Embed Size (px)
Citation preview
ISSN 1851-1317
CURSOS DE GRADO
Fascıculo3
Gabriel Larotonda
CALCULO Y AN ALISIS
ANALISIS
ANALISISNUMERICO
CALCULO
CALCULO
DIFERENCIAL
f ≃ ax+b
Polinomiode Taylor
∑n anxn
CALCULO
INTEGRAL
∫f ≃
∑ f (xi )∆i
Vol(Ω)
∫ ∫Ω
F dΩ
ANALISISCOMPLEJO
ANALISISREAL
DEPARTAMENTO DEMATEMATICA
FACULTAD DE CIENCIAS EXACTAS Y NATURALES
UNIVERSIDAD DE BUENOSA IRES
2010

Cursos de Grado
Fascıculo 3
Comite Editorial:
Carlos Cabrelli (Director).Departamento de Matematica, FCEyN, Universidad de Buenos Aires.E-mail: [email protected]
Guillermo Cortinas.Departamento de Matematica, FCEyN, Universidad de Buenos Aires.E-mail: [email protected]
Claudia Lederman.Departamento de Matematica, FCEyN, Universidad de Buenos Aires.E-mail: [email protected]
Auxiliar editorial:
Leandro Vendramin.Departamento de Matematica, FCEyN, Universidad de Buenos Aires.E-mail: [email protected]
ISSN 1851-1317(Version Electronica)ISSN 1851-1295(Version Impresa)
Derechos reservados© 2010 Departamento de Matematica, Facultad de Ciencias Exactas y Naturales,
Universidad de Buenos Aires.Departamento de MatematicaFacultad de Ciencias Exactas y NaturalesUniversidad de Buenos AiresCiudad Universitaria - Pabellon I(1428) Ciudad de Buenos AiresArgentina.http://www.dm.uba.are-mail:[email protected]/fax: (+54-11)-4576-3335

III
Este libro nacio como unas notas para un curso de Analisis,y de a poco se fue convir-tiendo en algo mas que unas notas. Trate de conservar un estilo coloquial, sumado alrigor de definiciones y teoremas, sin evitar ningun tema, a´un aquellos que suelen tener(inmerecida) fama de intratables. Pienso que todos los temas que aquı se estudian sonaccesibles para un estudiante que haya hecho un curso de calculo en una variable real,y otro de algebra lineal, si se abordan de la manera adecuada. En lo posible intente evi-tar el uso de coordenadas, y aunque en muchos casos es necesario volver a ellas paradar un sentido concreto a las ideas geometricas, puede decirse que en general, conmodificaciones menores, las pruebas se adaptan a un contextomas amplio. Esa fuemi intencion al preparar las clases, y es la intencion de este libro: hacer accesiblestemas sutiles del analisis y el calculo en una y varias variables reales, y vincular estostemas de manera intrınseca con la geometrıa del espacio, sin permitir que el uso decoordenadas oscurezca esta relacion.
Si bien el libro contiene problemas que surgen naturalmentea lo largo de la presenta-cion de los temas, estos no suplen una verdadera practica donde los conceptos se traba-jen a partir de ejemplos progresivamente mas sofisticados.En este caso, las practicasde la materia Analisis I (dictada por el Departamento de Matematica de la Facultadde Ciencias Exactas y Naturales de la Universidad de Buenos Aires) son el comple-mento ideal para estas notas, que fueron pensadas con estas practicas en la mano. Sepuede acceder a las mismas a traves de la pagina delDepartamento de Matematica,cms.dm.uba.ar.
Agradecimientos:
A Sam por su entusiasmo y apoyo constante, a mis hijos por darle color a losgrises.
A Cristian Conde por hacer de editor y corrector en las sombras, en forma to-talmente desinteresada.
A Pablo Groisman porque cuando solo habıa unas notas en borrador, me hizonotar que las notas podıan tener algun valor para los alumnos.

IV

Es supersticiosa y vana la costumbre de buscarsentido en los libros, equiparable a buscarlo enlos suenos o en las lıneas caoticas de las manos.
J. L. BORGES
En este libro queremos estudiar problemas que involucren varias variables o incognitas, todas ellas nume-ros reales. Como aprendimos en cursos de calculo elementales, lo mas practico es darle nombre a las varia-bles y despues pensar cuales son las funciones que modelanel problema; estas funciones van a depender deesas variables. Es la estrategia de “nombrar y conquistar”.
Por ejemplo, si queremos saber que formadebe que tener un terreno rectangular dearea 100m2, para gastar la menor cantidadde alambre en su borde, al perımetro lo lla-mamosP, el areaA, y llamamosb a la basedel rectangulo ya a su altura.
a
b
A= 100m2
Se tieneA = b.a = 100 y por otro ladoP = 2a+ 2b. Despejando de la ecuacion del area nos queda unaecuacion en una sola variable,P(a) = 2a+ 2.100
a . Entonces aparece una funcionP, de variable reala, ala cual le buscamos el mınimo. Es importante entender el dominio de la funcion, que esa > 0. Por otrolado, para buscarle el mınimo, ¿que hacemos? Simplemente le buscamos los extremos locales aP. ¡Y paraeso hace falta calcular la derivada deP! Hagamoslo: se tieneP′(a) = 2− 2100
a2 . Igualando a cero se tienea2 = 100, y comoa debe ser un numero positivo,a= 10, y en consecuenciab= 10. Es decir el terreno debeser cuadrado.
Vemos como para resolver un problema muy simple, aparecen herramientas que no son “obvias”. Enprimer lugar la nocion de dominio, que requiere entender unpoco el conjunto de los numeros reales. Ensegundo lugar, la nocion de derivada, que si la pensamos un poquito era pensar en las rectas tangentes algrafico deP, que a su vez se obtenıan como lımite de rectas secantes. S´ı, aparecio el lımite. Y todo paraprobar que el terrenito era cuadrado.
En la proxima figura se representa el grafico de una funcionP, y una recta secante al grafico en el punto
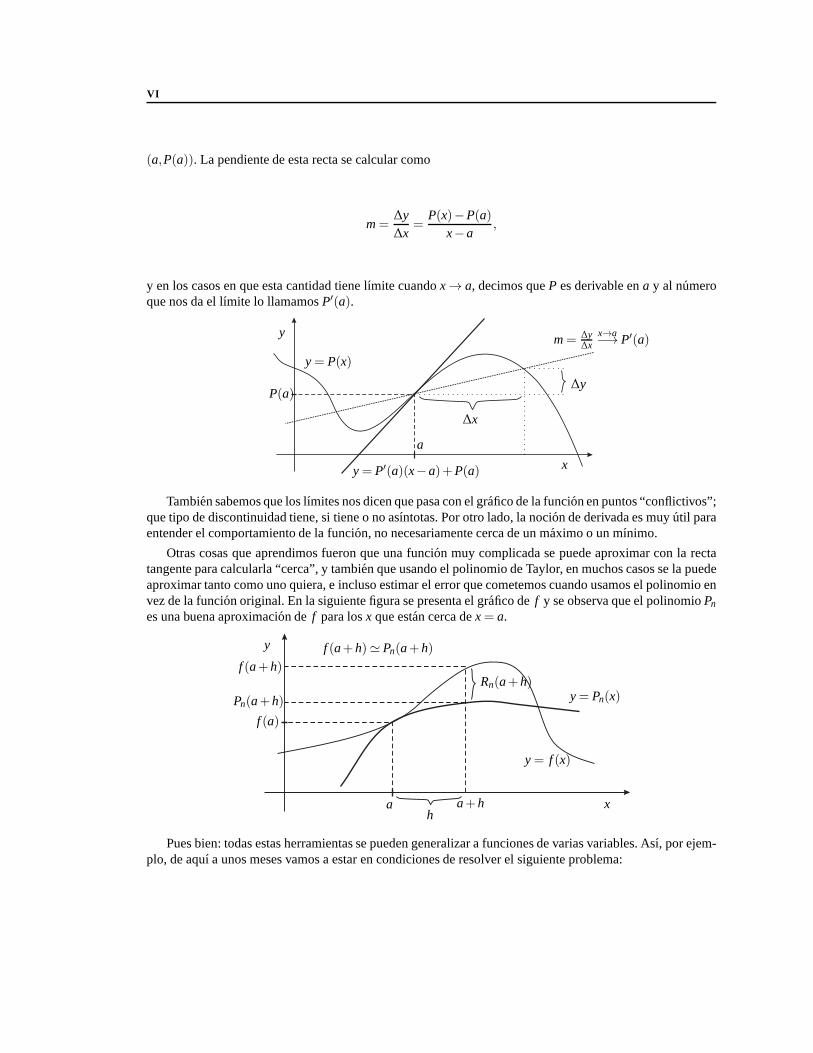
VI
(a,P(a)). La pendiente de esta recta se calcular como
m=∆y∆x
=P(x)−P(a)
x−a,
y en los casos en que esta cantidad tiene lımite cuandox→ a, decimos queP es derivable ena y al numeroque nos da el lımite lo llamamosP′(a).
y
xy= P′(a)(x−a)+P(a)
y= P(x)
a
P(a)
∆x
∆y
m= ∆y∆x
x→a−→ P′(a)
Tambien sabemos que los lımites nos dicen que pasa con el grafico de la funcion en puntos “conflictivos”;que tipo de discontinuidad tiene, si tiene o no asıntotas. Por otro lado, la nocion de derivada es muy util paraentender el comportamiento de la funcion, no necesariamente cerca de un maximo o un mınimo.
Otras cosas que aprendimos fueron que una funcion muy complicada se puede aproximar con la rectatangente para calcularla “cerca”, y tambien que usando el polinomio de Taylor, en muchos casos se la puedeaproximar tanto como uno quiera, e incluso estimar el error que cometemos cuando usamos el polinomio envez de la funcion original. En la siguiente figura se presenta el grafico def y se observa que el polinomioPn
es una buena aproximacion def para losx que estan cerca dex= a.
y
x
f (a+h)
Pn(a+h)
ah
Rn(a+h)
a+h
y= f (x)
y= Pn(x)
f (a)
f (a+h)≃ Pn(a+h)
Pues bien: todas estas herramientas se pueden generalizar afunciones de varias variables. Ası, por ejem-plo, de aquı a unos meses vamos a estar en condiciones de resolver el siguiente problema:

Notar que, en el problema que aquı se presenta,hay demasiadas variables (y pocas ecuaciones)como para intentar el truco de despejar y llevartodo el problema a una sola variable. Volveremosa este problema en el Capıtulo 5, cuando dispon-gamos de otras herramientas. Mientras tanto, in-vitamos al lector a resolverlo usando argumentosde simetrıa en las variablesa, l , p que lo modelan.
Queremos armar una caja rectan-gular, tal que la suma del ancho,el largo y la profundidad de lacaja no excedan los tres metros(a+ l + p≤ 300cm). ¿Cual es elmaximo volumen que puede tenerla caja, y cuales seran sus dimen-siones?
Por el camino, van a surgir ideas, herramientas y ejemplos que tienen valor por sı mismos, y que nosolamente van a servir para resolver problemas de maximos ymınimos como el de arriba. Van a surgirproblemas que en principio solo tienen que ver con la formulacion de estas definiciones, es decir, problemasintrınsecos de la matematica. ¡Comencemos!

VIII

Indice general IX
1. Calculo enRn 1
1.1. Numeros reales. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1.1. Axiomas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.1.2. Sucesiones. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.2. El espacio como n-uplas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.2.1. Distancia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
1.2.2. Producto escalar. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
1.2.3. Entornos y conjuntos abiertos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
1.2.4. Lımites enRn . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
1.2.5. Puntos de acumulacion y conjuntos cerrados. . . . . . . . . . . . . . . . . . . . . 24
1.2.6. Conjuntos acotados. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
1.3. Problemas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2. Funciones 31
2.1. Dominio, grafico, imagen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
2.1.1. Funcionesf : Rn →R . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
2.1.2. Curvas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.1.3. Grafico, curvas y superficies de nivel. . . . . . . . . . . . . . . . . . . . . . . . . 33
2.1.4. Lımite. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
2.2. FuncionesF : Rn → Rm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
2.2.1. Composicion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
2.2.2. Curvas y el lımite. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
2.2.3. Lımite y sucesiones. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
2.3. Continuidad. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
2.3.1. Propiedades de las funciones continuas. . . . . . . . . . . . . . . . . . . . . . . . 45
2.3.2. Caracterizacion de las funciones continuas. . . . . . . . . . . . . . . . . . . . . . 48

X INDICE GENERAL
2.3.3. Continuidad uniforme. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
2.4. Problemas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
3. Derivadas y Diferencial 51
3.1. Derivadas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
3.1.1. Curvas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
3.1.2. Derivadas direccionales. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
3.1.3. Derivadas parciales. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
3.2. Plano tangente y Diferencial. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
3.2.1. Unicidad de la diferencial. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
3.2.2. Algebra de funciones diferenciables. . . . . . . . . . . . . . . . . . . . . . . . . . 67
3.2.3. Repaso de los teoremas en una variable. . . . . . . . . . . . . . . . . . . . . . . . 70
3.2.4. Criterio de diferenciabilidad. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
3.2.5. FuncionesF : Rn →Rm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
3.3. Teoremas de Lagrange y Fermat enRn . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
3.4. NOTAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
4. Funcion inversa e implıcita 85
4.1. Funcion Inversa. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
4.1.1. Funciones de claseCk . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
4.1.2. Transformaciones lineales. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
4.2. Superficies de nivel y funciones implıcitas. . . . . . . . . . . . . . . . . . . . . . . . . . . 93
4.2.1. Funcion implıcita enRn . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
4.3. NOTAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
5. Taylor y extremos 107
5.1. Polinomio de Taylor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
5.1.1. Varias variables. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
5.1.2. Demostracion alternativa de la formula de Taylor de orden 2 enRn . . . . . . . . . . 115
5.2. Extremos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
5.2.1. Formas cuadraticas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
5.2.2. El Hessiano y los extremos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
5.3. Extremos con restricciones, multiplicadores de Lagrange . . . . . . . . . . . . . . . . . . . 127
5.3.1. Extremos en una region. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
5.3.2. Extremos en regiones con borde que se puede parametrizar . . . . . . . . . . . . . . 127
5.3.3. Multiplicadores de Lagrange. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
5.3.4. Multiplicadores enR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131

INDICE GENERAL XI
5.3.5. Un ejemplo elemental. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132
5.3.6. Varias ligaduras. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
6. Integrales enR 135
6.1. Integrales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
6.1.1. Propiedades. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141
6.2. Integrales impropias. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 146
6.2.1. Intervalos infinitos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 148
6.2.2. Convergencia condicional y absoluta. . . . . . . . . . . . . . . . . . . . . . . . . . 149
6.2.3. Criterios de comparacion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 150
6.3. NOTAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 157
7. Integrales multiples 159
7.1. Integrales en el plano. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
7.1.1. Rectangulos y particiones. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
7.1.2. Integral de Riemann. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162
7.1.3. Integrales iteradas y el Teorema de Fubini. . . . . . . . . . . . . . . . . . . . . . . 166
7.2. Integrales enR3 y Rn . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172
7.3. Propiedades. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 177
7.3.1. Medida de una region y Teorema del valor medio. . . . . . . . . . . . . . . . . . . 178
7.4. NOTAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 180
8. Teorema de cambio de variables 183
8.1. El metodo de sustitucion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183
8.2. Particiones generales. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183
8.3. Transformaciones lineales. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185
8.4. Cambio de variable. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 187
8.4.1. Cambio de variable enR3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193
Bibliografıa 201

XII INDICE GENERAL

¡No soy un numero! ¡Soy un hombre libre!
El Prisionero
1.1. Numeros reales
Lo primero que notamos en la charla del prefacio, es que es relevante entender como es el dominio deuna funcion, que es un subconjunto deR; y si vamos a hablar de lımites y derivadas, es bueno entender unpoco mejor los numeros reales.
Observacion 1.1.1. ¿Que es un numero real? Esta pregunta inocente es mas difıcil de contestar de lo queparece. Una primer aproximacion intuitiva (o que aprendimos en la escuela) nos dice que es el conjunto delos numeros que ocupan la recta numerica, es decir, hay una correspondencia entre los numeros reales y loselementos de la recta.
R
0
Pero esto trae otras preguntas, como por ejemplo que es una recta y si todas las rectas son iguales o almenos equivalentes en algun sentido, y como es la tal correspondencia. Esto no quiere decir que la idea latengamos que descartar, ¡por el contrario! esta idea es fundamental para poder imaginar mentalmente losnumeros y los problemas que sobre ellos consideremos.
Si repasamos un poco lo aprendido, veremos que lo mas importante no es que son, sino que propiedadestienen. En realidad, desde un punto de vista mas formal, uno podrıa pensar que la pregunta ¿que son? secontesta haciendo una lista de las propiedades mas importantes, y viendo que si un conjunto cumple estaspropiedades entoncesesR. Pero ¿quien garantiza que hay algun conjunto que cumpla esas propiedades enabstracto? Si alguien dice ”el conjunto que las verifica esR”, pues yo le contestarıa ¡que no lo puede ponercomo ejemplo si todavıa no nos pusimos de acuerdo en que es un numero real!
Repasemos: los numeros naturalesN = 1,2,3, · · · son todos numeros reales. Los numeros enteros(que se obtienen tomando los inversos de los naturales respecto de la suma y agregando el neutro 0 de lasuma),Z = · · · ,−2,1,0,1,2,3, · · · son todos reales. Si uno considera cocientes de numeros enteros (algobastante natural al pensar en la division), obtiene los racionalesQ= p/q : p,q∈Z,q, 0.

2 Calculo enRn
Sabemos que con esto NO alcan-za. Por ejemplo en un triangulo decatetos unitarios, la hipotenusa esh =
√2, que no es ningun numero
racional.
1
1
h2 = 12+12 = 2
Esta ultima afirmacion requiere una prueba: supongamos que√
2 es racional. Entonces existenp,q numerosnaturales tales que
√2 = p/q. Vamos a suponer que cancelamos todos los factores posiblesde p y q de
manera que no tengan ningun factor comun. Elevando al cuadrado,
2=p2
q2 ,
o equivalentemente2q2 = p2.
Ahora pensemos cuantas veces aparece el factor 2 en la factorizacion dep2. Como p2 = p · p, el factor2 aparece un numero par de veces en la factorizacion dep2, pues aparece el doble de veces que en lafactorizacion dep. En el caso en el que no aparece (o sea sip es impar) esta afirmacion sigue siendo ciertapues vamos a adoptar la convencion de que 0 es un numero par (pues se puede escribir como 0= 2 · 0).Entonces a la derecha de la igualdad, tenemos un numero par de factores 2. El mismo razonamiento aplicadoa q2 nos dice que a la izquierda el factor 2 aparece un numero impar de veces. Esto es imposible, lo queprueba que
√2 no es racional.
Todo numero real que no es racional se denominairracional, y al conjunto de numeros irracionales se losuele denotar con la letraI. Se tienen las obvias inclusiones estrictas
N⊂Z⊂Q⊂ R.
Observacion 1.1.2. Como curiosidad, los irracionales tambien se pueden clasificar como algebraicos otrascendentes. Los primeros son los que son ceros de polinomios con coeficientes enteros, por ejemplo
√2
es algebraico puesto que es raız del polinomio p(x) = x2−2. Ejemplos de numeros trascendentes son e yπ. Por supuesto, ¡probar que estos numeros NO son algebraicos tampoco es elemental! Para una prueba asolo un clic puede verse la Wikipedia1 (en ingles).
1.1.1. Axiomas
Volvamos al asunto de las cosas que hacen queR seaR. Veamos primero los axiomas que hacen deR
un cuerpo ordenado. Esto es, propiedades que no se demuestran sino que se suponen validas.
1http://en.wikipedia.org/wiki/Transcendental_number

1.1 Numeros reales 3
Entre triviales y excesivamente abstractos para nuestra intuicion, son la base sobre la que se construyentodos los resultados del analisis.
Axiomas de la suma:
S1) Conmutatividad: sia,b∈ R, a+b= b+a.
S2) Asociatividad: sia,b,c∈ R, a+(b+ c) = (a+b)+ c.
S3) Elemento Neutro: existe y lo llamamos ”0”. Sia∈ R, a+0= a.
S1) Inverso Aditivo: sia∈R, existe un inverso aditivo, lo llamamos ”−a”, verifica a+(−a) = 0.
En general escribimosa−b en vez dea+(−b).
Axiomas del producto:
P1) Conmutatividad: sia,b∈ R, a.b= b.a.
P2) Asociatividad: sia,b,c∈ R, a.(b.c) = (a.b).c.
P3) Elemento Neutro: existe y lo llamamos ”1”. Sia∈ R, 1.a= a.
P4) Inverso Multiplicativo: sia ∈ R, a , 0, existe un inverso multiplicativo, lo llamamos ”a−1”, verificaa.a−1 = 1.
En general omitimos el punto, es decir escribimosa.b= ab. Tambien es usual escribir1a = a−1.
Propiedad distributiva:
D) Distributividad: sia,b,c∈ R, a(b+ c) = ab+ac.
Axiomas del orden:
O1) Tricotomıa: sia,b∈ R, hay solo tres posibilidades (excluyentes), que sona< b, a= b, a> b.
O2) Transitividad: sia,b,c∈ R son tales quea< b y b< c, entoncesa< c.

4 Calculo enRn
O3) Monotonıa de la suma: Sia,b,c∈ R son tales quea< b, entoncesa+ c< b+ c.
O4) Monotonıa del producto: sia,b,c∈ R, son tales quea< b y c> 0, entoncesac< bc.
En particular dados dos numeros reales distintossiempre hay un tercero en el medio, y siguien-do este razonamiento se ve que hay infinitos. Sia,b ∈ Q, el promedio esta enQ y entonces seve que hay infinitos racionales. Estos hechos losusaremos sin otra aclaracion.
Se tiene 0< 1 ¡justificarlo conlos axiomas! Se deduce facilmenteque sia< b, entonces el promediop= a+b
2 es un numero real tal quea< p< b.
Algo mas sutiles, son las pruebas de que entre dos reales siempre hay un racional, y de que entre dosracionales siempre hay un irracional, pruebas que dejaremos para el Corolario1.1.12.
Hasta aquı las propiedades que hacen deR un cuerpo ordenado. El problema es que no es el unico. Esdecir,Q cumple todos estos axiomas. Lo que falta es el axioma de completitud, es decir, ver que no hayagujeros enR, cuando por ejemplo si los hay enQ.
Intentamos formalizar un poco. ¿Esta claro que siA⊂R es no vacıo, y tiene un tope por encima, entoncespodemos buscar el tope mas chiquito? Pensarlo en la recta: indicamos al conjuntoA con lıneas mas gruesas
RA
cc optima
Un tope por encima es unacota superior. Es decir,
Definicion 1.1.3. Una cota superior es un numero real M tal que para todo a∈ A, se tiene a≤ M.
Si hay una cota superior, hay infinitas (cualquiera mas grande sirve). El asunto es encontrar la optima (lamas pequena). Esta se denominasupremodel conjuntoA, y se anota supA. Es decir,
Definicion 1.1.4. s∈ R es el supremo de A si para todo a∈ A, a≤ M y ademas si s′ es otra cota superior,s≤ s′.
Lo relevante, que hay que tener en cuenta en esta discusion es el axioma de completitud de los numerosreales, que dice que
Axioma. Si A⊂R es no vacıo, y esta acotado superiormente, entonces A tiene supremo s.
Se dice que ”R es completo en el orden”. Algo obvio:
Proposicion 1.1.5. El supremo de un conjunto esunico.

1.1 Numeros reales 5
Demostracion. Si hay otro,s′, se tiene por un lados′ ≤ s (puess es cota superior ys′ es la menor cotasuperior), y por otro lados≤ s′ (puess tambien es la menor cota superior).
Analogamente se definecota inferiore ınfimo,
Definicion 1.1.6. Una cota inferior es un numero real m tal que para todo a∈ A, se tiene a≥ m. El numeroi ∈R es elınfimo de A si para todo a∈ A, a≥ i y ademas si i′ es otra cota inferior, i≥ i′. Es decir elınfimoes la mas grande de las cotas inferiores, y tambien si existe esunico.
Definicion 1.1.7. Un conjunto A⊂ R se dice acotado si esta acotado tanto superiormente como inferior-mente.
El supremo (o el ınfimo) puede pertenecer o noal conjunto. Hagamos algunos ejemplos con cui-dado, por mas que parezcan obvios. Queda comoejercicio para el lector el siguiente problema, cu-yo resultado usaremos de aquı en mas:
Problema 1.1.8.Probar que sir ∈ R, r > 0 y r2 = 3, entoncesr <Q. Es decir, probar que
√3 es
irracional. Se sugiere ver laprueba de que
√2 no es racional.
Con este resultado a mano, podemos hallar el supremo del siguiente conjunto.
Ejemplo 1.1.9. Hallar el supremo s del conjunto A= x∈ R : x2 < 3.
El candidato ess=√
3. Notemos queses cota superior pues six∈ A, entoncesx2 < 3 implica|x|<√
3,luegox ≤ |x| <
√3. ¿Como probamos que es la menor? Por el absurdo: supongamos que hay otra cota
superior mas pequena, digamoss′ <√
3. Ahora entres′ y s hay al menos un numero reala (hay infinitos).Se tienea< s=
√3, luegoa2 < 3, es decira∈ A. Por otro lados′ < a, con lo cuals′ no serıa cota superior.
El absurdo proviene de suponer que hay otra cota superior mas pequena ques.
Observacion 1.1.10.Notar que si uno busca el supremo del conjunto A= x∈Q : x2 < 3, el supremo vaa ser nuevamente s=
√3, ¡que no es un numero racional! Esto nos dice que la propiedad de completitud
es inherente a los numeros reales. Es decir, hay subconjuntos deQ que estan acotados superiormente enQ,pero que NO tienen supremo enQ.
Demostremos mejor esta ultima observacion. Para ello necesitamos algunas herramientas tecnicas.
Proposicion 1.1.11.Arquimedianeidad o principio de Arquımedes:Si x es un numero real, entonces existen∈N tal quen> x. Permite comparar cualquier numero con un natural. Se puede deducir del axioma decompletitud.

6 Calculo enRn
Demostracion. Seax∈R, y consideremosX = k∈N : k≤ x. SiX = /0, en particular 1> x, luego se puedetomarn= 1. Si X no es vacıo, como esta acotado superiormente (porx), tiene un supremos= supX ∈ R.Comos−1 no puede ser cota superior deX (puess es la mas chica), debe existirk0 ∈ X tal ques−1< k0.Tomandon= k0+1 se tienen∈N y ademasn> s. Por esto ultimon< X, lo que nos dice quen> x.
Con esta herramienta podemos probar algo que todos sabemos que es cierto. En nuestra formacion inicialy media, aprendimos algunos hechos supuestamente utiles sin ninguna pista del por que de su validez (¡o elpor que de su relevancia!).
Corolario 1.1.12. Entre dos numeros reales distintos siempre hay un numero racional. Entre dos numerosreales distintos siempre hay un numero irracional.
Demostracion. Seana< b numeros reales (elegimos los nombres para que queden en eseorden, es decir,llamamosa al mas chico yb al mas grande). Entoncesb−a> 0, y en consecuencia1
b−a > 0. Existe por el
principio de Arquımedes un numero naturaln tal quen> 1b−a. Observemos que
nb= na+n(b−a)> na+1.
R
1
na na+1 nb
En consecuencia, tiene que existir un numero enterok entrenb y na. Es decir, existek ∈ Z tal quena< k< nb. Dividendo porn se obtienea< k
n < b, que nos dice quekn ∈Q esta entrea y b.
Ahora veamos que entre dos numeros reales siempre hay un irracional. Vamos a volver a suponer quea< b. Multiplicando por 1√
2obtenemos1√
2a< 1√
2b. Por lo anterior existe un numero racionalk
n entre ellos,
es decir 1√2a< k
n < 1√2b. Multiplicando por
√2 se obtienea< k
n
√2< b. Afirmamos que este numero del
medio es irracional: si fuera racional, existirıanj,m enteros tales quekn√
2 = jm. Pero entonces
√2 = jn
mkserıa racional, lo cual es falso, como ya probamos.
Ejemplo 1.1.13.Sea A= x∈Q : x2 < 2 y x> 0. Entonces A⊂Q es no vacıo y esta acotado superiormenteenQ, pero no tiene supremo enQ.
Demostracion. Que es no vacıo es evidente pues 1∈ A. Por otro lado,C = 2 ∈ Q es una cota superior deA pues six ∈ A entoncesx2 < 2< 4, con lo cual|x| < 2, y comox es positivo, se tienex < 2. Por ultimo,supongamos que existes∈Q tal ques= supA. Es decir,ses una cota superior, y es la mas pequena de ellas.Hay tres posibilidades: la primeras=
√2 es imposible pues
√2 no es racional. La segunda es ques<
√2 (
y podemos suponers≥ 1 pues 1∈ A). Pero si tomamosr un numero racional tal ques< r <√
2, llegamos aun absurdo pues elevando al cuadrado obtenemosr2 < 2, y comor es positivo (por ser mayor ques), se tiener ∈ A. Esto contradice queses cota superior deA. La ultima posibilidad ess>
√s. Pero entonces volvemos
a elegirt ∈Q tal que√
s< t < s, y este numero es una cota superior deA enQ mas pequena ques, lo cuales imposible.

1.1 Numeros reales 7
Corolario 1.1.14. El cuerpoQ no es completo en el orden (no verifica el axioma de completitud).
Ejemplo 1.1.15. Hallar el supremo s del conjunto A= 1− 1n : n∈N. ¿s∈ A?
Aquı el candidato natural ess= 1 (que NO es un elemento deA). Es una cota superior pues 1− 1n ≤ 1 para
todon natural. Falta ver que es la menor. De nuevo: si hubiera otra cota superior, digamoss′ < 1, tomemosn0 ∈ N tal quen0 >
11−s′ que siempre se puede por el principio de Arquımedes. Entonces despejando se
obtienes′ < 1− 1n0
lo que contradice ques′ sea cota superior.
Observacion 1.1.16.Puede probarse que si A es conjunto que es un cuerpo ordenado (cumple los axiomasde arriba S,P,D,O), y A es completo en el orden, entonces A ESR (o mas bien se lo puede identificar conRrespetando las operaciones y el orden)2.
Algo que quedo en el tintero y que no vamos a tratar aquı, es como se pueden construir (si, construir apartir de los numeros racionales) los numeros reales, para de esa forma estar seguros de que hay un conjuntoque verifica todo lo que queremos. ¡Recordemos que nunca dijimos quien esR! Hay varias maneras de haceresta construccion, por ejemplo usando cortaduras de Dedekind o sucesiones de Cauchy; el lector insaciablecon acceso a Internet puede leer sobre estas construccionesen la Wikipedia3, aunque hay otras fuentes enpapel mejor escritas de donde leerlo, como por ejemplo, el libro de Birkhoff-McLane deAlgebra [1].
Volvamos al supremo de un conjuntoA⊂ R. Una caracterizacion util es la siguiente, en terminos de ε(algo habitual en las definiciones de lımite)
Proposicion 1.1.17.s es el supremo de A si y solo si
1. s≥ a para todo a∈ A
2. dadoε > 0, existe a∈ A tal que s− ε < a.
R
ε = s− s′
sa∈ As′ = s− ε
Demostracion. Empecemos con la definicion vieja, entonces obviamente se cumple 1). Por otro lado, dadoε > 0, se tienens− ε < s y esto nos dice ques− ε no es cota superior deA (recordemos ques era la maschica). O sea, existe alguna∈ A tal ques− ε < a, lo cual prueba 2).
Si partimos de esta definicion, tenemos que probar que unsque verifica 1) y 2) es el supremo. Claramentes es cota superior, falta probar que es la mas chica. Si hubiera una cota superior mas chica, digamoss′,entonces tomamosε = s− s′ > 0 y llegamos a un absurdo pues 2) nos dice que existea∈ A tal ques− (s−s′)< a, es decir,s′ < a lo que contradice ques′ es cota superior.
2http://planetmath.org/?op=getobj&from=objects&id=56073http://en.wikipedia.org/wiki/Construction_of_real_numbers

8 Calculo enRn
Analogamente, se tiene el siguiente resultado que deja-mos como ejercicio al lector.
¿Que se puede decir de un conjuntoA ⊂ R tal queınf(A) = sup(A)?
¿Y si B ⊂ R es tal que ınf(A) ≤ ınf(B) y sup(B) ≤sup(B)?
Problema 1.1.18.i es elınfimo de A si y solo si
1. i ≤ a para todo a∈ A
2. dadoε > 0, existe a∈ Atal que i+ ε > a.
1.1.2. Sucesiones
Una sucesion se puede pensar como un cierto conjunto de numeros reales, ordenado de alguna manera.Mas precisamente, es una funcions :N→R, que en general se anotasn en vez des(n). Es decir, si ponemossn = 1/n, lo que queremos nombrar es la sucesion cuyos primeros terminos son 1, 1
2,13,
14, · · · y ası sucesi-
vamente. Es importante observar que no es lo mismo que la sucesion 1, 13,
12,
15,
14, · · · (en otro orden). Estas
sucesiones tienen todos sus terminos distintos. Pero estono tiene por que ser ası. Por ejemplo
1,2,1,2,1,2, · · ·
toma solo dos valores distintos, y como caso extremo
3,3,3,3,3,3, · · ·
es una sucesion que se denominasucesion constante. Las sucesiones son utiles para describir problemasde aproximacion. Ası, si quiero descubrir que pasa con 1/x cuandox tiende a infinito, basta mirar algunosterminos como 1;110 = 0,1; 1
100 = 0,01 para descubrir que tiende a cero.
Definicion 1.1.19. Se dice que una sucesion an tiende al numero l cuando n→ ∞, si dadoε > 0 existen0 ∈N tal que si n≥ n0, entonces|an− l |< ε. En ese caso escribimos
lımn→∞
an = l o bien ann→∞−→ l .
Es decir quean tiende al si todos los terminos dean estan tan cerca del como uno quiera a partir de untermino dado. Recordemos que|an− l |< ε quiere decir
l − ε < an < l + ε,
como se indica en la figura:
R
εε
lan an+1an+p l + εl − ε

1.1 Numeros reales 9
La condicion de que todos los terminos de la su-cesion esten suficientemente cerca del lımite apartir de unn0 se simplifica cuando sabemosapriori que todos los terminos estan a un lado deuna constante dada. Dejamos el siguiente proble-ma que pone de manifiesto esta simplificacion.
Problema 1.1.20.Si an ≤ lpara todo n∈N, para probarque lım
n→∞an = l basta probar que
l −an < ε. Analogamente, sian ≥ l, basta probar quean− l < ε.
Para una exposicion mas detallada (pero todavıa elemental) sobre sucesiones, puede verse el libro deNoriega [5], o la guıa de Analisis del CBC de la UBA. Nosotros vamos a irdirectamente a lo que nosinteresa, que para empezar es una caracterizacion del supremo.
Definicion 1.1.21.Recordemos que una sucesion es creciente si
a1 ≤ a2 ≤ a3 ≤ ·· · ,
y estrictamente creciente si
a1 < a2 < a3 < · · · .
Analogamente se define sucesion decreciente y estrictamente decreciente. Una sucesion se dice monotona sies creciente o decreciente, y estrictamente monotona si es estrictamente creciente o decreciente.
Como vimos, todo conjunto no vacıoA⊂ R, si esta acotado superiormente, tiene supremo. Se tiene elsiguiente resultado util que relaciona el supremo con las sucesiones:
Proposicion 1.1.22. Si s= supA, entonces existe una sucesion crecientean de elementos de A tal quean
n→∞−→ s. Si s< A, se puede elegir an estrictamente creciente.
Demostracion. Si s∈ A, basta tomaran = s la sucesion constante (que es creciente). Si no, tomamos algunelementoa1 ∈ A, y ponemosa1 := a1. Ahora consideramosa2 =
a1+s2 el promedio, que es un numero menor
estrictamente menor ques. Existe entonces algun elementoa2 ∈ A tal quea2 < a2 < s (sino a2 serıa cotasuperior deA, lo cual es imposible puesa2 < s).
Ası vamos definiendoan como el promedioan−1+s2 , y tomamos comoan cualquier elemento deA que
esta entrean y s. Ciertamentean es creciente puesan > an > an−1, y por otro lado 0< s− an <s−an−1
2 .Luego, repitiendo esta acotacion se consigue bajar hastaa1, y por cada vez que bajamos, aparece un numero2 dividiendo, con lo cual obtenemos.
0< s−an <s−an−1
2< · · ·< s−a1
2n−1 .
Esto ultimo prueba que lımn→∞
an = s, usando la definicion de lımite, puess−a1 esta fijo.

10 Calculo enRn
Dejamos como ejercicio para el lector, un resulta-do analogo para el ınfimo de un conjunto. Recor-dar que es clave verificar quetodos los terminosan de la sucesion deben ser elementos del conjun-to A.
Problema 1.1.23.Si i= ınfA,entonces existe una sucesiondecrecientean de elementosde A tal que an → i. Si i < A,se puede elegir anestrictamente decreciente.
Subsucesiones
Una herramienta extremadamente util son las subsucesiones. Recordemos que son simplemente unaeleccion de un subconjunto de la sucesion original, provisto del mismo orden que tenıa la sucesion original.Ası por ejemplo, sian =
1n, una subsucesion esbk =
12k , es decir, tomamos
14,16,18, · · ·
que son algunos de los terminos de la sucesion original. Para dar mas precision a esta idea, recordemos queuna sucesion es simplemente una funcions : N→R.
Definicion 1.1.24.Sea a:N→R una sucesion. Una subsucesion de a es una nueva sucesion b:N→R quese puede construir a partir de la original de la siguiente manera: existe una funcion estrictamente crecientej : N→N tal que para todo k∈N, b(k) = a j(k). Mas coloquialmente: si
a1,a2, · · · ,an, · · ·
es una sucesion, entonces una subsucesionank dean es una sucesion de la forma
an1,an2, · · · ,ank, · · ·
donde n1 < n2 < · · ·< nk < · · · .
Observacion 1.1.25.Se puede seguir esta idea un paso mas: una subsucesion de una subsucesion se defineen forma analoga. Pero si lo pensamos un poco, nos hemos quedado con un conjunto aun mas reducidode la sucesion original, y losındices deben seguir siendo estrictamente crecientes. Luego una subsucesionde una subsucesion dean no es mas que otra subsucesion de la sucesion original an (y si todavıa noconseguı marearlos es porque lo dije muy despacito).
Una consecuencia de la Proposicion1.1.22, es que toda sucesion creciente y acotada tiene lımite, elcualcoincide con el supremo:
Proposicion 1.1.26. Si an es una sucesion creciente (an+1 ≥ an ≥ ·· · ≥ a1) y acotada superiormente,entonces si s= supan, se tienelım
n→∞an = s.

1.1 Numeros reales 11
Demostracion. Consideremos el conjunto de puntos que forma la sucesion, es decirA = an Por la Pro-posicion1.1.22, existe una sucesion dentro deA que es creciente y tiende as= supA. Pero esto es lo quellamamos una subsucesion, es decir la nueva sucesion consta de algunos de los elementos dean, y la ano-tamosank. En consecuencia, dadoε > 0, existek0 tal quek ≥ k0 implica s−ank < ε. Tomandon0 = nk0
se observa que sin≥ n0, entonces por seran creciente se tiene
s−an ≤ s−an0 = s−ank0< ε,
que es lo que querıamos probar.
Se tiene un resultado analogo con el ınfimo de una su-cesion decreciente y acotada inferiormente, cuya pruebauna vez mas queda como ejercicio.
Proposicion 1.1.27.Si an esuna sucesion decreciente(an+1 ≤ an ≤ ·· · ≤ a1) yacotada inferiormente,entonces si i= ınfan, setiene lım
n→∞an = i.
Volvamos a pensar en sucesiones que no son monotonas.
Hay algo bastante evidente: si una sucesion no esta acotada (por ejemplo, no esta acotada superiormen-te), entonces podemos extraer de ella una subsucesion creciente. De la misma manera, si no esta acotadainferiormente, podemos extraer una sucesion decreciente.
Lo que sigue es un resultado clave que nos va a ser muy util mas adelante, que generaliza esta idea acualquier sucesionde numeros reales. Su demostracion es un tanto tecnica (paciencia).
Proposicion 1.1.28. Seaan una sucesion de numeros reales. Entonces existe una subsucesion ank dean que es monotona.
Demostracion. Para armar la subsucesion, nos interesan los terminos de la sucesion que son mas grandesque todos los terminos que les siguen, es decir, losan tales quean ≥ ak para todok≥ n. Los vamos a llamarterminosdominantes. Hay dos casos: hay infinitos terminos dominantes o hay finitos. Pensemos primero elcaso en el que la sucesion tiene infinitos terminos dominantes
an1,an2,an3, · · · conn1 < n2 < n3 < · · ·
Por ser todos dominantes,an1 ≥ an2 ≥ an3 ≥ ·· · . Hemos construido una subsucesion decreciente.
Veamos ahora el caso en el que hay finitos terminos dominantes (incluyendo la posibilidad de que nohaya ninguno). Por ser finitos, hay uno que es el ultimo (es decir, de allı en adelante ningun termino de la

12 Calculo enRn
sucesion es dominante). Tomemosan1 el primer termino de la sucesion que viene despues de esteultimodominante (si no hay ningun termino dominante en la sucesion tomamosn1 = 1). Existe entonces masadelante algunn2 > n1 tal quean2 > an1 (¡existe sinoan1 serıa dominante!). Ası siguiendo, vamos hallandonk > · · ·> n3 > n2 > n1 tales queank > · · ·> an3 > an2 > an1. En este caso hemos construido una subsucesioncreciente.
Se obtiene ası un corolario fundamental, que luego generalizaremos aRn.
Corolario 1.1.29(Bolzano-Weierstrass). Seaan una sucesion acotada de numeros reales. Entonces existeuna subsucesionank dean que es convergente.
Demostracion. Por la proposicion previa, podemos extraer dean una subsucesion monotona (que esta aco-tada por estar acotada la original). Por la Proposicion1.1.26, esta subsucesion tiene a su vez una subsucesionconvergente, que segun lo observado antes, no es mas que una subsucesion de la sucesion original.
Por ultimo recordemos que quiere decir que una sucesion “tiende a infinito”.
Definicion 1.1.30. Una sucesion an de numeros reales tiende a mas infinito si para todo M> 0 existen0 ∈N tal que n≥ n0 implica an > M. Lo anotamos
lımn→∞
an =+∞ o bien ann→∞−→ +∞.
Analogamente, decimos quelımn→∞
an =−∞ si para todo M< 0 existe n0 ∈N tal que n≥ n0 implica an < M.
Es decir que para cualquier cota que a mi se me ocurra, todos los terminos de la sucesion son mas grandesque esa cota a partir de unn0 (en el caso+∞).
1.2. El espacio como n-uplas
En esta seccion vamos a establecer las herramientas basicas para poder hablar de lımites enRn. Necesi-tamos recordar nociones de vectores, norma, producto interno y tambien extender la idea de entorno de unpunto deRn. Muchas de las primeras definiciones (las que involucran norma, distancia y producto interno)les van a resultar familiares, aunque algunas demostraciones de propiedades tal vez no las hayan visto antes.
Dadon∈N, unan-upla es una tira ordenada de numeros,
(x1,x2,x3, · · · ,xn),
no necesariamente distintos.

1.2 El espacio como n-uplas 13
El plano en el cual estamos acostumbra-dos a pensar lo podemos describir con 2-uplas (que en general llamamospares or-denados):
R2 = (x1,x2) : xi ∈R.
La primer coordenada la llamamosabcisay la segundaordenada. En un grafico lasrepresentamos en el eje horizontal y verti-cal respectivamente.
p1
p2P= (p1, p2)
x
y
Lo mismo ocurre con el espacioR3, al cual representamos usando tres ejes:
ab
c
z
(a,b,0)x y
P= (a,b,c)
1.2.1. Distancia
p1
p2P= (p1, p2)
x
y ¿Cual es la distancia de un puntoP= (p1, p2)al origen? Si observamos nuevamente la fi-gura del planoxy, se ha formado un triangu-lo rectangulo, con vertices en(0,0),(p1,0) y(p1, p2).
Por lo tantod =√
p21+ p2
2. En el caso general, la distancia deP= (p1, p2, · · · , pn) ∈ Rn al origen (queescribimos con un cero gordo,O ∈ Rn) esta dada por
d =√
p21+ p2
2+ · · ·+ p2n,
como puede observarse por ejemplo en el dibujo enR3 de arriba.
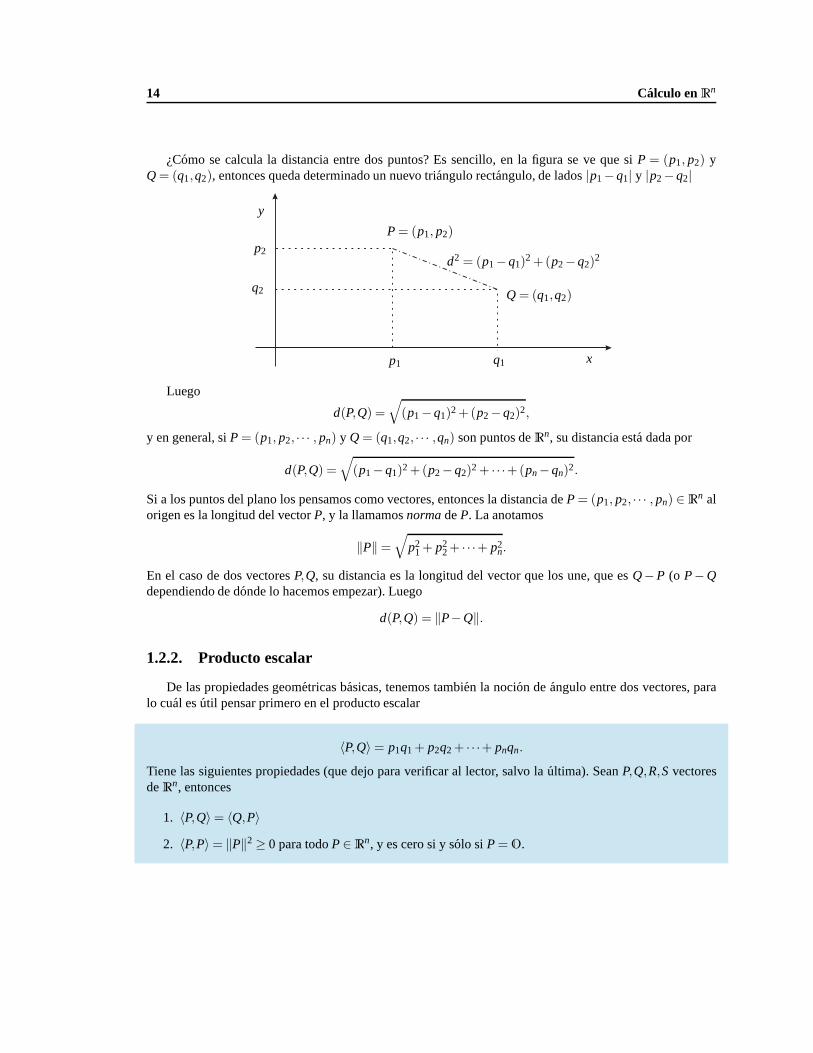
14 Calculo enRn
¿Como se calcula la distancia entre dos puntos? Es sencillo, en la figura se ve que siP = (p1, p2) yQ= (q1,q2), entonces queda determinado un nuevo triangulo rectangulo, de lados|p1−q1| y |p2−q2|
p1
p2
P= (p1, p2)
q1
q2 Q= (q1,q2)
x
d2 = (p1−q1)2+(p2−q2)
2
y
Luego
d(P,Q) =√
(p1−q1)2+(p2−q2)2,
y en general, siP= (p1, p2, · · · , pn) y Q= (q1,q2, · · · ,qn) son puntos deRn, su distancia esta dada por
d(P,Q) =√
(p1−q1)2+(p2−q2)2+ · · ·+(pn−qn)2.
Si a los puntos del plano los pensamos como vectores, entonces la distancia deP= (p1, p2, · · · , pn) ∈ Rn alorigen es la longitud del vectorP, y la llamamosnormadeP. La anotamos
‖P‖=√
p21+ p2
2+ · · ·+ p2n.
En el caso de dos vectoresP,Q, su distancia es la longitud del vector que los une, que esQ−P (o P−Qdependiendo de donde lo hacemos empezar). Luego
d(P,Q) = ‖P−Q‖.
1.2.2. Producto escalar
De las propiedades geometricas basicas, tenemos tambien la nocion de angulo entre dos vectores, paralo cual es util pensar primero en el producto escalar
〈P,Q〉= p1q1+ p2q2+ · · ·+ pnqn.
Tiene las siguientes propiedades (que dejo para verificar allector, salvo la ultima). SeanP,Q,R,S vectoresdeRn, entonces
1. 〈P,Q〉= 〈Q,P〉
2. 〈P,P〉= ‖P‖2 ≥ 0 para todoP∈ Rn, y es cero si y solo siP=O.

1.2 El espacio como n-uplas 15
3. 〈αP,βQ〉= αβ〈P,Q〉 para todo par de numerosα,β ∈ R.
4. 〈P+R,Q〉= 〈P,Q〉+ 〈R,Q〉.
5. |〈P,Q〉| ≤ ‖P‖‖Q‖ (desigualdad de Cauchy-Schwarz).
Demostracion. (de la desigualdad de C-S). Dadot ∈R, consideremos la funcion realg(t) = ‖P− tQ‖2. Porlas propiedades anteriores se tiene
‖P− tQ‖2 = 〈P− tQ,P− tQ〉= 〈P,P〉−2t〈P,Q〉+ t2〈Q,Q〉.
ComoP,Q estan fijos,g es un polinomio de grado 2,g(t) = at2+bt+ c dondea= ‖Q‖2, b= −2〈P,Q〉 yc = ‖P‖2. Por otro lado, comog(t) = ‖P− tQ‖2 ≥ 0, este polinomio tiene a lo sumo una raız real. Comoa≥ 0, debe tener discriminante no positivo, es decir, se debe cumplir b2−4ac≤ 0. Pero esto es
(2〈P,Q〉)2−4‖Q‖2‖P‖2 ≤ 0,
una expresion de la que se deduce facilmente la desigualdad deseada pasando el termino negativo a la derechay tomando raız cuadrada a ambos miembros.
Observacion 1.2.1. La igualdad en la desigualdad de C-S vale si y solo si P,Q estan alineados, es decirsi existeα ∈ R tal que P= αQ. En efecto, de la demostracion anterior se deduce que para que valga laigualdad el discriminante del polinomio g debe ser igual a cero. Pero en ese caso, el polinomio g tiene unaraız (doble), es decir existeα ∈ R tal que g(α) = ‖P−αQ‖2 = 0. En consecuencia debe ser P−αQ= O,puesto que la norma se anulaunicamente en el origen.
Volviendo al angulo entre dos vectores, como
−1≤ 〈P,Q〉‖P‖‖Q‖ ≤ 1,
podemos pensar que la cantidad del medio define el coseno del ´anguloα(P,Q) entre los vectores, es decir
〈P,Q〉= ‖P‖‖Q‖cos(α).
Ciertamente en los casos que podemos dibujar (R2 y R3) ustedes saben que el angulo ası definido es elangulo que los vectoresP,Q sustentan cuando uno los dibuja. En el cason≥ 4, siempre se puede pensar quedos vectores generan un planoP,Q deRn, y la figura que corresponde es el angulo formado en este plano(independientemente de que no nos podamos imaginar el espacio en el cual este plano esta metido).
Propiedades de la norma
La norma tiene tambien una serie de propiedades bastante utiles, que enunciamos a continuacion. SeanP,Q∈ Rn.

16 Calculo enRn
1. ‖P‖ ≥ 0, y ‖P‖= 0 si y solo siP=O.
2. ‖λP‖= |λ|‖P‖ para todoλ ∈ R.
3. ‖P+Q‖ ≤ ‖P‖+ ‖Q‖ (desigualdad triangular).
Las dos ultimas requieren alguna demostracion. Pensemosprimero que quieren decir. La propiedad de sacarescalares simplemente refleja el hecho de que si uno multiplica un vector por un numero, lo que esta haciendo(si el numero es positivo) es estirar o achicar el vector sinmodificar su direccion. Si el numero es negativo,el vector simplemente se da vuelta y la magnitud relevante esentonces el modulo del numero.
Por otro lado, la ultima propiedad se conoce comodesigualdad triangular, y es un simple reflejo delhecho de que en la figura de abajo, es mas corto el camino yendopor la diagonal que primero recorriendoun lado y despues el otro.
P
Q
P+Q
Demostremos la desigualdad triangular. Tenemos
‖P+Q‖2 = 〈P+Q,P+Q〉= ‖P‖2+ ‖Q‖2+2〈P,Q〉.
Por la desigualdad de C-S,
〈P,Q〉 ≤ |〈P,Q〉| ≤ ‖P‖‖Q‖.
Es decir, nos quedo
‖P+Q‖2 ≤ ‖P‖2+ ‖Q‖2+2‖P‖‖Q‖= (‖P‖+ ‖Q‖)2 .
Tomando raız cuadrada a ambos terminos se obtiene la desigualdad triangular.
La desigualdad triangular en este punto parece un tanto tecnica, pero si recordamos que queremos hablarde lımites, nos dice algo fundamental: si dos puntos estancerca del origen, entonces ¡su suma tambienesta cerca del origen!
Asimismo, siX esta cerca del origen eY esta cerca deX, entonces la desigualdad triangular nos dice queY esta cerca del origen pues
‖Y‖ ≤ ‖Y−X‖+ ‖X‖.
1.2.3. Entornos y conjuntos abiertos

1.2 El espacio como n-uplas 17
Pensando en la norma como distancia, po-demos definir un cierto entorno de un pun-to P∈ Rn de la siguiente manera: nos que-damos con el conjunto de puntos que estana distancia menor que un numero positivor de un puntoP dado. Es decir, si pensa-mos en el plano, con un disco alrededor delpunto, como en la figura de la derecha.
Pr
Br(P)
Lo denotamos ası:Br(P) = Q∈ Rn : d(Q,P) = ‖Q−P‖< r
Observemos que los puntos del borde del disco NO pertenecen aeste conjunto. El conjunto se denominabola abierta de radio r con centro en P. En el caso de la recta real (n= 1) se obtiene un intervalo: si tomamosun numerox0 ∈ R y consideramosBr(x0) = x∈ R : |x− x0|< r, lo que obtenemos es el intervalo abiertode largo 2r (el “diametro”) centrado enx0.
( )x0− r
R
x0+ rx0
Las siguiente definicion generaliza esta idea.
Definicion 1.2.2. Un conjunto U⊂ Rn esabiertosi para cada punto P∈ U existe una bola abierta Br(P)centrada en P tal que Br(P)⊂U (el radio puede depender del punto P).
La idea intuitiva es que en un conjunto abierto, no hay puntosque esten en el borde, sino que estantodos propiamente adentro. Porque los puntos del borde no tienen esta propiedad, ya cualquier bola centradaen ellos, tiene puntos tanto de fuera del conjunto como de adentro. Insisto con una parte importante de ladefinicion: el radior, para cada puntoP del conjunto abiertoU , va variando para adecuarse a la forma delconjunto y permitir queBr(P)⊂U .
Un ejemplo ilustrativo se obtiene tomando algunos puntos enuna figura en el plano como la siguiente:

18 Calculo enRn
r5
P1r1
B1
P2r2
B2
P3r3
B3
P4
r4B4
P5
r6 B6P6
B7P7
r5
B5
U
Se imaginan que una bola abierta deberıa cumplir la definicion de abierto (¡si no, estamos mal!). Veamossu demostracion, que se deduce del dibujo
PQ
‖Q−P‖t
t
t = r −‖Q−P‖> 0
Br(P)Bt (Q)
Lema 1.2.3. Sea Br(P) una bola abierta enRn. Para cada Q∈ Br(P) existe t> 0 tal que Bt(Q) ⊂ Br(P).En particular una bola abierta es un conjunto abierto.
Demostracion. ComoQ∈ Br(P), se tiened = ‖Q−P‖< r. Si d = 0, es porqueQ= P y tomamost = r. Elcaso interesante es 0< d < r. En el dibujo se ve queBt(Q) ⊂ Br(P), dondet = r −d > 0. Demostremoslo.TomemosX ∈ Br−d(Q), entonces‖X−Q‖< r −d. En consecuencia
‖X−P‖= ‖X−Q+Q−P‖≤ ‖X−Q‖+ ‖Q−P‖< (r −d)+d = r
donde hemos usado la desigualdad triangular. Esto nos dice queX ∈ Br(P), como afirmabamos.
Tenemos la siguiente equivalencia:
Proposicion 1.2.4. Un conjunto U⊂ Rn es abierto si y solo si U se puede escribir como union de bolasabiertas.

1.2 El espacio como n-uplas 19
Demostracion. Veamos⇒), supongamos queU es abierto. Entonces para cada puntoP ∈ U exister > 0tal queBr(P) ⊂ U . En consecuencia∪P∈UBr(P) ⊂ U pues todas las bolas estan enU . Y por otro lado esevidente queU ⊂ ∪P∈UBr(P). Es decir hemos probado que
U ⊂ ∪P∈UBr(P)⊂U,
lo que nos asegura la igualdadU = ∪P∈UBr(P), o seaU es una union de bolas abiertas.
Veamos ahora⇐), supongamos queU = ∪Pi Br(Pi) es una union de bolas abiertas, donde losPi sonalgunos de los puntos deU (pueden ser todos). SiQ∈U , tenemos que ver que existet > 0 tal queBt(Q)⊂U .ComoU es union de bolas abiertas, el puntoQ debe estar en alguna de ellas, digamosQ ∈ Br0(P0). Peropor el Lema1.2.3, existet > 0 tal queBt(Q) ⊂ Br0(P0). Por propiedad transitiva de la inclusion, se tienenBt(Q)⊂U .
Y una propiedad fundamental:
Proposicion 1.2.5. SiUii∈I es una familia de conjuntos abiertos deRn, entonces la union U = ∪i∈IUi esun conjunto abierto.
Demostracion. Cada abiertoUi se puede escribir como una union de bolas abiertas por la proposicion an-terior. EntoncesU es la union de todas las bolas de todos los abiertos, y resulta ser abierto de nuevo por laproposicion anterior.
Algo similar ocurre con la interseccion, pero teniendo cuidado porque solo es cierto el resultado si sonfinitos conjuntos. Basta verlo para dos, ese es el contenido del siguiente lema.
Lema 1.2.6. Si U,V son conjuntos abiertos deRn, entonces su interseccion U∩V es un conjunto abierto.
Demostracion. DadoP∈U∩V, existenr1 > 0 y r2 > 0 tales queBr1(P)⊂U (por serU abierto) yBr2(P)⊂V (por serV abierto). Sir = mınr1, r2, entoncesBr(P)⊂U ∩V lo que prueba que este ultimo es abierto.
Se extiende el resultado anterior a finitos conjuntos abier-tos.Sin embargo, el resultado esfalsosi consideramos infini-tos abiertos.
Problema 1.2.7.Comprobarque si Un = (0, n+1
n )⊂ R,entonces∩nUn = (0,1], que noes abierto.
Antes de seguir, quisiera que discutamos brevemente que estamos haciendo.

20 Calculo enRn
Si recordamos la definicion de lımite enR, la idea central es establecer con claridad que quiere decir“estar cerca” de un puntox0. Para eso usamos el orden deR, y alrededor dex0 establecemos un intervalo(x0− ε,x0+ ε) para unε > 0 dado,
( )x0− ε
R
x0+ εx0
Observemos que hay solo dos direcciones desde donde acercarnos ax0 (por la izquierda o por la derecha),que se corresponden con los lımites laterales. Esto es asıporque los numeros reales estan ordenados, y porlo tanto solo se puede ser mayor o menor quex0 (o igual). Sin embargo, en el plano (o el espacio) no hay unorden entre puntos. Por lo tanto hay infinitas direcciones desde donde acercarse a un puntoP∈ Rn.
P
De hecho, acercarnos por rectas no agota todas las posibilidades porque uno podrıa acercarse con una espiralu otra curva. Sin embargo, con las nociones de bola y abierto queda claro que quiere decir estar cerca delpuntoP.
Otra nocion util que necesitamos es la de interior de un conjunto.
Definicion 1.2.8. Si C⊂ Rn, un punto P∈ C esinterior si existe una bola abierta centrada en P tal queBr(P)⊂C. El conjunto de todos los puntos interiores de C se denominainterior deC y lo denotamos Co.
Un conjunto puede no tener ningun punto interior, es decirCo = /0. Por ejemplo siC es una recta en elplano. Aunque es evidente, esta afirmacion requiere demostracion. Seamos entonces concretos.
Ejemplo 1.2.9. Si C= (x,y) : y= x, entonces Co = /0.
Demostracion. La manera mas simple de probar lo enunciado es por el absurdo. Es decir, suponemos quehay un punto interior y llegamos a una contradiccion. Supongamos entonces queP∈C es interior. Debe serP = (a,a) para algun numero reala. Si P es interior, exister > 0 tal queBr(P) ⊂ C. Nos guiamos por eldibujo siguiente
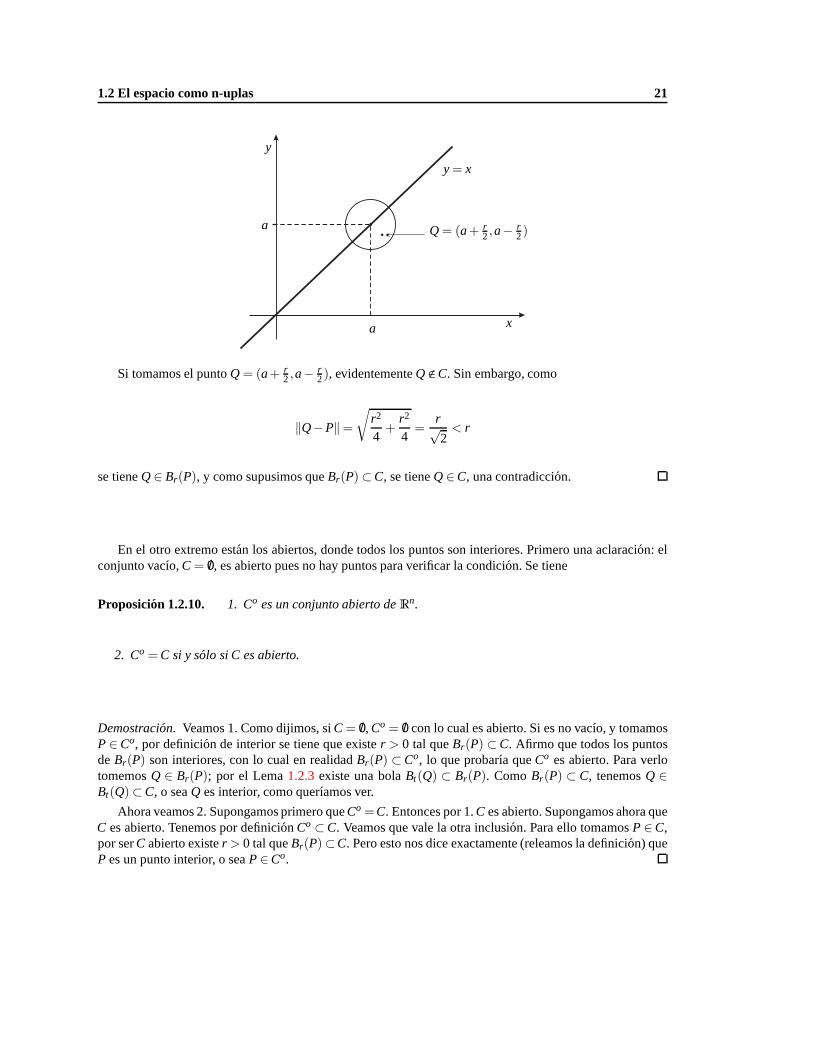
1.2 El espacio como n-uplas 21
a
a
x
y
y= x
Q= (a+ r2,a− r
2)
Si tomamos el puntoQ= (a+ r2,a− r
2), evidentementeQ<C. Sin embargo, como
‖Q−P‖=√
r2
4+
r2
4=
r√2< r
se tieneQ∈ Br(P), y como supusimos queBr(P)⊂C, se tieneQ∈C, una contradiccion.
En el otro extremo estan los abiertos, donde todos los puntos son interiores. Primero una aclaracion: elconjunto vacıo,C= /0, es abierto pues no hay puntos para verificar la condicion. Se tiene
Proposicion 1.2.10. 1. Co es un conjunto abierto deRn.
2. Co =C si y solo si C es abierto.
Demostracion. Veamos 1. Como dijimos, siC= /0, Co = /0 con lo cual es abierto. Si es no vacıo, y tomamosP∈Co, por definicion de interior se tiene que exister > 0 tal queBr(P) ⊂C. Afirmo que todos los puntosdeBr(P) son interiores, con lo cual en realidadBr(P) ⊂ Co, lo que probarıa queCo es abierto. Para verlotomemosQ ∈ Br(P); por el Lema1.2.3existe una bolaBt(Q) ⊂ Br(P). ComoBr(P) ⊂ C, tenemosQ ∈Bt(Q)⊂C, o seaQ es interior, como querıamos ver.
Ahora veamos 2. Supongamos primero queCo =C. Entonces por 1.C es abierto. Supongamos ahora queC es abierto. Tenemos por definicionCo ⊂C. Veamos que vale la otra inclusion. Para ello tomamosP∈C,por serC abierto exister > 0 tal queBr(P)⊂C. Pero esto nos dice exactamente (releamos la definicion) queP es un punto interior, o seaP∈Co.

22 Calculo enRn
El interior Co de un conjunto es, en algun sentido, elabierto mas grande contenido enC, segun nos ensena elejercio que dejamos para el lector.
Problema 1.2.11.Probar queCo se puede escribir como launion de todos los conjuntosabiertos de C, es decirCo = ∪Ui , donde Ui ⊂C esabierto enRn.
1.2.4. Lımites enRn
Vamos a generalizar la nocion de sucesion de numeros reales a sucesiones de vectores.
Definicion 1.2.12.Una sucesionPkk∈N de puntos deRn es una tira ordenada de vectores
P1,P2,P3, · · · ,Pk, · · ·
Equivalentemente, es una funcion P: N→ Rn.
Ejemplo 1.2.13. 1. Tomemos Pk = (1k ,cos1
k). EntoncesPkk∈N es una sucesion deR2.
2. Si ponemos Qk = (e−k,k2, 1k), entoncesQkk∈N es una sucesion deR3.
3. Si Xj =(
e− j , 1j sen(2 j), 1
j2,(1+ 1
j )j)
entoncesXj j∈N es una sucesion deR4.
Observemos que como un vectorP ∈ Rn esta determinado por susn coordenadas (que son numerosreales), entonces una sucesion deRn se puede pensar como una tira ordenada den sucesiones de numerosreales, y alk-esimo termino de la sucesion (que es un vector deRn) lo anotamos ası
Pk = ((Pk)1,(Pk)2, · · · ,(Pk)n) .
Es decir, usamos un parentesis y un subındice para senalar que coordenada nos interesa. Ası por ejemplo, siPk es la sucesion deR2 dada por
Pk = (1−1/k,2k),
se tiene(Pk)1 = 1−1/k y (Pk)2 = 2k.
Ahora que sabemos que es una sucesion, podemos dar la definicion de lımite de sucesiones usando lanorma (que nos provee de los entornos).
Definicion 1.2.14. Si Pkk∈N es una sucesion deRn, y P∈ Rn, decimos que Pk tiende a P si para todoε > 0 existe k0 ∈N tal que
‖Pk−P‖< ε para todo k≥ k0,
y lo escribimoslımk→∞
Pk = P o bien Pkk→∞−→ P.

1.2 El espacio como n-uplas 23
Observemos que esta definicion coincide con la definicion de lımite de una sucesion en el cason= 1. Sepuede definir tambien que quiere decir que una sucesion de vectores tienda a infinito, pero en el cason≥ 2lo que queremos decir es que la norma de los vectores se hace arbitrariamente grande, es decir
Definicion 1.2.15.Si Pkk∈N es una sucesion deRn, decimos que Pk tiende a infinito si para todo M> 0existe k0 ∈N tal que
‖Pk‖> M para todo k≥ k0,
y lo escribimoslımk→∞
Pk = ∞ o bien Pkk→∞−→ ∞. Tambien es habitual decir que la sucesionPk diverge.
Lo que uno imagina, si piensa en las coordenadas del vector que forma la sucesion, es que si tiene lımitecada coordenada entonces tiene lımite la sucesion original. Esto no solo es ası sino que vale la recıproca.Para verlo, primero una observacion util sobre la norma.
Observacion 1.2.16.Si P= (p1, p2, · · · , p j , · · · , pn) es un vector deRn, entonces se tiene, para cualquier jdesde1 hasta n,
|p j | ≤ ‖P‖ ≤√
n maxj=1...n
|p j |. (1.1)
Para verlo basta recordar que
‖P‖=√
p21+ p2
2+ · · ·+ p2j + · · · p2
n,
y en consecuencia se tiene
p2j ≤ p2
1+ p22+ · · ·+ p2
j + · · · p2n ≤ n max
j=1...np2
j .
Ahora sı, escribimos el resultado que establece que la convergencia enRn es simplemente la convergen-cia en todas y cada una de las coordenadas.
Proposicion 1.2.17.SeaPk una sucesion deRn. Entonces P= (p1, p2, · · · , pn) es el lımite de la sucesionPk si y solo si cada coordenada del vector sucesion tiene como lımite la correspondiente coordenada de P.Es decir
lımk→∞
Pk = P ⇐⇒(
lımk→∞
(Pk) j = p j para todo j= 1. . .n
)
.
Demostracion. Supongamos primero que todas las coordenadas convergen al correspondientep j . Esto quie-re decir, que dadoε > 0,
1. existek1 ∈N tal que|(Pk)1− p1|< ε√n si k≥ k1.

24 Calculo enRn
2. existek2 ∈N tal que|(Pk)2− p2|< ε√n si k≥ k2.
3. · · ·
4. existekn ∈N tal que|(Pk)n− pn|< ε√n si k≥ kn.
Si tomamosk0 = maxj=1...n
k j , entonces
‖Pk−P‖=√
((Pk)1− p1)2+ · · ·+(Pk)n− pn)2 <
√
ε2
n+ · · ·+ ε2
n=√
ε2 = ε.
Esto prueba que lımk
Pk = P.
Supongamos ahora que lımk
Pk = P, queremos ver que todas las coordenadas convergen a la correspon-
diente coordenada deP. Pero por la definicion, tenemos que dadoε > 0, existek0 ∈N tal quek≥ k0 implica‖Pk−P‖< ε. Pero si miramos la ecuacion (1.1) de arriba, se deduce que
|(Pk) j − p j | ≤ ‖Pk−P‖< ε
para todoj = 1. . .n, siempre quek ≥ k0. Esto nos dice que la sucesion de cada coordenada converge alacoordenada correspondiente deP.
Observacion 1.2.18.Atenti, que el resultado anterior no vale para sucesiones divergentes. Por ejemplo, si
Pk = (k, 1k), entonces‖Pk‖ =
√
k2+ 1k2 →+∞, es decir Pk tiende a infinito o diverge de acuerdo a nuestra
definicion. Sin embargo,no es cierto que ambas coordenadas tiendan a infinito.
Problema 1.2.19.Calcular los lımites de las sucesiones del Ejemplo1.2.13.
1.2.5. Puntos de acumulacion y conjuntos cerrados
Ahora vamos a usar la nocion de lımite para pensar en otro tipo de conjuntos, que son los acompanantesnaturales de los conjuntos abiertos que estuvimos charlando mas arriba. Hagamos una lista de los objetosque nos interesan.
Definicion 1.2.20.Sea C⊂Rn un conjunto.
Decimos que P es unpunto de acumulacion deC si existe una sucesion Pk de puntos de C tal queP= lım
k→∞Pk.
La clausuradel conjunto C es la union de todos los puntos de acumulacion de C. La denotamosC.
Decimos queC es un conjuntocerradosi para toda sucesion convergentePk, tal que todos sus terminosson puntos de C, se tiene P= lım
k→∞Pk ∈C.

1.2 El espacio como n-uplas 25
Observemos queC ⊂ C puesto que dado un puntoP∈ C, la sucesion constantePk = P nos dice quePes punto de acumulacion deC. A partir de estas definiciones, se tienen la siguiente propiedad fundamental,que relaciona los conjuntos abiertos con los cerrados:
Proposicion 1.2.21.Un conjunto C⊂ Rn es cerrado si y solo si su complemento Cc es abierto.
Demostracion. Supongamos primero queC es cerrado, pongamosU = Cc y veamos queU es abierto. Deacuerdo a la definicion, basta probar que todo punto deU es interior. TomemosP∈U , supongamos que noes interior y llegaremos a un absurdo. SiP no es interior, entonces para todok ∈N se tieneB1
k(P) 1U , es
decir existePk ∈Uc =C tal quePk ∈ B1k(P). Observemos quePk → P, pues‖Pk−P‖< 1
k . Hemos llegado a
una contradiccion, puesPk ∈C, P<C y por hipotesisC es cerrado.
Supongamos ahora queU = Cc es abierto, y veamos queC es cerrado. TomemosPk una sucesion depuntos deC con lımiteP∈Rn. Queremos ver queP∈C. Si esto no fuera ası, serıaP∈U que por hipotesis esabierto. En consecuencia existirıar > 0 tal queBr(P)⊂U . Tomemosk∈N tal que‖Pk−P‖< r (recordemosquePk → P). Se tendrıaPk ∈ Br(P) ⊂U , lo cual es imposible puesPk ∈ C = Uc. Luego debe serP∈ C, yesto prueba queC es cerrado.
Observacion 1.2.22. Atencion, que hay conjuntos que no son ni abiertos, ni cerrados. Porejemplo, elintervalo I= [0,1) enR. Que no es abierto se deduce de que0∈ I no es un punto interior (¿por que?). Queno es cerrado se deduce de que la sucesion an = 1− 1
n, de puntos de I, tiene lımite1, que no es un punto deI.
Con esta dualidad entre abiertos y cerrados es facil establecer los siguientes hechos, a partir de lasdemostraciones que ya hicimos para conjuntos abiertos.
SeaC⊂ Rn.
1. La clausuraC es un conjunto cerrado.
2. C=C si y solo siC es cerrado.
3. SiCii∈I es una familia de conjuntos cerrados, entonces∩i∈ICi es un conjunto cerrado.
4. SiC1 y C2 son conjuntos cerrados, su unionC1∪C2 es un conjunto cerrado.
Demostracion. Veamos 1. SiA=Cc, y P∈ A, entonces exister > 0 tal queBr(P)∩C= /0 (de lo contrario,
uno podrıa fabricar una sucesionXk de puntos deC tal queXk → P, lo que dirıa queP∈C, contradiciendoqueP∈C
c). Afirmo queBr(P)⊂ A, lo que probarıa queA es abierto, y entoncesC serıa cerrado. Tomemos
Q∈ Br(P), ‖Q−P‖= d < r. Si fueraQ < A, tendrıamosQ∈C. Existirıa entonces una sucesionYk ∈C talqueYk → Q. Pero conk suficientemente grande, tendrıamos
‖Yk−P‖ ≤ ‖Yk−Q‖+ ‖Q−P‖< (r −d)+d= r

26 Calculo enRn
lo que nos dice queYk ∈ Br(P), contradiciendo queBr(P)∩C= /0.
Veamos 2. Supongamos primero queC=C. Entonces por el ıtem previo,C es cerrado. Recıprocamente,si C es cerrado, entonces dado un puntoP ∈ C, existe una sucesion de puntosPk deC tal quePk → P, ycomoC es cerrado debe serP∈C. Esto prueba queC⊂C, y como la otra inclusion siempre vale, obtuvimosC=C.
La propiedad 3. se verifica observando que, por las leyes de deMorgan,(A∩B)c = Ac∪Bc. En conse-cuencia,
(∩i∈ICi)c = ∪i∈IC
ci .
Si cadaCi es cerrado, por la Proposicion1.2.21, cadaCci es abierto. Pero una union arbitraria de abiertos
es abierta por la Proposicion1.2.5. Ası que el lado derecho de la ecuacion es un conjunto abierto (y por lotanto el lado izquierdo es un conjunto abierto). Si volvemosa tomar complementos, obtenemos que∩iCi escerrado (recordar que(Ac)c = A).
La propiedad 4. se verifica en forma identica, usando ahora que (A∪B)c = Ac∩Bc y el Lema1.2.6.¡Escribirlo!
Se deduce del ultimo ıtem que siC1, · · · ,Cm sonfinitosconjunto cerrados, su union es un conjunto cerrado. Sinembargo una union infinita de cerrados puede no ser ce-rrada, como muestra el siguiente problema.
Problema 1.2.23.Consideremos los cerrados deR dados por Cj = [0,1− 1
j ], conj ∈N. Verificar que∪ jCj = [0,1), queno es unconjunto cerrado.
Observacion 1.2.24.Si Br(P) es una bola abierta enRn, su clausura se denominabola cerradade radio rcentrada en P, y es el conjunto
Br(P) = Q∈ Rn : ‖Q−P‖ ≤ r.
Aunque bastante obvia, esta afirmacion requiere alguna demostracion
Br(p) = Br(P).
Queremos ver que el conjunto de puntos de acumulacion de Br(P) esBr(P). Sea Q un punto de acumu-lacion de Br(P). Entonces existe Qk ∈ Br(P) tal que Qk → Q. En consecuencia,
‖Q−P‖≤ ‖Q−Qk‖+ ‖Qk−P‖< ‖Q−Qk‖+ r.
Tomando lımite para k→ ∞ se obtiene‖Q−P‖ ≤ r, es decir hemos probado que si Q es un punto deacumulacion de Br(P), entonces Q∈ Br(P) (o sea hemos probado queBr(p) ⊂ Br(P)). Veamos ahora que

1.2 El espacio como n-uplas 27
vale la recıproca. Tomemos un punto Q∈ Br(P), es decir‖Q−P‖ ≤ r. Consideremos la sucesion Qk =P+(1− 1
k)(Q−P). Ciertamente
‖Qk−P‖= |1− 1k|‖Q−P‖ ≤ |1− 1
k|r < r
para todo k∈ N, pues|1− 1k | = 1− 1
k < 1, lo que prueba que Qk ∈ Br(P). Y por otro lado, como Qk =Q− 1
k(Q−P), se tiene
‖Qk−Q‖= 1k‖Q−P‖
lo que prueba que Qk → Q. Entonces Q es punto de acumulacion de Br(P), lo que prueba la inclusionBr(P)⊂ Br(p) que faltaba para tener la igualdad.
1.2.6. Conjuntos acotados
Antes de pasar a hablar de funciones, extendamos la idea de conjunto acotado aRn y veamos sus pro-piedades basicas.
Definicion 1.2.25.Un conjunto A⊂ Rn esacotadosi existe M> 0 tal que
‖P‖ ≤ M para todo P∈ A.
Observacion 1.2.26.Es decir, un conjunto es acotado si lo podemos poner dentro deuna bola. Se deducede la Observacion 1.2.16que un conjunto es acotado si y solo si todas las coordenadas del conjunto estanacotadas, ya que por un lado, cada coordenada esta acotada por la norma, y por otro lado, la normaesta acotada por n veces el maximo de las coordenadas.
Toda sucesion convergente es acotada, pues si Pk → P enRn, existe k0 ∈ N tal que k≥ k0 implica‖Pk−P‖ ≤ 1, con lo cual
‖Pk‖ ≤ ‖Pk−P‖+ ‖P‖≤ 1+ ‖P‖para todo k≥ k0. Y los primeros terminos de la sucesion estan acotados (pues es un conjunto finito). Esdecir, si tomamos M= max
k=1...k0‖Pk‖,‖P‖+1, se tiene
‖Pk‖ ≤ M para todo k∈N,
lo que nos dice que la sucesion esta acotada por M.
Ahora podemos escribir una generalizacion del Teorema de Bolzano-Weierstrass que probamos paraR.La idea es simplemente que cada coordenada tiene una subsucesion convergente, pero hay que elegir enforma ordenada para no arruinar la convergencia de la anterior. Un hecho importante que vale en general, yque usamos aquı, es que una subsucesion de una sucesion convergente es siempre convergente.
Teorema 1.2.27.SiPk ⊂ Rn es una sucesion acotada, entonces existe una subsucesion convergente.

28 Calculo enRn
Demostracion. Si Pk es una sucesion acotada, entonces todas las sucesiones(Pk) j que forman sus coor-denadas (conj = 1. . .n) son sucesiones acotadas de numeros reales. Por el Teoremade B-W (Corolario1.1.29), como la sucesion(Pk)1 de la primer coordenada esta acotada, tiene una subsucesi´on (Pkl )1 conver-gente. Ahora miramos la segunda coordenada, pero solo los terminos que corresponden a la subsucesion queya elegimos en la primer coordenada. Es decir, miramos la subsucesion(Pkl )2. Esta es de nuevo una sucesionacotada, por ser una subsucesion de una sucesion acotada.Entonces por el Teorema de B-W, existe una sub-sucesion(Pkls
)2 que es convergente. Seguimos ası hasta llegar a la ultima coordenada del vector que formala sucesion. Observemos que en cada paso nos estamos quedando con una subsucesion, por lo tanto esto noaltera el hecho de que en la coordenada anterior nos quedamoscon una subsucesion convergente (pues unasubsucesion de una sucesion convergente es convergente). Obtenemos ası una subsucesion convergente encada coordenada, y por ende, tenemos una subsucesion convergente de la sucesionPk original.
Definicion 1.2.28. Sea C⊂ Rn. La frontera deC es elconjunto de puntos de acumulacion de C que no son inte-riores. La denotamos
∂C=C−Co.
Problema 1.2.29.Probar quela frontera de la bola (abierta ocerrada) es la esfera queforman los puntos del borde. Esdecir
∂Br(P)= Q∈Rn : ‖Q−P‖= r.
Probar que si C es cerrado, coninterior vacıo (por ejemplo, unsubespacio), entonces∂C=C.¿Se les ocurre algun ejemplo enel que∂C= /0?
1.3. Problemas
1.I. Probar usando los axiomas de cuerpo ordenado que 0< 1, y que sia< b entonces el promediop= a+b2
verificaa< p< b.
1.II. Probar quei ∈ R es el ınfimo deA⊂ R si i ≤ a para todoa∈ A y ademas, dadoε > 0, existea∈ A talquei + ε > a.
1.III. Probar que siann∈N es una sucesion de numeros reales tales quean ≤ l para todon, entonces
[∀ ε > 0 ∃ n0 ∈N tal quel −an < ε (∀n≥ n0)]⇒ lımn→∞
an = l .

1.3 Problemas 29
1.IV. Probar que si ınfA < A, existe una sucesion estrictamente decreciente de elementos deA que convergeal ınfimo.
1.V. Probar que sian es una sucesion decreciente y acotada inferiormente, entonces lımn→∞
an = ınfan.
1.VI. Supogamos quean es una sucesion que no esta acotada superiormente. Probarquean tiene unasubsucesion estrictamente creciente que tiende a+∞.
1.VII. SeaUn la coleccion de intervalos abiertos enR dados porUn = (0, n+1n ). Probar que∩nUn = (0,1] y
concluir que la interseccion arbitraria de conjuntos abiertos no es necesariamente abierta.
1.VIII. SeaC ⊂ Rn, y seaUii∈I la familia de todos los conjuntos abiertos deRn tales queUi ⊂ C. ProbarqueC0 = ∪iUi .
1.IX. Probar que(A∩B)c = Ac∩Bc para todo par de conjuntos. Concluir que la union finita de conjuntoscerrados es un conjunto cerrado (asumiendo que la interseccion finita de conjuntos abiertos es abierta).
1.X. Consideremos los cerrados deR dados porCj = [0,1− 1j ], con j ∈N. Probar que∪ jCj = [0,1), queno
es un conjunto cerrado.
1.XI. SeaC ⊂ Rn, y seaCii∈I la familia de todos los conjuntos cerrados deRn tales queC ⊂ Ci . ProbarqueC= ∩iCi .
1.XII. Probar que la frontera de la bola de radior > 0 alrededor deP∈Rn son losX ∈Rn tales que‖X−P‖=r. A este conjunto se lo denominaesfera centrada en P de radio r.
1.XIII. Probar que siC es cerrado y tiene interior vacıo entonces∂C=C. Dar un ejemplo de un conjunto enR2 tal que∂C= /0.

30 Calculo enRn

Equality is not in regarding different thingssimilarly, equality is in regarding differentthings differently.
TOM ROBBINS
2.1. Dominio, grafico, imagen
Podemos empezar a pensar en funciones de varias variables; ya desarrollamos las herramientas parapensar en dominios, lımites y demas nociones que involucren conjuntos enRn.
2.1.1. Funcionesf : Rn → R
Recordemos primero que el dominio natural de una funcion esel conjunto de puntos donde tiene sentidoaplicar la funcion. Ya estuvimos trabajando sin decirlo con funciones deRn enR.
Ejemplo 2.1.1. Veamos primero algunos ejemplos donde Dom( f ) = Rn. Sea X= (x1, · · · ,xn) ∈ Rn.
1. La norma‖X‖=√
x21+ x2
2+ · · ·+ x2n es una funcion.
2. Si miramos una coordenada concreta, la asignacion X 7→ x j es una funcion. Estas se llamanfuncionescoordenadaso proyeccionesa las coordenadas.
3. Si fijamos P∈ Rn y movemos X en el producto escalar〈P,X〉 lo que tenemos es una funcion X 7→〈P,X〉.
4. Si x,y∈R, entonces la f(x,y) = xy es la funcion producto de las coordenadas, y por otro lado g(x,y)=x+ y es la funcion suma de las coordenadas (ambas funciones deR2 enR).
Ahora consideremos ejemplos donde el dominio sea un subconjunto propio deRn.

32 Funciones
1. f(x,y) = yx . El dominio es el conjunto Dom( f ) = (x,y) ∈R2 : x, 0, es decir, todo el plano salvo el
eje y.
2. f(x,y,z) = 1x2+y2+z2 = 1
‖X‖2 . En este caso, para que se anule el denominador, debe ser x= y= z= 0.
Luego Dom( f ) = R3−O.
3. Sea
f (x,y) =
x−y(x2+y2)(x−y+1)
si (x,y) , (0,0)
0 si (x,y) = (0,0)
En este caso es Dom( f ) = (x,y) ∈R2 : y, x+1, que esR2 menos una recta.
2.1.2. Curvas
Una curva es una funcionα : I → Rn, dondeI es algun subconjunto (en general un intervalo) deR.Ejemplos de curvas son
1. α : R→ R2 dada porα(t) = (cos(t),sen(t)).
2. β : R→ R3 dada porβ(x) = (x,x−1,3)
3. γ : R→R4 dada porγ(y) = (y,y2,y3,y4).
4. Si f : Dom( f )⊂ R→ R, δ(x) = (x, f (x)) es una curva en el plano.
Observemos que en el ultimo ejemplo la curvaδ tiene como imagen lo que llamamos elgrafico de f,Gr( f ). En el caso de curvas a valores enR2 o R3, lo que interesa en general es la imagen de la misma(a diferencia de las funciones de mas variables, donde lo que interesa es el grafico como vimos). Ası porejemplo, la imagen de la curvaα es una circunferencia de radio unitario centrada en el origen,
y
x
α(t)
α(0) = (1,0)
α( 54π)=(−
√2
2 ,−√
22 )
cos(t)
sen(t)Im(α)
Mientras que la imagen deβ es una recta en el espacioR3 como se deduce de(x,x−1,3) = x(1,1,0)+(0,−1,3). A las curvas tambien se las suele denominartrayectoriaso arcos.

2.1 Dominio, grafico, imagen 33
2.1.3. Grafico, curvas y superficies de nivel
¿Se acuerdan del grafico de una funcionf : R→R? La siguiente definicion es general, e incluye el casoque todos conocemos:
Definicion 2.1.2. Sea f: Dom( f ) ⊂ Rn → R. El grafico de f es el subconjunto deRn+1 formado por lospares ordenados(X, f (X)), donde X∈ Dom( f ). Lo denotamos Gr( f ) ⊂ Rn+1.
Ası, por ejemplo, el grafico de una funcionf : Dom( f ) ⊂ R → R es un subconjunto del planoR2, quemuchas veces sif no es muy complicada podemos dibujar. Por ejemplo el graficode f (x) = (x−1)2−1 esuna parabola, mientras que el def (x) = x+1
x−1 es una hiperbola.
y y
x x
y= (x−1)2−1
y= x+1x−1
Pensemos un poco en el cason= 2, donde segun la definicion, el grafico sera un subconjunto deR3. Porejemplo, sif (x,y) = 3 (¡una funcion constante!), se tiene (ya queDom( f ) = R2)
Gr( f ) = (x,y,3) : x,y∈ R.
Como puntos del espacio, tienen la unica restriccion de tener z= 3, mientras quex e y pueden moverselibremente. Es decir, el grafico se representa simplementecomo un plano horizontal puesto a alturaz= 3.
Si tomamos un ejemplo un poquito mas complicado,g(x,y) = x+ y, se tiene
Gr(g) = (x,y,x+ y) : x,y∈ R.
Los puntos del grafico verifican entonces la relacionz= x+ y, lo que nos dice que el grafico lo podemosrepresentar enR3 como un plano por el origen, de normalN = (1,1,−1) (puesto quex+ y− z= 0).
Veamos un par de ejemplos mas interesantes. Consideremosh(x,y) = x2 + y2, y tambien j(x,y) =√
x2+ y2. Ambas tienen como dominioR2. Los puntos del grafico deh verificanz= x2 + y2, mientrasque los del grafico dej verificanz=
√
x2+ y2. ¿Como podemos descubrir que figuras representan enR3 lospuntos que verifican estas relaciones?
Se recurre a lascurvas de nivel. Esto quiere decir que tratamos de pensar que figura queda si cortamos elgrafico con distintos planos. Por ejemplo, si consideramosplanos horizontales, es decirz= cte, se observaque en ambos casos no puede serz negativo. Dicho de otra forma, la curva de nivel que corresponde aznegativo es el conjunto vacio.

34 Funciones
Esto nos dice que los graficos de ambasfunciones estan por encima del planoxydeR3. Por otro lado, si pensamos en valorespositivos dez, como por ejemploz= 1, ob-tenemos en ambos casos la relacion 1=x2 + y2. Esta figura es una circunferencia.Estrictamente hablando, la curva de niveles una circunferencia en el planoR2.
y
x
x2+ y2 = 1
Sin embargo, hemos descubierto que si cortamos cualquiera de los dos graficos con un plano de altura 1,queda formada una circunferencia de radio 1, lo que nos permite dibujar lo siguiente:
z
yx
z= 1
Probemos ahora conz= 4. En el caso deh obtenemosx2+y2 = 4, que es una circunferencia de radio 2,mientras que en el caso dej obtenemosx2+ y2 = 16, que es una circunferencia de radio 4.
z
yx
z= 2
z= 1
z= 0
En general, siz= z0 es un numero positivo fijo, la ecuacionx2+ y2 = z0 es una circunferencia de radio√z0, mientras que la ecuacionx2+ y2 = z2
0 es una circunferencia de radioz0. Pareciera que las dos figuras,salvo el ancho, son muy parecidas. Incluso el casoz= 0 en ambos casos da la ecuacionx2+ y2 = 0, cuyaunica solucion es el par(0,0).
Sin embargo, la tecnica no se agota aquı. No necesariamente tenemos que cortar con planos horizontales.

2.1 Dominio, grafico, imagen 35
¡Podemos elegir cualquier plano!
Por ejemplo, si tomamosx= 0 estamos considerando la pared formada por el planoyz. En el caso de lafuncionh se obtiene la ecuacion 02+y2 = z. Es decir,z= y2, que es una parabola. Por lo tanto el grafico deh es lo que se conoce comoparaboloide
x y
z
(x,y,x2+ y2)
z= y2
el grafico deh es unparaboloide
Por otro lado, en el caso de la funcionj se obtiene 02+ y2 = z2. Esto esz2 − y2 = 0, que se factorizacomo diferencia de cuadrados(z− y)(z+ y) = 0. En consecuencia debe ser la rectaz= y o bien la rectaz=−y. Recordemos que tenıa que serz≥ 0, con lo cual la figura que se obtiene es la siguiente,
x y
z
(x,y,√
x2+ y2)
z= |y|
el grafico dej es uncono
que es lo que se conoce comocono. Miremos la diferencia de las dos figuras en el origen: ciertamente van atener distintas propiedades cuando pensemos en las derivadas.

36 Funciones
Superficies de nivel
En el caso de funcionesf : R3 →R, el grafico es un subconjunto deR4. Para dibujarlo hay que recurrira sustancias ilegales. Sin embargo, si recurrimos a la tecnica de antes se pueden dibujar lo que se conocencomosuperficies de nivelde f , que nos dan una idea del comportamiento def .
Definicion 2.1.3. Dada f : Dom( f )⊂ Rn → R y un numero real c, se denominasuperficie de nivel def alsubconjunto del dominio dado por
Sc( f ) = (x1, · · · ,xn) ∈ Dom( f ) : f (x1, · · · ,xn) = c.
Por ejemplo, consideremosf (x,y,z) = x2+ y2− z2. La superficie de nivel que corresponde ac= 0 es elconjunto(x,y,z) ∈ R3 : z2 = x2+ y2, que como vimos antes, es un cono (aunque hay que destacar queeneste caso el grafico se extiende en forma simetrica a ambos lados del planoz= 0).
2.1.4. Lımite
Pasemos ahora a hablar de lımite de funciones. Escribimos la definicion, que contiene al caso conocidocuandon= 1.
Definicion 2.1.4. Sea f: Rn → R, P∈ Rn. Decimos que l∈ R es el lımite de f cuando X tiende a P (y loanotamoslım
X→Pf (X) = l) si para todoε > 0 existeδ > 0 tal que
0< ‖X−P‖< δ implica | f (X)− l |< ε.
Notar que la definicion de lımite excluye al puntoP en cuestion. Ası por ejemplo, el lımite de la funcionreal de la figura de abajo, cuandox→ 2, es igual a 1, independientemente de cuanto valgaf enx0 = 2 (nisiquiera tiene por que estar definida enx0 = 2):
y
x
f (2)
l = 1
2
y= f (x)
Observacion 2.1.5. En el caso en el que el dominio de la funcion no sea todoRn (esto es usual), se puederazonar de la siguiente manera. Lo que queremos ver es a que valor se aproxima f(X) cuando X se aproximaa P, para una f: A→ R (con A⊂ Rn). Por lo tanto tiene sentido considerar como P no solo a cualquierpunto del conjunto A donde f este definida, sino acualquier punto de acumulacion A. Es decir, es lıcitotomar P∈ A. Hay que hacer la salvedad de que nos aproximemos con puntosdonde se pueda evaluar f .

2.1 Dominio, grafico, imagen 37
A
P∈ Ao
P∈ ∂A
Con esto, se obtiene la definicion de lımite que cubre todoslos casos relevantes:
Definicion 2.1.6.Sea f: A⊂Rn →R. Sean P∈A y l un numero real cualquiera. Decimos quelımX→P
f (X) = l
en A si para todoε > 0 existeδ > 0 tal que
0< ‖X−P‖< δ y X ∈ A implican | f (X)− l |< ε.
Algebra de lımites, propiedades
En general probar a mano que un lımite existe es muy engorroso (aunque a veces no queda otra). Sinembargo, si uno establece algunas propiedades que permitandesarmar el lımite en lımites mas simples, estofacilita la tarea. Este es el objetivo del algebra de lımites.
Antes, una observacion: si tenemos dos funciones distintas, pueden estar definidas en subconjuntos dis-tintosA,B deRn. En consecuencia la suma, resta, producto y division de ellas solo va a tener sentido en lainterseccionA∩B de estos conjuntos. Y los puntos donde tiene sentido calcular el lımite tienen que ser en-tonces puntos de la clausura deA∩B, de acuerdo a lo discutido en la Observacion2.1.5. Ademas el cocientesolo se puede hacer en aquellos puntos donde no se anula el denominador, que es la interseccion deA conB−C0(g).
Vamos a suponer que ya hicimos la interseccion de dominios,con lo cualf ,g estan definidas en el mismoconjuntoA⊂Rn.
Teorema 2.1.7.Sean f,g : A→R, dos funciones, con A⊂ Rn. Sea P∈ A, y supongamos que
lımX→P
f (X) = l1 ∈ R y lımX→P
g(X) = l2 ∈ R.
Entonces
1. lımX→P( f ±g)(X) = l1± l2 en A.

38 Funciones
2. lımX→P( f .g)(X) = l1.l2 en A.
3. Si l2 , 0, lımX→P(fg)(X) = l1
l2en A−C0(g).
Demostracion. Veamos 1, la suma. Dadoε > 0, existeδ1 > 0 tal que| f (X)− l1| < ε2 siempre que 0<
‖X−P‖< δ1 y X ∈A (pues lımX→P f (X) = l1). Analogamente, existeδ2 > 0 tal que|g(X)− l2|< ε2 siempre
que 0< ‖X−P‖< δ2 y X ∈ A (pues lımX→Pg(X) = l2). En consecuencia, siX ∈ A y 0< ‖X−P‖< δ =mınδ1,δ2, entonces
|( f +g)(X)− (l1+ l2)| ≤ | f (X)− l1|+ |g(X)− l2|<ε2+
ε2= ε.
Lo que prueba que lımX→P( f +g)(X) = l1+ l2. La resta es analoga.
Vemos 2, el producto. Tengamos presente que podemos conseguir que| f (X)− l1| y |g(X)− l2| sean tanchicos como nosotros queramos, por hipotesis. Escribimos
| f g(X)− l1l2|= | f (X)g(X)− f (X)l2+ f (X)l2− l1l2| ≤ | f (X)||g(X)− l2|+ | f (X)− l1||l2|.
El unico termino que no es evidente que esta acotado es| f (X)|. Pero de nuevo por la desigualdad triangular,
| f (X)| ≤ | f (X)− l1|+ |l1|,
con lo cual| f g(X)− l1l2| ≤ | f (X)− l1|(|g(X)− l2|+ |l2|)+ |l1||g(X)− l2|. (2.1)
En consecuencia, comol1 y l2 estan fijos, y las cantidades| f (X)− l1| y |g(X)− l2| se pueden hacer tanchicas como uno quiera (eligiendo convenientemente el entorno deP), se obtiene que| f g(X)− l1l2| es tanchico como uno quiera. Mas precisamente, consideremos losdos casosl1 = 0, l1 , 0.
1. l1 = 0. Entoncesl1l2 = 0, y por la cuenta (2.1) de arriba,
| f g(X)− l1l2|= | f (x)g(X)| ≤ | f (X)|(|g(X)− l2|+ |l2|) .
Dadoε > 0, elegimosδ2 > 0 tal que 0< ‖X−P‖ < δ2 implique |g(X)− l2| < 1, y elegimosδ1 > 0tal que 0< ‖X−P‖< δ1 implique| f (X)|< ε
(1+|l2|) . Si tomamosδ = mınδ1,δ2, entonces
| f g(X)− l1l2|<ε
(1+ |l2|)(1+ |l2|) = ε.
2. l1 , 0. Dadoε > 0, i elegimosδ2 > 0 tal que 0< ‖X−P‖< δ2 implique|g(X)− l2|< ε2|l1| , y elegimos
δ1 > 0 tal que 0< ‖X −P‖ < δ1 implique | f (X)− l1| < ε2(
ε2|l1|
+|l2|) . Si tomamosδ = mınδ1,δ2,
nuevamente por la cuenta (2.1) de arriba,
| f g(X)− l1l2|<ε2+
ε2= ε.

2.1 Dominio, grafico, imagen 39
Veamos 3, el cociente. Observemos primero quef/g tiene sentido en el conjuntoA−C0(g) pues remo-vimos los ceros deg. Sacando denominadores comunes tenemos
| f/g(X)− l1/l2|=1
|l2||g(X)| | f (X)l2−g(X)l1|.
El numerador se puede hacer tan chico como uno quiera pues
| f (X)l2−g(X)l1|= | f (X)l2− l1l2+ l1l2−g(X)l1| ≤ |l2|| f (X)− l1|+ |l1||l2−g(X)|.Falta acotar el primer factor por alguna constante, es decir, falta ver que existeM > 0 tal que 1
|g(X)| < M si
0< ‖X−P‖< δ y X ∈ A−C0(g). Para simplificar la demostracion, supongamos quel2 > 0 (el casol2 < 0es analogo). Como lımX→P g(X) = l2, se tiene|g(X)− l2|< l2/2 para algunδ0 > 0 conveniente, es decir
−l2/2< g(X)− l2 < l2/2,
de donde se deduce quel2/2< g(X) si 0< ‖X−P‖ < δ0 y X ∈ A−C0(g). En particularg(X)> 0 en esteentorno deP, y ademas 1
|g(X)| =1
g(X) <2l2
, como querıamos. Con esto, llamandoM = 2l22
tenemos
1|g(X)||l2|
< M
siempre que 0< ‖X−P‖< δ0.
Ahora, comof tiende al1 y g tiende al2, se tiene
| f (X)− l1||l2| → 0 y |g(X)− l2||l1| → 0
por la propiedad del producto que ya probamos. Entonces existenδ1,δ2 > 0 tal que 0< ‖X−P‖<mınδ1,δ2implica
| f (X)− l1||l2|<ε
2My |g(X)− l2||l1|<
ε2M
.
En consecuencia, siδ = mınδ0,δ1,δ2, se tiene
| f/g(X)− l1/l2| ≤1
|l2||g(X)| (|l2|| f (X)− l1|+ |l1||g(X)− l2|)< M(ε
2M+
ε2M
) = ε.
Observacion 2.1.8. Una observacion importante y muy sencilla: si fj : Rn → R es una de las funcionescoordenadas (la que se queda con la j-esima coordenada), es decir
f j(x1,x2, · · · ,x j , · · ·xn) = x j ,
entonces si P= (p1, · · · , pn), se tienelımX→P f j (X) = lımX→P x j = p j .
Por ejemplo, si f: R3 → R es la proyeccion a la segunda coordenada f(x,y,z) = y, entonces se tienelım(x,y,z)→(2,3,−1) f (x,y,z) = lım(x,y,z)→(2,3,−1) y= 3.
Este hecho se demuestra a partir de la definicion de lımite observando que
| f j(X)− p j |= |x j − p j | ≤√
(x1− p1)2+ · · ·+(xn− pn)2 = ‖X−P‖,
con lo cual si‖X−P‖ es pequeno, entonces| f j (X)− p j | es pequeno.

40 Funciones
Como comentario adicional (para confundir) observemos quede acuerdo a la notacion que usamos parasucesiones, cuando querıamos senalar laj-esima coordenada de una sucesionPk escribıamos(Pk) j . Ahorapodemos decir que(Pk) j = f j(Pk) (¡para pensarlo, es una tonterıa de la notacion nomas!).
Ejemplo 2.1.9. Juntando el Teorema2.1.7con la Observacion 2.1.8, se deduce que tomar lımite en lasfunciones que involucran sumas, restas, productos y cocientes de las coordenadas, se traduce simplementeen evaluar las funciones en el punto dado (siempre y cuando eldenominador no se anule). Ası por ejemplo
lım(x,y,z)→(1,3,−4)
xy+ z2+ y3x+ z+ y2 =
13+16+33−4+9
=328
= 4.
2.2. FuncionesF : Rn → Rm
Una funcion de este tipo esta dada por una tira de funcionesfi : Rn → R (coni = 1. . .m), es decir
F(x1,x2, · · · ,xn) = ( f1(x1,x2, · · · ,xn), f2(x1,x2, · · · ,xn), · · · , fm(x1,x2, · · · ,xn)).
La definicion de lımite es enteramente analoga, simplemente hay que tener en cuenta que ahora los valoresdeF son vectores y no numeros. ConsideremosA⊂ Rn como siempre.
Definicion 2.2.1. Sea F: A⊂ Rn → Rm. Sean P∈ A y L∈ Rm. Decimos quelımX→P
F(X) = L en A si para
todoε > 0 existeδ > 0 tal que
0< ‖X−P‖< δ y X ∈ A implican ‖F(X)−L‖< ε.
2.2.1. Composicion
Podemos componer funciones de la manera obvia. Por ejemplo si por un ladoF(x,y)= (x+ey,xy,cos(x)y)y por otro ladoG(x,y,z) = (x+ y+ z,xyln(y)), se tiene
(GF)(x,y) = (x+ey+ xy+ cos(x)y,(x+ey)xyln(xy)),
con las restricciones de dominio que corresponda en cada caso. Por ejemplo aquı
Dom(GF) = (x,y) ∈R2 : xy> 0.
En general hay que tener cuidado de que se pueda hacer la composicion. Ademas de poder encadenar
Rn F−→ Rm G−→Rk

2.2 FuncionesF : Rn →Rm 41
con el espacioRm intermedio, hay que recordar que el dominio de una composicion, siF : A⊂Rm →Rm yG : B⊂ Rm →Rk es
Dom(GF) = X ∈ A : F(X) ∈ B.
Y tenemos la propiedad correspondiente del algebra de lımites:
Teorema 2.2.2.Sean F: A⊂ Rn → Rm y G : B⊂ Rm →Rk.
Si P∈ A es tal quelımX→P F(X) = L1 ∈ B, y lımY→L1 G(Y) = L2, entonces existe el lımite de la compo-sicion lımX→P(GF)(X) en Dom(GF), y ademas lımX→P(GF)(X) = L2, siempre y cuando F(X) , L1
para X, P.
Demostracion. Dadoε > 0, existeδ > 0 tal que
‖(GF)(X)−L2‖= ‖G(F(X))−L2‖< ε
siempre y cuando 0< ‖F(X)− L1‖ < δ y F(X) ∈ B, por ser lımY→L G(Y) = L2 (simplemente llamandoY = F(X)).
Pero dadoδ > 0 existeδ′ > 0 tal que 0< ‖F(X)−L1‖< δ siempre que 0< ‖X−P‖< δ′ y X ∈ A, pueslımX→PF(X) = L1 enA, y F(X) , L1 si X , P.
Luego 0< ‖X−P‖< δ′ y X ∈ Dom(GF)⊂ A garantizan‖(GF)(X)−L2‖< ε.
Observacion 2.2.3.La condicion F(X) , L1 esta puesta para que no ocurran situaciones ridıculas como lasiguiente: sea f: R→ R la funcion nula (es decir f(x) = 0 para todo x∈ R) y sea
g(x) =
1 si x, 00 si x= 0
Entonces g f (x) = 0 para todo x∈ R, con lo cual
lımx→0
(g f )(x) = 0.
Pero el lımite de gnoes cero, pueslımx→0
g(x) = lımx→0
1= 1.
Con el teorema previo, se pueden calcular algunos lımites de funcionesg : Rn → R de manera muysencilla, si uno descubre la composicion.
Ejemplo 2.2.4. 1. Como lım(x,y,z)→(0,0,0)
x2+ y+ z= 0, entonces
lım(x,y,z)→(0,0,0)
sen(x2+ y+ z)x2+ y+ z
= 1.
2. Como lım(x,y,z)→(3,2,1)
exycos(x2) ln(z) = 0, se tiene
lım(x,y,z)→(3,2,1)
(
1+exycos(x2) ln(z))1/exycos(x2) ln(z)
= e.

42 Funciones
2.2.2. Curvas y el lımite
Un caso particular (y bastante importante) de funcionF : Rn →Rm son las curvas, que es lo que se tienecuandon= 1.
Que exista el lımite de una funcionF : Rn →Rm a lo largo de una trayectoria, no garantiza que el lımitevaya a existir. Pero, de acuerdo al Teorema2.2.2, si el lımite existe entonces el lımite de la composiciontieneque dar lo mismo,independientementede con que curva uno componga. Tenemos entonces la siguienteherramienta util:
Observacion 2.2.5. Sea F: A ⊂ Rn → Rm. Seanα : I → A y β : J → A dos curvas enRn tales quelımt→t0 α(t) = P y lımt→t1 β(t) = P. Supongamos ademas queα(t) , P para t, t0 y β(t) , P para t, t2.Entonceslımt→t0 F(α(t)) , lımt→t1 F(β(t)) implica queno existe el lımite lımX→P F(X).
Ejemplo 2.2.6. Sea f(x,y) = x2+y2
x2−y2 , y P= (0,0). Consideremos la curvaα(t) = (t,mt), que es una recta dependiente m∈R por el origen. Observemos que el denominador de f se anula a lolargo de las rectas y= x,y=−x, por lo que hay que excluir las posibilidades m=±1. Calculemos el lımite de la composicion, paracada m,±1:
lımt→0
f (α(t)) = lımt→0
t2+(mt)2
t2− (mt)2 = lımt→0
t2
t2
1+m2
1−m2 =1+m2
1−m2 .
Esto prueba que el lımite lım(x,y)→(0,0) f (x,y) no existe, pues si nos acercamos a lo largo del eje x (conm= 0), el lımite de la composicion da1, mientras que si nos acercamos a lo largo de la recta y= 2x (conm= 2), el lımite de la composicion da−5/3.
Dom( f )Dom( f )
y=0 (m=0)
y=2x (m=2)
lımt→0
f (t,0)=1 lımt→0
f (t,2t)=− 53
Ejemplo 2.2.7. Una funcion tal que Dom(g) , R2.

2.2 FuncionesF : Rn →Rm 43z
y= x2
Dom( f )
Sea g(x,y) = x2+yx2−y
, P= (0,0). Con-
sideremosα(t) = (t,mt) como an-tes. El denominador de f se anulaen la parabola y= x2, pero si t eschico (y, 0) la recta y=mx no cor-ta la parabola.
Para cada m∈ R:
lımt→0
f (α(t)) = lımt→0
t2+mtt2−mt
= lımt→0
tt
(
t +mt −m
)
=−1.
¡Esto no nos sirve! ¿Podrıa ser que el lımite exista? Probemos con algunas trayectorias mas. Nos falto con-siderar, entre las rectas, el eje y. Para esto tomamosβ(t) = (0, t). Se tiene
lımt→0
f (β(t)) = lımt→0
0+ t0− t
=−1
tambien; seguimos sin saber si el lımite existe o no. Mirando la funcion, vemos que el numerador se anula alo largo de la curva y=−x2. Esto nos da una pista, tomamosγ(t) = (t,−t2). Entonces
lımt→0
f (γ(t)) = lımt→0
t2− t2
t2+ t2 = lımt→0
0= 0.
Esto prueba que el lımite lım(x,y)→(0,0) f (x,y) no existe.
2.2.3. Lımite y sucesiones
¿Se pueden usar sucesiones para calcular lımites?
Proposicion 2.2.8. Sea F: A⊂ Rn → Rm. Sean P∈ A y L∈ Rm. Las siguientes afirmaciones son equiva-lentes:
1. lımX→P
F(X) = L
2. Paratodasucesion de puntos Pk ∈ A tal que Pk , P y Pk → P, se tienelımk F(Pk) = L.
Demostracion. 1 ⇒ 2) Supongamos que lımX→P
F(X) = L, y tomemosPk una sucesion de puntos delA que
tiende aP. Entonces por la definicion de lımite de funcion dadoε > 0 existeδ > 0 tal que
0< ‖X−P‖< δ y X ∈ A implican ‖F(X)−L‖< ε.
ComoPk , P, claramente vale 0< ‖Pk−P‖. Si tomamosk0 ∈N tal quek ≥ k0 implique‖Pk−P‖< δ, elrenglon de arriba nos garantiza que‖F(Pk)−L‖ < ε. O seaF(Pk)→ L de acuerdo a la definicion de lımitede sucesiones, aplicado a la sucesionQk = F(Pk).
2⇒ 1) Razonemos por el absurdo. Negar que lımX→P F(X) = L es decir que existeε > 0 tal que paratodo δ > 0 existeX ∈ A con 0< ‖X −P‖ < δ y ‖F(X)− L‖ ≥ ε. Tomemosδ = 1
k , conk ∈ N, y seaPk
el punto correspondiente. Vemos quePk → P y Pk , P, pero por otro lado‖F(Pk)− L‖ ≥ ε, con lo cualF(Pk) 6→ L, contradiciendo la hipotesis.

44 Funciones
Es decir que ”usar sucesiones” no es muy practico porque no basta probar con una. Sin embargo, usarsucesiones sı sirve para ver que el lımiteno existe. La idea es la misma que la de las trayectorias.
Observacion 2.2.9. SeanPk y P′k dos sucesiones de puntos de A, tales que ambas tienden a P, y las
sucesiones Qk = F(Pk) y Q′k = F(P′
k) tienen lımites distintos, entoncesno existeel lımite lımX→P
F(X).
Aquı hay que hacer la salvedad, al igual que en el caso de las curvas, de que esto vale siempre quePk yPk sean distintos deP, al menos parak suficientemente grande.
Ejemplo 2.2.10. Si f(x,y) = x+yx−y , se tiene Dom( f ) = (x,y) : x, y. Veamos que no existe
lım(x,y)→(0,0)
f (x,y).
Tomando Pk = (1k ,0) y P′
k = (0, 1k) se observa que ambas son sucesiones del dominio que tienden acero.
Pero lımk f (Pk) = lımk1/k+01/k−0 = 1, y por otro ladolımk f (P′
k) = lımk0+1/k0−1/k =−1.
Y de la Proposicion2.2.8tambien se desprende el siguiente hecho mas o menos obvio,que nos permitemirar cada coordenada por separado.
Corolario 2.2.11. Sea F: A → Rm, con A⊂ Rn. Sean L∈ Rm, P ∈ A. Entonces F tiende a L cuandoX → P si y solo si cada coordenada de F converge a la coordenada correspondiente de L. Es decir, siF = ( f1, f2, · · · , fm) y L= (l1, l2, · · · , lm), entonces
lımX→P
F(X) = L ⇐⇒(
lımX→P
f j (X) = l j para cada j= 1. . .m)
.
Y desde este momento siempre que tengamos una funcionF : Rm → Rm, siempre podemos chequearcada coordenada por separado.
Lımites infinitos
Se definen en forma analoga al caso real los lımites ”en infinito” y los lımites ”que dan infinito”.
Definicion 2.2.12.Lımites infinitos. Sea F: A⊂ Rn → Rm, L ∈ Rm y P∈ A.
1. Decimos quelımX→∞
F(X) = L en A si paratoda sucesion Xk de A que tiende a infinito se tiene
lımk F(Xk) = L.
Equivalentemente, dadoε > 0 existe M> 0 tal que
‖X‖> M y X ∈ A implican ‖F(X)−L‖< ε.

2.3 Continuidad 45
2. Decimos quelımX→P F(X) = ∞ en A (o que Fdivergecuando X→ P) si para cualquier sucesionXk de A tal que Xk → P, se tienelımk F(Xk) = ∞.
Equivalentemente, dado M> 0 existeδ > 0 tal que
0< ‖X−P‖< δ y X ∈ A implican ‖F(X)‖ ≥ M.
2.3. Continuidad
La nocion de continuidad es identica al caso conocido en una variable. Necesitamos que tomar lımitecoincida con evaluar.
Definicion 2.3.1. Sean F: A⊂ Rn →Rm y P∈ A.
1. Decimos que Fes continua enP si lımX→P F(X) = F(P).
2. Decimos que Fes continua enA si F es continua en P para todo P∈ A.
Probar que una funcion es continua enP, es asegurarse de que la diferencia‖F(X)−F(P)‖ se puedehacer tan chica como uno quiera, pidiendo que‖X−P‖ sea pequeno.
Observacion 2.3.2.Es importante observar que, a diferencia de los lımites en general, el punto P debe estaren el conjunto A donde F esta definida, para poder calcular F(P). Eso no quita que, dado P∈ ∂A, podamospreguntarnos si la funcion se puede extender (redefinir) en el punto P de manera que quede continua. Estolo podremos hacer si y solo si el lımite lım
X→PF(X) existe en A. En ese caso diremos que la discontinuidad en
P esevitable.
Observacion 2.3.3. Puesto que el lımite se calcula en cada coordenada por separado, se tiene que F =( f1, · · · , fm) es continua en P= (p1, · · · , pm) si y solo si cada fj : A→ R es continua en P, y tambien que Fes continua en A si cada fj es continua en A.
Dado que el lımite de una composicion es la composicion delos lımites (Teorema2.2.2),
Teorema 2.3.4.Sean F: A ⊂ Rn → Rm y G : B ⊂ Rm → Rk funciones continuas. Entonces GF es unafuncion continua en Dom(GF) = X ∈ A : F(X) ∈ B.
2.3.1. Propiedades de las funciones continuas
En toda esta seccion,f : A⊂ Rn → R, y P∈ A.
Probemos un par de propiedades sencillas que nos van a resultar utiles mas adelante. La primera diceque si f (X) ≥ 0, entonces lımf (X) ≥ 0. La segunda dice que si una funcion continua es no nula, hayunentorno donde no se anula, y se deduce de la primera.

46 Funciones
Lema 2.3.5. Supongamos que f es continua en P. Entonces
1. SiXk es una sucesion tal que Xk →k P en A, y f(Xk)≤ 0 para todo k∈N, entonces f(P)≤ 0.
2. SiXk es una sucesion tal que Xk →k P en A, y f(Xk)≥ 0 para todo k∈N, entonces f(P)≥ 0.
3. Si f(P)> 0, entonces existe r> 0 tal que si U= Br(P)∩A, se tiene f(X) > 0 para todo X∈U.
4. Si f(P)< 0, entonces existe r> 0 tal que si U= Br(P)∩A, se tiene f(X) < 0 para todo X∈U.
Demostracion. El ıtem 1. lo probamos por el absurdo. Si fueraf (P)> 0, tomamosε = f (P)2 , y existe enton-
cesk0 ∈N tal quek≥ k0 implica | f (Xk)− f (P)|< f (P)2 . Es decir,
− f (P)2
< f (Xk)− f (P)<f (P)
2.
Despejando del lado izquierdo se obtienef (Xk)>f (P)
2 > 0 si k≥ k0 lo cual contradice la hipotesis.
El ıtem 2. tiene una demostracion analoga, es un buen ejercicio esciribirlo.
El ıtem 3. tambien lo probamos por el absurdo: supongamos que para todok∈N existeXk ∈ B1k(P)∩A
tal que f (Xk) ≤ 0. EntoncesXk → P enA y por ser f continua enP, 0< f (P) = lımk f (Xk) ≤ 0, lo cual esimposible (en la ultima desigualdad usamos el ıtem previo). La demostracion de 4. es analoga.
Definicion 2.3.6. 1. Un conjunto A⊂ Rn esacotadosi es acotado en norma, es decir, existe M> 0 talque‖X‖ ≤ M para todo X∈ A.
2. Un conjunto K⊂ Rn cerrado y acotado es un conjuntocompacto.
3. Un conjunto A⊂ Rn esarcoconexosi dados P,Q∈ A existe una curva continuaα : [0,1]→ A tal queα(0) = P yα(1) = Q.
Observacion 2.3.7. Por la desigualdad
|xi | ≤ ‖X‖ ≤√
n maxi=1...n
|xi |
se deduce que un conjunto A es acotado si y solo si cada una de sus coordenadas esta acotada.
Recordemos el teorema del valor medio en una variable:
Teorema 2.3.8.(Bolzano) Si f: [a,b]→ R es continua, y f(a) f (b) < 0, entonces existe c∈ (a,b) tal quef (c) = 0.
Demostracion. Supongamos quef (a)> 0 y f (b)< 0. SeaA= x∈ [a,b] : f (x)> 0, que es no vacıo (puesa∈ A). ComoA⊂ [a,b], esta acotado superiormente ası que tiene supremos= supA. Existe una sucesioncrecientean de puntos deA que tiende as∈ [a,b]. Como f (an) > 0 (puesan ∈ A), el ıtem 1 del Lema2.3.5nos dice que debe serf (s) ≥ 0. Afirmo que f (s) = 0. Si no fuera ası, serıaf (s) > 0. Pero entonces elıtem 3 del mismo lema nos dice que hay un entorno desde la pinta(s− r,s+ r)∩ [a,b], tal quef (x)> 0 allı.
Comos< b puesf (b)< 0, podemos tomarx0 ∈ [a,b] tal quex0 ∈ (s,s+ r). Estex0 ∈ A y es mayor queel supremo, lo que es imposible. Debe ser puesf (s) = 0.

2.3 Continuidad 47
Teorema 2.3.9. (Bolzano) Sea f: A ⊂ Rn → R. Supongamos que existen P,Q ∈ A tales que f(P) < 0 yf (Q)> 0. Si A es arcoconexo y f es continua, entonces existe R∈ A tal que f(R) = 0.
Demostracion. Por serA arcoconexo existeα : [0,1]→ A continua conα(0) = P y α(1) = Q. Consideremosg : [0,1]→R la composiciong(t) = f α(t), que es una funcion continua por ser composicion de funcionescontinuas. Se tieneg(0) = f (P) < 0 y g(1) = f (Q) > 0. Por el teorema del valor medio en una variable,existec∈ (0,1) tal queg(c) = 0. SiR= α(c), entoncesR∈ A y ademasf (R) = f (α(c)) = g(c) = 0.
Y se tienen los corolarios habituales,
Corolario 2.3.10. Sea f: A⊂ Rn → R continua. Supongamos que A es arcoconexo. Entonces
1. Dados P,Q∈ A, f toma todos los valores intermedios entre f(P) y f(Q).
2. Sean P∈ A y Q∈ A. SilımX→Q f (X) = l y f (P) < l, entonces[ f (P), l) ⊂ Im( f ).
Demostracion. Para probar 1, supongamosf (P)< f (Q) (si son iguales no hay nada que probar). Tomemosc∈ [ f (P), f (Q)] y consideramosfc : A→ R dada porfc(X) = f (X)− c. Entoncesfc(P) = f (P)− c< 0 yfc(Q) = f (Q)−c> 0. Ademasfc es continua, ası que por el teorema anterior existeR∈ A tal quefc(R) = 0.Esto esf (R)− c= 0, es decirf (R) = c.
Para probar 2, tomemosc∈ ( f (P), l). Observemos que como lımX→Q f (X) = l , existe una sucesionXk
de puntos deA tales que, dadoε = l − c> 0, si k ≥ k0 entonces| f (Xk)− l | < ε = l − c. Desarmando estemodulo se tiene−(l − c) < f (Xk)− l < l − c, y considerando solo el lado izquierdo se tienec < f (Xk).TomemosQ′ = Xk0 ∈ A. Entoncesf (Q′)> c, y como f (P)< c por el ıtem 1. se tiene quec∈ Im( f ).
Teorema 2.3.11.(Weierstrass) Si A es un conjunto compacto deRn, y f es continua en A, entonces exis-ten m,M ∈ R tales que m≤ f (X) ≤ M para todo X∈ A. Ademas, existen Pm,PM ∈ A tales que f(Pm) =mın f (X) : X ∈ A y f(PM) = max f (X) : X ∈ A.
Demostracion. Supongamos primero quef no es acotada. Si no existeM tal quef (X)≤ M, entonces existeuna sucesion de puntosXk ∈ A tal que f (Xk)≥ k para todok∈N. ComoA es cerrado y acotado,Xk tieneuna subsucesion convergenteXkj, tal queXkj → j P∈ A. Se tienef (Xkj )≥ k j , y como f es continua enP,esto es imposible. De la misma manera se prueba que existem∈R tal quem≤ f (X).
Ahora veamos quef alcanza sus valores maximo y mınimo enA. Como Im( f ) ⊂ [m,M], Im( f ) esun conjunto acotado deR. En particular es acotado superiormente, luego tiene supremo s. Veamos que enrealidad es un maximo, es decir veamos que existePM ∈ A tal que f (PM) = s. Para ello, tomamos unasucesion creciente de puntos deIm( f ) que tienda al supremo. Tenemos entonces que existe una sucesion depuntosXk enA tales que lımk f (Xk) = s. De la sucesionXk extraemos una subsucesion convergenteXkj ,y llamamos al lımitePM (que es un punto deA). Se tienef (PM) = lım j f (Xkj ) = s por ser f continua. Deforma analoga se prueba quef alcanza su valor mınimo, construyendo una sucesion de puntos que tienda alınfimo deIm( f ).
Corolario 2.3.12. Sea F: A⊂ Rn → Rm continua. Si A es compacto, entonces F(A)⊂ Rm es compacto.

48 Funciones
Demostracion. ComoF = ( f1, · · · , fm), y cadafi es continua, por el teorema anterior cada coordenada delconjuntoF(A) esta acotada, y en consecuenciaF(A) es acotado. Por otro lado, siQ∈ F(A), existeXk ∈ Auna sucesion de puntos tal queF(Xk)→ Q enRm. Extraemos deXk una subsucesion convergenteXkj a unpuntoP∈ A. Se tiene, por la continuidad deF,
Q= lımj
F(Xkj ) = F(lımj
Xkj ) = F(P).
Esto prueba queQ∈ F(A), y por lo tantoF(A) es cerrado.
2.3.2. Caracterizacion de las funciones continuas
Se tiene la siguiente caracterizacionF es continua si y solo si la preimagen de cualquier abierto esun abierto relativo, con mas precision:
Teorema 2.3.13.Sea F: A⊂ Rn → Rm. Entonces F es continua si y solo si para todo abierto W⊂ Rm, elconjunto
F−1(W) = X ∈ A : F(X) ∈Wse puede escribir como la interseccion A∩U de un conjunto U⊂ Rn abierto, con el conjunto A.
Demostracion. Supongamos queF es continua, tomemosW abierto enRm. TomemosP tal queF(P) ∈W,es decir,P∈ F−1(W). ComoW es abierto, existerP > 0 tal queBrP(F(P))⊂W. ComoF es continua, dadoesterP > 0 existeδP > 0 tal que‖X−P‖< δP, X ∈A, implican‖F(X)−F(P)‖< rP. Es decir, existeδP > 0tal queX ∈ A∩BδP
(P) implica F(X) ∈ BrP(P)⊂W. Dicho de otra forma,F(BδP(P)∩A) ⊂W. Como esto
se puede hacer para cualquierP∈ F−1(W), podemos tomarU = ∪P∈F−1(W)BδP(P) que por ser de union de
abiertos es abierto, y se tieneF−1(W) =U ∩A
como querıamos.
La otra implicacion es similar, queda como ejercicio.
2.3.3. Continuidad uniforme
Para terminar, una definicion y un teorema
Definicion 2.3.14.Decimos que una funcion f : A⊂ Rn → Rm esuniformemente continuasi dadoε > 0,existeδ > 0 tal que X,Y ∈ A y‖X−Y‖< δ implican‖F(X)−F(Y)‖< ε.
La definicion nos dice que pequenos movimientos en el dominio provocan pequenos movimientos en laimagen, independientemente de en que punto hagamos estos movimientos.
Observacion 2.3.15. Una funcion uniformemente continua es continua, puesto que dado P∈ A, y ε >0, se tiene por la definicion que existeδ > 0 tal que‖X −P‖ < δ implica ‖ f (X)− f (P)‖ < ε. Es decir,lımX→P f (X) = f (P).
Observemos sin embargo, que es habitual para funciones continuas el hecho siguiente: dadoε, el δnecesario para conseguir‖F(X)− l‖ < ε puede depender no solo de ε, sino tambien del punto P encuestion. Un ejemplo sencillo de funcion continua que no es uniformemente continua es el siguiente.

2.4 Problemas 49
Ejemplo 2.3.16. Tomemos f(x) = x2 en el intervalo(0,+∞). Entonces si f fuera uniformemente continua,dadoε = 2 existirıa δ > 0 tal que si x,y > 0 y |x− y| < δ, entonces|x2− y2| < 2. Pero si tomamos y= 2
δ ,
x= y+ δ2 (que verifican las hipotesis), entonces
|x2− y2|=∣
∣
∣
∣
(y+δ2)2− y2
∣
∣
∣
∣
= 2+δ2
4≥ ε = 1.
Sin embargo, en dominios cerrados y acotados, no hay distincion, pues
Teorema 2.3.17.(Heine-Cantor) Si F: A⊂ Rn → Rm es continua y A es compacto, entonces F es unifor-memente continua.
Demostracion. Si F no fuera uniformemente continua, existirıaε > 0 tal que para cadak∈N existirıanXk
eYk enA tales que‖Xk−Yk‖< 1k , pero
‖F(Xk)−F(Yk)‖ ≥ ε. (2.2)
ComoA es compacto, se tiene una subsucesionXkj convergente a un puntoX ∈ A. Observemos que
‖Ykj −X‖ ≤ ‖Ykj −Xkj‖+ ‖Xkj −X‖< 1k j
+ ‖Xkj −X‖,
luego debe ser tambienYkj → j X. ComoF es continua, lımj F(Xkj ) = lım j F(Ykj ) = F(X). Pero esto contra-dice la desigualdad (2.2).
2.4. Problemas
2.I. Graficar las curvas de nivel de las siguiente funciones y hacer un dibujo aproximado deGr( f )⊂ R3.
f (x,y) = x2− y2
f (x,y) = 2x+3y
2.II. SeaP∈ A⊂ Rn y f : A→R una funcion continua enP.
Suponiendo queXk es una sucesion de puntos enA que tiende aP, y f (Xk) ≥ 0 para todok ∈N,probar quef (P)≥ 0.
Suponiendo quef (P)< 0, probar que exister > 0 tal que siU =Br(P)∩A, entonces se tienef (X)< 0para todoX ∈U .
2.III. Seaf : A→ Rk conA⊂ Rn arcoconexo. Probar que sif es continua, entoncesIm( f ) = f (A) ⊂ Rk esarcoconexo. En particular, sik= 1, la imagen def debe ser un intervalo.
2.IV. SeaK ⊂ Rn un compacto conexo. Sif : K → R es continua, probar queIm( f ) es un intervalo cerrado[a,b]. ¿Quienes sona,b?
2.V. SeaF : A ⊂ Rn → Rk. Supongamos que para todo abiertoW ⊂ Rk, existeU ⊂ Rn abierto tal queF−1(W) = A∩U . Probar quef es continua.

50 Funciones

Considero aquı las magnitudes matematicas nocomo compuestas de partesextraordinariamente pequenas, sino comodescritas por el movimiento continuo
Sir Isacc Newton
3.1. Derivadas
Empecemos repasando la derivada de una funcion de una variable. Recordemos la idea de “recta quemejor aproxima”, que segun la figura de abajo, es la recta tangente al grafico def .
y
x
y= f ′(a)(x−a)+ f (a)
y= f (x)
a
f (a)
Para armar una recta, hacen falta dos puntos distintos del plano. O un punto del plano y la pendiente.Entonces fijando(a, f (a)), hallamosm= f ′(a) de la siguiente manera. Tomamos otro puntox ∈ Dom( f ),construimos la recta secante

52 Derivadas y Diferencial
y
x
y= f (x)
a
f (a)
f (x)
∆x
∆y
m= ∆y∆x
x→a−→ f ′(a)
La pendiente de esta secante depende dex y a, es
∆y∆x
=f (x)− f (a)
x−a
Si hacemos tenderx al puntoa, se obtiene (si existe el lımite) la pendiente de la recta deseada, y por lo tantolas pendientes de arriba tienden a la pendiente de la recta tangente, con lo cual
f ′(a) = lımx→a
f (x)− f (a)x−a
.
O sea existe la derivada si y solo si existe el lımite de los cocientes incrementales. Y decimos que ”f esderivable ena”. Con el cambio de variableh= x−a se puede escribir
f ′(a) = lımh→0
f (a+h)− f (a)h
.
Recordemos tambien la ecuacion de la recta tangente al gr´afico def enx= a, que es
y= f ′(a)(x−a)+ f (a),
que en forma parametrica es simplemente
La : (a, f (a))+λ(1, f ′(a)),
puesto que la pendiente de la recta tangente debe ser∆y∆x = f ′(a)
1 = f ′(a). Esto nos dice que un incrementoen una unidad en el dominio, nos produce un incremento def ′(a) unidades en la imagen.
Por su parte, la recta normal pasa por el mismo punto segun indica el grafico
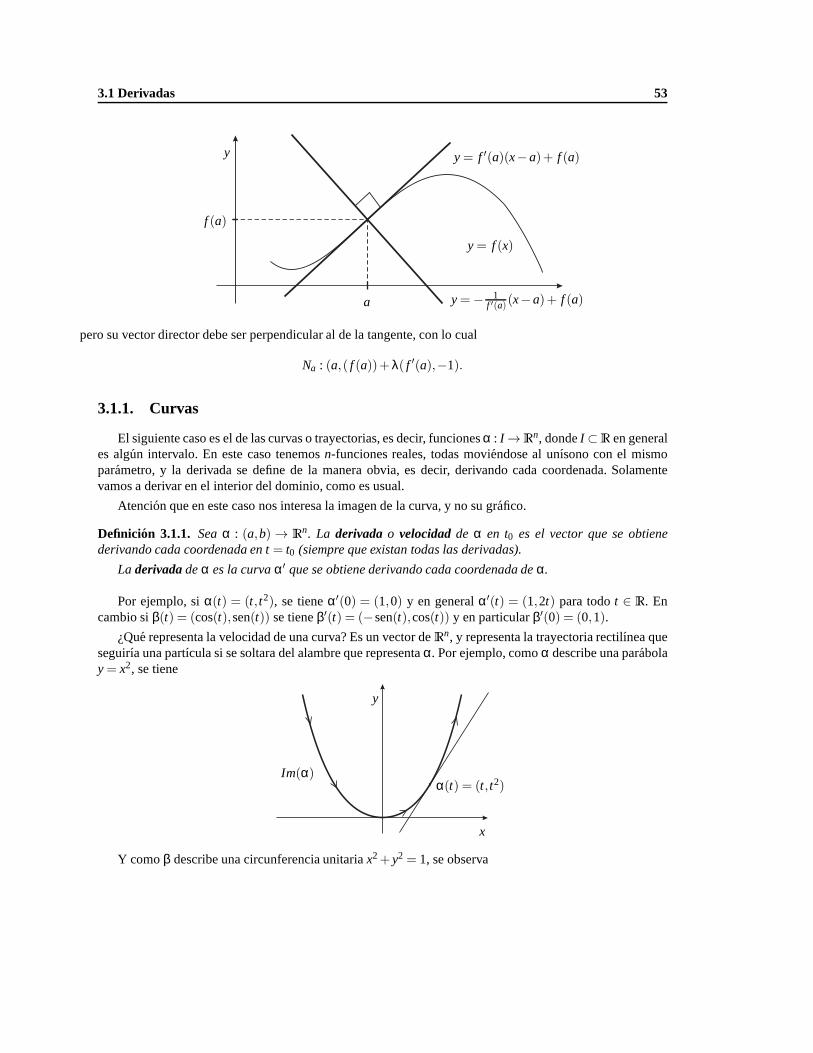
3.1 Derivadas 53
y y= f ′(a)(x−a)+ f (a)
y=− 1f ′(a)(x−a)+ f (a)
y= f (x)
a
f (a)
pero su vector director debe ser perpendicular al de la tangente, con lo cual
Na : (a,( f (a))+λ( f ′(a),−1).
3.1.1. Curvas
El siguiente caso es el de las curvas o trayectorias, es decir, funcionesα : I →Rn, dondeI ⊂R en generales algun intervalo. En este caso tenemosn-funciones reales, todas moviendose al unısono con el mismoparametro, y la derivada se define de la manera obvia, es decir, derivando cada coordenada. Solamentevamos a derivar en el interior del dominio, como es usual.
Atencion que en este caso nos interesa la imagen de la curva,y no su grafico.
Definicion 3.1.1. Seaα : (a,b) → Rn. La derivadao velocidadde α en t0 es el vector que se obtienederivando cada coordenada en t= t0 (siempre que existan todas las derivadas).
La derivadadeα es la curvaα′ que se obtiene derivando cada coordenada deα.
Por ejemplo, siα(t) = (t, t2), se tieneα′(0) = (1,0) y en generalα′(t) = (1,2t) para todot ∈ R. Encambio siβ(t) = (cos(t),sen(t)) se tieneβ′(t) = (−sen(t),cos(t)) y en particularβ′(0) = (0,1).
¿Que representa la velocidad de una curva? Es un vector deRn, y representa la trayectoria rectilınea queseguirıa una partıcula si se soltara del alambre que representaα. Por ejemplo, comoα describe una parabolay= x2, se tiene
y
x
Im(α)α(t) = (t, t2)
Y comoβ describe una circunferencia unitariax2+ y2 = 1, se observa

54 Derivadas y Diferencial
y
x
1
Im(β)
β(t) = (cos(t),sen(t))
Por supuesto que la derivada en realidad representa el vector director, que nosotros dibujamos pinchadoen el punto correspondiente. La recta tangente a la curva tiene en general ecuacion
Lt0 : α(t0)+λα′(t0). (3.1)
Hay que tener presente que el grafico de una funcionf : R→R, que es el conjunto
Gr( f ) = (x, f (x)) : x∈ Dom( f ) ⊂ R2
se puede parametrizar siempre con la curvaα(x) = (x, f (x)), dondeα : Dom( f )→R2. Esta curva sera deri-vable ena si y solo si f es derivable ena, y su recta tangente coincide por supuesto con la recta tangente algrafico def en el punto(a, f (a)).
Observacion 3.1.2. Cambiemos el punto de vista. Supongamos que queremos dar la ecuacion de la rectatangente al grafico de f: R→R, pero en forma parametrica, es decir como en la ecuacion (3.1). Entoncesse tiene en cuenta que el grafico de f se puede parametrizar con la curvaα(x) = (x, f (x)) con x∈ Dom( f )como mencionamos antes. Y por lo tanto, si f es derivable, la derivada esα′(x) = (1, f ′(x)). Con lo cual
La : α(a)+λα′(a) = (a, f (a))+λ(1, f ′(a)).
Es fundamental observar que la primer coordenada del vectorderivada es constantemente uno, mientrasque la segunda coordenada expresa la razon de cambio, pues∆y/∆x= f ′(a)/1= f ′(a). Es decir, que porcada unidad que avanzamos en el eje de las x, se avanza f′(a) unidades en el eje de las y. Estoultimo, porsupuesto, es una aproximacion, y solo es exacta esta afirmacion cuando f es una recta, con lo cual coincidecon su recta tangente.
Resumiendo, el vector derivada nos dice cuanto hay que moverse en y por cada unidad que nos movemosen x, si nos movemos desde el punto(a, f (a)), pero a lo largo de la recta tangente al grafico de f en esepunto.
Se deduce de lo anterior que un vector normal al grafico de f es( f ′(a),−1), pues como
〈(1, f ′(a)),( f ′(a),−1)〉= f ′(a)− f ′(a) = 0,
se concluye que son ortogonales. Observemos que esta escritura es valida incluso en el caso f′(a) = 0,donde se obtiene el vector normal(0,1).

3.1 Derivadas 55
3.1.2. Derivadas direccionales
Supongamos que tenemos una funcionf : R2 →R, como por ejemplo
f (x,y) =√
1− x2− y2.
El dominio de esta funcion es la bola cerrada unitaria en el plano, centrada en el origen
Dom( f ) = B1(O) = (x,y) ∈R2 : x2+ y2 ≤ 1.
Si miramos las curvas de nivel,z= cte, debe serz≥ 0 puesz esta igualado a una raız cuadrada. Es decir elgrafico esta por sobre el piso. Ademas comoz2
0 = 1−x2−y2, se tienex2+y2 = 1−z20 lo que nos indica que
debe serz0 ≤ 1. Las curvas de nivel son circunferencias como se puede observar, pero podemos decir mas:comox2+ y2+ z2
0 = 1, esto nos dice que‖(x,y,z0)‖= 1.
Entonces los puntos estan sobre la cascara de la esfera unitaria centrada en el origen. Pero es solo el casquetesuperior, pueszdebe ser positivo. El grafico def es entonces una media esfera
yx
z
Pensemos que pasa si nos movemos a lo largo de una trayectoria en la esfera. Si en algun momento lafuerza que nos sostiene atados a la superficie se rompe, lo queocurrirıa es que saldrıamos disparados enlınea recta, en forma tangente a la esfera (¿es esto intuitivo?). Pero dado un puntoP en la esfera, hay muchasdirecciones tangentes. Se puede ver que forman un plano, quese denominaplano tangente
yx
z
las rectas tangentes a la semi-esfera,en un punto dado, forman un plano
Ahora tomemosg(x,y) =√
x2+ y2. Las curvas de nivel son nuevamente circunferencias, el gr´aficosolo existe paraz≥ 0. Cortando con los planosx = 0 e y = 0 se obtienen las ecuacionesz= |y|, z= |x|respectivamente. Estamos en presencia de un cono, como ya discutimos con anterioridad.

56 Derivadas y Diferencial
yx
z
o ?
Si nos movemos en esta superficie cerca de un punto que no sea elvertice, nuevamente direccionestangentes forman (al menos eso imaginamos) un plano. Exceptuando el origen. Allı, si uno dibuja algunasrectas tangentes, lo que observa es nuevamente un cono. Es decir, no hay plano tangente en el origen. Esmas, si uno mira cuidadosamente una direccion y ambos sentidos, obtiene distintas rectas como en el casode la funcion real modulof (x) = |x|. De hecho, en el verticeno hayrectas tangentes, ya que, como sabemos,la funcion f (x) = |x| no tiene derivada en el origen. Dicho de otra manera, las derivadas laterales
lımx→0+
f (x)− f (0)x−0
= 1 y lımx→0−
f (x)− f (0)x−0
=−1
no coinciden, por mas que cada una de ellas existe por separado.
Pongamos un poco de precision a estas ideas graficas.
Definicion 3.1.3. Sea V∈ Rn, ‖V‖= 1. Sea f: A⊂ Rn →R, y P∈ Ao. El lımite
lımt→0
f (P+ tV)− f (P)t
(si existe) es laderivada direccional def enP en la direccion deV. Lo anotamos
∂ f∂V
(P) o bien fV(P).
Observemos quefV(P) (si existe) es un numero real.¿Que paso con nuestra intuicion grafica? Es sencillo, bas-ta recordar el cason= 1. Allı, la definicion nos da en elpuntox = a un numero real que representa la pendientede la recta tangente al grafico def en el punto(a, f (a)).
y
x
m= f ′(a)
y= f (x)
a
f (a)
La recta tangente la armamos sabiendo la pendiente y el puntopor el que pasa. La situacion aquı essimilar. El punto por el que pasa lo tenemos, lo que nos falta es relacionar la derivada direccional∂ f
∂V (P) conel vector director de la recta.

3.1 Derivadas 57
Conviene introducir la siguiente notacion. Usaremos(X,xn+1) para denotar al vector deRn+1 formadopor el vectorX = (x1,x2, · · · ,xn) ∈Rn en las primerasn coordenadas, y el numeroxn+1 en la ultima.
Si P∈ Ao y ‖V‖= 1, en el dominio def el vectorP+ tV se representa ası:
P
Ao
P+ tV
O
tV
Y lo que que estamos haciendo cuando calculamos
f (P+ tV)− f (P)
es calcular la diferencia de alturas def segun el siguiente grafico:
Gr( f )=(X, f (X)):X∈A
P
Ao P+tV
(P+tV, f (P+tV)) (P, f (P))
Si dividimos port y hacemos tendert a cero, tendremos la derivada direccional en la direccion de V.Antes de hacerlo, pensemos cual es la ecuacion parametrica de las rectas secantes. El punto por el que pasantodas esP. Y el vector director es, como se observa del grafico, el vector que une los puntos(P, f (P)) con(P+ tV, f (P+ tV)). Entonces el vector que nos interesa (el vector director de la recta tangente) es
lımt→0
1t[(P+ tV, f (P+ tV))− (P, f (P))] = lım
t→0
(
P+ tV−Pt
,f (P+ tV)− f (P)
t
)
,

58 Derivadas y Diferencial
es decir(
V,∂ f∂V
(P)
)
.
Esta ecuacion, aunque la dedujimos del grafico de una funcion particular, es completamente general, y nosdice que la recta tangente se arma formando el vector deRn+1 dado porV en las primerasn coordenadas yla derivada direccional (que es un numero) en la ultima. Esdecir su ecuacion parametrica es
LP,V : (P, f (P))+λ(V, fV(P)) .
Observacion 3.1.4. Observemos que en el caso de una funcion f : R → R, dado un punto del dominioP= a∈R, hay solo dos vectores de norma unitaria para considerar, que son el V = 1 y V =−1. Si usamosV = 1, obtenemos
∂ f∂V
(P) = lımt→0
f (a+ t1)− f (a)t
= f ′(a),
con lo cual(
V,∂ f∂V
(P)
)
= (1, f ′(a)),
que es el vector que obtuvimos al escribir la recta tangente en forma parametrica. Mientras que si usamosV =−1, obtenemos
∂ f∂V
(P) = lımt→0
f (a+ t(−1))− f (a)t
= lımt→0
f (a− t)− f (a)t
.
En estaultima cuenta podemos hacer el cambio de variable t=−h con lo que se obtiene
∂ f∂V
(P) = lımh→0
f (a+h)− f (a)−h
=− f ′(a).
Con lo cual(
V,∂ f∂V
(P)
)
= (−1,− f ′(a)),
pero la recta tangente es la misma por ser esteultimo vector multiplo del primero. Esto podrıamos haberlodeducido sin hacer ninguna cuenta, del solo hecho de que si f es derivable entonces hay una sola rectatangente.
3.1.3. Derivadas parciales
Vamos a denotar conEi (i = 1. . .n) a los vectores de la base canonica deRn, es decirE1 = (1,0,0, · · · ,0),E2 = (0,1,0, · · · ,0), . . . ,En = (0,0, · · · ,1). Para abreviar, vamos a usar la siguiente notacion.
Definicion 3.1.5.Sea Ei ∈Rn, f : A⊂Rn →R, P∈Ao. La i-esima derivada parcialde f en P es la derivadadireccional de f en la direccion de Ei , y la denotamos∂ f
∂xi(P) o bien fxi . Es decir
fxi (P) = lımt→0
f (P+ tEi)− f (P)t
.

3.2 Plano tangente y Diferencial 59
Es decir, las derivadas parciales son las derivadas en las direcciones de los ejes de coordenadas. Ası, porejemplo, sif (x,y) = 3x2+4y y P= (0,0)
∂ f∂x
(0,0) = lımt→0
[1t
3(0+ t1)2+0−0=] lımt→0
3t = 0,
mientras que∂ f∂y
(0,0) = lımt→0
1t[302+4t−0] = lım
t→04= 4.
Si prestamos atencion a la definicion de derivada direccional, vemos que lo unico que hacemos es poner unincremento en la coordenadai-esima. Por ejemplo sin= 3 y tomamosi = 2, se tiene
∂ f∂y
(p1, p2, p3) = lımt→0
f (p1, p2+ t, p3)− f (p1, p2, p3)
t.
Si llamamosg(y) = f (x,y,z), lo que tenemos es una funcion de una sola variable, y de acuerdo a la definicionde derivada para funcionesg : R→ R,
g′(p2) = lımh→0
g(p2+h)−g(p2)
h=
∂ f∂y
(p1, p2, p3).
Es decir que una derivada parcial es simplemente una derivada respecto de una variable dada, que se calculahaciendo de cuenta que todas las demas variables son constantes. Y podemos calcularla en cualquier puntousando las reglas generales
Por ejemplo, sif (x,y) = 3x2+4y, entonces∂ f∂x (x,y) = 6x para cualquier(x,y)∈R2, y tambien∂ f
∂y (x,y) =4.
Hay que hacer la salvedad de que las derivadas existan, y por supuesto, de que los puntos esten en eldominio. El resultado exacto es el siguiente:
Proposicion 3.1.6. Sea f: A⊂ Rn →R, P= (p1, · · · , pn) ∈ Ao. La funcionderivada parcial def respectodexi es la funcion ∂ f
∂xique se obtiene de f de la siguiente manera
∂ f∂xi
(p1, · · · , pn) = lımt→0
f (p1, · · · , pi + t, · · · , pn)− f (p1, · · · , pn)
t
siempre que el lımite exista. Se tiene Dom( ∂ f∂xi
) ⊂ Ao con inclusion estricta si existe algun punto donde noexista el lımite.
3.2. Plano tangente y Diferencial
En general, la existencia de una derivada parcial nos dice que en una direccion dada, el grafico es suave.Pero acercandonos por otras direcciones podrıa tener saltos, y la funcion podrıa no ser continua.
Ejemplo 3.2.1. Un ejemplo a tener en cuenta es el siguiente:
f (x,y) =
x2yx4+y2 si (x,y) , (0,0)
0 si (x,y) = (0,0)

60 Derivadas y Diferencial
Afirmo que existen todas las derivadas direccionales de f en el origen. Tomamos V= (v1,v2) ∈ R2 (con‖V‖= 1), y si v2 , 0 calculamos
lımt→0
f (tv1, tv2)− f (0,0)t
= lımt→0
1t
t3v21v2
t2(t2v41+ v2
2)=
v21v2
v22
=v2
1
v2.
En particular (con V= (0,1)) se tiene fy(0,0) = 0. Falta calcular fx(0,0), que tambien da cero puesto que
fx(0,0) = lımt→0
f (t,0)− f (0,0)t
= lımt→0
0t= 0.
Sin embargo, fno es continua en(0,0) pues si consideramosα(t) = (t, t2), entonces
lımt→0
f α(t) = lımt→0
t2t2
t4+ t4 =12, 0.
¿Como podemos recuperar la idea de que una funcion derivable es una funcion suave, en particularcontinua? El ultimo ejemplo es desalentador ya que contradice la intuicion, al existir en este caso todas lasderivadas direccionales, pero no ser esto garantıa de continuidad.
Lo que haremos sera recurrir a la idea de aproximacion lineal. Para ello, supongamos que tenemos unafuncion f : Rn → R para la cual existen todas sus derivadas parciales. Lo que nos tenemos que preguntar essi estas derivadas forman un hiperplano enRn+1, y si este plano aproxima a la funcion.
El plano en cuestion que queremos considerar es, dadoP∈ Ao, el plano generado por todas las derivadasparciales. Es decir el plano enRn+1 que pasa por el punto(P, f (P)) y esta generado por los siguientesnvectores deRn:
(E1, fx1(P)) , · · · , (En, fxn(P)).
¿Cual es la ecuacion de este plano, que como dijimos es un hiperplano enRn?
Recordemos que para dar un hiperplano deRn+1, basta con dar una ecuacion
〈N,Y−Q〉= 0
dondeN,Q∈Rn+1 estan fijos. Esta ecuacion nos dice que el plano tiene normal N y pasa por el puntoQ.
Observemos que si ponemosNP = ( fx1(P), fx2(P), · · · , fxn(P),−1) ∈ Rn+1 como normal del plano, estaes perpendicular a todos los vectores generados por las derivadas parciales, pues
〈NP,(Ei , fxi (P))〉 = 〈( fx1(P), fx2(P), · · · , fxn(P),−1) , (0, · · · ,0,1,0, · · · ,0, fxi (P))〉= fxi (P)− fxi (P) = 0.
Entonces la ecuacion del plano debe ser
ΠP : 〈NP,(X−P,xn+1− f (P))〉= 0
pues este plano tiene normalNP y pasa por(P, f (P)) = (p1, · · · , pn, f (P)) ∈Rn+1.
Despejando se obtiene la ecuacion

3.2 Plano tangente y Diferencial 61
ΠP : xn+1 = f (P)+ fx1(P)(x1− p1)+ fx2(P)(x2− p2)+ · · ·+ fxn(P)(xn− pn).
Ası por ejemplo sif (x,y) =√
x2+ y2, como
fx(x,y) =x
√
x2+ y2y fy(x,y) =
y√
x2+ y2, (3.2)
dadoP= (x0,y0) , (0,0) se tiene
ΠP : z=√
x20+ y2
0+x0
√
x20+ y2
0
(x− x0)+y0
√
x20+ y2
0
(y− y0).
Por ejemplo si tomamosP= (3,4) entoncesf (P) = 5 con lo cual
ΠP : z= 5+35(x−3)+
45(y−4),
es decirz= 5+ 35x+ 4
5y− 95 − 16
5 = 35x+ 4
5y−5 o lo que es lo mismo
ΠP : 3x+4y−5z= 25.
¿Que pasa en el vertice, es decir, enP = (0,0)? Se tienef (P) = 0, y las formulas (3.2) de las derivadasparciales allı no tienen sentido, pero cuidado que eso no quiere decir que no existan. Las intentamos calcularusando la definicion
fx(0,0) = lımt→0
1t
(√
t2+02−0)
= lımt→0
|t|t
que no existe y lo mismo ocurre confy(0,0). Por lo tanto en este casono hay plano en el vertice del cono,lo cual nos devuelve un poco de la intuicion que queremos desarrollar.
Veamos ahora lo que ocurre con el Ejemplo3.2.1de mas arriba. Como vimos,f no es continua en elorigen. Sin embargo, existıan todas las derivadas direccionales y en particular
∂ f∂x
(O) = 0, y∂ f∂y
(O) = 0.
Con esto, el plano tangente en(0,0) tiene ecuacion
z−0= 0(x−0)+0(y−0)
pues f (0,0) = 0. Es decir, hay un plano, y es el planoz= 0. ¿Como puede ser, si vimos quef no eracontinua?
Lo que veremos es que el problema aquı no es que no haya un plano en P, sino que este plano noaproxima suficientemente bien a la funcion cerca deP.

62 Derivadas y Diferencial
Lo que vamos a pedir es que la distancia entre este planoΠP y la funcion f no solamente tienda a cero(lo cual siempre que haya plano ocurre, puesto que el plano y la funcion se tocan en el punto(P, f (P)) yallı la distancia es cero), sino que la distanciad = d(X) entre ambos como se indica en la figura,
Gr( f )
d
ΠP
(X, f (X))
(P, f (P))
tienda a ceromas rapido que la distancia entreX y P. Es decir, llamandoΠP a una parametrizacion delplano tangente, vamos a pedir que siX → P, entonces
dist(ΠP(X), f (X))
dist(X,P)→ 0.
Cuando esto ocurra diremos quef es diferenciable enP. Recordemos que los puntos del plano tangente (siel plano existe) verifican la ecuacion
xn+1 = f (P)+ fx1(P)(x1− p1)+ · · ·+ fxn(P)(xn− pn).
Veamos la definicion precisa.
Definicion 3.2.2. Sea f: A⊂ Rn →R, P∈ Ao. Si existen las derivadas parciales de f en P, decimos que fes diferenciable enP si
lımX→P
| f (X)− f (P)− fx1(P)(x1− p1)−·· ·− fxn(P)(xn− pn)|‖X−P‖ = 0.
En ese caso a la funcion (x1, · · · ,xn) 7→ fx1(P)x1+ · · ·+ fxn(P)xn la denominamosdiferencial de f en P yla anotamos D fP.
Si A es abierto yf es diferenciable en todos los puntos deA, entonces decimos quef es diferenciableenA.

3.2 Plano tangente y Diferencial 63
Veamos algunos ejemplos. Volvamos al ultimo que nos desconcertaba. El plano tangente enP= (0,0)estaba dado por la ecuacionz= 0. Entonces para quef sea diferenciable enP el siguiente lımite deberıa darcero.
lım(x,y)→(0,0)
| x2yx4+y2 −0−0|
√
(x−0)2+(y−0)2= lım
(x,y)→(0,0)
x2yx4+y2
√
x2+ y2= lım
(x,y)→(0,0)
x2y
(x4+ y2)√
x2+ y2.
Pero tomandoα(t) = (t, t), con t > 0 (o lo que es lo mismo, tomandoy = x, es decir aproximandonos alorigen por la diagonal del primer cuadrante) se tiene
lımt→0+
t2t
(t4+ t2)√
t2+ t2= lım
t→0+
t3
t2(t2+1)√
2|t|= lım
t→0+
1
(t2+1)√
2=
1√2, 0.
Es decir, el lımite no puede ser cero. Con lo cual, de acuerdoa nuestra definicion, la funcionf no esdiferenciable en el origen.
Veamos otro ejemplo. Si tomamosf (x,y) = x2+y2 (el paraboloide), las derivadas parciales sonfx(x,y)=2x, fy(x,y) = 2y. Con lo cual las dos derivadas parciales en el origen existeny son nulas. Entonces el planotangente en el origen es el planoz= 0. Calculamos
lım(x,y)→(0,0)
|x2+ y2−0−0|√
(x−0)2+(y−0)2= lım
(x,y)→(0,0)
x2+ y2√
x2+ y2= lım
(x,y)→(0,0)
√
x2+ y2 = 0,
lo que confirma nuestra intuicion, pues en este caso la funcionsi es diferenciable en el origen.
Observacion 3.2.3. Algunas observaciones y definicionesutiles.
1. Una condicion necesaria para que f sea diferenciable en P es que existan las derivadas parciales def en P. Sin embargo esto no es suficiente, como vimos.
2. Al vector formado por las n derivadas parciales de f en P lo llamamosgradiente def en P, y lodenotamos∇ fP (se lee “nabla” de f ). Es decir
∇ fP = ( fx1(P), · · · , fxn(P)) .
3. La diferencial de f en P (si f es diferenciable) es una transformacion lineal deRn enR, pues segunla definicion
D fP(Y) = 〈∇ fP,Y〉= ∑i=1...n
fxi (P)yi .
4. La ecuacion del plano tangente a f en P es
xn+1 = f (P)+ 〈∇ fP,X−P〉.
5. Se tiene, por la desigualdad de Cauchy-Schwarz,
|D fP(X)|= |〈∇ fP,X〉| ≤ ‖∇ fP‖‖X‖. (3.3)

64 Derivadas y Diferencial
6. Asimismo, con esta notacion, f es diferenciable en P si y solo si
lımX→P
| f (X)− f (P)−〈∇ fP,X−P〉|‖X−P‖ = 0.
7. Si f es diferenciable en P se puede escribir la condicion equivalente
lımX→P
| f (X)− f (P)−D fP(X−P)|‖X−P‖ = 0.
Con la definicion correcta recuperamos la propiedad “si es derivable es continua”, como muestra lasiguiente
Proposicion 3.2.4. Sea f: A⊂ Rn →R, P∈ Ao. Si f es diferenciable en P entonces f es continua en P.
Demostracion. Se tiene
| f (X)− f (P)| ≤ | f (X)− f (P)−D fP(X−P)|+ |D fP(X−P)|≤ | f (X)− f (P)−D fP(X−P)|+ ‖∇ fP‖‖X−P‖,
donde en el ultimo termino usamos la desigualdad (3.3). Si en el primer sumando multiplicamos y dividimospor‖X−P‖, se obtiene
| f (X)− f (P)| ≤ | f (X)− f (P)−D fP(X−P)|‖X−P‖ ‖X−P‖+ ‖∇ fP‖‖X−P‖.
Tanto el primero como el segundo sumando de la derecha tienden a cero cuandoX → P, con lo cual seobtiene lımX→P f (X) = f (P), es decir,f es continua enP.
3.2.1. Unicidad de la diferencial
El siguiente teorema tiene su utilidad para probar propiedades generales. Recordemos primero que unatransformacion linealT : Rn → Rm es una funcion que verifica que siα,β ∈ R, X,Y ∈ Rn entonces
T(αX+βY) = αT(X)+βT(Y).
En particular, toda tranformacion linealT : Rn →R tiene la expresion
T(x1, · · · ,xn) = v1x1+ v2x2+ · · ·+ vnxn
para algunan-upla de numeros reales fija(v1, · · · ,vn). Equivalentemente, existe un vectorV ∈Rn tal que
T(X) = 〈V,X〉 para todoX ∈ Rn,
y cada coordenada deV se puede recuperar aplicandoleT al vectorEi de la base canonica, es decir
vi = T(Ei).
Con estas herramientas estamos en condiciones de enunciar el teorema de unicidad.

3.2 Plano tangente y Diferencial 65
Teorema 3.2.5.Sea f: A⊂Rn → R, P∈ Ao. Si existe una transformacion lineal TP : Rn →R tal que
lımX→P
| f (X)− f (P)−TP(X−P)|‖X−P‖ = 0,
entonces
1. Existen todas las derivadas direccionales de f en P, y vale
∂ f∂V
(P) = TP(V) para todo V∈ Rn, ‖V‖= 1.
2. En particular existen todas las derivadas parciales de f ,se tiene fxi (P) = TP(Ei) y la transformacionTP esunica.
3. Se tiene TP(X) = D fP(X) = 〈∇ fP,X〉 para todo X∈Rn, y f es diferenciable en P. En particular,
∂ f∂V
(P) = 〈∇ fP,V〉= D fP(V) si f es diferenciable en P.
Demostracion. Veamos que existen todas las derivadas direccionales, tomemosV ∈ Rn tal que‖V‖= 1. Siexiste el lımite del enunciado, existe en particular el lımite componiendo con cualquier curva que tenga lımiteP. En particular, si ponemosX = P+ tV (cont suficientemente chico para queX ∈ A), se tieneX−P= tVcon lo cual‖X−P‖= |t|. Entonces
lımt→0
∣
∣
∣
∣
f (P+ tV)− f (P)t
−Tp(V)
∣
∣
∣
∣
= lımt→0
| f (P+ tV)− f (P)−TP(tV)||t| = 0.
Esto prueba quefV(P) = lımt→0f (P+tV)− f (P)
t = TP(V). En particular existen todas las derivadas parciales.
Ademas, comoTP(Ei) = fxi (P) vale para todos losEi , y una transformacion lineal queda determinadapor su valor en una base deRn, se deduce queTP(X) = 〈∇ fP,X〉.
La unicidad deTP se desprende de que si hay otra transformacion linealSP que verifique la condiciondel lımite, entonces tambien va a cumplirSP(X) = 〈∇ fP,X〉.
Lo que se afirma en 3. es, en primer lugar, que
lımX→P
| f (X)− f (P)−〈∇ fP,X−P〉|‖X−P‖ = 0.
Pero esto es evidente pues〈∇ fP,X −P〉 = TP(X −P) por lo que dijimos recien, y el lımite da cero porhipotesis del teorema. Tambien es evidente entonces queTP = D fP.
Hay que observar que reemplazamos la idea geometrica de plano tangente por la idea de aproximacionlineal, y vimos que ambas nociones son equivalentes. Es decir, una funcion es diferenciable si y solo sise puede aproximar bien con un transformacion lineal, y esta transformacion representa, en terminos degraficos, al plano tangente que aproxima bien al grafico de la funcion.

66 Derivadas y Diferencial
Observacion 3.2.6. Si f es diferenciable en P, entonces tomando V de norma unitaria se tiene
fV(P) = 〈∇ fP,V〉 ≤ |〈∇ fP,V〉| ≤ ‖∇ fP‖‖V‖= ‖∇ fP‖,
lo que nos muestra que la derivada direccional a lo sumo vale‖∇ fP‖. Y por otro lado, si∇ fP ,O, poniendoVP = ∇ fP
‖∇ fP‖ se tiene
fVP = 〈∇ fP,VP〉= 〈∇ fP,∇ fP
‖∇ fP‖〉= ‖∇ fP‖
lo que muestra que este maximo siempre se alcanza.
Esto nos dice que∇ fP es la direccion de mayor crecimiento def enP.
Ejemplo 3.2.7. Consideremos la funcion f(x,y) =√
1− x2− y2 con dominio en el disco unitario
Dom( f ) = (x,y) : x2+ y2 ≤ 1.
En esta discusion vamos a excluir los bordes para hablar de derivadas. Es decir, vamos a considerar X=(x,y) ∈ B1(0,0). Recordemos que el grafico de f es el casquete superior de la esfera unitaria, pues de laecuacion z= f (x,y) se despeja x2+ y2+ z2 = 1.
El gradiente de f se calcula facilmente:
∇ fX =
(
−x√
1− x2− y2,
−y√
1− x2− y2
)
=− 1√
1− x2− y2(x,y) =−λ(x,y) X.
Es decir, el gradiente de f en X es un multiplo negativo del vector X. Si miramos el grafico de f desde elcostado y desde arriba,
x
xx
yy
z Gr( f )
vista superior de Gr( f )
(X, f (X))
X
X
−λXX(0,0)

3.2 Plano tangente y Diferencial 67
observamos que, parados en el punto X∈Dom( f ), la direccion de mayor crecimiento es aquella que noslleva al polo norte. En la vista superior del grafico, podemos observar que lo que hay que hacer es caminar,justamente (empezando en X), en la direccion contraria del vector X que es la que nos lleva hacia el centrodel dominio y por lo tanto al punto mas alto si caminamos por la esfera.
3.2.2. Algebra de funciones diferenciables
Se tienen las propiedades habituales de las derivadas. La primera es que la diferencial de una funcionconstante (en cualquier punto) es la transformacion lineal nula.
Observacion 3.2.8. Sea c∈ R y f : Rn →R la funcion constante f(X)≡ c. Entonces f es diferenciable enRn y D fP(X) = 0 para todo P∈Rn y todo X∈Rn. Esto se deduce de
lımX→P
| f (X)− f (P)−0|‖X−P‖ = lım
X→P
0‖X−P‖ = 0.
y el Teorema3.2.5.
Dadas dos funcionesf ,g, nos interesan los puntos del interior de la interseccion de los dominios. Parasimplificar consideramos que tienen el mismo dominio, y que es un conjunto abierto (lo que se consigue,como dijimos, tomando el interior de la interseccion de losdominios correspondientes).
Teorema 3.2.9.Sean f,g : A⊂ Rn →R, con A abierto. Si P∈ A, y f,g son diferenciables en P, entonces
1. La suma f+g es diferenciable en A y se tiene la formula
D( f +g)P(X) = D fP(X)+DgP(X).
2. El producto f g es diferenciable en A, y se tiene
D( f g)P(X) = D fP(X)g(P)+ f (P)DgP(X).
En particular siλ ∈ R,D(λ f )P(X) = λD fP(X).
3. El conjunto A−C0(g) es abierto, allı el cociente f/g es diferenciable y se tiene
D( f/g)P(X) =D fP(X)g(P)− f (P)DgP(X)
g(P)2 .
Demostracion. Veamos 1. Ciertamente sif ,g son diferenciables existenD fp y Dgp. ComoTP : X 7→D fp(X)+Dgp(X) es una transformacion lineal deRn enR, por el Teorema3.2.5, solo hay que ver que
lımX→P
|( f +g)(X)− ( f +g)(P)− (D fp+Dgp) (X−P)|‖X−P‖ = 0,
pues esto probarıa que la suma es diferenciable y su diferencial es la propuesta. Entonces
| f (X)− f (P)+g(X)−g(P)−D fp(X−P)−Dgp(X−P)|‖X−P‖ ≤

68 Derivadas y Diferencial
≤ | f (X)− f (P)−D fP(X−P)|‖X−P‖ +
|g(X)−g(P)−DgP(X−P)|‖X−P‖ .
Los ultimos dos sumandos tienden a cero por hipotesis cuandoX → P, lo que prueba que el primer terminode la desiguldad tiende a cero, como querıamos.
Ahora veamos 2. Usamos la misma idea (el Teorema3.2.5). Observemos que, para cadaP∈ A,
TP : X 7→ D fP(X)g(P)+ f (P)DgP(X)
es una transformacion lineal deRn enR, puesf (P),g(P) ∈R estan fijos. Entonces, evaluandoTP enX−P,sumamos y restamosf (X)g(P) para obtener
| f g(X)− f g(P)−D fP(X−P)g(P)− f (P)DgP(X−P)| ≤≤ | f (X)g(X)− f (X)g(P)− f (P)DgP(X−P)|
+| f (X)g(P)− f (P)g(P)−g(P)D fP(X−P)|.
Para terminar la demostracion de 2., veamos que cada uno de estos dos sumandos (divididos por‖X−P‖)tiende a cero cuandoX →P. En el primer caso, sumando y restandof (X)DgP(X−P), este termino es menoro igual que
| f (X)g(X)− f (X)g(P)− f (X)DgP(X−P)|‖X−P‖ +
| f (X)DgP(X−P)− f (P)DgP(X−P)|‖X−P‖ =
=| f (X)||g(X)−g(P)−DgP(X−P)|
‖X−P‖ +| f (X)− f (P)||DgP(X−P)|
‖X−P‖ .
En el primer termino, se tiene que existeM > 0 tal que| f (X)| ≤ M si ‖X−P‖ ≤ δ puesf es continua porser diferenciable (y toda funcion continua en un compacto alcanza maximo y mınimo). Y entonces
| f (X)||g(X)−g(P)−DgP(X−P)|‖X−P‖ ≤ M
|g(X)−g(P)−DgP(X−P)|‖X−P‖ →X→P 0
por serg diferenciable. En el segundo termino, comog es diferenciable se tiene|DgP(X−P)| ≤ ‖∇gP‖‖X−P‖ por la desigualdad de C-S (ver el ıtem 5. de la Observacion3.2.3). En consecuencia,
| f (X)− f (P)||DgP(X−P)|‖X−P‖ ≤ | f (X)− f (P)|‖∇gP‖→X→P 0
por serf continua enP.
Por ultimo, veamos la afirmacion 3. sobre el cociente. QueA−C0(g) = X ∈ A : g(X) , 0 es abiertose deduce de lo siguiente: siX ∈ A−C0(g), entoncesg(X) > 0 o g(X) < 0. Pero entonces existe una bolaabiertaB alrededor deX, contenida enA, dondeg no se anula, por serg continua. Es decirB⊂ C0(g)∩A,que es lo que querıamos probar.
Ahora hay que observar una vez mas que la transformacion propuesta
TP : X 7→ D fP(X)g(P)− f (P)DgP(X)
g(P)2

3.2 Plano tangente y Diferencial 69
es lineal enX. Usamos nuevamente el Teorema3.2.5, tenemos que ver que la siguiente expresion tiende acero cuandoX → P:
| f (X)g(X)
− f (P)g(P) −TP(X−P)|‖X−P‖ .
Observemos que esta expresion esta bien definida en un entorno 0< ‖X−P‖< r, puesg, como es diferen-ciable, es continua, y como|g(P)|> 0 existe un entorno digamosBr(P) donde|g(X)|> c> 0.
Sigamos con la prueba de que el cociente es diferenciable. Sireescribimos la expresion de arriba, obte-nemos
1|g(X)||g(P)|
| f (X)g(P)− f (P)g(X)−g(X)g(P)TP(X−P)|‖X−P‖ .
Segun dijimos, 1|g(X)| <
1c ası que no es un problema si queremos ver que esta expresiontiende a cero. Si
escribimos la expresion deTP propuesta (evaluada ahora enX−P), se obtiene (omitiendo el termino inicial1
|g(X)||g(P)| que esta acotado)
∣
∣
∣ f (X)g(P)− f (P)g(X)−g(X)g(P)D fP(X−P)g(P)− f (P)DgP(X−P))g(P)2
∣
∣
∣
‖X−P‖ =
=1
|g(P)|2
∣
∣ f (X)g(P)2− f (P)g(P)g(X)−g(X)(D fP(X−P)g(P)− f (P)DgP(X−P))∣
∣
‖X−P‖ .
Un vez mas omitimos el primer termino1|g(P)| pues esta acotado y lo unico que queremos ver es que esta
expresion tiende a cero cuandoX → P. Si distribuimosg(X) en los diferenciales, tenemos
∣
∣ f (X)g(P)2− f (P)g(P)g(X)−g(X)g(P)D fP(X−P)+g(X) f (P)DgP(X−P)∣
∣
‖X−P‖ .
Sumamos y restamos tres cantidades:f (P)g(P)2, g(P)2D fP(X −P), f (P)g(P)DgP(X −P). Usando la de-sigualdad triangular y agrupando convenientemente, quedala suma de las siguientes cuatro expresiones
1. |g(P)|2| f (X)− f (P)−D fP(X−P)|‖X−P‖ .
2. | f (P)||g(P)||g(X)−g(P)−DgP(X−P)|‖X−P‖ .
3. |g(P)||g(X)−g(P)||D fP(X−P)|‖X−P‖ .
4. | f (P)||g(X)−g(P)||DgP(X−P)|‖X−P‖ .
Las dos primeras tienden a cero por serf ,g diferenciables enP. En las dos ultimas, por la desigualdad deC-S, se tiene|D fP(X −P)| ≤ ‖∇ fP‖‖X−P‖ y lo mismo parag. Con esto, cancelamos el denominador enambas expresiones, y comog es continua enP (por ser diferenciable), tambien tienden a cero las dos ultimasexpresiones.
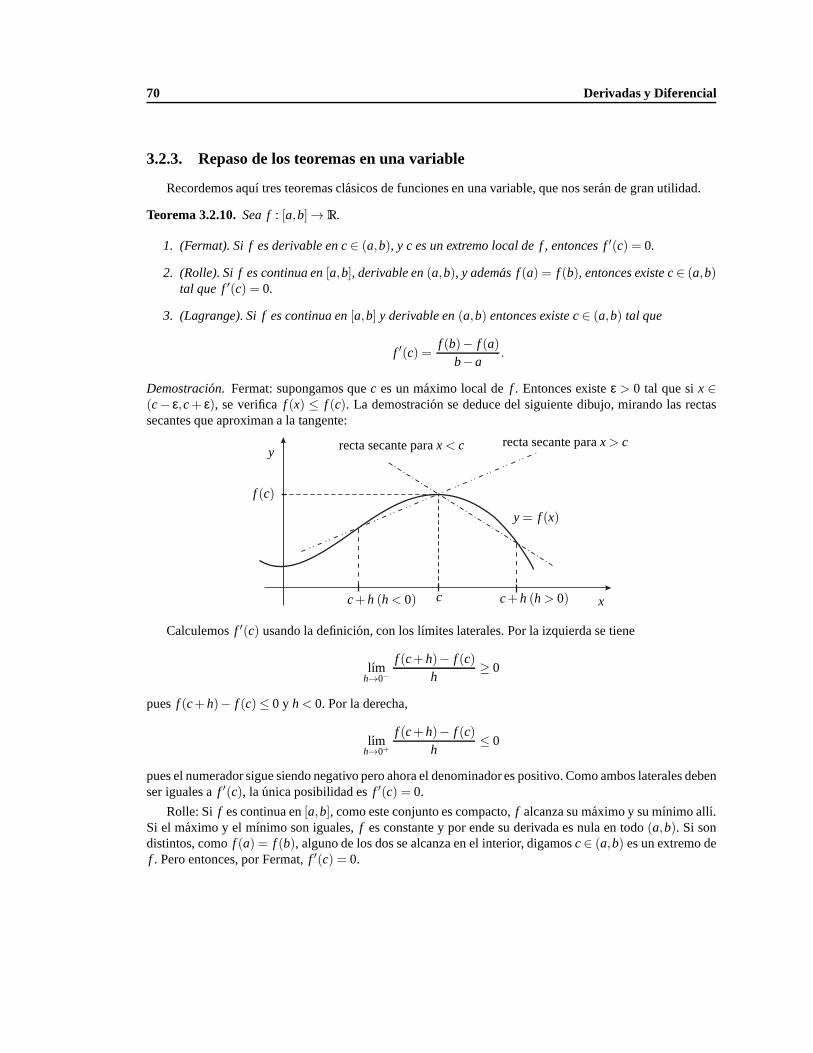
70 Derivadas y Diferencial
3.2.3. Repaso de los teoremas en una variable
Recordemos aquı tres teoremas clasicos de funciones en una variable, que nos seran de gran utilidad.
Teorema 3.2.10.Sea f: [a,b]→R.
1. (Fermat). Si f es derivable en c∈ (a,b), y c es un extremo local de f , entonces f′(c) = 0.
2. (Rolle). Si f es continua en[a,b], derivable en(a,b), y ademas f(a) = f (b), entonces existe c∈ (a,b)tal que f′(c) = 0.
3. (Lagrange). Si f es continua en[a,b] y derivable en(a,b) entonces existe c∈ (a,b) tal que
f ′(c) =f (b)− f (a)
b−a.
Demostracion. Fermat: supongamos quec es un maximo local def . Entonces existeε > 0 tal que six ∈(c− ε,c+ ε), se verificaf (x) ≤ f (c). La demostracion se deduce del siguiente dibujo, mirando las rectassecantes que aproximan a la tangente:
un
x
y
cc+h (h< 0) c+h (h> 0)
y= f (x)
f (c)
recta secante parax< c recta secante parax> c
Calculemosf ′(c) usando la definicion, con los lımites laterales. Por la izquierda se tiene
lımh→0−
f (c+h)− f (c)h
≥ 0
puesf (c+h)− f (c)≤ 0 y h< 0. Por la derecha,
lımh→0+
f (c+h)− f (c)h
≤ 0
pues el numerador sigue siendo negativo pero ahora el denominador es positivo. Como ambos laterales debenser iguales af ′(c), la unica posibilidad esf ′(c) = 0.
Rolle: Si f es continua en[a,b], como este conjunto es compacto,f alcanza su maximo y su mınimo allı.Si el maximo y el mınimo son iguales,f es constante y por ende su derivada es nula en todo(a,b). Si sondistintos, comof (a) = f (b), alguno de los dos se alcanza en el interior, digamosc∈ (a,b) es un extremo def . Pero entonces, por Fermat,f ′(c) = 0.

3.2 Plano tangente y Diferencial 71
Lagrange: Consideramos la siguiente funcion auxiliar, que es la resta entref y la rectaL que une(a, f (a))con(b, f (b)): g(x) = f (x)−L(x).
x
y
a b
f (a)
f (b)
y= f (x)
L
g
Entonces como la recta yf se tocan ena y b, se tieneg(a) = g(b) = 0. Por otro lado,g verifica lasotras hipotesis del teorema de Rolle puesf las verifica yL es una recta, y por ende existec ∈ (a,b) talqueg′(c) = 0. Perog′(x) = f ′(x)−m, dondem es la pendiente de la rectaL. Evaluando enc, se obtienef ′(c) = m. Pero si la recta pasa por los puntos dados, su pendientem se calcula comom= ∆y/∆x, que esexactamente
m=f (b)− f (a)
b−a.
Por ultimo, veamos como se puede deducir la regla de L’Hospital a partir del teorema del valor medio.Antes vamos a enunciar un resultado tecnico con ese solo proposito.
Proposicion 3.2.11(Cauchy). Si f,g son continuas en[a,b] y derivables en(a,b) entonces existe c∈ (a,b)tal que
f ′(c)(g(b)−g(a)) = g′(c)( f (b)− f (a)) .
Demostracion. Consideremos
h(x) = ( f (x)− f (a))(g(b)−g(a))− (g(x)−g(a))( f (b)− f (a)) .
Entonces la funcionh verifica todas las hipotesis del teorema de Rolle en[a,b]. Por otra parte
h′(x) = f ′(x)(g(b)−g(a))−g′(x)( f (b)− f (a)) .
Luego, existec ∈ (a,b) tal queh′(c) = 0. Reemplazando en la ecuacion deh′ y despejando se obtiene laconclusion.
Es importante observar que las derivadas en el teorema de Cauchy estan evaluadas enel mismo puntoc∈ (a,b).
Cuandog(b), g(a), f (b), f (a), el resultado anterior tiene la siguiente interpretaciongeometrica: consi-deremos la curva en el plano dada porα(t) = ( f (t),g(t)), y sus extremosP= ( f (a),g(a)), Q= ( f (b),g(b)).Entoncesα′(t) = ( f ′(t),g′(t)) es el vector velocidad de la curva.

72 Derivadas y Diferencial
Supongamos que no hay ningun puntodonde se anule esta velocidad en(a,b). En-tonces de la expresion
f ′(c) =f (b)− f (a)g(b)−g(a)
g′(c)
se deduce que en el puntoc tambien se tie-neg′(c) , 0. Esto es porque en el caso con-tario tendrıamosα′(c) = O, lo cual es ab-surdo.
α(c)
α′(c)
f (b)− f (a)
g(b)−g(a)
P
Q
Luego podemos escribirf ′(c)g′(c)
=f (b)− f (a)g(b)−g(a)
.
Esta expresion nos dice que hay algun puntoR= α(c) en la curva, donde la recta tangente a la misma esparalela al vector que une los extremosP y Q, segun indica la figura, puesto que la pendiente de la recta
generada por el vectorα′(c) es exactamentef′(c)
g′(c) .
Ahora enunciamos la regla de L’Hospital para calcular lımites.
Proposicion 3.2.12(L’Hospital). Sean f,g funciones derivables en un entorno del punto x= a (exceptuandotal vez el mismo punto x= a). Supongamos que g′(x) , 0 para todo x, a, y que
lımx→a
f (x) = lımx→a
g(x) = 0.
Si existe el lımite
lımx→a
f ′(x)g′(x)
= L
entonces existe el lımite de f/g y coincide con el de las derivadas, es decir
lımx→a
f (x)g(x)
= L.
Demostracion. Primero observemos que podemos extender a las funcionesf ,g al puntox= a como f (a) =g(a) = 0, y quedan continuas por la hipotesis. Analicemos un lımite lateral, el otro se calcula en formaidentica. Comof ,g eran derivables en un entorno dea, existeδ > 0 tal que tantof comog son continuas en[a,a+δ] y derivables en(a,a+delta). Afirmo queg no se anula en(a,a+δ): en efecto, si se anulara, por elteorema de Rolle aplicado ag en el intervalo[a,a+ δ] tendrıa que anularseg′ en(a,a+ δ), contradiciendola hipotesisg′(x) , 0. Tomemosx∈ (a,a+δ), y apliquemos el teorema de Cauchy en[a,x] para obtener queexistec∈ (a,x) donde
f ′(c)g′(c)
=f (x)− f (a)g(x)−g(a)
=f (x)g(x)
.
Si hacemos tenderx→ a+, se deduce quec→ a+ tambien con lo cual la expresion de la izquierda tiende aL por hipotesis. Luego la expresion de la derecha tambien tiende aL.
Se pueden deducir de aquı (pero no lo haremos) los corolarios habituales que nos permiten calcularlımites cuandox→ ∞, y cuandof ,g→ ∞.

3.2 Plano tangente y Diferencial 73
3.2.4. Criterio de diferenciabilidad
Necesitamos algun criterio efectivo para ver si una funci´on es diferenciable en un punto o no. Vamosa denotar un punto generico deR2 comoP = (a,b), y otro punto cercano aP comoX = (a+ h,b+ k).Aquı h,k denotan los incrementos enx e y respectivamente, yX−P= (h,k).
Dada f : R2 → R, observemos que si las dos derivadas parciales def existen en todas partes, entoncespor el teorema de Lagrange en una variable, existenc entrea y a+h, d entreb y b+ k, tales que
f (a+h,b+ k)− f (a,b) = f (a+h,b+ k)− f (a,b+ k)+ f (a,b+k)− f (a,b)
=∂ f∂x
(c,b+ k)h+∂ f∂y
(a,d)k.
En efecto, las funciones realesx 7→ f (x,b+ k) e y 7→ f (a,y) son derivables, con lo cual se puede aplicar elteorema. Volviendo a la ecuacion de arriba, tenemos
f (a+h,b+ k)− f (a,b)−〈∇ f(a,b),(a+h−a,b+ k−b)〉 =
=
(
∂ f∂x
(c,b+ k)− ∂ f∂x
(a,b)
)
h+
(
∂ f∂y
(a,d)− ∂ f∂y
(a,b)
)
k.
Luego, como|h| ≤ ‖(h,k)‖= ‖(a+h,b+ k)− (a,b)‖ (y lo mismo ocurre con|k|), descubrimos que
| f (a+h,b+ k)− f (a,b)−〈∇ f(a,b),(a+h−a,b+ k−b)〉|‖(a+h,b+ k)− (a,b)‖ ≤
≤∣
∣
∣
∣
∂ f∂x
(c,b+ k)− ∂ f∂x
(a,b)
∣
∣
∣
∣
+
∣
∣
∣
∣
∂ f∂y
(a,d)− ∂ f∂y
(a,b)
∣
∣
∣
∣
.
Si las derivadas parciales def fueran continuas, haciendo tenderh,k→ 0 tendrıamos que el ultimo terminotiende a cero, con lo cual el primer termino tambien. Pero esto ultimo es exactamente lo que debe ocurrirpara quef sea diferenciable enP= (a,b).
Resumiendo, hemos probado el siguiente teorema, que resulta un criterio util para ver si una funciones diferenciable en un punto. Observemos que las condiciones sonsuficientespero nonecesarias(ver elEjemplo3.2.16).
Teorema 3.2.13.Sea f: A⊂R2 →R con A abierto, y sea P∈A. Si las dos derivadas parciales de f existenen un entorno de P, y ambas son continuas allı, entonces f es diferenciable en P.
El criterio en su forma general se enuncia de la siguiente manera, y tiene una prueba similar que omiti-mos:
Teorema 3.2.14.Si A⊂ Rn es abierto, todas las derivadas parciales de una funcion f : A→ R existen enA, y todas las derivadas parciales son continuas en A, entonces f es diferenciable en A.
Es decir, basta chequear la continuidad de lasn derivadas parciales def . Se puede pedir un poquitomenos, ver la NOTAI del final del capıtulo.

74 Derivadas y Diferencial
Ejemplo 3.2.15. Tomemos f(x,y,z) = ycos(x)+zln(x)1+z2ey , con dominio
Dom( f ) = (x,y,z) : x> 0.
Entonces es mas o menos evidente que todas las derivadas parciales de f existen y son funciones continuasen todo el dominio, con lo cual se deduce que f es diferenciable en todo su dominio. ¿Se imaginan probandoa mano, en cada punto del dominio, que f es diferenciable?
Otro ejemplo, para pensar:
Ejemplo 3.2.16. Tomemos f: R2 → R dada por
f (x,y) =
xysen(
1x2+y2
)
si (x,y) , (0,0)
0 si (x,y) = (0,0)
Entonces queda como ejercicio ver que
1. fx(0,0) = fy(0,0) = 0.
2. lım(x,y)→(0,0)
| f (x,y)−0|‖(x,y)‖ = 0 (o sea fes diferenciable en el origen).
3. Ninguna de las dos derivadas parciales es continua en el origen.
3.2.5. FuncionesF : Rn →Rm
En general, dadas dos bases deRn y Rm respectivamente, una transformacion linealT : Rn → Rm serepresenta como una matrizM den×m, donde las columnas deM se calculan haciendoT(Ei) con i = 1..n.Esta matriz actua sobre vectores columna de la manera usual.
Podemos extender la nocion de diferenciabilidad a funciones a valores vectoriales ası:
Definicion 3.2.17.Sea F: A⊂ Rn → Rm, sea P∈ Ao. Si TP : Rn → Rm es una transformacion lineal queverifica
lımX→P
‖F(X)−F(P)−TP(X−P)‖‖X−P‖ = 0
entonces decimos que Fes diferenciable enP. A la transformacion lineal la llamamosdiferencial deF enP, y la anotamos DFP.
Entonces extendimos la idea de diferenciabilidad a funciones a valores enRm usando la nocion deaproximacion lineal.
Observacion 3.2.18. Una tal funcion se escribe como F= ( f1, · · · , fm) donde fi : A → R. Ademas, la i-esima coordenada del vector TP(X −P) se obtiene (si pensamos a la transformacion lineal como matriz)

3.2 Plano tangente y Diferencial 75
haciendo el producto escalar de la i-esima fila de TP con X−P.
(TP)11 (TP)12 . . . (TP)1n
(TP)21 (TP)22 . . . . . .. . . . . . . . . . . .
(TP)i1 (TP)i2 . . . . . .. . . . . . . . . . . .. . . . . . . . . (TP)mn
x1− p1
. . .
. . .
. . .
. . .xm− pm
Como el lımite existe y da cero si y solo si existe el lımite en cada coordenada y da cero, se deduce que Fesdiferenciable enP si y solo si cadafi es diferenciable enP. Ademas, si usamos la notacion
∂ fi∂x j
para denotar la derivada j de la funcion i, se tiene quela diferencial deF es la matriz que se obtieneponiendo como filas los gradientes de lasfi , es decir
DFP =
∇ f1(P)∇ f2(P). . .
∇ fm(P)
=
∂ f1∂x1
(P) ∂ f1∂x2
(P) . . . ∂ f1∂xn
(P)
∂ f2∂x1
(P) ∂ f2∂x2
(P) . . . . . .
. . . . . . . . . . . .
. . . . . . . . . ∂ fm∂xn
(P)
Observemos que se puede recuperar cada coordenada usando labase canonica:
∂ fi∂x j
(P) = 〈DFP(E j),Ei〉.
Tambien es importante observar que, si F es diferenciable en P y V∈Rn, entonces poniendoα(t) = P+ tVse tiene
0= lımt→0
‖F(P+ tV)−F(P)−DFP(tV)‖|t| = lım
t→0
∥
∥
∥
∥
F(P+ tV)−F(P)t
−DFP(V)
∥
∥
∥
∥
,
lo que prueba que
DFP(V) = lımt→0
F(P+ tV)−F(P)t
.
para cualquier V∈ Rn.
De lo ya probado se deduce el criterio siguiente:
Teorema 3.2.19.Sea F: A⊂ Rn → Rm, con A abierto y P∈ A. Si existen todas las derivadas parciales deF en un entorno de P y son todas continuas en P, entonces F es diferenciable en P.

76 Derivadas y Diferencial
Observacion 3.2.20. Por supuesto que la suma de funciones diferenciables es diferenciable como vimos.Para funciones a valores vectoriales, digamos G,H : A ⊂ Rn → Rm, tiene tambien sentido considerar suproducto escalar
F(X) = 〈G(X),H(X)〉que es una funcion diferenciable F: A→ R a valores reales, por ser suma y producto de funciones diferen-ciables. Ademas se tiene
lımt→0
F(P+ tX)−F(P)t
= lımt→0
1t[〈G(P+ tX),H(P+ tX)〉− 〈G(P),H(P)〉]
= lımt→0
1t[〈G(P+ tX),H(P+ tX)〉− 〈G(P),H(P+ tX)〉+
+〈G(P),H(P+ tX)〉− 〈G(P),H(P)〉]
= lımt→0
1t〈G(P+ tX)−G(P),H(P+ tX)〉+ 1
t〈G(P),H(P+ tX)−H(P)〉.
Esto prueba queD〈G(X),H(X)〉PV = 〈DGPV,H(P)〉+ 〈G(P),DHPV〉,
que es una regla facil de recordar pues es identica a la regla de derivacion de un producto de funcionesreales.
Ya que la diferencial de una funcion la asimilamos a una matriz o transformacion lineal, es bueno sabercomo controlar su tamano. Para eso definiremos una norma en el espacio vectorial de las matrices, y veremosun par de propiedades utiles:
Lema 3.2.21. 1. Si T : Rn → Rm es una transformacion lineal, existe una constante positiva C tal que‖TX‖ ≤C‖X‖ para todo X∈Rn. A la mas chica de estas constantes la denotaremos‖T‖∞, y se tiene
‖T‖∞ = max‖TX‖ : ‖X‖ ≤ 1.
En particular‖TX‖ ≤ ‖T‖∞‖X‖ para todo X∈ Rn.
2. La funcion‖ · ‖∞ : Rn×m →R es una norma, es decir, si T,S∈Rn×m entonces
a) ‖T‖∞ ≥ 0 y es‖T‖∞ = 0 si y solo si T= 0.
b) ‖λT‖∞ = |λ|‖T‖∞ para todoλ ∈R.
c) ‖T +S‖∞ ≤ ‖T‖∞ + ‖S‖∞.
3. Si F : A ⊂ Rn → Rm es diferenciable en P∈ Ao, existe r> 0 y una constante positiva Cr tal queX ∈ Br(P) implica
‖F(X)−F(P)‖ ≤Cr‖X−P‖.

3.2 Plano tangente y Diferencial 77
Demostracion. Veamos 1. Observemos que, comoT(X) es en cada coordenada una suma y producto de lascoordenadas deX, se tiene que cada coordenada es continua, y en consecuenciaT es continua. Como lafuncion norma deR2 enR, Y 7→ ‖Y‖, tambien es continua, pues
|‖X‖−‖Y‖| ≤ ‖X−Y‖,
se tiene queX 7→ ‖TX‖ es una funcion continua deRn enR. Consideremos la bola cerrada unitaria,
B1 = X ∈Rn : ‖X‖ ≤ 1.
Es un conjunto compacto pues es cerrado y acotado. Entonces,la funcionX 7→ ‖TX‖ es acotada enB1, yademas alcanza maximo y mınimo. Pongamos‖T‖∞ = maxX∈B1
‖TX‖. Entonces, dado cualquierX ,O,
‖T
(
X‖X‖
)
‖ ≤ ‖T‖∞,
con lo cual comoT es lineal se tiene‖TX‖ ≤ ‖T‖∞‖X‖ como querıamos, ademas por como la elegimos esla mejor cota.
Veamos 2. Que‖T‖∞ es positivo es evidente por que es un maximo de cantidades positivas. Por otrolado, siT = 0, entoncesTX =O para todoX ∈ Rn, con lo cual‖T‖∞ = 0. Recıprocamente, si‖T‖∞ = 0 esporque el maximo es cero, y entonces debe ser‖TX‖ = 0 para todoX ∈ B1, con lo cualTX = 0 para todoX ∈ B1. Pero entonces, por la linealidad deT, dado cualquierX ,O, se tiene
TX = ‖X‖T
(
X‖X‖
)
= ‖X‖O=O
es decir,T es la transformacion lineal nula. Que saca escalares con elmodulo es tambien obvio de la defini-cion.
Por ultimo, veamos que verifica la desigualdad triangular.Si S,T ∈Rn×m, entonces dadoX ∈ B1,
‖(T +S)X‖= ‖TX+SX‖≤ ‖TX‖+ ‖SX‖≤ ‖T‖∞‖X‖+ ‖S‖∞‖X‖ ≤ ‖T‖∞ + ‖S‖∞.
Luego el maximo debe ser menor o igual que‖T‖∞ + ‖S‖∞.
Veamos 3. ComoF es diferenciable enP, existe una bolaBr(P) alrededor deP donde el cociente famosoes menor que uno. Con esto,
‖F(X)−F(P)‖‖X−P‖ ≤ ‖F(X)−F(P)−DFP(X−P)‖
‖X−P‖ +‖DFP(X−P)‖
‖X−P‖ ≤ 1+ ‖DFP‖∞,
siempre queX ∈Br(P), puesto queDFP es una transformacion lineal. Si ponemosCr = 1+‖DFP‖∞, tenemosla cota deseada.
Podemos componer dos funciones, y se tiene laregla de la cadena
Teorema 3.2.22.Sea F: A⊂Rn →B⊂Rm, y G: B→Rk, con A,B abiertos. Si F es diferenciable en P∈ A,y G es diferenciable en Q= F(P) ∈ B, entonces GF es diferenciable en P y ademas

78 Derivadas y Diferencial
D(GF)P = DGF(P)DFP,
donde el producto denota composicion de transformaciones lineales.
Demostracion. Tenemos que probar que
lımX→P
‖G(F(X)−G(F(P))−DGQDFP(X−P)‖‖X−P‖ = 0.
Si sumamos y restamosDGQ(F(X)−Q), se tiene que la expresion de la izquierda es menor o igual que
‖G(F(X))−G(Q)−DGQ(F(X)−Q)‖‖X−P‖ +
‖DGQ‖∞‖F(X)−F(P)−DFP(X−P)‖‖X−P‖ .
El segundo termino ciertamente tiende a cero puesF es diferenciable enP. Por otro lado, comoF es dife-renciable enP, en particular es continua enP pues cada coordenada deF es diferenciable y entonces cadacoordenada es continua. EntoncesF(X)→ Q= F(P) y si en el primer sumando multiplicamos y dividimospor‖F(X)−Q‖, se tiene
‖G(F(X))−G(Q)−DGQ(F(X)−Q)‖‖F(X)−Q‖
‖F(X)−F(P)‖‖X−P‖ .
El ultimo cociente esta acotado por la parte 3. del lema previo, mientras que el primer cociente, comoF(X)→ Q, y G es diferenciable enQ, tiende a cero.
Observacion 3.2.23.Ademas de la propiedad general que establece la regla de la cadena, el teorema tienela siguiente aplicacion. Si F=Rk →Rn dada por F=( f1, · · · , fn) la componemos con g:Rn →R, entoncespor la regla de la cadena (suponiendo que ambas son diferenciables)
D(gF)P = ∇gF(P)DFP =
(
∂g∂x1
, · · · , ∂g∂xn
)
F(P)
∂ f1∂x1
∂ f1∂x2
. . . ∂ f1∂xk
∂ f2∂x1
∂ f2∂x2
. . . . . .
∂ f3∂x1
∂ f3∂x2
. . . . . .
. . . . . . . . . . . .∂ fn∂x1
. . . . . . ∂ fn∂xk
P
=
=
(
∂g∂x1
∂ f1∂x1
+∂g∂x2
∂ f2∂x1
+ · · ·+ ∂g∂xn
∂ fn∂x1
, . . . . . . . . . ,∂g∂x1
∂ f1∂xk
+ · · ·+ ∂g∂xn
∂ fn∂xk
)
,
donde en cada producto el primer factor esta evaluado en F(P), mientras que el segundo esta evaluado enP.

3.2 Plano tangente y Diferencial 79
En particular, la coordenada i-esima del gradiente de gF : Rk → R (o lo que es lo mismo, la i-esimaderivada parcial de gF), para cualquier i= 1. . .k esta dada por
∂(gF)∂xi
=∂g∂x1
∂ f1∂xi
+ · · ·+ ∂g∂xn
∂ fn∂xi
=n
∑j=1
∂g∂x j
∂ f j
∂xi,
expresion en la que hay que recordar que las derivadas de F estan evaluadas en P, mientras que las de gestan evaluadas en F(P).
Hagamos un ejemplo para descifrar la sopa de letras.
Ejemplo 3.2.24. Sea F: R2 →R3 dada por
F(u,v) = ( f1(u,v), f2(u,v), f3(u,v)) = (u2−2v,cos(u)+ v+3,uv).
Sea g: R3 → R dada por g(x,y,z) = x2y+ sen(zy).
Entonces, si consideramos gF : R2 →R, se tiene por ejemplo
∂(gF)∂u
=∂g∂x
∂ f1∂u
+∂g∂y
∂ f2∂u
+∂g∂z
∂ f3∂u
.
Tenemos∂g∂x
= 2xy,∂g∂y
= x2+ cos(zy)z,∂g∂z
= cos(zy)y,
mientras que∂ f1∂u
= 2u,∂ f2∂u
=−sen(u),∂ f3∂u
= v.
Con esto, recordando que al componer x= f1(u,v), y= f2(u,v), z= f3(u,v), se tiene
∂(gF)∂u
= 2(u2−2v)(cos(u)+ v+3) ·2u
+(
(u2−2v)2+ cos(uz(cos(u)+ v+3))uv)
· (−sen(u))
+cos(uv(cos(u)+ v+3))(cos(u)+ v+3) ·v.
Observacion 3.2.25. Es habitual usar la notacion x(u,v) en lugar de f1(u,v), ası como y(u,v) en lugarde f2(u,v), y tambien z(u,v) en lugar de f3(u,v). Con lo cual se escribe F(u,v) = (x(u,v),y(u,v),z(u,v))y la formula de la derivada parcial respecto de la primer coordenada de la composicion queda escrita demanera sugestiva como
∂(gF)∂u
=∂g∂x
∂x∂u
+∂g∂y
∂y∂u
+∂g∂z
∂z∂u
,
lo que permite desarrollar una regla mnemotecnica sencilla para usar la regla de la cadena.

80 Derivadas y Diferencial
3.3. Teoremas de Lagrange y Fermat enRn
Supongamos quef es diferenciable. Entonces tiene sentido relacionarf con su diferencial, tal comohicimos en una variable. El siguiente resultado es la generalizacion del Teorema de Lagrange a varias varia-bles.
Proposicion 3.3.1. (Lagrange) Sea f: Br(P) ⊂ Rn → R diferenciable. Entonces para todo Q,R∈ Br(P)existe un punto P0 en el segmento que une Q con R tal que
f (Q)− f (R) = 〈∇ fP0,Q−R〉.
Demostracion. Consideremos la parametrizacion del segmento que uneQ conP, g(t) = R+ t(Q−R). En-toncesh(t) = f g(t) esta definida en[0,1], y es diferenciable en(0,1) por la regla de la cadena. Es mash : [0,1]→ R es una funcion continua puesf es continua por ser diferenciable. Entonces, por el Teoremade Lagrange en una variable, existec ∈ (0,1) tal queh(1)− h(0) = h′(c). Pero por la regla de la cadena,h′(c) = D fg(c)g
′(c) = D fg(c)(Q−R). Si llamamosP0 = g(c), se tiene la afirmacion.
Observacion 3.3.2. Lo relevante del dominio de f en el teorema previo, no es tantoque sea una bola,sino que el segmento que une X con Y este contenido en el dominio. El teoremano es valido en abiertosarbitrarios.
En funciones a valores vectoriales el teoremaes falso, como muestra el siguiente contraejemplo.
Ejemplo 3.3.3. Sea F: R → R2 la curva dada por F(t) = (t2, t3). Consideremos el intervalo[0,1] en eldominio de F. Entonces por un lado
F(1)−F(0) = (1,1)
y por otro lado F′(t) = (2t,3t2), con lo cual es evidente que no existe ningun c∈ (0,1) que satisfaga
(1,1) = (2c,3c2).
Sin embargo, se tiene el siguiente resultado util:
Proposicion 3.3.4. Si G: Br(P)⊂Rn →Rn es diferenciable, y‖DGQ‖∞ ≤ M para todo Q∈ Br(P), se tiene
‖G(X)−G(Y)‖ ≤ M‖X−Y‖
para todo X,Y ∈ Br(P).
Demostracion. Si G(X) = G(Y) no hay nada que probar. Supongamos queG(X) ,G(Y). Tomemos nueva-menteg(t) =Y+ t(X−Y) el segmento que uneX conY enBr(P), pongamos ahora
h(t) = 〈Gg(t),G(X)−G(Y)〉.

3.4 NOTAS 81
Entoncesh′(t) = 〈DGg(t)g′(t),G(X)−G(Y)〉, luego por el teorema de Lagrange enR (ıtem 3. del Teorema
3.2.10), existec∈ (0,1) tal queh(1)−h(0) = h′(c)(1−0),
lo que nos lleva a la siguiente expresion, escribiendo quienes sonh y h′:
〈G(X)−G(Y),G(X)−G(Y)〉= 〈DGY+c(X−Y)(X−Y),G(X)−G(Y)〉.
Es decir
‖G(X)−G(Y)‖2 ≤ ‖DGY+c(X−Y)(X−Y)‖∞‖G(X)−G(Y)‖ ≤ M‖X−Y‖‖G(X)−G(Y)‖.
Como supusimos queG(X) ,G(Y), podemos dividir por‖G(X)−G(Y)‖ para terminar.
Y por ultimo, la aplicacion mas concreta para extremos deuna funcion, que desarrollaremos con cuidadomas adelante. Sif : Rn → R, un maximo local es un puntoP tal que
f (P)≥ f (X)
para todoX en un entornoBr(P) deX. De la misma manera se define un mınimo local, y diremos queP esun extremo local de f si es maximo o mınimo local.
Teorema 3.3.5.(Fermat enRn) Sea f: A⊂ Rn → R diferenciable, con A abierto. Supongamos que P∈ Aes un extremo local de f . Entonces D fP = ∇ fP = O. Equivalentemente, todas las derivadas parciales de fse anulan en P.
Demostracion. Supongamos queP es un maximo local def . ComoP∈ A es un punto interior, podemos su-poner que exister > 0 y una bola abiertaBr(P)⊂A tal quef (P)≥ f (X) para todoX ∈Br(P). Consideremosla funcion auxiliarg(t) = f (P+ tEi), dondeEi es un vector de la base canonica. Entoncesg : (−r, r) → R
es una funcion derivable, que tiene une maximo local ent = 0 puesg(0) = f (P) ≥ f (P+ tEi) = g(t). Enconsecuencia, debe serg′(0) = 0. Pero esta derivada en cero es exactamente (usando la definicion) la deri-vada parciali-esima def enP. Esto prueba quefxi (P) = 0, y comoi es cualquiera entre 1 yn, se tiene queel gradiente def es cero enP.
3.4. NOTAS
I. Vamos a mostrar aquı que el criterio de diferenciabilidad se puede mejorar. Enunciamos el resultado concreto,seguido de su prueba.
Sea f: A⊂Rn → R, P∈ Ao. Supongamos que
a) Existen todas las derivadas parciales de f en P.
b) De las n derivadas parciales hay n−1 que existen en un entorno Br(P) de P, y estas n−1 funciones soncontinuas en P.
Entonces f es diferenciable en P.
Como existen todas las derivadas parciales enP, tenemos que probar que
lımX→P
| f (X)− f (P)−〈∇ fP,X−P〉|‖X−P‖ = 0.

82 Derivadas y Diferencial
En esta prueba vamos a usarfi para denotar lai-esima derivada parcial. Para simplificar la prueba vamos asuponerque la unica derivada parcial que no esta definida en un entorno deP es lan-esima (la ultima). Empecemos conun caso donde las cuentas son mas faciles, supongamos primero queP=O y f (P) = 0. Con esto, lo que hay queprobar es que
lımX→O
| f (X)−〈∇ fO,X〉|‖X‖ = 0.
Observemos que
f (X) = f (x1,x2, · · · ,xn)− f (0,x2,x3, · · · ,xn)+ f (0,x2,x3, · · · ,xn). (3.4)
DadoX = (x1,x2, · · · ,xn) fijo, consideremos la funcion auxiliarg1(t) = f (t,x2, · · · ,xn). Calculemosg′1(t). Se tiene
g′1(t) = lımh→0
f (t +h,x2, · · · ,xn)− f (t,x2, · · · ,xn)
h.
Pero este lımite es exactamente la primera derivada parcial de f evaluada en(t,x2, · · · ,xn). Es decir,g′1(t) =f1(t,x2, · · · ,xn). Por el Teorema del valor medio de Lagrange, existec1 ∈ (0,x1) tal que
f (x1,x2, · · · ,xn)− f (0,x2, · · · ,xn) = g1(x1)−g1(0) = g′1(c1)(x1−0) = f1(c1,x2, · · · ,xn)x1.
Volviendo a (3.4), nos quedo
f (X) = f1(c1,x2, · · · ,xn)x1+ f (0,x2,x3, · · · ,xn).
Ahora, con un argumento similar,
f (0,x2,x3, · · · ,xn) = f (0,x2,x3, · · · ,xn)− f (0,0,x3, · · · ,xn)+ f (0,0,x3, · · · ,xn)
= f2(0,c2,x3, · · · ,xn)x2+ f (0,0,x3, · · · ,xn),
dondec2 ∈ (0,x2) como antes. Seguimos ası hasta la penultima variable, conlo cual nos queda
f (X) = f1(c1,x2, · · · ,xn)x1+ f2(0,c2,x3, · · · ,xn)x2+ · · ·+ · · ·+ fn−1(0,0, · · · ,cn−1,xn)xn−1+ f (0,0,0, · · · ,0,xn),
conci ∈ (0,xi) para todoi = 1. . .n−1. Ahora observemos que, comoP=O,
〈∇ fO,X〉= f1(O)x1+ f2(O)x2+ · · ·+ · · ·+ fn−1(O)xn−1+ fn(O)xn.
Al restar y agrupar, usamos la desigualdad triangular para obtener
| f (X)−〈∇ fO,X〉| ≤ | f1(c1x1,x2, · · · ,xn)− f1(O)||x1|+ · · ·+| fn−1(0,0, · · · ,cn−1xn−1,xn)− fn−1(O)||xn−1|++| f (0,0,0, · · · ,0,xn)− fn(O)xn|
Recordemos que|xi | ≤ ‖X‖ para todoi = 1..n. Luego al dividir por la norma de‖X‖, la expresion original nosqueda acotada por
| f (X)−〈∇ fO,X〉|‖X‖ ≤ | f1(c1x1, · · · ,xn)− f1(O)|+ · · ·
+| fn−1(0, · · · ,cn−1xn−1,xn)− fn−1(O)|
+| f (0,0,0, · · · ,0,xn)− fn(O)xn|
‖X‖

3.4 NOTAS 83
Tomemosε > 0. Como cadaci ∈ (0,xi), y como lasn−1 primeras derivadas parciales son continuas enX =O porhipotesis, todos estos terminos tienden a cero cuandoX →O, con lo cual se pueden hacer todos menores queε/nsi 0< ‖X‖< δ1 para algunδ1 > 0.
Falta ver que el ultimo termino se puede hacer menor queε/n (de esta manera la suma es menor o igual quenε
n = ε). Si xn = 0, ya terminamos. Sixn , 0, observemos que, si‖X‖ , 0, entonces 1/‖X‖ ≤ 1/|xn|. Tambienrecordemos quef (O) = 0, con lo cual el ultimo termino es menor o igual que
| f (O+xnEn)− f (O)− fn(O)xn||xn|
=
∣
∣
∣
∣
f (O+xnEn)− f (O)xn
− fn(O)
∣
∣
∣
∣
.
Pero
lımt→0
f (O+ tEn)− f (O)t
= fn(O)
segun la definicion de derivada direccional, lo que pruebaque este ultimo termino tambien tiende a cero. Elegimosentoncesδ2 > 0 tal que la ultima diferencia sea menor queε/n siempre y cuando|xn|< δ2.
Tomandoδ = mınδ1,δ2, se tiene que, si 0< ‖X‖ < δ, entonces los primerosn−1 terminos son menores queε/n, y el ultimo tambien pues|xn| ≤ ‖X‖< δ ≤ δ2.
Hemos probado, en este caso particular dondeP=O, f (O) = 0, que f es diferenciable enO. Supongamos ahoraque f cumple todas las hipotesis, peroP,O, f (P) , 0. Si ponemos
f (X) = f (X+P)− f (P),
entoncesf verifica f (O) = 0, y es facil ver que las derivadas parciales def en un entorno del origen existen ycoinciden con las derivadas parciales def en un entorno deP, puesX esta cerca de cero si y solo siX+P esta cercadeP, con lo cual
f i(X) = lımt→0
f (X+ tEi)− f (X)
t= lım
t→0
f (X+ tEi +P)− f (P)− ( f (X+P)− f (P))t
= lımt→0
f (X+ tEi +P)− f (X+P)t
= fi(P+X).
En particular∇ fP = ∇ fO, y ademasf verifica todas las hipotesis que pusimos para hacer las cuentas, con lo cuales diferenciable enO segun acabamos de demostrar. PoniendoY = X−P se tiene
lımX→P
| f (X)− f (P)−〈∇ fP,X−P〉|‖X−P‖ = lım
Y→O| f (Y+P)− f (P)−〈∇ fP,Y〉|
‖Y‖
= lımY→O
| f (Y)−〈∇ fO,Y〉|‖Y‖ = 0,
luego f es diferenciable enP.

84 Derivadas y Diferencial

La naturaleza no da saltos.
Gottfried Leibniz
4.1. Funcion Inversa
Empezamos esta seccion con un par de observaciones simples. Observemos que siF es diferenciable einversible, y su inversa tambien es diferenciable, entonces por la regla de la cadena aplicada aF−1(F(X)) =X se tiene
DF−1F(X)DFX = I
dondeId es la transformacion lineal identidad deRn. De aquı se deduce queDF−1 (la diferencial de lainversa) es la inversa de la diferencial deF , es decir
DF−1F(X) = (DFX)
−1.
Supongamos ahora queF es diferenciable solamente ¿Sera cierto que si su diferencial es una transformacionlineal inversible, entoncesF tiene una funcion inversa, diferenciable?
En el caso de una variable, el grafico defnos induce a pensar que sı, pues derivadano nula en un entorno dex= a nos dice quepor lo menosf es localmente inyectiva, esdecir existe un entorno(a−ε,a+ε) dondef es inyectiva y su inversa es derivable.
y
x
m= f ′(a) , 0
y= f (x)
aa− ε a+ ε
f (a)
Atencion que en general no podremos exhibir explıcitamente esta inversa, sino solamente probar queexiste y que verifica ciertas propiedades (y es para esto casos en los cuales no se pueda mostrar la formulade la inversa, donde el teorema que queremos enunciar mas adelante tiene mayor sentido y utilidad).
Ejemplo 4.1.1. Consideramos f(x) = x+ ex. Esta funcion es derivable y estrictamente creciente puesf ′(x) = 1+ex > 0, con lo cual tiene una inversa en todoR, y la inversa es derivable. Sin embargo, despejaruna formula para la inversa a partir de la ecuacion f(x) = y es imposible pues la ecuacion x+ex = y nopuede resolverse explıcitamente.

86 Funcion inversa e implıcita
Para enunciar y demostrar un resultado de estas caracterısticas enRn, necesitamos pensar en todos losingredientes necesarios, que son: propiedades de las transformaciones lineales, continuidad de las derivadasparciales.
4.1.1. Funciones de claseCk
Queremos garantizar que si la derivada no se anula en un punto, no se anula en un entorno del punto.Para esto podemos pedir que la derivada sea una funcion continua. Eso motiva la siguiente definicion.
Definicion 4.1.2. Sea f: A⊂ Rn → Rm, con A abierto.
Dado k∈N, decimos que fes de claseCk en A si para todo punto P∈ A existen todas las derivadasparciales hasta orden k y son funciones continuas en A. Al conjunto de todas las funciones de clase Ck en Alo anotamos Ck(A).
Decimos que f es de clase C∞ (o que f∈C∞(A)) si existen todas las derivadas parciales de cualquierorden y son todas continuas en A.
Decimos que f es C0 en A (o que f∈C0(A)) cuando f es continua en A.
Ejemplo 4.1.3.
Cualquier polinomio es una funcion C∞ enR.
Las funciones trigonometricassen, cosy la exponencial son C∞ enR.
El logaritmo es una funcion C∞ en(0,+∞).
Si f(x) = x73 , entonces como f′(x) = 7
3x43 y f ′′(x) = 28
9 x13 se tiene f∈C2(R). Sin embargo f<C3(R) pues
la derivada tercera de f no existe en cero.
Observacion 4.1.4. Que la derivada de una funcion f exista no quiere decir que la derivada f′ sea unafuncion continua. Por ejemplo, si
f (x) =
x2sen(1/x) si x, 00 si x= 0
entonces f′(0) = lımh→0h2 sen(1/h)−0
h = lımh→0hsen(1/h) = 0, mientras que
f ′(x) = 2xsen(1/x)+ x2cos(1/x)−1x2 = 2xsen(1/x)− cos(1/x).
Esto prueba que f es derivable en todoR. Sin embargo,lımx→0 f ′(x) no existe, con lo cual la derivada noes una funcion continua pues no verifica
lımx→0
f ′(x) = f ′(0).
Es decir, f<C1(R) aunque f si es derivable enR.

4.1 Funcion Inversa 87
4.1.2. Transformaciones lineales
Algunas observaciones sobre transformaciones linealesT : Rn → Rk.
1. Toda transformacion linealT es diferenciable, conTP = T para todoP∈ Rn, pues
T(X)−T(P) = T(X−P),
con lo cual el lımite de la expresion‖T(X)−T(P)−T(X−P)‖‖X−P‖ es trivialmente cero.
2. Si F : Rn → Rn es diferenciable (oCk) y T es una transformacion lineal que sale deRn, entoncesT F es diferenciable (oCk), y ademas
D(T F)P = DTF(P)DFP = T DFP.
3. Una transformacion linealT es inyectiva si y solo siNu(T) = O. En efecto, supongamos primeroqueT es inyectiva. ComoTO = O no puede haber otroV ,O tal queTV = O, y esto prueba que elnucleo es solo el cero. Y recıprocamente, siNu(T) =O, entonces siTV=TW, se tieneTV−TW=O,y comoT es lineal,T(V −W) = O. Por la hipotesis se concluye queV −W = O, es decirV =W loque prueba queT es inyectiva.
4. Cuandon= k, se tiene queT es inversible (es decir biyectiva) si y solo siNu(T) = O, si y solo siT es sobreyectiva. En efecto por el teorema de la dimension (ver el libro de Lang [3]),
dim(Nu(T))+dim(Im(T)) = n,
se deduce que elNu(T) = O si y solo siT es sobreyectiva. Es decir, cuandon= k, ser sobreyectivao ser inyectiva son equivalentes, y por ende cualquiera de las dos condiciones son equivalentes a serbiyectiva.
5. Indicaremos conI : Rn → Rn a la transformacion lineal identidad,IX = X para todoX ∈ Rn.
Observacion 4.1.5.Sea T:Rn →Rn transformacion lineal, tal que‖I −T‖∞ < 1. Entonces T es inversible.
Demostracion. Supongamos que existeV , O tal queTV = O. Es decir, supongamos que kerT (el nucleodeT) es no trivial. Entonces
‖V‖= ‖V −O‖= ‖V −TV‖= ‖(1−T)V‖ ≤ ‖I −T‖∞‖V‖< ‖V‖,
una contradiccion. Luego debe serNu(T) = O, y el teorema de la dimension para transformaciones linea-les nos dice queT es inversible.
Por ultimo veamos cual es la relacion entre serC1 y las diferenciales, para ello necesitamos un lemaprevio de numeros reales.
Lema 4.1.6. Si ai ,bi (con i= 1. . .n) son numeros reales, entonces
n
∑i=1
aibi ≤(
n
∑i=1
a2i
) 12(
n
∑i=1
b2i
) 12

88 Funcion inversa e implıcita
Demostracion. Consideremos los vectoresA= (a1, . . . ,an) y B= (b1, . . . ,bn). Entonces por la desigualdadde C-S,
n
∑i=1
aibi = 〈A,B〉 ≤ |〈A,B〉| ≤ ‖A‖‖B‖=(
n
∑i=1
a2i
) 12(
n
∑i=1
b2i
) 12
.
Lema 4.1.7. Sea T: Rn → Rn una transformacion lineal, T= (Ti j ). Entonces
∣
∣Ti j∣
∣≤ ‖T‖∞ ≤ n maxi, j=1...n
∣
∣Ti j∣
∣ .
Demostracion. La primer desigualdad se deduce de que, comoT(Ei) es la columnai-esima de la matriz deT en la base canonica, el lugari j lo obtenemos haciendo〈TEi ,E j〉. Como siempre conEii=1···n denotamosla base canonica deRn. Luego
∣
∣Ti j∣
∣= |〈TEi ,E j〉| ≤ ‖TEi‖‖E j‖= ‖TEj‖ ≤ ‖T‖∞‖E j‖= ‖T‖∞.
Para probar la otra desigualdad, tomemosX ∈Rn tal que‖X‖≤ 1. Entonces escribimosX =∑ni=1xiEi donde
Ei son los vectores de la base canonica; observemos que∑ni=1 |xi |2 = ‖X‖2 ≤ 1. Entonces
‖TX‖= ‖n
∑i=1
xiTEi‖ ≤n
∑i=1
|xi |‖TEi‖.
Esta ultima suma por el lema previo es menor o igual que el producto
(
n
∑i=1
|xi |2) 1
2(
n
∑i=1
‖TEi‖2
) 12
≤(
n
∑i=1
‖TEi‖2
) 12
.
Tomando maximo sobre losX de norma menor o igual a uno se tiene
‖T‖∞ ≤(
n
∑i=1
‖TEi‖2
) 12
.
Por otra parte, para cadai ∈ 1, . . . ,n, TEi devuelve la columnai-esima de la matrizT en la base canonica,con lo cual
‖TEi‖2 =n
∑j=1
T2ji ≤ n max
j=1...nT2
ji .
Esto nos dice quen
∑i=1
‖TEi‖2 ≤ n2 maxi, j=1...n
T2ji .
Tomando raız cuadrada se obtiene la desigualdad deseada.

4.1 Funcion Inversa 89
Lema 4.1.8. Sea G: A⊂ Rn → Rn con A abierto. Supongamos que G= (g1, · · · ,gn) es diferenciable en A.Entonces, dados P,Q∈ A se tiene
‖DGP−DGQ‖∞ ≤ n maxi, j=1...n
∣
∣
∣
∣
∂gi
∂x j(P)− ∂gi
∂x j(Q)
∣
∣
∣
∣
.
En particular si G es C1 en A,‖DGP−DGQ‖∞ → 0 si Q→ P.
Demostracion. Le aplicamos el lema previo aT = DGP−DGQ.
Enunciamos el teorema de la funcion inversa.
Teorema 4.1.9(Teorema de la funcion inversa). Sean F: A⊂ Rn → Rn, con A abierto y P∈ A. Si F es C1
en A y DFP : Rn → Rn es una transformacion lineal inversible, entonces existen entornos abiertos V,W deP y F(P) respectivamente, tales que F: V →W es biyectiva, la inversa es diferenciable y ademas
DF−1F(Q) = (DFQ)
−1
para todo Q∈V. En particular la diferencial de F es inversible en V.
Para demostrarlo conviene separar la demostracion en una serie de enunciados. La demostracion, y elejemplo que le sigue, estan extraidos del libroCalculo en variedadesde M. Spivak [9].
Teorema 4.1.10.Sean F: A⊂ Rn → Rn, con A abierto y P∈ A. Si F es C1 en A y DFP : Rn → Rn es unatransformacion lineal inversible, entonces
1. Existe r> 0 tal que F : Br(P)→ F(Br(P)) es biyectiva en Br(P), y la funcion inversa es continua ensu dominio.
2. Existen abiertos V⊂ Br(P) y W ⊂ F(Br(P)) tales que P∈ V y F−1 : W → V es diferenciable, condiferencial
DF−1F(Q) = (DFQ)
−1 para todo Q∈V.
3. La funcion inversa es C1 en su dominio. Si ademas F∈ Ck(V), entonces F−1 ∈ Ck(W). Esto no loprobaremos (hace falta ver que T7→ T−1 es C∞ en las matrices inversibles).
Demostracion. Supongamos primero queDFP = I .
Veamos 1. Elegimosr0 > 0 tal queBr0(P)⊂A, de manera que‖DFQ− I‖∞ ≤ 12 siempre que‖Q−P‖< r0
(usando el Lema previo). Tomamos cualquierr positivo tal quer < r0 positivo, para asegurarnos que
Br(P) = Q∈ Rn : ‖Q−P‖ ≤ r ⊂ A.
Si llamamosG(X) = F(X)−X se tieneDG = DF − I , con lo cual por el Teorema del valor medio paracampos se tiene
‖X−Y−F(X)+F(Y)‖= ‖X−F(X)− (Y−F(Y))‖ = ‖G(X)−G(Y)‖ ≤ 12‖X−Y‖,

90 Funcion inversa e implıcita
siempre queX,Y ∈ Br(P), puesBr(P)⊂ Br0(P). Por otra parte, por la desigualdad triangular, se tiene
‖X−Y‖ ≤ ‖X−Y−F(X)+F(Y)‖+ ‖F(X)−F(Y)‖,
con lo cual
‖X−Y‖−‖F(X)−F(Y)‖ ≤ ‖X−Y−F(X)+F(Y)‖ ≤ 12‖X−Y‖,
es decir
‖X−Y‖ ≤ 2‖F(X)−F(Y)‖ (4.1)
siempre queX,Y ∈Br(P). Esto prueba queF es inyectiva enBr(P), y en particular es inyectiva en su interiorBr(P). Ademas, la desigualdad (4.1) se puede leer ası:
‖F−1(Z)−F−1(W)‖ ≤ 2‖Z−W‖
siempre queZ,W ∈ F(Br(P)), y esto prueba que la funcion inversa es continua.
Veamos 2. Construyamos primero el abiertoW ⊂ F(Br(P)). PongamosSr(P) = Q∈Rn : ‖Q−P‖= r,que es un conjunto compacto deRn, conSr(P) ⊂ A. ComoF es inyectiva enBr(P), se tieneF(X) , F(P)para todoX ∈ Sr(P). ComoF es continua enA (por ser diferenciable), entonces la distanciadP : Sr(P)→R
dada pordP(X) = ‖F(X)−F(P)‖ alcanza un mınimo enSr(P), digamos
d = mınX∈Sr (P)
‖F(X)−F(P)‖> 0,
y se tiene en general‖F(X)−F(P)‖ ≥ d para todoX ∈ Sr(P).
P
F(P)
F
d
Sr(P) F(Sr(P))
Es decir, el numero positivod indica la distancia entreF(Sr(P)) y el puntoF(P).
Ponemos comoW a la bola abierta centrada enF(P) de radiod/2:
W = Y ∈Rn : ‖Y−F(P)‖< d/2.

4.1 Funcion Inversa 91
PF(P)
F
d/2
d
W = Bd/2(F(P))
Sr(P)F(Sr(P))
Tenemos que ver queW ⊂ F(Br(P)), es decir, que dadoY ∈ W, existeX ∈ Br(P) tal queF(X) = Y.Consideremos (conY ∈W fijo) la funcionh : Br(P)→ R dada por
h(X) = ‖Y−F(X)‖2 = 〈Y−F(X),Y−F(X)〉,
que es una funcion continua en el compactoBr(P) y diferenciable enBr(P). Por ser continua tiene unmınimo, digamosPY ∈ Br(P) es el mınimo deh. Afirmo quePY verifica F(PY) = Y, lo que probarıa queY ∈ F(Br(P)).
Observemos que siX es un punto del borde de la bola, entonces
d ≤ ‖F(P)−F(X)‖ ≤ ‖F(P)−Y‖+ ‖Y−F(X)‖< d/2+ ‖Y−F(X)‖,
con lo cual‖Y−F(X)‖ > d/2, es decirh(X)> d2/4. Por otro lado, evaluando enP se tieneh(P) = ‖Y−F(P)‖2 < d2/4 lo que nos dice que el mınimo deh se debe hallar en el interior de la bola, es decirPY ∈Br(P).Comoh es diferenciable en la bola abierta, y el puntoPY es un extremo local, por el Teorema de Fermat enRn debe serDhPY = 0. De acuerdo a la regla de derivacion del producto escalar se tiene
0= DhPYV =−2〈DFPYV,Y−F(PY)〉=−2〈V,DFtPY(Y−F(PY))〉
para todoV ∈ Rn, dondeDFtPY
denota la transformacion lineal transpuesta deDFPY. Si reemplazamosV portodos los vectores de la base canonica, se deduce que debe ser
DFtPY(Y−F(PY)) =O.
Como‖DFQ− I‖∞ ≤ 12 si‖Q−P‖< r, entoncesDFQ es inversible por la Observacion4.1.5, y entoncesDF t
PYes inversible. Debe ser entoncesY−F(PY) =O, que es lo que querıamos probar, pues se tienePY ∈ Br(P) yF(PY) =Y.
Observemos queF−1(W) es un conjunto abierto puesF es continua. Si ponemosV =Br(P)∩F−1(W) =X ∈ Br(P) : F(X) ∈W, entonces claramenteP∈V, V ⊂ Br(P), F : V →W es una biyeccion bicontinua yademasV es abierto pues es la interseccion de dos conjuntos abiertos.

92 Funcion inversa e implıcita
Veamos 3. Tenemos una funcion inversaF−1 : W → V, definida en un abierto, que es continua. Restaprobar que es diferenciable. Para ello recordemos nuevamente que, como‖DFQ− I‖∞ ≤ 1
2 si ‖Q−P‖ < r,entoncesDFQ es inversible por la Observacion4.1.5. Resta ver que la diferencial propuesta funciona, esdecir, tenemos que ver que
lımZ→F(Q)
‖F−1(Z)−F−1F(Q)−DF−1Q (Z−F(Q))‖
‖Z−F(Q)‖ = 0.
Si hacemos el cambio de variable (valido por serF biyectiva)Z = F(Y), se tiene
‖F−1(Z)−F−1F(Q)−DF−1Q (Z−F(Q))‖
‖Z−F(Q)‖ =‖Y−Q−DF−1
Q (F(Y)−F(Q))‖‖F(Y)−F(Q)‖
=‖DF−1
Q (DFQ(Y−Q)−F(Y)+F(Q))‖‖F(Y)−F(Q)‖ ≤ ‖DF−1
Q ‖∞‖F(Y)−F(Q)−DFQ(Y−Q)‖
‖F(Y)−F(Q)‖
≤ 2‖DF−1Q ‖∞
‖F(Y)−F(Q)−DFQ(Y−Q)‖‖Y−Q‖
donde en el ultimo paso hemos usado la desigualdad (4.1), y el hecho de que siZ , F(Q), entoncesY ,Q.El teorema queda entonces probado, puesY → Q cada vez queZ = F(Y) → F(Q), puesto que la inversaF−1 es continua en su dominio, con lo cual el ultimo termino tiende a cero puesF es diferenciable enQ.
Nos queda ver que el teorema vale en general, sin suponer queDFP = I . Pero siF es cualquier funcionque verifica las hipotesis del teorema, y ponemos
F(X) = DF−1P F(X),
entoncesF sigue verificando todas las hipotesis y ademasDFP = DF−1P DFP = I , con lo cual por las cuentas
que hicimos recien se tiene queF verifica todos lo ıtems del enunciado. En consecuencia,F = DFP Ftambien.
Observacion 4.1.11.La hipotesis F∈C1(A) es esencial. El por que, tiene que ver con el hecho siguiente:aunque F sea diferenciable, y su diferencial sea inversibleen un punto P, puede no haber ningun entorno deP donde su diferencial sea tambien inversible. El mas curioso puede ver un ejemplo concreto en las notasdel final del capıtulo (NotaII ).
Ejemplo 4.1.12. Consideremos F(r,θ) = (r cos(θ), r sen(θ)). Entonces se tiene
DF(r,θ) =
cos(θ) −r sen(θ)
sen(θ) r cos(θ)
.
Pongamos T= DF(r,θ). Entonces det(T) = r(cos2(θ)+ sen2(θ)) = r. Esto nos dice que, salvo en la rectar = 0, la diferencial de la funcion F es inversible.
Ası que, para cada punto(r,θ), con r, 0, existe un entorno donde F es inversible, y un entorno de F(r,θ)donde F−1 es diferenciable.

4.1 Funcion Inversa 93
Sin embargo, observemos que F no es biyectiva, pues por ejemplo, F(1,0) = (1,0) = F(1,2π). ¿Comopuede ser? Lo que ocurre es que el teorema nos asegura que F es localmente inyectiva (y por lo tantoinversible) pero si los puntos estan lejos, se pierde la inyectividad.
Sin embargo, si nos restringimos al conjunto r> 0, 0≤ θ < 2π, la funcion F es inyectiva. Veamos porque. Si F(r1,θ1) = F(r2,θ2), entonces
r1cos(θ1) = r2cos(θ2) y r1sen(θ1) = r2sen(θ2).
Elevando al cuadrado y sumando se tiene r21 = r2
2, con lo cual r1 = r2. Pero entonces de la primera ecuacionse deduce quecos(θ1) = cos(θ2), con lo cual, como el coseno es inyectivo en[0,2π), se tiene tambienθ1 = θ2.
Para tener en cuenta es que, fijado r= r0, esta transformacion manda la recta vertical r= r0 en unacircunferencia de radio r.
y
x
θF
r=r0r
r 0
Asimismo, si fijamosθ = θ0, esta recta horizontal tiene como imagen un rayo que parte del origen,formando unanguloθ0 con el eje x.
θ y
x
θ0
F
θ=θ0
r
La funcion F con la restriccion que hicimos para que sea biyectiva nos da un cambio de variable(x,y) 7→ (r cos(θ), r sen(θ)), que se suelen denominarcoordenadas polares.

94 Funcion inversa e implıcita
4.2. Superficies de nivel y funciones implıcitas
Recordemos que dada una funcionf : Rn → R, las superficies de nivel eran los conjuntos
Lc = X ∈ Dom( f ) : f (X) = c,
dondec∈ R es una constante.
Observemos que este conjunto puede ser vacıo, por ejemplo si f (x,y) = x2 + y2, y tomamosc = −1,entonces la ecuacionx2+ y2 =−1 no tiene ninguna solucion.
Estamos interesados en pensar a estas superficies como graficosde funciones diferenciables. Para ello pensemos en un ejemploelemental: la circunferencia unitaria. Se obtiene como curva denivel de f (x,y) = x2+ y2 tomandoc= 1, es decir es el conjunto
Lc( f ) = (x,y) : x2+ y2 = 1.
Sabemos que podemos despejary, obteniendo en este casoy =±√
1− x2. El problema es que esta expresion no esta dada poruna unica funcion, para ello hay que elegir un signo.
x
1
x2+ y2 = 1
y
Si queremos la parte superior, consideramosy =√
1− x2, con lo cual si ponemosϕ(x) =√
1− x2, lamitad superior de la circunferencia es el grafico de la funcion ϕ, es decir, se escribe como los puntos de lapinta(x,ϕ(x)) = (x,
√1− x2). Si queremos la parte inferior, basta tomarϕ(x) =−
√1− x2.
¿Que pasa si queremos parametrizar algun pedazo alrededordel punto(1,0)? No podemos tomar funciones dex, puescualquier entorno de la circunferencia en ese punto no es elgrafico de ninguna funcion.
x(1,0)
x2+ y2 = 1
Sin embargo, podemos despejarx para pensarla como funcion dey. Se obtiene entoncesx=±√
1− y2,y como queremos el lado derecho de la circunferencia tomamosϕ(y) =
√
1− y2. Ahora esta porcion de lacircunferencia es el grafico de la funcionϕ pensada con dominio en el ejey, es decir son los puntos de lapinta(ϕ(y),y) = (
√
1− y2,y).
Observemos quef (ϕ(y),y) = ϕ(y)2+ y2 = 1− y2+ y2 = 1 para todoy en el dominio deϕ. Esto quieredecir que en efecto los puntos de la pinta(ϕ(y),y) son puntos de la circunferencia.

4.2 Superficies de nivel y funciones implıcitas 95
x
(x,y)
∇ f(x,y) = 2(x,y)y
Otro hecho que se observa en este ejemplo sencillo esque, en cada punto(x,y) de la circunferencia, el gradientede la funcionf (x,y) = x2+ y2 esta dado por
∇ f(x,y) = (2x,2y) = 2(x,y).
Resulta evidente que el gradiente es perpendicular a larecta tangente de la curva, en cada punto.
Observacion 4.2.1. Observemos que en general, siα parametriza la curva
S= (x,y) : f (x,y) = 0,
entonces fα(t) = 0 para todo t en el dominio deα. Entonces (asumiendo que todas las funciones sonderivables), por la regla de la cadena se deduce que
〈∇ fα(t),α′(t)〉= 0 para todo t.
Es decir, que∇ f(x,y) es la direccion de la recta normal a la curva en el punto(x,y) ∈ S.
Tambien observemos que, en general, la derivada parcialrespecto de y sera nula en P∈ S si y solo si el vector gra-diente es horizontal, con lo cual la curva de nivel S, en unentorno de ese punto, no puede pensarse como el grafico deuna funcionϕ(x). Asimismo,∂ f
∂x sera nula en Q∈ S si y solosi el vector gradiente es vertical, con lo cual la curva no pue-de parametrizarse en un entorno del punto como grafico deunaϕ(y).
y
x
∇ fPP
∇ fQ
Q
S
Todo esto nos lleva a enunciar una version sencilla del teorema de la funcion implıcita:
Teorema 4.2.2.(Funcion implıcita enR2)
Sea f: A⊂R2 →R una funcion C1, y S= (x,y) ∈R2 : f (x,y) = 0 una curva de nivel de f . Suponga-mos que∂ f
∂y (P) , 0 para algun P∈ S. Entonces
1. Existen un intervalo abierto I⊂ R, una funcion derivableϕ(x), ϕ : I → R, y una bola B alrededor deP tales que S∩B= Gr(ϕ).
2. ∂ f∂y (x,y) , 0 para todo(x,y) ∈ S∩B, y∇ f(x,y) es perpendicular a S en S∩B.
3. Para todo x∈ I se tiene
ϕ′(x) =−∂ f∂x∂ f∂y
(x,ϕ(x)).

96 Funcion inversa e implıcita
La figura a tener en cuenta es la siguiente:
( )p1 ∈ I x
∇ fP
P=(p1,p2)
SS∩B= Gr(ϕ)
Demostracion. ConsideramosF(x,y) = (x, f (x,y)) que es una funcionC1 enA. Tenemos
DF =
(
1 0∂ f∂x
∂ f∂y
)
.
En particularDFP es inversible. Luego tiene (en una bola abiertaB entorno deP) una inversaG definida ydiferenciable en un entorno abiertoW deF(P) = (p1, f (p1, p2)) = (p1,0), digamosG= (g1,g2). Se tiene
(x,y) = F G(x,y) = (g1(x,y), f (g1(x,y),g2(x,y)),
lo que nos dice (mirando la primer coordenada) queg1(x,y) = x, y que (mirando la segunda)
y= f (x,g2(x,y)), (4.2)
relacion valida para todo(x,y) en un entorno abierto de(p1,0). Es decir
G(x,y) = (x,g2(x,y)).
En particular, volviendo a la ecuacion (4.2), tomandoy= 0 se tiene
0= f (x,g2(x,0))
se verifica para todox en un entornoI de p1, con lo cual si tomamosϕ(x) = g2(x,0) con dominoI , estafuncion es derivable y ademas cumple
f (x,ϕ(x)) = 0
para todox∈ I . Esto nos dice queGr(ϕ)⊂ S, pero como ademasϕ se obtiene como una restriccion deG, esdecir(x,ϕ(x)) = G(x,0), tambien se tieneGr(ϕ) ⊂ B. Esto prueba queGr(ϕ) ⊂ S∩B. Por otra parte dadoQ∈ B, existeZ ∈W tal queG(Z) = Q, con lo cual
(q1,q2) = (z1,g2(z1,z2))

4.2 Superficies de nivel y funciones implıcitas 97
y si ademasQ∈ S, debe serf (q1,q2) = 0 lo que nos dice que
z2 = f (z1,g2(z1,z2)) = f (q1,q2) = 0
y entonces(q1,q2) = (z1,g2(z1,0)) = (z1,ϕ(z1)),
lo que prueba la otra inclusionS∩B⊂ Gr(ϕ).
ComoDFQ es inversible enB, debe ser∂ f∂y (x,y) , 0 para todo(x,y) ∈ S∩B; ciertamente por la regla de
la cadena aplicada af (x,ϕ(x)) = 0 se tiene
〈∇ f(x,y),(1,ϕ′(x))〉 = 0
lo que prueba que el gradiente es perpendicular al grafico, yademas desarrollando queda
∂ f∂x
·1+ ∂ f∂y
·ϕ′(x) = 0,
de donde se deduce despejando la ultima formula del enunciado del teorema.
El teorema tambien vale si intercambiamosx cony, con la misma prueba.
Teorema 4.2.3.Sea f: A⊂R2 →R una funcion C1, y S= (x,y) ∈R2 : f (x,y) = c una curva de nivel def . Supongamos que∂ f
∂x (P) , 0 para algun P∈ S. Entonces
1. Existen un intervalo abierto J⊂ R, una funcion derivableφ(y), φ : J → R, y una bola B alrededor deP tales que S∩B= Gr(φ).
2. ∂ f∂x (x,y) , 0 para todo(x,y) ∈ S∩B, y∇ f(x,y) es perpendicular a S en S∩B.
3. Para todo y∈ J se tiene
φ′(y) =−∂ f∂y∂ f∂x
(φ(y),y).
En este caso la figura a tener en cuenta es la que sigue:
(
)
p2 ∈ J
y
∇ fPP=(p1,p2)
S
S∩B=Gr(φ)

98 Funcion inversa e implıcita
Observacion 4.2.4. Algunos ejemplos sencillos, donde el teorema no se puede aplicar, se ilustran en lasiguiente figura. En todos los casos el punto relevante es P= (0,0).
xxx
y yy
y2− x3− x2 = 0 x2− y3 = 0 (x2+ y2)2+3x2y− y3 = 0
En los tres ejemplos, la funcion f es C1 (pues es un polinomio). En los tres ejemplos, el gradiente defse anula en el punto P= (0,0). En ninguno de los tres ejemplos se puede aplicar el teorema para hallar unentorno de cero y una funcion C1 que parametrize la curva.
En el ejemplo del medio, sin embargo, podemos despejar y= x2/3, luego la curva se puede describircomo el grafico deϕ(x) = x2/3. Lo que ocurre aquı es que estaϕ no es C1 en x= 0, y por lo tanto no sepuede obtener usando el teorema general que enunciamos arriba.
Observacion 4.2.5. La hipotesis de que f es C1 es esencial para asegurar que si una derivada parcial nose anula en P∈ S, entonces no se anula en un entorno de P. El lector curioso puede ver el ejemplo en laNotaIII al final de este capıtulo, para entender como puede fallar.
Sin embargo, puede probarse que si f: R2 →R es una funcion continua y la derivada parcial∂ f∂y existe
y no se anulaen un entorno de(x0,y0) ∈ S, entonces existe una funcionϕ = ϕ(x) definida en un entorno dex= x0 y continua en un x0, que parametriza S en un entorno de(x0,y0). Y que si ademas f es diferenciableen el punto(x0,y0), esta funcionϕ resulta derivable en x= x0. Ver el Vol. 2 de Rey Pastor [7], Seccion 68.1para una prueba.
4.2.1. Funcion implıcita enRn
El teorema de la funcion implıcita que estudiamos en la seccion anterior se generaliza a mas variables.En ese caso lo que queremos encontrar son formas de parametrizar -con una funcion diferenciableϕ- unasuperficie de nivel
S= X ∈ Rn : f (X) = 0,
(o un pedazo de ella) usando la cantidad adecuada de variables.
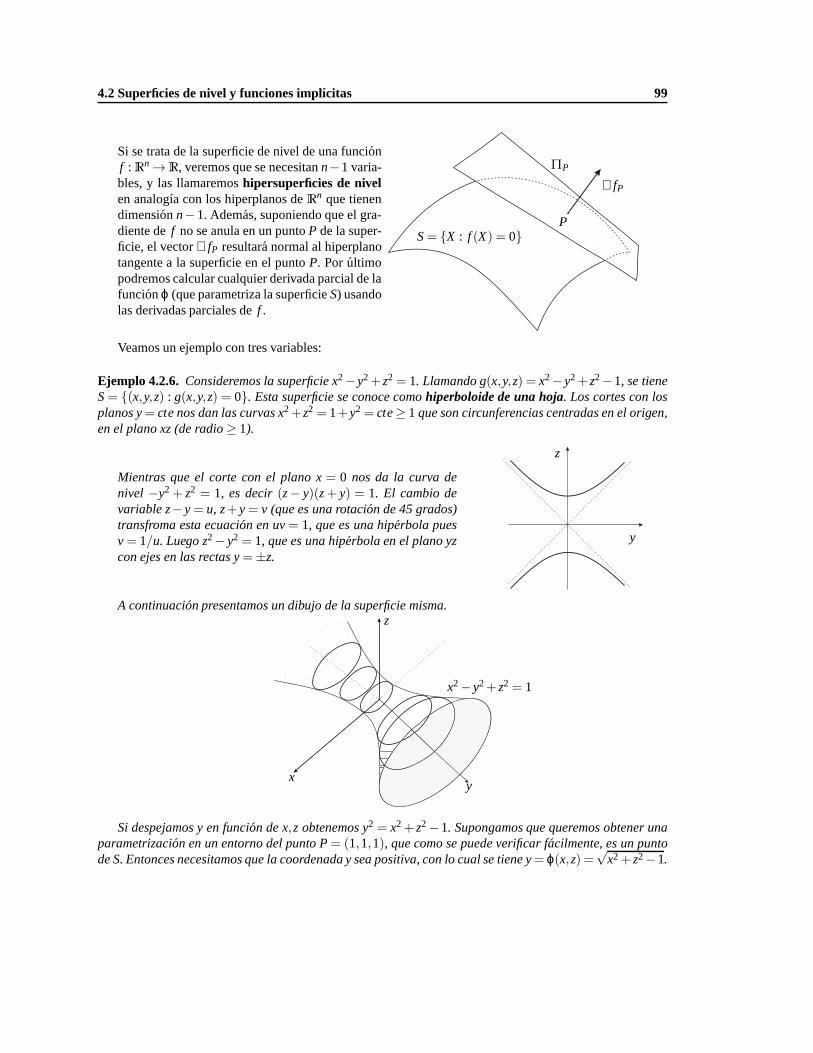
4.2 Superficies de nivel y funciones implıcitas 99
Si se trata de la superficie de nivel de una funcionf : Rn →R, veremos que se necesitann−1 varia-bles, y las llamaremoshipersuperficies de nivelen analogıa con los hiperplanos deRn que tienendimensionn−1. Ademas, suponiendo que el gra-diente def no se anula en un puntoP de la super-ficie, el vector∇ fP resultara normal al hiperplanotangente a la superficie en el puntoP. Por ultimopodremos calcular cualquier derivada parcial de lafuncionϕ (que parametriza la superficieS) usandolas derivadas parciales def .
S= X : f (X) = 0
ΠP
∇ fP
P
Veamos un ejemplo con tres variables:
Ejemplo 4.2.6. Consideremos la superficie x2−y2+z2 = 1. Llamando g(x,y,z) = x2−y2+z2−1, se tieneS= (x,y,z) : g(x,y,z) = 0. Esta superficie se conoce comohiperboloide de una hoja. Los cortes con losplanos y= cte nos dan las curvas x2+z2 = 1+y2 = cte≥ 1 que son circunferencias centradas en el origen,en el plano xz (de radio≥ 1).
Mientras que el corte con el plano x= 0 nos da la curva denivel −y2 + z2 = 1, es decir(z− y)(z+ y) = 1. El cambio devariable z− y= u, z+ y= v (que es una rotacion de 45 grados)transfroma esta ecuacion en uv= 1, que es una hiperbola puesv= 1/u. Luego z2− y2 = 1, que es una hiperbola en el plano yzcon ejes en las rectas y=±z.
y
z
A continuacion presentamos un dibujo de la superficie misma.
xy
z
x2− y2+ z2 = 1
Si despejamos y en funcion de x,z obtenemos y2 = x2+ z2−1. Supongamos que queremos obtener unaparametrizacion en un entorno del punto P= (1,1,1), que como se puede verificar facilmente, es un puntode S. Entonces necesitamos que la coordenada y sea positiva,con lo cual se tiene y= ϕ(x,z) =
√x2+ z2−1.

100 Funcion inversa e implıcita
Por supuesto que esta expresion tiene sentido so-lamente en el dominio x2+ z2−1≥ 0, que comoel lector puede verificar, es la parte externa de lacircunferencia unitaria en el plano xz dada porx2 + z2 = 1. Entonces se obtiene una parametri-zacion de la superficie S en un entorno del puntoP = (1,1,1), pensada como el grafico de la fun-cionϕ(x,z), es decir
(x,√
x2+ z2−1,z) : x2+ z2 ≥ 1.x
y
z
Gr(ϕ(x,z))
Observemos que∇g(x,y,z) = (2x,−2y,2z) y en particular∇gP = (2,−2,2) lo que nos dice que el planotangente a la superficie S en el punto P= (1,1,1) debe ser
ΠP : 〈NP,X−P〉= 0 es decir〈(2,−2,2),(x,y,z)− (1,1,1)〉= 0,
lo que se traduce en2x−2y+2z= 2. Por ultimo, como
g(x,ϕ(x,z),z) = 0,
derivando respecto de x se obtiene
∂g∂x
·1+ ∂g∂y
· ∂ϕ∂x
+∂g∂z
·0= 0,
de donde se despeja
∂ϕ∂x
=−∂g∂x∂g∂y
(x,ϕ(x,z),z).
De forma analoga se puede calcular∂ϕ∂z . Obviamente la formula tiene mayor utilidad cuandono sabemos
quien esϕ. En este caso particular, en cambio, podrıamos derivar directamente la expresion que despejamosdeϕ,
ϕ(x,z) =√
x2+ z2−1.
Enunciamos el resultado con mas precision para demostrarlo:
Teorema 4.2.7.(Funcion Implıcita enRn)
Sea A⊂ Rn+1 abierto y sea f: A→R una funcion C1. Sea
S= X = (x1, · · · ,xn+1) ∈Rn+1 : f (X) = 0
una superficie de nivel de f . Si P∈ S es tal que alguna de las derivadas parciales de f no se anula en P,entonces
1. Existen una bola abierta B⊂Rn, un abierto V⊂Rn+1 entorno de P, y una funcionϕ : B→R tal queS∩V = Gr(ϕ).

4.2 Superficies de nivel y funciones implıcitas 101
2. Se tiene∇ fQ ,O para todo Q∈ S∩V, y allı el plano tangente a S en Q esta dado por la ecuacion
〈∇ fQ,X−Q〉= 0,
es decir,∇ fQ es la normal del hiperplano tangente en Q.
3. Si la derivada que no se anula es la k-esima (con k∈ 1, . . . ,n+1), entonces no se anula en S∩V, yla i-esima derivada parcial deϕ (con i∈ 1, . . . ,n,n+1, i , k) se calcula de la siguiente manera:
∂ϕ∂xi
(Y) =−∂ f∂xi
∂ f∂xk
(Y,ϕ(Y)), para Y∈ B.
Demostracion. Para la demostracion, suponemos que∂ f∂xn+1
(P) , 0. El caso general se deduce intercambian-do el nombre de las variables. Observemos que esto quiere decir, en el caso de tres variables, que la normala la superficieSno es horizontal, es decir, tiene componente vertical.
La figura de la derecha con-tiene los datos del teoremaen ese caso, y nos da unaidea de la situacion general,el puntoP∈ S⊂ Rn+1, don-de
P= (p1, · · · , pn, pn+1)
es donde se verifica que∂ f
∂xn+1(P) , 0.
S⊂ Rn+1
ΠP∇ fP
P
V ⊂ Rn+1
V ∩S
(p1,··· ,pn)
ϕ : B→ R
V ∩S= Gr(ϕ),
B⊂ Rn
Volviendo al caso den variables, consideremos la funcionC1 auxiliarF : A→Rn+1 dada por
F(x1, · · · ,xn,xn+1) = (x1, · · · ,xn, f (x1, · · · ,xn+1)),

102 Funcion inversa e implıcita
con lo cual la matriz de la diferencial deF enP = (p1, · · · , pn, pn+1) esta dada por la siguiente matriz de(n+1)× (n+1):
DFP =
1 0 0 . . . 0
0 1 0 . . . 0
. . . . . . . . . . . . . . .
0 0 . . . 1 0
∂ f∂x1
∂ f∂x2
. . . . . . ∂ f∂xn+1
P
Como supusimos que la ultima derivada parcial es no nula, esta matriz resulta inversible, y por el teorema dela funcion inversa (Teorema4.1.9) existe un entorno abiertoV deP enRn+1 y una bola abiertaW de radioRcentrada en
F(P) = (p1, . . . , pn, f (p1, · · · , pn+1)) = (p1, . . . , pn,0),
tambien enRn+1 tales queF−1 : W →V es diferenciable.
Si escribimosF−1(Z) = F−1(z1, . . . ,zn,zn+1) = (g1(Z), . . . ,gn(Z),gn+1(Z)), la funcion inversa debe ve-rificar, para todoZ ∈W,
(g1(Z), . . . ,gn(Z), f (g1(Z), . . . ,gn+1(Z))) = F(g1(Z), . . . ,gn(Z),gn+1(Z))
= F(F−1(Z)) = Z.
En particular debe ser, mirando cada una de las primerasn coordenadas,
zi = gi(Z).
Luego, mirando la ultima coordenada, tambien debe ser
zn+1 = f (z1, . . . ,zn,gn+1(Z))
y en particular
0= f (z1, . . . ,zn,gn+1(z1, . . . ,zn,0)). (4.3)
Ahora tomamos el corte de la bolaW con el plano del pisoRn×0, pero pensada enRn, es decir
B= (y1, · · · ,yn) ∈ Rn : ‖(y1− p1, · · · ,yn− pn)‖< R
segun indica la figura (recordemos queF(P) = (p1, · · · , pn,0)):

4.2 Superficies de nivel y funciones implıcitas 103
F(P)
W = BR(F(P))⊂ Rn+1
W∩Rn×0
y ası definimosϕ : B→ R como la restriccion degn+1 a B, es decir
ϕ(y1, . . . ,yn) = gn+1(y1, . . . ,yn,0),
dondeY = (y1, . . . ,yn) ∈ B⊂ Rn, la que verificaGr(ϕ)⊂ S∩V pues la ecuacion (4.3) dice que
0= f (y1, . . . ,yn,ϕ(y1, . . . ,yn)) = f (Y,ϕ(Y)). (4.4)
Tambien se verifica que dadoQ ∈ V, existeZ = (z1, . . . ,zn,zn+1) ∈ W tal queF−1(Z) = Q, y si ademasQ∈ S, debe ser forzosamente
zn+1 = f (z1, . . . ,zn,gn+1(z1, . . . ,zn,zn+1)) = 0,
lo que prueba queS∩V ⊂ Gr(ϕ).Veamos que la normal del plano tangente enQ∈S∩V esta dada por∇ fQ. Observemos que este gradiente
en primer lugar es no nulo, pues segun indica el teorema de lafuncion inversa, en este entorno deP se tieneDFQ inversible, y esto solo puede ocurrir mirando la matriz de arriba si ∂ f
∂xn+1(Q) , 0. Por otro lado, el
plano tangente enQ esta generado por lasn derivadas parciales deϕ. EscribimosQ= (Y,ϕ(Y)), conY ∈ B.Entonces solo resta probar que
〈∇ fQ,(Ei ,∂ϕ∂yi
(Y))〉= 0
para todoi = 1. . .n, es decir, que
∂ f∂xi
(Q)+∂ f
∂xn+1(Q)
∂ϕ∂yi
(Y) = 0.
Pero esto se deduce usando la regla de la cadena, derivando enla expresion (4.4) respecto deyi en el puntoY, pues se tiene
0=∂ f∂xi
(Y,ϕ(Y))+∂ f
∂xn+1(Y,ϕ(Y))
∂ϕ∂xi
(Y).
Por ultimo, observemos que despejando de esta ultima ecuacion se obtiene
∂ϕ∂xi
(Y) =−∂ f∂xi
∂ f∂xn+1
(Y,ϕ(Y))
como afirma el teorema.

104 Funcion inversa e implıcita
El teorema se generaliza para funciones a valores enRn.
Teorema 4.2.8.(Funcion Implıcita para campos) Sea A⊂ Rn abierto, y sea F: A → Rk una funcion C1
(con k≤ n). Sea
S= Z ∈ A : F(Z) =O
una superficie de nivel de F. Si P∈ S es tal que DFP : Rn → Rk es sobreyectiva, entonces existen abiertosU ⊂ Rn−k, V ⊂ Rn entornos deO y P respectivamente, y una funcionϕ : U →Rn tal que S∩V = ϕ(U).
Demostracion. Daremos solo una idea de la demostracion. Como la diferencial deF enP es sobreyectiva,esta matriz (den columnas pork filas) tienek columnas linealmente independientes (es porque la imagen deDFP tiene que generar todoRk). Para simplificar vamos a suponer que son las primerask columnas (el caso
general se deduce intercambiando las variables deF para que esto ocurra). EscribimosDFP =(
DFkP DFn−k
P
)
para indicar conDFkP a la matriz inversible dek× k formada por las primerask columnas.
Tenemos entonces, escribiendoRn comoRk×Rn−k, y un punto genericoZ ∈ Rn comoZ = (X,Y) con(X,Y) ∈ Rn×Rn−k, que la funcionF : A→ Rn se puede escribir comoF(Z) = F(X,Y). Consideramos lafuncion auxiliar
H(X,Y) = (F(X,Y),Y),
que es una funcion deRn=Rk×Rn−k en sı mismo (y esC1 puesF esC1). La diferencial deH enP=(P1,P2)es de la pinta
DHP =
DFkP DFn−k
P
0 In−k
P
dondeIn−k indica la identidad de tamanon− k. Esta matriz es inversible puesDFkP lo es, y por lo tanto el
teorema de la funcion inversa nos da una funcionH−1 : W ⊂ Rk×Rn−k →V ⊂ Rk×Rn−k conW entornodeH(P) = (F(P),P2) y V entorno deP= (P1,P2). Esta inversa es de la pinta
H−1(X,Y) = (G(X,Y),Y),
conG : Rk×Rn−k → Rk, lo cual se ve usando que es la inversa deH y H tiene esta pinta (ejercicio, ver elcaso anterior). El entornoU enRn−k se construye como antes tomando un entorno productoU ′×U ⊂W enRn, y la funcionϕ : U → Rn se construye tomando, paraY ∈ Rn−k,
ϕ(Y) = (G(O,Y),Y).
Se tiene(X,Y) = H(H−1(X,Y)) = (F(G(X,Y),Y),Y) lo que prueba que
F(ϕ(Y)) = F(G(O,Y),Y) =O
lo que nos dice queϕ parametriza la superficie de nivel deF, y el resto de las verificaciones quedan a cargodel lector.

4.3 NOTAS 105
4.3. NOTAS
I. Que los ceros de la derivada de una funcion se pueden acumular en un puntox= x0, aunque en ese puntof ′(x0) , 0,lo muestra el siguiente ejemplo. Observemos en primer lugarque la funcion
g(z) =12
z+2sen(z)−zcos(z)
tiene infinitos ceros, puesto que sin∈N, entonces
g(nπ) = nπ[12− (−1)n]
que es un numero positivo sin es impar, y negativo sin es par. Por el teorema de Bolzano,g tiene al menos un cerozn en cada intervalo[nπ,(n+1)π]. Cambiando la variablez por 1
x , se deduce que la ecuacion
12x
+2sen(1x)− 1
xcos(
1x) = 0
tieneinfinitos ceros en cualquier entorno dex= 0. Ahora tomemos la funcionF : R→ R dada por
F(x) =x2+x2 sen(1/x),
extendida como 0 enx= 0. Es facil probar queF es derivable enR, y ademasF ′(0) = 12 , 0 (ver la Observacion
4.1.4). Sin embargo, parax, 0 se tiene
F ′(x) =12+2xsen(
1x)−cos(
1x).
Y de acuerdo a lo recien senalado, esta derivada se anula arbitrariamente cerca de cero (basta igualar a cero ydividir por x).
II. Si F es la funcion del ıtem anterior, entoncesF es derivable en todoR, F(0) = 0, y su derivada enx = 0 es nonula. Sin embargo, no puede existir ninguna funcionderivable F−1 en un entorno dey= 0 que sea inversa deF .Esto es porqueF−1, de existir, tendrıa que verificarF−1(F(x)) = x para todox en un entorno de cero, con lo cualderivando tendrıa que valer la relacion
(
F−1)′(F(x)) ·F ′(x) = 1
Pero para cadax0 que anuleF ′ (y en cualquier entorno de cero hay infinitos) se tendrıa
0=(
F−1)′(F(x0)) ·0=
(
F−1)′(F(x0)) ·F ′(x0) = 1,
un absurdo. Este ejemplo, aunque bastante natural, se lo debemos al libro de M. Spivak [9].
III. El siguiente ejemplo muestra, en el teorema de la funci´on implıcita, no alcanza con que el gradiente no se anule,ni aun siendof diferenciable. SeaF(y) = 1
2y+ y2 sen( 1y) (extendida como cero eny = 0), la funcion de la nota
anterior, que como vimos es derivable en todoR, su derivada en cero esF ′(0) = 12 , pero en cualquier entorno de
cero existen infinitos puntos dondeF ′ se anula. Pongamosf : R2 →R dada por
f (x,y) = x+F(y),
y la curva de nivelS= (x,y) : f (x,y) = 0. El puntoP= (0,0) es un punto deS. Es facil ver quef es diferenciableen todoR2, y como
∇ f (0,0) = (1,12), ∇ f (x,y) = (1,F ′(y)) para(x,y) , (0,0)

106 Funcion inversa e implıcita
entonces∇ f (x,y) ,O para todo(x,y)∈R2. Observemos que∂ f∂y (0,0)=
12 . Sin embargo, no existe ninguna funcion
derivableϕ = ϕ(x) definida en algun entorno dex = 0 tal queGr(ϕ) ⊂ S. Para ver por que, supongamos quesiexiste y llegaremos a un absurdo. Supongamos entonces que existe un intervalo(−δ,δ) alrededor dex= 0 y unafuncion derivableϕ : (−δ,δ)→ R tal queϕ(0) = 0 y ademas
f (x,ϕ(x)) = x+F(ϕ(x)) = 0
para todox∈ (−δ,δ). Derivando con la regla de la cadena se tiene
1+F ′(ϕ(x))ϕ′(x) = 0 (4.5)
para todox ∈ (−δ,δ). En particular, parax = 0 se tiene 1+F ′(0)ϕ′(0) = 0, es decirϕ′(0) = −2. Observemosahora queϕ no puede ser identicamente nula, puesto que eso dirıa que su derivada es identicamente nula. Tomaentonces algun valorb , 0. Pero por ser derivable,ϕ es una funcion continua, y entonces toma (por el Teoremade Bolzano) todos los valores intermedios entre 0 yb. En particularϕ tiene en su imagen alguno de los cerosy0 , 0 de la derivada de la funcionF , que recordemos son infinitos en cualquier intervalo alrededor de cero. Seax0 , 0 en el dominio deϕ tal queϕ(x0) = y0. Entonces, por la ecuacion (4.5) llegamos a una contradiccion, ya quereemplazandox por x0 tenemos
1= 1+0= 1+F ′(y0)ϕ′(x0) = 0.

Todos estuvimos de acuerdo en que tu teorıa esloca. Lo que nos divide es si es suficientementeloca como para tener alguna chance de sercorrecta. Mi impresion es que no essuficientemente loca.
Niels Bohr, en una carta a W. Pauli
5.1. Polinomio de Taylor
Dada una funcion derivable en un intervalo abiertoI ⊂ R, y un puntoa ∈ I , podemos escribir paracualquierx∈ I , mediante el teorema de Lagrange,
f (x) = f (a)+ f ′(c)(x−a)
dondec es un punto entrex y a. Esta formula vale para todox en el intervalo, pero con precaucion porquepara cadax el c puede ser distinto.
La idea del polinomio de Taylor es aproximar a una funcion que sean veces derivable con un polinomiode gradon. Vamos a usar la siguiente notacion:f (k) denota la derivadak-esima de una funcion y usamos elcero para incluir a la funcion original, es decirf (0) = f .
Recordemos la definicion con alguna precision.
Proposicion 5.1.1. Sea I un intervalo abierto enR, y sea f∈Cn(I). El polinomio de Taylor de grado n def en el punto a∈ Io es elunico polinomio P(x) de grado n que verifica
P(k)(a) = f (k)(a)
para todo k∈ 0, . . . ,n. La expresion de P es la siguiente:
P(x) = f (a)+ f ′(a)(x−a)+12
f ′′(a)(x−a)2+ · · ·+ 1n!
f (n)(a)(x−a)n.
Ademas para todo x∈ I se tienef (x) = P(x)+R(x)
donde R(x) = f (x)−P(x) es el resto que verificalımx→a
R(x)(x−a)n = 0.

108 Taylor y extremos
Todo lo enunciado es conocido, lo unico para aclarar es la validez de la ultima afirmacion, que se deduceusando la regla de L’Hospital aplicada (n veces) a
r(x)(x−a)n =
f (x)−P(x)(x−a)n .
Un resultado mas refinado incluye una expresion concreta para el resto, y es el siguiente:
Proposicion 5.1.2. (Taylor con resto de Lagrange)
Sea I un intervalo abierto enR, y sea f: I → R una funcion n+ 1 veces derivable. Entonces dadosx,a∈ I, existe c estrictamente entre x y a tal que
f (x) = f (a)+ f ′(a)(x−a)+f ′′(a)
2(x−a)2+ · · ·+ f (n)(a)
n!(x−a)n+
f (n+1)(c)(n+1)!
(x−a)n+1.
Es decir,f (x) = Pn(x)+Rn(x).
Demostracion. Fijadosx,a∈ I , consideramos la siguiente funcion auxiliar de variablet dada porg : I →R,
g(t) = f (x)− f (t)− f ′(t)(x− t)− 12
f ′′(t)(x− t)2−·· ·− 1n!
f (n)(t)(x− t)n− K(n+1)!
(x− t)n+1
dondeK ∈ R es una constante adecuada elegida de manera queg(a) = 0. Observemos que se trata sim-plemente de la resta def (x) con el polinomio def centrado ent, escrito en la variablex. Se tiene queges una funcion derivable de la variablet, y continua en el intervalo cerrado entrex y a. Ademas se tieneg(x) = g(a) = 0. Con lo cual, por el teorema de Rolle existe una constantec entrex y a tal queg′(c) = 0.Pero si derivamosg se van cancelando terminos y finalmente se tiene
g′(t) =K − f (n+1)(t)
n!(x− t)n,
luego reemplazando ent = c se deduce queK = f (n+1)(c). La demostracion del teorema concluye si evalua-mos la expresion deg ent = a y despejamosf (x).
5.1.1. Varias variables
Las derivadas sucesivas de una funcion juegan un papel relevante en el enunciado del proximo resultado,tengamos antes una pequena discusion sobre ellas. Dada una funcion f : Rn → R, tiene sentido calcular (siexisten) las derivadas sucesivas de la funcion, por ejemplo
∂∂xi
∂ f∂x j
,
que denotaremos para simplificar como∂2 f
∂xi ∂xj. Hay que tener la precaucion de respetar el orden, ya que en
principio podrıa ser∂2 f
∂xi∂x j(P) ,
∂2 f∂x j∂xi
(P).

5.1 Polinomio de Taylor 109
Por ejemplo: Seaf : R2 →R dada por
f (x,y) =
xy3−x3yx2+y2 si (x,y) , (0,0)
0 si (x,y) , (0,0)
Entonces las derivadas parciales cruzadas no coinciden en(0,0). Esta verificacion queda como ejercicio.
Sin embargo, bajo ciertas condiciones estas derivadas coinciden:
Teorema 5.1.3(Clairaut-Schwarz). Sea f: A⊂Rn →R con A abierto. Si f∈C2(A), entonces las derivadascruzadas coinciden, es decir, para todo i, j ∈ 1, . . . ,n se tiene
∂2 f∂xi∂x j
(P) =∂2 f
∂x j∂xi(P)
para todo P∈ A.
Demostracion. La demostracion es mas sencilla si consideramos una funcion deR2 enR, y no se pierdegeneralidad ya que dada una funcion cualquiera, la restriccion a las dos variables que nos interesan nos dauna funcion de solo dos variables. Consideremos entoncesf (x,y) y un puntoP= (a,b) ∈ A, y pongamos
g(t) = f (a+ t,b+ t)− f (a+ t,b)− f (a,b+ t)+ f (a,b).
Para recordarla sirve de guıa el diagrama siguiente:
f (a,b)
f (a,b+ t) f (a+ t,b+ t)
f (a+ t,b)
Si ponemosϕ(x) = f (x,b+ t)− f (x,b), entonces podemos escribir usando Taylor
g(t) = ϕ(a+ t)−ϕ(a) = ϕ′(a)t +ϕ′′(c)t2
2
puesϕ es una funcion dos veces derivable, dondec esta entrea y t.
Se tiene
g(t) =
(
∂ f∂x
(a,b+ t)− ∂ f∂x
(a,b)
)
t +
(
∂2 f∂x2 (c,b+ t)− ∂2 f
∂x2 (c,b)
)
t2
2.
Si dividimos port2 y hacemos tendert a cero, se tiene
lımt→0
g(t)t2 =
∂2 f∂y∂x
(a,b),

110 Taylor y extremos
ya que, como∂ f 2
∂x2 es continua, el ultimo termino tiende a cero.
Ahora podemos repetir el argumento, considerandoψ(y) = f (a+ t,y)− f (a,y). Se tiene entonces
g(t) = ψ(b+ t)−ψ(b) = ψ′(b)t +ψ′′(c)t2
2,
para algun otroc entreb y b+ t. Escribiendo las derivadas y razonando como antes,
lımt→0
g(t)t2 =
∂2 f∂x∂y
(a,b)
lo que prueba la igualdad.
Definicion 5.1.4.Diremos que un conjunto A⊂Rn esconvexosi dados X,Y ∈A, el segmento que une X conY esta completamente contenido en A. Equivalentemente, la funcion g(t) = tY+(1− t)X tiene su imagencontenida en A para todo t∈ [0,1].
Para extender la idea del polinomio de Taylor aRn necesitamos hablar de derivadas segundas y terceras.
Si A⊂ R2 es abierto yg : A→R, vamos a llamarmatriz Hessianao Hessianodeg enP= (a,b) ∈ A ala siguiente matriz de las derivadas segundas deg (suponiendo que existen todas las derivadas segundas):
D2g(a,b) = Hg(a,b) =
∂2g∂x2
∂2g∂y∂x
∂2g∂x∂y
∂2g∂y2
P
.
En general, se define para una funciong : A⊂Rn →R que tenga todas sus derivadas segundas, la matrizHessiana deg enP∈ A, como la matriz den×n siguiente:
HgP =
· · · ∇ ∂g∂x1
· · ·· · · ∇ ∂g
∂x1· · ·
...
· · · ∇ ∂g∂x1
· · ·
P
.
Razonamos de la siguiente manera: sig : Rn →R es una funcionC2, entonces la funcion∇g : P 7→ ∇gP
es una funcion∇g : Rn → Rn, que resultaC1. Es decir∇g es un campoC1. Recordemos que para uncampo diferenciable cualquieraH : Rn → Rn dado porH(P) = (h1(P), · · · ,hn(P)) su diferencial se calculaformando la matriz den×n que tiene por filas los gradientes de lashi, es decir
DHP =
· · · ∇h1 · · ·· · · ∇g2 · · ·
...· · · ∇hn · · ·
P
.
En el caso particularH = ∇g, se deduce que
D2gP = DDgP = D∇gP = HgP,

5.1 Polinomio de Taylor 111
puesto que si reemplazamoshi por ∂g∂xi
en la matriz de arriba, obtenemos el Hessiano deg. Como corolario,por la regla de la cadena, siα : I ⊂ R→ A⊂ Rn es una curva derivable,
(
∇gα(t))′= Hgα(t) ·α′(t).
La matriz Hessiana de una funcionf ∈C2(A) es simetrica por el teorema de Clairaut. Ası por ejemplosi f : R3 →R entonces
H f =
∂2 f∂x2
∂2 f∂y∂x
∂2 f∂z∂x
∂2 f∂x∂y
∂2 f∂y2
∂2 f∂z∂y
∂2 f∂x∂z
∂2 f∂y∂z
∂2 f∂z2
,
y la matriz es simetrica pues podemos intercambiar el ordende las derivadas segundas por serf una funcionC2.
Notemos que, para una funcionf (x,y) de dos variables, hay 8 derivadas de orden 3 que son
∂3 f∂x3 ,
∂3 f∂y3
∂3 f∂x2∂y
,∂3 f
∂y∂x2 ,∂3 f
∂x∂y∂x
∂3 f∂y2∂x
,∂3 f
∂x∂y2 ,∂3 f
∂y∂x∂y.
Sin embargo, de las derivadas mixtas hay en realidad solo dos distintas sif esC3. En efecto, se tiene porejemplo
∂3 f∂x∂y∂x
=∂2
∂x∂y
(
∂ f∂x
)
=∂2
∂y∂x
(
∂ f∂x
)
=∂3 f
∂y∂x2
puesto que∂ f∂x esC2 si f esC3.
¿Que ocurre en general con las derivadas de orden 3? De acuerdo a los calculos de mas arriba, dadauna funcionf : Rn → R diferenciable, su Hessiano se obtiene como la matriz en la que cada fila aparece elgradiente de la respectiva derivada parcial def , es decir
H fP =
∇ ∂ f∂x1
∇ ∂ f∂x2...
∇ ∂ f∂xn
P
.
Observemos que, visto como funcion de la variableP, el gradienteD fP = ∇ fP toma valores enRn, mientraque el Hessiano toma valores en las matrices den×n, es decirD2 f = H f : Rn → Rn×n. Si derivamos una

112 Taylor y extremos
vez mas, serıa razonable que nos quedeD3 f : Rn →Rn×n×n. Esto no esta mal, pero es poco practico. Vamosa usar queRn×n×n se puede identificar con las transformaciones lineales deRn enRn×n, y para cadaP∈Rn,presentaremosD3 fP como una transformacion lineal deRn enRn×n.
Para ver como es este termino de orden 3, calculemos
(H fα(t))′ = DH fα(t) ·α′(t) = DD2 fα(t) ·α′(t) = D3 fα(t) ·α′(t),
que debe ser (para cadat fijo) una matriz den×n.
Hay que derivar cada fila deH fα(t):
(H fα(t))′ =
(
∇ ∂ f∂x1 α(t)
)′
(
∇ ∂ f∂x2 α(t)
)′
...(
∇ ∂ f∂xn α(t)
)′
.
Por la formula que ya probamos,(∇gα(t))′ = Hgα(t) ·α′(t), se tiene en cada fila
(H fα(t))′ =
H ∂ f∂x1 α(t) ·α′(t)
H ∂ f∂x2 α(t) ·α′(t)
...
H ∂ f∂xn α(t) ·α′(t)
. (5.1)
Tomandoα(t) = X+ tV y evaluando ent = 0 se tiene que, comoα(0) = X,α′(0) =V, entonces
D3 fX(V) =
H ∂ f∂x1
X ·V
H ∂ f∂x2
X ·V...
H ∂ f∂xn X ·V
.
para todoX ∈ Rn donde existan las derivadas terceras, para todoV ∈ Rn. CiertamenteD3 fX(V) es lineal enV (fijadoX) y toma valores enRn×n.
Para controlar el tamano de esta expresion, que surgira al escribir el resto cuando escribamos el polino-mio de grado 2, usamos el siguiente lema:
Lema 5.1.5. Sean Ai ∈ Rn×n una famillia de n matrices cuadradas de n× n, y sea X∈ Rn. Si los vector

5.1 Polinomio de Taylor 113
Ai ·X los ordenamos por filas, nos queda
M(X) =
A1 ·XA2 ·X
...An ·X
,
que es una matriz cuadrada de n×n. Entonces
‖M(X)‖∞ ≤(
n
∑i=1
‖Ai‖2∞
) 12
‖X‖.
Demostracion. SeaY ∈ Rn tal que‖Y‖ ≤ 1. Entonces
‖M(X) ·Y‖2 =
∥
∥
∥
∥
∥
∥
∥
∥
∥
〈A1 ·X,Y〉〈A2 ·X,Y〉
...〈An ·X,Y〉
∥
∥
∥
∥
∥
∥
∥
∥
∥
=n
∑i=1
|〈Ai ·X,Y〉|2.
Por otro lado, para cadai = 1. . .n, se tiene
|〈Ai ·X,Y〉| ≤ ‖Ai ·X‖‖Y‖ ≤ ‖Ai ·X‖ ≤ ‖Ai‖∞‖X‖.
Estamos en condiciones de enunciar y demostrar el siguienteteorema sobre el polinomio de Taylor.Recordemos que la formula de Taylor para grado 2 nos dice quesi g es una funcionC3 en un intervaloabiertoI ⊂ R, entonces dadosx,a∈ I , se tiene
g(x) = g(a)+g′(a)(x−a)+12
g′′(a)(x−a)2+13!
g′′′(c)(x−a)3,
dondec esta entrex y a. En particular, six= 1 y a= 0, se tiene
g(1) = g(0)+g′(0)+12
g′′(0)+13!
g′′′(c),
dondec∈ (0,1).
Observemos tambien que sif esC3, en particular esC2 y por el teorema de Clairaut se tiene queH fP esuna matriz simetrica para todoP∈ A.
Teorema 5.1.6(Taylor de orden dos, enRn, con resto de Lagrange). Sea f : A ⊂ Rn → R con A abiertoconvexo. Supongamos f es C3 en A. Entonces dado P∈ A, para todo X∈ A se tiene
f (X) = f (P)+ 〈∇ fP,X−P〉+ 12〈H fP · (X−P),X−P〉+RP(X−P),

114 Taylor y extremos
donde
RP(X−P) =16〈D3 fC(X−P) · (X−P),X−P〉
es el resto (C es algun punto en el segmento entre X y P). El resto verifica
lımX→P
RP(X−P)‖X−P‖2 = 0.
Demostracion. TomemosP,X ∈ A, y consideramos la funcion auxiliar
g(t) = f (P+ t(X−P)),
que esC3 en un entorno del intervalo[0,1]. Derivando, obtenemos
g′(t) = 〈∇ fP+t(X−P),X−P〉,
g′′(t) = 〈(∇ fP+t(X−P))′,X−P〉= 〈H fP+t(X−P) · (X−P),X−P〉,
y por ultimog′′′(t) = 〈D3 fP+t(X−P)(X−P) · (X−P),X−P〉.
Por otro lado, por la formula de Taylor en una variable,
g(1) = g(0)+g′(0)+12
g′′(0)+16
g′′′(c),
dondec esta entre 0 y 1. Entonces
f (X) = f (P)+ 〈∇ fP,X−P〉+ 12〈H fP · (X−P),X−P〉
+16〈D3 fP+c(X−P)(X−P) · (X−P),X−P〉,
dondec∈ (0,1) con lo cualC= P+ c(X−P) esta en el segmento entreP y X. Por ultimo, observemos que
|〈D3 fC(X−P) · (X−P),X−P〉| ≤ ‖D3 fC(X−P)‖∞‖X−P‖2,
y por el Lema previo,
‖D3 fC(X−P)‖∞ ≤n
∑i=1
(
‖H∂ f∂xi
|C‖2∞
) 12
‖X−P‖.
Notemos queH ∂ f∂xi
involucra, para cadai, las derivadas de orden 3 def . Como cada una de ellas es unafuncion continua por hipotesis, en particular es acotadaen un entorno dado deP. Con lo cual
‖H∂ f∂xi
|C‖∞ ≤ nmax| ∂3 f∂x jxkxl
(C)| ≤ M
si X esta cerca deP. Luego, siX esta cerca deP, se tiene
|RP(X−P)|= 16|〈D3 fC(X−P) · (X−P),X−P〉| ≤ M‖X−P‖3,

5.1 Polinomio de Taylor 115
y de aquı se deduce inmediatamente la ultima afirmacion del teorema, pues
|RP(X−P)|‖X−P‖2 ≤ M‖X−P‖
para todoX suficientemente cerca deP.
5.1.2. Demostracion alternativa de la formula de Taylor de orden 2 enRn
Otra forma de presentar la formula de Taylor del Teorema5.1.6es posible, y con otra demostracion.Atencion que se trata de la misma formula. La diferencia esque abandonamos la notacion vectorial y pasa-mos a los ındices y sumas. Ası por ejemplo, siX = (x1, · · · ,xn) y P= (p1, · · · , pn) entonces
〈∇ fP,X−P〉=n
∑i=1
∂ f∂xi
(P)(xi − pi),
y lo mismo con los demas terminos del Teorema5.1.6. Usaremos reiteradas veces la siguiente identidad,que es una simple aplicacion de la regla de la cadena: sig es una funcion diferenciable, entonces como(pi + t(xi − pi))
′ = (xi − pi), se tiene
g(P+ t(X−P))′ =n
∑i=1
∂g∂xi
(P+ t(X−P))(xi − pi).
Teorema 5.1.7(Taylor de orden dos, enRn, con resto de Lagrange). Sea f : A ⊂ Rn → R con A abiertoconvexo. Supongamos f es C3 en A. Entonces dado P= (p1, · · · , pn) ∈ A, para todo X= (x1, · · · ,xn) ∈ A setiene
f (X) = f (P)+n
∑i=1
∂ f∂xi
(P)(xi − pi)+12
n
∑i=1
n
∑j=1
∂2 f∂x j∂xi
(P)(x j − p j)(xi − pi)+RP(X−P).
La expresion del resto es
RP(X−P) =16
n
∑i=1
n
∑j=1
n
∑k=1
∂3 f∂xk∂x j∂xi
(C)(xk− pk)(x j − p j)(xi − pi).
con C algun punto en el segmento entre X y P, y verifica
lımX→P
RP(X−P)‖X−P‖2 = 0.
Demostracion. TomemosP,X ∈ A, y consideramos la funcion auxiliar
g(t) = f (P+ t(X−P)),
que esC3 en un entorno del intervalo[0,1]. Derivando, obtenemos
g′(t) =n
∑i=1
∂ f∂xi
(P+ t(X−P))(xi − pi).

116 Taylor y extremos
Derivando nuevamente, tenemos
g′′(t) =n
∑i=1
(
∂ f∂xi
(P+ t(X−P))
)′(xi − pi)
=n
∑i=1
(
n
∑j=1
∂∂x j
∂ f∂xi
(P+ t(X−P))(x j − p j)
)
(xi − pi)
=n
∑i=1
n
∑j=1
∂2 f∂x j∂xi
(P+ t(X−P))(x j − p j)(xi − pi).
Derivamos una vez mas para obtener
g′′′(t) =n
∑i=1
n
∑j=1
(
∂2 f∂x j∂xi
(P+ t(X−P))
)′(x j − p j)(xi − pi)
=n
∑i=1
n
∑j=1
n
∑k=1
∂3 f∂xk∂x j∂xi
(P+ t(X−P))(xk− pk)(x j − p j)(xi − pi).
Ahora invocamos la formula de Taylor de orden dos, en una variable para la funciong en el intervalo[0,1],que nos dice que
g(1) = g(0)+g′(0)+12
g′′(0)+16
g′′′(c),
dondec ∈ (0,1). Observemos queC = P+ c(X −P) es en efecto un punto en el segmento que uneX conP. Reemplazando en esta formula los valores deg y sus derivadas se tiene la formula del enunciado delteorema. Por ultimo, para ver que el lımite indicado da cero, observemos que las derivadas terceras sonfunciones continuas, con lo cual, tomando algun entorno compacto deP, son funciones acotadas, y con esto,si X esta cerca deP se tiene
n
∑i=1
n
∑j=1
n
∑k=1
| ∂3 f∂xk∂x j∂xi
(C)| ≤ M.
Como
|xk− pk||x j − p j ||xi − pi| ≤ ‖X−P‖3,
se deduce que
|RP(X−P)| ≤ 16
M‖X−P‖3
si X esta cerca deP. Dividiendo por‖X−P‖2 y tomando lımite paraX → P se tiene la conclusion.
¿Como quedan estas formulas en los casos concretos? Veamos paran = 2: ponemosP = (a,b) ∈ R2,X = (x,y) ∈ R2. Entonces

5.2 Extremos 117
f (x,y) = f (a,b)+∂ f∂x
(x−a)+∂ f∂y
(y−b)+
12
∂2 f∂x2 (x−a)2+
12
∂2 f∂y2 (y−b)2+
∂2 f∂x∂y
(x−a)(y−b)+R(a,b)(x−a,y−b),
donde todas las derivadas parciales estan evaluadas enP= (a,b), y R es el resto dado por las derivadasde orden 3 def ,
16
∂3 f∂x3 (C)(x−a)3+
16
∂3 f∂y3 (C)(y−b)3+
12
∂3 f∂x2∂y
(C)(x−a)2(y−b)+12
∂3 f∂x∂y2 (C)(x−a)(y−b)2,
donde las derivadas parciales estan evaluadas en un punto intermedioC = (c1,c2) en el segmento queuneP conX.
Paran= 3 el polinomio de grado dos esta dado por (aquıP= (a,b,c))
P(x,y,z) = f (a,b,c)+∂ f∂x
(x−a)+∂ f∂y
(y−b)+∂ f∂z
(z− c)
+12
∂2 f∂x2 (x−a)2+
12
∂2 f∂y2 (y−b)2+
∂2 f∂z
(z− c)2+
+∂2 f∂x∂y
(x−a)(y−b)+∂2 f∂x∂z
(x−a)(z− c)+∂2 f∂y∂z
(y−b)(z− c)
donde todas las derivadas parciales estan evaluadas enP= (a,b,c). No daremos la expresion explıcitadel resto, aunque se puede calcular desarrollandoRP en el teorema anterior, tal cual lo hicimos paran= 2.
5.2. Extremos
Recordemos que si una funcionf : A⊂Rn →Rk es diferenciable en un puntoP∈ Ao, y este punto es unextremo local def , entonces la diferencial def debe anularse enP. Equivalentemente, el vector gradientees cero, es decir∇ fP =O.
Recordemos un criterio sencillo para funciones enR para determinar si el extremo es maximo o mınimo:

118 Taylor y extremos
Proposicion 5.2.1. (Criterio de la derivada segunda)
Si f es dos veces derivable en un intervalo abierto I, y se tiene f′(a) = 0 para algun a∈ I, entonces
1. Si f′′(a)> 0, el punto x= a es un mınimo local de f .
2. Si f′′(a)< 0, el punto x= a es un maximo local de f .
Observacion 5.2.2. Atencion que si la derivada segunda tambien se anula, el criterio no nos dice nada. Dehecho, el punto no tiene ni siquiera que ser un extremo: consideremos f(x) = x3. Entonces si a= 0, se tienef ′(a) = 0 y f ′′(a) = 0, mientras que x= 0 no es un extremo local de f .
Por otro lado, si consideramos g(x) = x4, se tiene g′(0) = 0 y g′′(0) = 0, pero sin embargo x= 0 es unmınimo local (de hecho, absoluto) de g.
De manera analoga, si consideramos h(x)=−x4, las dos primeras derivadas se anulan en cero, mientrasque este punto es un maximo de h.
Vamos a pensar un poco como se generaliza este criterio a dos variables y luego lo demostramos. Recor-demos que sif esC2, el Hessiano es la matriz simetrica de las derivadas segundas, evidentemente tiene quejugar un papel dominante en la formulacion del mismo.
5.2.1. Formas cuadraticas
Dada una matriz cuadradaT den×n, consideramos la siguiente funcion
Q(X) = 〈TX,X〉,
denominadaforma cuadratica asociada aT. Observemos que
Q(tX) = t2Q(X) para todot ∈ R,
de allı el nombre.
Supongamos queT esta diagonalizada, con autovaloresλ1, . . . ,λn ∈R. Entonces
TX = T(x1, . . . ,xn) = (λ1x1, . . . ,λnxn)
con lo cualQ(x1, . . . ,xn) = λ1x2
1+λ2x22+ · · ·+λnx
2n. (5.2)
Observemos que losλi pueden ser positivos, negativos o cero.
1. Si son todos no nulos, decimos queQ esno degenerada.
2. Si alguno (o varios) de losλi son nulos, decimos queQ esdegenerada.
3. Q esdefinida positivasi λi > 0 para todoi = 1. . .n.
4. Q esdefinida negativasi λi < 0 para todoi = 1. . .n.
5. Q esindefinida si algunosλi son positivos y otros son negativos.

5.2 Extremos 119
Observemos que una forma indefinida puede ser tanto degenerada como no degenerada. En el casodegenerado, pero no indefinido, decimos queQ es
1. semidefinida positivasi λi ≥ 0 para todoi = 1. . .n.
2. semidefinida negativasi λi ≤ 0 para todoi = 1. . .n.
Observemos que, inspeccionando la ecuacion (5.2), se tiene
1. Q esdefinida positivasi y solo siQ(X)> 0 para todoX ,O.
2. Q esdefinida negativasi y solo siQ(X)< 0 para todoX ,O.
3. Q essemidefinida positivasi y solo siQ(X)≥ 0 para todoX.
4. Q essemidefinida negativasi y solo siQ(X)≤ 0 para todoX.
5. Q esindefinida si y solo si existenX1,X2 tales queQ(X1)> 0 y Q(X2)< 0.
Pasemos ahora al caso general. Recordemos que siT es una matriz simetrica, es diagonalizable. Es decir,existe una base ortonormalB= V1, . . . ,Vn deRn tal que
T =CBE D CEB,
dondeD = MBB(T) es una matriz diagonal que tiene a los autovalores deT. Recordemos tambien queU =CBE es la matriz de cambio de base, con los vectores de la baseB escritos en la base canonica puestoscomo columnas, y se tiene la siguiente propiedad:
CtBE =CEB =C−1
BE, es decirU t =U−1,
con lo cualT =UDU t . Luego
Q(X) = 〈TX,X〉= 〈UDU tX,X〉= 〈D(U tX),U tX〉.
Ahora llamamosY =U tX =CEBX; notar queY es simplementeXB, o seaXB = (y1, . . . ,yn). Entonces
Q(X) = 〈DY,Y〉= 〈(λ1y1, . . . ,λnyn),(y1, . . . ,yn)〉= λ1y21+ · · ·+λny2
n. (5.3)
Se observa que, salvo un cambio de base, la forma cuadraticaQ se puede describir completamente con losautovalores.
Para los que se perdieron con la idea de la matriz de cambio de base, hacemos otra demostracion: dadoX ∈ Rn, lo escribimos en la baseB, es decir como combinacion lineal de los vectores de la baseB:
X =n
∑i=1
yiVi = y1V1+ y2V2+ · · ·+ ynVn.
Entonces, por las propiedades del producto escalar se tiene
Q(X) = 〈TX,X〉=n
∑i=1
n
∑j=1
yiy j〈TVi ,Vj〉.

120 Taylor y extremos
ComoTVi = λiVi por ser losVi autovectores deT, se tiene
Q(X) =n
∑i=1
n
∑j=1
yiy j〈λiVi ,Vj〉=n
∑i=1
n
∑j=1
yiy jλi〈Vi ,Vj〉.
Como losVi son una base ortonormal se tiene〈Vi ,Vj〉 = 0 si i , j, con lo cual solo quedan los terminos enlos quei = j,
Q(X) =n
∑i=1
y2i λi〈Vi ,Vi〉.
Por ultimo, como〈Vi ,Vi〉= ‖Vi‖2 = 1, se tiene
Q(X) =n
∑i=1
λiy2i = λ1y2
1+λ2y22+ · · ·+λnV
2n ,
que es la misma expresion que obtuvimos en (5.3), con otra prueba.
Si nos convencimos de que el signo deQ(X) solo depende de los autovalores deT, y no deX, entoncesvamos a decir (para cualquierT simetrica), siguiendo la logica de antes, queQ(X) = 〈TX,X〉 es
1. degeneradasi TX =O para algunX ,O.
2. no degeneradasi T es inversible.
3. definida positivasi Q(X)> 0 para todoX ,O.
4. definida negativasi Q(X)< 0 para todoX ,O.
5. semidefinida positivasi Q(X)≥ 0 para todoX.
6. semidefinida negativasi Q(X)≤ 0 para todoX.
7. indefinida si existenX1,X2 tales queQ(X1)> 0 y Q(X2)< 0.
El siguiente es un criterio util que usa el determinante. Recordemos que los menores principales de unamatriz cuadrada son las submatrices que se obtienen comenzando por la esquina superior izquierda. Porejemplo, si
T =
T11 T12 T13
T21 T22 T23
T31 T32 T33
,
entonces los menores principales deT son las siguientes tres matrices de 1×1, 2×2 y 3×3 respectivamente:
T11,
(
T11 T12
T21 T22
)
, T.
Proposicion 5.2.3. Sea T simetrica y Q(X) = 〈TX,X〉 la forma cuadratica asociada. Entonces Q es
1. no degeneradasii det(T) , 0.

5.2 Extremos 121
2. definida positivasii todos los determinantes de los menores principales son estrictamente positivos.
3. definida negativasii todos los determinantes de los menores principales tienen signos alternados,empezando por un numero negativo.
Demostracion. El ıtem 1. es evidente. Demostraremos los ıtems 2 y 3 solamente en el caso 2×2. El casogeneral se deduce por induccion. SeaB= V1,V2 una base ortonormal de autovectores deT con autovaloresλ1,λ2 respectivamente (que existe por serT simetrica). Entonces vimos que, siXB = (y1,y2),
Q(X) = λ1y21+λ2y2
2.
Veamos 2. Supongamos primero que los dos determinantes son positivos. Es decirT11 > 0 y det(T) > 0.Entonces como det(T) = λ1λ2, los dos autovalores deben tener el mismo signo. Por otro lado, 0< T11 =〈TE1,E1〉 = Q(E1) con lo cual no pueden ser los dos negativos pues serıaQ(X) < 0 para todoX , 0 porla expresion de arriba. Entonces son los dos positivos, es decir T es definida positiva. Recıprocamente, siT es definida positiva,T11 = Q(E1) > 0 y por otro lado los dos autovalores deben ser positivos con lo cualdet(T)> 0.
Supongamos ahora queT11 < 0 y det(T) > 0. Nuevamente los dos autovalores tienen el mismo signopero ahoraQ(E1) = T11 < 0 con lo cual tienen que ser los dos negativos ası queT es definida negativa.Recıprocamente, siT es definida negativa, det(T) > 0 pues los dos autovalores son negativos, y ademasT11 = Q(E1)< 0.
En general uno se refiere indistintamente aT o a su forma cuadratica asociadaQ. Ası “T es definidapositiva” quiere decir queQ es definida positiva. Veamos los casos mas relevantes de formas no degeneradas.
EnR2×2, tenemos
T =
(
λ1 00 λ2
)
.
Entonces
1. T es definida positiva si y solo siλ1 > 0 y λ2 > 0.
2. T es definida negativa si y solo siλ1 < 0 y λ2 < 0.
3. T sera indefinida si y solo siλ1λ2 = det(T)< 0.
Conviene tener presentes los dos ejemplos mas simples de formas definida positiva y negativa. En amboscasos debe serdet(T)> 0. Se indican a un lado de la matriz los signos de los determinantes de los menores.
(
+ 00 +
)
++
(
− 00 −
)
−+
Solo con estos signos se consiguen formas respectivamentepositivas y negativas, mientras que sidet(T)<0 se tiene una forma indefinida como dijimos.

122 Taylor y extremos
Veamos ahora que ocurre enR3×3. Tenemos
T =
λ1 0 00 λ2 00 0 λ3
.
Conviene tener presentes los dos ejemplos sencillos de forma definida positiva y negativa respectivamente,y recordar de allı los signos de los menores:
+ 0 00 + 00 0 +
+++
− 0 00 − 00 0 −
−+−
.
Observacion 5.2.4. Negando estos casos, se tiene que en matrices3× 3, la forma sera no degenerada eindefinida si y solo si det(T) , 0 y ocurre alguno de los dos casos siguientes:
1. El segundo menor tiene determinante menor a cero.
2. El segundo menor es estrictamente positivo y ademasdet(T)T11 < 0.
5.2.2. El Hessiano y los extremos
Recordemos que para que un punto sea un extremo relativo de una funcion diferenciablef , se debe tener∇ fP = O. Sin embargo, como en el caso de una variable esto solo me da candidatos, resta ver si en efectoson extremos. A estos puntos donde el gradiente def se anula los llamamos puntos crıticos. Entran tambienen esta denominacion aquellos puntos dondef no es diferenciable, pero por ahora nos concentraremos en elprimer caso.
Toda la discusion de la seccion previa fue para establecerun criterio efectivo para decidir si un puntocrıtico de una funcionf : Rn →R es un extremo local o no, y si es un extremo, si es maximo o mınimo.
Una aclaracion: todos los extremos consideradosson locales, y un extremo es estricto sif (P) >f (X) para todoX en un entorno deP, sin contarP. Un caso sencillo de mınimo (no estricto) es eldado por la parabola trasladada,f (x,y) = x2 cuyografico presentamos a la derecha. Aquı se observaque cualquier punto del ejey es un mınimo def ,pero no es estricto porque si nos movemos a lolargo de este eje la funcion es constante.
x y
z

5.2 Extremos 123
Definicion 5.2.5. Diremos que P espunto silla de f si existen dos trayectoriasα,β (no necesaritamenterectas) que tienden a P (o sea son continuas yα(0) = β(0) = P), y tales que fα tiene un maximo en t= 0y f β tiene un mınimo en t= 0. Es decir, si hay dos trayectorias continuas de manera que f tiene maximoy mınimo a lo largo de ellas en P. En este caso P no es ni maximo ni mınimo de f .
Vamos a referirnos indistintamente al Hessiano def enP y a su forma cuadratica asociada
QP(V) =12〈H fPV,V〉.
Lema 5.2.6. Sea f: A ⊂ Rn → R una funcion C3, con A es abierto y P∈ A. Supongamos que∇ fP = O.Entonces
1. Si existe V∈ Rn tal que QP(V) < 0, entonces a lo largo de la recta P+ tV (para t suficientementepequeno) la funcion f tiene un maximo en P. Es decir g(t) = f (P+ tV) tiene un maximo local ent = 0.
2. Si existe W∈ Rn tal que QP(W) > 0, entonces a lo largo de la recta P+ tW (para t suficientementepequeno) la funcion f tiene un mınimo en P. Es decir h(t) = f (P+ tW) tiene un mınimo local ent = 0.
Demostracion. Probamos la primera afirmacion, la segunda se deduce de manera similar. Por la formula deTaylor, escribiendoX = P+ tV, se tiene
f (P+ tV) = f (P)+ t2QP(V)+RP(tV)
parat suficientemente pequeno. Sacando factor comunt2‖V‖2 se obtiene
f (P+ tV) = f (P)+ t2‖V‖2[
QP(V)
‖V‖2 +RP(tV)
‖tV‖2
]
. (5.4)
Si hacemos tendert → 0, el cocienteRP(tV)‖tV‖2 tiende a cero. En particular, tomandoε = −QP(V)
‖V‖2 , que es un
numero positivo puesQP(V)< 0, existeδ > 0 tal que
−ε <RP(tV)
‖tV‖2 < ε
si |t|< δ. Se deduce de la desigualdad de la derecha, recordando quien esε, que
QP(Z1)
‖Z1‖2 +R(tZ1)
‖tZ1‖2 < 0.
Esto es lo mismo, observando la ecuacion (5.4), que decir quef (P+ tV) < f (P) parat suficientementepequeno.
Observacion 5.2.7.Dada T∈Rn×n, la funcion Q:Rn →R dada por la forma cuadratica Q(X) = 〈TX,X〉es una funcion continua. De hecho, es diferenciable. Para simplificar, supongamos que, como en toda estaseccion, la matriz T es simetrica. Entonces afirmamos que para cualquier X∈ Rn, se tiene
DQX(V) = 2〈TX,V〉.

124 Taylor y extremos
Para verlo, fijado X∈Rn, basta probar queQ(Y)−Q(X)−DQX(Y−X)‖Y−X‖ tiende a cero cuando Y→ X. Pero, usando
las propuedades del producto escalar,
Q(Y)−Q(X)−2〈TX,Y−X〉 = 〈TY,Y〉− 〈TX,X〉−2〈TX,Y〉+2〈TX,X〉= 〈TY,Y〉+ 〈TX,X〉−2〈TX,Y〉= 〈TY,Y〉+ 〈TX,X〉−2〈TX,Y〉= 〈TY,Y〉− 〈TX,Y〉+ 〈TX,X〉− 〈TX,Y〉.
Ahora, como T es simetrica (y el producto escalar tambien) se tiene〈TX,Y〉 = 〈X,TY〉 = 〈TY,X〉, con locual podemos agrupar de la siguiente manera
Q(Y)−Q(X)−DQX(Y−X) = 〈TY,Y−X〉+ 〈TX,X−Y〉= 〈TY,Y−X〉+ 〈−TX,Y−X〉= 〈TY−TX,Y−X〉= 〈T(Y−X),Y−X〉.
Con esto, por la desigualdad de C-S, se tiene
|Q(Y)−Q(X)−DQX(Y−X)| ≤ ‖T(Y−X)‖‖Y−X‖ ≤ ‖T‖∞‖Y−X‖2.
Luego|Q(Y)−Q(X)−DQX(Y−X)|
‖Y−X‖ ≤ ‖T‖∞‖Y−X‖,
lo que prueba que este cociente tiende a cero cuando Y→ X.
Teorema 5.2.8.Sea f: A⊂ Rn → R una funcion C3, con A es abierto y P∈ A. Supongamos que∇ fP =O.Entonces
1. Si H fP es definido negativo, P es un maximo estricto de f .
2. Si H fP es definido positivo, P es un mınimo estricto de f .
3. Si H fP es indefinida, P es un punto silla de f .
Demostracion. Supongamos primero queP es un punto dondeH fP es definido positivo. Entonces por elTeorema de Taylor (Teorema5.1.6), paraX suficientemente cerca deP se tiene
f (X) = f (P)+12〈H fP(X−P),X−P〉+R(X−P)
= f (P)+ ‖X−P‖2[
12〈H fP
X−P‖X−P‖ ,
X−P‖X−P‖〉+
R(X−P)‖X−P‖2
]
(5.5)
pues∇ fP =O. LlamandoQP(V) = 〈12H fPV,V〉, esta expresion se reescribe ası:
f (X) = f (P)+ ‖X−P‖2[
QP
(
X−P‖X−P‖
)
+R(X−P)‖X−P‖2
]
. (5.6)

5.2 Extremos 125
Observemos que para cualquierX , P, el vector en el cual esta evaluadoQP tiene norma unitaria, es decir∥
∥
∥
∥
X−P‖X−P‖
∥
∥
∥
∥
=1
‖X−P‖‖X−P‖= 1.
ComoSn−1 = V ∈ Rn : ‖V‖ = 1 es un conjunto compacto yQp : Rn → R es una funcion continua, estafuncion tiene un mınimomP en la esfera, es decir existeVP de norma unitaria tal queQ(VP) = mP. ComoVP ,O, este mınimomP debe ser mayor a cero puesH fP es definido positivo por hipotesis. Entonces, comoR(X−P)‖X−P‖2 → 0 cuandoX → P, tomandoε = mP, existeδ > 0 tal queX ∈ Bδ(P) implica
−mP <R(X−P)‖X−P‖2 < mP.
En consecuencia, usando quemP es el mınimo deQp en la esfera, y usando el lado izquierdo de esta ultimadesigualdad, se tiene
QP
(
X−P‖X−P‖
)
+R(X−P)‖X−P‖2 ≥ mP+
R(X−P)‖X−P‖2 > 0
siempre que‖X − P‖ < δ. Luego, lo que le sigue af (P) en la ecuacion (5.6) es positivo siempre que‖X−P‖< δ, y esto prueba quef (X)> f (P) si X ∈ Bδ(P). Es decir,P es un mınimo local def .
La demostracion para el caso definido negativo es similar.
Si QP es indefinida, existen dos vectoresZ1,Z2 ∈ Rn tales queQP(Z1) > 0 y QP(Z2) < 0. Por el lemaprevio, a lo largo de las trayectoriasP+ tZ1,P+ tZ2, la funcion f es respectivamente mayor y menor quef (P), con lo cualP no puede ser ni maximo ni mınimo, y es un punto silla por definicion.
Ejemplo 5.2.9. Veamos algunos ejemplos.
1. Sea f(x,y) = 4xy− x4− y4. Entonces∇ f = (4y−4x3,4x−4y3) = (0,0) si y solo si y= x3, x= y3.Entonces y= y9, es decir y(y8−1) = 0, de donde se deduce que y= 0 o bien y= ±1. Entonces lospuntos crıticos son(0,0), (1,1), (−1,−1). Calculamos el Hessiano de f :
H f =
(
−12x2 44 −12y2
)
,
con lo cual
H f(0,0) =
(
0 44 0
)
, H f(1,1) =
(
−12 44 −12
)
= H f(−1,−1).
Comodet(H f(0,0)) =−16< 0 se deduce que el origen es un punto silla. Los otros dos puntosverificanque el lugar1,1 es estrictamente negativo, mientras que el determinante esigual a (−12)2− 16=144− 16> 0, con lo cual los dos autovalores son negativos ası que se trata en ambos casos demaximos.
2. Si f(x,y,z) = x4−2x2+ y2+ yz+ z2, entonces∇ f = (4x3−4x,2y+ z,2z+ y) = (0,0,0) si y solo six3 − x = 2y+ z= 2z+ y = 0. Se deduce que x= 0 o bien x= ±1, y por otro lado que y= z= 0.Entonces los puntos crıticos son(0,0,0), (±1,0,0). La matriz Hessiana de f es
H f =
12x2−4 0 00 2 10 1 2
,

126 Taylor y extremos
luego en el origen se tiene
H f(0,0,0) =
−4 0 00 2 10 1 2
.
Los determinantes de los menores correspondientes son−4, −4 ·2= −8 y −4 ·3= −12. Como sontodos negativos, el origen es un punto silla de f . Por otro lado,
H f(±1,0,0) =
8 0 00 2 10 1 2
.
Ahora los determinantes son8, 8·2= 16y 8·3= 24. Como son todos positivos, los puntos(±1,0,0)son mınimos de f .
Observacion 5.2.10.Notemos que en el caso degenerado no podemos asegurar que P sea un extremo de f .Por ejemplo, si f(x,y) = x2+ y3, entonces
∇ f = (2x,3y2),
luego∇ f(0,0) = (0,0) con lo cual el origen es un punto crıtico de f . Tambien
H f =
(
2 00 6y
)
, con lo cual H f(0,0) =
(
2 00 0
)
,
que es ciertamente semidefinida positiva (un autovalor positivo y el otro nulo). Sin embargo, si nos acerca-mos al origen a lo large del eje y se observa que
f (0,y) = y3,
con lo cual el origen no es ni maximo ni mınimo de f .
Sin embargo, hay una relacion, dada por el siguiente teorema
Teorema 5.2.11.Sea f: A⊂ Rn →R una funcion C3 (A es abierto). Entonces
1. Si P es un maximo local de f , entonces H fP es semidefinido negativo.
2. Si P es un mınimo local de f , entonces H fP es semidefinido positivo.
Demostracion. En el caso del maximo, sabemos que exister > 0 tal quef (X)≤ f (P) para todoX ∈ Br(P).Si H fP no fuera semidefinido negativo, existirıaV ∈Rn tal queQP(V)> 0. Por el Lema5.2.6, a lo largo dela trayectoriaX(t) = P+ tV se tendrıa
f (P+ tV)> f (P)
parat suficientemente pequeno, lo cual es una contradiccion. Lademostracion para el caso de un mınimo esanaloga.

5.3 Extremos con restricciones, multiplicadores de Lagrange 127
El criterio del Hessiano nos asegura que si el mismo es indefinido, entonces el puntoP es punto silla,y las trayectorias son dos rectas como se desprende de la demostracion. Sin embargo, si el Hessiano esdegenerado podrıa ocurrir queP fuera un punto silla pero que a lo largo de cualquier recta se encuentresiempre maximo (o siempre mınimo). Un ejemplo de esta situacion bastante anti-intuitiva es el siguiente:
Ejemplo 5.2.12. Consideremos f(x,y) = 2x4+ y2−3yx2. Entonces es facil ver que P= (0,0) es un puntocrıtico de f , y que
H f(0,0) =
(
0 00 2
)
.
Esto nos dice que a lo largo del eje de las y, f tiene un mınimo en(0,0). Tambien se verifica que a lo largo decualquier recta la funcion f tiene un mınimo en el origen. Sin embargo, considerando la trayectoria y= 3
2x2
(es decirα(x) = (x, 32x2), con x alrededor del cero), se obtiene
( f α)(x) =−14
x4,
con lo cual a lo largo de esta trayectoria f tiene un maximo en el origen. Luego el origen es un punto sillaaunque a lo largo de cualquier recta se consiga un mınimo.
5.3. Extremos con restricciones, multiplicadores de Lagrange
5.3.1. Extremos en una region
Dada una funcion continuaf : A⊂ Rn → R conA un conjunto cualquiera, el problema que nos interesaes el de hallar extremos (tanto relativos como absolutos si los hubiera) def enA.
Para los puntos del interiorAo, primero buscamos los puntos crıticos def con el gradiente. Despues haydos situaciones:
1. La frontera deA la podemos parametrizar con una funcionϕ (o varias de ellas), de manera queIm(ϕ)=∂A.
2. La frontera deA esta dada en forma implıcita por una ecuacion, de manera que no resulta conveniente(o es directamente imposible) parametrizarla explıcitamente.
En el primer caso, lo que hacemos es estudiar la funcionf restringida al borde componiendo con laparametrizacion, es decir, hallamos los punto crıticos de g= f ϕ. Recordemos que siA es compacto yfes continua, debe haber tanto maximo como mınimo absolutode f enA. En el caso general, puede no haberextremos absolutos.
Tambien nos interesan los casos en los que el conjuntoA no tiene interior. Tıpicamente, cuandoA es unacurva o una superficie de nivel. Estos los tratamos como en el ´ıtem 2 recien mencionado.
5.3.2. Extremos en regiones con borde que se puede parametrizar
Hagamos algunos ejemplos de este caso:

128 Taylor y extremos
Ejemplo 5.3.1. Sea f: R2 → R dada por f(x,y) = x2+ y2+ x. Hallar los extremos de f restringidos a labola unitaria cerrada, es decir
B= (x,y) : x2+ y2 ≤ 1.El interior es la bola abierta, allı calculamos
∇ f = (2x+1,2y), H f =
(
2 00 2
)
y el unico punto crıtico es P1 = (− 12,0). Como H fP es definido positivo, se trata de un mınimo local de f .
Por otra parte, la frontera se parametriza medianteα(t) = (cost,sent), para t∈ [0,2π). La composiciones la funcion real g(t) = cos2 t + sen2 t + cost = 1+ cost, cuya derivada es g′(t) =−sent, que se anula ent = 0,π. Entonces f tiene extremos en P2 = (1,0) y en P3 = (−1,0). Evaluando se tiene
f (P1) =14− 1
2=−1
4, f (P2) = f (P3) = 2,
lo que nos dice que en P1 se alcanza el mınimo absoluto de f , mientras que en P2 y P3 se alcanza el maximoabsoluto de f .
Ejemplo 5.3.2. Sea f(x,y,z) = x2− 12x+exy en el cuadrado[0,1]× [0,1]. En el interior el gradiente y el
Hessiano de f son
∇ f = (2x+exyy− 12,exyx), H f =
(
2+exyy2 exyxyexyxy exyx2
)
.
El gradiente se anulaunicamente en P1 = (0, 12). Allı el Hessiano es
H f =
(
94 00 0
)
que es es semidefinido positivo, luego el criterio no se puedeusar.
Por otro lado, a lo largo de los cuatro lados se tiene:
1. En x= 0, hay que buscar los extremos de g(y) = f (0,y) = 1 en el intervalo[0,1]. Como es constanteno hay nada para hacer ( f vale constantemente uno en el lado izquierdo del cuadrado).
2. En x= 1, hay que buscar los extremos de g(y) = f (1,y) = 12 +ey en el intervalo[0,1]. Como g′(y) = ey
no se anula nunca, lounico relevante son los extremos, g(0) = f (1,0) = 32 y g(1) = f (1,1) = 1
2 +e.
3. En y= 0, hay que buscar los extremos de g(x) = f (x,0) = x2 − 12x+ 1 en el intervalo[0,1]. Como
g′(x) = 2x− 12 = 0 unicamente en x= 1
4, los puntos relevantes son los bordes (que ya los consideramosporque son los vertices del cuadrado) y el punto P2 = (1
4,0).
4. Por ultimo, en y= 1, hay que buscar los extremos de g(x) = f (x,1) = x2− 12x+ex en el intervalo
[0,1]. Como g′(x) = 2x− 12 +ex no se anula nunca (pues ex ≥ 1 para x≥ 0), lo unico relevante son
los extremos, que son dos vertices del cuadrado que ya consideramos.

5.3 Extremos con restricciones, multiplicadores de Lagrange 129
En sıntesis,
f (0,12) = 1, f (
14,0) =
1516
,
f = 1 en todo el lado izquierdo del cuadrado (incluyendo los vertices), y porultimo
f (1,0) =32, f (1,1) =
12+e.
De esta lista se deduce que el vertice(1,1) es el maximo absoluto de f , mientras que el mınimo absolutose alcanza en el punto(1
4,0) de la base.
5.3.3. Multiplicadores de Lagrange
No siempre se puede parametrizar la region de manera sencilla. Consideremos el siguiente ejemplo:
Ejemplo 5.3.3. Hallar los maximos y mınimos de f(x,y) = x2 + 2x+ y2 restringida a la curva de nivelg(x,y) = (x−1)2+4y2−1= 0 de la funcion g.
Aquı resulta conveniente otra estrategia, ya que la region A = (x,y) ∈ R2 : g(x,y) = 0 esta dada enforma implıcita.
Recordemos que para una funcion escalarf , dado un puntoP dondef es diferenciable, la direccion demayor crecimiento esta dada por∇ fP (y la direccion opuesta es hacia dondef decrece mas rapido). Tambiense deduce de
∂ f∂V
(P) = 〈∇ fP,V〉
que si miramos las direcciones perpendiculares al gradiente, las derivadas direccionales son nulas, ya queallı el producto escalar da cero.
Obsevemos la siguiente figura. A la izquierda estan representados algunos valores de∇ f , para algunospuntos del plano. A la derecha, superponemos sobre estos valores de∇ f una curva dadaS.
t))
∇ f
S
P
En la figura de la derecha, hay que observar que en algunos puntos de la curva, como en el que indicamoscomoP, el gradiente def es perpendicular a la curvaS. En esos puntos, la direccion de mayor crecimientoes imposible de seguir (habrıa que salirse de la curva), y por otro lado si nos movemos a lo largo de la curva,

130 Taylor y extremos
nos estaremos moviendo en forma ortogonal a∇ fP, con lo cual la derivada direccional def allı sera nulapor lo antes dicho. Estos puntos son los candidatos naturales a extremos, si recordamos la idea del teoremade Fermat que dice que sif tiene un extremo entonces su derivada se anula.
Dicho de otra manera, si estamos buscando puntos crıticos de f restringidos a una curva, los candidatosnaturales son aquellos puntos de la curva donde esta tiene una direccion ortogonal al gradiente def . Sila curvaS esta dada por el conjunto de ceros de una funciong : R2 → R, entonces la normal de la curvaesta dada por∇g (en el caso en queg seaC1 y su gradiente no se anule).
Luego, buscamos los puntosP tales queg(P) = c, donde ademas
∇ fP = λ∇gP
para algun numero realλ. Este metodo se conoce como metodo de losmultiplicadores de Lagrange.
Volvamos al ejemplo concreto: calculamos
∇ f = (2x+2,2y), ∇g= (2(x−1),8y)
y planteamos la igualdad(2x+2,2y) = λ(2(x−1),8y).
De aquı se deduce que debe ser2x+2= λ2(x−1), 2y= λ8y.
De la segunda ecuacion, se deduce que hay dos posibilidades:
1. λ= 14, con lo cual (reemplazando en la primera), se tiene 4x+4= x−1 es decirx=− 5
3. Como el puntotiene que estar en la curva de nivel deg, debe verificar la ecuacion implıcita. Entonces obtenemos
649+4y2 = 1, es deciry2 =− 55
4 ·9,
de donde se deduce que no hay ninguna solucion conx=− 53, o equivalentemente, que no hay ninguna
solucion conλ = 14.
2. y = 0, con lo cual reemplazando nuevamente en la ecuacion se tiene (x− 1)2 = 1, es decirx = 0 yx= 2. En este caso hay dos puntos que son el(0,0) y el (2,0) que son solucion.
¿Como sabemos si son maximos o mınimos? Observemos que laecuacion deg
(x−1)2+4y2 = 1
define una elipse en el planoR2, que es un conjunto cerrado y acotado (es decir compacto). Como la funcionf es continua,f debe alcanzar maximo y mınimo absoluto en la elipse. Calculamos
f (0,0) = 0 f (2,0) = 8.
Se concluye que(0,0) es el mınimo absoluto def restringida a la curvaS, y que(2,0) es el maximo absolutode f allı.

5.3 Extremos con restricciones, multiplicadores de Lagrange 131
5.3.4. Multiplicadores enR
¿Como se generaliza el metodo al espacio? Dada una funcion f y una superficie
S= (x,y,z) ∈ R3 : g(x,y,z) = c,
nuevamente el gradiente∇ fP indica la direccion de mayor crecimiento (partiendo del puntoP), y lo que que-remos identificar son aquellos puntos donde las direccionestangentes a la superficie hacen que las derivadasdireccionales def se anulen. Observemos el siguiente grafico:
S
∇ fPΠP
NP
P
VP
Si el gradiente def en P tiene alguna componenteVP en el plano tangenteΠP a S en P, entoncesmoviendonos en esa direccion, sobre la superficie, la funcion crecerıa (pues como dijimos el gradiente es ladireccion de mayor crecimiento). La manera de conseguir que no haya ninguna direccion (en la superficie,o equivalentemente en su plano tangente), donde la funcioncrezca, es pidiendo que el gradiente∇ fP seaperpendicular al plano tangente. Equivalentemente, que el gradiente def sea paralelo a la normalNP alplano tangente enP, lo que se traduce en la condicion
∇ fP = λ∇gP
para algun numeroλ ∈R. No hay que olvidar la condiciong(P) = ctepara que el punto este en la superficie.Estas dos condiciones se pueden resumir en el siguiente enunciado, que generaliza lo que ya discutimos enel plano y en el espacio:
Proposicion 5.3.4. (Multiplicadores de Lagrange)
Para hallar los puntos crıticos de una funcion f : Rn → R restringida a la superficie de nivel g(X) = cde una funcion g: Rn →R, basta estudiar los puntos crıticos de la funcion de n+1 variables dada por
f (X)−λ(g(X)− c).
Mas precisamente: si P∈ Rn es un extremo de f restringida a la superficie de nivel g(X) = c, y ∇gP , O,entonces existeλ ∈ R tal que
∇ fP = λ∇gP.

132 Taylor y extremos
Demostracion. Si el gradiente deg no se anula enP, entonces por el teorema de la funcion implıcita, existenuna bolaB ⊂ Rn−1 y una parametrizacionϕ : B → R de la superficieS en un entorno deP. LlamemosZ0 ∈ Rn−1 al centro de la bolaB, y para simplificar supongamos que la derivada que no se anuladeg es laultima, de manera que(Z0,ϕ(Z0)) = P, y ademas
g(Z,ϕ(Z)) = c para todoZ ∈ B.
Es importante recordar que los vectores(Ei ,∂ϕ∂zi(Z0)) (con i = 1. . .n) son generadores del plano tangente a
la superficieSenP.
Ahora siP es (por ejemplo) un maximo def restringida aS, debe serf (P) ≥ f (X) para todoX ∈ Senun entorno deP. Esto es
f (Z0,ϕ(Z0))≥ f (Z,ϕ(Z))
para todoZ ∈U suficientemente cerca deZ0. Entonces la funcionh(Z) = f (Z,ϕ(Z)) tiene un extremo localenZ0, con lo cual su gradiente se anula en ese punto, o equivalentemente todas sus derivadas parciales sonnulas en el punto. Pero por la regla de la cadena,
∂h(Z)∂zi
|Z0 =∂
∂zif (Z,ϕ(Z))Z0 = 〈∇ fP,(Ei ,
∂ϕ∂zi
(Z0))〉
o sea el gradiente def enP es perpendicular a todos los generadores del plano tangentea la superficie, y enconsecuencia tiene que ser paralelo a la normal. Como la normal es el gradiente deg en el punto, se tiene laconclusion.
Atencion que nada garantiza que los puntos crıticos hallados seanextremos.
5.3.5. Un ejemplo elemental
Veamos ahora un ejemplo del uso del metodo con tres variables. Con este ejemplo empezamos estasnotas.
Ejemplo 5.3.5. Hallar las dimensiones de la caja rectangular, de lados a,b, l y de volumen maximo, sujetaa la restriccion a+b+ l ≤ 300.
La funcion a maximizar esV(x,y,z) = xyz, y la region que nos interesa estudiar es la comprendida porx+ y+ z≤ 300,x,y,z> 0 (observemos que six,y o z son cero entonces el volumen es cero). Si calculamosel gradiente deV se tiene
∇V = (yz,xz,xy)
que se anula solo en los caso que no nos interesan. Resta ver que ocurre en la superficiex+y+z= 300, quees un plano (sujeta por supuesto a las restriccionesx,y,z> 0).

5.3 Extremos con restricciones, multiplicadores de Lagrange 133
Nuevamente los bordes no son interesantes por dar cero allıel volumen, y lo que nos resta ver es siftiene extremos restringida al plano. Para ello planteamos∇ f = λ∇g, obteniendo
yz= λ, xz= λ, xy= λ
pues∇g= (1,1,1). Como ninguna de las variables puede ser nula, se deduce facilmente quex= y= z, conlo cual reemplazando en la ecuacion del plano se obtiene 3x = 300, es decirx = y = z= 100. Entonces elpunto en cuestion debe serP= (100,100,100) (o sea la caja es un cubo de lado 100), que es un maximo puesla region es compacta y los otros son mınimos def . El volumen maximo entonces esV = 1003 = 1000000.
5.3.6. Varias ligaduras
Por ultimo, una breve discusion sobre el caso en el que uno quiere hallara extremos de unaf con res-tricciones dadas por mas de una superficie de nivel. Por ejemplo, hallar los extremos def (x,y,z) sujeta alas condicionesg1(x,y,z) = c1, g2(x,y,z) = c2. En este caso, si los gradientes deg1, g2 son no nulos, ambasecuaciones definen superficies en el espacio. Si hay algun menor no nulo en la matriz que se obtiene apilandolos gradientes, esto indica que la interseccion es una curva. En ese caso, los extremos def en esta curva sehallan planteando
∇ f (P) = α∇g1(P)+βg2(P)
para valores genericos deα,β ∈R. No hay que olvidar queP tambien debe verificar
g1(P) = c1 y g2(P) = c2
para estar en la curva. La explicacion de porque el gradiente de f en un extremo es combinacion lineal delos gradiente deg1 y g2 esta en que un vector generico, ortogonal a la intersecci´on de los planos tangentesde ambas superficies, se puede escribir como combinacion lineal de las normales a los planos.

134 Taylor y extremos
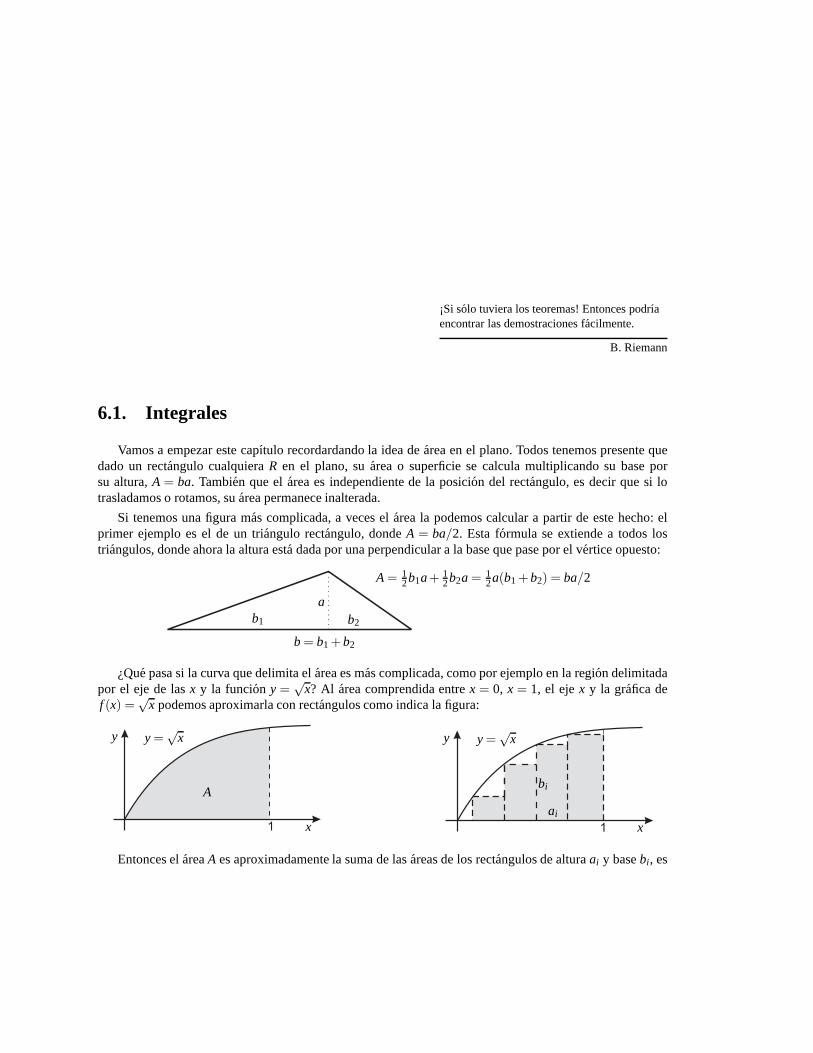
¡Si solo tuviera los teoremas! Entonces podrıaencontrar las demostraciones facilmente.
B. Riemann
6.1. Integrales
Vamos a empezar este capıtulo recordardando la idea de area en el plano. Todos tenemos presente quedado un rectangulo cualquieraR en el plano, su area o superficie se calcula multiplicando subase porsu altura,A = ba. Tambien que el area es independiente de la posicion del rectangulo, es decir que si lotrasladamos o rotamos, su area permanece inalterada.
Si tenemos una figura mas complicada, a veces el area la podemos calcular a partir de este hecho: elprimer ejemplo es el de un triangulo rectangulo, dondeA = ba/2. Esta formula se extiende a todos lostriangulos, donde ahora la altura esta dada por una perpendicular a la base que pase por el vertice opuesto:
A= 12b1a+ 1
2b2a= 12a(b1+b2) = ba/2
a
b= b1+b2
b2b1
¿Que pasa si la curva que delimita el area es mas complicada, como por ejemplo en la region delimitadapor el eje de lasx y la funciony =
√x? Al area comprendida entrex = 0, x = 1, el ejex y la grafica de
f (x) =√
x podemos aproximarla con rectangulos como indica la figura:
11
tV
x x
y yy=√
x y=√
x
ai
Abi
Entonces el areaA es aproximadamente la suma de las areas de los rectangulosde alturaai y basebi , es
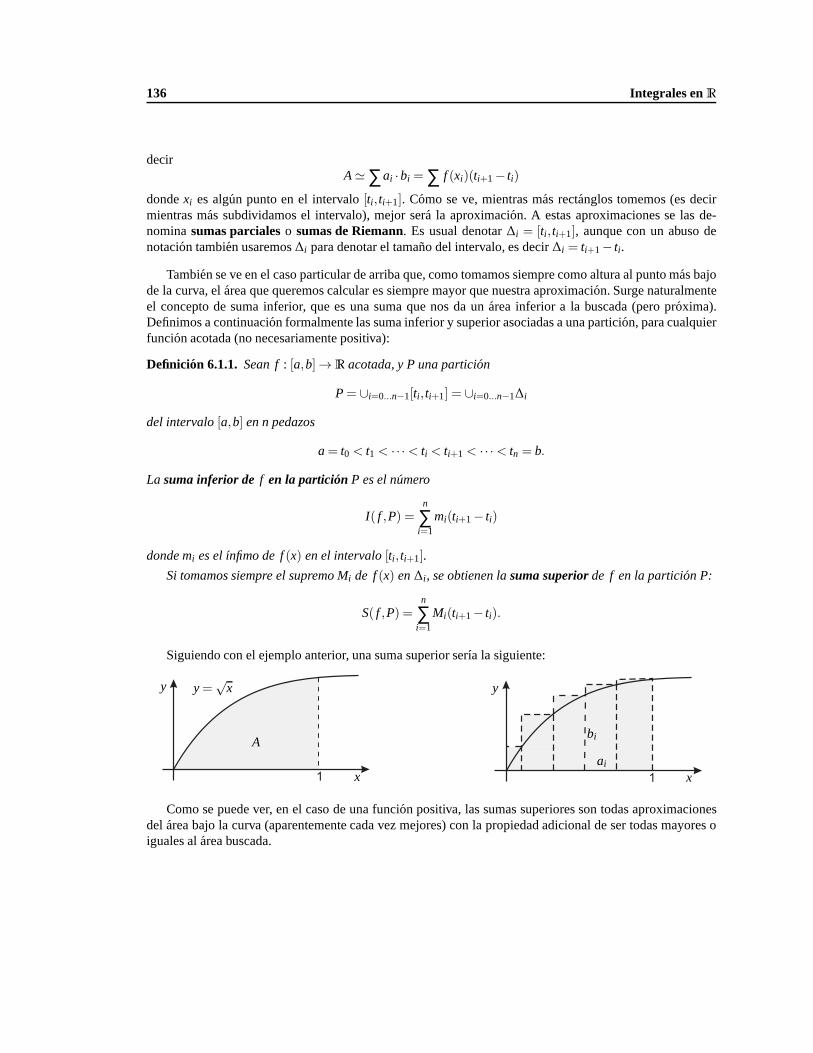
136 Integrales enR
decirA≃ ∑ai ·bi = ∑ f (xi)(ti+1− ti)
dondexi es algun punto en el intervalo[ti , ti+1]. Como se ve, mientras mas rectanglos tomemos (es decirmientras mas subdividamos el intervalo), mejor sera la aproximacion. A estas aproximaciones se las de-nominasumas parcialeso sumas de Riemann. Es usual denotar∆i = [ti , ti+1], aunque con un abuso denotacion tambien usaremos∆i para denotar el tamano del intervalo, es decir∆i = ti+1− ti.
Tambien se ve en el caso particular de arriba que, como tomamos siempre como altura al punto mas bajode la curva, el area que queremos calcular es siempre mayor que nuestra aproximacion. Surge naturalmenteel concepto de suma inferior, que es una suma que nos da un area inferior a la buscada (pero proxima).Definimos a continuacion formalmente las suma inferior y superior asociadas a una particion, para cualquierfuncion acotada (no necesariamente positiva):
Definicion 6.1.1. Sean f: [a,b]→ R acotada, y P una particion
P= ∪i=0...n−1[ti , ti+1] = ∪i=0...n−1∆i
del intervalo[a,b] en n pedazos
a= t0 < t1 < · · ·< ti < ti+1 < · · ·< tn = b.
La suma inferior de f en la particion P es el numero
I( f ,P) =n
∑i=1
mi(ti+1− ti)
donde mi es elınfimo de f(x) en el intervalo[ti , ti+1].
Si tomamos siempre el supremo Mi de f(x) en∆i , se obtienen lasuma superiorde f en la particion P:
S( f ,P) =n
∑i=1
Mi(ti+1− ti).
Siguiendo con el ejemplo anterior, una suma superior serıala siguiente:
11 x x
y yy=√
x
ai
Abi
Como se puede ver, en el caso de una funcion positiva, las sumas superiores son todas aproximacionesdel area bajo la curva (aparentemente cada vez mejores) conla propiedad adicional de ser todas mayores oiguales al area buscada.

6.1 Integrales 137
Diremos que la particionP′ del intervalo[a,b] es unrefinamiento de la particionP si P′ se puede obtenerdeP subdividiendo los intervalos deP. Asimismo diremos que la norma de‖P‖ es el tamano del intervalomas grande de la particion.
Evidentemente, dada una particion cualquieraP del intervalo, comomi ≤Mi para todoi, se tiene siempre
I( f ,P)≤ S( f ,P).
Algunas propiedades sencillas que se deducen de este hecho:
Proposicion 6.1.2. Sea f: [a,b]→ R acotada. Entonces
1. Si P′ es un refinamiento de P, entonces I( f ,P′)≥ I( f ,P) y tambien S( f ,P′)≤ S( f ,P).
2. I( f ,P)≤ S( f ,Q) para todo parde particiones P,Q.
Demostracion. Observemos la siguiente figura, donde puede observarse que al refinar la particion, el areacubierta por la suma inferior es cada vez mayor:
(φ)
x x
y y
a ab b
Si P′ refinaP, entonces dado un intervalo cualquiera∆i de P este se descompone como una union deintervalos deP′,
[ti , ti+1] = ∆i = ∪ j=1...ki∆′j = ∪ j=1...ki [t
′j , t
′j+1].
Entonces comomi ≤ mj para todoj = 1. . .ki (pues el ınfimo en un conjunto es menor o igual que el ınfimoen un subconjunto), se tiene
mi(ti+1− ti) = mi
(
ki
∑j=1
t ′j+1− t ′j
)
=ki
∑j=1
mi(t′j+1− t ′j)≤
ki
∑j=1
mj(t′j+1− t ′j).
Sumando sobrei se tieneI( f ,P) ≤ I( f ,P′).
Esto prueba que al refinar la particion las sumas inferioresaumentan. Con un argumento analogo se deduceque al refinar la particion las sumas superiores disminuyen.

138 Integrales enR
Para probar el segundo ıtem, tomemosP′ un refinamiento en comun de las particionesP,Q. Este siemprese puede conseguir subdividiendo el intervalo en partes mas pequenas que incluyan los puntos de corte dePy Q. Entonces por el ıtem anterior,
I( f ,P) ≤ I( f ,P′)≤ S( f ,P′)≤ S( f ,Q),
lo que prueba queI( f ,P) ≤ S( f ,Q).
Este resultado nos dice algo importante: que las sumas superiores descienden (esperamos que hasta elvalor del area buscada, en el caso de una funcion positiva)y que las sumas inferiores ascienden. Tomemoslos siguientes conjuntos de numeros reales:
I( f ) = I( f ,P) : P es una particion de[a,b]
S( f ) = S( f ,P) : P es una particion de[a,b].
Estos conjuntos pueden ser no acotados, pero sif es una funcion acotada entonces son ambos acotados, puesen cada intervalo
ınf( f )≤ mi( f )≤ Mi( f ) ≤ sup( f ),
donde ınf( f ) y sup( f ) denotan respectivamente al ınfimo def en[a,b] y al supremo def en[a,b]. Multipli-cando por∆i y sumando sobrei se tiene
ınf( f )∑i∆i ≤ ∑
imi( f )∆i ≤ ∑
iMi( f )∆i ≤ sup( f )∑
i∆i .
Pero
∑∆i = tn− tn−1+ tn−1− tn−2+ · · ·+ t2− t1+ t1− t0 = tn− t0 = b−a,
luego
ınf( f )(b−a)≤ I( f ,P) ≤ S( f ,P)≤ sup( f )(b−a).
De hecho, como probamos queI( f ,P)≤ S( f ,Q) para todo par de particionesP,Q del intervalo, entonces
ınf( f )(b−a)≤ I( f ,P) ≤ S( f ,Q)≤ sup( f )(b−a).
Si denotamoss= sup( f ) en [a,b], en la figura que sigue se representa la desigualdadS( f ,P)≤ s(b−a)para el caso particular de unaf positiva:

6.1 Integrales 139
x
y
Gr( f )
a b
s
∑Mi∆i ≤ ∑s∆i = s(b−a)
Se define laintegral superior de f como el ınfimo de las sumas superiores (sobre cualquier particion),y la integral inferior de f como el supremo de las sumas inferiores (sobre cualquier particion), es decir
I∗( f ) = supI( f ), mientras queI∗( f ) = ınfS( f ).
Si f es acotada, comoınf( f )(b−a)≤ I( f ,P)≤ S( f ,Q)≤ sup( f )(b−a)
para cualquier par de particiones, si tomamos ınfimo sobre particionesQ (fijandoP) se deduce que
ınf( f )(b−a)≤ I( f ,P)≤ I∗( f ) ≤ sup( f )(b−a).
Pero comoP tambien era cualquiera, tomando supremo sobre particionesP se deduce que
ınf( f )(b−a)≤ I∗( f ) ≤ I∗( f ) ≤ sup( f )(b−a).
Es decir que en general,I∗( f ) ≤ I∗( f ). Diremos quef esRiemann integrableen [a,b] si I∗( f ) = I∗( f ), ydenotaremos a este numero con el sımbolo integral
∫ b
af =
∫ b
af (x)dx.
Un criterio para decidir si una funcion es integrable es el siguiente:
Proposicion 6.1.3.Si f : [a,b]→R es acotada, entonces f es integrable en[a,b] si y solo si para todoε > 0existe una particion P de[a,b] tal que
S( f ,P)− I( f ,P)< ε.
Demostracion. Supongamos primero que vale la condicion. Entonces para todoε > 0 existe una particionPtal que
I∗( f )− I∗( f ) ≤ S( f ,P)− I( f ,P)< ε,
con lo cualI∗( f )≤ I∗( f ). Como la otra desigualdad vale siempre,f is integrable.

140 Integrales enR
Supongamos ahora quef es integrable, entonces dadoε > 0 existe por las propiedades de ınfimo ysupremo una particionP tal que
∫ b
af − I( f ,P)< ε/2 y tambienS( f ,P)−
∫ b
af < ε/2.
Juntando estas dos desigualdades se tiene
S( f ,P)− I( f ,P)< ε
como querıamos.
En particular toda funcion constante es integrable, y
∫ b
ac dx= c(b−a) = c
∫ b
a1dx.
Tambien se deduce que toda funcion monotona y acotada es integrable.
Proposicion 6.1.4. Sea f: [a,b]→ R una funcion monotona y acotada. Entonces f es integrable en[a,b].
Demostracion. Supongamos quef es creciente. Entonces dada una particion, en cada intervalo de la parti-cion se tienef (ti) = mi , f (ti+1) = Mi con lo cual
S( f ,P)− I( f ,P) = ∑i(Mi −mi)(ti+1− ti) = ∑
i[ f (ti+1)− f (ti)](ti+1− ti)
≤ ∑i[ f (ti+1)− f (ti)]max(ti+1− ti) = [ f (b)− f (a)]‖P‖,
puesto quet0 = a, tn = b y ademas
f (t1)− f (t0)+ f (t2)− f (t1)+ f (t3)− f (t2)+ · · ·+ f (tn)− f (tn−1) = f (b)− f (a).
Con lo cual si refinamos la particion, haciendo tender‖P‖ → 0, por la Proposicion6.1.3deducimos quefes integrable. El casof decreciente es analogo.
Teorema 6.1.5.Sea f: [a,b]→ R una funcion continua. Entonces f es integrable en[a,b].
La demostracion la dejamos para mas adelante, en el Corolario 6.1.10.
Ejemplo 6.1.6. Un caso de funcion no integrable Riemann es la funcion de Dirichlet, definida en el intervalo[0,1] como:
f (x) =
1 si x∈Q
0 si x<Q
Si tomamos una particion cualquiera P del[0,1], en cada intervalo∆i de la particion tendremos por lomenos un numero racional y un numero racional. Por lo tanto el supremo de f en cada∆i es1, y el ınfimo es0. Con esto, las sumas inferiores para cualquier particion dan cero, mientras que las superiores dan siempre1. En consecuencia, f no es integrable porque la integral superior I∗( f ) da 1 y la inferior I∗( f ) da 0.

6.1 Integrales 141
6.1.1. Propiedades
Puede ser util, dadaf , considerar las siguientes funciones positivas en[a,b] que se obtienen a partir def :
f+(x) =
f (x) si f (x)> 0
0 en cualquier otro caso
f−(x) =
− f (x) si f (x)< 0
0 en cualquier otro caso
Entonces podemos escribir, para todox∈ [a,b],
f (x) = f+(x)− f−(x).
Una de las propiedades mas utiles que tienenf+, f−, es que nos permiten calcular el moduloa partir de una suma:
| f (x)|= f+(x)+ f−(x) para todox∈ [a,b].
Problema 6.1.7.Probar que, si f esacotada, entonces f es integrable en[a,b] si y solo si f+, f− son ambasfunciones integrables en[a,b], y ademas
∫ b
af =
∫ b
af+−
∫ b
af−.
Algunas propiedades sencillas de la integral:
Proposicion 6.1.8. Sean f,g : [a,b]→R funciones integrables. Entonces
1. Siα ∈R entoncesα f es integrable,∫ b
a α f = α∫ b
a f .
2. f +g es integrable,∫ b
a f +g=∫ b
a f +∫ b
a g.
3. Si a≤ c≤ b entonces f es integrable en[a,c] y en[c,d] y ademas∫ b
a f =∫ c
a f +∫ b
c f .
4. Si f≤ g, entonces∫ b
a f ≤ ∫ ba g.
5. Si f es integrable entonces| f | es integrable y ademas|∫ ba f | ≤ ∫ b
a | f |.
Demostracion. Las primeras tres propiedades se deducen de escribir la definicion como lımite de sumassuperiores.
La cuarta propiedad se deduce de lo siguiente: sih≥ 0 y h es integrable, sus sumas parciales son positivasy entonces
∫ ba h≥ 0. Luego sif ≤ g, se tiene queg− f ≥ 0 es una funcion integrable por los items 1 y 2, y
por lo recien dicho∫ b
a (g− f )≥ 0. Nuevamente por los ıtems 1 y 2, se deduce que
∫ b
ag−
∫ b
af ≥ 0.

142 Integrales enR
Por ultimo, si f es integrable, entoncesf+ y f− son integrables. Luego| f | = f+ + f− es integrable, yademas
|∫ b
af | = |
∫ b
af+−
∫ b
af−| ≤ |
∫ b
af+|+ |
∫ b
af−|=
∫ b
af++
∫ b
af− =
∫ b
af++ f− =
∫ b
a| f |.
Tambien es usual definir (para funciones integrables en[a,b])
1.∫ b
a f como−∫ a
b f cuandoa> b, es decir
∫ y
xf =−
∫ x
yf para todox,y∈ [a,b].
2.∫ x
x f = 0 para todox∈ [a,b].
Recordemos que toda funcion continua en un conjunto compacto es uniformemente continua.
Proposicion 6.1.9. Si h : [a,b] → [c,d] es integrable, yϕ : [c,d] → R es una funcion continua, entoncesϕh : [a,b]→R es integrable.
Demostracion. Comoh es integrable, dadoε1 > 0 existe una particionP de[a,b] tal que
S(h,P)− I(h,P) = ∑(Mi −mi)∆i < ε1. (6.1)
Observemos que, comoMi es el supremo deh en∆i , y mi es el ınfimo, entonces
Mi −mi = suph(x) : x∈ ∆i− ınfh(y) : y∈ ∆i= suph(x)−h(y) : x,y∈ ∆i,
puesto que la diferencia entre el valor mas grande y mas chico deh coincide con la diferencia mas grandede valores deh. Comoϕ es uniformemente continua, dadoε2 > 0, existeδ > 0 tal que|t − s| < δ en [c,d]implica |ϕ(s)−ϕ(t)|< ε2.
Queremos probar que la siguiente cantidad es arbitrariamente pequena:
S(ϕh,P)− I(ϕh,P)= ∑(M∗i −m∗
i )∆i ,
dondeM∗i , m∗
i son respectivamente, el supremo y el ınfimo deϕh en∆i . Notemos que, como antes
M∗i −m∗
i = supϕ(h(x))−ϕ(h(y)) : x,y∈ ∆i.
Consideremos los dos conjuntos de ındices de la particion
A= i : Mi −mi < δ, B= i : Mi −mi ≥ δ
Si i ∈ A, entoncesM∗
i −m∗i < ε2

6.1 Integrales 143
por la uniforme continuidad deϕ. En consecuencia,
∑i∈A
(M∗i −m∗
i )∆i < ε2 ∑i∈A
∆i ≤ ε2(b−a).
Es decir, eligiendoε2 pequeno podemos asegurar que las sumas superiores e inferiores estan tan cerca comoquerramos, siempre restringiendonos al subconjunto de[a,b] dondeMi −mi < δ.
Veamos que pasa en el resto del conjunto. Comoϕ es una funcion continua en un compacto, alcanzamaximo, es decir existeM > 0 tal queϕ(x)≤ M para todox∈ [c,d]. En general, podemos asegurar que
M∗i −m∗
i = supϕ(h(x))−ϕ(h(y)) : x,y∈ ∆i ≤ 2M.
Luego
∑i∈B
(M∗i −m∗
i )∆i ≤ 2M ∑i∈B
∆i =2Mδ ∑
i∈Bδ∆i ≤
2Mδ ∑
i∈B(Mi −mi)∆i <
2Mδ
ε1
por la ecuacion (6.1). Ası que eligiendoε1 pequeno (o sea eligiendo una particionP suficientemente fina)podemos asegurar que la diferencia entre la suma superior y la inferior es tan pequena como uno quiera,tambien en este caso. Luego podemos hacer que las sumas superiores esten tan proximas a las inferiorescomo queramos, lo que prueba queϕh es integrable.
Corolario 6.1.10. Sean f,g : [a,b]→ R. Entonces
1. Si f es continua entonces f es integrable.
2. Si f es integrable entonces fn = f · f · · · f es integrable para todo n∈N.
3. Si f,g son integrables entonces f g es integrable.
Demostracion. Para ver 1. tomamosh(x) = x, ϕ(x) = f (x) y usamos el teorema anterior, puesϕ h(x) =f (x). Queh es integrable se deduce del hecho de que es una funcion monotona y acotada en[a,b].
Para ver 2. tomamosh= f , ϕ(x) = xn.
Para ver 3. escribimos
f g=12( f +g)2− 1
2f 2− 1
2g2
y usamos quef +g es integrable y el ıtem previo conn= 2.
Observacion 6.1.11.En general esfalsoque la composicion de dos funciones integrables resulta integrable.Un ejemplo esta dado por las funciones siguientes, ambas definidas en el intervalo[0,1]:
f (x) =
1/q si x= p/q es racional (y esta simplificado todo lo posible)
0 si x<Q
g(x) =
0 si x= 0
1 si x, 0

144 Integrales enR
Se define f(0) = 1 para evitar ambiguedades, aunque no es muy relevante desde el punto de vista delaintegral. Entonces f es integrable (difıcil, ver la NotaI al final de este capıtulo), g es integrable (obvio),pero g f es la funcion de Dirichlet, que como vimos no es integrable.
Dada una funcion continua en[a,b], su restriccion al intervalo[a,x] para cualquierx∈ [a,b] sigue siendocontinua. Luego es integrable, y llamamos a
F(x) =∫ x
af (t)dt
funcion primitiva de f . Esta primitiva es una funcion derivable, y su derivada coincide conf , resultadoconocido TFCI:
Teorema 6.1.12(Teorema Fundamental del Calculo Integral). Sea f : [a,b] → R una funcion continua.Dado x∈ [a,b], sea F: [a,b]→ R definida como
F(x) =∫ x
af =
∫ x
af (t)dt.
Entonces F es continua en[a,b], derivable en(a,b) y ademas, para todo x∈ (a,b) se tiene
F ′(x) = f (x).
Demostracion. Seas= max| f (t)| : t ∈ [a,b] (que es finito porquef es continua). Veamos queF es conti-nua en los bordes. Observemos queF(a) = 0.
|F(x)−F(a)|= |∫ x
af | ≤
∫ x
a| f |= ınfS(| f |,P)
dondeP es una particion del intervalo[a,x], es decir (siMi es el supremo de| f (t)| en el intervalo∆i)
|F(x)−F(a)| ≤ S(| f |,P) = ∑i
Mi∆i ≤ s∑i∆i = s(x−a).
Con esto es evidente queF(x)→ F(a) si x→ a+. Por otro lado,
|F(b)−F(x)|= |∫ b
af −
∫ x
af |= |
∫ b
xf | ≤
∫ b
x| f |= ınfS(| f |,P)≤ s(b− x)
donde ahora la particionP es del intervalo[x,b]. Esto prueba queF(x)→ F(b) cuandox→ b−.
Tomemos ahora un puntox0 interior del intervalo[a,b]. Sixes otro punto cualquiera en(a,b), calculamos
F(x)−F(x0)
x− x0=
∫ xa f − ∫ x0
a fx− x0
=
∫ xx0
f
x− x0

6.1 Integrales 145
Queremos ver que esta expresion tiende af (x0) cuandox→ x0. Esto probarıa queF es derivable, queF ′ = f ,y en particularF es continua en el interior.
Como f es continua entrex y x0, existen dos numeros reales (el maximo y el mınimo def allı) tales que
mx ≤ f (t)≤ Mx
para todot entrex0 y x. Supongamos primero quex> x0. Entonces integrando se tiene
mx(x− x0)≤∫ x
x0
f ≤ Mx(x− x0).
Luego, comox− x0 > 0,
mx ≤1
x− x0
∫ x
x0
f ≤ Mx.
Cuandox→ x+0 , tantomx comoMx tienden af (x0), por serf continua. Esto prueba que
lımx→0+
F(x)−F(x0)
x− x0= f (x0).
Si x < x0, con un razonamiento analogo se obtiene que el otro lımitelateral tambien daf (x0). Hay quetener cuidado solamente en el siguiente hecho: six < x0, entoncesx− x0 < 0, luego las desigualdades seinvierten.
Entonces, dada una funcion continuaf , existe por lo menos una funcion derivable tal queF ′ = f .¿Cuantas puede haber? El siguiente lema muestra que no son muchas, en el sentido de que no son muydistintas todas las que hay:
Lema 6.1.13. Si F,G son funciones continuas en[a,b], derivables en el interior, tales que F′(x) = G′(x)allı, entonces existe una constance c∈ R tal que
F(x) = G(x)+ c.
Demostracion. Si H(x) = F(x)−F(x), entonces
H ′(x) = (F −G)′(x) = F ′(x)−G′(x) = 0
en el interior, entonces por el teorema de LagrangeH es constante allı pues
H(x)−H(y) = H ′(c)(x− y) = 0.
Es decir, dos primitivas def difieren a lo sumo en una constante, o lo que es lo mismo, si uno conoceuna primitivaF, entonces todas las primitivas def estan dadas por la familia
∫f = F + c : c∈ R.

146 Integrales enR
Para calcular una integral definida basta encontrar entonces alguna primitiva def y se tiene
∫ b
af = F(b)−F(a).
En efecto, esto es obvio siF es la primitiva hallada en el TFC, es decir, siF(x) =∫ x
a f . Pero siG es otraprimitiva, entoncesG= F + c y en consecuencia
G(b)−G(a) = F(b)+ c− (F(a)+ c) = F(b)−F(a) =∫ b
af .
Este resultado se conoce comoRegla de Barrow.
Del teorema de arriba tambien se deduce elteorema del valor medio para integrales(TVMI),
Proposicion 6.1.14.Si f : [a,b]→R es continua, entonces existe c∈ (a,b) tal que
∫ b
af = f (c)(b−a).
Demostracion. Basta aplicar el teorema de Lagrange a la funcionF(x) =∫ x
a f :
∫ b
af = F(b)−F(a) = F ′(c)(b−a) = f (c)(b−a)
para algunc entrea y b.
Este teorema, cuandof es positiva, tiene contenido geometrico, pues nos dice queel area bajo el graficode f (entrea y b) esta dada por el area de algun rectangulo de baseb−a, cuya alturaf (c) es alguna alturaintermedia entre el mınimo y el maximo def en[a,b].
x
y
Gr( f )
a b
f (c)
c
La idea es que si tomamos un rectangulo de base[a,b], y hacemos variar la altura entre el maximo defy el mınimo def , en algun momento el area obtenidacon el rectangulo coincide con el area bajo el graficode f en[a,b].
6.2. Integrales impropias
Dada una funcion continua en un intervalo[a,b), podemos calcular su integral en cualquier intervalo maspequeno. Surge la pregunta de si existira el lımite de estas integrales cuando el intervalo tiende al intervalototal. Es decir, dadoa≤ x< b, pongamos
F(x) =∫ x
af (t)dt.

6.2 Integrales impropias 147
Entonces podemos definir a la integral impropia como un lımite, es decir∫ b
af = lım
x→b+F(x),
en el supuesto de que este lımite exista. En este caso diremos que∫ b
a f converge.
Las mismas consideraciones se aplican para el otro extremo.
Ejemplo 6.2.1. Consideremos f(t) = t−12 , que es una funcion con una discontinuidad en t= 0. Entonces
∫ 1
0f = lım
x→0+
∫ 1
x
1√tdt = lım
x→0+2√
t|1x = lımx→0+
2−2√
x= 2.
Esto es, elarea encerrada por el grafico de f , los ejes, y la recta x= 1 esfinita.
¿Que pasa si la discontinuidad esta dentro del intervalo yno en el borde? Por ejemplo, tomemosf (t) =
t−23 en el intervalo[−1,1]−0. Tenemos, por un lado∫ x
−1f (t)dt = 3t
13 |x−1 = 3(x
13 +1) si x< 0,
y por otro lado ∫ 1
yf (t)dt = 3t
13 |1y = 3(1− y
13 ) si y> 0.
En el caso particular en el que tomamosx=−y, se tiene
lımy→0+
∫ −y
−1f (t)dt+
∫ 1
yf (t)dt = lım
y→0+3(−y
13 +1)+3(1− y
13 ) = 3+3= 6.
Esta manera de calcular una integral impropia (tomando un intervalo simetrico alrededor de la discontinui-dad) se conoce comovalor principal de la integral, es decir
v.p.∫ 1
−1t−
23 dt = 6;
en general, dadaf : [a,b]−x0→ R definiremos
v.p.∫ b
af (t)dt = lım
ε→0+
∫ x0−ε
af (t)dt+
∫ b
x0+εf (t)dt
.
Hay que tener presente que en muchos casos modificando el intervalo, se puede modificar este lımite.
Ejemplo 6.2.2. Tomemos f(t) = 1t en el intervalo[−1,1]. Se tiene
v.p.∫ 1
−1
1t= lım
x→0+
∫ −x
−1
1t
dt+∫ 1
x
1t
dt = lımx→0+
ln |− x|− ln|x|= 0,
mientras que si no miramos el valor principal, podemos obtener otro resultado:
lımx→0+
∫ −2x
−1
1t
dt+∫ 1
x
1t
dt = lımx→0+
ln |−2x|− ln|x|= ln2.
Estos ejemplos nos muestran que tenemos que tener claro lo que queremos calcular cuando integramosuna funcion no acotada; en casos concretos puede desprenderse del problema que estamos estudiando cuales la interpretacion correcta que tenemos que hacer.

148 Integrales enR
6.2.1. Intervalos infinitos
El otro caso que nos interesa es el de un intervalo infinito, y se piensa de la misma manera, es decir,como un lımite.
Ejemplo 6.2.3. Si f(t) = 11+t2
, entonces
∫ +∞
0f (t)dt = lım
x→+∞
∫ x
0
11+ t2 dt = lım
x→+∞arctg(x)−arctg(0) =
π2.
Nuevamente surgen las mismas consideraciones si hay dos infinitos; si tomamos un intervalo simetricoalrededor del cero diremos que es el valor principal.
Ejemplo 6.2.4. Consideremos f(t) = 2t1+t2
. Entonces v.p.∫+∞−∞ f (t)dt es el lımite
lımx→+∞
∫ x
−xf (t)dt = lım
x→+∞ln(1+ t2)|x−x = lım
x→+∞ln(1+ x2)− ln(1+ x2) = 0
Por otro lado, si no tomamos un intervalo simetrico, el lımite puede dar distinto:
lımx→+∞
∫ 2x
−xf (t)dt = lım
x→+∞ln(1+ t2)|2x
−x = lımx→+∞
ln(1+4x2)− ln(1+ x2) = ln4.
Ejemplo 6.2.5. Un caso relevante es el de la integral∫ +∞
11t p dt, para p> 0. Como
∫ x
1t−pdt =
t−p+1
−p+1|x1 =
x1−p
1− p− 1
1− p
para cualquier p> 0, p, 1, la expresion de la derecha tiene lımite cuando x→ +∞ si y solo si 1− p< 0.¿Que pasa si p= 1? En este caso la primitiva es el logaritmo y por lo tanto la integral diverge. En resumen,
∫ ∞
1
1t pdt
converge si p> 1
diverge si0< p≤ 1.
Como se pueden imaginar, si uno reemplaza elintervalo [1,+∞) por el intervalo(0,1], el com-portamiento def (t) = 1/t p no es similar (esbueno en este punto, graficar 1/
√t, 1/t y 1/t2
en[0,+∞) en el mismo sistema de ejes para teneralguna intuicion de lo que esta ocurriendo). De-jamos como ejercicio ver que vale un resultadoanalogo al enunciado arriba, con similar demos-tracion, en el intervalo(0,1].
Problema 6.2.6.Probar que
∫ 1
0
1t pdt
converge si0< p< 1
diverge si p≥ 1.

6.2 Integrales impropias 149
6.2.2. Convergencia condicional y absoluta
Diremos que∫ b
a f converge absolutamentesi∫ b
a | f | converge. Si no es ası, pero la integral def conver-ge, diremos que la integral def converge condicionalmente.
El siguiente lema generaliza una idea que ya desarrollamos para sucesiones. Nos va a resultar util paralas integrales de funciones positivas.
Lema 6.2.7. 1. Sea G: [a,b) → R una funcion creciente (b puede ser+∞). Entonces existe el lımitelım
x→b+G(x). Este lımite es finito si y solo si G es acotada superiormente.
2. Las mismas consideraciones valen para G: (a,b]→R y el lımite lımx→a−
G(x).
Demostracion. Veamos 1. Supongamos queG es creciente, seal = supx∈[a,b)
G(x). Afirmamos quel =
lımx→b+
G(x). En efecto, por definicion de supremo, dadoε > 0 existex0 ∈ [a,b) tal que l −G(x0) < ε. Si
|b− x|= b− x< δ = b− x0, entonces comox≥ x0 y G es creciente,G(x)≥ G(x0). Entonces
l −G(x)≤ l −G(x0)< ε,
lo que prueba que el lımite existe y coincide con el supremo.En particular el lımite es finito si y solo siG esacotada superiormente.
La demostracion de 2. es analoga y queda como ejercicio.
Observacion 6.2.8. Un hecho importante es que, en el caso de funciones integrables y positivas f≥ 0, elLema6.2.7nos dice que el problema de convergencia se reduce a probar que la integral
∫ xa f (t)dt esta aco-
tada, ya que es una funcion creciente de x.
Teorema 6.2.9.Si f es continua en[a,b), y∫ b
a f converge absolutamente, entonces converge. Es decir, siexiste lım
x→b+
∫ xa | f (t)|dt y es finito entonces existelım
x→b+
∫ xa f (t)dt y es finito.
Demostracion. Si lımx→b+
∫ xa | f (t)|dt < +∞, entonces cada una de las funciones positivasf+, f− deben veri-
ficar la misma condicion. En efecto, en primer lugar comof es continua, es integrable, y entonces ambasfuncionesf+, f− son integrables en[a,x]. Pongamos
F+(x) =∫ x
af+(t)dt, F−(x) =
∫ x
af−(t)dt, F(x) = F+(x)+F−(x).
Como | f (t)| = f+(t) + f−(t), se tieneF(x) =∫ x
a | f (t)|dt. Las tres funcionesF+,F−,F son crecientes ypositivas. Ademas como lım
x→b+F(x) es finito,F esta acotada superiormente por este lımite. Entonces
F+(x)≤ F+(x)+F−(x) = F(x)≤∫ b
a| f (t)|dt = lım
x→b+F(x).

150 Integrales enR
Esto prueba queF+ (y con un argumento identicoF−) es una funcion acotada superiormente. Por el lemaprevio, existen los los lımites
l1 = lımx→b+
F+(x) = lımx→b+
∫ x
af+(t)dt,
l2 = lımx→b+
F−(x) = lımx→b+
∫ x
af−(t)dt.
En consecuencia, comof = f+− f−,
lımx→b+
∫ x
af (t)dt = lım
x→b+
∫ x
af+(t)dt− lım
x→b+
∫ x
af−(t)dt = l1− l2.
6.2.3. Criterios de comparacion
Dadas dos funciones positivas,f ,g : [a,b)→R (b puede ser+∞) si las suponemos integrables en[a,b),entonces la convergencia deg implica la convergencia def siempre quef ≤ g. Mas precisamente:
Proposicion 6.2.10.Sean f,g : [a,b)→ R funciones integrables (b puede ser+∞) y no negativas.
1. Si f(t)≤ g(t) para todo t∈ [a,b), entonces si∫ b
a g converge, tambien converge∫ b
a f .
2. Si f(t)≤ g(t) para todo t∈ [a,b), entonces si∫ b
a f diverge, tambien diverge∫ b
a g.
Demostracion. TomemosF(x) =∫ x
a f (t)dt, y G(x) =∫ x
a g(t)dt. Ambas son crecientes en[a,b), por serf ,g≥ 0 allı. Ademas
F(x)≤ G(x)
para todox ∈ [a,b) por ser f ≤ g. Como∫ b
a g converge, se tiene ademas queG(x) ≤ ∫ ba g. LuegoF es
creciente y acotada, con lo cual tiene lımite finito cuandox→ b+ por el Lema6.2.7.
El segundo ıtem es consecuencia del primero.
Corolario 6.2.11. Sean f,g : [a,b)→R funciones integrables (b puede ser+∞).
Si | f (t)| ≤ |g(t)| para todo t∈ [a,b), y la integral de g converge absolutamente, entonces tambien con-verge absolutamente la integral de f , y si la integral de f no converge absolutamente entonces tampococonverge absolutamente la integral de g.
Teorema 6.2.12.Sean f,g son positivas en[a,b), donde b puede ser+∞. Si lımx→b−
f (x)g(x) = L existe, entonces
hay solo tres posibilidades, que se detallan a continuacion:
1. L es finito y no nulo. Entonces∫ b
a f converge si y solo si∫ b
a g converge.
2. L= 0. Entonces∫ b
a g<+∞ ⇒ ∫ ba f <+∞.

6.2 Integrales impropias 151
3. L=+∞. Entonces∫ b
a g diverge⇒ ∫ ba f diverge.
Demostracion. Dadoε > 0, siL es finito, se tiene
(L− ε)g(t)< f (t)< (L+ ε)g(t)
para todot tal quex0 < t < b. Observemos queL ≥ 0 siempre que exista, por serf ,g positivas.
1. SiL no es cero entonces podemos elegirε positivo de manera queL−ε siga siendo positivo. Entoncespor el criterio de comparacion, se tiene que una es convergente si y solo si la otra tambien.
2. Si L = 0, el lado izquierdo es negativo por lo tanto solo podemos asegurar que la convergencia deggarantiza la def , y no la recıproca.
3. SiL =+∞, entonces dadoM positivo existex0 tal que
f (t) ≥ Mg(t)
para todox0 < t < b. Si la integral def converge se deduce que la deg tambien, sin poder decir nada sobrela recıproca.
Observacion 6.2.13. Los mismos resultados valen si tomamos intervalos(a,b] donde ahora el extremoizquierdo es abierto.
Criterio integral de Cauchy
En general, dada una integral impropia definida en un intervalo, es posible decidir la convergencia de lamisma comparandola con una serie adecuada. Recordemos primero algunos hechos elementales de series.Seaak una sucesion de numeros reales y
Sn =n
∑k=0
ak
la sucesion de sumas parciales. Entonces
1. ak → 0 no implica que la serie converge.
2. Sı es cierto que si la serie converge entoncesak → 0.
3. Una serie de terminos positivosak ≥ 0 es convergente si y solo si sus sumas parciales estan acotadas,pues en este casoSn es una sucesion creciente de numeros reales.
Teorema 6.2.14(Criterio de comparacion de Cauchy). Sea f: [N,+∞)→ R una funcion decreciente y nonegativa. Entonces la integral
∫ +∞N f converge si y solo si la sucesion de sumas parciales
Sn =n
∑k=N
f (k)
es convergente. Es decir, si llamamos ak = f (k), la integral converge si y solo si la serie∑ak converge.
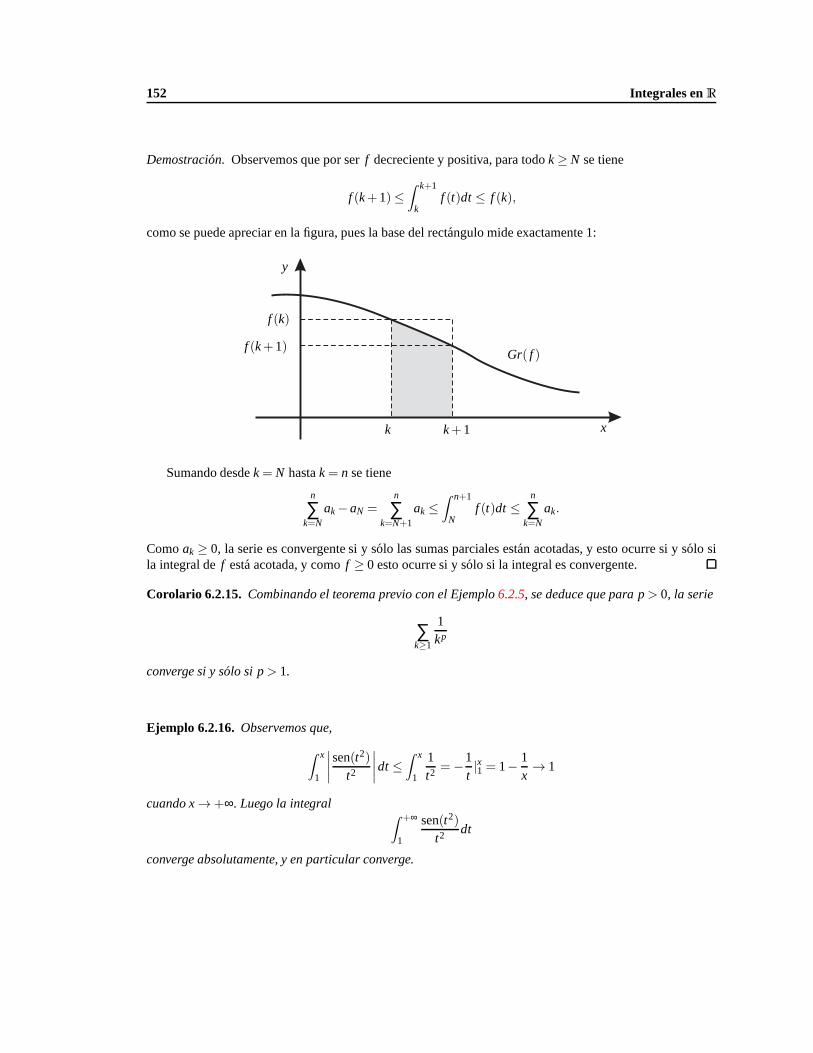
152 Integrales enR
Demostracion. Observemos que por serf decreciente y positiva, para todok≥ N se tiene
f (k+1)≤∫ k+1
kf (t)dt ≤ f (k),
como se puede apreciar en la figura, pues la base del rectangulo mide exactamente 1:
x
y
Gr( f )
k k+1
f (k+1)
f (k)
Sumando desdek= N hastak= n se tiene
n
∑k=N
ak−aN =n
∑k=N+1
ak ≤∫ n+1
Nf (t)dt ≤
n
∑k=N
ak.
Comoak ≥ 0, la serie es convergente si y solo las sumas parciales est´an acotadas, y esto ocurre si y solo sila integral def esta acotada, y comof ≥ 0 esto ocurre si y solo si la integral es convergente.
Corolario 6.2.15. Combinando el teorema previo con el Ejemplo6.2.5, se deduce que para p> 0, la serie
∑k≥1
1kp
converge si y solo si p> 1.
Ejemplo 6.2.16. Observemos que,
∫ x
1
∣
∣
∣
∣
sen(t2)
t2
∣
∣
∣
∣
dt ≤∫ x
1
1t2 =−1
t|x1 = 1− 1
x→ 1
cuando x→+∞. Luego la integral ∫ +∞
1
sen(t2)
t2 dt
converge absolutamente, y en particular converge.

6.2 Integrales impropias 153
Por otro lado, integrando por partes,
∫ x
1cos(t2)dt =
sen(t2)
2tx
1+
∫ x
1
sen(t2)
2t2 dt =sen(x2)
2x− sen(1)
2+
12
∫ x
1
sen(t2)
t2 dt.
Como lımx→+∞
sen(x2)2x = 0, se deduce que
∫ +∞1 cos(t2)dt es convergente.
Sin embargo, como|cos(x)| es periodica, continua, y se mueve entre0 y 1, existeδ > 0 tal que para todok∈N,
|cos(x)| ≥ 12
siempre que x∈ [kπ− δ,kπ+ δ]. Luego
|cos(t2)| ≥ 12
siempre que√
kπ− δ ≤ t ≤√
kπ+ δ, para cualquier k∈N. Entonces como|cos(t2)| es positiva,
∫ nπ+ π2
1|cos(t2)|dt ≥
n
∑k=1
∫ √kπ+δ
√kπ−δ
|cos(t2)|dt ≥n
∑k=1
12(√
kπ+ δ−√
kπ− δ)
= δn
∑k=1
1√kπ+ δ+
√kπ− δ
.
Como√
kπ+ δ+√
kπ− δ ≤ 2√
kπ+ δ ≤ 2√
δ+π√
k para todo k∈N, se deduce que
∫ nπ+ π2
1|cos(t2)|dt ≥C
n
∑k=1
1√k.
Estaultima serie es divergente por el criterio de la integral, luego la integral decos(t2) no converge abso-lutamente. Como vimos antes, converge sin el modulo, luego la convergencia es condicional.
Criterios de convergencia de series
En general, si podemos comparar dos sucesiones de terminospositivos podemos razonar como en el casode funciones. Se tiene el siguiente resultado, de demostracion sencilla que queda como ejercicio:
Proposicion 6.2.17. Seanak,bk dos sucesiones de terminos positivos. Si ak ≤ bk a partir de un k0,entonces
1. Si∑bk < ∞ entonces∑ak < ∞.
2. Si∑ak diverge, entonces∑bk diverge.
Ejemplo 6.2.18. Un ejemplo importante y simple de serie, contra la que es facil comparar, es la llamadaserie geometrica: si c> 0, entonces la serie
∑k≥0
ck = 1+ c+ c2+ c3+ . . .

154 Integrales enR
es convergente si c< 1 y divergente si c≥ 1. En efecto, si Sn =n∑
k=0ck, se tiene
Sn = 1+ c+ c2+ c3+ · · ·+ cn.
Si c= 1, esta serie es evidentemente divergente pues Sn = n. Supongamos que c, 1, entonces multiplicandopor c,
cSn = c+ c2+ c3+ · · ·+ cn+ cn+1 = Sn+ cn+1−1,
de donde se deduce despejando que
Sn = 1+ c+ c2+ c3+ · · ·+ cn =1− cn+1
1− c.
En esta expresion es evidente la afirmacion sobre la convergencia.
Diremos que una serie∑an converge absolutamente si∑ |an| es convergente. Dejamos para mas adelantela demostracion del hecho siguiente:
∑ |an|< ∞ ⇒ ∑an < ∞.
Repasemos un par de criterios utiles y conocidos por todos:
Proposicion 6.2.19.Seaan una sucesion de numeros reales.
1. Criterio de D’Alembert (cociente). Si
L = lımn→∞
|an+1
an|
existe, entonces L> 1⇒ ∑ak diverge, mientras que L< 1⇒ ∑ak converge absolutamente.
2. Criterio de Cauchy (raız enesima). SiC= lım
n→∞n√
|an|
existe, entonces C> 1⇒ ∑ak diverge, mientras que C< 1⇒ ∑ak converge absolutamente.
Demostracion. 1. Supongamos queL < 1. Elegimosε > 0 chico tal quec= L+ ε < 1. Entonces tomamosn0 ∈N tal que sin≥ n0,
− ε <∣
∣
∣
∣
an+1
an
∣
∣
∣
∣
−L < ε. (6.2)
Despejando del lado derecho se deduce que
|an+1|< (L+ ε)|an|= c|an|.
Como esto vale para cualquiern≥ n0, se tiene para cualquierp∈N
|an0+p|< c|an0+p−1|< c2|an0+p−2|< · · ·< cp|an0|= cn0+p |an0|cn0
= Kcn0+p.
Esto prueba que|an|< Kcn para todon≥ n0, y por el criterio de comparacion con la serie geometrica,comoc < 1, se deduce que∑an converge absolutamente. La demostracion de que diverge siL > 1 es analoga:

6.2 Integrales impropias 155
ahora hay que elegirε > 0 tal queL− ε > 1, y despejar del lado izquierdo de la desigualdad (6.2). Iterandonuevamente, se compara (ahora por debajo) contra la serie geometrica enc= L− ε, que ahora diverge.
2. La idea de la demostracion es similar. Ahora hay que observar que podemos conseguirn0 tal quen≥ n0 implica
C− ε < n√
|an|<C+ ε,
y con esto(C− ε)n < |an|< (C+ ε)n.
Si ε es suficientemente pequeno, se consigueC−ε > 0. Queda como ejercicio terminar de escribir la demos-tracion en este caso, comparando la serie|an| con las series geometricas deC−ε y C+ε respectivamente.
Observacion 6.2.20. En ambos casos, si el lımite da1 no podemos usar el criterio. Para convencernos,basta considerar an = 1/n, que nos da una serie divergente, y donden
√
1/n → 1 = L, mientras que siconsideramos an = 1/n2, nos da una serie convergente, y tambien n
√n2 → 1= L.
Necesitamos, antes de seguir, un resultado fundamental sobre sucesiones (que enunciaremos en particularpara series).
Teorema 6.2.21.Seaak una sucesion de numeros reales, Sn =n∑
k=0ak. Entonces existe el lımite S=
lımn
Sn =∞∑
k=0ak si y solo si la cola de la serie tiende a cero. Es decir, si y solo si dadoε > 0, existe n0 ∈N
tal que, para cualquier p∈N,
|Sn0+p−Sn0|= |n0+p
∑k=n0+1
ak|< ε.
Demostracion. Supongamos primero que la serie es convergente, es decirSn → S. Entonces, dadoε > 0,existen0 tal que|Sn−S|< ε/2 para todon≥ n0, con lo cual
|Sn0+p−Sn0| ≤ |Sn0+p−S|+ |S−Sn0|< ε/2+ ε/2= ε,
y esto vale para cualquierp∈N.
Supongamos ahora que se verifica la condicion del teorema, es decir, la cola tiende a cero. En particular,se tiene, dadoε = 1, que sin≥ n0 entonces
|Sn| ≤ |Sn−Sn0|+ |Sn0|< 1+ |Sn0|
para todon ≥ n0. Es decir, todos los terminos de la sucesionSn, de n0 en adelante, estan acotados por1+ |Sn0|. Entonces toda la sucesionSn es acotada pues los primeros terminos, que son finitos, tambienestan acotados. Se deduce que existe una subsucesion convergente,Snk → L cuandok→ ∞. Afirmo que estenumeroL es el lımite de la serie. Para verlo, dadoε> 0, existe por la condicion que es hipotesis unn0 ∈N tal

156 Integrales enR
que|Sn−Sn0|< ε/2 para todon> n0. ComoSnk tiende aL, tambien existe unk0 ∈N tal que|Snk −L|< ε/2si k≥ k0. Podemos suponer, agrandandok0, quenk0 ≥ n0. Entonces, sin> n0
|Sn−L| ≤ |Sn−Snk0|+ |Snk0
−L|< ε/2+ ε/2= ε
lo que prueba queSn → L cuandon→ ∞.
Observacion 6.2.22.Se deduce facilmente ahora que la serie∑ak converge cuando∑ |ak| es convergente,pues
|n+p
∑k=n+1
ak| ≤n+p
∑k=n+1
|ak|.
Estaultima cantidad tiende a cero cuando n→ ∞ si la serie de los modulos converge, por el teorema. Sededuce que la cola de la serie tiende a cero, y nuevamente invocando el teorema, se deduce que la serie∑ak es convergente. Este resultado se suele mencionar diciendoquela convergencia absoluta implica laconvergencia de una serie, al igual que con las integrales.
Antes de pasar a una aplicacion veamos un criterio para series alternadas.
Proposicion 6.2.23. Criterio de Leibniz (series alternadas). Si an ≥ 0,an → 0 y an+1 < an para todo n,
entonces S= ∑(−1)kak <+∞. Ademas|S−Sn|< an+1, donde Sn es la suma parcialn∑
k=0(−1)kak.
Demostracion. Consideremos la cola, y supongamos quen, p son pares para simplificar. Todos los otroscasos tienen identica demostracion. Observemos que, como la sucesionak es estrictamente decreciente,cada uno de los terminos entre parentesis es estrictamente positivo:
|Sn+p−Sn| = |n+p
∑k=n+1
(−1)kak|= |an+p−an+p−1+ · · ·−an+3+an+2−an+1|
= |(an+1−an+2)+ (an+3−an+4)+ · · ·+(an+p−1−an+p)|= an+1−an+2+an+3−an+4+ · · ·+an+p−1−an+p
= an+1− (an+2−an+3)−·· ·− (an+p−an+p−1).
El ultimo termino entonces siempre es menor quean+1. Esto prueba que|Sn+p−Sn|< an+1, y comoak → 0,se deduce que la cola tiende a cero. Por el Teorema6.2.21, la serie es convergente. Haciendo tenderp ainfinito se deduce que|S−Sn|< an+1.
Ejemplo 6.2.24. Sabemos que la serie∑n≥11n es divergente por el criterio integral. Sin embargo, por el
criterio de Leibniz la serie
∑n≥1
(−1)n1n=−1+
12− 1
3+
14− . . .
es convergente y su suma S difiere de S2 = − 12 en menos que a3 =
13. Este ejemplo tambien nos dice que
la recıproca de lo enunciado en la Observacion 6.2.22es falsa, pues la serie converge pero no convergeabsolutamente.

6.3 NOTAS 157
6.3. NOTAS
I. La funcion f definida en[0,1], con f (0) = 1 y dada por
f (x) =
1q si x= p
q ∈Q y p,q no tienen divisores comunes
0 six<Q.
es integrable en[0,1] y ademas∫ 1
0 f = 0. Para probarlo, contemos un poco:
¿Cuantos numeros racionalesp/q hay en(0,1) con la propiedad de tener un numero 2 en el denominador?Unicamente uno, el numero12 , pues si ponemos en el numerador2 un numero mayor o igual a 2, obtenemosel numero2
2 , que tiene factores comunes, o numeros mayores que 1.
¿Cuantos numeros racionales3 hay en(0,1]? Hay dos, que son13 ,23 , por los mismos motivos.
¿Cuantos numeros racionales4 hay en(0,1]? Hay dos, que son14 ,34 , por los mismos motivos. Observemos
que el24 no hay que contarlo pues no verifica quep y q no tienen factores comunes.
En general, habra a los sumoj −1 racionalesj en el intervalo(0,1].
Luego, los que tienen denominador menor queK, que se obtienen juntando todos los de la lista de arriba, sonfinitos.Dadoε > 0, usemos el criterio de integrabilidad: alcanza con encontrar una particion del[0,1] dondeS( f ,P)−I( f ,P) < ε. Como en cualquier intervalo de cualquier particion, habra siempre un numero irracional, esta claroque las sumas inferiores dan todas cero. Basta probar entonces que, dadoε > 0, hay una particion tal que la sumaS( f ,P) < ε. TomemosK ∈ N tal que 1
K < ε2 . Por lo que observamos recien, hay finitos numeros racionales no
nulosr = pq en el intervalo[0,1] tales queq< K, contandor = 1. Digamos que sonN = N(K), los ordenamos de
menor a mayor y los nombramosr ii=1···N, con rN = 1. Ahora tomamosα suficientemente pequeno de maneraque la siguiente sucesion resulte bien ordenada
0, r1−α, r1, r1+α, r2−α, r2, r2+α, r3−α, · · · , rN −α, rN.
Podemos definir una particionP del intervalo[0,1] de la siguiente manera: separamos en intervalos que tienenracionales conq< K y en intervalos que no tienen racionales conq< K, como indica la figura:
α0
r1 r2
r1−α r1+α r2−α r2+α
2α
11−α
Es decir, tomamos primero los intervalos∆′k remarcados en la figura, que son aquellos de ancho 2α, centrados en
los puntosr i (como por ejemplo[r1 −α, r1 +α]). De estos hayN− 1. Incluimos tambien los intervalos[0,α] y[1−α,1].Si a los intervalos restantes los denominamos∆
′′k , se observa que son aquellos intervalos que quedan entre medio
(como por ejemplo[r1+α, r2−α]), donde no hay ningun numero racional conq< K:
α0
r1 r2
r1−α r1+α r2−α r2+α 11−α

158 Integrales enR
Esto define una particionP = ∆k del intervalo[0,1]. CalculemosS( f ,P) = ∑Mk∆k, pero separando en dosterminos:
S( f ,P) =∑M′k∆
′k+∑M′′
k∆′′k ,
dondeM′k es el supremo def en∆′
k, mientras queM′′k es el supremo def en∆′′
k . Observemos que, comof (x) ≤1 para todox ∈ [0,1], se tiene en particular queM′
k ≤ 1 para todok. Por otro lado, como senalamos antes, encualquiera de los intervalos∆′′
k , cualquier racional es de la pintar = pq conq≥ K, con lo cual:f (x) = 0 si x<Q,
mientras quef (p/q) = 1/q≤ 1/K. Esto nos dice queM′′k < ε
2 para todok. Con esto,
S( f ,P)≤ 1·∑∆′k+
ε2 ∑∆
′′k .
Ciertamente∑∆′′k ≤ 1 pues estos intervalos son solo una parte del[0,1]. Por otro lado, cada intervalo∆′
k tieneancho 2α, y hayN de ellos (en realidad sonN−1 y despues hay que contar las dos mitades de los extremos), conlo cual
S( f ,P)≤ 2αN+ε2.
Si elegimos (achicando si es necesario)α de manera queα < ε4N , se tieneS( f ,P) < ε, que es lo que querıamos
probar.
II. La funcion f definida en la nota anterior verifica la siguiente propiedad:para cualquiera∈ [0,1], se tiene lımx→a
f (x)=
0.
Para probarlo, seana∈ [0,1], ε > 0, y tomemos cualquier numero naturalK tal que 1K < ε. Recordemos que por
lo obsevado en el item previo, los numeros que tienen denominador menor queK, que se obtienen juntando todoslos de la lista de arriba, son finitos. Esto quiere decir que tiene que haber algun entorno(a−δ,a+δ) del puntoaen el intervalo[0,1] donde no hay ningun racionalp/q conq< K (con la posible excepcion dep/q= a, pero noimporta porque estamos mirando el lımite lım
x→af (x), y entonces el puntox= a no nos interesa). Para convencernos
de esta ultima afirmacion sobre el entorno, pensemos en la afirmacion opuesta: serıa decir que para todoδ > 0hay algun racionalp/q , a con q< K y tal que|p/q−a| < δ; pero esto nos permitirıa fabrica infinitos de estospuntos contradiciendo lo que contamos anteriormente. Ahora veamos que el lımite es en efecto 0. Tomemosx con|x−a| < δ, x , a. Entonces six < Q, se tienef (x) = 0 por definicion y ciertamente| f (x)| < ε. Por otra parte six∈Q, por como elegimosδ, debe serx= p/q conq≥ K, luego
| f (x)|= | f (p/q)|= 1q≤ 1
K< ε,
que es lo que querıamos probar.
En particular, observando la definicion def , resulta quef es continua en los irracionales, y discontinua en losracionales. Esto permitirıa otra prueba de la integrabilidad def , pero para ello necesitarıamos probar (y no vamosa hacerlo aquı) que una funcion acotada, que es continua salvo un conjunto numerable de puntos, es integrable.

Los matematicos son como los franceses; loque sea que les digas ellos lo trasladan a supropio lenguaje e inmediatamente es algocompletamente distinto.
Goethe
7.1. Integrales en el plano
Comencemos por definir integrales para funciones con dominio en algun subconjuntoD ⊂ R2. Nosvamos a encontrar con dificultades propias de los dominios deeste tipo. Para comenzar es bueno entender elcaso mas simple, en el que el dominio es un rectangulo.
7.1.1. Rectangulos y particiones
El analogo de un intervalo en el plano es un rectangulo, quese puede escribir siempre como el productocartesiano de dos intervalos:
x
y
R= [a,b]× [c,d]
a b
c
d
En este casoR= [a,b]× [c,d] que es lo mismo que decir queX = (x,y) ∈ R si y solo six ∈ [a,b] ey∈ [c,d]. Su medida o area es el producto de los lados, que denotaremosµ. Es decir, el numero positivo.
µ(R) = (b−a)(d− c).

160 Integrales multiples
El diametro δ(R) del rectanguloR es la mayor distancia entre dos de los puntos del rectangulo, que comose puede observar, es simplemente el largo de la diagonal delrectangulo:
x
y
δ(R)
a b
c
d
El hecho a rescatar de esta definicion esX,Y ∈ R⇒‖X−Y‖ ≤ δ(R).
Si tenemos una funcionf (x,y) definida enR, po-demos preguntarnos cual es el sentido de calcularla integral def en R. La respuesta es simple sipensamos en el grafico def , que es un subconjun-to deR3, y por ahora, hacemos la simplificacionde suponer quef ≥ 0. Entonces la integral defqueremos que represente el volumen de la figuraformada por el rectangulo con piso el planoz= 0y techo el grafico def , como en la figura de laderecha.
Gr( f )
R
R
z= c
Observemos lo que pasa en un ejemplo senci-llo: si f (x,y) = 1, obtenemos un “paralelepıpe-do” (ladrillo) de baseR y altura 1, cuyo volu-men es 1(b−a)(d− c). En general, sif (x,y) = ccon c ≥ 0, obtenemos que la figura es un ladri-llo de baseR y alturac, por lo que su volumen esc(b−a)(c−d).

7.1 Integrales en el plano 161
Vamos a definir las sumas superiores e inferiores de una funcion en forma analoga a como hicimos enla recta. Dado un rectanguloR, podemos subdividirlo siempre en una cantidad finita de rectangulos maspequenos, es decirR= ∪Ri donde losRi son rectangulos (disjuntos salvo los bordes) del plano, como se veen la figura:
R
Ri
Esto es lo que denominamos una particionP deR, y en general lo anotamos comoP= Ri. Un refi-namientoP′ deP es otra particion que descomponga cada uno de los rectangulosRi en una union (disjuntasalvo los bordes) deRi = ∪ jRi
j de nuevos rectangulos, como indica la figura:
RRi = ∪ j Ri
j
Rij
de manera que ahoraR= ∪i, jRij .
El diametro δ(P) de una particion (tambien llamadonorma de la particion y denotado‖P‖) es el maxi-mo de los diametros de todos los rectangulos que forman la particion. Indica que tan pequenos son losrectangulos: a menor diametro, mas chicos los rectangulos de la particion. Observemos que dada una par-ticion P cualquiera del rectangulo originalR, y un numero positivoε, siempre podemos obtener un refina-mientoP′ deP de manera tal queδ(P′)< ε.
Definicion 7.1.1. Dada una funcion positiva f: R→R y acotada, y una particion P= ∪Ri de R,
1. La suma superior de f en la particion P es
S( f ,P) = ∑i
Miµ(Ri)
donde Mi es el supremo de f en el rectangulo Ri .

162 Integrales multiples
2. La suma inferior esI( f ,P) = ∑
imiµ(Ri)
donde ahora mi indica el ınfimo de f en Ri .
7.1.2. Integral de Riemann
Claramente, siM = sup( f ) enR y m= ınf( f ) enR, entonces para cualquier particionP= ∪Ri deR setiene
m≤ mi ≤ Mi ≤ M
para todoi, dondemi ,Mi indican el supremos e ınfimo def enRi. Entonces se tiene
I( f ,P) ≤ S( f ,P)
para cualquier particion. Como en el caso de una variable, es facil ver que las sumas superiores decrecen amedida que la particion se refina (pues el supremo en un conjunto mas pequeno es menor o igual que en elconjunto mas grande), y tambien es facil ver que las sumasinferiores crecen. Tambien se deduce entoncesque dado un par arbitrarioP,Q de particiones,
I( f ,P)≤ S( f ,Q).
Se observa que las sumas inferiores estan acotadas superiormente. Luego estas cantidades tiene un su-premo que denotaremosI∗( f ), la integral inferior de Riemann. Analogamente, al ınfimo de las sumassuperiores lo denotaremosI∗( f ), y evidentemente
I∗( f )≤ I∗( f ).
Cuando ambas cantidades coinciden decimos quef esRiemann integrable enR. A esta cantidad la deno-tamos con
∫R f , y la llamamosintegral doble de f , y lo usual es usar la notacion
∫ ∫R
f
para aclarar que se trata de una funcion de dos variables.
Dominios generales
Cuando una funcion esta definida en un dominioD ⊂ R2 acotado, pero que no es necesariamente unrectangulo, se considera la siguiente funcion auxiliarf . Se toma un rectanguloR cualquiera tal queD ⊂ R
R
D

7.1 Integrales en el plano 163
y se define
f (X) =
f (X) si X ∈ D0 si X ∈ R−D
Se definen las sumas superiores e inferiores def utilizando f , y decimos quef es integrable enD si f esintegrable enR.
Esta integral no depende del rectangulo elegido, puesto que si cambiamos el rectangulo por otroR′, enla diferencia de ambos rectangulo la funcionf es nula.
Se define la integral def enD como la integral def enR, es decir∫
Df :=
∫R
f .
Una pregunta clave, a la que volveremos mas adelante, es como saber si esta funcion extendida es inte-grable o no. Dicho de otra manera, ¿como sabemos si dada una funcion definida en un dominio que no es unrectangulo, si esta funcion es integrable o no?
Definicion 7.1.2.Dado un conjunto acotado D⊂R2, de-cimos que D esmediblesi la funcion f = 1 es integrableen D, y en ese caso la medida de D se calcula como
µ(D) =∫
D1.
Este numero es elareadel conjunto D, como puede ob-servarse en la figura, pues la altura es constantementeuno.
R
D
z= 1
Dada cualquier funcion acotadaf definida en un dominio acotadoD, consideramos sus partes positiva ynegativa dadas por
f+(X) =
f (X) si f (X) > 00 si f (X) ≤ 0
,
f−(X) =
− f (X) si f (X)< 00 si f (X)≥ 0
Ambas son funciones positivas, yf es integrable Riemann enD si f+ y f− lo son, y comof = f+− f−,∫
Df =
∫D
f+−∫
Df−
Observemos que, como en el caso de una variable,| f |= f++ f−.
El criterio para ver si una funcion integrable es analogo al de una variable, con la misma demostracionque por lo tanto omitimos.

164 Integrales multiples
Teorema 7.1.3.Sea D⊂ R2 un conjunto acotado. Entonces f: D → R es integrable en D si y solo si paratodoε > 0 existe una particion P de un rectangulo que contenga a D tal que
S( f ,P)− I( f ,P)< ε.
De acuerdo a lo que discutimos, si el dominio no es un rectangulo, hay que integrar la funcion extendidapor cero en algun rectangulo que contenga al dominio. Perosurge el problema de si esta nueva funcion esintegrable en el rectangulo.
R
D
Gr( f )
∂D
Supongamos que tenemos un dominioD comoen el dibujo, y lo extendemos a un rectanguloRque lo contenga, haciendo quef sea cero fueradel dominioD, como discutimos antes. El pro-blema, es que esta funcion no es mas continuaenR, aunque lo sea enD, pues en el borde deD tenemos un salto, aun en el caso en el quefsea constante, como se observa en la figura.
La observacion importante es que allı, en∂D, es en el unico lugar donde no es continua, pues fueraes continua por ser constante. Nos alcanzarıa con ver que esta region, la curva∂D, no aporta nada a laintegral en el rectanguloR. En el caso general, esto no es necesariamente cierto. Sin embargo, bajociertas condiciones razonables, como por ejemplo si la curva∂D se obtiene como union finita de graficos defunciones continuas, se puede integrar con tranquilidad.
2
R
D
La idea es cubrir el borde con rectangulos de manera que la suma de las areas de estos rectangulos seaarbitrariamente pequena. Veamos que esto es posible.
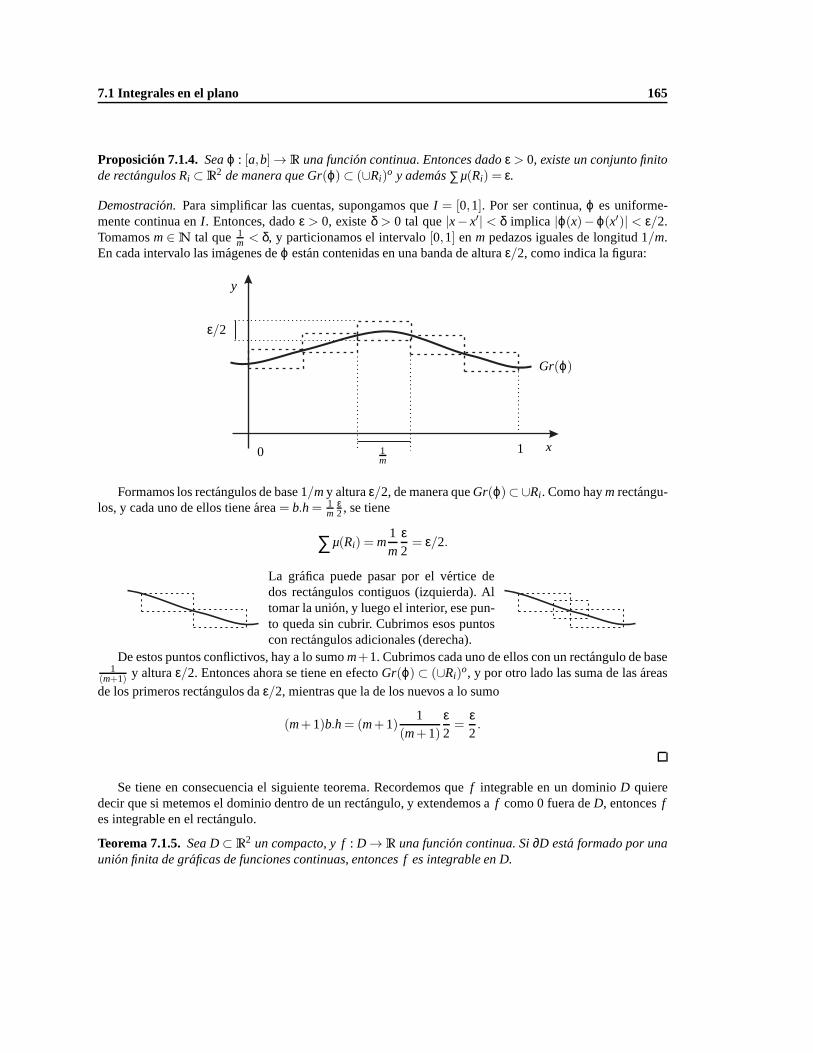
7.1 Integrales en el plano 165
Proposicion 7.1.4. Seaϕ : [a,b]→ R una funcion continua. Entonces dadoε > 0, existe un conjunto finitode rectangulos Ri ⊂ R2 de manera que Gr(ϕ)⊂ (∪Ri)
o y ademas∑µ(Ri) = ε.
Demostracion. Para simplificar las cuentas, supongamos queI = [0,1]. Por ser continua,ϕ es uniforme-mente continua enI . Entonces, dadoε > 0, existeδ > 0 tal que|x− x′| < δ implica |ϕ(x)−ϕ(x′)| < ε/2.Tomamosm∈N tal que 1
m < δ, y particionamos el intervalo[0,1] enm pedazos iguales de longitud 1/m.En cada intervalo las imagenes deϕ estan contenidas en una banda de alturaε/2, como indica la figura:
Gr(ϕ)
0 x
y
1m
ε/2
1
Formamos los rectangulos de base 1/my alturaε/2, de manera queGr(ϕ)⊂∪Ri . Como haym rectangu-los, y cada uno de ellos tiene area= b.h= 1
mε2, se tiene
∑µ(Ri) = m1m
ε2= ε/2.
La grafica puede pasar por el vertice dedos rectangulos contiguos (izquierda). Altomar la union, y luego el interior, ese pun-to queda sin cubrir. Cubrimos esos puntoscon rectangulos adicionales (derecha).
De estos puntos conflictivos, hay a lo sumom+1. Cubrimos cada uno de ellos con un rectangulo de base1
(m+1) y alturaε/2. Entonces ahora se tiene en efectoGr(ϕ)⊂ (∪Ri)o, y por otro lado las suma de las areas
de los primeros rectangulos daε/2, mientras que la de los nuevos a lo sumo
(m+1)b.h= (m+1)1
(m+1)ε2=
ε2.
Se tiene en consecuencia el siguiente teorema. Recordemos que f integrable en un dominioD quieredecir que si metemos el dominio dentro de un rectangulo, y extendemos af como 0 fuera deD, entoncesfes integrable en el rectangulo.
Teorema 7.1.5.Sea D⊂ R2 un compacto, y f: D → R una funcion continua. Si∂D esta formado por unaunion finita de graficas de funciones continuas, entonces f es integrable en D.

166 Integrales multiples
Demostracion. Tomamos un rectangulo cualquieraR tal queD ⊂ R, y extendemos af por cero enR−D.Seaε > 0. Queremos ver que existe una particionP deR tal que
S( f ,P)− I( f ,P)< ε.
Seas= max( f )−mın( f ) enR (s> 0 si f , 0 enR). Cubrimos primero el borde deD con finitos rectangulosRii∈A, de manera que
∑µ(Ri) =ε2s
.
ComoR− (∪Ri)o es compacto, yf es continua allı, es uniformemente continua (teorema de Heine-Borel).
Es decir, dadoε′ = ε2µ(R) > 0, existeδ > 0 tal que‖X−Y‖ ≤ δ (X,Y ∈ R− (∪Ri)
o) implica
| f (X)− f (Y)| ≤ ε′.
Tomamos ahora una particionP= Rii∈F deRque contenga a los rectangulosRii∈A que cubren al bordede D, como indica la figura (estamos subdividiendo aquellos rectangulos que estaban superpuestos parapensarlos como rectangulos disjuntos):
RR
DD
Es decirP= (∪i∈ARi)⋃(∪i∈F−ARi). Refinando, podemos suponer que la particion tiene diametroδ(P)<
δ. Entonces
S( f ,P)− I( f ,P) = ∑i∈F
(Mi −mi)µ(Ri) = ∑i∈A
(Mi −mi)µ(Ri)+ ∑i∈F−A
(Mi −mi)µ(Ri)
< ∑i∈A
sµ(Ri)+ ∑i∈F−A
ε′µ(Ri)
≤ sε2s
+ ε′µ(R) = ε.
7.1.3. Integrales iteradas y el Teorema de Fubini
En general puede ser muy complicado calcular integrales multiples usando la definicion. Sin embargo,el siguiente teorema nos dice que, bajo ciertas condicionesbastante generales, el calculo se reduce al calculosucesivo de integrales en una variable, donde podemos aplicar los metodos que conocemos.

7.1 Integrales en el plano 167
Estas integrales se conocen comointegrales iteradas, un ejemplo elemental es el siguiente:∫ 1
0
(∫ 3
2x2ydy
)
dx=∫ 1
0x2 y2
2|32dx=
12
∫ 1
0(9−4)x2dx=
52
∫ 1
0x2dx=
52
13
x3|10 =56.
En los proximos parrafos veremos que lo que acabamos de calcular puede interpretarse como la integralde f (x,y) = x2y en el rectanguloR= [0,1]× [2,3], la cual tambien puede calcularse integrando en el otroorden (primerox y luegoy).
La idea del siguiente teorema es que, si queremos calcular laintegral def , pensandola como el volumenindicado en la figura,
S
R
a
bc
c d
d
x= cte
A(x)A(x)
podemos cortar con planosx= cte., y luego calcular el areaA(x) de la figura que se obtiene integrando lafuncion fx(y) = f (x,y) respecto de la variabley de la manera usual. Finalmente integramos estas areas parax moviendose entrea y b. Esto se conoce comoprincipio de Cavalieri . Parax∈ [a,b], seafx : [c,d]→R lafuncion que se obtiene al fijarx∈ [a,b], es decirfx(y) = f (x,y). Entonces
A(x) =∫ d
cfx(y)dy,
y el principio de Cavalieri establece que bajo ciertas condiciones
vol =∫ b
aA(x)dx.
Vamos a ver bajo que condiciones se puede aplicar este principio. Daremos una version simplificada delteorema, que sera la que usaremos en las aplicaciones. La version general del teorema puede verse en lasnotas del final del capıtulo (NotaI).

168 Integrales multiples
Teorema 7.1.6(Fubini simplificado). Sea R= [a,b]× [c,d], un rectangulo enR2, y f : R→ R una funcionintegrable en R.
1. Si para todo x∈ [a,b], fx : [c,d]→ R es integrable, entonces
∫ ∫R
f =∫ b
a
∫ d
cf (x,y)dydx.
2. Si para todo y∈ [c,d], fy : [a,b]→R es integrable, entonces
∫ ∫R
f =∫ d
c
∫ b
af (x,y)dxdy.
Demostracion. Consideremos una particionP del rectangulo, donde∆i = [xi ,xi+1] es una particion de[a,b]y ∆
′j = [y j ,y j+1] es una particion de[c,d], de manera que los rectangulosRi j = ∆i ×∆
′j de area(xi+1 −
xi)(yi+1−yi) forman la particionP del rectangulo original. Como antes, abusamos un poquito de la notaciony usamos∆ para denotar al intervalo y a su longitud. Entonces
I( f ,P) = ∑i, j
mi j ( f )∆i∆′j = ∑
i(∑
jmi j ( f )∆′
j )∆i ,
dondemi j ( f ) indica el ınfimo def enRi j .
Vamos a demostrar solo 1., la demostracion de 2. es analoga. Supongamos entonces quefx es integrablepara todox∈ [a,b], y bautizemosI : [a,b]→R a la integral defx respecto dey:
I (x) =∫ d
cfx(y)dy=
∫ d
cf (x,y)dy.
Si x∈Ri j , entoncesmj( fx) (que es el ınfimo de la funcionfx en∆′
j ) es mayor o igual que el ınfimo def enRi j , pues
mj( fx) = ınf f (x,y) : x fijo ,y∈ ∆′j,
y el ınfimo en un subconjunto -en este casox×∆′j -
siempre es mayor o igual que el ınfimo en el conjuntooriginal -en este caso∆i ×∆
′j -, como indica la figura. x= cte∆i
∆′j
x×
∆′ j
R= ∆i ×∆′j
Se deduce que, cualquiera seax∈ ∆i ,
∑j
mi j ( f )∆′j ≤ ∑
jmj( fx)∆
′j ≤ I∗( fx) =
∫ d
cfx(y)dy= I (x).
Si en el extremo derecho tomamos el ınfimo parax ∈ ∆i - que anotamosmi(I )-, multiplicamos por∆i ysumamos, se deduce que
I( f ,P) = ∑i(∑
jmi j ( f )∆′
j )∆i ≤ ∑i
mi(I )∆i ≤ I∗(I ),
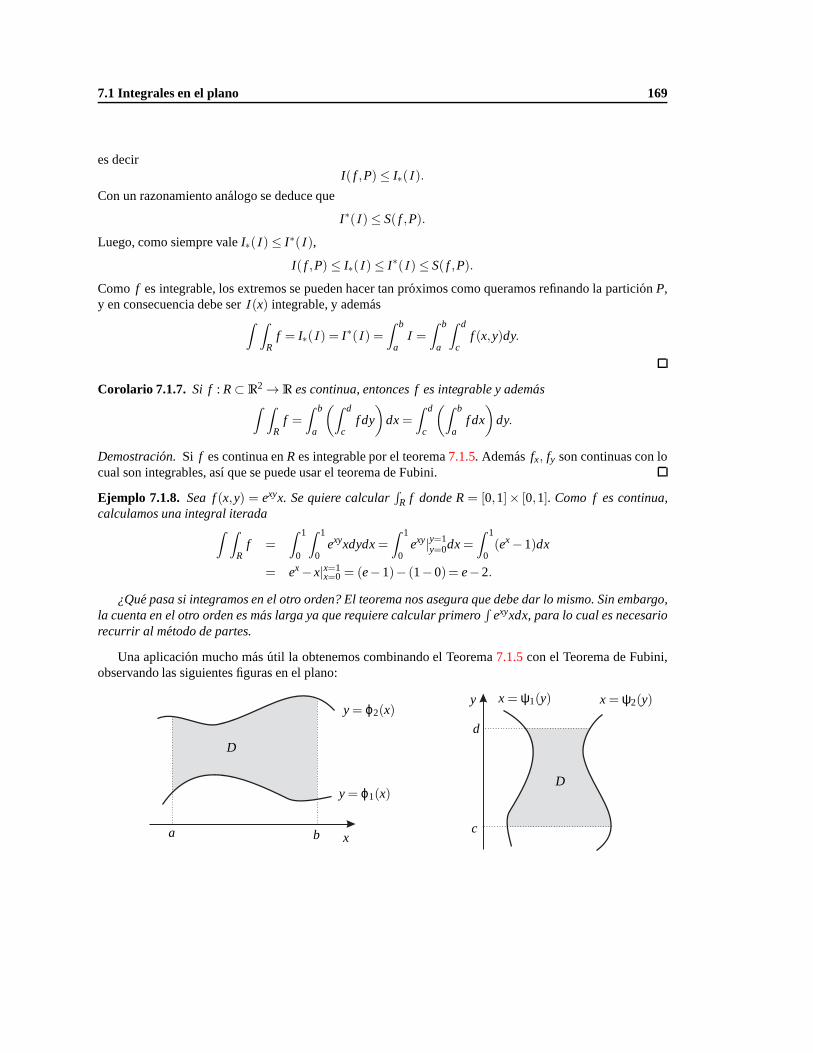
7.1 Integrales en el plano 169
es decirI( f ,P)≤ I∗(I ).
Con un razonamiento analogo se deduce que
I∗(I )≤ S( f ,P).
Luego, como siempre valeI∗(I )≤ I∗(I ),
I( f ,P) ≤ I∗(I )≤ I∗(I )≤ S( f ,P).
Como f es integrable, los extremos se pueden hacer tan proximos como queramos refinando la particionP,y en consecuencia debe serI (x) integrable, y ademas
∫ ∫R
f = I∗(I ) = I∗(I ) =∫ b
aI =
∫ b
a
∫ d
cf (x,y)dy.
Corolario 7.1.7. Si f : R⊂ R2 →R es continua, entonces f es integrable y ademas∫ ∫
Rf =
∫ b
a
(∫ d
cf dy
)
dx=∫ d
c
(∫ b
af dx
)
dy.
Demostracion. Si f es continua enR es integrable por el teorema7.1.5. Ademasfx, fy son continuas con locual son integrables, ası que se puede usar el teorema de Fubini.
Ejemplo 7.1.8. Sea f(x,y) = exyx. Se quiere calcular∫
R f donde R= [0,1]× [0,1]. Como f es continua,calculamos una integral iterada
∫ ∫R
f =∫ 1
0
∫ 1
0exyxdydx=
∫ 1
0exy|y=1
y=0dx=∫ 1
0(ex−1)dx
= ex− x|x=1x=0 = (e−1)− (1−0)= e−2.
¿Que pasa si integramos en el otro orden? El teorema nos asegura que debe dar lo mismo. Sin embargo,la cuenta en el otro orden es mas larga ya que requiere calcular primero
∫exyxdx, para lo cual es necesario
recurrir al metodo de partes.
Una aplicacion mucho mas util la obtenemos combinando elTeorema7.1.5con el Teorema de Fubini,observando las siguientes figuras en el plano:
x
y
a b c
d
y= ϕ1(x)
y= ϕ2(x)x= ψ1(y) x= ψ2(y)
D
D
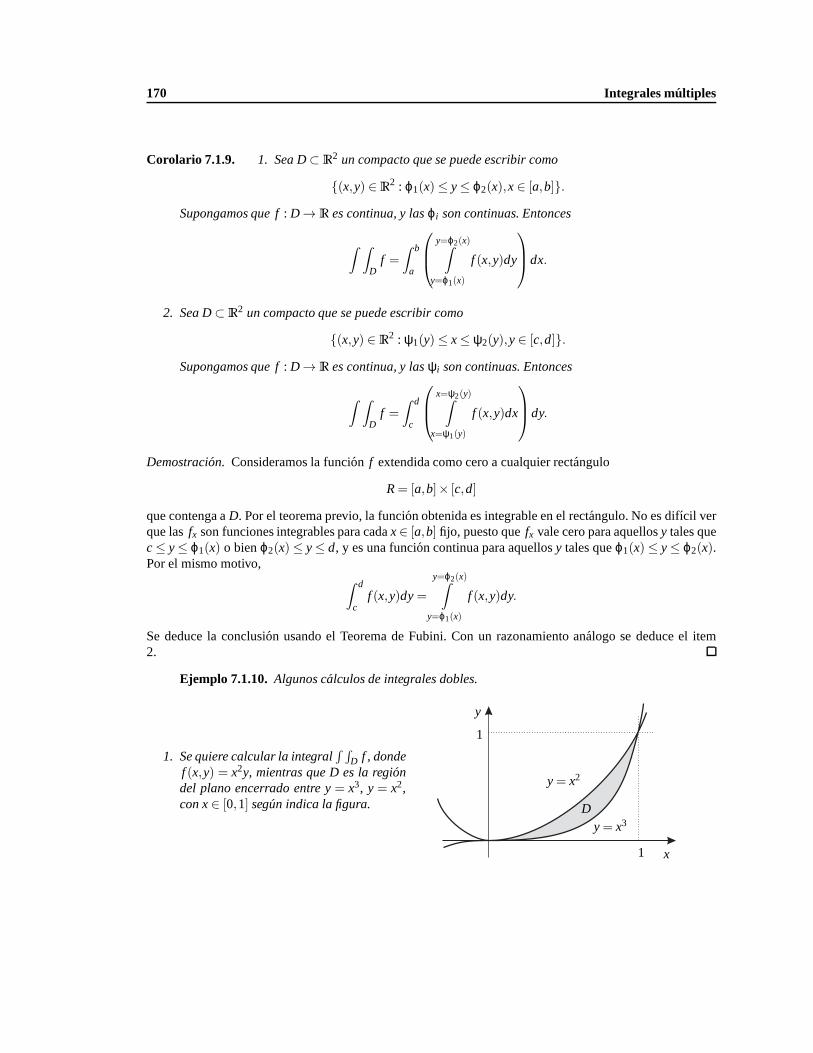
170 Integrales multiples
Corolario 7.1.9. 1. Sea D⊂ R2 un compacto que se puede escribir como
(x,y) ∈R2 : ϕ1(x)≤ y≤ ϕ2(x),x∈ [a,b].
Supongamos que f: D → R es continua, y lasϕi son continuas. Entonces
∫ ∫D
f =∫ b
a
y=ϕ2(x)∫
y=ϕ1(x)
f (x,y)dy
dx.
2. Sea D⊂ R2 un compacto que se puede escribir como
(x,y) ∈ R2 : ψ1(y)≤ x≤ ψ2(y),y∈ [c,d].
Supongamos que f: D → R es continua, y lasψi son continuas. Entonces
∫ ∫D
f =∫ d
c
x=ψ2(y)∫
x=ψ1(y)
f (x,y)dx
dy.
Demostracion. Consideramos la funcionf extendida como cero a cualquier rectangulo
R= [a,b]× [c,d]
que contenga aD. Por el teorema previo, la funcion obtenida es integrable en el rectangulo. No es difıcil verque lasfx son funciones integrables para cadax∈ [a,b] fijo, puesto quefx vale cero para aquellosy tales quec≤ y≤ ϕ1(x) o bienϕ2(x)≤ y≤ d, y es una funcion continua para aquellosy tales queϕ1(x)≤ y≤ ϕ2(x).Por el mismo motivo,
∫ d
cf (x,y)dy=
y=ϕ2(x)∫
y=ϕ1(x)
f (x,y)dy.
Se deduce la conclusion usando el Teorema de Fubini. Con un razonamiento analogo se deduce el item2.
Ejemplo 7.1.10. Algunos calculos de integrales dobles.
1. Se quiere calcular la integral∫ ∫
D f , dondef (x,y) = x2y, mientras que D es la regiondel plano encerrado entre y= x3, y= x2,con x∈ [0,1] segun indica la figura.
x
y
1
1
y= x2
y= x3D
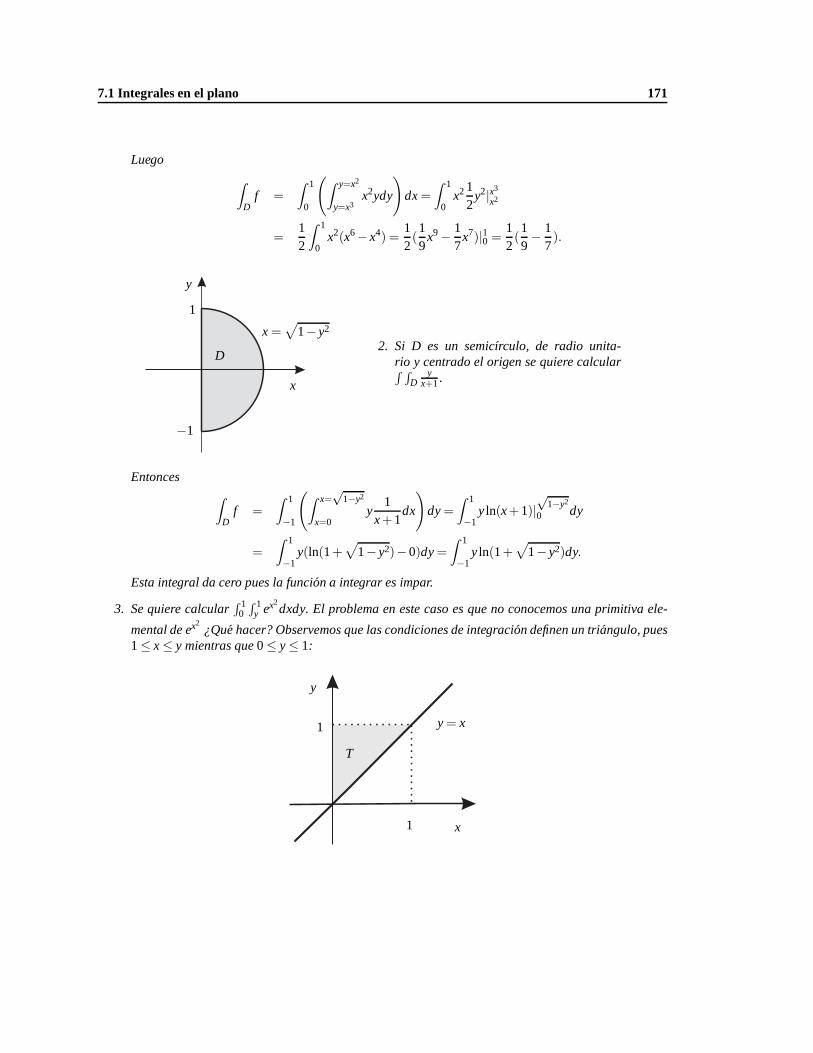
7.1 Integrales en el plano 171
Luego
∫D
f =
∫ 1
0
(∫ y=x2
y=x3x2ydy
)
dx=∫ 1
0x2 1
2y2|x3
x2
=12
∫ 1
0x2(x6− x4) =
12(19
x9− 17
x7)|10 =12(19− 1
7).
x
y
1
−1
x=√
1− y2
D2. Si D es un semicırculo, de radio unita-
rio y centrado el origen se quiere calcular∫ ∫D
yx+1.
Entonces∫
Df =
∫ 1
−1
(∫ x=√
1−y2
x=0y
1x+1
dx
)
dy=∫ 1
−1yln(x+1)|
√1−y2
0 dy
=
∫ 1
−1y(ln(1+
√
1− y2)−0)dy=∫ 1
−1yln(1+
√
1− y2)dy.
Esta integral da cero pues la funcion a integrar es impar.
3. Se quiere calcular∫ 1
0
∫ 1y ex2
dxdy. El problema en este caso es que no conocemos una primitiva ele-
mental de ex2
¿Que hacer? Observemos que las condiciones de integracion definen un triangulo, pues1≤ x≤ y mientras que0≤ y≤ 1:
x
y
1
1 y= x
T

172 Integrales multiples
Entonces, usamos Fubini para cambiar el orden de integracion. Se tiene
∫ 1
0
∫ 1
yex2
dxdy =
∫T
ex2=
∫ 1
0
∫ x
0ex2
dydx
=
∫ 1
0ex2
y|x0dx=∫ 1
0ex2
xdx=12
ex2|10 =12(e−1).
7.2. Integrales enR3 y Rn
Observemos ahora el caso de integrales de funciones con dominio enR3. Aquı el analogo de un intervaloes un ladrillo, que seguiremos llamandoR por comodidad,
x
y
z
R= [a,b]× [c,d]× [e, f ]
Sumedida es el volumenµ(R) = (b−a)(d− c)( f −e), y su diametroδ(R) el largo de la diagonal mayordel ladrillo. Una particionP deR es una subdivisiondeR en ladrillos disjuntosPi como en la figura, y unrefinamientoP′ deP una subdivision de cada uno delos ladrillosPi =∪Pi
j . El diametroδ(P) de la particionel diametro del ladrillo mas grande que la conforma.
¿Que querrıa decir aquı la integral de una funcion? En principio, esperamos que la integral de la funcionf (x,y,z) = 1 nos devuelva la medida del cubo
volumen= 1(b−a)(d− c)( f −e),
aunque no podamos visualizar el grafico def . La integral se define usando particiones de manera analogaal

7.2 Integrales enR3 y Rn 173
cason= 2, y cuando existe la integral def se denominaintegral triple , y se denota∫ ∫ ∫
Rf .
En general, para cualquiern≥ 1, unrectanguloRes el producto cartesiano den intervalo
R= [a1,b1]× [a2,b2]×·· ·× [an,bn],
sumedidaes el productoµ(R) = (b1−a1)(b2−a2) · · · (bn−an),
y su diametroδ(R) el largo de la diagonal mayor, es decir, la mayor distancia posible entre dos puntos deR.La integral se define de la manera obvia.
El siguiente es un corolario inmediato del Teorema de Fubini:
Corolario 7.2.1. Si R= [a1,b1]× [a2,b2]×·· ·× [an,bn] es un rectangulo enRn y f : R→R es una funcioncontinua en R, entonces
∫R
f =∫ b1
a1
∫ b2
a2
· · ·∫ bn
an
f (x1,x2, . . . ,xn)dx1dx2 · · ·dxn,
donde la integracion se puede efectuar en cualquier orden.
Demostracion. Hay que observar que sif es continua, entonces es continua en cada una de sus variablespor separado, y entonces cada ∫ bi
ai
f (x1,x2, · · · ,xn)dxi
existe y es una funcion continua en[ai ,bi ], en particular integrable. Usando el teorema de Fubini repetidasveces se obtiene el corolario.
Lo que es mas interesante es pensar que ocurre cuando el dominio no es un ladrillo enR3. Con razona-mientos similares a los del plano, se puede probar lo siguiente:
Teorema 7.2.2.Sea D⊂ R3 un compacto, y f: D → R una funcion continua. Si∂D esta formado por unaunion finita de graficos de funciones continuas definidas en conjuntos compactos del plano, entonces f esintegrable en D.
Aquı las superficies reemplazan a las curvas como borde de laregion, y la idea central es que unasuperficie enR3, que es grafica de una funcion continua en un compacto, tiene volumen nulo, y por lo tantoel borde de la region no influye en la existencia de la integral.
Respecto del calculo, aquı hay mas posibilidades, simplemente por ser tres las variables. Observemos lassiguientes figuras. En el primer caso, se trata de de la region encerrada por los graficos de funcionesfi(x,y),cuyo dominio comunA se indica como una sombra en el planoxy. En los otros casos se tienen las variantesobvias.
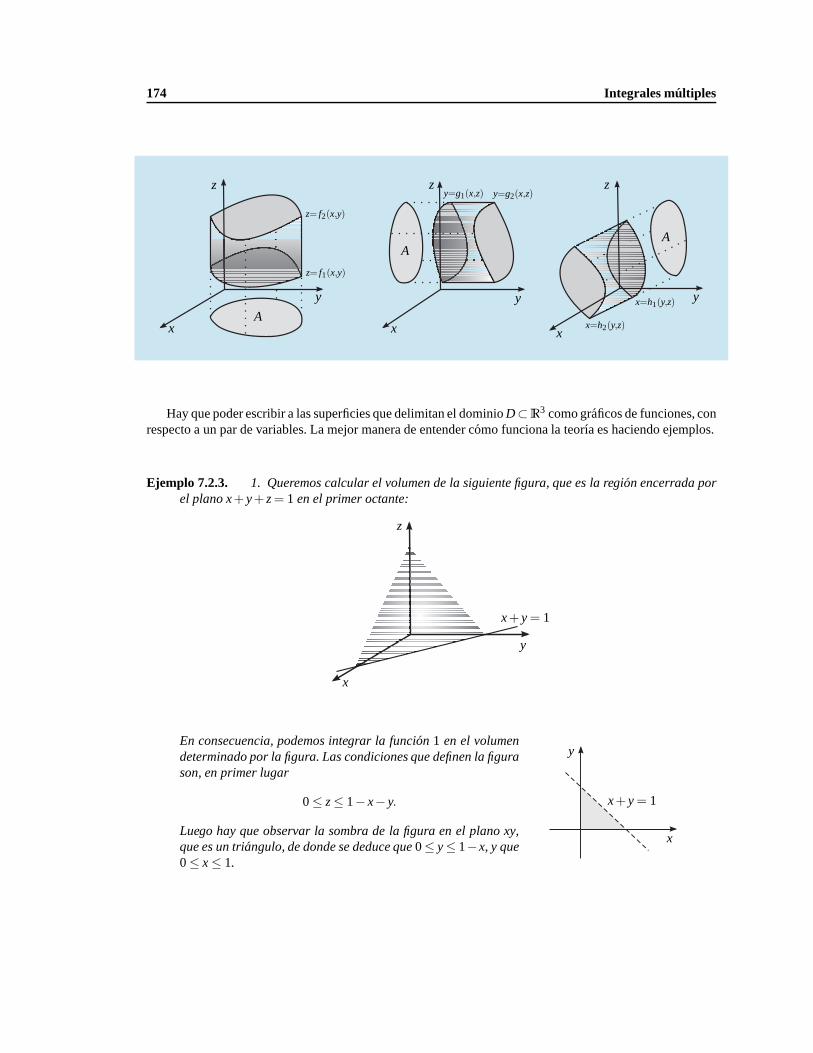
174 Integrales multiples
x=h1(y,z)
x=h2(y,z)
y=g1(x,z) y=g2(x,z)
z= f1(x,y)
z= f2(x,y)
AA
Ax xx
y yy
z zz
Hay que poder escribir a las superficies que delimitan el dominioD⊂R3 como graficos de funciones, conrespecto a un par de variables. La mejor manera de entender c´omo funciona la teorıa es haciendo ejemplos.
Ejemplo 7.2.3. 1. Queremos calcular el volumen de la siguiente figura, que esla region encerrada porel plano x+ y+ z= 1 en el primer octante:
x+ y= 1
x
y
z
En consecuencia, podemos integrar la funcion 1 en el volumendeterminado por la figura. Las condiciones que definen la figurason, en primer lugar
0≤ z≤ 1− x− y.
Luego hay que observar la sombra de la figura en el plano xy,que es un triangulo, de donde se deduce que0≤ y≤ 1−x, y que0≤ x≤ 1.
x+ y= 1
x
y

7.2 Integrales enR3 y Rn 175
Luego
vol(D) = µ(D) =
∫ ∫ ∫D
1=
∫ 1
0
∫ 1−x
0
∫ 1−x−y
01 dzdydx
=
∫ 1
0
∫ 1−x
0(1− x− y)dydx=
∫ 1
0(y− xy− 1
2y2)|1−x
0 dx
=
∫ 1
0(1− x− x(1− x)− 1
2(1− x)2)dx
=
∫ 1
0(1−2x+ x2− 1
2(1− x)2)dx
= x− x2+13
x3+16(1− x)3|10 = 1−1+
13− (0+
16) =
16.
2. Masa, volumen y densidad.
Se quiere calcular la masa del octavo de esfera quese halla en el primer octante. De acuerdo al principiofısico que establece queρ = m/v, la masa se puedecalcular como el producto m= ρv, en el caso en quela densidadρ es constante. Se sabe que la densidadesta dada por la funcion ρ(x,y,z) = z, es decir, au-menta a medida que ascendemos.
z
x
y
Si recordamos que una integral triple se calcula como lımite del volumen de pequenas cajitas Cimultiplicadas por la funcionρ(x,y,z)
∫ ∫ ∫D
ρ = lım∑ρ(x,y,z)vol(Ci),
donde(x,y,z) es algun punto en la caja Ci , entonces lo que estamos haciendo al integrar, es sumarlas masas aproximadas de las cajas. Al refinar la particion, las cajas son mas pequenas pero el valorρ(x,y,z)vol(Ci) es cada vez mas parecido a la masa real de la caja Ci . Idealmente, si la densidad novarıa bruscamente de un punto a otro cercano, se tiene la formula para la masa total del objeto dadapor el lımite
m=
∫ ∫ ∫D
ρ.
En este caso se tiene0≤ z≤√
1− x2− y2, mientras que mirando la sombra en el piso se observa que

176 Integrales multiples
0≤ y≤√
1− x2, 0≤ x≤ 1. Entonces
m(D) =
∫ 1
0
∫ √1−x2
0
∫ √1−xy−y2
0z dzdydx=
∫ 1
0
∫ √1−x2
0
12(1− x2− y2)dydx
=12
∫ 1
0
(
(y− x2y− 13
y3)|√
1−x2
0
)
dx
=12
∫ 1
0
√
1− x2(1− x2)− 13(1− x2)
32 dx
=12
∫ 1
0
23(1− x2)
32 dx=
13
∫ π2
0cos3(u)cos(u)du=
13
∫ π2
0cos4(u)du
=13(14
cos(u)3sen(u)+38
cos(u)sen(u)+38
u)|π20 =
13
3π16
=π16
.
donde hicimos la sustitucion x= sen(u), y luego integramos por partes (¡o mejor, usamos una tabla!).
3. Dadas dos partıculas puntuales (ideales) de masas m1 y m2, ubicadas respectivamente en los puntosV1 y V2 del espacio, se define sucentro de masao baricentrocomo la ubicacion promediada de lasposiciones, teniendo en cuenta sus respectivas masas. Estoes, si m1+m2 =mT la masa total, entoncesel centro de masa CM se define de la siguiente manera:
CM =m1V1+m2V2
m1+m2=
m1V1+m2V2
mT.
Si las partıculas tiene la misma masa, el centro de masa es simplemente el punto medio del segmentoque una la posicion de ambas. En el caso general, el centro de masa es algun punto de este segmento,mas cercano siempre a la partıcula de mayor masa:
m1m2
CM
Dada una nube de partıculas mi de posiciones Vi ∈ R3, se define en forma analoga el centro de masade la nube como
CM =∑miVi
∑mi.
Es facil ver que si todas las partıculas tienen la misma masa este es el centro geometrico de susubicaciones.
En el caso de objetos solidos D⊂R3, de densidadρ, si pensamos a la masa infinitesimal de una cajaCi como dada porρvol(Ci), entonces el centro de masa puede pensarse como la suma
CM =∑ρ(Pi)vol(Ci)Pi
∑ρ(Pi)vol(Ci).

7.3 Propiedades 177
donde Pi = (xi ,yi ,zi) es un punto generico en la caja Ci . Es decir, las coordenadas del centro de masase piensan como
(CM)x ≃ ∑xiρ(Pi)µ(Ci)
∑ρ(Pi)µ(Ci),
(CM)y ≃ ∑yiρ(Pi)µ(Ci)
∑ρ(Pi)µ(Ci),
(CM)z ≃∑ziρ(Pi)µ(Ci)
∑ρ(Pi)µ(Ci).
Estas expresiones, pasando al lımite de cajas cada vez mas pequenas nos dan las expresiones de lascoordenadas del baricentro del solido D:
(CM)x =
∫ ∫ ∫D x ρ(x,y,z)m(D)
,
(CM)y =
∫ ∫ ∫D y ρ(x,y,z)m(D)
,
(CM)z =
∫ ∫ ∫D zρ(x,y,z)m(D)
,
donde m(D) indica la masa total de D como en el ejemplo anterior. Esto esta fundamentado por elTeorema7.3.2que enunciamos y demostramos mas abajo, que nos dice que para calcular la integralde Riemann de una funcion integrable, se puede tomar cualquier punto en el rectangulo y evaluar fallı (no es necesario tomar elınfimo o el supremo).
7.3. Propiedades
La proxima proposicion establece una serie de propiedades de la integral, tanto en el plano como elespacio, cuya demostracion es analoga al cason= 1 y por tanto es omitida.
Proposicion 7.3.1.Sea D⊂Rn un conjunto acotado, sean f,g : D→R funciones integrables en D. Entonces
1. Siα ∈R, α f es integrable en D y ademas∫
Dα f = α
∫D
f .
2. Siϕ : Im( f )→ R es continua, entoncesϕ f es integrable en D.
3. Las funciones| f |, f k = f · f · · · f (k∈N), f +g, f g son integrables en D. Ademas
|∫
Df | ≤
∫D| f |,
∫D( f +g) =
∫D
f +∫
Dg.

178 Integrales multiples
4. Si D′ ⊂ Rn es otro conjunto acotado tal que µ(D∩D′) = 0, entonces si f es integrable en D∪D′, setiene ∫
D∪D′f =
∫D
f +∫
D′f .
Por ultimo una propiedad que usaremos de aquı en adelante:no es necesario tomar el ınfimo o el supremode f para calcular su integral de Riemann:
Teorema 7.3.2.Sea f: R⊂ Rn → R es integrable,Pi una particion de R y Ri ∈ Pi un punto cualquieraen el rectangulo Ri . Entonces
∫R f se puede calcular como lımite de sumas
∑ f (Pi)µ(Ri),
en el sentido siguiente: al refinar la particion estas sumas tienden a la integral de f en R.
Demostracion. Simplemente hay que observar que, para cualquier particion P del rectanguloR, y cualquierrectanguloRi en la particionP, dado un puntoPi ∈ Ri se tiene
mi ≤ f (Pi)≤ Mi .
EntoncesI( f ,P)≤ ∑ f (Pi)µ(Ri)≤ S( f ,P),
y como las cantidades de los extremos tienden a la integral def enR, la cantidad del medio tambien.
7.3.1. Medida de una region y Teorema del valor medio
Recordemos que definimos la medida de una regionD ⊂ Rn como la integral (si existe) de la funcion 1.Es decir
µ(D) =
∫D
1.
Si existe, en el plano esta cuenta nos devuelve la superficie de la regionD, mientras que en el espacio nosdevuelve el volumen de la regionD. ¿Podemos dar condiciones para que este numero exista? Sı, es sencilloa partir de lo ya hecho, pues la funcion 1 es continua, y por lotanto se tiene el siguiente resultado:
Teorema 7.3.3. Sea D⊂ Rn compacto, f: D → R continua, y supongamos que∂D esta formado poruna union finita de graficos de funcionesϕ : Ki ⊂ Rn−1 → R continuas, con Ki compactos. Entonces f esintegrable en D, y ademas
∫D f se puede calcular con n integrales iteradas.
En particular D es medible y
µ(D) =
∫D
1= sup ∑∪Ri⊂D
µ(Ri) = ınf ∑D⊂∪R∗
j
µ(R∗j ).

7.3 Propiedades 179
Demostracion. Lo unico nuevo son las ultimas igualdades que danµ(D). Son consecuencia del siguientehecho: para calcular
∫D 1 tomamos un rectanguloR que contenga aD, extendemos a la funcion como cero
enR−D. Es decir,f = 1 enD y f = 0 enR−D.Ahora particionamosR= ∪Ri . Si Ri es un rectangulo ınte-gramente contenido enD (como el que indicamos conR1 enla figura), entonces allı la integral inferior def vale siempre1, por lo tanto estos rectangulos aportan algo a la integral.Mientras que si el rectangulo toca el exterior deD (o sea noesta contenido enD, como los que senalamos comoR2 y R3
en la figura), entonces allı el ınfimo def es cero y estos noaportan nada a la integral inferior.
R
R1
R2
R3
D
En cambio para la integral superior aportan todos los rectanculos que tocanD pues en ellos el supremode f es 1.
Observacion 7.3.4.El teorema previo generaliza una idea que para intervalos I⊂R es mucho mas sencilla.Por ejemplo si I= [0,1], uno puede obtener la medida del intervalo aproximandolo por dentro con intervalosde la pinta[1
n,1− 1n]. O bien por fuera con intervalos de la pinta[− 1
n,1+1n].
Podemos relacionar la integral de cualquier funcion continua conµ(D) mediante el siguiente Teoremadel Valor Medio Integral:
Teorema 7.3.5.Sea D⊂ Rn compacto, f: D → R continua, y supongamos que∂D esta formado por unaunion finita de graficos de funcionesϕ : Ki ⊂ Rn−1 → R continuas, con Ki compactos. Entonces
1. Si M= max( f ) en D y m= mın( f ) en D, entonces
mµ(D)≤∫
Df ≤ Mµ(D).
2. Si D es arcoconexo entonces existe X0 ∈ D tal que
f (X0)µ(D) =
∫D
f .
Demostracion. 1. Se deduce de la definicion de integral, pues para cualquier particionP suficientementefina, si consideramos a los rectangulos que estan dentro deD se tiene
m ∑Ri⊂D
µ(Ri)≤ ∑Ri⊂D
mi( f )µ(Ri)≤ I( f ,P)≤ I∗( f ) =∫
Df .
Refinando la particion se tiene que∑Ri⊂D
µ(Ri)→ µ(D) y entonces
mµ(D)≤∫
Df .
Con un argumento similar, pero ahora usando los rectangulos dentro deD mas los que cubren el borde deDse tiene
Mµ(D)≥ I∗( f ) =∫
Df .

180 Integrales multiples
Se deduce lo enunciado juntando las ultimas dos desigualdades.
2. Siµ(D) = 0 no hay nada que probar. Siµ(D) , 0, entonces dividiendo la desigualdad del item previoporµ(D) se deduce que
m≤ 1µ(D)
∫D
f ≤ M.
Como f es continua en un arcoconexo toma todos los valores intermedios entrem y M, en particular existeX0 donde
f (X0) =1
µ(D)
∫D
f .
Observacion 7.3.6. Atencion que elultimo enunciado es falso si el dominio no es arcoconexo. Porejemplosi D es la union de dos cuadrados disjuntos de lado1, y f vale−1 en uno de ellos y1 en el otro:
C C′
Entonces ∫ ∫D
f =∫ ∫
Cf +
∫ ∫C′
f = 1 ·1+(−1) ·1= 0,
mientras que f no se anula en D.
7.4. NOTAS
I. El Teorema de Fubini que enunciamos es una version mas d´ebil del que sigue en esta nota. La diferencia esta enque en realidad, no es necesario suponer que cadafx, fy es integrable. SiR= [a,b]× [c,d] es un rectangulo enR2,y f : R→R es una funcion integrable enR, usamos la notacionfx(y) = f (x,y) = fy(x) como antes. Tomamos
I (x) = I∗( fx) = supI( fx,P) : P particion de[c,d],
S(x) = I∗( fx) = ınfS( fx,P) : P particion de[c,d].Entonces (sin ninguna hipotesis sobre lasfx o las fy), vale queI ,S son funciones integrables en[a,b] y ademas
∫R
f =∫ b
aS(x)dx=
∫ b
aI (x)dx.
Vale el resultado analogo parafy.
Para la demostracion, consideremos una particionP del rectangulo, donde∆i = [xi ,xi+1] es una particion de[a,b] y∆′j = [y j ,y j+1] es una particion de[c,d], de manera que los rectangulosRi j =∆i ×∆
′j de area(xi+1−xi)(yi+1−yi)
forman la particionP del rectangulo original. Como antes, abusamos un poquito de la notacion y usamos∆ paradenotar al intervalo y a su longitud. Entonces
I( f ,P) =∑i, j
mi j ( f )∆i∆′j =∑
i(∑
jmi j ( f )∆′
j )∆i ,

7.4 NOTAS 181
dondemi j ( f ) indica el ınfimo def enRi j . Si x∈ Ri j , entoncesmj ( fx) (el ınfimo defx en∆′j ) es mayor o igual que
el ınfimo def enRi j , puesmj( fx) = ınf f (x,y) : x fijo ,y∈ ∆
′j,
y el ınfimo en un subconjunto -en este casox×∆′j - siempre es mayor o igual que el ınfimo en el conjunto original
-en este caso∆i ×∆′j . Se deduce que, cualquiera seax∈ ∆i ,
∑j
mi j ( f )∆′j ≤ ∑
jmj( fx)∆
′j ≤ I∗( fx) = I (x).
Si en el extremo derecho tomamos el ınfimo parax∈ ∆i - que anotamosmi(I )-, multiplicamos por∆i y sumamos,se deduce que
I( f ,P) =∑i(∑
jmi j ( f )∆′
j )∆i ≤ ∑i
mi(I )∆i ≤ I∗(I ),
es decirI( f ,P)≤ I∗(I ). Con un razonamiento analogo se deduce queI∗(S) ≤ S( f ,P). Luego, comoI (x) ≤ S(x)para todox ∈ [a,b], tambien se tiene la desigualdadI∗(I ) ≤ I∗(S). Juntando estas desigualdades se obtiene lacadena
I( f ,P)≤ I∗(I )≤ I∗(I )≤ I∗(S)≤ S( f ,P).
Como f es integrable, los extremos se pueden hacer tan proximos como queramos refinando la particionP, y enconsecuencia debe ser ∫
Rf = I∗(I ) = I∗(I ) =
∫ b
aI ,
lo que prueba queI es integrable en[a,b], con integral igual a la integral doble def .
La prueba para la integral deSes identica y la omitimos, lo mismo vale para las afirmaciones respecto defy.

182 Integrales multiples

Si yo estuviera comenzando mis estudiosnuevamente, seguirıa el consejo de Platon ycomenzarıa por las matematicas.
Galileo Galilei
8.1. El metodo de sustitucion
Nuestro objetivo para terminar con estas notas es entender como funciona el teorema de cambio devariables en dimensiones 2 y 3, teorema que generaliza la idea del metodo de sustitucion para integrales enR.
Recordemos que sif es una funcion continua en un intervalo cerradoI ⊂ R, y g es una funcionC1
en [a,b] tal que se puede hacer la composicionf g en [a,b], entoncesh(x) = f (g(x))g′(x) es una funcionintegrable y ademas ∫ b
af (g(x))g′(x)dx=
∫ g(b)
g(a)f (u)du. (8.1)
En efecto, siF es una primitiva def , es decirF ′(t) = f (t) para todot en el intervaloI , entonces se che-quea facilmente (derivando) queH(x) = F(g(x)) es una primitiva def (g(x))g′(x). Si aplicamos el TeoremaFundamental del Calculo Integral a la funcionf en el intervalo con extemosg(a),g(b), obtenemos
F(g(b))−F(g(a)) =∫ g(b)
g(a)f (u)du
puesto queF es primitiva def . Por otro lado, aplicando el mismo teorema a la funcionH ′ en el intervalo[a,b] obtenemos
F(g(b))−F(g(a)) = H(b)−H(a) =∫ b
af (g(x))g′(x)dx,
lo que prueba la igualdad (8.1).
8.2. Particiones generales
Empecemos por una consideracion general que no demostraremos con gran detalle, pero que es razonabley permite simplificar los razonamientos que seguiran. Paracalcular integrales dobles, dado un dominio

184 Teorema de cambio de variables
D ⊂ R2 con una frontera buena, lo que hacemos es subdividir el dominio en rectangulos, de lados paralelosa los ejes. Mientras mas pequenos sean los rectangulos, mejor es la aproximacion del dominio, y una integralla pensamos como lımite de las sumas
lım∑ f (Pi)µ(Ri)
dondePi ∈ Ri . En particular, el area deD se calcula sumando las areas de los rectangulos. Sin embargo,la eleccion de estas figuras (rectangulos de lados paralelos a los ejes) es en cierta medida arbitraria. Esconsecuencia de que el area de un rectangulo es facil de calcular. Pero esto ultimo tambien es cierto paramuchas otras figuras, y nada impide calcular integrales usando estas figuras, es decir, enmarcando al dominioD con estas figuras, particionandolo y calculando las sumas como arriba, y luego tomando el lımite al refinarla particion. Un caso concreto es el siguiente: podemos tomar paralelogramos, es decir, figuras de ladosparalelos dos a dos, y hacer una particion deD como indica la figura:
D
Puede probarse que existe la integral def enD usando rectangulos comunes si y solo si existe la integralusando estos paralelogramos. La idea de por que funciona esto es la siguiente: dado un rectanguloR delados paralelos a los ejes, puede tomarse una particion delmismo usando paralelogramos, que aproximetanto como uno quiera al rectanguloR.
R
Recıprocamente, dado un para-lelogramoR′, se lo puede apro-ximar tanto como uno quierausando rectangulos de lados pa-ralelos a los ejes.
R′
Vamos a usar este hecho: sif es integrable enD, entonces su integral se puede calcular como
∫ ∫D
f = lım∑ f (Pi)µ(R′i)
dondeR′i es una familia de paralelogramos que aproxima la regionD, y Pi ∈ R′
i .

8.3 Transformaciones lineales 185
8.3. Transformaciones lineales
Observemos primero que ocurre en el plano, con una transformacion linealT : R2 → R2 inversible.Dados dos vectores linealmente independientes, estos van aparar porT a otros dos vectores linealmenteindependientes. Y entonces todo rectangulo (o mejor dicho, todo paralelogramo) va a parar a otro paralelo-gramo. Veamos la relacion entre las areas deR∗ y R= T(R∗), razonando primero sobre un caso particular.
Dado un rectangulo de lados paralelos a los ejes, su area secalcula comobase por altura,µ(R∗) = AB. Podemos suponer que el rectangulo tieneuno de sus vertices en el origen, como indica la figura de abajo, pues unatraslacion no modifica su area. Es decir, los lados miden exactamenteAy B.
R∗
x(A,0)
(0,B)
y
Si la transformacion linealT esta dada por la matriz
(
a bc d
)
en la base canonica, entonces se tiene
T(A,0) = T(A(1,0)) = AT(1,0) = A(a,c) = (Aa,Ac)
mientras queT(0,B) = BT(0,1) = B(b,d) = (Bb,Bd).
Entonces nuestro rectanguloR∗ va a parar al paralelogramoR= T(R∗) que esta generado porT(A,0) yT(0,B).
Ahora recordemos que dados dos vectoresv,w ∈R3, el area del parelelogramo determinado porv,wse puede calcular como la norma del producto vec-torial entrev y w, es decirarea= ‖v×w‖. To-memos entonces el paralelogramo imagen, peropensado en el planoxy enR3 como indica la fi-gura de la derecha. Los vectores son simplementev= (Aa,Ac,0), w= (Bb,Bd,0).
x
z
v=(T(A,0),0)
w=(T(0,B),0)
y
El area deR= T(R∗) es entonces
‖v×w‖= ‖det
∣
∣
∣
∣
∣
∣
i j kAa Ac 0Bb Bd 0
∣
∣
∣
∣
∣
∣
‖= ‖(0,0,AaBd−AcBb)‖= |AB||ad−bc|= µ(R∗)|detT|.
Hemos descubierto el siguiente hecho fundamental:
Proposicion 8.3.1. Si T : R2 → R2 es una transformacion lineal inversible, y R∗ es un rectangulo de ladosparalelos a los ejes, entonces elarea del paralelogramo R= T(R∗) que se obtiene como la imagen de R por

186 Teorema de cambio de variables
T esµ(R) = |detT|µ(R∗).
Pero entonces, dada cualquier figuraD∗ ⊂ R2 que sea medible, siD = T(D∗) indica la imagen deD∗
por una transformacion linealT inversible, podemos cubrirD∗ con rectangulosR∗i que aproximen la figura,
y ası estaremos llenandoD = T(D∗) con paralelogramosRi = T(R∗i ) que aproximan esa figura, como en el
dibujo:
D∗ D = T(D∗)T
R∗i
Ri
En consecuencia,µ(D) = µ(T(D∗)) = |detT|µ(D∗). En efecto,
µ(T(D∗)) = lım∑µ(Ri) = lım∑µ(T(R∗i )) = lım∑ |detT|µ(R∗
i ) = |detT|µ(D∗).
Esta misma idea se puede aplicar para calcular integrales. Observemos en la figura, que sif : R2 → R
esta definida enD = T(D∗), entoncesf T esta definida enD∗:
D∗ D = T(D∗)T
f
R
f T
Teorema 8.3.2(Cambio de variable, version lineal). Si D∗ ⊂R2, T : R2 →R2 es una transformacion linealinversible y f: D = T(D∗)→R es integrable, entonces
∫D
f =∫
D∗( f T) |detT|.
Demostracion. TomamosR∗i rectangulos que aproximenD∗, de manera queRi = T(R∗
i ) aproximenD =

8.4 Cambio de variable 187
T(D∗). Entonces, siPi ∈ Ri , se puede escribirPi = T(Qi) conQi ∈ R∗i , luego
∫T(D∗)
f = lım∑ f (Pi)µ(Ri) = lım∑( f T)(Qi)µ(T(R∗i ))
= lım∑ |detT|( f T)(Qi)µ(R∗i ) =
∫D∗( f T) |detT|.
Ejemplo 8.3.3. Supongamos sabido que elarea de un disco de radio R en el plano esπR2. Se quiere calcularel area de una elipse E de radios a,b> 0 dada por la parte interna de la curva de ecuacion
(xa
)2+(y
b
)2= 1.
Si consideramos T(x,y) = (ax,by), es una transformacion lineal cuya matriz es simplemente
T =
(
a 00 b
)
.
Como a,b, 0, T es inversible y en particular|detT|= |ab|= ab. Observemos que la circunferencia unitariaD∗ = x2+ y2 ≤ 1 va a parar a E si le aplicamos T :
D∗ E = T(D∗)T
Entonces
µ(E) =∫
E1=
∫T(D∗)
1=
∫D∗
1|detT|= µ(D∗)|detT|= πab.
8.4. Cambio de variable
Obsevemos la analogıa en la formula del Teorema8.3.2con la formula (8.1), que representa el caso deuna variable:|detT| juega el papel deg′. Por ahora este teorema tiene utilidad limitada. Lo que queremos esextender el resultado a funciones inyectivas cuya diferencial sea inversible salvo un conjunto muy pequeno(de medida nula). Es decir, dado un dominioD∗ y una funcionT : R2 → R2 inyectiva, queremos hallarprimero la relacion entreµ(D∗) y µ(T(D∗)) = µ(D),

188 Teorema de cambio de variables
D∗ D = T(D∗)T
f
R
f T∫ ∫D∗ f T
∫ ∫D=T(D∗) f
y luego ver cual es la relacion entre la integral def en un dominio y la def T en el otro.
Si T es inyectiva, el dominioD = T(D∗) se puede pensar cubierto con las imagenes de los rectangulosque cubrenD∗, es decir si∪R∗
i aproximanD∗ entonces∪T(R∗i ) aproximanD = T(D∗). ¿Como calcular
la medida de cadaT(R∗i )? En principio es un problema difıcil, ya queT no es lineal y cadaRi = T(R∗
i )esta deformado como indica la figura:
R∗i
Ri = T(R∗i )T
La idea ahora es la siguiente. Podemos escribir, dadoPi ∈R2, una expresion aproximada
T(X) = T(Pi)+DT(Pi)X+O(X),
dondeO(X) es simplemente ”lo que falta despues del termino lineal”.Esta afirmacion es imprecisa y luegoharemos una demostracion formal, pero por ahora pensemos que T se puede escribir ası. Tenemos comohipotesis queDT es inversible, salvo tal vez un conjunto de medida nula. Entonces podemos imaginarque, como el primer termino es solo un desplazamiento por un vector fijoT(Pi) ∈ R2, que no modifica elarea, mientras queO(X) es suficientemente pequeno, y no aporta nada sustancial al ´area, entonces para unrectangulo pequenoR∗
i con vertice enPi ,
µ(T(R∗i ))≈ µ(DT(Pi)R
∗i ) = |detDT(Pi)|µ(R∗
i ).
Siguiendo con esta lınea de pensamiento, se tendrıa para un dominioD∗ y un conjunto de rectangulosR∗i
que aproximenD∗,
µ(T(D∗)) = lım∑µ(T(R∗i ))≈ lım∑µ(DT(Pi)R
∗i )
= lım∑ |detDT(Pi)|µ(R∗i ) =
∫D∗
|detDT|,
es decirµ(D) = µ(T(D∗)) =
∫D∗
|detDT|.
Mientras que sif : D = T(D∗)→ R es integrable, con un razonamiento analogo tambien se tendrıa∫
Df =
∫T(D∗)
f =∫
D∗( f T)|detDT|.

8.4 Cambio de variable 189
Vamos a llamar aJT = |detDT| el determinante Jacobianode la funcionT.
Antes de pasar a una demostracion veamos unos ejemplos paraver como se usa este resultado, conocidocomoteorema de cambio de variable.
Ejemplo 8.4.1. Una transformacion que se usa frecuentemente es la dada por el cambio de coordenadaspolares, donde
T(r,θ) = (r cos(θ), r sen(θ)).
En este caso se tiene
DT =
(
cos(θ) −r sen(θ)sen(θ) r cos(θ)
)
,
con lo cual JT= r cos2(θ)+ r sen2(θ) = r.
1. Calculamos elarea del disco BR de radio R> 0. Se tiene que, si0 ≤ θ < 2π y 0 ≤ r < R, entoncesT(r,θ) recorre la circunferencia. Esto es D∗ = [0,R]× [0,2π] mientras que T(D∗) = BR. En conse-cuencia,
µ(BR) =
∫ 2π
0
∫ R
0rdrdθ = 2π
12
r2|R0 = πR2.
2. Se quiere integrar la funcion
f (x,y) =xy
(x2+ y2)52
en la region anular A de arcoπ/4 entre R1 y R2 segunindica la figura de la derecha. Luego
D∗ = [R1,R2]× [0,π4],
mientras que T(D∗) = A, con lo cual
A
x
y
R1
R2
∫ ∫A
f =
∫ ∫D∗( f T)JT =
∫ π4
0
∫ R2
R1
r cos(θ)r sen(θ)r5 rdrdθ
=
∫ π4
0cos(θ)sen(θ)dθ
∫ R2
R1
1r2 dr =
12
sen2(θ)|π40 (−
1r)|R2
R1
= −12
12(
1R2
− 1R1
) =R2−R1
4R1R2.
Pasemos ahora a la demostracion del teorema. La idea central esta extraıda del libro “Calculo en varie-dades”, de M. Spivak [9].

190 Teorema de cambio de variables
Teorema 8.4.2.Sea T: R2 →R2 inyectiva y C1. Sea D∗ ⊂R2 acotado y f: D = T(D∗)→R integrable. SiDT es inversible en D∗ y JT= |detDT|, entonces
∫D
f =∫
D∗( f T)JT.
Demostracion. Basta probar, dadoP∈ D∗, que existe un entorno deR∗ deP donde vale el teorema es decir∫
T(R∗)f =
∫R∗( f T)JT.
En efecto, si esto es cierto entonces dividiendoD∗ en un conjunto finito de entornosR∗i donde vale el teorema,
y sumando las integrales, se tiene el resultado en el conjunto totalD∗.
La idea de la demostracion es descomponer a la funcionT como la composicion de dos funciones, cadauna moviendo una sola variable, y usar sustitucion en una variable en cada una de las funciones.
T = K H
H K
D∗
H(D∗)
D = T(D∗)
SeaP= (a,b) ∈ D∗, y T(x,y) = (t1(x,y), t2(x,y)) y supongamos primero queDT(P) = I2. En particular∇t1(P) = (1,0). Si ponemosH(x,y) = (t1(x,y),y), H es una funcionC1 y tambien se tieneDH(P) = I2,puesto que
DH =
(
∂t1∂x
∂t1∂y
0 1
)
.
Observemos queJH = |detDH|= | ∂t1∂x |=
∂t1∂x pues como esta derivada parcial vale uno enP, y es una funcion
continua puesT esC1, podemos suponer que estamos en un entorno donde es positiva. Es decir
JH =∂t1∂x
.
ComoDH(P) = I2, por el teorema de la funcion inversa existe un entornoU (que vamos a suponer que esun rectangulo abierto) deP dondeH es inversible. Ahora ponemos
K(x,y) = (x, t2(H−1(x,y)))

8.4 Cambio de variable 191
definida en un entorno deH(P). Reemplazando se ve queK H = (t1(x,y), t2(x,y)) = T. Observemos queDT = DKH DH, donde porDKH queremos decir la diferencial deK evaluada enH(X). Luego detDT =detDKH detDH, con lo cual
JT = JKH ·JH.
Tomemos un conjuntoW∗ ⊂U alrededor deP, y una funciong integrable allı. Podemos suponer queW∗ essuficientemente pequeno para que se pueda tomar un rectangulo R∗ = [a,b]× [c,d]⊂U que contengaW∗, yextendemosg como cero enR∗−W∗ como es habitual. Entonces por el Teorema de Fubini,
∫H(W∗)
g=∫[c,d]
∫Iv
g(u,v)dudv,
dondeIv es el intervalo dado por la imagen de[a,b] via g1(u,v) conv ∈ [c,d] fijo, segun indica la figura,puesH fija [c,d]:
x
y
c
d
v
Iv
H(R∗)
Ahora hacemos la sustitucionu= uv(x) = t1(x,v). Derivando respecto dex se tiene
du=∂t1∂x
(x,v)dx,
y cuandox recorre[a,b], u recorreIv. Entonces∫
Ivg(u,v)du=
∫[a,b]
g(t1(x,v),v)∂t1∂x
(x,v)dx,
con lo cual ∫H(W∗)
g=
∫[c,d]
∫[a,b]
g(t1(x,v),v)∂t1∂x
(x,v)dxdv=∫
W∗(gH)JH.
Con una cuenta analoga se tiene, para cualquier entorno abiertoV∗ deH(P) suficientemente pequeno,∫
K(V∗)f =
∫V∗( f K)JK.
Luego ∫T(R∗)
f =∫
KH(R∗)f =
∫H(R∗)
( f K)JK.
LLamandog= ( f K)JK y usando que∫
H(W∗) g=∫W∗(gH)JH se deduce que
∫H(R∗)
( f K)JK =
∫W∗
( f K H)JKH JH.

192 Teorema de cambio de variables
ComoDT(X) = DKH(X)DH(X), tomando determinante se tieneJKHJH = JT (donde conJKH queremosindicar al Jacobiano deK, evaluado enH), y juntando las ultimas dos ecuaciones se tiene
∫T(R∗)
f =∫
R∗( f T)JT.
Por ultimo, siDT(P) , I2, basta llamarA = DT(P) que es una transformacion lineal inversible, y lla-mandoT = A−1T, se tiene
∫T(R∗)
f =∫
AT(R∗)f =
∫T(R∗)
( f A)|detA|,
usando el resultado para transformaciones linealesA. Si aplicamos lo que probamos en el parrafo de arribaa la funcionT (que ahora verificaDT(P) = I2), se tiene entonces
∫T(R∗)
( f A)|detA|=∫
R∗( f AA−1T)JT|detA|=
∫R∗( f T)JT
puesJT = |det(A−1)||detT|= |detA|−1JT.
Terminemos esta seccion con un ejemplo sutil.
Ejemplo 8.4.3. Se quiere calcular el volumen encerrado bajo el cono z2 = x2 + y2 y sobre el piso z= 0,pero en el rectangulo R= [0,1]× [0,1] del primer cuadrante. En resumen, se quiere calcular
∫ ∫R
√
x2+ y2dxdy.
Presenta ciertas dificultades la integral en coordenadas cartesianas, luego hacemos el cambio de variablea coordenadas polares, es decir T(r,θ) = (r cosθ, r senθ). El integrando queda como
( f T)JT = rr = r2,
muy sencillo de integrar.
El problema es el dominio R. Tenemos que identificar el dominio D∗ da-do en coordenadas polares tal que T(D∗) = R. Para ello es convenientedibujar R y partirlo al medio por la diagonal, como en la figurade laderecha:
x
y
RT2
T1
Se tienen dos triangulos T1,T2 de igualarea, y por la forma del cono sabemos que el volumen lo podemoscalcular como
vol =∫ ∫
T1
f +∫ ∫
T2
f .

8.4 Cambio de variable 193
El tri angulo T1 esta determinado por las condiciones0 ≤ y ≤ x, 0 ≤ x ≤ 1. En coordenadas polares, seobserva que0≤ θ ≤ π
4 , mientras que para cadaθ fijo r se mueve entre cero y la recta vertical x= 1. Peroesta recta en coordenadas polares es rcos(θ) = 1, es decir
r =1
cos(θ).
Luego debe ser D∗1 el dominio en(r,θ) dado por las condiciones
0≤ r ≤ 1cos(θ)
, mientras que0≤ θ ≤ π4.
Se tiene entonces
12
vol =∫ ∫
T1
f =∫ ∫
T(D∗1)
f =∫ ∫
D∗1
( f T)JT =
∫ π4
0
∫ 1/cos(θ)
0r2drdθ.
Luego
12
vol =13
∫ π4
0
1cos3(θ)
dθ =13
12
(
sen(r)+ ln(sec(r)+ tan(t))cos2(r)cos2(r)
)
π40
=13
12(√
2+ ln(1+√
2)),
donde usamos una tabla para calcular la primitiva.
8.4.1. Cambio de variable enR3
Para el espacio, se tiene un resultado analogo. En primer lugar, no es difıcil probar que siR∗ es un parale-logramo solido enR3, y T es una transformacion lineal inversible, entoncesR= T(R∗) es otro paralelogramosolido y ademas
µ(R) = |detT|µ(R∗).
Con esto, se tiene un enunciado equivalente al del Teorema8.3.2, con una demostracion analoga:
Teorema 8.4.4. Si D∗ ⊂ R3 y T : R3 → R3 es una transformacion lineal inversible, entonces si D∗ esmedible, D= T(D∗) es medible y ademas
µ(D) = |detT|µ(D∗).
Finalmente, usando las mismas ideas que antes, toda funcion inyectivaT : R3 → R3 con diferencialinversible nos permite hacer un cambio de variable que transforma una integral enD∗ en una integral enD = T(D∗), de la siguiente manera.
Teorema 8.4.5.Sea T: R3 →R3 inyectiva y C1. Sea D∗ ⊂R3 acotado y f: D = T(D∗)→R integrable. SiDT es inversible en D∗ y JT= |detDT|, entonces
∫D
f =∫
D∗( f T)JT.

194 Teorema de cambio de variables
La demostracion usa las mismas ideas que el cason = 2 y la omitimos. El unico comentario a teneren cuenta es que ahora hay que descomponer aT como una aplicacion que primero mueve dos variablesy despues una, y usar el resultado que ya tenemos para dos variables. Es decir, es una demostracion porinduccion.
Para terminar este libro, calculamos integrales en algunosejemplos que ilustran el poder del teoremacombinado con los cambios de variables cilındricos y esfericos ¿Puede haber mejor manera de cerrar unapunte? Nos gusta creer que, como dijo el gran matematico ruso V. I. Arnold (1937-2010), la matematica esuna ciencia experimental, con un laboratorio muy facil de mantener.
Ejemplo 8.4.6. 1. Coordenadas cilındricas.La transformacion T esta dada por
T(r,θ,z) = (r cos(θ), r sen(θ),z).
Esto es x= r cos(θ), y= r sen(θ), z= z.
Es muy conveniente cuando la region D a integrar presenta simetrıa alrededor de un eje, el “eje derotacion”. En este caso alrededor del eje z, pero con pequenas modificaciones pueden considerarseotras rectas como eje de rotacion. Aquı
DT =
cos(θ) −r sen(θ) 0sen(θ) r cos(θ) 0
0 0 1
,
luego JT= |detT|= r. Esta transformacion manda un ladrillo vertical, en el espacio(r,θ,z) (de ladosr,2π,z0) en un cilindro vertical en el espacio(x,y,z) (de radio r y altura z0) como indica la figura:
x
y
z
z= z0
T(r,θ,z0)
θ r
r
Si fijamos la altura z= z0, la transformacion T(r,θ,z0) recorre una circunferencia horizontal de radior en la altura del plano z= z0, donde x e y se pueden calcular observando que en la figura, el vectorT(r,θ,z0) mirado en el piso tiene componentes
x= r cos(θ), y= r sen(θ).

8.4 Cambio de variable 195
El anguloθ se mide desde el eje x, en contra del reloj como si mirasemos el plano xy desde arriba. Elnumero r=
√
x2+ y2 nos da la distancia del punto(x,y,z) al punto(0,0,z), es decir, la distancia aleje z.
Aquı z esta libre, peroθ debe ser un numero entre[0,2π] para que sea una funcion inyectiva (sino es-tamos pasando dos veces por el mismoangulo), y r un numero positivo pues representa una distancia.
Es decir, si(r,θ,z) viven en[0,+∞]× [0,2π)×R, entonces T(r,θ,z) recorre todo el espacio en formainyectiva, con una salvedad: si r= 0, y z= z0 esta dado, cualquiera sea elanguloθ no nos moveremosdel punto(0,0,z0). Esto no es un problema pues r= 0 representa la recta del eje z, que es una regionque no tienen ningun volumen que pueda afectar el calculo de una integral.
a) Se quiere calcular el volumen delsolido de revolucion que se obtiene al girar elarea bajo elgrafico de una funcion f en el intervalo[a,b]. Se supone que f es positiva allı, de manera quese obtiene una figura solida:
x xa b
f (a) f (x)
El volumen es independiente de la posicion, ası que para aprovechar las coordenadas cilındricaspensamos a f como funcion de z, en el plano yz, es decir y= f (z) > 0 como indica la figura:
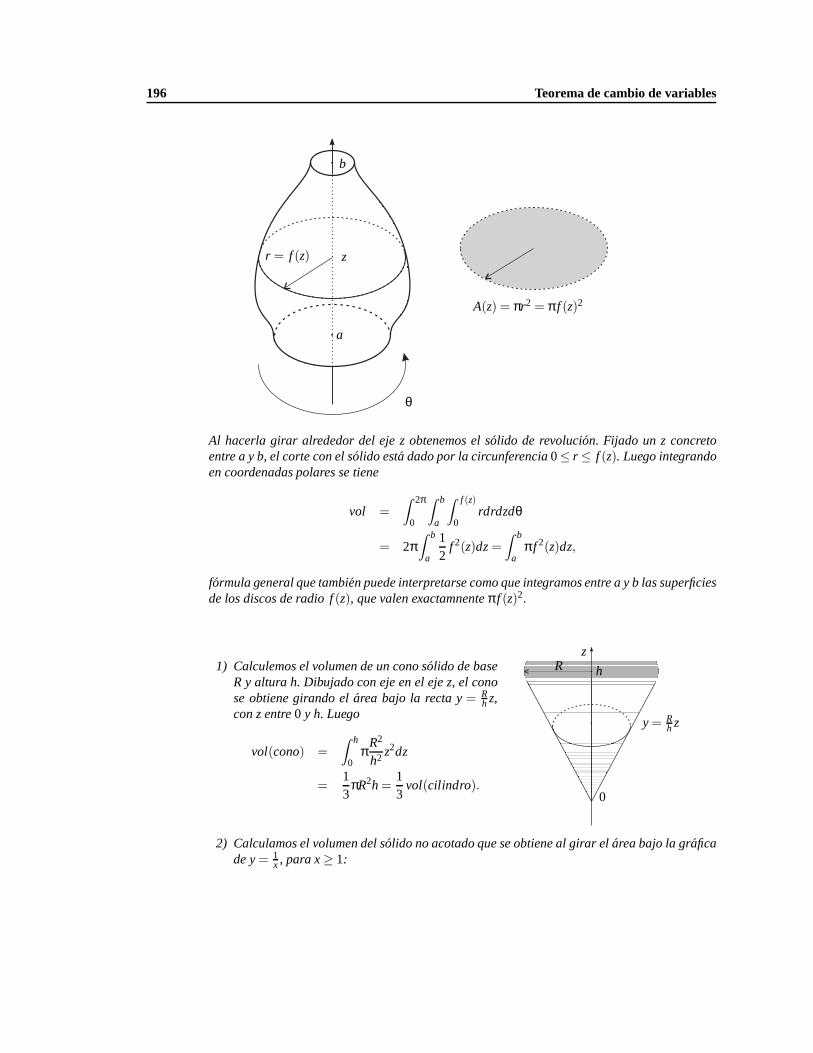
196 Teorema de cambio de variables
θ
z
a
b
r = f (z)
A(z) = πr2 = π f (z)2
Al hacerla girar alrededor del eje z obtenemos el solido de revolucion. Fijado un z concretoentre a y b, el corte con el solido esta dado por la circunferencia0≤ r ≤ f (z). Luego integrandoen coordenadas polares se tiene
vol =
∫ 2π
0
∫ b
a
∫ f (z)
0rdrdzdθ
= 2π∫ b
a
12
f 2(z)dz=∫ b
aπ f 2(z)dz,
formula general que tambien puede interpretarse como que integramos entre a y b las superficiesde los discos de radio f(z), que valen exactamnenteπ f (z)2.
1) Calculemos el volumen de un cono solido de baseR y altura h. Dibujado con eje en el eje z, el conose obtiene girando elarea bajo la recta y= R
h z,con z entre0 y h. Luego
vol(cono) =
∫ h
0π
R2
h2 z2dz
=13
πR2h=13
vol(cilindro).
z
h
0
R
y= Rh z
2) Calculamos el volumen del solido no acotado que se obtiene al girar elarea bajo la graficade y= 1
x , para x≥ 1:
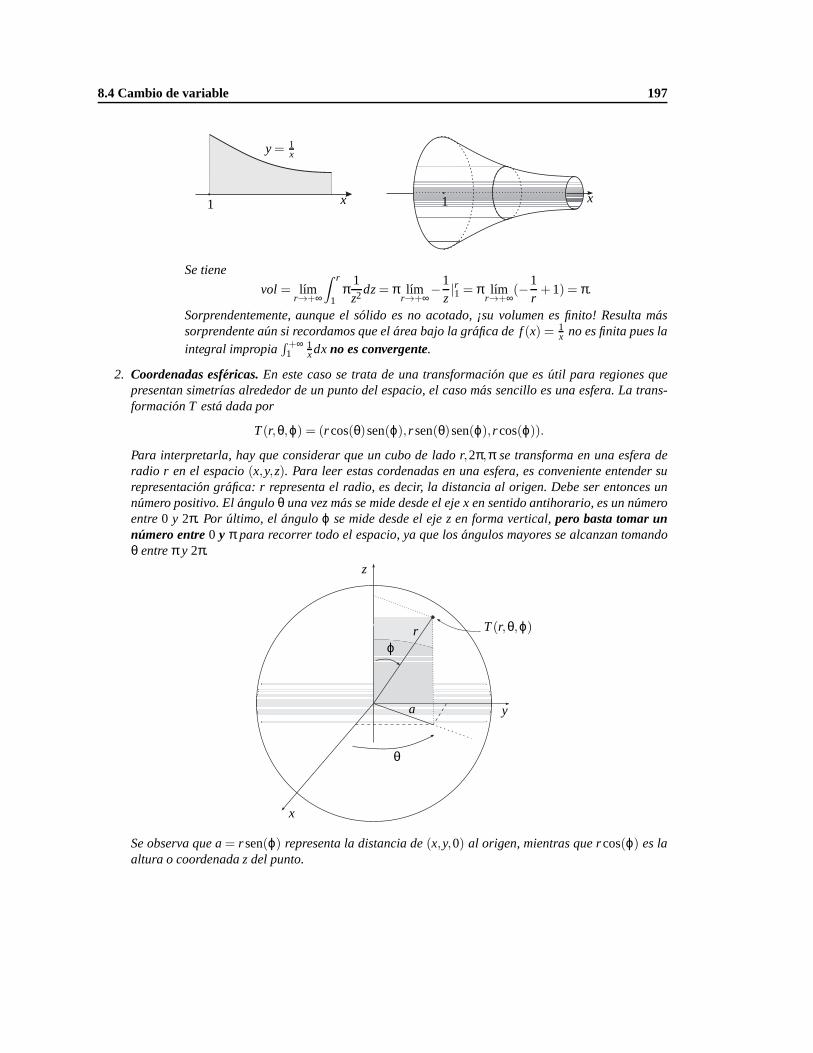
8.4 Cambio de variable 197
xx 11
y= 1x
Se tiene
vol = lımr→+∞
∫ r
1π
1z2dz= π lım
r→+∞−1
z|r1 = π lım
r→+∞(−1
r+1) = π.
Sorprendentemente, aunque el solido es no acotado, ¡su volumen es finito! Resulta massorprendente aun si recordamos que elarea bajo la grafica de f(x) = 1
x no es finita pues laintegral impropia
∫ +∞1
1xdxno es convergente.
2. Coordenadas esfericas.En este caso se trata de una transformacion que esutil para regiones quepresentan simetrıas alrededor de un punto del espacio, el caso mas sencillo es una esfera. La trans-formacion T esta dada por
T(r,θ,ϕ) = (r cos(θ)sen(ϕ), r sen(θ)sen(ϕ), r cos(ϕ)).
Para interpretarla, hay que considerar que un cubo de lado r,2π,π se transforma en una esfera deradio r en el espacio(x,y,z). Para leer estas cordenadas en una esfera, es conveniente entender surepresentacion grafica: r representa el radio, es decir, la distancia al origen. Debe ser entonces unnumero positivo. Elanguloθ una vez mas se mide desde el eje x en sentido antihorario, es un numeroentre0 y 2π. Por ultimo, el anguloϕ se mide desde el eje z en forma vertical,pero basta tomar unnumero entre0 y π para recorrer todo el espacio, ya que losangulos mayores se alcanzan tomandoθ entreπ y 2π.
z
x
y
r
a
ϕ
θ
T(r,θ,ϕ)
Se observa que a= r sen(ϕ) representa la distancia de(x,y,0) al origen, mientras que rcos(ϕ) es laaltura o coordenada z del punto.

198 Teorema de cambio de variables
La diferencial de T es la matriz
DT =
cos(θ)sen(ϕ) −r sen(θ)sen(ϕ) r cos(θ)cos(ϕ)sen(θ)sen(ϕ) r cos(θ)sen(ϕ) r sen(θ)cos(ϕ)
cos(ϕ) 0 −r sen(ϕ)
,
luego desarrolando por laultima fila se tiene
JT = |detT| =∣
∣cos(ϕ)[
−r2sen2(θ)sen(ϕ)cos(ϕ)− r2cos2(θ)cos(ϕ)sen(ϕ)]
−r sen(ϕ)[
r cos2(θ)sen2(ϕ)+ r sen2(θ)sen2(ϕ)]∣
∣
= |r2 cos2(ϕ)sen(ϕ)+ r2sen2(ϕ)sen(ϕ)|= |r2sen(ϕ)|.
Como en[0,π] el seno es positivo, se tiene
JT = r2sen(ϕ).
a) Para empezar, calculamos el volumen de una esfera de radio R.
vol(BR) =
∫ 2π
0
∫ π
0
∫ R
0r2sen(ϕ)drdϕdθ
= 2π13
R3∫ π
0sen(ϕ)dϕ =
23
πR3(−cos(ϕ)|π0) =43
πR3.
b) De acuerdo a las leyes del electromagnetismo, la cargatotal electrica QT de un objeto es simplemente la su-ma de las cargas puntuales. Al igual que en el caso dela masa, en el caso de un objeto solido D provisto deuna densidad de cargaρ, la carga total se consigue in-tegrandoρ en el solido D. Queremos calcular la car-ga total de una cascara esferica segun las restricciones0< R1 < r < R2, |z| ≤
√
x2+ y2 cuya densidad de cargaesρ(x,y,z) =
√
x2+ y2/(x2+y2+z2). La segunda ecua-cion es la de un cono, luego en el corte con el plano yz ve-remos la region anular encerrada por las rectas z=±y.
y
z
ϕ
R1
R2
Entonces, comoρ(r,θ,ϕ) =r senϕ
r2 =senϕ
r,
QT =∫ 2π
0
∫ 3π/4
π/4
∫ R2
R1
senϕr
r2 senϕdrdϕdθ
= 2π∫ 3π/4
π/4sen2 ϕdϕ
12(R2
2−R21) = π(R2
2−R21)(
π4+
12).
Ocurre aquı un fenomeno curioso. Observemos que la densidad de carga tiende a infinito cuandor → 0. Sin embargo las esferas de radio pequeno aportan poca carga total, con lo cual, haciendo

8.4 Cambio de variable 199
tender R1 → 0, se tiene
QT = πR22(
π4+
12)
que nos dice que la carga total es finita aun en el caso de que la region toque el origen.
En el juicio final, cuando me pidan justificar mivida, me levantare orgulloso y dire “Fui uno delos senescales de la matematica, y nosufrio ningun dano bajo mi cuidado”.
U. DUDLEY

200 Teorema de cambio de variables

[1] G. Birkhoff, S. MacLane,Algebra Moderna. Ed. Vicens Vives, Barcelona, 1963.
[2] R. Courant, J. Fritz,Introduccion al calculo y el analisis matematico. Vol. 1 y 2, Ed. Limusa-Wiley ,Mejico, 1998.
[3] S. Lang,Introduccion al algebra lineal. Ed. Addison-Wesley Iberoamericana, Argentina, 1990.
[4] J.E. Marsden, A.J. Tromba,Calculo vectorial. Ed. Addison-Wesley Iberoamericana, Argentina, 1991.
[5] R. J. Noriega,Calculo diferencial e integral. Ed. Docencia, Buenos Aires, 1987.
[6] J. Rey Pastor, P. Pi Calleja, C. Trejo,Analisis Matematico. Vol. I. Ed. Kapelusz, 1973.
[7] J. Rey Pastor, P. Pi Calleja, C. Trejo,Analisis Matematico. Vol. II. Ed. Kapelusz, 1973.
[8] M. Spivak,Calculo infinitesimal. Ed. Reverte, Barcelona, 1991.
[9] M. Spivak,Calculo en variedades. Ed. Reverte, Barcelona, 1970.










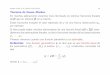











![Álgebra lineal y Cálculo en varias variablesmate.dm.uba.ar/~glaroton/Larotonda_ALyCVV-2021-web.pdf · como el de Stewart “Cálculo de varias variables” [6], o el texto del que](https://img.pdfslide.tips/doc/110x75/613a4aab0051793c8c00f58c/lgebra-lineal-y-clculo-en-varias-glarotonlarotondaalycvv-2021-webpdf-como.jpg)






