Embed Size (px)
Citation preview

RÉPUBLIQUE ALGÉRIENNE DÉMOCRATIQUE ET POPULAIRE
MINISTÈRE DE L'ENSEIGNEMENT SUPÉRIEUR
ET DE LA RECHERCHE SCIENTIFIQUE
UNIVERSITÉ IBN KHALDOUN - TIARET
FACULTÉ DES SCIENCES ET DES SCIENCES DE L’INGÉNIEUR
DÉPARTEMENT DE L’INFORMATIQUE
MÉMOIRE DE FIN D’ÉTUDES
POUR L’OBTENTION DU DIPLÔME
D'INGÉNIEUR D’ÉTAT EN INFORMATIQUE
OPTION : Systèmes d’informations avancés
Présenté par
Jaouaf Mohamed Amine
Mehenni Noureddine
THÈME
Dirigé par : Mr. Berber El-Mehdi
Année universitaire : 2009-2010
Génération automatique des requêtes de médiation dans un contexte relationnel

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 3
RemerciementRemerciementRemerciementRemerciementssss
Nous tenons à remercier toutes les personnes ayant contribué et facilité la
réalisation de ce travail dans de bonnes conditions.
Nous tenons à remercier plus particulièrement.
Monsieur Berber El-Mehdi qui nous a encadrés, Nous a orientés tout au
long de ce travail et nous a guidés avec ses conseils et ses critiques
bienveillants .
Nos remerciements s’adressent également au président et aux
membres de jury, qui nous ont fait le grand plaisir d’accepter de
juger ce travail.
Nous tenons à remercier l’ensemble des personnels du département de
l’informatique de l’université d’IBN KHALDOUN.

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 4
Dédicace
Je dédie ce modeste travailJe dédie ce modeste travailJe dédie ce modeste travailJe dédie ce modeste travail ::::
ÁÁÁÁ mon père qui sait sacrifier afin que rien ne m’empêche du bon déroulement de mes études.
Á Á Á Á ma mère qui n’a pas cessé de m’encourager et de me soutenir dans les moments difficiles.
Á Á Á Á tous mes frères, et sœurs.
ÁÁÁÁ toute la promotion sortante 5ème année informatique 2010.
[email protected] r Amine.

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 5
DédicaceDédicaceDédicaceDédicace
A mes très chers parents,
Pour leur soutien permanent et inépuisable,
Que Dieu les protège.
A mes frères et sœurs.
A tous la famille Younes.
Et à tous ceux qui me sont chers.
A mon collaborateur Amine qui m’a encouragé…
A tous mes amis et mes collègues.
Noureddine

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 6
Table des matiéres
Introduction générale .............................................................................................. 1
Chapitre I : Intégration des Données Hétérogènes : Etat de l’art
1. Introduction ............................................................................................................. 2
2. Systèmes d’intégration de données ............................................................................. 2
2.1 Définition et Composante ...................................................................................................... 3
2.2. Classification des systèmes d’intégration ............................................................................. 3
2.2.1 - Localisation de données intégrées. .................................................................................... 4
2.2.2. Mapping de données / Nature du mapping ......................................................................... 7
2.2.3. Processus d’intégration / Automaticité du mapping ........................................................... 8
2.2.4. Langages de représentation de données intégrées : ............................................................ 8
3. Système de médiation ................................................................................................ 8
3.1 Introduction : ......................................................................................................................... 8
3.2 Définition : ............................................................................................................................. 8
3.3 Problématique : ...................................................................................................................... 9
3.4 Objectifs : ............................................................................................................................ 10
Chapitre II :Java et Bases de données relationnelles
1. Introduction ........................................................................................................ 11
2. Java est un langage orienté objet ........................................................................... 11
3. Bases de données relationnelles ............................................................................. 11
3.1 Notion de base de données ............................................................................................. 11
3.1.1 Description générale .................................................................................................... 11
3.1.2 Base de données informatisée ...................................................................................... 11
3.2 Modèles des bases de données........................................................................................ 12
3.2.1 Modèle hiérarchique .................................................................................................... 12
3.2.2 Modèle réseau .............................................................................................................. 12
3.2.3 Modèle relationnel ....................................................................................................... 12
3.2.4 Modèle déductif ........................................................................................................... 12
3.2.5 Modèle objet................................................................................................................. 12
3.3 Système de gestion de base de données (SGBD) ........................................................... 12

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 7
3.4 Bases de données relationnelles: .................................................................................... 13
3.4.1 Le modèle relationnel................................................................................................... 13
3.4.2. Algèbre relationnelle ........................................................................................................ 14
3.4.3. Langage SQL..................................................................................................................... 14
4. Java et les bases de données relationnelles ............................................................. 16
4.1 JDBC et les architectures client serveur .............................................................................. 16
4.1.1 Architecture client-serveur 2/tiers ...................................................................................... 16
4.1.2 Architecture 3/tiers ............................................................................................................. 17
4.2 API JDBC ......................................................................................................................... 18
4.2.1 Structure générale ............................................................................................................... 18
4.2.2 Bibliothèques nécessaires ................................................................................................... 18
4.2.3 Charger un pilote en mémoire ............................................................................................ 18
4.2.4 Etablir une connexion ........................................................................................................ 20
4.2.5 Traitement des requêtes SQL ............................................................................................. 21
4.2.6 Gestion des transactions ..................................................................................................... 22
4.2.7 Fermeture de connexion ..................................................................................................... 22
4.2.8 Informations de la structure de la base de données............................................................ 23
5. Conclusion .......................................................................................................... 23
Chapitre III : Génération des requêtes de médiation 1. Introduction ........................................................................................................ 24
2. Métadonnées utilisées ........................................................................................... 25
2.1 Métadonnées au niveau des sources ................................................................................... 25
2.2 Métadonnées au niveau de la médiation ............................................................................ 25
2.3 Métadonnées entre la médiation et les sources ................................................................... 25
3. Recherche des relations de mapping ...................................................................... 26
3.1 Recherche des mapping étendus ..................................................................................... 26
3.2 Recherche des mapping de transition ............................................................................. 27
4. Recherche du graphe d’opération ......................................................................... 29
5. Recherche des chemins de calcul et définition des requêtes de médiation ................. 30
6. Prise en compte de l’hétérogénéité ........................................................................ 31
6.1 Les métadonnées utilisées .................................................................................................. 32

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 8
6.2 Exploitation des métadonnées ............................................................................................ 32
7. Conclusion .......................................................................................................... 34
Chapitre IV : Implémentation
1. Introduction ........................................................................................................ 35
2. Architecture générale ........................................................................................... 35
3. Description de la méta-base .................................................................................. 36
4 La description des différents modules ....................................................................... 37
4.1 La recherche des relations de mapping étendu ................................................................... 37
4.2 La recherche des relations de transition .............................................................................. 38
4.3. La recherche des opérations de jointures ......................................................................... 38
4.4 La recherche des chemins de calcul ................................................................................ 39
4.5 La recherche des requêtes de médiation ........................................................................... 40
5 Scénario de fonctionnement .................................................................................. 40
5.1 Administrateur ................................................................................................................ 40
5.1.1 Configuration des connexions aux bases de données ....................................................... 41
5.1.2 Fenêtre de création d’une relation de médiation ............................................................... 42
5.1.3 La configuration de la méta-base ...................................................................................... 42
5.1.4 Fenêtre de gestion des Comptes ....................................................................................... 43
5.2 Partie Utilisateur ............................................................................................................. 43
5.2.1 Fenêtre de génération des relations de mapping étendu .............................................. 44
5.2.2 Fenêtre de génération des relations de mapping transition ......................................... 44
5.2.3 Fenêtre de génération des opérations de jointure ........................................................ 45
5.2.4 Fenêtre Génération des chemins de calcul................................................................... 45
5.2.5 Fenêtre Génération des requêtes de médiation ............................................................ 46
6 Conclusion ........................................................................................................... 46
Conclusion et Perspectives ..................................................................................... 47
Bibliographie ........................................................................................................... 48
Glossaire .................................................................................................................. 49

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 9
Liste des figures Figure 1.1: Système d’intégration d’information……………………………………...…………….......3 Figure 1.2 : Architecture matérialisée vs architecture virtuelle…………………………………........….5 Figure 1.3 : Comparaison des architectures GAV et LAV………………………………….........……....7 Figure 1.4. Architecture d’un système de médiation…………………..……………………...…...……..9
Figure 2.1 : Architecture client-serveur 2/tiers………………………………………………….........…17
Figure 2.2 : Architecture client-serveur 3/tiers…………………………………………………........….17
Figure 2.3 : Fenêtre administrateur de source de données ODBC…………………………….……..…20
Figure 4.1 : Architecture du prototype de génération automatique des requêtes de médiation……..…35
Figure 4.2 : La description du Méta-Base …………………………………………………………....…37
Diagramme 1 : La recherche des relations de mapping étendu………………………………….....…...37
Diagramme 2 : La recherche des relations de transition………………………………………………...38
Diagramme 3 : La recherche des opérations de jointure…………………………………….……....…..39
Diagramme 4 : La recherche des chemins de calcul………………………………………..………...…39
Diagramme 5 : La génération des requêtes de médiation………………………………….…...…..…. 40
Figure 4.3 Interface Administrateur………………………………………………………………....…..40
Figure 4.4 Configuration de la méta-base…………………………………………………………....….41
Figure 4.5 Création d’une relation de médiation………………………………………………………...42
Figure 4.6 Configuration de la méta-base…………………………………………………………..........42
Figure 4.7 Gestion des comptes……………………………………………………………….….........…43
Figure 4.8 Fenêtre utilisateur……………………………………………………….………...….........….43
Figure 4.9 Fenêtre de mapping étendu ……………………………………………………….………….44
Figure 4.10 Fenêtre de mapping de transition …………………………………………………...............44
Figure 4.11 Fenêtre de génération des opérations de jointure …………………………………...…........45
Figure 4.12 Fenêtre de génération des chemins de calcul ……………………………………….............45 Figure 4.13 Fenêtre de génération des requêtes de médiation…………………………………….….....46

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 10
ــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــ
Introduction générale ــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــ

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 11
Introduction générale
1. Contexte
De nos jours, les systèmes multi-source sont de plus en plus développés.
Ils sont définis comme l’intégration de plusieurs sources hétérogènes et distribuées.
Parmi ces systèmes d’informations, nous distinguons les entrepôts de données, les systèmes
d’informations basés sur le web, les systèmes de bases de données fédérées, ou encore les
systèmes de médiation.
Notre travail se focalise principalement sur les systèmes de médiation dans un contexte
relationnel. Il s’agit d’automatiser la génération de requêtes de médiation calculant une relation
du schéma global à partir d’un ensemble de sources de données.
2. Organisation du mémoire
Ce mémoire est organisé autour de quatre chapitres :
Le chapitre I donne des généralités sur les systèmes d’intégration des Données.
Le chapitre II décrit les bases de données relationnelles et le langage Java.
Le chapitre III décrit les différentes étapes de génération des requêtes de médiation.
Le chapitre IV présente l’implémentation d’un prototype de génération automatique des requêtes
de médiation.

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 12
Chapitre I ــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــ
Intégration des Données Hétérogènes:
Etat de l’art ــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــ

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 13
1. Introduction
L’accès «transparent» aux ressources et de manière plus générale à l’information constitue
un des challenges actuels majeurs de l’informatique.
L’avènement du Web et des réseaux informatiques tout comme l’accroissement des données et
des services produits font que les utilisateurs finaux se trouvent confrontés à des problèmes de
localisation et d’accès à l’information pertinente qu’ils requièrent. L’hétérogénéité, la quantité, la
dispersion et la « volatilité » des ressources constituent autant de verrous que les systèmes
d’intégration doivent lever.
Les systèmes d’intégration de données permettent aux utilisateurs d’accéder, à travers un schéma
global unifié, à plusieurs sources de données ayant chacune un schéma local. Bien que les
systèmes actuels puissent surmonter la difficulté principale d’intégration qui est l’hétérogénéité
des sources (XML, HTML, fichiers plats, etc.), leur mise en œuvre pose un certain nombre de
problèmes, tant en ce qui concerne la génération des liens sémantiques entre le schéma de
médiation et les sources de données (requêtes de médiation) qu'en ce qui concerne l'adaptation de
l'accès aux besoins des utilisateurs ou la mesure de la qualité des données obtenues.
Ces problèmes sont d’autant plus cruciaux lorsque les sources sont nombreuses et hétérogènes.
Tout système d’intégration doit fournir les solutions aux problèmes suivants : (1) Comment
fournir une vue globale intégrée des données représentées à travers différentes conceptualisations
? (2) Comment identifier et spécifier le mapping entre des données sémantiquement liées? (3)
Comment mettre à jour les données de différentes bases étant donnée une telle vue globale
intégrée ? [BOUSSIS 08].
2. Systèmes d’intégration de données
Les systèmes d’intégration de données offrent des architectures d’interopérabilité sur une
fédération de sources de données distribuées, autonomes et hétérogènes. Les entrepôts de
données, les systèmes de médiation et les architectures P2P sont des exemples d’infrastructures
qui permettent l’intégration de données, c'est-a-dire l’accès à des données produites par des
sources autonomes. A travers des schémas virtuels, des métadonnées et des correspondances
sémantiques, ils permettent d’accéder à ces sources de données de façon uniforme et
transparente, en transformant, par réécriture, les requêtes d’un utilisateur en sous requêtes
envoyées aux sources de données les plus appropriées. L’hétérogénéité des données extraites des

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 14
sources nécessite leur réconciliation, en d’autres termes, leur mise en correspondance par rapport
au schéma global, avant de les présenter à l’utilisateur.
2.1 Définition et Composante
Un système d'intégration de données fournit une vue unifiée de données provenant de sources
multiples et hétérogènes. Il permet d'accéder à ces données à travers une interface uniforme, sans
se soucier de leur structure ni de leur localisation [BAR 03].
Un système d'intégration se compose de deux parties [RAH 05] (Voir figure 1.1):
- Une partie (1) externe et correspond aux utilisateurs du système intégré (décideurs) ou
autres systèmes.
- Une partie (2) interne et comprend des sources d’informations et une interface uniforme
qui permet à la partie externe d’interroger d'une manière transparente les sources de
données, comme s’il n’y avait qu’une source unique.
Figure 1.1: Système d’intégration d’information
2.2. Classification des systèmes d’intégration

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 15
Plusieurs approches et systèmes d’intégration ont été proposés dans la littérature, souvent
classifiés, à travers des critères différents, une vue générale est présentée dans [HUL 97].
[BOUSSIS 08] a proposé une classification des systèmes d’intégration de données en se basant
sur quatre critères orthogonaux :
2.2.1 - Localisation de données intégrées.
2.2.2 - Nature de correspondance (mapping).
2.2.3 - L’automaticité du processus d’intégration.
2.2.4 -Langages de représentation de données intégrées
2.2.1 - Localisation de données intégrées.
Ce critère spécifie si les données des sources locales sont dupliquées au niveau du système
intégré ou pas. Les données du système intégré peuvent être virtuelles : (architecture médiateur)
ou matérialisées : (architecture d’un entrepôt de données).
2.2.1.1. Systèmes Multibases
Les systèmes multibases sont des systèmes dits faiblement couplés. On les caractérise de
cette manière car ils n’offrent pas une vision unifiée des données. Il n’existe pas de schéma
global permettant un accès transparent aux différentes sources de données.
La coopération est seulement assurée par l’intermédiaire d’un langage commun : le langage
multibase de type SQL notamment.
2.2.1.2. Systèmes Fédérés
A l’inverse des systèmes multibases, les systèmes fédérés sont dits fortement couplés. Ils se
caractérisent par l’existence d’un schéma unifié appelé schéma fédéré qui constitue l’interface
d’accès au système intégré. L’intégration se situe au niveau des schémas.
2.2.1.3. Systèmes Médiateurs
L’approche d’intégration par médiation constitue, sans doute aujourd’hui, la solution la plus
courante pour relier différentes sources qui ne correspondent pas nécessairement à des bases de
données.

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 16
La notion de médiateur a été initialement proposée par [WIE92].Il définit un médiateur comme
suit: «A mediator is a software module that exploits encoded knowledge about some sets or
Subsets of data to create information for a higher layer of applications ». Un médiateur doit être
vu comme une couche logicielle permettant d’accéder, de manière transparente pour
l’utilisateur, à différentes ressources (Bases de données, fichiers) réparties et hétérogènes.
Pour cet accès, le médiateur exploite des connaissances (métadonnées) qui sont utiles à différents
services (interrogation, localisation des ressources notamment).
L’approche par médiation est fondée sur la définition de vues [ROU 02]. Les données ne sont
pas stockées dans le système de médiation mais résident dans leurs sources d’origine (comme
pour les systèmes fédérés). L’utilisateur a une vision unifiée des données sources :
l’interrogation se fait par l’intermédiaire d’un schéma global. Il n’a pas connaissance des
schémas locaux.
L’architecture générale d’un système de médiation est présentée en figure 1.2.
Une requête globale est posée via le schéma global et celle-ci est ensuite décomposée en sous
requêtes, traduites pour être exécutées sur les différentes sources concernées.
Le médiateur est chargé de localiser les données pertinentes pour répondre à la requête (en
utilisant les métadonnées).
L’interrogation effective des sources se fait par des adaptateurs (ou « wrappers ») qui
constituent une interface d’accès aux différentes sources.
Ces adaptateurs traduisent les sous requêtes exprimées dans le langage de requête spécifique de
chaque source. Les résultats sont ensuite renvoyés au médiateur qui se charge de les intégrer
avant de les présenter à l’utilisateur. Par analogie à l’architecture des systèmes fédérés, on peut
considérer que le schéma global du médiateur correspond au schéma fédéré et que l’adaptateur
inclut les schémas d’export et les schémas pivots.

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 17
Figure 1.2 : Architecture matérialisée vs architecture virtuelle.
Notre étude s’inscrit principalement dans le contexte des systèmes de médiation.
2.2.1.4. Entrepôts de Données
Un entrepôt de données (Data Warehouse) se définit comme « une collection de données
intégrées, orientées sujet, non volatiles, historiées, résumées et disponibles pour l’interrogation et
l’analyse ». Les entrepôts de données sont conçus dans un but bien particulier : rassembler
l’ensemble des informations d’une entreprise dans une base unique, pour faciliter l’analyse et la
prise de décision rapide.
2.2.1.5. Médiateurs / Entrepôt de données (Architecture Mixte/Hybride)
Avec le développement du Web et des technologies de l'information ces dernières années,
d'autres approches d'intégration, tels que les systèmes hybrides (Approche mixte), ont été
proposes. Ces systèmes combinent, à la fois, l’approche Médiateur et l’approche Entrepôt.
Il s’agit, par exemple, d’un système médiateur qui intègre plusieurs sources de données externes
et qui exploite un entrepôt de données contenant des données conformes au schéma global du
médiateur.
2.2.1.6. Systèmes P2P (Pair à Pair)

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 18
L'émergence de systèmes pair à pair (Peer-to-Peer) de partage de fichiers a conduit les
chercheurs à considérer l'architecture P2P dans le contexte de l'intégration et le partage de
données.
Les architectures pair à pair se présentent actuellement comme une solution viable pour
permettre le partage de ressources à l'échelle de l'Internet. En effet, aussi bien d'un point de vue
commercial que scientifique, les architectures pair à pair suscitent un véritable engouement.
Le paradigme du P2P garantit un fonctionnement à large échelle. Un très grand nombre de pairs
peut interagir dans le réseau, de manière à permettre le partage d’une grande quantité de
ressources. Aussi appelé d’égal à égal, chaque participant à un système P2P peut être à la fois
client et serveur. Le fonctionnement du système ne repose sur aucune coordination centralisée.
Ainsi, le comportement global du réseau résulte uniquement des interactions locales entre les
pairs qui se connectent et se déconnectent.
Les systèmes pair à pair sont caractérisés par quatre grands principes : 1- Auto organisation des
pairs, 2- Gestion décentralisée, 3- Tolérance aux pannes, 4- Autonomie des pairs.
2.2.2. Mapping de données / Nature du mapping
La méthode la plus ancienne pour définir un schéma intégré et la correspondance schéma
global/schémas locaux, consiste à utiliser le concept classique de "vue SQL" existante dans les
bases de données. GaV (Global-as-View), LaV (Local-as- View), GLaV (Generalized -Local-
as-View), BGLaV (Global-Local-as-View) et BaV (Bothas-View) représentent les méthodes de
mapping connues. GaV et LaV en sont les principales, GLaV , BGLaV et BaV sont des
approches mixtes.
Dans l'approche GAV, la transformation d'une requête sur le schéma global en requête sur le
schéma local est une simple opération faite par le gestionnaire de vues. Dans le cas d’une
approche LAV, la requête sur le schéma global doit être reformulée suivant les schémas des
sources locales. D'un autre coté, dans une architecture GAV, une modification sur l'ensemble
des sources locales ou sur leur schéma entraîne une reconsidération complète du schéma global.
Dans l'architecture LAV, chaque source est spécifiée de manière indépendante. Un changement
local de schéma est pris en compte en mettant à jour la vue locale. De plus, si les données des
sources locales n'ont pas le même format (relationnel, semi structuré . . .), il est difficile de
définir le schéma global comme vue des sources de différents formats. En utilisant une approche

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 19
LAV, chaque source peut être décrite séparément par un mécanisme de vue spécifique à son
format [GARD 05].
Figure 1.3 : Comparaison des architectures GAV et LAV
2.2.3. Processus d’intégration / Automaticité du mapping
Un troisième critère important permet de caractériser l’automaticité de génération du système
intégré. La notion de passage à l’échelle, étant, de plus en plus, un aspect essentiel, on peut
caractériser cette automaticité par l’automaticité d’intégration d’une nouvelle source
(éventuellement convenablement préparée) au sein d’un système intégré.
On peut distinguer plusieurs niveaux d’automaticité :
Manuel
Semi automatique
Automatique
2.2.4. Langages de représentation de données intégrées :
Selon ce quatrième critère, les systèmes d’intégration sont structurés en fonction du langage
de représentation des connaissances, exprimant le schéma global. En effet, un langage de
représentation de données doit permettre de représenter la sémantique, la structure des données
et des informations additionnelles (ontologies, requêtes).

Génération automatique des requêtes de médiation dans un contexte relationnel
________
3. Système de médiation
3.1 Introduction :
Parmi les systèmes d’intégration
systèmes de médiation.
3.2 Définition :
Un système de médiation est un système qui permet d’interopérer sur un ensemble de sources
hétérogènes et distribuées. Ses composants essentiels sont : le schéma global appelé schéma de
médiation, les mappings du schéma global avec les s
requêtes et les fonctions de composition des résultats. Les mappings du schéma global avec les
sources sont des requêtes, appelées requêtes de médiation, dont l’expression varie selon
l’approche choisie :
1) approche descendante (Global As View ou GAV)
défini par une requête sur les sources.
2) approche ascendante (Local As View ou LAV)
défini par une requête sur le schéma global.
La figure suivante illustre l’architecture d’un système de médiation :
Figure
Génération automatique des requêtes de médiation dans un contexte relationnel
________
3. Système de médiation
Parmi les systèmes d’intégration de données que nous avons présentés
Un système de médiation est un système qui permet d’interopérer sur un ensemble de sources
hétérogènes et distribuées. Ses composants essentiels sont : le schéma global appelé schéma de
médiation, les mappings du schéma global avec les sources, les fonctions de réécriture de
requêtes et les fonctions de composition des résultats. Les mappings du schéma global avec les
sources sont des requêtes, appelées requêtes de médiation, dont l’expression varie selon
(Global As View ou GAV) où chaque objet du schéma global est
défini par une requête sur les sources.
(Local As View ou LAV) où chaque objet d’une source de données est
défini par une requête sur le schéma global.
La figure suivante illustre l’architecture d’un système de médiation :
Figure 1.4. Architecture d’un système de médiation
Génération automatique des requêtes de médiation dans un contexte relationnel
20
s, nous distinguons les
Un système de médiation est un système qui permet d’interopérer sur un ensemble de sources
hétérogènes et distribuées. Ses composants essentiels sont : le schéma global appelé schéma de
ources, les fonctions de réécriture de
requêtes et les fonctions de composition des résultats. Les mappings du schéma global avec les
sources sont des requêtes, appelées requêtes de médiation, dont l’expression varie selon
où chaque objet du schéma global est
où chaque objet d’une source de données est
Architecture d’un système de médiation

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 21
3.3 Problématique :
Plusieurs problèmes de conception émergent lors de l’utilisation de ces médiateurs.
L’une des principales difficultés rencontrée dans un système de médiation est la définition du
schéma global et la définition des mapping (requêtes de médiation) qui relient le schéma global
aux sources de données.
L’écriture manuelle des requêtes de médiation donne, sans doute, le résultat le plus pertinent au
regard des besoins des utilisateurs. Cependant, il est difficile de l’entreprendre en raison du
grand nombre de sources de données qui peuvent être impliquées (des centaines ou des milliers)
et du volume important de méta-données les décrivant (description des schémas des sources et
du schéma global, assertions de correspondance linguistique, assertions intra-source et inter-
source, etc.).
La question principale est de savoir comment automatiser la génération de requêtes de
médiation ?
3.4 Objectifs :
Au vu des articles de recherche étudiés, deux catégories de travaux se distinguent. Celle qui
vise à interroger les sources de données distribuées et hétérogènes et à la définition de requêtes
de médiation, et celle qui vise à intégrer les données et à construire le schéma global.
Le travail mené dans ce mémoire est concerné par la première catégorie. A partir de la
description d’un ensemble de sources de données distribuées et hétérogènes et de méta-données,
Il s’agit de produire un ensemble de requêtes de médiation possibles. Un outil est développé,
permettant de générer, automatiquement, des requêtes de médiation dans un environnement

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 22
Chapitre II ــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــ
Java et Bases de données relationnelles
ــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــ

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 23
1. Introduction
Un médiateur est basé sur l'interaction avec un ou plusieurs systèmes de gestion de bases de
données (SGBD) ; dans notre contexte, il s’agit des systèmes de gestion de bases de données
relationnelles (SGBDR).
Java fournit un ensemble d'outils très flexibles pour l'accès aux SGBDR via des API. Les classes
de base de l'API sont incluses dans le package java.sql et sont distribuées dans le cadre du JDK
standard.
2. Java est un langage orienté objet
Java est un langage orienté objet développé par la société Sun. La syntaxe générale est très
proche de celle du C, mais Java n'est pas une surcouche du C et la syntaxe est beaucoup plus
claire que celle du C++.
Les avantages de Java sont nombreux. Le byte-code, tout d'abord, qui assure à Java une
portabilité complète vers de très nombreux systèmes. L'importance des API de base qui offre
tous les services de base, notamment pour la construction des interfaces graphiques. La 3ème
force de Java, c'est son adaptabilité dans de nombreux domaines, autant pour le web que pour les
systèmes embarqués.
3. Bases de données relationnelles [Dev09]
3.1 Notion de base de données
3.1.1 Description générale
Définition 1 -Base de données- Un ensemble organisé d’informations avec un objectif
commun.
3.1.2 Base de données informatisée
Définition 2 -Base de données informatisée- Une base de données informatisée est un
ensemble structuré de données enregistrées sur des supports accessibles par l’ordinateur,
représentant des informations du monde réel et pouvant être interrogées et mises à jour par une
communauté d’utilisateurs.

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 24
3.2 Modèles des bases de données
3.2.1 Modèle hiérarchique
Les données sont classées hiérarchiquement, selon une arborescence descendante. Ce modèle
utilise des pointeurs entre les différents enregistrements. Il s'agit du premier modèle de SGBD.
3.2.2 Modèle réseau
Comme le modèle hiérarchique, ce modèle utilise des pointeurs vers des enregistrements.
Toutefois la structure n'est plus forcément arborescente dans le sens descendant.
3.2.3 Modèle relationnel
Une base de données relationnelle est une base de données structurée suivant les principes de
l’algèbre relationnelle.
3.2.4 Modèle déductif
Les données sont représentées sous forme de tables, mais leur manipulation se fait par le
calcul de prédicats.
3.2.5 Modèle objet
Les données sont représentées sous forme d'objets, c'est-à-dire de structures appelées classes présentant
des données membres. Les champs sont des instances de ces classes.
3.3 Système de gestion de base de données (SGBD)
La gestion et l’accès à une base de données sont assurés par un ensemble de programmes qui
constituent le Système de gestion de base de données (SGBD). Un SGBD doit permettre l’ajout,
la modification et la recherche de données. Un système de gestion de bases de données héberge
généralement plusieurs bases de données, qui sont destinées à des logiciels ou des thématiques
différentes.
Actuellement, la plupart des SGBD fonctionnent selon un mode client/serveur. Le serveur (sous
entend la machine qui stocke les données) reçoit des requêtes de plusieurs clients et ceci de
manière concurrente. Le serveur analyse la requête, la traite et retourne le résultat au client. Le
modèle client/serveur est assez souvent implémenté au moyen de l’interface des sockets; le
réseau étant Internet.

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 25
3.4 Bases de données relationnelles:
3.4.1 Le modèle relationnel
Dans ce modèle, les données sont représentées par des tables, sans préjuger de la façon dont
les informations sont stockées dans la machine. Les tables constituent donc la structure logique
du modèle relationnel. Au niveau physique, le système est libre d’utiliser n’importe quelle
technique de stockage (fichiers séquentiels, indexage, adressage dispersé, séries de pointeurs,
compression, …) dès lors qu’il est possible de relier ces structures à des tables au niveau logique.
Les tables ne représentent donc qu’une abstraction de l’enregistrement physique des données en
mémoire.
Le succès du modèle relationnel auprès des chercheurs, concepteurs et utilisateurs est dû à la
puissance et à la simplicité de ses concepts. En outre, contrairement à certains autres modèles, il
repose sur des bases théoriques solides, notamment la théorie des ensembles et la logique des
prédicats du premier ordre.
Les objectifs du modèle relationnel sont de:
• proposer des schémas de données faciles à utiliser ;
• améliorer l’indépendance logique et physique ;
• mettre à la disposition des utilisateurs des langages de haut niveau ;
• optimiser les accès à la base de données ;
• améliorer l’intégrité et la confidentialité ;
• fournir une approche méthodologique dans la construction des schémas.
De façon informelle, on peut définir le modèle relationnel de la manière suivante :
• les données sont organisées sous forme de tables à deux dimensions, encore appelées
relations, dont les lignes sont appelées n-uplets ou tuples en anglais ;
• les données sont manipulées par des opérateurs de l’algèbre relationnelle ;
• l’état cohérent de la base est défini par un ensemble de contraintes d’intégrité.
Au modèle relationnel est associée la théorie de la normalisation des relations qui permet de se
débarrasser des incohérences au moment de la conception d’une base de données relationnelle.

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 26
3.4.2. Algèbre relationnelle
L’algèbre relationnelle est un support mathématique cohérent sur lequel repose le modèle
relationnel.
On peut distinguer trois familles d’opérateurs relationnels :
Les opérateurs unaires (Sélection, Projection) :
Ce sont les opérateurs les plus simples, ils permettent de produire une nouvelle table à
partir d’une autre table.
Les opérateurs binaires ensemblistes (Union, Intersection Différence) :
Ces opérateurs permettent de produire une nouvelle relation à partir de deux relations de
même degré et de même domaine.
Les opérateurs binaires ou n-aires (Produit cartésien, Jointure, Division) :
Ils permettent de produire une nouvelle table à partir de deux ou plusieurs autres tables.
3.4.3. Langage SQL
3.4.3.1 Introduction
Le langage SQL (Structured Query Language) peut être considéré comme le langage d’accès
normalisé aux bases de données. Il est aujourd’hui supporté par la plupart des produits
commerciaux, que ce soit par les systèmes de gestion de bases de données tels que Microsoft
Access ou par les produits plus professionnels tels que Oracle. Il a fait l’objet de plusieurs
normes ANSI/ISO dont la plus répandue aujourd’hui est la norme SQL2 qui a été définie en
1992.

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 27
3.4.3.2Catégories d’instructions
Les instructions SQL sont regroupées en catégories en fonction de leur utilité et des entités
manipulées. Nous pouvons distinguer cinq catégories, qui permettent :
1. la définition des éléments d’une base de données (tables, colonnes, clefs, index,
contraintes, …),
2. la manipulation des données (insertion, suppression, modification, extraction, …),
3. la gestion des droits d’accès aux données (acquisition et révocation des droits),
4. la gestion des transactions,
5. et enfin le SQL intégré.
3.4.3.2.1 Langage de définition de données
Le langage de définition de données (LDD, ou Data Definition Language, soit DDL en
anglais) est un langage orienté au niveau de la structure de la base de données. Le LDD permet
de créer, modifier, supprimer des objets. Il permet également de définir le domaine des données
(nombre, chaîne de caractères, date, booléen, …) et d’ajouter des contraintes de valeur sur les
données. Il permet enfin d’autoriser ou d’interdire l’accès aux données et d’activer ou de
désactiver l’audit pour un utilisateur donné.
Les instructions du LDD sont : CREATE, ALTER, DROP, AUDIT, NOAUDIT, ANALYZE,
RENAME, TRUNCATE.
3.4.3.2.2 Langage de manipulation de données
Le langage de manipulation de données (LMD, ou Data Manipulation Language, soit
DML en anglais) est l’ensemble des commandes concernant la manipulation des données dans
une base de données. Le LMD permet l’ajout, la suppression et la modification de lignes, la
visualisation du contenu des tables et leur verrouillage.
Les instructions du LMD sont : INSERT, UPDATE, DELETE, SELECT, EXPLAIN, PLAN,
LOCK TABLE.
Ces éléments doivent être validés par une transaction pour qu’ils soient pris en compte.

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 28
3.4.3.2.3 Langage de protections d’accès
Le langage de protections d’accès (ou Data Control Language, soit DCL en anglais) s’occupe de
gérer les droits d’accès aux tables.
Les instructions du DCL sont : GRANT, REVOKE.
3.4.3.2.4 Langage de contrôle de transaction
Le langage de contrôle de transaction (ou Transaction Control Language, soit TCL en anglais) gère
les modifications faites par le LMD, c’est-à-dire les caractéristiques des transactions et la validation et
l’annulation des modifications.
Les instructions du TCL sont : COMMIT, SAVEPOINT, ROLLBACK, SET TRANSACTION
3.4.3.2.5 SQL intégré
Le SQL intégré (Embedded SQL) permet d’utiliser SQL dans un langage de troisième
génération (C, Java, Cobol, etc.) :
• déclaration d’objets ou d’instructions ;
• exécution d’instructions ;
• gestion des variables et des curseurs ;
• traitement des erreurs.
Les instructions du SQL intégré sont : DECLARE, TYPE, DESCRIBE, VAR, CONNECT,
PREPARE, EXECUTE, OPEN, FETCH, CLOSE, WHENEVER.
4. Java et les bases de données relationnelles
Java nous propose le JDBC (Java DataBase Connectivity) qui est un API très efficace et très
flexible permettant de se connecter à diverses structures de stockage.
4.1 JDBC et les architectures client serveur
4.1.1 Architecture client-serveur 2/tiers
Dans une architecture client-serveur 2/tiers, un programme client accède directement à une
base de données sur une machine distante (le serveur) pour échanger des informations, via des
commandes SQL JDBC automatiquement traduite dans le langage de requête propre au SGBD.

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 29
Le principal avantage de ce type d’architecture est qu’en cas de changement de SGBD, il n’y a
qu’à mettre à jour ou changer le driver JDBC du coté client. Cependant, pour une grande
diffusion du client, cette architecture devient problématique, car une telle modification nécessite
la mise à jours de chaque client.
4.1.2 Architecture 3/tiers
Dans une architecture 3/tiers, un programme client n’accède pas directement à la base de
données, mais à un serveur d’application qui fait lui-même les accès à la base de données.
Il y a plusieurs avantages à cette architecture. Tout d’abord, il est possible de gérer plus
efficacement les connexions au niveau du serveur d’application et d’optimiser les traitements.
De plus, contrairement à l’architecture 2 /tiers, un changement de SGBD ne nécessite pas une
mise à jour des drivers sur tous les clients, mais seulement sur le serveur d’application.
Figure 2.1: Architecture client-serveur 2/tiers
Figure 2.2 : Architecture client-serveur 3/tiers

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 30
4.2 API JDBC [Oliv05]
4.2.1 Structure générale
Pour effectuer un traitement avec une base de données, il faut :
1. Charger un pilote en mémoire,
2. Etablir une connexion avec la base de données,
3. Récupérer les informations relatives à la connexion,
4. Exécuter des requêtes SQL et/ou des procédures stockées,
5. Récupérer les informations renvoyées par la base de données (si nécessaire),
6. Fermer la connexion,
4.2.2 Bibliothèques nécessaires
Pour instancier les objets nécessaires au dialogue avec une base de données, il faut
importer les bibliothèques suivantes :
• Java.sql.* ;
• Sun.jdbc.odbc.* ;
4.2.3 Charger un pilote en mémoire
4.2.3.1 Différents types de pilotes
Il existe quatre types de pilotes JDBC :
1. Type1 (JDBC-ODBC bridge) : le pont JDBC-ODBC qui s’utilise avec ODBC est un pilote
ODBC spécifique pour la base à accéder. Cette solution fonctionne très bien sous Windows.
C’est la solution idéale pour des développements avec exécution sous Windows d’une
application locale.
Cette solution « simple » pour le développement possède plusieurs inconvénients :

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 31
• La multiplication du nombre de couches rend l’architecture complexe (bien que transparentes
pour le développeur) et détériore les performances,
• Lors du déploiement, ODBC et son pilote doivent être installés sur tous les postes où
l’application va fonctionner,
• La partie native (ODBC et son pilote) rend l’application moins portable et dépendante d’une
plateforme.
2. Type 2 : un pilote écrit en java appelle l’API native à la base des données.
Ce type de pilote convertit les ordres JDBC pour appeler directement les APIs de la base de
données. Il est de ce fait nécessaire de fournir au client l’API native de la base de données.
ils sont généralement écrits en C ou en C++.
3. Type 3 : un pilote écrit en Java utilise un protocole réseau spécifique pour dialoguer avec un
serveur intermédiaire.
Ce type de pilote utilise un protocole réseau propriétaire spécifique à une base de données. Un
serveur dédié reçoit les messages par ce protocole et dialogue directement avec la base de données.
Ce type de driver peut être facilement utilisé par une applet, mais dans ce cas, le serveur
intermédiaire doit obligatoirement être installé sur la machine contenant le serveur Web.
4. Type 4 : un pilote Java natif.
Ce type de pilote, écrit en java, appelle directement le SGBD par le réseau. Ils sont fournis par
l'éditeur de la base de données. Ce type de driver est la solution idéale, tant au niveau de la
simplicité que des performances et du déploiement.
Liste de quelques pilotes :
• Pour une base Oracle : oracle.jdbc.driver.OracleDriver
• Pour une base Access : sun.jdbc.odbc.JdbcOdbcDriver
• Pour une base PostgreSQL : postgresql.Driver
• Pour une base MySQL : org.gjt.mm.mysql.Driver
4.2.3.2 Principe

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 32
Le pilote JDBC connaît les méthodes pour se connecter à une base de données, c’est
pourquoi celui-ci est essentiel.
Ce pilote est généralement disponible dans un package jar. Le chemin doit être ajouté à la
variable d’environnement CLASSPATH pour permettre au programme de l’utiliser.
La première étape est de charger le pilote en utilisant la méthode Class.forName(String driver).
Cette classe permet ainsi au programme de rester totalement indépendant de la base de données
utilisée en conservant le nom du pilote dans un fichier de propriétés.
La méthode Class.forName(String driver) peut lever une exception de type
ClassNotFoundException s’ il y a une erreur lors du chargement du driver.
Voici un exemple avec le pilote de Sun utilisé pour se connecter à une base de données via ODBC
(sun.jdbc.odbc.JdbcOdbcDriver) :
4.2.4 Etablir une connexion
4.2.4.1. Définir la base de données
En premier lieu, il faut définir la base de données.
Voici comment paramétrer une source de données ODBC :
1. Ouvrir le Panneau de configuration
2. Sélectionner l'Administrateur de source de données ODBC,
3. Cliquer sur l'onglet DSN Système,
4. Cliquer sur le bouton Ajouter,

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 33
5. Sélectionner dans la liste le pilote Microsoft Access driver (*.mdb), puis cliquer sur le
bouton Terminer.)
6. Indiquer un nom pour la source de données, une description.
7. Cliquer sur le bouton Sélectionner pour définir la localisation de la base, puis sur Ok, et
fermer la fenêtre de l'administrateur de source ODBC.
Le nom de la base de données étant celui déclaré dans le panneau de configuration ODBC, c'est-
à-dire le nom du DSN. La syntaxe de l'URL peut varier légèrement selon le type de la base de
données.
Il s'agit généralement d'une adresse de la forme:
4.2.4.2. Utilisation de l’interface Connection
La connexion à une base de données se fait par le biais de l’instanciation d’un objet de
l’interface Connection.
Elle représente une session de travail avec une base de données.
L’interface Connection utilise les méthodes getConnection(…) de la classe DriverManager
pour établir la connexion avec la base de données. Pour cela, on passe l’URL de la base de
données en paramètre à la méthode.
Figure 2.3 : Fenêtre administrateur de source de données ODBC

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 34
Les méthodes getConnection(…) peuvent lever une exception de la classe
java.sql.SQLException.
La création d'une connexion simple se fait grâce à la méthode suivante :
4.2.5 Traitement des requêtes SQL
Pour traiter une requête SQL, ils y a plusieurs objets capables d'envoyer celle-ci à la base de
données :
• Statement : objet utilisé pour l'exécution d'une requête SQL statique retournant les résultats
qu'elle produit.
• PreparedStatement : utilisé lorsqu'il est nécessaire d'exécuter une requête plusieurs fois,
avec des paramètres différents.
• CallableStatement : objet utilisé pour appeler une procédure stockée.
Des instances de ces objets sont disponibles grâce à l'instance de Connection.
4.2.6 Gestion des transactions
Il existe deux façons de gérer les transactions dans une application Java:
• Grâce à l'API JDBC, en local pour chaque client, avec les méthodes appropriées.
• Grâce à l'API JTA (Java Transaction API), partagée entre plusieurs clients.

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 35
4.2.7 Fermeture de connexion
Après toutes les actions effectuées sur la base de données, il faut fermer les instances qui
permettent la connexion à celle-ci.
Cette action est effectuée par l'appel de la fonction close () des objets Statement,
PreparedStatement , CallableStatement , Connection , ResultSet.
Exemple :
4.2.8 Informations de la structure de la base de données
4.2.8.1 Objet DatabaseMetaData
Il est aussi possible d'accéder aux informations de la structure de la base de données grâce à la
méthode de l'interface Connection :
4.2.8.2 Objet ResultSetMetaData
On peut facilement récupérer l'ensemble de la structure liée à une requête SQL.
Pour cela, il faut appeler la méthode : getMetaData() de l’objet ResultSet. Cette méthode
retourne un objet de type : ResultSetMetaData.
5. Conclusion
A travers ce chapitre, nous avons rappelé des notions classiques sur les bases de données
relationnelles, ainsi que l’API Java les manipulant. La plupart de ces concepts seront exploités
pour l’implémentation de l’outil de génération automatique des requêtes en Chapitre IV.

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 36
Chapitre III ــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــ
Génération automatique des requêtes de médiation
ــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــ

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 37
1. Introduction
Un des principaux problèmes rencontrés dans la conception d’un système de médiation est le
problème de définition de requêtes calculant une relation de médiation. En raison du grand
nombre de sources de données qui peuvent être impliquées (des centaines ou des milliers) et du
volume important de métadonnées les décrivant (description des schémas des sources et du
schéma global, assertions de correspondance linguistique, assertions intra-source, . . . etc.), il est
difficile d’envisager une écriture manuelle des requêtes de médiation. La question principale est
de savoir comment automatiser la génération de requêtes de médiation ?
En réponse à cette problématique, nous adoptons l’approche proposée par [SOUKANE 05] en
vue de la génération automatique de requêtes de médiation, pour le contexte relationnel.
Les schémas de médiation sont supposés, déjà définis, ainsi que l’ensemble de métadonnées.
On se place dans une approche GAV (Global As View) où chaque objet du schéma global est
défini par une requête sur les sources de données.
On peut résumer le processus de génération automatique de requêtes de médiation, calculant une
relation Rm du schéma de médiation, par les étapes suivantes :
1- Identification des relations sources pertinentes pour la définition d’une requêtes de
médiation Q du schéma de médiation, et génération des relation de mapping Ti qui sont
obtenues par la projection des relations sources sur leurs attributs communs avec la
relation Rm .
2- Identification des opérations relationnelles possibles entre les relations de mapping Ti en
fonction de leur schéma et de leurs clés, et génération du graphe d’opérations.
3- Recherche des chemins de calcul à partir du graphe d’opération pour calculer la relation
de médiation Rm.
4- Génération de requêtes de médiation déduites à partir des chemins de calcul de la relation
de médiation Rm.
Dans un premier temps, on suppose que nous sommes dans un environnement «semi
hétérogène», les conflits sémantiques liés à l’hétérogénéité des données sont supposés résolus.
Ensuite, dans le cas d’un environnement hétérogène, la notion de type étendu, pour chaque
attribut source, est introduite.

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 38
2. Méta données utilisées
Avoir une bonne connaissance du schéma global et de chaque schéma local est nécessaire
dans la définition de requêtes de médiation pour répondre, au mieux, aux besoins des utilisateurs.
Nous présentons l’ensemble de métadonnées exploitées par le processus de génération de
requêtes de médiation. Certaines de ces connaissances sont prédéfinies par le concepteur du
système de médiation telles que : la description des schémas de relations, les clés des relations,
les dépendances fonctionnelles, les contraintes référentielles entre relations, et d’autres sont
ajoutées dans la base de connaissances au fur et à mesure de leur découverte automatique, au
cours du processus de génération de requêtes de médiation telles que : les correspondances
linguistiques entre les concepts des sources et les concepts du schéma de médiation, et les
correspondances linguistiques entre les relations de sources différentes.
La base de connaissances notée A est constituée de trois catégories de métadonnées à savoir :
2.1 Métadonnées au niveau des sources
Les métadonnées définies au niveau des sources décrivent le schéma de chaque source de
données, l’ensemble des relations sources appartenant à chaque schéma source, les clés des
relations, les dépendances fonctionnelles éventuelles, les attributs de chaque relation, les
assertions intra-source et inter-source entre les relations.
2.2 Métadonnées au niveau de la médiation
Les métadonnées définies au niveau de la médiation caractérisent le schéma de médiation,
l’ensemble des relations de médiation appartenant à ce schéma de médiation, les clés des
relations, les dépendances fonctionnelles éventuelles, et les attributs de chaque relation.
- Un schéma de médiation est constitué d’un ensemble de relations de médiation.
- L’ensemble d’assertions définies sur une relation de médiation est composé, essentiellement, de
dépendances fonctionnelles qui relient l’attribut clé aux attributs non clés.
2.3 Métadonnées entre la médiation et les sources
Les métadonnées entre la médiation et les sources sont des correspondances linguistiques
reliant un attribut d’une relation de médiation à un attribut d’une relation source. En d’autres
termes, un attribut A d’une relation de médiation Rm est relié par une correspondance

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 39
linguistique à un attribut B d’une relation source Ri. Cette assertion est notée a = Rm.A Ri.B
où A et B sont deux attributs équivalents liés par une correspondance linguistique (synonymie,
abréviations, équivalence linguistique des noms).
Ces métadonnées permettent de résoudre les conflits sémantiques au niveau du schéma liés à
l’utilisation d’une terminologie différente pour designer deux concepts identiques. Par exemple,
l’attribut prix dans la relation de médiation Rm et l’attribut prix-produit dans la relation source Ri
sont reliés par une correspondance linguistique (équivalence des noms) sous la forme de
a = Rm.prix Ri.prix-veh pour désigner qu’il s’agit bien du même concept.
Ces métadonnées n’existent pas au préalable dans la base de connaissances, elles sont
recherchées, automatiquement, et ajoutées au fur et à mesure de leur découverte au cours du
processus de génération de requêtes de médiation.
3. Recherche des relations de mapping
3.1 Recherche des mapping étendus
La première étape de la génération de requêtes de médiation consiste à identifier les relations
sources pertinentes au calcul de la relation de médiation Rm, et à générer des relations de
mapping Ti qui sont obtenues par la projection des relations sources sur leur attributs communs
avec la relation Rm.
Pour une relation de médiation donnée Rm, la recherche des relations de mapping s’effectue en
considérant, successivement, les relations de chaque source de données. Pour chaque relation
source Ri, chaque attribut B de Ri est comparé aux attributs de la relation de médiation en se
basant sur les correspondances linguistiques définies entre un attribut d’une relation source et un
attribut d’une relation de médiation.
Lorsque l'ensemble des attributs communs noté E, entre la relation de médiation et la relation
source, est différent de l'ensemble vide, les clés primaires et étrangères sont recherchées en se
basant sur les dépendances fonctionnelles, les contraintes référentielles et sur les assertions inter-
source. Les relations obtenues sont alors appelées relations de mapping étendu.
L'ensemble des relations de mapping étendu associées à une relation de médiation sur l'ensemble
des sources S est noté Me. L'algorithme suivant illustre le principe de la recherche des relations de
mapping étendu.

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 40
3.2 Recherche des mapping de transition
Une fois les relations de mapping étendu Ti générées, le but est de trouver des
opérations relationnelles pour les combiner, lorsqu' il n'y pas d'attributs communs entre deux
relations de mapping étendu Ti et Tj, aucun opérateur relationnel ne peut leur être appliqué. Cela
revient donc à chercher en plus des relations de mapping étendu, une ou plusieurs relations dans
les sources pouvant être utilisés pour combiner les deux relations de mapping. Nous désignons
ces relations par des relations de transition.
La recherche des relations de mapping de transition pour une relation de médiation particulière
revient à chercher, pour chaque paire de relations de mapping étendu (Ti, Tj) entre lesquelles
aucune assertion n'est définie, s'il existe, parmi les assertions définies dans la base de méta-
connaissances A une séquence d'assertions permettant de lier la relation Ri(respectivement Rj) à
d'autres relations sources hormis les relations contributives. Ri et Rj sont les relations sources qui ont
conduit à dériver Ti et Tj.
La recherche des séquences d'assertions est effectuée par une procédure qui est appelée par
l'algorithme de recherche des transitions. Cette procédure prend en entrée les relations source Ri et
Rj et la base de connaissances A. Elle cherche, pour toute assertion a contenue dans la base A, s'il
existe un lien entre la relation d'origine Ri avec d'autres relations. S'il existe, la procédure concatène
l'assertion a identifiée à la séquence d'assertions courante notée SeqCourante, elle continue à
Algorithme 1 : Algorithme de recherche de mapping étendu

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 41
chercher des assertions jusqu'à ce qu'elle identifie une séquence d'assertions pertinente
permettant de lier la relation origine Ri à la relation cible Rj. RechercheSéquence est une procédure
complexe et récursive, elle cherche toutes les séquences possibles entre Ri et Rj.
Une fois les séquences d'assertions calculées, l'algorithme de recherche de transitions prend en
entrée les séquences d'assertions pertinentes contenues dans l'ensemble SéqTrouvée, il déduit, pour
chaque séquence pertinente, la (les) relation(s) de transition. Ces relations sont obtenues par la
projection des relations sources intermédiaires sur leurs attributs clés.
L'ensemble des relations de mapping de transition associées à une relation de médiation sur
l'ensemble des sources S est noté Mt.
Ci-dessous est donné le principe de l'algorithme de recherche de mapping de transition et le
principe de la procédure de recherche de séquence.
Algorithme 3 : procédure de recherche de séquence d’assertions
Algorithme 2 : Algorithme de recherche de mapping de transition

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 42
4. Recherche du graphe d’opération
Étant donné l'ensemble de relations de mapping étendu Me, et l'ensemble de relations de
mapping de transition Mt générés par la recherche des relations de mapping, le but de cette étape
est de trouver les opérations relationnelles susceptibles de combiner chaque paire de relations en
tenant compte des métadonnées.
La recherche de ces opérations est guidée par des règles d'intégration spécifiées sur les
connaissances. Ces règles d'intégration permettent, pour une relation de médiation
particulière, de déterminer l'ensemble des jointures candidates, et ce pour chaque paire de
relations de mapping. Une opération de jointure déterminée entre deux relations de mapping peut
combiner soit une relation de mapping étendu avec une autre relation de mapping étendu,
soit une relation de mapping étendu avec une relation de transition, ou encore une relation de
transition avec une autre relation de transition. L'ensemble de ces opérateurs est représenté par un
graphe d'opérations noté GRM où chaque nœud correspond à une relation de mapping, et chaque
arc entre deux nœuds correspond à une jointure candidate déterminée à l'aide d'une règle
d'intégration.
Règle 1 : Si les deux relations appartiennent à la même source et que leurs schémas ne sont pas
disjoints, et où l'une des relations référence l'autre, alors l'opération candidate est une jointure
naturelle déterminée par la règle suivante :
Règle 2 : Si les deux relations n'appartiennent pas à la même source de données, on ne pourra
pas disposer de contraintes référentielles auquel cas on utilisera la correspondance linguistique
entre deux attributs, où l'un des deux attributs est clé dans l'une ou l'autre des relations. Dans ce cas, la
règle d'intégration est la suivante :

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 43
Compte tenu de ces règles d’intégration, nous présentons ci-dessous le principe de l'algorithme de
recherche du graphe d’opération.
5. Recherche des chemins de calcul et définition des requêtes de médiation
Les règles d’intégration permettent, pour une relation de médiation et pour l’ensemble de
relations de mapping associées, de déterminer l’ensemble des opérations de jointures candidates,
et ce pour chaque paire de relations de mapping. L’ensemble de ces opérations est représenté
dans le graphe d’opérations décrit précédemment, où chaque nœud correspond à une relation de
mapping, et chaque arc entre deux nœuds correspond à un opérateur candidat déterminé à l’aide
d’une règle d’intégration.
La génération de requêtes de médiation se fait en recherchant des chemins de calcul dans le
graphe d’opérations GRM.
Un chemin de calcul CRM associé à la relation de médiation Rm est un sous-graphe connexe et
acyclique du graphe GRM où chaque attribut de la relation de médiation est équivalent à un
attribut figurant dans le sous-graphe. En d’autres termes, chaque attribut de la relation de
médiation figure dans au moins une des relations de mapping du sous graphe. Il peut arriver que
tous les attributs de Rm figurent tous dans une seule relation de mapping. Dans ce cas, le chemin
de calcul est constitué d’un seul nœud représentant une relation de mapping.
Algorithme 4 : Algorithme de recherche du graphe d’opérations

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 44
L’algorithme de recherche des chemins de calcul est un processus récursif complexe qui consiste
à chercher dans le graphe de jointures GRM tous les chemins possibles permettant de calculer la
relation de médiation Rm.
Il prend, en entrée, le graphe d’opérations et la relation de médiation. Il teste tout d’abord pour
une jointure donnée reliant deux relations de mapping si tous les attributs de la relation de
médiation figurent dans les deux relations, si oui un chemin de calcul est déjà identifié, sinon il
ajoute la jointure J au chemin de jointures courant ChemCourant et il continue à chercher dans
le graphe une jointure ayant un lien avec le chemin de jointures courant jusqu’à ce qu’il trouve
un chemin de calcul pertinent où tous les attributs de Rm figurent. Un lien entre une jointure
donnée et un chemin courant est établi si l’extrémité droite ou gauche de la jointure est égale à
l’une des extrémités du chemcourant.
Le processus de recherche des chemins de calcul est réitéré jusqu’à ce tous les chemins possibles
soient identifiés.
6. Prise en compte de l’hétérogénéité
Lors du processus de génération de requêtes de médiation, deux types de conflits liés à
l’hétérogénéité des sources sont distingués à savoir :
- les conflits sémantiques liés au schéma,
- les conflits sémantiques liés aux données.
Algorithme 5 : Algorithme de recherche des chemins de calcul

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 45
A- les conflits sémantiques liés au schéma,
L’utilisation d’une terminologie différente pour désigner deux concepts identiques entraîne la
présence de conflits sémantiques liés au schéma. Par exemple, dans une relation de médiation
produit (Num-produit, désignation, prix) et dans la relation produit (Num-produit, désignation,
prix-produit), les attributs prix et prix-produit ont deux terminologies différentes mais une
sémantique identique.
B- les conflits sémantiques liés aux données.
La provenance de données de diverses origines, leur saisie à des moments distincts par des
personnes différentes qui n’ont pas la même perception du réel, et qui utilisent des conventions
différentes entraîne ce type de conflits. Par exemple, différence d’unité de mesure, de précision,
d’échelle, de format de date, etc.
6.1 Les métadonnées utilisées
En plus des métadonnées décrites dans la base de connaissances initiale, il existe :
- Un dictionnaire linguistique automatique pour détecter et résoudre automatiquement les conflits
liés au schéma,
- Un type étendu d’un attribut pour détecter les conflits sémantiques liés aux données,
- Une librairie de fonctions de transformations pour transformer les données hétérogènes et
garantir leur conformité mutuelle et leur conformité par rapport au schéma global.
6.2 Exploitation des métadonnées
L’approche présentée ici consiste à revisiter chaque étape principale de l’algorithme de
génération de requêtes de médiation afin de détecter et de résoudre les conflits liés à
l’hétérogénéité des sources au cours du processus de génération de requêtes de médiation.
On ajoute trois procédures : Compare, CheckType et Search qui exploitent les métadonnées
précédentes à savoir le dictionnaire linguistique, le type étendu, et la librairie de fonctions de
transformations pour l’identification et la résolution des conflits liés à l’hétérogénéité des
données. Ces procédures sont appelées au cours de la génération de requêtes de médiation.

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 46
Nous présentons le principe et la spécification de chaque procédure.
La procédure Compare
Elle prend comme paramètres d’entrée un attribut A de la relation de médiation Rm et un
attribut B d’une relation source R. Elle teste tout d’abord la correspondance linguistique des
attributs A et B en utilisant le dictionnaire linguistique. Si A et B sont sémantiquement
équivalents(A B), elle appelle la procédure CheckType (algorithme 7) sinon elle retourne
faux.
La procédure CheckType
Elle est appelée pour détecter les conflits sémantiques liés aux données entre les attributs A
et B. Elle exploite le type étendu des attributs. Elle prend comme paramètres d’entrée le type
étendu de l’attribut A et le type étendu de l’attribut B.
Algorithme 6 : La procédure Compare
Algorithme 7 : La procédure CheckType

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 47
La procédure Search
Elle prend comme paramètres d’entrée l’élément ei à traiter (ex : unité), sa valeur en entrée
(ex : francs) et sa valeur en sortie (ex : euros), elle exploite la librairie de fonctions et cherche
une fonction de transformation f qui a une valeur de paramètre d’entrée (valeur_in) égale à la
valeur de l’élément ej et qui a une valeur de paramètre de sortie (valeur_out) égale à la valeur de
l’élément ei. Si cette fonction existe, la procédure Search retourne la fonction f, la procédure
CheckType retourne vrai et l’ensemble de fonctions CF, Compare retourne vrai et l’ensemble de
fonctions de transformation CF, sinon CheckType et Compare retournent faux.
7. Conclusion
Lors de la conception d’un système de médiation, la définition de requêtes de médiation est
l’une des tâches les plus complexes à effectuer manuellement, surtout lorsque le nombre de
sources et le volume de métadonnées qui les décrivent sont importants. Cette complexité se
multiplie avec présence de données hétérogènes dans les sources. Ainsi, l’automatisation de la
génération de ces requêtes constitue, sans aucun doute, une avancée importante pour les
systèmes de médiation. Le chapitre suivant va donner l’implémentation des différents
algorithmes vus précédemment.
Algorithme 8 : La procédure Search

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 48
Chapitre IV ــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــ
Implémentation
ــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــ
Génération automatique des requêtes de médiation dans un contexte relationnel
________ 49
1. Introduction
L’ensemble des algorithmes spécifiés dans le chapitre III ont été implémentés et composés
pour former un outil de génération des requêtes de médiation dans le contexte relationnel.
L’implémentation du notre prototype de génération automatique des requêtes de médiation a été
réalisée en Java (JDK 1.6), sous l’IDE NetBeans 6.8 et la méta-base est stockée sous Microsoft
Access.
2. Architecture générale
Notre prototype de génération automatique des requêtes de médiation comporte,
essentiellement, une Meta-Base et sept modules : comme le montre la figure 4.1.
� 1) interface graphique utilisateur.
� 2) interface graphique administrateur.
� 3) recherche des relations de mapping.
� 4) recherche des relations de transitions.
� 5) recherche des opérations de jointures.
� 6) recherche des chemins de calcul.
� 7) génération de requêtes de médiation.
Figure 4.1 : Architecture du prototype de génération automatique des requêtes de médiation

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 50
L’interface graphique administrateur permet de mettre à jour (ajout, suppression et modification)
toutes les métadonnées utilisées pour la génération des requêtes de médiation.
L’interface graphique utilisateur permet d’interagir avec les cinq autres modules, et de montrer
au fur et à mesure les résultats de chaque module du processus de génération des requêtes.
Tous les modules communiquent avec la méta-base, les résultats produits sont également stockés
dans cette dernière.
3. Description de la méta-base
La méta-base exploitée par le processus de génération des requêtes est constituée de :
� Métadonnées au niveau de la médiation : la description du schéma global
(Schéma_Médiation) comporte les schémas des relations de médiation, les clés des
relations. Chaque relation (Relation_Médiation) est constituée d’un ensemble d’attributs
de médiation (Attribut_Médiation), et pour chaque attribut d’une relation son type étendu
(Element_Médiation).
� Métadonnées au niveau des sources : la description du schéma local (Schéma_Source)
à chaque sources de données comporte les schémas des relations sources, les clés des
relations. Chaque relation (Relation_Source) est constituée d’un ensemble d’attributs
source (Attribut_Source), et pour chaque attribut d’une relation, son type étendu
(Element_Source).
� Métadonnées au niveau intermédiaire : ce niveau décrit les assertions intra-source
(Contrainte_Ref) définies entre deux attributs d’une même source, les assertions inter-
source (Corresp Ling (S-S)) définies entre deux attributs de sources différentes, les
correspondances linguistiques (Corresp Ling (S-M)) définies entre un attribut médiation
et un attribut source, et les fonctions de transformations (Fonction) qui transforment la
valeur d’un élément du type étendu d’un attribut source en une autre valeur.

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 51
4 La description des différents modules
4.1 La recherche des relations de mapping étendu
Ce module permet d’identifier les relations sources pertinentes au calcul de la relation de
médiation, et de générer, en sortie, les relations de mapping étendu. Les fonctionnalités de ce
module se trouvent dans la classe MappingEtendu.
Il récupère les méta-données relatives à un schéma de médiation, a partir de l’accès via JDBC à
la Méta-Base.
Il appelle la classe Compare qui a pour objectif de mettre en conformité les données hétérogènes
par rapport au schéma global, cette classe prend en paramètres d’entrée un attribut de médiation
et un attribut source, et pour chaque attribut son type étendu, elle compare tout d’abord
l’équivalence linguistique entre les deux attributs, et ensuite elle compare terme à terme chaque
élément du type étendu de l’attribut de médiation avec chaque élément du type étendu de
l’attribut source, elle accède à la table Fonction de la méta-base par la classe Connexion Meta-
base, elle retourne en paramètre de sortie un ensemble de fonctions de transformations CF.
Diagramme 1 : La recherche des relations de mapping étendu
Figure 4.2 : La description du Méta-Base

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 52
4.2 La recherche des relations de transition
Ce module identifie des relations sources intermédiaires pour établir des liens entre les
relations de mapping étendu.
Les fonctionnalités de ce module se trouvent dans la classe MappingTransition.
Il prend en paramètre d’entrée l’ensemble de relations de mapping étendu généré par la classe
MappingEtendu. Il appelle la classe RechercheSeq qui a pour objectif de calculer la séquence
d’assertions entre chaque paire de relations de mapping étendu.
La classe MappingTransition accède, via un accès JDBC, à la méta-base des tables
Contrainte_Ref et Corresp Ling (S-S), elle retourne en sortie un ensemble de séquences
d’assertions pertinentes entre chaque relation de mapping étendu.
Lorsque deux relations de mapping étendu n’appartiennent pas à la même source, la classe
MappingTransition appelle la classe Compare pour gérer les conflits liés à l’hétérogénéité des
données qui génère en sortie un ensemble de fonctions de transformations CF.
Le diagramme de classe suivant montre les fonctionnalités de ce module :
4.3. La recherche des opérations de jointures
Ce module identifie les jointures candidates pour combiner les relations de mapping.
Il génère en sortie un graphe d’opérations de jointures.
Les fonctionnalités de ce module se trouvent dans la classe GrapheOperations.
Il prend comme paramètres d’entrée l’ensemble de relations de mapping étendu Me et
l’ensemble de relations de mapping de transition Mt, il récupère via un accès JDBC les tables
Contrainte_Ref et Corresp Ling (S-S).
Diagramme 2 : La recherche des relations de transition
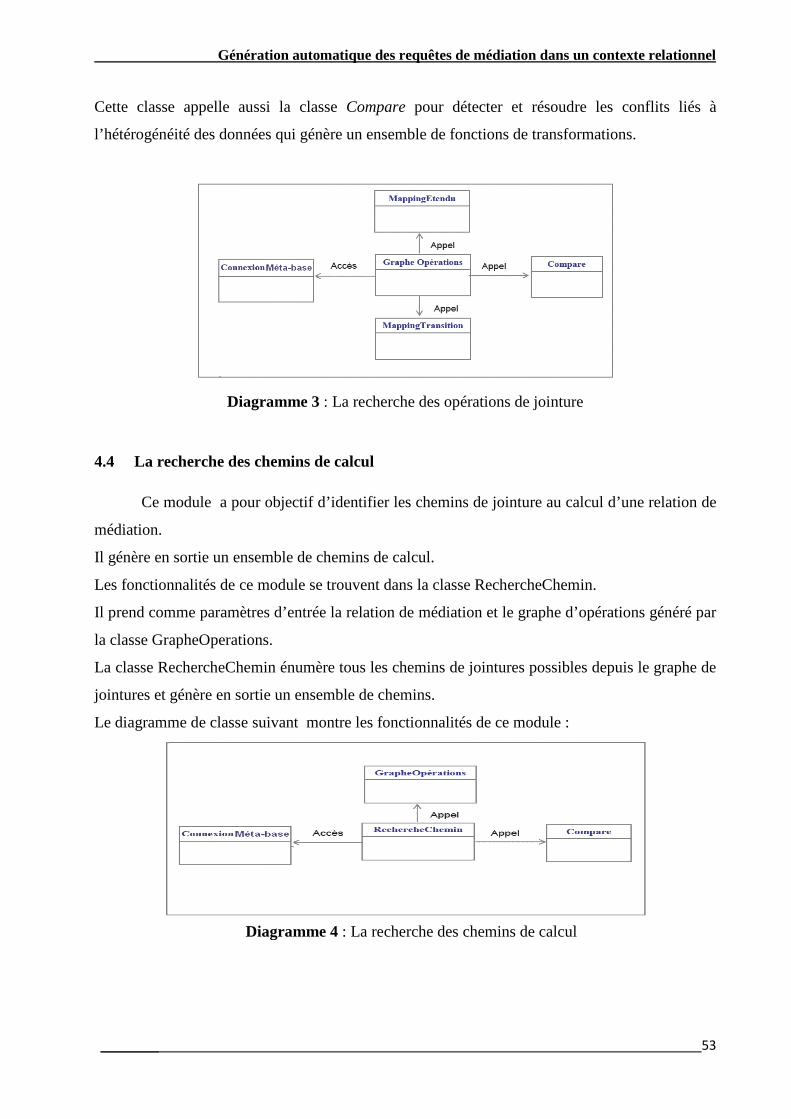
Génération automatique des requêtes de médiation dans un contexte relationnel
________ 53
Cette classe appelle aussi la classe Compare pour détecter et résoudre les conflits liés à
l’hétérogénéité des données qui génère un ensemble de fonctions de transformations.
Diagramme 3 : La recherche des opérations de jointure
4.4 La recherche des chemins de calcul
Ce module a pour objectif d’identifier les chemins de jointure au calcul d’une relation de
médiation.
Il génère en sortie un ensemble de chemins de calcul.
Les fonctionnalités de ce module se trouvent dans la classe RechercheChemin.
Il prend comme paramètres d’entrée la relation de médiation et le graphe d’opérations généré par
la classe GrapheOperations.
La classe RechercheChemin énumère tous les chemins de jointures possibles depuis le graphe de
jointures et génère en sortie un ensemble de chemins.
Le diagramme de classe suivant montre les fonctionnalités de ce module :
Diagramme 4 : La recherche des chemins de calcul

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 54
4.5 La recherche des requêtes de médiation
Ce module a pour objectif de générer les requêtes de médiation relatives à une relation de
médiation particulière. Il génère en sortie des requêtes SQL.
Les fonctionnalités de ce module se trouvent aussi dans la classe RechercheChemin.
Cette classe déduit des requêtes SQL à partir des chemins de calcul.
Le diagramme de classe suivant montre les fonctionnalités de ce module :
5 Scénario de fonctionnement
Le prototype implémenté génère les requêtes de médiation, qui à partir des schémas sources
et de médiation, produit un ensemble de requêtes potentiel calculant cette relation. Pour ce faire,
l’administrateur doit configurer d’abord la Méta-Base, pour que l’utilisateur puisse générer les
requêtes de médiation.
5.1 Administrateur
La fenêtre suivante regroupe les tâches effectuées par l’administrateur.
Diagramme 5 : La génération des requêtes de médiation
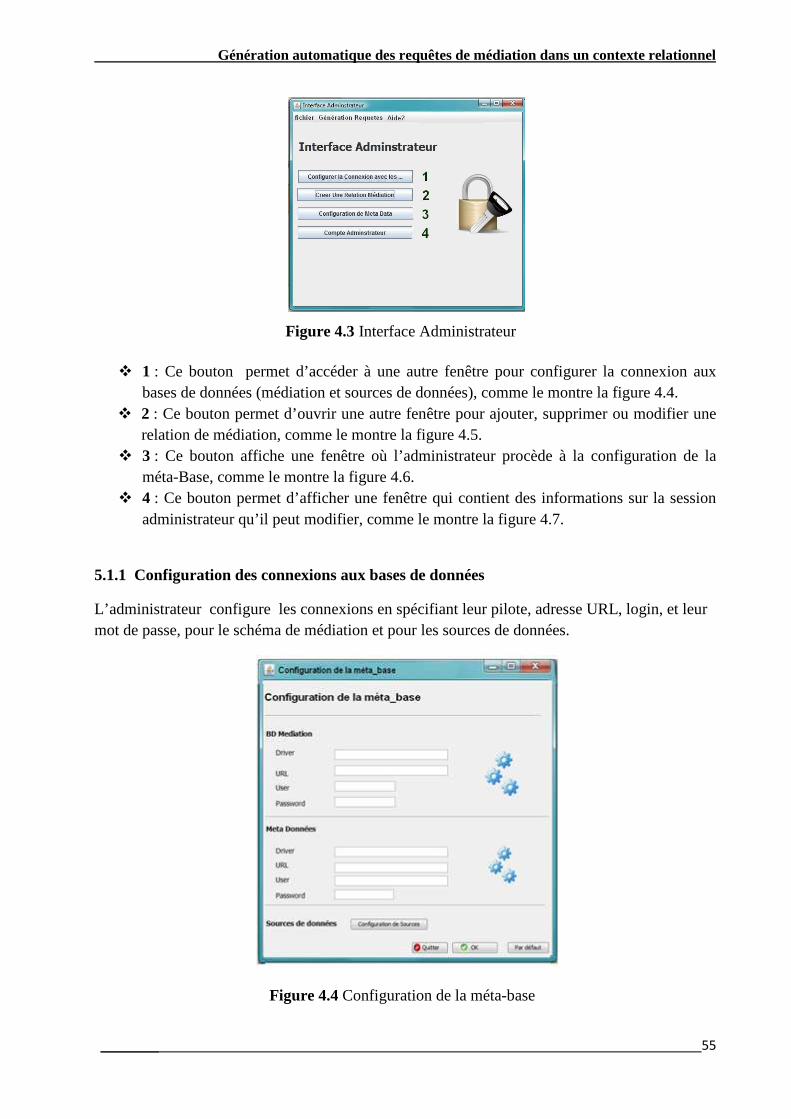
Génération automatique des requêtes de médiation dans un contexte relationnel
________ 55
� 1 : Ce bouton permet d’accéder à une autre fenêtre pour configurer la connexion aux bases de données (médiation et sources de données), comme le montre la figure 4.4.
� 2 : Ce bouton permet d’ouvrir une autre fenêtre pour ajouter, supprimer ou modifier une relation de médiation, comme le montre la figure 4.5.
� 3 : Ce bouton affiche une fenêtre où l’administrateur procède à la configuration de la méta-Base, comme le montre la figure 4.6.
� 4 : Ce bouton permet d’afficher une fenêtre qui contient des informations sur la session administrateur qu’il peut modifier, comme le montre la figure 4.7.
5.1.1 Configuration des connexions aux bases de données
L’administrateur configure les connexions en spécifiant leur pilote, adresse URL, login, et leur mot de passe, pour le schéma de médiation et pour les sources de données.
Figure 4.3 Interface Administrateur
Figure 4.4 Configuration de la méta-base

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 56
5.1.2 Fenêtre de création d’une relation de médiation
5.1.3 La configuration de la méta-base
Cette fenêtre permet de configurer la Méta-Base en suivant les étapes :
� 1 : permet de charger automatique les informations sur le schéma médiation via la Méta-Base.
� 2 : charge automatiquement les informations sur les sources. � 3 : permet d’ouvrir la fenêtre de configuration du type étendu d’un attribut. � 4 : pour ouvrir la fenêtre de configuration des contraintes linguistiques inter-sources. � 5 : pour ouvrir la fenêtre de configuration des contraintes linguistique source-médiation. � 6 : pour ouvrir la fenêtre de configuration des contraintes référentielles. � 7 : pour ouvrir la fenêtre de configuration de la liste des fonctions.
Figure 4.6 Configuration de la méta-base
Figure 4.5 Création d’une relation de médiation

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 57
5.1.4 Fenêtre de gestion des Comptes
5.2 Partie Utilisateur
La fenêtre principale de l’utilisateur de notre prototype se présente comme suit :
L’utilisateur peut consulter la base de méta connaissances pour demander la génération des requêtes de médiation selon les étapes suivantes :
Figure 4.7 Gestion des comptes
Figure 4.8 Fenêtre utilisateur
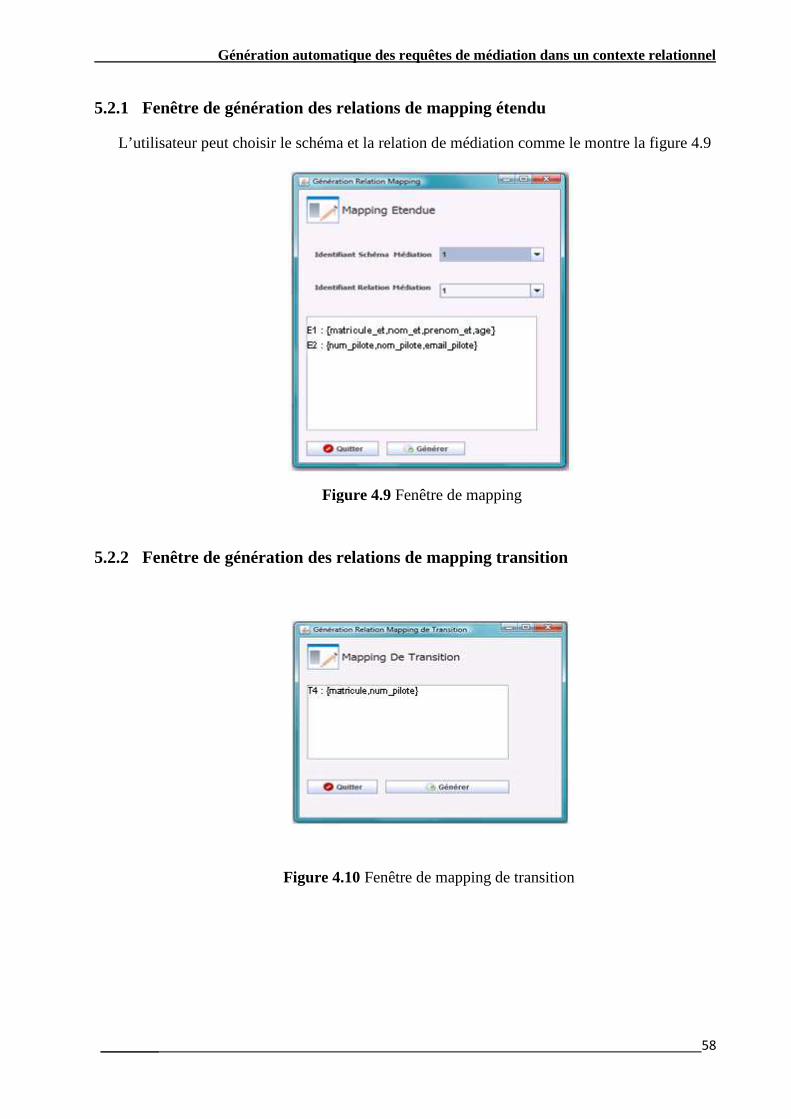
Génération automatique des requêtes de médiation dans un contexte relationnel
________ 58
5.2.1 Fenêtre de génération des relations de mapping étendu
L’utilisateur peut choisir le schéma et la relation de médiation comme le montre la figure 4.9
5.2.2 Fenêtre de génération des relations de mapping transition
Figure 4.9 Fenêtre de mapping étendu
Figure 4.10 Fenêtre de mapping de transition
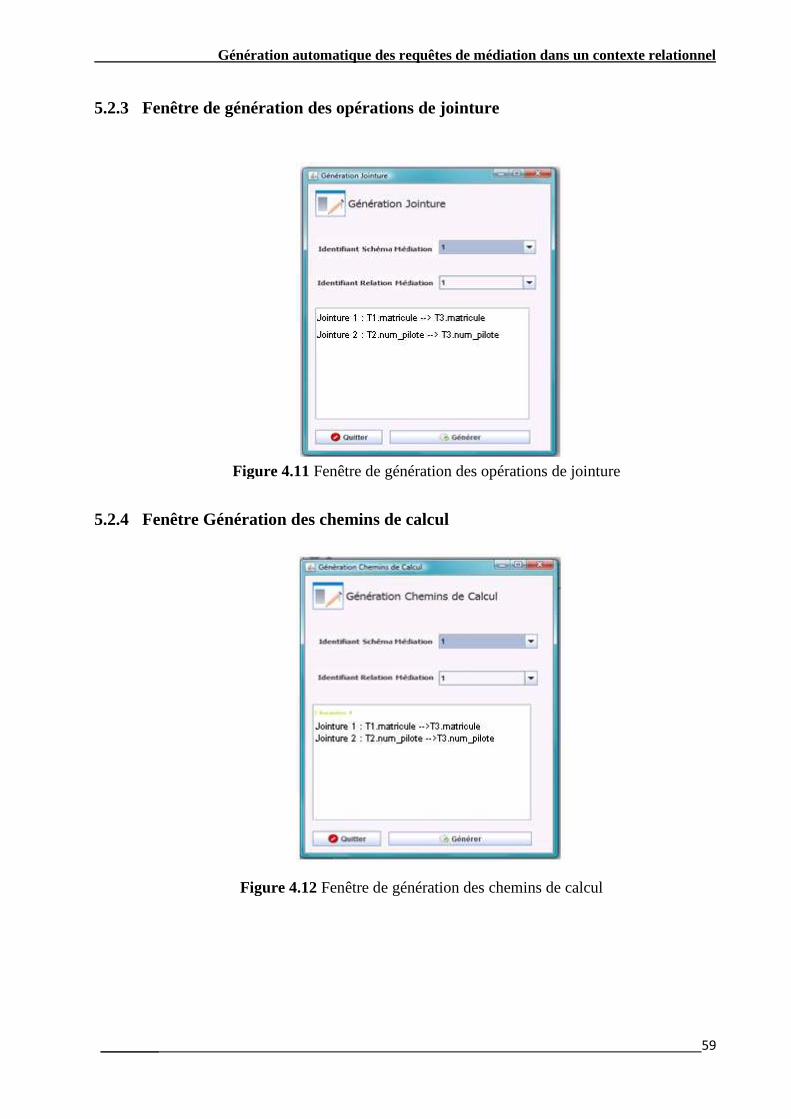
Génération automatique des requêtes de médiation dans un contexte relationnel
________ 59
5.2.3 Fenêtre de génération des opérations de jointure
5.2.4 Fenêtre Génération des chemins de calcul
Figure 4.11 Fenêtre de génération des opérations de jointure
Figure 4.12 Fenêtre de génération des chemins de calcul
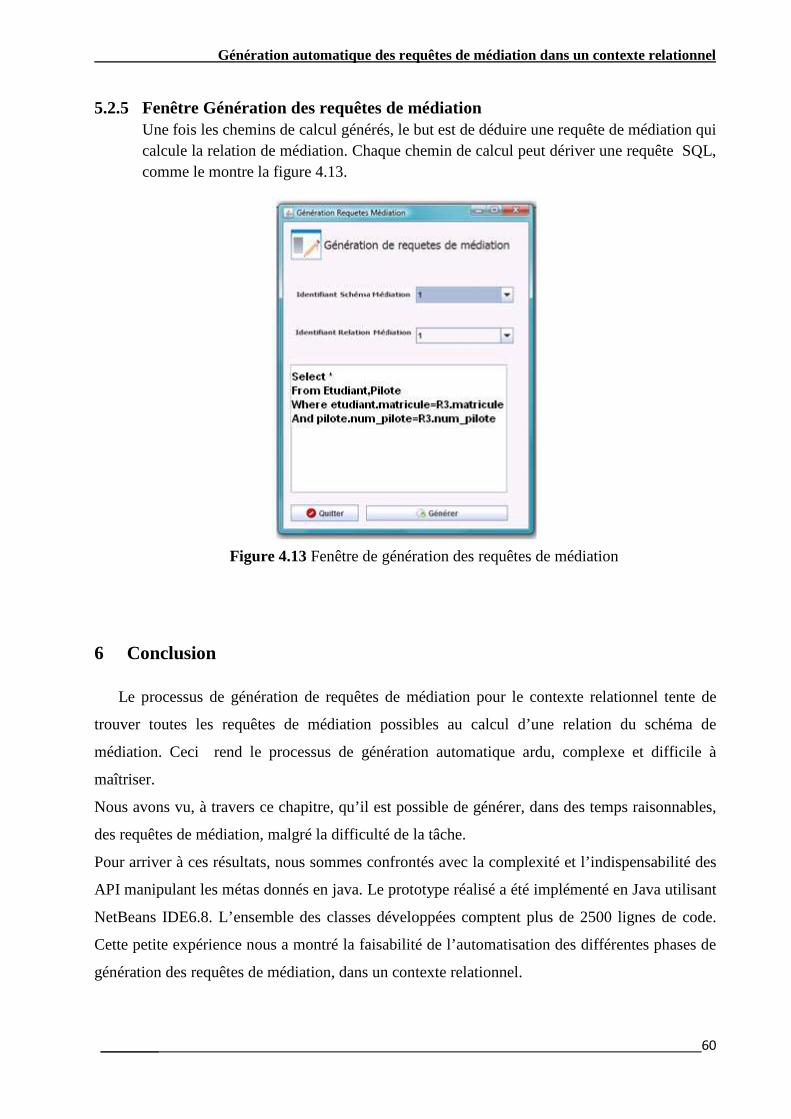
Génération automatique des requêtes de médiation dans un contexte relationnel
________ 60
5.2.5 Fenêtre Génération des requêtes de médiation Une fois les chemins de calcul générés, le but est de déduire une requête de médiation qui calcule la relation de médiation. Chaque chemin de calcul peut dériver une requête SQL, comme le montre la figure 4.13.
6 Conclusion
Le processus de génération de requêtes de médiation pour le contexte relationnel tente de
trouver toutes les requêtes de médiation possibles au calcul d’une relation du schéma de
médiation. Ceci rend le processus de génération automatique ardu, complexe et difficile à
maîtriser.
Nous avons vu, à travers ce chapitre, qu’il est possible de générer, dans des temps raisonnables,
des requêtes de médiation, malgré la difficulté de la tâche.
Pour arriver à ces résultats, nous sommes confrontés avec la complexité et l’indispensabilité des
API manipulant les métas donnés en java. Le prototype réalisé a été implémenté en Java utilisant
NetBeans IDE6.8. L’ensemble des classes développées comptent plus de 2500 lignes de code.
Cette petite expérience nous a montré la faisabilité de l’automatisation des différentes phases de
génération des requêtes de médiation, dans un contexte relationnel.
Figure 4.13 Fenêtre de génération des requêtes de médiation

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 61
ــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــ
Conclusion générale ــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــ

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 62
Conclusion et Perspectives
Le problème de définition des requêtes de médiation est un problème complexe en raison de la
grande diversité des sources hétérogènes et distribuées qui peuvent intervenir dans un système de
médiation et du grand volume de métadonnées qui les décrivent, mais aussi en raison des conflits
liés à l’hétérogénéité des données qui peuvent exister entre deux sources de données.
Face à cette problématique, nous avons réalisé, pour le contexte relationnel, un outil de
génération automatique des requêtes de médiation.
Etant donné le schéma d’une relation de médiation, de dépendances fonctionnelles définies sur
cette relation, d’assertions de correspondance linguistique existant entre les sources et le schéma
de médiation, et d’assertions intra-source et inter-source reliant les relations sources entre elles,
cet outil peut produire un ensemble de requêtes potentiel calculant cette relation, tenant en
compte des conflits liés à l’hétérogénéité des sources, et s’appuyant sur un ensemble de
connaissances regroupées dans une base de méta-connaissances.
La conception du prototype réalisé est modulaire, ce qui lui permet d’être amélioré par de
nouvelles fonctionnalités dont :
- Adaptation du système de génération de requêtes de médiation au contexte XML et Objet
- Implémenter un gestionnaire de coûts et de statistiques pour tester les performances de
l’outil en vue de son passage à l’échelle.
- Intégrer des ontologies locales au niveau des sources et une ontologie de domaine au
niveau du médiateur pour faciliter l’ajout de nouvelles sources . . . etc.

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 63
ــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــ
Bibliographie ــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــ

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 64
Bibliographie [BAR 03] Xavier BARIL. Un modèle de vues pour l’intégration de sources de données XML :
VIMIX. Thèse de Doctorat en Informatique, de l’Université des sciences et techniques du
Languedoc. Décembre 2003.
[RAH 05] Ahmed RAHNI. AMIDHA : Une approche médiateur d’intégration de sources de
données hétérogènes et autonomes. Mémoire de stage effectué à l’ENSMA, Université de
Poitiers. Juillet 2005.
[HUL 97] R. Hull. Managing semantic heterogeneity in databases: A theoretical perspective.
Proceedings of the Sixteenth ACM SIGACT-SIGMOD-SIGART Symposium on Principles of
Database Systems, pages 51–61, May 1997.
[BOUSSIS 08] Amel Boussis , Intégration de sources de données à base ontologique dans un
environnement P2P, Thèse de magistère. L'institut national d'informatique 2008.
[WIE92] Wiederhold G. Mediators in the architecture of future information systems. IEEE
computers, March 1992.
[ROU 02] Wiederhold G, Mediators in the architecture of future information systems. IEEE
computers, 25(3), p 38J49, March
[GARD 05] Georges Gardarin, Tuyet-Tram Dang-Ngoc "Intégration de données hétérogènes
distribuées", Cours N°8, 2005.
[SOUKANE 05] Assia soukane, « génération automatique des requêtes de médiation dans un environnement hétérogène », Thèse de doctorat,université de versailles saint-quentin yvelynes Décembre 2005 [Oliv05] : JDBC connexion à une base de données ; Olivier Corgeron; version n°02 16 mai 2005.
Webographie [Dev09] : url : http://laurent-audibert.developpez.com/Cours-BD/html/
Titre : Base de Données et Langage SQL Auteur : Laurent Audibert, décembre 2009

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 65
ــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــ
Glossaire ــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــــ

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 66
Glossaire XML [ eXtensible Markup Language]
XML est un langage de balises analysable, destiné à une diffusion à grande échelle sur le Web, lisible par l’homme, flexible et adaptable.
HTML [ Hyper Text Markup Language]
C’est un standard web reconnu par tous les navigateurs, permettant la mise en forme d’un texte.
P2P [Peer to Peer]
Communication de pair à pair, les deux machines qui communiquent
sont sur un pied d'égalité elles peuvent être toutes les deux client ou serveur.
SQL [Structured Query Language]
SQL est un langage de requêtes de base de données, ce langage permet de poser des requêtes complexes à une base de données le supportant, par exemple : DB2, Oracle,…
GAV [Global-as-View]
C’est une approche de médiation descendante où chaque objet du schéma global est
défini par une requête sur les sources.
LAV [ Local as View]
C’est approche de médiation ascendante où chaque objet d’une source
de données est défini par une requête sur le schéma global.
SGBD [System de Gestion de Base de Données]
C’est un système qui permet de stocker et manipuler les données.
SGBDR [System de Gestion de Bases de Données Relationnelles]
Système de Gestion de base de données Relationnel. RDB ou RDBMS en anglais. Un
SGBDR est un système ou les données sont organisées en fonction de leur utilisation
(données fixes dans une table, données variables dans une autre, etc.).

Génération automatique des requêtes de médiation dans un contexte relationnel
________ 67
API [Application Programming Interface]
Interface de programmation d'applications, contenant un ensemble de fonction courantes
de bas niveau, bien documentées, permettant de programmer des applications de « Haut
Niveau ».
JDK [Java Development Kit]
Environnement de développement de Sun permettant de produire du code Java
Et servant de référence.
ANSI/ISO [American National Standard Institute/ International Standard Organization]
ANSI : Organisme de normalisation américain, constitué de producteurs, de consommateurs
et de groupes d'intérêt général, et qui est le représentant US à l'ISO.
ISO : Organisation internationale de standardisation.
JDBC [Java Data Base Connectivity]
C’est une API Java composée d’interfaces, comme DriverManager et Connection, pour interagir avec les bases de données relationnelles : exécuter des requêtes SQL et récupérer les résultats.
ODBC [Open Data Base Connectivity]
C’est une interface d’accès aux base de données SQL, conçue par Microsoft.
DSN [Data Set Name]
Il permet de faire un lien avec une base de données ODBC.
IDE [Integrated Development Environment]
Environnement de développement intégré, réunissant tous les outils nécessaires
à la création d'applications.