Embed Size (px)
Citation preview

- 1 -
・・‥……━━━━━━━━━━━━━━━━━━━━━━━━━……‥・・
データベース技術者のための DOA入門(1/2)・・‥……━━━━━━━━━━━━━━━━━━━━━━━━━……‥・・
佐藤正美

- 2 -
本講演は、以下の点を論旨とします。
RDBMS の基本的動作を理解する。
目次
1. 事例1-1. パフォーマンス1-2. ソース・コード
2. データの独自性2-1. 物理データ独立性2-2. 論理データ独立性3-3. 3階層構造★ 今回は、分散アーキテクチャには言及しない。
3. データ・モデル3-1. データ構造3-2. データ演算3-3. Integrity 制約
4. データ構造4-1. テーブル構造4-2. 関係モデル
5. リレーショナル代数演算5-1. 集合演算5-2. リレーショナル代数演算5-3. セット・アット・ア・タイム法
6. キーと indexing6-1. キー概念6-2. indexing とB-tree(レコード・アット・ア・タイム法)
7. INDEX-only
8. 基本的なモニタリング・チューニング8-1. I/O関連8-2. I/O関連以外

- 3 -
▼ 事例
‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾
RDBの高パフォーマンス 正当なデータ構造があれば、
RDBは、「驚異的な」パフォーマンスを実現する。
プログラムのソース・コード 正当なデータ構造があれば、
プログラムのソース・コードが削減される。
▼ データの独立性
‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾
外部層(external layer) 外部モデル ● 応用(application)
② 論理独立性
概念層(conceptual layer) 概念モデル ● データ構造
① データ独立性
内部層(internal layer) 内部モデル ● 物理構造
(注意)今回は、入門編なので、分散したデータベース・システムを対象にしない。
★ 参考
「概念」という用語の使いかたは、データの独立性とデータ設計では違うので注意
してください。
データ設計
① 概念設計 ② 論理設計 ③ 物理設計
(conceptual) (logical) (physical)
データベース化の対象を 特定のプロダクトを考慮 使うプロダクトを考慮
調べる。 しない。 する。

- 4 -
▼ データ・モデル
‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾
データ・モデル
データ構造 データ演算 Integrity 制約
① スキーマ(schema) ① データ定義(DDL) ① 実体 integrity 制約
② 例(instance) ② データ演算(DML) ② 参照 integrity 制約
実現値(occurrence)、状態(state)とも云う。
Data Definition(スキーマに対して)Data Manipulation(例に対して)
(1)Integrity を乱す更新演算を拒否する。(2)Integrity が崩れないように、他のデータを更新する。
(cascading、nullfied)
★[ tips ]
たとえば、以下のデータを前提にして、nullified を考えます。
{従業員番号、従業員名称、...部門コード(R)}.001 A 01
部門テーブルから部門コード 01が削除されたとき、上記の部門コードは、nullfied にします。ただ、RDB のなかで、null の使用は危険であることを注意してください。たとえば、以下のデータを使って、null の危険性を調べてみてください。
SELECT name salary + bonus FROM employee.
従業員のなかに、ボーナスのない(null)従業員がいれば、その従業員は、「salary + bonus」も、null になってしまいます。

- 5 -
▼ データ構造
‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾
● 直積集合
直積集合 2つの集合に対して、それぞれのメンバーの組を直積集合という。
A A×B
B
A={0, 1} B={1, 2}
直積(A×B) (0, 1)(0, 2)(1, 1)(1, 2)
一般形 R={s1, s2, ..., sn|s1∈X1, s2∈X2,..., sn∈Xn}.
★ 個々のセットから選んで構成された{s1, s2, ..., sn}を「タプル(tuple)」という。
● 関係の論理(aRb)
関係の論理
aRb aはbに対して関係R(Relation)にある。
aRb ≡ R(a, b)
性質 関係
f(x) f(x, y)
関数

- 6 -
● 関係モデル
関係スキーマ 直積集合
① 統語論 集合演算
代数演算
リレーショナル演算
関数従属性
② 意味論 従属性
包含従属性
[ 注釈 ]
用語 意味
統語論 記号の間に成立する関係(対象言語の構造)を扱う。
意味論 事実と言明(叙述文)の対応関係を扱う。
スキーマ 時間不変な論理単位、「組織化された知識」のこと。
直積集合 R={s1, s2, ..., sn|s1∈X1, s2∈X2,..., sn∈Xn}.
集合演算 和集合や共通集合などの演算
リレーショナル演算 SELECT, JOIN, PROJECTION
関数従属性 1つのテーブルのなかで、1つの属性値に対して、べつの属性
値が、一意にきまること。
包含従属性 或るテーブルのなかのキーの値は、他のテーブルのなかにも
存在していなければならない。
● テーブル構造(タプルに実際値を入れた「表」、flat-file とも云う。)
table
→ row
↓ column

- 7 -
▼ セット・アット・ア・タイム法(set-at-a-time)‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾
● traversal-table
「物」テーブル SQL
NAME ・・・・ 色 ・・・・ SELECT....FROM 物ROW-ID WHERE
A ・・・・ 緑 ・・・・ NAME="B"① OR
B ・・・・ 黒 ・・・・ 色 ="赤".②
B ・・・・ 赤 ・・・・
③
traverse-table(同一 row 上の検証をする)
ROW-ID
traverse-table ② B
③ B
③ 赤
③ のBと③の赤は、同一 row 上にある。
セット・アット・ア・タイム法
MAX-SIO の無制限 同一 row 上の検証
(1)テーブルのなかのデータを 機能的依存関係は row 単位に記述され、すべて scan する(table-scan)。 集合は column 単位に記述されている
(2)ORDER-BY句を記述すれば、 ので、同一 row 上の検証をするために、並びを保証するために、traverse- traverse-table を生成する。table を生成する。
★[ tips ]
かならず、execution-plan(実行プラン)を確認してください。(多量データ、多量トランズを対象にしているのであれば、)
以下の表示がされたら、「しまった(Darn it !)」と思ってください。
table-scan ×××

- 8 -
▼ キー(keys)‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾
● キーの種類
① native -key データをロードするときに物理配置をきめる。
② master-key 一意性を検証する。
③ (n-key、m-key以外の)keys 1つ以上のレコードを検索する。
④ cluster-key データの物理配置を編成する。
⑤ null-key キーの値を nullにする。
⑥ inverted-key 「1つのキー値-複数データアドレス」方式
⑦ hash-key Indexing を使わないで、ページをアクセスする。
● native-key と master-key
emp-no sec-no
01 13
02 8
03 10
emp-no を master-key とする。
sec-ne を native-key とする。 ★ space-management① no reclamation② reclamation③ wrap-around
emp-no sec-no ④ clustering(insert)
→ 02 8
(reject) 03 10 (deleted)
01 13↓ (insert)
02 8 50 48

- 9 -
● master-key と keys
① ②
master-key duplicate-master-key y n
keys change-master-key y n
● cluster-key
clustering
① multi-tables in one dataset ② merge of tables
複数のテーブルを1つの物理データセットのなか 複数のテーブルを merge して、1つの物理に分離格納する。 データセットにする。
● キーの系統樹
keys
the master-key null-keys
the native-key cluster-key
★[ tips ]
RDBは、バージョンアップのなかで、「CRETAE INDEX」や「IF...THEN...」を搭載してきました。これらが、RDBを、ファイルのように使う弊害を生んだようです。すなわち、INDEX を使って、row 単位にアクセスして、SQL を使って、「構造的プログラミング」をおこなう、と。SQL は、基本的には、「I/O言語」と考えたほうが、効果的・効率的に使うことができます。

- 10 -
▼ レコード・アット・ア・タイム法(record-at-a-time)‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾
レコード・アット・ア・タイム法
テーブル インデックス・ファイル
CUST table CREATE INDEX (CUST-NO)
NO NAME ・・・・ (1)常駐ファイル(resident)
1 A ・・・・ (2)B-tree 構造
2 B ・・・・
: : ・・・・
B-tree 構造(Compound Relational Index)
root
branch
leaf
(1)最上位をルート(root)といい、最下位をリーフ(leaf)という。途中の階層をブランチ(branch)という。
(2)2階層までを「high-level index」という。3階層から最下位までを「low-level index」という。
(3)最下位には、キーの値とデータ・アドレスが納められている。
データ・アドレスは相対アドレス(始まり点から+αのアドレス)である。
B-tree 構造の弱点
B-tree 構造は(rootを起点にして leafに至るまで)「手繰る」構造になっている。したがって、
(1)indexing を使って、すべてのデータを順次的にアクセスすれば、おそい。(この弱点を回避するには、leaf の「GETNEXT」を使えばよい。)
(2)B-tree 構造の階層が多くなれば、おそい。(null-keys を使って、階層を生成しないようにすればよい--後述。)
(3)「low-level index」が split すれば、「high-level index」は再編成される。

- 11 -
▼ キー(index-key)の定義表‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾
● 「キーの定義表」のフォーマット(テーブルごとに作成する)
キー N 2 3 4 5 6 7 8 9 10データ M
一意性を検証する keys
● 「キーの定義表」の具体例
受注テーブルのキー定義書: 受注テーブル
キー N 2 3 4 5 受注 E
データ M受注 NO 受注日
受注 NO ② 顧客 NO(R) 受注数品目コート (゙R)
顧客 NO ① ①
品目コード
受注日 ②
受注数 ③
(1)顧客ごとに、受注番号は連続番号が付与されている。
受注番号は、一意性を実現しない。
(2)顧客ごとに、受注数の推移を知りたい。

- 12 -
▼ INDEX-only‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾
セット・アット・ア・タイム法 レコード・アット・ア・タイム法
できる view できない
悪い パフォーマンス セット系に比べて、良い
traverse-table の罠がある B-tree 構造の罠がある
同一 rowの検証 MAX-SIOの無制限 手繰る(たぐる) 揺らぐ(ゆらぐ)
「INDEX-only」w/ null-keys
traverse-table を生成しない B-tree 構造を手繰らない
高パフォーマンスを実現する
レコード・アット・ア・タイムをセット・アット・ア・タイムとして使う。
★[ tips ]
RDBMS側から観れば、「INDEX」と「VIEW」は、アクセス単位として、区分がないのです。というのは、「INDEX」は、セット・アット・ア・タイム法に対して、「上積み」されたにすぎないから。
★[ tips ]
以下の実験をしてみてください。
(1)3つの column を用意する。{a, b, c}.(2){a, b, c}に対して、「CREATE INDEX」を、default のまま
--つまり、ascending のまま--生成する。(3){a, b, c}に対して、「CREATE INDEX」を、descending で、
生成する。
さて、{a, b, c}の indexing を使って、DB2・ORACLE で、降順にデータを並べてください。SQL/Serverで、昇順にデータを並べてください。
- 13 -
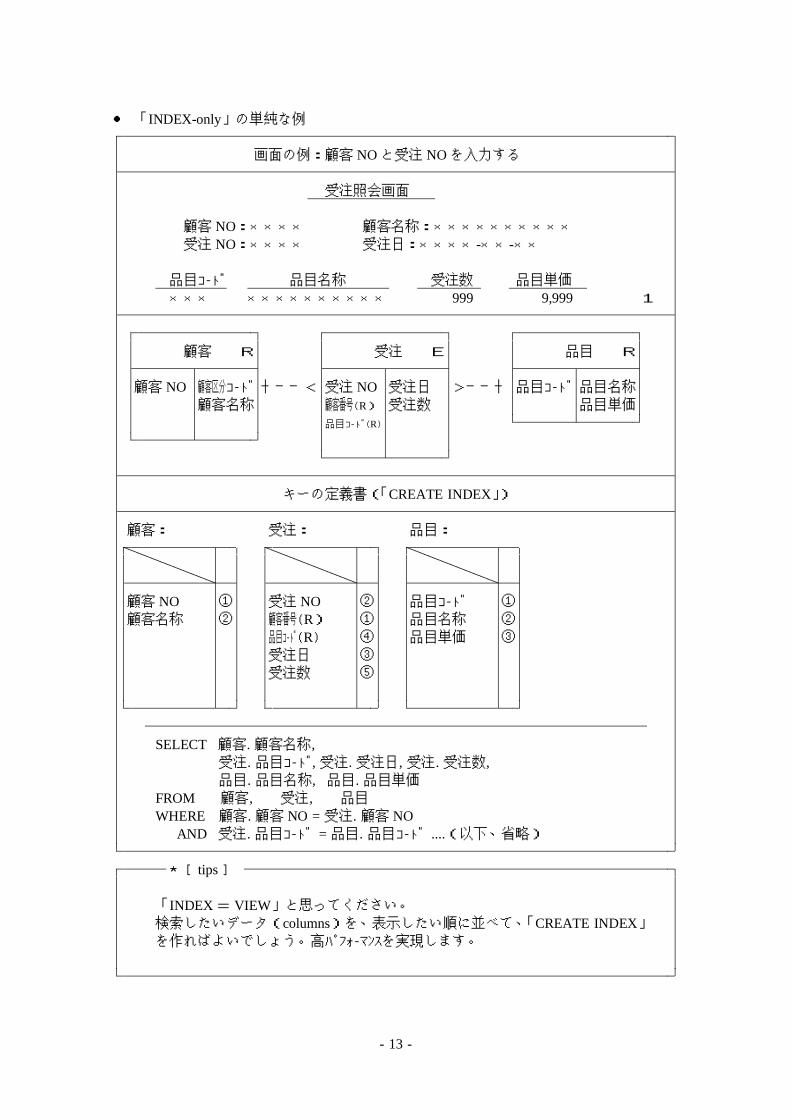
● 「INDEX-only」の単純な例
画面の例:顧客 NOと受注 NOを入力する
受注照会画面
顧客 NO:×××× 顧客名称:××××××××××
受注 NO:×××× 受注日:××××-××-××
品目コード 品目名称 受注数 品目単価
××× ×××××××××× 999 9,999 1
顧客 R 受注 E 品目 R
顧客 NO 顧客区分コード ┼──< 受注 NO 受注日 >──┼ 品目コード 品目名称
顧客名称 顧客番号(R) 受注数 品目単価
品目コード(R)
キーの定義書(「CREATE INDEX」)
顧客: 受注: 品目:
顧客 NO ① 受注 NO ② 品目コード ①
顧客名称 ② 顧客番号(R) ① 品目名称 ②
品目コード(R) ④ 品目単価 ③
受注日 ③
受注数 ⑤
SELECT 顧客. 顧客名称,受注. 品目コード, 受注. 受注日, 受注. 受注数,品目. 品目名称, 品目. 品目単価
FROM 顧客, 受注, 品目
WHERE 顧客. 顧客 NO = 受注. 顧客 NOAND 受注. 品目コード = 品目. 品目コード ....(以下、省略)
★[ tips ]
「INDEX= VIEW」と思ってください。検索したいデータ(columns)を、表示したい順に並べて、「CREATE INDEX」を作ればよいでしょう。高パフォーマンスを実現します。

- 14 -
● 「INDEX-only」と曖昧選択(LIKE句)
(1)環境:ORACLE7, UNIX(2)テーブル:(100%正規化されている)
① 顧客テーブル(データ総数は 300万件である)② 店テーブル(データ総数は 300万件である)③ 契約テーブル(データ総数は 70万件である)
(3)以上の3つのテーブルを join した曖昧選択:SELECT 顧客. 顧客氏名, 契約. 契約 NO, 店. 店名称, 契約. 売上元金FROM 顧客, 契約, 店WHERE 顧客. 顧客 NO = 契約. 顧客 NO
AND 顧客. 顧客氏名 LIKE '佐藤%'AND 店. 店 NO LIKE '% 12%'AND 契約. 売上元金 > 1500000;
(4)選択されたデータ件数は 540件で、レスポンスは「瞬き」の速さだった。[ 「LIKE '%値%'」を使っても高パフォーマンスは保証できる。]
● 「INDEX-only」使用上の注意点
① データ件数が少なければ効果はない。
② データのロードがおそくなる。
③ index-file が大きくなる。(容量計算に注意する。)
★[ tips ]
「INDEX-only」を使ったら、かならず、execution-planを確認してください。以下の表示になっていれば、成功です。
index-scan ××
★[ tips ]
RDB の最大特徴は、JOIN 操作です。RDB を使っているなら、inner join を最大限に活用してください。
「INDEX-only」は、複合検索条件(AND/OR)や JOIN に対して、きわめて、有効に作用します。複合検索条件では、「INDEX-only」を前提にしていれば、「OR」を使っても、複数の「OR」条件に該当したデータは、1件として、表示されるので、大丈夫です。

- 15 -
● 論理 I/O の計算式
READ 2
ADD 1+N
UPDATE CHANGE 3(+N)
DELETE 2+N
Nは、(当該 column をふくんでいる)index-key の数である。
ADD が、いちばんに、論理 I/O が少ない。「ADD-only」を考えればよい。
● pipeline 機能
DBMS(3) INDEX
→
→
THREAD-1 →
→ (2)DATA
→
→ (1)THREAD-2 →
→
LOGmemory buffers
① DELETE, UPDATE requests ③ Physical writes② Logical updates to buffers in memory
★[ tips ]
RDBMS の internals には、更新を高速にするパラメータは用意されていますが、READ を高速にするパラメータはない。
したがって、「INDEX-only」と「ADD-only」を、できるかぎり、使えばよい。

- 16 -
▼ Null-keys‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾
● 基本的作用
null-key-1(正社員) null-key-2(パート) emp-no 従業員区分コード
01 //////////////////////////////// 01 正社員
////////////////////////////// 02 02 パート
03 //////////////////////////////// 03 正社員
Null-key は、B-tree から排除されることが前提である。
● 補集合と null-key
受注 E 契約 E
受注 NO 受注日 ┼────┼ 契約 NO 契約日
受注数 受注 NO (R) 契約数
受注は「仮契約」である。
契約されていない受注(補集合)を一覧表示したい
受注の「キーの定義書」
keys-1 null-key ・・・・
受注 NO ① ○
受注日 ②
受注数 ③
受注テーブルの実装形
受注 NO(null) 受注 NO 受注日 受注数
///////////////////////// 01 1999-12-13 10002 02 1999-12-14 150
///////////////////////// 03 1999-12-15 80///////////////////////// 04 1999-12-16 120
(1)契約された受注 NOは、受注 NO(null)を null 値(HEX'00')にする。(2)受注 NO(null)を「CREATE INDEX」すればよい。
null-key を使えば、契約されていない受注 NO(補集合)が得られる。

- 17 -
● データの圧縮
tableI/Oは block単位
memory
DATA buffers
block
圧縮 record 圧縮 record 圧縮 record
program 排他は record単位
拡張 buffers
アクセスは view単位
★[ tips ]
data-compress は、DBMS に対して、多大な負荷を及ぼします。データを圧縮すれば、(block のなかに格納される record が多くなるので、)データのヒット率が高くなる、というような俗説もありますが、もし、
DISK の圧縮効果が、30%以下であれば、data-compress をしないほうがよいでしょう。
★[ tips ]
(1) directory と log-file は、それぞれ、(data および index とは)べつのdisk に割り当てる。
(2) data と index は、できるかぎり、数多くの disk を用意して、べつべつの disk に散らすように割り当てる。(index と data は、同じ disk に割り当てない。)

- 18 -
▼ DBMS の使用状況(monitor and tune-up)‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾
算 式 原 因
データ構造が正規
I/O 関係 ③ ÷ ② ≧ 0.05 化されていない。
① requests 総数② 1次排他の requests 回数 ④ ÷ ① ≧ 0.5 SEQBUFS が少な
③ 1次排他の conflicts 回数 い
④ READ-AHEADの I/O回数 CHECKPOINT の⑤ 2次排他の conflicts回数 ⑤ ÷ ② ≧ 0.25 interval が大きい
過ぎる
「≧」(超える数値)
になったら危険である、
ということ。
I/O 以外
(1)buffers の refresh回数(2)INDEX の split 状況 データの更新時の排他制御のこと
(3)data-compression(4)DISK が busy
transaction-backout/rollbackが起こったときの排他制御のこと
accounting
LOGIO EXCP ETIME RTIME I/O回数ではない
多 少 少 少 (理想的)
多 多 多 少 (「pipeline機能」の効果がない。wait-timeが多い。)

- 19 -
END

- 20 -
■ あとがき
(1)弊社(株式会社SDI)のホームページ
本日のプレゼンテーションを補足するために、弊社のホームページを御覧いただければ
幸いです。以下の4つのなかで、本日、お話いたしました中味を補足しております。
「ベーシックス(数学基礎論とデータベースの基礎知識)」
http://www.sdi-net.co.jp
(2)メールのアドレス
本プレゼンテーションに対する御質問・ご意見がございましたら、
ご一報いただければ幸いです。
(3)謝辞
情報システム・コンサルタントとして、実地の仕事のなかで使っている技術(技術の根
底にある前提)を、DOA+ の観点から、概略ですが述べてみました。皆様のシステム構築に少しでも役立てば幸いです。
御聴講いただきました皆様の御活躍をお祈りしております。
佐藤正美
株式会社 SDI107-0052 東京都港区赤坂 7-3-37
プラースカナダ 1 階電話:03-6894-7446
[ 作成 ] 佐藤正美 All Rights Reserved. 本テキストの複写・転載を禁止いたします。

![[Lab [Lab 3 333]]]] OracleOracle からのデータベース …3 1. はじめに このハンズオンでは、Oracleデータベースのオブジェクトを、DB2V9.7のデータベースに作](https://img.pdfslide.tips/doc/110x75/5f0f26017e708231d442ba19/lab-lab-3-333-oracleoracle-ffff-3-1-ffforacleffffffdb2v97ffffoe.jpg)



























