Embed Size (px)
Citation preview

서버 이중화 솔루션(HA 클러스터) 기본 개념
한국NEC 주식회사
2021년 06월
제품 데모 및 비즈니스 파트너 문의[email protected]
NEC 클러스터 소개자료 (클릭)


HA 클러스터 기초
[제 1장] 서버 다운 발생에 대해서
[제 2장] 모든 구성 요소를 중복 구성
[제 3장] 다수의 서버를 클러스터링 구성
[제 4장] 장애 발생시 업무 인수인계
© NEC Corporation 20214
고 가용성 시스템 구성의 필요성 증가
▌기업의 모든 비즈니스가 디지털화 되면서, 고 가용성이 보장된 서비스를 제공 해야 되는
케이스가 점점 많이 발생되고 있다
▌물리 서버, 가상화, 클라우드 등 다양한 IT플랫폼이 혼재 되고 있기 때문에
고 가용성을 구현하기 위해 고려해야 되는 내용, 방법은 점점 복잡해지고 있다
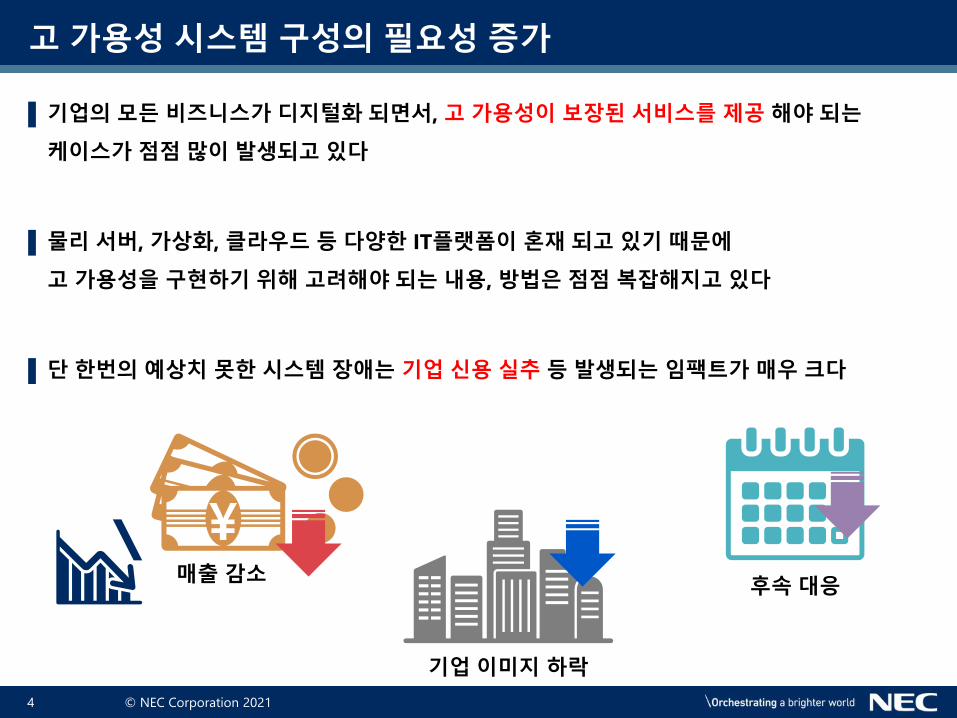
▌단 한번의 예상치 못한 시스템 장애는 기업 신용 실추 등 발생되는 임팩트가 매우 크다
매출 감소
기업 이미지 하락
후속 대응
© NEC Corporation 20215
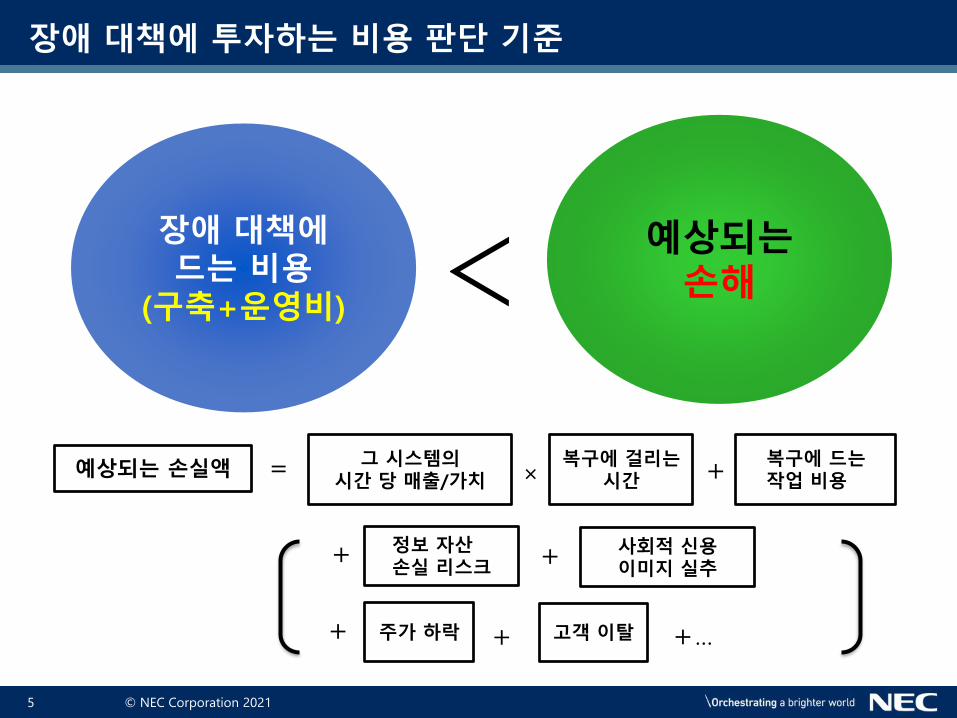
장애 대책에 투자하는 비용 판단 기준
장애 대책에드는 비용
(구축+운영비)
예상되는손해
= ×
<
+
+ +
예상되는 손실액그 시스템의
시간 당 매출/가치복구에 걸리는
시간복구에 드는작업 비용
사회적 신용이미지 실추
주가 하락 고객 이탈 +…
정보 자산손실 리스크
+
+

© NEC Corporation 20216
HA 클러스터 기초 - 제 1장 서버 다운 발생에 대해서 -
▌ [Design for Failure]라는 개념을 알고 계십니까?
▌ 장애는 반드시 발생한다는 전제로 시스템 설계를 진행 해야 합니다.
▌ 장애가 반드시 발생한다는 것은 무엇을 의미할까요? 이것은 시스템을 구성하는 모든 구성요소는
[언젠가는 반드시 고장이 발생 할 것]으로 간주하는 것입니다.
▌ 조금 추상적이므로 구체적인 예를 들어 생각해 봅시다.
▌ 1대의 Web 사이트를 운영하는 경우, 어떤 구성 요소에서 고장이 발생 될까요?
▌ 보통 흔히 [서버가 장애 났다]라고 말합니다만, 그 장애 발생 원인은 굉장히 다양합니다.
▌ 우선 하드웨어 관점에서 살펴 보겠습니다.
시작하기에 앞서
© NEC Corporation 20217
HA 클러스터 기초 - 제 1장 서버 다운 발생에 대해서 -
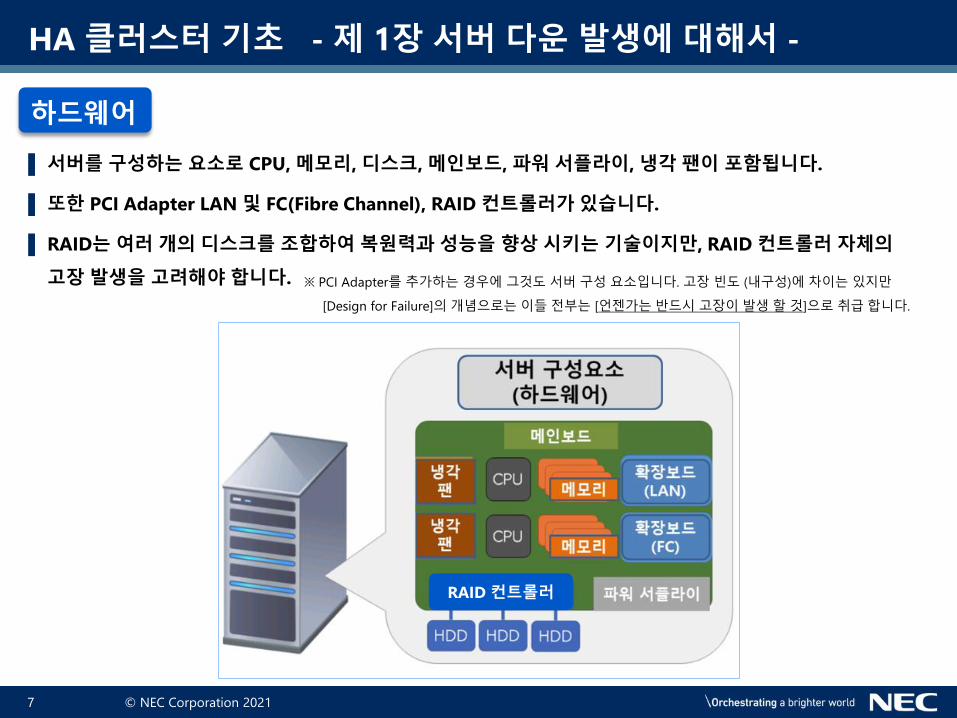
▌ 서버를 구성하는 요소로 CPU, 메모리, 디스크, 메인보드, 파워 서플라이, 냉각 팬이 포함됩니다.
▌ 또한 PCI Adapter LAN 및 FC(Fibre Channel), RAID 컨트롤러가 있습니다.
▌ RAID는 여러 개의 디스크를 조합하여 복원력과 성능을 향상 시키는 기술이지만, RAID 컨트롤러 자체의
고장 발생을 고려해야 합니다.
하드웨어
RAID 컨트롤러
※ PCI Adapter를 추가하는경우에그것도서버구성요소입니다. 고장빈도 (내구성)에차이는있지만
[Design for Failure]의개념으로는이들전부는 [언젠가는반드시고장이발생할것]으로취급합니다.
© NEC Corporation 20218
HA 클러스터 기초 - 제 1장 서버 다운 발생에 대해서 -
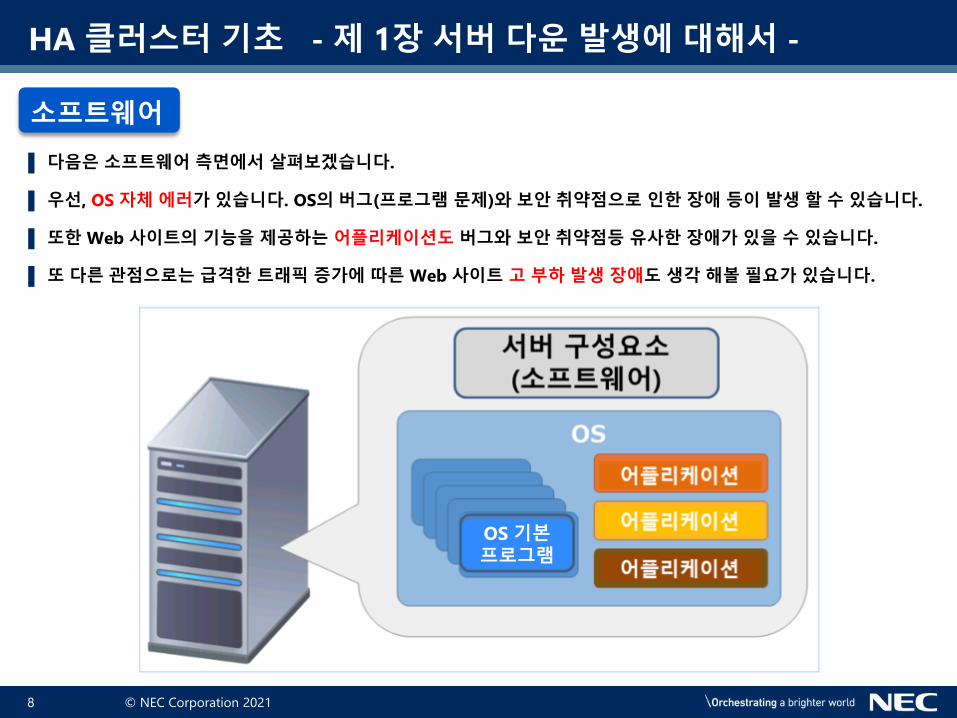
▌ 다음은 소프트웨어 측면에서 살펴보겠습니다.
▌ 우선, OS 자체 에러가 있습니다. OS의 버그(프로그램 문제)와 보안 취약점으로 인한 장애 등이 발생 할 수 있습니다.
▌ 또한 Web 사이트의 기능을 제공하는 어플리케이션도 버그와 보안 취약점등 유사한 장애가 있을 수 있습니다.
▌ 또 다른 관점으로는 급격한 트래픽 증가에 따른 Web 사이트 고 부하 발생 장애도 생각 해볼 필요가 있습니다.
소프트웨어
OS 기본프로그램
© NEC Corporation 20219
HA 클러스터 기초 - 제 1장 서버 다운 발생에 대해서 -
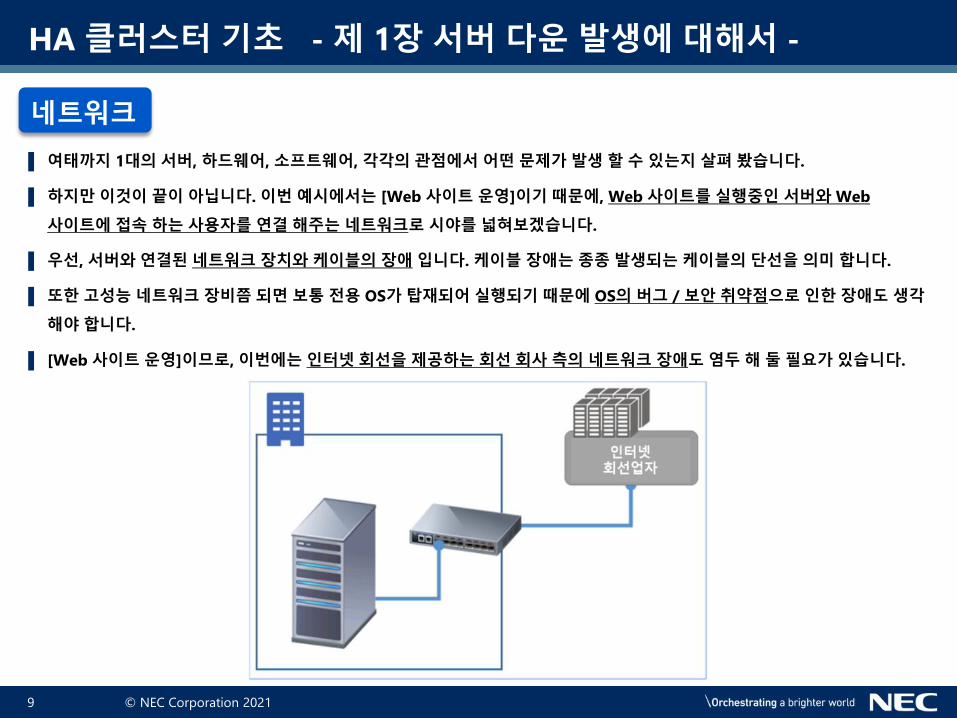
▌ 여태까지 1대의 서버, 하드웨어, 소프트웨어, 각각의 관점에서 어떤 문제가 발생 할 수 있는지 살펴 봤습니다.
▌ 하지만 이것이 끝이 아닙니다. 이번 예시에서는 [Web 사이트 운영]이기 때문에, Web 사이트를 실행중인 서버와 Web
사이트에 접속 하는 사용자를 연결 해주는 네트워크로 시야를 넓혀보겠습니다.
▌ 우선, 서버와 연결된 네트워크 장치와 케이블의 장애 입니다. 케이블 장애는 종종 발생되는 케이블의 단선을 의미 합니다.
▌ 또한 고성능 네트워크 장비쯤 되면 보통 전용 OS가 탑재되어 실행되기 때문에 OS의 버그 / 보안 취약점으로 인한 장애도 생각
해야 합니다.
▌ [Web 사이트 운영]이므로, 이번에는 인터넷 회선을 제공하는 회선 회사 측의 네트워크 장애도 염두 해 둘 필요가 있습니다.
네트워크

© NEC Corporation 202110
HA 클러스터 기초 - 제 1장 서버 다운 발생에 대해서 -
▌ 어떻습니까? 단 1대의 서버로 Web 사이트를 운영하는 단순한 구성임에도 이만큼의 많은 장애 발생
포인트를 생각하여 시스템 설계를 진행 해야 합니다. 그리고 그 개념을 표현한 것이 [Design for Failure]
이며, 시스템을 설계 할 때 기본 원칙이라고 할 수 있습니다.
▌ 언제 발생 될 지 모르는 장애를 불안해 하지 말고, 반드시 장애는 발생 할 것이라고 간주 하여 미리 대비책을
설계 해 놓아야 신뢰성이 높은 시스템을 설계 할 수 있습니다.
▌ 더 나아가면, 서버가 설치되어 있는 건물 자체의 네트워크 회선 장애, 대규모 재해에 의한 정전, 지진
발생으로 빌딩 붕괴 등도 염두 해 둘 필요가 있습니다.
정리
© NEC Corporation 202111
[참고] 네트워크 구성
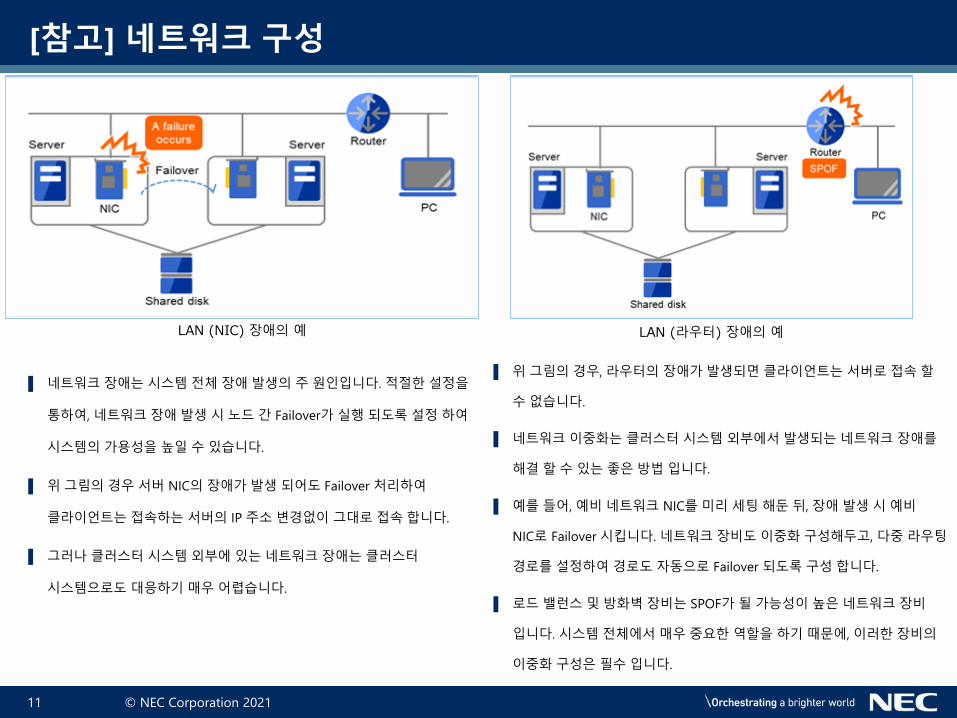
▌ 네트워크장애는시스템전체장애발생의주원인입니다. 적절한설정을
통하여, 네트워크장애발생시노드간 Failover가실행되도록설정하여
시스템의가용성을높일수있습니다.
▌ 위그림의경우서버 NIC의 장애가발생되어도 Failover 처리하여
클라이언트는 접속하는서버의 IP 주소변경없이그대로접속합니다.
▌ 그러나클러스터시스템외부에있는네트워크장애는클러스터
시스템으로도 대응하기매우어렵습니다.
LAN (NIC) 장애의 예 LAN (라우터) 장애의 예
▌ 위그림의경우, 라우터의 장애가발생되면클라이언트는서버로접속할
수없습니다.
▌ 네트워크이중화는클러스터 시스템외부에서발생되는네트워크장애를
해결할수있는좋은방법입니다.
▌ 예를들어, 예비네트워크 NIC를미리세팅해둔뒤, 장애발생시예비
NIC로 Failover 시킵니다. 네트워크장비도이중화구성해두고, 다중라우팅
경로를설정하여경로도자동으로 Failover 되도록구성합니다.
▌ 로드밸런스및방화벽장비는 SPOF가될가능성이높은네트워크장비
입니다. 시스템전체에서매우중요한역할을하기때문에, 이러한장비의
이중화구성은필수입니다.

© NEC Corporation 202112
HA 클러스터 기초 - 제 2장 모든 구성 요소를 중복 구성 -
시작하기에 앞서
▌ 이전 단계에서는 [Design for Failure]에 대한 개념을 소개했습니다.
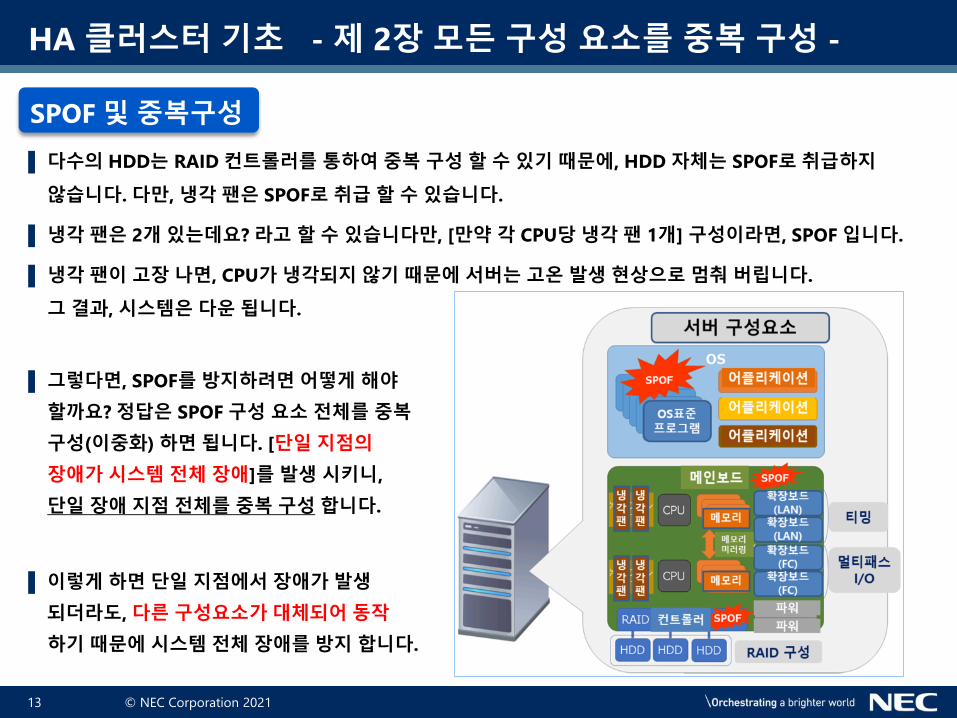
▌ 이번에는 [Single Point of Failure] 입니다. 한국어로 표현하면 [단일 장애 지점]이라고 표현 합니다만,
여기서는 [SPOF]라고 표현 하겠습니다. 원래 [SPOF]는 [장애가 발생하면 시스템 전체가 다운 되는 지점]을
말합니다. 여기서 포인트는 장애 발생의 원인 포인트가 [단 1개]인 것 입니다. 다음 그림을 보며, 어디가
[SPOF]에 해당 되는지 살펴보겠습니다.
SPOF 및 중복구성
▌ 우측 그림 서버의 거의 대부분이 [SPOF]에
해당하는 구성요소가 있습니다.
© NEC Corporation 202113
HA 클러스터 기초 - 제 2장 모든 구성 요소를 중복 구성 -
SPOF 및 중복구성
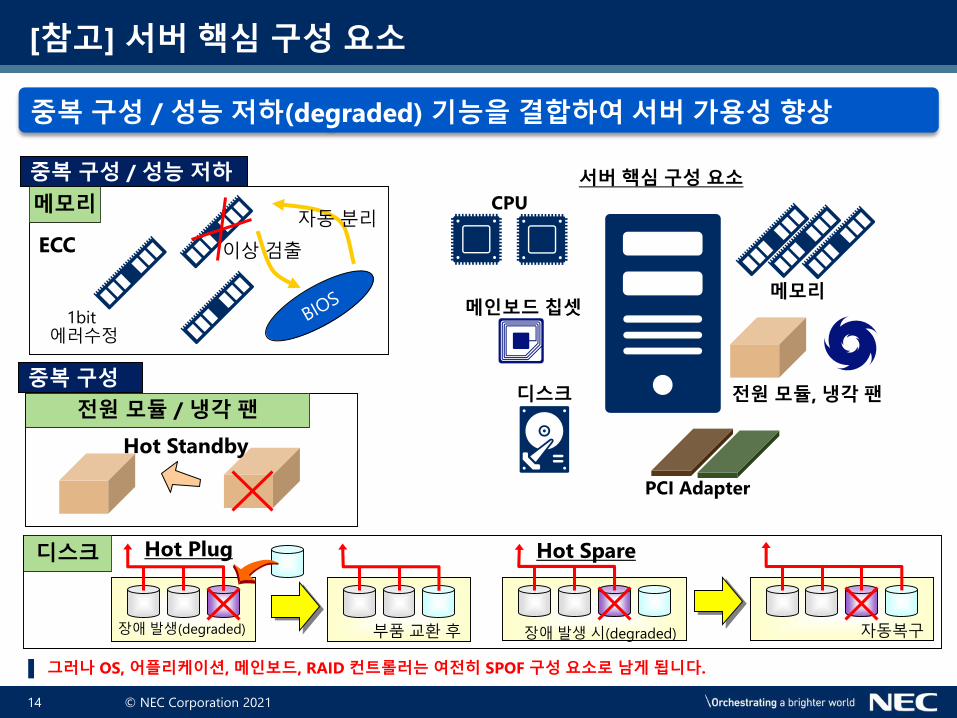
▌ 다수의 HDD는 RAID 컨트롤러를 통하여 중복 구성 할 수 있기 때문에, HDD 자체는 SPOF로 취급하지
않습니다. 다만, 냉각 팬은 SPOF로 취급 할 수 있습니다.
▌ 냉각 팬은 2개 있는데요? 라고 할 수 있습니다만, [만약 각 CPU당 냉각 팬 1개] 구성이라면, SPOF 입니다.
▌ 냉각 팬이 고장 나면, CPU가 냉각되지 않기 때문에 서버는 고온 발생 현상으로 멈춰 버립니다.
그 결과, 시스템은 다운 됩니다.
▌ 그렇다면, SPOF를 방지하려면 어떻게 해야
할까요? 정답은 SPOF 구성 요소 전체를 중복
구성(이중화) 하면 됩니다. [단일 지점의
장애가 시스템 전체 장애]를 발생 시키니,
단일 장애 지점 전체를 중복 구성 합니다.
▌ 이렇게 하면 단일 지점에서 장애가 발생
되더라도, 다른 구성요소가 대체되어 동작
하기 때문에 시스템 전체 장애를 방지 합니다.
© NEC Corporation 202114
중복 구성 / 성능 저하(degraded) 기능을 결합하여 서버 가용성 향상
서버 핵심 구성 요소
PCI Adapter
부품교환후장애발생(degraded)
Hot Plug
자동복구장애발생시(degraded)
Hot Spare
Hot Standby
중복 구성 / 성능 저하
ECC 이상검출
자동분리
1bit 에러수정
메모리
디스크
전원 모듈 / 냉각 팬
중복 구성
메모리메인보드 칩셋
전원 모듈, 냉각 팬
CPU
디스크
[참고] 서버 핵심 구성 요소
▌ 그러나 OS, 어플리케이션, 메인보드, RAID 컨트롤러는 여전히 SPOF 구성 요소로 남게 됩니다.

© NEC Corporation 202115
HA 클러스터 기초 - 제 2장 모든 구성 요소를 중복 구성 -
SPOF 및 중복구성
▌ 각파트별로중복 구성(이중화) 하는 방법이 다르기때문에, 하나씩살펴보겠습니다. (일반서버에서
사용되는기술베이스로설명하겠습니다.)
▌ CPU : 메인보드및 OS가지원하는경우, 장애발생된 CPU는분리처리한뒤, 남아있는 CPU로 OS가계속
돌아가도록할수있습니다. 다만, 최근에는이기능을지원하지않는서버가대부분입니다.
▌ 메모리 : 메모리미러링기능을사용하여중복구성이가능합니다. 그러나 OS에서인식되는메모리용량은
장착한전체메모리용량의절반으로줄어듭니다.
▌ HDD : 다수의 HDD를 RAID 구성하여중복구성이가능합니다. 일반적으로 RAID 컨트롤러가없는경우도
OS의소프트웨어 RAID 기능을활용하여 RAID 구성할수있습니다. 전용 RAID 컨트롤러보다성능은
떨어지지만, 비용을절감할수있습니다.
▌ PCI 장치(LAN, FC) : 다수의아답터를 1개의아답터처럼인식시켜주는기술이있습니다.
*LAN = 티밍 or 본딩, FC = Multipath I/O or Device Mapper Multipath
▌ PSU : PSU를서버에다수장착하여중복구성할수있습니다. 여기에 UPS도추가하여정전까지대비하는
것이일반적인구성입니다.
▌ 냉각 팬 : 냉각팬을보다여유있게다수장착하여, 중복구성할수있습니다.
© NEC Corporation 202116
HA 클러스터 기초 - 제 3장 다수의 서버를 클러스터링 구성 -
시작하기에 앞서
▌ 서버의 구성 요소를 중복 구성 하여, SPOF(단일 장애 지점)을 방지 할 수 있지만, OS 자체에서 발생되는
장애는 방지 할 수 없습니다. 즉, 중복 구성한다고 쳐도 반드시 한계가 있습니다.
▌ 그래서 이번에는 여러 서버를 사용하는 중복 구성에 대해 설명 하겠습니다.
▌ 다수의 서버를 중복 구성 하는 걸 클러스터링이라고 합니다. 시스템 장애 발생 영향을 최소화 하기 위해
자주 사용 패턴은 부하 분산 클러스터와 HA 클러스터 구성 입니다.
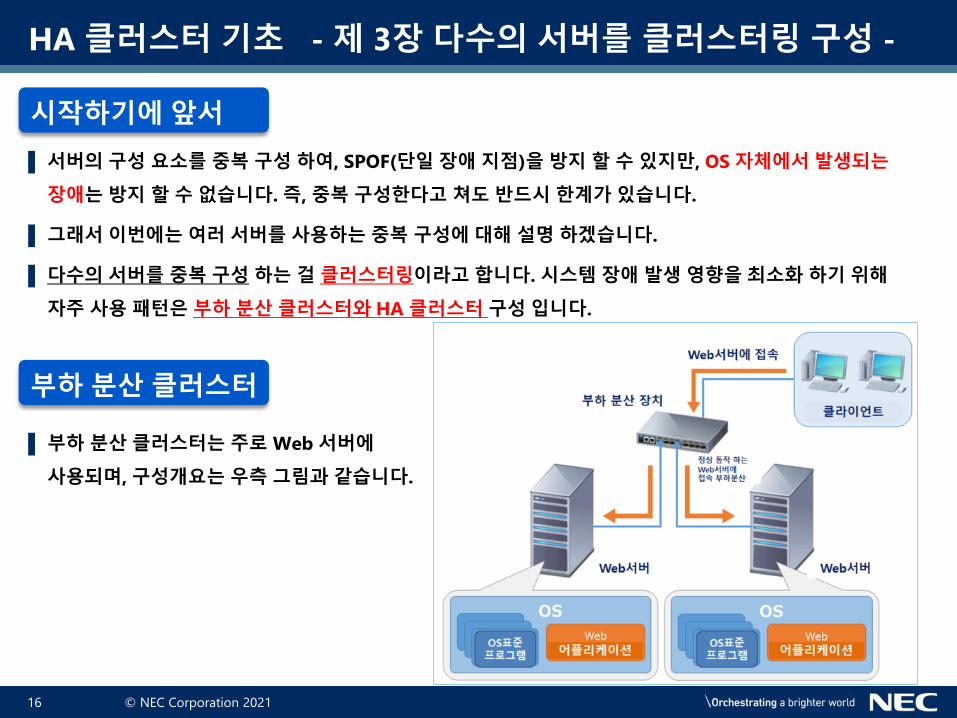
부하 분산 클러스터
▌ 부하 분산 클러스터는 주로 Web 서버에
사용되며, 구성개요는 우측 그림과 같습니다.
© NEC Corporation 202117
HA 클러스터 기초 - 제 3장 다수의 서버를 클러스터링 구성 -
부하 분산 클러스터
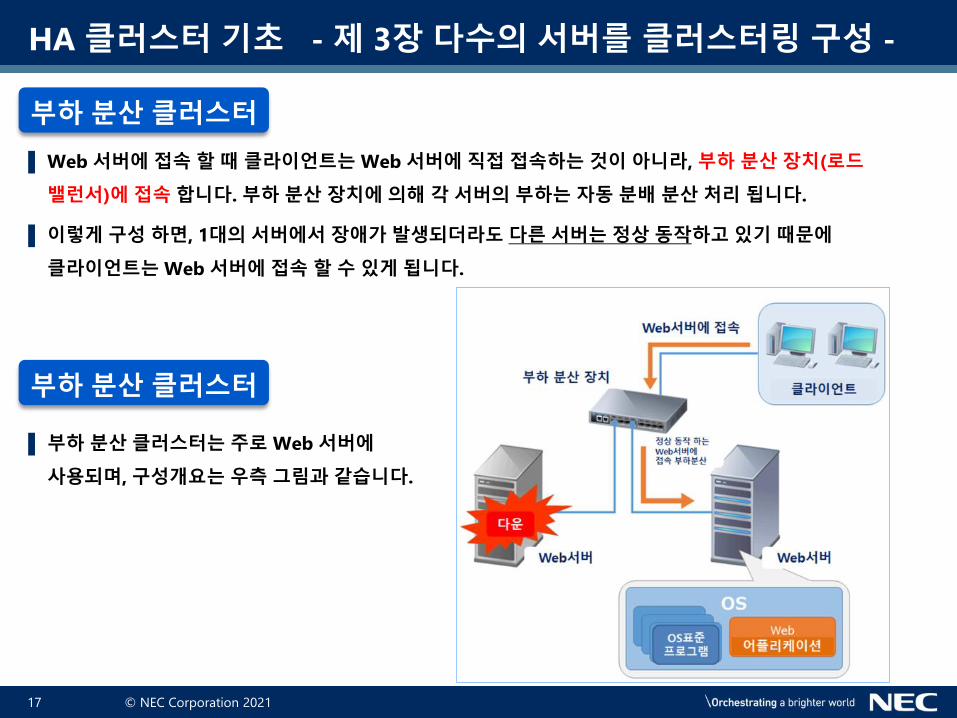
▌ Web 서버에 접속 할 때 클라이언트는 Web 서버에 직접 접속하는 것이 아니라, 부하 분산 장치(로드
밸런서)에 접속 합니다. 부하 분산 장치에 의해 각 서버의 부하는 자동 분배 분산 처리 됩니다.
▌ 이렇게 구성 하면, 1대의 서버에서 장애가 발생되더라도 다른 서버는 정상 동작하고 있기 때문에
클라이언트는 Web 서버에 접속 할 수 있게 됩니다.
부하 분산 클러스터
▌ 부하 분산 클러스터는 주로 Web 서버에
사용되며, 구성개요는 우측 그림과 같습니다.
© NEC Corporation 202118
HA 클러스터 기초 - 제 3장 다수의 서버를 클러스터링 구성 -
HA 클러스터
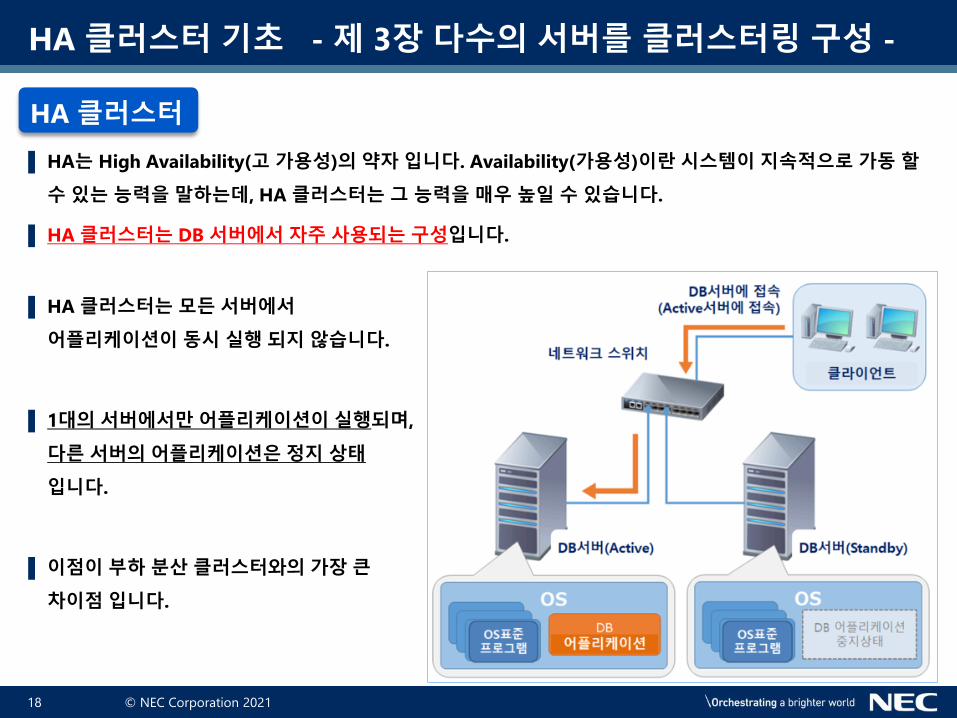
▌ HA는 High Availability(고 가용성)의 약자 입니다. Availability(가용성)이란 시스템이 지속적으로 가동 할
수 있는 능력을 말하는데, HA 클러스터는 그 능력을 매우 높일 수 있습니다.
▌ HA 클러스터는 DB 서버에서 자주 사용되는 구성입니다.
▌ HA 클러스터는 모든 서버에서
어플리케이션이 동시 실행 되지 않습니다.
▌ 1대의 서버에서만 어플리케이션이 실행되며,
다른 서버의 어플리케이션은 정지 상태
입니다.
▌ 이점이 부하 분산 클러스터와의 가장 큰
차이점 입니다.
© NEC Corporation 202119
HA 클러스터 기초 - 제 3장 다수의 서버를 클러스터링 구성 -
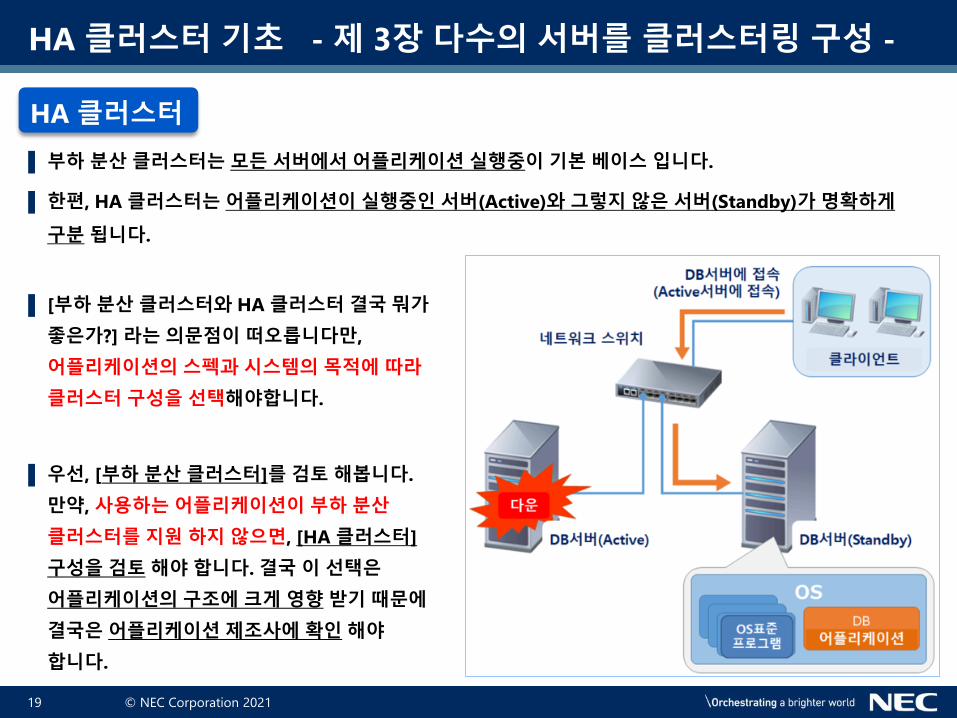
▌ 부하 분산 클러스터는 모든 서버에서 어플리케이션 실행중이 기본 베이스 입니다.
▌ 한편, HA 클러스터는 어플리케이션이 실행중인 서버(Active)와 그렇지 않은 서버(Standby)가 명확하게
구분 됩니다.
▌ [부하 분산 클러스터와 HA 클러스터 결국 뭐가
좋은가?] 라는 의문점이 떠오릅니다만,
어플리케이션의 스펙과 시스템의 목적에 따라
클러스터 구성을 선택해야합니다.
▌ 우선, [부하 분산 클러스터]를 검토 해봅니다.
만약, 사용하는 어플리케이션이 부하 분산
클러스터를 지원 하지 않으면, [HA 클러스터]
구성을 검토 해야 합니다. 결국 이 선택은
어플리케이션의 구조에 크게 영향 받기 때문에
결국은 어플리케이션 제조사에 확인 해야
합니다.
HA 클러스터
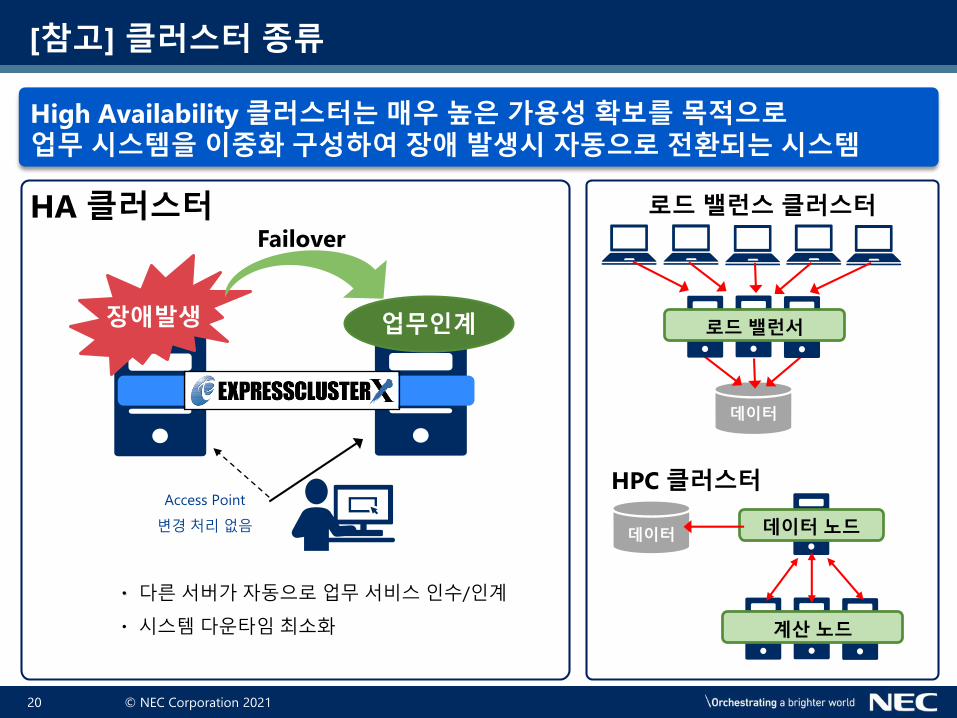
© NEC Corporation 202120
High Availability 클러스터는 매우 높은 가용성 확보를 목적으로업무 시스템을 이중화 구성하여 장애 발생시 자동으로 전환되는 시스템
・다른서버가자동으로업무서비스인수/인계
・시스템다운타임최소화
HA 클러스터
Access Point
변경처리없음
데이터
로드 밸런서
로드 밸런스 클러스터
HPC 클러스터
계산 노드
데이터 노드
업무인계
데이터
[참고] 클러스터 종류
장애발생
Failover
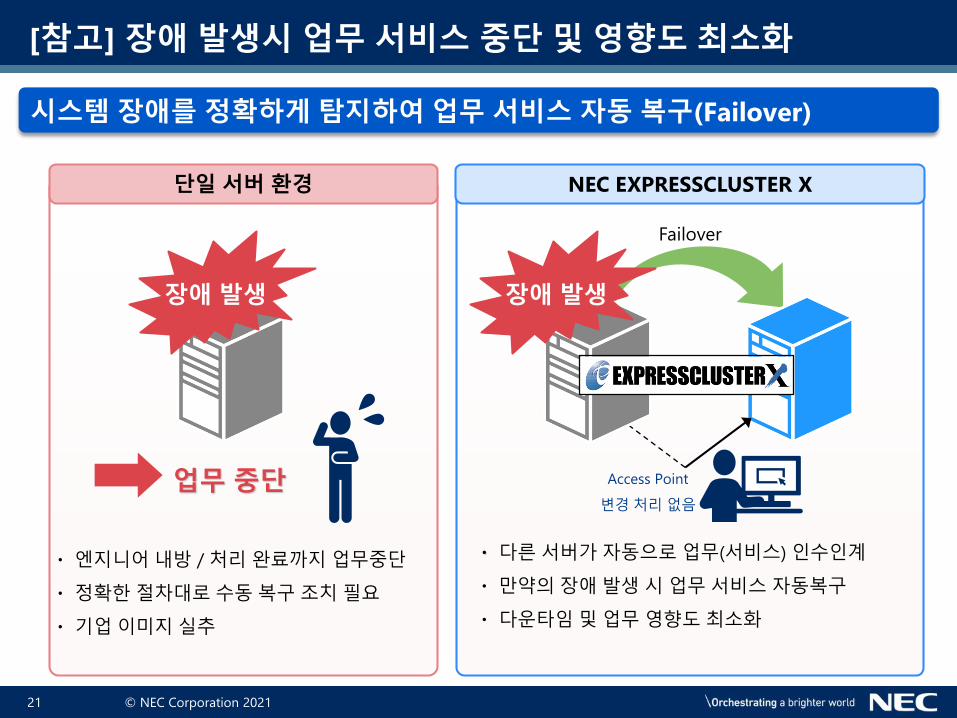
21 © NEC Corporation 2021
[참고] 장애 발생시 업무 서비스 중단 및 영향도 최소화
시스템 장애를 정확하게 탐지하여 업무 서비스 자동 복구(Failover)
Access Point
변경처리없음
업무 중단
・엔지니어내방 / 처리완료까지업무중단
・정확한절차대로수동복구조치필요
・기업이미지실추
・다른서버가자동으로업무(서비스) 인수인계
・만약의장애발생시업무서비스자동복구
・다운타임및업무영향도최소화
단일 서버 환경 NEC EXPRESSCLUSTER X
장애 발생 장애 발생
Failover
© NEC Corporation 202122
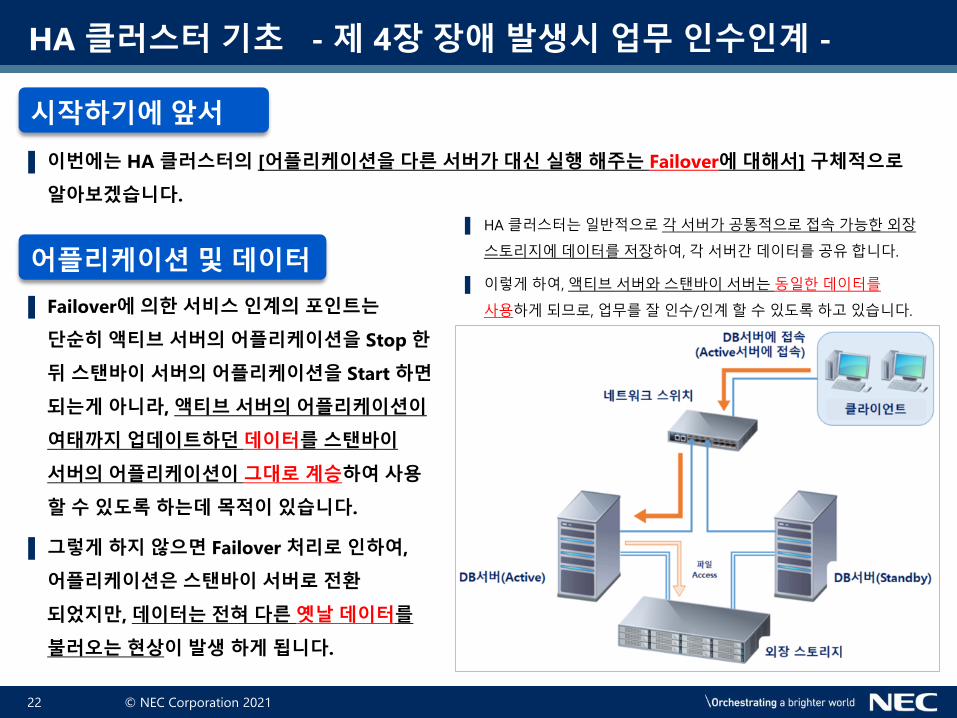
HA 클러스터 기초 - 제 4장 장애 발생시 업무 인수인계 -
▌ 이번에는 HA 클러스터의 [어플리케이션을 다른 서버가 대신 실행 해주는 Failover에 대해서] 구체적으로
알아보겠습니다.
▌ Failover에 의한 서비스 인계의 포인트는
단순히 액티브 서버의 어플리케이션을 Stop 한
뒤 스탠바이 서버의 어플리케이션을 Start 하면
되는게 아니라, 액티브 서버의 어플리케이션이
여태까지 업데이트하던 데이터를 스탠바이
서버의 어플리케이션이 그대로 계승하여 사용
할 수 있도록 하는데 목적이 있습니다.
▌ 그렇게 하지 않으면 Failover 처리로 인하여,
어플리케이션은 스탠바이 서버로 전환
되었지만, 데이터는 전혀 다른 옛날 데이터를
불러오는 현상이 발생 하게 됩니다.
시작하기에 앞서
어플리케이션 및 데이터
▌ HA 클러스터는일반적으로각서버가공통적으로접속가능한외장
스토리지에데이터를저장하여, 각서버간데이터를공유합니다.
▌ 이렇게하여, 액티브서버와스탠바이서버는동일한데이터를
사용하게되므로, 업무를잘인수/인계할수있도록하고있습니다.
© NEC Corporation 202123
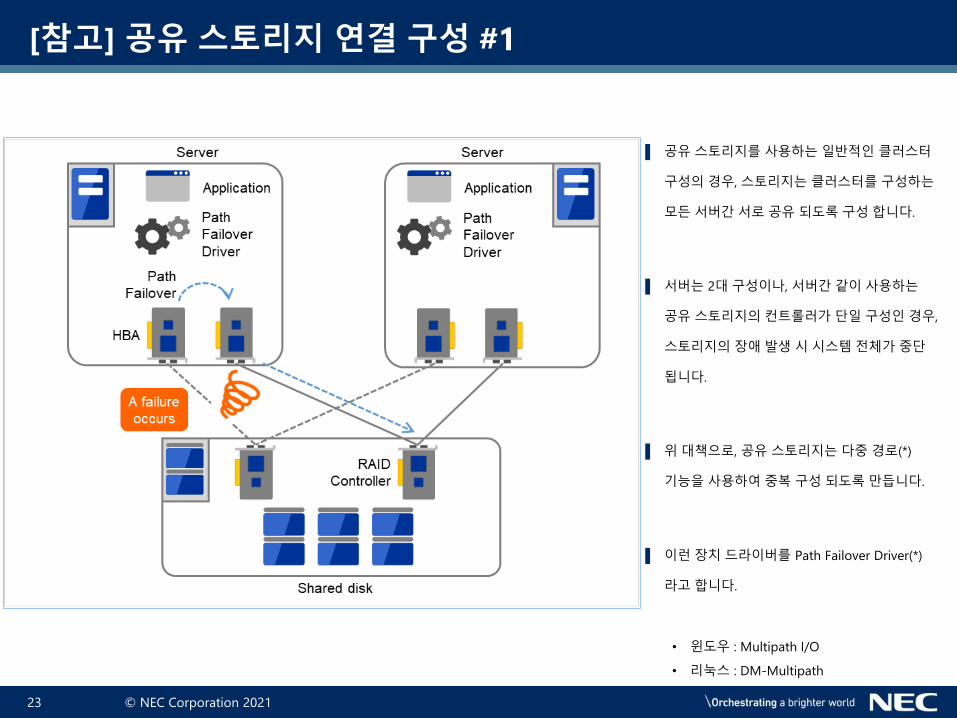
[참고] 공유 스토리지 연결 구성 #1
▌ 공유스토리지를사용하는일반적인 클러스터
구성의경우, 스토리지는 클러스터를구성하는
모든서버간서로공유되도록구성합니다.
▌ 서버는 2대구성이나, 서버간같이사용하는
공유스토리지의컨트롤러가 단일구성인경우,
스토리지의 장애발생시시스템전체가중단
됩니다.
▌ 위대책으로, 공유스토리지는다중경로(*)
기능을사용하여중복구성되도록만듭니다.
▌ 이런장치드라이버를 Path Failover Driver(*)
라고합니다.
• 윈도우 : Multipath I/O
• 리눅스 : DM-Multipath
© NEC Corporation 202124
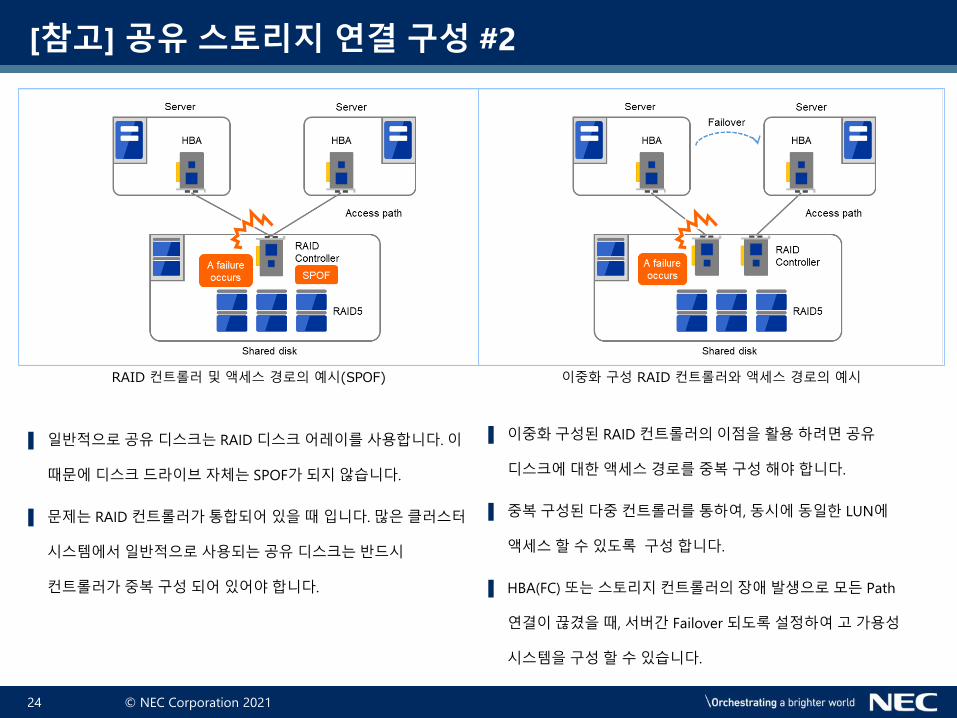
[참고] 공유 스토리지 연결 구성 #2
▌ 일반적으로공유디스크는 RAID 디스크어레이를사용합니다. 이
때문에디스크드라이브자체는 SPOF가되지않습니다.
▌ 문제는 RAID 컨트롤러가통합되어있을때입니다. 많은클러스터
시스템에서일반적으로사용되는공유디스크는반드시
컨트롤러가중복구성되어있어야합니다.
▌ 이중화구성된 RAID 컨트롤러의이점을활용하려면공유
디스크에대한액세스경로를중복구성해야합니다.
▌ 중복구성된다중컨트롤러를통하여, 동시에동일한 LUN에
액세스할수있도록 구성합니다.
▌ HBA(FC) 또는스토리지컨트롤러의장애발생으로모든 Path
연결이끊겼을때, 서버간 Failover 되도록설정하여고가용성
시스템을구성할수있습니다.
RAID 컨트롤러 및 액세스 경로의 예시(SPOF) 이중화 구성 RAID 컨트롤러와 액세스 경로의 예시
© NEC Corporation 202125
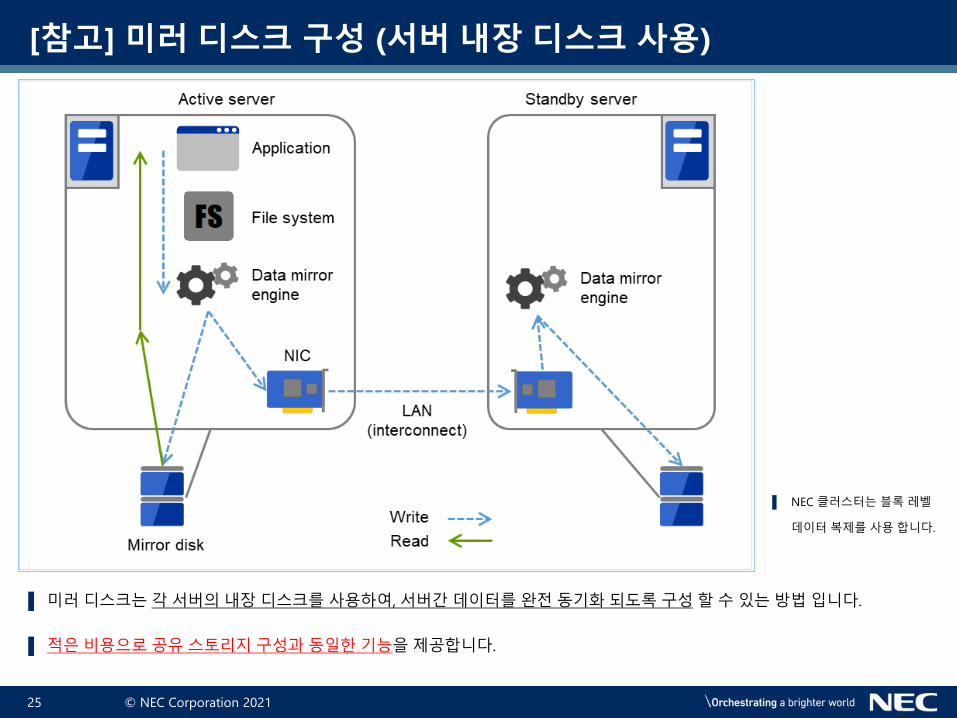
[참고] 미러 디스크 구성 (서버 내장 디스크 사용)
▌ 미러디스크는각서버의내장디스크를사용하여, 서버간데이터를완전동기화되도록구성할수있는방법입니다.
▌ 적은비용으로공유스토리지구성과동일한기능을제공합니다.
▌ NEC 클러스터는블록레벨
데이터복제를사용합니다.
© NEC Corporation 202126
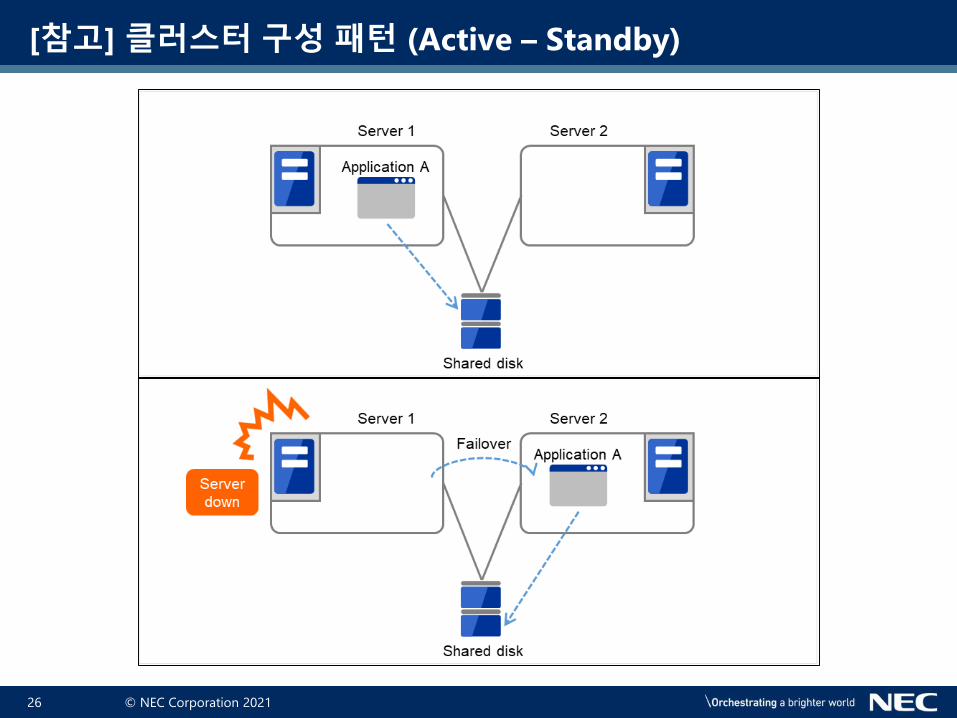
[참고] 클러스터 구성 패턴 (Active – Standby)
© NEC Corporation 202127
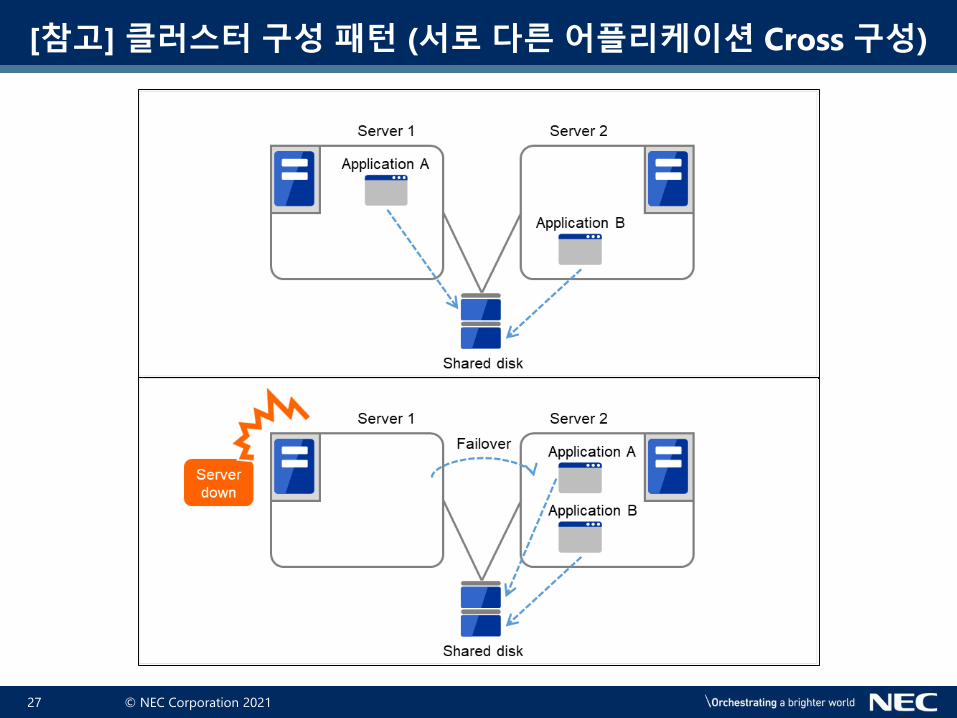
[참고] 클러스터 구성 패턴 (서로 다른 어플리케이션 Cross 구성)

© NEC Corporation 202128
[참고] 클러스터 구성 패턴 (N : 1)
▐ 지금까지 설명 했던 구성을 응용 하여, 더 많은 노드로 클러스터 구성을 확장 할 수 있습니다.
▐ 위 그림의 N:1 구성에서는 3대의 서버에서 3개의 서로 다른 어플리케이션이 실행되며, 만약의 장애 발생
시 1대의 스탠바이 서버가 어플리케이션을 Failover 받습니다.
▐ 일반 Active-Standby 클러스터 시스템은 항상 2대의 서버 중 1대는 스탠바이 서버로 동작 하게 됩니다.
▐ 그러나 N:1 구성에서는 4대의 서버 중 1대의 서버만 스탠바이로 동작 합니다.
© NEC Corporation 202129
HA 클러스터 기초 - 제 4장 장애 발생시 업무 인수인계 -
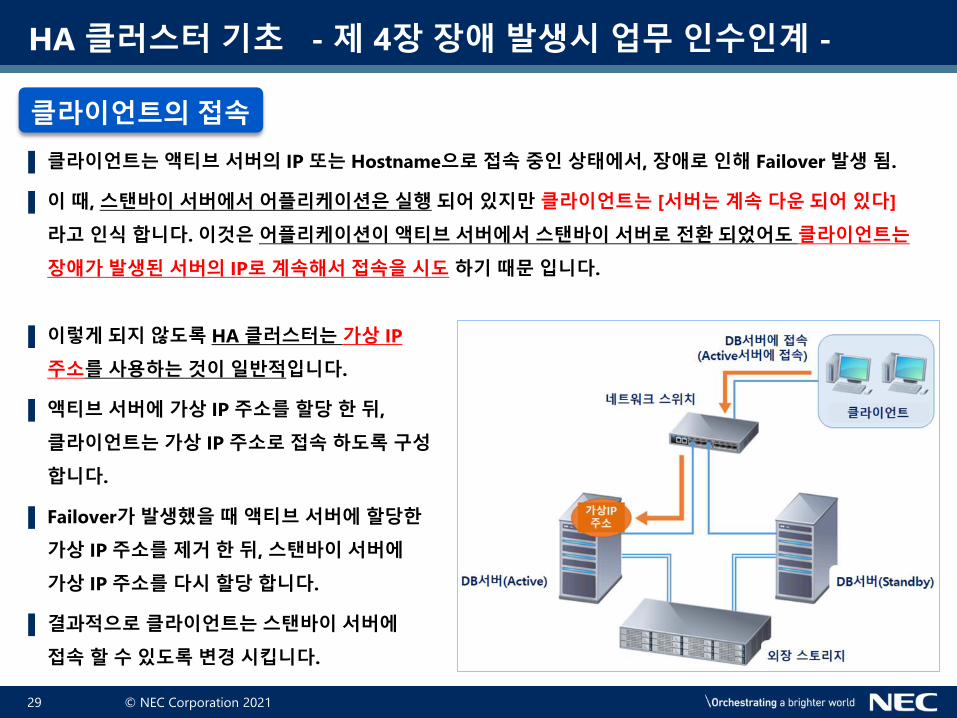
▌ 클라이언트는 액티브 서버의 IP 또는 Hostname으로 접속 중인 상태에서, 장애로 인해 Failover 발생 됨.
▌ 이 때, 스탠바이 서버에서 어플리케이션은 실행 되어 있지만 클라이언트는 [서버는 계속 다운 되어 있다]
라고 인식 합니다. 이것은 어플리케이션이 액티브 서버에서 스탠바이 서버로 전환 되었어도 클라이언트는
장애가 발생된 서버의 IP로 계속해서 접속을 시도 하기 때문 입니다.
클라이언트의 접속
▌ 이렇게 되지 않도록 HA 클러스터는 가상 IP
주소를 사용하는 것이 일반적입니다.
▌ 액티브 서버에 가상 IP 주소를 할당 한 뒤,
클라이언트는 가상 IP 주소로 접속 하도록 구성
합니다.
▌ Failover가 발생했을 때 액티브 서버에 할당한
가상 IP 주소를 제거 한 뒤, 스탠바이 서버에
가상 IP 주소를 다시 할당 합니다.
▌ 결과적으로 클라이언트는 스탠바이 서버에
접속 할 수 있도록 변경 시킵니다.
© NEC Corporation 202130
HA 클러스터 기초 - 제 4장 장애 발생시 업무 인수인계 -
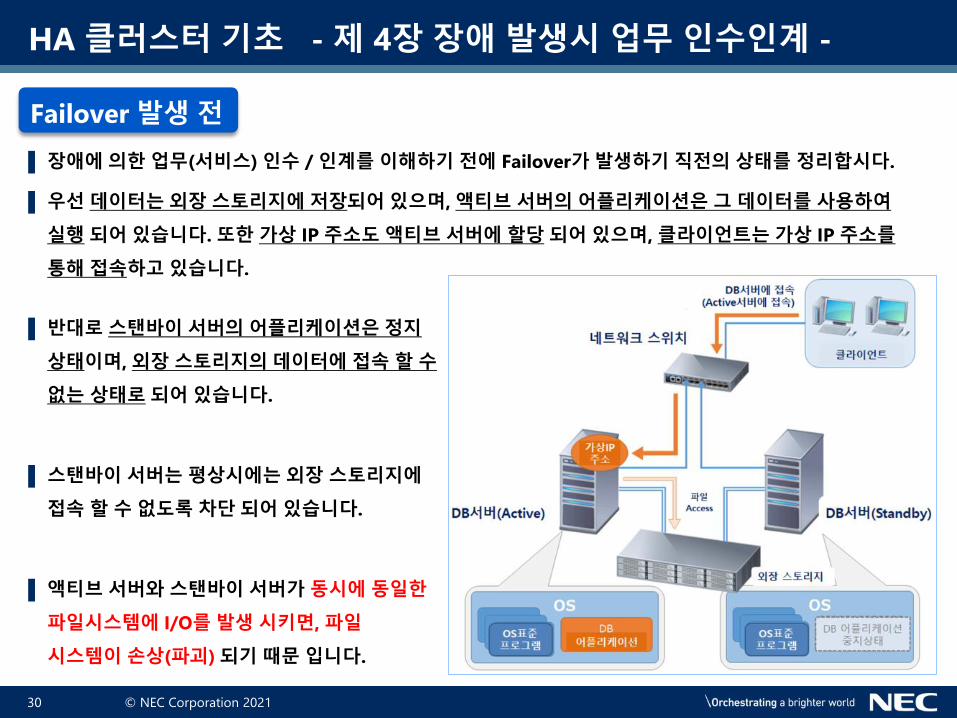
▌ 장애에 의한 업무(서비스) 인수 / 인계를 이해하기 전에 Failover가 발생하기 직전의 상태를 정리합시다.
▌ 우선 데이터는 외장 스토리지에 저장되어 있으며, 액티브 서버의 어플리케이션은 그 데이터를 사용하여
실행 되어 있습니다. 또한 가상 IP 주소도 액티브 서버에 할당 되어 있으며, 클라이언트는 가상 IP 주소를
통해 접속하고 있습니다.
Failover 발생 전
▌ 반대로 스탠바이 서버의 어플리케이션은 정지
상태이며, 외장 스토리지의 데이터에 접속 할 수
없는 상태로 되어 있습니다.
▌ 스탠바이 서버는 평상시에는 외장 스토리지에
접속 할 수 없도록 차단 되어 있습니다.
▌ 액티브 서버와 스탠바이 서버가 동시에 동일한
파일시스템에 I/O를 발생 시키면, 파일
시스템이 손상(파괴) 되기 때문 입니다.
© NEC Corporation 202131
[참고] 스플릿 브레인 현상 (네트워크 파티션) ※ 매우 중요
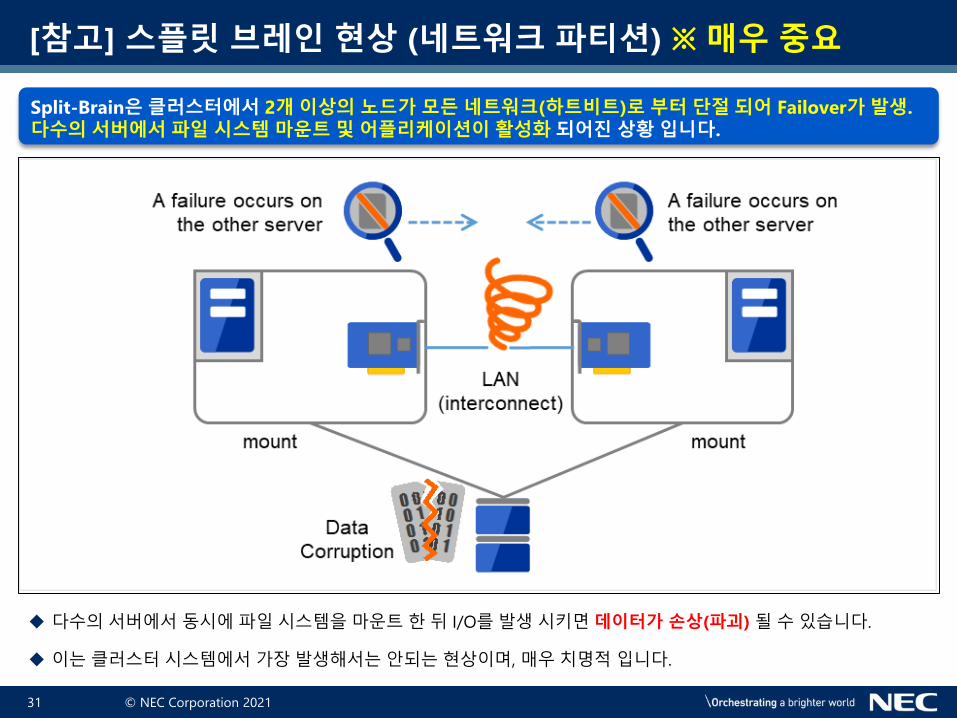
Split-Brain은 클러스터에서 2개 이상의 노드가 모든 네트워크(하트비트)로 부터 단절 되어 Failover가 발생.
다수의 서버에서 파일 시스템 마운트 및 어플리케이션이 활성화 되어진 상황 입니다.
◆ 다수의서버에서동시에파일시스템을마운트한뒤 I/O를발생시키면 데이터가 손상(파괴) 될수있습니다.
◆ 이는클러스터시스템에서가장발생해서는안되는현상이며, 매우치명적입니다.
© NEC Corporation 202132
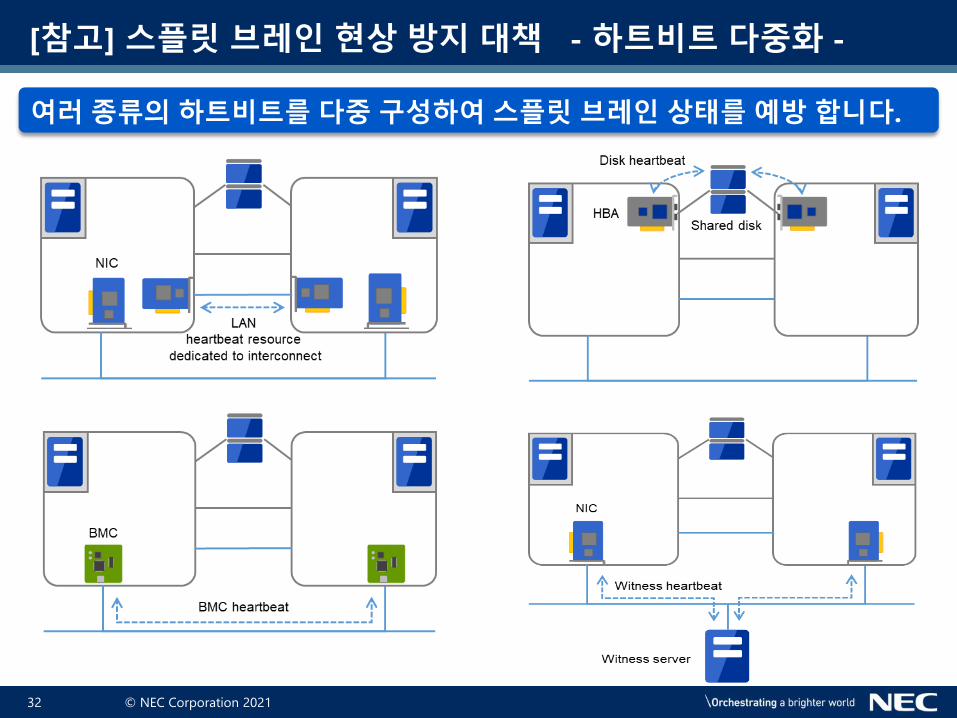
여러 종류의 하트비트를 다중 구성하여 스플릿 브레인 상태를 예방 합니다.
[참고] 스플릿 브레인 현상 방지 대책 - 하트비트 다중화 -
© NEC Corporation 202133
HA 클러스터 기초 - 제 4장 장애 발생시 업무 인수인계 -
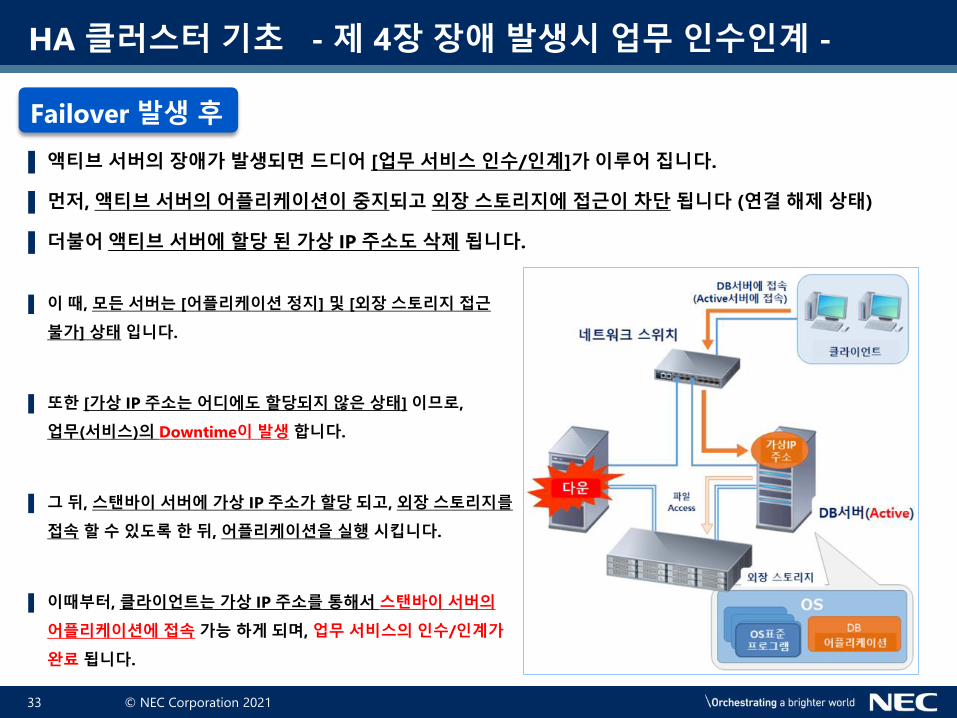
▌ 액티브 서버의 장애가 발생되면 드디어 [업무 서비스 인수/인계]가 이루어 집니다.
▌ 먼저, 액티브 서버의 어플리케이션이 중지되고 외장 스토리지에 접근이 차단 됩니다 (연결 해제 상태)
▌ 더불어 액티브 서버에 할당 된 가상 IP 주소도 삭제 됩니다.
Failover 발생 후
▌ 이 때, 모든 서버는 [어플리케이션 정지] 및 [외장 스토리지 접근
불가] 상태 입니다.
▌ 또한 [가상 IP 주소는 어디에도 할당되지 않은 상태] 이므로,
업무(서비스)의 Downtime이 발생 합니다.
▌ 그 뒤, 스탠바이 서버에 가상 IP 주소가 할당 되고, 외장 스토리지를
접속 할 수 있도록 한 뒤, 어플리케이션을 실행 시킵니다.
▌ 이때부터, 클라이언트는 가상 IP 주소를 통해서 스탠바이 서버의
어플리케이션에 접속 가능 하게 되며, 업무 서비스의 인수/인계가
완료 됩니다.
© NEC Corporation 202134
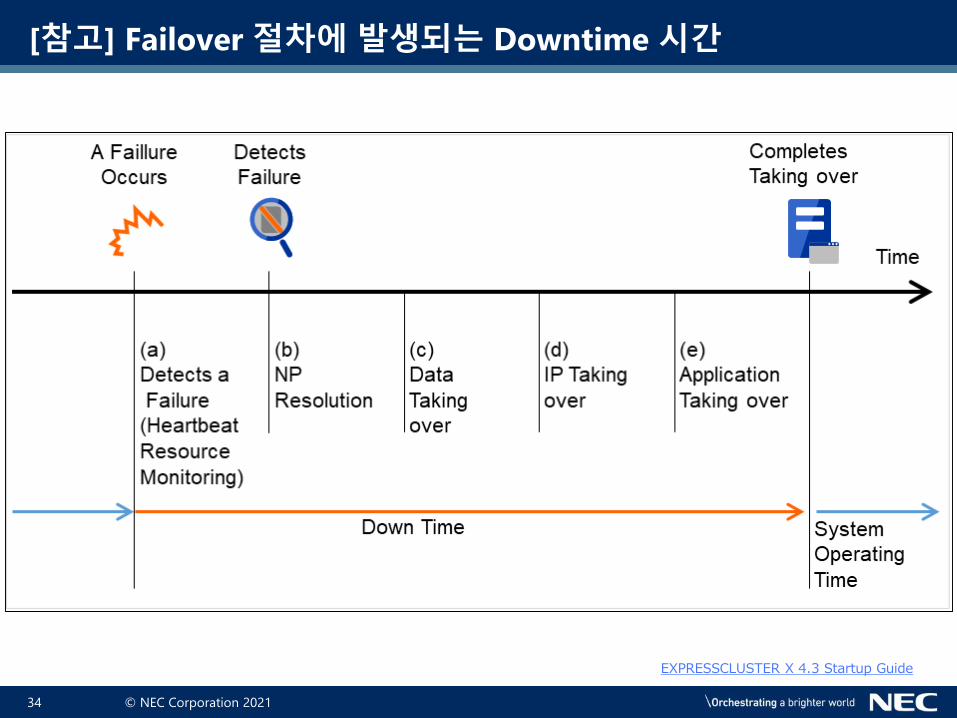
[참고] Failover 절차에 발생되는 Downtime 시간
EXPRESSCLUSTER X 4.3 Startup Guide
35 © NEC Corporation 2021
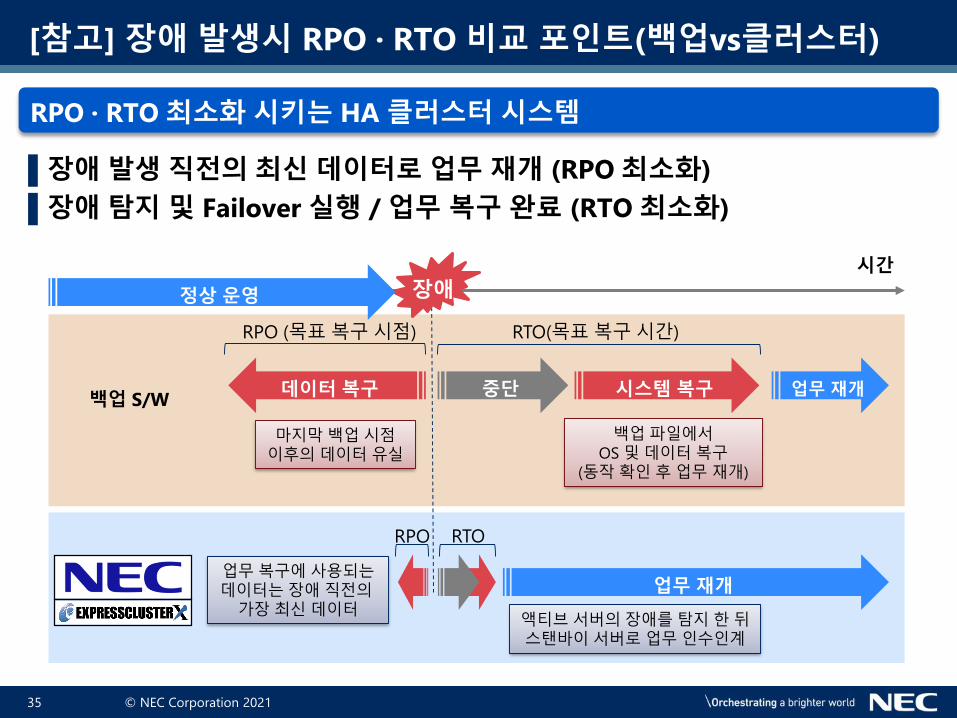
[참고] 장애 발생시 RPO · RTO 비교 포인트(백업vs클러스터)
RPO · RTO 최소화 시키는 HA 클러스터 시스템
▌장애 발생 직전의 최신 데이터로 업무 재개 (RPO 최소화)
▌장애 탐지 및 Failover 실행 / 업무 복구 완료 (RTO 최소화)
시스템 복구 업무 재개
시간
RTO(목표복구시간)RPO (목표복구시점)
장애정상 운영
업무 재개업무복구에사용되는데이터는장애직전의가장최신데이터
액티브서버의장애를탐지한뒤스탠바이서버로업무인수인계
백업파일에서OS 및데이터복구
(동작확인후업무재개)
중단백업 S/W
데이터 복구
마지막백업시점이후의데이터유실
RTORPO
© NEC Corporation 202136
EXPRESSCLUSTER X 4.3 Startup Guide
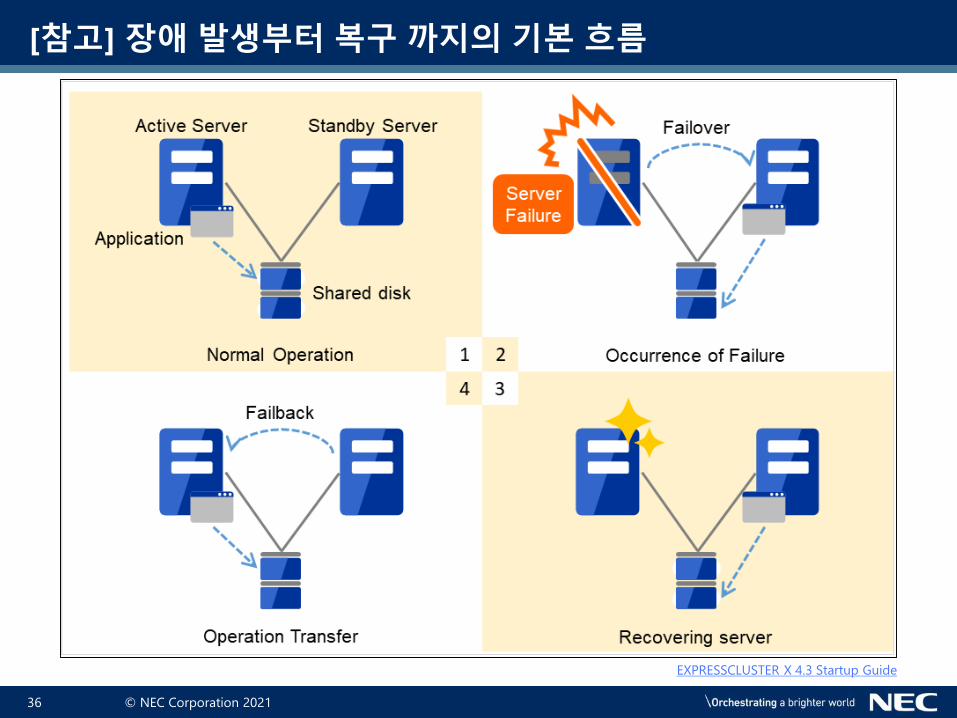
[참고] 장애 발생부터 복구 까지의 기본 흐름

시스템 가용성 향상을 위한 접근 방법
© NEC Corporation 202138
하드웨어
가용성
高
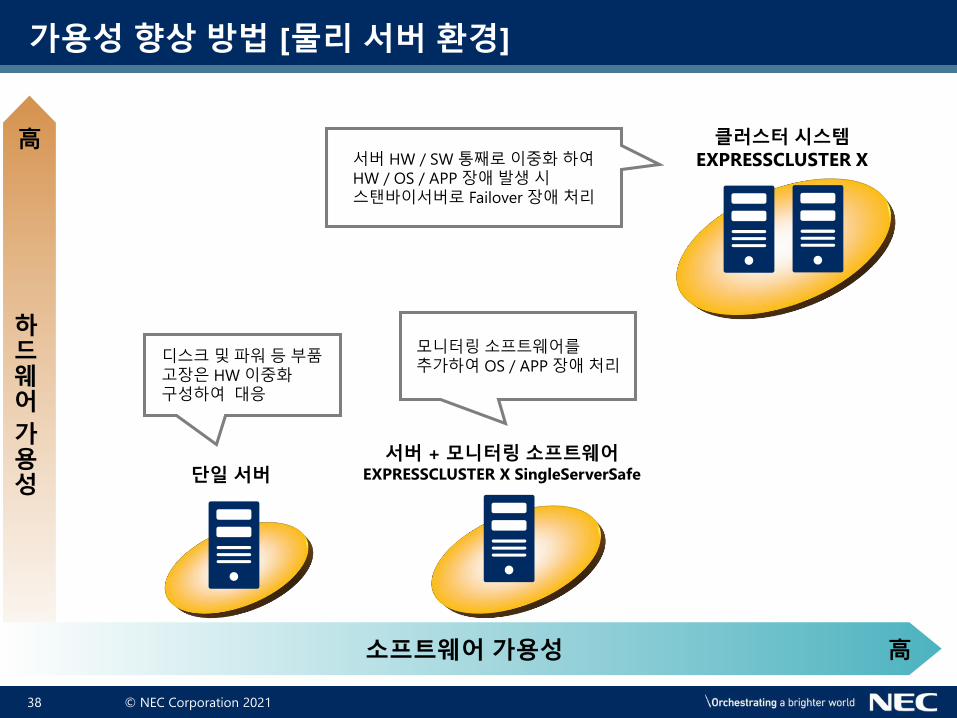
가용성 향상 방법 [물리 서버 환경]
클러스터 시스템EXPRESSCLUSTER X
단일 서버
서버 HW / SW 통째로이중화하여HW / OS / APP 장애발생시스탠바이서버로 Failover 장애처리
서버 + 모니터링 소프트웨어EXPRESSCLUSTER X SingleServerSafe
디스크및파워등부품고장은 HW 이중화구성하여 대응
모니터링소프트웨어를추가하여 OS / APP 장애처리
소프트웨어 가용성 高
© NEC Corporation 202139
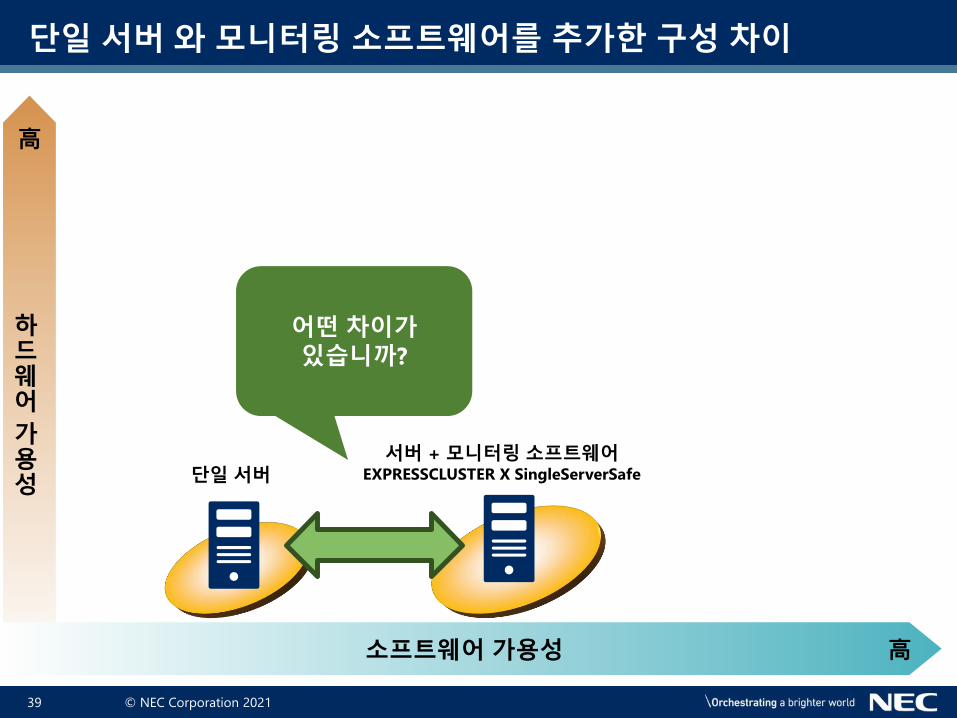
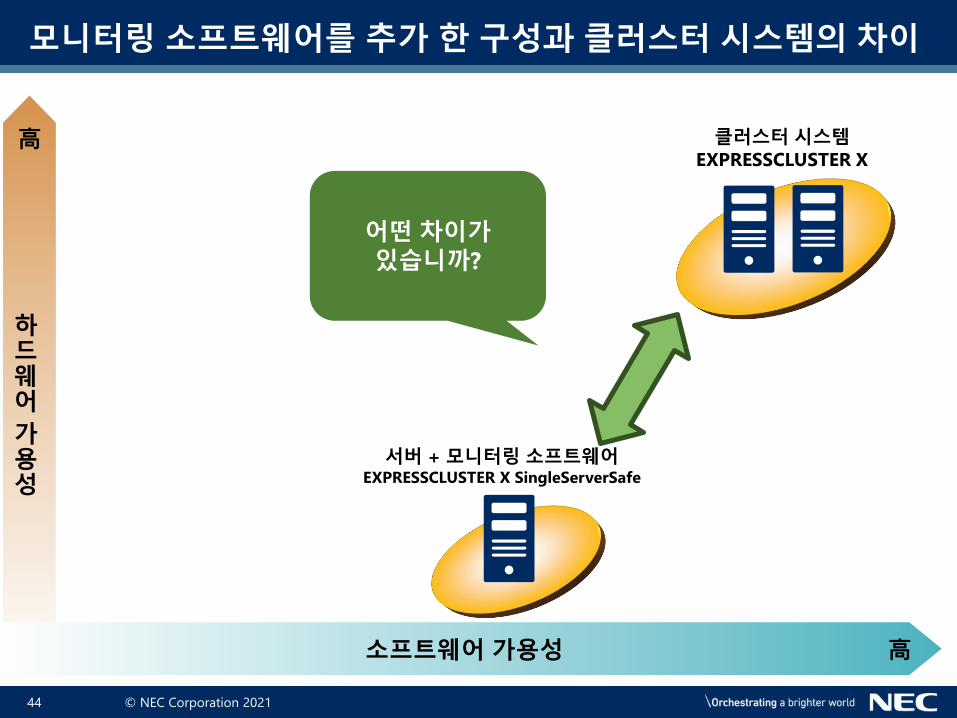
단일 서버 와 모니터링 소프트웨어를 추가한 구성 차이
어떤 차이가있습니까?
단일 서버서버 + 모니터링 소프트웨어
EXPRESSCLUSTER X SingleServerSafe
하드웨어
가용성
高
소프트웨어 가용성 高
© NEC Corporation 202140
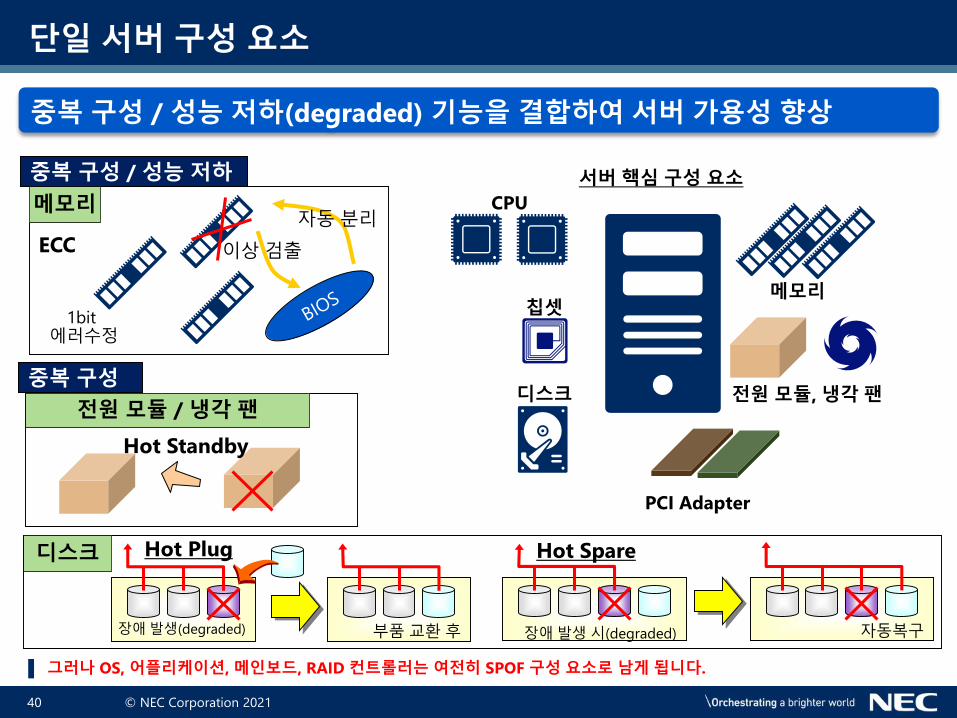
중복 구성 / 성능 저하(degraded) 기능을 결합하여 서버 가용성 향상
서버 핵심 구성 요소
PCI Adapter
부품교환후장애발생(degraded)
Hot Plug
자동복구장애발생시(degraded)
Hot Spare
Hot Standby
중복 구성 / 성능 저하
ECC 이상검출
자동분리
1bit 에러수정
메모리
디스크
전원 모듈 / 냉각 팬
중복 구성
메모리칩셋
전원 모듈, 냉각 팬
CPU
디스크
단일 서버 구성 요소
▌ 그러나 OS, 어플리케이션, 메인보드, RAID 컨트롤러는 여전히 SPOF 구성 요소로 남게 됩니다.

© NEC Corporation 202141
중복 구성 / 성능 저하(degraded) 기능을 결합하여 서버 가용성 향상
서버 핵심 구성 요소
PCI Adapter
부품교환후장애발생(degraded)
Hot Plug
자동복구장애발생시(degraded)
Hot Spare
Hot Standby
중복 구성 / 성능 저하
ECC 이상검출
자동분리
1bit 에러수정
메모리
디스크
전원 모듈 / 냉각 팬
중복 구성
메모리칩셋
전원 모듈, 냉각 팬
CPU
디스크
단일 서버 구성의 경우
▌ 그러나 OS, 어플리케이션, 메인보드, RAID 컨트롤러는 여전히 SPOF 구성 요소로 남게 됩니다.
과제소프트웨어 장애 대비책이 없기 때문에
・프로세스 중지, 서비스 중지・OS 행업, OS 에러・어플리케이션 행업, 에러
가 발생 하는 경우 업무 시스템 중단

© NEC Corporation 202142
OS 장애
2. 어플리케이션 또는OS를 재 실행(재 부팅)
✓ 장애 탐지시 어플리케이션 또는 OS 재 부팅 처리하여 시스템 중단 방지
✓ 어플리케이션의 행업 및 상태 이상도 감시
✓ 이벤트 발생시 E-Mail 알림
하드웨어, OS, 어플리케이션의 상태를 모니터링장애 탐지 시 어플리케이션 및 OS 재 실행(재 부팅)시켜 업무 복구
Single Server Safe저 비용
1. 장애 모니터링 ▶ APP / OS를 재 실행(재 부팅)
어플리케이션장애
단일 서버+SingleServerSafe
Apache
Oracle
© NEC Corporation 202143
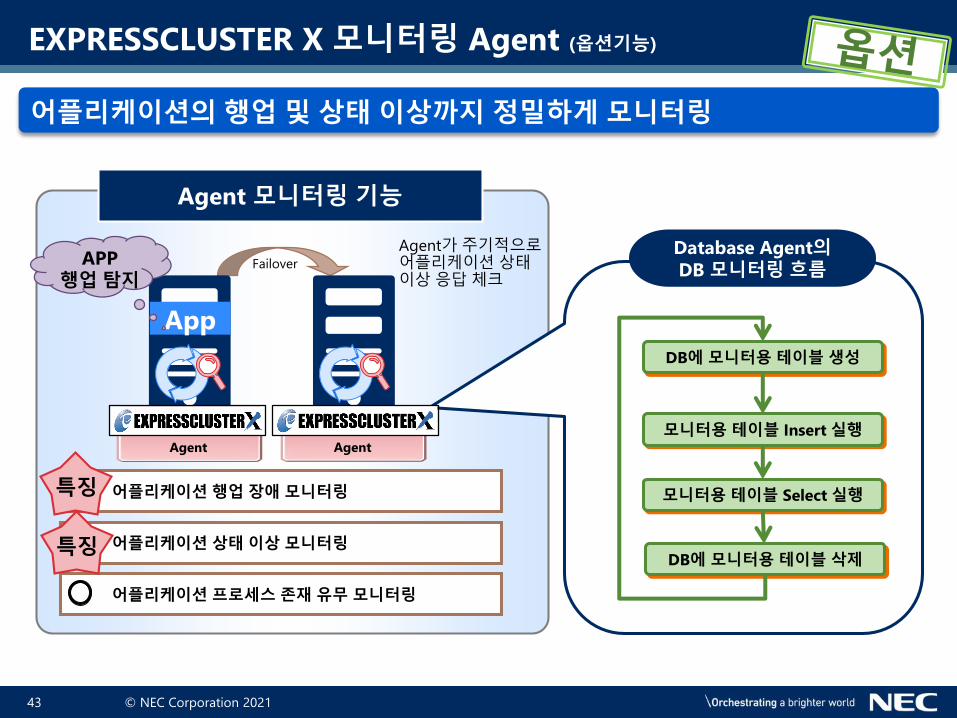
어플리케이션의 행업 및 상태 이상까지 정밀하게 모니터링
어플리케이션 행업 장애 모니터링
어플리케이션 상태 이상 모니터링
어플리케이션 프로세스 존재 유무 모니터링
Agent가주기적으로어플리케이션상태이상응답체크
Agent Agent
Database Agent의DB 모니터링 흐름
DB에 모니터용 테이블 생성
모니터용 테이블 Insert 실행
모니터용 테이블 Select 실행
DB에 모니터용 테이블 삭제
특징
특징
EXPRESSCLUSTER X 모니터링 Agent (옵션기능)
Agent 모니터링 기능
App
APP
행업 탐지Failover
© NEC Corporation 202144
모니터링 소프트웨어를 추가 한 구성과 클러스터 시스템의 차이
클러스터 시스템EXPRESSCLUSTER X
서버 + 모니터링 소프트웨어EXPRESSCLUSTER X SingleServerSafe
어떤 차이가있습니까?
하드웨어
가용성
高
소프트웨어 가용성 高

© NEC Corporation 202145
OS 장애 발생
2. 어플리케이션 또는OS를 재 실행(재 부팅)
✓ 장애 탐지시 어플리케이션 또는 OS 재 부팅 처리하여 시스템 중단 방지
✓ 어플리케이션의 행업 및 상태 이상도 감시
✓ 이벤트 발생시 E-Mail 알림
단일 서버+SingleServerSafe 구성의 경우
하드웨어, OS, 어플리케이션의 상태를 모니터링장애 탐지 시 어플리케이션 및 OS 재 실행(재 부팅)시켜 업무 복구
Single Server Safe저 비용
1. 장애 모니터링 ▶ APP / OS를 재 실행(재 부팅)
어플리케이션장애 발생
과제1중복 구성 되지 않은 부품의
하드웨어 고장 발생시 대비책이 없기 때문에
・RAID컨트롤러 고장・CPU 고장・메인보드 칩셋 고장
이 발생 하는 경우 업무 시스템 중단

© NEC Corporation 202146
OS 장애 발생
2. 어플리케이션 또는OS를 재 실행(재 부팅)
✓ 장애 탐지시 어플리케이션 또는 OS 재 부팅 처리하여 시스템 중단 방지
✓ 어플리케이션의 행업 및 상태 이상도 감시
✓ 이벤트 발생시 E-Mail 알림
단일 서버+SingleServerSafe 구성의 경우
하드웨어, OS, 어플리케이션의 상태를 모니터링장애 탐지 시 어플리케이션 및 OS 재 실행(재 부팅)시켜 업무 복구
Single Server Safe저 비용
1. 장애 모니터링 ▶ APP / OS를 재 실행(재 부팅)
어플리케이션장애 발생
과제2서버(OS)는 실제 1개 이기 때문에
• 장애 발생 시 백업 된 시점 이후의 데이터 손실
• 장애 발생 시 복구처리 작업이 완료 될 때 까지 업무
중단
• 계획된 유지보수 작업 시 업무 중지가 필요
(OS 업데이트, APP 패치 적용, 유지보수 작업 등)
© NEC Corporation 202147
OS
1.EXPRESSCLUSTER가HW, OS, APP 장애 감시
2. Failover 처리 하여업무(서비스) 복구
APP
HW
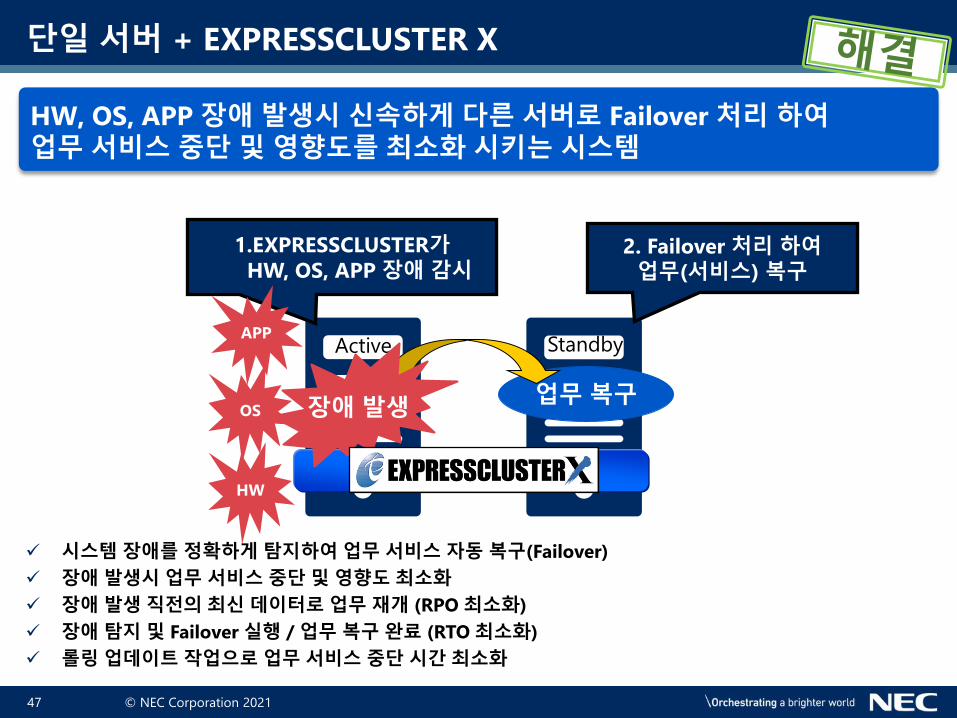
HW, OS, APP 장애 발생시 신속하게 다른 서버로 Failover 처리 하여업무 서비스 중단 및 영향도를 최소화 시키는 시스템
업무 복구
StandbyActive
장애 발생
✓ 시스템 장애를 정확하게 탐지하여 업무 서비스 자동 복구(Failover)
✓ 장애 발생시 업무 서비스 중단 및 영향도 최소화
✓ 장애 발생 직전의 최신 데이터로 업무 재개 (RPO 최소화)
✓ 장애 탐지 및 Failover 실행 / 업무 복구 완료 (RTO 최소화)
✓ 롤링 업데이트 작업으로 업무 서비스 중단 시간 최소화
단일 서버 + EXPRESSCLUSTER X
© NEC Corporation 202148
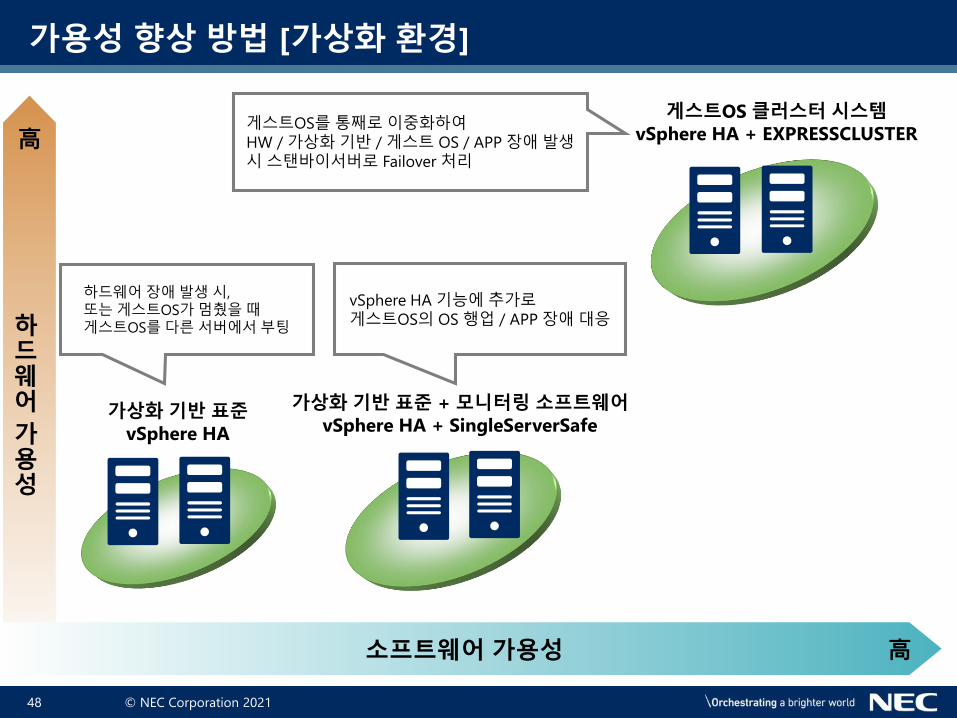
게스트OS 클러스터 시스템vSphere HA + EXPRESSCLUSTER
가상화 기반 표준vSphere HA
게스트OS를통째로이중화하여HW / 가상화기반 / 게스트 OS / APP 장애발생시스탠바이서버로 Failover 처리
하드웨어장애발생시,
또는게스트OS가멈췄을때게스트OS를다른서버에서부팅
가상화 기반 표준 + 모니터링 소프트웨어vSphere HA + SingleServerSafe
vSphere HA 기능에추가로게스트OS의 OS 행업 / APP 장애대응
가용성 향상 방법 [가상화 환경]
하드웨어
가용성
高
소프트웨어 가용성 高
49 © NEC Corporation 2021
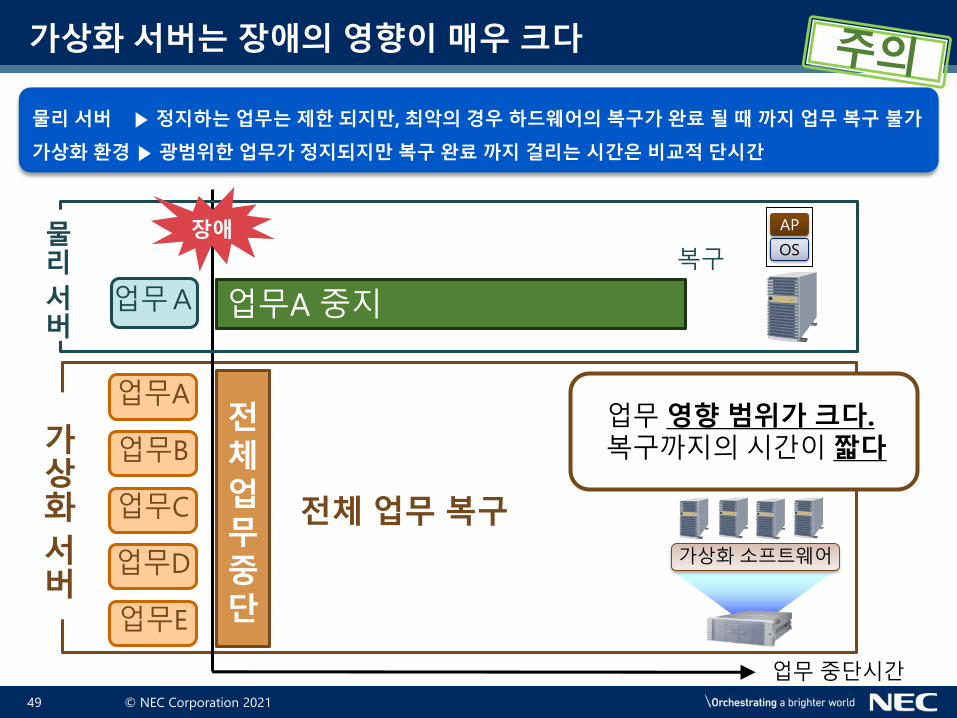
가상화 서버는 장애의 영향이 매우 크다
물리 서버 ▶ 정지하는 업무는 제한 되지만, 최악의 경우 하드웨어의 복구가 완료 될 때 까지 업무 복구 불가
가상화 환경 ▶ 광범위한 업무가 정지되지만 복구 완료 까지 걸리는 시간은 비교적 단시간
전체업무중단
업무D
업무B
업무A
업무E
업무C
업무중단시간
전체 업무 복구
업무A 중지업무A
복구물리
서버
장애
업무 영향 범위가 크다.
복구까지의시간이 짧다
가상화소프트웨어
OS
AP
가상화
서버
© NEC Corporation 202150
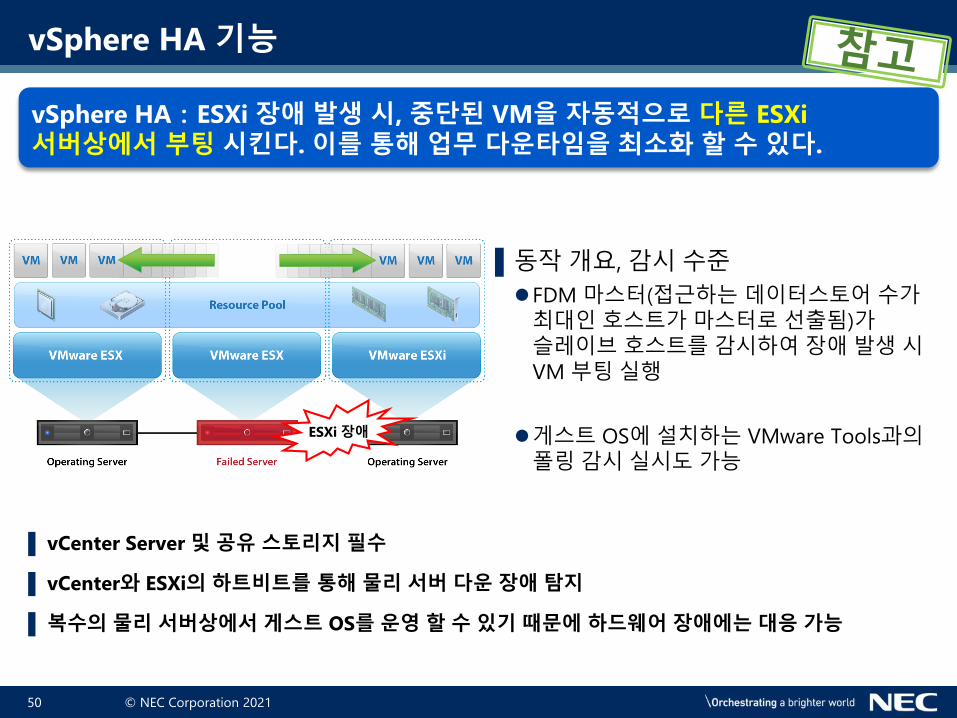
vSphere HA 기능
vSphere HA:ESXi 장애 발생 시, 중단된 VM을 자동적으로 다른 ESXi
서버상에서 부팅 시킨다. 이를 통해 업무 다운타임을 최소화 할 수 있다.
▌ vCenter Server 및 공유 스토리지 필수
▌ vCenter와 ESXi의 하트비트를 통해 물리 서버 다운 장애 탐지
▌복수의 물리 서버상에서 게스트 OS를 운영 할 수 있기 때문에 하드웨어 장애에는 대응 가능
▌동작개요, 감시수준
⚫FDM 마스터(접근하는데이터스토어수가최대인호스트가마스터로선출됨)가슬레이브호스트를감시하여장애발생시VM 부팅실행
⚫게스트 OS에설치하는 VMware Tools과의폴링감시실시도가능
ESXi 장애
© NEC Corporation 202151
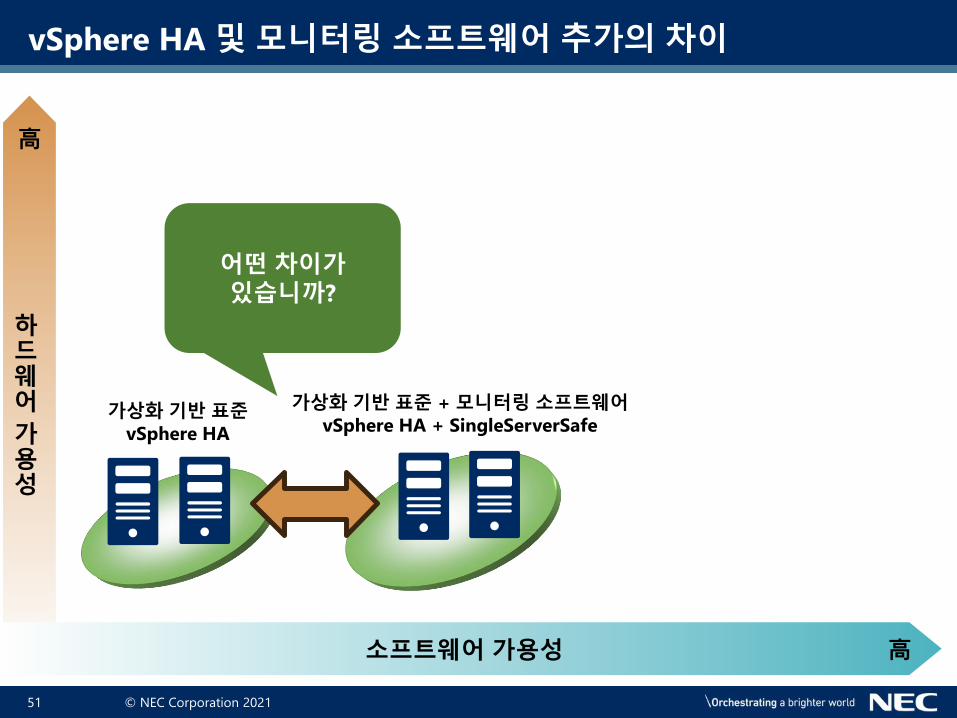
vSphere HA 및 모니터링 소프트웨어 추가의 차이
어떤 차이가있습니까?
가상화 기반 표준vSphere HA
가상화 기반 표준 + 모니터링 소프트웨어vSphere HA + SingleServerSafe
하드웨어
가용성
高
소프트웨어 가용성 高

© NEC Corporation 202152
vSphere HA 구성만 되어 있을 경우
vSphere HA:ESXi 장애 발생 시, 중단된 VM을 자동적으로 다른 ESXi
서버상에서 부팅 시킨다. 이를 통해 업무 다운타임을 최소화 할 수 있다.
▌vCenter Server 및 공유 스토리지 필수
▌동작개요, 감시수준
⚫FDM 마스터(접근하는데이터스토어수가최대인호스트가마스터로선출됨)가슬레이브호스트를감시하여장애발생시VM 부팅실행
⚫게스트 OS에설치하는 VMware Tools과의폴링감시실시도가능
ESXi 장애
과제1소프트웨어 장애 대비책이 없기 때문에
・프로세스 중지, 서비스 중지・OS 행업・어플리케이션 행업, 에러
가 발생 하는 경우 업무 시스템 중단
© NEC Corporation 202153
vSphere HA + SingleServerSafe
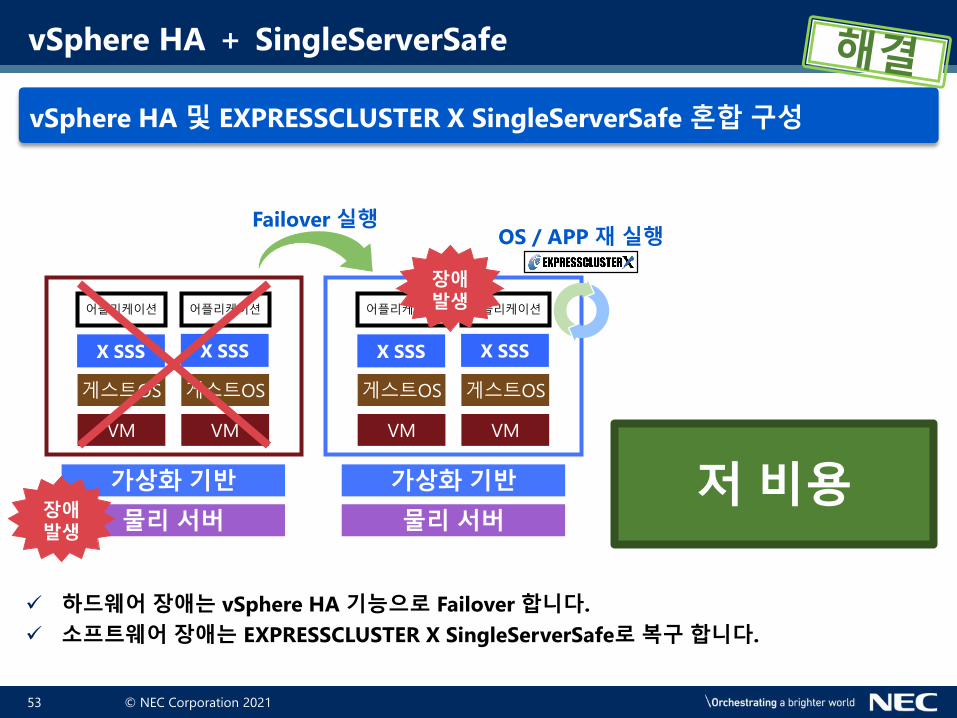
vSphere HA 및 EXPRESSCLUSTER X SingleServerSafe 혼합 구성
물리 서버
가상화 기반
어플리케이션 어플리케이션
VM VM
게스트OS 게스트OS
X SSS X SSS
✓ 하드웨어 장애는 vSphere HA 기능으로 Failover 합니다.
✓ 소프트웨어 장애는 EXPRESSCLUSTER X SingleServerSafe로 복구 합니다.
저 비용물리 서버
가상화 기반
어플리케이션 어플리케이션
VM VM
게스트OS 게스트OS
X SSS X SSS
Failover 실행
장애발생
장애발생
OS / APP 재 실행
© NEC Corporation 202154
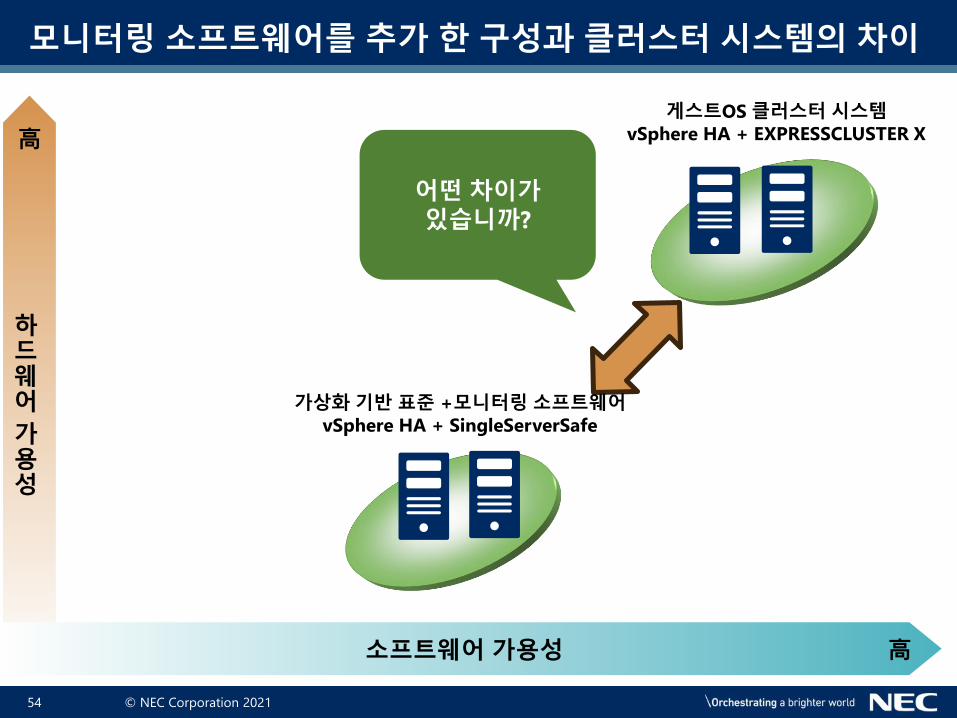
모니터링 소프트웨어를 추가 한 구성과 클러스터 시스템의 차이
어떤 차이가있습니까?
가상화 기반 표준 +모니터링 소프트웨어vSphere HA + SingleServerSafe
게스트OS 클러스터 시스템vSphere HA + EXPRESSCLUSTER X
하드웨어
가용성
高
소프트웨어 가용성 高

© NEC Corporation 202155
vSphere HA 및 EXPRESSCLUSTER X SingleServerSafe 혼합 구성
물리 서버
가상화 기반
어플리케이션 어플리케이션
VM VM
게스트OS 게스트OS
X SSS X SSS
✓ 하드웨어 장애는 vSphere HA 기능으로 Failover 합니다.
✓ 소프트웨어 장애는 EXPRESSCLUSTER X SingleServerSafe로 복구 합니다.
저 비용물리 서버
가상화 기반
어플리케이션 어플리케이션
VM VM
게스트OS 게스트OS
X SSS X SSS
Failover 실행
장애발생
장애발생
OS / APP 재실행
과제1vSphere의 HW 모니터링은 vCenter 및
ESXi 의 관리 네트워크를 통하여 모니터링 하기 때문에
· 업무용 네트워크 NIC의 장애 발생 시, Failover하지 않는다
vSphere HA + SingleServerSafe 구성의 경우

© NEC Corporation 202156
vSphere HA 및 EXPRESSCLUSTER X SingleServerSafe 혼합 구성
물리 서버
가상화 기반
어플리케이션 어플리케이션
VM VM
게스트OS 게스트OS
X SSS X SSS
✓ 하드웨어 장애는 vSphere HA 기능으로 Failover 합니다.
✓ 소프트웨어 장애는 EXPRESSCLUSTER X SingleServerSafe로 복구 합니다.
저 비용물리 서버
가상화 기반
어플리케이션 어플리케이션
VM VM
게스트OS 게스트OS
X SSS X SSS
Failover 실행
장애발생
장애발생
OS / APP 재실행
과제2서버(Guest OS)는 실제 1개 이기 때문에
• 장애 발생 시 백업 된 시점 이후의 데이터 손실
• 장애 발생 시 복구처리 작업이 완료 될 때 까지 업무
중단
• 계획된 유지보수 작업 시 업무 중지가 필요
(OS 업데이트, APP 패치 적용, 유지보수 작업 등)
vSphere HA + SingleServerSafe 구성의 경우

© NEC Corporation 202157
vSphere HA 및 EXPRESSCLUSTER X SingleServerSafe 혼합 구성
물리 서버
가상화 기반
어플리케이션 어플리케이션
VM VM
게스트OS 게스트OS
X SSS X SSS
✓ 하드웨어 장애는 vSphere HA 기능으로 Failover 합니다.
✓ 소프트웨어 장애는 EXPRESSCLUSTER X SingleServerSafe로 복구 합니다.
저 비용물리 서버
가상화 기반
어플리케이션 어플리케이션
VM VM
게스트OS 게스트OS
X SSS X SSS
Failover 실행
장애발생
장애발생
OS / APP 재실행
vSphere HA + SingleServerSafe 구성의 경우
과제3서버(OS)는 실제 1개 이기 때문에
• vSphere HA는 게스트 OS의 리셋 & 재부팅이라는
복구 동작을 실시 하기 때문에 게스트 OS가
정상적으로 부팅된 뒤 업무(서비스)를 실행 하므로,
복구 완료 까지의 시간이 길다

© NEC Corporation 202158
vSphere HA + EXPRESSCLUSTER X
가상화 자체 HA 기능으로 처리 할 수 없는 어플리케이션 장애 탐지 및 Failover
▌정밀한 어플리케이션 모니터링 및 하드웨어 장애를 탐지하여 자동으로 Failover
▌가상화 HA 기능보다 보다 더 빠른 Failover 실시
▌가상화 기반 Live Migration 기능과 연계 동작 가능
하드웨어 장애 어플리케이션 장애
가상화 자체 HA 기능 ✔ 시스템 중단
EXPRESSCLUSTER X ✔ ✔
가상화 기반가상화 기반
어플리케이션장애
어플리케이션 장애는 Failover 하지 않는다 !
가상화자체 HA 기능으로는장애탐지불가

© NEC Corporation 202159
가상화 장애 대책 기능과 EXPRESSCLUSTER 비교
가상화 HA 가상화 FT EXPRESSCLUSTER X
호스트장애 (ESXi 다운)●VM을다른 ESXi 호스트로
Failover
◎세컨더리가상머신이동작을계속
●Standby VM으로 Failover
업무(서비스) 네트워크장애 × Failover 하지않음(*1) × Failover 하지않음(*1) ●Standby VM으로 Failover
스토리지 Path 장애●가상머신을다른호스트로
Failover(*4)× Failover하지않음(*2) ●Standby VM으로 Failover
게스트OS 행업 or 패닉●동일한호스트에서 VM 다시시작
× 처리불가(*3) ●Standby VM으로 Failover
어플리케이션의비정상적인종료발생, 또는행업
× 별도제작필요(*5) × 처리불가(*3) ●Standby VM으로 Failover
공유스토리지필요성 필수 필수 필수아님
Failover 시작부터업무복구까지걸리는시간
▲VM이재부팅처리되므로EXPRESSCLUSTER에비해복구가느리다.
◎세컨더리 VM이즉시업무를인계하여무중단.
●평상시 Standby VM의OS가동작하고있기때문에,
vSphere HA에비하여업무복구가빠르다.
비고▲HW장애는처리가능하나,
OS 및 APP장애처리어려움.
▲HW장애는매우강력하게대응가능하나, OS 및APP장애처리어려움.
◎HW, OS, APP 어떤장애라도처리할수있다.
가상화 HA, 가상화 FT, EXPRESSCLUSTER의 주요 차이점
(* 1) 네트워크는일반적인하드웨어이중화구성입니다.
(* 2) 스토리지 Path는일반적인 하드웨어이중화구성입니다.
(* 3) 복구처리는운영자의개입이필요하며, VM 재시작등수동처리가필요할수있습니다.
(* 4) 가상화컴포넌트보호(VMCP)를유효하게하고있는경우만.
(* 5) 가상화벤더가제공하는 SDK를이용한제작이필요.이상검출시회복동작은 VM Reset(강제재부팅) 뿐.

![연료전지 기본개념 및 응용분야...[ High-pressure type Nickel-hydrogen Battery unit ] 수소에너지에대한전망 8. 촉매연소 수소의또다른독특한성질은platinum](https://img.pdfslide.tips/doc/110x75/5f052a7f7e708231d41199cd/eoe-eeeoee-e-e-high-pressure-type-nickel-hydrogen.jpg)




























