa za treniranje) sadržavao je 10% (oko 8583) primjera.
Konacna evaluacija obavljena je koristeci statisticki ispravniju (ali vremenski za-
htjevniju) stratified k-fold cross validation metodu. Skup za treniranje podjeljen je
62

u k = 10 disjunktnih podskupova. Za svaki podskup je trenirana mreža koristeci
sve primjere skupa za ucenje koji nisu u tom podskupu (dakle ostalih 9 podskupova).
Trenirana mreža evaluirana je na svom podskupu. Primjeri razlicitih razreda jednoliko
su rasporedeni po podskupovima. Konacni rezultat evaluacije je aritmeticka sredina
rezultata evaluacije podskupova.
6.5. Obavljeni pokusi, najbolja mreža
U postupku traženja najbolje arhitekture mreže i hiperparametara nije bilo moguce is-
probavati sve kombinacije potencijalno prikladnih vrijednosti jer bi ih bilo previše1.
Stoga smo pokuse podijelili na nekoliko skupova. U svakom skupu pokusa se mjenjao
mali broj hiperparametara (ili arhitektura) dok su ostali bili fiksirani na okvirno dobre
vrijednosti. Cijeli postupak je više intuitivan nego egzaktan i cesto se bazira na vrijed-
nostima videnim u literaturi. Stoga ne tvrdimo da su rezultati i izvedeni zakljucci opce
vrijedeci.
Rijetkost aktivacije
Prvi set pokusa varirao je rijetkost aktivacije neurona u fazi predtreniranja. Svi pokusi
su radeni na arhitekturi mreže 768 × 600 × 600 × 9. Predtreniranje je vršeno perzis-
tentnom kontrastnom divergencijom kroz 30 epoha, sa stopom ucenja ε = 0.05. Fino
podešavanje je provedeno u 30 epoha sa stopom ucenja ε = 0.1.
Trošak rijetkosti je fiksiran na cs = 0.15 kad se rijetkost koristi, izveli smo pokuse
i bez rijetkosti. Navedeni trošak rijetkosti je namjerno previsok (inace se trošak od
cs = 0.1 pokazao prikladnim), kako bi naglasio utjecaj rijetkosti. Sama rijetkost se
koristi u prvom i drugom skrivenom sloju, isprobane su sve kombinacije treniranja bez
rijetkosti ili sa stopama s ∈ {0.05, 0.10}.Evaluacija pokazuje da je rijetkost bitna u prvom sloju. Rijetkost u drugom sloju
osjetno manje utjece na rezultate. Bez korištenja rijetkosti u prvom sloju tocnost klasi-
fikacije je 0.92− 0.93, dok s korištenjem rijetkosti u prvom sloju, bez obzira na stopu,
rezultati postaju 0.97 − 0.98. Najbolji rezultati se postižu za rijetkost prvog sloja
s1 = 0.1 i rijetkost drugog sloja s2 ∈ {0.05, 0.10}.1Vrijeme potrebno da bi se samo jedna duboka mreža istrenirala takvo je da onemogucava iscrpna
istraživanja utjecaja arhitekture i hiperparametara na rezultate. Cak i vrhunska istraživanja cesto se
oslanjaju na intuitivne pretpostavke pri osmišljanju vremenski izvedivog broja pokusa.
63

Arhitektura mreže
Arhitektura koju smo najcešce koristili pri evaluaciji je 768× 600× 600× 9. Velicina
prvog skrivenog sloja bazira se na mreži iz rada [6]. Velicina drugog skrivenog sloja
i odluka da dodatni skriveni slojevi nisu potrebni bazira se na inicijalnom ispitivanju
koje je davalo vrlo dobre rezultate s tako definiranom arhitekturom.
Pokusi su obavljeni s dubljom mrežom arhitekture 768×600×600×600×9, dakle
s mrežom koja ima jedan skriveni sloj više, širok 600 neurona. Nadalje, isprobana
je i mreža sa širim slojevima, arhitekture 768 × 1000 × 1000 × 9. Oba pokusa su
indicirala da je inicijalna arhitektura prikladnija. Moramo napomenuti da ovi pokusi
nisu kvalitetno izvršeni. Naime, broj parametara u pokusnim arhitekturama je osjetno
veci nego broj parametara referentne arhitekture, ali smo koristili jednaku kolicinu
treniranja (50 epoha predtreniranja i 100 epoha finog podešavanja). U tom smislu je
za ocekivati da se veci broj parametara nije jednako brzo adaptirao. Iscrpnije i bolje
osmišljeno testiranje bi bilo potrebno kako bi se mogli povuci kvalitetniji zakljucci.
Pred kraj rada smo eksperimentirali s dubljim arhitekturama koje imaju uže slojeve,
primjerice sa 768 × 200 × 200 × 200 × 200 × 9. Takva arhitektura ima cak tri puta
manje parametara od arhitekture 768× 600× 600× 9. Rezultati su bili obecavajuci te
planiramo nastaviti testiranje u buducnosti.
6.6. Rezultati
Arhitektura odabrana za konacnu evaluaciju je 768× 600× 600× 9. Za predtreniranje
se koristila jednokoracna kontrastna divergencija, 80 epoha po svakom sloju uz stopu
ucenja ε = 0.05. Prvi skriveni sloj ima stopu rijetkosti s1 = 0.085 uz trošak rijetkosti
cs = 0.1. Drugi skriveni sloj predtreniran je bez rijetkosti. Fino podešavanje param-
etara izvršeno je backpropagation algoritmom, pri cemu je izlazni sloj definiran kao
softmax. Fino podešavanje trajalo je 1000 epoha, uz stopu ucenja ε = 0.1.
Trajanje treniranja navedenog klasifikatora je otprilike 6 sati na Intel i5 procesoru.
Pošto se koristila 10-fold-cross-validation evaluacija, sveukupno trajanje evaluacije je
otprilike 60 sati.
Za evaluaciju je korištena F1macro mjera. Konacni rezultati su 0.982± 0.002.
64
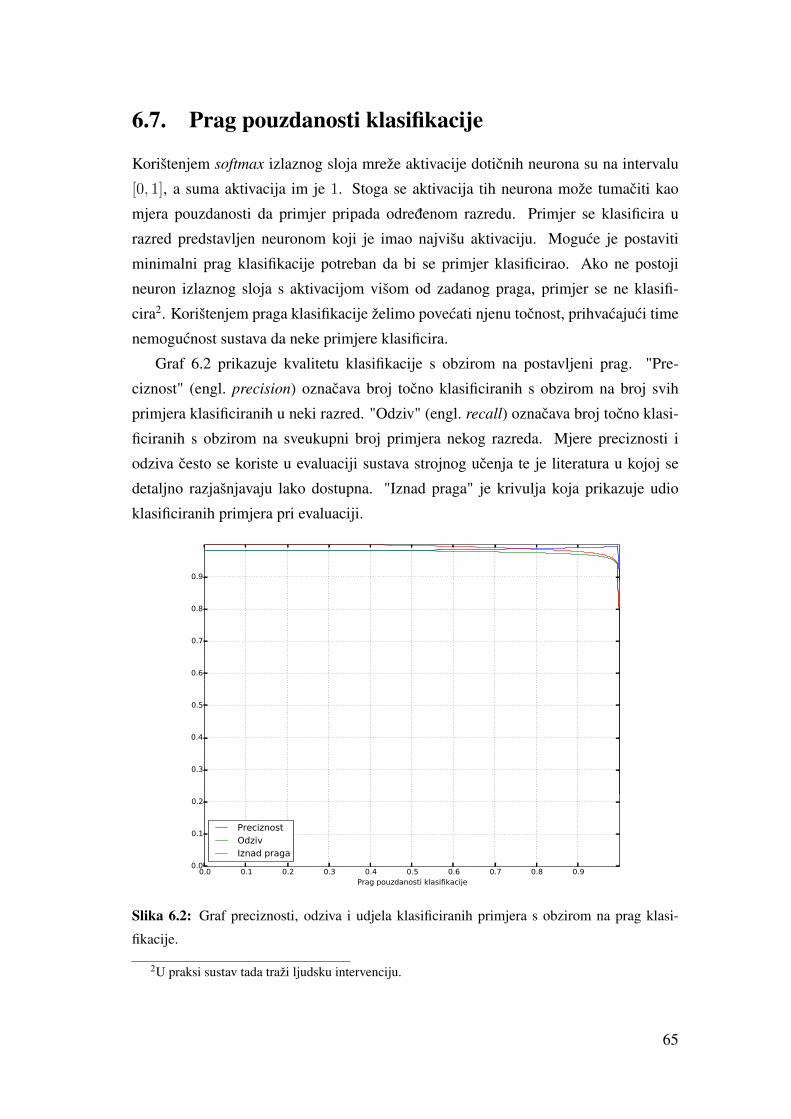
6.7. Prag pouzdanosti klasifikacije
Korištenjem softmax izlaznog sloja mreže aktivacije doticnih neurona su na intervalu
[0, 1], a suma aktivacija im je 1. Stoga se aktivacija tih neurona može tumaciti kao
mjera pouzdanosti da primjer pripada odredenom razredu. Primjer se klasificira u
razred predstavljen neuronom koji je imao najvišu aktivaciju. Moguce je postaviti
minimalni prag klasifikacije potreban da bi se primjer klasificirao. Ako ne postoji
neuron izlaznog sloja s aktivacijom višom od zadanog praga, primjer se ne klasifi-
cira2. Korištenjem praga klasifikacije želimo povecati njenu tocnost, prihvacajuci time
nemogucnost sustava da neke primjere klasificira.
Graf 6.2 prikazuje kvalitetu klasifikacije s obzirom na postavljeni prag. "Pre-
ciznost" (engl. precision) oznacava broj tocno klasificiranih s obzirom na broj svih
primjera klasificiranih u neki razred. "Odziv" (engl. recall) oznacava broj tocno klasi-
ficiranih s obzirom na sveukupni broj primjera nekog razreda. Mjere preciznosti i
odziva cesto se koriste u evaluaciji sustava strojnog ucenja te je literatura u kojoj se
detaljno razjašnjavaju lako dostupna. "Iznad praga" je krivulja koja prikazuje udio
klasificiranih primjera pri evaluaciji.
0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9Prag pouzdanosti klasifikacije
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
PreciznostOdzivIznad praga
Slika 6.2: Graf preciznosti, odziva i udjela klasificiranih primjera s obzirom na prag klasi-
fikacije.
2U praksi sustav tada traži ljudsku intervenciju.
65
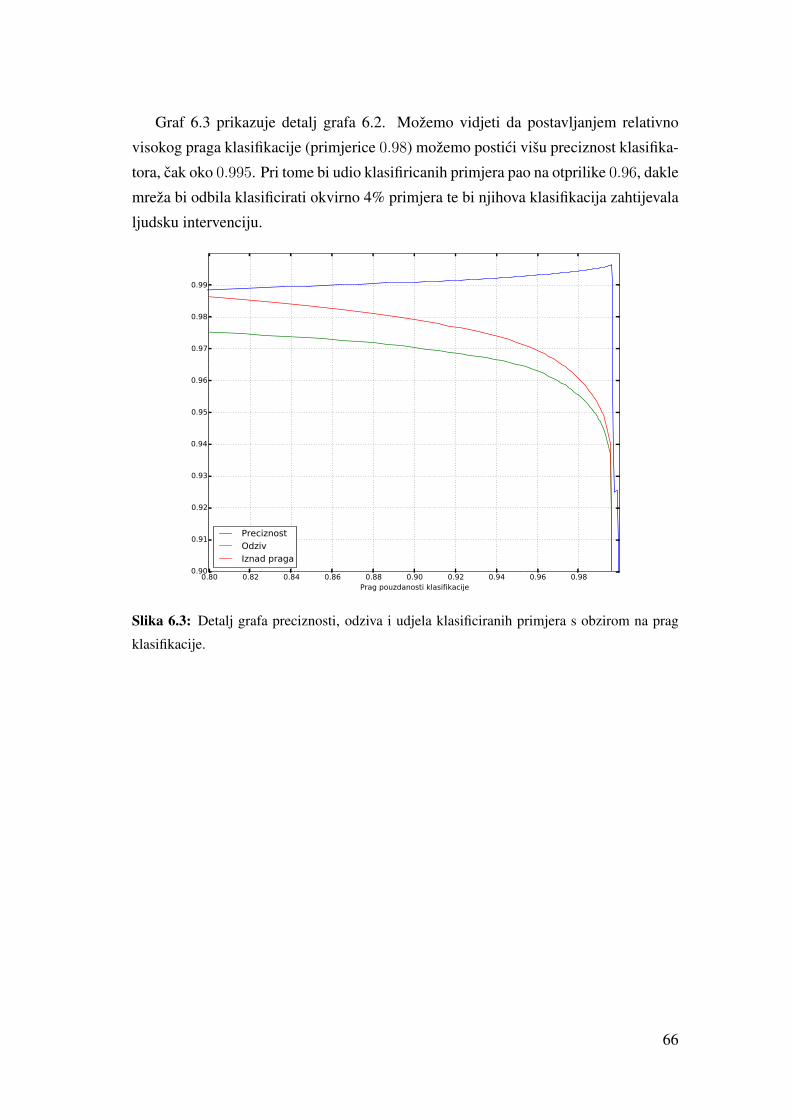
Graf 6.3 prikazuje detalj grafa 6.2. Možemo vidjeti da postavljanjem relativno
visokog praga klasifikacije (primjerice 0.98) možemo postici višu preciznost klasifika-
tora, cak oko 0.995. Pri tome bi udio klasifiricanih primjera pao na otprilike 0.96, dakle
mreža bi odbila klasificirati okvirno 4% primjera te bi njihova klasifikacija zahtijevala
ljudsku intervenciju.
0.80 0.82 0.84 0.86 0.88 0.90 0.92 0.94 0.96 0.98Prag pouzdanosti klasifikacije
0.90
0.91
0.92
0.93
0.94
0.95
0.96
0.97
0.98
0.99
PreciznostOdzivIznad praga
Slika 6.3: Detalj grafa preciznosti, odziva i udjela klasificiranih primjera s obzirom na prag
klasifikacije.
66

7. Zakljucak
Duboke neuronske mreže bazirane na ogranicenom Boltzmannovom stroju na stan-
dardnim testovima daju rezultate koji su medu najboljima ikad postignutim. Kroz ovaj
seminar razmotrili smo konstrukciju i treniranje takvih neuronskih mreža. Na prak-
ticnim primjerima smo utvrdili da predloženi algoritmi funkcioniraju kako je zamišl-
jeno i daju predvidene rezultate.
Istovremeno, ne treba zaboraviti da su neuronske mreže inspirirane prirodnim (ljud-
skim odnosno životinjskim) neuronskim sustavima. Podrucja neurologije i mekog
racunarstva postaju sve bliže, neurološki modeli se sve cešce izravno preslikavaju u
racunalne sustave. U tom smislu možemo ocekivati da ce sa sve vecim razumijevanjem
bioloških sustava sposobnost izrade umjetnih neuronskih mreža isto tako napredovati.
Svakako se radi o podrucju s obecavajucom buducnošcu.
67

8. Literatura
[1] Yoshua Bengio i Olivier Delalleau. Justifying and generalizing contrastive diver-
gence. Technical report, 2007.
[2] G. E. Hinton i T. J. Sejnowski. Analyzing cooperative computation. 1983.
[3] Geoffrey E. Hinton. Products of experts, 1999.
[4] Geoffrey E. Hinton. Training products of experts by minimizing contrastive
divergence. Neural Comput., 14(8):1771–1800, Kolovoz 2002. ISSN 0899-
7667. doi: 10.1162/089976602760128018. URL http://dx.doi.org/10.
1162/089976602760128018.
[5] Geoffrey E. Hinton. A practical guide to training restricted boltzmann ma-
chines. U Grégoire Montavon, Genevieve B. Orr, i Klaus-Robert Müller, ured-
nici, Neural Networks: Tricks of the Trade (2nd ed.), svezak 7700 od Lecture
Notes in Computer Science, stranice 599–619. Springer, 2012. ISBN 978-3-
642-35288-1. URL http://dblp.uni-trier.de/db/series/lncs/
lncs7700.html#Hinton12.
[6] Geoffrey E. Hinton i Simon Osindero. A fast learning algorithm for deep belief
nets. Neural Computation, 18:2006, 2006.
[7] J. J. Hopfield. Neural networks and physical systems with emergent collective
computational abilities. Proceedings of the National Academy of Sciences of the
United States of America, 79(8):2554–2558, apr 1982. ISSN 0027-8424. URL
http://view.ncbi.nlm.nih.gov/pubmed/6953413.
[8] Ruslan Salakhutdinov Iain Murray. Notes on the KL-divergence between a
Markov chain and its equilibrium distribution, 2008. Available from http:
//www.cs.toronto.edu/~murray/pub/08mckl/.
68

[9] Honglak Lee, Chaitanya Ekanadham, i Andrew Y. Ng. Sparse deep belief net
model for visual area v2. U Advances in Neural Information Processing Systems
20. MIT Press, 2008.
[10] R. Neal. Connectionist learning of belief networks. U Artificial Intelligence,
stranica 56:71–113, 1992.
[11] P. Smolensky. Parallel distributed processing: Explorations in the microstruc-
ture of cognition, vol. 1. poglavlje Information Processing in Dynamical Sys-
tems: Foundations of Harmony Theory, stranice 194–281. MIT Press, Cam-
bridge, MA, USA, 1986. ISBN 0-262-68053-X. URL http://dl.acm.org/
citation.cfm?id=104279.104290.
[12] Tijmen Tieleman. Training restricted boltzmann machines using approximations
to the likelihood gradient. U Proceedings of the 25th international conference on
Machine learning, stranice 1064–1071, 2008.
[13] M. Cupic, Dalbelo Bašic B., i Golub M. Neizrazito, evolucijsko i neuroracu-
narstvo. 2013.
69

9. Sažetak
Duboka probabilisticka mreža (engl. deep belief net). Razmatranje Hopfieldovih mreža,
Boltzmannovog stroja, ogranicenog Boltzmannovog stroja te konacno dubokih neu-
ronskih mreža. Primjena mreže na diskriminacijskom (klasifikacijskom) problemu.
Prednost nad konvencionalnim unaprijednim neuronskim mrežama.
70