Embed Size (px)
Citation preview

ES-Hadoop: Bridging the world of Hadoop and Elasticsearch
Bala Venkatrao ([email protected])
June 2015
h"ps://github.com/elas3c/elas3csearch-‐hadoop
www.elastic.co
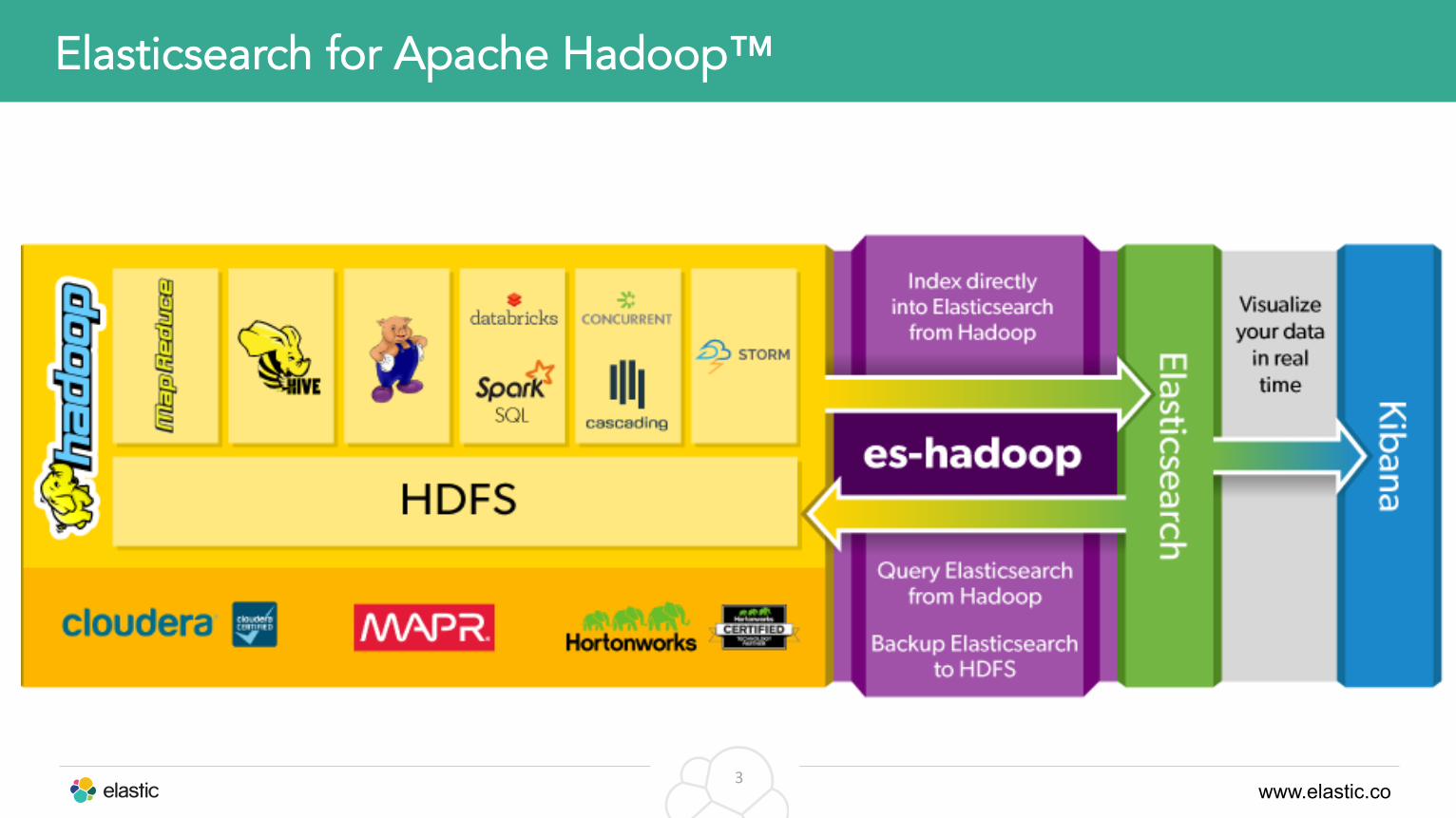
Elasticsearch for Apache Hadoop™
3

www.elastic.co
Certified to work
4
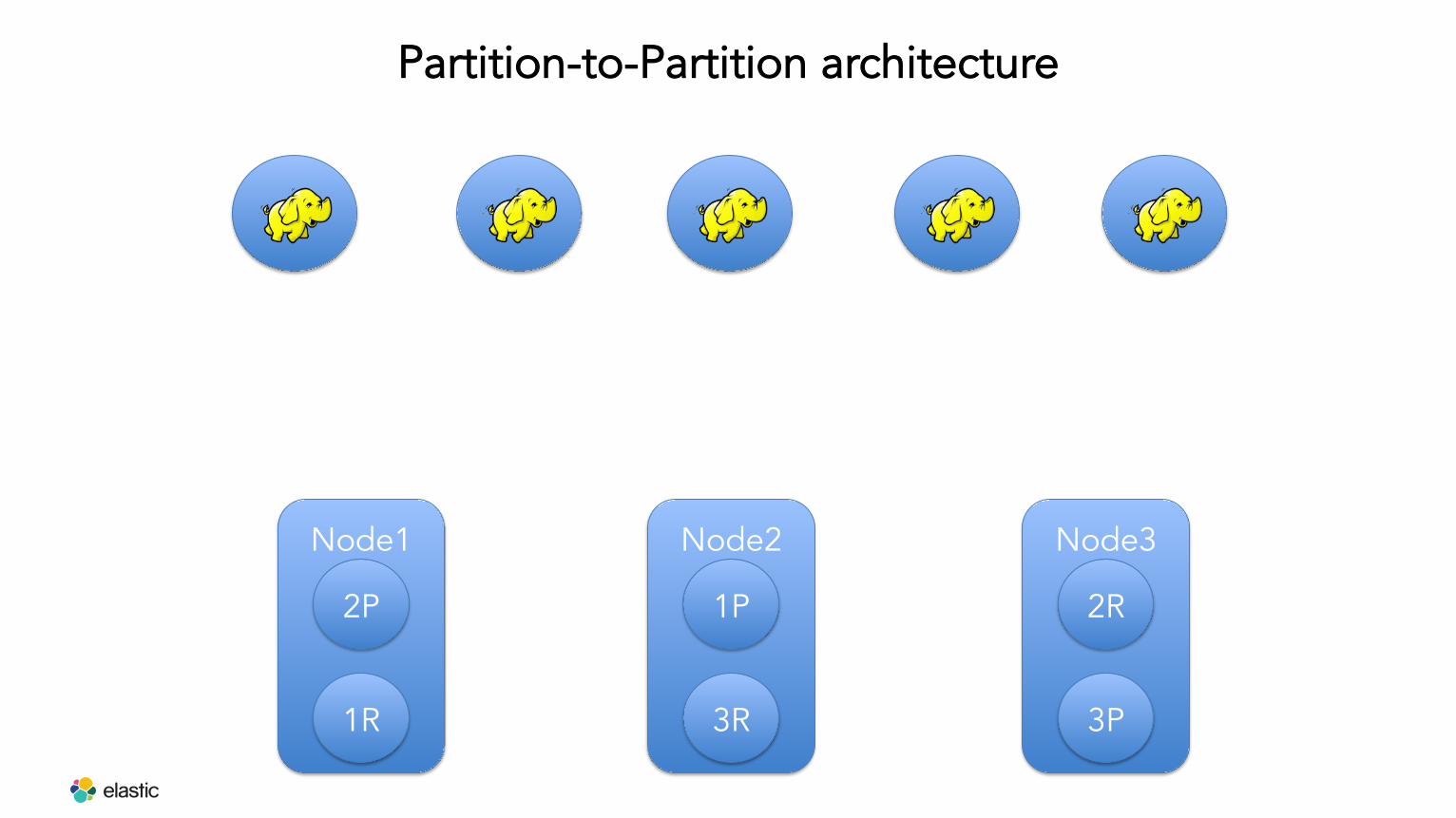
Partition-to-Partition architecture
Node1
2P
1R
Node2
1P
3R
Node3
2R
3P
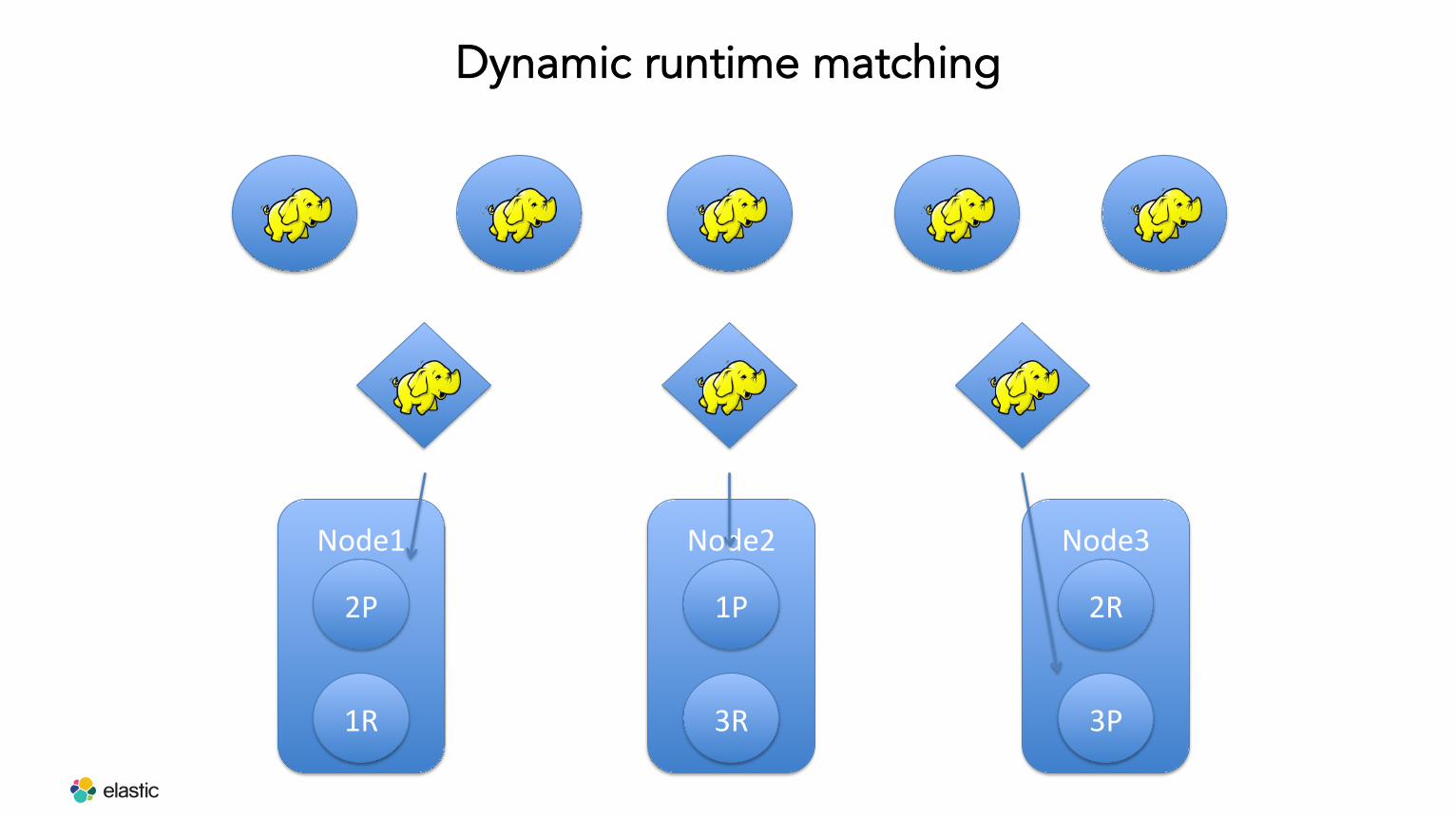
Dynamic runtime matching
Node1
2P
1R
Node2
1P
3R
Node3
2R
3P
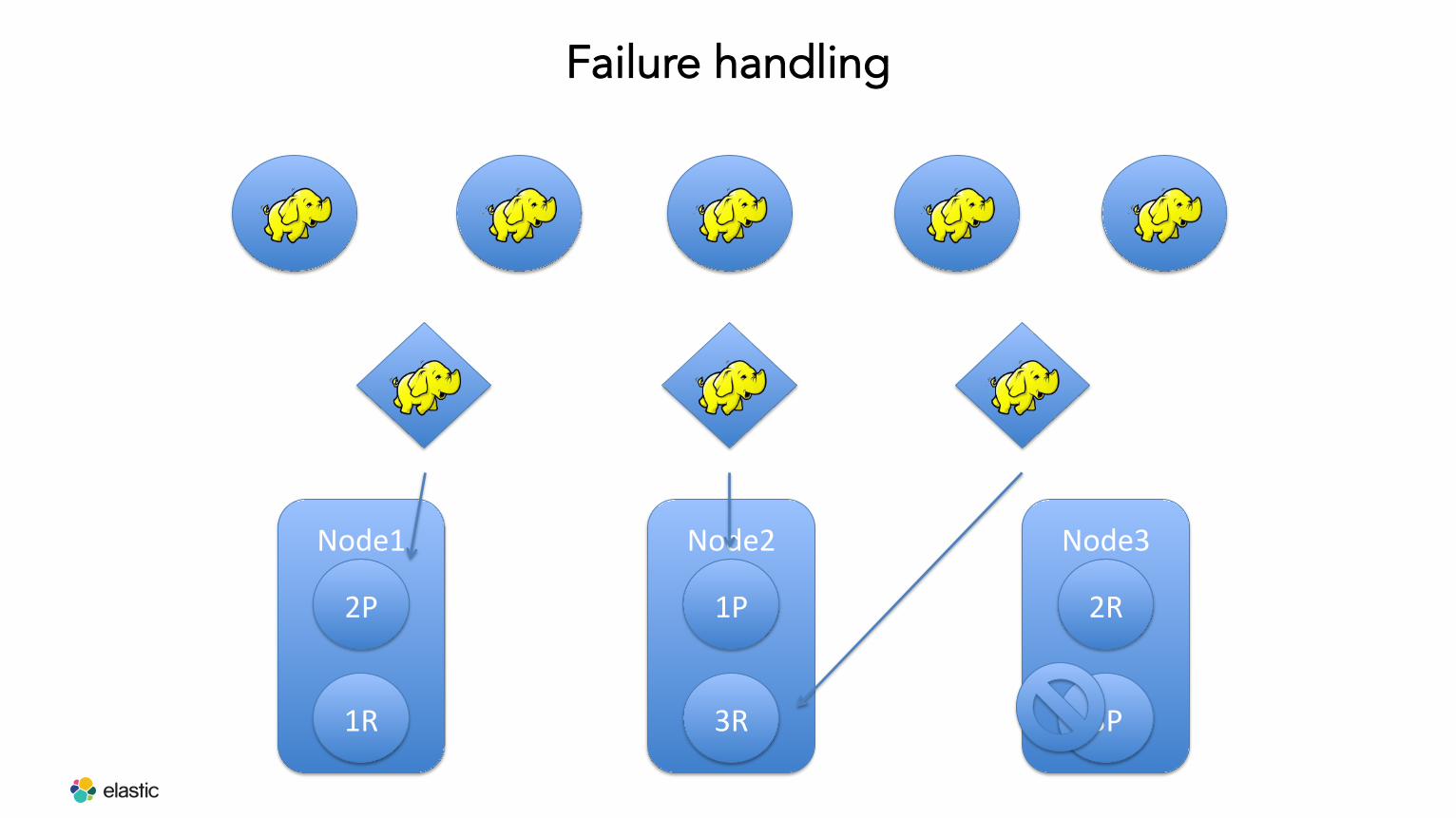
Failure handling
Node1
2P
1R
Node2
1P
3R
Node3
2R
3P
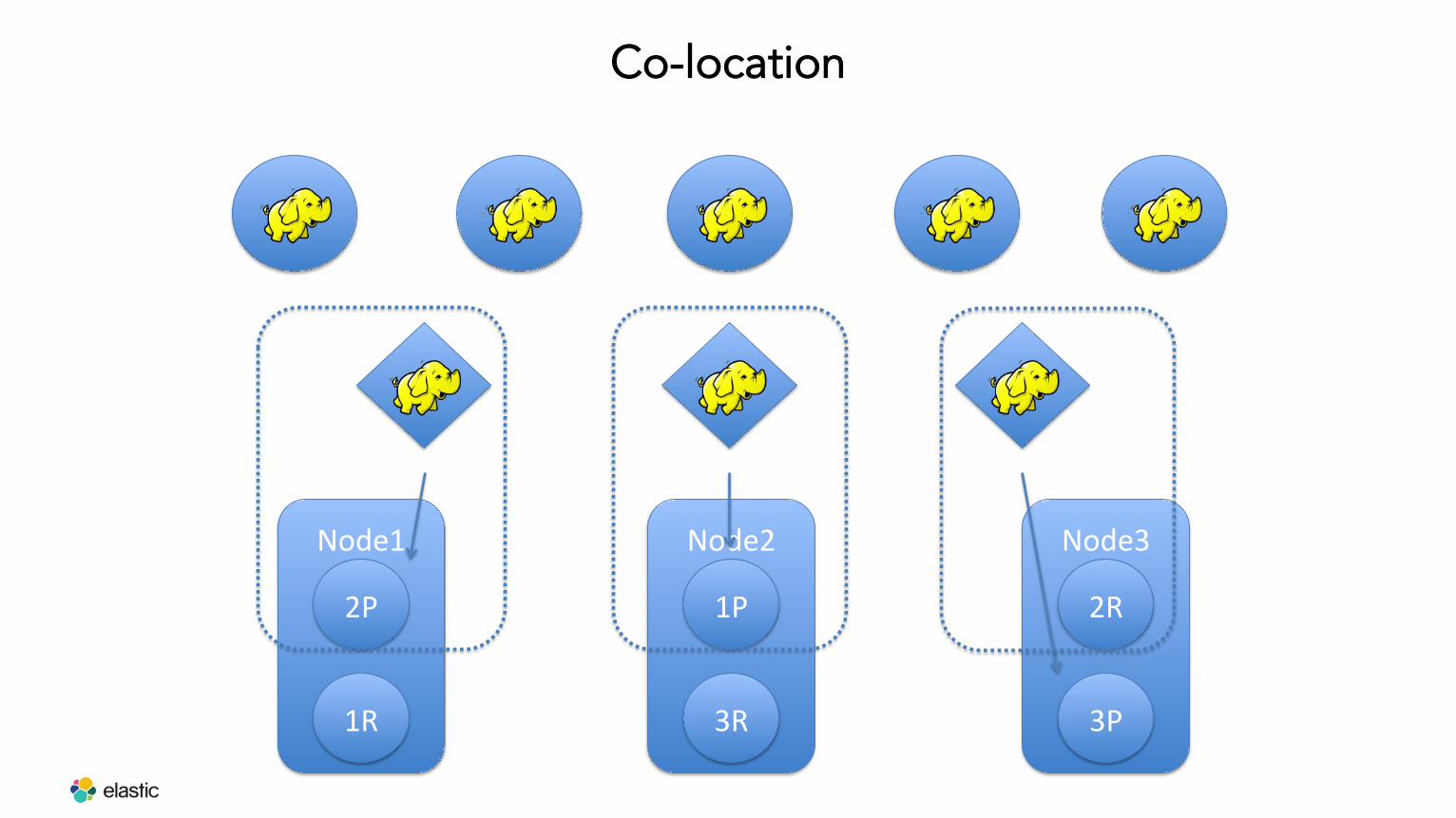
Co-location
Node1
2P
1R
Node2
1P
3R
Node3
2R
3P

www.elastic.co
Native integration - Map / Reduce
JobConf conf = new JobConf(); conf.setInputFormat(EsInputFormat.class); conf.set("es.resource", "radio/artists"); conf.set("es.query", "?q=me*"); JobClient.runJob(conf);
JobConf conf = new JobConf(); conf.setOutputFormat(EsOutputFormat.class); conf.set("es.resource", "radio/artists"); JobClient.runJob(conf);
9

www.elastic.co
Native integration - Cascading
Tap in = new EsTap("radio/artists","?q=me*"); Tap out = new StdOut(new TextLine()); new LocalFlowConnector(). connect(in, out, new Pipe(“pipe")).complete(); JobClient.runJob(conf);
Tap in = Lfs(new TextDelimited( new Fields("id", "name", "url", "picture")), "artists.dat"); Tap out = new EsTap("radio/artists", new Fields("name", "url", "picture")); new HadoopFlowConnector(). connect(in, out, new Pipe(“pipe")).complete();
10
www.elastic.co
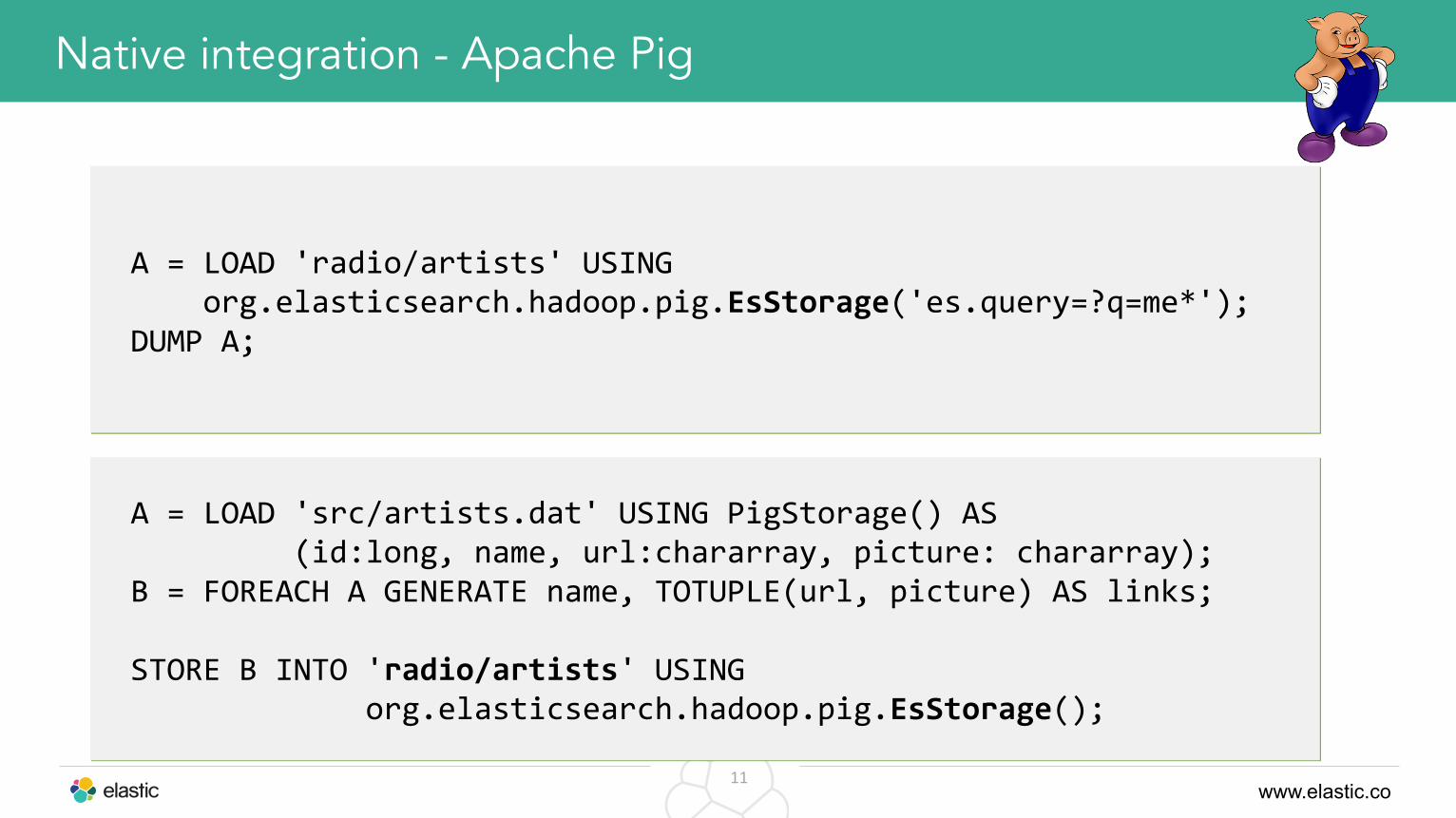
Native integration - Apache Pig
A = LOAD 'radio/artists' USING org.elasticsearch.hadoop.pig.EsStorage('es.query=?q=me*'); DUMP A;
A = LOAD 'src/artists.dat' USING PigStorage() AS (id:long, name, url:chararray, picture: chararray); B = FOREACH A GENERATE name, TOTUPLE(url, picture) AS links; STORE B INTO 'radio/artists' USING org.elasticsearch.hadoop.pig.EsStorage();
11

www.elastic.co
Native integration - Apache Hive
CREATE EXTERNAL TABLE artists ( id BIGINT,name STRING, links STRUCT<url:STRING, picture:STRING>) STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler' TBLPROPERTIES('es.resource'='radio/artists','es.query'='?q=me*'); SELECT FROM artists;
CREATE EXTERNAL TABLE artists ( id BIGINT,name STRING, links STRUCT<url:STRING, picture:STRING>) STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler' TBLPROPERTIES('es.resource'='radio/artists'); INSERT OVERWRITE TABLE artists SELECT s.name, named_struct('url', s.url, 'picture', s.pic) FROM source s;
12

www.elastic.co
Native integration - Apache Spark
import org.elasticsearch.spark._ val sc = new SparkContext(new SparkConf()) val rdd = sc.esRDD("radio/artists", "?me*")
import org.elasticsearch.spark._ case class Artist(name: String, albums: Int) val u2 = Artist("U2", 12) val bh = Map("name"-‐>"Buckethead","albums" -‐> 95, "age" -‐> 45) sc.makeRDD(Seq(u2, h2)).saveToEs("radio/artists")
13

www.elastic.co
Native integration - Spark SQL
val sql = new SQLContext... val df = sql.load("radio/artists", "org.elasticsearch.spark.sql") df.filter(df("age") > 40)
val sql = new SQLContext... val table = sql.sql("CREATE TEMPORARY TABLE artists " +
"USING org.elasticsearch.spark.sql " + "OPTIONS(resource=`radio/artists`) ")
val names = sql.sql("SELECT name FROM artists")
14

www.elastic.co
Native integration - Apache Storm
TopologyBuilder builder = new TopologyBuilder(); builder.setBolt("esBolt", new EsBolt("twitter/tweets"));
TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("esSpout",new EsSpout("twitter/tweets","?q=nfl*",5); Builder.setBolt("bolt“, new PrinterBolt()).shuffleGrouping("esSpout");
15

www.elastic.co
Resource Management

www.elastic.co
YARN support – In Beta
• Run Elasticsearch on YARN
• But YARN doesn’t support long-lived services (yet): • No provisioning • No ip/network guarantees • Data/node affinity
• Next YARN releases plan to address this • Tracking projects like Apache Slider
17
www.elastic.co
Storage

www.elastic.co
HDFS integration
• Snapshot/Restore • Use HDFS as a shared storage • Backup and recover data • Works great with snapshot immutable data
• HDFS as a File-System – not recommended / tread carefully
• Incomplete FS semantics (last-delete-on-close, fsync) • NFSv3 (metadata issues) • See Elasticsearch issue #9072
19

www.elastic.co 20
• Support for Spark, Spark SQL, Storm • Includes support for Spark (core and SQL) 1.2, 1.3 and 1.4 • Support for all Spark SQL filters and relationship traits
• Certification with Hadoop distributions • Currently certified with CDH5.x, HDP2.x, MapR 4.x and Databricks Spark
• Security enhancements • Basic HTTP authentication allowing Hadoop jobs running against a restricted Elasticsearch cluster to identify themselves
accordingly • SSL/TLS support for cryptographic connections between Elasticsearch and Hadoop cluster, enabling data-sensitive
environments to transparently encrypt the data at transport level and thus prevent snooping and preserve data confidentiality.
• Support for Shield-enabled Elasticsearch clusters
• Several enhancements and performance improvements, including • Client node routing • Return raw JSON and metadata while reading documents from ES • Inclusion / Exclusion of fields to be written to ES
What’s New in ES-Hadoop 2.1

www.elastic.co
• Support for ES aggregations • Marvel integration • Integration with Machine Learning libraries e.g Mllib • Others? (Suggestions)
Roadmap
21
www.elastic.co 22
Documentation – https://www.elastic.co/guide/en/elasticsearch/hadoop/index.html Project home page/ Source repository - https://github.com/elastic/elasticsearch-hadoop Issue tracker - https://github.com/elastic/elasticsearch-hadoop/issues Mailing list / forum - https://discuss.elastic.co/c/elasticsearch-and-hadoop
More Questions?
www.elastic.co
Thank you!



















![[2D1]Elasticsearch 성능 최적화](https://img.pdfslide.tips/doc/110x75/547e865ab379594e2b8b54a6/2d1elasticsearch-.jpg)








