Embed Size (px)
Citation preview

GREEN BOOK
Host DB2 애플리케이션 튜닝 가이드
저자 소개
오은숙 컨설턴트 | [email protected]
한국IBM DB2 Specialist로 DB2 데이터베이스 설계 및 애플리케이션 개발, 튜닝 업무를 진행했으며,
현재는 프리랜서로 DB2 설계 및 튜닝 관련 프로젝트를 수행하고 있다.
Host DB2 애플리케이션 튜닝 가이드
1/58

Contents
Part 1 | DB2 응답시간 분석에 대한 이해 ------------------------------------------------ 4
Part 2 | 튜닝 flow에 대한 이해와 성능에 영향을 주는 요인 ---------------------- 7
Part 3-1 | DB2 Access Path에 영향을 주는 요인 -1 -----------------------------------12
Part 3-2 | DB2 Access Path에 영향을 주는 요인 -2 -----------------------------------18
Part 4 | Plan_테이블의 이해 및 Access Path에 변형을 주는 요인 ---------- 23
Part 5 | 효율적인 인덱스 설계 ------------------------------------------------------------- 28
Part 6 | 효율적인 테이블스페이스 물리설계 ------------------------------------------- 35
Part 7 | 버퍼 풀 실행에 대한 이해 -------------------------------------------------------- 39
Part 8 | DB2 Locking에 대한 이해 ------------------------------------------------------- 44
Part 9 | 효율적인 DB2 애플리케이션 점검 방안 10 -------------------------------- 53
Host DB2 애플리케이션 튜닝 가이드
2/58

시작하기에 앞서
다음의 3가지 질문에 바로 대답할 수 있다면, 아래 글을 읽지 않아도 됩니다.
1. 프로그램을 변경하지도 않았는데, 잘 돌아가던 업무 시스템의 성능 저하가 발생할 경우, 성능저하의 요인이
무엇인지 생각해 보고 그 원인을 분석해야 한다. 이때 당신은 어떤 자료를 보나요?
2. DB2 응답시간 중 Class 1 Time과 Class 2 Time, Class3 Time의 차이가 무엇인지 아시나요?
3. 새로 SQL을 수정해야 할 일이 생겼는데, 이 SQL의 접속 경로가 어떻게 변할지, 또한 새로이 생성하는
인덱스가 다른 프로그램에 어떠한 영향을 미칠지 등을 어떤 방법으로 예측할 수 있을까요?
만약 이 세가지 질문 중 하나라도 이해되지 않거나, 이해는 되지만 답이 쉽게 생각나지 않는다면 앞으로 이 글을
통해 알고 있는 정보는 한번 더 정리하는 기회로, 모르고 있던 정보는 숙지하는 기회로 활용하시기 바랍니다.
시작하면서
DB2에 대한 튜닝 프로젝트를 수행하다 보면 일의 성격에 따라, DBA 팀과 일을 하는 경우보다 개발 팀과 함께 일을
하는 경우도 많다. 하지만 대부분의 경우 개발자들이 DB2에 대한 이해도가 부족한 것이 사실이다. 이러한 경우 실제
튜닝 작업에 앞서 개발자들에 대한 DB2 교육을 먼저 수행해야 할 때가 많다.
DA(Data Architecture)나 DB 접속 경로에 대해 책임을 지고 있는 전담 팀이 있어서 개발자들이 SQL 코딩을 하기
전에 검증을 해 줄 수 있다면 문제가 없겠지만, 인덱스의 설계나 데이터베이스 물리 설계 등 많은 부분을 개발자들이
관여하고 있는 것이 현실임을 감안하면 DB2에 대한 이해가 부족한 개발자들이 DB2 업무를 개발하고 있다는 것은
매우 비효율적일 수밖에 없다.
일반적으로 ‘튜닝’이라 하면 문제가 발생한 후의 문제 해결, 혹은 운영중인 업무에 대해 성능 저하의 요인을 찾아서
이를 개선하는 것을 생각할 수 있지만, 사실은 성능을 고려한 데이터베이스 설계나 SQL 코딩 작업이 튜닝의 중요한
부분이다. 따라서 데이터베이스를 설계하거나 개발하는 사람이 DB2의 Access Path와 같은 DB2에 대한 충분한
지식을 가지고 있다는 것은 곧, 튜닝에 소요되는 많은 시간과 노력을 덜어주는 결과가 될 것이다.
Host DB2 애플리케이션 튜닝 가이드
3/58

Part 1- DB2 응답 시간 분석에 대한 이해
이 글은 이미 DB2에 대해 어느 정도 지식이 있는 사람에게는 다시금 정리하는 기회를 제공하고, 적절한 교육의
기회가 없어 지식이 부족한 사람에게는 SQL 코딩, 데이터베이스 설계, 혹은 프로그램의 성능저하 시 문제 해결을
위해 알아 두어야 할 요인들에 대해 간단히 배워보는 기회로써 많은 도움이 되기를 바란다.
DB2 업무의 응답시간에 대한 이해
업무의 응답시간이 길다고 하면 개발자들은 Access Path에 대한 검토를 시작하는 것이 일반적이다. 하지만
응답시간의 지연 요인이 어느 부분에 있는지(SQL에 문제가 있어서 CPU Time을 높이는지, I/O 시간에 대한
지연요인이 있는지 등)에 대한 분석은 튜닝에 대한 불필요한 노력을 많이 덜어줄 것이다.
<그림 1> 업무 응답시간의 이해
<그림 1>에서 보는 바와 같이 DB2 애플리케이션 응답시간의 분석을 위해 알아야 할 시간은 크게 Class
1 Time(애플리케이션 응답시간), Class 2 Time(DB2 응답시간), Class 3 Time(DB2 대기시간)의 3가지
타입이 있다.
Class 1 Time
하나의 TRAN(혹은 PLAN) 내에서 첫 SQL 문을 DB2가 실행하기 위해 쓰레드를 생성(CREATE THREAD)한
Host DB2 애플리케이션 튜닝 가이드
4/58

이후부터 쓰레드가 다른 사용자에 의해 다시 사용되는 시점 (Sign-On) 혹은 쓰레드가 종결되기 전까지의 경과
시간(Elapsed Time)으로, 쓰레드 생성과 종결을 위해 소요되는 시간은 제외된다. 따라서 일반적으로
CICS와 같은 TP Monitor에서 모니터링 되는 경과시간과 차이가 나는 이유는 쓰레드와 관련된 시간이
포함되지 않기 때문이다.
Class 2 Time
하나의 TRAN 수행 시 TRAN 내 모든 Package/DBRM 내에서 수행되는 SQL이 DB2 Address Space
내에서 소요되는 시간으로, 실제 SQL이 DB2 내에서 수행된 시간이다. Class 2 Time에는 다음의
세가지 구성요소가 있다
DB2 CPU Time
DB2 Suspension Time (CLASS 3 Time)
Not Accounting Time
Class 3 Time
Class 2 Time 내에서 SQL 수행 시에 발생하는 모든 Wait suspension에 소요되는 시간으로, 주요한
Class 3 Time 은 다음과 같다
Lock/Latch: SQL 수행 시 Lock/Latch를 처리하기 위한 대기 시간
Sync I/O: 동기적인(Synchronous) I/O를 처리하기 위한 대기 시간으로, DB Sync I/O 처리를 위한 대기 시간과
Sync Log Write를 위한 대기 시간이 모두 이에 속한다.
Other Read I/O: 다른 쓰레드에 의한 Sequential Prefetch, List Prefetch, Dynamic Prefetch와 같은
비동기적인(Asynchronous) I/O나 Sync I/O로 인한 대기시간이다. 대부분 같은 볼륨 혹은 데이터셋 내의
데이터에 대한 I/O 경합(contention)으로 인해 발생한다.
Other Write I/O: 다른 쓰레드에 의한 비동기적인 Write I/O나 동기적인 Write I/O로 인한 대기 시간으로, Other
Read I/O로 인한 suspension과 마찬가지로 같은 볼륨 혹은 데이터셋 내의 데이터에 대한 I/O 경합에 대한
튜닝이 필요하다.
Service Task Switch: 현재의 쓰레드를 수행하는데 필요한 Synchronous execution unit switch를 위한 대기
시간으로, 실제 Task 발생 요인에 대한 상세 분석이 필요하다.
Not Accounting Time
Class 2 경과 시간 CPU 시간이나 대기 시간으로 기록되지 않는 시간으로서 다음과 같은 요인으로 인하여
발생한다
CPU queuing, MVS paging
DDF Requester 환경에서 서버로부터 VTAM 이나 TCP/IP를 통해 데이터가 리턴(return)되기
위한 대기 시간이 이에 해당되며 네트워크 응답 시간 등이 이에 포함된다.
Class 7 Time
Host DB2 애플리케이션 튜닝 가이드
5/58
해당 Package/DBRM 내에서 SQL 수행 시 소요시간 (PLAN 내 Class 2 Time 과 동일)
Class 8 Time
해당 Package의 SQL 수행 시 소요되는 Wait Suspension Time (PLAN 내 Class 3 Time 과 동일)
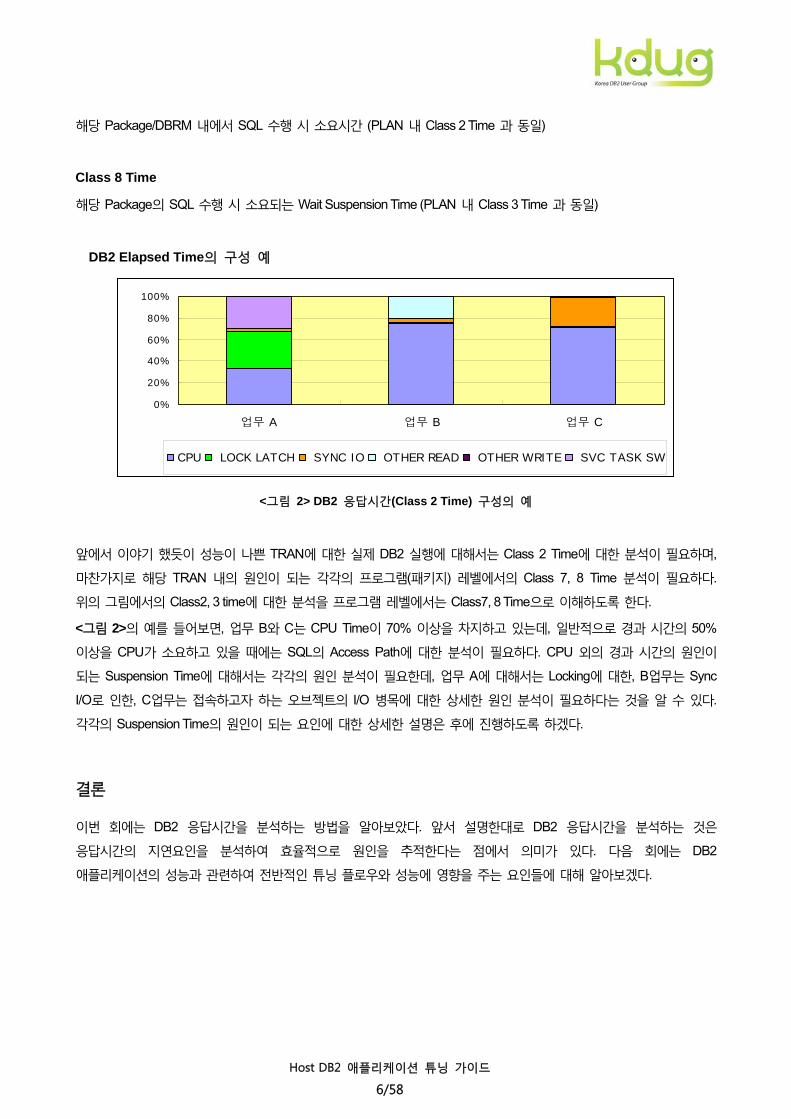
DB2 Elapsed Time의 구성 예
0%
20%
40%
60%
80%
100%
업무 A 업무 B 업무 C
CPU LOCK LATCH SYNC IO OTHER READ OTHER WRITE SVC TASK SW
<그림 2> DB2 응답시간(Class 2 Time) 구성의 예
앞에서 이야기 했듯이 성능이 나쁜 TRAN에 대한 실제 DB2 실행에 대해서는 Class 2 Time에 대한 분석이 필요하며,
마찬가지로 해당 TRAN 내의 원인이 되는 각각의 프로그램(패키지) 레벨에서의 Class 7, 8 Time 분석이 필요하다.
위의 그림에서의 Class2, 3 time에 대한 분석을 프로그램 레벨에서는 Class7, 8 Time으로 이해하도록 한다.
<그림 2>의 예를 들어보면, 업무 B와 C는 CPU Time이 70% 이상을 차지하고 있는데, 일반적으로 경과 시간의 50%
이상을 CPU가 소요하고 있을 때에는 SQL의 Access Path에 대한 분석이 필요하다. CPU 외의 경과 시간의 원인이
되는 Suspension Time에 대해서는 각각의 원인 분석이 필요한데, 업무 A에 대해서는 Locking에 대한, B업무는 Sync
I/O로 인한, C업무는 접속하고자 하는 오브젝트의 I/O 병목에 대한 상세한 원인 분석이 필요하다는 것을 알 수 있다.
각각의 Suspension Time의 원인이 되는 요인에 대한 상세한 설명은 후에 진행하도록 하겠다.
결론
이번 회에는 DB2 응답시간을 분석하는 방법을 알아보았다. 앞서 설명한대로 DB2 응답시간을 분석하는 것은
응답시간의 지연요인을 분석하여 효율적으로 원인을 추적한다는 점에서 의미가 있다. 다음 회에는 DB2
애플리케이션의 성능과 관련하여 전반적인 튜닝 플로우와 성능에 영향을 주는 요인들에 대해 알아보겠다.
Host DB2 애플리케이션 튜닝 가이드
6/58

Part 2 - 애플리케이션 성능에 영향을 주는 요인들
DB를 사용하는 곳이라면 어디나 그렇겠지만, 운영중인 DB 시스템에 대해 지속적으로 성능을
모니터링하고 튜닝 하는 것은 조금도 게을리해서는 안 될 업무다. 지난 회에 DB2 응답 시간 분석의
이해에 대해 알아본 데 이어, 이번에는 튜닝의 기본적인 흐름을 이해하고, 성능에 영향을 주는 요인에는
어떠한 것이 있는지 살펴보자.
튜닝 Flow에 대한 이해
모니터링과 튜닝은 크게 네 가지 측면에서 이야기할 수 있다. Access Path의 분석 및 튜닝, 비 효율적인 응답시간을
가진 업무에 대한 튜닝, DB 설계의 조정, DB2 시스템의 튜닝이 그것이다.
‘Access Path의 분석 및 튜닝’은 개발자들이 코딩된 SQL에 대한 성능 검증을 위해 수행해야 할 사항으로 잘 알려져
있다.
‘비효율적인 응답시간을 가진 업무에 대한 튜닝’은 일반적으로 대부분의 회사에서 주기적으로 전 업무를 대상으로,
혹은 특정 업무의 성능에 대한 점검이 필요하다고 생각했을 때 수행한다. 이 과정에서 우리는 응답시간의 어느
부분이 병목(bottleneck)인지, 이러한 문제의 원인이 어디에 있는지를 분석하게 된다.
그 분석 결과 데이터베이스 설계에 대한 변경이 필요하다고 판단될 때, 일반적으로 ‘DB 설계의 조정’을 하게 된다.
또는 DB2 시스템의 파라미터를 조정하는 ‘DB2 시스템의 튜닝’을 하게 된다.
<그림 1> 효율적인 DB2 애플리케이션 튜닝을 위한 흐름
Host DB2 애플리케이션 튜닝 가이드
7/58
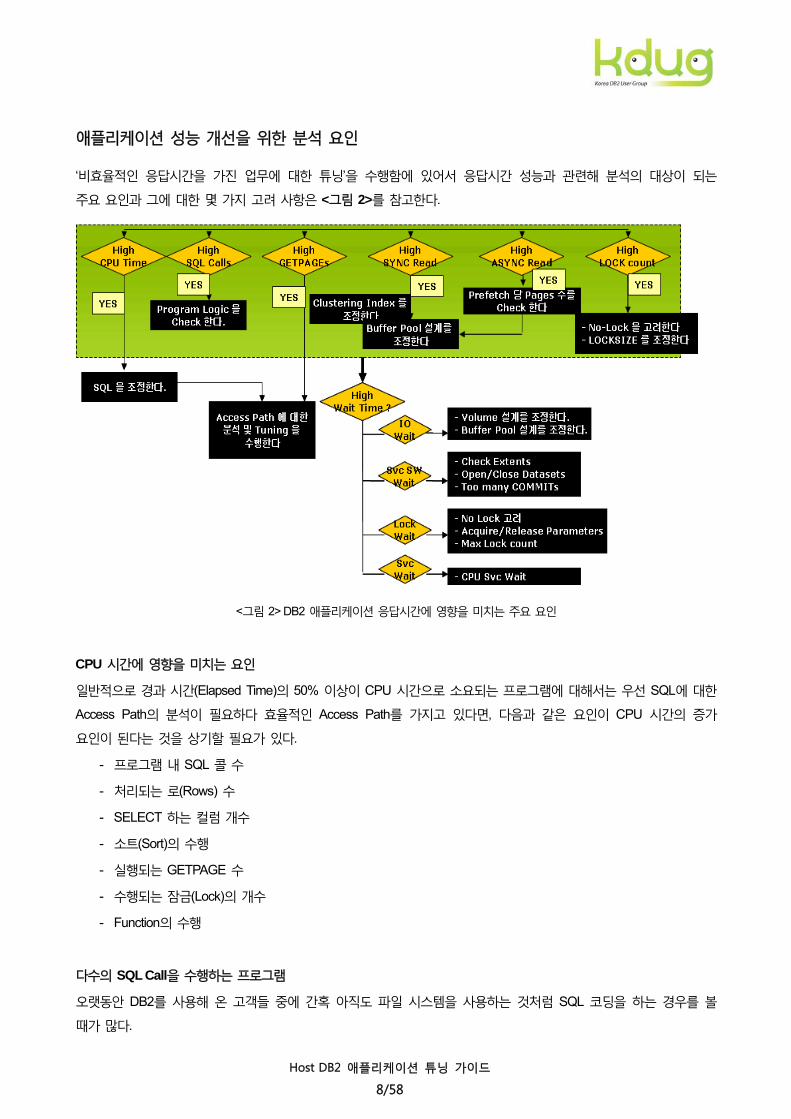
애플리케이션 성능 개선을 위한 분석 요인
‘비효율적인 응답시간을 가진 업무에 대한 튜닝’을 수행함에 있어서 응답시간 성능과 관련해 분석의 대상이 되는
주요 요인과 그에 대한 몇 가지 고려 사항은 <그림 2>를 참고한다.
<그림 2> DB2 애플리케이션 응답시간에 영향을 미치는 주요 요인
CPU 시간에 영향을 미치는 요인
일반적으로 경과 시간(Elapsed Time)의 50% 이상이 CPU 시간으로 소요되는 프로그램에 대해서는 우선 SQL에 대한
Access Path의 분석이 필요하다 효율적인 Access Path를 가지고 있다면, 다음과 같은 요인이 CPU 시간의 증가
요인이 된다는 것을 상기할 필요가 있다.
- 프로그램 내 SQL 콜 수
- 처리되는 로(Rows) 수
- SELECT 하는 컬럼 개수
- 소트(Sort)의 수행
- 실행되는 GETPAGE 수
- 수행되는 잠금(Lock)의 개수
- Function의 수행
다수의 SQL Call을 수행하는 프로그램
오랫동안 DB2를 사용해 온 고객들 중에 간혹 아직도 파일 시스템을 사용하는 것처럼 SQL 코딩을 하는 경우를 볼
때가 많다.
Host DB2 애플리케이션 튜닝 가이드
8/58

최근에 튜닝을 수행한 프로그램 중에는 ‘GROUP BY’를 이용하면 하나의 SQL로 수행할 수 있는 것을 몇 만의
FETCH를 수행하는 경우를 본 적이 있다. 담당자에게 이유를 물어보니 선배의 프로그램을 받았는데 DB2는 그렇게
SQL을 수행해야만 하는 줄 알았다고 한다. (담당자는 오랫동안 오라클 DBMS를 사용했던 개발자다)
이 경우에 더욱 놀라운 것은 이러한 프로그램이 튜닝 없이, 오랫동안 사용되어 왔다는 것이다. 이것이 가능했던
이유는 이 프로그램의 경우 해당 SQL은 인덱스를 사용하여 한 건의 row를 가져오는 조건으로 운영돼, Access
Path에는 이상이 없는 것으로 모니터링 되었기 때문에 한번도 튜닝의 대상이 되지 않았었던 것이다. 이제껏 대부분의
튜닝이 SQL의 Access Path에 대해 수행되다 보니, 이런 공백이 생긴 것이다. 특히 튜닝 대상 검토시 SQL Call
하나에 사용되는 CPU 시간을 고려하는데, 최근에 프로그램이 점차 모듈화되면서, 업무의 경로 길이(path length)가
매우 길어진 것도 SQL Call 수가 증가하게 된 하나의 요인이 되겠다.
일반적인 SQL Call 수를 줄이기 위해 고려해야 할 사항은 다음과 같다.
- Correlated SUBSELECT는 되도록 Join으로 바꾸도록 한다
- Singleton SELECT가 가능한 SQL에 대해서는 DECLARE CURSOR 하지 않도록 한다
- UPDATE/ INSERT/DELETE를 위한 불필요한 SELECT는 하지 않도록 한다.
대량 GETPAGE를 수행하는 SQL
‘GETPAGE’란 논리적인 I/O를 의미하며 결국은 물리적인 I/O의 원인이 된다. 또한 버퍼 풀 내에 있는 데이터(혹은
인덱스) 페이지의 사용으로 물리적인 I/O를 수행하지 않더라도 결과적으로 높은 CPU 비용(High CPU Cost)을
발생시킨다.
대량 GETPAGE를 수행하는 SQL은 대부분 다음의 원인으로 인해 Access Path가 비효율적인 경우에 발생한다.
따라서 다음의 요인에 대한 튜닝을 실행해야 한다.
- Tablespace Scan
- Non-Matching Index Scan
- Multi-Index Scan
- List Prefetch
- Sort
그 외의 업무적 요건에 의한 필요성일지라도, 성능에 영향을 준다는 것을 고려해야 한다.
대량 잠금 요청의 수행
많은 고객들이 초기 버전의 DB2가 S-LOCK을 거는 것이 성능에 영향을 준다는 것에 대해 불평을 하는 경우가 있다.
(사실 S-Lock은 데이터의 보호를 위해 필요한 것인데도 불구하고 말이다.)
그런데 이후 버전에서 필요에 따라 S-Lock을 걸지 않을 수 있는데도 많은 개발자들이 “Lock Avoidance” 메커니즘이나
‘Uncommitted Lock”을 사용하는 것에 대해 많은 걱정을 한다. (반드시 필요한 경우가 아니면 S-Lock을 걸지 않고
데이터를 ‘읽기’ 함으로써 성능을 좋게 할 수 있는데도 말이다)
앞의 CPU에 영향을 주는 요인에서도 이야기했듯이 잠금 요청은 DB2 CPU 사용을 높일 뿐만 아니라 메모리의
사용도 높인다. 따라서 자주 업데이트 되지 않고, 반드시 현 상태의 데이터를 갱신(Insert/ Update/ Delete)하지 않아도
Host DB2 애플리케이션 튜닝 가이드
9/58

되는 업무에 대해서는 “Lock Avoidance”나 ‘Uncommitted Lock”을 사용하여 잠금 요청 수를 최소화 하도록 한다.
잠금 관련해서는 향후 ‘잠금 고려사항’을 주제로 한 글에서 자세히 설명하도록 하겠다
애플리케이션 성능에 영향을 주는 요인
간혹 데이터베이스의 설계는 업무 요건을 반영한다는 중요한 사실을 잊는 경우가 많다. 즉, 많은 회사들이 업무
요건에 대한 지식을 가지고 프로그래밍 하는 개발자들이 데이터베이스의 파라미터 설계에는 전혀 관여를 하지
않는데, 이러한 상황은 결국 효율적인 데이터베이스 설계가 이뤄지지 않게 된다고 할 수 있다.
예를 들면 데이터는 순차적으로 입력이 되는데 ‘Freespace(Freespace는 향후에 일어나는 데이터의 입력을 위해 한
페이지에 남겨두는 빈 공간을 의미한다)’를 랜덤하게 설계한다면 공간의 낭비일 뿐 아니라 데이터 갱신 시 불필요한
I/O를 일으키는 원인이 될 수 있다.
또한 ‘개시일 + 부점코드 + 계정과목 + 계좌번호’의 컬럼으로 논리 ERD에서 정의된 Primary Key에 대해 생각해 보자.
만약 ‘계좌번호’ 자체만으로도 Uniqueness가 보장되고 테이블 사이의 Referential Integrity를 데이터베이스 측면으로
정의하지 않는다면, 이 경우 ‘계좌번호’만을 가지고 Unique 인덱스를 만드는 것이 훨씬 효율적이다. Referential
Integrity가 필요하지 않은 Primary Key에 대한 Unique 인덱스는 불필요하게 인덱스 키를 길게 가져감으로써
비효율적인 인덱스일 뿐 만 아니라 물리적으로 인덱스의 크기를 크게 함으로서 불필요한 I/O를 일으키는 요인이 된다.
Host DB2 애플리케이션 튜닝 가이드
10/58
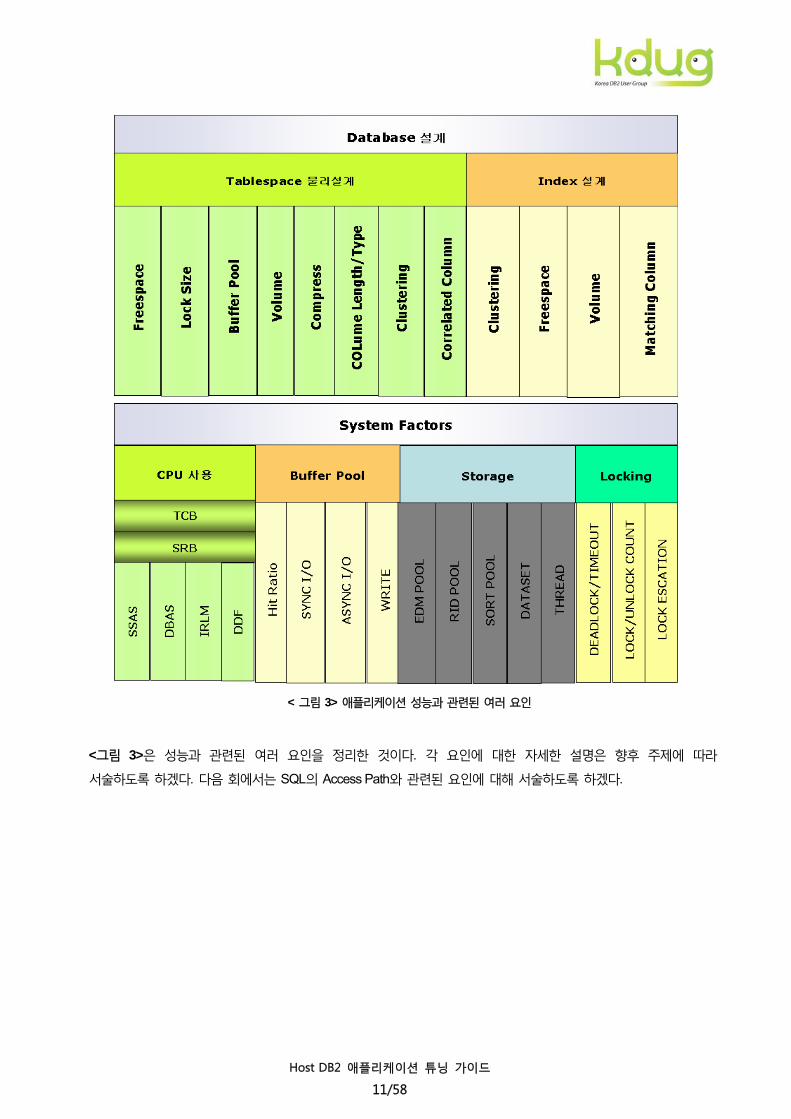
< 그림 3> 애플리케이션 성능과 관련된 여러 요인
<그림 3>은 성능과 관련된 여러 요인을 정리한 것이다. 각 요인에 대한 자세한 설명은 향후 주제에 따라
서술하도록 하겠다. 다음 회에서는 SQL의 Access Path와 관련된 요인에 대해 서술하도록 하겠다.
Host DB2 애플리케이션 튜닝 가이드
11/58

Part 3-1: Access Path에 영향을 주는 요인
Part 2에서는 튜닝 Flow에 대한 이해와 애플리케이션 성능에 영향을 주는 다양한 요인들을 살펴봤다. 이번에는
SQL의 Access Path에 영향을 주는 요인에 대해 살펴본다.
SQL의 Access Path에 영향을 주는 요인은 2회에 걸쳐 설명하고자 한다. 우선 여러 요인들 중에서도 SQL 내
predicate 유형에 따라 어떻게 Access Path가 달라지는 지에 대한 설명을 먼저하고, 다음 회에 인덱스의 사용여부를
결정하는 요인인 Filter Factor에 대한 설명과 Access Path에 영향을 주는 프로그래밍에 대한 설명을 계속 하도록
하겠다.
Predicate 유형에 따른 Access Path의 선택
SQL predicate의 유형에 대해서는 다음의 사항에 대한 이해와 각 경우에 선택되는 Access Path에 대한 이해가
필요하다
Indexable vs. Non-Indexable
Matching vs. Non-matching
Index Screening
Boolean Term
Non-Indexable predicate
아직도 많은 개발자들이 인덱스에 정의된 컬럼을 SQL 내의 predicate으로 코딩하면 자동적으로 DB2가 인덱스를
사용하는 것으로 이해하고 있는 경우가 많다. 결론적으로 이야기 하면, 코딩된 SQL predicate 형태에 따라 해당
컬럼이 있는 인덱스를 사용하지 않을 수 있으며, 이러한 predicate을 Non-Indexable predicate이라고 한다
다음과 같은 Non-Indexable predicate은 해당 컬럼(COL1, COL2)에 대한 인덱스가 설계되어 있더라도 인덱스를
사용하지 않는 대표적인 경우인데, 보다 더 자세한 내용은 ‘DB2 V7-Administration Guide 표 101’을 참조한다
<컬럼에 대한 expression 비교>
COL1 = 연산식
COL1 + value = value
COL1 CONCAT COL2 = value
<서로 다른 Data Type 컬럼의 비교, Numeric 컬럼>
NOT 비교연산자의 사용
COL1 <> value
T1.COL1 <> T2.COL2
COL1 NOT ... ( 예, NOT NULL, NOT BETWEEN, NOT IN, NOT LIKE, 등)
<같은 Table 내 컬럼끼리의 비교>
Host DB2 애플리케이션 튜닝 가이드
12/58

T1.COL1 = T1.COL2
COL1 BETWEEN COL2 AND COL3
EXISTS (correlated SUBSELECT)
NOT EXISTS (correlated SUBSELECT)
COL1 op (correlated SUBSELECT)
Matching vs. Non-Matching
위에서 이야기한 바와 같이 SQL을 어떻게 코딩 하느냐에 따라(predicate type에 따라) 인덱스의 사용 여부가
결정된다. 그렇다면 현재 설계되어 있는 인덱스를 얼마나 효율적으로 사용하는지를 판단할 수 있는 기준은
무엇일까? 얼마나 많은 인덱스 내의 컬럼에 대해 matching predicate으로 사용하는가에 따라 결정된다고 할 수 있다.
즉, 해당 컬럼이 인덱스 키로서 설계 되어 있더라도 위에서 서술한 바와 같은 non-Indexable predicate으로 코딩 되어
있으면 non matching predicate으로 수행하게 된다. 이러한 경우 전체 테이블스페이스나, 혹은 인덱스 전체를 풀
스캔(full scan) 하는 경우가 발생한다.
<예 1> Non Matching Index Scan
Index IX1 : YMD + CODE_1 + CODE_2
SQL 1: Matching 컬럼 개수 : 0
SELECT 1 FROM TABLEA
WHERE YMD = CURRENT_DATE
AND CODE_1 = ?
AND CODE_2 = ? ;
SQL 2: Matching 컬럼 개수 : 3
SELECT 1 FROM TABLEA
WHERE YMD = ?
AND CODE_1 = ?
AND CODE_2 = ? ;
<예 1>의 SQL1은 ‘WHERE YMD = CURRENT_DAT’와 같은 기능을 사용함으로써 인덱스 IX1의 1st key 로 정의되어
있는 YMD 컬럼에 대한 조건이 non-Indexable이 되어 인덱스에 대해 Matching 되지 않는다.(Matching 컬럼 =1 )
그러나 CODE_1과 CODE_2가 2nd 컬럼과 3rd 컬럼으로 인덱스에 정의되어 있음으로 해서 DB2는 IX1을 사용하지
않고 케이블 풀 스캔을 하는 것 보다는 non-matching Index scan으로 인한 Index full scan을 수행하여 Row의 RID를
가지고 테이블에 액세스 한다.
SQL1의 ‘WHERE YMD = CURRENT_DATE’로 인한 non-matching predicate을 SQL2의 ’WHERE YMD=?‘의 matching
predicate으로 변경하여 matching predicate으로 수정하여 성능을 향상할 수 있다.
Index Screening
Host DB2 애플리케이션 튜닝 가이드
13/58

간혹 오래 전부터 DB2를 사용하던 고객과 같이 튜닝을 하다 보면 DB2의 새로운 버전에서의 새로운 기능에 대한
업데이트가 잘 되어 있지 않은 경우를 보게 된다.
그 중의 하나가 ‘Index Screening’에 대한 개념인데, 위의 <예 1>에서와 같은 경우에(인덱스의 1st 컬럼 이 non
matching일 경우) DB2 V5 이전에는 인덱스를 사용하지 않고 테이블 풀 스캔을 수행하였다. 그러나 V5 이후에는
predicate의 컬럼에 대해 matching 되지는 않지만 인덱스를 통해 해당 데이터의 위치를 인식해서 테이블을
액세스하는 Index Screening의 Access path를 통해 테이블 풀 스캔으로 인한 I/O를 줄일 수 있다.
<예 2> Index Screening
Table Rows : 1,000,000
Index IX3: DEPT_CD + YMD + JOB_CD
YN : Cardinality = 2 ( Y = 99%, N = 1%)
SELECT 1 FROM TABLEB
WHERE DEPT_CD =’AAA’
AND YN = ‘N’ ;
위의 <예 2>의 SQL이 ‘YN =N’ (전체 rows 의 1%)의 결과값이 매우 적은 양의 데이터 임을 고려한다면 ‘DEPT_CD +
YN’에 대한 인덱스를 생성하는 것이 도움이 될 것이다. 하지만 해당 테이블에 대한 입력/삭제가 빈번하다면 가능한
한 적은 수의 인덱스를 생성하는 것이 바람직할 것이다. 이러한 경우에 IX3 인덱스 에 YN 을 추가함으로써 Index
screening을 하게 함으로서 결과적으로 테이블에 대한 I/O가 현저하게 줄어들 수 있다.
Boolean Term(BT) predicate
해당 predicate이 false일 경우 SQL 전체 predicate이 false가 되는 경우를 BT predicate이라고 하며, compound
Index를 사용하는 경우 BT predicate만이 Matching predicate에 해당되어 인덱스를 효율적으로 사용하게 된다.
다음 SQL의 경우 Boolean Term predicate은 다음과 같으며 결과적으로 인덱스의 Matching predicate으로의
선택사항이 된다.
SELECT ……. WHERE P1 AND (P2 OR P3) ;
- P1 : simple BT predicate
- P2, P3 : simple non-BT predicate
- (P2 OR P3): compound BT predicate
- P1 AND (P2 OR P3): compound BT predicate
따라서 SQL의 조건 절이 BT predicate인가 non-BT predicate인가에 따라 위와 같이 여러 개의 컬럼에 의한 조건에
대해서는 compound Index를 설계하는 것이 효율적일 수도 있고, 각각의 컬럼에 대해 개별 인덱스를 설계하는 것이
효율적일 수도 있다. 이러한 예에 대해서는 <표 1>을 참조한다.
Host DB2 애플리케이션 튜닝 가이드
14/58
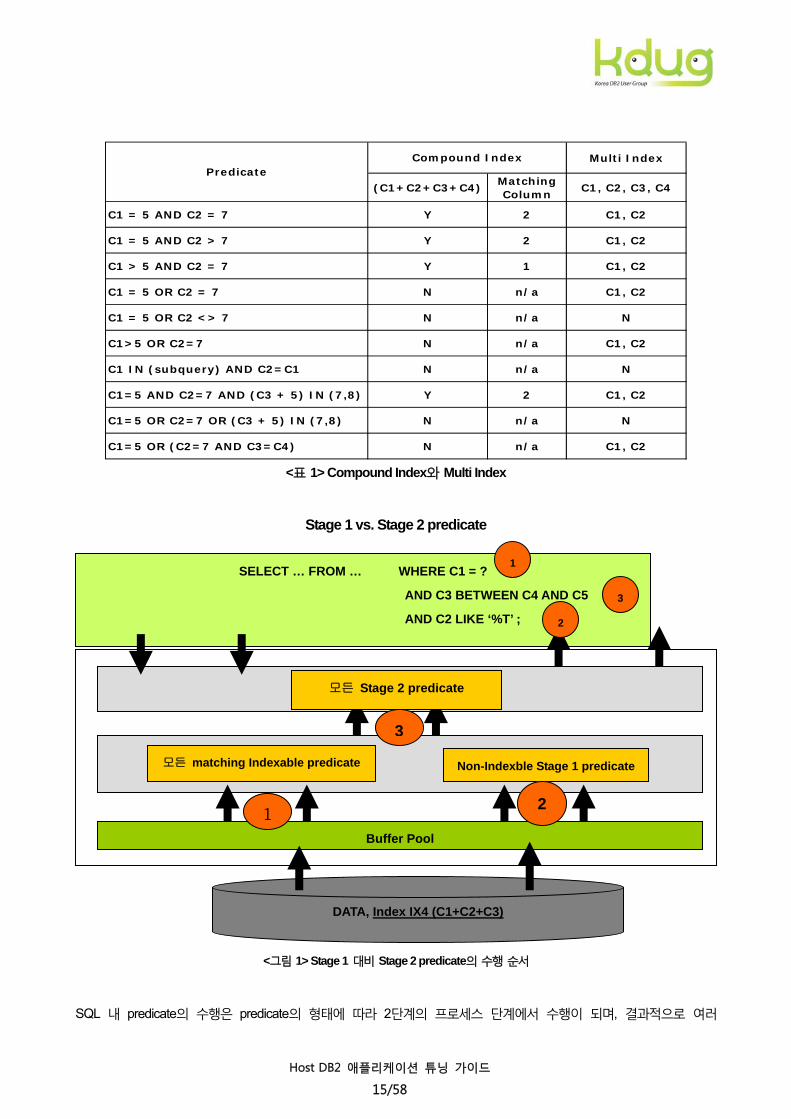
Multi Index
(C1+C2+C3+C4)MatchingColumn
C1, C2, C3, C4
C1 = 5 AND C2 = 7 Y 2 C1, C2
C1 = 5 AND C2 > 7 Y 2 C1, C2
C1 > 5 AND C2 = 7 Y 1 C1, C2
C1 = 5 OR C2 = 7 N n/a C1, C2
C1 = 5 OR C2 <> 7 N n/a N
C1>5 OR C2=7 N n/a C1, C2
C1 IN (subquery) AND C2=C1 N n/a N
C1=5 AND C2=7 AND (C3 + 5) IN (7,8) Y 2 C1, C2
C1=5 OR C2=7 OR (C3 + 5) IN (7,8) N n/a N
C1=5 OR (C2=7 AND C3=C4) N n/a C1, C2
PredicateCompound Index
<표 1> Compound Index와 Multi Index
Stage 1 vs. Stage 2 predicate
SELECT … FROM … WHERE C1 = ?
AND C3 BETWEEN C4 AND C5
AND C2 LIKE ‘%T’ ;
Buffer Pool
모든 matching Indexable predicate
3
2
1
모든 Stage 2 predicate
3
2 1
Non-Indexble Stage 1 predicate
DATA, Index IX4 (C1+C2+C3)
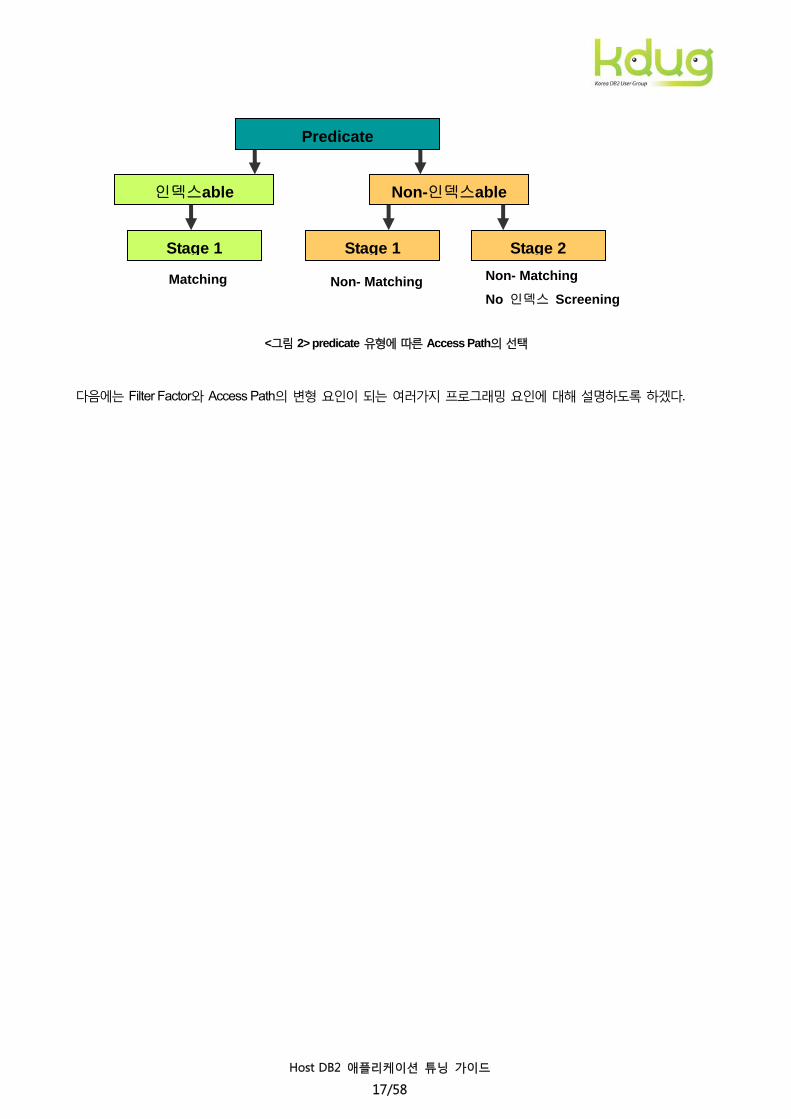
<그림 1> Stage 1 대비 Stage 2 predicate의 수행 순서
SQL 내 predicate의 수행은 predicate의 형태에 따라 2단계의 프로세스 단계에서 수행이 되며, 결과적으로 여러
Host DB2 애플리케이션 튜닝 가이드
15/58

predicate의 수행 순서가 된다.
<그림 1>의 예에서 보는 바와 같이 SQL의 코딩 순서(1 -> 3 -> 2)와 관계없이 stage 1 predicate이 먼저 수행된 후에
stage 2 predicate이 수행(1 -> 2-> 3) 되는 것을 볼 수 있는데, ‘C1 = ?’이 Matching Indexable predicate으로 가장 먼저
수행되며, ‘C2 like ‘%T’는 non Indexable이지만 stage 1 predicate으로 다음에 수행이 된다. 하지만 ‘C3 BETWEEN C4
AND C5’ 은 동일 테이블 내 컬럼에 대한 비교로 인하여 non-Indexable이면서 stage 2 predicate이 된다. 이 경우
C2는 stage 1 predicate으로 Index screening이 되지만, Stage 2 predicate인 C3에 대해서는 Index screening이 수행되지
않는다. 따라서 가능한 Indexable stage 1 predicate으로 코딩하는 것을 고려한다.
SQL 내 Predicate의 수행 순서
많이 받는 질문 중의 하나가 SQL 내 predicate 코딩 순서가 access path에 영향을 주는가 하는 것이다. 대답은
‘인덱스에 정의되지 않은 컬럼에 대해서는 “고려할 것”‘이다. SQL 내 predicate의 수행순서를 정리하면 다음과 같다.
<Level 1>
모든 Indexable predicates
All matching predicates on Index key 컬럼s
Index Screening 을 통한 stage 1 predicates
<Level 2>
Indexable predicate 을 제외한 stage 1 predicates
예: COL <> ?, COL LIKE ‘%T’ ..
<Level 3>
Stage 2 predicates
예: COL1 BETWEEN COL2 AND COL3 ..
<동일 level에서의 실행 순서>
All EQUAL predicates (하나의 Element를 가진 IN List 포함)
Range Predicates (NOT NULL 포함)
그 외의 Predicates
동일 level 에서의 수행순서를 고려할 때, 가장 많이 filtering 되는 조건을 먼저 코딩 하도록 한다
<그림2>에서 보는 바와 같이 SQL의 predicate 유형에 의해 인덱스의 사용 여부가 결정되는 것을 고려하여 최대한의
matching 컬럼을 가지는 SQL을 코딩하도록 한다.
Host DB2 애플리케이션 튜닝 가이드
16/58
Non-인덱스able
Stage 1Stage 1 Stage 2
Predicate
인덱스able
Non- Matching
No 인덱스 Screening
Matching Non- Matching
<그림 2> predicate 유형에 따른 Access Path의 선택
다음에는 Filter Factor와 Access Path의 변형 요인이 되는 여러가지 프로그래밍 요인에 대해 설명하도록 하겠다.
Host DB2 애플리케이션 튜닝 가이드
17/58
Part 3-2: Access Path에 영향을 주는 요인 ‘Filter Factor’
지난 회에 이어 DB2의 Access Path에 영향을 주는 요인 중 인덱스의 사용여부를 결정하는 요인인
Filter Factor에 대한 설명과 이러한 Filter factor를 포함하여 DB2 Access Path 결정에 영향을 주는 DB2
Catalog 정보에 대한 설명을 계속 하도록 하겠다.
Filter Factor
Filter factor는 SQL의 predicate 요건에 해당되는(filtering 되는) 데이터의 예상치라고 할 수 있으며, 0부터 1까지의
값으로 표현된다. 즉 테이블 컬럼 중에 ‘성별’에 대한 값은 ‘여자(F)’이거나 ‘남자(M)’라고 할 때, 이때 컬럼에 대한
데이터의 경우 수(컬럼 Cardinality = COLCARD)는 2가 된다.
이 경우 ‘where 성별=’M’’이 될 확률은 0.5가 되고, 이 predicate에 대한 Filter Factor는 전체 데이터의 0.5가 된다고
표현한다. 이 때 예상되는 return rows 수는 (전체 rows x 1/2)가 되는데 이것을 수식으로 표현하면 다음과 같다..
이러한 Filter Factor는 DB2 Optimizer가 해당 Predicate을 수행하는 Access Path를 생성할 때, 어떤 인덱스를 사용할
것인지 혹은 인덱스를 사용하지 않고 테이블스캔을 할 것인지 등을 결정하는 중요한 요인이 된다. 즉 Filter Factor가
클수록 대량의 row가 return되기 때문에 인덱스를 사용할 확률이 적어진다. 하지만 이 때 DB2 Optimizer는 DB2
Catalog Table의 데이터를 참조하여 filter factor를 결정하게 되므로, 실제 사용자가 알고 있는 데이터와는 다른 결과를
가져올 수도 있다. 이러한 경우 적절한 튜닝이 필요하다.
Access Path와 관련된 Catalog table에 대한 정보와 Access Path에 영향을 줄 수 있는 몇 가지 요인에
대해서는 뒤에서 언급하도록 하겠다.
Predicate 유형에 따른 Filter Factor
이러한 Filter Factor는 predicate의 유형에 따라 계산되는 공식이 조금씩 다르다.
Default Filter Factor
: RUNSTATS 유틸리티가 수행되지 않아 Catalog 테이블정보가 업데이트 되지 않은 경우로, 필요한
Catalog 컬럼 값이 -1로 세팅되어 있다.
Predicate 유형 Filter Factor
Col = literal 1/25
Col IS NULL 1/25
Col IN (literal list) (number of literals)/25
Col Op literal 1/3
Col LIKE literal 1/10
Col BETWEEN literal1 and literal2 1/10
예상 되는 Return Row 수 = 전체 Rows * FF
Host DB2 애플리케이션 튜닝 가이드
18/58
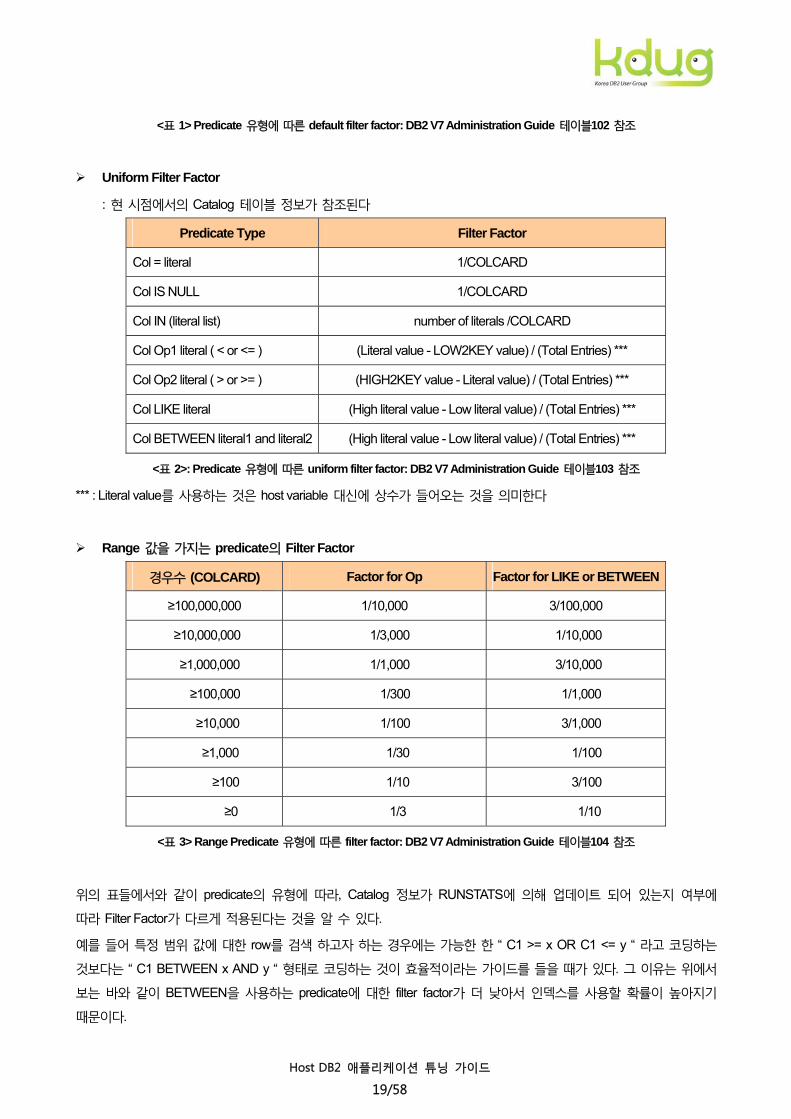
<표 1> Predicate 유형에 따른 default filter factor: DB2 V7 Administration Guide 테이블102 참조
Uniform Filter Factor
: 현 시점에서의 Catalog 테이블 정보가 참조된다
Predicate Type Filter Factor
Col = literal 1/COLCARD
Col IS NULL 1/COLCARD
Col IN (literal list) number of literals /COLCARD
Col Op1 literal ( < or <= ) (Literal value - LOW2KEY value) / (Total Entries) ***
Col Op2 literal ( > or >= ) (HIGH2KEY value - Literal value) / (Total Entries) ***
Col LIKE literal (High literal value - Low literal value) / (Total Entries) ***
Col BETWEEN literal1 and literal2 (High literal value - Low literal value) / (Total Entries) ***
<표 2>: Predicate 유형에 따른 uniform filter factor: DB2 V7 Administration Guide 테이블103 참조
*** : Literal value를 사용하는 것은 host variable 대신에 상수가 들어오는 것을 의미한다
Range 값을 가지는 predicate의 Filter Factor
경우수 (COLCARD) Factor for Op Factor for LIKE or BETWEEN
≥100,000,000 1/10,000 3/100,000
≥10,000,000 1/3,000 1/10,000
≥1,000,000 1/1,000 3/10,000
≥100,000 1/300 1/1,000
≥10,000 1/100 3/1,000
≥1,000 1/30 1/100
≥100 1/10 3/100
≥0 1/3 1/10
<표 3> Range Predicate 유형에 따른 filter factor: DB2 V7 Administration Guide 테이블104 참조
위의 표들에서와 같이 predicate의 유형에 따라, Catalog 정보가 RUNSTATS에 의해 업데이트 되어 있는지 여부에
따라 Filter Factor가 다르게 적용된다는 것을 알 수 있다.
예를 들어 특정 범위 값에 대한 row를 검색 하고자 하는 경우에는 가능한 한 “ C1 >= x OR C1 <= y “ 라고 코딩하는
것보다는 “ C1 BETWEEN x AND y “ 형태로 코딩하는 것이 효율적이라는 가이드를 들을 때가 있다. 그 이유는 위에서
보는 바와 같이 BETWEEN을 사용하는 predicate에 대한 filter factor가 더 낮아서 인덱스를 사용할 확률이 높아지기
때문이다.
Host DB2 애플리케이션 튜닝 가이드
19/58
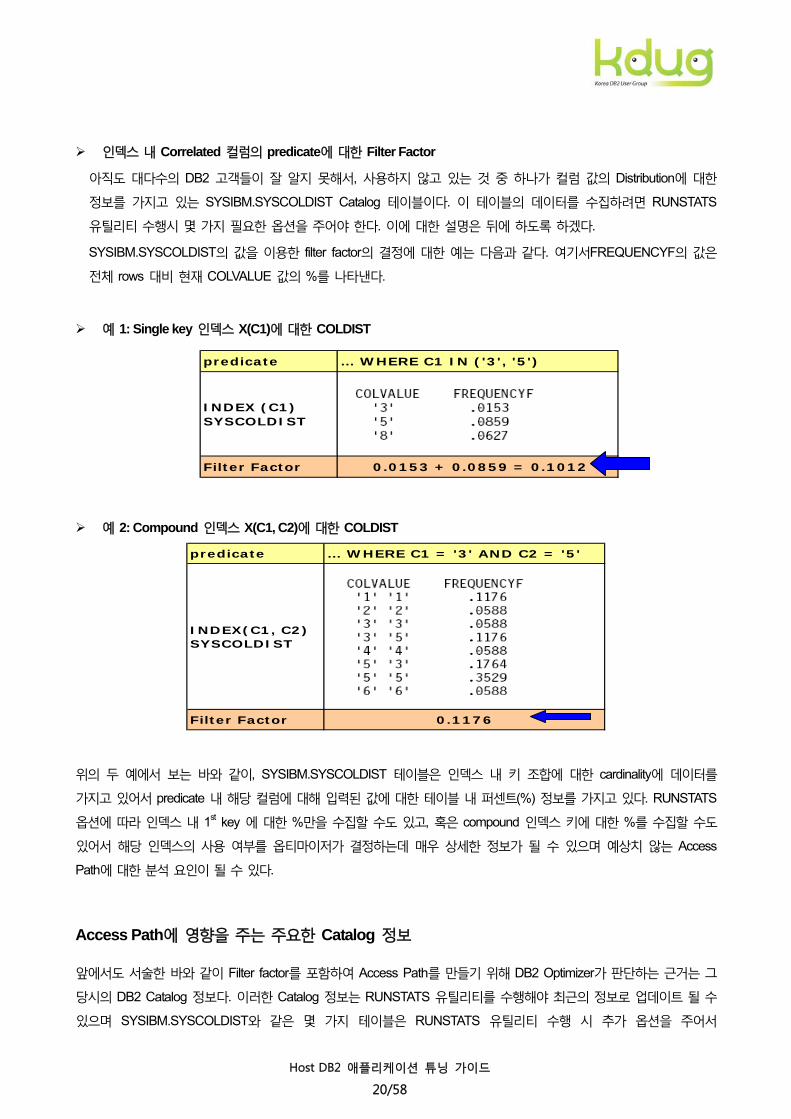
인덱스 내 Correlated 컬럼의 predicate에 대한 Filter Factor
아직도 대다수의 DB2 고객들이 잘 알지 못해서, 사용하지 않고 있는 것 중 하나가 컬럼 값의 Distribution에 대한
정보를 가지고 있는 SYSIBM.SYSCOLDIST Catalog 테이블이다. 이 테이블의 데이터를 수집하려면 RUNSTATS
유틸리티 수행시 몇 가지 필요한 옵션을 주어야 한다. 이에 대한 설명은 뒤에 하도록 하겠다.
SYSIBM.SYSCOLDIST의 값을 이용한 filter factor의 결정에 대한 예는 다음과 같다. 여기서FREQUENCYF의 값은
전체 rows 대비 현재 COLVALUE 값의 %를 나타낸다.
예 1: Single key 인덱스 X(C1)에 대한 COLDIST
예 2: Compound 인덱스 X(C1, C2)에 대한 COLDIST
위의 두 예에서 보는 바와 같이, SYSIBM.SYSCOLDIST 테이블은 인덱스 내 키 조합에 대한 cardinality에 데이터를
가지고 있어서 predicate 내 해당 컬럼에 대해 입력된 값에 대한 테이블 내 퍼센트(%) 정보를 가지고 있다. RUNSTATS
옵션에 따라 인덱스 내 1st key 에 대한 %만을 수집할 수도 있고, 혹은 compound 인덱스 키에 대한 %를 수집할 수도
있어서 해당 인덱스의 사용 여부를 옵티마이저가 결정하는데 매우 상세한 정보가 될 수 있으며 예상치 않는 Access
Path에 대한 분석 요인이 될 수 있다.
Access Path에 영향을 주는 주요한 Catalog 정보
앞에서도 서술한 바와 같이 Filter factor를 포함하여 Access Path를 만들기 위해 DB2 Optimizer가 판단하는 근거는 그
당시의 DB2 Catalog 정보다. 이러한 Catalog 정보는 RUNSTATS 유틸리티를 수행해야 최근의 정보로 업데이트 될 수
있으며 SYSIBM.SYSCOLDIST와 같은 몇 가지 테이블은 RUNSTATS 유틸리티 수행 시 추가 옵션을 주어서
predicate … WHERE C1 IN ('3', '5')
INDEX (C1)SYSCOLDIST
Filter Factor 0.0153 + 0.0859 = 0.1012
predicate … WHERE C1 = '3' AND C2 = '5'
INDEX(C1, C2)SYSCOLDIST
Filter Factor 0.1176
Host DB2 애플리케이션 튜닝 가이드
20/58

실행해야 한다.
Access Path에 영향을 주는 주요한 Catalog 정보는 다음과 같다.
SYSTABLES
CARDF: 테이블 내 Rows 수
N페이지SF: 테이블 내 Rows가 차지하는 페이지 수. 테이블 스캔시 읽어야 하는 페이지 수를 판단할 수
있다.
SYSINDEXES
NLEAF: 인덱스 내 테이블의 RID를 포함하고 있는 leaf 페이지 개수. 인덱스 스캔시 읽어야 하는 인덱스
페이지 수를 판단할 수 있다.
NLEVELS: 인덱스 트리 내 인덱스 레벨 수
CLUSTERING: Y = explicit하게 클러스터링 인덱스로 정의된 인덱스임을 표현한다. DB2는 클러스터링
인덱스를 선호하는 경향이 있다.(클러스터링 인덱스에 대해서는 추후 추가 설명 예정)
CLUSTERRATIOF: 인덱스 키에 따른 데이터의 클러스터링 정도를 %로 표현한다. 클러스터 비중이
85% 이하인 인덱스에 대한 데이터는 인덱스를 사용하여 데이터 검색시 list prefetch를 수행한다
FULLKEYCARDF: 인덱스 내 모든 키 값의 조합에 대한 경우의 수(Cardinality)
FIRSTKEYCARDF: 인덱스의 첫번째 키 값의 경우의 수 (Cardinality)
SYSCOLUMNS
CARDF: 컬럼 cardinality
HIGH2KEY: 컬럼의 두번째로 큰 키 값 -1st 2000 bytes. Filter factor에 사용된다
LOW2KEY: 컬럼의 두번째로 작은 키 값 -1st 2000 bytes. Filter factor에 사용된다
SYSCOLDIST
COLVALUE: 해당 컬럼의 값. 디폴트로 가장 분포도가 많은(most frequent value) 10개의 값이 대상이
된다
FREQUENCYF: COLVALUE의 Frequency(%)
NUMCOLUMNS: Statistics에 사용된 컬럼의 개수. 예를 들어 C1, C2, C3에 대해서는 1, 2, 3의
NUMCOLUMNS를 가진 값이 각각 생성될 수 있다.
CARDF : N개의 concatenated 컬럼에 대한 경우의 수 (Cardinality)
COLDIST 정보를 수집하기 위한 RUNSTATS 유틸리티 옵션
해당 인덱스 키의 Frequent Value에 대한 COLDIST 정보를 수집하기 위해서는 다음과 같은 옵션을 사용하여
RUNSTATS를 수행한다
Host DB2 애플리케이션 튜닝 가이드
21/58

RUNSTATS TABLESPACE_Name (인덱스_Name)
FREQVAL NUMCOLS nnn
COUNT nnn
NUMCOLS nnn: N개의 인덱스 키 중에 필요에 따라 nnn 개의 키 조합에 대한 데이터를 수집한다. 예를
들어 인덱스 (C1, C2, C3)에 대해 ‘COUNT 2’ 옵션을 사용할 경우, C1, C1+C2의 concatenated key에
대한 데이터가 각각 COUNT nnn개 만큼 수집된다
COUNT nnn: 디폴트 로 10개의 frequent value에 대한 값이 수집되지만 필요에 따라 nnn개의 다른 값에
대해 데이터를 수집할 수 있다
이번 회에서는 DB2 optimizer가 access path를 결정하는데 중요한 요인인 filter factor와 결정 요인이 되는 DB2
Catalog 정보에 대해 대체적으로 설명하였다. 다음에는 결정된 Access Path를 분석하기 위한 Plan 테이블에 대한
분석과 또한 필요시 Access Path에 변형 요인이 될 수 있는 요인들에 대해 설명하도록 하겠다.
Host DB2 애플리케이션 튜닝 가이드
22/58

Part 4 - Plan Table 분석 및 Access Path에 변형을 주는 요인
연재를 시작할 때 잠시 언급한 바 있듯이, 개발자들이 가장 궁금해 하는 것 중 하나는 자신이 코딩한 SQL이 DB2에
의해 어떠한 Access Path로 실행되는지에 대한 것이다. 실제 튜닝 프로젝트를 수행하다 만나는 많은 개발자들이
SQL의 Access Path를 분석할 수 있는 기능인 EXPLAIN 기능을 전혀 이용하지 않거나 못하는 경우를 보게 된다.
대부분 기능이 있다는 것은 알고 있어도 실제 내용에 대한 분석 스킬이 부족해 활용할 엄두를 내지 못하는
경우들이다.
이런 개발자들에게 좋은 정보가 될 수 있도록, Part 4에서는 DB2 EXPLAIN 기능을 이용하여 어떠한 내용을 분석할 수
있는지, 그리고 Part 3에서 설명한 바 있는 ‘DB2 Access Path에 영향을 주는 요인’ 외에 필요에 따라 자주 사용되는
Access Path 변형 요인에 대해 살펴보도록 하겠다
EXPLAIN 수행에 의한 Access Path 분석
SQL의 예상 Access Path에 대한 분석을 할 수 있는 EXPLAIN 기능은 개발자들이 보다 효율적인 SQL 코딩을 하기
위해 반드시 숙지하고 활용해야 되는 기능이라고 할 수 있다.
EXPLAIN 기능은 <그림 1>에서 보는 바와 같이 각각의 SQL에 대해서, 혹은 프로그램 내에 코딩되어 있는 모든
SQL에 대해 수행이 가능한데, 수행 결과는 다음의 2 테이블에 정보가 기록된다.
Owner. PLAN_TABLE: SQL의 Access Path에 대한 정보 수록
Owner. DSN_STATEMNT_TABLE: SQL 수행시 예상 Cost 수록
<그림 1> EXPLAIN 수행 방법
PLAN_TABLE 및 DSN_STATEMNT Table의 주요한 항목에 대해서는 뒷부분에 따로 정리한다. 2 테이블의 데이터를
Host DB2 애플리케이션 튜닝 가이드
23/58
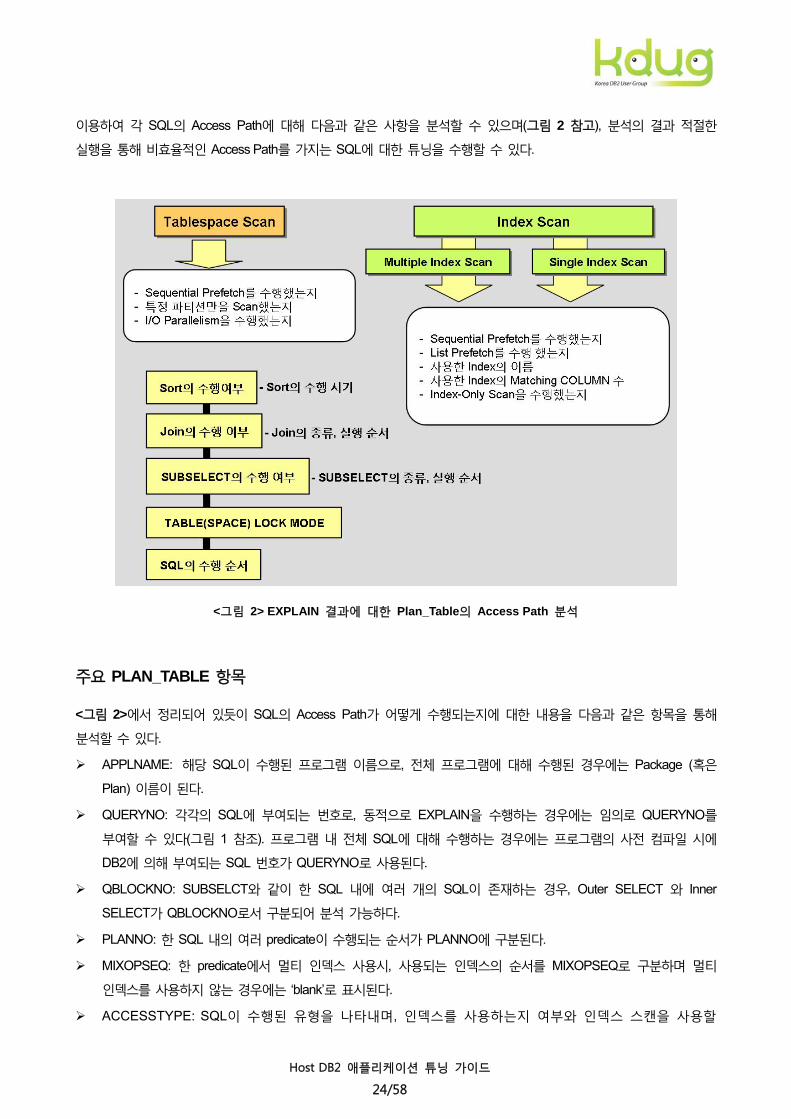
이용하여 각 SQL의 Access Path에 대해 다음과 같은 사항을 분석할 수 있으며(그림 2 참고), 분석의 결과 적절한
실행을 통해 비효율적인 Access Path를 가지는 SQL에 대한 튜닝을 수행할 수 있다.
<그림 2> EXPLAIN 결과에 대한 Plan_Table의 Access Path 분석
주요 PLAN_TABLE 항목
<그림 2>에서 정리되어 있듯이 SQL의 Access Path가 어떻게 수행되는지에 대한 내용을 다음과 같은 항목을 통해
분석할 수 있다.
APPLNAME: 해당 SQL이 수행된 프로그램 이름으로, 전체 프로그램에 대해 수행된 경우에는 Package (혹은
Plan) 이름이 된다.
QUERYNO: 각각의 SQL에 부여되는 번호로, 동적으로 EXPLAIN을 수행하는 경우에는 임의로 QUERYNO를
부여할 수 있다(그림 1 참조). 프로그램 내 전체 SQL에 대해 수행하는 경우에는 프로그램의 사전 컴파일 시에
DB2에 의해 부여되는 SQL 번호가 QUERYNO로 사용된다.
QBLOCKNO: SUBSELCT와 같이 한 SQL 내에 여러 개의 SQL이 존재하는 경우, Outer SELECT 와 Inner
SELECT가 QBLOCKNO로서 구분되어 분석 가능하다.
PLANNO: 한 SQL 내의 여러 predicate이 수행되는 순서가 PLANNO에 구분된다.
MIXOPSEQ: 한 predicate에서 멀티 인덱스 사용시, 사용되는 인덱스의 순서를 MIXOPSEQ로 구분하며 멀티
인덱스를 사용하지 않는 경우에는 ‘blank’로 표시된다.
ACCESSTYPE: SQL이 수행된 유형을 나타내며, 인덱스를 사용하는지 여부와 인덱스 스캔을 사용할
Host DB2 애플리케이션 튜닝 가이드
24/58

경우 그 유형도 알 수 있다. 멀티 인덱스 스캔(M)을 수행하는 것은 가능한 피하는 것이 좋으나
싱글 컴파운드 인덱스 사용시 Predicate 유형에 따른 조합(Matching) 여부는 ‘Part 3-1 Access Path에
영향을 주는 요인’의 <표 1>을 참조한다. 주요한 값은 다음과 같다.
• R: Table space scan
• I: Index Scan
• I1: One-fetch index scan
• N: IN Predicate에 의한 Index scan
• M: Multiple index scan의 수행(MX, MI, or MU에 의해 자세한 내용 분석)
• MX: ACCEENAME에 있는 Index에 의한 Multiple index scan
• MI: ‘AND’ 요건에 의한 multiple indexes의 Intersection
• MU: ‘OR’ 요건에 의한 multiple indexes의 Union
ACCESSNAME: 해당 SQL predicate 수행시 사용된 인덱스 이름
MATCHCOLS: ACCESSTYPE I, I1, N 또는 MX에서 사용되는 인덱스의 조합된 컬럼 수로, 인덱스 사용이 얼마나
효율적인가를 볼 수 있다. MATCHCOLS=0인 경우는 전체 인덱스의 leaf page를 모두 스캔하게 됨으로
Tablespace Scan에 비해서는 효율적이지만, 인덱스 키 일부가 조합되도록 설계 조정, 혹은 SQL의 조정을
고려한다.
INDEX ONLY: 테이블을 액세스하지 않고 인덱스 만을 액세스하여 처리하였음을 나타내며, 가장 효율적인
Access Path이다.
METHOD
1: Nested Loop Join
2: Merge Scan Join
4: Hybrid Join
3: 다음의 원인으로 Sort 수행
- ORDER BY, GROUP BY, SELECT DISTINCT, UNION, JOIN
- Sort의 원인에 대해서는 다음의 Column =’Y’을 참조한다
• ORDER BY: SORTC_ORDER BY = Y
• GROUP BY: SORTC_GROUP BY = Y
• COUNT(DISTINCT.. ): SORTC_UNIQ = Y
• SELECT DISTINCT..: SORTC_UNIQ = Y
• UNION: SORTC_UNIQ = Y
• JOIN: SORN_JOIN = Y 혹은 SORTC_JOIN = Y
• 특정 SQL을 사용한 Non-Correlated SUBSELECT: SORTC_UNIQ = Y & SORTC_ORDERBY = Y
TSLOCKMODE: SQL 수행시 해당 Tablespace에 처리되는 Locking Mode
PREFETCH: 대량 데이터의 retrieve시 사용되는 접속 방식으로, 대량 데이터를 처리하면서 prefetch 수행이
되지 않으면 테이블의 클러스터링 인덱스에 대한 설계조정을 고려한다.
• S: Sequential Prefetch 수행
Host DB2 애플리케이션 튜닝 가이드
25/58

• L: List Prefetch 수행
주요 DSN_STATEMNT_TABLE 항목
DSN_STATEMNT_TABLE의 Cost는 시스템 용량과 예상 I/O에 의해 산정된 비용으로, 절대적인 값에 대해 얼마나
정확한가에 대한 의구심이 있을 수 있지만 상대적인 값으로는 의미가 있다.
COST CATEGORY: 디폴트 값을 사용해 정확하지 않은 Cost일 수 있다
PROCMS: 밀리세컨즈(1000분의 1초) 단위 값으로의 예상 프로세서 비용
PROCSU: 서비스 단위 값으로의 예상 프로세서 비용
Access Path에 변형을 줄 수 있는 요인
RUNSTATS의 수행
DB2 옵티마이저는 DB2 카탈로그 정보를 이용해 적절한 Access Path를 생성한다. 따라서 가장 up-to-date한
카탈로그 정보를 가지는 것은 가장 정확한 Access Path를 생성하는 방법이기도 하다. Access Path와 관련된
주요한 카탈로그 테이블 정보는 ‘Part 3-2 Access Path 요인’ 중 ‘Access Path 에 영향을 주는 주요한 카탈로그
정보’를 참고하면 된다.
Catalog Table의 수정
앞서 정리한 바와 같이 DB2 카탈로그 정보를 이용하여 Access Path가 생성되는 것이 가끔은 현실과 맞지 않는
경우가 있을 수 있다.
예를 들어 대량 데이터 내의 ‘고객’ 테이블에 있는 ‘예전 고객번호’ 컬럼이 새로 추가되었을 때 초기에는
데이터가 별로 없어서 대부분의 blank와 몇 개의 컬럼 값이 들어가 있는 경우 컬럼의 COLCARD가 매우
낮아진다. 이러한 경우 낮은 COLCARD로 인해서 인덱스를 사용하지 않을 수 있다. 하지만 인덱스를 사용하는
접속 방식이 효율적이라고 한다면, SYSIBM.SYSCOLUMNS의 해당 컬럼의 COLCARD 값을 크게
변경시켜줌으로써 인덱스 접속이 가능하게 조정할 수 있다. 그러나 이러한 카탈로그 값의 변경은 주기적인
RUNSTATS 수행시 매우 주의해서 관리해야 하므로 유의하도록 한다.
BIND .. REOPT(VARS)
애플리케이션 튜닝 시에 가장 많이 보는 사례 중의 하나가 <표 1>이다. 여러 경우 수를 하나의 SQL을 통해
실행하고자 생성한 SQL이다.
<표 1> 여러 경우 수를 하나의 SQL을 통해 실행하는 SQL
이러한 SQL의 Access Path는 COLA, COLB, COLC, COLD 중 Static Bind시 가장 필터 팩터(filter factor)가 좋은
Host DB2 애플리케이션 튜닝 가이드
26/58

컬럼(예를 들어 COLC)에 대해 Access Path를 생성하게 될 것이다. 그러나 실제 수행 시에 COLC는 값이
들어오지 않고, 다른 컬럼에만 데이터가 들어 온다고 하면 실제 bind 시에 생성된 Access Path는 효율적이지
않게 된다. 이 경우 REOPT(VARS) 옵션을 이용하여 Bind를 수행하면 SQL 수행 시에 들어온 변동 값을
이용하여 다시 최적화를 수행, 현재 수행되는 SQL에 적정한 access path를 생성하게 된다.
이 경우는 SQL 실행 시에 다시 한번 최적화를 하기 위한 코스트가 예상되지만, 대량 데이터를 처리하는 여러
경우의 수를 가지는 SQL에 대해서는 실제 수행 코스트를 고려하면 훨씬 효율적이라고 할 수 있다.
HINT의 사용
해당 SQL이 원하는 Access Path를 지정하여 수행하도록 하는 방법으로 HINT를 이용할 수 있다. 이를 사용하는
방법에 대해서는 ‘DB2 V7 Administration Guide’ p757을 참조하도록 한다.
Extra Predicate의 추가
predicate의 여러 컬럼에 대한 access path 분석 결과, 원하지 않는 컬럼에 대해 인덱스 접속을 수행하는 경우,
다음과 같이 non-indexable predicate으로 변경하여 부적절한 인덱스 스캔을 피할 수 있다.
OPTIMIZE FOR n ROWS의 사용
많은 개발자들이 다소 혼돈하여 사용하고 있는 것 중의 하나가 ‘OPTIMIZE FOR n ROWS’와 ‘FETCH FIRST n
ROWS ONLY’의 기능이다. 어느 고객의 경우 성능이 좋아진다는 이유로 특정 애플리케이션의 SQL 대부분을
‘OPTIMIZE FOR 1 ROWS’로 코딩한 것을 본 적이 있는데, 아마 몇 개의 SQL에 대해 이 기능을 이용해서
성능이 좋아진 사례가 있었던 것 같다.
결론부터 이야기하면 위의 두 가지 기능은 잘못 사용하면 원하지 않는 access path를 생성할 수 있으므로
정확한 의미를 알고 사용하는 것이 반드시 필요하다.
‘FETCH FIRST n ROWS ONLY’는 predicate 조건에 맞는 SQL 수행 결과 n개의 rows 만을 return하라는
의미이다. 따라서 다른 옵션이 없으면 n rows를 수행하는 access path를 생성하게 된다. 반면에 ‘OPTIMIZE FOR
n ROWS’는 SQL 수행 결과 모든 rows를 다 return하라는 의미를 가진다.
따라서 “FETCH FIRST n ROWS ONLY OPTIMIZE FOR m ROWS”가 동시에 코딩되는 경우, ‘m’ rows의
Optimization을 통해 ‘n’ rows의 데이터를 Return 한다.
‘OPTIMIZE FOR n ROWS’의 사용시 ‘n’ 값을 적게 함으로서 RETURN 되는 값이 적다는 의미를 DB2에게
전달하게 되고, 경우에 따라서는 다음과 같은 access path를 가지게 할 수 있다.
• Sequential Prefetch나 List Prefetch를 사용하지 않을 수 있다
• JOIN의 경우 Nested Loop Join을 사용할 수 있다
• ‘OPTIMIZE FOR 1 ROW ONLY’를 이용하여 불필요한 소트를 하지 않게 한다
지금까지 4회에 걸쳐 DB2 Access Path에 영향을 주는 요인과 Access Path를 분석하는 방법에 대해 간단히 정리했다.
Part 5에서는 Access Path와 성능에 대한 가장 중요한 요인 중 하나인 인덱스 설계에 대한 내용을 이야기하도록
하겠다.
Host DB2 애플리케이션 튜닝 가이드
27/58

Part 5 - 효율적인 인덱스 설계
효율적인 인덱스 설계시의 가장 중요한 고려사항은 술부(Predicate) 내의 조건에 대한 매칭 인덱스 컬럼을 최대화
하는 것이라 할 수 있다. 이에 대해서는 이미 ‘Part 3. DB2 Access Path에 영향을 주는 요인 -1’에서 설명한 바 있으니,
다시 한번 Indexable / non-Indexble predicate에 대한 이해를 충분히 할 필요가 있다.
인덱스의 주요 기능
“인덱스를 만드는 이유가 무엇인가?“라고 누군가 묻는다면, 대부분 “SQL의 성능을 향상시키기 위해서”라고 대답할
것이다. 하지만 비효율적인 인덱스 설계는 오히려 SQL의 성능을 저하시키는 요인이 되기도 한다. 몇가지 인덱스의
주요 기능을 정리해보면 다음과 같다.
GETPAGE와 I/O의 감소
적절한 인덱스를 생성함으로써 불필요한 테이블 스캔을 피하고, 결과적으로 GETPAGE와 I/O를 감소
시킴으로써 SQL의 성능을 향상시키는 것이 인덱스 생성의 첫번째 이유임에는 틀림이 없다. 특히 자주
사용되는 조건이 소량의 컬럼을 검색(retrieve)하는 경우에는 해당 컬럼만으로 인덱스를 생성, ‘Index-only
scan’을 하게 함으로써 SQL의 성능 향상에 크게 도움을 줄 수 있다.
Uniqueness의 보장
Unique Index를 생성하여 데이터 입력시 중복을 피하게 된다. 테이블에 Primary Key를 정의하는 경우에는
Primary Key에 대해 반드시 Unique Index를 생성한다.
Sort의 감소
ORDER BY나 GROUP BY와 같이 Sort를 수행하는 SQL의 경우 술부 및 컬럼에 대해 적절한 인덱스를
생성하여 사용하게 함으로서 Sort로 인한 성능 저하를 피할 수 있다.
병행성(Concurrency)의 증가
Index Only Scan은 인덱스만을 참조하여 데이터를 검색하는 것이다. 따라서 테이블에 대한 잠금이 이뤄지지
않음으로써 테이블에 대한 병행성(Concurrency)이 증대된다.
클러스터링
모든 테이블에는 명시적(explicit)으로(해당 인덱스 생성시 CLUSTER 옵션을 줌으로서) 혹은
묵시적(implicit)으로(CLUSTER 옵션을 가진 인덱스가 없을 시에는 첫 번째 생성된 인덱스) 클러스터링
인덱스가 존재하게 된다. 클러스터링 인덱스라 함은 해당 인덱스의 키값 순서대로 테이블의 데이터가
정렬되는 것을 의미한다. 이러한 데이터의 클러스터링은 해당 인덱스가 생성된 이후 REORG가 수행되어야
적용되며, 매번 데이터 입력시 클러스터링 키에 의해 정렬되어 입력되도록 하기 위해 여유 공간(free
space)을 검색한다. (MEMBER CLUSTER 옵션 제외)
이러한 클러스터링 인덱스를 어떠한 키로 가져가는가 하는 것은 성능에 매우 큰 영향을 주게 되는데, 많은 고객들이
이 부분에 대해 소홀히 하는 경우가 많다. 뒤에 클러스터링 인덱스에 대해서는 좀 더 상세히 설명하도록 하겠다.
Host DB2 애플리케이션 튜닝 가이드
28/58

인덱스의 효율적인 설계
여러 번 이야기하였듯이 적절한 인덱스는 SQL의 “Query” 성능을 향상시킨다. 그러나 많은 인덱스를 가진 테이블에
대해 INSERT, DELETE, 해당 키에 대한 UPDATE가 많이 발생하는 경우 SQL의 성능을 저하시키는 요인이 되기도
한다. 또한 REORG나 Load에 많은 시간이 소요될 수 있다. 따라서 각 개발자가 필요에 의해 “내 SQL”만을 위해
인덱스 설계를 하는 것이 아니라, 전체적인 성능을 고려한 통합된 인덱스 설계 구조를 가지는 것이 매우 중요하다.
이 장에서는 많은 고객들이 일반적으로 경험하는 인덱스 설계와 관련된 사항을 설명하도록 하겠다.
Primary Key 인덱스의 생성
이 질문은 주제에서 약간 벗어난 이야기가 될 수도 있겠지만, 반드시 짚고 넘어가야 할 사안이다. “Primary Key는
반드시 생성해야 되는가?”에 대한 것이다. Primary Key라는 것은 한 엔터티(Entity)의 유일한 식별자(Unique
identifier)로서의 중요한 역할을 하고 있으며 동시에 RI로 관련된 엔터티 사이의 관계를 정의해 주고 있다.
이와 같이 Uniqueness를 보장하기 위해 인덱스를 생성하는 대표적인 예로, Primary Key 인덱스를 이야기 할 수 있다.
고객들 중에는 ERD 상의 엔터티를 테이블로 만들면서 Primary Key를 무조건 정의하는 경우가 많은데, 결론부터
이야기하면 자식(child) 테이블의 Foreign Key에 의하여 RI가 정의되지 않는 Primary key는 반드시 필요하지는 않다.
Primary Key를 정의하면 해당되는 키에 대해서는 Unique Index를 반드시 생성해 주어야 한다. 물론 테이블 내의
유일한 식별자로서의 의미가 있어서 Unique Index를 생성하는 것은 필요하지만 Primary Key로서의 의미를 부여하기
위해 불필요하게 인덱스 키가 길어지는 것은 바람직하지 않다. 경우에 따라서는 Primary Key 내의 일부 키만으로도
이미 Unique Index가 생성될 수 있다. 불필요하게 큰 인덱스는 불필요한 I/O를 일으키게 된다.
이러한 이유 외에도 이와 관련하여 자주 듣게 되는 질문 중의 하나가 “어차피 같은 키 구성을 가진다면 굳이 Primary
Key 인덱스 보다 단순한 Unique Index를 권고하는 이유가 무엇인가?“이다. Primary Key를 생성하면 해당 테이블의
데이터가 DELETE 될 때 foreign key로 정의되어 있을 수도 있는(실제로는 RI 가 정의되어 있지 않더라도) 테이블의
RI를 점검하기 위해 카탈로그 테이블을 점검하게 되고 따라서 대량 데이터의 DELETE 시에는 성능에 영향을 줄 수
있다.
따라서 RI가 정의되지 않을 Primary Key에 대해서는 테이블 생성시 Primary Key로 반드시 정의할 필요가 없으며
또한 Unique Index 생성시에도 Primary Key 내의 부분 키로서 Unique Index가 가능할 경우 불필요하게 긴 인덱스
키를 가지지 않도록 한다.
Foreign Key 인덱스의 생성
Foreign Key에 대해서는 반드시 인덱스를 생성하지 않아도 된다. <예제 1>과 같은 경우를 의외로 많이 접하게 된다.
이 경우 현황 테이블의 IX_FK1(주민번호)는 이미 IX_PK(주민번호+계좌번호)에 의해 생성되어 있으므로 불필요한
인덱스가 된다. 뒤에서 언급하겠지만 Foreign Key 인덱스는 클러스터링 인덱스의 좋은 후보라고 할 수 있다.
Host DB2 애플리케이션 튜닝 가이드
29/58

<예제 1> 불필요한 Foreign Key 인덱스의 생성
인덱스 키 순서의 설계
물론 인덱스 키의 순서는 술부(Predicate)의 다양한 조건을 고려하여 매칭 컬럼을 최대화하는 것을 가장 큰 목표로
한다. 그런데 <예제 1>과 같이 인덱스의 Primary key 컬럼의 기수 순서(Cardinality)가 매우 낮은 인덱스를 보는
경우가 많이 있는데, 이러한 경우는 대부분 ERD 상의 정의된 Primary Key 순서에 치중하여 인덱스를 생성한 것으로
예측할 수 있다. <예제 2>의 IX_PK1는 Primary Key로 정의된 Unique Index로서 취급번호와 취급점을 맨 나중에
위치하고 있다. 괄호( ) 안의 경우의 수(Colcard)를 비교해 보면 취급번호(151,552)로 인한 필터링이 가장 크게
이뤄지기 때문에 인덱스 내의 다른 컬럼은 그다지 조건으로서 충분하지 못하다. 따라서 IX_PK2 같이 인덱스 키
순서를 조정하여 IX_1을 없애는 것이 가능하다.
구분코드1 + + +.. 와 같이 나머지 컬럼의 순서는 최대한 매칭되도록 설계하지만 상대적으로 경우의 수가 낮음으로
인덱스 적격 심사(Screening)에 의해 사용될 수 있음을 고려한다.
Host DB2 애플리케이션 튜닝 가이드
30/58
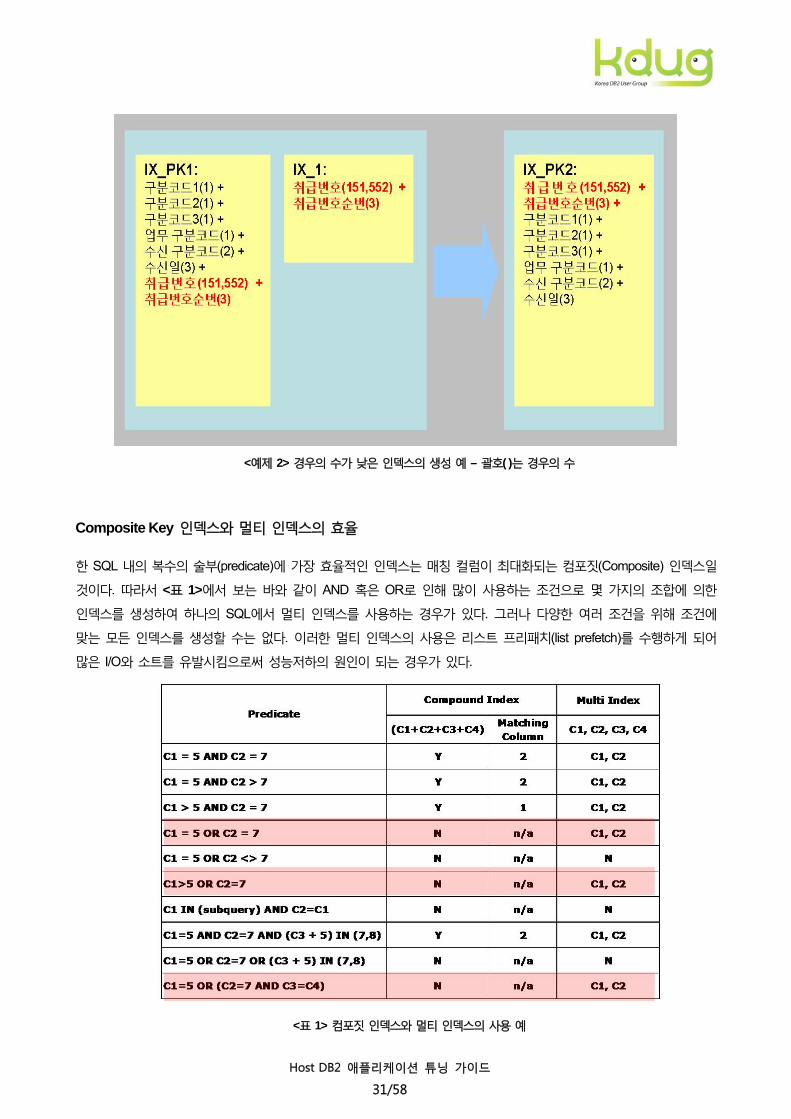
<예제 2> 경우의 수가 낮은 인덱스의 생성 예 – 괄호( )는 경우의 수
Composite Key 인덱스와 멀티 인덱스의 효율
한 SQL 내의 복수의 술부(predicate)에 가장 효율적인 인덱스는 매칭 컬럼이 최대화되는 컴포짓(Composite) 인덱스일
것이다. 따라서 <표 1>에서 보는 바와 같이 AND 혹은 OR로 인해 많이 사용하는 조건으로 몇 가지의 조합에 의한
인덱스를 생성하여 하나의 SQL에서 멀티 인덱스를 사용하는 경우가 있다. 그러나 다양한 여러 조건을 위해 조건에
맞는 모든 인덱스를 생성할 수는 없다. 이러한 멀티 인덱스의 사용은 리스트 프리패치(list prefetch)를 수행하게 되어
많은 I/O와 소트를 유발시킴으로써 성능저하의 원인이 되는 경우가 있다.
<표 1> 컴포짓 인덱스와 멀티 인덱스의 사용 예
Host DB2 애플리케이션 튜닝 가이드
31/58

멀티 인덱스를 사용하지 않게 하기 위해 <예제 3>에서 보는 바와 같이 인덱스 적격 심사(Screening)를 이용하는
것도 고려한다.
대량 데이터의 테이블에 쿼리 1이 수행되면서 IX와 IX를 멀티 인덱스로 사용하는 것은 IX의 Cluster Ratio)=45%를
고려할 때 많은 I/O가 발생하며 또한 AND 조건에 의한 리스트 프리패치를 수행하여 소트를 발생시킨다.
IX2의 Cluster Ratio=95%를 고려할 때 IX2를 (계약부서번호+ 계약YMD + 취급부서번호)로 조정하면 취급부서번호는
매칭되지 않지만 인덱스 적격 심사를 통해 불필요한 리스트 프리패치를 피할 수 있다.
<예제 3> 멀티 인덱스 사용 SQL의 예
클러스터링 인덱스 설계
클러스터링 인덱스의 주요한 기능은 인덱스 키 순서대로 데이터를 물리적으로 유지하고자 하는데 있다. 클러스터링
인덱스의 설계는 인덱스 설계의 과정에서 가장 중요한 부분이라고 할 수 있는데, 많은 고객들이 이 부분에 대해
소홀히 하고 있는 것을 경험할 때가 많다.
첫째는 많은 고객들이 클러스터링 인덱스를 명시적(explicit)으로 생성하지 않음으로써 해당 테이블에 처음으로
생성되는 인덱스가 자동적으로 클러스터링 인덱스의 기능을 가지게 된다. 또한 많은 경우에 Primary Key 인덱스를
클러스터링 인덱스로 생성하는 경우가 많다.
실제로 성능 개선 프로젝트를 수행하면서 가장 많은 효과를 보는 부분 중의 하나가 클러스터링 인덱스의 재조정이다.
그렇다면 어떠한 경우에 성능에 도움이 되는 것일까?
쿼리 성능을 생각한다면, 대량 데이터를 검색하는 조건에 대해 클러스터링 인덱스를 생성하도록 한다. 즉 여러개
인덱스의 기수 순서(Cardinality)를 비교해 볼 때, 기수 순서가 낮은 인덱스(해당 조건에 해당되는 데이터가 한 곳에
몰려있게 되므로)가 상대적으로 클러스터링 인덱스로서 효율적이고 결국 대량 GETPAGE를 줄일 수 있다. 따라서
대부분의 Primary Key 인덱스 혹은 Unique Index로 정의되어 있는 클러스터링 인덱스는 다시 검토할 필요가 있다.
<예제 4>에서 보는 바와 같이 IX1의 Cluster Ratio=45%로 인하여 Query1을 수행하는데 많은 I/O가 발생하게 된다.
하지만 실제 클러스터링 인덱스인 IX_PK_CLUSTER를 사용하는 Query2는 Unique Key이므로 클러스터링 인덱스의
효과를 보지 않는다. 따라서 Query2 성능에 영향을 주지 않으면서, IX1을 클러스터링 인덱스로 조정하여 Query 1의
성능을 향상시킬 수 있다.
Host DB2 애플리케이션 튜닝 가이드
32/58

이와 같은 설계의 조정이 필요한 테이블이 여러분의 DB에 얼마나 많이 존재하는지 확인해보라.
<예제 4> 경우의 수가 낮은 인덱스의 생성 예 – 괄호( )는 경우의 수
결과적으로 대량 데이터를 검색하는 SQL, 혹은 대량 조인(Join)에 사용되는 컬럼에 대해서는 해당 조건에 대한
클러스터링 인덱스의 설계를 고려한다.
파티션된 테이블의 경우는 반드시 파티션드(Partitioned) 인덱스가 클러스터링 인덱스로서 정의되어야 하며, 위의 기수
순서보다 업무의 중요도에 의해 클러스터링 인덱스를 조정하도록 한다.
INSERT/DELETE가 많은 테이블에 대해 클러스터링 인덱스를 설계할 경우에는 잠금 경합(Locking Contention)을
고려해야 하는데 SQL INSERT 시에 클러스터링 인덱스를 무시한 채로 데이터를 입력하고자 할 때는 MEMBER
CLUSTER 옵션을 사용한다.
인덱스의 물리요건
테이블과 마찬가지로 인덱스를 생성하면서 고려하는 물리 파라미터는 다분히 해당 인덱스를 사용하는 쿼리의
업무적인 요건이 반영되어야 한다. 많은 경우 디폴트 값이 정의되어 있다. 주요한 물리 파라미터는 성능과 밀접히
관련되어 있음을 고려한다.
PCTFREE, FREEPAGE
랜덤 입력이 많은 인덱스에 대해서는 여유 공간(Free space)을 충분히 주어서 페이지 분리(Page split)가
발생하지 않도록 한다. 또한 조회만 하는 테이블에 대한 인덱스는 PCTFREE=0으로 주어서 불필요한
인덱스 공간을 줄이도록 한다.
MEMBER CLUSTER
데이터의 로드나 Reorg 시에는 클러스터링 인덱스의 순서를 따르지만, SQL INSERT 시에는 클러스터링
인덱스를 무시하고 INSERT 가능한 공간에 데이터가 입력되는 옵션이다. 대량 INSERT를 수행하는
Host DB2 애플리케이션 튜닝 가이드
33/58

테이블에 유효하다. 그러나 해당 키를 조회하는 쿼리에 대해서는 성능 저하가 예상된다.
인덱스의 설계는 SQL의 성능과 가장 밀접하게 연관되어 있는 요인 중의 하나이므로 효율적인 설계와 함께 Access
Path의 분석을 통한 인덱스 사용 여부에 대한 관찰이 반드시 필요하다. 따라서 효율적으로 사용되지 않는 인덱스가
있는지 여부를 주기적으로 검토할 필요가 있다. 다음 회에는 테이블스페이스 및 테이블의 물리 설계 요인에 대해
설명하도록 하겠다.
Host DB2 애플리케이션 튜닝 가이드
34/58
Part 6 - 효율적인 테이블스페이스 물리 설계
데이터베이스는 애플리케이션 요건을 데이터 형태로 표현하기 위해 설계되는 것이며, 결과적으로 데이터베이스의
물리 설계에도 시스템적인 요건 외에 업무 요건이 충분히 반영되어야 한다. 따라서 이번 회에서는 테이블의
물리설계에 업무적인 요건이 더욱 충실히 반영되도록 테이블의 설계에 직, 간접적으로 관여하는 개발자들이
알아두어서 애플리케이션 성능을 향상시킬 수 있는 테이블스페이스 물리 파라미터에 대해서 알아보겠다.
일반적으로 테이블이나 인덱스의 설계는 개발자들이 많이 관여하지만 테이블스페이스 파라미터는 DBA 팀에 의해
설계되는 경우가 많다. 실제적으로 테이블스페이스의 설계는 업무 요건에 의해 설계되어야 되는 파라미터들이
많으며 결과적으로 애플리케이션의 성능에 매우 큰 영향을 끼치게 된다.
그러나 대다수 고객사의 많은 테이블스페이스 파라미터들이 기본 설정 값이거나 업무요건이 충분히 반영되지 않은
상태로 정의되어 있는 경우가 많다. 그런데 이는 테이블이나 인덱스 설계와는 달리 업무적 요건이 테이블스페이스
설계 시에 많이 반영되지 않기 때문이라고 할 수 있다.
따라서 이번 회에서는 업무의 요건이 반영되어야 할 테이블스페이스 파라미터에 대해서 개발자들이 고려하여 할
사항에 대해 설명하도록 하겠다.
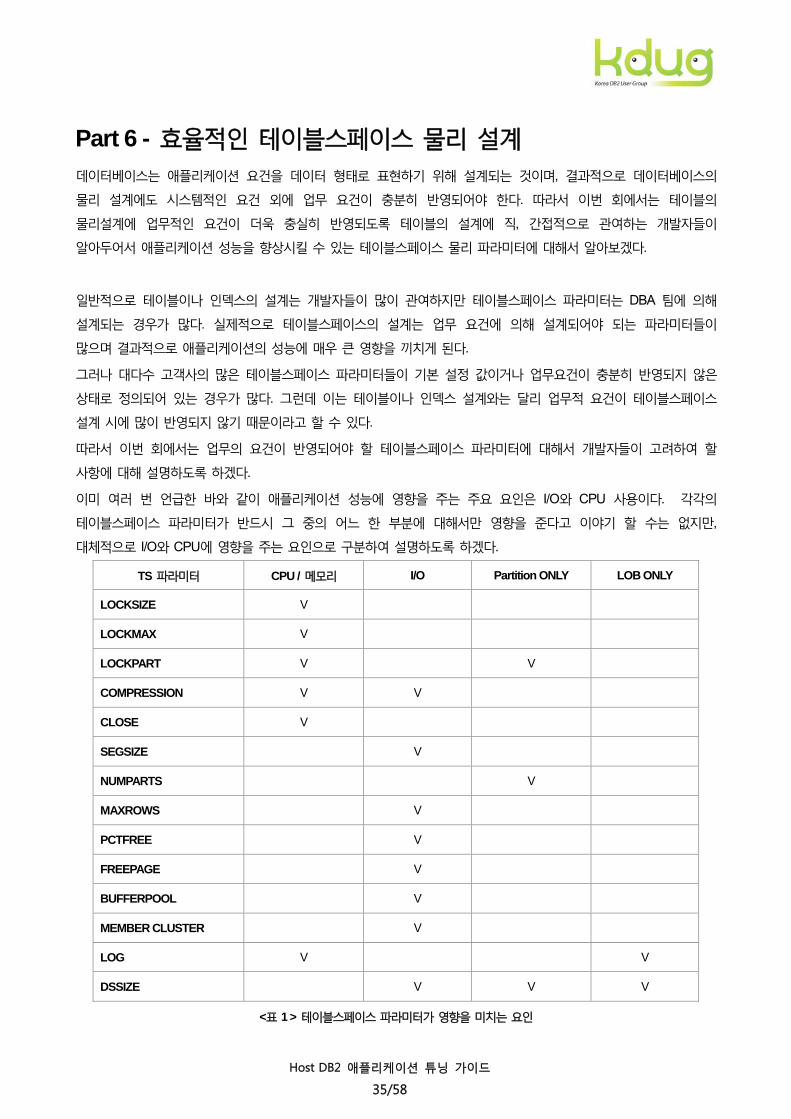
이미 여러 번 언급한 바와 같이 애플리케이션 성능에 영향을 주는 주요 요인은 I/O와 CPU 사용이다. 각각의
테이블스페이스 파라미터가 반드시 그 중의 어느 한 부분에 대해서만 영향을 준다고 이야기 할 수는 없지만,
대체적으로 I/O와 CPU에 영향을 주는 요인으로 구분하여 설명하도록 하겠다.
TS 파라미터 CPU / 메모리 I/O Partition ONLY LOB ONLY
LOCKSIZE V
LOCKMAX V
LOCKPART V V
COMPRESSION V V
CLOSE V
SEGSIZE V
NUMPARTS V
MAXROWS V
PCTFREE V
FREEPAGE V
BUFFERPOOL V
MEMBER CLUSTER V
LOG V V
DSSIZE V V V
<표 1 > 테이블스페이스 파라미터가 영향을 미치는 요인
Host DB2 애플리케이션 튜닝 가이드
35/58

CPU / 메모리 사용과 관련된 파라미터
LOCKSIZE
DB2는 LOCK을 걸 때마다 250 byte의 IRLM 메모리를 사용하며 CPU가 일을 하게 된다. 많은 고객사의
LOCKSIZE 파라미터 설계의 유형을 보면 ANY로 설계되어 있는 것이 대부분이다. ‘LOCKSIZE=ANY’는 초기에
LOCKSIZE=PAGE로 시작하여 NUMLKTS 혹은 NUMLKUS와 같은 동시에 발생할 수 있는 Lock 개수의 한계를
초과하면 Lock Escalation을 허용함을 의미한다.
많은 고객사에서 온라인 중에 배치 프로그램을 가동할 경우 Lock Escalation이 발생하곤 한다. 이는
동시성(Concurrency)에 큰 영향을 주게 된다. 이러한 테이블에 대해서는 LOCKMAX 파라미터를 조정하거나
LOCKSIZE=PAGE로 조정하는 것을 고려한다. 특히 온라인 중에 100% 조회만 발생하는 테이블에 대해서는
LOCKSIZE를 테이블이나 테이블스페이스로 조정하여 불필요한 CPU 가동을 줄이도록 한다.
배치와 관련하여서 LOCKSIZE를 조정할 필요가 있을 때는 배치 프로그램 내에 ‘LOCK 테이블..‘의 SQL을
사용하여 해당 프로그램에서 필요시에만 LOCKSIZE를 조정하는 것을 고려한다.
LOCKMAX
시스템 파라미터에서 정의되어 있는 NULKTS, NUMLKUS로 인한 Lock escalation을 방지하기 위해 특정
테이블스페이스에 대해 LOCKMAX를 증가시킬 수 있다. 특히 대량 검색(retrieval)이 수행되는 테이블이
LOCKSIZE=ROW 되어 있는 경우에는 애플리케이션의 요건에 따라 LOCKMAX 수를 증가하여 Lock
escalation을 방지하도록 한다. LOCKMAX=0으로 하여 Lock Escalation을 방지할 수도 있으나 IRLM에 영향을
줄 수 있으므로 사용하지 않도록 한다.
LOCKPART
파티션 된 테이블스페이스에 대해 LOCKPART=YES를 사용하면, 현재 사용하고 있는 데이터가 존재하는
파티션에 대해서만 잠금이 가능하게 된다. 만약 대량 데이터를 처리하는 테이블에 대해 CPU의 부담을
줄이기 위해 LOCKSIZE=테이블(혹은 테이블스페이스)로 정의하였을 경우 LOCKSIZE=YES로 정의하면 해당
파티션에 대해서만 S,U,X Lock이 가능하게 되어 다른 파티션에 대한 동시성이 향상된다.
압축
데이터를 압축하는 이유를 물어보면 대부분의 경우는 “스페이스를 절약하기 위해서” 라고 답하게 된다. 물론
스페이스의 절약은 테이블 압축의 중요한 이유가 된다. 그런데 많은 고객들이 데이터 압축을 걱정하는 큰
이유는 압축/압축 해제로 인한 CPU 오버헤드일 것이다.
그렇다면 가령 대량 데이터를 검색해야 하는 통계 테이블을 압축했다면 애플리케이션의 성능에 어떤 일이
발생할까? 한 금융회사는 디스크 스페이스를 절약하기 위하여 대량의 테이블에 대해 압축을 수행한 결과
뜻밖의 수확을 얻었는데, 엄청난 CPU 절감이 그것이다. 그 이유는 데이터 압축으로 인해 I/O가 감소되고, 또
그로 인해 CPU 오버헤드가 감소했기 때문이다.
따라서 대량의 데이터를 처리하는 테이블에 대해서는 압축=YES를 적용하는 것을 고려한다. 실제 압축을
수행하기 전에 DSN1COMP 유틸리티를 수행하여 압축 정도를 시뮬레이션하는 것도 바람직하다.
LOG
LOB 컬럼에 대해서 로그에 기록하는 것이 필요하지 않을 때 LOG=NO 옵션을 사용할 수 있다(기본 값은
YES). 하지만 이러한 컬럼은 복구 유틸리티 수행시 Log Apply 시점에 ‘INVALID’로 처리되어
Host DB2 애플리케이션 튜닝 가이드
36/58

SELECT/FETCH가 불가능하게 된다.
I/O와 관련된 파라미터
압축
위의 내용과 동일하다.
MAXROWS
데이터의 동시성을 최대화 하기 위한 방법으로 MAXROWS=n(n=1~255)을 사용하여 한 페이지 내에 최대로
저장될 수 있는 줄(Rows) 수(n)를 지정할 수 있다. 그러나 많은 양의 줄(rows)을 검색하는 경우에는
불필요한 I/O가 발생할 수 있다.
MEMBER CLUSTER
테이블에 데이터가 입력될 때 명시적(explicit)으로 정의되어 있는 클러스터링 인덱스 키와 상관없이 입력
가능한 스페이스에 입력(INSERT) 되도록 하기 위한 옵션으로 사용할 수 있다. 입력 시에 클러스터링 키에
의한 스페이스 검색으로 I/O가 감소되기도 하고, 클러스터링 키에 의한 입력시 발생할 수 있는
경합(Contention) 방지할 수 있다. 그러나 해당 클러스터링 키 값에 의한 데이터 검색 시에 추가적인 I/O가
발생할 수 있다.
PCTFREE
새로운 줄(row) 입력시 DB2는 검색 매커니즘에 의해 클러스터링 순서에 맞는 적절한 스페이스를 찾게 된다.
이러한 경우를 위하여 필요한 스페이스를 확보해 두는 것이 필요하다.
PCTFREE는 랜덤으로 입력되는 줄을 위한 스페이스를 각 페이지 별로 몇 %씩 미리 확보해 두는 역할을
한다. 따라서 이러한 %의 비율은 줄 길이와 데이터의 주기적 입력 패턴에 따라 초기 LOAD 시에 확보되어
있다가 실제 줄 입력이 이뤄지면 필요에 따라 REORG를 하여 다시 확보할 필요가 있다.
그런데 많은 고객들의 경우에 기본 설정 값을 사용하거나 업무의 요건이 반영되지 않은 설계를 보는 경우가
많다. 만약 랜덤으로 입력되는 450bytes 줄의 테이블에 PCTFREE=10%로 설계하였다면, 이 테이블은
전체적으로 10%의 디스크를 낭비하면서(실제 한 페이지의 10%는 400bytes 정도됨) 실제로는 데이터의
클러스터링도 유지하지 못하게 된다.
데이터베이스 설계에 대한 튜닝을 하다 보면 이런 설계를 가진 테이블을 의외로 많이 보게 된다. 그러나
불필요하게 PCTFREE 값을 크게 확보할 경우 대량 데이터를 검색하다 보면 많은 I/O를 발생시키게 된다. 또한
순차적으로 입력되는 줄의 성격을 가진 테이블은 PCTFREE=0으로 명시하여(기본 설정 값은 5%) 불필요한
스페이스의 낭비를 줄이는 것이 바람직하다.
FREEPAGE
FREEPAGE=n이라 함은 데이터의 입력을 위하여 LOAD / REORG 시에 n개의 페이지마다 하나의 전체
페이지를 비워놓는 것을 의미한다. 줄 길이가 긴 테이블(일반적으로 한 페이지의 25% 이상)에 대해서는
PCTFREE 보다는 FREEPAGE를 설계하는 것이 바람직하다.
많은 고객들이 테이블스페이스 형태를 분할형(Segmented)으로 설계하는 경우가 많은데, 반드시 SEGSIZE >
FREEPAGE이어야 한다. 그렇지 않을 경우 FREEPAGE가 SEGSIZE보다 작게 확보되면서 예상보다 많은
디스크가 확보될 수 있다.
Host DB2 애플리케이션 튜닝 가이드
37/58

SEGSIZE
<그림 1>에서 보는 바와 같이 분할형(segmented) 테이블스페이스의 스페이스 검색 매커니즘은 해당
세그먼트 내에서 필요한 스페이스를 먼저 찾게 된다. 따라서 SEGSIZE는 가능한 크게(4~64페이지) 설정하는
것이 데이터의 클러스터링에 효율적이다. 그러나 크기가 64페이지가 되지 않는 작은 테이블에 대해서는
4페이지 단위로 테이블 크기보다 조금 크게 설계하는 것이 효율적이다.
<그림 1> 분할형 테이블스페이스의 스페이스 검색 매커니즘
BUFFERPOOL
버퍼 풀 설계에 대해서는 뒷장에서 다시 상세히 설명할 예정이므로, 테이블스페이스 설계와 관련된 영향에
대해서만 간략히 서술하겠다. 기본적으로 버퍼 풀의 특성에 따라 대량으로 처리되는 테이블과 랜덤하게
처리되는 테이블 그리고 다시 재참조되는 데이터가 많은 테이블 등으로 성격에 따라 버퍼 풀을 지정하여
버퍼 히트율(Buffer Hit Ratio)을 최대화하여 I/O를 줄이는 것이 바람직하다.
DSSIZE
파티셔닝된 테이블스페이스의 각 파티션 크기나 LOB 테이블의 데이터 셋 크기를 1GB, 2GB, 4GB, 8GB,
16GB, 32GB, 64GB로 지정할 수 있는데, 4GB 이상의 크기를 가지는 테이블의 인덱스 PIECESIZE는 최대
254GB까지 지정하여 최대한의 I/O 경합을 줄일 수 있다.
항상 이야기하듯이 데이터베이스는 애플리케이션 요건을 데이터 형태로 표현하기 위해 설계되는 것이며, 결과적으로
데이터베이스의 물리 설계에도 시스템적인 요건 외에 업무 요건이 충분히 반영되어야 한다. 따라서 이번 회에서는
테이블의 물리설계에 업무적인 요건이 더욱 충실히 반영되도록 테이블의 설계에 직, 간접적으로 관여하는
개발자들이 알아두어서 애플리케이션 성능을 향상시킬 수 있는 테이블스페이스 물리 파라미터에 대해서 알아보았다.
Part 7에서는 주요 성능 요인인 I/O에 많은 영향을 주는 버퍼 풀의 실행 매커니즘과 설계 가이드에 대해서
설명하도록 하겠다.
Host DB2 애플리케이션 튜닝 가이드
38/58

Part 7 - 버퍼 풀 실행에 대한 이해
DB2 시스템에서 버퍼 풀은 메모리 영역에 대한 사용이기 때문에 DBA에 의해 설계되는 것이 일반적이다. 그러나
이러한 버퍼 풀에 대한 설계는 버퍼 내에서 읽혀져 들어온 데이터가 다른 사용자에 의해 재사용될 때 I/O를 다시
발생하지 않도록 효율적으로 설계되어야 하는데 이 또한 업무의 요건이 충분히 반영이 되어야 할 것이다.
간단한 예로 일계 테이블에 대해서는 대체적으로 당일 데이터에 대해 여러 사용자들이 지속적으로 사용하는 것이
일반적인데, 만약 대량으로 읽히는 다른 테이블이 같은 버퍼를 사용하고 있다면, 이 대량 처리 테이블에 의해 버퍼
안에 있던 일계 테이블 데이터는 디스크로 쓰기가 이뤄지고 따라서 필요시에 다시 I/O를 발생시킴으로써 성능저하를
가져오게 된다.
이와 같이 버퍼 풀 설계가 업무의 요건이 충분히 고려되어야 하는 것을 고려할 때 개발자들도 데이터 처리를 위한
버퍼 실행과 버퍼 풀이 어떠한 설계요인에 의해 운영되는지 알아둘 필요가 있겠다.
GET 페이지(논리적 I/O)와 디스크 I/O(물리적 I/O)의 차이
앞에서 튜닝 대상이 되는 SQL의 중요한 요인으로 GET 페이지가 많은 SQL에 대해 이야기 한 바 있다. 이미 이야기
했듯이 ‘GET 페이지’란 논리적인 I/O를 의미하며 결국은 물리적인 I/O의 원인이 된다. 또한 버퍼 풀 내에 있는
데이터(혹은 인덱스) 페이지의 사용으로 물리적인 I/O를 수행하지 않더라도 결과적으로 높은 CPU 비용(Cost)을
발생시킨다.
<그림 1> 논리적 I/O와 물리적 I/O
이러한 GET 페이지와 디스크 I/O가 버퍼 풀과 어떻게 연관이 되는지 다시 한번 그림으로 이해해 보도록 한다. <그림
1>에서 보는 바와 같이 필요한 데이터(혹은 인덱스) 페이지가 이미 버퍼에 있을 경우 디스크 I/O를 수행하지 않는다.
Host DB2 애플리케이션 튜닝 가이드
39/58

버퍼 Hit Ratio
버퍼 Hit Ratio는 SQL을 처리하기 위한 GET 페이지 수 대비 얼마의 물리적인 I/O를 수행해야 하는가를 비율로
나타내는 것인데, 결과적으로 버퍼 내에 처리하고자 하는 데이터가 많을수록 SQL의 성능은 향상된다고 할 수 있다.
Case 1> 테이블 스페이스 스캔에 의한 ‘일계일=2008-06-30’을 처리하는 SQL의 수행
일계일에 대한 인덱스가 없는 상태에서 <그림2>의 SQL을 처리하기 위해서는 일계 테이블 전체를 읽기
(테이블스페이스 스캔) 해야 될 것이고 따라서 이 경우의 GET 페이지는 테이블 전체 페이지 수인 10,000이 된다.
만약 일계 테이블의 일부 페이지가 이미 버퍼 내에 존재할 경우에는 해당 페이지를 읽지 않는다.
<그림 2> “일계일=2009-06-30” 조건에 대한 테이블스페이스 스캔에 의한 SQL의 처리
하지만 대부분의 테이블스페이스 스캔은 연속적인 프리패치(Sequential Prefetch)를 수행하게 됨으로써 대부분의 일계
테이블에 대한 물리적인 읽기가 발생하게 되면 버퍼 Hit Ratio는 0에 가깝게 된다. 이 경우 만약 4,000 페이지의
데이터 페이지가 이미 버퍼 내에 존재한다면 6,000페이지만 읽게 되고 이때의 버퍼 풀 Hit Ratio는 다음의 공식에
의하여 60%가 된다.
버퍼 Hit Ratio(%)
= ((GET 페이지 수 – PHYSICAL READ 페이지 수) / GET 페이지 수) x 100
Case 2> 일계일 인덱스에 의한 ‘일계일=2008-06-30’을 처리하는 SQL의 수행
만약에 ‘일계일’에 대해 인덱스(일계X1)가 생성된다면, 인덱스를 통해 데이터를 접속하게 되고 이때에는 “인덱스
페이지(Root 페이지 + non-leaf 페이지 + A10100의 RID가 들어있는 leaf 페이지) + (2008-06-30이 들어있는 데이터
Host DB2 애플리케이션 튜닝 가이드
40/58
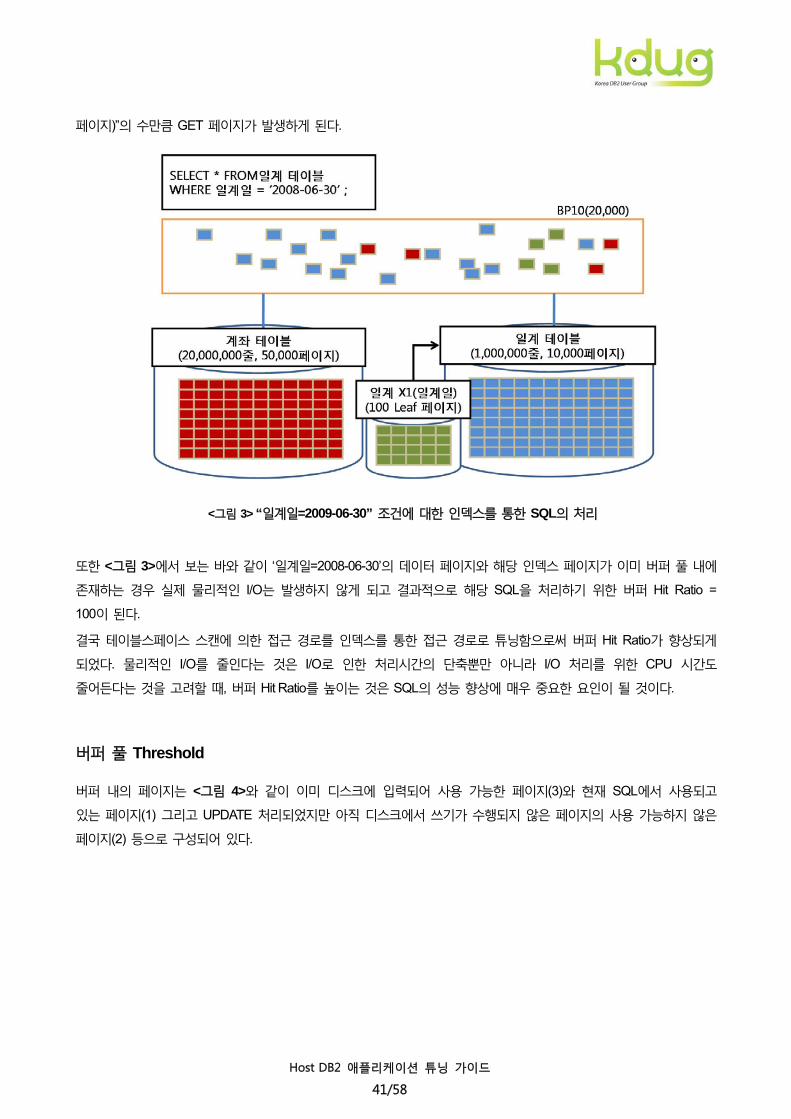
페이지)”의 수만큼 GET 페이지가 발생하게 된다.
<그림 3> “일계일=2009-06-30” 조건에 대한 인덱스를 통한 SQL의 처리
또한 <그림 3>에서 보는 바와 같이 ‘일계일=2008-06-30’의 데이터 페이지와 해당 인덱스 페이지가 이미 버퍼 풀 내에
존재하는 경우 실제 물리적인 I/O는 발생하지 않게 되고 결과적으로 해당 SQL을 처리하기 위한 버퍼 Hit Ratio =
100이 된다.
결국 테이블스페이스 스캔에 의한 접근 경로를 인덱스를 통한 접근 경로로 튜닝함으로써 버퍼 Hit Ratio가 향상되게
되었다. 물리적인 I/O를 줄인다는 것은 I/O로 인한 처리시간의 단축뿐만 아니라 I/O 처리를 위한 CPU 시간도
줄어든다는 것을 고려할 때, 버퍼 Hit Ratio를 높이는 것은 SQL의 성능 향상에 매우 중요한 요인이 될 것이다.
버퍼 풀 Threshold
버퍼 내의 페이지는 <그림 4>와 같이 이미 디스크에 입력되어 사용 가능한 페이지(3)와 현재 SQL에서 사용되고
있는 페이지(1) 그리고 UPDATE 처리되었지만 아직 디스크에서 쓰기가 수행되지 않은 페이지의 사용 가능하지 않은
페이지(2) 등으로 구성되어 있다.
Host DB2 애플리케이션 튜닝 가이드
41/58
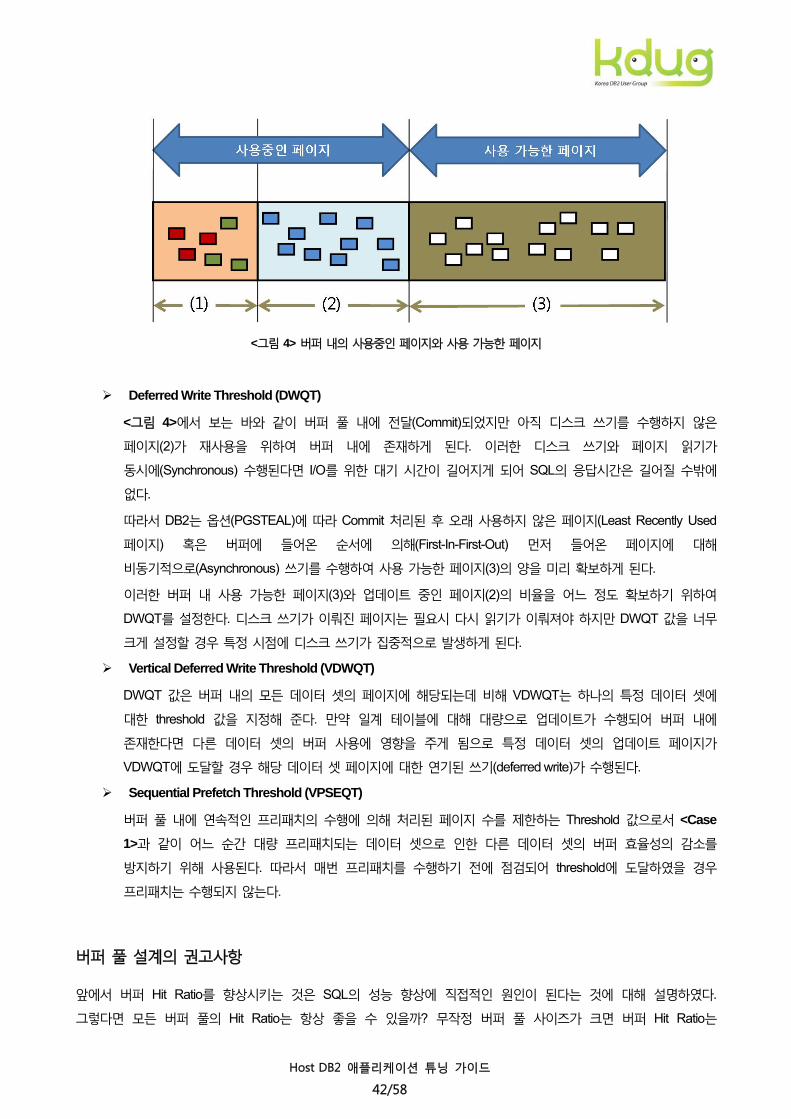
<그림 4> 버퍼 내의 사용중인 페이지와 사용 가능한 페이지
Deferred Write Threshold (DWQT)
<그림 4>에서 보는 바와 같이 버퍼 풀 내에 전달(Commit)되었지만 아직 디스크 쓰기를 수행하지 않은
페이지(2)가 재사용을 위하여 버퍼 내에 존재하게 된다. 이러한 디스크 쓰기와 페이지 읽기가
동시에(Synchronous) 수행된다면 I/O를 위한 대기 시간이 길어지게 되어 SQL의 응답시간은 길어질 수밖에
없다.
따라서 DB2는 옵션(PGSTEAL)에 따라 Commit 처리된 후 오래 사용하지 않은 페이지(Least Recently Used
페이지) 혹은 버퍼에 들어온 순서에 의해(First-In-First-Out) 먼저 들어온 페이지에 대해
비동기적으로(Asynchronous) 쓰기를 수행하여 사용 가능한 페이지(3)의 양을 미리 확보하게 된다.
이러한 버퍼 내 사용 가능한 페이지(3)와 업데이트 중인 페이지(2)의 비율을 어느 정도 확보하기 위하여
DWQT를 설정한다. 디스크 쓰기가 이뤄진 페이지는 필요시 다시 읽기가 이뤄져야 하지만 DWQT 값을 너무
크게 설정할 경우 특정 시점에 디스크 쓰기가 집중적으로 발생하게 된다.
Vertical Deferred Write Threshold (VDWQT)
DWQT 값은 버퍼 내의 모든 데이터 셋의 페이지에 해당되는데 비해 VDWQT는 하나의 특정 데이터 셋에
대한 threshold 값을 지정해 준다. 만약 일계 테이블에 대해 대량으로 업데이트가 수행되어 버퍼 내에
존재한다면 다른 데이터 셋의 버퍼 사용에 영향을 주게 됨으로 특정 데이터 셋의 업데이트 페이지가
VDWQT에 도달할 경우 해당 데이터 셋 페이지에 대한 연기된 쓰기(deferred write)가 수행된다.
Sequential Prefetch Threshold (VPSEQT)
버퍼 풀 내에 연속적인 프리패치의 수행에 의해 처리된 페이지 수를 제한하는 Threshold 값으로서 <Case
1>과 같이 어느 순간 대량 프리패치되는 데이터 셋으로 인한 다른 데이터 셋의 버퍼 효율성의 감소를
방지하기 위해 사용된다. 따라서 매번 프리패치를 수행하기 전에 점검되어 threshold에 도달하였을 경우
프리패치는 수행되지 않는다.
버퍼 풀 설계의 권고사항
앞에서 버퍼 Hit Ratio를 향상시키는 것은 SQL의 성능 향상에 직접적인 원인이 된다는 것에 대해 설명하였다.
그렇다면 모든 버퍼 풀의 Hit Ratio는 항상 좋을 수 있을까? 무작정 버퍼 풀 사이즈가 크면 버퍼 Hit Ratio는
Host DB2 애플리케이션 튜닝 가이드
42/58

좋아질까? 물론 ‘아니다’.
사용 가능한 버퍼 풀 사이즈는 한정되어 있으며, 따라서 무한정으로 크게 설계하는 것은 불가능하다. 그렇다면 이미
이야기 하였듯이 데이터를 접속하는 업무의 요건에 맞는 버퍼 Threshold 설계에 의한 버퍼 풀의 분리가 바람직하다.
자주 재사용되고(re-referenced) 자주 업데이트되는 오브젝트
이러한 오브젝트는 가능한 DWQT나 경우에 따라서는 VDWQT를 크게 설정하여 재사용율을 높이도록 하며 대량으로
연속적인 프리패치를 수행하는 오브젝트와는 분리하여 설계한다.
자주 재사용되지 않는 오브젝트
이러한 오브젝트는 버퍼 Hit Ratio가 낮을 수밖에 없다. 따라서 가능한 한 DWQT나 VDWQT의 설정을 낮게 하여
디스크 쓰기로 인한 경합(contention)을 줄이도록 한다.
대량 처리되는 쿼리성 오브젝트, 작업 테이블
VPSEQT=100으로 설계하는데, 병렬 프로세싱이 수행되는 경우에는 VPPSEQT 또한 100으로 설정한다. 이러한
테이블에 대해서는 16K나 32K 버퍼를 사용하게 하여 I/O 당 읽혀지는 줄 수를 늘리는 것도 고려한다.
이러한 버퍼 풀에 대한 설계 옵션은 필요에 따라 다음과 같은 신택스(Syntax)를 이용하여 변경(ALTER) 가능하다.
Part 8에서는 잠금(Locking)과 관련하여 애플리케이션에 고려하여 할 사항에 대해 이야기 한다.
Host DB2 애플리케이션 튜닝 가이드
43/58

Part 8 - DB2 Locking에 대한 이해
최근에 어느 사이트에서 “왜 DB2에는 READ Lock이 있는가”라는 것 때문에 한 개발자가 매우 흥분하는 것을 본적이
있다. 다른 DB를 오래 사용하던 그 개발자가 그렇게까지 흥분한 이유는 DB2의 READ Lock으로 인해 불필요하게
DEADLOCK이 많이 발생한다는 것 때문이었다.
그럼 READ Lock이 없다면 어떻게 될까?
내 트랜잭션이 데이터를 READ 해서 계산 처리하고 있는 동안에 다른 트랜잭션이 해당 데이터를 UPDATE 한다면?
실제로 다른 트랜잭션이 UPDATE 해도 되기 때문에 Locking 경합(contention)을 피하기 위해 READ Lock을 걸지 않고 싶다면?
SQL 자체에 상당히 튜닝이 잘 되어있는 애플리케이션도 Locking 경합이나 DEADLOCK으로 응답시간에 저하를
가져오는 경우가 많은데, 이번 장에는 DB2 트랜잭션 Locking과 관련된 여러 요인에 대해 이야기 하도록 하겠다.
트랜잭션 Locking의 대상
SQL이 수행되는 동안 다음의 DB2 Object에 대해서 테이블의 Lock Size에 따라, SQL의 유형에 의한 Lock Mode로서,
BIND 파라미터 option에 따른 duration 만큼의 Lock이 점유된다. 이 경우 RI에 의해 연결된 테이블에 대해서도
Locking이 걸린다는 것을 유의한다.
SQL이 처리하는 테이블스페이스 / 테이블 / 페이지 / 열
RI에 의해 연결된 테이블스페이스 / 테이블 / 페이지 / 열
Type 1 Index
DB2 Catalog
DB2 Directory
트랜잭션 Locking에 영향을 미치는 요인
트랜잭션 Locking에 영향을 미치는 요인은 크게 여섯 가지로 분류할 수 있다. 트랜잭션 Lock Mode, 테이블스페이스
물리설계 파라미터, BIND 파라미터, DB2 서브시스템 파라미터, 트랜잭션 내 Commit 주기, SQL 코딩 등이 그것이다.
이들이 어떻게 영향을 미치는지 차례로 살펴본다.
1. SQL 유형에 따른 Locking Mode
SQL 유형에 따라 Locking Mode가 결정되며 Lock 사이의 다음과 같은 비교성을 갖는다.
SQL 유형 LOCK MODE
SELECT S
FETCH FOR UPDATE OF S
Host DB2 애플리케이션 튜닝 가이드
44/58

FOR UPDATE OF 없을 때 U
INSERT, UPDATE, DELETE X
<표 1> SQL 유형에 따른 LOCK Mode
<표 2 > SQL 유형에 따른 TS Lock Mode 비교
<표 3 > SQL 유형에 따른 Page (혹은 Row) Lock 비교
2. 테이블스페이스 물리설계 파라미터
CREATE TABLESPACE … LOCKSIZE.. LOCKMAX.. LOCKPART..
MAXROWS.. PCTFREE.. COMPRESS
트랜잭션 Locking의 단위 – LOCKSIZE
Host DB2 애플리케이션 튜닝 가이드
45/58

<그림 1> 테이블 형태에 따른 Lock Size 종류 – DB2 V7 Admin Guide p.651 참조
TABLESPACE LOCK TABLE LOCK PAGE LOCK ROW LOCK
Low CPU Cost High Concurrency
<그림 2> Lock Size에 따른 CPU 비용과 동시성의 관계
LOCKSIZE ANY를 사용하는 것은 Lock Escalation을 발생시킬 가능성이 있음으로 가능한 사용하지 않도록 한다.
<그림 2>에서 보는 바와 같이 Lock 횟수가 많은 것은(LOCKSIZE가 작은 경우) CPU 오버헤드와 메모리에 대한
비용이 많이 발생하게 되므로 Access 요건에 맞는 LOCKSIZE를 설계하는 것이 매우 중요하다.
통계나 정보계 업무와 같은 Read Only 테이블에 대해서는 LOCKSIZE 테이블 혹은 테이블스페이스로 정의하여 CPU
비용을 줄이는 것을 고려한다. 변경, 입력 및 조회가 다양하게 또한 빈번하게 일어나는 경우 동시성을 위해 Row로
지정하는 것을 고려하되, 그 외에는 IRLM에 의한 CPU 오버헤드 줄이기 위해 일반적으로 PAGE를 지정하도록 한다.
또한 Single Row를 처리하는 경우에는 PAGE Lock 사이즈와 비교하여 CPU 오버헤드기 같고 다음과 같은 테이블은
Hot spot일 경우가 많으므로 동시성을 고려하여 Row Level Lock이 바람직하다.
소형 테이블이면서 CRUD가 동시에 일어나는 경우
순차적으로 데이터가 입력되는 테이블들
LOCKMAX 파라미터
테이블 하나 당 동시에 발생할 수 있는 Page 혹은 Row 단위의 최대 Lock 개수이며, 다음과 같은 경우의 LOCKMAX
수를 초과하는 경우 Lock Escalation이 발생한다.
SYSTEM : DSNZPARM NUMLKTS 값에 의해 결정되며 LOCKSIZE ANY의 경우 default 값
Host DB2 애플리케이션 튜닝 가이드
46/58

0: Lock escalation이 일어나지 않음. LOCKSIZE가 Page나 Row인 경우 default 값
1 – 2,147,483,647까지의 값이 사용 가능하다
LOCKPART 파라미터
파티션 된 테이블스페이스에 대해 LOCKPART=YES로 정의하면 해당 파티션에 대해서만 S,U,X Lock이 가능하게
되어 다른 파티션에 대한 동시성이 향상된다.
PCTFREE, MAXROWS, COMPRESS 파라미터
페이지의 PCTFREE, MAXROWS, COMPRESS 파라미터는 각 페이지 내 저장되는 row의 개수에 영향을 주게 되며
LOCKSIZE PAGE의 경우 점유되는 row 수에 영향을 주게 된다.
3. BIND 파라미터
테이블스페이스, 테이블 Locking Duration의 결정 – ACQUIRE/ RELEASE
1) ACQUIRE 파라미터
ACQUIRE (ALLOCATE)
첫 번째 SQL 수행시 “thread를 create할 때” thread 내에서 필요한 모든 테이블스페이스/테이블에 대해 Locking
acquire 한다.
ACQUIRE (USE)
“각 SQL 수행 시점”에서 SQL 내에서 필요한 테이블스페이스/테이블에 대해서만 Lock acquire 한다.
Package나 Dynamic SQL은 ACQUIRE(USE)만 적용된다
2) RELEASE 파라미터
RELEASE (DEALLOCATE)
“thread가 terminate 될 때” 모든 테이블스페이스/테이블에 대한 Lock release 한다.
RELEASE (COMMIT)
“COMMIT” 시점에 테이블스페이스/테이블에 대한 Lock release 한다.
CICS 트랜잭션에서 thread reuse 효율성을 높이기 위하여 RELEASE(DEALLOCATE)를 사용하는 것을 고려한
다.
Page, Row Locking Duration의 결정 – ISOLATION LEVEL
1) ISOLATION LEVEL 파라미터
ISOLATION LEVEL (RR)
해당 페이지나 Row를 접근 시작할 때(실제 SQL에서는 Qualify 되지 않은 페이지나 Row 일지라도) S lock을
걸었다가 “COMMIT” 시점에 지금까지 점유된 모든 페이지나 Row의 Lock을 release 한다. LOCKSIZE ANY의
경우에는 Lock Escalation이 발생할 가능성이 높다.
ISOLATION LEVEL (CS)
Host DB2 애플리케이션 튜닝 가이드
47/58

해당 페이지나 Row를 접근 시작할 때 S lock을 걸었다가 이에 대한 “access가 완료 되었을 때” 해당 페이지
나 Row의 lock을 release 한다.
ISOLATION LEVEL (UR)
Read Cursor에 대해 Lock Request 없이 수행하게 되어 커미트되지 못한 데이터(해당 데이터가 UPDATE 되었
지만 아직 commit 처리 되지 않은 데이터) 에 대해서도 Lock request 없이 수행하게 되며, 결과적으로 Lock 경
합으로 인한 대기는 없지만 데이터 영속성에 대해 문제가 있을 수 있다. 따라서 반드시 업무적인 요건을 고려
하여 사용한다. ISOLATION(UR)으로 Bind 된 Package 내의 다음 SQL은 CS ISOLATION으로 변형된다.
– INSERT, DELETE, UPDATE
– FOR UPDATE OF를 사용한 Cursor
X-LOCK의 경우
ISOLATION 옵션에 상관없이 해당 페이지나 Row를 접근 시작하는 시점에 X lock을 걸었다가 “commit” 시점에
Lock release한다.
U-LOCK의 경우
Commit 후에 S lock으로 되었다가 “Cursor가 옮겨가거나 CLOSE 되면” Lock Release 한다.
2) CURRENT 데이터 파라미터
ISOLATION LEVEL(CS)과 같이 사용되면서 Dirty 데이터의 사용여부를 결정하며, ‘Lock Avoidance’ 여부를 결정한
다.
ISOLATION LEVEL(CS) CURRENT 데이터(YES)
<그림 3> ISOLATION LEVEL(CS) CURRENT 데이터(YES)의 Locking 처리
ISOLATION LEVEL(CS) CURRENT 데이터(NO)
Read Only Cursor 수행시 Commit 처리된 데이터에 대해서는 Lock을 걸지 않으면서 수행하며, Uncommitted
데이터에 대해서는 S Lock Request 한다.
<그림 4> ISOLATION LEVEL(CS) CURRENT 데이터(NO)의 Lock Avoidance
Host DB2 애플리케이션 튜닝 가이드
48/58

<그림 3>과 <그림 4>에서 보는 바와 같이 업무적으로 데이터 연속성에 영향이 없는 cursor에 대해서는
CURRENT 데이터(NO)를 사용하는 것이 Locking 경합과 동시에 Lock 오버헤드를 줄이는 방법이 된다.
이러한 Lock Avoidance의 이득을 가지려면 Cursor가 Read Only Cursor여야 하므로, Read만이 확실한 Cursor에
대해서는 ‘.. FOR FETCH ONLY’를 명시적으로 코딩하도록 하며 UPDATE 하고자 하는 Cursor에 대해서는 ‘..
FOR UPDATE OF..’를 코딩하도록 한다.
4. 트랜잭션 Locking 관련 시스템 파라미터
DEADLOCK
deadlock detection cycle time으로서 deadlock 여부 판단을 위한 로직을 수행하여 deadlock을 resolve 한다.
Default는 5초로 설정한다.
IRLMRWT
테이블스페이스, 테이블 혹은 페이지, Row 등의 Locking 대상 리소스에 대해 lock request 후 대기 하는 시간으
로서 ‘-911 Time out’ 현상이 발생한다. Default는 60초다.
RRULOCK
ISOLATION RR 혹은 RS의 경우에 U lock 사용을 가능하게 할 것인가를 결정한다. 동시성을 위해서는 Default
를 NO로 지정한다.
NUMLKUS
하나의 thread에서 동시에 hold 할 수 있는 Lock의 총 개수(max. Locks per one user)로 해당 thread에서 접근
하는 모든 테이블스페이스에 대한 Lock의 개수를 모두 포함한다. 이 값을 초과할 경우 ‘-904’를 return 한다.
NUMLKTS
하나의 테이블스페이스에 여러 Thread에서 동시에 점유할 수 있는 Lock의 총 개수 (max. Locks per one 테이블
스페이스)로, LOCKSIZE ANY의 경우 “CREATE TABLESPACE … LOCKMAX SYSTEM ..”에서 정의된 Lock
escalation의 기준 값인 SYSTEM 값을 지정한다.
5. 트랜잭션 내 Commit 주기
적절하게 COMMIT 처리한 오브젝트에 대한 Locking Time이 경과 시간의 10%를 넘지 않게 한다. 경우에 따라
COMMIT으로 인한 Locking release를 방지하기 위해서 SAVEPOINT(혹은 ROLLBACK TO..)를 이용한다. SAVEPOINT
이용시 COMMIT 시까지 Locking이 유지되며 SAVEPOINT 시점까지의 ROLLBACK이 가능하다.
Host DB2 애플리케이션 튜닝 가이드
49/58
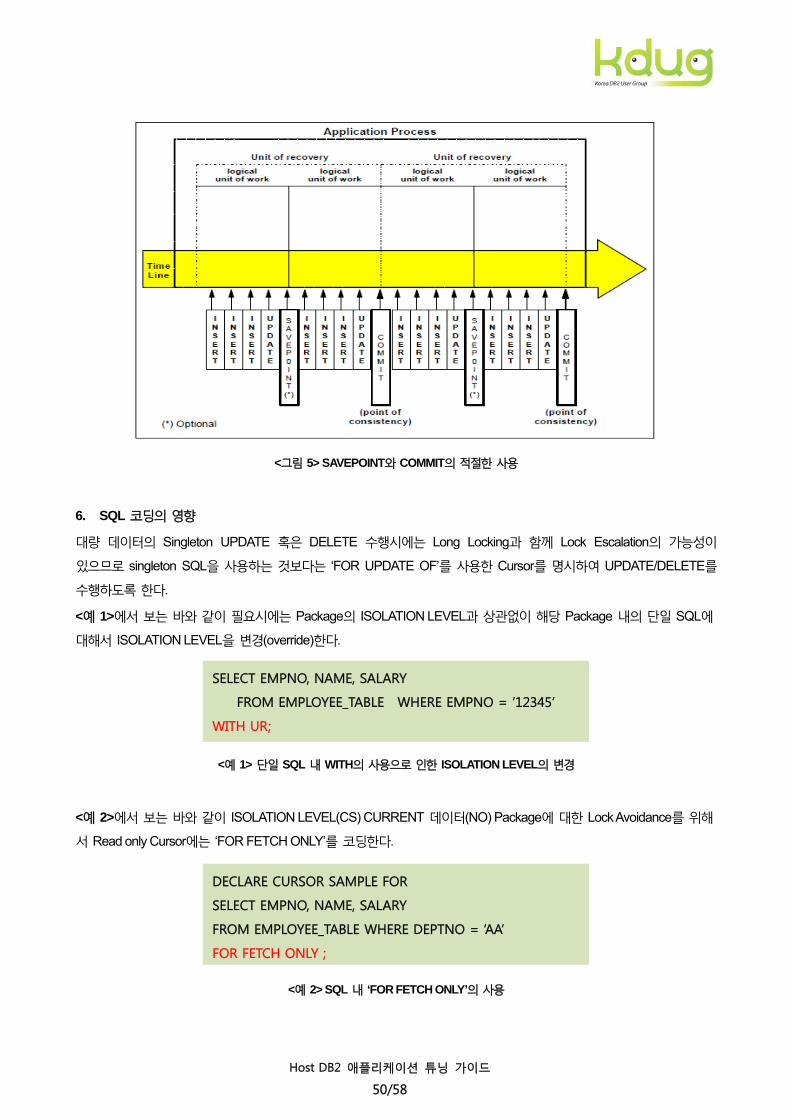
<그림 5> SAVEPOINT와 COMMIT의 적절한 사용
6. SQL 코딩의 영향
대량 데이터의 Singleton UPDATE 혹은 DELETE 수행시에는 Long Locking과 함께 Lock Escalation의 가능성이
있으므로 singleton SQL을 사용하는 것보다는 ‘FOR UPDATE OF’를 사용한 Cursor를 명시하여 UPDATE/DELETE를
수행하도록 한다.
<예 1>에서 보는 바와 같이 필요시에는 Package의 ISOLATION LEVEL과 상관없이 해당 Package 내의 단일 SQL에
대해서 ISOLATION LEVEL을 변경(override)한다.
SELECT EMPNO, NAME, SALARY
FROM EMPLOYEE_TABLE WHERE EMPNO = ‘12345’
WITH UR;
<예 1> 단일 SQL 내 WITH의 사용으로 인한 ISOLATION LEVEL의 변경
<예 2>에서 보는 바와 같이 ISOLATION LEVEL(CS) CURRENT 데이터(NO) Package에 대한 Lock Avoidance를 위해
서 Read only Cursor에는 ‘FOR FETCH ONLY’를 코딩한다.
DECLARE CURSOR SAMPLE FOR
SELECT EMPNO, NAME, SALARY
FROM EMPLOYEE_TABLE WHERE DEPTNO = ‘AA’
FOR FETCH ONLY ;
<예 2> SQL 내 ‘FOR FETCH ONLY’의 사용
Host DB2 애플리케이션 튜닝 가이드
50/58
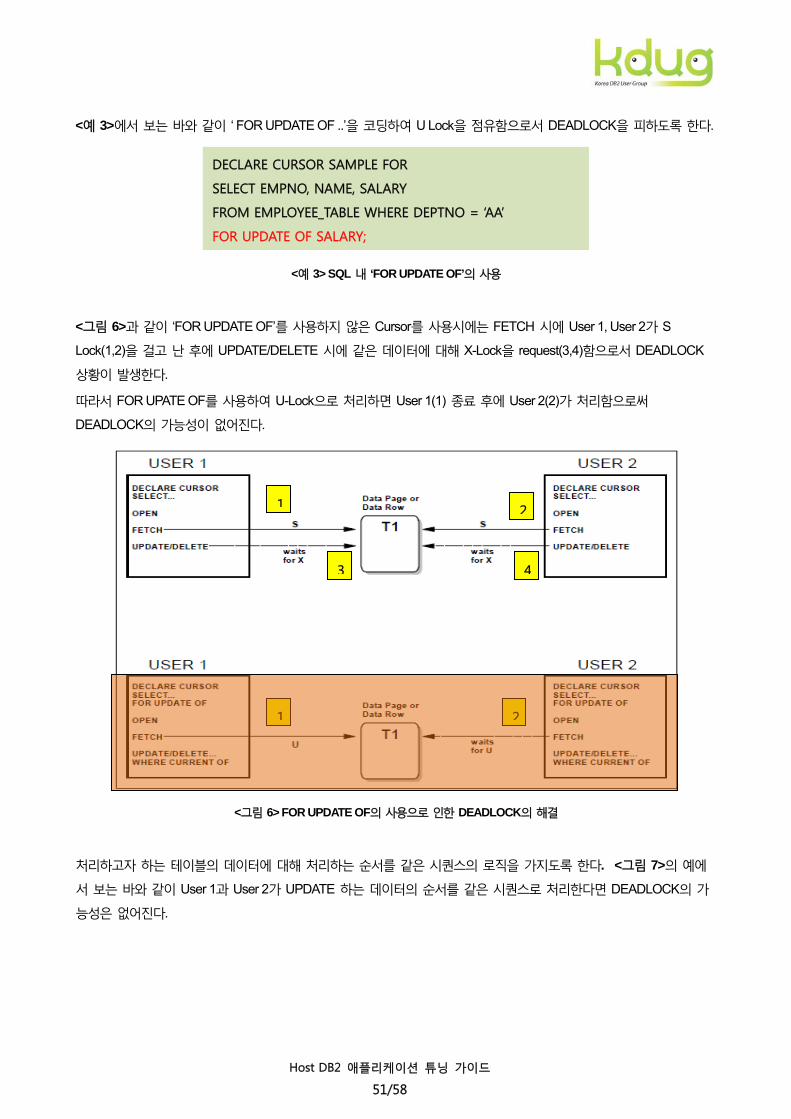
<예 3>에서 보는 바와 같이 ‘ FOR UPDATE OF ..’을 코딩하여 U Lock을 점유함으로서 DEADLOCK을 피하도록 한다.
DECLARE CURSOR SAMPLE FOR
SELECT EMPNO, NAME, SALARY
FROM EMPLOYEE_TABLE WHERE DEPTNO = ‘AA’
FOR UPDATE OF SALARY;
<예 3> SQL 내 ‘FOR UPDATE OF’의 사용
<그림 6>과 같이 ‘FOR UPDATE OF’를 사용하지 않은 Cursor를 사용시에는 FETCH 시에 User 1, User 2가 S
Lock(1,2)을 걸고 난 후에 UPDATE/DELETE 시에 같은 데이터에 대해 X-Lock을 request(3,4)함으로서 DEADLOCK
상황이 발생한다.
따라서 FOR UPATE OF를 사용하여 U-Lock으로 처리하면 User 1(1) 종료 후에 User 2(2)가 처리함으로써
DEADLOCK의 가능성이 없어진다.
1 2
3 4
1 2
<그림 6> FOR UPDATE OF의 사용으로 인한 DEADLOCK의 해결
처리하고자 하는 테이블의 데이터에 대해 처리하는 순서를 같은 시퀀스의 로직을 가지도록 한다. <그림 7>의 예에
서 보는 바와 같이 User 1과 User 2가 UPDATE 하는 데이터의 순서를 같은 시퀀스로 처리한다면 DEADLOCK의 가
능성은 없어진다.
Host DB2 애플리케이션 튜닝 가이드
51/58

21
3 4
1 2
3 4
<그림 7> Unordered UPDATE에 의한 DEADLOCK 예
앞에서 이야기 하였던 어느 고객 사이트에서의 기억이 Locking에 대해 다소 상세하게 설명하고자 하는 의욕을 불러
일으켰다. 그 때문에 내용이 다소 길어졌음을 이해해 주길 바라면서, 다음 장에는 전반적으로 개발자들이 프로그램
안에 코딩하면서 사용하는 여러 가지 팁에 대해 설명하기로 하겠다.
Host DB2 애플리케이션 튜닝 가이드
52/58
Part 9 - 효율적인 DB2 애플리케이션 점검 방안 10
이번 글을 마지막으로 개발자를 대상으로 한 ‘Host DB2 애플리케이션에 튜닝’ 에 대한 이야기를 마무리하고자 한다.
마지막으로 여러분의 애플리케이션이 얼마나 효율적으로 코딩되어 있는지 최소한 10가지 내용을 가지고 자가점검을
해보도록 하자.
1. SQL 내에서 반드시 필요한 컬럼 만을 되살린다
특히 소트(sort)를 수행하는 SQL에 대해서는 SELECT하는 컬럼이 Sort key에 들어간다는 것을 명심한다. 아래의
예에서 보는 바와 같이 31개의 컬럼을 SELECT 하는 SORT #1과 단지 2개의 컬럼 만을 SELECT하는 SORT
#2의 성능 차이는 -51%의 평균 응답시간의 감소효과가 있다는 것을 알 수 있다.
<SQL 예 1>: 동일 SQL에 대한 SELECT 컬럼 개수 차이로 인한 응답시간의 비교
2. 2개 이상의 테이블에 대해 Join을 사용한다
아직도 많은 고객 사이트 중에 ‘Join’을 사용하지 않는 경우가 많다. 가장 간단한 경우는 회사 정책적으로 Join을
사용하지 않는 경우와 최근에는 ‘프로그램의 재사용을 위한 모듈화’가 Join을 사용하지 않는 큰 요인으로 작용하고
있다. 성능 향상을 위한 적절한 설계조정이 필요할 수 있다.
3. Indexable, Stage 1 Predicate이 되도록 SQL을 코딩한다
4. 데이터 확인을 위한 SELECT의 수를 줄이도록 한다
INSERT나 UPDATE를 수행하기 전에 혹은 후에 데이터의 존재 여부를 점검하기 위해 동일 조건에 대해
SELECT를 수행하는 것은 매우 보편화 되어 있다. 그러나 경우에 따라서는 INSERT 혹은 UPDATE를 수행한 후에
필요에 따라 LOGIC을 수행해도 되는 경우가 있다.
최근의 한 고객의 경우 반복적으로 동일 회수의 SELECT와 UPDATE를 수행하는 SQL에 대해 UPDATE 후에
필요한 처리를 하도록 수정한 결과, 다음과 같은 성능 개선의 효과를 보았다.
Host DB2 애플리케이션 튜닝 가이드
53/58
성능 개선 효과(%)
GETPAGE 수 -73.8
DB2 CPU -35.0
DB2 Elapsed -42.0
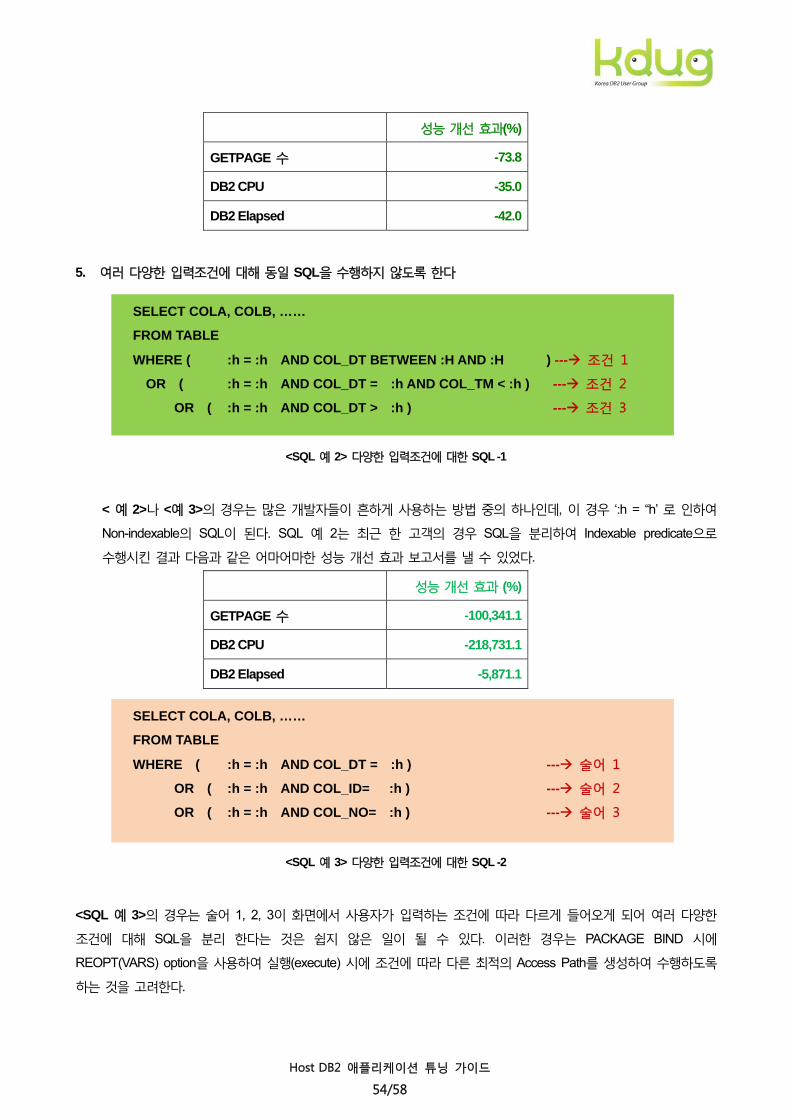
5. 여러 다양한 입력조건에 대해 동일 SQL을 수행하지 않도록 한다
SELECT COLA, COLB, ……
FROM TABLE
WHERE ( :h = :h AND COL_DT BETWEEN :H AND :H ) --- 조건 1
OR ( :h = :h AND COL_DT = :h AND COL_TM < :h ) --- 조건 2
OR ( :h = :h AND COL_DT > :h ) --- 조건 3
<SQL 예 2> 다양한 입력조건에 대한 SQL -1
< 예 2>나 <예 3>의 경우는 많은 개발자들이 흔하게 사용하는 방법 중의 하나인데, 이 경우 ‘:h = “h’ 로 인하여
Non-indexable의 SQL이 된다. SQL 예 2는 최근 한 고객의 경우 SQL을 분리하여 Indexable predicate으로
수행시킨 결과 다음과 같은 어마어마한 성능 개선 효과 보고서를 낼 수 있었다.
성능 개선 효과 (%)
GETPAGE 수 -100,341.1
DB2 CPU -218,731.1
DB2 Elapsed -5,871.1
SELECT COLA, COLB, ……
FROM TABLE
WHERE ( :h = :h AND COL_DT = :h ) --- 술어 1
OR ( :h = :h AND COL_ID= :h ) --- 술어 2
OR ( :h = :h AND COL_NO= :h ) --- 술어 3
<SQL 예 3> 다양한 입력조건에 대한 SQL -2
<SQL 예 3>의 경우는 술어 1, 2, 3이 화면에서 사용자가 입력하는 조건에 따라 다르게 들어오게 되어 여러 다양한
조건에 대해 SQL을 분리 한다는 것은 쉽지 않은 일이 될 수 있다. 이러한 경우는 PACKAGE BIND 시에
REOPT(VARS) option을 사용하여 실행(execute) 시에 조건에 따라 다른 최적의 Access Path를 생성하여 수행하도록
하는 것을 고려한다.
Host DB2 애플리케이션 튜닝 가이드
54/58

6. Nested Table Expression(V.7) 혹은 Common Table Expression(V.8)을 사용한다
Full SELECT 결과를 SQL 내에서 사용하는 방법으로 <SQL 예 4>에서 보는 바와 같은 Nested Table
Expression(NTE)을 많이 사용한다. 이러한 E, M과 같은 Full SELECT 결과는 임시 파일에 저장되어 하나의 SQL
수행 과정 중의 한 형태로 사용될 수 있다.
<SQL 예 4> Nested Table Expression을 사용한 SQL
그러나 <SQL 예 5>와 같이 ‘WITH..‘를 사용하여 Common Table Expression(CTE)을 정의하면 쿼리 내에서 좀더
다양한 방법으로 사용 가능하다.
<SQL 예 5> Common Table Expression을 사용한 SQL
이러한 CTE는 프로그램 내에서 여러 번 사용이 가능하여 경우에 따라서는 성능 향상에 효율적인 결과를 가져올 수
있다. <자료 참조: DB2 zOS V8 Everything you ever wanted to know>
7. 프로그램에서 처리하는 SQL Call 수를 최소화 한다
이미 앞에서 여러 번 언급하였듯이 애플리케이션 엔진과 DB2 사이의 빈번한 SQL Call의 수행은 CPU 사용과
직접적인 관련을 가지고 있으며, 따라서 프로그램 내에서 SQL Call 수를 가능한 적게 하는 것은 성능과 매우
밀접한 관계를 가지고 있다고 할 수 있다. 다음은 DB2 V8의 새로운 기능과 함께 이러한 SQL Call 수를 줄이는
Host DB2 애플리케이션 튜닝 가이드
55/58

몇 가지 방법을 소개한다.
Recursive SQL의 사용
<SQL 예 6>에서의 PARTLIST 테이블과 같이 Bill of Material(BOM) 구조를 가지고 있는 테이블에 대해서는 CTE를
이용한 Recursive SQL을 수행하여 Subpart에 대한 정보를 되살리기 쉽게 할 수 있다.
<SQL 예 6:> CTE를 이용한 Recursive SQL
결과적으로 <그림 1> 에서 보는 바와 같이 Initialization SELECT에 대한 반복적인 Iteration SELECT의 수행 결과
생성된 RPL에 대해 Main SELECT가 수행되어 결과(Final report table)가 회복된다.
<그림 1:> SQL 예제 6 Recursive SQL의 수행 결과
이와 같이 CTE를 이용한 recursive SQL은 프로그램 상의 로직을 포함한 많은 SQL을 하나의 SQL로 수행하여 CPU
사용과 응답시간의 감소 효과를 가져올 수 있다. <자료 참조: DB2 zOS V8 Everything you ever wanted to know>
Host DB2 애플리케이션 튜닝 가이드
56/58

single FETCH에 의한 multi row의 처리
10열을 복구하기 위해 10 FETCH가 수행(그림 2) 되는 대신에 1 FETCH가 수행(그림 3)된다면 실제 수행되는 SQL의
상당한 감소 효과가 있게 된다. 최근 수행된 50,000random read rows에 대해 1 Row-1 FETCH 대비 20 Rows-1
FETCH에 대한 테스트 결과 25%의 CPU 감소 효과가 있는 것으로 보고되어 있다. <자료 참조 :IDUG 2008>
<그림 2> 10rows에 대한 10FETCH 수행
<그림 3> 10rows에 대한 1FETCH 수행
이러한 multi row FETCH를 수행하기 위해서는 <그림 4>와 같이 어레이가 정의되어서 FETCH 시에 사용되어야
한다.
<그림 4> 10rows에 대해 1 FETCH 수행하기 위한 COBOL 프로그램 샘플
8. 경우에 따라 SYSDUMMY 테이블의 사용보다는 시스템 기능을 이용한다
CURRENT DATE나 CURRENT TIME, CURRENT TIMESTAMP와 같은 데이터를 되살리기 위한 방법으로
Host DB2 애플리케이션 튜닝 가이드
57/58

Host DB2 애플리케이션 튜닝 가이드
58/58
“SELECT CURRENTTIMESTAMP FROM SYSIBM.SYSDUMMY’와 같은 SQL을 수행하는 경우가 있다. 이러한
SQL은 경우에 따라 엄청난 양의 SQL이 수행되는 결과를 초래할 수가 있는데, 프로그램 기능 혹은 시스템
기능을 이용하는 것을 고려한다.
9. Parallel Processing을 수행하게 한다
10. 불필요한 잠금을 하지 않는다
연재를 끝내면서
처음 이 연재를 시작하면서 가장 주안점을 두고자 했던 부분은 개발자들이 Host DB2 애플리케이션의 성능과 관련해
최소한 알고 있어야 할 내용을 정리하는 것이었다. 시작하면서 이야기 하였듯이, 많은 고객 사이트에서 성능 개선 관
련 프로젝트를 수행하면서 개발과 DB 설계의 실제적인 일을 수행하는 개발자들이 의외로 DB2에 대한 지식이 부족
하다는 것을 새삼 느끼게 된다. 개발자들이 성능 개선에 대해 가장 직접적으로 관여해야 되는 역할인데도 불구하고
말이다.
최근에 한 고객사 개발팀장에게서 개발자들을 대상으로 체계적인 교육과 기술 전수를 위한 OJT 형식의 커리큘럼을
만들어서 수행해 달라는 부탁을 받았다. 교육이 한달 쯤 진행된 후에 그 중에 10년쯤 DB2 프로그램을 개발하신 분으
로부터 “교육을 조금 받고 나니, 이제는 테이블 하나 만드는데도 SQL 조건 하나 하나가 신경이 쓰이더라”라는 얘기
를 들었다.
개발자들이 조금 더 DB2에 대해 관심을 갖고 지식을 축적하고, 또 이를 기반으로 보다 효과적으로 성능을 개선할 수
있는 방법을 찾기를 바란다. 물론 지금의 현실이 이 연재를 계기로 바로 변할 것이라 기대하기는 힘들지만, 적어도
DB2 시스템의 성능 개선을 고려할 때 이 문서가 기본적인 가이드라인이 되기를 기대하며 연재를 마무리한다.





























