Embed Size (px)
Citation preview

Financial Econometrics
Alfonso NovalesDepartamento de Economia Cuantitativa
Universidad Complutense
4 de diciembre de 2011
Contents
I Econometrics 9
1 Preliminaries 101.1 Momentos poblacionales: momentos de una distribución de prob-
abilidad. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101.2 Media, Varianza, Desviación Típica, Covarianza y Coe�ciente de
correlación muestrales: . . . . . . . . . . . . . . . . . . . . . . . . 141.3 Distribuciones marginales y condicionadas . . . . . . . . . . . . . 161.4 El caso del proceso autoregresivo . . . . . . . . . . . . . . . . . . 171.5 Distribuciones condicionales e incondicionales en procesos tem-
porales: El caso del proceso autoregresivo . . . . . . . . . . . . . 18
2 Regression models 192.1 Properties of estimators . . . . . . . . . . . . . . . . . . . . . . . 19
2.1.1 Unbiasedness . . . . . . . . . . . . . . . . . . . . . . . . . 192.1.2 Variance-covariance matrix of estimates . . . . . . . . . . 192.1.3 E¢ ciency . . . . . . . . . . . . . . . . . . . . . . . . . . . 202.1.4 Consistency . . . . . . . . . . . . . . . . . . . . . . . . . . 202.1.5 Instrumental variables . . . . . . . . . . . . . . . . . . . . 21
2.2 Hypothesis testing . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3 Stochastic Processes 233.1 Some simple stochastic processes . . . . . . . . . . . . . . . . . . 233.2 Stationarity, mean reversion, impulse responses . . . . . . . . . . 283.3 Numerical exercise: Simulating simple stochastic processes . . . . 313.4 Stationarity . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 343.5 Valoración por simulación . . . . . . . . . . . . . . . . . . . . . . 353.6 Contrastes de camino aleatorio . . . . . . . . . . . . . . . . . . . 36
3.6.1 Coe�cientes de autocorrelación . . . . . . . . . . . . . . . 37
1

3.6.2 Contrastes Portmanteau . . . . . . . . . . . . . . . . . . . 373.6.3 Ratios de varianza . . . . . . . . . . . . . . . . . . . . . . 383.6.4 Ratios y diferencias de varianzas . . . . . . . . . . . . . . 39
4 Modelos VAR 414.1 Introducción . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 414.2 El modelo VAR(1) . . . . . . . . . . . . . . . . . . . . . . . . . . 424.3 Un modelo estructural . . . . . . . . . . . . . . . . . . . . . . . . 434.4 Identi�cación en un modelo VAR . . . . . . . . . . . . . . . . . . 45
4.4.1 Identi�cación y respuestas del sistema . . . . . . . . . . . 474.4.2 Generalizando el orden del VAR . . . . . . . . . . . . . . 48
4.5 Condiciones de estabilidad . . . . . . . . . . . . . . . . . . . . . . 494.6 VAR y modelos univariantes . . . . . . . . . . . . . . . . . . . . . 504.7 Estimación de un modelo VAR . . . . . . . . . . . . . . . . . . . 514.8 Contrastación de hipótesis . . . . . . . . . . . . . . . . . . . . . . 51
4.8.1 Contrastes de especi�cación . . . . . . . . . . . . . . . . . 514.8.2 Contrastes de causalidad . . . . . . . . . . . . . . . . . . . 53
4.9 Representación MA de un modelo VAR . . . . . . . . . . . . . . 544.10 Funciones de respuesta al impulso . . . . . . . . . . . . . . . . . 554.11 Descomposición de la varianza . . . . . . . . . . . . . . . . . . . 58
4.11.1 Identi�cación recursiva: la descomposición de Cholesky . 594.12 Ejercicios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 604.13 Apéndice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
4.13.1 Transformando un VAR con covarianza no nula en otrocon tal propiedad . . . . . . . . . . . . . . . . . . . . . . . 61
4.13.2 Las innovaciones de un modelo estructural deben estarincorrelacionadas entre sí. . . . . . . . . . . . . . . . . . . 61
4.13.3 Errata en Enders, página 299, . . . . . . . . . . . . . . . . 62
5 Modelos no lineales 625.1 Minimos Cuadrados no Lineales . . . . . . . . . . . . . . . . . . . 635.2 Aproximación del modelo . . . . . . . . . . . . . . . . . . . . . . 64
5.2.1 Estimación de modelos MA(q) . . . . . . . . . . . . . . . 655.3 Modelo exponencial con constante. Aproximación lineal . . . . . 665.4 Minimización de una función . . . . . . . . . . . . . . . . . . . . 675.5 Estimación por Mínimos Cuadrados . . . . . . . . . . . . . . . . 68
5.5.1 Algoritmo de Newton-Raphson . . . . . . . . . . . . . . . 695.5.2 Algoritmo de Gauss-Newton . . . . . . . . . . . . . . . . . 695.5.3 Condiciones iniciales . . . . . . . . . . . . . . . . . . . . . 70
5.6 Estimador de Máxima Verosimilitud . . . . . . . . . . . . . . . . 715.7 Criterios de convergencia . . . . . . . . . . . . . . . . . . . . . . 745.8 Di�cultades prácticas en el algoritmo iterativo de estimación . . 755.9 Estimación condicionada y precisión en la estimación . . . . . . . 765.10 Algunos modelos típicos . . . . . . . . . . . . . . . . . . . . . . . 78
5.10.1 Ejemplo 1: Modelo exponencial sin constante. . . . . . . . 785.10.2 Ejemplo 2: Un modelo no identi�cado . . . . . . . . . . . 81
2

5.10.3 Ejemplo 3: Modelo potencial . . . . . . . . . . . . . . . . 825.10.4 Ejemplo 4: Modelo AR(1), sin autocorrelación . . . . . . 835.10.5 Ejemplo 5: Modelo constante, con autocorrelación . . . . 865.10.6 Ejercicio . . . . . . . . . . . . . . . . . . . . . . . . . . . . 905.10.7 Ejemplo 6: Estimación de Máxima Verosimilitud del mod-
elo AR(1) con perturbaciones AR(1) . . . . . . . . . . . . 91
6 Modelos ARCH 996.1 Un poco de historia . . . . . . . . . . . . . . . . . . . . . . . . . 996.2 Propiedades estadísticas . . . . . . . . . . . . . . . . . . . . . . . 1006.3 Primeras de�niciones y propiedades . . . . . . . . . . . . . . . . . 1016.4 Momentos incondicionales . . . . . . . . . . . . . . . . . . . . . . 1016.5 Proceso con residuos ARCH . . . . . . . . . . . . . . . . . . . . . 1036.6 El modelo ARCH(q) . . . . . . . . . . . . . . . . . . . . . . . . . 1046.7 El modelo ARCH(1) . . . . . . . . . . . . . . . . . . . . . . . . . 1066.8 Modelo AR(1)-ARCH(1) . . . . . . . . . . . . . . . . . . . . . . . 1086.9 Modelos ARMA-ARCH . . . . . . . . . . . . . . . . . . . . . . . 1106.10 El modelo ARCH(q) de regresión . . . . . . . . . . . . . . . . . . 1106.11 Modelos ARMA-ARCH . . . . . . . . . . . . . . . . . . . . . . . 1116.12 Modelos GARCH . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
6.12.1 Modelos GARCH(p,q) . . . . . . . . . . . . . . . . . . . . 1116.12.2 El modelo GARCH(1,1) . . . . . . . . . . . . . . . . . . . 1136.12.3 Modelo IGARCH . . . . . . . . . . . . . . . . . . . . . . . 1146.12.4 Predicción de la varianza futura . . . . . . . . . . . . . . 1146.12.5 Modelo ARCH(p) . . . . . . . . . . . . . . . . . . . . . . 1146.12.6 Modelo AR(1)-ARCH(1) . . . . . . . . . . . . . . . . . . . 1156.12.7 Modelo GARCH(1,1) . . . . . . . . . . . . . . . . . . . . . 1156.12.8 Modelo EGARCH(p,q) . . . . . . . . . . . . . . . . . . . . 1166.12.9 Otras especi�caciones univariantes en la familia ARCH . 118
6.13 Modelos ARCH en media (ARCH-M) . . . . . . . . . . . . . . . 1226.14 Contrastes de estructura ARCH . . . . . . . . . . . . . . . . . . . 1246.15 Contrastes de especi�cación . . . . . . . . . . . . . . . . . . . . . 125
6.15.1 Estimación . . . . . . . . . . . . . . . . . . . . . . . . . . 1276.16 Estimación por Cuasi-máxima verosimilitud . . . . . . . . . . . . 1326.17 Contrastación de hipótesis . . . . . . . . . . . . . . . . . . . . . . 1336.18 Modelos de varianza condicional como aproximaciones a difusiones.1356.19 Modelos de varianza condicional y medidas de volatilidad . . . . 138
6.19.1 Canina, L. y S. Figlewski: �The informational content ofimplied volatility� . . . . . . . . . . . . . . . . . . . . . . 138
6.19.2 Day, T.E. y C.M. Lewis, �Forecasting futures market volatil-ity�, . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139
6.19.3 Day, T.E. y C.M. Lewis, �Stock market volatility and theinformation content of stock index options� . . . . . . . . 140
6.19.4 Engle, R.F., y C. Mustafa: �Implied ARCH models fromoption prices�: . . . . . . . . . . . . . . . . . . . . . . . . 142
3

6.19.5 Noh, J., R.F. Engle, y A. Kane, �Forecasting volatilityand option prices of the S&P500 index� . . . . . . . . . . 142
6.19.6 French, K.R., G.W. Schwert, y R.F. Stambaugh, �Ex-pected stock returns and volatility� . . . . . . . . . . . . 143
6.20 Referencias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1436.20.1 Libros: . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1436.20.2 Artículos: . . . . . . . . . . . . . . . . . . . . . . . . . . . 1446.20.3 1a Parte: Estructura temporal de volatilidades. Evidencia
empírica desde los mercados. . . . . . . . . . . . . . . . . 1446.20.4 2a Parte: Transmisión de volatilidades entre mercados . . 1446.20.5 3a Parte: Implicaciones para la cobertura de carteras. . . 145
7 Panel data sets 1457.1 Estimation approaches . . . . . . . . . . . . . . . . . . . . . . . . 148
8 The static linear model 1508.1 Pooled OLS estimates . . . . . . . . . . . . . . . . . . . . . . . . 150
8.1.1 Hypothesis testing . . . . . . . . . . . . . . . . . . . . . . 1548.2 Generalized pooled least squares estimation . . . . . . . . . . . . 154
9 The Fixed E¤ects model 1559.0.1 Testing the signi�cance of the group e¤ects . . . . . . . . 1579.0.2 Fixed time e¤ects . . . . . . . . . . . . . . . . . . . . . . . 158
10 Within and between estimators 15910.1 The Within groups estimator . . . . . . . . . . . . . . . . . . . . 16010.2 The Between groups estimator . . . . . . . . . . . . . . . . . . . 160
11 Estimating in �rst di¤erences 162
12 The Random E¤ects estimator 16312.1 Relationship to other estimators . . . . . . . . . . . . . . . . . . 16412.2 Practical implementation of the Random E¤ects estimator . . . . 16612.3 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16712.4 Testing for random e¤ects . . . . . . . . . . . . . . . . . . . . . . 168
12.4.1 Hausman test . . . . . . . . . . . . . . . . . . . . . . . . . 16812.4.2 Alternative tests for the comparison between the Fixed
E¤ects and the Random E¤ects models . . . . . . . . . . 16912.5 Goodness of �t in panel data models . . . . . . . . . . . . . . . . 17012.6 Instrumental variables estimators of the Random E¤ects model . 171
12.6.1 The Hausman and Taylor estimator . . . . . . . . . . . . 172
13 Dynamic linear models 17413.1 Linear autoregressive models . . . . . . . . . . . . . . . . . . . . 17413.2 General Method of Moments (GMM) estimation . . . . . . . . . 17713.3 Dynamic models with exogenous variables . . . . . . . . . . . . . 179
4

II Risk Measurement 180
14 Volatilidad 18114.1 Midiendo la volatilidad . . . . . . . . . . . . . . . . . . . . . . . . 181
14.1.1 La medición del riesgo inherente a un activo . . . . . . . . 18114.1.2 La importancia de medir el riesgo . . . . . . . . . . . . . . 18214.1.3 Estadísticos descriptivos en la estimación del Riesgo . . . 18414.1.4 La varianza como indicador de volatilidad: Limitaciones . 18714.1.5 Volatilidad histórica, volatilidad GARCH, volatilidad im-
plícita . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19014.1.6 Algunas cuestiones estadísticas previas . . . . . . . . . . . 19114.1.7 Rentabilidades continuas . . . . . . . . . . . . . . . . . . . 19314.1.8 Rango esperado de precios bajo el supuesto de Normalidad 20114.1.9 La varianza como variable temporal . . . . . . . . . . . . 20314.1.10Rendimientos diarios y bandas de con�anza . . . . . . . . 206
14.2 Utilización de información intradía en la medición de la volatili-dad de un activo �nanciero . . . . . . . . . . . . . . . . . . . . . 20714.2.1 Medidas de Parkinson y Garman-Klass . . . . . . . . . . . 20714.2.2 Uso de rentabilidades intradiarias . . . . . . . . . . . . . . 21014.2.3 Estacionalidad intra-día en volatilidad . . . . . . . . . . . 21114.2.4 Agregación temporal de volatilidades . . . . . . . . . . . . 21214.2.5 Volatilidad implícita versus volatilidad histórica . . . . . . 214
14.3 Modelización y predicción de la volatilidad . . . . . . . . . . . . . 21714.3.1 El modelo de alisado exponencial . . . . . . . . . . . . . . 21914.3.2 El modelo GARCH(1,1) . . . . . . . . . . . . . . . . . . . 22114.3.3 Estructura temporal de volatilidad . . . . . . . . . . . . . 22514.3.4 Predicción de volatilidad . . . . . . . . . . . . . . . . . . . 22614.3.5 Extensiones . . . . . . . . . . . . . . . . . . . . . . . . . . 22714.3.6 Estimación de correlaciones . . . . . . . . . . . . . . . . . 228
14.4 Estimación de covarianzas condicionales . . . . . . . . . . . . . . 22914.5 Modelización de correlaciones condicionales . . . . . . . . . . . . 230
14.5.1 Modelos de suavizado exponencial (Exponential smoother) 23014.5.2 Correlaciones dinámicas GARCH (DCC GARCH ) . . . . 23114.5.3 Estimación por cuasi-máxima verosimilitud . . . . . . . . 232
15 Valor en Riesgo 23215.1 RiskMetrics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23515.2 Varianza de una cartera a partir de activos individuales . . . . . 235
15.2.1 Uso de información intradía . . . . . . . . . . . . . . . . . 23615.3 Incertidumbre paramétrica en el cálculo del VaR . . . . . . . . . 236
16 Desviaciones de Normalidad 24316.1 Contrastes de Normalidad: Jarque-Bera, Kolmogorov, QQ-plots . 24316.2 La distribución t de Student estandarizada . . . . . . . . . . . . 243
16.2.1 Estimación de la densidad t de Student . . . . . . . . . . 244
5

16.2.2 Estimación del número de grados de libertad por el Métodode Momentos . . . . . . . . . . . . . . . . . . . . . . . . . 246
16.2.3 QQ plots para distribuciones t de Student . . . . . . . . . 24616.2.4 Cálculo del valor en riesgo (VaR) bajo una distribución ~t(d)247
16.3 La aproximación Cornish-Fisher . . . . . . . . . . . . . . . . . . . 248
17 Teoría de valores extremos (EVT) 24917.1 Estimación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25017.2 Construcción del QQ-plot bajo la EVT. . . . . . . . . . . . . . . 25217.3 Cálculo del VaR bajo EVT . . . . . . . . . . . . . . . . . . . . . 25217.4 Pérdida esperada (Expected shortfall) . . . . . . . . . . . . . . . 253
17.4.1 Aplicación práctica de los procedimientos de EVT . . . . 25417.5 Valoración de opciones en presencia de asimetría y curtosis. El
modelo Gram-Charlier. . . . . . . . . . . . . . . . . . . . . . . . . 25417.6 El modelo GARCH de valoración de opciones . . . . . . . . . . . 258
18 Teoría de valores extremos (versión 2) 26218.1 Estimación del modelo . . . . . . . . . . . . . . . . . . . . . . . . 263
18.1.1 Máxima verosimilitud . . . . . . . . . . . . . . . . . . . . 26318.1.2 Método de Regresión . . . . . . . . . . . . . . . . . . . . . 26318.1.3 Método no paramétrico . . . . . . . . . . . . . . . . . . . 263
19 The single-factor model 26319.1 An introduction to factor models . . . . . . . . . . . . . . . . . . 26319.2 The structure of the single-factor model . . . . . . . . . . . . . . 266
19.2.1 Characteristics of the single factor model . . . . . . . . . 26819.3 Estimating portfolio characteristics from a single factor model . . 269
20 Multi-factor models 27120.1 Style attribution analysis . . . . . . . . . . . . . . . . . . . . . . 27220.2 Multi-factor models in international portfolios . . . . . . . . . . . 27320.3 Estimation of fundamental factor models . . . . . . . . . . . . . . 27520.4 Zero coupon curve estimation . . . . . . . . . . . . . . . . . . . . 27620.5 A factor model of the term structure by regression . . . . . . . . 277
20.5.1 Regression analysis . . . . . . . . . . . . . . . . . . . . . . 27820.5.2 A duration vector . . . . . . . . . . . . . . . . . . . . . . 280
20.6 Cointegration analysis . . . . . . . . . . . . . . . . . . . . . . . . 28120.7 Permanent components . . . . . . . . . . . . . . . . . . . . . . . 28120.8 Open questions in the analysis of a term structure . . . . . . . . 28220.9 Permanent-transitory component decomposition . . . . . . . . . . 283
20.9.1 Maximum-likelihood decomposition . . . . . . . . . . . . 28420.9.2 Granger-Gonzalo decomposition . . . . . . . . . . . . . . 28420.9.3 Decomposition based on principal component analysis . . 28420.9.4 Técnicas de cointegración en el análisis de �Asset allocation�284
6

21 Principal components 28621.1 The analytics of PCA . . . . . . . . . . . . . . . . . . . . . . . . 28621.2 Exercise: Principal components analysis of a set of interest rates 28821.3 An alternative presentation of PCs: . . . . . . . . . . . . . . . . . 29721.4 First applications of principal components . . . . . . . . . . . . . 298
21.4.1 Risk decomposition . . . . . . . . . . . . . . . . . . . . . . 29821.4.2 An application to stock market management . . . . . . . 299
21.5 Present value of a basis point: PV01 . . . . . . . . . . . . . . . . 30021.5.1 Approximations to PV01 . . . . . . . . . . . . . . . . . . 30121.5.2 Interest rate risk . . . . . . . . . . . . . . . . . . . . . . . 30221.5.3 Summary of expressions . . . . . . . . . . . . . . . . . . . 303
21.6 Applications of Permanent Components to Fixed Income man-agement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 303
21.7 Appendix 1: Principal components . . . . . . . . . . . . . . . . . 30921.7.1 Lack of scale-invariance in principal components (Mardia,
Kent, Bibby) . . . . . . . . . . . . . . . . . . . . . . . . . 31421.7.2 Hypothesis testing on eigenvalues and eigenvectors . . . . 31421.7.3 La capacidad predictiva de las betas históricas . . . . . . 31521.7.4 Frontera e�ciente . . . . . . . . . . . . . . . . . . . . . . . 31921.7.5 Técnicas sencillas de determinación de la frontera e�ciente 32321.7.6 Apéndice: Algunas secciones anteriores, en castellano . . 326
22 Un modelo general de tipos de interés 33022.1 Discretización exacta . . . . . . . . . . . . . . . . . . . . . . . . . 33022.2 Discretización aproximada . . . . . . . . . . . . . . . . . . . . . . 33122.3 Estimación por máxima verosimilitud . . . . . . . . . . . . . . . 331
22.3.1 Modelo no restringido . . . . . . . . . . . . . . . . . . . . 33122.3.2 Merton (1973): � = 0; = 0 . . . . . . . . . . . . . . . . . 33222.3.3 Vasicek (1977): = 0 . . . . . . . . . . . . . . . . . . . . 33322.3.4 Cox, Ingersoll, Ross (1985): = 1=2: . . . . . . . . . . . . 33322.3.5 Dothan: � = 0; � = 0; = 1 . . . . . . . . . . . . . . . . . 33422.3.6 Movimiento browniano geométrico: � = 0; = 1 . . . . . 33422.3.7 Brennan y Schwartz (1980): = 1 . . . . . . . . . . . . . 33522.3.8 Cox, Ingersoll, Ross (180): � = 0; � = 0; = 3=2: . . . . . 33622.3.9 Elasticidad de la varianza constante: � = 0: . . . . . . . . 33722.3.10Condiciones iniciales . . . . . . . . . . . . . . . . . . . . . 33722.3.11Algoritmos numéricos en la estimación por máxima verosimil-
itud . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33822.3.12Algunas simpli�caciones . . . . . . . . . . . . . . . . . . . 33922.3.13Criterios de convergencia . . . . . . . . . . . . . . . . . . 34022.3.14Di�cultades prácticas en el algoritmo iterativo de estimación34122.3.15Estimación condicionada . . . . . . . . . . . . . . . . . . . 342
22.4 Estimación por método generalizado de los momentos . . . . . . 342
III Stock Market 347
7

23 El modelo de valoración de activos 34823.1 Introducción . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34823.2 Deducción sencilla del modelo CAPM . . . . . . . . . . . . . . . 34923.3 Deducción rigurosa del modelo CAPM . . . . . . . . . . . . . . . 35223.4 El modelo CAPM en la valoración de inversiones . . . . . . . . . 35323.5 El CAPM cuando no se permiten ventas (posiciones) a corto . . 354
23.5.1 Modi�caciones sobre los préstamos y créditos al tipo sinriesgo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 354
23.5.2 Los inversores no pueden prestar ni pedir prestado a untipo sin riesgo. . . . . . . . . . . . . . . . . . . . . . . . . 354
23.6 Las carteras de beta-cero . . . . . . . . . . . . . . . . . . . . . . 35623.7 Se permite prestar, pero no pedir prestado, al tipo de interés sin
riesgo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35823.8 Supuestos alternativos acerca de la capacidad de prestar y pedir
prestado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35923.9 Impuestos sobre la renta. . . . . . . . . . . . . . . . . . . . . . . 36023.10Activos sin mercado . . . . . . . . . . . . . . . . . . . . . . . . . 361
24 El modelo APT: Introducción 36324.1 Una deducción sencilla del modelo . . . . . . . . . . . . . . . . . 36324.2 Una deducción más rigurosa . . . . . . . . . . . . . . . . . . . . . 36524.3 Estimación y contraste . . . . . . . . . . . . . . . . . . . . . . . . 36624.4 Determinación simultánea de factores y características . . . . . . 36724.5 Un enfoque alternativo . . . . . . . . . . . . . . . . . . . . . . . . 369
24.5.1 Especi�cación de los atributos de los activos . . . . . . . . 36924.5.2 Especi�cando las in�uencias que afectan sobre el proceso
de generación de rentabilidades . . . . . . . . . . . . . . . 37024.6 Relaciones entre los modelos CAPM y APT . . . . . . . . . . . . 370
25 Contrastes empíricos del modelo de valoración de activos: In-troducción 37325.1 Contrastes empíricos del modelo CAPM . . . . . . . . . . . . . . 37425.2 Hipótesis del modelo CAPM . . . . . . . . . . . . . . . . . . . . . 37425.3 Un contraste sencillo . . . . . . . . . . . . . . . . . . . . . . . . . 37425.4 Algunos contrastes iniciales . . . . . . . . . . . . . . . . . . . . . 37525.5 Algunos problemas metodológicos . . . . . . . . . . . . . . . . . . 37525.6 El contraste de Black, Jensen y Scholes . . . . . . . . . . . . . . 37725.7 Los contrastes de Fama y MacBeth . . . . . . . . . . . . . . . . . 37925.8 Dos recientes contrastes del modelo CAPM . . . . . . . . . . . . 38025.9 Contrastes de la versión neta de impuestos del modelo CAPM . . 38125.10Algunas di�cultades con los contrastes tradicionales de las rela-
ciones de equilibrio en le mercado de activos . . . . . . . . . . . . 382
8

26 Contratos forward y contratos de futuros 383
26.1 Precios forward . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38426.2 Arbitraje . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38626.3 Costes de acarreo (Costs of carry) . . . . . . . . . . . . . . . . . 38626.4 El valor de un contrato de futuro . . . . . . . . . . . . . . . . . . 38826.5 Swaps . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38826.6 Precio de un swap de bienes . . . . . . . . . . . . . . . . . . . . . 38926.7 Valor de un swap de tipos de interés . . . . . . . . . . . . . . . . 39026.8 Aspectos básicos de los contratos de futuros . . . . . . . . . . . . 39026.9 El riesgo de base . . . . . . . . . . . . . . . . . . . . . . . . . . . 392
27 Valoración de un futuro sobre un bono 39327.1 Rentabilidad de una posición en futuros sobre bonos . . . . . . . 39527.2 Posición cubierta . . . . . . . . . . . . . . . . . . . . . . . . . . . 39527.3 Posición especulativa . . . . . . . . . . . . . . . . . . . . . . . . . 396
27.3.1 Observaciones: . . . . . . . . . . . . . . . . . . . . . . . . 39627.4 El bono nocional . . . . . . . . . . . . . . . . . . . . . . . . . . . 397
27.4.1 Observaciones: . . . . . . . . . . . . . . . . . . . . . . . . 40027.5 Futuro sobre MIBOR a 90 días . . . . . . . . . . . . . . . . . . . 40027.6 Características del contrato . . . . . . . . . . . . . . . . . . . . . 400
27.6.1 Observaciones: . . . . . . . . . . . . . . . . . . . . . . . . 40027.7 Cobertura de carteras de renta �ja . . . . . . . . . . . . . . . . . 40127.8 Número de contratos necesario . . . . . . . . . . . . . . . . . . . 40227.9 Análisis de un caso práctico . . . . . . . . . . . . . . . . . . . . . 405
27.9.1 No hay variaciones en los tipos de interés . . . . . . . . . 40527.9.2 El tipo de interés aumenta . . . . . . . . . . . . . . . . . . 40627.9.3 Descenso de tipos . . . . . . . . . . . . . . . . . . . . . . . 407
27.10Cobertura cruzada . . . . . . . . . . . . . . . . . . . . . . . . . . 408
28 La Hipótesis de las Expectativas: Tipos de interés forward 40928.1 1.1La hipótesis de Expectativas acerca de la formación de tipos
de interés. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41128.2 1.2El tipo forward como predictor de tipos a corto futuros . . . . 413
28.3 1.3El tipo forward como predictor del tipo a largo . . . . . . . . 414
29 Valoración por simulación 417
30 Sobre simulación de procesos brownianos 41830.1 Distribución de los cambios en precio . . . . . . . . . . . . . . . . 41830.2 Distribución del logaritmo del precio . . . . . . . . . . . . . . . . 41930.3 Distribución de la rentabilidad . . . . . . . . . . . . . . . . . . . 420
9

Part I
Econometrics1 Preliminaries
1.1 Momentos poblacionales: momentos de una distribu-ción de probabilidad.
Toda variable aleatoria está caracterizada por su distribución de probabilidad,que no es sino el conjunto de valores posibles de la variable aleatoria, acom-pañados de sus respectivas probabilidades. El modo en que se representa ladistribución de probabilidad depende de que la variable aleatoria en cuestiónsea de naturaleza discreta o continua.Si denotamos por P (xi) la masa de probabilidad en cada punto xi del soporte
de la distribución de probabilidad de una variable aleatoria X; (conjunto devalores posibles de la variable aleatoria X), y por f(xi) la función de densi-dad que la representa, cuando ésta existe (distribuciones de tipo continuo), laesperanza matemática de la variable X se de�ne:
E(X) = �x =
Z 1
�1xf(x)dx;
si la medida de probabilidad es continua, o:
E(X) = �x =Xxi
xidP (xi)
si la medida de probabilidad es discreta. En este último caso, xi denota cadauno de los valores posibles de la variable aleatoria X, en número �nito o no.La mediana m está de�nida por el punto del soporte valor numérico para el
cual se cumple: Z m
�1f(x)dx =
1
2
en el caso de una variable aleatoria o distribución de probabilidad continuas,y:
Med(X) = inf
(m j
mXxi
dP (xi) =1
2
)en el caso de una variable discreta. Esta formulación de la de�nición se
debe a que en distribuciones discretas puede aparecer alguna ambigüedad en sucálculo.La moda es el valor más probable de una distribución, es decir, el punto xM
del soporte de la distribución, tal que:
10

P (X = xM ) � P (X = x) 8x 2 ;
La moda puede no ser única. No existen condiciones bajo las cuales lamediana o la moda deban preferirse a la esperanza matemática como medidarepresentativa de la distribución, pero hay que considerar tal posibilidad, de-pendiendo de las características de la distribución de probabilidad.La esperanza matemática [suma de los valores numéricos ponderada por
probabilidades] de las desviaciones entre los valores del soporte de la distribucióny su esperanza matemática es igual a cero:
E(X � �x) = E(X)� E(�x) = �x � �x = 0
El valor numérico que minimiza la expresión: Eh(X � a)2
ies: a = �x. El
valor minimizado es la varianza de X.El valor numérico que minimiza la expresión: E(j X � a j) es: a = m.La varianza de una variable aleatoria (cuando existe), es la esperanza matemática
del cuadrado de las desviaciones entre los valores de la variable y su esperanzamatemática:
�2x = E (X � �x)2=
Z 1
�1(x� �x)
2f(x)dx
�2x =Xxi
(xi � �x)2dP (xi)
en distrib uciones continuas y discretas, respectivamente.La varianza puede escribirse también:
�2x = Eh(X � �)2
i= E
�X2 � 2�X + �2
�= E
�X2�� �2
�2x =Xxi
(xi � �x)2dP (xi) =
Xxi
x2i dP (xi)� 2Xxi
xi�xdP (xi) +Xxi
�2xdP (xi) =
=Xxi
x2i dP (xi)� 2�xXxi
xidP (xi) + �2x
Xxi
dP (xi) = E(x2i )� 2�2x + �2x = E(x2i )� �2x
Como en muchas ocasiones se quiere poner dicho indicador en relación conel valor medio de la variable, se pre�ere un indicador que tenga unidades com-parables a las de la rentabilidad por lo que, cuando hablamos de volatilidadsolemos referirnos a la desviación típica: raíz cuadrada de la varianza, tomadacon signo positivo:
DT (X) = �x =p�2x
Otros momentos poblacionales son:
Coeficiente de variaci�on = 100�x�x
11

que considera la desviación típica (volatilidad) como porcentaje del nivelalrededor del cual �uctúa la variable, lo cual es útil al comparar la volatilidadde variables que tienen una esperanza matemática diferente; por ej., al compararla volatilidad de dos índices bursátiles distintos.
Coeficiente de asimetr�{a =Eh(x� �x)
3i
�3x
que es positivo cuando la distribución es asimétrica hacia la derecha, en cuyocaso la moda es inferior a la mediana, y ésta es, a su vez, inferior a la mediaaritmética. El coe�ciente de asimetría es negativo cuando la distribución esasimétrica hacia la izquierda, en cuyo caso la moda es mayor que la mediana,y ésta es, a su vez, superior a la media aritmética. Toda distribución simétricatiene coe�ciente de asimetría igual a cero.
Coeficiente de curtosis =Eh(x� �x)
4i
�4x
también llamado coe�ciente de apuntamiento, es un indicador del peso queen la distribución tienen los valores más alejados del centro. Toda distribuciónNormal tiene coe�ciente de curtosis igual a 3. Un coe�ciente de curtosis superiora 3 indica que la distribución es más apuntada que la de una Normal teniendo,en consecuencia, menos dispersión que dicha distribución. Se dice entonces quees leptocúrtica, o apuntada. Lo contrario ocurre cuando el coe�ciente de curtosises superior a 3, en cuyo caso la distribución es platicúrtica o aplastada. A vecesse utiliza el Coe�ciente de exceso de curtosis, que se obtiene restando 3 delcoe�ciente de curtosis.La covarianza entre dos variables mide el signo de la asociación entre las
�uctuaciones que experimentan ambas. Esencialmente, nos dice si, cuando unade ellas está por encima de su valor de referencia, p.ej., su media, la otra variabletiende a estar por encima o por debajo de su respectiva media:
Cov(X;Y ) = E [(X � EX)(Y � EY )] = E(XY )� E(X)E(Y )
Siempre se cumple que:
Cov(X;Y ) = E [X(Y � EY )] = E [(X � EX)Y ]
Cuando alguna de las dos variables tiene esperanza cero, entonces:
Cov(X;Y ) = E (XY )
El coe�ciente de correlación lineal entre dos variables es el cociente entre sucovarianza, y el producto de sus desviaciones típicas:
Corr(X;Y ) =Cov(X;Y )p
V ar(X)pV ar(Y )
12

Mientras que la covarianza puede tomar cualquier valor, positivo o negativo,el coe�ciente de correlación solo toma valores numéricos entre -1 y +1. Estoocurre porque, por la desigualdad de Schwarz, la covarianza está acotada envalor absoluto por el producto de las desviaciones típicas de las dos variables.Un caso importante es el de la covariación entre los valores de una variable
con sus propios valores pasados. Así, tenemos, para cada valor entero de k:
k = Cov(Xt; Xt�k); k = 0; 1; 2; 3; :::
sucesión de valores numéricos que con�gura la función de autocovarianza dela variable Xt, así como su función de autocorrelación:
�k =Cov(Xt; Xt�k)
V ar(Xt)= k 0
El primer valor de la función de autocovarianza, 0; es igual a la varianzade la variable. El primer valor de su función de autocorrelación, �0, es siempreigual a 1.Dos variables aleatorias son independientes si su función de densidad con-
junta es igual al producto de sus funciones de densidad marginales:
f(x; y) = f1(x):f2(y)
dentro del rango de variación de ambas variables.En el caso de distribuciones discretas (aquéllas en las que la variable en
estudio toma valores en un conjunto discreto de puntos, que puede ser in�nito),dos distribuciones son independientes si:
P (X = x; Y = y) = P (X = x):P (Y = y)
En general, en el caso continuo, la función de densidad de una variable Y ,condicionada en otra variable X viene dada por:
f(y=x) =f(x; y)
f2(x)
pudiendo de�nirse de modo similar la función de densidad de la variable X,condicionada por la variable Y .En el caso discreto, se tiene:
P (Y = y=X = x) =PXY (X = x; Y = y)
PY (Y = y)
Ver Ejemplo 1.Es fácil probar que si dos variables aleatorias son independientes, entonces
su covarianza es cero.La varianza de una suma o de una diferencia de dos variables aleatorias es:
13

V ar(X + Y ) = V ar(X) + V ar(Y ) + 2Cov(X;Y )
V ar(X � Y ) = V ar(X) + V ar(Y )� 2Cov(X;Y )
de modo que solo si ambas variables son independientes se tiene que lavarianza de su suma es igual a la varianza de su diferencia:
V ar(X + Y ) = V ar(X) + V ar(Y )
En tal caso, el riesgo (medido por la desviación típica) de una cartera seríafunción de las ponderaciones con que entran en ella cada uno de los activos quela con�guran y del riesgo de cada uno de dichos activos, pero no dependería desi la posición adoptada en cada activo es corta o larga, es decir, de si estamoscomprados o vendidos en cada uno de ellos.Estas expresiones pueden extenderse análogamente a cualquier combinación
lineal den variables. Un ejemplo sería la suma de dichas n variables.Desigualdad de Chebychev:
E [g(X)] =
Z 1
�1g(x)f(x)dx � "2
ZS
f(x)dx
siendo S el conjunto de puntos del soporte de X donde la función g essuperior o igual a "2: Por tanto,
E [g(X)] � "2ZS
f(x)dx = "2P�g(X) � "2
�y, �nalmente:
P�g(X) � "2
�� E [g(X)]
"2
1.2 Media, Varianza, Desviación Típica, Covarianza y Co-e�ciente de correlación muestrales:
En general, contamos con observaciones históricas acerca de una o varias vari-ables (precios, rentabilidades, etc.) y queremos calcular medidas de posicióncentral, de dispersión y de correlación con el objeto de resumir las propiedadesbásicas de dichos datos.El conjunto de datos observados de�ne un histograma de frecuencias, o dis-
tribución muestral de frecuencias, que contiene toda la información disponibleacerca de la variable considerada. Un histograma de frecuencias es similar a unadistribución de frecuencias, pero es diferente de ella. Para entender la diferen-cia entre ambos, hemos de comprender el concepto de proceso estocástico, y elmodo de utilizarlo en el análisis de datos de series temporales.
14

Un proceso estocástico Xt; t = 1; 2; 3; :::es una sucesión de variables aleato-rias, indexadas por la variable tiempo. Las variables aleatorias pueden ser inde-pendientes entre sí o no, y pueden tener la misma distribución de probabilidad,o una distribución de probabilidad diferente.Cada dato de una serie temporal debe interpretarse como una muestra de
tamaño 1 de la distribución de probabilidad correspondiente a la variable aleato-ria de ese instante. Por ej., el dato de cierre del IBEX35 (suponiendo quedisponemos de datos de cierre diarios) de hoy es una realización, es decir, unamuestra de tamaño 1 de la variable aleatoria �precio de la cesta IBEX35�(comoíndice) el día de hoy. La distribución de probabilidad de esta variable puedeser diferente de la variable aleatoria IBEX35 hace un año por tener, por ejem-plo, una esperanza matemática menor, una volatilidad mayor, o no ser Normal,mientras que hace un año sí lo era.Vamos a suponer inicialmente que las variables Xt tienen todas la misma
distribución de probabilidad, y son independientes entre sí. Este es el caso mássencillo, y constituye un proceso de ruido blanco. Sólo en este caso está to-talmente justi�cado la utilización de momentos muestrales como característicasde �la variable X�. Esta observación debe servir como llamada de atención allector, dada la excesiva frecuencia con que se calculan estadísticos muestrales,calculados con datos históricos, para representar características de una vari-able; por ej., la desviación típica de la rentabilidad bursátil de un determinadomercado.Las medidas de posición central y dispersión análogas a la esperanza, vari-
anza y desviación típica son:
�x =
Pni=1 xin
; S2x =
Pni=1 (xi � �x)
2
n� 1 ; DTx = S2x
mientras que la covarianza y coe�ciente de correlación muestrales son:
Cov(X;Y ) =1
T
TXt=1
(xt � �x) (yt � �y) =1
T
TXt=1
xtyt � �x�y
La media, varianza, mediana, covarianza y coe�ciente de correlación mues-trales satisfacen propiedades similares a las ya mencionadas para sus análogospoblacionales. Entre ellas:
� La suma de las desviaciones de la variable respecto de su media, es iguala cero:
nXi=1
(xi � �x) =nXi=1
xi �nXi=1
�x = n�x� n�x = 0
� Como consecuencia de lo anterior, la media muestral de las diferenciasxi � �x; i = 1; 2; :::; n es igual a cero.
� Si una de las dos variables, X o Y tiene esperanza cero, tenemos:
15

Cov(X;Y ) =1
T
TXt=1
xtyt = E(XY )
� La varianza de X puede escribirse:
1
n
nXi=1
(xi � �x)2 =1
n
nXi=1
x2i � 21
n
nXi=1
xi�x+1
n
nXi=1
�x2 =1
n
nXi=1
x2i � �x2
Al igual que en el caso de una distribución de probabilidad, otras medidasutilizadas en la representación de una muestra son:
Coeficiente de variaci�on = 100DTx�x
Coeficiente de asimetr�{a =1T
PTt=1 (xt � �x)
3
DT 3x
Coeficiente de curtosis =1T
PTt=1 (xt � �x)
4
DT 4x
siendo T el tamaño muestral.El recorrido o rango es la diferencia entre el mayor y el menor valor obser-
vados de una variable. Los cuartiles son los datos que dividen a la muestra, unavez ordenada crecientemente, en cuatro submuestras de igual tamaño (aproxi-madamente). El segundo cuartil es la mediana. El rango intercuartílico es ladistancia entre los cuartiles primero y tercero. Estos estadísticos tienen la vir-tud de no verse afectados por la presencia de valores atípicos. De modo análogose de�nen los deciles y percentiles.En una variable temporal, las funciones de autocovarianza y autocorrelación
muestrales se de�nen:
k = Cov(Xt; Xt�k) =1
T
TXt=k+1
(xt � �x) (xt�k � �x)
�k = Corr(Xt; Xt�k) =Cov(Xt; Xt�k)p
S2xpS2x
=1T
PTt=k+1 xtxt�k � �x2
S2x
siendo siempre: 0 = V ar(Xt) y �0 = 1.
1.3 Distribuciones marginales y condicionadas
Consideremos la distribución de probabilidad bivariante,
16

X1
�2 �1 0 1 2X2 �1 2=24 0 2=24 4=24 0
0 0 1=24 2=24 0 2=242 0 3=24 2=24 0 6=24
donde X1 puede tomar valores -2,-1,0,1,2, mientras que X2 puede tomar val-ores -1, 0,2. El cuadro recoge probabilidades; por ejemplo, P [X1 = �1; X2 = 0] =1=24: Las 15 probabilidades del cuadro suman 1.La distribución marginal de X1 es,V alores de X1 �2 �1 0 1 2Pr obabilidades 2=24 4=24 6=24 4=24 8=24con E(X1) = 1=2; V ar(X1) = 1=28;siendo la distribución de X2;V alores de X2 �1 0 2Pr obabilidades 8=24 5=24 11=24con E(X2) = 7=12; V ar(X2) = 263=144:La distribución d eprobabilidad de X1 condicional en un valor numérico de
X2 es,V alores de X1 �2 �1 0 1 2Si X2 = �1 1=4 0 1=4 1=2 0Si X2 = 0 0 1=5 2=5 0 2=5Si X2 = 2 0 3=11 2=11 0 6=11con E(X1=X2 = �1) = 0; E(X1=X2 = 0) = 3=5; E(X1=X2 = 2) = 9=11:Luego E(X1=X2) es una variable aleatoria que toma valores 0, 3/5, 9/11,
con probabilidades respectivas: 8/24, 5/24, 11/24. Por tanto, su esperanzamatemática es 1/2, que coincide con E(X): Este es un resultado general, puessiempre se tiene,
E [E (X1=X2)] = E(X1)
Las dos variables que hemos analizado no son independientes, pues ningunade ellas satisface la condición de que su distribución marginal coincida con sudistribución condicionada en cualquier valor de la otra. Dicho de otro modo, elvalor que toma una variable X2 es informativo acerca de los posibles valores dela otra variable X1:
1.4 El caso del proceso autoregresivo
Especialmente interesante en el análisis de datos �nancieros es el modelo au-toregresivo,
yt = �0 + �1yt�1 + ut; �1 < �1 < 1
donde suponemos que ut es un proceso sin autocorrelación (correlación tem-poral consigo mismo). Es decir, Corr(ut; ut�k) = 0 8k:En estas condiciones, si ut sigue una distribución Normal ut � N(0; �2u),
entonces yt sigue una distribución
17

yt � N(�0
1� �1;
�2u1� �21
)
Esta es la distribución marginal o incondicional, de yt:Por otra parte, condicional en la historia pasada de yt; sin incluir el dato de
fecha t; la distribu8ión de probabilidad condicional de yt es,
yt � N(�0 + �1yt�1; �2u)
que tiene una menor varianza. De hecho, la varianza incondicional de ytes tanto mayor cuanto más se acerque el parámetro �1 a 1, creciendo dichavarianza sin límite. Sin embargo, la varianza condicional es siempre �2u; conindependencia del valor numérico del parámetro �1:La varianza condicional de yt es igual a la varianza de ut, �2u; mientras que
la varianza incondicional de yt es siempre mayor que �2u:Además,
E(yt=yt�1) = �0 + �1yt�1; E(yt) =�0
1� �1
1.5 Distribuciones condicionales e incondicionales en pro-cesos temporales: El caso del proceso autoregresivo
Especialmente interesante en el análisis de datos �nancieros es el modelo au-toregresivo,
yt = �0 + �1yt�1 + ut; �1 < �1 < 1
donde suponemos que ut es un proceso sin autocorrelación (correlación tem-poral consigo mismo). Es decir, Corr(ut; ut�k) = 0 8k:En estas condiciones, si ut sigue una distribución Normal ut � N(0; �2u),
entonces yt sigue una distribución
yt � N(�0
1� �1;
�2u1� �21
)
Esta es la distribución marginal o incondicional, de yt:Por otra parte, condicional en la historia pasada de yt; sin incluir el dato de
fecha t; la distribu8ión de probabilidad condicional de yt es,
yt � N(�0 + �1yt�1; �2u)
que tiene una menor varianza. De hecho, la varianza incondicional de ytes tanto mayor cuanto más se acerque el parámetro �1 a 1, creciendo dichavarianza sin límite. Sin embargo, la varianza condicional es siempre �2u; conindependencia del valor numérico del parámetro �1:La varianza condicional de yt es igual a la varianza de ut, �2u; mientras que
la varianza incondicional de yt es siempre mayor que �2u:
18

Además,
E(yt=yt�1) = �0 + �1yt�1; E(yt) =�0
1� �1
2 Regression models
2.1 Properties of estimators
2.1.1 Unbiasedness
Explanatory variables are supposed to be deterministic in elementary Econo-metrics, to show unbiasedness of Least squares estimates of linear models.In more general treatments, the alternative assumption is made: E(u=X) =
0; which means: E(xit:us) = 08t; s; which we usually know as strict exogeneity.It is usually hard to make a strong argument on the validity of that condition.It is easy to �gure out why can it fail to hold, but it is much harder to argue
in its favor.Since
� = � + (X 0X)�1X 0u
The condition implies:
E(�) = � + E�(X 0X)�1X 0u
�= � + E
�(X 0X)�1X 0E(u=X)
�= �
But, should we care about unbiasedness in Economics, being a property thatrelates to the universe of possible samples?
2.1.2 Variance-covariance matrix of estimates
If the vector error term has covariance matrix,
V ar(u) = �2u�
The variance-covariance matrix of least squares estimates is,
V ar(�) = �2u(X0X)�1(X 0�X)(X 0X)�1 (1)
If de not allow for a scalar factor �2u; which is not necessary, then V ar(u) = �and V ar(�) = (X 0X)�1(X 0�X)(X 0X)�1:To estimate � we will need to use residuals from some initial estimation.So, we can start by using OLS, and use the residuals to estimate the structure
we assume in �:If, for instance, we postulate that E(ui:uj) = 08i 6= j; while E(ui:uj) = kzi
for i = j; we will then run a regression of the square OLS residuals on z; withoutintercept.
19

Whether we identify �2u with k and � with a diagonal matrix with zi alongthe diagonal, or make those elements equal to kzi and skip the �2u factor, isirrelevant.There are special cases, those in which � is almost diagonal, when the
variance-covariance matrix reduces to �2u(X0X)�1; but it is unfortunate that
this matrix is widely presented in a �rst discussion of least squares methodsin econometrics textbooks as being the variance covariance matrix of the leastsquares estimator.The elements of �2u(X
0X)�1 are biased estimates of the variances and co-variances of the least squares estimator, not bearing any speci�c relationshipwith the unbiased �2u(X
0X)�1(X 0�X)(X 0X)�1 values. The biased, standardestimates may be either larger or smaller than the unbiased ones without anyspecial reason.Nothing is lost by computing (1) in all situations.
2.1.3 E¢ ciency
The standard, e¢ ciency properties of least squares shown in introductory coursesemerge from its coincidence with Maximum Likelihood under a Normal distri-bution for the error term, and provided we have a right speci�cation for thevariance-covariance matrix of the error term.The �rst condition is unlikely in many situations in Economics.In general, e¢ ciency is shown only under deterministic or strictly exogenous
explanatory variables.Heteroscedasticity leads to lack of e¢ ciency in least squares estimation.It does not bias the estimates or produce inconsistency.Autocorrelation in static models has similar implicationsDealing with Heteroscedasticity or autocorrelation as usual (Feasible GLS)
is usually subject to important sample errors) Use OLS and compute robust variance-covariance matrix of estimates:
White, Newey-WestIn general, it is hard to �gure out the properties of least squares estimates.) we need to worry about consistency and precision (related to e¢ ciency).
2.1.4 Consistency
Consistency is a one-sample property, and all it requires is: p lim�1TX
0u�= 0k:
p lim(�) = �+p lim
"�1
TX 0X
��1�1
TX 0u
�#= �+
"p lim
�1
TX 0X
��1# �p lim
�1
TX 0u
��= �
Under light conditions (law of large numbers) this condition will hold if theerror term is uncorrelated with the set of explanatory variables.It is important that we now do not need exogeneity.All we need is lack of correlation between regressors and error term, i.e., we
do not need zero autocorrelation at all leads and lags of X and u.
20

Situations when correlation is not zero:
� Simultaneity
� Errors in variables
� Dynamic models with autocorrelated errors
2.1.5 Instrumental variables
We then need instrumental variables, Z; satisfying E(Z=u) = 0; :at the sametime E(Z:X) 6= 0:We lose consistency if the �rst condition fails to hold, and we lose precision
because the correlation between Z and X is less than one (otherwise, we wouldstill have the lack of consistency situation).In most cases, it is usually hard to �gure out what are valid instruments
outside the model, and often, models are silent with respect to valid instruments.Models with expectations, or dynamic panel data models suggest instru-
ments that are already present in the model.Precision means that standard errors are small relative to estimated para-
meters.Precision depends, among others on: the quantity and quality of data, pa-
rameter stability.
2.2 Hypothesis testing
Most often, we compare nested models, and versions of likelihood ratio tests areappropriateWe should speci�cally worry about testing hypothesis in the face of low
precision estimates.Do not run hypothesis tests in the face of estimates obtained with low pre-
cisionLow precision in estimation leads to a bias in the results of any given test
by too often not rejecting the null hypothesis (any null hypothesis)So, when running signi�cance tests, we would tend to conclude for non in-
formative explanatory variables to often.The t-statistic for signi�cance ids the ratio between the estimated coe¢ cient
and its estimated standard error. The t-statistic can be too low, leadgin to notrejecting the null hypothesis of lack of signi�cance if: i) the estimated coe¢ cientis small to the point of being numerically irrelevant, ii) the standard deviationis large enough, i:e:; precision is very low, even if the estimated coe¢ cient isnumerically sizeable, iii) both, i) and ii):Summarizing the sample information regarding the validity of a given null
hypothesis in the value of a single test statistic value is too much informationis an excessive reduction of the available informationAlways examine residuals (or �t) from restricted and unrestricted modelsRelative to signi�cance tests:
21

� statistical signi�cance of a given coe¢ cient and economic relevance (orquantitative relevance) of the accompanying variable are very di¤erentconcepts
� to evaluate the relevance of an estimated coe¢ cient, multiply it by thestandard deviation of the associated variable, and divide by the standarddeviation of the dependent variable. Or do a similar computation for thewhole sample range or the interquartilic intervals of x and y:
� we can never test for the information content of a given variable in thecontext of a multiple regression model
� we can only test for whether a given variable adds information to thatcontained in the other explanatory variables already included in the model
� to test for information content in an absolute sense, we should estimate asimple regression model
� the estimated coe¢ cient in a simple regression is a biased estimate of thepartial e¤ect of x: But is is an unbiased estimate of the global e¤ect (directe¤ect plus indirect e¤ects) on y of a change in x:
� each estimated coe¢ cient in a multiple regression is an unbiased estimateof the partial e¤ect (conditional on the other explanatory variables) on yof a change in x: It is a biased estimate of the e¤ect on y of a change in x:
� A few time series conceptsEconomics is full of statements relating the dynamic properties of key vari-
ables. For instance, we may say that in�ation is very persistent, that aggregateconsumption and GNP experience cyclical �uctuations, or that hours workedand productivity move independently from each other. These statements havedirect implications in terms of the time series representations of these variables.Sometimes we are more speci�c, as when we state that stock exchange returnsare white noise, thereby justifying the usual belief that they are unpredictable.The unpredictability statement comes from the fact that the forecast of a whitenoise process, no matter how far into the future, is always the same. Thatforecast is equal to the mean of the white noise process, which would likely beassumed to be zero in the case of asset returns. If returns are logarithmic, i.e.,the �rst di¤erence of logged market prices, then prices themselves would followa random walk structure. These properties cannot be argued separately fromeach other, since they are just two di¤erent forms of making the same statementon stock market prices. We may also say at some point that the economy islikely to repeat next year its growth performance from the previous year, whichincorporates the belief that annual GNP growth follows a random walk, its bestone-step ahead prediction being the last observed value. A high persistencein real wages or in in�ation could be consistent with �rst order autoregressivemodels with an autoregressive parameter close to1. We brie�y review in thissection some concepts regarding basic stochastic processes, of the type that areoften used to represent the behavior of economic variables.
22

3 Stochastic Processes
3.1 Some simple stochastic processes
A stochastic process is a sequence of random variables indexed by time. Each ofthe random variables in a stochastic process, corresponding to a given time indext, has its own probability distribution. These distributions can be di¤erent, andany two of the random variables in a stochastic process may either exhibitdependence of some type or be independent from each other.A white noise process is,
yt = "t; t = 1; 2; 3; :::
where "t; t = 1; 2; ::: is a sequence of independent, identically distributedzero-mean random variables, known as the innovation to the process. A whitenoise is sometimes de�ned by adding the assumption that "t has a Normaldistribution. The mathematical expectation of a white noise is zero, and itsvariance is constant: V ar(yt) = �2": More generally, we could consider a whitenoise with drift, by incorporating a constant term in the process,
yt = a+ "t; t = 1; 2; 3; :::
with mathematical expectation E(yt) = a, and variance: V ar(yt) = �2":The future value of a white noise with drift obeys,
yt+s = a+ "t+s;
so that, if we try to forecast any future value of a white noise on the basisof the information available1 at time t, we would have:
Etyt+s = a+ Et"t+s = a;
because of the properties of the "t-process. That is, the prediction of a futurevalue of a white noise is given by the mean of the process. In that sense, a whitenoise process is unpredictable. The prediction of such process is given by themean of the process, with no e¤ect from previously observed values. Becauseof that, the history of a white noise process is irrelevant to forecast its futurevalues. No matter how many data points we have, we will not use them toforecast a white noise.A random walk with drift is a process,
yt = a+ yt�1 + "t; t = 1; 2; 3; ::: (2)
so that its �rst di¤erences are white noise. If yt = ln(Pt) is the log of somemarket price, then its return rt = ln(Pt) � ln(Pt�1); will be a white noise, as
1That amounts to constructing the forecast by application of the conditional expectationoperator to the analytical representation of the future value being predicted, where the con-ditional expectation is formed with respect to the sigma algebra of events known at timet:
23

we already mentioned. A random walk does not have a well de�ned mean orvariance.In the case of a random walk without drift, we have,
yt+s = yt+s�1 + "t+s; s � 1
so that we have the sequence of forecasts:
Etyt+1 = Etyt + Et"t+1 = yt;
Etyt+2 = Etyt+1 + Et"t+2 = Etyt+1 = yt
and the same for all future variables. In this case, the history of a randomwalk process is relevant to forecast its future values, but only through the lastobservation. All data points other than the last one are ignored when forecastinga random walk process.First order autoregressive processes, AR(1), are of the form,
yt = �yt�1 + "t; j � j< 1;
and can be represented by,
yt =1Xs=0
�s"t�s
the right hand side having a �nite variance under the assumption thatV ar("t) = �2" only if j�j < 1: In that case, we would have:
E(yt) = 0; V ar(yt) =�2"
1� �2
Predictions from a �rst order autoregression can be obtained by,
Etyt+1 = �Etyt + Et"t+1 = �yt;
Etyt+2 = Et (�yt+1) + Et"t+2 = �2Etyt+1 = �2yt
and, in general,
Etyt+s = �syt; s � 1
which is the reason to impose the constraint j � j< 1: The parameter � issometimes known as the persistence of the process. As the previous expressionshows, an increase or decrease in yt will show up in any future yt+s; althoughthe in�uence of that yt-value will gradually disappear over time, according tothe value of �: A value of � close to 1 will therefore introduce high persistencein the process, the opposite being true for � close to zero.The covariance between the values of the �rst order autoregressive process
at two points in time is:
24

Cov(yt; yt+s) = �sV ar(yt); s ? 0;so that the linear correlation is:
Corr(yt; yt+s) =Cov(yt; yt+s)
V ar(yt)= �s
which dies away at a rate of �: In an autoregressive process with a value of� close to 1, the correlation of yt with past values will be sizeable for a numberof periods.A �rst order autoregressive process with constant has the representation,
yt = a+ �yt�1 + "t; j � j< 1;Let us assume by now that the mathematical expectation exists and is �nite.
Under that assumption, Eyt = Eyt�1, and we have:
Eyt = a+ E(�yt�1) + E"t = a+ �Eyt
so that: Eyt = a1�� : To �nd out the variance of the process, we can iterate
on its representation:
yt = a+ �yt�1 + "t = a+ �(a+ �yt�2 + "t�1) + "t =
a(1 + �+ �2 + :::+ �s�1) + �syt�s +��s�1"t�s+1 + :::+ �
2"t�2 + �"t�1 + "t�
and if we proceed inde�nitely, we get
yt = a(1 + �+ �2 + :::) +�:::+ �2"t�2 + �"t�1 + "t
�since lim
s!1�syt�s = 0:
2 Then, taking the variance of this expression:
V ar(yt) = V ar�:::+ �2"t�2 + �"t�1 + "t
�=
1Xs=0
�2s�2" =�2"
1� �2
so that the variance of the yt-process increases with the variance of theinnovation, �2"; but it is also higher the closer is � to 1.Si el proceso siguiese una estructura dependiente de su pasado, pero del tipo:
yt = �0 + �1yt�1 + "t t = 1; 2; :::; �1 < �1 < 1
sus propiedades serían bastante distintas, con:
yt = �01� �t11� �1
+ �s1y0 +tX
s=1
�t�s1 "s
2This is the limit of a random variable, and an appropriate limit concept must be used. Itsu¢ ces to say that the power of � going to zero justi�es the zero limit for the product randomvariable.
25

y si consideramos que el proceso ha durado in�nitos períodos,
E(yt) =�0
1� �1; V ar(yt) =
�2"1� �21
estarían bien de�nidas, son constantes, y el proceso es estacionario. Se de-nomina proceso autoregresivo de primer orden.Los momentos condicionales de este proceso son,
Et�1(yt) = �0 + �1yt�1; V ar(yt) = �2"
Como se ve, la esperanza condicional es cambiante en el tiempo, en funciónde la información disponible en cada instante. La esperanza incondicional esla mejor predicción que podríamos proporcionar del proceso yt sin disponer deinformación muestral para el mismo, pero conociendo la estructura estocásticade dicho proceso, incluidos los valores numéricos de los parámetros. Si dis-pusiéramos de muestra pero ignorásemos el proceso estocástico que sigue yt,podríamos sustituir �0
1��1por la media muestral. Esta es la mejor predicción
en cuanto a minimizar el error cuadrático medio de la predicción, pero no es lapredicción óptima, que es �0+�1yt�1 y requiere estimaciones de los parámetros.Esta predicción minimiza el error cuadrático medio condicional.Por otra parte, la varianza condicional, que es constante, es siempre inferior
a la varianza incondicional. La diferencia entre ambas es tanto mayor cuantomás se aproxima el valor numérico del coe�ciente � a �1 ó +1: En ambos límites,además, la varianza del proceso autoregresivo de primer orden tiende a in�nito.A future value of the �rst order autoregression can be represented:
yt+s = a+ �yt+s�1 + "t+s; j � j< 1; s � 1;
which can be iterated to,
yt+s = a(1 + �+ �2 + :::+ �s�1) + �syt +��s�1"t+1 + �
s�2"t+2 + :::+ "t+s�
so that its forecast is given by,
yt+s = a1� �s1� � + �
syt
So, as the forecast horizon goes to in�nity, the forecast converges to,
limEtyt+s =a
1� �the mean of the process.
As � approaches 1, the �rst order autoregression becomes a random walk,for which this expression would give an in�nite variance. This is because if werepeat for the random walk the same argument we have made here, we get,
26

yt = a+ yt�1 + "t = a+ (a+ yt�2 + "t�1) + "t =
as+ yt�s + ("t�s+1 + :::+ "t�2 + "t�1 + "t)
so that the past term yt�s does not die away no matter how far we moveback into the past, and the variance of the sum in brackets increases withoutbound as we move backwards in time. The random walk process has an in�nitevariance. Sometimes, it can be assumed that there is a known initial conditiony0: The random walk process can then be represented:
yt = a+ yt�1 + "t = a+ (a+ yt�2 + "t�1) + "t =
= ::: = at+ y0 + ("1 + :::+ "t�2 + "t�1 + "t)
with E(yt) = y0 + ta and V ar(yt) = t�2": Hence, both moments change overtime, the variance increasing without any bound.Ello se debe a que el último sumando en la representación anterior,
Pts=1 "s;
es un ejemplo de tendencia estocástica. Cuanto mayor sea el número de obser-vaciones consideradas, mayor será la varianza muestral del camino aleatorio: uncamino aleatorio tiene menor varianza a lo largo de una hora que a lo largo deun día, a lo largo de un día que a lo largo de una semana, etc.. El aumento dela varianza a lo largo del tiempo no tiene nada que ver con el término t� quesiendo determinista, tiene varianza cero.However, if we compare in a same graph time series realizations of a random
walk together with some stationary autoregressive processes, it will be hard totell which is the process with an in�nite variance.Esto es lo que ocurrirá con la inmensa mayoría de los precios cotizados en los
mercados �nancieros. Aunque la presencia de tendencias estocásticas se producegeneralmente junto con estructuras más complejas que la de un camino aleatorio,la implicación acerca de una varianza creciente con el tiempo se mantiene cuandose añaden a ésta componentes autoregresivos o de medias móviles para yt. Paraevitarlo, caracterizamos la volatilidad de un mercado o de un activo analizandoel comportamiento de la rentabilidad que ofrece a lo largo del tiempo, no de suprecio o cotización.En este caso, la tendencia estocástica aparece debido al coe�ciente unitario
del retardo de yt en la ecuación que explica el comportamiento de esta variable.En el lenguaje estadístico, se dice que el proceso yt tiene una raíz unitaria.La diferenciación elimina las tendencias estocásticas, pues tendríamos,
yt � yt�1 = �yt = �+ "t; t = 1; 2; :::
con E(yt) = �; V ar(yt) = �2"; para todo t:Como veremos más adelante, el concepto de proceso browniano está bastante
ligado al de camino aleatorio. Por tanto, la a�rmación anterior es coherente conestablecer la hipótesis de que la rentabilidad de un determinado activo sigue unproceso browniano, pero no tanto con efectuar dicha hipótesis sobre su precio.
27

La diferenciación elimina asimismo las tendencias deterministas, como fácil-mente puede comprobarse algebraicamente. De este modo, si el precio de undeterminado activo tiene una tendencia temporal determinista lineal, su primeradiferencia estará libre de dicha tendencia,
yt = �0 + �1t+ "t
cuya primera diferencia es:
�yt = yt � yt�1 = �1 + ("t � "t�1)
Un proceso con una tendencia determinista cuadrática sigue trayectorias conformas parabólicas, cóncavas o convexas, dependiendo del signo del coe�cientedel término de segundo grado. Su primera diferencia presentará una tendencialineal, mientras que su segunda diferencia estará libre de tendencia. Un procesocon una tendencia determinista representada por un polinomio de grado trespuede tener ciclos. La primera diferencia de este proceso tendrá una tendenciacuadrática.Si consideramos una tendencia de grado 2:
yt = �0 + �1t+ �2t2 + "t
cuya primera diferencia es:
�yt = yt � yt�1 = (�1 � �2) + 2�2t+ ("t � "t�1)
siendo su segunda diferencia:
�2yt = �yt ��yt�1 = yt � 2yt�1 + yt�2 = 2�2 + ("t � 2"t�1 + "t�2)
De modo análogo, un proceso puede tener asimismo varias raíces unitarias.Los tipos de interés ya son rentabilidades, por lo que tienen, generalmente,un orden de no estacionariedad (es decir, un número de tendencias) menosque las series de índices bursátiles o de precios de derivados, por ejemplo. Enocasiones, sin embargo, algunas series de precios son no estacionarias de orden2 (tienen 2 raíces unitarias), por lo que incluso las rentabilidades pueden ser noestacionarias, presentando una raíz unitaria.
3.2 Stationarity, mean reversion, impulse responses
A stochastic process is stationary when the distribution of k-tuples (yt1 ; yt2 ; :::; ytk)is the same with independence of the value of k and of the time periods t1; t2; :::; tkconsidered. It is a property of any stationary stochastic process that the forecastof a future value converges to its mean as the forecast horizon goes to in�nity.This is obviously ful�lled in the case of a white noise process. Another char-acteristic is that any time realization crosses the sample mean often, while anonstationary process would spend arbitrarily large periods of time at either
28

side of its sample mean. As we have seen above for the �rst order autoregres-sion, the simple autocorrelation function of a stationary process, made up by thesequence of correlations between any two values of the process, will go to zerorelatively quickly, dieing away very slowly for processes close to nonstationarity.When they are not subject to an stochastic innovation,3 stationary autore-
gressive processes converge smoothly and relatively quickly to their mathemat-ical expectation. The yt-process will converge to a
1�� either from above or frombelow, depending on whether the initial value, y0; is above or below a
1�� : Thespeed of convergence is given by the autoregessive coe¢ cient. When the processis subject to a nontrivial innovation, the convergence in the mean of the processwill not be easily observed. This is the case because the process experiencesa shock through the innovation process every period, which would start a newconvergence that would overlap the previous one, and so on. Under normalcircumstances we will just see a time realization exhibiting �uctuations aroundthe mathematical expectation of the process, unless the process experiences ahuge innovation, or the starting condition y0 is far enough from a
1�� ; in units of
its standard deviation,q
�2"1��2 :
The property of converging to the mean after any stochastic shock is calledmean reversion, and is characteristic of stationary processes. In stationaryprocesses, any shock tends to be corrected over time. This cannot be appreci-ated because shocks to yt are just the values of the innovation process, whichtake place every period. So, the process of mean reversion following a shockgets disturbed by the next shock, and so on. But the stationary process willalways react to shocks as trying to return to its mean. Alternatively, a nonstationary process will tend to depart from its mean following any shock. As aconsequence, the successive values of the innovation process "t will take yt everytime farther away from its mean.An alternative way of expressing this property is through the e¤ects of purely
transitory shocks or innovations. A stationary process has transitory responsesto purely transitory innovations. On the contrary, a nonstationary process mayhave permanent responses to purely transitory shocks. So, if a stationary vari-able experiences a one-period shock, its e¤ects may be felt longer than that,but will disappear after a few periods. The e¤ects of such a one-period shockon a nonstationary process will be permanent. A white noise is just an in-novation process. The value taken by the white noise process is the same asthat taken by its innovation. Hence, the e¤ects of any innovation last as longas the innovation itself, re�ecting the stationary of this process. The situationwith a random walk is quite di¤erent. A random walk takes a value equal tothe one taken the previous period, plus the innovation. Hence, any value of theinnovation process gets accumulated in successive values of the random walk.The e¤ects of any shock last forever, re�ecting the nonstationary nature of thisprocess. In a stationary �rst order autoregression, any value of the innovation"t gets incorporated into yt that same period. It will also have an e¤ect of size
3That is, if the inovation "t has zero variance.
29

�"t on yt+1. This is because yt+1 = �yt + "t+1 so, even if "t+1 = 0; the e¤ect of"t would still be felt on yt+1 through the e¤ect it previously had on yt:This argument suggests how to construct what we know as an impulse re-
sponse function. In the case of a single variables, as with the stochastic processeswe consider in this section, that response is obtained by setting the innovationto zero every period except by one, in which the impulse is produced. At thattime, the innovation takes a unit value.4 The impulse response function willbe the di¤erence between the values taken by the process after the impulse inits innovation, and those that would have prevailed without the impulse. Theresponse of a white noise to an impulse in its own innovation is a single unitpeak at the time of the impulse, since the white noise is every period equalto its innovation, which is zero except at that time period. In the case of ageneral random walk, a zero innovation would lead to a random walk growingconstantly at a rate de�ned by the drift a from a given initial condition y0. Ifat time t� the innovation takes a unit value, the random walk will increase bythat amount at time t�; but also at any future time. So the impulse response isin this case a step function, that takes the value 1 at t� and at any time afterthat. Consider now a stationary �rst order autoregression. A unit innovationat time t� will have a unit response at that time period, and a response of size�s each period t+ s; gradually decreasing to zero.Another important characteristic of economic time series is the possibil-
ity that they exhibit cyclical �uctuations. In fact, �rst order autoregressiveprocesses may display a shape similar to that of many economic time series, al-though to produce regular cycles we need a second order autoregressive processes,
yt = �1yt�1 + �2yt�2 + "t;
with "t being an innovation, a sequence of independent and identically dis-tributed over time. Using the lag operator: Bsyt = yt�s in the representationof the process:
yt � �1yt�1 � �2yt�2 =�1� �1B � �2B2
�yt = "t;
The dynamics of this process is characterized by the roots of its characteristicequation,
1� �1B � �2B2 = (1� �+B) (1� ��B) = 0which are given by:
�+; �� =��1 �
p�21 + 4�2
2�2
Stationary second order autoregressions have the two roots of the charac-teristic equation smaller than 1. A root greater than one in absolute size will
4When working with several variables, responses can be obtained for impulses in morethan one variable. To make the size of the responses comparable, each innovation is supposedto take a value equal to its standard deviation, which may be quite di¤erent for di¤erentinnovations.
30

produce an explosive behavior. A root equal to one also signals nonstationarity,although the sample realization will not be explosive. It will display extremelypersistent �uctuations, very rarely crossing its mean, as it was the case with arandom walk. This is very clear in the similar representation of a random walk:(1�B) yt = "t:Since the characteristic equation is now of second degree, it might have as
roots two conjugate complex numbers. When that is the case, the autoregressiveprocess displays cyclical �uctuations. The response of yt to an innovation "twill also display cyclical �uctuations, as we will see in dynamic macroeconomicmodels below.
3.3 Numerical exercise: Simulating simple stochastic processes
The Simple_simul.xls EXCEL book presents simulations of some of these simplestochastic processes. Column A in the Simulations spreadsheet contains a timeindex. Column B contains a sample realization of random numbers extractedfrom a N(0; 1) distribution. This has been obtained from EXCEL using the se-quence of keys: Tools/Data Analysis/Random Number Generator and selectingas options in the menu number of variables =1, observations = 200, a Normaldistribution with expectation 0 and variance 1, and selecting the appropriateoutput range in the spreadsheet.A well constructed random number generator produces independent real-
izations of the chosen distribution. We should therefore have in column B 200independent data points from a N(0,1), which can either be interpreted as a sam-ple of size 200 from a N(0,1) population, or as a single time series realizationfrom a white noise where the innovation follows a N(0,1) probability distribu-tion. The latter is the interpretation we will follow. At the end of the column,we compute the sample mean and standard deviation, with values of 0.07 and1.04, respectively. These are estimates of the 0 mathematical expectation andunit standard deviation with this sample. Below that, we present the standarddeviation of the �rst and the last 100 observations, of 1.09 and .98. Estimatesof the variance obtained with the full sample or with the two subsamples seemreasonable. A di¤erent sample would lead to di¤erent numerical estimates.Panel 2 contains sample realizations from three di¤erent random walks with-
out drift, The only parameter in such processes is the variance of the innovation,which takes values 1, 25 and 100, respectively. At a di¤erence of a white noise,an initial condition is needed to generate a time series for a random walk, be-cause of the time dependence between successive observations, as can be seenin (2) : The three sample realizations are graphed in the RandomWalks spread-sheet. All exhibit extreme persistence, crossing the sample mean just once in200 observations. We know by construction that these three processes lack awell de�ned mean and have a time increasing variance. We can always computesample averages and standard deviations, as shown in the spreadsheet at theend of the series, but it is not advisable to try to interpret such statistics. Inparticular, in this case, by drawing di¤erent realization for the white noise incolumn B, the reader can easily check how sample mean and standard devia-
31

tions may drastically change. In fact, standard deviations are calculated in thespreadsheet for the �rst and last 100 sample observations, and they can turnout to be very di¤erent, and di¤erent from the t�2" theoretical result. The pointis we cannot estimate that time-varying moment with much precision.Panel 3 compares a random walk to three �rst-order autoregressive processes,
with autoregressive coe¢ cients of 0.99, 0.95 and 0.30. As mentioned above, arandom walk can be seen as the limit of a �rst order autoregression,as theautoregressive coe¢ cient converges to 1, although the limit presents some dis-continuity since, theoretically, autoregressive processes are stationary so longas the autoregressive coe¢ cient is below 1 in absolute value, while the randomwalk is nonstationary. The autoregressive processes will all have a well-de�nedmean and variance, which is not the case for the limit random walk process.0.99. The sample time series realizations for the four processes are displayedin the AR-processes spreadsheet, where it can be seen that sample di¤erencesbetween the autoregressive process with the 0.99 coe¢ cient and the randomwalk are minor, in spite of the theoretical di¤erences between the two processes.In particular, the autoregressive process crosses its sample mean in very fewoccasions. That is also the case for the 0.95-autoregressive process, although itsmean reverting behavior is very clear at the end of the sample. On the otherhand, the time series realization from the 0.30-autoregressive process exhibitsthe typical behavior in a clearly stationary process, crossing its sample meanrepeatedly.Panel 4 presents sample realizations from two white noise processes with drift
and N(0,1) innovations. As shown in the enclosed graph, both �uctuate aroundtheir mathematical expectation, which is the value of the constant de�ning thedrift, crossing their sample means very often. Panel 5 contains time seriesrealizations for two random walk processes with drift. These show in the graphin the form of what could look as deterministic trends. This is because thevalue of the drifts, of 1.0 and 3.0, respectively, is large, relative to the innovationvariance which is of 25 in both cases. If the value of the drift is reduced, orthe variance of the innovation increased, the shape of the time series wouldbe di¤erent, since the �uctuations would then dominate over the accumulatede¤ect of the drift, as the reader can check by reducing the numerical values ofthe drift parameters5 used in the computation of these two columns.Panel 6 presents realizations of a stationary �rst order autoregression with
coe¢ cient of .90. In the second case we have not included an innovation process,so that it can be considered as a deterministic autoregression. It is interestingto see in the enclosed graph the behavior of a stationary process: starting froman initial condition, in the absence of an innovation, the process will alwaysconverge smoothly to its mathematical expectation. That is not the case in thestochastic autoregression, just because the innovation variance, of 25, is largerelative to the distance between the initial condition, 150, and the mathematicalexpectation, 100. The reader can check how reducing the standard deviation
5Or signi�cantly increasing the innovation variance. What are the di¤erences beetwen bothcases in terms of the values taken by the process?
32

used in column S from 5 to 0.5, the pattern of the time series changes drastically,and the convergence process becomes then evident.Panel 7 contains realizations for second order autoregressions. The �rst two
columns present sample realizations from stationary autoregressions,
Model 1: yt = 10 + :6yt�1 + :3yt�2 + "t; "t � N(0; 1) (3)
Model 2: yt = 30 + 1:2yt�1 � :5yt�2 + "t; "t � N(0; 1) (4)
and are represented in an enclosed graph. The two time series display �uc-tuations around their sample mean of 100, which they cross a number of times.The second time series, represented in red in the graph can be seen to exhibita more evident stationary behavior, with more frequent crosses with the mean.The next three columns present realizations for nonstationary second order au-toregressions. There is an important di¤erence between them: the �rst twocorrespond to processes:
Model 3 : yt = :7yt�1 + :3yt�2 + "t; "t � N(0; 1) (5)
Model 4 : yt = 1:5yt�1 � :5yt�2 + "t; "t � N(0; 1) (6)
that contain exactly a unit root, the second one being stable.6 The rots ofthe characteristic equation for Model 3 are 1 and -0.3, while those for Model 2are 1 and 0.5. The last autoregression
Model 5 : yt = :3yt�1 + 1:2yt�2 + "t; "t � N(0; 1) (7)
has a root greater than one, which produces an explosive behavior. The tworoots are -0.95 and 1.25.The Impulse responses spreadsheet contains the responses to a unit shock
for the stochastic processes considered above: a random walk, three �rst-orderautoregressions, two stationary second-order autoregressions, and three nonsta-tionary second-order autoregressions. The innovation in each process is sup-posed to take a zero value in each case for ten periods, to be equal to 1, thestandard deviation assumed for the innovation in all cases at t� = 11, and beagain equal to zero afterwards. We compare that to the case when the in-novation is zero at all time periods. Impulse responses are computed as thedi¤erence between the time paths followed by each process under the scenariowith a shock at t� = 11; and in the absence of that shock. The �rst-orderautoregressions are supposed to start from an initial condition y0 = 100; whentheir mathematical expectations is zero, so in the absence of any shock, theyfollow a smooth trajectory gradually converging to zero at a speed determinedby its autoregressive coe¢ cient. The second order autoregressions are assumed
6The two polynomials can be written as 1 � a1B � a2B2 = (1 � B)(1 � �B); the secondroot being 1=�: The reader just need to �nd the value of � in each case.
33

to start from y0 = y1 = 100; which is also their mathematical expectations. So,in the absence of any shock, the processes would stay at that value forever.7
The �rst graph to the right displays impulse responses for a random walkas well as for the three �rst order autoregressions considered above, with coe¢ -cients 0.99, 0.95 and 0.30. A random walk has the constant, permanent impulseresponse that we mentioned above when describing this process. The responsesof the �rst order autoregressions can be seen to gradually decrease to zero fromthe initial unit value. The response is shorter the lower it is the autoregres-sive coe¢ cient. For high autoregressive coe¢ cients, the process shows strongpersistence, which makes the e¤ects of the shock to last longer.The second graph shows the impulse responses of the two stationary second-
order autoregressions. As the reader can easily check, the characteristic equationfor Model 1 has roots -0.32 and 0.92, so it is relatively close to nonstationarity.The characteristic equation for Model 2 has roots 0:6� 0:374 17i; with modulus0.5. This di¤erence shows up in a much more persistent response of Model 1.The complex roots of Model 2 explain the oscillatory behavior of the impulseresponse of this model.The third graph displays impulse responses for the three nonstationary sec-
ond order autoregressions. In the two cases when there is a unit root (Models3 and 4), the graph shows a permanent response to the purely transitory, one-period shock. The response of Model 5 is explosive because of having one rootabove 1, and its values are shown on the right Y-axis.
3.4 Stationarity
� Wald decomposition: Any linearly regular stochastic process yt admits arepresentation:
yt = f(t) +1Xs=0
as"t�s
with "t white noise, and ar = 0 for s > r; for some r; possibly in�nite.In this representation f(t) is a purely deterministic function, i.e., it is perfectlypredictable from its own past, and other than for this component, the stochasticprocess yt admits a possibly in�nite MA representation.But we also know that such a MA representation can be inverted, provided
the roots of the lag polynomial satisfy the appropriate requirements, to obtaina possibly in�nite AR representation.A stochastic process is said to have a unit root if the characteristic equation
of its AR representation has such a root. A stochastic process may have morethan one unit root.The �rst di¤erence of a process having a unit root is stationary. A stochastic
process is said to be integrated of order d; if its d-th order di¤erence is stationary.7We could have done otherwise, like starting the �rst-order autoregresisons at their mathe-
matical expectation, and the second-order autoreegressions outside their expected values. Thereader can experiment with these changes.
34

Characteristics of a stationary process:
� It has �nite variance
� Its simple and partial autocorrelation functions converge to zero quickly
� The time series realization crosses its sample mean level often
� A one-period shock has purely transitory e¤ects
� Its forecast converges to its mathematical expectations as the forecasthorizon goes to in�nity
Characteristics of a non-stationary stochastic process
� Its variance increases with the sample size
� Its autocorrelation functions do not go to zero quickly
� The number of periods between successive crosses with its sample meanis in�nity
� A one-period shock has permanent e¤ects
� Its forecast does not converge to its mathematical expectation as the fore-cast horizon goes to in�nity
3.5 Valoración por simulación
La valoración de una opción mediante simulación se ajusta a la idea generalde simular el precio del subyacente desde el instante en que se valora la opciónhasta el vencimiento de la misma. En el caso de una opción Europea, basta conconsiderar en cada simulación el precio resultante al �nal de la serie temporalsimulada, que coincide con el instante de vencimiento de la opción. Mediante unelevado número de realizaciones simuladas, podemos aproximar la distribuciónde probabilidad del precio del activo subyacente al vencimiento de la opción. Deeste modo, obtenemos el valor intrínseco de la opción a vencimiento para cadarealización y, por tanto, una aproximación a la distribución de probabilidad dedicho valor intrínseco. De dicha distribución de probabilidad inferimos un pre-cio actual para la opción a partir de un determinado mecanismo de valoración:una posibilidad es calcular la esperanza matemática de la distribución de prob-abilidad del valor intrínseco a vencimiento, y descontarlo al instante en que seefectúa la valoración.En el caso de otros tipos de opciones, puede utilizarse, en general, un pro-
cedimiento análogo, si bien teniendo en cuenta a) todos los posibles instantes deejercicio, b) el valor intrínseco en cada uno de ellos, c) el descuento apropiadoa utilizar.Sin embargo, hay otras posibilidades: una, interesante, consistiría en consid-
erar los tipos de interés como estocásticos, y simular simultáneamente los tipos
35

de interés y el precio del subyacente, una vez que hubiéramos recogido en elmodelo la dependencia entre ambos. Por ejemplo,
yt = �0 + �1rt + "yt
rt = �0 + �1rt�1 + "2t
con ("1t; "2t) � N
��00
�;
��21 �12�12 �22
��: Téngase en cuenta que, en un
modelo de estas características, la relación entre los tipos de interés rt y larentabilidad del activo subyacente yt se produce por dos vías: una, explícita,por la presencia de los tipos en la ecuación de la rentabilidad; otra, implícita,por la correlación entre las innovaciones de ambas ecuaciones.En el caso en que la rentabilidad y los tipos tengan estructuras de volatilidad
condicional no trivial, entonces podríamos establecer un modelo ARCH bivari-ante, en el que se pueden recoger las dependencias tanto entre rentabilidadescomo entre volatilidades.
3.6 Contrastes de camino aleatorio
Existen en la literatura distintas de�niciones de camino aleatorio, no todasequivalentes entre sí. Una de�nición requiere que las rentabilidades sean in-dependientes e idénticamente distribuidas. Esta de�nición, que puede resultarinteresante en determinados contextos, no lo es tanto cuando tratamos la posiblepredicitibilidad de la serie de rentabilidades. La razón es que una estructura deheterocedasticidad condicional (la varianza depende en cada período de las re-alizaciones recientes de la serie de rentabilidades), por ejemplo, introduce claradependencia temporal, pero no por ello permite predecir la serie de rentabili-dades si, por ejemplo, mantiene una estructura de ruido blanco con este tipo deheterocedasticidad.Una de�nición más general [Granger y Mortensen (1970)] se basa en las
condiciones: a) esperanza matemática constante y b) ausencia de correlaciónserial. En este caso, la predicción lineal óptima de ua rentabilidad futura es suesperanza incondicional, que estamos suponiendo constante.Si pretendemos contrastar la hipótesis la de que la serie de rentabilidades
obedece una estructura de camino aleatorio, tenemos que introducir condicionesadicionales [ver Lo y MacKinlay (1988)].Una tercera de�nición [Samuelson (1965)] es: E[rt+1=It] = � para cierta
constante � y para todo instante t y toda historia pasada: It = frt�i; i � 0g:La tercera de�nición implica la segunda, siempre que las rentabilidades ten-
gan varianza �nita. La diferencia entre ambas es menor. Los contrastes decamino aleatorio que utilizan funciones de autocorrelación se basan en la se-gunda de�nición. Suponiendo varianza �nita, si un test de este tipo rechaza lasegunda de�nición, rechaza también la tercera de�nición.
36

3.6.1 Coe�cientes de autocorrelación
La manera más directa de contrastar si un determinado proceso estocástico tienenaturaleza de camino aleatorio, o lo que es lo mismo, la hipótesis de martingala,es analizando los coe�cientes de correlación entre dos variables constituyentes dedicho proceso estocástico en dos instantes distintos de tiempo. Bajo la hipótesisnula, todos los coe�cienets de autocorrelación deberían ser nulos, lo que complicaen cierta medida el diseño del contraste, pues el número de hipótesis a contrastares potencialmente ilimitado. Pero, una vez más, para llevar a cabo el contrastenos habremos de servir de sus análogos muestrales, en cuyo cálculo perdemosobservaciones muestrales, por el hecho de tener que retardar la serie temporalde datos.Fuller (1976) caracteriza la distribución asintótica del vector de losm primeros
coe�cientes de autocorrelación, siendo ésta Normal multivariante:
pT �k ! N(0; 1) (8)
En muestras �nitas, si el proceso estocástico tiene estructura de caminoaleatorio (RW1-Taylor antiguo), con varianza �nita �2 y momentos de ordenseis �nitos, se tiene:
E (�k) = � T � kT (T � 1) +O(T
�2)
V ar(�k) =T � kT 2
+O(T�2)
Cov (�k; �l) = O(T�2)
Por tanto, los coe�cientes de autocorrelación muestrales de un camino aleato-rio están sesgados a la baja.8 En muestras pequeñas, tal sesgo puede ser impor-tante. Para evitar el sesgo, Fuller (1976) propone la corrección:
~�k = �k +T � k(T � 1)2
�1� �2k
�;
con:
T
T � k ~�k ! N(0; 1)
E (~�k) = O(T�2)
3.6.2 Contrastes Portmanteau
Para recoger adecuadamente un concepto de camino aleatorio que implica quetodos los coe�cientes de autocorrelación son cero, Box y Pierce (1970) pro-pusieron un contraste conjunto basado en el estadístico:
8La razón es que un coe�ciente de autocorrelación se estima mediante productos cruzadosde desviaciones respecto de la media muestral. Como dichas desviaciones suman cero, unadesviación positiva tenderá a venir seguida de desviaciones negativas, y viceversa.
37

Qm �mXk=1
�2k
Bajo la hipótesis nula (RW1), (8) implica que: Qm �Pmk=1 �
2k se distribuye
como una �2m: Ljung y Box (1978) propusieron una corrección en muestras�nitas:
Q0m � T (T + 2)mXk=1
�2kT � k
Al agregar los coe�cientes de autocorrelación al cuadrado, el contraste tienepotencia frente a diversas alternativas. Sin embargo, la elección del orden mes ambigua, y puede condicionar los resultados del contraste. Si se utiliza unm pequeño, puede no detectarse la autocorrelación de orden superior. Si seutiliza m grande, el contraste pierde potencia debido a la acumulación de auto-correlaciones no signi�cativas. Si se dispone de una alternaitva concreta, puedediseñarse un contarste con mejores propiedades estadísticas.
3.6.3 Ratios de varianza
Recordando que las rentabilidades continuas son aditivas, es decir, que la rentabil-idad sobre 2 períodos es la suma de las rentabilidades sobre cada uno de ellos:r2t = r1t + r
1t�1, tenemos la razón de varianzas a 2 períodos,
RV (2) =V ar(r2t )
2V ar(r1t )=V ar(r1t + r
1t�1)
2V ar(r1t )=2V ar(rt) + 2Cov(r
1t ; r
1t�1)
2V ar(r1t )= 1 + �1
que está determinada por el primer valor de la función de autocorrelaciónsimple.Si las rentabilidades son ruido blanco (white noise), el coe�ciente de auto-
correlación de orden 1 es igual a cero, y la razón de varianzas es igual a 1. Conautocorrelación positiva, la razón de varianzas será mayor que uno, siendo infe-rior a la unidad si las rentabilidades están negativamente autocorrelacionadas,lo que es infrecuente en datos �nancieros.Para contrastar la signi�catividad de este estadístico, puede utilizarse la
distribución asintótica:
p2n (RV (2)� 1) � N(0; 2)
que sugiere que,
RV (2) � N(1;1
n)
por lo que, manteniendo un 95% de con�anza, la razón de varianzas de orden2 no debería separarse de 1.0 en más del doble del inverso del tamaño muestral.
38

Existe un contraste más amplio, que incorpora los coe�cientes de autocor-relación hasta orden q. La razón de varianzas es entonces:
RV (q) =V ar(rqt )
qV ar(r1t )= 1 + 2
q�1Xi=1
�1� i
q
��i
que muestra que el ratio de varianzas RV (q) es una combinación lineal delos q � 1 primeros coe�cientes de autocorrelación, tomados con ponderacionesdecrecientes. En el caso q = 2 tenemos la expresión que antes vimos para RV (2):Nuevamente, si el proceso es ruido blanco, el ratio de varianzas RV (q) es iguala 1 para todo q:Si, por ejemplo, se trata de un proceso autoregresivo de primer orden,
rt = �rt�1 + "t
se tiene:
RV (q) = 1 + 2
q�1Xi=1
�1� i
q
��i = 1 +
2
1� �
��� �q
q� �� �q
q(1� �)
�una expresión que puede utilizarse para diseñar un contraste de camino
aleatorio teniendo una estructura AR(1) como hipótesis alternativa.
3.6.4 Ratios y diferencias de varianzas
A partir de una serie de precios Pt; t = 0; 1; :::; 2n; de longitud 2n+ 1; si deno-tamos por pt a la serie de logaritmos, pt = ln(Pt); t = 1; 2; :::; 2n:Supongamos elmodelo:
pt = �+ "t; "t � i:; i:d:;N(0; �2)
tenemos los estimadores de � y �2 :
� = �r =1
2n
2nXi=1
(pt � pt�1) =1
2n(p2n � p0)
�2a =1
2n
2nXi=1
(pt � pt�1 � �)2
�2b =1
2n
nXi=1
(p2t � p2t�2 � 2�)2
done �2b hace uso de la naturaleza de camino aleatorio de rt bajo la hipótesisnula, puesto que la varianza puede entonces estimarse a partir de la mitad delos incrementos de las observaciones de orden par. Los tres estimadores sonconsistentes:
39

p2n��a � �2
�� N(0; 2�4)
p2n��b � �2
�� N(0; 4�4)
Como �2a es un estimador asintóticamente e�ciente bajo la hipótesis nula(RW1), podemos utilizar el clásico argumento de Hausman, para mostrar que lavarianza asintótica de la diferencia de un estimador consistente y un estimadorasintóticamente e�ciente es simplemente la diferencia de las varianzas asintóticasde ambos estimadores. por tanto, si denotamos DV (2) = �2b � �2a; tenemos elestadístico de Diferencia de varianzas de orden 2:
p2nDV (2) � N(0; 2�4)
por lo que la hipótesis nula de camino aleatorio puede contrastarse utilizandocualquier estimador consistente de �4 como, por ejemplo, 2
��2a�2: Entonces, el
estadístico estandarizado,pnDV (2)=
p�4 sigue una distribución N(0,1) bajo la
hipótesis nula.De modo similar, el estadístico de razón de varianzas que se obtiene mediante
RV (2) = �2b=�2a sigue una distribución:
p2n(RV (2)� 1) � N(0; 2)
como puede probarse a partir de una aproximación de Taylor de primer ordeno mediante el llamado método delta.En consecuencia, el estadístico estandarizado
p2n(RV (2)�1)=
p2 =
pn(RV (2)�
1) sigue una distribución N(0; 1): Lo y MacKinley (1988) sugieren utilizar uncontraste basado en esta distribución. Sin embargo, aunque suele preferirse elestadístico ratio de varianzas al de diferencia de varianzas, por estar libre de es-cala, ambos conducen a las mismas conclusiones, puesto que si se utiliza 2
��2a�2
para estimar 2�4; se tiene:
DV (2)p�4
=�2b � �2a�2a
=�RV (2)� 1
�� N
�0;1
n
�La potencia de este tipo de contrastes aumenta si se reduce la posible pres-
encia de heterocedasticidad en los datos.Las de�niciones y estadisticos pueden extendersea intervalos de más de 2
períodos, con:
� = �r =1
qn
2qXt=1
(pt � pt�1) =1
qn(pqn � p0)
�2a =1
qn
qnXt=1
(pt � pt�1 � �)2
�2b =1
qn
nXt=1
(pqt � pqt�q � q�)2
40

y las distribuciones:
pqnDV (q) � N(0; 2(q � 1)�4)
pqn(RV (q)� 1) � N(0; 2(q � 1))
siendo q el número de períodos. Dos re�namientos mejoran las propiedadesde muestras �nitas de estos contrastes. Uno consiste en estimar:
�2c =1
q2n
nqXt=q
(pt � pt�q � q�)2
y el segundo en corregir un sesgo en los estimadores �2a y �2c antes de dividir
uno por otro.
4 Modelos VAR
4.1 Introducción
Utilizamos un modelo del tipo vector autoregresivo (VAR) cuando queremoscaracterizar las interacciones simultáneas entre un grupo de variable. Un VARes un modelo de ecuaciones simultáneas formado por un sistema de ecuacionesde forma reducida sin restringir. Que sean ecuaciones de forma reducida quieredecir que los valores contemporáneos de las variables del modelo no aparecencomo variables explicativas en las distintas ecuaciones. El conjunto de variablesexplicativas de cada ecuación está constituido por un bloque de retardos de cadauna de las variables del modelo. Que sean ecuaciones no restringidas signi�caque aparece en cada una de ellas el mismo grupo de variables explicativas.Así, en un modelo vectorial autoregresivo de primer orden, VAR(1), las
variables explicativas de cada ecuación son: una constante, más un retardode cada una de las variables del modelo. Si el modelo pretende explicar elcomportamiento temporal de 3 variables, habría 3 variables explicativas, másconstante, en cada ecución, para un total de 12 coe�cientes a estimar. Si elmodelo fuera de segundo orden, VAR(2), habría 7 coe�cientes a estimar en cadauna de las 3 ecuaciones que componen el modelo VAR. Como puede verse, todaslas variables son tratadas simétricamente, siendo explicadas por el pasado detodas ellas.Pueden incluirse también como variables explicativas algunas variables de
naturaleza determinista, como una posible tendencia temporal, variables �cticiasestacionales, o una variable �cticia de tipo impulso o escalón, que sirve parallevar a cabo un análisis de intervención en el sistema. Por último, podríaincluirse como explicativa una variable, incluso en valor contemporáneo, quepueda considerarse exógena respecto a las variables que integran el modelo VAR.El modelo VAR es muy útil cuando existe evidencia de simultaneidad entre
un grupo de variables, y que sus relaciones se transmiten a lo largo de un
41

determinado número de períodos. Al no imponer ninguna restricción sobre laversión estructural del modelo, no se incurre en los errores de especi�cación quedichas restricciones pudieran causar al ejercicio empírico. De hecho, la principalmotivación detrás de los modelos VAR es la di�cultad en identi�car variablescomo exógenas, como es preciso hacer para identi�car un modelo de ecuacionessimultáneas.Por el contrario, en un modelo VAR todas las variables se tratan de igual
modo: el modelo tienen tantas ecuaciones como variables, y los valores retar-dados de todas las ecuaciones aparecen como variables explicativas en todaslas ecuaciones. Una vez estimado el modelo, puede procederse a excluir algu-nas variables explicativas, en función de su signi�cación estadística, pero hayrazones para no hacerlo. Por un lado, si se mantiene el mismo conjunto de vari-ables explicativas en todas las ecuaciones, entonces la estimación por mínimoscuadrados ordinarios ecuación por ecuación es e�ciente, por lo que el procesode estimación del modelo es verdaderamente sencillo. Por otro, la presencia debloques de retardos como variables explicativas hace que la colinealidad entrevariables explicativas sea importante, lo que hace perder precisión en la esti-mación del modelo y reduce los valores numéricos de los estadísticos tipo t deStudent.
4.2 El modelo VAR(1)
En el caso más simple, con sólo dos variables y un retardo, el modelo VAR2(1)es,
y1t = �10 + �11y1t�1 + �12y2t�1 + u1t (9)
y2t = �20 + �21y1t�1 + �22y2t�1 + u2t
o, en forma matricial,�y1ty2t
�=
��10�20
�+
��11 �12�21 �22
��y1t�1y2t�1
�+
�u1tu2t
�(10)
donde los términos de error satisfacen,
E(u1t) = E(u2t) = 0; 8tE(u1tu1s) = E(u2tu2s) = E(u1tu2s) = 0; 8t 6= s
V ar
�u1tu2t
�=
��21 �12�12 �22
�= �; 8t (11)
En el modelo VAR anterior, valores negativos de �12 y �21 tienden a inducircorrelación negativa entre y1t e y2t si bien no la garantizan.Un shock inesperado en y2t; en la forma de un valor no nulo de la innovación
u2t; además de afectar a y2t; in�uye sobre y1t; a través de de la correlaciónentre las innovaciones de ambas variables. En general, una sorpresa en y2t
42

vendrá acompañada de un valor no nulo de la innovación u1t; salvo en el casoexcepcional en que �u1u2 = 0: Estos efectos se propagan en el tiempo debido ala presencia de los valores retardados como variables explicativas.En general, un modelo VAR se especi�ca,
Yt = A0 +KXs=1
AsYt�s + ut (12)
donde Yt es un vector columna nx1; K es el orden del modelo VAR, onúmero de retardos de cada variable en cada ecuación, y ut es un vector nx1 deinnovaciones, es decir, procesos sin autocorrelación, con V ar(ut) = �; constante.El elemento (i; j)en la matriz As; 1 � s � K mide el efecto directo o efectoparcial de un cambio en Yj en el instante t sobre la variable explicativa al cabode s períodos, Yi;t+s. El elemento i-ésimo en ut es el componente de Yit que nopuede ser previsto utilizando el pasado de las variables que integran el vectorYt:Con esta notación el modeloVAR(1) se escribiría: Yt = A0 +A1yt�1 + ut:
4.3 Un modelo estructural
Es útil interpretar el modelo VAR como forma reducida de un modelo estruc-tural,
y1t = �10 + �11y2t + �12y1t�1 + �13y2t�1 + "1t (13)
y2t = �20 + �21y1t + �22y1t�1 + �23y2t�1 + "2t
donde y1t; y2t son variables estacionarias, y "1t; "2t son innovaciones, pro-cesos ruido blanco con esperanza cero y varianzas �2"1 ; �
2"2 : Este es un modelo
de ecuaciones simultáneas con la única peculiaridad de que sus dos variablesson endógenas. Un shock inesperado en y2t; en la forma de un valor no nulode la innovación estructural "2t; afecta directamente a y2t; pero también in�uyesobre y1t a través de la presencia de y2t como variable explicativa en la primeraecuación. Además, este efecto se propaga en el tiempo, debido a la presenciade los valores retardados como variables explicativas. Es natural pensar que lostérminos de error del modelo estructural estén mutuamente incorrelacionados,puesto que la correlación contemporánea entre y1t e y2t ya está capturada por lapresencia de sus valores contemporáneos como variables explicativas en ambasecuaciones. Por tanto, suponemos que Cov("1t; "2t) = �"1;"2 = 0:Si dicha covaraizna no fuese cero, el sistema podría transformarse en otro
sistema, observacionalmente equivalente, con tal propiedad (ver Apéndice).De forma resumida, la representación matricial del modelo estructural ante-
rior puede escribirse,
Byt = �0 + �1yt�1 + "t
con,
43

B =
�1 ��11��21 1
�; �0 =
��10�20
�; �1 =
��12 �13�22 �23
�y si suponemos que la matriz B tiene inversa, lo cual requiere que �11�21 6= 1;
tenemos,
yt = B�1�0 +B�1�1yt�1 +B
�1"t = A0 +A1yt�1 + ut
donde,
B�1 =1
1� �11�21
�1 �11�21 1
�
ut =
�u1tu2t
�= B�1"t = B�1
�"1t"2t
�=
1
1� �11�21
�"1t + �11"2t"2t + �21"1t
�;(14)
A1 =
��11 �12�21 �22
�=
1
1� �11�21
��12 + �11�22 �13 + �11�23�22 + �21�12 �23 + �13�21
�(15)
A0 =
��10�20
�=
1
1� �11�21
��10 + �11�20�20 + �21�10
�(16)
con lo que habremos pasado a la forma reducida, o modelo VAR.Como puede verse, si los términos de error del modelo estructural eran ruido
blanco, también los términos de error del modelo VAR tandrán estructura ruidoblanco. Sin embargo, las innovaciones del VAR estarán correlacionadas entre sí,puesto que,
V ar
�u1tu2t
�=
1
(1� �11�21)2��2"1 + �
211�
2"2 �21�
2"1 + �11�
2"2
�21�2"1 + �11�
2"2 �21�
2"1 + �
2"2
�de modo que, incluso si los términos de error del modelo estructural es-
tán incorrelacionados, �"1"2 = 0; las perturbaciones del modelo VAR tendráncorrelación no nula, a no ser que �11 = �21 = 0.Es importante examinar las relaciones entre los parámetros de ambos mode-
los, que son, en el caso del modelo VAR(1), las 6 relaciones entre los parámetros� y los parámetros � que aparecen en (??) y (15), más las 3 relaciones entre loselementos de las respectivas matrices de covarianzas,
�2u1 =1
(1� �11�21)2��2"1 + �
211�
2"2
��2u2 =
1
(1� �11�21)2��2"2 + �
221�
2"1
��u1u2 =
1
(1� �11�21)2��21�
2"1 + �11�
2"2
�
44

4.4 Identi�cación en un modelo VAR
De�nition 1 Recuperación de los parámetros del modelo estructural a partirde estimaciones de los parámetros del modelo en forma reducida.
La estimación de un modelo VAR(1) bivariante proporciona valores numéri-cos para 9 parámetros: las dos constantes más los cuatro coe�cientes en lasvariables retardadas, más los 3 parámetros de la matriz de covarianzas del vec-tor ut en (11). Sin embargo, el modelo estructural consta de 10 parámetros: lasdos constantes, los 6 coe�cientes, y los 3 parámetros de la matriz de covarian-zas del vector "t; por lo que no es posible recuperar los parámetros del modeloestructural. Recordemos que los dos términos de perturbación del modelo enforma estructural tienen correlación cero.En el ejercicio 1 se prueba que el modelo estructural recursivo bivariante de
orden 1,
y1t = �10 + �11y2t + �12y1t�1 + �13y2t�1 + "1t (17)
y2t = �20 + �22y1t�1 + �23y2t�1 + "2t
está exactamente identi�cado, es decir, que sus parámetros pueden recuper-arse de forma única a partir de las estimaciones del modelo VAR asociado. Estees un modelo interesante, en el que se consigue identi�car todos los parámetrosdel modelo estructural a partir de las estimaciones de la forma reducida (modeloVAR), introduciendo la hipótesis de que la variable y1t afecta a la variable y2túnicamente con un retardo, mientras que la dirección de in�uencia de y2t haciay1t se mani�esta ya dentro del mismo período.No sólo se pueden recuperar estimaciones de todos los parámetros que apare-
cen en el modelo estructural. También las series temporales de los residuos delmodelo estructural pueden recuperarse a partir de los residuos obtenidos en laestimación del modelo VAR, mediante las relaciones,
u2t ="2t
1� �11�21; u1t =
"1t + �11"2t1� �11�21
Un modelo más restringido,
y1t = �10 + �11y2t + �12y1t�1 + �13y2t�1 + "1t
y2t = �20 + �23y2t�1 + "2t
implicaría que la variable y1t no afecta ni de forma contemporánea, ni re-tardada, a la variable y2t; por lo que ésta puede considerarse exógena respectode y1t, puesto que Cov("1; "2) = 0: Examinando los modelos anteriores, es fácilver que las dos restricciones que hemos impuesto, �21 = �22 = 0 hacen que en elmodelo VAR, �21 = 0; restricción que puede contrastarse utilizando el estadís-tico tipo t habitual de dicho coe�ciente, sin más que las di�cultades habitualesen el uso de este estadístico.
45

Al haber introducido una restricción más, el modelo estructural está ahorasobreidenti�cado, es decir, hay más de una manera de recuperar valores numéri-cos para los parámetros de dicho modelo, a partir de las estimaciones numéricasdel modelo VAR.Más di�cultades plantea el modelo,
y1t = �10 + �11y2t + �12y1t�1 + "1t
y2t = �20 + �21y1t + �23y2t�1 + "2t
que está asimismo sobreidenti�cado, habiendo todo un continuo de manerasde recuperar las estimaciones de los parámetros del modelo estructural. Sinembargo, en este caso no hay ninguna restricción contrastable sencilla que nospermita discutir esta representación. En este caso, las restricciones del modeloestructural introducen restricciones no lineales entre los parámetros del modeloVAR. Una posible estrategia consiste en estimar el modelo VAR sujeto a lasrestricciones no lineales generadas por las condiciones de sobreidenti�cación.El problema de obtener las innovaciones estructurales a partir de las las es-
timaciones de los residuos del modelo VAR equivale a la posibilidad de disponerde valores numéricos para los elementos de la matriz B, puesto que "t = But:Esta matriz tiene unos en la diagonal principal, pero no es simétrica, por loque tiene k2 � k parámetros por determinar. Además, debemos encontrar lask varianzas de las innovaciones estructurales; recuérdese que sus covarianzasson nulas. Así, tenemos k2 parámetros del modelo estructural, que querríamosrecuperar a partir de los
�k2 + k
�=2 elementos de V ar(ut): Necesitamos, por
tanto,�k2 � k
�=2 restricciones adicionales, si queremos tener alguna posibili-
dad de identi�car el modelo. En el caso de un modelo VAR(1) con 2 variables,hemos de imponer
�22 � 2
�=2 = 1 restricciones para identi�car el sistema exac-
tamente, como hemos constatado en los ejemplos anteriores. En un modelo con3 variables necesitaríamos imponer
�32 � 3
�=2 = 3 restricciones. El número de
restricciones necesarias para identi�car el modelo es independiente del orden deretardos del modelo VAR.Si imponemos condiciones de recursividad en un modelo con 3 variables,
tenemos,
u1t = "1t
u2t = c21"1t + "2t
u3t = c31"1t + c32"2t + "3t
que implica imponer 3 restricciones sobre los elementos de la matriz B�1; porlo que el modelo estaría, en principio, exactamente identi�cado. Esta estructurarecursiva es consistente con una estructura de covarianzas que se conoce comode tipo Cholesky, dado que la matriz que transforma el vector " en el vectoru es triangular inferior. La recursividad mediante una matriz B trinagular
46

inferior o superior, como en este caso, proporciona siempre el número exacto derestricciones que se precisan para identi�car un modelo VAR, que es de k2 � k.Hay conjuntos alternativos de restricciones, como,
u1t = "1t + c13"3t
u2t = c21"1t + "2t
u3t = c32"2t + "3t
que también lograría la identi�cación exacta del modelo.Otro tipo de restricciones consistiría en imponer un determinado valor numérico
para una respuesta. Por ejemplo, podemos pensar que la innovación "2t tieneun efecto unitario sobre y1t: Esto equivaldría a suponer �11 = �1en la matriz:
"t = But =
�1 ��11��21 1
�ut
Una posibilidad diferente consistiría en identi�car el modelo estructural im-poniendo restricciones sobre la matriz de covarianzas, ya sea imponiendo unvalor numérico para la varianza de "1t; la varianza de "2t; o la covarianza entreambos. Este tipo de restricciones conduce generalmente a soluciones múltiples(aunque en número �nito), por lo que el modelo estructural está en tal caso,sobreidenti�cado.Por último, puede conseguirse la identi�cación imponiendo restricciones ra-
zonables entre los valores numéricos de los parámetros estructurales. Por ejem-plo, puede imponerse una condición de simetría, �11 = �21, o cualquier otraque resulte adecuada en la aplicación que se analiza. En el caso del modelode 2 variables, esta condición de simetría de efectos conduce asimismo a unacondición de igualdad de varianzas para las innovaciones estructurales, lo queno ocurre en modelos con más de 2 variables.
4.4.1 Identi�cación y respuestas del sistema
Otra manera de entender los problemas de identi�cación es la siguiente: supong-amos que, sin considerar el posible modelo estructural, hemos estimado un mod-elo VAR(1) bivariante, (10) ; en el que queremos calcular cómo reacciona cadavariable ante una innovación en una de ellas, lo que denominamos como fun-ciones de respuesta al impulso. Sería poco adecuado, sin embargo, calcular lasrespuestas a un impulso en una de las innovaciones, u1; por ejemplo, sin queu2 experimente ningún impulso, pues ambas innovaciones están correlacionadasentre sí. Por tanto, hemos de transformar primero el modelo estimado en otromodelo en que los términos de error, siendo innovaciones, estén incorrelaciona-dos entre sí. Para ello, podríamos seguir una estrategia similar a la discutidamás arriba, proyectando por mínimos cuadrados una de los dos innovaciones,u1t; por ejemplo, sobre u2t;
u1t = �u2t + at
47

cuyo residuo at; de�nido por at = u1t � �u2t; estaría incorrelacionado, porconstrucción, con u2t:
Premultiplicando el modelo (10) por la matriz�1 ��0 1
�; tendríamos,
y1t = (�10 � ��20) + �y2t + (�11 � ��21)y1t�1 + (�12 � ��22)y2t�1 + aty2t = �20 + �21y1t�1 + �22y2t�1 + u2t
Cov(at; u2t) = 0;
un modelo en el que la variable y2 tiene efectos contemporáneos sobre y1: Estees el modelo estructural exactamente identi�cado (17) que antes consideramos.En este modelo, tiene sentido preguntarse por las respuestas de ambas vari-
ables a una perturbación en at o en u2t; puesto que ambos están incorrela-cionados, por construcción. En respuesta a un impulso en u2t, ambas variablesreaccionarán en el mismo instante, y también en períodos siguientes, hasta quedichas respuestas decaigan a cero. En cambio, en respuesta a una perturbaciónen at, y1 responderá en el mismo período y períodos siguientes, mientras que y2sólo responderá en períodos siguientes al de la perturbación.
4.4.2 Generalizando el orden del VAR
Como es sabido, dada una matriz simétrica, de�nida positiva, como �; existeuna única matriz triangular inferior A; con unos en su diagonal principal, yuna única matriz diagonal D, con elementos positivos a lo largo de su diagonalprincipal, tal que � admite una descomposición,
� = ADA0
Si consideramos la transformación lineal del vector de error precisamentecon esta matriz, "t = A�1ut; tenemos,
V ar ("t) = E("t"0t) = E(A�1utu
0t
�A�1
�0) = E(A�1�
�A�1
�0) = D;
que es una matriz diagonal, por lo que, a diferencia de los componentes delvector u; los elementos del vector " están incorrelacionados entre sí. Deshaciendola transformación, tenemos,
ut =
0BBBB@u1tu2tu3t:::ukt
1CCCCA = A"t =
0BBBB@1 0 0 ::: 0a12 1 0 ::: 0a13 a23 1 ::: 0::: ::: ::: ::: :::a1k a2k a3k ::: 1
1CCCCA0BBBB@
"1t"2t"3t:::"kt
1CCCCApor lo que,
"kt = ukt � a1k"1t � a2k"2t � :::� ak�1;k"k�1;t (18)
48

Si los coe�cientes a1k; a2k; :::; ak�1;k se obtienen mediante una estimación demínimos cuadrados ordinarios de la ecuación (18), que tiene a ukt como variabledependiente, y a "1t; "2t; :::; "k�1;t como variables explicativas,
"kt = ukt � a1k"1t � a2k"2t � :::� ak�1;k"k�1;t (19)
entonces tendremos, por construcción, E("kt:"1t) = E("kt:"2t) = ::: = E("kt:"k�1;t) =0: Dicho de otra manera, si estimamos regresiones de cada innovación uit sobretodas las que le preceden dentro del vector u y nos quedamos con el residuo dedicha regresión, llamémosle "it; tendremos un componente de uit que, por con-strucción, estará incorrelacionado con u1t; u2t; :::; ui�1;t: Nótese que los espaciosgenerados por las variables u1t; u2t; :::; ui�1;t y por las variables "1t; "2t; :::; "i�1;tson los mismos, es decir, que ambos conjuntos de variables contienen la mismainformación. La única diferencia entre ambos es que las variables u1t; u2t; :::; ui�1;ttiene correlaciones no nulas, mientras que las variables "1t; "2t; :::; "i�1;t estánincorrelacionadas entre sí.
4.5 Condiciones de estabilidad
Si resolvemos recursivamente el modelo VAR(1) tenemos,
Yt = A0 +A1Yt�1 + ut = A0 +A1(A0 +A1Yt�2 + ut�1) + ut =
= (Ik +A1)A0 +A21Yt�2 + (A1ut�1 + ut) =
= (Ik +A1 +A21 + :::+A
n�11 )A0 +A
n1Yt�n +
n�1Xi=0
Ai1ut�i
Como puede verse, para la estabilidad del sistema es preciso que las sucesivaspotencias de la matriz A1 decaigan hacia cero, pues de lo contrario, el futurolejano tendría efectos sobre el presente, en contra de la rápida amortiguacióntemporal de efectos inherente a todo proceso estacionario. Esto requiere que lasraíces del polinomio característico de dicha matriz j Ik �A1� j= 0; caigan fueradel círculo unidad, condición análoga a la que se tiene para un proceso autore-
gresivo univariante. Recordemos que en este modelo: A =��11 �12�21 �22
�:
Cuando se cumplen las condiciones de estabilidad, tomando límites, tenemos,
Yt = �+1Xi=0
Ai1ut�i
donde � = E(Y ) es el vector de esperanzas matemáticas, que viene dadopor,
� = (Ik �A1)�1A0Además,
49

V ar(Yt) = E�(Yt � �)2
�= E
" 1Xi=0
Ai1ut�i
#2=
1Xi=0
Ai1 (V ar(ut�i))�Ai1�0=
1Xi=0
Ai1��Ai1�0
En el caso bivariante, �1 = E(u1t); �2 = E(u2t), con
� =
��1�2
�=
�I2 �
��11 �12�21 �22
���1��10�20
�=1
�
��10(1� �22) + �12�20�20(1� �11) + �21�10
�siendo � = (1� �11)(1� �22)� �12�21, y
V ar(Yt) =
1Xi=0
��11 �12�21 �22
�i��2u1 �u1u2�u1u2 �2u2
���11 �12�21 �22
�i0Un modelo VAR estable de�ne momentos incondicionales para cada una de
las variables del vector Yt: En ese caso, hay que distinguir entre la distribucióny los momentos incondicionales y condicionales del vector Yt
4.6 VAR y modelos univariantes
Es útil asimismo pensar en términos de cuáles son los modelos univariantes quese deducen de una representación VAR, en línea con el trabajo de Zellner yPalm (19xx). En este sentido, si partimos de un VAR(1), como (10), escrito enfunción del operador de retardos,
y1t = �10 + �11Ly1t + �12Ly2t + u1t
y2t = �20 + �21Ly1t + �22Ly2t + u2t
tenemos,
y2t =�20 + �21Ly1t + u2t
1� �22Lcon lo que,
(1� �11L) y1t = �10 + �12L�20 + �21Ly1t + u2t
1� �22L+ u1t
y, �nalmente,
(1� �11L) (1� �22L) y1t = [(1� �22)�10 + �12�20]+[(1� �22L)u1t + �12u2t�1]
que es un proceso ARMA(2,1).
50

4.7 Estimación de un modelo VAR
Como ya hemos mencionado, en ausencia de restricciones, la estimación pormínimos cuadrados, ecuación por ecuación, de un modelo VAR produce esti-madores e�cientes a pesar de que ignora la información contenida en la matrizde covarianzas de las innovaciones. Junto con el hecho de que la colinealidadentre las variables explicativas no permite ser muy estricto en la interpretaciónde los estadísticos t, sugiere que es preferible mantener todas las variables ex-plicativas iniciales en el modelo.El estimador es consistente siempre que los términos de error sean innova-
ciones, es decir, procesos ruido blanco, pues en tal caso, estarán incorrelaciona-dos con las variables explicativas, por la misma razón que en un modelo univari-ante. Por tanto, la ausencia de autocorrelación en los términos de error de todaslas ecuaciones es muy importante. Tomando ambos hechos conjuntamente, esfácil concluir que debe incluirse en cada ecuación como variable explicativas, elmenor número de retardos que permita eliminar la autocorrelación residual entodas las ecuaciones. Existen contrastes del tipo de razón de verosimilitud sobreel número de retardos a incluir en el jmodelo.Un modelo VAR no se estima para hacer inferencia acerca de coe�cientes
de variables individuales. Precisamente la baja precisión en su estimación, de-saconseja cualquier análisis de coe�cientes individuales. Tiene mucho sentido,por el contrario, el análisis conjunto de los coe�cientes asociados a un bloquede retardos en una determinada ecuación.Bajo hipótesis de Normalidad del vector de innovaciones, el logaritmo de la
función de verosimilitud es,
l = �Tk2(1 + ln 2�)� T
2ln j � j
siendo � la estimación de la matriz de covarianzas del vector de innovacionesu,
� =1
T
TXt=1
utu0t
una matriz simétrica, de�nida positiva, por construcción.
4.8 Contrastación de hipótesis
4.8.1 Contrastes de especi�cación
Uno de los contrates más habituales en un modelo VAR es el relativo al númerode retardos que deben incluirse como variables explicativas. Hay que tener encuenta que en cada ecuación entra un bloque de retardos de todas las vari-ables del vector y. Si, por ejemplo, trabajamos con 4 variables y establecemosun orden 3 para el VAR, tendremos 12 variables explicativas, más el términoconstante, en cada ecuación, con un total de 52 coe�cientes en el sistema de
51

ecuaciones, más 10 parámetros en la matriz de varianzas-covarianzas de las in-novaciones. El número de parámetros a estimar crece muy rápidamente con elnúmero de retardos. Si pasamos de 3 a 4 retardos, tendríamos 68 coe�cientesmás los 10 parámetros de la matriz de covarianzas. Por eso ya comentamos conanterioridad que debe incluirse en cada ecuación el menor número de retardosque permita eliminar la autocorrelación del término de error de todas ellas.Existe un contraste formal de signi�cación de un conjunto de retardos, que
utiliza un estadístico de razón de verosimilitudes,
� = (T � k)(ln j �R j � ln j �SR j
donde j �R j; j �SR j denotan los determinantes de las matrices de covari-anzas de los modelos restringido y sin restringir, respectivamente. Si queremoscontrastar si un cuarto retardo es signi�cativo, deberíamos estimar el modelocon 3 y con 4 retardos, y construir el estadístico anterior, que tiene una dis-tribución chi-cuadrado con un número de grados de libertad igual al númerode restricciones que se contrastan. Al pasar del modelo con 3 retardos al mod-elo con 4 retardos, hay que añadir un retardo más de cada variable en cadaecuación, por lo que el número de restricciones es igual al incremento en elnúmero de retardos, por el número de variables al cuadrado.Sin embargo, no puede olvidarse que la elección del número de retardos debe
tener muy en cuenta la eliminación de autocorrelación residual en los resid-uos. Los estadísticos anteriores no examinan este importante aspecto y, portanto, no deben utilizarse por sí sólos. En consecuencia, una buena estrategiaes comenzar de un número reducido de retardos, y examinar las funciones deautocorrelación de los residuos, junto con estadísticos del tipo Ljung-Box o Box-Pierce para contrastar la posible existencia de autocorrelación, lo que requeriríaaumentar el número de retardos y con ello, el número de parámetros a estimar.Lamentablemente, sin embargo, es muy poco probable que pueda eliminarse laautocorrelación residual con menos de 4 retardos cuando se trabaja con datostrimestrales, o con menos de 12 retardos, cuando se trabaja con datos mensuales.Una estrategia distinta para encontrar el orden del modelo VAR consiste
en examinar los denominados criterios de Información, que son determinadascorrecciones sobre el valor muestral de la función logaritmo de Verosimilitud.Los más conocidos son los de Akaike y Schwartz,
AIC = �2 lT+ 2
n
T
SBC = �2 lT+ n
ln(T )
T
siendo n = k(d+pk) el número de parámetros estimados en el modelo VAR.d es el número de variables exógenas, p el orden del VAR, y k el número devariables. En ocasiones, se ignora el término constante, y los criterios anterioresse aproximan por,
52

AIC = T ln j � j +2nSBC = T ln j � j +n ln(T )
siendoN el número de parámetros que se estima, y � la matriz de covarianzasde los residuos. Estos estadísticos se calculan para una sucesión de modelos condistinto número de retardos y se comparan, seleccionando aquél modelo queproduce un menor valor del estadístico.Un estadístico de razón de verosimilitudes como el antes descrito puede uti-
lizarse para contrastar cualquier tipo de hipótesis, y no sólo la signi�cación degrupos de variables, siempre que el modelo restringido esté anidado dentro delmodelo sin restringir.
4.8.2 Contrastes de causalidad
Un contraste especialmente interesante es el conoce como de causalidad en elsentido de Granger: supongamos que estamos explicando el comportamientode una variable y utilizando su propio pasado. Se dice que una variable zno causa a la variable y si al añadir el pasado de z a la ecuación anterior noañade capacidad explicativa. El contraste consiste en analizar la signi�caciónestadística del bloque de retardos de z en la ecuación mencionada, y la hipótesisnula es que la variable z no causa, en el sentido de Granger, a la variable y.En realidad, la propuesta inicial de Granger hacía referencia a que la predic-
ción de y basada en el pasado de las dos variables y y z, sea estrictamente mejor(es decir, con menos error) que la predicción de y basada exclusivamente en supropio pasado. Así, se diría que la variable z no causa a la variable y si se tiene,
E(yt = yt�1; yt�2;:::; zt�1; zt�2; :::) = E(yt = yt�1; yt�2;:::)
Sin embargo, esta propiedad no suele analizarse; se contrasta exclusivamentela signi�cación del bloque de retardos de z en la ecuación de y; y se supone quesi dicho bloque de variables es signi�cativo, contribuirá a mejorar la predicciónde la variable y: Esta manera de proceder se basa en que, analíticamente, esevidente que la presencia del bloque de retardos de z en la ecuación de y haceque la esperanza de y condicional en el pasado de las dos variables, y y z; seadistinta de la esperanza de y condicional en su propio pasado exclusivamente,si bien esta propiedad teórica no siempre se mani�esta en resultados prácticos,y es bien sabido que un buen ajuste no necesariamente conduce a una buenapredicción.El contraste puede llevarse a cabo utilizando el estadístico F habitual en
el contraste de signi�cación de un bloque de variables, o mediante el estadís-tico de razón de verosimilitudes anterior. Con más de dos variables, existenmuchos posibles contrastes de causalidad y en algunos casos, el estadístico derazón de verosimilitudes puede resultar más útil que el estadístico F , al per-mitir contrastar la exclusión de algún bloque de retardos en varias ecuacionessimultáneamente.
53

Asimismo, el contraste de causalidad o, lo que es lo mismo, el contrastede signi�cación de un bloque de retardos puede llevarse a cabo mediante unestadístico de razón de verosimilitudes, en el que el modelo restringido excluyeun grupo de retardos de una ecuación
4.9 Representación MA de un modelo VAR
Para simpli�car la notación, sin perder ningún elemento relevante del modelo, enesta sección ignoramos la presencia de constantes en las ecuaciones del modeloVAR. Un modo de justi�car tal ausencia es pensar que las variables del modeloestán en diferencias con respecto a sus respectivas medias muestrales.Todo modelo VAR admite una representación de medias móviles (MA),
Yt =1Xs=0
Bsut�s
a la que se llega tras sucesivas sustituciones de Yt�s en (12) : La repre-sentación MA puede obtenerse asimismo en función de las innovaciones estruc-turales. Esta representación permite resumir las propiedades de las relacionescruzadas entre las variables que componen el vector Yt; que queda represen-tado como una combinación lineal de valores actuales y pasados del vector deinnovaciones. La simultaneidad vuelve a quedar palpable en el sentido de quecualquier innovación uit afecta a todas las variables Yj;t+s.Si volvemos al modelo de dos variables de orden 1, tenemos,�
y1ty2t
�=
��10�20
�+
��11 �12�21 �22
��y1t�1y2t�1
�+
�u1tu2t
�que, como vimos, puede escribirse,�
y1ty2t
�=
��1�2
�+
1Xs=0
��11 �12�21 �22
�s�u1t�su2t�s
�y, en términos de las innovaciones del modelo estructural, incorrelacionadas
entre sí,
�y1ty2t
�=
��1�2
�+
1
1� �11�21
1Xs=0
��11 �12�21 �22
�s�1 �11�21 1
��"1t�s"2t�s
�=(20)
=
��1�2
�+
1Xs=0
��11(s) �12(s)�21(s) �22(s)
��"1t�s"2t�s
�= �+
1Xs=0
�(s)"t�s
donde,
��11(s) �12(s)�21(s) �22(s)
�=
1
1� �11�21
��11 �12�21 �22
�s�1 �11�21 1
�(21)
54

Existe un procedimiento recursivo para obtener las matrices de coe�cientesde la representación de medias móviles que utiliza la relación que buscamos,
Yt = A1Yt�1 + :::+ApYt�p + ut = (Ik �A1L�A2L� :::�ApLp)�1ut == (�0 + �1L+ �2L
2 + :::)ut
de modo que tenemos,
Ik = (Ik �A1L�A2L� :::�ApLp)(�0 + �1L+ �2L2 + :::) == �0 + (�1 �A1�0)L+ (�2 �A1�1 �A2�0)L2 + :::
que conduce a,
�0 = Ik; �1 �A1�0 = 0; �2 �A1�1 �A2�0 = 0; :::de donde, �nalente, obtenemos:
�0 = Ik
�1 = A1
�2 = A1�1 +A2
:::
�s = A1�s�1 +A2�s�2 + :::+Ap�s�p
que pueden utilizarse para calcular recursivamente las matrices de coe�-cientes de la representación de medias móviles.Si trabajamos con un modelo VAR(1), es facil ver de lo anterior que las
matrices �s son las sucesivas potencias de la matriz A1:
4.10 Funciones de respuesta al impulso
La ecuación (20) es la representación de medias móviles del modelo VAR(1)bivariante. Los coe�cientes de la sucesión de matrices �(s) representan el im-pacto que, a lo largo del tiempo, tienen sobre las dos variables del modelo y1te y2t una perturbación en las innovaciones "1t; "2t: Por ejemplo, los coe�cientes�12(s) re�ejan el impacto que en los distintos períodos s; s � 1; tiene sobre y1una perturbación del tipo impulso en "2:Es decir, consideramos que "2 está en su valor de equilibrio, cero, excepto
en un período, en que toma un valor igual a 1; como consecuencia, tanto y1como y2 reaccionan, porque "2t aparece en ambas ecuaciones en (20), y dicharespuesta se extiende a varios períodos, hasta que la sucesión �12(s) se hacecero. La sucesión de valores numéricos f�12(s)g se conoce como la respuesta dey1 a un impulso en "2: El efecto, multiplicador o respuesta a largo plazo es lasuma
P1s=0 �12(s): Esta suma existe si las variables son estacionarias, pues en
tal caso ha de cumplirse que jP1s=0 �12(s) j<1:
55

El problema al que nos enfrentamos al tratar de calcular las funciones derespuesta al impulso es que, si bien contamos con estimaciones numéricas de losparámetros �ij ; i; j = 1; 2; desconocemos los parámetros �11 y �21 que aparecenen (21). En el modelo recursivo que antes vimos, se tiene �21 = 0: Además, seprueba en el ejercicio 1 que en este modelo el parámetro �11 puede recuperarsemediante �11 = �u1u2=�
2u2 : En ese caso, u2t = "2t y u1t = "1t + �11"2t =
"1t + �11u2t:Las funciones de respuesta al impulso sólo puden obtenerse bajo restricciones
de identi�cación de este tipo. La que hemos descrito es la más habitual, y equiv-ale a admitir que una de las dos variables afecta a la otra sólo con retraso, si bienpermitimos que en la otra dirección haya respuesta contemporánea. Estaremoscaracterizando las respuestas del sistema a un impulso en cada una de las in-novaciones del modelo estructural o, lo que es lo mismo, en la innovación u2t yen u1t ��11u2t: Esta última es la componente de u1t que no está explicada poru2t o, si se pre�ere, la componente de u1t que no está correlacionada con u2t9 :De hecho, si �21 = 0; entonces u1t � �11u2t es, precisamente, igual a la
perturbación estructural "1t:Como hemos visto, las funciones de respuesta al impulso sólo pueden obten-
erse después de haber introducido restricciones acerca del retraso con que unasvariables inciden sobre otras. Esta elección condiciona bastante, en general, elaspecto de las funciones de respuesta, excepto si las innovaciones del modeloVAR, u1t y u2t están incorrelacionadas, en cuyo caso, coinciden con las innova-ciones del modelo estructural.Las funciones de respuesta al impulso generan una gran cantidad de números,
pues se calcula el impacto que, en cada instante futuro tendría, sobre cadavariable del modelo, un impulso en una determinada innovación, y ello puederepetirse para las innovaciones en cada una de las ecuaciones. Por eso, suelenrepresentarse en varios grá�cos, cada uno de los cuales incluye las respuestasa través del tiempo, de una determinada variable a un impulso en cada unade las innovaciones; de este modo se tiene tantos grá�cos como variables enel modelo, cada uno de ellos conteniendo tantas curvas como variables. Alter-nativamente, pueden construirse grá�cos, cada uno de los cuales representa larespuesta temporal de todas las variables del modelo a un impulso en una delas innovaciones. Nuevamente hay tantos grá�cos como variables, cada uno deellos conteniendo tantas curvas como variables. El inconveniente del segundotipo de representación es que las respuestas de las distintas variables dependende sus respectivas volatilidades, por lo que la comparación de las respuestasde dos variables diferentes a un determinado impulso no permite decir cuál delas variables responde más. Recordando que la desviación típica es una medidaadecuada del tamaño de toda variable aleatoria de esperanza nula, debemosdividir las respuestas de cada variable por su desviación típica antes de repre-sentarlas en un mismo grá�co. Tampoco un impulso de tamaño unidad tiene el
9En general, si proyectamos u1t sobre u2t; el coe�ciente estimado será igual aCov(u1;u2)pV ar(u2)
:
Pero u1t ="1t+�11"2t
�y u2t =
"2t+�21"1t�
; por lo que Cov(u1; u2) =�11�
2"2+�21�
2"1
(1��11�21)2
56

mismo signi�cado en cada variable, por lo que conviene calcular las respuestasnormalizadas a un impulso de tamaño igual a una desviación típica en cadainnovación.Consideremos un VAR(1) sin constante (es decir, las variables tiene esper-
anza igual a cero),0@ y1ty2ty3t
1A =
0@ 0; 5 0 00; 1 0; 1 0; 30 0; 2 0; 3
1A0@ y1t�1y2t�1y3t�1
1A+0@ u1t
u2tu3t
1Ay supongamos que antes del instante t0 las innovaciones toman un valor
cero en todos los períodos, las variables están en sus niveles de equilibrio, yi =y�i = 0; i = 1; 2; 3. En dicho instante, la innovación u1t0 toma un valor unitario,u1t0 = 1; y vuelve a ser cero en los períodos siguientes. ¿Cuál es la respuestadel sistema?En el instante t0; 0@ y1t0
y2t0y3t0
1A =
0@ u1t0u2t0u3t0
1A =
0@ 100
1Apor lo que y2t0 e y3t0 estarán en sus niveles de equilibrio, y2 = y�2 = 0; y3 =
y�3 = 0, mientras que y1t0 = y�1 + 1 = 1:Posteriormente,
0@ y1t0+1y2t0+1y3t0+1
1A =
0@ 0; 5 0 00; 1 0; 1 0; 30 0; 2 0; 3
1A0@ y1t0y2t0y3t0
1A+0@ u1t0+1
u2t0+1u3t0+1
1A =
=
0@ 0; 5 0 00; 1 0; 1 0; 30 0; 2 0; 3
1A0@ y�1 + 1y�2y�3
1A+0@ 000
1A =
0@ 0; 50; 10
1A0@ y1t0+2
y2t0+2y3t0+2
1A =
0@ 0; 5 0 00; 1 0; 1 0; 30 0; 2 0; 3
1A0@ y1t0+1y2t0+1y3t0+1
1A+0@ u1t0+2
u2t0+2u3t0+2
1A =
=
0@ 0; 5 0 00; 1 0; 1 0; 30 0; 2 0; 3
1A0@ 0; 50; 10
1A+0@ 000
1A =
0@ 0; 250; 060; 02
1Aque van proporcionando la primera columna de las matrices que obtenemos
calculando las sucesivas potencias de la matriz de coe�cientes A1:De este modo, tendríamos las respuestas del sistema a sorpresas en las in-
novaciones del modelo VAR. Si queremos calcular las respuestas a innovacionesestructurales, debemos utilizar la representación,
57

�y1ty2t
�=
��1�2
�+
1
1� �11�21
1Xs=0
��11 �12�21 �22
�s�1 �11�21 1
��"1t�s"2t�s
�y examinar la sucesión de�nida en (21).Nótese que en este modelo VAR las respuestas al impulso iniciales (en t = 0)
son todas nulas.
4.11 Descomposición de la varianza
Si utilizamos la representación MA para obtener predicciones de las variablesy1; y2; tenemos,
Etyt+n = Et
�y1t+ny2t+n
�= �+
1Xs=n
�(s)"t+n�s
donde � es la misma matriz que aparece en (20).por lo que el error de predicción es,
et(n) = yt+n � Etyt+n = �+
1Xs=0
�(s)"t+n�s
!� �+
1Xs=n
�(s)"t+n�s
!=
n�1Xs=0
�(s)"t+n�s =
=
�(�11(0)"1t+n + :::+ �11(n� 1)"1t+1) + (�12(0)"2t+n + :::+ �12(n� 1)"2t+1)(�21(0)"1t+n + :::+ �21(n� 1)"1t+1) + (�22(0)"2t+n + :::+ �22(n� 1)"2t+1)
�cuya varianza es,
V ar
�e1t(n)e2t(n)
�=
��2"1
Pn�1s=0 �11(s)
2 + �2"2Pn�1s=0 �12(s)
2
�2"1Pn�1s=0 �21(s)
2 + �2"2Pn�1s=0 �22(s)
2
�que, inevitablemente, aumentan con el horizonte de predicción. La expresión
anterior nos permite descomponer la varianza del error de predicción en dosfuentes, según tenga a "1 o a "2 como causa. Con ello, estamos examinandoel inevitable error de predicción en cada variable a un determinado horizonte,y atribuyéndolo a la incertidumbre acerca de la evolución futura en cada unade las variables. Es, por tanto, una manera de hacer inferencia acerca de lasrelaciones intertemporales entre la variables que componen el vector y: Paraello, se expresan los componentes de cada varianza en términos porcentuales,
�2"1
Pn�1s=0 �11(s)
2
V ar (e1t(n));�2"2
Pn�1s=0 �12(s)
2
V ar (e1t(n))
!y
�2"1
Pn�1s=0 �21(s)
2
V ar (e2t(n));�2"2
Pn�1s=0 �22(s)
2
V ar (e2t(n))
!
Si una variable es prácticamente exógena respecto a las demás, entoncesexplicará casi el 100% de la varianza de su error de predicción a todos loshorizontes posibles. Esto es lo más habitual a horizontes cortos, mientras que a
58

horizontes largos, otras variables pueden ir explicando un cierto porcentaje dela varianza del error de predicción.La descomposición de la varianza está sujeta al mismo problema de iden-
ti�cación que vimos antes para las funciones de respuesta al impulso, siendonecesario introducir alguna restricción como las consideradas en la sección an-terior. Nuevamente, si la correlación entre las innovaciones del VAR es muypequeña, la ordenación que se haga de las variables del vector y o, lo que es lomismo, las restricciones de exclusión de valores contemporáneos que se introduz-can serán irrelevantes. En general, sin embargo, tales restricciones condicionanmuy signi�cativamente la descomposición de la varianza resultante. De hecho,con las restricciones de identi�cación de la sección anterior, "2 explica el 100%de la varianza del error de predicción un período hacia adelante en la variabley2: Si, en vez de dicha restricción, excluyéramos y2t de la primera ecuación,entonces "1 explicaría el 100% de la varianza del error de predicción un períodohacia adelante en la variable y1:
4.11.1 Identi�cación recursiva: la descomposición de Cholesky
Para eliminar la correlación contemporánea existente entre las innovaciones utde distintas ecuaciones, podemos transformar el vector ut en un vector et medi-ante la transformación de�nida por la descomposición de Cholesky de la matrizde covarianzas �; � = V ar(ut): Esta descomposición nos proporciona una ma-triz triangular inferior G tal que GG0 = �: Como consecuencia, G�1�G0�1 = I;y el sistema VAR puede escribirse,
Yt =1Xs=0
Asut�s =1Xs=0
(AsG)�G�1ut�s
�=
1Xs=0
eAset�s (22)
con eAs = AsG; et�s = G�1ut�s; V ar (et�s) = G�1V ar(ut�s)G�10 = I:
El efecto de eit sobre Yj;t+s viene medido por el elemento (j; i) de la matriz~As: La sucesión de dichos elementos, para 1 � s � 1 proporciona la respuestadinámica de la variable Yj a una innovación en la variable Yi: esto se conocecomo función de respuesta de Yj a un impulso sorpresa en Yi: Como eit esel error de predicción un período hacia adelante en Yit, la representación MAortogonalizada nos permite computar el error de predicción de Yit; m-períodoshacia adelante, en el instante t�m+1, a través del elemento i-ésimo en le vectorPm�1s=0
eAset�s: Su varianza, el elemento i-ésimo en la diagonal de Pm�1s=0
eAs eA0s;puede escribirse,
PKj=1
Pm�1s=0 eas (i; j)eas (j; i) ; siendo eas (i; j) el elemento (i; j)
genérico de la matriz element ~As: Al aumentar m; a partir de m = 1, esta de-scomposición de la varianza del error de predicción de Yit+m entre las k variablesdel vector Yt se conoce como descomposición de la varianza de Yit: Proporcionauna estimación de la relevancia de cada variable del sistema para explicar loserrores de predicción de las �uctuaciones futuras en Yit:
59

4.12 Ejercicios
� Considere el modelo estructural recursivo,
y1t = �10 + �11y2t + �12y1t�1 + �13y2t�1 + "1t
y2t = �20 + �22y1t�1 + �23y2t�1 + "2t
donde y1t afecta a y2t sólo con cierto retraso. Note que este modelo permiteidenti�car el término de error "2t a partir de las observaciones de la variabley2t: Pruebe que este modelo está exactamente identi�cado, en el sentido de quetodos sus coe�cientes, así como las varianzas de los dos términos de error puedenrecuperarse a partir de la estimación del modelo VAR(1) en estas dos variables.
�10 = �10 + �11�20; �11 = �12 + �11�22; �12 = �13 + �11�23;
�20 = �20; �21 = �22; �22 = �23;
�2u1 = �2"1 + �211�
2"2 ; �
2u2 = �2"2 ; �u1;u2 = �11�
2"2 ;
sistema que puede resolverse para obtener los 9 parámetros del modelo es-tructural recursivo.Muestre que en este modelo, no sólo se pueden recuperar estimaciones de
todos los parámetros que aparecen en el modelo estructural, sino también lasseries temporales de los términos de error "1t y "2t:
60

4.13 Apéndice
4.13.1 Transformando un VAR con covarianza no nula en otro contal propiedad
Supongamos que en el sistema,
y1t = �10 + �11y2t + �12y1t�1 + �13y2t�1 + u1t
y2t = �20 + �21y1t + �22y1t�1 + �23y2t�1 + u2t
se tiene: Cov(u1t; u2t) = �12 6= 0: Si estimamos la proyección: u2t =�u1t + "2t por mínimos cuadrados, tendremos: � = �12
�21; con Cov("2t; u1t) = 0:
Premultiplicando el sistema por la matriz�
1 0�� 1
�; se tiene:
y1t = �10y2t + u1t
y2t =� + �201 + ��10
y1t +1
1 + ��10"2t
cuyos dos términos de error tiene covarianza nula, como queríamos.
4.13.2 Las innovaciones de un modelo estructural deben estar incor-relacionadas entre sí.
De hecho, si dicha covarianza no fuese nula, podríamos transformar el modelodel siguiente modo: proyectaríamos uno de los dos errores, "2t; por ejemplo,sobre "1t;
"2t = �"1t + at
teniendo que el residuo at; de�nido por at = "2t � �"1t; estaría incorrela-cionado, por construcción, con "1t:Si representamos el modelo estructural en forma matricial,
�1 ��11��21 1
��y1ty2t
�=
��10�20
�+
��12 �13�22 �23
��y1t�1y2t�1
�+
�"1t"2t
�y premultiplicamos por la matriz
�1 0�� 1
�; tendríamos,
y1t = �10 + �11y2t + �12y1t�1 + �13y2t�1 + "1t (23)
(1 + ��11)y2t = (�20 � ��10) + (�+ �21)y1t + (�22 � ��12)y1t�1 + (�23 � ��13)y2t�1 + atun modelo VAR en el que, una vez despejáramos y2t en la segunda ecuación,
sería indistinguible del modelo (13) con Cov("1t; at) = 0: Siempre debemos es-tar considerando esta última representación con errores ortogonalizados, por loque la condición de ausencia de correlación entre los errores de las distintasecuaciones en el modelo VAR estructural debe satisfacerse siempre.
61

4.13.3 Errata en Enders, página 299,
V ar(Yt) = E�(Yt � �)2
�= E
" 1Xi=0
Ai1ut�i
#2=
1Xi=0
A2i1 (V ar(ut�i)) = (Ik�A21)�1�
V ar(Yt) = (I2 �A21)�1� =1
M
��21�12 + �
222 �(�11 + �22)�12
�(�11 + �22)�21 �21�12 + �211
�con M =
�1�
��21�12 + �
211
�� �1�
��21�12 + �
222
��� (�11 + �22)2�12�21:
5 Modelos no lineales
Es bien conocido que el estimador de Mínimos Cuadrados Ordinarios de unmodelo de relación lineal,
yt = x0t� + ut; t = 1; 2; :::; T (24)
viene dado por la expresión matricial,
� = (X 0X)�1XY
siendo X la matriz Txk que tiene por columnas las T observaciones de cadauna de las k variables explicativas contenidas en el vector xt; e Y el vectorcolumna, de dimensión T , formado por las observaciones de yt: Este estimador,que es lineal (función lineal del vector Y ), es insesgado. Es el de menor varianzaentre los estimadores lineales si la matriz de covarianzas de los términos de errortiene una estructura escalar,
V ar(u) = �2uIT
Si, además de tener dicha estructura de covarianzas, el término de errortiene una distribución Normal, entonces el estimador de Mínimos Cuadradoscoincide con el estimador de Máxima Verosimilitud, siendo entonces e�ciente:estimador de menor varianza, entre todos los estimadores insesgados, sea cualsea su dependencia respecto del vector de Y .Supongamos que se pretende estimar la relación,
yt = f(xt; �) + ut; (25)
donde f(xt; �) es una función no lineal de los componentes del vector kx1; �:Si f(xt; �) es no lineal únicamente en las variables explicativas xt; un cambio devariable permite transformar el modelo anterior en un modelo lineal. Excluimos,sin embargo, inicialmente, la estimación de relaciones implícitas, representablesa partir de un modelo general del tipo,
g(yt; xt; �) + ut;
62

5.1 Minimos Cuadrados no Lineales
El procedimiento de Mínimos Cuadrados no Lineales en este modelo consiste enresolver el problema de optimización:
min�
SR(�) = min�
TXt=1
ut
���= min
�
TXt=1
[yt � f(xt; �)]2
resolver el sistema de ecuaciones,�@f(xt; �)
@�
�0y =
�@f(xt; �)
@�
�0f(X;�)
donde el vector gradiente es Txk, y f(X;�) es Tx1. Este sistema puedeno tener solución, o tener múltiples soluciones. A diferencia del estimador deMínimos Cuadrados aplicado a un modelo lineal, el estimador no es insesgado.La matriz de covarianzas del estimador resultante es:
V ar(�) = �2u
"�@f(xt; �)
@�
�0�@f(xt; �)
@�
�#�1que se reduce a la de la sección anterior en el caso de un modelo lineal.Si quisiéramos aplicar Mínimos Cuadrados directamente, en el modelo ex-
ponencial,
yt = f(xt; �) + ut = �+ �1e�2xt + ut
con � = (�; �1; �2) ; tendríamos que resolver el problema,
min�
SR(�) = min�
TXt=1
hut
���i2
= min�
TXt=1
�yt � (�+ �1e�2xt)
�2que conduce a las condiciones de optimalidad,
Xyt = �T + �1
Xe�2xtX
yte�2xt = �
Xe�2xt + �1
Xe2�2xtX
ytxte�2xt = �
Xxte
2�2xt + �1X
xte2�2xt
que carece de solución explícita, por lo que debe resolverse por procedimien-tos numéricos.
63

5.2 Aproximación del modelo
Un primer enfoque consiste en estimar la aproximación lineal del modelo (25) ;alrededor de una estimación inicial,
yt = f(xt; �) +
�@f(xt; �)
@�
��=�
�� � �
�+ ut;
que consiste en estimar, por el procedimiento habitual de Mínimos Cuadra-dos, la relación lineal,
y�t '�@f(xt; �)
@�
��=�
� + ut;
donde la variable y�t se genera numéricamente mediante su de�nición. y�t =
yt � f(xt; �) +�@f(xt;�)@�
��=�
�; y hay que generar asimismo �datos�para cada
una de las k variables de�nidas por el gradiente�@f(xt;�)@�
��=�
:
La estimación es,
~� =
"�@f(xt; �)
@�
�0�=�
�@f(xt; �)
@�
��=�
#�1�@f(xt; �)
@�
�0�=�
y�
donde el vector gradiente es una matriz de pseudo-datos, de dimensión Txk;e y� es un vector Tx1.El estimador puede escribirse también,
~� = � +
"�@f(xt; �)
@�
�0�=�
�@f(xt; �)
@�
��=�
#�1�@f(xt; �)
@�
�0�=�
u:
Este resultado es muy interesante, pues permite poner en práctica un pro-cedimiento iterativo, en el que, en cada etapa, los errores calculados a partir dela estimación � se utilizan para calcular la corrección que hay que introducir enel vector de estimaciones en dicha etapa.El estimador resultante tras la convergencia del procedimiento tiene una
distribución asintótica Normal, con esperanza matemática igual al verdaderovector de parámetros �; y su matriz de covarianzas puede estimarse por,
�2u
"�@f(xt; �)
@�
�0�=~�
�@f(xt; �)
@�
��=~�
#�1(26)
con �2u =1
T�kPTt=1 ~u
2t ;siendo el residuo ~ut = yt � f(xt; ~�):
64

5.2.1 Estimación de modelos MA(q)
Una aplicación interesante de este procedimiento consiste en la estimación deestructuras de medias móviles en modelos lineales de series temporales. Comoejemplo, consideremos un modelo MA(2),
yt = "t � �1"t�1 � �2"t�2que puede aproximarse linealmente por,
"t ' "0t +��1 � �01
�� @"t@�1
��=�0
+��2 � �02
�� @"t@�2
��=�0
siendo �0 =��01; �
02
�una estimación inicial de los parámetros del modelo.
En este modelo se tiene,
@"t@�1
= "t�1;@"t@�2
= "t�2
por lo que podemos escribir la aproximación anterior como,
"0t � �01�@"t@�1
��=�0
� �02�@"t@�2
��=�0
= ��1�@"t@�1
��=�0
� �2�@"t@�2
��=�0
+ "t
es decir,
"0t � �01"0t�1 � �02"0t�2 = ��1"0t�1 � �2"0t�2 + "tque conduce a estimar el modelo lineal de regresión,
wt = �1x1t + �2x2t + "t
donde,
wt = "0t � �01"0t�1 � �02"0t�2x1t = "0t�1
x2t = "0t�2
Para obtener los errores en este caso, se �jan los 2 primeros igual a suesperanza matemática, cero, y se utiliza la propia expresión del modelo MA(2),escrito en la forma,
"t = yt + �01"t�1 + �
02"t�2
para generar la serie temporal "0t ; t = 1; 2; ::::T:
65

5.3 Modelo exponencial con constante. Aproximación lin-eal
Consideremos nuevamente la estimación del modelo exponencial:
yt = �+ �1e�2xt + ut = f(xt; �) + ut
con � = (�; �1; �2) : El gradiente de la función f que de�ne la relación entrevariable dependiente e independiente, es,
@f(xt; �)
@�=�1; e�2xt ; �1xte
�2xt�0
por lo que la aproximación lineal al modelo original es,
yt ' f(xt; �) +
�@f(xt; �)
@�
�0�=�
�� � �
�+ ut; t = 1; 2; :::; T;
que de�niendo variables:
y�t = yt � f(xt; �) +�@f(xt; �)
@�
�0�=�
� = yt + �1�2e�2xt
z1t = e�2xt
z2t = �1xte�2xt
conduce a estimar el modelo,
y�t = �+ �1z1t + �2z2t + ut; t = 1; 2; :::; T (27)
A partir de unas estimaciones iniciales denotadas por el vector � =��; �1; �2
�;
generamos observaciones numé�cas para la variable y�t , así como para las varaiblesz1t; z2t; y procedemos a estimar el modelo (27) ; obteniendo las nuevas estima-ciones numéricas de los tres parámetros. Con ellos, podríamos volver a obtenerobservaciones numéricas de y�t , z1t; z2t; e iterar el procedimiento.Como hemos visto antes, este procedimiento puede también ponerse en prác-
tica estimando la regresión de los residuos sobre el vector gradiente:
ut = �0 + �1z1t + �2z2t
Tanto el cálculo del vectror de residuos como la generación de datos parael vector gradiente dependerán de la estimación concreta disponible en ese mo-mento, y procederemos a la actualización de valores numéricos de los parámet-ros, mediante:
�n = �n�1 + �0; �1;n = �1;n�1 + �1; �2;n = �2;n�1 + �2
siendo ut = yt � f(xt; �n�1):
66

5.4 Minimización de una función
Supongamos que queremos hallar el valor del vector de parámetros � que min-imiza una función F (�) : A partir de una estimación inicial del valor de dichovector, �n�1, aproximamos la función F (:) :
F (�) ' F��n
�+hrF
��n
�i0 �� � �n
�+1
2
�� � �n
�0 hr2F
��n
�i�� � �n
��M (�)
Si quisiéramos minimizar la función M (�) ;resolveríamos el sistema de ecua-ciones,
M (�) =hrF
��n
�i+hr2F
��n
�i�� � �n
�= 0
que conduce a,
� = �n �hr2F
��n
�i�1 hrF
��n
�ivalor numérico que puede tomarse como la nueva estimación, �n+1: Por
supuesto, convendrá comprobar que el Hessiano r2F��n
�es de�nido positivo.
Este es un algoritmo iterativo, conocido como algoritmo de Newton-Raphson.Converge en una sóla etapa al mínimo local cuando la función F (�) es cuadrática.En los demás casos, no hay ninguna seguridad de que el algoritmo vaya a con-verger. Incluso si lo hace, no hay seguridad de que converja al mínimo global,frente a hacerlo a un mínimo local. Además, no es posible saber si el límitealcanzado es o no un mínimo de naturaleza local. Por eso, conviene repetirel ejercicio partiendo de condiciones iniciales muy distintas para, si converje,certi�car que lo hace a un mínimo local peor que el alcanzado previamente.Las iteraciones continúan hasta que se satisfacen las condiciones de conver-
gencia que hallamos diseñdo. Estas pueden ser una combinación de condicionesde diverso tipo,
��n � �n�1
�0 ��n � �n�1
�< "1h
rF��n
�i0 hrF
��n
�i< "2
F��n
�� F
��n�1
�< "3
En este tipo de algoritmos puede utilizarse un parámetro � de longitud depaso, para tratar de controlar la velocidad de convergencia y, con ello, posibilitarque nos aproximemos al mínimo global, o que no abandonemos demsiado prontouna determinada región del espacio paramétrico:
� = �n � �hr2F
��n
�i�1 hrF
��n
�i
67

5.5 Estimación por Mínimos Cuadrados
En este caso tenemos,
F (�) =TXt=1
(yt � f(xt; �))2 = SR(�)
y la regla iterativa,
�n = �n�1 �hr2F
��n�1
�i�1 hrF
��n�1
�ies fácil ver que,
rF��n�1
�=
@SR(�)
@�= �2
TXt=1
@f(xt; �)
@�ut
r2F��n�1
�=
@2SR(�)
@�@�0= 2
TXt=1
�@f(xt; �)
@�
��@f(xt; �)
@�
�0� 2
TXt=1
@2f(xt; �)
@�@�0ut
en este caso, el algoritmo de Newton-Raphson consiste en:
�n = �n�1+
"TXt=1
�@f(xt; �)
@�
��@f(xt; �)
@�
�0� @2f(xt; �)
@�@�ut
#�1 " TXt=1
@f(xt; �)
@�ut
#
El estimador resultante es asintóticamente insesgado, con matriz de covari-anzas,
�2u
hr2F
��n
�i�1estimándose el parámetro �2u del modo antes referido, mediante el cociente
de la Suma de Cuadrados de los errores de ajuste y el número de grados delibertad del modelo.El algoritmo de Gauss-Newton consiste en ignorar la presencia de la segunda
derivada en la matriz inversa anterior, y considerar el esquema iterativo,
�n = �n�1 +
"TXt=1
�@f(xt; �)
@�
��@f(xt; �)
@�
�0#�1 " TXt=1
@f(xt; �)
@�ut
#
Al despreciar la segunda derivada, este algoritmo entra en di�cultades cuandola super�cie a optimizar no tiene su�ciente curvatura que, como veremos másadelante, son las situaciones que en términos estadísticos, corresponden a iden-ti�cación imperfecta de los parámetros del modelo.
68

El interés de este segundo algoritmo estriba en que la expresión matricialque aparece en el segundo sumando corresponde con las estimaciones de mín-imos cuadrados del vector de errores, calculado con las estimaciones actuales,sobre las variables de�nidas por el vector gradiente @f(xt;�)
@� , que son k. Lasestimaciones resultantes son las correcciones a introducir sobre las actuales es-timaciones del vector � para tener la siguiente. La matriz de covarianzas delestimador resultante responde de nuevo a la expresión (26) :
5.5.1 Algoritmo de Newton-Raphson
Consideremos de nuevo la estimación del modelo exponencial. Si denotamospor F (�) la función Suma de Cuadrados de Residuos, tenemos el gradiente ymatriz hessiana,
rF (�) = �2X @f (xt; �)
@�ut = �2
X @ft@�
ut = �2X�
1; e�2xt ; �1xte�2xt
�ut
r2F (�) = 2X�
@ft@�
��@ft@�
�0� 2
X @2ft
@�2ut =
= 2TXt=1
0@ 1 e�2xt �1xte�2xt
e�2xt e2�2xt �1xte2�2xt
�1xte�2xt �1xte
2�2xt �21x2t e2�2xt
1A� 2 TXt=1
0@ 0 0 00 0 xte
�2xt
0 xte�2xt �1x
2t e�2xt
1A ut =
= 2TXt=1
0@ 1 e�2xt �1xte�2xt
e�2xt e2�2xt �xte�2xt ut + �1xte2�2xt�1xte
�2xt xte�2xt
��1e
�2xt � ut�
�1x2t e�2xt
��1e
�2xt � ut�1A
y el algoritmo de Newton-Raphson consiste en actualizar los valores numéri-cos de los parámetros mediante el esquema,
�n = �n�1 �hr2F
��n�1
�i�1rF
��n�1
�5.5.2 Algoritmo de Gauss-Newton
Este algoritmo es una versión simpli�cada del anterior, sustituyendo la matrizhessiana por el producto,
TXt=1
�@ft@�
��=�
�@ft@�
�0�=�
teniendo así el esquema de actualización,
�n = �n�1 +
"TXt=1
�@ft@�
��=�n�1
�@ft@�
�0�=�n�1
#�1 " TXt=1
@f(xt; �)
@�ut
#
69

por lo que en este modelo, tenemos el esquema iterativo,
�n = �n�1+
24 TXt=1
0@ 1 e�2xt �1xte�2xt
e�2xt e2�2xt �1xte2�2xt
�1xte�2xt �1xte
2�2xt �21x2t e2�2xt
1A35�1 24 TXt=1
0@ ute�2xt ut�1xte
�2xt ut
1A35Pero lo veraderamente interesante del algoritmo de Gauss-Newton es que
la actualización en el estimador puede llevarse a cabo mediante una regresiónde los errores de ajuste, calculados con el estimador actualmente disponible,sobre el vector gradiente de la función f . Los coe�cientes estimados en estaregresión auxiliar se añaden a los actuales valores numéricos de los parámetrospara obtener el nuevo estimador, y se continúa de modo iterativo hasta lograra convergencia del algoritmo.
5.5.3 Condiciones iniciales
En algunos casos, puede comenzarse de estimaciones iniciales sencialles, pero nodemasiado. La estructura de este modelo sugiere comenzar de �2 = 0; con lo quedesaparecería el término exponencial, y � = 0; con lo que tendríamos �1 = �y; yresiduos: ut = yt � �y: Sin embargo, en este caso, las matrices a invertir en losalgoritmos de Newton- Raphson y Gauss-Newton resultan, respectivamente:
2
TXt=1
0@ 1 1 �yxt1 1 �xtut + �yxt�yxt �xtut + �yxt �x2t �yut + �y2x2t
1A = 2
TXt=1
0@ 1 1 �yxt1 1 �xtyt + 2�yxt�yxt �xtyt + 2�yxt �x2t �yyt + 2�y2x2t
1A ;TXt=1
0@ 1 1 �yxt1 1 �yxt�yxt �yxt �y2x2t
1Asiendo la segunda de ellas singular.Afortunadamente, las condiciones de optimalidad del procedimiento de Mín-
imos Cuadrados no Lineales nos sugiere cómo obtener estimaciones iniciales ra-zonables, que garanticen un buen comportamiento de los algoritmos iterativos.Para ello, notemos que la primera condición puede escribirse,
� = m(y)� �1m(e�2xt)
que, sustituida en la segunda, nos proporciona,
m(yte�2xt) = m(e�2xt)m(y)� �1
�m(e�2xt)
�2+ �1m(e
2�2xt)
Dado un valor numérico de �2; tenemos,
�1 =m(yte
�2xt)�m(e�2xt)m(y)m(e2�2xt)� [m(e�2xt)]2
70

que, como es habitual, tiene la forma de cociente entre una covarianza y unavarianza muestrales.La última condición de optimalidad nos dice,
m�ytxte
�2xt�= �m
�xte
2�2xt�+ �1m
�xte
2�2xt�
que proporcionaría otra elección de �1;
�1 =m(ytxte
�2xt)�m(xte2�2xt)m(y)m(xte2�2xt)� [m(xte2�2xt)]2
Podríamos optar por escoger el valor numérico de �1 con cualquiera de ellas,o aquél valor numérico común a ambas expresiones, si existe: Se trataría entoncesde caracterizar la intersección, si existe, de las dos curvas como función delparámetro �1, para la elección hecha del parámetro �2.
5.6 Estimador de Máxima Verosimilitud
Otra estrategia de estimación consiste en utilizar un procedimiento de MáximaVerosimilitud, lo que requiere establecer un determinado supuesto acerca deltipo de distribución que sigue el término de error (innovación) del modelo. Elestimador resultante es e�ciente supuesto que la hipótesis acerca del tipo dedistribución sea correcta. En el caso de que supongamos que ut � N(0; �2u), lafunción de verosimiltud es,
L(�; �2u) =
�1
2��2u
�T=2exp
"� 1
2�2u
TXt=1
(yt � f(xt; �))2#
y su logaritmo,
lnL(�; �2u) = �T
2ln 2� � T
2ln�2u �
1
2�2u
TXt=1
(yt � f(xt; �))2
cuyo gradiente, de dimensión k + 1 hay que igualar a 0k+1 para obtener laestimación de Máxima Verosimilitud. Su matriz de covarianzas es la inversa dela matriz de información,
V ar��MV
�=�I(�; �2u)
��1=
��E@
2 lnL(�)
@2�
��1= �
"TXt=1
E@2 ln lt(�)
@2�
#�1
donde � =��; �2u
�y ln lt(�) denota el logaritmo de la función de densidad
correspondiente a un período de tiempo.Es fácil probar que esta matriz es diagonal a bloques, en � y �2u; por lo que
la estimación del vector � y del parámetro �2u son independientes, siendo portanto, estadísticamente e�ciente llevarlas a cabo por separado.En el aso del modelo exponencial:
71

lnL(yt; xt; �; �2u) = �
T
2ln 2� � T
2ln�2u �
1
2�2u
TXt=1
�yt � (�+ �1e�2xt)
�2tendremos el conocido resultado de que la elección de valores numéricos
para los componentes de � que maximiza la función de verosimilitud resultantecoinciden con los valores numéricos que minimizan la suma de cuadrados de loserrores de estimación.En este procedimiento, sin embargo, a diferencia de la estimación por Míni-
mos Cuadrados, consideramos la estimación de la varianza del término de error,�2u; simultáneamente con la de los parámetros que componen el vector �: Laecuación de optimalidad correspondiente nos dirá, como también es habitual,que la estimación de máxima verosimilitud de dicho parámetro se obtiene divi-diendo por T la suma de cuadrados de los residuos que resultan al utilizar lasestimaciones de máxima verosimilitud de los parámetros que entran en �:Si queremos maximizar el logaritmo de la función de verosimilitud, ten-
dremos F (�) = � lnL(�; �2u) y el algoritmo Newton-Raphson es,
�n = �n�1 ��@2 lnL(�)
@�@�0
��1�=�n�1
:
�@ lnL(�)
@�
��=�n�1
y el estimador resultante es asintóticamente insesgado, con distribución Nor-mal y matriz de covarianzas,
V ar��n
�=
�@2 lnL(�)
@�@�0
��1�=�n
El algoritmo conocido como quadratic hill-climbing consiste en sustituir encada iteración la matriz hessiana por,
r2F��n�1
�+ �Ik
de modo que sea siempre de�nida positiva. Cuando esta corrección se intro-duce en el algoritmo de Gauss-Newton, se tiene el algoritmo de Marquardt.El algoritmo de scoring consiste en sustituir la matriz hessiana del logaritmo
de la verosimilitud, por su esperanza matemática, la matriz de informacióncambiada de signo, lo que simpli�ca mucho su expresión analítica y, por tanto,los cálculos a efectuar en cada etapa del algoritmo,
�n = �n�1 +hI(�n�1)
i�1�=�n�1
:
TXt=1
@ ln lt(�)
@�
!�=�n�1
y la matriz de covarianzas del estimador resultante es, por supuesto, la in-versa de la matriz de información.El algoritmo de Gauss-Newton, aplicado a la estimación por máxima verosimil-
itud, es,
72

�n = �n�1 +
"TXt=1
�@ ln lt(�)
@�
��@ ln lt(�)
@�
�0#�1�=�n�1
:
TXt=1
@ ln lt(�)
@�
!�=�n�1
En este caso, el algoritmo Gauss-Newton está justi�cado por la conocidapropiedad teórica de la función de verosimilitud,
E
"�@ lnL(�)
@�
��@ lnL(�)
@�
�0#= �
�E@2 lnL(�)
@2�
��1En el caso del modelo exponencial, el gradiente de la función logaritmo de
la verosimilitud es,
r lnL(yt; xt; �; �2u) =1
�2u
0BBB@PTt=1 utPTt=1 e
�2xt utPTt=1 �1xte
�2xt ut� T2�2u
+ 12(�2u)
2
Pu2t
1CCCAy la matriz hessiana es,
H = � 1
�2u
TXt=1
0BBBB@1 e�2xt �1xte
�2xt � 1�2u
PTt=1 ut
e�2xt e2�2xt �1xte2�2xt � 1
�2u
PTt=1 e
�2xt ut
�1xte�2xt �1xte
2�2xt �21x2t e2�2xt � 1
�2u
PTt=1 �1xte
�2xt ut
� 1�2u
PTt=1 ut � 1
�2u
PTt=1 e
�2xt ut � 1�2u
PTt=1 �1xte
�2xt utT
2(�2u)2 � 1
(�2u)3
Pu2t
1CCCCAAl tomar esperanza matemática en los elementos de la matriz hessiana y
cambiar su signo, obtenemos la matriz de información, que tendrá ceros en laúltima �la y columna, correspondientes a la estimación de �2u; excepto en suelemento diagonal.
I��; �2u
�=1
�2u
TXt=1
0BB@1 e�2xt �1xte
�2xt 0e�2xt e2�2xt �1xte
2�2xt 0
�1xte�2xt �1xte
2�2xt �21x2t e2�2xt 0
0 0 0 T2(�2u)
2
1CCAque demuestra que el estimador de máxima verosimilitud de dicho modelo es
estadísticamente independiente de los estimadores de los restantes parámetros,lo que no sucede con los estimadores de máxima verosimilitud de estos entre sí,que tienen covarianzas no nulas.
73

5.7 Criterios de convergencia
Antes de ello, vamos a establecer criterios de convergencia: decimos que el algo-ritmo iterativo anterior ha convergido, y detenemos el procedimeitno numéricode estimación, cuando se cumple alguna de las siguientes condiciones:
� el valor numérico de la función objetivo varía menos que un cierto umbralpreviamente establecido al pasar de una estimación �n�1, a la siguiente,�n;
� el gradiente de la función objetivo, evaluado en la nueva estimación,rF��n
�;
es pequeño, en el sentido de tener una norma reducida. Para comprobar elcumplimiento de esta condición, puede utilizarse la norma euclídea: raizcuadrada de la suma de los cuadrados de los valores numéricos de cadacomponente del gradiente, o puede utilizarse el valor numérico de cualquierforma cuadrática calculada con el vector gradiente y una matriz de�nidapositiva.
� la variación en el vector de estimaciones es inferior a un umbral pre-viamente establecido. Para comprobar esta condición utilizaríamos unanorma del vector diferencia �n � �n�1;
� se ha alcanzado el máximo número de iteraciones establecido en el pro-grama de cálculo numérico que lleva a cabo la actualización de estima-ciones descrita en (76) : Esto se hace con el objeto de que el programade estimación no continúe iterando durante un largo período de tiempo,especialmente, si no está mejorando signi�cativamente la situación de es-timación.
El programa de estimación puede diseñarse para que se detenga cuando secumple uno cualquiera de estos criterios, o todos ellos. Es importante puntu-alizar, por tanto, que al estimar mediante un algoritmo numérico, el investigadorpuede controlar: i) las estimaciones iniciales, ii) el máximo número de itera-ciones a efectuar, y iii) el tamaño del gradiente, iv) la variación en el vectorde parámetros y v) el cambio en el valor numérico de la función objetivo pordebajo de los cuales se detiene la estimación. Cuando se utiliza una rutinaproporcionada por una librería en un determinado lenguaje, dicha rutina incor-pora valores numéricos para todos los criterios señalados, que pueden no serlos que el investigador preferiría, por lo que es muy conveniente poder variardichos parámetros en la rutina utilizada. Alternativamente, lo que es muchomás conveniente, el investigador puede optar por escribir su propio programade estimación numérica.Estos aspectos afectan asimismo a la presentación de los resultados obtenidos
a partir de un esquema de estimación numérica: como generalmente no sabemossi hemos alcanzado un óptimo local o global, esto debe examinarse volviendoa repetir el ejercicio de estimación a partir de condiciones inniciales sustan-cialmente diferentes de las utilizadas en primer lugar, con objeto de ver si se
74

produce la convergencia, y cual es el valor de la función objetivo en dicho punto.Conviene repetir esta prueba varias veces. Asimismo, cuando se presentan es-timaciones, deberían acompañarse de la norma del graidnet en dicho punto, asícomo de los umbrales utilizados para detener el proceso de estimación, tantoen términos del vector gradiente, como de los cambios en el vector de estima-ciones, o en el valor numérico de la función objetivo, como hemos explicado enel párrafo anterior.
5.8 Di�cultades prácticas en el algoritmo iterativo de es-timación
� Cuando se utilizan algoritmos numéricos para la maximización de la fun-ción de verosimilitud es frecuente encontrar situaciones en las que el al-goritmo numérico encuentra di�cultades para encontrar una solución alproblema de optimización. Es muy importante que, en todos los casos enque la rutina de estimación o de optimización se detenga, examinemos cuáles el criterio de parada que ha actuado. Cuando el programa se ha escritode modo que se detenga cuando se cumple alguno de los criterios antesseñalados, conviene incluir en el programa un mensjae que haga explícitocuál de los criterios ha conducido a su parada, de modo que reduzcamosel umbral asociado a dicho criterio.
� Si la razón es que se ha excedido el máximo número de iteraciones prop-uesto en el programa, siempre se debe volver a ejecutar dicho programa.En la mayoría de los casos, es razonable elevar el número máximo de it-eraciones y, posiblemente, comenzar a partir del vector de parámetros enel que se haya detenido.
� En ocasiones la rutina numérica itera un número reducido de veces y,sin exceder del máximo número de iteraciones, se detiene en un puntomuy próximo al que hemos utilizado como condiciones iniciales. Estopuede deberse a que los umbrales de parada que hemos seleccionado, oque están escritos como valores por defecto en la rutina que implemente elalgoritmo numérico son demasiado grandes. Así, en los primeros cálculos,los cambios en las estimaciones o en el valor de la función objetivo soninferiores a dichos umbrales, y el algoritmo se detiene. Deben reducirsedichos umbrales y volver a estimar.
� Si el programa se detiene sin exceder el máximo número de iteraciones,es importante comparar los valores paramétricos en los que se detiene,con los que se utilizaron como condiciones iniciales. Esta comparaciónque, lamentablemente, no suele efectuarse, muestra frecuentemente queen alguno de los parámetros el algoritmo no se ha movido de la condicióninicial. Salvo que tengamos razones sólidas para creer que dicha condicióninicial era ya buena, esto signi�ca que, o bien el algoritmo está teniendodi�cultades para encontrar en que sentido mover en la dirección de di-cho parámetro para mejorar el valor numérico de la función objetivo, o
75

no ha tenido su�ciente posibilidad de iterar en esa dirección, dadas lasdi�cultades que encuentra en otras direcciones (o parámetros). En estoscasos quizá conviene ampliar el número máximo de iteraciones, y quizátambién reducir la tolerancia del algoritmo (la variación en � o en F quese ha programado como criterio de parada), para evitar que el algoritmose detenga demasiado pronto.
� Todo esto no es sino re�ejo, en general, de un exceso de parametrización,que conduce a que la super�cie que representa la función objetivo, comofunción de los parámetros, sea plana en algunas direcciones (o parámet-ros). Esto hace que sea di�cil identi�car los valores numéricos de cadauno de los parámetros del modelo por separado de los demás, por lo que elalgoritmo encuentra di�cultades en hallar una dirección de búsqueda en laque mejore el valor numérico de la función objetivo. Una variación, inclusosi es de magnitud apreciable, en la dirección de casi cualquier parametro,apenas varía el valor numérico de la función objetivo. Por eso, el algoritmono encuentra un modo de variar los valores paramétricos de modo que lafunción objetivo cambie por encima de la tolerancia que hemos �jado, yse detiene. En estos casos, el gradiente va a ser también muy pequeño,que puede ser otro motivo por el que el algoritmo se detenga. De hecho,la función objetivo varía de modo similar (poco, en todo caso) tanto siel algoritmo varía uno como si cambia varios parámetros, que es lo quegenera el problema de identi�cación, similar al que se obtiene en el mod-elo lineal general cuando existe colinealidad entre alguna de las variablesexplicativas. Las di�cultades en la convergencia del algoritmo producidaspor una excesiva sobreparametrización del modelo se re�ejan en unas ele-vadas correlaciones de los parámetros estimados. Como en cualquier otroproblema de estimación, conviene examinar no sólo las varianzas de losparámetros estimados, sino también las correlaciones entre ellos.
� Otra di�cultad puede presentarse en la forma de cambios muy bruscosen el estimador. Ello se corrige introduciendo en el algoritmo (76) unparámetro � que se conoce como longitud de salto,
� = �0 � �hr2F
��0
�i�1rF
��0
�(28)
Hay que tener en cuenta que posiblemente esté incorporado en el programauna determinada magnitud para �, que el investigador puede alterar cuandoobserve cambios bruscos en el vector de parámetros.
5.9 Estimación condicionada y precisión en la estimación
Para tratar estas situaciones, cuando se identi�can uno o dos parámetros al-tamente correlacionados con los demás, puede llevarse a cabo una estimacióncondicionada, �jando valores alternativos de dichos parámetros a lo largo deuna red, maximizando la verosimilitud respecto de los demás, y comparando
76

resultados para alcanzar el máximo absoluto. En otras ocasiones, sin necesidadde incurrir en di�cultades numéricas, se aprecia que imponer un valor unméricopara uno o dos parámetros simpli�ca enormemente la estructura del modelo aestimar, por ejemplo, haciéndola linear. Si este es el caso, puede establecerseuna red de búsqueda en dichos parámetros y, para cada uno de ellos, estimarel modelo lineal resultante. Se resuelve así un conjunto de muchos problemassimples, frente a la alternativa de resolver un único problema complicado quees, en ocasiones, mucho más difícil.Una limitación de esta estrategia de estimación, que tantas veces simpli�ca
el problema computacional, es que no nos proporciona una estimación de la var-ianza para el parámetro o los parámetros sobre los que se ha hecho la estimacióncondicional. Según cuál sea el grado de simpli�cación alcanzado, podríamos notener varianzas para ninguno de los parámetros. Esto sugiere una cuestión aúnmás profunda, acerca del signi�cado real de las varianzas proporcionadas porel problema de estimación. En realidad, lo que el investigador quiere tener esuna medida del grado de precisión obtenido en su estimación, y ello bien puededepender del objetivo �nal de la estimación del modelo. Por ejemplo, consid-eremos el habitual problema de calcular la volatilidad implícita de una opción.Obtener las sensibilidades de la respuesta a dicha pregunta a variaciones en elvalor de alguno de los parámetros que se �ja equivale a determinar un rango decon�anza para el parámetro que se estima.Consideremos que el subyacente de una opción call cotiza a 100, que el precio
de ejercicio de la misma es 95, el tipo de interés, supuesto constante hasta elvencimiento, es 7,5%, el plazo residual es 3 meses, y el preico de la opción es de10. La inversión de la fórmula de Black Scholes (BS) proporciona una volatilidadde 31,3%. Este no es un problema estadístico, y no se ha llevado a cabo ningúnproceso de muestreo. Sin embargo, el usuario que conoce la limitación delmodelo BS por los supuestos que incorpora, puede estar dispuesto a aceptar unrango de valores de volatilidad que no generen un precio teórico que se separeen más de 0,25 del precio observado en el mercado. Ello le llevará a considerarun rango de volatilidades entre 29,8% y 32,7%.La misma idea puede aplicarse en un problema de estimación para evaluar
la precisión con que se ha estimado un determinado parámetro. En función dela utilidad que se vaya a dar al modelo, el usuario puede determinar que estádispuesto a aceptar variaciones de hasta un 1% alrededor del valor de la funciónobjetivo que ha obtenido en su estimación. Se trata entonces de perturbar elvalor numérico del parámetro cuya precisión se quiere medir, y estimar condi-cionando en dicho valor mientras que el valor resultante para la función objetivosatisfaga la condición pre�jada. Se obtiene así numericamente, un intervalo decon�anza alrededor de la estimación inicialmente obtenida. En principio, estaregión no tiene por qué coincidir con la tradicional región de con�anza. Puederesultar extraño hablar de regiones de con�anza paramétricas en el caso delcálculo de la volatilidad implícita pues, como hemos dicho, no es realmente unproblema estadístico. Existe un razonamiento distinto del anterior, con másbase estadística que conduce asimismo a una región de con�anza paramétrica.Para ello, consideremos que el usuario de la expresión BS, consciente de que
77

el tipo de interés relevante no va a permanecer constante hasta vencimiento,y desconociendo su evolución establece un conjunto de posibles escenarios deevolución de los tipos, cada uno acompañado de una probabilidad que recogela mayoor o menor verosimilitud asignada a dicho escenario, e identi�ca cadaescenario con distintos niveles constantes del tipo de interés. Calculando lavolatilidad implícita para cada nivel de tipos de interés considerado, mientrasse mantienen constantes los restantes parámetros, generaríamos una distribu-ción de probabilidad para la volatilidad implícita. Por supuesto, este argumentose puede generalizar el caso en que la incertidumbre a priori se recoge en la formade una distribución de probabilidad multivariante para el vector de parámetrossobre los que se condiciona en el proceso de estimación.
5.10 Algunos modelos típicos
5.10.1 Ejemplo 1: Modelo exponencial sin constante.
Consideremos ahora la estimación del modelo,
yt = �e�xt + ut = f(xt; �) + ut
con � = (�; �) : El gradiente de la función f que de�ne la relación entrevariable dependiente e independiente, es,
@f(xt; �)
@�=�e�xt ; �xte
�xt�0
Es importante apreciar la expresión analítica de las derivadas parciales deesta función,
@y
@x= ��e�xt ;
@2y
@x2= ��2e�xt ;
Como la función exponencial es positiva con independencia del signo de �y de xt; tenemos que la primera derivada tendrá el signo del producto ��,mientras que la segunda derivada tendrá el signo del parámetro �: Esto nospuede dar pautas para la elección de condiciones iniciales. Por ejemplo, si lanube de puntos de yt sobre xt tiene un per�l decreciente y convexo, tendríamosun valor positivo de �; debido a la convexidad, junto con un valor negativo de�:
Aproximación lineal por lo que la aproximación lineal al modelo original es,
yt ' f(xt; �) +
�@f(xt; �)
@�
�0�=�
�� � �
�+ ut; t = 1; 2; :::; T;
que, de�niendo las variables y�t = yt � f(xt; �) +�@f(xt;�)@�
�0�=�.�; z1t =
e�xt ; z2t = �xte�xt ; puede escribirse:
78

y�t = �z1t + �z2t + ut; t = 1; 2; :::; T; (29)
A partir de unas estimaciones iniciales denotadas por el vector � =��; �
�;
generamos observaciones numéricas para la variable y�t , así como para las vari-ables z1t; z2t; y procedemos a estimar el modelo (29) ; obteniendo las nuevasestimaciones numéricas de � y �. Con ellos, podríamos volver a obtener seriestemporales para las variables y�t , z1t; z2t; e iterar el procedimiento.Como es sabido, este procedimiento puede también ponerse en práctica es-
timando la regresión,
ut = �1z1t + �2z2t
y procediendo a la actualización de valores numéricos de los parámetros,
�n = �n�1 + �1; �n = �n�1 + �2
siendo ut = yt � f(xt; �n�1):
Algoritmo de Newton-Raphson Si denotamos por F (�) la función Sumade Cuadrados de Residuos,
min�
SR(�) = min�
TXt=1
ut
���= min
�
TXt=1
(yt � f(xt; �)2 = min�
TXt=1
�yt � �e�xt
�2que conduce a las condiciones de optimalidad,
Xyte
�xt = �X
e2�xtXytxte
�xt = �X
xte2�xt
donde la primera condición sugiere tomar como estimación inicial,
� =m(ye�x)
m(e2�x)
mientras que de la segunda condición tenemos:
� =m(yxe�x)
m(xe2�x)
79

Ejercicio práctico: Estimación de una función de demanda de dineroConsiderando nuevamente la función Suma de Cuadrados de Residuos,
min�
SR(�) = min�
TXt=1
ut
���= min
�
TXt=1
(yt � f(xt; �)2 = min�
TXt=1
�yt � �e�xt
�2Vamos apensar en la aplicación a la estimación de una función de demanda dedinero: �
Mt
Pt
�d= �e��
et + ut; t = 1; 2; :::; T; � > 0; � < 0
Comenzamos generando una serie temporal de datos simulando la tasa dein�ación a partir de un proceso i., id., N(��e; �2�); y para el témrino de error delmodelo a partir de un proceso N(0; �2u): Por último, generamos la serie temporalde datos para los saldos monetarios reales utilizando la estructura del modeloy las series temporales de in�ación y de ut, una vez que hemos �jado valoresnuméricos para los parámetros � y �:Con las series temporales fyt; xtgTt=1; podemos estimar el modelo siguiendo
varios procedimientos:
� Utilizando la instrucción "fminu" o "fminunc" de Matlab, para minimizar
la suma de cuadrados de los residuos o errores de ajusteMin�;�
PTt=1
��Mt
Pt
�d� �e��et
�2:
� Utilizando la instrucción "fsolve" de Matlab, que encuentra las raices osoluciones de una ecuación lineal o no lineal, lo que se puede aplicar alsistema formado por las dos condiciones de optimalidad o de primer ordendel problema de minimización de la suma de cuadrados de los errores,
�2TXt=1
�Mt
Pt
�d� �e��
et
!e��
et = 0
�2TXt=1
�Mt
Pt
�d� �e��
et
!��ete
��et = 0
� Utilizando el algoritmo de Gauss-Newton (33), con expresiones analíticaspara el gradiente (30) y el hessiano (31) de la función objetivo, que esla Suma de Cuadrados de los errores de ajuste. tenemos el gradiente ymatriz hessiana,
rF (�) = �2X @f (xt; �)
@�ut = �2
X @ft@�
ut = �2X�
e�xt ; �xte�xt�ut (30)
80

r2F (�) = 2TXt=1
�e2�xt �xte
2�xt
xt�e2�xt �2x2t e
2�xt
�� 2
TXt=1
�0 xte
�xt
xte�xt x2t�e
�xt
�ut(31)
= 2TXt=1
�e2�xt xte
�xt��e�xt � ut
�xte
�xt��e�xt � ut
�x2t�e
�xt��e�xt � ut
� �por lo que el algoritmo de Newton-Raphson sería,
�n = �n�1�"TXt=1
�e2�xt xte
�xt��e�xt � ut
�xte
�xt��e�xt � ut
�x2t�e
�xt��e�xt � ut
� �#�1 " TXt=1
�e�xt
�xte�xt
�ut
#(32)
mientras que el algoritmo de Gauss-Newton sería,
�n = �n�1 �"TXt=1
�e2�xt �xte
2�xt
�xte2�xt �2x2t e
2�xt
�#�1 " TXt=1
�e�xt
�xte�xt
�ut
#(33)
� Utilizando el algoritmo de Gauss-Newton (33), con evaluación numéricade las derivadas parciales que aparecen en el gradiente (30) y el hessiano(34) de la función objetivo, que es la Suma de Cuadrados de los Errores:
@f
@xi= lim"!0
f(x1; ::; xi + "; ::; xn)� f(x1; ::; xi � "; ::; xn)2"
; i = 1; 2; :::; n
siendo las derivadas segundas: @2f@xi@xj
= @g@xj
; donde g = @f@xi
; de modo que:
@2f
@xi@xj= lim"!0
f(x1; ::; xi + "; ::; xj + "; ::; xn)� f(x1; ::; xi + "; ::; xj � "; ::; xn)� f(x1; ::; xi � "; ::; xj + "; ::; xn) + f(x1; ::; xi � "; ::; xj � "; ::; xn)4"2
5.10.2 Ejemplo 2: Un modelo no identi�cado
Supongamos, por último, que pretendemos estimar el modelo,
yt = �+ �1�2xt + ut
en el que la aplicación del algoritmo de Newton-Raphson resulta en,0@ 1 �2xt �1xt�2xt �22x
2t �1�2x
2t
�1xt �1�2x2t �21xt
2
1A�0@ 0 0 00 0 xt0 xt 0
1Aut
mientras que el algoritmo de Gauss-Newton consistiría en,0@ 1 �2xt �1xt�2xt �22x
2t �1�2x
2t
�1xt �1�2x2t �21xt
2
1A
81

5.10.3 Ejemplo 3: Modelo potencial
Las condiciones de optimalidad correspondientes a la estimación por mínimoscuadrados del modelo potencial,
Ct = �1 + �2Y t + ut
son,
TXt=1
(Ct � �1 � �2Y t ) = 0
TXt=1
(Ct � �1 � �2Y t )Y
t = 0
�2
TXt=1
(Ct � �1 � �2Y t )Y
t lnYt = 0
que constituyen las ecuaciones normales del problema de estimación. De lasdos primeras ecuaciones, obtenemos,
TXt=1
Ct = T�1 + �2
TXt=1
Y t ) Tm(C) = T�1 + �2Tm(Y )) �1 = m(C)� �2m(Y )
TXt=1
CtY t = �1
TXt=1
Y t + �2
TXt=1
Y 2 t ) Tm(CY ) = Tm(C)m(Y )� �2Tm(Y )2 + �2Tm(Y 2 ))
) �2 =m(CY )�m(C)m(Y )m(Y 2 )�m(Y )2
El primer resultado sugiere que la estimación del término independiente seobtenga, una vez estimados �2 y ; de modo similar a como se recupera eltérmino independiente en la estimación de un modelo lineal.Lo más interesante es observar que la segunda ecuación sugiere estimar el
parámetro �2 en función de momentos muestrales de algunas funciones delconsumo y la renta. Para calcular dichos momentos precisamos conocer elparámetro , pero también podemos poner en marcha una búsqueda de redpuesto que, por las características de la función de consumo, dicho parámetroha de ser positivo y no muy elevado. Por tanto, una red que cubra el inter-valo (0:5; 2:0) puede ser su�ciente. De hecho, para valor numérico admisiblede podemos utilizar la expresión anterior para estimar �2;sin necesidad deoptimizar, y después utilizar la primera condición de optimalidad para estimar�1:
82

5.10.4 Ejemplo 4: Modelo AR(1), sin autocorrelación
Encuentre las expresiones analíticas del estimador de Máxima Verosimilitud yde su matriz de varianzas y covarianzas, en el modelo AR(1):
yt = �+ �yt�1 + "t; t = 1; 2; :::
E"t = 0; E("t"t�s) = 0 8s 6= 0; E("2t ) = �2�
La distribución de probabilidad de yt condicional en su propio pasado es
N��+ �yt�1; �
2�
�: Es decir, una vez observado el valor numérico de yt; el
valor esperado de yt+1 es � + �yt; y la varianza de los posibles valores de yt+1alrededor de �+ �yt es �2� : Como puede apreciarse, la esperanza condicional esuna variable aleatoria, tomando valores numéricos cambiantes en el tiempo. Lavarianza condicional de yt es igual a la varianza de la innovación, �2� ; re�ejandoel hecho de que es ésta la única fuente de error en la predicción del valor de ytun período hacia adelante.Esto es válido para todo t � 2: Son embargo, para t = 1 no podemos
condicionar y1 en ningún valor previo, por lo que no podemos hablar de sudistribución condicional. La distribución marginal, absoluta o incondicional
de y1 es N�
�1�� ;
�2�1��2
�; es decir, que si no contamos con ninguna observación
previa, el valor esperado de y1 es �1�� ; y la dispersión esperada alrededor de dicho
valor es de�2�1��2 ; mayor de la que tendríamos si dispusiésemos de la observación
del período anterior. Nótese que: E (Et�1yt) = E(� + �yt�1) = � + �Eyt�1;pero Eyt�1 = �
1�� ; por lo que: E (Et�1yt) = � + � �1�� =
�1�� = Eyt, lo cual
no hace sino comprobar que se cumple en este ejemplo concreto, la conocidapropiedad: Eyt = E (Et�1yt) :La función de verosimilitud muestral puede escribirse:
L(y1; y2; :::; yT ) = L(y1)L(y2=y1)L(y3=y2):::L(yT =yT�1)
de modo que,
lnL = ln(y1) +
TX2
lnL(yt=yt�1) =
=
�12ln 2� � 1
2ln
�2"1� �2
� 1� �2
2�2"
�y1 �
�
1� �
�2!� T � 1
2ln 2� �
�T � 12
ln�2" �1
2�2"
TX2
(yt � �� �yt�1)2
El problema de maximización de esta función se simpli�ca si ignoramos losprimeros términos, que proceden de la distribución marginal de y1, L(y1); yconsideramos:
83

lnL� = �T � 12
ln 2� � T � 12
ln�2" �1
2�2"
TX2
(yt � �� �yt�1)2 (34)
que es la función de verosimilitud condicionada en el valor numérico de y1;frente a la anterior, que era la función de verosimilitud exacta. Las condicionesde maximización de esta función de verosimilitud condicionada, que resultan deigualar a cero su gradiente, son,
@ lnL�
@�=
1
�2"
TX2
(yt � �� �yt�1) = 0)TX2
ut = 0
@ lnL�
@�=
1
�2"
TX2
(yt � �� �yt�1)yt�1 = 0)TX2
utyt�1 = 0
@ lnL�
@�2"= �T � 1
2
1
�2"+
1
2 (�2")2
TX2
(yt � �� �yt�1)2 = �T � 12
1
�2"+
1
2 (�2")2
TX2
ut2
= � 1
2 (�2")2
TX2
��2" � ut2
�= 0
donde hemos utilizado el hecho de que, para estimaciones numéricas de �y �; la diferencia yt � � � �yt�1 es igual al residuo, ut: Vemos, por tanto, quelas estimaciones de máxima verosimilitud condicionada de � y � son aquellosvalores numéricos que generan unos residuos de suma cero, a la vez que estánincorrelacionados con yt�1: Ello signi�ca que son residuos con correlación nulacon las dos variables explicativas del modelo, (1; yt�1) y coincide, en consecuen-cia, con el estimador de mínimos cuadrados ordinarios del modelo AR(1), queutilizaría datos desde t = 2 hasta T .Por otra parte, la tercera ecuación nos proporciona el estimador de máxima
verosimilitud condicionada de �2" :
�2" =
PT2 ut
2
T � 1ligeramente diferente del estimador de mínimos cuadrados del model AR(1),
que habría sido: �2" =PT
2 ut2
T�2 :
Si sustituimos la expresión de �2" en (34) ; tenemos:
lnL� = �T � 12
ln 2� � T � 12
lnTX2
ut2 +
T � 12
ln(T � 1)� T � 12PT
2 ut2
TX2
ut2 =
=
��T � 1
2ln 2� +
T � 12
ln(T � 1)� T � 12
�� T � 1
2ln
TX2
ut2
84

que se conoce como función de verosimilitud condicional concentrada, y quemuestra que maximizar lnL� equivale, claramente, a minimizar la suma decuadrados de residuos,
PT2 ut
2:La matriz de información del estimador de máxima verosimilitud es la in-
versa de la matriz de información, para lo que hemos de obtener las derivadassegundas,
@2 lnL�
@�2= � 1
�2"
TX2
(�1) = �T � 1�2"
@2 lnL�
@�2= � 1
�2"
TX2
y2t�1 ) E
�@2 lnL�
@�2
�= �T � 1
�2"
�2"
1� �2+
�2
(1� �)2
!@2 lnL�
@ (�2")2 =
T � 12
1
(�2")2 �
1
(�2")3
TX2
ut2 ) E
@2 lnL�
@ (�2")2
!= �T � 1
(�2")2
@2 lnL�
@�@�= � 1
�2"
TX2
yt�1 ) E
�@2 lnL�
@�@�
�= �T � 1
�2"
�
1� �
@2 lnL�
@�@�2"= � 1
(�2")2
TX2
ut ) E
�@2 lnL�
@�@�2"
�= 0
@2 lnL�
@�@�2"= � 1
(�2")2
TX2
utyt�1 ) E
�@2 lnL�
@�@�2"
�= 0
donde, para obtener la esperanza matemática en la última línea, hemosutilizado:
E
�@2 lnL�
@�@�2"
�= E
�Et�1
�@2 lnL�
@�@�2"
��= � 1
(�2")2E
"Et�1
TX2
utyt�1
!#=
= � 1
(�2")2E
"TX2
yt�1 (Et�1ut)
#= 0
por lo que,
0@ �
�
�2"
1A � N
0BB@ ���2"
;�2"
T � 1
0B@ 1 �1�� 0
�1��
�2"1��2 +
�2
(1��)2 0
0 0 12�2"
1CA�11CCA
donde la matriz de varianzas y covarianzas debería evaluarse en los estima-ciones de máxima verosimilitud obtenidas para los tres parámetros del modelo.Para estimar este modelo mediante el algoritmo de Newton-Raphson, habría
que iterar mediante,
85

�n = �n�1+
0B@ T � 1PT
2 yt�1PT
2 utPT2 yt�1
PT2 y
2t�1
PT2 utyt�1PT
2 utPT
2 utyt�11
(�2")3
PT2
��2" � ut2
�1CA�10B@
PT2 utPT2 utyt�1
� 12�2"
PT2
��2" � u2t
�1CA
donde � denota el vector de parámetros, � =��; �; �2"
�; mientras que el
algoritmo de scoring, más sencillo, aproxima el hessiano del logaritmo de lafunción de verosimilitud por la matriz de información,
�n = �n�1+1
T � 1
0B@ 1 �1�� 0
�1��
�2"1��2 +
�2
(1��)2 0
0 0 12�2"
1CA�10B@
PT2 utPT2 utyt�1
� 12�2"
PT2
��2" � u2t
�1CA
y el algoritmo de Gauss-Newton, que no requiere calcular segundas derivadas,pero incurre en un mayor error de aproximación numérico, consistiría en:
�n = �n�1 + �2"
0B@PT
2 u2t
PT2 u
2tyt�1 � 1
2�2"
PT2 ut
��2" � u2t
�PT2 u
2tyt�1
PT2 u
2ty2t�1 � 1
2�2"
PT2 utyt�1
��2" � u2t
�� 12�2"
PT2 ut
��2" � u2t
�� 12�2"
PT2 utyt�1
��2" � u2t
�14�2"
PT2
��2" � u2t
�21CA�1
:
:
0B@PT
2 utPT2 utyt�1
� 12�2"
PT2
��2" � u2t
�1CA
5.10.5 Ejemplo 5: Modelo constante, con autocorrelación
Encuentre las expresiones analíticas del estimador de Máxima Verosimilitud yde su matriz de varianzas y covarianzas, en el modelo constante con autocor-relación:
yt = �+ ut; t = 1; 2; :::;
ut = �ut�1 + "t = 0 E"t = 0; E ("t"s) = 0;8s 6= 0; E("2t ) = �2"
El modelo puede escribirse en función de la innovación del mismo,
yt = � (1� �) + �yt�1 + "tque muestra que, dado yt�1; la distribución de probabilidad de yt condicional
en su propio pasado es N�� (1� �) + �yt�1; �2"
�: Es decir, una vez observado
el valor numérico de yt; el valor esperado de yt+1 es � (1� �) + �yt�1; y lavarianza de los posibles valores de yt+1 alrededor de dicho valor esperado es �2":La esperanza condicional es una variable aleatoria, tomando valores numéricoscambiantes en el tiempo. La varianza condicional de yt es igual a la varianza de
86

la innovación, �2"; re�ejando el hecho de que es ésta la única fuente de error enla predicción del valor de yt un período hacia adelante.Esto es válido para todo t � 2: Son embargo, para t = 1 no podemos
condicionar y1 en ningún valor previo, por lo que no podemos hablar de sudistribución condicional. La distribución marginal, absoluta o incondicional de
y1 es N��;
�2"1��2
�; es decir, que si no contamos con ninguna observación previa,
el valor esperado de y1 es �1�� ; y la dispersión esperada alrededor de dicho valor
es de �2"1��2 ; mayor de la que tendríamos si dispusiésemos de la observación del
período anterior.La función de verosimilitud muestral puede escribirse:
L(y1; y2; :::; yT ) = L(y1)L(y2=y1)L(y3=y2):::L(yT =yT�1)
de modo que,
lnL = ln(y1) +
TX2
lnL(yt=yt�1) =
= �12ln 2� � 1
2ln�2u �
1
2�2uy21 �
T � 12
ln 2� � T � 12
ln�2" �1
2�2"
TX2
(yt � � (1� �)� �yt�1)2 =
= �T2ln 2� � T
2ln�2" �
1
2ln(1� �2)� 1� �
2
2�2"(y1 � �)2 �
1
2�2"
TX2
(yt � � (1� �)� �yt�1)2
donde hemos utilizado el hecho de que la distribución incondicional de y1 esN(0; �2u):Esta función de verosimilitud es similar, pero no idéntica, a la que llegaríamos
estableciendo la hipótesis de Normalidad directamente sobre la innovación delmodelo, "t: En efecto, si "t i.,i.d., N(0; �2"); tendríamos:
lnL = �T2ln 2� � T
2ln�2" ��
1
2�2"
TX1
"2t =
= �T2ln 2� � T
2ln�2" �
1
2�2"[y1 � � (1� �)� �y0]2 �
1
2�2"
TX2
(yt � � (1� �)� �yt�1)2
en la que y0; no observable, sería un parámetro más a estimar. Utilizandola representación de la innovación del modelo: "t = yt � � (1� �) + �yt�1; lascondiciones de optimalidad serían,
87

@ lnL
@�=
1� ��2"
"(y1 � � (1� �) + �y0) +
TX2
"t
#= 0
@ lnL
@�=
1
�2"
"(y1 � � (1� �)� �y0) (y0 � �) +
TX2
"t (yt�1 � �)#= 0
@ lnL
@�2"= �T
2
1
�2"+
1
2 (�2")2
TX2
(yt � � (1� �) + �yt�1)2 = 0
Una vez más, calcularemos el estimador de Máxima Verosimilitud condi-cional en la primera observación, que tomaremos como dada.
lnL� = �T � 12
ln 2� � T � 12
ln�2" ��1
2�2"
TX2
"2t =
= �T � 12
ln 2� � T � 12
ln�2" �1
2�2"
TX2
(yt � � (1� �)� �yt�1)2
con condiciones de optimalidad:
@ lnL�
@�=
1� ��2"
TX2
(yt � � (1� �)� �yt�1) = 0)TX2
"t = 0
@ lnL�
@�=
1
�2"
TX2
(yt � � (1� �)� �yt�1) (yt�1 � �) = 0)TX2
"t (yt�1 � �) = 0
@ lnL�
@�2"= �T � 1
2
1
�2"+
1
2 (�2")2
TX2
(yt � � (1� �)� �yt�1)2 =
= � 1
2 (�2")2
TX2
(�2" � "2t ) = 0) �2" =
PT2 "
2t
T � 1
Las dos primeras condiciones muestran que el estimador de MV condi-cionada puede obtenerse estimando por Mínimos Cuadrados Ordinarios el mod-elo: yt = �0 + �1yt�1 + "t; pues las estimaciones numéricas resultantes gener-arían residuos "t con suma cero, e incorrelacionados con la variable explicativade dicha regresión, yt�1; satisfaciendo así las dos primeras de las condicionesde optimalidad anteriores. Posteriormente, la estimación de �2" se obtendríaa partir de la tercera condición. Una vez estimado el modelo, los parámetrosdel modelo original se obtendrían mediante las condiciones de identi�cación:
� = �1; � =�01��1
: Como sabemos, la estimación de mínimos cuadrados puede
efectuarse, excepto para el término constante, estimando el modelo en desvia-ciones respecto de la media: ~yt = �1~yt�1 + "t; en el que una vez estimado �1;
88

que resultaría numéricamente igual a la estimación en el modelo que incluyeun término constante, tendríamos: �0 = �y � �1�y: Finalmente, recuperaríamos� y � a partir de las expresiones previas. Como Ey = �; esperararímos que
�y ' �; por lo que la expresión � = �01��1
debe proporcionar un buen estimador
del término independiente.La matriz de información del estimador de máxima verosimilitud es la in-
versa de la matriz de información, para cuyo calculo hemos de obtener la es-perana matemática de los elementos del hessiano de la función logaritmo de laverosimilitud condicionada,
@2 lnL�
@�2= �T � 1
�2"(1� �)2
@2 lnL�
@�2= � 1
�2"
TX2
(yt�1 � �)2 ) E
�@2 lnL�
@�2
�=T � 1�2"
�2u
@2 lnL�
@ (�2")2 =
T � 12
1
�4"� 1
�6"
TX2
"t2 ) E
@2 lnL�
@ (�2")2
!= �T � 1
2�4"
@2 lnL�
@�@�= � 1
�2"
TX2
[(yt�1 � �) (1� �) + "t]) E
�@2 lnL�
@�@�
�= 0
@2 lnL�
@�@�2"= �1� �
�4"
TX2
"t ) E
�@2 lnL�
@�@�2"
�= 0
@2 lnL�
@�@�2"= � 1
�4"
TX2
"t (yt�1 � �)) E
�@2 lnL�
@�@�2"
�= 0
E
�@2 lnL�
@�@�2"
�= E
�Et�1
�@2 lnL�
@�@�2"
��= E
"Et�1
TX2
"tut�1
!#= 0
donde en la última igualdad hemos utilizado el hecho de que ut�1 dependede "t�1; "t�2; "t�3; :::, pero no de "t ni de sus valores futuros.Por tanto,
0@ ��
�2"
1A � N
0BB@ ���2"
;�2"
T � 1
0B@ (1� �)2 0 0
0�2"1��2 0
0 0 1�2"
1CA�11CCA
donde la matriz de varianzas y covarianzas debería evaluarse en los estima-ciones de máxima verosimilitud obtenidas para los tres parámetros del modelo.La estructura diagonal de la matriz de información muestra que los estimadoresde los tres parámetros son independientes entre sí. Ello hace que en, este mod-elo, una estimación condicional que generase estimaciones numéricas de unosparámetros condicionales en estimaciones de los otros, sería tan e�ciente comola estimación simultánea de todos ellos.
89

Para estimar este modelo mediante el algoritmo de Newton-Raphson, habríaque iterar mediante,
�n = �n�1 + �2"
0B@ (T � 1) (1� �)2PT
2 [ut�1(1� �) + "t] (1� �)PT
2 "tPT2 [ut�1(1� �) + "t]
PT2 u
2t�1
PT2 "tut�1
(1� �)PT
2 "tPT
2 "tut�11�2"
PT2
�12�
2" � "t2
�1CA�1
:
:
0B@ (1� �)PT
2 "tPT2 "tut�1
� 12�2"
PT2 (�
2" � "2t )
1CAEl algoritmo de scoring, más sencillo, aproxima el hessiano del logaritmo de
la función de verosimilitud por la matriz de información,
�n = �n�1+1
T � 1
0@ (1� �)2 0 00 �2u 00 0 1
2�2"
1A�10B@ (1� �)PT
2 "tPT2 "tut�1
� 12�2"
PT2 (�
2" � "2t )
1CA = �n�1+1
T � 1
0B@11+�
PT2 "t
1�2u
PT2 "tut�1
�PT
2 (�2" � "2t )
1CAy el algoritmo de Gauss-Newton, con mayor error de aproximación numérico,
consistiría en:
�n = �n�1 +
0B@ (1� �)2PT
2 "2t (1� �)
PT2 "
2tut�1 � 1��
2�2"
PT2 "t(�
2" � "2t )
(1� �)PT
2 "2tut�1
PT2 ("tut�1)
2 � 12�2"
PT2 "tut�1(�
2" � "2t )
� 1��2�2"
PT2 "t(�
2" � "2t ) � 1
2�2"
PT2 "tut�1(�
2" � "2t ) 1
4�4"
PT2 (�
2" � "2t )2
1CA�1
:
:
0B@ (1� �)PT
2 "tPT2 "tut�1
� 12�2"
PT2 (�
2" � "2t )
1CA5.10.6 Ejercicio
1. Obtener la estimaciones, por el Método Generalizado de Momentos, de losparámetros �; �; �2" del modelo de regresión constante con errores AR(1).
Solución: Utilizaríamos el hecho de que, bajo el supuesto de que el modeloesté correctamente especi�cado, se tienen las propiedades: Eyt = �; V ar(yt) =
�2u; � = Cov(yt;yt�1)V ar(yt)
; �2" = �2u�1� �2
�; por lo que, sustituyendo momentos
poblacionales por muestrales en las igualdades anteriores, tendríamos,
� =1
T
TX1
yt; � =
PT1 (yt � �y) (yt�1 � �y)PT
1 (yt � �y)2
�2u =1
T
TX1
(yt � �y)2 ; �2" = �2u�1� �2
�=
1
T
TX1
(yt � �y)2!0@1� "PT
1 (yt � �y) (yt�1 � �y)PT1 (yt � �y)
2
#21A90

La estimación de � coincide con la estimación de mínimos cuadrados quehemos propuesto más arriba. No así la de �2" ni la de �
2u: Tampoco será exacta-
mente coincidente la estimación del término independiente � si bien, el argumeoefectuado al presentar el estimador de Máxima Verosimilitud garantiza que ladiferencia entre los valores numéricos de ambos estimadores no será muy elevadaen muestras grandes.
5.10.7 Ejemplo 6: Estimación de Máxima Verosimilitud del modeloAR(1) con perturbaciones AR(1)
Consideramos en esta sección la estimación de Máxima Verosimilitud y de su ma-triz de varianzas y covarianzas, del modelo AR(1) con término de error AR(1):
yt = �yt�1 + ut; t = 1; 2; ::: (35)
ut = �ut�1 + "t = 0 E"t = 0; E("t"t�s) = 0 8s 6= 0; E("2t ) = �2"
donde como se ve, hemos supuesto, por simplicidad, que no hay términoindependiente. Bajo el supuesto de que E"t = 0; se tiene: Eyt = Eut = 0: Elcálculo de la varianza de yt es bastante más complejo. Para ello, representamosPara t � 2; el modelo puede escribirse:
yt = (�+ �) yt�1 � ��yt�2 + "t (36)
que es un modelo cuyo término de error no presenta autocorrelación. En con-secuencia, la presencia de los retardos de la variable dependiente como variablesexplicativas no deteriora las propiedades estadísticas del estimador de mínimoscuadrados de los parámetros del modelo:
yt = �1yt�1 + �2yt�2 + "t
donde tendríamos únicamente el problema de identi�car o recuperar losparámetros �; � del modelo original a partir de estimaciones de �1; �2: Estose debe a que los parámetros �; � entran de forma totalmente simétrica en elmodelo transformado (36) de modo que un vez que hubiéramos obtenido unasolución �; � del sistema:
�+ � = �1
�� = ��2
podríamos intercambiar los valores numéricos de ambos parámetros y ten-dríamos otra solución. Por tanto, existensiempre dos soluciones, y el modelo sedice que está subidenti�cado.Para obtener la expresión analítica de la varianza del proceso (35), utilizamos
el hecho de que la varianza de un proceso AR(2) es (1��2)�2"(1+�2)[(1��2)2��1]
: Como en
nuestro caso, �1 = �+ �; �2 = ��; tenemos:
91

V ar (yt) =(1 + ��)
(1� ��)h(1 + ��)
2 � (�+ �)2i�2"
Si dispusiéramos de algún tipo de información adicional acerca de algunacaracterística de la distribución de probabilidad de yt; quizá podríamos iden-ti�car los dos parámetros por separado. Este no es el caso, sin embargo deque conociéramos, al menos aproximadamente, la relación existente entre lasvolatilidades de yt y "t pues, como puede verse en la expresión anterior, dicharelación debe ser igual al valor numérico de la fracción que en ella aparce, peroambos parámetros entran de forma simétrica, por lo que intercambiarlos no al-tera el valor numérico de la volatilidad relativa de ambas variables. Algo similarocurriría para cualquier información relativa al valor numérico de cualquier es-tadístico de yt; cuya expresión analítica depende de �1 y �2; por lo que � y �entran siempre de modo simétrico.Cuestión distinta sería si dispusiéramos de alguna información acerca de la
volatilidad relativa de yt y ut puesto que, como V ar(ut) =�2"1��2 ; tendríamos:
V ar (yt)
V ar(ut)=
(1 + ��)�1� �2
�(1� ��)
h(1 + ��)
2 � (�+ �)2i
que es distinto para las combinaciones de valores numéricos��; ��y��; ��:
Por ejemplo, si � = 0; 6; � = 0; 9; tendríamos: V ar (yt) = 5; 23V ar(ut); mientrasque si � = 0; 9; � = 0; 6; tendríamos: V ar (yt) = 17; 62V ar(ut):La función de verosimilitud muestral del proceso (35) puede escribirse:
L(y1; y2; :::; yT ) = L(y1; y2)L(y3=y2; y1)L(y4=y3; y2):::L(yT =yT�1; yT�2)
donde la necesidad de condicionar ahora la función de densidad de cadaobservación en los valores numéricos tomados por las dos observaciones previases bastante evidente.Ignorando el primer factor, tenemos la función de verosimilitud condicional
en (y1; y2); cuyo logaritmo es,
lnL = ln(y1) +TX2
lnL(yt=yt�1) =
= �12ln 2� � 1
2ln
�2"1� �2
� T � 12
ln 2� � 12ln�2" �
1� �2
2�2"y21 �
1
2�2"
TX2
(yt � �� �yt�1)2 =
= �T2ln 2� � T
2ln�2" +
1
2ln�1� �2
�� 1� �
2
2�2"y21 �
1
2�2"
TX2
(yt � �� �yt�1)2
92

El problema de maximización de esta función se simpli�ca si ignoramos lostérminos tercero y cuarto, que proceden de la distribución marginal de y1, L(y1);y consideramos:
lnL� =TX3
lnL(yt=yt�1; yt�2) = �T � 22
ln 2��T � 22
ln�2"�1
2�2"
TX2
(yt�(�+ �) yt�1+��yt�2)2
cuyas condiciones de optimalidad son,
@ lnL�
@�=
1
�2"
TX3
[(yt � (�+ �) yt�1 + ��yt�2) (yt�1 � �yt�2)] =1
�2"
TX3
(yt�1 � �yt�2) "t = 0
@ lnL�
@�=
1
�2"
TX3
(yt�1 � �yt�2) "t = 0
@ lnL�
@�2"= �T � 2
2�2"+
1
2 (�2")2
TX2
(yt � (�+ �) yt�1 + ��yt�2)2 = �T � 22�2"
+1
2 (�2")2
TX2
"t2 = 0
Por tanto, las estimaciones de Máxima Verosimilitud Condicionada de � y� son aquellos valores numéricos que generan unos residuos incorrelacionadossimultáneamente con yt�1 � �yt�2 y yt�1 � �yt�2; lo que vuelve a mostrar lasimetría existente entre estos parámetros. Escribiendo el modelo (36) en laforma,
yt � �yt�1 = �(yt�1 � �yt�2) + "tvemos que la primera condición sugiere estimar por Mínimos Cuadrados Or-
dinarios esta ecuación en variables cuasidiferenciadas para obtener la estimaciónMVC del parámetro �: Por otra parte, la segunda ecuación sugiere obtener elestimador MVC del parámetro � estimando por MCO la ecuación:
yt � �yt�1 = �(yt�1 � �yt�2) + "tque también equivale a (36) : Por último, la tercera ecuación nos proporciona
el estimador de Máxima Verosimilitud Condicionada de �2" :
�2" =
PT3 "t
2
T � 2Esta interpretación sugiere que el estimador MVC puede obtenerse esti-
mando la regresión en variables transformadas ~yt = yt � �yt�1; para un de-terminado valor numérico de �; para obtener la estimación de �; y utilizar éstapara llevar a cabo la transformación: ~yt = yt � �yt�1 para estimar � comoel coe�ciente en un modelo AR(1) en esta variable. Esta última transformadapuede interpretarse como el residuo del modelo AR(1) original, dada la esti-mación �: Ha de notarse, sin embargo, que tal esquema precisaría de un valor
93

inicial para uno de los dos parámetros, � o �; para comenzar a partir de élestimando, sucesiva y recursivamente, cada uno de ellos. Tal procedimiento it-erativo aproximaría el estimador MVC. Sin embargo, éste requiere la estimaciónsimultánea de ambos parámetros, como sugiere la solución del sistema de ecua-ciones de optimalidad anterior. El esquema iterativo puede conducir o no a lamisma solución que la solución simultánea que requiere, en todo caso, de unalgoritmo numérico. Ambas soluciones coincidirán si el modelo propuesto es laespeci�cación correcta, pero no en caso contrario, y el investigador nunca puedeestar seguro de este aspecto en su trabajo empírico. También coincidirán si losestimadores MVC de ambos parámetros fuesen independientes.La matriz de información del estimador de máxima verosimilitud es la in-
versa de la matriz de información, para lo que hemos de obtener las derivadassegundas,
@2 lnL�
@�2= � 1
�2"
TX3
u2t�1 ) E
�@2 lnL�
@�2
�= �T � 2
�2"
�2"1� �2 = �
T � 21� �2
@2 lnL�
@�2= � 1
�2"
TX3
(yt�1 � �yt�2)2 ) E
�@2 lnL�
@�2
�= �T � 2
�2"
�2"1� �2
@2 lnL�
@ (�2")2 =
T � 22
1
(�2")2 �
1
(�2")3
TX3
"t2 ) E
@2 lnL�
@ (�2")2
!= �T � 2
(�2")2
@2 lnL�
@�@�= � 1
�2"
TX3
["tyt�2 + (yt�1 � �yt�2) (yt�1 � �yt�2)]
@2 lnL�
@�@�2"= � 1
(�2")2
TX3
"t (yt�1 � �yt�2)) E
�@2 lnL�
@�@�2"
�= E
�Et�1
�@2 lnL�
@�@�2"
��= 0
@2 lnL�
@�@�2"= � 1
(�2")2
TX3
"t (yt�1 � �yt�2)) E
�@2 lnL�
@�@�2"
�= E
�Et�1
�@2 lnL�
@�@�2"
��= 0
donde hemos utilizado la propiedad:
E ["t (yt�1 � �yt�2)] = E (Et�1 ["t (yt�1 � �yt�2)]) = E [(yt�1 � �yt�2)Et�1"t] = 0
así como la propiedad análoga cuando la transformación de variables utilizael parámetro �: Asimismo:
94

Eh(yt�1 � �yt�2)2
i= E
1Xs=0
�s"t�s�1
!2=
�2"1� �2
E ["t (yt�1 � �yt�2)] = E
""t
1Xs=0
�s"t�s�1
#= E ("t"t�1 + �"t"t�2 + :::) = 0
E ("tyt�2) = E
"t
1Xs=0
�sut�s�2
!= 0
E [(yt�1 � �yt�2) (yt�1 � �yt�2)] = E
ut�1
1Xs=0
�s"t�s�1
!= E
" 1Xi=0
�i"t�i
! 1Xs=0
�s"t�s
!#=
=�2"
1� ��
Por tanto,
0@ �
�
�2"
1A � N
0BB@ ���2"
;�2"
T � 2
0B@�2"1��2
11��� 0
11���
11��2 0
0 0 12�2"
1CA�11CCA
donde la matriz de varianzas y covarianzas debería evaluarse en los estima-ciones de máxima verosimilitud obtenidas para los tres parámetros del modelo.ELa estructura de esta matriz de información prueba que, si bien los estimadoresde MVC de los parámetros � y � son independientes del estimador MVC de �2";sin embargo los dos primeros no son independientes entre sí.Para estimar este modelo mediante el algoritmo de Newton-Raphson, habría
que iterar mediante,
�n = �n�1 +
0B@PT
3 (yt�1 � �yt�2)2 PT
3 ["tyt�2 + ut�1 (yt�1 � �yt�2)]PT
3 "tut�1A21
PT3 u
2t�1
PT3 "t (yt�1 � �yt�2)PT
3 "tut�1PT
3 "t (yt�1 � �yt�2) 1�4
PT3
�12�
2" � "t2
�1CA�1
:
:
0B@PT
3 (yt�1 � �yt�2) "tPT3 ut�1"t
� 12�2
PT2
��2" � "t2
�1CA
mientras que el algoritmo de scoring, más sencillo, aproxima el hessiano dellogaritmo de la función de verosimilitud por la matriz de información,
�n = �n�1+1
T � 1
0B@ 1 �1�� 0
�1��
�2"1��2 +
�2
(1��)2 0
0 0 12�2"
1CA�10B@
PT3 (yt�1 � �yt�2) "tPT3 ut�1"t
� 12�2
PT2
��2" � "t2
�1CA
95

y el algoritmo de Gauss-Newton, aún más simple, pero con mayor error deaproximación numérico, consistiría en:
�n = �n�1 +
+
0B@PT
3 (yt�1 � �yt�2)2"2t
PT3 (yt�1 � �yt�2) "2tut�1 � 1
2�4
PT2
��2" � "t2
�(yt�1 � �yt�2) "tPT
3 (yt�1 � �yt�2) "2tut�1PT
3 u2t�1"
2t � 1
2�4
PT2
��2" � "t2
�ut�1"t
� 12�4
PT2
��2" � "t2
�(yt�1 � �yt�2) "t � 1
2�4
PT2
��2" � "t2
�ut�1"t
14�8
PT2
��2" � "t2
�21CA�1
:
:
0B@PT
3 (yt�1 � �yt�2) "tPT3 ut�1"t
� 12�4
PT2
��2" � "t2
�1CA
Sesgo asintótico en el modelo AR(1) con autocorrelación Consider-amos otra vez la estimación del modelo AR(1) con residuos autocorrelacionados,asimismo mediante una estructura AR(1):
yt = �+ �yt�1 + ut; t = 1; 2; :::; j � j< 1ut = �ut�1 + "t = 0 j � j< 1; E"t = 0; E("t"t�s) = 0 8s 6= 0; E("2t ) = �2"
Comencemos notando que, dados los límites que hemos supuesto mpara losvalores numéricos de los parámetros � y �; yt y ut admiten las representaciones:
yt =
1Xs=0
�sut�s; ut =
1Xi=0
�i"t�i;
Ahora bien, también tenhemos una representación de yt en función de lainnovación del modelo:
yt = (� + �) yt�1 � ��yt�2 + "t (37)
Si multiplicamos esta expresión por yt�1; sumamos de 3 a T y divimos porPT2 y
2t�1; tenemos,
�MCO =1T
PT3 ytyt�1
1T
PT3 y
2t�1
= (� + �)� ��1T
PT3 yt�1yt�2
1T
PT3 y
2t�1
+1T
PT3 "tyt�1
1T
PT3 y
2t�1
Ahora, tomando límites en probabilidad y notando que:
p lim1
T
TX3
ytyt�1 = E (ytyt�1) = p lim1
T
TX3
yt�1yt�2
tenemos:
96

p lim �MCO = (� + �)� (��) p lim �MCO +p lim 1
T
PT3 "tyt�1
p lim 1T
PT3 y
2t�1
La última fracción es igual a cero, yan que el numerador converge a E ("tyt�1)y ya hemos visto que yt�1 es combinación lineal de "t�1; "t�2; :::; pero no de "t:Así, tenemos,
p lim �MCO =� + �
1 + ��= � +
��1� �2
�1 + ��
que, como puede comprobarse, está entre �1 y 1:Por tanto,
Sesgo a sin t�otico��MCO
�= p lim �MCO � � =
��1� �2
�1 + ��
de modo que si � > 0; el estimador �MCO sobreestima a �; subestimando elverdadero valor del parámetro cuando � < 0:Consideremos ahora el estimador de � :
�MCO =1T
PT3 utut�1
1T
PT3 u
2t�1
siendo ut = yt � �MCO:yt�1:Para obtener el límite en probabilidad del estimador �MCO notemos, en
primer lugar, que:
u2t�1 =�yt�1 � �yt�2
�2= y2t�1 � 2�yt�1yt�2 + �
2y2t�2 =
= y2t�1 � 2���yt�2 + ut�1
�yt�2 + �
2y2t�2
Dividimos por T , sumamos y tomamos límites en probabilidad, obteniendo:
p lim1
T
TX3
u2t�1 = p lim1
T
TX3
y2t�1 � 2p lim��2�p lim
1
T
TX3
y2t�2
!�
�2p lim���p lim
1
T
TX3
ut�1yt�2
!+ p lim
��2�p lim
1
T
TX3
y2t�2
!
es decir,
p lim1
T
TX3
u2t�1 =
�1�
�p lim �
�2�p lim
1
T
TX3
y2t�1�2p lim���p lim
1
T
TX3
ut�1yt�2
!
97

pero el último término es igual a E (ut�1yt�2) ; que es igual a cero por seryt�2 una variable explicativa en la regresión en la que se generó el residuo demínimos cuadrados ut�1:En segundo lugar:
utut�1 =�yt � �MCO:yt�1
��yt�1 � �MCO:yt�2
�=
= ytyt�1 � �y2t�1 � �ytyt�2 + �2yt�1yt�2
de modo que:
p lim1
T
TX3
utut�1 =�1 + p lim �
2�p lim
1
T
TX3
yt�1yt�2 ��p lim �
�p lim
1
T
TX3
y2t�1 �(38)
��p lim �
�p lim
1
T
TX3
ytyt�2
Pero, utilizando la representación (37) ; tenemos:
p lim1
T
TX3
ytyt�2 = p lim1
T
TX3
(� + �) yt�1yt�2���p lim1
T
TX3
y2t�2+p lim1
T
TX3
"tyt�2
(39)donde el último término converge a E ("tyt�2) ; que es igual a cero porque
yt�2depende de "t�2 y anteriores, pero no de "t:Sustituyendo (39)en (38) tenemos:
p lim1
T
TX3
utut�1 =
�1 +
�p lim �
�2��p lim �
�(� + �)
�p lim
1
T
TX3
ytyt�1 � p lim � p lim
1
T
TX3
y2t�1
!+ ��
�p lim �
�p lim
1
T
TX3
y2t�2 =
=
�1 +
�p lim �
�2��p lim �
�(� + �)
��p lim �
�p lim
1
T
TX3
y2t�1 � p lim � p lim
1
T
TX3
y2t�1
!+ ��
�p lim �
�p lim
1
T
TX3
y2t�2 =
=
��p lim �
�3��p lim �
�2(� + �) + ��
�p lim �
��p lim
1
T
TX3
y2
de modo que:
p lim (�MCO) =
�p lim �
�3��p lim �
�2(� + �) + ��
�p lim �
�1�
�p lim �
�2Proposition 2 p lim (�MCO) = �� �+�
1+��
98

Demostración:
p lim (�MCO) =1
1���+�1+��
�2 � + �1 + ��
"�� + �
1 + ��
�2� (� + �)
2
1 + ��+ ��
#=
=1
1���+�1+��
�2 � + �1 + ��
"�� + �
1 + ��
�2� 1#(���) = ��
� + �
1 + ��
Corollary 3 En consecuencia, tenemos: Sesgo a sin t�otico (�MCO) = p lim �MCO�� = �� 1��
2
1+��
Corollary 4 plim��MCO + �MCO
�= � + �
Como muestra el último corolario, la suma de ambos parámetros se estimaconsistentemente, a pesar del sesgo asintótico en que se incurreal estimar porMCO cada uno de ellos. Una vez más, hay que observar que, aunque el prob-lema de correlación no nual entre variables explicativas y término de error seproduce tan sólo en la primera ecuación del modelo, que tiene a yt por variabledependiente, ambos parñametros se estiman inconsistentemente.Hay que notar también que la estimación �MCO puede subestimar de modo
apreciable la autocorrelación existente en ut:Además, no es posible evaluar dichaautocorrelación únicamente a partir de �MCO pues dicha estimación numéricapuede estar muy sesgada hacia cero. Como consecuencia, el estadístico Durbin-Watson está sesgado asintóticamente a la baja cuando � > 0:
Proposition 5 Sesgo a sin t�otico (�MCO) = p lim �MCO � � = ��� 1+�1+��
Demostración:
Sesgo a sin t�otico (�MCO) = p lim �MCO � � = p limh�1� �MCO
��yi� � =
�1� p lim �MCO
�Ey � � =
=
�1� � � � 1� �
2
1 + ��
��
1� � � � =�1� � 1 + �
1 + ��� 1�� = ��� 1 + �
1 + ��
6 Modelos ARCH
6.1 Un poco de historia
Los modelos ARCH aparecen en los años 80 con el objeto de recoger los episodiosde agrupamiento temporal de volatilidad que suele observarse en las series derentabilidad de casi todo mercado �nanciero. Desde entonces, su variedad y
99

su aplicación práctica ha crecido de manera espectacular. En realidad, hayprecursores más antiguos[Bachelier (1900) y Mandelbrot(1963,1967)], trabajosen los que comenzó a caracerizarse las propioedades estadísticas de los preciosde activos �nancieros.
6.2 Propiedades estadísticas
Los modelos que hemos analizado hasta ahora mantenían el supuesto de que lainnovación tiene una varianza constante en el tiempo, a pesar de que la esperanzacondicional es cambiante. Sin embargo, para agentes aversos al riesgo, quetoman sus decisiones en un régimen de incertidumbre, la varianza condicional,es decir, la varianza de la distribución de los rendimientos en cada instantefuturo de tiempo, juega un papel de la mayor importancia. Este es el aspèctoque modelizamos en este capítulo.Las características más relevantes de las series �nancieras recogidas con fre-
cuencias elevadas [Ruiz (1994)], son:1) ausencia de estructura regular dinámica en la media, lo que aparece re-
�ejado en estadísticos Ljung-Box generalmente no signi�cativos,2) distribuciones leptocúrticas o exceso de curtosis,3) suelen ser simétricas, aunque también se encuentran en algunos casos
coe�cientes de asimetría signi�cativamente distintos de cero,4) agrupamiento de la volatilidad sobre intervalos de tiempo, lo cual se re�eja
en funciones de autocorrelación simple signi�cativas para los cuadrados de lasvariables,5) persistencia en volatilidad: los efectos de un shock en volatilidad tardan
un tiempo en desaparecer.6) efecto apalancamiento: se observa una respuesta asimétrica de la volatil-
idad al nivel de los rendimientos, en el sentido de queMuchos de estos efectos quedan recogidos en los modelos ARCH, GARCH,
EGARCH, que vamos a analizar. Estos modelos recogen en sus formulacionesla idea de que existen agrupaciones de volatilidad, es decir, que fuertes �uc-tuaciones inesperadas en los mercados tienden a venir seguidas de períodos deiguales características, mientras que períodos de estabilidad tienden a venirseguidos de períodos asimismo estables. Los modelos de esta familia recogeneste comportamiento inercial en volatilidad a la vez que el comportamientodinámico, con autocorrelación que suelen presentar las series �nancieras.Una de las contribuciones importantes de la literatura de procesos ARCH es
mostrar que las variaciones que aparentemente se producen en la volatilidad delas series temporales económicas pueden expliacrse mediante una determinadaforma de dependencia no lineal, que permite además predecir dichos cambiosen volatilidad sin necesidad de recurrir a la modelización explícita de cambiosestructurales en la varianza.
Frente a estas observaciones empíricas, fórmulas de valoración del tipo Black-Scholes suponen una volatilidad constante para el precio del activo subyacente,que permite dudicr la expresión analítica del precio teórico de una opción Euro-
100

pea sobre dicho activo. La fórmula BS es utilizada habitualmente para deducirde ella la volatilidad implícita, forzando el precio que de ella se deriva a coin-cidri con el precio observado en el mercado. La volatilidad implícita así obtenidase interpreta como el nivel de volatilidad vigente en el mercado desde el mo-mento de inversión de la fórmula BS hasta el vencimiento de la opción. Sinembargo, no siendo dicha volatilidad constante en el tiempo, es cuestionable lainterpretación del valor numérico obtenido para la volatilidad implícita. Sueleinterpretarse como una expectativa de mercado y en términos del valor mediode volatildad vigente para el período mencionado, pero tal interpretación noestá justi�cada por el análisis BS.Para poder proceder al estudio empírico de este tipo de modelos de varianza
condicional cambiante en datos reales, es preciso concretar antes la estructurade las funciones de esperanza y varianza condicionales, lo que pasamos a hacera continuación.
6.3 Primeras de�niciones y propiedades
6.4 Momentos incondicionales
Los momentos de los procesos ARCH han sido analizados en Engel(1982), Mil-hoj(1985), Bollerslev(1986) entre muchos otros. Para su cálculo, es clave la leyde iteración de expectativas: dadas dos sigma-álgebras 1;2; con 1 � 2 yuna variable aleatoria escalar y, se tiene:
E (y j 1) = E [E (y j 2) j 1]
En nuestro caso, las dos sigma-álgebras son las generadas por la historiapasada de las variables del modelo, en dos instantes distintos de tiempo. uncaso particular de esta ley que resulta especialmente útil es cuando 1 = �;pues entonces,
E (y) = E [E (y j 2)]
que relaciona un moomento incondicional y un momento condicional.Sea f"t (�)g un proceso estocástico, de�nido en tiempo discreto, cuyas es-
peranza y varianza condicionales dependen de un vector de parámetros �; dedimensión m. Sea �0 el verdadero valor de dicho vector de parámetros. Ini-cialmente, consideramos que "t (�) es escalar, aunque la generalización al casomultivariante es relativamente simple.Denotamos por Et�1 la esperanza matemática condicional en la sigma-
álgebra t�1 generada por las realizaciones pasadas de las variables observablesen el instante t�1 o anteriores, que de�ne el conjunto de información disponibleen t� 1.
De�nition 6 Decimos que f"t (�)g sigue un proceso ARCH si su esperanzacondicional es igual a cero:
101

Et�1"t (�0) = 0; t = 1; 2; 3; :::
y su varianza condicional,
h2t (�0) � V art�1 ["t (�0)] = Et�1�"2t (�0)
�= g ("t�1; "t�2; :::)
depende, en forma no trivial, del sigma-álgebra t�1 generada por las ob-servaciones pasadas. La notación h2t hace referencia al hecho de que trabajamoscon un segundo momento del proceso estocástico. Debe apreciarse que, a pesardel subíndice temporal, h2t es una función de variables pertenecientes al instantet� 1 o anteriores.La esperanza y varianza incondicionales del proceso "t (�0) son la esperanza
matemática de los momentos análogos condicionales,
E("t) = E (Et�1"t) = 0
V ar ("t) = E"2t = E�Et�1"
2t
�= Eh2t
El proceso estandarizado:
zt (�0) ="t (�0)p
h2t
tendrá esperanza condicional igual a cero, y varianza condicional igual a uno,
Et�1zt (�0) = 0; t = 1; 2; 3; :::
V art�1 [zt (�0)] = V art�1
""t (�0)p
h2t
#=1
h2tV art�1 ["t (�0)] = 1; t = 1; 2; 3; :::
Sus momentos incondicionales serán, por tanto, iguales a los momentoscondicionales, que son constantes:
E("t) = E (Et�1"t) = 0; V ar [zt (�0)] = 1; t = 1; 2; 3; :::
Por tanto, si bien la varianza condicional cambia en el tiempo, la varianzaincondicional es constante, por lo que el proceso ARCH es incondicionalmentehomocedástico. Hay que notar, además, que la variable aleatoria zt (�0) esindependiente del pasado de "t (�0) ; pues la presencia de
ph2t en su de�nición
no hace sino reducir su varianza10 a 1.10Alternativamente, podríamos de�nir el proceso ARCH mediante,
yt = "tht
con "t � N(0; 1);independiente en el tiempo, y h2t (�0) � g ("t�1; "t�2; :::). Con esta no-tación, la a�rmación del texto equivaldría a decir que "t y ht son independientes, comoclaramente ocurre.
102

Si añadimos el supuesto de Normalidad condicional para "t; y suponemosque la distribución condicional de zt (�0) tiene momento de cuarto orden �nito,se tendrá, por la desigualdad11 de Jensen:
E�"4t (�0)
�= E
�z4t (�0)
�E�h4t (�0)
�� E
�z4t (�0)
� �E�h2t (�0)
��2= E
�z4t (�0)
� �E�"2t (�0)
��2Por tanto, el coe�ciente de curtosis del proceso ARCH "t (�) será,
E�"4t�
[E ("2t )]2 � E
�z4t�= 3
y la desigualdad se cumplirá como igualdad sólo en el caso de una varianzacondicional constante. En caso contrario, si la distribución de zt (�0) es Normal,entonces la distribución incondicional de "t será leptocúrtica.Por otra parte, si la distribución condicional de "t es Normal, se tiene para
todo entero impar m que E ("mt (�0)) = E [Et�1 ("mt (�0))] = E(0) = 0; por lo
que el coe�ciente de asimetría de "t es nulo. Al ser "t una variable aleatoriacontinua, esto implica que su densidad es simétrica.
6.5 Proceso con residuos ARCH
Aunque nos centremos en las propiedades del proceso f"t (�)g, en general, ten-dremos un proceso fyt (�0)g, objeto de estudio, cuya esperanza condicional seráuna función de �0,
Et�1yt = �t�1 (�0)
En general, entendemos que yt representa el rendimiento ofrecido por unactivo �nanciero, cuyo valor actual descomponemos mediante una identidad, endos componentes: a) el componente anticipado, �t�1 (�0) ; que pudimos haberprevisto en base a información pasada, y b) la innovación en el proceso derentabilidad. Es ésta última la que se supone que tiene una estructura de tipoARCH.Denotemos por f"t (�0)g el residuo de dicha relación, o error de predicción
un período hacia adelante,
yt = �t�1 (�0) + "t (�0)) "t (�0) = yt � �t�1 (�0)
que satisface,
Et�1 ["t (�0)] = 0
y supongamos que tiene la estructura ARCH de�nida en (??).Para el proceso yt tendremos,
11El lector puede comprobar la facilidad con que obtiene este resultado utilizando la notaciónpropuesta en el pie de página previo.
103

Et�1yt = �t�1 (�0) ;
V art�1yt = Et�1 [yt � Et�1yt]2 = Et�1 ["t (�0)]2= V art�1 ["t (�0)] = h2t
por lo que su varianza condicional coincide con la de "t (�0) ; mientras quesu varianza incondicional es,
V ar(yt) = E�h2t�
En consecuencia, mientras que los momentos incondicionales son constantesen el tiempo aunque, como veremos, pueden no existir, los momentos incondi-cionales cambian a lo largo del tiempo. Un modelo ARCH consta de: a) unaecuación representando el modo en que la esperanza condicional del procesovaría en el tiempo, b) una ecuación mostrando el modo en que su varianzacondicional cambia en el tiempo, y c) una hipótesis acerca de la distribuciónque sigue la innovación de la ecuación que describe el proceso seguido por suesperanza matemática.
6.6 El modelo ARCH(q)
La estructura básica de este modelo es,
yt = "tht
h2t = �0 +
qXi=1
�iy2t�i; �0 > 0; �i � 0;
qXi=1
�i � 1
donde, una vez más, suponemos que "t es un proceso ruido blanco, conE("t) = 0; V ar("t) = 1. Por simplicidad, estamos suponiendo asimismo que lavariable yt carece de autocorrelación, así como de la imposibilidad de utilizarotras variables que puedan explicar su evolución temporal. En todo caso, laescasa estructura dinámica que se observa en datos frecuentes de rentabilidadesde mercados �nancieros justi�ca la simplicidad en la especi�cación de la ecuaciónde la media del proceso yt: Alternativamente, si el investigador detecta algunasvariables que pueden explicar el comportamiento de yt; posiblemente incluyendoalgunos retardos de la propia variable, entonces h2t sería la varianza condicionaldel término de error del modelo que explica el comportamiento de yt: Esto es loque haremos en algunos modelos analizados en las próximas secciones.Aunque no son necesarias, las restricciones de signo de los coe�cientes de
la ecuación de varianza garantizan que la varianza condicional será positiva entodos los períodos. En realidad, lo que necesitamos es que, una vez que el modelohaya sido estimado, genere una serie de varianzas positiva, lo cual es compatiblecon que alguno de los coe�cientes �i sean negativos. Esto debe tomarse comoun contraste de validez del modelo, que no sería aceptable si generase varianzasestimadas negativas. Es preferible no imponer las restricciones en la estimación
104

del modelo, y poder contrastar la propiedad del modo que hemos descrito, queestimar bajo las restricciones de signo.La restricción sobre la suma de los coe�cientes de la ecuación de varianza
garantiza que el proceso sea estacionario en varianza. Para ello, es necesarioque las raíces del polinomio característico,
�0 � �1z � �2z2 � :::� �qzq = 0
estén fuera del círculo unidad, es decir, tengan valor absoluto mayor que unoo, si son complejas, módulo mayor que la unidad. Cuando son no-negativas, elloes equivalente a la condición sobre su suma.De acuerdo con este modelo, una sorpresa en yt importante en magnitud,
positiva o negativa, hará que la varianza del proceso sea elevada durante uncierto número de períodos.Si, condicional en t�1, "t sigue una distribución Normal, la distribución
condicional de yt será asimismo Normal, pues yt = "t
q�0 +
Pqi=1 �iy
2t�i y el
componente dentro de la raíz es conocido en t� 1. Se tiene, además,
V ar (yt=yt�1; yt�2; ::::) = E�y2t =yt�1; yt�2; ::::
�= �0 +
qXi=1
�iy2t�i
Por el contrario, su distribución incondicional no es fácilmente caracterizable,debido a la nolinealidad de la relación entre yt y "t. De hecho al no seguirincondicionalmente una distribución Normal, no se tiene la equivalencia entreausencia de correlación e independencia, como veremos en detalle en el caso delmodelo ARCH(1). Es fácil probar, sin embargo, que sus momentos de ordenimpar son todos igual a cero, por lo que dicha distribución es simétrica.De�niendo vt = y2t�h2t ; que cumple E (vt) = 0; este proceso puede escribirse,
y2t = �0 +
qXi=1
�iy2t�i + vt
por lo que pasamos a tener un proceso AR(q) en el cuadrado de la variable aexplicar, yt; que podrían ser los rendimientos que ofrece un determinado activo�nanciero. Esta es otra interpretación del modelo ARCH (q) cuando no hayestructura de variables explicativas en la ecuación de la media del proceso.La varianza incondicional de este proceso es,
�2y = V ar yt =�0
1�Pqi=1 �i
Aunque los sucesivos valores de yt están incorrelacionados, no son indepen-dientes, debido a la relación que existe entre sus segundos momentos.Para evitar trabajar con un elevado número de parámetros en ocasiones en
que se percibe una alta persistencia en volatilidad, suele utilizarse una repre-sentación,
105

h2t = �0 + �1
qXi=1
wiy2t�i; wi =
(q + 1)� i12q (q + 1)
;
qXi=1
wi = 1
Este es el modelo ARCH(q) restringido, introducido ya por Engle(1982). Entodo caso, la estructura lineal en los coe�cientes de los retardos en la ecuación dela varianza pude contrastarse, frente a la alternativa formada por una estructuralibre de coe�cientes, siguiendo los métodos que describiremos más adelante.Taylor (1986) prueba que la función de autocorrelación simple de y2t cuando
el proceso yt tiene una estructura ARCH(q) presenta la misma con�guraciónque la función de autocorrelación simple de un proceso AR(q); lo que puedeservir para detectar este tipo de estructura.
6.7 El modelo ARCH(1)
Un caso especialmente interesante surge cuando q = 1, teniendo el modeloARCH(1), que puede escribirse:
yt = "tht = "t
q�0 + �1y2t�1
siendo "t un proceso ruido blanco con varianza igual a 1.Su esperanza y varianza condicionales son,
Et�1yt =
�q�0 + �1y2t�1
�Et�1("t) = 0
V art�1(yt) = Et�1y2t =
��0 + �1y
2t�1�Et�1("
2t ) = �0 + �1y
2t�1
por lo que la varianza condicional varía, en función de la realización delproceso yt.La ley de iteración de expectativas nos dice, E ("t) = E [E ("t j It�1)] ; pero
como la especi�cación del modelo incluye el supuesto E ("t j t�1) = 0; se tieneque E ("t) = 0; lo cual es cierto para todo modelo ARCH(q):Al ser independiente en el tiempo, "t también es independiente de valores
pasados de yt; por lo que la esperanza y varianza marginal o incondicional deyt son:
E (yt) = E
�"t
q�0 + �1y2t�1
�= E ("t)E
�q�0 + �1y2t�1
�= 0
V ar (yt) = E�y2t�= E
�"2t�E��0 + �1y
2t�1�= �0 + �1E
�y2t�1
�donde hemos utilizado nuevamente la independencia estadística de "t e yt�1:Si j �1 j< 1; el proceso yt es estacionario, con E
�y2t�= E
�y2t�1
�, lo que
implica que,
106

V ar (yt) =�0
1� �1que, a diferencia de lo que ocurre con la varianza incondicional, es constante
en el tiempo.La autocovarianza de orden � ; � �1 del proceso ARCH(1) es:
E (ytyt�� ) = E
�"t
q�0 + �1y2t�1 yt��
�= E ("t)E
�q�0 + �1y2t�1 yt��
�= 0
por lo que el proceso ARCH(1) no está autocorrelacionado, es decir, noexisten relaciones lineales entre sus valores en distintos instantes de tiempo.Sin embargo, su cuadrado, y2t ; sí está autocorrelacionado. Por ejemplo, su
autocovarianza de orden 1 es:
1�y2t�= E
�y2t y
2t�1�= E
��y2t �
�01� �1
��y2t�1 �
�01� �1
��=
= � �01� �1
�Ey2t + Ey
2t�1�+
��0
1� �1
�2+ E
�y2t y
2t�1�
pero: y2t = "2t��0 + �1y
2t�1�, y ya hemos visto que: Ey2t = �0+�1E
�y2t�1
�,
por lo que,
1�y2t�= � �0
1� �12
�01� �1
+
��0
1� �1
�2+ E
�"2t��0 + �1y
2t�1�y2t�1
�=
= ��
�01� �1
�2+��0E
�y2t�1
�+ �1E
�y4t�1
��y de, hecho, puede probarse [Taylor (1986)] que la función de autocorrelación
simple del cuadrado de un proceso ARCH(q) tiene las mismas característicasque la función de autocorrelación simple de un proceso AR(q).Por otra parte, podemos repetir en este caso particular el análisis que hicimos
antes para el caso general, acerca del momento de cuarto orden. La condiciónnecesaria para la existencia del cuarto momento del proceso ARCH(1) es 3�21 <1:Bajo este supuesto, y añadiendo la hipótesis de Normalidad de "t; tenemos,
E(y4t ) = Eh"4t��0 + �1y
2t�1�2i
= 3�20 (1 + �1)
1� 3�21por lo que la autocovarianza de orden 1 de y2t es:
1�y2t�=
2�20�1
(1� �1)2 (1� 3�21)que es no nula.
107

Bajo estos supuestos, la curtosis del proceso ARCH(1) es �nita, e igual a:
Curtosis(yt) =E�y4t�
E (y2t )2 = 3
1� �211� 3�21
siendo igual a in�nito en caso contrario. Si �1 > 0, entonces la curtosises mayor que 3 y, por tanto, mayor que la de la distribución N(0; 1), por loque el proceso ARCH tiene colas más gruesas que dicha distribución. Esta esuna propiedad conocida de las series �nancieras. Por otra parte, que el modeloARCH no imponga necesariamente una varianza �nita es deseable en el sentidode que esta debe ser una propiedad del verdadero proceso generador de datosque aparezca en los resultados de la estimación.La ausencia de autocorrelación del proceso ARCH le hace deseable para
la modelización de series temporales �nancieras. La hipótesis de mercadose�cientes se describe en ocasiones como la incapacidad de predecir rentabil-idades futuras a partir de rentabilidades pasadas. Si una rentabilidad rt esun proceso ARCH puro (es decir, sin variables explicativas), entonces se tieneE (rt j It�1) = E (rt) = 0: Por tanto, la existencia de efectos ARCH no con-tradice esta versión de la hipótesis de mercados e�cientes.La presencia de efectos ARCH no afecta, teóricamente, a la predicción de
valores futuros del proceso, aunque se gana e�ciencia y se obtienen estimacionespuntuales distintas, una vez que se modelizan estos efectos. En cualquier caso,el potencial de un modelo ARCH estriba en que proporciona una medida deriesgo cambiante en el tiempo, que puede ser un input importante en otro tipode análisis, como por ejemplo, si se quiere cuanti�car la remuneración que enun determinado mercado se ofrece al riesgo que se asume en el mismo.Sin embargo, este modelo es susceptible de provocar algunos problemas de
signo. En particular, los valores numéricos de la serie temporal de volatilidadh2t que resultan del proceso de estimación, deben ser todos positivos.Como el proceso ARCH carece de autocorrelación y tiene media cero, es
débilmente estacionario si existe su varianza. Una propiedad notable de esteproceso es que puede no ser débilmente estacionario (porque su varianza noexista) y, sin embargo, ser estrictamente (o fuertemente) estacionario pues paraeste último concepto no es precisa la existencia de momentos.
6.8 Modelo AR(1)-ARCH(1)
Comencemos recordando el modelo AR(1) sin perturbaciones ARCH,
yt = �yt�1 + "t; j � j< 1
siendo "t un proceso ruido blanco, con E ("t) = 0; V ar ("t) = �2": En estemodelo se tienen momentos condicionales,
Et�1yt = �yt�1;
V art�1yt = V art�1"t = �2"
108

mientras que los momentos incondicionales son,
Eyt = 0;
V ar (yt) =�2"
1� �2
Como puede verse, la expresión de la esperanza condicional recoge el hechode que es posible prever este proceso si se dispone de sus valores pasados. Comoconsecuencia, la varianza condicional es inferior a la varianza incondicional.
Más generalmente, el modelo AR(1) con perturbación ARCH(1) es,
yt = �yt�1 + "t; j � j< 1Et�1"t = 0; V art�1"t = h2t = �0 + �1"
2t�1
El supuesto j � j< 1 garantiza que el proceso es estacionario en media. Suvarianza será positiva en todos los períodos si restringimos los valores de losparámetros mediante �0 � 0; �1 � 0:La esperanza y varianza condicionales de yt son,
Et�1yt = �yt�1;
V art�1yt = V art�1"t = �0 + �1"2t�1 = �0 + �1 (yt � �yt�1)2
La varianza incondicional es �nita si �1 < 1, y los momentos incondicionales,son entonces,
E yt = 0;
V ar yt =�0
1� �21La varianza condicional puede escribirse,
h2t � �2 = �1�"2t�1 � �2
�de modo que la varianza condicional excede de la varianza incondicional
siempre que la inovación (o sorpresa) al cuadra, es mayor que su esperanzaincondicional, �2:Aunque las innovaciones están incorrelacionadas a través del tiempo, no son
independientes, puesto que están relacionadas a través de sus momentos de or-den 2. Aunque yt sigue una distribución condicional Normal, su distribuciónconjunta con valores en otros instantes de tiempo, no lo es. Tampoco su distribu-ción de probabilidad incondicional o marginal es Normal, si bien será simétrica,si la distribución de probabilidad condicional de "t lo es. Si "t tiene ua distribu-ción condicional Normal, entonces su cuarto momento incondicional excederá
109

de 3�4; por lo que la distribución marginal de "t tendrá colas más gruesas quela Normal. Su momento de orden cuatro será �nito siempre que 3�21 < 1:
En muchas aplicaciones empíricas, el orden del modelo ARCH que es precisoutilizar para recoger la dependencia temporal en la varianza es elevado, por loque es útil considerar una representación más simple de este tipo de estructuras:
6.9 Modelos ARMA-ARCH
El análisis anterior puede generalizarse a cualquier modelo univariante de se-ries temporales de la familia ARIMA, en el que puede tener perfecto sentidoepeci�car que la varianza del término de error es vcambiante en el tiempo. Porejemplo, el modelo AR(p)�ARCH(m) es,
yt = �1yt�1 + �2yt�2 + :::+ �pyt�p + "t; j � j< 1Et�1"t = 0; V art�1"t = h2t = �0 + �1"
2t�1 + �2"
2t�2:::+ �m"
2t�m
6.10 El modelo ARCH(q) de regresión
Consideremos un modelo dinámico de regresión lineal,
yt = x0t� + "t; t = 1; 2; :::; T
siendo xt un vector kx1 de variables explicativas que pueden incluir retardosde la variable dependiente. El modelo ARCH de regresión especi�ca, condi-cional en las observaciones pasadas de la variable dependiente y de las variablesexplicativas, el término de error del modelo anterior se distribuye,
"t j t�1 � N(0; h2t )
siendo,
h2t = �0 + �1"2t�1 + :::+ �q"
2t�q
con �i � 0;Pqi=1 �i � 1; para asegurar que la varianza resultante sea posi-
tiva en todos los períodos. Como "t�1 = yt�1 � x0t�1�; se tiene que h2t es una
función de la información contenida en t�1: Una vez más, al ser la varianzacondicional del período t una función creciente de la magnitud de las últimasinnovaciones, se produce el clustering o agrupamiento temporal de volatilidades.El orden q de la representación ARCH es un indicador de la persistencia de losshocks en varianza.
En muchas aplicaciones empíricas, el orden del modelo ARCH que es precisoutilizar para recoger la dependencia temporal en la varianza es elevado, por loque es útil considerar una representación más simple de este tipo de estructuras:
110

6.11 Modelos ARMA-ARCH
6.12 Modelos GARCH
6.12.1 Modelos GARCH(p,q)
En muchos casos, la especi�cación ARCH que recoge la estructura de autocor-relación en varianza precisa de un elevado número de retardos. Para evitar queel alto número de coefcientes en términos autoregresivos, generalmente bastanterelacionados, produzca una importante pérdida de precisión en su estimación,se ha propuesto una parametrización alternativa, restringida, dependiente de unnúmero reducido de parámetros. El modelo GARCH(p; q) de Bollerslev (1986)es,
yt = "tht
h2t = �0 +
qXi=1
�iy2t�i +
pXi=1
�jh2t�j ; �0 > 0; �i; �j � 0;
qXi=1
�i +
pXi=1
�j < 1
Las condiciones anteriores garantizan (si bien no son necesarias) que la vari-anza condicional estimada sea positiva en todos los períodos. En realidad, Nel-son y Cao (1992), mostraron condiciones más débiles que garantizan varianzapositiva en todos los períodos. por ejemplo, en un GARCH(1; 2), es su�cienteque: �0 > 0; �1 � 0; �1 � 0; �1�1 + �2 � 0: Este modelo puede transformarseen un modelo ARCH de orden in�nito [Bera y Higgins, Volatility], restringidoen sus parámetros.En la especi�cación anterior hemos supuesto, nuevamente por simplicidad,
que yt carece de autocorrelación, así como que no disponemos de variablesepclicativas para le esperanza condicional de dicho proceso. Los mismos co-mentarios que hicimos acerca del modelo ARCH(q) aplican a este caso.La esperanza matemática del proceso GARCH(p; q) es cero, y su varianza,
V ar yt =�0
1�Pqi=1 �i �
Ppi=1 �j
=�0
1� �(1)� �(1)y la distribución es nuevamente leptocúrtica e incondicionalmente homo-
cedástica.Con la misma de�nición de la inovación que antes hicimos, tenemos, h2t =
y2t � vt, y el proceso GARCH(p; q) puede escribirse,
y2t = �0 + (� (L) + � (L)) y2t�1 � � (L) vt�1 + vt
o, lo que es lo mismo,
(1� � (L)� � (L)) y2t = �0 + (1� � (L)) vty es necesario que todas las raíces del polinomio 1�� (L)�� (L) estén fuera
del círculo unidad para que el proceso sea estacionario. En tal caso, su varianzaincondicional será �nita, y estará dada por la expresión anterior.
111

El modelo GARCH(p; q) puede escribirse,
y2t = �0 +rXi=1
��i + �j
�y2t�i �
rXi=1
�j�y2t�j � h2t�j
�+�y2t � h2t
�;
�0 > 0; �i; �j � 0;qXi=1
�i +
pXi=1
�j < 1
siendo r = max(p; q): Nuevamente, E�y2t � h2t
�= 0; por lo que puede con-
siderarse como la innovación en la ecuación anterior. En consecuencia, un mod-elo GARCH(p; q) para la rentabilidad yt puede interpretarse como un modeloARMA para y2t : Aunque su estimación como tal proceso ARMA sería ine�-ciente, sin embargo las expresiones habituales para la predicción en modelosARMA son utilizables.Examinemos el cálculo del a varianza incondicional en el caso del proceso
GARCH(1; 1);
V ar("t) = E�"2t�= E
�E�"2t j t�1
��= E(h2t ) =
= �0 + �1E�"2t�1
�+ �1E
�h2t�1
�= �0 + (�1 + �1)E
�"2t�1
�que es una ecuación en diferencias en E
�"2t�que si converge, tiene como
límite,
V ar yt =�0
1� �1 � �1lo cual ocurre siempre y cuando �1+�1 < 1: En el caso general, la condición
necesaria y su�ciente de existencia de la varianza incondicional es � (1)+� (1) =Pqi=1 �i �
Ppi=1 �j < 1: Bollerslev(1986) proporciona condiciones analíticas
sobre los parámetros del modelo para garantizar la existencia de momentos enun proceso GARCH(p; q).Si yt sigue un proceso GARCH(p; q), su cuadrado, y2t tiene una función
de autocorrelación simple análoga a la de un proceso ARMA(p�; q); con p� =maxfp; qg; parámetros autoregresivos �i = �i + �i; y parámetros de mediamóvil, �j = ��j ; para j = 1; 2; :::; q: Precisamente esta similitud con los modelosARMA hace que se utilicen técnicas de identi�cación para los modelos ARCH yGARCH basadas en las funciones de autocorrelación simple y parcial, del mismomodo que se hace en el análisis del tipo Box-Jenkins, pero esta vez utilizandolos cuadrados de los residuos. Sin embargo, la dependencia estadística de losprocesos de varianza condicional hace que la estimación de dichas funciones seapoco e�ciente.
El modelo más habitual dentro de esta clase es el GARCH(1; 1):
112

6.12.2 El modelo GARCH(1,1)
Este es un modelo de suavizado exponencial de la varianza, análogo a los queconsideramos para la volatilidad condicional,
yt = "tht
h2t = ! + �y2t�1 + �h2t�1
con � > 0; ! > 0; � � 0; �+ � < 1:En este modelo, la varianza condicional es,
V art�1yt = h2t
mientras que la varianza incondicional es:
V ar yt =!
1� �� �Los retardos medio y mediano en h2t son,
Re tardo medio =
P1i=1 i�iP1i=1 �i
=1
1� �
Re tardomediano = � ln 2ln�
El modelo GARCH(1; 1) puede escribirse:
y2t = ! + (�+ �) y2t�1 � ��y2t�1 � h2t�1
�+�y2t � h2t
�donde los dos últimos términos tienen esperanza condicional igual a cero,
por lo que este modelo es, en muchos aspectos, similar al modelo ARMA(1; 1).De hecho, el modo de identi�car una estructura GARCH(1; 1) es porque lasfunciones de autocorrelación simple y parcial de los cuadrados de yt tengan elaspecto de las funciones correspondientes a un proceso ARMA(1; 1): La funciónde autocorrelación simple del proceso GARCH(1; 1) es:
� (1) = �1� �� � �2
1� 2�� � �2
� (k) = (�+ �)k�1
� (1) ; k > 1
Como ocurría con el modelo ARCH(q), aunque la distribución condicionalde este proceso es Normal cuando lo es la innovación "t, su distribución incondi-cional no es conocida. Sabemos, sin embargo, que su esperanza es cero y suvarianza viene dada por la expresión anterior. Es fácil probar que sus momen-tos impares son nulos y, por tanto, la distribución es simétrica. Además, esleptocúrtica.
113

Si "t es Normal y �2+2��+3�2 < 1, entonces su coe�ciente de curtosis es:
Curtosis(yt) = 3 +6�2
1� �2 � 2�� � 3�2
si el denominador es positivo.
6.12.3 Modelo IGARCH
En algunas aplicaciones se tiene un valor de �(1) + �(1) muy cercano a launidad, lo que conduce al modelo GARCH(p; q) Integrado, denotado comoIGARCH(p,q) [Engle y Bollerslev (1986)]. En él, el polinomio autorregresivoen la ecuaciónde la varianza tiene una raíz exactamente igual a 1. En el casoparticular p = 1; q = 1, el modelo IGARCH puede escribirse:
yt = "tht
h2t = ! + h2t�1 + ��y2t�1 � h2t�1
�; t = 1; 2; :::
lo que hace que un shock en la varianza condicional sea persistente, nodesapareciendo nunca su efecto, a diferencia de lo que ocurre en el modeloGARCH(1; 1): Además, la varianza no muestra reversión a la media, por lo quetranscurren períodos largos antes de que la varianza vuelva a tomar su valorpromedio. Esto es totalmente paralelo a la diferencia que existe entre modelosARMA y ARIMA en lo relativo a las respuestas a una innovación transitoria.El proceso puede escribirse también,
y2t = ! + h2t�1 + ��y2t�1 � h2t�1
�+�y2t � h2t
�; t = 1; 2; :::
Este proceso no es débilmente estacionario, puesto que su varianza incondi-cional no es �nita. Sin embargo, si !>0, el proceso es estrictamente estacionarioy ergódico [Nelson (1990)].
6.12.4 Predicción de la varianza futura
En esta sección desarrollamos epxresiones analíticas para el cálculo de la predic-ción k-períodos hacia delante, de la varianza
6.12.5 Modelo ARCH(p)
Teniendo en cuenta la expresión de su varianza incondicional, el modeloARCH(q)puede representarse,
h2t � �2y =qXi=1
�i�y2t�i � �2y
�;
por lo que,
114

Eth2t+1 = �2y +
q�1Xi=0
�i�y2t�i � �2y
�;
Eth2t+2 = �2y + �1
�y2t�1 � �2y
�+
q�1Xi=2
�i�y2t�i � �2y
�En general,
Eth2t+1 = �2y +
q�1Xi=0
�i�Eth
2t�i � �2y
�;
donde Eth2s = h2s para s � t, donde h2s denota el valor ajustado para lavarianza condicional en el período s en la estimación del modelo ARCH.
6.12.6 Modelo AR(1)-ARCH(1)
Escribiendo la ecuación que representa la evolución temporal de yt en este mod-elo en un instante de tiempo futuro, tenemos,
yt+k = �kyt +
kXi=1
�k�i"t+1
de modo que la predicción óptima de la varianza condicional de yt+k en elinstante t es,
V art yt+k = �0+�1Et�h2t+i�1 � �2
�= �2
k�1Xi=0
�2i+�k�11
�h2t+1 � �2
� k�1Xi=0
�2i��i1
que es claramente dependiente del conjunto de información disponible en elinstante t. Sin embargo, al aumentar el horizonte de predicción, la dependenciarespecto de h2t+1��2 va reduciéndose, y la expresión de predicción de la varianzapuede aproximarse por,
V art yt+k = �2k�1Xi=0
�2i
que es la expresión que utilizaríamos para prever la varianza incondicionalen ausencia de estructura ARCH en la innovación del proceso.
6.12.7 Modelo GARCH(1,1)
Mediante sucesivas iteraciones, es fácil probar [Engle y Bollerslev (1986)] que lapredicción de la varianza que se deduce de un modelo GARCH(1; 1), a partirde la predicción un período hacia adelante, es:
115

Eth2t+k =
!
1� �� � + (�+ �)k�1
�Eth
2t+1 �
!
1� �� �
�que converge, según se aleja el horizonte de predicción, a la varianza incondi-
cional, !1���� .
Las predicciones de volatilidad que se obtienen de un modelo como éstepueden utilizarse para valorar una opción utilizando la fórmula de Black-Scholes.Para ello, una vez obtenidas las predicciones de la volatilidad diaria desde elinstante actual hasta el vencimiento de la opción, obtendríamos la volatilidadmedia que, anualizada, utilizaríamos en la expresión de Black-Scholes:
1
T � t
T�tXk=1
Eth2t+k =
!
1� �� � +1
T � t
T�tXk=1
(�+ �)k�1
�Eth
2t+1 �
!
1� �� �
�=
=!
1� �� � +�Eth
2t+1 �
!
1� �� �
�1
T � t (�+ �)1� (�+ �)T�t
1� �� �
En el modelo IGARCH(1; 1), la predicción de la varianza es:
Eth2t+k = ! (k � 1) + h2t
Eth2t+k = !k + �y2t + (1� �)h2t
que no converge a la varianza condicional, pues crece linealmente con el hor-izonte de predicción. De hecho, puede observarse en esta expresión que unaperturbación en la varianza del instante T , incluso si resulta ser de caráctertransitorio, se extrapola a las predicciones de la volatilidad a todos los hor-izontes.Sin embargo, Kleigbergen y Van Dijk (1993) han sugerido que, tantoen el modelo GARCH como en el IGARCH, las predicciones de la varianza seobtengan mediante simulación del modelo.
6.12.8 Modelo EGARCH(p,q)
Los modelos anteriores recogen adecuadamente las propiedades de distribucionesde colas gruesas, y de agrupamiento de volatilidades, pero son simétricos: enellos, la varianza condicional depende de la magnitud de las innovaciones re-tardadas, pero no de su signo. Para recoger los efectos apalancamiento ob-servados en series �nancieras fue propuesto el modelo exponencial GARCH, oEGARCH(p; q):
yt = "tht
lnh2t = ! +
qXi=1
�i lnh2t�i +
pXj=1
�jg ("t�j)
116

donde los "t tienen todos distribución N(0,1), y carecen de correlación se-rial, y g (") = �" + � (j " j �E (j " j)) ; de modo que ln(h2t ) sigue un procesoARMA(q; p), que debe satisfacer las condiciones de estacionariedad habitualesen estos modelos. Generalmente, se utiliza en esta formulación el error es-tandarizado, es decir, dividido por su desviación típica condicional. En tal caso,
E (j " j) =q
2� :12 La sucesión g ("t) es independiente, con esperanza cero y
varianza constante, si es �nita.La persistencia en volatilidad viene indicada por el parámetro �, mientras
que � mide la magnitud del efecto apalancamiento. En este modelo se espera que� < 0, lo que implicaría que innovaciones negativas tuviesen un mayor impactosobre la volatilidad que innovaciones positivas de igual tamaño. El término en�"t permite la existencia de correlación entre el término de error y las varainzascondicionales futuras. Si, por ejemplo, � = 0 y � < 0, entonces un "t negativoharía que el error fuese negativo, y que la innovación en el proceso de varaiznafuese positiva. Por último, la innovación en la varianza condicional es lineal atrozos en "t con pendientes �i (� + �) cuando "t es positivo, y �i (� � �) cuando"t es negativo, lo que genera la asimetría en la varianza condicional.Como caso particular, cuando es Normal, la ecuación de la varianza en el
modelo EGARCH(1; 1) es:
yt = "tht
lnh2t = ! + � lnh2t�1 + �"t�1 + ��j "t�1 j �
p2=�
�puesto que, en tal caso, E ("t) =
p2=�, que es un proceso estacionario si
j � j< 1, y como varianza condicional,
V art�1yt = e!
1��
como puede verse tomando esperanzas en la ecuación que de�ne el proceso.Por otra parte, la esperanza y varianza incondicionales o marginales pueden
aproximarse a partir de:
E�ln y2t
�= �1; 27 + !
1� �
V ar�ln y2t
�=
�2
2+ 2 + �2
�1� 2
�
�1� �2
12
E j "t j=Z 1
�1j "t j
1p2�e�"
2t=2d"t = 2
Z 1
0
1p2�e�udu =
= 21p2�
�e�ut j10
�=
r2
�
where we have made the change of variable "2t =2 = ut
117

Las expresiones para la predicción de la varianza s períodos hacia adelanteson bastante complejas [ver Ruiz (1994) o Nelson (1991)] para el caso del modeloEGARCH(1; 0)].
6.12.9 Otras especi�caciones univariantes en la familia ARCH
En todas las especi�caciones que siguen, mantenemos la hipótesis simpli�cadorade que carecemos de variables epxlicativas para yt: En caso contrario, h2t repre-sentaría la varianza condicional de "t; on de yt:El modelo GARCH(1; 1) no recoge a plena satisfacción las característica
de asimetría y curtosis que se observan en series �nancieras. Para resolverel problema de la curtosis, suele utilizarse una distribución t en lugar de unadistribución Normal para las innovaciones. Por otra parte, existe una versiónasimétrica del modelo GARCH (Engle 1990, Review of Financial Studies), elmodelo AGARCH, que trata de recoger de modo más apropiado la asimetríade las series �nancieras. El modelo AGARCH(1; 1) es:
yt = "tht
h2t = ! + � (yt�1 + �)2+ �h2t�1
con ! > 0; � > 0; � > 0:
En este modelo, � < 0 signi�ca que los shocks negativos sobre los rendimien-tos incrementan más la volatilidad condicional que los shocks positivos, lo queconstituye el efecto apalancamiento, que es habitual en los mercados �nancieros(Black (1976), Christie (1982)), para lo que también fue propuesto el modeloque consideramos a continuación.Taylor (1986) y Schwert (1989a,b) han propuesto que sea la desviación típica
quien dependa del valor absoluto de los residuos:
yt = "tht
h2t = �0 +
qXi=1
�i j "t�i j +pXi=1
�jh2t�j ; �0 > 0; �i; �j � 0;
qXi=1
�i +
pXi=1
�j < 1
Alternativamente, Higgins y Bera (1992) han propuesto una clase de modelosmás general, denominada NARCH (Non-linear ARCH):
yt = "tht
h t = �0 +
qXi=1
�i j "t�i j +pXi=1
�jh t�j ; �0 > 0; �i; �j � 0;
qXi=1
�i +
pXi=1
�j < 1
que, para =1, genera el modelo anterior.Si este modelo se modi�ca para pasar a:
118

yt = "tht
h t = �0 +
qXi=1
�i j "t�i � k j +pXi=1
�jh t�j ; �0 > 0; �i; �j � 0;
qXi=1
�i +
pXi=1
�j < 1
para alguna constante no nula k, las innovaciones en t dependerán deltamaño, pero también del signo, de las innovaciones pasadas.La formulación del modelo NARCH con =2 es un caso especial del modelo
ARCH Cuadrático(QARCH ) con q = 1; p = 1, introducido por Sentana (1991),en el que la varianza condicional se modeliza a través de una forma cuadráticade las innovaciones retardadas:
yt = "tht
h2t = ! + �y2t�1 + �yt�1;
que, con el objeto de garantizar la no-negatividad de la varianza condicional,puede escribirse en función de parámetros b; c; d, tales que:
�1 = d > 0; ! = b2d+ c > 0; � = �2bd ? 0por lo que eligiendo c > 0; d > 0 se garantiza �1 > 0; ! > 0; mientras que �
tendrá el mismo signo que b:La varianza incondicional derivada de este modelo se obtiene tomando es-
peranzas en la ecuación de h2t , teniendo:
Eh2t = ! + �Ey2t�1 + �Eyt�1
que implica,
V ar(yt) = ! + �V ar (yt�1)
ya que Eyt�1 = 0: Suponiendo estacionariedad, llegamos a,
V ar yt =!
1� �El modelo QARCH(1; 1) puede generalizarse al modelo GQARCH(1; 1),
que recoge bastante apropiadamente las características de volatilidad de losrendimientos �nancieros:
yt = "tht
h2t = ! + �y2t�1 + �yt�1 + �h2t�1;
que comprende como caso particular al modelo GARCH(1; 1) cuando � = 0.La varianza incondicional que se deriva de este modelo es igual a la del modeloGARCH(1; 1);
119

V ar yt =!
1� �� �Ambos modelos generan una asimetría igual a cero. Genera una mayor
curtosis el modelo generalizado GQARCH(1; 1).Una versión sencilla de dicho modelo es el ARCH asim�etrico (AARCH)
[Engle (1990)], siendo el modelo AARCH(1,1):
h2t = ! + �y2t�1 + �yt�1 + �h2t�1;
donde un valor negativo de signi�ca que rendimientos positivos incrementanla volatilidad menos que rendimientos negativos (apalancamiento).Otra especi�cación es el modelo Non-linear asymmetric GARCH, o NA-
GARCH. El modelo NAGARCH(1; 1) es
h2t = ! + ��"t�1 +
pht�1
�+ �"t�1 + �h
2t�1;
Un último modo de introducir efectos asimétricos es a través de la especi�-cación:
h t = ! +
qXi=1
��+i I ("t�i > 0) j "t�i j +�
�i I ("t�i � 0) j "t�i j
�+
pXj=1
�jh t�j
donde I denota una función indicatriz que toma el valor 1 cuando se dala condición que aparece dentro del paréntesis, y toma el valor cero en casocontrario.El modelo Threshold ARCH (TARCH) [Zakoian (1990)] corresponde al
caso =1,
ht = ! +
qXi=1
��+i I ("t�i > 0) j "t�i j +�
�i I ("t�i � 0) j "t�i j
�+
pXj=1
�jht�j
Glosten, Jagannathan y Runkle (1993) proponen trabajar con =2. Sumodelo, conocido por sus iniciales, GJR, permite una respuesta cuadrática dela volatilidad a las sorpresas recibidas en el mercado, con distintos coe�cientespara las malas noticias y para las buenas noticias, a la vez que mantiene lahipótesis de que la menor volatilidad se alcanzará cuando no haya sorpresas,
h2t = ! +
qXi=1
��+i I ("t�i > 0) "
2t�i + �
�i I ("t�i � 0) "2t�i
�+
pXj=1
�jh2t�j
En realidad, no es preciso incluir las dos variables indicadores, pudiendoutilizarse,
120

h2t = ! +
qXi=1
��i"
2t�i + �
�i I ("t�i � 0) "2t�i
�+
pXj=1
�jh2t�j
Los parámetros � no son los mismos en ambos modelos, si bien existe unarelación entre ambos. En el primer caso, �+i mide el efecto de una innovaciónpasada negativa, mientras ��i mide el efecto de una innovación pasada positiva;en el segundo caso, el efecto de una innovación pasada negativa es �i + ��imientras que el de una innovación positiva es �i: Un valor positivo de �
�i en esta
representación indicaría que una innovación negativa genera mayor volatilidadque una innovación positiva de igual tamaño, y la interpretación contraria setendría para un valor negativo de ��i .En el caso q = p = 1; se tendría, con esta segunda formulación,
h2t = ! + (�+ Dt�1) "2t�1 + �h
2t�1
donde el signo del parámetro es libre mientras que ! > 0; �; � � 0; [verEngle y Ng (19xx)], y la variable �cticia Dt se de�ne igual a 1 si "t < 0; e iguala cero en caso contrario. La varianza incondicional de este proceso es,
V ar yt =!
1� �� � � =2Este modelo incluye como caso particular al modelo GARCH(1; 1) cuando
=0. Cuando 6= 0, el modelo explica posibles asimetrías en la varianza de yt :valores positivos de los parámetros ��i implican mayores respuestas de la volatili-dad ante innovaciones negativas (malas noticias) que ante innovaciones positivas(buenas noticias), mientras que lo contrario ocurre para valores negativos de losparámetros ��i . Sin embargo, en mercados de renta �ja, la interpretación debuenas y malas noticias es la opuestas, por lo que cabría esperar coe�cientes ��ipositivos.Una representación bastante genérica, propuesta por Henstchel (1995), es,
h�t � 1�
= ! +
qXi=1
�iht�1 [f ("t�i)]�+
pXi=1
�ih�t�1 � 1
�
f ("t�i) = j "t � b j �c ("t � b)
en la que se sustituye h�t �1� por lnht cuando � = 0: De esta formulación
pueden obtenerse muchas especi�caciones como casos particulares. Así,
� � = � = 2 y b = c = 0) GARCH
� � = � = 2 y b = 0) GJR�GARCH
� � = � = 1 y b = 0; j c j� 1) TARCH
� � = � = 1; j c j� 1) AGARCH
121

� � = 0; � = 1 y b = 0) EGARCH
� � = � 6= 0 y b = c = 0) NARCH
� � = � = 2 y c = 0) NAGARCH
� � = � 6= 0 y c = 0) Non� linear GARCH [Engle�Ng(1993)]
� � = � 6= 0 y b = 0; j c j� 1) APARCH(Asymmetric Power Arch)[Ding et al(1993)]
Otros dos modelos propuestos recientemente son el Structural ARCH (STARCH),de Harvey, Ruiz y Sentana (1992), y el Switching ARCH (SWARCH) [Cai,Journal of Business and Economic Statistics (1994)], que postula que la variableen estudio se ajusta a una variedad de modelos ARCH, entre los cuales se muevede acuerdo con la estructura de una cadena de Markov, lo cual puede ser útilpara recoger episodios como el hundimiento de los mercados de valores obser-vados en octubre de 1987 y agosto de 1998 [Campbell y Harrtschell, Journal ofFinancial Economics (1992)].
6.13 Modelos ARCH en media (ARCH-M)
Por último, en todos estos modelos pueden introducirse medias no nulas, lo queconduce a los modelos ARCH de regresión. Para ello, la primera ecuación sesubstituye por,
yt = �t + ut = x0t� + ut
ut = "tht
En particular, resulta de gran interés contrastar si, cuando yt es la rentabil-idad de un activo o mercado, una de las potenciales variables explicativas xtes precisamente la varianza condicional o la desviación típica condicional esti-madas, ht, con coe�ciente positivo, lo que sugeriría que la rentabilidad del activoaumenta con el nivel de riesgo que impone al inversor.En tal caso, tenemos los modelos denominados en media: ARCH-M y
GARCH-M o sus variantes [Engle, Lilien, Roobins (1987)], en los que una vari-able explicativa es h2t , o ht. La presencia de esta variable introducirá auto-correlación en el proceso de rentabilidades, yt, a diferencia de los procesos sinestructura en media que hemos analizado en las secciones precedentes.En general, estos modelos son del tipo,
�t (�) = �0 + �g�h2t (�) ; �
�o,
�t (�) = x0t� + �g�h2t (�) ; �
�
122

donde suponemos que g es una función monótona de la varianza condicional,con g (�; �) = 0; es decir, que la función es no nula unicamente si la varianzacondicional es cambiante en el tiempo.La interpretación del término �g
�h2t (�) ; �
�es de una prima de riesgo, por la
que un incremento en la varianza de la rentabilidad conduce a un aumento en larentabilidad esperada. La posible existencia de tales primas en los mercados dedivisas, así como en la formación de la estructura temporal de tipos de interésha sido y es motivo de un amplio númeor de estudios.Para analizar las propiedades de este tipo de modelos, consideremos una
versión sencilla,
yt = �h2t + "t; con "t j t�1 � N(0; h2t )
h2t = �0 + �1"2t�1
que permite escribir,
yt = ��0 + ��1"2t�1 + "t
donde "t es un proceso ARCH(1). A partir de esta expresión, utilizandoE�"2t�1
�= �0= (1� �1) ; se tiene,
E (yt) = ��0
1� �1que puede interpretarse como la esperanza incondicional de la rentabilidad
de mantener un activo con riesgo.De modo análogo, tenemos,
V ar (yt) =�0
1� �1+
(��1)22�20
(1� �1)2 (1� 3�21)(40)
Si no hay prima por riesgo, tendríamos: V ar (yt) = �0= (1� �1) : Por tanto,el segundo componente en (40) indica la presencia de una prima de riesgo, quehace que la dispersión de yt aumente. Finalmente, el efecto ARCH -en mediaintroduce autocorrelación en yt; puesto que, én el caso del modelo,
yt = �ht + "t; con "t j t�1 � N(0; h2t )
h2t = �0 + �1"2t�1
se tienen los coe�cientes de autocorrelación,
�1 = Corr(yt; yt�1) =2�31�
2�0
2�21�2�0 + (1� �1) (1� 3�21)
�k = Corr(yt; yt�k) = �k�11 �1; k = 2; 3; ::::
123

Examinando las expresiones de �1 y �2 se aprecia que la región admisiblepara (�1; �2) es muy restrictiva.En aplicaciones prácticas, las funciones más utilizadas son: g
�h2t�= h2t ; g
�h2t�=p
h2t ; g�h2t�= ln
�h2t�:
Bollerslev, Engle y Woolridge (1988) consideraron la versión multivariantede este modelo en el contexto del modelo de valoración de activos, CAPM.
6.14 Contrastes de estructura ARCH
Dada una relación del tipo: yt = xt� + "t;el contraste de los Multiplicadores deLagrange (ML) propuesto por Engle (1982) considera la hipótesis nula:
"t j t�1 � N(0; �2)
donde It denota la información disponible en el instante t, y siendo xt unvector de variables debilmente exógenas, o retardos de la variable dependiente.El interés de un contraste del tipo de los Multiplicadores de Lagrange (ML)reside en que, como es conocido, requiere únicamente la estimación del modelorestringido y, en este caso, la estimación del modelo bajo la hipótesis nula es muysimple. La hipótesis alternativa es que los residuos tienen una estructura de tipoARCH(q). Engle (1984) probó que T veces el R2 de la regresión del cuadrado delos residuos obtenidos bajo la hipótesis nula, "2t , sobre una constante y q retardosde los propios residuos al cuadrado, "2t�1, "
2t�2; :::; "
2t�q sigue, bajo la hipótesis
nula, una distribución chi-cuadrado, con un número de grados de libertad igualal número de retardos incluidos en dicha regresión auxiliar, q. La intuición delcontraste es bastante evidente: si la varianza de la perturbación es constante,entonces no podrá ser prevista a partir de los valores de los residuos pasados,cuyas �uctuaciones serán puramente aleatorias. Si, por el contrario, hay efectosARCH, residuos recientes de elevado valor absoluto tenderán a sugerir un residuocorriente de elevada magnitud. Existe capacidad predictiva en la magnitud delos residuos pasados acerca de la magnitud de los residuos futuros. Dicho deotro modo, el valor absoluto del residuo mostrará autocorrelación temporal.Sin embargo, la posible omisión de un regresor en el modelo de la media
condicional, así como no tener en cuenta alguna no-linealidad o cierta autocor-relación, conduciría a un rechazo de la hipótesis nula, sugiriendo la presencia deestructura ARCH, incluso si ésta no existe, disminuyendo con ello el tamañodel contraste. Otra forma de llevar a cabo este contraste consiste en excluir laconstante de la regresión auxiliar, restar una estimación de la varianza incondi-cional de la variable dependiente �2, y utilizar la mitad de la Suma Residual(suma de cuadrados de residuos) como estadístico de contraste. Otra posibili-dad es un contraste del tipo portmanteau, como el de Ljung y Box (1978), para"2t .Como los parámetros del modelo ARCH(q) deben ser positivos, el contraste
debería ser de una cola, aunque para un orden q superior a 1, no es sencillasu puesta en práctica [Demos y Sentana (1991)]. Otra di�cultad es que elcontrasteML no tiene siempre mucha potencia cuando la alternativa es el modelo
124

GARCH(1; 1), debido a la imposibilidad de identi�car �1 y �1 por separadocuando el modelo GARCH es próximo al modelo incluido en H0:; De hecho,el contrate ML para GARCH(1; 1) es idéntico al correspondiente al modeloARCH(1), y algo similar ocurre para cualquier modelo GARCH(p; q). Porotra parte, no es válido utilizar un test de Wald en el modelo GARCH(1; 1),que se basaría en el ratio t del coe�ciente �1 pues, en presencia de estructuraARCH, dicho estadístico no sigue una distribución t de Student. El contrasteRV tiene la di�cultad de que la distribución del estadístico bajo la hipótesisnula no es fácil de caracterizar, pero parece ser muy potente.Por último, un contraste útil es el de insesgadez de las previsiones de volatil-
idad generadas por el modelo, para lo que se estima por mínimos cuadradosuna regresión de y2t sobre las varainzas h
2t , en la que se esperaría encontrar una
pendiente igual a 1 y una ordenda en el origen no signi�cativa. Desviaciones deesta hipótesis conjunta pueden indicar preblemas de especi�cación en el modelode la varianza condicional [Pagan y Schwert (1990)].
6.15 Contrastes de especi�cación
Los contrastes de Normalidad de la innovación "t pueden basarse en los residuosnormalizados, una vez estimada la serie temporal de las varianzas condicionales.Tests habituales son: Jarque-Bera y Kolmogorov-Smirnov. También puede pen-sarse en un contraste mediante la �2 de Pearson.La ausencia de sesgo en las estimaciones puede contrastarse mediante una
regresión del cuadrado de la variable sobre una constante y las estimaciones dela varianza [Pagan y Schwert (1990)],
y2t = b0 + b1Et�1y2t
Bajo una correcta especi�cación, los residuos de esta regresión no deberíanpresentar autocorrelación. Como las predicciones de la volatilidad un períodohacia adelante deberían ser insesgadas, puede contrastarse la hipótesis nula:H0 : b0 = 0; b1 = 1: Además, el R2 de esta regresión puede utilizarse como unamedida de bondad de ajuste.Para poner en práctica las posibles desviaciones de Normalidad que puedan
detectarse, se ha propuesto sustituir el supuesto de Normalidad en la estimaciónde Máxima Verosimilitud por las distribuciones t de Student, la distribuciónestándar generalizada (DEG), que incluye a la anterior como caso particular, yla distribución t generalizada, que incluye a ambas.En general, los contrastes a llevar a cabo consisten en:
� a) contrastes de existencia de autocorrelación en media en los errores delmodelo mediante técnicas Box-Jenkins,
� b) contrastes de existencia de efectos ARCH no modelizados mediantetécnicas Box-Jenkins aplicadas a los cuadrados de los residuos del modelode la media,
125

� c) contrastes tipo Wald y de razón de verosimilitudes sobre la especi�-cación de la ecuación de la media,
� d) contrastes de efectos asimétricos en la ecuación de la varianza, medianteel uso de variables �cticias de signo,
� e) contrastes de variables omitidas en la ecuación de la varianza,
� f) contraste de posible existencia de efectos ARCH en media.
La familia de estadísticos Ljung-Box para el contraste de autocorrelaciónpuede utilizarse tanto sobre los errores como sobre sus cuadrados (en este últimocaso como contraste de estructura ARCH). Su forma es,
Q(k) = T
kXi=1
T + 2
T + i�2i
siento �i el coe�ciente de autocorrelación de orden i. Bajo la hipótesis nula,Q(k) se distribuye como una chi-cuadrado con k grados de libertad.Un contraste usualmente potente es el de los Multiplicadores de Lagrange,
que utiliza una regresión de los residuos al cuadrado sobre una constante y sus kprimeros retardos. El producto del tamaño muestral por el R2 de dicha regresiónse distribuye como una �2 con k grados de libertad. Sin embargo, este contrasteno permite discriminar entre estructuras ARCH y GARCH.Estos contrastes se utilizan asimismo para evaluar un modelo ARCH ya
estimado. En ese caso, hay que utilizar, lógicamente, los residuos de la ecuaciónde la media, estandarizados por la desviación típica condicional estimada, ht:Los contrastes tipo Wald para variables omitidas consisten en estimar el
modelo más general, y contrastar la signi�cación conjunta de los parámetros quedistinguen el modelo restringido del modelo general. El contraste de razón deverosimilitudes estima ambos modelos: restringido y sin restringir, y comparala signi�catividad de la diferencia en los logaritmos de los máximos valoresalcanzados por la función de verosimilitud en ambos casos. Para ello, se utilizael resultado:
RV = �2 (lnLR � lnLSR)
se distribuye asintóticamente, bajo la hipótesis nula, como una �2 con unnúmero de grados de libertad igual al número de restricciones que se contrastan.Para el contraste de asimetrías se utilizan los contrastes de signo propp-
puestos por Engle y Ng (1993): De�niendo unas variables �cticias S�t�1 quetoma el valor 1 si el residuo del período anterior "t�1 fue negativo, y el valorcero en caso contrario, y S+t�1;que toma el valor 1 si el residuo del período an-terior "t�1 fue positivo, y el valor cero en caso contrario, y de�niendo el residuoestandarizado zt (�) =
"t(�)ht(�)
se estiman las regresiones,
126

Modelo I:
z2t = �0 + �1S�t�1
H0 : �1 = 0;
Modelo II:
z2t = �0 + �1S�t�1"t�1
H0 : �1 = 0;
Modelo III:
z2t = �0 + �1S+t�1"t�1
H0 : �1 = 0;
Modelo IV:
z2t = �0 + �1S�t�1 + �2S
+t�1"t�1 + �3S
�t�1"t�1
H0 : �1 = �2 = �3 = 0;
utilizando un estadístico tipo t en los tres primeros casos, y un estadísticotipo F en el último caso. Dada la posible existencia de autocorrelación y het-erocedasticidad residual en los residuos estandarizados, dede utilizarse en loscontrastes las varianzas de los parámetros estimadas del modo propuesto porNewey-West, que resultan robustas a la presencia de estos dos efectos.Las correlaciones entre los residuos estandarizados y sus cuadrados pueden
sugerir asimismo posibles asimetrías, y se utilizan a tal �n.
6.15.1 Estimación
La estimación se lleva a cabo, generalmente, por máxima verosimilitud, para loque suponemos una determinada densidad f(zt (�) ; �) para el término de errortipi�cado,
zt (�) ="t (�)
ht (�)=yt � �t (�)[h2t (�)]
1=2
que tiene esperanza cero y varianza uno. Dado un vector de observacionesfy1; y2; :::; yT g, el logaritmo de la función de verosimilitud para la observación tes:
lt(yt; �) = ln
�f(zt (�) ; �)�
1
2ln�h2t (�)
��
127

donde el último término es el Jacobiano de la transformación que pasa delas innovaciones estandarizadas a las observaciones muestrales, que en el casomultivariante se convertirá en:
lt (yt; �) = lnhf�"t (�) [�t (�)]
�1; ��i� 12ln j �t (�) j
donde � es una matriz no singular, de igual dimensión que �; tal que ��0 =�: Es bien sabido que para toda matriz de�nida positiva � existe tal matriz�. Si la matriz � es diagonal, aunque con elementos diferentes a lo largo de ladiagonal principal, entonces � es la matriz diagonal que tiene por elementos laraiz cuadrada de los elementos en la diagonal de �: Como los elementos de estaúltima, los h2t (�) son todos positivos, no hay ninguna di�cultad en este tipo decálculo.Por otra parte, utilizando un argumento estándar para la descomposición
del error de predicción, la función de verosimilitud para la muestra completapuede escribirse como la suma de los logaritmos de la función de verosimilitudcondicional:
LT (y1; y2; :::; yT ) =TXt=1
lt(yt; ) (41)
cuya maximización generará estimadores de MV de los parámetros del mod-elo, = (�; �) :Si la función de densidad condicional y las funciones que recogen los modelos
de la media y la varianza son diferenciables, el estimador de MV se obtieneresolviendo el sistema de m+ k ecuaciones:
ST (y1; y2; :::; yT ; ) =
TXt=1
st(yt; ) = 0 (42)
donde st(yt; ) = r lt(yt; ) es el vector score correspondiente a la obser-vación t. Si denotamos por f 0 (zt (�) ; �) la derivada parcial de la función frespecto de su primer argumento, tendremos,
r�lt(yt; ) =f 0 (zt (�) ; �)
f (zt (�) ; �)r�zt (�)�
1
2
r�h2t (�)h2t (�)
expresión en la que hay que incorporar:
r�zt (�) = �r�"t (�)ph2t (�)
� 12"t (�)
r�h2t (�)[h2t (�)]
3=2
y la resolución del conjunto de m+k ecuaciones (42) habrá de ser numérica.Para proceder con la estimación MV hay que establecer una determinada
hipótesis acerca del tipo de distribución que sigue la innovación. Si se consideraque obedece a una distribución Normal, tenemos:
128

f (zt (�)) =1p2�exp
"�zt (�)
2
2
#=
1p2�exp
��12(yt � �t (�))
2
�En este caso, como la distribución está totalmente determinada por sus dos
primeros momentos, sólo la media y varianza condicionales aparecen en la fun-ción de verosimilitud (41) ; por lo que = �; y la función score adopta la forma:
st (yt; �) = r��t (�)"t (�)ph2t (�)
+1
2
r�h2t (�)ph2t (�)
""t (�)
2
h2t (�)� 1#
En este caso, puede probarse [Hamilton (1994)] que la expresión analíticadel score es,
st (yt; �) ="t (�)
2 � h2t (�)2 [h2t (�)]
2
266664�2Pmj=1 �j"t�jxt�j
1"2t�1:::"2t�m
377775+�xt"t=h
2t
0m+1
�
donde ambos vectores columna tienen dimensión qx1, siendo q = k+m+1;con k el número de variables explicativas en el modelo de la media, y m elnúmero de retardos del modelo ARCH(m).El gradiente de la función de verosimilitud puede entonces expresarse analíti-
camente como la suma de los scores,
r lnL =TXt=1
st (yt; �)
o puede también evaluarse numéricamente a través de derivadas numéricasde la función de verosimilitud.Es habitual suponer que el error del modelo tiene distribución condicional
Normal, en cuyo caso,
lnL = �T2ln 2� � 1
2
TXt=1
lnh2t �1
2
TXt=1
"2th2t
en el que hay que substituir las expresiones de "t y h2t que se obtienen de laespeci�cación del modelo para la esperanza y la varianza condicionales de yt: Enrealidad, las funciones de densidad que entran en esta expresión de la funciónde verosimilitud son funciones de densidad condicionales, debido a la presenciade h2t = g ("t�1; "t�2; :::) en la densidad correspondiente a "t: Así, el logaritmode la función de verosimilitud condicional en las primeras m observaciones es,
129

TXt=m+1
ln f(yt = xt; xt�1; :::; yt�1; :::) = �T
2ln(2�)�1
2
TXt=m+1
ln(h2t )�1
2
TXt=m+1
ln
"�yt � �t�1 (�)
�2h2t
#
siendo m el orden de un proceso ARCH; o el número de retardos de lavarianza condicional en el caso de un modelo GARCH. En el caso de un modeloARCH, para calcular el valor numérico de la función de verosimilitud, se utiliza,
h2t = !+�1"2t�1+:::+�m"
2t�m = !+�1
�yt�1 � �t�2 (�)
�2+:::+�m
�yt�m � �t�m�1 (�)
�2Por ejemplo, en el caso de un simple modelo ARCH(1), con
yt = "t; "t � N(0; h2t )
h2t = �0 + �1"2t�1
la función logaritmo de la función de Verosimilitud condicional es,
lnL =
TXt=m+1
ln f(yt = xt; xt�1; :::; yt�1) = �T
2ln 2��1
2
TXt=1
ln��0 + �1y
2t�1��12
TXt=1
y2t�0 + �1y2t�1
En el caso de un modelo GARCH(1; 1), utilizaríamos,
h2t = ! + �"2t�1 + �h2t�1 = ! + �
�yt�1 � �t�2 (�)
�2+ �h2t�1
a partir de un valor inicial h20 =!
1���� : En el caso de un modelo GARCHde orden superior, actuaríamos de modo aálogo, inicializando todos los retardosprecisos de la varianza condicional en el valor numérico de la varianza incondi-cional.Como se observa, las funciones de verosimilitud de los modelos ARCH son
no lineales en los parámetros del modelo, por lo que la estimación de MáximaVerosimilitud, que es el procedimiento de estimación habitualmente utilizado,requiere el uso de algoritmos numéricos de optimización. Para llevar a cabo talesprocedimientos, es preciso dar valores iniciales a los parámetros del modelo. Losparámetros de la ecuación del primer momento condicional de yt se obtienenmediante estimación de dicha ecuación, ignorando la presencia de estructuradel tipo ARCH.Para dar valores iniciales a los parámetros de la ecuación de la varianza
condicional, existen varias posibilidades: una posibilidad consistiría en tomarpara la constante la varianza incondicional obtenida para el término de errorde la ecuación de la media, que se ha estimado previamente para inicializar losparámetros de dicha ecuación. En este caso, habría que dar valores iniciales atodos los restantes parámetros de la ecuación de la varianza. Otra alternativaconsiste en dar valores razonables a los parámetros de la ecuación de la varianza,
130

como � = :10; � = :80 en el caso de un modelo GARCH(1; 1), pero entonceshay que dar a la constante ! un valor inicial: ! = (1 � � � �)�2", siendo �
2" la
varianza estimada para el término de error de la ecuación de yt:Si el modelo GARCH no tiene estructura ARCH en media, entonces la es-
timación por separado de los parámetros en la ecuación de la esperanza condi-cional y de los que entran en la ecuación de la varianza condicional es e�ciente.Ello se debe a que la matriz de información presenta una estructura diagonala bloques en ambos subvectores de parámetros. Esto no ocurre en el modeloEGARCH.Para tratar de recoger toda la leptocurtosis de la distribución empírica, se
utiliza en ocasiones la distribución t estandarizada con grados de libertad �>2:
f (zt (�)) =1p
� (� � 2)���+12
����2
� 1ph2t
1h1 + zt(�)
��2
i(�+1)=2donde � denota la función Gamma. La distribución t es simétrica alrededor
de cero, y converge a la Normal cuando � ! 1: Para valores �>4 tiene colasmás gruesas que la Normal, con coe�ciente de curtosis igual a 3(n� 2)=(n� 4),que es superior a 3. El logaritmo de la función de verosimilitud condicional enlas primeras m observaciones es,
TXt=m+1
ln f(yt = xt; xt�1; :::; yt�1; :::) = T ln
"���+12
��1=2�
��2
� (� � 2)�1=2#�12
TXt=m+1
ln(h2t )�
�� + 12
TXt=m+1
ln
"1 +
�yt � �t�1 (�)
�2h2t (� � 2)
#Se utiliza asimismo la distribución t-Generalizada, que depende de 2 parámet-
ros y es simétrica, con densidad absolutamente continua, con esperanza 0 yvarianza 1. Su función de densidad puede escribirse,
f ("t) =p
2{B�1p ;
12s
� �1 + j "t jp{p
��( 1p+ 12s )
donde p > 0; s > 0 son parámetros a estimar que han de satisfacer: p�4s > 0:
El parámetro { es { =q�( 1p )
q�( 1
2s )q�( 3p )
q�( 1
2s�2p )y B (:) ;� (:) denotan las funciones Beta
y Gamma, respectivamente.Se utiliza también la Distribución Generalizada de Error [Nelson (1991)]:
f (zt (�)) =�
�
1
21+1�
1
��1�
� exp��12j zt (�)
�j��; con � =
vuuut 1
22=n
��1�
���3�
�
131

que para �=2 coincide con la densidad Normal. Para �<2, esta distribucióntiene colas más gruesas que la Normal, mientras que para �>2 tiene colas más�nas que la distribución Normal. Esta densidad fue propuesta en un análisis derentabilidades diarias del mercado de valores, en exceso de las ofrecidas por elactivo sin riesgo. Para ello, Nelson (1991) especi�có el modelo
rt = a+ brt�1 + h2t + ut
con ut = "tht; siendo "t independiente, Normal(0,1). Suponiendo una es-tructura EGARCH(1; 1) para la varianza condicional, tendríamos,
lnh2t = ! + � lnh2t�1 + �"t�1ht�1
+ �
j "t�1ht�1
j �r2
�
!y, suponiendo una función de densidad generalizada, el logaritmo de la fun-
ción de verosimilitud sería,
lnL = T
�ln�
���1 +
1
�
�ln 2� ln �
�1
�
���12
TXt=1
"j�rt � a� brt�1 � �h2t
��ht
j#��12
TXt=1
lnh2t
donde, para evaluar la función lnL es preciso, una vez más, generar datospara la varianza condicional como en otros casos, utilizando iterativamente laexpresión que de�ne la varianza condicional del proceso EGARCH,
lnh2t+1 = ! + � lnh2t + �"tht+ �
j "thtj �r2
�
!con,
"t =rt � a� brt�1 � �h2t
ht
a partir de valores paramétricos (a; b; ; !; �; �; �) iniciales. Los valores ini-ciales de la varianza condicional (uno sólo en este caso), se �jan igual a suesperanza matemática, Eh2t =
!1�� .
En otros casos [Engle y González-Rivera (1991)] se ha propuesto utilizar unprocedimiento de estimación semiparamétrico.
6.16 Estimación por Cuasi-máxima verosimilitud
En muchos casos en el ámbito de los mercados �nancieros, la hipótesis de Nor-malidad del término de error de la ecuación de la media de una rentabilidadno es aceptable.Uuna posibilidad consiste en estiomar el modelo por máximaverosimilitud bajo un supuesto distinto acerca de la distribución de dicho tér-minon de error, ya sea mediante una distribución t de Student, una distribuciónGED, una mixtura de Normales, etc.. Alternativamente, si se supone Normal-idad en el cálculo de la función de verosimilitud, el estimador que resulta es de
132

Cuasi-máxima verosimilitud, que es consistente, pero no e�ciente. Todo lo quese precisa para este resultado es que las ecuaciones de la esperanza y varianzacondicionales se hayan especi�cado correctamente, lo cual puede resumirse enlas condiciones,
E�"2t=xt; yt�1; yt�2; :::
�= 0; V ar
�"2t=xt; yt�1; yt�2; :::
�= 1:
La pérdida de e�ciencia en la estimación se debe precisamente a la desviaciónrespecto de la Normal, de la verdadera distribución de probabilidad del términode error del modelo. En tal caso, debe utilizarse una estimación de la matriz decovarianzas de los parametros que sea robusta a desviaciones de Normalidad,como la propuesta por Bollerslev y Wooldridge (1992).Esta estrategia de estimación es similar a Máxima Verosimilitud, pero re-
quiere corregir las desviaciones típicas resultantes. La distribución asintóticadel estimador es,
pT�� � �
�! N(0; D�1SD�1)
donde,
S = p limT!1
1
T
TXt=1
st (�) st (�)0
siendo st (�) el vector score, mientras que la matriz D es,
D = �p limT!1
1
T
TXt=1
E
�@st (�)
@�0j xt; yt�1; yt�2; :::
�Ambas pueden estimarse consistentemente evaluando numéricamente el vec-
tor score bajo los parámetros resultantes en la estimación [ver Hamilton (1994)],obteniéndose desviaciones típicas asintóticamente robustas a errores de especi-�cación en la densidad del término de error, tomando raíces cuadradas del pro-ducto, 1
T D�1T ST D
�1T . Si el modelo está correctamente especi�cado y la dis-
tribución del término de error es normal, entonces S = D; y resulta la matirzde covarianzas asintótica habitual del estimador de Máxima Verosimilitud.
6.17 Contrastación de hipótesis
Crowder probó ya en 1976 que, bajo determinadas condiciones de regularidad, elestimador MV es consistente y tiene distribución asintótica Normal en modeloscon observaciones dependientes. Si la densidad condicional está correctamenteespeci�cada y el verdadero vector de parámetros 0 está en el interior del espacioparamétrico considerado, un argumento del tipo utilizado en el Teorema Centraldel Límite conduce a:
T 1=2� T � 0
�! N(0; A�10 )
133

siendo la matriz de covarianzas asintótica del estimador MV igual a la inversade la matriz de información, evaluada en el verdadero vector de parámetros:
A0 = �T�1TXt=1
E [r s (yt; 0)]
que es inferior a la matriz de covarianzas de cualquier otro estimador. En lapráctica, se obtiene un estimador consistente de A0 evaluando el análogo mues-tral en el vector estimado de parámetros T ; es decir, sustituyendo E [r s (yt; 0)]por r s
�yt; T
�. Además, las segundas derivadas tienen generalmente esper-
anza nula, y pueden omitirse. Por último, bajo el supuesto de que la densidadesté correctamente especi�cada, se tiene la igualdad A0 = B0; siendo:
B0 = T�1TXt=1
E�s (yt; 0) s (yt; 0)
0� (43)
es decir, que la esperanza del producto del gradiente por sí mismo propor-ciona asimismo un estimador de la matriz de covarianzas asintótica. Nueva-mente, esta expresión se evaluaría en el vector estimado de parámetros.En la estimación de modelos ARCH suelen utilizarse derivadas numéricas,
pues las derivadas analíticas son bastante complejas. El estimador propuestoen (43) tiene la ventaja de que sólo precisa derivadas de primer orden, pueslas derivadas numéricas de segundo orden suelen ser bastante inestables. Engeneral, el vector de parámetros de un modelo ARCH puede particionarse:�0=��01; �
02
�, donde el primer subvector es el que aparece en el modelo de la esper-
anza condicional, mientras que el segundo es quien aparece en la determinaciónde la varianza condicional. Es, además, posible probar que, en algunos casos,la matriz de información es diagonal a bloques con esta partición. Como con-secuencia, pueden calcularse estimadores asintóticamente e�cientes para uno delos subvectores, a partir de una estimación consistente para el otro. Así, puedeestimarse el modelo de la media por MCO (debe utilizarse un estimador consis-tente), para obtener un estimador asintóticamente e�ciente de los parámetrosde la varianza condicional a partir de los residuos MCO de la ecuación de lamedia. Sin embargo, la pérdida de e�ciencia en los coe�cientes del modelo dela media puede ser importante.Las desviaciones típicas habituales no son apropiadas, debido a la presencia
de heterocedasticidad, por lo que deben corregirse del modo sugerido por White(1980). En particular, la habitual desviación típica para los valores de la funciónde autocorrelación (1=T ) puede ser muy sesgada en presencia de estructurasARCH.La diagonalidad a bloques de la matriz de información no se cumple, sin
embargo, en el modelo EGARCH ni en los modelos ARCH-M. En estos cassos,para obtener una estimación consistente es preciso que las funciones que rep-resentan la meia y varianza condicionales estén correctamente especi�cadas, yestimadas simultáneamente.
134

Si se quiere contrastar una hipótesis nula de interés, del tipo: H0 : r ( 0) =0;siendo el rango l de la función r inferior a m+k; el estadístico de Wald adoptala forma:
WT = T:r� T
�0 ��r r
� T
��C�1T
�r r
� T
��0��1r� T
�siendo CT una estimación consistente de la matriz de covarianzas del vec-
tor de parámetros bajo la hipótesis alternativa. Bajo la hipótesis nula, y sise satisfacen las condiciones de regularidad, el estadístico de Wald tiene unadistribución chi-cuadrado con (m + k) � l grados de libertad, el número deparámetros bajo la hipótesis alternativa.También puede utilizarse un contraste de RV (Razón de verosimilitudes),
cuyo estadístico seguirá una distribución asimismo chi-cuadrado con (m+k)� lgrados de libertad, el número de restricciones (número de parámetros bajo lahipótesis alternativa).La contrastación de hipótesis acerca de parámetros de la ecuación de varianza
condicional está sujeta a dos di�cultades: a) en primer lugar, dichos parámetrosdeben ser positivos, por lo que, como ya hemos dicho, los contrastes e�cientesdeberían ser de una cola, b) en segundo lugar, existen a veces problemas deidenti�cación, a los que ya hemos hecho referencia, por lo que la matriz deinformación se hace singular. En el modelo GARCH(1; 1), bajo la hipótesisnula: H0 : �1 = 0; los parámetros ! y �1 no están identi�cados:De igual modo, en el modelo ARCH �M , el coe�ciente de la varianza (o
desviación típica) condicional está identi�cado sólo si dicha varianza es cam-biante en el tiempo, por lo que no es posible un contraste del tipo habitual parala hipótesis conjunta de presencia de efectos ARCH, junto con la signi�cacióndel coe�ciente de la ecuación de la media.Otra cuestión de indudable relevancia se re�ere a las propiedaddes en mues-
tras �nitas de los estimadores de máxima verosimilitud de modelos ARCH. Así,por ejemplo, con errores condicionalmente Normales, la estimación de �1 + �1resulta sesgada a la baja y asimétrica a la derecha en muestras �nitas. El sesgoen la suma de los coe�cientes proviene de un sesgo a la baja en la estimación de�1, junto con un sesgo al alza en la estimación de �1:
6.18 Modelos de varianza condicional como aproximacionesa difusiones.
Denotemos por Yt el precio de un activo, y por �t la volatilidad instantáneade su rendimiento. Consideremos la representación conjunta de la evoluciónseguida por (Yt, �t) a partir de valores iniciales (Y0, �0) por medio del procesoen tiempo continuo,
dYt = �Ytdt+ Yt�tdW1;t
d�ln�2t
�= ��
�ln�2t � �
�dt+ dW2;t (44)
135

donde W1;t y W2;t denotan movimientos brownianos independientes de lascondiciones iniciales, que satisfacen:�
dW1;t
dW2;t
��dW1;t dW2;t
�=
�1 �� 1
�dt
es decir, con correlación igual a �.Aunque los datos se observan únicamente a intervalos de tiempo discretos,
es muy útil formular representaciones continuas de los precios de un activo. Esútil, en particular, para análisis teóricos en la formación de precios de opciones.El lema de Ito permite escribir la ecuación anterior como:
dyt =
��� �2t
2
�dt+ �tdW1;t
donde yt = ln(Yt):Si un modelo teórico propone la representación acontinua anterior, ¿es posi-
ble formular un proceso ARCH cuyas realizaciones muestrales sean indistin-guibles de las generadas por el proceso de difusión cuando el intervalo de tiempotranscurrido entre observaciones sea muy reducido? Melino y Turnbull (1990)utilizan una aproximación de Euler para probar que la difusión (44) puede aprox-imarse por:
yt+h = yt +
��� �2t
2
�h+ h1=2�tZ1;t+h; t = h; 2h; 3h; ::: (45)
ln��2t+h
�= ln
��2t�� h�
�ln��2t�� �
�+ h1=2 Z2;t+h; t = h; 2h; 3h; :::
siendo (Z1;t; Z1;t) una variable aleatoria Normal bivariante, con vector deesperanzas (0,0), y matriz de covarianzas:
V ar
�Z1;tZ2;t
�=
�1 �� 1
�Este proceso converge, efectivamente, a la difusión de la que hemos partido,
cuando h tiende a cero. En efecto, es fácil ver que,
h�1Et
�yt+h � ytln��2t+h
�� ln
��2t� � = " �� �2t
2���ln��2t�� �
� #
h�1V art
�yt+h � ytln��2t+h
�� ln
��2t� � = � �2t �t�
�t 2
�que reproducen el proceso de media y la matriz de difusión en (44). Sin
embargo, este no es estrictamente un proceso ARCH, pues �2t es la varianzacondicional de yt+h � yt dada toda la realización continua del proceso (no ob-servable), pero no es la varianza condicional, dada la información reocgida aintervalos discretos de tiempo.
136

Para obtener un modelo ARCH aproximado a la difusión anterior, reem-plazamos la segunda ecuación del sistema (45) por:
ln��2t+h
�= ln
��2t�� h�
�ln��2t�� �
�+ h1=2g (Z1;t+h) ; t = h; 2h; 3h; :::
para una función g (:) medible, con E�j g (Z2;t+h) j2+�
�< 1 para algún
� > 0; y
V ar
�Z1;tg (Z1;t)
�=
�1 �
� 1 2
�(46)
Para completar la formulación de la aproximación ARCH, necesitamos unaespeci�cación para la función g(:). Puesto que,
E (j Z1;t j) =r2
�; E (Z1;t j Z1;t j) = 0; V ar (j Z1;t j) = 1�
2
�
una posible especi�cación es,
g (Z1;t) = �Z1;t +
s1� �21� 2=�
j Z1;t j �
r2
�
!que corresponde al modelo EGARCH.Alternativamente, podría haberse escogido,
g (Z1;t) = �Z1;t +
r1� �22
�Z21;t � 1
�que también satisface (46).También se puede contestar a la pregunta inversa: Dado un modeloARCH¿cuál
es el proceso de difusión que mejor lo aproxima? Para ello, consideremos, a modode ejemplo, una estructura de martingala con error GARCH(1; 1):
yt+h = yt + �thzt+h = yt + "t+h
y:
�2t+h = !h+�1� �h� �h1=2
��2t + h
1=2�"2t+h
que tiende a un modelo IGARCH(1; 1) cuando h! 0:Como se prueba en Nelson (1990a),
h�1Et
�yt+h � yt�2t+h � �2t
�=
�0! � ��2t
�
h�1V art
�yt+h � yt�2t+h � �2t
�=
��2t 00 2�2�4t
�para el que puede probarse que la difusión aproximada es,
137

dxt = �tdW1;t
d�2t =�! � ��2t
�dt+
p2��2tdW2;t
donde W1;t y W2;t denotan movimientos brownianos independientes, lo cualpuede utilizarse para estimar un proceso de difusión, y luego comparar parámet-ros.
6.19 Modelos de varianza condicional y medidas de volatil-idad
Las estructuras ARCH tienen el atractivo de recoger, de modo bastante ade-cuado, la agrupación de episodios de alta volatilidad que se observa en seriestemporales �nancieras de alta frecuencia.Foster y Nelson (1992) probaron que, incluso si la varianza no cambia a lo
largo de un mes, el procedimiento de utilizar promedios de rentabilidades diariasal cuadrado como estimador de volatilidad es ine�ciente y sesgado. Parkinson(1980) sugirió utilizar un estimador basado en los precios alto y bajo para aprox-imar la varianza de un proceso de camino aleatorio continuo, lo que se demuestramás e�ciente que el uso de observaciones de �nal de período. Otra alternativaes el cálculo de volatilidades implícitas a través de la fórmula de valoraciónde opciones de BS, pero si la varianza condicional del precio de la opción escambiante en el tiempo, no es evidente qué se obtienen de dicha fórmula. Dayy Lewis (1992) muestran que para opciones sobre el índice bursátil, un modeloGARCH(1,1) simple para la varianza condicional del rendimiento implícito en elíndice proporciona información estadísticamente signi�cativa, que es adicionala las estimaciones de volatilidad implícita de BS. En esta misma línea, Engle yMustafá (1992) probaron que ...Buena parte de la investigación reciente [Amin y Ng (1992), Heston (1993),
Hull y White (187), Melino y Turnbull (1990), Scott (1987) y Wiggins (1987)] seha destinado a desarrollar fórmulas teóricas de valoración de opciones en pres-encia de volatilidad estocástica. Aunque una expresión analítica de los preciosresultantes puede obtenerse sólo en algunos casos relativamente sencillos, es gen-eralmente cierto en todos ellos que cuanto más volátil es el activo subyacente,más elevado es el precio resultante para la opción.
6.19.1 Canina, L. y S. Figlewski: �The informational content of im-plied volatility�
Review of Financial Studies,(1993)En este trabajo se analiza la capacidad que tiene la volatilidad implícita
obtenida a partir de opciones sobre S&P100 para predecir la volatilidad futurade dicho índice. El interés del análisis se basa en el hecho de que la volatilidadimplícita se interpreta, generalmente, como la predicción del mercado acercadel nivel de volatilidad futuro. Se encuentra que la capacidad de la volatilidad
138

implícita para predecir la volatilidad futura es mínima, tanto cuando se trabajacon todas las opciones existentes (que garantizan una liquidez mínima y que noincumplen las relaciones básicas que deben satisfacer los precios de las opciones),como cuando se trabaja con clases de opciones, según su vencimeinto y su preciode ejercicio.Una posible explicación de este resultado negativop sería la posible di�cultad
para prever la volatilidad durante el período muestral analizado en el mercadoconsiderado. Sin embargo, cuando se utiliza la desviación típica anualizadadel logartimo de las rentabilidades del S&P100 sobre una ventana móvil de60 días previos al momento de cálculo de la volatilidad implícita, se encuentraque esta medida de volatilidad histórica tiene cierta capacidad de prever lavolatilidad futura. La amplitud de la ventana considerada no es crítica en estosresultados. Sin embargo, esta medida de volatilidad histórica incumple el testde racionalidad de la predicción.En el trabajo se considera asimismo la posibilidad de que la volatilidad
implícita incorpore la información contenida en la volatilidad recientemente ob-servada en el mercado, rechazando asimismo dicha hipótesis.
6.19.2 Day, T.E. y C.M. Lewis, �Forecasting futures market volatil-ity�,
The Journal of Derivatives, winter 1993.Se compara la capacidad predictiva de diversos métodos para anticipar la
volatilidad del precio en el mercado de futuros sobre petróleo. Para ello, secalcula la volatilidad condicional resultante de un modeloGARCH para el preciodel futuro sobre el barril de petróleo, así como la volatilidad implícita a partirde opciones call sobre dicho futuro.Se encuentra que ambas medidas contienen cierta capacidad explicativa sobre
la volatilidad futura del precio del futuro. Se considera asimismo la posibilidadde utilizar un modelo EGARCH, pero no se detecta evidencia de efectos asimétri-cos en volatilidad. Como las volatilidades GARCH se calculan para cada unode los días que quedan entre el instante de valoración y el vencimiento, dichaspredicciones deben consolidarse en un único nivel de volatilidad asociado al díade vencimiento de la opción. En el trabajo se utiliza un promedio simple delas volatilidades prevista para cada uno de dichos dias, pero es claro que po-drían utilizarse otras alternativas. Cada día se estima el modelo GARCH conuna ventana móvil, se obtienen las previsiones para cada uno delos días desdeel último contenido en la muestra hasta el vencimiento de la opción, y se cal-cula su promedio. Este procedimiento de ventana móvil permite generar unaserie temporal de predicción GARCH de la volatilidad para el instante (día) devencimiento de la opción.La capacidad predictiva de una serie temporal de volatilidades se estima
mediante el ajuste de una regresión,
�2H;t+1 = b0 + b1�2F;t+1 + �t+1
139

donde �2H;t+1 denota la volatilidad realizada (observada) durante los perío-dos desde que se calcula la predicción hasta el vencimiento de la opción, y �2F;t+1es la predicción de dicha volatilidad, calculada con información hasta el instantet:Las volatilidades GARCH y EGARCH incumplen la propiedad de reacional-
idad, mientras que las volatilidades implícitas satisfacen dicha propiedad. Lacuarta medida utilizada es una medida ingenua, pero sus resultados son peoresque los obtenidos con la volatilidad implícita. Una peculiaridad no discutida enel trabajo es que el modelo GARCH que se utiliza es un modelo con componenteen media, siendo un GARCH(1; 1)�M , mientras que el modelo EGARCH notiene tal componente, incorporando en cambio una estructura AR(1) en rentabil-idad.Se muestra asimismo que las predicciones extra-muestrales a partir de mod-
elos tipo GARCH no contienen información que no estuviese ya recogida en laserie temporal de volatilidad implicita. Las predicciones que se obtienen lle-vando a cabo ajustes de sesgo predictivo o combinando predictores no tienen uncomportamiento signi�cativamente mejor que la volatilidad implícita sin ajus-tar.Para calcular la volatlidad implícita se utiliza la técnica de árbol binomial,
dado que las opciones sobre futuro de barril de petróleo permiten el ejercicioanticipado, al ser opciones Americanas.
6.19.3 Day, T.E. y C.M. Lewis, �Stock market volatility and theinformation content of stock index options�
Journal of Econometrics (1992), 52:267-287.Este trabajo compara la capacidad predictiva de modelosGARCH y EGARCH
estimados para el índice S&P100 acerca de la volatilidad futura del exceso derentabilidad ofrecido por el índice. A pesar de disponer de observaciones di-arias, el trabajo se lleva a cabo con rentabilidades semanales. Para evitar (a lavez que estimar) posibles efectos dia de la semana, el estudio se realiza tantocon los datos correspondientes a los miércoles, como con los correspondientes alos viernes. Otra razón para ello es evitar la autocorrelación existente en datosdiarios que, aparentemente surge por problemas de negociación no simultáneaen el índice (nonsynchronous trading). Se utilizan dos series de rentabilidad se-manal: por un lado, las rentabilidades (sin ajustar), que se obtienen de los datosde cierre; por otro, las estimaciones del nivel del índice implícito en el precio deopciones call sobre dicho índice. Sólo se reportan los resultados obtenidos conla primera de las medidas.Se eliminan los precios diarios de opciones con menos de 100 contratos de
negociación, o aquellas cuyo precio a cierre de mercado di�ere sustancialmentedel precio de ejercicio (en más de $15). Se eliminan asimismo las opcionesconprecio de mercado muy reducido (inferior a 0,25$), porque la horquilla bid-askes entonces un porcentaje muy elevado del precio de la opción. Los dividendosefectivamente pagados a posteriori se toman como proxy de las expectativas dedividendos a recibir durante la vida de la opción. Para estimar la volatilidad
140

implícita se utiliza la fórmula Black-Scholes ajustada de una tasa constante dedividendos.Las predicciones obtenidas a partir de volatilidades condicionales deducidas
de modelos GARCH y EGARCH se comparan con la volatilidad implícita,interpretada como estimador de la volatilidad del índice a vencimiento de laopción.Resumir los precios observados para todas las opciones negociadas sobre el
índice en determinado momento requiere cierto trabajo estadístico. Si denota-mos por Ck(�0 (�)) el precio teórico de una opción con tiempo a vencimiento �y precio de ejercicio indicado por k; dada una estimación �0 (�) de la volatili-dad de la rentabilidad del índice hasta el instante de vencimiento de la opción,construimos la función objetivo,
F� =
N�Xk=1
[�k� (Ck� � Ck(�0 (�)))]2
donde �k� denota la proporción del volumen de negociación que se lleva acabo en opciones con vencimiento � que corresponde al contrato con precio deejercicio k; y N� es el número de precios de ejercicio diferentes de opciones convencimiento � : Por tanto, la función de pérdida anterior se asocia al vencimiento� :En cada iteración, la nueva estimación de la volatilidad viene dada por,
� (�) = �0 (�) +�(X)
0(X)
��1(X)
0(Y )
siendo la matriz diagonal N�xN� que tiene por elementos el porcentajede volumen de negociación en las opciones call con vencimiento � en cada unode los precios de ejercicio negociados, X es un vector N�x1 que contiene lasderivadas parciales de los precios de las opciones call respecto de la volatilidaddel subyacente, �0 (�) : Por último, Y es un vector N�x1 cuyos elementos sonlas diferencias entre precios teóricos, calculados con la estimación �0 (�) delavolatilidad, y los precios de mercado.La volatilidad histótica con cuyas realizaciones se comparan las predicciones
de volatilidad se calcula de dos maneras diferentes: a) mediante el cuadrado dela rentabilidad semanal, y b) mediante la varianza de las rentabilidades diarias,multiplicada por el número de dias de negociación en dicha semana.Los resultados apuntan a que la volatilidad implícita contiene información
no contenida en la volatilidad condicional que se deriva de los modelos GARCHy EGARCH. Se obtiene asimismo el resultado dual: la volatilidad condicionalque surge de los modelos GARCH y EGARCH contiene información adicionala la incorporada en la volatilidad implícita. Por tanto, ambas deben combinarseal predecir la volatilidad futura del índice. La volatilidad condicional obtenidaa partir del modelo EGARCH no contiene información signi�cativa que no estéya incorporada en la volatilidad condicional del modelo GARCH.Se utiliza un procedimientoo de ventanas móviles, al igual que en el trabajo
anterior, para obtener predicciones de volatilidad a partir de modelos GARCH
141

y EGARCH. Las estimaciones de estos modelos parecen ser insesgadas, al con-trario de lo que ocurre con las volatilidades implícitas. Sin embargo, la volatili-dad semanal parece difícil de predecir, y los ajustes entre predicción de volatili-dad y volatilidad observada futura no presentan valores muy altos del estadísticoR2. Los modelos GARCH parecen ofrecer mejores resultados que los modelosEGARCH.
6.19.4 Engle, R.F., y C. Mustafa: �Implied ARCH models fromoption prices�:
Estimación de los procesos estocásticos que para la volatilidad de un activo sededucen de los precios de las opciones que tienen a dicho activo como subya-cente. Se supone que dicha volatilidad responde a una representación del tipoGARCH. Se propone estimar el modelo GARCH mediante un procedimientode minimización de los cuadrados de los errores en precio; para ello, partiendode unas pre-estimaciones para los parámetros del modelo GARCH, se obtienepor simulación el precio de la opción, y se compara con su precio de mercado.Inicialmente, se toma como función objetivo la suma de los cuadrados de lasdiferencias en precio, que se minimiza, iterando en el espacio de parámetrosGARCH. La propuesta se generaliza en la forma de un método de mínimoscuadrados generalizados, ponderando los errores cometidos en el precio de cadaopción de manera inversa a la precisión con que se calcula su precio teórico.Conocer la persistencia de la volatilidad es importante para los agentes que
operan en un mercado de derivados, en el que estarán dispuestos a pagar unprecio más alto poropciones de largo plazo si perciben que los shocks actualesen volatilidad son altos y permanentes, en relación con la vida residual de laopción.Se obtiene que la persistencia de los shocks de volatilidad que se obtiene en
el modelo que se in�ere a partir de precios de opciones del S&P500es similara la que se estima a partir de datos históricos sobre el índice. Sin embargo,la persistencia después del crash bursátil de 19 Octubre 2987 se estima comosigni�cativamente más débil.
6.19.5 Noh, J., R.F. Engle, y A. Kane, �Forecasting volatility andoption prices of the S&P500 index�
Journal of Derivatives, (1994), 17-30.Este trabajo compara la capacidad de la volatilidad implícita, con la de
la volatilidad condicional, paraanticipar la volatildad futura de la rentabilidadofrecida por el índice S&P500. La comparación se efectúa mediante la gestión deuna cartera de straddles, llevada a cabo utilizando las predicciones de volatilidadproporcionadas por ambos métodos.El modelo GARCH se supone que rep resenta la volatilidad condicional
del error de un modelo AR(1) para la rentabilidad del índice S&P500: En elmodelo de volatilidad condicional se incorpora una corrección por el número dedias naturales transcurridos entre dos días sucesivos de negociación.
142

Los procedimientos para resumir en una única medida de volatilidad laspredicciones dle modelo GARCH, así como para trabajar con todas las op-ciones negociadas, son los mismos que se han expuesto para otros trabajos.Una aportación de este trabajo es obtener predicciones de volatilidad implícitamediante relacioens lineales de la misma sobre sus valores previos, obtenidostanto a partir de opciones put como de opciones call, de la rentabilidad pasadadel mercado, y de 2 variables �cticias que tratan de incorporar el efecto día dela semana que se ha observado en volatilidad los lunes y viernes.Se construyen straddles con al menos 15 dias hasta vencimiento, y una nego-
ciación mínima de 100 contratos diarios. Se considera cada día el straddle conprecio de ejercicio más cercano al índice S&P500: Se usa el tipo de interés enLetras del Tesoro a un mes de vencimiento como tipos de interés sin riesgo. Sila predicción del precio del straddle es superior al precio de mercado, se compradicho straddle. En caso contrario, se vende. Invertimos $100 en el contrato másat-the money. Cuando se vende un straddle, se invierte el dinero en el activosin riesgo.En sucesivas repeticiones del ejercico de simulación, se aplican �ltros, com-
prando o vendiendo únicamente si la diferencia entre precio teórico y precio demercado es superior a $0,05 o $0,25 sin que esto afecte al resultado fundamental,que es que las predicciones de volatilidad del modelo GARCH generan bene�ciossigni�cativos, superiores a los costes de transacción.
6.19.6 French, K.R., G.W. Schwert, y R.F. Stambaugh, �Expectedstock returns and volatility�
Journal of Financial Economics (1987), 19, 3-29.En este trabajo se examina la relación entre rentabilidades de activos de
renta variable, y la volatilidad del mercado. Se encuentra evidencia favorable alque la prima de riesgo esperada (de�nida como diferencia entre la rentabilidadesperada de una determinada cartera de renta variable y la rentabilidad ofrecidapor una cartera de letras del Tesoro), depende positivamente del componentepredecible de la volatilidad de la rentabilidad del activo de renta variable.Se encuentra asimismo una relación negativa entre el componente no antici-
pado de la rentabilidad del mercado y el cambio no anticipado en la volatilidadde la rentabilidad. Este resultado proporciona evidnecia indirecta a favor deuna relación positiva entre primas de riesgo y volatilidad.
6.20 Referencias
6.20.1 Libros:
Mills, T.C., The econometric modelling of �nancial time series, Cambridge U.Press, 1993Taylor, S., Modelling �nancial time series, Wiley, Nueva York, 1986.Novales, A., Econometría, McGraw-Hill, 1993, 1996.Campbell, J.Y., A.W. Lo, y A.C.MacKinlay, The Econometrics of �nancial
markets, Princeton U. Press, 1997.
143

6.20.2 Artículos:
Bollerslev, T., R.F. Engle y J.M. Wooldridge, A capital asset pricing model withtime-varying covariances, Journal of Political Economy, 96, 1, 116-132, 1988.Engle, R.F. y M. Rothschild, ARCH models in Finance, Journal of Econo-
metrics, 52, 5-59, 1992.Bollerslev, T., R.F. Engle y D.B. Nelson, ARCH models, The Handbook of
Econometrics, vol.4, capítulo 11, 1994.Ruiz, E., Modelos para series temporales heterocedásticas,Cuadernos económi-
cos de ICE, 1994.Engle, R.F., T. Ito, y W.L. Lin, Meteor showers or heat waves? Het-
eroskedastic intra daily volatility in the foreign exchange market, Econometrica,58, 525-542, 1990.Engle,R. y T.Bollerslev, 1986, �Modelling the persistence of conditional vari-
ances�, Econometric Reviews, 5, 1-50.Bollerslev,T., R.Y.Chou y K.F.Kroner, 1992, �ARCH modeling in �nance:
A review of the theory and empirical evidence�, Journal of Econometrics, 52,5-59.Engle, R.F., 1982, �Autoregressive conditional heteroskedasticity with esti-
mates of the variance of U.K. in�ation�, Econometrica, 50, 987-1008.Engle, R.F., D.Lilien y R.Robins, 1987, �Estimating time varying risk premia
in the term structure: the ARCH-M model�, Econometrica, 55, 391-408.Engle, R.F., 1982, Autoregressive conditional heteroskedasticity with esti-
mates of the variance of UK in�ation, Econometrica, 50, 4.Bollerslev, T., 1986, Generalized autoregressive conditional heteroskedastic-
ity, Journal of Econometrics, 31.
6.20.3 1a Parte: Estructura temporal de volatilidades. Evidenciaempírica desde los mercados.
Bessembinder, Coughenour, Seguin, Smoller: �Is there a term structure ofvolatilities? Reevaluating the Samuelson hypothesis�, The Journal of Deriv-atives, winter 1996, 45-58.Heynen, Kemna, Vorst, �Analysis of the term structure of implied volatili-
ties�, The Journal of Business, v.29, 1994,Xu y Taylor, �The term structure of volatility implied by foreign exchange
options�, Journal of Financial and Quantitative Analysis, 1994.
6.20.4 2a Parte: Transmisión de volatilidades entre mercados
Koutmos y Tucker, �Temporal relationships and dynamic interactions betweenspot and futures stock markets�, Journal of Futures Markets, 1996Iihara, Hato y Tokunaga, �Intraday return dynamics between the cash and
futures markets in Japan�, Journal of Futures Markets, 1996
144

6.20.5 3a Parte: Implicaciones para la cobertura de carteras.
Myers, �Estimating time-varying optimal hedge ratioson futures markets�, Jour-nal of Futures Markets, 1991.Engle y Chowdhury, �Implied ARCH models from option prices�, Journal
of Econometrics, 1992.Noh, Engle y Kane, �Forecasting volatility and option prices of the S&P 500
index�, Journal of Derivatives, 1994.Lien y Luo, �Multiperiod hedging in the presence of conditional heteroskedas-
ticity�, Journal of Futures Markets, 1994
7 Panel data sets
Economic data sets that combine time series and cross sections are increasinglybeing available. Sometimes, they are created by a researcher that collects dataon a given set of variables over a period of time for a set of countries. Butoften, they are produced because a cross section of individuals or �rms arefollowed over time, and the values of some of their characteristics and decisionsare collected in what is known as a Panel Data set. Examples of the latter are:
� National Longitudinal Surveys on Labor Market Experience (NLS) http://www.bls.gov/nls/nlsdoc.htm,
� Michigan Panel Study of Income Dynamics (PSID) http://psidonline.isr.umich.edu/in which 8,000 families and 15,000 individuals, interviewed periodicallyfrom 1968 to the present.
� The Bank of Spain puts together the Encuesta Financiera de las Familias,http://www.bde.es/estadis/e¤/e¤.htm, a still short panel data on �nan-cial decisions.
� British Household Panel Survey (BHPS), http://www.iser.essex.ac.uk/ulsc/bhps,follows several thousand housegholds (over 5,000) anually, since 1991.
� German Socioeconomic Panel Data (GSOEP), http://dpls.dacc.wisc.edu/apdu/gsoep_cd_TOC.html,
� Medical Expenditure Panel Survey (MEPS), http://www.meps.ahrq.gov/
� Current Population Survey(CPS), http://www.census.gov/eps/, is a monthlysurvey of about 50,000 households. Each household is interviewed eachmonth over a 4-month period, followed by a 8-month period without in-terviews, to be interviewed again afterwards. These are known as rotationpanels.
A panel data has a cross section (N) and a time dimension (T ). Dependingon the type of panel Usually, the time dimension of the panel (T ) is short,with a very large cross-sectional dimension (N). In that case, we search forconsistency of estimates along the N -dimension. This is because panel data areusually oriented toward cross-section analysis, and heterogeneity across units
145

is the central focus of the analysis. However, other possibilities also exist, likehaving relatively long time series for a short number of countries.The general, linear panel data model is of the form:
yit = x0it�i + z0i�+ "it; i = 1; 2; :::; N; t = 1; 2; :::; T
in which variables in vector xit change over time and across individuals,while those in vector zi change only across individuals while remaining constantover time for each individual. The speci�cation above is generally designed fora large N; short T: The model above would then imply estimation of a largenumber of parameters, so it is usually assumed that coe¢ cients are the samefor all individuals, to allow for enough degrees of freedom. An example wouldestimate how family income, as well as the age and the level of education of thehousehold head help a¤ect family savings:
family savingsit = �+ �1incomeit + �2ageit + �3educit + uit
A panel data is very di¤erent of a SURE system of equations. In the latter,we have a set of equations with a di¤erent endogenous variable in each oneof them. In a panel data we have always the same endogenous variable. Wecould see it as a system of equations for each time period, but it has a tightstructure, that determines the correlation structure of the error term,as we willsee later, contrary to what happens in a SURE system where we have to proceedby assumption. A panel data set is said to be balanced when all individuals areobserved for the same number of time periods, while it is unbalanced when theopposite happens. If there is some self-selection, with individuals deciding whento be interviewed, or some systematic decision on when to interview subjects,then estimates may easily be biased. This requires some special treatment.Some examples:
ln(wageit) = �0 + �0D91t + �2D92t + �3computerit + �4 exp erit +
+�5educit + �6femalei + uit
which is considered by Wooldridge (2002) to estimate the e¤ect of computerusage (measured by hours of use in year t) on wages. The dummy variablefemalei is invariant through time, as it might be the case with the number ofyears of education (educit). Two dummy variables, invariant across the cross-section, are also included to allow for a time e¤ect on wages. This speci�cationallows for intercepts speci�c of each decision unit, while slope coe¢ cients areassumed to be the same for each individual. We could also allow for cross e¤ectsby introducing the product of some explanatory variables like computerit andfemalei:A di¢ culty when working with panel data is that since we repeatedly observe
the same units, it is usually no longer appropriate to assume that observationsare independent, which may complicate the analysis in dynamic and nonlinearmodels. On the other hand, an advantage is that it allows us to deal with
146

unobserved characteristics, and to identify certain facts at the individual level.Panel data are not only suitable to model why individuals behave di¤erently,but also to model why a given unit behaves di¤erently at di¤erent points in time.The double dimension structure of the panel data allows for testing hypothesisthat could not be addressed in either a single cross-section or in a single setof time series: does consumption increase by 2% because everybody increasesconsumption by 2% or because half of the population increases consumption by4%?. Ben-Porath (1973) observed that over time, 50% of women appear to beworking at any time period. However, it is unclear whether these are always thesame women or rather, each woman has a probability of 1/2 of being working atany time period. The two possibilities would have very di¤erent policy implica-tions. Another typical example refers to the possibility of separating economiesof scale from technological change. The former could be explored in a crosssection, while the second is a proper hypothesis for tine series data, althoughthen, the two e¤ects would be confused. Usually constant returns to scales isassumed and then the time series data is used to test for technological change.A panel data can provide information on both issues at the same time.Panel data techniques have clear advantages in dealing with unobserved in-
dividual characteristics. Consider estimates of a Cobb-Douglas production func-tion with data on a number of �rms. Suppose the true model is,
yit = �+ x0it� +mi�k+1 + "it
where mi is the management quality for �rm i; which is assumed to beconstant over time. The unobserved mi variable is expected to be negativelycorrelated with the other explanatory variables, since a high quality manage-ment will possibly require a more e¢ cient use of inputs. Therefore, excludingmi from the estimation because of not being observable will bias estimates forthe other parameters. With panel data, we can consider a �rm speci�c e¤ect,de�ned as �i = �+mi�k+1; and even hope to estimate its size, although it willbe impossible to identify �k+1 by itself.Similarly, a �xed time e¤ect can be included in the model to capture the
e¤ect of all (observed and unobserved) variables that do not vary across theindividual units. A �nal, more technical advantage, is that panel data modelsprovide internal instruments for regressors that are endogenous, or are subjectto measurement error. Usually, it can be argued that some transformations ofthe original variables are uncorrelated with the model�s error term while beingcorrelated with the explanatory variables themselves. This is interesting, sinceexternal instruments, which are often harder to justify, or for which data maybe hard to �nd, may not be needed. For instance, if xit is correlated with anomitted explanatory variable �i (which will then be part of the error term), itcan be argued that xit � �xi; where �xi is the time average for individual i; isuncorrelated with �i and hence, it provides a valid instrument for xit:
147

7.1 Estimation approaches
The individual or group time-invariant e¤ects in zi may be observed, like sex,race, location, or unobserved, like family speci�c characteristics, individual het-erogeneity in skill or preferences, all of them being constant over time. If ziis observed for all individuals, the model can be handled easily, as a standardregression model, to estimate vectors � and � in,
yit = x0it�i + z0i�+ "it; i = 1; 2; :::; N; t = 1; 2; :::; T
which is identi�ed by the standard condition,
E("it=xit; zi) = 08i; t
This condition implies,
E(yit=xit; zi) = x0it�i + z0i�; i = 1; 2; :::; N; t = 1; 2; :::; T
As in any regression model, this expectation is what we are interested on.Often, the error term "it is also assumed to be independent and identicallydistributed over individuals and over time, with mean zero and variance �2":Obviously, in the usually available short panels, the individual speci�c e¤ects
cannot be consistently estimated. Besides, the small number of observationswould lead to a huge loss of precision. Hence, we need to collapse the linearcombination of individual characteristics z0i� into a single number; z
0i� = �i;
yit = x0it�i + �i + "it; i = 1; 2; :::; N; t = 1; 2; :::; T
We then substitute our interest on the previous conditional expectation, E(yit=xit; zi);by a focus on:
E (yt=xit) = E (�i=xit) + x0it�
An important complication arises under standard estimation procedureswhen zi is unobservable. Examples include the determination of wages on thebasis of experience and education, with no observation of the productivity ofthe worker, or a study on health status of individuals with no data on usageof health services.Also, the determination of pro�ts at the �rm level lackingdata on the quality of management. We cannot then compute the expectationconditioned on the values of these unobserved variables.Here, there are two possibilities: if we are willing to accept the Mean-
independence assumption, that the unobserved individual characteristics areindependent of the variables in xit: E (�i=xit) = �i; constant, we will have,
E (yt=xit) = �i + x0it�
and the model has an error term with two di¤erent components,
yit = �i + x0it� + ["it + (�i � �i)]
148

Under the Mean independence assumption, this speci�cation does not poseserious estimation di¢ culties. This leads to the Random E¤ects model.However, in many applications it may be natural to believe that zi and xit
will be correlated, so that E (�i=xit) = �i+h(xit); and this dependence will beincorporated into the error term,
yit = �i + x0it� + ["it + (�i � fE (�i=xit)� h(xit)g)]
This leads to the Fixed E¤ects model. The correlation between explana-tory variables and the error term will then lead to inconsistent least-squaresestimates, so whenever there is reason to believe that unobserved individual ef-fects are correlated with the observed explanatory variables, we need to explorealternative estimation approaches.13
The estimation approach suggested depends on the assumptions on the cor-relations between "it and either zi� or �i:
� Pooled regression: Vector zi contains only a constant term, the same forall individuals in the sample. Ordinary least squares estimates of thecommon parameters � and � in
yit = �+ x0it� + "it
using all the data on all the individuals for all time periods are then consis-tent and e¢ cient.
� Fixed e¤ects: If some zi are unobserved, but correlated with some xit; wehave,
yit = x0it� + �i + "it
where �i = z0i� captures all individual speci�c e¤ects. The least squaresestimator of � is biased and inconsistent, because of the omitted variable bias.The Fixed E¤ects approach considers �i as an individual-speci�c constant
term in the regression. The term "�xed" does not refer to the individual e¤ectbeing non-stochastic but rather, to being correlated with the variables in xit.It will be impossible with this speci�cation to distinguish between �i and anyother individual e¤ect that is constant over time, so can just hope to identify asingle individual-speci�c e¤ect. The estimation approach in this situation will
13We are usually interested in estimating the partial e¤ects:
@E[yt=xjt]
@xjt= �j ; j = 1; 2; :::; k for all t
after correcting for individual characteristics. These marginal e¤ects can be identi�ed even ifthe conditional mean is not. For instance, it is possible to identify the e¤ects on earnings ofan additional year of schooling, controlling for individual e¤ects, even though the individuale¤ects and the conditional mean are not identi�ed.
149

consist of transforming the data so as to get rid of the individual e¤ects pro-ducing the inconsistent estimates. We can estimate constant individual speci�ce¤ects, �i; that can be treated in estimation as N unknown parameters, and themodel is referred to as the Fixed E¤ects model. Because of these data transfor-mations, we will have some di¢ culty in identifying the e¤ects of time-invariantcharacteristics, like race or gender.
� Random e¤ects: If the unobserved heterogeneity can be assumed to beuncorrelated with any other explanatory variable, and we assume thatindividual e¤ects can be jointly considered as z0i� = � + �i; with �i �[0; �2�], the model can then be written,
yit = x0it�+E(z0i�=xit)+[z
0i��E(z0i�=xit)]+"it = x0it�+�+(�i+"it) = x0it�+�+uit
where uit = �i + "it; with �i being an individual speci�c element similar to"it; except for the fact that there is a single draw for �i that enters the regressionidentically every period. Individual intercepts are then treated as draws from adistribution with mean � and variance �2�: The essential assumption is that thesedraws are independent of the explanatory variables in xit: The error term hasthen two components, a time invariant component, �i; and the "it component,which is uncorrelated over time. It is sometimes referred to as Random e¤ectsmodel or Error Components model.The presence of the �i component in the error term induces necessarily some
autocorrelation structure, even if the original error term in the model "it wasindependent over time and across individuals, since:
E(wit:wis) = E [(�i + "it) (�i + "is)] = �2� if t 6= s and = �2� + �2" if t = s
8 The static linear model
8.1 Pooled OLS estimates
Consider the general panel data model,
yit = z0i�+ x0it� + "it; i = 1; 2; :::; N ; t = 1; 2; :::; T
where we assume that individual characteristics are either observable, ornon-observable but uncorrelated with the variables in xit:Suppose that we are willing to make the crucial assumption:
E (z0i�=Xi) = � 8i
Then,
yit = �+ x0it� + ["it + (z0i�� E (z0i�=Xi))] ; i = 1; 2; :::; N ; t = 1; 2; :::; T
150

and we will have the same vector of coe¢ cients across individuals or decisionunits. Here Xi includes both, the observable zi and the xit variables. We canthen write the panel data model as the system:
y1t = x01t� + u1t; t = 1; 2; :::; T1
y2t = x02t� + u2t; t = 1; 2; :::; T2
:::
yNt = x0Nt� + uNt; t = 1; 2; :::; TN
with error term: uit = "it + (z0i�� E (z0i�=Xi)) ; and we can think of the
model as having a single regression with:
X =
0BB@X1
X2
:::XN
1CCA ; y =0BB@
y1y2:::yN
1CCA ; � = � ��
�
where each Xi matrix is Tixk; while yi is Tix1:But the central point of this model is that the assumption we have made
on E (z0i�=Xi) = � is inappropriate in most panel data situations, in which theopposite will be likely to occur.The pooled OLS estimator consists of applying OLS to the stacked y and X
above:
�POLS =
NXi=1
X 0iXi
!�1 NXi=1
X 0iyi
!=
NXi=1
TXt=1
x0itxit
!�1 NXi=1
TXt=1
x0ityit
!
The properties of the alternative estimators will depend on two things: a)the stochastic characteristics of the errror term in the original model, "it; and b)the relationship between the unobservable, ommitted individual characteristics,and the variables included in the model.Regarding the �rst point, alternative possibilities are:
� The xit are contemporaneously exogenous: E("it=xit) = 0
� A stronger assumption: The xit are strictly exogenous: E("it=xis) =0 8t; s
Strict exogeneity fails if xit = (1; yit�1); because: E("it=xi1;xi2; :::; xiT ) =E("it=y0; y1; :::; yT�1) = "itFor the OLS estimator to be consistent we need lack of correlation between
explanatory variables and error term, together with existence of second ordermoments of explanatory variables.Consistency
151

The estimator is consistent for N ! 1 under conditions: i) E(x0ituit) =
0k; t = 1; 2; :::; T; ii) rankhE(PTt=1 x
0itxit)
i= k;with an asymptotic probability
distribution:
pN��POLS � �
�!dN�0; A�1BA�1
�where A = E(X 0
iXi) is estimated by A = N�1PNi=1X
0iXi, and B =
V ar(X 0iui) = E(X 0
iuiu0iXi) is estimated by B = N�1PN
i=1X0iuiu
0iXi;
14 so thatthe covariance matrix is estimated by:15
�(�POLS) =1
N
1
N
NXi=1
X 0iXi
!�1 1
N
NXi=1
X 0iuiu
0iXi
! 1
N
NXi=1
X 0iXi
!�1=
NXi=1
TXt=1
xitx0it
!�10@ NXi=1
TXt=1
xituit
!NXi=1
TXt=1
xituit
!01A NXi=1
TXt=1
xitx0it
!�1
E¢ ciencyIt will not be an e¢ cient estimator, because the structure of the error term
induces autocorrelation: E(uituis) = �2u when t 6= s: The variance-covariancematrix above incorporates the fact that unobserved individual characteristicsintroduce autocorrelation in the error term. The practical consequence of thedescribed autocorrelation is that with the panel data we have less informationthan with NT independent observations.
Unobservable individual e¤ects We now suppose that some of the indi-vidual e¤ects are not observable, and we include them into a single variable �i:Let us denote uit = "it+�i; i = 1; 2; :::; N ; t = 1; 2; :::; T: That would have twoimplications:
1. if any of the unobservables in �i is correlated with any of the xit variables,then condition i) above will no longer hold, and the pooled least squaresestimate will be biased and inconsistent,
14This is the generalization of the standard variance-covariance matrix for the OLS estima-tor: �(�OLS) = (X
0X)�1(X0�X)(X0X)�1
15Since Xi =
0@ xi11 ::: xi1T::: ::: :::xik1 ::: xikT
1A ; then:PNi=1X
0iXi =
PNi=1
0@ PTt=1 x
2i1t :::
PTt=1 xi1txikt
::: ::: :::PTt=1 xiktxi1t :::
PTt=1 x
2ikt
1A ;the same kxk matrix we obtain
from adding up over i = 1; 2; :::; N and over time the kxk matrices of products:
xitx0it =
0@ xi1t:::xikt
1A� xi1t ::: xikt�
152

2. estimating by pooled least-squares we have that the presence of individuale¤ects in the error term introduces a speci�c form of autocorrelation,because error terms corresponding to a same individual will be correlatedwith each other:
E(uituis) = �2�; t 6= s
The estimate of the variance-covariance matrix proposed in White (19xx) isrobust against possible cross correlation among error terms across equations inthe same time period, or against a di¤erent variance for the error term in eachequation (time-varying variances). The conditional variance is also allowed todepend on Xi arbitrarily. However, it does not take into account the possibleautocorrelation of the error term, as it will be the case if we estimate by Pooledleast-squares the Fixed E¤ects model. This is taken into account in the esti-mate proposed above. Alternatively, we can follow the Newey-West approachto obtain a panel-robust estimate of the variance-covariance matrix :
�(�POLS) =
NXi=1
X 0iXi
!�1 NXi=1
X 0iuiu
0iXi
! NXi=1
X 0iXi
!�1=
NXi=1
TXt=1
xitx0it
!�1 NXi=1
TXt=1
TXs=1
(uitxit) (uisxis)0!
NXi=1
TXt=1
xitx0it
!�1If the conditional covariance of uit is independent of xis for all s; then,
�(�POLS) =
NXi=1
TXt=1
xitx0it
!�1 " TXt=1
TXs=1
NXi=1
uituis
!xitx
0is
# NXi=1
TXt=1
xitx0it
!�1We need to be aware of the fact that the term �robust�applied to the variance-
covariance matrix produced by some statistical packages may refer to just thecorrection for heteroskedasticity. However, in many relevant cases, the impor-tant e¤ect in panel data is the autocorrelation induced by the repeated obser-vations in a same individual.
Example: Using the Cornwell-Ruport (1988) data set, Green (6ed.), p187,example 9.1, show estimates of the returns to schooling by an equation in whichlogged wages are explained by working experience, their squared value, weeksworked, years of education, and a set of dummy variables to represent whethera given worker: has a blue collar occupation, works in manufacturing industry,resides in the south, resides in an SMSA, is married, the wage is set by a unioncontract, is a female, is black. The sample is made of 595 workers, which arefollowed over a 7-year period, 1976-1982. Each year of education is estimatedto increase wages by 5.67%. OLS standard errors are in this example of similarsize to White�s robust standard errors, while both of them are about half size
153

of the Panel robust standard errors. It means that ignoring the within-groupcorrelations in this case matters a lot, substantially a¤ecting inference throughthe implied autocorrelation of the error term.The model can also be estimated using individual sample means, for a sample
of 595 observations. We will still have the inconsistency of least-squares esti-mates in the �xed e¤ects model, but the within-group autocorrelation now dis-appears. Table 9.2 in Green (6ed.) shows similar coe¢ cient estimates. White�srobust standard errors are now similar to the Panel robust standard errors forthe whole Panel data sample.
8.1.1 Hypothesis testing
Linear hypothesis of the form: H0 : R� = r can be tested by the usual Waldstatistic:
W = (R� � r)0�R�(�POLS)R
0�(R� = r)
that obeys a chi-square distribution with q degrees of freedom, q being thenumber of rows in R and r (the number of independent restrictions being tested).
8.2 Generalized pooled least squares estimation
When we have some structure on the form of the conditional covariance matrixof ui; we can prefer to use GLS estimation, in search of improved e¢ ciency.Since we use random sampling, the unconditional covariance matrix should bethe same for each observation unit: = E(uiu
0i); a TxT matrix. As usual, the
numerical values of the elements in the variance-covariance will be unknown, andwe will have to estimate them �rst, then moving into what is usually known asFeasible GLS estimation (FGLS).Remember we have one equation for each time period, with N observa-
tions in each equation. It is important to bear in mind that consistency ofGLS estimator needs of a stronger condition on lack of correlation betweenexplanatory variables and error terms. Now, each element in Xi must be un-correlated with ui [Wooldridge (2002)]. This is because for consistency we now
need p lim�1N
PNi=1X
0iui
�= 0: A typical case when this will not hold is in
dynamic panel data estimates under autocorrelation of the error term.To construct the GLS estimator, we would follow the standard practice of
pre-multiplying the equation by �1=2; and:
�GLS =
NXi=1
X 0iXi
!�1 NXi=1
X 0iyi
!The reason to need a more strict condition on lack of correlation to show
consistency is that we now need: E(X 0iui) = 0k:The asymptotic distribution
is:
154

pN��GLS � �
�!dN�0; A�1BA�1
�where A = E(X 0
i�1Xi) and B = E(X 0
i�1uiu
0i
�1Xi) which are estimatedby using a consistent estimate of , computed using the residuals from a �rst-step set of consistent, but ine¢ cient least squares regressions.In most applications, it is natural to assume that: E(X 0
i�1uiu
0i
�1Xi) =E(X 0
i�1Xi) , which implies B = A and hence, the asymptotic variance of
�GLS becomes: �(�GLS) = A�1=N =�E(X 0
i�1Xi)
��1=N; which can be esti-
mated by: �(�GLS) = (PNi=1X
0i
�1Xi): This assumption essentially requiresconditional homoskedasticity (constant conditional variances and covariances),i:e:; that the expectation E(u0i
�1Xi) does not depend on Xi.
9 The Fixed E¤ects model
This model embeds the idea that all the unobservable individual e¤ects for eachobservation are aggregated in a single term �i:Under the assumption that:
E(�i=Xi) = h(Xi);
is constant over time, that constant being the Fixed individual E¤ect, eachindividual e¤ect �i can be treated as an unknown parameter to be estimated,and we get a linear regression model in which the intercept is allowed to varyacross individuals,
yit = �i + x0it� + uit;
with
uit = "it + (�i � h(Xi)) ; with "it � i:; i:d:(0; �2")
The model will usually imply a rather large number N of regressors whichit could lead to a noticeable loss of precision. It can be implemented in asimpler way by taking into account that individual e¤ects disappear if we applythe Within transformation, to transform the data in deviations with respectto individual means. Taking averages in the previous equation: �ui = �"i +(�i � h(Xi)) ; so that uit � �ui = "it � �"i; and:
yit � �yi = (xit � �xi)0� + ("it � �"i); i = 1; 2; :::; N ; t = 1; 2; :::; T
Applying least squares to this model, we get the Within estimator of theFixed E¤ects model,
�FE =
NXi=1
TXt=1
(xit � �xi)0(xit � �xi)!�1 NX
i=1
TXt=1
(xit � �xi)0(yit � �yi);
155

The estimator will be consistent as N !1 if E[(xit � �xi)"it] = 0:This willhold if xit is uncorrelated with "it and �xi has no correlation with the errorterm. These are implied by strict exogeneity of the regressors:
E(xit"is) = 0 8t; s
Strict exogeneity precludes the inclusion in xit of lagged dependent vari-ables or variables that depend upon the history of yit: For instance, explaininglabour supply of an individual, we may want to include as a regressor years ofexperience, but experience will clearly depend upon the person�s labour history.By applying the Within transformation, the individual speci�c constant
characteristics will have dropped from the model. Individual e¤ects can laterbe recovered by,
�i = �yi � �xi0�FE ; i = 1; 2; :::; N
which are unbiased, but will not be consistent if just the cross-section di-mension tends to in�nity. For consistency we will need T ! 1: The reasonthat these are not consistent as N !1 if T is short is that that leaves us witha very limited amount of information to estimate each individual �xed e¤ect,and x and y averages do not converge to any well de�ned limit as the numberof individuals increases. This is an interesting situation in which it is possibleto estimate the � coe¢ cients consistently, even if the �i cannot be estimatedconsistently because of a short time dimension.As we can see, we can just recover a single �i variable for each individual,
which is the reason why the speci�c e¤ects for a same infdividual need to beconsidered as aggregated in a single variable �i:If there are some observed individual e¤ects zi; their joint in�uence can be
recovered by regression,
(�yi � �xi0�FE) = z0i +h�i + �"i � �xi0
��FE � �
�ileading to consistent estimates of if each variable in vector z is uncorrelated
with "it and with �i: As in the case of the unobservable, time invariant individuale¤ects, the estimated coe¢ cient will not be very reliable with a short timedimension T .The variance-covariance matrix,
V ar(�FE) = �2�
NXi=1
TXt=1
(xit � �xi)0(xit � �xi)!�1
assumes that individual e¤ects are independent across individuals and time.Unless T is large, this will underestimate the true variance. The reason is thatthe error covariance matrix in the transformed regression is singular (since theT transformed errors for each individual add up to zero), and the variance of"it��"i is (T �1)=T�2"; rather than �2": If, for instance, T = 3; then the variance
156

of "it � �"i will be 2�2"3 . A consistent estimator for �2" can obtained from the
Within groups estimation,
�2" =1
N(T � 1)
NXi=1
TXt=1
(yit��i�x0it�FE)2 =1
N(T � 1)
NXi=1
TXt=1
h(yit � �yi)� (xit � �xi)0�FE
i2although the appropriate number of degrees of freedom would beN(T�1)�k;
and we will have to introduce a correction factor.A panel-robust estimate of the variance-covariance matrix is,
�(�POLS) =
NXi=1
TXt=1
(xit � �xi) (xit � �xi)0!�1 " TX
t=1
TXs=1
NXi=1
("it � �"i) ("is � �"i)0 (xis � �xi) (xit � �xi)0#:
:
NXi=1
TXt=1
(xit � �xi) (xit � �xi)0!�1
A variance for individual e¤ects can be obtained from:
V ar(�i) =�2�T+ �x0iV ar(�FE)�xi
showing that estimates of individual e¤ects �i are inconsistent, since eventhough V ar(�FE) converges to zero with N; that is not the case with the �rstterm in V ar(�i): This is because of estimating each individual e¤ect with asmall number T of observations.De�ning N individual dummy variables (Dij = 1;if i = j; j = 1; 2; :::; N; and
Dij = 0 otherwise) the model can also be written,
yit =NXj=1
�jDij + x0it� + "it
which is known as the least squares dummy variable (LSDV) estimator. As men-tioned above, a limitation of this model is that all time invariant, unobservableindividual e¤ects get confused with each other in a single �i variable for eachindividual, and we are just able to estimate their aggregate in�uence over yit:
9.0.1 Testing the signi�cance of the group e¤ects
Even though we can use the above results to tests for signi�cance of either oneof the individual e¤ects, the natural hypothesis is to test that they are all equalto each other. If that is the case, the restricted model leads to the pooled leastsquares estimate, and we have an F -test,
F (N � 1; NT �N � k) = (R2LSDV �R2POLS)=(N � 1)(1�R2LSDV )=(NT �N � k)
157

The correction for the F -test comes from the fact that in the Pooled OLSestimator we have NT � k � 1 coe¢ cients, while in the LSDV estimator weestimated NT �N � k coe¢ cients, with a di¤erence of N � 1:
9.0.2 Fixed time e¤ects
The model can be extended to accommodate �xed time e¤ects through timedummy variables. However, to avoid perfect collinearity, we should just includeT � 1 of the possible time e¤ects. Alternatively, we can specify the model,
yit = x0it� + �+ �i + �t + "it; withNXi=1
�i =TXt=1
�t = 0
Least-squares estimates of the slopes � can be obtained by a regression ofy�it on vector x
�it; with,
y�it = yit � �yi � �yt + �y
where �yi = T�1PTt=1 yit; �yt = N�1PN
t=1 yit; �y = N�1T�1PNt=1
PTt=1 yit;
and similar expressions apply to vector x:Once we have estimates for the vector �; we can recover estimates for the
remaining parameters from,
� = �y � �x0��i = (�yi � �y)� (�xi � �x)0��t = (�yt � �y)� (�xt � �x)0�
The variance-covariance matrix is obtained from the standard cross-momentproduct of transformed explanatory variables, with an estimate of �2" beingobtained from �2" = RSS=[NT � (N�1)� (T �1)�k�1]: As we will see below,there are more general models allowing for time e¤ects.Example: Green (6ed.), ex. 9.4, estimates the model in the previous ex-
ample, for logged wages, with a constant intercept and T � 1 time dummies.The constant individual characteristics: education, sex (female-dummy) andrace (white-dummy), need to be dropped now, so that we lose the main inter-est of estimating the returns to education. Pooled least squares estimates areobtained for an initial speci�cation that includes a single, common interceptand no time dummies. A second model includes again a single intercept butalso time dummies. A third speci�cation allows allowing for individual speci�cintercepts and no �xed time e¤ects, while a �nal model allows for both, �xedtime and individual characteristics. In this �nal speci�cation, we need to dropan additional time dummy variable, because the Experience variable is a nat-ural time trend. The signi�cance of individual e¤ects and/or �xed time e¤ectscan now be tested by comparing the Residual Sums of Squares of appropriatelychosen speci�cations. Green also suggests comparing the conventional estimate
158

and the robust estimate, the latter with data in group mean deviations form, ofthe variance-covariance matrices as a speci�cation test for the individual e¤ectsmodel. If the speci�cation is correct, there should not be any heterogeneity inthe error term and hence, not heteroscedasticity or autocorrelation left. In theexample, robust standard errors are of the order of 20 times as large as theconventional ones, clearly pointing out to misspeci�cation errors.
10 Within and between estimators
The original Panel data speci�cation,
yit = �i + x0it� + "it
can be written in terms of group means,
�yi = �i + �x0i� + �"i
and in deviations from group means:
yit � �yi = (xit � �xi)0 � + ("it � �"i)
All three models could be consistently estimated (although possibly not ef-�ciently) by least-squares. Consider the overall second order matrices,
Stotalxx =
NXi=1
TXt=1
(xit � �x) (xit � �x)0 ; Stotalxy =
NXi=1
TXt=1
(xit � �x) (yit � �y)0
the within group matrices,
Swithinxx =NXi=1
TXt=1
(xit � �xi) (xit � �xi)0 ; Swithinxy =NXi=1
TXt=1
(xit � �xi) (yit � �yi)0
and the between-groups matrices,
Sbetweenxx =NXi=1
TXt=1
(�xi � �x) (�xi � �x)0 = TNXi=1
(�xi � �x) (�xi � �x)0 ;
Sbetweenxy =NXi=1
TXt=1
(�xi � �x) (�yi � �y)0 = TNXi=1
(�xi � �x) (�yi � �y)0
Notice that:
NXi=1
TXt=1
(xit � �xi) (�xi � �x)0 =NXi=1
TXt=1
(xit � �xi)!(�xi � �x)0 = 0
159

because the inside bracket is equal to zero. Therefore, we have,
NXi=1
TXt=1
(xit � �x) (xit � �x)0 =NXi=1
TXt=1
(xit � �xi) (xit � �xi)0+TNXi=1
(�xi � �x) (�xi � �x)0
so that,
Stotalxx = Swithinxx + Sbetweenxx ; Stotalxy = Swithinxy + Sbetweenxy ;
10.1 The Within groups estimator
The Within-groups estimator is de�ned,
�within
=�Swithinxx
��1Swithinxy =
NXi=1
TXt=1
(xit � �xi) (xit � �xi)0!�1 NX
i=1
TXt=1
(xit � �xi) (yit � �yi)!
so that it is the OLS estimator in the model,
yit � �yi = (xit � �xi)0 � + ("it � �"i) ; 1; 2; :::; Nwhere the possible individual speci�c intercepts have cancelled out. For that
reason, it yields consistent estimates of the panel data model under the FixedE¤ects assumption, whereas the Pooled OLS and the Between estimator thatwe are about to see, do not. The Within Groups estimator is the same asthe Fixed E¤ects estimator and the Least-Squares Dummy Variable estimatorthat we saw above. It can also be thought of as estimating regressions fromdependent and time-varying independent variables on individual dummies andestimating a regression between the residuals from these auxiliary regressions.Of course, the limitation of this approach is the impossibility to estimate thecoe¢ cients of time-invariant individual characteristics like race and gender.
10.2 The Between groups estimator
The Between groups estimator above is obtained applying least squares to thedata averaged for each individual, in deviations from the global sample average,
�yi � �y = (�xi � �x)0 � + (�i + �"i) ; 1; 2; :::; Nso that,
�between
=
NXi=1
(�xi � �x)0(�xi � �x)!�1 NX
i=1
(�xi � �x)0(�yi � �y)!=�Sbetweenxx
��1Sbetweenxy
This estimator is a cross section regression with N data points.The Betweengroups estimator uses just the cross-sectional variation in the data, while the
160

pooled OLS estimator uses variation both over time and across individuals. TheBetween groups estimator uses only information on how each individual di¤ersfrom the global average, ignoring the variation over time for each individual inthe sample.An interesting feature of the Between estimator is that it tends to reduce the
e¤ect of measurement errors, since it uses time averages. It would be consistentwith T !1 but that is un unlikely condition in most panel data sets.Strong exogeneity is needed for consistency, since we need the individual
means �xi to be uncorrelated with �i. Su¢ cient, although not necessary con-ditions for consistency are: E(�ixit) = 08t; and E("itxis) = 08s; t: These areof course very strict assumptions. The problem is that the transformation indi¤erences with respect to group or individual means does not solve the issue ofthe possible correlation between unobserved individual characteristics and ob-served explanatory variables: E(�i=Xi) = h(Xi). Mundlak (1978) analyzes thecase when it can be assumed that such expectation is a function of the groupmeans: E(�i=Xi) = �x0i . We would then have: yit = � + x0it� + �x
0i + "it;
and taking averages: �yi = �x0i (� + ) + �"i; so that with the Between estimatorwe would be estimating the sum � + ;a biased estimator of the partial e¤ects� we are interested on.Even when it is consistent, the Between estimator will be ine¢ cient, since it
does not exploit the structure of autocorrelation and heteroscedasticity in theerror term.Relationship among estimatorsThe least-squares estimator can be written,
�total
=�Stotalxx
��1Stotalxy =
�Swithinxx + Sbetweenxx
��1 �Swithinxy + Sbetweenxy
�=
=�Swithinxx + Sbetweenxx
��1 hSwithinxx �
Within+ Sbetweenxx �
Betweeni
and if we de�ne:
FW =�Swithinxx + Sbetweenxx
��1Swithinxy
FB = I � FW =�Swithinxx + Sbetweenxx
��1 �Swithinxx + Sbetweenxx
���Swithinxx + Sbetweenxx
��1Swithinxy =
=�Swithinxx + Sbetweenxx
��1Sbetweenxy
then,
�total
= FW �W+ FB�
B
so that the least-squares estimater can be written as a matrix linear convex
combination of the Within and the Between estimators: �total
= F�within
+
(I � F )�between
: We will later see that it is not the only estimator admittingsuch a representation.
161

11 Estimating in �rst di¤erences
An alternative transformation that eliminates individual e¤ects is to take timedi¤erences in the model, obtaining:
�yit = �x0it� +�"it; i = 1; 2; :::; N; t = 2; 3; ::; T
even though if the error term of the original model was a white noise, theerror term in the �rst-di¤erenced model will have a MA(1) structure, with �rst-order autocorrelation. So, we have changed the autocorrelation structure of theerror term.Estimating in First di¤erences is useful no matter whether the Random
E¤ects or the Fixed E¤ects models are appropriate. Estimating in First di¤er-ences may be specially indicated in panels with a very short time dimension,for which individual sample means may be subject to important sampling error.However, a limitation of this approach is again the impossibility to estimate thecoe¢ cients in any time invariant explanatory variable.Consistency of the First-di¤erences estimator requires,
E [("it � "i;t�1) = (xit � xi;t�1)] = 0a stronger condition than E ["it=xit] = 0; but weaker than the strong exo-
geneity condition that is need for consistency of the Within estimator.We have,
V ar(�"it) = �2H
where H is a symmetric, (T �1)x(T �1) matrix whose elements are equal to+2 along the main diagonal, equal to -1 in the two diagonals next to the maindiagonal, and equal to -1 everywhere else.The least squares estimator is:
� =
"NXi=1
(�xit) (�xit)0#�1 " NX
i=1
(�xit) (�yit)
#
V ar(�) = �2"
"NXi=1
(�xit) (�xit)0#�1 " NX
i=1
(�xit)H (�xit)0#"
NXi=1
(�xit) (�xit)0#�1
This approach will provide consistent, although ine¢ cient, estimates. Ma-trices in these expressions have T � 1 rows. An alternative would be to use theNewey-West robust estimate of the variance-covariance matrix, since we knowthe exact order of autocorrelation in the error term.Since the structure of the covariance matrix of the error term is known, we
could also try to improve e¢ ciency by using Generalized least squares:
� = � =
"NXi=1
(�xit)H�1 (�xit)
0#�1 " NX
i=1
(�xit)H�1 (�yit)
#
162

In practice, it is usually the case that Generalized least squares estimatesin levels and in �rst di¤erences are noticeably di¤erent, which suggests theexistence of unobservable individual e¤ects that bias the estimation in levels.This approach is not preferable to other estimation methods.It is speci�cally appropriate for estimation of Treatment e¤ects in two-period
panels, with a speci�cation like,
yit = �i + x0it� + �St + "it;
with t = 1; 2; where St = 0 in t = 1; and St = 1 in t = 2: The �rst period isthe before-treatment period, while the second period comes after the treatmenthas been applied. The treatment e¤ect is:
E [�yit j (�xit = 0)] = �;
which it can therefore be estimated as the constant in the model in �rstdi¤erences.The �rst-di¤erences estimator is less e¢ cient that the Within estimator for
T > 2 if "it is i:; i:d:: It coincides with the between estimator in panels withT = 2; since: yi1��y = yi1� y1+y2
2 = yi1�yi22 and yi2��y = yi2� y1+y2
2 = �yi1�yi22 ;
and similarly for the xit variables. Under the assumption that the "it are i.,i.d.,then it can be shown that the GLS estimator of the First-di¤erences modelequals the Within estimator. However, the First-Di¤erenced model estimatesthe �rst di¤erenced equation by OLS and it is therefore less e¢ cient than theWithin estimator.
12 The Random E¤ects estimator
Under this approach, we view all the factors that a¤ect the dependent variableand have not been included as regressors, as being included in the random errorterm. The usual assumption for this model is that the unobserved �i-terms areindependently and identically distributed across individuals. The model is then,
yit = �+ x0it� + (�i + "it); "it � i:; i:d:(0; �2"); �i � i:; i:d:(0; �2�)
with assumptions:
E("it=X) = E(�i=X) = 0;8iE("2it=X) = �2"
E(�2i =X) = �2�
E("it�j=X) = 0 8i; j; tE("it"js=X) = 0 8t 6= s; i 6= j
E(�i�j=X) = 0 8i 6= j
163

Even if "it is uncorrelated, there will be some serial correlation in the errorterms �i+"it; coming from the �i component. We assume that the components�i and "it are independent from each other, as well as independent of theexplanatory variables xis for all time periods t; s: This leads to a particular formof time correlation, and the standard OLS covariance matrix is inappropriate,while the estimator itself is ine¢ cient. For each individual i; all error terms canbe stacked as the Tx1 column vector: �i1T + "it; with covariance matrix,
V ar (�i1T + "it) = = �2�1T 10T+�
2"IT =
0BBBB@�2" + �
2� �2� ::: �2� �2�
�2� �2" + �2� ::: �2� �2�
::: ::: ::: ::: :::�2� �2� ::: �2" + �
2� �2�
�2� �2� ::: �2� �2" + �2�
1CCCCATo compute the GLS estimator, we transform the data by premultiplying
each vector of variables by �1; where:
�1 = ��2"
�IT �
�2��2" + T�
2�
1T 10T
�= ��2"
��IT �
1
T1T 1
0T
�+
1
T1T 1
0T
�where: = �2"
�2"+T�2�: Since IT � 1
T 1T 10T transforms the data in deviations
from their individual means and 1T 1T 1
0T takes individual means, the GLS esti-
mator for � can be written as,
�GLS =
NXi=1
TXt=1
(xit � �xi)0(xit � �xi) + TNXi=1
(�xi � �x)0(�xi � �x)!�1
NXi=1
TXt=1
(xit � �xi)0(yit � �yi) + TNXi=1
(�xi � �x)0(�yi � �y)!
Two special cases deserve some discussion:
� when T !1; the unobserved becomes observable, and it is unlikely that�i can be constant, unless it is not random. The Fixed E¤ects estimatorwould then be e¢ cient, and it would coincide with GLS,
� if �2"=�2� ! 0; then the stochastic component is dominated by �i; whichare constant over time, so we are left again with the Fixed E¤ects estima-tor. In these two cases, the GLS estimator coincides with the Fixed E¤ects
estimator.
12.1 Relationship to other estimators
As it was the case with the Pooled OLS estimator, we can show that the RandomE¤ects GLS estimator is a vector convex linear combination of the Between andthe Fixed E¤ects estimators.
164

From the general expression for the GLS estimator, it can be shown that,
�GLS = (Ik ��)�B +��FEwhere:
� =�Swithinxx + Sbetweenxx
��1Swithinxx =
= T
NXi=1
TXt=1
(xit � �xi)0(xit � �xi) + TNXi=1
(�xi: � �x)0(�xi: � �x)!�1 " NX
i=1
(xi: � �xi)0(xi: � �xi)#
with being the parameter that we de�ned above: = �2"�2"+T�
2�:
The matrix � is proportional to the inverse of the covariance matrix of �B ;so that the GLS estimator is a matrix-weighted average of the Between and theWithin estimators, where the weight depends on the relative variances of thetwo estimators, the more accurate estimator receiving the heavier weight.The Between estimator discards the time series information in the data set.
The GLS estimator is the optimal combination of the Between and the Withinestimators, and is therefore more e¢ cient than either one of them. The POLSestimator is also a linear combination of the two estimators, as seen in previoussections, which di¤ers from the previous one by the presence of the parameterin the de�nition of the � weight. It is a special case of the previous linearcombination, for = 1. Hence, the Pooled OLS estimator is not the e¢ cientlinear combination of the Between and the Fixed E¤ects estimators. GLS willbe more e¢ cient than OLS, as usual.It is easy to see that for = 0 we get the Fixed E¤ects orWithin estimator,
since then, � = 0. As we saw above, since ! 0 when T !1; it follows thatthe Random E¤ects and the Fixed E¤ects estimators are equivalent for largeT: If = 1; the GLS estimator reduces to the Pooled OLS estimator. The parameter can be thought of as being the relevance given to variation acrossindividuals in the panel. The Fixed E¤ects or Within estimator, with = 0;ignores that variation. The Pooled least squares estimator, with = 1; assignsto variation across individuals the same importance as to the variation over timeamong observations from a given individual, without taking into account thatsome of their variability comes from variation in �i across individuals.The GLS estimator will be unbiased if the explanatory variables are inde-
pendent of all "it and all �i: It will be consistent for N or T or both tending toin�nity if in addition to i) E[(xit � �xi)"it] = 0 we also have ii) E(�xi"it) = 0;and even most importantly, iii) E(�xi�i) = 0: These conditions are also requiredfor the Between estimator to be consistent (Verbeek).Under weak regularity conditions, the Random e¤ects estimator , �RE ; also
known as the Balestra-Nerlove estimator, is asymptotically Normal, with co-variance matrix,
165

V ar(�RE) = �2"
NXi=1
TXt=1
(xit � �xi)0(xit � �xi) + TNXi=1
(�xi � �x)0(�xi � �x)!�1
which shows that the Random E¤ects estimator is more e¢ cient than theFixed E¤ects estimator as long as > 0: The gain in e¢ ciency is due to the useof the between variation in the data (�xi� �x) as it appears in the second term inthe expression of the variance-covariance matrix: The covariance matrix aboveis obtained when estimating by OLS the transformed model (??).We must remember that if we do not feel very con�dent on the analytical
structure we are imposing on the variance-covariance matrix of the error term,we can always proceed by applying ordinary least-squares and a robust inferenceby using an appropriately corrected empirical covariance matrix, as explainedin previous sections.
12.2 Practical implementation of the Random E¤ects es-timator
An easy way to compute the GLS estimator is obtained by applying OLS totransformed variables:
yit � ��yi = �(1� �) + (xit � ��xi)0� + "it
where � = 1� 1=2; so that a �xed proportion � of the individual means issubtracted from the data to obtain the transformed model.The error term in this transformed regression is still i., i.d. over individuals
and over time. Again, � = 1 ( = 0) corresponds to the Fixed E¤ects orWithinestimator, while � = 0 corresponds to the Pooled OLS estimator: As T !1; � ! 1; and we get the Fixed E¤ects estimator.We need estimates of the variances of the two error components �i and �"i;to
implement GLS. To that end, we use the variance of the Fixed E¤ects residuals,with denominator NT �N � k as the estimate of �2": The denominator relfectsthe fact that we are estimating N intercepts and k slope coe¢ cients. The errorvariance for the Between regression is �2� + �2"=T; which can be consistentlyestimated by,
�2B =1
N � k
NXi=1
(�yi � �B � �x0i�B)2
This leads to a consistent estimator for �2� :
�2� = �2B �1
T�2"
Again, the correction for degrees of freedom can be achieved by subtractingk + 1 from the denominator of �2B :
166

As an alternative, Green (6 ed.) proposes the equality,
�2POLS = �2" + �2�
to compute an estimate of �2� after estimating by POLS and Fixed E¤ects.The Residual sum of squares from the Pooled OLS estimator must be dividedby NT � k � 1; since there is a single intercept.
12.3 Summary
� The Between estimator exploits the di¤erences between individuals, andit is determined as OLS in a regression of individual averages. Consis-tency, for N ! 1; requires two types of conditions: i) E(�xi�i) = 0; andii) E(�xi�"i) = 0; which will usually require explanatory variables to beuncorrelated with the individual e¤ects �i, as well as strictly exogenous.
� The Fixed E¤ects (or Within) estimator exploits the di¤erences withinindividuals, and it is determined as OLS in a regression using all observa-tions in deviations from individual means. It is consistent for T ! 1 orN !1 provided E[(xit� �xi)"it] = 0. This requires explanatory variablesto be strictly exogenous, but it does not impose any restrictions upon therelationship between xit and �i:
� The OLS estimator exploits both dimensions, although less than e¢ ciently.It is determined as OLS in the original model, and it can be written asa convex linear combination of the two previous estimators. Consistencyfor T ! 1 or N ! 1 requires that E[xit("it + �i)] = 0. This requiresexplanatory variables to be uncorrelated with �i, but it does not imposethat they are strictly exogenous. It su¢ ces with xit and "it to be contem-poraneously uncorrelated. It also requires explanatory variables to haveno correlation with the unobservable individual e¤ects �i:
� The Random e¤ects estimator combines the information in the Betweenand the Within estimators in an e¢ cient way. It is consistent for T !1or N !1 under the combined conditions that imply consistency for theBetween and the Within estimators. It can be obtained as the e¢ cientweighted average of the Within and the Between estimators, or as theOLS estimator in a regression with variables transformed as yit � ��yi;
with � = 1� 1=2 = 1�q
�2"�2"+T�
2�:
� Fixed E¤ects estimation is a conditional analysis, measuring the e¤ects ofxit on yit, controlling for the individual e¤ects �i: Prediction is possibleonly for individuals in the particular sample being used, and even thenit is only possible if the panel is long enough that �i can be consistentlyestimated. Random E¤ects estimation is instead an example of marginalanalysis or population averaged analysis, as the individual e¤ects are in-tegrated out as i., i.d. random variables. The Random E¤ects estimator
167

can be applied outside the sample. If the true model is a Random E¤ectsmodel, then whether to perform a conditional or marginal analysis willvary with the application. If analysis is for a random sample of countries,then one uses random e¤ects, but if one is intrinsically interested in theparticular countries in the sample, then one does Fixed E¤ects estimationeven though this can entail a loss of e¢ ciency. However, if some unob-served individual speci�c e¤ects are correlated with regressors, then theRandom E¤ects estimator does not make sense, being inconsistent, andwe will need either the Fixed E¤ects estimator or the First Di¤erencesestimator.
12.4 Testing for random e¤ects
The treatment applied to the individual e¤ects can imply substantial di¤erencesin numerical estimates in the usual case in which the time dimension of the paneldata is small. The Fixed e¤ects approach fE(yit=xit) = x0it� + �ig is conditionalupon the values for �i: It considers the distribution of yit given �i; where the �0iscan be estimated. This makes sense if the individuals in the sample are "one of akind", and cannot be taken as random draws from some underlying population.That would be the case if the number of units is relatively small. Inferencesare made with respect to the e¤ects that happen to be included in the sample.The Random e¤ects approach fE(yit=xit) = x0it�g is not conditional upon theindividual �0is but "integrates them out". We are then not usually interested inthe value of �i for a given individual. Inferences are made with respect to thepopulation characteristics.Even if we are interested in a large number of individual units and the
Random e¤ects approach seems appropriate, we may prefer the Fixed e¤ectsestimator if xit is clearly correlated with �i; since that would lead to inconsistentleast-squares estimators as used in the Random e¤ects estimator. This problemdisappears in the Fixed e¤ects estimator because �i is eliminated from themodel.
12.4.1 Hausman test
Hausman (1978) suggested a test for the null hypothesis that xit and �i areuncorrelated. Two estimators are compared: one that it is consistent under boththe null and alternative hypothesis, and a second estimator which is consistentonly under the null hypothesis. A signi�cant di¤erence between both estimatorsis interpreted as the null hypothesis not being true. In our case, the Fixed E¤ectsestimator is consistent with independence of the possible correlation between xitand �i , while the Random E¤ects estimator will be consistent and e¢ cient onlyif the null hypothesis of lack of correlation is true. Usually, to compare the twoestimators, we would have to compute the covariance between the two estimates.The essential result in Hausman (1978) is that the covariance between an
e¢ cient estimator and its di¤erence with respect to an ine¢ cient estimator is
168

zero. Hence, since the Random E¤ects estimator is e¢ cient under the null, thenif the null hypothesis is true, we will have:
Cov(�RE ; �FE � �RE) = 0so that,
Cov(�RE ; �FE) = �V ar(�RE)and therefore,
V ar(�FE � �RE) = V ar(�FE)� V ar(�RE)and the test statistic is computed as:
H = (�FE � �RE)0hV ar(�FE)� V ar(�RE)
i�1(�FE � �RE)
where the two variance-covariance matrices must be substituted by their re-spective estimates. Under the null hypothesis, the statistic follows a chi-squareddistribution with k degrees of freedom, where k is the number of elements in �:A word of caution: the matrix in square brackets may not be positive de�nitein small samples. We should in that case conclude that the covariance matricesare not di¤erent, thereby not rejecting the Random e¤ects model, since if thetwo estimators were di¤erent, then the statistic should be positive and relativelylarge. Even if the statistic turned out to be negative, we would still be able toimplement the test for a subset of elements in �: Another strategy would be tomove to asymptoticalley equivalent versions of the test statistic. One of themis,
H = (�FE � �B)0hV ar(�FE) + V ar(�B)
i�1(�FE � �B)
Hausman test can be applied to any other pair of estimators with propertiessimilar to the ones we have used here, as the estimator in First di¤erences versusthe Pooled OLS estimator, since, in the absence of Random E¤ects, the POLSestimator is e¢ cient.
12.4.2 Alternative tests for the comparison between the Fixed Ef-fects and the Random E¤ects models
When we introduced the Between estimator, we mentioned Mundlak (1978)assumption that the conditional expectation E(�i=Xi) can be assumed to be afunction of the group means: E(�i=Xi) = �x
0i . That led to the model:
yit = �+ x0it� + �x0i + "it
Mundlak�s assumption preserves the speci�cation of the Random E¤ectsmodel while modelling the correlation between individual e¤ects and the ob-served time varying explanatory variables. This speci�cation is also a com-promise between the Fixed E¤ects model and the Random E¤ects model, the
169

di¤erence between them coming from the vector of coe¢ cients : Hence, a sig-ni�cance test for this vector of coe¢ cients is an alternative to the Hausmanspeci�cation testy described above, so long as the assumption on E(�i=Xi) isapproximately correct.An asymptotically equivalent way to implement the speci�cation test is to
perform the Wald test of = 0 in the auxiliary OLS regression,
yit � ��yi = (1� �)�+ (xit � ��xi)0 �1 + (xit � �xi)0 + uit
where � is the same parameter used in the alternative implementation of theRandom E¤ects estimator, which is a special case for = 0: If instead, the FixedE¤ects estimator is appropriate, then the error term (uit � (1� �)�i + ("it � ��"i))will be correlated with the regressors, and additional functions of the regressorssuch as (xit � �xi) may have signi�cant coe¢ cients in the previous equation.Breusch and Pagan (1980) proposed a Lagrange multiplier type of test for
signi�cance of random e¤ects, H0 : �2� = 0; versus the alternative that it is
positive, based on OLS residuals. We therefore, test for lack of autocorrelationin the sum "it + �i. The Lagrange multiplier statistic,
LM =NT
2(T � 1)
264PNi=1
hPTt=1 "it
i2PNi=1
PTt=1 "
2it
� 1
3752
=NT
2(T � 1)
" PNi=1
�T "i�2PN
i=1
PTt=1 "
2it
� 1#2
follows a chi-square distribution with one degree of freedom. The residualsin this expression come from the restricted model, estimated with OLS.Example: Green (6ed., examples 9.5 and 9.6) applies this test for the logged
wages model that excludes the time invariant characteristics, and also computesestimates of the variance component parameters.
12.5 Goodness of �t in panel data models
Goodness of �t under panel data has peculiar features, since we want to weightdi¤erently the ability of a model to explain the Between and the Within vari-ation in the data. On the other hand, the R2 is appropriate only under OLSestimation. It is standard to use a R2 de�ned as the square of the correlationbetween the actual and �tted values, which is always in [0; 1]; and collapses tothe usual R2 under OLS estimation. Since Total variation can be decomposedinto Between and Within variation:
1
NT
TXt=1
NXi=1
(yit � �y)2 =1
NT
TXt=1
NXi=1
(yit � �yi)2 +1
N
NXi=1
(�yi � �y)2
The Fixed E¤ects estimator is constructed to explain the Within variations,and it maximizes the Within R2:
170

R2within =�corr
�yFEit � yFEi ; yit � �y
�2=hcorr
n(xit � �xi)�
FE; yit � �y
oi2The Between estimator maximizes the Between R2:
R2between =�corr
�yBi ; �y
�2=hcorr
n�x0i�
B; �yoi2
The OLS estimator maximizes the Overall goodness of �t:
R2overall = [corr fyit; yitg]2
where yi = 1T
PTt=1 yit and yi =
1TN
PPyit where the intercept terms are
omitted. If we take into account the variation explained by the N estimatedintercepts �i; then the �xed e¤ects estimator captures perfectly the betweenvariation. This however, does not mean that it �ts the data well, since it is onlythat the dummy variables capture the data perfectly, and that should not beincorporated into a goodness of �t measure.The point is that it is possible to de�ne Within, Between and Overall
R2 measures for any arbitrary estimator, using �tted values yit and averagesyi =
1T
PTt=1 yit and yi =
1TN
PTt=1
PNi=1 yit; omitting intercept terms. As we
have mentioned, for the Fixed E¤ects estimator, this would ignore the variationcaptured by the �i individual intercept estimates.For the Random E¤ects estimator, the Within, the Between and the Overall
R2 will necessarily be smaller than for the Fixed E¤ects, Between and OLSestimators, respectively. This again, shows that goodness of �t measures bythemselves are not adequate to choose between alternative (potentially non-nested) speci�cations of the model.Example: Verbeek (p. 358), logged wages. RATS program.
12.6 Instrumental variables estimators of the Random Ef-fects model
As we have seen, the use of the Fixed E¤ects estimator to solve the problemof correlation between explanatory variables and individual e¤ects may be un-desirable, if we are interested in the e¤ect of time invariant variables on thedependent variable.The Fixed E¤ects estimator can be written:
�FE =
NXi=1
TXt=1
(xit � �xi)0xit
!�1 " NXi=1
TXt=1
(xit � �xi)0yit
#which can be interpreted as an instrumental variable estimator in model:
yit = �+ x0it� + �i + "it
171

where each explanatory variable is instrumented by its value in deviations
from the individual speci�c mean. SincePNi=1
PTt=1 [(xit � �xi)0�i] =
PNi=1
hPTt=1(xit � �xi)0
i�i =
0, then all that it is needed for consistency is E [(xit � �xi)0"it] = 0 , which isimplied by the strict exogeneity of the xit variables. If a particular element inxit happens to be uncorrelated with �i; it can be used as its own instrumentwithout taking di¤erences with respect to the individual mean. That is the caseof time invariant e¤ects, whose e¤ect on the dependent variable can thereforebe estimated under this approach.
12.6.1 The Hausman and Taylor estimator
A more general approach was introduced by Hausman and Taylor (1981), in theline of the Random E¤ects estimate, as follows: The random e¤ects approachto the linear model:
yit = x0it� + z0i�+ "it
is based on the assumption that the unobserved individual speci�c e¤ects ziare uncorrelated with the included variables xit: This is a major shortcoming,since it is a very strong assumption to make. However, the Random E¤ects treat-ment allows for observed time-invariant characteristics, to appear explicitely inthe estimated model, while the Fixed E¤ects estimator does not, since they areabsorbed into the �xed e¤ects. Hausman and Taylor�s (1981) estimator sug-gests a way to overcome the �rst limitation while accommodating the secondadvantage, and using only the information in the model.These authors consider the model
yit = x01it�1 + x02it�2 + z
01i�1 + z
02i�2 + ("it + ui)
where x1 is a k1-vector, x2 is a k2-vector, z1 is a l1-vector, z2 is a l2-vector,and all individual e¤ects in zi are assumed to be observed. Unobserved e¤ectswould be contained into the individual-speci�c random term ui: Variables withthe 2-index are correlated with ui; while those carrying the 1-index are assumedto be uncorrelated with ui. Hence, OLS and GLS estimates will be biased andinconsistent. Assumptions on random terms are:
E(ui=x1it; z1i) = 0; although E(ui=x2it; z2i) 6= 0V ar (ui=x1it; x2it; z1i; z2i) = �2u;
Cov ("it; ui=x1it; x2it; z1i; z2i) = 0;
V ar ("it + ui=x1it; x2it; z1i; z2i) = �2 = �2" + �2u;
Corr ("it + ui; "is + ui=x1it; x2it; z1i; z2i) = � = �2u=�2
The group mean deviations x1it � �x1i; x2it � �x2i can be used as k1 + k2instrumental variables. Since z1 is uncorrelated with the disturbances, it can beused as a set of l1 instrumental variables for themselves. So, we need another l2
172

instrumental variables. Hausman and Taylor show that the individual (group)means for x1 can be used as such, so the identi�cation condition16 is k1 � l2:Feasible GLS is better than OLS, and it is also an improvement on the simple
instrumental variable estimator, which is consistent, but ine¢ cient.Taking deviations from group means:
yit � �yi = (x1it � �x1i)0 �1 + (x2it � �x2i)0�2 + ("it � �"i)
which can be consistently estimated by LS, in spite of the correlation be-tween x2 and u: This is, of course, the Fixed E¤ects, Least-Squares DummyVariable (LSDV) estimator. However, it would not identify the values of coef-�cients for time invariant variables. It is also ine¢ cient, since x1t is needlesslyinstrumented.We can describe four steps to compute the Hausman and Taylor instrumental
variable estimator, the �rst three of which provide us with the -parameterneded to transform the data and compute the estimator in a last step.
� Step 1: Obtain the LSDV (�xed-e¤ects) estimator of � = (�1; �2) basedon x1 and x2: The residual variance from this step is a consistent estimatorof �2":
� Step 2: Form the within groups residuals eit from LSDV regression inStep 1. Stack the group (individual) means, conveniently repeated, in afull sample length data vector, e�it = �ei; i = 1; 2; :::; N; t = 1; 2; :::; T: Theresiduals are computed excluding the estimate of the constant term. Theseare used as the dependent variable in an instrumental variable regressionon z1 and z2 with instrumental variables z1 and x1 (assuming k1 � l2):Time invariant variables are repeated T times in the data matrices in thisregression. This provides a consistent estimator of �1; �2.
� Step 3: The residual variance from step 2 is a consistent estimator of��2 = �2� + �2"=T: From this estimator and the estimator of �2" from step1, we deduce an estimator: �2� = ��2� �2"=T; and compute the weight forthe GLS estimator: =
q�2"
T�2�+�2"
� Step 4: A weighted instrumental variable estimator. Consider the full setof explanatory variables: w0it = (x
01it; x
02it; z
01i; z
02i) ; for which we have nT
observations. We perform the usual GLS transformation as for the randome¤ects model: w�0it = w0it�(1� ) �w
0
i; y�it = yit�(1� )�yi; and collect these
transformed data in a matrix W � and a column vector y�: For the time-invariant variables, the group mean is equal to the original variable, andthe transformation just multiplies the original data by 1� : The instru-mental variables are: v0it =
�(x01it � �x1i)
0; (x02it � �x2i)
0; z01i; �x
01i
�: These are
16To estimate the original model, Hausman and Taylor suggest using x1it; z1i; x2it � �x2and �x1i as instruments. We can use time averages of those time-varying regressors thatare uncorrelated with �i as instruments for the time-invariant regressors. The identi�cationcondition is then that we have enough of those instruments: k1 � l2:
173

stacked as rows in an nTx(k1 + k2 + l1 + l2) matrix V: For the third andfourth sets of instruments, the time invariant variables and group meansare repeated for each time period for that individual or group. The in-strumental variable estimator would be:�
�0; �0�0IV=��W �0V )(V 0V )�1(V 0W ����1 ��W �0V )(V 0V )�1(V 0y�
��For the sake of comparison, the FGLS random-e¤ects17 estimator would be:�
�0; �0�0RE
= (W �0W �)�1W �0y�:
The instrumental variable is consistent if the data is not weighted, that is,if W , rather than W �; is used in estimation. But that would be ine¢ cient, inthe same way as OLS is ine¢ cient in estimation of the simpler random e¤ectsmodel.
13 Dynamic linear models
13.1 Linear autoregressive models
Consider an autoregressive panel data model with a vector of exogenous ex-planatory variables:
yit = �i + yi;t�1 + x0it� + "it; "it � i:; i:d:(0; �2")
Here the problem is that the lagged dependent variable will depend upon�i irrespective of how we treat the individual e¤ect �i: To see this, assume, forsimplicity, that there are not exogenous explanatory variables:
yit = �i + yi;t�1 + "it; "it � i:; i:d:(0; �2")
Denoting �yi;�1 =PTt=2 yi;t�1=(T � 1); di¤erent from �yi = (1=T )
PTt=1 yi;t;
the Fixed E¤ects estimator is:
FE =
PP(yit � �yi)(yit�1 � �yi;�1)PP
(yit�1 � �yi;�1)2= +
1N(T�1)
PP("it � �"i)(yit�1 � �yi;�1)
1N(T�1)
PP(yit�1 � �yi;�1)2
which will be biased and inconsistent forN !1 and �xed T: This is becausethe last term in the right-hand side does not have expectation zero due to thecorrelation between �yi;�1 and �"i, and it does not converge to zero. In fact Nickell(1981), Hsiao (2003) show that:
p lim1
NT
XX("it � �"i)(yit�1 � �yi;�1) = �
�2"T 2(T � 1)� T + T
(1� )2 6= 0
17This denotes the Feasible GLS estimator of the Random E¤ects model, the noe we de-scribed in the Implementation section.
174

Notice that the inconsistency is not produced by any assumption we canmake on the �i; since it gets eliminated in the transformation, but rather, by thefact that the Within transformed lagged dependent variable is correlated withthe Within transformed error.18 Therefore, at a di¤erence of what happens ina static model, the Fixed E¤ects estimator does not solve the inconsistency ina dynamic model.On the other hand, if T !1; then the expression above converges to zero,
and the Fixed E¤ects estimator is consistent if both T !1 and N !1: Butin �nite samples, this lack of consistency can be a serious problem. For instance,if = 0:5; then we have, as N !1 :
p lim FE = �0:25 if T = 2p lim FE = �0:04 if T = 3p lim FE = 0:33 if T = 10
To avoid the inconsistency, we make a di¤erent transformation to eliminatethe individual e¤ects �i, by taking First di¤erences:
yit � yi;t�1 = (yi;t�1 � yi;t�2) + ("it � "i;t�1); t = 2; 3; :::; T "it � i:; i:d:(0; �2")
Once again, least squares would be inconsistent in this model because of thecorrelation between yi;t�1 and "i;t�1; even when T !1: But the transforma-tion suggests an instrumental variable approach (Anderson and Hsiao (1981))so long as "it does not exhibit autocorrelation, since yi;t�2 is clearly correlatedwith the explanatory variable, but not with the error term,
IV =
PNi=1
PTt=2(yit � yit�1)yi;t�2PP
t=3(yit�1 � yi;t�2)yi;t�2A standard argument shows that consistency of this instrumental variable
estimator depends on p lim 1N(T�2)
PNi=1
PTt=3("it � "i;t�1)yit�2 = 0 for either
N; T or both going to 1: Anderson and Hsiao suggested an alternative instru-mental variable estimator, using yi;t�2 � yi;t�3 as instrumental variable:
IV =
PNi=1
PTt=3(yit � yit�1)(yi;t�2 � yi;t�3)PN
i=1
Pt=3(yit�1 � yi;t�2)(yi;t�2 � yi;t�3)
which will be consistent if p lim 1N(T�1)
PNi=1
PTt=3("it�"i;t�1)(yit�2�yi;t�3)
= 0 for either N; T or both going to 1: As in the previous estimator, thiscondition will hold whenever "it lacks serial correlation. If there are exogenousregressors in the model, then not only their contemporaneous and lagged values,but also their future values, are valid instruments as well. If they are prede-termined, their contemporaneous and lagged values will be valid instruments.
18Cov(yi;t�1; ci + "i) = �2c + Cov(yi;t�2; ci + "i); and the Covariance would converge, for
T large, to �2c1�� :
175

The number of instruments increases with time, and it can easily get very large.However, the latter set of instruments requires an additional lag, and hence, welose an additional sample period.The instrumental variable estimator is,
�IV =
24 nXi=1
�X 0iZi
! nXi=1
Z 0iZi
!�1 nXi=1
Z 0i�Xi
!35�1 24 nXi=1
�X 0iZi
! nXi=1
Z 0iZi
!�1 nXi=1
Z 0i�yi
!35where the X matrix includes the lagged endogenous variable in addition to
possible predetermined or exogenous variables, and Z is the matrix of choseninstruments. The variance-covariance matrix is,
V ar��IV
�= �2�"
24 nXi=1
�X 0iZi
! nXi=1
Z 0iZi
!�1 nXi=1
Z 0i�Xi
!35�1
where an estimate for �2�" could be obtained from the residual sum of squaresof the diferenced model: �2�" = RSS=[N(T � 2)]. But this will be an under-estimate, since it ignores the fact that the di¤erence operator introduces �rstorder serial correlation. In fact, the previous footnote suggests that the previouscalculation will be an approximate estimate of 2�2". But there is also the addi-tional problem that the observations are autocorrelated. Hence, the standardIV variance-covariance matrix is inappropriate, and we must use,
V ar(�IV ) = A
24 nXi=1
�X 0iZi
! nXi=1
Z 0iZi
!�1�2"
nXi=1
Z 0iGZi
! nXi=1
Z 0iZi
!�1 nXi=1
Z 0i�Xi
!35A
with19 G being a TxT matrix: G =
0BB@2 �1 0 :::�1 2 ::: 00 ::: ::: �1::: 0 �1 2
1CCA ;where,
A =
24 nXi=1
�X 0iZi
! nXi=1
Z 0iZi
!�1 nXi=1
Z 0i�Xi
!35�1
While one could discuss whether it is preferable to use levels or di¤erences asinstruments, the Generalized Method of Moments provides a uni�ed approachto instrumental variable estimation.19V ar("i2 � "i1) = 2�2"; Cov("i2 � "i1; "i3 � "i2) = ��2"
176

13.2 General Method of Moments (GMM) estimation
Rather than arguing about which instrumental variable estimator we should use,a GMM argument would lead us to using both instruments, while eliminatingthe disadvantage of reduced sample sizes.The two previous instrumental variable estimators use the moment condi-
tions: E [("it � "i;t�1)(yit�2 � yi;t�3)] = 0 and E [("it � "i;t�1)yit�2] = 0. Arel-lano and Bond (1991) suggest that the list of instruments can be extended byexploiting additional moment conditions and letting their number vary with t ,thereby increasing e¢ ciency. For instance, when T = 4; we have, for t = 2 themoment condition:20
E[("i2 � "i1)yi0] = 0
while for t = 3; we have:
E[("i3 � "i2)yi1] = 0
E[("i3 � "i2)yi0] = 0
and, for t = 4 :
E[("i4 � "i3)yi0] = 0
E[("i4 � "i3)yi1] = 0
E[("i4 � "i3)yi2] = 0
So, in general, we have a matrix of instruments:
Zi =
0BB@[yi;0] 0 ::: 00 [yi0; yi1] ::: 0::: ::: 00 ::: ::: [yi0; yi1; :::; yi;T�2]
1CCAand the vector of transformed error terms:
�"i =
0@ "i2 � "i1:::
"i;T � "i;T�1
1Aand a set of 1 + 2 + 3 + :::+ (T � 1) = (T�1)T
2 moment conditions:21
E[Z 0i�"i] = E[Z 0i(�yi � �yi;�1)] = 020Assuming there is an initial y0 observation. Otherwise, we would have one moment
condition less at each point in time,21With T = 4 time observations, we will have 6 instruments or orthogonality conditions if
there is an initial condition yi0; and 3 such conditions if there is not known initial conditionyi0.
177

Since the number of moment conditions will usually exceed the number ofunknown parameters, as it is the case in this example, we will minimize thequadratic form:
min
"1
N
NXi=1
Z 0i(�yi � �yi;�1)#0WN
"1
N
NXi=1
Z 0i(�yi � �yi;�1)#
where WN is a symmetric, positive de�nite weighting matrix which willdepend on the sample size, N: Di¤erentiating with respect to and solving:
GMM =
" NXi=1
�y0i;�1Zi
!WN
NXi=1
Z 0i�yi;�1
!#�1 " NXi=1
�y0i;�1Zi
!WN
NXi=1
Z 0i�yi
!#
This estimator is consistent for any choice of positive de�nite weighting ma-trix WN so long as orthogonality (moment) conditions are true. GMM theoryshows that the optimal choice of weighting matrix, in order to minimize thevariance-covariance matrix of the resulting estimator, is the inverse of the co-variance matrix of the sample moments:
p limN!1
WN = [V ar(Z0i�"i)]
�1= [E(Z 0i�"i�"iZi)]
�1
If no restrictions are imposed upon the covariance matrix, then it can beestimated by the sample average of a function of the residuals " from a consistentinitial estimate. Usually, this is obtained with the identity matrix as the initialweighting matrix:
W optN =
1
N
NXi=1
Z 0i�"i�"iZi
!�1where "i denote the residuals from an initial GMM estimate obtained with
an identity as weighting matrix: WN = I:The general GMM approach does not need that the "it be i., i.d. over
individuals, and the optimal weighting matrix is estimated without imposingsuch constraint. However, the moment conditions are valid only under lack ofautocorrelation. And if autocorrelation is present, there is no point in computinga robust estimate of the variance-covariance matrix of estimates, since they willbe inconsistent.Under weak regularity conditions, the GMM estimator for is asymptoti-
cally Normal for N !1 and �xed T; with covariance matrix,
p limN!1
24 NXi=1
�y0i;�1Zi
! 1
N
NXi=1
Z 0i�"i�"iZi
!�1 NXi=1
Z 0i�yi;�1
!35�1
178

With i., i.d. errors, the middle term reduces to,
�2"WoptN = �2"
1
N
NXi=1
Z 0iGZi
!�1with G being the TxT matrix we introduced above, so long as there is no
autocorrelation in the error term: Alvarez and Arellano (2003) show that theGMM estimator is also consistent when both, N and T tend to in�nity despitethe fact that the number of moment conditions tends to in�nity with the samplesize.For large T; however, the GMM estimator will be close to the Fixed E¤ects
estimator, which provides a more attractive alternative.
13.3 Dynamic models with exogenous variables
In the case of the more general model:
yit = �i + yi;t�1 + x0it� + "it; "it � i:; i:d:(0; �2")
we will have di¤erent instruments as a function of the assumptions we makeon the xit variables. If they are assumed to be strictly exogenous, in the senseof being uncorrelated with all error terms at all time periods, we will also have:E(xit�"is) = 0 8s; t; so that xi1; xi2; :::; xiT can be added as instruments tothe model in �rst di¤erences. But that would make the number of rows in Zitoo large. Almost the same amount of information can be obtained if we usethe �rst di¤erenced xit as their own instruments. Then, we would be imposingmoment conditions:
E(�xit�"it) = 0;8t
and the matrix of instruments can be written:
Zi =
0BB@[yi;0;�x
0i2] 0 ::: 0
0 [yi0; yi1;�x0i3] ::: 0
::: ::: 00 ::: ::: [yi0; yi1; :::; yi;T�2;�x
0iT ]
1CCAIf the xit variables are not strictly exogenous, but only predetermined:
E(xit"is) = 0;8s � t: Then, E [(xit � xi;t�1) ("it � "i;t�1)] 6= 0, and onlyxi;t�1; :::; xi1 are valid instruments for the �rst-di¤erenced equation in period t. The moment conditions imposed would then be:
E(xi;t�j�"it) = 0; for j = 1; 2; :::; t� 1; for each t
Usually, one should expect to have a mixture of some exogenous and somepredetermined variables to be used as instruments. Arellano and Bond (1995)
179

explain how this approach can be integrated into the instrumental variable es-timator of Hausman and Taylor (1981). They also discuss how information inlevels of original variables can also be used in estimation.Example: VerbeekVerbeek refers to the estimation of a demand for labour equation based on
data from 2800 large Belgium �rms over 1986-1994. Using a theoretical modelof union bargaining as reference, the authors estimate a static version:
logLit = �0 + �1 logwit + �2 logKit + �3 log Yit + �4 logwjt + uit
where wjt denotes the industry average real wage, acting as an indicator ofthe reference negotiation wage level for unions, Kit is the stock of capital andYit is output, as well as adynamic version of the demand equation,
logLit = �0+�1 logwit+�2 logKit+�3 log Yit+�4 logwjt+ logLi;t�1+�i+"it
where it is assumed that the error term has two components, the �rst one be-ing unobservable �rm-speci�c time-invariant heterogeneity. If we �rst-di¤erencethe equation, then� logLi;t�1 will be correlated with�"it: In addition, it is verylikely that wages and employment are jointly bargained, wages then becomingan endogenous explanatory variable in the previous equation. Therefore,
E(� logwit�"it) 6= 0;
and we need to use an instrumental variables approach. Valid instrumentsfor � logwit are logwi;t�2; logwi;t�3; ::: while logLi;t�2; logLi;t�3; ::: could bevalid instruments for � logLi;t�1. Hence, the number of instruments increaseswith t .
Estimation Labour demand equation [Konings and Roodhooft (1997)]Dependent variable: logLit
Static model Dynamic modellogLi;t�1 0:60(0:045)log Yit 0:021(0:009) 0:008(0:005)logwit �1:78(0:60) �0:66(0:19)logwjt 0:16(0:07) 0:054(0:033)logKit 0:08(0:011) 0:078(0:006)Test for overidentifying restrictions 29:7(df = 15; p = 0:013) 51:66(df = 29; p = 0:006)Number of observationsThe p-values for both models are close to 1%. The estimated short-run
wage elasticity of labour demand is -0.66%, but the long-run elasticity is -1.64%,higher than it had been estimated with macro data.22
22Although there were several di¢ culties with the way the data had been constructed. Seeoriginal article in De Economist.
180

Part II
Risk Measurement14 Volatilidad
14.1 Midiendo la volatilidad
14.1.1 La medición del riesgo inherente a un activo
La medición del riesgo incorporado en un determinado activo es, sin duda, unode los problemas más importantes de la economía �nanciera. El nivel de riesgoes una de las características de un activo que, junto con su rentabilidad esperada,su liquidez, etc..determinan las decisiones óptimas de inversión de los agentes.Es habitual identi�car la medición del riesgo con la varianza que ofrece la serietemporal de rentabilidad del activo. En el caso de un mercado �nanciero, elriesgo suele medirse mediante la varianza de las variaciones en el índice corre-spondiente (rentabilidades) observadas con una determinada frecuencia (hora,día, semana, mes). Podemos incluso hablar de volatilidad intradía (dentro deldía de negociación) si examinamos las variaciones en precio (o en índice) muyfrecuentemente; por ejemplo, para todas las operaciones cruzadas.Sin embargo, pocas veces re�exionamos su�cientemente acerca de lo que
estamos midiendo. Conviene pensar acerca de qué queremos medir, y si lavarianza es una medida adecuada de riesgo.La primera cuestión es que existen distintos tipos de riesgo, que requieren
medidas diferentes: riesgo sistemático o no diversi�cable dentro del mercado,riesgo especi�co del activo o riesgo diversi�cable en el mercado. Además delriesgo-precio o riesgo de reinversión, tenemos el riesgo de mercado, el riesgo deliquidez, el riesgo de crédito o de contrapartida, etc.. Por tanto, es importantesaber qué tipo de riesgo queremos medir en cada caso. En mercados de rentavariable, el riesgo-beta es útil para muchos �nes. En otras ocasiones, todo loque queremos es un umbral máximo de pérdidas en la forma de un Valor enRiesgo, es decir, un determinado percentil de la distribución de probabilidad dela rentabilidad esperada de una cartera en un horizonte estipulado previamente.Cunado analizamos un mercado concreto, el Riesgo total de un activo puede
descomponerse en un componente de Riesgo sistemático o de mercado, y uncomponente de Riesgo especí�co. Por ej., las acciones del mercado continuode Madrid, tienen un componente de riesgo explicado por el propio mercado,representado por el índice. Tienen también un segundo componente de riesgoque no puede explicarse por el riesgo del mercado. Algo similar ocurre con cadauna de las referencias que cotiza en el mercado secundario de deuda públicaespañol. De modo análogo a la consideración de un activo como parte de unmercado, a un nivel de agregación superior, puede considerarse cada índice deun mercado de valores internacionales como un activo individual, y resolver elproblema de diversi�cación de cartera o asset allocation.También en este caso podríamos hablar de un componente de riesgo global
181

o �de mercado�, así como de un componente de riesgo especí�co de cada índice.El componente de riesgo de mercado es un riesgo sistemático, que no puedeeliminarse mediante la inversión en activos distintos del mismo mercado. Poreso decimos que dicho riesgo no es diversi�cable. Viene caracterizado por labeta del activo, que se estima mediante procedimientos de regresión entre lasrentabilidades del activo y del mercado, ambas descontadas de la rentabilidadofrecida por el activo libre de riesgo. Este es el modelo CAPM. De este modo,este componente no diversi�cable del riesgo del activo está determinado por lacovariación de su rentabilidad con la rentabilidad del índice del mercado al quepertenece.Por el contrario, el componente de riesgo especí�co mide un riesgo no vin-
culado al mercado al que pertenece el activo. Este es un riesgo que puedeeliminarse por diversi�cación, si existe una variedad de activos su�cientementerica en el mercado. Este componente del riesgo puede deberse, en unos casos, alas características del emisor, y en otras, a las características técnicas del activo.Entre el primer grupo, tenemos el riesgo especí�co que se percibe en las
acciones de una determinada empresa, por las inversiones que ha asumido, lagestión de sus directivos, etc.. En el caso de una divisa, un fuerte deterioro desu balanza por cuenta corriente, o de sus cuentas públicas, su situación política,etc., pueden sugerir una posible devaluación, lo que reduciría signi�cativamentela rentabilidad de un inversor extranjero.Una liquidez reducida es otro componente del riesgo especí�co de un activo, si
bien en ocasiones es todo un mercado el que está sujeto a una reducida liquidez.Por ej., la mayor parte de una emisión de deuda privada puede estar en manosde un gran fondo, que no la saca al mercado. Los propietarios del resto de laemisión se enfrentan a un riesgo de liquidez.En el segundo grupo, tenemos aspectos como el riesgo de precio en renta
�ja, por desconocer los tipos de interés futuros a que podremos invertir loscupones recibidos sobre un bono. Hablamos entonces de riesgo precio, o riesgode reinversión. A igualdad de condiciones, un bono cupón cero tiene un menorcomponente de riesgo, debido a la ausencia de reinversiones, si bien está sujetoen cualquier caso a riesgo-precio, por cuanto que desconocemos las posibles�uctuaciones que pueda experimentar su precio. Por supuesto que un activo derenta variable está sujeto a estas consideraciones, además de las propias de suemisor, por lo que tiene riesgo de mercado o riesgo-precio, riesgo de emisor, etc..Distinguir entre estos tipos de riesgo y disponer de procedimientos para
la estimación de cada uno de ellos es un aspecto importante de la gestión decarteras.
14.1.2 La importancia de medir el riesgo
Disponer de medidas numéricas del nivel de riesgo asociado a la inversión enun determinado activo �nanciero durante un determinado período de tiempo esuna herramienta clave en muchos aspectos de la gestión de carteras. Algunosejemplos notables son,Gestión de carteras mediante el análisis rentabilidad/riesgo: Markowitz.
182

Este enfoque, supone que los inversores tienen preferencias dependientes dedos argumentos: riesgo y rentabilidad esperada pre�riendo, entre dos activos queofrecen igual rentabilidad esperada, aquél que ofrece un menor riesgo y entredos activos que ofrecen igual riesgo, aquél que ofrezca una mayor rentabilidadesperada.Por tanto, tales inversores pueden estar dispuestos a asumir un mayor nivel
de riesgo, si reciben también una mayor rentabilidad, aunque no cualquier com-binación es preferible: estos inversores tendrán un mapa de curvas de utilidadconstante en el plano (riesgo, rentabilidad esperada). Cada una de estas curvases el lugar geométrico de los pares de valores para dichas variables que ofrecenun mismo nivel de utilidad. Curvas más elevadas en dicho plano correspondena niveles de utilidad superiores.Una vez que dispusiéramos de valores numéricos para el nivel de riesgo y la
rentabilidad esperada de cada uno de los activos disponibles, el inversor elegiríaaquél que pre�ere a los demás. Aunque habrá, generalmente un activo preferibleal resto, un análisis que comparase únicamente los activos individualmente entresí ignoraría la posibilidad de construir carteras diversi�cadas, como estudiaremosposteriormente. Esta es la base del análisis de carteras propuesto por Markowitz.Pero antes de poder escoger una inversión (activo o cartera), hemos de hacer
frente a dos di�cultades: 1) por un lado, lo que interesa al inversor es la rentabil-idad esperada, para cada activo, a lo largo del período en que se va a llevar acabo la inversión, 2) por otro, el riesgo no es observable, por lo que hemos deutilizar alguna medida del mismo, para lo que generalmente se identi�ca riesgocon volatilidad. Es muy importante observar que, desde el punto de vista dela teoría �nanciera, ambas deberían ser medidas hacia el futuro y, sin embargo,suelen ser inadecuadamente sustituidas por medidas históricas.Valoración de opciones:El precio de una opción depende de: a) el precio de ejercicio de la opción,
b) el tiempo que resta hasta su vencimiento, c) el tipo de interés del activosin riesgo, d) los dividendos ofrecidos por el activo subyacente, si los hay, e) elprecio del activo subyacente, f ) su volatilidad, que no es observable.Para evaluar si el precio de mercado de una opción es correcto ha de dispon-
erse de una estimación de la volatilidad del activo subyacente. Para ello, senecesita la volatilidad estimada del precio del subyacente durante el períodoresidual hasta el vencimiento de la opción. Con dicha medida, podríamos uti-lizar alguno de los modelos disponibles que, condicionado en la validez de lashipótesis en él incorporadas, nos proporcionaría el precio teórico de la opción.La comparación con su precio de mercado nos permitiría evaluar el interés quepueda tener tomar posiciones cortas o largas en la misma.Cobertura de riesgos en inversiones a largo plazo:El diseño de estrategias de cobertura de carteras depende crucialmente de la
estimación del riesgo de los activos que con�guran la cartera. Además, en estecaso, tan importante como las medidas de volatilidad de los mercados del activosubyacente y del activo que se utiliza en la cobertura, es la medida de covariaciónentre ambos. De hecho, es ya habitual hablar de un riesgo de correlación entreactivos.
183

La utilización de medidas de volatilidad y de covariación alternativas puedeconducir a estrategias de cobertura bastante diferentes, lo que implicará a)costes bastante distintos para las mismas y b) resultados asimismo diferentes,que pueden depender del tipo de evolución temporal seguido por la cotizacióndel activo subyacente.
14.1.3 Estadísticos descriptivos en la estimación del Riesgo
En general, contamos con observaciones históricas acerca de una o varias vari-ables (precios, rentabilidades, etc.) y queremos calcular medidas de posicióncentral, de dispersión y de correlación con el objeto de resumir las propiedadesbásicas de dichos datos.El conjunto de datos observados de�ne un histograma de frecuencias, o dis-
tribución muestral de frecuencias, que contiene toda la información disponibleacerca de la variable considerada. Un histograma de frecuencias es similar a unadistribución de frecuencias, pero es diferente de ella. Para entender la diferen-cia entre ambos, hemos de comprender el concepto de proceso estocástico, y elmodo de utilizarlo en el análisis de datos de series temporales.Un proceso estocástico Xt; t = 1; 2; 3; :::es una sucesión de variables aleato-
rias, indexadas por la variable tiempo. Las variables aleatorias pueden ser inde-pendientes entre sí o no, y pueden tener la misma distribución de probabilidad,o una distribución de probabilidad diferente.Cada dato de una serie temporal debe interpretarse como una muestra de
tamaño 1 de la distribución de probabilidad correspondiente a la variable aleato-ria de ese instante. Por ej., el dato de cierre del IBEX35 (suponiendo quedisponemos de datos de cierre diarios) de hoy es una realización, es decir, unamuestra de tamaño 1 de la variable aleatoria �precio de la cesta IBEX35�(comoíndice) el día de hoy. La distribución de probabilidad de esta variable puedeser diferente de la variable aleatoria IBEX35 hace un año por tener, por ejem-plo, una esperanza matemática menor, una volatilidad mayor, o no ser Normal,mientras que hace un año sí lo era.Vamos a suponer inicialmente que las variables Xt tienen todas la misma
distribución de probabilidad, y son independientes entre sí. Este es el caso mássencillo, y constituye un proceso de ruido blanco. Sólo en este caso está to-talmente justi�cado la utilización de momentos muestrales como característicasde �la variable X�. Esta observación debe servir como llamada de atención allector, dada la excesiva frecuencia con que se calculan estadísticos muestrales,calculados con datos históricos, para representar características de una vari-able; por ej., la desviación típica de la rentabilidad bursátil de un determinadomercado.
Example 7 La importancia de calcular indicadores de variabilidad en relacióna una medida de posición central. El Cuadro 1 presenta algunos estadísticos bási-cos para los índices bursátiles: NIKKEI 225, DAX 30, MILAN, MCI-SWISS,CAC 40, FTSE 100, S&P 500, MEXICO IPC, MERVAL, BOVESPA y CHILEGENERAL durante agosto de 1999, mientras que el Cuadro 2 presenta algunos
184

de estos mismos estadísticos para cada uno de los años comprendidos entre 1993y 1999 (de este último, sólo los primeros 8 meses). Con objeto de valorar elriesgo asociado a la inversión en cada uno de los mercados de renta variablecuyos índices se recogen en el cuadro, queremos valorar cuáles de ellos son másvolátiles, y cuáles lo son menos.
Example 8 Enseguida apreciamos que no toda la información estadística quepresenta el Cuadro 1 es útil para el gestor de riesgos: conocer la media o lamediana de cada índice nos da una idea de su nivel durante dicho mes pero, porsí solas, no nos dicen si agosto de 199 fue un mes especialmente bueno, o malo, oneutral. Mucho menos nos dan ninguna indicación de riesgo. Además de que lasdiferencias de nivel di�cultan la comparación de los estadísticos, su cálculo envariables tendenciales (no estacionarias) se presta a una difícil interpretación.
Sin embargo, podemos comparar media muestral y mediana para cada índice;vemos que, o bien coinciden prácticamente, o la mediana es mayor, como ocur-riría en distribuciones asimétricas hacia la izquierda, signi�cando que los valoresmenores (las cotizaciones bajas) se alejan de la media más que los valores altos.Esto es lo que ocurre en Nikkei, Dax, MCI-Swiss, CAC40 y FTSE100. Estehecho es relevante respecto al cálculo de probabilidades en las colas, como es elcaso del Valor en Riesgo, para el que habría que tener en cuenta la asimetría deestas distribuciones. Sin embargo, hay que tener presente que estamos tratandoaún con cotizaciones, no con rentabilidades.Vemos asimismo que todos los índices tiene un exceso de curtosis negativo,
es decir, menos curtosis que una distribución Normal.Tampoco las cotizaciones máxima o mínima, por sí solas, son muy informati-
vas. Ni siquiera el rango muestral lo es, a pesar de que ya establece un intervalode valores cubierto por la variable. Sin embargo, parece evidente que su posi-ble interés descansa en expresarlo como porcentaje de una medida de posicióncentral. En esta comparación, ya aparecen CAC, Merval y Bovespa como losíndices de mayor variabilidad, seguidos de cerca por DAX. Hay que observar,sin embargo, que un rango amplio no implica volatilidad si los valores separadosde la media no aparecen apenas en la muestra; por tanto, una limitación delrango es que sólo utiliza como información los valores máximo y mínimo. Noestamos considerando todavía la distribución de frecuencias o de probabilidadesa lo largo de todos los valores numéricos incluídos en el rango de variación decada índice.Una medida similar es la relación entre rango centrado del 80% y media: de
acuerdo con ella, CAC y Merval continúan re�ejando una mayor variabilidad enagosto 1999. Milán, DAX y Bovespa también re�ejan una apreciable, aunquemenor, variabilidad [Ver Cuadro 2]. Ahora hemos descartado los valores muyseparados de la media, tanto por encima como por debajo, y estamos analizandola amplitud del rango en el que recaen el 80% de los valores muestrales. Bovespatomó valores muy alejados de la cotización media, pero, sin embargo, comoindica su rango intercuartílico que luego analizaremos, el 50% de sus valoresquedaba bastante agrupado en torno a la media.
185

Establecemos así una diferencia entre valores normales y valores extremos.Si los valores extremos del rango de variación aparecen con relativa frecuencia,entonces un rango como el del 80% tenderá a ser más amplio que si los valoresseparados de la media aparecen infrecuentemente. Por tanto, si un índice quetiene un rango total amplio pasa a tener un rango del 80% relativamente másestrecho (como es el caso de Bovespa) ello se debe a que los valores extremosocurren con poca frecuencia. Si la amplitud del rango del 80% es relativamentemayor que la del rango total, en relación con otros índices, se deberá a que sibien los valores separados de la media no son demasiado extremos, ocurren conuna relativa frecuencia. Este es el caso del índice de Milán.Nuevamente, la desviación típica ni la varianza por sí solas nos proporcionan
información relevante, pero sí el coe�ciente de variación, que incide en presentarMerval y CAC como los índices más volátiles, a la vez que al Chile general comoel menos volátil en ese mes. La ventaja de estos estadísticos es que utilizan todala información disponible, a través de la frecuencia con que aparece cada uno delos valores (o de los subintervalos) observados. Pero la volatilidad es un conceptorelativo: Supongamos que la varianza del IGBM a lo largo de un cierto períodoha sido de 1.261, mientras que la varianza del índice NIKKEI, en el mismoperíodo, ha sido de 4.225. ¿Puede decirse que el NIKKEI ha sido más volátil?No, porque no tiene sentido comparar las varianzas por sí solas. Supongamosque el IGBM ha tenido una cotización media en dicho período de 7.255, mientrasque el índice NIKKEI se situó en 15.256 en media. ¿Cuál ha sido más volátil?Podemos comparar las desviaciones típicas, siempre como proporción del nivelmedio respecto al cual se han calculado. El uso de desviaciones típicas comoporcentaje de la media permite la comparación entre mercados o activos, otambién comparar la volatilidad en un mismo mercado en distintos instantes detiempo. Este es el coe�ciente de variación:
� = 100sx�x
Como vemos en el Cuadro, el co�ciente de variación nos proporciona un rankingde índices, de acuerdo con su volatilidad, no muy diferente del proporcionadopor el rango del 80%.Alternativamente, cuando se pretende comparar variables medidas en difer-
entes unidades, es útil tipi�car o estandarizar las variables, restando de cadaobservación la media muestral, y dividiendo por la desviación típica. Medi-ante esta transformación, eliminamos las unidades de cada variable, por lo quepueden ser comparables entre sí, en términos de volatilidad. De hecho, bajoel supuesto de que la serie temporal relativa a cada una de las variables estácompuesta de observaciones independientes, extraídas de una determinada dis-tribución, con esperanza � y varianza �2 constantes, las variables tipi�cadastienen esperanza cero y varianza igual a uno. El carácter de la distribución nojuega ningún papel en este resultado.Cuando se pretende inspeccionar en un grá�co la posible correlación entre
variables, es asimismo útil utilizar esta transformación. Esto corrige, además elefecto que produciría el que los distintos índices toman magnitudes diferentes,
186

lo que haría que, en un grá�co de sus niveles, se observasen las �uctuaciones detan sólo uno o dos de ellos, apareciendo los demás como líneas suaves.Despuésde este pormenorizado análisis, no podríamos dudar en cali�car de índices másvolátiles durante agosto de 1999 a Merval y CAC, seguidos de cerca por DAX yBovespa. Los índices más estables habrían sido el Nikkei y Mexico IPC y, muyespecialmente (y quizá sorprendentemente) el Chile General.Por supuesto que el análisis de volatilidad de un mes puede estar condi-
cionado por acontecimientos especí�cos de dicho mes, y no ser extrapolable enel tiempo. En efecto, en una perspectiva temporal más amplia, nuestros resul-tados son distintos: Los índices lationamericanos, Bovespa, Mexico IPC, Chilegeneral y Merval están, año tras año, entre los más volátiles, mientras que, porel lado estable, tan sólo el S&P500 ofrece sistemáticamente una baja volatilidad[ver Cuadros 3 y 4].
14.1.4 La varianza como indicador de volatilidad: Limitaciones
En una población estadística, la varianza es el promedio ponderado (con pesosdados por la masa de probabilidad en cada punto del soporte) de la desviacióncuadrática entre un punto extraído al azar del soporte de la distribución (dondela probabilidad de extracción es igual a la masa de probabilidad en cada punto) yla esperanza matemática. En una muestra, la varianza es el promedio ponderadode las desviaciones cuadráticas respecto a la media muestral. Las ponderacionesson las frecuencias relativas de observación de los datos.Por tanto, la desviación típica, raíz cuadrada de la varianza, puede inter-
pretarse (pero no es exactamente igual) como el tamaño medio de las desvia-ciones de una variable alrededor de un valor de referencia, ya sea su esperanzamatemática (en el caso de la población), o su media muestral (en el caso dela muestra). En el caso de una variable aleatoria para la que se disponen deobservaciones a través del tiempo, la desviación típica puede interpretarse comoel tamaño medio de sus �uctuaciones. Por consiguiente, cuando se trabaja convariables aleatorias de esperanza (o media muestral) igual a cero, la desviacióntípica es un buen indicador del tamaño de dicha variable.La varianza y la desviación típica (poblacional o muestral) sólo tienen sentido
frente a una medida de posición central de la distribución de probabilidad,que sirve de referencia. Sin embargo, no siempre las medidas de posición sonestables en el tiempo. Cuando no lo son, el uso de la varianza como indicadorde volatilidad queda en entredicho, como iremos viendo sucesivamente.Hay distintas situaciones en que estos problemas ocurren:
� cuando existe una tendencia en la serie de datos, ya sea de naturalezadeterminista o aleatoria. En tal caso, el primer problema es que, general-mente, no tiene sentido calcular la varianza a partir de una muestra, puesla medida de posición central no está bien de�nida, variando signi�cativa-mente con la longitud de la muestra.
� la segunda di�cultad estriba en que, en presencia de una tendencia deter-minista, el nivel seleccionado como referencia para el comportamiento de
187

la variable, que habitualmente es la media o la mediana muestrales, noserá representativo de la evolución de la variable: si la tendencia es cre-ciente, la primera parte de la muestra estará sistemáticamente por debajode la media, mientras que la segunda parte estará sistemáticamente porencima. El estadístico de posición central no representa ni la primera nila segunda parte de la muestra. Si calculamos la varianza muestral comoindicador de volatilidad en este caso, imputaremos como tal lo que noes sino tendencia, y podríamos llegar a a�rmar, erróneamente, que unavariable es muy volátil, cuando lo que presenta es una fuerte tendenciadeterminista. De hecho, la varianza de una variable tendencial puede serelevada incluso si ésta apenas experimenta �uctuaciones. En presenciade una tendencia lineal, la varianza está midiendo la tasa de crecimiento;lo sorprendente es que este aspecto, que es positivo si estamos hablandodel precio o cotización de un activo, será considerado negativo, al ser im-putado como volatilidad y, por tanto, como riesgo asociado a la inversiónen el mismo. Ver Grá�co.
� algo similar ocurre en presencia de tendencias estocásticas (es decir, deraíces unitarias). Ya hemos visto que en tales procesos la varianza crececon el tiempo, por lo que el cálculo de su análogo muestral no proporcionamucha información acerca del riesgo inherente a la toma de posición en unactivo cuyo precio presenta tal característica. En tal caso, la varianza dela primera diferencia es bastante más útil. Si el precio o cotización tieneuna única raíz unitaria, su variación (ganancia o pérdida de capital), esdecir, la rentabilidad, es estacionaria. Este es el caso del comportamientode los precios en muchos mercados.
� cuando, aun no existiendo tendencia, se ha producido un cambio de nivelen la media. En este caso, la media calculada con toda la muestra norepresentará ni la primera parte de ella, ni la segunda. Lo que ocurrees que la media ha sido distinta en la primera y segunda submuestras,y deberíamos recoger este hecho. De lo contrario, estaremos imputandocomo volatilidad lo que no es sino una ruptura en la media de la variableen estudio.
� Por un lado, la rentabilidad que interesa al inversor es la rentabilidad queespera obtener durante el horizonte de su inversión, por lo que, en realidad,debería utilizar una predicción de la rentabilidad durante dicho período.Generalmente, los modelos teóricos (selección de cartera de Markovitz, val-oración de opciones de Black-Scholes) se basan en una medida de riesgoesperado durante el horizonte dela inversión, que es substituida general-mente por una medida histórica de riesgo, y ésta es calculada como lavarianza muestral, sin llevar a cabo el tipo de predicción requerido por elmodelo teórico.Para ello, el análisis de series temporales es imprescindible:especi�cando y estimando un modelo estadístico para la serie temporal derentabilidades, podríamos obtener tal previsión. El modelo en cuestióndebería incorporar todas aquellas variables que se considera que pueden
188

in�uir sobre la rentabilidad del activo, si bien entonces necesitaremos pr-ever asimismo el comportamiento de tales factores durante el horizontede inversión. Una alternativa consiste en utilizar un modelo univariantede series temporales (por ej., según el enfoque Box-Jenkins), con�ando enque dicho modelo capture su�cientemente bien la dinámica de la evolucióntemporal de la rentabilidad a lo largo del horizonte de inversión; otra posi-bilidad consistiría en utilizar modelos vectoriales autoregresivos (VAR).
� Por otro, tampoco el nivel de riesgo del activo es observable, pero se identi-�ca riesgo con volatilidad. Ha sido asimismo tradicional asociar la volatil-idad a un momento de segundo orden de la distribución de probabilidad ode frecuencias de una determinada rentabilidad. Así, la identi�cación entrevolatilidad y varianza o, más precisamente, entre volatilidad y desviacióntípica, es habitual. Por tanto, la volatilidad se de�ne con respecto a unnivel de referencia, generalmente la esperanza matemática de la rentabil-idad analizada, que es una medida de posición central. Pero hay otrasmedidas que pueden ser útiles bajo condiciones de asimetría: mediana,moda, percentiles, etc. De hecho, veremos más adelante que la identi-�cación entre volatilidad y desviación típica no conduce a una medidaadecuada del riesgo asumido en la inversión en un determinado activo.
� Asimismo, en la práctica habitual se entiende que el riesgo es una carac-terística relativamente estable de un activo (en el caso del riesgo especí�co,no diversi�cable) o de un mercado (en el caso del riesgo sistemático, diver-si�cable) que puede, por tanto, estimarse a partir de datos históricos, uti-lizando la desviación típica de la rentabilidad de un activo. Sin embargo,debemos hacernos varias preguntas: ¿es el nivel de riesgo o de volatilidadestable en el tiempo? ¿deberíamos medir volatilidad sobre períodos rel-ativamente breves de tiempo, obteniendo así una medición numérica queevoluciona de manera más o menos suave?
� El uso que habitualmente se hace de la desviación típica como indicadorde volatilidad/riesgo, se fundamenta en el supuesto de Normalidad dela variable cuya volatilidad hemos calculado. Por ejemplo, la varianzaestimada en un instante determinado puede utilizarse para construir unintervalo de con�anza para los valores que puede tomar la rentabilidadque está siendo objeto de análisis. Sin embargo, la gran mayoría de lasrentabilidades de activos �nancieros no siguen una distribución Normal,con clara evidencia de asimetría y exceso de curtosis.
� Si llevamos a cabo una inversión con un determinado horizonte, es ha-bitual considerar que el riesgo asumido viene medido por la varianza dela suma de las variaciones diarias en precio (rentabilidades continuas di-arias). Asimismo, es habitual aproximar dicha varianza multiplicadndola varianza diaria, supuesta constante, por el número de días contenidosen el horizonte de inversión. Sin embargo, este procedimiento no es cor-recto si el proceso con el que trabajamos (precios o rentabilidades) pre-senta autocorrelación, en cuyo la varianza no es aditiva temporalmente.
189

Esta práctica conduce a sobre-estimacion (bajo autocorrelación negativa)o sub-estimación (bajo autocorrelación positiva) de la volatilidad de larentabilidad en estudio.En tal situación, conviene utilizar una estructuratemporal de volatilidades (volatilidad como función del horizonte), másque trabajar con una volatilidad constante para todos los plazos de inver-sión
� otra matización que conviene hacer acerca del uso de la varianza es queésta mide toda la �uctuación que experimenta una variable (sea precioo rentabilidad), y seguramente querremos pensar que el riesgo es sólouna parte (quizá la parte no predecible) de dicha �uctuación (esto seráanalizado en detalle en la Sección 4.i). Como caso extremo, una funcióntrigonométrica como yt = A:sen
�2� t
T
�; t = 1; 2; :::; T; para una constante
A dada, experimenta �uctuaciones de un tamaño arbitrario, determinadopor el valor de A, pero son de naturaleza puramente determinista. Ellosigni�ca que el valor de yt+s en cualquier período futuro es perfectamentepredecible en el instante t. Perfectamente predecible signi�ca que el er-ror de predicción es cero; además, la información muestral disponibleen el instante t sería irrelevante, pues no necesitaríamos utilizarla paraobtener dicha predicción. Las �uctuaciones en este proceso podrían serarbitrariamente grandes, pues bastaría para ello con alterar el valor de lasconstantes. A pesar de que un activo cuyo precios siguiese tal compor-tamiento, no implicaría riesgo alguno para el inversor, la varianza de dichoproceso podría resultar arbitrariamente grande.
14.1.5 Volatilidad histórica, volatilidad GARCH, volatilidad implícita
En de�nitiva, si bien es útil discutir acerca de la elección óptima de uno entre unconjunto propuesto de indicadores de volatilidad, hay que tener en cuenta que laelección de una medida adecuada de volatilidad no �naliza con el análisis de lasmedidas hasta ahora analizadas. Un indicador de tal tipo es una medida de lavolatilidad de un precio o una rentabilidad. Sin embargo, el concepto de riesgoque interesa al inversor es el del tamaño de la componente de la �uctuación queexperimenta la rentabilidad de un activo que no es predecible con la informacióndisponible en el momento de efectuar la inversión.Por tanto, una primera solución consiste en especi�car modelos de predicción
de rentabilidades. En ellos, la rentabilidad de un determinado activo se hacedepender de su propio pasado (como en el caso de los modelos ARIMA), o dela evolución de un cierto conjunto de indicadores, por ejemplo:
rt = �0 + �1rt�1 + �2rt�2 + ut; ut � N(0; �2u)
con
rt+1 = �0 + �1rt + �2rt�1 + ut+1;
en el período t+ 1; siendo todas las variables conocidas excepto ut+1o,
190

rt = �0 + �1xt�1 + �2zt�1 + ut; ut � N(0; �2u)
con
rt+1 = �0 + �1xt + �2zt + ut+1
Las variables explicativas de la volatilidad podrían aparecer en el instante t,
rt = �0 + �1xt + �2zt + ut; ut � N(0; �2u)
pero entonces antes de poder predecir la evolución futura de la rentabilidadde nuestro activo, deberíamos utilizar modelos de predicción de las variablesexplicativas, puesto que,
rt+1 = �0 + �1xt+1 + �2zt+1 + ut+1
Una vez estimado dicho modelo de predicción de la rentabilidad, la varianzadel residuo resultante proporciona una indicación del tamaño medio de la compo-nente no predecible de la �uctuación temporal que experimenta la rentabilidad.Esta estrategia de cálculo de un indicador de volatilidad todavía mantiene
una limitación: se supone que la volatilidad es constante en el tiempo. Estopuede superarse en la práctica, pues el modelo se re-estimaría continuamente, yla estimación resultante para la desviación típica residual cambiaría en el tiempo.Una mejor opción proviene del uso de modelos de varianza condicional, ARCH,GARCH, EGARCH, AGARCH, que analizaremos en detalle más adelante,
rt = �0 + �1xt + �2zt + ut; ut � N(0; ht)
ht = �0 + �1ht�1 + �2u2t�1 + �3rt
Estos modelos tratan de cuanti�car una medida de volatilidad con dos car-acterísticas importantes: a) es cambiante en el tiempo, b) se re�ere tan sóloal tamaño de la componente no predecible de la �uctuación de la variable enestudio. Por tanto, es adecuada a nuestros intereses.
14.1.6 Algunas cuestiones estadísticas previas
Contrastes de Normalidad Bera y Jarque propusieron el contraste de Nor-malidad que lleva su nombre, que utiliza los coe�cientes de asimetría AS y decurtosis K:
BJ = T
AS2
6+(K � 3)2
24
!que se distribuye como una chi-cuadrado con 2 grados de libertad.Este es un contraste paramétrico de la hipótesis de Normalidad, existiendo
asimismo varios contrastes no paramétricos, quizá más aconsejables:
191

� el contraste de Kolmogorov-Smirnov, que se basa en el supremo de los val-ores absolutos de las diferencias entre la función de distribución empíricay la función de distribución teórica de una variable Normal de esperanzay varianza iguales a las muestrales. Para ello se divide el rango observadoen intervalos pequeños, y se comparan los valores de ambas funciones enuno de los extremos de cada intervalo.
� el contraste chi-cuadrado o de Pearson, basado en la comparación de lasfrecuencias teórica y empírica en cada uno de los subintervalos en que seha dividido previamente el rango de valores observados.
Al igual que muchos contrastes cuyo estadístico hace intervenir al tamañomuestral de modo multiplicativo, el contraste de Bera-Jarque tiene una pecu-liaridad, y es que para tamaños muestrales elevados, el estadístico del contrastetoma un valor alto, que puede conducir al rechazo de la hipótesis nula en �de-masiadas ocasiones�. Dicho de otro modo, para muestras grandes, el contrastetiene un tamaño muy superior al teórico.
Intervalo de con�anza para la varianza Si la población de la que se extraeuna muestra aleatoria simple es Normal, con esperanza � y varianza �2, ambasconstantes, y s2x denota la cuasi-varianza muestral, el cociente
(n�1)s2x�2 sigue una
distribución �2n�1. Por tanto, si observamos una muestra de 25 observacionessucesivas de una rentabilidad que estamos dispuestos a suponer que evolucionaindependientemente en el tiempo, y calculamos una cuasi-varianza muestral de12,5, tendremos que (24)(12;5)
�2 se distribuye como una �224.Por tanto, tendremos:
0; 95 = P
�12; 4 � (24)(12; 5)
�2� 39; 4
�= P
�7; 61 � �2 � 24; 19
�un intervalo no muy preciso, que tendríamos que tener en cuenta al establecer
nuestras conclusiones acerca de la volatilidad de un mercado. Por supuesto,que el número de datos utilizados es muy importante para la precisión de laestimación y, como consecuencia, para la amplitud del intervalo de con�anza.Si la cuasi-varianza de 12,5 hubiese sido obtenida a partir de 10 datos, entonces125�2 se distribuiría como una �
210, y tendríamos:
0; 95 = P
�3; 25 � 125
�2� 20; 5
�= P
�6; 10 � �2 � 38; 46
�Sesgos al estimar la desviación típica La cuasi-varianza muestral 1
T�1PTt=1 r
2t ,
calculada a partir de una muestra aleatoria simple, es decir, una muestra cuyoselementos son independientes entre sí, es un estimador insesgado de la varianza
poblacional. Por tanto, E�
1T�1
PTt=1 r
2t
�= �2r: Esto es válido para cualquier
población con esperanza y varianza constantes. Sin embargo, la estimación que
192

deducimos para la desviación típica tomando la raíz cuadrada de la estimaciónde la varianza no es insesgada, debido a que la esperanza matemática de una fun-ción no lineal no es igual al valor de la función en dicha esperanza matemática.De hecho, la desigualdad de Jensen nos dice que: E [g(X)] � g (EX) si la fun-ción g es cóncava, y lo contrario ocurre si la función g es convexa. Si calculamosla desviación típica muestral como la raíz cuadrada (función cóncava) de la var-
ianza muestral: DT (r) =q
1T�1
PTt=1 r
2t , en promedio (aunque no para el valor
numérico obtenido en una sola muestra) será menor que la desviación típicapoblacional, ya que por la desigualdad de Jensen:
E (DT (r)) = E
0@vuut 1
T � 1
TXt=1
r2t
1A �
vuutE
1
T � 1
TXt=1
r2t
!! �2r
El sesgo de sobre-estimación así cometido al estimar la desviación típicapuede evaluarse en el caso de una población Normal.
Una medida no paramétrica de volatilidad Se dice que una variablealeatoria X es más volátil que otra variable Y si se tiene:
P (j X j> c) > P (j Y j> c) 8c > 0
Sin embargo, este concepto sólo permite establecer un ranking de variablesde acuerdo con su volatilidad, pero no asignar un valor numérico a la misma.Además, no es fácil que la condición anterior se satisfaga, sino más bien, quepara algunos valores numéricos de c se tendrá la ordenación reseñada, y paraotros, la contraria, por lo que no podremos a�rma que X es más volátil que Y ,ni tampoco que Y es más volátil que X. End e�nitiva, es poco verosimil queeste concepto introduzca un orden completo entre distribuciones.Si aplicamos este concepto a la sucesión de variables aleatorias que con�guran
un proceso estocástico, tendremos que el proceso Xt se hace más volátil si setiene que:
P (j Xt+1 j> c) > P (j Xt j> c) 8c > 0
Si el proceso sigue una distribución Normal con esperanza constante, lacondición anterior sólo se producirá si: �2t+1 > �2t , por lo que estaríamos denuevo en el criterio de la varianza.
14.1.7 Rentabilidades continuas
Hay varias razones estadísticas que justi�can el uso de rentabilidades, en vez deprecios o cotizaciones, al analizar los mercados �nancieros. Una, importante, esla general ausencia de estacionariedad en los precios de los activos �nancieros,así como en los índices de los principales mercados, que puede re�ejarse dediversas formas: presencia de tendencias estocásticas, presencia de tendencias
193

deterministas en los precios de mercado, volatilidad cambiante en el tiempo, etc..Una tendencia determinista es una función exacta del tiempo, generalmentelineal o cuadrática. Una tendencia estocástica es un componente estocásticocuya varianza tiende a in�nito con el paso del tiempo.Si una variable presenta una tendencia determinista, su valor esperado ten-
derá a aumentar o disminuir continuamente, con lo que será imposible mantenerel supuesto de que la esperanza matemática de la sucesión de variables aleato-rias que con�gura el proceso estocástico correspondiente a dicha variable, esconstante. En consecuencia, tampoco podrá mantenerse que la distribución deprobabilidad de dichas variables es la misma a través del tiempo. Sin embargo,si efectuamos una correcta especi�cación de la estructura de dicha tendencia,podrá estimarse y extraerse del precio, para obtener una variable estacionaria,que no presentaría las di�cultades antes mencionadas. Un ejemplo claro es latendencia cuadrática en el índice SP500, que puede estimarse mediante un poli-nomio de grado 2 del tiempo, con coe�ciente positivo en la segunda potencia,
SP500t = a+ bt+ ct2 + ut
Las diferencias entre los valores del índice y los que toma dicha funcióndeterminista del tiempo podrían servirnos como la versión sin tendencia delíndice SP500 y, como se ve en los grá�co /s de la pestaña SP500 trend en elarchivo Indices_work.xls, ambas versiones de la variable son de naturaleza muydiferente. Ene ste caso, el gra�co ilustra que la eliminación de la tendenciacuadrática determinista deja un comportamiento un tanto extraño, que podemosadmitir de carácter estocástico, que habría que modelizar. La volatilidad de laserie SP500 haci el �nal de la muestra,. que es enorme en términos históricos,queda claramente re�ejada al eliminar la tendencia determinista.Mayor di�cultad entraña el caso en que una variable precio incluye una ten-
dencia estocástica pues, en tal caso, su esperanza y varianza no están de�nidas.La presencia de una tendencia estocástica requiere transformar la variable, gen-eralmente en primeras diferencias temporales, o tomando las diferencias entrelas observaciones correspondientes a una misma estación cronológica, en el casode una variable estacional. La transformación mediante diferencias resulta bas-tante natural en el análisis de datos �nancieros, por cuanto que la primeradiferencia del logaritmo de un precio, es la rentabilidad del activo. Por esto esque también la transformación logarítmica es utilizada habitualmente cuandose trabaja con precios o índices de mercado. En el caso del SP500, el grá�co dela rentabilidad, obtenida como priemra diferencia logarítmica muestra períodosde mayor y de menor volatilidad, como sucede con todo activo �nanciero.Como prácticamente ningún precio o índice �nanciero es estacionario, el uso
indiscriminado de un estadístico como la varianza o la desviación típica comoindicador de riesgo conduce a medidas sesgadas al alza.
Rentabilidad en mercados cotizados en tipos de interés Si se trabajacon datos de un mercado que cotiza en TIRes o en tipos de interés, como sucedecon un mercado interbancario, calculamos la rentabilidad de dicho mercado
194

considerando la variación en el precio de una cartera invertida en el mismo. Larentabilidad en dicho mercado no es el tipo de interés cotizado, excepto si semantiene el activo a vencimiento. Si queremos generar la rentabilidad sobre unperiodo de tiempo, actuamos del siguiente modo: generamos un índice de preciossobre 100, mediante la expresión: Pr = 100=(1 + rt), y calculamos la variaciónporcentual o logarítmica en dichos precios. Por ejemplo, si una rentabilidadcotizada se ha reducido de 5,32% a 4,25%, la cartera habrá incrementado suvaloración en el mercado. El descenso de tipos se puede evaluar por medio de:
Pt � Pt�1Pt�1
=
1001+rt
� 1001+rt�1
1001+rt�1
=
1001;00425 �
1001;0532
1001;0532
=95; 9233� 94; 9487
94; 9487=0; 9476
94; 9486= 0; 010264
y la revalorización habrá sido del 1,02%.Un procedimiento más simple, aunque quizá más di�cil de recordar, consiste
en sumar 1 a las rentabilidades porcentuales cotizadas y calcular su tasa devariación:
Rt100
=
�1 + rt1 + rt�1
��1�1 = P�1t
P�1t�1=
�1; 0425
1; 0532
��1�1 = 1; 010264�1 = 0; 010264
obteniéndose en ambos casos la misma rentabilidad, de 1,0264%.
Rentabilidad continua equivalente Distinguimos entre rentabilidades por-centuales y rentabilidades logarítmicas. Estas últimas se conocen asimismocomo rentabilidades continuas.Rentabilidad porcentual:
Rt = 100Pt � Pt�1Pt�1
Rentabilidad logarítmica:
rt = 100(lnPt � Pt�1)donde vemos la diferencia en la transformación logarítmica a que antes nos
referíamos.Ambas rentabilidades son aproximadamente iguales si Rt es pequeña, puesto
que:
rt100
= lnPt � lnPt�1 = lnPtPt�1
= ln(1 +Rt100
) � Rt100
mientars que la relación exacta entre ambas, siempre válida, está dada por:
ln(1 +Rt100
) =rt100
y rt se dice que es la rentabilidad continua equivalente a Rt:
195

Example 9 Las rentabilidades porcentuales de los índices bursátiles S&P 500,DAX30, NIKKEI, FTSE100 en el mes de agosto de 1999, fueron de -0,63%,3,31%, -2,38%, 0,23%, mientras que las rentabilidades logarítmicas en igualperíodo fueron: -0,63%, 3,26%, -2,41%, 0,23%. Las diferencias son pequeñassobre períodos cortos de tiempo, así como en períodos de estabilidad de los mer-cados, pues entonces las rentabilidades son menores.
La transformación logarítmica en presencia de varianza cambianteen el tiempo La transformación logarítmica aminora la heterocedasticidad,fenómeno que consiste en que la varianza de un proceso cambia en el tiempo,en función de unos factores determinantes, xt. Por ejemplo, en el modelo: yt =ex
0t�+ut , donde ut es Normal(0,�2u), y las variables xt son deterministas, yt tiene
una distribución lognormal, ya que su logaritmo es Normal: ln yt = x0t� + ut.Este es un modelo bastante natural, en que el logaritmo de la variable en estudiose hace depender de una combinación lineal de distintos factores explicativos,así como de un término estocástico, no representable en términos de factoresobservables. La combinación lineal x0t� representa el componente de yt quepodemos explicar, mientras que ut representa el componente de yt que quedasin explicar.Bajo esta representación, tendríamos:
V ar(yt) = V ar(eut)(ex0t�)2 = (ex
0t�)2e�
2u
�e�
2u � 1
�por lo que yt tiene heterocedasticidad. Sin embargo, su logaritmo es homo-
cedástico, es decir, tiene varianza constante en el tiempo, puesto que:
V ar(ln yt) = V ar(ut) = �2u
Como aplicación, este argumento sugiere que, incluso si la varianza de Rt(en realidad, la varianza de 1+Rt/100) es cambiante en el tiempo, de acuerdocon la evolución de ciertos factores xt, la varianza de rt tenderá a presentar talcaracterística en mucha menor medida.
Comparación de volatilidades entre activos o entre mercados.
Example 10 El Cuadro 5 muestra algunas características estadísticas de lasrentabilidades logarítmicas diarias de los índices bursátiles que venimos con-siderando.
Hay que observar que, contrariamente al análisis de volatilidad de las cotiza-ciones, en este caso no conviene tomar los rangos de variación como porcentajede la media. La razón es que, en la mayoría de los mercados, la rentabilidadpromedio durante un intervalo de tiempo se aproximará a cero, por lo que los co-cientes rango/media serán arbitrariamente grandes, sesgando cualquier posibleinterpretación. Lo mismo ocurre con el coe�ciente de variación. Precisamente,una ventaja de trabajar con rentabilidades es que carecen de unidades, siendohomogéneas a lo largo de distintos índices, con independencia de los niveles
196

medios alrededor de los que estos �uctúen, por lo que no es preciso ponerlasen relación con la media. Por otra parte, cuando la media muestral es pe-queña, como ocurre con rentabilidades de mercados �nancieros sobre períodosde tiempos reducidos, la varianza puede calcularse, aproximadamente, como elpromedio de los cuadrados de los valores tomados por la variable (el promediode las rentabilidades observadas, al cuadrado).Centrándonos en el mes de agosto de 1999, el rango observado de rentabil-
idades en las bolsas latinoamericanas [Cuadro 6, pestaña Agosto 1999 en elarchivo Indices_work.xls] tiende a ser superior al del resto, con la excepción delíndice Chile-general. Esto sucede tanto con el rango total como con el rango del80% o el rango intercuartílico. Por otra parte, las rentabilidades de los índicesde Milán, MCI-Swiss y S&P 5000 ofrecieron un comportamiento más estableque la del resto de los mercados considerados, con rangos de rentabilidades másreducidos.En una escala temporal más amplia, los rankings anuales de volatilidad de
rentabilidades muestran que FTSE100, Milán, MCI-Swiss y S&P 5000 han sidolos índices con rentabilidades menos volátiles, con Bovespa, Merval y MexicoIPC como los más volátiles. Los Cuadros 7 y 10 contienen este tipo de informa-ción, el primero a través de la varaianza de las rentabilidades diarias observadasdurante el año, y el segundo calculando la volatilidad como promedio de rentabil-idades diarias al cuadrado [ver pestaña Anuales en el archivo Indices_work.xls].
El supuesto de rendimientos lognormales Se dice que una variable aleato-ria X, de�nida sobre el subespacio de números reales positivos, sigue una dis-tribución de probabilidad Lognormal cuando la variable aleatoria que se obtienecomo su logaritmo neperiano, Y = ln(X), sigue una distribución Normal(�,�2).En tal caso, la función de densidad de Y es:
f(y) =1
�p2�e�
(y��)2
2�2 ; �1 < y <1
y la función de densidad de X,
f(x) =1
xp2�e�
(ln x��)2
2�2 ; x > 0
La esperanza y varianza de X son:
E(X) = e�+12�
2
; V ar(X) = e2�+�2�e�
2
� 1�
Es habitual suponer que el proceso seguido por el precio o cotización de unactivo es tal que el rendimiento porcentual bruto correspondiente a un períodosigue una distribución lognormal, es decir, que su logaritmo, el tipo continuo,tiene una distribución Normal:
rt100
= ln(1 +Rt100
) � N��; �2
�
197

Una ventaja de suponer una distribución lognormal para el rendimiento por-centual es que asegura que 1+Rt/100 sea no negativo, lo que no ocurriría sisupusiéramos Normalidad de Rt.Pero conviene recordar que la distribución lognormal no es simétrica de modo
qeu bajo este supuesto, el tamaño medio de las rentabilidades por encima de lamedia es superior al promedio de las rentabilidades por debajo de la media.Bajo este supuesto, la esperanza y varianza de la rentabilidad simple Rt son:
E(Rt=100) = e�+12�
2
� 1; V ar(Rt=100) = e2�+�2�e�
2
� 1�
estas fórmulas son muy útiles para obtener predicciones a partir de modelosestimados para los logaritmos de los rendimientos, pues si � es la predicción parael logaritmo del rendimiento y �2 es la varianza condicional estimada para dichologaritmo del rendimiento (es decir, la varianza de la innovación del proceso parael logaritmo del rendimiento), entonces la predicción para el propio rendimientoy la varianza asociada, que nos servirá para construir intervalos de con�anzapara dicha predicción, se obtienen a partir de las expresiones anteriores.En el otro sentido, si m1 y m2 son la esperanza y varianza del proceso de
rentabilidades, los momentos análogos para el logaritmo de la rentabilidad son,
E(rt) = ln
0@ m1 + 1q1 + m2
[1+m1]2
1A ; V ar(rt) = ln 1 + m2
[1 +m1]2
!
Agregación temporal de rentabilidades continuas La transformaciónlogarítmica hace que podamos obtener rentabilidades continuas compuestas me-diante sumas. Supongamos que queremos calcular la rentabilidad sobre dosperíodos. Observando que:
r1t100
+r1t�1100
= lnPtPt�1
+ lnPt�1Pt�2
= lnPt � lnPt�1 + lnPt�1 � lnPt�2 =
= lnPt � lnPt�2 = lnPtPt�2
= r2t
vemos que la rentabilidad continua a 2 períodos es, simplemente, la sumade las rentabilidades continuas a 1 período obtenidas durante los dos últimosperíodos. Algo similar ocurre para inversiones llevadas a cabo durante n y mperíodos de tiempo, respectivamente, siendo n un múltiplo de m (n = km),pero siempre que las rentabilidades sean continuas. En ese caso, la suma de lasrentabilidades continuas obtenidas durante los últimos k intervalos de tiempo,cada uno de ellos de duración n períodos, es igual a la rentabilidad continuaobtenida durante los últimos m períodos.Por el contrario, la suma de rentabilidades porcentuales sobre k períodos de
tiempo de longitud m no proporciona exactamente la rentabilidad porcentualsobre un intervalo de longitud n, y el error de aproximación va aumentando conk.
198

Es importante observar que, para realizar la agregación temporal de lasrentabilidades de tipo continuo no es preciso suponer independencia temporalde las mismas.No ocurre lo mismo si queremos hacer la misma extrapolación temporal para
las volatilidades:
V ar
�r2t100
�= V ar
�r1t100
+r1t�1100
�= V ar
�r1t100
�+V ar
�r1t�1100
�+2Cov
�r1t100
;r1t�1100
�por lo que la varianza de la rentabilidad durante un período amplio no es
igual a la suma de las varianzas de las rentabilidades durante los períodos máscortos comprendidos en el intervalo amplio. La diferencia entre ambos cálculosestriba en que el segundo ignora las covarianzas entre cada par de rentabilidadessobre períodos cortos.Por tanto, si dichas rentabilidades fuesen independientes, sus covarianzas
serían nulas, y tendríamos que la varianza sobre el horizonte largo sería igual ala varianza de las rentabilidades sobre los períodos cortos.Recordemos, además, que la suma de variables aleatorias Normales, inde-
pendientes o no, sigue asimismo una distribución de probabilidad Normal. Portanto, si suponemos que las rentabilidades continuas durante un período sonindependientes y obedecen a la misma distribuciónNormal, tendremos, a lo largo de T períodos:
rt + rt�1 + rt�2 + :::+ rt�T+1100
� N(T�; T�2)
de modo que la rentabilidad porcentual (o simple) a lo largo del intervalo detiempo (t� T; t) tiene por esperanza y varianza:
E
�Rt100
�= eT�+
12T�
2
� 1; V ar�Rt100
�= e2T�+T�
2�eT�
2
� 1�
Si las rentabilidades no fuesen independientes a lo largo del tiempo, su sumatendría una distribución Normal, pero su varianza no sería tan sencilla comoT�2. Como antes, un análisis similar aplica a intervalos de tiempo n y m, conn = km.Este análisis sugiere, por tanto, que un modo de contrastar la independencia
de rentabilidades consiste en analizar si la varianza muestral aumenta lineal-mente con la amplitud de la ventana muestral. En variables con covariaciónpositiva, al agregar temporalmente tendremos un crecimiento más que lineal dela varianza, y lo contrario ocurrirá bajo covariación negativa.
Agregación de volatilidades en una cartera. La volatilidad de una carterano es simplemente el resultado de agregar la volatilidad de los activos que lacomponen, a diferencia de lo que ocurre con las rentabilidades. Podría pensarseen construir un indicador agregado de volatilidad ponderando las volatilidades
199

de los activos individuales, de acuerdo con los pesos con que cada activo entraen el índice o la cartera. Este procedimiento ignora la existencia de covariaciónentre la rentabilidad de los distintos activos: la volatilidad del indice conjunto noes igual a la suma ponderada de las volatilidades. Para calcular una estimaciónde la volatilidad de una cartera debe calcularse la forma cuadrática resultante deutilizar la matriz de varianzas y covarianzas de las rentabilidades de los activosindividuales.Esto se debe a que toda cartera no es sino el resultado de distribuir un capital
N entre k activos:
N = N1 +N2 + :::+Nk = x1N + x2N + :::+ xkN
donde xi , i = 1; 2; ::; k son las proporciones del capital N invertidas en cadaactivo i, que suman 1. La rentabilidad de la cartera, que es una variable aleato-ria, será una combinación lineal de las rentabilidades de los activos individuales(asimismo aleatorias a priori), utilizando como ponderaciones los porcentajesinvertidos en cada uno de ellos:
rc = x1r1 + x2r2 + :::+ xk�1rk�1 + xkrk
de modo que la rentabilidad esperada de la cartera será:
�rc = x1�r1 + x2�r2 + :::+ xk�1�rk�1 + xk�rk
Precisamente porque la varianza de una suma no es igual a la suma de var-ianzas, la varianza (volatilidad) de la cartera no puede obtenerse componiendode un modo similar la varianza (volatilidad) de los activos individuales. Por elcontrario, hemos de escribir la rentabilidad de la cartera como:
rc = (x1; x2; :::; xk)
0BBBB@r1r2r3:::rk
1CCCCAde manera que:
V ar(rc) = (x1; x2; :::; xk)X
0BBBB@x1x2x3:::xk
1CCCCAdonde � es la matriz de varianzas-covarianzas de las rentabilidades de los
activos que forman parte de la cartera. El resultado de esta operación es unescalar (un número).
200

14.1.8 Rango esperado de precios bajo el supuesto de Normalidad
Si la rentabilidad de un activo obedece a una distribución Normal, la proba-bilidad de que dicha rentabilidad se sitúe entre su esperanza matemática y unrango alrededor de ella de más o menos una desviación típica, es del 68,26%.Pasa a ser del 95,46% cuando el intervalo tiene dos desviaciones típicas de am-plitud, y es del 99,87% para tres desviaciones típicas. El intervalo de con�anzadel 95% está delimitado por la esperanza matemática más y menos 1,96 veces ladesviación típica, mientras que el intervalo de con�anza del 99% está delimitadopor la esperanza matemática más y menos 2,33 veces la desviación típica.La cotización media del IBEX35 durante diciembre de 1997 fue de 7.152,52.
A lo largo del mismo mes, la volatilidad diaria de las cotizaciones, medidapor su desviación típica, fue de 91,93. Bajo el supuesto de que la cotizacióndel índice sigue una distribución Normal con esperanza y varianza constantes,los fundamentos estadísticos que acabamos de recordar nos permitirían con-struir intervalos de con�anza para las cotizaciones de días futuros, llevando aizquierda y derecha de la cotización mensual media, tomada como predicción dela cotización en días sucesivos, un determinado número de veces su desviacióntípica. Esto nos produciría intervalos de con�anza que cambiarían a través deltiempo según fuesen variando la predicción puntual de la cotización futura, y ladesviación típica muestral.Si creemos que el proceso de cotizaciones no es estacionario, entonces tal
ejercicio es bastante cuestionable, puesto que se basa en la hipótesis de que ladistribución de probabilidad del proceso de cotizaciones que se analiza es rela-tivamente estable. En general, la ausencia de estacionariedad va a aparecer enla forma de esperanza y varianza cambiantes en el tiempo, por lo que interva-los centrados alrededor de una cotización media histórica pueden ser muy pocorepresentativos de la evolución futura del mercado.Existe un modo razonable de construir intervalos de valores esperados bajo
los supuestos que hemos hecho acerca de la distribución de probabilidad de lasrentabilidades continuas.Retomemos la hipótesis de que ln(1+Rt) o, lo que es lo mismo, ln(Pt=Pt�1),
se distribuye como una Normal(�,�2) y, por estabilidad temporal, lo mismoocurre con ln(Pt+1=Pt). Ello signi�ca que, una vez que ln(Pt) es conocido,entonces podemos considerar que ln(Pt+1) se distribuye como una Normal( �+ln(Pt), �2).Para ello, es importante observar que la desviación típica de las rentabili-
dades fue, a lo largo de diciembre de 1997, de 0,0135363. Como primera aproxi-mación, vamos a ignorar la rentabilidad diaria media durante diciembre de 1997,que fue de 0,198%, y en cuya repetición quizá el inversor no quiera con�ar. Estees el parámetro � de la expresión anterior, que supondremos igual a cero, porlo que centraremos nuestro intervalo exclusivamente alrededor de ln(Pt).En tales condiciones, el rango de cotizaciones del 68,26% para el día siguiente
de mercado (primer día de mercado de enero) es de:
ln(7152; 52)�p1(0; 0135363) < lnS < ln(7152; 52) +
p1(0; 0135363)
201

es decir,
8; 8616387 < lnS < 8; 888756
7:056; 4 < S < 7:250; 0
siendo el último un cálculo aproximado.El rango de cotizaciones del 95,46% para el día siguiente de mercado es de:
ln(7152; 52)� 1; 96p1(0; 0135363) < lnS < ln(7152; 52) + 1; 96
p1(0; 0135363)
es decir:
8; 848147 < lnS < 8; 902293
6:961; 5 < S < 7:348; 8
mientras que el rango del 99% está determinado por:
ln(7152; 52)� 2; 33p1(0; 0135363) < lnS < ln(7152; 52) + 2; 33
p1(0; 0135363)
es decir:
8; 843680 < lnS < 8; 906760
6:930; 5 < S < 7:381; 7
lógicamente, más amplio que el anterior.Por último, el rango del 99% para cinco días de negociación (una semana)
después, es:
ln(7152; 52)� 2; 33p5(0; 0135363) < lnS < ln(7152; 52) + 2; 33
p5(0; 0135363)
es decir:
8; 804695 < lnS < 8; 945745
6:666; 5 < S < 7:675; 2
Puede observarse que:
� los intervalos construidos no son centrados en torno a la cotización del día,7.152,52, como consecuencia del supuesto de lognormalidad, que hace másprobables aumentos importantes que descensos importantes (es decir, elincremento medio esperado es mayor que el descenso medio esperado),
202

� la amplitud de los intervalos aumenta con el grado de con�anza que quer-emos tener en que el intervalo construido contenga a la cotización que sepretende anticipar,
� la amplitud de los intervalos aumenta con el horizonte temporal para elcual establecemos la predicción.
Con este procedimiento podemos aprovecharnos de la aditividad de las rentabil-idades continuas. Recordemos que esta propiedad garantiza que la rentabilidadcontinua sobre un determinado período de tiempo puede obtenerse agregando lasrentabilidades continuas sobre subperíodos del mismo. Además, si las rentabil-idades continuas son independientes, y cada una de ellas sigue una distribuciónNormal, todas ellas con igual esperanza y varianza, entonces su suma obedeceasimismo una distribución Normal, con esperanza y varianza igual a la esperanzay varianza de cada una de las rentabilidades sobre un subperíodo, multiplicadaspor el número de rentabilidades incluido en el período amplio.Por tanto, si quisiésemos tomar en consideración el incremento diario medio
en rentabilidad, estimado en un 0,198%, cuando calculamos un rango admisi-ble para dentro de una semana, lo que haríamos sería añadir 5 veces 0,00198al logaritmo de la cotización actual, 7.152,52, antes de tomar 2,33 veces a suizquierda y a su derecha, la desviación típica, de 0,0135363.Así,
[ln(7152; 52) + 5 (0; 00198)]� 2; 33p5(0; 0135363) < lnS <
< [ln(7152; 52) + 50 (; 00198)] + 2; 33p5(0; 0135363)
es decir,
6:731; 8 < S < 7:751; 5
14.1.9 La varianza como variable temporal
Una generalización importante en el análisis de datos �nancieros, consiste enconsiderar los estadísticos muestrales no como constantes, sino siendo a su vezfunciones del tiempo, en cuyo caso estaremos interesados en disponer de seriestemporales de los mismos. Si identi�camos volatilidad con desviación típica,sólo generando series temporales de la varianza de su rentabilidad podremoshablar de variaciones en la volatilidad de dicho activo.Sin embargo, la varianza es un momento poblacional o muestral y, como tal
es constante. ¿Cómo podemos generar una serie temporal para la varianza?Utilizando las denominadas ventanas muestrales, que son submuestras cortas,cada una de las cuales se obtiene a partir de la previa, añadiendo un último dato,y prescindiendo del primero. La amplitud de la ventana ha de ser su�ciente comopara creer que, con cada una de ellas podemos estimar el parámetro en cuestión(por ej., la varianza) con su�ciente aproximación. De este modo, estaremos
203

generando un valor numérico de la varianza en cada instante para el cual tenemosun dato. Sólo perderemos un número de observaciones iniciales, igual al númerode ellas incluidas en cada ventana. Si, por ej., cada ventana consta de 20 datos,entonces podremos generar datos de varianza a partir de la observación 21.Hay que mantener un equilibrio, no siempre fácil, al decidir la amplitud de
la ventana que se utiliza en el cálculo de la varianza: por un lado, una ventanamás corta tendrá más posibilidad de utilizar una media estable, y representarámejor la situación actual, pero la varianza resultante será bastante volátil, entreotras cosas, porque no la estimaremos con su�ciente precisión. Por otro, unaventana amplia proporcionará una medida de volatilidad suave, pero calculadarespecto a una medida de referencia posiblemente no constante. En la valoraciónde opciones, se recomienda generalmente utilizar una ventana de longitud igualal período que resta hasta el vencimiento de la opción.
Example 11 El Grá�co 1 presenta la volatilidad del NIKKEI, medida a travésdel promedio de las rentabilidades diarias, al cuadrado, calculadas con datos de1 mes de mercado. Por tanto, se han utilizado ventanas móviles de 22 datos (porsimplicidad, se han utilizado el mismo número de datos, incluso en presenciade festivos). Las desviaciones típicas son anualizadas. La elevada volatilidadde algunos meses de agosto y octubre en años recientes aparece claramente enel grá�co. Este es un mercado con un nivel de volatilidad relativamente alto.Pero lo más signi�cativo en él son las �uctuaciones que experimenta su nivelde volatilidad (por ej., mensual). En este mercado, la volatilidad es muy er-rática. Por comparación, en el Grá�co 2 se muestra asimismo la serie temporalde volatilidades, calculadas sobre una ventana móvil de 3 meses (66 sesiones).Puede apreciarse que la serie temporal de volatilidad calculada con una ventanamuestral más amplia es más suave que la calculada con una ventana muestralmás corta. Esto siempre ocurre así, por construcción. Este grá�co continúamostrando notables variaciones en el nivel de volatilidad.
Los grá�cos 3 y 4 superponen las series temporales de volatilidades, conventanas trimestrales, para el índice MILAN por un lado, y el DAX 30 y MCI-Swiss por otro, en ambos casos, para un período largo: enero 1990 a septiembre1999. Los grá�cos sugieren que existe cierta asociación entre las �uctuacionesque experimenta la volatilidad en estos mercados, aunque la relación es menosque perfecta. Tanto el DAX como el MCI-Swiss han sido algo menos volátilesque el índice de Milán, pudiendo apreciarse una mayor diferencia en el casodel índice suizo, que alcanza niveles de volatilidad claramente inferiores. ElGrá�co 5 presenta la volatilidad comparada del Nikkei y del índice S&P 500,pudiendo apreciarse la mucha mayor �uctuación experimentada por el nivel devolatilidad del mercado japonés. Además, los momentos álgidos de volatilidaden el Nikkei no parecen venir acompañados de una situación similar en el índiceestadounidense.Sin embargo, si nos interesa el grado de asociación existente entre los niveles
de volatilidad en dos mercados, es difícil apreciarlo en un grá�co temporal. Es
204

mucho más útil considerar nubes de puntos de volatilidades para los mismospares de índices, que aparecen en los Grá�cos 6, 7 y 8 desde enero de 1996. Seaprecia en ellos que existe una apreciable asociación entre los niveles de volatili-dad de los índices europeos, si bien no tanto entra la volatilidad experimentadapor el Nikkei y la del S&P 500, como ya sugería el grá�co temporal. Si bienes fácil imaginar una relación aproximadamente unitaria entre los niveles devolatilidad de los índices MCI-Swiss, Milán y DAX, la situación es menos claraen la comparación entre las bolsas de Tokio y Nueva York.Sería interesante estimar modelos estadísticos de relación (regresión) entre
estos pares de volatilidades: por un lado, un modelo que relacionase sus nivelesen cada día de la muestra podría conducir a una pendiente próxima a la unidaden el caso de las comparaciones entre mercados europeos. Ello sería, además,consistente con la idea de que existe quizá un factor de volatilidad que explicauna buena parte de los niveles de volatilidad en estos mercados. En la com-paración Nikkei vs. S&P 500, la relación parece estar bastante condicionadapor los episodios de alta volatilidad que han sido comunes a ambos mercados.Por último, el Grá�co 9 ilustra que la asociación entre los niveles de volatilidadtrimestral es bastante mayor que la existente entre los niveles de volatilidadmensual, como quizá cabría esperar.El mayor interés que presenta el cálculo de la varianza en la forma de una se-
rie temporal es que, con ella, podemos plantearnos la predicción de la volatilidadfutura, que discutiremos en detalle más adelante. Un segundo aspecto de impor-tancia reside en la capacidad que nos prestan las series temporales de cuanti�carel grado de asociación de la volatilidad en distintos mercados, así como las car-acterísticas dinámicas de su relación. Si detectamos que una mayor volatilidaden un índice de mercado, como Dow Jones, anticipa un aumento de volatilidaden otro índice, como el DAX, quizá podamos utilizar dicha información paramejorar nuestras predicciones de la volatilidad en este último mercado.Ahora bien, ¿sobre qué intervalo de tiempo debe estimarse la volatilidad? Ya
hemos dicho que la elección de una longitud para la ventana muestral dista deser trivial. En algunos casos, como cuando se quiere extrapolar hacia el futuro(predecir) volatilidad, es habitual utilizar una misma longitud en su cálculo quela del período sobre el que se quiere predecir. Esto es más evidente en algunoscasos, como los conos de volatilidad que veremos en la Sección XX, que en otros.Que no haya unanimidad sobre cuestiones de este tipo ayuda a generar mercado,pues distintos agentes valorarán la volatilidad de distinta manera, entre otrascosas, porque estén interesados en distintos horizonte de inversión.Pero, incluso �jado un intervalo temporal ¿debemos de dar a todas las ob-
servaciones pasadas la misma relevancia en el cálculo de la volatilidad? Puedeparecer razonable ponderar más las observaciones más recientes. Utilizando laspotencias de un factor �, 0<�<1 , conseguimos que las observaciones vayanperdiendo importancia cuanto más se alejan en el tiempo.La medida de volatilidad es entonces:
205

�2 =
vuut 1
�
nXi=1
�ix2t�i
donde n es el número de datos utilizado en el cálculo de la volatilidad, y:� =
Pni=1 �
i = � 1��n
1�� ; que se reduce a: � =1
1�� cuando no ponemos un límiteal número de datos utilizado. En tal caso, el uso del factor � substituye a lanecesidad de �jar de antemano un número de observaciones para el cálculo dela volatilidad. Reducir el valor de � equivale a acortar el intervalo temporalutilizado en la estimación.Un análisis similar podría aplicarse al cálculo de la correlación entre dos
rentabilidades:
� =1
�
nXi=1
�ixt�iyt�i
con el objeto de aminorar el efecto de acontecimientos relativamente alejados.
Example 12 El Cuadro 9 muestra este cálculo, aplicado a la volatilidad delDAX 30 y el índice MEXICO IPC durante 1999 (hasta 16/8), utilizando comopesos las potencias de 0,97 y 0,66, alternativamente. Puede apreciarse que losniveles de volatilidad disminuyen, en este caso, al aplicar las ponderacionesrelativas y tanto más cuanto menor es la ponderación, es decir, cuanto más sedescuentan los valores más alejados en el tiempo. Esto se debe a que duranteel período considerado, los niveles de volatilidad fueron superiores al comienzoque al �nal de la muestra.
14.1.10 Rendimientos diarios y bandas de con�anza
Exercise 13 Este tipo de análisis proporciona una primera evaluación acercade si un dato de mercado de un día concreto, puede considerarse como anómalo.Los Grá�cos 7 y 8 muestran, la rentabilidad del índice S&P 500 (variación encotización), junto con las bandas de con�anza del 99%. El primer grá�co cubredesde enero 1990 a septiembre 1999, mientras que el segundo comienza en enero1997.
En segundo lugar, este tipo de evaluaciones es claramente importante aldiseñar estrategias de cobertura, pues establecemos a�rmaciones acerca delrango esperado de �uctuación de la rentabilidad de un determinado activo. Esasimismo importante al calcular el Valor en riesgo de un determinado activo omercado.En este sentido, debe notarse que, aunque nos hemos limitado a calcular
intervalos de con�anza, en realidad disponemos de una distribución de prob-abilidad centrada alrededor de la última cotización o precio observados. Por
206

consiguiente, no sólo podemos construir el rango de �uctuación esperado a undeterminado nivel de con�anza, sino que también podemos asociar probabili-dades a cada uno de los posibles eventos, dentro o fuera de dicho rango.Este análisis se ha basado en dos supuestos:
� Independencia de las rentabilidades sobre subperíodos no solapados. Estesupuesto facilita enormemente el cálculo. Sin embargo, no es necesario, ypodría substituirse por una determinada parametrización de las correla-ciones existentes entre rentabilidades de subperíodos sucesivos.
� Normalidad de las rentabilidades continuas. En muchas ocasiones, talsupuesto no resulta admisible para variables de rentabilidad �nanciera,como hemos visto ya en algunos ejemplos. En ocasiones, las distribucionesde frecuencias presentan cierto grado de asimetría. Más frecuentemente,en el caso de variables �nancieras, la distribución muestral o de frecuenciasde las rentabilidades observadas presenta desviaciones respecto de su valorcentral que son mayores de lo que la Normalidad podría explicar. Dichode otro modo, las colas de la distribución son muy gruesas o los valoresextremos demasiado frecuentes, en relación con la distribución Normal.
14.2 Utilización de información intradía en la medición dela volatilidad de un activo �nanciero
14.2.1 Medidas de Parkinson y Garman-Klass
Generalmente, entendemos por volatilidad de un activo �nanciero el valor anu-alizado de un indicador de variabilidad de su tasa de rendimiento. Tradicional-mente, se ha tomado como como indicador de variabilidad la desviación típicaaunque, posteriormente, se han ido introduciendo otras medidas alternativasde volatilidad que se consideran superiores en términos de e�ciencia informa-tiva, algunas de las cuales discutimos en esta sección, dejando las restantes paracapítulos sucesivos. Se entiende que la volatilidad es una medida del riesgo delactivo, aunque ya hemos adelantado algunas razones para tomar con precaucióndicha interpretación.Enlazando con los estadísticos hasta ahora considerados, extendamos el cál-
culo de la volatilidad histórica de una variable, que puede hacerse, disponiendode la información relativa a un día de negociación, a través de:1) Con precios de cierre (u otro dato representativo del día)2) Con precios de apertura y cierre3) Con los precios máximo y mínimo4) Con el máximo, mínimo, apertura y cierre5) Con precios bid y ask (en otro sentido)Si disponemos de precios cotizados continuamente, como ocurre cuando
hemos almacenado todas las transacciones realizadas a lo largo de un día demercado:
207

V olatilidad : V =p252
vuut 1
T � 1
TXt=1
(rt � �r)2
donde �r denota la rentabilidad media del día. La segunda raíz calcula ladesviación típica de la rentabilidad a lo largo de dicho día de mercado, mientrasque el producto por la raíz de 252 anualiza dicha volatilidad.La rentabilidad media sobre un período reducido de tiempo, como el tran-
scurrido entre dos transacciones, será muy pequeña, en cuyo caso, podemoscalcular la volatilidad, muy aproximadamente, como:
V olatilidad : V =p252
vuut 1
T � 1
TXt=1
r2t
En el caso de que dispongamos de precios de cierre (o cualquier otro datoúnico por día) observados con regularidad inferior a la diaria:
V olatilidad : V =
rN
T
vuut 1
T � 1
TXt=1
(rt � �r)2
donde �r denota la rentabilidad media durante los T días considerados enel cálculo. Si, por ejemplo, son datos de cierre observados el último dia denegociación de cada mes, tendremos N = 252; T = 21.Con el máximo y mínimo de la sesión [Parkinson (1980)], el rango se de�ne
como la diferencia entre los logaritmos de los precios máximo Ht y mínimo Ltdiarios,
Dt = ln(Ht)� ln(Lt)
y mide, aproximadamente, el porcentaje en el que el precio máximo excededel mínimo. Puede probarse que,
ED2t = 4 ln(2)�
2
por lo que un estimador natural de la volatilidad, basado en el rango obser-vado es,
�2 =1
4 ln(2)
1
T
TX1
D2t
!es decir,
V olatilidad : V =p252
vuutPTt=1
hln (Ht=Lt)
2i
T4 ln 2
Con apertura, cierre, máximo y mínimo [Garman-Klass]:
208

V olatilidad : V =p252
vuutPTt=1
12
hln (Ht=Lt)
2i� 0; 386
PTt=1
hln (Ct=At)
2i
T
Nota: 2 ln(2)-1 = 0,386.Las medidas de volatilidad de Parkinson y Garman-Klass producen impor-
tantes ganancias de e�ciencia: con un número de datos 5 ó 7 veces menor,generan estimaciones de la varianza poblacional que son igualmente precisasque las que se obtienen con datos diarios de cierre.Para un día cualquiera, puede utilizarse como proxy de la volatilidad:
�2r;t =1
4 ln(2)D2t ' :361D2
t
Este estimador es, generalmente, menos errático que la rentabilidad diariaal cuadrado, y tiene más persistencia que las rentabilidades diarias. Ello sugierela posibilidad de utilizar el estimador basado en el rango para validar el modelode predicción de varianza,
�2r;t+1 = �+ ��2t+1 + ut+1
Alternativamente, podríamos utilizar el rango en la predicción de volatili-dades, como en,
�2t+1 = ! + �R2t + ��2t + D
2t
dependiendo de cuál sea nuestro objetivo.
Example 14 El Cuadro 9 presenta la comparación entre estas medidas devolatilidad y la volatilidad más estándar, calculadas para las cotizaciones deBBV, TELEFONICA, ENDESA y REPSOL, desde 9/10/97 a 10/11/99.
Para tratar de tener en cuenta que las medidas de apertura/cierre y máx-imo/mínimo se obtienen en un intervalo inferior a 24 horas, suele ajustarse lavolatilidad resultante por
p24=8; 5: De este modo, las medidas Parkinson y
Garman-Klass de volatilidad de BBV aumentan a 3,80% y 3,75%, respectiva-mente.Algunas observaciones:a) Nótese en todas estas de�niciones la diferencia entre días hábiles y días
naturales.b) El trading de activos es un proceso que, en muchos casos, tiene lugar
de modo continuo a lo largo del día. Sin embargo, se observa en momentosdiscretos de tiempo.c) Los valores de trading overnight no se registran, por lo que los valores
realmente observados como alto y bajo no son necesariamente el máximo ymínimo realmente producidos a lo largo de las 24 horas. Esto produce un sesgo
209

a la baja en el estimador del alto, y un sesgo al alza en la estimación del bajo.El rango de precios queda subestimado, siendo un subintervalo del verdaderorango de precios.d) Este sesgo que se produce por generar un proceso discreto a partir de un
proceso que es realmente continuo, es algo signi�cativo en la medida de Parkin-son, y queda bastante atenuada en la medida de Garman-Klass. La direccióndel sesgo no es evidente cuando se utilizan exclusivamente datos de cierre.e) El sesgo puede ser importante en el caso de las opciones.f) Ejercicios de simulación sugieren que la mayor liquidez del mercado tiende
a reducir el sesgo, lo que prsta en tal situación mayor justi�cación al uso de lasmedidas de Parkinson, y Garman-Klass [ver Wiggins, J. (1992)]
14.2.2 Uso de rentabilidades intradiarias
Si observamos los precios negociados de un activo a intervalos regulares detiempo, podemos de�nir,
Rt+j=m = ln(St+j=m)� ln(St+(j�1)=m)
donde suponemos m observaciones diarias, para estimar la varianza diaria,
�2m;t+1 =
mXj=1
R2t+j=m
que podría utilizarse, nuevamente, en la validación de modelos de previsiónde volatilidad, en sustitución del cuadrado de la rentabilidad diaria, o utilizarsedirectamente en la predicción de volatilidad. Según aumenta el número deobservaciones intradia m, la medida de varianza realizada anterior converge ala verdadera varianza diaria.El uso de rentabilidades intradia se ve condicionado en el caso de activos
poco líquidos por la imposibilidad de observar el precio con mucha frecuencia.Lo que obtenemos entonces no es el precio fundamental del activo, que no esobservable, sino una secuencia de precios bid y ask [ver simulación en Figure 2.7en Christo¤ersen]. Los precios diarios intradía pueden contener mucha volatili-dad espúrea, que no existe en el precio fundamental del activo, por los rebotesobservados en las transacciones entre precios bid y ask. Como consecuencia,las medidas de varianza realizada basadas en rentabilidades intradía puedentener también este problema, especialmente en mercados poco líquidos. Enun contexto de limitada liquidez, el máximo puede calcularse como el máximorealmente observado menos la mitad del spread bid-ask, mientras el mínimo escalculado como el mínimo realmente observado más la mitad del spread bid-ask.Sin embargo, en ausencia de fricciones, las medidas de varianza basadas en elrango de precios contienen información equivalente únicamente a la contenidaen 4 rendimientos horarios intradía. Lamentablemente, es difícil extender laidea a la estimación de covarianzas y correlaciones, a diferencia de lo que sucedecon las medidas de varianza realizada como veremos más adelante.
210

Por el contrario, las medidas basadas en el rango observado son relativamenteinmunes a este problema. En todo caso, dado que la existencia de ticks impideque los precios �uctúen de modo continuo, haciendo que se tienda a sobreestimarla volatilidad [ver Ball, C.A., (1988)], este sesgo se suele corregir en la medidade Parkinson por medio del ratio c = d=vP , siendo d el tamaño del tick, vla volatilidad diaria estimada, y P el precio del activo. Si c �1,77, se utilizak=0,50
p�c , mientras que si c<1,77, se utiliza k=
p1� c2=6:
La hipótesis de Normalidad del logaritmo de �2m;t+1 suele no rechazarse endatos intradía, por lo que podemos utilizar un modelo de predicción basado enla volatilidad realizada,
ln�2m;t+1 = �+ � ln�2m;t + ut+1; con ut+1 � N(0; �2u)
Cuando se utiliza un modelo de previsión en logaritmos, conviene recordarque,
ut+1 � N(0; �2u)) E (eut+1) = e�2u=2
por lo que en un modelo autoregresivo como el anterior,
Et�2t+1 = Ete
�+� ln�2m;t+ut+1 = e�+� ln�2m;t :Ete
ut+1 =��2m;t
��e�+�
2u=2
14.2.3 Estacionalidad intra-día en volatilidad
Tratar de caracterizar pautas de estacionalidad, tanto en rentabilidad comoen volatilidad, puede producir información de enorme interés para un inversor.Ha sido muy popular durante mucho tiempo buscar efectos estacionales en lasrentabilidades ofrecidas por los mercados de valores. Así, existe el denominadoefecto Enero, mes en el que las Bolsas tienden a ofrecer una rentabilidad superiora la de otros meses, debido a la recomposición de carteras de muchos inversores,que liquidaron parte de las mismas antes de �nal de año por razones �scales.Asimismo, se ha debatido durante mucho tiempo la existencia de efectos esta-cionales entre semana o efectos días de la semana, a�rmando algunos autoresque existe efecto lunes en algunos mercados.Menos estudiada ha sido la posible existencia de pautas estacionales en
volatilidad. Evidentemente, la posible existencia de tales pautas sería asimismoun fenómeno muy a tener en cuenta por todos los que gestionan riesgo de unou otro modo.Parece, sin embargo, bastante probada la existencia de pautas �estacionales�
de volatilidad intradía, que se re�ejan en una mayor volatilidad en el períodosiguiente a la apertura del mercado, un descenso en las horas centrales del día,y un incremento posterior, según se acerca la hora de cierre.A este per�l en forma de U de la volatilidad a lo largo del día de negociación
suele venir unido un per�l similar de los volúmenes negociados. Por tanto,las pautas de negociación tienen mucho que ver con esta posible regularidadhoraria en la volatilidad de algunos mercados. Una de las �guras adjuntas,
211

acompañada de una tabla, tomadas de Daigler (19xx), muestra el per�l mediode la volatilidad intra-día, cuando se agrupan los precios en intervalos de 15minutos. Se utiliza como medidas de volatilidad: la desviación típica de lasrentabilidades, la medida de Garman-Klass (que veremos más adelante), y elnúmero de ticks observados en cada intervalo de tiempo. En todos los casosse tiene un per�l en forma de U , si bien el máximo local de volatilidad no seproduce en el instante de cierre del propio mercado de futuros, sino algo antes,coincidiendo con el cierre del mercado de contado. La tabla que se acompañaes de este mismo trabajo. Dos grá�cos tomados de Lafuente (1999) presentanla volatilidad del IBEX 35, así como del futuro sobre este índice, en dos tramoshorarios: 11 a 12 de la mañana, y 12 a 13 horas, apreciándose claramente lamayor volatilidad al comienzo del día. En las tablas que se acompañan, sepresenta nuevamente evidencia a favor de un per�l de volatilidad en forma deU a lo largo del día. Chan, Chan y Karolyi (19xx), presentan una evidencia deestacionalidad intra-día similar a la mencionada.
14.2.4 Agregación temporal de volatilidades
En Finanzas, suele agregarse a lo largo de un determinado período de referencia,generalmente anual, la estimación de la volatilidad obtenida a lo largo de unperíodo de tiempo más breve. La anualización de la volatilidad permite com-parar el riesgo de varios activos, independientemente del intervalo de tiempoconsiderado en su análisis.La anualización puede conseguirse a partir de la volatilidad calculada para
cada período de una determinada frecuencia, sin más que multiplicar por la raízcuadrada del número de datos de dicha frecuencia que hay en un año.Así, si se utilizan datos diarios, y �2 denota una estimación de la variabilidad
diaria (varianza u otra medida), entonces se toma 252�2 como estimación de lavariabilidad (varianza) anual (252 es el número aproximado de días de mercadodentro de un año), y
p252� como estimación de la volatilidad anual. Con datos
semanales, la volatilidad anual se obtiene a partir de la desviación típica de losdatos semanales mediante:
p52�, mientras que si se dispone de datos mensuales,
la volatilidad típica anual se obtiene a partir de la desviación típica de losdatos mensuales mediante:
p12�. Se procede de igual modo si se trabaja con
indicadores de volatilidad alternativos a la desviación típica. Una vez obtenidoun indicador de volatilidad, genéricamente denotado por S2 , se extrapolaría auna medida anual del modo que acabamos de describir.En general, dada una desviación típica calculada con datos de una deter-
minada frecuencia, si queremos obtener la estimación de la desviación típicasobre un intervalo de tiempo que comprende N observaciones de las utilizadasen el cálculo de dicha desviación típica, multiplicamos por
pN . Esto es lo que
hicimos en el párrafo anterior.Así, si hemos estimado �2 con datos diarios, entonces:la Volatilidad semanal se estima por:
p5�
la Volatilidad mensual se estima por:p21�
la Volatilidad anual se estima por:p252�
212

Como ya discutimos en la Sección 3.d, esta práctica habitual de extrapolaruna estimación de la volatilidad a un intervalo amplio de tiempo es aplicable enrigor sólo al cálculo de la volatilidad de rentabilidades continuas, y se basa en lahipótesis de que los datos básicos utilizados, ya sean rentabilidades mensuales,diarias, horarias, etc. son independientes.Si se está calculando la varianza de las rentabilidades, deben ser independi-
entes éstas, no necesariamente los precios o cotizaciones que las generaron. Estose corresponde con la extendida idea de que el logaritmo del precio de un activo�nanciero tiene una estructura estocástica de camino aleatorio. En tal caso, larentabilidad de dicho activo, de�nida como la primera diferencia del logaritmodel precio, es un ruido blanco. Es decir, la serie temporal de rentabilidadesobedece a un proceso formado por variables aleatorias independientes e idénti-camente distribuidas, posiblemente con distribución Normal, etc., y el métodode extrapolación de la varianza es correcto.Sin embargo, la existencia de autocorrelación en el proceso estocástico de
rentabilidades hace que las rentabilidades de períodos sucesivos no sean inde-pendientes, y el método lineal de extrapolación de varianzas resulta sesgado.Cuando las rentabilidades están autocorrelacionadas, la acumulación de var-
ianzas es un estimador sesgado del riesgo. En el caso de tipos de interés, ex-iste generalmente elevada autocorrelación positiva, mientras que en rentabili-dades bursátiles diarias de valores individuales se detecta, en ocasiones, auto-correlación negativa. Como la varianza de una suma de variables es igual a lasuma de varianzas más el doble de su covarianza, tenderemos a subestimar lavarianza de la rentabilidad sobre el horizonte temporal amplio en el caso deautocorrelación positiva (creeremos que, sobre el período amplio, la rentabili-dad es menos volátil de lo que realmente es), y a sobre-estimarla en el caso deautocorrelación negativa (creeremos que es más volátil de lo que realmente es).Por tanto, la habitual agregación temporal de volatilidades está directamente
relacionada con la posible presencia de autocorrelación en la series temporal derentabilidades. A su vez, la existencia de autocorrelación ofrece la posibilidadde predecir rentabilidades. Por el contarrio, en ausencia de correlación serial, larentabilidad (supongamos que logarítmica) es un ruido blanco, y la predicciónóptima de cualquier valor futuro es cero, lo que equivale a decir que la predicciónde cualquier precio futuro es el último precio observado, ya que el logaritmo delprecio tiene entonces una estructura de camino aleatorio. Por último, la pre-dictibilidad de las rentabilidades (o la posible capacidad del analista de redeciruna rentabilidad futura no nula) o la predictibilidad de los precios de un activo(o la posible capacidad de predecir un precio diferente del actual) contradicen lahipótesis de mercados e�cientes, según la cual el precio de mercado de un activorecoge, en cada momento, toda la información disponible (por tanto, actual opasada) relevante acerca de la formación de precios futuros.En de�nitiva, la agregación de volatilidades descansa en la independencia
temporal de las rentabilidades del activo en cuestión, lo que equivale a que elprecio de dicho activo obedezca a una estructura de camino aleatorio. Existendistintos enfoques estadísticos para el contraste de dicha hipótesis, que puedenverse en la sección 3.6
213

14.2.5 Volatilidad implícita versus volatilidad histórica
La volatilidad implícita es la estimación de volatilidad que se obtiene al imponerel precio observado en el mercado en una expresión teórica de valoración quehace depender el precio de dicho activo de una sola componente no observada,su volatilidad (además de depender de otras componentes observables). Engeneral, nos interesa calcular volatilidades implícitas, porque para este tipo dederivados disponemos de modelos de valoración del tipo descrito.Al efectuar este ejercicio, se está suponiendo que el modelo teórico de valo-
ración del activo es correcto, y que el mercado forma expectativas de volatilidadutilizando e�cientemente la información de que dispone. Ello hace que el preciode mercado resuma de manera adecuada toda la información disponible acercadel activo.Estamos interesados en obtener volatilidades implícitas por dos razones:
� Una vez determinada la volatilidad cotizada en el mercado para un deter-minado subyacente, podremos poder evaluar si una determinada opciónestá subvalorada, correctamente valorada o sobrevalorada por el mercado,lo que podría sugerir diversas estrategias de inversión, y
� Generalmente, nos interesa utilizar la volatilidad implícita en un sentidotemporal, pues si podemos obtener buenas previsiones de la volatilidadimplícita futura de un determinado activo, dispondremos de previsionesde precios futuros de las opciones sobre dicho subyacente. En esta línea,pueden establecerse diversos ejercicios:
a) para tener un indicador de la percepción del mercado acerca de la volatil-idad de un activo y poder analizar el modo en que dicha percepción cambia enel tiempo,b) utilizar la serie temporal de la volatilidad implícita para especi�car un
modelo univariante predictivo de la volatilidad implícita futura, para lo quenecesitaremos haber calculado la volatilidad implícita durante todos los días através de un largo período de tiempo,c) para ponerla en relación con alguna de las medidas de volatilidad histórica:
estas son las medidas que se basan exclusivamente en precios de mercado históri-cos del subyacente, sin utilizar modelo de valoración alguno, como ocurre conuna desviación típica estimada a través de ventanas muestrales, o la medida deGorman-Klass, por ej..Puesto que las fórmulas teóricas de valoración de un producto derivado son
funciones altamente no lineales de sus argumentos y, en particular, de la volatil-idad, la resolución de la ecuación que iguala el precio teórico (es decir, el quese obtiene de la fórmula) con el precio observado en el mercado para obtenerla volatilidad no puede llevarse a cabo analíticamente, siendo preciso recurrir aalgoritmos numéricos, del tipo de los que analizaremos en módulos posteriores.La volatilidad implícita no hace sino re�ejar la visión del mercado acerca
del grado de incertidumbre que entraña la evolución temporal de la rentabilidadque ofrece un activo. Cambios en la información disponible (resultados de una
214

empresa, intervenciones de política económica, publicación de algún dato clavesorprendente) pueden incidir sobre tal percepción.Existe una importante distinción entre ambos tipos de volatilidad: por un
lado, tenemos la volatilidad histórica, que mira hacia el pasado, y se basa exclu-sivamente en información histórica del precio o de la rentabilidad cuya volatil-idad se pretende calcular. Por otra parte, la volatilidad implícita afecta a lavaloración de un producto derivado y, en consecuencia, mira hacia el futuro,tratando de estimar una característica no observable, por cuanto que aún no seha realizado, como es la volatilidad futura del subyacente.Sólo si pensáramos que la volatilidad futura es igual a la pasada estaríamos
estimando el mismo concepto, aunque por método distintos, que nos propor-cionarán valores numéricos diferentes. Por otra parte, la volatilidad histórica,calculada en forma de serie temporal a través de ventanas móviles, como de-scribimos anteriormente, también podría utilizarse para predecir la volatilidadfutura. Por tanto, ambos conceptos pueden ponerse en relación. La mayor difer-encia estriba en la forma de calcular las volatilidades. Por un lado, en la formade desviación típica; por otro, resolviendo en una formula como la de Black-Scholes de modo que el precio teórico resultante coincida con el observado en elmercado.Una hipótesis interesante estriba en si la volatilidad implícita responde a
variaciones en la volatilidad histórica. La intuición es que si se produce unavariación en la rentabilidad de un activo que modi�ca su volatilidad histórica,el mercado puede percibir un mayor riesgo futuro, lo que debería elevar el preciode las opciones sobre el mismo, conduciendo a una mayor volatilidad implícita.Sin embargo, la respuesta no es evidente. Algunos estudios realizados [AnálisisFinanciero no.50, febrero]
V olatilidadimpl�{citat+1 � V olatilidadimpl�{citat =
= �(V olatilidadhist�oricat � V olatilidadhist�oricat�1)Trabajando con datos para el bono nocional, en dicho trabajo se encuentran
coe�cientes de determinación en torno a 0,77, y pendientes estimadas próximasa 0,80.Hay que tener en cuenta que la existencia de una relación estadística estable
entre volatilidad histórica e implícita no precisa que los niveles de volatilidad es-timados por cada uno de los dos procedimientos coincidan. De hecho, esperamosmás bien lo contrario; en todo caso, no importa que ambos niveles de volatil-idad sean los mismos, sino que variaciones en el nivel de volatilidad históricaanticipen cambios en el nivel de volatilidad implícita, que puedan utilizarse parala gestión de carteras.
Conos de volatilidad Una vez que se dispone de la serie temporal de rentabil-idades de un activo, puede calcularse su volatilidad muestral sobre intervalos dedistinta amplitud temporal. Queremos representar el modo en que la volatilidadvaría con la amplitud de dichos intervalos temporales. Ya sabemos que, bajo
215

supuestos de independencia temporal de las rentabilidades, la varianza sería unafunción lineal de la amplitud del intervalo. Sin embargo, esta es una hipótesisque no siempre se cumple.Para ello, seleccionamos distintas amplitudes para ventanas muestrales: se-
mana, quincena, mes, trimestre, semestre, o año, y calculamos en cada períodola volatilidad de la rentabilidad ofrecida por dicho activo desde el comienzo decada una de dichas ventanas. De este modo, construimos una serie temporal devolatilidades para cada una de las ventanas seleccionadas.Asi, �jada una determinada amplitud temporal, por ej., un mes, vemos cómo
ha ido cambiando la volatilidad a través del tiempo: si estamos a 15 de noviem-bre de 2001, y disponemos de datos desde comienzos de enero de 1996, em-pezaríamos calculando la volatilidad muestral para todo el mes de enero de1996, por ejemplo (el comienzo es relativamente arbitrario), e iríamos añadi-endo un día al �nal de la muestra, y quitando un día al comienzo de la misma,para volver a calcular la volatilidad registrada a lo largo de un mes de mercado.El procedimiento puede seguir hasta el último dato disponible. De este modohabremos generado una serie temporal de volatilidad, a lo largo de un mes,desde el 1 de enero de 1996, hasta el 15 de octubre de 2001.En esta ocasión, sin embargo, no nos detenemos en analizar la variación
temporal de la volatilidad, sino en estudiar algunos de sus estadísticos descrip-tivos, pues queremos analizar cómo cambian las propiedades de la volatilidadal cambiar la amplitud del intervalo de tiempo considerado. De hecho, vamos aconsiderar los valores que con�guran la serie temporal de volatilidades de unadeterminada ventana como valores extraídos al azar de la distribución de prob-abilidad de la varianza correspondiente a dicha ventana. Inicialmente, tomamoslos valores máximo y mínimo de las volatilidades así calculadas, y los repre-sentamos en la vertical sobre el eje de abscisas, en el punto correspondiente a1 mes. El mismo procedimiento puede llevarse a cabo para cada una de lasventanas escogidas: para intervalos de 1 semana, comenzaríamos nuevamente alinicio de enero de 1996, obteniendo un máximo y un mínimo de las volatilidadescalculadas sobre un rango temporal de una semana.De este modo tendríamos una serie temporal para cada una de las volatili-
dades calculadas sobre intervalos de: una semana, dos semanas, un mes, trimestre,semestre, o año, y podríamos calcular su máximo y su mínimo. Cuando se rep-resentan dichos máximos y mínimos, se observa generalmente, que la volatilidadmáxima es mayor en los intervalos menores (una semana) que en los intervalosamplios de tiempo. Por otra parte, la volatilidad mínima es menor asimismocuando se calcula sobre intervalos breves de tiempo que cuando se calcula sobreintervalos amplios. Algo similar ocurre cuando tomamos percentiles simétricospara cada una de las series temporales de volatilidad, por ejemplo, percentiles5% y 95%: el primero será menor para ventanas de una semana que para lasde un mes, mientras que el percentil 95% será generalmente superior en lasventanas más cortas.Esto se debe a que la volatilidad toma valores más extremos cuanto menor es
el intervalo de tiempo sobre el que se ha calculado. Es como si las distribucionesde frecuencias de las distintas volatilidades tuviesen más curtosis cuanto menor
216

fuese la amplitud de la ventana correspondiente. Dicho de otro modo, el rangode valores de volatilidad calculados sobre una semana, tiende a incluir al rangode volatilidades calculado sobre un mes, éste al rango calculado sobre tres meses,y así sucesivamente. De este modo, habremos obtenido un cono de volatilidad.Los conos de volatilidad desempeñan un papel importante cuando se quiere
apreciar si una opción está relativamente cara o barata en el mercado. Paraello, se trata de comparar la volatilidad implícita en el precio de mercado de laopción, con el rango de volatilidades que históricamente se ha estimado sobreun período de tiempo igual al que queda hasta la expiración de la opción.Si, por ejemplo, la volatilidad implícita cuando queda un mes para la ex-
piración de la opción está por debajo del percentil 10 de la distribución defrecuencias de las volatilidades que hemos calculado sobre intervalos de un mes,diremos que el mercado está infravalorando dicha opción, puesto que está dandoun precio que se corresponde con una volatilidad que es poco creíble que se pro-duzca, por lo reducido de su cuantía.Esto signi�ca que, en base a la experiencia histórica, la volatilidad que cabría
esperar es superior a la que el mercado espera. Si no hay razones para que asíresulte, habría que pensar que la opción está barata. Lo contrario ocurriría sila volatilidad implícita fuese superior al percentil 90, por ej.. Salvo que hu-biese razones para esperar una volatilidad excesivamente alta para los registroshistóricos, habría que pensar que el mercado está sobrevalorando dicha opción.Al construir un cono de volatilidad cabría introducir un ajuste si realmenteexiste una discrepancia permanente entre los niveles de volatilidad histórica eimplícita.Los percentiles escogidos determinan el número de señales que puedan obten-
erse acerca de posibles situaciones de mispricing (error en precio). Percentilesmenos extremos producirán más señales de precio incorrecto, pero tambiénmayor nivel de riesgo, porque las señales tenderán a ser incorrectas más fre-cuentemente. Seleccionar unos determinados percentiles es similar a seleccionarun determinado nivel de riesgo para el cálculo del VaR.El Grá�co presenta el cono de volatilidad para el SP500 calculado con datos
de enero 1997 a agosto 1997, con percentiles 10 y 90, para el S&P 500. ElGrá�co 12, tomado de Lamothe (Opciones Financieras, McGraw-Hill), ilustrala comparación con el precio real de la opción, en el caso del bono nocional.
14.3 Modelización y predicción de la volatilidad
Repasamos en este documento distintas alternativas para la modelización y pre-visión de la volatilidad en mercados �nancieros. Generalmente, consideramosque trabajamos con series temporales de rentabilidades de activos �nancieros ob-servadas frecuentemente, pues entonces cuando resulta habitual observar volatil-idades cambiantes en el tiempo. En el caso más sencillo, consideramos que larentabilidad obedece al proceso estocástico,
Rt+1 = �t+1zt+1; con zt+1 � i:; i:d:;N(0; 1)
217

El objetivo fundamental de la modelización de la evolución temporal de lavolatilidad consiste en lograr que las rentabilidades estandarizadas al cuadradoR2t =�
2t muestren ausencia de correlación temporal. La autocorrelación en las
rentabilidades al cuadrado podría venir a través de la evolución de �2t ; por loque al corregir las rentabilidades del posible efecto persistente de la volatilidad,la autocorrelación en las rentabilidades al cuadrado debería desaparecer.Si las propias rentabilidades tienen autocorrelación (lo que es poco habitual
en datos frecuentes), realizaremos este ejercicio de modelización con el cuadradode las innovaciones del modelo que explica la evolución temporal de Rt: Es decir,modelizaremos la evolución temproal de la desviación típica o de la varianza dedichas innovaciones, y pretenderemos que sus valores normalziados carezcan deautocorrelación. Por tanto, la función de autocorrelación de las rentabilidadesestandarizadas al cuadrado es un estadístico fundamental en este análisis demodelización de la varianza.Una característica de los mercados �nancieros es que suelen observarse in-
tervalos concretos de tiempo en los que sistemáticamente se produce cada díauna alta volatilidad, seguidos de períodos de reducida volatilidad. Esto se man-i�esta en que el cuadrado de las rentabilidades diarias tenga generalmente unaalta autocorrelación. En efecto, nótese que con datos de frecuencia relativa-mente alta, la rentabilidad media de un activo es practicamente cero, por lo queel cuadrado de la rentabilidad es una aproximación a la varianza. En consecuen-cia, si queremos prever el nivel de volatilidad el próximo día de mercado, unasencilla posibilidad es utilizar como previsión la volatilidad media observada enlos últimos m días de mercado,
�2t+1 =1
m
m�1Xi=0
R2t�i
En esta expresión se ha incorporado ya el supuesto habitual de que, traba-jando con rentabilidades en frecuencias altas, la rentabilidad media es práctica-mente cero. Además, su estimación numérica podría introducir mayor distorsiónque la incorporación directa de una valor medio nulo. Una ventaja de esta expre-sión es que nos permite generar una estimación del nivel de volatilidad al cierredel mercado en el período t, sin necesidad de efectuar ningún cálculo adicional.Tiene varias desventajas:
� no es claro cómo debe elegirse el número de díasm . Este número suele de-nominarse amplitud de la ventana. Un número reducido tenderá a generaruna serie temporal de volatilidad muy errática, mientras que un númeroelevado de días generará una serie de volatilidad que puede considerarseexcesivamente suave. La elección de la amplitud de ventana debe de-pender de la utilización que quiera hacerse de la previsión de volatilidadresultante.
� la serie de volatilidades reacciona al alza sólo después de que se hayaobservado en el mercado una rentabilidad diaria elevada. En este sentido,
218

su naturaleza no es tanto la de anticipar el comportamiento futuro de lavolatilidad, como el de re�ejar el comportamiento reciente de la misma.
� precisamente por esta razón, es un indicador que va reaccionando a incre-mentos de volatilidad con cierto retraso, pues se trata de un promedio delos niveles de volsatilidad en los últimos m días de mercado.
� pondera por igual cada uno de los m días utilizados en su calculo. Ellohace que la presencia de un día de alta volatilidad elevará la previsión devolatilidad la primera ocasión en que dicha rentabilidad se utilice en elcálculo, y tenderá a mantener la volatilidad elevada durante m días, re-duciéndose nuevamente de manera drástica. La función de autocorrelaciónde las rentabilidades al cuadrado sugiere bastante persistencia, siendo portanto contraria a estas variaciones bruscas al inicio y al �nal del períodode m dias.
14.3.1 El modelo de alisado exponencial
Al igual que cualquier otro momento de una distribución, la varianza otorgaa todas las observaciones disponibles la misma ponderación. Por tanto, lasdesviaciones respecto del nivel de referencia tienen la misma importancia tantosi se produjeron recientemente como si se produjeron hace ya algún tiempo.Esto puede no ser totalmente deseable en el análisis de mercados �nancieros.En ocasiones, es conveniente abandonar este supuesto, dando pie a esquemascon ponderaciones, del tipo,
�2t+1 =
m�1Xi=0
�iR2t�i
donde Rs = ln(Ps=Ps�1); es la rentabilidad de un determinado activo �-nanciero, �i > 0;
Pm�1i=0 �i = 1; y 1 < i < j < m� 1) �i > �j : Esta expresión
calcula la varianza como media ponderada de las rentabilidades al cuadrado.No utiliza las desviaciones respecto de la rentabilidad media, porque se suponeque en datos de alta frecuencia, ésta es despreciable.Si los pesos no suman uno, hay que dividir en la expresión anterior por su
suma. En ocasiones se utilizan como pesos las potencias de una constante �comprendida entre 0 y 1, lo que conduce a,
�2t+1 = (1� �)1Xi=0
�iR2t�i (47)
y que en la práctica es preciso truncar:
�2t+1 = (1� �)m�1Xi=0
�iR2t�i + �m�20
donde el último término, que es función de la volatilidad en un períodoinicial, �20; pierde relevancia con el paso del tiempo.
219

Cuando cuando se utiliza un modelo como el anterior para generar una serietemporal de volatilidad histórica, es necesario estimar la volatilidad inicial �20 , loque puede hacerse de dos modos: 1) mediante la varianza de las rentabilidadesprevias a dicha fecha, que pasaría a ser tomada como origen de tiempo; esdecir, utilizamos una primera submuestra (por ejemplo, 200 observaciones) paracalcular dicha varianza y comenzamos a extrapolar la varianza en el tiempopartir de la observación 201; 2) alternativamente, suele partirse de un valorinicial igual a la varianza muestral de la serie temporal, es decir, se substituye �20en la expresión anterior por la varianza muestral, 1T
PTs=1R
2s, que se interpreta
como el nivel de volatilidad de largo plazo, obteniendo:
�2t+1 = (1� �)m�1Xi=0
�iR2t�i + �m
1
T
TXs=1
R2s
!
La suma de los pesos en el primer término a la derecha de la igualdad es,
(1� �)m�1Xi=0
�i = (1� �) 1� �m
1� � = 1� �m
por lo que la suma total de los pesos en el miembro derecho de la expresiónanterior es igual a 1, como debería suceder.Un simple cálculo en (47) muestra la relación,
�2t+1 = ��2t + (1� �)R2tque suele denominarse como modelo de alisado exponencial. De acuerdo con
este modelo, si el nivel de volatilidad estimado un determinado día es del 1%, yla variación porcentual en precio dicho día es del 2%, utilizando un parámetro� = 0:90; estimaríamos una volatilidad para el día siguiente de 1,14%. Estees el modelo utilizado por RiskMetrics que calcula la volatilidad del próximodia, mediante un promedio ponderado del nivel de volatilidad que calculamospreviamente para hoy, y el cuadrado de la rentabilidad del mercado hoy. Risk-Metrics utiliza sistemáticamente un valor numérico � = 0:94; por considerar quelas estimaciones no di�eren mucho entre diferentes activos.Este modelo tiene alguna ventaja adicional, como es el hecho de que no nece-
sita una gran cantidad de datos, pues las potencias de � serán prácticamentecero al cabo de 100 períodos. Además, una vez calculada la volatilidad para undeterminado día, la fórmula de actualización anterior no precisa utilizar nue-vamente los datos históricos. El modelo considera esencialmente un horizontein�nito, no estando sujeto a los problemas de elección del número de días mque se utilizan en la estimación de volatilidad mediante ventanas móviles. Porúltimo, es un modelo simple, que sólo tiene un parámetro para estimar, �:
220

14.3.2 El modelo GARCH(1,1)
Un inconveniente del modelo previo es que no incluye una constante, por lo queel modelo no proporciona un nivel de referencia para la volatilidad a largo plazo.El modelo mejora si se incorpora un nivel de volatilidad de largo plazo, �2, querecibe una cierta ponderación en la expresión de la varianza,
�2t+1 = �2 +m�1Xi=0
�iR2t�i
donde ahora, la suma de los pesos �i debería ser igual a 1 � : Este es unmodelo ARCH(m). Si denotamos ! = �2, tenemos,
�2t+1 = ! +m�1Xi=0
�iR2t�i
El modelo GARCH(1,1) combina las dos ideas anteriores en la expresión,
�2t+1 = �2 + �R2t�1 + ��2t�1
que requiere que � + � < 1 para que la varianza sea estable. En casocontrario, el peso aplicado a la varianza de largo plazo sería negativo. El alisadoexponencial de la sección anterior, utilizado en RiskMetrics, es un caso particulardel modelo GARCH(1; 1); cuando �+ � = 1 y = 0.El modelo GARCH(1,1) puede escribirse también,
�2t = ! + �R2t�1 + ��2t�1
que nos permitiría prever la volatilidad del próximo día a partir de la volatil-idad prevista para hoy y de la rentabilidad observada al cierre del mercado:
�2t+1 = ! + �R2t + ��2t
Por ejemplo, si hemos estimado el modelo,
�2t = 0; 000002 + 0; 13R2t�1 + 0; 86�
2t�1
tendríamos,
= 1� �� � = 0; 01; �2 = !
1� �� � = 0; 0002;
Al considerar las �uctuaciones en volatilidad, si la volatilidad estimada paraun determinado día es de �t = 1; 6%, y ese día el precio del activo �nanciero varíaun 1% al alza o a la baja, estimaríamos para el día siguiente una volatilidad,
�2t = 0; 000002 + 0; 13 (0; 0001) + 0; 86 (0; 000256) = 0; 00023516
que equivale a una volatilidad diaria del 1,53%.
221

Mediante sustituciones reiteradas, el modelo puede escribirse en la forma,
�2t = ! + !� + !�2 + �R2t�1 + ��R2t�2 + ��
2R2t�3 + �3�2t�3
que es similar al alisado exponencial, excepto en que asigna una ponderacióntambién a la varianza de largo plazo. En el límite, tenemos,
�2t =!
1� � + �1Xs=1
�s�1R2t�s
que hace depender la volatilidad �2t de una constante y de las rentabilidadeshistóricas al cuadrado, con ponderaciones decrecientes, según nos alejamos haciael pasado. El parámetro � es la tasa a la cual el tamaño de las rentabilidadespasadas (o su volatilidad, si se quiere, pues están al cuadrado) inciden sobre lavolatilidad actual del activo. Esta expresión puede truncarse al cabo de unoscuantos períodos, sin incurrir en un grave error de aproximación.De acuerdo con este modelo,
�2 � E��2t+1
�= ! + �E
�R2t�+ �E
��2t�= ! + ��2 + ��2
por lo que, la volatilidad incondicional, o volatilidad de largo plazo es,
�2 =!
1� �� �El modelo anteriormente estimado implica un nivel de volatilidad de largo
plazo �2, dep0; 0002 = 1; 41%. Esta expresión muestra que el nivel de volatili-
dad a largo plazo no está bien de�nido en el modelo de RiskMetrics, que impone�+ � = 1: Ello afectará más a las previsiones de volatilidad a largo plazo que acorto plazo. Que esto sea o no importante depende de que creamos que existeun nivel de volatilidad media relativamente estable, a la cual revierte el mercadocada vez que se separa del mismo al alza o a la baja. Por el contrario, el modeloGARCH puede escribirse,
�2t+1 = (1� �� �)�2 + �R2t + ��2t = �2 + �(R2t � �2) + �(�2t � �2)
que expresa que la previsión de la varianza el próximo día se obtiene cor-rigiendo el nivel de volatilidad de largo plazo, en función de que la rentabilidadal cuadrado y el nivel de volatilidad en t hayan estado por encima o por debajodel nivel de largo plazo.
Estimación del modelo de volatilidad por máxima verosimilitud Bajoel supuesto de Normalidad para las rentabilidades logarítmicas, Rt = �tzt; conzt � i:; i:d:N(0; 1); tendemos la función de verosimilitud,
L =TYt=1
"1p2��2t
exp
��R2t2�2t
�#
222

cuya maximización equivale a maximizar su logaritmo neperiano,
lnL =T
2ln(2�)� 1
2
TXt=1
�ln�2t +
R2t�2t
�que se puede maximizar bien mediante algoritmos numéricos, o bien medi-
ante procedimientos de búsqueda. En todo caso, lo primero que hemos de haceres substitutir en la expresión anterior la volatilidad �2t por un determinadomodelo dependiente de un vector de parámetros �: En las próximas seccionesveremos cómo se lleva a cabo este proceso. Como en cualquier otro problema deestimación, hemos de tener en cuenta que estamos maximizando la verosimilitudbajo el supeusto de estabilidad paramétrica, lo que puede condicionar el númerode observaciones utilizado en dicho proceso de estimación.
Quasi-máxima verosimilitud El supuesto de Normalidad no es facilmentesostenible cuando se trabaja con rentabilidades de activos �nancieros. El métodode quasi-máxima verosimilitud consiste en maximizar el logaritmo de la funciónde verosimilitud bajo el supuesto de Normalidad, pues el estimador resultantees consistente incluso cuando la verdadera distribución condidional de Rt no esNormal, siempre que las ecuaciones de la media y la varianza condicionales deRt estén bien especi�cadas. Unicamente hay que prestar atención al cálculo dela matriz de covarianzas de los estimadores resultantes.
Primer caso: rentabilidades incorrelacionadas con media cero Supong-amos que las rentabilidades obtenidas en la unidad temporal de observacióncarecen de autocorrelación, lo que puede contrastarse a partir de un examende sus funciones de autocorrelación simple y parcial, así como llevando a cabocontrastes formales del tipo Ljung-Box o Box-Pierce.Para estimar los parámetros del modelo en una hoja de cálculo, se estima
inicialmente �2t0 por alguno de los dos procedimientos que mencionamos antes,y comienza la recursión a partir de dicho instante temporal, después de haber �-jado valores iniciales para los parámetros �; �; !. Una vez evaluada la función deverosimilitud para los valores parámetricos inicialmente escogidos (condicionesiniciales), se trata de buscar en el espacio paramétrico con el objeto de obtenerlos valores que maximizan la función de verosimilitud,
lnL(!; �; �) =T
2ln(2�)� 1
2
TXt=1
�ln�2t (!; �; �) +
R2t�2t (!; �; �)
�Finalmente, la varianza de largo plazo, �2, se estima a partir de las expresionesanteriores y las estimaciones obtenidas para �; �; !: �2 = !=(1� �� �):La alternativa denominada variance targetting consiste en �jar un nivel
de volatilidad de largo plazo �2, por ejemplo igual a la varianza muestral, yutilizando la expresión analítica de la varianza a largo plazo para �jar ! =�2 (1� �� �), estimando así sólo 2 parámetros, � y �.
223

Si queremos estimar un modelo de alisado exponencial como el utilizado enRiskMetrics, se �ja ! = 0; � = 1� �; � = �; y se efectúa una búsqueda sobre elvalor numérico de �; � 2 (0; 1);en la función
lnL(�) =T
2ln(2�)� 1
2
TXt=1
�ln�2t (�) +
R2t�2t (�)
�
Segundo caso: rentabilidades posiblemente correlacionadas, conmedia no nula Como alternativa, consideremos la posibilidad de que lasrentabilidades obedezcan al modelo
Rt = �0 + �1Rt�1 + "t
que recoge la presencia de autocorrelación, es decir, de dependencia temporalen las rentabilidades. Tendría sentido entonces hacer el supuesto de estructuraGARCH de volatilidad, pero ahora sobre la innovación "t del proceso estocásticode rentabilidades, por lo que �2t sería ahora: �
2t = V ar("t); con función de
verosimilitud,
L =
TYt=1
"1p2��2t
exp
��"2t2�2t
�#con,
lnL = �T2ln(2�)�1
2
TXt=1
�ln�2t +
"2t�2t
�= cons tan te�1
2
TXt=1
ln�2t +
(Rt � �0 � �1Rt�1)2
�2t
!
y la estimación del modelo se lleva a cabo buscando en los parámetros�; �; !; �0; �1:En este caso habría que tener en cuenta que el procedimiento nos daría la
evolución temporal de la volatilidad de la innovación "t; el componente no pre-decible de la rentabilidad, que es la volatilidad de Rt condicional en su pasado;pero no su volatilidad incondicional. En todo caso, la volatilidad incondicional(un número) es la media de la volatilidad condicional (una variable). La relaciónentre las volatilidades incondicionales de la Rentabilidad y su innovación es,
V ar(Rt) =V ar("t)
1� �21
Contrastes del modelo de volatilidad Un contraste del modelo consisteen un test de ausencia de autocorrelación en las rentabilidades al cuadrado, R2t :Puesto que hemos pretendido recoger los cambios en volatilidad a lo largo deltiempo, no deberia existir tal autocorrelación. Para ello hemos de utilizar lasrentabilidades normalizadas o estandarizadas al cuadrado, R
2t
�2t: Para un contraste
riguroso, puede utilizarse el conjunto de estadísticos del tipo Ljung-Box,
224

TkXi=1
T � 2T � i
2i
que se distribuye como una �2k:Contrastes relevantes son asimismo los pertenecientes a la familia de tests de
razón de verosimilitudes, que permiten contrastar un modelo restringido frentea una alternativa más general, del cual el primero se obtiene imponiendo deter-minadas restricciones. El estadístico del contraste es,
LRT = �2 [lnLR � lnLNR]y tiene una distribución asintótica igual a una chi-cuadrado con grados de
libertad igual al número de restricciones que transforman el modelo más generalen el modelo restringido.Otro contraste habitual consiste en analizar si la serie temporal de varianza,
�2t ; es un predictor insesgado de la rentabilidad al cuadrado futura,
R2t+1 = �+ ��2t+1 + ut+1
Se dice que �2t+1 es un predictor insesgado de R2t+1 si � = 0 y � = 1: Sin
embargo, conviene notar que,
V artR2t+1 = Et
�(R2t+1 � �2t+1)2
�= Et
h��2t+1
�z2t+1 � 1
��2i=
= �4t+1Et
h�z2t+1 � 1
�2i= �4t+1 (�� 1)
siendo � la curtosis de la innovación del proceso GARCH, zt;que sería igual a3 si suponemos Normalidad condicional: zt � i:; i:d:;N(0; 1). El valor numéricode la expresión anterior puede ser elevado, por lo que el cuadrado de la rentabil-idad de un período R2t+1 es, generalmente, una proxy muy contaminada de lavarianza condicional �2t+1: Por ello, puede ser preferible utilizar medidas intradíaen la estimación de la volatilidad.
14.3.3 Estructura temporal de volatilidad
Consideremos una opción que vence en t + N: Podemos utilizar la expresiónanterior para predecir el nivel medio de volatilidad del activo subyacente durantedicho período, mediante,
V olatilidad a horizonte N per�{odos =
vuut 1
N
N�1Xi=0
E�2t+i
Cuando este ejercicio se lleva a cabo para opciones sobre el mismo activosubyacente, con distinta fecha de vencimiento, se tiene una Estructura Temporalde Volatilidades. Esta es la relación entre las volatilidades implícitas de lasopciones y su vencimiento residual.
225

Cuando se utiliza el modelo GARCH, se obtiene un per�l creciente o decre-ciente, precisamente por su propiedad de reversión al nivel medio de volatilidad.Por tanto, este modelo predice una curva de volatilidades bien creciente o de-creciente respecto del vencimiento de las opciones.Puede calcularse asimismo cual sería el efecto sobre cada una de dichas
previsiones, de una variación por ejemplo, de un 1% en la volatilidad actual delactivo subyacente. Esta variación en volatilidad no será la misma para todoslos vencimientos, y tendrá un per�l análogo al de la Estructura Temporal deVolatilidades, lo que debería tenerse en cuenta al computar la exposición deuna cartera de opciones a variaciones en volatilidad del activo subyacente. Alhacer una simulación de este tipo y calcular una vega, no debería suponerse unavariación análoga en volatilidad a lo largo de todos los vencimientos.
14.3.4 Predicción de volatilidad
El modelo GARCH(1; 1) puede escribirse,
�2t � �2 = ��R2t�1 � �2
�+ �
��2t�1 � �2
�es decir,
�2t+k � �2 = ��R2t+k�1 � �2
�+ �
��2t+k�1 � �2
�que conduce a,
E��2t+k � �2
�= (�+ �)
��2t+k�1 � �2
�puesto que, ER2t+k�1 = �2t+k�1:La previsión de volatilidad k días hacia el
futuro es,
Et��2t+k
�� �2 = (�+ �)k�1
��2t+1 � �2
�donde �2t+1es nuestra estimación de volatilidad para el próximo día, que
puede calcularse con la información de que disponemos en el período t:La suma � + � se denomina persistencia en volatilidad. Si la volatilidad
actual es más alta que el nivel de largo plazo �2, la previsión será a la baja,y lo contrario ocurrirá si el nivel actual es de reducida volatilidad. Cuando�+� < 1; el último término va perdiendo importancia, y la predicción convergea la varianza de largo plazo, al aumentar el horizonte de la predicción. Lavelocidad de convergencia está inversamente relacionada con la proximidad de�+ �a 1. Se dice que este modelo tiene reversión al nivel medio de volatilidad,�2, a una tasa 1� �� �:Por el contrario, en el modelo de alisado exponencial utilizado por RiskMet-
rics � + � = 1; y la predicción a cualquier horizonte coincide con la varianzaactual:
Et��2t+k
�= �2t+18k
226

por lo que este modelo tiene persistencia igual a 1. Se espera que todoshock en volatilidad persista para siempre, y cualquier incremento observadoen volatilidad elevará la previsión de volatilidad de todos los períodos futurosen la cuantía del shock. El modelo de RiskMetrics extrapola la situación devolatilidad actual a todos los períodos en el futuro, mientras que el modeloGARCH genera una reversión al nivel medio de volatilidad a largo plazo.Algo más delicada es la predicción de la volatilidad de la rentabilidad acu-
mulada a lo largo de k días de mercado. Nótese la diferencia con el ejercicioanterior, en el que se preveía la rentabilidad diaria k-períodos hacia adelante.En términos de rentabilidades continuas, sabemos que dicha rentabilidad acu-mulada será, por construcción, la suma de las rentabilidades continuas obtenidaspara cada uno de los días del período. Bajo el supuesto de que las rentabilidadesson temporalmente independientes, tendremos,
Et
kXi=1
Rt+i
!2=
kXi=1
Et�2t+i
de manera que con RiskMetrics tenemos,
Et
kXi=1
Rt+i
!2= k�2t+1
mientras que con el modelo GARCH tenemos,
Et
kXi=1
Rt+i
!2= k�2 +
kXi=1
(�+ �)i�1 �
�2t+1 � �2�
que es distinta de la expresión anterior. Si partimos de un mismo nivel de�2t+1;la predicción del model GARCH será superior a la de RiskMetrics si y sólosi el nivel de �2t+1 es inferior al nivel de largo plazo, �
2:
14.3.5 Extensiones
� Modelo GARCH(p,q):
�2t+1 = �2 +pPi=1
�iR2t+1�i +
qPj=1
�j�2t+1�j
� Modelo GARCH de componentes, que permite variación temporal en elnivel de varianza de largo plazo, �t+1 :
�2t+1 = �t+1 + �(R2t � �t) + �(�2t � �t)
�t+1 = ! + ��(R2t � �2t ) + ���t
227

� Efecto apalancamiento (leverage): El argumento básico es que una rentabil-idad negativa de una ación implica una caida en el valor de mercado dela empresa, lo que aumenta su apalancamiento �nanciero, aumentando sunivel de riesgo (a igual nivel de deuda). Podemos modi�car el modeloGARCH(1,1) para recoger este efecto de varias maneras:
�2t+1 = ! + �R2t + ���I�t R
2t
�+ ��2t
donde I�t es una variable �cticia que toma el valor 1 cuando la rentabilidades negativa, siendo igual a cero en caso contrario. De�nida de este modo, unarentabilidad R tiene una contribución al nivel de volatilidad el período siguientede �R2t ; si dicha rentabilidad fue positiva, y de � (1 + �)R
2t si fue negativa Este
modelo se conoce como GJR-GARCH.Bajo el supuesto mantenido de que la rentabilidad sigue un proceso: Rt =
�tzt; con zt � i:; i:d:N(0; 1); otra posibilidad es el modelo NGARCH,
�2t+1 = ! + �(Rt � ��t)2 + ��2t = ! + ��2t (zt � �)2 + ��2tde modo que, si � > 0; noticias positivas tienen menos impacto sobre la
varianza que noticias negativas. La persistencia de la varianza en este modeloes �
�1 + �2
�+ �, mientras que el nivel de varianza de largo plazo es: �2 =
!1��(1+�2)�� :
Una última posibilidad es el modelo GARCH exponencial, o EGARCH:
ln�2t+1 = ! + �(�Rt + hj Rt j �
p2=�
i+ � ln�2t
que presenta efecto apalancamiento si �� < 0: Por otra parte, la especi�-cación logarítmica garantiza que la varianza resultante será positiva en todoslos períodos. En la expresión anterior,
p2=� aparece por ser la esperanza
matemática del valor absoluto de la rentabilidad:p2=� = E(j Rt j):
� Inclusión de variables explicativas, como el efecto �n de semana, medi-ante una variable �cticia que tome el valor 1 los lunes, así como tras díasfestivos, anuncios macroeconómicos, reuniones de la Fed, etc. También po-dría considerarse la inclusión de un índice de volatilidad tipo VIX cuandoqueremos prever la volatilidad del subyacente de las opciones con las quese ha calculado dicho índice.
14.3.6 Estimación de correlaciones
Los modelos anteriores pueden tranformarse al cálculo de correlaciones medi-ante,
covt = �covt�1 + (1� �)ut�1vt�1en el caso del alisado exponencial, o
228

covt = ! + �covt�1 + �ut�1vt�1
en el caso del modelo GARCH(1; 1):Con un alisado exponencial de parámetro � = 0; 95; y correlación actual de
0,60, supongamos que las volatilidades diarias estimadas para dos activos son�u =1% y �v =2%. Su covarianza sería 0,000012. Si se producen variacionesdiarias en precios de 0,5% y 2,5%, respectivamente, las nuevas varianzas serían,0,981% y 2,028%. El nuevo coe�ciente de correlación sería 0,6044.
14.4 Estimación de covarianzas condicionales
La representación más sencilla de una covarianza cambiante en el tiempo sería,
�ij;t+1 =1
m
m�1Xs=0
Ri;t+1�sRj;t+1�s
con las limitaciones que ya conocemos por la presencia de la amplitud deventana m; donde estamos incorporando el supuesto de que las rentabilidadestienen media cero, lo que será muy aceptable en datos de alta frecuencia. Estetipo de modelización puede genrar excesiva variabilidad en la serie de covarian-zas.Alternativamente, podemos introducir persistencia mediante un suavizado
exponencial en covarianzas,
�ij;t+1 = (1� �)Ri;tRj;t + ��ij;t (48)
que tiene la limitación que ya vimos en el caso de estimación de la varianza,en el sentido de que no existe un nivel de referencia que puediera interpretarsecomo la covarianza a largo plazo. Por tanto, al igual que en aquél caso, estemodelo implica que no existe reversión a la media en las covarianzas. En todocaso, este es el modelo utilizado por RiskMetrics, con � = 0; 94:Ejemplo: Con un alisado exponencial de parámetro � = 0; 95; y una cor-
relación lineal en t de 0,60, supongamos que las volatilidades diarias estimadaspara dos activos son �i;t = 1% y �j;t = 2%. Por tanto, su covarianza sería0,000012. Si se observan durante ese día t variaciones diarias en sus precios de0,5% y 2,5%, respectivamente, las nuevas varianzas serían, 0,981% y 2,028%. Elnuevo coe�ciente de correlación sería 0,6044.Por el contrario, el modelo GARCH(1,1) de covarianza presenta reversión en
media,
�ij;t+1 = ! + �Ri;tRj;t + ��ij;t
según el cual la covarianza revertirá a su nivel de largo plazo,
�ij =!
1� �� �
229

Imponer los mismos parámetros de persistencia, � y � para los distintos ac-tivos garantiza una matriz de covarianzas de�nida positiva, lo que entendemoscomo matriz de covarianzas internamente consistente.23 Sin embargo, tal ho-mogeneidad puede ser una restricción poco razonable, por lo que consideramosahora modelos que no la imponen.
14.5 Modelización de correlaciones condicionales
La correlación condicional, cociente entre la covarianza condicional y la raizcuadrada del producto de varianzas condicionales, podría modelizarse utilizandoen el numerdaor y denominador del cociente que de�ne cada coe�ciente de cor-relación condicional una expresión del tipo (48) ; pero esto está sujeto a distintaslimitaciones.Es preferible seguir el siguiente razonamiento: Como:
�ij;t+1 = �i;t+1�j;t+1�ij;t+1
tenemos, en notación matricial,
�t+1 = Dt+1�t+1Dt+1
donde Dt+1 es una matriz con desviaciones típicas condicionales en la diag-onal y ceros fuera de la diagonal, y �t+1es una matriz con unos en la diagonal,y con las correlaciones condicionales fuera de dicha diagonal principal.Suponemos que las volatilidades de cada activo ya han sido estimadas pre-
viamente. Por tanto, estandarizamos las rentabilidades,
zi;t+1 =Ri;t+1�i;t+1
; 8i; t
por lo que las variables zi;t+1 tienen desviación típica condicional igual a 1.Por tanto, la covarianza condicional entre dos cualesquiera de ellas coincide consu correlación condicional.
14.5.1 Modelos de suavizado exponencial (Exponential smoother)
Suponemos que la evolución dinámica de la correlación está guiada por las vari-ables auxiliares qij;t+1; que juegan el papel de covarianzas condicionales, y quese actualizan a partir de valores iniciales mediante el esquema,
qij;t+1 = (1� �) zi;tzj;t + �qij;t8i; jobteniéndose la correlación condicional entre dos rentabilidades mediante el
esquema:
�ij;t+1 =qij;t+1p
qii;t+1pqjj;t+1
23Hay consistencia interna cuando !0�t+1! � 0 para toda cartera de�nida por le vectorde ponderaciones !:
230

lo que asegura que dicha correlación estará siempre en el intervalo (�1; 1).El algoritmo recursivo anterior puede inicializarse tomando como valor inicial
qij;1 el promedio de los productos zi;tzj;t a lo largo de toda la muestra. Estoes útil en el caso en que queremos estimar a posterior cómo ha variado dichacorrelación condicional. En alguna otra situación podemos no querer imponercomo condición inicial la media de toda la muestra, y preferimos utilizar elpromedio de un número inicial de observaciones, 50 por ejemplo, y actualizarqij;t a partir de la observación siguiente, desechando los primeros 50 datos. Lacondición inicial para las varianzas condicionales qii;1debe ser 1 en el caso deque queramos utilizar toda la información muestral aunque, alternativamente,también podemos utilizar una submuestra inicial, del modo que acabamos dedescribir.En notación matricial,
Qt+1 = (1� �) ztz0t + �Qt
14.5.2 Correlaciones dinámicas GARCH (DCC GARCH )
Para permitir reversión a la media en las correlaciones condicionales, podemosutilizar,
qij;t+1 = �ij + ��zi;tzj;t � �ij
�+ �
�qij;t � �ij
�y nuevamente utilizamos la expresión,
�ij;t+1 =qij;t+1p
qii;t+1pqjj;t+1
para calcular los coe�cientes de correlación condicional. Las condicionesiniciales para las variables qij;t+1 pueden escogerse como en el modelo anterior.En este modelo estamos restringiendo a que los parámetros de persisten-
cia de las correlaciones, � y � sean los mismos para cualquier par de activos.La persistencia en los coe�cientes de correlación condicional será por tanto lamisma para cada par de activos, aunqnue no seran iguales los niveles de dichoscoe�cientes de correlación. Tampoco será igual la persistencia en correlación ala persistencia en volatilidad, que puede ser distinta para distintos activos.Aunque el parámetro �ij ; que es especí�co a cada par de activos, puede
tratarse como un parámetro más a estimar, junto con � y �; puede tener sen-tido imponer en el modelo reversion a un nivel de correlación de largo plazo,E(zi;tzj;t); que podemos denotar por ��ij ; teniendo entonces el modelo:
qij;t+1 = ��ij + ��zi;tzj;t � ��ij
�+ �
�qij;t � ��ij
�En notación matricial, este modelo es:
Qt+1 = E(ztz0t)(1� �� �) + � (ztz0t) + �Qt
que para dos activos resulta,
231

�q11;t+1 q12;t+1q12;t+1 q22;t+1
�=
�1 �12�12 1
�(1����)+�
�z21;t z1;tz2;t
z1;tz2;t z22;t
�+�
�q11;t q12;tq12;t q22;t
�En ambos casos, la matriz Qt+1 es de�nida positiva por construcción, por
lo que también lo serán las matrices de covarianzas �t+1 y de correlaciones�t+1:
24 Una ventaja de este modelo es que sus parámetros pueden estimarse envarias etapas: Primero estimamos los parámetros de los modelos de volatilidadcondicional univariantes por los procedimientos vistos en secciones previas. Acontinuación, estandarizamos las rentabilidades y estimamos la matriz de cor-relaciones incondicionales que, en este caso sencillo consta de un sólo parámetro��ij =
1T
Pz1;tz2;t. Finalmente, estimamos los parámetros � y �; que determi-
nan la persistencia en los coe�cientes de correlación.
14.5.3 Estimación por cuasi-máxima verosimilitud
Apelando al procedimeinto de Cuasi-máxima verosimilitud, tiene sentido traba-jar bajo el supuesto de Normalidad. El logaritmo de la función de verosimilitudes entonces,
lnL = �12
TXt=1
"ln(1� �212;t) +
z21;t + z22;t � 2�12;tz1;tz2;t1� �212;t
#en la que la correlación condicional �12;t se obtiene a partir del modelo
particular de correlación que se utilice y la regla de normalización escogida, queserán distintos en el modelo de alisado exponencial y en el modelo DCC. Comoya dijimos antes, el algoritmo numérico puede inicializarse con q11;0 = q22;0 =
1; q12;0 = T�1PTt=1 z1;tz2;t: Nótese que estamos utilizando en todo momento
las rentabilidades estandarizadas, para lo que utilizamos modelos de volatilidadunivariante que hayamos estimado previamente. Se trata, por tanto, de unaestimación secuencial, que resulta bastante sencilla, aunque a riesgo de perdere�ciencia estadística. Pero la estimación simultánea se puede hacer facilmenteimposible.En el caso de un vector de n activos, la función a maximizar sería,
lnL = �12
Xt
�ln j �t j +z0t��1t zt
�15 Valor en Riesgo
El Valor en Riesgo responde a la pregunta: ¿cuál es la revalorización por encimade la cual va a estar nuestra cartera con una probabilidad de 1 � p% , o unporcentaje 1 � p% de días? Dicha rentabilidad será, generalmente negativa,
24Nótese que: E��
z21;t z1;tz2;tz1;tz2;t z22;t
��=
�1 �12�12 1
�
232

por lo que la pregunta puede formularse: ¿cuál es el nivel de pérdida que serásobrepasado sólo con una probabilidad del p%;o un porcentaje p% de los días?Para posiciones largas, tal pérdida se producirá ante una caída del precio dela cartera de magnitud poco habitual, mientras que en una posición corta, lapérdida se producirá ante una elevación del precio en cuantía poco habitual. ElVaR puede calcularse para períodos de inversión de un día o también superiores,como una semana o un mes.Sea �V (l) la variación en el valor de los activos de una posición �nanciera
entre t y t+ l; medida en unidades monetarias. En t; esta cantidad es aleatoria,y denotamos por Fl(x) la función de distribución de �V (l). De�nimos el VaRnominal de una posición larga en el horizonte de l días, con probabilidad p;como la cantidad V aR que satisface las dos igualdades equivalentes:
p = P [�V (l) � V aR] = Fl(V aR) (49)
Para valores reducidos de la probabilidad p; el V aR será habitualmentenegativo, representando una pérdida. Por supuesto, la interpretación dual esque con probabilidad 1� p; el propietario de dicha posición experimentará bienuna pérdida igual o inferior a V aR; o un bene�cio.Para una posición corta, tendríamos:
p = P [�V (l) � V aR] = 1� P [�V (l) � V aR] = 1� Fl(V aR)
y para una p pequeña, tal cantidad será positiva. Por tanto, la cola izquierda dela distribución de Fl(x) es la relevante para posiciones largas, mientras que lacola derecha es la relevante para las posiciones cortas. Asimismo, la de�nición(49) es válida para posiciones cortas si utilizamos la distribución de ��V (l):Por tanto, es su�ciente analizar los métodos de cálculo del V aR para posicioneslargas. Nótese que esta a�rmación no tiene nada que ver con la posible simetríadel a distribución de �V (l); que no es preciso que se produzca.Para una distribución univariante, Fl(x) y una probabilidad p; 0 < p < 1; la
cantidad:
xp = inf fx j Fl(x) � pg
es el cuantil p-ésimo de Fl(x); donde inf denota la menor de las cantidadesque satisface la desigualdad indicada. Si se conociese la distribución Fl(x);entonces el V aR sería simplemente el cuantil p-ésimo de Fl(x): Sin embargo,esta distribución se desconoce en la práctica, y el cálculo del V aR requiereestimar Fl(x) o su cuantil p-ésimo.También cabe enfocar el cálculo del VaR en términos de rentabilidades: ¿cuál
es el nivel de rentabilidad por encima del cual va a estar nuestra cartera conuna probabilidad de 1� p% , o un porcentaje 1� p% de días? Por lo tanto, elVaR es el valor numérico que resuelve la ecuación,
P (R < �V aR) = p
233

Si podemos suponer que la rentabilidad mañana sigue una distribución Nor-mal con media cero y varianza �2c , entonces, tendríamos,
P
�R
�c< �V aR
�c
�= p) �
��V aR
�c
�= p) V aR = ��c��1(p)
Si la predicción de la varianza de la rentabilidad es 9% y p = 99%;tendríamos:V aR = �(:03)(2:33) = �:07 ó 7%:Como se ve, para el cálculo del Valor enRiesgo, todo lo que necesitamos es una predicción de la volatilidad de la rentabil-idad del activo al horizonte para el cual se quiere calcular el VaR. El cálculo delVaR es, precisamente, una de las razones por las que conviene disponer de unbuen modelo de predicción de volatilidad.La cuantía en unidades monetarias del V aR es igual al V aR de la distribución
de rentabilidades, multiplicado por el valor de la posición. En ocasiones se utilizala aproximación:
V aR = (V alor cartera) : [V aR (rentabilidades log ar�{tmicas)] �=�= (V alor cartera) : (exp [V aR (rentabilidades log ar�{tmicas)]� 1)
Es importante observar que, como tantos otros conceptos �nancieros, el V aRse re�ere a la distribución prevista para las rentabilidades de la cartera, en elhorizonte �jado. Por tanto, se trata de prever la posible evolución de la dis-tribución de probabilidad de la rentabilidad del activo o cartera en el horizonteen que se quiere calcular el VaR.Limitaciones del VaR:
� No entra en consideraciones sobre cuál pueda ser la pérdida esperada encaso de que el activo o la cartera caigan por encima del nivel indicadopor el VaR. Esto se conoce como Expected Shortfall, y será analizado másadelante.
� Cuando se calcula a un horizonte determinado, por ejemplo, en un mes, espreciso suponer que la composición de la cartera va a quedar inalterada,lo cual no es muy razonable.
� Asimismo, se supone que la estructura de la matriz de covarianzas es in-variante a lo largo del horizonte temporal de cálculo del VaR. Cuando noes asi, es preciso reconstruir históricamente el precio de la cartera cadavez que se cambia su composición, para modelizar su varianza. Alternati-vamente, hemos de modelizar la volatilidad de los activos individuales quepueden entrar a formar parte de nuestra cartera.
� Tampoco es muy evidente como seleccionar el horizonte de cálculo o elumbral de probabilidad.
234

Existen distintos enfoques para el cálculo del VaR: i) el modelo lineal, ii)el VaR histórico, y iii) el método de simulación de Monte Carlo, y sólo parael primero de ellos es necesario el supuesto de Normalidad, lo cual es bastanteconveniente.
15.1 RiskMetrics
Para el cálculo del V aR; RiskMetrics supone que la rentabilidad diaria continuade la cartera sigue una distribución Normal: rt j Ft�1 � N(�t; �
2t ); con:
�t = 0;
�2t = ��2t�1 + (1� �)r2t�1; 0 < � < 1
Equivalentemente, el logaritmo del precio: pt = ln(Pt); obedece un procesoIGARCH(1,1) sin constante: pt � pt�1 = at; con at = �t"t; y "t � N(0; 1): Elvalor de � suele tomarse en el intervalo (0; 9; 1) ; siendo 0,94 un valor bastantehabitual.Una propiedad interesante de esta distribución es su facilidad para el calculo
de la distribución sobre horizontes temporales:
15.2 Varianza de una cartera a partir de activos individ-uales
Si tenemos una cartera de n activos de�nida mediante pesos !i;con rentabilidad
Rc;t+1 =
nXi=1
Ri;t+1
la varianza de la rentabilidad de la cartera puede escribirse en notaciónmatricial (con n = 2),
�2c;t+1 = !��t+1! = (!1; !2)
��21;t+1 �212;t+1�212;t+1 �22;t+1
��!1!2
�siendo � la matriz de covarianzas de las rentabilidades de los activos indi-
viduales.Si suponemos Normalidad, tendríamos,
V aRct+1 = ��c;t+1��1(p)El cálculo del VaR de una cartera requiere, por tanto, disponer de estima-
ciones de las covarianzas o de las correlaciones entre las rentabilidades de losactivos que la integran, lo que ha suscitado la necesidad de generar métodos quesimpli�quen la alta dimensionalidad de este problema.Una estrategia consiste en establecer un número reducido de factores que
explique todas las correlaciones. Este punto será comentado en detalle más
235

adelante. Baste ahora decir que, en un caso extremo, si se cuenta con una carterade activos de renta variable bien diversi�cada dentro de un mismo mercado,podemos utilizar la varianza del índice de mercado como factor,
�2c;t+1 = �2c�2M;t+1
donde �2M;t+1denota la predicción de la varianza de la rentabilidad del índicede mercado, y �c es la beta de la cartera.En general, si contamos con una lista de r factores y !F denota la exposición
a cada factor de riesgo, y �Ft+1su matriz de covarianzas condicional, tendríamos,
�2c;t+1 = !F��Ft+1!F
La exposición o sensibilidad al riesgo debería estimarse mediante una proyec-ción de la rentabilidad de la cartera sobre los factores de riesgo seleccionados.
15.2.1 Uso de información intradía
15.3 Incertidumbre paramétrica en el cálculo del VaR
Once we start thinking about the moments of the distribution of returns asevolving over time, then a speci�c model to describe their time evolution isneeded. Historical time series data will be used to estimate the parameters insuch a model. Unfortunately, we often tend to act as if estimated parametervalues were the true values, thereby ignoring parameter uncertainty. This notedeals with the implications for risk management of parameter uncertainty and itsuggests a speci�c way of dealing with it. For that description, we will considerthe case of a portfolio manager that constructs a portfolio with two assets.In our �rst example, the fund manager can either invest in the US or the
Canadian stock markets, represented here by the S&P500 and Toronto StockExchange (TSE) indexes. We are at December 31, 2001, and we have a dailysample available of closing quotes, starting at January 3, 1997. Under thestatistically acceptable assumption that there is no serial correlation in dailyreturns, we start by �tting a GARCH(1,1) model for each index,
�21t = 1:09E � 05 + 0:100"21;t�1 + 0:834�21;t�1 for S&P500�22t = 0:62E � 05 + 0:078"22;t�1 + 0:889�22;t�1 for TSE
and use them to standardize daily returns, [FIGURE 1]
236
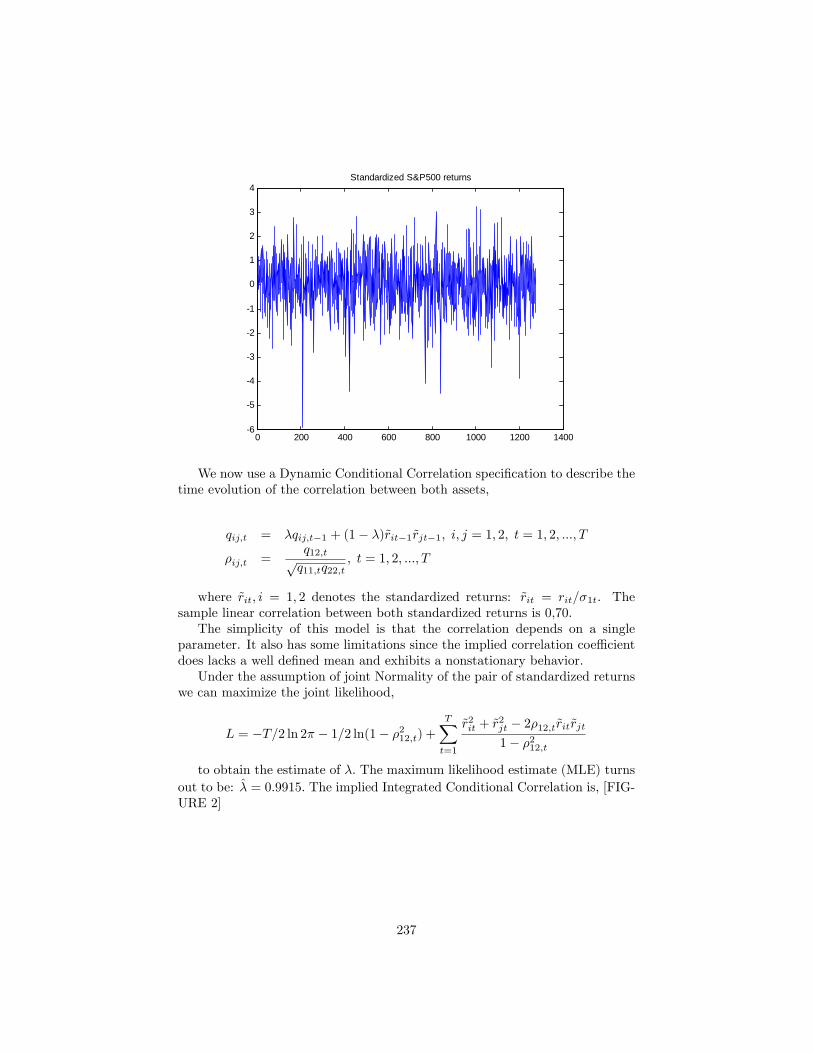
0 200 400 600 800 1000 1200 14006
5
4
3
2
1
0
1
2
3
4 Standardized S&P500 returns
We now use a Dynamic Conditional Correlation speci�cation to describe thetime evolution of the correlation between both assets,
qij;t = �qij;t�1 + (1� �)~rit�1~rjt�1; i; j = 1; 2; t = 1; 2; :::; T
�ij;t =q12;tpq11;tq22;t
; t = 1; 2; :::; T
where ~rit; i = 1; 2 denotes the standardized returns: ~rit = rit=�1t. Thesample linear correlation between both standardized returns is 0,70.The simplicity of this model is that the correlation depends on a single
parameter. It also has some limitations since the implied correlation coe¢ cientdoes lacks a well de�ned mean and exhibits a nonstationary behavior.Under the assumption of joint Normality of the pair of standardized returns
we can maximize the joint likelihood,
L = �T=2 ln 2� � 1=2 ln(1� �212;t) +TXt=1
~r2it + ~r2jt � 2�12;t~rit~rjt1� �212;t
to obtain the estimate of �: The maximum likelihood estimate (MLE) turnsout to be: � = 0:9915: The implied Integrated Conditional Correlation is, [FIG-URE 2]
237
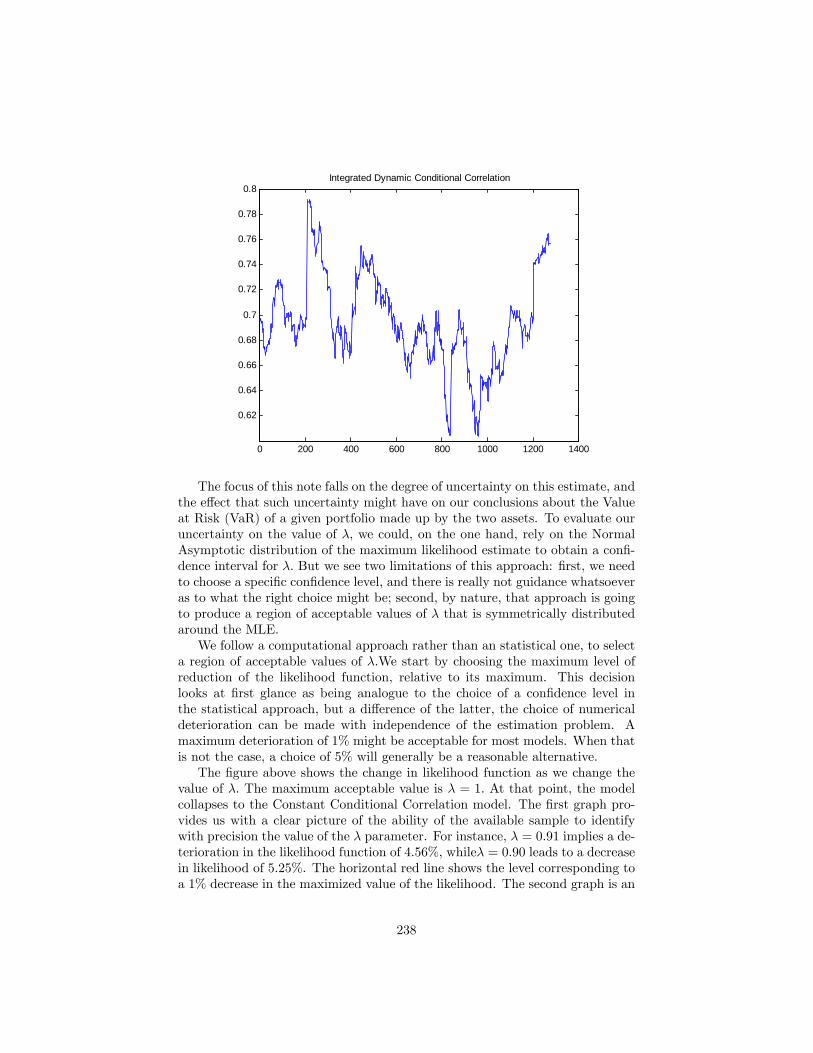
0 200 400 600 800 1000 1200 1400
0.62
0.64
0.66
0.68
0.7
0.72
0.74
0.76
0.78
0.8 Integrated Dynamic Conditional Correlation
The focus of this note falls on the degree of uncertainty on this estimate, andthe e¤ect that such uncertainty might have on our conclusions about the Valueat Risk (VaR) of a given portfolio made up by the two assets. To evaluate ouruncertainty on the value of �; we could, on the one hand, rely on the NormalAsymptotic distribution of the maximum likelihood estimate to obtain a con�-dence interval for �: But we see two limitations of this approach: �rst, we needto choose a speci�c con�dence level, and there is really not guidance whatsoeveras to what the right choice might be; second, by nature, that approach is goingto produce a region of acceptable values of � that is symmetrically distributedaround the MLE.We follow a computational approach rather than an statistical one, to select
a region of acceptable values of �:We start by choosing the maximum level ofreduction of the likelihood function, relative to its maximum. This decisionlooks at �rst glance as being analogue to the choice of a con�dence level inthe statistical approach, but a di¤erence of the latter, the choice of numericaldeterioration can be made with independence of the estimation problem. Amaximum deterioration of 1% might be acceptable for most models. When thatis not the case, a choice of 5% will generally be a reasonable alternative.The �gure above shows the change in likelihood function as we change the
value of �: The maximum acceptable value is � = 1: At that point, the modelcollapses to the Constant Conditional Correlation model. The �rst graph pro-vides us with a clear picture of the ability of the available sample to identifywith precision the value of the � parameter. For instance, � = 0:91 implies a de-terioration in the likelihood function of 4.56%, while� = 0:90 leads to a decreasein likelihood of 5.25%. The horizontal red line shows the level corresponding toa 1% decrease in the maximized value of the likelihood. The second graph is an
238
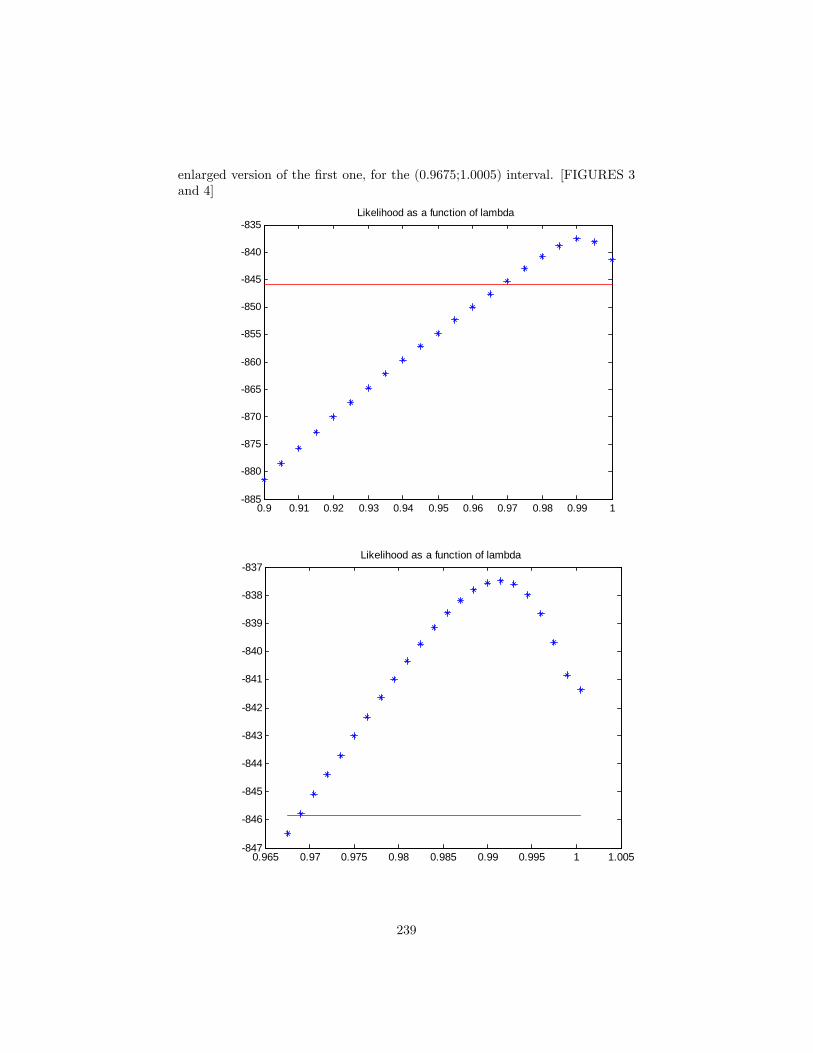
enlarged version of the �rst one, for the (0.9675;1.0005) interval. [FIGURES 3and 4]
0.9 0.91 0.92 0.93 0.94 0.95 0.96 0.97 0.98 0.99 1885
880
875
870
865
860
855
850
845
840
835Likelihood as a function of lambda
0.965 0.97 0.975 0.98 0.985 0.99 0.995 1 1.005847
846
845
844
843
842
841
840
839
838
837Likelihood as a function of lambda
239
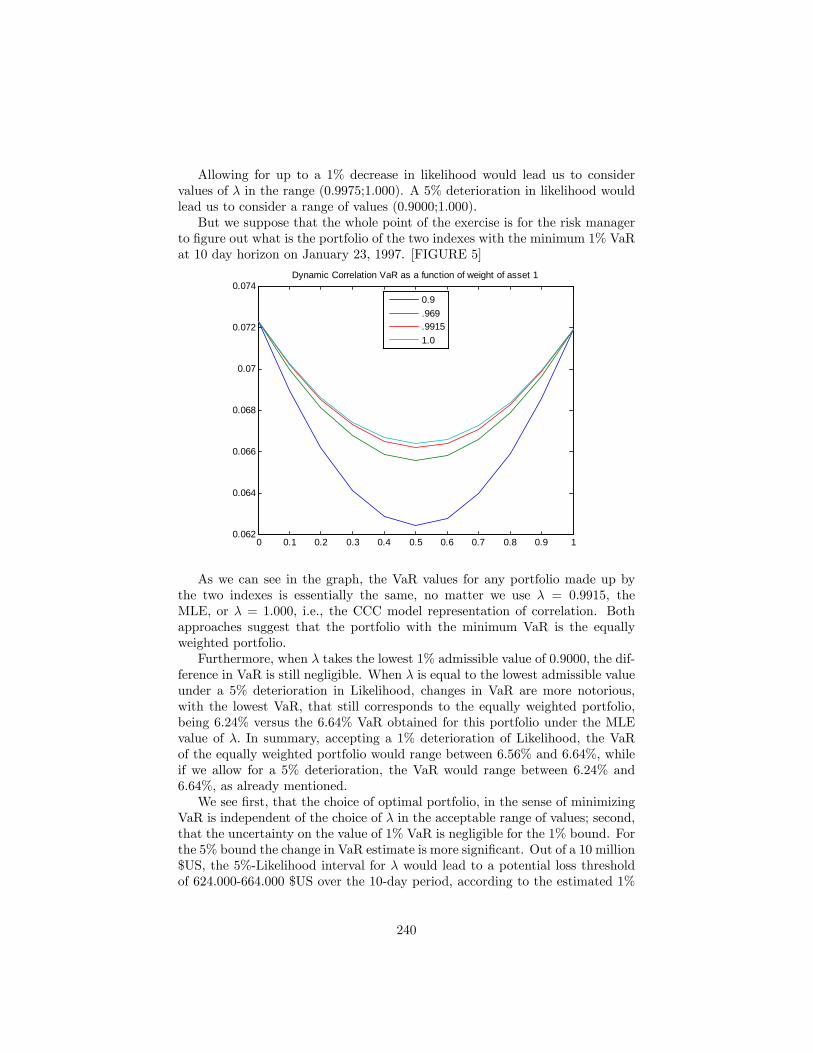
Allowing for up to a 1% decrease in likelihood would lead us to considervalues of � in the range (0.9975;1.000). A 5% deterioration in likelihood wouldlead us to consider a range of values (0.9000;1.000).But we suppose that the whole point of the exercise is for the risk manager
to �gure out what is the portfolio of the two indexes with the minimum 1% VaRat 10 day horizon on January 23, 1997. [FIGURE 5]
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10.062
0.064
0.066
0.068
0.07
0.072
0.074Dynamic Correlation VaR as a function of weight of asset 1
0.9.969.99151.0
As we can see in the graph, the VaR values for any portfolio made up bythe two indexes is essentially the same, no matter we use � = 0:9915, theMLE, or � = 1:000; i.e., the CCC model representation of correlation. Bothapproaches suggest that the portfolio with the minimum VaR is the equallyweighted portfolio.Furthermore, when � takes the lowest 1% admissible value of 0:9000; the dif-
ference in VaR is still negligible. When � is equal to the lowest admissible valueunder a 5% deterioration in Likelihood, changes in VaR are more notorious,with the lowest VaR, that still corresponds to the equally weighted portfolio,being 6.24% versus the 6.64% VaR obtained for this portfolio under the MLEvalue of �: In summary, accepting a 1% deterioration of Likelihood, the VaRof the equally weighted portfolio would range between 6.56% and 6.64%, whileif we allow for a 5% deterioration, the VaR would range between 6.24% and6.64%, as already mentioned.We see �rst, that the choice of optimal portfolio, in the sense of minimizing
VaR is independent of the choice of � in the acceptable range of values; second,that the uncertainty on the value of 1% VaR is negligible for the 1% bound. Forthe 5% bound the change in VaR estimate is more signi�cant. Out of a 10 million$US, the 5%-Likelihood interval for � would lead to a potential loss thresholdof 624.000-664.000 $US over the 10-day period, according to the estimated 1%
240
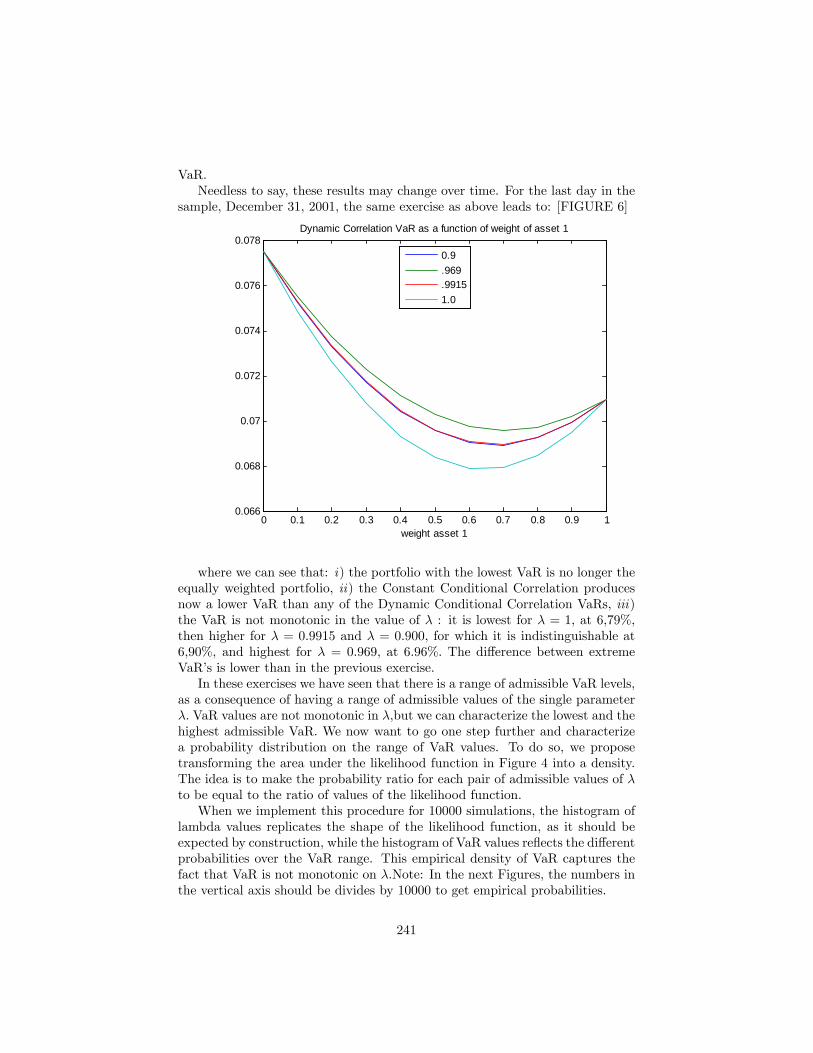
VaR.Needless to say, these results may change over time. For the last day in the
sample, December 31, 2001, the same exercise as above leads to: [FIGURE 6]
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10.066
0.068
0.07
0.072
0.074
0.076
0.078Dynamic Correlation VaR as a function of weight of asset 1
weight asset 1
0.9.969.99151.0
where we can see that: i) the portfolio with the lowest VaR is no longer theequally weighted portfolio, ii) the Constant Conditional Correlation producesnow a lower VaR than any of the Dynamic Conditional Correlation VaRs, iii)the VaR is not monotonic in the value of � : it is lowest for � = 1; at 6,79%;then higher for � = 0:9915 and � = 0:900; for which it is indistinguishable at6,90%, and highest for � = 0:969; at 6.96%: The di¤erence between extremeVaR�s is lower than in the previous exercise.In these exercises we have seen that there is a range of admissible VaR levels,
as a consequence of having a range of admissible values of the single parameter�: VaR values are not monotonic in �;but we can characterize the lowest and thehighest admissible VaR. We now want to go one step further and characterizea probability distribution on the range of VaR values. To do so, we proposetransforming the area under the likelihood function in Figure 4 into a density.The idea is to make the probability ratio for each pair of admissible values of �to be equal to the ratio of values of the likelihood function.When we implement this procedure for 10000 simulations, the histogram of
lambda values replicates the shape of the likelihood function, as it should beexpected by construction, while the histogram of VaR values re�ects the di¤erentprobabilities over the VaR range. This empirical density of VaR captures thefact that VaR is not monotonic on �:Note: In the next Figures, the numbers inthe vertical axis should be divides by 10000 to get empirical probabilities.
241
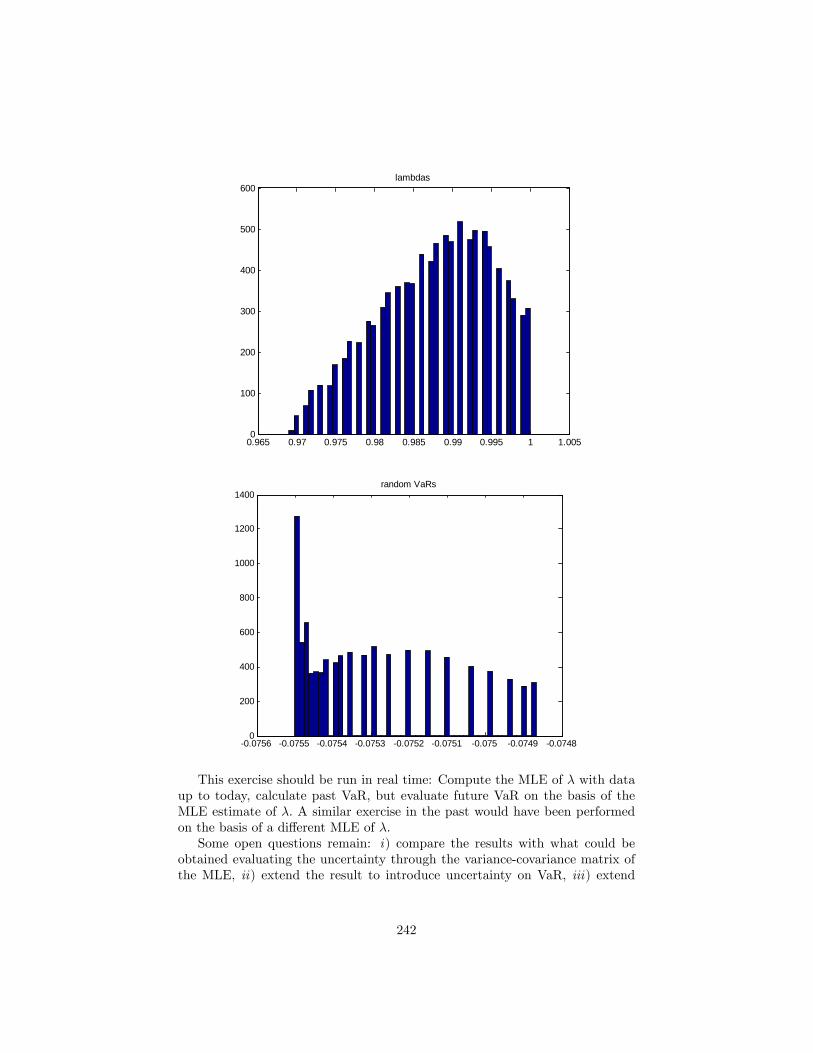
0.965 0.97 0.975 0.98 0.985 0.99 0.995 1 1.0050
100
200
300
400
500
600lambdas
0.0756 0.0755 0.0754 0.0753 0.0752 0.0751 0.075 0.0749 0.07480
200
400
600
800
1000
1200
1400random VaRs
This exercise should be run in real time: Compute the MLE of � with dataup to today, calculate past VaR, but evaluate future VaR on the basis of theMLE estimate of �: A similar exercise in the past would have been performedon the basis of a di¤erent MLE of �:Some open questions remain: i) compare the results with what could be
obtained evaluating the uncertainty through the variance-covariance matrix ofthe MLE, ii) extend the result to introduce uncertainty on VaR, iii) extend
242

the methodology to the case of more than one parameter (think about how tosimulate from a multivariate density).
16 Desviaciones de Normalidad
16.1 Contrastes de Normalidad: Jarque-Bera, Kolmogorov,QQ-plots
Junto a los contrastes de Normalidad habituales, del tipo Jarque-Bera, o con-trastes no-paramétricos, del tipo Kolmogorov-Smirnov o de Fisher, existen losgra�cos QQ (quantile-quantile), en el que se representa los cuantiles de la mues-tra de una variable, contra los cuantiles que se obtendrían de una distribuciónNormal. Se utilizan habitualmente las rentabilidades estandarizadas medianteun modelo de volatilidad previamente estimado, que se comparan con una Nor-mal(0,1). Esto se hace porque siendo la heterocedasticidad tan habitual enseries temporales �nancieras, especialmente en rentabilidades, se supone inicial-mente su existencia, estimando un modelo para la misma y corrigendo de dichoefecto, pues el QQ-plot contrasta el ajuste con una distribución normal de var-ianza constante (de hecho, de varianza unitaria). Para ello, se ordena en ordencreciente la muestra y se establece la red de valores i , 0 < i � T . A contin-uación, el grá�co QQ se obtiene representando el cuantil i�:5T de la distribuciónde rentabilidades25 , en ordenadas, contra ��1( i�:5T ); en abscisas.
16.2 La distribución t de Student estandarizada
Un candidato habitual para modelizar desviaciones de la Normal, es utilizarla distribución t de Student, t(d). Esta distribución admite algunas variantes.Recordemos que la función de densidad t de Student es:
ft(d)(x; d) =��d+12
���d2
�p�d�2
1 +
1
d
(x� �)2
�2
!� 1+d2
; d > 2;
con esperanza igual a �; varianza igual a �2 = dd�2 ; asimetría igual a cero y
exceso de curtosis igual a 6d�4 :
La densidad t de Student habitual está centrada en el origen, con función dedensidad:
ft(d)(x; d) =��d+12
���d2
�p�d�2
�1 +
1
d
x2
�2
�� 1+d2
; d > 2;
con los mismos momentos que la anterior, excepto la esperanza matemática,que es cero.
25El cuantil �% de una distribución de probabilidad es el valor numérico del soporte de dichadistribución que deja a su izquierda una probabilidad menor o igual a �%: En distribucionescon componentes discretos, tal de�nición puede estar sujerta a ambiguedades.
243

Si estandarizamos la variable aleatoria x;suponiendo que sigua la distribución
t de Student anterior con : z = x�E(x)DT (x)
qd�2d ; esta nueva variable sigue una
densidad del mismo per�l que la t de Student, pero con varianza unitaria. Seconoce como distribución t de Student estandarizada, que denotamos ~t(d); cuyadensidad depende únicamente del parámetro d; que denominamos grados delibertad de la distribución:26
f~t(d)(z; d) =��d+12
���d2
�p�(d� 2)
�1 +
z2
d� 2
�� 1+d2
; d > 2
que tiene colas más gruesas que una Normal. Esta distribución es simétricaalrededor del origen, con esperanza igual a cero, varianza igual a 1, coe�cientede asimetría nulo y un exceso de curtosis igual a 6
d�4 : Al igual que sucede con ladistribución t de Student habitual, al aumentar el número de grados de libertad,d , la distribución converge a una Normal(0,1).Por tener esta última distribución una varianza igual a 1, debe utilizarse para
rentabilidades que han sido estandarizadas mediante una varianza condicionalpreviamente estimada.En ocasiones, la densidad t de Student se representa en función de tres
parámetros,
ft(�)(x; �; �; �) =���+12
����2
� r �
��
1 +
� (x� �)2
�
!� 1+�2
siendo � un parámetro que caracteriza el per�l de la función de densidad,� indica su localización, y � su dispersión, con E(x) = �; V ar(x) = 1
����2 : El
parámetro � juega el papel de d en la expresión anterior, mientras que � es elinverso de �2: Centrada en el origen, la densidad es:
ft(�)(x; �; �) =���+12
����2
� r �
��
�1 +
�x2
�
�En tal caso, la distribución t de Student estandarizada es:
f~t(�)(x; �) =���+12
����2
� 1p�(� � 2)
�1 +
z2
� � 2
�� 1+�2
16.2.1 Estimación de la densidad t de Student
Si modelizamos las rentabilidades como,
26Esta distribución se obtiene a partir de la distribución z de Student:
fn(w) =�(n2 )
��n�12
�p�
�1 + w2
��n2 ;
haciendo primero el cambio de variable: t = wpn� 1 y posteriormente el cambio: t = x��
�;
y denotando d = n� 1:
244

Rt = �tzt
con zt � ~t(d); e ignoramos el hecho de que la serie temporal de varian-zas es una estimación sujeta a error estadístico, podemos tratar el rendimientoestandarizado como una única variable aleatoria. Al tener zt una varianza uni-taria, podemos utilizar la distribución t de Student estandarizada, y tenemos laverosimilitud,
lnL1 =TXt=1
ln�f~t(d)(z; d)
�= T
�ln �
�d+ 1
2
�� ln �
�d
2
�� ln�
2� ln d� 2
2
��
�12
TXt=1
(1 + d) ln
1 +
(Rt=�t)2
d� 2
!
Este sería un procedimiento de Quasi-máxima Verosimilitud, al estimarpor separado los parámetros del modelo de varianza, que se utilizan para es-tandarizar las rentabilidades, y luego el parámetro de grados de libertad de lafunción de densidad utilizando la verosimilitud anterior.Si, por el contrario, queremos estimar el parámetro d simultáneamente con
los parámetros de los modelos de varianza, debemos ajustar la distribución paratener en cuenta la varianza. Para ello, suponiendo que las rentabilidades tienenesperanza nula, utilizariamos la distribución t de Student estándar, ya que lavarianza no es unitaria, teniendo, para un valor d > 2:
ft(d)(Rt; d) =��d+12
���d2
�p�(d� 2)�2t
�1 +
1
d� 2Rt
2
�2t
�� 1+d2
=��d+12
���d2
�p�(d� 2)�2t
�1 +
z2td� 2
�� 1+d2
; d > 2;
y, por tanto, la función de verosimilitud,
lnL2 =TXt=1
ln�f~t(d)(zt; d)
�= lnL1 �
TXt=1
ln�2t2
Por ejemplo, supongamos que tratamos con un único activo (quizá unacartera de activos, cuyas ponderaciones se han mantenido constantes durante elperíodo muestral), cuya rentabilidad sigue un proceso GARCH(1,1) con lever-age, del tipo:
�2t+1 = ! + �(Rt � ��t)2 + ��2t = ! + ��2t (zt � �)2 + ��2tEl logaritmo de la función de verosimilitud, que se trataría de maximizar,
sería entonces:
245

lnL1 =TXt=2
ln�f~t(d)(z; d)
�= T
�ln �
�d+ 1
2
�� ln �
�d
2
�� ln�
2� ln d� 2
2
��
�:5TXt=2
ln�! + ��2t�1(zt�1 � �)2 + ��2t�1
�� :5(1 + d):
:TXt=2
ln
�1 +
1
d� 2R2t
! + ��2t�1(zt�1 � �)2 + ��2t�1
�ignorando, en todo caso, la primera observación. El algoritmo numérico de
cálculo de la función de verosimilitud debe inicializarse con una elección para�1; para lo que puede utilizarse la varianza incondicional a lo largo del períodomuestral, aunque esta puede ser una opción discutible en algunos casos.
16.2.2 Estimación del número de grados de libertad por el Métodode Momentos
Teniendo en cuenta la expresión de la curtosis que antes vimos para la dis-tribución t de Student de una serie de rentabilidades estandarizadas, podemosutilizar la lógica del método de momentos para estimar el número de grados delibertad de dicha distribución mediante,
d =6
EC+ 4
siendo EC el exceso de curtosis muestral.Si trabajamos con rentabilidades sin estandarizar, podemos utilizar la ex-
presión anterior del exceso de curtosis, pero también la expresión de la varianza,que conduce a:
d =2�2
�2 � 1y podría plantearse un problema de optimización para minimizar luna forma
cuadrática con las holguras de ambas ecuaciones.
16.2.3 QQ plots para distribuciones t de Student
Hemos visto que la distribución ~t(d) estandarizada puede obtenerse a partir dela distribución t(d) ordinaria mediante el cambio de variable:
z =x� ��
rd� 2d
;
246

donde x sigue una distribución t(d) ordinaria; y z sigue una distribución ~t(d)
estandarizada,27 con f~t(d)(z; d) = ft(d)(z(x); d)�q
dd�2 :
Pero la relación entre sus cuantiles es más sencilla. El p-cuantil de la dis-tribución t de Student estandarizada es el valor numérico y de�nido mediante:
p = P�f~t(d)(z; d) < ~y
�o, lo que es lo mismo, ~y = ~t�1p (d):
Por simplicidad, en lo sucesivo, denotamos ~t�1p (d) = f�1~t(d);p(z; d); t�1p (d) =
f�1t(d);p(z(x); d)
Suponiendo que trabajamos con rentabilidades estandarizadas (por tanto,convarianza unitaria), tenemos:
P�~t�1p (d) < ~y
�= P
t�1p (d)
rd� 2d
< ~y
!= P
t�1p (d) < ~y
rd
d� 2
!= P
�t�1p (d) < y
�;
donde hemos de�nido: y = ~yq
dd�2 ; de modo que:
y = t�1p (d) = ~y
rd
d� 2 =~t�1p (d)
rd
d� 2Por tanto, los cuantiles de la distribución estandarizada ~t(d) pueden calcu-
larse, en función de los cuantiles análogos de las distribución no estandarizada,
utilizando la relación: ~t�1p (d) =q
d�2d t�1p (d), y el QQ-plot para juzgar la
adecuación del ajuste proporcionado por una densidad ~t(d) puede construirse
tomando en abscisas los valores numéricosq
d�2d t�1i�:5
T
(d) y en ordenadas, las
rentabilidades estandarizadas, zi:
16.2.4 Cálculo del valor en riesgo (VaR) bajo una distribución ~t(d)
Una vez que tenemos estimado el modelo
Rt+1 = �t+1zt+1; con zt+1 � ~t(d)
el VaR se calcula utilizando su de�nición:
V aRpt+1 = ��t+1~t�1p (d) = ��t+1rd� 2d
t�1p (d)
27Recordemos que si y = h(x); la densidad g(y) se obtiene a partir de la densidad f(x)mediante: g(y) = f(h�1(y)) dx
dy:
247

16.3 La aproximación Cornish-Fisher
Una limitación importante de la distribución t-Student en la modelización delas rentabilidades condicionales está originada por su dependencia de un sóloparámetro, el número de grados de libertad, d: Ello no permite reproducir niel tipo de asimetría ni el elevado grado de curtosis que sería deseable explicaren las rentabilidades estandarizadas empíricas. Una alternativa consiste en uti-lizar la aproximación de Cornish-Fisher, que permite mayor �exibilidad en losvalores numéricos de los momentos de la distribución de rentabilidades, y quepuede aproximar el comportamiento de muchas densidades distintas de la Nor-mal. La expresión de Cornish-Fisher proporciona aproximaciones a los cuantilesde una distribución de rentabilidades estandarizadas, a partir de estimacionesnuméricas de su asimetría y curtosis. Incorpora posibles asimetrías mediantela consideración de un coe�ciente de asimetría no nulo. Una limitación de esteenfoque es que puede verse in�uido por rentabilidades estandarizadas próximasa cero, lo cual puede resolverse mediante la Teoría de Valores Extremos, queexaminamos más adelante.La aproximación Cornish-Fisher a la inversa de la función de distribución de
una variable N(0; 1) es,
CF�1p = ��1p +�16
h���1p
�2 � 1i+ �224
h���1p
�3 � 3��1p i+ �2136 h2 ���1p �3 � 5��1p isiendo �1 el coe�ciente de asimetría y �2 el exceso de curtosis de las rentabili-
dades estandarizadas, y � la función de distribución N(0; 1). Esta expresión nosproporciona el cuantil de Cornish-Fisher mediante un desarrollo en serie de Tay-lor alrededor de la distribución Normal. Cuando ambos coe�cientes (asimetríay curtosis) son cero, tenemos el cuantil N(0; 1):Consideremos, por ejemplo, el VaR 1%. Bajo Normalidad, tenemos: ��1:01 =
�2:33: Alternativamente, la aproximación de Cornish-Fisher del cuantil 1% es:
CF�1p = �2; 33 + 0; 74�1 � 0; 24�2 � 0; 38�21Supongamos que la asimetría es: �1 = �1 y el exceso de curtosis: �2 = 4:
Tendríamos entonces,
CF�1p = �2; 33� 0; 74� 4(0; 24)� 0; 38 = �4; 41
Una vez obtenida la aproximación Cornish-Fisher, el VaR puede calcularse,
V aRpt+1 = ��t+1CF�1py en el ejemplo anterior:
V aRpt+1 = �4; 41�t+1casi el doble de lo que habríamos obtenido suponiendo la Normalidad de los
rendimientos estandarizados.
248

17 Teoría de valores extremos (EVT)
La aproximación de Cornish-Fisher proporciona estimaciones de los cuantiles dela distribución de rendimientos estandarizados a partir de estimaciones de loscoe�cientes de asimetría y de exceso de curtosis de dicha distribución. Pero lasestimaciones de estos estadísticos pueden estar excesivamente condicionadas porel amplio conjunto de rentabilidades en el entorno de cero, lo que entenderíamospor rentabilidades "estándar". Por esta razón puede ser conveniente un enfoquebasado únicamente en los rendimientos más extremos.Además, el mayor riesgo al que se enfrenta una cartera es la ocurrencia
repentina de una rentabilidad negativa extremadamente grande, por lo que es-timar con precisión la probabilidad de tales sucesos es la esencia de la gestiónde riesgos.El resultado básico sobre el que se basa la EVT es que la cola extrema de una
amplia familia de distribuciones F puede describirse aproximadamente por unadistribución relativamente sencilla, la llamada distribución de Pareto. La teoríase basa en el supuesto de independencia e idéntica distribución de los rendimien-tos. Como la dependencia temporal surge en muchos casos debido a la persis-tencia en volatilidades, es conveniente trabajar con rendimientos estandarizadosmediante un modelo de volatilidad condicional previamente estimado:
zt+1 = Rt+1=�t+1
que, generalmente, ya podemos suponer i:; i:d:, con esperanza nula y varianzaunitaria.Por otra parte, los rendimientos en períodos de tiempo relativamente largos
se aproximan a la distribución Normal, por lo que la EVT tiene mayor interéspara rendimientos observados a alta frecuencia. Por tanto, este enfoque se utilizacon rentabilidades de alta frecuencia, estandarizadas.Supongamos que un rendimiento estandarizado sigue la distribución incondi-
cional F; y consideremos la probabilidad de que el rendimiento z observado undeterminado instante, excediendo de un cierto umbral u; lo haga en menos deuna cuantía x. Esto es lo que se conoce como una distribución de probabilidadtruncada, que podemos calcular:28
Fu(x) = P [z � u+ x j u < z] = P [z � u � x j u < z] =
=P (u < z � u+ x)
P (z > u)=F (u+ x)� F (u)
1� F (u)
Es una función paramétrica del umbral �jado, u; y, como acabamos de ver,puede escribirse en función de la distribución de rendimientos estandarizados F .El resultado fundamental de la EVT es que para casi toda distribución F ,
la distribución condicional Fu converge a la distribución generalizada de Pareto,G(x ; �; �) :
28Se dice truncada, porque es la densidad a la derecha del umbral u:
249

Fu(x) � G(x ; �; �) = 1��1 +
�x
�
�con � � 0; � > 0:En particular, este resultado aplica a la mayoría de las distribuciones con
colas pesadas, como la t de Student. Para la Normal, el parámetro � sería igual a0, mientras que para distribuciones con colas ligeras, no muy útiles en Finanzas,el parámetro � sería negativo.29
17.1 Estimación
Si en la expresión:
Fu(x) =F (u+ x)� F (u)
1� F (u)hacemos el cambio de variable: y = x+ u; tenemos:
F (y) = 1� [1� F (u)] [1� Fu(y � u)]
Si T denota el tamaño muestral total, y Tuel número de observaciones queexceden del umbral u;el término [1� F (u)] puede estimarse mediante el co-ciente Tu=T . Utilizando la aproximación anterior, tenemos, para los valores queexceden del umbral u, la distribución:
F (y) = 1� TuT
�1 +
�(y � u)�
��1=�Vamos a utilizar este resultado para estimar el parámetro � , que determina
el grosor de la cola de la distribución F; por máxima verosimilitud. Para ello,suponemos que para valores de y superiores al umbral u, es decir, para y > u;la función anterior puede aproximarse por:30
F (y) = 1� L(y)y�1=� � 1� cy�1=�
con función de densidad:
f(y) =1
�cy�1=��1
La aproximación se basa en el hecho de que la función L(y) varía lentamentecon y para la mayoría de las distribuciones F; por lo que podemos suponerlaconstante. De este modo, tenemos en F (y) � 1 � cy�1=� una expresión aprox-imada para el valor de un amplio conjunto de funciones de distribución en sucola superior.
29Cuando � = 0; la distribución se reduce a G(x ; �; �) = 1 � exp(�x=�) para valoresx � u, mientras que para valores negativos de � la distribución vuelve a adoptar la forma:
G(x ; �; �) = 1��1 + �x
�
�, pero esta vez de�nida únicamente en el intervalo: u � x � u��=�:
30En esta aproximación, la función L(y) es: L(y) = TuT
���
�1=� �1 +
�=��uy
��1=�
250

Utilizando la de�nición de distribución condicional tenemos la función dedensidad de rendimientos a la derecha del umbral u:
f(y=y > u) =f(y)
P (y > u)
Recordemos que, esencialmente, una función de densidad truncada se obtienenormalizando la función de densidad original por la probabilidad existente en laregión que se considera tras el truncamiento (en este caso, la región a la derechadel umbral u).Suponiendo independencia de los rendimientos, tenemos la verosimilitud:
L =
TuYi=1
f(yi)
1� F (u) =TuYi=1
1
�
cy�1=��1i
cu�1=�
!para las observaciones yi > u: Por tanto, el logaritmo de dicha función es:
lnL =
TuXi=1
�ln � �
�1
�+ 1
�ln yi +
1
�lnu
�Derivando respecto de � e igualando a cero, tenemos el estimador de Hill del
parámetro de grosor de cola:
� =1
Tu
TuXi=1
ln�yiu
�Ya solo nos falta estimar el parámetro c de la aproximación a la distribución
F: Para ello, notamos que:
F (u) = 1� TuT= 1� cu�1=�
lo que nos lleva al estimador:
c =TuTu1=�
por lo que nuestra estimación de la función de distribución para observa-ciones que exceden del umbral u es:
F (y) = 1� cy�1=� = 1� TuT
�yu
��1=�(50)
Por tanto, bajo el supuesto que antes hicimos, tenemos estimadores sencillos,sin tener que recurrir a la optimización numérica de la función de verosimilitud.Elección del umbral uLa elección del umbral u es siempre delicada. Si escogemos un umbral ex-
cesivamente pequeño, entonces estaremos trabajando con algunos rendimientosno excesivamente atípicos, y la aproximación funcional a la cola de la distribu-ción en que nos hemos basado puede no ser su�cientemente buena para dichos
251

valores numéricos. Si, por el contrario, escogemos un umbral excesivamente el-evado, tendremos muy pocas observaciones para estimar los parámetros de ladistribución, por lo que tendremos baja precisión en la estimación de dichosparámetros y, consecuentemente, en los cálculos posteriores de Valor en Riesgo,Pérdida Esperada y otros, que veremos a continuación. Una regla relativamentehabitual es elegir un umbral que deje un 5% de los datos en la cola de la dis-tribución, aunque en función del número de observaciones con que contemos,podríamos variar dicho criterio.
17.2 Construcción del QQ-plot bajo la EVT.
Hemos desarrollado la EVT para la cola derecha de la distribución. Por tanto,para aplicar dicha teoría a rendimientos hemos de trabajar con pérdidas, no conrentabilidades.Si de�nimos la pérdida estandarizada:
yi = �Ri�i
tenemos, a partir de (50) para el cuantil 1 � p, de�nido como es habitual,por: F (y) = 1� p; que:
1� p = 1� TuT
�yu
��1=�por lo que dicho cuantil es:
y = F�11�p = u
�TuT
1
p
��y el QQ-plot se construye utilizando los pares de puntos:
fXi; Yig =(u
�TuT
1
p
��; yi
)=
(u
�Tu
i� 0; 5
��; yi
)ya que p se estima mediante: p = i�0;5
T : Las coordenadas yi del QQ-plot sonlas (Tu=T ) mayores pérdidas realmente observadas en la muestra.
17.3 Cálculo del VaR bajo EVT
El cálculo del VaR es ahora sencillo:
V aRpt+1 = �t+1F�11�p = �t+1u
�TuT
1
p
��que puede compararse con el que habríamos calculado bajo Normalidad:
V aRpt+1 = ��t+1��1p : Como puede verse, hay dos diferencias: a) utilizamos laprobabilidad 1� p en el cálculo del cuantil, y b) no cambiamos de signo.La razón por la que hemos usado en el VaR de EVT el cuantil 1 � p es
porque el cuantil para el que 100p% de las pérdidas son superiores (que será
252

generalmente negativo) es, cambiado de signo, el cuantil para el que 100(1�p)%de las rentabilidades estandarizadas (no pérdidas) es inferior.
17.4 Pérdida esperada (Expected shortfall)
El VaR proporciona información acerca del número de pérdidas que puede ex-ceder de dicho nivel, pero no acerca de su cuantía. Sin embargo, dicha magnitudes muy importante en la gestión de riesgos, pues es la que, en de�nitiva, puededeterminar el resultado de la gestión de cartera.De hecho, un mismo VaR al 1%, por ejemplo, puede ser compatible con
per�les en la cola de la densidad muy diferentes. En realidad, querríamos tnerinformación acerca de toda la cola de la distribución, pero eso tampoco seríaútil. Un camino intermedio consiste en el cálculo de la pérdida esperada, tambiénllamda en ocasiones el TailVaR, que se de�ne:
ESpt+1 = �Et�Rt+1 j Rt+1 < �V aRpt+1
�medido en términos de rentabilidades logarítmicas, no en términos nomi-
nales.En el caso de una distribución Normal, tenemos:
ESpt+1 = �Et�Rt+1 j Rt+1 < �V aRpt+1
�= �t+1
�(�V aRpt+1=�t+1)�(�V aRpt+1=�t+1)
donde � denota la función de densidad y � la función de distribución de unaN(0; 1): Pero en el caso de la Normal, ya sabemos que: V aRpt+1 = ��t+1��1p ;por lo que:
ESpt+1 = �t+1�(�V aRpt+1=�t+1)�(�V aRpt+1=�t+1)
= �t+1����1p
�p
La ratio entre Pérdida Esperada y VaR es:
ESpt+1V aRpt+1
= �����1p
�p��1p
Si, por ejemplo, p = 0:01; tenemos: ��1p � �2; 33; por lo que:
ESpt+1V aRpt+1
= �����1p
�p��1p
= � (2�)�1=2 exp[�(�2; 33)2=2]0; 01(�2; 33) � 1; 15
En la distribución Normal, esta ratio converge a 1 según p converge a cero.
En general, para distribuciones con cola gruesa, la ratioESpt+1V aRp
t+1será superior
al valor de la Normal, Para la distribución de EVT, cuando p tiende a 0, dicharatio converge a:
ES0t+1V aR0t+1
=1
1� �
253

de modo que, cuanto más gruesa sea la cola, mayor será la ratio de PérdidaEsperada a VaR.
17.4.1 Aplicación práctica de los procedimientos de EVT
1. Comenzamos estandarizando las rentabilidades utilizando un modelo devolatilidad previamente estimado, y convirtiéndolas en pérdidas estandarizadas,mediante un simple cambio de signo.
2. Fijado un umbral de signi�cación (1% ó 5%, por ejemplo) calculamos elumbral u calculando el percentil correspondiente en las rentabilidadesestandarizadas (no en las pérdidas estandarizadas). El umbral será unarentabilidad negativa.
3. Estimamos el parámetro � de grosor de cola. Hemos de utilizar el umbralu cambiado de signo, positivo, puesto que estamos trabajando ahora conla distribución de las pérdidas.
4. Calculamos F�11�p = u�TuT1p
��y multiplicamos por la volatilidad de cada
día para obtener el V aR:
5. Para generar un QQ-plot, representamos las Tu rentabilidades estandarizadasmenores (las más negativas, recordemos que estamos modelizando la colaizquierda de la distribución de rentabilidades) frente a los cuantiles de lasdistribución que queremos utilizar como referencia en el QQ-plot. En el
caso de la EV T , los cuantiles están dados por F�11�p = u�TuT1p
��17.5 Valoración de opciones en presencia de asimetría y
curtosis. El modelo Gram-Charlier.
El precio de una opción call debe ser igual al valor esperado y descontado de supago a vencimiento, donde la expectativa se calcula de acuerdo con la distribu-ción libre de riesgo:
c = e�rTE�t [Max(St+T �X; 0)]
El modelo de Black Scholes Merton supone que las rentabilidades diarias delactivo subyacente se distribuyen independientemente en el tiempo, de acuerdocon una distribución Normal con esperanza y varianza constantes, N(�; �2). Ental caso, la rentabilidad sobre el horizonte a vencimiento de la opción seguiráuna distribución N(T�; T�2); y el precio del activo subyacente al vencimientode la opción será: St+T = Ste
Rt+1;t+T :Esto conduce a:
254

c = e�rTZ 1
�1Max(Ste
x� �X; 0)f(x�)dx� =
= e�rTZ 1
ln(X=St)
Stex�f(x�)dx� �
Z 1
ln(X=St)
Xf(x�)dx�
donde x�denota la variable riesgo-neutro correspondiente a la rentabildaddel activo subyacente entre t y t+ T: La integral anterior resulta:
cBSM = e�rThSte
rT�(d)�X�(d� �pT )i= St�(d)�Xe�rT�(d� �
pT )
donde � denota la función de distribución de la variable N(0; 1); y d =ln(St=X)+T (r+�
2=2)
�pT
:
La paridad put-call es una relación de ausencia de arbitraje, que no precisade ningún modelo de valoración:
St + p = c+Xe�rT
y, junto con la expresión anterior para el precio de la opción call, conduce alprecio de la opción put:
cBSM = c+Xe�rT � St = Xe�rT�(�pT � d)� St�(�d)
255

En el caso en que el activo reparte una tasa de dividiendos ( u otro tipo de
rentas) constante, anual, igual a q; la expresión para d es: d = ln(St=X)+T (r�q+�2=2)�pT
;
puesto que el inversor que tiene la opción en su cartera recibe al vencimientode la opción tan sólo el activo subyacente,pero no la renta que su posesión hagenerado desde que se compró la opción.En consecuencia, de acuerdo con el modelo BS, el precio de una opción call
es una función: cBS = c(St; r;X; T; q;�) y, si disponemos de una muestra de nopciones negociadas un determinado día sobre un mismo activo subyacente, lavolatilidad de dicho subyacente puede estimarse mediante el problema:
Min�
MSEBSM =Min�
1
n
nPi=1
�cmkti � cBSM (St; r;Xi; Ti; q;�)
�2La volatilidad implícita se de�ne:
�viBSM = c�1BSM (St; r;X; T; q;�)
que puede calcularse para cada opción por separado. De acuerdo con elmodelo BSM, dicha volatilidad debería serúnica para cada activo subyacente,con independencia del vencimiento del opción considerada, o de su precio deejercicio. Sin embargo, se observa que esto no es así, apareciendo sonrisas omuecas de volatilidad. En el primer caso, la curva de volatilidad sobre el gradode Moneyness describe una curva cóncava, indicando la infravaloración de lasopciones muy out-of-the-money por parte del modelo BSM, debido a un excesode curtosis en la distribución de rentabilidades del activo subyacente. La muecare�eja una infravaloración de una cola del mercado por parte del modelo BSM,habitualmente la formada por las opciones muy in-the-money. Estadísticamente,se debe a una asimetría en la distribución de rentabilidades del activo subya-cente. En consecuencia, las opciones put muy out-of-the-money están asimismoinfravaloradas por el modelo BSM.Consideremos ahora la existencia de asimetría y curtosis en la distribución
de rentabilidades del activo subyacente. Es sencillo ver que los coe�cientesde asimetría y curtosis de la rentabilidad sobre un período de longitud T serelacionan con los coe�cientes de las rentabilidades diarias mediante: �1T =�11=
pT ; �2T = �21=T: Por tanto, si de�nimos la rentabilidad estandarizada:
!T =Rt+1;t+T � T�p
T�
tenemos: Rt+1;t+T = T�+pT�!:
Si suponemos ahora que las rentabilidades estandarizadas siguen una dis-tribución caracterizada por la expansión de Gram-Charlier, tenemos:
f(!T ) = �(!T )� �1T1
3!D3�(!T ) + �2T
1
4!D4�(!T )
donde �(:) denota la función de densidad de la N(0; 1);y Di denota el oper-ador derivada.
256

Tenemos, por tanto:
D1�(!) = �!�(!); D2�(!) = (!2 � 1)�(!);D3�(!) = �(!3 � 3!)�(!); D4�(!) = (!4 � 6!2 + 3)�(!);
La función de densidad Gram-Charlier f(!T ) es una expansión alrededor dela función de densidad Normal, que permite asimetría y curtosis no nulas, peroque se reduce a la densidad N(0; 1) cuando el coe�cinte de asimetría y el excesode curtosis son ambos cero. La expansión de Cornish-Fiser, por el contrario, seaplica a la inversa de la función de distribución de una variable aleatoria.Para poner precio a opciones Europeas, partimos de nuevo de la fórmula
libre de riesgo de valoración de una opción:
c = e�rTE�t [Max(St+T �X; 0)]
por lo que debemos resolver:
c = e�rTZ 1
ln(X=St)
(Stex� �X)f(x�)dx�
Antes trabajamos con la distribución Normal con esperanza r y varianza�2 diariamente. Ahora, en cambio, de�nimos la rentabilidad estandarizad ahorizonte T :
!T =x� � rTp
T�
y suponemos que sigue una distribución Gram-Charlier.Bajo tal supuesto, el precio de la opción call es aproximadamente igual a:
cGC � St�(d)�Xe�rT�(d� �pT ) + St�(d)
pT�
��1T3!(2pT� � d)� �2T
4!(1� d2 + 3d
pT� � 3T�2)
�=
= St�(d)�Xe�rT�(d� �pT ) + St�(d)�
��13!(2pT� � d)� �21
4!(1� d2 + 3d
pT� � 3T�2)
�La expresión es aproximada porque hemos prescindido de los términos en
�3y �4; lo que nos permite mantener la misma de�nición para el parámetro dque en el modelo BSM. De este modo, el modelo Gram-Charlier (GC) es unaextensión del modelo BSM para el caso en que hay asimetría y curtosis. Laexistencia de dividendos o rentas puede ser tenida en cuenta del modo habitual.El modelo GC tiene tres parámetros desconocidos: �; �11; �21:Pueden esti-
marse por un procedimiento numérico resolviendo el problema de optimización:
Min�;�11;�21
MSEGC = Min�;�11;�21
1
n
nPi=1
�cmkti � cGC(St; r;Xi; Ti;�; �11; �21)
�2
257

mientras que la volatilidad implícita puede calcularse para cada opción me-diante:
�viGC = c�1BSM (St; r;X; T ; cGC)
de modo que, una vez que se dispone de valores numéricos para los parámet-ros �; �11; �12; se lleva el precio teórico generado por el modelo GC a la fórmulade valoración del modelo BSM, y se invierte para encontrar así la volatilidadimplícita.Puede utilizarse asimismo la expresión aproximada:
�viGC = c�1BSM (St; r;X; T ; cGC) � �pT
1� �11=
pT
3!d� �21=T
4!(1� d2)
!que se reduce a la expresión habitual en ausencia de asimetría y curtosis. El
modelo CG proporciona una formula de valoración cerrada, en un contexto deasimetria y curtosis, que permite recoger las puatas sistemáticas de volatilidadque se observan en los mercados.
17.6 El modelo GARCH de valoración de opciones
El modelo de Gram-Charlier para valorar opciones es capaz de recoger la asimetríay curtosis en volatilidad, pero tiene la desventaja de que supone que ésta esconstante en el tiempo, contrariamente a la robusta observación empírica alcontrario en todos los mercados. Puede decirse, que mientras que el modelo GCcaptura la estructura de precios de las opciones a través de los precios de ejerci-cio, sin embargo no recoge la estructura existente a lo largo de los vencimientos.En esta sección consideramos la formación de precios de opciones cuando larentabilidad esperada del subyacente sigue un proceso GARCH. La diferenciaestriba en que bajo volatilidad constante, la estructura temporal de volatilidadeses constante, ya que la varianza de la rentabilidad a un horizonte de T periodoses igual a T�2; siento �2 la varianza de la rentabilidad sobre un período.Suponemos que el proceso GARCH especi�ca que la rentabilidad esperada
es igual a la tasa libre de riesgo, r; más una prima por riesgo de volatilidad �; asícomo un término de normalización. Por otro lado, se supone que la rentabilidadobservada cada período es igual a la rentabilidad esperada r; más una primapor el riesgo de volatilidad, ��t+1; un término de normalización, � 1
2�2t+1; más
una innovación. Se supone que dicha innovación sigue una distribución condi-cional N(0; �2t );donde �
2t evoluciona de acuerdo con un proceso GARCH(1,1)
con apalancamiento, lo que crea asimetría en la distribución de rentabilidades,lo cual es importante para explicar la asimetría observada en los precios de lasopciones:
Rt+1 = lnSt+1 � lnSt = r + ��t+1 �1
2�2t+1 + �t+1zt+1; zt+1=t � N(0; 1)
�2t+1 = ! + �(�tzt � ��t)2 + ��2t
258

que implican una esperanza y varianza condicional para las rentabilidades:
EtRt+1 = r + ��t+1 �1
2�2t+1;
VtRt+1 = �2t+1
Utilizando la conocida propiedad: x � N(�; �2) ) E(ex) = e�+�2=2; ten-
emos:
Et(St+1=St) = Et(Rt) = Et
her+��t+1�
12�
2t+1+�t+1zt+1
i= er+��t+1�
12�
2t+1Et [e
�t+1zt+1 ] =
= er+��t+1�12�
2t+1e
12�
2t+1 = er+��t+1
que muestra el papel que juega el parámetro � como precio del riesgo devolatilidad.Si partimos nuevamente de la expresión genérica para el precio de una opción
call:
c = e�rTE�t [Max(St+T �X; 0)]
Bajo neutralidad al riesgo, debemos tener una rentabilidad esperada igual ala tasa libre de riesgo, y una volatilidad esperada igual a la del proceso original:
E�t (St+1=St) = r
V �t (Rt+1) = �2t+1
Consideremos ahora el proceso:
Rt+1 = lnSt+1 � lnSt = r � 12�2t+1 + �t+1z
�t+1; (51)
z�t+1=t � N(0; 1) (52)
�2t+1 = ! + �(�tz�t � ��t � ��t)2 + ��2t
cuya esperanza condicional, bajo la distribución de probabilidad libre deriesgo es: E�t (St+1=St) = r; y cuya varianza condicional bajo esa misma dis-tribución es:
V �t (Rt+1) = E�t �2t+1 = E�t
�! + �(�tz
�t � ��t � ��t)2 + ��2t
�=
[Por (51) ] = Et
"! + �
�Rt � r �
1
2�2t � ��t � ��t
�2+ ��2t
#=
= Et�! + �(�tzt � ��t)2 + ��2t
�= Et�
2t+1 = �2t+1
259

Por tanto, (51) satisface las dos condiciones que debe satisfacer un procesolibre de riesgo.La ventaja de este modelo es su �exibilidad, pudiendo ser adaptado a cualquiera
de las especi�caciones GARCH vistas. Además, ajusta los precios de las op-ciones con bastante aproximación. La limitación es que no existe una fórmulacerrada para el precio de las opciones,que deben valorarse mediante simulación.Para ello notemos que podemos eliminar un parametro mediante la especi�-cación:
�2t+1 = ! + �(�tz�t � ��t � ��t)2 + ��2t = ! + �(�tz
�t � ���t)2 + ��2t
donde �� = �+ �:Para llevar a cabo las simulaciones con objeto de valorar una opción, a
partir de una observación para �2t+1; generamos N observaciones N(0; 1) paraz�t+1=t: Como queremos calcular la esperanza matemática E
�t utilizando el
proceso estocástico libre de riesgo, calculamos ahora la rentabilidad y varianzariesgo-neutro en el período t+ s para la simulación j-ésima mediante:
R�j;t+s = r � 12�2j;t+s + �j;t+sz
�j;t+s; j = 1; 2; :::N
�2j;t+s+1 = ! + �(�j;t+sz�j;t+s � ���j;t+s)2 + ��2j;t+s; s = 1; 2; :::
Repitiendo el ejercicio de simulación, obtenemos N realizaciones para el hor-izonte deseado. El precio hipotético del activo a vencimiento bajo la distribuciónriesgo-neutro puede calcularse, para cada realización:
S�j;t+T = StePT
s=1 R�j;t+s ; j = 1; 2; :::; N
y el precio de la opción se calcula mediante el promedio descontando lospagos hipotéticos a vencimiento:
cGH � e�rT1
N
NPj=1
Max�S�j;t+T �X; 0
�que converge a la esperanza matemática según aumenta el número de simu-
laciones. N = 5000 debería ser su�ciente para proporcionar una aproximaciónsu�cientemente buena en la mayoría de los casos.Los parámetros del modelo GARCH deben estimarse previamente, lo que
puede hacerse mediante el procedimiento de Máxima Verosimilitud. Alternati-vamente, si la muestra de opciones disponible para un determinado día es su�-cientemente amplia, podemos estimar resolviendo el problema de optimización:
Min�2t+1;!;�;�;�
�MSEGH = Min
�2t+1;!;�;�;��
1
n
nPi=1
�cmkti � cGH(St; r;Xi; Ti;�
2t+1; !; �; �; �
�)�2
260

donde estamos tratando �2t+1 como un parámetro desconocido. Debe tenerseen cuenta, sin embargo, que según el algoritmo numérico va buscando en el es-pacio paramétrico un vector de valores numéricos para �2t+1; !; �; �; �
�; hay queproceder a la valoración de las opciones mediante simulación, por lo que se tratade un procedimiento bastante exigente desde el punto de vista computacional.Por otra parte, este procedimiento permitiría analizar la variabilidad temporalde los valores numéricos de los parametros del modelo, �2t+1; !; �; �; �
�:Existe una especi�cación GARCH algo más particular que la anterior, que
genera una fórmula cerrada para el precio de la opción:
Rt+1 = lnSt+1 � lnSt = r + ��2t+1 + �t+1zt+1; zt+1=t � N(0; 1)
�2t+1 = ! + �(zt � ��t)2 + ��2t
La persistencia de la varianza en este modelo viene dada por ��2 + �; y lavarianza incondicional es !+�
1���2�� :
La versión riesgo-neutro de este proceso es:
Rt+1 = lnSt+1 � lnSt = r � 12�2t+1 + �t+1z
�t+1; z
�t+1=t � N(0; 1)
�2t+1 = ! + �(z�t � ���t)2 + ��2t
siendo sencillo ver que:
E�t (St+1=St) = r
V �t (Rt+1) = �2t+1
Bajo este proceso GARCH, el precio de una opción call europea es:
cCFG = StP1 �Xe�rTP2con:
P1 =1
2+1
�
Z 1
0
Re
�X�i'f�(i'+ 1)
i'f�(1)
�d'; P2 =
1
2+1
�
Z 1
0
Re
�Xi'f�(i')
i'
�d';
donde la función f(:) está de�nida por:
f(') = S't eAt;t+T (')+Bt;t+T (')�
2t+1
con expresiones recursivas:
At;t+T (') = At+1;t+T (') + 'r +Bt+1;t+T (')! �1
2ln (1� 2�Bt+1;t+T ('))
At;t+T (') = ' (�+ �)� 12�2 + �Bt+1;t+T (')! �
1
2
('� �)2=21� 2�Bt+1;t+T (')
261

que pueden resolverse a partir de condiciones terminales:
At+T;t+T (') = 0; Bt+T;t+T (') = 0
18 Teoría de valores extremos (versión 2)
Consideremos una serie de rentabilidades diarias de una cartera: fr1; r2; :::; rng ;cuyos estadísticos de orden extremos son r(1) y r(n): r(1) = min1�j�nfrjg; yr(n) = max1�j�nfrjg: Nos vamos a centrar en las propiedades del mínimo, queson las relevantes para el cálculo del V aR de una posición larga. Sin embargo,la misma teoría es válida para el cálculo de la rentabilidad máxima de la cartera,mediante un cambio de signo:
r(n) = � min1�j�n
f�rjg = �rc(1)
donde rct = �rt.Supongamos que las rentabilidades son incorrelacionadas e igualmente dis-
tribuidas, de acuerdo con F (x); y con un rango [l; u] ; :donde los extremos puedenser �nitos o no. La función de distribución de r(1); Fn;1(x); es:
Fn;1(x) = 1� [1� F (x)]n
que tiende a ser degenerada según n!1 : Fn;1(x)! 0 si x � l; y Fn;1(x)!1 si x > l:La Teoría de Valores Extremos se re�ere a la posible existencia de sucesiones
f�ng ; (factores de escala) f�ng ; (parámetros de localización), con �n > 0; talesque las distribución de:
r(1�) �r(1) � �n
�n
converja a una distribución no degerada cuando n!1:La Teoría de Valores Extremos tiene dos implicaciones importantes:
� la distribución límite del mínimo normalizado, F�(x); está caracterizadapor el comportamiento en las colas de la distribución F (x) de rt; no porla distribución especí�ca de las rentabilidades, por lo que es aplicablea una gama amplia de distribuciones de rentabilidades. Sin embargo,las sucesiones f�ng y f�ng dependerán de la distribución concreta derentabilidades,
� el índice de cola k; o el parámetro de per�l, no depende del intervalotemporal considerado para las rentabilidades, lo que resulta útil en elcálculo del V aR:
262

18.1 Estimación del modelo
Los parámetros del modelo: k; escala, �n; per�l, �n; localización, puedes es-timarse por métodos paramétricos (Máxima Verosimilitud o regresión) o pormétodos no paramétricos.
18.1.1 Máxima verosimilitud
18.1.2 Método de Regresión
18.1.3 Método no paramétrico
19 The single-factor model
19.1 An introduction to factor models
A fund manager who is investing in a given stock market needs to keep trackof the time evolution of returns in all stocks trading in that market. Evenrelatively small markets like the Spanish one, have a large enough list of stocksthat precludes the consideration of the possible evolution of their prices overthe management horizon. If we need to propose an strategy for asset allocationamong a wide variety of markets, the number of assets multiplies by a signi�cantfactor. That makes the problem particularly hard in most �nancial applicationsof portfolio management or risk management, because we need to have estimatesnot only for future prices, but also for future variances and correlations. If wehave a vector of N assets, we will need to forecast N returns and N(N + 1)=2covariances or correlations. In most stock markets, N can easily be of the orderof 500, so that the number of estimates we need to update whenever we solve theasset allocation problem or we perform an evaluation of the risk in our portfoliois huge.In this common situation, a very sensible question refers to the possibility
of identifying a reduced number of common factors that may i) capture most ofthe �uctuation in the whole Nx1 vector of asset returns, i.e., most of the infor-mation provided by the vector of assets we need to consider for our managementproblem, and ii) closely reproduce the structure of correlations among returns.This would in principle look like an impossible task. But, on the contrary,
it turns out to produce an interesting and positive answer in many cases. Thechance to obtain an important reduction in the dimensionality of the vector oftime series we need to keep track of is larger the higher the correlations amongthe returns of the original Nx1 vector of assets.Consider the estimation of the Value at Risk (VaR) of a given fund at time
T . The VaR at p% and horizon h-periods from now, will be the correspondingpercentile of the return distribution at T + h: To solve the problem we need toextrapolate the distribution of Rp; the returns of the fund portfolio at time T+h;which requires two statements: i) the character of the distribution: Normal,Student�s-t, Generalized distribution, a given Extreme Value distribution, and
263

ii) the need to forecast how the distribution of returns will change between Tand T + h:Let us forget for now about the very important second issue by assuming
that the distribution of returns is invariant over time. The computation of theVaR will require the use of the variance-covariance matrix of returns at T + h:Under Normality (if we are willing to make that assumption), the 1% VaR wouldbe E(Rp)� 2:32635V arT+h(Rp): But,
V arT+h(Rp) = w0V arT+h(r)w
where w is the vector of weights de�ning the portfolio, and V arT+h(r) isthe NxN variance-covariance matrix of returns of the original N assets at timeT+h: Even for a moderate N; the number of estimates in this covariance matrixwill easily become too large.Now, suppose we have found a short number m of factors, able to capture
a signi�cant proportion, say 95% of the variation in the Nx1�vector r: Thatmeans that we have a system of equations,
rit = �i+�i1f1t+�i2f2t+ :::+�imfmt+ "it; t = 1; 2; :::; T ; i = 1; 2; :::; k (53)
where fjt; j = 1; 2; :::;m represent the m common factors, m << k; �ijdenote the factor loads, and "it are the speci�c component of return for thei-asset.We assume the vector of factors ft = (f1t; f2t; :::; fmt) follows anm-dimensional
process with:
E(ft) = �f
Cov(ft) = �f ; symmetric, positive de�nite, mxm matrix
E("it) = 0 for all i; t
Cov(fjt; "is) = 0 for all j; i; t; s
Cov("it; "js) = �2i if i = j; t = s; being equal to 0 otherwise
These conditions characterize a good factor model. In fact, the most relevantconditions are the last two: the presence of correlation between factors andspeci�c components, or between speci�c components for two di¤erent assetswould mean that we are missing some relevant factor, and the model wouldneed to be re-speci�ed.These assumptions imply a very particular covariance structure for theN�vector
r :
Cov(r) = �0�f� +D
where �f has a much shorter dimension than V arT+h(r); � is nxm; andD is a diagonal, mxm matrix, thereby containing just m di¤erent elements,the variances of the "ij elements. Under some factor model approaches, factors
264

are uncorrelated by construction, in which case, the number of elements in �fcomes down to justm; rather thanm(m+1)=2: There is still a large dimension inmatrix �; but the total number of parameters needed to represent the variance-covariance matrix of returns is much smaller now. Besides, the general idea isthat it is the correlation among the factors, as captured by �f , more than thesensitivities to them, captured in � that needs to be updated frequently.To measure portfolio risk, we will just need to introduce some scenarios on
the future evolution of the factors, rather than doing so with the large vectorof returns, r: The same applies to forecasting or simulation. If we want toforecast the future evolution of returns in r between T and T + h; we justneed to forecast the m factors, and then use the representation of returns (53)to obtain forecasts for each element in r. It is important no notice that solong as the common factors are well speci�ed, when we compute forecasts foreach individual return in r; the obtained time series will preserve the samplecorrelation observed among the components in r: As a matter of fact, this canbe used to test the quality of the factor model.Standard approaches to factor model evaluation are based on some of the
model implications:
� whether the correlation matrix of returns implied by the factor modelreproduces the sample correlation matrix,
� the correlation matrix of speci�c return components, which must be zero
� the correlation between factors and speci�c components of returns mustbe zero, although this is guaranteed if the factor model is estimated byleast squares,
� the comparison of the implied global minimum variance portfolio. Thisproblem is de�ned by,
Minw
�2p = w0�w
subject to : w01n = 1
and it has as solution the vector of weights:
w =��11
10�1
when it is obtained from either the sample correlation or the correlationmatrix of �tted components in (53) :Applications of factor models include:
� VaR computation
� identify principal sources of risk in a portfolio
265

� construct portfolios hedged against major sources of risk
� consider scenarios to measure portfolio risk
� stress-testing is more easily done on identi�ed factors than on individualassets (interest rates or stocks)
and examples of all these will be discussed in the next sections
19.2 The structure of the single-factor model
A single-factor model explains the covariances between asset returns throughthe common in�uence of a single factor. The model is:
rit = ait + �iIt
where return has a speci�c component, ait ; and a second component, �iIt;that re�ects the common in�uence of a single factor It; over all returns. Fluc-tuations over time in a given return is due to both of these components. Thecommon factor It could be the in�ation rate, It = �t, or the market return,It = rmt
, for instance.Subtracting the mathematical expectation of the random variable ai we have:
ai = �i + ui, where �i is a constant speci�c to each asset �i = E(ai), while uiis the speci�c random component of each asset. So, we have:
rit = �i + �iIt + uit (54)
A convenient condition of any index model is,
� Cov(uit ; It) = E(uit ; It) = 0:
This condition can be guaranteed through least squares estimation, and itmeans that how well (71) explains the return on the i asset is independent ofwhat the market return happens to be.But the key assumption of the one-index market is the lack of correlation
between speci�c return components:
� Cov(uit ; ujt) = 0; all i 6= j
It means that in the case of the 35 assets in Ibex35, the 595 di¤erent cor-relations between the residuals of the projections on the single factor for twodi¤erent assets must be zero. These residuals would be the speci�c componentsof returns, according to this factor model. There is nothing in the least squaresestimation procedure that will guarantee this property. But how well the modelperforms depends on how good or bad this assumption on the lack of crosscorrelation between speci�c return components is just an approximation.We must distinguish between the One-factor model, characterized by the two
conditions mentioned above, and the Market model,
266

rit = �i + �irmt + uit
which does not make the assumption that the speci�c components of returnsare uncorrelated across assets and hence, it does not lead to simple analyticalexpressions for variances and covariances as the one-factor model does.The single model factor is more a theoretical construction than a model with
strict empirical validity. Suppose we take the return on the market portfolio asthe single factor. The return on individual assets might also depend on thedividend policy, and this might be similar for assets in the same class (banks,utilities, building companies). That would induce correlations among the returncomponents that are not explained by the single factor, which is not supposedto happen under the factor model.To clarify notation, we assume the market return as the single factor. De-
noting V ar(ui) = �2ui ; i = 1; 2; :::; N , V ar(It) = V ar(rm) = �2m; we have, underthe model hypothesis:
ri = �i + �irm
�2i = �2i�2m + �
2ui
�ij = �i�j�2m
so that:
� expected return has two components: one form the market return andanother from �i;
� the variance of the return on any given asset also has two components.The second one is due to the volatility of the speci�c component uit ; sothat there is a component of market risk, �2i�
2m; and an speci�c component
of risk, �2ui ;
� the covariance between the returns on two assets is only due to marketrisk.
The previous representations allow us to write the expected value and vari-ance of the return on a given portfolio:
rc =NXi=1
Xiri ) rc =NXi=1
Xiri =NXi=1
Xi�i+NXi=1
Xi�irm = �c+
NXi=1
Xi�i
!rm = �c+�crm
where the alpha and beta of the portfolio, �c , �c are de�ned from those forthe individual assets:
�c =NXi=1
Xi�i
�c =NXi=1
Xi�i
267

Furthermore,
�2c =NXi=1
X2i �
2i+2
NXi=1
NXj=1;j 6=i
XiXj�ij =NXi=1
X2i �
2i�
2m+2
NXi=1
NXj=1;j 6=i
XiXj�i�j�2m+
NXi=1
X2i �
2ui
so that we can estimate expected return and risk for any portfolio fromestimates for �i; �i; �
2ui ; rm; �
2m; a total of 3N+2 parameters, rather than 2N+
N(N � 1)=2: In the case of the 35 assets in Ibex35, the number of requiredparameters reduces from 665 to 107, the reduction being even more impressivein a larger market. Alternatively, the analysis could also be performed fromestimates for ri; �2ui ; �i; rm; �
2m; again 3N + 2 parameters.
19.2.1 Characteristics of the single factor model
The volatility (risk) of a portfolio can be written:
�2c =
0@ NXi=1
NXj=1;j 6=i
XiXj�i�j
1A�2m +
NXi=1
X2i �
2ui =
NXi=1
Xi�i
! NXi=1
Xj�j
!�2m +
NXi=1
X2i �
2ui
= �2c�2m +
NXi=1
X2i �
2ui
Consider a well diversi�ed portfolio: a) it invests in a broad set of assets, b)it does not concentrate the invested capital in a subset of assets. To be speci�c,let us consider the special case of a portfolio that distributes its capital equallyamong a set of N assets, with N large31 .The volatility of such portfolio is:
�2c = �2c�2m +
NXi=1
�1
N
�2�2ui = �2c�
2m +
1
N
NXi=1
1
N�2ui
!So that the component of portfolio risk that cannot be eliminated by diver-
si�cation is the one associated to market risk, so that:
�c ' �2c�2m = �m
NXi=1
Xi�i
!Since �m is common to all assets in the portfolio, we have that the contri-
bution of an individual asset to portfolio risk is given by its beta, �i:The risk of an individual asset is �2i = �2i�
2m + �2ui ; that depends on beta
and on the variance of its speci�c component. Since the e¤ect of �2ui on the riskof the portfolio can be eliminated by increasing N , we call that diversi�able or
31The previous expression does not hold for the market portfolio, illustrating that theassumptions of the single factor model are inconsistent for the case �2c = �
2m:
268

idiosyncratic risk. On the contrary, �2i�2m (systematic volatility or risk) does
not decrease by increasing N , and �i is the measure of the non diversi�able orsystematic risk in any individual asset.
19.3 Estimating portfolio characteristics from a single fac-
tor model
A risk manager uses the above expressions to construct historical time series formany di¤erent portfolios, so that she can compare their characteristics in rela-tively short histories, allowing for time variation in parameters (this is becausethe time series of historical portfolio returns will have been constructed main-taining constant the current weights). On the other hand, an asset managerwill compare the characteristics of many individual assets using long histories(three to �ve years of monthly or weekly data).Once we have estimated the one-factor model, we can proceed to compute i)
historical mean returns as well as their ii) standard deviations and covariances(alternatively volatilities and correlations) and iii) the correlation matrix of thespeci�c return components, and compare them with the value that would beobtained from the mean and variance market return and the estimated alphasand Betas, according to the expressions presented above.Example II.1.1: For two di¤erent assets, compute weekly returns, examine
their market betas, and compare the size of systematic and speci�c risk. Aggre-gate their alphas and betas for a given portfolio composition. Compute themfrom a single time series for the portfolio return. With weekly data from thebeginning of January 2000 to end of August 2008 for NWL y Microsoft, las alfasestimadas son 0,358 (0,161), y -0,066(0,178) y las betas estimadas: 0,506 (0,071)y 1,104 (0,079). Los componentes de riesgo especí�co se estiman en 23,17% y25,74%, respectivamente. Una cartera constituida en un 70% por NWL y un30% por Microsoft, tendría un alfa de 0,231 y una beta de 0,685, con un riesgoespecí�co de 23,97%.Example II.1.2: Estimate portfolio alpha and beta
Estimating portfolio risk using Exponentially weighted moving aver-age models (EWMA) Risk management requires monitoring on a frequentbasis (daily and even intra-daily) and parameter estimates must be left to varyto re�ect current risk conditions. So we consider:
rt = at + �tIt + ut
The simplest possible way to estimate time varying parameters is through anExponentially Weighted Moving Average mechanism (EWMA), using a smooth-ing constant � :
269

��t =Cov�(rt; It)
V ar�(It)
Cov�(rt; It) � �12t = (1� �)rt�1It�1 + ��12t�1 = (1� �)1Xi=1
�i�1rt�iIt�i
V ar�(It) � �2t = (1� �)I2t�1 + ��2t�1 = (1� �)1Xi=1
�i�1I2t�i
where we are assuming that the asset�s return and the factor have zeroexpectation. A time varying correlation coe¢ cient could similarly be de�nedby division of the covariance of both returns by the square root of the productof variances, both statistics de�ned as above. The value of �;between 0 and 1,determines the persistence of the process of covariance or variance. A zero valuewould produce immediate reactions to events, while a value close to one wouldmake the variance or covariance almost constant. The higher the value of �; thelonger it will take for the e¤ects on moments of events to die away. The EWMAmechanism is justi�ed only if returns are i:; i:d::The value of � can also be chosen to optimize a measure of �t, like the
value of the log-likelihood function under Normality. It is sometimes chosensubjectively a it is the case with the 0.94 value used in Riskmetrics with dailydata or the 0.97 value used with monthly data. A value of � = 0:95 amounts toa half-life of 25 days, close to one month. That is the length of time needed forthe process to close half the initial distance to its long-run level.Exercise: For assets of di¤erent nature, compute covariances and variances
for alternative values of �: Compare with moments computed with rolling win-dows of di¤erent length. Estimate the value of �:
Under the EWMA speci�cation, systematic risk is estimated by:
Systematic Risk =ph�
�
t
pV ar�(It)
where h denotes the number of returns per year, which will be around 250when working with daily data. This analysis produces time varying betas andcorrelations. It is obviously interesting to observe the time changes in beta,one of the two components of systematic risk of the asset. Systematic riskwill change over time as a function of changes in beta and changes in factorvariance. Systematic risk may be low even for assets with beta above one, andthe opposite can also happen. A graphical comparison of time variation in betaand systematic risk may provide interesting information.There is an interesting relationship between the equity beta and the relative
volatility of the asset and the market:
��t = ��
sV ar�(rt)
V ar�(It)
270

In the example(Figures II.2.1 to II.2.3), it is obvious that Cisco has a greatersystematic risk than Amex. The average market correlation is similar for Ciscoand Amex, but Cisco is much more volatile than Amex, relative to the marketand hence, EWMA correlation is much more unstable and Cisco beta is oftenconsiderably higher than Amex beta.In the single factor model, risk can be decomposed:
Total variance = Systematic variance+ Specific variance
Total risk =p(Systematic risk2 + Specific risk2)
20 Multi-factor models
Failure of the assumptions embedded in the single-factor model move to con-sidering multi-factor models, the arbitrage pricing theory developed by Ross(1976) being an example. A multi-factor model is:
Yt = �+ �1X1t + :::+ �kXkt + ut
or in matrix form:
y = �+X 0� + u; u � i:; i:d:(0; �2u)
which implies:
Expected return = �+ �0E(X)
Re turn variance = �0� + �2u
where = V ar(X) is the kxk factor covariance matrix. This expressionfor the variance represents the dispersion of returns around the expected return�+ [E(X)]
0�; but not around any other reference.
Example II.1.3: Suppose the total volatility of returns on a stock is 25%. Alinear model with two risk factors indicates that the stock has betas of 0.8 and1.2. The two factors have volatility of 15% and 20% and a correlation of -0.5.How much of the stock�s volatility can be attributed to the risk factors, and howlarge is the stock�s speci�c risk? R: Volatility due to the two factors is 20,78%,while speci�c risk is 13,89%.
Actually, we have one of such previous equations for each asset. So, for aset of assets, we have:
Y = A+XB +; � (0;�)
where each column in Y contains T data points for a given asset, so it isTxm; A is also Txm; X is Txk; B is kxm; and is a Txm matrix of randomshocks or innovations, with:
271

V ar() = � =
0@ �21 �12 ::: �1m::: ::: ::: :::�1m �m2 ::: �2m
1AIn a completely speci�ed factor model, this covariance matrix should be
diagonal, ash it has been discussed above. However, we are going to proceed atthis point as if we are at an intermediate point of specifying the factor model,which is still incomplete, producing some correlations between the unexplainedcomponents of the vector of asset returns.Consider now a portfolio made up of the assets in vector Y , with weights:
w = (w1; w2; :::; wm): The historical data on the portfolio, using �current weights�is:
y = Y w
and we have:
y = Y w = Aw +X(Bw) + w; � (0;�)
so the portfolio alpha and beta are: � = Aw; � = Bw; and the portfolio�sspeci�c return is given by: " = w; the weighted sum of the asset�s speci�creturns.This expression for the portfolio�s speci�c return shows the need to take
into account the correlation between asset speci�c returns when estimating thespeci�c risk of the portfolio. Assuming lack of correlation between factor returnsand each asset�s speci�c return, we have,
V ar(y) = �0� + w0�w
displaying the three sources of risk: i) the risks coming from the portfolio�sfactor sensitivities �; ii) the risks of the factors themselves, represented by ,iii) the idiosyncratic risks of the assets in the portfolio, represented by w0�w:
Example II.5 : Consider a portfolio invested in three assets with weights: -0.25, 0.75 and 0.50, respectively. Each asset has a factor model representationwith the same risk factors as in Example II.1.3, and betas: (0.2,1.2), (0.9, 0.2),and (1.3, 0.7). The two factors have volatilities: 15% and 20%, respectively.What is the volatility due to the risk factors (i.e., the systematic risk) for thisportfolio? R: The portfolio factor betas are 1,275 and 0,20, and the volatilitydue to the two factors is 17,47%
20.1 Style attribution analysis
Using some speci�c assets (indices or portfolios) as references for factors, itis interesting to estimate the management style of a given portfolio. This isimportant to evaluate fund management which is sometimes subject to someregulations or to some indications from the �nancial director of the managementinstitution. Specially important is this analysis to evaluate the management
272

and performance of hedge funds. Factors for style management may be stockmarket indices, bond indices, or interbank or many market rates. But they canalso be indexes of value or growth stocks. To evaluate hedge funds, additionalfactors may include option price indices, exchange rates, credit spreads. A valuestock is one that trades below book value. The asset value per share is highrelative to the share price, and we could expect the price to raise. Usually itsprice-earnings ratio will be below the market average. A growth stock is onewith a lower than average price-earnings to growth ratio. The rate of growthof earnings is high relative to its price-earnings ratio. These appear attractivebecause of potential growth in the �rm assets. Value indicators may include thebook-to-price ratio and the dividend yield, while growth indicators may includethe growth in earnings per share and the return on equity. Value and growthstyle indices exist from di¤erent �nancial institutions: S&P 500 value index,S&P 500 growth index, Russell 1000 value index, etc.. As the number of �rmsincrease, their average market capitalization decreases. So the S&P500 valueindex contains value stocks with an average market capitalization much higherthan those �rms in the Wilshire 5000 value index.References: These indices can be downloaded from Yahoo! Finance. Look at
the left side menus of: http://�nance.yahoo.com/funds (Funds by family, Topperformers)Obviously, the choice of style factors is very important for the results. We
should include a large enough family representing the basic asset classes whichare relevant to the portfolio being analyzed, without adding up too much collinear-ity. Style attribution is based on solving the problem:
min�(y �X�)2
subject to :kXi=1
�i = 1; �i � 0; i = 1; 2; :::; k
Example II.1.4: Perform style attribution on the mutual funds: VIT: Van-guard Index Trust 500 index, FAA: Fidelity Advisor Aggressive Fund, FID: Fi-delity Main Mutual Fund, using as style factors: a) Russell 1000 value: midcap, value factor, b) Russell 1000 growth: mid cap, growth factor, c) Russell2000 value: small cap, value factor, d) Russell 2000 growth: small cap, growthfactor.
20.2 Multi-factor models in international portfolios
Consider an investment in a single foreign asset. The exchange rate is de�nedas the number of units of the domestic currency that must be delivered for eachunit of the foreign currency. The log returns satisfy:
P dt = P ft E ) Rd = Rf +X = �R+X
273

where we have assumed a single foreign market risk factor representation.Hence, there are two risk factors a¤ecting the domestic return on the asset: a)the exchange rate, with a beta of 1, and b) the foreign market index or riskfactor, with a beta of �: Therefore,
Systematic variance = V ar(�R+X) = �2V ar(R) + V ar(X) + 2�Cov(R;X)
and the systematic variance has three components: a) the equity variance,�2V ar(R); b) the forex variance, V ar(X), c) the equity-forex covariance: 2�Cov(R;X):If we have a portfolio of assets in the same class, we will have a similar decom-position, with the beta of the portfolio being related to the betas of individualassets in the standard fashion.To generalize the analysis, let us consider a large international portfolio with
exposure to k di¤erent countries. For simplicity, we assume that there is a singlemarket risk factor in each country. We denote by R1; :::; Rk the returns to themarket risk factors, by �1; :::; �k the portfolio betas with respect to each marketfactor, and byX1; :::Xk the foreign exchange rates. Assuming R1 is the domesticrisk factor, then X1 = 1 and there are k equity risk factors, but only k�1 foreignexchange risk factors. Let w = (w1; :::; wk)
0 be the country portfolio weights.The systematic return on the portfolio is:
w1�1R1 + w2(�2R2 +X2) + :::wk(�kRk +Xk) = (Bw)0x (55)
where x is the 2kx1 vector of equity and forex risk returns, and B is the(2k � 1)xk matrix of risk factor betas:
x = (R1; R2; :::; Rk; X2; :::; Xk)0 and B =
0BBBBBBBBBB@
�1 0 0 00 �2 0 0::: ::: ::: ::: :::0 0 0 �k0 1 0 00 0 1 0::: ::: ::: ::: :::0 0 0 1
1CCCCCCCCCCATaking variances in (55) we get:
Systematic variance = (Bw)0(Bw)
where Bw is a (2k � 1)x1 vector, and is a (2k � 1)x(2k � 1) matrix::
=
0BB@V ar(R1) Cov(R1; R2) Cov(R1; Xk)
Cov(R1; R2) V ar(R2) Cov(R2; Xk):::
Cov(R1; Xk) Cov(R2; Xk) V ar(Xk)
1CCAwhich can be partitioned as:
274

=
�E EX0EX X
�where E is the kxk covariance matrix of the equity risk factor returns, X
is the (k�1)x(k�1) covariance matrix of the forex risk returns, and EX is thekx(k � 1) �quanto�covariance matrix containing the cross-covariances betweenthe equity risk factor returns and the forex risk factor returns, which can beeither positive or negative. In the latter case, the systematic variance will beless than the sum of the equity variance and the forex variance.Hence, we can decompose systematic variance into its equity, forex and
equity-forex components, as:
Systematic variance = ~�0E~� + ~w0X ~w + 2~�
0EX ~w
where ~w = (w2; :::; wk) , ~� = w0diag(�1; ::; �k) = (w1�1; :::; wk�k)0:
Example II-6: A UK investor holds 2.5 million pounds in UK stocks with aFTSE100 market beta of 1.5, 1 million pounds in US stocks with an S&P500market beta of 1.2, and 1.5 million pounds in German stocks with a DAX30market beta of 0.8. The volatilities and correlations of the FTSE100, S%&P500and DAX30 indices, and the USD/GBP and EUR/GBP exchange rates areestimated. Calculate the systematic risk of the portfolio and decompose it intoequity and forex and equity-forex components. R:
20.3 Estimation of fundamental factor models
The proposed Case Study considers the risk decomposition of two stocks (Nokiaand Vodafone) using historical prices and four fundamental risk factors: i) abroad market index, the NYSE composite index, ii) an industry factor, the OldMutual communications fund, iii) a growth style factor, the Riverside growthfund, and iv) a capitalization factor, the AFBA Five Star Large Cap fund.The selection of the risk factors is a major issue, that depends on the user�sexperience and knowledge.We consider a portfolio made up by 3 million US dollars of Nokia stock and
1 million US dollars of Vodafone stock. We start by estimating the total riskof the portfolio based on the historical returns on the two assets. The portfoliovolatility is 42.5%. We estimate projections of each of the two assets on thefour risk factors, to obtain the two vectors of 4 betas each. From that, we canestimate the vector of portfolio betas. We also compute the covariance matrixof factor returns. The variance attributed to the risk factors, or systematicvariance, is 24.7%, much lower than the total risk of the portfolio we estimatedbefore. That means that the factor model does not explain the portfolio returnsvery well. Indeed, the R-squared statistics were 58.9% for Vodafone and 67.9%for Nokia. An additional problem is the important colinearity among the riskfactors. The lowest correlation between any two of them is 0.69. Then, a set ofregressions is estimated including one additional risk factor at a time, and thebeta values can be seen to change dramatically.
275

As an approach to avoid the e¤ect of collinearity, an orthogonal regressionis also estimated for each asset using the �rst two principal components for the4 risk factors. The systematic risk increases to 30.17%, but it remains still wellbelow the estimate with historical portfolio returns.
20.4 Zero coupon curve estimation
Before describing the use of the Principal Component technique for risk man-agement in �xed income markets, let us remember the main idea behind zerocoupon curve estimation.Note: Zero coupon curves are estimated using market prices for bonds that
pay coupon. As illustration for those of you interested, I leave the �polynomialzero coupon curve.xls��le, that solves the following exercise. A .zip �le named�nelson_siegel�will also be made available for those of yo interested in estimatingNelson-Siegel and Svensson models of zero coupon curves using Matlab.Consider the following exercise. Today is November 5, 2011. The �rst col-
umn of �le �polynomial zero coupon curve.xls�contains the coupon of each bondtraded in the secondary market for Government debt. The second column con-tains the maturity date, the third column the date the bond was �rst issued,which is assumed to be the same for all bonds, 15/08/2011. Each bond is as-sumed to have a nominal of 100 monetary units. This is just for simpli�cation,and it cold be changed without any di¢ culty. Finally, we see the (average)market price for each bond.We assume a polynomial discount function,
d(t) = a+ bt+ ct2 + dt3 + et4
to be applied to each cash �ow.Hence, the price of a bond can be represented:
Pit =
niXj=1
cijdj(t) =
niXj=1
cij�a+ btij + ct
2ij + dt
3ij + et
4ij
�where ni denotes the number of cash-�ows to be paid by the i-th bond
before maturity. We assume that all bonds pay coupon each semester (half ofthe annual amount).For each vector of parameter values (a; b; c; d) we have a theoretical price for
each bond. We want to �nd the parameter values so that
Min(a;b;c;d)
NXi=1
(PMit � PTit )2
where PMit denotes the market price for each bond, and PTit denotes the the-
oretical price for that parameter vector.The market price is �ex coupon�, meaning that we need to add to it the part
of the coupon which would correspond to the current holder since the last datethat a coupon was paid. To calculate that amount, we multiply the size of the
276

next coupon payment by the proportion of the 2-month interval that has alreadygone by. Adding that to the �ex coupon�market price, we get the true tradedprice.The polynomial function dj(t) is the discount function, giving us the price
of a bond that would mature at any future date, with a single payment, to bee¤ective at maturity. This would be a zero coupon bond maturing t periodsfrom now.Estimate a discount function using a polynomial of degree 2, and another
one using a polynomial of degree 4, and represent both discount functions. Drawa bar diagram with the market and the theoretical prices for each bond undereach speci�cation of the discount function.The zero coupon curve itself, that represents zero coupon interest rates as a
function of maturity, is obtained from:
rt = 100
�1
dt
�1=t� 1!
Draw a diagram with the zero coupon curves that obtain from the two dis-count functions you have estimated. In view of the results do you consider asecond degree polynomial to be adequate for this market?
20.5 A factor model of the term structure by regression
The TSIR is a curve made up by zero-coupon curve rates for a large number ofmaturities. In some markets, like secondary debt markets, we need to estimatean analytical model that provides us with a continuous representation of zerocoupon interest rates across the maturity range considered. In some other cases,like interbank markets, or interest rate swaps, we have already zero coupon ratesobserved at �xed maturities. The re may be a fairly large number of maturities,as in swap markets, or just a few of them, as in markets for interbank deposits.Trading in such markets, or managing a fund in them requires evaluating therisk associated to each maturity, but there may be a large number of them.It makes sense then to try to summarize the time �uctuations in a large ofmaturities by those in a short number of them. This is a crucial aspect of riskmanagement.Essentially, we try to identify the risk factors along the term structure. As
an alternative, we could search for risk factors in the form of macroeconomicvariables: in�ation, growth, oil prices, and so on. That a reduced number offactors can capture the uncertainty in changes in the TSIR is an interesting issue,since many equilibrium �xed income valuation models assume that bond pricesare a function of a small number of state variables that follow a di¤usion process[Vasicek, O.A. (1977), �An equilibrium characterization of the term structure�,Journal of Financial Economics, 5, 177-188, Cox, J., Ingersoll, J., and S. Ross,(1985), �A theory of the term structure of interest rates�, Econometrica, 53,385-408] In these models, interest rates at pre-speci�ed maturities are used asproxies for the unobserved state variables. That the models do not show a clear
277

superiority over simpler alternatives in empirical tests is usually explained bythe somewhat arbitrary choice of proxies for the risk factors.There is a variety of techniques that can be used in this analysis.
20.5.1 Regression analysis
In this approach, spot rates at di¤erent maturities are used as potential riskfactors, and can break the arbitrariness mentioned above in the implementationof equilibrium valuation models. Elton, E.J., M.J. Gruber and R. Michaely[(1990) �The structure of interest rates and immunization�, Journal of Finance45, 629-642] assume that unexpected changes in interest rates are linearly relatedto two unknown factors F1 and F2;
dri;t = �i;0 + �i;1dF1;t + �i;2dF2;t + ui;t (56)
The factors will be identi�ed with speci�c interest rates. These authorsassume that interest rate changes are zero, thereby ignoring the constant termin the previous equation although that might produce some misspeci�cationproblem. The model is speci�ed as,
dri;t = aidrz;t + bi (drx;t � drz;t) + ui;t (57)
where it is clear that any other number of factors could also be considered.It can be alternatively written as,
dri;t = (ai � bi)drz;t + bidrx;t + ui;t (58)
The coe¢ cient of determination between dri;t and drz;t and drx;t � drz;t isgiven by,
R2i;(z;x) = 1�V ar(ui;t)
V ar (dri;t)
which amounts to,
R2i;(z;x)V ar (dri;t) = V ar (dri;t)� V ar(ui;t)
showing that minimizing the residual variance over the set of possible pairsof factors is equivalent to maximizing R2iV ar (dri;t) :When solving this problem, weights may be applied to the maximized terms
of interest rates at di¤erent maturities to capture the perceived relative impor-tance of each one of them. That way, the problem becomes,
Max(z;x)
Xi
!iR2i;(z;x)V ar (dri;t) (59)
That could help to focus on the region of the TSIR relevant to a fund man-ager. If are using the technique to design a �xed income portfolio on public debt,we should weigh more heavily the maturities associated to outstanding bonds.Once again, the idea is that when dealing with a public or private debt market,
278

we would have to start by estimating the TSIR, selecting a set of maturities,and generating interest rates time series for those maturities.We also need to de�ne what we understand by unexpected changes in interest
rates. Usually these are taken as di¤erences between spot rates at t and thecorresponding forward rate computed from the TSIR for time t-1, which agreeswith the Pure Expectations Theory of the TSIR. Alternatively, the actual changein interest rates is used, as if it was completely unexpected. This correspondsto the assumption that each interest rates behaves as a random walk. Forfrequently observed data (weekly), di¤erences between these two alternativesare very minor.Once we have found the factor solving (59) ; we can estimate the sensitivity
of ri to changes in the factors, by estimating either (57) or (58) : From them,we can estimate sensitivity parameters for any other maturity by interpolatingthe estimated sensitivities, or by parameterizing a function like,
ai = c0 + c1 ln i+ c2(ln i)2 + "i
in the case of a one-factor model.When a one-factor model is considered, results on the optimal factor di¤er
across countries. In Spain, the 3-year rate seems to do a good job [Navarro,E., and J.M. Nave (1997) �A two-factor duration model for interest rate riskmanagement�, Investigaciones Económicas]. For two-factor models, the 3-yearand the 2-month rates were chosen in the Spanish market.Naturally, relating the factors used in TSIR in di¤erent markets, and test
for the explanatory power of those from one market to the other, remains asan interesting issue for further research. Elton et al. found the six-year andthe eight-month as the best factors. A standard result is that a third factoris usually needed to capture the curvature of the TSIR, since the resulting R-squared statistics are not very high for some maturities.It is also interesting to point out that estimated sensitivities become some-
times non-signi�cant in an interesting manner: in the Spanish market, for ma-turities over three years, interest rates are not sensitivity to the two-month ratefactor, while for maturities below two-months, interest rate changes are notsensitive to changes in the three-year rate factor.For the Spanish case, Navarro and Nave interpolate for the whole term struc-
ture by using the functions,
(a� b)i =k0 + k1 ln i+ k2(ln i)
2
1 + k3 ln i+ k4(ln i)2
bi =h0 + h1 ln i+ h2(ln i)
2
1 + h3 ln i+ h4(ln i)2 + h5(ln i)3
which should be constrained by,
(a� b)2�month = 1; b3�year = 1;
(a� b)3�year = 0; b2�month = 0;
279

In addition, these authors also impose,
(a� b)03�year = 0; b02�month = 0;
The model obtained through this approach can be tested against competingalternatives (like on-factor models with di¤erent choices for proxies, or di¤erenttwo-factor models) by using estimated regressions of the type (57) or (58) topredict actual interest rate changes.
20.5.2 A duration vector
The price of a bond paying coupon is,
P =
kXj=1
C�1 +Rtj
�tj + N
(1 +Rtk)tk
where sometimes a tax e¤ect is modelled by,
P =kXj=1
C (1 + )�1 +Rtj
�tj + N
(1 +Rtk)tk
[see Vasicek, O.A. and Fong, H.G. (1982), �Term structure modeling usingexponential splines, Journal of Finance]. From this expression,
dP =
kXj=1
�@P
@Rtj
@Rtj@R2�month
dR2�month +@P
@Rtj
@Rtj@R3�year
dR3�year
�which can be seen to imply,
�P
P= �D1�R2�month �D2R3�year (60)
where,
D1 =
Pkj=1 tj(a� b)tjC
�1 +Rtj
��tj�1+ tk(a� b)tkN (1 +Rtk)
�tk�1
P
D2 =
Pkj=1 tjbtjC
�1 +Rtj
��tj�1+ tkbtkN (1 +Rtk)
�tk�1
P
which become equal to Macaulay�s modi�ed duration in case the TSIR is�at and interest rate movements are of a parallel kind. This expression allowsus to anticipate the percent price change in a bond that can be expected fromchanges in the two factors. That way a simulation of di¤erent scenarios canbe done, to estimate the change in the value of a bond that could be producedunder each one of them.
280

The results can be extended to a portfolio of bonds. The relative pricechange caused on the portfolio by an interest rate movement can be estimatedusing a portfolio duration calculated as a weighted average of the duration ofthe bonds included in this portfolio, the weights being the percentage of thetotal portfolio assigned to each bond. It can be easily shown that an expressionsimilar to (60) applies to changes in the market value of a portfolio, if durationsD1 and D2 are de�ned as convex linear combinations of the analogue durationsfor the individual bonds, each one weighted by the relative proportion that eachbond represents of total portfolio value.Navarro an Nave provide an expression for the expected change in the market
value of a portfolio under the Pure Expectations Theory of the term structure,that allows for testing for management quality in �xed income portfolios,
�V = V (R) (1 +RH)H
��H (a� b)H1 +RH
�D1
��R2�month +
�HbH1 +RH
�D2
��R3�year
�where H denotes the planning or investment horizon.
20.6 Cointegration analysis
On the one hand, since interest rates in almost all markets are integrated vari-ables, we have to look at the vector of rates in a large number of maturities asbeing a vector of (possibly) cointegrated variables. Hopefully, we might �nd alarge number of cointegrating relationships and hence, a small number of com-mon trends among the set of interest rates. If that is the case, then a long-runinvestor only needs to care about the time behavior of the small set of commontrends. Each one of them will be a linear combination of the whole set of interestrates, but still, the exercise reduces to updating the time series of those linearcombinations, and follow them.A di¢ culty is that to this point, maximum likelihood estimation of the
common trends has not yet been included in the standard statistical packages.There is a way of recovering estimated trends using CATS in RATS.
20.7 Permanent components
The principal components technique is designed to �nd factors explaining mostof the variance in a vector of time series. The factors are linear combinations ofthe original variables. An advantage of the technique is that it is very simple toimplement. A drawback is that the obtained factors may not easy be interpret.However, when we can �nd an interpretation for them, the analysis may gainin interest.We start by identifying a vector of interest rates to summarize through their
principal components. To do so, we might have to start by estimating a termstructure. Once the TS has been estimated, we may select a vector of maturities,and the associates interest rates form the vector of time series to analyze. It isuseful to start by computing correlations among changes in interest rates.
281

The principal components technique consists of computing the eigenvaluesof the variance matrix of the standardized variables. The eigenvectors associ-ated to the eigenvalues (they are all positive) of highest size de�ne the linearcombinations to be used as principal components. It can be shown that theproportion of variance in the original data set that each principal component isable to explain is given by the size of the associated eigenvalue as a proportionof the sum of all them.In many international �xed income markets has been obtained [D�Ecclesia, L.
and S.A. Zenios (1994) �Risk factor analysis and portfolio immunization in theItalian bond market�, The Journal of Fixed Income, sept., p. 51-58, Navarro, E.and J.M. Nave (1995) �Análisis de los factores de riesgo en el mercado españolde deuda pública�, Cuadernos Aragoneses de Economía, 5, 2, 331-341, Steeley,J.M. (1990), �Modelling the dynamics of the term structure of interest rates�,The Economic and Social review, 21, 4, 337-361] that three factors are enough toexplain most of the variance across the TSIR. Furthermore, their interpretationis the same in all cases: the �rst factor captures the general level of interest rates.Changes in this component can be seen as parallel shifts in the TSIR. The secondcomponent captures the slope of the TS, while the third component representsthe curvature of the TSIR, and describes changes in the concavity/convexity ofthe TSIR.This result has direct a bearing on immunization, suggesting that a standard
approach of choosing a portfolio having as duration the investment horizon pro-duces a less than complete immunization, since it covers only the risk involvedin parallel shifts of the TSIR. Hence, the level of risk covered can be estimatedby the proportion of variance explained by the �rst principal component.The implication then is that a technique of vector immunization, covering
against multiple risk factors, should lead to improved results. One of the possi-bilities that has been explored is to construct functions using the time series ofestimated parameters in an interest rate model like the one proposed by Nelsonand Siegel.
20.8 Open questions in the analysis of a term structure
� Cuestiones abiertas Reducing dimensionality of volatility along the termstructure of interest rates
� Volatility transmission along the term structure of interest rates
� Term structure of volatilities
� International linkages in the term structure of interest rates
� International transmission of volatility
� Forward rates as predictors of future short-term rates
According to the Expectations Hypothesis, forward rates should be unbiasedpredictors of future (short-term) spot rates. However, not much e¤ort has been
282

placed to actually test for the predictive ability of forward rates. From thebeginning, the statement was tested by �tting regressions like,
rmt = �0 + �1fmt�s;t + ut
and testing the joint hypothesis,
H0 : �0 = 0; �1 = 1
but....
� The predictive ability of the term structure
The term structure has been found to contain some useful information re-garding future business cycle activity. Initially, it was discovered that the spreadbetween a short and along-term rate could anticipate future output. Such aspread, known as the term structure slope, was included as one of the indicatorsin the index of leading economic indicators, and has been detected to containpredictive ability in a variety of countries. This empirical result is quite strik-ing, since it is a spread between nominal rates which is found to anticipate realeconomic activity.
� General equilibrium characterization of the term structure
Recently, there has been some e¤ort to characterize a term structure ofinterest rates in stochastic, general equilibrium economies. The idea is to analyzesimulated series for interest rates at di¤erent maturities, to discuss whetherthey reproduce some of the regularities observed in actual interest rate data.Some of the di¢ culties with this exercise are: a) it is hard to solve for sucha set of interest rates, since the system easily becomes close to singular, b) toobtain nominal interest rates, we need to use a monetary model, which maybe harder to solve. To this point, most of the work has been devoted to: 1)explain di¤erences in volatility across the term structure [den Haan (19xx)], 2)reproduce ARCH features present in actual interest rate data, 3) reproduce thepredictive ability that the term structure seems to contain with respect to thebusiness cycle [Dominguez and Novales (19xx)].
20.9 Permanent-transitory component decomposition
A short-term investor needs to also worry about the short-term �uctuationsin interest rates. So, two issues arise: on the one hand, how to produce anacceptable decomposition of interest rates in permanent-transitory components.Secondly, whether transitory components show high correlations among them.If that is the case, we will still be able to reduce the dimensionality of theshort-run fund manager.
283

20.9.1 Maximum-likelihood decomposition
20.9.2 Granger-Gonzalo decomposition
20.9.3 Decomposition based on principal component analysis
Surprisingly enough, permanent components are able to extract the (stochastic)trend from a set of random variables. That means that, if we have a vector ofinterest rates, and are able to characterize a small set of principal componentsable to explain a large amount of the �uctuations in interest rates, a (linear least-squares) projection on the �rst principal component is often enough to producea stationary residual [see Gourieroux (19xx)]. That is, each interest rate maybe cointegrated with the �rst principal component. That is not surprising, fromhow principal components are computed: the �rst principal component is builtso that it captures a high proportion of the variance in the set of variables inthe vector. If they are not stationary, and share a single common trend, the�rst principal component will not be very di¤erent from that trend. That isthe case, in markets for interbank deposits, or euromarkets, where just 1-, 3-,6- and 12-month rates are usually considered.In markets where a wider set of maturities is traded, we may need to project
on the �rst two or three principal components to produce stationary residuals,but we might still be able to obtain that trend extraction property. This is avery simple procedure to implement. Its drawback is that part of the stationarycomponent of the series is included in the component which is �tted by the linearcombination of principal components estimated by the least-squares projection.
20.9.4 Técnicas de cointegración en el análisis de �Asset allocation�
Válidas para decisiones de inversión a largo plazoSi las decisiones se toman en base a tendencias de largo plazo, no requieren
una actualización muy frecuente.El análisis de cointegración trata de maximizar la estacionariedad y, con
ello, minimizar la varianza del �tracking error�. En contraste con el análisis defrontera e�ciente, en el que nada asegura que los �tracking errors�sean �mean-reverting�.Los modelos de benchmarking o de index tracking utilizan generalmente
regresiones con logaritmos de precios. La variable dependiente puede ser ellog de un índice más un pequeño incremento que equivalga a un % anual.Las variables explicativas son los logs delos precios de los activos que puedenincluirse en la cartera que sigue al índice.El problema tiene dos partes: a) seleccionar los activos, b) optimizar las
ponderaciones de la cartera. El primero es difícil. Opciones: �fuerza bruta�:estimar muchos modelos con distintas combinaciones de activos y ver cuál ajustamejor. Basarse en las preferencias de riesgo del inversor, o en las limitaciones deinversión que se nos impongan. Segundo problema: Técnicas de regresión, deanálisis de series temporales multivariante, o de cointegración. Si se construye
284

una cartera mediante regresión o cointegración, as ponderaciones se normalizande modo que sumen 1, para ser ponderaciones de cartera.En global asset management: primero, elegir los países, y después, comprar
o vender futuros sobre los índices de los países, o repetir el problema dentro decada país, para obtener carteras de seguimiento de cada índice.En modelos de un sólo país: Primero, seleccionar los sectores; después, se-
leccionar los activos dentro de cada sector.Constrained allocations:Ejemplos:� Seleccionar una cartera que invierte al menos un 50% en España.� Fijar como rentabilidad benchmark la del SP100 más un 5% anual� Construir un fondo corto-largo en 12 países pre�jados, con un índice
mundial como benchmarkUtilizar como variable dependiente, el índice que se quiere replicar, menos
w-veces el precio del activo en el que se nos restringe a tomar una posición delw%. Si se nos exige una posición en el activo �no superior al w%�el problemaes más difícil. Primero, resolver el problema sin restringir, a ver si hay suerte:¿satisface la solución la restricción?Supongamos que no podemos tomar posiciones cortas. Si alguna ponderación
es negativa, se �ja en cero, y se vuelve a resolver, iterando de este modo. Con�aren alcanzar una solución.Selección de parámetros:El modelo básico de �index tracking�mediante cointegración se de�ne en
función de ciertos parámetros:� Una rentabilidad �alfa�por encima de l índice� El intervalo de datos diarios que se utiliza en la estimación �training
period�� La relación de activos en la cartera� Las posibles restriccionesLos parámetros se selecciona en base al resultado de pruebas dentro y fuera
de la muestra.Dentro de la muestra:� Estadísticos ADF� Standarad error of regresión� Turnover�Testing period�:� Tracking error variance: varianza delos errors de réplica diarios RMSE� Di¤erencial de rentabilidades entre la cartera y el índice� Information ratio: (Mean daily tracking error)/(desviación típica del
daily tracking error) a lo largo del �testing period�� La decisión puede basarse sobre un �alfa�o sobre el número de activos
que queremos incluir en la cartera.
285

21 Principal components
21.1 The analytics of PCA
The principal components technique is used to reduce the dimensionality of alarge vector of variables under study That is the case, for instance, of a fundmanager who can invest in a number of markets, each of them made up by arelatively large number of assets. It is impossible to keep track of the evolutionof all them, or make the kind of post-sample evaluation, via forecasting orsimulation, that would be needed for risk and portfolio management. Similarly,it is almost impossible to maintain a portfolio that exactly matches a givenindex, since its composition is changing continuously. Factor model techniquesare needed to try to �nd a small number of factors that can be combined toreproduce the �uctuations in the market or index that is the object of theinvestment strategy. Principal components is a technique that can be used tocharacterize such factors.Principal components are linear combinations of the original variables, so it
may not be very simple to interpret them. On the other hand, they have theadvantage that they are uncorrelated by construction. Therefore, each principalcomponent adds new information to the previous ones. Principal componentsshould be used with stationary variables, like returns or growth rates, ratherthan prices.Principal components are linear combinations de�ned by the eigenvectors of
the variance-covariance matrix of the variables whose information we want tosummarize by the set of factors. If the variables considered show very di¤erentdegrees of volatility, then the results of PCA (Principal Component Analysis)will di¤er depending on whether we implement them on the covariance or onthe correlation matrix of the vector of returns. To avoid that the estimationof PCs (Principal Components) might be dominated by the variables with thehighest variance, it may be then convenient to standardize the data �rst.It may be convenient to remember some of the main properties of the eigen-
vectors of a symmetric nxn matrix V : i) an eigenvector x is an n-column vectorde�ned by the equation: V x = �x; where � is a real number, the eigenvalue asso-ciated to x, ii) eigenvectors corresponding to di¤erent eigenvalues are orthogonalto each other, i.e., their inner product is equal to zero, ii) the eigenvalues ofa positive de�nite matrix are all positive, iii) the sum of the eigenvalues of asymmetric matrix is equal to its trace, iv) the product of the eigenvalues ofa symmetric matrix is equal to its determinant, v) since the eigenvectors of amatrix are de�ned up to a constant factor, we can multiply or divide them by agiven constant, or change their sign, and they will still be eigenvectors of V forthe same associated eigenvalue. This also implies that they must be normalizedin a given manner. Some software programs (Matlab orders them from smallestto largest) normalize them so that their euclidean norm is equal to one.Suppose we have a data matrix X , Txk , with each variable in a column.
We assume we have standardized variables, so that each column has zero meanand unit variance. PC analysis is based on eigenvalues and eigenvectors of the
286

covariance/correlation matrix V = X 0X=T; kxk. Let W be the kxk matrixhaving as columns the eigenvectors of V: Then, the eigenvectors and eigenvaluescan be arranged so that,
VW =W�
where � is the diagonal kxk matrix of eigenvalues of V; �i; i = 1; 2; :::; k: Thesum of the eigenvalues of V is equal to the trace of V . But, with orthogonalizedvariables, trace(V ) is equal to the number of variables k; since V has ones alongits main diagonal. Suppose that the eigenvalues that make the columns ofW have been ordered according to the size of the eigenvalues of V , whichare the elements in the diagonal of �; where we assume �1 > �2 > ::: > �k:Whenever we use some software to compute the eigenvectors and eigenvalues ofa given matrix, we must pay attention to whether they are given back to us in aspeci�c order. Since the eigenvectors corresponding to di¤erent eigenvalues areorthogonal to each other (their scalar product is equal to zero), if the Euclideannorm has been used, then W is an orthogonal matrix : W�1 =W 0:The i-th PC is de�ned by:
Pi = w1iX1 + w2iX2 + :::+ wkiXk = Xwi
a linear combination of the columns of X; i.e., a linear combination of theoriginal variables, with weights given by the components of the i-th eigenvectorof matrix V , i.e., the i-th column of matrix W: The matrix of time series datafor all PCs is,
P = XW (61)
The di¤erence between W and P is that matrix W is kxk, and each columncontains the weights that characterize the linear combination that de�nes thecorresponding eigenvector. On the other hand, matrix P is Txk, and it containstime series observations for all the principal components.We also have:
P 0P =W 0X 0XW =W 0TVW = TW�1W� = T�
a diagonal matrix. This shows that:
� The time series data for the Principal Components are uncorrelated,
� The variance of the i-th Principal Component is equal to �i:
According to the propositions above for the principal components, the sum ofthe eigenvalues is equal to the sum of variances of the variables in X :
Pkj=1 �j
=Pki=1 V ar(xi). Hence, the proportion of the variance of the vector X that is
explained by the i-th Principal Component is �i=Pkj=1 �j . With standardized
variables, that proportion is equal to �i=k. If the original variables are highlycorrelated, the �rst PC, related to the largest eigenvalue, will be signi�cantly
287

larger than the other eigenvalues, and it will explain a high percentage of thejoint variability.Since W 0 =W�1; equation (61) is equivalent to:
X = PW 0
i.e.,
Xi = wi1P1 + wi2P2 + :::+ wikPk
so that each variable in the original system can be written as a linear com-bination of the set of PCs. For instance, variable i-th, whose data occupied thei-th column in matrix X , can be reproduced by the expression above, forminga linear combination of all the Principal Components with weights given by theelements of the i-th row of matrix W: This is known as the representation ofthe original vector of variables as a function of PCs.This representation makes easy to compute the variance-covariance matrix
of X; since, as we have seen, the covariance matrix of P is �: Therefore:
V ar(X) =WV ar(P )W 0 =W�W 0
All this just re�ects the fact that Principal Components are a linear trans-formation of the data. This transformation can also easily be inverted, to re-produce the data as a function of the time series for the Principal Components.There are therefore as many Principal Components as variables in the originalinformation set, and both sets of variables, those in X and the set of PrincipalComponents, jointly considered, contain exactly the same information.But the reason why we construct Principal Components is because provided
there is enough correlation among the original data set, then a few PrincipalComponents will be able to capture a large proportion of the �uctuations overtime by the whole set of original variables. Suppose we decide to choose the �rstn principal components (n << k) because �n=
Pkj=1 �j is su¢ ciently small. The
vector made up by these n principal components associated to the n largestprincipal components will contain less information than the variables in X , butthe idea is that we may not lose much information while reducing signi�cantlythe number of variables to consider.
21.2 Exercise: Principal components analysis of a set ofinterest rates
Example: Consider the set of interest rates contained in US_tipos:prn. Thisis daily data from January 5, 1995, to December 31, 1997 on interest rates atmaturities: 1-, 3-, 6- and 12-months, and 2-, 3-, 4-, 5-, 7- and 10-years. Whenthe original data is a set of variables similar in nature, as in this case, the needto transform them into stationarity or to standardize them is not so important.So, we are going to analyze the data without any transformation in spite of thefact that the interest rates are not stationary:
288
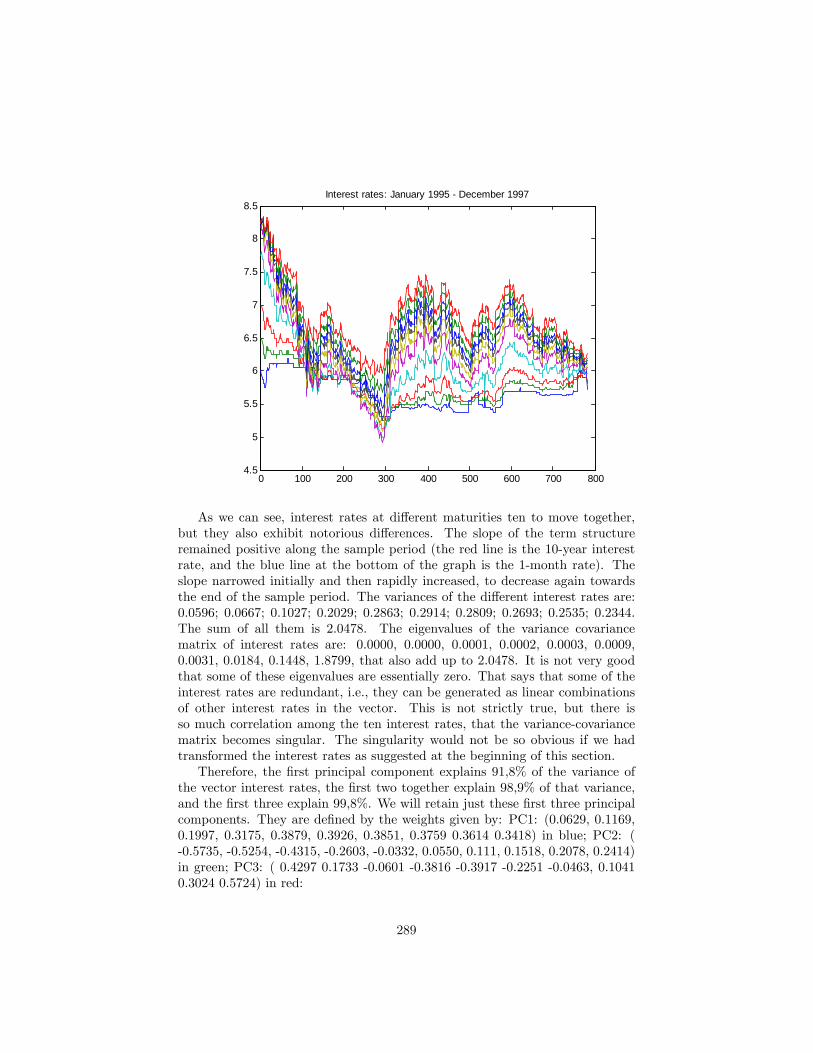
0 100 200 300 400 500 600 700 8004.5
5
5.5
6
6.5
7
7.5
8
8.5Interest rates: January 1995 December 1997
As we can see, interest rates at di¤erent maturities ten to move together,but they also exhibit notorious di¤erences. The slope of the term structureremained positive along the sample period (the red line is the 10-year interestrate, and the blue line at the bottom of the graph is the 1-month rate). Theslope narrowed initially and then rapidly increased, to decrease again towardsthe end of the sample period. The variances of the di¤erent interest rates are:0.0596; 0.0667; 0.1027; 0.2029; 0.2863; 0.2914; 0.2809; 0.2693; 0.2535; 0.2344.The sum of all them is 2.0478. The eigenvalues of the variance covariancematrix of interest rates are: 0.0000, 0.0000, 0.0001, 0.0002, 0.0003, 0.0009,0.0031, 0.0184, 0.1448, 1.8799, that also add up to 2.0478. It is not very goodthat some of these eigenvalues are essentially zero. That says that some of theinterest rates are redundant, i.e., they can be generated as linear combinationsof other interest rates in the vector. This is not strictly true, but there isso much correlation among the ten interest rates, that the variance-covariancematrix becomes singular. The singularity would not be so obvious if we hadtransformed the interest rates as suggested at the beginning of this section.Therefore, the �rst principal component explains 91,8% of the variance of
the vector interest rates, the �rst two together explain 98,9% of that variance,and the �rst three explain 99,8%. We will retain just these �rst three principalcomponents. They are de�ned by the weights given by: PC1: (0.0629, 0.1169,0.1997, 0.3175, 0.3879, 0.3926, 0.3851, 0.3759 0.3614 0.3418) in blue; PC2: (-0.5735, -0.5254, -0.4315, -0.2603, -0.0332, 0.0550, 0.111, 0.1518, 0.2078, 0.2414)in green; PC3: ( 0.4297 0.1733 -0.0601 -0.3816 -0.3917 -0.2251 -0.0463, 0.10410.3024 0.5724) in red:
289
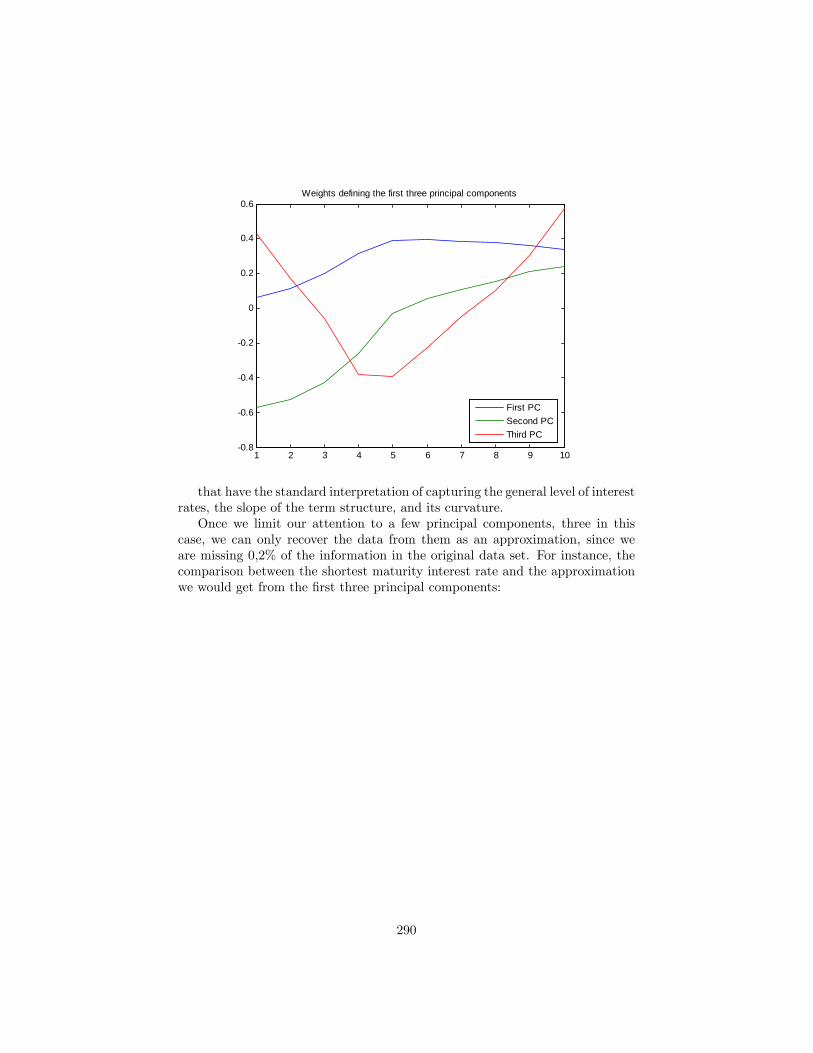
1 2 3 4 5 6 7 8 9 100.8
0.6
0.4
0.2
0
0.2
0.4
0.6Weights defining the first three principal components
First PCSecond PCThird PC
that have the standard interpretation of capturing the general level of interestrates, the slope of the term structure, and its curvature.Once we limit our attention to a few principal components, three in this
case, we can only recover the data from them as an approximation, since weare missing 0,2% of the information in the original data set. For instance, thecomparison between the shortest maturity interest rate and the approximationwe would get from the �rst three principal components:
290
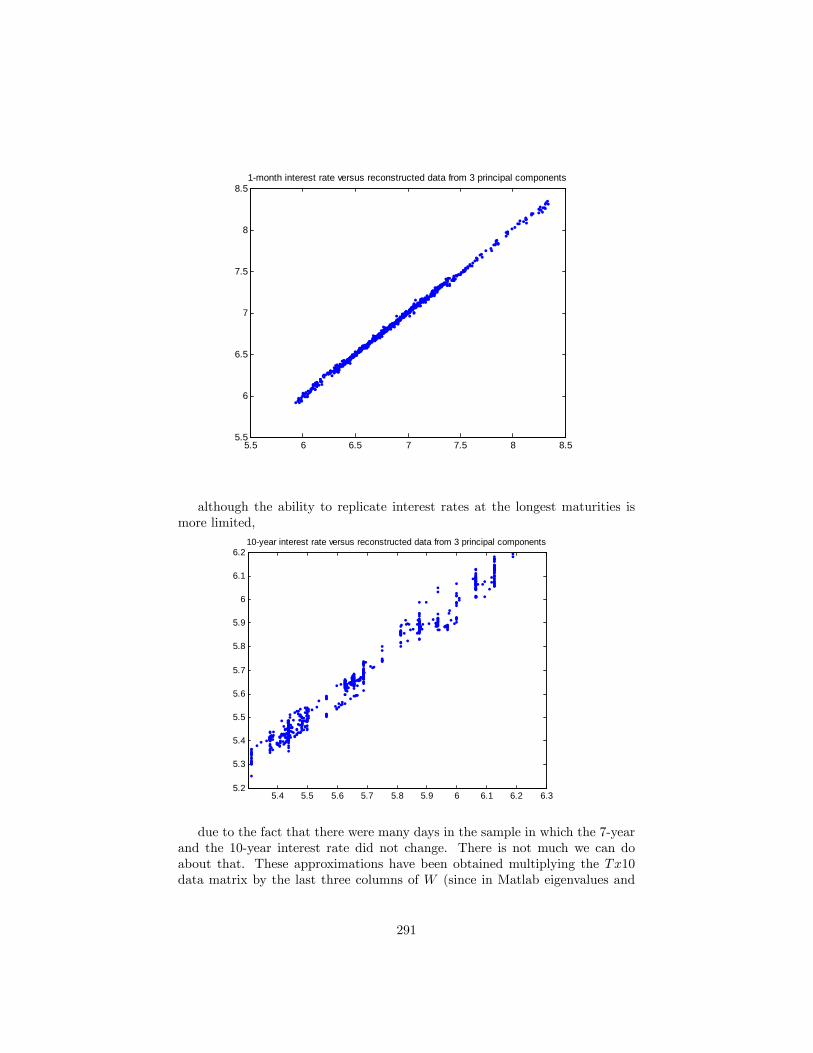
5.5 6 6.5 7 7.5 8 8.55.5
6
6.5
7
7.5
8
8.51month interest rate versus reconstructed data from 3 principal components
although the ability to replicate interest rates at the longest maturities ismore limited,
5.4 5.5 5.6 5.7 5.8 5.9 6 6.1 6.2 6.35.2
5.3
5.4
5.5
5.6
5.7
5.8
5.9
6
6.1
6.210year interest rate versus reconstructed data from 3 principal components
due to the fact that there were many days in the sample in which the 7-yearand the 10-year interest rate did not change. There is not much we can doabout that. These approximations have been obtained multiplying the Tx10data matrix by the last three columns of W (since in Matlab eigenvalues and
291

eigenvectors are ordered from smallest to largest), transposed to form a 3x10matrix:
X = (P8P9P10) � (W8W9W10)0 (62)
The last three columns of W give us the 3 betas for each interest rate asa function of the three chosen principal components. As a matter of fact, thesame approximation to the original data as we have described from the productmatrix can be obtained by least square, estimating a regression of each interestrate on the three chosen principal components. The estimated coe¢ cients willnot exactly coincide with the regression coe¢ cients, but the �tted time seriesfrom the regression and the time series recovered from the matrix product abovewill have a correlation of 1.0.There are many uses of the principal component representation. Let us
describe the main one, regarding portfolio/risk management in �xed incomemarket. Suppose we have a portfolio in such market with 50 bonds in it. Weknow the current market value of the portfolio PT , but we want to �gure out thepossible evolution of that price in the horizon of h days, that is, between T andT + h:To do so,we must have an idea about the possible values of the discountfunction at T + h. We will need to discount all the cash �ows remaining atT +h and that can be a number signi�cantly higher than the number of bonds.Suppose that at T + h there will be 300 cash �ows to be paid on the portfoliobonds. The maturities will easily be arbitrary: 13 days, 56 days, 86 days, 143days, and so on. We assume that the cash �ow paying the farthest away is lessthan 10 years.We start from the interest rate database that we have analyzed and for which
we have already characterized three principal components as explained above.We assume these were zero-coupon interest rates. Now, we have to �gure outwhat evolution these principal components may follow between T and T + h:Once we do that, the same representation (62) will allow us to get the expectedevolution for the 10 interest rates, by doing:
�X = (�P8�P9�P10) � (W8W9W10)0
Suppose we consider a �rst scenario in which the monetary authority cutsdown the intervention interest rate by 25 basis points as a consequence of whichthe slope increases by 10 basis points, with no change in curvature. The impliedchanges for the di¤erent maturities would be:32
32That may happens because the short term rate comes down by 25 basis points while thelongest end of the term structure decreases by only 10 basis points.
292
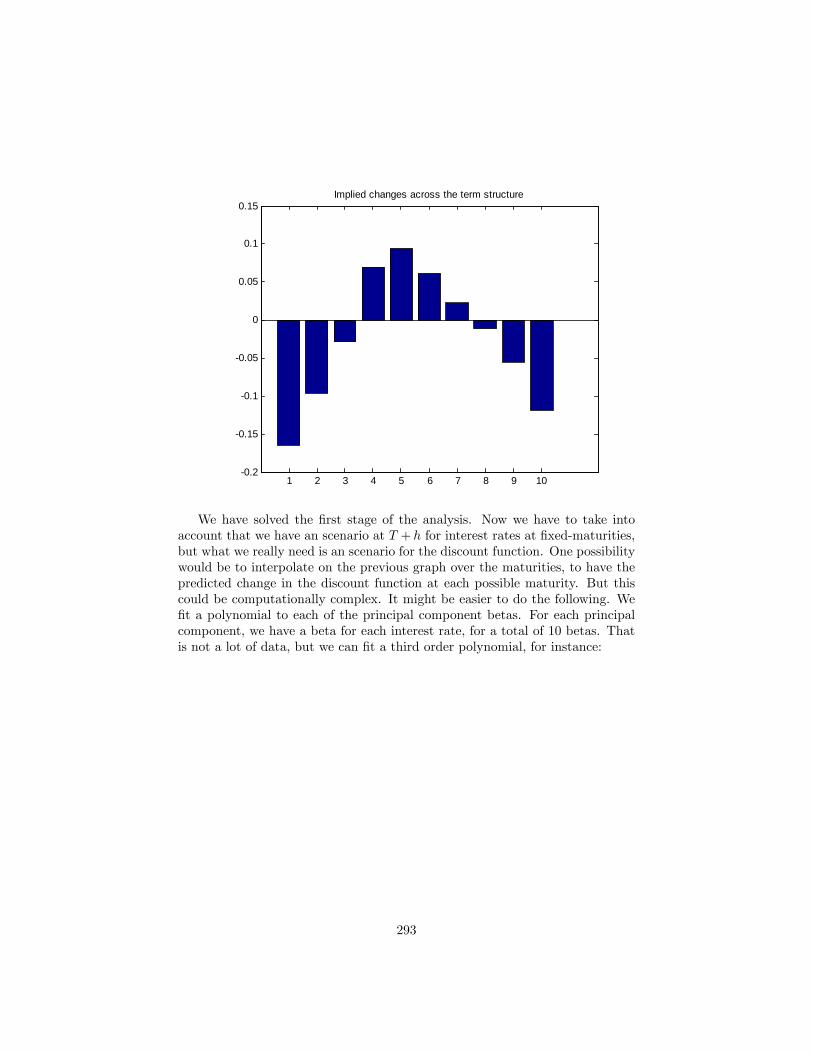
1 2 3 4 5 6 7 8 9 100.2
0.15
0.1
0.05
0
0.05
0.1
0.15Implied changes across the term structure
We have solved the �rst stage of the analysis. Now we have to take intoaccount that we have an scenario at T + h for interest rates at �xed-maturities,but what we really need is an scenario for the discount function. One possibilitywould be to interpolate on the previous graph over the maturities, to have thepredicted change in the discount function at each possible maturity. But thiscould be computationally complex. It might be easier to do the following. We�t a polynomial to each of the principal component betas. For each principalcomponent, we have a beta for each interest rate, for a total of 10 betas. Thatis not a lot of data, but we can �t a third order polynomial, for instance:
293
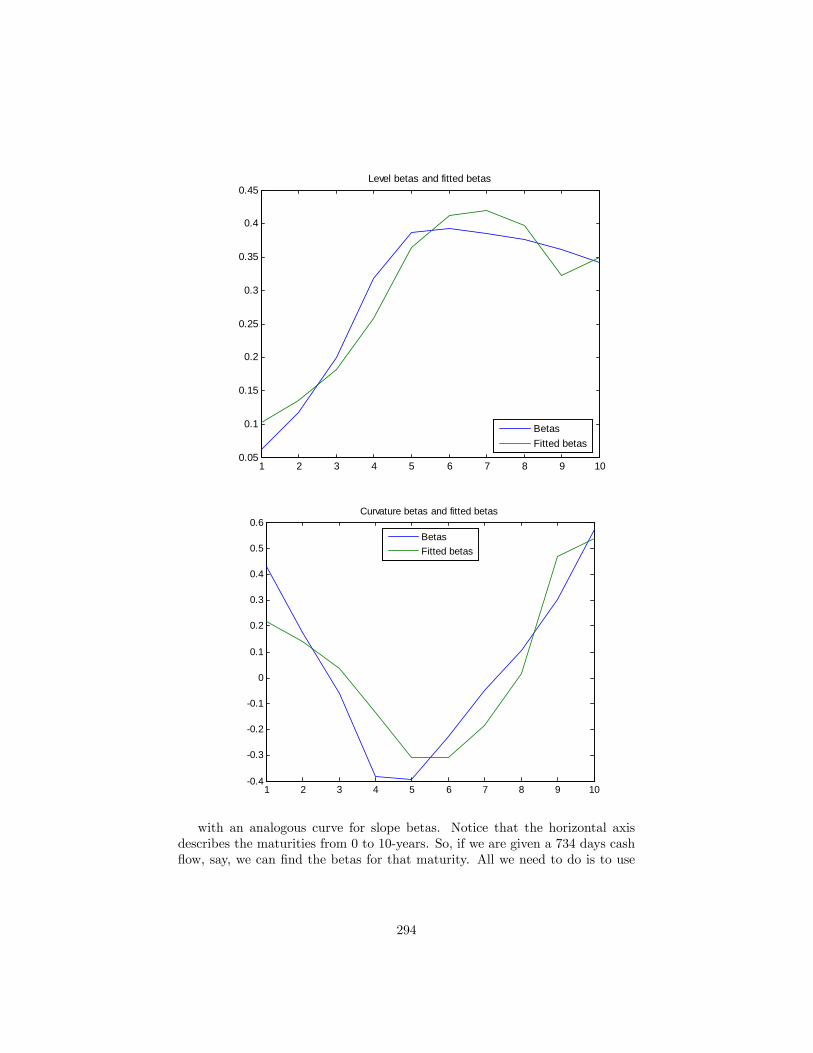
1 2 3 4 5 6 7 8 9 100.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45Level betas and fitted betas
BetasFitted betas
1 2 3 4 5 6 7 8 9 100.4
0.3
0.2
0.1
0
0.1
0.2
0.3
0.4
0.5
0.6Curvature betas and fitted betas
BetasFitted betas
with an analogous curve for slope betas. Notice that the horizontal axisdescribes the maturities from 0 to 10-years. So, if we are given a 734 days cash�ow, say, we can �nd the betas for that maturity. All we need to do is to use
294

the estimated regression coe¢ cients, that were:
� =
0BBBB@Level Slope Curvature
Constant 0:0840 �0:5942 0:2602�L 0:2151 0:3589 �0:5198�S �0:0422 �0:0546 0:1338�C 0:0023 0:0027 �0:0079
1CCCCA (63)
and the product �m = �0M where M = (1;m;m2;m3)0 will give us the3-vector of betas �m for maturity m: All we need to do is to keep in memorythe vector of 300 maturities, from which we can immediately construct a 4x300matrix M generalizing the M -vector above, and premultiplying by �0, we havea 3x300 matrix of betas, a 3-vector for each of the 300 maturities. That waywe would obtain a value for each zero coupon rate at each maturity, and thediscount factor is obtained as usual: dm = (1 + rm)�1:The �nal stage relates to constructing the scenarios for T + h: There are
essentially two possibilities: i) to write down a number of r scenarios, similar tothe one we described above. They would try to capture the di¤erent alternativesfor monetary policy or for market �uctuations we consider reasonable for thenext h market days. Next, we have to assign a probability to each scenario,re�ecting the likelihood we associate to each one. This could be by assigning aweight to each scenario and dividing each weight by their sum. That way, weget something looking like probabilities. Since each scenario will be de�ned interms of a given change in level, in slope and in curvature of the term structure,we cold follow the steps above to translate each scenario into an implied changefor the vector of 300 discount factors.The alternative procedure consists of ii) modelling the time series evolu-
tion of each �xed-maturity interest rate. This could be made with univariateprocesses or in a multivariate fashion. Unfortunately, working with a multi-variate process for 10 variables is going to be rather complex. The principalcomponents may help, by specifying processes describing the time evolution ofthe three principal components. Not only we have a shorter number of vari-ables, but also, since they are uncorrelated, we do not gain anything by �ttingmultivariate model. Hence, we can �t a univariate model to each principal com-ponent, and then run a large number of simulations, 5000 say, for each one ofthem. That would give us an empirical density for each principal componentat time T + h: Suppose we take the estimated mean value for each one of thosedensities at T +h: The principal component betas would give us the implied val-ues for the 10 interest rates, and the �-matrix representation above (63) wouldgive us the values for the 200 discount factors. Of course, we could have takenthe median values for the components at T + h; or we could also compute somekind of VaR market price of our portfolio by taking some extreme percentiles ofeach density in the direction of a decrease in the portfolio market price.If we work with standardized interest rates, the eigenvalues are: ( 0.0001,
0.0001, 0.0003, 0.0008, 0.0030, 0.0069, 0.0255, 0.1061, 1.6868, 8.1703), so thatone of them is zero, even though some are small, relative to the largest one. The
295
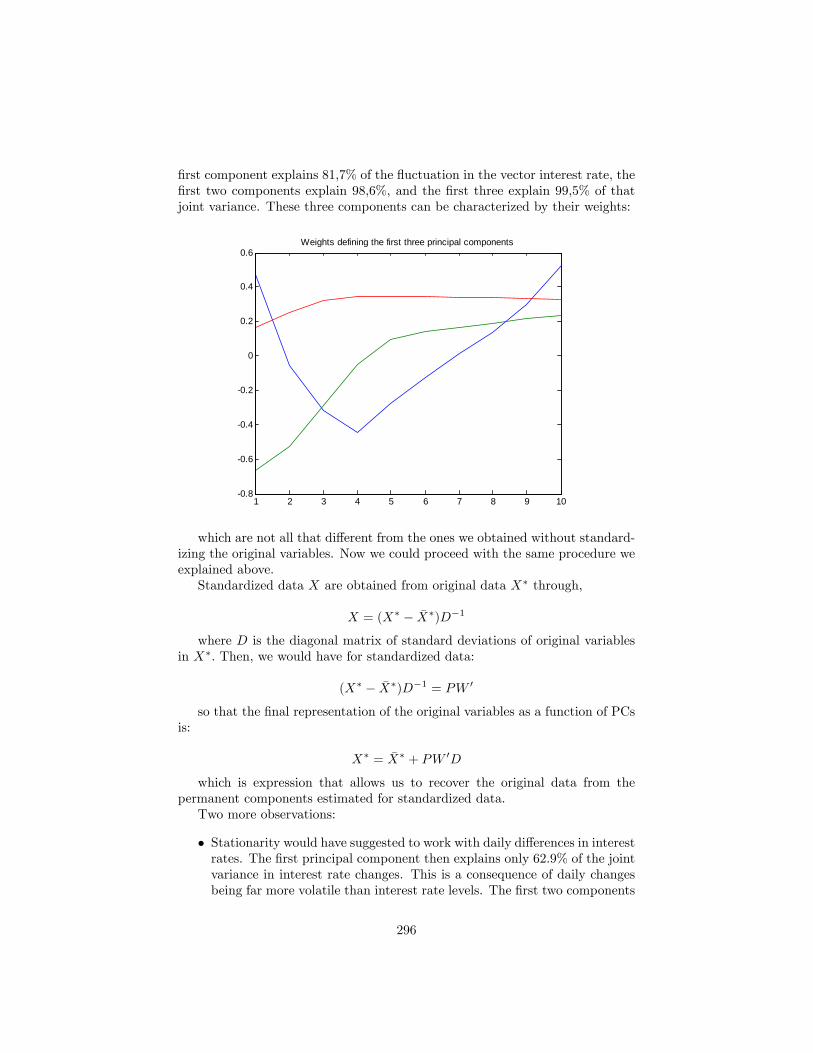
�rst component explains 81,7% of the �uctuation in the vector interest rate, the�rst two components explain 98,6%, and the �rst three explain 99,5% of thatjoint variance. These three components can be characterized by their weights:
1 2 3 4 5 6 7 8 9 100.8
0.6
0.4
0.2
0
0.2
0.4
0.6Weights defining the first three principal components
which are not all that di¤erent from the ones we obtained without standard-izing the original variables. Now we could proceed with the same procedure weexplained above.Standardized data X are obtained from original data X� through,
X = (X� � �X�)D�1
where D is the diagonal matrix of standard deviations of original variablesin X�: Then, we would have for standardized data:
(X� � �X�)D�1 = PW 0
so that the �nal representation of the original variables as a function of PCsis:
X� = �X� + PW 0D
which is expression that allows us to recover the original data from thepermanent components estimated for standardized data.Two more observations:
� Stationarity would have suggested to work with daily di¤erences in interestrates. The �rst principal component then explains only 62.9% of the jointvariance in interest rate changes. This is a consequence of daily changesbeing far more volatile than interest rate levels. The �rst two components
296

explain 86,7% of the variance in daily changes in interest rates, and the�rst three components explain 94,6%.
� A completely di¤erent approach could consist of estimating a given ana-lytical model for the zero coupon curve, like the Nelson_Siegel model. Ifwe estimate the model with daily data for a given period, we would havetime series for each of the parameters in the model, and a multivariatemodel (there are 4 parameters in the Nelson-Siegel model) could help usto simulate their behavior or to predict their values at the desired horizon.Using the predicted values (or the mean values for each parameter fromits empirical density if we have a run a large number of simulations) wecould directly compute the zero coupon discount rate and then the dis-count factor at each maturity for which a bond in the portfolio is supposedto pay coupon after T + h:I this case, we would be taking as risk factorsthe parameters in the Nelson-Siegel model. But they will not be uncorre-lated, so care must be paid when running the simulations to preserve thecorrelation structure observed in actual data.
21.3 An alternative presentation of PCs:
The PCs of a vector of returns r are linear combinations like:
y = w0r
with covariance matrix: V ar(y) = w0�rw: We want to obtain uncorrelatedlinear combinations with the largest possible variance. Since that could bearti�cially obtained by increasing the norm of vector w; we restrict our attentionto vectors w with w0w = 1; and consider:
Max w01�rw1
sujeto a : w01w1 = 1
with Lagrangian: L(w1; q) = w01�rw1 � q(w01w1 � 1)and optimality conditions:
@L
@w1= 2�rw1 � 2qw1 = 0
@L
@q= w01w1 � 1 = 0
so that w1 should satisfy:
�rw1 = qw1
then being an eigenvector of the sample covariance matrix �r; while theLagrange multiplier q is the eigenvalue associated to that eigenvector.
297

Multiplying through the previous equation by w01 , we have,:
w01�rw1 = qw01w1 = q
so that w01�rw1 is maximized by taking as vector w1 in the linear combina-tion the eigenvector associated to the largest eigenvalue of �r : q = �1:The second PC will also be a linear combination of returns in r , w02r;
uncorrelated with the �rst PC. With standardized variables,
Cov(w01r; w2r) = w01�rw2 = w01rr0w2
Transposing, we have:
Cov(w01r; w2r) = (rr0w2)
0w1 = (�rw2)0w1
so that the covariance between both linear combinations will be equal to zeroif w2 is chosen so that (�rw2)0w1 = 0. Suppose we take as w2 an eigenvectorof �r di¤erent from w1: Its associated eigenvalue � will satisfy: �rw2 = �2w2;and the previous equation becomes:
0 = (�2w2)0w1 = �2w
02w1
which we know it holds, since eigenvectors corresponding to di¤erent eigen-values are orthogonal to each other.Hence, if we want to solve the optimization problem:
Max w02�rw2
sujeto a : w02w2 = 1
w02w1 = 0
we need to choose as vector w2 an eigenvector of �r; di¤erent from w1; tomaximize the quadratic form w02�rw2: But,
w02�rw2 = w02(�w2) = �w02w2 = �
which will take its highest value if � is the second eigenvalue of the variance-covariance matrix (and correlation matrix because of the standardization) �r:Asimilar argument would lead to the remaining PCs of vector r:
21.4 First applications of principal components
21.4.1 Risk decomposition
Suppose we need to estimate the covariance matrix of a large vector mx1 ofinterest rates. The representation of each interest rate as a function of a set ofprincipal components can be written is,
r�it = wi1p1t + :::+ wikpkt
298

with r�it being the standardized version of rit, r�it =
rit��ri�i
; �i =pV ar(ri):
In terms of original variables, we will have,
rit = w�i1p1t + :::+ w�ikpkt + uit
where w�ij = wij�j and where the error term indicates the approximationerror when we take a subset of k of the m PCs.Since PCs are uncorrelated, their variance-covariance matrix is,
V =W �DW �0 +�u
where V is the variance-covariance matrix of them interest rates,W � is themxkmatrix of weights, w�ij ; D is the kxk diagonal matrix of standard deviations of theprincipal components, and �u is the covariance matrix of approximation errorsnot necessarily diagonal. The latter can be reduced by increasing the numberof PCs considered in the representation of interest rates, and it is standard toignore it in the previous expressionThis estimation of the variance-covariance matrix of interest rates may turn
out to be positive semide�nite, if we take a number of PCs lower than thenumber of original variables. However, the big advantage is that we just needto estimate k variances, rather than m(m+ 1)=2 variances and covariances.In the decomposition above, W �DW �0 represents the systematic risk in the
set of assets, due to the uncertainty in the future evolution of the principalcomponents, while �u represents the size of idiosyncratic risk.
21.4.2 An application to stock market management
A similar argument can be applied to solve the asset allocation problem in stockmarkets. Let us consider a vector time series of international stock marketindices, on which a manager would like to diversify his/her position. It is initself interesting to analyze how much �uctuation in the markets it is commonsince, at a di¤erence of the TSIR, it is far from obvious that comovements maybe very important. Once again, even though the linear combinations that ariseas factors may not be easy to interpret, we may get a nice discussion when wesucceed in doing so. A speci�c market index, or the spread between two marketsmay be some of the principal components arising in this analysis.Once the components have been characterized, it is clear that a manager
investing in them will be capturing the �uctuation in the markets he/she wasplanning to invest. notice that each component can be considered as a portfolio.In this case, it will be a portfolio of index portfolios, but our same argumentwould apply to choosing a portfolio in a given stock market.An equal weight portfolio might run into important redundancies, thereby
producing an ine¢ cient solution to the asset allocation problem. An interestingempirical exercise has to do with following the performance of a portfolio whichdiversi�es among the components, in relation to the performance of the portfoliowhich is allocated equally among the indices. Not even the diversi�cation amongthe components is obvious, since we might want to invest more heavily in the
299

�rst component than in the second, more in this than in the third component,and so on.A di¤erent question relates to the construction of a market index. It is a
standard practice that stocks are weighted by capitalization to produce a marketindex. That implies that in some markets like the Spanish, �ve or six assetsrepresent 85% of the market index. However, that does not mean that investingin these assets is an e¢ cient strategy, and it might be better to invest in theportfolio de�ned by the �rst principal component, or to diversify between theportfolios de�ned by the �rst two or three components.
21.5 Present value of a basis point: PV01
A preliminary concept is �01; the basis point sensitivity of the discount factor,de�ned as,
�01t =1
(1 +RT � :01)T� 1
(1 +RT )T
where we initially assume T to be an integer number of years. �01 willusually be less than 10 basis points, it increases with maturity and the increaseis more pronounced for low levels of interest rates.The present value of a basis point measures the absolute change in the value
of a cash �ow sequence because of a fall of on basis point in the yield curve(term structure):
PV 01(C; r) = PV (C; r�)� PV (C; r)
where PV (C; r) denotes the present value of the cash �ow sequence C (akx1 vector), and r is the discount rate vector, while r� = r � (:01%)1k:For a single bond, PV01 is very similar to the standard duration, which is
the change in present value of the bond per unit change in the bond yield. Thereare two di¤erences:
1. In general, the PV01 is the exact cash �ow sensitivity to a parallel shift inthe zero coupon yield curve, whereas duration is just an approximation.Both concepts coincide just if a shift in the zero coupon curve caused theyields on all the bonds in the portfolio to change by the same amount,which is very unlikely.
2. Duration cannot be extended to cover all interest rate sensitive instru-ments. For instance, it cannot apply to negative cash �ows.
Then, the present value of a basis point of a cash �ow CT at time T can beobtained by multiplying the cash �ow by the change in the discount factor as aconsequence of the change of one basis point in interest rates:
PV 01T = CT :�01T
300

and for a cash �ow sequence,
PV 01 =kXi=1
CTi :�01Ti
� Exercise III.1.18: A bond with nominal 1 million pounds, that pays a 6%coupon until maturity, 4 years from now, trades at 103.62, exactly one yearfrom the next coupon. Current zero coupon rates at 1, 2, 3 and 4 years are4.50%, 4.75%, 4.85% and 5.00%, respectively. Compute the present valueof a basis point for this bond and compare it with Macaulay�s duration.Solution: The PV01 is 36,312.75, which will be the pro�t made by theholder if zero coupon rates decrease by one basis point at all maturities.The increase in price will be from the current 103.6216 to 103.6579. Theyield (internal rate of return) of the bond is 4.9796%, and the value dura-tion, which approximates the change in the price of the bond, is 36,326.59.
21.5.1 Approximations to PV01
Let us derive a �rst order (linear) approximation to �01 and hence, from that,an approximation to PV 01: If T is an integer number of years, the discountfactor is �T = (1 +RT )�T and so,
�01T ' �d�TdRT
10�4 = T (1 +RT )�(T+1)10�4
This is for a single basis point change. If there is a change of m basis points,this expression must be multiplied by m:Then, a useful approximation to the PV 01 of a cash �ow CT at time T when
T is an integral number of years is:
PV 01T � TCT (1 +RT )�(T+1)10�4
When T is less than a year,
�T = (1 + TRT )�T ) �01T ' T (1 + TRT )
�210�4
Sometimes, continuously compounded interest rates are preferred. It pro-vides approximated expressions for PV 01 valid for any maturity. The continu-ously compounded discount factor is,
�T = exp(�rTT )with rT being the continuously compounded rate of interest at maturity T:
Thus,
�01T ' �d�TdrT
10�4 = T exp(�rTT )10�4 = T�T 10�4
and therefore, the approximation to the PV 01 for a cash �ow at any maturityunder continuous compounding is:
301

PV 01T � TCT exp(�rTT )10�4
� Exercise III.1.19: Compare the exact and the approximate values for PV 01in a cash �ow that has been mapped to vertices 1 and 2 years, with 10million euros mapped to the 1-year vertex and 5 million euros mapped tothe 2-year vertex. Suppose current zero coupon rates at 1 and 2 years are4.00% and 4.50%, respectively. R: The exact PV01, calculated from thechange of a 1 basis point in the discount factor is 1801,07 euros, whilethe approximate PV01, calculated from the expression introduced in thissection, is 1801,85 euros.
21.5.2 Interest rate risk
Let us think of today as time zero: t = 0 Today, we can use current zero couponrates to compute the current present value of a cash �ow CT ; to be paid at timeT: There is no uncertainty involved in that. We also know for certain what thepresent value will be at maturity. But the present value at any intermediatetime t between today (t = 0) and maturity, t = T; is uncertain today becauseof uncertainty on:
� by how much the discount rate might change, and
� how sensitive is the present value to changes in the discount rate
To answer the �rst question we need a measure of variance for the discountrate. To answer the second, we use the concept of present value of one basispoint.The best forecast of the appropriate discount rate at time t is the forward
zero coupon rate Ft;T�t; starting at time t with maturity T � t: We calculatetoday using current interest rates. Today�s expected discounted value of CTat time t is CT times the appropriate discount factor, based on this forwardrate. The sensitivity of this time t value to movements in the forward rate ismeasured by the PV 01; that is approximately given by the expression above,for T � t maturity. Assuming both are integer numbers,
PV 01t;T � (T � t)CT (1 + Ft;T�t)�(T�t+1)10�4
The interest rate risk of a cash-�ow of CT refers to the uncertainty about thediscounted value of this cash �ow at some future time t: Assuming that changesin that rate are independent and identically distributed, the t-period standarddeviation of the forward rate, can be obtained by using the square-root rule:pt�t;T�t:The standard deviation of the future discounted value above is the product
of both quantities. With continuously compounded forward rates:
�(PVt) = 10�4pt�t;T�t(T � t)CT exp [�(T � t)ft;T�t]
302

21.5.3 Summary of expressions
Discrete compounding Continuous compoundingDiscount factor �T = (1 +RT )
�T �T = exp(�rTT )Interest rate sensitivity �01T ' T (1 +RT )
�(T+1)10�4 �01T ' T exp(�rTT )10�4 = T�T 10�4
PV of one basis point for CT PV 01T � TCT (1 +RT )�(T+1)10�4 PV 01T � TCT exp(�rTT )10�4
Expected PV of CT at t PV 01t;T � (T � t)CT (1 + Ft;T�t)�(T�t+1)10�4 PV 01t;T � (T � t)CT exp [�(T � t)ft;T�t]
21.6 Applications of Permanent Components to Fixed In-come management
Example II.2.1: Principal Component factor model for a UK bond portfolio(http://www.bankofengland.co.uk/statistics/yieldcurve/index.htm).A portfolio of UK government bonds has been mapped to interest rates at
maturities 1 year, 2 years,..., 20 years. The cash �ow over 20 years is given. Weare supposed to build a PC factor model for this portfolio. Remember that thechange in price of a bond can be approximated by the change in interest rateat each relevant maturity, multiplied by the present value a one basis point ateach of those maturities:
Pt � Pt�1 =nXi=1
PV 01i(Ri;t �Ri;t�1)) �Pt =nXi=1
PV 01i�Ri;t
that is, in matrix notation:
�Pt = PV 010�Rt
where PV 01 denotes the vector of present values of a one basis point at eachmaturity.But once we construct the Principal components, we can approximate the
change in each interest rate as a function of changes in the factors (the principalcomponents in this case):
�Ri;t = wi1PC1t + wi1PC2t + :::+ wikPCkt
so that,
�Pt =nXi=1
PV 01i
0@ kXj=1
wijPCjt
1A =kXj=1
nXi=1
PV 01iwij
!PCjt =
kXj=1
�jPCjt
(64)with the beta on each Principal Component being de�ned by,
�j =
nXi=1
PV 01iwij (65)
303

Coming back to the example, we can use this expression to compute thesensitivities of the Pro�t&Loss of the portfolio to the PCA factors:
P&Lt ' L=651:82PC1t + L=1045:49PC2t � L=1051:15PC3tthat represent the approximate change in price as a change of any given
magnitude in each Principal Component. If we have interpreted the PCs as thegeneral level in interest rates, the slope of the term structure and its curvature,we can compute the expected change in the nominal value of the portfolio ofsay, 25 basis points increase in interest rates, coming together with a 15 basispoints reduction in slope and no change in curvature, for instance.Example II.2.2 : Factor model for currency forward positions:At time t we face a sequence of foreign currency payments (C1; :::; Cn) at
future times (T1; :::; Tn). Let us denote by �P dt the change in the present valueof the entire sequence of cash �ows in domestic currency when the domesticinterest rates change by amounts:
�Rdt = (�Rd1t; :::;�R
dnt)
Then,
�P dt =nXi=1
PV 01di�Rdit
where PV 01di is the PV 01 sensitivity of the cash �ow in domestic currencyat maturity Ti: Similarly,
�P ft =nXi=1
PV 01fi�Rdit (66)
is the change in present value of the sequence of payments in foreign currencywhen the domestic interest rates change.If St denotes the domestic foreign exchange rate, then: P dt = StP
ft ; so that
taking logs and di¤erencing over time, we get: Rdt ' Rst +Rft ; where Rdt is the
return on the cash �ow in domestic currency, Rft is the return on the cash �owin foreign currency, and Rst is the return on the spot exchange rate.Now we can approximately decompose the risk on a sequence of foreign
currency forward payments into exchange rate and interest rate risks:
V ar(Rdt ) ' V ar(Rst ) + V ar(Rft ) + 2Cov(R
st ; R
ft )
However, although the exchange rate risk is de�ned in terms of the varianceof returns, the interest rate risk is de�ned in terms of the variance of the P&Lposition, and not the variance of returns. But we can rewrite the previousexpression:
V ar(�P dt ) =��P d�2V ar(Rst ) + �S2V ar(�P ft ) + 2 �P
d �SCov(Rst ;�Pft )
304

where �P f ; �P d denote the present values of the cash �ows in domestic andforeign currencies respectively, and �S is the exchange rate at the time the riskis measured. Thus �P f ; �P d and �S are �xed. The terms on the right hand sideare quadratic forms based on covariance matrices of a very large number ofdi¤erent domestic interest rates. In the next example, we consider a scheduleof 60 monthly foreign currency payments, so V ar(�P ft ) would be calculatedfrom a quadratic form with a 60x60 covariance matrix, while Cov(Rst ;�P
ft )
would have 60 components. These would clearly be very painful to compute.Assuming that the currency is very liquid so that the forward prices are closeto their fair value, Principal Components are very helpful:
1. We start by using the term structure of interest rate form each country tocompute the present value of the sequence of cash-�ows. We can use theexchange rate to write the two present values in the domestic currency.They will not be equal to each other, since we have used a di¤erent termstructure to compute them.
2. For the second term, we want to compute the variance of the price of theportfolio at the foreign currency. Hence, we compute the PV 01 in theforeign currency at the di¤erent maturities and use them, together withthe structure of the Principal Components, to obtain the betas for theportfolio of cash �ows as in (65) : Then, (64) would allows us to computethe variance of the change in the price of the portfolio from the varianceof each Principal Component (i.e., its eigenvalue) and the betas we justobtained.
3. The �rst term is easy: we compute the volatility of the exchange rate inour sample, and multiply it by the price of the portfolio (sequence of cash�ows) at the domestic currency.
4. For the last term, we need the Covariance between daily returns on theexchange rate and portfolio price changes in the foreign currency. Thesechanges can be approximated from (66) : To compute Cov(Rst ;�P
ft ) we
will use the representation of �P ft as a function of the three Principal
Components. We have: �P ft =nXi=1
PV 01fi�Rdit together with �R
di;t =
wi1PC1t + wi1PC2t + ::: + wikPCkt:The two expressions together, leadto �P ft =
Pkj=1 �jPCjt, so that: V ar(�P
ft ) =
Pkj=1 �
2jV ar(PCjt) and
Cov(Rst ;�Pft ) =
Pkj=1 �jCov(R
st ; PCjt): So, we �rst compute the co-
variance between the time series for each Principal Component and thereturns on the exchange rate. Each such covariance is multiplied by thecorresponding portfolio beta, �j =
Pni=1 PV 01
fi wij , and we add the ob-
tained products. Finally, that covariance is multiplied by the exchangerate and the present value of the cash �ow sequence, in the domestic cur-rency.
305

Example II.2.2 : Let us suppose that a UK re�nery has purchased crude oilin the US paying in US dollars through futures contracts, so that there is nocommodity price risk. However, some other risks remain: i) exchange rate risk,arising from uncertainty on the sterling value of future payments in dollars, ii)interest rate risk, arising from the change in present value of the sterling cash�ows, iii) the correlation risk, arising from the correlation between UK interestrates and the sterling-dollar exchange rate (see exchange rate data and interestrate data in http://www.bankofengland.co.uk/). We assume the UK companyhas forward payments of $1 million on the 5th of every month over the next 5years.We �rst approximate the change in present value of the sequence of pay-
ments in foreign currency when the domestic interest rates change: �P $t =8:2248PC1t + 12:9120PC2t � 0:3101PC3t and use this expression to obtain:V ar(�P $t ) = 44; 685; which we need to estimate: IR�RISK =
p250 �S L=6; 654:
The 250 factor is used because of dealing with daily data. The volatility of theexchange rate is obtained as
p250V ar(Rst );and the foreign exchange risk is
obtained multiplying the previous volatility by the present value of the cash-�ow in the domestic currency: FX � RISK = L=2; 118; 347: For Correlationrisk, we use expression Cov(Rst ;�P
ft ) =
Pkj=1 �jCov(R
st ; PCjt), introducing
again a 250 factor, and multiply the covariance estimate by the present value ofthe sequence of cash �ows in the domestic currency and by the exchange rate.The result is Correlation Risk = L=71; 024: Finally, TOTAL RISK is equal toL=2; 119; 548, most of it explained by exchange rate risk:Example II.2.3 : PCA factor models for crude oil (commodity) futuresExample II.2.4 : Bond portfolio immunization. Data from Example II.2.1.
Let us now see how to immunize a portfolio against the main sources of risk inthe term structure of interest rates. We assume the risk factors are appropriatelysummarized by the �rst three principal components. We now ask the questionof how much of the 10-year bond should we add so that the new portfolioPro�t&Loss is invariant to changes in the �rst principal component. We takethis as an approximation to the immunization of the sequence of cash-�owsagainst parallel shifts in the term structure. As shown in the spreadsheet, weneed a negative cash �ow of L=-44,224,695 at 10-year maturity, which amounts totaking a short position of L=-2,716,474, that is, selling now this nominal amountof the 10-year bond. With this strategy, we get the factor risk model:
P&Lt ' L=1243:80PC2t � L=582:88PC3tThe choice of maturity is arbitrary, so long as there is a bond instrument
that can be traded.Now we could ask which positions should we add in the 5- and 15-year
bonds to immunize the cash-�ow sequence against changes in slope of the termstructure. We will need to take positions at two di¤erent maturities to achievethat hedge. The answer is a negative cash �ow of L=-7,369,609 at the 5-yearmaturity, and a long position of L=4,725,167 at 15-year maturity, which amountto selling now L=-5,938,242 of the 5-year bond, and purchasing L=2,451,747 of the
306

15-year bond. With these added positions, the risk factor model becomes,
P&Lt ' L=391:15PC3tand we could additionally �nd three positions at di¤erent maturities that
could immunize the cash �ow sequence against changes in the third principalcomponent.Example II.2.5 : Asset-liability management : A single curve PCA factor
model can be used to balance assets and liabilities. For example, considera pension fund that asks how to invest its income from contributors in �xedincome securities so that its P&L is insensitive to the most common movementsin interest rates, as captures by the �rst three principal components. Similarly,a corporate may have a series of �xed liabilities, such as payments on a �xedrate loan, and seek to �nance these payments by issuing �xed coupon bonds ornotes. In Example II.2.5, we consider a UK �rm with a �xed stream of liabilitiesof £ 1 million per month over the next 5 years. It seeks to �nance these by issuingzero coupon bonds at 1-, 3- and 5-years to maturity. How many bonds shouldit issue or purchase on 31 December 2007 so that the portfolio of assets andliabilities has zero sensitivity to parallel shifts and changes in slope of the UKgovernment spot yield curve?The present value of the liabilities on 31 December 2007 is £ 53,887,892. The
factor model for the original stream of cash �ows is,
P&Lt ' L=38:6341PC1t + L=63:9891PC2t + L=0:6776PC3tWe want to �nd cash �ows at 1-, 3- and 5-year maturities such that a) the
present value of the increased sequence of cash �ows remains the same as before,£ 53,887,892, and b) the net position of assets and liabilities has a Pro�t&Lossthat has zero sensitivities to the �rst and second principal components of the UKspot curve. As shown in the spreadsheet, if we add cash �ows of £ 19,068,089,£ 19,537,974 and £ 22,921,668 at the 1-, 3- and 5-year maturities, respectively, thenew stream of cash �ows will have the required zero sensitivities. This amountsto issuing £ 18,202,846.57 of 1-year bonds, and purchasing £ 18,469,691.95 and£ 17,215,353.04 of 3- and 5-year maturity bonds, respectively.Example II.2.6 : Stress testing a UK bond portfolio. Stress tests have become
unfortunately popular during the current �nancial crisis. They consist of pass-ing a given portfolio through what is considered an extreme market situation.Of course, the de�nition of what we mean by such situation is crucial for theresult of the test. We start this exercise by computing the portfolio Pro�t&Lossvolatility based on a one-, two-, and three-principal component representationof the term structure, and comparing the results with the ones obtained withoutusing the factor model.From the Pro�t&Loss factor representation,
P&Lt ' L=651:82PC1t + L=1045:49PC2t � L=1051:15PC3twe get an estimate of the variance of the P≪ based on one principal
component, of V olatility(P&Lt) = $186; 951: If we base the computation on
307

two components, we get: V olatility(P&Lt) = $216; 949; while if we use threeprincipal components we get: V olatility(P&Lt) = $220; 680. The variancenecessarily increases by increasing the number of principal components we usein tis calculus. As we see, the result we obtain with two and three componentsis very similar.The alternative procedure consists of using the representation based on the
present value of a one basis point change: �Pt =nXi=1
PV 01i�Rit = PV 010�R;to
obtain:
V ar(P&Lt) = (PV 01) [V ar(�Rit)] (PV 01)0= $220; 941
very close to the result obtained with the principal components. Since we aredealing with monthly data, a factor of 12 was used to compute the V ar(P&Lt):We now move to the proper stress testing, by estimating the P&L that could
emerge from an extreme scenario. It is standard to think of that as a 6 standarddeviations change in each of the risk factors.Example II.2.7 : Multiple curve factor models: PCA on curves with di¤erent
credit ratingExample II.2.8 : Multiple curve factor models: PCA on curves in di¤erent
currenciesExample II.2.9 : Equity PCA factor models. Principal components are also
very useful to reduce the dimensionality of an analysis of a stock market. Theyare therefore an essential instrument for risk management and portfolio man-agement in those markets. One possibility is to compute them to summarizethe information on a large vector of returns. If we regress the return for eachstock on the k chosen principal components:
rit = �i + �i1P1t + �i2P2t + :::+ �ikPkt
we can estimate a vector of betas and a scalar alpha for each stock. Sincethe Principal Components are obtained form a covariance or from a correlationmatrix, they have E(Pit) = 0; and we then have:
E(rit) = �i;
V ar(rit) =kX
m=1
�2im�m;
Cov(rit; rjt) =kX
m=1
�im�jm�m
where �m denotes them-the principal component of the covariance/correlationmatrix of stock returns, and where we have used the zero covariance propertyof the principal components. In matrix form, if we denote by R the vector of Nstock returns, we have:
308

V ar(R) = B�B0
where � denotes the NxN variance-covariance matrix of the principal com-ponents, which will be a diagonal matrix with the eigenvalues � along the di-agonal, and B is the kxN matrix that has in each column the k-vector of betasfor each stock.If we have a portfolio de�ned by the vector of weights on each stock, w0 =
(w1; w2; :::; wN ), the alpha and beta of the portfolio is obtained from those forthe individual stocks by the usual relationships: �P = w0� and �p = Bw: Thespeci�c or idiosyncratic risk component of the portfolio is:
specific risk =�w0w � �0p��p
�1=2which should be converted to annual volatility using the factor that corre-
sponds to the frequency of the observed data.Stock data are usually not very highly correlated, so that it is not possi-
ble to capture a high percentage of the joint variation with a small numberof principal components. However, the number of stocks trading in a givenmarket is huge, so that the need to reduce the dimensionality of the problemis unquestionable. Principal components become a very useful tool for equityfund management. The spreadsheet contains daily data for 30 stocks tradingin the Dow Jones Industrial from 31 December 2004 to 26 April 2006. The�rst 5 principal components explain 60% of the variance. We also present therepresentation model for each stock as a function of the �ve components, andwe can see that the R2 for the GM stock in those representations is almost 1.The Principal Components technique allows to easily decompose the total riskin each stock, as well as for any portfolio. We see that for the equally weightedportfolio (same cash amount invested in each stock) the market risk is equal tothe total risk, with an speci�c risk of zero. For the DJIA index, the systematicrisk is 10.05% versus a total risk of 10.11%, with a small speci�c risk, of only1.02%. To compute this, we take into account that the DJIA is the portfoliomade up of 1 share of each stock, and calculate the weight using prices from 26April 2006: wit = pit=
PNi=1 pjt. We then use these weights, as constant over
time, to compute the portfolio betas and the risk decomposition. Notice thatthis is the right evaluation to make of risk at 26 April 2006 for an investmenton DJIA. If we regressed the actual historical time series of the DJIA on the�ve principal components we would have found a di¤erent result, because theDJIA needs rebalancing, as the prices of the di¤erent stocks change over time.
21.7 Appendix 1: Principal components
Given T data points on k variables, the principal component methodology triesto �nd a representation of the vector of k variables through a small set of plinear combinations of them.Let Y be the Txk data matrix having as columns the observations on each
variable. We consider the model,
309

~yi;t = yi;t� �yi = bi;1z1;t+ bi;2z2;t+ :::+ bi;pzp;t+ "i;t; i = 1; 2; ::; k; t = 1; 2; :::; T(67)
where �yi; denotes the sample mean of the i-th variable, and zj;t denotesthe t-th observation on the j-th principal component. The model is written toexplain the behavior of di¤erences in observed variables around their samplemeans. This is convenient to avoid numerical problem that could arise for verydi¤erent measurement scales among the observed variables.In vector terms, we have,
~yi = bi;1z1 + bi;2z2 + :::+ bi;pzp + "i; i = 1; 2; ::; k;
a relationship between column vectors Tx1 containing observations for thei-th variable and each of the principal components.Principal components are de�ned as,
zj = aj;1~y1 + aj;2~y2 + :::+ aj;k~yk; j = 1; 2; ::; p;
and we want to �nd the vectors (aj;1; aj;2; :::; aj;k) ; j = 1; 2; :::; p that bestsummarize the information in the matrix ~Y of standardized data. Principalcomponents have zero mean. We want to minimize the error in �tting ~Y by(67) : It can be shown that choosing the principal components satisfying thatcondition amounts to choosing those with the highest variance.Hence, we need to solve an optimization problem having as objective function
the variance of the resulting principal components. Since the �rst principalcomponent is de�ned by,0BB@
z11z12::z1T
1CCA =
0BB@~y1;1 ~y2;1 ~yk;1~y1;2 ~y2;2 ~yk;2
~y1;T ~y2;T ~yk;T
1CCA0BB@
a1;1a1;2::a1;k
1CCAor,
z1 = ~Y a1
with variance,
V ar(z1) =1
Tz01z1 =
1
T
�~Y a1
�0 �~Y a1
�=1
Ta01Sya1
Since V ar(z1) can be maximized without bound by just increasing the normof vector a1; we need to impose some restriction on the feasible parameter spacefor a1: We do that by constraining ourselves to k a1 k= a01a1 � 1: In fact, thesolution will be achieved by some a1 with k a1 k= 1:The �rst principal component is then found as solution to,
310

Max T:V ar(z1) = a01Sya1
subject to a01a1 = 1
with Lagrangian,
L(a1; �) = a01Sya1 � � (a01a1 � 1)
leading to the optimality conditions,
@L
@a1= 2Sya1 � 2�a1 = 0
@L
@�= a01a1 � 1 = 0
whose solution satis�es,
Sya1 = �a1
so that the Lagrange multiplier � turns out to be an eigenvalue of the samplecovariance matrix Sy; a1 being the associated eigenvector. To determine whicheigenvalue should be chosen, we multiply the previous equation through by a01;
a01Sya1 = �a01a1 = �
so that � turns out to be equal to V ar(z1). We have already mentioned thatchoosing the best �tting at (67) amounts to choosing the principal componentswith the highest possible variance. Hence, � should be chosen as the largesteigenvalue of Sy: The associated eigenvector de�nes the weights to be usedto produce the principal component as a linear combination of the originalvariables.It is clear that we can construct a set of up to k principal components,
decreasing in variance, by just using as weights the elements in the eigenvectorsassociated to successive eigenvalues decreasing in size.If we want to choose two principal components, z1 = ~Y a1; z2 = ~Y a2, for kx1
vectors a1; a2; the objective function is the sum of their variances,
Max T: (V ar(z1) + V ar(z2)) = a01Sya1 + a02Sya2
subject to a01a1 = a02a2 = 1
with Lagrangian,
L(a1; a2; �1; �2) = a01Sya1 + a02Sya2 � �1 (a01a1 � 1)� �2 (a02a2 � 1)
leading to the optimality conditions,
311

@L
@a1= 2Sya1 � 2�1a1 = 0;
@L
@a2= 2Sya2 � 2�2a2 = 0
@L
@�1= a01a1 � 1 = 0;
@L
@�2= a02a2 � 1 = 0
whose solution satis�es,
Sya1 = �1a1
Sya2 = �2a2
so that �1; �2 are eigenvalues of Sy, and a1; a2 their associated eigenvectors.The result extends with no di¢ culty to the case of p principal components,
with 1 � p � k: So, we need to �nd the eigenvalues of the sample covariancematrix of the data Sy by solving its characteristic equation,
j Sy � �Ik j= 0
and �nding the associated eigenvectors.In matrix terms, the relationship between principal components and original
data can be written,
Z = ~Y �
where Z is the Txk matrix of principal components, � is the kxk matrixhaving as columns the eigenvectors of Sy, and ~Y is the Txk matrix of data indeviations to the sample mean. It is important that we use a numerical routinethat orders eigenvalues and associated eigenvectors by eigenvalue size.If we are just interested on p components, then � will have just p columns,
being then a kxp matrix, each column being the eigenvector associated to oneof the �rst p eigenvalues, and the resulting Z-matrix will be of dimension Txp.As a consequence, variables in the original set can also be written in terms
of the principal components as,
~Y = Z�0
that is,
Y = Z�0 + 1T �y
where 1T denotes a column vector of T ones and �y is the row vector madeup by the sample means of the k original variables.Since the variance of each principal component is equal to the corresponding
eigenvalue of Sy, each one of them explains a percentage,
pj =�jPku=1 �u
312

Notice that the spectral decomposition theorem guarantees that any positivede�nite matrix can be written as,
� = ���0
where � is the diagonal matrix with elements equal to the eigenvalues of �,and � is an orthogonal matrix made up with the standardized eigenvectors of �:Of course, the elements of � and the columns of � are ordered correspondingly.Hence,
j � j=j ���0 j=j � jj � jj �0 j=j � j=kYj=1
�j
tr� = tr (���0) = tr (�0��) = tr� =kXj=1
�j
in our case, with � = Sy; we have,
j Sy j=kYj=1
�j =kYj=1
V ar(zj)
tr (Sy) =kXj=1
�j =kXj=1
V ar(zj)
that is, the sum of the variances of the principal components is equal to thesum of the variances of variables in the original data set.Furthermore, being eigenvectors, any two principal components are uncor-
related with each other in the sample.As an example, let us suppose that we have two variables, y1; y2; which have
been standardized to have zero mean and unit variance. Matrix Sy is then,
Sy =
�1 �� 1
�with eigenvalues 1��: If y1; y2 are positively correlated, then the �rst (largest)
eigenvalue is 1+ �; with associated eigenvector (1; 1) : Hence, the �rst principalcomponent of y1; y2 is,
z1 =1p2(y1 + y2)
which is proportional to the sum of the original variables. Notice that, infact, as we already know, V ar (z1) = 1 + �: The second principal componentcorresponds to the second (smallest) eigenvalue, 1� �; being,
z2 =1p2(y1 � y2)
313

which is proportional to the di¤erence between the elements of y1 and y2: Itis easy to check that its variance is, in fact, V ar (z2) = 1��: If � < 0; the orderof the eigenvectors would be reversed.
21.7.1 Lack of scale-invariance in principal components (Mardia,Kent, Bibby)
An important di¢ culty with principal components is that they are not scale-invariant, the reason being that eigenvectors are not scale-invariant either. If wedivide the i-th variable by di; the covariance matrix of the new variables becomesDSyD; where D = diag(d�1i ): However, if x is an eigenvector of Sy; then D�1xis not an eigenvector of DSyD: That is, eigenvectors are not scale-invariant.In the 2-variable case, we have,
Sy =
��21 ��1�2��1�2 �22
�where � > 0: The larger eigenvalue is �1 = 1
2
��21 + �
22
�+ 1
2�; with � =h��21 � �22
�2+ 4�21�
22�2i1=2
; and associated eigenvector proportional to,
(a1; a2) =��21 � �22
�+� ; 2��1�2) (68)
When �1=�2 = 1; the ratio a2=a1 = 1: If �1 = �2 and the �rst variable ismultiplied by a factor k, we would like the a2=a1-ratio to also get multiplied byk. however, changing �1 to k�1 in (68) easily shows that this is not the case.The lack of scale invariance means that we need to worry about the way
scales are chosen and, in particular, about the units of measurement for eachvariable. Sometimes, variables are homogenized by standardizing them, i.e.,dividing them by their respective sample standard deviation, �nding principalcomponents of their correlation matrix. However, this practice produces somedi¢ culties in hypothesis testing.
21.7.2 Hypothesis testing on eigenvalues and eigenvectors
Under some regularity conditions, it can be shown that if l1; l2; :::; lk denotesample eigenvalues, then, asymptotically,
ln lj � N(ln�j ;2
T � 1)
where the second argument is the variance of the distribution.If gj denotes the j-th sample eigenvector, then, asymptotically,
gj � Nk
� j ;
1
T � 1Vj�
where,
314

Vj = �jXi 6=j
�i
(�j � �i)2 j
0i
21.7.3 La capacidad predictiva de las betas históricas
Algunas de las di�cultades en la estimación de �i y �i provienen del hecho deque cabe esperar que ninguno de ellos sea constante, sino que varíen en fun-ción de cambios en las características de la empresa. Aunque las betas suleneestimarse utilizando mínimos cuadrados ordinarios en un modelo lineal de re-gresión del exceso de rentabilidad del activo sobre el exceso de rentabilidad delmercado, caben muchas posibilidades, como la utilización de ventanas móviles,la estimación de un modelo de parámetros cambiantes, la utilización del �ltro deKalman, que permitirían obtener alfas y betas cambiantes en el tiempo. Consid-erar alfas y betas cambiantes abre la posibilidad de predecir sus valores futurosa partir de series temporales de valores estimados para ambos parametros, y ellopermitiría mejorar la gestión de riesgos sobre un determiando horizonte, igualal utilizado en la previsión de la alfa y beta de cada activo.Una de las primeras cuestiones analizadas en relación con la posibilidad de
predecir betas, se re�ere al grado de asociación que pueda existir entre las betasen un determinado período o intervalo de tiempo, y las betas del período sigu-iente. Blume [12] estimó betas utilizando datos mensuales sobre dos intervalosno solapados de 7 años de duración. Generó betas para carteras de un sólo ac-tivo, de 2, 4 activos, y así sucesivamente hasta carteras de 50 activos. Para cadauno de estos tamaños, examinó la correlación entre los betas de un período ylos del otro. Las correlaciones resultaron aumentar con el número de activos in-cluidos en la cartera, oscilando desde 0,60 para carteras de un sólo activo, hasta0,98 para carteras de 50 activos. Por tanto, las betas de activos individuales nocontienen mucha información acerca de sus valores futuros. Esto puede debersea que a) el riesgo del activo puede cambiar, b) la beta de cada período se estimacon un error aleatorio, y cuanto mayor es el error, menos capacidad predictivatendrán las betas de un período para las del período siguiente. Los cambiosen las betas de activos individuales pueden producirse al alza o a la baja, porlo que al construir carteras de múltiples activos, estos cambios tenderán a can-celarse mutuamente, haciendo que las betas de tales carteras cambien menos.Asimismo, también los errores producidos al estimar las betas, que pueden serpositivos o negativos, tenderán a cancelarse dentro de una cartera, siendo menorel error cometido al estimar la beta de una cartera que el cometido al estimarlas betas de activos individuales. Por ambas razones, la beta de una carteraserá más fácilmente predecible que la de activos individuales.
Ajustes sobre los betas estimados Supongamos por un momento que elverdadero beta de todos los activos fuese igual a uno. Al estimarlos, algunasde nuestras estimaciones estarían por debajo y otras por encima de su valorverdadero, que es uno. La beta que estimaríamos sería, en parte, una función delverdadero beta y, en parte, una función del error de muestreo. Si estimamos una
315

beta muy elevada, habrá una alta probabilidad de que el error en la estimaciónhaya sido positivo, mientras que si estimamos una beta muy baja, habrá unaelevada probabilidad de que el error de estimación haya sido negativo. Si el errorde estimación es puramente aletorio y, por tanto, independiente en el tiempo, lasbetas estimadas en sucesivos intervalos de tiempo tenderán a converger hacia 1:betas estimadas muy por encima de 1 tenderán a venir seguidos por betas máspróximas a 1 y, por tanto, menores, y lo contrario ocurriría con betas estimadosinferiores a 1. Nuevamente, Blume [12] proporciona evidencia empírica en estesentido.Por tanto, parece natural corregir los betas estimados para recoger esta
conversión hacia 1. Blume propuso ajustar las betas hacia uno, y suponerque el ajuste efectuado en un período es asimismo adecuado para el períodosiguiente. Para ello, estimamos una regresión de los betas del segundo períodocon respecto a las betas de las mismas carteras durante el período anterior.Blume obtuvo: �i2 = 0; 343 + 0; 677�i1. De acuerdo con esta regresión, unabeta de 2,0 pasaría a ser de 1,67 el período siguiente, mientras que una beta de0,5 pasaría a ser de 0,682, reduciendo los valores de las betas altas, y elevandolos de la betas bajas. Asimismo, la ecuación permite modi�car el promedio delas betas en la población de activos: si el promedio de las betas ha aumentadodel primer período al segundo (lo cual ocurrirá si la beta es menor que 1,062),el modelo anterior implica que la beta promedio va a volver a aumentar (salvoque haya sobrepasado ya el umbral de 1,062). Si, por el contrario, no hay razónpara creer que esto va a pasar, nuestras estimaciones de las betas individuales,obtenidas utilizando la regresión anterior mejorarían si las ajustamos de modoque su promedio sea igual al promedio de las betas del período previo. Paraello, puede utilizarse un factor de escala, preferiblemente, o bien una traslaciónpor una constante.Si queremos predecir las betas para un tercer período utilizaríamos nueva-
mente la regresión anterior. Además, puede suponerse que la misma regresiónserviría para predecir las betas de activos o carteras no incluidos en la muestra.
El ajuste de Vasicek Hemos visto que la verdadera beta para el períodopara el cual estamos prediciendo tiende a estar más próxima a la media delas betas (en la sección cruzada de activos), que la predicción obtenida porun procedimiento econométrico habitual de predicción. Otro modo de efectuareste ajuste consiste en combinar la beta promedio y la predicción de una betaindividual. Para que la combinación de ambas no sea arbitraria, Vasicek propusoque las ponderaciones utilizadas en esta combinación estuviesen determinadaspor el tamaño del error muestral de la beta estimada. Cuanto mayor sea unabeta respecto de la media de las betas de los activos, �, mayor es la probabilidadde que el error de estimación sea importante, por lo que el ajuste debe ser mayor.Vasicek propuso:
�i =�2�
�2�i + �2�
�i +�2�i
�2�i + �2�
�i
316

donde �2�i denota la varianza de la estimación de la beta del activo, y �2�la
varianza de la beta promedio. Este es un ajuste bayesiano, pues la expresión dela esperanza matemática a posteriori de una población Normal, a partir de laesperanza de la distribución a priori y de la media muestral.Aunque este ajuste no genera una tendencia en las betas, tiene el mismo
sesgo que el procedimiento de Blume: como los activos de beta elevado tienenasociados errores mayores, la reducción proporcional en el valor de sus betas coneste ajuste será superior al ajuste al alza de los betas que se hallan por debajodel promedio. Por tanto, la estimación de la beta promedio futura tenderá a serinferior a la beta promedio actual. Por tanto las betas deben ajustarse al alzapara incorporar este efecto.
Las betas como predictores de los coe�cientes de correlación Los coe-�cientes de correlación son un input preciso a muchos efectos esenciales: análisisde carteras, Valor en Riesgo, etc., y las betas estimadas pueden utilizarse paraestimar los coe�cientes de correlación, como alternativa al uso de coe�cientesde correlación en muestras históricas. Para ello, basta escribir:
�ij =�ij�i�j
=�i�j�
2m
�i�j
Elton, Gruber, Urich [31] compararon diversos métodos de predecir las cor-relaciones entre rentabilidades de activos individuales: a) la matriz de correla-ciones históricas, b) predicciones obtenidas estimando las betas del períodohistórico previo, c) predicciones obtenidas estimando las betas para 2 períodosprevios y actualizando sus valores mediante la técnica de Blume, d) prediccionesobtenidas como en el caso anterior, pero con la actualización bayesiana de Va-sicek. Lo más sorprendente es que las correlaciones históricas resultaron ser elpeor de los predictores de las correlaciones futuras, lo que sugiere que una partede las mismas se debe a ruido aleatorio. A pesar de ser una simpli�cación dela realidad, el. modelo de un índice puede utilizarse para obtener prediccionessuperiores a la mera extrapolación de las estimadas en series temporales.La comparación entre los tres métodos basados en las betas resultó más
ambigua: el ajuste de Blume funcionó signi�cativamente mejor que el ajustebayesiano y que las betas no ajustadas en los dos períodos considerados. Elajuste bayesiano funcionó mejor que las betas no ajustadas en un período, ypero en el otro, en ambos casos signi�cativamente.Cabe interpretar estos métodos en conjunto: dado que el modelo supone que
las correlaciones entre rentabilidades se producen únicamente por su relación conel comportamiento del mercado, en la medida en que existan otras fuentes decorrelación, y que tal correlación sea positiva (como cabe esperar), las betas sinajustar subestimarán la correlación media entre rentabilidades. El pocedimientode Blume incorpora este sesgo, y tiene otros dos más: uno se debe a que ajustatodas las betas hacia 1, lo que eleva el coe�ciente de correlación estimado,puesto que dicho coe�ciente depende del producto de las betas y se tiene que,por ejemplo: 1; 1 � 0; 9 > 1; 2 � 0; 8. El segundo sesgo proviene de su ajuste
317

en función del cambio entre períodos 1 y 2. Si este cambio ha sido positivo(negativo), el método de Blume ajusta todas las betas hacia arriba (abajo),lo cual, si se cree que tal tendencia es persistente, es adecuado, pero sólo ental caso. Ambos hechos tienden a generar predicciones de correlaciones máselevadas de las verdaderas..También el ajuste bayesiano corrige las betas hacia 1, pero no proyecta una
tendencia en ellas. Incorpora, sin embargo, una nueva fuente de sesgo: losactivos de alto beta se ajustan más hacia la media que los de bajo beta, lo quereduce las betas estimadas, y produce un sesgo a la baja en los coe�cientes decorrelación.Sin embargo, la importancia de estos sesgos será aleatoria de unos períodos a
otros, y es difícil anticipar qué procedimiento proporcionará mejores resultados,especialmente si no hay una tendencia de�nida en las betas. Precisamente, unamanera de eliminar tales tendencias es forzar que el coe�ciente de correlaciónpromedio estimado con cada uno de estos procedimientos coincida con el coe-�ciente de correlación promedio obtenido para el período en que se estimó elmodelo33 . Cuando se lleva a cabo este ajuste adicional, el método bayesianofunciona signi�cativamente mejor que los demás procedimientos.. Cuando secompara además con una predicción ingenua, que �ja el valor de todas las betasigual a 1, también se obtienen mejores resultados..En resumen, hemos examinado el uso de las betas estimadas para a) prede-
cir betas futuras, b) predecir coe�cientes de correlación, que puedan utilizarsecomo input en el problema de gestión de cartera. Para predecir betas futuras, espreferible utilizar betas ajustadas, si bien no es evidente qué ajuste sea preferi-ble. Para predecir coe�cientes de correlación, el ajuste bayesiano es preferible,especialmente una vez que se hace el ajuste entre los coe�cientes de correlaciónpromedio, como parece aconsejable.
Betas fundamentales Factores históricos determianntes de la Beta de unactivo, como la volatilidad, el rango de precios observado, o el volumen medionegociado, tardan tiempo en incorporar de manera signi�cativa los cambios queen ellos puedan producirse. Al estimar con un conjunto de datos temporales, delos cuales sólo los últimos recogen cambios en los factores históricos, las Betasestimadas respecto a dichos factores tendrán una fuerte inercia respecto de lasBetas estimadas en el pasado.Otra línea de investigación se ha encaminado a tratar de caracterizar deter-
minantes de las Betas de un activo basadas en los fundamentales de la empresaa que representa. A diferencia de factores históricos, los factores fundamen-tales recogen cambios inmediatamente. Dichos fundamentales pueden ser: a)los dividendo pagados, como porcentaje de los bene�cios (efecto negativo sobrelas betas, al reducir la percepción de riesgo sobre la rentabilidad de la empresa),b) la tasa de crecimiento de los activos (efecto positivo), c) el apalancamiento(capital emitido sobre activos) (efecto positivo), d) la liquidez (activos sobre
33Cuando el ajuste se hizo con el coe�ciente de correlación promedio sobre el período depredicción, el ranking de procedimientos fue el mismo que en el caso descrito.
318

pasivos) (efecto negativo), e) el tamaño total de los activos (efecto negativo),f ) la variabilidad en los bene�cios (desviación típica del PER-price earningsratio) (efecto positivo), g) la beta contable o beta de bene�cios (calculada me-diante una regresión de bene�cios de la empresa sobre bene�cios promedio dela economía).Otros estudios han utilizado una inmensa variabilidad de posibles determi-
nantes de las betas. En particular, se han utilizado también variables �cticiassectoriales. Este análisis tiene dos tipos de limitaciones: una, que el núemro dedeterminantes considerados de las Betas puede ser muy elevado, di�cultando lainterpretación de cuáles de ellos son realmente relevantes, debido ala colineal-idad; la segunda, que las regresiones de sección cruzada de Betas de empresasindividuales sobre sus fundamentales suponen que el efecto sobre la Beta de unavariación en algún fundamental es el mismo para todas las empresas, lo cual notiene por qué ser cierto.
21.7.4 Frontera e�ciente
Permitiendo posiciones cortas y con posibilidad de préstamos a tipode interés sin riesgo Denotemos por B el punto de tangencia sobre la fron-tera e�ciente de la recta que viene del eje de ordenadas a la altura del tipo deinterés sin riesgo, rF : Se trata de encontrar la recta rFB con la máxima pendi-ente. Dicha recta es la frontera e�ciente en este contexto. Para ello, hemos deresolver el problema,
Max � =�rc � rF�c
sujeto a :
NXi=1
Xi = 1
Frente a la posibilidad de aplicar el principio de Kuhn-Tucker y multipli-cadores de Lagrange, vamos a sustituir la restricción en la función objetivo, parapasar a maximizar la función objetivo sin estar sujeta a restricciones. Podemosescribir,
rF = 1rF =
NXi=1
Xi
!rF =
NXi=1
XirF
por lo que la función objetivo es,
� =
NXi=1
Xi (�ri � rF )24 NXi=1
X2i �
2i +
NXi=1
NXj=1;i 6=j
XiXj�ij
351=2
319

con condiciones de optimalidad: @�@Xi
= 0; i = 1; 2; :::; N: Dichas condicionesson,
@�
@Xi= �
��X1�1i + �X2�2i + :::+ �Xi�
2i + :::+ �XN�1�N�1;i + �XN�Ni
�+(�ri�rF ) = 0
De�nimos nuevas variables: Zi = �Xi; i = 1; 2; :::; N: Así, tenemos,
�ri� rF = Z1�1i+Z2�2i+ :::+Zi�2i + :::+ZN�1�N�1;i+ZN�Ni; i = 1; 2; :::; N
(69)donde las Zi son proporcionales a las cantidades óptimas que deben invertirse
en cada activo. Para ello, resolvemos primero los valores de las Zi; y luegocalculamos ponderaciones Xi; mediante Xi = Zi=
PNj=1 Zi:
Ejemplo: Determinar la cartera óptima con tres activos con rentabilidadesesperadas 14%, 8% y 20% y volatilidades (desviaciones típicas de rentabilidades)de 6%, 3% y 15%. La correlación entre las rentabilidades de los activos 1 y 2 esde 0,5; entre los activos 1 y 3 es de 0,2; y entre los activos 2 y 3 es de 0,4. Eltipo de interés sin riesgo es 5%. R: La cartera óptima consiste en invertir 14/18de la cartera en el activo 1, 1/18 en el activo 2 y 3/18 en el activo 3, con unarentabilidad esperada de 44/3 y una varianza de 203/6.
Apéndice: Determinación de la derivada de la función objetivo Si
escribimos la función objetivo como: � =
"NXi=1
Xi (�ri � rF )#24 NX
i=1
X2i �
2i +
NXi=1
NXj=1;i 6=j
XiXj�ij
351=2 ;tenemos:
@�
@Xk=
"NXi=1
Xi (�ri � rF )#264�1
2
0@ NXi=1
X2i �
2i +
NXi=1
NXj=1;i 6=j
XiXj�ij
1A�3=20@2Xk�2k + 2
NXj=1;j 6=k
Xj�kj
1A375+
+
24 NXi=1
X2i �
2i +
NXi=1
NXj=1;i 6=j
XiXj�ij
351=2i
(�rk � rF )
que hemos de igualar a cero, y simpli�cando,
�
NXi=1
Xi (�ri � rF )
NXi=1
X2i �
2i +
NXi=1
NXj=1;i 6=j
XiXj�ij
0@Xk�2k +
NXj=1;j 6=k
Xj�kj
1A+ (�rk � rF ) = 0
320

y de�niendo como � al primer factor, que no es sino: � = �rc�rF�2c
; tenemos�nalmente,
��
0@Xk�2k +
NXj=1;j 6=k
Xj�kj
1A+ (�rk � rF ) = 0que es la expresión que antes vimos.
Con posiciones cortas, pero sin posibilidad de préstamos a tipo deinterés sin riesgo El enfoque que podemos seguir en este caso consiste encaracterizar la cartera óptima para distintos niveles del tipo de interés sin riesgo,lo que permite ir describiendo la frontera e�ciente. Puede probarse que la pro-porción óptima de cada activo que debe invertirse en cada activo es una funciónlineal de rF : Por otro lado, como es sabido, basta con caracterizar dos activosen la frontera e�ciente, pues ello nos permite trazar toda la frontera e�ciente.Si resolvemos el sistema (69) para obtener los valores de cada Zk como
funciones del nivel del tipo de interés sin riesgo; tenemos,
Zk = C0k + C1krF (70)
para determinadas constantes C0k; C1k: Son constantes en el sentido de queno cambian con rF : Basta resolver el sistema para dos niveles de rF para deter-minar estas constantes para cada activo.Ejemplo: Para los activos del ejemplo anterior, tenemos:
Z1 =42
189
Z2 =118
189� 23
189rF
Z3 =4
189+
1
189rF
y es interesante representar gra�camente estas rectas para saber bajo quéniveles del tipo de interés sin riesgo se tomarán posiciones cortas o largas encada activo. Este es un modo de describir la frontera e�ciente en este caso. Paracada nivel de rF determinamos los valores de las Z y dividimos por su sumapara que el resultado sume 1 y podamos interpretarlos como ponderaciones.En particular, cuando rF = 5; tenemos: X1 = 14=18; X2 = 1=18; X3 = 3=18:
Si encontramos la cartera óptima pra rF veremos que Z1 = 42=189; Z2 =72=189; Z2 = 6=189, que conduce a una cartera e�ciente: X1 = 7=20; X2 =12=20; X3 = 1=20; con rentabiliad esperada: 107
10 y varianza: 5481400 : Si llevamos
los valores de Z2 en ambas carteras e�cientes a la ecuación (70) ; tenemos: C02 =118189 ; C12 = �
23189 : Haciendo lo mismo para todos los activos, podemos describir
la frontera e�ciente. Por tanto, solo necesitamos resolver el sistema (69) parados valores de rF :
321

Otra posibilidad distinta de describir la frontera e�ciente, que no precisade encontrara los valores numéricos de las Z ni las C, consiste en calcular lacovarianza entre las rentabilidades de ambas carteras. Para ello formamos unacartera arbitraria, por ejemplo, con ponderaciones 1/2 a cada una de las doscarteras previas, y calculamos su varianza. La comparación del valor numéricode la varianza de la cartera con las varianzas de las dos carteas que la componen,permiten calcular el valor numérico de la covarianza entre ambas y, con ella,calculamos la frontera e�ciente completa.En el ejemplo anterior, la cartera equiponderada entre las dos que hemos
calculado para rF = 2 y rF = 5; es: X1 = 203=360; X2 = 118=360; X3 = 39=360;con varianza: 21; 859: Pero siendo una cartera formada con las dos anteriores,su varianza debe ser igual a:
21; 859 =
�1
2
�2203
6+
�1
2
�25481
400+ 2
�1
2
��1
2
��12
de donde obtenemos: �12 = 19; 95: Conociendo la covarianza podemosconstruir la frontera e�ciente del modo habitual: tomamos un parámetro �y formamos la cartera: � (14=18; 1=18; 3=18) + (1� �) (7=20; 12=20; 1=20) cuyarentabilidad esperada y varainza son funciones de �: Al variar � describimos lafrontera e�ciente.
Sin posiciones cortas Si permitimos la posibilidad de prestar y pedir prestadoal tipo de interés sin riesgo, se trata entonces de resolver el problema de opti-mización:
Max � =�rc � rF�c
sujeto a :
NXi=1
Xi = 1
Xi � 0; i = 1; 2; :::; N
que necesita ser resuelto numéricamente con una rutina de programaciónadecuada.Si tampoco permitimos préstamos al tipo de interés sin riesgo, habremos
de resolver el problema de minimizar la varianza para un determinado nivel deriesgo, r�:
322

MinimizeX1;X2;:::;Xn
NXi=1
X2i �
2i + 2
NXi=1
NXj=1;j 6=i
XiXj�ij
sujeto a :NXi=1
Xi = 1; Xi � 0; i = 1; 2; :::; N
NXi=1
Xiri = r�
Haciendo variar r� a partir de la rentabilidad de la cartera de mínima var-ianza y hasta la rentabilidad máxima, describimos la frontera e�ciente. Denuevo, el problema anterior debe resolverse para cada nivel de r� utilizando unsoftware adecuado para resolver problemas de optimización no lineal.Por supuesto, que a cada uno de los problemas anteriores pueden añadirse
restricciones como un nivel de dividendos esperados, o una cota máxima en laponderación que puede invertirse en cada activo, o un nivel de liquidez min-ima, o un nivel de VaR, si bien la solucion de los mismos puede complicarsesustancialmente.
21.7.5 Técnicas sencillas de determinación de la frontera e�ciente
Elton, Gruberg y Padberg propusieron un procedimiento sorprendentementesencillo de generar una cartera óptima bajo el supeusto de que el modelo de uníndice es válido, con la rentabilidad de mercado como índice, que presentamosen esta sección.
Sin posiciones cortas Supongamos que contamos con N activos. Comen-zamos estableciendo un ranking de los mismos de acuerdo con la ratio entre suexceso de rentabilidad y su Beta:
�ri � rF�i
donde �ri denota la rentabilidad esperada sobre el horizonted e inversión, quepuede aproximarse por una media muestral histórica. Este ranking representa laconveniencia de que un determinado activo entre en la cartera. Estableceremosun umbral C�; e incluiremos en la cartera aquellos activos con una ratio derentabilidad en exceso respecto de Beta superior a C�; no incluyendo ningúnactivo con una ratio inferior a este umbral.El umbral crítico C� es escogido del siguiente modo: vamos a calcular uno
de dichos umbrales Ci para cada conjunto de activos; es decir, un umbral C1para una cartera con un solo activo, otro umbral C2 para una cartera con losdos activos de mayor ratio entre rentabilidad en exceso y Beta, otro umbral C3para una cartera de tres activos, etc.. El umbral seleccionado es el único de losumbrales mencionados que cumple la condición de que el número de activos con
323

una ratio superior a ese particular Ci es exactamente el número de activos quehemos utilizado en el cálculo de Ci: Siempre hay uno y sólo uno de los Ci quesatisface tal condición. A ese umbral Ci lo denotamos por C�:Cada uno de los umbrales mencionados es calculado mediante:
Ci =�2mPij=1
(�ri�rF )�j�2uj
1 + �2mPij=1
��2j�2uj
�donde puede verse el papel relevante que juegan tanto las Betas estimadas
como los tamaños �2uj de los componentes especí�cos de las rentabilidades.Los umbrales pueden escribirse asimismo,
Ci =(�rc � rF )�ic
�i
donde �ic representa el cambio esperado en la rentabilidad del activo i-ésimo asociado a un 1% de variación en la rentabilidad de la cartera óptima.Esta expresión no puede utilizarse en el cálculo de la cartera óptima ni para laselección ade activos, porque obviamente, ignoramos las propiedades de dichacartera antes de construirla. Pero es muy útil para entender el procedimientopropuesto. Añadimos activos a la cartera hasta el punto en que �ri�rF
�i> Ci; es
decir, mientars que se cumpla: �ri�rF > �ic (�rc � rF ) : El término de la derechaes la rentabilidad en exceso esperada como consecuencia del resultado obtenidopor la cartera. El término de la izquierda es la estimación de la rentabilidad enexceso esperada para el activo individual. Si creemos que un activo va a obtenermejor resultado del que cabria esperar de su pertenencia a la cartera, debemosincorporarlo a la misma.Una vez determiandos los activos, debemos determianr sus pesos en la cartera
óptima, para lo que comenzamos calculando:
Zi =�2i�2ui
��ri � rF�i
> Ci
�que luego normalizamos mediante: Xi =
ZiPincluidos Zj
; i = 1; 2; :::; k; siendok el número de activos incluidos en la cartera:
Apéndice: El sistema de ecuaciones que debemos resolver es:
�rk � rF = Zk�2k +
NXj=1;j 6=k
Zj�kj ; k = 1; 2; :::N
que bajo el modelo de un índice se convierte en:
�rk�rF = Zk��2k�
2m
�+
NXj=1;j 6=k
Zj�k�j�2m = Zk�
2uk+
NXj=1
Zj�k�j�2m; k = 1; 2; :::N
324

por lo que,
Zk =�rk � rF�2uk
� �k�2m
�2uk
NXj=1
Zj�j =�k�2uk
��rk � rF�k
� C��; k = 1; 2; :::N
donde: C� = �2mPNj=1 Zj�j :
Si multiplicamos la expresión anterior por �k y sumamos, tenemos,
NXj=1
Zj�j =NXj=1
(�rk � rF )�k�2uk
� �2mNXj=1
�j�2uj
NXj=1
Zj�j
de donde:
NXj=1
Zj�j =
PNj=1
(�rk�rF )�k�2uk
1 + �2mPNj=1
�j�2uj
y:
C� = �2m
NXj=1
Zj�j =�2mPNj=1
(�rk�rF )�k�2uk
1 + �2mPNj=1
�j�2uj
Para obtener una expresión alternativa para C�; tenemos en cuenta que Zj =�rc�rF�2c
Xj y tambien quePNj=1Xj�j e sla Beta de la cartear, por lo que:
C� = �2m
NXj=1
Zj�j = �2m
NXj=1
�rc � rF�2c
Xj�j = �2m�rc � rF�2c
�c
Dividiendo y multiplicando por �i y teniendo en cuenta que �i�c�2m es la
covarianza entre el activo i-ésimo y la cartear, tenemos:
C� =�rc � rF�2c
1
�iCov(i; c) =
�ic�i(�rc � rF )
donde �ic es el estiamdor d eminimos cuadrados de la pendiente de la regre-sión de ri sobre rm:
Permitiendo posiciones cortas Si se permiten posiciones cortas, todos losactivos van a formar parte de la cartera óptima. Si su ratio de rentabilidad enexceso a Beta es atractivo entrarán con pesos positivos (posiciones largas) y, encaso contrario, entrarán con pesos negativos (posiciones cortas). En este caso,debe tomarse como umbral crítico C� el que se calcula con todos los activosconsiderados. Calculamos los pesos Zi del mismo modo anterior, pero no esevidente cómo normalizar estos pesos en este caso. Podría hacerse del modoanterior, aunque algunos Zi sean negativos, o seguir la propuesta de Lintner dehacerlo mediante:
325

Xi =ZiPN
j=1 jZj j; i = 1; 2; :::; N
Ambas normalizaciones pueden dar lugar, en general, a ponderaciones muydistintas. La normalización habitual suele conducir a ponderaciones muy el-evadas, mientras que la propuesta de Lintner suele conducir a carteras másrazonables. Las proporciones en que entran enl a cartera óptima los activos quese incluian en la cartera cuando no se permiten posiciones a corto no guardanuna relación igual a la de aquella cartera. Esto es lógico, por cuanto que permi-tir posiciones cortas altera sustancialmente el conjunto de activos con el que secon�gura la cartera.
21.7.6 Apéndice: Algunas secciones anteriores, en castellano
El modelo de un índice Hasta ahora, hemos presentado el análisis de Markowitzpara la selección de carteras e�cientes, que se basa en la consideración de larentabilidad esperada y la volatilidad de cada uno de los activos disponibles..Este análisis precisa conocer asimismo las covarianzas o, lo que es lo mismo,los coe�cientes de correlación entre las rentabilidades de cada par de activos.Este requerimiento signi�ca, en la mayoría de las situaciones de interés, que elanalista necesita disponer de muchos parámetros estimados. Por ejemplo, enel caso de considerar la inversión en los 35 valores que con�guran el Ibex35,el analista necesitaría: 35 rentabilidades esperadas, más 35 volatilidades, más35*17 correlaciones, un total de 665 parámetros.Los modelos de índices tienen como ventaja que reducen considerablemente
la dimensionalidad del problema de gestión de carteras. El modelo de un índicepostula:
rit = ait + �iIt
que la rentabilidad aleatoria de cada uno de los activos disponibles tienedos componentes: uno, ait ; especí�co del activo, y otro, �iIt; que re�eja unefecto común a todos los activos, debido al factor It; común a las rentabilidadesde todos ellos. Las �uctuaciones que a lo largo del tiempo experimenta larentabilidad de un activo se debe a variaciones en estos dos factores. El factorIt podría ser la tasa de in�ación, It = �t, o la rentabilidad de un índice demercado, It = rmt
, por ejemplo.Si extraemos la esperanza matemática de ai tendremos: ai = �i+ui, donde
�i es una constante especí�ca de cada activo, mientras que ui es el elementoaleatorio especí�co de cada uno de ellos. Por tanto, tenemos:
rit = �i + �iIt + uit (71)
El modelo de 1 índice está de�nido por dos características:a) Cov(uit ; It) = E(uit ; It) = 0;b) Cov(uit ; ujt) = 0:
326

La primera condición signi�ca que el grado en que el modelo de 1 íondicerepresenta el comportamiento de la rentabilidad de un activo es independientedel valor del índice (es independiente de la rentabilidad del mercado, en elejemplo propuesto). La primera condición puede conseguirse, por construcción,si se utilizan datos de series temporales para estimar por mínimos cuadradosordinarios el modelo 71. Se trataría de escoger un índice de entre los muchosposibles, y estimar por el procedimiento citado una regresión del tipo 71 parala rentabilidad de cada activo. El residuo de dicha regresión se tomaría como elcomponente aleatorio, de media cero, especi�co de cada activo. Como es biensabido dicho residuo está incorrelacionado con las variables explicativas de laregresión. Cabe observar, por tanto, dos cosas: en primer lugar, que un analistapuede construir empíricamente tantos modelos de un índice como quiera. Ensegundo lugar, que un modelo de un índice no debe ser objeto de un análisiseconométrico detallado, conducente a obtener sus mejores estimaciones. Si unanalista lleva a cabo correcciones de autocorrelación o de heterocedasticidad,o estima por métodos de variables instrumentales, en general no obtendrá lapropiedad de independencia entre uit y It:La segunda hipótesis es la que realmente de�ne el modelo, por cuanto que es,
en general poco probable que se cumpla, al menos estrictamente. Hay que pensarque, considerando el caso de inversión en los 35 activos del Ibex35, tendríamosque comprobar que las 595 correlaciones que pueden obtenerse entre los residuosde las regresiones correspondientes a 2 activos distintos, fuesen todos ellos igual acero. Por tanto, hay que tomar el modelo de 1 factor más como una construcciónteórica que como una realidad empírica. Como modelo teórico, es muy útil paraayudarnos a pensar acerca del modo adecuado de medir el riesgo de una activo�nanciero, como veremos enseguida.Esta segunda hipótesis signi�ca que el factor es realmente informativo, pues
recoge todo lo que de común hay en las �uctuaciones en las rentabilidades de losactivos considerados. Dicho factor es la única razón que explica los movimien-tos conjuntos entre rentabilidades de activos. Pueden existir otros elementosademás del índice, pero han de ser estrictamente especí�cos. Por ejemplo,supongamos que utilizamos como índice la rentabilidad de un índice de mer-cado. Podría pensarse que el elemento especí�co, es decir, el residuo de laregresión de rentabilidad el activo sobre rentabilidad de mercado, venga ex-plicado por los dividendos distribuidos, y que estos tienen un comportamientoespecí�co de cada activo. Sin embargo, en muchos casos no es así pues, aunsiendo relativamente incorrelacionados entre activos, los dividendos podrían es-tar muy correlacionados entre activos de un mismo sector (bancos, construcción,eléctricas, etc.).A partir de ahora, por aclarar la notación, suponemos que se utiliza como
factor la rentabilidad del índice de mercado. Si denotamos por V ar(ui) =�2ui ; i = 1; 2; :::; N , V ar(It) = V ar(rm) = �2m; bajo las hipótesis del modelo,
327

tenemos:
ri = �i + �irm
�2i = �2i�2m + �
2ui
�ij = �i�j�2m
que muestran que: a) la rentabilidad esperada de un activo tiene dos com-ponentes: uno debido a la rentabilidad esperada del mercado, y otro debido a�i; b) la varianza de la rentabilidad de un activo tiene asimismo dos compo-nentes, un nuevamente debido a la volatilidad de la rentabilidad del mercado,y otro debido a la volatilidad del componente especí�co uit ; de modo que elriesgo de un activo tiene un componente de riesgo especí�co y otro de riesgode mercado, c) por último, la covarianza entre la rentabilidad de dos activos sedebe exclusivamente al riesgo de mercado.Las representaciones anteriores nos sirven para expresar el valor esperado
y la varianza de la rentabilidad de una cartera, sin más que recordar que laexpresión de su rentabilidad es: rc =
PNi=1Xiri; por lo que tenemos:
rc =
NXi=1
Xiri =
NXi=1
Xi�i +
NXi=1
Xi�irm = �c +
NXi=1
Xi�i
!rm = �c + �crm
donde hemos de�nido el alfa y la beta de la cartera, �c y �c a partir de loscorrespondientes a los activos que la componen, por:
�c =
NXi=1
Xi�i
�c =
NXi=1
Xi�i
Además,
�2c =NXi=1
X2i �
2i+2
NXi=1
NXj=1;j 6=i
XiXj�ij =NXi=1
X2i �
2i�
2m+2
NXi=1
NXj=1;j 6=i
XiXj�i�j�2m+
NXi=1
X2i �
2ui
Estas expresiones muestran que podemos estimar la rentabilidad esperaday el riesgo de cualquier cartera a partir de estimaciones de �i; �i; �
2ui ; rm; �
2m;
un total de 3N + 2 parámetros, frente a los 2N + N(N � 1)=2: En el casode los 35 valores del Ibex35, el número de parámetros requerido se reduce de665 a 107, pero si seguimos un mercado amplio, la reducción es muy superior.Alternativamente, el mismo análisis puede efectuarse a partir de estimaciones deri; �
2ui ; �i; rm; �
2m; nuevamente 3N + 2 parámetros, pues de un conjunto puede
obtenerse el otro sin ninguna di�cultad.
328

Características del modelo El riesgo-volatilidad de una cartera puede es-cribirse:
�2c =
0@ NXi=1
NXj=1
XiXj�i�j
1A�2m +NXi=1
X2i �
2ui =
NXi=1
Xi�i
! NXi=1
Xj�j
!�2m +
NXi=1
X2i �
2ui
= �2c�2m +
NXi=1
X2i �
2ui
Consideremos ahora una cartera bien diversi�cada. Esta es una carteraque: a) invierte en un amplio conjunto de activos, b) no concentra el valornominal invertido en un subconjunto reducido de los activos en los que invierte.En particular, una cartera de este tipo es una cartera que distribuye su valornominal a partes iguales entre un conjunto de N activos, siendo N grande34 .La volatilidad de dicha cartera es:
�2c = �2c�2m +
NXi=1
�1
N
�2�2ui = �2c�
2m +
1
N
NXi=1
1
N�2ui
!El término en corchete es el promedio de las varianzas de los términos especí-
�cos de las rentabilidades de los activos considerados. En términos empíricos,dicho término es el promedio de las varianzas residuales de las N regresionesestimadas en la construcción del modelo de un factor. Aunque su valor numéricovariará con la muestra utilizada, no hay ninguna razón para que no sea estable(salvo que las rentabilidades de activos individuales y del mercado, no siendoestacionarias, no estén cointegradas). Por tanto, su cociente por N tenderá acero al aumentar el número de activos en la cartera. El componente del riesgode una cartera que no puede eliminarse es el asociado al riesgo de mercado, porlo que nos queda:
�c ' �2c�2m = �m
NXi=1
Xi�i
!Como �m es común a cualquier cartera que podamos construir, tenemos que
la contribución de un activo individual al riesgo de una cartera se mide a travésde su beta, �i:Hemos visto que el riesgo de un activo individual es �2i = �2i�
2m+�
2ui ; que de-
pende en parte de su beta, y en parte de la varianza de su componente especí�co.Puesto que el efecto de �2ui sobre el riesgo de una cartera puede eliminarse alaumentar N , se conoce a dicho componente como riesgo diversi�cable, o riesgoidiosincrático del activo. Por el contrario, �2i�
2m no disminuye al aumentar N ,
y �i es la medida del componentes no diversi�cable del riesgo de un activo.
34Puede apreciarse que la expresión anterior no se satisface exactamente para la cartera demercado, lo que ilustra que las hipótesis del modelo de un indice son inconsistentes para elcaso �2c = �
2m:
329

22 Un modelo general de tipos de interés
Para explicar la evolución temporal de los tipos de interés, consideremos lasiguiente ecuación diferencial estocástica
drt = (�+ �rt) dt+ �r t dWt
como en Chan et al. (1992a) [CKLS], donde rt; t > 0; es un proceso es-tocástico real en tiempo continuo, y �; �; y � son parámetros estructuralescuyo valor numérico es desconocido. Esta ecuación general anida como casosparticulares diversos modelos que han sido propuestos en la literatura.
22.1 Discretización exacta
Bergstrom (1984) prueba que el modelo discreto correspondiente al anterior es,
rt = e�rt�1 +�
�
�e� � 1
�+ �t; t = 1; 2; :::; T (72)
con,
E (�t�s) = 0; s 6= t
E��2t�=
�2
2�
�e2� � 1
�r2 t�1 = m2
2t
Si denotamos por � =��; �; ; �2
�el vector de parámetros del modelo, ten-
emos el logaritmo de la función de verosimilitud L (�),
Le (�) = �T
2ln 2� � 1
2
TXt=2
0B@lnm22t +
hrt � e�rt�1 � �
�
�e� � 1
�i2m22t
1CA (73)
y tenemos,
L (�) = �T2ln 2� � 1
2
TXt=2
�2 lnm2t + "
2t
�donde "t; t = 1; 2; :::; T puede calcularse utilizando,
m2t"t = �t
ya que "t no es sino la versión normalizada en varianza de �t:
330

22.2 Discretización aproximada
Una discretización rápida del modelo en tiempo continuo puede obtenerse como,
rt � rt�1 = �+ �rt�1 + �t (74)
con,
E�t = 0 (75)
E��2t�= �2r2 t�1
La aproximación lineal de la función e� alrededor de � = 0 es: e� = 1 + �,por lo que (72) puede escribirse,
rt = (1 + �) rt�1 + �+ �t; t = 1; 2; :::; T
que coincide con (74), lo que nos da una idea de la diferencia entre ambasexpresiones, que será mayor cuanto mayor sea el valor absoluto de �:Bajo Normalidad del término de error, tendremos,
La (�) = �T
2ln 2��T ln��
TXt=2
ln rt�1�1
2�2
TXt=2
�(rt � rt�1)� �� �rt�1
r t�1
�2
22.3 Estimación por máxima verosimilitud
La discretización exacta puede estimarse por máxima verosimilitud, buscando enel espacio paramétrico el valor numérico de � que maximiza (73) : Cabe esperarque, en general, la función de verosimilitud no esté bien de�nida, por lo que esconveniente comenzar estimando versiones sencillas del modelo general, para irtratando de ganar generalidad, si procede, en estimaciones posteriores.Comenzamos agrupandolas expresiones para el caso general,
22.3.1 Modelo no restringido
Modelo en tiempo continuo,
drt = (�+ �rt) dt+ �r t dWt
Discretización exacta,
rt = e�rt�1 +�
�
�e� � 1
�+ �t; t = 1; 2; :::; T
Discretización aproximada
rt � rt�1 = �+ �rt�1 + �t; E�t = 0; E��2t�= �2r2 t�1
con funciones de verosimilitud,
331

Le (�) = �T
2ln 2��1
2
TXt=2
0B@lnm22t +
hrt � e�rt�1 � �
�
�e� � 1
�i2m22t
1CA ; m22t =
�2
2�
�e2� � 1
�r2 t�1
La (�) = �T
2ln 2��T ln��
TXt=2
ln rt�1�1
2�2
TXt=2
�(rt � rt�1)� �� �rt�1
r t�1
�2Veremos que cuando � = 0; las dos discretizaciones, exacta y aproximada,
coinciden. En los distintos casos particulares, tenemos,
22.3.2 Merton (1973): � = 0; = 0
Modelo en tiempo continuo,
drt = �dt+ �dWt
Discretización exacta,
rt = rt�1 + �+ �t; t = 1; 2; :::; T
Discretización aproximada
rt � rt�1 = �+ �t; E�t = 0; E��2t�= �2
con funciones de verosimilitud,
Le (�) = �T
2ln 2� � 1
2
TXt=2
lnm2
2t +[rt � rt�1 � �]2
m22t
!; m2
2t = �2; constante
La (�) = �T
2ln 2� � T ln� � 1
2�2
TXt=2
((rt � rt�1)� �)2
donde hemos utilizado que lim�!0
e��1� = 1; lim
�!0
�2
2�
�e2� � 1
�= �2: En este
caso, las funciones de verosimilitud de ambas discretizaciones coinciden.La estructura de dicha función de verosimilitud revela que la estimación de �
ha de ser la media muestral de las variaciones en el nivel del tipo de interés, � =1T
PTt=1 (rt � rt�1) ;mientras que la estimación de �2 es la suma de cuadrados de
los errores de ajuste, dividida por el tamaño muestral: �2= 1T
PTt=1 (rt � rt�1 � �)
2:
332

22.3.3 Vasicek (1977): = 0
Modelo en tiempo continuo,
drt = (�+ �rt) dt+ �dWt
Discretización exacta,
rt = e�rt�1 +�
�
�e� � 1
�+ �t; t = 1; 2; :::; T
Discretización aproximada
rt � rt�1 = �+ �rt�1 + �t; E�t = 0; E��2t�= �2
con funciones de verosimilitud,
Le (�) = �T
2ln 2��1
2
TXt=2
0B@lnm22t +
hrt � e�rt�1 � �
�
�e� � 1
�i2m22t
1CA ; m22t =
�2
2�
�e2� � 1
�
La (�) = �T
2ln 2� � T ln� � 1
2�2
TXt=2
((rt � rt�1)� �� �rt�1)2
La verosimilitud aproximada se maximiza mediante: � =PT
t=1(rt�rt�1)rt�1PTt=1 r
2t�1
; � =
1T
PTt=1 (rt � rt�1)� � 1
T
PTt=1 rt�1; �
2= 1T
PTt=1 (rt � rt�1 � �)
2:
22.3.4 Cox, Ingersoll, Ross (1985): = 1=2:
Modelo en tiempo continuo
drt = (�+ �rt) dt+ �r0:5t dWt
Discretización exacta,
rt = e�rt�1 +�
�
�e� � 1
�+ �t; t = 1; 2; :::; T
Discretización aproximada
rt � rt�1 = �+ �rt�1 + �t; E�t = 0; E��2t�= �2rt�1
con funciones de verosimilitud,
Le (�) = �T
2ln 2��1
2
TXt=2
0B@lnm22t +
hrt � e�rt�1 � �
�
�e� � 1
�i2m22t
1CA ; m22t =
�2
2�
�e2� � 1
�rt�1
333

La (�) = �T
2ln 2��T ln�� 1
2
TXt=2
ln rt�1�1
2�2
TXt=2
�(rt � rt�1)� �� �rt�1
r0:5t�1
�2La verosimilitud aproximada se maximiza aplicando mínimos cuadrados gen-
eralizados, tras imponer la estructura de heterocedasticidad de este modelo, esdecir, estimando por mínimos cuadrados ordinarios el modelo,
rt � rt�1prt�1
= �1
prt�1
+ �prt�1 +
�tprt�1
; V ar
��tprt�1
�=�2rt�1rt�1
= �2
obteniendo así las estimaciones de � y � y, posteriormente, �2= 1T
PTt=1
�rt � rt�1 � �� �rt�1
�2:
22.3.5 Dothan: � = 0; � = 0; = 1
Modelo en tiempo continuo
drt = �rtdWt
Discretización exacta,
rt = rt�1 + �t; t = 1; 2; :::; T
Discretización aproximada
rt � rt�1 = �t; E�t = 0; E��2t�= �2r2t�1
con funciones de verosimilitud,
Le (�) = �T
2ln 2� � 1
2
TXt=2
lnm2
2t +[rt � rt�1]2
m22t
!; m2
2t = �2r2t�1
La (�) = �T
2ln 2� � T ln� �
TXt=2
ln rt�1 �1
2�2
TXt=2
�rt � rt�1rt�1
�2Ambas funciones de verosimilitud coinciden, y se maximizan mediante �2= 1
T
PTt=1
(rt�rt�1)2r2t�1
:
22.3.6 Movimiento browniano geométrico: � = 0; = 1
Modelo en tiempo continuo
drt = �rtdt+ �rtdWt
Discretización exacta,
334

rt = e�rt�1 + �t; t = 1; 2; :::; T
Discretización aproximada
rt � rt�1 = �rt�1 + �t; E�t = 0; E��2t�= �2r2t�1
con funciones de verosimilitud,
Le (�) = �T
2ln 2�� 1
2
TXt=2
lnm2
2t +
�rt � e�rt�1
�2m22t
!; m2
2t =�2
2�
�e2� � 1
�r2t�1
La (�) = �T
2ln 2� � T ln� �
TXt=2
ln rt�1 �1
�2
TXt=2
�(rt � rt�1)� �rt�1
rt�1
�2La verosimilitud aproximada se maximiza aplicando mínimos cuadrados gen-
eralizados, tras imponer la estructura de heterocedasticidad de este modelo, esdecir, estimando por mínimos cuadrados ordinarios el modelo,
rt � rt�1rt�1
= � +�trt�1
; V ar
��trt�1
�=�2r2t�1r2t�1
= �2
obteniendo así la estimación de �; � = 1T
PTt=1
rt�rt�1rt�1
y, posteriormente,
�2= 1T
PTt=1
�rt � rt�1 � �rt�1
�2:
22.3.7 Brennan y Schwartz (1980): = 1
Modelo en tiempo continuo
drt = (�+ �rt) dt+ �rtdWt
Discretización exacta,
rt = e�rt�1 +�
�
�e� � 1
�+ �t; t = 1; 2; :::; T
Discretización aproximada
rt � rt�1 = �+ �rt�1 + �t; E�t = 0; E��2t�= �2r2t�1
con funciones de verosimilitud,
Le (�) = �T
2ln 2��1
2
TXt=2
0B@lnm22t +
hrt � e�rt�1 � �
�
�e� � 1
�i2m22t
1CA ; m22t =
�2
2�
�e2� � 1
�r2t�1
335

La (�) = �T
2ln 2� � T ln� �
TXt=2
ln rt�1 �1
�2
TXt=2
�(rt � rt�1)� �� �rt�1
rt�1
�2La verosimilitud aproximada se maximiza aplicando mínimos cuadrados gen-
eralizados, tras imponer la estructura de heterocedasticidad de este modelo, esdecir, estimando por mínimos cuadrados ordinarios el modelo,
rt � rt�1rt�1
= �1
rt�1+ � +
�trt�1
; V ar
��trt�1
�=�2r2t�1r2t�1
= �2
obteniendo así las estimaciones de � y � y, posteriormente, �2= 1T
PTt=1
�rt � rt�1 � �� �rt�1
�2:
22.3.8 Cox, Ingersoll, Ross (180): � = 0; � = 0; = 3=2:
Modelo en tiempo continuo
drt = �r3=2t dWt
Discretización exacta,
rt = rt�1 + �t; t = 1; 2; :::; T
Discretización aproximada
rt � rt�1 = �t; E�t = 0; E��2t�= �2r3t�1
con funciones de verosimilitud,
Le (�) = �T
2ln 2� � 1
2
TXt=2
lnm2
2t +[rt � rt�1]2
m22t
!; m2
2t = �2r3t�1
La (�) = �T
2ln 2� � T ln� � 3
2
TXt=2
ln rt�1 �1
�2
TXt=2
�rt � rt�1r3t�1
�2Ambas funciones de verosimilitud coinciden, y se maximizan aplicando mín-
imos cuadrados generalizados, tras imponer la estructura de heterocedasticidadde este modelo, es decir, estimando por mínimos cuadrados ordinarios el modelo,
rt � rt�1qr3t�1
= �1qr3t�1
+ �1
prt�1
+�tqr3t�1
; V ar
0@ �tqr3t�1
1A =�2r3t�1r3t�1
= �2
obteniendo así las estimaciones de � y � y, posteriormente, �2= 1T
PTt=1
�rt � rt�1 � �� �rt�1
�2:
336

22.3.9 Elasticidad de la varianza constante: � = 0:
Modelo en tiempo continuo
drt = �rtdt+ �r t dWt
Discretización exacta,
rt = e�rt�1 + �t; t = 1; 2; :::; T
Discretización aproximada
rt � rt�1 = �rt�1 + �t; E�t = 0; E��2t�= �2r2 t�1
con funciones de verosimilitud,
Le (�) = �T
2ln 2�� 1
2
TXt=2
lnm2
2t +
�rt � e�rt�1
�2m22t
!; m2
2t =�2
2�
�e2� � 1
�r2 t�1
La (�) = �T
2ln 2� � T ln� �
TXt=2
ln rt�1 �1
�2
TXt=2
�(rt � rt�1)� �rt�1
r t�1
�2La maximización de la función de verosimilitud aproximada puede llevarse a
cabo condicionando en un valor numérico de ; para aplicar mínimos cuadradosgeneralizados, estimando el modelo
rt � rt�1r t�1
= �r1� t�1 +�tr t�1
; E�t = 0; E
��tr t�1
�2=�2r2 t�1
r2 t�1= �2
para obtener � ( ) y, posteriormente, �2 ( )= 1T
PTt=1
�rt � rt�1 � �rt�1
�2:
Una vez realizado este ejercicio para una red de valores de ; selecionaríamosaquél que proporciona la menor estimación de �2 ( ) ; junto con la estimaciónasociada de �:
22.3.10 Condiciones iniciales
Puesto que la estimación por máxima verosimilitud requiere generalmente lautilización de un algoritmo numérico, es importante comenzar de buenas condi-ciones iniciales. En el caso de la discretización aproximada, es lógico estimarpor mínimos cuadrados el modelo (74) y tomar las estimaciones de � y � comocondiciones iniciales para estos parámetro. Respecto de � y , una posibilidadcompatible con el modelo sería utilizar como �2 la varianza residual de la re-gresión de mínimos cuadrados anterior, junto con = 0: Esto puede resultaratractivo en aquellos casos en que se quiere huir de la posibilidad de detectar
337

evidencia espúrea de heterocedasticidad. Si, por el contrario, se quiere extraertoda la información posible de los datos, en el caso de modelos que no restrin-gen el valor de ;puede ser preferible utilizar los residuos de la regresión anteriorpara estimar posteriormente el modelo,
ln �2t = �0 + �1r2t�1
y tomar como estimaciones iniciales: �2 = exp(�0); = �1; dado que estaúltima regresión procede de sustituir la esperanza matemática en la segundacondición en (75) por el valor observado del residuo, y tomar logaritmos. Nóteseque, por razones de signo, no puede estimarse una regresión similar utilizandoln �t como variable dependiente.
22.3.11 Algoritmos numéricos en la estimación por máxima verosimil-itud
Teóricamente, para estimar por máxima verosimilitud deberíamos derivar la fun-ción de verosimilitud o su logaritmo (lo que suele ser más sencillo, al menos bajoNormalidad), respecto a cada uno de los parámetros del modelo, y al igualar acero cada una de dichas derivadas, tendríamos tantas condiciones de optimalidadcomo parámetros a estimar. Resolveríamos dicho sistema encontrando valoresnuméricos para cada parámetro del modelo. Si se cunplen las condiciones desegundo orden (hessiano del logaritmo de la función de verosimilitud de�nidonegativo en el vector de valores paramétricos que hemos obtenido como solu-ción al sistema anterior, si estamos buscando un mínimo, o de�nido positivo,si estamos buscando un máximo), entonces podríamos decir que hemos halladoun mínimo o un máximo local, respectivamente. Nótese nuestra insistencia enque no habremos obtenido la solución al problema de optimización salvo si lafunción de verosimilitud es globalmente cóncava, en caso de buscar un máximo,o convexa, en caso de buscar un mínimo.El problema básico es que, excepto en .casos muy especí�cos, el sistema de
condiciones de primer orden no tiene solución analítica, es decir, no puedendespejarse en él los parámetros desconocidos. Ello hace necesaria la utilizaciónde un algoritmo numérico de optimización.Consideremos una función F (�) cuyo mínimo estamos buscando. Supong-
amos que disponemos de una estimación inicial de los parámetros desconocidos,�0; y queremos obtener otra estimación más próxima al verdadero vector. Siaproximamos el valor de la función objetivo F en el entorno del punto �0, ten-emos,
F (�) = F��0
�+rF
��0
�0 �� � �0
�+1
2
�� � �0
�0 hr2F
��0
�i�� � �0
�donde rF
��0
�;r2F
��0
�denotan, respectivamente, el vector gradiente y
la matriz hessiana de la función F; evaluados en el punto �0: Para encontrar una
338

estimación numérica que mejore la que teníamos hasta ahora, �0; podemos min-imizar el valor numérico del miembro derecho de la expresión anterior, tomadocomo función del vector de parámetros �;M(�): Al igualar a cero la derivada dedicha función respecto de � tenemos,
rF��0
�+hr2F
��0
�i�� � �0
�= 0
es decir,
� = �0 �hr2F
��0
�i�1rF
��0
�(76)
La derivada segunda de M(�) es igual ahr2F
��0
�i; por lo que si este
hessiano es de�nido positivo, estaremos aproximándonos al mínimo de la funciónF (�) : Una vez calculado el valor numérico de � en (76) lo tomamos como lapróxima estimación, �1: El procedimiento puede volver a repetirse, hasta que seconsiga la convergencia a un punto mínimo. Cuando esto ocurra, sin embargo,no sabremos si el mínimo alcanzado es de naturaleza local o global, lo quehabremos de explorar siguiendo las pautas que daremos más adelante.En el caso de la estimación por máxima verosimilitud, la función que quer-
emos minimizar es � lnL (�) ; donde L (�) denota la función de verosimilitud.Así, tenemos el algoritmo numérico,
� = �0 �hr2 lnL
��0
�i�1r lnL
��0
�(77)
La matriz de covarianzas, una vez lograda la convergencia, es
Cov��n
�= �
hr2 lnL
��0
�i�1que será de�nida positiva en el caso de una distribución de probabilidad
Normal para la innovación del modelo, puesto que la densidad Normal es estric-tamente cóncava.El estimador de máxima verosimilitud es e�ciente, pero nos encontramos
a dos di�cultades: una, la referida acercad e nuestro desconcimietno sobre sihemos alcanzado un máximo local o global; otro, que las buenas propiedadesdel estimador de máxima verosimilitud descansan en que el supuesto acerca dela distribución de probabilidad que sigue la innovación del modelo sea correcto.En muchas ocasiones se calcula el estimador bajo supuestos de Normalidadporque es más sencillo, aun a sabiendas de que la distribución de probabilidadde la innovación dista de ser Normal. El estimador resultante se conoce comoestimador de quasi-máxima verosimilitud.
22.3.12 Algunas simpli�caciones
La puesta en práctica del algoritmo anterior requiere obtener las expresionesanalíticas de las derivadas primeras y segundas de la función F . Ello signi�cacalcular k
�k+32
�derivadas, que hay que evaluar para cada dato, utilizando los
339

valores numéricos de los parámetros que en ese momento se tienen como es-timación, lo que puede ser un gran trabajo. Para evitar esta tarea puedenadoptarse algunas posibles soluciones:
� sustituir el hessiano r2F��0
�por el producto del vector gradiente por sí
mismo, rF��0
�rF
��0
�0; lo que genera una matriz cuadrada, simétrica,
de�nida positiva,
� sustituir las derivadas analíticas por derivadas numéricas. Para ello, cuandodisponemos de un vector de estimaciones �n�1; variamos ligeramente unode los parámetros, y evaluamos numéricamente la función objetivo en elvector resultante. El cambio en el valor numérico de F , dividido por lavariación introducida en el parámetro considerado, nos da una aproxi-mación numérica a la derivada parcial con respecto a dicho parámetro,evaluada en el vector de estimaciones disponibles en ese momento,
� las derivadas analíticas se simpli�can mucho, generalmente, si utilizamossu esperanza matemática. Ello nos llevarí al algoritmo iterativo,
� = �0 +hI��0
�i�1r lnL
��0
�donde I
��0
�denota la matriz de información correspondiente a la dis-
tribución de probabilidad que se ha supuesto para la innovación del modelo:
I��0
�= E
h�r2 lnL
��0
�i: Este procedimiento se conoce como algoritmo de
scoring, y es muy utilizado, por su simplicidad. en tal caso, la matriz de covar-ianzas del estimador resultante es,
Cov��n
�=hI��0
�i�122.3.13 Criterios de convergencia
Antes de ello, vamos a establecer criterios de convergencia: decimos que el algo-ritmo iterativo anterior ha convergido, y detenemos el procedimeitno numéricode estimación, cuando se cumple alguna de las siguientes condiciones:
� el valor numérico de la función objetivo varía menos que un cierto umbralpreviamente establecido al pasar de una estimación �n�1, a la siguiente,�n;
� el gradiente de la función objetivo, evaluado en la nueva estimación,rF��n
�;
es pequeño, en el sentido de tener una norma reducida. Para comprobar elcumplimiento de esta condición, puede utilizarse la norma euclídea: raizcuadrada de la suma de los cuadrados de los valores numéricos de cadacomponente del gradiente, o puede utilizarse el valor numérico de cualquier
340

forma cuadrática calculada con el vector gradiente y una matriz de�nidapositiva.
� la variación en el vector de estimaciones es inferior a un umbral pre-viamente establecido. Para comprobar esta condición utilizaríamos unanorma del vector diferencia �n � �n�1;
� se ha alcanzado el máximo número de iteraciones establecido en el pro-grama de cálculo numérico que lleva a cabo la actualización de estima-ciones descrita en (76) : Esto se hace con el objeto de que el programade estimación no continúe iterando durante un largo período de tiempo,especialmente, si no está mejorando signi�cativamente la situación de es-timación.
El programa de estimación puede diseñarse para que se detenga cuando secumple uno cualquiera de estos criterios, o todos ellos. Es importante puntu-alizar, por tanto, que al estimar mediante un algoritmo numérico, el investigadorpuede controlar: i) las estimaciones iniciales, ii) el máximo número de itera-ciones a efectuar, y iii) el tamaño del gradiente, iv) la variación en el vectorde parámetros y v) el cambio en el valor numérico de la función objetivo pordebajo de los cuales se detiene la estimación. Cuando se utiliza una rutinaproporcionada por una librería en un determinado lenguaje, dicha rutina incor-pora valore snuméricos para todos los criterios señalados, que pueden no serlos que el investigador preferiría, por lo que es muy conveniente poder variardichos parámetros en la rutina utilizada. Alternativamente, lo que es muchomás conveniente, el investigador puede optar por escribir su propio programade estimación numérica.Estos aspectos afectan asimismo a la presentación de los resultados obtenidos
a partir de un esquema de estimación numérica: como generalmente no sabemossi hemos alcanzado un óptimo local o global, esto debe examinarse volviendoa repetir el ejercicio de estimación a partir de condiciones inniciales sustan-cialmente diferentes de las utilizadas en primer lugar, con objeto de ver si seproduce la convergencia, y cual es el valor de la función objetivo en dicho punto.Conviene repetir esta prueba varias veces. Asimismo, cuando se presentan es-timaciones, deberían acompañarse de la norma del graidnet en dicho punto, asícomo de los umbrales utilizados para detener el proceso de estimación, tantoen términos del vector gradiente, como de los cambios en el vector de estima-ciones, o en el valor numérico de la función objetivo, como hemos explicado enel párrafo anterior.
22.3.14 Di�cultades prácticas en el algoritmo iterativo de estimación
� En ocasiones observamos di�cultades en el proceso de convergencia: larutina numérica itera un número reducido de veces, y se detiene en unpunto muy próximo al que hemos utilizado como condiciones iniciales.Esto puede deberse a que los umbrales de parada que hemos seleccionado,o que están escritos como valores por defecto en la rutina que implemente el
341

algoritmo numérico son demasiado grandes. Así, en los primeros cálculos,los cambios en las estiamciones o en el valor de la función objetivo soninferiores a dichos umbrales, y el algoritmo se detiene. Deben reducirsedichos umbrales y volver a estimar. Cuando el programa se ha escritode modo ques e detenga cuando se cumple alguno de los criterios antesseñalados, convien incluir en el programa un mensjae que haga explícitocuál de los criterios ha conducido a su parada, de modo que reduzcamosel umbral asociado a dicho criterio.
� Otra di�cutad puede presentarse en la forma de cambios muy bruscos en elestimador. Ello se corrige introduciendo en el algoritmo (76) un parámetro� que se conoce como longitud de salto,
� = �0 � �hr2F
��0
�i�1rF
��0
�(78)
Hay que tener en cuenta que posiblemente esté incorporado en el programauna determinada magnitud para �, que el investigador puede alterar cuandoobserve cambios bruscos en el vector de parámetros.
� También podría ocurrir que
22.3.15 Estimación condicionada
Cuando se utilizan algoritmos numéricos para la maximización de la función deverosimilitud es frecuente encontrar situaciones de multicolinealidad, es decir, dealta correlación entre las estimaciones de algunos de los parñametros del modelo,lo que hace que la super�cie de verosimilitud cuyo máximo buscamos sea plana,lo que se traduce en un gradiente reducido, que es lo que hace que el valorde la función objetivo (la altura de la super�cie sobre la que nos movemos)apenas varíe incluso si variamos mucho los parámetros que están altamentecorrelacionados entre sí. Decimos que los parámetros que, por su alta correlaciónmutua causan esta situación, no están identi�cados, ya que variaciones notablesen ellos no alteran apenas el valor numérico de la función objetivo. En estoscasos, el algoritmo se detiene al satisfacerse el criterio de tener un gradiente denorma reducida, pero en modo alguno signi�ca que el proceso de estimación ha�nalizado satisfactoriamente.Para tratar estas situaciones, cuando se identi�can uno o dos parámetros
altamente correlacionados con los demás, puede llevarse a cabo una estimacióncondicionada, �jando valores alternativos de dichos parámetros a lo largo deuna red, maximizando la verosimilitud respecto de los demás, y comparandoresultados para alcanzar el máximo absoluto.
22.4 Estimación por método generalizado de los momen-tos
Si consideramos nuevamente la discretización aproximada del modelo de tiposde interés,
342

rt � rt�1 = �+ �rt�1 + �t
con,
Et�1�t = 0 (79)
Et�1�2t = �2r2 t�1
La condición sobre el momento de segundo orden puede escribirse,
Et�1
��2t � �2r
2 t�1
�= 0 (80)
por lo que tenemos en el modelo que dos funciones del término de errortienen esperanza condicional igual a cero. Un criterio de estimación se basaríaen explotar la idea de que si el modelo es correcto y las condiciones poblacionalesson ciertas, sus análogos muestrales no deberían ser muy diferentes de cero.En realidad, utilizamos en la estimación condiciones algo más débiles, como
son,
E [Xt�1�t] = 0 (81)
EhXt�1
��2t � �2r
2 t�1
�i= 0
donde Xt�1 es cualquier variable contenida en el conjunto de informacióndisponible en t � 1: Las variables Xt�1 utilizadas en la estimación del modeloreciben el nombre de instrumentos, en línea con la denominación habitual eneconometría, puesto que (81) muestra que son variables incorrelacionadas conel término de error del modelo.Para cada conjunto de instrumentos tenemos un estimadorMGM . Además,
hemos de tener presente que este estimador utiliza un conjunto de condicionesmás débiles que las que realmente tenemos disponibles. Si escribimos las condi-ciones anteriores como,
Eh1t (Xt�1; rt; rt�1; �) = 0; h1t � Xt�1�t
Eh2t (Xt�1; rt; rt�1; �) = 0; h2t � Xt�1
��2t � �2r
2 t�1
�formamos un vector de funciones de dimensión 2k (en general, qk), siendo
k el número de variables instrumentales seleccionadas, y buscar en el espacioparamétrico el valor numérico del vector � que minimiza una norma (formacuadrática con matriz de�nida positiva) de dicho vector de funciones, evaluadasen la muestra disponible,
Min�
JT =Min�
k 1T
TXt=1
ht k (82)
343

donde h0t = (h11t; h
12t; h
21t; h
22t; :::; h
k1t; h
k2t; ); es un vector �la de dimensión 2k,
y la diferencia entre hi1; hj1 estriba en que utilizamos en su cálculo instrumentos
distintos Xit�1; X
jt�1;
h11 =1
T
XX1t�1�t; h
21 =
1
T
XX2t�1�t; :::; h
k1 =
1
T
XXkt�1�t
h12 =1
T
XX1t�1�t; h
22 =
1
T
XX2t�1�t; :::; h
k2 =
1
T
XXkt�1�t
donde las variables Xit�1; X
jt�1 pueden ser: 1, rt�1; rt�2; etc.. Como puede
apreciarse, el número de condiciones de ortogonalidad muestrales de que disponemosen la estimación es igual al producto del número de condiciones de ortogonal-idad poblacionales por el número de instrumentos que utilicemos en cada unade ellas, que supondremos el mismo.Para de�nir una norma del vector h = (h1; h2; :::; hT ); escogemos una matriz
AT de�nida positiva, y consideramos el problema,
Min�
k 1T
TXt=1
ht k=Min�
24 1T
TXt=1
ht
!0AT
1
T
TXt=1
ht
!35La distribución de probabilidad asintótica del estimador resultante depende
de la elección de la matriz A. Hansen y Singleton (1982) probaron que laelección óptima de matriz de ponderaciones A en el sentido de minimizar lamatriz de covarianzas del estimador MGM resultante se consigue utilizandouna aproximación muestral a la inversa de la esperanza matemática,
S0 = E [(hh0)]S = �0 +
i=lXi=0
(�i + �0i) ; donde �i = E (htht�i)
lo que se consigue escogiendo como matriz AT ;
AT =
24 1T
LXj=�L
TXt=j+1
hth0t�j
35�1 =0@ LXj=�L
ST (j)
1A�1
(83)
donde ST (j) es cada una de las matrices de covarianzas retardadas,
ST (j) =1
T
TXt=j+1
hth0t�j
y donde L debe escogerse igual al orden de la autocorrelación que se estimapara el vector ht:El estimador que minimiza la forma cuadrática anterior se distribuye, asin-
tóticamente,
pT (�T � �)! N (0;�)
344

siendo � =�D0S
�10 D0
0
��1; donde S0 es la matriz de varianzas y covarianzas
de las condiciones de ortogonalidad antes de�nida, que se estima mediante (83) yD0 es el Jacobiano de dichas restricciones respecto a los parámetros del modelo,
D = E
�@h (Xt�1; rt; rt�1; �)
@�
�= E
Xt�1
@�t@�
Xt�1@(�2t��
2r2 t�1)@�
!Por tanto, podemos aproximar:
�T ! N
��0;
1
T�T
�siendo la matriz �T una aproximación a �; de�nida mediante �T = (DTAD
0T )�1;
con:
DT =1
T
Xt
Xt�1
@�t@�
Xt�1@(�2t��
2r2 t�1)@�
!En consecuencia, puede apreciarse que la expresión analítica para la obten-
ción del estimador MGM puede escribirse, tomando derivadas en (82) ;
1
T
TXt=1
t
Xt�1
@�t@�
Xt�1@(�2t��
2r2 t�1)@�
!0A
1
T
TXt=1
Xt�1�t
Xt�1
��2t � �2r
2 t�1
� != 0
donde los órdenes de los factores son qxnk; nkxnk y nkx1; siendo n elnúmero de condiciones de ortogonalidad poblacionales, 2 en nuestro caso, yk el número de instrumentos. Estas ecuaciones serán lineales si el gradiente
@�t@�
@(�2t��2r2 t�1)
@�
!lo es, como ocurre en un modelo lineal y sin heterocedastici-
dad.Para iniciar el proceso iterativo de estimación, en el que la matriz AT se va
actualizando en cada etapa, se comienza tomando AT = Ink; para obtener en
la primera etapa el estimador que minimiza��
1T
PTt=1 ht
��1T
PTt=1 ht
�0�. A
partir de las estimaciones obtenidas, se calculan las matrices arriba indicadas yse itera el procedimiento.Como el número de condiciones de ortogonalidad utilizado en la estimación
debe ser mayor que el número de parámetros a estimar, existe un número degrados de libertad, y podemos contrastar la medida en que las condiciones deortogonalidad no utilizadas para obtener las estimaciones de los parámetros, sesatisfacen. Para ello, conviene saber que el valor mínimo alcanzado por la formacuadrática (82) ; multiplicado por el tamaño de la muestra, T , se distribuyecomo una �2gdl; siendo gdl el número de grados de libertad la diferencia entre elnúmero de condiciones de ortogonalidad utilizadas, y el número de parámetrosestimados.Si tomamos como instrumento una constante, tenemos las condiciones,
345

E�t = E [rt � rt�1 � �� �rt�1] = 0
E��2t � �2r
2 t�1
�= E
h(rt � rt�1 � �� �rt�1)2 � �2r2 t�1
i= 0
que implican en la muestra,
1
T
TXt=1
h11;t = �+ ��r = 0
1
T
TXt=1
h12;t =1
T
TXt=1
h(rt � (1 + �) rt�1 � �)2 � �2r2 t�1
i= 0
mientras que si tomamos rt�1 como instrumento, tenemos,
1
T
TXt=1
h21;t =1
T
TXt=1
�rtrt�1 � (1 + �) r2t�1 � �rt�1
�= 0
1
T
TXt=1
h22;t =1
T
TXt=1
nrt�1
h(rt � (1 + �) rt�1 � �)2 � �2r2 t�1
io= 0
cuatro ecuaciones que dependen de momentos muestrales de distintas fun-ciones de los tipos de interés, todas ellas calculables a partir de la informaciónmuestral, y de los cuatro parámetros desconocidos. El problema es que, comofácilmente se aprecia, el sistema de ecuaciones no puede resolverse analítica-mente, fundamentalmente porque, salvo en casos muy simples, es un sistema deecuaciones no lineales en las incógnitas, que son los parámetros del modelo.En este caso, si tomamos L = 0; las matrices DT y AT tienen una estructura:
DT =1
T � 1
TXt=2
0BB@�1 �rt�1 0 0�rt�1 �r2t�1 0 0
0 0 �2�r2 t�1 �2�r2 +1t�10 0 �2�r2 t�1 ln� �2�r2 +1t�1 ln rt�1
1CCA ;
A =1
T � 1
TXt=2
26640BB@
h11;th12;th21;th22;t
1CCA� h11;t h12;t h21;t h22;t�3775 =
=1
T � 1
TXt=2
0BB@h211;t h11;th12;t h11;th21;t h11;th22;t
h12;th11;t h212;t h12;th21;t h12;th22;th21;th11;t h21;th12;t h221;t h21;th22;th22;th11;t h22;th12;t h22;th21;t h222;t
1CCAEn realidad, en el cálculo del estimador del método generalizado de momen-
tos se utilizan más condiciones de ortogonalidad que parámetros se pretendenestimar, lo que permite contrastar la sobreidenti�cación del modelo.
346

Part III
Stock Market
347

23 El modelo de valoración de activos
23.1 Introducción
Una vez que hemos examinado el modo en que un inversor puede seleccionaruna cartera de activos, estamos en condiciones de caracterizar el modo en que sedeterminan los precios y, como consecuencia, las rentabilidades, en un mercado.Al igual que en cualquier mercado de un bien físico, un mercado �nanciero nohace sino recoger las interacciones de todos los participantes. En ausencia defricciones o restricciones, muy infrecuentes en mercados �nancieros, la igualdadde oferta y demanda, es decir, el aclarado del mercado, determinará el preciode un activo.Como vamos a ver, este ejercicio de calcular el precio (y rentabilidad) de
equilibrio de un activo, conduce a establecer una relación de equilibrio entrerentabilidad esperada y riesgo de un activo cualquiera de un mercado. A su vez,los modelos de equilibrio, que toman como punto de partida los modelos de con-strucción de cartera, tiene asimismo implicaciones acerca de las característicasde una cartera óptima.Veremos inicialmente el modelo de valoración de activos de capital, o capital
asset pricing model, en su versión más restringida. Posteriormente, eliminare-mos alguna de las hipótesis que subyacen a dicho modelo, para construir ver-siones válidas en condiciones más generales (y realistas). Más adelante, repasare-mos algunos de los contrastes empíricos de modelos de equilibrio general devaloración de activos. Finalmente, examinaremos una teoría adicional de val-oración de activos �nancieros, el modelo de precios de arbitraje, o arbitragepricing theory.
Hipótesis incorporadas en el modelo da valoración de activos �nancieros:1)ausencia de costes de transacción,2)activos continuamente divisibles3)ausencia de impuestos personales sobre la renta4)un inversor no puede, por sí sólo, in�uir sobre el precio de un activo,
mediante compras o ventas del mismo,5) los inversores toman sus decisiones considerando únicamente la rentabili-
dad esperada y el riesgo del activo en consideración,6) se permiten posiciones cortas, sin ninguna limitación,7) existe un activo sin riesgo a cuyo tipo de interés se permite a los inversores
prestar y pedir prestado, cualquier cantidad que deseen,8)todos los inversores de�nen el período relevante de igual manera,9) todos los inversores tienen idénticas expectativas respecto a la rentabilidad
esperada y riesgo de cada activo, así como respecto al a matriz de correlacionesentre las rentabilidades de cada par de activos,10) todos los activos (incluido el capital humano) son negociables en el mer-
cado.Puesto que vamos a desarrollar modelos teóricos bastante restringidos y,
por tanto, relativamente poco realistas, es conveniente recordar la polémicaacerca de la forma apropiada de contrastar o validar un modelo: el modelo será
348

adecuado en la medida en que represente adecuadamente el comportamiento delmercado o la economía que pretenda representar.El modelo de valoración de activos �nancieros fue introducido, de modo sep-
arado, por Sharpe, Lintner y Mossin. Comenzamos con una deducción simple,aunque no totalmente rigurosa, del modelo:
23.2 Deducción sencilla del modelo CAPM
Consideramos un mercado en el que se permiten posiciones cortas o ventas acorto, pro no se permite préstamos ni créditos al tipo de interés sin riesgo. Cadainversor se enfrenta a una frontera e�ciente como la de la Figura 1. En ella, eltramo BC representa la frontera e�ciente, mientras que ABC es el conjunto decarteras de mínima varianza. La frontera e�ciente diferirá entre inversores sitiene distintas expectativas acerca de los estadísticos de los activos del mercado.Si se permite prestar y pedir prestado al tipo de interés sin riesgo, entonces
la cartera de activos con riesgo escogida por cada inversor puede caracterizarsecon independencia de las preferencias de dicho inversor. Esta caracterizadapor la tangente de mayor pendiente trazada desde el punto que representa alactivo sin riesgo. Bajo expectativas homogéneas, todos los inversores compran lamisma cartera de renta variable, si bien diversi�can en distinta cuantía respectoal activo sin riesgo, pues lo hacen en función de sus preferencias. Este es elteorema de los dos fondos. Una consecuencia de todo esto es que, en equilibrio,la cartera P que compran todos los inversores no puede ser sino la cartera-mercado. Esta es una cartera formada por todos los activos del mercado, cadauno de los cuales entra en una proporción igual a su capitalización relativa.La línea recta de la Figura 2 es conocida como la recta del mercado de capital
(capital market line).Todos los inversores se posicionarán en algún punto de lamisma, y todas las carteras e�cientes están alineadas a lo largo de ella. Sinembargo, no todos los activos individuales están sobre la recta. De hecho, yasabemos que las carteras que combinan el activos in riesgo con activos con riesgo,estarán por debajo de la línea de mercado, excepto si son e�cientes.Ya vimos anteriormente que la ecuación de dicha recta es:
rce = rF +rM � rF�M
�ce
donde ce denota una cartera e�ciente.El cociente que aparece en dicha expresión puede ser interpretado como el
precio de mercado del riesgo para las carteras e�cientes. Es la rentabilidad,en exceso de la que ofrece el activo sin riesgo, que puede esperar obtenerse porincrementar el riesgo de una cartera e�ciente en una unidad. Multiplicada por elfactor que le acompaña, nos da la rentabilidad que se espera recibir por asumirriesgo en una cartera e�ciente. El primer término es el precio del tiempo, ola rentabilidad que se requiere por retrasar durante un período los planes deconsumo, al menos en parte, e invertir la cantidad correspondiente en el activosin riesgo. Por tanto, la rentabilidad esperada de una cartera e�ciente es igual
349

al precio del tiempo más el producto del precio unitario del riesgo por el riesgode la cartera.Este ecuación establece la relación entre rentabilidad esperada y riesgo de
carteras e�cientes, pero no nos dice mucho acerca de las relaciones similarespara carteras no e�cientes, o para activos individuales.Anteriormente, ya vimos que la beta de una cartera bien diversi�cada es
una buena medida del riesgo de un activo de la misma. También sabemos que,si todos los inversores comparten las mismas expectativas, todos compran lacartera de mercado, que es una cartera bien diversi�cada. Como suponemosque los inversores se preocupan únicamente de rentabilidad esperada y riesgo,rentabilidad esperada y beta son las únicas características de un activo quenecesitamos considerar.En el mapa que recoge estas características, todos los activos están alineados
a lo largo de una recta. Supongamos que no es así, y construyamos la línea rectaque pasa por dos de ellos (rA; �A) y (rB ; �B); de modo que (rC ; �C) quede porencima de la recta. Las carteras formadas combinado A y B están en la rectaque acabamos de trazar. Ello se debe a que tanto la rentabilidad esperada comola beta de una cartera son combinación lineal de los activos que la componen,con las ponderaciones con que con�guran dicha cartera.Tenemos, por tanto, una situación en que dos carteras (una formada por
un sólo activo) tienen el mismo riesgo pero distinta rentabilidad esperada. Lasoperaciones de arbitraje conducirían a vender aquella de menor rentabilidadesperada, y comprar la de mayor. Con ello, disminuiría el precio de la primera yaumentaría la de la segunda, aumentando la rentabilidad esperada de la primera,y reduciéndose la de la segunda, hasta que ambas se igualasen.Por tanto, todos los activos, así como todas las carteras de activos deben
estar sobre una recta en el plano (r; �):
ri = a+ b:�i
Como basta dos puntos para identi�car una línea recta, tomamos el activo sinriesgo, caracterizado por el punto (rF ; 0); y la cartera de mercado, caracterizadapor (rM ; 1) pues ya vimos que la beta del mercado es igual a 1. El activo sinriesgo no tiene ningún riesgo sistemático, que es lo que es capturado por la beta,por lo que su beta es cero.Resolviendo las ecuaciones:
rF = a+ b:0
rM = a+ b:1
tenemos: a = rF y b = rM � a; que llevados a la ecuación de la recta, laconvierte en:
ri = rF + (rM � rF ) :�i
350

Este es el modelo de valoración del mercado de activos, o CAPM. La rectaanterior es la recta del mercado de activos, o security market line, y describe larentabilidad esperada para cualquier activo o cartera en la economía, tanto si ese�ciente como si no lo es. Por otra parte, ni rF ni rM son características de unactivo o cartera individual, de modo que la importancia de la ecuación anteriorestriba en que a�rma que la diferencia entre las rentabilidades esperadas de dosactivos depende exclusivamente de diferencias entre sus betas. Además, hemosprobado que la relación entre rentabilidad esperada y la beta de un activo ocartera es lineal. El CAPM es un modelo de equilibrio, que a�rma que losactivos de beta alto tenderán a producir rentabilidades superiores, porque sonactivos de mayor riesgo.Como suele ocurrir con frecuencia en este tipo de relaciones, tan importante
es lo que en ella aparece como determinante de la rentabilidad esperada de unactivo, como lo que no aparece. En particular, recordemos que el riesgo de unactivo puede descomponerse en un componente sistemático y otro especí�co delactivo, y que su beta es un indicador del componente sistemático de riesgo.En consecuencia, la ecuación anterior muestra que el riesgo especí�co de unactivo no es remunerado en el mercado. No es la incertidumbre total en la�uctuación que pueda experimentar la rentabilidad de un activo lo que reciberemuneración en el mercado, sino sólo el componente de la misma que no puedeeliminarse diversi�cando una cartera. Por supuesto que estas implicaciones soncontrastables empíricamente.Para �nalizar, notemos que es consistente con el modelo anterior que un año
concreto, un activo de beta alto pueda obtener una rentabilidad inferior a la deotro de menor beta. El modelo dice que, en promedio a lo largo de un períodosu�cientemente largo, esto no va a ocurrir.Recordando que el beta de un activo es:
�i =�iM�2M
la recta del mercado de activos puede escribirse:
ri = rF +rM � rF�M
�iM�M
(84)
que es la ecuación de una recta en el plano�ri;
�iM�2M
�. Pero �iM
�2Mes la
contribución al riesgo de una cartera de variaciones en la proporción del activoi, por lo que puede ser interpretado como una medida del riesgo de un activoindividual o una cartera. En consecuencia, la recta del mercado de activosmuestra que la rentabilidad esperada de un activo es igual al tipo de interés sinriesgo más el precio de mercado del riesgo por el nivel de riesgo del activo ocartera.En ocasiones, la ecuación del CAPM se escribe:
ri = rF +rM � rF�2M
�iM
351

y se de�ne la fracción que en ella aparece como precio unitario del riesgo, y�iM como medida del riesgo del activo i. Sin embargo, ya hemos mostrado quela primera representación es más fácilmente interpretable.A continuación, desarrollamos una derivación más rigurosa del modelo CAPM.
A pesar de ser matemáticamente más exigente, será de mayor interés cuandoqueramos discutir el modelo bajo supuestos menos restrictivos que los que hastaahora hemos considerado.
23.3 Deducción rigurosa del modelo CAPM
Recordemos que la cartera óptima se escoge maximizando, sobre la fronterae�ciente, la pendiente de la recta que une una cartera de la frontera con elpunto que representa el activo sin riesgo. Dicha pendiente es:
� =rce � rF�ce
Al derivar � respecto a cada una de las ponderaciones de la cartera e igualara cero, obtuvimos:
��X1�1k +X2�2k + :::+Xk�
2k + :::+Xn�nk
�= rk � rF
que es un conjunto de n ecuaciones simétricas, una para cada activo en elmercado. Bajo expectativas homogéneas, todos los inversores escogen la mismacartera óptima que, en equilibrio, ha de ser la cartera de mercado. Por tanto, lasponderaciones que resultan al resolver el sistema han de ser las capitalizacionesque los distintos activos tiene en el mercado, y que denotamos por Xk�:Por otra parte, el paréntesis en la expresión anterior es igual a Cov(rk; rM );
por lo que:
�Cov(rk; rM ) = rk � rFecuación que debe satisfacerse para todos los activos, por lo que también
para el mercado:
��2M = rM � rFde modo que:
� =rM � rF�2M
que llevado a la ecuación de un activo individual, proporciona:la recta del mercado de activos, para lo que no hemos tenido que suponer
que la beta de un activo es la medida relevante del nivel de riesgo del mismo.
352

23.4 El modelo CAPM en la valoración de inversiones
El modelo CAPM puede utilizarse para valorar activos nuevos o, incluso másgeneralmente, para valorar proyectos de inversión. Todo lo que necesitamos estransformar la ecuación de valoración de activos, que está expresada en términosde rentabilidades, a ser expresada en términos de precios.Sea Pi el precio actual de un activo o proyecto de inversión, y sea Pi� su
precio futuro. la rentabilidad de dicho proyecto es:
ri =Pi�� PiPi
=Pi�
Pi� 1
Si denotamos por PM el actual precio de la cartera de mercado, y por Pi�suprecio futuro, tendremos asimismo:
rM =PM�� PM
PM=PM�
PM� 1
Sustituyendo en (84); tenemos:
P i�
Pi� 1 = rF +
�PM�
PM� 1� rF
��iM�2M
por lo que:
Cov(ri; rM ) = E
��Pi�� PiPi
� P i�� PiPi
��PM�� PM
PM� PM�� PM
PM
��=
= E
��Pi�� P i�Pi
��PM�� PM
PM
��=
1
PiPMCov(Pi; PM )
Análogamente:
�2M =1
P 2MV ar(PM )
y sustituyendo ambas en la ecuación anterior, tenemos:
P i�
Pi= (1 + rF ) +
�PM�
PM� (1 + rF )
� 1PiPM
Cov(Pi�; PM�)1P 2MV ar(PM�)
multiplicando en ambos miembros por Pi y simpli�cando:
P i�= (1 + rF )Pi +�PM�� (1 + rF )PM
� Cov(Pi�; PM�)V ar(PM�)
y despejando:
Pi =1
1 + rF
�P i��
�PM�� (1 + rF )PM
� Cov(Pi�; PM�)V ar(PM�)
�
353

que sugiere que se debe restar del precio esperado futuro una compensaciónpor asumir riesgo, y calcular el valor presenta de la cantidad que resulte. Eltérmino dentro del corchete es el equivalente cierto del pago esperado futuro.Aunque esta idea no es en absoluto nueva, el CAPM proporciona una modoconcreto y riguroso de calcular dicho equivalente cierto. Puede probarse que:
PM�� (1 + rF )PM[V ar(PM�)]
1=2
es igual a la medida del precio de mercado de una unidad de riesgo, y que:
Cov(Pi�; PM�)
[V ar(PM�)]1=2
es la medida relevante de riesgo para cualquier activo.Uno de los aspectos que mejor re�eja que el CAPM que hemos presentado
no re�eja adecuadamente el comportamiento de inversores individuales es quela mayoría de estos mantienen carteras distintas de la de mercado. Esta es unarazón para desarrollar versiones del CAPM bajo hipótesis menos restrictivasque las que citamos al comienzo. Ello nos ayudará, además, a tener diversasespeci�caciones que podamos contrastar empíricamente. Por último, es intere-sante generalizar el modelo para que recoja algunos aspectos del mundo real,como pueda ser la �scalidad, porque, de lo contrario, es imposible discutir loscambios que esperamos que se produzcan en el comportamiento de los inversoresindividuales como consecuencia de cambios �scales.
23.5 El CAPM cuando no se permiten ventas (posiciones)a corto
Hasta ahora, hemos permitido que un inversor pueda vender un activo, conindependencia de que lo tenga o no en su cartera, y utilizar los ingresos parainvertir en otros activos. Sin embargo, esta no es una hipótesis necesaria. Puestoque en equilibrio, todos los inversores tienen la cartera de mercado, y en ellano se tiene ninguna posición corta, la prohibición de ventas a corto no altera elequilibrio. Por tanto, se obtendrá la misma relación CAPM.
23.5.1 Modi�caciones sobre los préstamos y créditos al tipo sin riesgo.
En este epígrafe modi�camos la hipótesis acerca del acceso de los inversores a untipo sin riesgo, tanto para prestar como para solicitar créditos. Consideramosprimero que ninguna de ambas cosas es posible. Posteriormente, consideraremosque los tipos de interés de ambas operaciones di�eren.
23.5.2 Los inversores no pueden prestar ni pedir prestado a un tiposin riesgo.
Como hicimos con el modelo CAPM más restringido, efectuamos primero unadeducción simple del modelo, para pasar a una derivación más rigurosa del
354

mismo posteriormente.
Deducción sencilla Ya hemos argumentado varias veces que el componentesistemático del riesgo es una medida adecuada del riesgo de una cartera o activo,y que dos activos con el mismo riesgo sistemático no pueden ofrecer distintasexpectativas de rentabilidad. Todos los activos o carteras, incluso si no sone�cientes, deben alinearse a lo largo de una curva en el plano (r; �):
r = a+ b:�
En particular, la cartera de mercado, que tiene una beta igual a uno, estarátambién sobre la recta. Denotemos por rz la rentabilidad esperada de unacartera de beta cero. Tenemos las ecuaciones:
rz = a+ b:0) a = rz
rM = a+ b:1) b = rM � rzpor lo que la ecuación de la recta se convierte en:
ri = rz + (rM � rz) :�ique es la versión beta-cero del modelo de valoración del mercado de activos
o CAPM [Figura]. Esta forma de la relación de equilibrio general es un modelode dos factores.
Deducción rigurosa Supongamos que la cartera de mercado está sobre lafrontera e�ciente en el plano de rentabilidad esperada y riesgo. Ya veremos másadelante que tiene que ser así. Ya sabemos que podemos de�nir cada carterade la frontera e�ciente hallando la tangencia con las rectas que pasan por elpunto que representa en dicho plano al activo sin riesgo, y haciendo variar larentabilidad del mismo. Dicha rentabilidad es, en este análisis, �cticia, y elactivo sin riesgo puede no existir.De�namos rF� como la rentabilidad sin riesgo a la que, si pudieran prestar
y pedir prestado los inversores, seleccionarían de entre las carteras de rentavariable, la cartera de mercado. Dicho inversor, para encontrar las proporcionesde su cartera óptima, resolvería el sistema de ecuaciones:
��X1�1k +X2�2k + :::+Xk�
2k + :::+Xn�nk
�= rk � rF�
siendo la solución las proporciones de mercado: Xk = Xk�; k = 1; 2; :::; n: Yasabemos que el miembro de la izquierda en esta ecuación es igual a Cov(rk; rM ),de modo que:
rk = rF�+ �Cov(rk; rM )
La rentabilidad esperada para la cartera de mercado es una combinaciónlineal (media aritmética ponderada) de las rentabilidades esperadas sobre los
355

activos individuales. Como tenemos una ecuación de este tipo para cada activoindividual, tendremos también:
rM = rF�+ �V ar(rM )
de modo que:
� =rM � rF��2M
por lo que:
rk = rF�+rM � rF��2M
Cov(rk; rM ) = rF�+ �k (rM � rF�)
que es nuevamente el beta-cero CAPM.
23.6 Las carteras de beta-cero
Ahora bien, en realidad, no existe un activo sin riesgo, con rentabilidad rF�. Sin embargo, existe todo un continuo de activos y carteras ofreciendo unarentabilidad esperada rF�, y están alineados a lo largo del segmento ZC enla Figura. La ecuación (85) nos dice que cuando un activo o cartera tienerentabilidad esperada: rk = rF�, entonces su beta (es decir, la covarianza entresu rentabilidad y la del mercado) ha de ser cero. Aunque en el modelo CAPMpodría utilizarse cualquier activo de beta cero, tiene sentido utilizar el de mínimavarianza. Este es equivalente al activo o cartera de beta cero de mínimo riesgo,y su rentabilidad esperada es rz: Por tanto, tenemos:
rk = rz + �k (rM � rz)
que es exactamente la expresión (85) que ya obtuvimos antes para la líneadel mercado de activos.Queremos identi�car ahora la posición de esta cartera de beta cero y mínima
varianza, que juegan un papel tan importante en el modelo que acabamos dedesarrollar.En primer lugar, sabemos que la rentabilidad esperada de una de tales
carteras debe ser inferior a la de la cartera de mercado. Estamos suponiendoque ésta es e�ciente, por lo que estará en el tramo creciente de la frontera demínima varianza, y la pendiente de la curva en ella debe ser positiva. Por tanto,al movernos sobre la tangente hacia el eje de ordenadas, la rentabilidad esper-ada descenderá. Como rz es la intersección de dicha tangente con el eje deordenadas, ésta será inferior a rM : En segundo lugar, la cartera de beta cero demínima varianza no puede ser e�ciente.Para probar este último resultado, denotemos por s la cartera de mínima
varianza. Esta cartera puede formarse combinando la cartera de mercado y lacartera de beta cero, con una varianza:
356

�2s = X2z�
2z + (1�Xz)
2�2M
que se minimiza para la ponderación:
Xz =�2M
�2z + �2M
con:
V ar(s) =�2M
�2z + �2M
�2z < �2z
Puesto que las varianzas son positivas, la cartera s de mínima varianza seforma con ponderaciones positivas, tanto para la cartera de beta cero, comopara la cartera de mercado. Por otra parte, como rz < rM , cualquier carteraque se forme con ponderaciones positivas de ambas, tendrá una rentabilidadesperada superior a rz. Por tanto, la cartera de mínima varianza tiene menorvarianza, y mayor rentabilidad esperada que la cartera de beta cero, por lo queésta no puede ser e�ciente.{La Figura XX muestra la localización de todas las carteras e�cientes en
el mapa rentabilidad esperada-riesgo (r; �): Todos los inversores mantendráncarteras en el arco SMC. Los inversores con carteras de rentabilidad esperadacomprendida entre s y rM comprarán combinaciones de la cartera de beta ceroy la cartera de mercado. Aquellos que se sitúen a la derecha de M construiránsu cartera vendiendo la cartera Z y comprando la cartera de mercado. Ningúninversor mantendrá únicamente la cartera Z, puesto que es ine�ciente. Porúltimo, las tenencias agregadas de la cartera Z por parte de todos los inversores,han de ser cero. Tenemos nuevamente un teorema de dos fondos. Los inversoressólo necesitan comprar la cartera de mercado y la cartera de beta cero de mínimavarianza.Hemos supuesto en esta análisis que la cartera de mercado es e�ciente. Si
los inversores tienen expectativas homogéneas, todos se enfrentan a la mismafrontera e�ciente. Además, cuando se permiten ventas a corto, todas las combi-naciones de dos carteras de mínima varianza (es decir, del menor riesgo posibledada su rentabilidad esperada) es asimismo una cartera de mínima varianza.Por tanto, combinando las carteras de dos inversores cualesquiera tendremosuna cartera de mínima varianza. La cartera de mercado es una combinaciónlineal de las carteras de todos los inversores, con pesos igual a la proporción quecada inversor posee de todos los activos con riesgo. Por tanto, es de mínima var-ianza. Puesto que: a) la cartera de cada inversor es e�ciente, y b) la rentabilidaddel mercado es un promedio de las rentabilidades de las carteras de los inver-sores individuales, la rentabilidad de mercado es la rentabilidad de una carteraen el segmento e�ciente de la frontera de mínima varianza. En consecuencia, lacartera de mercado es no sólo de mínima varianza, sino e�ciente.
357

23.7 Se permite prestar, pero no pedir prestado, al tipode interés sin riesgo
En ausencia de la posibilidad de pedir prestado al tipo de interés rF , tenemosla situación de la Figura XX. Ya sabemos que todas las cartera formadas conel activo sin riesgo y una cartera con riesgo están sobre la recta que une dichacartera y el punto que representa el activo sin riesgo en el plano de rentabilidadesperada-riesgo (r; �): de entre todas éstas, las combinaciones preferidas son lasque están sobre la recta tangente a la frontera e�ciente, el segmento rFT en laFigura.En ella, T aparece a la izquierda y por debajo de la cartera de mercado M.
Por tanto, rz > rF : Esto es lo que debe ocurrir: si los inversores no pudiesenprestar ni pedir prestado, se posicionarían en SMC, como ya vimos. Cuandopuede prestar a tipo rF , un inversor puede situarse sobre el segmento rFT .En tal caso, estaría utilizando parte de su dotación para comprar el activo sinriesgo, y el resto para comprar la cartera T. Este inversor no compraría unacartera distinta de T. Si hay algún inversor que no invierte en el activo sinriesgo, comprará una cartera a la derecha de T y, como consecuencia, la carterade mercado ha de estar a la derecha de M.Esto, a su vez, implica que rz > rF ; puesto que rF es la intersección sobre
el eje de ordenadas de una recta tangente en el punto , mientras que rz es laintersección con el mismo eje de una recta tangente a la frontera e�ciente en elpunto M. Como la pendiente de ésta última es menor que la de la primera, y Mestá a la derecha de T, se tiene la citada ordenación de rentabilidades.La frontera e�ciente está dada por el segmento lineal rFT; junto con el
arco TMC. A diferencia del caso anterior, ahora no todas las combinaciones decarteras e�cientes es e�ciente: combinaciones de una cartera del segmento rFTcon una cartera del arco TMC está dominada por una cartera en dicho arco.La cartera T puede obtenerse combinando las carteras Z yM . Los inversores
que escogen una cartera en el segmento rFT colocan parte de su dinero en lacartera T ( que se construye a partir de las carteras Z y M), y parte en el activosin riesgo. Quienes seleccionan una cartera en el arco TM colocan parte desu dinero en M y parte en Z. Quienes seleccionan una cartera en MC estánvendiendo la cartera Z en corto, y comprando M . Tenemos ahora un teoremade tres fondos: Todos los inversores se conforman comprando el activo sin riesgo,la cartera de beta cero de mínima varianza, la cartera de mercado, y el activosin riesgo.Si nos trasladamos ahora al plano (r; �), podemos generar la línea del mer-
cado de activos, de modo similar a como hicimos en el análisis previo del modeloCAPM. La cartera de mercado continuará siendo e�ciente, por lo que el mismoanálisis continúa siendo válido. Todos los activos contenidos en M ofrecen unarentabilidad esperada:
ri = rz + �i (rM � rz) (85)
Análogamente, todas las carteras compuestas únicamente por activos conriesgo tendrán rentabilidad esperada dada por (85). Ello genera la recta rzTMC
358

en la Figura XX. Sin embargo, esta ecuación no describe el comportamiento dela rentabilidad ofrecida por carteras que contienen el activo sin riesgo.Sabemos, por análisis anteriores, que las combinaciones del activo sin riesgo
y una cartera con riesgo se sitúan, dentro del plano (r; �) a lo largo de la rectaque une dicha cartera con el punto que representa al activo sin riesgo. Ennuestro caso, todos los inversores que prestan a tipo rF y compran activos conriesgo, compran la cartera T, por lo que el segmento relevante es rFT .Por tanto, mientras que el segmento rzM es la línea del mercado de activos
para todos los activos con riesgo y para todas las carteras compuestas única-mente por activos de este tipo, no recoge el comportamiento de rentabilidadesperada-riesgo de las carteras que contienen el activo sin riesgo. Las carterase�cientes ofrecen rentabilidades esperadas en los dos segmentos lineales rFT yTC. En consecuencia, para determinados niveles de beta, algunas carteras e�-cientes ofrecen una rentabilidad inferior a la que ofrecen activos individuales,lo que puede resultar algo sorprendente. Sin embargo, conviene recordar quela rentabilidad ofrecida por los activos o carteras en rzT tiene una desviacióntípica más elevada que la de las carteras de igual rentabilidad esperada situadassobre el segmento rFT . Para comprender esto, recordemos que la rentabilidadde la cartera Z es aleatoria a pesar de tener un beta cero, mientras que larentabilidad del activo sin riesgo es determinista.En resumen, en este modelo, en equilibrio, los inversores ya no mantienen
todos la misma cartera; sin embargo, mantienen un buen número de activos enposiciones cortas (están vendidos en dichos activos). Si no se permite prestarni pedir prestado a un tipo sin riesgo rF , tenemos un teorema de dos fondos,mientras que si permitimos préstamos a dicho tipo, tenemos un teorema de tresfondos. Al igual que en la versión más restrictiva del modelo CAPM, tenemosuna línea del mercado de activos.
23.8 Supuestos alternativos acerca de la capacidad de prestary pedir prestado
Supongamos ahora que el inversor puede prestar y pedir prestado, pero a tiposdiferentes. Parece natural considerar el caso en que es más alto el tipo al cualpide prestado, rB ; que el tipo al que presta, rL. Si todos los inversores tienenexpectativas homogéneas, y se enfrentan a los mismo tipos, todos tendrán unafrontera e�ciente como en la Figura XX. En ella, L es la cartera de activos conriesgo que será comprada por todos los inversores que prestan dinero a tiporL, mientras que B será la cartera que compren aquellos inversores que pidenprestado dinero.La cartera de mercado debe estar en la frontera e�ciente; además, debe situ-
arse entre L y B. La razón es que las únicas carteras de activos con riesgocompradas son L , B, y las que ocupan posiciones intermedias entre éstas.Además, sabemos que las combinaciones de carteras e�cientes son asimismoe�cientes. Esto lo probamos en un contexto en que no permitíamos prestar nipedir prestado, por lo que bastó demostrar que las combinaciones de carterasen el tramo e�ciente de la frontera de mínima varianza estaban asimismo en
359

dicho tramo e�ciente. La cartera de mercado es una combinación lineal de lascarteras de todos los inversores, y cada una de ellas es e�ciente, lo que haceque la cartera de mercado esté en el tramo e�ciente de la frontera de mínimavarianza. Además, la rentabilidad ofrecida por el mercado es un promedio pon-derado de las rentabilidades ofrecidas por las carteras L , B, y todas las carterasintermedias, por lo que su rentabilidad debe estar entre L y B. Por tanto, lacartera de mercado está en el tramo e�ciente, entre L y B.Ahora estamos en condiciones de obtener la línea del mercado de activos,
al igual que en secciones anteriores. El mismo razonamiento todavía es válido,y la recta tiene la misma ecuación (85). Sin embargo, esta ecuación recogeráahora únicamente el comportamiento de activos y carteras que no contienen elactivo sin riesgo, in en posiciones cortas ni largas. Por tanto, no es aplicablea la rentabilidad que puedan ofrecer carteras entre L y rL, o con rentabilidadesperada superior a rB :
23.9 Impuestos sobre la renta.
En su versión simple, el modelo CAPM ignora la existencia de impuestos, loque hace que un inversor sea indiferente entre recibir dividendos o ganancias decapital. Sin embargo, las últimas reciben, están sometidas, a un tipo impositivoinferior a los dividendos, por lo que los inversores pre�eren ser remuneradosen la forma de ganancias de capital. En todo caso, al tomar sus decisiones, uninversor considerará la rentabilidad que espera obtener de una inversión, despuésde impuestos.Esto hace que, incluso si las expectativas de los agentes acerca de la rentabil-
idad de una cartera antes de impuestos son homogéneas, la frontera e�ciente ala que se enfrentes después de impuestos, pueda ser diferente. Se debe´cumplir,sin embargo, una condición de equilibrio, que puede probarse que conduce a laecuación:
rk = rF + �k [(rM � rF )� �(�M � rF )] + �(�i � rF ) (86)
donde �M denota la rentabilidad por dividendo (dividendo/precio) de lacartera de mercado, �i es la rentabilidad por dividendo del activo i, y � es unfactor positivo que mide los tipos impositivos relevantes sobre las ganancias decapital y la renta. Depende, de modo complejo, de los tipos impositivos de losinversores y de su riqueza.Los inversores requieren una rentabilidad superior cuando reciben una buena
parte de su renta en la formad e dividendos, debido a unos tipos impositivosmás elevados. El último término se debe al distinto tratamiento de los interesessobre préstamos y créditos. Como los pagos por intereses están gravados muyaproximadamente del mismo modo que los dividendos, entran en la relación deun modo similar, aunque con signo opuesto. Puede apreciarse que si se tomacomo activo i la cartera de mercado, la ecuación se cumple como una identidad.Sin embargo, ahora una línea del mercado de activos ya no es su�ciente
para representar la relación de equilibrio. Si en versiones anteriores del modelo
360

tan sólo la beta era la única característica de un activo que condicionaba surentabilidad esperada, ahora, la rentabilidad por dividendo también in�uye.Esto implica que necesitaríamos un espacio de 3 dimensiones (ri; �i; �i); en elque la relación de equilibrio estaría representada por un plano, no por una recta.En él, para cada valor de la beta, la rentabilidad esperada aumentaría con larentabilidad por dividendo, y para cada valor posible de la rentabilidad pordividendo, la rentabilidad esperada aumentaría con la beta.La representación (86) podría utilizarse para obtener carteras óptimas para
cada inversor, como función de sus tipos impositivos sobre las ganancias decapital y los dividendos [Elton y Gruber (19xx)]. En equilibrio, todos los inver-sores mantendrán carteras bien diversi�cadas, próximas a la cartera de mercado,aunque se desviarán hacia aquellos activos en los que un inversor particulartiene una ventaja �scal comparativa. Como dicha ecuación sugiere, el inver-sor cuyo tipo impositivo es inferior al tipo efectivo promedio (entre inversores)tenderá a mantener en su cartera una ponderación de los activos que propor-cionan altos dividendos, superior a la que reciben en la cartera de mercado, yuna ponderación inferior de los que ofrecen una rentabilidad por dividendo in-ferior. El inconveniente �scal que reportan los activos de altos dividendos paralos inversores en tramos impositivos inferiores es menor que el que ofrecen a losinversores en tramos impositivos más altos, por o que los primeros tienen unaventaja comparativa.
23.10 Activos sin mercado
Existen muchos activos sin mercado que es preciso valorar: capital humano,bene�cios de la S. Social, programas de retiro, etc.. En otros casos, existe unmercado para un activo, pero el inversor nunca consideraría intercambiar dichoactivo en su mercado como parte de la composición de su cartera óptima, debidoa unos costes de transacción excesivos, como ocurre con las viviendas. A todoslos efectos, los consideraríamos activos sin mercado.Sea:rH : rentabilidad en un período de los activos sin mercadoPH : valor total de los activos sin mercadoPM : valor total de los activos con mercadoPuede probarse [Mayers (19xx)]:
rj = rF +rM � rF
�2M + PH=PMCov(rM ; rH)
�Cov(ri; rM ) +
PHPM
Cov(ri; rH)
�que mantiene la forma de la relación de equilibrio del caso más simple,
aunque cambiando algunos elementos. Ahora, la relación de intercambio en-tre rentabilidad y riesgo viene dada por:
rM � rF�2M + PH=PMCov(rM ; rH)
361

Parece razonable que la rentabilidad ofrecida por el conjunto de los activosque no son de mercado esté positivamente correlacionada con la rentabilidad delmercado, lo que sugiere que la relación de mercado entre rentabilidad y riesgosea inferior a la sugerida por el modelo simple. Es tanto menor cuanto mayorsea dicha covarianza. Si los activos que no son de mercado tienen un valor muypequeño en relación con los activos de mercado, o si hubiera una correlaciónextremadamente pequeña entre las rentabilidades de activos con y sin mercado,entonces no se cometería mucho error utilizando el modelo CAPM estándar. Sinembargo, ejemplos como la remuneración del capital humano sugieren más bienlo contrario.También la de�nición de riesgo ha variado. Con activos fuera del mercado, el
riesgo depende de la covarianza entre la rentabilidad del activo y la de los activosde mercado, así como de la covarianza entre la rentabilidad del activo y la delos activos que no son de mercado. Este último término recibe una ponderaciónque depende del tamaño de los activos que no son de mercado, en relacióncon aquéllos que sí lo son. Si la rentabilidad de un activo está positivamentecorrelacionada con el total de activos fuera de mercado, será superior al riesgopropuesto por el modelo CAPM habitual.Teniendo en cuenta ambos cambios, la rentabilidad esperada de equilibrio
puede resultar inferior o superior a la sugerida por el modelo CAPM simple. Siel activo tiene correlación negativa con los activos fuera de mercado, entonces surentabilidad será, en equilibrio, inferior a la proporcionada por el modelo CAPMpara su nivel de riesgo, y el precio del riesgo será asimismo inferior para esteactivo. Si su rentabilidad tiene correlación positiva con los activos de mercado,su rentabilidad podrá ser inferior o superior, dependiendo de si el incremento deriesgo es su�cientemente elevado como para compensar el descenso en el preciode mercado del riesgo.Cabe esperar [Mayer (19xx)] que, en relación con la composición del mercado,
los inversores mantendrán una menor ponderación de aquellos activos con los quesus activos fuera de mercado estén más altamente correlacionados. Brito (19xx)ha mostrado el cumplimiento de un teorema de tres fondos: a) una cartera quetiene con cada activo de mercado una covarianza igual, pero de signo opuesto,a que tiene la cartera de bienes fuera de mercado del inversor, b) el activo sinriesgo, y c) la cartera de mercado excluyendo el agregado de las inversioneshechas por todos los inversores en el primer fondo. La composición del primerfondo varía para los distintos inversores.. El primer fondo está eliminando, pordiversi�cación, un componente tan grande del riesgo de fuera de mercado, comoes posible. Ello permite al inversor tratar los activos de fuera del mercado, comosi fueran activos de mercado.Este análisis tiene implicaciones para la puesta en práctica de contrastes
empíricos del modelo de equilibrio de valoración de activos. En dichos tests,siempre trabajamos con un conjunto incompleto de activos, por lo que rH cor-respondería a aquellos activos que no se consideran al efectuar el contraste.
362

24 El modelo APT: Introducción
Los modelos de equilibrio que hemos visto hasta ahora variantes del modeloCAPM, consideran la esperanza y la varianza de la rentabilidad de un activocomo los criterios a tener en cuenta por un inversor. El modelo de preciosde arbitraje que examinamos a continuación, adopta un enfoque diferente paraexplicar la formación de precios de los activos �nancierosEl modelo se basa en la ausencia de arbitraje: dos activos perfectamente
sustitutivos no pueden negociarse a precios diferentes. No es preciso hacerninguna hipótesis acerca de las preferencias de los inversores, como hicimosal desarrollar el modelo CAPM. En este sentido, el modelo APT es más general.Alternativamente, introducimos un supuesto acerca del proceso de generación derentabilidades de activos individuales, que dependen linealmente de un conjuntode índices:
rit = ai + bi1I1t + bi2I2t + :::+ binInt + eit (87)
donde ai denota la rentabilidad que tendría el activo si todos los índicesfuesen cero, y bij denota la sensibilidad que presenta la rentabilidad del activoi a variaciones en el índice j. El componente de rentabilidad no explicado porlos índices, eit se supone de esperanza nula y varianza constante, �2ei: Además,suponemos:
E(eitejs) = 0; 8i 6= j; 8t; s
E�eit(Ijs � Ij)
�= 0; 8j;8t; s
es decir, los términos de error de distintas rentabilidades no están correla-cionados, ni contemporáneamente, ni con retardos. Los términos de error tam-poco están correlacionados con ninguno de los índices, ni contemporáneamente,ni con retardos.Por supuesto, estas hipótesis nos traen de nuevo al contexto de los modelos
de índices, ya estudiados. La contribución de la teoría de precios de arbitraje(APT) es mostrar cómo se puede pasar de un modelo de múltiples índices a unadescripción del equilibrio de un mercado de activos �nancieros.
24.1 Una deducción sencilla del modelo
Supongamos que las rentabilidades obedecen un modelo de dos índices:
rit = ai + bi1I1t + bi2I2t + eit (88)
Si el inversor mantiene una cartera bien diversi�cada, el riesgo idiosincráticoo especí�co de la cartera se aproximará a cero, y sólo importará el riesgo sis-temático que, de acuerdo con (88) viene determinado por bi1 y bi2: Si el inversorestá interesado en decidir utilizando medidas de rentabilidad esperada y riesgo,todo lo que necesita conocer es: rc; bc1 y bc2:
363

Consideremos tres activos: A, con rentabilidad esperada 15% y bA1=1,0,bA2 =0,6, B, con rentabilidad esperada 14% y bB1=0,5, bB2 =1,0, y C, conrentabilidad esperada 10% y bC1=0,3, bC2 =0,2. La ecuación del plano quepasa por los tres puntos (ri; bi1; bi1) ; i = A;B;C, es:
ri = 7; 75 + 5; 00bi1 + 3; 75bi2 (89)
Toda combinación lineal de estos tres vectores estará asimismo en dichoplano. Pero tal combinación lineal no es sino una cartera formada a par-tir de los tres activos, con ponderaciones positivas o negativas. Una de talescarteras estará de�nida por un vector d e ponderaciones: X = (X1; X2; X3);
conP3i=1Xi = 1. La rentabilidad esperada de dicha cartera, y sus medidas de
riesgo, vendrán dadas por:
rc =
3Xi=1
Xiri; bc1 =
3Xi=1
Xibi1; bc2 =
3Xi=1
Xibi2
No puede haber una cartera D fuera del plano (89), pues ello posibilitaríaoportunidades de arbitraje, del modo habitual. Por ejemplo, supongamos queexistiese una cartera con rentabilidad esperada del 15%, bD1 = 0; 6; bD2 = 0; 6:Si construimos una cartera equiponderada de los activos A;B; y C, tenemos unacartera con bc1 = 0; 6; bc2 = 0; 6, pero con rentabilidad esperada 13%. Esto sus-citaría oportunidades de arbitraje, comprando D y vendiendo una cuantía igualde la cartera equiponderada, hasta que las rentabilidades esperadas de ambasse igualasen, a través de los ajustes de precios producidos por las operacionesde arbitraje.La ecuación general del plano de equilibrio en el espacio (ri; bi1; bi2) es:
ri = �0 + �1bi1 + �2bi2 (90)
donde �1 representa el incremento en la rentabilidad esperada por un au-mento unitario en bi1; mientras que �2 representa el incremento en la rentabili-dad esperada por un aumento unitario en bi2:Una cartera con b1 = b2 = 0 es una cartera de beta nulo, y su rentabilidad
esperada sería �0; que denotaremos, como hicimos anteriormente, por rz: Siconsideramos la existencia de un activo sin riesgo, al cual se puede prestar ypedir prestado, entonces rF = rz:Si ahora consideramos una cartera C1; con b1 = 1; b2 = 0; y rentabilidad
esperada r1 ; tendremos: �1 = r1�rz, mientras que si consideramos una carteraC2; con b1 = 0; b2 = 1; y rentabilidad esperada r2 ;tendremos: �2 = r2� rz. Engeneral, �j es el diferencia de rentabilidad esperado, en relación con la carterade beta nulo, de una cartera expuesta únicamente a riesgo del índice j, y conuna cantidad unitaria de dicho tipo de riesgo.Finalmente, tenemos:
ri = rz + (r1 � rz) bi1 + (r2 � rz) bi2y un modelo similar se obtiene en el caso de que existan n índices.
364

24.2 Una deducción más rigurosa
Supongamos nuevamente, por simplicidad, la existencia de sólo dos índices. Sitomamos esperanzas matemáticas en (88) y restamos la propia ecuación (88),tenemos:
rit = ri + bi1(I1t � I1) + bi2(I2t � I2) + eitUna condición su�ciente para la validez de la APT es que existan en el
mercado su�cientes activos como para que se pueda construir una cartera conlas características:
nPj=1
Xj = 0; bc1=nPj=1
Xjbj1 = 0; bc2 =nPj=1
Xjbj2 = 0;nPj=1
Xjej ' 0 (91)
La última condición dice que el riesgo residual es aproximadamente nulo,mientras que la primera dice que la construcción de la cartera requiere unainversión neta nula. Las otras dos condiciones dicen que el riesgo sistemático dela cartera es nulo. En consecuencia, la rentabilidad esperada de la cartera debeser cero, es decir:
rc =nPi=1
Xiri = 0
Las condiciones (91) dicen que el vector X es ortogonal al vector nx1 for-mado por las bj1; al vector nx1 formado por las bj2; y a un vector nx1 de unos.Pero hemos aprobado que toda cartera que satisfaga las tres condiciones de or-togonalidad mencionadas, es necesariamente ortogonal asimismo al vector nx1formado por las rentabilidades esperadas de los n activos inicialmente escogi-dos. por un conocido teorema de álgebra lineal, esto implica que el vector derentabilidades esperadas puede escribirse como combinación lineal de los tresvectores mencionados, es decir:
ri = �0 + �1bi1 + �2bi2 (92)
y por el mismo procedimiento que antes llevamos acabo, llegamos a:
ri = rz + (r1 � rz) bi1 + (r2 � rz) bi2o, en el caso de N activos:
ri = rz + (r1 � rz) bi1 + (r2 � rz) bi2 + :::+ (rN � rz) biNLa teoría APT es muy general, lo cual es una virtud, pero también una
debilidad, pues no nos dice nada acerca de cuál son los índices adecuados, nitampoco su número. Además, tampoco sugiere cual es la magnitud de loscoe�cientes �, ni tampoco su signo, por lo que, incluso si hallamos un indicadorque ajusta bien, no sabremos si el indicador es la variable incluida en el modelode rentabilidades individuales, o la misma variable cambiada de signo.
365

24.3 Estimación y contraste
El proceso multifactorial generador de rentabilidades puede escribirse:
rit = ai +NPj=1
bijIjt + eit (93)
del cual se obtiene el modelo APT:
ri = rz +NPj=1
bij�j (94)
Notemos que, de acuerdo con la APT, cada activo i tiene una sensibilidadespecí�ca a cada índice j, y es un atributo del activo representada por los coe�-cientes bij , como, por ejemplo, su rentabilidad por dividendo. Por el contrario,cada índice j toma el mismo valor para todos los activos. Cada factor afecta amás de un activo, pues, d e o contrario, estaría incluido en el término de errordel único activo al que afectase. Los índices, también denominados factores, sonlas fuentes de covarianza entre las rentabilidades de activos diferentes.Asimismo, �j es la rentabilidad esperada en exceso de la rentabilidad de
referencia, debido a la sensibilidad del activo respecto al atributo j-ésimo. Laecuación (93) es totalmente análoga a la utilizada en las regresiones de primeraetapa en los contrastes del modelo CAPM, mientras que (94) se asemeja a lasregresiones de segunda etapa. La única diferencia es que mientras que para elmodelo CAPM el (los) índice(s) está(n) bien de�nido(s), por ej., la rentabilidadde la cartera de mercado en el caso del modelo CAPM simple, en el modelomultifactorial y en el modelo APT, los indicadores no están de�nidos por lateoría. En consecuencia, para contrastar el APT a partir de la ecuación (94)necesitamos estimaciones de los bij , que pueden obtenerse a partir de (93). Lomás habitual es estimar simultáneamente los factores Ij y los atributos bij :Sin embargo, habría otras alternativas: Una consiste en establecer una
hipótesis acerca de los factores (tipos de interés, tasa de in�ación, etc.) quepueden in�uir sobre las rentabilidades, y estimar los bij en (93). Un segundoprocedimiento consiste en especi�car un conjunto de atributos bij (caracterís-ticas de la empresa) que pueden in�uir sobre las rentabilidades35 . Con esteenfoque las bij se especi�can directamente, pudiendo incluir la rentabilidad pordividendo, la beta del activo respecto del mercado, etc.. En cualquiera de es-tos dos casos, se estará contrastando la hipótesis conjunta de que el modeloAPT es correcto, junto con la relevancia de los factores, o alternativamente,características seleccionados.35Si, por ej., se considera que las variaciones en los tipos de interés son un índice en (93),
entonces las bij estimadas podrían utilizarse para calcular �j : Alternativamente, podríamospartir del hecho de que la duración del activo es la medida adecudad de sensibilidad, y utilizarduraciones numéricas como valores de las bij para estimar las �j .
366

24.4 Determinación simultánea de factores y característi-cas
La especi�cación de (93) requiere de�nir factores y atributos, de modo quela covarianza entre los residuos de las ecuaciones de dos activos cualesquierasea nula. La técnica de análisis factorial no garantiza esta propiedad pero esbastante adecuada en este contexto.El análisis factorial determina un conjunto de factores Ij y otro de atributos
bij tales que la covarianza entre residuos sea mínima. En esta metodología, lasvariables Ij se denominan, precisamente, factores, mientras que los bij se de-nominan cargas de los factores. El análisis factorial se efectúa, sucesivamente,para 2, 3, ... factores, y se escoge el número de los mismos tales que la prob-abilidad de que el próximo factor explique una parte signi�cativa de la matrizde covarianzas, sea inferior a un determinado nivel36 . Esta elección es subjetivaprecisamente porque la teoría APT no especi�ca el número de factores.El análisis factorial proporciona una estimación tanto de los factores como de
sus cargas. Estas son medidas de sensibilidad de las rentabilidades respecto delos factores, y son similares a las �i del modelo CAPM. Hasta aquí, habríamosllevado a cabo un contraste del tipo de los efectuados en la primera etapa delos contrastes del modelo CAPM, con la diferencia de que habríamos estimadono sólo las cargas, sino también los factores, así como su número. Cada índicees una combinación lineal de las rentabilidades de los activos utilizados en elanálisis factorial.La siguiente etapa consiste en llevar a cabo un conjunto de contrastes análo-
gos a los de la segunda etapa de Fama y McBeth para el CAPM. Mediante unaregresión de sección cruzada, estimamos los �j para cada período, y calculamossu varianza a través del tiempo [Roll-Ross]. Hay algunas di�cultades: primero,tenemos con las cargas de los factores el mismo problema de errores en variablesque teníamos con los �i al contrastar el CAPM estándar, por lo que los con-trastes de signi�cación son válidos sólo asintóticamente. En segundo lugar, lossignos de los bij y los �j no están de�nidos, por lo que podrían intercambiarse.Tercero, los valores numéricos de los bij y los �j están de�nidos sólo salvo fac-tores de escala, por lo que podrían multiplicarse y dividirse, respectivamente,por un mismo factor, sin que nada cambiase. Cuarto, no hay ninguna garantíaa priori acerca del orden en que resultarán escogidos los factores, por lo quecuando se lleva a cabo el análisis en muestras distintas, el primer factor de unamuestra puede ser el tercer factor en otra.RR (19xx) aplicaron el análisis factorial a 42 grupos de 30 activos cada uno,
desde 7/1962 a 12/1972, encontrando que en 38% de los grupos, había unaprobabilidad inferior a 0,10 de que un sexto factor tuviese alguna capacidadexplicativa, y en más de un 75% de los grupos había una probabilidad superiora 0,50 de que 5 factores fuesen su�cientes. Estos autores intentaron diversoscontrastes de segunda etapa, encontrando que al menos 3 factores son signi�ca-
36El análisis de componentes principales es similar al análisis factorial, extrayendo de losdatos el conjunto de índices que explica mejor la varianza ( en vez de la covarianza) de losdatos. Los índices se van extrayendo en orden de importancia.
367

tivos cuando se pretende explicar los precios de equilibrio, pero que es altamenteimprobable que cuatro factores resulten signi�cativos. Esto sugiere que se en-cuentran más factores de los que uno esperaría encontrar bajo las versionessimple o beta-cero del modelo CAPM.Tiene interés, por tanto, preguntarse en qué medida estos resultados son
inconsistentes con el modelo CAPM. Cho, Elton, Gruber (19xx) probaron quehabía más in�uencias determinando las rentabilidades que las sugeridas porel modelo CAPM, encontrando, en un período posterior, incluso más factoresque RR. Estos autores simularon rentabilidades temporales a partir de la ver-sión beta-cero del modelo CAPM, forzando que las medias y varianzas de lasrentabilidades de los activos individuales coincidiesen con las de los datos reales.A la vez, permitieron que la rentabilidad de la cartera beta-cero, así como ladel activo sin riesgo, variasen en el tiempo. Aplicando la metodología de RRa estos datos arti�ciales, el número de factores resultante es consistente conla versión beta-cero del modelo CAPM, por lo que el resultado obtenido conrentabilidades realmente observadas sugiere que hay más factores en los datosque los sugeridos por el modelo beta-cero CAPM teórico. Sin embargo, comoveremos posteriormente, el modelo CAPM todavía puede ser consistente coneste resultado.La utilidad del modelo APT no puede separarse de la metodología utilizada
en su estimación. Un problema con el uso de análisis factorial para estimar si-multáneamente factores y sensibilidades es que es tan complejo analíticamente,que sólo puede aplicarse a un número reducido de activos. De hecho, se cuentacon evidencia acerca de que el número de factores tiende a aumentar con elnúmero de activos considerados, pues DFG (19xx) encuentran hasta 7 activoscuando consideran grupos de 60 activos. Al hacer grupos, pueden estar ignorán-dose ciertas fuentes de covarianza entre activos.Por otra parte, la estimación del APT para grupos reducidos de activos
permite contrastar teoría y metodología conjuntamente. De acuerdo con elmodelo teórico (94), el precio de mercado de cada factor �j y la ordenada enel origen deben ser iguales para cada grupo. Sin embargo, recordemos que losfactores pueden aparecer en orden distinto en grupos diferentes de activos. Sinembargo, los resultados de este tipo de contrastes parecen ser bastante ambiguos.DFG (19xx) muestran que un modelo multifactorial APT tiene más capaci-
dad explicativa de las rentabilidades que un modelo de un sólo factor. Sinembargo, ambas capacidades explicativas son reducidas, habiendo duda de quelas primas de riesgo o precios de cada uno de los cinco factores considerados porRR sean signi�cativamente diferentes de cero.Un test del APT que daría bastante con�anza consistiría en probar que el
riesgo residual de un activo no es remunerado cuando se añade como un factoradicional a la ecuación de precios de equilibrio de mercado, puesto que los bijrecogen la remuneración de todos los componentes sistemáticos de riesgo. RRno encuentran este efecto, mientras que DFG encuentran que los coe�cientesde la desviación típica residual, o del coe�ciente de asimetría son generalmenteno signi�cativos, si bien la frecuencia con que resultan signi�cativos es casi tangrande como la de los factores de RR. Reinganum ha explorado la observación
368

de que las empresas de menor capitalización tienden a ofrecer una rentabilidadsuperior a la predicha por el modelo CAPM, encontrando que el modelo multi-factorial de RR no explica este efecto mejor que el modelo CAPM estándar.Un tipo de contraste muy poco explotado se centra en la estabilidad temporal
de la estructura de factores. Si, efectivamente, fuesen estables, tendría interéscontrastar si los bij también son estables.
24.5 Un enfoque alternativo
En ocasiones, podemos estar dispuestos a especi�car a priori bien los factoresque in�uyen sobre ñlas rentabilidades, o las características de los activos quein�uyen sobre las rentabilidades promedio, lo que facilita el problema de esti-mación, además de proporcionar una mayor fuerza a los contrastes..
24.5.1 Especi�cación de los atributos de los activos
Si especi�camos a priori los bij , los �j podrían estimarse mediante análisis deregresión. Este procedimiento es análogo a la segunda etapa de los contrastesdel modelo CAPM. De hecho, el modelo utilizado por Fama y McBeth paracontrastar el modelo CAPM podría considerarse asimismo como un contrastedel modelo APT, en el que las características de la empresa son: su beta, su betaal cuadrado, y el riesgo residual. Condicional en este conjunto de características,el modelo multifactorial no funciona mejor que la versión beta-cero le modeloCAPM, pues ninguna de las características citadas parece estar remunerada porle mercado.
Un segundo enfoque consiste en incluir otros factores especí�cos de la em-presa. Así, LR (19xx) encontraron que la rentabilidad por dividendo era es-tadísticamente signi�cativa.Continuando con la idea de encontrar factores, Sharpe (19xx) parte de la
hipótesis de que las rentabilidades pueden estar in�uidas por: el beta del activocon el índice S&P, su rentabilidad por dividendo, el tamaño de la empresa, subeta con los bonos a largo plazo, el valor previo de su alfa (el término indepen-diente de la regresión de exceso de rentabilidad del activo el período anteriorsobre el exceso de rentabilidad del índice), y variables de adscripción sectorialdel activo. Los dos primeros factores deberían in�uir positivamente sobre larentabilidad. El tamaño, al actuar como proxy de la liquidez podría entraranegativamente. Un alfa signi�cativo podría deberse a autocorrelación resid-ual, y podría sugerir que hay alguna variable que explica las diferencias entrerentabilidades en las sección cruzada, y que no está recogida en el modelo.Sus resultados, obtenidos con datos mensuales de 2.197 activos entre 1931
y 1979 son consistentes con estas creencias a priori, siendo bastante alto elporcentaje de casos en que los indicadores propuestos son signi�cativos. Elincremento en el R-cuadrado respecto al caso en que la beta se utiliza comoúnica característica es asimismo importante. Por tanto, éstas son características,adicionales a la beta del activo con un índice de mercado, que son relevantespara explicar rentabilidades.
369

24.5.2 Especi�cando las in�uencias que afectan sobre el proceso degeneración de rentabilidades
Alternativamente, podríamos especi�car a priori los índices que entran en elproceso de generación de rentabilidades.Chen, Roll, Ross (19xx) establecen, como hipótesis, que las rentabilidades
deberían verse afectadas por toda in�uencia que afecte los cash-�ow futurosque se recibirían por mantener dicho activo en la cartera, o por los factores queafectan al valor de dichos cash-�ows, como podrían se cambios en el factor dedescuento que se les aplique. Entre ellos:1) la tasa de in�ación, que afecta tanto a la tasa de descuento como a los
cash-�ow futuros,2) la estructura temporal de tipos de interés: cambios en el spread entre el
largo y el corto plazo (pendiente de la curva de rendimientos) afecta al valor delos pagos a recibir en el futuro, relativamente a los recibidos próximamente.3) la prima de riesgo: diferencias entre la rentabilidad de bonos privados
seguros (Aaa) y los de más riesgo (Baa), utilizada como remuneración del riesgoen el mercado,4) la producción industrial, pues cambios en la misma afectan a las oportu-
nidades disponibles al inversor y al valor real de los cash-�ows.CRR examinaron este conjunto de índices para comprobar: a) si estaban
correlacionados con el conjunto de índices obtenido por al análisis factorial deRR, b) si explicaban las rentabilidades de equilibrio.Estos autores encontraron una fuerte relación entre factores e indicadores
macroeconómicos, que se mantiene además, para el período posterior a la con-strucción de los factores. La segunda cuestión se analiza mediante una regresiónanáloga a las de la segunda etapa de Fama y Mcbeth. En la primera etapa seutilizan series temporales para un conjunto de carteras para estimar la sensibil-idad de cada una de ellas a cada una de las variables macroeconómicas; en lasegunda etapa se estima el precio del riesgo mediante una regresión de seccióncruzada cada mes, y considerando el promedio de los precios de mercado delriesgo. CRR encuentran que las variables macroeconómicas son signi�cativasal explicar las rentabilidades. Además, cuando la beta de cada cartera con elmercado se introduce como una variable adicional, junto con la sensibilidad decada cartera a las variables macroeconómicas en la regresión de segunda etapa,no resulta signi�cativa.
24.6 Relaciones entre los modelos CAPM y APT
Veamos, por último, si la existencia de un modelo multifactorial es necesaria-mente inconsistente con algunas de las versiones del modelo CAPM.El caso más sencillo en que el modelo APT es consistente con la versión sim-
ple del modelo CAPM es aquél en que el proceso de generación de rentabilidadeses:
rit = ai + �irMt + eit
370

Si las rentabilidades responden a un único índice, dicho índice es la rentabili-dad de la cartera de mercado, y existe un tipo de interés libre de riesgo, entoncesla discusión de comienzo del capítulo conduce a:
ri = rF + �i(rM � rF )
Pero, ¿y si el proceso generador de rentabilidades es más complejo? ¿im-plicaría esto necesariamente que el modelo CAPM no es válido? No es así,puesto que el modelo CAPM no supone que el comportamiento de la cartera demercado sea la única fuente de covarianza entre rentabilidades.Supongamos que la generación de rentabilidades responde al modelo multi-
factorial:
rit = ai + bi1I1t + bi2I2t + eit
donde los ídices pueden ser índices de industria, o indicadores macroeconómi-cos, como la tasa de in�ación. Todo lo que suponemos es que los índices recogentodas las fuentes de covarianza entre activos, es decir, que E(eitejt) = 0.El modelo APT de equilibrio correspondiente a este modelo multifactorial,
en presencia de un tipo libre de riesgo, es:
ri = rF + �1bi1 + �2bi2
Si el modelo CAPM se cumple, ha de ser válido para todos los activos, asícomo para todas las carteras. Supongamos que los índices pueden representarsecomo carteras de activos. En realidad, hemos visto que �1 es el exceso derentabilidad recibido en la cartera que tiene bcj = 1 y bck = 0 8k 6= j: Por tanto,si el modelo CAPM se satisface, la rentabilidad de equilibrio de cada �j vienedada por el modelo CAPM:
�1 = ��1(rM � rF )
�2 = ��2(rM � rF )
que llevado a la ecuación anterior proporciona:
ri = rF +��1(rM � rF )bi1+��2(rM � rF )bi2 = rF +(��1bi1+��2bi2)(rM � rF )
y de�niendo �i = ��1bi1+��2bi2, tenemos que la rentabilidad esperada vienemedida por el modelo CAPM:
ri = rF + �i(rM � rF )
de modo que la solución APT con múltiples factores adecuadamente re-munerados es totalmente consistente con la versión simple (Sharpe, Lintner,Mossin) del modelo CAPM. Es decir, que encontrando más de un �j distintode cero no constituye su�ciente evidencia para rechazar el modelo CAPM. Si
371

los �j estimados no resultan signi�cativamente distintos de ��j (rM � rF ), en-tonces los resultados empíricos podrían ser consistentes con la versión estándardel modelo CAPM: es perfectamente posible que la estructura de covarianzasentre rentabilidades sea explicada por más de un factor, a pesar de lo cual, elmodelo CAPM sea válido. Un razonamiento análogo conduciría a mostrara quehay valores de los �j que harían consistente el modelo APT con las versionesmenos simples del modelo CAPM.
372

25 Contrastes empíricos del modelo de valoraciónde activos: Introducción
La mayoría de los contrastes de modelos de equilibrio se re�eren a alguna delas variantes del modelo CAPM, pero fundamentalmente, utilizan su versiónestándar, o la versión beta-cero del mismo. La versión simple del modelo es:
E(ri) = rF + �i [E(rM � rF )] (95)
La versión del mismo en que no permitimos prestar ni pedir prestado a untipo sin riesgo rF es:
E(ri) = E(rz) + �i [E(rM )� E(rz)] (96)
donde E(rz) denota la rentabilidad esperada de la cartera de mínima vari-anza que está incorrelacionada con la cartera de mercado.En ambos modelos aparecen rentabilidades esperadas a lo largo del horizonte
de inversión, por lo que, en muchas ocasiones los contrastes se efectúan entérminos de rentabilidades ex-post, lo cual, evidentemente, introduce un errorde observación en el modelo. Una defensa tradicional y sencilla ante esta críticaes que las expectativas son, en promedio, correctas, por lo que , sobre períodos detiempo su�cientemente largos, las realizaciones pueden utilizarse como proxiesde las expectativas.Un argumento más complejo supone que la rentabilidad de cada activo se
relaciona linealmente con la de la cartera de mercado, de modo que se tiene elmodelo de mercado:
rit = �i + �irMt + et (97)
de modo que:
E(rit) = �i + �iE(rMt) (98)
y:
E(rit)� �i � �iE(rMt) = 0 (99)
por lo que de (97):
rit = E(rit) + �i [rMt � E(rMt)] + et (100)
y, a partir de (95):
rit = rF + �i(rMt � rF ) + et (101)
Sobre el modelo genérico de un índice, le modelo CAPM impone cierta es-tructura: a) que el índice es la rentabilidad de la cartera de mercado, y b) que:�i = rF (1� �i):
373

Aunque tiene sentido utilizar datos ex-post para contrastar este modelo, sibien hay que tener presente la tres hipótesis incorporadas en el mismo:a) se cumple el modelo de mercado en todos los períodos,b) el modelo CAPM es válido en todos los períodos,c) las betas son estables en el tiempo.por lo que estaremos contrastando conjuntamente estas tres hipótesis, y no
sólo la segunda de ellas.Por un razonamiento similar, si utilizamos el modelo de 2 factores, lle-
garíamos a:
rit = rzt + �i(rMt � rzt) + et (102)
y, nuevamente, estaríamos contrastando conjuntamente tres hipótesis, aunquela primera se ría ahora: a´) la versión beta-cero del modelo CAPM se satisfaceen todos los períodos.
25.1 Contrastes empíricos del modelo CAPM
Para organizar la discusión de los muchos contrastes que se han llevado acabo, haremos explícitos los supuestos que deberían contrastarse, revisaremoslos primeros contrastes que se efectuaron, y analizaremos las di�cultades en lacontrastación. Por último, repasaremos algunos de los contrastes más rigurosos.
25.2 Hipótesis del modelo CAPM
Son válidas para las dos formulaciones del mismo:a) mayor riesgo, medido por la beta, debe ir asociado con mayor rentabilidadb) la rentabilidad está relacionada linealmente con la beta: el incremento
en rentabilidad que se produce por una aumento de riesgo es independiente delnivel de riesgo,c) el mercado no remunera por asumir riesgo diversi�cable,d) desviaciones de la rentabilidad de un activo o cartera con respecto a su
nivel de equilibrio deben ser puramente transitorias, y no pueden utilizarse paragenerar bene�cio sistemático,Por último, la versión estándar del modelo implica que: e) la recta del mer-
cado de activos, en el plano (r; �) debe tener ordenada en el origen igual a rFy pendiente rM � rF ; mientras que la versión de dos factores requiere que laordenada en el origen sea igual a rz y la pendiente sea rM � rz:
25.3 Un contraste sencillo
Un contraste simple consiste en examinar si, a través del tiempo, un mayorriesgo ha estado asociado con una mayor rentabilidad [Sharpe y Cooper (19xx)].SC dividieron los activos en deciles una vez al año, de acuerdo con las betasestimadas. Sin embargo, en cada estimación se utilizan 60 meses, es decir, 5años. Posteriormente, se construye una cartera equiponderada dentro de cadadecil, y se mantienen durante un año. Los activos de una determinada cartera
374

van cambiando, debido a la reinversión de los dividendos, y a que las betascambian una vez al año.La relación entre la rentabilidad de las diez distintas carteras-deciles y su
riesgo no es perfecta, pero es bastante estrecha. La correlación de rangos es0,93, que es signi�cativa al 1%.Si se hubiesen utilizado betas previstas para constituir las carteras, el resul-
tado habría sido muy similar: la correlación de rangos sería de 0,95, nuevamentesigni�cativa.La relación estimada con las diez carteras es:
ri = 5; 54 + 12; 75�i
y un 95% de la variación en rentabilidad es explicada por diferencias en lasbetas.
25.4 Algunos contrastes iniciales
La mayoría de los primeros contrastes utilizaron dos etapas: en una primera,se estimaban las betas por mínimos cuadrados, y en una segunda etapa, seestimaba una regresión de sección cruzada para relacionar la rentabilidad ob-servada con el riesgo [Lintner (19xx), Douglas (19xx)]. L. estimó en una primeraetapa las betas de 301 activos en su muestra, utilizando rentabilidades anualespara 1954-1963:
rit = �i + �irMt + eit
y después, en la segunda etapa:
ri = a1 + a2b�i + a3b�2i + �idonde b�2i denota la varianza residual de cada regresión de la primera etapa.
Cada parámetro en esta regresión tiene un determinado valor teórico: si elmodelo CAPM es válido, a1 debería ser cero, a2 debería ser igual bien a rF o arz, y a3 debería ser igual a rM � rF o a rM � rz; según qué versión del modeloCAPM sea cierta.L. obtuvo: ba1 = 0; 108;ba2 = 0; 063;ba3 = 0; 237; y los dos últimos coe�-
cientes eran signi�cativamente distintos de cero, con coe�cientes t de Studentde 6,9 y 6,8, respectivamente. Esto parece incumplir las restricciones del modeloCAPM, pues el término de riesgo residual afecta positivamente a la rentabilidadesperada.. Además, la estimación de la constante parece superior a cualquierevaluación de rF o rz, mientras que a3 tiene un valor algo menor de lo queesperaríamos.
25.5 Algunos problemas metodológicos
Miller y Scholes (19xx) describieron algunos de los problemas envueltos en estetipo de contrastes, y llevaron a cabo algunas simulaciones para medir el posiblesesgo de los contrastes anteriores.
375

Un primer problema es el error de especi�cación de las ecuaciones básicas:si las rentabilidades están generadas por un proceso igual al a versión básica delmodelo CAPM, entonces la ecuación de series temporales utilizada para estimarlas betas debería ser consistente con el modelo CAPM, que en su forma de seriestemporales es:
rit = rFt + �i(rMt � rFt) = (1� �i)rFt + �irMt (103)
mientras que la ecuación de L. y D. fue:
rit = �+ �irMt (104)
Si rF hubiese constante durante el período muestral, no habría problema,y su estimación debería ser igual a (1 � �i)rF . Ahora bien, si ha �uctuadoa lo largo del tiempo, y está corelacionado con rMt; entonces tenemos un casode sesgo por variables ausentes y tendremos una estimación sesgada de las ver-daderas betas.Además, si la mencionada correlación fuese negativa, como cabe esperar, ello
sesgaría al alza la ordenada en el origen de la regresión de la segunda etapa,y sesgaría a la baja la estimación de la pendiente, lo que podría explicar lasdesviaciones observadas por L. y D.. M.-S. estiman, en efecto una correlaciónnegativa entre las rentabilidades del activo sin riesgo y la de la cartera de mer-cado, pero evalúan que los sesgos descritos no son de la cuantía su�ciente comopara explicar las desviaciones observadas por D. y L.Otro posible error de especi�cación que podría explicar una ordenada en el
origen excesivamente alta y una pendiente excesivamente reducida, podría surgirporque la relación entre rentabilidad esperada y riesgo no fuese lineal. Nueva-mente, M.S. evaluaron que cualquier desviación de la linealidad que pudieseexistir en dicha relación no sería su�ciente para explicar los sesgos observadospor L. y D.Un tercer error posible de especi�cación sería la existencia de heterocedasti-
cidad. Ello haría que la componente de rentabilidad no explicada por el mercadode los activos con betas más altas tuviese mayor varianza que la de los activoscon betas menores. Nuevamente, esta no parece ser la explicación pues, si acaso,sesgaría los estimadores en dirección contraria a la observada.A continuación, M.S. consideraron la posibilidad de errores en la de�nición
de las variables.Una forma de sesgo se debería al error cometido al cuanti�car las betas
para la regresión de la segunda etapa. Sólo disponemos de betas estimadasque, aunque posiblemente libres de sesgo, no están exentas de error muestral.Cualquier error en las betas genera un problema de errores en variables en lasegunda etapa de los contrastes, lo que hará que el coe�ciente estimado de lasb�i esté sesgado a la baja, mientras que la ordenada en el origen esté sesgadaal alza. M.S. probaron que este efecto era importante, y que el coe�cienteestimado para las b�i podría estar por debajo de las 2/3 partes de su verdaderovalor, produciendo un incremento porcentual correspondiente en la estimaciónde la ordenada en el origen.
376

Hay otro efecto aún más importante: En la medida que el verdadero valorde las betas esté positivamente correlacionado con la varianza residual de larentabilidad, dicha varianza actuará como proxy de la verdadera beta, y larentabilidad estará positivamente correlacionada con el riesgo residual. M.S.concluyeron que este efecto estaba presente en los contrastes de L.. De estemodo, aunque la rentabilidad no depende de la varianza residual, ésta puedeaparecer como estadísticamente signi�cativa en la regresión de sección cruzada.Finalmente, M.S. demostraron que las distribuciones empíricas de rentabili-
dades son asimétricas, lo que genera una asociación espuria entre riesgo residualy rentabilidad. Algunos autores [M.-S. y Roll (19xx)] han debatido acerca de sila elección de uno u otro índice de mercado altera signi�cativamente los resul-tados.
25.6 El contraste de Black, Jensen y Scholes
BJS (19xx) fueron los primeros en efectuar un contraste de series temporalesdel modelo CAPM, utilizando la especi�cación:
rit � rFt = �i + �i(rMt � rFt) + eit (105)
en la que la estimación de �i debería ser cero si la versión simple del mod-elo CAPM describe adecuadamente el proceso de formación de rentabilidades.Para contrastar el modelo CAPM, es importante contar con datos de un ele-vado número de activos. Entonces, una posibilidad consistiría en estimar (105)para cada uno de ellos, y examinar la distribución de probabilidad de b�i paracontrastar su signi�cación estadística. Sin embargo, este procedimiento no esmuy apropiado, porque los residuos beit y bejt no son independientes, y habríaque tenerlo en cuenta. De hecho, habría que examinar la distribución conjuntadel vector de las b�i, lo cual sería muy complicado.Una posible solución es estimar (105) para carteras. La varianza residual de
tales regresiones incorpora el efecto de interdependencias entre los activos quecon�guran la cartera, por lo que la desviación típica del término independientepodría utilizarse para contrastar la hipótesis nula H0:�i = 0 .BJS propusieron formar carteras de modo que la diferencia entre sus be-
tas fuese la mayor posible, de modo que se pudiese examinar e�cientemente elefecto de las betas sobre las rentabilidades. Un modo evidente de hacerlo esestableciendo una ranking de activos de acuerdo con sus verdaderos betas. Sinembargo, todo lo que tenemos son betas estimados, que, utilizados para elab-orar un ranking, generan un sesgo de selección: los activos con un beta mayorson aquellos en los que, muy probablemente, se ha cometido un error de medidapositivo en la estimación. Esto introducirá un sesgo positivo en las estimacionesde las betas en las carteras de beta elevado, y un sesgo negativo en la estimaciónde la ordenada en el origen �i. Para evitar este problema, se utiliza un pro-cedimiento de variables instrumentales para generar el ranking de activos. Unavariable instrumental es, en este contexto, una variable que está correlacionada
377

con la verdadera beta, pero que puede observarse independientemente de ésta.Generalmente, se utiliza como tal la beta estimada el período anterior.El procedimiento seguido por BJS consistió en utilizar 5 años de datos men-
suales para estimar las betas y clasi�car los activos en deciles. Cada decil es unacartera que se mantiene durante el año siguiente (el sexto año en la muestra).Entonces, se utilizan datos del segundo al sexto años para un proceso similar,y se continúa hasta agotar la muestra. Cada decil constituye una cartera, cuyacomposición cambia una vez al año, y se consideran las rentabilidades anuales decada una de ellas. A continuación, se estima una regresión de la serie temporalde rentabilidades anuales sobre una constante y la rentabilidad del mercado, yse estima la beta y el coe�ciente de correlación de cada ecuación [ver Tabla].El modelo explica bien los excesos de rentabilidad, puesto que los coe�cientes
de correlación (R-cuadrados) son elevados, lo que da cierto soporte a la relaciónlineal estimada como explicativa del proceso de rentabilidades. Sin embargo, lasordenadas en el origen di�eren de cero. Se observa cierta regularidad, por cuantoque las carteras con b�>1 son carteras con b� < 0, mientras que las carteras conb�<1 son carteras con b� > 0: Como veremos enseguida, este resultado es másconsistente con el modelo CAPM de dos factores que con el modelo CAPMestándar.La versión de beta-cero del modelo CAPM implica:
rit = rz(1� �i) + �irMt
mientras que el model que se contrasta es:
rit = �i + rF (1� �i) + �irMt
Si el modelo de beta-cero explicase realmente el proceso de rentabilidades,podríamos arreglar las ecuaciones para eliminar �irMt y, despejando �i ten-dríamos:
�i = (rz � rF ) (1� �i)
Como vimos en otro capítulo, rz ha de ser mayor que rF , por o que el primerfactor es positivo. Por tanto, si �i es menor que 1, �i debería ser positivo, ylo contrario ocurrirá si �i fuese mayor que 1, explicando la observación anteriorde BJS, que se repite para distintos sub-períodos muestrales..Hasta ahora hemos repasado los contrastes de series temporales del modelo
CAPM realizados por BJS, quienes también llevaron a cabo contrastes con datosde sección cruzada. Ya hemos mencionado que la mayor di�cultad en este tipo decontrastes es que las betas no se observan directamente, sino que sólo disponemosde estimaciones numéricas de las mismas, lo que sesga al alza la ordenada enel origen en la regresión de la segunda etapa, a la vez que sesga a la baja supendiente, y hace que el riesgo residual actúe como proxy del riesgo beta. Unmodo de reducir sustancialmente el error en las betas es, de nuevo, estimarbetas para carteras, en vez de hacerlo para activos individuales, puesto que los
378

errores de medida individuales tenderán a cancelarse entre sí. Trabajando conas carteras-deciles antes descritas, los resultados fueron:
rit � rF = 0; 00359 + 0; 01080�i; �2 = 0; 98
la ordenada en el origen, positiva y signi�cativa, constituye una evidenciapotente a favor del modelo de dos factores. Este resultado parece surgir cuandose utiliza datos de distintos subperíodos muestrales.
25.7 Los contrastes de Fama y MacBeth
FM (19xx) formaron 20 carteras de activos para estimar las betas en una primeraetapa, utilizando el mismo procedimiento de BJS. Sin embargo, estos autoresestimaron una regresión de segunda etapa para cada mes durante el período1935 a 1968. La ecuación estimada cada mes con datos de sección cruzada fue:
rit = 0t + 1t�i + 2t�2i + 3tSei + �it (106)
prestando atención al modo en que los parámetros varían de un mes a otro.Sobre esta ecuación se llevaron a cabo los siguientes contrastes:1) E(b 3t) = 0: el riesgo residual no afecta a la rentabilidad2) E(b 2t) = 0: no hay no-linealidades en la línea del mercado de activos3) E(b 1t) > 0: el mercado remunera el riesgoSi E(b 2t) y E(b 3t) resultasen no ser signi�cativamente diferentes de cero,
entonces un examen de E(b 0t) y E(b 1t) permitiría saber si es el modelo CAPMestándar o la versión de beta cero la que mejor representa las rentabilidades demercado. Además, en cualquiera de los dos casos, la esperanza en t de 2t+1y 3t+1 deben ser cero. Si es la versión beta-cero la que es válida, entonces lasdesviaciones de b 0t respecto de su esperanza rz; así como de b 1t respecto desu esperanza rM � rz deberían ser aleatorias, con independencia e lo ocurridoen períodos anteriores. Si es la versión estándar del modelo la que es válida, lomismo cabría decir, sustituyendo rz por rF :FM estimaron cada uno de los 4 parámetros en (106), así como de �2�i para
cada mes entre 1/1935 y 6/1968. El promedio de cada b it, denotado por b i;puede calcularse promediando las estimaciones temporales, y puede contrastarsesi dicha media es igual a cero, pues, por el teorema central del límite, la media sedistribuye, asintóticamente, como una Normal con esperanza matemática iguala la de la población, y varianza igual a la varianza poblacional, dividido por eltamaño de la muestra.En la tabla se recogen las estimaciones de FM de (106), así como d versiones
restringidas de la misma, con objeto de ganar e�ciencia si alguna variable noes relevante. Por ejemplo, si, como predice la teoría y los resultados empíricosiniciales, ni �2i ni el riesgo residual afectan a la rentabilidad, entonces al excluirestas variables eliminamos también la posible multicolinelidad entre �i y �
2i y
el riesgo residual.La tabla muestra que sobre le período completo, b 3 es pequeño y no signi-
�cativamente diferente de cero, resultado que se mantiene en subperíodos, lo que
379

sugiere que el riesgo residual no tiene efectos sobre la rentabilidad. Sin embargo,aún podría ocurrir que, una desviación de b 3t en un período respecto de ceronos proporcione información acerca de su valor el próximo período. Para ello,se calcular su coe�ciente de autocorrelación de primer orden, bajo el supuestode que la media es cero, obteniendo un valor numérico pequeño, y no signi�cati-vamente diferente de cero. Este resultado se mantiene para retardos superioresa uno.Los resultados de FM son opuestos a los de LD en cuanto a la relevancia
del riesgo residual, pero estamos en condiciones de interpretar la discrepancia.MS mostraron que si las betas estaban sujetas a error muestral grande, el riesgoresidual actuaría como proxy de la verdadera beta. Ahora bien, FM tienenmucho menor error muestral que LD por trabajar con carteras, lo que conducea que el riesgo residual no sea signi�cativo.Los resultados relativos a b 2 son similares, por lo que el término en �2i no
parece in�uir sobre las rentabilidades, ni su coe�ciente contiene informaciónrelevante para diseñar estrategias de inversión futuras.Por tanto, hay que pasar a la versión simple del modelo:
rit = 0t + 1t�i + �it
La evidencia acerca de b 1 muestra que la relación entre beta y rentabili-dad es positiva y lineal.. Por otra parte, la información histórica acerca de lasestimaciones b 1t no proporcionan información útil para el diseño de estrate-gias de inversión, puesto que la predicción de series temporales no mejora a laproporcionada por la media b 1:FM encontraron que b 0 es generalmente mayor que rF y, sobre la muestra
completa, b 1 es signi�cativamente mayor que cero, aunque menor que rM �rF : Estas dos observaciones, unidas, sugieren que el modelo beta-cero es másconsistente con las condiciones de equilibrio que la versión simple del modeloCAPM.Por último, si el modelo de equilibrio describe condiciones de mercado, la
desviación en la rentabilidad de un activo individual respecto del modelo no de-bería contener información útil, es decir, un residuo positivo no debería contenerinformación relevante respecto al resultado futuro ofrecido por dicho activo. Losresiduos deberían estar libres de autocorrelación, lo que, efectivamente, encon-traron FM.
25.8 Dos recientes contrastes del modelo CAPM
Gibbons (19xx) utiliza el hecho de que el CAPM impone una restricción no-lineal sobre el conjunto de N regresiones de los activos individuales. En efecto,el modelo de mercado requiere:
rit = �+ �irMt + eit (107)
pero, si el modelo de mercado y el CAPM se cumplen simultáneamente,tenemos:
380

rit = 1(1� �i) + �irMt + eit
es decir:
� = 1(1� �i)
donde 1 es la misma para todos los activos individuales. En el modeloCAPM estándar, 1 debería ser igual a rF ;mientras que en la versión beta-cerodebería ser igual a rz; que es mayor que rF . Para contrastar estas hipótesis,debe estimarse simultáneamente un conjunto de ecuaciones como (107), bajola restricción de que todos los �i son iguales a la constante, multiplicada por1��i. Gibbons de�ne el mercado como una cartera equiponderada de los activosen el New York Stock Exchange, estima mediante regresiones aparentemente norelacionadas, y lleva a cabo un contraste de razón de verosimilitudes, rechazandotanto la forma estándar del modelo CAPM, como su versión beta-cero.Stambaugh (19xx) adopta un enfoque similar, aunque utiliza un contraste de
multiplicadores de Lagrange, porque cree que es más potente dada la longitudde las muestras utilizadas. Encuentra fuerte evidencia a favor de la versión beta-cero del modelo CAPM, y en contra de la versión estándar. Repite el contrastecon diversas de�niciones de la cartera de mercado, que incluye en ocasionesdeuda privada, deuda pública, Letras del tesoro, viviendas residenciales, coches,y otros activos, pero sus conclusiones son bastante robustas a cambios en lade�nición.
25.9 Contrastes de la versión neta de impuestos del mod-elo CAPM
Black y Scholes (19xx) contrastaron una versión del modelo CAPM incluyendoun término de dividendos y concluyeron que estos no afectaban a la relación deequilibrio. Como en la versión neta de impuestos aparece un término de divi-dendos, su resultado constituye evidencia indirecta a favor de la versión antes deimpuestos del modelo CAPM. Sin embargo, Litzenberger y Ramaswamy (19xx)encontraron un efecto positivo y fuerte de los dividendos sobre las rentabili-dades. Mientras BS suponían que los se recibían en igual cuantía cada mes, LSllevaron a cabo su contraste suponiendo que los dividendos se recibían en el mesen que que razonablemente podrían esperase recibir. El método de estimaciónde ambos grupos de autores es diferente.LS estimaron:
rit � rFt = 0 + 1�it + 2(�it � rFt) + eitdonde �it denota el dividendo, dividido por el precios del activo i en el mes
t. Este modelo se asemeja a un modelo de dos factores, con la incorporaciónde un nuevo término, recogiendo los dividendos. La forma del modelo es com-patible con la versión después de impuestos del modelo CAPM, con 2 jugando
381

el papel de � : LS encontraron un término de dividendos positivo, y estadística-mente signi�cativo. Además, es fácilmente interpretable: por cada $1 adicionalde dividendos, los inversores reciben 23,6 centavos de rentabilidad adicional. Elmodelo nos proporciona, además, los tipos impositivos efectivos parea determi-nar el equilibrio en le mercado puesto que 2=� .Probamos en capítulos previos que � es un promedio de los � i individuales,
con:
� i =tdi � tgi1� tgi
siendo tdi el tipo impositivo sobre los dividendos, y tgi el tipo impositiv0sobre las rentas de capital., suponiendo que ambas se pagasen al �nal de cadaperíodo (un año). Estos autores también hallaron que los inversores en tramosimpositivos más elevados mantenían en sus carteras un porcentaje superior deactivos con alta rentabilidad por dividendos.
25.10 Algunas di�cultades con los contrastes tradicionalesde las relaciones de equilibrio en le mercado de ac-tivos
Roll (19xx) ha sugerido que los modelos de equilibrio general como el CAPMpueden no ser susceptibles de ser contrastados. Para entender el argumento,veamos que: si cualquier cartera e�ciente ex-post en el sentido media-varianzase selecciona como cartera de mercado, la ecuación:
ri = rzc + �i(rc � rzc)
debe satisfacerse. De hecho, esta es una a�rmación tautológica, que no tienenada que ver con el modo en que se determina el equilibrio en los mercados decapitales, o con la actitud de los inversores hacia al riesgo.Para ello, debemos volver al problema de maximización de la pendiente de
la recta que une al activo sin riesgo con la frontera e�ciente, llegando a:
��X1�1k +X2�2k + :::+Xk�
2k + :::+Xn�nk
�= rk � rF
para cada activo. Si las proporciones Xi son las que de�nen la carterae�ciente C, podemos escribir la expresión como:
�Cov(rk; rC) = rk � rF (108)
válida para todo activo en C, por lo que, en particular,
��2M = rM � rFde modo que, despejando �, sustituyendo en (108) y arreglando términos:
rk = rF +�kC�2C
(rC � rF ) = rF + �kC (rC � rF )
382

Supongamos que no podemos prestar ni pedir prestado al tipo libre de riesgo,sin embargo, existe todo un continuo de carteras c con rentabilidad rF : Sea rzC larentabilidad esperada de la cartera de mínima varianza que está incorrelacionadacon la cartera C. entonces, como rzC = rF , tendremos:
rk = rzC + �kC (rC � rzC )
como queríamos probar. De modo que la rentabilidad esperada de cualquieractivo o cartera es una función lineal de un beta incluso cuando los betas secalculan respecto a cualquier cartera e�ciente. Recíprocamente, si la caretraescogida para calcular las betas no es e�ciente, entonces al rentabilidad nos seráuna función lineal de las betas.En consecuencia, la versión de dos factores del CAPM siempre es válida en
los datos observados si la proxy escogida para representar al mercado es e�cienteen sentido ex-post. Roll propone que los contrastes efectuados con una carteradistinta de la cartera de mercado no son contrastes del modelo CAPM, sino tansólo de si dicha cartera es e�ciente. Por otra parte, el modelo podría rechazarsesimplemente porque la cartera utilizada como proxy del mercado no es e�ciente.A pesar de que la correlación entre distintos proxies de la cartera de mercado esmuy alta, ello no quiere decir que la elección sea irrelevante, pues una podríanser e�cientes y otras no serlo. De hecho, Roll mostró que había una carterae�ciente, con correlación 0,895 con la proxy de mercado utilizada por B, y quesoportaba el modelo CAPM perfectamente.La consecuencia de este argumento es que la teoría de equilibrio no es con-
trastable a menos que se utilice la composición exacta de la cartera de mercado,si es conocida. El verdadero contraste del modelo generalizado CAPM de dosparámetros es si la cartera de mercado es e�ciente en el sentido media-varianza.Dos versiones distintas pueden compararse entre sí, sólo si se está utilizando laverdadera cartera de mercado en los contrastes.
26 Contratos forward y contratos de futuros
Un contrato de futuros estipula un precio F0 al cual el comprador del contratode futuro comprará, al vendedor del mismo, un determinado bien, en un instantefuturo T: En un contrato forward �rmado el 17 de mayo, se puede acordar elintercambio de 200.000 kilos de maíz, a 5,50 ptas./kg., el próximo 24 de sep-tiembre. Si, en el instante de vencimiento del contrato, el día 24 de septiembre,el precio de mercado del maíz resulta ser superior a 5,50 ptas./kg., por ejemplo,5,80 ptas./kilo, el comprador del contrato realizará un bene�cio, pues una vezcomprados los 200.000 kilos, podría venderlos en el mercado, con un bene�ciode 0,50 ptas./kilo. El maíz es, en este ejemplo, el activo subyacente del contratoforward.Los contratos forward, así como los contratos de futuros, se utilizan para
transferir el riesgo de �uctuaciones en el precio de un determinado bien. Así,quien compra un contrato de futuro adelanta en el tiempo la compra del bien,
383

mientras que quien vende el contrato, adelanta la venta del bien, cuya entregaefectiva se producirá al vencimiento del contrato.Se dice que el comprador del contrato toma una posición larga de 200.000
kilos de maíz, mientras que el vendedor del contrato adopta una posición corta.Los contratos de futuros, que se desarrollaron inicialmente sobre bienes físicos,se han extendido e las últimas décadas, a los casos en que el activo subyacenteno es un activo real, sino un activo �nanciero, como un índice de bolsa, un bono,una acción, etc.. Además de un documento legal, un contrato forward es en símismo un activo �nanciero, con un precio que está determinado, entre otrosfactores, por la evolución temporal del precio de mercado del activo subyacente.Generalmente, el pago inicial asociado al contrato forward es nulo, si bien
suele llevarse a cabo un depósito de garantía. El precio forward es el precioespeci�cado para la fecha de vencimiento del contrato; precisamente, este preciose escoge de modo que el valor inicial del contrato sea cero. El mercado enel que el activo subyacente se negocia para su entrega inmediata se conocecomo mercado spot o de contado a diferencia del mercado forward, en el que senegocian los contratos que acuerdan la entrega futura del bien.
Ejemplo 1 (Tipos de interés forward). Queremos acordar ahora los términosde un préstamos por 6 meses, comenzando dentro de 90 días. Supongamos queel tipo forward para dicho período es 10%. Una manera de llevarlo a cabo esacordar que un banco (el comprador del contrato) nos entregue dentro de 90 díasuna Letra que se encuentre en dicho instante a 6 meses de su vencimiento, encuyo instante pagará su nominal, 10.000 ptas. El precio al cual hemos de acordarhoy que se llevará a cabo la entrega de la Letra está determinado por el actualtipo forward, que es del 5% semestral. Por tanto, el precio que acordaremoshoy pagar dentro de 90 días por dicha Letra será: 10.000/1,05=9.523,80 ptas..Seis meses después recibiremos 10.000 ptas., lo que equivaldrá a haber prestado9.523,80 ptas. durante 6 meses a un 10% anual.
26.1 Precios forward
Denotamos por F0 el precio que se acuerda a la �rma del contrato forward parala entrega del activo subyacente, al vencimiento del contrato forward. Deno-tamos el valor del contrato forward en cada instante por ft: Aunque F0 sueledeterminarse de manera que f0 = 0, a lo largo de la vida del contrato, su valorserá distinto de cero, debido a variaciones en el precio del subyacente, cambiosen los tipos de interés, u otros factores. De igual modo, El precio forward quese �ja cada día, incluso en contratos que tienen igual fecha de vencimiento,mvaría por las razones mencionadas.En el caso más simple, supongamos ausencia de costes de transacción, y que
el activo subyacente puede dividirse de modo continuo. Supongamos asimismo,que el subyacente puede almacenarse, sin coste y sin depreciación, y que puedevenderse en corto (bajo préstamo). Supongamos que el precio spot en el mo-
384

mento de �rma del contrato forward es S0. El precio acordado en el futuro hade ser:
F0 =S0
d(0; T )= S0(1 + r0;T )
donde d(0; T ) es el factor descuento apropiado. El tipo de interés utilizadodebe ser el consistente con el coste de acceso al mercado monetario, que gen-eralmente es el tipo de operaciones repo.En algunas ocasiones, durante el vencimiento del futuro de este bien sub-
yacente podría percibir una rentabilidad media por ciertos ingresos, de y. Si,para simpli�car, suponemos que la curva de tipos es plana en el tramo relevante,tendríamos la expresión:
F0 = S0(1 + r � y)t
Si no se cumple esta expresión, podrían instrumentarse estrategias de arbi-traje, en las cuales se obtiene un bene�cio neto seguro. Esto se debe a que,como vamos a ver, un contrato forward puede utilizarse conjuntamente con elmercado de contado, para reproducir un préstamo en o un crédito en el activosin riesgo.Antes de ello, baste observar que, bajo nuestros supuesto, hay dos modos de
disponer del activo subyacente en la fecha T . Una es comprar el contrato frowardy �jar hoy el precio de compra, F0. Otra, es comprar hoy el bien, pagando S0y almacenarlo, asumiendo el coste �nanciero de dicho almacenamiento. Ambasestrategias deben conducir a un mismo pago.De otro modo, supongamos F0 > S0
d(0;T ) , es decir, que el contrato forward estásobrevalorado por el mercado. Venderíamos dicho contrato, y pedimos prestadodurante T períodos a interés r0;T , comprando con dicho crédito el subyacente,a precio S0. Cuando lleguemos a T devolvemos el préstamo S0
d(0;T ) y recibimosF0, materializando un bene�cio. Nótese que ninguno de los términos de estaoperación es incierto, por lo que el bene�cio neto es seguro. Estas operacionespodrían llevarse a cabo en cuantías importantes, lo que hará que el precio delcontado se eleve, a la vez que desciende el precio forward, hasta que la condiciónanterior se satisfaga.El caso en que F0 < S0
d(0;T ) es análogo: pedimos prestado el subyacente dealguien que pensaba tenerlo inmovilizado entre 0 y T , y lo vendemos a precioS0, cantidad que prestamos hasta el instante T , a la vez que compramos unfuturo con vencimiento en T: En dicho instante, pagamos F0 por el bien, quedevolvemos a quien nos lo prestó, a la vez que recibimos S0
d(0;T ) , realizando unbene�cio cierto.En el ejemplo de los 200.000 kilos de maíz, supongamos que existe una Letra
con vencimiento 24 de septiembre, cuyo precio en el mercado secundario eshoy de 9708,70. El precio forward F0 debe ser: F0 = 5; 50=0; 97087 = 5; 665ptas./kilo. Si se utiliza una composición continua, el precio debería ser: F0 =5; 50e5;83=3, donde hemos aproximado el período (0; T ) a 4 meses.
385

26.2 Arbitraje
Arbitraje es la posibilidad de llevar a cabo una operación que produce un ben-e�cio neto seguro. Aunque, cuando se producen, el margen es mínimo, comotal operación no requiere �nanciación, puede llevarse a cabo en enorme cuantía(hasta que la �uctuación inducida en los precios la elimine), generando un ben-e�cio importante. Por supuesto, al valorar posibles arbitrajes hay que tener encuenta los costes de transacción, costes de transporte, liquidez, etc...La igualdad fundamental entre los mercados de futuro y contado es:
Bene�cio por compra de un futuro + Bene�cio por inversión en activo sinriesgo = Bene�cio producido por inversión en subyacente
La razón es que la compra del futuro en t = 0 con vencimiento en T , más unainversión en t = 0 en activos in riesgo en cuantía igual a la compra del subyacenteequivale, a todos los efectos, a una inversión en subyacente en t = 0. Por tanto,hemos creado una cartera réplica del subyacente por lo que, en ausencia dearbitraje y costes de transacción, sus precios han de coincidir. Así, tenemos:
Bene�cio producido por inversión en subyacente = Bene�cio por compra deun futuro + Bene�cio por inversión en activo sin riesgo
Bene�cio por inversión en activo sin riesgo = Bene�cio producido por com-pra de subyacente y venta de futuro
Bene�cio por compra de un futuro = Bene�cio producido por compra desubyacente-Coste de un crédito a tipo de interés libre de riesgo.
Estas relaciones, en términos de bene�cios, son equivalentes a las que ante-riormente obtuvimos en términos de precios, pues, por ejemplo, la última puedeescribirse:
FT � F0 = ST � S0 � L
Pero a vencimiento: FT = ST . Por otra parte: L = S0r, por lo que:
�F0 = �S0 � S0r ) F0 = S0(1 + r)
26.3 Costes de acarreo (Costs of carry)
Supongamos ahora que existen costes de almacenamiento o acarreo, como pri-mas de seguro, alquiler de naves, etc.. En algunos casos, también existen costesnegativos por almacenar o mantener el subyacente, como dividendos (en el casode acciones) o cupones (en el caso de bonos). Supongamos que los pagos dedichos costes (positivos o negativos) se producen periódicamente, y que existenM de dichos períodos en (0; T ). El coste de acarreo es el agregado de cadauno de dichos costes, en valor presente. En consecuencia, la estructura de tiposforward determina, junto con dicha estructura de costes y el precio de contadodel subyacente, el precio forward:
386

F0 =S0
d (0;M)+M�1Xk=0
ckd(k;M)
donde d(k;M) es el factor descuento relevante entre k y M .De modo equivalente:
S0 =M�1Xk=0
d(0; k)c(k) + d(0;M)F0
puesto que: d(0;m) = d(0; k)d(k;M) para todo 0 � k �M .En el caso de un futuro sobre renta variable, si conocemos las fechas de
recepción de dividendos y su cuantía, tendremos: ck = �Dk; y:
F0 =S0
d (0;M)�M�1Xk=0
Dk
d(k;M)
Ejemplo 2.- Supongamos que el precio actual del maíz es 5,50 ptas./kilo, yqueremos hallar el precio forward del maíz, entregable en 4 meses. El coste deacarreo del maíz se estima en un 1,5% por mes, pagadero a comienzos de mes,y el tipo de interés es constante, a un 9% anual.El tipo de interés mensual es: 0;0912 = 0; 0075: Por tanto, le factor descuento,
para cada mes, es: 11+0;0075 ; con lo que tenemos:
F0 = (1; 0075)4(5; 50) + (0; 015)[(1; 0075)4 + (1; 0075)3 + (1; 0075)2 + 1; 0075] =
= 5; 6669 + 0; 0 15� 4; 0756 = 5; 728
Ejemplo 3.- Consideremos un bono del tesoro, de nominal 10.000 ptas. ycupón 8% semestral, que se está vendiendo a 9.260 ptas, y que justo acaba depgar un cupón. ¿Cuál es su precio forward a 1 año?. Supongamos que los tiposde interés a 1 año son planos al 9%.En este período se pagarán dos cupones, por lo que tenemos:
9:260 =F0 + 400
(1; 045)2 +
400
1; 045
de donde obtenemos: F0 = 9:294; 15:
En ocasiones, las expresiones anteriores de ausencia de arbitraje no se cumplen,bien por ausencia de liquidez en los mercados del subyacente o del futuro. Porotra parte, la expresión nos muestra que le precio debería aumentar con M , locual tampoco es necesariamente cierto, al menos en contratos donde el suby-acente es un producto agrícola con una estacionalidad bien de�nida. Aunque
387

aparentemente existen posibilidades de arbitraje, estas no se pueden explotar,porque quienes disponen del bien en momentos de escasez no querrán despren-derse de él.Cuando el subyacente es almacenable, tendremos:
F0 �S0
d (0;M)+M�1Xk=0
ckd(k;M)
En estos casos suele de�nirse la rentabilidad de conveniencia (convenienceyield) y; como aquella cantidad tal que:
F0 =S0
d (0;M)+M�1Xk=0
ck � yd(k;M)
26.4 El valor de un contrato de futuro
Supongamos que le precio forward acordado a la �rma del contrato fue F0; yque en el instante t el precio forward, con igual fecha de vencimiento, es Ft. Elvalor del primer contrato es:
ft = (Ft � F0)d(t; T )
donde d(t; T ) es el factor de descuento libre de riesgo entre t y T .Comprar en t un contrato de futuro con precio de entrega Ft y vender un
contrato con precio de entrega F0 nos genera un cash �ow de �ft. A vencimiento(en T ) produce un cash �ow de F0�Ft: Esta cartera proporciona una secuenciadeterminista. de ingresos y pagos, por lo que su rentabilidad ha de coincidir conla del activo sin riesgo, d(t; T ).
26.5 Swaps
Un swap es un contrato por el que se acuerda intercambiar una secuencia de�ujos de ingresos y pagos por otra. El más común es el plain vanilla swapen el que una de las partes entrega una serie de pagos o ingresos de cuantíaconstante, a cambio de otra secuencia de pagos o ingresos, de cuantía variable.Un swap puede reducirse a un conjunto de contratos forward, lo que facilita �jarsu precio. Consideremos el caso en que A acuerda entregar pagos semestrales aB; de acuerdo con una rentabilidad constante sobre un principal nocional. Seutiliza este término porque no existe ningún subyacente, y sólo se lleva a caboel intercambio de �ujos. El principal nocional sirve para determinar el nivelde los pagos a intercambiar. A cambio, B hace efectivos pagos semestrales aA a tipo variable (por ej., el MIBOR a 6 meses). Generalmente, los swaps seintercambian en términos netos, es decir, se hace efectiva solamente la diferenciaentre ambos �ujos, por la parte que corresponda. El swap podría obedecer a
388

que B ha hecho un préstamo a una tercera parte C a interés variable, aunquepre�ere recibir unos ingresos constantes, lo que consigue, a efectos prácticos,con el swap con A:
26.6 Precio de un swap de bienes
Consideremos que A acuerda recibir N unidades de un bien cada período, a lavez que paga una cantidad �ja X por unidad. Si el acuerdo cubre M períodos,el �ujo neto que recibe A es:
(S1 �X)N; (S2 �X)N; (S3 �X)N; :::; (SM �X)N
donde Si denota el precio de contado del bien en el instante i.En el instante inicial, 0, sea Fi el precio forward de una unidad del bien,
entregable en i: Estamos, entonces, indiferentes entre recibir Si, que es ahoraincierto, en el instante i, o acordar ahora recibir Fi con certeza en dicho in-stante. Descontando al instante inicial, tenemos que el valor presente, libre deincertidumbre, de recibir Si en el instante i es d(0; i)Fi.Aplicando este argumento a cada instante en que se produce un �ujo, ten-
emos:
V =MXi=1
d(0; i)(Fi �X)N
Por lo que, conocidos los precios forward, podemos valorar el swap. Gen-eralmente, X se escoge de modo que el precio del swap sea cero.
Ejemplo 4.- Una empresa quiere recibir oro a precio de contado, a cambiode pagos �jos. Supongamos que el oro es almacenable con coste nulo. En talcaso, sabemos que Fi = S0
d(0;i)) , por lo que, de la expresión anterior:
V =
MS0 �
MXi=1
d(0; i)X
!N
pero el sumatorio es el valor presente de los pagos por cupón de un bono,cupón X, por lo que tenemos:
V =
�MS0 �
X
C[B(M;C)� 100d(0;M)]
�N
donde B(M;C) denota el precio (base 100) de un bono con vencimiento enM períodos y cupón C: En esta expresión puede utilizarse cualquier valor de C.
389

26.7 Valor de un swap de tipos de interés
Consideremos que se ha acordado que A paga un tipo �jo r sobre un principalnocional N , a la vez que recibe pagos a interés variable (�oating rate) sobre elmismo principal, durante M períodos. El �ujo neto percibido por A es:
((c0 � r)N; (c1 � r)N; (c2 � r)N; (c3 � r)N; :::; (cM � r)N)
donde c0; c1; c2; ::: denotan los tipos de interés variables.Aunque podríamos calcular el valor el swap a partir de precios forward,
seguimos otro método: la rama �otante del swap es igual a la generada porun bono a interés variable, de principal N y vencimiento M: Sabemos que elvalor inicial de un bono de rentabilidad variable, incluyendo el pago �nal delprincipal, es a la par. Por tanto, el valor de la rama �otante del swap es par,menos el valor presente del principal, recibido en M :
N � d(0;M)N
El valor de la rama �ja es la suma de los pagos �jos descontados de acuerdocon la estructura temporal de tipos vigente en el momento de acordar el swap.Por tanto, el valor del swap es:
V =
"1� d(0;M)� r
MXi=1
d(0; i)
#N
que podría simpli�carse del modo que antes hicimos.
26.8 Aspectos básicos de los contratos de futuros
Cuando el volumen de negociación en contratos forward se hizo importante, sehizo clara la conveniencia de estandarizar dichos contratos, a la vez que crearuna cámara de compensación que se encargase de supervisar el cumplimientode los mismos. Este proceso no está exento de di�cultades, pues aunque puedenestandarizarse los bienes, las fechas de vencimiento, las cantidades a entregar,e incluso la calidad de los bienes especi�cados en estos contratos, no es posibleestandarizar el precio forward, que cambia continuamente. Ello hace que habríaque seguir un número enorme de contratos, que di�riesen en cada una de estasvariables.Para evitar esta di�cultad, se crearon mercados de futuros organizados, como
alternativa a los mercados forward. La multiplicidad de precios forward se elim-ina revisando los contratos según va variando el precio del subyacente, tiempoa vencimiento, etc.. Si se escribe un contrato a precio F0 y el nuevo precio eldía siguiente es F1, el precio del contrato es cambiado a F1, y el comprador delcontrato recibe de la entidad liquidadora la diferencia F1 � F0 si es positiva, ose le carga en su cuenta, si es negativa. De este modo, estaría en las mismas
390

condiciones con el contrato de precio F1, que lo estaba con el contrato primitivo.Lo opuesto ocurre con el vendedor del contrato de futuros.Este proceso se conoce como marking to market. Cada parte debe abrir una
cuenta de márgenes (margin account) con la cámara de compensación o conun broker, que juegan el papel de entidad liquidadora. Esta cuenta debe tenerinicialmente un porcentaje del valor del contrato, que puede oscilar entre el 10%y el 30%. Las cuentas se ajustan al cierre diario del mercado. Si el precio delcontrato de futuro ha aumentado, la posición larga recibe un bene�cio igual alincremento en el precio, multiplicado por la cantidad acordado en el contrato defuturos. La parte corta pierde la misma cantidad, que se deduce de su cuenta demárgenes. De este modo, cada posición larga tiene siempre el mismo contrato, aligual que le ocurre a cada posición corta. A vencimiento, la entrega se efectúaal precio del contrato de futuros de ese día, que puede ser muy diferente delprecio acordado a la �rma del contrato. Pueden ignorarse las �uctuacionesproducidas en el precio del futuro desde que se suscribió, porque el perdedorhabrá ido pagando, las cantidades parciales perdidas, mediante los cargos quese han ido haciendo en su cuenta de garantías. El depósito de garantías, juntocon el sistema de liquidación diario, eliminan totalmente el riesgo de crédito deambas contrapartidas de un contrato de futuros.De hecho, en más del 90% de las operaciones con futuros se cierran las
posiciones antes de la fecha de entrega, haciendo efectivo solo el saldo netomonetario, pero sin proceder a la entrega física del bien. Los futuros se utilizanpara inmunizar la compra o venta futura de un bien, pero la compra o ventareales se llevan a cabo por lo general directamente de los proveedores habituales.La cuentas de márgenes no reciben intereses. Sin embargo, en ocasiones se
permite depositar en ellas Letras u otros activos que sí reciben interés. Existe,además, un margen mínimo de mantenimiento, por debajo del cual, el poseedorde un contrato de futuros recibe una llamada requiriendo márgen adicional(margin call). De no efectuarla, la posición en futuros se cierra tomando unaposición igual y de signo opuesto. Sin embargo, en ocasiones se permite eldepósito en las cuentas de márgenes de Letras del Tesoro u otros activos quereciben intereses, lo que equivale, a todos los efectos prácticos, a que dichossaldos estuviesen remunerados.El hecho de que unicamente se deposite una proporción reducida del importe
que se suscribe en el contrato de futuros conduce a un elevado apalancamiento.Si, por ejemplo, disponemos de 1 millón de ptas. para invertir y el depósitoes del 10%, podremos invertir hasta por 100 millones, depositando entoncescomo depósito de garantías todo nuestro patrimonio. En caso de acertar conla evolución futura del mercado del subyacente, el elevado apalancamiento nosproporcionaría un bene�cio mucho mayor del que hubiésemos podido lograroperando en el mercado de contado. Sin embargo, es evidente que con elloasumismo un riesgo muy elevado.El interés abierto es el número de contratos no cancelados (abiertos). Una
posición se deshace abriendo otra de igual cuantía y signo opuesto. Por tanto,un comprador de un contrato que quiere deshacer su posición no se deshace desu contrato, que sigue manteniendo; lo que hace es vender un contrato de igual
391

vencimiento. A partir de entonces, nuestro bene�cio o pérdida ya no cambiarán,con independencia de las �uctuaciones que experimente el precio del futuro hastasu vencimiento, como puede comprobarse fácilmente con un ejemplo.
26.9 El riesgo de base
Parece bastante intuitivo que, a vencimiento, el precio de un futuro deba co-incidir con el precio de contado del subyacente, pues de lo contrario, podríaproducirse una operación de arbitraje en dicho instante. La base es, precisa-mente, la diferencia entre el precio del futuro y el precio de contado; por tanto,de acuerdo con este argumento, la base convergerá a cero. Sin embargo, paraque ello ocurra, el subyacente y el bien descrito en el futuro han de ser idénticos,lo que, en muchos casos, no ocurre:a) supongamos que queremos inmunizar un ingreso de 1 millón de dólares
Canadienses que vamos a percibir dentro de 90 días, eliminando el riesgo deprecio. Para ello, querríamos vender futuros por dicha cantidad, a la cotizaciónactual del dólar canadiense. Sin embargo, no existe tal contrato, aunque existencontratos sobre $US, divisa cuya cotización tiene una alta correlación con el $Canadiense,b) en muchas ocasiones, no existen contratos disponibles con vencimeinto
igual al momento en que se va a efectuar la operación cuyo riesgo queremos elim-inar, por lo que tendremso que deshacer nuestra posición antes de vencimientodel contrato de futuros; en otros casos, nuestro horizonte es muy largo, y habre-mos de renovar (rollover) nuestra posición de futuros. Nuevamente, asumimosinicialmente un riesgo de base.
392

27 Valoración de un futuro sobre un bono
Un futuro sobre un bono es un producto derivado de�nido sobre un bono especí-�co como subyacente. Al vencimiento del contrato, la parte vendedora entregaráa la parte compradora el bono estipulado como subyacente, y el comprador delfuturo pagará al vendedor del mismo el precio estipulado en el momento en quese intercambió el contrato de futuro. Una vez más, para valorar los contratos defuturos de�nidos sobre un bono, apelamos al principio de ausencia de arbitraje.Para ello, consideramos una cartera réplica del futuro o, lo que es lo mismo, unaestrategia de inversión que genere exactamente la misma secuencia de ingresosy pagos, y en las mismas fechas, que las que genera el futuro.Como en los demás futuros, a la compra del futuro no se efectúa pago al-
guno; sin embargo, el comprador se bene�cia desde dicho momento de cualquierganancia de capital (o sufre cualquier pérdida de capital) que pueda experimen-tar en el mercado de contado el bono subyacente. El comprador del futuro haadelantado la compra del bono, en el sentido de �jar el precio al cual compraráel bono al vencimiento del futuro..Una cartera réplica consiste en pedir un préstamo igual al precio de contado
del bono, y comprar el bono. En este caso, se incurre en el coste �nanciero delpréstamo, pero se reciben intereses sobre el bono, de modo que debe cumplirse:
F0 = B0 + CF � I
para que las dos estrategias de inversión, que son equivalentes, tengan elmismo coste. En el primer caso, el comprador del futuro pagará F0 al vencimientodel mismo. En el segundo caso, abonará el principal del préstamo más intereses,aunque habrá recibido un �ujo de intereses o cupones cuyo valor actualizado avencimiento del futuro denotamos por I.Por tanto, el precio del futuro puede escribirse:
F0 = B0 + CF � I = B0 +B0tr �B0tc = B0(1 + t(r � c))
donde denotamos por c la tasa a la que se recibe el �ujo continuo de cupones.Tal �ujo no es continuo, pero siempre existe una tasa continua equivalente, c.La diferencia entre el precio del futuro y el precio de contado del bono
subyacente en cada instante es:
F0 �B0 = CF � I
lo que se conoce como base del contrato, siendo igual a la diferencia entreel coste �nanciero que tendría la compra del bono al contado en ese instante,menos los intereses a percibir, en ambos casos hasta la fecha de vencimiento delcontrato de futuro.Por tanto, que la base del contrato de futuro sea positiva o negativa depende
de la relación entre ambas magnitudes. La existencia de primas de riesgo enlos mercados de deuda hace que, generalmente, los cupones sean superiores altipo de interés sin riesgo y, con ello, que la base del futuro sea positiva. Al
393

vencimiento del futuro, la base será cero pues en ese momento no existe costes�nancieros ni está pendiente ningún pago de intereses.Ejemplo: Consideremos un bono a tres años, cupón anual del 12%. Supong-
amos que la rentabilidad del mercado y, con ella, la TIR del bono, es asimismodel 12%. Supongamos que el tipo de interés libre de riesgo es 10%, y consider-emos un contrato de futuro a un año sobre este bono.Puesto que el cupón es igual a la TIR, el precio de contado del bono será
100:
P0 =3Xi=1
(0:12) � 100(1 + 0:12)i
+100
(1 + 0:12)3= 100
El coste �nanciero de pedir prestado para comprar el bono hoy, y mantenerlodurante un año, es:
Coste financiero = tipo de inter�es � duraci�on del pr�estamo; en a~nos � Cuant�{adel pr�estamo = (0; 10)(1)100 = 10
Intereses acumulados = cup�on � tiempo transcurrido � nominal del bono == (0; 12)(1)100 = 12
Por tanto, el precio actual del futuro a un año debe ser:
F0 = B0 + CF � I = 100 + 10� 12 = 98Si el precio de mercado del futuro fuese de 90, podríamos proceder a una
operación de arbitrage pidiendo prestado el bono, que venderíamos. Simultánea-mente, compraríamos el futuro, que está barato en términos relativos.Cash-�ow : Al vender el bono hoy, recibo 100, que invierto al tipo de interés
sin riesgo. Al vencimiento del futuro, recibo 10 de intereses, más el principal,100. Pago un precio de compra por el bono igual al precio estipulado en elcontrato, 90, y lo devuelvo a quien me lo prestó. También he de devolver aquien me cedió el bono, los intereses devengados por los cupones, que en elplazo del año, serán por una cuantía de 12. El �ujo neto es:
Flujo neto a vencimiento = 10 + 100� 90� 12 = 110� 102 = 8
un bene�cio que hoy puedo �jar con certeza, igual a la cuantía de la minus-valoración del futuro. Como consecuencia, se desencadenarían operaciones dearbitraje que elevarían el precio del futuro hasta su nivel teórico, eliminado laposibilidad de realizar un bene�cio cierto.Si el precio del futuro fuese superior a 98, venderíamos el futuro, que está
relativamente caro. Simultáneamente, pedimos un préstamos y compramos elbono en el contado, recibiendo los cupones. Al vencimiento del futuro entreg-amos el bono a quien nos compró el contrato. Si el precio del futuro fuese
394

102, por ejemplo, vendemos un contrato, pedimos un préstamo por 100 u.m. ycompro el bono. Al vencimiento del futuro he recibido 12 u.m. en pagos porcupones, recibo 102 por el bono, que entrego, y devuelvo el principal, 100 u.m.,más intereses, 10 u.m..
Flujo neto a vencimiento = 102� 100� 10 = 114� 110 = 4
nuevamente con un bene�cio cierto igual a la cuantía del error de precio delbono (sobrevaloración, en este caso).
27.1 Rentabilidad de una posición en futuros sobre bonos
27.2 Posición cubierta
Consideremos un inversor con 100 u.m. en liquidez, ganando una rentabilidaddel 10%, que decide comprar un futuro a un año, cupón anual del 12%, a unprecio justo de 98. Al vencimiento del futuro, paga el precio estipulado, 98,y recibe un bono que vale 100 um.. Asimismo, recibe los intereses sobre eldepósito, 10 um. Así:
Flujo neto = 100 + 10� 98 = 12
que es la misma rentabilidad que habría obtenido manteniendo el bono. Estose debe a que una posición en liquidez, más la compra de un futuro sobre unbono, nos da la misma rentabilidad que comprando el bono en el mercado decontado. Esta a�rmación es válida para bene�cios, pero no para rentabilidadesporcentuales.Esta a�rmación no es sino una reordenación de la fórmula de valoración del
bono, suponiendo ausencia de arbitraje:
�F0 + CF = �B0 + I
El caso dual es el de un inversor que, teniendo un bono en su cartera, decidevender un futuro sobre el mismo. Al vencimiento del futuro recibiría 98 um. yentregaría el bono, que vale 100 um.. Hasta entonces, habría recibido 12 um.en pagos por cupones.
Flujo neto = 98� 100 + 12 = 10
que sería la remuneración que habría recibido la posición en liquidez. Unacartera formada por un bono y la venta de un futuro sobre dicho bono, equivalena una cartera en liquidez.
F0 �B0 + I = CF
395

27.3 Posición especulativa
Consideremos ahora el caso en que el futuro se compra para asegurar unarentabilidad futura, no para cubrir una cartera de contado: supongamos uninversor que prevé realizar dentro de un año una inversión a 3 años. Como an-ticipa un posible descenso de tipos, quiere asegurarse la rentabilidad de mercadoactual, que es una TIR del 12%, para lo que compra un futuro a un año sobreun bono a 3 años. Con ello, mantendrá una posición abierta (descubierta) en elmercado de futuros.Este inversor compra el futuro a 98, que es lo que pagará al vencimiento del
futuro por recibir el bono. Si no se produce el descenso previsto en los tipos, yestos continúan siendo del 12%, el bono seguirá teniendo un precio de mercadoigual a 100 um., y el inversor habrá ganado:
Cash flow = 100� 98 = 2
que, junto con el bene�cio de la posición de liquidez, 10 um., nos da larentabilidad del bono, de 12 um.. En este caso no se ha producido ningúnbene�cio o pérdida especulativos. La posición especulativa aspira a generaralgún bene�cio si se cumplen las previsiones de tipos, aunque a sabiendas deque puede conducir a pérdidas si ocurre un movimiento de signo contrario alprevisto.Supongamos, alternativamente, que los tipos descienden, efectivamente, al
11%. El precio del bono será, al vencimiento del futuro:
PT =
3Xi=1
(0:12) � 100(1 + 0:11)i
+100
(1 + 0:11)3= 102: 44
por lo que habremos ganado 4,44 um..Por último, si nuestra previsionesresultan ser muy equivocadas y, contrariamente a lo que esperábamos, los tiposse elevan al 13%, el bono valdrá:
PT =
3Xi=1
(0:12) � 100(1 + 0:13)i
+100
(1 + 0:13)3= 97: 639 (109)
y habremos perdido 0,361 um..
27.3.1 Observaciones:
� Estamos suponiendo que el precio de mercado del futuro coincide consu precio teórico, es decir, no hay error en precio, o mispricing. Salvofricciones en el mercado, esto siempre ocurrirá, pues de lo contrario, seproducirían oportunidades de arbitraje, hasta que tales errores en preciosdesaparecieran. En ocasiones, se producen pequeñas discrepancias debidoa posibles di�cultades en el acceso a crédito, la existencia de costes detransacción, comisiones, etc.
396

� Hemos supuesto que mantenemos en nuestra cartera el contrato de futurohasta su vencimiento. Si lo vendiésemos antes, podríamos incurrir enpérdidas producidas por posibles errores en precio en el momento de laventa.
� Suponemos que el futuro se re�ere a un bono idéntico al que poseemos ennuestra cartera. Como veremos enseguida, esto no es exactamente lo queocurre en la realidad.
27.4 El bono nocional
Los contratos de futuros sobre deuda pública no pueden construirse sobre cadauna de las referencias vivas en dicho mercado. Sin embargo, la multiplicidadde referencias cotizadas en el mercado secundario de deuda pública haría que laconsiguiente diversidad de contratos de futuros produjese una muy reducida liq-uidez, con la consiguiente elevación de costes de transacción, y precios elevadospor primas de iliquidez, resultando el mercado inviable. Por tanto, es frecuenteque el futuro que se utiliza en la cobertura de un bono tenga un subyacenteque no coincide exactamente con el activo que se quiere cubrir. Esto produce elllamado riesgo de correlación, que aparece cuando los precios de ambos activostienen una correlación inferior a la unidad.Para evitar la multiplicidad de contratos a que nos hemos referido, se de�ne
un bono (hipotético) nocional, con unas características que conduzcan a unamáxima correlación con la mayoría de las emisiones del mercado. Al ser unúnico contrato, su liquidez está casi garantizada.El futuro sobre bonos del Estado se re�ere a un bono nocional como activo
subyacente, con características:
� Amortización: 3 y 10 años
� cupón: bono a 3 años: 10% anual, con pagos semestrales del 5%. Bono a10 años: 9% anual.
� nominal: 10 millones de ptas.
� Precio: cotiza como porcentaje del nominal, en centésimas. Cada puntovale 100.000 ptas. Par 100. A la par, la TIR del bono nocional a 3 añoses 10,25%.
� Fecha de emisión hipotética: fecha de vencimiento del futuro.
� Vencimiento del futuro: tercer miércoles de los meses de marzo, junio,septiembre y diciembre
� negociación de los dos contratos más próximos a vencimiento, como mín-imo.
� �uctuación mínima diaria del precio: un punto básico, que equivale a 1.000ptas..
397

� �uctuación máxima diaria: 2% del nominal, es decir, 200.000 ptas., ex-cepto en el primer y último día de negociación.
� margen de garantía inicial o depósito inicial: 4% del valor del contrato.
Sin embargo, el bono nocional no existe físicamente. Cuando se emite elcontrato de futuro, se hace explícita la relación de bonos entregables, esdecir, la lista de aquellos que el vendedor del contrato de futuro puedeentregar al vencimiento del mismo. El vendedor puede elegir entre estalista aquél que desee entregar y, lógicamente, escogerá el bono entregablemás barato (EMB), o cheapest to delivery (CTD).
Ejemplo: Supongamos un tipo de interés libre de riesgo del 10%, y que elbono nocional a 3 años ofrece una TIR del 12,36%, que equivale a un 6,00%semestral, en capitalización compuesta. El precio que tendría hoy al contado elbono nocional que compramos a futuro sería:
PBN =6Xi=1
(0:05) � 100(1 + 0:06)i
+100
(1 + 0:06)6= 95: 0827
por lo que el precio teórico del futuro sobre el bono nocional es:
F0 = B0(1 + t(r � c)) = 95; 0827 � (1 + (1)(0; 10� 0; 10)) = 95; 0827
donde t=1 año. Suponemos que no hay sesgo de precio del futuro, y quecotiza, exactamente a su precio teórico de 95,0827. Comprando a este precio,aseguramos una TIR del 12,36% al vencimiento del futuro. Obtendremos unapérdida si, al vencimiento del futuro, los tipos de interés de mercado son supe-riores al 12,36%, realizando un bene�cio en caso contrario. Si, al vencimientodel futuro, el tipo de interés del mercado de deuda continúa siendo de 12,36%, ysi continúa sin haber mispricing, el bono nocional tendrá un precio de mercadode 95; 0827; y la operación debería saldarse con resultado nulo:Supongamos que, en dicho momento, el bono entregable más barato es uno
con 2 años de vida residual y cupón anual del 14%, pagadero semestralmente.Si este bono cotizase de acuerdo con la TIR del mercado, su precio sería:
PTEMB =4Xi=1
(0:07) � 100(1 + 0:06)i
+100
(1 + 0:06)4= 103: 4651
Sin embargo, supongamos que este bono cotiza en el mercado a 103,06. Esfácil ver que la TIR resultante es de 6,115% semestral, o 12,603% anual, lo quele hace ser un bono relativamente barato.El factor de conversión que hace comparables al bono nocional y al EMB se
obtiene dividiendo por 100 el precio que se obtendría para el EMB descontandosus �ujos a la TIR-par del bono nocional, que es del 10,25%:
398

PEMB =4Xi=1
(0:07) � 100(1 + 0:05)i
+100
(1 + 0:05)4= 107: 0919
por lo que el factor de conversión es:
f = 1:0709
de modo que el comprador del futuro tendrá que pagar el precio acordado de95,0827 y recibirá el equivalente a un bono nocional, que es 1/f = 1=1:0709 =0: 9338 bonos, vencimiento a 2 años, 14% cupón, pagos semestrales.Dado que no se puede partir de manera continua un bono, lo que se hace
para saldar la operación es que el vendedor entrega al comprador una unidaddel EMB y éste abona el precio acordado en el contrato de futuro, multiplicadopor el factor de conversión:
V alor del EMB = Pr ecio acordado en el futuro�f = 95:0827�1:0709 = 101: 8241
Con esta operación, el comprador del contrato de futuro paga 101: 8241 porun bono que le dará 4 cupones de 7%, más un principal de 100. La TIR durantelos dos años de vida del bono tras el vencimiento del contrato de futuro esde 13,35%, que es superior al 12,36% por 3 años que se había asegurado conla compra del futuro. En realidad, está obteniendo ésta última rentabilidad,puesto que si una vez que venza el bono de 2 años coloca la inversión en liquidezdurante 1 año, al �nal del período global de 3 años se tendrá la rentabilidad del12,36%, pues la solución a la ecuación:
PEMB =
4Xi=1
(0:07) � 100(1 + TIR)i
+110
(1 + TIR)6= 101:8241
es TIR = 0:06; ó 12,36% en términos anuales.Por último hay que notar que la capacidad de escoger el EMB ofrece al
vendedor del futuro una posibilidad de bene�cio, que se conoce como opción deentrega. En nuestro caso, el vendedor ha entregado un bono que le ha costadoen el mercado 103,06 como si su valor fuese de 103,4651, quedándose con los 40pb. de diferencia como rentabilidad adicional de la operación.El bono EMB se obtiene comparando, para cada uno de los bonos de la cesta
de entregables, el precio que se recibiría por cada uno de ellos (igual al PF porel factor de conversión fi) con el precio de contado del mismo, Pci : por tanto,el bono EMB es el que maximiza la diferencia:
PF fi � Pcique es la base del futuro, cambiada de signo, que será negativa para todos
ellos. Si fuese positiva, podríamos arbitrar comprando el bono correspondi-ente, vendiendo el futuro, y noti�cando inmediatamente la intención de hacer laentrega. Por tanto, el bono EMB es aquél que tiene una menor base negativa.
399

Este cálculo es válido al vencimiento del futuro. Antes de dicha fecha seactúa como si dicho día fuese el de entrega del bono subyacente.
27.4.1 Observaciones:
� Estamos suponiendo que la negociación del contrato de futuro se lleva acabo inmediatamente tras un pago de cupón. Cuando no es este el caso,el pago que el comprador debe hacer efectivo al vendedor es:
V alor del EMB = Pr ecio acordado en el futuro � f + cup�on corrido
� Si se quiere evitar la entrega física de los títulos, se cierra la operación eldía antes a la expiración del contrato. Como el precio del futuro convergeal precio de contado, el precio que pagaremos por el futuro será práctica-mente el mismo que el del bono nocional. Esta forma de operar suele sermás barata que comprar bonos en el mercado de contado.
27.5 Futuro sobre MIBOR a 90 días
27.6 Características del contrato
Ver fotocopia
27.6.1 Observaciones:
� Se negocia como el bono nocional. El sistema de depósitos y de liquida-ciones diarias es el mismo. Es distinto el depósito total y los límites de�uctuación máxima diaria de los precios.
� Se cotiza en base 100, aproximando hasta las centésimas. Un punto equiv-ale a 100.000 ptas., por lo que el nominal es de 10 millones de ptas.. Elprecio de liquidación a vencimiento es:
Pr ecio vencimiento = 100:00�MIBOR
El tipo de interés implícito en cada instante de negociación:
Tipo inter�es = 100:00� precio cot izaci�on
Un movimiento de un punto básico sobre un préstamo de 10 millones deptas. a 90 días representa:
0:01
100
90
36010:000:000 ptas: = 250 ptas:
que es, en consecuencia, la variación mínima diaria en la cotización.
400

� con objeto de reducir al mínimo los costes de transacción, se liquida pordiferencias. Si se ha comprado un futuro sobre MIBOR90 a 91,00, esta-mos comprando un interés implícito de 9,00% anual, sobre un depósitoa constituir durante 3 meses, a partir del vencimiento del futuro. Si alvencimiento, el precio del futuro está en 92,50, es porque el tipo de interéssobre tal depósito es de 7,50%. Al haber bajado los tipos de interés, nue-stro depósito vale más. Dicho de otro modo, si ahora depositamos durante90 días, recibiríamos en el mercado 0,075*10.000.000 ptas.. Sin embargo,aseguramos al suscribir el contrato una remuneración del 10,00%, por loque el vendedor del contrato debe remunerarnos ahora la diferencia de 150puntos básicos. La liquidación es:
0; 0150 � 10:000:000 ptas: = 150:000 ptas:
� En conjunción con el futuro sobre bono nocional a vencimiento más largo,3 o 10 años, este futuro permite gestionar el riesgo de variaciones en laestructura temporal de tipos.
27.7 Cobertura de carteras de renta �ja
Al igual que en el caso de carteras de renta variable, la cobertura consiste entomar en el mercado de futuros una posición de signo opuesto a la que tenemosen el mercado de contado. Es decir, se trata de adelantar la operación que hemosde hacer dentro de un tiempo. Si pensamos que los tipos de interés pueden subiry, con ello, el valor de nuestra cartera puede descender, venderemos futuros porel valor de nuestra cartera de contado. Con ello, habremos �jado el valor dela cartera, con independencia de lo que ocurra con los tipos de interés. Comovimos antes, la venta ahora de los futuros equivale a vender la cartera de contadoahora e invertir los ingresos resultantes en el activo sin riesgo.Para una empresa que prevé lanzar una emisión de deuda dentro de unos
meses, también la cobertura con futuros es interesante. Si la empresa prevéuna subida de tipos y, con ello, un encarecimiento de su operación, habrá devender futuros por el importe de la emisión, comprometiéndose a pagar unarentabilidad inferior a la que espera que esté vigente en el momento de realizarla emisión de deuda. Ello equivale a realizar la emisión de deuda ahora.Al realizar la cobertura, puede haber varios contratos de futuros disponibles.
Hay que tener en cuenta:
� la liquidez de la emisión, por si tenemos que cerrar posiciones en un mo-mento determinado,
� que el futuro tenga una volatilidad similar a la de nuestra cartera. Parauna cartera de duración corta será preferible utilizar el futuro sobre MI-BOR�90, mientras que para una cartera de duración más larga, será preferi-ble utilizar el futuro sobre bono nocional.
401

� que tenga un riesgo reducido sesgo de precio (mispricing), pues si existedicho sesgo, la cobertura será imperfecta. Generalmente, una mayor liq-uidez implica un menor sesgo de precio.
27.8 Número de contratos necesario
El principio básico de la cobertura consiste en completar nuestra cartera de con-tado con una posición de futuros de signo opuesto. Así, si tenemos compradauna cartera de deuda, realizaremos la cobertura vendiendo futuros. Recordemosque el per�l de resultados de una posición de futuros es similar a la del contado,que es por lo que tomamos posiciones de signo opuesto, de modo que un resul-tado negativo en uno de los componentes (futuro o contado), se compense conun resultado positivo del otro.El valor de la cartera así constituida será: V C = PcNc � PFNF ; donde
Nc; NF representan los nominales de las posiciones en futuros y contado. Uncambio en su valor de mercado puede expresarse: �V C = �PcNc � �PFNF ,de modo que:
NFNc
=�Pc�PF
) �V C = 0
Sin embargo, seguir esta regla para inmunizar el valor de la cartera supon-dría estar comprando y vendiendo contado y/o futuros continuamente con elconsiguiente incremento en costes y comisiones.En algunos casos, nos encontraremos con una correlación entre precios de
futuros y de contado prácticamente igual a 1 y con similar volatilidad en ambosprecios. En tal caso, las �uctuaciones en el precio del contado tienden a venirasociadas con variaciones de igual signo y cuantía del futuro, y con un nominalinvertido en futuros igual al de la posición de contado, tendríamos la cartera decontado cubierta. Ello no signi�ca que hayamos inmunizado nuestra posición,en primer lugar porque el coe�ciente de correlación entre ambos precios no esnunca exactamente igual a uno, lo que se conoce como riesgo de correlación,especialmente si queremos cubrir un activo de contado que no es subyacente deningún contrato de futuro (este es el caso de la cobertura cruzada). La condiciónde igual volatilidad es importante: si los precios tienen correlación igual a uno,pero la desviación típica del contado es doble que la del futuro, entonces lasvariaciones en ambos precios de corresponderán en signo exactamente, peroserán de amplitud doble en el precio del contado que en el precio del futuro.En esta situación, necesitaríamos invertir en futuros un nominal doble del de laposición de contado. Con coe�ciente de correlación unitaria, podemos inmunizarla cartera de contado, eligiendo un ratio de cobertura h:
h =volatilidad cartera
volatilidad futuro
En cualquiera de estos casos, la cobertura deberá ser revisada periódica-mente, según se produzcan variaciones en los determinantes de las volatilidadesy correlación de los precios de contado y futuro.
402

Por otra parte, ya hemos visto que:
Pr ecio futuro =Pr ecioEMB
f
por lo que escribiendo esta ecuación en t y en t� 1 y restando, tenemos:
Senbilidad precio futuro =Sensibilidad precioEMB
f
y, �nalmente:
h =volatilidad cartera
volatilidadEMB
volatilidadEMB
volatilidad futuro=volatilidad cartera
volatilidadEMB� f
Incluso si suponemos correlación unitaria, deberíamos considerar utilizar unnúmero de contratos igual al valor de nuestra cartera de renta �ja, dividido porel nominal de cada contrato de futuros. Así, si tenemos una cartera de 10 m.m.de ptas., y el contrato de futuros es por 10 millones de ptas., necesitaríamos1.000 contratos. Este ratio debe ajustarse por la diferencia de volatilidades quepueda existir entre el entregable más barato (EMB) y nuestra cartera, pues éstaes la relación en que una determinada �uctuación en tipos de interés afectará alprecio del EMB ( y, con él, al precio del futuro) y al valor de mercado de nuestracartera.Por tanto, el número de contratos de futuros con los que constituir la cober-
tura es:
N =
�valor nomin al cartera
valor nomin al futuro
��volatilidad cartera
volatilidadEMB
�� f
Hay varias maneras de calcular la volatilidad de contado y futuros: 1) uti-lizando la duración de un activo de renta para aproximar el cambio que seproduce en el valor de la cartera cuando varía un punto básico el rendimientodel bono. Por supuesto que este cálculo puede incorporar asimismo la convex-idad del activo, 2) aumentando o disminuyendo la TIR de la cartera en 1 pb.,y calculando la variación que se produce en el precio. Dividiendo dicho cambioen precio por el valor de la cartera se obtiene el valor de un punto base, que esotra medida de la volatilidad de la cartera, 3) mediante un procedimiento deregresión.
Ejemplo (Soldevilla, p.113).- Una situación sencilla es la que surge cuandola posición de contado está invertida en el bono EMB respecto de un contratode futuros. En ese caso, el segundo factor en la expresión anterior es igual a 1,y únicamente hay que ajustar el cociente de valores nominales con el factor deconversión del EMB. Esto es válido si la cobertura se quiere mantener hasta elvencimiento del futuro. Si, posiblemente debido a que el horizonte de inversiónno coincide con el vencimiento del futuro, se quiere deshacer la cobertura antesdel vencimiento del futuro, existe un riesgo de base, debido a que ésta es iguala cero sólo a vencimiento del futuro.
403

En tal caso, querríamos estimar el precio esperado a un día distinto. Paraello, a) multiplicamos el precio del futuro por el factor de conversión del EMB,b) interpolamos linealmente entre el precio actual del EMB y el precio queacabamos de estimar al vencimiento del futuro, utilizando como ponderacioneslos intervalos de tiempo desde hoy hasta la fecha para que queremos estimar elprecio, y desde esta fecha hasta el vencimiento del futuro. Este cálculo puedehacerse asimismo analizando la evolución de la base: a) calculamos su valoractual restando el precio del futuro del cociente entre el precio del EMB y sufactor de conversión, b) interpolamos linealmente como antes.
Ejemplo.- Cuando se pretende cubrir una cartera de contado que está inver-tida en un bono que no es el EMB [ver hoja de cálculo Valorpb.xls].En el ejemplo de la hoja de cálculo [Soldevilla, p.117] se tiene una cartera
por $20.000.000, y un contrato de futuros con nominal $100.000. El número decontratos puede obtenerse:
NF =
�Nomin al bonoNO � EMB
Nomin al futuro
�fEMB
�V PBBonoNO�EMB
V PBEMB
�=20:000:000
100:000(1; 1806)
0; 04120
0; 06835= 142; 33
Podemos hacer un cálculo alternativo: como V PBEMB =�PEMB
�TIR y PEMB =fEMB � PF , se tiene que: V PBEMB = fEMB � V PBF ; por lo que fEMB =V PBEMB
V PBF:
En el ejemplo de la hoja de cálculo [Soldevilla, p.117] se tiene una carterapor $20.000.000, con un V PBc = 0; 04120 (por 100), y se dispone de un futurocuyo EMB actual tiene f = 1; 1806 y un V PBEMB = 0; 06835 (por cada $100).El valor nominal del contrato de futuros es $100.000, por lo que su VPB es:0,6835. Tendríamos:
V PBF =V PBEMB
fEMB=0; 6835
1; 1806= 0; 5790
El número de contratos de futuros lo obtendríamos:
NF =V PBcarteraV PBF
=82; 40
0; 5790= 142 contratos
También en este caso podemos estimar el precio esperado del bono de con-tado a una determinada fecha futura: primero, el producto del precio actualdel futuro por el factor de conversión del EMB nos proporciona el precio es-perado para el EMB al vencimiento el futuro y, de él, calculamos la variaciónesperada en el precio del EMB. Utilizando el cociente entre V PBNO�MBE yel V PBMBE , obtenemos la variación esperada en el precio del bono de contado(no-EMB) al vencimiento del futuro, y de ésta, el precio esperado de este bono.Para fechas intermedias, operaríamos mediante interpolación lineal.
404

27.9 Análisis de un caso práctico
Retomemos el ejemplo anterior, con una cartera de 10 m.m. de ptas., convencimiento promedio a 3 años, y TIR del 12,36% anual (6% semestral). Supong-amos que la volatilidad de nuestra cartera (desviación típica anualizada) fuesede 0,023%. Mantenemos el supuesto de que el EMB es el bono a 2 años, 14%cupón, pagadero semestralmente, de nominal 10 m. de ptas., que cotiza a 103,06.A ese precio, su TIR es 12,60%, superior a la del mercado, que es de 12,36%,por lo que está barato en términos relativos. Supongamos que su volatilidadfuese de 0,016% y su factor de conversión f=1,07092. Estos valores de volatil-idad (hipotéticos, pues necesitaríamos datos de series temporales para su esti-mación), no di�eren mucho del valor del punto base: si la TIR del 6% semestraldescendiese al 5.99%, el precio del bono vencimiento 3 años, cupón 6% pasaría aser de 99,9754, con una variación en precio de 0,0246. El precio del EMB caeríade 103,465 a 103,447, con un descenso de 0,0177.Tendríamos un ratio de cobertura:
h =0; 023%
0; 016%� 1; 07092 = 1; 5309
por lo que necesitaríamos vender 1.539 contratos de futuros para llevar acabo la cobertura.Vendemos 1.539 contratos de futuros a 95,083. Suponemos que, a vencimiento,
no ha habido cambio de EMB. Examinemos 3 escenarios diferentes:
27.9.1 No hay variaciones en los tipos de interés
Los tipos de mercado se mantienen en 12,36%. Al vencimiento del futuro:
� entregamos 1.539 bonos EMB. Si su error de precio continuase igual al queantes supusimos, cada uno valdría en el mercado 103,06:
1; 0306 � 10millones ptas: � 1:539 = 15:860; 934millones ptas:
� recibimos por ellos una cantidad (número*precio de futuro*factor de con-versión):
1:539 � 0; 95083 � 1; 07092 � 10:000:000 ptas: = 15:671; 065millones ptas:
� nuestra cartera mantiene su valor de 10 m.m. de ptas., al no haber variadola rentabilidad del mercado.
� Flujos cartera de futuros: 15:671; 065 � 15:860; 934 = �190; 284 millonesde ptas.
Flujos cartera de bonos: 1:200; 00 millones de ptas. de intereses.
Bene�cio total de la cartera: 1:009; 716 millones de ptas.
405

� Este bene�cio se corresponde, aproximadamente, con el bene�cio que sehabría tenido invirtiendo el capital de 10 m.m. de ptas. en el activosin riesgo, al 10% de rentabilidad, de modo que el bene�cio obtenido almantener la cartera de deuda y vender futuros es el interés libre de riesgo.
27.9.2 El tipo de interés aumenta
Supongamos que, al vencimiento del futuro, el tipo de interés ha subido hastael 14,49% (composición anual de un 7% semestral). Suponemos que el EMBcontinúa siendo el mismo, por lo que el factor de conversión seguirá siendotambién el de antes. Por tanto, recibiremos la misma cantidad del caso anterior.
� Pérdida de capital: es fácil calcular que el precio de nuestro bono, cupón12%, pago semestral, vencimiento a 3 años, desciende a 95,233 cuando eltipo de interés aumenta de 12% a 14%. Por tanto, el valor de la carteraes de 9.523,3 m.m. de ptas.. Podríamos haber aproximado la variación enprecios por la duración de Macaulay de este bono que, cuando la TIR esde 12% anual, puede calcularse en 2,606. Por tanto, el cambio estimadoen su precio sería: (14% � 12%)(�2; 606) = �5:212%; lo que genera unaestimación del nuevo valor de mercado de la cartera de: (1 � 0; 05212) �10 m:m: de ptas: = 9:478; 8 millones de ptas. que se aproxima, aunquesobrestima (como siempre ocurre), el descenso producido por la elevaciónde tipos de interés. Si utilizamos la volatilidad de la cartera, que es 0,023%,al haberse elevado los tipos en 200 pb., estimaríamos un descenso en preciode: 0:023 � 200 = 4; 6%, por lo que el valor de la cartera será ahora de9.540 millones de ptas.. Estos errores de aproximación se deben a que lavariación en tipos de interés es grande.
� hemos de entregar 1.539 bonos EMB. Como los nuevos tipos de interés sonla composición continua del 7% semestral, los bonos EMB valdrán 100 sino existe error en precio. Si existiera tal error, quizá podríamos comprarlosmás baratos. [Si no existe, no hace falta liquidar nuestra cartera, puespodemos entregar al comprador del futuro los bonos de la cartera que yatenemos, por un valor de]. El coste de entrega de los EMB es:
1 � 10millones de ptas: � 1:539 bonos = 15:390millones de ptas:
� Flujos cartera de futuros: 15:671; 065� 15:390; 000 = 281; 065 millones deptas.
Flujos cartera de bonos: a) minusvalías: 9:523; 3 � 10:000; 0 = �476; 7millones de ptas.
b) intereses: 1.200 millones de ptas.)Bene�cio cartera de bonos: 1:200; 0�476; 7 = 723; 3 millones de ptas.
� Bene�cio global de la cartera: 281; 065+723; 3 = 1:004; 365 m.m. de ptas.,que es el bene�cio aproximado que habríamos obtenido si, en el momento
406

de vender el futuro, hubiéramos vendido la cartera de bonos, e invertidoen liquidez. La pérdida de capital de nuestra cartera debida a la subidade tipos queda compensada sobradamente con los bene�cios obtenidos enla cartera de futuros.
27.9.3 Descenso de tipos
Supongamos que los tipos descienden al 10,25% (composición anual compuestade un 5% semestral). Nuevamente, recibiremos 15.671,065 millones de ptas.,por las mismas razones de antes.Sin embargo, los bonos EMB valdrán ahora:
PEMB =4Xi=1
(0:07) � 100(1 + 0:05)i
+100
(1 + 0:05)4= 107: 0919
Supongamos que hay un mispricing, y que este bono se compra por 106,722.En tal caso,
� la entrega de los EMB nos costaría:
1; 06722 � 10millones de ptas: � 1:539 bonos = 16:424; 516millones de ptas:
� Ganancia de capital: como la volatilidad de nuestra cartera es 0,023%y los tipos han descendido en 200 pb., estimaríamos un aumento en elvalor de mercado de la cartera: 0; 023 � 200 = 4; 6%, por lo que el nuevovalor estimado sería de 10.460 millones de ptas.. Utilizando la duración,tendríamos un valor de 10:491; 7 millones de ptas. (10+ (2:606=1:06) � 2):El nuevo precio es, realmente, de 105,076 por lo que el nuevo valor demercado de nuestra cartera es de 10.507,6 m.m. de ptas.. La duración,como siempre, subestima la cuantía de la ganancia de capital producidapor descenso de tipos.
� Flujos cartera de futuros: 15:671; 065 � 16:424; 516 = �753; 451 millonesde ptas.
Flujos cartera de bonos: a) plusvalía: 10:507; 6�10:000; 0 = 507; 6millonesde ptas., b) intereses cobrados: 1.200,0 millones de ptas. ) Bene�ciocartera bonos: 1.707,6 millones de ptas.
� Bene�cio global de la cartera: 1:707; 6 � 753; 451 = 954; 149 millones deptas.
En este caso, la cobertura con futuros ha sido mayor de lo preciso, lo queha generado un rendimiento inferior en 46 pb. al tipo de interés librede riesgo, lo que parece excesivo, ya que no debería exceder de unos 10pb.. Esta desviación se produce porque el ajuste entre las volatilidades delEMB y de la cartera no es exacto, debido a que la volatilidad de un bono
407

cambia continuamente con su precio. Por esto, es óptimo, si se puede,utilizar como bono EMB aquél que tenga una duración más similar a lade nuestra cartera.
27.10 Cobertura cruzada
En ocasiones, el subyacente sobre el que se de�ne el contrato de futuro nocoincide con el bono que tenemos en nuestra cartera. Si ambos activos no sonsimilares, pueden producirse incluso diferencias en rentabilidad, en la formade primas de riesgo. Esto es lo que ocurre si, por ejemplo, queremos cubriruna cartera de renta �ja privada con contratos de futuros sobre deuda pública.Esto constituye una cobertura cruzada. Tendremos que prever no sólo posibles�uctuaciones en los tipos, sino también en la prima de riesgo. Una posibilidadconsiste en estimar una regresión entre rentabilidades:
Rprivada = �+ �Rp�ublica
donde una � estimada igual a uno implicaría que la prima de riesgo esindependiente del nivel de los tipos de interés, e igual a �. Si, por ejemplo,tenemos:
Rprivada = 0; 006 + 1; 2Rp�ublica
esto querría decir que la prima de riesgo de la deuda privada es de 0,6%,más un 20% del nivel de la rentabilidad ofrecida por la deuda pública. Unaumento de un punto en ésta incrementa el diferencial por riesgo entre ambosmercados en 20 pb.. En este caso, el número de contratos de futuro precisospara la cobertura sería:
h =valor nomin al cartera
valor nomin al futuro� volatilidad carteravolatilidadEMB
� f � beta
Los riesgos asociados a la cobertura son, en resumen:
� Minusvaloración del futuro (mispricing) en el momento de su venta. Enese caso, la cobertura no será perfecta, obteniendo una rentabilidad algoinferior a la que se tendría de una posición de liquidez.
� Riesgo de base, que se produce al no mantener el futuro hasta vencimiento,debido posiblemente a que el horizonte de nuestra inversión no coin-cide con la vida residual del contrato, incurriendo en un riesgo de in-fra/sobrevaloración en el momento de cerrar la posición. En todo caso, sila infravaloración se mantiene relativamente constante desde que se con-struye la cobertura hasta que se cierra la posición, este factor de riesgo esreducido.
� Riesgos por diferencias entre la volatilidad real y la volatilidad estimada.Si sobre-estimamos la volatilidad de nuestra cartera, venderemos un númeroexcesivo de contratos de futuro. En consecuencia, tendremos un exceso de
408

exposición, que estará sometido a las ganancias o pérdidas de capital quepuedan producirse por descensos o elevaciones de tipos de interés.
28 La Hipótesis de las Expectativas: Tipos deinterés forward
Los tipos forward implícitos son tipos que se calculan en t (hoy), para un in-stante futuro. Se obtienen por comparación entre tipos cupón cero observadosa vencimientos m;n, con m > n: Por eso se dicen que están implícitos en laestructura temporal que hoy se observa. Son tipos a descuento, y se obtienenasimismo a partir de tipos de emisiones a descuento, como puedan ser tiposcupón cero, o tipos del mercado interbancario.
En el momento t un inversor puede invertir a m períodos a un tipo rmt , oa n períodos a un tipo rnt : El principio de ausencia de arbitraje implica que elinversor deba estar indiferente entre qué plazo tomar, es decir, que:
(1 + rmt )m = (1 + rnt )
n(1 + fm�nt;n )m�n
donde fm�nt;n denota el tipo forward impícito obtenido mediante comparaciónde rmt y rnt . En la notación utilizada para el tipo forward, el primer subíndicehace referencia al instante en que se calcula, mientras que el segundo se re�ereal instante en el cual estaría vigente. Por último, el superíndice se re�ere alplazo al cual se llevaría a cabo la inversión a dicha rentabilidad.
Por ejemplo, consideremos: m=2 años, n = 1 año. Tendríamos:
(1 + r2at )2 = (1 + r1at )(1 + f
1at;1a)
La expresión anterior puede utilizarse también para plazos inferiores a unaño. Por ejemplo, consideremos: m=6 meses, n = 3 meses. Tendríamos:
(1 + r6mt )6 = (1 + r3mt )3(1 + f3mt;3m)3
es decir,
(1 + r6mt )2 = (1 + r3mt )(1 + f3mt;3m)
mientras que si: m=3 meses, n = 1 mes,
(1 + r3mt )3 = (1 + r1mt )(1 + f2mt;1m)2
donde debe notarse que ahora, el subíndice y el superíndice temporales delforward no coinciden.
Si los plazos son inferiores a un año, con capitalización continua, tendríamos:
409

1 +m
360rmt = (1 +
n
360rnt )(1 +
m� n360
fm�nt;n )
Por ejemplo, consideremos: m=6 meses, n = 3 meses. Tendríamos:
1 +180
360r6mt = (1 +
90
360r3mt )(1 +
180� 90360
f3mt;3m)
mientras que para m=3 meses, n = 1 mes,
1 +90
360r3mt = (1 +
30
360r1mt )(1 +
60
360f2mt;1m)
Ejemplos:
r1at = 7; 100%; r2at = 8; 200%) f1at;1a = 9; 311%r6mt = 7; 100%; r12mt = 8; 200%) f6mt;6m = 9; 311%r1mt = 7; 100%; r3mt = 8; 200%) f2mt;1m = 8; 754%
mientras que, con capitalización continua:
r1at = 7; 100%; r2at = 8; 200%) f1at;1a = 8; 683%r6mt = 7; 100%; r12mt = 8; 200%) f6mt;6m = 9; 137%r1mt = 7; 100%; r3mt = 8; 200%) f2mt;1m = 8; 698%
Si trabajamos con tipos continuos, los valores futuros de 1 u.m. invertida am y n períodos, deben satisfacer la relación con el forward fm�nt;n :
ermt m = er
nt n:ef
m�nt;n
es decir,
rmt m = rnt n+ fm�nt;n (m� n)
por lo que:
fm�nt;n =mrmt � nrntm� n (110)
que, en el caso particular n = 2m, se convierte en,
Nota 1: Los tipos forward a horizonte 0, coinciden con los tipos cupón ceroactuales.Nota 2: A partir de n tipos contado pueden calcularse muchos tipos forward,
tantos como pares de plazos pueden compararse.
410

28.1 1.1La hipótesis de Expectativas acerca de la forma-ción de tipos de interés.
En su versión fuerte, La Hipótesis de las Expectativas establece que un tipo deinterés a vencimiento largo es el promedio del tipo de interés observado a unperíodo y los tipos a un período esperados hasta cubrir el vencimiento largo,
rmt =1
m
m�1Xj=0
Etr1t+j
donde el primero de los tipos que aparece a la derecha no precisa sr previsto,pues es observado junto con el tipo a largo plazo.
Una versión más débil de la hipótesis permite la existencia de primas deriesgo o de plazo constantes, �m;1;
rmt =1
m
m�1Xj=0
Etr1t+j + �
m;1 (111)
La misma hipótesis puede establecerse, de modo más general, para plazos my n; siendo m un múltiplo de n : m = kn;
rmt =1
k
k�1Xi=0
Etrnt+in + �
m;n (112)
Un caso especialmente utilizado surge cuando m = 2n;
rmt =1
2(rnt + Etr
nt+n) + �
m;n (113)
Si añadimos el supuesto de que los agentes forman racionalmente sus expec-tativas de tipos de interés futuros, tenemos:
rnt+n = Etrnt+n + "
nt+n (114)
donde "nt+n tendrá una estructuraMA(n�1), como ocurre en todo problemade predicción bajo expectativas racionales.
Uniendo 114 y 113, tenemos,
rmt � rnt =1
2(rnt+n � rnt )�
1
2"nt+n + �
m;n
que muestra que el diferencial entre los tipos a largo y corto plazo tienecapacidad explicativa sobre la variación futura en el tipo a corto plazo. Estosugiere estimar la regresión,
411

rnt+n � rnt = �+ �(rmt � rnt ) + ut+n (115)
donde � = �2�m;n, ut+n = �"nt+n:Por ejemplo, si m=6 meses, y n=3 meses, se tiene:
r3t+3 � r3t = �+ �(r6t � r3t ) + ut+3
Si los tipos de interés, tanto a largo como a corto plazo son procesos integra-dos de orden 1 (I(1)), es decir, tienen una raíz unitaria, entonces sus primerasdiferencias serán estacionarias. Por otra parte, el error de predicción racionaltiene una estructuraMA(n�1);por lo que es estacionario. En estas condiciones,si la prima de riesgo o de plazo es estacionaria, el diferencial largo/corto tambiénhabrá de serlo. Por tanto, los tipos de interés a corto y a largo están cointegra-dos, con vector de cointegración (1,-1). Este resultado es válido para cualquierpar de tipos, siempre que el período de tiempo que de�ne el vencimiento largosea múltiplo del que de�ne el vencimiento corto. Como esto es cierto siempreque tomamos el tipo de interés a vencimiento igula a un período, tendremos quelos diferencales respecto al plazo más corto, que podemos tomar como unidad detiempo, habrán de ser estacionarios. Ahora bien, el diferencial entre dos tipos avencimientos cualesquiera m y n, puede escribirse como la diferencia entre losdiferenciales de ambos tipos respecto al tipo a corto plazo, por lo que si estos dosúltimos son estacionarios, también el primero lo será. En de�nitiva, todos losdiferenciales entre pares de tipos d einterés habrán de ser estacioanrios. Comose ve, a) la Hipótesis de Expectativas, junto con b) el supuesto de racionalidadde expectativas, y c) el supuesto de primas de riesgo o de plazo estacionarias,tiene una gran cantidad de implicaciones.
Volviendo a la expresión anterior acerca de la capacidad explicativa delspread largo/corto, en el caso general, obtenemos,
rmt � rnt = Et
m�nnXj=1
m� njm
(rnt+nj � rnt+n(j�1)) + �m;n
es decir,
rmt � rnt = Et
k�1Xj=1
�1� j
k
�(rnt+nj � rnt+n(j�1)) + �m;n
que sugiere estimar una regresión:
k�1Xj=1
�1� j
k
�(rnt+nj � rnt+n(j�1)) = �+ �(rmt � rnt ) + ut+m�n
412

cuyo término de error debe tener una estructura MA(m� n+ 1), en la queel diferencial largo/corto se utiliza para anticipar variaciones futuras en el tipode interés a corto plazo.
En el caso general, habrá más de una variación futura en el miembro izquierdode la ecuación, por lo que estaremos tratando de anticipar variaciones acumu-ladas desde t hasta t+m-n. Si, por ejemplo, m=12 meses y n=3 meses, tenemos:
r12t � r3t = Et
3Xj=1
�1� j
4
�(r3t+3j � r3t+3(j�1)) + �12;3
que sugiere estimar una regresión:
3Xj=1
�1� j
4
�(r3t+3j � r3t+n(j�1)) = �+ �(r12t � r3t ) + ut+9
apareciendo en el miembro izquierdo los diferenciales: r3t+9�r3t+6; r3t+6�r3t+3y r3t+3 � r3t .
28.2 1.2El tipo forward como predictor de tipos a cortofuturos
Si retomamos 115, tenemos que:
rnt+n � rnt = �2�m;n + 2(rmt � rnt )� "nt+n
es decir,
rnt+n = �2�m;n + (2rmt � rnt )� "nt+nque sugiere que el tipo forward debe ser un buen predictor del tipo a corto
futuro, y sugiere estiamr la regresión,
rnt+n = �+ �fm�nt;n + ut+n (116)
en la que, nuevamente, � = �2�m;n, ut+n = �"nt+n.
En esta regresión, el contraste de la hipótesis nula: H0 : � = 0; � = 1;seríaun contraste conjunto de: a) la Hipótesis de Expectativas acerca de la formaciónde tipos de interés, y b) el supuesto de que los agentes forman sus expectativasde modo racional.
Cuando la hipótesis no se rechaza, suele decirse que el tipo forward es unpredictor insesgado del tipo contado futuro, aunque en muchos pocos casos selleve a cabo, realmente, un análisis de predicción, y el ejercicio sea puramenteun ajuste de mínimos cuadrados.
413

Por los problemas que pueden derivarse de la ausencia de estacionariedad,tanto de los tipos de interés de contado como de los tipos forward, suelen esti-marse variantes de esta regresión,
rnt+n � rnt = �+ �(fm�nt;n � rnt ) + ut+n
que, bajo H0, sería equivalente a la anterior.
Otra posibilidad, utilizada en ocasiones, ha consistido en estimar la ecuación116 en primeras diferencias,
�rnt+n = �+ ��fm�nt;n + ut+n
que, nuevamente bajo H0, sería equivalente a la anterior.
Por último, más recientemente, y dada la constatación empírica acerca deque tanto los tipos de interés de contado como los tipos forward tienen raicesunitarias, se ha examinado 116 como una relación de cointegración entre ambostipos. Bajo las hipótesis antes citadas, los tipos contado y forward deberían estarcointegrados con vector (1,-1) y (bajo la versión fuerte de la HE ), la relación decointegración no debería incluir una constante.
En el caso general, con m=kn, es preciso incorporar hipótesis del tipo:Etr
1t+1 = Etr
1t+2: Con ella, y utilizando la de�nición del tipo forward, que
es ahora: f2t;t+1 =3r3t�r
1t
2 , tendríamos una ecuación como
rnt+n = �+ �fm�nt;n + ut+n
en la que, ahora, � = � 32�
3;1, ut+1 = �"1t+1.
28.3 1.3El tipo forward como predictor del tipo a largo
A partir de 112, por ejemplo, en el caso n=6, m=2, tenemos,
r6t =1
3
�Et�r2t + r
2t+2 + r
2t+4
��(117)
que implica37 ,
37Nota: Para obtener 118, escribimos 117 en t+ 2,
r4t+2 =1
2Et+2
�r2t+2 + r
2t+4
�y, por la ley de expectativas iteradas:
Etr4t+2 =
1
2Et�r2t+2 + r
2t+4
�que utilizamos para eliminar Etr4t+2 en 118
r6t =1
3r2t +
2
3Etr
4t+2
414

Etr4t+2 � r6t =
1
2(r6t � r2t ) (118)
que sugiere estimar la regresión,
r4t+2 � r6t = �+ �r6t � r2t2
+ �t+2
o, lo que es lo mismo,
r4t+2 � r6t = �+ �S6;2t2+ �t+2
donde S6;2t = r6t � r2t denota el diferencial largo/corto. En esta regresióndebería contrastarse la Hipótesis de expectativas, ya sea en su versión fuerteH0 : � = 0; � = 1; o en su versión débil H0 : � = 1.
Bajo racionalidad de expectativas: E( S6;2t :�t+2) = E[(r6t � r2t ):�t+2] = 0,por lo que MCO es un estimador consistente.
En general, tendremos,
Etrm�nt+n � rmt =
n
m� n (rmt � rnt )
que sugiere estimar,
rm�nt+n � rmt = �+ �Sm;ntm�nn
+ �t+n
Siguiendo con el mismo ejemplo, a partir de 117, y de�niendo una nuevavariable, eS6;2t = 2
3�2r2t+2 +
13�
2r2t+4, con �2r2t+2 = r2t+2 � r2t , tenemos38 :
Et eS6;2t =2
3�2r2t+2 +
1
3�2r2t+4 = S6;2t (119)
es decir,
Etr4t+2 =
3
2r6t �
1
2r2t
o, lo que es lo mismo,
Etr4t+2 � r6t =
1
2(r6t � r2t ) =
1
2S6;2t
38Nota: La expresión 119 se obtiene restando r2t de 117, para obtener,
S6;2t = �23r2t +
1
3
�Etr
2t+2 + Etr
2t+4
�=2
3
�Etr
2t+2 � r2t
�+1
3
�Etr
2t+4 � Etr2t+2
�= Et eS6;2t
415

por lo que el spread observado S6;2t es un predictor óptimo de una mediaponderada de cambios futuros en el tipo r2t :
En general, si de�nimos,
eSm;nt =k�1Xi=1
�1� i
k
��nrnt+in
tenemos,
Et eSn;mt = Sn;mt
que sugiere estimar la regresión:
eSn;mt = �+ �Sn;mt + !t
y contrastar las hipótesis: H0 : � = 0; � = 1; o H0 : � = 1.
416

29 Valoración por simulación
La valoración de una opción mediante simulación se ajusta a la idea generalde simular el precio del subyacente desde el instante en que se valora la opciónhasta el vencimiento de la misma. La práctica de valoración de derivados porsimulación del precio del subyacente ha alcanzado un alto grado de so�sticacióncomputacional. Sin embargo, la calidad de la valoración resultante dependetanto de la complejidad y realismo so�sticación del modelo como de la calidaddel modelo estadístico utilizado en la simulación del precio del subyacente. Haydos componentes a tener en cuenta,
1. un buen modelo de evolución temporal del precio del subyacente
2. unas hipótesis adecuadas acerca de las características estocásticas de lainnovación de dicho proceso.
Así, por ejemplo, suponer Normalidad de la innovación, al generar sendasfuturas para el precio del subyacente, cuando existe evidencia de asimetría ycurtosis puede generar errores de aproximación muy importantes al llevar acabo la valoración. Es importante disponer de un modelo dinámico del preciodel subyacente su�cientemente bueno y utilizar una distribución de probabili-dad adecuada al generar realizaciones simuladas para la innovación del proceso.Estas serán dos de las cuestiones a las que prestaremos atención en este curso.En el caso de una opción Europea, basta con considerar en cada simulación
el precio resultante al �nal de la serie temporal simulada, que coincide con elinstante de vencimiento de la opción. Mediante un elevado número de realiza-ciones simuladas, podemos aproximar la distribución de probabilidad del preciodel activo subyacente al vencimiento de la opción. De este modo, obtenemos elvalor intrínseco de la opción a vencimiento para cada realización y, por tanto,una aproximación a la distribución de probabilidad de dicho valor intrínseco. Dedicha distribución de probabilidad inferimos un precio actual para la opción apartir de un determinado mecanismo de valoración: una posibilidad es calcularla esperanza matemática de la distribución de probabilidad del valor intrínsecoa vencimiento, y descontarlo al instante en que se efectúa la valoración.En el caso de otros tipos de opciones, puede utilizarse, en general, un pro-
cedimiento análogo, si bien teniendo en cuenta a) todos los posibles instantes deejercicio, b) el valor intrínseco en cada uno de ellos, c) el descuento apropiadoa utilizar.Sin embargo, hay otras posibilidades: una, interesante, consistiría en consid-
erar los tipos de interés como estocásticos, y simular simultáneamente los tiposde interés y el precio del subyacente, una vez que hubiéramos recogido en elmodelo la dependencia entre ambos. Por ejemplo,
yt = �0 + �1rt + "yt
rt = �0 + �1rt�1 + "2t
417

con ("1t; "2t) � N
��00
�;
��21 �12�12 �22
��: Téngase en cuenta que, en un
modelo de estas características, la relación entre los tipos de interés rt y larentabilidad del activo subyacente yt se produce por dos vías: una, explícita,por la presencia de los tipos en la ecuación de la rentabilidad; otra, implícita,por la correlación entre las innovaciones de ambas ecuaciones.En el caso en que la rentabilidad y los tipos tengan estructuras de volatilidad
condicional no trivial, entonces podríamos establecer un modelo ARCH bivari-ante, en el que se pueden recoger las dependencias tanto entre rentabilidadescomo entre volatilidades.
30 Sobre simulación de procesos brownianos
De acuerdo con un proceso generalizado de Wiener, el precio de un activo evolu-cionaría de acuerdo con,
dSt = �dt+ �dz
donde dz denolta un proceso de Wiener básico, es decir, un proceso es-tocástico de Markov, con una variación promedio igual a cero, y una tasa devarianza anual igual a 1.0. Se conoce también como movimiento Browniano:1) su variación durante un intervalo pequeño de tiempo, de amplitud �t es�z = "�t, siendo " independiente en el tiempo, Normal(0,1), 2) los valores de�z son independientes en el tiempo.Sin embargo, el proceso anterior no recoge algunas de las características
importantes de los precios de los activos �nancieros. Más interesante resulta elsupuesto �S = �S�t que, en el límite se convierte en, dS = �Sdt, es decir,dS=S = �dt, de modo que,
ST = S0e�T
Para incorporar volatilidad, suponemos que la variabilidad en la rentabilidadporcentual del activo es independiente del precio del mismo, es decir, que lavolatilidad del precio es proporcional a su nivel,
dSt = �Stdt+ �Stdz
30.1 Distribución de los cambios en precio
Si el precio de un activo que no paga dividendos tiene una volatilidad anual del30% y una rentabilidad esperada del 15% anual, compuesta de modo continuo,el proceso que sigue es,
dStSt
= �dt+ �dz = 0:15dt+ 0:30dz
y sobre intervalos �nitos, pero cortos de tiempo,
418

�StSt
= 0:15�t+ 0:30"tp�t
Por ejemplo, para un intervalo de una semana (una fracción 0,0192 de unaño), si el precio inicial es 100, la variación semanal sería,
�St = 100�0:15 (0:0192) + 0; 30"t
p0:0192
�= 0; 288 + 4; 16"t
siguiendo una distribución Normal(0; 288; 4; 16) : Al cabo de un año,
�St = S0 (0:15 + 0:30"t) = 15 + 30"t
con una distribución Normal(15; 30); si bien esta extrapolación temporal esbastante más cuestionable.Deberíamos obtener una muestra de la innovación "t; y sustituir repetida-
mente en la ecuación anterior. Así podríamos generar una distirbución de fre-cuencias (probabilidad) del precio al �nal del intervalo de tiempo deseado.Generalmente, el valor de un derivado sobre una acción es independente del
valor de �: Por el contrario el valor de � es clave, y normalmente oscila entre20% y 40%.Puede probarse que la volatilidad anual del precio de una acción es igual a
la desviación típica de la rentabilidad ofrecida por dicho acción, compuesta demodo continuo, durante un año.
30.2 Distribución del logaritmo del precio
Asimismo, el lema de Ito implica que,
d lnSt =
��� �2
2
�dt+ �dz
siguiendo por tanto un proceso deWiener generalizado. Por tanto, la variación
en lnS se distribuye N(��� �2
2
�T; �
pT ); y tenemos,
lnST � Normal
�lnS0 +
��� �2
2
�T; �
pT
�En consecuencia,
E (ST ) = S0e�T ; V ar(ST ) = S20e
2�T�e�
2T � 1�
que muestra que � puede interporetarse como una tasa de rentabilidad es-perada.Al cabo de un año, tendríamos,
E (ST ) = 100e:30x1 = 134; 99; V ar(ST ) = 100
2e2x:3x1�e:3
2
� 1�= 1715; 97; DT (ST ) = 41; 42
419

30.3 Distribución de la rentabilidad
La propia rentabilidad cumple, por de�nición,
E (ST ) = S0e�T
por lo que,
� =1
TlnSTS0
y utilzando la distribución de lnST ; tenemos que,
� ��N
��� �2
2
�;�pT
�
420





























