Embed Size (px)
Citation preview

Technische Universität Dortmund
Fakultät Informatik
Lehrstuhl für Künstliche Intelligenz
Fakultät Kulturwissenschaften
Institut für deutsche Sprache und Literatur
Lehrstuhl für Linguistik der deutschen
Sprache und Sprachdidaktik
Handbuch
Korpus-basierte linguistische Recherche und Analyse
mithilfe des RapidMiner
Nutzung des KobRA-Plug-ins
BMBF-Verbundprojekt:
Korpus-basierte linguistische Recherche und Analyse
mithilfe von Data-Mining (KobRA)
Förderkennzeichen: 01UG1245A
Projektlaufzeit: 01.09.2012 bis 31.12.2015
Dortmund, den 18.01.2015
Dieses Vorhaben wird mit Mitteln des Bundesministeriums für Bildung und Forschung (BMBF) unter den För-
derkennzeichen 01UG1245A-D gefördert. Die Verantwortung für den Inhalt dieser Veröffentlichung liegt bei
den Autoren.

2 Handbuch: Nutzung des KobRA-Plug-ins
Inhalt
1 Allgemeines ....................................................................................................................... 3
1.1 Operatoren (Auswahl) ..................................................................................... 3
1.2 Prozesse ........................................................................................................... 4
2 Benutzeroberfläche .......................................................................................................... 6
3 Installation ........................................................................................................................ 7
3.1 Programmdownload und Installation .............................................................. 7
3.2 Installation der benötigten Plug-ins ............................................................... 11
4 Nutzung ........................................................................................................................... 15
4.1 Datenimport, Suche, Tagging, Microsoft-Excel®-Export ............................ 15
4.2 Zufallsstichprobe, Microsoft-Excel®-Export ............................................... 25
4.3 Überwachte Klassifikation mit aktivem Lernen ............................................ 34
Prozesszugriff .......................................................................................................................... 34
Konfiguration und Ausführung ............................................................................................... 37
Sicherung und Weiterverwendung der annotierten Daten ....................................................... 44
Evaluation ................................................................................................................................ 47
4.4 Unüberwachte Disambiguierung und Visualisierung mit Topic-Modellen .. 48
Prozesszugriff .......................................................................................................................... 48
Konfiguration und Ausführung ............................................................................................... 50
Visualisierung .......................................................................................................................... 54

Allgemeines 3
1 Allgemeines
RapidMiner ist eine Umgebung für maschinelles Lernen und Data-Mining, die 2001 am Lehr-
stuhl für Künstliche Intelligenz der Technischen Universität Dortmund in der ersten Version
entwickelt und seitdem sukzessive erweitert wurde. Das Unternehmen RapidMiner betreut die
Software inzwischen kommerziell (http://www.rapidminer.com); die Vorgängerversion der
jeweils neusten Programmversion ist weiterhin kostenlos erhältlich. RapidMiner wurde in der
Programmiersprache Java geschrieben und lässt sich daher auf allen gängigen Betriebssyste-
men ausführen.
Mithilfe von verschiedenen Operatoren (z. B. für Dateneingabe und -ausgabe, maschinelles
Lernen etc.) können Prozesse erzeugt werden, die auf der Benutzeroberfläche sichtbar und
editierbar sind (s. Kapitel 2). Einzelne Operatoren, die aus einem Pool von insgesamt mehr als
500 Operatoren ausgewählt werden können, lassen sich verketten, verschachteln und durch
Bestimmen der zugehörigen Parameter dem jeweiligen Prozessziel anpassen.
1.1 Operatoren (Auswahl)
Folgende Operatoren des Korpusanalyse-Plug-ins sind für die in diesem Handbuch beschrie-
benen Prozesse von besonderem Interesse:
TEIQueryOperator: Liest eine XML/TEI-Datei ein.
Read Excel: Liest eine Tabelle im Microsoft-Excel®-Format ein.
GeneratePosTaggedSequences: Zerlegt Korpusbelege (KWIC-Snippets)
in Wortformen und weist ihnen Wortarten zu (= Tagging).
Data to Documents und Process Documents: Wandeln eine Datentabelle
mit Korpusbelegen und Metadaten in eine für das maschinelle Lernen
geeignete Repräsentation um.
Write Excel: Schreibt eine Datentabelle in eine Datei im Microsoft-
Excel®-Format.
Shuffle: Mischt die Belege einer Suchanfrage nach dem Zufallsprinzip.

4 Handbuch: Nutzung des KobRA-Plug-ins
Filter Example: Generiert eine Stichprobe nach vorgegebenen Eigen-
schaften.
AL: Operator für das überwachte Lernen, wobei manuell zu klassifizie-
rende Trainingsdatensätze anhand eines Konfidenzwertes automatisch
ausgewählt werden.
Latent Dirichlet Allocation: Operator für das unüberwachte Lernen;
kann z. B. zur automatischen Disambiguierung verschiedener Lesarten
eines gesuchten Ausdrucks verwendet werden.
1.2 Prozesse
In diesem Handbuch werden vier Prozesse näher beschrieben:
Datenimport, Suche, Tagging, Microsoft-Excel®-Export (s. Kapitel 4.1)
Mithilfe dieses Prozesses können Sie ein Datenset einlesen lassen, eine Suchanfrage auf die-
sen Daten stellen und sich die Ergebnisse getaggt in RapidMiner anzeigen lassen bzw. nach
Microsoft-Excel® exportieren.
Zufallsstichprobe, Microsoft-Excel®-Export (s. Kapitel 4.2)
Der zweite Prozess generiert eine Zufallsstichprobe aus den Belegen der Suchanfrage und gibt
diese in Microsoft-Excel® aus.
Überwachte Klassifikation mit aktivem Lernen (s. Kapitel 4.3)
Der dritte Prozess dient der überwachten automatischen Klassifikation von Datensätzen. Der
ActiveLearning-Operator generiert dazu auf Grundlage des Datenmaterials und einer Trai-
ningsdatenmenge selbstständig das Modell für die Klassifikation. Ein Konfidenzwert gibt die
Sicherheit der Klassifikation für jeden Datensatz an. Unsichere Fälle können per Hand nach-
annotiert werden, um das Klassifikationsmodell zu verbessern. Beispielhaft werden auf den
Diskussionsseiten der deutschsprachigen Wikipedia verwendete Aktionswörter klassifiziert;
dabei wird gezeigt, wie innerhalb der Wikipedia-Diskussionsseiten ein bestimmter Suchterm
abgefragt werden kann.

Allgemeines 5 5
Unüberwachte Disambiguierung mit Topic-Modellen (LDA) (s. Kapitel 4.4)
Der vierte Prozess führt eine automatische Einteilung von Korpusbelegstellen (KWIC-
Snippets) und Wörtern nach semantischen Zusammengehörigkeiten aus. Dafür wir ein soge-
nanntes Topic-Modell verwendet. Dieses Modell ordnet den Korpusbelegen (KWIC-Snippets)
und den Wörtern der Belege sogenannten Topics mit bestimmten Wahrscheinlichkeiten zu.
Ein Topic stellt eine semantische Gruppe dar, die sich aus häufig zusammen vorkommenden
Wortkombinationen ergibt. Als Anwendungsbeispiel haben wir ein Szenario gewählt, bei dem
eine Ergebnisliste einer Korpusrecherche Belege für mehrere Lesarten eines gesuchten Aus-
drucks enthält, die disambiguiert werden sollen.
6 Handbuch: Nutzung des KobRA-Plug-ins
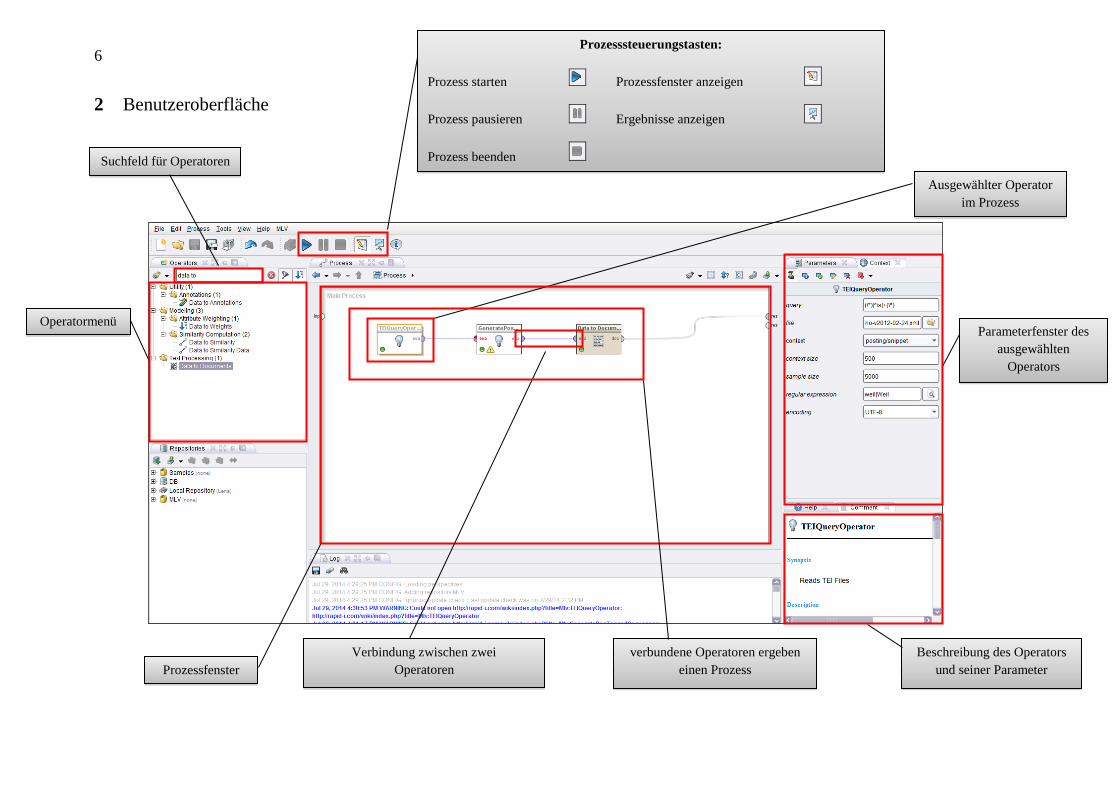
2 Benutzeroberfläche
Parameterfenster des
ausgewählten
Operators
Ausgewählter Operator
im Prozess
Beschreibung des Operators
und seiner Parameter Prozessfenster
Suchfeld für Operatoren
Operatormenü
Prozesssteuerungstasten:
Prozess starten Prozessfenster anzeigen
Prozess pausieren Ergebnisse anzeigen
Prozess beenden
Verbindung zwischen zwei
Operatoren
verbundene Operatoren ergeben
einen Prozess
Installation 7 7
3 Installation
3.1 Programmdownload und Installation
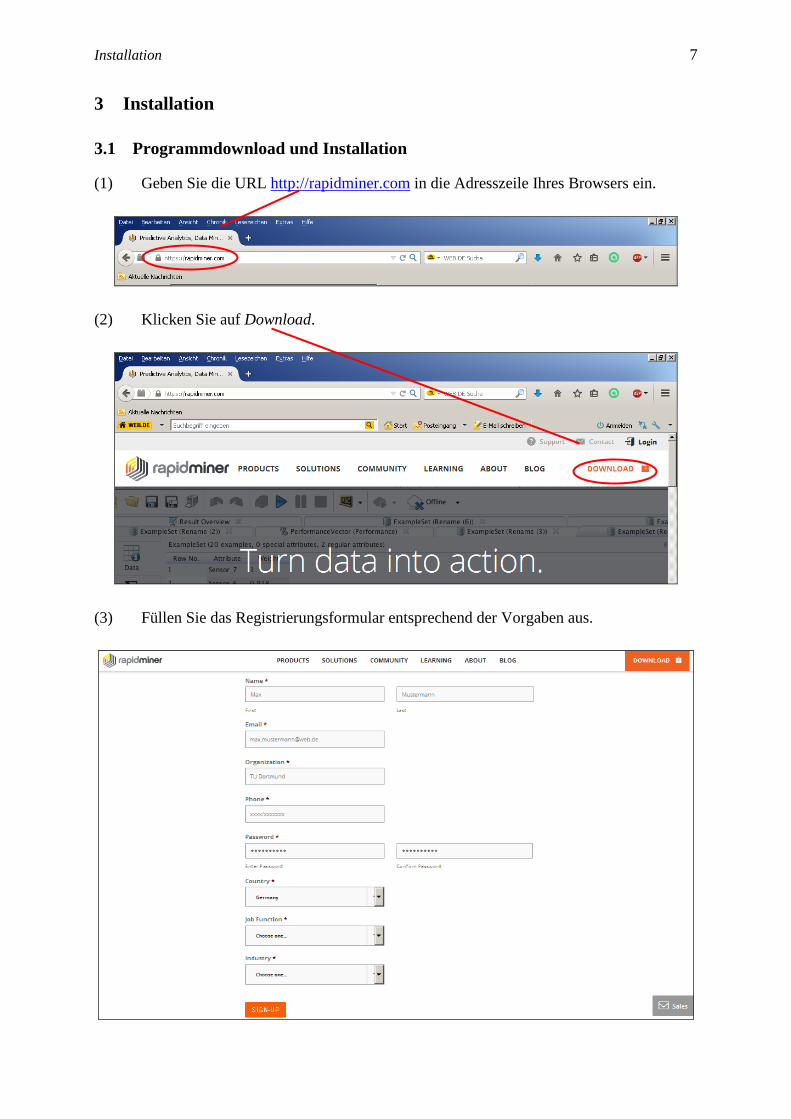
(1) Geben Sie die URL http://rapidminer.com in die Adresszeile Ihres Browsers ein.
(2) Klicken Sie auf Download.
(3) Füllen Sie das Registrierungsformular entsprechend der Vorgaben aus.
8 Handbuch: Nutzung des KobRA-Plug-ins
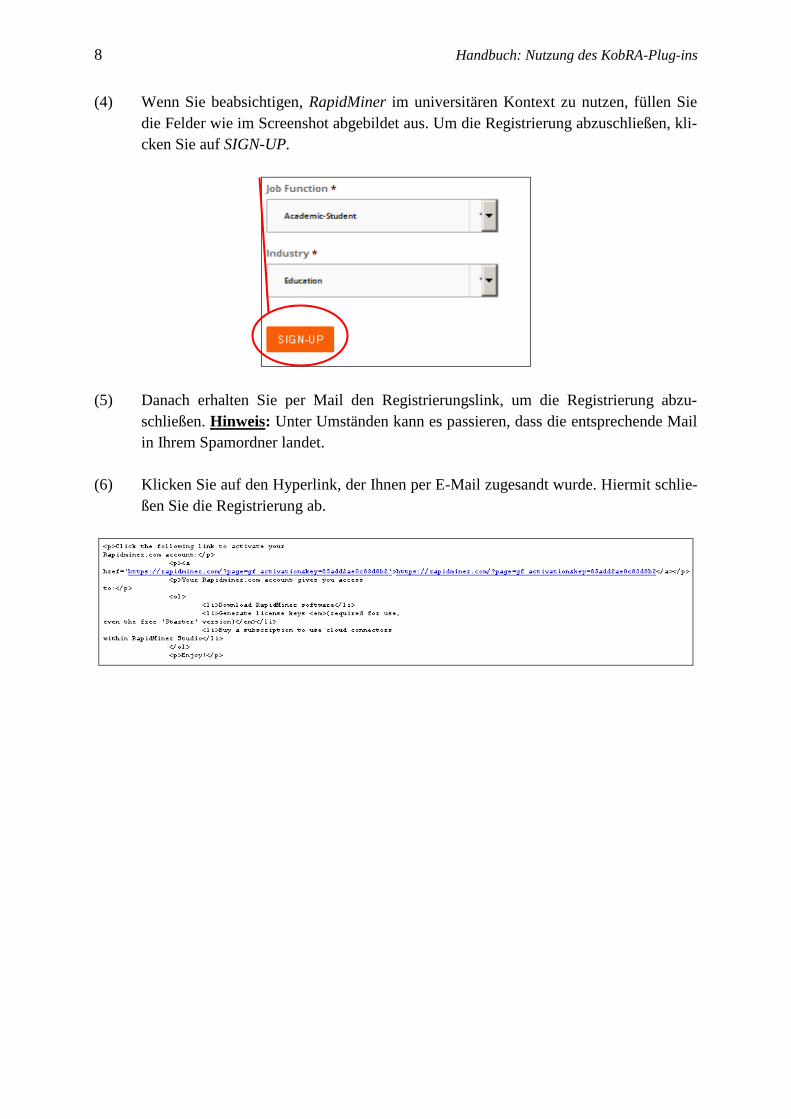
(4) Wenn Sie beabsichtigen, RapidMiner im universitären Kontext zu nutzen, füllen Sie
die Felder wie im Screenshot abgebildet aus. Um die Registrierung abzuschließen, kli-
cken Sie auf SIGN-UP.
(5) Danach erhalten Sie per Mail den Registrierungslink, um die Registrierung abzu-
schließen. Hinweis: Unter Umständen kann es passieren, dass die entsprechende Mail
in Ihrem Spamordner landet.
(6) Klicken Sie auf den Hyperlink, der Ihnen per E-Mail zugesandt wurde. Hiermit schlie-
ßen Sie die Registrierung ab.

Installation 9 9
(7) Durch die Aktivierung des Links werden Sie automatisch auf den Download-Bereich
der RapidMiner-Homepage weitergeleitet. Dort erhalten Sie den Hinweis, dass ihr Ac-
count erfolgreich freigeschaltet wurde.
(8) Zur Installation der für dieses Handbuch maßgeblichen RapidMiner-Version 5.3 kli-
cken Sie auf die (blaue) Schaltfläche Looking for RapidMiner v5.3. Die entsprechende
Version wird daraufhin angezeigt:
(9) Wählen Sie Ihr Betriebssystem aus: Windows, Macintosh oder Linux. Hinweis: Ach-
ten Sie darauf, dass Java 7 auf Ihrem PC installiert ist. Sollte dies nicht der Fall sein,
laden Sie sich die aktuelle Version unter https://www.java.com/de/download/ herunter.
10 Handbuch: Nutzung des KobRA-Plug-ins
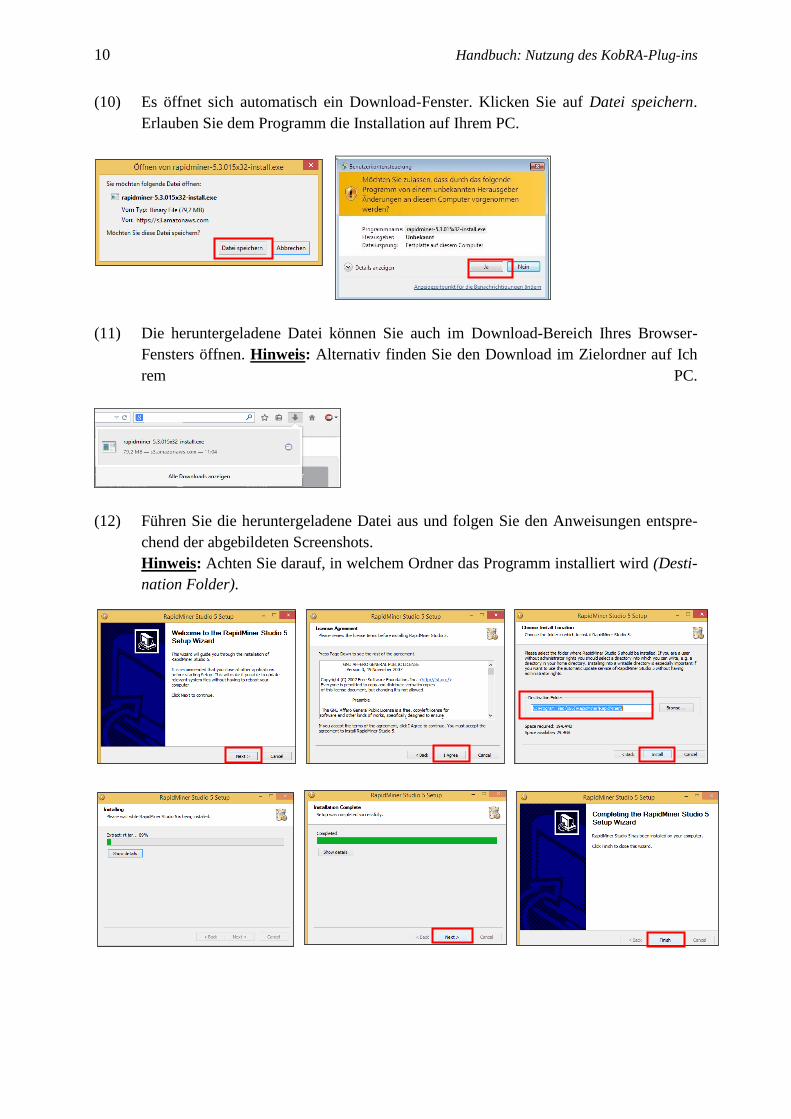
(10) Es öffnet sich automatisch ein Download-Fenster. Klicken Sie auf Datei speichern.
Erlauben Sie dem Programm die Installation auf Ihrem PC.
(11) Die heruntergeladene Datei können Sie auch im Download-Bereich Ihres Browser-
Fensters öffnen. Hinweis: Alternativ finden Sie den Download im Zielordner auf Ich
rem PC.
(12) Führen Sie die heruntergeladene Datei aus und folgen Sie den Anweisungen entspre-
chend der abgebildeten Screenshots.
Hinweis: Achten Sie darauf, in welchem Ordner das Programm installiert wird (Desti-
nation Folder).

Installation 11 11
(13) Wenn die Installation erfolgreich war, finden Sie den Shortcut von RapidMiner auf
Ihrer Desktopoberfläche.
3.2 Installation der benötigten Plug-ins
Nachdem Sie RapidMiner erfolgreich auf Ihrem PC installiert haben, benötigen Sie noch fol-
gende Plug-ins, um auf die in diesem Handbuch beschriebenen Funktionen zugreifen zu kön-
nen:
(a) German-Fast.Tagger
http://nlp.stanford.edu/software/stanford-postagger-full-2011-04-20.tgz
(b) rapidminer-Kobra-5.3.002
http://kobra.tu-dortmund.de/mediawiki/images/1/10/Rapidminer-Kobra-
5.3.002.zip (ZIP-Archiv bitte entpacken: rapidminer-Kobra-5.3.002.jar)
(c) rapidminer-ActiveLearningBA-5.3.000
http://kobra.tu-dortmund.de/mediawiki/images/4/41/Rapidminer-
ActiveLearningBA-5.3.000.zip (ZIP-Archiv bitte entpacken: rapidminer-
ActiveLearningBA-5.3.000.jar)
(d) Text-Mining-Extension
Über den RapidMiner-Marketplace (s.u.)
Für die Plug-ins (a)−(c) gilt: Hier ist keine weitere Installation nötig. Sie müssen die Plug-ins
lediglich in den Plug-in-Ordner von RapidMiner abspeichern. Kopieren Sie die oben aufgelis-
teten Plug-ins dazu in den Ordner plugins (standardmäßig: C:\Program Files\RapidMiner\
RapidMiner5\lib\plugins). Auf diesem Weg kann das Programm auf die entsprechenden Ope-
ratoren und Plug-ins zugreifen.
Der Fall der Text-Mining-Extension 5.3.2 nimmt sich etwas anders aus. Hier ist eine Installa-
tion über RapidMiner notwendig:
(1) Starten Sie daher zunächst RapidMiner; klicken Sie anschließend auf die Schalfläche
Help und wählen Sie dort die Option Updates and Extensions (Marketplace) aus.
12 Handbuch: Nutzung des KobRA-Plug-ins
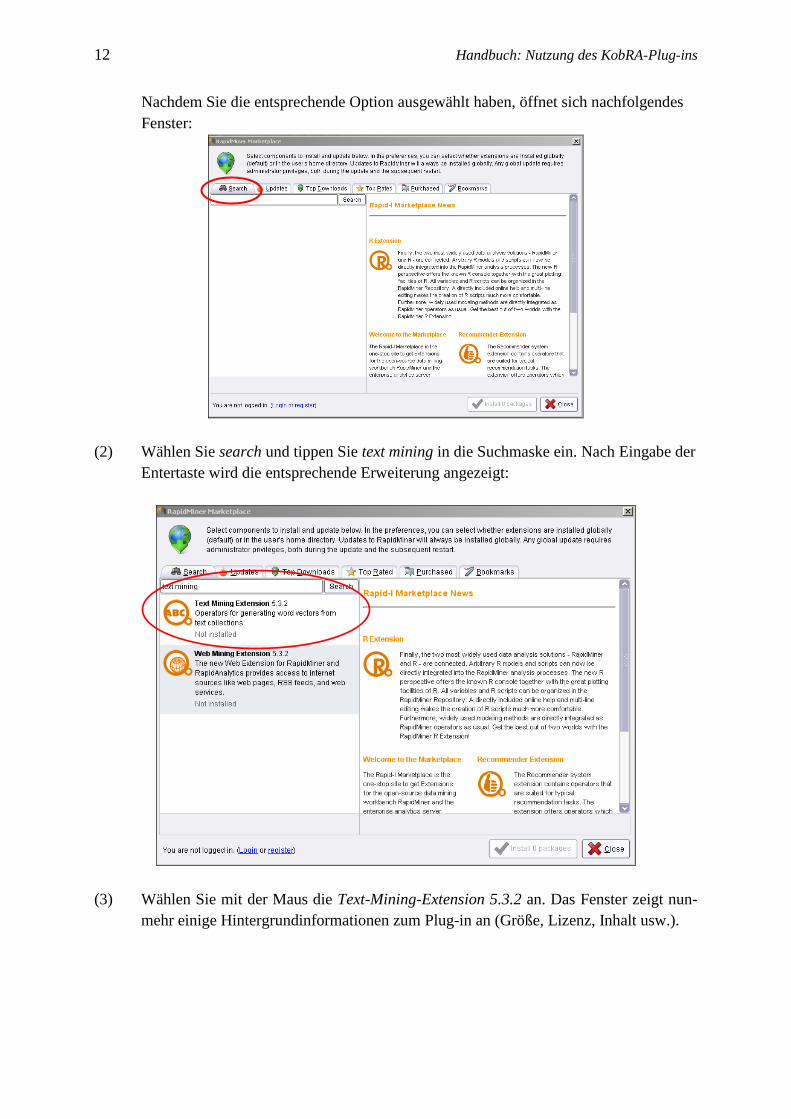
Nachdem Sie die entsprechende Option ausgewählt haben, öffnet sich nachfolgendes
Fenster:
(2) Wählen Sie search und tippen Sie text mining in die Suchmaske ein. Nach Eingabe der
Entertaste wird die entsprechende Erweiterung angezeigt:
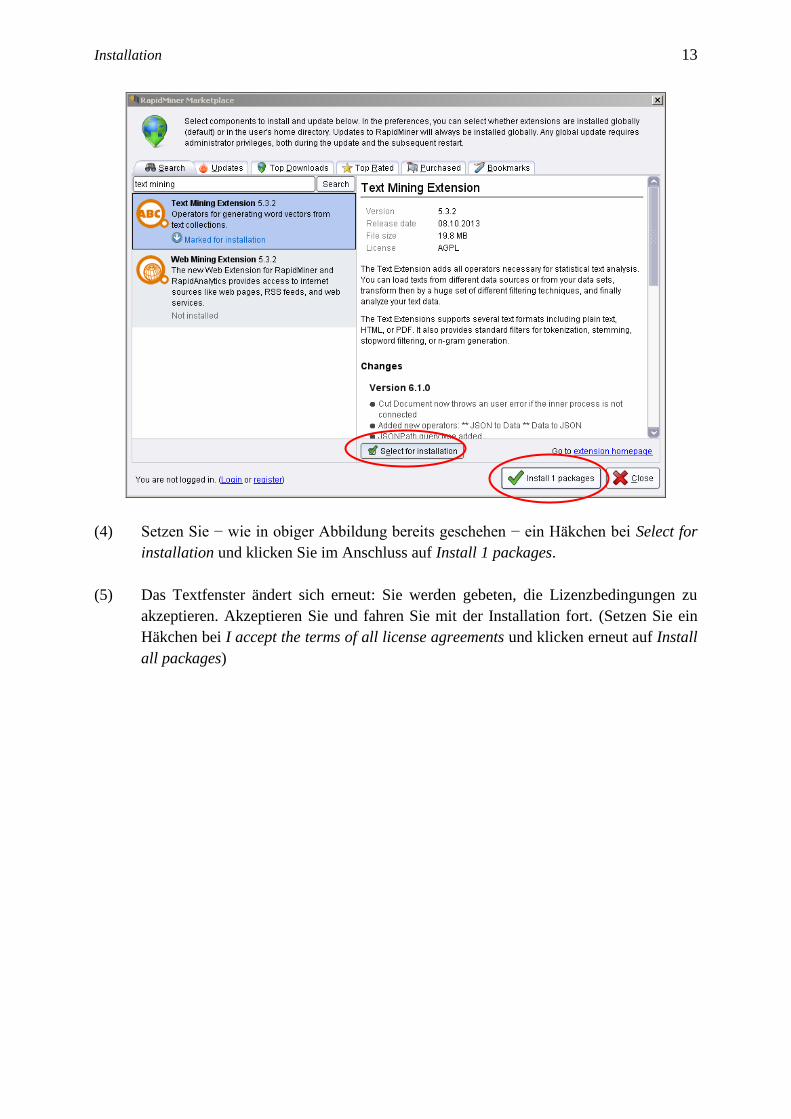
(3) Wählen Sie mit der Maus die Text-Mining-Extension 5.3.2 an. Das Fenster zeigt nun-
mehr einige Hintergrundinformationen zum Plug-in an (Größe, Lizenz, Inhalt usw.).
Installation 13 13
(4) Setzen Sie − wie in obiger Abbildung bereits geschehen − ein Häkchen bei Select for
installation und klicken Sie im Anschluss auf Install 1 packages.
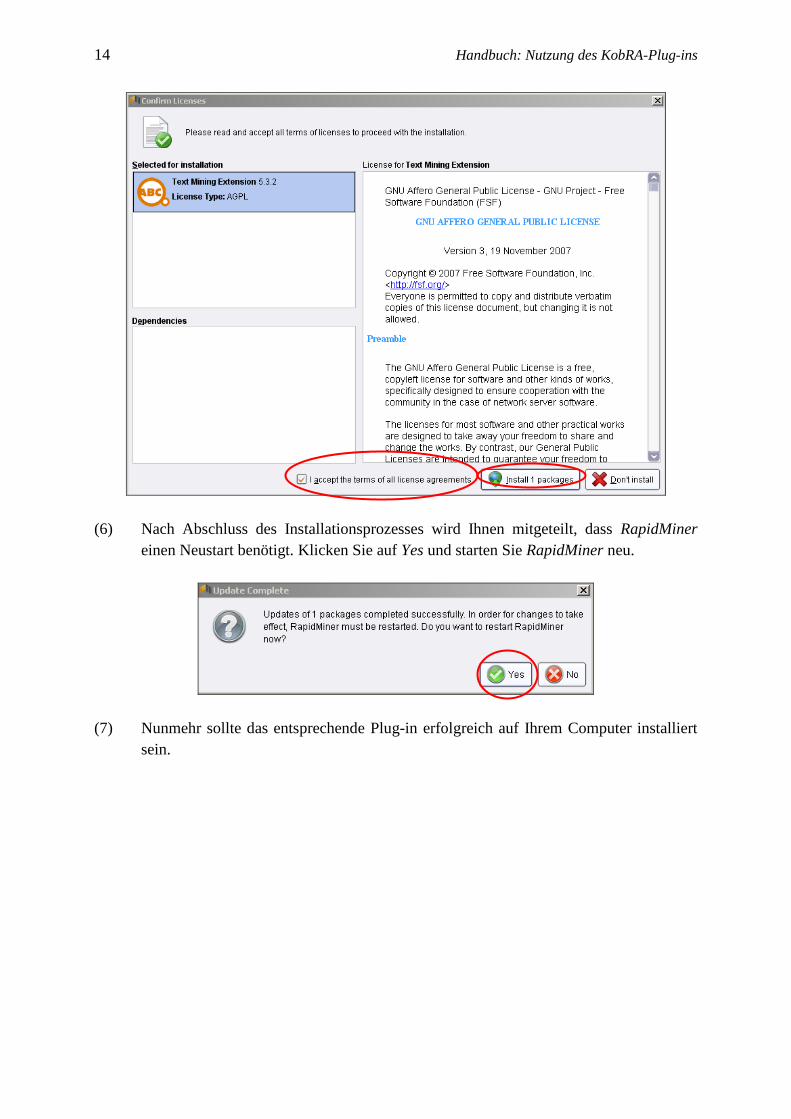
(5) Das Textfenster ändert sich erneut: Sie werden gebeten, die Lizenzbedingungen zu
akzeptieren. Akzeptieren Sie und fahren Sie mit der Installation fort. (Setzen Sie ein
Häkchen bei I accept the terms of all license agreements und klicken erneut auf Install
all packages)
14 Handbuch: Nutzung des KobRA-Plug-ins
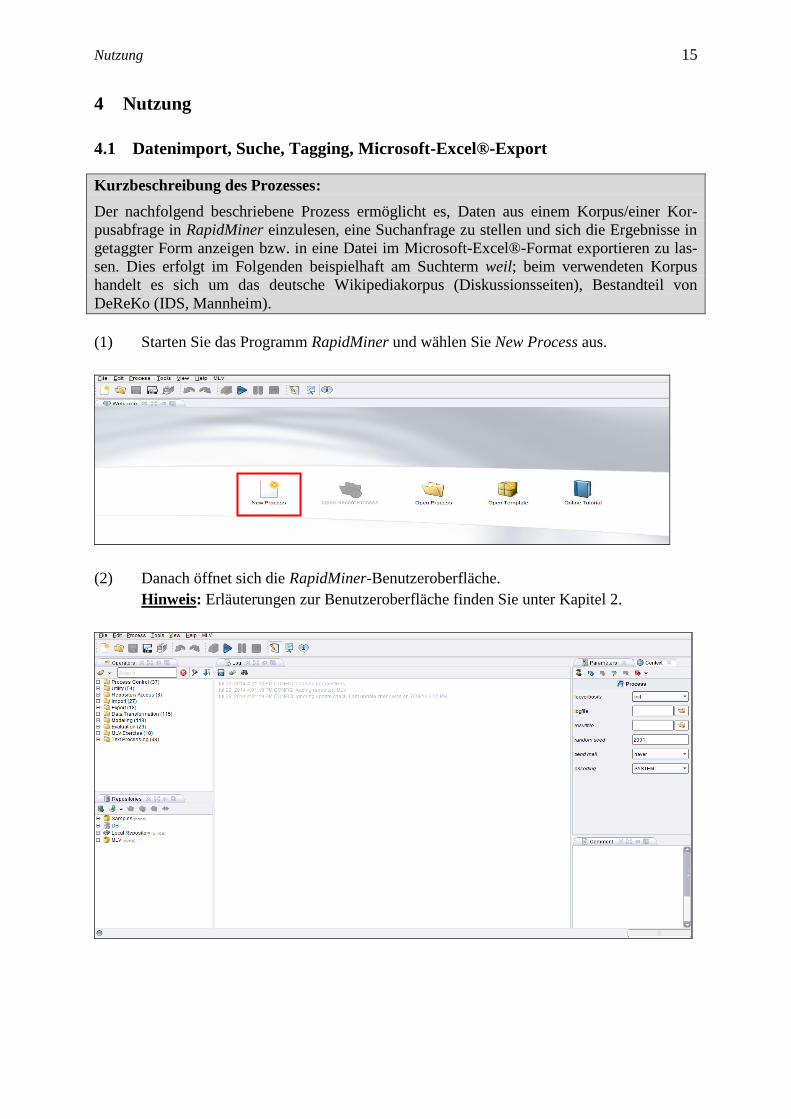
(6) Nach Abschluss des Installationsprozesses wird Ihnen mitgeteilt, dass RapidMiner
einen Neustart benötigt. Klicken Sie auf Yes und starten Sie RapidMiner neu.
(7) Nunmehr sollte das entsprechende Plug-in erfolgreich auf Ihrem Computer installiert
sein.
Nutzung 15 15
4 Nutzung
4.1 Datenimport, Suche, Tagging, Microsoft-Excel®-Export
Kurzbeschreibung des Prozesses:
Der nachfolgend beschriebene Prozess ermöglicht es, Daten aus einem Korpus/einer Kor-
pusabfrage in RapidMiner einzulesen, eine Suchanfrage zu stellen und sich die Ergebnisse in
getaggter Form anzeigen bzw. in eine Datei im Microsoft-Excel®-Format exportieren zu las-
sen. Dies erfolgt im Folgenden beispielhaft am Suchterm weil; beim verwendeten Korpus
handelt es sich um das deutsche Wikipediakorpus (Diskussionsseiten), Bestandteil von
DeReKo (IDS, Mannheim).
(1) Starten Sie das Programm RapidMiner und wählen Sie New Process aus.
(2) Danach öffnet sich die RapidMiner-Benutzeroberfläche.
Hinweis: Erläuterungen zur Benutzeroberfläche finden Sie unter Kapitel 2.
16 Handbuch: Nutzung des KobRA-Plug-ins
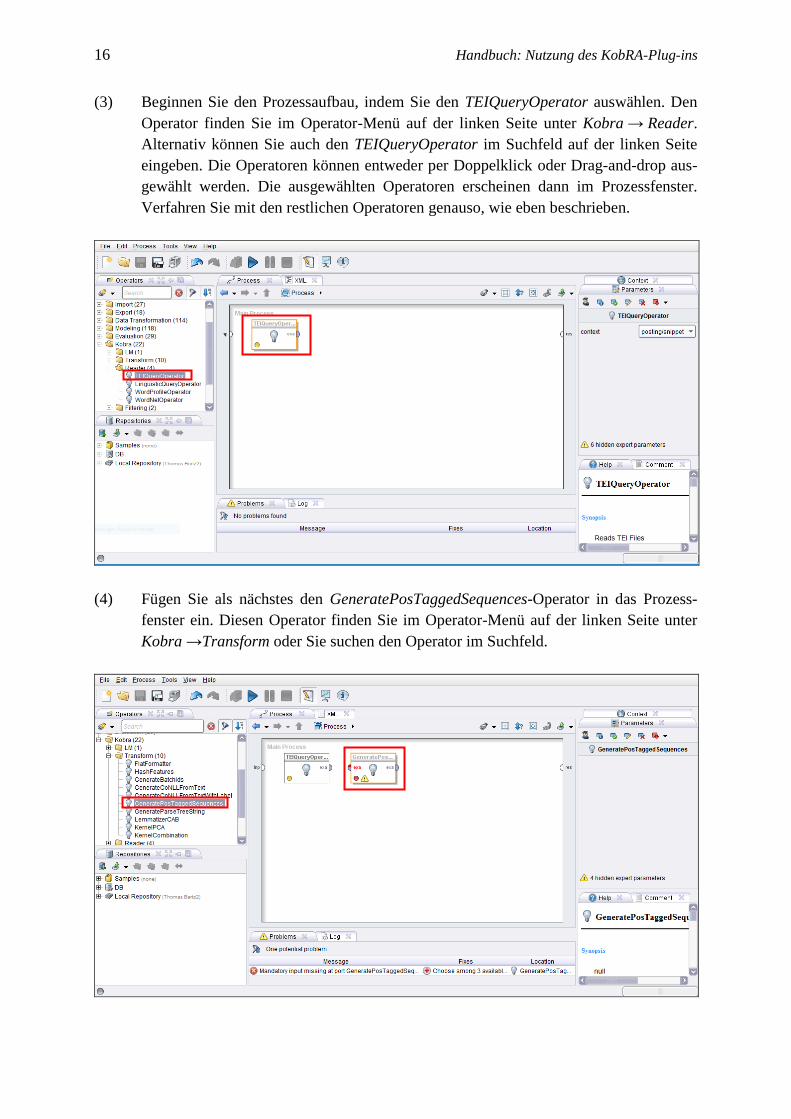
(3) Beginnen Sie den Prozessaufbau, indem Sie den TEIQueryOperator auswählen. Den
Operator finden Sie im Operator-Menü auf der linken Seite unter Kobra → Reader.
Alternativ können Sie auch den TEIQueryOperator im Suchfeld auf der linken Seite
eingeben. Die Operatoren können entweder per Doppelklick oder Drag-and-drop aus-
gewählt werden. Die ausgewählten Operatoren erscheinen dann im Prozessfenster.
Verfahren Sie mit den restlichen Operatoren genauso, wie eben beschrieben.
(4) Fügen Sie als nächstes den GeneratePosTaggedSequences-Operator in das Prozess-
fenster ein. Diesen Operator finden Sie im Operator-Menü auf der linken Seite unter
Kobra →Transform oder Sie suchen den Operator im Suchfeld.
Nutzung 17 17
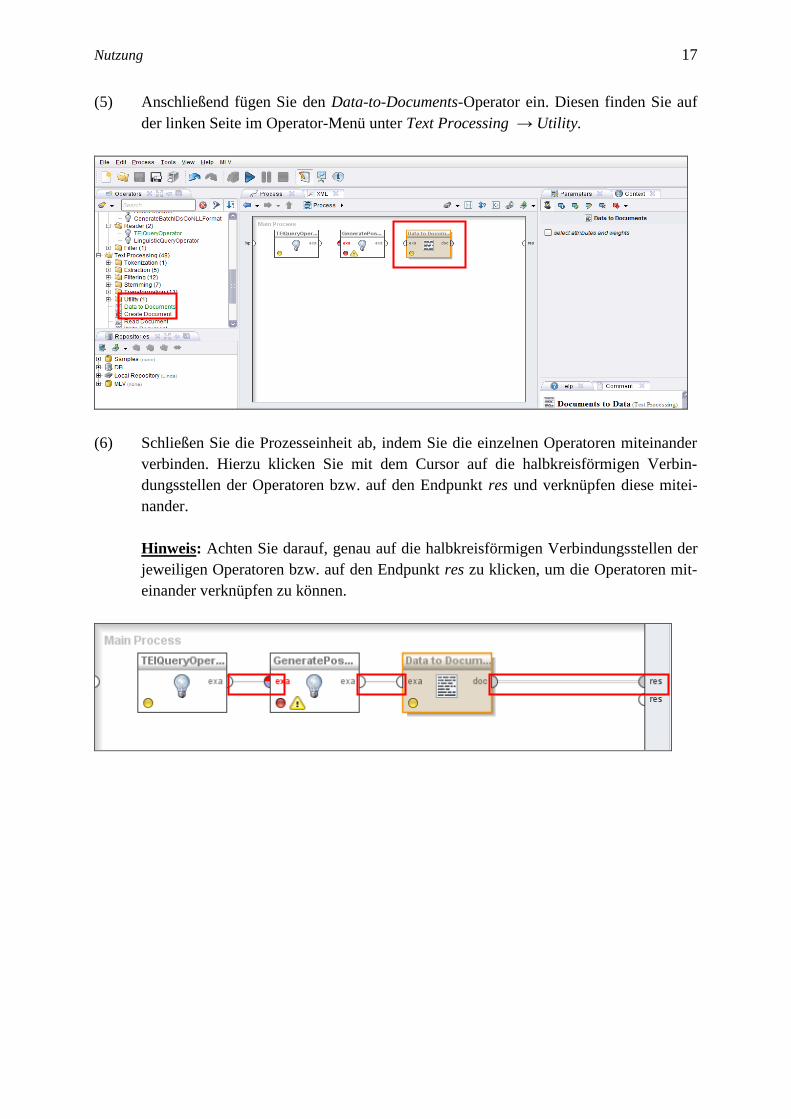
(5) Anschließend fügen Sie den Data-to-Documents-Operator ein. Diesen finden Sie auf
der linken Seite im Operator-Menü unter Text Processing → Utility.
(6) Schließen Sie die Prozesseinheit ab, indem Sie die einzelnen Operatoren miteinander
verbinden. Hierzu klicken Sie mit dem Cursor auf die halbkreisförmigen Verbin-
dungsstellen der Operatoren bzw. auf den Endpunkt res und verknüpfen diese mitei-
nander.
Hinweis: Achten Sie darauf, genau auf die halbkreisförmigen Verbindungsstellen der
jeweiligen Operatoren bzw. auf den Endpunkt res zu klicken, um die Operatoren mit-
einander verknüpfen zu können.
18 Handbuch: Nutzung des KobRA-Plug-ins
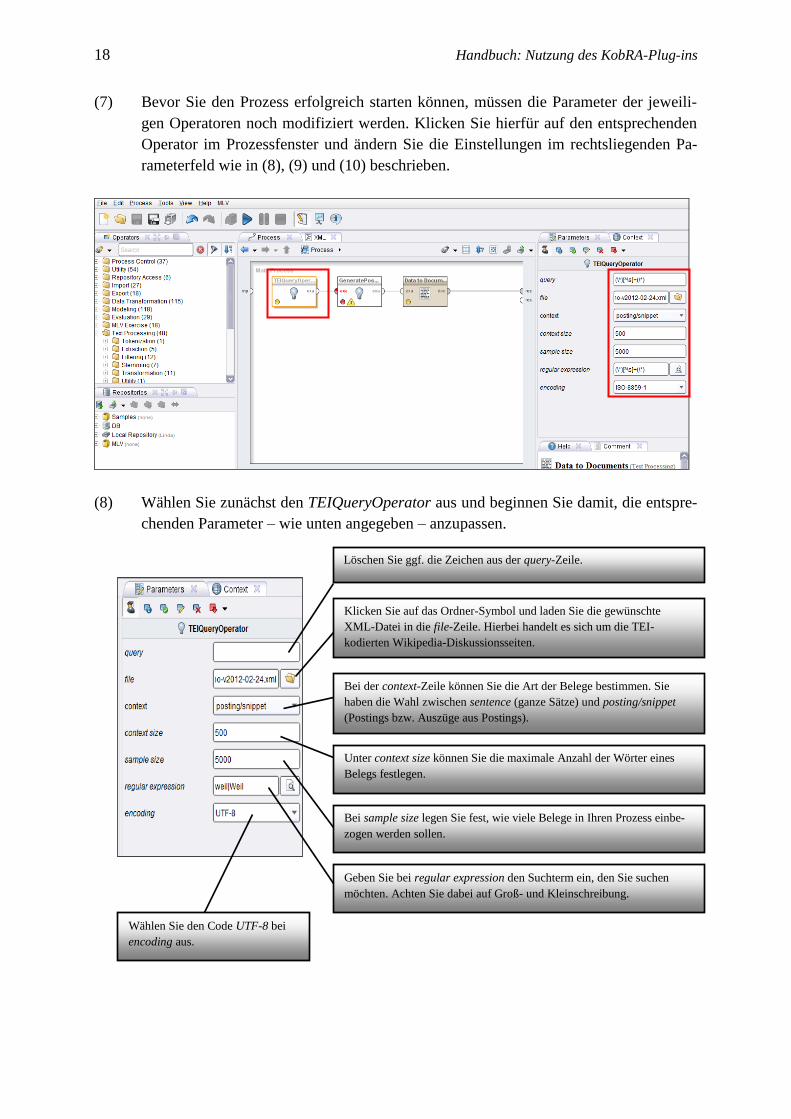
(7) Bevor Sie den Prozess erfolgreich starten können, müssen die Parameter der jeweili-
gen Operatoren noch modifiziert werden. Klicken Sie hierfür auf den entsprechenden
Operator im Prozessfenster und ändern Sie die Einstellungen im rechtsliegenden Pa-
rameterfeld wie in (8), (9) und (10) beschrieben.
(8) Wählen Sie zunächst den TEIQueryOperator aus und beginnen Sie damit, die entspre-
chenden Parameter – wie unten angegeben – anzupassen.
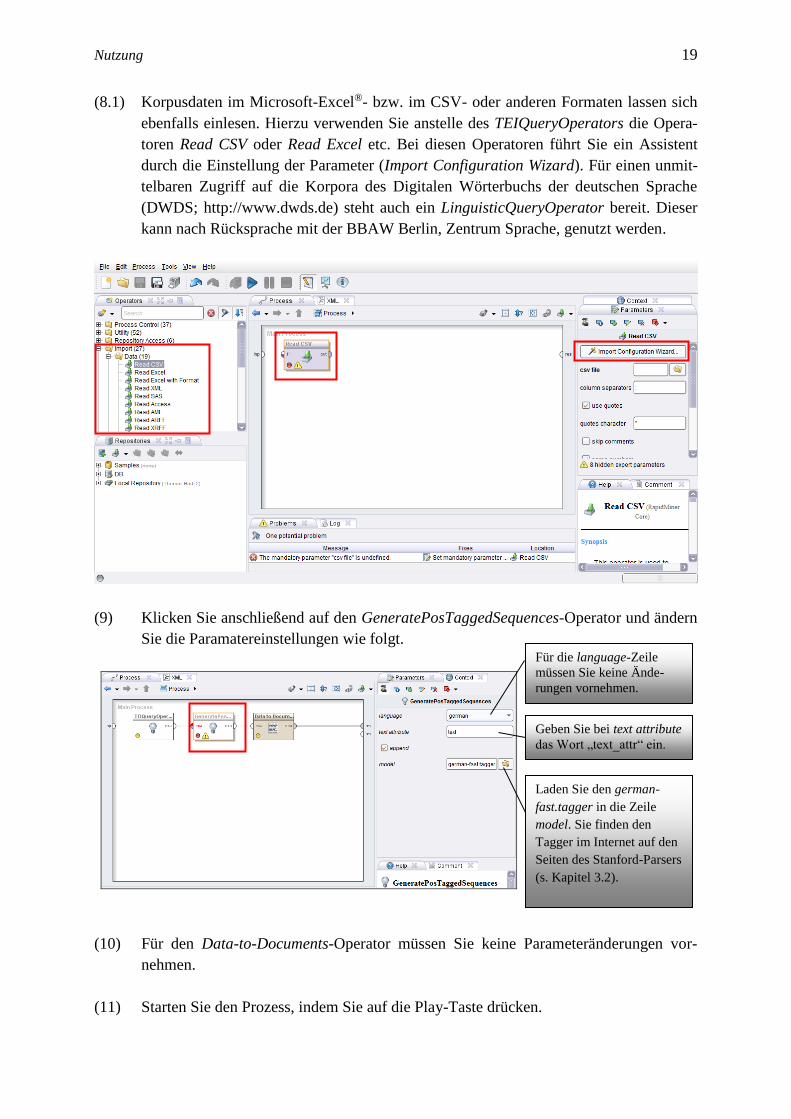
Löschen Sie ggf. die Zeichen aus der query-Zeile.
Klicken Sie auf das Ordner-Symbol und laden Sie die gewünschte
XML-Datei in die file-Zeile. Hierbei handelt es sich um die TEI-
kodierten Wikipedia-Diskussionsseiten.
Bei der context-Zeile können Sie die Art der Belege bestimmen. Sie
haben die Wahl zwischen sentence (ganze Sätze) und posting/snippet
(Postings bzw. Auszüge aus Postings).
Unter context size können Sie die maximale Anzahl der Wörter eines
Belegs festlegen.
Bei sample size legen Sie fest, wie viele Belege in Ihren Prozess einbe-
zogen werden sollen.
Geben Sie bei regular expression den Suchterm ein, den Sie suchen
möchten. Achten Sie dabei auf Groß- und Kleinschreibung.
Wählen Sie den Code UTF-8 bei
encoding aus.
Nutzung 19 19
(8.1) Korpusdaten im Microsoft-Excel®- bzw. im CSV- oder anderen Formaten lassen sich
ebenfalls einlesen. Hierzu verwenden Sie anstelle des TEIQueryOperators die Opera-
toren Read CSV oder Read Excel etc. Bei diesen Operatoren führt Sie ein Assistent
durch die Einstellung der Parameter (Import Configuration Wizard). Für einen unmit-
telbaren Zugriff auf die Korpora des Digitalen Wörterbuchs der deutschen Sprache
(DWDS; http://www.dwds.de) steht auch ein LinguisticQueryOperator bereit. Dieser
kann nach Rücksprache mit der BBAW Berlin, Zentrum Sprache, genutzt werden.
(9) Klicken Sie anschließend auf den GeneratePosTaggedSequences-Operator und ändern
Sie die Paramatereinstellungen wie folgt.
(10) Für den Data-to-Documents-Operator müssen Sie keine Parameteränderungen vor-
nehmen.
(11) Starten Sie den Prozess, indem Sie auf die Play-Taste drücken.
Für die language-Zeile
müssen Sie keine Ände-
rungen vornehmen.
Geben Sie bei text attribute
das Wort „text_attr“ ein.
Laden Sie den german-
fast.tagger in die Zeile
model. Sie finden den
Tagger im Internet auf den
Seiten des Stanford-Parsers
(s. Kapitel 3.2).
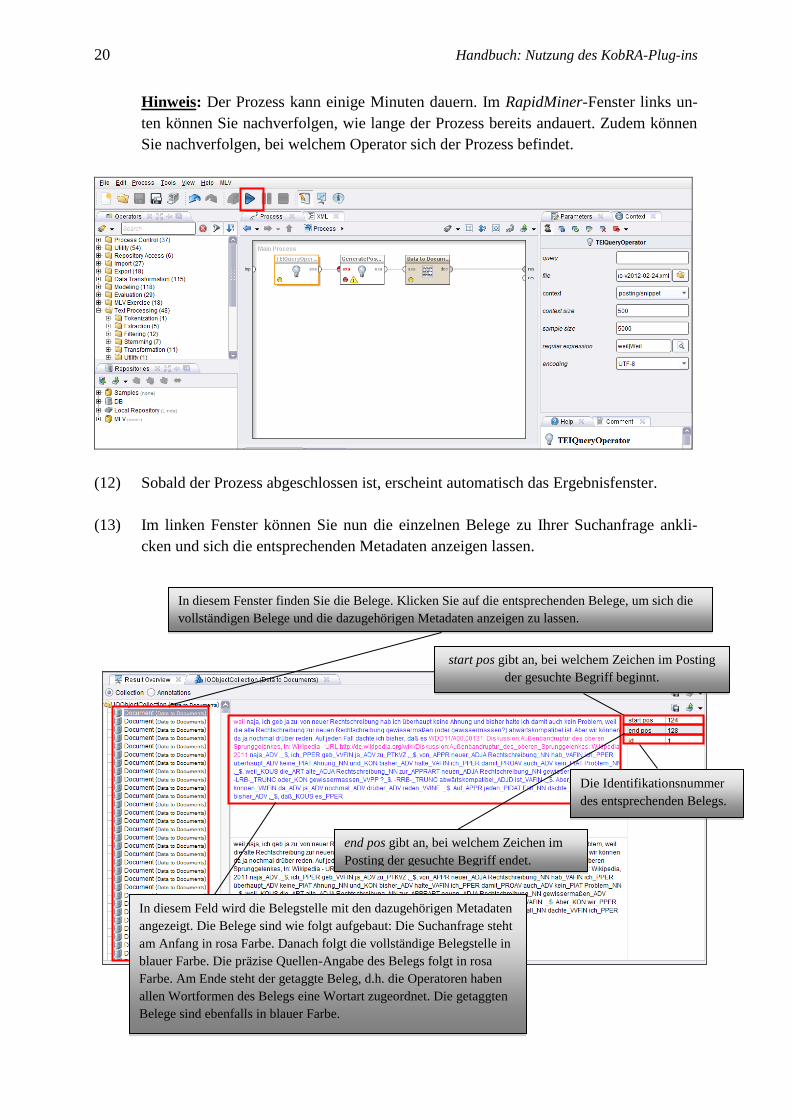
20 Handbuch: Nutzung des KobRA-Plug-ins
Hinweis: Der Prozess kann einige Minuten dauern. Im RapidMiner-Fenster links un-
ten können Sie nachverfolgen, wie lange der Prozess bereits andauert. Zudem können
Sie nachverfolgen, bei welchem Operator sich der Prozess befindet.
(12) Sobald der Prozess abgeschlossen ist, erscheint automatisch das Ergebnisfenster.
(13) Im linken Fenster können Sie nun die einzelnen Belege zu Ihrer Suchanfrage ankli-
cken und sich die entsprechenden Metadaten anzeigen lassen.
In diesem Fenster finden Sie die Belege. Klicken Sie auf die entsprechenden Belege, um sich die
vollständigen Belege und die dazugehörigen Metadaten anzeigen zu lassen.
start pos gibt an, bei welchem Zeichen im Posting
der gesuchte Begriff beginnt.
In diesem Feld wird die Belegstelle mit den dazugehörigen Metadaten
angezeigt. Die Belege sind wie folgt aufgebaut: Die Suchanfrage steht
am Anfang in rosa Farbe. Danach folgt die vollständige Belegstelle in
blauer Farbe. Die präzise Quellen-Angabe des Belegs folgt in rosa
Farbe. Am Ende steht der getaggte Beleg, d.h. die Operatoren haben
allen Wortformen des Belegs eine Wortart zugeordnet. Die getaggten
Belege sind ebenfalls in blauer Farbe.
Die Identifikationsnummer
des entsprechenden Belegs.
end pos gibt an, bei welchem Zeichen im
Posting der gesuchte Begriff endet.
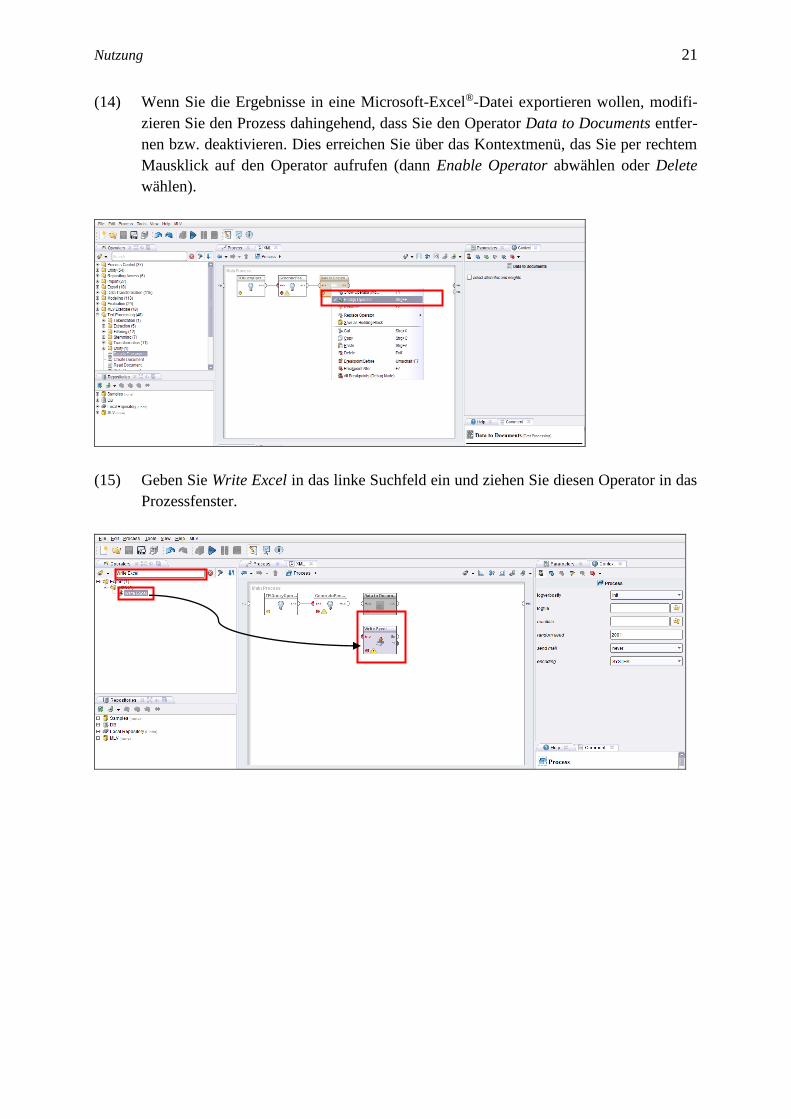
Nutzung 21 21
(14) Wenn Sie die Ergebnisse in eine Microsoft-Excel®-Datei exportieren wollen, modifi-
zieren Sie den Prozess dahingehend, dass Sie den Operator Data to Documents entfer-
nen bzw. deaktivieren. Dies erreichen Sie über das Kontextmenü, das Sie per rechtem
Mausklick auf den Operator aufrufen (dann Enable Operator abwählen oder Delete
wählen).
(15) Geben Sie Write Excel in das linke Suchfeld ein und ziehen Sie diesen Operator in das
Prozessfenster.
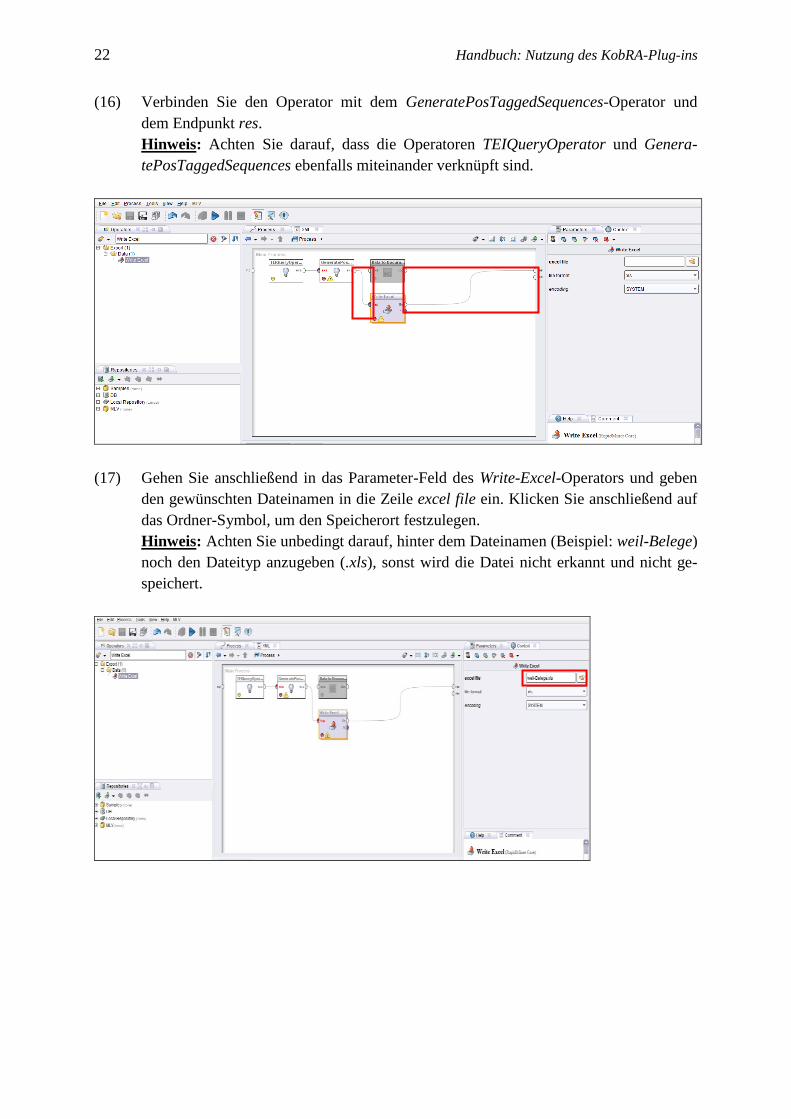
22 Handbuch: Nutzung des KobRA-Plug-ins
(16) Verbinden Sie den Operator mit dem GeneratePosTaggedSequences-Operator und
dem Endpunkt res.
Hinweis: Achten Sie darauf, dass die Operatoren TEIQueryOperator und Genera-
tePosTaggedSequences ebenfalls miteinander verknüpft sind.
(17) Gehen Sie anschließend in das Parameter-Feld des Write-Excel-Operators und geben
den gewünschten Dateinamen in die Zeile excel file ein. Klicken Sie anschließend auf
das Ordner-Symbol, um den Speicherort festzulegen.
Hinweis: Achten Sie unbedingt darauf, hinter dem Dateinamen (Beispiel: weil-Belege)
noch den Dateityp anzugeben (.xls), sonst wird die Datei nicht erkannt und nicht ge-
speichert.
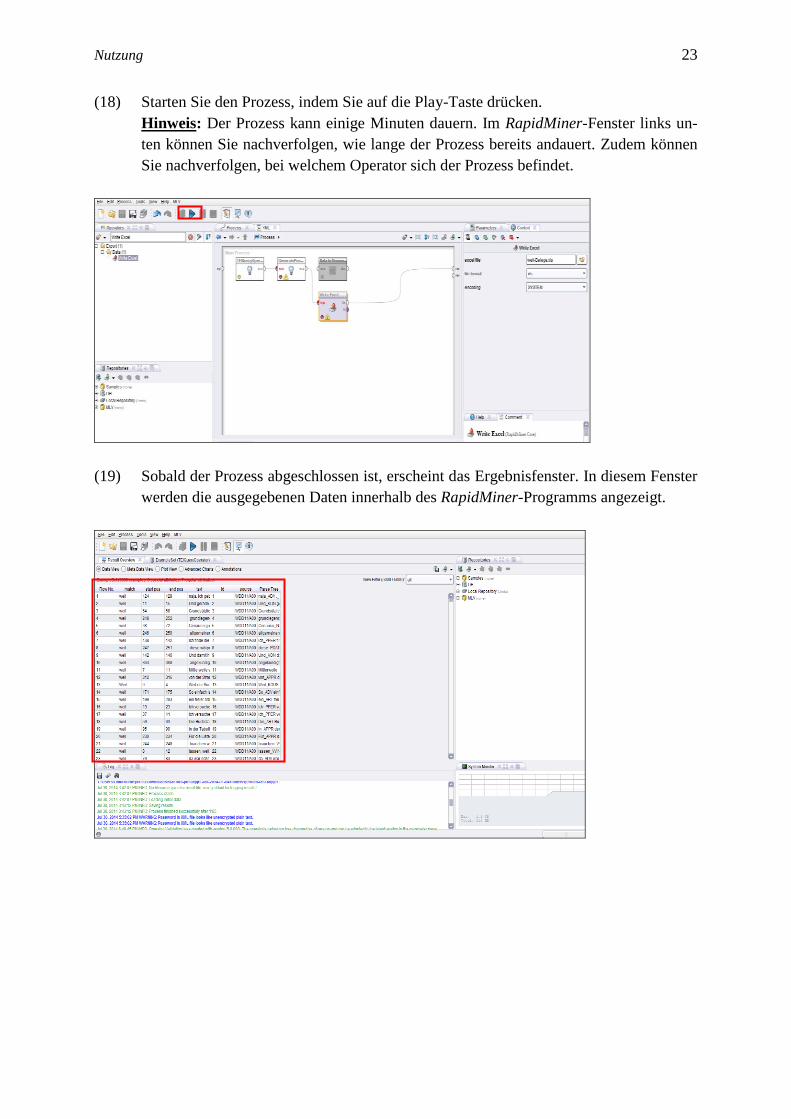
Nutzung 23 23
(18) Starten Sie den Prozess, indem Sie auf die Play-Taste drücken.
Hinweis: Der Prozess kann einige Minuten dauern. Im RapidMiner-Fenster links un-
ten können Sie nachverfolgen, wie lange der Prozess bereits andauert. Zudem können
Sie nachverfolgen, bei welchem Operator sich der Prozess befindet.
(19) Sobald der Prozess abgeschlossen ist, erscheint das Ergebnisfenster. In diesem Fenster
werden die ausgegebenen Daten innerhalb des RapidMiner-Programms angezeigt.

24 Handbuch: Nutzung des KobRA-Plug-ins
Außerdem können die Ergebnisse als Microsoft-Excel®-Datei angesehen und bearbei-
tet werden. Die Datei befindet sich in dem Zielordner, den Sie in Schritt (17) angege-
ben haben.
Die Ergebnisse werden in verschiedenen Spalten präsentiert. Die Spaltenbezeichnungen in
RapidMiner stimmen mit denen in der Excel-Datei überein:
In der Spalte links (Row Number) werden die Ergebnisse durchnummeriert.
Die Spalte match enthält den Trefferausdruck.
Die Spalten start pos und end pos geben die zeichengenaue Position der Suchan-
frage (weil|Weil) innerhalb der Belegstelle an.
In der Spalte text finden Sie das komplette Posting/den kompletten Beleg, in dem
der Suchbegriff vorkommt.
Die id ist die zugewiesene Nummer der Belegstelle innerhalb des ursprünglichen
Datenkorpus.
Die Spalte source gibt die präzise Quellenangabe des Belegs an. Hier im Beispiel
ist dieses unter anderem die URL zu der jeweiligen Wikipedia-Diskussionsseite.
Nutzung 25 25
4.2 Zufallsstichprobe, Microsoft-Excel®-Export
Kurzbeschreibung des Prozesses:
Die Zufallsstichproben ermöglichen es dem Nutzer, empirisch gestützte Aussagen zum durch-
schnittlichen Auftreten eines bestimmten Phänomens zu tätigen. Der nachfolgende Prozess
nun ermöglicht es dem Nutzer, sich Zufallsstichproben (im Microsoft-Excel®-Format) aus
den Belegen der Suchanfrage ausgeben zu lassen. Wir benötigen jeweils eine Stichprobe zum
Trainieren der Data-Mining-Verfahren und eine Stichprobe für die Evaluation. Dies erfolgt im
Folgenden beispielhaft am Suchterm weil; beim verwendeten Korpus handelt es sich um das
deutsche Wikipediakorpus (Diskussionsseiten), Bestandteil von DeReKo (IDS, Mannheim).
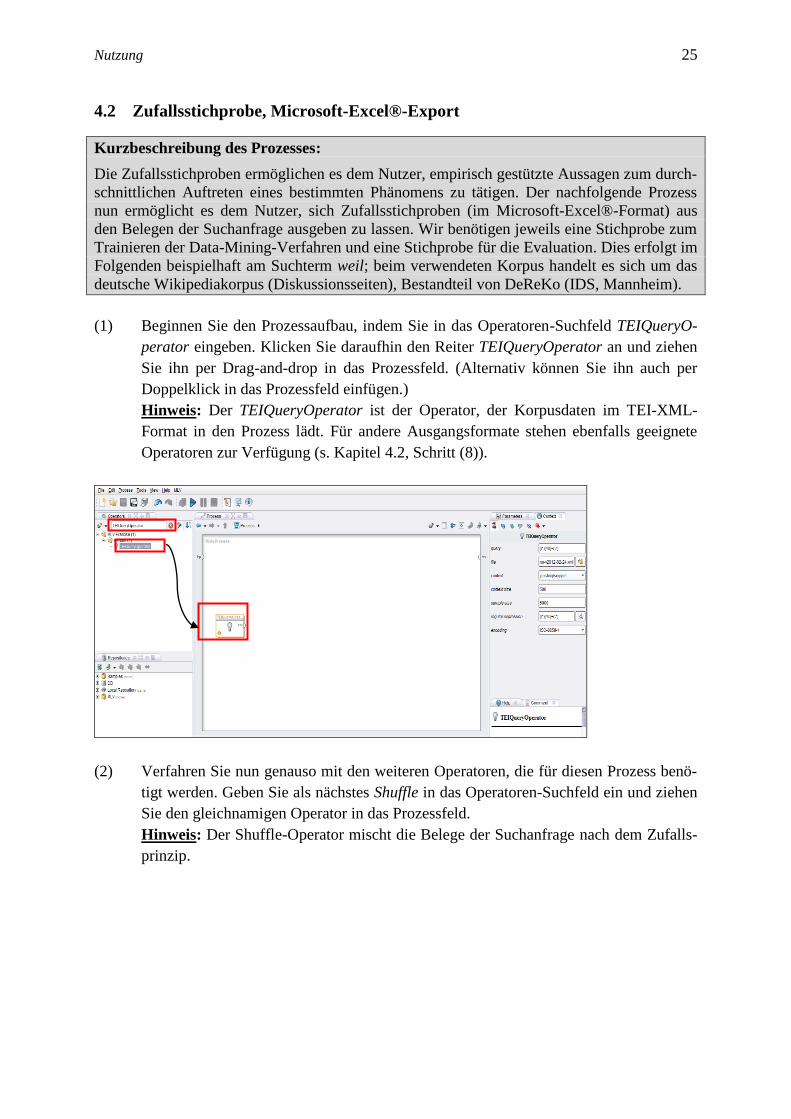
(1) Beginnen Sie den Prozessaufbau, indem Sie in das Operatoren-Suchfeld TEIQueryO-
perator eingeben. Klicken Sie daraufhin den Reiter TEIQueryOperator an und ziehen
Sie ihn per Drag-and-drop in das Prozessfeld. (Alternativ können Sie ihn auch per
Doppelklick in das Prozessfeld einfügen.)
Hinweis: Der TEIQueryOperator ist der Operator, der Korpusdaten im TEI-XML-
Format in den Prozess lädt. Für andere Ausgangsformate stehen ebenfalls geeignete
Operatoren zur Verfügung (s. Kapitel 4.2, Schritt (8)).
(2) Verfahren Sie nun genauso mit den weiteren Operatoren, die für diesen Prozess benö-
tigt werden. Geben Sie als nächstes Shuffle in das Operatoren-Suchfeld ein und ziehen
Sie den gleichnamigen Operator in das Prozessfeld.
Hinweis: Der Shuffle-Operator mischt die Belege der Suchanfrage nach dem Zufalls-
prinzip.

26 Handbuch: Nutzung des KobRA-Plug-ins
(3) Fügen Sie als nächstes dreimal den Operator Filter Example Range in das Prozessfeld
ein. Ordnen Sie die drei Operatoren wie abgebildet an.
Hinweis: Der Operator Filter Example Range wählt eine bestimmte Zahl an Beispie-
len aus Ihrem Datensatz aus.
(4) Den Prozess vervollständigt zum Schluss noch der Operator Write Excel. Fügen Sie
diesen zweimal in das Prozessfeld ein und ordnen Sie die beiden Operatoren wie ab-
gebildet an.
Hinweis: Die zwei Operatoren geben die zwei Stichproben im Microsoft-Excel®-
Format aus.

Nutzung 27 27
(5) Im nächsten Schritt müssen die verschiedenen Operatoren zu einem Prozess verbun-
den werden. Beginnen Sie damit, die Operatoren TEIQueryOperator, Shuffle und Fil-
ter Example Range miteinander zu verknüpfen. Klicken Sie dazu mit dem Mauszeiger
auf die halbkreisförmigen Verbindungsstellen (exa).
Hinweis: Achten Sie darauf, genau auf die halbkreisförmigen Verbindungstellen der
jeweiligen Operatoren bzw. auf den Endpunkt res zu klicken, um die Operatoren mit-
einander verknüpfen zu können.
(6) Verfahren Sie nun genauso und verbinden Sie die Operatoren Filter Example Range,
Filter Example Range (2), Write Excel und den Endpunkt res. Achten Sie dabei da-
rauf, die Verbindungsstelle exa (Filter Example Range (2)) mit der Verbindungsstelle
inp (Write Excel) zu verknüpfen. Außerdem müssen Sie die Verbindungsstelle thr
(Write Excel) mit dem Endpunkt res verbinden.

28 Handbuch: Nutzung des KobRA-Plug-ins
(7) Verbinden Sie nun als letztes die Operatoren Filter Example (2), Filter Example (3),
Write Excel (2) und den Endpunkt res.
Verknüpfen Sie dabei die Verbindungsstellen ori (Filter Example (2)) und exa (Filter
Example (3)). Verbinden Sie dann die Verbindungsstelle exa (Filter Example (3)) mit
inp (Write Excel (2)). Zuletzt koppeln Sie die Verbindungsstellen thr (Write Excel (2))
und den Endpunkt res.
(8) Bevor Sie den Prozess starten können, müssen Sie die Parameter der einzelnen Opera-
toren bestimmen. Klicken Sie dazu den entsprechenden Operator im Prozessfenster an
und ändern Sie die Parameter im rechts liegenden Paramenterfenster.

Nutzung 29 29
(9) Beginnen Sie damit, die Parameter zu dem Operator TEIQueryOperator anzupassen.
(10) Für den Operator Shuffle müssen sie keine Parameteränderungen vornehmen.
(11) Ändern Sie nun die Parameter des Operators Filter Example Range. Dabei handelt es
sich um den ersten Filter Example Range, der mit dem Shuffle-Operator verbunden ist.
Löschen Sie ggf. die Zeichen aus der Zeile query
Klicken Sie auf das Ordner-Symbol und laden Sie die gewün-
schte XML-Datei in die Zeile file.
Bei der Zeile context können Sie die Art der Belege bestim-
men. Sie haben die Wahl zwischen sentence (ganze Sätze) und
posting/snippet (Postings bzw. Auszüge aus Postings).
Unter sample size legen Sie fest, wie viele Belege für Ihren
Prozess einbezogen werden sollen. Da eine Zufallsstichprobe
erstellt werden soll, wählen Sie eine möglichst hohe Zahl. In
diesem Beispiel wurde 1.000.000 genommen, um alle Belege
des Korpus abzudecken.
Geben Sie bei regular expressions den Ausdruck ein, nach
dem Sie suchen möchten. Achten Sie dabei auf Groß- und
Kleinschreibung.
Wählen Sie den Code UTF-8 bei en-
coding aus.

30 Handbuch: Nutzung des KobRA-Plug-ins
(12) Mit Hilfe der Parameter des Filter Example Range legen Sie fest, wie viele Belege aus
Ihrer XML-Datei (nach dem Mischen durch den Operator Shuffle) für Sie herausgezo-
gen werden sollen.
Beispiel: In diesem Beispiel laden wir in Punkt (9) eine XML-Datei mit allen weil-
Belegen aus der deutschsprachigen Wikipedia in den TEIQueryOperator. Diese sollen
daraufhin mit dem Shuffle-Operator per Zufallsprinzip gemischt werden. In den Para-
metern des Filter Example Range legen wir fest, dass uns die Belege 1−1.200 später
zur Verfügung stehen sollen.
(13) Im nächsten Schritt stellen Sie die Parameter des Operators Filter Example Range (2)
ein. Hier legen Sie fest, aus wie vielen Belegen ihre spätere erste Excel-Datei bestehen
soll. Wenn Sie also in Schritt (12) gesagt haben, dass Sie 1.200 Belege erhalten möch-
ten, können Sie nun festlegen, dass die erste Excel-Datei davon beispielsweise die ers-
ten 600 Belege enthalten soll.
In den Zeilen first example und
last example geben Sie den Be-
reich der Belege an, die Sie am
Ende des Prozesses erhalten
möchten.
Nutzung 31 31
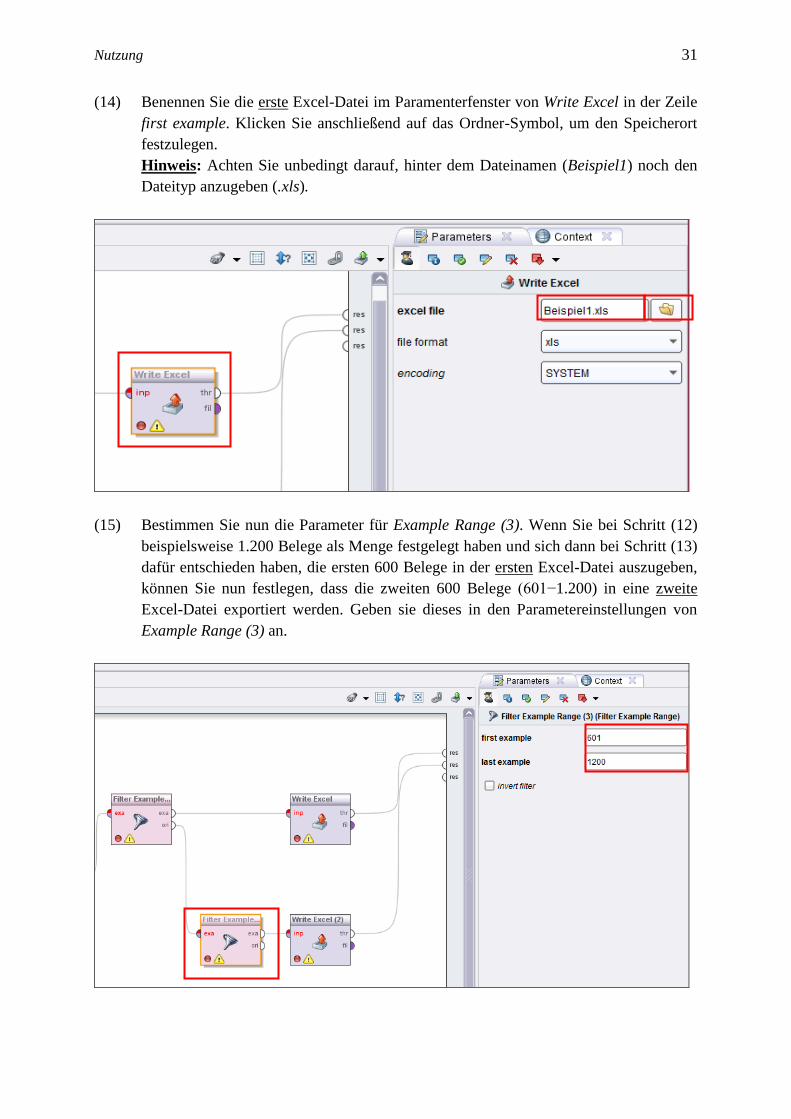
(14) Benennen Sie die erste Excel-Datei im Paramenterfenster von Write Excel in der Zeile
first example. Klicken Sie anschließend auf das Ordner-Symbol, um den Speicherort
festzulegen.
Hinweis: Achten Sie unbedingt darauf, hinter dem Dateinamen (Beispiel1) noch den
Dateityp anzugeben (.xls).
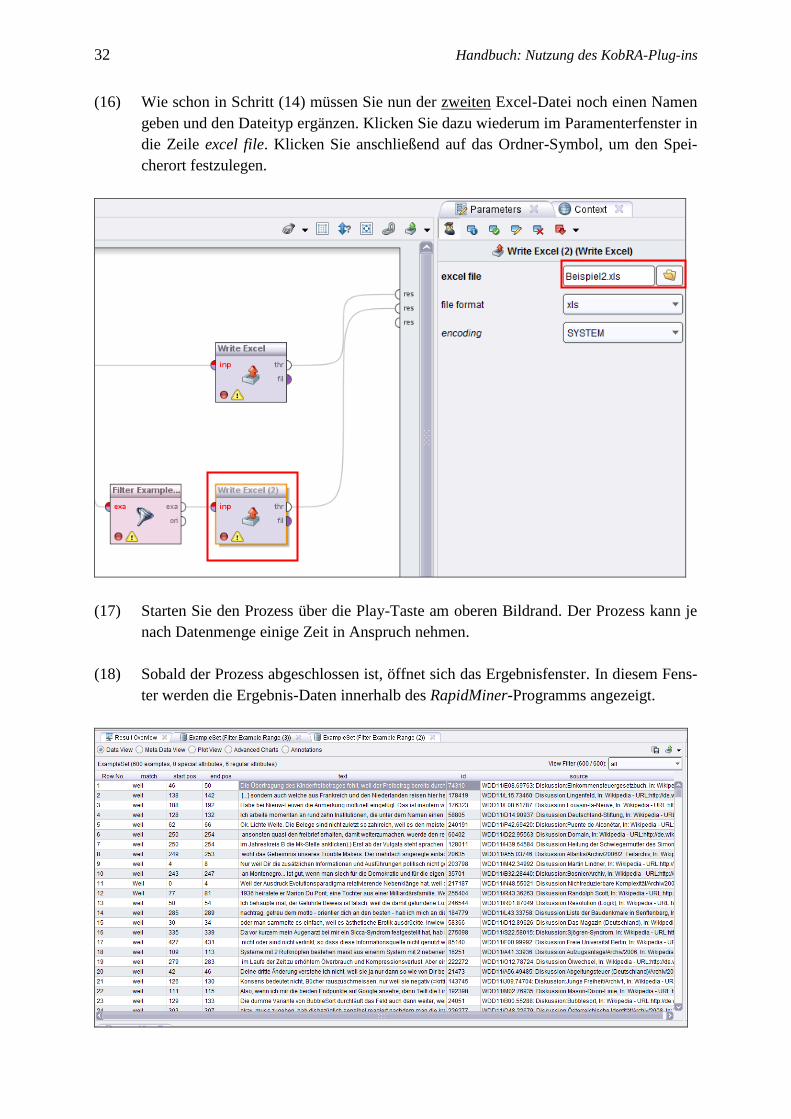
(15) Bestimmen Sie nun die Parameter für Example Range (3). Wenn Sie bei Schritt (12)
beispielsweise 1.200 Belege als Menge festgelegt haben und sich dann bei Schritt (13)
dafür entschieden haben, die ersten 600 Belege in der ersten Excel-Datei auszugeben,
können Sie nun festlegen, dass die zweiten 600 Belege (601−1.200) in eine zweite
Excel-Datei exportiert werden. Geben sie dieses in den Parametereinstellungen von
Example Range (3) an.
32 Handbuch: Nutzung des KobRA-Plug-ins
(16) Wie schon in Schritt (14) müssen Sie nun der zweiten Excel-Datei noch einen Namen
geben und den Dateityp ergänzen. Klicken Sie dazu wiederum im Paramenterfenster in
die Zeile excel file. Klicken Sie anschließend auf das Ordner-Symbol, um den Spei-
cherort festzulegen.
(17) Starten Sie den Prozess über die Play-Taste am oberen Bildrand. Der Prozess kann je
nach Datenmenge einige Zeit in Anspruch nehmen.
(18) Sobald der Prozess abgeschlossen ist, öffnet sich das Ergebnisfenster. In diesem Fens-
ter werden die Ergebnis-Daten innerhalb des RapidMiner-Programms angezeigt.

Nutzung 33 33
Außerdem können die Ergebnisse als Microsoft-Excel®-Datei angesehen und bearbei-
tet werden. Die Datei befindet sich in dem Zielordner, den Sie in Schritt (14) und (16)
angegeben haben.
Die Ergebnisse werden in verschiedenen Spalten präsentiert. Die Spaltenbezeichnungen
im RapidMiner stimmen mit denen in der Excel-Datei überein:
In der Spalte links (Row Number) werden die Ergebnisse durchnummeriert.
Unter match findet sich die konkrete Suchanfrage, die in der Belegstelle gefunden
wurde. In diesem Beispiel ist das entweder weil oder Weil.
Die Spalten start pos und end pos geben die zeichengenaue Position der Suchanfrage
(weil|Weil) innerhalb der Belegstelle an.
In der Spalte text finden Sie das komplette Posting, in dem der Suchbegriff vorkommt.
Die id ist die zugewiesene Nummer der Belegstelle innerhalb des ursprünglichen Da-
tenkorpus (XML-Datei aus Schritt (9)).
Die Spalte source gibt die präzise Quellenangabe des Belegs an. Hier im Beispiel ist
dieses unter anderem die URL zu der jeweiligen Wikipedia-Diskussionsseite.

34 Handbuch: Nutzung des KobRA-Plug-ins
4.3 Überwachte Klassifikation mit aktivem Lernen
Kurzbeschreibung des Prozesses und Downloadmöglichkeit:
Nachfolgend wird der Umgang mit einem Prozess zum aktiven Lernen beschrieben, der am
Lehrstuhl für Künstliche Intelligenz der Informatik der TU Dortmund entwickelt wurde. Der
Prozess steht unter folgendem Link zum Download bereit:
http://kobra.tu-dortmund.de/mediawiki/images/3/38/ActiveLearningProzess.zip (ZIP-Archiv
bitte entpacken: ActiveLearningProzess.rmp)
Die Active-Learning-Operatoren ermöglichen es, die für eine automatische Klassifikation
entscheidenden Annotationen in einem Datenset aktiv auszuwählen. Um z. B. ein Modell zu
generieren, mithilfe dessen ein bestimmtes sprachliches Phänomen in Korpusbelegen (KWIC-
Snippets) identifiziert werden kann, werden Beispiele benötigt, für die bereits die Zuordnung
zu diesem Phänomen gegeben ist. Die Auswahl der am besten geeigneten Beispiele überneh-
men beim aktiven Lernen die Active-Learning-Operatoren selbst. Sie wählen in einem iterati-
ven Verfahren Beispiele aus, die jeweils von Hand zu klassifizieren sind. Nach der Zuordnung
von Hand wird das Klassifikationsmodell mit den neuen Beispielen aktualisiert und die nächs-
ten Beispiele werden vorgeschlagen. Der Nutzer bekommt aber jeweils nur diejenigen Bei-
spiele zur Annotation vorgelegt, die das Data-Mining-Verfahren noch nicht mit genügend
hoher Sicherheit automatisch klassifizieren kann. Damit soll der manuelle Annotationsauf-
wand minimiert werden.
Als Beispiel soll der nachfolgende Prozess selbstständig ein Modell generieren, anhand des-
sen er innerhalb der Wikipedia-Diskussionsseiten nach sogenannten Aktionswörtern (wie *g*,
*freu*, *lach* usw.) sucht und diese annotiert. Ebenfalls wird beschrieben, wie ein bestimm-
ter Suchterm abgefragt werden kann.
All dies erfolgt auf Basis einer zuvor manuell annotierten Microsoft-Excel®-Tabelle, die als
Trainingsdatenset fungiert, sowie dem Wikipedia-Diskussionsseiten-Korpus in DEREKO, das
vom Institut für deutsche Sprache unter
http://www.ids-mannheim.de/kl/projekte/korpora/verfuegbarkeit.html
als XML-Datei bereitgestellt wird. Freilich kann der Prozess auch mit anderen Daten arbeiten,
sofern diese im CSV- bzw. Microsoft-Excel®-Tabellenformat vorliegen oder es sich um
XML-Dateien handelt.
Prozesszugriff
(1) Laden Sie den Prozess unter dem oben genannten Link herunter und speichern Sie ihn
an einem Ort ihrer Wahl. Der Name ist ActiveLearningProzess.rmp.
(2) Starten Sie nun RapidMiner. Wählen Sie anschließend auf dem Startbildschirm von
RapidMiner die Option File an und klicken Sie anschließend auf Import Process.
Nutzung 35 35
(3) Wählen Sie den Prozess von dem Ort aus, an dem Sie ihn in Schritt (1) hinterlegt haben.
(Klicken Sie zunächst einfach auf den Prozess und anschließend auf Open.)
Das Prozessfenster des RapidMiner sollte sich wie folgt präsentieren:

36 Handbuch: Nutzung des KobRA-Plug-ins
(4) Speichern Sie den Prozess ab, indem Sie zunächst (wie in Schritt (2)) auf File klicken
und anschließend die Option Save Process as... anwählen. Im sich öffnenden Dialog-
fenster wählen Sie den Ort aus, an dem der Prozess hinterlegt werden soll.
(4.1) Im Feld Repositories (links unten auf der Benutzeroberfläche des RapidMiner) können
Sie auch einen eigenen Ordner erstellen. Klicken Sie dazu zunächst einfach auf Local
Repository, dann auf in folgender Abbildung rot umkreistes Symbol.
Benennen Sie anschließend den neu erstellten Ordner und wählen Sie die Schaltfläche
OK an.
Bei einem Neustart des RapidMiner können Sie den Prozess nun direkt öffnen.
(4.2) Klicken Sie dazu im Startmenü des RapidMiner auf die Option Open Process und
wählen Sie im sich öffnenden Dialogfenster anschließend den Prozess von dem Ort
aus, an dem Sie ihn hinterlegt haben.
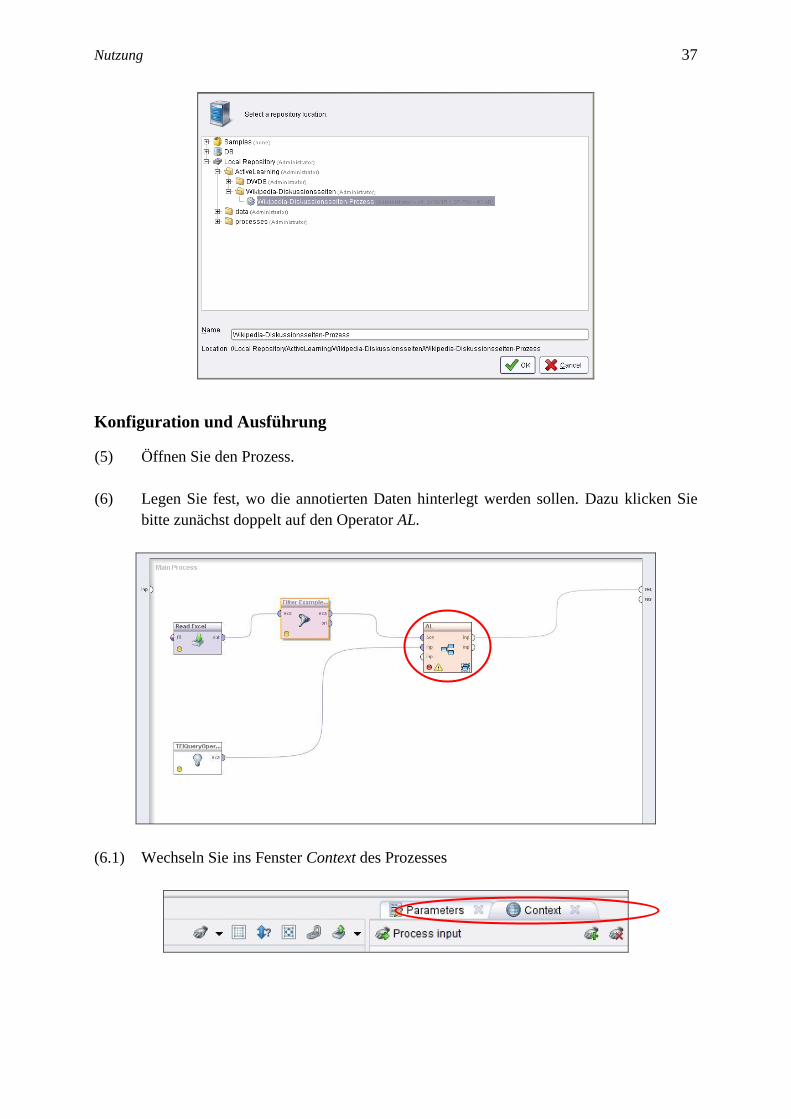
Nutzung 37 37
Konfiguration und Ausführung
(5) Öffnen Sie den Prozess.
(6) Legen Sie fest, wo die annotierten Daten hinterlegt werden sollen. Dazu klicken Sie
bitte zunächst doppelt auf den Operator AL.
(6.1) Wechseln Sie ins Fenster Context des Prozesses
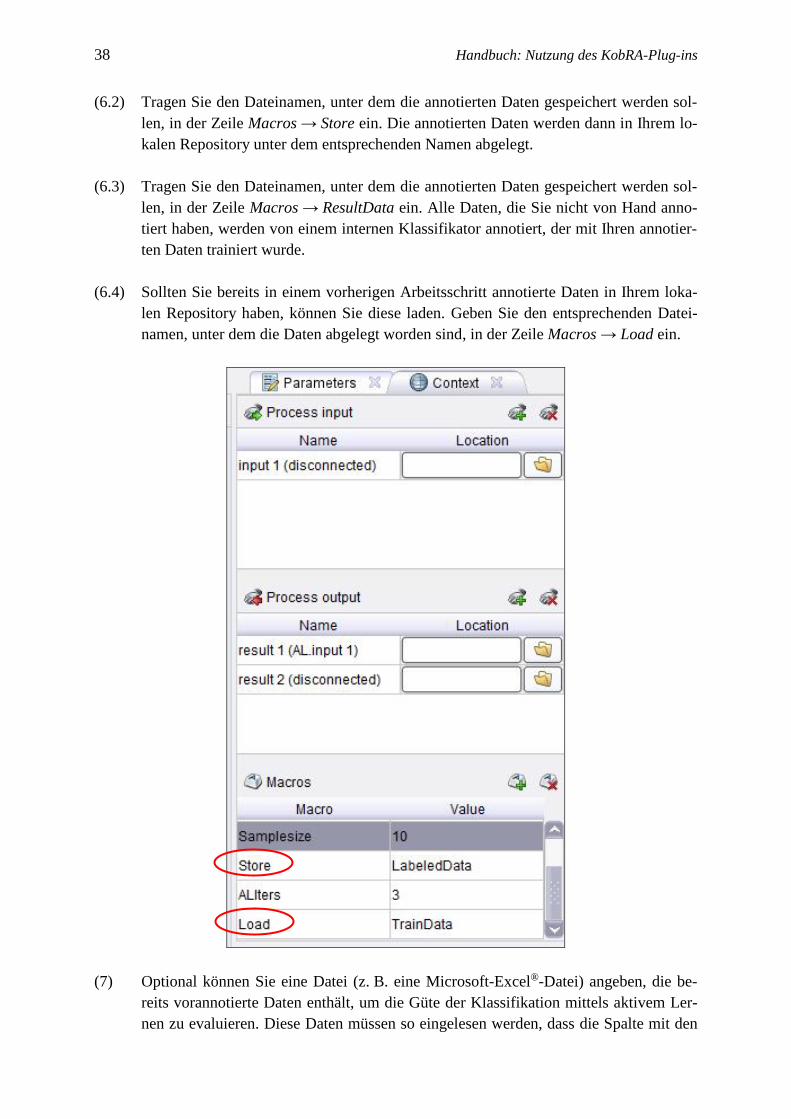
38 Handbuch: Nutzung des KobRA-Plug-ins
(6.2) Tragen Sie den Dateinamen, unter dem die annotierten Daten gespeichert werden sol-
len, in der Zeile Macros → Store ein. Die annotierten Daten werden dann in Ihrem lo-
kalen Repository unter dem entsprechenden Namen abgelegt.
(6.3) Tragen Sie den Dateinamen, unter dem die annotierten Daten gespeichert werden sol-
len, in der Zeile Macros → ResultData ein. Alle Daten, die Sie nicht von Hand anno-
tiert haben, werden von einem internen Klassifikator annotiert, der mit Ihren annotier-
ten Daten trainiert wurde.
(6.4) Sollten Sie bereits in einem vorherigen Arbeitsschritt annotierte Daten in Ihrem loka-
len Repository haben, können Sie diese laden. Geben Sie den entsprechenden Datei-
namen, unter dem die Daten abgelegt worden sind, in der Zeile Macros → Load ein.
(7) Optional können Sie eine Datei (z. B. eine Microsoft-Excel®-Datei) angeben, die be-
reits vorannotierte Daten enthält, um die Güte der Klassifikation mittels aktivem Ler-
nen zu evaluieren. Diese Daten müssen so eingelesen werden, dass die Spalte mit den

Nutzung 39 39
Textbelegen (KWIC-Snippets) den Namen text_attr und die Spalte mit der Klassifika-
tion den Namen label_attr bekommt. Zum Einlesen von Microsoft-Excel®-Dateien
und anderen Dateien lesen Sie bitte die entsprechenden Referenzen von RapidMiner
durch. Sollten Sie keine vorannotierten Dateien vorliegen haben, deaktivieren Sie bitte
die beiden Operatoren Read Excel und Filter Examples über das Kontextmenü (Klick
mit rechter Maustaste auf Operatoren).
(7.1) Für eine Microsoft-Excel®-Datei klicken Sie nun einfach auf den Operator Read Excel
und wechseln Sie ins Parameterfenster des Operators. Klicken Sie auf den Import
Configuration Wizard oben im Parameterfenster. Wählen Sie die entsprechende Excel-
Datei auf Ihrem Rechner aus und weisen Sie den Spalten mit dem Belegtext (KWIC-
Snippets) und der Klassifikation folgende Namen und Typen zu:
Die Textspalte bekommt den Namen text_attr und den Typ text.
Klassifikationsspalte bekommt den Namen label_attr, den Typen polynominal
und die Rolle label. Bemerkung: Falls in der ersten Zeile diese Namen bereits
stehen, wählen Sie bitte first row as names aus.
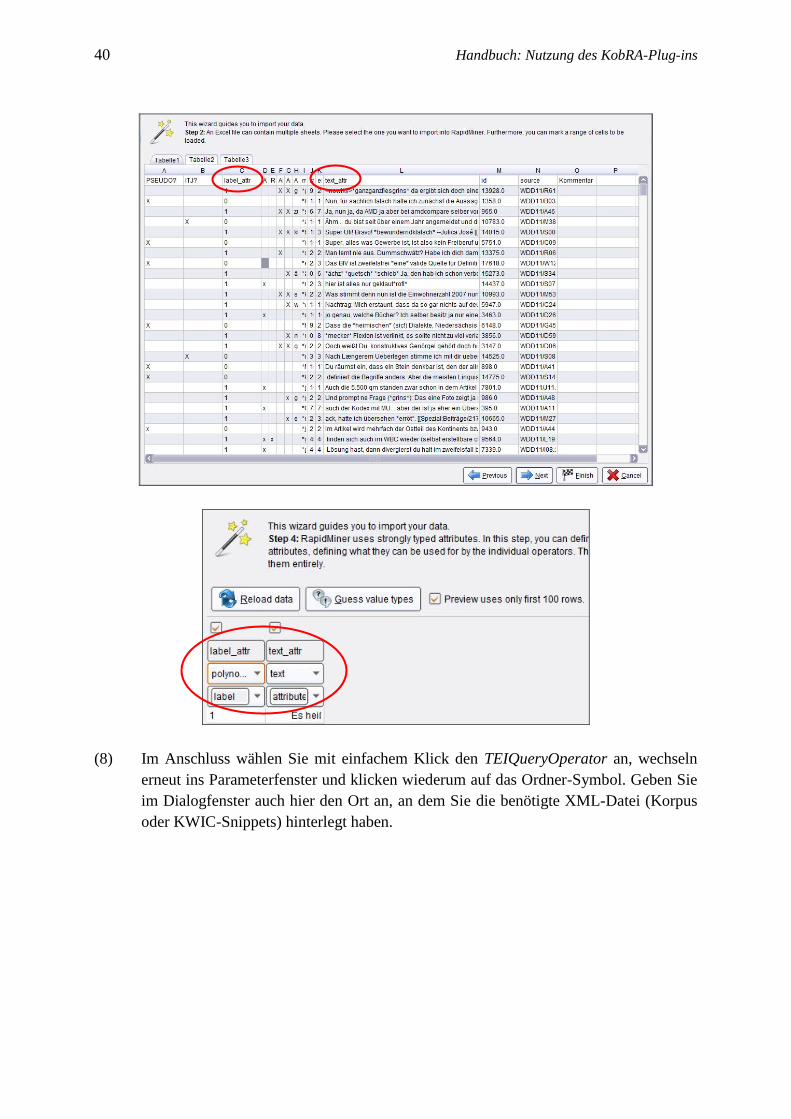
40 Handbuch: Nutzung des KobRA-Plug-ins
(8) Im Anschluss wählen Sie mit einfachem Klick den TEIQueryOperator an, wechseln
erneut ins Parameterfenster und klicken wiederum auf das Ordner-Symbol. Geben Sie
im Dialogfenster auch hier den Ort an, an dem Sie die benötigte XML-Datei (Korpus
oder KWIC-Snippets) hinterlegt haben.
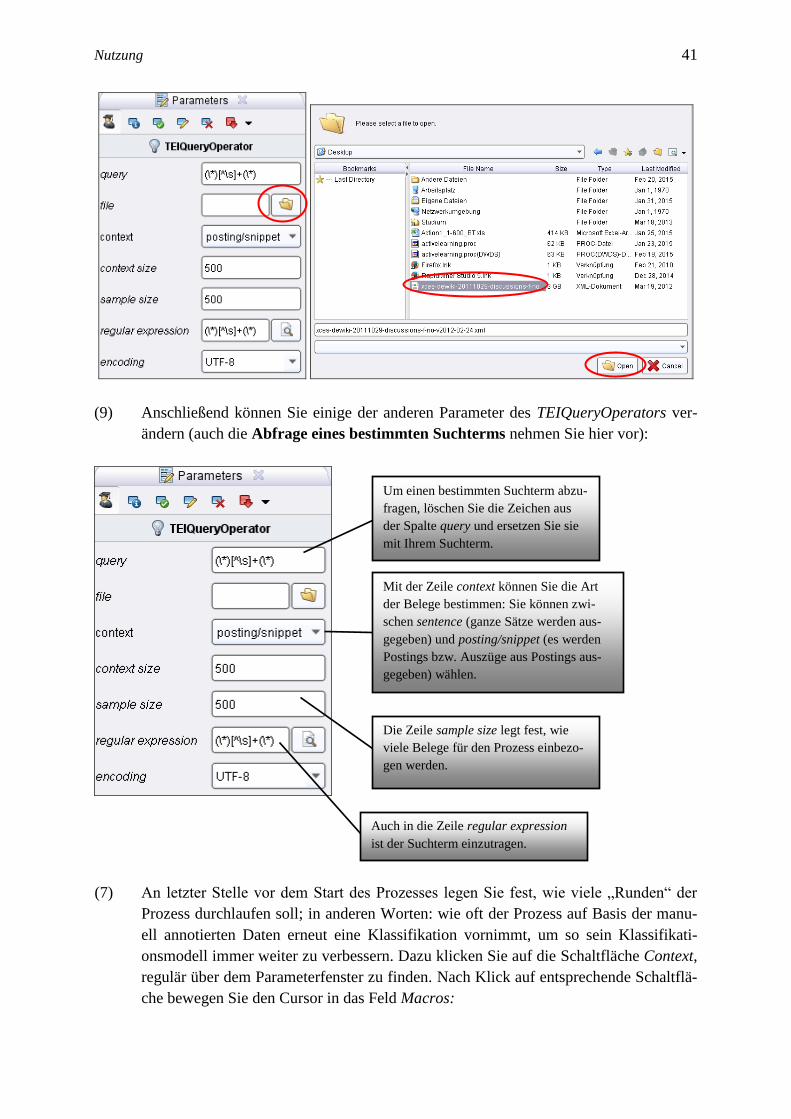
Nutzung 41 41
(9) Anschließend können Sie einige der anderen Parameter des TEIQueryOperators ver-
ändern (auch die Abfrage eines bestimmten Suchterms nehmen Sie hier vor):
(7) An letzter Stelle vor dem Start des Prozesses legen Sie fest, wie viele „Runden“ der
Prozess durchlaufen soll; in anderen Worten: wie oft der Prozess auf Basis der manu-
ell annotierten Daten erneut eine Klassifikation vornimmt, um so sein Klassifikati-
onsmodell immer weiter zu verbessern. Dazu klicken Sie auf die Schaltfläche Context,
regulär über dem Parameterfenster zu finden. Nach Klick auf entsprechende Schaltflä-
che bewegen Sie den Cursor in das Feld Macros:
Um einen bestimmten Suchterm abzu-
fragen, löschen Sie die Zeichen aus
der Spalte query und ersetzen Sie sie
mit Ihrem Suchterm.
Mit der Zeile context können Sie die Art
der Belege bestimmen: Sie können zwi-
schen sentence (ganze Sätze werden aus-
gegeben) und posting/snippet (es werden
Postings bzw. Auszüge aus Postings aus-
gegeben) wählen.
Die Zeile sample size legt fest, wie
viele Belege für den Prozess einbezo-
gen werden.
Auch in die Zeile regular expression
ist der Suchterm einzutragen.
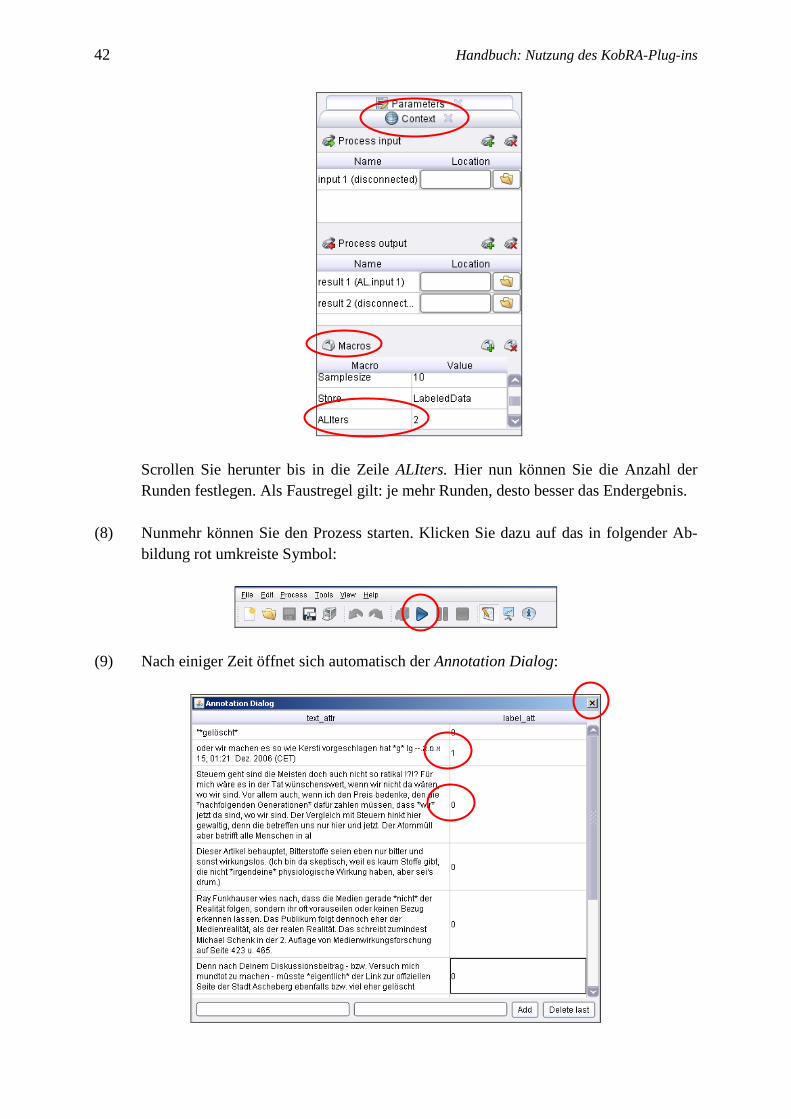
42 Handbuch: Nutzung des KobRA-Plug-ins
Scrollen Sie herunter bis in die Zeile ALIters. Hier nun können Sie die Anzahl der
Runden festlegen. Als Faustregel gilt: je mehr Runden, desto besser das Endergebnis.
(8) Nunmehr können Sie den Prozess starten. Klicken Sie dazu auf das in folgender Ab-
bildung rot umkreiste Symbol:
(9) Nach einiger Zeit öffnet sich automatisch der Annotation Dialog:
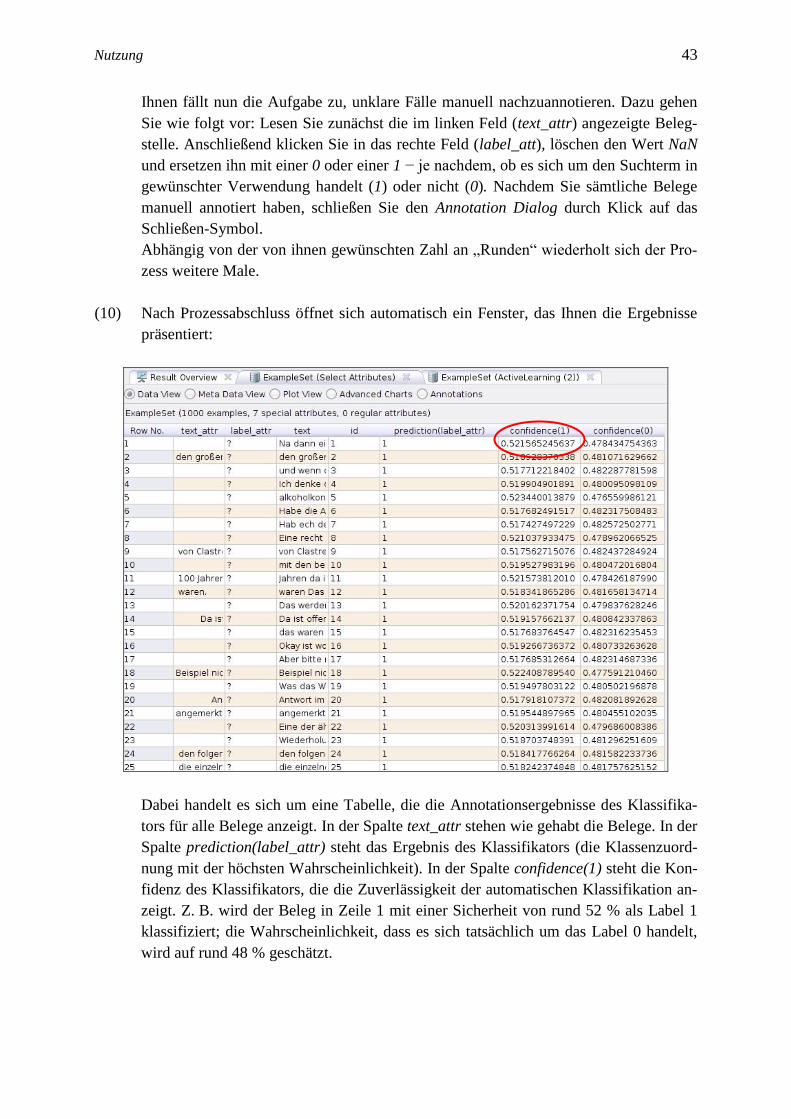
Nutzung 43 43
Ihnen fällt nun die Aufgabe zu, unklare Fälle manuell nachzuannotieren. Dazu gehen
Sie wie folgt vor: Lesen Sie zunächst die im linken Feld (text_attr) angezeigte Beleg-
stelle. Anschließend klicken Sie in das rechte Feld (label_att), löschen den Wert NaN
und ersetzen ihn mit einer 0 oder einer 1 − je nachdem, ob es sich um den Suchterm in
gewünschter Verwendung handelt (1) oder nicht (0). Nachdem Sie sämtliche Belege
manuell annotiert haben, schließen Sie den Annotation Dialog durch Klick auf das
Schließen-Symbol.
Abhängig von der von ihnen gewünschten Zahl an „Runden“ wiederholt sich der Pro-
zess weitere Male.
(10) Nach Prozessabschluss öffnet sich automatisch ein Fenster, das Ihnen die Ergebnisse
präsentiert:
Dabei handelt es sich um eine Tabelle, die die Annotationsergebnisse des Klassifika-
tors für alle Belege anzeigt. In der Spalte text_attr stehen wie gehabt die Belege. In der
Spalte prediction(label_attr) steht das Ergebnis des Klassifikators (die Klassenzuord-
nung mit der höchsten Wahrscheinlichkeit). In der Spalte confidence(1) steht die Kon-
fidenz des Klassifikators, die die Zuverlässigkeit der automatischen Klassifikation an-
zeigt. Z. B. wird der Beleg in Zeile 1 mit einer Sicherheit von rund 52 % als Label 1
klassifiziert; die Wahrscheinlichkeit, dass es sich tatsächlich um das Label 0 handelt,
wird auf rund 48 % geschätzt.
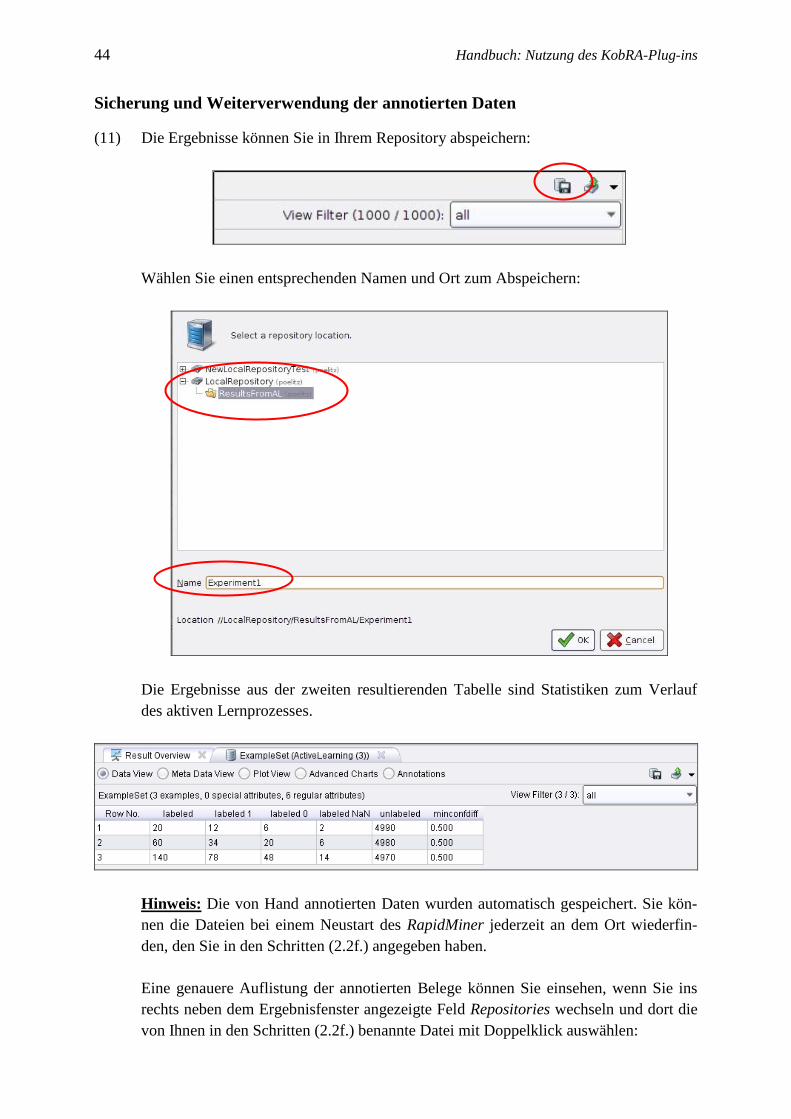
44 Handbuch: Nutzung des KobRA-Plug-ins
Sicherung und Weiterverwendung der annotierten Daten
(11) Die Ergebnisse können Sie in Ihrem Repository abspeichern:
Wählen Sie einen entsprechenden Namen und Ort zum Abspeichern:
Die Ergebnisse aus der zweiten resultierenden Tabelle sind Statistiken zum Verlauf
des aktiven Lernprozesses.
Hinweis: Die von Hand annotierten Daten wurden automatisch gespeichert. Sie kön-
nen die Dateien bei einem Neustart des RapidMiner jederzeit an dem Ort wiederfin-
den, den Sie in den Schritten (2.2f.) angegeben haben.
Eine genauere Auflistung der annotierten Belege können Sie einsehen, wenn Sie ins
rechts neben dem Ergebnisfenster angezeigte Feld Repositories wechseln und dort die
von Ihnen in den Schritten (2.2f.) benannte Datei mit Doppelklick auswählen:

Nutzung 45 45
Das Ergebnisfenster ändert sich wie folgt:
Insbesondere folgende Zeilen sind von Interesse:
label_attr: Gibt an, wie der entsprechende Begriff manuell annotiert wurde
text_attr: Hier finden Sie die Belegstelle. Verharren Sie mit dem Mauszeiger einige
Augenblicke auf einer Zeile, wird Ihnen die Belegstelle nochmals angezeigt.
Die in der Abbildung rot umrahmten Spalten zeigen die Belege (aus text_attr) in ih-
rer Repräsentation als Bag-of-Words, wie sie vom Klassifikator erwartet werden.
Diese Werte sind nur intern von Bedeutung.

46 Handbuch: Nutzung des KobRA-Plug-ins
(12) Die mithilfe des gelernten Klassifikators automatisch annotierten Daten können an-
schließend weiter verarbeitet werden. Laden Sie dafür die eben erzeugten Ergebnisse
aus dem Repository in einen neuen Prozess. Dies geschieht mithilfe des Operators
Retrieve. Der Operator Write Excel kann anschließend genutzt werden, um die Ergeb-
nisse in einer Datei im Microsoft-Excel®-Format zu speichern (Bitte Dateinamen und
Speicherort bei den Parametern des Operators angeben; Endung „.xls“ nicht verges-
sen!).
(13) Die exportierten Daten können Sie nun per Hand nachannotieren, indem Sie in der
Spalte label_attr das richtige Label 0 oder 1 einsetzen. Dies können Sie zum Beispiel
in Microsoft-Excel® erledigen. In der Tabelle sind natürlich die von Ihnen bereits wäh-
rend des aktiven Lernprozesses per Hand annotierten Belege enthalten.
(13.1) Eine Alternative zu Microsoft-Excel® ist die Verwendung des Operators Annotation
wie z.B. in Schritt 8. Dafür verbinden Sie einfach den Operator Retrieve mit dem Ope-
rator Annotation und geben bei den Parametern text_attr als text attribute und la-
bel_attr als label attribute an.
Nutzung 47 47
Evaluation
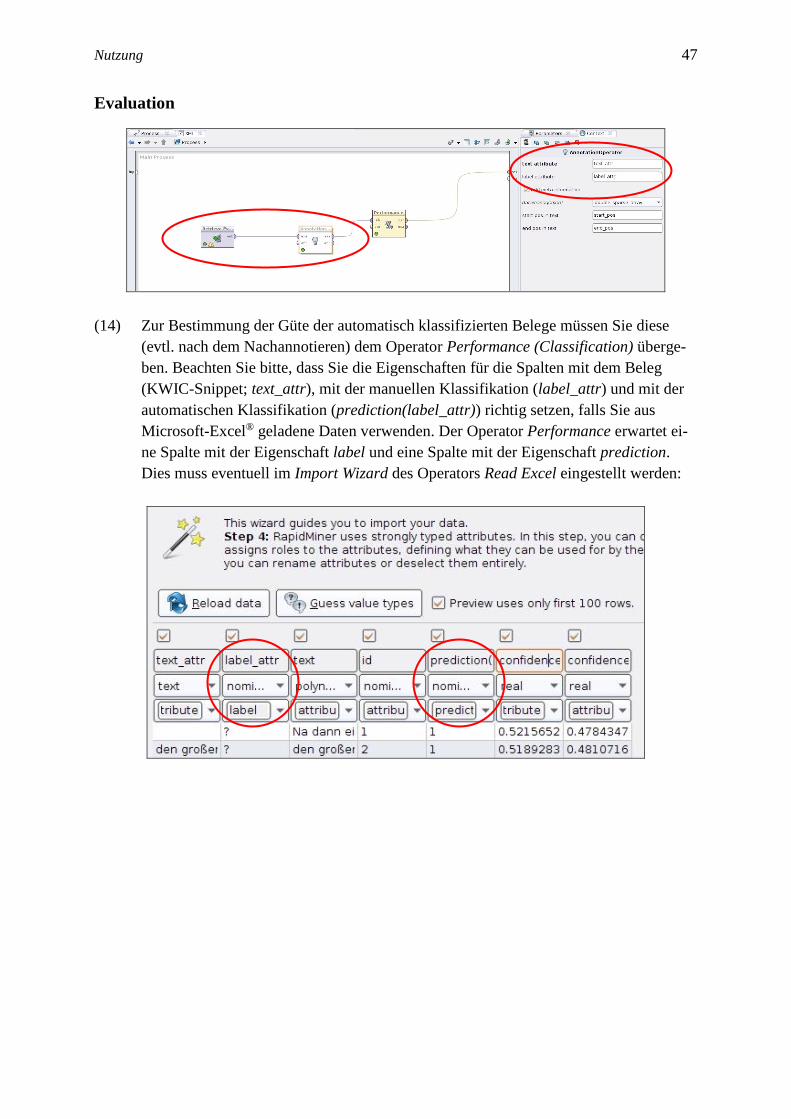
(14) Zur Bestimmung der Güte der automatisch klassifizierten Belege müssen Sie diese
(evtl. nach dem Nachannotieren) dem Operator Performance (Classification) überge-
ben. Beachten Sie bitte, dass Sie die Eigenschaften für die Spalten mit dem Beleg
(KWIC-Snippet; text_attr), mit der manuellen Klassifikation (label_attr) und mit der
automatischen Klassifikation (prediction(label_attr)) richtig setzen, falls Sie aus
Microsoft-Excel® geladene Daten verwenden. Der Operator Performance erwartet ei-
ne Spalte mit der Eigenschaft label und eine Spalte mit der Eigenschaft prediction.
Dies muss eventuell im Import Wizard des Operators Read Excel eingestellt werden:

48 Handbuch: Nutzung des KobRA-Plug-ins
4.4 Unüberwachte Disambiguierung und Visualisierung mit Topic-Modellen
(LDA)
Kurzbeschreibung des Prozesses:
Der Prozess führt eine automatische Einteilung von Korpusbelegstellen (KWIC-Snippets) und
Wörtern nach semantischen Zusammengehörigkeiten aus. Dafür wir ein sogenanntes Topic-
Modell verwendet. Dieses Modell ordnet den Korpusbelegen (KWIC-Snippets) und den Wör-
tern der Belege sogenannten Topics mit bestimmten Wahrscheinlichkeiten zu. Ein Topic stellt
eine semantische Gruppe dar, die sich aus häufig zusammen vorkommenden Wortkombinati-
onen ergibt.
Als Anwendungsbeispiel haben wir ein Szenario gewählt, bei dem eine Ergebnisliste einer
Korpusrecherche mit Belegen für mehrere Lesarten eines gesuchten Ausdrucks als CSV- oder
Microsoft-Excel®-Tabelle vorliegt bzw. in dieses Format gebracht wurde. Bei der Ergebnislis-
te handelt es sich um KWIC-Snippets für den Ausdruck Platte, die im Kernkorpus des 20.
Jahrhunderts des Digitalen Wörterbuchs der deutschen Sprache (DWDS; Berlin-Branden-
burgische Akademie der Wissenschaften, Berlin) erhoben wurden.
Der entsprechende Prozess steht unter folgendem Link zum Download bereit:
http://kobra.tu-dortmund.de/mediawiki/images/6/62/LDAProzess.zip (ZIP-Archiv bitte entpa-
cken: LDAProzess.rmp)
Prozesszugriff
(1) Laden Sie den Prozess unter dem oben genannten Link herunter und speichern Sie ihn
an einem Ort ihrer Wahl. Der Name ist LDAProzess.rmp.
(2) Starten Sie nun RapidMiner und importieren Sie den Prozess über die Option Fi-
le → Import Process (s. Kapitel 4.3, Schritte 2-4).
Sie erhalten folgenden Prozessaufbau:

Nutzung 49 49
Der Prozess besteht aus:
einem Operator zum Einlesen der Belege (Read Excel)
den Operatoren Data to Documents und Process Documents zum Umwandeln der
Texte in Bag-of-Words-Representation
Durch Doppelklick auf den Operator Process Documents gelangen Sie zu den
Operatoren für die Tokenisierung und verschiedene Filterschritte, die Sie bei Be-
darf konfigurieren können (über das Parameterfenster rechts).Standardmäßig wer-
den alle Groß- in Kleinbuchstaben umgewandelt und häufige Funktionswörter
(sog. Stopwords) sowie Tokens mit weniger als 2 oder mehr als 25 Buchstaben
entfernt.
Über die Parameter des Operators Process Documents können Sie zudem Wörter
ausfiltern, die sehr selten oder sehr häufig vorkommen. Die Einstellungen dazu
finden Sie ab der Zeile prune method.
Der Operator Latent Dirichlet Allocation generiert ein Topic Model. Die Parame-
ter des Operators hängen von den Daten ab. Als Faustregel gilt: alpha = 50/T wo-
bei T die Anzahl der Topics ist; beta = 0.1
Anschließend werden die Ergebnisse des Topic Models noch mit den Belegen
verbunden und als Ergebnistabellen präsentiert, die weiterverarbeitet werden kön-
nen.

50 Handbuch: Nutzung des KobRA-Plug-ins
Konfiguration und Ausführung
(3) Stellen Sie sicher, dass die Korpusdaten zur Disambiguierung in folgendem Format
vorliegen: Tabelle mit mindestens einer Spalte, die die Korpusbelege (KWIC-
Snippets) enthält, ein Beleg pro Zeile. In der ersten Zeile muss der Ausdruck text_attr
stehen. Jahresangaben zur zeitlichen Einordnung der Belege, Textsortenangaben oder
weitere Metadaten in weiteren Spalten können berücksichtigt werden (s. u.).
Im Folgenden wird davon ausgegangen, dass die Daten in einer Microsoft-Excel®-
Tabelle vorliegen. Möglich sind aber auch CSV-Tabellen (über den Operator Read
CSV), TEI-XML-Dateien (TEIQueryOperator) oder eine Direktabfrage der DWDS-
Korpora nach Rücksprache mit der Berlin-Brandenburgischen Akademie der Wissen-
schaften, Zentrum Sprache, über den LinguisticQueryOperator; s. Kapitel 4.1, Schritte
8-8.1).
(4) Importieren Sie die Daten über den Operator Read Excel. Klicken Sie dazu diesen an
und wählen Sie anschließend im rechten Parameterfenster die Schaltfläche Import
Configuration Wizard.
Nutzung 51 51
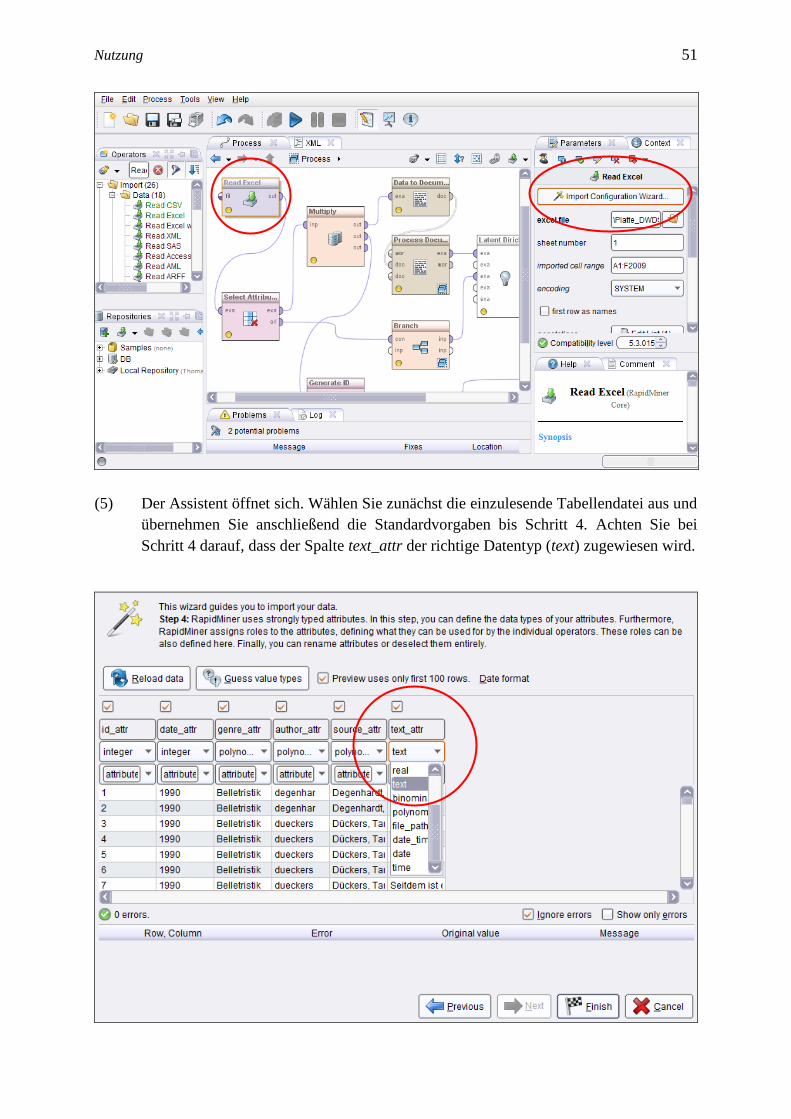
(5) Der Assistent öffnet sich. Wählen Sie zunächst die einzulesende Tabellendatei aus und
übernehmen Sie anschließend die Standardvorgaben bis Schritt 4. Achten Sie bei
Schritt 4 darauf, dass der Spalte text_attr der richtige Datentyp (text) zugewiesen wird.
52 Handbuch: Nutzung des KobRA-Plug-ins
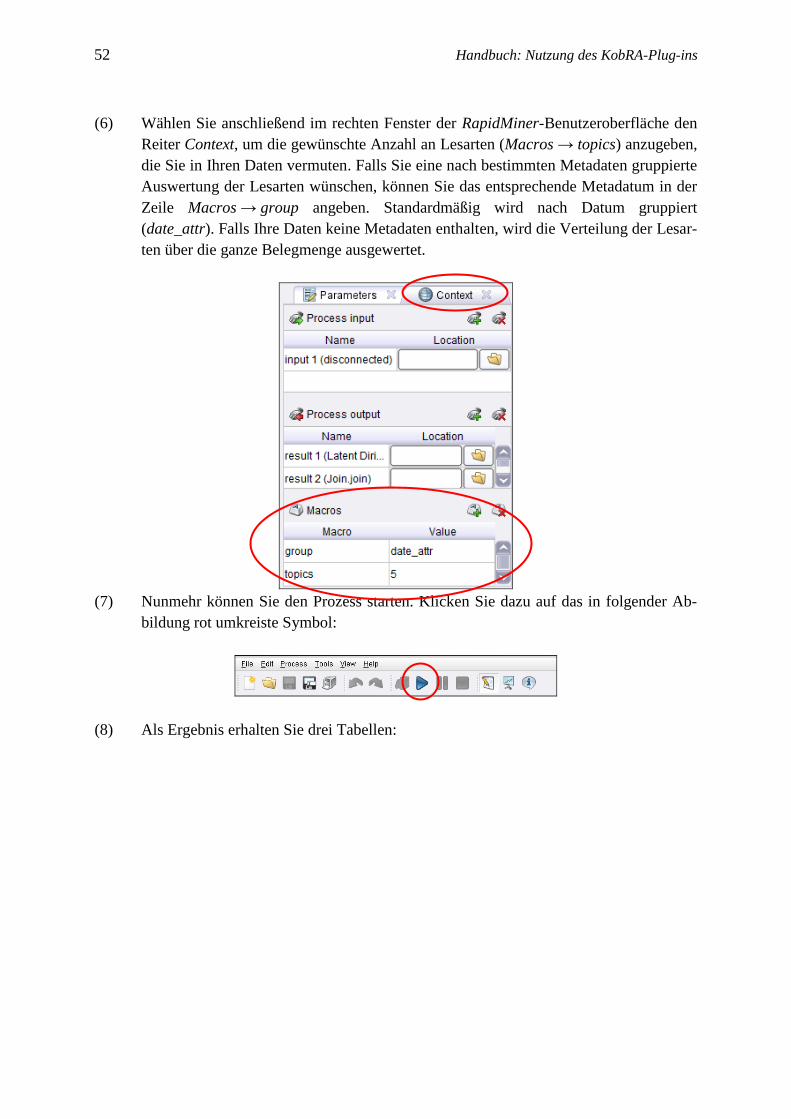
(6) Wählen Sie anschließend im rechten Fenster der RapidMiner-Benutzeroberfläche den
Reiter Context, um die gewünschte Anzahl an Lesarten (Macros → topics) anzugeben,
die Sie in Ihren Daten vermuten. Falls Sie eine nach bestimmten Metadaten gruppierte
Auswertung der Lesarten wünschen, können Sie das entsprechende Metadatum in der
Zeile Macros → group angeben. Standardmäßig wird nach Datum gruppiert
(date_attr). Falls Ihre Daten keine Metadaten enthalten, wird die Verteilung der Lesar-
ten über die ganze Belegmenge ausgewertet.
(7) Nunmehr können Sie den Prozess starten. Klicken Sie dazu auf das in folgender Ab-
bildung rot umkreiste Symbol:
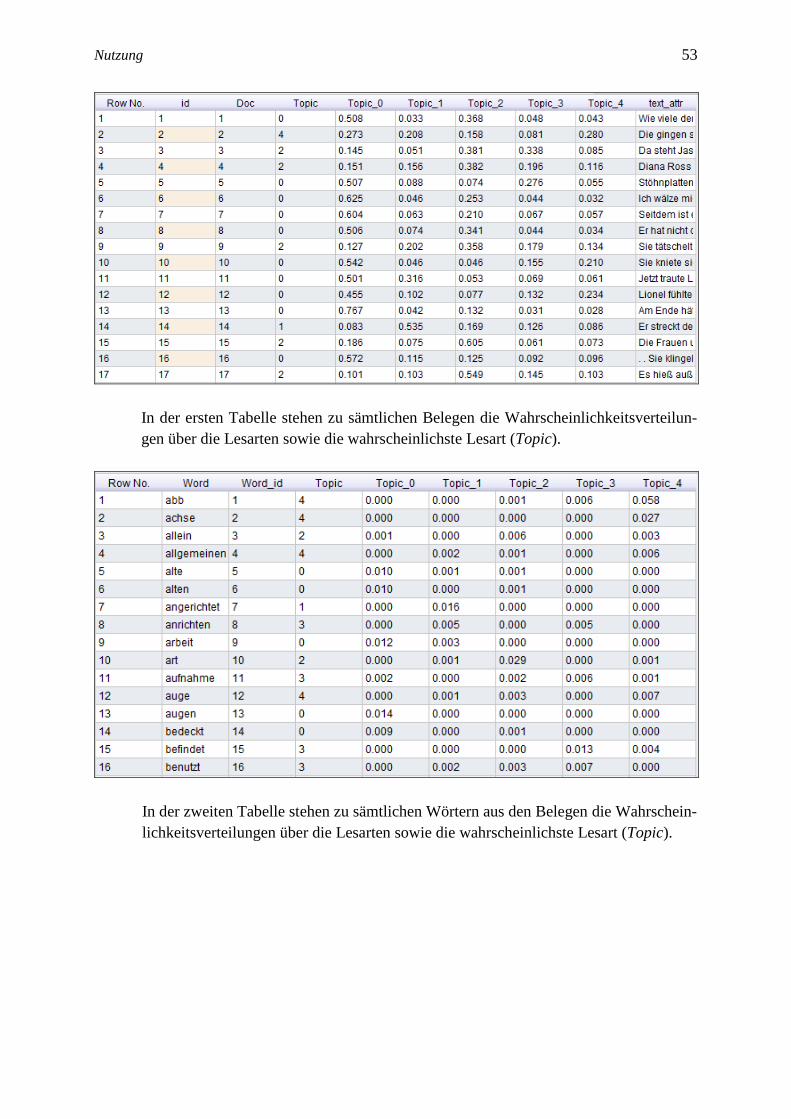
(8) Als Ergebnis erhalten Sie drei Tabellen:
Nutzung 53 53
In der ersten Tabelle stehen zu sämtlichen Belegen die Wahrscheinlichkeitsverteilun-
gen über die Lesarten sowie die wahrscheinlichste Lesart (Topic).
In der zweiten Tabelle stehen zu sämtlichen Wörtern aus den Belegen die Wahrschein-
lichkeitsverteilungen über die Lesarten sowie die wahrscheinlichste Lesart (Topic).
54 Handbuch: Nutzung des KobRA-Plug-ins
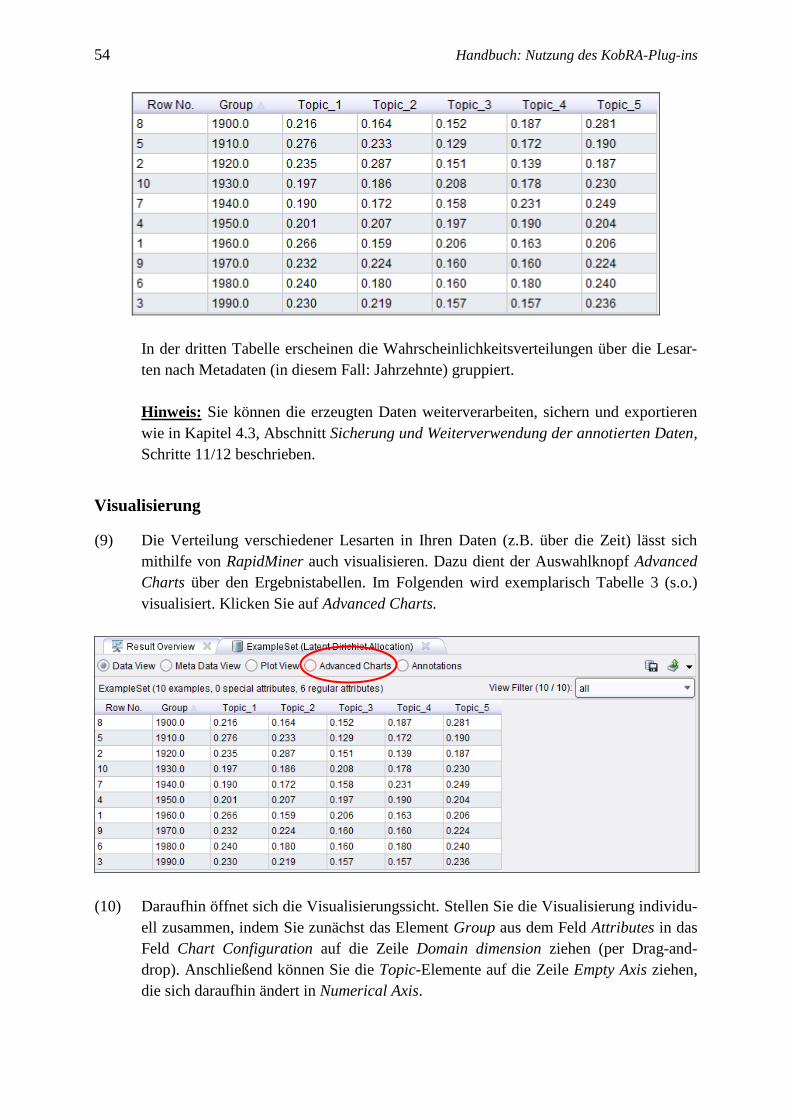
In der dritten Tabelle erscheinen die Wahrscheinlichkeitsverteilungen über die Lesar-
ten nach Metadaten (in diesem Fall: Jahrzehnte) gruppiert.
Hinweis: Sie können die erzeugten Daten weiterverarbeiten, sichern und exportieren
wie in Kapitel 4.3, Abschnitt Sicherung und Weiterverwendung der annotierten Daten,
Schritte 11/12 beschrieben.
Visualisierung
(9) Die Verteilung verschiedener Lesarten in Ihren Daten (z.B. über die Zeit) lässt sich
mithilfe von RapidMiner auch visualisieren. Dazu dient der Auswahlknopf Advanced
Charts über den Ergebnistabellen. Im Folgenden wird exemplarisch Tabelle 3 (s.o.)
visualisiert. Klicken Sie auf Advanced Charts.
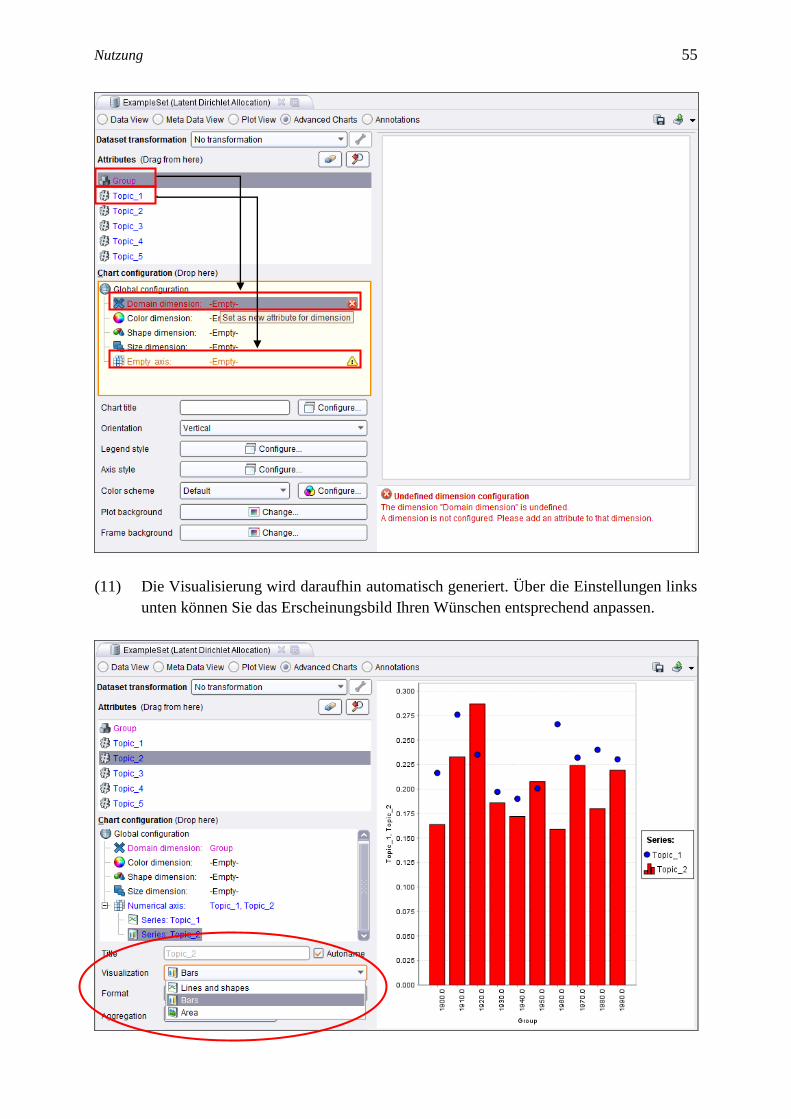
(10) Daraufhin öffnet sich die Visualisierungssicht. Stellen Sie die Visualisierung individu-
ell zusammen, indem Sie zunächst das Element Group aus dem Feld Attributes in das
Feld Chart Configuration auf die Zeile Domain dimension ziehen (per Drag-and-
drop). Anschließend können Sie die Topic-Elemente auf die Zeile Empty Axis ziehen,
die sich daraufhin ändert in Numerical Axis.
Nutzung 55 55
(11) Die Visualisierung wird daraufhin automatisch generiert. Über die Einstellungen links
unten können Sie das Erscheinungsbild Ihren Wünschen entsprechend anpassen.





























