Embed Size (px)
Citation preview

Estadística Parte 2
Francisco J. Carrera Troyano
Instituto de Física de Cantabria Consejo Superior de Investigaciones Científicas
y Universidad de Cantabria
Octubre 2016

Índice 1. Incertidumbres y errores
– Incertidumbres en las medidas • Errores en la medida: sistemáticos y estadísticos. Incertidumbres.
Distribuciones original y de la muestra. Momentos de una distribución. Medidas del valor central. Medidas de la dispersión. Puntos aislados.
– Análisis de errores • Propagación de errores. Barras de error asimétricas.
2. Contrastes de hipótesis paramétricos y no paramétricos – Comparación de dos distribuciones
• Comparación de las medias. Comparación de las varianzas. Test χ2. Test de Kolmogorov-Smirnov. Comparación de distribuciones bidimensionales
• Análisis de varianza: ANOVA • Correlación lineal. Test no-paramétricos. Correlaciones parciales.
Variables con límites superiores e inferiores – Significancia de una detección
• Cociente señal-ruido. 3. Modelado estadístico de datos
– Métodos de máxima verosimilitud • Modelos frente a datos. Verosimilitud. χ2: Introducción, Estimación de
parámetros. Bondad del ajuste. Incertidumbre en los parámetros. Regresión lineal.
• Verosimilitud en régimen Poissoniano

Comparación de dos distribuciones: Introducción • Sólo se puede probar la diferencia, nunca la igualdad • Hipótesis: H, hipótesis nula H0
– Suele ser “las dos distribuciones son iguales” – La alternativa HA
– Definimos un estadístico X (función de los datos) y tratamos de definir una probabilidad P(X|H0)
• Niveles de significancia: – 0.01, 0.05, ... ciencias de la vida – 1σ, 2σ... (gaussianas) ciencias “duras”
• Grados de libertad (d.o.f.): ν=N-no de ligaduras adicionales • Dos muestras:
– A con número de datos NA
– B con número de datos NB
– N=NA+NB

Pruebas paramétricas de la media (Press et al. 1994)
• Si σA=σB:
– Distribución t de Student con ν=NA+NB-2 – P~0 si las distribuciones son distintas, I función beta incompleta
• Si σA≠σB: – Cuidado; si σ diferentes posiblemente la forma de la distribución
sea distinta también y la media quizá sea inútil
– t distribuida ~como t de Student con ν grados de libertad • Basadas en distribución gaussiana
t = xA − xBSD
SD =xi,A − xA( )
2+ xi,B − xB( )
2
B∑
A∑
NA + NB − 21NA
+1NB
⎛
⎝⎜
⎞
⎠⎟
P(H0 ) =1− A(t |ν ) = I νν+t2
ν2, 12
⎛
⎝⎜
⎞
⎠⎟
11
2222
222
22
−
⎟⎟⎠
⎞⎜⎜⎝
⎛
+−
⎟⎟⎠
⎞⎜⎜⎝
⎛
⎟⎟⎠
⎞⎜⎜⎝
⎛+
=
+
−=
B
B
B
A
A
A
B
B
A
A
B
B
A
A
BA
NNs
NNs
Ns
Ns
Ns
Ns
xxt ν

Prueba paramétrica de la varianza (Press et al. 1994)
• Test F:
• I función beta incompleta: – P~0 distribuciones muy diferentes – El 2 es porque buscamos “igual”, no mayor o menor
• Basada en distribución gaussiana
F = sA2
sB2 , sA > sB νA = NA −1,νB = NB −1
P(H0 ) = 2I νBνB+νAF
νB
2,ν A
2⎛
⎝⎜
⎞
⎠⎟

Prueba no paramétrica de la media (Wall & Jenkins 2003)
• No supone distribución gaussiana • Rango: se trata de sustituir {xA},{xB} por el rango
(lugar) que ocupan al unirlas y ordenarlas: {rA}{rB} – Ojo con los empates: se asigna el rango promedio
• Prueba de la suma de rangos (test U de Wilcoxon-Mann-Whitney): RA=ΣrA RB=ΣrB – NA>10 y NB>10: RA gaussiana N( NA(N+1)/2 , √NANB(N+1)/12 ) – NA<10, NB<10 tablas – Eficiente, y útil para muestras pequeñas – También sensible a distintas formas de la distribución – Equivale al test t con rangos

Pruebas no paramétricas de la media y de la varianza para N grande
• Se trata de aplicar pruebas conocidas a los rangos – Si valores muy diferentes a los originales, probablemente
distribuciones no gaussianas – Se basan en que para N>> distribución ~gaussiana
• Prueba de la media: test t con rangos • Prueba de la varianza: test F con rangos • Eficientes y sensibles a forma distribución

Prueba de la varianza para N grande (Hines & Montgomery 1990)
• No requiere distribución gaussiana • Requiere N >>
• Test Z: – Paramétrico: sólo usa varianzas y número de datos – Aceptamos H0 si Z~0 (varianzas iguales)
Z = sA − sBsD / 2
P(H0 ) =1− 2 12π
dx e−x2
2
0
Z
∫

Pruebas generales (Press et al. 1994)
• Se usan para comparar la distribución general de dos conjuntos de datos
• Se pueden comparar: – Datos con datos, o datos con distribución – Datos agrupados, discretos o continuos
• Test χ2: datos agrupados en n bines {NAi}{NBi}, NA=ΣNAi, NB=ΣNBi
– Si n>> ó NAi,NBi>>: Q(χ2|ν) Γ incompleta buena aproximación a P(H0) – Si comparamos con modelo {nBi}, nB=ΣnBi
χ 2 =NAi − NBi( )2
NAi + NBi
NA = NB ν = n−1i=1
n
∑
χ 2 =
NAiNB
NA
− NBiNA
NB
#
$%
&
'(
2
NAi + NBi
NA ≠ NB ν = ni=1
n
∑
( )∑= ⎩
⎨⎧
≠=
=−=−=
n
i AB
AB
Bi
BiAi
NnnNnn
nnN
1
22 1
ν
νχ

Pruebas generales (Press et al. 1994)
• Test de Kolmogorov-Smirnov (KS): – Para datos sin agrupar, continuos o discretos – Se comparan las distribuciones cumulativas
– Aproximación buena si Ne≥4 – Sensible a desplazamientos pero no a dispersiones, ni a
diferencias en rangos pequeños
BA
BAeNBNA
x
eNx
NNNNNxSxSD
NNxPxSD
+=−=
=−=
∞<<∞−
∞<<∞−
)()(
)()(
max
max
λ = Ne + 0.12+0.11Ne
!
"##
$
%&&D
QKS (λ) = 2 −1( ) j−1 e−2 j2λ2
j=1
∞
∑

¿Cuál usar? • Si distribuciones gaussianas:
– t – F – χ2
• Si no se sabe o no gaussiano – U – KS:
• pero no demasiado sensible a colas
• Si N>> χ2 vale en cualquier caso • En general, transformación de rango es buena idea:
– t (U), F con rangos: eficientes y sensibles a forma distribución
• Ver tablas 5.4, 5.5 y 5.6 de Wall & Jenkins (2003)
Siempre valen, pero no usan toda la información de la muestra: – Menos eficientes – Requieren muestras
mayores, en general

Ejercicio 2
• Archivos dat1.dat,dat2.dat,dat3.dat en http://venus.ifca.unican.es/~carreraf/Estadistica/Ejercicios
• Utilizar varias de las pruebas que hemos visto para comparar esas tres distribuciones de datos, en particular para responder a las siguientes preguntas: – ¿Tienen la misma media? – ¿Tienen la misma varianza? – ¿Son compatibles con ser la misma distribución?
• A la vista de los resultados, comentar si las pruebas realmente responden a lo que se espera de ellas

Test KS en dos dimensiones (Press et al. 1994)
• Idea de Peacock y Fasano & Franceschini • Esencialmente es una generalización de KS a 2D:
– D es la diferencia entre las fracciones de los puntos que están en cada cuadrante (el máximo de los máximos de los cuatro)
– r coeficiente de correlación lineal
• Expresión OK si N≥20 o P<0.2: – Si P>0.2 distribuciones compatibles, pero P no es preciso – Más precisión comparando distribución D simulaciones con D obs.
⎪⎩
⎪⎨⎧
+=
−
⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
⎟⎠⎞
⎜⎝⎛ −−+
=>
dist-distmodelodist
75.025.011)(
2BA
BAKSobsNNNNN
N
Nr
NDQDDP

Test KS en dos dimensiones (Press et al. 1994)
• Idea de Peacock y Fasano & Franceschini • Esencialmente es una generalización de KS a 2D:
– D es la diferencia entre las fracciones de los puntos que están en cada cuadrante (el máximo de los máximos de los cuatro)
– r coeficiente de correlación lineal
• Expresión OK si N≥20 o P<0.2: – Si P>0.2 distribuciones compatibles, pero P no es preciso – Más precisión comparando distribución D simulaciones con D obs.
⎪⎩
⎪⎨⎧
+=
−
⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
⎟⎠⎞
⎜⎝⎛ −−+
=>
dist-distmodelodist
75.025.011)(
2BA
BAKSobsNNNNN
N
Nr
NDQDDP

Índice 1. Incertidumbres y errores
– Incertidumbres en las medidas • Errores en la medida: sistemáticos y estadísticos. Incertidumbres.
Distribuciones original y de la muestra. Momentos de una distribución. Medidas del valor central. Medidas de la dispersión. Puntos aislados.
– Análisis de errores • Propagación de errores. Barras de error asimétricas.
2. Contrastes de hipótesis paramétricos y no paramétricos – Comparación de dos distribuciones
• Comparación de las medias. Comparación de las varianzas. Test χ2. Test de Kolmogorov-Smirnov. Comparación de distribuciones bidimensionales
• Análisis de varianza: ANOVA • Correlación lineal. Test no-paramétricos. Correlaciones parciales.
Variables con límites superiores e inferiores – Significancia de una detección
• Cociente señal-ruido. 3. Modelado estadístico de datos
– Métodos de máxima verosimilitud • Modelos frente a datos. Verosimilitud. χ2: Introducción, Estimación de
parámetros. Bondad del ajuste. Incertidumbre en los parámetros. Regresión lineal.
• Verosimilitud en régimen Poissoniano

Análisis de varianza: ANalysis Of Variance (ANOVA)
• Detecta diferencias entre las medias de más de dos distribuciones o de varias submuestras de la misma distribución – Mediante el análisis de las variaciones (varianzas) entre las
submuestras
• Supone: – Iguales varianzas entre las (sub)muestras – Estadística gaussiana
– Pero es robusto frente a incumplimientos (moderados) de esta suposición
• La hipótesis nula H0 es que todas las (sub)muestras tienen la misma media: – No distingue entre las distintas hipótesis alternativas (p. ej. sólo una
de las submuestras es diferente de las demás...)

ANOVA: un factor de variación I (Gorgas, Cardiel & Zamorano 2009)
• De una muestra se extraen t poblaciones independientes de tamaños n1,n2...nt. – Definimos tratamiento como la característica que diferencia a estas
muestras
• Condiciones: – t poblaciones distribución normal – misma varianza poblacional σ2 de las t poblaciones – t muestras elegidas aleatoriamente
• Hipótesis nula H0: las medias son todas iguales µ1=µ2=...=µt – HA: al menos dos de las medias son diferentes
• Método se basa en estudiar las variaciones entre los datos dentro y fuera de las distintas muestras: – VDT variación dentro de los tratamientos: intrínsecas, debidas al azar – VET variación entre tratamientos: entre las distintas poblaciones – VT variación total

ANOVA: un factor de variación II • xij valor de la variable correspondiente al elemento i del
tratamiento j: i=1...nj, j=1...t. Número total N=Σj nj – Medias muestrales ⟨x⟩j=(Σi xij)/nj
– Media total ⟨x⟩=(ΣjΣi xij)/N=(Σjnj⟨x⟩j)/N
• VT= ΣjΣi(xij-⟨x⟩)2 =...= ΣjΣi(xij-⟨x⟩j)2 + Σj nj(⟨x⟩j-⟨x⟩)2 VT=VDT+VET Ecuación fundamental de ANOVA
• Ahora tenemos en cuenta el número de datos usado: – VDT: s2
VDT=[ΣjΣi(xij-⟨x⟩j)2]/(N-t)=VDT/(N-t)≡ME estimación de la varianza poblacional, únicamente por efectos aleatorios
– VET: s2VET=[Σjnj(⟨x⟩j-⟨x⟩)2]/(t-1)=VET/(t-1)≡MT tiene en cuenta efectos
aleatorios y diferencias entre medias por tratamientos – MT≥ME
• Se usa el test F para ver “cuánto de distintas” F=MT/ME con d.o.f. υMT=t-1 y υME=N-t – Si H0 ambas iguales: F~1

ANOVA: un factor de variación. Ejemplo (Hines & Montgomery 12-1.1)
Un fabricante de papel para bolsas de la compra está interesado en mejorar la resistencia a la tensión de las bolsas, que se piensa que está relacionada con la concentración de madera dura en la pulpa, con valores típicos entre el cinco y el veinte por ciento. El ingeniero a cargo del estudio hace seis muestras para algunas concentraciones y mide su resistencia a la tensión con los siguientes resultados: Emplear un análisis ANOVA para ver si efectivamente cambia la resistencia como función de la concentración de madera dura en la pulpa
Concentración (%) Medidas 5 7 8 15 11 9 10 10 12 17 13 18 19 15 15 14 18 19 17 16 18 20 19 25 22 23 18 20

ANOVA: dos factores de variación I (Hines & Montgomery 1980)
• De una muestra se extraen poblaciones independientes según dos características: – t tratamientos: T1...Tt – b bloques: B1...Bb
• Condiciones: – t,b poblaciones distribución normal – misma varianza poblacional σ2 de las t,b poblaciones – t,b muestras elegidas aleatoriamente todas con el mismo número n
• Ahora más hipótesis: – H0: todas las medias de los tratamientos iguales µT1=µT2=...=µTt
– H´0: todas las medias de los bloques iguales µB1=µB2=...=µBb
– HA (H´A ): al menos dos de las medias de los tratamientos (bloques) son diferentes
– Término de interacción: no hay diferencia entre las medias por tratamientos, por bloques y por ambos a la vez H´´0

ANOVA: dos factores de variación II • De nuevo, el método se basa en estudiar las variaciones
entre los datos: – VDT variación debida al azar – VET variación debida al azar más las posibles diferencias
sistemáticas entre los tratamientos – VEB variación debida al azar más las posibles diferencias entre los
bloques – VTB variación de interacción – VT variación total
• xijk valor de la variable correspondiente al elemento i=1...n, del tratamiento j=1...t, y del bloque k=1...b. El número total N=tbn – Medias tratamiento ⟨x⟩Tj=(ΣiΣk xijk)/bn – Medias bloque ⟨x⟩Bk=(ΣiΣj xijk)/tn – Medias tratamiento-bloque ⟨x⟩jk=(Σi xijk)/n – Media total ⟨x⟩=(ΣiΣjΣk xijk)/N

ANOVA: dos factores de variación III
• VT= ΣiΣjΣk(xijk-⟨x⟩)2 =VDT+VET+VEB+VTB =VT – VDT = ΣiΣjΣk(xijk-⟨x⟩jk)2 – VET = nbΣj(⟨x⟩Tj-⟨x⟩)2 – VEB = ntΣk(⟨x⟩Bk-⟨x⟩)2
– VTB = nΣjΣk(⟨x⟩jk-⟨x⟩Tj-⟨x⟩Bk+⟨x⟩)2
• Ahora tenemos en cuenta el número de datos usado: – ME ≡ s2
VDT=VDT/[tb(n-1)] únicamente por efectos aleatorios – MT ≡ s2
VET=VET/(t-1)>ME tiene en cuenta efectos aleatorios y diferencias entre medias por tratamientos
– MB ≡ s2VEB=VEB/(b-1)>ME tiene en cuenta efectos aleatorios y
diferencias entre medias por bloques – MTB ≡ s2
VTB=VTB/[(t-1) (b-1)]>ME tiene en cuenta efectos aleatorios y diferencias entre medias por tratamientos y bloques

ANOVA: dos factores de variación IV • Se usa el test F para ver “cuánto de distintas”:
– FT =MT/ME con d.o.f. υME=tb(n-1) y υMT=t-1 : si H0 FT~1 – FB=MB/ME con d.o.f. υME=tb(n-1) y υMB=b-1 : si H´0 FB~1 – FTB=MTB/ME con d.o.f. υME=tb(n-1) y υMTB=(t-1)(b-1) : si H´´0 FTB~1

ANOVA: dos factores de variación. Ejemplo (Hines & Montgomery Ejemplo 13-3)
Las pinturas de imprimación para aviones se aplican sobre el aluminio con dos métodos distintos (con pistola y por inmersión). Se realiza un experimento para investigar el efecto del tipo de imprimación y del método de aplicación sobre la adhesión de las siguientes capas de pintura, con los siguientes resultados: Emplear un análisis ANOVA para ver si cambia la adhesión de la pintura con el tipo de imprimación y el método de aplicación
Imprimación Inmersión Pistola 1 4.0,4.5,4.3 5.4,4.9,5.6 2 5.6,4.9,5.4 5.8,6.1,6.3 3 3.8,3.7,4.0 5.5,5.0,5.0

ANOVA: dos factores de variación, 1 dato I (Gorgas, Cardiel & Zamorano 2009)
• De una muestra se extraen datos independientes según dos características: – t tratamientos: T1...Tt – b bloques: B1...Bb
• Condiciones: – 1 dato tomado para cada combinación t,b
• Ahora tres hipótesis: – H0: todas las medias de los tratamientos iguales µT1=µT2=...=µTt
– H´0: todas las medias de los bloques iguales µB1=µB2=...=µBb
– HA (H´A ): al menos dos de las medias de los tratamientos (bloques) son diferentes
– No hay término de interacción, puesto que no podemos definir la varianza para cada combinación t,b

ANOVA: dos factores de variación, 1 dato II • De nuevo, el método se basa en estudiar las variaciones
entre los datos: – VDT variación debida al azar – VET variación debida al azar más las posibles diferencias
sistemáticas entre los tratamientos – VEB variación debida al azar más las posibles diferencias entre los
bloques – VT variación total
• xjk valor de la variable correspondiente al elemento del tratamiento j=1...t, y del bloque k=1...b. El número total N=tb – Medias tratamiento ⟨x⟩Tj=(Σk xjk)/b – Medias bloque ⟨x⟩Bk=(Σj xjk)/t – Media total ⟨x⟩=(ΣjΣk xjk)/N

ANOVA: dos factores de variación, 1 dato III
• VT= ΣjΣk(xjk-⟨x⟩)2 =VDT+VET+VEB =VT – VDT = ΣjΣk(xjk-⟨x⟩Tj-⟨x⟩Bk+⟨x⟩)2 – VET = bΣj(⟨x⟩Tj-⟨x⟩)2 – VEB = tΣk(⟨x⟩Bk-⟨x⟩)2
• Ahora tenemos en cuenta el número de datos usado: – ME ≡ s2
VDT=VDT/[(t-1) (b-1)] únicamente por efectos aleatorios – MT ≡ s2
VET=VET/(t-1)>ME tiene en cuenta efectos aleatorios y diferencias entre medias por tratamientos
– MB ≡ s2VEB=VEB/(b-1)>ME tiene en cuenta efectos aleatorios y
diferencias entre medias por bloques
• Se usa el test F para ver “cuánto de distintas”: – FT =MT/ME con d.o.f. υME=(t-1) (b-1) y υMT=t-1 : si H0 FT~1 – FB =MB/ME con d.o.f. υME=(t-1) (b-1) y υMB=b-1: si H´0 FB~1

Índice 1. Incertidumbres y errores
– Incertidumbres en las medidas • Errores en la medida: sistemáticos y estadísticos. Incertidumbres.
Distribuciones original y de la muestra. Momentos de una distribución. Medidas del valor central. Medidas de la dispersión. Puntos aislados.
– Análisis de errores • Propagación de errores. Barras de error asimétricas.
2. Contrastes de hipótesis paramétricos y no paramétricos – Comparación de dos distribuciones
• Comparación de las medias. Comparación de las varianzas. Test χ2. Test de Kolmogorov-Smirnov. Comparación de distribuciones bidimensionales
• Análisis de varianza: ANOVA • Correlación lineal. Test no-paramétricos. Correlaciones parciales.
Variables con límites superiores e inferiores – Significancia de una detección
• Cociente señal-ruido. 3. Modelado estadístico de datos
– Métodos de máxima verosimilitud • Modelos frente a datos. Verosimilitud. χ2: Introducción, Estimación de
parámetros. Bondad del ajuste. Incertidumbre en los parámetros. Regresión lineal.
• Verosimilitud en régimen Poissoniano
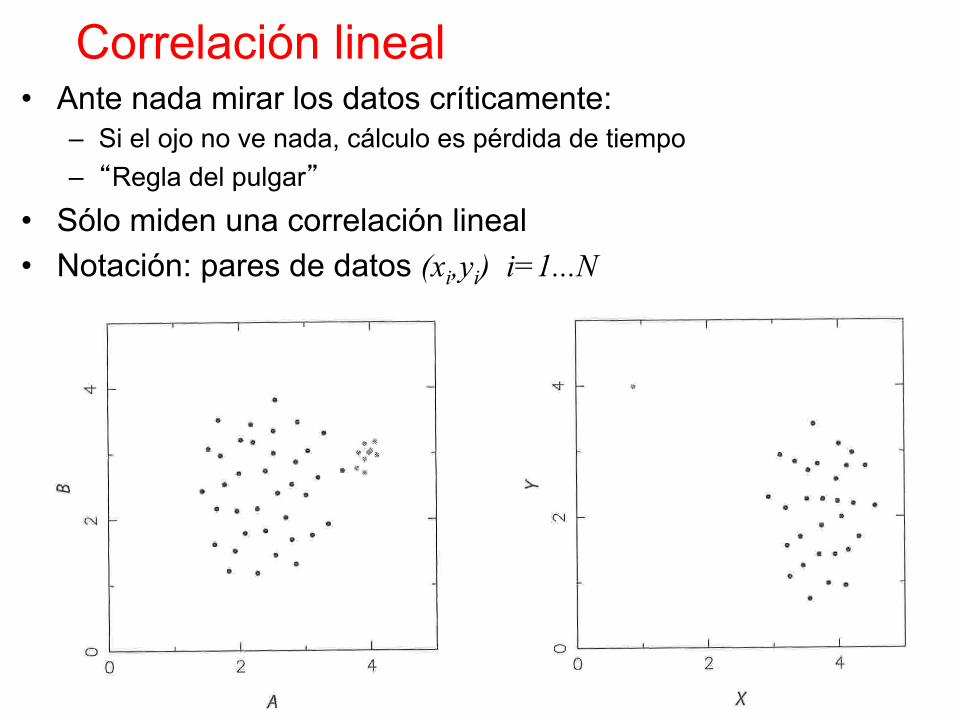
• Ante nada mirar los datos críticamente: – Si el ojo no ve nada, cálculo es pérdida de tiempo – “Regla del pulgar”
• Sólo miden una correlación lineal • Notación: pares de datos (xi,yi) i=1...N
Correlación lineal

• Ante nada mirar los datos críticamente: – Si el ojo no ve nada, cálculo es pérdida de tiempo – “Regla del pulgar”
• Sólo miden una correlación lineal • Notación: pares de datos (xi,yi) i=1...N
Correlación lineal

Cuarteto de Anscombe (1973)
• Importancia de gráficas • Los cuatro con idénticos:
– Medias de X e Y – Coeficientes de regresión lineal – Líneas de regresión – Residuos en Y – Errores en la pendiente – Matriz de covarianza
• Diferencia entre independencia y correlación • Aplicación de la “regla del pulgar” • Correlación no lineal • Sigma clipping

• “Buena correlación” – Pues claro: no podemos detectar fuentes distantes si no son muy
brillantes
• “Esquina superior izquierda vacía” – Pues claro: fuentes brillantes son escasas, difíciles de encontrar en
volumen pequeño
Efectos de selección
Sandage (1972)

Coeficiente de correlación lineal: paramétrico (Press et al. 1994)
• -1≤r≤1: según si y↓ó↑ cuando x↑ ó no – r~0: no correlación
• Si x,y colas cortas (p. ej. gaussiana) y N>500: – en ausencia de correlación: r distribución N(0,1/√N)
• Si N no tan grande y gaussianas, H0 ≡no correlación:
• r es un estadístico débil para decidir si: – Una correlación es significativa – Una correlación es mayor que otra
∑∑
∑−−
−−=
ii
ii
iii
yyxx
yyxxr
22 )()(
))((
⎟⎠
⎞⎜⎝
⎛=−=−−
=+
21,
2)(2
12
202
νν
ν
ν
t
IHPNr
Nrt

Test robustos no paramétricos (Press et al. 1994)
• Transformación de rango: rangos uniformes • Coeficiente de correlación de rangos de Spearman: rS
– {Ri}{Si} rango de datos en cada distribución – Si N>30: t de Student con ν=N-2 (ver anterior) – Si 4<N<30: Tabla 2.5 (Wall & Jenkins 2003) – Eficiente: merece la pena hacer transformación de rangos
xi → Riyi → Si
"#$
%$rS =
(Ri − R)(Si − S)i∑
(Ri − R)2 (Si − S)
2
i∑
i∑
∈ [0,1] t = rSN − 21− rS
2

Test robustos no paramétricos (Press et al. 1994)
• τ de Kendall: similar al anterior, idénticos en mayor parte casos – Sólo usa rangos relativos N(N-1)/2 pares:
• concordantes: xi>xj e yi>yj ó xi<xj e yi<yj • discordantes: xi>xj e yi<yj ó xi<xj e yi>yj • extra-y: xi=xj • extra-x: yi=yj
– H0≡ no correlación
⎟⎟⎠
⎞⎜⎜⎝
⎛
−+
=−∈++++
−=
)1(9104,0)(]1,1[
)x-extradiscon)(y-extradiscon(discorconcor
0 NNNNHPτ
Ojo! Si ambos se descarta

Si dudas sobre aplicabilidad estadístico
• Test de permutaciones: – Suponer H0=no correlación – Simulaciones, repetir muchas veces:
• Para cada xi, tomar yi al azar • Calcular estadístico preferido
– Comparar distribución estadístico simulado con estadístico original

Ejercicio 3
• Archivos dat5.dat,dat6.dat http://venus.ifca.unican.es/~carreraf/Estadistica/Ejercicios
• Utilizar varias de las pruebas que hemos visto para ver si hay correlaciones entre las dos columnas de cada uno de esos ficheros

Correlaciones parciales (Wall & Jenkins 2003)
• Se pueden encontrar correlaciones entre cantidades aparentemente inconexas: – Altura niños y calidad escritura (edad) – Tamaño pies China y precio pescado en Puerto Pesquero (tiempo)
• Técnica para ver si una correlación entre dos cantidades depende de una tercera: si tres variables {x1,x2,x3} con N datos cada una
– t12,3 de Student con ν=N-2 – También se pueden hacer simulaciones para “calibrar” t12,3
( )( ) 23,12
3,123,12
23,12
223
213
2313123,12 1
23
111 3,12 r
NrtNr
rrrrrr r −
−=
−
−=
−−
−= σ

Variables con límites superiores o inferiores (Feigelson & Nelson, 1985, ApJ, 293, 192)
• Cuando datos X sólo pueden registrarse si están en un intervalo [A,C]: – Si A=-∞: datos censurados por la derecha, límites inferiores – Si C=∞: datos censurados por la izquierda, límites superiores – Si la existencia de medidas fuera de [A,C] no se puede determinar: distribución
truncada • Se denomina Análisis de supervivencia o Datos de duración de vida:
– Origen en cálculos de tarifas de seguros (Halley 1693): • Personas de riesgo (vivas) • Personas fallecidas • Personas que han salido de la muestra (datos censurados)
– Estrategia común es ignorar límites, pero derroche de datos y sesgos • Mayor parte literatura con límites inferiores, pero en Física más común
límites superiores: – Tiempo de exposición – Sensibilidad del aparato ⇒ Puede haber que cambiar límites superiores por inferiores: si M es el máximo
de los valores, definimos X´i=M-X, o simplemente X´i=-Xi

Conceptos de análisis de supervivencia (Feigelson & Babu, 2012, CUP)
• Datos censurados: cuando se conoce su existencia, pero no el valor del parámetro para ellos
– Censurado por la izquierda: límite superior • Datos truncados: cuando se desconoce incluso su existencia • Idealmente: censura por la izquierda al azar
– La causa de la no-detección es independiente de la cantidad a medir – Métodos desarrollados para este caso
• Definiciones: – Se tienen i=1...N variables {Xi}, independientes e idénticamente distribuidas, con función
densidad f(x), y función de distribución F(x)=∫x-∞dt f(t) – Cada uno con un límite asociado Ci – δi=1 si detectado (se mide Xi), δi=0 si no detectado (sólo se sabe que Xi<Ci) – Ti=min(Xi, Ci) ⇒ datos definidos en términos de pares (Ti, δi) – Función de supervivencia S(x)=P(X>x)=1-F(x)
• Probabilidad de que un objeto se estropee tras un cierto uso – Tasa de riesgo: h(x)=f(x)/S(x)=-d LnS(x)/dx – f(x)=S(x) h(x)
• S(x), h(x) más fáciles de modelar en muchas situaciones

Análisis de supervivencia I (Feigelson & Babu, 2012, CUP)
• Estimación paramétrica: si se conoce f(x) de antemano – Verosimilitud L=ΠiP(Ti, δi)=Πi[f(Ti) ]δi[1-S(Ti)]1-δi
– Y se estiman los parámetros maximizando la verosimilitud (Sección 3 del curso) • Estimación no paramétrica: Kaplan-Meier
– Estimador de la función de riesgo cumulativa HKM(x)=Σxi≥x di/Ni • {xi} datos observados ordenados • Ni número de datos (observados o no) con valores mayores o iguales que xi • di número de datos con valor xi (si no repetidos di=1)
– Estimador de la función de supervivencia SKM(x)=Πxi≥x (1-di/Ni) – Redistribuir a la izquierda: Redistribuyendo el “peso” del límite superior igualmente entre
las detecciones a valores inferiores SKM(xi)=SKM(xi-1)×(Ni-di)/Ni – Si la muestra es grande SKM aproximadamente gaussiano con varianza estimable – KM propiedades deseables, si censura al azar
• Pruebas con dos muestras: comparación de distribuciones – Más generales que KM, porque no piden censura al azar – Gehan: dos muestras {x1i} i=1...N {x2j} j=1...M se define Uij
• WG=ΣiΣjUij • Para muestras grandes es gaussiano con media 0 y varianza estimable
• Otras pruebas para más muestras
+1 , x1i < x2 j (x1i puede estar censurado)
−1 , x1i > x2 j (x2 j puede estar censurado)
0 , x1i = x2 j (o indefinido)
"
#
$$
%
$$
&
'
$$
(
$$

Análisis de supervivencia II (Feigelson & Babu, 2012, CUP)
• Correlaciones: normalmente generalizaciones de la τ de Kendall – Permiten censura en ambas direcciones – Helsel:
– donde: • nc: pares concordantes, teniendo en cuenta datos censurados • nd: pares discordantes, teniendo en cuenta datos censurados • nt,x, nt,y: empates o indeterminados
– Cuando aumenta el número de datos censurados tanto el numerador como el denominador disminuyen
– Significancia como para τ de Kendall pero ajustando por empates e indeterminados • Correlaciones parciales: uso de la τ de Kendall generalizada
– Que es asintóticamente gaussiana – Si no seguro de suposiciones: simulaciones (bootstrap)
• Y más, literatura muy abundante
τ H =nc − nd
N(N −1)2
− nt,x"
#$
%
&'
N(N −1)2
− nt,y"
#$
%
&'
τ12,3 =τ12 −τ13τ 231−τ 213( ) 1−τ 223( )

Índice 1. Incertidumbres y errores
– Incertidumbres en las medidas • Errores en la medida: sistemáticos y estadísticos. Incertidumbres.
Distribuciones original y de la muestra. Momentos de una distribución. Medidas del valor central. Medidas de la dispersión. Puntos aislados.
– Análisis de errores • Propagación de errores. Barras de error asimétricas.
2. Contrastes de hipótesis paramétricos y no paramétricos – Comparación de dos distribuciones
• Comparación de las medias. Comparación de las varianzas. Test χ2. Test de Kolmogorov-Smirnov. Comparación de distribuciones bidimensionales
• Análisis de varianza: ANOVA • Correlación lineal. Test no-paramétricos. Correlaciones parciales.
Variables con límites superiores e inferiores – Significancia de una detección
• Cociente señal-ruido. 3. Modelado estadístico de datos
– Métodos de máxima verosimilitud • Modelos frente a datos. Verosimilitud. χ2: Introducción, Estimación de
parámetros. Bondad del ajuste. Incertidumbre en los parámetros. Regresión lineal.
• Verosimilitud en régimen Poissoniano

Significancia de una detección
• ¿Con qué nivel de confianza podemos decir que hemos detectado un efecto?
• Se pueden usar los métodos anteriores de comparación de distribuciones si se tiene un modelo para la ausencia de señal (“ruido”)
• Alternativamente: – Escoger un estadístico y calcularlo para los datos reales – Hacer simulaciones de la distribución en ausencia de señal – Calcular el estadístico para las simulaciones – Comparar estadístico observado con la distribución de estadísticos
simulados – Si el valor observado es poco frecuente, es que los datos reales tienen
algo que no está en las simulaciones

Cociente señal ruido (SNR) I (≈Bradt 2004, http://www.eso.org/~ohainaut/ccd/sn.html)
• Definido como el cociente entre la señal S y el ruido R : – SNR=S/R
– Trasfondo Gaussiano • Situación: cuenta de fotones (Poisson) con números
suficientemente altos (Gauss) – Señal medida a partir de diferencia entre cuentas totales T (=S+B) y
cuentas en el fondo B: S=T-B ⇒σ2S~σ2
T+σ2B
– En estas circunstancias varianza σ2=N ⇒σ2S~σ2
T+σ2B=T+B=S+2B
• Definiciones: – Señal: tasa de cuentas rS, tiempo total t=nτ: S=nτrS
– Ruido: diversos ingredientes en varianza • De la propia fuente, varianza S= nτrS
• Del fondo con tasa de cuentas rB, varianza 2B= 2nτrB
• Del ruido de lectura rL, varianza = nrL2
⇒ R2=nτrS + 2nτrB + nrL2

• Así que SNR=nτrS / √nτrS + 2nτrB + nrL
2
• Se distinguen distintos regímenes: – Fuente brillante: rS>> ⇒ SNR~√nτrS∝√t
• Mejora aumentando el tiempo de exposición • Problema más bien no saturar
– Dominado por el fondo: rB>> ⇒ SNR~nτrS /√2nτrB∝√t=√nτ • Mejora aumentando el tiempo de exposición • Puede convenir n>> τ<< (si cielo puede saturar)
– Dominado por el ruido de lectura rL>>: SNR~nτrS /rL√n∝τ/√n
• Al contrario, conviene ahora τ>> con n<<
Cociente señal ruido (SNR) II (≈Bradt 2004, http://www.eso.org/~ohainaut/ccd/sn.html)





























