Embed Size (px)
Citation preview

2012年5月
加藤 努
株式会社 ソフテック
G-DEP 第3回 セミナー
なぜ、ディレクティブベースのプログラミングが有望なのか?
〜失敗しない並列プログラミングの始め⽅〜
ツールで始めるGPGPU
なぜ、GPUプログラミング?
1
CPU + GPUハイブリッド型へ
失敗しない並列プログラミングの始め⽅=背景をきちんと理解した上で⾏うこと
GPU computing 時代の本流に!
HPCアーキテクチャはどこへ向かうのか?
今、何が起きているのか?
現状のCPUを知るマルチコアCPU
の限界性能劣化の原因
GPUを知る性能・能力の違い
GPU活用のための現実的な勘所
プログラミングを知る並列化が必須
一般の並列化手法は、ディレクティブベース
確実に移行中
「適用実現性の判断」「納得」「確信」
Why?
OpenMPOpenACC

現在のCPUの限界
2
現状のCPUを知る
今のマルチコアCPUの性能
3
現在の最先端プロセッサ(Intel / AMD)
• 高クロック化• SSE/AVXによるベクトル化• マルチコア化(2,4,6,8,12,16)
HPCの用途では、高機能演算機構、複数のコアがあっても、その能力を十分に活かしきれない。
年 プロセッサ名 周波数 Core数 GFLOPS 電力
2000 Pentium 4 2.0GHz 1 7.6 75W
2011 Sandy Bridge 3.3GHz 6 158.4 130W
理論値
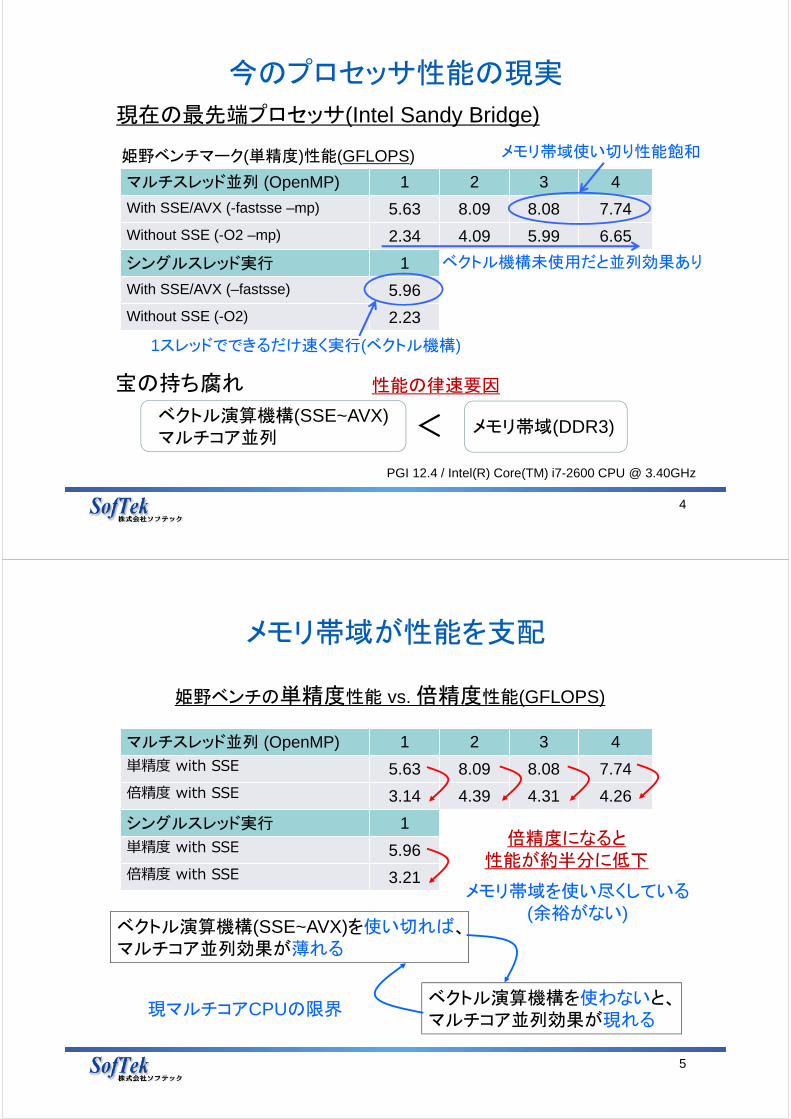
今のプロセッサ性能の現実
4
現在の最先端プロセッサ(Intel Sandy Bridge)
ベクトル演算機構(SSE~AVX)マルチコア並列
性能の律速要因
マルチスレッド並列 (OpenMP) 1 2 3 4
With SSE/AVX (-fastsse –mp) 5.63 8.09 8.08 7.74
Without SSE (-O2 –mp) 2.34 4.09 5.99 6.65
シングルスレッド実行 1
With SSE/AVX (–fastsse) 5.96
Without SSE (-O2) 2.23
PGI 12.4 / Intel(R) Core(TM) i7-2600 CPU @ 3.40GHz
メモリ帯域使い切り性能飽和姫野ベンチマーク(単精度)性能(GFLOPS)
1スレッドでできるだけ速く実行(ベクトル機構)
メモリ帯域(DDR3)<
宝の持ち腐れ
ベクトル機構未使用だと並列効果あり
メモリ帯域が性能を支配
5
姫野ベンチの単精度性能 vs. 倍精度性能(GFLOPS)
ベクトル演算機構(SSE~AVX)を使い切れば、マルチコア並列効果が薄れる
マルチスレッド並列 (OpenMP) 1 2 3 4
単精度 with SSE 5.63 8.09 8.08 7.74
倍精度 with SSE 3.14 4.39 4.31 4.26
シングルスレッド実行 1
単精度 with SSE 5.96
倍精度 with SSE 3.21
倍精度になると性能が約半分に低下
ベクトル演算機構を使わないと、マルチコア並列効果が現れる
メモリ帯域を使い尽くしている(余裕がない)
現マルチコアCPUの限界

最新プロセッサ技術の理想と現実
6
プロセッサ・メーカー曰く
SSE命令からAVX命令へ
これらのinnovationを否定する訳ではないが、HPC用途の一般ユーザ・コードにとっては、あまり意味がない。(高価なプロセッサを買っている!)
無理
マルチコアを増やす
ベクトル性能が2倍に上がるよ!
並列効果が上がるよ! 無理
本当かよ!
メモリ帯域の制約
多くのユーザにとっての懸念
7
ユーザの要求
• 数値モデルの大型化、高解像解析を要求
ユーザプログラム
• レガシーなプログラム資産が存在• 1コア/シングルスレッドしか使っていない• 他のCPUコアは死んでいる
計算が終わらない!
マルチコア&マルチスレッド化
• たとえマルチコア上の並列化を行っても理想性能を享受できず!
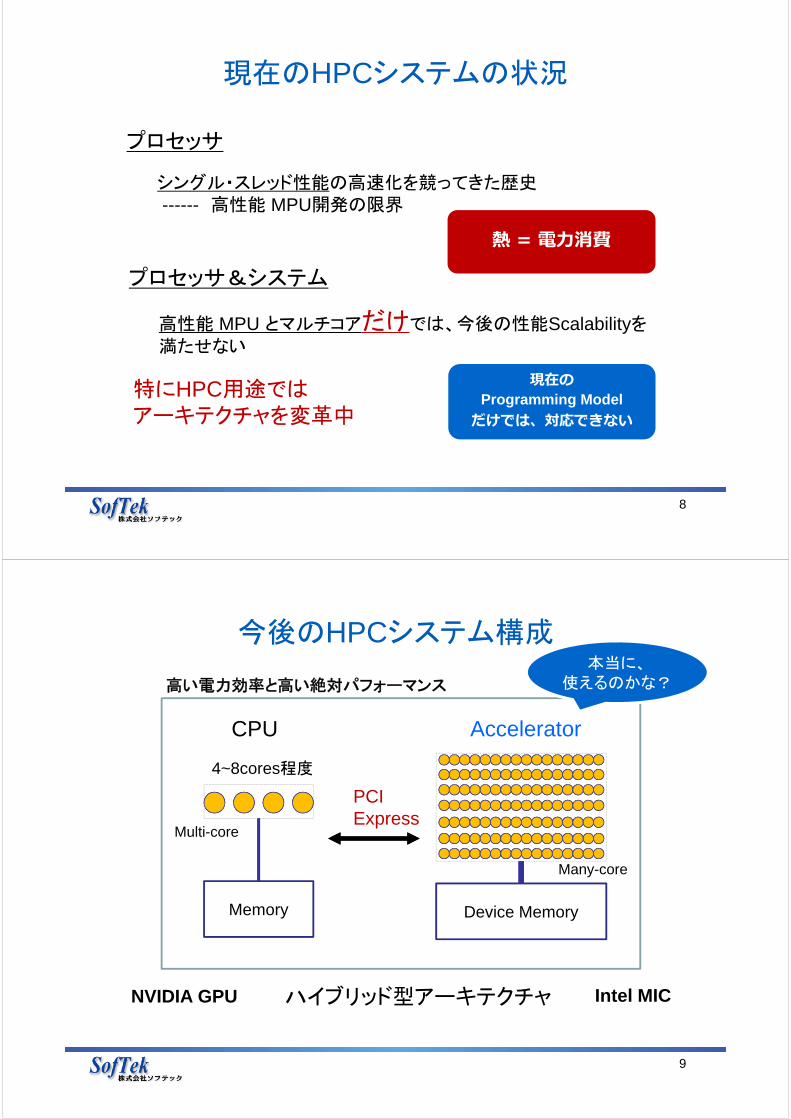
現在のHPCシステムの状況
8
プロセッサ
シングル・スレッド性能の高速化を競ってきた歴史------ 高性能 MPU開発の限界
高性能 MPU とマルチコアだけでは、今後の性能Scalabilityを満たせない
プロセッサ&システム
特にHPC用途ではアーキテクチャを変革中
現在のProgramming Model
だけでは、対応できない
熱 = 電⼒消費
今後のHPCシステム構成
9
4~8cores程度
AcceleratorCPU
ハイブリッド型アーキテクチャ
Memory Device Memory
PCIExpress
NVIDIA GPU Intel MIC
Multi-core
Many-core
本当に、使えるのかな?高い電力効率と高い絶対パフォーマンス

今後のHPCシステムの方向付け
10
今後のH/W方向性(ほとんどのベンダーの共通認識)
• Many-Cores• CPU + Accelerator ハイブリッド
Re-compile and Runで性能が出せる“ツール”は存在しない
ユーザが直面するレガシー・ソフトウェアへの対応
NVIDIA GPU
Intel MIC
並列化を行い、プログラムの再構築が必須
並列性の抽出必須できるだけ簡単に!
11
CPUとGPUのハードウェア的能力の違い
• マルチコアCPU並列挙動時のしがらみ• NVIDIA GPUスレッドの自由奔放さ
GPUを知る
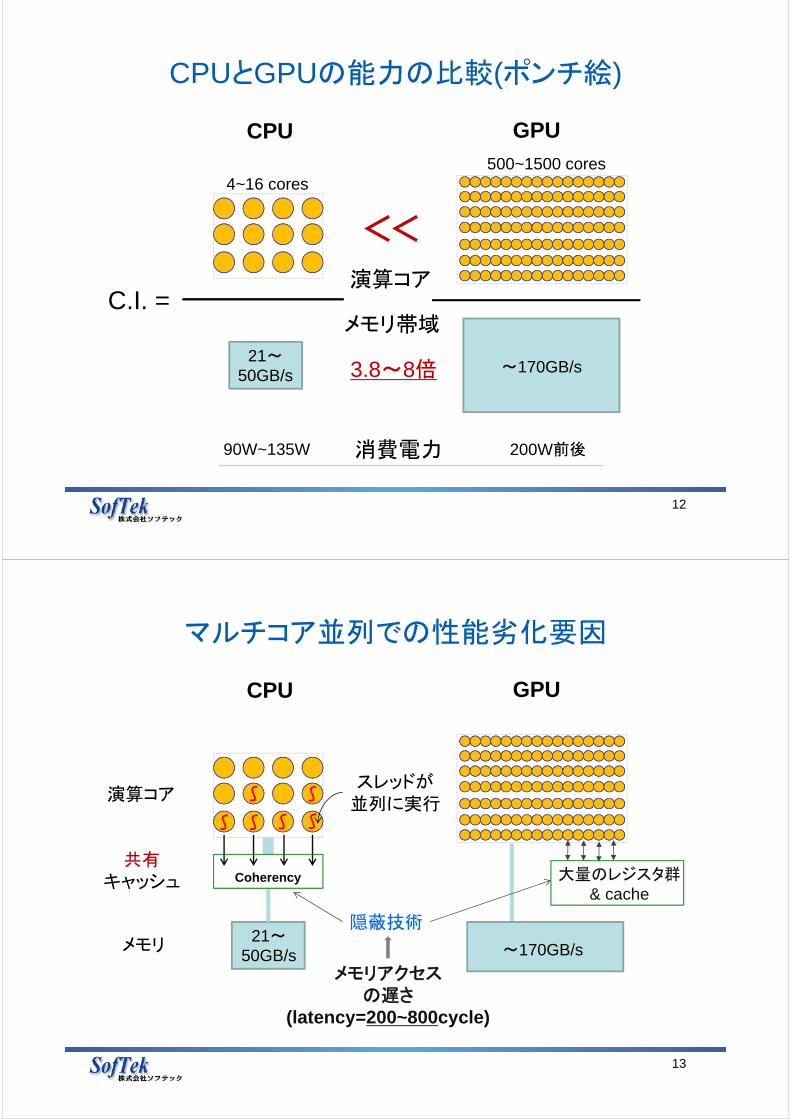
CPUとGPUの能力の比較(ポンチ絵)
12
200W前後
500~1500 cores4~16 cores
90W~135W
GPUCPU
21~50GB/s ~170GB/s3.8~8倍
メモリ帯域
演算コア
消費電力
<<
C.I. =
マルチコア並列での性能劣化要因
13
GPUCPU
21~50GB/s
メモリアクセスの遅さ
(latency=200~800cycle)
メモリ
演算コアスレッドが
並列に実行
Coherency 大量のレジスタ群& cache
~170GB/s
隠蔽技術
共有キャッシュ
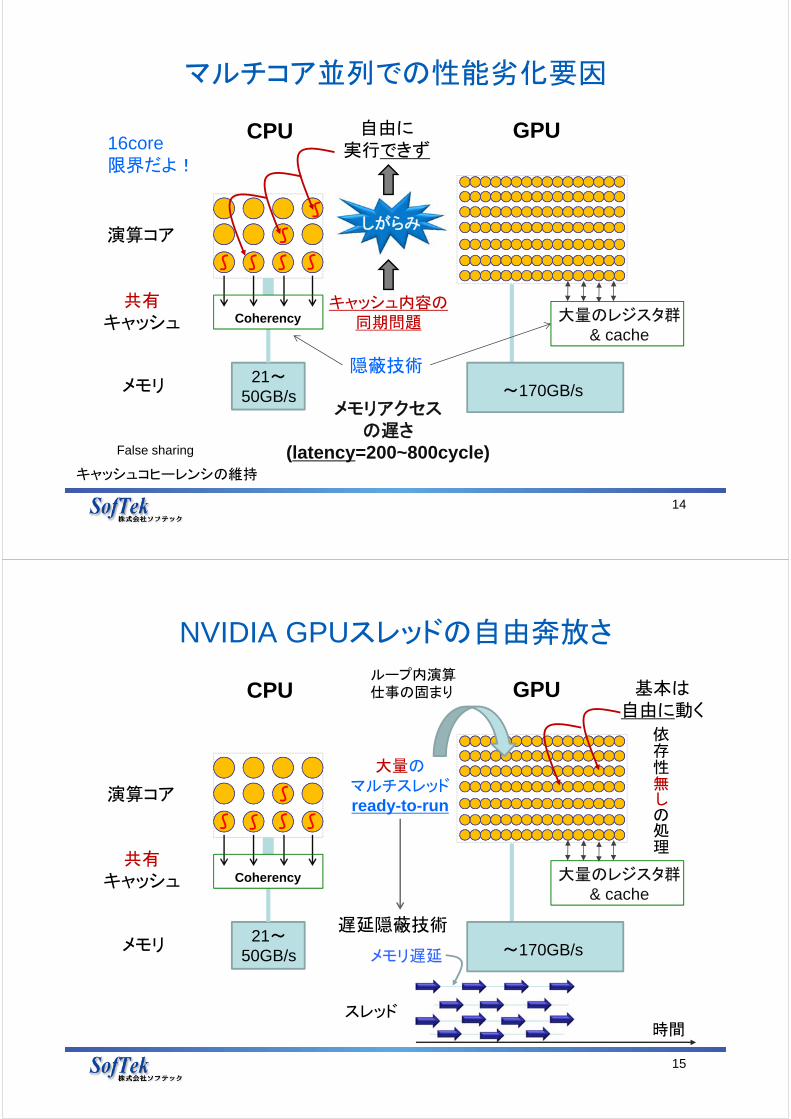
マルチコア並列での性能劣化要因
14
GPUCPU
21~50GB/s
メモリアクセスの遅さ
(latency=200~800cycle)
メモリ
演算コア
自由に実行できず
共有キャッシュ
キャッシュ内容の同期問題Coherency
しがらみ
大量のレジスタ群& cache
~170GB/s
隠蔽技術
16core限界だよ!
キャッシュコヒーレンシの維持
False sharing
NVIDIA GPUスレッドの自由奔放さ
15
GPUCPU
21~50GB/s
メモリ
演算コア
共有キャッシュ Coherency
基本は自由に動く
しがらみ
大量のレジスタ群& cache
~170GB/s
遅延隠蔽技術
依存性無しの処理
大量のマルチスレッドready-to-run
ループ内演算仕事の固まり
メモリ遅延
時間スレッド
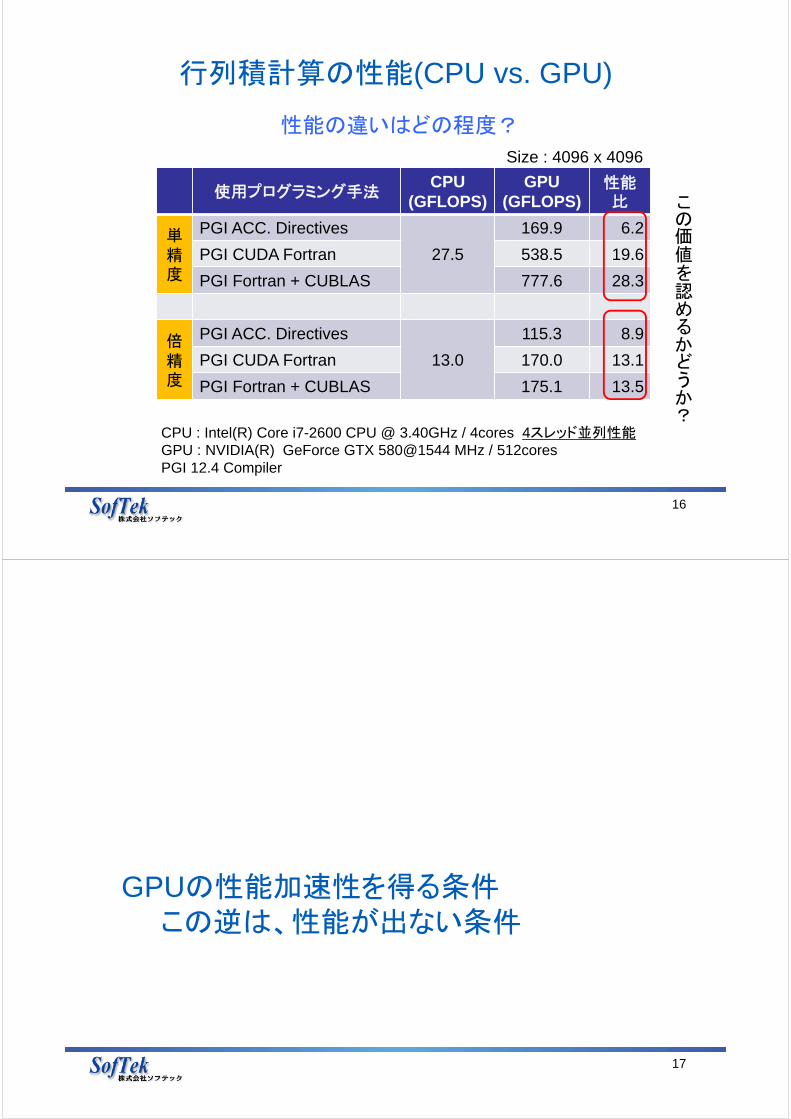
行列積計算の性能(CPU vs. GPU)
16
使用プログラミング手法CPU
(GFLOPS)GPU
(GFLOPS)性能比
単精度
PGI ACC. Directives
27.5
169.9 6.2
PGI CUDA Fortran 538.5 19.6
PGI Fortran + CUBLAS 777.6 28.3
倍精度
PGI ACC. Directives
13.0
115.3 8.9
PGI CUDA Fortran 170.0 13.1
PGI Fortran + CUBLAS 175.1 13.5
Size : 4096 x 4096
CPU : Intel(R) Core i7-2600 CPU @ 3.40GHz / 4cores 4スレッド並列性能GPU : NVIDIA(R) GeForce GTX 580@1544 MHz / 512coresPGI 12.4 Compiler
性能の違いはどの程度?
この価値を認めるかどうか?
GPUの性能加速性を得る条件この逆は、性能が出ない条件
17
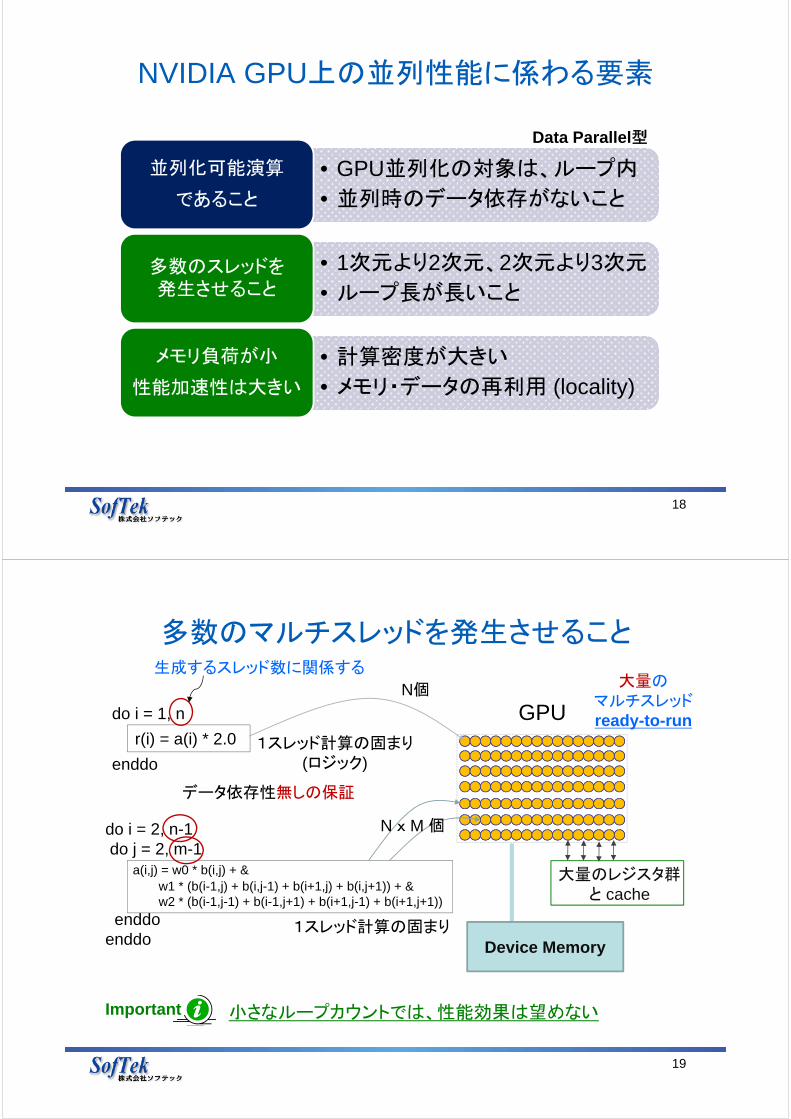
NVIDIA GPU上の並列性能に係わる要素
18
• GPU並列化の対象は、ループ内
• 並列時のデータ依存がないこと
並列化可能演算
であること
• 1次元より2次元、2次元より3次元
• ループ長が長いこと多数のスレッドを発生させること
• 計算密度が大きい
• メモリ・データの再利用 (locality)
メモリ負荷が小
性能加速性は大きい
Data Parallel型
多数のマルチスレッドを発生させること
19
GPU
Device Memory
大量のレジスタ群と cache
do i = 1, n
r(i) = a(i) * 2.0
enddo
do i = 2, n-1do j = 2, m-1
a(i,j) = w0 * b(i,j) + &w1 * (b(i-1,j) + b(i,j-1) + b(i+1,j) + b(i,j+1)) + &w2 * (b(i-1,j-1) + b(i-1,j+1) + b(i+1,j-1) + b(i+1,j+1))
enddoenddo
1スレッド計算の固まり(ロジック)
データ依存性無しの保証
生成するスレッド数に関係する
1スレッド計算の固まり
大量のマルチスレッドready-to-run
Important 小さなループカウントでは、性能効果は望めない
N個
N x M 個

GPU/CPUの演算時間比較
20
do i = 1, n
r(i) = sin(a(i)) ** 2 + cos(a(i)) ** 2
enddo
do i = 2, n-1do j = 2, m-1
a(i,j) = w0 * b(i,j) + &w1 * (b(i-1,j) + b(i,j-1) + b(i+1,j) + b(i,j+1)) + &w2 * (b(i-1,j-1) + b(i-1,j+1) + b(i+1,j-1) + b(i+1,j+1))
enddoenddo
Important GPU上での処理には、CPU~GPU間のデータ転送時間も含まれる(Overhead)
N GPU CPU
1000 286 22
10000 324 216
100000 658 1588
N / M GPU CPU
100 51806 65
1000 53544 7540
10000 531075 897902
ループ長 マイクロ秒
生成スレッド数少ない
Core i7 GTX580
GPU上での性能加速性
21
500~1500 coresGPU
~160GB/sメモリ
演算コア
メモリアクセスの負荷が小さいと
自由に動けるスレッド(コア)が十二分にある
8コア程度のマルチコアのレベルとは違う
一方、メモリバウンドな特性の場合は、
3.8~8倍Important「CPUのメモリ帯域」 対 「GPUメモリ帯域」比で性能加速性が支配される
Latency200~600cycle
性能の勘所

「演算密度」 (Computational Intensity)
22
C.I.が小さい程、メモリバウンドな特性を帯びる。実効メモリ帯域が「性能」を支配する。
浮動小数点演算数
メモリアクセス数
do i = 1, na(i) = b(i) + c(i)
end do
ループ内の「演算数」と「メモリのロード・ストア数」との比率を表し、演算とメモリ参照のバランスを見るための指標
演算 1回メモリアクセス 3回
C.I. = 0.333
C.I. =
演算器が遊ぶ
Computation Intensity for GPU
23
( 292) do loop=1,nn( 293) gosa= 0.0( 294) do k=2,kmax-1( 295) do j=2,jmax-1( 296) do i=2,imax-1( 297) s0=a(I,J,K,1)*p(I+1,J,K) &( 298) +a(I,J,K,2)*p(I,J+1,K) &( 299) +a(I,J,K,3)*p(I,J,K+1) &( 300) +b(I,J,K,1)*(p(I+1,J+1,K)-p(I+1,J-1,K) &( 301) -p(I-1,J+1,K)+p(I-1,J-1,K)) &( 302) +b(I,J,K,2)*(p(I,J+1,K+1)-p(I,J-1,K+1) &( 303) -p(I,J+1,K-1)+p(I,J-1,K-1)) &( 304) +b(I,J,K,3)*(p(I+1,J,K+1)-p(I-1,J,K+1) &( 305) -p(I+1,J,K-1)+p(I-1,J,K-1)) &( 306) +c(I,J,K,1)*p(I-1,J,K) &( 307) +c(I,J,K,2)*p(I,J-1,K) &( 308) +c(I,J,K,3)*p(I,J,K-1)+wrk1(I,J,K)( 309) ss=(s0*a(I,J,K,4)-p(I,J,K))*bnd(I,J,K)( 310) GOSA=GOSA+SS*SS( 311) wrk2(I,J,K)=p(I,J,K)+OMEGA *SS( 312) enddo( 313) enddo( 314) enddo
~/Himeno> pgf90 -fast -Minfo=intensity himenoBMTxp.f90jacobi:
292, Intensity = [symbolic], and not printable, try the -Mpfi -Mpfo options294, Intensity = [symbolic], and not printable, try the -Mpfi -Mpfo options295, Intensity = [symbolic], and not printable, try the -Mpfi -Mpfo options
296, Intensity = 1.06
~/Himeno> pgf90 -fast -Minfo=intensity himenoBMTxp.f90 -Mpfojacobi:
292, Intensity = 12.37294, Intensity = 1.06295, Intensity = 1.06296, Intensity = 1.06
GPUの場合は、C.I.が大きい程、性能加速率は高くなる
姫野ベンチマークの場合
C.I. < 1.0 ???
C.I. > 2.0 大きい程良い
Important
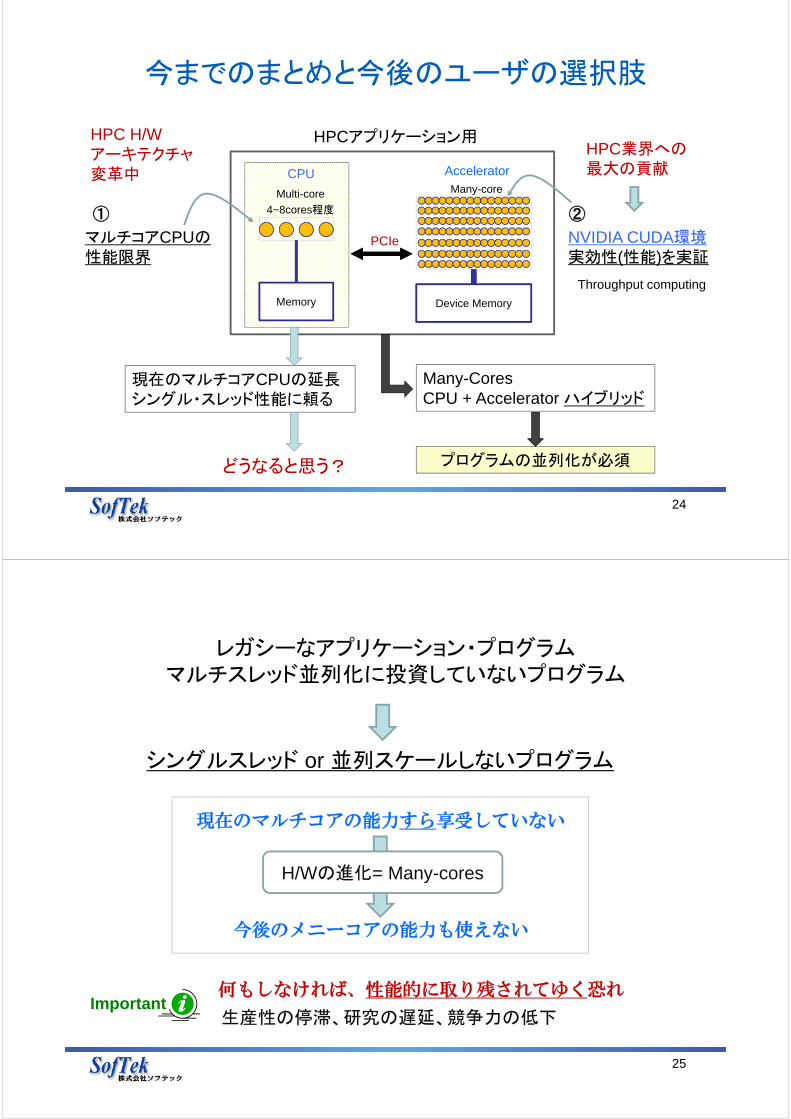
今までのまとめと今後のユーザの選択肢
24
Many-Cores CPU + Accelerator ハイブリッド
現在のマルチコアCPUの延長シングル・スレッド性能に頼る
4~8cores程度
AcceleratorCPU
Memory Device Memory
PCIe
Multi-core Many-core
NVIDIA CUDA環境実効性(性能)を実証
HPC業界への最大の貢献
HPCアプリケーション用
マルチコアCPUの性能限界
① ②
HPC H/Wアーキテクチャ変革中
プログラムの並列化が必須どうなると思う?
Throughput computing
25
レガシーなアプリケーション・プログラムマルチスレッド並列化に投資していないプログラム
シングルスレッド or 並列スケールしないプログラム
現在のマルチコアの能力すら享受していない
何もしなければ、性能的に取り残されてゆく恐れ
今後のメニーコアの能力も使えない
生産性の停滞、研究の遅延、競争力の低下
H/Wの進化= Many-cores
Important

並列プログラミングの話
26
プログラミング方法を知る
今後のプログラミングの方向性
27
Re-compile and Runで性能が出せる“genericなツール”は存在しない
明示的に並列化を行い、プログラムの再構築が必須
• データパラレル(ループレベル並列性)OpenMP/OpenACC, CUDA
• タスクパラレル(大きな仕事の固まりを分配実行)MPI
どうであれ、プログラムの「並列化」がどうしても必要
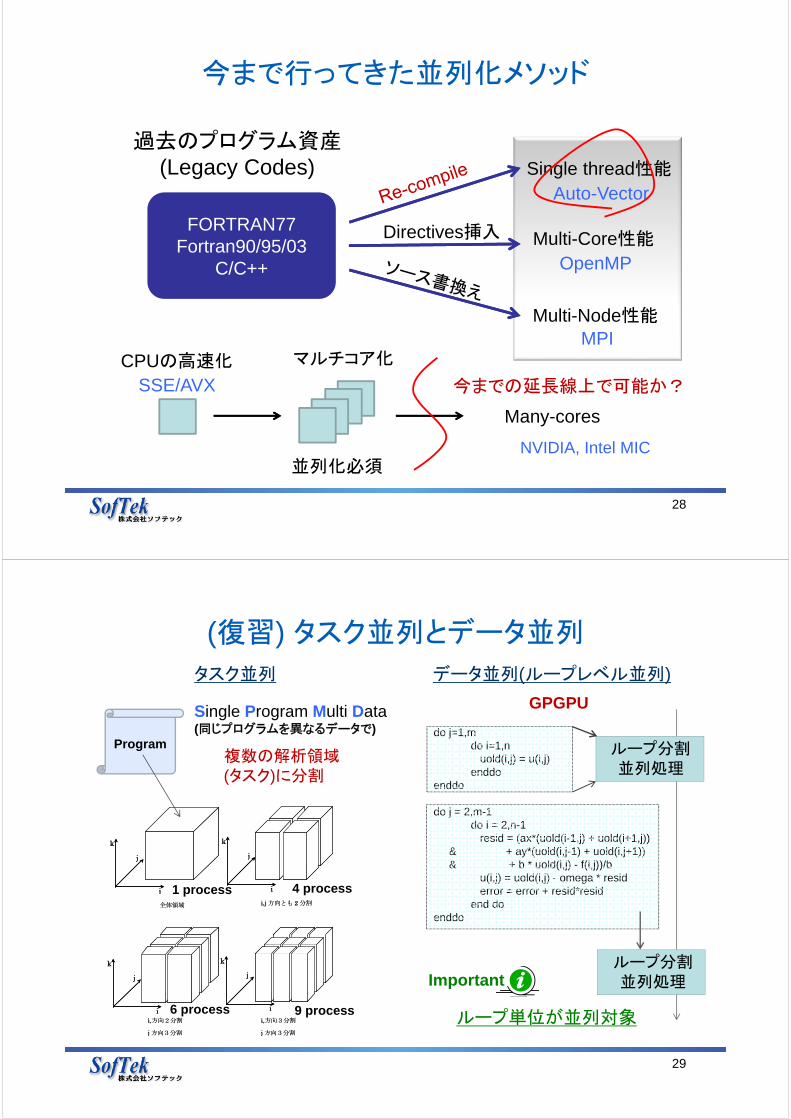
今まで行ってきた並列化メソッド
28
過去のプログラム資産(Legacy Codes)
FORTRAN77Fortran90/95/03
C/C++
Directives挿入
Single thread性能
Multi-Core性能
Multi-Node性能
Auto-Vector
OpenMP
MPICPUの高速化
SSE/AVX
マルチコア化
Many-cores
NVIDIA, Intel MIC並列化必須
今までの延長線上で可能か?
(復習) タスク並列とデータ並列
29
k
j
i
全体領域 i,j方向とも 2分割
i,方向2分割
j方向3分割
i,方向3分割
j方向3分割
k
j
i
k
j
i
k
j
i
k
j
i
全体領域 i,j方向とも 2分割
i,方向2分割
j方向3分割
i,方向3分割
j方向3分割
k
j
i
k
j
i
k
j
i
Single Program Multi Data(同じプログラムを異なるデータで)
Program複数の解析領域(タスク)に分割
1 process 4 process
6 process 9 process
do j=1,mdo i=1,n
uold(i,j) = u(i,j)enddo
enddo
do j = 2,m-1do i = 2,n-1
resid = (ax*(uold(i-1,j) + uold(i+1,j))& + ay*(uold(i,j-1) + uold(i,j+1))& + b * uold(i,j) - f(i,j))/b
u(i,j) = uold(i,j) - omega * residerror = error + resid*resid
end doenddo
タスク並列 データ並列(ループレベル並列)
ループ分割並列処理
ループ分割並列処理
GPGPU
Important
ループ単位が並列対象

並列化を行うまでの手間 - MPI -
30
FORTRAN77(Legacy)
Include 文で変数・配列の取り込み配列サイズの指定COMMON文
共通配列の指定
1. 配列サイズを自由に変更できるようにDynamic Allocation 型の配列へ変更
2. Moduleを活用し、COMMON化
1. 解析空間を領域分割するロジック追加
2. 各領域用の配列演算を「相対アドレス」で実行可能になるように変更
3. DOループ・インデックスを「相対アドレス」添字に変更
4. 並列実行時にデータ依存性が存在する部分を回避する
5. 袖との通信のためにMPIルーチン追加
Fortran90/95
分割対象の配列を使用するルーチンの全てを「変更」する必要がある
段階的なポーティングができず
---- param.inc file --------parameter n=1000,m=500common /array/ a(n,m),b(n,m),c(n,m)--------------------------------
program maininclude “param.inc”..do j=,1,ndo i=1,n( .... )
end dodnd do
①
②
並列化を行うまでの手間OpenMP(ディレクティブ型)
31
FORTRAN77(Legacy)
Include 文で変数・配列の取り込み配列サイズの指定COMMON文
共通配列の指定
1. 配列サイズを自由に変更できるようにDynamic Allocation 型の配列へ変更
2. Moduleを活用し、COMMON化
1. スレッド並列の対象となるループを探すホットスポットを調べる(プロファイル)
2. Doループ内に、並列計算上の依存性がないかを調べる
3. 並列実行したいループに並列化ヒント(ディレクティブ)を挿入する
4. テスト&修正&並列化範囲を広げる
Fortran90/95
ソースに大きな変更がほとんどない
段階的なポーティングが可能
①
②①
---- param.inc file --------parameter n=1000,m=500common /array/ a(n,m),b(n,m),c(n,m)--------------------------------
program maininclude “param.inc”#pragma omp parallel for do j=,1,ndo i=1,n( .... )
end dodnd do
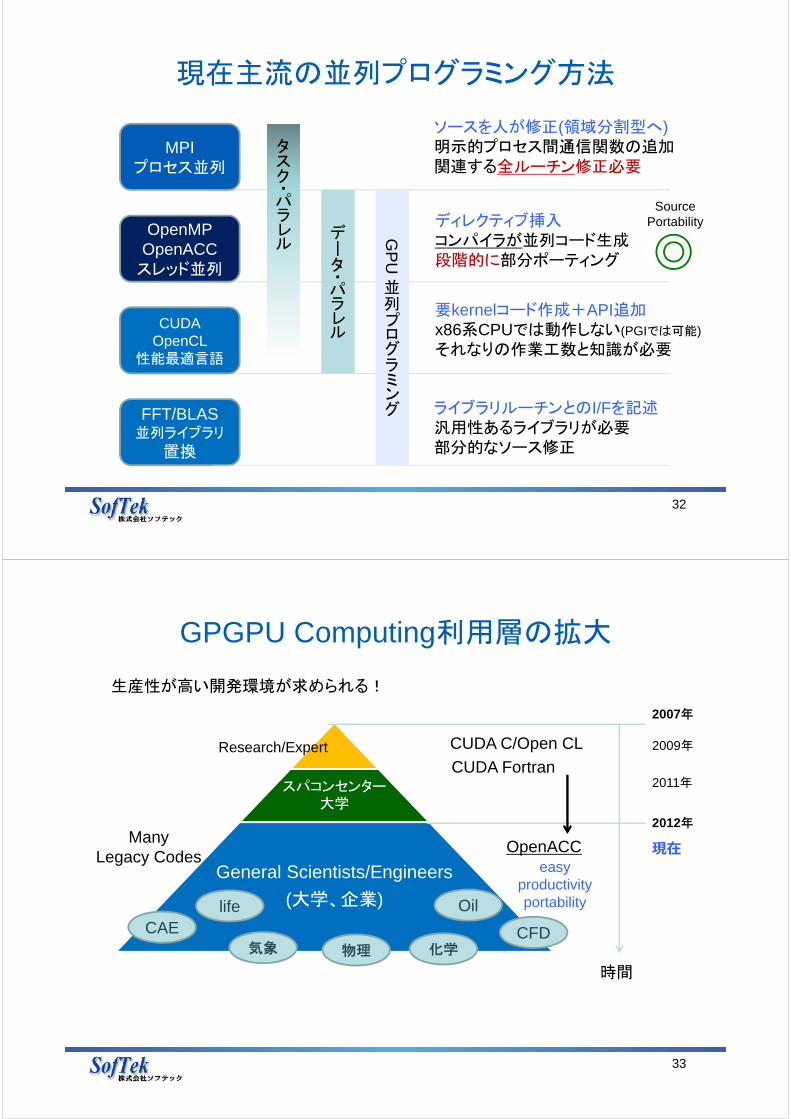
現在主流の並列プログラミング方法
32
MPIプロセス並列
OpenMPOpenACC
スレッド並列
FFT/BLAS並列ライブラリ
置換
CUDAOpenCL
性能最適言語
ディレクティブ挿入コンパイラが並列コード生成段階的に部分ポーティング
ソースを人が修正(領域分割型へ)明示的プロセス間通信関数の追加関連する全ルーチン修正必要
タスク・パラレル
データ・パラレル
要kernelコード作成+API追加x86系CPUでは動作しない(PGIでは可能)
それなりの作業工数と知識が必要
ライブラリルーチンとのI/Fを記述汎用性あるライブラリが必要部分的なソース修正
SourcePortability
GP
U
並列プログラミング
GPGPU Computing利用層の拡大
33
スパコンセンター大学
General Scientists/Engineers
(大学、企業)
Research/Expert
CAE CFD化学物理気象
Oillife
CUDA C/Open CL
ManyLegacy Codes
時間
現在
2009年
2012年
2011年
2007年
easyproductivityportability
OpenACC
CUDA Fortran
生産性が高い開発環境が求められる!

Scientist, Engineerにとっての並列化手法
34
1. 手間暇をあまり掛けずに、それなりの性能を!2. 新しいH/W技術革新があっても、以下のことが大事
• 「プログラムソース資産」の可搬性(ポータビリティ)• 「性能」の可搬性
計算機科学の専門家ではない既存のレガシーコードが多い!
MPI明示的プロセス並列
OpenMPディレクティブ・ベース
1. 1.2. 2.
この20年間で最も成功したプログラミングモデル
CUDA C/Fortranは、開発コストが掛かる!
(生産性) (生産性)(ポータブル性) (ポータブル性)
GPU Accelerator用にもディレクティブ・ベース
35
1. 手間暇をあまり掛けずに、それなりの性能を!• CPU/GPUメモリ帯域性能比の 3~8倍程度が妥当
2. 「プログラムソース資産」の可搬性• ディレクティブは「コメント行扱い」、ソースは変化せず• OpenACC標準化で、「性能」の可搬性あり
3. 段階的ポーティング可能
PGI Accelerator Programming Model (directiveベース)
CUDA GPGPU対応PGI アクセラレータコンパイラ製品
2010年リリース、2年以上の実装実績
CAPS HMPP Workbench
GPUプログラムをポータブルかつ高生産性に! OpenACC Standard

OpenACC Standardとは
36
2012/3/27ディレクティブ・ベース(ソース上に指示行を挿入する形態)
GPU用Programmingfor Fortran/C/C++
(2011年11月)
PGI Accelerator Directivesをベースとして策定された
OpenACCコンパイラPGI ベータリリース中
OpenMPの取組
37
2012/3/27アナウンス
OpenACC
OpenMP 4.0 新バージョン
知見妥当性確認反映
(2012年)
取り込み
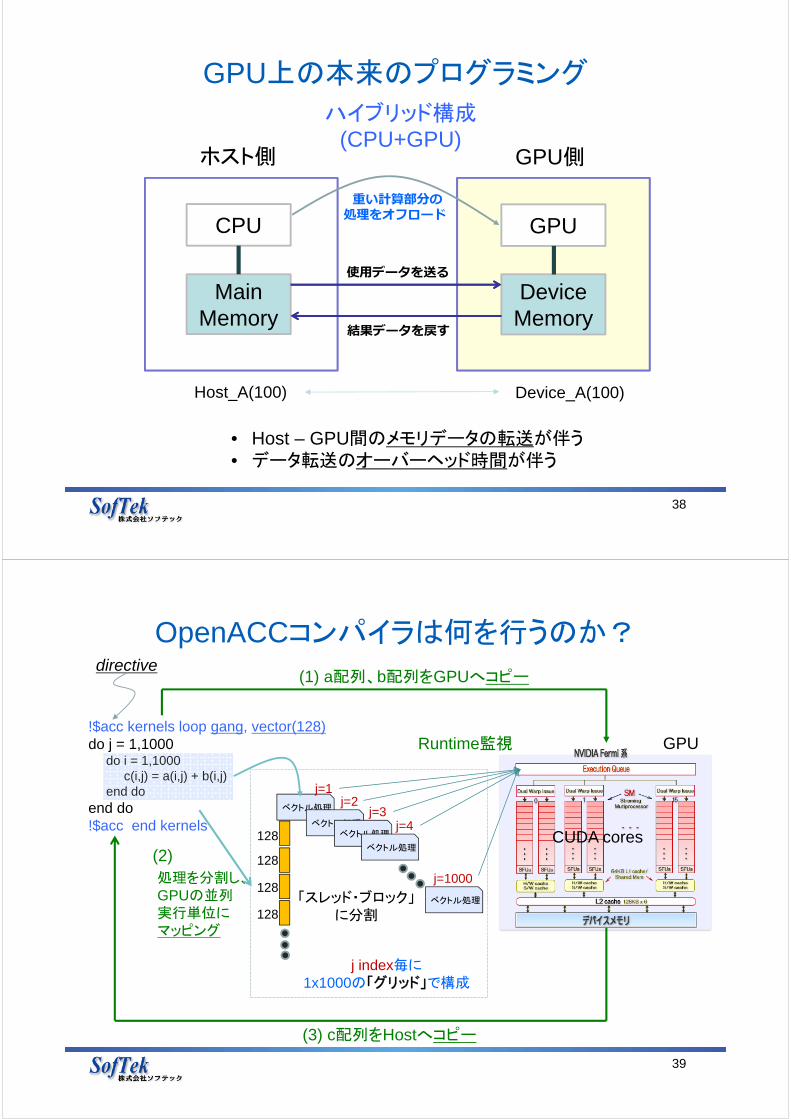
GPU上の本来のプログラミング
38
CPU
MainMemory
GPU
DeviceMemory
使用データを送る
ホスト側 GPU側
• Host – GPU間のメモリデータの転送が伴う• データ転送のオーバーヘッド時間が伴う
ハイブリッド構成(CPU+GPU)
重い計算部分の処理をオフロード
Host_A(100) Device_A(100)
結果データを戻す
!$acc kernels loop gang, vector(128)do j = 1,1000
do i = 1,1000c(i,j) = a(i,j) + b(i,j)
end doend do!$acc end kernels
OpenACCコンパイラは何を行うのか?
39
j=1
ベクトル処理j=2
ベクトル処理j=3
ベクトル処理j=4
ベクトル処理
j=1000
ベクトル処理
j index毎に1x1000の「グリッド」で構成
CUDA cores
「スレッド・ブロック」に分割
128
128
128
128
GPURuntime監視
(1) a配列、b配列をGPUへコピー
処理を分割し、GPUの並列実行単位にマッピング
(3) c配列をHostへコピー
(2)
directive
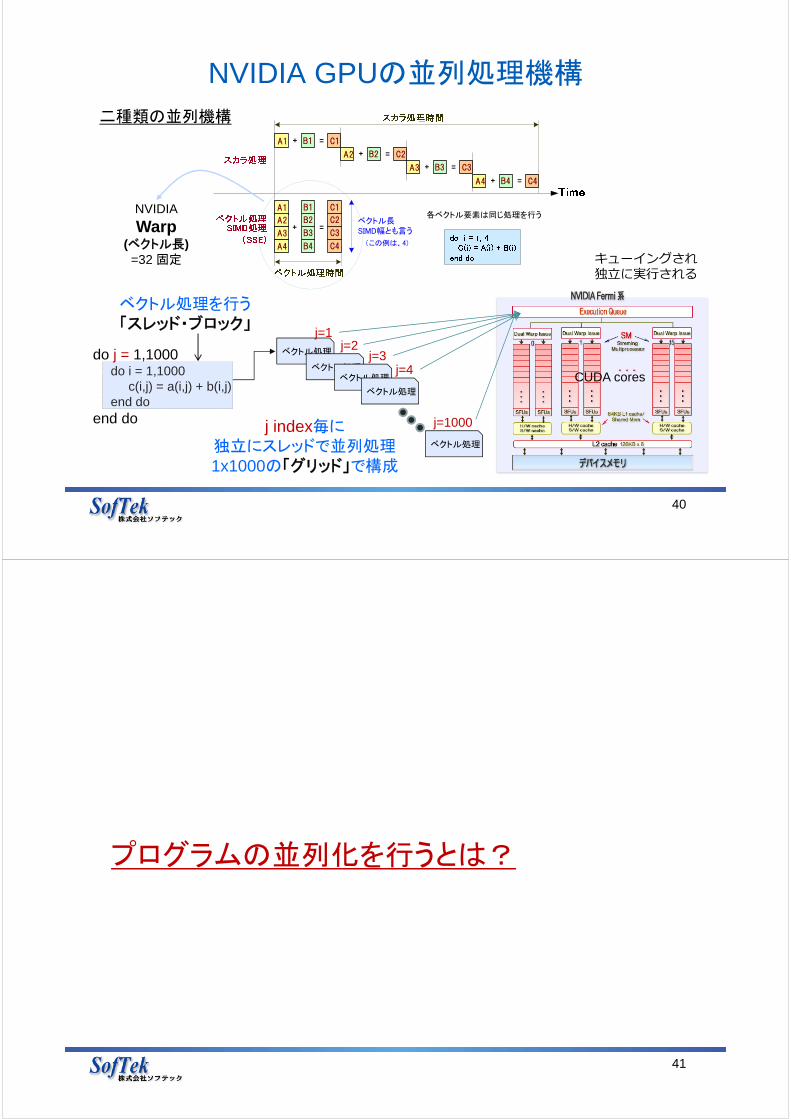
NVIDIA GPUの並列処理機構
40
do j = 1,1000do i = 1,1000
c(i,j) = a(i,j) + b(i,j)end do
end do
j=1
ベクトル処理j=2
ベクトル処理j=3
ベクトル処理j=4
ベクトル処理
j=1000
ベクトル処理
j index毎に独立にスレッドで並列処理1x1000の「グリッド」で構成
CUDA cores
ベクトル処理を行う「スレッド・ブロック」
ベクトル長SIMD幅とも言う
A1 + =B1 C1
A2 + =B2 C2
A3 + =B3 C3
A4 + =B4 C4
+
A1
A2
A3
A4
B1
B2
B3
B4
C1
C2
C3
C4
=
( 、 ) この例は 4
各ベクトル要素は同じ処理を行うNVIDIA
Warp(ベクトル長)
=32 固定 キューイングされ独⽴に実⾏される
二種類の並列機構
41
プログラムの並列化を行うとは?

ループレベルで並列化すると言うこと(1)
42
Q. 並列化可能とは?
MPI並列化、OpenMP並列化、ベクトル化が可能であると言うことになる
計算の順番に結果が依存しないこと
for( i = 0; i < n; i++ ) {A[i] = A[i-1] + B[i];
}
for( i = 0; i < n; i++ ) {A[i] = A[i] + B[i];
}
i 添字に関する順序で
“同じ”配列で定義~参照関係があるとき依存性の検討要
並列化○ 並列化×
回帰参照という
ループ内配列に依存性がなければ
ループレベルで並列化すると言うこと(2)
43
Q. 並列化を行うとは?
コンパイラが並列コードを生成する
ループ内の依存性を排除するように変更
#pragma omp parallel for for( i = 0; i < n; i++ ) {
A[i] = A[i] + B[i];}
Q. ディレクティブベースで並列化を行うとは?
ループの前に“ヒント”(ディレクティブ)を挿入する
#pragma acc kernels loopfor( i = 0; i < n; i++ ) {
A[i] = A[i] + B[i];}
OpenMP OpenACC
マルチコア用並列コード Accelerator(GPU)用並列コード

ディレクティブベースでないと辛い場面
44
do k = 2,nz-1km = k-1k0 = kkp = k+1do j=2,ny-1
jp=j+1j0=jjm=j-1do i=2,nx-1
ip=i+1i0=iim=i-1gxxc = lgxx(i0,j0,k0)gxyc = lgxy(i0,j0,k0)gxzc = lgxz(i0,j0,k0)gyyc = lgyy(i0,j0,k0)gyzc = lgyz(i0,j0,k0)gzzc = lgzz(i0,j0,k0)kxxc = 1.5D0*ADM_kxx_stag_p(i,j,k)
& -0.5D0*ADM_kxx_stag_p_p(i,j,k)kxyc = 1.5D0*ADM_kxy_stag_p(i,j,k)
& -0.5D0*ADM_kxy_stag_p_p(i,j,k)kxzc = 1.5D0*ADM_kxz_stag_p(i,j,k)
& -0.5D0*ADM_kxz_stag_p_p(i,j,k)kyyc = 1.5D0*ADM_kyy_stag_p(i,j,k)
& -0.5D0*ADM_kyy_stag_p_p(i,j,k)kyzc = 1.5D0*ADM_kyz_stag_p(i,j,k)
& -0.5D0*ADM_kyz_stag_p_p(i,j,k)kzzc = 1.5D0*ADM_kzz_stag_p(i,j,k)
& -0.5D0*ADM_kzz_stag_p_p(i,j,k)
detg_tempxx = gyyc*gzzc-gyzc*gyzcdetg_tempxy = gxzc*gyzc-gxyc*gzzcdetg_tempxz = -gxzc*gyyc+gxyc*gyzcdetg_tempyy = gxxc*gzzc-gxzc*gxzcdetg_tempyz = gxyc*gxzc-gxxc*gyzcdetg_tempzz = gxxc*gyyc-gxyc*gxycdetg_detcg = (detg_tempxx*gxxc+
& detg_tempxy*gxyc+detg_tempxz*gxzc)detg_detg = detg_psi4**3*detg_detcguppermet_fdet = 1d0/(detg_psi4*detg_detcg)uppermet_uxx = detg_tempxx*uppermet_fdetuppermet_uxy = detg_tempxy*uppermet_fdetuppermet_uxz = detg_tempxz*uppermet_fdetuppermet_uyy = detg_tempyy*uppermet_fdetuppermet_uyz = detg_tempyz*uppermet_fdetuppermet_uzz = detg_tempzz*uppermet_fdetfac = idx2*dxdg_psi4delgb111 = i2dx*(lgxx(ip,j0,k0)-lgxx(im,j0,k0))
dda_dzzda = idz2*(lalp(i0,j0,kp)-2D0*lalp(i0,j0,k0)+& lalp(i0,j0,km))
cdcda_cdzzda = (dda_dzzda-gamma133*da_dxda-gamma233*& da_dyda-gamma333*da_dzda)
dkdt_dkzzdt = lalp(i0,j0,k0)*(ricci_R33-2*KK33+kzzc& *trk_trK)-cdcda_cdzzda
ADM_kzz_stag(i,j,k) = ADM_kzz_stag_p(i,j,k)+& dkdt_dkzzdt*dt
end doend do
end do
----- さらに、500行位続く (省略) ------
例えば、600ステップ位のdoループをCUDA Fortran/C言語で書き換えることは大変な労力が必要
!$acc kernels loop gang, vector(128)
5x in 5 Hours: Porting a 3D Elastic Wave Simulator to GPUs Using PGI Accelerator
45
by Mathew Colgrove, PGI Applications Engineer
VersionMPI
ProcessesOpenMP Threads
GPUsExecution Time (sec)
Programming Time (min)
Original Host 2 4 0 951 -
ACC Step 2 2 - 2 3100 10
ACC Step 3 2 - 2 580 60
ACC Step 4 2 - 2 163 120
ACC Step 5 2 - 2 150 120
Problem Size: 101x641x128
System Information: 4 Core Intel Core-i7 920 Running at 2.67Ghz with 2 Tesla C2070 GPU
Compiler: PGI 2012 version 12.3
http://www.pgroup.com/lit/articles/insider/v4n1a3.htm
SEISMIC_CPML
x6.34
x1.00
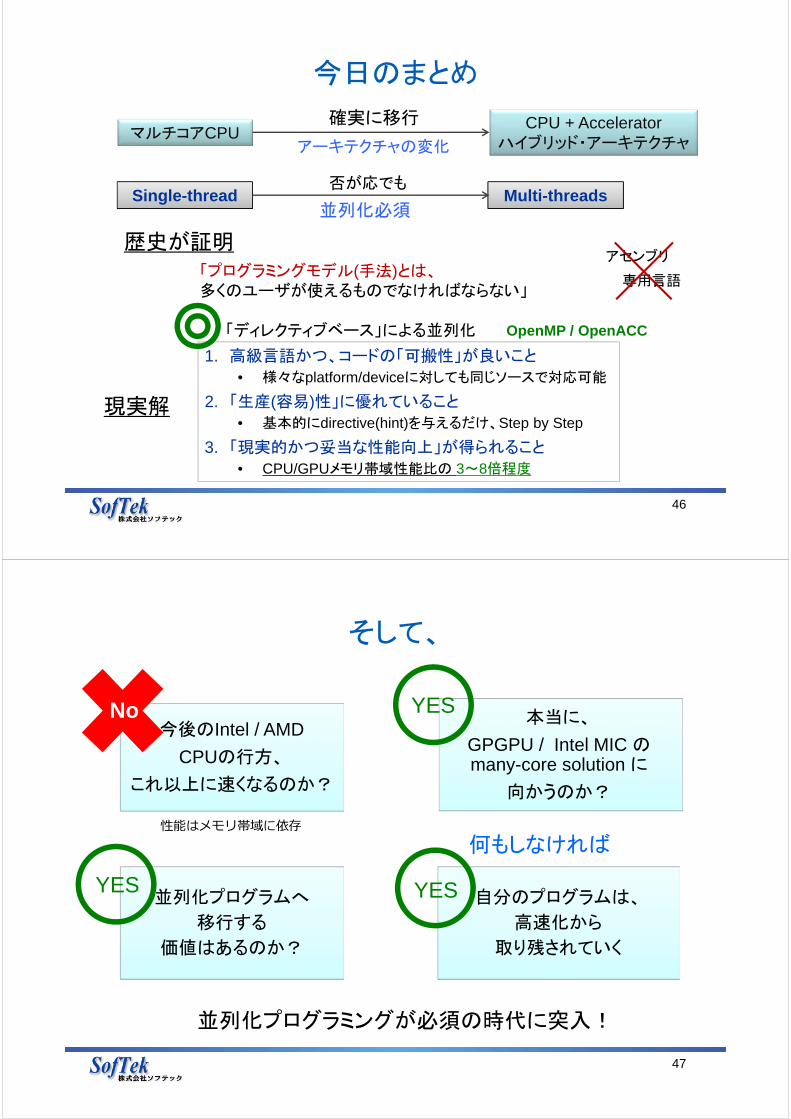
今日のまとめ
46
1. 高級言語かつ、コードの「可搬性」が良いこと
• 様々なplatform/deviceに対しても同じソースで対応可能
2. 「生産(容易)性」に優れていること
• 基本的にdirective(hint)を与えるだけ、Step by Step
3. 「現実的かつ妥当な性能向上」が得られること
• CPU/GPUメモリ帯域性能比の 3~8倍程度
現実解
CPU + Acceleratorハイブリッド・アーキテクチャ
「プログラミングモデル(手法)とは、多くのユーザが使えるものでなければならない」
マルチコアCPU確実に移行
アーキテクチャの変化
Single-thread Multi-threads否が応でも
歴史が証明アセンブリ
専用言語
並列化必須
「ディレクティブベース」による並列化 OpenMP / OpenACC
そして、
47
今後のIntel / AMD
CPUの行方、
これ以上に速くなるのか?
自分のプログラムは、
高速化から
取り残されていく
並列化プログラムへ
移行する
価値はあるのか?
本当に、
GPGPU / Intel MIC のmany-core solution に
向かうのか?
何もしなければ
YES
YESYES
No
並列化プログラミングが必須の時代に突入!
性能はメモリ帯域に依存

Copyright 2012 SofTek Systems Inc. All Rights Reserved.
48
本ドキュメントに記述された各製品名は、各社の商標または登録商標です。