Embed Size (px)
Citation preview

Hierarchical Evolutionary Learning of Growing Incremental Self-Organizing Maps for Phoneme Classification Hanen CHIHI, Najet AROUS
International Journal of Digital Content Technology and its Applications Vol.5 No.5, May 2011
Hierarchical Evolutionary Learning of Growing Incremental Self-Organizing Maps for Phoneme Classification
1Hanen CHIHI, 2Najet AROUS
Institut Supérieur d’Informatique, Tunis Tunisia [email protected], [email protected]
doi : 10.4156/jdcta.vol5.issue5.25
Abstract The aim of this work is to design a hierarchical model which represents a multi-layer extension of
Self-Organizing Map (SOM) variant. The purpose of the proposed system is to create autonomous systems that can learn independently and cooperate to provide a better decision of the phoneme classification. The basic SOM variant is a hybrid model of SOM and Genetic Algorithm (GA) using a growing incremental technique to adapt the map structure and extra information in the map units to optimise the map codebooks. The hierarchical evolutionary learning algorithm classifies data according to tow hierarchical levels ensuring the representation of the hierarchical relations of the data. Our experiments yielded a high recognition rate of 77.73% on TIMIT acoustic-phonetic continuous speech corpus.
Keywords: Self-organizing Map, Genetic Algorithm, Phoneme Classification, Growing Incremental Map
1. Introduction
The Self-Organizing Map (SOM) is an artificial Neural Network (NN) aimed at discovering structure within a given set of realizations [21, 25]. The network generates mappings from high-dimensional sample spaces to lower-dimensional topological structures of processing units, by means of an unsupervised learning algorithm. This property has attracted the interest of researchers in applying the SOM to pattern recognition and data compression problems. Because the SOM model was not actually conceived for these applications, various deficiencies of the approach have been pointed out in these contexts. Most notably, the requirement of deciding a priori the network architecture, i.e., the number of processing units, limits the ability of the network to deliver satisfactory solutions for pattern classification, and vector quantization applications. Structural adaptation models for the SOM are not very popular as it is known that given a sufficiently large number of processing units the mapping formed will be usually adequate. While this may be a satisfactory condition for topological mapping applications, the use of large SOM for vector quantization or clustering will likely yield sub-optimal solutions.
Genetic Algorithms (GA) are a stochastic optimization algorithms proposed by Holland [3, 10]. Their robustness in finding optimal or near optimal solutions and their domain independent nature motivates their applications in various fields like pattern recognition [23] and machine learning [16]. GA combine a principle of survival of the fittest with a random information exchange. Despite its random behavior, the GA is far different than a simple random walk. It has the ability to recognize trends toward optimal solutions and exploit such information by guiding the search toward them. GA maintains a population of potential solutions to the objective function being optimized. They research for these potential solutions until a specified termination criterion is met [4, 13]. Even though, GA are not guaranteed to find the global optimum, they can find an acceptable solution relatively in a wide range of problems.
GA are very attractive for training NN, which can find global optimal solutions [9]. It has also been shown that evolutionary methods may find better solutions compared to those found by back-propagation approach [8]. However, these results are dependent on the model architecture and parameters chosen. The purpose of using the GA has been twofold. A detailed study of hybrid models based on Kohonen map and GA is presented in [28]. Arous [1] and Stanley [24], used the GA to determine the best weights of SOM connections. The best rules of SOM training or to get a better topology are presented in [24, 10]. Many authors [11, 18] use GA for the research of NN parameters.
- 226 -

Hierarchical Evolutionary Learning of Growing Incremental Self-Organizing Maps for Phoneme Classification Hanen CHIHI, Najet AROUS
International Journal of Digital Content Technology and its Applications Vol.5 No.5, May 2011
The contribution of this work is to design a hierarchical model which represents a multi-layer extension of a new variant of the SOM model according to two-level hierarchical. This SOM variant is an evolutionary SOM using incremental growing learning algorithm and integrating extra information in the map units.
The purposes of this paper are: - Using the Growing Hierarchical SOM (GHSOM) to adapt the structure of the map. - Using the GA to optimize the map weights. - Integrating extra information during training to ameliorate the recognition of the map. - Using multiple Best Matching Units (BMU) for a given input incorporating an overlapping
processing to update the weights of the map. - Using an incremental destructive method to reduce the size of the map in order to ameliorate
the recognition phase. - Using a hierarchical strategy to create autonomous systems that can learn independently and
cooperate to provide a better decision of the phoneme classification. - Using a hierarchical classification model to represent the hierarchical relations of the data. Section 2 details the Kohonen self-organizing map. Section 3 presents an overview of hierarchical
NN. Section 4 proposes the hierarchical evolutionary learning of growing incremental SOM. Finally, we illustrate experimental results of the classification models. The introduced method is applied and tested for continuous speech recognition using the TIMIT corpus database.
2. Self-organizing map
The self-organizing map, introduced by Kohonen, is an artificial neural network based on an
unsupervised competitive learning. We concentrate on the SOM network known as a Kohonen network which has a feed-forward structure with a single computational layer of neurons arranged in rows and columns. Each neuron is fully connected to all the source units in the input layer. Figure 1 shows a bidimensional SOM.
The learning process of the Kohonen network is the following. In fact, when an input vector is fed to the network, its Euclidean distance to all weight vectors is computed with equation 1 [19]. The unit with the weight vector the most similar to the input called the BMU is selected. Then, its weight and its neighborhoods’ weight are adjusted towards the input vector (equations 2 and 3). In addition, the algorithm must update the learning parameters. In particular, at the beginning of the learning process the radius of the neighborhood is fairly large, but it is made to shrink during learning. This ensures that the global order is already obtained at the beginning. Towards the end, when the radius gets smaller, corrections of the weight vectors will be estimated locally. The factor ε(t) also decreases during learning. The learning rule around the winner unit 1n is as follows:
Nntwtn nn Î"-= ,)()(minarg1 x (1)
)()()1( twtwtw nD+=+ (2)
)()()()()(
1, twtthttw nnnn -=D xe (3)
where ε (t) is a monotonically decreasing learning coefficient and ξ(t) is the input vector. The neighborhood function
1,nnh depends on the lattice distance between the BMU ( 1n ) and unit n. In the simplest form, it is one for all units close enough to the BMU and zero for others, but a Gaussian function is a common choice, too.
- 227 -

Hierarchical Evolutionary Learning of Growing Incremental Self-Organizing Maps for Phoneme Classification Hanen CHIHI, Najet AROUS
International Journal of Digital Content Technology and its Applications Vol.5 No.5, May 2011
Figure 1. Bidimentional SOM
For the SOM, the topology has to be chosen before training. This can be a difficult step since NN
are often used for problems where the properties of the training data are not well known. Choosing large map promotes the training rates compared to the generalization rates. A too small map may not be able to capture the relations underlying the training data and will show poor results on new data, too. For this reason, different methods to adapt the network topology have been investigated extensively [7]. In fact, there are two broad categories: the statics and the dynamics SOM. The latter are characterized by a number of units that varies during learning.
Approaches like the Growing Cell Structures (GCS) [6] or the growing neural gas [5] have been proposed for addressing the network size issue in the context of self-organization. Fixing an upper bound for the number of units in the network (as in the GCS model) is equivalent to defining a global minimum error, because adding a new units to the map will always reduce or at least keep the quantization errors unchanged. It is easy to see that the use of this complexity measure will usually yield maps with a large number of processing units. Similar remarks can be made with respect to the growing neural Gas [5]. One other category is the growing hierarchical SOM or GHSOM [22, 27]; it is a NN model with hierarchical architecture composed of independent growing self-organizing maps. By providing a global orientation of the independently growing maps in the individual layers of the hierarchy, navigation across branches would be easier.
3. Hierarchical neural networks
A hierarchical classifier is a classifier that maps input data into defined output categories. The
classification occurs first on a high-level with highly-specific fragments of input data. The classifications of the individual fragments of data are then combined systematically and classified on a higher level iteratively until one output will be produced. This final output is the overall classification of the data. Generally, such systems rely on relatively simple individual units having only one universal function to do. These machines rely on the power of the hierarchical structure itself instead of the computational abilities of the individual components. This makes them relatively simple, easily expandable and powerful.
Work in speech recognition and in particular phoneme classification imposes the assumption that different classification errors are of the same importance [15]. However, since the set of phoneme are embedded in a hierarchical structure some errors are likely to be more tolerable than others. For example, it seems less severe to classify a phoneme as the phoneme /oy/ (as in boy) instead of /ow/ (as in boat), than predicting /w/ (as in way) instead of /ow/. Furthermore, often we cannot extend a high-confidence prediction for a given phoneme, while still being able to accurately identify the phonetic macro-class of the phoneme. Often we cannot prolong a forecast of high confidence for a given expression, while always being able to identify exactly the phonetic group of expression. Given this finding, we can infer that the use of hierarchical classifiers can be a promising solution.
Generally a hierarchical neural networks refers to a tree of networks, where each level is associated filtering. The higher level is more abstract than the lower one. Luttrell [17, 18] thinks that having more layers to a vector quantifier leads to a higher distortion; however, it effectively reduces the complexity of the task by using different structures according to different levels representations. Lampinen and Oja [14] propose a hierarchical SOM for multi-layer classification for the arrangement of the documents
- 228 -

Hierarchical Evolutionary Learning of Growing Incremental Self-Organizing Maps for Phoneme Classification Hanen CHIHI, Najet AROUS
International Journal of Digital Content Technology and its Applications Vol.5 No.5, May 2011
database. In this approach the BMU of an input vector is presented to the first layer of the map and its index is presented as input to the second layer. Arous and Ellouze [2] proposes a hierarchical self-organizing map models (hierarchical SOM) for phoneme classification. The hierarchical SOM uses an unsupervised learning and a spatial organization of data. This classification approach extends the Kohonen map by introducing the principle of multiple prototype vectors by means of an enrichment auxiliary information method in a map. Jlassi et al. [12] propose a growing Hierarchical Recurrent SOM (Hierarchical RSOM) for phoneme recognition. The model proposed in [12] is like the basic growing hierarchical SOM, however, in the proposed method each map of each layer is a Recurrent SOM (RSOM) it is characterized for each unit of the map by a difference vector which is used for selecting the best matching unit and to adapt the map weights.
4. Hierarchical evolutionary learning of growing incremental self-organizing maps
The Hierarchical Evolutionary Learning of Growing Incremental Self-Organizing Maps
(Hierarchical EL-GISOM) was introduced as a dynamical NN that adapts its architecture to satisfy the unsupervised learning process and to represents the hierarchical relation of the data.
4.1. Learning algorithm for the growing incremental Kohonen maps
To train the maps of the hierarchical structure, we propose an Evolutionary Learning of Growing Incremental Self-Organizing map (EL-GISOM) that integrates extension and reduction rules to adapt map units according to GA requirements. Figure 2 schematizes the general structure of the proposed hybrid model. The learning algorithm is divided into 3 steps. First, we use the principle of GHSOM algorithm for the map growing while fixing the depth to N layers. Then, the learning process is done to adapt the weight of the extended map. Finally, the map is reduced to have the initial map structure. In the following we detail these different steps.
4.1.1. Extension processing
The EL-GISOM model proposes a growing process in order to have a sufficient map size. The
growing incremental algorithm extends the map size by adding units to the map in order to minimise the map quantisation error. The algorithm is able to create a non-symmetric hierarchical structure. It is a fully adaptive architecture for the inherent patterns present in the data. This lead to the development of a new architecture grows both in a hierarchical way according to the data distribution and in a horizontal way. The size of each individual map adapts itself to the requirements of the input space.
In order to adapt the size of the first layer, the mean quantization error of the map is computed ever after a fixed number of training iterations. In particular, the algorithm will add a new row or a new column to the map. The major difference to the training process of the second layer map is that only the fraction of the input data is selected for training which is represented by the corresponding first layer unit. The same process is applied for any subsequent layers of the model. The training process is terminated when no more units require further expansion or when the maximum number of units is reached.
4.1.2. learning process
During the training process, we begin by building the initial GA population. Next, these units are
optimized and maintained using genetic operators. The genetic learning applied to the population of the BMU operates in the same way of the traditional GA, it required then:
· Genetic representation: We used the real encoding to represent each weight. · Initial population: The initial population is composed by a set of BMU. · Evaluation function: We affect to each individual a score representing the Euclidian distance
between the input vector and the BMU.
- 229 -

Hierarchical Evolutionary Learning of Growing Incremental Self-Organizing Maps for Phoneme Classification Hanen CHIHI, Najet AROUS
International Journal of Digital Content Technology and its Applications Vol.5 No.5, May 2011
· Genetic reproduction: We use a tournament selection method, tow-points crossover and uniform mutation allowing bringing closer the chromosomes to the input. Furthermore, we use the elitism strategy to protect the best individual during genetic learning process.
TIMIT Vowels database
Training by genetic operators
GA
SOM
Map training
SOM reduction size
SOM size extension
EL-GISOM
Figure 2. Block-diagram of EL-GISOM
After that, the map units and the training parameters are updated taking into account of the
neighborhood area of each winner unit. Figure 3 presents an example of an overlapping area. By applying the Kohonen learning rule for all the BMU, redundant operations are produced; units are updated many time. To solve this problem, the suggested method integrates an adapted algorithm. The EL-GISOM algorithm attributes a priority to each winner. These priorities preserve its neighbors and they remove the overlapping area for the unit having the lower priority. Indeed, the priority associated with the BMU protects the winners’ neighbors according to their priorities. Consequently, the units contained in the overlapping area are updated only once. To update the winner like their neighbors, the equation 4 is used :
)()()()()( , twtthttw nnnn bmui
-=D xe (4) where ε(t) is a learning coefficient,
bmuinnh , is the neighbourhood function and ibmu is a priority.
Nntwtn nbmuiibmui Î"-= ,)()(minarg x (5)
Since TIMIT corpus is labelled, we suggest saving more information inside each unit during the training phase of a Kohonen map. Therefore, each unit of the map is characterized by the following information:
· a General Centroid Vector (GCV): determined by the Kohonen learning rule ; · the characteristics relative to each class of phoneme :
o a centroid vector, o a label, o an activation frequency.
This process specifies the information relating to membership of the input vector to a phoneme class during the classification process. We integrate this principle in the EL-GISOM model; the resulting model is called Enriched EL-GISOM. During the decision process, we begin by finding the BMU unit. Then, we search for the best centroid vector the must semilar to the input signal.
- 230 -

Hierarchical Evolutionary Learning of Growing Incremental Self-Organizing Maps for Phoneme Classification Hanen CHIHI, Najet AROUS
International Journal of Digital Content Technology and its Applications Vol.5 No.5, May 2011
4.1.3. Reduction processing
The units of the map are supposed to contain the maximum of information available to carry out a prediction as precise as possible. Two close classes must have a great number of common characteristics. When the number of SOM units is large, similar units must be grouped to eliminate the redundancy and to improve the recognition phase. In order to obtain the initial map structure, the incremental Kohonen map algorithm seeks, and removes lines or columns while maintaining the quantization error sTable. In addition, the proposed algorithm removes levels form the GHSOM hierarchy while conserving their information in the superior levels. Then, a training process is applied for any subsequent layers of the model. The reduction process is repeated until having the initial map structure.
4.2. Hierarchical learning and decision strategy
The hierarchical model imposes a severity concept of the forecast errors which is in conformity with
a preset hierarchical structure. In fact, the proposed evolutionary learning algorithm is sensitive to the presence of noise and the model will no longer preserve the topology of the input space. In addition, SOM is not able to separate "near" phonemes. It is shown that the nonlinear nature of the algorithm makes it difficult to analyze the algorithm except in some trivial cases. Therefore, the network will not effectively represent the topological structure of the data under study. In this sense, we propose a hierarchical hybrid SOM in order to reach such separation.
The phonetic theory of speech signal includes the vowels of the Western languages in a phonetic hierarchy. The phonemes constitute the sheets of a tree while the macro-classes (phonemes’ groups) correspond to the internal tops. Such regrouping of phonemes was described in [15]. This model incorporates the concept of the intra-class similarity (phonemes of the same macro-classes). In a similar way, it treats the inter-classes dissimilarity (phonemes included in a different macro-class).
Figure 3. Overlapping area scheme
The purpose of the proposed system is to create autonomous systems that can learn independently
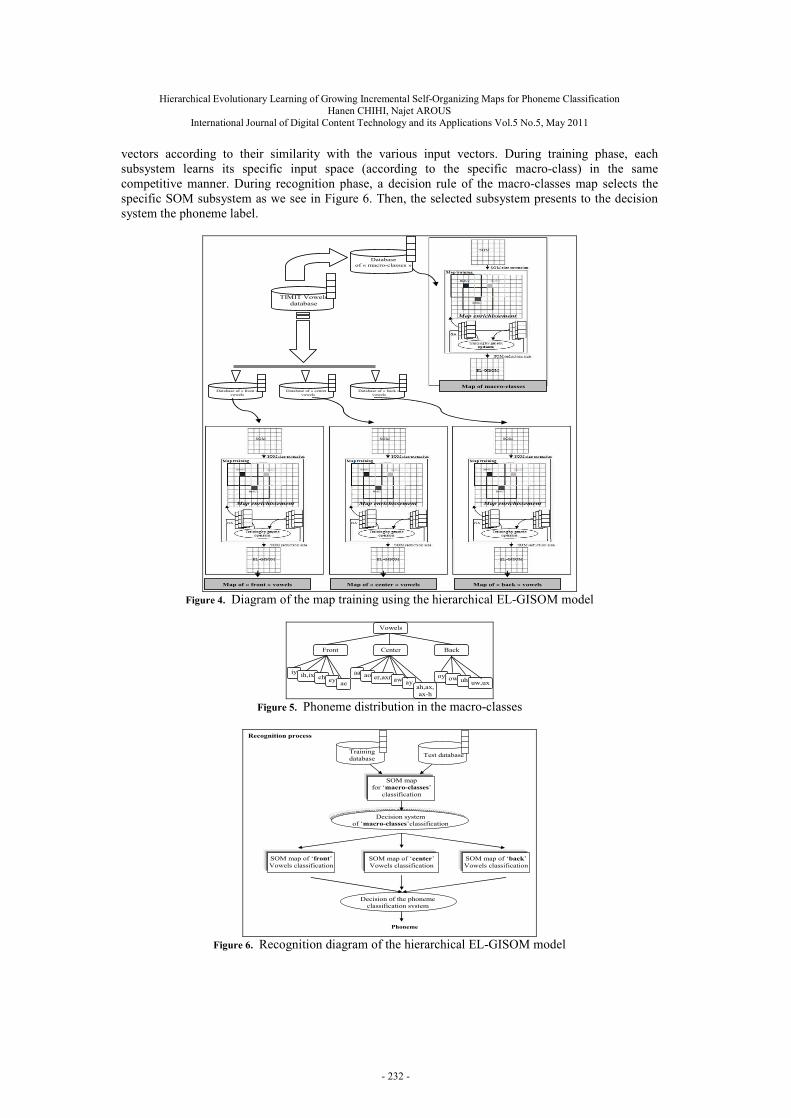
and cooperate to provide a better decision in classifying samples of entries. The hierarchical EL-GISOM reduces the complexity of the classification task and each layer provides its specific corresponding information for an input sample. The proposed hierarchical model learning scheme is described in Figure 4.
At the first level of the hierarchy, we retrain the specific information of the macro-class label of the input sample. At the second level of the hierarchy, we retrain the specific information of the phoneme label in its macro-class of the input samples. The database is divided into tree macro-classes including ”front”, ”center” and ”back”. The first layer of the hierarchy is trained by all phonemes labelled by identifiers of macro-classes. The second layer is composed of three classifiers. Each element of this layer can be regarded as an isolated subsystem. Thus, each element is associated a training database of a macro-class. Figure 5 shows the list of phonemes of each macro-class of the vowels of the TIMIT database.
The goal of such representation is to create a hierarchical system of different trained map based on similar evolutionary incremental learning. Each isolated subsystem can be considered as an autonomous system. The resulting of each subsystem is a phonotopic map. In this paper, we describe a hierarchical classification approach based on the enriched EL-GISOM model. We associate a weight vector for each phoneme on one hand and each macro-class on the other. We classify these weight
- 231 -
Hierarchical Evolutionary Learning of Growing Incremental Self-Organizing Maps for Phoneme Classification Hanen CHIHI, Najet AROUS
International Journal of Digital Content Technology and its Applications Vol.5 No.5, May 2011
vectors according to their similarity with the various input vectors. During training phase, each subsystem learns its specific input space (according to the specific macro-class) in the same competitive manner. During recognition phase, a decision rule of the macro-classes map selects the specific SOM subsystem as we see in Figure 6. Then, the selected subsystem presents to the decision system the phoneme label.
TIMIT Vowels database
Database of « front » vowels
Database of « center » vowels
Database of « back » vowels
Map of macro-classes
Map of « center » vowels Map of « back » vowels Map of « front » vowels
Database of « macro-classes »
Map enrichissement
Map enrichissement
Map enrichissement
Map enrichissement
Figure 4. Diagram of the map training using the hierarchical EL-GISOM model
aa ao
Vowels
Front Center Back
iy ih,ix eh ey ae er,axr aw ay
ah,ax,ax-h
oy ow uh uw,ux
Figure 5. Phoneme distribution in the macro-classes
Recognition process
SOM map for ‘macro-classes’
classification
SOM map of ‘front’ Vowels classification
Decision of the phoneme classification system
Decision system of ‘macro-classes’classification
Phoneme
SOM map of ‘center’ Vowels classification
SOM map of ‘back’ Vowels classification
Training database Test database
Figure 6. Recognition diagram of the hierarchical EL-GISOM model
- 232 -

Hierarchical Evolutionary Learning of Growing Incremental Self-Organizing Maps for Phoneme Classification Hanen CHIHI, Najet AROUS
International Journal of Digital Content Technology and its Applications Vol.5 No.5, May 2011
5. Experimental results We have implemented a hierarchical system of hybrid models for continuous speech recognition
based on growing incremental Kohonen map and GA composed of three main components. The first component is a pre-processor for vowels sounds and producing mel cepstrum vectors (MFCC). The second component is a classification model. The third component is a phoneme decision module. In the following, we describe the used database and the models parameterization and we present a detailed discussion of the experimental results obtained on the classification of vowels of TIMIT corpus.
5.1. Data analysis and models’ parameterization
In order to investigate the changes what we made, we tested our models for speaker independent
continuous speech recognition. In this work, we have used the MFCC vectors [26]. They are extracted from the TIMIT corpus. It contains a total of 6300 sentences, 10 sentences spoken by each of 630 speakers from 8 major dialect regions of the United States. The data were recorded at a sample rate of 16 KHz and a resolution of 16 bits. In our experiments, we have used the New England dialect region (DR1) composed of 31 males and 18 females. The corpus contains 13 699 phonetic unit for training. Each phonetic unit is represented by three frames selected at the middle of each phoneme to generate data vectors.
The development of an evolutionary self-organizing map is a delicate task which requires many experiments. In fact, model performance depends on parameters chosen at the initialization and at the training phases. The training rate decrease linearly from 0.99 to 0.02 and the neighborhood radius decreases also linearly from the half of the diameter of the map to 1. For the training of the sequential SOM, the EL-GISOM and Enriched EL-GISOM, the map size is set to 20x20. Concerning the hierarchical model, the size of the individual maps is represented in the Table 1. Since the complexity of GA is directly proportional to the number of generations, the size of the population, and the complexity of the evaluation function, we kept the size of the population, and the maximum number of generations rather small. The parameters of GA used in the experiments are the following:
· The size of the population varies according to the parameter of the growing incremental extension/reduction algorithm. Thus, we used a constant population composed by 3 BMU.
· The size of the population used for the training of the sub-components of the hierarchical system is described in the Table 1.
· The maximum number of generations is 40. · The probability of crossover is 0.8. · The probability of mutation is 0.01. · The method of proportional selection is used. · The elitism strategy is used to save a copy of the best individual.
Table 1. Parameters of the sub-system of the Hierachical EL-GISOM
Level Map Map size
Population size
First level Macro-classes 30x30 4
Second level
Front macro-class
20x20 3
Center macro-class
20x20 3
Back macro-class
20x20 3
During the experimental section we use some notations which are: · EL-GISOM(n,r) where n represents the population size and r is the map growing parameter.
In this paper, we denote by the classic GA the model incorporating a roulette selection, a uniform mutation operator and a tow-point crossover operator. The mutation operator exchange's a random
- 233 -

Hierarchical Evolutionary Learning of Growing Incremental Self-Organizing Maps for Phoneme Classification Hanen CHIHI, Najet AROUS
International Journal of Digital Content Technology and its Applications Vol.5 No.5, May 2011
selected gene with a random value within the range of the gene's minimum value and the gene's maximum value. During crossover process, pairs of genomes are “mated” by taking a randomly selected string of bits from one and inserting it into the corresponding place in the other, and vice versa, thus producing two new genomes. In this experiment, 5% of the best individuals are guaranteed a place in the new population. This process of fitness-measurement, reproduction, crossover and mutation is repeated for 100 generations.
5.2. Discussion
In the following, we study the proposed models: the EL-GISOM, the enriched EL-GISOM and the
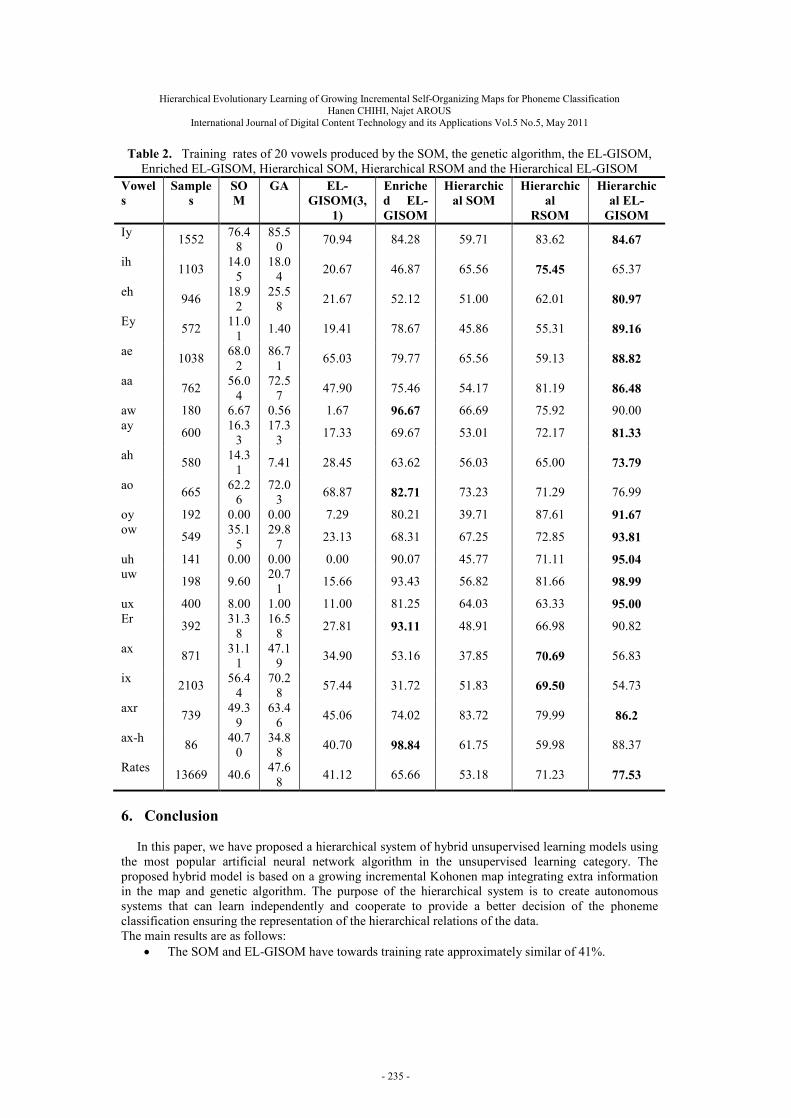
hierarchical EL-GISOM model. Specifically, we interest on three aspects: the study of evolutionary learning algorithm and the extension/reduction technique, the contribution of the enrichment technique and the hierarchical method. Moreover, we use for comparison the sequential SOM, the classic GA, the hierarchical SOM [1, 2] and the hierarchical RSOM [12]. The training rates of the different studied models are presented in Table 2.
We concentrate on the study of the evolutionary growing incremental algorithm for the training of the SOM model. According to the Table 2, we note that the EL-GISOM gives training rates similar to those obtained by the sequential SOM of about 41%. On the other side, the classic GA gives better results (47.68%) compared with these tow models. However, they are not able to classify some phonemes like /aw/, /oy/, /uh/ and /ux/.
We should note that recognition rate depends on the number of phoneme frames presented during training phase. That is why, we propose to present phonemes to SOM with the same probability. For example, for vowel /iy/ we remark that is well recognized even for SOM and also the best accuracy for the classical GA and the EL-GISOM. We can conclude also that phonemes which resemble each other phonetically such as /ih/ and /eh/ do not provide even a mean recognition rate. So we conclude that sequential SOM, classic GA and EL-GISOM are not able to separate “near” phonemes.
Studying the technique of enrichment of the map units, we conclude that the Enriched EL-GISOM model remedy to the problem of dependence to the phoneme distribution. It provides training rates better than those given by the sequential SOM, the classic GA and the EL-GISOM. It reach training rate of about 65.66%. In addition, we note that the phonemes /aw/, /oy/, /uh/ and /ux/ which using the SOM, the classic GA and the EL-GISOM, have a very low or even zero recognition rates, have reached training rate greater than 80%.
The enriched EL-GISOM and the hierarchical EL-GISOM provide better result than the result given by the hierarchical SOM. So, extra information integrated into the map units used with genetic learning process can separate near phonemes. Moreover, we can see that both the hierarchical RSOM and the hierarchical EL-GISOM give best training rates. Thereby, combination of the hierarchical approach and a modified SOM algorithm (like using a recurrent SOM or a hybrid SOM and GA) increases the classification rates. In particular, the hierarchical approach combined with GA integrating extra information generates the best results of about 77.53%, whereas the pure usual SOM has clearly the lowest results.
The hierarchy of the proposed hierarchical model is composed of tow-level. The first level allows classifying the phonemes into three macro-classes “front”, “center” and “back”. The second level is composed of three sub systems used to classify the phonemes of each macro-class. The training rate of the first level is of about 85.53%. The training rate of the sub-systems of “front”, “center” and “back” are respectively 85.29%, 82.97% and 95.14%. Morover, the hierarchical classification brings together the phoneme classes that have some similarity to form homogeneous groups. The disadvantage of this technique is that the misclassification of the first level is propagated to the second level. Therefore, this propagation leads to a weakening for total classification rates.
- 234 -
Hierarchical Evolutionary Learning of Growing Incremental Self-Organizing Maps for Phoneme Classification Hanen CHIHI, Najet AROUS
International Journal of Digital Content Technology and its Applications Vol.5 No.5, May 2011
Table 2. Training rates of 20 vowels produced by the SOM, the genetic algorithm, the EL-GISOM, Enriched EL-GISOM, Hierarchical SOM, Hierarchical RSOM and the Hierarchical EL-GISOM
Vowels
Samples
SOM
GA EL-GISOM(3,
1)
Enriched EL-GISOM
Hierarchical SOM
Hierarchical
RSOM
Hierarchical EL-
GISOM Iy 1552 76.4
8 85.5
0 70.94 84.28 59.71 83.62 84.67
ih 1103 14.05
18.04 20.67 46.87 65.56 75.45 65.37
eh 946 18.92
25.58 21.67 52.12 51.00 62.01 80.97
Ey 572 11.01 1.40 19.41 78.67 45.86 55.31 89.16
ae 1038 68.02
86.71 65.03 79.77 65.56 59.13 88.82
aa 762 56.04
72.57 47.90 75.46 54.17 81.19 86.48
aw 180 6.67 0.56 1.67 96.67 66.69 75.92 90.00 ay 600 16.3
3 17.3
3 17.33 69.67 53.01 72.17 81.33
ah 580 14.31 7.41 28.45 63.62 56.03 65.00 73.79
ao 665 62.26
72.03 68.87 82.71 73.23 71.29 76.99
oy 192 0.00 0.00 7.29 80.21 39.71 87.61 91.67 ow 549 35.1
5 29.8
7 23.13 68.31 67.25 72.85 93.81
uh 141 0.00 0.00 0.00 90.07 45.77 71.11 95.04 uw 198 9.60 20.7
1 15.66 93.43 56.82 81.66 98.99
ux 400 8.00 1.00 11.00 81.25 64.03 63.33 95.00 Er 392 31.3
8 16.5
8 27.81 93.11 48.91 66.98 90.82
ax 871 31.11
47.19 34.90 53.16 37.85 70.69 56.83
ix 2103 56.44
70.28 57.44 31.72 51.83 69.50 54.73
axr 739 49.39
63.46 45.06 74.02 83.72 79.99 86.2
ax-h 86 40.70
34.88 40.70 98.84 61.75 59.98 88.37
Rates 13669 40.6 47.68 41.12 65.66 53.18 71.23 77.53
6. Conclusion
In this paper, we have proposed a hierarchical system of hybrid unsupervised learning models using
the most popular artificial neural network algorithm in the unsupervised learning category. The proposed hybrid model is based on a growing incremental Kohonen map integrating extra information in the map and genetic algorithm. The purpose of the hierarchical system is to create autonomous systems that can learn independently and cooperate to provide a better decision of the phoneme classification ensuring the representation of the hierarchical relations of the data. The main results are as follows:
· The SOM and EL-GISOM have towards training rate approximately similar of 41%.
- 235 -

Hierarchical Evolutionary Learning of Growing Incremental Self-Organizing Maps for Phoneme Classification Hanen CHIHI, Najet AROUS
International Journal of Digital Content Technology and its Applications Vol.5 No.5, May 2011
· The enriched EL-GISOM model, integrating the map enrichment technique, gives the training rate and generalization rate better than those given by the SOM and the EL-GISOM.
· The hierarchical EL-GISOM has the highest training rate of 77.53%. · For the models enriched EL-GISOM and hierarchical EL-GISOM, we notice an improvement
in the training rate for the phonemes /aw/, /oy/, /uw/ and /ux/. They reach training rate levels greater than 90%.
· The advantage of such a hierarchical model is the construction of several elementary models as isolated modules, which can learn independently and cooperate.
· The proposed hierarchical EL-GISOM model provide more accurate vowels classification rates in comparison with the basic SOM model, the evolutionary variants of SOM and the variants of the hierarchical SOM.
Our future research will incorporate new parameters for genetic algorithms describing the map structure. Also, we suggest modelling a self-organizing genetic algorithm. Through the proposed modification, weak points of SOM could be improved.
7. References [1] N. Arous, “Hybridization of kohonen maps by genetic algorithms for phoneme classification”,
Ph.D. thesis, ENIT, Tunisia, 2003. [2] N. Arous and N. Ellouze, “Modèles de cartes auto-organisatrices hiérarchiques pour la
classification phonémique”, Revue d'intelligence artificielle, vol. 22, no. 6, pp. 697-723, 2008. [3] N. Arous, N. Ellouze, “On the Search of Organization Measures for a Kohonen Map Case
Study: Speech Signal Recognition”, JDCTA: International Journal of Digital Content Technology and its Applications, vol. 4, no 3, pp. 75-84, June 2010.
[4] I. Falcoa, A. Cioppa, and E. Tarantino, “Mutation-based genetic algorithm : performance evaluation”, Applied Soft Computing, vol. 1, no. 4, pp. 285–299, 2002.
[5] B. Fritzk, “A growing neural gas network learns topologies”, In Proceedings of the Advances in neural information processing systems 7, pp. 625–632, 1995.
[6] B. Fritzke, “Growing cell structures—A self-organizing network for unsupervised and supervised learning”, Neural Networks, vol. 7, no. 9, pp. 1441-1460, 1994.
[7] B. Fritzk, “Growing self organizing networks why?”, In Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, pp. 61-72, 1996.
[8] A. Grüning, “Backpropagation as Reinforcement for Simple Recurrent Networks”, Neural Computation, vol. 17, no. 11, pp 3108-3131, November 2007.
[9] C. Guoqiang, J. Limin, Y. Jianwei, L. Haibo, “Improved Wavelet Neural Network Based on Hybrid Genetic Algorithm Applicationin on Fault Diagnosis of Railway Rolling Bearing”, JDCTA: International Journal of Digital Content Technology and its Applications, vol. 4, no. 2, pp. 13-41, 2010.
[10] M.L. Jensen, “Evolving poker players using neuroevolution of augmenting topologies”, SIGEVO newsletter vol. 1, 2006.
[11] H.D. Jin, K.S. Leung, M. Wong, and Z. Xu, “An efficient self-organizing map designed by genetic algorithms for the traveling salesman problem”, Systems, Man, and Cybernetics, Part B : Cybernetics, IEEE Transactions, vol. 33, no. 6, pp. 877–888, 2003.
[12] C. Jlassi, N. Arous and N. Ellouze, “The Growing Hierarchical Recurrent Self Organizing Map for Phoneme Recognition”, In Proceedings of the Nonlinear Analyses and Algorithms for Speech Processing - NOLISP, pp. 184-190, 2009.
[13] H. Kim and K. Shin, “A hybrid approach based on neural networks and genetic algorithms next term for detecting temporal patterns in stock markets”, Applied Soft Computing vol. 7, no. 2, pp.569–576, March 2007.
[14] J. Lampinen and E. Oja, “Self-organizing maps for spatial and temporal models”, In Matti Pietikainen, Juha Roning, editors, Proceedings of The 6th Scandinavian Conference on Image Analysis, Oulu, Finland, pp. 120-127, 1989.
- 236 -

Hierarchical Evolutionary Learning of Growing Incremental Self-Organizing Maps for Phoneme Classification Hanen CHIHI, Najet AROUS
International Journal of Digital Content Technology and its Applications Vol.5 No.5, May 2011
[15] F. Lefeevre, “Probability for non-parametric markov of speech recognition”, Ph.D. thesis, Pierre et marie curie university, Frence, pp. 187–189, 2000.
[16] D.S. Lin and J.J. Leou, “A genetic algorithm approaches to Chinese handwritten normalization”, Proceedings of the International Computer Symposium, Taiwan, ROC, vol. 27, no. 6, pp. 638–644, 1984.
[17] S.P. Luttrell, “Hierarchical vector quantizations”, IEEE Proceedings, vol. 136, no. 11, pp. 405-413, 1989.
[18] S.P. Luttrell, “Hierarchical self-organizing networks”, In Proceedings of 1st IEE Conference of Artificial Neural Networks, London, vol. 1, no. 313, pp. 2-6, 1989.
[19] T. Nomura and T. Miyoshi, “An adaptive fuzzy rule extraction using model of the fuzzy selforganizing map and the genetic algorithm with numerical chromosomes”, Journal of Intelligent and Fuzzy Systems, vol. 6, no. 1, pp. 39–52, 1998.
[20] T. Pallaver, “Self-adaptivity and topopogie in Kohonen maps”, Master’s thesis, University of laval, Frence, 2006.
[21] T.H. Roh, K.J. Ohb, and I. Hana, “The collaborative filtering recommendation based on SOM cluster indexing CBR”, Expert Systems with Applications, vol. 25, no. 3, pp. 413–423, 2003.
[22] J.Y. Shih, Y.J. Chang and W.H. Chen, “Using GHSOM to construct legal maps for Taiwan’s securities and futures markets”, Expert Systems with Applications, vol. 34, no. 2, pp. 850-858, 2008.
[23] A. Spalanzani, “Evolutionary algorithms for the robustness study of automatic speech recognition systems”, Ph.D. thesis, Joseph Fourier University - Grenoble I, 28 Octobre 1999.
[24] K.O. Stanley and R. Miikkulainen, “Efficient evolution of neural network topologies”, Congress on evolutionary computation (CEC’02), IEEE, vol. 2, no. 1, pp. 1784–1781, 2002.
[25] J. Vesanto and E. Alhoniemi, “Clustering of the self-organizing map”, IEEE transactions on neural networks, vol. 11, no. 3, pp. 586–600, 2000.
[26] G. Xiaoqiao, “Intention recognition for the human-robot interaction”, Master’s thesis, Institute of Intelligent Systems and Robotics University Pierre and Marie Curie, Frence, 2007.
[27] Y.H. Yang, R.H. Tsaih, H. Bhikshu, “The Research of Multi-Layer Topic Map Analysis using Co-word Analysis with Growing Hierarchical Self-organizing Map”, JDCTA: International Journal of Digital Content Technology and its Applications, vol. 5, no. 3, pp. 355-363, March 2011.
[28] Q. Zhao, “A co-evolutionary algorithm for neural network learning”, ICNN 97 IEEE, vol. 1, no. 1, pp. 432–437, 1997.
- 237 -


![A Research of Evolutionary Computation for Combinatorial … · 2017-04-23 · as a set of Evolutionary Strategies (ES) [3]. Also there were appeared Evolutionary Programming (EP)](https://img.pdfslide.tips/doc/110x75/5f9e7966b1067e646f269f37/a-research-of-evolutionary-computation-for-combinatorial-2017-04-23-as-a-set-of.jpg)


























