Embed Size (px)
Citation preview

HPSG parser developmentat U-tokyo
Takuya Matsuzaki
University of Tokyo

Topics
• Overview of U-Tokyo HPSG parsing system• Supertagging with Enju HPSG grammar

Overview of U-Tokyo parsing system
• Two different algorithms:– Enju parser: Supertagging + CKY algo. for TFS– Mogura parser: Supertagging + CFG-filtering
• Two disambiguation models:– one trained on PTB-WSJ– one trained on PTB-WSJ + Genia (biomedical)
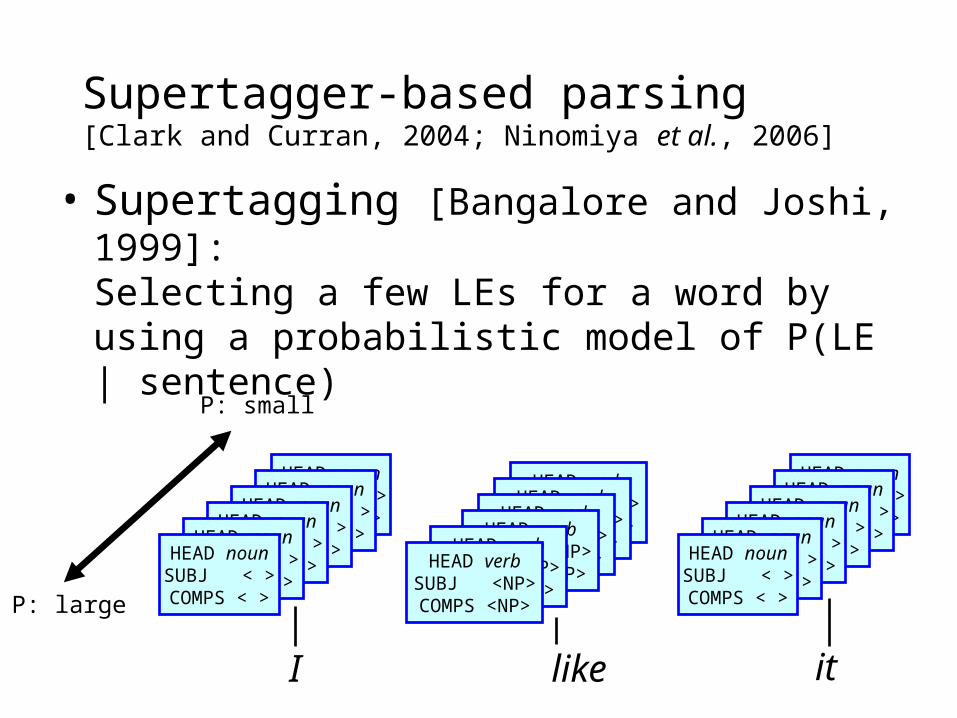
Supertagger-based parsing [Clark and Curran, 2004; Ninomiya et al., 2006]• Supertagging [Bangalore and Joshi, 1999]:
Selecting a few LEs for a word by using a probabilistic model of P(LE | sentence)
I like it
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >P: large
P: small

• Ignore the LEs with small probabilities
I like it
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >P: large
P: small
Supertagger-based parsing [Clark and Curran, 2004; Ninomiya et al., 2006]
Input to the parser
LEs with P > threshold
I like it
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
threshold

Flow in Enju parser
1. POS tagging by a CRF-based model2. Morphological analysis (inflected base
form) by the WordNet dictionary3. Multi-Supertagging by a MaxEnt model4. TFS CKY parsing + MaxEnt disambiguation on
the multi-supertagged sentence

Flow in Mogura parser
1. POS tagging by a CRF-based model2. Morphological analysis (inflected base
form) by the WordNet dictionary3. Supertagging by a MaxEnt model4. Selection of (probably) constraint-satisfying
supertag assignment5. TFS shift-reduce parsing on singly-
supertagged sentence
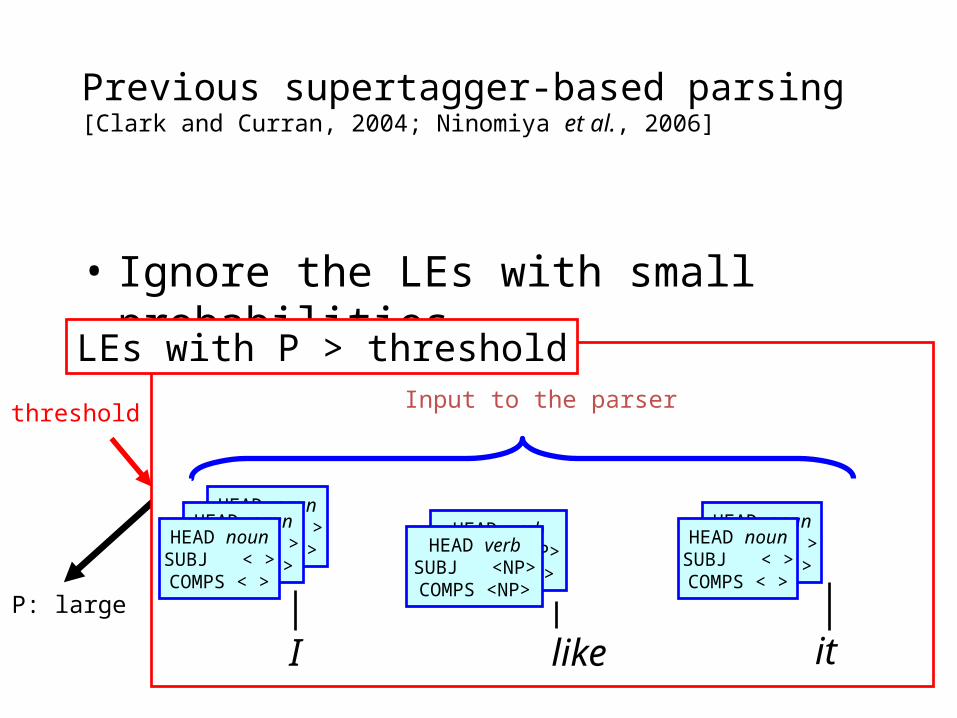
• Ignore the LEs with small probabilities
I like it
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >P: large
P: small
Previous supertagger-based parsing [Clark and Curran, 2004; Ninomiya et al., 2006]
Input to the parser
LEs with P > threshold
I like it
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD nounSUBJ < >
COMPS < >
HEAD nounSUBJ < >
COMPS < >
threshold
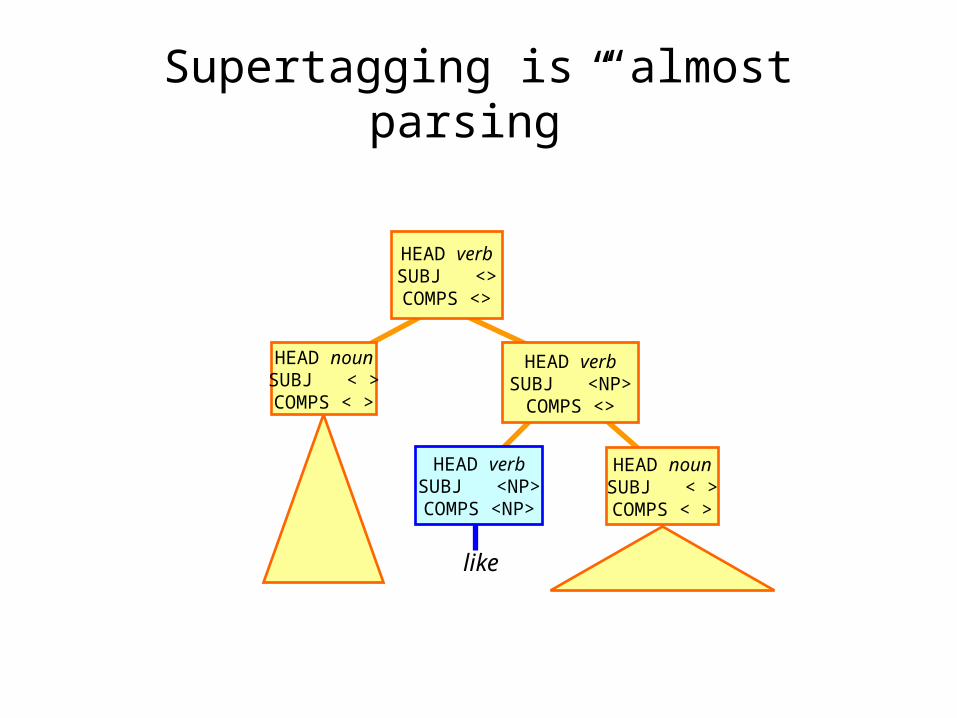
HEAD nounSUBJ < >
COMPS < >
HEAD verbSUBJ <NP>COMPS <>
HEAD nounSUBJ < >
COMPS < >
HEAD verbSUBJ <>
COMPS <>
like
HEAD verbSUBJ <NP>
COMPS <NP>
Supertagging is “almost parsing”
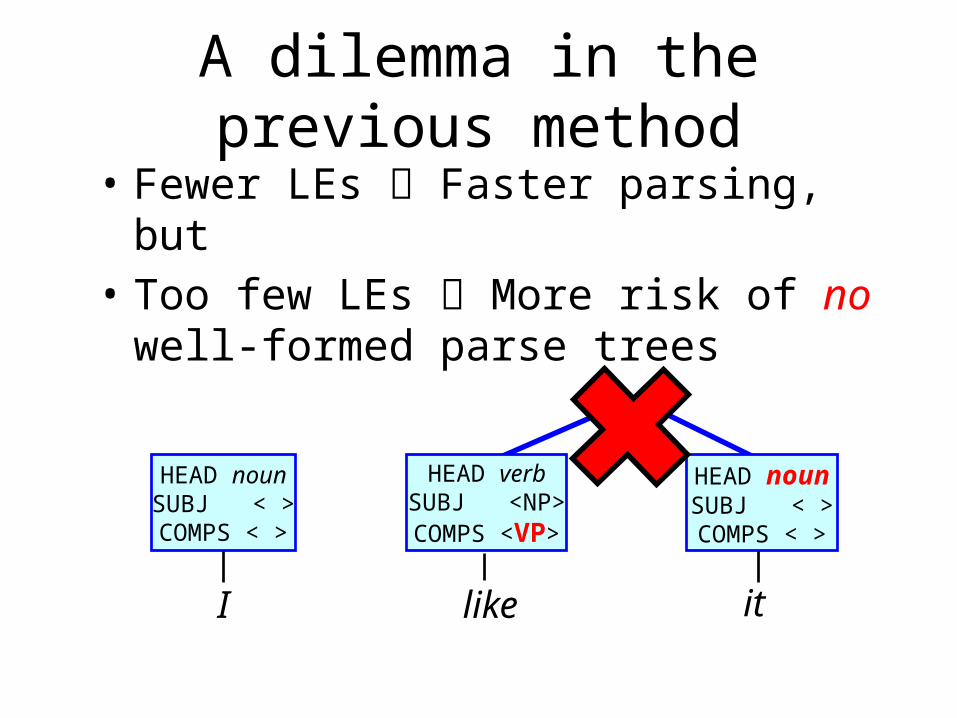
A dilemma in the previous method• Fewer LEs Faster parsing, but• Too few LEs More risk of no well-formed
parse trees
I like it
HEAD nounSUBJ < >
COMPS < >
HEAD verbSUBJ <NP>
COMPS <VP>
HEAD nounSUBJ < >
COMPS < >
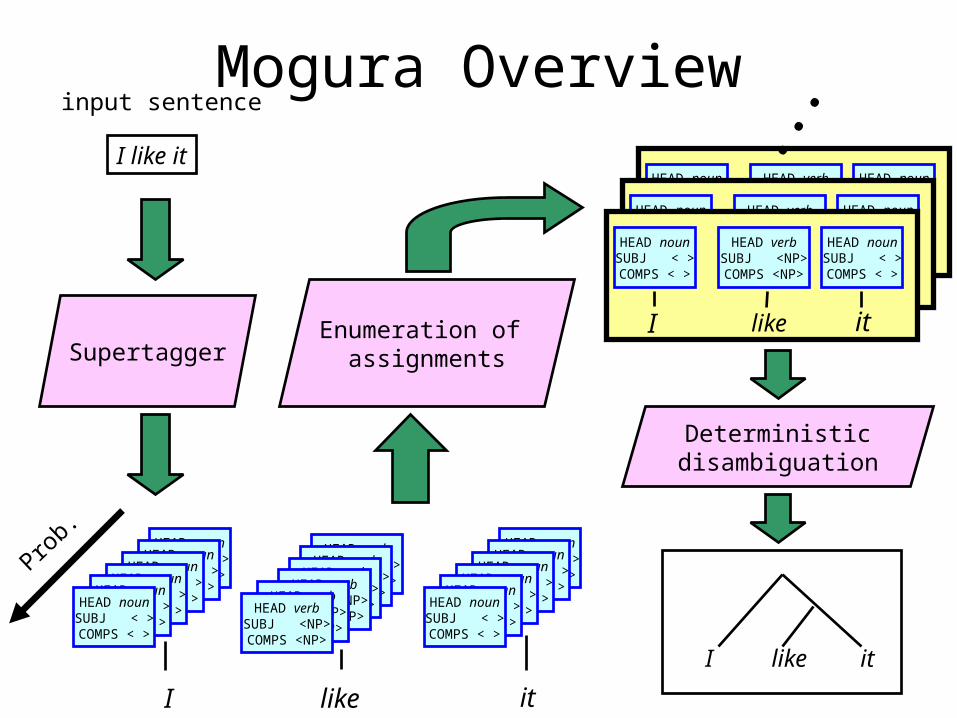
Mogura Overview
I like it
HEAD nounSUBJ < >
COMPS < >HEAD nounSUBJ < >
COMPS < >HEAD nounSUBJ < >
COMPS < >HEAD nounSUBJ < >
COMPS < >HEAD nounSUBJ < >
COMPS < >HEAD nounSUBJ < >
COMPS < >
HEAD verbSUBJ <NP>
COMPS <NP>HEAD verb
SUBJ <NP>COMPS <NP>
HEAD verbSUBJ <NP>
COMPS <NP>HEAD verb
SUBJ <NP>COMPS <NP>
HEAD verbSUBJ <NP>
COMPS <NP>HEAD verb
SUBJ <NP>COMPS <NP>
HEAD nounSUBJ < >
COMPS < >HEAD nounSUBJ < >
COMPS < >HEAD nounSUBJ < >
COMPS < >HEAD nounSUBJ < >
COMPS < >HEAD nounSUBJ < >
COMPS < >HEAD nounSUBJ < >
COMPS < >
Supertagger
I like it
input sentence
Enumeration of assignments
I like it
HEAD nounSUBJ < >
COMPS < >
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD nounSUBJ < >
COMPS < >
I like it
HEAD nounSUBJ < >
COMPS < >
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD nounSUBJ < >
COMPS < >
I like it
HEAD nounSUBJ < >
COMPS < >
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD nounSUBJ < >
COMPS < >
...
Deterministicdisambiguation
I like it
Prob.
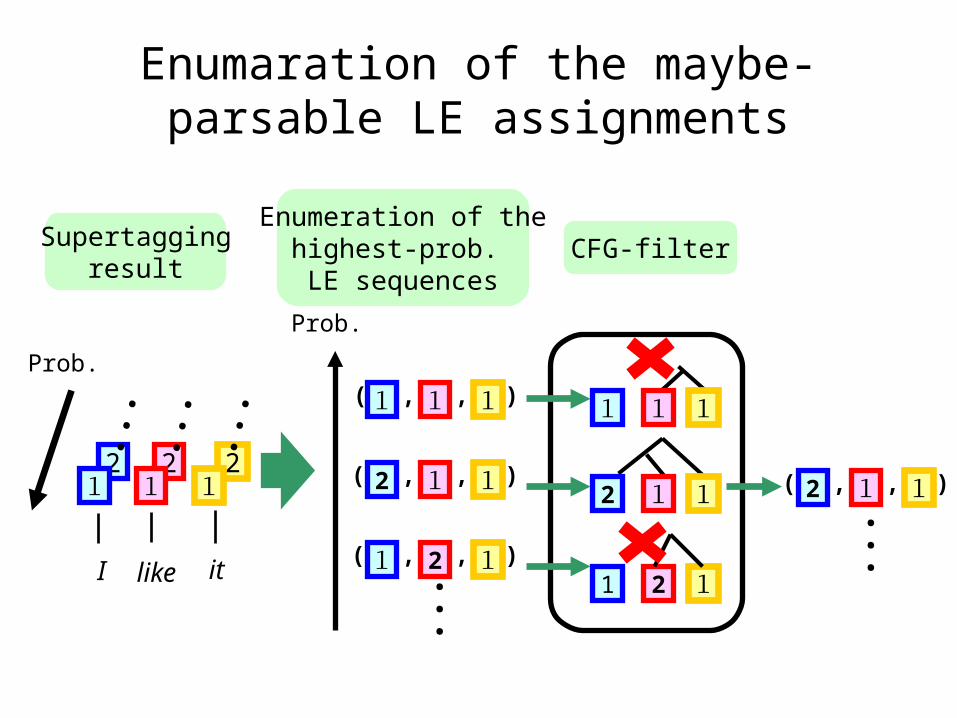
Enumaration of the maybe-parsable LE assignments
( 1 1 1
2 1 1
1 2 1
( , , )2 1 1
...
I like it
21
21
21
... ... ...
Prob.
...
, , )1 1 1
( , , )2 1 1
( , , )1 2 1
Prob.
Supertaggingresult
Enumeration of thehighest-prob. LE sequences
CFG-filter

CFG-filter
• Parsing with a CFG that approximates the HPSG [Kiefer and Krieger, 2000; Torisawa et al, 2000]
– Approximation = elmination of some constraints in the grammar (long-distance dep., number, case, etc.)
– Covering property: if a LE assignment is parsable by the HPSG it is also parsable by the approx. CFG
– CFG parsing is much faster than HPSG parsing
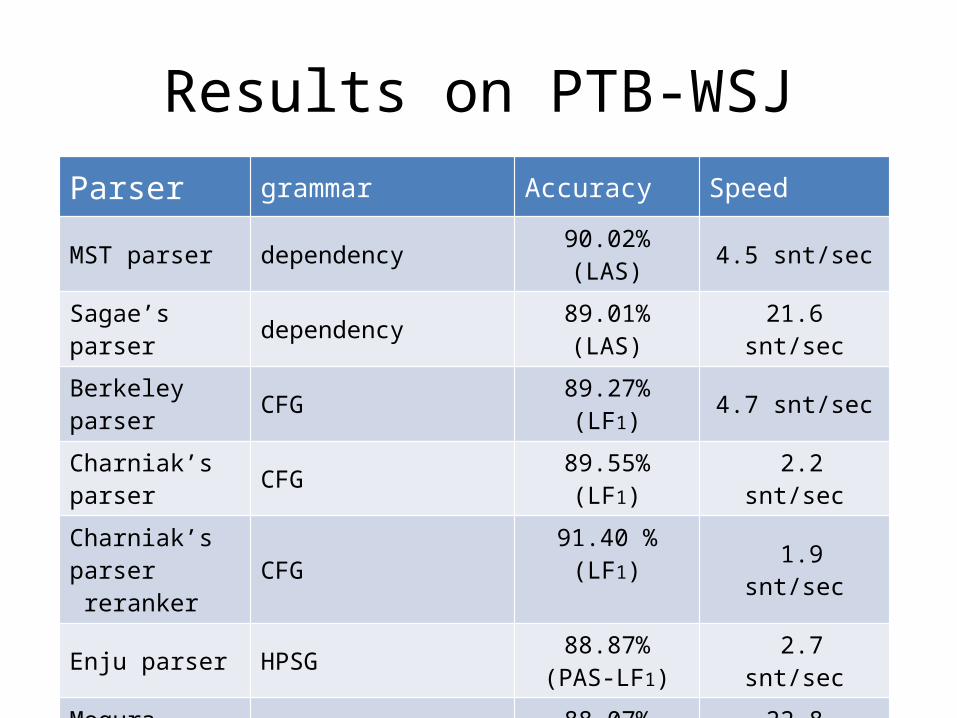
Parser grammar Accuracy Speed
MST parser dependency90.02%
(LAS) 4.5 snt/sec
Sagae’s parser dependency 89.01%(LAS) 21.6 snt/sec
Berkeley parser CFG 89.27%(LF1) 4.7 snt/sec
Charniak’s parser CFG 89.55%(LF1) 2.2 snt/sec
Charniak’s parser reranker CFG
91.40 %(LF1) 1.9 snt/sec
Enju parser HPSG 88.87%(PAS-LF1) 2.7 snt/sec
Mogura parser HPSG 88.07%(PAS-LF1) 22.8 snt/sec
Results on PTB-WSJ

Supertagging with Enju grammar• Input: POS-tagged sentence
• Number of supertags (lexical templates): 2,308
• Current implementation– Classifier: MaxEnt, point-wise prediction (i.e., no dependencies among
neighboring supertags)– Features: words and POS tags in -2/+3 window
• 92% token accuracy (1-best, only on covered tokens)
• It’s “almost parsing”: 98-99% parsing accuracy (PAS F1) given correct lexical assignments
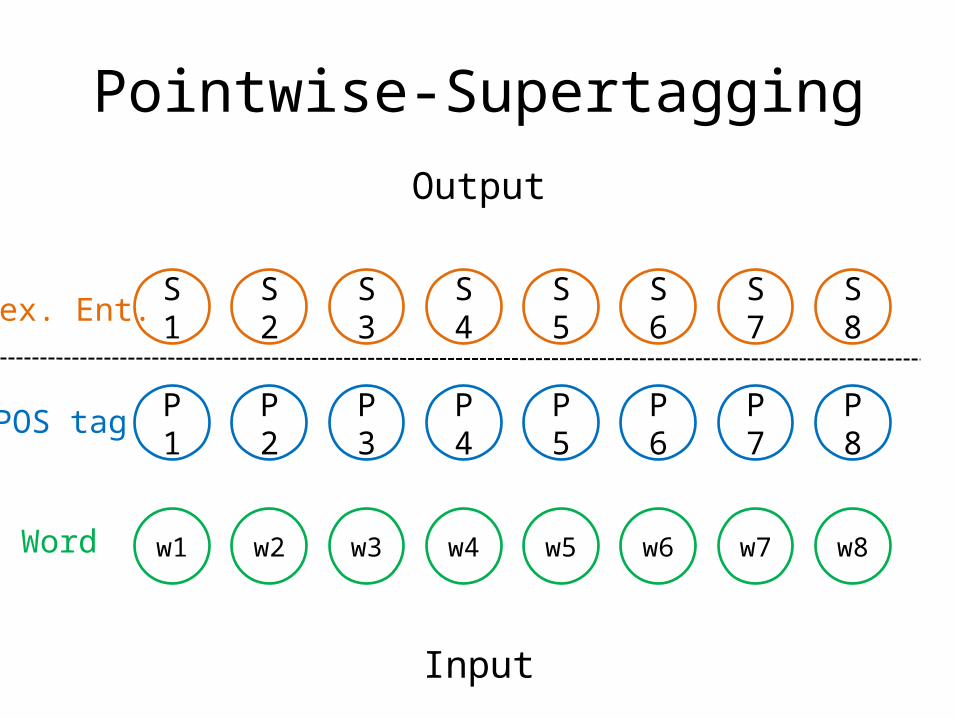
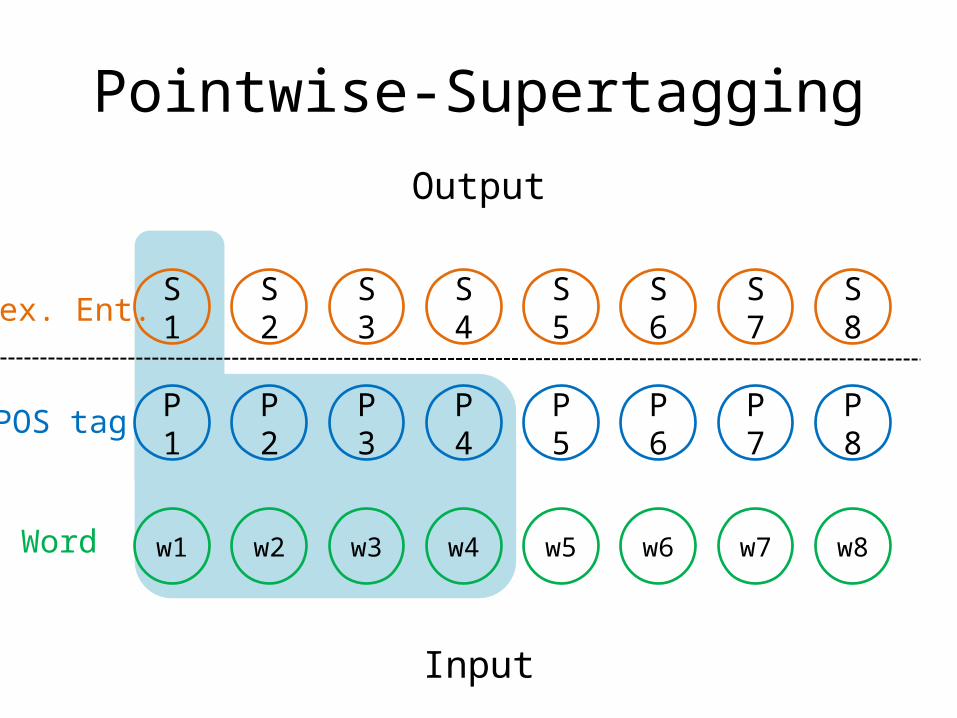
Pointwise-Supertagging
P1 P2 P3 P4 P5 P6 P7 P8
w1 w2 w3 w4 w5 w6 w7 w8
S1 S2 S3 S4 S5 S6 S7 S8
Input
Output
Lex. Ent.
POS tag
Word
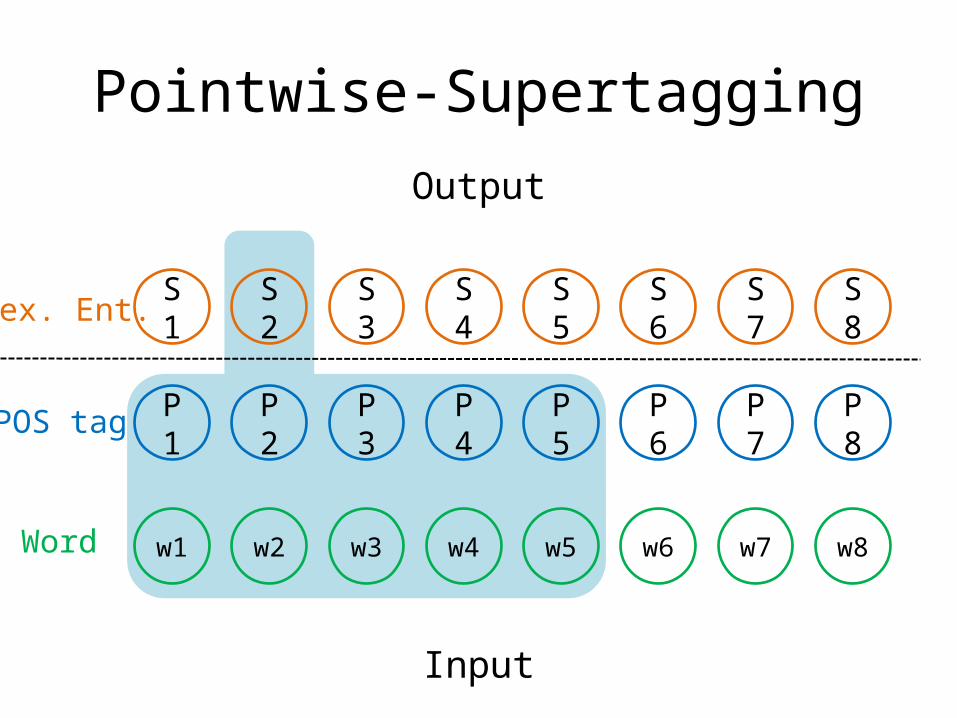
Pointwise-Supertagging
P1 P2 P3 P4 P5 P6 P7 P8
w1 w2 w3 w4 w5 w6 w7 w8
S1 S2 S3 S4 S5 S6 S7 S8
Input
Output
Lex. Ent.
POS tag
Word
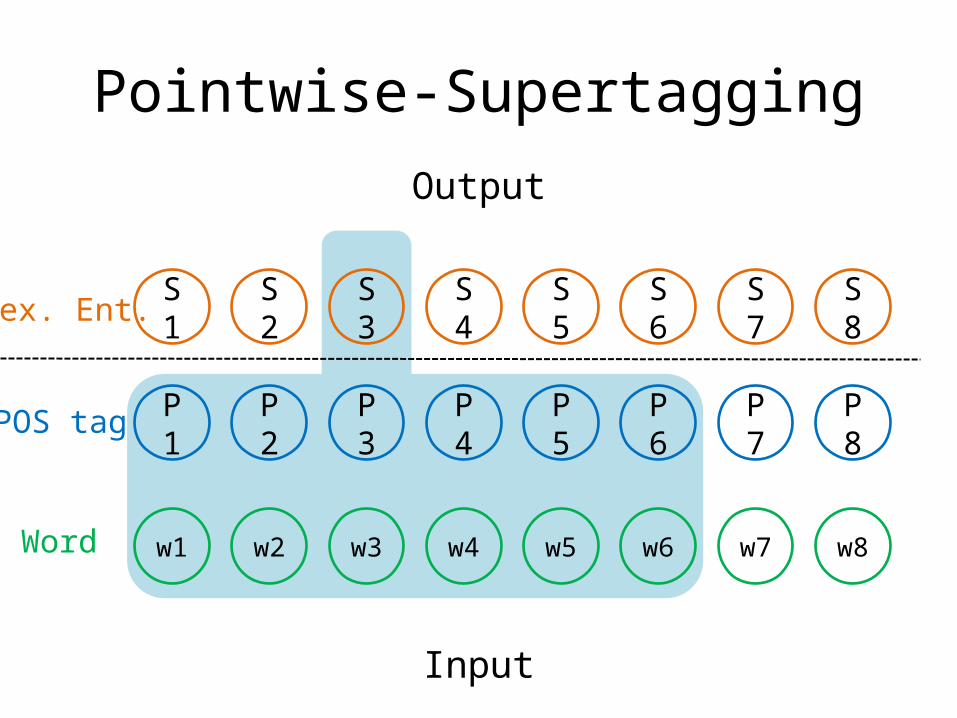
Pointwise-Supertagging
P1 P2 P3 P4 P5 P6 P7 P8
w1 w2 w3 w4 w5 w6 w7 w8
S1 S2 S3 S4 S5 S6 S7 S8
Input
Output
Lex. Ent.
POS tag
Word
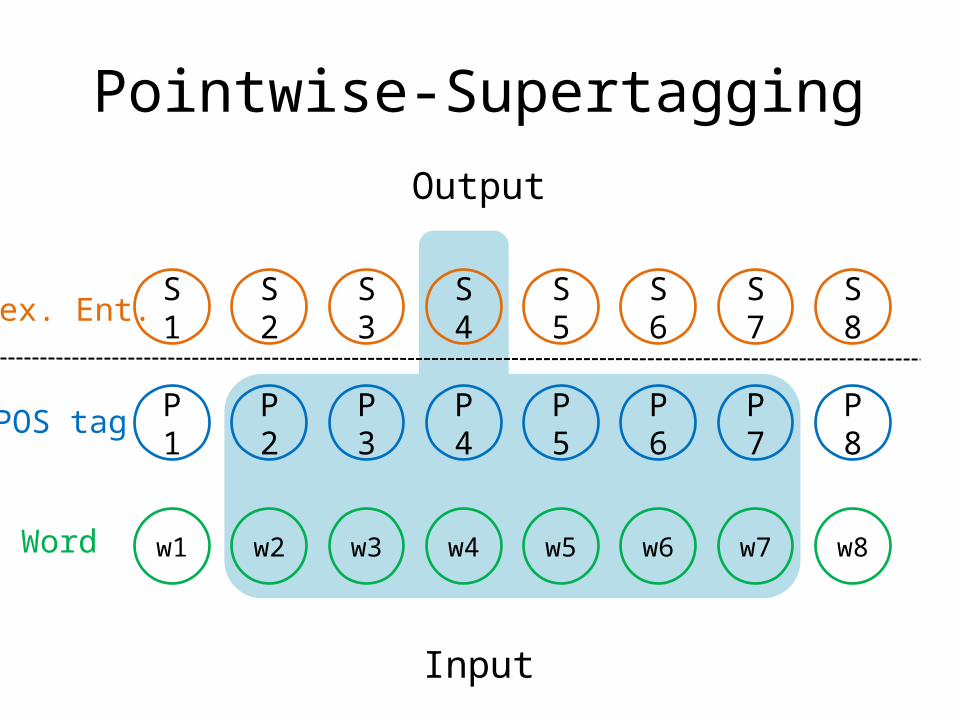
Pointwise-Supertagging
P1 P2 P3 P4 P5 P6 P7 P8
w1 w2 w3 w4 w5 w6 w7 w8
S1 S2 S3 S4 S5 S6 S7 S8
Input
Output
Lex. Ent.
POS tag
Word
Pointwise-Supertagging
P1 P2 P3 P4 P5 P6 P7 P8
w1 w2 w3 w4 w5 w6 w7 w8
S1 S2 S3 S4 S5 S6 S7 S8
Input
Output
Lex. Ent.
POS tag
Word

Pointwise-Supertagging
P1 P2 P3 P4 P5 P6 P7 P8
w1 w2 w3 w4 w5 w6 w7 w8
S1 S2 S3 S4 S5 S6 S7 S8
Input
Output
Lex. Ent.
POS tag
Word

Supertagging: future directions
• Basic strategy: do more work in supertagging (rather than in parsing)
• Pros– Model/algorithm is simpler Easy error analysis Various features without extending the parsing algorithm Fast try-and-error cycle for feature engineering
• Cons– No tree structure Feature design is sometimes tricky/ad-hoc:
e.g., “nearest preceding verb/noun”, instead of “possible modifiee of a PP”

Supertagging: future directions
• Recovery from POS-tagging error in supertagging stage
• Incorporation of shallow processing results (e.g., chunking, NER, coordination structure prediction) as new features
• Comparison across other languages/grammar frameworks

Thank you!

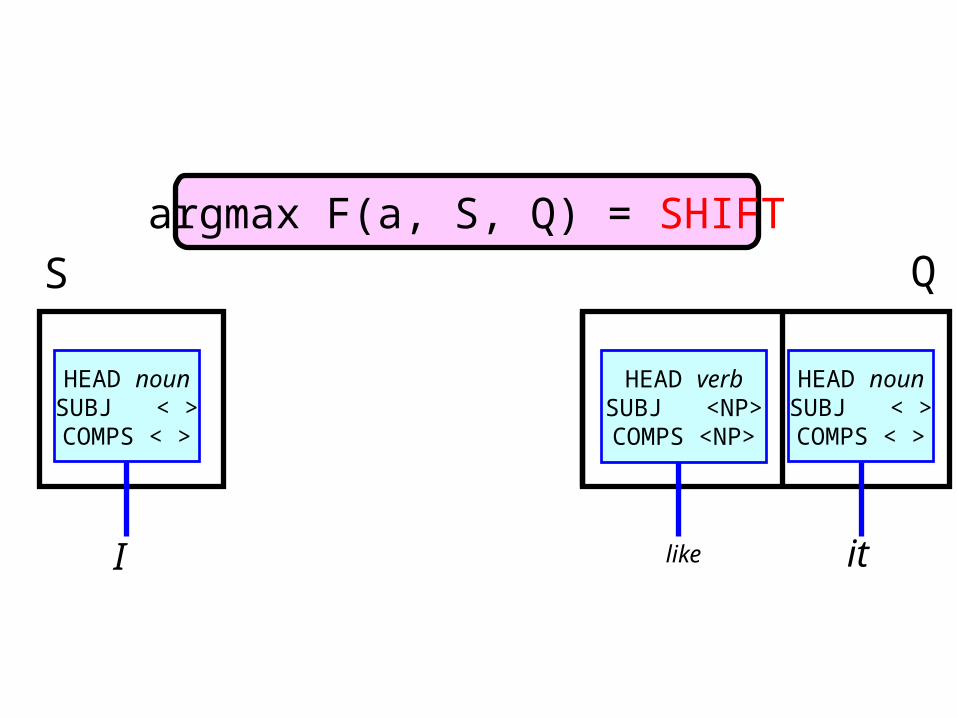
Deterministic disambiguation• Implemented as a shift-reduce parser– Deterministic parsing: only one analysis at one time– Next parsing action is selected using a scoring
function
next action ),,(maxarg QSaFaAa
• F: scoring function (averaged-perceptron algorithm [Collins and Duffy, 2002])• Features are extracted from the stack state S and lookahead queue Q• A: the set of possible actions (CFG-forest is used as a `guide’)

Example
I like it
HEAD nounSUBJ < >
COMPS < >
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD nounSUBJ < >
COMPS < >
Initial stateS Q
HEAD nounSUBJ < >
COMPS < >
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD nounSUBJ < >
COMPS < >
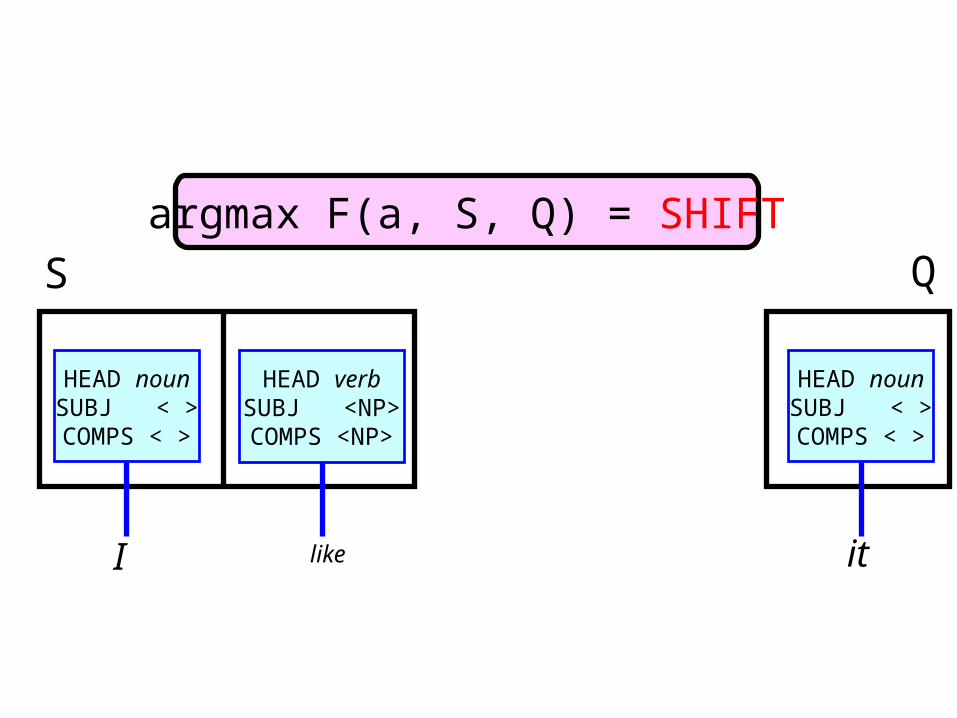
argmax F(a, S, Q) = SHIFT
I like it
S Q
HEAD nounSUBJ < >
COMPS < >
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD nounSUBJ < >
COMPS < >
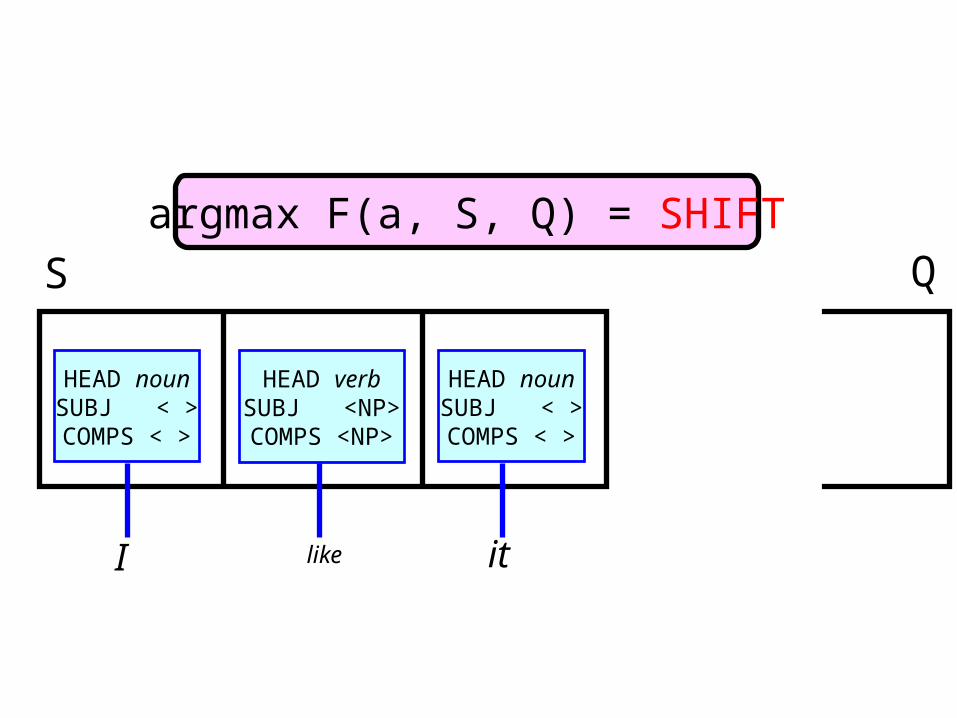
I like it
S Qargmax F(a, S, Q) = SHIFT
HEAD nounSUBJ < >
COMPS < >
HEAD verbSUBJ <NP>
COMPS <NP>
HEAD nounSUBJ < >
COMPS < >
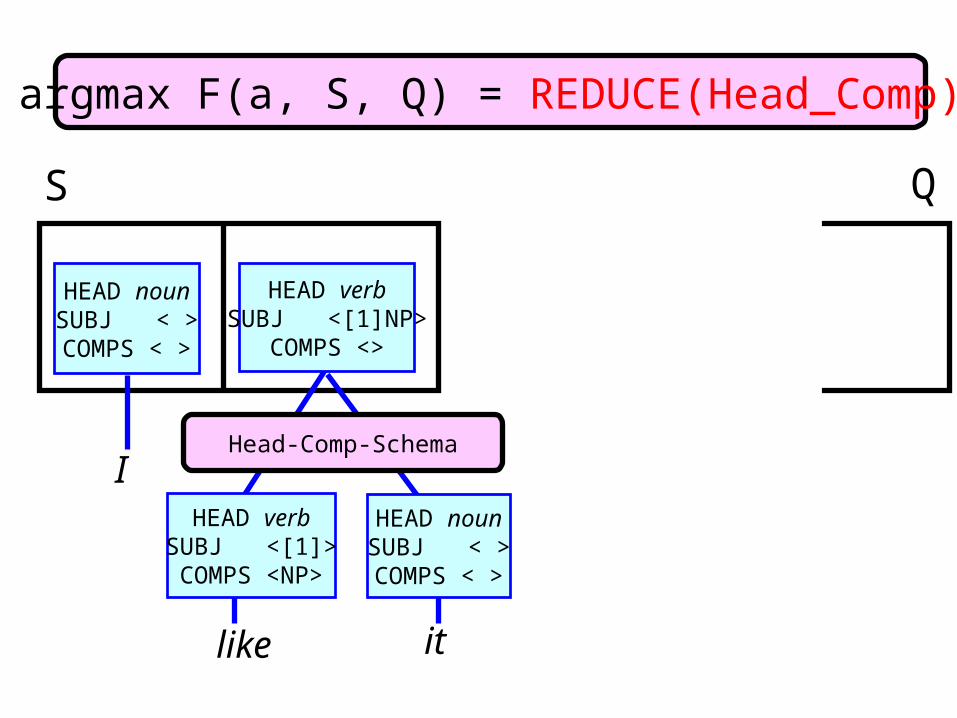
I like it
S Qargmax F(a, S, Q) = SHIFT
HEAD nounSUBJ < >
COMPS < >
argmax F(a, S, Q) = REDUCE(Head_Comp)
I
like it
HEAD verbSUBJ <[1]>
COMPS <NP>
HEAD nounSUBJ < >
COMPS < >
HEAD verbSUBJ <[1]NP>
COMPS <>
Head-Comp-Schema
S Q
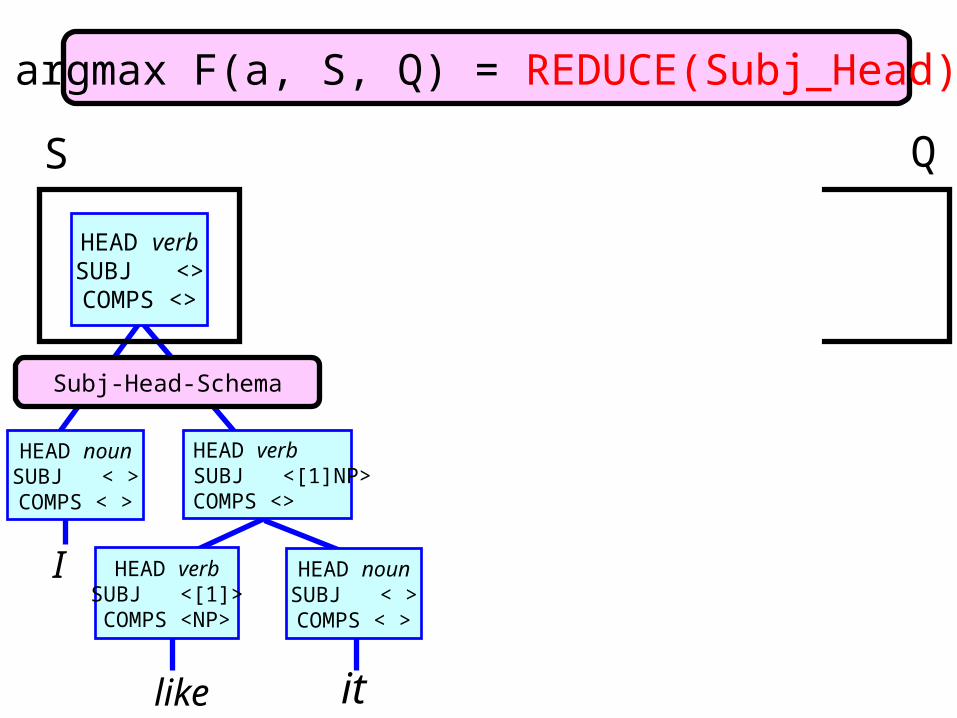
argmax F(a, S, Q) = REDUCE(Subj_Head)
I
like it
HEAD verbSUBJ <[1]>
COMPS <NP>
HEAD nounSUBJ < >
COMPS < >
HEAD verbSUBJ <[1]NP>COMPS <>
HEAD nounSUBJ < >
COMPS < >
HEAD verbSUBJ <>
COMPS <>
Subj-Head-Schema
S Q





























