Embed Size (px)
Citation preview

III. 분석이론
1. 개요
(1) Analytics의 개념
분석 (Analytics)이란 " 데이터로부터 의미있는 패턴을 발견하는 것” 이다.1 이는 데이터 마이닝의 정의와
상당히 유사한데 마이닝이 알고리즘에 집중하는 반면 분석은 이러한 알고리즘 내지 모델과 함께 이를
활용하여 궁극적으로 문제를 해결하는 데에 초점을 맞춘 것이라 하겠다. 물론 빅 데이터 분석에서은 여기서
한 걸음 나아가서 이러한 분석 알고리즘을 MapReduce 프레임워크에 적용해서 (앞서 언급한 3VC 특징을
가지는) 빅데이터 로 확장하려는 것이다.
한편 분석은 의사결정 전체의 한 부분으로서 궁극적으로는 적용 내지 실행을 목표로 한다는 점을 염두에
둘 필요가 있다. 분석 결과가 실행을 통해 또 다른 의사결정의 기초가 되는 순환적 관점으로 바라 볼 때 조직
내의 지속적인 프로세스로 자리잡을 수 있게 되기 때문이다. 2
1 Analytics 와 Analysis 는 모두 '분석'에 해당되지만 analysis 가 '복잡한 것을 보다 단순한 형태로 나누는 행위'를 뜻한다면
analytics 는 그러한 '분석행위(analysis)을 위한 각종 기법을 체계적으로 정리한 것'(학문)으로 볼 수 있겠다. 이미 통계학,
데이터 마이닝, 데이터 분석, 예측분석 등을 포함하는 포괄적 의미로 Analytics 가 사용되고 있으므로 본서에서는 이를 주로
사용한다.
2 M.A.Berry & G.S.Linoff 의 ‘Data Mining Techniques for Marketing, Sales, and CRM’ 2nd Edition, Wilely, 2004 의
p. 84 의 그림을 일부 수정.

2
분석은 일회성 작업이 아니라
궁극적으로 실행을 향한 반복되는 과정의 하나이다.
(2) 예측분석, BI, 데이터마이닝의 비교
(예측)분석 즉, (Predictive) Analytics 와 BI 및 데이터마이닝은 큰 범주에서는 같은 의미라 하겠으나
강조점에 있어 약간의 차이를 가지는데 다음 표에서 이들을 정리하였다.
데이터마이닝 예측분석 BI 기타
단서를 찾아
나서는 것
문제의 답을 찾고,
“what next”라는
action 으로 나아감.
업무 프로세스 자체
내재화도 가능.
데이터를 분석해서
dashboard 및
보고서 작성. 분석가
중심의 작업이 됨
서술모델 의사결정
모델
데이터 내의
유용한 패턴을
찾는 과정을
자동화 함
Analyst-guided 로서
데이터 패턴을
이용해서 복잡한
상황의 서술과
미래예측 시도.
BI 를 통해
업무담당자는
사업성과 및 추세를
알 수 있다.
고객을
구매패턴에 따라
분류
특정 액션을 취하면
어찌 될지를 예측
예측모델
구축의 한
단계.
분석가는 주요변수와
패턴을 가지고 수학적
모델을 작성.

3
데이터마이닝 예측분석 BI 기타
Hidden
insight
What to do 과거/현재, trend
고객에게 어떻게 할지
결정하게 함
Macro 한 의미에서의
통찰력 정도
대표적 활동:
통계/계량 분석,
마이닝, 다변량 검증
KPI/Alert/Score-
card, OLAP (Cubes,
Slice & Dice 등)
Analytics, BI, 마이닝의 비교
특히 데이터마이닝이란 데이터 속에서 흥미로운 지식을 발견하고 도출하는 작업이며 기능적으로 다음과
같이 분류해 볼 수 있다.
개념/class 기술(記述) – 개념을 정의하고 계층화하며 데이터 패턴을 간결하게 상위계층 용어로 특성화,
차별화하고 요약하는 것.
연관규칙 (Association Rule) 분석 –데이터 집합에 내재한 연관성과 상관관계를 찾아내고 분석하는 것.
분류 (Classification) - 데이터 class 또는 개념을 기술하고 특징지음으로써 class label등의 성격을
모르는 데이터에 대해 예측하려는 것.
예측과 경향 (Trend) 분석 – 현재 데이터로부터 미래를 예측
군집화 (Clustering) – 비슷한 성격의 객체를 그룹으로 묶는 것.
이상치 (Outlier) 분석 – 해당 데이터 집단의 일반적 성격과는 다른 모습을 보이는 특이한 데이터를 구
분짓고 그 특성을 밝히는 것
Social Network 분석 - SNS에서의 각종 객체간의 관계를 분석(객체에는 사람, 지식 등이 모두 포함되
며 그래프 이론을 활용)
지리공간정보 분석 - 공간정보 및 공간 내 객체의 정보를 분석함.
웹 분석 – 웹 사용자분석, 웹 페이지 별 클릭(click-stream) 현황, 트래픽 분석 등을 포함한다.
멀티미디어 데이터 분석 – 음성파일, 동영상 및 정지화상의 분석
기타 (스트림 데이터 분석, 순차 데이터 (Sequence Data) 분석, 편차분석, 유사성 분석 등)
분석시스템은 DBMS/DW 시스템과 결합되어 운영되기도 하고 (밀결합, 소결합, 준밀결합 등) 또는 별개로
운영되기도 하지만 다음 과정을 거친다는 공통점을 가진다.
데이터의 선정 (DB에 데이터가 있을 때 해당 테이블로부터 추출)
데이터 정제 (데이터 일관성 확인 및 잡음의 제거)와 데이터 통합
데이터 변환
데이터 분석 (마이닝 모델의 선정, 적용 및 수정적용)

4
데이터 패턴 평가 및 해석 (분석결과 도출된 데이터 패턴을 평가)
출력 (다양한 방식으로 도출된 지식을 표현)
아래 그림에서 데이터의 전(前)처리 (preprocessing)는 데이터의 정제, 통합, 선택을 통한 준비단계에 해당되며 데
이터의 축소(data reduction)3 작업이 포함되기도 한다.
한편 데이터 분석작업은 분석엔진을 통해 데이터의 패턴을 추출하고 평가하는 작업으로서 좁은 의미의
마이닝에 해당한다.
끝으로 사용자 인터페이스는 복잡한 데이터의 패턴을 보다 알기 쉽게 표현하여 추가의 분석 또는 최종적
결론을 실행에 옮기는 것을 용이하게 하는 기능으로 일반적으로 표(table)와 다양한 형태의 (2D/3D 의)
그래픽으로 표현해 준다.
(3) 데이터 분석을 위한 통계이론 기초
가. 측정 데이터의 속성 문제
수치 데이터의 경우 그 값의 종류에 따라 달리 취급된다. 예컨대 50 과 100 이 50Kg, 100 Km 일 수도
있고, 50%, 100 배의 비율일 수도 있다.
3 전체적 모습(integrity)을 잃지 않으면서도 데이터 크기를 축소조절하여 분석을 용이하게 하는 것.

5
명목적 (Nominal level) 데이터
대상 항목을 분류하는데 이용 것이다. 예를 들면 4 지 선다형에서의 답안 번호, 주민등록번호, 우편번호
등이 여기에 해당된다.
순서적 (Ordinal level) 데이터
순서가 중요한 의미를 가지는 데이터이다. 예를 들면 각종의 순서/순위 (시험석차, 열차 출발순서, …) 및
시간 등이 여기에 해당된다.
구간 (Interval level) 데이터
연속 숫자 사이에 일정한 구간거리가 적용되는 데이터. 이 숫자 사이의 거리에 따라 데이터의 의미도
비례적으로 값이 증가 또는 감소된다.
비율 (Ratio level) 데이터
서로 다른 데이터 사이의 비율을 나타내는 데이터이다. 예를 들면 기온, 무게, 거리, 100 분율 등이
여기에 해당된다.
데이터의 속성이 중요한 이유는 데이터에 적용되는 통계기법이 데이터의 성격에 따라 모수통계와 비모수
통계로 달라진다는 점이다.
모수통계 - 모집단이 특정 분포를 갖는다고 가정하는 통계모형으로서 구간 데이터와 비율데이터를 대상
으로 하는 경우에 이용됨.
비모수통계 - 모집단의 분포형태에 관한 전제를 필요로 하지 않는 명목데이터와 순서 데이터를 대상으로
사용되는 통계방법이다.
나. 기술통계학 과 추론통계학 및 확률 통계
기술(記述) 통계학 (Descriptive Statistics)
현재 주어진 데이터의 특징을 설명하는 것으로서 각종의 평균, 분산도, 분위 표시, 선형 (linear) 관계 및
각종의 그래프 표시 등이 포함된다.
추론통계학 (Inferential Statistics)
미래 데이터에 대한 추정으로서 추출된 표본집단의 특성을 통해 모집단의 특성을 추정하고 그 신뢰구간을
밝힌다.

6
확률통계학
불확실성을 확률이론으로 설명 또는 추정하려는 것으로서 오늘날 대부분의 통계기법에서 확률이론이
활발히 적용되고 있다.
각각의 구체적인 통계 이론에 대한 설명은 본서의 범위를 벗어나므로 생략하고 대신 다음 페이지에 주요
통계기법을 나열하는 것으로 대신 하였다.


(4) 예측분석 (Predictive Analytics)
최근 빅데이터와 관련하여 예측분석이라는 말을 많이 사용한다. 기존의 ‘분석’이라는 말과 혼용되기도
하고 실제 단순히 강조점의 차이가 아닌가 생각되지만 워낙 많이 쓰이는 말이므로 간단히 살펴본다.
예측분석은 과거 데이터에서 정보를 추출하고 이를 통해 추세와 행동패턴을 예측하는 것으로서 범죄
용의자 식별을 위한 프로파일링 (Profiling), 신용카드 사기의 방지를 위한 활동 등이 그 예이다.
예측분석은 데이터를 단순화함으로써 가치를 높이는 효과가 있다.4
이러한 예측분석의 핵심은 데이터를 통해서 설명변수 (explanatory variables)와 예측되는 변수
(predicted variables) 사이의 관계를 파악하고 이를 예측에 이용하는 것이다.
신용평점을 대상으로 한 예측모델링의 예가 다음 그림에 표시되어 있다.
4 출처: FICO (www.fico.com )

9
가. 종류
예측모델 (Predictive model) - 소비자의 행태와 과거 실적을 분석해서 미래를 예측하고자 하는 것이다.
서술 모델 (Descriptive model) - 데이터에 내재하는 관계를 밝혀내고 이를 계량화하는 것으로서 간혹
이를 이용하여 고객 또는 미래의 가능고객을 세분화하고 그룹화하는 것까지 포함하기도 한다. 예측모델
이 특정 영역을 중심으로 고객을 분석(예: 신용위험 분석)하는데 비해 서술모델에서는 고객 또는 상품간
의 다양한 많은 관계를 식별해 내는 데에 목적을 둔다.
의사결정 모델 (Decision model) – 의사결정에 영향 주는 요인들간의 관계를 설명함으로써 그 과정과
결과를 추측한다. 이를 통해 의사결정 로직이나 업무규칙 (business rule)을 개발한다.
처방적 모델 (Prescriptive model) – 예상되는 문제에 선제적으로 해결책을 제시하는 것을 말한다.
이들의 주요한 예가 다음 표에 정리되어 있다.
서술 설명 예측 의사결정 처방적
숫자 총량화 (합계/평균),
비율, 가중치
군집화,
회귀분석,
연관성분석,
모델관리 목표탐색 시뮬레이셧 (Monte
Carlo)
텍스트 단어(term) 추출 벡터공간 내적 패턴확장
이미지 Edge 탐지 Feature 비교
나. 예측분석의 장점
미래에 대한 통찰력과 예측력을 높인다. 즉, 추측에 의존했던 것들을 과학에 기반한 합리적 의사결정으
로 전환하고 위험과 불확실성을 명확히 측정할 수 있게 된다.
의사결정의 일관성을 기할 수 있다. 특히 고객관련 행위를 규칙기반으로 하여 자동화하고 그 결과
ruleset 수립이 단순해지면서 과거 수십 개의 규칙이 이제 수백 개로 세분화될 수 있게 된다.
고객 세분화의 정확성을 높이고 특정 고객 군에 초점을 맞춘 마케팅 활동이 가능해진다.
(5) 각종의 Analytics 활용
가. 마케팅 정보 분석
마케팅 믹스 최적화와 모델링
최적의 마케팅 활동 배합 (marketing mix)를 찾아내기 위해 다변량 회귀분석을 통해 영업 및 마케팅
시계열 데이터를 분석한다.

10
고객 분석
마케팅 분석의 한 부분이지만 그 중요성으로 인해 따로 분리하여 생각하는 경향이 있다. 특히 고객행태 및
인구통계학적 분석을 통해 고객행태를 연구하고 충성도 증진을 위해 다음 기법을 많이 사용한다.
고객 세분화
생애 (Life time) 가치의 계량화 및 분석
계약 해지 (解止 attrition) 위험성 분석 –식별과 예방 활동
나. 위험 분석
신용카드, 금융기관에서의 고 위험 고객을 판별을 위한 분석활동 이다.
고객의 신규 획득에 대한 모델링- 흔히 신청 시점에 획득된 데이터에 대해 실시하고 미래의 부도 위험
계산에도 활용할 수 있다.
행동평점 (Behavioral scoring) - 거래내역 및 신용도 분석을 통해 미래 위험과 수익성을 추정하고
risk profile에 기반하여 고객을 분류한다.
Basel II analytics – Basel II 협정을 통해 금융기관의 위험관리활동을 개선하도록 되어 있다. 이에 따
라 방대한 데이터를 관리할 필요가 있고 적절한 분석을 하면 위험노출과 재무/운영 위험에 대비하여 적
립할 자본금 등을 추정할 수 있다. 다음이 포함된다.
부도확률 (PD: Probability of Default)의 계산
부도 시 손실 (LGD: Loss given Default) 계산
부도 시 신용리스크 노출액 (EAD: Exposure at Default)
채권회수 Scorecard 개발
다. 웹 분석
웹 사이트의 방문자 수와 페이지 뷰, 인기도 변화추이 등을 분석해서 잠재고객을 사이트로 유도하기 위한
동인 (動因: drivers)을 분석하고 KPI 와 연계하여 사이트를 개선하거나 캠페인에 활용한다.
라. 인사정보 분석 및 Sports Analytics
인사정보 (채용, 보상 및 승진/실적분석. skill 평가)를 분석해서 퇴사위험 직원을 판별하고 사전 조치하며
우수사원에 대해서는 별도 관리하기도 하고 교육수요의 판별과 조기 대처에 이용하기도 한다. 뿐만 아니라
최근에는 스포츠 구단의 선수관리에도 적극 이용되는데 이를 Sports Analytics 라고 부르기도 한다.5.
5 축구의 AC Milan 과 Patriots (미식축구), 미국 야구에서의 Money Ball 등이 유명하며 특히 Money Ball 은 큰 반향을
일으켜 영화화되기까지 했다.

11
마. 부정방지를 위한 분석 (Fraud Analytics)
은행 (카드 분실, 수표위조), 보험회사 (보험사기, 손해 부풀리기) 등에서는 오래 전부터 부정거래의
패턴에 해당하는지 여부 등 검사하는데 Logistic regression, 신경망, 의사결정 등의 기법을 활용하고 있다.
바. 생명공학
DNA 염기서열 분석 등의 유전자 분석, 임상실험결과에 대한 분석(Clinical Analytics), 각종 생명자료를
분석하는 Bioinformatics 등은 대표적인 빅데이터 분석 분야인데 그 영역이 날로 확대되고 있다.

12
2. 모델링과 데이터의 전처리
(1) 데이터의 전처리 문제
분석 작업의 전제가 되는 것은 정확한 소스 데이터이다. 그러나 현실에서는 원 소스 데이터의 품질이
불완전하고, 오염되거나 (즉, 잡음이 있거나) 또는 서로 모순된 내용을 담고 있어서 일관성을 잃은 경우가
많다. 데이터의 전처리 (Preprocessing)란 이를 제거 또는 수정하여 최대한 소스 데이터의 정확성을 높히는
것을 말한다. 나아가 중요성이 현저히 낮은 데이터가 과도하게 많이 포함된 경우 이들을 적절히 축소
조절하여 관리와 사용이 용이한 형태로 변경시켜 준다.
데이터 전처리에는 데이터 정제, 데이터 통합, 데이터 변환, 데이터 축소등이 포함되는데 특히 데이터
정제는 결측치를 채워넣고, 잡음있는 데이터를 평활화(smoothing) 하고, 이상치를 식별하고, 데이터
불일치를 교정하는 것이다.
주요 전처리 작업을 그림으로 표시하였다.
가. 데이터 정제
결측치 (Missing Value)
중간에 결손된 데이터에 대해서는 다음의 방법 중 하나를 적용한다.

13
수작업으로 채워 넣는다.
전역상수 (全域常數: global constant)를 적용한다.
속성 평균값 (attribute mean)을 적용한다.
해당 레코드와 같은 클래스에 해당하는 표본값 평균을 적용한다.
해당 레코드를 무시한다. (단, 최후의 수단으로 사용할 것)
잡음 있는 (noisy) 데이터의 처리
잡음이란 측정된 변수에 무작위(random)의 오류 또는 분산이 존재하는 것을 말하며 다음과 같이
대처한있다.
구간화 (Binning) – 구간평균 또는 평활화를 통해 bucket 적용.
단순 또는 복합 회귀값을 적용 – 데이터를 함수처리하여 평활화하거나 선형회귀 내지 다중회귀분석을
통해 속성값을 대상으로 “최적(best)” line을 추정한다.
군집화 (clustering) 적용 – 유사한 값들을 하나의 그룹으로 처리한다. 이는 결과적으로 이상치를 발견
하는데 이용되기도 한다.
한편 데이터의 결손이 항상 오류는 아니라는 점도 유의할 필요가 있다. 예컨대 운전면허증 번호를
입력하라고 요청할 때 미성년자에게 해당사항 없음이라고 표시할 수 있도록 미리 조처해야 한다.
데이터 불일치 (discrepancy)의 문제
데이터 불일치는 여러 원인에 의해 초래된다. (i) 데이터의 입력설계가 잘못된 경우 (ii) 입력자의 오류
(iii) 의도적 오류(예: 응답자가 특정 사항에 대한 답변을 회피), (iv) 데이터의 노후화 (예: 주소변경) 등 그
종류가 다양하다. 이러한 불일치를 발견해 내기 위해서는 무엇보다 해당분야의 직무지식이 중요하지만 그
외에도 코드사용에서 일관성이 결여된 것은 없는지를 살핀다. (예: 날짜표시: “2004/12/25”와
“25/12/2004” 등).
나. 데이터 통합
데이터 통합은 일관된 데이터를 형성하도록 여러 출처로부터의 데이터들을 결합하는 것을 말하며
메타데이터, 상관성 분석, 데이터 충돌 탐지, 그리고 의미적 이질성의 해소 등이 포함된다. 특히 여러
소스로부터 데이터를 통합하는 대표적인 예가 데이터웨어하우스이다.
데이터 통합에서의 주요 고려사항은 다음과 같다
(1) 스키마 통합과 객체의 일치; 서로 다른 소스에서 발견되지만 실제 그 내용이 동일한 항목을 가리키는
경우 이들을 어떻게 대응시킬 것이가? 즉, entity 식별의 문제인데 한 DB 에서는 customer–id 로 그리고
다른 DB 에서는 cust_id 로 표시된 경우이다..
(2) 중복 (Redundancy); 데이터가 여러 소스에 걸쳐 중복된 경우 이를 선별하고 중복값을 제거해야 한다.
이때 속성간의 불일치 또는 차원의 호칭 문제가 발생하기도 하는데 흔히 개별 값들을 먼저 정한 후 총액은
계산을 통해 채워 넣는 등의 방법을 취한다.

14
한편 일부 중복은 상관관계 분석을 통해 드러나기도 한다. 2 개 속성에서, 하나의 속성값이 다른 속성값에
가지는 상관관계를 상관계수로 계산하는 것이다.
범주형(categorical 또는 discrete) 데이터의 경우에는 두 속성값 간의 상관관계에 대해 (chi-square)
검정를 이용하는데 Pearson 의 통계량으로도 불리우는 이 값의 계산은 다음과 같다.
만약 A 가 a1, a2, …, ac의 형태로 c 개의 값을 가지고 B 는 b1, b2, …, br의 형태로 r 개의 값을 가진다면
분할표(contingency table)로 나타낼 수 있다. 다음은 남녀간에 독서 시 선호하는 책의 유형을 분할표로
나타낸 것이다.
통계량은 (r-1)x(c-1) 자유도를 가지는 신뢰수준하에서 A 와 B 가 서로 독립적이라는 가설을 세우고
이를 검증한다. 그리고 이러한 가설이 reject 되면 우리는 A 와 B 가 서로 통계적으로 관련되어 있다고
(statistically related) 말할 수 있다.
(3) 여러 tuple 에서 값이 중복되거나 하나의 속성에 대해 여러 상충되는 값이 발견될 때 이러한 불일치를
해소하는 문제도 있다. 이는 여러 소스의 데이터를 온전한 (coherent) 하나의 데이터로 합치는 것을 말하며
특히 다음의 사항에 유의할 필요가 있다.
개체 식별 (entity identification)의 문제
개체식별(NER: Named-entity recognition)이란 텍스트 내에서 특정 항목의 위치를 찾아내고 이것이
어떤 카테고리에 속하는지 분류하는 것이다. 카테고리는 미리 정하는데 사람이름, 조직이름, 위치, 시간에
대한 표현, 비율, ...등이 모두 포함된다. 아래에 “Kim bought 300 shares of POSCO in 2013”라는
문장에서 객체식별을 할 때 XML 의 element 를 이용하여 관심있는 항목을 카테고리 분류 하였다.
<ENAMEX TYPE="PERSON">Kim</ENAMEX>bought
<NUMEX TYPE="QUANTITY">300</NUMEX>shares of
<ENAMEX TYPE="ORGANIZATION">POSCO</ENAMEX> in
<TIMEX TYPE="DATE">2013</TIMEX>.

15
속성 중복(redundancy) 및 데이터 값 충돌의 제거 문제
하나의 속성에서 파생된 새로운 속성들이 중복 현상을 보이는 문제이다.
다. 데이터 축소 (Reduction)
중복되거나 불필요하게 나열된 데이터를 축소하여 크기를 줄이면서도 고유 특성은 유지하게 하여 분석의
편의성과 효율을 증진시키려는 것이다.
데이터 큐브 집계 (data cube aggregation)
데이터 큐브를 작성하면서 관련 cuboiod 의 집계작업을 지정한다.
속성 subset의 선택
관련성이 없거나 약한 데이터와 중복 속성 및 중복차원을 제거한다.
차원 축소 (dimensionality reduction)
DWT (discrete Wavelet transformation) 등 신호처리 및 주성분 분석 (PCA: Principal Components
Analysis)이 대표적인 예이다.
주성분 분석의 경우 원본 데이터의 벡터가 (k 차원, N 개 tuple)일 때 최적의 데이터 표현을 위한 c 개의
k 차원 직교벡터를 찾는데 이때 원본 데이터가 훨씬 작은 공간에 투영되면서 압축되는 결과를 낳는다.
아래는 주성분 분석의 모습인데 Y1, Y2는 데이터의 첫 2 개 주성분이다.
주성분 분석은 계산이 비교적 간단하고 sparse 데이터나 비대칭 형태를 가지는 경우에도 적용이
가능하다는 장점이 있다. 보통 다중회귀분석 및 군집분석에서 입력데이터에 대해 많이 이용된다. 반면
Wavelet 변환은 고차원 데이터에 주로 적용한다.
수량축소 (numerosity reduction)
데이터의 크기를 인위적으로 줄이는 것으로서 모수형과 비모수형으로 나누어 볼 수 있다.

16
모수(母數)형의 경우에는 실 데이터 대신 데이터의 파라미터만 저장하는데 대표적인 것이 다차원의
이산치 확률분포를 추정하는 log-linear 모델6이다. 비모수형에 있어서는 히스토그램7, 군집화, 샘플링 등을
들 수 있고 그 밖에도 회귀분석, Log-선형 모델, 막대그래프의 활용, 군집화, 표본채취 등이 포함된다.
표본 채취 (Sampling)
표본채취는 데이터 집합을 무작위로 만들어진 샘플에 의해 대표되도록 하는 것으로서 결과적으로 데이터
축소기법의 하나라 할 수 있다. 샘플 채취방법에는 다음과 같은 것이 있다.
복원형 비복원형 단순 무작위 샘플
군집 샘플 (cluster sample)
층화샘플 (stratified sample) – 각 층에서 샘플을 얻는 것을 말한다. (예: 고객분석에서 나이별로 그룹
화)
라. 데이터 변환
데이터 불일치기 있을 경우 이를 교정하기 위해 변환의 원칙을 정한 후 이를 적용하는데 특별히 이러한
작업을 위해 작성된 솔루션이 ETL (extraction/transformation/loading) 도구이다. 구체적인 데이터
변환기법으로는 다음과 같은 것이 있다.
평활화 (smoothing)
집계 (aggregation)
일반화 (generalization)
6 선형회귀는 최소자승법에 의거하여 데이터를 직선형태에 맞도록 모델링하여 회귀계수 ( )를 구한다.
반면 선형 로그모델은 기대치의 로그값이 모수의 선형함수로 모형화되는 것인데 두 범주형 변수 사이의 독립성과 연관성을
알아보는 검정의 확장개념이다. 다만 범주형 변수가 2 개인 경우에는 검정이 간편하므로 로그선형모형은 범주형 변수가
3 개 이상인 경우 주로 사용하게 된다.
7 구간화를 통해 데이터 분포의 근사치를 구하는 것이다. 속성 A 에 대한 막대그래프는 A 의 데이터 분포를 서로 소 인
부분집합 즉, bucket 으로 분할한다. Bucket 의 결정방식으로는 다음과 같은 것이 있다.
동일 폭 (equiwidth): 각 bucket의 구간 폭이 같은 것
동일 깊이 (equi-depth or equi-height): 각 bucket의 빈도가 대략 일정하도록 하는 것
V 최적 (V-optimal): 각각의 bucket에서 최소 분산을 가지도록 하는 것. 이때 histogram의 분산은 각
bucket의 데이터 값의 가중치 합이며 bucket 가중치는 bucket에 있는 값의 개수와 같다.
최대차이 (MaxDiff): 인접한 값들의 각 쌍 사이의 차이를 고려하는데 bucket의 수를 사용자가 β로 지
정한 경우 β -1 최대차이를 가지는 쌍에 대해 각 쌍 사이에 bucket 경계를 정한다.

17
정규화 (normalization)
속성생성 (attribute construction)
(2) 모델링 (모델개발)
가. 모델개발의 단계
모델개발의 단계를 정리하면 다음과 같다.
① 해결해야 할 문제를 정의한다.
② 개발 샘플과 관련 실적데이터를 준비한다
③ 데이터 분석을 통해 예상패턴을 파악한다.
④ 상세모델을 개발하고 미세조정한 후 검증한다.
⑤ 모델을 완성한 후 설치, 실제 현실에 적용한 후 평가한다.
모델 수립에 있어서는 일반적으로 데이터가 많을수록 좋다. 정확성도 높아진다. 그러나 현실적으로
데이터가 한정될 때 다음을 고려할 수 있다.
Custom 모델 –보유고객에 대한 데이터만 가지고 특화모델 설정
Pooled 데이터 모델 – 해당 산업 전반과 같은 광범위한 데이터를 가지고 분석한 후 적용이 가능한 분야
를 추려낸다.
전문가 모델 –분석가의 전문의견과 주관적인 판단
나. 데이터 편향성의 해결
모델 개발의 과정에서 여러 가지 편향성(bias)이 게재되기 쉽다. 편향성이란 적절치 않은 샘플의 수
등으로 인한 왜곡을 포함하여 여러 가지가 있는데 거절자 추론이 이를 조정하는 방법 중 하나이다.
거절자 추론 (reject inference )
거절된 신청자의 데이터를 이용해서 scorecard 의 품질을 높이는 것이다. 즉, 원칙적으로 샘플은 모집단의
특성을 대표할 수 있어야 하지만 현실세계에서는 표본 Bias 가 생길 수 있기 때문에 이를 최소화할 필요가
있다. 워낙 자명해서 특별한 의사결정이 필요 없을 때 이를 미리 배제하며 신용평가 등의 경우 많이 이용된다.
구체적으로 다음 형태를 가진다.
Augmentation
외삽 (外揷: Extrapolation)8
인위적 조작 (Manual Intervention)
8 함수 f(x) 값이 알려진 구간 밖에서 f(x)를 추정하는 것

18
다. 모델의 검증 (validation)
모델의 예측력을 평가하는 기법들에는 다음과 같은 것이 있다.
발산도 (divergence)
K-S (Kolmogorov-Smirnov) 통계
ROC (receiver operating characteristic)
이와 함께 중요한 것이 과적합의 문제이다. 일반적으로 분석의 첫 단계로서 학습단계를 거치게 되는데 여기에 사용하는 데이터
집합을 훈련 데이터 집합(Training Data Set)이라고 한다. 분석 알고리즘은 주어진 훈련 데이터 집합으로부터 패턴이나 관계를
찾아내게 되는데 일단 찾아낸 패턴은 이후 발생(입력)되는 데이터 집합에도 들어맞을 수도 있지만, 그렇지 않을 수도 있다. 이는
훈련 데이터 집합이 전체 모집단을 대표하느냐와 밀접한 관계를 가진다. 여기에는 여러가지 요인이 있을 수 있지만 그 중 하나가
훈련 데이터 집합은 특징을 가지지만 전체 모집단에는 이 특징이 없는 경우이다. 이처럼 알고리즘이 전체 집단에는 없지만
우연히 훈련데이터에만 존재하는 특징을 학습하여 불필요하게 배우는 현상을 과적합(過適合 Overfitting) 이라고 부른다. 즉,
특정 표본고객에 너무 초점이 맞추어져 그에게는 적합하지만 다른 데이터에 적합치 않은 경우를 말한다.
어떤 분석 기법을 채택할 것인가의 문제는 단순치 않은데 보통 여러 가지를 적용한 후 결과에 따라
골라내거나 또는 가용성에 따라 어쩔 수 없이 적용하는 경우도 많다. 일반적으로 다음 지침을 이용할 수 있다.
너무 정밀한 것 대신 단순한 것, 안정적인 것, 쉽게 설명이 가능한 것을 택할 것.
시간 오래 걸리거나 세련된 분석보다는 신속성을 우선시하여 (quick-and-dirty) 빨리 결과를 보는 것도
유리하다.
즉각 복잡한 모델을 구축하는 것 보다는 상황을 이해하는 데에 더 많은 노력을 기울인다.
(3) 기계학습
기계학습 (Machine learning)은 인공지능의 한 종류로서 컴퓨터가 주어진 데이터를 통해 스스로
학습하도록 하는 것을 말한다. 쉬운 예로 이메일에 대해 꾸준히 학습하면서 spam 과 non-spam 폴더로
자동 분류해주는 것을 들 수 있다.
기계학습의 핵심은 다음의 2 가지 이다.
데이터의 표현과 이들에 대한 평가를 위한 함수
일반화 (Generalization) 즉, 현재 모형이 새로운 데이터에도 그대로 적용도록 하는 것을 말한다.
기계학습의 종류를 크게 다음과 같이 나누어 볼 수 있다.
지도학습 (Supervised learning)
자율학습 (Unsupervised learning)
강화학습 (Reinforcement learning)
학습방식 학습 (Learning to learn)
이들 기계학습의 주요 기법에 대해서는 이 책의 뒷부분에서 설명하기로 한다.

19
3. 주요 분석 기법9
(1) OLAP 분석 (DW/OLAP)
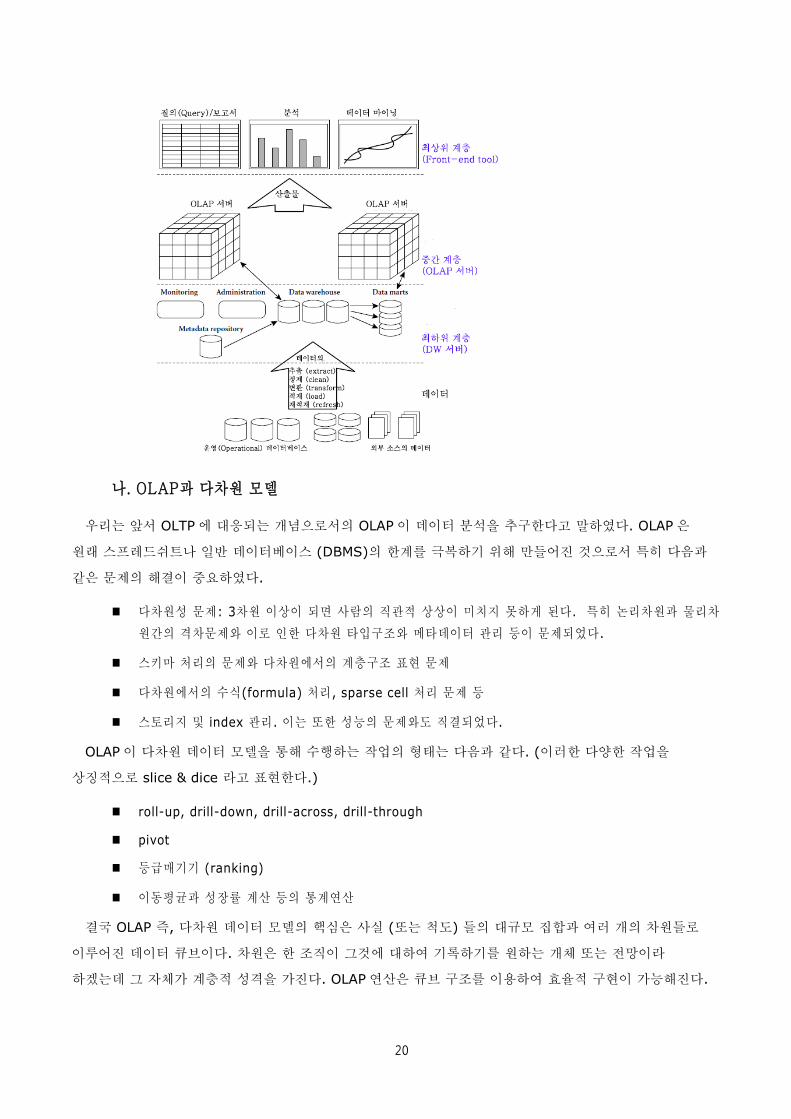
가. 데이터웨어하우스의 3계층 모델
데이터웨어하우스는 한마디로 잘 정리된 데이터 종합저장소 (repository) 라 하겠는데 아키텍처 관점에서
3 가지 모델로 나눌 수 있다.
전사적 웨어하우스(Enterprise warehouse): 전사적 차원의 모든 주제를 포괄하는 (cross-
functional) 데이트웨어하우스.
데이터 마트: 특정 그룹의 사용자를 위한 데이터 웨어하우스
가상 웨어하우스 (Virtual warehouse): 운영 데이터베이스의 view10를 DW에 저장하여 질의처리를 효
율화 한 것.
데이터웨어하우스와 데이터 마트의 설계에는 주로 다차원 데이터 모델이 이용되는데 여기에는 Star
스키마, 눈송이 스키마 또는 성군 (星群) 스키마 등이 있다.
데이터웨어하우스는 흔히 다음 그림과 같은 3 계층 구조를 채택한다.
9 본 주요분석기법의 설명 중 일부는 다음 서적을 포괄적으로 인용하였다.
Han/Kamber/Pei, Data Mining: Concepts and Techniques (3rd Ed.), 2012
I. Witten(외), Data Mining: Practical Machine Learning Tools, MK, 2011
Misbet(외), Handbook of Statistical Analysis & Data Mining, AP, 2009
10 데이터베이스에서 view 란 미리 지정된 질의어 또는 map-reduce 함수의 결과 데이터로서 일종의 가상 테이블이 생성되어
사용자가 간단히 이용할 수 있도록 만들어진 것을 말한다.
20
나. OLAP과 다차원 모델
우리는 앞서 OLTP 에 대응되는 개념으로서의 OLAP 이 데이터 분석을 추구한다고 말하였다. OLAP 은
원래 스프레드쉬트나 일반 데이터베이스 (DBMS)의 한계를 극복하기 위해 만들어진 것으로서 특히 다음과
같은 문제의 해결이 중요하였다.
다차원성 문제: 3차원 이상이 되면 사람의 직관적 상상이 미치지 못하게 된다. 특히 논리차원과 물리차
원간의 격차문제와 이로 인한 다차원 타입구조와 메타데이터 관리 등이 문제되었다.
스키마 처리의 문제와 다차원에서의 계층구조 표현 문제
다차원에서의 수식(formula) 처리, sparse cell 처리 문제 등
스토리지 및 index 관리. 이는 또한 성능의 문제와도 직결되었다.
OLAP 이 다차원 데이터 모델을 통해 수행하는 작업의 형태는 다음과 같다. (이러한 다양한 작업을
상징적으로 slice & dice 라고 표현한다.)
roll-up, drill-down, drill-across, drill-through
pivot
등급매기기 (ranking)
이동평균과 성장률 계산 등의 통계연산
결국 OLAP 즉, 다차원 데이터 모델의 핵심은 사실 (또는 척도) 들의 대규모 집합과 여러 개의 차원들로
이루어진 데이터 큐브이다. 차원은 한 조직이 그것에 대하여 기록하기를 원하는 개체 또는 전망이라
하겠는데 그 자체가 계층적 성격을 가진다. OLAP 연산은 큐브 구조를 이용하여 효율적 구현이 가능해진다.

21
데이터 큐브는 cuoid11와 lattice 로 구성되는데 각 cuboid 는 주어진 다차원 데이터의 요약단계에
해당한다.
부분 구체화 (partial materialization)는 lattice에 있는 cuboid들의 부분집합에 대해 선택적으로 계
산을 수행하는 것을 말한다.
완전 구체화 (full materialization)는 격자에 있는 모든 cuboid들을 계산하는 것이다.
다음 그림은 6 차원 데이터 큐브를 보여주고 있다.
다음 그림에서 이에 대한 분석작업의 대표적 항목을 예시하고 있다.
6-차원의 데이터를 처리하여 표시
다. OLAP의 종류
OLAP 서버 구현방식에는 다음과 같은 것이 있다.
ROLAP (관계 OLAP) – 다차원 데이터에 대한 OLAP연산을 표준의 관계연산으로 대응시키는 확장 관계
DB를 사용한다.
11 DW 에서 각각의 data cube 를 cuboid 라고 부른다. 즉, 몇 개 차원이 존재할 때 이들 차원의 하위집합별로 각각의
cuboid 를 생성해낼 수 있고 결과적으로 cuboid 의 격자 (lattice of cuboid)를 형성하는데 이들은 각각의 수준에 있어서의
합계치를 간직한다.

22
MOLAP (다차원 OLAP) – 다차원 데이터 view를 배열구조로 직접 사상(대응)한다.
HOLAP (혼합형 OLAP) – HOAP은 ROLAP과 MOLAP을 혼용한다. 예를 들면 이력 데이터를 위해서는
ROLAP을 사용하고 자주 이용하는 데이터는 별도의 MOLAP 저장소에 보관한다.
한편 Index 기술을 통해 OLAP 질의처리의 효율을 높일 수 있다. Bitmap Index 의 경우 Join, 집계,
비교연산을 bit 산술로 축소시키기 위해 각 속성은 자신들의 bitmap Index 테이블을 가진다.
Join index 는 관계 데이터베이스에서 둘 이상의 relation 이 OLAP join 할 때 계산비용을 줄여준다.
OLAP 다차원 분석의 절차는 다음과 같다.
현재 및 미래의 데이터 흐름을 이해한다.
cube를 정의한다
차원의 단위 (dimension level) 및 계층구조를
정의한다.
차원과 각 구성요소 및 link를 정의한다.
집계사항 등 각종의 수식연관성을 정의한다.
(2) 개념서술과 데이터 이산화 및 개념계층 생성
가. 개념서술과 데이터 일반화
개념서술이란 작업 데이터에 대해 짧은 요약을 시도하는 것으로서 이를 통해 데이터의 일반적 특징을
표현하게 된다.
한편 데이터 일반화란 특정 DB 내의 데이터 집합에 대해서 이를 낮은 개념수준에서 높은 개념수준으로
추상화하는 것을 말한다. 예를 들면 특정인의 주소를 최하위 단위로 서술할 수 있지만 이를 조금씩
일반화하여 도시 또는 국가에 속한 것으로 일반화하는 것을 들 수 있다.
많은 경우 이러한 계층구조는 DB 의 스키마 안에 묵시적으로 존재하기도 한다. 또한 한 차원의 속성들은
격자 형태를 띄우면서 부분순서를 구성하기도 한다. 한 데이터베이스 스키마에 있는 속성들 사이에 전체
또는 부분의 순서인 개념계층이 존재할 때 이를 스키마 계층 (schema hierarchy)라고 부른다.
23
다음 그림은 음료식품의 차원에 따른 개념체계를 보여주고 있다.
다음 그림은 창고 dimension 의 속성을 보여주는데 (a)는 주소개념의 계층구조를 그리고 (b)에서는 시간
개념의 격자구조를 보여주고 있다.
데이터 일반화는 모두 차원을 기반으로 하며 다음 2 가지로 나누어진다.
데이터 큐브 OLAP 기반 접근법
속성 중심 귀납법 - 다른 relation이나 데이터 큐브 구조를 사용하여 구현된다.
개념 특성화
특성화란 속성에 관련된 분석형태이다. 즉, 귀납처리에 앞서서 관련이 없거나 약한 관련을 가지는 속성을
추출하기 위해 속성과 차원의 관련성을 분석해 내는 것이다. 구체적 속성관련 분석방법으로는 정보이득,
지니계수, 불확실지수, 상관계수 등이 있다.
개념 비교
여러 데이터 집합을 비교함으로써 비교 또는 판별 작업을 수행한다. 개념 비교에는 속성 중심적
유도기법과 데이터 큐브 접근법이 있는데 목표 클래스나 대조 클래스로부터 일반화된 tuple 을 정량적으로
비교하고 대조하게 된다. 흥미 척도에는 t-weight (특이성: typicality)와 d-weight (판별성:
discriminality)가 있다.

24
나. 데이터 이산화와 개념계층 생성
데이터 이산화 (Data Discretization)
데이터 이산화를 통해 속성의 범위를 구간별로 나누면 데이터의 크기를 줄일 수 있다. 여기서 구간화란
속성값들을 구간 별로 분산화한 후 구간평균 또는 구간중앙값으로 대체하여 이산화하는 것을 말한다.
이산화 기법은 다양한데 이를 다음과 같이 분류할 수 있다.
Supervised 이산화 – 이산화 과정에서 class 정보를 이용함.
Unsupervised 이산화 – 이산화 과정에서 class 정보를 이용하지 않는 경우
또는
하향식 이산화 – 하나 내지 작은 수의 분리점(split)에서 출발하여 반복적으로 세분화 작업을 실시하는
것
상향식 이산화 – 원본 데이터(raw data)에서 출발하여 단계적으로 상향 통합(merge)하는 방식을 취하
는 것.
엔트로피 (Entropy)에 근거한 이산화
정보이득 (Information Gain)이란 속성이 하나의 데이터가 다른 데이터로부터 얼마나 잘 구분되는가를
수치로 나타내는 것을 말한다. 엔트로피란 예제 데이터 집합에서의 혼합성 (impurity)을 내는데12 결국 이
개념을 통해 데이터 구분을 위한 이산화 작업을 실시하게 된다.
정보이득은 다음 식으로 표현된다.
다음과 같이 속성값/class 의 쌍(pairs)이 있다고 가정한다.
(0,P),(4,P),(12,P), (16,N), (16,N),(18,P),(24,N),(26,N),(28,N)
엔트로피 기반의 이산화는 구간화를 위한 최적의 구분점을 찾는 것이며 정보이득이 최대가 되는 것을
말한다. 즉, S 가 위의 9 개 쌍일 때 p=4/9 는 P 쌍의 일부가 되고 n=5/9 는 N pair 의 일부가 된다.
Entropy(S) = -p log P – nlog n
entropy 가 적다면 최소값이 0, entropy 가 크면 최대값이 1 이 된다.
12 엔트로피는 열역학에서 자연 물질이 변형되어, 다시 원래 상태로 환원될 수 없게 되는 현상을 말한다. 통신이론에서는
잡음으로부터 신호를 구분해 내는 것을 말하며 데이터 분석에서는 한 걸음 더 나아가 정보가 여러 가능성의 하나를 지정할 때
사상(事象)되는 정보의 불확실성비율로 정의한다.

25
분석을 이용한 구간 통합 (Interval Merging)
ChiMerge 는 기반의 이산화 기법이다. 상향식으로 최적의 이웃 구간을 찾는 후 이를 재귀적으로 반복
merge 하여 보다 더 큰 구간을 만들어 나간다. 보다 정교한 이산화를 위해서는 만약 2 개의 인접한 구간이
유사한 class 분포를 가진다면 이를 통합하고 그렇지 않다면 이들을 별개의 것으로 유지시키는 방법이 있다.
Cluster 분석
군집화를 통해 수치속성을 이산화할 수 있다. 수치속성의 분포와 함께 데이터 점의 근접정도를 감안하여
군집화를 함으로써 개념의 계층체계를 생성할 수 있다. (군집화에 대해서는 뒤에서 자세히 설명함)
다. 개념계층(Concept Hierarchy)생성
범주형 데이터의 속성 값들 사이에 순서개념은 존재하지 않지만 나름대로 구별값을 가진다. 개념계층 생성
방법은 다음과 같다.
사용자 또는 전문가들이 스키마 차원에서 명시적으로 지정: 예를 들어 특정 데이터에 주소관련 속성데이
터가 존재하는 경우 스키마 차원에서 국가/도/시/군/… 등과 같은 계층체계를 정의하는 것을 말한다.
명시적 데이터 그룹화를 통해 계층의 일부를 지정: 수작업으로 그룹화 하는 것으로서 데이터베이스에서
도 중간단계 데이터의 일부를 그룹화할 수 있다.
속성의 부분집합만을 정의하고 부분 순서정보는 생략: 시스템이 자동으로 속성 순서를 작성하여 의미있
는 개념계층화를 시도한다.
(3) 데이터 상호관련성의 분석
데이터의 상호관련성이란 얼핏 보아서는 알아차릴 수 없지만 실제로는 내제하는 데이터 사이의
연관성(association rule)을 찾아내고자 하는 것을 말한다.
가. 빈발 항목 분석 (Frequent Itemset)
개요
빈발 패턴(Frequent patterns)은 하나의 데이터셋에 나타나는 패턴13을 찾는 것이다. 대표적인 활용 중
하나가 장바구니 분석 (market basket analysis)이다. 구매 행태와 관련하여 예컨대 고객이 우유를 살 때
빵을 함께 구매할 가능성이 얼마나 되는지를 살펴보는 것이다.
13 구체적으로는 항목집합, subsequence, substructure 등 여러가지가 있다. substructure 란 구조적 유형을 말하며 이를
subgraph, subtree 로 분류한다. 만약 위 장바구니 분석 사례에서 이러한 substructure 가 자주 발생한다면 이를 빈발
(frequent structured) 패턴이라 부른다.

26
상점에서 판매되는 상품 전체를 하나의 세계14라고 보고 이를 구성하는 각 상품의 장바구니에서의
존재유무를 이진변수로 표현한다면 각각의 고객 장바구니는 이들 변수들에 부여된 값으로 구성된 이진
벡터로 표현될 수 있다. 그리고 이러한 이진벡터는 자주 함께 구매되는 상품에 관한 구매패턴의 분석에
이용되는데 주로 연관규칙의 형태로 표현된다. 예컨대 컴퓨터를 구매한 사람이 개인자산관리 소프트웨어를
구매할 가능성에 대한 정보를 다음과 같은 연관규칙으로 표현할 수 있다.
computer antivirus_software [support=3%, confidence=65%]
여기서 규칙의 지지도(support)와 신뢰도 (confidence)는 규칙의 흥미도를 표현하는 기준이 되며 해당
규칙의 유용성과 확실성을 반영한다. 위 예에서 지지도 3%란 분석 대상이 된 모든 거래활동의 3%가
컴퓨터와 금융 S/W 를 함께 구매했다는 것이고 65%의 신뢰도는 컴퓨터를 구매한 고객의 65%가 그
S/W 를 구매했다는 것을 말한다. 보통 연관규칙은 분석가가 설정하는 최소지지도 임계값(minimum
support threshold)과 최소신뢰도 임계값(minimum confidence threshold)으로 표시된다.
주요 개념: 빈발항목집합과 연관(Association) 규칙
I ={ I1, I2, … , Im} 를 항목집합이라 하고 각각의 거래 관련 데이터를 D 라고 하면 각각의 거래 T 에는
해당 구매상품이 존재하게 되어 T I 의 관계가 형성된다. 여기서, A 와 B 를 각각 항목의 집합이라고 할 때
연관규칙은 A B 의 형태로 표현한다. 이때 거래 집합 D 에서 항목 A 와 B 를 동시에 포함하고 있을 확률
즉, P(A B)의 백분율이 s 라면 지지도 s 를 갖는다고 말한다. 또한 규칙 A B 가 D 에서 A 항목을
가지는 거래에서 B 도 역시 포함되어 있을 확률을 c 라면 D 거래에서는 신뢰도가 c 인데 이는 조건부 확률
P(B | A)의 형태로 계산할 수 있다.
support(A B) = P(A B)
confidence(A B) = P(B|A)
어떤 연관규칙이 최소 지지도 임계치 (min_sup)와 최소 신뢰도 임계치 (min_conf)를 모두 만족할 때
이를 강한 규칙 (strong rule)이라 하는데 지지도와 신뢰도는 주로 백분율로 표시한다.
이하 논의를 위해 몇 가지 용어를 정리한다.
연관규칙을 논의할 때 여러 항목의 집합을 항목집합(Itemset)이라 표현하고 하나의 거래에서 k개의 항
목을 가지는 항목집합을 k-항목집합이라고 한다. 예컨대 3개 항목으로 이루어진 경우 이를 3-항목집합
이라 한다.
항목집합의 출현빈도는 해당 항목집합이 포함된 거래 건수이다.
14 universe 즉, 전체집합의 의미로 사용된 용어이다.

27
항목집합의 발생빈도가 최소지지도 임계치와 전체 거래 수의 곱과 같거나 크다면 이는 최소지지도
(minimum support count)를 만족하는 것이 된다. 최소지지도를 만족하면 이를 빈발항목집합이라고
하고 크기가 k개인 빈발항목집합을 보통 Lk로 표현한다.
연관규칙 분석은 다음의 절차에 따라 진행된다.
① 빈발항목집합 전체를 찾는다. 즉, 모든 항목집합은 사전에 지정된 최소지지도 개수 이상 빈번하게
발생된 건들을 모두 찾아낸다.
② 빈발항목집합에서 강한 연관규칙을 발견해 낸다. 이들 규칙은 최소지지도와 최소신뢰도를 모두
만족해야 한다.
③ 필요 시 추가로 흥미도를 적용, 선별할 수 있다.
이들 각 단계 중 중요한 것은 (1)번 항목이지만 특히 최소지지도 (min_sup) 임계치를 만족하는
빈발항목집합의 수가 엄청나므로 이들 가능성을 놓치지 않으면서도 효율성을 높하기 위해 닫힌
빈발항목집합 (closed frequent itemset)의 개념을15 적용할 수 있다는 점이다.
장바구니 분석은 빈발패턴 분석의 한 종류에 불과하다. 이하에서 다양한 기준에 따른 빈발패턴 분석의
유형을 살펴본다.
분석하려는 패턴의 완전성 정도에 따른 분류: 빈발항목 전체를 대상으로 할 수도 있고, 닫힌 빈발항목 내
지 최소지지도 임계치를 기준으로 한 최빈 빈발항목으로 제한하여 살펴볼 수도 있다. 또한 근사치 빈발
항목, near-match 빈발항목, 최상위 k개에 대한 빈발 항목 등 분석기준의 완전성에 따라 여러 형태가
가능하다.
애플리케이션에서의 패턴 완전성 요구조건에 따른 분류: 각 애플리케이션마다 패턴의 완전성에 대한 요
구가 다르므로 이에 따라 평가방법 및 최적화 방법이 달라진다: 닫힌 빈발항목집합, constrained 빈발
항목집합 등이 그 예이다.
연관규칙에 포함된 추상화 정도에 따른 분류: 예를 통해 살펴보자.
Age(X,”30…39”) ⇒ buys(X,”notebook computer)
Age(X,”30…39”) ⇒ buys(X,” computer)
똑 같은 데이터를 가지고도 컴퓨터라는 상위항목으로 연관성을 분석하는 경우와 하위의
notebook 컴퓨터로 분석하는 경우 그 결과가 달라지는데 이를 다층 연관규칙 이라 한다. 이와 달리
연관규칙이 계층적으로 다른 항목과 속성을 참조하지 않는 경우 단일계층 연관규칙이라고 한다.
15 데이터집합 S 내의 항목집합 X 가 닫혀있다면 참전체 항목집합 (proper super-itemset)인 Y 가 존재하지 않아서 Y 가
S 내의 X 와 같은 지지도 개수를 가짐을 의미한다.
X가 닫혀있고 S내에서 빈발하면 X항목집합은 닫힌 빈발항목집단이 된다.
X가 빈발하고 동시에 참 전체집단항목 Y가 존재하지 않는다면 X항목집합은 닫혀있는 최빈 빈발항목집단 (max-itemset) 이
된다

28
규칙에서 다루는 값의 데이터 타입에 따른 분류: 규칙이 항목 유무만 분석하는 경우 이진 연관분석
(Boolean association rule)이 되고, 이와 달리 항목들 사이의 계량적 연관성을 설명하고자 한다면 이
는 계량적 연관규칙이 된다. 다음은 계량적 연관규칙의 예이다. (단, X는 고객을 나타내는 변수)
age(X,”30…39) income (X,”42k…48k”) ⇒ buys (X,high resolution TV)
분석하고자 하는 패턴의 종류에 따른 분류: 빈발 항목패턴 외에도 패턴의 종류에 따라 다양한 분석이 가
능하다. 각각의 항목 또는 행동의 순서를 알아보고자 할 때 순차패턴 분석을 실시할 수도 있다. 또한 패
턴이 그래프, 격자, Tree, 집합, 기타의 조합 등의 구조를 띄고 있을 때 이들 하위 구조의 패턴을 분석할
수도 있다. 이제 모든 분석의 출발점이 되는 주로 빈발 항목집합을 알아본다.
Apriori 알고리즘: 후보군 생성을 통한 빈발항목집합 찾기
Apriori 알고리즘16 은 사전에 지정한 특성에 따라 계층단위로 분석하는 연관규칙 분석 알고리즘이다.
여기서는 k-항목집합 (k 개 품목으로 이루어진 항목집합)이 정해지면 이에 대해 추가 작업 실시하여 k+1
항목집합을 탐색한다. 여기서 Apriori 특성이 중요한데 이는 하나의 빈발항목집합이 있다면 그 부분집합도
역시 빈번하다는 것이다.
Apriori 알고리즘은 다음의 2 개 과정으로 이루어진다.
(1) Join 단계 – Lk를 구하기 위해 Lk-1을 자신과 조합하여 k-항목집합 을 후보로 생성하고 이를 Ck라고
한다. L1과 l2를 항목집합 Lk-1에 있는 항목집합이라 하고 li[j]를 li의 j 번째 항목이라고 하면 Lk-1과 Lk-1의
join 인 Lk-1 Lk-1은 앞 (k-2)개 항목이 공통될 경우에만 가능해진다.
(2) 가지치기 (prune)단계
아래에 빈발 항목집합을 발견하기 위한 Apriori 알고리즘이 제시되었다.
Apriori 알고리즘
(목적) 후보생성을 위한 계층별 반복작업을 통해 빈발항목집합을 찾아내고자 함.
(입력항목)
D: DB 에서의 거래항목 (transaction)
min_support: 최소지지도 임계치
Ck: Candidate itemset of size k
Lk:frequent itemset of size k
(출력항목)
* L: D 에서의 빈발항목집합 (frequent itemset)
16 사전(事前)지식을 이용한다는 점에서 apriori 라는 이름이 붙여졌다.

29
(Method)
L1 = {frequent items};
for (k= 1; Lk !=0; k++) do begin
Ck+1 = candidates generated from Lk;
for each transaction t in database do
increment the count of all candidates in Ck+1 that are contained in t
Lk+1 = candidates in Ck+1 with min_support
end
return ∪kLk;
<빈발항목집합으로부터 연관규칙의 생성하는 방법>
일단 전체 거래에서부터 빈발항목집합들을 찾아내었다면 이제 강한 연관규칙17들을 찾는 것은 비교적
간단하다. 다음의 신뢰도 방정식에서 얻어지는데 이 조건부 확률은 항목집합에 대한 지지도 개수로 표시된다.
Confidence (A B) = P(B|A) =
여기서 support_count (A B)는 항목집합 A B 를 포함하는 거래의 건수이고, support_count (A) 는
항목 A 가 포함되는 거래의 건수이다. 위의 식을 토대로 다음과 같이 연관규칙이 생성된다.
각 빈발항목집합 l에 대해 l의 모든 공집합 아닌 부분집합을 생성한다.
l의 모든 공집합이 아닌 부분집합 s에 대하여 만약 최소신뢰도 임계치를 min_sup이라고 할 때
를 만족하는 “s ⇒ (l-s)” 규칙을 출력한다.
규칙은 주로 빈발항목집합으로부터 생성되므로 각 규칙은 최소지지도를 만족한다. 빈발항목집합은 각
항목의 개수와 함께 hash 테이블에 미리 저정되어 신속한 접근을 꾀할 수 있다.
<Apriori 알고리즘의 효율증대>
Apriori 알고리즘의 효율향상을 위해 몇 가지 수정사항이 제안되었다.
Hash 기반 방법 (항목집합의 개수를 hashing): Hash 기반 기법은 후보 k-항목집합 Ck (K > 1)의 크
기를 줄이는데 주목한다.
17 강한 연관규칙이란 최소지지도와 최소신뢰도를 만족하는 것을 말한다.

30
2-항목집합 후보에 대한 Hash테이블 H2가 제시되고 있다.
거래 감축: 다음 단계에서 scan할 거래의 건수를 감축하는 것이다. 빈발 k-항목집합을 포함하지 않는 거
래는 당연히 빈발 (k+1)-항목집합을 포함하지 않으므로 다음 단계의 j-항목집합에 (j > k) 대한 DB 스
캔은 더 이상 필요치 않고 따라서 이 거래는 제거시킨다.
분할: 2 단계로 구성되는데 첫째 단계에서는 D거래를 중복이 없도록 하면서 n개의 partition으로 분할
한다. 만약 D 거래에 대한 최소지지도 임계치가 min_sup이면 분할된 거래에 대한 최소품목지지도는
“min_sup x Partition의 거래 수”가 된다. 각 partition에 대하여 이들 각각에 존재하는 모든 항목집
합을 발견하는데 이를 로컬 빈발항목집합이라고 한다. 그런데 로컬 빈발항목집합은 전체 데이터베이스
D에서는 빈발할 수도 있고 그렇지 않을 수도 있다. 모든 partition의 빈발항목집합의 집단은 D에 대한
전역 후보항목집합을 형성하게 된다. 이제 둘째 단계에서 D에 대한 2번째 scan이 수행되고 전역빈발항
목집합을 정하기 위해 각 후보의 실질적 지지도가 평가된다. 아래 그림에서 데이터 분할을 통한 분석 마
이닝 절차를 보여주고 있다.
표본채취: 주어진 데이터의 부분집합에 대해서만 마이닝 작업한다. 즉, 주어진 데이터베이스 D에서 임
의의 표본 S를 취한 후 S에서 빈발항목집합을 탐색하는 것이다. 물론 D에서가 아닌 S에서의 빈발항목집
합 탐색이므로 전역빈발항목집합의 일부가 누락될 수 있는데 이런 위험을 줄이기 위해 S (L2로 표시한
다)에 국한된 빈발항목집합을 탐사하는데 필요한 지지도 임계값을 최소지지도 임계값보다 더 작게 설정
한다. 그런 후 L2에 모든 전역빈발항목집합이 포함되었는지 여부를 판단하게 되는데 L2가 D의 모든 빈
발항목집합을 실제 포함한다면 D에 대해 한번만 scan하면 되고, 그렇지 않다면 누락된 빈발항목집합 탐
색을 위해 두번째 scan을 해야 한다.
동적항목집합 카운팅 (Dynamic itemset counting): 각 DB에 대한 전체 scan 직전에만 새 후보항목
집합을 결정하는 Apriori와 달리 새 후보항목집합을 임의의 시작위치에 추가할 수 있도록 한다. 계산된
전체 항목집합의 지지도를 계산하여 모든 부분집합들이 빈번한 경우에 새 후보항목집합을 추가하므로 동
적이 된다.
빈발패턴 증가 (Frequent-Pattern Growth) 알고리즘
Apriori 에서의 후보집합 생성 및 검사방법에는 다음의 단점이 있다.
엄청난 수의 후보집합 생성이 필요하다.
반복적으로 데이터베이스를 scan하고 대규모 후보집합에 대한 pattern-match 작업이 이루어진다.

31
이에 따라 후보를 생성하지 않으면서도 빈발항목집합을 발견할 수 있도록 하는 노력하게 기울여졌는데
대표적인 것이 빈발패턴 증가18 기법이다. 먼저 원래의 거래 데이터베이스를 압축해서 매우 간결한 데이터
구조 (FP-tree)를 생성한다. 그리고 Apriori 에서와 같이 생성-검사 절차를 통해 고비용으로 후보를
생성하는 대신에 분할정복 형태의 전략을 채택하고 특히 빈발패턴 증가에 주목한다.
다음은 거래 DB 인 D 를 빈발패턴 증가기법을 통해 분석하는 예인데 FP-tree 가 압축된 빈발패턴 정보를
등록하는 모습을 보여주고 있다.19
형성된 트리를 탐색을 하기 위해서는 항목헤더 테이블을 만든 후 각 항목을 node-link 의
연속(chain)으로서 트리 내 해당 노드와 연결시킨다. 그 결과 DB 에서 빈발패턴을 분석하는 문제가 이제는
FP-tree 를 분석하는 문제로 변환되었는데 이는 다음과 같은 방법으로 수행된다. 즉, 길이가 1 인
빈발패턴에서 출발하여 조건부 패턴 (conditional pattern base)20를 생성하고 조건부 FP-tree 를 생성한다.
그리고 이 tree 에 대해 재귀적으로 마이닝한다. 다음 그림은 조건부 (sub-)pattern 을 생성하는 방식으로
FP-tree 를 분석하는 모습이다.
FP 증가 알고리즘은 다음과 같다.
FP-Growth 알고리즘
18 FP Growth 라고 줄여서 부르기도 한다.
19 앞의 Han (외)의 책 3rd edition 의 p258 이하의 예를 인용
20 FP-tree 에서 접미부 패턴과 함께 발생하는 접두부 경로 (prefix path)집합으로 구성되는 subdatabase 이다.

32
(목적)
빈발패턴을 FP-Growth 방식에 의해 찾아냄
(입력항목)
D: 데이터베이스 (FP-tree)
Min_support: 최소지지도 임계치
(출력항목)
* L: D 에서의 빈발항목집합 (frequent itemset)
Method: FP-growth(FP-tree, null).
Procedure FP-growth(Tree, a) {
// single prefix-path FP-tree 의 분석
if Tree contains a single prefix path then {
let P be the single prefix-path part of Tree;
let Q be the multipath part with top branching node replaced by a null root;
for each combination (denoted as ß) of the nodes in the path P do
generate pattern ß ∪ a with support = minimum support of nodes in ß ;
let freq pattern set(P) be the set of patterns so generated;
}
else let Q be Tree;
// multipath FP-tree 의 분석
for each item ai in Q do {
generate pattern ß = ai ∪ a with support = ai .support;
construct ß’s conditional pattern-base and then ß’s conditional FP-tree Tree ß;
if Tree ß ≠ Ø then
call FP-growth(Tree ß , ß);
let freq pattern set(Q) be the set of patterns so generated;
}
return(freq pattern set(P) ∪ freq pattern set(Q) ∪ (freq pattern set(P) × freq
pattern set(Q)))
}
후보 생성 없이 빈발 항목집합을 발견하는 FP-growth 알고리즘의 예
나. 연관규칙의 세부 분석
연관성 규칙을 중심으로 2 개 그룹간의 연관 정도 (degree of association)를 분석하는 것이다. 이를 위해
빈발항목집합을 먼저 찾은 후 A B 형식의 연관규칙을 생성한다. 이러한 규칙들은 최소신뢰도 임계값
(A 를 만족하는 조건에서 B 를 만족하는 확률)도 만족한다.

33
또한 연관규칙은 기준에 따라 여러 유형으로 나뉘어진다.
(1) 규칙에서 다루는 데이터의 값의 종류에 따라
이진 연관규칙–이산형(범주형) 개체들 간의 관계를 보여준다.
정량적 연관규칙 – 동적으로 이산화할 수 있는 수치속성을 가지는 다차원 연관규칙을 말하며 여기에 범
주형 속성도 포함된다.
(2) 규칙에 포함된 차원을 기반으로
1차원 연관규칙 - 하나의 술어 (predicate)와 차원을 가진다
다차원 연관규칙 - 여러 개의 서로 다른 술어와 차원을 가진다.
즉, 1차원 연관규칙은 속성 내 (intraattribute) 관계성이고,
다차원 연관규칙은 속성간 (interattribute) 관계성을 나타낸다.
(3) 규칙에 포함된 항목의 개념계층에 따라
단일계층 연관규칙 – 항목과 술어를 다른 계층에서 고려하지 않는다.
다중계층 연관규칙 - 여러 개의 서로 다른 개념계층을 고려한다.
(4) 상호관련성의 특징에 따라
상관분석 - 상관된 항목들의 존재 유무를 나타낸다.
최빈분석 (max-pattern)
빈발닫힘 항목집합 분석
연관성 규칙에는 유사그룹의 분류 (Affinity grouping)와 규칙귀납 (rule induction)이 대표적인
기법인데 이는대규모 데이터로부터 특정 군집에 반복 출현할 가능성에 대한 규칙을 만들어서 패턴을
식별하는 것이다. 대표적인 예가 상점에서 묶음 상품을 만들어 내는 것, 웹 상에서 추천 시스템 구축 등이다.
다만 이 경우 자칫 수 많은 상품군에서 무한히 많은 조합을 만들어 내는 과정에서 당연한 사실에 대한
중복정보를 생산할 수 있기 때문에 측정기준을 설정하는 것이 필요하다. (예: 시간대별 구매행태의 변화양상
등.)
다층 (多層)연관규칙의 분석
많은 경우 다차원 공간에서 서로 다른 계층 사이의 강한 연관규칙을 찾아내기가 쉽지 않다. 그러나 한
사람에게 당연한 것이 다른 사람에게는 새로운 정보가 될 수도 있으므로 다중 차원의 항목들 간의
연관규칙을 찾는 것이 필요하다. 각 계층마다 최소지지도를 어떻게 정의하는가에 따라 다양한 전략이
가능하다.
하위계층에서 감소된 최소지지도를 사용하는 경우 단일항목에 의한 계층간 여과와 k-항목집합에 의한
계층간 여과에 의해 가지치기를 수행한다.
중복 다중계층 (하향) 연관규칙에 대해서는 지지도와 신뢰도가 자신의 조상규칙을 기반으로 한 기대값에

34
근사한 값을 가진다면 제거가 가능하다.
다음은 Task 관련 데이터 D 이다.21
이들 항목으로부터 다음의 개념체계가 생성되었다.
여기서 하위제품 간의 구매패턴을 찾기란 쉽지 않다. {IBM desktop computer, Sony b/w printer}의
항목집합은 최소지지도를 만족시키기 어렵기 때문인데 대신 ‘sony b/w printer’를 ‘b/w printer’로
일반화하면 이들 간 강한 연관관계가 드러난다. 이처럼 “{IBM desktop computer, b/w printer}”와
{computer, printer}처럼 일반화하면 보다 손쉽게 최소지지도를 만족할 수 있다. 일반적으로는 하향식으로
각 계층에서 빈번한 항목집합을 계산한 후 그 숫자를 누적시켜 나간다.
모든 계층에서 동일한 최소지지도를 사용 (uniform support라고 부름): 모든 계층에서 규칙을 찾아낼
때 동일한 최소지지도 임계값을 사용하여 계산을 단순화 하는 방법이다. 다만, 임계값이 높다면 낮은 계
층에서 일부 연관규칙을 놓치게 되고, 반대로 임계값이 낮다면 불필요하게 많은 규칙이 생성된다는 단점
이 있다.
낮은 계층에서 작은 값의 최소지지도를 사용: 각 계층의 항목들은 그들의 최소지지도 임계값을 가지는데
낮은 계층에서는 상위계층보다 더 작은 지지도를 가진다. 감소된 지지도를 이용하여 규칙을 찾아내기 위
해서는 (i) 계층 마다의 독립성 (level-by-level independence) (ii) 단일항목을 이용한 계층간
21 앞의 Han (외)의 책 2nd edition 의 p250 이하의 예를 인용하였음

35
Filtering, (iii) k-항목집합을 이용한 계층간 연관성 등이 있다.
항목 또는 그룹기반의 최소지지도를 이용한다. 이를 그룹기반 지지도라 부른다.
관계형 DB와 DW에서의 다차원 연관관계 분석
앞서 하나의 술어 (buys)를 가지는 다음과 같은 연관규칙을 보았다.
Buys(X, “IBM desktop computer”) ⇒ buys (X, “Sony b/w printer”)
이러한 규칙을 1 차원 또는 차원 내 (intradimensional) 연관규칙이라고 한다. 그런데 매출관련 정보가
관계형 DB 나 DW 에 있다면 다차원의 성격을 가지게 된다. 이처럼 속성이 DW 차원의 술어인 경우 다음과
같이 다중 술어를 가지는 연관규칙을 분석하는 것이 필요해진다.
age(X, “20 … 29) occupation(X, “student”) ⇒ buys (X, “laptop”)
중복술어를 가지지 않는 다차원 연관규칙을 차원간 연관규칙 (interdimensional association
rule)이라고 한다. 때때로 특정술어가 규칙 내에서 여러 번 발생하여 중복된 술어들을 가지는
다차원연관규칙 마이닝이 이루어지는 경우 이러한 규칙을 혼성차원 연관규칙 이라고 한다. 다음이 그러한
예인데 여기서는 술어 buys 가 중복되어 있다.
age(X, “20 … 29) buys(X, “laptop) ⇒ buys (X, b/w printer)
데이터베이스 속성은 범주형이거나 계량적일 수 있는데 여기서 계량적 속성은 수량을 나타내면서도
명확한 순서를 가지는 것을 말한다. 다차원 연관규칙의 분석 방법은 세가지 기본적인 접근법으로 나뉜다.
첫째 방법: 정량속성을 사전 정의된 개념계층를 사용하여 이산화한다.
둘째 방법: 계량 속성을 데이터 분포를 근거로 “구간”들로 이산화한다.
셋째 방법: 계량적 속성을 구간 데이터의 의미를 나타낼 수 있는 방식으로 이산화 한다. 이와 같은 동적
이산화 과정은 데이터들 간의 거리를 고려하게 되므로 거리기반 연관규칙이라고도 한다.
연관규칙 마이닝으로부터 상관관계 분석으로 이전
강한 연관규칙이라고 해서 모두 유용한 것은 아니다. 이와 관련하여 통계적으로 관련 항목을 분석할 수도
있는데 규칙의 유용성 여부는 주관적으로 결정되기도 하지만 데이터 이면에 숨겨진 통계값을 기반으로
객관적 척도를 얻음으로써 유용하지 않은 규칙을 제거할 수도 있다.
지지도-신뢰도 프레임워크는 실제로 A 의 발생이 B 의 발생에 영향을 미치지 않는데도 불구하고 A⇒ B 를
흥미있는 규칙으로 잘못 유도할 수 있다. 이를 해결하기 위해서는 상관관계를 파악하는 상관규칙 분석이
필요해진다. 상관규칙은 {i1, i2, …, im}의 형태로 표현되는데 이는 {i1, i2, …, im} 들의 발생이 서로

36
관련성이 가지고 있음을 의미한다. 그리고 이러한 상관정도를 나타내는 척도로는 다음의 몇가지가 이용되고
있다.
(1) Lift
(2) 척도
(3) all_confindence 척도
(4) cosine 척도
제약 기반의 연관패턴 분석
제약기반 마이닝은 사용자가 제시한 제약조건에 따라 규칙탐색 프로세스가 진행되도록 하는 것이다.
제약조건의 종류는 다음과 같다.
지식 종류 제약: 연관과 같이 마이닝할 지식의 종류를 지정한다.
데이터 제약: 작업관련 데이터 집합을 정의한다.
차원/계층 제약: 데이터의 차원이나 개념계층에서의 계층을 지정한다.
흥미도 제약: 지지도나 신뢰도와 같이 규칙 흥미도에 대한 통계적 임계값을 설정한다.
규칙제약: 발견되는 규칙의 형태를 지정하며 규칙의 선행조건부와 결과부의 술어의 최대/최소 개수, 속
성 간의 관계, 속성값이나 집계 등을 사용한 메타규칙 (규칙 template)을 이용해 표시된다.
(4) 분류 (Classification)
분류는 데이터에 대한 class label 이 없는 상태에서 자동으로 이들을 분류하는 것을 말한다. 분류와
예측은 데이터 class 를 서술하는 모델을 추출하여 항후 데이터의 추세를 예측할 수 있게 해 준다는 공통점을
가진다. 단지 분류는 범주형 레이블22 내지 범주형 class 을 예측 대상으로 하는 반면 예측은 연속형 속성에
22 categorical (discrete, unordered) labels,

37
대한 함수형태의 모델을 설정한다는 차이가 있을 뿐이다. 즉, 분류는 이산치나 명목형 값을 예측하는 반면
예측모델은 연속적이거나 정렬된 데이터 값을 예측하는데 사용한다.
예를 들어 분류모델에서 은행이 대출심사를 하면서 대출해도 안전한지를 구분한다면, 예측모델에서는
특정 고객군의 주택소비가 앞으로 일정 기간 동안 어떻게 변화할 것인지를 예측하는 식이다
대표적인 분류기법에는 다음과 같은 것들이 있다.
의사결정 및 의사결정트리
CART(classification and regression tree)
회귀분석과 Logistic 회귀분석
베이지언 (Bayesian) 분류와 단순 베이지언 (Naïve Bayesian)
SVM (Scalable Vector Machine)
K-NN(k-nearest neighbor)
규칙 기반의 분류와 사례기반추론(case based reasoning)
가. 분류 작업 개요
데이터 분류는 통상 다음과 같은 단계로 진행한다.
(1) 분류 및 예측을 위한 데이터의 준비작업
예측 정확성, 효율성 등을 향상시키기 위한 전처리(前處理) 를 말한다.
데이터 정제
관련성 (Relevance) 분석: 데이터의 많은 속성들이 분류작업과 무관하거나 중복될 수 있으므로 이를 제
거하는 것을 말한다. 기계학습에서는 이 단계를 특성선택 (feature selection)이라 부른다.
데이터 변환과 데이터 축소: 데이터를 상위계층 개념으로 일반화하기 위해 개념계층을 이용하거나 신경
망 또는 거리척도로 정규화한다.
(2) 모델 구축
여기서는 사전 정의된 데이터 class 혹은 개념집합을 서술하는 모델을 구축한다. 이 모델은 속성으로
서술된 DB tuple23들을 분석해서 생성된다. 모델 구축을 위해서 데이터를 분석하는 경우 이들 데이터
tuple 들을 훈련데이터집합 (training data set)이라 하고 이때 훈련 데이터집합을 구성하는 개별
tuple 들을 훈련 데이터 또는 훈련 샘플이라 한다. 이들 훈련 샘플은 같은 모집단으로부터 무작위 선택된다.
한편 모델의 학습은 다음 두 가지로 나누어 볼 수 있다.
23 분류영역에서 data tuple 들을 표본(sample), 예제(example), 객체라고도 부른다.

38
감독(supervised) 학습 – 훈련샘플이 속하는 class가 제공된다. 훈련 데이터와 이에 대한 class가 제
공되면 이를 기반으로 모델을 생성하고 이에 의거하여 새 데이터를 예측한다. SVM, LDA, KNN,
Decision Tree, Neural Network, Naïve Bayes 등이 있다.
무감독 (unsupervised) 학습 - 각 훈련샘플이 속하는 class label이 제공되지 않으며 사례학습 결과에
따른 class의 수나 집합이 알려져 있지 않은 것을 의미한다.
(3) 모델을 이용하여 분류작업 진행
모델 (classifier)의 예측 정확도를 추정한다. 여기서 모델의 정확도란 그 모델에 의해 분류되는 것들중
정확하게 분류된 항목의 백분율로서 측정하는데 이 평가결과는 학습된 모델이 데이터에 과잉적합되는
경향이 있으므로 주의할 필요가 있다.
모델 정확도가 확인된 후 이를 이용해서 새로운 데이터 tuple (또는 class label 이 알려져 있지 않은
객체)을 분류하게 된다.
다음 그림이 그 과정을 보여준다.
(a) 학습 단계: 훈련데이터를 분류 알고리즘을 통해 분석한다. 그림에서는 대출의사결정이 class label
속성이 되고, 분류 규칙이 분리기 (classifier 또는 학습모델: learned model)이다.
(b) 분류(Classification)단계: 테스트 데이터를 통해 분류규칙이 제대로 되었는지 검사하고 만족스러울
때 새 데이터를 적용하여 이용한다.

39
나. KNN (K Nearest Neighbors)
KNN 분석은 분류할 때 category 분류 중 많이 속한 곳에 배정하는 것을 말한다. KNN 은 'nearest
neighbors(NN)' 기법을 개량한 것이다. NN 기법은 새로운 항목을 분류할 때 가장 유사한 instance 를
찾아서 그와 같은 class 에 일방적으로 분류했기 때문에 잡음 섞인 데이터에는 성능이 좋지 못했었다. 이를
보완하기 위한 KNN 은 NN 과 달리, 가장 근접한 k 개 데이터에 대한 다수결 내지 가중합계의 방식으로
분류를 한다.
단점으로는 모수(parameter)가 적용되는 대부분 모델들이 그렇듯, KNN 역시 모수 k 를 정하는 것이
쉽지 않다. 통상 여러 k 값에 대해 모델링을 한 후, 가장 성능이 좋은 모델의 k 값을 선택하게 된다.
(데이터가 노이즈가 심할 수록 k 값이 큰 것으로 알려져 있다.)
한편 공간정보 예측모델에서는 특정 이벤트의 발생은 일정하지도 않고 그렇다고 무작위적인 것도
아니라고 본다. 즉, 공간상의 요인, 사회문화적, 지형학적 등 제반 요인들이 영향을 준다는 것이다. 공간예측
모델에서는 geographic filter 를 통해 이들 영향 주는 것들과 제약사항을 모델로 표현하고 이를 예측에
활용한다.
KNN 의 목적은 속성(attribute)과 훈련표본에 근거하여 새로운 항목을 분류하는 것인데 질의항목과
훈련데이터 사이의 거리를 통해 판단하는데 KNN 알고리즘의 데이터는 Xi 라는 여러 개의 다변량 속성으로
구성되며 이를 이용해서 Y 를 분류한다. 즉, KNN 을 수집하고 여기서 단지 다수의 것(majority)만을
예측치로서 채택하게 된다.
예를 중심으로 살펴 본다.
(가정) A 라는 제품의 품질검사를 (a) 성분함량과 (b) 강도측정 이라는 2 개 속성을 중심으로 판단한다고
가정한다. 다음은 4 개의 훈련 데이터 샘플이다.

40
(과제) 새 시제품의 검사결과가 x1= 3, x2=7 에 대해 이를 합격
또는 불합격으로 분류하고자 한다.
이 데이터를 좌표상에 표시하면 다음과 같다.
만약 파라미터가 k=8 로 주어졌다면 이는 곧 가장 가까운 8 개의 이웃을 참조하는 의미로서 항목별
좌표를 기준으로 질의항목과 훈련데이터의 거리를 구하고24 이를 정렬한 후 지정된 K 번째 까지의 최소
거리범위 내에 있는 것만 nearest neighbor 로 포함시킨다. 위 예의 경우 다음 표에 nearest 열에 (+) 또는
(-) 표시가 된 항목이 8 개의 Nearest Neighbor 이다.
24 문제의 상황에 맞추어 여러 거리개념을 적용할 수 있고 필요 시 가중치를 메길수도 있다. 여기서는 가장 간단하게
Euclidean distance 를 적용한다.

41
이제 이들 Nearest Neighbor 의 표시부호 중 다수를 이루는 것이 (–) 이므로 여기서는 (-)가 선정된다.
KNN알고리즘 요약
KNN 알고리즘의 동작원리는 다음과 같이 간략화 할 수 있다.
** 각각의 훈련샘플항목 <x,f(x)>을 훈련샘플 리스트에 넣는다.
** 분류할 대상이 되는 질의항목 Xq 가 주어지면
X1, X2, ..., Xk 를 주어진 파라미터 k 개의 근접항목으로 표시한 후
이들이 가장 많이 표시하는 class 의 내용으로 분류한다.
고려할 사항
그러나 실제 응용단계에서는 고려할 사항이 많이 있다.
거리척도 문제 – 산술적 유클리드거리 외에도 상황에 맞추어 Minowski 를 비롯한 다양한 거리를
적용할 수 있다. 25
차원 복잡도 문제 – 모든 속성이 거리에 영향을 주며 특히 직접 관련되지 않은 속성들로 인해
엉뚱한 class 로 분류되는 경우 이를 '차원의 저주(curse of dimensionality)'라고 한다.
장점
훈련 데이터에 잡음이 있는 경우에도 적용이 가능하다.
훈련 데이터의 크기가 클 경우 효과적이다
단점
25 3. 주요분석기법 ▶ (5) 군집이론 ▶ 나. 군집분석에서의 데이터 유형 ▶ 구간척도변수 에 다양한 거리개념이 소개되었다

42
K 파라미터 값 및 거리 개념의 선택이 중요한 영향을 미친다.
모든 훈련 샘플과의 거리를 구해야 하므로 계산비용이 높다.
KNN과 Hadoop 적용
이러한 KNN 는 평활화를 통한 내삽(interpolation))과 예측 (즉, 외삽=extrapolation)에도 사용할 수
있다. 분류 시에는 종속변수 Y 가 범주형 데이터였지만 이 경우에는 정량 데이터가 될 것이다. 아울러
KNN 이 대량 데이터를 대상으로 할 때 성능개선을 목적으로 Hadoop 에 적용되는 사례가 늘어나고 있다.
우선 기본 알고리즘을 정리해 본다.
(목적) KNN 알고리즘을 MapReduce 에 적용
Map()
(입력항목)
All points
Query point P
(출력항목)
KNN (local)
Emit te k closest pin
- - - - - - - - - - - - - -
Reduce()
(입력항목)
Key: null
Values: local neighbot
Query point P
(출력항목)
KNN (global)
Emit the k closest points to P among all local neighbors
한편 KNN 의 Hadoop 적용과 관련한 흥미로운 사례로 H-zkNNJ MapReduce 을 참조할 만 하다. 다음은
그 수행도이다.26
26 http://www.cs.utah.edu/~lifeifei/papers/mrknnj.pdf
또한 KNN Join 의 다양한 병렬처리 방법에 대해서는 같은 저자의 다음 자료를 참조할 것.
http://ww2.cs.fsu.edu/~czhang/knnjedbt/knnslides.pdf

43
1단계
2단계

44
다. 의사결정트리 귀납 (Decision Tree Induction)
의사결정트리를 하나의 예측모델로 삼아서 관측치를 가지고 목표변수의 값 (target value)을 예상해 내는
것을 의사결정 귀납방법론 또는 의사결정트리 학습 (Decision tree learning)라고 한다. 27 원래
의사결정트리가 의사결정 규칙을 도표화하고 트리구조로 추론규칙을 표현하므로 이 방법은 이해와 설명이
용이하다는 장점이 있다.
하나의 트리를 학습하기 위해서는 소스 집합을 속성값을 기준으로하여 node 를 여러 개 하위집합으로
반복적으로 나누어 나간다. 하향식 DTI (TDIDT: top-dwn induction of decision trees)가 대표적인
기법이다.
의사결정트리 분석의 단계
분석작업이 한번에 끝나지 않는 경우에는 반복적으로 수행하여 다양한 의사결정트리를 얻고 비교
검토한다. 이 과정에서 분리기준, 정지규칙, 평가기준등을 어떻게 적용하느냐에 따라 의사결정트리가
다르게 형성된다. 이산형 목표변수에 사용되는 분리기준은 다음과 같다.
χ2 의 P 값: P 값이 작은 예측변수와 그 때의 최적분리에 의해서 마디를 형성
지니 (Gini) 지수: 불순도를 측정하는 지수로서 지니지수를 감소시키는 예측변수와 그 때의 최적분리에
의해서 자식마디를 선택한다.
엔트로피 지수
연속형 목표 변수에 사용되는 분리기준은 다음과 같다.
F 통계량: P값이 작은 예측변수와 그 최적분리에 의해 자식마디 형성
분산의 감소량: 예측오차를 최소화하는 것과 마찬가지로 분의 감소량을 최대화하는 최적분리
27 분류트리 (classification trees )라고 부르는 사람도 있다.

45
의사결정트리 귀납방법론의 기본전략
1980 년대 초 Hunt 이론을 확장하여 ID3 알고리즘이 제시되었다. 또한 1984 년에는
CART(Classification and Regression Trees) 알고리즘을이 제시되었다. 이들 2 개 알고리즘을 기반으로
하여 수 많은 응용 알고리즘이 탄생했는데 특히 ID3, C4.5, CART 등은 역계산을 할 수 없도록 하는
하향재귀형 (top-down recursive) greedy 모델을 채택하였다.
의사결정트리 귀납 알고리즘의 기본 전략은 다음과 같다.
Tree는 훈련샘플들을 나타내는 단일 node로 시작한다.
샘플이 같은 class라면 node는 잎이 되고 해당 class로 label을 부여한다.
그렇지 않다면 정보이득의 정도를 기준으로 각 class로 가장 분리가 잘되는 속성을 선택하기 위해
heuristic한 방법을 사용한다. 이 속성은 그 node에서 “검사” 또는 “의사결정” 속성이 된다.
가지는 검사속성의 값에 대해 각각 생성되고 샘플은 적절하게분할한다.
분할된 각 샘플에 대한 의사결정트리를 형성하기 위해 동일한 과정이 재귀적으로 수행된다.
아래는 훈련 레코드에서 의사결정트리를 유도하는 귀납 알고리즘이다.
의사결정트리 귀납 (Decision Tree Induction) 알고리즘
(목적)
훈련데이터로부터 의사결정트리를 생성.
(입력항목)
D: Data partition. (이는 훈련데이터 및 이와 관련된 class label 의 집합)
속성 list. (즉, 후보 속성의 집합)
속성선택 method 의 지정.
(데이터를 class 별로 가장 잘 분리시키는 기준을 정하는 procedure)
(출력항목)
의사결정 트리
(Method)
create a node N;
if tuples in D are all of the same class, C then
return N as a leaf node labeled with the class C;
// 과반수 투표 결정
if attribute list is empty then
return N as a leaf node labeled with the majority class in D;
apply Attribute selection method(D, attribute list) to find the “best” splitting criterion;
label node N with splitting criterion;

46
if splitting attribute is discrete-valued and
multiway splits allowed then
// 이진트리에만 한정되지 않는다
attribute list attribute list splitting attribute; // splitting 속성을 제거
for each outcome j of splitting criterion
// 데이터 tuple 을 분리(partition)하고 각각의 partition 에 대해 subtree 를
생성시킨다
let Dj be the set of data tuples in D satisfying outcome j; // a partition
if Dj is empty then
attach a leaf labeled with the majority class in D to node N;
else attach the node returned by Generate decision tree(Dj, attribute list) to node
N;
endfor
return N;
속성 선택 방법
분리규칙 (splitting rules)을 속성선택이라고도 하는데 이는 class 로 이름붙여진 tuple 을 각각의
class 로 분리시키는 것을 말한다. D 를 보다 작은 parition 으로 분할하는 경우 이들이 순수한 상태를
유지하게 하는 것이 좋다. 여기서 순수한 상태란 한 parition 에 속하는 tuple 들이 역시 동일한 class 에
속하는 것을 말한다. 속성선택을 위한 척도를 이용해서 훈련용 tuple 에 대한 각각의 속성에 대해 등급을
매길 수 있게 된다. 분리 속성이 연속값 또는 이진값이라면 분리점 또는 분리 집합 역시 분리기준의 하나로
결정되어야 한다.
범주형 변수에 대한 분할을 평가하는 순수성 척도는 다음과 같다.
Gini (모집단 다양성이라고도 부름)
Entropy (정보이득 이라고도 부름)
정보이득 비율
카이제곱 ( )검정
수치형 목표변수에 대해 흔히 사용되는 척도는 다음과 같다.
분산도의 감소
F 검정
여기서는 (i)정보이득 (ii) Gain 비율 (iii) gini 계수의 3 개의 대표적인 속성선택 척도를 살펴본다. 설명의
편의상 다음 표기를 가정한다. 즉, S 는 s 개의 표본데이터를 가지는 집합이고 class label 속성은 m 개의
상이한 클래스 Ci(i=1,2,…, m)을 정의한다고 가정하고 주어진 샘플을 분류하는데 요구되는 기대정보량울
각 이론체계 속에서 살펴본다.

47
정보이득
ID3 알고리즘은 정보이득 개념을 통해 속성을 선택한다. 28 노드 N 이 D 파티션의 tuple 이라고 가정한 후
정보이득이 가장 큰 속성을 노드 N 에 대한 분리속성 (splitting attribute)으로 선정한다. 이 경우 이 속성은
결과적으로 만들어지는 파티션 내에서 정보를 분류하는데 필요한 정보의 양을 최소화하고 이들 파티션
내에서의 불순도 내지 최소 임의성 (least randomness)을 반영하게 된다. D 내의 tuple 을 분류하는데
필요한 기대정보는 다음과 같다.
단, pi는 D 에서의 임의의 tuple 이 Ci class 에 속할 확률로서 |Ci,D| / |D| 를 통해 추정된다. 여기서
Info(D) 를 D 의 entropy 라고 한다.
한편 실제 세계에서는 각각의 파티션이 불순할 확률이 훨씬 크므로 정확한 분류를 이루기 위한
정보필요양은 다음과 같이 수정된다.
이제 정보이득이란 class 의 비율에 의거한 원래의 정보요구량과 A 에 대한 분할이후 얻어진 새로운
요구량과의 차이로 정의된다.
즉, Gain(A)는 속성 A 의 값을 알고 있음에 따른 entropy 의 기대감소량이며 각 속성의 정보이득을
계산하고 최대 기대정보량이 가지는 속성이 주어진 집합 S 에 대한 검사속성으로 선택된다.
이득 (Gain) 비율
정보이득은 빈도가 큰 쪽으로 bias 가 생긴다. C4.5 알고리즘은 Gain 비율을 이용하는데 여기서는
정보이득에 대한 정규화 방법을 적용한다. 구체적으로 분리정보값을 다음과 같이 정의한다.
이 값은 훈련 데이터셋 D 를 v 개 파티션으로 분리함에 따라 생성되는 잠재정보를 나타낸다. Gain 비율은
다음과 같이 정의된다.
28 정보이득은 원래 Claude Shannon 의 정보이론에 근거를 두어 개발되었다. Shannon 의 정보이론은 메시지 내의
“정보컨텐츠”를 중심으로 한 것이다.

48
그리고 Gain 비율이 가장 큰 속성이 분리 속성(splitting attribute) 으로 선정된다.
Gini 지수
Gini 지수는 CART 알고리즘에서 이용되며 D 의 불순도를 측정한다.
단, pi는 D 에서 임의 tuple 이 Ci 클래스에 속할 확률로서 |Ci,D| / |D| 로 추정된다.
Gini와 Entropy를 이용한 의사결정트리 분할의 예29
단순한 예를 통해 의사결정트리에서의 분할 이용을 살펴 본다.
이진변수에서는 순수도가 높은 것이 좋은 분할이다
(상황)
위 그림에서 부모노드는 흰색과 검은 색의 점을 각각 10 개씩 가지고 있다. 자식 노드의 경우 왼쪽에서는
9 개의 검은색과 한 개의 흰색 점을, 그리고 오른쪽에서는 9 개의 흰색점과 한 개의 검은색 점을 가지고 있다.
(Gini 척도)
Gini 척도는 class 비율의 제곱의 합으로 계산하며 앞서의 부모노드의 경우 흰색과 검은 색의 숫자가
동일하므로
Gini 값 = 0.52 + 0.52 = 0.5
반면 분할 이후의 각각의 노드에 대한 지니점수는
0.12 + 0.92 = 0.82 이다.
(Entropy 감소 즉, 정보이득)
위 그림과 관련하여 분할 이전의 노드의 엔트로피는
29 Berry & Linoff, ‘Data Mining Techniques’’, 2004 pp. 177~182 를 요약 및 수정

49
-1 x {P(검은 색) x log2P(검은 색) + P(흰 색) x log2P(흰 색) }
= -1 {0.5 x log20.5 + 0.5 x log20.5 }
분할 후의 노드들의 엔트로피는
-1 {0.1 x log20.1 + 0.9 x log20.9} = 0.33 + 0.14 = 0.47
이제 조금 현실에 근접한 형태를 살펴 본다. 앞서의 그림과 조금 다른 2 가지의 의사결정트리가
제시되었는데 이를 Gini 와 엔트로피라는 두가지 척도를 이용해서 어떤 것이 보다 나은 분할인지를 평가해
본다.
<Gini 를 이용하는 경우>
첫번째 것은 앞서 본 바와 같이
분할에 대한 Gini 점수는 = 0.12 + 0.92 = 0.82
두번째 것은
왼쪽은 = 1 (왜냐하면 검은 색 100%)이고
오른쪽의 Gini 점수
Giniright = (4/14)2 + (10/14)2 = 0.082 + ).510 = 0.592
분할에 대한 Gini 점수는
= (6/20) Ginileft + (14/20) Giniright
= 0.3 x 1 + 0.7 x x0.592 = 0.714
첫째 분할 Gini 점수 (0.82) > 둘째 분할 Gini 점수 (0.714) 이므로 결국 첫번째 분할이 더욱 좋다고
판단된다.
<Entropy 를 이용하는 경우>
부모노드의 entropy 는 1 이다.

50
첫번 째 분할에 대한 entropy 는 앞서 계산된 바와 같이 0.47 이므로 첫번 째 분할에 대한 정보이득 값은
1-0.47 = 0.53
두번 째 분할에 대한 entropy 를 보면
왼쪽 child 는 순수(pure)하므로 엔트로피 = 0
오른쪽 child 는 -(P(dark)log2P(dark) + P(light)log2P(light))
이를 계산하면
Entropyright = -((4/14)log2(4/14) + (10/14)log2(10/14))
= 0.516 + 0.347 = 0.863
분할에 대한 엔트로피는 산출된 노드들 각각에 대한 entropy 의 가중합이므로
0.3*Entropyleft + 0.7*Entropyright
= 0.3*0 + 0.7*0.863 = 0.604
부모노드의 entropy 값 1 - 0.604 = 0.396 즉, 정보이득 값은 0.396
이것은 0.53 보다 작으므로 더 바람직한 것으로 판단된다.
entropy 분할기준에 의해서도 이 수치가 작을 수록 순수한 것으로서 바람직하다고 평가받기 때문이다.
가지치기 (Tree Pruning)
의사결정트리가 만들어질 때 잡음과 이상치로 인해 많은 가지들에 훈련 데이터의 이상(異狀)이 반영되게
된다. 트리 가지치기는 신뢰도가 낮은 가지들을 제거하는 것을 말한다. 가지치기 작업에는 사전 가지치기와
사후 가지치기의 2 가지 접근법이 있고 이 두 가지는 혼용이 가능하다.
(1) 사전 가지치기 (Prepruning)
트리가 생성되는 초기에 수행되는 것으로서 가지치기가 정지되면 그 노드는 잎이 된다. 트리를 생성할 때
정보이득, 통계적 유의성, χ2 등을 사용하여 분기의 적합성을 평가할 수 있다.
(2) 사후 가지치기 (postpruning)
모두 완성된 트에서 가지를 제거해 나가는 것이다. 대표적인 것이 CART 알고리즘인데 여기서는 사용하는
비용복잡도에 의거하여 가지치기를 한다.
구체적인 가지치기 알고리즘은 다양하다. C4.5 알고리즘에서는 pessimistic 가지치기 알고리즘을
이용하고 이 밖에도 MDL (Minimum Description Length, 최소서술길이) 기준 등의 여러 방법이 있다..
의사결정 귀납 (Decision Tree Induction)의 확장
최근 확장된 알고리즘이 개발되어 이용되고 있다.
SLIQ – 속성 리스트를 디스크에 저정한 후 메모리 상주 class 리스트를 이용한다

51
SPRINT – 서로 다른 속성 리스트의 데이터 구조를 이용하며 여기에는 class와 RID 정보가 수록된다.
의사결정 귀납 (Decision Tree Induction)법의 세부기법
앞서 보았듯 다양한 의사결정트리 기법 중 대표적인 것은 다음과 같다.
ID3 (Iterative Dichotomiser 3)
C4.5 (successor of ID3)
CART (Classification And Regression Tree) - CART 는 비모수적 (non-parametric)
의사결정트리 학습기법이다.
CHAID (CHi-squared Automatic Interaction Detector) - 원래 χ2 에 기반하여 변수 간의
통계적 관계를 찾는 데 사용되었으나 이를 의사결정트리를 통해 분류기법에도 많이
사용된다.
이하에서는 이중 CART 만을 간단히 살펴본다.
CART (Classification And Regression Test)
전체 데이터서 시작하여 반복해서 2 개의 자식노드를 생성하기 위해 모든 예측변수를 사용하여
데이터셋의 부분집합을 쪼갬으로써 의사결정트리를 생성한다.
CART 에는 다음의 2 가지가 포함된다.
종속변수가 카테고리형인 경우 분류 의사결정트리를 산출한다.
종속변수가 수치형인 경우 회귀분석트리를 산출한다.
--
CART 알고리즘은 일련의 질문을 던지고 그에 대한 대답에 따라 다음 질문이 제시된다. 그리고 최종적으로
더 이상의 질문이 없는 상태가 되었을 때 종단 노드가 된다. 결국 CART 의 핵심은 다음과 같다.
① 변수 값에 따라 데이터를 분리시키는 규칙 (Splitting Rule)의 결정

52
② 추가 질문을 할지 또는 종단노드로 할지를 결정하는 중단규칙 (Stopping rule)의 결정
③ 종단노드에서의 목표변수(target variable)에 대한 예측.
다음은 의사결정트리를 예측활동에 이용한 예이다.
위 그림에서는 2008 년의 미국의 민주당 후보 선거에서 오바마 후보가 대부분의 교육수준이 높거나 흑인
우세의 자치주에서 우세하고 힐러리 클링턴은 교육수준이 높지 않은 백인 우세지역에서 우세함을
분석적으로 보여주고 있다.
라. Bayes 이론
Bayesian 분류기는 통계적 분리기로서 Bayesian 이론에 기반하고 있으며 단순 베이지언 분류기 (naive
Bayesian classifier)에서는 주어진 클래스의 한 속성 값이 다른 속성의 값과 상호 독립적이라고 가정한다.
베지지언 신뢰네트워크 (Bayesian belief networks)는 속성의 부분집합이 가지는 종속관계를 표현하는
그래픽 모델이다.

53
Bayes’ 정리(整理)
베이즈의 법칙의 핵심은 사전확률 P(A)과 우도확률30 P(B|A)를 안다면 사후확률 P(A|B)를 알 수 있다는
것이다.
즉 사건이 발생하고 난 후, 사건발생의 원인에 대한 확률(사후)을 사건발생 전에 이미 알고 있는
정보(사전)를 이용하여 구하는 것으로서 주요 개념을 먼저 살펴 본다.
사전확률: A(원인)가 발생할 확률 P(A)와 같이 결과가 나타나기 전에 결정되어 있는 확률이다. 즉, 사
건발생 전에 사건의 원인이 될 수 있는 사건들에 관한 분포를 의미
사후확률: 사후확률은 B(결과)가 발생하였다는 조건하에서 A(원인)가 발생하였을 확률을 나타낸다.
우도확률(likelihood probability): A (원인)가 발생하였다는 조건하에서 B(결과)가 발생할 확률
P(B|A)을 나타낸다.
베이지안 이론은 특정한 사건이 발생한 후 그 사건의 원인이 될 수 있는 사건들에 대한 사전확률분포를
이용하여 사후에 원인이 될 수 있는 사건들에 관한 사후확률분포를 도출하는 방법을 말한다.
베이즈의 법칙(Bayes’ Law)
결과 B 를 발생시키는 원인들이 A1, A2, …, Ak 라고 할 떄 사전확률 P(A1), P(A2), …, P(Ak) 과 우도확률
P(B|A1), P(B|A2),…, P(B|Ak) 가 알려져 있다면 사후확률 즉 결과 B 가 발생하였다는 조건 하에서 원인 Ai
가 발생하였을 확률은 다음과 같다.
이를 정리하면 사후확률을 사전확률들과 우도확률들로 나타낼 수 있는데 결국 사전(prior)확률을 이용해
사후(posterior)확률을 추정하는 것이며 확률법칙(덧셈.곱셈법칙)에 따라 다음과 같이 정리된다.
30 우도(尤度, likelihood)확률은 가능도(可能度)를 뜻힌다
P(A|B) = P(B) = P(A)P(B|A) + P(A)P(B|A) + P( A )P(B| A )
Bayes 정리(情理) P(A|B) =

54
단순 베이즈 분류 기법
분류 작업 시 베이즈 규칙을 자주 사용하는데 그 이유는 조건부 확률을 구하는 것이 용이해지기 때문이다.
분류를 위해 d 를 입력 문서라 하고 c 를 분류할 Class 중 하나라 한다면 다음과 같이 표현할 수 있다.
분류가 여러 개일 때는 각 class 에 대해 해당 조건부 확률을 계산할 수 있는데 입력 문서는 고정되어
있으므로 가장 높은 확률을 가지는 부류가 해당 문서가 속할 부류가 된다. 31
입력 문서는 여러 단어로 이루어져 있으며 단어의 수가 n 이라 할 때 P(d|c)는 다음과 같이 변형이
가능하다.
단순 베이지언 분류기는 이 베이즈 규칙에다 각 단어가 부류에 독립적이라는 가정을 추가함으로써 변형된
조건부 확률을 계산하여 분류한다. 결국 최종 단순 베이지언 분류 식은 다음과 같다.
베이지언 신뢰 네트워크 (Bayesian Belief Networks)
베이지언 신뢰네트워크는 사건들 사이의 인과관계 및 random 변수들 사이의 관계를 그림 또는 수학적
모델로 나타내 주며 나아가 인과관계의 정도를 연결조건 확률분포 (CPT: conditional probability)의
행렬표로 표현하도록 한다. 이에 따라 변수의 부분집합들 간에 class 조건독립이 정의될 수 있는데 이것은
또한 인과관계를 표현하는 그래픽 모델을 통해 학습할 수도 있다.
달리 말하자면 베이지안 신뢰 네트워크는 비순환 방향성 그래프(DAG: directed acyclic graph) 를
통해서 확률 변수 및 그들의 조건 관계를 표현하는 일종의 확률 그래프 모델이라 하겠다.
31 max(f(x))는 f(x)의 최대값, arg max(f(x))는 f(x)를 최대로 만드는 x 값을 뜻한다. 마찬가지로 min(f(x))는 f(x)의
최소값, arg min(f(x))는 f(x)를 최소로 만드는 x값을 뜻한다. 즉, arg max 는 argument of the maximum 으로 이해할 수
있겠다.

55
한편 네트워크 구조에 대한 정보는 미리 주어질 수도 있고 또는 데이터로부터 추론될 수도 있다. 즉,
네트워크 변수를 훈련 표본으로부터 관찰할 수 있는데 이 경우 네트워크를 훈련시키는 것은 그리 어렵지
않다. 이 과정은 단순 베이지언 분류에서 확률 계산할 때와 마찬가지로 CPT 항목의 값을 계산하면 된다.
네트워크 구조가 주어졌지만 변수에 대한 정보가 누락된 경우에는 미분 감소 (gradient descent) 방식을
이용하여 신뢰네트워크를 훈련시킬 수 있다. 학습의 목적은 CPT 의 값들을 학습하는 것이다. 미분 감소
전략은 소위 “탐욕스런 언덕 오르기 (greedy hill-climbing)”를 수행하는데 가중치를 갱신하면서 작업을
반복함으로써 결국은 지역 최적화로 수렴해 나가는 것이다. 다음과 같은 방식으로 알고리즘이 진행된다.
① 미분계산
② 미분방향으로 한 발짝 진행
③ 가중치를 재 정규화
아래에서 다른 예를 들어 살펴 본다.
잔디밭을 젖게 하는 2 가지 event 가 비와 살수장치(스프링클러)라고 하자. 즉,
비가 내리면 잔디가 젖는다. 또한 비가 내림에 따라 스프링클러 (살수
소화장치)가 가동되고 그에 따라 다시 잔디가 젖어 들게 된다.
(질문) 잔디밭이 젖어 있다면 비가 오고 있을 확률은 얼마나 되는가?
비가 오거나 살수장치가 동작하는 등의 상태에 따라 그 값을 참(T: true)과 거짓 (F: false)로 나눈다면
동시확률함수는 다음과 같이 정의될 수 있다. 단, 편의상 변수 이름은: G: Grass wet (잔디밭), S:
Sprinkler (살수장치), R: Rain (비)로 표기한다.
이를 계산하면

56
마. 신경망을 이용한 역전파(逆傳播) 분류기법
신경망은 인간의 두뇌활동을 본 따서 패턴을 탐지탐지하고 경험에 기반하여 학습과 예측을 하도록 하는
기법이다. 일반적으로 수학적 정의가 명확치 않는 문제들을 순차 계산하면 시간이 많이 소요된다.
그런데 인간의 뇌는 신경세포(뉴런, neuron)가 세포체와 수상돌기, 축색돌기 등의 신경섬유로 구성되어
정보를 처리하고 전달한다. 바로 이 점에 착안하여 모방 구현한 것이 신경망인데 대규모 병렬처리가
가능해서 자료들 간의 관계를 파악하는 종합적 작업에 유리하다. 다만 아직 인간과 같은 직관력은 없으므로
한번에 하나씩만 학습한다는 한계가 있다. 신경망에서 얻어진 결과는 설명이나 해석이 쉽지 않아서 그
과정을 블랙박스로 처리하는 경우가 적지 않다. 이는 해답은 있는데 그 도출과정을 명확히 추적하기 어려울
수 있다는 뜻이다.
그러므로 입력변수 및 예상변수에 대해 어느 정도 그 내용과 성격을 잘 이해하고 있을 때 또는
모델링하고자 하는 것이 무엇인지와 그 업무에 대해 잘 알고 있을 때 사용하는 것이 좋다.
신경망은 일종의 임의예측 (random prediction)을 한 후 이에 대해 데이터 각각을 적용시키고
체계적으로 업데이트해 나가는 방식으로 학습을 시킨다. 클러스터링 기법 등을 중심으로 한 자율학습으로서
흔히 사기탐지, 신용평가, 상권분석 등에 많이 이용된다.
인공신경망은 입력층 (input layer), 출력층 (output layer) 그릭 하나 이상의 은닉층 (hidden
layer)으로 구성되어있다. 각 층은 다수의 유닛 혹은 뉴런으로 구성되어있고 각 층의 뉴런은 수정 가능한
연결 가중치로 다른 층의 뉴런과 연결되어있다. 인공신경망에서의 하나의 뉴런은 생물학적 신경망에서의
하나의 생물학적 신경세포의 역할을 한다.
신경망의 이용에는 데이터 표준화가 중요하다. 민감도 분석을 통해 입력변수의 상대적 중요성을 이해할 수
있으며 데이터 상호간의 관계가 복잡할 때는 그 관계를 체계적으로 분석하는 것이 중요하다.
또한 신경망 모델은 일종의 블랙박스로 동작하며 여러 입력변수를 선택해서 이들 관계를 찾아내는 등의
수학적 모델의 정립이 중요하다. 신경망 기법은 이미 많은 상용 및 오프소스 S/W 에 모듈형태로 구현되어
비교적 손쉽게 적용할 수 있다.
다계층 전방향 (Multilayer Feed-Forward)신경네트워크
역전파(Backpropagation) 는 알고리즘을 학습해 나가는 신경망을 말한다. 신경망은 입출력 단위들의
집합으로서 이들의 각 연결점이 가중치를 가지도록 하고 있다. 그리고 학습단계에서 입력 표본들의 정확한
class label 을 예측할 수 있도록 가중치를 조절해 나가게 된다.32
32 신경망 학습은 node 들 간의 연결을 중시하므로 이를 연결자 학습 (connectionist learning)이라고 부르기도 한다.

57
역전파 는 분류를 위한 알고리즘으로서 최급 하강법 (gradiant desent)33을 사용한다. 이는 신경망에
의한 class 와 실제 class label 과의 평균제곱거리를 최소로 하는 가중치 집합을 찾아내는 것을 말한다.
입력은 입력계층를 구성하는 노드들의 계층에 동시에 분배되며 여기서 각 훈련 샘플에서 측정된 속성을
받아들이고 가중치 적용된 결과값이 다시 은닉계층으로 알려진 2 번째 계층에 주어진다. 이때 은닉계층의
가중치 출력은 또 다른 은닉계층에 계속 전달되기도 하는데 최종적으로 마지막 은닉계층의 가중치 출력이
출력계층으로 전달되며 여기에서 주어진 샘플에 대한 네트워크 예측값이 최종계산된다.
이처럼 지도학습법를 따르는 인공신경망은 입력층에 훈련 패턴을 제시하고 신경망 내의 연산을 거쳐
출력을 산출하는 과정과 산출된 출력 값과 원하는 타겟 값이 일치하도록 신경망 내의 연결 가중치의 값을
수정하는 과정을 거치는데 전자의 과정을 피드포워드 연산(feedforward operation),34 후자의 과정을
학습(learning)이라 한다.
유명한 신경망 알고리즘의 하나는 1980 년 대에 제안된 역전파 (back-propagation)알고리즘이다.
역전파는 학습 샘플의 집합을 반복적으로 처리하면서 각 샘플에 대한 네트워크 예측과 실제 알려진 class
label 을 비교하면서 학습을 계속한다. 즉, 각 학습 데이터에 대해 신경망에 의한 예측값과 실제 class 값의
33 기울기 하강 (gradient descent)이란 현재 위치에서 기울기에 비례하여 단계적으로 함수의 최소 또는 최대에 접근하는
점근적인 언덕 오르기(hill climbing) 알고리즘을 말한다.
34 피드포워드 연산은 다음과 같은 절차를 따른다. 우선 입력 벡터들이 입력 층의 각 입력 뉴런에 제시된다. 각 은닉 뉴런은
입력들의 가중된 합을 계산해서 스칼라 네트 활성화(이하 네트)를 만들어낸다. 이 값은 입력 값과 입력 - 은닉층 사이의 연결
가중치의 내적이다.
단, i, j 는 각각 입력층, 은닉층의 뉴런 index 를, NI는 입력 vector 의 차수, 는 입력층-은닉층 사이의 연결가중치 등을
표시하며 , 를 가정하여 벡터의 내적으로 표현하였음

58
차이에 대해 평균제곱오차가 최소가 되도록 하는데 이러한 작업은 출력계층으로부터 각 은닉계층을 거쳐서
첫 은닉계층으로 거슬러 역방향으로 진행한다. 그리고 이러한 과정을 거쳐서 가중치 값들은 최종적으로
수렴되어 학습과정은 중지되는데 아래에 이러한 알고리즘이 요약되어 있다.
Backpropagation 알고리즘.
(목적)
신경망 이론에 의한 학습을 통해 분류 또는 예측.
(입력항목)
D: 훈련데이터와 이에 관련된 목표 값(target values)
L: 학습률
Network: 다계층의 feed-forward 네트워크.
(출력항목)
신경망 (trained neural network)
(Method)
Initialize all weights and biases in network;
while terminating condition is not satisfied {
// 입력값을 전파
for each training tuple X in D {
for each input layer unit j {
Oj = Ij; // 입력 unit 에 대한 출력물은 실제의 입력 값이 됨
for each hidden or output layer unit j {
Ij = wij +qj;
//앞의 i 계층과 관련한 j 항목의 순 입력을 계산
Oj = ; } // 각 unit j 의 출력물을 계산
// 오류를 역전파:
for each unit j in the output layer
Errj = Oj(1 - Oj)(Tj - Oj); // error 를 계산
for each unit j in the hidden layers, from the last to the first hidden layer
Errj = Oj(1 - Oj) Errkwjk; // 차상위 계층 k 에 대한 error 를 계산
for each weight wij in network f
wij = (l)ErrjOi; // 가중치 증가
wij = wij + wij; } // 가중치 업데이트

59
for each bias qj in network f
j = (l)Err j; // bias increment
j = j + j; } // bias 업데이트
} }
위의 알고리즘을 통해 다음과 같은 순서로 진행됨을 알 수 있다.
(1) 입력항목을 초기화한다. 이때의 비중치는 임의의 값을 적용한다.
(2) neuron B 에 대한 에러값을 계산한다.
이때 에러값이란 (원하는 값 - 실제 얻은 값)을 뜻한다. 즉,
Error B = Output B (1-Output B)(Target B– Output B)
이때 Sigmoid 함수35로 인해 Output(1-Output)를 유의해야 한다.
(3) 비중값을 변경한다.
W+AB를 조정된(trained) 비중, WAB를 초기 비중값이라 하면
W+AB = WAB
+ (Error B x Output A)
(4) 은닉계층의 에러값을 계산한다. 에러 값은 출력계층으로부터 역계산한다. 예컨대 neuron A 가 B 와
C 에 연결되어 있다면 B 와 C 로부터 에러값을 가져와서 A 에 대한 에러값을 계산한다.
ErrorA = OutputA(1 - OutputA)(ErrorB WAB + ErrorC WAC)
(3)번 단계를 반복하여 은닉계층의 비중값을 변경한다.
이러한 반복의 결과 계층의 깊이가 많은 네트워크 경우에도 훈련이 가능해진다.
다음에서 은닉, 출력계층 (unit j)로서 앞 layer 의 출력이 j 에 입력된다.
35 sigmoid 함수란 "S" 자 모양을 가지는 (sigmoid 커브) 함수를 말한다.

60
알고리즘의 수행 시 은닉계층과 출력계층의 각 노드는 활성함수 (activation function)의 적용을
받는다.36 오차 역시 신경망 예측값의 오차를 반영하는 가중치와 편향을 적용하면서 역 전파된다. 이
과정에서 가중치와 편향은 오차의 역전파를 반영하도록 하기 위해 신경망의 class 예측과 실제 class
label 간의 평균거리제곱를 최소화하는 방식으로 끊임없이 갱신되는데 이때 학습률이 적용된다.37
역전파의 해석문제
신경망의 가장 큰 문제점은 지식의 표현에 있는데 이에 따라 추출된 지식을 표현하고 이로부터 규칙을
추출하기 위한 다양한 노력이 경주되었다. 이를 위해 먼저 신경망 가지치기를 수행하고 나서 링크, 노드 또는
활성치 (activation value)의 군집화를 수행한다.
바. SVM (Support Vector Machine)
svm 은 1995 년 Vapnik 등에 의해 개발된 vc-이론 (Vapnik-Chervonenkis theorem)이 기반이 되었다.
여기서는 학습데이터와 범주 정보를 학습하면서 얻어진 확률분포를 이용해 의사결정함수를 추정한다.
그리고 이 함수에 따라 새로운 데이터를 이원 분류한다.
SVM 같은 감독학습의 목적은 훈련데이터에 의거하여 대상을 특정 class 로 분류하는 것이다.
훈련데이터는 측정가능한 정량속성 (예: 크기, 무게, 선호도 등)을 가진다. 한편 이들 각각의 훈련데이터에
대해서는 class 가 미리 정해져 있다.
선형 분리가 가능하도록 데이터를 분류하는 선형분리함수는 매우 많이 존재할 수 있다. 따라서 이들
중에서 어떤 선형분리함수를 최적의 것으로 선택할 것인가가 SVM 의 핵심이 된다. 일차 직선을 데이터 점과
36 노드에서 표현된 뉴런의 활성화 정도를 표현하는데 주로 logistic 함수 또는 sigmoid 함수가 이용된다.
37 학습률((learning rate)이 너무 크면 부적합한 결과들 간의 왕복(oscillation) 현상이 발생하고 학습률이 너무 작으면 학습
자체가 매우 느리게 진행된다.

61
만날 때까지 확장한 거리를 마진이라고 한다면, 마진 크기가 최대가 되도록 중심을 이등분 하는 초평면38을
'최적분류 초평면(OSH: optimum separation hyperplane)'이라 하고, 이때 마진 영역에 접하는
데이터들을 'Support Vector'라고 한다.39
svm 은 분석대상의 차원이 어떠하든 상관없이 함수의 복잡도를 특성화할 수 있으며 각종의 표현형식에
적용할 수 있다. 40
SVM 은 Support point 사이의 마진을 극대화시키는 조건을 통해 class 사이의 결정선(decision
boundary)을 찾는 것이다. 그리고 그 복잡도에 따라: linearly separable linearly non-separable
multi-class non-linear 모델로 전개된다.
다음 그림에서 결정선은 이러한 class 를 분리시키는 역할을 하는데 여러 개의 결정선 중 어떤 것이
최적인가를 찾는 것이 그 핵심을 이룬다.
38 초평면(Hyperplane)은 어떤 공간 Rn 이 있을 때, 이 공간의 한 점을 통과하는 해집합을 말한다. 즉, 다차원 데이터를
분석함에 있어 n 차원 공간 개념을 적용한 것인데 여기서 초평면은 ‘평평하고’ 그 공간의 부분집합이 되는 (n-1)차원의
집합으로 본다.
39 SVM 은 매우 방대한 이론이고 수학적으로도 복잡하다. 여기서는 ‘최대마진분류기(Maximum Margin Classifier)로서의
SVM 만 이야기한다.
40 예컨대 신경망, rbf, spline, 다항식 추정량 등에 모두 적용이 가능하다. 여기서 참고로 RBF 는 Radial Basis Function 의
약자로서 원점 또는 특정 지점(center)에서의 거리에 따라서만 값이 달라지는 실수 함수이다. 한편 spline 함수는 다항식의
일종으로서 구간적 보간 다항식 중에서 가장 발전된 것이다. 등이 매끄러운 곡선을 그릴 경우에 주로 사용된다.

62
좋은 결정선이란 새 데이터가 들어와도 변경될 필요가 없는 견고한 것을 말한다. 또한 과적합41 현상이
발생할 수 있으므로 주의를 요한다. Risk 최소화를 위해서는 양쪽의 마진이 큰 것이 좋다.
SVM 의 이론이 고급 기하학에 기초하여 복잡한데도 불구하고 큰 인기를 끄는 것은 선형모델에서의
다차원성 문제, 비선형모델에서의 vc-차원42 추정의 난이성 등을 극복할 수 있기 때문이다.
사. 분류 모델의 선택
다양한 분류기법이 존재하지만 각각 장단점을 가지므로 비교평가가 용이하지 않다. 일반적으로 이론과
모형을 평가하는 기준은 다음과 같다.
예측정확성
연산속도
견고성 (robustness)
확장적용성
해석력 (interpretability)
연구에 따르면 많은 알고리즘이 정확성에서는 거의 비슷하지만 학습시간은 상당히 큰 차이가 있다고
알려져 있다. 일반적으로 대부분의 신경망 분석과 스플라인(spline)을 포함하는 통계적 분류기법들은
의사결정트리에 비해 많은 계산량을 필요로 한다.
41 과적합(over-fitting)이란 훈련데이터에는 좋지만 예측에는 좋지 않은 것을 말한다. III. 분석기법 ▶2. 모델링과 데이터의
전처리 ▶ (2) 모델링 ▶ 다. 모델의 검증 을 참조할 것
42 vc 차원(vc-dimension)이란 분류알고리즘의 능력을 재는 척도로서 알고리즘이 shatter 할 수 있는 최대 집합의
cardinality 를 의미한다.

63
(5) 군집 이론
가. 개요
군집(clustering) 이론이란 수 많은 데이터에서 유사성이 큰 것들끼리 모음으로써 하나의 그룹 내에서는
원소의 동질성을 극대화하고 서로 다른 그룹 상호 간에는 그 차이(이질성)를 극대화시키는 것을 말한다. 43
계층적 기법과 분할적 기법
군집 기법의 대표적인 것으로 다음 2 가지가 있다.
(1) 계층적 기법- 큰 군집 안에 작은 군집들이 속하도록 군집간의 계층체계를 구축하는 것이다. 계층적
기법은 진행방식에 따라 집괴적 기법과 분할적 기법의 두 가지로 나누어진다.44
(2) 비 계층적 기법 – 구성요소들 사이에 또는 구성요소의 하위계층 간에 계층관계가 없을 때의 군집화
방법을 말한다. 비계층 군집방법은 상대적으로 계산비용이 높지 않은데 다음과 같은 기법이 대표적이다.
1 회 실시 (single-pass) 기법; 한번만 순서를 지켜 군집화하면 추가 작업이 필요 없는
군집화 기법. (예: Leader 알고리즘)
재배치 (relocation) 기법: 구성요소를 초기 군집 (seed cluster)에 할당한 후 반복적으로
재배정하면서 더 나은 군집화가 가능한지를 찾아 나가는 기법으로서 k-means 가 대표적이다.
적용이 편리하지만 자칫 부분 최적화(local optima)에 그칠 수 있고 또한 과연 전체
최적화(global optimum)에 도달했는지 여부를 판단할 기준이 명확하지 않다는 문제가 있다.
근접이웃 (Nearest Neighbor) 알고리즘 – 중심부에서 이웃한 항목들을 분석하여
군집여부를 결정짓는 것으로 본장의 뒤에서 세부설명한다.
클러스터링은 주로 다음과 같은 경우에 많이 활용된다.
주로 세분화 작업에 많이 사용된다. 특히 고객 세분화, 패턴인식, 생물연구, 공간데이터 분석, 웹 문서분
류 등이 대표적이다.
이상상태 (異狀狀態: anomaly) 탐지 (예: 사기성 거래의 식별). 이는 정상적 거래(“normal)와 비정상
거래를 구분하거나 약품 부작용의 검사, 통신사에서의 통화패턴 분석을 통한 사기탐지에 사용된다.
대규모 데이터를 나누어서 작은 데이터 그룹으로 분리.
43 분류가 정의된 class 와 class label 훈련경험에 의존하는 즉, 예제에 의한 학습인 반면 군집화는 관찰에 의한 학습이라고 할
수 있다.
44 집괴적 기법과 분할적 기법에 대해서는 본 장의 뒤에서 상세히 설명함.

64
군집화가 잘 되었는지 여부는 각 군집들 간의 객체 상이성 정도에 의해 평가하는데 이를 위해 데이터의
유형에 대해 구간척도, 이항, 명목, 순서, 비율척도 혹은 이러한 변수의 조합 같은 것들을 계산한다.
데이터의 유형
군집화 알고리즘은 다음 2 개 데이터 유형 중 하나로 표시하게 된다.
데이터 행렬 (Data Matrix: 객체 x 변수 구조): 사람의 나이, 키, 몸무게, 성별, 인종 등의 변수 (척도
나 속성으로 불려지는)를 나타낸다. 행렬의 구조는 n x p 형태이다. (객체: n x 변수: p)
상이도 행렬 (Dissimilarity matrix: 객체 x객체 구조): 이것은 n개 객체들의 모든 쌍에 대해 근사도를
저장한다.
d(i,j)는 객체 i 와 객체 j 간에 측정된 차이 내지 상이도를 나타낸다. 통상 d(i,j)는 음이 아닌
수로서 0 에 가까울수록 객체 i,j 서로가 높은 유사성을 가짐을 뜻하고 차이가 더 커질 수록 값이
커진다.
상이도 행렬은 1-모드 행렬 (one-mode matrix)이라 부르는 반면 데이터 행렬은 종종 2-모드 행렬 (two-
mode matrix)이라 한다. 보통 군집 알고리즘에서는 상이도 행렬을 많이 이용한다.
나. 구간척도 변수 (interval-scaled variable)
개요
구간척도변수란 선형의 연속형 척도로서 객체들의 상이도를 계산하는데 이용된다. 주의할 것은 이때
사용된 측정단위가 군집화 분석에 영향 미칠 수 있다는 것이다. 예를 들어 높이를 미터에서 인치로
측정단위를 바꾸거나 무게를 킬로그램에서 파운드로 바꾸면 군집화 구조가 크게 달라지게 된다. 일반적으로
변수를 작은 단위로 표현하면 그 변수의 범위가 넓어지므로 군집화 구조의 결과에 큰 영향을 미치며 이러한
측정단위의 의존성을 막기 위해서는 데이터를 표준화하여 모든 변수에 같은 비중을 주어야 한다.
구체적인 표준화 방법으로 원데이터를 단위가 없는 변수로 변환하는 것을 들 수 있다. 변수 f 에 대한
척도가 주어지면 다음과 같이 할 수 있다.
(1) 절대평균편차 sj를 계산한다.

65
(2) 표준화된 척도로서의 z-점수 (z-score)를 계산한다.
절대평균편차 sj는 표준편차 σf보다 이상치의 영향을 덜 받게 된다. 절대평균편차를 구할 때
평균으로부터의 편차 (|xif -mf|)는 제곱하지 않으므로 이상치의 z-점수가 너무 작게 되지 않는다는
장점이 있어서 이상치를 찾는데 용이하다.
구간척도의 주요한 것은 다음과 같다.
이름 공식
유클리드 거리 (Euclidean D.)
유클리드 제곱거리
(Squared Euclidean D.)
맨해턴 거리 (Manhattan D. )
최대 거리 (Max. distance)
Mahalanobis 거리
S 는 공분산행렬 (covariance matrix)
코사인 유사도
(cosine similarity)
이하에서는 유클리드 거리와, 맨해턴 거리 및 Minowski 거리의 3 가지에 대해 설명한다.
주요 구간척도
유클리드 거리 (Euclidean Distance)
가장 흔한 거리척도는 유클리드 거리로서 다음과 같이 정의한다.
Manhattan 거리
Manhattan 거리 (혹은 city block)는 다음과 같이 정의한다.

66
유클리드 거리와 Manhattan 거리는 다음 거리함수 조건을 만족한다.
① d(i,j) 0 : 거리는 음이 아닌 수이다.
② d(i,j) = 0 : 한 객체에서 자신으로의 거리는 0.
③ d(i,j) = d(j,i) : 거리는 대칭함수이다.
④ d(i,j) d(i,h) + d(h,j) : i 에서 j 로 직접 가는 것은 어떤 객체 k 를 우회하여 가는 것보다
크지않다.
Minkowski 거리
Minkowski 거리는 유클리드 거리와 맨해턴 거리 둘의 일반형이다.
q 는 양의 정수로서 q=1 이면 Manhattan 거리를, q=2 이면 유클리드 거리이다. 가중된 유클리드 거리는
다음으로 계산된다.
이항 변수 (Binary Variables)
이항변수는 오로지 0 과 1 의 2 개 상태만을 가지는 것을 말한다. 이항변수를 구간척도형 변수로 취급하면
잘못된 군집화 결과를 가져오므로 상이도를 계산할 때 이항변수에 맞는 고유한 방법이 필요하다. 한가지
접근은 주어진 이항자료로부터 상이도 행렬을 계산하는 것이다. 아래는 이항 변수 분할표의 예이다.

67
단, q 는 객체 i,j 모두 1 인 변수의 수,
r 은 객체 i 는 1 이지만 j 는 모두 0 인 변수의 수,
s 은 객체 i 는 0 이지만 j 는 모두 1 인 변수의 수
t 은 객체 i,j 모두 0 인 변수의 수,
변수의 총 갯수는 p = q + r + s + t
대칭인 이항변수에서 유사성은 이항변수의 몇몇 혹은 전부가 달리 기술되어도 결과는 변치 않으며 이를
유사성 불변 (invariant similarity) 이라 부른다. 유사성 불변에 대해 객체 i,j 간의 상이성을 측정하는
계수가 단순 결합계수 (simple matching coeeficient)이며 다음으로 정의된다.
이항변수가 비대칭인 경우는 상태의 결과가 균일하지 않은 것을 말한다. 예컨대 질병검사의
positive/negative 와 같이 중요도가 달리 취급되는 것이다. 보통 빈도가 작은 중요한 결과를 1 로 표현하고
(HIV positive), 나머지는 0 으로 (HIV negative) 표시하는데 두 비대칭 이항변수가 모두 1 로 동일한 것
(양성 적합)은 둘다 0 인 것 (음성 적합)보다 더 중요하게 여겨지므로 이를 "단항성”으로 여긴다. 또 그러한
변수에 기초한 유사성을 유사성 변경이라 하는데 Jaccard 계수가 대표적이다.45
범주형, 서수형, 비율형 척도변수
범주형 (Categorical) 변수
범주형 변수란 명목변수라고도 불리우며 하나의 변수가 여러 개의 값 중 하나를 취할 수 있는 변수를
말한다. 명목변수의 상태 수를 M 이라하면 상태는 1,2, ..., M 과 같은 정수 집합으로 표시할 수 있다.
그러한 정수는 단지 데이터 조작을 위해 사용되는 것이지 특정한 순서를 나타내는 것이 아니다. 어떤
의미에서 0 과 1 중 하나의 값만을 취하는 이항변수를 일반화 한 것이라고 할 수도 있겠다.
범주형 변수에서 두 객체 i 와 j 간의 상이도는 단순적합 (simple matching) 접근을 통해 계산할 수 있다.
45 Jaccard index 는 샘플 데이터들 사이의 유사성과 이질성을 나타내는 지표이다. 여기에는 Jaccard 계수와 Jaccard 거리의
2 가지가 있다.
우선 Jaccard 계수 또는 Jaccard 유사도계수 (Jaccard similarity coefficient)는 유사성을 측정한다.
반면 Jaccard distance 는 샘플 데이터들 사이의 이질성을 측정한다.

68
단, m 은 i 와 j 가 동일 상태인 변수의 수, p 는 변수 전체 개수를 의미
가중치는 m 의 효과를 증가시키기 위해 또는 상태 중에 큰 수를 가지는 변수의 일치된 쌍의 개수에 더 큰
가중을 두기 위해 부여될 수 있다. 명목변수는 각 M 개의 명목상태에 새로운 이항변수를 부여하여 비대칭의
이항변수로 코딩할 수 있다. 주어진 상태값을 가지는 객체에 대해 그 상태를 나타내는 이항변수는 1 로,
나머지 이항변수들은 0 으로 표시한다.
서수형 (Ordinal) 변수
서수형 변수는 순서값을 가지는 변수로서 이항서열변수와 연속서열변수의 2 가지가 있다.
서열변수는 구간척도 양을 유한한 그룹의 수로 분리하여 얻어지기도 한다. 서열변수의 값은 순위로 표현될
수 있다. 예를 들어 M 개의 상태를 갖는 서열변수 f 가 있다면 순서화된 상태는 순위 1, ... M 으로 정의된다.
객체간의 상이도를 계산할 때 서열변수의 취급은 구간척도형 변수와 매우 비슷하다. f 를 n 개의 객체를
표현하는 서열변수의 집합으로부터의 변수라고 하자. f 를 고려한 상이도 계산은 다음의 각 단계를 거친다.
① i 번째 객체의 f 값은 xif이고 f 는 순위 1, ..., Mf로 표현된 Mf개의 서열을 가진다. 각 xif는 그와
관련된 순위 로 대체한다.
② 각 서열변수가 상태에 따라 다른 수를 가질 수 있기 때문에 각 변수들에 같은 가중치를 주기 위해
때로는 각 변수의 범위를 [0.0, 1.0]으로 표시하는 것이 필요하다.
③ 상이도는 i 번째 객체의 f 값을 나타내는 zif를 사용하여 구간척도 변수에서 설명된 어떤
거리측도를 사용해도 계산할 수 있다.
비율척도변수 (ratio-scaled variable)
비율척도변수는 대략 지수 형태로서 비선형 범위에서의 양의 값을 가지는 척도를 말한다. 대표적인 예로는
박테리아 모집단의 성장이나 방사성원소의 부패등이 포함된다.
객체간의 상이성을 계산하는데 있어서 비율척도 변수를 이용하는 방법에는 다음의 세가지가 있다.
비율척도 변수를 구간척도 변수처럼 다룬다. 그런데 이것은 범위가 왜곡될 가능성이 있기 때문에 항상
좋은 선택이 되지는 않는다.
객체 i에 대해 xif값을 갖는 비율척도변수 f에 yif = log (xif)식을 이용한 로그변환을 적용한다. yif는 묘
사된 구간형 값으로 다룰 수 있다. 몇몇비율척도변수가 정의에 따라 log-log 변환될 수 있다.
xif를 연속적 서열형 데이터로, 그 순위는 구간형 값으로 다룬다.

69
마지막 2 개 방법이 비록 주어진 응용에 따라 방법의 선택이 달라지지만 가장 효율적이다.
종류가 다른 변수로 구성된 경우의 군집분석
간혹 여러 종류의 변수가 혼합된 형태로 구성된 경우가 있다. 이 경우 변수타입별로 그룹화하여 변수의
종류별로 각각 군집분석을 할 수도 있으나 어떨 때는 한번의 군집분석으로 모든 변수를 함께 다루어야 할
때도 있다. 이를 위해서는 모든 의미있는 변수들을 어떤 공통의 범위로 가져오는 것이 필요하다. 예컨대 구간
[0.0, 1.0]의 범위로 가져와서 마치 한 종류의 변수처럼 취급하면서 상이성 행렬로 분석하는 것이다.
일반화시켜 본다면 데이터 집합이 혼합된 종류의 p 개 변수를 가지고 있다고 할 때 객체 i,j 간의 상이성
d(i,j)는 다음과 같이 정의된다.
(1) xif 혹은 xjf가 결측치일 때, 지시값 (indicator) (예, 객체 i 나 j 의 변수 f 의 측정값이 없을 때),
아니면 (2) xif = xjf = 0 이고 변수 f 가 비대칭인 이항형이거나 그렇지 않을 경우는 이다.
물론 타입에 따라 변수 f 가 i,j 간의 상이도에 미치는 영향은 달라진다.
f가 이항형이나 명목형일 때: xif =xjf 이면
그외 경우는
f가 구간에 기초했을 때: 단, k는 변수 f의 객체의 모든 결측치 아닌 값에 해당
f가 서열형이나 비율척도형이면: 순위 rif와 를 계산하고 zif를 구간척도형으로 다룬다.
이와 같은 방법을 통해 다른 타입으로 표현된 변수로 이루어진 경우에도 객체간의 상이도를 계산할 수
있다.
다. 분할기법에 의한 군집화
분할기법(partitioning methods)은 맨 먼저 k 개의 초기분할을 만든 후 각각의 객체를 하나의 그룹에서
다른 그룹으로 재배치하는 식으로 작업을 반복함으로써 개선해 나간다.
이를 좀 더 자세히 살펴보자면 먼저 n 개의 객체 혹은 tuple 이 주어졌을 때 k n 이 되도록 군집을
나타내는 데이터 분할을 k 개 만든다. 이때 데이터가 다음 요구를 만족하도록 한다. (1) 각 그룹은 적어도
하나의 객체를 질 것. (2) 각 객체는 정확히 하나의 그룹에 속할 것. (몇몇 fuzzy 분할기법에서는 이
요구사항을 완화시킨다) 그리고 나서 분할을 향상시키기 위해서 객체를 하나의 그룹에서 다른 곳으로
이동시키는 반복적인 재배정기법 (iterative relocation technique)을 사용한다. 좋은 분할을 만들기

70
위해서는 같은 군집 안에 있는 객체들은 "가깝게" 그리고 서로 관련되어 있도록 하는 반면 다른 군집의
객체들끼리는 "멀리 떨어져"있거나 매우 다르도록 해야 한다.
DB 속성 관점에서 군집 내 객체들은 "유사성"을 가지는 반면 다른 군집의 개체들과는 "상이성"을 갖도록
하는 비유사성 (dissimilarity) 함수를 최적화하도록 군집을 형성해야 한다.
분할의 질을 판단하는 기준은 매우 다양한데 분할에 기초한 군집화를 최적화하기 위해서는 모든 가능한
분할에 대한 완전한 계산이 필요하다. 대부분 다음의 두 가지 경험기법 중 하나를 사용한다.
① 각 군집이 군집 내의 객체의 평균값으로 대표되는 k-means 알고리즘
② 각 군집이 군집의 중앙에 가장 가까이 위치한 객체 중의 하나로 대표되는 k-medoids 알고리즘.
이런 경험적 군집화 기법은 작거나 중간크기의 데이터베이스에서 구형 군집을 찾는데 더 효율적이다.
k-means 기법
데이터와 이에 대응되는 그룹의 중심(centroid) 간의 제곱합계를 최소화 시키는 방식의 군집화 작업
알고리즘을 말한다. 즉, k-means 알고리즘은 k 값이 파라미터로 제공된 상태에서 군집내 유사성은 높고
군집들 사이의 유사성은 낮도록 n 개의 객체 집합을 k 개의 군집으로 분해한다. 군집유사성은 군집에서
군집의 평균값을 기준으로 산정한다. 군집의 무게중심으로 볼 수 있기 때문이다.
<알고리즘>
(1 단계) K = cluster 개수를 파라미터로 전달받는다
(무작위로 초기 centroid 로 정할 수도 있다)
(2 단계) 안정화될 때까지 즉, 아무 항목도 더 이상 움직이지 않을 때까지 다음 작업을 반복 수행한다. 즉,
항목에 partition 을 적용한다. 이때 무작위로 할 수도 있고 체계적으로 실시할 수도 있다.
a. 첫 k 개의 훈련샘플을 단일항목의 cluster 로 취한다
b. 남은 (N-k)개의 훈련샘플 각각을 최근접 centroid 의 cluster 에
배정한 후 거리를 재계산한다.
(3 단계) 각 샘플에 대해 거리를 계산하되 만약 샘플이 현재 최근접 centroid 에 속하지 않았다면 이를
수정한다. 즉, 최소거리에 따라 항목을 군집화 한다.
(4 단계) 새로운 배정이 필요 없게 될 때까지 3 단계를 반복 한다.

71
<예제>
다음 4 개 제품 (약품 A ~ D)가 A 와 B 의 2 개 그룹에 속하는 상태에서 무게 및 산성도의 검사 결과가
다음과 같이 주어져 있다고 가정한다.
속성 1 (X) 무게지수 속성 2 (Y) 산성도
약품 A 1 1
약품 B 2 1
약품 C 4 3
약품 D 5 4
1. Centroid 의 초기값: Medicine A 와 B 를 첫 centroid 로 이용한다고 가정할 때 각각의 좌표값은
다음과 같다.
C1 = (1,1)
C2 = (2,1)
2. 항목-Centroid 간의 거리 계산 (Euclidean 거리)
D0 =
3. 객체를 그룹화 한다
최소 거리에 따라 항목을 배정한다. 약품-A 는 그룹 1 에, 약품-B 는 그룹-2 에, 약품-C 는 그룹-2 에,
약품-D 는 그룹-2 에 배정하는 식이다.
C0= [1 0 0 0
0 1 1 1]
4. Iteration-1, Centroid 수정:
C1=(1,1) , C2 = ((2+4+5)/3, (1+3+4)/3) = (11/3, 8/3)

72
5. Iteration-1: 거리계산
6. 항목의 군집화: 새로운 거리 행렬에 의거하여 그룹배정을 수정한다.
7. Iteration-2, centroid 수정:
c1 = ((1_2)/2, (1+2)/2) = (3/2, 1)
c2 = ((4+5)/2, (3+4)/2)
8. Iteration-2: 거리 계산
<"k-means 알고리즘의 진행방법">
우선 군집 평균이나 중심을 나타내는 값으로 객체들에서 k 개를 임의로 뽑는다. 남겨진 객체들은 객체와
군집평균에 따라 가장 유사한 군집에 할당된다. 그리고 각 군집에 새로운 평균을 구한다. 이 과정을
기준함수가 수렴할 때까지 반복한다. 통상 제곱오차 기준이 사용된다.
단, E 는 데이터베이스에서 모든 객체들의 제곱오차를 합한 것
p 는 주어진 객체를 나타내는 공간의 점,
mj는 군집 Ci의 평균 (p 와 mi는 다차원)
이러한 기준은 결과로 산출된 k 개의 군집을 가능한 압축 혹은 분리되도록 하는데 목적이 있다.
k-means 절차는 다음과 같다.
k-means 알고리즘

73
목적: 각 군집의 중앙이 군집 내의 객체의 평균값이 되도록 분할(partitioning).
입력항목
k: 군집의 개수
D: n 개의 객체를 가지는 데이터 집합
출력항목
k 개 군집의 집합
Method:
arbitrarily choose k objects from D as the initial cluster centers;
repeat
(re)assign each object to the cluster to which the object is the most similar, based on
the mean value of the objects in the cluster;
update the cluster means, i.e., calculate the mean value of the objects for each cluster;
until no change;
또한 아래에는 KMM 기법에 의거하여 군집화하는 모습인데 “+” 표시된 부분이 군집평균값을 가지는
곳이다.
알고리즘은 제곱오차함수를 최소화하도록 k 개 분할을 만든다. 군집이 다른 군집과는 서로 떨어져서
밀집되어 있을 때 잘 수행되는데 n 이 전체 객체 수이고 k 가 군집의 수, t 가 반복의 수일 때 알고리즘의
복잡도가 O(nkt)이기 때문에 큰 데이터 집합을 다루는데 상대적으로 효율적이다.
<K-Mean 의 활용>
여러 개의 객체를 각각의 속성에 따라서 분류하려는 경우 사용되며 신경망, 패턴 인식, 분류, 이미지 처리,
machine vision 등이 그 예이다. 대상을 분류할 때 부여된 기준 (centroid 까지의 최소거리)에만 의거하여
자동으로 분류한다는 의미에서 무감독 학습의 하나로 볼 수 있다. 즉, 분류가 잘되었건 잘못되었건 이를
감독(supervise)하지 않는다.
<K-Mean Clustering 의 약점>
데이터가 많을 때는 초기 군집화 작업이 전체 군집화에 큰 영향을 준다.

74
군집의 크기 K 가 미리 정해져야 한다.
실제의 군집을 알 수 없으며 데이터 수가 적으면 데이터 입력순서에 따라 다른 결과가 나타날 수
있다.
초기 조건에 민감하다. 따라서 자칫 지역최적화(local optimum)에 갖힐 수도 있다.
(각각의 속성이 동일한 비중을 가지므로) 어떤 속성이 군집화 절차에 더 큰 기여를 하는지 알
수가 없다
산술평균은 이상치 (outlier)에 취약할 수도 있다.
<k-means 알고리즘의 확장과 변형>
몇가지 k-means 기법의 변형이 있는데 초기 k 개의 평균의 선택과 상이도의 계산, 군집평균을 계산하는
방법 등에서 차이가 있다.
먼저 계층적 집괴적 알고리즘을 적용하여 군집의 수와 초기 군집을 찾고 나서 군집화를 향상시키기 위해
반복적으로 재배정 하는 방법이 있다. 또다른 k-means 기법의 변형은 k-means 기법을 범주형 데이터로
확장하는 k-modes 기법이다. 여기서는 범주형 객체를 다루기 위해 새로운 상이도 척도를 사용하는데
군집평균 대신 최빈값으로 대체하고 군집 모드를 수정하기 위해 빈도기반 방법을 사용한다.
수치형 값과 범주형 값이 혼합된 데이터를 분류하기 위해 k-means 기법과 k-mode 기법을 통합한 것을
k-prototype 기법이라고 한다.
EM (Expectation Maximization) 알고리즘은 k-means 방법을 다른 방식으로 확장한다. 각 객체를
지정된 군집에 할당하는 대신 구성요소의 확률을 나타내는 가중치에 따라 군집에 할당한다. 즉, 군집간에
확실한 구분이 없으며 가중치를 적용하여 새로운 평균을 계산해 내는 것이다.
k-means 알고리즘을 확장적용하기 위해 데이터의 영역을 3 종류로 구분하는 방법이 제시되었다.
압축할 수 있는 영역
메인메모리에 남아 있어야 하는 영역
폐기할 수 있는 영역
군집 내에서 그 구성요소가 확인되면 그 객체는 폐기할 수 있다. 폐기할 수 없고 확실히 하부군집에
속한다면 그 객체를 압축할 수도 있다.
확장이 가능하려면 반복적 군집화 알고리즘은 압축가능 객체와 군집화 특성과 주기억 장치에 남아야 하는
객체만을 포함하여 보조기억장치-기반 알고리즘을 주기억장치 알고리즘으로 바꾸어야 한다.
k-medoids 기법
k-means 알고리즘에서는 극도로 큰 값이 데이터 분포를 왜곡할 수도 있으며 이상치에 민감해지므로 이를
해결해야 했다. 이에 대한 해답으로는 군집에서 객체들의 평균값을 취하는 대신 군집에서 가장 중심에

75
위치한 객체인 medoids 를 사용하는 방법이 있다. 따라서 분할기법은 객체와 그것과 연관된 참조점 간의
상이도의 합을 최소화하는 원칙에 따라 수행되는데 이것이 k-medoids 이다.
k-medoids 군집화 알고리즘의 원칙은 각 군집에서 대표 객체 (medoids)를 임의로 찾음으로써 n 개의
객체 중에서 k 개의 군집을 찾는 것이다. 남은 각각의 객체는 가장 비슷한 medoids 에 군집된다. 이 방법은
산출물로서의 군집의 성능이 향상될 수만 있다면 반복적으로 비-medoids 중 하나를 medoids 로 바꾼다.
k-means 와 k-medoids 를 비교하자면 잡음치나 이상치가 존재할 때 medoids 값이 평균에 비해
이상치나 다른 극단적인 값들의 영향을 덜 받으므로 k-medoids 가 더 견고한 대신 k-medoids 는
계산비용이 높다. 그러나 사용자가 군집의 수 k 를 정해야 한다는 면에서는 공통점이 있다.
CLARA와 CLARANS
CLARA
k-medoids 분할기법은 소규모 데이터 집합에서 좋은 효과를 내지만 대규모 데이터셋에는 적용이 쉽지
않다. 큰 데이터 집합을 다루기 위해서 CLARA (clustering LARge Application)라 불리는 표본기반 방법이
제시되었다. CLARA 개념은 다음과 같다.
데이터 집합 전체를 고려하는 대신 실제 데이터의 일부만을 대표 값으로 뽑아낸 후 PAM 을 사용한
표본으로부터 medoids 가 선택된다. 표본이 공정하게 뽑혔다면 원데이터를 근사하게 대표한다고 볼 수 있을
것이다. 이처럼 원데이터를 대표하는 객체들 (medoids)은 전체 데이터집합에서 추출된 것과 비슷힌 특징을
가진다. CLARA 는 각 표본에 PAM 을 적용하여 데이터 집합의 다중의 표본을 뽑고 가장 좋은 군집을
출력하는데 기대한 것처럼 CLARA 는 PAM 보다 대규모의 데이터집합을 다룰 수 있다. 이제 각 본복의
복잡도는 s 가 표본의 크기이고, k 가 군집의 수이고 n 이 객체의 총 개수일 때 매 반복작업의 복잡도는
O(ks2+k(n-k))가 된다.
CLARANS
PAM 에 표본추출 기법을 합친 CLARANS (Clustering Large Applications based upon RANdomized
Search)라는 k-medoids 알고리즘이 제안되었다. 그런데 CLARA 와 달리 CLARANS 는 어느 주어진 시점에
어느 표본으로 제한하지 않는다. CLARA 가 탐색의 각 단계에 고정된 표본을 가지는 반면 CLARANS 는
탐색의 각 단계에 임의성을 가지고 표본을 추출한다. 모든 점이 잠재적 해법인 그래프 탐색과정과 같이
군집화 과정에서 k 개의 medoids 집합이 제시된다. 단일의 medoids 로 대치한 후에 얻어진 군집화는 현재
군집화의 이웃이라 부른다. 임의적으로 시행된 이웃의 수는 사용자가 정한 인자에 의해 제한된다. 더 나은
이웃이 찾아지면 (예: 낮은 제곱오차를 가지는) CLARANS 는 이웃의 노드로 이동하고 과정이 다시 시작된다.
그렇지 않으면 현재의 군집화가 지역최적점을 만든다. 지역최적점을 찾으면 CLARANS 는 새로운 지역
최적점을 찾기 위해 임의로 새롭게 뽑은 노드에서 시작한다.

76
CLARANS 는 실루엣 계수를 사용하여 가장 "자연스런" 군집의 수를 찾을 때 사용할 수 있다. 실루엣
계수란 얼마나 많은 객체가 그 군집에 진짜 속해야 하는지 나타내는 객체의 성질이다.
라. 계층적 기법 (hierarchical method)에 의한 군집
데이터 객체들의 군집들을 트리구조로 그룹화하는 것으로서 집괴적 (agglomerative) 또는 분할적
(divisive) 접근이 있다.
집괴적 군집화와 분할적 군집화
일반적으로 계층적 군집화 기법에는 2 가지 형태가 있다.
집괴적 계층군집화: 모든 그룹이 하나로 합쳐질 때까지 혹은 종료의 조건이 될 때까지 서로의 근처에 객
체 또는 그룹을 연속적으로 합치는 상향식 접근이다. 즉, 각각의 객체를 자신의 군집에 배치하고, 그 원
자 군집들을 병합하면서 더 큰 군집으로 만들어 간다. 대부분의 계층군집화 기법은 여기에 속하며 단지
군집 내부의 유사도에 대한 정의만 다를 뿐이다.
분할적 계층군집화: 연속적인 반복으로 군집은 결국 각 객체가 하나의 군집이 되거나 종료의 조건이 될
때까지 더 작은 군집으로 분할하는 하향식 접근이다. 각 객체가 하나의 군집을 형성하게 될 때까지 혹은
적절한 갯수의 군집이 얻어지거나 가까운 군집들 간의 거리가 어떤 한계거리를 넘어서는 것과 같은 특정
한 종료조건이 만족할 때까지 군집을 작은 조각으로 세분화한다.
다음 그림은 집괴적 및 분할적 기법의 모습을 하나로 나타내고 있다.
계층 군집화는 체계적이고 전체 계층에서 하위계층을 어떤 기준으로 선택할지에 따라 다양한 알고리즘
구현이 가능하다.
집괴적 계층 군집화와 분할적 군집화에서 사용자는 적절한 군집의 수를 정해서 종료조건으로 삼을 수 있다.
군집간 거리를 재는데 많이 사용되는 4 가지 척도는 다음과 같다. |p - p'| 는 두 객체 내지 점 p 와 p'간의
거리이고, mi는 군집 Ci의 평균이며 ni는 Ci에 있는 객체의 수이다.
최소거리:

77
최대거리:
평균값 (mean) 거
리:
평균 (average)거
리:
계층적 군집화 기법은 단순하지만 한번 객체의 그룹과 합쳐지거나 분할되면 다음 단계의 과정은 새로
생성된 군집 하에서 이루어지기 때문에 이전단계로 되돌릴 수도 없고 군집간에 객체를 바꿀 수도 없으며
따라서 합병과 분할에 관한 결정이 제대로 이루어져야 한다. 계층적 군집화의 능력 향상을 위해 다른
군집화기법과 통합할 수 있는데 이하에서 BIRCH 와 Chameleon 을 소개한다.
BIRCH
BIRCH(Balanced Iterative Reducing and Clustering using Hierarchies)는 통합 계층 군집화
기법이다. 우선 군집대표를 요약할 때 사용되는 군집화 특성과 군집화 특성트리 (clustering feature tree:
CF tree)의 개념을 이해할 필요가 있다. 군집화 특성 (CF)는 객체들의 하부군집에 대해 3 가지가 요약된
정보로서 다음과 같이 정의된다.
CF 트리는 계층적 군집화를 위해 군집화 특성을 저장한 높이균형(height-balanced) 트리이며 아래
그림에 나타나 있다.
CF 는 트리 가지인자 (branching factor) B 와 임계값 T 의 2 개 인자를 가지는데 이 2 개 값은 트리의
크기에 영향을 미친다.
가지인자는 내부 노드의 최대 자식 수를 나타낸다.
임계값 인자는 하부군집의 최대 직경을 나타낸다.
BIRCH 알고리즘은 다음 2 단계로 이루어진다.
1단계: 데이터의 여러 단계 압축으로 보여질 수 있는 초기의 CF트리를 만들기 위해 데이터베이스를 살핀다.

78
2단계: CF트리의 단말노드 군집을 위해 군집화 알고리즘을 적용한다.
Chameleon
Chameleon 은 동적으로 계층군집화로 하는 군집화 알고리즘이다. 이 군집화 과정에서 두 군집간
상호연결성과 근접성을 계산하여 내부 상호연결성과 군집내 객체들의 근접성이 높은 상관관계를 가지면 이
두개 군집을 합해서 하나로 만든다. 동적으로 합병시켜 나감으로써 자연스럽고 균질한 군집의 발견을
촉진하게 된다. 만약 유사도 함수만 정해질 수 있다면 이 기법은 모든 데이터 유형에 적용이 가능하다.
Chameleon 기법은 군집 Ci와 Cj간의 유사도를 상대적 연결성 (relative interconnectivity) RI(Ci, Cj)
및 그들간의 근접성 (closeness) RC(Ci, Cj)에 따라 결정한다.
2개 군집 Ci, Cj 사이의 상대적 연결성 RI(Ci, Cj)은 다음과 같다.
2개 군집 Ci, Cj 사이의 근접성 RC(Ci, Cj)는 다음으로 정의된다.
마. 밀도 기반의 기법 (density-based method)
대부분의 분할기법은 객체간의 거리에 기초하여 객체들을 군집한다. 그러한 기법들은 구형(球形)의
군집망을 찾을 수 있게 해주는 반면 임의의 형태의 군집을 찾는데는 어려움이 있다.
데이터 공간 내에서 객체들이 조밀한 영역을 군집으로 여긴다.
밀도기반의 군집화 알고리즘에서는 지역연결성과 밀도함수에 기반하여 군집화를 진행한다. 즉,
전형적으로 낮은 밀도의 영역 (잡음영역)을 경계로 군집을 분리시킨다. "이웃 (neighborhood)"의 밀도가
어떤 한계점을 능가할 때까지 계속하는 것이다. 즉, 주어진 군집 내에서 각 데이터포인트가 주어진 반경
근처에 최소한의 개수 이상 가지도록 한다. 대표적인 밀도기반 군집화 알고리즘에는 다음과 같은 것이 있다.
DBSCAN: Ester (외) (KDD’96)

79
GDBSCAN: Sander (외) (KDD’98)
OPTICS: Ankerst (외) (SIGMOD’99).
DENCLUE: Hinneburg 와 D. Keim (KDD’98)
CLIQUE: Agrawal (외). (SIGMOD’98)
밀도 기반 군집화 알고리즘의 주요 개념을 살펴 보면 다음과 같다.
2 개의 전역 파라미터로서 Eps (이웃간 최대 반경)와 MinPts (Eps 반경 내 이웃으로 판정하기
위한 최소 개수)를 이용한다.
주어진 객체의 반경 내 이웃을 그 객체의 -neighborhood 라고 한다. 또한 객체의 집합 D 가
있을 때 p 가 q 의 -neighborhood 안에 있고 q 가 중심객체이면 객체 p 를 객체 q 로부터
"직접밀도 도달가능"하다고 부른다.
밀도도달가능성과 밀도연결의 개념 - 밀도도달가능성 (density reachability)은 직접 밀도
도달가능성의 전이폐쇄 (transitive closure)이고 이 관계는 비대칭이다. 중심객체만이 서로
밀도도달 가능이다. 그러나 밀도연결성 (density connectivity)은 대칭관계를 가진다. 밀도기반
군집은 밀도 도달가능 객체에 대하여 최대인 밀도연결 객체들의 집합이다. 어떤 군집에도
포함되어 있지 않은 모든 객체는 잡음값 객체로 여긴다.
중심객체 (Core Object: 반경 내에 MinPts 이상의 점을 가지는 객체)와 Border 객체 (군집의
변경에 위치한 객체)
DBSCAN
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) 은 밀도를 기준으로
군집화하는 기법이다. 즉, 군집을 밀도 연결점의 최대화 집합으로 정의한다. DBSCAN 알고리즘은 임의
점으로부터 이웃 점을 추출하고 근처에 다른 점들이 충분히 존재한다면 군집으로 처리하고 그렇지 않다면 그
점은 noise 로 처리한다.

80
DBSCAN 의 장점
k-means 과 달리 몇 개 군집을 생성할지 지정 안해도 된다.
그 어떤 형태로도 군집을 생성해 낼 수 있다.
잡음의 개념이 이용되어서 군집의 분석에 도움을 준다
DBSCAN 에 사용되는 2 개의 파라미터는 분석대상이 되는 여러 점들의 순서와는 무관하게
이용된다.
DBSCAN 의 단점
DBSCAN 은 거리측정치에 의해 좌우된다.
밀도의 차이가 클 때는 모든 군집에 적용될 수 있는 minPts- 의 조합을 선택할 수 없게 되고
효과가 떨어진다.
OPTICS
OPTICS(Ordering Points to Identify the Clustering Structure) 알고리즘은 데이터베이스에서
객체들의 순서화와 추가적으로 줌심거리의 각 객체의 적절한 도달 가능거리를 만들어준다.
데이터베이스 SCAN 이 와 MinPts 와 같은 주어진 입력인자에 의해 객체를 군집하지만 인자의 설정에는
경험이 필요하고 대부분 알고리즘이 인자 값에 매우 만감하므로 이를 극복하기 위해 명시적 집합군집화 대신
자동적이고 점진적으로 군집순서를 계산한다. 이는 데이터의 밀도기반 군집화구조를 나타낸다.
바. 격자기반 (Grid-Based) 군집화 기법
격자기반 기법은 객체공간을 격자구조로 이루어진 유한개의 공간으로 만들고 모든 군집화 작업은 이러한
격자구조에서 실행하게 된다.
격자기반 기법의 대표적인 것으로 다음과 같은 것이 있다.
STING (STatistical INformation Grid): 격자셀이 저장된 통계적인 정보를 이용하는 방식이다.
WaveCluster: Wavelet 변환기법을 통해 객체들을 군집한다.
CLIQUE: 고차원 데이터공간의 군집화를 위한 기법.

81
STING 군집화를 위한 계층구조이다.
사. 모델 기반의 군집화
모델기반기법은 각 군집에 모델을 설정하고 주어진 모델에서 가장 잘 맞는 데이터를 찾는다. 일반적인
모델 기반 방법에는 (COBWEB, CLASSIT, AutoClass 같은) 통계적 접근법도 있고 (경쟁학습과 자기 구성
특성지도 같은) 네트워크 접근법도 있다.
Expectation-Maximization
가장 그럼직한 모델(maximum likelihood estimate)을 반복적으로 실시하는 알고리즘으로서 관측
데이터에 적합한 모델의 모수를 추정한다.
a. 초기에 임의의 모수를 설정하고 관측데이터(X)가 설정된 모델 (lambda_0)로부터 생성되었을 확률을
계산한다.
즉, P(X | lambda_0 )
b. 그리고 모델을 약간 수정한 새로운 모델을 lamda_1 이라고 하고 다시 관측데이터의 사후확률을
구한다.
즉, P(X | lambda_1)
c. 그리고 이들 상호를 비교하여
IF P(X | lambda_1 ) 이 더 크다면 THEN
lambda_1이 lamda_0 보다 더 관측데이터(X)로 적합하다고 판단한다.
d. 이러한 작업을 다음 조건을 만족할 때까지 반복한다.
새 모델 lambda 에 대한 P( X | lambda)가 기존 모델보다 부적합한 경우 (likelihood 가 더 작은 경우)에
도달하는가?
개념적 군집화
개념의 군집화는 일종의 통계적 접근으로서 이름이 없는 객체의 집단이 주어졌을 때 객체들의 분류구조를
만든다. 관찰된 특성 또는 사실들을 수학적인 수치에 의해 나누어서 어떤 기술적 개념에 대응하는 집단으로
조정하는 것이다. 이 경우 일반 군집화에서는 기하학적 거리에 기초하여 유사성을 측정하는 하는 것과 달리
개념 군집화에서는 (1) 적절한 class 를 찾고 (2) 분류와 같은 방식으로 class 에 대해 서술한다.

82
비슷한 객체의 그룹을 인식하는 보통의 군집화와 달리 개념군집화는 한발 나아가 개념이나 class 를
나타내는 각 그룹에 대해 특징적 설명을 찾는다. 따라서 (i) 군집화가 먼저 수행된 후 (ii)특성화가 뒤따른다.
COBWEB
COBWEB 에서는 입력객체들을 범주적 속성 값의 쌍으로 포현한다. COBWEB 은 트리의 구성범주
효용값이라 부르는 경험적 평가측도를 사용한다. 범주효용값 (category utility: CU)는 다음과 같이
정의된다.
여기서 n 은 어느 트리 레벨에서 분할 {C1,C2, ... , Cn}을 형성하는 노드들, 개념들 또는 분류들을 말한다.
그리고 범주 효용값은 class 내 유사성과 class 간 비유사성을 보인다.
Class내 유사성 (intraclass similarity)은 확률 P(Ai = Vij | Ck)이다. 이 값이 클수록 속성 - 값의 쌍을
공유하는 class 원소의 비율은 더 커지고 class 원소쌍의 예측가능성이 높아진다.
Class간 비유사성 (interclass dissimilarity)은 확률 P(Ck | Ai = Vij) 이다. 이 값이 커질 수록 이 속
성-값의 쌍을 공유하는 대조 class들의 객체들은 더 적어지고 class쌍이 더 예측가능하다.
CLASSIT
COBWEB 을 확장한 알고리즘으로서 개별 속성에 대한 연속형 정규분포를 저장하고 수정된 category
utility 척도를 이용한다.
신경망 접근법
여기서는 각 군집을 견본으로 표현하는 경향이 있는데 견본은 군집의 기본형 (prototype)으로 작용한다.
대표적 방법론으로는 경쟁학습 (competitive learning)과 자가구성 특성지도 (self-organizing feature
maps)가 있다.
(6) 예측이론
가. 개요
불확실한 미래를 예측하려는 노력은 거의 본능의 영역에 속하지만 예측이 가능하려면 어떤 변수들이
미래상황에 영향을 준다는 일종의 인과관계가 전제되어야 한다. 미래가 전혀 무작위로 - 즉 예측불가로 -
움직인다면 예측행위 자체가 성립될 수 없기 때문이다. 단, 인과관계를 몰라도 변수 간의 상호관련성
만으로도 예측을 하는 것이 가능하다.
예측의 종류
질적 예측: 나름의 판단과 의견에 따르는 것이다. Delphi 기법, 여론조사, 빈발항목 분석을 통한 상황예

83
측이 이에 속한다.
양적 예측: 수리적 모델을 설정하고 이에 따라 예측하는 것이다. 여기에는 회귀분석과 시계열 분석 등이
있다.
기타 (인과관계분석, 시뮬레이션 등)
나. 회귀분석
회귀분석을 통해 패턴 또는 패턴에 영향을 주는 변수들 간의 관계를 추측, 식별할 수 있다. 예를 들어 특정
마케팅 전략의 유효성을 검증하기 위해 기간별, 매체 별, 마케팅 캠페인의 효과분석을 실시하게 된다. 특히
단순 상관관계에 비해서 관심 있는 변수(즉, “target” 변수)에 영향 주는 많은 요소를 통제할 수 있다는
것이다. 예컨대 가격변경 또는 경쟁행위가 특정 브랜드의 매출에 영향 주는 경우 회귀분석 모델을 통해 이들
각 요소가 매출에 끼치는 영향도를 조사할 수 있다. 회귀분석에는 다음과 같은 여러 종류가 있는데 여기서는
선형회귀분석만 언급한다.
Regression 분석의 유형
유형 주요 내용
단순 선형회귀
(simple linear regression)
예측변수 (또는 요소: factor)와 목표변수
(target variable) 사이에 선형관계가 있는
것으로 가정.
다항식회귀 (polynomial R.) 다항(多項)관계의 모델에 의거한 회귀분석
다중선형 회귀
(multiple linear Regression)
2 개 이상의 예측변수로부터 목표변수를 예측할
때 사용된다.
다변량 회귀 (multivariate R.) 설명변수로부터 여러 개 종속변수를 예측하는
것.
로지스틱회귀분석
(logistic Regression)
target 변수가 이항(二項: binomial)일 때 사용
(1,0 – Accept 또는 Reject).
Poisson 회귀
(Poisson Regression)
예외적 상황을 대상으로 하는 Poission 분포를
따르는 회귀모델
Cox 비례위험 모형 (Cox
proportional hazards)
여러 개의 설명변수로부터 특정 사건(event)에
대한 시간을 예측하고자 하는 경우
시계열 (time-series) 과거 시계열 데이터로부터 미래 행위를 예측.
비선형 회귀분석 예측변수와 목표변수 사이에 선형관계가 없을
때 이용한다.
비모수형 회귀분석 모델이 데이터로부터 도출된 것이 아닌, 경우
사용

84
선형회귀분석
선형 관계. 독립변수를 x, 종속변수를 y 라고 할 때 관계는 다음과 같다.
y=a+ ßx(1)
단, 실제 연구에서 모집단에서의 a 와 ß 의 값을 추정할 필요가 있으므로
y=a + ßx+ ε(2) (ε는 오차항.)
여기서 최소제곱법에 의해 a 와 ß 를 추정하게 된다.
a 와 ß 의 추정 값의 신뢰도를 검토하기 위해서는 신뢰구간을 계산하거나 t 검정을 이용하고 독립변수가
여럿일 때 F 검정을 이용한다.
다. 시계열 분석을 통한 예측
개요
여러 기간 동안 측정된 값들은 일정한 내부 구조을 가지며 이를 규명하기 위해 추세, 계절성 및 순환적
요소를 구분해 낸다.
추세분석
통계적 시계열에서는 수학 모델을 통해 시간적 변동법칙을 추출하려 한다. 예컨대 매일의 특정 주식의
종가를 Y 라 한다면 이는 시간 t 에 대한 함수 Y= F(t)이며 시간에 따라 움직이는 점으로서의 시계열
그래프로 표현할 수 있다. 시계열 데이터에는 4 가지의 주요요소로 분해한다.
장기 또는 추세적 움직임 (trend movements) - 이는 장기적, 일반적인 방향성을 말하며 추세선으로
표시된다. <그림>에서의 점선이 그것이며 통상 가중이동평균법과 최소제곱법으로 도출한다.
주기적 변동 (cyclic variation) - 추세선에 대해 장기적 변동으로서 영향주는 변동요인을 말한다.
계절변화 (seasonal variation) - 해 또는 달마나 일어나는 동일한 패턴을 말한다. 단, 이러한 계절변화
가 반드시 정확하게 같은 패턴을 가질 필요는 없으며 어느정도의 유사성 만으로도 충분하다.
임의 변동 (random movement) - 임의적 또는 우연한 사건에 의한 우발적 특성에 따른 움직임을 말한
다.

85
위 4 가지 요소를 각각 T, G, S, I 로 나타내면 시계열 변수 Y 는 4 개 변수의 곱 또는 그들의 합으로
모형화할 수 있다. 예컨대:
Y = T x G x S x I
시계열 분석모델에 의거하여 주로 많이 활용되는 모델은 autoregressive models (AR) 및 moving
average (MA) 모델이다.
Box-Jenkins 모델 (1976)에서는 AR와 MA 모델을 결합해서 ARMA (autoregressive moving
average) 모델을 탄생시킴.
ARIMA(autoregressive integrated moving average models) 은 non-stationary 시계열에 주로
초점이 맞추어짐.
시계열 분석 수행절차
(1) 모델을 선택한다. 즉 정상 시계열 (Stationary Time Series), 계절형 시계열 (seasonal time
series) 등 여러가지 모델을 분석한다.
(2) 예측치와 관측치와 최대한 부합하도록 모델의 파라미터를 결정.
(3) 실제 예측을 하면서 신뢰구간을 추정한다. 여기서 예측이란 모델을 통해 미래 상황을
추정(extrapolated)하는 행위가 된다.
이동 평균법 (Moving Average)
이동편균법은 지난기간의 N 개 값의 평균이 유지될 것으로 가정한다. 그리고 관측시점이 경과할 때마다
새로운 기간 N 을 적용하는 방식으로 이동하면서 평균값을 계산한다.
Ft =
이러한 이동평균은 기간 N 의 크기는 물론 예측변수에 대한 가중치 적용에 따라 여러가지로 응용이
가능하다.

86
Ft =
지수평활법 (指數平滑法 :)과 이중 지수평활법
최근의 데이터에 제일 큰 큰 가중치를 적용하고 이후 경과에 따라 가중치가 기하학적으로 감소되는 이동
평균법이다.
이동평균(MA)과 지수평활(ES)의 비교
<유사성>
정상 진행상태를 가정하고 있다.
하나의 파라미터만 이용한다. (MA에서는 N, ES에서는 a만 이용한다)
추세에 대해서는 이를 뒤따라갈 뿐이다.
<차이점>
사용하는 데이터의 양이 다르다.
실제 수행시의 컴퓨터 자원사용 양태가 다르다.
(7) 의사결정 트리(Decision Tree)
가. 개요
일련의 의사결정 대안을 나무 모양으로 늘어놓는 예측모델이다. 여기서 중요한 것은 단계별 분기점을 찾는
것 즉, 적절한 질문을 찾는 것이다.
가장 많이 사용되는 3 가지 방법은 다음과 같다.
gini
Chi-square
정보이득 (Information gain)
목표변수가 연속적이면 (예: 확률, 소득) F-검정을 이용하도록 한다.
의사결정트리의 장점은 다음과 같다.
그림이어서 이해하기가 쉽다.
자동화도 용이하고 SQL로 변환하기도 쉽다. 따라서 다른 정보시스템과 통합도 용이한 편이다. 예측모델
외에도 데이터 탐색의 단계에서 각종 변수의 영향도를 쉽게 이해할 수 있게 해준다.
누락된 값을 귀속시키는데 사용되기도 한다.

87
실무에서 수 천 개의 변수와 판단기준을 설정하기도 하지만 효과적 운영을 위해서는 역시 변수 개수를
최소한으로 유지시키는 좋다.
나. 사례: 대출상환 연체 분석
한 은행이 최근 2~5 년 사이에 증가된 연체율에 대해 여신정책을 엄격히 운영하려 한다. 은행 측에서는
연체 대출자의 특성(profile)을 파악하여 정상 상환하는 고객과 차이가 있는지를 밝히고 신규 대출시
연체집단에 해당는 사람에게는 대출을 자제하고자 하였다.
의사결정트리는 10,000 명의 대출자를 대상으로 하였는데 이들 중 200 명이 연체하여 연체발생율은
0.2%였다. 첫 단계에서 한 집단(A)은 연체율이 0.4%인 반면 다른 집단(B)은 75%에 달하였다. 조사결과
A 집단의 경우 월 평균소득이 월 불입액의 1.2 배 이상인 반면 B 집단은 그 이하의 소득을 가지고 있었다.
따라서 B 집단의 특성을 가지는 사람에게는 대출을 엄격히 제한해야 한다는 결론에 도달하였다. 나아가
대출신청자의 특성에 따라 그 집단에 해당되는 질문을 던짐으로써 더욱 세분화시켜 나갈 수 있었고
최종적으로 연체율이 50%가 넘는 3 개의 소 집단을 찾아낼 수 있었다. 여기에 의사결정 tree 의 분석 예가
나와 있다.
해당자: 9800
정상상환: 9450상환지체: 350
대출상환 연체그룹 분석
표본집단: 10,000명
정상상환: 9,800명상환지체: 200명
해당자: 200
정상상환: 50상환지체: 150
월 소득 > 월 상환액 x 1.2
다른 대출 건 수 < 2
해당자: 8800
정상상환: 8550상환지체: 250
해당자: 1000
정상상환: 900상환지체: 100
해당자: 400
정상상환: 200상환지체: 200
해당자: 8400
정상상환: 8350상환지체: 50
월 소득 < 월 상환액 X 2.5
이전에도 상환지체가 있었는가?
해당자: 150
정상상환: 50상환지체: 80
해당자: 850
정상상환: 830상환지체: 20
예 아니오
예 아니오
예 아니오 예 아니오
다. 의사결정트리와 MapReduce
얼핏 보기에 의사결정트리는 단순히 여러 판단문을 나열한 것으로 보일 수 있으나 실제로 의사결정트리의
적용범위는 의외로 넓어서 수 백만 내지 수 천만개의 node 로 구성된 경우도 적지 않다. 예컨대 수 많은

88
데이터셋을 분류하면서 의사결정트리 기법을 이용하는 경우 MapReduce 방식의 병렬처리를 통해 큰 효과를
거둘 수 있게 된다.

89
(8) 스트림 데이터 (data stream)의 분석
가. 개요
데이터 스트림 (data stream)이란 끊임없이 생산되어 흘러나오는 연속된 형태의 데이터를 말한다.
대표적인 예로는 통신회사에서 통신내역을 기록하는 CDR 데이터46나 전력회사에서의 전력생산 및 송배전과
관련된 데이터, 각종 센서 데이터나 보안장비에서 발생되는 침입탐지 관련 데이터 등을 들 수 있다. 여기서
데이터 스트림의 몇 가지 특징을 보면 다음과 같다.
순서. 시간 순으로 나열된다 – 순서가 데이터의 값과 함께 분석상 의미를 가진다는 것이다. 단, 이때 반
드시 엄밀하게 특정 시점으로 또는 특정한 주기로 기록되어야 하는 것은 아니며 단지 시간 순으로 발생
하고 필요 시 이를 순서대로 기록하는 것을 의미한다.
재생 불가- 순식간에 지나므로 한번 놓치면 복원이 불가능하다.
고속성 – 성격 상 고정된 값을 가지는 경우가 거의 없고 그 값이 끊임없이 매우 빠르게 변화한다.
무한생성 – 대량의 데이터가 산출된다. 한번에 발생되는 데이터는 클 수도 있고 작을 수도 있겠으나 시
점 별로 끊임없이 발생되기 때문에 결과적으로는 그 데이터의 크기가 매우 커지거나 극단적인 경우 무한
대로 증가할 수 있다.
고차원성: 여러 소스에서 동시에 데이터가 수집될 수 있으며 차원분류 상 다차원의 성격을 가진다.
동태적 성격 –고정된 값을 가지는 경우가 거의 없고 시시각각 그 값이 변한다.
우선 스트림데이터의 분석 시 이들 데이터를 random access 보다는 single scan 하는 경우가
대부분임을 유의할 필요가 있다. 그리고 이들 데이터의 속성값의 범위가 크므로 데이터를 요약하기 위한
요약 데이터 구조 (synopses data structure)47가 제시되며 그 내용은 다음과 같다.
무작위 표본추출 (random sampling)
Sliding window – 최근의 데이터만 이용한다. Window의 크기를 w라고 할 때 (t-w) 시점의 데이터 까
지만 이용한다.
히스토그램 – 데이터를 구간으로 나누어서 표시한다. 주로 많이 사용되는 형식이 V-Optimal
Histogram이다.
46 유무선의 모든 전화는 우리가 전화를 걸거나 수신자와 통화가 이루어질 때마다 진행되는 모든 호(call) 설정 데이터와
통화시간 등 내역이 교환기를 통해 CDR(Call Detail Records)로 기록된다. 과거 통신업계에서는 이를 단순히 요금부과에
이용했지만 이제는 사용자 각각의 통화, 문자, 데이터 이용 패턴을 분석하고 이를 활용하여 사용자 별 맞춤 요금제로 응용하고
있다.
47 요약 데이터 구조란 원본 데이터 (base dataset)보다 현젹하게 그 크기가 작은 데이터 구조를 통칭하여 일컫는 말이다.

90
나. Stream OLAP분석
스트림 데이터에 숨겨진 의미 있는 패턴을 찾기 위해서는 - 위에서의 synopses 데이터 구조와 함께 -
각종의 총량 데이터에 대한 다차원분석이 필요하다. 이는 앞서 보았던 OLAP 분석에 해당되지만 스트림
데이터의 다양한 특징으로 인해 일반적 거래 데이터 형태의 데이터 웨어하우스와 OLAP 분석은 사실상
불가능하다. 따라서 다음과 같은 데이터의 압축기법이 동원된다.
시간 축의 축소: 경사 시간모델 (Tilted Time Frame)
오래 전의 데이터에 대해서는 채집주기를 길게 하고, 최근의 데이터에 대해서는 채집주기를 짧게 한다.
예컨대 분석기준 1 년 이전의 데이터는 월별로, 최근 6 개월은 주 별 데이터를, 그리고 최근 1 개월의
데이터는 매일 채집하여 분석 데이터를 구성하는 것이 그 예가 되겠다.
그림: tilted-time frame의 3가지 예
위 그림에서 (a) natural tilted time frame 이란 자연적 시간단위를 달리하는 것을 말하며 (b)
logarithmic tilted time frame 은 로그 (log 즉, 대수(對數))적으로 시간단위를 결정하는 것을 말한다.
임계 계층 (critical layer)
스트림 데이터의 빠른 처리를 위해 위의 경사 시간모델 외에 추가적인 기법이 동원된다. 임계계층이란
전체의 cuboid 중에서 특히 의미 있는 계층만을 선택하는 것으로서 개념적으로 다음과 같이 두 가지로
구분한다.
최소 관심계층 (minimal interest layer) = 분석자가 관심 있는 데이터만 최소한도로 추출하는 것
관측계층 (observation layer) = 분석자가 지속적으로 검토하고자 하는 대상을 지정하는 것
다. Stream 데이터에서의 빈발패턴 분석
앞서의 일반적인 빈발패턴 분석기법을 stream 데이터에 대해서도 그대로 적용할 수 있다. 단지 일반적
빈발패턴의 분석이 정적 분석이라고 한다면 스트림 데이터의 그것은 동적 분석이라는 차이가 있다. 즉,
스트림 데이터의 성격으로 인해 일반적인 빈발패턴 분석에 일정한 제약이 가해진다고 하겠는데 이를
극복하기 위해 데이터의 일부분을 선별적으로 분석하든가 또는 빈발패턴 규칙성에서의 엄밀성을 완화시키는
방법이 흔히 동원된다.

91
라. stream 데이터에 대한 분류 알고리즘
이 역시 앞서 본 일반적인 분류기법을 준용되지만 스트림 데이터의 동태적 성격으로 인해 몇 가지 변형이
필요하다. 특히 데이터 생성이 순식간에 이루어지기 때문에 일반 분류 알고리즘에서의 초기작업 즉,
batch 형태로 이루어지는 훈련 데이터의 scan 작업이 생략된다. 또한 시시각각 데이터 값이 달라지므로
대상이 되는 분류모델이 시간에 따라 달라지는 현상이 나타나는데 이를 개념 변경 (concept drift)라고
부른다. 다음과 같은 몇 가지의 스트림 데이터 분류 알고리즘이 제시되었다.
Hoeffding Tree 알고리즘
VFDT (Very Fast Decision Tree)와 CVFDT (Concept-adapting Very Fast Decision Tree)
연관 분류
Adaptive Nearest Neighbor 분류 알고리즘
마. stream 데이터에 대한 군집 알고리즘
STREAM과 CluStream
기존의 정적 데이터 대상의 알고리즘 (BIRCH, COBWEB) 이용
(9) 시계열 및 순차데이터에 대한 분석
가. 시계열 (time-series) 데이터의 분석 마이닝
앞서 우리는 시계열 분석을 통한 예측기법에 대해 알아본 바 있다. 여기서는 축적된 시계열 데이터를 통해
미래에 대한 예측을 하는 대신 그 안에 내재된 규칙과 숨겨진 모습을 찾아내는 분석기법에 대해 알아본다.
우선 시계열 데이터는 시시각각 변하는 값 또는 시간에 따라 발생하는 사건의 순차(순서)로 이루어져
있는데 이들 값은 보통 일정한 시간 간격으로 측정된다. 대표적 예로 증권시세, 각 지역별 교통량데이터,
다양한 종류의 센서로부터 발생되는 센서 데이터 등을 들 수 있다.
시계열 분석에서의 유사성 탐색
일반적 유사성 탐색에서 정확히 일치하는 (exact match) 데이터를 탐색하는 것이라면 시계열 데이터에
대한 유사성 탐색에서는 query sequence 상의 약간의 차이가 용인된다. 이러한 예로는 주식 시세에 관한
유사성 탐색 또는 전력 소비패턴의 분석을 통해 시간대별 소비패턴을 구별해 내는 것이 있다. 유사성 탐색의
절차는 다음과 같다.
(1) 사전에 다차원 인덱스를 생성한다. 이때는 앞서의 기법을 이용한 Fourier 계수를 적용한다.
(2) 분석자가 질의어를 입력한다.
(3) 질의어상의 검색어와 인덱스 사이의 유사도를 거리 개념에 입각하여 계산한 후 가장 근접한 것을
산출한다.

92
(4) (3)번에서의 산출에 대한 후처리를 통해 시간축 내에서의 sequence 간 거리를 계산하고 이를 통해
실제 인접된 것만을 골라낸다.
(5) 분석자에게 최종 결과물을 출력한다.
유사성 분석을 위해서는 인덱스의 생성이 중요한데 시간과 계산비용이 매우 많이 소요되기 때문에 이를
단축시키고자 많은 노력을 하고 있다. 구체적으로 시계열 데이터 S 가 주어졌을 때 유사성 탐색의 방법에는
크게 2 가지가 있다. 부분순차일치 (sub-sequence matching)에서는 찾고자 하는 순차데이터와 근접하는
데이터를 질의어를 통해 찾는다. 반면 전체순차일치 (whole sequence matching)에서는 S 안에 있는
순차데이터 중 서로 비슷한 것들을 찾아낸다.
데이터 축소와 변환기법
시계열 데이터베이스는 데이터의 크기와 차원이 매우 높기 때문에 처리속도의 개선이 필요한데 이를 위해
우선 데이터 축소를 시도한다. 앞서도 본 바와 같이 데이터 축소에는 다음의 몇 가지 접근법이 있다.
속성부분집합 선택 (attribute subset selection) - 관련이 없거나 중복되는 속성 및 차원을 제거하는
것
차원축소 (dimensionality reduction) - 신호처리기술을 원용해서 원래의 데이터를 압축된 형식으로
축소시키는 것.
수치 축소 (numerosity reduction) - 데이터의 수치값을 대체값으로 변경시킴으로써 데이터의 크기를
줄이는 것이며 예를 들어 histogram, 군집화, 표본추출 등의 기법을 이용한다.
시계열 데이터는 각각의 시간요소가 차원의 의미를 가진다는 의미에서 차원이 매우 높기 때문에 특히 시간
또는 빈도 등과 관련한 차원축소를 중요시하는데 차원축소의 기법으로는 다음과 같은 것들이 있다.
이산 푸리에 변환 (DFT: Discrete Fourier Transformation)
이산 wavelet 변환 (DWT: Discrete Wavelet Transformation)
Singular Value Decomposition (SVD)-주성분 분석에 기반함.
임의투사 (random projection) 기반의 sketch기법
나. 순차데이터 분석
개요
순차 (Sequence)데이터란 순서를 가지는 데이터 요소의 집합 (Ordered set of elements)을 말한다.
s = a1,a2,..an
이때 각 항목는 수치 데이터일 수도 있고 범주형일 수도 있으며 복수의 속성을 가지는 경우도 많다. 단,
이때 각 순차 (즉, 시점별 데이터)는 특별히 고정된 길이를 가지지 않으며 다양한 형태가 가능하다.

93
순차 데이터베이스는 시계열 데이터와 같은 개념이지만 시간측정 없이 사건데이터의 순서로만 구성될
수도 있다. 예컨대 사용자의 웹 페이지 방문순서에 대해 하나의 페이지에서 다음 페이지로 link 를 따라
움직이는 경우 순차 데이터에 해당되지만 시계열 데이터는 아닐 수도 있다.
이러한 순차데이터의 예는 매우 광범위하여 그 쓰임새가 매우 넓다. 예컨대 사람의 대화를 각종 언어 요소
(또는 발성 요소)의 순서로 보고 분석하기도 하고 최근 관심을 모으는 각종의 생명데이터 분석
(Bioinformatics)과 관련한 것들도 들 수 있다. 예를 들어 유전자 정보에서의 4 가지의 nucleotides
(핵산의 구성요소)의 경우 |S|=4
예: AACTGACCTGGGCCCAATCC
또는 단백질을 20 가지 아미노산의 순차데이터로 볼 수도 있다 |S|=20
기타의 예로는 통신망에서의 침입탐지를 위한 패킷분석이라든가 e-store 에서의 session 정보 분석 등을
들 수 있겠다.
순차데이터에 대한 분석
순차데이터 마이닝 개요
순차 패턴분석은 상징적 패턴과 함께 다음의 몇몇 요인도 중시한다.
(1) 시간순차의 지속기간 (duration) T – 지속기간은 데이터베이스에서 특정 사건 전후의 매 1 주일 또는
1 개월과 같이 분할된 순차의 집합으로 정할 수 있는데 이를 통해 주기패턴을 발견하고자 한다.
(2) 사건 접음 윈도우 (event folding window) - 특정 기간 내에 발생하는 사건의 집합을 분석해서 이들
사이에 연관된 패턴을 발견할 수 있다. 만약 윈도우의 크기를 w 라 할 때 (예컨대 24 시간 내로 지정) 이
거래들은 그 기간 내에 발생된 것으로서 이들 순차를 묶어서 처리할 수 있게 된다.
(3) 시간 간격 (interval)– 발견된 패턴에 있는 시간 간격으로서 만약 시간간격 int = 0 로 설정하면
간격을 설정하지 않는 즉, 엄격하게 순차적, 연속적으로 발생하는 것만을 의미하게 된다.
순차데이터 분석기법
순차데이터에 대한 분석기법은 초기에 Apriori 부류의 알고리즘이 주류를 이루었는데 기본형태는 다음과
같다.
If a sequence S is not frequent
Then none of the super-sequences of S is frequent
이후 이를 응용한 다음의 알고리즘이 큰 인기를 끌고 있다.

94
GSP 알고리즘
Equivalence class를 이용한 순차패턴의 발견 (SPADE)
FreeSpan과 PrefixSpan

95
(10) 이상치 분석 (Outlier Analysis)
이상치 (異狀値: outlier)란 주어진 데이터의 일반적 특성 또는 모델에서 크게 벗어난 것 즉, 데이터가
정상적이지 않거나 예상되는 패턴(expected pattern)을 준수하지 않는 것을 말하며48. 이상치 분석이란
이들 이상 데이터를 찾아내고 그 특징을 구명하는 것을 말한다. 금융, 보안, 침입탐지 등 많은 분야에 응용이
가능하다. 다만, 전체 데이터 에서 정상범위를 어떻게 규정할 것인지가 문제이다. 특히 에메모호한 경계가
존재할 수 있기 때문이고 또한 정해진 규칙도 시간에 따라 달라질 것이다.
이상치의 유형에는 다음과 같은 것이 있다.
Global outlier - 특정한 하나의 측정치가 현저하게 벗어나 있는 point anomaly를 말한다.
Contextual outlier - "현재 기온이 30도 이다" 이것이 이상치인지 정상치 인지는 상황에 따라 달리 해
석된다. 이처럼 상황을 설정해 놓고 이상치를 탐지하는 것을 말한다.
Collective outlier - 관측된 여러 값들이 나머지에 비해 현저하게 벗어나 있는 것을 말한다.
가. 이상치 발견 기법의 분류
Instance 기반의 여러 분석 방법
감독하의 분류 기법 – 속성정보가 구비된 (labeled) 훈련데이터 분류 기법을 정상치 데이터와
이상치 데이터에 적용하는데 주로 Bayeisn filtering 기법과 신경망및 SVM 등이 이용된다. 다만
이상치 데이터의 경우 label 이 없는 경우가 많으므로 신뢰성이 저해될 수 있다는 단점이 있다.
다변량 확률분포 분석 – 확률이 낮은 현상을 나타내는 데이터는 이상치일 가능성이 높다
근접성 기반의 분석 – 다차원 속성공간에서의 데이터간 거리를 비교하는 방법
상대밀도 기반의 분석 – 밀도란 이웃과의 거리평균의 역수이다.
공유된 인접이웃 기반 분석, 군집분석 및 기타(정보이론 등)
순차데이터 기반의 분석
악의적 행태가 연속해서 노출될 때 이를 이상치로 판단하는 것이다.
48 anomaly라고도 부른다.

96
Markov chain - 관측상태와 이들 상태의 변동확률을 검토한다.
Hidden Markov Model - 은닉된 (hidden) 상태정보와 관측 (observable) 상태정보를 모두
가지도록 한다.
이제 몇 가지 주요 이상치 분석 기법을 살펴본다.
나. 통계적 기법에 의한 이상치 발견
주어진 데이터에 대한 확률모델을 가정하고 이에 대한 불일치 검증 (discordance test)를 사용한다.
통계적 이상치 발견기법에서는 작업가설과 대안가설의 2 가지 가설을 검토하는데 구체적으로는
모수기법과 비모수기법 로 나뉜다.
모수기법 - 정상데이터는Θ 라는 파라미터를 가지는 매개변수적 분포 (parametric distribution)을 가
진다고 가정한다. 이때 이 매개변수적 분포의 확률밀도함수 f(x, Θ)에 의해 x의 확률을 도출해 내게 된
다. 여기에는 (i) 정규분포에 기반한 단변량 이상치 (univariate outlier) 탐지 (ii) 다변량 이상치
(multivariate outlier) 탐지 (iii) 여러 매개변수분포를 혼합하여 탐지 등의 여러가지 방법이 있다.
비 모수 기법 - 선험적인 확률 모델을 가정하지 않고 입력데이터로부터 모델을 직접 추정한다.
다. 근접도 (Proximity)에 의한 이상치 발견
가장 가까운 이웃과의 거리가 특정 영역 R 내에서 주어진 임계치보다 큰 경우에 이를 이상치로 판단하는
것이다.
우선 거리 임계치 r(r >0)과 π (0 < π ≤1)을 지정한다. 이 때 다음 조건이 만족되는 객체는 DB(r, π)
특성을 가지는 이상치라고 할 수 있다.
DB(r, π) 특성을 가지는 이상치 검출을 위한 Nested 루프 알고리즘이 다음에 제시되어 있다.
거리기반 이상치 발견 알고리즘
(목적)
거리 개념을 기준으로 이상치를 발견코자 함
(입력항목)
D: 임계치 인 객체의 집합 D = {o1, …, on} 인
(출력항목)

97
D 에서의 이상치 DB(
(Method)
for i=1 to n do
count 0
for j =1 to n do
if i j and dis(oij, oj) then
count count++
if count then
exit { oi cannot be a DB( outlier}
endif
endif
endfor
print oi { oi is a DB( outlier
endfor
라. 군집에 의한 이상치 발견
여기서는 정상 데이터는 밀도가 높고, 크기가 큰 군집에 속하는 반면 이상치는 작고, 밀도가 낮은 군집에
속하는 것으로 정의한다.
마. 밀도함수를 이용한 이상치 발견법
하나의 집단을 구성하는 요소들 간에는 서로 다른 군집보다 높은 밀도를 가진다는 측면에서 각 요소간의
밀도를 측정하고 이를 기반으로 비 정상적으로 낮은 밀도를 가지는 요소를 이상치로 판단하는 것이다.





























