Embed Size (px)
Citation preview

Faculdade de Engenharia da Universidade do Porto
Algoritmos de Big Data
Alexandra Mendes
Fábio Oliveira
Henrique Ferreira
Joana Ramos
Pedro Franco
Relatório elaborado no âmbito do Projeto FEUP
Supervisor: Prof. Jorge G. Barbosa Monitora: Anaís Dias

Algoritmos de Big Data
3 de Novembro de 2016
Resumo
Vivemos na era da informação. Estima-se que cerca de mais de 90% dos dados
existentes foram gerados durante os últimos 5 anos. Faz parte do âmbito deste relatório
aprofundar o conceito de Big Data e dar uma contextualização ao surgimento deste novo
paradigma. Vão ser explorados de modo superficial vários algoritmos relacionados com o
modelo ETL (Extract , Transform , Load) e as suas vantagens e desvantagens consoante as
situações. Vai ser ainda abordado superficialmente computação paralela enquanto
fundamento essencial para a análise em tempo real e distribuída de dados. No final vai ser
proposto um software ambicioso mas estritamente possível face às possibilidades e técnicas
do paradigma Big Data que vão ser apresentadas e analisadas ao longo deste relatório.
FEUP 2

Algoritmos de Big Data
Introdução
O desenvolvimento tecnológico decorrente das últimas décadas deu origem ao
surgimento exponencial de novas formas de obtenção de dados em grande escala. No
entanto, o aumento do poder de processamento computacional não seguiu o mesmo ritmo e
dessa forma tornou-se imprescindível criar formas de lidar com estes dados em tempo real,
otimizando as técnicas já existentes de data analysis . É cada vez mais importante para as
empresas de todos os setores saber extrair conhecimento eficazmente a partir de dados
recolhidos de forma a ter uma maior vantagem sobre a concorrência.
O termo Big Data refere-se ao conjunto abismal de dados brutos provenientes das
mais variadas fontes e às tecnologias empregues para os organizar, tratar e eventualmente
armazenar de forma segura. Enquanto a estatística aplicada se preocupa com o tratamento
manual de dados com bastante intervenção humana, Big Data procura automatizar este
processo recorrendo a técnicas de Machine Learning para procurar padrões, correlações e
efetuar previsões. Para otimizar ao máximo este processo é necessário escolher os algoritmos
mais adequados em função do tipo de informação que se pretende extrair.
FEUP 3

Algoritmos de Big Data
Agradecimentos
Este trabalho não teria sido possível sem a ajuda de alguns indivíduos que estiveram
sempre presentes para nos guiar.
De entre os quais gostaríamos de salientar o nosso supervisor Jorge Barbosa por nos
ter traçado o caminho a seguir desde logo a primeira aula e por ter permanecido ao nosso
lado durante todo este processo, tendo estado sempre apto a tirar todas as dúvidas que nos
surgiram.
Gostaríamos ainda de agradecer aos oradores das palestras da primeira semana e à
nossa monitora Anaís Dias pela sua ajuda imprescindível na elaboração do relatório e por todo
o apoio que nos deu ao longo do tempo.
FEUP 4

Algoritmos de Big Data
Índice
-Resumo……………………………………………………………………………………………….2
-Introdução……………………………………..……………………………..…………………..3
-Agradecimentos……………………….……………………….………………………………..4
-Índice………………………………………………………………………………………………….5
-Lista de figuras……………………………………………….………………………………...6
-Lista de tabelas…………………………………………………………………………………..7
1. Introdução ao conceito de Big Data……………………………………………………………………..8 2. Big Data e as Empresas……………………………………………………………………..………………….9 3. Big data e o Governo…………………………………………………………………………….…………...10 4. Processamento em Tempo Real e Distribuído…………………………………………………....11 5. Data Science………………………………………………………………………………………..……………..12
5.1. Aplicações de Data Science…………………………………………………….…………………..13 6. Data Mining………………………………………………………………………………………...……………….14 7. Machine Learning…………………………………………………………………………….………………...15 8. Da Recolha de Dados à Visualização de Informação………………………….…………………16
8.1. Algoritmos de Machine Learning……………………………………………….………………..17 8.2. Algoritmos de Data Mining…………………………………………………………..……………...18
9. Segurança e Criptografia…………………………………………………………………..………………...21 9.1 Algoritmos de encriptação…………………………………………………………..………………...21
10. Proposta do grupo……………………………………………………………………………..………………….23
-Conclusão…………………………………………………………………………………………..24
-Referências Bibliográficas…………………………………………………………………..25
FEUP 5

Algoritmos de Big Data
Lista de figuras
Figura 1 – Gráfico da Informação criada e Espaço de Armazenamento disponível em Exabytes nos anos 2005-2011.
Figura 2 - Fundamentos da Data Science.
Figura 3 - Representação visual de um exemplo de um algoritmo de Decision Tree .
Figura 4 - Representação visual de uma implementação do algoritmo de Regressão Logística.
Figura 5 - Representação visual de uma implementação do algoritmo Support Vector Machine.
Figura 6 - Esquema de uma Árvore de Decisão (decision tree).
Figura 7 - Alterações a uma conjunto de dados antes e depois de classificado pelo k-means .
Figura 8 - O funcionamento da etapa “SubBytes” do algoritmo AES.
Figura 9 - Possível design do site da nossa proposta.
FEUP 6

Algoritmos de Big Data
Lista de tabelas
Tabela 1 - Comparação entre os algoritmos C4.5, k-means e Apriori.
FEUP 7

Algoritmos de Big Data
1. Introdução ao conceito de Big Data
Big Data representa conjuntos de informação tão complexos ou extensos, que aplicações tradicionais de processamento de informação são incapazes de lidar com eles.
Com esta enorme quantidade de informação complexa, podemos, através de métodos de análise de dados avançados - como a análise do comportamento do público-alvo, análise preditiva, entre outras - extrair relações entre vários dados que podem ser usadas para prever tendências em áreas como negócios ou moda, prevenir doenças, combater crime, sugerir produtos com base em compras anteriores, entre muitas outras possibilidades.
“Big Data” é um termo relativamente novo, que surgiu no início dos anos 90. Não há certezas em relação a quem criou esta expressão, mas muitos dão crédito a John Mashey que, pode não a ter inventado, mas contribuiu para a sua popularidade.
O termo “Big Data” tornou-se mais popular a partir de 2000, quando Doug Laney, um famoso analista, associou a definição de Big Data com os três V’s:
- Volume: É a quantidade produzida e armazenada de informação. O tamanho desta determina a sua utilidade. Organizações armazenam dados de uma grande variedade de fontes, incluindo transações comerciais, redes sociais e informações de sensores ou dados transmitidos de máquina a máquina. No passado, armazenar tamanha quantidade de informações teria sido um problema – mas novas tecnologias têm aliviado a carga. Desde 2012 que aproximadamente 2,5 exabytes de informação são criados por dia, e esse número está a duplicar a cada 40 meses. Mais dados atravessam a internet a cada segundo que a quantidade total existente nesta há apenas 20 anos atrás.
- Velocidade: Para muitas situações, a velocidade da criação é ainda mais importante que o seu volume. Os dados fluem com uma velocidade sem precedentes e devem ser tratados rapidamente. Quanto mais rápida for a análise destes dados, mais flexível será uma empresa em relação aos seus concorrentes, por exemplo.
- Variedade: O tipo e natureza da informação. Os dados são gerados em todos os tipos de formatos - de dados estruturados, dados numéricos em bancos de dados tradicionais, até documentos de texto não estruturados, e-mail, vídeo, áudio, dados de cotações da bolsa e transações financeiras. Qualquer imagem postada numa rede social, sinais GPS de telemóveis. Muitas das mais importantes fontes de informação são relativamente recentes (Facebook , Instagram , Tumblr , entre outras).
Podemos também considerar duas dimensões adicionais quando nos referimos a Big
Data:
- Variabilidade: Além da velocidade e variedade de dados cada vez maiores, os fluxos de dados podem ser altamente inconsistentes com picos periódicos. Ainda mais quando falamos de dados não estruturados.
- Complexidade: Os dados vêm de várias fontes, o que torna difícil estabelecer uma relação, corresponder, limpar e transformar dados entre diferentes sistemas.
Para além disso, a veracidade da informação recolhida também é muito importante visto que a qualidade dos dados captados pode afetar drasticamente a exatidão da análise.[1][2]
FEUP 8

Algoritmos de Big Data
2.Big Data e as Empresas
Para explicar a importância e o impacto que Big Data provocou nas empresas,
tomemos como exemplo as livrarias.
Até agora, os livreiros conseguiam manter-se a par de que livros vendiam, quantos
vendiam e quais aqueles que permaneciam nas prateleiras. E o conhecimento acerca dos seus
clientes e transações ficava por aqui.
Assim que surgiram os negócios online como a Amazon ou o eBay , os vendedores
passaram a ter acesso a uma quantidade muito maior de informação em relação aos seus
consumidores: conseguiam saber não só o que os clientes compraram, mas também aquilo
para que olharam, como navegaram pelo site, quão influenciados por promoções e críticas
eram e similaridades entre indivíduos e grupos.
Pouco tempo depois, desenvolveram algoritmos para prever que livros os seus clientes
gostariam de ler a seguir, que iam tendo melhor desempenho cada vez que um consumidor
respondia ou ignorava uma recomendação.
Vendedores tradicionais em livrarias simplesmente não conseguiam aceder a esta
informação, não sendo, por isso, surpreendente que a Amazon tenha conseguido revolucionar
o conceito de livraria. Temos, contudo, de ter em mente, que este não foi o único fator em
jogo que resultou no declínio das livrarias : o surgimento de e-readers, preços mais baixos
praticados pelos vendedores online, maior facilidade de compra, maior variedade oferecida
pelas lojas online, etc.
Com este exemplo, conseguimos ver como a utilização de Big Data por parte das
empresas influencia o sucesso destas. Podemos portanto concluir que companhias geridas
tendo em conta informação dada por Big Data têm melhor desempenho, simplesmente porque
decisões com base em dados concretos são melhores que aquelas baseadas em intuição.[3]
FEUP 9

Algoritmos de Big Data
3.Big Data e o Governo
O desenvolvimento da ciência e da tecnologia levou ao aparecimento de novos
campos informáticos que procuram a automação face à interação pessoa-computador. Novas
oportunidades surgiram nestas últimas décadas relacionadas com a recolha e análise de
dados, uma área que antes era predominantemente ligada à estatística e à matemática, e
novas técnicas e aplicações continuam a ser descobertas com elevada frequência.
Em 2013 Edward Snowden chocou o mundo com as suas revelações polémicas. Nunca
em tempos anteriores tinha sido pensado sequer que existiam as ferramentas necessárias
para vigiar digitalmente 320 milhões de pessoas. Muitos países, nomeadamente as maiores
potências mundiais como os Estados Unidos da América, Inglaterra e França, adotaram esta
iniciativa clandestinamente, embora tal facto seja uma clara violação da lei e da privacidade
individual. É, portanto, necessário usar eticamente todas as informações recolhidas e ainda
ter o dever de as armazenar seguramente de modo a evitar qualquer tipo de fugas. [4] [5] [6]
É impossível negar o papel de Big Data nestes programas de vigilância. Através da
recolha de metadados e posterior análise dos mesmos, um perfil para cada cidadão é
construído com base nas suas interações digitais com outras pessoas. As técnicas de Machine
Learning e processamento distribuído são fundamentais para este processo, permitindo uma
eficiente e distribuída análise em tempo real de todas a informações recolhidas. [7]
FEUP 10

Algoritmos de Big Data
4.Processamento em Tempo Real e Distribuído
A capacidade de armazenar grandes quantidades de informação já é possível desde o
século passado e não é nada de excecional. O principal propósito de Big Data é a análise em
tempo real à medida que os dados vão surgindo (real-time big data analytics ). Para algumas
empresas, isto significa a capacidade de ter um avanço significativo sobre a concorrência,
enquanto para outras é uma etapa vital na construção de inteligência artificial e de sistema
autónomos. Para nós enquanto indivíduos as implicações também são bastante abrangentes,
desde aplicações para nos ajudar a saber as ruas com menos trânsito até sugestões mais
significativas de conteúdo e produtos em plataformas como a Netflix ou a Amazon .
Essencialmente, a análise de informação sofreu uma mudança de paradigma total, estando
cada vez mais centrada na recolha do maior número de amostras possível e demorando o
menor tempo possível para as analisar, obtendo no final conclusões mais próximas da
realidade, podendo assim ser efetuadas previsões com um alto grau de precisão.
No entanto, é também importante armazenar a informação após esta passar pelo
processo de interpretação, embora este passo seja cada vez menos importante com a redução
significativa do tamanho das amostras. Isto leva-nos de volta a outro problema. É
absolutamente necessário organizar a informação consoante o seu significativo mas sem
perder a capacidade de a manipular e analisá-la como um todo de maneira breve. Ainda há
cerca de 2 15anos atrás, uma espera de 40 minutos para obter o resultado de uma query à
base de dados era o habitual. Hoje em dia, esse tempo foi reduzido para menos de 1 minuto,
o que é praticamente instantâneo quando comparado com os processos analíticos do século
passado que podiam demorar dias. [5]
A grande quantidade de dados patente do paradigma Big Data e a velocidade com que
estes surgem obriga a uma análise distribuída em vários centros de processamento. A
variedade das amostras constitui ainda outro desafio, exigindo um pré-processamento logo
após a recolha destas, o que também auxilia na redução do tamanho. [8] [9]
Figura 1 – Informação criada e Espaço de Armazenamento disponível em Exabytes nos anos 2005-2011 (gráfico).
FEUP 11

Algoritmos de Big Data
5. Data Science
A Data Science afeta as pesquisas aplicadas e académicas em muitos domínios,
incluindo a tradução automática, o reconhecimento de voz, a robótica, os motores de busca,a
economia digital e por outro lado, também as ciências biológicas, informática médica,
cuidados de saúde, ciências sociais e humanidades. Há no entanto um grande influenciamento
sobre a economia, negócios e finanças.
Do ponto de vista empresarial, a Data Science é uma parte integrante da inteligência
competitiva - um campo emergente que engloba uma série de actividades como a Data
Analytics e a Data Mining . Do ponto vista geral Data Science é um campo interdisciplinar de
processos e sistemas com o objetivo de extrair conhecimento de dados em várias formas,
estruturadas ou não estruturadas, de alguns dos campos de análise de dados como
estatísticas, Machine Learning , Data Mining e Data Analysis .[10]
Em termos simples, é o guarda-chuva das técnicas utilizadas quando se tenta extrair
“insights” e informações a partir de dados.[11]
FEUP 12

Algoritmos de Big Data
5.1. Aplicações da Data Science
Pesquisa na Internet: Os motores de busca fazem uso de algoritmos de Data Science
para entregar melhores resultados para consultas de pesquisa em fração de segundos.
Anúncios digitais: Todo o espectro de marketing digital utiliza os algoritmos de Data
Science a partir de banners de exibição de “outdoors digitais”. Esta é a razão média para
anúncios digitais receberem CTR(Click-through rate) maior do que anúncios tradicionais.
Sistemas de recomendação: Os sistemas de recomendação não só tornam fácil,
encontrar produtos relevantes a partir de milhares de milhões de produtos disponíveis, mas
também acrescenta muito a experiência do usuário. Um grande número de empresas usam
este sistema para promover seus produtos e sugestões de acordo com as demandas do usuário
e relevância da informação. As recomendações são baseadas em resultados de pesquisa
anteriores dos usuários.[11]
Figura 2 – Fundamentos da Data Science
FEUP 13

Algoritmos de Big Data
6. Data Mining
Data mining , muito relacionado com o Big data , é a análise de conjuntos de
informação, desde 10 megabytes até 10 terabyte ou mais. A natureza destes sets pode ser
qualquer coisa armazenada num computador que se queira analisar. O objetivo do Data
mining é descobrir relações entre dados, agregá-los baseando-se nessas semelhanças e prever
relações em entradas novas com as mesmas características das já analisadas, ou seja, analisar
grupos de dados mais facilmente a partir de relações descobertas entre estes.[8]
Por exemplo; se o programa tem posse de dados relativos a pacientes num hospital, como o
histórico de doenças, regularidade de exercício físico, se é fumador,etc, este pode prever
que um paciente fumador que faz pouco exercício físico terá cancro.[9]
FEUP 14

Algoritmos de Big Data
7. Machine Learning
Como um esforço científico, a Machine Learning cresceu a partir da busca por
inteligência artificial. Já nos primeiros dias desta ideia, alguns pesquisadores estavam
interessados no desenvolvimento das máquinas de modo a conseguir que elas “aprendessem”
por si próprias através dos dados. Machine Learning é, então, o ramo da ciência da
computação que dá aos computadores a capacidade de aprenderem, sem ser introduzida
qualquer tipo de programação explícita. Por outras palavras, ela explora o estudo e
construção de algoritmos que podem aprender e fazer previsões sobre os dados.[7]
Existem alguns problemas que são resolvidos através da Machine Learning , como por
exemplo, um computador aprender a jogar um partida contra um adversário. Nesta situação,
o computador teria que avaliar as jogadas do adversário de modo a determinar os objetivos
do jogo e a compreender a estratégia para os concluir. Com o passar do tempo haveria maior
acumulação de dados a serem analisados e consequentemente um maior desenvolvimento da
estratégia. Entretanto, existem outros tipos de problemas aplicados a Machine Learning que
se distinguem através da forma como a máquina analisa a informação, por exemplo, a análise
visual da máquina que é feita por captação de imagens da realidade e comparação das
mesmas de modo a serem analisadas semelhanças e/ou igualdades.
São no entanto, aplicados diferentes algoritmos para cada tipo de problema
encontrado dependendo da forma de como os dados serão recolhida e analisados pela
Máquina.[7]
FEUP 15

Algoritmos de Big Data
8. Da Recolha de Dados à Visualização de Informação.
8.1. Algoritmos de Machine Learning
Aqui apresentamos algumas classes de algoritmos muito ligados a
aprendizagem por máquina, e portanto fundamentais no campo de Data
Mining.
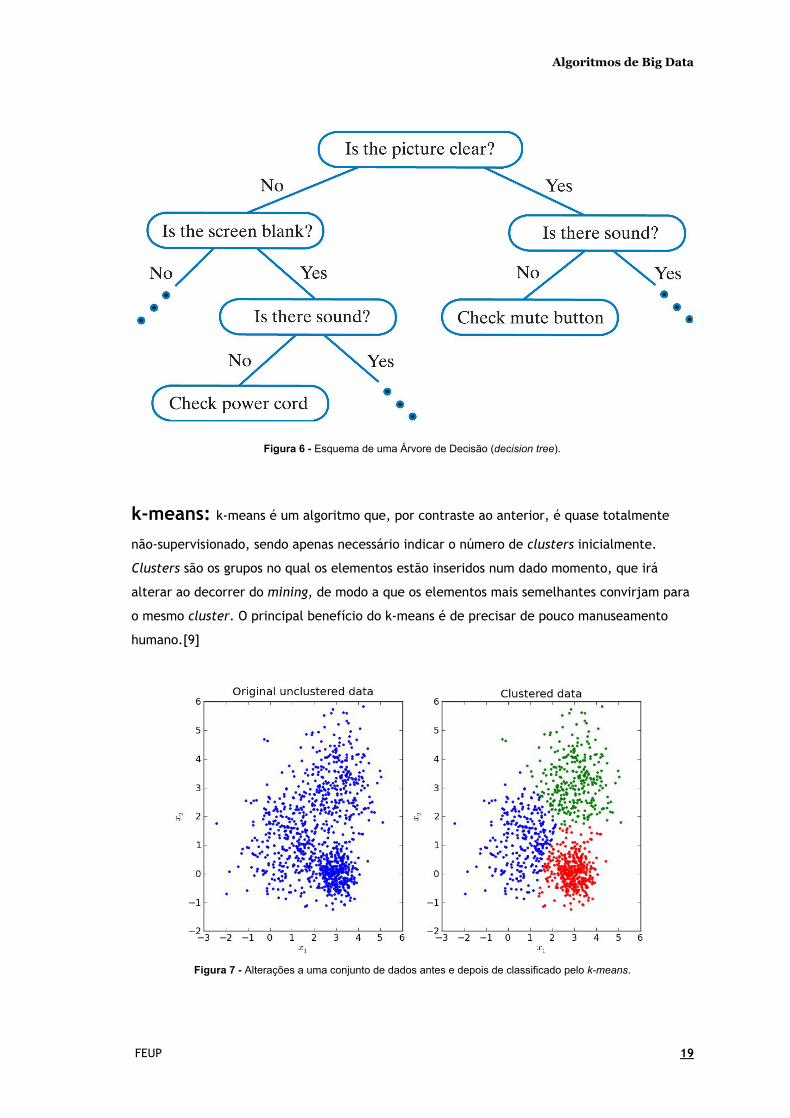
Decision trees: Ferramenta de apoio que utiliza um gráfico com o formato de uma
árvore que possui decisões e suas possíveis consequências, incluindo resultados,
possibilidades de ocorrências, custos de recursos e utilidade. C4.5 é um exemplo de um
algoritmo que recorre a decision trees para efetuar classificações.[9]
Figura 3- Representação visual de um exemplo de um algoritmo de Decision Tree .
Naïve Bayes Classification: Família de classificadores probabilísticos simples com
base na aplicação de teorema de Bayes com fortes premissas de independência entre as
características.[10]
Por exemplo o classificador P(A|B) = (P(A\B)P(A))/P(B)
FEUP 16
Algoritmos de Big Data
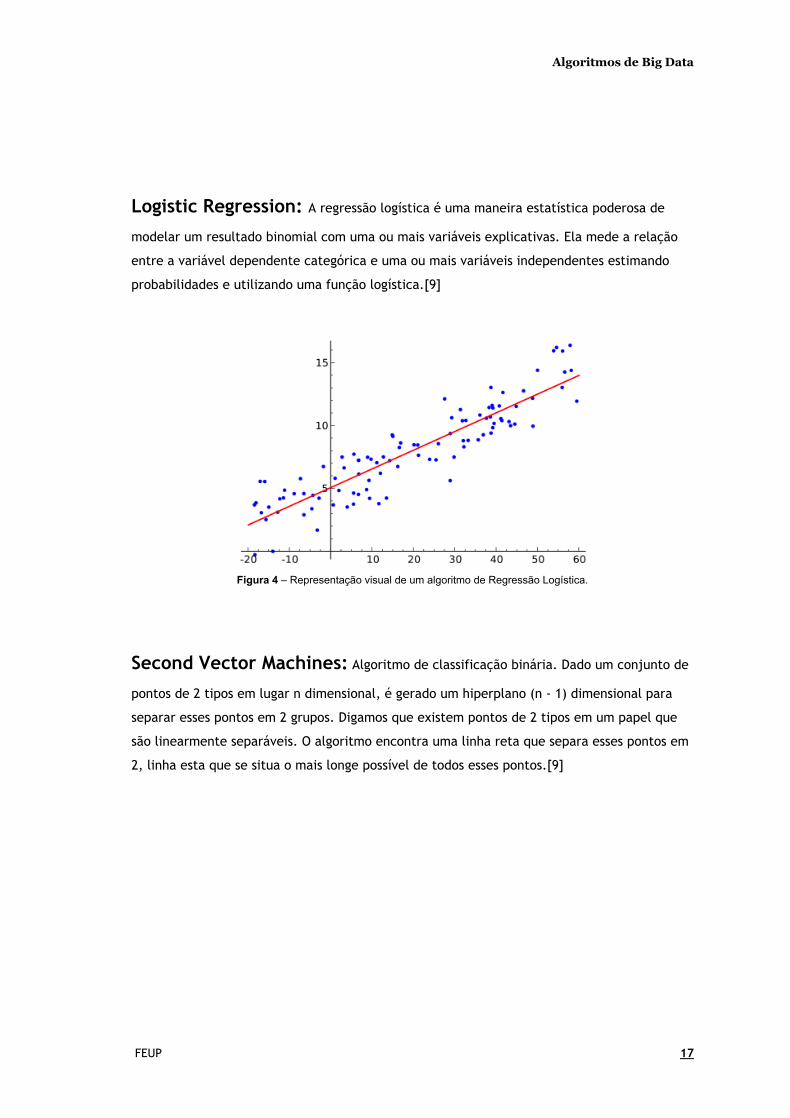
Logistic Regression: A regressão logística é uma maneira estatística poderosa de
modelar um resultado binomial com uma ou mais variáveis explicativas. Ela mede a relação
entre a variável dependente categórica e uma ou mais variáveis independentes estimando
probabilidades e utilizando uma função logística.[9]
Figura 4 – Representação visual de um algoritmo de Regressão Logística.
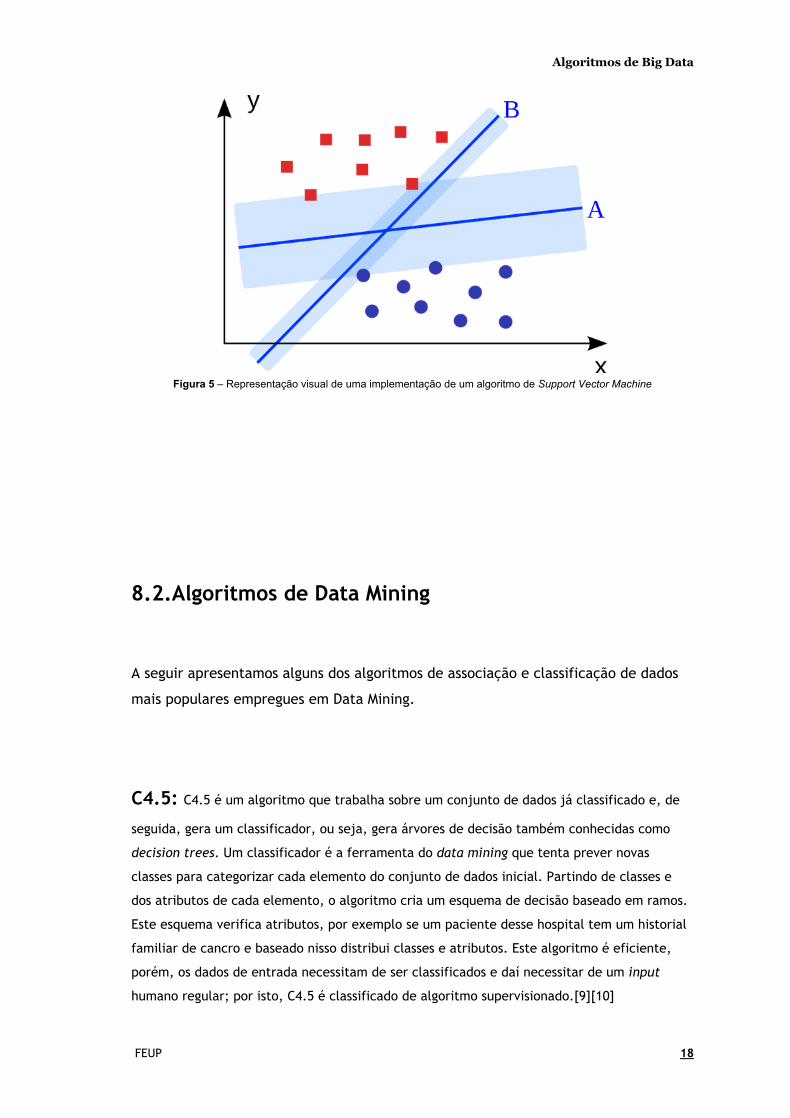
Second Vector Machines: Algoritmo de classificação binária. Dado um conjunto de
pontos de 2 tipos em lugar n dimensional, é gerado um hiperplano (n - 1) dimensional para
separar esses pontos em 2 grupos. Digamos que existem pontos de 2 tipos em um papel que
são linearmente separáveis. O algoritmo encontra uma linha reta que separa esses pontos em
2, linha esta que se situa o mais longe possível de todos esses pontos.[9]
FEUP 17
Algoritmos de Big Data
Figura 5 – Representação visual de uma implementação de um algoritmo de Support Vector Machine
8.2.Algoritmos de Data Mining
A seguir apresentamos alguns dos algoritmos de associação e classificação de dados
mais populares empregues em Data Mining.
C4.5: C4.5 é um algoritmo que trabalha sobre um conjunto de dados já classificado e, de
seguida, gera um classificador, ou seja, gera árvores de decisão também conhecidas como
decision trees . Um classificador é a ferramenta do data mining que tenta prever novas
classes para categorizar cada elemento do conjunto de dados inicial. Partindo de classes e
dos atributos de cada elemento, o algoritmo cria um esquema de decisão baseado em ramos.
Este esquema verifica atributos, por exemplo se um paciente desse hospital tem um historial
familiar de cancro e baseado nisso distribui classes e atributos. Este algoritmo é eficiente,
porém, os dados de entrada necessitam de ser classificados e daí necessitar de um input
humano regular; por isto, C4.5 é classificado de algoritmo supervisionado.[9][10]
FEUP 18
Algoritmos de Big Data
Figura 6 - Esquema de uma Árvore de Decisão (decision tree ).
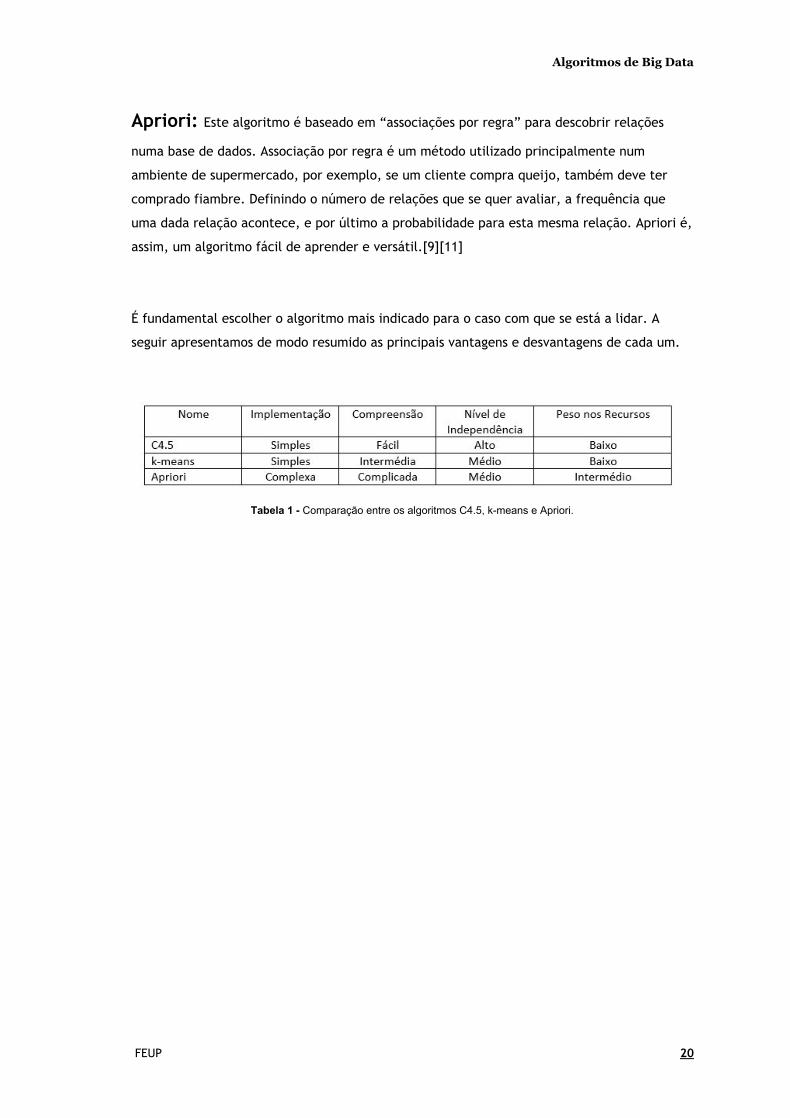
k-means: k-means é um algoritmo que, por contraste ao anterior, é quase totalmente
não-supervisionado, sendo apenas necessário indicar o número de clusters inicialmente.
Clusters são os grupos no qual os elementos estão inseridos num dado momento, que irá
alterar ao decorrer do mining , de modo a que os elementos mais semelhantes convirjam para
o mesmo cluster . O principal benefício do k-means é de precisar de pouco manuseamento
humano.[9]
Figura 7 - Alterações a uma conjunto de dados antes e depois de classificado pelo k-means .
FEUP 19
Algoritmos de Big Data
Apriori: Este algoritmo é baseado em “associações por regra” para descobrir relações
numa base de dados. Associação por regra é um método utilizado principalmente num
ambiente de supermercado, por exemplo, se um cliente compra queijo, também deve ter
comprado fiambre. Definindo o número de relações que se quer avaliar, a frequência que
uma dada relação acontece, e por último a probabilidade para esta mesma relação. Apriori é,
assim, um algoritmo fácil de aprender e versátil.[9][11]
É fundamental escolher o algoritmo mais indicado para o caso com que se está a lidar. A
seguir apresentamos de modo resumido as principais vantagens e desvantagens de cada um.
Tabela 1 - Comparação entre os algoritmos C4.5, k-means e Apriori.
FEUP 20

Algoritmos de Big Data
9. Segurança e criptografia
A própria natureza do processo do Big Data cria um desafio para a segurança dos
dados e do seu armazenamento. Se as ferramentas tradicionais não eram úteis para processar
e analisar os dados modernos, seriam ainda mais ineficientes na segurança desse processo.
Com o crescente uso de soluções tecnológicas de Big Data pelas empresas, existem
diversos riscos associados, como a exposição de dados sensíveis e confidenciais na internet e
o comprometimento dessas bases de dados com a exclusão, inclusão ou modificação de
informações.
As maiores falhas que estas soluções tecnológicas incorporam no seu desenvolvimento
estão relacionadas com a ausência de um mecanismo de autenticação, como nome de
utilizador e respetiva palavra-passe, e de canais seguros que permitam o acesso a essas
bases.
De modo a ser possível uma segurança sólida e consistente, devemos considerar
alguns pilares: profissionais capacitados para lidar com a proteção de dados e liderar equipas
que tenham esse objetivo, seguimento de boas práticas de mercado e a criação de canais
seguros para acessamento recorrendo, por exemplo, à encriptação. [12]
9.1. Algoritmos de encriptação
Atualmente existem diversos algoritmos de encriptação concebidos com os mais
variados objetivos.
Um algoritmo de encriptação tem como parâmetro uma chave criptográfica: um
“valor” secreto que modifica o algoritmo. Geralmente, os algoritmos de encriptação podem
ser conhecidos, mas não a respetiva chave. Para diferentes objetivos, existem dois tipos de
chaves: chaves simétricas e assimétricas (públicas). Os algoritmos de encriptação que
utilizam chaves simétricas fazem uso da mesma chave para encriptar e para desencriptar o
texto enquanto que os que utilizam chaves assimétricas lidam com duas chaves distintas: uma
de encriptação (geralmente pública) e uma de desencriptação (apenas conhecida pelo
destinatário da informação).
FEUP 21
Algoritmos de Big Data
Atualmente, o padrão de criptografia é o AES (Advanced Encryption System ou, em
português, sistema de encriptação avançada). Adotado inicialmente pelo governo dos Estados
Unidos, tornou-se um padrão efetivo em 2002. Este algoritmo é uma cifra de bloco, ou seja,
divide a informação por blocos, neste caso, de 128 bits cada. Após ter feito essa divisão,
coloca cada um dos 16 bytes (128 bits = 16 bytes) de cada bloco numa matriz (arranjo
bidimensional). Depois de ter atingido este tipo de organização, iniciam-se as manipulações
da informação: trocam-se os valores dos bytes, movem-se linhas, misturam-se colunas, numa
série de rondas que se repetem várias vezes. Um dos requisitos exigidos pelo governo e que
se mantém até hoje é o facto de o algoritmo utilizar uma chave simétrica, o que significa
que, neste caso, o processo de desencriptação é exatamente inverso ao de encriptação.
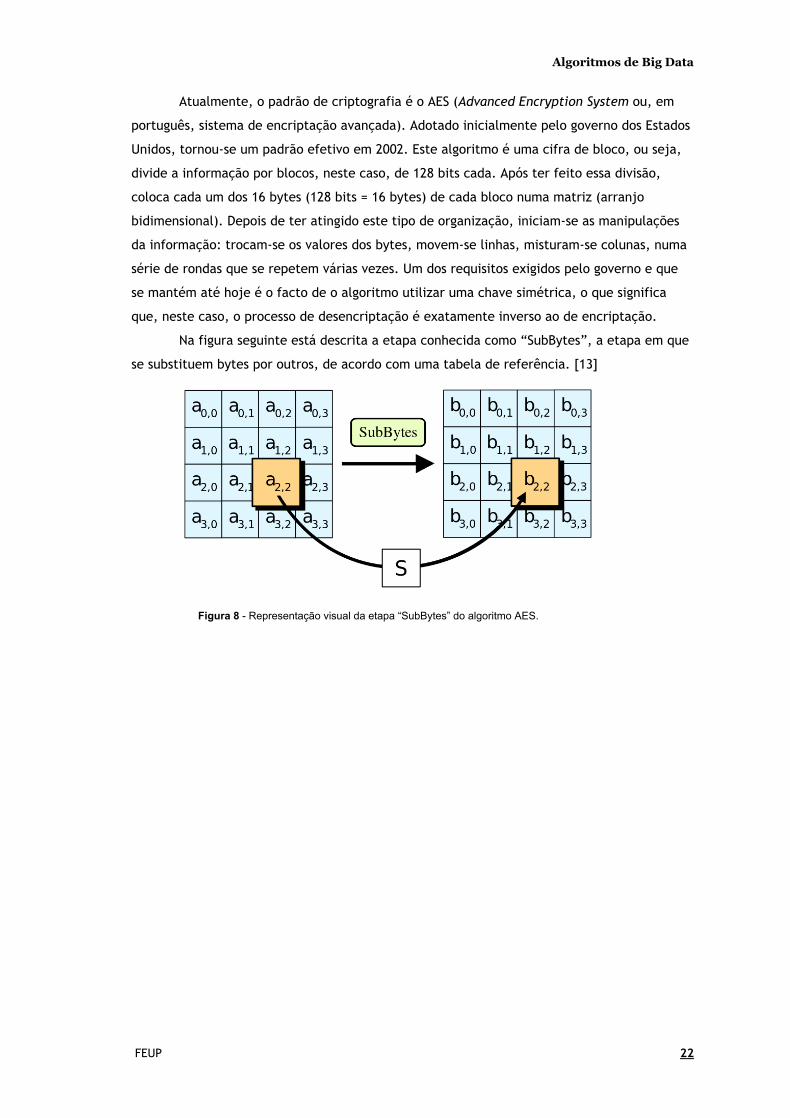
Na figura seguinte está descrita a etapa conhecida como “SubBytes”, a etapa em que
se substituem bytes por outros, de acordo com uma tabela de referência. [13]
Figura 8 - Representação visual da etapa “SubBytes” do algoritmo AES.
FEUP 22
Algoritmos de Big Data
10. Proposta do grupo
Figura 9 - Possível design do site da nossa proposta
Uma aplicação útil e inovadora deste processo pensada e sugerida por nós, iria
inserir-se no mercado imobiliário. Encontrar um novo sítio para viver é uma tarefa
dispendiosa tanto a nível de tempo como a nível emocional. A ideia que concebemos consiste
de uma forma simples numa aplicação com foco em pessoas que procuram casa, que se
conecta com as redes sociais da pessoa que a usa (mediante a sua aprovação) e procura nelas
dados como a existência de filhos, qual o tipo de entretenimento que o indivíduo prefere,
gostos que influenciam no formato da casa, informações globais que interferem na escolha de
uma residência. Após recolher e tratar toda esta informação, criaria todo um perfil do
comprador e sugeria assim um leque de opções que estivesse em concordância com esse
perfil. Alguns dos critérios para selecionar as recomendações seriam a distância ao local de
trabalho da pessoa, intensidade do trânsito ou presença de paragens de transportes públicos
perto de casa, proximidade a sítios de lazer como locais de espetáculos ou recintos
desportivos e ainda a proximidade a espaços verdes, tudo tendo em conta os gostos do
utilizador.
FEUP 23

Algoritmos de Big Data
Conclusão
Com base no que foi abordado ao longo do relatório concluímos que Big Data é um
campo muitíssimo abrangente e em crescimento exponencial. Com a quantidade de
informação criadas a cada momento a aumentar drasticamente, novos métodos e novos
algoritmos têm que ser criados para assegurar que a eficiência dos atuais é mantida ou
melhorada enquanto que o tempo de processamento se mantenha o mesmo ou seja
otimizado. Podemos ainda concluir que as possibilidades de manipular os dados são imensas,
o que pode dar origem a software e produtos inovadores no futuro.
FEUP 24

Algoritmos de Big Data
Referências Bibliográficas
[1] Hilbert, Martin, 2015 “Big Data for Development: A Review of Promises and Challenges. Development Policy Review." Acedido a 22 de outubro de 2016 em http://www.martinhilbert.net/big-data-for-development/ [2] John R. Mashey, 1998 "Big Data ... and the Next Wave of InfraStress" (PDF). Acedido a 22 de outubro de 2016. [3] Andrew McAfee, Erik Brynjolfsson, 2012, “Big Data:The Management Revolution”. Acedido a 22 de outubro de 2016 em http://www.rosebt.com/uploads/8/1/8/1/8181762/big_data_the_management_revolution.pdf [4] Ewen Macaskill, Gabriel Dance, 2013, “NSA Files Decoded: What the Revelations mean for you ” . Acedido a 19 de Outubro em https://www.theguardian.com/world/interactive/2013/nov/01/snowden-nsa-files-surveillance-revelations-decoded/ [5] Andrew Griffin, 2016, “UK surveillance agencies illegally kept data on British citizens' communications, spying court finds ”. Acedido a 20 de Outubro de 2016 em http://www.independent.co.uk/life-style/gadgets-and-tech/news/uk-spying-surveillance-investigatory-powers-bill-tribunal-gchq-intelligence-agencies-a7366386.html [6] Angelique Chrisafis, 2013, “France runs vast electronic spying operation using NSA-style methods ”. Acedido a 20 de Outubro de 2016 em https://www.theguardian.com/world/2013/jul/04/france-electronic-spying-operation-nsa [7] Russell, Stuart; Norvig, Peter (2003) [1995]. “Artificial Intelligence: A Modern Approach” (Segunda edição) [8] Bill Palace, 1996, “Data Mining: What is Data Mining?”. Acedido a 19 de Outubro de 2016 em [9] Raymond Li, 2015, “Top 10 Data Mining Algorithms, Explained”. Acedido a 19 de Outubro de 2016 em http://www.kdnuggets.com/2015/05/top-10-data-mining-algorithms-explained.html [10] Wikipedia, 2016, “C4.5 algorithm”. Acedido a 21 de outubro de 2016 em https://en.wikipedia.org/wiki/C4.5_algorithm [11] Wikipedia, 2016, “Association rule learning”. Acedido a 31 de outubro de 2016 em https://en.wikipedia.org/wiki/Association_rule_learning [12] Segurança da Informação, “Criptografia”. Acedido a 29 de outubro de 2016 em http://seguranca-da-informacao.info/criptografia.html [13] National Institute of Standards and Technology, 2001, “ADVANCED ENCRYPTION STANDARD (AES)”. Acedido a 31 de outubro de 2016 em http://csrc.nist.gov/publications/fips/fips197/fips-197.pdf
FEUP 25

Algoritmos de Big Data
Figura 1 - Gráfico da Informação criada e Espaço de Armazenamento disponível em
Exabytes nos anos 2005-2011. Adapatado de https://www-01.ibm.com/software/se/SmarterBusiness2013/
Figura 2 - Fundamentos da Data Science. Retirado de https://www.flickr.com/photos/altimetergroup/16139945728
Figura 3 - Representação visual de um exemplo de um algoritmo de Decision Tree . Retirado de http://www.kdnuggets.com/2016/08/10-algorithms-machine-learning-engineers.html
Figura 4 - Representação visual de uma implementação de um algoritmo de Regressão Logística. Retirado de http://www.kdnuggets.com/2016/08/10-algorithms-machine-learning-engineers.html
Figura 5 - Representação visual de uma implementação de um algoritmo de Support Vector Machine. Retirado de http://www.kdnuggets.com/2016/08/10-algorithms-machine-learning-engineers.html
Figura 6 - Esquema de uma Árvore de Decisão (decision tree). Retirado de http://www.sfs.uni-tuebingen.de/~vhenrich/ss12/java/homework/hw7/
Figura 7 - Alterações a uma conjunto de dados antes e depois de classificado pelo k-means . Retirado de https://phrasee.co/the-three-types-of-machine-learning/
Figura 8 - O funcionamento da etapa “SubBytes” do algoritmo AES. Retirado de
https://pt.wikipedia.org/wiki/Advanced_Encryption_Standard#/media/File:AES-SubBytes.svg
Figura 9 - Possível design do site da nossa proposta. Adapatado de um template retirado de http://w3layouts.com
Tabela 1 - Comparação entre os algoritmos C4.5, k-means e Apriori. Adaptado da tese de mestrado “Ferramenta para Text Mining em Textos completos” de Hugo Rodrigues que pode ser obtida em https://sigarra.up.pt/feup/pt/pub_geral.pub_view?pi_pub_base_id=143466
FEUP 26





























