Embed Size (px)
Citation preview

• El artículo científico es un informe escrito y publicado que describe resultados originales de investigación
• Es el método principal para comunicar los resultados científicos

• Para escribir estos consejos me he basado en las siguientes fuentes y en mi propia experiencia







IMRAD

IMRaD • Introducción
– ¿Por qué hiciste la investigación?
• Materiales y método – ¿Qué usaste y cómo lo usaste?
• Resultados: – ¿Qué encontraste?
• And • Discusión:
– ¿Qué significa, qué implica lo que encontraste?
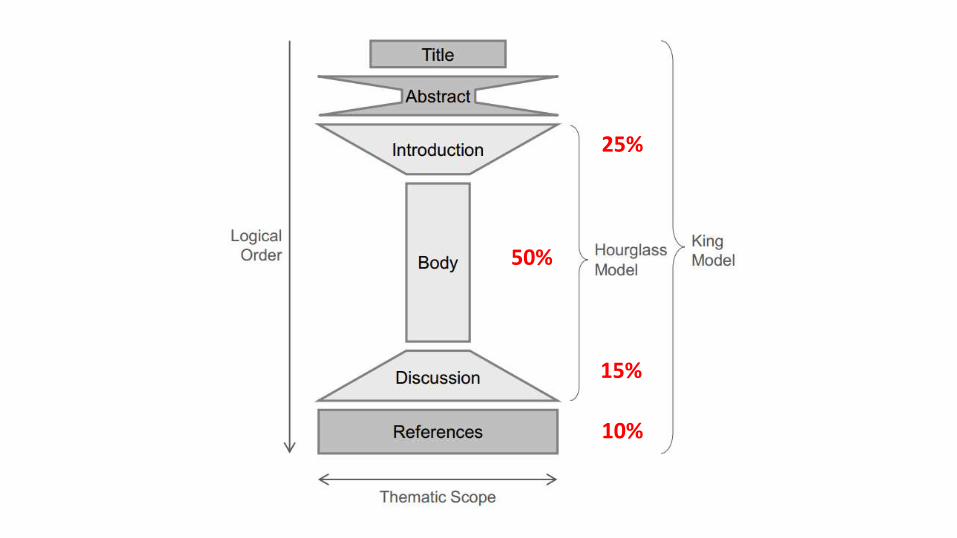
25%
50%
15%
10%


• ¿El estilo? ¿Cómo se escriben las cosas?


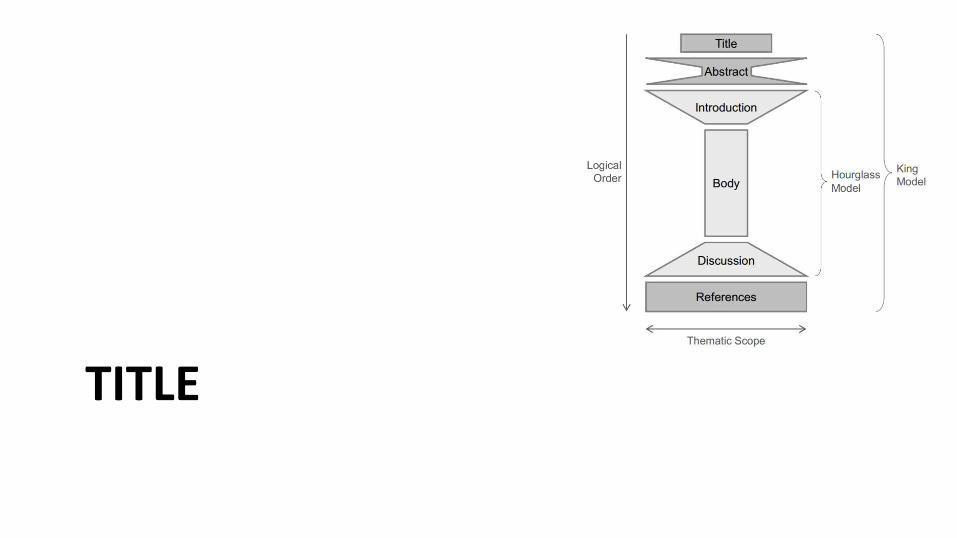
LA TARJETA DE PRESENTACIÓN

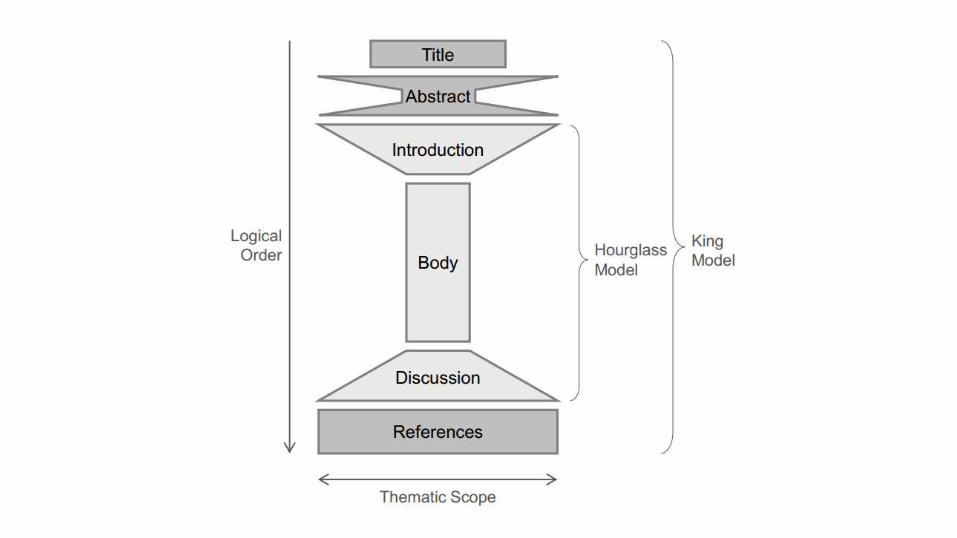
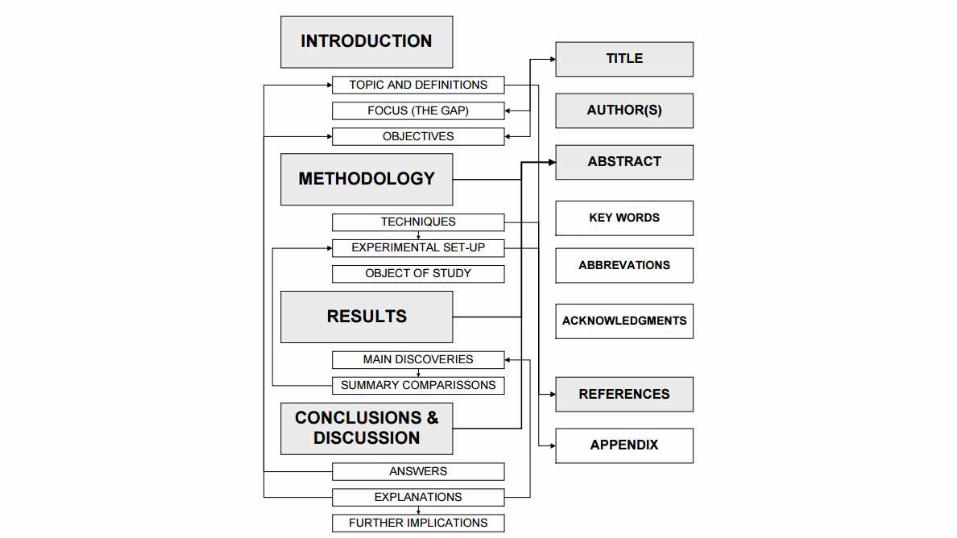
• Title
• Abstract
• Introduction
• Es lo último que se debe escribir, aunque sea lo primero que se va a leer
TITLE

Make it catchy! (que sea pegadizo): - Atractivo - Debe destacar entre miles de títulos
Accurate
Include some keywords

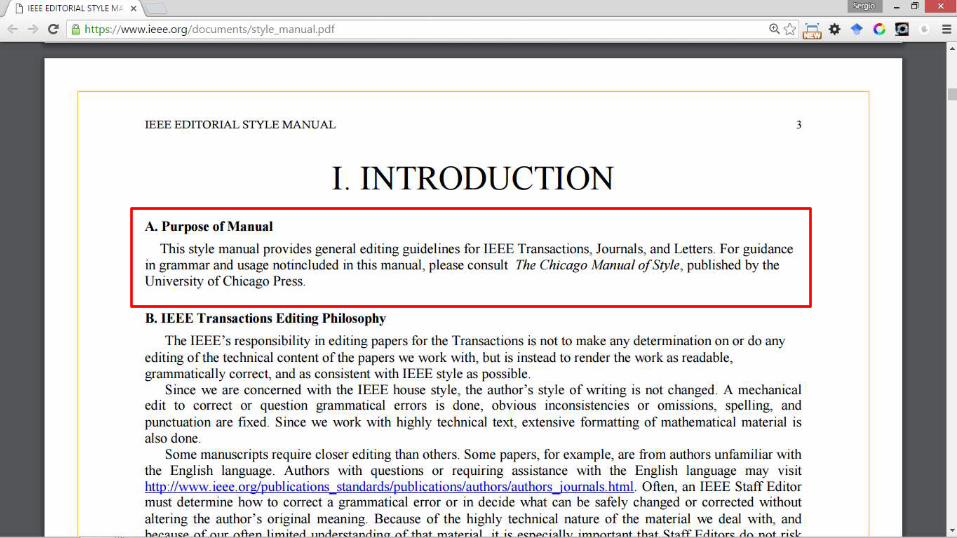
IEEE Editorial Style Manual • In the paper title, capitalize the first letter of the first and last word
and all nouns, pronouns, adjectives, verbs, adverbs, and subordinating conjunctions (If, Because, That, Which).
• Capitalize abbreviations that are otherwise lower case (i.e., use DC, not dc or Dc) except for unit abbreviations and acronyms. Articles (a, an, the), coordinating conjunctions (and, but, for, or, nor), and most short prepositions are lower case unless they are the first or last word.
• Prepositions of more than three letters (Before, Through, With, Versus, Among, Under, Between, Without.) should be capitalized.

• Define un título provisional desde el principio: – Lista de palabras clave – Lista de varios posibles títulos
• La ironía, los juegos de palabras y el humor son peligrosos
• Se deben evitar los acrónimos desconocidos y los neologismos (nuevos términos)
• Utiliza el mínimo posible de palabras que describan correctamente el contenido

Trece tipos de títulos • 1 Titles that announce the general subject, for example:
– The age of adolescence. – Designing instructional and informational text. – On writing scientific articles in English.
• 2 Titles that particularise a specific theme following a general heading, for example: – Pre-writing: The relation between thinking and feeling. – The achievement of black Caribbean girls: Good practice in Lambeth
schools. – The role of values in educational research: The case for reflexivity.

Trece tipos de títulos • 3 Titles that indicate the controlling question, for example:
– Is academic writing masculine? – What is evidence-based practice – and do we want it too? – What price presentation? The effects of typographic variables on essay
grades.
• 4 Titles that just state the findings, for example: – Supramaximal inflation improves lung compliance in patients with
amyotrophic lateral sclerosis. – Asthma in schoolchildren is greater in schools close to concentrated
animal feeding operations. – Angiopoetin-2 levels are elevated in exudative pleural effusions.

Trece tipos de títulos • 5 Titles that indicate that the answer to a question will be revealed,
for example: – Abstracts, introductions and discussions: How far do they differ in
style? – The effects of summaries on the recall of information. – Current findings from research on structured abstracts.
• 6 Titles that announce the thesis – i.e. indicate the direction of the author’s argument, for example: – The lost art of conversation. – Plus ça change . . . Gender preferences for academic disciplines. – Down with ‘op. cit.’.

Trece tipos de títulos • 7 Titles that emphasise the methodology used in the research, for
example: – Using colons in titles: A meta-analytic review. – Reading and writing book reviews across the disciplines: A survey of
authors. – Is judging text on screen different from judging text in print? A
naturalistic email study.
• 8 Titles that suggest guidelines and/or comparisons, for example: – Seven types of ambiguity. – Nineteen ways to have a viva. – Eighty ways of improving instructional text.

Trece tipos de títulos • 9 Titles that bid for attention by using startling or effective openings, for
example: – ‘Do you ride an elephant’ and ‘never tell them you’re German’: The
experiences of British Asian, black and overseas student teachers in the UK. – Something more to tell you: Gay, lesbian and bisexual young people’s
experiences of secondary schooling. – Making a difference: An exploration of leadership roles in sixth form colleges.
• 10 Titles that attract by alliteration, for example: – A taxonomy of titles. – Legal ease and ‘legalese’. – Referees are not always right: The case of the 3-D graph.

Trece tipos de títulos • 11 Titles that attract by using literary or biblical allusions, for example:
– From structured abstracts to structured articles: A modest proposal. – Low! They came to pass. The motivations of failing students. – Lifting the veil on the viva: The experiences of postgraduate students.
• 12 Titles that attract by using puns, for example: – Now take this PIL (Patient Information Leaflet). – A thorn in the Flesch: Observations on the unreliability of computerbased
readability formulae (Rudolph Flesch devised a method of computing the readability of text).
– Unjustified experiments in typographical design (Text set with equal word-spacing and a ragged right-hand edge is said to be set ‘unjustified’: text set with variable word-spacing and a straight righthand edge is set ‘justified’.)

Trece tipos de títulos
• 13 Finally, titles that mystify, for example:
– Outside the whale.
– How do you know you’ve alternated?
– Is October Brown Chinese?

• Soler, V. (2007). Writing titles in science: An exploratory study. English for Specific Purposes, 26(1), 90–102. – 570 titles used in articles in the biological and
social sciences
– Some 480 of these were from research papers, and 90 from reviews
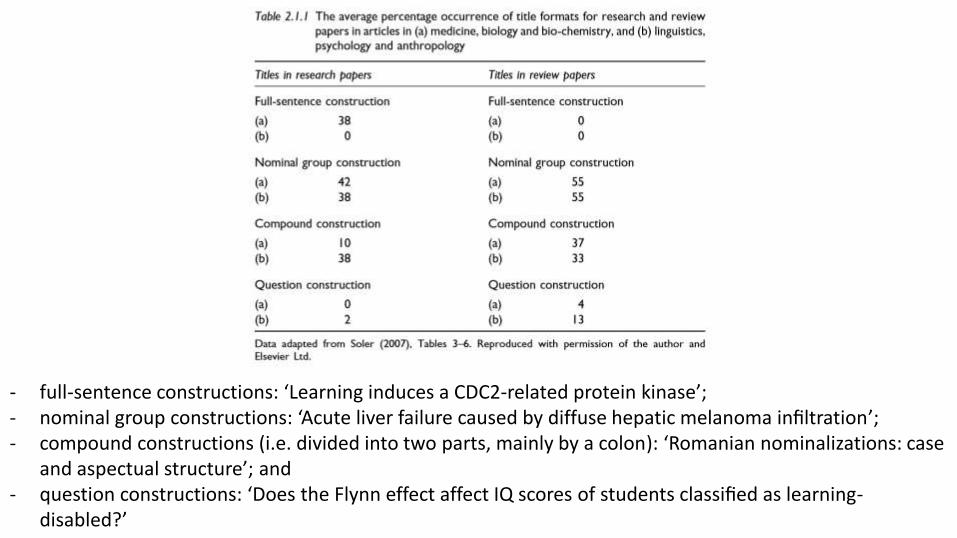
- full-sentence constructions: ‘Learning induces a CDC2-related protein kinase’; - nominal group constructions: ‘Acute liver failure caused by diffuse hepatic melanoma infiltration’; - compound constructions (i.e. divided into two parts, mainly by a colon): ‘Romanian nominalizations: case
and aspectual structure’; and - question constructions: ‘Does the Flynn effect affect IQ scores of students classified as learning-
disabled?’

AUTHOR

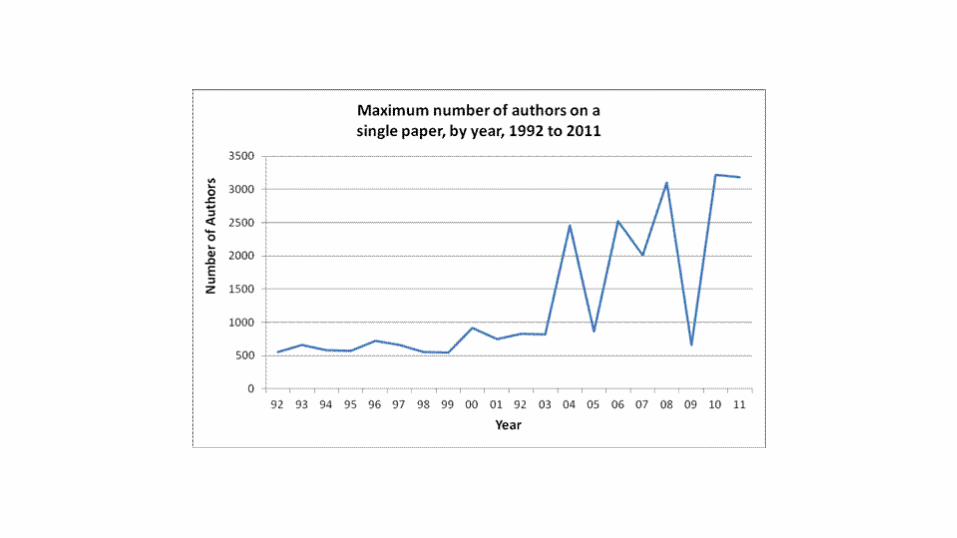
• ¿Quiénes son los autores de un artículo?
• ¿Cuántos autores puede tener un artículo?
• ¿En qué orden se escriben los nombres de los autores?
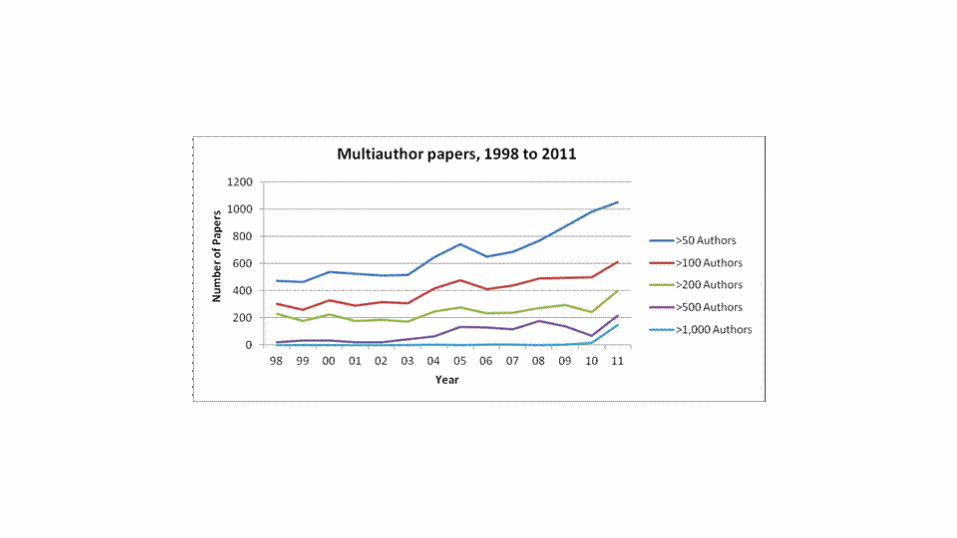





• APA Publication Manual: – The sequence of names of the authors to an article must reflect the
relative scientific or professional contribution of the authors, irrespective of their academic status.
– The general rule is that the name of the principal contributor should come first, with subsequent names in order of decreasing contribution.
– Mere possession of an institutional position on its own, such as Head of the Research team, does not justify authorship.
– A student should be listed as a principal author on any multi-authored article that is substantially based on the student’s dissertation or thesis.


¿QUIÉN ES AUTOR?
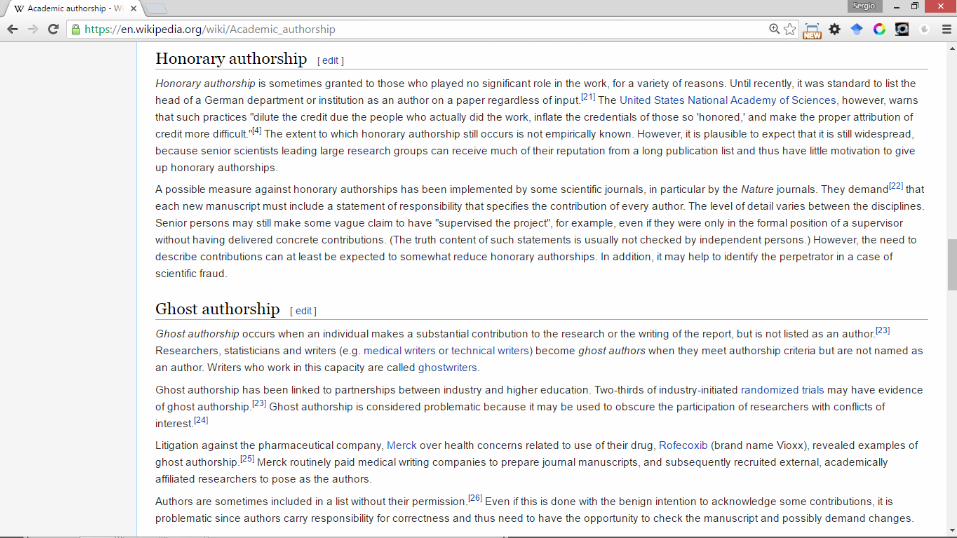

• A veces hay autores que no saben que han sido autores (increíble, pero cierto)
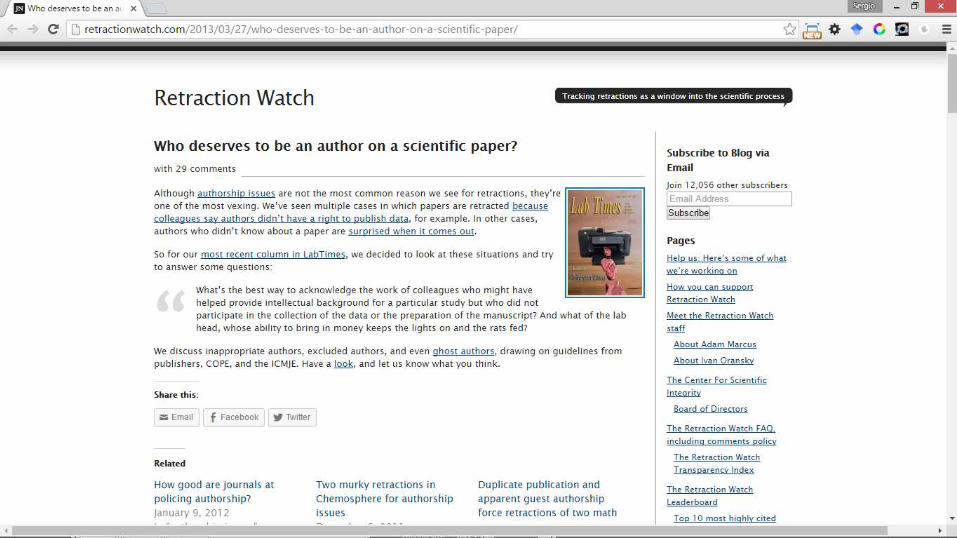
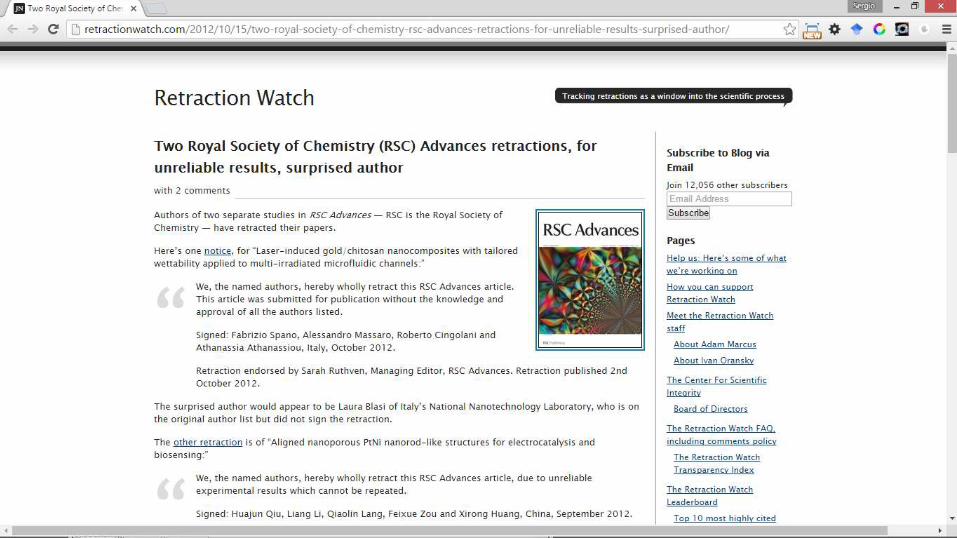

• Solución:
– Establecer un criterio de autoría desde el primer momento, desde que se inicia la investigación Se debe negociar
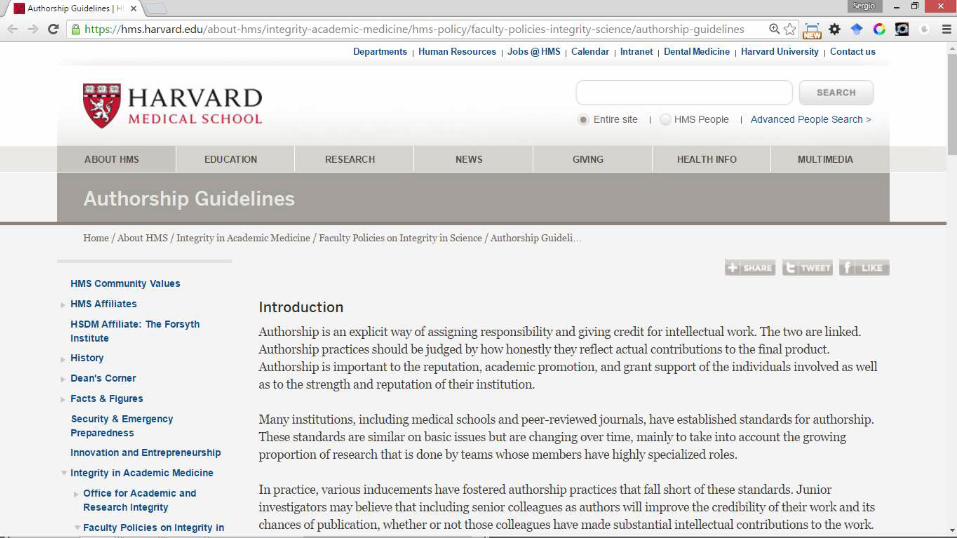
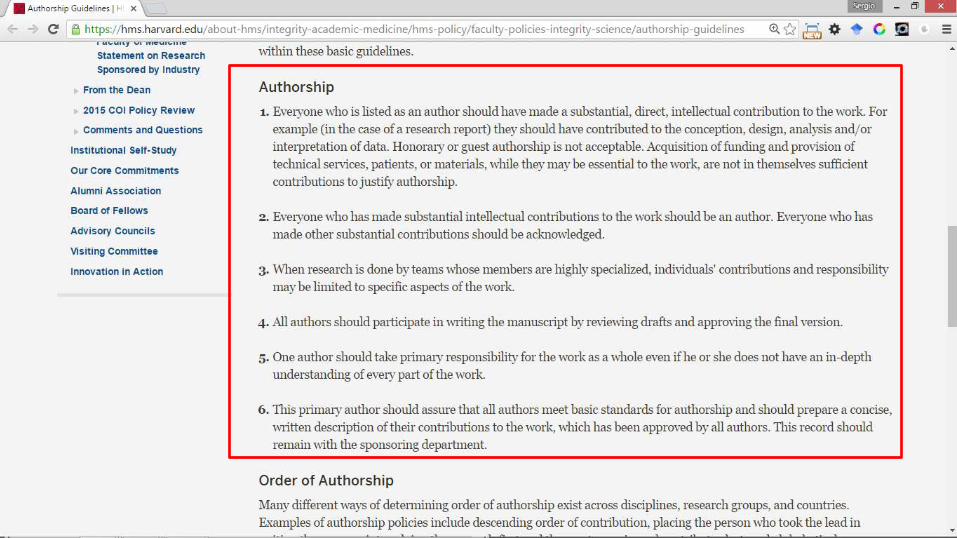

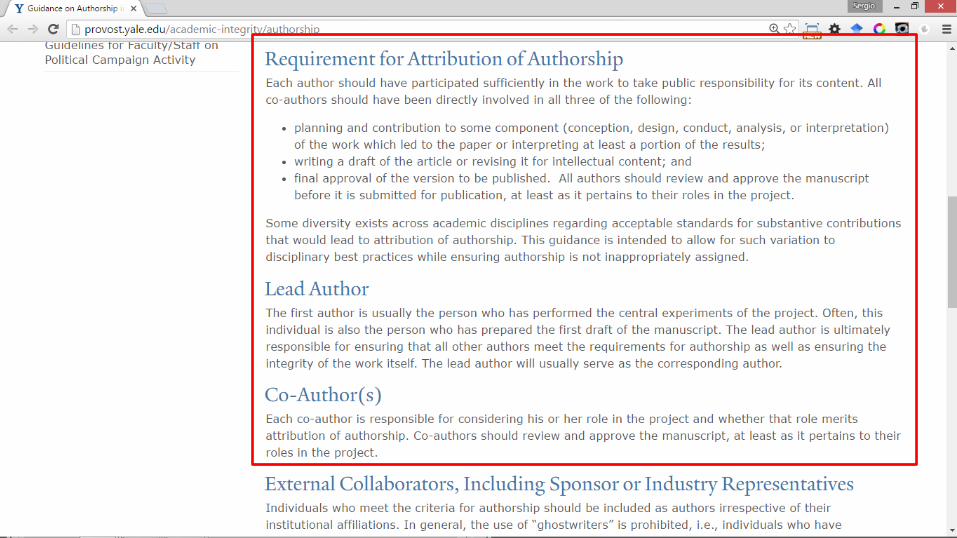







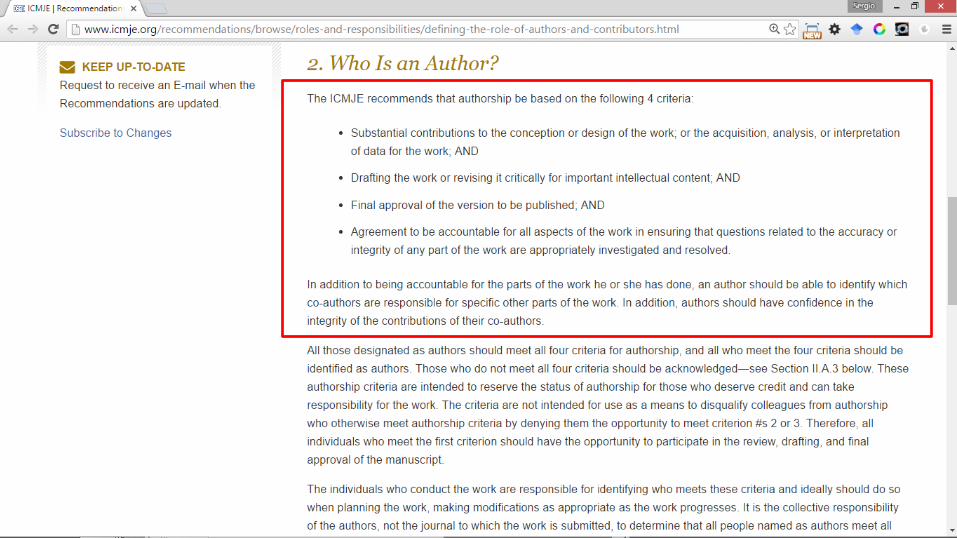
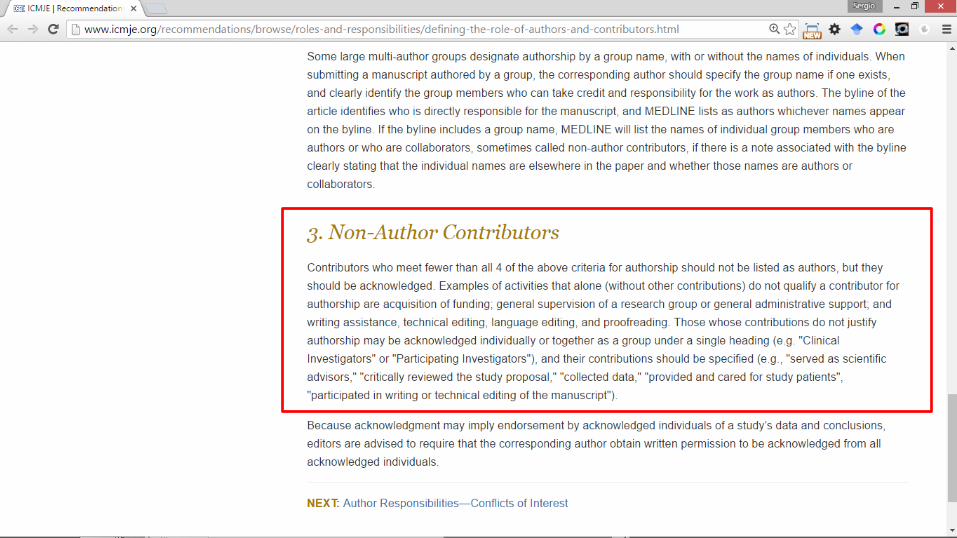

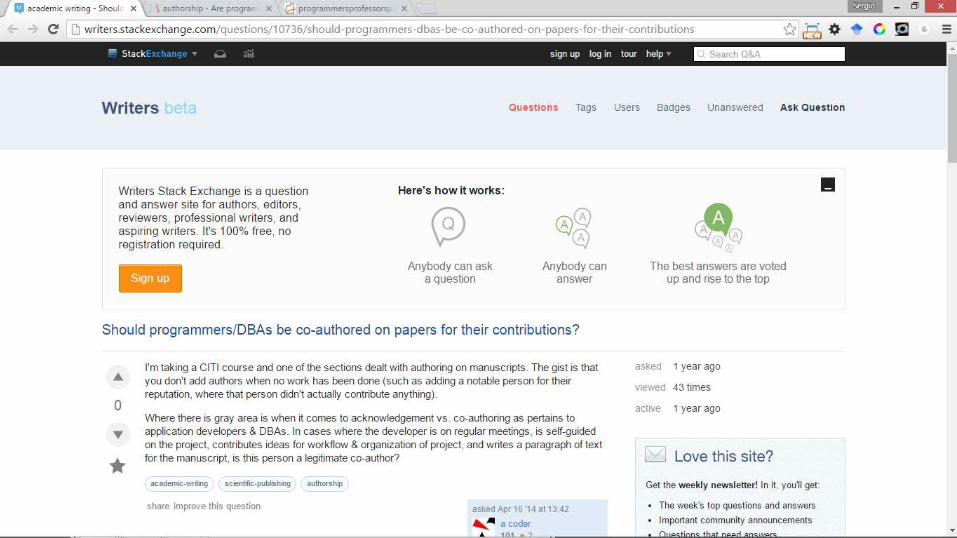
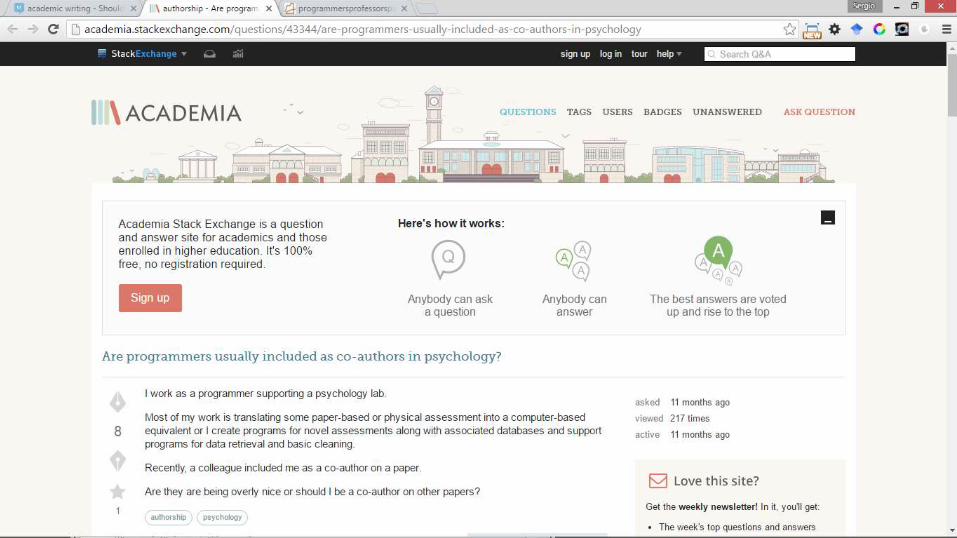
• ¿Alguien que programa “algo” debe ser autor de un artículo científico?


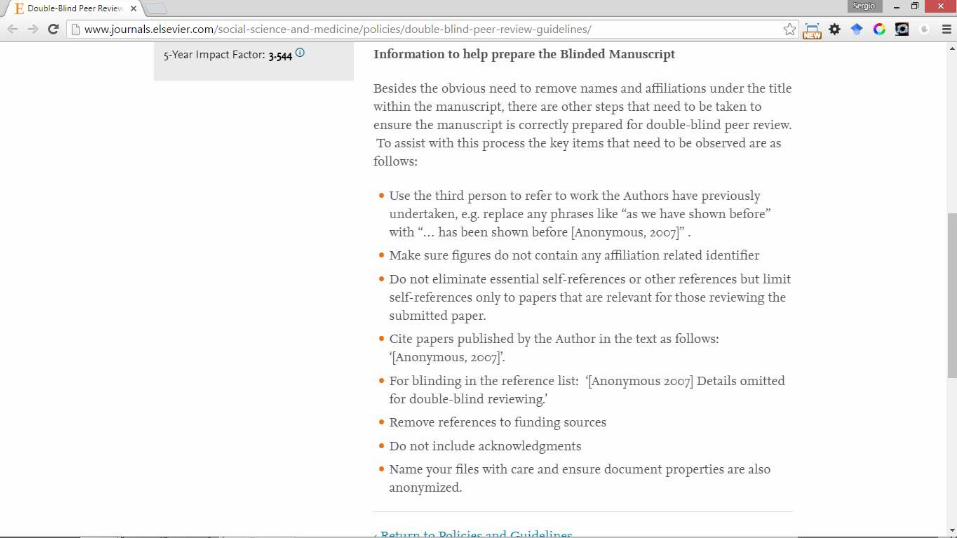
REVISIÓN DOBLE CIEGA

• Revisión doble ciega Sin los nombres de los autores… y más cosas
• ¿Cómo se hace?



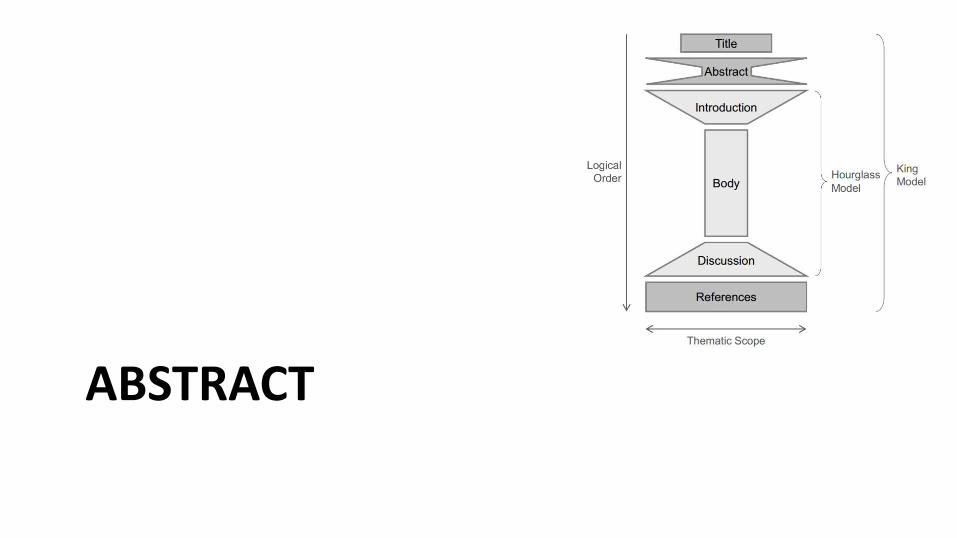
ABSTRACT

• Que quede claro:
– No es fácil escribir un buen abstract
– Pero es muy importante escribir un buen abstract, porque es lo primero (y quizás lo único, si no logra convencer) que va a leer cualquiera que se interese por el artículo


Función principal Estilo preferido Consejo
- De 100 a 300 palabras - Puede reproducir la estructura IMRaD Structured abstract

IEEE Editorial Style Manual
• All variables should appear lightface italic; numbers and units will remain bold.
• Abstracts should be a single paragraph.
• By nature, Abstracts shall not contain numbered mathematical equations nor numbered references.
• Numbered reference citations are not allowed. If a citation is made, reword the sentence to exclude citation numbers.

IEEE Editorial Style Manual • The abstract must be a concise yet comprehensive reflection of what is in
your article. In particular: – The abstract must be self-contained, without abbreviations, footnotes, or
references. It should be a microcosm of the full article. – The abstract must be between 150-250 words. Be sure that you adhere to
these limits; otherwise, you will need to edit your abstract accordingly. – The abstract must be written as one paragraph, and should not contain
displayed mathematical equations or tabular material. – The abstract should include three or four different keywords or phrases, as
this will help readers to find it. It is important to avoid over-repetition of such phrases as this can result in a page being rejected by search engines.
– Ensure that your abstract reads well and is grammatically correct.

IARIA Editorial Rules • avoid abbreviations in the abstract • introduce the problem you are dealing with by one succinct sentence • make it clear why the paper is related to the conference you are
submitting to • specify if it is a survey, an evaluation of existing work, or new ideas with
new results • end the abstract with one sentence reflecting the conclusion of the paper • don't use references /no [x]s in the abstract/ • follow the style of the template • "Abstract - The paper..... "


• Secuencia de preguntas (en este orden) que ayudan a escribir el resumen: 1. ¿Cuál es el problema? 2. ¿Por qué el problema es importante? 3. ¿Qué hicieron otros que no funcionó? 4. ¿Cuál es la solución propuesta? 5. ¿Cuáles son los principales resultados? 6. ¿Qué consecuencias o implicaciones conlleva la
solución?

• Junto con el título, es lo último que se escribe
• No se debe repetir:
– El título exactamente con las mismas palabras
– Frases exactas que aparezcan luego en la introducción
• Evita detalles demasiado concretos

241 palabras 3 párrafos

In this paper, we present Google, a prototype of a large-scale search engine which makes heavy use of the structure present in hypertext. Google is designed to crawl and index the Web efficiently and produce much more satisfying search results than existing systems. The prototype with a full text and hyperlink database of at least 24 million pages is available at http://google.stanford.edu/.
To engineer a search engine is a challenging task. Search engines index tens to hundreds of millions of web pages involving a comparable number of distinct terms. They answer tens of millions of queries every day. Despite the importance of large-scale search engines on the web, very little academic research has been done on them. Furthermore, due to rapid advance in technology and web proliferation, creating a web search engine today is very different from three years ago. This paper provides an in-depth description of our large-scale web search engine -- the first such detailed public description we know of to date.
Apart from the problems of scaling traditional search techniques to data of this magnitude, there are new technical challenges involved with using the additional information present in hypertext to produce better search results. This paper addresses this question of how to build a practical large-scale system which can exploit the additional information present in hypertext. Also we look at the problem of how to effectively deal with uncontrolled hypertext collections where anyone can publish anything they want.

In this paper, we present Google, a prototype of a large-scale search engine which makes heavy use of the structure present in hypertext. Google is designed to crawl and index the Web efficiently and produce much more satisfying search results than existing systems. The prototype with a full text and hyperlink database of at least 24 million pages is available at http://google.stanford.edu/.
To engineer a search engine is a challenging task. Search engines index tens to hundreds of millions of web pages involving a comparable number of distinct terms. They answer tens of millions of queries every day. Despite the importance of large-scale search engines on the web, very little academic research has been done on them. Furthermore, due to rapid advance in technology and web proliferation, creating a web search engine today is very different from three years ago. This paper provides an in-depth description of our large-scale web search engine -- the first such detailed public description we know of to date.
Apart from the problems of scaling traditional search techniques to data of this magnitude, there are new technical challenges involved with using the additional information present in hypertext to produce better search results. This paper addresses this question of how to build a practical large-scale system which can exploit the additional information present in hypertext. Also we look at the problem of how to effectively deal with uncontrolled hypertext collections where anyone can publish anything they want.
Directo al grano, ¿qué se presenta en este artículo?
Explica una novedad frente a las soluciones existentes: makes heavy use of the structure present in hypertext
Comenta una ventaja frente a las soluciones existentes:
crawl and index the Web efficiently and produce much more satisfying search results than existing systems

In this paper, we present Google, a prototype of a large-scale search engine which makes heavy use of the structure present in hypertext. Google is designed to crawl and index the Web efficiently and produce much more satisfying search results than existing systems. The prototype with a full text and hyperlink database of at least 24 million pages is available at http://google.stanford.edu/.
To engineer a search engine is a challenging task. Search engines index tens to hundreds of millions of web pages involving a comparable number of distinct terms. They answer tens of millions of queries every day. Despite the importance of large-scale search engines on the web, very little academic research has been done on them. Furthermore, due to rapid advance in technology and web proliferation, creating a web search engine today is very different from three years ago. This paper provides an in-depth description of our large-scale web search engine -- the first such detailed public description we know of to date.
Apart from the problems of scaling traditional search techniques to data of this magnitude, there are new technical challenges involved with using the additional information present in hypertext to produce better search results. This paper addresses this question of how to build a practical large-scale system which can exploit the additional information present in hypertext. Also we look at the problem of how to effectively deal with uncontrolled hypertext collections where anyone can publish anything they want.
¿Por qué es importante el problema?: Search engines index tens to hundreds of millions of web pages involving a comparable number of distinct terms. They answer tens of millions of queries every day. Despite the
importance of large-scale search engines on the web

In this paper, we present Google, a prototype of a large-scale search engine which makes heavy use of the structure present in hypertext. Google is designed to crawl and index the Web efficiently and produce much more satisfying search results than existing systems. The prototype with a full text and hyperlink database of at least 24 million pages is available at http://google.stanford.edu/.
To engineer a search engine is a challenging task. Search engines index tens to hundreds of millions of web pages involving a comparable number of distinct terms. They answer tens of millions of queries every day. Despite the importance of large-scale search engines on the web, very little academic research has been done on them. Furthermore, due to rapid advance in technology and web proliferation, creating a web search engine today is very different from three years ago. This paper provides an in-depth description of our large-scale web search engine -- the first such detailed public description we know of to date.
Apart from the problems of scaling traditional search techniques to data of this magnitude, there are new technical challenges involved with using the additional information present in hypertext to produce better search results. This paper addresses this question of how to build a practical large-scale system which can exploit the additional information present in hypertext. Also we look at the problem of how to effectively deal with uncontrolled hypertext collections where anyone can publish anything they want.
Estado de la cuestión, ¿qué hicieron otros que no funcionó?:
Despite the importance of large-scale search engines on the web, very little academic research has been done on them
due to rapid advance in technology and web proliferation, creating a web search engine
today is very different from three years ago

In this paper, we present Google, a prototype of a large-scale search engine which makes heavy use of the structure present in hypertext. Google is designed to crawl and index the Web efficiently and produce much more satisfying search results than existing systems. The prototype with a full text and hyperlink database of at least 24 million pages is available at http://google.stanford.edu/.
To engineer a search engine is a challenging task. Search engines index tens to hundreds of millions of web pages involving a comparable number of distinct terms. They answer tens of millions of queries every day. Despite the importance of large-scale search engines on the web, very little academic research has been done on them. Furthermore, due to rapid advance in technology and web proliferation, creating a web search engine today is very different from three years ago. This paper provides an in-depth description of our large-scale web search engine -- the first such detailed public description we know of to date.
Apart from the problems of scaling traditional search techniques to data of this magnitude, there are new technical challenges involved with using the additional information present in hypertext to produce better search results. This paper addresses this question of how to build a practical large-scale system which can exploit the additional information present in hypertext. Also we look at the problem of how to effectively deal with uncontrolled hypertext collections where anyone can publish anything they want.
¿Cuál es la solución propuesta?:
This paper provides an in-depth description of our large-scale web search engine -- the first such detailed public description we know of to date.
there are new technical challenges involved with using the additional information present in
hypertext to produce better search results. This paper addresses this question of how to build a practical large-scale system which can exploit the additional information present in
hypertext. Also we look at the problem of how to effectively deal with uncontrolled hypertext collections where anyone can publish anything they want.

In this paper, we present Google, a prototype of a large-scale search engine which makes heavy use of the structure present in hypertext. Google is designed to crawl and index the Web efficiently and produce much more satisfying search results than existing systems. The prototype with a full text and hyperlink database of at least 24 million pages is available at http://google.stanford.edu/.
To engineer a search engine is a challenging task. Search engines index tens to hundreds of millions of web pages involving a comparable number of distinct terms. They answer tens of millions of queries every day. Despite the importance of large-scale search engines on the web, very little academic research has been done on them. Furthermore, due to rapid advance in technology and web proliferation, creating a web search engine today is very different from three years ago. This paper provides an in-depth description of our large-scale web search engine -- the first such detailed public description we know of to date.
Apart from the problems of scaling traditional search techniques to data of this magnitude, there are new technical challenges involved with using the additional information present in hypertext to produce better search results. This paper addresses this question of how to build a practical large-scale system which can exploit the additional information present in hypertext. Also we look at the problem of how to effectively deal with uncontrolled hypertext collections where anyone can publish anything they want.
¿Cuáles son los principales resultados, conclusiones que se prueban en el artículo?:
Google is designed to crawl and index the Web efficiently and produce much more satisfying search results than existing systems.

In this paper, we present Google, a prototype of a large-scale search engine which makes heavy use of the structure present in hypertext. Google is designed to crawl and index the Web efficiently and produce much more satisfying search results than existing systems. The prototype with a full text and hyperlink database of at least 24 million pages is available at http://google.stanford.edu/.
To engineer a search engine is a challenging task. Search engines index tens to hundreds of millions of web pages involving a comparable number of distinct terms. They answer tens of millions of queries every day. Despite the importance of large-scale search engines on the web, very little academic research has been done on them. Furthermore, due to rapid advance in technology and web proliferation, creating a web search engine today is very different from three years ago. This paper provides an in-depth description of our large-scale web search engine -- the first such detailed public description we know of to date.
Apart from the problems of scaling traditional search techniques to data of this magnitude, there are new technical challenges involved with using the additional information present in hypertext to produce better search results. This paper addresses this question of how to build a practical large-scale system which can exploit the additional information present in hypertext. Also we look at the problem of how to effectively deal with uncontrolled hypertext collections where anyone can publish anything they want.
¿Cuáles son los principales resultados, conclusiones que se prueban en el artículo?:
using the additional information present in hypertext to produce better search results.
how to effectively deal with uncontrolled hypertext collections where anyone can publish anything they want.

• Analiza el siguiente resumen en base a las preguntas básicas: 1. ¿Cuál es el problema? 2. ¿Por qué el problema es importante? 3. ¿Qué hicieron otros que no funcionó? 4. ¿Cuál es la solución propuesta? 5. ¿Cuáles son los principales resultados, conclusiones
que se prueban en el artículo?

152 palabras 3 párrafos

The Web has been growing in size and complexity and is used for the most diverse activities in our everyday life, becoming almost indispensable. Besides, Web applications are becoming more popular, and consequently used by a wide range of people. Thus, it is important to evaluate the accessibility of those applications to guarantee that everyone can access the information.
Currently, there are some tools to evaluate the accessibility of classical Web pages, which use WCAG guidelines. However, Web applications impose different challenges, so it is mandatory to find a way to automatically obtain the dynamically introduced HTML code, in order to evaluate what users really experience.
This paper details a new process of accessibility evaluation of Web applications, which evaluates the content by triggering possible events that partially change the Web page. It also presents an experimental study with several Web applications, demonstrating the potential of this framework in evaluating Web applications.

175 palabras 1 párrafo

The fact that several web accessibility metrics exist may be evidence of a lack of a comparison framework that highlights how well they work and for what purposes they are appropriate. In this paper we aim at formulating such a framework, demonstrating that it is feasible, and showing the findings we obtained when we applied it to seven existing automatic accessibility metrics. The framework encompasses validity, reliability, sensitivity, adequacy and complexity of metrics in the context of four scenarios where the metrics can be used. The experimental demonstration of the viability of the framework is based on applying seven published metrics to more than 1500 web pages and then operationalizing the notions of validity-as-conformance, adequacy and complexity. Our findings lead us to conclude that the Web Accessibility Quantitative Metric, Page Measure and Web Accessibility Barrier are the metrics that achieve the highest levels of quality (out of the seven that we examined). Finally, since we did not analyse reliability, sensitivity and validity-in-use, this paper provides guidance to address them in what are new research avenues.

191 palabras 1 párrafo

The Web and especially major Web search engines are essential tools in the quest to locate online information for many people. This paper reports results from research that examines characteristics and changes in Web searching from nine studies of five Web search engines based in the US and Europe. We compare interactions occurring between users and Web search engines from the perspectives of session length, query length, query complexity, and content viewed among the Web search engines. The results of our research shows (1) users are viewing fewer result pages, (2) searchers on US-based Web search engines use more query operators than searchers on European-based search engines, (3) there are statistically significant differences in the use of Boolean operators and result pages viewed, and (4) one cannot necessary apply results from studies of one particular Web search engine to another Web search engine. The wide spread use of Web search engines, employment of simple queries, and decreased viewing of result pages may have resulted from algorithmic enhancements by Web search engine companies. We discuss the implications of the findings for the development of Web search engines and design of online content.

134 palabras 1 párrafo

The advent and rise of Massive Open Online Courses (MOOCs) have brought many issues to the area of educational technology. Researchers in the field have been addressing these issues such as pedagogical quality of MOOCs, high attrition rates, and sustainability of MOOCs. However, MOOCs personalisation has not been subject of the wide discussions around MOOCs. This paper presents a critical literature survey and analysis of the available literature on personalisation in MOOCs to identify the needs, the current states and efforts to personalise learning in MOOCs. The findings illustrate that there is a growing attention to personalisation to improve learners’ individual learning experiences in MOOCs. In order to implement personalised services, personalised learning path, personalised assessment and feedback, personalised forum thread and recommendation service for related learning materials or learning tasks are commonly applied.

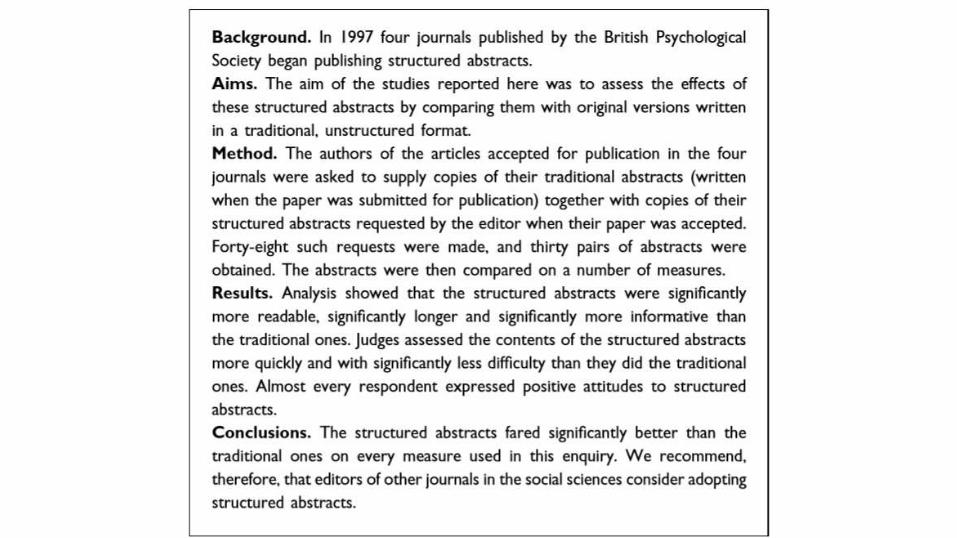
STRUCTURED ABSTRACT

• Típico en las revistas de medicina desde los años 80

• Hartley, J. (2004). Current findings from research on structured abstracts. Journal of the Medical Library Association, 92(3), 368–71. – I concluded that, compared with traditional abstracts,
structured abstracts: • contained more information • were easier to read • were easier to search • facilitated peer review for conferences • were generally welcomed by readers and by authors.


• Truco:
– Si un structured abstract ofrece numerosas ventajas, pero no se usa en la publicación que estás escribiendo, realiza una transformación


EXTENDED ABSTRACT
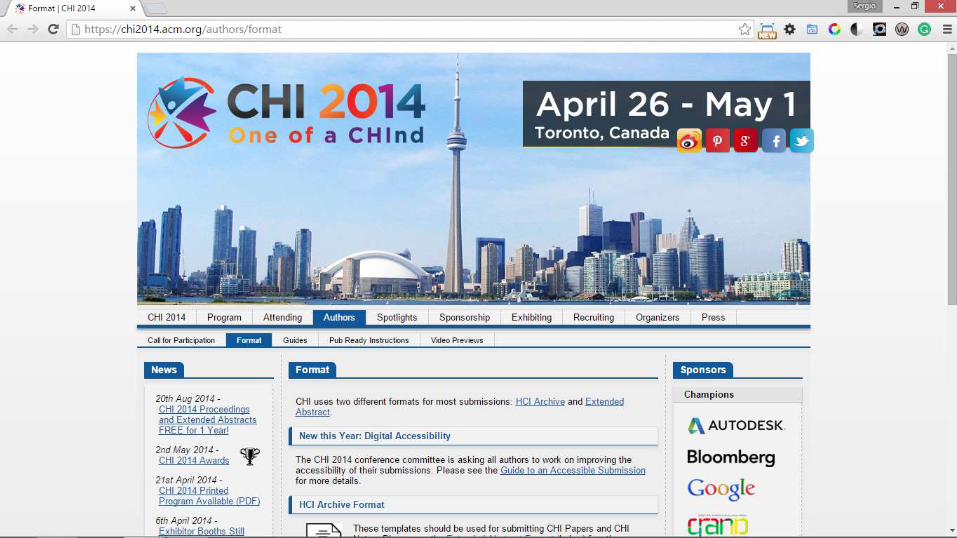
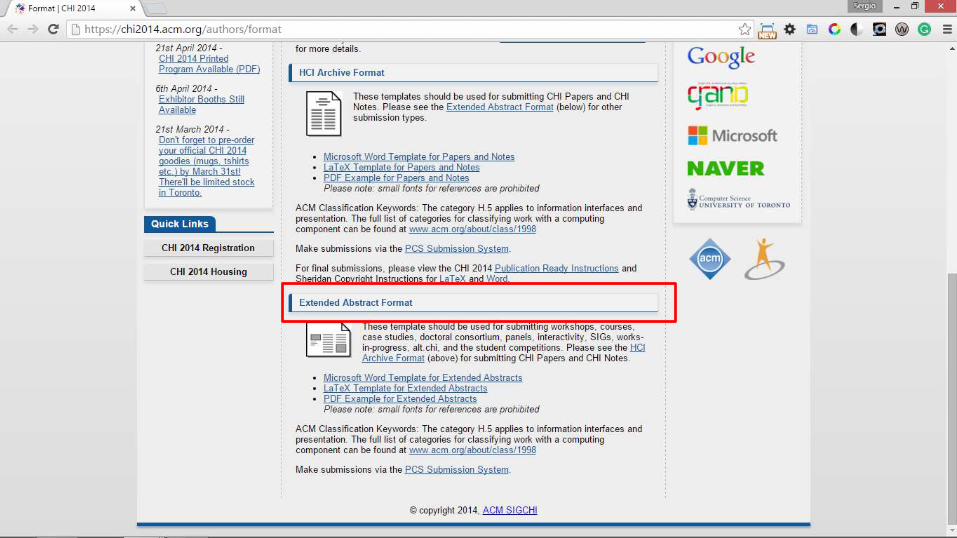
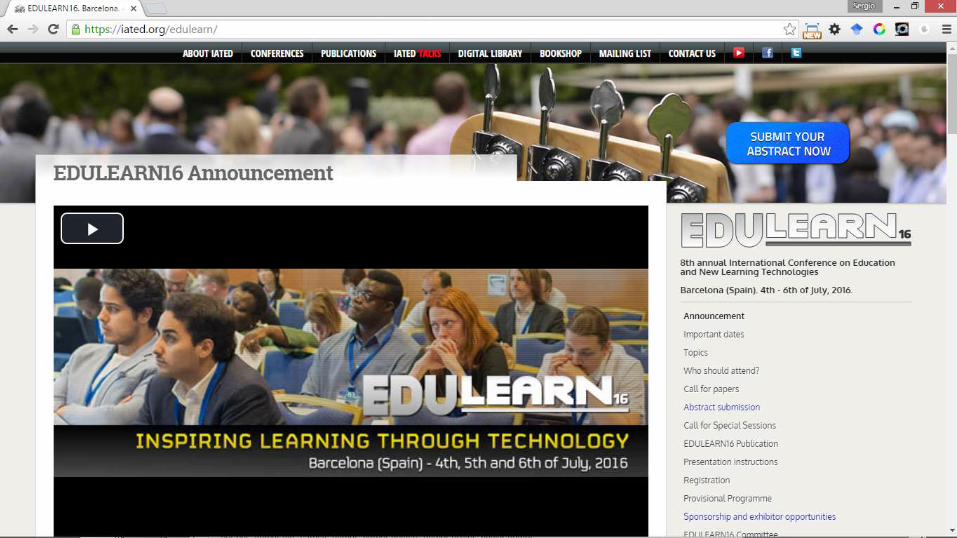
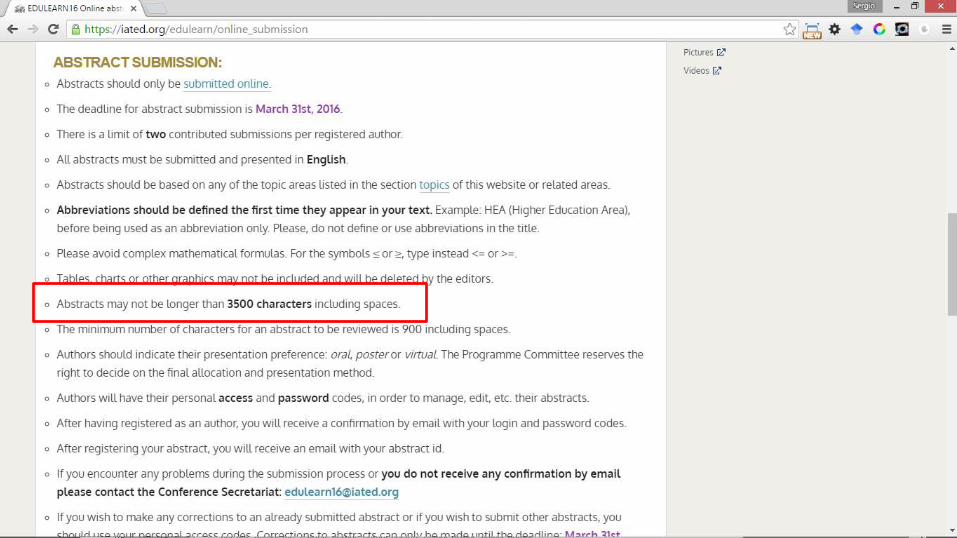

KEYWORDS

• Key words typically: 1. allow readers to judge whether or not an article contains material
relevant to their interests; 2. provide readers with suitable terms to use in web-based searches to
locate other materials on the same or similar topics; 3. help indexers/editors group together related materials in, say, the endof-
year issues of a particular journal or a set of conference proceedings; 4. allow editors/researchers to document changes in a subject discipline
(over time); and 5. link the specific issues of concern to issues at a higher level of
abstraction.

• Who chooses the key words? – Authors supply them with no restrictions on the numbers allowed. – Authors supply up to a fixed number (e.g. six). – Authors supply key words as appropriate from a specified list. – Editors supplement/amend authors’ key words. – Editors supply key words. – Editors supply key words from a specified list. – Referees supply key words from a specified list. – Key words are allocated according to the ‘house-rules’ applied to all
journals distributed by a specific publisher. – Key words are determined by computer program at proof stage.

IEEE Editorial Style Manual • All papers must contain Index Terms. These are keywords provided
by the authors. Request them if they are not provided. • Index Terms appear in bold type in the same style as the Abstract,
in alphabetical order, and as a final paragraph of the Abstract section.
• Separate Abstract and Index Terms by a 6-pt. space. • Capitalize the first word of the Index Terms list; lower case the rest
unless capitalized in text. • Include the definition of an acronym followed by the acronym in
parentheses.

IEEE Editorial Style Manual
• Example:
Index Terms—Abstraction, computer-aided system engineering (CASE), conceptual schema, data model, entity type hierarchy, ISO reference model, layered architecture meta model, reverse engineering.

IARIA Editorial Rules
• no more than 45 keywords
• follow the style of the template
• "Keywords-component; formatting; style; styling; insert (key words)."
• note: use a semicolon between keywords words
• note: the listing ends with a period "."

• Si tienes que elegir las keywords, imagina que buscas tu artículo en una base de datos



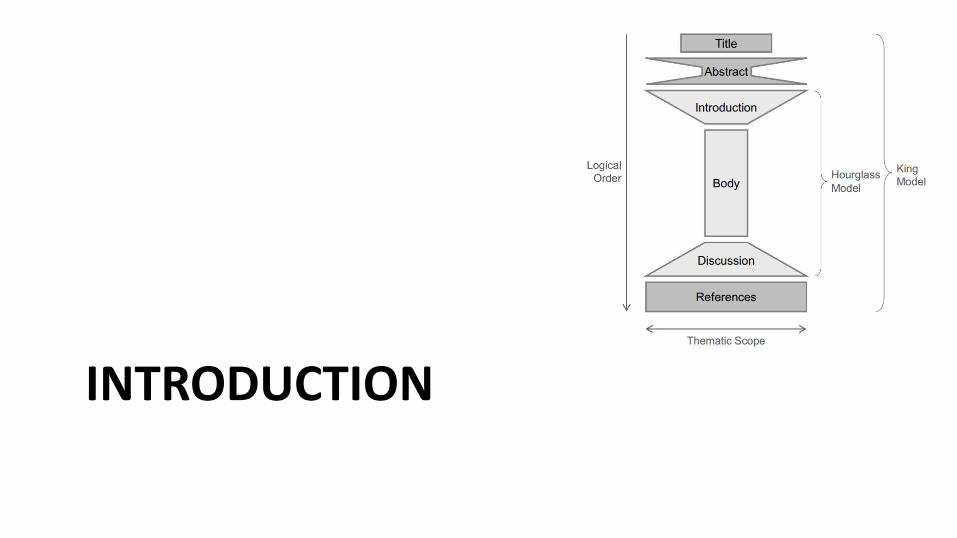
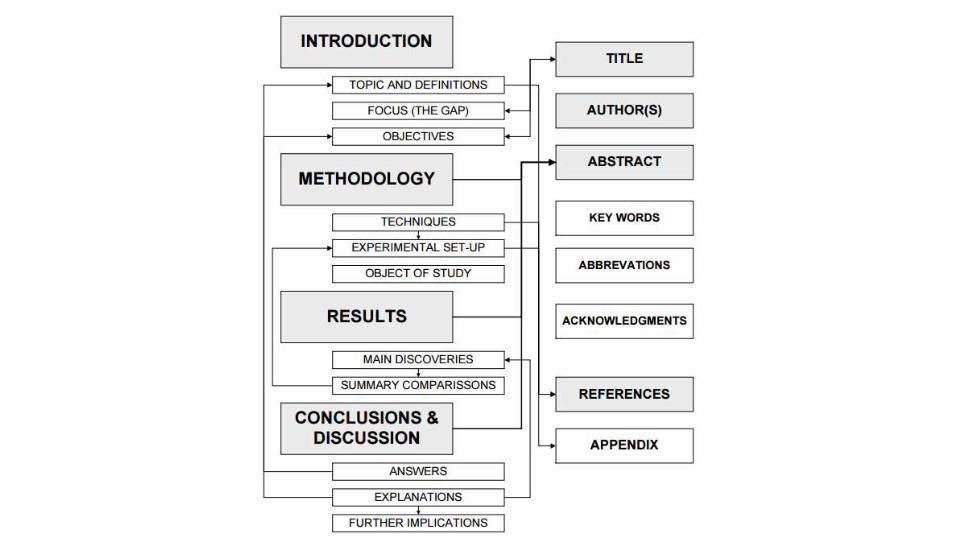
INTRODUCTION

Función principal Estilo preferido Consejo

Función principal Estilo preferido Consejo
Si el trabajo relacionado es muy extenso, se puede crear una sección individual: - State of the art Estado de la cuestión - Related work Trabajos relacionados - Theoretical background Marco teórico

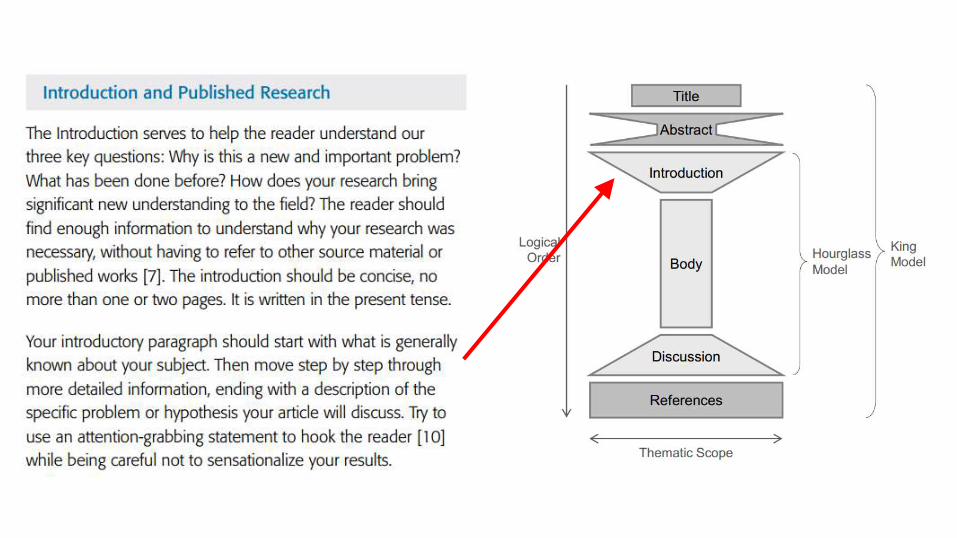


• Contestar de forma clara y objetiva: 1. ¿Cuál es la naturaleza y el alcance del problema investigado? 2. ¿Cuáles son las dificultades, obstáculos, desafíos de la investigación? 3. ¿Cuál es la importancia del problema? (versión extendida respecto
el resumen) 4. ¿Cuál es la idea principal de lo que se pretende hacer? 5. ¿Preguntas de la investigación? 6. ¿Cuáles son los límites de la investigación? 7. ¿Cuál es el propósito del artículo? 8. Finaliza la introducción con un párrafo describiendo sección por
sección la estructura y contenido del artículo
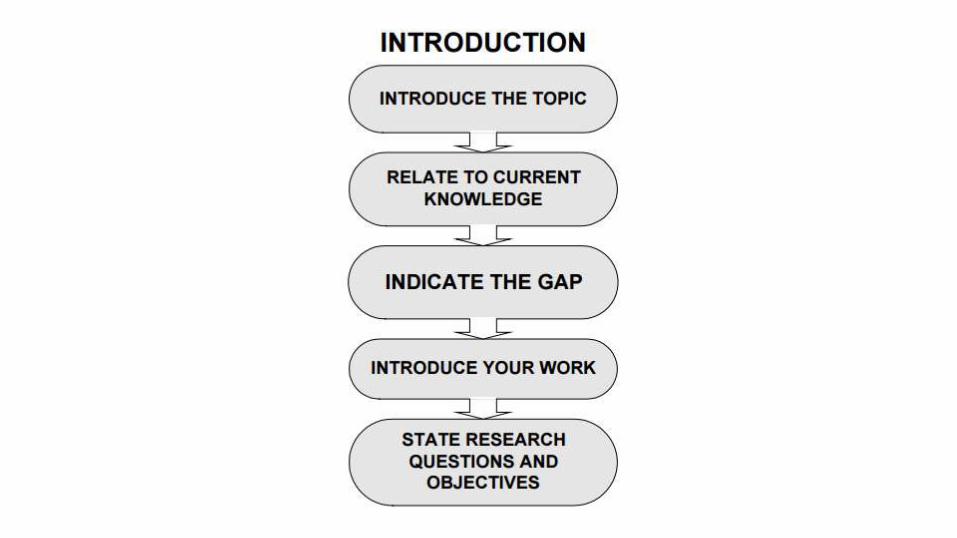

• La introducción suele acabar con una explicación de la estructura del artículo
– ¿Obligatorio? No, pero si no la pones, muchos revisores la van a exigir…
– …pero alguno también puede decir que se está desperdiciando un espacio valioso






INTRODUCTION – STATE OF THE ART

• State of the art, Related work, Related studies, Theoretical background, Literature review
• A veces se escribe al final del artículo, para no interrumpir el ritmo de lectura de lo más importante, la aportación del artículo

• Destaca lo siguiente: – Qué han hecho los otros
– Qué falta en lo que han hecho los otros Destaca las diferencias con tu trabajo y las razones que apoyan que alguien elija tu solución en vez de la solución de los otros
• Finaliza con lo que quieres hacer/mejorar (punto de conexión con el siguiente apartado)

• ¿Qué tiempo verbal, presente o pasado?

Función principal Estilo preferido Consejo


Hasta ahora, todo en presente, pero…

METHODOLOGY (MATERIALS & METHOD)

• Es lo más fácil de escribir Empezar un artículo por esta parte

Función principal Estilo preferido Consejo

RESULTS
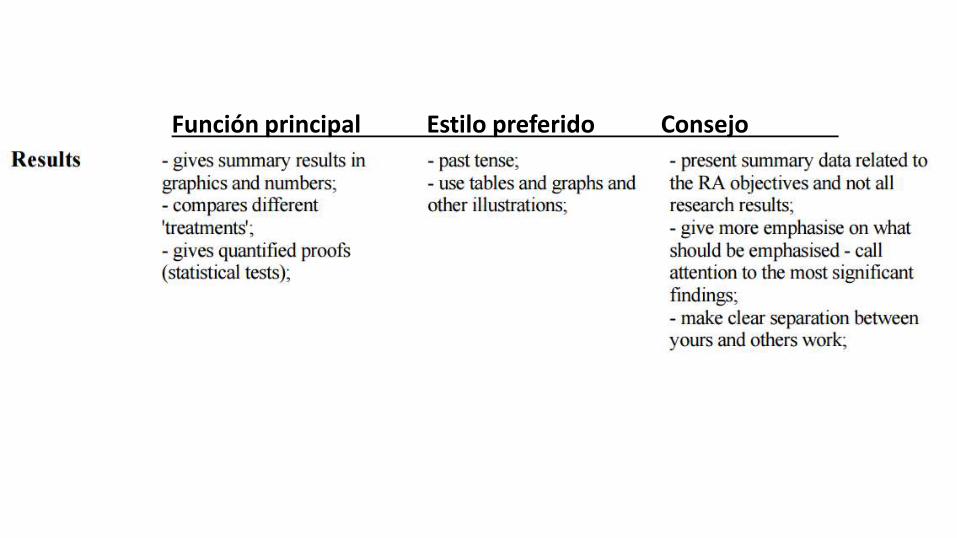
Función principal Estilo preferido Consejo

IARIA Editorial Rules • clarify the tools used for obtaining the results /benchmarks, software,
hardware, etc./ • for special tools, provide a reference • when theory is the core, a concrete application greatly increases the value
of the contribution • when pure applications/systems are the main scope of the contribution,
stressing out the concepts and theories behind them • gives more value to the work • when simulations are shown, explain why particular parameters where
chosen • diagrams must be explained /what?/ and interpreted /why?/

IARIA Editorial Rules • summarize the results by comparison tables/graphs/etc. with the
prior art; it proves your understanding and makes your message • clearer • defend new proposals by general metrics such as performance,
robustness, complexity, scalability, etc. in addition to the metrics • specific to your contribution • conclude with "lesson learned' • provide next steps by 'future work', usually in "Conclusion and
Future Work"


• Hay que destacar las resultados esperados… y los no esperados
• Hay que ser objetivos: no esconder los resultados que nos perjudiquen
• Utiliza tablas o gráficos para mostrar los datos: – Todo artículo debería tener un par de tablas y de gráficos – Elige el más apropiado según el caso – No repitas, no muestres los mismos datos como tabla y
como figura
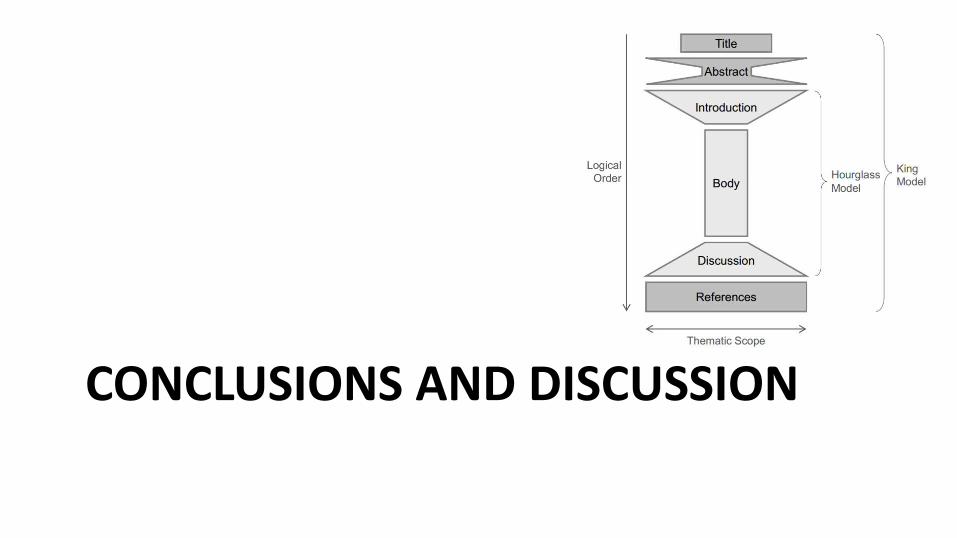
CONCLUSIONS AND DISCUSSION

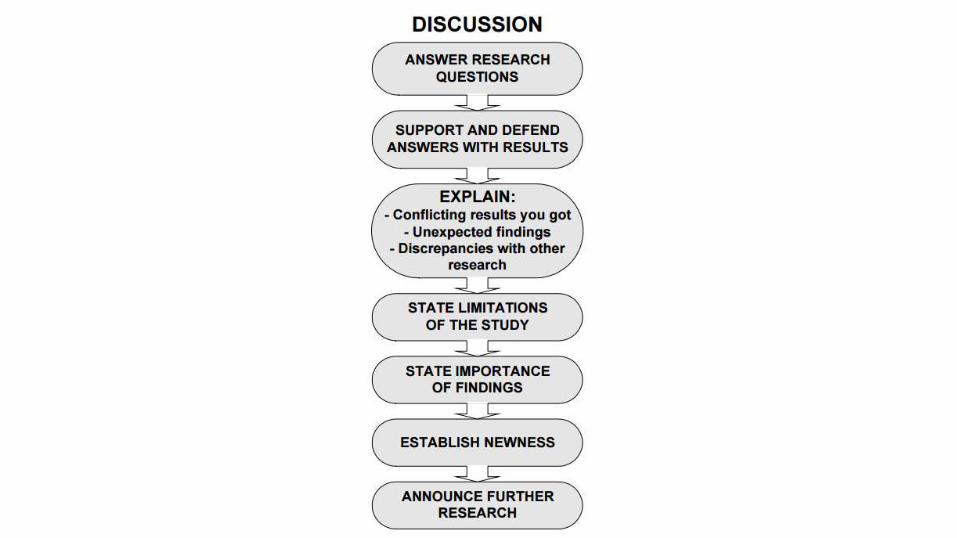
Función principal Estilo preferido Consejo


ACKNOWLEDGMENT

IEEE Editorial Style Manual • The placement of the Acknowledgment appears after
the final text of the paper, just before the References and after any Appendix(es).
• The spelling of the heading for the Acknowledgment section is always singular, with no “e” between the “g” and the “m.”
• As noted previously in the Text Headings section, the Acknowledgment head is a primary heading. Do not enumerate the Acknowledgment heading.
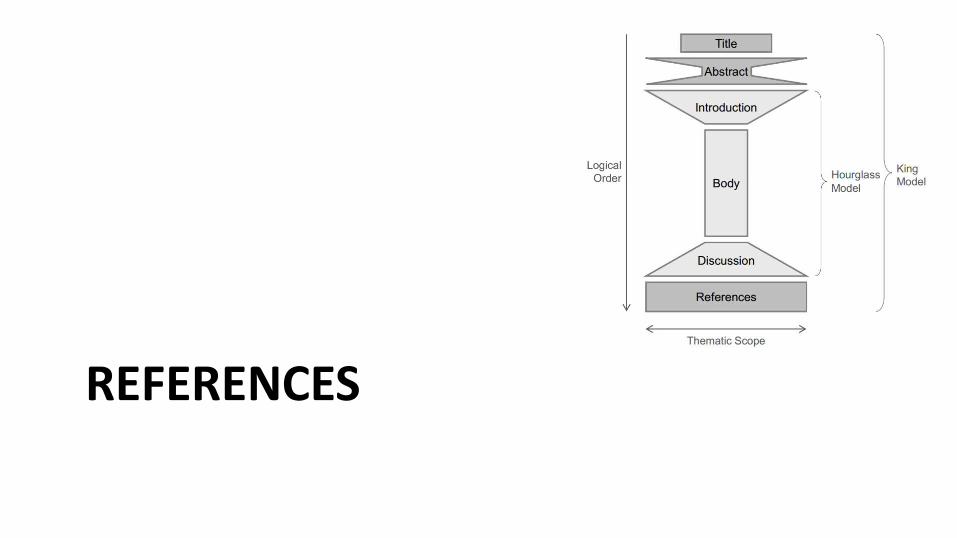
REFERENCES

Función principal Estilo preferido Consejo
Cite up-to-date references




BIOGRAPHY

IEEE Editorial Style Manual • IEEE Transactions author biographies are generally divided
into three paragraphs. However, if appropriate information for each paragraph is not provided by the author, the biography may be only one or two paragraphs.
• The biography begins with the author’s full name and IEEE membership history as listed in the IEEE Membership Directory. The author’s name appears in boldface type and must match the byline.
• Personal notes such as hobbies should be deleted from the biography.

IEEE Editorial Style Manual • First Paragraph: If provided by the author, the first
paragraph may contain a place and/or date of birth (list place, then date).
• Next, the author’s educational background is listed. When listing degrees earned, the biography should state “[S]he received the Ph.D. degree from …” (not “[S]he received [her] his Ph.D. degree from …”).
• Always add the word degree after a degree title if it is not included. Include the years degrees were received.
• Use lower case for the author’s major field of study.

IEEE Editorial Style Manual
• Second Paragraph: The second paragraph of the biography should list military and work experience, including summer and fellowship jobs and consultant positions. Job titles are capitalized.
• The current job must have a location; previous positions may be listed without one (retain if given).
• Do not repeat the author’s name in the second paragraph; use “he” or “she.”

IEEE Editorial Style Manual • Third Paragraph: The third paragraph begins with the
author’s title and last name (e.g., Dr. Smith, Prof. Jones, Mr. Kajor, Ms. Hunter).
• It lists the author’s memberships in professional societies other than the IEEE and his or her status as a Professional Engineer if given.
• Finally, list awards and work for IEEE committees and publications, affiliation with other professional societies, and symposia.


RESUMEN



TODO ESTÁ RELACIONADO

APRENDE LEYENDO