Embed Size (px)
Citation preview

1
1
Hardware Dinámicamente ReconfigurableJulio Septién del CastilloHortensia Mecha López
Curso 3er Ciclo Abril 2003Departamento de Arquitectura de Computadores y Automática
Universidad Complutense de Madrid
2
TemarioTema 1. Introducción al Hw reconfigurableTema 2. Arquitecturas comerciales de Hwdinámicamente reconfigurableTema 3. Arquitecturas académicasTema 4. Arquitecturas grano gruesoTema 5. Problemas de gestión de recursos hwdinámicamente reconfigurablesSesiones prácticasPresentación de trabajos

2
3
Tema 4. Arquitecturas de grano grueso
La estructura de grano fino de las FPGAs provoca que para ciertas estructuras, fundamentalmente aritméticas, el rendimiento del circuito se degrade entre un 20% a un 100%.Las estructuras de grano grueso poseen recursos orientados a computación intensiva, como ALUs, multiplicadores, registros y memorias configurables dentro de caminos de datos segmentados.Los computadores reconfigurables se encuentran en un punto intermedio entre los ASICs, que proporcionan una gran velocidad, y los computadores de propósito general que permiten una gran flexibilidad.
4
Tema 4. Arquitecturas de grano grueso
1. Chameleon2. MATRIX3. RaPiD4. KressArrays5. MorphoSys

3
5
Chameleon
BibliografíaReconfigurable Computing in Wireless.B. Salefski, L. Caglar, 38th Design Automation Conference 2001
6
ChameleonEspecialmente orientado al procesamiento de señales digitales.
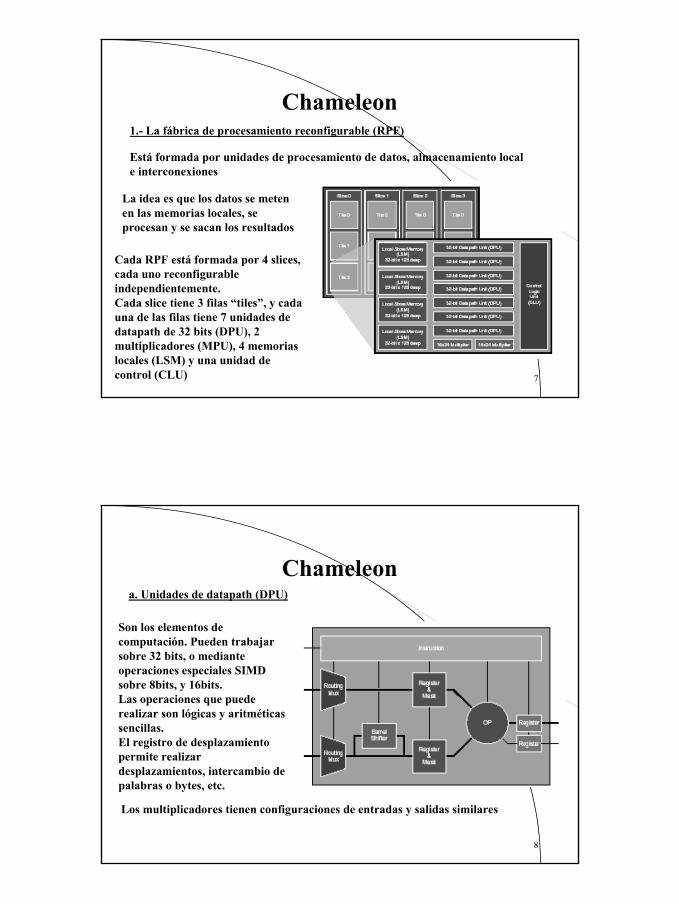
Formado por 3 subsistemas:1.- La fábrica de procesamiento reconfigurable (RPF)2.- Los bancos de E/S PIO3.- El procesador empotradoEstos módulos se conectan mediante un bus de 128 bits
4
7
Chameleon1.- La fábrica de procesamiento reconfigurable (RPF)
Está formada por unidades de procesamiento de datos, almacenamiento local e interconexiones
La idea es que los datos se meten en las memorias locales, se procesan y se sacan los resultados
Cada RPF está formada por 4 slices, cada uno reconfigurableindependientemente.Cada slice tiene 3 filas “tiles”, y cada una de las filas tiene 7 unidades de datapath de 32 bits (DPU), 2 multiplicadores (MPU), 4 memorias locales (LSM) y una unidad de control (CLU)
8
Chameleona. Unidades de datapath (DPU)
Son los elementos de computación. Pueden trabajar sobre 32 bits, o mediante operaciones especiales SIMD sobre 8bits, y 16bits.Las operaciones que puede realizar son lógicas y aritméticas sencillas.El registro de desplazamiento permite realizar desplazamientos, intercambio de palabras o bytes, etc.
Los multiplicadores tienen configuraciones de entradas y salidas similares

5
9
Chameleonb. Memoria de almacenamiento local
•Cada LSM es una memoria de 32bit*128 palabras, pero uniendo varios módulos mediante configuración es posible obtener otras configuraciones (64*128, 32*256).•Los datos no cambian entre configuraciones•Se puede utilizar una configuración para cargar datos (p.e, 128 palabras de 128bits) y otra para procesarlos (palabras de 16 bits)
c. Interconexionado
•Las interconexiones de las DPUs son buses de 32 bits de datos y líneas de control.•Las DPUs vecinas se conectan mediante un crossbar.•Las DPUs lejanas se conectan mediante conexiones que necesitan un ciclo de reloj.•El interconexionado puede cambiar ciclo a ciclo, ya que viene determinado por los multiplexores de control, cuyas entradas se determinan por la instrucción en curso.
10
Chameleond. Lógica de control
Cada DPU se programa mediante 8 instrucciones determinadas por el usuario.Cada instrucción determina el interconexionado de E/S, las operaciones sobre memoria, operaciones, etc.Además cada CLU implementa una máquina de estados para seleccionar la siguiente instrucción de la DPU y MPU almacenada en la memoria de instrucciones
La PLA contiene el siguiente estado, que depende de los bits de estado, los flags de la DPU, y los bits de control de las CLUs de la filas adyacentes. La PLA también proporciona información de estado a las filas adyacentes.

6
11
Chameleon2.- Entrada/Salida
•Existen 4 bancos de 40 pines cada uno•Permiten conseguir hasta 2 Gbit/s con una gran variedad de Interfaces•Pueden configurarse para cargar los datos directamente sobre las LSM, y de las LSM hacia la salida
3. Procesador empotrado
•Se trata de un procesador ARC modificado para aplicaciones sin cable•Cache de instrucciones 8K•Memoria de datos de 8K•Los elementos de almacenamiento de la fábrica de procesamiento se mapeanen el espacio de direcciones del ARC para lectura y escritura
12
ChameleonReconfiguración
Existe un controlador de configuración y 2 planos de configuración:1.- Uno activo, que controla la RPF2.- Otro en background que puede cargarse mientras se está
ejecutando un algoritmo con el otro plano.Se requieren unos 50.000 bits por plano, y unos 3 µs para cargar una nueva configuración.La conmutación de un plano a otro se realiza en un ciclo.Cada slice se puede reconfigurar independientemente.En una reconfiguración se mantiene los datos de las LSM.Además existe otro nivel de reconfiguración basado en la instrucción que controla la DPU. Esta reconfiguración puede hacerse dependiente de los datos.

7
13
Chameleon
Al diseñar hay que considerar:1.- La gran cantidad de elementos de proceso que permite explotar
todo el paralelismo inherente al algoritmo.
a.- Pueden utilizarse múltiples UFs para operar sobre múltiples datosb.- Las aplicaciones con varias etapas de computación pueden segmentarse.c. Pueden combinarse ambas opciones.
14
Chameleon
2.- La posibilidad de reconfigurar, y por tanto cambiar el comportamiento de los elementos de proceso, durante la ejecución de un algoritmo. Esto es interesante en aplicaciones basadas en grandes conjuntos de datos (frames) sobre los que hay que realizar varias operaciones
También se puede variar el algoritmo dependiendo de consideraciones ambientales.

8
15
Chameleon3.- La posibilidad de tener varias tareas ejecutándose simultáneamente, o bien conmutar de una a otra mediante reconfiguración
El sistema incluye un conjunto de herramientas para entrada de diseños, la generación de configuraciones para programar la RPF y el procesador, y la verificación de los mismos.Ha sido implementado en tecnología 0.25µm a 125MHz
16
Tema 4. Arquitecturas de grano grueso
1. Chameleon2. MATRIX3. RaPiD4. KressArrays5. MorphoSys

9
17
MATRIX
Investigador principal: A. DeHonBibliografía:
“Matrix: A reconfigurable Computing Architecture with Configurable Instruction Distribution and Deployable Resources”E. Mirsky, a. DeHonIEEE Symposium on FPGAs for Custom Computing Machines, FCCM 96
18
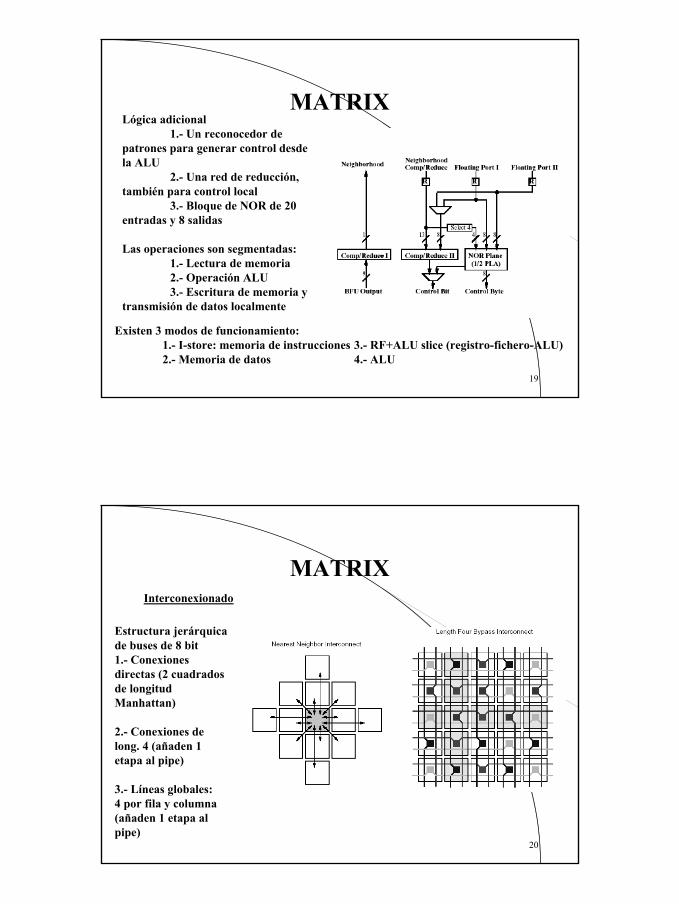
MATRIXSe trata de un array de UFs (Basic Functional Unit-BFU) de 8 bits y una red de interconexión configurableSe unifica el control de instrucciones, el procesamiento de datos y la memoria
Cada BFU contiene:Memoria 256*8bits configurable (doble puerto 128*8bit). ALU de 8 bits, que incluye un multiplicador 8*8 (2 ciclos)Lógica adicional
10
19
MATRIXLógica adicional
1.- Un reconocedor de patrones para generar control desde la ALU
2.- Una red de reducción, también para control local
3.- Bloque de NOR de 20 entradas y 8 salidas
Las operaciones son segmentadas:1.- Lectura de memoria2.- Operación ALU3.- Escritura de memoria y
transmisión de datos localmente
Existen 3 modos de funcionamiento:1.- I-store: memoria de instrucciones 3.- RF+ALU slice (registro-fichero-ALU)2.- Memoria de datos 4.- ALU
20
MATRIXInterconexionado
Estructura jerárquica de buses de 8 bit1.- Conexiones directas (2 cuadrados de longitud Manhattan)
2.- Conexiones de long. 4 (añaden 1 etapa al pipe)
3.- Líneas globales:4 por fila y columna(añaden 1 etapa al pipe)

11
21
MATRIXPuertos de BFU
Se pueden configurar de 3 modos:1.- Valor estático: El valor almacenado en la palabra de configuración se usa como cte (de datos o instrucción )2.- Fuente estática: El valor almacenado en la palabra de configuración selecciona el bus de donde se obtiene el dato3.- Fuente dinámica: Se ignora el valor almacenado en la palabra de configuración. La salida asociada al puerto flotante selecciona la fuente de entrada ciclo a ciclo. Esto permite variar la fuente de datos cada ciclo
22
MATRIXEj. Implementación de la función de convolución
yi=w1*xi+w2*xi+1+…+wk*xi+k-1
1ª opción: array sistólico (k=8)
1ª fila propaga datosLa multiplicación requiere 2 ciclosTodos los caminos usan modo fuente
Se podría mejorar el diseño con la mitad de sumadores y eliminando las celdas de propagación

12
23
MATRIX2ª opción: microcódigo Los pesos y los datos se almacenan en las memorias
Necesita 8BUFs y 8k+9 ciclos
24
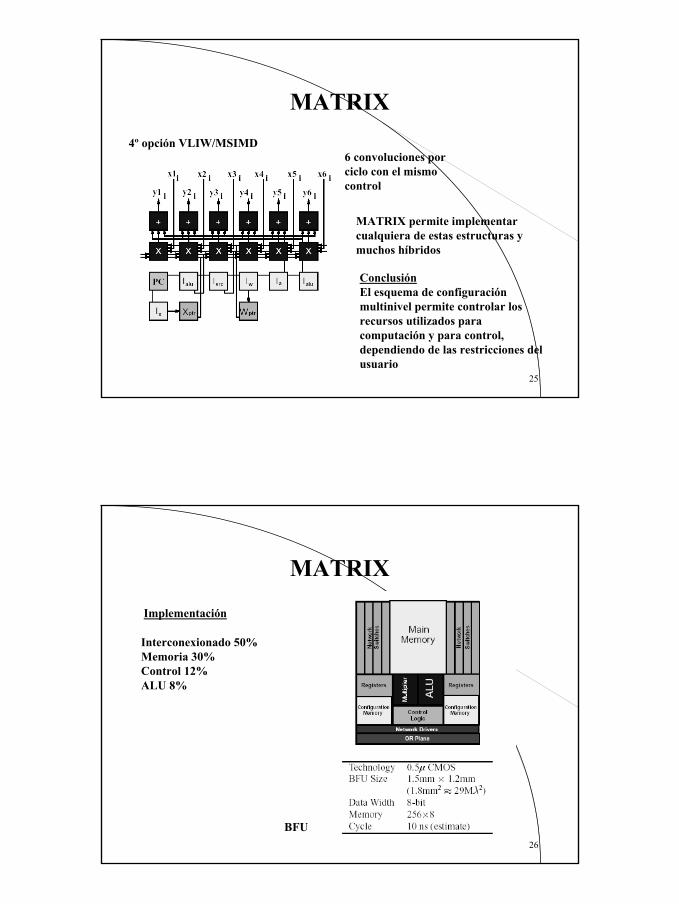
MATRIX3ª opción: VLIW 11 BUFs y 2k+1 ciclo
13
25
MATRIX4º opción VLIW/MSIMD
6 convoluciones por ciclo con el mismo control
MATRIX permite implementar cualquiera de estas estructuras y muchos híbridos
ConclusiónEl esquema de configuración multinivel permite controlar los recursos utilizados para computación y para control, dependiendo de las restricciones del usuario
26
MATRIX
Implementación
BFU
Interconexionado 50%Memoria 30%Control 12%ALU 8%

14
27
Tema 4. Arquitecturas de grano grueso
1. Chameleon2. MATRIX3. RaPiD4. KressArrays5. MorphoSys
28
RaPiD
Investigador principal: C. Ebeling. Univ. De WashingtonBibliografía:
“RaPiD: Reconfigurable Pipelined Datapath”C. Ebeling, D. C. Cronquist, P. Franklin“6th International Workshop on Field Programmable Logic and Aplications, pp. 126-135, FPL 96
“RaPiD- A Configurable Computing Architecture for Compute-Intensive Aplications”
C. Ebeling, D. C. Cronquist, P. Franklin, C. FisherTechnical Report UW-CSE-96-11-03
RaPid: Reconfigurable Pipelined Datapaths

15
29
RaPiDRaPiD es un computador reconfigurable optimizado para tareas de computación intensiva muy repetitivas. No es apto para tareas sin estructura o aquellas cuyo control dependa de los datos.Esta formado por un camino de datos, un controlador, las cadenas de E/S y la memoria.El sistema se configura programando el controlador del camino de datos y de las cadenas de E/S (microprogramados) y cargando la información de configuración en el array.
Los caminos de datos son arrays lineales de UFs que se comunican en una estructura de vecindad (orientado a pipeline lineal).
El control del camino de datos es dinámico
Se asume que el host controla el flujo de control y realiza las computaciones sin estructura
30
RaPiDArquitectura del Camino de datos
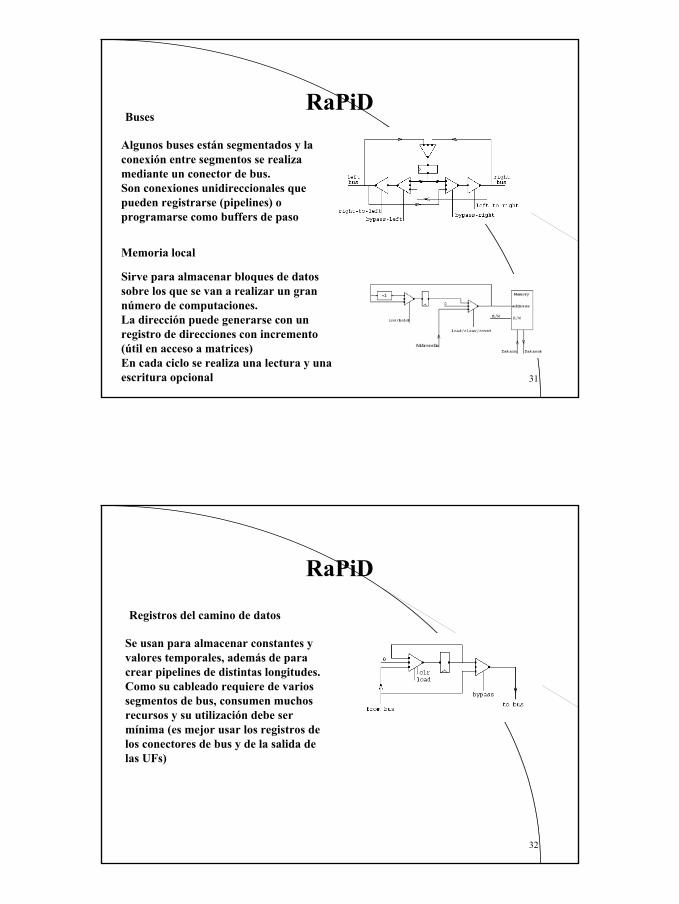
Rapid-I es una implementación particular de RaPiD formada por 16 celdas a 100MHz.Tiempo de configuración 2000 ciclosCada celda tiene:
• 1 multiplicador,• 3 ALUs, • 6 registros y • 3 memorias locales.
Operaciones de 16 bits encadenables a 32.Las UFs se conectan mediante 10 buses segmentados que recorren la longitud del camino de datos.
Entrada:un mux que selecciona 1 de 8 buses o la propia salidaSalida: Demux + driver para seleccionar 1 o varios de 8 busesLa salida puede registrarse (pipelines) y usarse como acumuladorPueden segmentarse internamente
16
31
RaPiDBuses
Algunos buses están segmentados y laconexión entre segmentos se realiza mediante un conector de bus.Son conexiones unidireccionales que pueden registrarse (pipelines) o programarse como buffers de paso
Memoria local
Sirve para almacenar bloques de datos sobre los que se van a realizar un gran número de computaciones.La dirección puede generarse con un registro de direcciones con incremento (útil en acceso a matrices)En cada ciclo se realiza una lectura y una escritura opcional
32
RaPiD
Registros del camino de datos
Se usan para almacenar constantes y valores temporales, además de para crear pipelines de distintas longitudes.Como su cableado requiere de varios segmentos de bus, consumen muchos recursos y su utilización debe ser mínima (es mejor usar los registros de los conectores de bus y de la salida de las UFs)
17
33
RaPiDEntrada/Salida
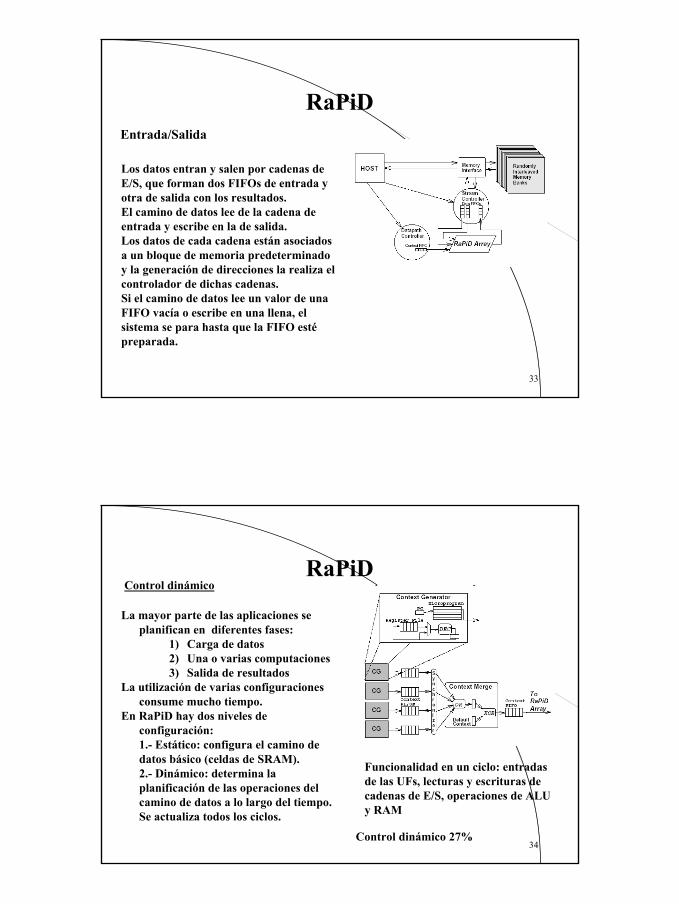
Los datos entran y salen por cadenas de E/S, que forman dos FIFOs de entrada y otra de salida con los resultados.El camino de datos lee de la cadena de entrada y escribe en la de salida.Los datos de cada cadena están asociados a un bloque de memoria predeterminado y la generación de direcciones la realiza el controlador de dichas cadenas.Si el camino de datos lee un valor de una FIFO vacía o escribe en una llena, el sistema se para hasta que la FIFO esté preparada.
34
RaPiDControl dinámico
La mayor parte de las aplicaciones se planifican en diferentes fases:
1) Carga de datos2) Una o varias computaciones3) Salida de resultados
La utilización de varias configuraciones consume mucho tiempo.
En RaPiD hay dos niveles de configuración:1.- Estático: configura el camino de datos básico (celdas de SRAM).2.- Dinámico: determina la planificación de las operaciones del camino de datos a lo largo del tiempo. Se actualiza todos los ciclos.
Funcionalidad en un ciclo: entradas de las UFs, lecturas y escrituras de cadenas de E/S, operaciones de ALU y RAM
Control dinámico 27%

18
35
RaPiDComo los caminos de datos suelen ser regulares, y en una aplicación suele haber uno o varios lazos anidados o en paralelo, el control del camino de datos y de las cadenas de E/S se describe mediante un microprograma, y las señales de control se insertan en un pipe paralelo al camino de datos.
Las microinstrucciones contienen información de control del camino de datos y construcciones de lazos
CG: Generador de contexto. Cada uno ejecuta una secuencia de lazos anidados
Los controladores van a doble frecuencia que el camino de datos
36
RaPiD
El camino de control está formado por un conjunto de buses segmentados de 1 bit.Cada señal de control dinámica se puede registrar, conectar a un bus dinámico mediante un inversor opcional o bien a 0 si el control es estático.Existen LUTs de 3 entradas para decodificar varios bits de contexto cuando sea necesario.También existen registros para construir máquinas de estado finitas para el control no segmentado
También es posible incorporar información de estado del camino de datos en el control dinámico

19
37
Tema 4. Arquitecturas de grano grueso
1. Chameleon2. MATRIX3. RaPiD4. KressArrays5. MorphoSys
38
KressArrays
Bibliografía:KressArray Xplorer: A New CAD Environment to Optimize Reconfigurable
Datapath Array Architectures; 5th Asia and South Pacific Design AutomationConference 2000, ASP-DAC 2000, A Datapath Synthesis System for the Reconfigurable Datapath Architecture; Asia and South Pacific Design Automation Conference, ASPDAC‘ 95, Using the KressArray for Configurable Computing; Proc. of SPIE Vol. 3526,
Conference on Configurable Computing: Technology and Applications, USA, Nov. 1998Investigadores principales: R. Hartenstein, M. Herz, Th. Hoffmann,
Lugar de desarrollo: Univ. De Kaiserslautern, Alemania

20
39
KressArrays
Se trata de una clase de arquitecturas.Los distintos miembros difieren en los recursos de comunicación y la funcionalidad de los operadoresSe basa en una red de grano grueso de 32 bitsLos operadores del hw mapean los de una descripción de alto nivel (lenguaje C)Pocas interconexiones y pocos bits de configuración
40
KressArrays•Los elementos de procesamiento (PEs orDPUs –reconfigurable data-path Unit) se distribuyen en arrays de N*M.•Se trata de una arquitectura escalable de forma transparente.•Una determinada aplicación se construye a partir de varios dispositivos KressArray idénticos•Las interconexiones locales se localizan en el borde del CI, permitiendo conectar varios dispositivos•Las conexiones de los límites de 32 bits se realizan en modo serie transparente al usuario•Existen buses globales que se comunican con cada dispositivo a través de unos switches internos. Esta red global permite implementar la E/S datos
Ancho 32 bits

21
41
KressArraysConexiones
Las conexiones locales permiten pasar resultados intermedios entre DPUs.
Un elemento de procesamiento puede servir:1.- Como operador2.- Como operador y elemento de interconexionado3.- Sólo como elemento de interconexionado
42
KressArrays
Además de la red global, las conexiones locales de borde también permiten la E/S datos.Cuando se implementa el sistema se puede generar una red global jerárquica, usando los switches de cada dispositivo y PEs como elementos de routing.Así la red global deja de ser un cuello de botella

22
43
KressArraysLas 8 salidas de un rDPU puede conectarse:
1. a todas las entradas2. a la salida de la UF3. al fichero de registros
El fichero de registros puede almacenar constantes o resultados intermediosLa UF proporciona la funcionalidad de los operadores del lenguaje C
44
KressArraysLa memoria de configuración consta de 4 layers independientes.El control de los multiplexores y la función aritmética se almacena en la memoria de configuración.Los layers no activos pueden configurarse en paralelo al procesamiento de datos, y es posible la reconfiguración parcialEl bus de configuración es independiente del bus de datosSe supone que la configuración la realiza un host a través del bus de configuraciónCada datos se escribe en dos ciclos:
– 1.- Primero una palabra de 32 bits especifica la rDPU, el layer y la dirección de memoria
– 2.- El dato de configuración
Memoria de configuración
23
45
KressArraysUn sistema global
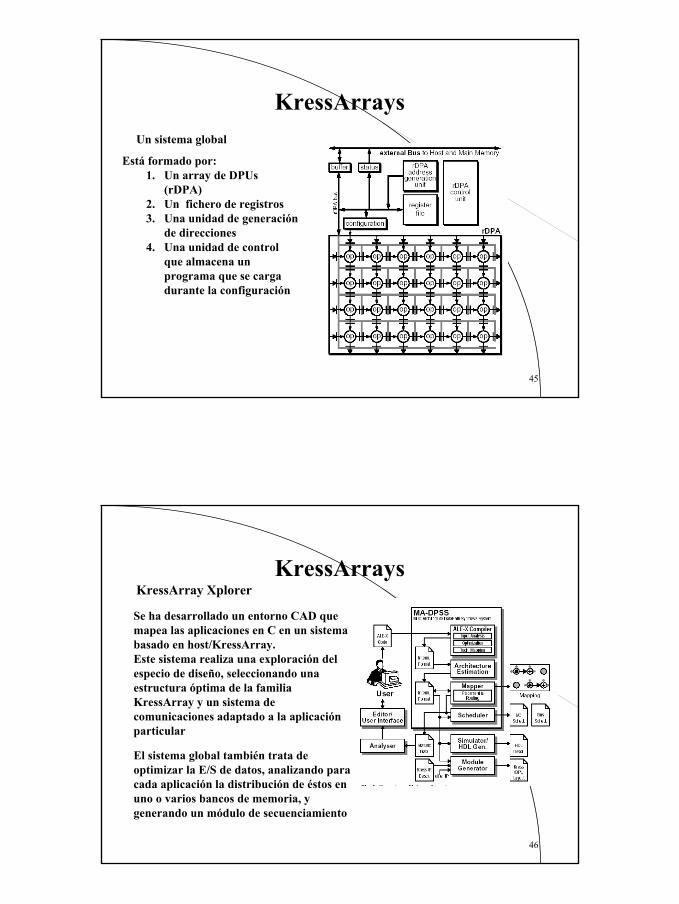
Está formado por:1. Un array de DPUs
(rDPA)2. Un fichero de registros3. Una unidad de generación
de direcciones4. Una unidad de control
que almacena un programa que se carga durante la configuración
46
KressArrays
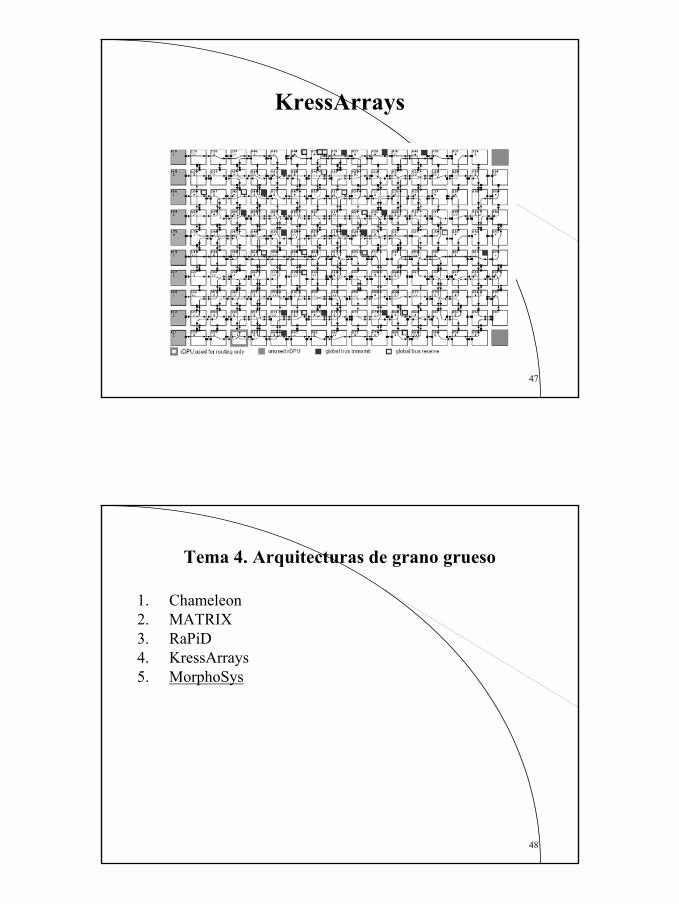
Se ha desarrollado un entorno CAD que mapea las aplicaciones en C en un sistema basado en host/KressArray.Este sistema realiza una exploración del especio de diseño, seleccionando una estructura óptima de la familia KressArray y un sistema de comunicaciones adaptado a la aplicación particular
El sistema global también trata de optimizar la E/S de datos, analizando para cada aplicación la distribución de éstos en uno o varios bancos de memoria, y generando un módulo de secuenciamiento
KressArray Xplorer
24
47
KressArrays
48
Tema 4. Arquitecturas de grano grueso
1. Chameleon2. MATRIX3. RaPiD4. KressArrays5. MorphoSys

25
49
MorphoSysBibliografíaMorphosys: An Integrated Re-configurable Architecture
Proceedings of NATO RTO Symposium of System Concepts andIntegration, Monterey, CA, April 98.
Design and Implementation of the MorphoSys Reconfigurable Computing Processor
– Journal of VLSI and Signal Processing-Systems for Signal, Image and VideoTechnology, Mar 2000
MorphoSys: An Integrated Reconfigurable System for Data-ParallelComputation-Intensive Applications
– Submitted to IEEE Transactions on Computers
Investigadores principales: F. Kurdahi, T. Lang
Lugar de desarrollo: Univ. De California http://www.eng.uci.edu/morphosys/
50
MorphoSys
Combina un array de elementos reconfigurables con un procesador RISC.Orientado a aplicaciones de computación intensiva, procesamiento de señales en tiempo real y reconocimiento de voz.
Camino de datos de 16 bits8*8 celdas reconf.Modo de operación: SIMDProcesador TinyRisc: •RISC 32 bits•Nuevas instrucciones para control RC

26
51
MorphoSys
Flujo de programa– El TiniRisc ordena la carga de los datos de configuración desde Memoria
principal a la Memoria de Contexto (DMA)– El TiniRisc ordena la carga de los datos desde memoria principal al buffer
de frames (DMA)– El TiniRisc emite instrucciones al ArrayRC para que ejecute un
determinado contexto– El funcionamiento puede ser por filas o por columnas
52
MorphoSys
Array Reconfigurable
64 celdas reconfigurablesOrganizadas en 4 cuadrantesComputación SIMD por filas o columnas
27
53
MorphoSysUna celda reconfigurable
Cada celda tiene:•ALU/mult•Unidad desplazamiento•Fichero de 4 registros•Ancho 16 bits•Registro contexto 32 bitsRegistro para realimentaciónRegistro para reusar operandos
54
MorphoSysMUXA (16 a 1):•4 vecinas•Otras celdas de misma fila/columna•Bus de datos•RegistrosMUXB (8 a 1):•4 registros•Bus de datos•3 vecinas
Puede realizar multiplicación-acumulación en un cicloLa cte puede usarse para ub-operacionesWR_Exp: “express lane”WR_BUS: buffer frames

28
55
MorphoSysInstrucciones del TinyRisc para Morphosys
Permiten la transferencia de instrucciones y datos desde memoria principal a la memoria de contexto y al buffer de frames.También sirven para ejecutar un contexto y elegir el modo broadcast
56
MorphoSysMemoria de Contexto
•Organizada en 2 bloques•Cada fila o columna del array RC puede recibir 1 palabra de contexto/ciclo•8 palabras de contexto forman un plano•Existen 16 planos /bloque•Puede capacitarse 1 fila o columna
Modelo SPMD (Single Program Multiple Data)Reconfiguración dinámica: una porción de la memoria de contexto se modifica mientras otra sirve para ejecutar un algoritmoLa carga de la memoria la controla el TinyRisc
29
57
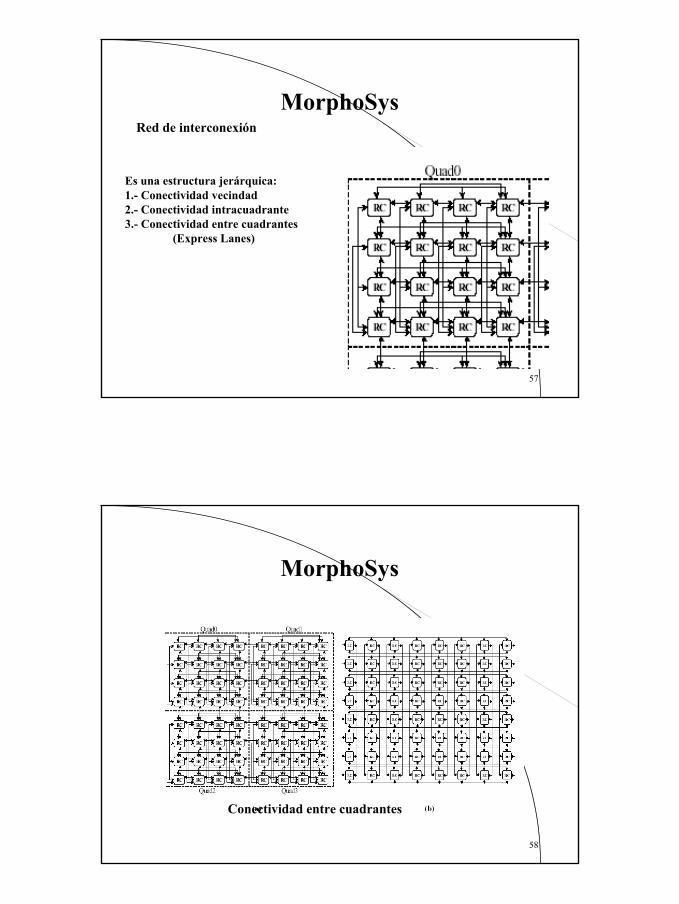
MorphoSysRed de interconexión
Es una estructura jerárquica:1.- Conectividad vecindad 2.- Conectividad intracuadrante3.- Conectividad entre cuadrantes
(Express Lanes)
58
MorphoSys
Conectividad entre cuadrantes

30
59
MorphoSysExpress Lanes: permiten llevar datos desde cualquier celda de un cuadrante a cualquier celda de la misma fila/columna en el cuadrante adyacente
60
MorphoSys
El Bus de datos: realiza una distribución de datos por columnas.– En un ciclo proporciona los 2 operandos de 8 bits a cada una de la
8 celdas de una columna– Las salidas de los elementos del array de cada columna se escriben
en el buffer a través del bus de datos del puerto AEl Bus de contexto(256 bits): Comunica la memoria de contexto con los registros de contexto. Permite cargar la misma palabra en todas las RCs de una misma fila o columna
Otros 2 niveles de conectividad adicionales

31
61
MorphoSysEjemplo de ejecución de un algoritmo
Todos los elementos de una fila realizan la misma operación
62
MorphoSysOtra posibilidad: primero ejecución por filas y luego por columnas

32
63
MorphoSysImplementación deMorphosys
Tecnología CMOS 0.35µ4 capas de metal3.3 v100MHz





























