Embed Size (px)
Citation preview

刘通,亚太及中国市场开发高级总监
Sept 2016
智能网络释放GPU集群性能

© 2016 Mellanox Technologies 2 - Mellanox Confidential -
Mellanox网络继续保持在高性能计算领域的优势
全球超算排名TOP500已经演变成为HPC与云计算 / 互联网系统的混合排名
Mellanox 互连Top500中70.4%的HPC系统
Mellanox 互连Top500近50%千万亿次系统(Petascale)
在高性能计算系统中使用最多的网
络依然是Mellanox InfiniBand

© 2016 Mellanox Technologies 3 - Mellanox Confidential -
智能网络加速实现百亿亿次计算
CPU为核心 Co-Design
数据移动中同步处理 实现更高性能和扩展
必须等待数据 造成性能瓶颈
受限于主机CPU 造成性能局限性
建立协同关系 实现更高性能和扩展性

© 2016 Mellanox Technologies 4 - Mellanox Confidential -
Switch-IB 2 EDR 100G 优势
实现MPI与SHMEM/PGAS性能 10倍 提升
Switch-IB 2 使得交换机成为协处理器
SHArP 使得 Switch-IB 2交换机能够在网络中
即可执行MPI操作

© 2016 Mellanox Technologies 5 - Mellanox Confidential -
支持 PCIe Gen3 与 Gen4
网卡内集成 PCIe 交换机
高级动态路由
硬件执行MPI集群操作
硬件执行MPI Tag Matching
网卡内置内存
100Gb/s 吞吐量
0.6usec 延迟 (端到端)
2亿消息/秒
ConnectX-5 EDR 100G 优势

© 2016 Mellanox Technologies 6 - Mellanox Confidential -
最高性能 100Gb/s 网络解决方案
收发器
光纤与铜缆
(10 / 25 / 40 / 50 / 56 / 100Gb/s) VCSELs, 硅光与铜线
36 EDR (100Gb/s) 端口, <90ns 延迟
吞吐量7.2Tb/秒
70.2 亿次消息/秒 (每端口195M 消息/秒)
100Gb/s 网卡, 0.6us 延迟
2亿消息/秒
(10 / 25 / 40 / 50 / 56 / 100Gb/s)
32 100GbE 端口, 64 25/50GbE 端口
(10 / 25 / 40 / 50 / 100GbE)
吞吐量 6.4Tb/s
© 2016 Mellanox Technologies 7 - Mellanox Confidential -
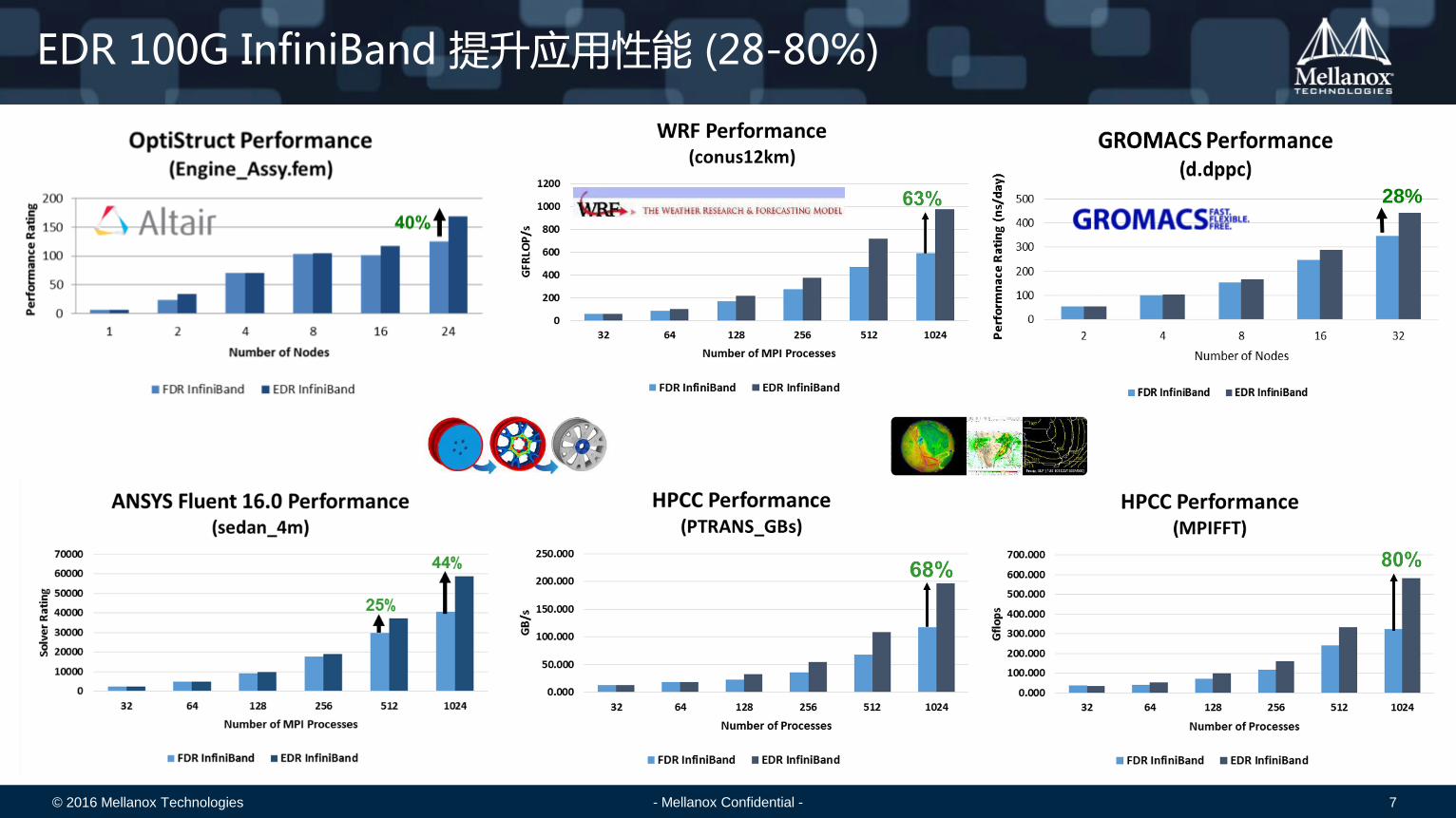
EDR 100G InfiniBand 提升应用性能 (28-80%)
28%

© 2016 Mellanox Technologies 8 - Mellanox Confidential -
实现GPU集群性能最大化
GPUDirect RDMA 技术

© 2016 Mellanox Technologies 9 - Mellanox Confidential -
GPU计算无处不在!
科学计算 自动驾驶 人脸识别
深度学习 媒体、影音 语音识别
能源
设计与制造

© 2016 Mellanox Technologies 10 - Mellanox Confidential -
Mellanox-京东 联合实验室
Mellanox 网络先进特性加速京东深度学习平台

© 2016 Mellanox Technologies 11 - Mellanox Confidential -
GPU集群计算加速技术
GPUDirect RDMA 实现GPU间通过 InfiniBand的直接通信 • 大幅降低GPU间通信延迟
• GPU通信通道中实现完整的CPU卸载

© 2016 Mellanox Technologies 12 - Mellanox Confidential -
GPU-GPU 节点间 MPI 通信延迟
越低越好
基于 GPUDirect RDMA 的MPI性能提升
延迟降低88%
GPU-GPU 节点间 MPI 通信带宽
越高越好
带宽提升10倍
来源: Prof. DK Panda
9.3X
2.18 usec
10x

© 2016 Mellanox Technologies 13 - Mellanox Confidential -
深度学习 – 将数据转化为人工智能
需要智能网络释放数据价值
GPUs
CPUs
Storage
更多数据 更复杂模型 更快计算

© 2016 Mellanox Technologies 14 - Mellanox Confidential -
NVIDIA DGX-1 深度学习一体机
8 x Pascal GPU (P100)
5.3TFlops 16nm FinFET NVLINK
4 张 ConnectX-4 EDR 100G InfiniBand 网卡

© 2016 Mellanox Technologies 15 - Mellanox Confidential -
RDMA 加速深度学习 (Hadoop)
RDMA 加速深度学习 Caffe + Hadoop
18.7倍性能提升, 80% 准确率, 10 小时训练 • 4台服务器,8块GPU,由 Mellanox InfiniBand互连
Spark Executor Data Feeding & Control
Enhanced Caffe w/ Multi-GPU in a node
Model Synchronizer across Nodes
Spark Driver
Spark Executor Data Feeding & Control
Enhanced Caffe w/ Multi-GPU in a node
Model Synchronizer across Nodes
Spark Executor Data Feeding & Control
Enhanced Caffe w/ Multi-GPU in a node
Model Synchronizer across Nodes
Dataset from HDFS
Model On HDFS
支持RDMA的InfiniBand网络
Large Scale Distributed Deep Learning on Hadoop Clusters - Yahoo Big ML Team [link]
为图像识别实现高级预测分析

© 2016 Mellanox Technologies 16 - Mellanox Confidential -
Big Sur – 开放人工智能平台 (Facebook)
OCP架构, GPU 人工智能平台
支持 8 GPU • NVidia
Mellanox Innova (ConnectX-4 + FPGA) 网卡
加速人工智能 • 文字处理
• 语音模型
• 人工智能
• 计算视觉
https://code.facebook.com/posts/1687861518126048/facebook-to-open-source-ai-hardware-design/
Mellanox 智能网络打造智能平台

© 2016 Mellanox Technologies 17 - Mellanox Confidential -
Mellanox 加速深度学习
GPUDirect RDMA / Sync
CPU
GPU Chip
set
GPU Memor
y
System
Memory
1

© 2016 Mellanox Technologies 18 - Mellanox Confidential -
应用性能
延迟
Mellanox InfiniBand 保持优势
高34-62% 低20%
消息传输率 性价比 (成本$/性能)
高68% 低20-35%
100 Gb/s
Link Speed
200 Gb/s
Link Speed
2014
保持今日竞争优势
面向未来
2017
智能系统需要智能网络 RDMA, 加速引擎, 可编程性
更高性能
极高可扩展性
更高弹性
成熟方案!






























