Embed Size (px)
Citation preview

COLEGIO DE POSTGRADUADOS
INSTITUCIÓN DE ENSEÑANZA E INVESTIGACIÓN EN CIENCIAS AGRÍCOLAS
CAMPUS MONTECILLO
SOCIOECONOMÍA, ESTADÍSTICA E INFORMÁTICA ESTADÍSTICA
EFICIENCIA DE LOS MÉTODOS DE ASIGNACIÓN DE NEYMAN Y PROPORCIONAL EN EL MUESTREO
ALEATORIO ESTRATIFICADO
ROSENDO ARTURO VELÁSQUEZ CABRERA
T E S I S PRESENTADA COMO REQUISITO PARCIAL PARA
OBTENER EL GRADO DE:
MAESTRO EN CIENCIAS
MONTECILLO, TEXCOCO, EDO. DE MÉXICO 2005

La presente tesis titulada: Eficiencia de los métodos de asignación de Neyman y Proporcional en el Muestreo Aleatorio Estratificado, realizada por el alumno: Rosendo Arturo Velásquez Cabrera, bajo la dirección del consejo particular indicado, ha sido aprobada por el mismo y aceptada como requisito parcial para obtener el grado de:
MAESTRO EN CIENCIAS SOCIOECONOMÍA, ESTADISTICA E INFORMÁTICA
ESTADÍSTICA
CONSEJO PARTICULAR CONSEJERO
DR. GILBERTO RENDÓN SÁNCHEZ
_________________
ASESOR
DR. VICENTE GONZÁLEZ ROMERO
_________________
ASESOR
DR. LUIS LANDOIS PALENCIA
_________________
MONTECILLO, TEXCOCO, EDO. DE MÉXICO 2005

AGRADECIMIENTOS
A la Secretaría de Educación Pública, a la Subsecretaría de Educación e Investigación Tecnológicas y al Consejo del Sistema de Educación Tecnológica por permitir dedicarme de tiempo completo al logro de este objetivo. Al Consejo Nacional de Ciencia y Tecnología por el apoyo brindado. A la Dirección de General de Educación Tecnológica Agropecuaria por la oportunidad que proporciona a sus trabajadores para poder superarse y ser mejores en el diario quehacer de la educación. Al Instituto Tecnológico Agropecuario No. 23 de Oaxaca por la formación que me ha dado y por arroparme en su espacio laboral. Al Dr. Salvador Lozano Trejo por brindarme las facilidades necesarias para poder emprender esta tarea. Al Colegio de Postgraduados por permitirme entrar a un recinto tan importante en la investigación agrícola de Latinoamérica. Al Instituto de Socioeconomía Estadística e Informática, en particular a los valiosos profesores del Programa en Estadística, sus enseñanzas han sido importantes para mí. Al Dr. Gilberto Rendón Sánchez por sus atinadas sugerencias para la realización de este trabajo, y sobre todo por representar un valuarte en la investigación sobre muestreo estadístico. Al Dr. Luis Landois Palencia por disponibilidad y valiosos comentarios para el enriquecimiento de esta tesis. Al Dr. Vicente González Romero por sus valiosas aportaciones al presente trabajo y por su apoyo para la realización del mismo. A las secretarias y a todos los trabajadores administrativos del ISEI, desde el primer día en el CP conté con su apoyo.
A Dios

DEDICATORIA A Sarahí, gracias por tu amor, apoyo y paciencia, sin ti negrita no hubiera iniciado esta aventura A mi hijo, Arturo, discúlpame si por cumplir con este objetivo te he hecho falta. Te amo A mis padres Rosendo Arturo y Alicia, por todo el amor y apoyo que siempre me han brindado. A mi hermano Víctor Hugo
A mis tíos Martha Elvia, Luis, Conchita, Toño, Zenén, Magdiel, Teresa, Roberto, Delfino, Lucila, Eira, Luz y Martha A mis primos Luis Rodrigo, Ariana, Martín Rolando, Héctor Julio, Indira, David Arturo, Magdiel, Olga, Máximo, Juan, Aída, Jorge, Yolanda, Amelia, Eduardo, Julissa, Abimelec, Bricia, Lorena, Adriana, Memo, Fernando, Tino, Norma, Sara y Esmeralda. A mis sobrinos Mara Alicia, Máximo Valente, Eugenia Guadalupe, Diana, Samantha, Viridiana, Jessica, Juanito, Miriam, Julio, Eric, Alan, Geovany, Gema, Cintia, Dixie, Caty y Héctor. A Celina, Mara Margarita, Sonia, Alonso, Arturo y Delia A mis amigos Jacobo, Gisela, Dalma, Ethel, Romeo, Adrián, Neto, Isidro, Max, Víctor, Alan, Pepe, Toño, Tino, Ayuso, Elmer, Paco, Joaquín, Omar. A mis compañeros del programa de estadística: Nayeli, Ana, Pedro, Jaime, Jesús Manuel, Jesús Flores, José Guadalupe, Eddy, Felipe y Miguel Ángel.
A Máximo Valente†

CONTENIDO
Pág. CONTENIDO .....................................................................................................................i ÍNDICE DE CUADROS Y FIGURAS............................................................................ iii RESUMEN........................................................................................................................vi ABSTRACT.....................................................................................................................vii I. INTRODUCCIÓN......................................................................................................1
1.1. Objetivo general ..................................................................................................3
1.1.1. Objetivos particulares......................................................................................3 1.2. Hipótesis..............................................................................................................3
II. REVISIÓN DE LITERATURA.................................................................................5 2.1. Muestreo Aleatorio Estratificado. .......................................................................5
2.1.1. Estimación de la media poblacional.................................................................7 2.1.2. Tamaño de muestra a seleccionar en los diferentes estratos. ...........................8 2.1.3. Funciones de varianza. ...................................................................................12
2.2. Dificultades prácticas para aplicar la asignación de Neyman. ..............................13
2.2.1. Interrogantes planteadas en la principal dificultad.........................................13 2.2.2. Solución a las interrogantes planteadas..........................................................14
III. METODOLOGÍA .....................................................................................................21 3.1. Población...............................................................................................................21
3.2. Muestreo................................................................................................................22
3.3. Análisis..................................................................................................................24
IV. RESULTADOS Y DISCUSIÓN ...............................................................................27 4.1 Programas generados .............................................................................................27
4.2. Distribución Normal..............................................................................................28
4.3. Distribución Ji-cuadrada. ......................................................................................34
4.4. Distribución Gama. ...............................................................................................40

ii
4.5. Distribución Poisson. ............................................................................................46
4.6. Consideraciones Generales. ..................................................................................52
V. CONCLUSIONES ......................................................................................................54 BIBLIOGRAFÍA .............................................................................................................56 ANEXO 1.........................................................................................................................58 ANEXO 2.........................................................................................................................66 ANEXO 3.........................................................................................................................69

ÍNDICE DE CUADROS Y FIGURAS
CUADROS Pág.
Cuadro 1. Distribuciones y sus parámetros a partir de las cuales se generaron las
doce poblaciones utilizadas.................................................................................... 22 Cuadro 2. Distribución de la muestra preliminar en los diferentes estratos, según la
población con media de 100 y desviación estándar de 25. .................................... 23 Cuadro 3. Resultados pertinentes al objetivo (a), desviaciones estándares, tamaños
de muestra total fijos, varianzas de estimadores e indicadores de la eficiencia del diseño, según las poblaciones normales bajo estudio. ..................................... 28
Cuadro 4. Resultados con relación al objetivo (b), tamaños de muestra total y preliminar, varianzas del estimador, indicadores de la eficiencia del diseño, según las poblaciones normales. ............................................................................ 30
Cuadro 5. Resultados con relación al objetivo (c), tamaños de muestra total y preliminar, varianzas del estimador, indicadores de la eficiencia del diseño, según las poblaciones normales bajo estudio......................................................... 31
Cuadro 6. Resultados pertinentes al objetivo (a), desviaciones estándares, tamaños de muestra total fijos, varianzas de estimadores e indicadores de la eficiencia del diseño, según las poblaciones Ji-cuadrada bajo estudio................................... 35
Cuadro 7. Resultados con relación al objetivo (b), tamaños de muestra total y preliminar, varianzas del estimador, indicadores de la eficiencia del diseño, según las poblaciones Ji-cuadrada bajo estudio. .................................................... 36
Cuadro 8. Resultados con relación al objetivo (c), tamaños de muestra total y preliminar, varianzas del estimador, indicadores de la eficiencia del diseño, según las poblaciones Ji-cuadrada bajo estudio. .................................................... 38
Cuadro 9. Resultados pertinentes al objetivo (a), desviaciones estándares, tamaños de muestra total fijos, varianzas de estimadores e indicadores de la eficiencia del diseño, según las poblaciones Gama bajo estudio............................................ 41
Cuadro 10. Resultados con relación al objetivo (b), tamaños de muestra total y preliminar, varianzas del estimador, indicadores de la eficiencia del diseño, según las poblaciones Gama bajo estudio.............................................................. 42
Cuadro 11. Resultados con relación al objetivo (c), tamaños de muestra total y preliminar, varianzas del estimador, indicadores de la eficiencia del diseño, según las poblaciones Gama bajo estudio.............................................................. 43

iv
Cuadro 12. Resultados pertinentes al objetivo (a), desviaciones estándares, tamaños de muestra total fijos, varianzas de estimadores e indicadores de la eficiencia del diseño, según las poblaciones Poisson bajo estudio. ....................... 47
Cuadro 13. Resultados con relación al objetivo (b), tamaños de muestra total y preliminar, varianzas del estimador, indicadores de la eficiencia del diseño, según las poblaciones Poisson bajo estudio. .......................................................... 48
Cuadro 14. Resultados con relación al objetivo (c), tamaños de muestra total y preliminar, varianzas del estimador, indicadores de la eficiencia del diseño, según las poblaciones Poisson bajo estudio. .......................................................... 49
FIGURAS Pág.
Figura 1. Índices de la eficiencia del diseño de muestreo considerando el promedio
de las varianzas estimadas de Neyman, la varianza paramétrica proporcional y la varianza paramétrica de Neyman, obtenidos a partir de una población normal con media igual a 100 y desviación estándar igual a 25............................ 32
Figura 2. Índices de la eficiencia del diseño de muestreo considerando el promedio de las varianzas estimadas de Neyman, la varianza paramétrica proporcional y la varianza paramétrica de Neyman, obtenidos a partir de una población normal con media igual a 100 y desviación estándar igual a 50............................ 33
Figura 3. Índices de la eficiencia del diseño de muestreo considerando el promedio de las varianzas estimadas de Neyman, la varianza paramétrica proporcional y la varianza paramétrica de Neyman, obtenidos a partir de una población normal con media igual a 100 y desviación estándar igual a 75............................ 33
Figura 4. Índices de la eficiencia del diseño de muestreo considerando el promedio de las varianzas estimadas de Neyman, la varianza paramétrica proporcional y la varianza paramétrica de Neyman, obtenidos a partir de una población Ji-cuadrada con 100 grados de libertad. ..................................................................... 39
Figura 5. Índices de la eficiencia del diseño de muestreo considerando el promedio de las varianzas estimadas de Neyman, la varianza paramétrica proporcional y la varianza paramétrica de Neyman, obtenidos a partir de una población Ji-cuadrada con 150 grados de libertad. ..................................................................... 39
Figura 6. Índices de la eficiencia del diseño de muestreo considerando el promedio de las varianzas estimadas de Neyman, la varianza paramétrica proporcional y la varianza paramétrica de Neyman, obtenidos a partir de una población Ji-cuadrada con 200 grados de libertad. ..................................................................... 40
Figura 7. Índices de la eficiencia del diseño de muestreo considerando el promedio de las varianzas estimadas de Neyman, la varianza paramétrica proporcional y la varianza paramétrica de Neyman, obtenidos a partir de una población Gama con parámetro α igual a 5. ........................................................................... 44
Figura 8. Índices de la eficiencia del diseño de muestreo considerando el promedio de las varianzas estimadas de Neyman, la varianza paramétrica proporcional y la varianza paramétrica de Neyman, obtenidos a partir de una población Gama con parámetro α igual a 10.......................................................................... 45
Figura 9. Índices de la eficiencia del diseño de muestreo considerando el promedio de las varianzas estimadas de Neyman, la varianza paramétrica proporcional y la varianza paramétrica de Neyman, obtenidos a partir de una población Gama con parámetro α igual a 20.......................................................................... 45

v
Figura 10. Índices de la eficiencia del diseño de muestreo considerando el promedio de las varianzas estimadas de Neyman, la varianza paramétrica proporcional y la varianza paramétrica de Neyman, obtenidos a partir de una población Poisson con parámetro λ igual a 200..................................................... 50
Figura 11. Índices de la eficiencia del diseño de muestreo considerando el promedio de las varianzas estimadas de Neyman, la varianza paramétrica proporcional y la varianza paramétrica de Neyman, obtenidos a partir de una población Poisson con parámetro λ igual a 200..................................................... 51
Figura 12. Índices de la eficiencia del diseño de muestreo considerando el promedio de las varianzas estimadas de Neyman, la varianza proporcional y la varianza paramétrica de Neyman, obtenidos a partir de una población Poisson con parámetro λ igual a 200. .................................................................... 51

RESUMEN
En el presente estudio se comparó la eficiencia de los estimadores de la media obtenidos a través de los métodos de asignación de Neyman y Proporcional del Muestreo Aleatorio Estratificado; así como la eficiencia de los mismos estimadores bajo asignación Proporcional y bajo la asignación de Neyman al estimar la varianza de los estratos (nueva varianza de Neyman). Para ello se generaron, a través de simulación, cuatro poblaciones con distribución Normal, cuatro con distribución Ji-cuadrada, cuatro con distribución Gama y cuatro con distribución Poisson. Por ser la media un estimador insesgado de la varianza, se utilizaron como indicadores de la eficiencia la diferencia entre las varianzas consideradas y el cociente de estas varianzas, también conocido como indicador de la eficiencia del diseño. Los resultados proporcionan, entre otras, las siguientes conclusiones, en poblaciones con diferentes distribuciones de probabilidad, la asignación de Neyman es más eficiente que la asignación Proporcional, independientemente del tamaño de muestra total fijo; la varianza censal del estimador de la media bajo asignación de Neyman, en general, fue menor que el promedio de la “nueva varianza de Neyman”. En general, para las poblaciones Normal, Ji-cuadrada, Gama y Poisson, puede afirmarse que la asignación de Neyman bajo estimación de las desviaciones estándares de los estratos proporciona, en promedio, estimadores de la media más precisos que los obtenidos a través de la asignación Proporcional, para tamaños de muestra preliminar moderadamente pequeños. En poblaciones normales heterogéneas es necesario un tamaño de muestra preliminar más grande o un mayor número de estratos para que, en promedio, los estimadores de la asignación de Neyman sean más precisos que los de la asignación proporcional. Palabras claves: Índice de eficiencia, precisión, tamaño de muestra.

ABSTRACT

I. INTRODUCCIÓN
Existen diferentes métodos de muestreo probabilístico, cuya selección dependerá
principalmente de los objetivos de la investigación, de las características de interés y de
la estructura de la población bajo estudio.
Por otra parte, para incrementar la precisión de los estimadores se tienen dos
alternativas, incrementar el tamaño de muestra o disminuir la variabilidad de los
estimadores. En el primer caso, al incrementarse el tamaño de muestra, se eleva el costo,
lo cual contradice el objetivo de la teoría del muestreo, lograr que el muestreo sea
eficiente. Por lo tanto, lo más razonable es disminuir la variabilidad de los estimadores.
Con la aplicación del muestreo estratificado, en muchas ocasiones, se puede incrementar
la precisión de los estimadores, sin aumentar el tamaño de muestra; sino más bien
disminuyendo la variabilidad del estimador.
En particular el denominado Muestreo Aleatorio Estratificado (MAE) consiste en dividir
a la población en subpoblaciones denominadas estratos, y posteriormente, seleccionar
una muestra aleatoria simple de cada estrato en forma independiente. Si los estratos se
construyen de tal manera que sean homogéneos dentro y heterogéneos entre estratos,
entonces, el MAE resulta más preciso que el Muestreo Aleatorio Simple (MAS), sin
necesidad de aumentar el tamaño de muestra. Esto se debe a que, en tal situación, la
varianza del estimador bajo MAE disminuye con relación a la varianza del estimador
bajo MAS.

2
Para determinar en el MAE el tamaño de muestra en cada estrato, existen dos
procedimientos ampliamente utilizados en la práctica, los cuales se basan en la
consideración de contar con un tamaño de muestra total, dado de antemano. Estos
métodos se denominan asignación de Neyman y asignación Proporcional. En la
asignación de Neyman la determinación de los tamaños de muestra en cada estrato
depende, entre otros factores, de las desviaciones estándares poblacionales de los
estratos; mientras que la asignación proporcional no depende de tales desviaciones.
Teóricamente, se puede demostrar que la asignación de Neyman es más eficiente que la
asignación proporcional.
La asignación de Neyman presenta algunas dificultades prácticas para su uso, las cuales
han sido mencionadas por Sukhatme (1962). Una de las dificultades, a las que se refiere
el autor antes mencionado, es el desconocimiento de las desviaciones estándares
paramétricas de los estratos.
Esta limitación se puede evitar al estimar las desviaciones estándares mediante el uso de
una muestra preliminar de tamaño n′ , la cual se distribuye entre los estratos en forma
proporcional para realizar las estimaciones mencionadas. Sin embargo, las estimaciones
de las desviaciones estándares están sujetas a error, además de que son sesgadas, con lo
cual, puede suceder que el método de asignación de Neyman sea menos eficiente que el
de asignación proporcional.
Este problema ha sido abordado, entre otros, por Evans (1951), Sukhatme (1962) y
Rendón (1976) quienes han propuesto principalmente soluciones teóricas, además de
considerar únicamente poblaciones con distribución normal. Por otro lado, en la
literatura revisada no se reporta el uso de herramientas computacionales como la
simulación y su aplicación en poblaciones con distribuciones probabilísticas diferentes a
la normal.
Con base en lo expuesto, para el presente trabajo se plantean los siguientes objetivos:

3
1.1. Objetivo general
Comparar la eficiencia de los métodos de asignación de Neyman y Proporcional del
muestreo aleatorio estratificado, mediante el uso de simulación y bajo poblaciones con
diferentes distribuciones de probabilidad.
1.1.1. Objetivos particulares.
a) Verificar de manera censal que la asignación de Neyman es más eficiente que la
Proporcional, lo cual se ilustra en poblaciones con diferentes distribuciones de
probabilidad.
b) Mostrar el comportamiento de la varianza del estimador bajo la asignación de
Neyman, cuando para distribuir la muestra total se estiman las desviaciones
estándares mediante una muestra preliminar, considerando diferentes
distribuciones probabilísticas.
c) Comparar la eficiencia de los métodos de asignación de Neyman y Proporcional;
cuando, para el método de Neyman, se hace la distribución de la muestra total
con base en las desviaciones estándares estimadas a partir de una muestra
preliminar; lo que se ilustra en poblaciones con diferentes distribuciones de
probabilidad.
1.2. Hipótesis
Se establecen las siguientes hipótesis con relación a los objetivos particulares:
a) La asignación de Neyman es más eficiente que la proporcional al considerar las
varianzas paramétricas de las medias poblacionales, independientemente del tipo
de distribución probabilística de la población.

4
b) El incremento en la varianza del estimador, bajo la asignación de Neyman, tiende a
disminuir cuando se incrementa el tamaño de muestra preliminar para estimar las
desviaciones estándares de los estratos, independientemente de la distribución de
probabilidades de la población.
c) La asignación de Neyman, al usar una muestra preliminar para estimar las
desviaciones estándares de los estratos, en la distribución de la muestra total,
resulta más eficiente que la asignación proporcional, independientemente de la
distribución probabilística de la población.

II. REVISIÓN DE LITERATURA
Al inicio del presente capítulo, se desarrollan las bases de la teoría del Muestreo
Aleatorio Estratificado para establecer los conceptos y notación a utilizar.
2.1. Muestreo Aleatorio Estratificado.
Rendón (1976) señala que la selección de un diseño de muestreo está en función de los
objetivos de la investigación, de las características de interés y de la estructura de la
población en estudio. Señala además que cuando se tiene una población heterogénea es
posible dividirla en subpoblaciones mutuamente excluyentes denominadas estratos.
Estos estratos deben ser homogéneos dentro de ellos y heterogéneos entre sí. Esta
técnica se considera una herramienta para reducir la variación.
Sukhatme (1962) indica que la precisión de la estimación de la media poblacional
depende de dos factores: a) el tamaño de la muestra, y b) la variabilidad o
heterogeneidad de la población. Por ello, aparte del tamaño de muestra, la única manera
de aumentar la precisión de una estimación, es diseñar procedimientos de muestreo que
reduzcan la heterogeneidad. Uno de estos procedimientos es el muestreo aleatorio
estratificado.
El mismo autor señala que el muestreo aleatorio estratificado consiste en dividir la
población en k clases y obtener muestras aleatorias independientes de tamaños

6
conocidos de cada uno de los estratos. El proceso garantiza cualquier representación
deseada en la muestra de todos los estratos en la población, ya que en muestreo aleatorio
simple, no siempre puede asegurarse una representación adecuada de todos los estratos,
y una muestra puede distribuirse de manera tal que alguno de los estratos puede estar
representado excesivamente, en tanto que otros pueden, incluso, no estar presentes. El
procedimiento de muestreo estratificado tiene por objeto dar una mejor representación
de la población, que la que proporciona el muestreo aleatorio simple.
Cochran (1948) describe que este tipo de muestreo (MAE) sigue el procedimiento
general del muestreo aleatorio simple, tomando un paso preliminar. La población de
tamaño N es primeramente dividida en subpoblaciones de tamaños kNNN ,...,, 21 , estas
divisiones son llamadas estratos. La estratificación se realiza porque si una población
heterogénea es dividida en estratos homogéneos dentro y heterogéneos entre, la
precisión del muestreo puede ser incrementada, en relación con el MAS.
Mendenhall et al. (1987) mencionan que los motivos para utilizar el muestreo aleatorio
estratificado en lugar del muestreo aleatorio simple son los siguientes:
• La estratificación puede producir un límite más pequeño para el error de
estimación que el que se generaría en una muestra aleatoria simple del mismo
tamaño, este resultado es particularmente cierto si las mediciones dentro de los
estratos son homogéneas.
• El costo por unidad de muestreo puede ser reducido mediante la estratificación
de los elementos de la población en grupos convenientes.
• Se pueden obtener estimaciones de parámetros poblacionales para subgrupos de
la población. Los subgrupos deben ser estratos identificables.

7
2.1.1. Estimación de la media poblacional.
Según Sukhatme P. y Sukhatme B. (1970), Ni denota el tamaño del estrato, es decir, el
número de unidades en el i-ésimo estrato, ni el tamaño de la muestra aleatoria simple a
seleccionar en el estrato i y k el número de estratos con:
1
NNk
ii =∑
=
y nnk
ii =∑
=1
donde N y n denotan el número total de unidades en la población y en la muestra
respectivamente. Por otra parte, si Y representa una característica de interés y ijy su
valor en la unidad j del estrato i, entonces la media poblacional Ny puede ser expresada
como:
ii N
k
iiN
k
iiN ypyN
Ny ∑∑
==
==11
1 ; 2.1
donde NN
p ii = es el “peso” o “ponderación” del estrato i, y
iNy es la media
poblacional para el i -ésimo estrato. Puesto que la muestra en cada estrato es una muestra
aleatoria simple, iny resulta ser un estimador insesgado de
iNy , por lo que es natural
considerar a:
in
k
iiw ypy ∑
=
=1
; 2.2
como un estimador de la media poblacional, el cual es una media ponderada de las
medias de los estratos por los “pesos” de los estratos. Es fácil observar que el estimador
(2.2) resulta ser un estimador insesgado de la media poblacional expresada en (2.1),
dado que:
NNi
k
ii
k
iniini
k
iiw yypyEpypEyE ===
= ∑∑∑=== 111
)()( 2.3

8
Ahora, si se considera que 2iS es el cuadrado medio (varianza) poblacional para el i -
ésimo estrato y que está dado por:
( )2
1
2
11 ∑
=
−−
=iN
jNiij
ii yy
NS i=1, 2, …,k 2.4
y que del MAS,
( ) 211i
iin S
NnyV
i
−= i=1, 2, …,k 2.5
entonces la varianza del estimador de la media en el MAE es dada por la expresión (2.6)
22
1 1
2 11)()( ii
k
i
k
i iiniiw Sp
NnyVpyV ∑ ∑
= =
−== 2.6
De acuerdo con el MAS, el cuadrado medio muestral del estrato i, denotado y expresado
por:
( )2
1
2
11 ∑
=
−−
=i
i
n
jnij
ii yy
ns i=1, 2, …,k 2.7
es un estimador insesgado de 2iS . De este modo, se sigue que un estimador insesgado
para la varianza dada en (2.6) es:
22
1 1
11)(ˆii
k
i iw sp
NnyV ∑
=
−= 2.8
2.1.2. Tamaño de muestra a seleccionar en los diferentes estratos.
Rendón (1976) establece que en el muestreo estratificado pueden considerarse dos
etapas para el diseño de la muestra:
a) Definición de la muestra total para la población.

9
b) Definición de la muestra para cada estrato.
Esta última se conoce como asignación, descomposición o distribución de la muestra
total en los estratos.
Por otra parte, el tamaño de muestra a seleccionar en cada estrato estará en función,
principalmente, de los siguientes factores: el tamaño, la variabilidad y el costo por
estrato. Rendón (1976) menciona como importantes los siguientes tipos de asignación,
de acuerdo a los factores considerados.
Asignación Óptima. El tamaño de muestra de cada estrato se determina considerando el
tamaño, la variabilidad y el costo por estrato.
Asignación de Neyman. No se toma en cuenta o considera un costo constante para cada
estrato, por lo cual, el tamaño de muestra en cada estrato está en función del tamaño del
estrato y de su variabilidad. Debe mencionarse que la asignación de Neyman es también
una asignación óptima
Asignación Proporcional. En este caso se considera el costo y la variabilidad constantes
en cada estrato, entonces, las unidades a seleccionar en cada estrato serán proporcionales
al tamaño del mismo.
La forma funcional de la asignación Óptima y las correspondientes a las de Neyman y
Proporcional, éstas como casos particulares de la Óptima, se derivan de acuerdo con
Sukhatme (1962) de la forma siguiente:
De la ecuación (2.6) se observa que la varianza del estimador de la media poblacional
está en función del tamaño de muestra de los estratos ( in , i=1,2,…,k). Aun cuando estos
tamaños de muestra pueden fijarse arbitrariamente, es recomendable determinarlos
considerando la precisión de la estimación y el costo total del muestreo, cuando menos.
De este modo, su determinación se puede hacer según el criterio siguiente:

10
a) Seleccionar los in , i=1,2,…,k de tal manera que la varianza del estimador de la media
sea mínima bajo la restricción de un costo total del muestreo fijo.
o bien,
b) Seleccionar los in , i=1,2,…,k de tal manera que el costo total del muestreo sea
mínimo bajo la restricción de una varianza del estimador de la media fija.
Para aplicar este criterio se requiere disponer de una función del costo total del
muestreo, por ejemplo:
∑=
=k
iii ncC
1
2.9
donde ci representa el costo promedio por unidad de muestreo en el i-ésimo estrato.
Así, para determinar el tamaño de muestra para cada estrato siguiendo el criterio (a) y
según las expresiones (2.6) y (2.9) se establece la ecuación Langrangiana:
( )
−+= ∑
=
k
iiiwi CncyVn
10)( λϕ ∀ i=1,2,…,k 2.10
donde C0 representa el costo total del muestreo fijo.
Luego, al derivar (2.10) con respecto a ni para todo i=1,2,…,k e igualar a cero, se
obtiene la solución:
0
1
CcSp
cpiS
ni
k
iii
i
i
i
∑=
= 2.11
ecuación conocida como asignación Óptima.

11
Ahora, si se considera que ci = c ∀ i= 1, 2, …, k; es decir, que el costo promedio por
unidad es constante en los estratos, entonces (2.9) y (2.11) se transforman
respectivamente en:
cnC =0 , c
Cn 0= 2.12
nSp
Spn k
iii
iii
∑=
=
1
, i=1,2,…,k 2.13
Nótese que según (2.12) el tamaño de muestra total resulta ser una cantidad fija o dada
de antemano, con lo cual los tamaños de muestra según (2.13) se pueden interpretar
como aquellas ni que minimizan la varianza del estimador de la media, bajo la
consideración de un tamaño de muestra fijo.
Este último resultado (2.13) fue encontrado primeramente por Tschuprow (1923; citado
por Sukhatme, 1962) pero permaneció desconocido hasta que, en forma independiente,
fue redescubierto por Neyman (1934; citado por Sukhatme, 1962). Por esta razón la
ecuación (2.13) es conocida como asignación de Neyman.
Una vez más, si en la asignación de Neyman se supone que Si = S para toda i=1,2,…,k;
entonces la ecuación (2.13) queda expresada como:
ii npn = , i=1,2,…,k 2.14
ecuación denominada asignación Proporcional.
Rendón (1998) indica que en la práctica tienen mayor aplicación las asignaciones de
Neyman y Proporcional, debido principalmente a que la Óptima presenta la dificultad de
disponer de una función única para el costo total del muestreo.

12
2.1.3. Funciones de varianza.
Como ya se mencionó, la varianza del estimador de la media poblacional en el MAE, la
cual está dada por la ecuación (2.6) y que se reproduce a continuación, es una función de
los ni, i=1,2,…,k.
22
1
11)( ii
k
i iiw Sp
NnyV ∑
=
−= 2.15
Por lo tanto, la forma que tome la ecuación (2.15) dependerá de la asignación particular
que se use. Así, cuando se aplica la asignación Óptima de la ecuación (2.11) que
considera la función del costo dada en la expresión (2.9) se obtendrá “la varianza del
estimador de la media bajo la asignación Óptima” en MAE, cuya forma es:
∑∑==
−
=
k
iii
k
i i
iiOw Sp
NcSp
CyV
1
2
2
10
11)( 2.16
Si la asignación que se usa es la de Neyman de ecuación (2.13) entonces se tendrá “la
varianza del estimador de la media bajo asignación de Neyman”, esto es:
∑∑==
−
=
k
iii
k
iiiNeyw Sp
NSp
nyV
1
22
1
11)( 2.17
Asimismo, sí es la Proporcional de ecuación (2.14) “la varianza del estimador de la
media bajo asignación Proporcional” será:
∑=
−=
k
iiiPw Sp
NnyV
1
211)( 2.18
Para el caso de estimadores insesgados la varianza del estimador es una de las medidas
de la precisión de la estimación. En particular, la diferencia entre las varianzas (2.18) y
(2.17) muestran lo siguiente:

13
( ) ( ) ( ) 011
2 ≥−=− ∑=
k
iiwiNeywPw pSS
nyVyV 2.19
donde ∑=
=k
iiiw SpS
1 es la media ponderada de las desviaciones estándares de los
estratos.
De (2.19) es claro que:
( ) ( )PwNeyw yVyV ≤ o ( )( ) 1≤
Pw
Neyw
yVyV
2.20
Por lo tanto de (2.19) se puede concluir que: “para un tamaño de muestra total fijo o
dado (n) el MAE bajo la asignación de Neyman será más preciso que bajo asignación
proporcional, en la medida que exista mayor variabilidad entre los estratos”.
2.2. Dificultades prácticas para aplicar la asignación de Neyman.
Sukhatme P. y Sukhatme B. (1970) mencionan que la asignación de Neyman presenta
algunas dificultades prácticas para su uso, la más importante es el desconocimiento de la
desviación estándar de cada estrato (Si , i=1,2,…,k). No obstante, tal limitación puede
evitarse al estimar dichas desviaciones a partir de una muestra preliminar de tamaño n’.
Estas estimaciones, sin embargo estarán sujetas a error y, por lo tanto, puede ocurrir que
en estas condiciones el uso de la asignación de Neyman resulte menos eficiente que la
asignación proporcional (2.14).
2.2.1. Interrogantes planteadas en la principal dificultad.
La estimación de la desviación estándar de cada estrato (Si , i=1,2,…,k) para así aplicar
la asignación de Neyman conduce a plantear algunas interrogantes de interés. Como son:

14
a) ¿Cuánto aumentaría la varianza del estimador de la media bajo la asignación de
Neyman, en promedio, si la asignación se basa en los valores estimados de Si ,
i=1,2,…,k?
b) ¿Cómo se compara la “nueva varianza del estimador de la media bajo asignación de
Neyman”, con la varianza del estimador de la media bajo asignación
Proporcional?
c) ¿Qué tan grande debe ser el tamaño de muestra preliminar para que la asignación de
Neyman, al usar estimaciones de Si , i=1,2,…,k, resulte más eficiente que la
asignación Proporcional?
2.2.2. Solución a las interrogantes planteadas.
Para responder las interrogantes (a), (b) y (c), Sukhatme P. y Sukhatme B. (1970)
obtuvieron una aproximación del valor esperado de la “nueva varianza de Neyman”; es
decir, de la varianza del estimador de la media que resulta al estimar Si , i=1,2,…,k, en la
asignación de Neyman (2.13).
Sea 2is un estimador insesgado de 2
iS , obtenido con base en una muestra preliminar de
tamaño n’. De este modo, la asignación de la muestra total entre los estratos, al seguir el
método de Neyman, se realizará con la ecuación siguiente:
nsp
spn k
iii
iii
∑=
=
1
ˆ , i=1,2,…,k 2.21
Así, al sustituir (2.21) en la expresión (2.15) se obtiene la “nueva varianza de Neyman”
denotada y dada por:

15
( )kwNNw sssyVyv ,...,,|)( 21=
∑∑ ∑== =≠
−
+=k
iii
k
i
k
ji j
ijjiii Sp
Nss
SppSpn 1
2
1 1
222 11 2.22
Nótese que (2.22) incluye los estimadores si de Si, i=1,2,…k, que variarán de muestra a
muestra, consecuentemente no se puede decir cuando se obtendrá un valor menor,
comparada con la varianza del estimador de la media bajo la asignación Proporcional
dada en (2.18).
Para dar una respuesta a las interrogantes planteadas en la sección 2.2.1, se obtendrá el
valor esperado (2.22) como sigue:
Sea
kiSs iii ,...2,1 ; 22 =+= ε 2.23
donde
( ) 0=iE ε , ( ) ( )22ii SVE =ε ∀ i
( ) 0=jiE εε , ∀ i ≠ j 2.24
De este modo, el cociente
j
is
s involucrado en (2.22) puede ser expresado por:
21
2
21
2 11−
+
+=
j
i
j
i
j
i
j
i
SSSS
ss εε 2.25
Ahora, al expandir en serie de McLaurin el lado derecho de (2.25), multiplicar y omitir
las potencias de ε mayores de dos; después sustituir el resultado en (2.22), tomar la
esperanza considerando (2.24) y que c i = cj = C ∀ i ≠ j son los coeficientes de
variación 2is y 2
js dados por ( )2
2
j
jj S
sVc = .

16
Se tendrá
( )[ ] ∑∑ ∑== =≠
−
++≅
k
iii
k
i
k
jijijiiiNNw Sp
NCSSppSp
nyvE
1
2
1 1
222 1
411
( ) ∑=≠
+=k
jijijiNeyw SSpp
nCyV
1
2
4
2.26
Al suponer que la característica o variable de interés tiene una distribución normal;
entonces para muestras preliminares de tamaño n’, el coeficiente de variación al
cuadrado (c2) será igual a '/2 n . De acuerdo con esto, (2.26) queda como:
( )[ ] ( ) ∑=≠
+≅k
jijijiNeywNNw SSpp
nnyVyvE
1´21
( )
−
+= ∑∑
==
k
iii
k
iiiNeyw SpSp
nnyV
1
222
1'21
2.27
Las expresiones (2.26) y (2.27) responden a la interrogante (a); esto es, cuánto se
incrementa, en promedio, la varianza de Neyman por usar estimadores de las
desviaciones estándares en la asignación de Neyman.
La respuesta a la interrogante (b) se obtiene al expresar (2.27) en términos de la varianza
Proporcional; esto se logra al considerar la ecuación (2.19), con lo cual se tendrá que:
( )[ ] ( ) ( )
−
+−−≅ ∑∑∑
===
k
iii
k
iii
k
iiwiPwNNw SpSp
nnpSS
nyVyvE
1
222
11
2
´211 2.28
La expresión (2.28) tendrá un valor más pequeño, comparado con la varianza del
estimador de la media bajo asignación Proporcional, si la suma de los dos últimos
términos del lado derecho es negativa. Luego entonces, una condición para que la
asignación de Neyman al estimar Si, i=1,2,…, k, no conduzca, en promedio, a una
pérdida de precisión comparada con la asignación Proporcional es que:

17
( )∑ ∑∑= ==
≤
−
+−−
k
i
k
iii
k
iiiiwi SpSp
nnpSS
n 1 1
222
1
2 0'2
11
es decir,
( )∑∑∑===
−≤
−
k
iiwi
k
iii
k
iii pSSSpSp
n 1
2
1
222
1'21
2.29
De (2.29) se puede dar una respuesta a la interrogante (c), estableciendo un límite
inferior para el tamaño de muestra preliminar n’; con el cual la asignación de Neyman,
al usar estimadores de Si, puede dar, en promedio, una estimación más precisa que la
Proporcional. Así, de (2.29)
( )∑
∑∑
=
==
−
−
≥ k
iiwi
k
iii
k
iii
pSS
SpSpn
1
2
1
222
1
2' 2.30
De este último resultado (2.30) se puede concluir que mientras mayor sea la variabilidad
entre las Si, menor será el tamaño de muestra preliminar n’. Consecuentemente, a menos
que las desviaciones estándares de los estratos sean muy similares, muestras
preliminares moderadamente pequeñas darán, en promedio, resultados más precisos que
la asignación Proporcional.
Por otro lado, también Sukhatme (1935; citado por Sukhatme, 1962) abordó el problema
tomando en cuenta la interrogante: ¿cuál es la probabilidad de que la “nueva varianza de
Neyman” sea menor que la varianza obtenida con la asignación Proporcional? Para dar
respuesta a la interrogante, obtuvo una aproximación de la Función de Distribución de la
“nueva varianza de Neyman”. El asumió que la distribución de la característica en
estudio era aproximadamente normal y simplificó “la nueva varianza de Neyman”
eliminando el factor de corrección por finitud. Para obtener la función de distribución,
determinó los cuatro primeros momentos de la “nueva varianza de Neyman” y con ellos
encontró la Curva de Pearson más apropiada que aproxima a la distribución. Después de

18
probar dicha aproximación concluyó que, en muchos casos, el método propuesto resulta
mejor que el uso de la asignación Proporcional.
Dado que las soluciones anteriores para dar respuesta al problema son aproximadas y
que en algunos casos son difíciles de obtener, como lo es la interrogante de probabilidad
donde es necesario calcular cuando menos los tres primeros momentos de la nueva
varianza de Neyman y que además tienen una expresión larga y complicada; Rendón y
Carrillo (1976) consideraron conveniente estudiar el problema desde otro punto de vista,
en forma concreta abordaron dos aspectos:
i. Encontrar aquella expresión que proporcione la probabilidad de que la “nueva varianza
de Neyman” sea menor que la varianza Proporcional, mediante la deducción
exacta de la Función de Distribución de dicha varianza de Neyman.
ii. Con base en el punto anterior y en una muestra preliminar, cuyo tamaño dependerá de
la disposición económica para el estudio, establecer una condición que permita
determinar una primera aproximación del tamaño de muestra definitivo que
garantice que la asignación de Neyman será más eficiente que la Proporcional.
Debido a las dificultades que presenta el punto (i), Rendón y Carrillo (1976) obtuvieron
la solución sólo para el caso de dos estratos que, aun cuando restringida, tiene áreas de
aplicación. Para tal efecto, asumieron que la característica de interés se distribuye
normal. De este modo encontraron que la función de distribución exacta de la “nueva
varianza de Neyman” está dada como sigue:
( ) ( ) ( )[ ] ( ) ( ) dtttyVyvPpFx
x
r
rrPwNNwV
r
∫ −−Β
=<=−2
1
2121
21
12
22
1,
1 2.31
donde ( )NNwyv y ( )PwyV son las expresadas respectivamente por las ecuaciones (2.22)
y (2.18), 212
221
221
1 SrSrSrx+
= , 222
211
211
2 SrSrSrx+
= , 1,2i 1 =∀−= ii nr

19
Del análisis de (2.31) obtuvieron conclusiones como las siguientes:
a) Para muestra pequeñas, n: ri = ni -1 para toda i=1,2 (o grandes) mientras mayor sea
la diferencia entre 21S y 2
2S , la asignación de Neyman al usar estimadores de Si, i
= 1,2 , será más eficiente que la proporcional con una probabilidad que tiende a
la unidad. Este resultado es similar al que proporciona la ecuación (2.30) dada
por Sukhatme (1970).
b) Si la distancia o “abertura” de x1 y x2 (similitud con la diferencia de 21S y 2
2S )
permanece constante y se hacen variar a r1 = n1 -1 y r2 = n2 -1 (n=n1+n2) los
cuales pueden ser del mismo valor o diferentes, entonces existen valores r1 y r2
que proporcionan un valor de probabilidad próximo a la unidad.
c) Al tomar en cuenta el inciso (b) establecieron una condición que permite determinar
una primera aproximación al tamaño de muestra total definitivo y su distribución
en los estratos, de tal manera que se garantice con cierta probabilidad que la
asignación de Neyman (con la estimación de Si, i=1,2) será mejor que la
Proporcional.
Tal condición fue establecida como sigue:
( ) ( ) ( ) α−≥−Β
= ∫ −−
11,
1'2
'1
2121
21
12
22
dtttpFx
x
r
rrV
r
2.32
donde
212
221
221'
1 ˆˆˆ
srsrsrx+
= , 222
211
211'
2 ˆˆˆ
srsrsrx+
= ,
1,2i y ˆ 2 =∀ii sr : estimadores de ri y 2iS obtenidos con base en una muestra
preliminar de tamaño n’.
α > 0.

20
La condición (2.32) indica que si se calculan los límites '1x y '
2x , usando los estimadores
ir̂ y 2is de una muestra preliminar, es posible fijar un valor de probabilidad para la
expresión (2.31) en la vecindad de uno. De esta forma se estará en la condición de
seleccionar aquel miembro de la familia Beta que mediante sus valores r1 y r2 asegure
que la probabilidad de que la “nueva varianza de Neyman” sea menor que la varianza
Proporcional quede comprendida en dicha vecindad. Estos últimos valores r1 y r2
determinan una primera aproximación del tamaño de muestra a seleccionar en los
estratos 1 y 2, a través de ni = ri -1 para toda i=1,2. El tamaño de muestra total en la
primera aproximación queda definido por n=n1+n2.

III. METODOLOGÍA
3.1. Población.
Para lograr los objetivos del trabajo se generaron aleatoriamente 12 poblaciones, cada
una de tamaño N = 1000 unidades, tres de ellas miembros de la familia Normal, tres de
la familia Gama, tres de la familia Ji-cuadrada y , finalmente, tres de la familia Poisson.
Las doce poblaciones se dividieron en tres estratos con los siguientes tamaños: 1N =200,
2N =300, 3N =500. Para obtener los estratos, la población se ordenó de menor a mayor y
en el primer estrato se ubicaron las 200 unidades de menor magnitud, en el segundo
estrato se ubicaron las 300 unidades, y por último se ubicaron las 500 unidades de mayor
magnitud.
En el Cuadro 1 se presentan las distribuciones y sus parámetros a partir de las cuales se
generaron las 12 poblaciones utilizadas, las distribuciones son continuas, con excepción
de la distribución Poisson, pero dada la magnitud del parámetro λ, esta distribución se
comporta como una distribución continua.
Para responder al objetivo (a), con los datos de cada una de las poblaciones, divididas en
estratos, se procedió al cálculo de las varianzas y desviaciones estándares para cada

22
estrato. Con esta información censal se realizó el cálculo de las varianzas del estimador
de la media bajo el método de asignación de Neyman, y bajo el método de asignación
Proporcional, según las ecuaciones (2.17) y (2.18), respectivamente.
Cuadro 1. Distribuciones y sus parámetros a partir de las cuales se generaron las doce poblaciones utilizadas.
No. Distribución Parámetros 1 Normal µ=100, σ = 25 2 Normal µ=100, σ = 50 3 Normal µ=100, σ = 75 4 Gamma α=5 5 Gamma α=10 6 Gamma α=20 7 Poisson λ = 200 8 Poisson λ = 250 9 Poisson λ = 300 10 Ji-cuadrada ν = 100 11 Ji-cuadrada ν = 150 12 Ji-cuadrada ν = 200
3.2. Muestreo.
Para trabajar los objetivos (b) y (c), en cada una de las poblaciones estratificadas se
consideraron tres tamaños de muestra totales fijos (TMTF): 0n = 50, 0n = 100, 0n =150,
estos tamaños fueron determinados de manera tal que representen el 5, 10 y 15 % de la
población. Para estimar la desviación estándar de cada estrato, y de esta manera
distribuir el TMTF entre los estratos, para cada uno de los TMTF se decidió usar
tamaños de muestra preliminares (TMP) diferentes, los cuales se distribuyeron en forma
proporcional al tamaño de los estratos, lo cual se ilustra en el Cuadro 2 para la población
normal µ=100 y σ=25. Se procedió de la misma forma para las once poblaciones
restantes.

23
Cuadro 2. Distribución de la muestra preliminar en los diferentes estratos, según la
población con media de 100 y desviación estándar de 25. Unidades asignadas al estrato TMTF TMP
E 1 E 2 E 3 =′n 13 1n′ = 3 2n′ = 4 3n′ = 6 =′n 20 1n′ = 4 2n′ = 6 3n′ = 10
=0n 50
=′n 26 1n′ = 5 2n′ = 8 3n′ = 13 =′n 13 1n′ = 3 2n′ = 4 3n′ = 6 =′n 20 1n′ = 4 2n′ = 6 3n′ = 10
=0n 100
=′n 30 1n′ = 6 2n′ = 9 3n′ = 15 =′n 16 1n′ = 3 2n′ = 5 3n′ = 8 =′n 30 1n′ = 6 2n′ = 9 3n′ = 15
=0n 150
=′n 46 1n′ = 9 2n′ = 14 3n′ = 23
Una vez que los tamaños de muestra preliminar fueron asignados a los estratos en forma
proporcional, se procedió a realizar el MAE, este muestreo se repitió 40 veces, y a partir
de las observaciones obtenidas se estimaron 40 desviaciones estándares para cada
estrato, en cada población. Por ejemplo:
=0n 50 =′n 13 jn1′ = 3: 1401211 ,...,, sss ′′′
jn2′ = 4: 2402221 ,...,, sss ′′′
jn3′ = 6: 3403231 ,...,, sss ′′′
Posteriormente, con la información de desviaciones estándares estimadas, peso de los
estratos y TMTF, se procedió a calcular la distribución del TMTF entre los estratos,
según el método de asignación de Neyman y en este caso particular se utilizó la
ecuación:
∑=
= k
iiji
ijiij
sp
spnn
1
0ˆ i =1,2, 3 j = 1, 2, …, 40 3.1
en donde:

24
0n : Tamaño de muestra total fijo (50, 100, 150)
ijn̂ : Tamaño de muestra correspondiente a la j-ésima repetición en el i-ésimo estrato.
ip : Proporción de unidades del estrato i-ésimo con respecto a la población total (“peso”
del estrato i).
ijs : Desviación estándar de la j-iésima repetición del i-ésimo estrato obtenida a partir de
la muestra preliminar ijn′ .
Para cada una de las 40 repeticiones mencionadas se calculó la denominada nueva
varianza de Neyman, obteniéndose el promedio de estas 40 varianzas, como sigue:
40
)()(
40
1∑
== jNNw
NNw
jyv
yv 3.2
en donde jNNwyv )( se obtuvo con la expresión siguiente, que es equivalente a la (2.22)
∑ ∑= =
=−=k
i
k
iii
ij
iiNNjw ,..., ,jSp
NnSp
yv1 1
22
4021 1ˆ
)( 3.3
donde 40,...,2,1 ;3,2,1 ;ˆ == jinij está dada según (3.1).
3.3. Análisis
El análisis de la información obtenida se realizó, principalmente, con el uso del
indicador denominado “eficiencia del diseño de muestreo (deff)”, la estructura de este
indicador es dada por un cociente de varianzas cuyo numerador es la varianza del
método que se desea comparar y el denominador es la varianza del método con que se
compara (Esquivel, 2003), esto es:
( ) ( )( )θθ
θ ˆˆ
ˆ)(
)()(
ba
aasp v
vdeff = 3.4

25
( )( )( ) comparara. se que elcon estimador del Varianza : ˆ
comparar. a método elcon estimador del Varianza : ˆmuestral. diseño del eficiencia la deIndicador :ˆ
:dondeen
)(
)(
)(
θ
θ
θ
ba
aa
sp
v
v
deff
Se considera que un método es más eficiente que otro, si la varianza del estimador
obtenida a través de este método es menor que la obtenida por el otro método. De esta
manera si el deff es mayor que 1, se considera que el método utilizado en el
denominador es más eficiente; si el deff es igual a 1, se considera que los dos métodos
tienen la misma eficiencia; y si el deff es menor que 1, se considera que el método
utilizado en el numerador es más eficiente.
De acuerdo con la expresión (3.4) y los objetivos del estudio, el indicador de la
eficiencia del diseño quedó de la siguiente manera:
a) Para comparar de forma censal el método de asignación de Neyman con el
Proporcional se calcularon los indicadores dados como:
Pw
NeywPNey yVar
yVdeff
)()(
=− NeywPwNeyP yVyVDif )()( −=− 3.5
En donde NeywyVar )( y PwyVar )( se obtuvieron, respectivamente, según (2.17) y (2.18).
b). En la comparación del método de asignación de Neyman; bajo la estimación de Si,
i=1,2,...,k, con la forma paramétrica se usaron como indicadores a:
Neyw
NNwNeyNN yVar
yvdeff
)()(
=− NeywNNwNeyNN yVyvDif )()( −=− 3.6

26
En donde NNwyv )( y NeywyVar )( se obtuvieron, respectivamente, con las expresiones
(3.2) y (2.17).
c) En el caso de la comparación del método de asignación de Neyman, bajo la
estimación de Si, i=1,2,...,k, con la forma paramétrica de la asignación Proporcional se
emplearon como estimadores de los indicadores a:
Pw
NNwPNN yVar
yvdeff
)()(
=− PwNNwPNN yVyvDif )()( −=− 3.7
En donde NNwyv )( y PwyVar )( se obtuvieron, respectivamente, según (3.2) y (2.18).
3.4. Programación
La simulación para generar las poblaciones bajo las 12 diferentes distribuciones, la
división de estas poblaciones en estratos, la realización del muestreo preliminar, la
obtención de las desviaciones estándares estimadas y la asignación del tamaño de
muestra total fijo en los estratos, fue realizada mediante comandos básicos de
programación, en la ventana file-script del paquete estadístico S-PLUS 2000.
Los cálculos de las varianzas paramétricas de los métodos de asignación de Neyman y
proporcional y los promedios de las varianzas estimadas de la media del método de
asignación de Neyman, fueron realizados con el apoyo de la hoja de cálculo de Excel de
Office 2000.

IV. RESULTADOS Y DISCUSIÓN
En este capítulo se presentan en primer lugar los programas generados con el paquete
estadístico S-PLUS 2000 y, a continuación, de acuerdo con las cuatro distribuciones
consideradas y el orden en que se plantearon los objetivos de estudio, se exponen y
discuten brevemente los resultados obtenidos.
4.1 Programas generados
Con el propósito de cumplir con los objetivos planteados, se generaron doce programas
con el paquete estadístico S-PLUS 2000, un programa para cada una de las doce
distribuciones, a partir de las cuales, a su vez, se generaron las poblaciones definidas en
el Cuadro 1; tres miembros de la familia Normal, tres de la Ji-cuadrada, tres de la Gama
y tres de la Poisson.
En el Anexo 1 se describen brevemente los comandos correspondientes al programa
utilizado en la distribución Normal con media igual a 100 y desviación estándar igual a
25. En el Anexo 2 se presentan las modificaciones y comandos utilizados en los
programas de las once distribuciones restantes.

28
4.2. Distribución Normal.
Para el caso de las poblaciones cuyas distribuciones son miembros de la familia Normal,
el Cuadro 3 muestra los resultados que son pertinentes al primer objetivo (a) de estudio.
Dicho cuadro presenta cantidades a nivel censal o paramétricas como son: la desviación
estándar de cada población, las desviaciones estándares de los estratos, las varianzas del
estimador de la media según los métodos de asignación de Neyman y Proporcional;
asimismo, los indicadores correspondientes a la eficiencia del diseño.
Cuadro 3. Resultados pertinentes al objetivo (a), desviaciones estándares, tamaños de muestra total fijos, varianzas de estimadores e indicadores de la eficiencia del diseño, según las poblaciones normales bajo estudio.
Desv. Están. 1S 2S 3S (1) TMTF
NeywyV )( PwyV )( deffNey-P DifP-Ney
50 2.4207 2.6545 0.91190 0.23 100 1.1405 1.2574 0.90701 0.12
25 9.79 6.88 14.58 11.71
150 0.7137 0.7917 0.90154 0.08 50 10.3179 11.4862 0.89829 1.17 100 4.8567 5.4408 0.89264 0.58
50 20.64 13.20 30.56 58.37
150 3.0363 3.4257 0.88632 0.39 50 23.2301 25.7591 0.90182 2.53 100 10.9372 12.2017 0.89637 1.26
75 33.14 19.37 45.24 126.41
150 6.8396 7.6825 0.89027 0.84 (1) Variabilidad entre desviaciones estándares de los estratos, calculada según la ecuación (2.19) sin el
factor (1/n)
En el mismo Cuadro 3, se observa que, en cada población, las desviaciones estándares
de los estratos son menores que la desviación estándar de la población, esto indica que
efectivamente se ha realizado un bloqueo de la variación. Asimismo, las desviaciones
estándares son diferentes de estrato a estrato; este hecho, junto con los tamaños de los
estratos diferentes, es suficiente para decir que el MAE bajo asignación de Neyman dará
estimaciones más precisas que con la asignación proporcional (Rendón, 1998). Lo
anterior se corrobora al notar que, en cada población, la varianza del estimador es menor
cuando se aplica la asignación de Neyman que cuando se usa la Proporcional,
independientemente del TMTF ( 0n ); aun cuando la diferencia de estas varianzas tiende a
ser menor, en valor absoluto, al incrementarse el TMTF; pero en términos relativos,
como lo muestra el deffNey-P calculado según (3.5), al incrementar el TMTF el valor de
este índice tiende a ser cada vez menor que la unidad. Esto último se puede apreciar
objetivamente en las Figuras 1, 2 y 3.

29
En esta parte es conveniente mencionar la simbología que se usa en general para todas
las figuras que se presentan. En el eje de las ordenadas los niveles del TMTF están
representados por: “A” el nivel bajo ( 0n =50), “B” el nivel medio ( 0n =100) y “C” el
nivel alto ( 0n =150). Cada uno de los niveles del TMTF están acompañados por los
niveles correspondientes al TMP, esto es, para el nivel “A” se tendrán; “a” como nivel
bajo (n’ =13) del TMP, “b” nivel medio (n’ =20) y “c” nivel alto (n’ =26); para el nivel
“B”, el nivel bajo “a” (n’ =13), el nivel medio “b” (n’ =20) y el nivel alto “c” (n’ =30);
para el nivel “C” del TMTF se tendrá, nivel bajo “a” (n’ =16), nivel medio “b” (n’ =30)
y nivel alto “c” (n’ = 46) para el TMP.
Por otra parte, en el Cuadro 3, también se aprecia que la variabilidad entre las
desviaciones estándares de los estratos es diferente de población a población; se observa
que el valor más pequeño de dicha variabilidad se presenta en la población con
desviación estándar de 25 y el valor mayor en la población con desviación estándar 75.
Ahora bien, si se pone atención en cualquier TMTF, por ejemplo 0n =50, se puede notar
que, tanto la varianza del estimador de la media bajo asignación de Neyman como la
correspondiente bajo la asignación Proporcional, se incrementan de una población a otra
y lo mismo ocurre con las diferencias entre tales varianzas (DifP-Ney). Este hecho
demuestra, numéricamente en términos absolutos, la conclusión que se deriva de la
ecuación (2.19); es decir, para un TMTF, el MAE bajo la asignación de Neyman será
más preciso que bajo la asignación Proporcional, en la medida que exista mayor
variabilidad entre los estratos.
En cuanto al objetivo (b), el Cuadro 4 muestra el comportamiento numérico de la “nueva
varianza de Neyman”, al considerar su promedio en 40 repeticiones ( NNwyv )( ), con
relación a la varianza paramétrica ( NeywyV )( ), la variabilidad de las poblaciones, los
TMTF y los TMP, considerados en el estudio, así como el indicador de la eficiencia del
diseño de muestreo.
Como era de esperarse, tanto en el Cuadro 4 como en las Figuras 1, 2 y 3, se observa
que, en cada una de las tres poblaciones normales, el valor del índice deffNN-Ney
(calculado según la expresión 3.6) es mayor de uno, lo cual indica que la varianza del
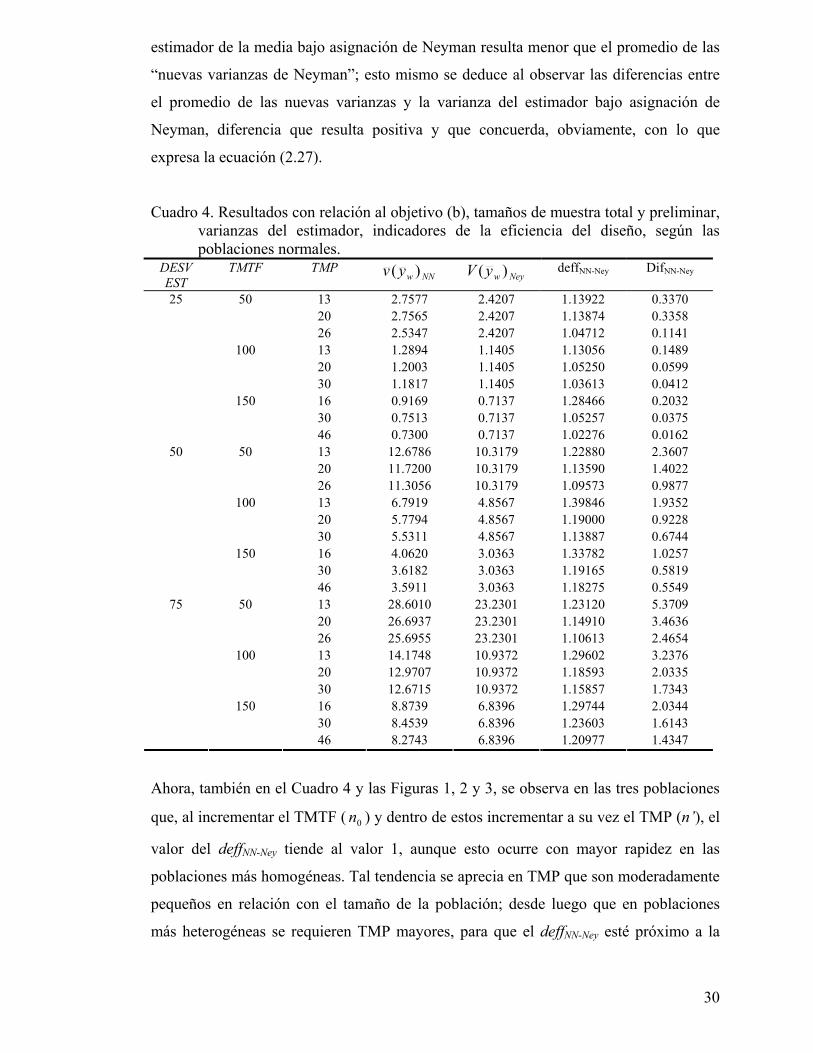
30
estimador de la media bajo asignación de Neyman resulta menor que el promedio de las
“nuevas varianzas de Neyman”; esto mismo se deduce al observar las diferencias entre
el promedio de las nuevas varianzas y la varianza del estimador bajo asignación de
Neyman, diferencia que resulta positiva y que concuerda, obviamente, con lo que
expresa la ecuación (2.27).
Cuadro 4. Resultados con relación al objetivo (b), tamaños de muestra total y preliminar, varianzas del estimador, indicadores de la eficiencia del diseño, según las poblaciones normales.
DESV EST
TMTF TMP NNwyv )( NeywyV )( deffNN-Ney DifNN-Ney
13 2.7577 2.4207 1.13922 0.3370 20 2.7565 2.4207 1.13874 0.3358
50
26 2.5347 2.4207 1.04712 0.1141 13 1.2894 1.1405 1.13056 0.1489 20 1.2003 1.1405 1.05250 0.0599
100
30 1.1817 1.1405 1.03613 0.0412 16 0.9169 0.7137 1.28466 0.2032 30 0.7513 0.7137 1.05257 0.0375
25
150
46 0.7300 0.7137 1.02276 0.0162 13 12.6786 10.3179 1.22880 2.3607 20 11.7200 10.3179 1.13590 1.4022
50
26 11.3056 10.3179 1.09573 0.9877 13 6.7919 4.8567 1.39846 1.9352 20 5.7794 4.8567 1.19000 0.9228
100
30 5.5311 4.8567 1.13887 0.6744 16 4.0620 3.0363 1.33782 1.0257 30 3.6182 3.0363 1.19165 0.5819
50
150
46 3.5911 3.0363 1.18275 0.5549 13 28.6010 23.2301 1.23120 5.3709 20 26.6937 23.2301 1.14910 3.4636
50
26 25.6955 23.2301 1.10613 2.4654 13 14.1748 10.9372 1.29602 3.2376 20 12.9707 10.9372 1.18593 2.0335
100
30 12.6715 10.9372 1.15857 1.7343 16 8.8739 6.8396 1.29744 2.0344 30 8.4539 6.8396 1.23603 1.6143
75
150
46 8.2743 6.8396 1.20977 1.4347
Ahora, también en el Cuadro 4 y las Figuras 1, 2 y 3, se observa en las tres poblaciones
que, al incrementar el TMTF ( 0n ) y dentro de estos incrementar a su vez el TMP (n’), el
valor del deffNN-Ney tiende al valor 1, aunque esto ocurre con mayor rapidez en las
poblaciones más homogéneas. Tal tendencia se aprecia en TMP que son moderadamente
pequeños en relación con el tamaño de la población; desde luego que en poblaciones
más heterogéneas se requieren TMP mayores, para que el deffNN-Ney esté próximo a la
31
unidad. Este mismo resultado se observa, también, con las diferencias entre el promedio
de la “nueva varianza de Neyman” y la varianza del estimador bajo asignación de
Neyman (DifNN-Ney), diferencias que tienden al valor cero; lo que indica mayor
semejanza entre ambas varianzas, lo anterior corrobora nuevamente lo que expresa la
ecuación (2.27).
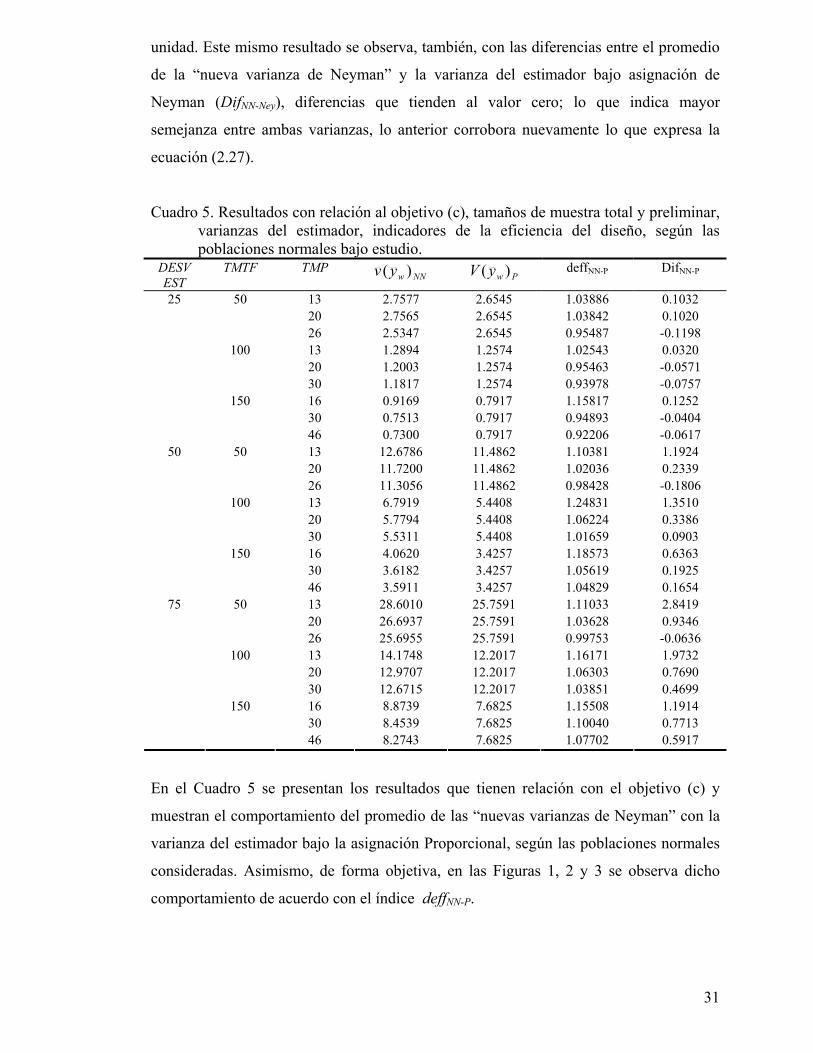
Cuadro 5. Resultados con relación al objetivo (c), tamaños de muestra total y preliminar, varianzas del estimador, indicadores de la eficiencia del diseño, según las poblaciones normales bajo estudio.
DESV EST
TMTF TMP NNwyv )( PwyV )( deffNN-P DifNN-P
13 2.7577 2.6545 1.03886 0.1032 20 2.7565 2.6545 1.03842 0.1020
50
26 2.5347 2.6545 0.95487 -0.1198 13 1.2894 1.2574 1.02543 0.0320 20 1.2003 1.2574 0.95463 -0.0571
100
30 1.1817 1.2574 0.93978 -0.0757 16 0.9169 0.7917 1.15817 0.1252 30 0.7513 0.7917 0.94893 -0.0404
25
150
46 0.7300 0.7917 0.92206 -0.0617 13 12.6786 11.4862 1.10381 1.1924 20 11.7200 11.4862 1.02036 0.2339
50
26 11.3056 11.4862 0.98428 -0.1806 13 6.7919 5.4408 1.24831 1.3510 20 5.7794 5.4408 1.06224 0.3386
100
30 5.5311 5.4408 1.01659 0.0903 16 4.0620 3.4257 1.18573 0.6363 30 3.6182 3.4257 1.05619 0.1925
50
150
46 3.5911 3.4257 1.04829 0.1654 13 28.6010 25.7591 1.11033 2.8419 20 26.6937 25.7591 1.03628 0.9346
50
26 25.6955 25.7591 0.99753 -0.0636 13 14.1748 12.2017 1.16171 1.9732 20 12.9707 12.2017 1.06303 0.7690
100
30 12.6715 12.2017 1.03851 0.4699 16 8.8739 7.6825 1.15508 1.1914 30 8.4539 7.6825 1.10040 0.7713
75
150
46 8.2743 7.6825 1.07702 0.5917
En el Cuadro 5 se presentan los resultados que tienen relación con el objetivo (c) y
muestran el comportamiento del promedio de las “nuevas varianzas de Neyman” con la
varianza del estimador bajo la asignación Proporcional, según las poblaciones normales
consideradas. Asimismo, de forma objetiva, en las Figuras 1, 2 y 3 se observa dicho
comportamiento de acuerdo con el índice deffNN-P.
32
Según el Cuadro 5 y las figuras mencionadas se observa que, en las tres poblaciones,
para cada TMTF ( 0n ) al incrementar el TMP (n’), el indicador deffNN-P tiende a tomar
valores menores que uno o muy cercanos a uno. El valor del deffNN-P menor que uno se
aprecia principalmente en las poblaciones más homogéneas. Por otra parte, estas
tendencias se notan para TMP que son relativamente pequeños, en relación con el
tamaño de la población. Tales resultados también se muestran con las diferencias entre
el promedio de las “nuevas varianzas de Neyman” y las varianzas del estimador bajo
asignación Proporcional (DifNN-P), en este caso, las diferencias tienden a tomar valores
negativos o cercanos a cero.
0.6
0.7
0.8
0.9
1
1.1
1.2
1.3
1.4
Aa Ab Ac Ba Bb Bc Ca Cb Cc
Efic
ienc
ia d
el d
iseñ
o de
mue
stre
o
deff NN-Ndeff NN-Pdeff N-P
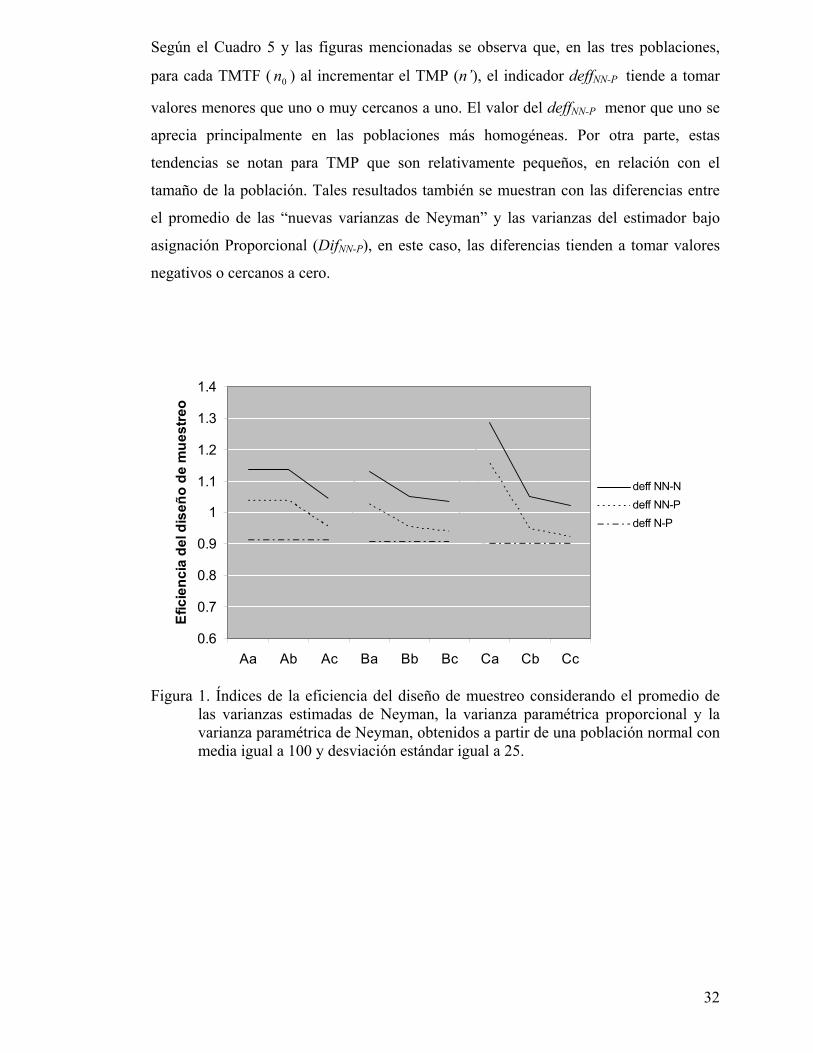
Figura 1. Índices de la eficiencia del diseño de muestreo considerando el promedio de
las varianzas estimadas de Neyman, la varianza paramétrica proporcional y la varianza paramétrica de Neyman, obtenidos a partir de una población normal con media igual a 100 y desviación estándar igual a 25.
33
0.6
0.7
0.8
0.9
1
1.1
1.2
1.3
1.4
1.5
Aa Ab Ac Ba Bb Bc Ca Cb Cc
Efic
ienc
ia d
el d
iseñ
o de
mue
stre
odeff NN-Ndeff NN-Pdeff N-P
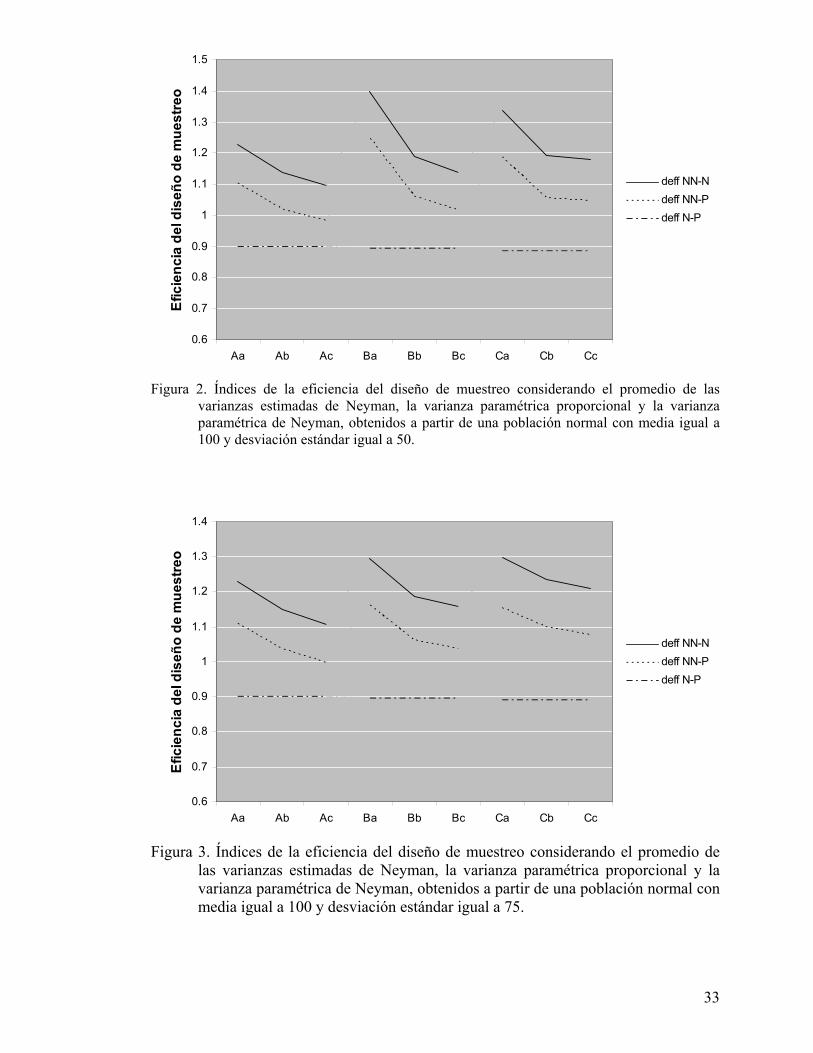
Figura 2. Índices de la eficiencia del diseño de muestreo considerando el promedio de las
varianzas estimadas de Neyman, la varianza paramétrica proporcional y la varianza paramétrica de Neyman, obtenidos a partir de una población normal con media igual a 100 y desviación estándar igual a 50.
0.6
0.7
0.8
0.9
1
1.1
1.2
1.3
1.4
Aa Ab Ac Ba Bb Bc Ca Cb Cc
Efic
ienc
ia d
el d
iseñ
o de
mue
stre
o
deff NN-Ndeff NN-Pdeff N-P
Figura 3. Índices de la eficiencia del diseño de muestreo considerando el promedio de
las varianzas estimadas de Neyman, la varianza paramétrica proporcional y la varianza paramétrica de Neyman, obtenidos a partir de una población normal con media igual a 100 y desviación estándar igual a 75.

34
De lo anterior se deduce que, para TMP moderadamente pequeños y en poblaciones
normales no muy heterogéneas, la asignación de Neyman bajo la estimación de las
desviaciones estándares de los estratos dará, en promedio, estimaciones más precisas que
la asignación Proporcional. Como se puede notar, para el caso de poblaciones más
heterogéneas, se requerirán TMP ligeramente mayores a los considerados en el presente
estudio, quizás muestras preliminares mayores al 5 % con relación al tamaño de la
población. Es claro que en las poblaciones más heterogéneas deberá pensarse en el
número de estratos en que será dividida la población.
Por otra parte, es necesario mencionar que los resultados obtenido, al menos para el caso
normal, no concuerdan con las conclusiones que se derivan de la ecuación (2.30), donde
se dice que mientras mayor sea la variabilidad entre las desviaciones estándares de los
estratos, menor será el TMP (n’) para que, en promedio, la asignación de Neyman dé
estimaciones más precisas que la asignación Proporcional (los cálculos de la variabilidad
entre estratos, a partir de la ecuación 2.30, para todas las poblaciones se presenta en el
Anexo 3). En este estudio la mayor variabilidad entre las desviaciones estándares de los
estratos se obtiene en aquellas poblaciones que son más heterogéneas, como es la
población con una desviación estándar de 75 y, como ya se dijo, en este caso se
requieren TMP ligeramente mayores a las consideradas para que la asignación de
Neyman dé, en promedio, estimaciones más precisas que la asignación Proporcional.
Nuevamente, deberá pensarse si existe alguna relación al construir más estratos en
poblaciones con mayor heterogeneidad.
4.3. Distribución Ji-cuadrada.
Ahora, para el caso de las poblaciones cuyas distribuciones pertenecen a la familia Ji-
cuadrada, el Cuadro 6 muestra resultados relacionados con el primer objetivo de estudio
(a). En este cuadro se observa a nivel censal o paramétrico los grados de libertad de la
población, la desviación estándar de cada población, las desviaciones estándares de los
estratos, las varianzas del estimador de la media según los métodos de asignación de
Neyman y Proporcional; asimismo, los indicadores correspondientes a la eficiencia del
diseño.
35
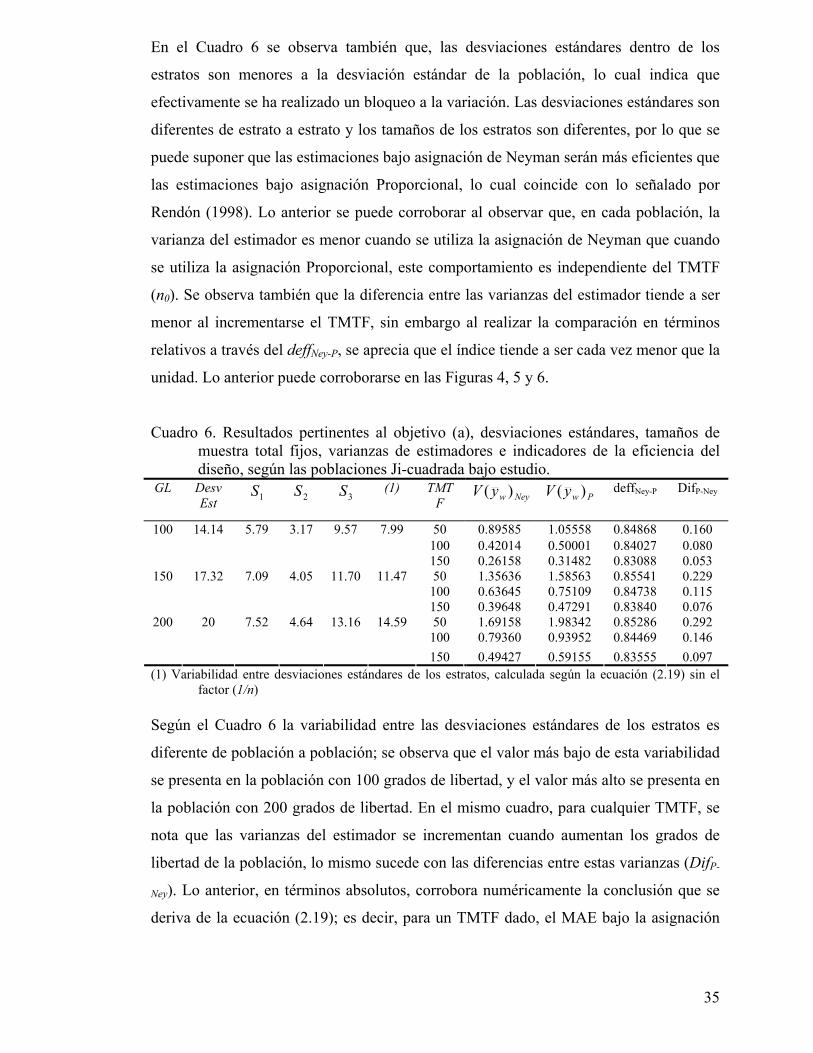
En el Cuadro 6 se observa también que, las desviaciones estándares dentro de los
estratos son menores a la desviación estándar de la población, lo cual indica que
efectivamente se ha realizado un bloqueo a la variación. Las desviaciones estándares son
diferentes de estrato a estrato y los tamaños de los estratos son diferentes, por lo que se
puede suponer que las estimaciones bajo asignación de Neyman serán más eficientes que
las estimaciones bajo asignación Proporcional, lo cual coincide con lo señalado por
Rendón (1998). Lo anterior se puede corroborar al observar que, en cada población, la
varianza del estimador es menor cuando se utiliza la asignación de Neyman que cuando
se utiliza la asignación Proporcional, este comportamiento es independiente del TMTF
(n0). Se observa también que la diferencia entre las varianzas del estimador tiende a ser
menor al incrementarse el TMTF, sin embargo al realizar la comparación en términos
relativos a través del deffNey-P, se aprecia que el índice tiende a ser cada vez menor que la
unidad. Lo anterior puede corroborarse en las Figuras 4, 5 y 6.
Cuadro 6. Resultados pertinentes al objetivo (a), desviaciones estándares, tamaños de muestra total fijos, varianzas de estimadores e indicadores de la eficiencia del diseño, según las poblaciones Ji-cuadrada bajo estudio.
GL Desv Est 1S 2S 3S (1) TMT
F NeywyV )(
PwyV )( deffNey-P DifP-Ney
50 0.89585 1.05558 0.84868 0.160 100 0.42014 0.50001 0.84027 0.080
100 14.14 5.79 3.17 9.57 7.99
150 0.26158 0.31482 0.83088 0.053 50 1.35636 1.58563 0.85541 0.229
100 0.63645 0.75109 0.84738 0.115 150 17.32 7.09 4.05 11.70 11.47
150 0.39648 0.47291 0.83840 0.076 50 1.69158 1.98342 0.85286 0.292
100 0.79360 0.93952 0.84469 0.146 200 20 7.52 4.64 13.16 14.59
150 0.49427 0.59155 0.83555 0.097 (1) Variabilidad entre desviaciones estándares de los estratos, calculada según la ecuación (2.19) sin el
factor (1/n) Según el Cuadro 6 la variabilidad entre las desviaciones estándares de los estratos es
diferente de población a población; se observa que el valor más bajo de esta variabilidad
se presenta en la población con 100 grados de libertad, y el valor más alto se presenta en
la población con 200 grados de libertad. En el mismo cuadro, para cualquier TMTF, se
nota que las varianzas del estimador se incrementan cuando aumentan los grados de
libertad de la población, lo mismo sucede con las diferencias entre estas varianzas (DifP-
Ney). Lo anterior, en términos absolutos, corrobora numéricamente la conclusión que se
deriva de la ecuación (2.19); es decir, para un TMTF dado, el MAE bajo la asignación

36
de Neyman será más preciso que bajo la asignación Proporcional, en la medida que
exista mayor variabilidad entre los estratos.
Para abordar el objetivo (b), el Cuadro 7 muestra, en poblaciones Ji-cuadrada, los grados
de libertad de las poblaciones, los TMTF y los TMP considerados en el estudio, el
promedio de las “nuevas varianzas”, la varianza paramétrica de Neyman, así como el
indicador de la eficiencia del diseño y la diferencia entre las dos varianzas consideradas.
Cuadro 7. Resultados con relación al objetivo (b), tamaños de muestra total y preliminar, varianzas del estimador, indicadores de la eficiencia del diseño, según las poblaciones Ji-cuadrada bajo estudio.
GL TMTF TMP NNwyv )( NeywyV )( deffNN-Ney DifNN-Ney
13 1.06276 0.89585 1.18632 0.167 20 0.99345 0.89585 1.10895 0.098
50
26 0.96356 0.89585 1.07559 0.068 13 0.48751 0.42014 1.16035 0.067 20 0.45097 0.42014 1.07337 0.031
100
30 0.44268 0.42014 1.05363 0.023 16 0.29358 0.26158 1.12235 0.032 30 0.27299 0.26158 1.04362 0.011
100
150
46 0.27036 0.26158 1.03358 0.009 13 1.70085 1.35636 1.25398 0.344 20 1.50889 1.35636 1.11246 0.153
50
26 1.44965 1.35636 1.06877 0.093 13 0.81754 0.63645 1.28453 0.181 20 0.71138 0.63645 1.11773 0.075
100
30 0.69853 0.63645 1.09754 0.062 16 0.51027 0.39648 1.28699 0.114 30 0.44723 0.39648 1.12798 0.051
150
150
46 0.43487 0.39648 1.09681 0.038 13 2.26488 1.69158 1.33891 0.573 20 1.84822 1.69158 1.09260 0.157
50
26 1.84785 1.69158 1.09238 0.156 13 0.96525 0.79360 1.21630 0.172 20 0.89694 0.79360 1.13022 0.103
100
30 0.88326 0.79360 1.11298 0.090 16 0.61668 0.49427 1.24766 0.122 30 0.56328 0.49427 1.13962 0.069
200
150
46 0.55193 0.49427 1.11667 0.058
Tanto en el Cuadro 7 como en las Figuras 4, 5 y 6 se observa que, en cada una de las tres
poblaciones Ji-cuadrada, el valor del índice deffNN-Ney es mayor que la unidad, lo cual
indica que la varianza paramétrica del estimador de la media bajo asignación de Neyman
resulta menor que el promedio de las “nuevas varianzas de Neyman”; se deduce lo
mismo al observar las diferencias entre el promedio de las “nuevas varianzas” y la

37
varianza del estimador bajo asignación de Neyman, la diferencia siempre es mayor a
cero, y concuerda, obviamente, con lo que expresa la ecuación (2.27).
Ahora, en el mismo Cuadro 7 y en las Figuras 4, 5 y 6, se observa en las tres poblaciones
que, para cada TMTF al incrementar el TMP, el valor del deffNN-Ney tiende al valor uno,
esto ocurre más rápidamente en las poblaciones más homogéneas. Tal tendencia se
aprecia en TMP que son moderadamente pequeños en relación con el tamaño de la
población, es obvio que, en poblaciones más heterogéneas se requieren TMP mayores,
para que el deffNN-Ney esté próximo a la unidad. Se observa el mismo comportamiento al
considerar las diferencias entre el promedio de las “nuevas varianzas de Neyman” y las
varianzas del estimador bajo asignación de Neyman (DifNN-Ney), ya que las diferencias
siempre son positivas y tienden a acercarse a cero cuando se incrementa el TMP, lo que
indica mayor similitud entre ambas varianzas
En el Cuadro 8 se presentan los resultados que tienen relación con el objetivo (c) y
muestran el comportamiento del promedio de las “nuevas varianzas de Neyman” con la
varianza del estimador bajo la asignación Proporcional, según las poblaciones Ji-
cuadrada consideradas.
Según el Cuadro 8 y las Figuras 4, 5 y 6 en las tres poblaciones Ji-cuadrada, para cada
TMTF al incrementar TMP, el indicador deffNN-P tiende a tomar valores menores que
uno. Se observa que, en general, el valor del indicador deffNN-P es menor en poblaciones
más homogéneas. Tales resultados también se muestran con las diferencias entre el
promedio de las “nuevas varianzas de Neyman” y las varianzas del estimador bajo
asignación proporcional (DifNN-P), en este caso las diferencias tienden a tomar valores
menores a cero.
Con base en lo anterior se deduce que con TMP moderadamente pequeños y en
poblaciones Ji-cuadrada, la asignación de Neyman bajo la estimación de las
desviaciones estándares de los estratos proporciona, en promedio, estimaciones más
precisas que la asignación proporcional, cuando se incrementa el TMP. Aunque, esto
ocurre en las tres poblaciones Ji-cuadrada, el resultado es más evidente en poblaciones
más heterogéneas.
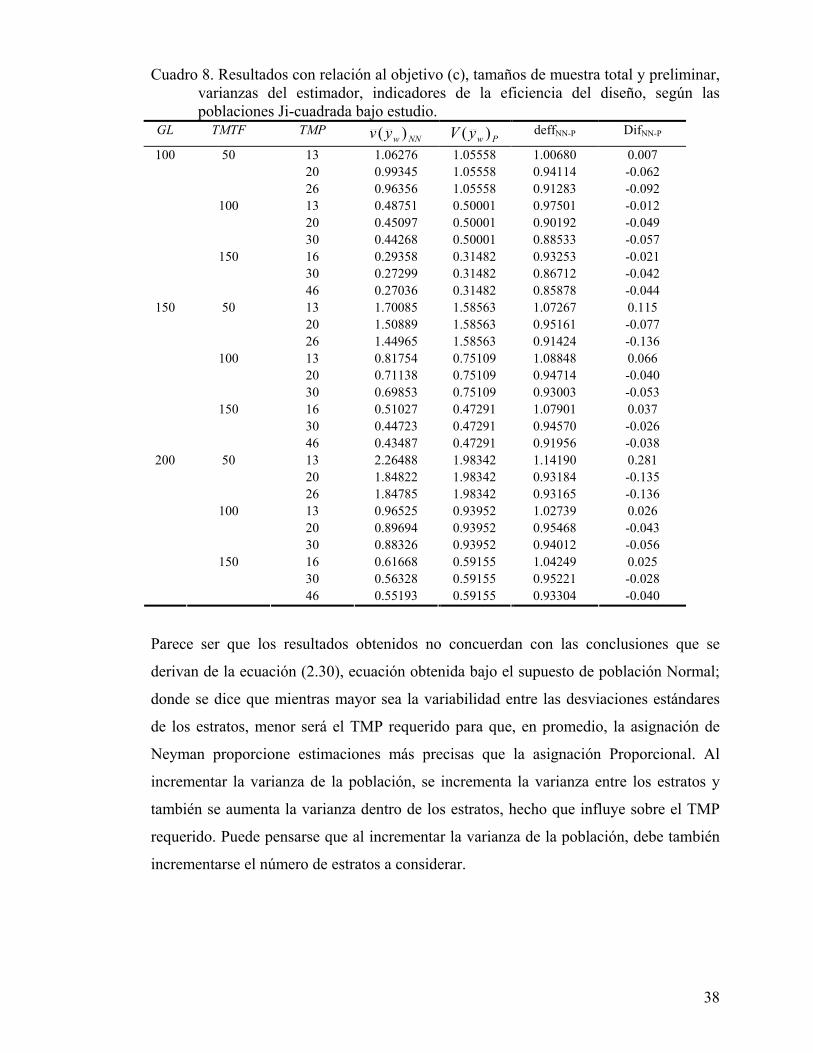
38
Cuadro 8. Resultados con relación al objetivo (c), tamaños de muestra total y preliminar, varianzas del estimador, indicadores de la eficiencia del diseño, según las poblaciones Ji-cuadrada bajo estudio.
GL TMTF TMP NNwyv )( PwyV )( deffNN-P DifNN-P
13 1.06276 1.05558 1.00680 0.007 20 0.99345 1.05558 0.94114 -0.062
50
26 0.96356 1.05558 0.91283 -0.092 13 0.48751 0.50001 0.97501 -0.012 20 0.45097 0.50001 0.90192 -0.049
100
30 0.44268 0.50001 0.88533 -0.057 16 0.29358 0.31482 0.93253 -0.021 30 0.27299 0.31482 0.86712 -0.042
100
150
46 0.27036 0.31482 0.85878 -0.044 13 1.70085 1.58563 1.07267 0.115 20 1.50889 1.58563 0.95161 -0.077
50
26 1.44965 1.58563 0.91424 -0.136 13 0.81754 0.75109 1.08848 0.066 20 0.71138 0.75109 0.94714 -0.040
100
30 0.69853 0.75109 0.93003 -0.053 16 0.51027 0.47291 1.07901 0.037 30 0.44723 0.47291 0.94570 -0.026
150
150
46 0.43487 0.47291 0.91956 -0.038 13 2.26488 1.98342 1.14190 0.281 20 1.84822 1.98342 0.93184 -0.135
50
26 1.84785 1.98342 0.93165 -0.136 13 0.96525 0.93952 1.02739 0.026 20 0.89694 0.93952 0.95468 -0.043
100
30 0.88326 0.93952 0.94012 -0.056 16 0.61668 0.59155 1.04249 0.025 30 0.56328 0.59155 0.95221 -0.028
200
150
46 0.55193 0.59155 0.93304 -0.040
Parece ser que los resultados obtenidos no concuerdan con las conclusiones que se
derivan de la ecuación (2.30), ecuación obtenida bajo el supuesto de población Normal;
donde se dice que mientras mayor sea la variabilidad entre las desviaciones estándares
de los estratos, menor será el TMP requerido para que, en promedio, la asignación de
Neyman proporcione estimaciones más precisas que la asignación Proporcional. Al
incrementar la varianza de la población, se incrementa la varianza entre los estratos y
también se aumenta la varianza dentro de los estratos, hecho que influye sobre el TMP
requerido. Puede pensarse que al incrementar la varianza de la población, debe también
incrementarse el número de estratos a considerar.
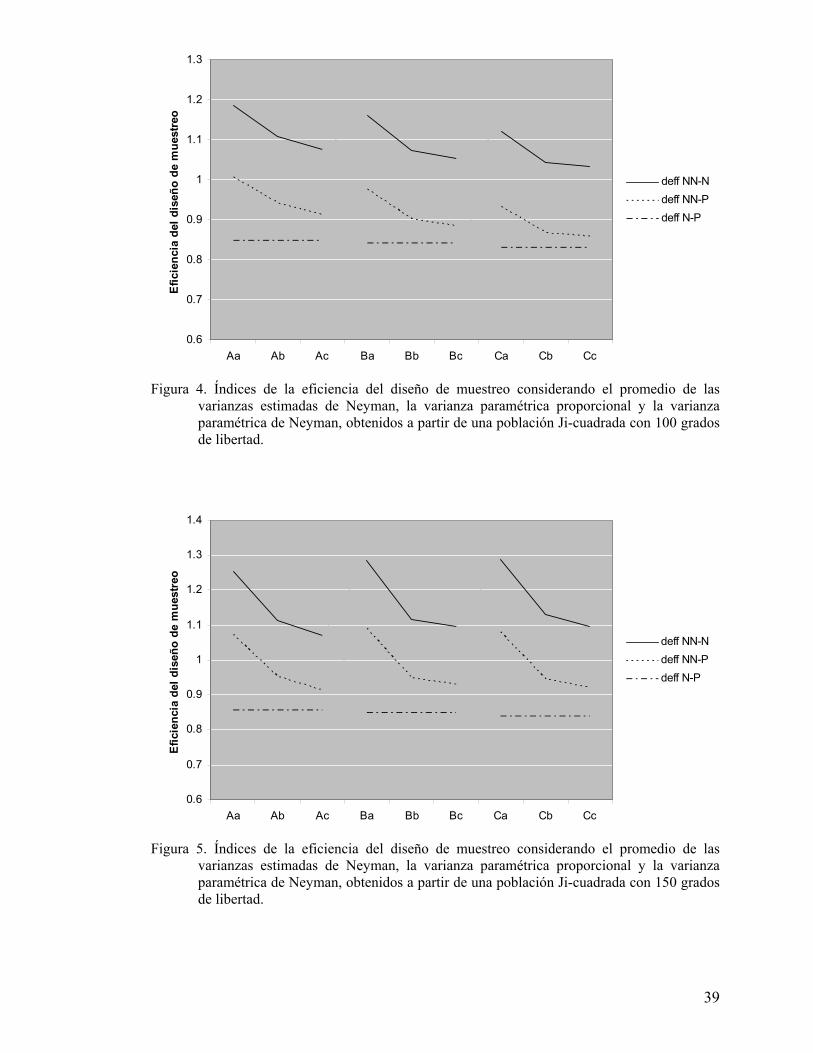
39
0.6
0.7
0.8
0.9
1
1.1
1.2
1.3
Aa Ab Ac Ba Bb Bc Ca Cb Cc
Efic
ienc
ia d
el d
iseñ
o de
mue
stre
odeff NN-Ndeff NN-Pdeff N-P
Figura 4. Índices de la eficiencia del diseño de muestreo considerando el promedio de las
varianzas estimadas de Neyman, la varianza paramétrica proporcional y la varianza paramétrica de Neyman, obtenidos a partir de una población Ji-cuadrada con 100 grados de libertad.
0.6
0.7
0.8
0.9
1
1.1
1.2
1.3
1.4
Aa Ab Ac Ba Bb Bc Ca Cb Cc
Efic
ienc
ia d
el d
iseñ
o de
mue
stre
o
deff NN-Ndeff NN-Pdeff N-P
Figura 5. Índices de la eficiencia del diseño de muestreo considerando el promedio de las
varianzas estimadas de Neyman, la varianza paramétrica proporcional y la varianza paramétrica de Neyman, obtenidos a partir de una población Ji-cuadrada con 150 grados de libertad.
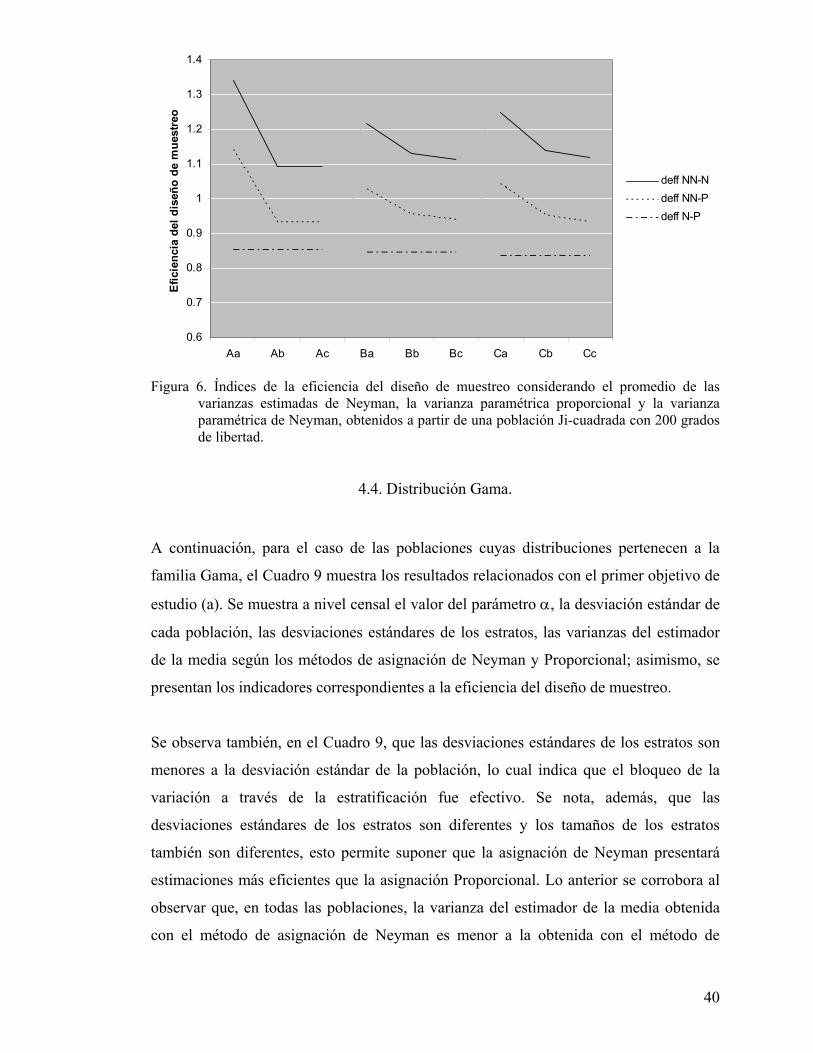
40
0.6
0.7
0.8
0.9
1
1.1
1.2
1.3
1.4
Aa Ab Ac Ba Bb Bc Ca Cb Cc
Efic
ienc
ia d
el d
iseñ
o de
mue
stre
odeff NN-Ndeff NN-Pdeff N-P
Figura 6. Índices de la eficiencia del diseño de muestreo considerando el promedio de las
varianzas estimadas de Neyman, la varianza paramétrica proporcional y la varianza paramétrica de Neyman, obtenidos a partir de una población Ji-cuadrada con 200 grados de libertad.
4.4. Distribución Gama.
A continuación, para el caso de las poblaciones cuyas distribuciones pertenecen a la
familia Gama, el Cuadro 9 muestra los resultados relacionados con el primer objetivo de
estudio (a). Se muestra a nivel censal el valor del parámetro α, la desviación estándar de
cada población, las desviaciones estándares de los estratos, las varianzas del estimador
de la media según los métodos de asignación de Neyman y Proporcional; asimismo, se
presentan los indicadores correspondientes a la eficiencia del diseño de muestreo.
Se observa también, en el Cuadro 9, que las desviaciones estándares de los estratos son
menores a la desviación estándar de la población, lo cual indica que el bloqueo de la
variación a través de la estratificación fue efectivo. Se nota, además, que las
desviaciones estándares de los estratos son diferentes y los tamaños de los estratos
también son diferentes, esto permite suponer que la asignación de Neyman presentará
estimaciones más eficientes que la asignación Proporcional. Lo anterior se corrobora al
observar que, en todas las poblaciones, la varianza del estimador de la media obtenida
con el método de asignación de Neyman es menor a la obtenida con el método de

41
asignación Proporcional, este comportamiento es independiente del TMTF (n0). En el
Cuadro y también en las Figuras 7, 8 y 9 se observa que el deffNey-P en todos los casos es
menor que uno y tiende a disminuir cuando se incrementa el TMTF; se observa además
que, el indicador antes mencionado presenta valores menores en las poblaciones menos
heterogéneas. En cuanto a la diferencia entre las varianzas del estimador obtenidas con
los métodos de asignación de Neyman y Proporcional (DifP-Ney), se observa que en todos
los casos es mayor a cero y tiende a disminuir cuando se incrementa el TMTF.
Cuadro 9. Resultados pertinentes al objetivo (a), desviaciones estándares, tamaños de muestra total fijos, varianzas de estimadores e indicadores de la eficiencia del diseño, según las poblaciones Gama bajo estudio.
α Desv Est 1S 2S 3S (1) TMTF
NeywyV )(
PwyV )( deffNey-P DifP-Ney
50 0.02735 0.03743 0.7306800 0.010 100 0.01269 0.01773 0.7157178 0.005
5 2.24 0.54 0.47 1.92 0.50
150 0.00780 0.01116 0.6989953 0.003 50 0.04582 0.05751 0.7967216 0.012 100 0.02140 0.02724 0.7854284 0.006
10 3.16 1.05 0.65 2.31 0.58
150 0.01325 0.01715 0.7728065 0.004 50 0.08962 0.10888 0.8231602 0.019 100 0.04195 0.05157 0.8133358 0.010
20 4.47 1.61 0.97 3.14 0.96
150 0.02605 0.03247 0.8023556 0.006 (1) Variabilidad entre desviaciones estándares de los estratos, calculada según la ecuación (2.19) sin el
factor (1/n)
Según el Cuadro 9 la variabilidad entre las desviaciones estándares de los estratos es
diferente de población a población; se observa que el valor más bajo de esta variabilidad
se presenta en la población cuyo parámetro α es de 5 unidades, y el valor más alto de
esta variabilidad se presenta en la población con parámetro a igual a 20. Para cualquier
TMTF se nota, en el mismo cuadro, que las varianzas del estimador se incrementan
cuando aumenta el valor del parámetro α, lo mismo sucede entre las diferencias entre
estas varianzas (DifP-Ney). Lo anterior coincide, en términos absolutos, con la conclusión
que se deriva de la ecuación (2.19); es decir, para un TMTF dado, el método de
asignación de Neyman proporcionará estimaciones más precisas que el método de
asignación Proporcional a medida que exista mayor variabilidad entre los estratos.
En el caso del objetivo (b), el Cuadro 10 muestra, en poblaciones Gama, los valores del
parámetro α, los TMTF y los TMP considerados en el estudio, el promedio de las
“nuevas varianzas de Neyman”, la varianza paramétrica de Neyman, así como indicador
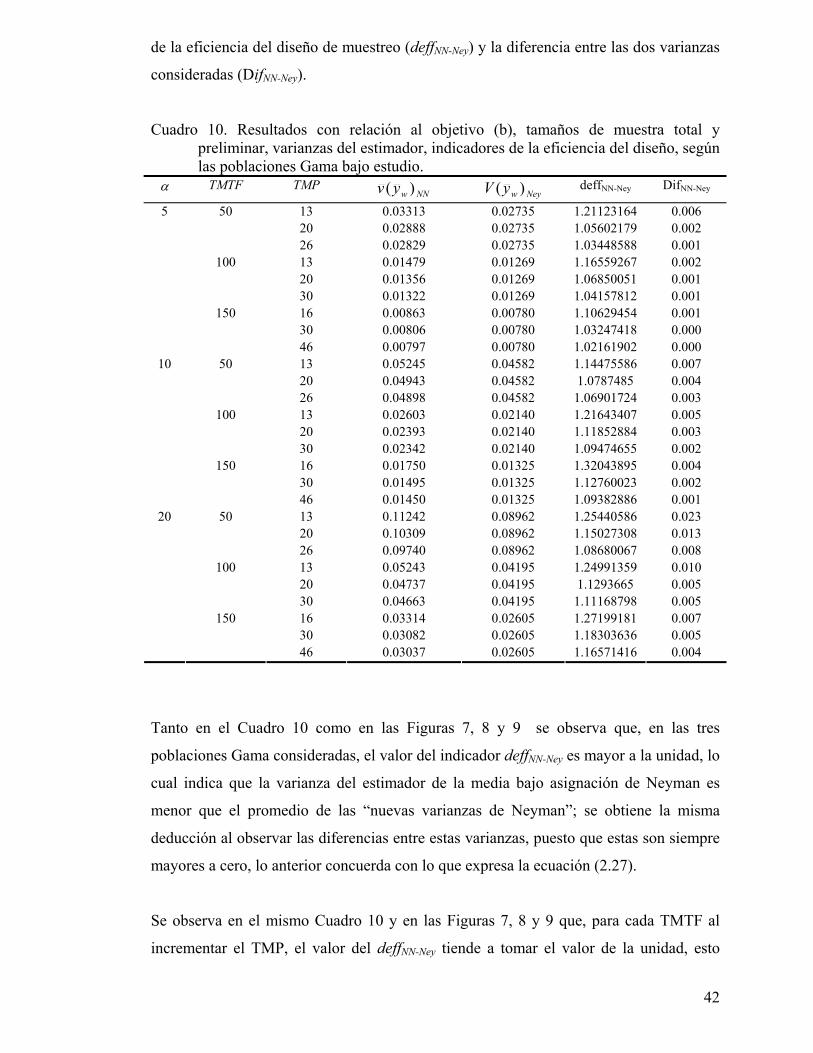
42
de la eficiencia del diseño de muestreo (deffNN-Ney) y la diferencia entre las dos varianzas
consideradas (DifNN-Ney).
Cuadro 10. Resultados con relación al objetivo (b), tamaños de muestra total y preliminar, varianzas del estimador, indicadores de la eficiencia del diseño, según las poblaciones Gama bajo estudio.
α TMTF TMP NNwyv )( NeywyV )( deffNN-Ney DifNN-Ney
13 0.03313 0.02735 1.21123164 0.006 20 0.02888 0.02735 1.05602179 0.002
50
26 0.02829 0.02735 1.03448588 0.001 13 0.01479 0.01269 1.16559267 0.002 20 0.01356 0.01269 1.06850051 0.001
100
30 0.01322 0.01269 1.04157812 0.001 16 0.00863 0.00780 1.10629454 0.001 30 0.00806 0.00780 1.03247418 0.000
5
150
46 0.00797 0.00780 1.02161902 0.000 13 0.05245 0.04582 1.14475586 0.007 20 0.04943 0.04582 1.0787485 0.004
50
26 0.04898 0.04582 1.06901724 0.003 13 0.02603 0.02140 1.21643407 0.005 20 0.02393 0.02140 1.11852884 0.003
100
30 0.02342 0.02140 1.09474655 0.002 16 0.01750 0.01325 1.32043895 0.004 30 0.01495 0.01325 1.12760023 0.002
10
150
46 0.01450 0.01325 1.09382886 0.001 13 0.11242 0.08962 1.25440586 0.023 20 0.10309 0.08962 1.15027308 0.013
50
26 0.09740 0.08962 1.08680067 0.008 13 0.05243 0.04195 1.24991359 0.010 20 0.04737 0.04195 1.1293665 0.005
100
30 0.04663 0.04195 1.11168798 0.005 16 0.03314 0.02605 1.27199181 0.007 30 0.03082 0.02605 1.18303636 0.005
20
150
46 0.03037 0.02605 1.16571416 0.004
Tanto en el Cuadro 10 como en las Figuras 7, 8 y 9 se observa que, en las tres
poblaciones Gama consideradas, el valor del indicador deffNN-Ney es mayor a la unidad, lo
cual indica que la varianza del estimador de la media bajo asignación de Neyman es
menor que el promedio de las “nuevas varianzas de Neyman”; se obtiene la misma
deducción al observar las diferencias entre estas varianzas, puesto que estas son siempre
mayores a cero, lo anterior concuerda con lo que expresa la ecuación (2.27).
Se observa en el mismo Cuadro 10 y en las Figuras 7, 8 y 9 que, para cada TMTF al
incrementar el TMP, el valor del deffNN-Ney tiende a tomar el valor de la unidad, esto
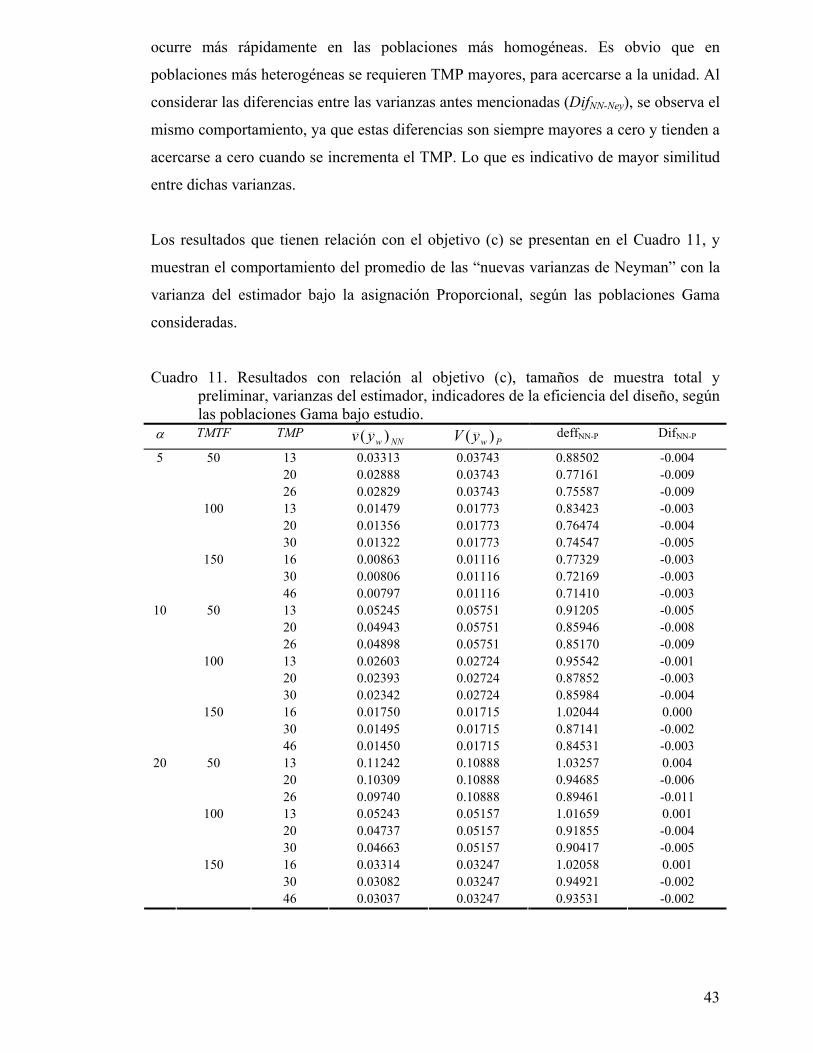
43
ocurre más rápidamente en las poblaciones más homogéneas. Es obvio que en
poblaciones más heterogéneas se requieren TMP mayores, para acercarse a la unidad. Al
considerar las diferencias entre las varianzas antes mencionadas (DifNN-Ney), se observa el
mismo comportamiento, ya que estas diferencias son siempre mayores a cero y tienden a
acercarse a cero cuando se incrementa el TMP. Lo que es indicativo de mayor similitud
entre dichas varianzas.
Los resultados que tienen relación con el objetivo (c) se presentan en el Cuadro 11, y
muestran el comportamiento del promedio de las “nuevas varianzas de Neyman” con la
varianza del estimador bajo la asignación Proporcional, según las poblaciones Gama
consideradas.
Cuadro 11. Resultados con relación al objetivo (c), tamaños de muestra total y preliminar, varianzas del estimador, indicadores de la eficiencia del diseño, según las poblaciones Gama bajo estudio.
α TMTF TMP NNwyv )( PwyV )( deffNN-P DifNN-P
13 0.03313 0.03743 0.88502 -0.004 20 0.02888 0.03743 0.77161 -0.009
50
26 0.02829 0.03743 0.75587 -0.009 13 0.01479 0.01773 0.83423 -0.003 20 0.01356 0.01773 0.76474 -0.004
100
30 0.01322 0.01773 0.74547 -0.005 16 0.00863 0.01116 0.77329 -0.003 30 0.00806 0.01116 0.72169 -0.003
5
150
46 0.00797 0.01116 0.71410 -0.003 13 0.05245 0.05751 0.91205 -0.005 20 0.04943 0.05751 0.85946 -0.008
50
26 0.04898 0.05751 0.85170 -0.009 13 0.02603 0.02724 0.95542 -0.001 20 0.02393 0.02724 0.87852 -0.003
100
30 0.02342 0.02724 0.85984 -0.004 16 0.01750 0.01715 1.02044 0.000 30 0.01495 0.01715 0.87141 -0.002
10
150
46 0.01450 0.01715 0.84531 -0.003 13 0.11242 0.10888 1.03257 0.004 20 0.10309 0.10888 0.94685 -0.006
50
26 0.09740 0.10888 0.89461 -0.011 13 0.05243 0.05157 1.01659 0.001 20 0.04737 0.05157 0.91855 -0.004
100
30 0.04663 0.05157 0.90417 -0.005 16 0.03314 0.03247 1.02058 0.001 30 0.03082 0.03247 0.94921 -0.002
20
150
46 0.03037 0.03247 0.93531 -0.002

44
Según el Cuadro 11 y las Figuras 7, 8 y 9, en las tres poblaciones Gama, para cada
TMTF al incrementar el TMP, el indicador deffNN-P tiende a disminuir, se observa que
este indicador es menor en las poblaciones menos heterogéneas. La misma tendencia se
observa con la diferencia entre el promedio de las “nuevas varianzas de Neyman” y la
varianza del estimador obtenida a través del método de asignación Proporcional (DifNN-
P), ya que en la población más homogénea todas las diferencias son menores a cero, cosa
que no sucede, en todos los casos, en las otras dos poblaciones con mayor variabilidad.
0.6
0.7
0.8
0.9
1
1.1
1.2
1.3
Aa Ab Ac Ba Bb Bc Ca Cb Cc
Efic
ienc
ia d
el d
iseñ
o de
mue
stre
o
deff NN-Ndeff NN-Pdeff N-P
Figura 7. Índices de la eficiencia del diseño de muestreo considerando el promedio de las
varianzas estimadas de Neyman, la varianza paramétrica proporcional y la varianza paramétrica de Neyman, obtenidos a partir de una población Gama con parámetro α igual a 5.
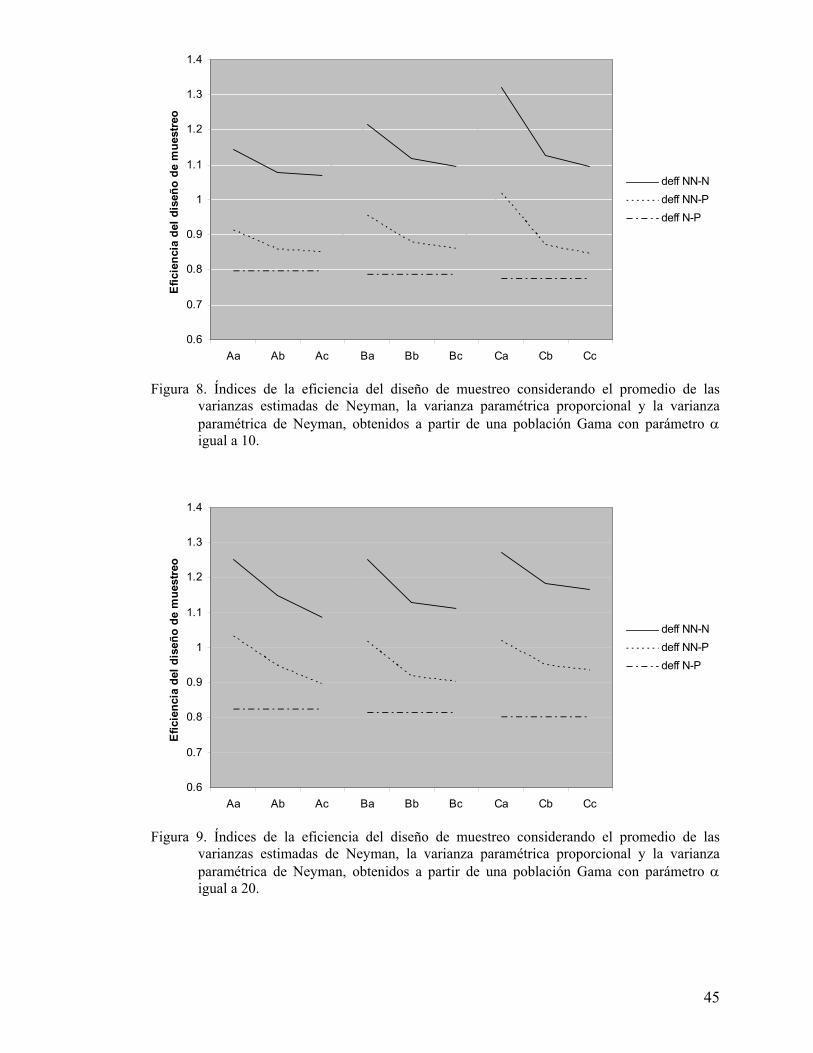
45
0.6
0.7
0.8
0.9
1
1.1
1.2
1.3
1.4
Aa Ab Ac Ba Bb Bc Ca Cb Cc
Efic
ienc
ia d
el d
iseñ
o de
mue
stre
odeff NN-Ndeff NN-Pdeff N-P
Figura 8. Índices de la eficiencia del diseño de muestreo considerando el promedio de las
varianzas estimadas de Neyman, la varianza paramétrica proporcional y la varianza paramétrica de Neyman, obtenidos a partir de una población Gama con parámetro α igual a 10.
0.6
0.7
0.8
0.9
1
1.1
1.2
1.3
1.4
Aa Ab Ac Ba Bb Bc Ca Cb Cc
Efic
ienc
ia d
el d
iseñ
o de
mue
stre
o
deff NN-Ndeff NN-Pdeff N-P
Figura 9. Índices de la eficiencia del diseño de muestreo considerando el promedio de las
varianzas estimadas de Neyman, la varianza paramétrica proporcional y la varianza paramétrica de Neyman, obtenidos a partir de una población Gama con parámetro α igual a 20.

46
Con base en lo anterior se deduce que, con TMP moderadamente pequeños y en
poblaciones Gama, la asignación de Neyman bajo la estimación de las desviaciones
estándares de los estratos proporciona, en promedio, estimaciones más precisas del
estimador de la media que la asignación proporcional.
Al igual que en las poblaciones normales, parece ser que los resultados obtenidos no
concuerdan con las conclusiones que se derivan de la ecuación (2.30), ecuación derivada
para poblaciones normales, donde se dice que mientras mayor sea la variabilidad entre
las desviaciones estándares de los estratos, menor será el TMP requerido para que, en
promedio la asignación de Neyman proporcione estimaciones más precisas que la
asignación Proporcional. Sin embargo, también en las poblaciones Gama, al incrementar
la varianza de la población, se incrementó la varianza entre los estratos y, se aumentó la
varianza dentro de los estratos, hecho que influye sobre el TMP requerido.
4.5. Distribución Poisson.
Ahora, el Cuadro 12 muestra los resultados pertinentes al primer objetivo de este estudio
(a), obtenidos en poblaciones con distribución Poisson; los resultados mostrados son la
desviación estándar de la población, las desviaciones estándares de loes estratos, las
variaciones entre los estratos, las varianzas censales del estimador de la media bajo las
asignaciones de Neyman y Proporcional, los indicadores de la eficiencia del diseño de
muestreo que compara las varianzas anteriores y las diferencias entre estas varianzas.
En el Cuadro 12 se muestra que las desviaciones estándares dentro de los estratos son
menores que la desviación estándar de la población, lo anterior indica que la
estratificación contribuyó a realizar un bloqueo sobre la variación. Se observa que las
desviaciones estándares son diferentes de estrato a estrato; asimismo los tamaños de los
estratos también son diferentes, por lo que se supone que el método de asignación de
Neyman bajo estimaciones de las desviaciones estándares de los estratos proporcionará
estimaciones más precisas del estimador de la media que el método de asignación
proporcional, lo anterior coincide con lo señalado por Rendón (1998).
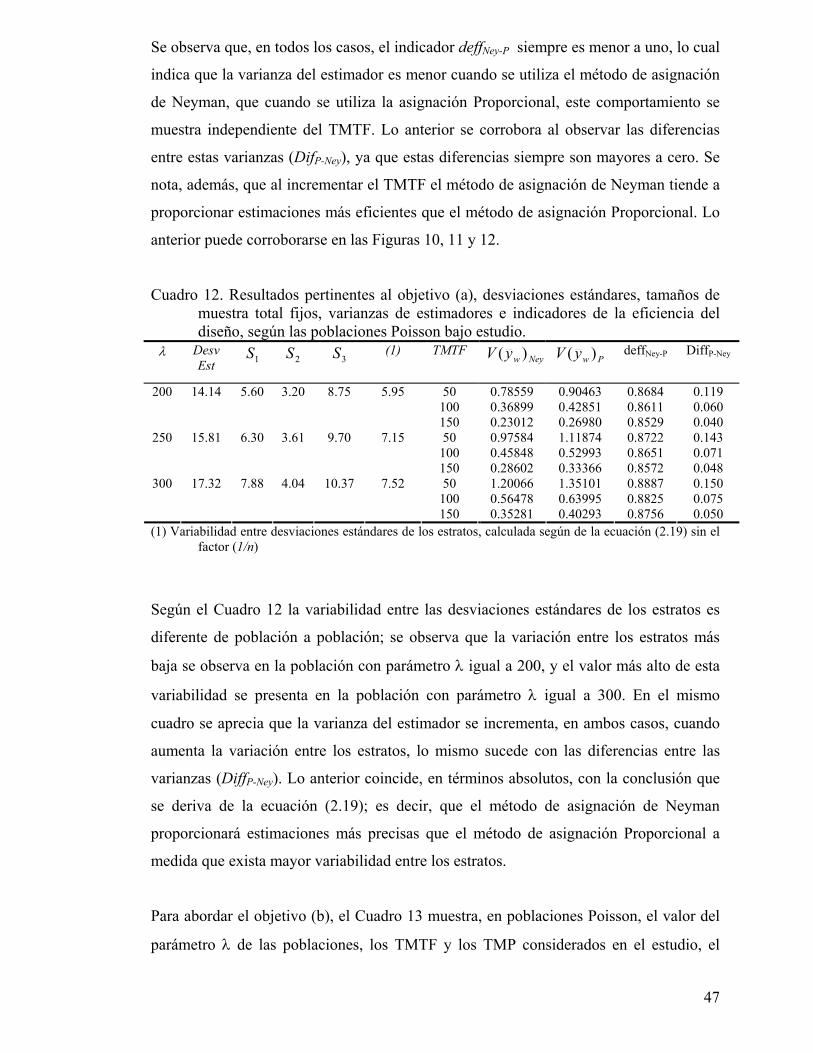
47
Se observa que, en todos los casos, el indicador deffNey-P siempre es menor a uno, lo cual
indica que la varianza del estimador es menor cuando se utiliza el método de asignación
de Neyman, que cuando se utiliza la asignación Proporcional, este comportamiento se
muestra independiente del TMTF. Lo anterior se corrobora al observar las diferencias
entre estas varianzas (DifP-Ney), ya que estas diferencias siempre son mayores a cero. Se
nota, además, que al incrementar el TMTF el método de asignación de Neyman tiende a
proporcionar estimaciones más eficientes que el método de asignación Proporcional. Lo
anterior puede corroborarse en las Figuras 10, 11 y 12.
Cuadro 12. Resultados pertinentes al objetivo (a), desviaciones estándares, tamaños de muestra total fijos, varianzas de estimadores e indicadores de la eficiencia del diseño, según las poblaciones Poisson bajo estudio.
λ Desv Est 1S 2S 3S (1) TMTF
NeywyV )(
PwyV )( deffNey-P DiffP-Ney
50 0.78559 0.90463 0.8684 0.119 100 0.36899 0.42851 0.8611 0.060
200 14.14 5.60 3.20 8.75 5.95
150 0.23012 0.26980 0.8529 0.040 50 0.97584 1.11874 0.8722 0.143
100 0.45848 0.52993 0.8651 0.071 250 15.81 6.30 3.61 9.70 7.15
150 0.28602 0.33366 0.8572 0.048 50 1.20066 1.35101 0.8887 0.150
100 0.56478 0.63995 0.8825 0.075 300 17.32 7.88 4.04 10.37 7.52
150 0.35281 0.40293 0.8756 0.050 (1) Variabilidad entre desviaciones estándares de los estratos, calculada según de la ecuación (2.19) sin el
factor (1/n)
Según el Cuadro 12 la variabilidad entre las desviaciones estándares de los estratos es
diferente de población a población; se observa que la variación entre los estratos más
baja se observa en la población con parámetro λ igual a 200, y el valor más alto de esta
variabilidad se presenta en la población con parámetro λ igual a 300. En el mismo
cuadro se aprecia que la varianza del estimador se incrementa, en ambos casos, cuando
aumenta la variación entre los estratos, lo mismo sucede con las diferencias entre las
varianzas (DiffP-Ney). Lo anterior coincide, en términos absolutos, con la conclusión que
se deriva de la ecuación (2.19); es decir, que el método de asignación de Neyman
proporcionará estimaciones más precisas que el método de asignación Proporcional a
medida que exista mayor variabilidad entre los estratos.
Para abordar el objetivo (b), el Cuadro 13 muestra, en poblaciones Poisson, el valor del
parámetro λ de las poblaciones, los TMTF y los TMP considerados en el estudio, el
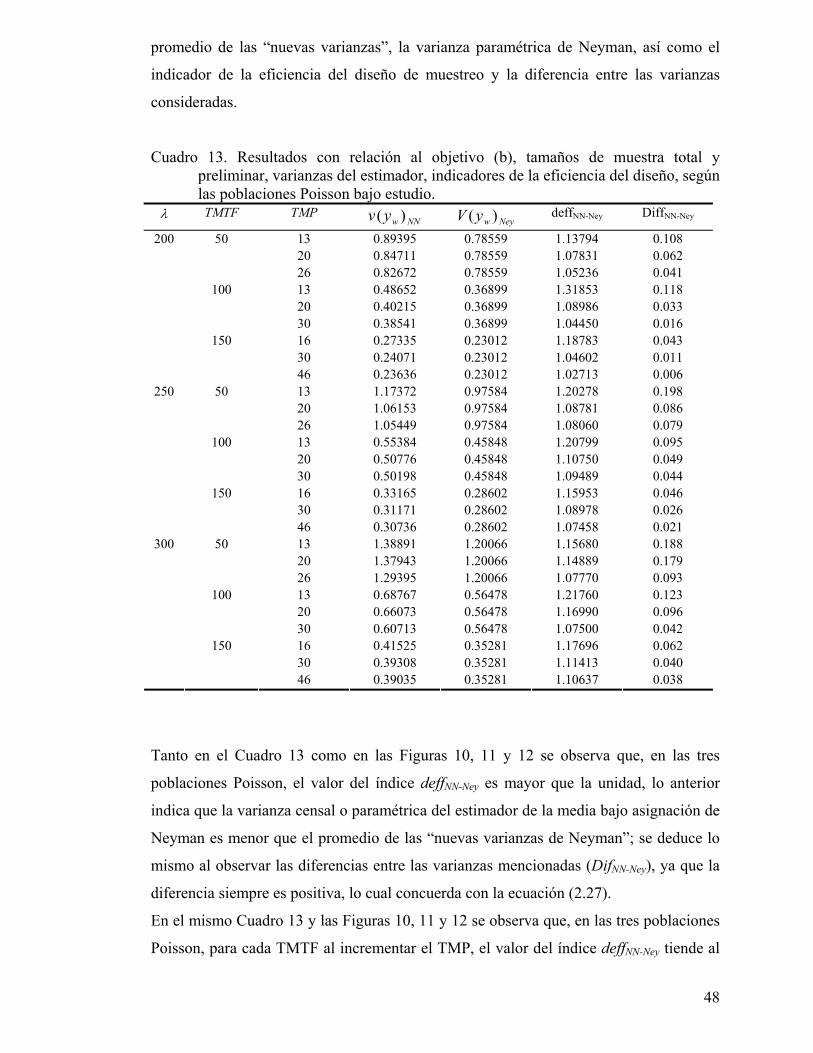
48
promedio de las “nuevas varianzas”, la varianza paramétrica de Neyman, así como el
indicador de la eficiencia del diseño de muestreo y la diferencia entre las varianzas
consideradas.
Cuadro 13. Resultados con relación al objetivo (b), tamaños de muestra total y preliminar, varianzas del estimador, indicadores de la eficiencia del diseño, según las poblaciones Poisson bajo estudio.
λ TMTF TMP NNwyv )( NeywyV )( deffNN-Ney DiffNN-Ney
13 0.89395 0.78559 1.13794 0.108 20 0.84711 0.78559 1.07831 0.062
50
26 0.82672 0.78559 1.05236 0.041 13 0.48652 0.36899 1.31853 0.118 20 0.40215 0.36899 1.08986 0.033
100
30 0.38541 0.36899 1.04450 0.016 16 0.27335 0.23012 1.18783 0.043 30 0.24071 0.23012 1.04602 0.011
200
150
46 0.23636 0.23012 1.02713 0.006 13 1.17372 0.97584 1.20278 0.198 20 1.06153 0.97584 1.08781 0.086
50
26 1.05449 0.97584 1.08060 0.079 13 0.55384 0.45848 1.20799 0.095 20 0.50776 0.45848 1.10750 0.049
100
30 0.50198 0.45848 1.09489 0.044 16 0.33165 0.28602 1.15953 0.046 30 0.31171 0.28602 1.08978 0.026
250
150
46 0.30736 0.28602 1.07458 0.021 13 1.38891 1.20066 1.15680 0.188 20 1.37943 1.20066 1.14889 0.179
50
26 1.29395 1.20066 1.07770 0.093 13 0.68767 0.56478 1.21760 0.123 20 0.66073 0.56478 1.16990 0.096
100
30 0.60713 0.56478 1.07500 0.042 16 0.41525 0.35281 1.17696 0.062 30 0.39308 0.35281 1.11413 0.040
300
150
46 0.39035 0.35281 1.10637 0.038
Tanto en el Cuadro 13 como en las Figuras 10, 11 y 12 se observa que, en las tres
poblaciones Poisson, el valor del índice deffNN-Ney es mayor que la unidad, lo anterior
indica que la varianza censal o paramétrica del estimador de la media bajo asignación de
Neyman es menor que el promedio de las “nuevas varianzas de Neyman”; se deduce lo
mismo al observar las diferencias entre las varianzas mencionadas (DifNN-Ney), ya que la
diferencia siempre es positiva, lo cual concuerda con la ecuación (2.27).
En el mismo Cuadro 13 y las Figuras 10, 11 y 12 se observa que, en las tres poblaciones
Poisson, para cada TMTF al incrementar el TMP, el valor del índice deffNN-Ney tiende al
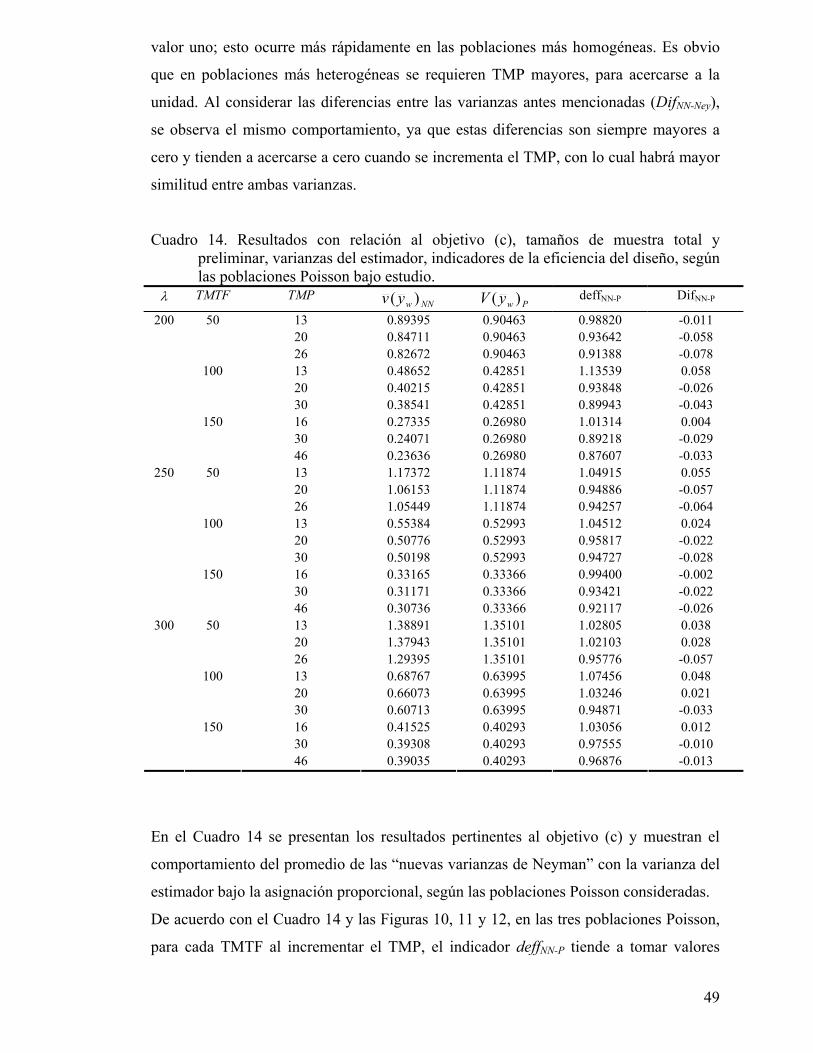
49
valor uno; esto ocurre más rápidamente en las poblaciones más homogéneas. Es obvio
que en poblaciones más heterogéneas se requieren TMP mayores, para acercarse a la
unidad. Al considerar las diferencias entre las varianzas antes mencionadas (DifNN-Ney),
se observa el mismo comportamiento, ya que estas diferencias son siempre mayores a
cero y tienden a acercarse a cero cuando se incrementa el TMP, con lo cual habrá mayor
similitud entre ambas varianzas.
Cuadro 14. Resultados con relación al objetivo (c), tamaños de muestra total y preliminar, varianzas del estimador, indicadores de la eficiencia del diseño, según las poblaciones Poisson bajo estudio.
λ TMTF TMP NNwyv )( PwyV )( deffNN-P DifNN-P
13 0.89395 0.90463 0.98820 -0.011 20 0.84711 0.90463 0.93642 -0.058
50
26 0.82672 0.90463 0.91388 -0.078 13 0.48652 0.42851 1.13539 0.058 20 0.40215 0.42851 0.93848 -0.026
100
30 0.38541 0.42851 0.89943 -0.043 16 0.27335 0.26980 1.01314 0.004 30 0.24071 0.26980 0.89218 -0.029
200
150
46 0.23636 0.26980 0.87607 -0.033 13 1.17372 1.11874 1.04915 0.055 20 1.06153 1.11874 0.94886 -0.057
50
26 1.05449 1.11874 0.94257 -0.064 13 0.55384 0.52993 1.04512 0.024 20 0.50776 0.52993 0.95817 -0.022
100
30 0.50198 0.52993 0.94727 -0.028 16 0.33165 0.33366 0.99400 -0.002 30 0.31171 0.33366 0.93421 -0.022
250
150
46 0.30736 0.33366 0.92117 -0.026 13 1.38891 1.35101 1.02805 0.038 20 1.37943 1.35101 1.02103 0.028
50
26 1.29395 1.35101 0.95776 -0.057 13 0.68767 0.63995 1.07456 0.048 20 0.66073 0.63995 1.03246 0.021
100
30 0.60713 0.63995 0.94871 -0.033 16 0.41525 0.40293 1.03056 0.012 30 0.39308 0.40293 0.97555 -0.010
300
150
46 0.39035 0.40293 0.96876 -0.013
En el Cuadro 14 se presentan los resultados pertinentes al objetivo (c) y muestran el
comportamiento del promedio de las “nuevas varianzas de Neyman” con la varianza del
estimador bajo la asignación proporcional, según las poblaciones Poisson consideradas.
De acuerdo con el Cuadro 14 y las Figuras 10, 11 y 12, en las tres poblaciones Poisson,
para cada TMTF al incrementar el TMP, el indicador deffNN-P tiende a tomar valores
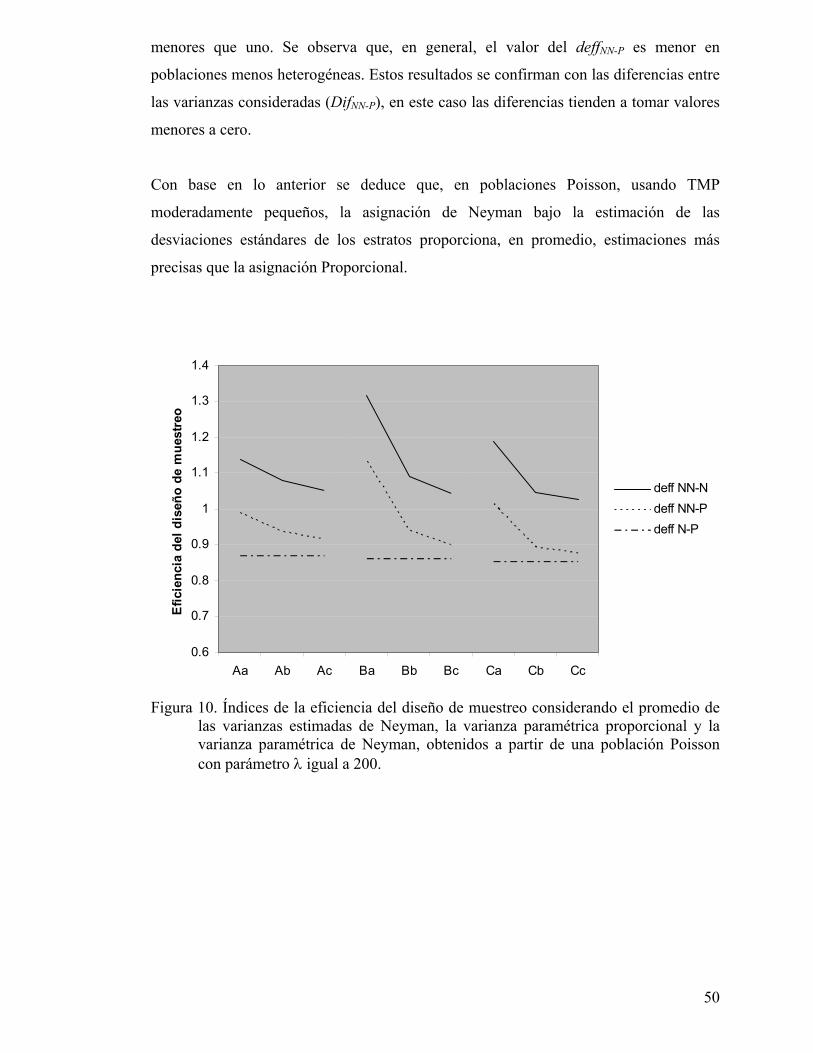
50
menores que uno. Se observa que, en general, el valor del deffNN-P es menor en
poblaciones menos heterogéneas. Estos resultados se confirman con las diferencias entre
las varianzas consideradas (DifNN-P), en este caso las diferencias tienden a tomar valores
menores a cero.
Con base en lo anterior se deduce que, en poblaciones Poisson, usando TMP
moderadamente pequeños, la asignación de Neyman bajo la estimación de las
desviaciones estándares de los estratos proporciona, en promedio, estimaciones más
precisas que la asignación Proporcional.
0.6
0.7
0.8
0.9
1
1.1
1.2
1.3
1.4
Aa Ab Ac Ba Bb Bc Ca Cb Cc
Efic
ienc
ia d
el d
iseñ
o de
mue
stre
o
deff NN-Ndeff NN-Pdeff N-P
Figura 10. Índices de la eficiencia del diseño de muestreo considerando el promedio de
las varianzas estimadas de Neyman, la varianza paramétrica proporcional y la varianza paramétrica de Neyman, obtenidos a partir de una población Poisson con parámetro λ igual a 200.
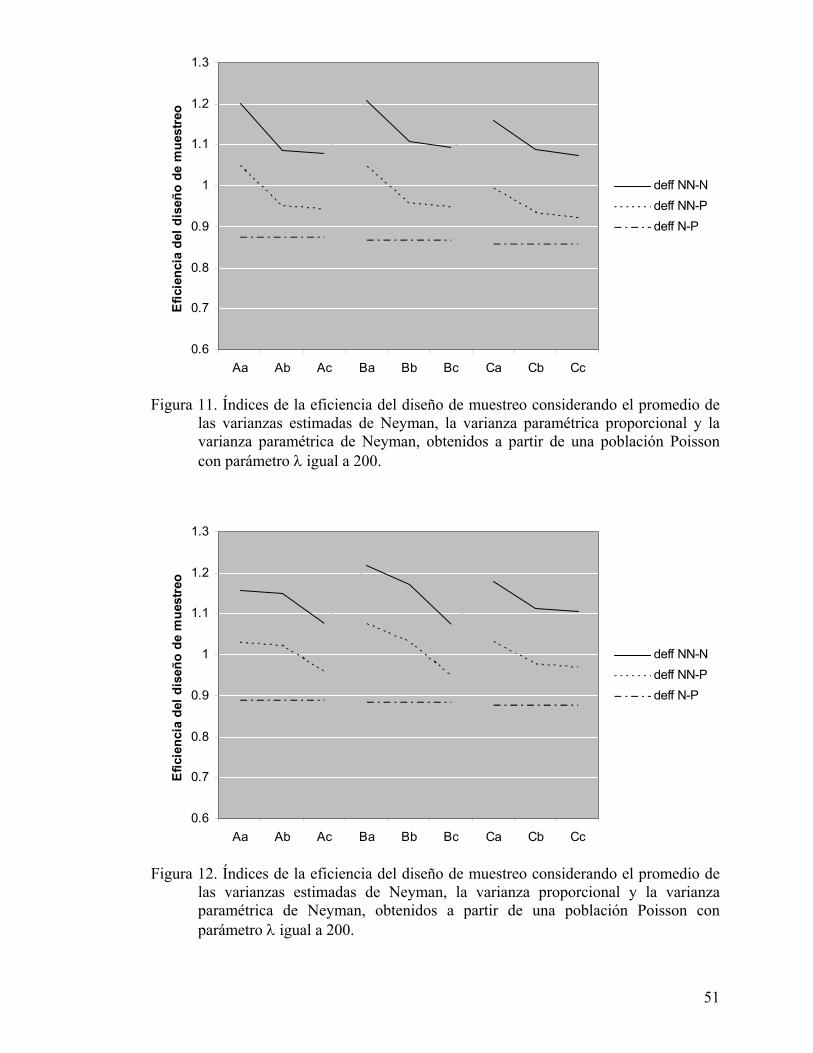
51
0.6
0.7
0.8
0.9
1
1.1
1.2
1.3
Aa Ab Ac Ba Bb Bc Ca Cb Cc
Efic
ienc
ia d
el d
iseñ
o de
mue
stre
odeff NN-Ndeff NN-Pdeff N-P
Figura 11. Índices de la eficiencia del diseño de muestreo considerando el promedio de
las varianzas estimadas de Neyman, la varianza paramétrica proporcional y la varianza paramétrica de Neyman, obtenidos a partir de una población Poisson con parámetro λ igual a 200.
0.6
0.7
0.8
0.9
1
1.1
1.2
1.3
Aa Ab Ac Ba Bb Bc Ca Cb Cc
Efic
ienc
ia d
el d
iseñ
o de
mue
stre
o
deff NN-Ndeff NN-Pdeff N-P
Figura 12. Índices de la eficiencia del diseño de muestreo considerando el promedio de
las varianzas estimadas de Neyman, la varianza proporcional y la varianza paramétrica de Neyman, obtenidos a partir de una población Poisson con parámetro λ igual a 200.

52
4.6. Consideraciones Generales.
Al considerar el caso del primer objetivo de estudio (a), se puede afirmar que; en las
poblaciones con distribuciones normales, Ji-cuadrada, Gama y Poisson, la varianza
censal del estimador de la media obtenido a través de la asignación de Neyman del MAE
es menor que la varianza censal del estimador obtenida mediante la asignación
Proporcional, independientemente del TMTF; es decir, la asignación de Neyman
proporciona estimaciones más precisas que la proporcional; hecho que puede
corroborarse al analizar el indicador deffNey-P, el cual siempre es mayor a la unidad. Los
mismos resultados se obtienen al analizar las diferencias entre las varianzas
anteriormente mencionadas, pues estas diferencias siempre son mayores a cero (DiffP-
Ney).
Al abordar el objetivo (b), para poblaciones con distribuciones Normal, Ji-cuadrada,
Gama y Poisson, puede señalarse que la varianza censal del estimador de la media bajo
asignación de Neyman del MAE, en general es menor que el promedio de la “nueva
varianza de Neyman”, ya que el indicador deffNN-N es mayor que uno y, las diferencias
entre estas varianzas (DiffNN-P), son mayores a cero. Sin embargo se observa que, con
cualquier TMTF al incrementar el TMP, el indicador deffNN-N tiende a tomar valores
cercanos a la unidad y la diferencia entre las varianzas consideradas (DiffNN-P), tiende a
tomar valores cercanos a cero. De hecho, para TMP moderadamente pequeños en
relación con la población, la varianza censal del estimador de la media bajo asignación
de Neyman y el promedio de la “nueva varianza de Neyman” tienden a ser semejantes.
Esto es, con TMP moderadamente pequeños, en promedio, la asignación de Neyman,
bajo estimación de las Si, i=1,2,…,k, dará estimaciones con una precisión similar que la
de Neyman sin estimación de las Si.
En lo concerniente al objetivo (c), en general, para poblaciones con distribuciones
Normal, Ji-cuadrada, Gama y Poisson, puede decirse que la asignación de Neyman bajo
estimación de las desviaciones estándares de los estratos proporciona, en promedio,
estimadores de la media más precisos que los obtenidos a través de la asignación
Proporcional, cuando se incrementa el TMP. Esto puede observarse en los valores del
índice deffNN-P , los cuales tienden a tomar valores menores que uno cuando se

53
incrementa el TMP, este hecho también puede corroborarse a través de las diferencias
entre el promedio de las “nuevas varianzas de Neyman” y las varianzas del estimador
obtenidas con la asignación Proporcional (DiffNN-P), pues estas tienden a ser menores a
cero a medida que se aumenta el TMP. Además, debe mencionarse que lo anterior
ocurre, en general, para TMP moderadamente pequeños; sin embargo, en el caso
Normal, cuando la población es muy heterogénea, para lograr mejor precisión, en
promedio, que la asignación Proporcional, se requerirán TMP ligeramente mayores a los
usados en este estudio, o bien, incrementar el número de estratos.
Lo referente al objetivo (c) era de esperarse por los resultados obtenidos para el objetivo
(b); ya que el promedio de la “nueva varianza de Neyman” para TMP moderadamente
pequeños, tiende a ser igual a la varianza del estimador de la media bajo asignación de
Neyman sin estimación de las desviaciones estándares de los estratos, y de acuerdo con
la conclusión del objetivo (a), la asignación de Neyman es más eficiente que la
Proporcional. Resultados que son obtenidos independientemente de la distribución de la
población (Normal, Ji-cuadrada, Gama o Poisson), y el tamaño de muestra total fijo.

V. CONCLUSIONES
Según el análisis de los resultados, en cuanto a la eficiencia de las asignaciones de
Neyman y Proporcional en el Muestreo Aleatorio Estratificado, se derivan las siguientes
conclusiones de acuerdo con los objetivos planteados en el presente estudio:
• La asignación de Neyman es más eficiente que la Proporcional,
independientemente del tamaño de muestra total fijo y en poblaciones con
distribuciones Normal, Ji-cuadrada, Gama y Poisson. Esto es, la asignación de
Neyman proporciona estimaciones más precisas que la asignación Proporcional.
• Para poblaciones con distribuciones Normal, Ji-cuadrada, Gama y Poisson, la
varianza del estimador de la media bajo asignación de Neyman, en general, es
menor que el promedio de la “nueva varianza de Neyman”. Sin embargo, para
cualquier tamaño de muestra total fijo y tamaños preliminares moderadamente
pequeños, el promedio de la “nueva varianza de Neyman” tiende a ser semejante
a la varianza del estimador de la media bajo asignación de Neyman.
• En general, para las poblaciones con distribuciones Normal, Ji-cuadrada, Gama y
Poisson, la asignación de Neyman bajo estimación de las desviaciones estándares
de los estratos proporciona, en promedio, estimadores de la media más precisos
que los obtenidos a través de la asignación Proporcional, lo que ocurre con
tamaños de muestra preliminares moderadamente pequeños, en relación con la

55
población. Sin embargo, en el caso de poblaciones normales heterogéneas, para
lograr mejor precisión, en promedio, que la asignación Proporcional, se
requerirán tamaños de muestra preliminares ligeramente mayores a los usados en
este estudio, o bien, incrementar el número de estratos o modificar la
estratificación.

BIBLIOGRAFÍA
Cochran, W.G. (1977). Sampling Techniques. Jonh Wiley and Sons. Third Edition. New
York. USA. pp. 428.
Esquivel B., F. (2003). Algunas alternativas para estimar la matriz de covarianza en un
modelo de regresión lineal bajo un diseño de muestreo complejo. Tesis de
Doctorado. Colegio de Posgraduados. Motecillo, Texcoco. México. pp. 4-7.
Evans, W.D. (1951). “On Stratification and Optimum Allocations”, Journal of the
American Statistical Association, Vol. 46, pp. 95-104.
Mendenhall W., Ott, L. y Scheaffer, R.L. (1987). Elementos de Muestreo. Grupo
Editorial Iberoamérica. México DF. pp 78-112.
Rendón S., G. (1976). Una nota sobre la descomposición de Neyman en muestreo
estratificado. Tesis de Maestría. Escuela Nacional de Agricultura, Colegio de
Posgraduados. Chapingo, Méx.

57
Rendón S., G. (1998). Muestreo, aplicación en la estimación simultánea de varios
parámetros. Universidad Autónoma Chapingo. México.
Rendón S., G. y Carrillo L., A. (1976). Una nota sobre la descomposición de Neyman en
muestreo estratificado. Agrociencias. No. 26: 63-73
Sukhatme, P.V. (1962). Teoría de encuestas por muestreo con aplicaciones. Fondo de
Cultura Económica. México-Buenos Aires.
Sukhatme, P. V. and Sukhatme, B. V. (1970). Sampling theory of surveys with
applications. Iowa State University Press. Iowa. U.S.A.

ANEXO 1
Programa utilizado en la distribución Normal con µ=100 y σ=25 (Se utilizan tres puntos
para indicar que el procedimiento se continua con la misma secuencia).
# Obtención de la población a partir de la distribución normal con p<-rnorm(1000,100,25) # comando para ordenar las unidades de la población en forma ascendente ps<-sort(p) vps<-var(ps) vps # División de la población en tres estratos e1<-ps[1:200] e2<-ps[201:500] e3<-ps[501:1000] # Construcción de una matriz concentradora de las varianzas de cada estrato ve<-matrix(1,1,3) ve[1,1]<-var(e1) ve[1,2]<-var(e2) ve[1,3]<-var(e3) # GRUPO A # Asignación de tamaños de muestra preliminares de cada estrato At1<-3 At2<-4 At3<-6 # Asignación del tamaño de muestra total fijo Ant<-50 # Simulación de la toma de 40 muestras del estrato 1 Am11<-sample(e1,At1) Am12<-sample(e1,At1) Am13<-sample(e1,At1) . .

59
. Am140<-sample(e1,At1) # Obtención de las desviaciones estándares de las muestras del estrato 1 As11<-stdev(Am11) As12<-stdev(Am12) As13<-stdev(Am13) . . . As140<-stdev(Am140) # Simulación de la toma de 40 muestras del estrato 2 Am21<-sample(e2,At2) Am22<-sample(e2,At2) Am23<-sample(e2,At2) . . . Am240<-sample(e2,At2) # Obtención de las desviaciones estándares de las muestras del estrato 2 As21<-stdev(Am21) As22<-stdev(Am22) As23<-stdev(Am23) . . . As240<-stdev(Am240) # Simulación de la toma de 40 muestras del estrato 3 Am31<-sample(e3,At3) Am32<-sample(e3,At3) Am33<-sample(e3,At3) . . . Am340<-sample(e3,At3) # Obtención de las desviaciones estándares de las muestras del estrato 3 As31<-stdev(Am31) As32<-stdev(Am32) As33<-stdev(Am33) . . . As340<-stdev(Am340) # Tamaños de muestra estimados para el estrato 1 usando la asignación de neyman An11<-((Ant*0.2*As11)/(0.2*As11+0.3*As21+0.5*As31)) An12<-((Ant*0.2*As12)/(0.2*As12+0.3*As22+0.5*As32)) An13<-((Ant*0.2*As13)/(0.2*As13+0.3*As23+0.5*As33)) . . . An140<-((Ant*0.2*As140)/(0.2*As140+0.3*As240+0.5*As340))

60
# Tamaños de muestra estimados para el estrato 2 usando la asignación de neyman An21<-((Ant*0.3*As21)/(0.2*As11+0.3*As21+0.5*As31)) An22<-((Ant*0.3*As22)/(0.2*As12+0.3*As22+0.5*As32)) An23<-((Ant*0.3*As23)/(0.2*As13+0.3*As23+0.5*As33)) . . . An240<-((Ant*0.3*As240)/(0.2*As140+0.3*As240+0.5*As340)) # Tamaños de muestra estimados para el estrato 3 usando la asignación de neyman An31<-((Ant*0.5*As31)/(0.2*As11+0.3*As21+0.5*As31)) An32<-((Ant*0.5*As32)/(0.2*As12+0.3*As22+0.5*As32)) An33<-((Ant*0.5*As33)/(0.2*As13+0.3*As23+0.5*As33)) . . . An340<-((Ant*0.5*As340)/(0.2*As140+0.3*As240+0.5*As340)) # Matriz concentradora de los tamaños de muestra estimados de los diferentes
estratos Ame<-matrix(1,40,3) Ame[1,1]<-An11 Ame[2,1]<-An12 Ame[3,1]<-An13 . . . Ame[40,1]<-An140 Ame[1,2]<-An21 Ame[2,2]<-An22 Ame[3,2]<-An23 . . . Ame[40,2]<-An240 Ame[1,3]<-An31 Ame[2,3]<-An32 Ame[3,3]<-An33 . . . Ame[40,3]<-An340 #GRUPO B # Asignación de tamaños de muestra preliminares de cada estrato Bt1<-4 Bt2<-6 Bt3<-10 # Asignación del tamaño de muestra total fijo

61
Bnt<-50 # Simulación de la toma de 40 muestras del estrato 1 Bm11<-sample(e1,Bt1) Bm12<-sample(e1,Bt1) Bm13<-sample(e1,Bt1) . . . Bm140<-sample(e1,Bt1) # Obtención de las desviaciones estándares de las muestras del estrato 1 Bs11<-stdev(Bm11) Bs12<-stdev(Bm12) Bs13<-stdev(Bm13) . . . Bs140<-stdev(Bm140) # Simulación de la toma de 40 muestras del estrato 2 Bm21<-sample(e2,Bt2) Bm22<-sample(e2,Bt2) Bm23<-sample(e2,Bt2) . . . Bm240<-sample(e2,Bt2) # Obtención de las desviaciones estándares de las muestras del estrato 2 Bs21<-stdev(Bm21) Bs22<-stdev(Bm22) Bs23<-stdev(Bm23) . . . Bs240<-stdev(Bm240) # Simulación de la toma de 40 muestras del estrato 3 Bm31<-sample(e3,Bt3) Bm32<-sample(e3,Bt3) Bm33<-sample(e3,Bt3) . . . Bm340<-sample(e3,Bt3) # Obtención de las desviaciones estándares de las muestras del estrato 3 Bs31<-stdev(Bm31) Bs32<-stdev(Bm32) Bs33<-stdev(Bm33) . . . Bs340<-stdev(Bm340)

62
# Tamaños de muestra estimados para el estrato 1 usando la asignación de neyman Bn11<-((Bnt*0.2*Bs11)/(0.2*Bs11+0.3*Bs21+0.5*Bs31)) Bn12<-((Bnt*0.2*Bs12)/(0.2*Bs12+0.3*Bs22+0.5*Bs32)) Bn13<-((Bnt*0.2*Bs13)/(0.2*Bs13+0.3*Bs23+0.5*Bs33)) . . . Bn140<-((Bnt*0.2*Bs140)/(0.2*Bs140+0.3*Bs240+0.5*Bs340)) # Tamaños de muestra estimados para el estrato 2 usando la asignación de neyman Bn21<-((Bnt*0.3*Bs21)/(0.2*Bs11+0.3*Bs21+0.5*Bs31)) Bn22<-((Bnt*0.3*Bs22)/(0.2*Bs12+0.3*Bs22+0.5*Bs32)) Bn23<-((Bnt*0.3*Bs23)/(0.2*Bs13+0.3*Bs23+0.5*Bs33)) . . . Bn240<-((Bnt*0.3*Bs240)/(0.2*Bs140+0.3*Bs240+0.5*Bs340)) # Tamaños de muestra estimados para el estrato 3 usando la asignación de neyman Bn31<-((Bnt*0.5*Bs31)/(0.2*Bs11+0.3*Bs21+0.5*Bs31)) Bn32<-((Bnt*0.5*Bs32)/(0.2*Bs12+0.3*Bs22+0.5*Bs32)) Bn33<-((Bnt*0.5*Bs33)/(0.2*Bs13+0.3*Bs23+0.5*Bs33)) . . . Bn340<-((Bnt*0.5*Bs340)/(0.2*Bs140+0.3*Bs240+0.5*Bs340)) # Matriz concentradora de los tamaños de muestra estimados de los diferentes
estratos Bme<-matrix(1,40,3) Bme[1,1]<-Bn11 Bme[2,1]<-Bn12 Bme[3,1]<-Bn13 . . . Bme[40,1]<-Bn140 Bme[1,2]<-Bn21 Bme[2,2]<-Bn22 Bme[3,2]<-Bn23 . . . Bme[40,2]<-Bn240 Bme[1,3]<-Bn31 Bme[2,3]<-Bn32 Bme[3,3]<-Bn33 . . . Bme[40,3]<-Bn340

63
#GRUPO C . . . #GRUPO I # Asignación de tamaños de muestra preliminares de cada estrato It1<-9 It2<-14 It3<-23 # Asignación del tamaño de muestra total fijo Int<-150 # Simulación de la toma de 40 muestras del estrato 1 Im11<-sample(e1,It1) Im12<-sample(e1,It1) Im13<-sample(e1,It1) . . . Im140<-sample(e1,It1) # Obtención de las desviaciones estándares de las muestras del estrato 1 Is11<-stdev(Im11) Is12<-stdev(Im12) Is13<-stdev(Im13) . . . Is140<-stdev(Im140) # Simulación de la toma de 40 muestras del estrato 2 Im21<-sample(e2,It2) Im22<-sample(e2,It2) Im23<-sample(e2,It2) . . . Im240<-sample(e2,It2) # Obtención de las desviaciones estándares de las muestras del estrato 2 Is21<-stdev(Im21) Is22<-stdev(Im22) Is23<-stdev(Im23) . . . Is240<-stdev(Im240)

64
# Simulación de la toma de 40 muestras del estrato 3 Im31<-sample(e3,It3) Im32<-sample(e3,It3) Im33<-sample(e3,It3) . . . Im340<-sample(e3,It3) # Obtención de las desviaciones estándares de las muestras del estrato 3 Is31<-stdev(Im31) Is32<-stdev(Im32) Is33<-stdev(Im33) . . . Is340<-stdev(Im340) # Tamaños de muestra estimados para el estrato 1 usando la asignación de neyman In11<-((Int*0.2*Is11)/(0.2*Is11+0.3*Is21+0.5*Is31)) In12<-((Int*0.2*Is12)/(0.2*Is12+0.3*Is22+0.5*Is32)) In13<-((Int*0.2*Is13)/(0.2*Is13+0.3*Is23+0.5*Is33)) . . . In140<-((Int*0.2*Is140)/(0.2*Is140+0.3*Is240+0.5*Is340)) # Tamaños de muestra estimados para el estrato 2 usando la asignación de neyman In21<-((Int*0.3*Is21)/(0.2*Is11+0.3*Is21+0.5*Is31)) In22<-((Int*0.3*Is22)/(0.2*Is12+0.3*Is22+0.5*Is32)) In23<-((Int*0.3*Is23)/(0.2*Is13+0.3*Is23+0.5*Is33)) . . . In240<-((Int*0.3*Is240)/(0.2*Is140+0.3*Is240+0.5*Is340)) # Tamaños de muestra estimados para el estrato 3 usando la asignación de neyman In31<-((Int*0.5*Is31)/(0.2*Is11+0.3*Is21+0.5*Is31)) In32<-((Int*0.5*Is32)/(0.2*Is12+0.3*Is22+0.5*Is32)) In33<-((Int*0.5*Is33)/(0.2*Is13+0.3*Is23+0.5*Is33)) . . . In340<-((Int*0.5*Is340)/(0.2*Is140+0.3*Is240+0.5*Is340)) # Matriz concentradora de los tamaños de muestra estimados de los diferentes
estratos Ime<-matrix(1,40,3) Ime[1,1]<-In11 Ime[2,1]<-In12 Ime[3,1]<-In13 . . . Ime[40,1]<-In140

65
Ime[1,2]<-In21 Ime[2,2]<-In22 Ime[3,2]<-In23 . . . Ime[40,2]<-In240 Ime[1,3]<-In31 Ime[2,3]<-In32 Ime[3,3]<-In33 . . . Ime[40,3]<-In340

ANEXO 2
Para las demás distribuciones se realizaron las siguientes modificaciones en el comando de
determinación del tipo de distribución:
n<-rnorm(1000,100, 50) se utilizó para la distribución normal con una media de
100 y una desviación estándar de 50 unidades
n<-rnorm(1000,100, 75) se utilizó para la distribución normal con una media de
100 y una desviación estándar de 75 unidades
n<-rpois(1000,200) se utilizó para la distribución Poisson con parámetro λ
igual a 200
n<-rpois(1000,250) se utilizó para la distribución Poisson con parámetro λ
igual a 250
n<-rpois(1000,300) se utilizó para la distribución Poisson con parámetro λ
igual a 300
n<-rgamma(1000,5) se utilizó para la distribución Gama con parámetro α igual a
5
n<-rgamma(1000,10) se utilizó para la distribución Gama con parámetro α igual a
10
n<-rgamma(1000,20) se utilizó para la distribución Gama con parámetro α igual a
20
n<-rshisq(1000,100) se utilizó para la distribución Ji-cuadrada con 100 grados
de libertad.
n<- rshisq(1000,150) se utilizó para la distribución Ji-cuadrada con 150 grados
de libertad.
n<- rshisq(1000,200) se utilizó para la distribución Ji-cuadrada con 200 grados
de libertad.

67
Para asignar los diferentes tamaños de muestra preliminar se realizaron las siguientes
modificaciones:
Para un tamaño de muestra total fijo de 50 unidades
Para un tamaño de muestra preliminar de 13 unidades de muestreo t1<-3 t2<-4 t3<-6 Para un tamaño de muestra preliminar de 20 unidades de muestreo t1<-4 t2<-6 t3<-10
Para un tamaño de muestra preliminar de 26 unidades de muestreo t1<-5 t2<-8 t3<-13
Para un tamaño de muestra total fijo de 100 unidades
Para un tamaño de muestra preliminar de 13 unidades de muestreo t1<-3 t2<-4 t3<-6 Para un tamaño de muestra preliminar de 20 unidades de muestreo t1<-4 t2<-6 t3<-10
Para un tamaño de muestra preliminar de 30 unidades de muestreo t1<-6 t2<-9 t3<-15
Para un tamaño de muestra total fijo de 150 unidades
Para un tamaño de muestra preliminar de 16 unidades de muestreo t1<-3 t2<-5 t3<-8

68
Para un tamaño de muestra preliminar de 30 unidades de muestreo t1<-6 t2<-9 t3<-15
Para un tamaño de muestra preliminar de 46 unidades de muestreo t1<-9 t2<-14 t3<-23
Para asignar los diferentes tamaños de muestra definitivos se realizaron las siguientes
modificaciones:
nt<-50, para un tamaño de muestral total de 50 unidades nt<-100, para un tamaño de muestral total de 100 unidades nt<-150, para un tamaño de muestral total de 150 unidades
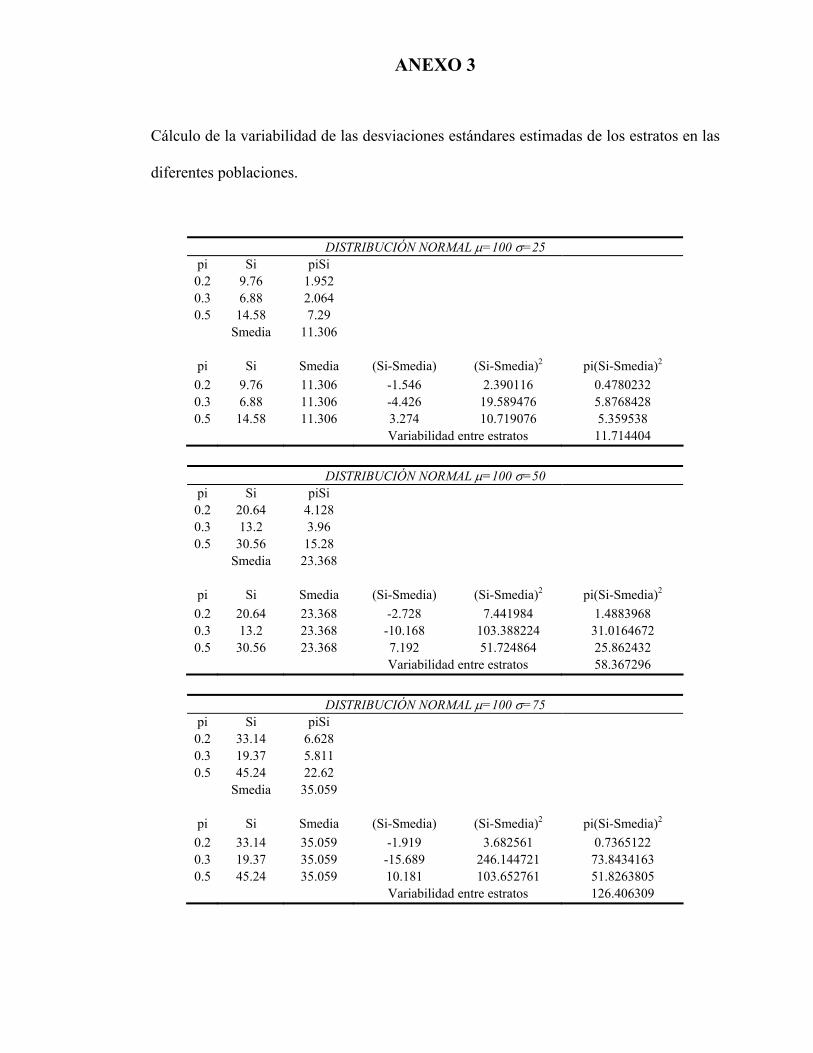
ANEXO 3
Cálculo de la variabilidad de las desviaciones estándares estimadas de los estratos en las
diferentes poblaciones.
DISTRIBUCIÓN NORMAL µ=100 σ=25 pi Si piSi 0.2 9.76 1.952 0.3 6.88 2.064 0.5 14.58 7.29
Smedia 11.306
pi Si Smedia (Si-Smedia) (Si-Smedia)2 pi(Si-Smedia)2 0.2 9.76 11.306 -1.546 2.390116 0.4780232 0.3 6.88 11.306 -4.426 19.589476 5.8768428 0.5 14.58 11.306 3.274 10.719076 5.359538
Variabilidad entre estratos 11.714404
DISTRIBUCIÓN NORMAL µ=100 σ=50 pi Si piSi 0.2 20.64 4.128 0.3 13.2 3.96 0.5 30.56 15.28
Smedia 23.368
pi Si Smedia (Si-Smedia) (Si-Smedia)2 pi(Si-Smedia)2 0.2 20.64 23.368 -2.728 7.441984 1.4883968 0.3 13.2 23.368 -10.168 103.388224 31.0164672 0.5 30.56 23.368 7.192 51.724864 25.862432
Variabilidad entre estratos 58.367296
DISTRIBUCIÓN NORMAL µ=100 σ=75 pi Si piSi 0.2 33.14 6.628 0.3 19.37 5.811 0.5 45.24 22.62
Smedia 35.059
pi Si Smedia (Si-Smedia) (Si-Smedia)2 pi(Si-Smedia)2 0.2 33.14 35.059 -1.919 3.682561 0.7365122 0.3 19.37 35.059 -15.689 246.144721 73.8434163 0.5 45.24 35.059 10.181 103.652761 51.8263805
Variabilidad entre estratos 126.406309
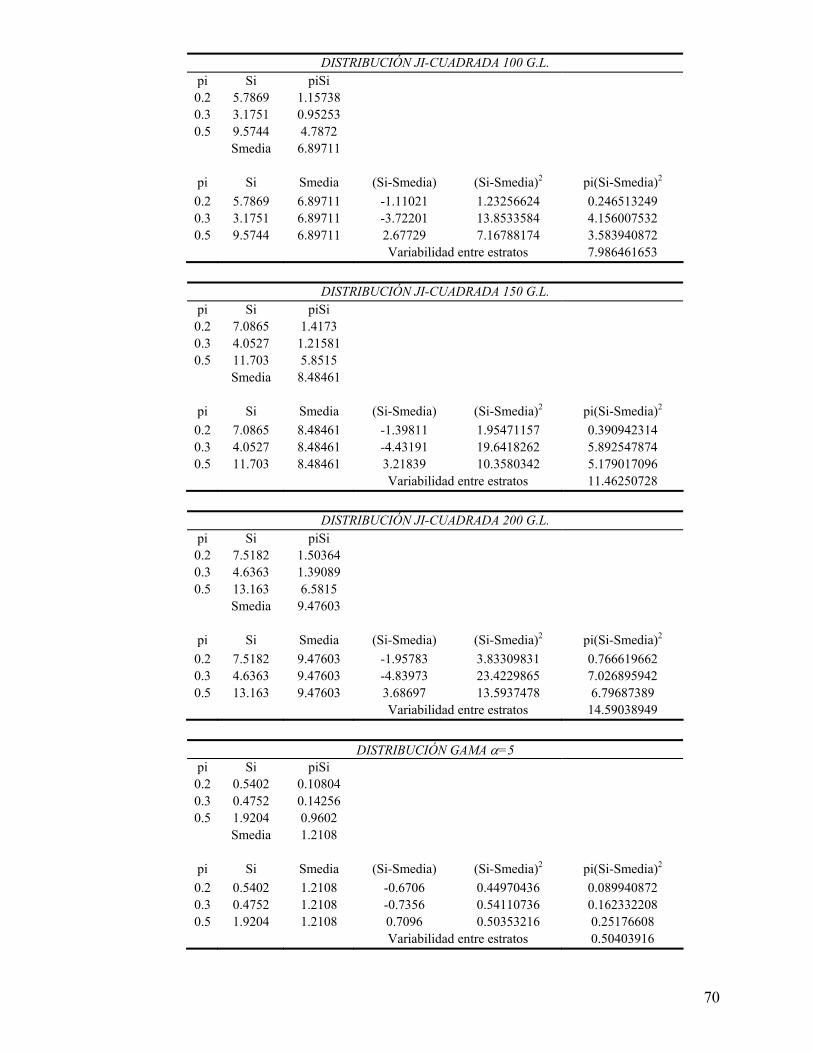
70
DISTRIBUCIÓN JI-CUADRADA 100 G.L.
pi Si piSi 0.2 5.7869 1.15738 0.3 3.1751 0.95253 0.5 9.5744 4.7872
Smedia 6.89711
pi Si Smedia (Si-Smedia) (Si-Smedia)2 pi(Si-Smedia)2 0.2 5.7869 6.89711 -1.11021 1.23256624 0.246513249 0.3 3.1751 6.89711 -3.72201 13.8533584 4.156007532 0.5 9.5744 6.89711 2.67729 7.16788174 3.583940872
Variabilidad entre estratos 7.986461653
DISTRIBUCIÓN JI-CUADRADA 150 G.L. pi Si piSi 0.2 7.0865 1.4173 0.3 4.0527 1.21581 0.5 11.703 5.8515
Smedia 8.48461
pi Si Smedia (Si-Smedia) (Si-Smedia)2 pi(Si-Smedia)2 0.2 7.0865 8.48461 -1.39811 1.95471157 0.390942314 0.3 4.0527 8.48461 -4.43191 19.6418262 5.892547874 0.5 11.703 8.48461 3.21839 10.3580342 5.179017096
Variabilidad entre estratos 11.46250728
DISTRIBUCIÓN JI-CUADRADA 200 G.L. pi Si piSi 0.2 7.5182 1.50364 0.3 4.6363 1.39089 0.5 13.163 6.5815
Smedia 9.47603
pi Si Smedia (Si-Smedia) (Si-Smedia)2 pi(Si-Smedia)2 0.2 7.5182 9.47603 -1.95783 3.83309831 0.766619662 0.3 4.6363 9.47603 -4.83973 23.4229865 7.026895942 0.5 13.163 9.47603 3.68697 13.5937478 6.79687389
Variabilidad entre estratos 14.59038949
DISTRIBUCIÓN GAMA α=5 pi Si piSi 0.2 0.5402 0.10804 0.3 0.4752 0.14256 0.5 1.9204 0.9602
Smedia 1.2108
pi Si Smedia (Si-Smedia) (Si-Smedia)2 pi(Si-Smedia)2 0.2 0.5402 1.2108 -0.6706 0.44970436 0.089940872 0.3 0.4752 1.2108 -0.7356 0.54110736 0.162332208 0.5 1.9204 1.2108 0.7096 0.50353216 0.25176608
Variabilidad entre estratos 0.50403916
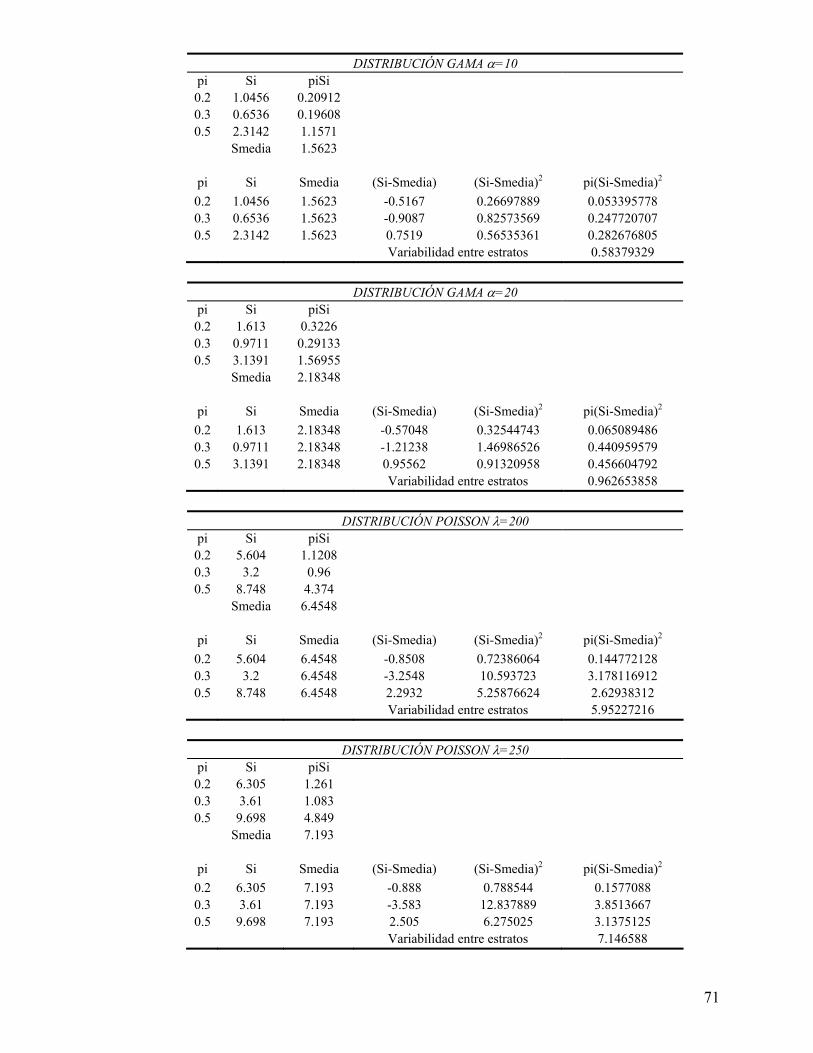
71
DISTRIBUCIÓN GAMA α=10
pi Si piSi 0.2 1.0456 0.20912 0.3 0.6536 0.19608 0.5 2.3142 1.1571
Smedia 1.5623
pi Si Smedia (Si-Smedia) (Si-Smedia)2 pi(Si-Smedia)2 0.2 1.0456 1.5623 -0.5167 0.26697889 0.053395778 0.3 0.6536 1.5623 -0.9087 0.82573569 0.247720707 0.5 2.3142 1.5623 0.7519 0.56535361 0.282676805
Variabilidad entre estratos 0.58379329
DISTRIBUCIÓN GAMA α=20 pi Si piSi 0.2 1.613 0.3226 0.3 0.9711 0.29133 0.5 3.1391 1.56955
Smedia 2.18348
pi Si Smedia (Si-Smedia) (Si-Smedia)2 pi(Si-Smedia)2 0.2 1.613 2.18348 -0.57048 0.32544743 0.065089486 0.3 0.9711 2.18348 -1.21238 1.46986526 0.440959579 0.5 3.1391 2.18348 0.95562 0.91320958 0.456604792
Variabilidad entre estratos 0.962653858
DISTRIBUCIÓN POISSON λ=200 pi Si piSi 0.2 5.604 1.1208 0.3 3.2 0.96 0.5 8.748 4.374
Smedia 6.4548
pi Si Smedia (Si-Smedia) (Si-Smedia)2 pi(Si-Smedia)2 0.2 5.604 6.4548 -0.8508 0.72386064 0.144772128 0.3 3.2 6.4548 -3.2548 10.593723 3.178116912 0.5 8.748 6.4548 2.2932 5.25876624 2.62938312
Variabilidad entre estratos 5.95227216
DISTRIBUCIÓN POISSON λ=250 pi Si piSi 0.2 6.305 1.261 0.3 3.61 1.083 0.5 9.698 4.849
Smedia 7.193
pi Si Smedia (Si-Smedia) (Si-Smedia)2 pi(Si-Smedia)2 0.2 6.305 7.193 -0.888 0.788544 0.1577088 0.3 3.61 7.193 -3.583 12.837889 3.8513667 0.5 9.698 7.193 2.505 6.275025 3.1375125
Variabilidad entre estratos 7.146588
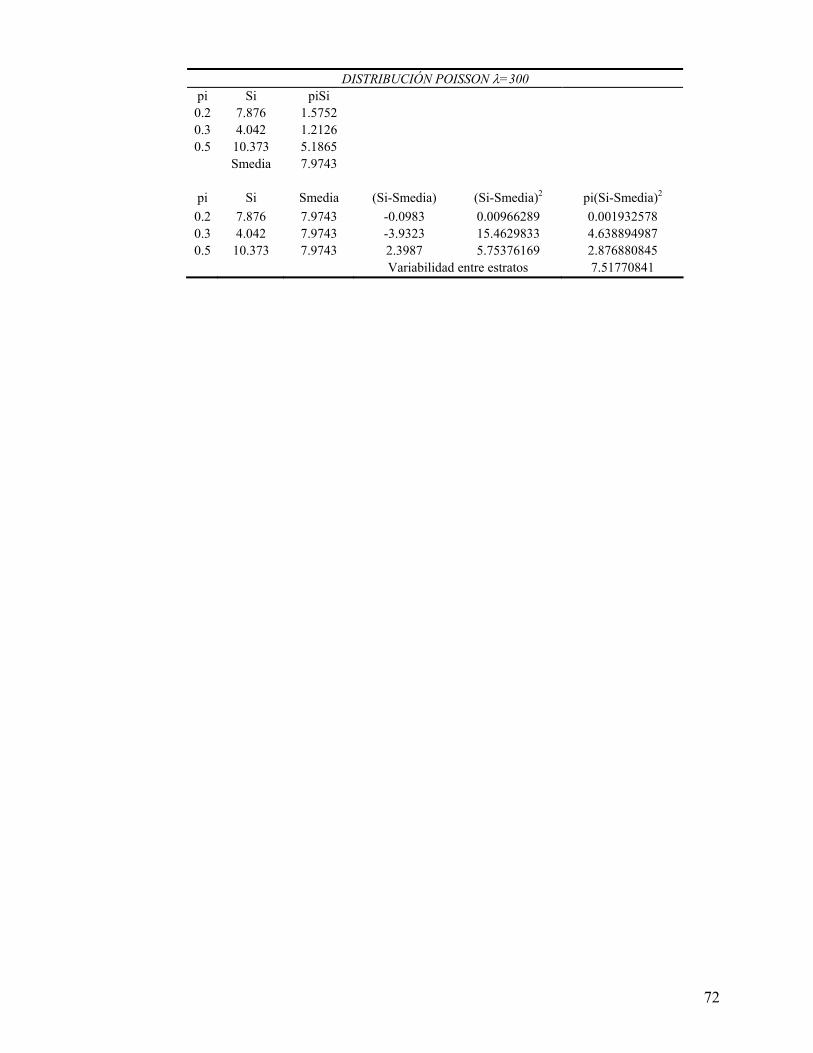
72
DISTRIBUCIÓN POISSON λ=300 pi Si piSi 0.2 7.876 1.5752 0.3 4.042 1.2126 0.5 10.373 5.1865
Smedia 7.9743
pi Si Smedia (Si-Smedia) (Si-Smedia)2 pi(Si-Smedia)2 0.2 7.876 7.9743 -0.0983 0.00966289 0.001932578 0.3 4.042 7.9743 -3.9323 15.4629833 4.638894987 0.5 10.373 7.9743 2.3987 5.75376169 2.876880845
Variabilidad entre estratos 7.51770841





























