Embed Size (px)
Citation preview

Large-scale Non-linear Classification: Algorithms and Evaluations
Zhuang (John) Wang, Ph.D.
IBM Global Business Services
IJCAI 2013 Tutorial, Aug. 5th, 2013

2
About the tutorialist
Work for IBM Global Business Services and before for
Siemens Research
Research interests: Support Vector Machine, Large-scale
learning, Online learning, Multiple-instance learning
20 or so papers on JMLR, MLJ, ICML, KDD, AISTATS,…

3
Agenda
Overview
Large-scale linear classification
Large-scale non-linear classification
Parallelism
Summary
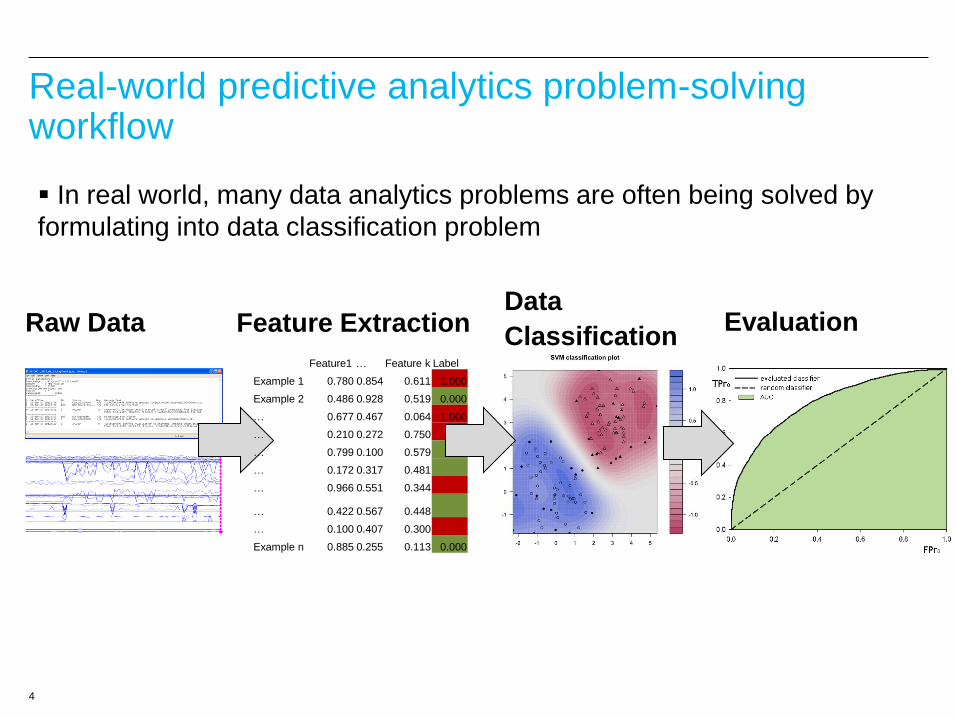
4
In real world, many data analytics problems are often being solved by
formulating into data classification problem
Feature1 … Feature k Label
Example 1 0.780 0.854 0.611 1.000
Example 2 0.486 0.928 0.519 0.000
… 0.677 0.467 0.064 1.000
… 0.210 0.272 0.750
… 0.799 0.100 0.579
… 0.172 0.317 0.481
… 0.966 0.551 0.344
… 0.422 0.567 0.448
… 0.100 0.407 0.300
Example n 0.885 0.255 0.113 0.000
Raw Data
Feature Extraction
Data
Classification
Evaluation
Real-world predictive analytics problem-solving workflow

5
Big data
Cheap, pervasive and networked
computing devices are enhancing
our ability to collect data to an
even greater extent.
What is big data?
No clear definition. A situation that exponentially grew complex data makes us cannot easily make sense of it. To make sense of it, we need a wide variety of technologies to tackle two difficulties: storage and analysis. Large-scale classification is a highly demanding technique which falls into the 2nd category.
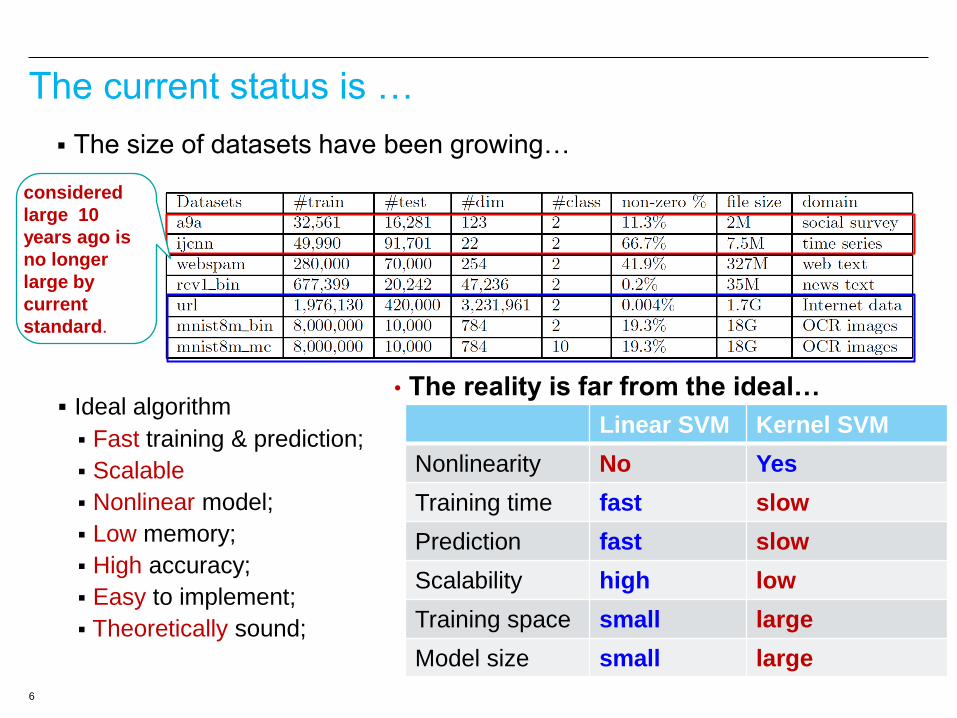
6
The size of datasets have been growing…
considered
large 10
years ago is
no longer
large by
current
standard.
• The reality is far from the ideal… Ideal algorithm
Fast training & prediction;
Scalable
Nonlinear model;
Low memory;
High accuracy;
Easy to implement;
Theoretically sound;
Linear SVM Kernel SVM
Nonlinearity No Yes
Training time fast slow
Prediction fast slow
Scalability high low
Training space small large
Model size small large
The current status is …

7
Large-scale Linear Classification

8
Problem Setting
Training examples:
Goal: train a linear classifier to separate D
( , ), 1,..., , , {1, 1}M
i i i iD y i N R y x x
sgn( ( )) sgn( ), where T Mf R x w x w
Note: we ignore bias term in f(x) for simplicity. Bias term can be implicitly incorporated by adding a constant feature in the data

9
Perceptron
Perceptron algorithm (Rosenblatt, 1957):
1. Initialize w
2. For each example i in D
• Do where
3. Repeat step 2 until stopping criteria (e.g. enough iterations)
Complexity: O(N) in time, O(M) in space*.
Theory: converge after finite steps if data is linearly separable (Novikoff,
1962)
i i w w x, if ( ) 0
0, otherwise
i i i
i
y y f
x
*: sequentially load data by chunk

10
Perceptron (cont.)
Pros:
–Both conceptually and computationally simple
–Constant memory consumption + online learning = scalable (to
arbitrary large data)
Cons:
–Fail to converge on non-linearly separable data
–Not sufficiently accurate
–Out of fashion…

11
Linear Support Vector Machine
Train an optimal linear classifier by solving the optimization (Cortes et al.,
1995)
Note: in linear case, we can explicitly work on w rather than through SVs,
which makes our life much easier!!!
2
1
λ 1min || || max 1 ( ),0
2
N
i i
i
y fN
w
w x
Fig. Source: http://www.ifp.illinois.edu/~yuhuang/sceneclassification.html
2
,
1min
2
s.t. ( ) 1
i
T
i i i
C
y
w
w
w x
Constrained form:
Unconstrained form:

12
Stochastic Gradient Descent for Linear SVM
SVM optimization
Train SVM using gradient descent 1. Initialize w
2. Do
3. Repeat step 3 until stopping criteria
SGD: approximate the exact gradient using the one on the instantaneous objective
Theory: when i is i.i.d. sampled and #iterations is large, with high probability, w converges to w* (Zhang, 2004; Shalev-Shwartz et al., 2008)
( )Obj
ww w
w
( , )InsObj i
ww w
w
2
1
λ 1min ( ) || || max 1 ( ),0
2
N
i i
i
Obj y fN
w
w w x
2λ( , ) || || max 1 ( ),0
2i iInsObj i y f w w x

13
Stochastic Gradient Descent for Linear SVM (cont.)
Train Linear SVM like Perceptron (Zhang, 04; Shalev-Shwartz et al., 08)
1. Initialize w
2. Randomly select an example i in D
• Do where
3. Repeat step 2 with enough iterations
O(N) training time, O(M) training space*
(1 ) i i w w x, if ( ) 1
0, otherwise
i i i
i
y y f
x
*: sequentially load data by chunk

14
Dual Coordinate Descent for Linear SVM
SVM optimization in dual form
maximize the dual objective by iteratively optimizing one alpha (i.e.
coordinate) at a time and keeping the rest variables fixed
Which leads the update rule:
where has closed-form solution
1max , where
2
T T T
ij i i i jy y α
1 α α Qα Q x x
* *
i i iyw x
( )new old
i i i w w x
i

15
Dual Coordinate Descent for Linear SVM (cont.)
Train Linear SVM like Perceptron (Hsieh et al., 08)
1.Initialize w and
2.For each example i in D
• Do where
3.Repeat step 2 until stopping criteria
O(N) training time, O(N+M) training space
( new old
i i i
old new
i i
w w )x2
( ) 1min max ,0 ,
|| ||
new old i ii i
i
y fC
x
x
, 1,...,old
i i N

16
Other popular approaches
Second-order stochastic gradient descent (Bordes et al., 2009)
Bundle approach (Teo et al., 2010)
Cutting plane approach (Joachims, 2006)
Methods for L1-regularized SVM and logistic regression
Refer to the survey paper “Recent advance on large-scale linear
classification” by Yuan et al.,
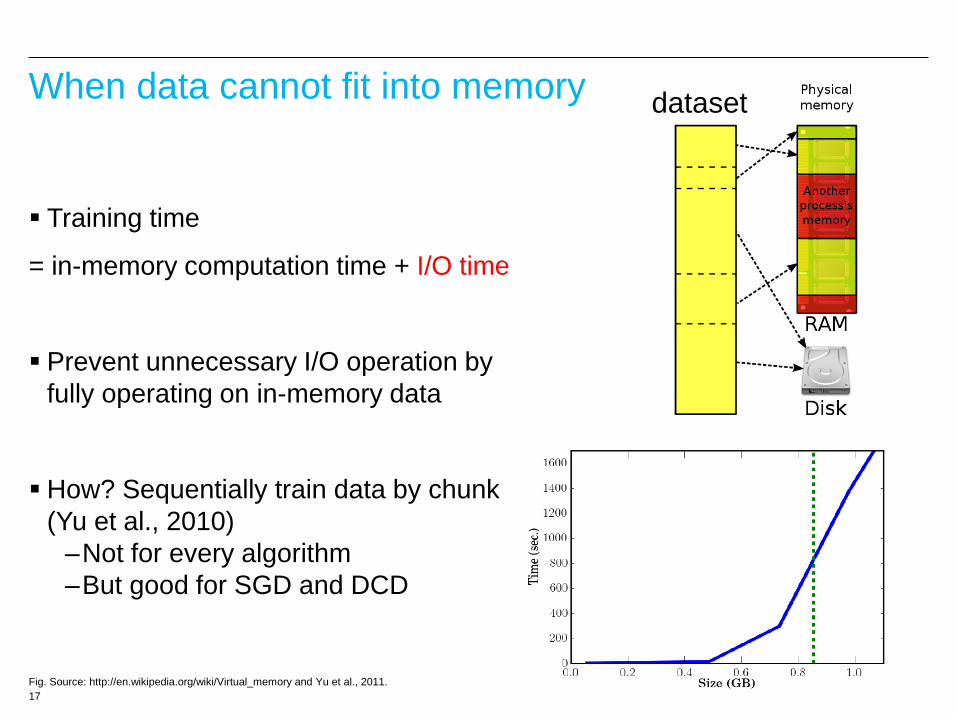
17
When data cannot fit into memory
Training time
= in-memory computation time + I/O time
Prevent unnecessary I/O operation by
fully operating on in-memory data
How? Sequentially train data by chunk
(Yu et al., 2010)
–Not for every algorithm
–But good for SGD and DCD
Fig. Source: http://en.wikipedia.org/wiki/Virtual_memory and Yu et al., 2011.
dataset

18
Off-the-shelf tools
Liblinear (Fan et al., 2008)
–Linear SVM, logistic regression
–Powered by dual coordinate descent
–Windows/Linux cmd-line tool with interfaces to many languages
–Well maintained project
–Train few GB data in a matter of secs/mins
–Good for single machine usage when data CAN/CANNOT fit into
memory
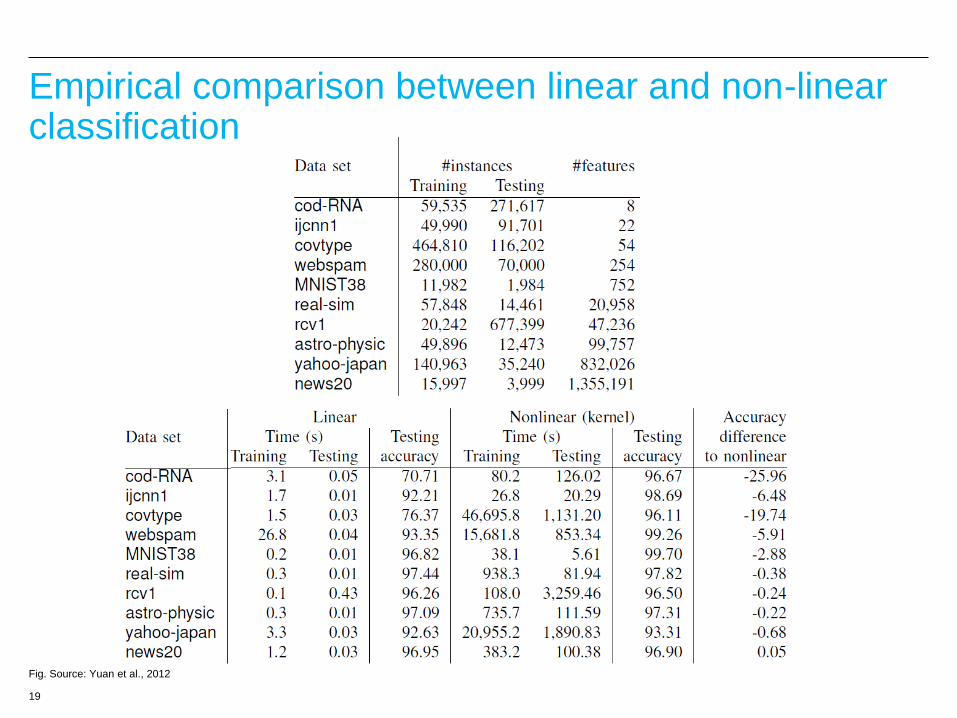
19
Empirical comparison between linear and non-linear classification
Fig. Source: Yuan et al., 2012

20
Why is linear classifier popular?
Because it is computationally cheap and deliver comparable accuracy to
non-linear classifiers in some applications:
–Carefully designed features already capture non-linear concepts, e.g.
computer vision applications
– In higher-dimensional feature spaces, data tends to be more linearly
separable, e.g. document classification (bag-of-words representation).

21
Where will the research of linear classification go?
A field tend to be mature
–A lot of good algorithms for a wide variety of practical problems
–Many off-the-shelf tools
Future directions
–Transfer the mature technologies to other learning scenarios.

22
Large-scale non-linear classification
23
When to use non-linear classifier?
Data has non-linear concepts
Sensitive to accuracy
24
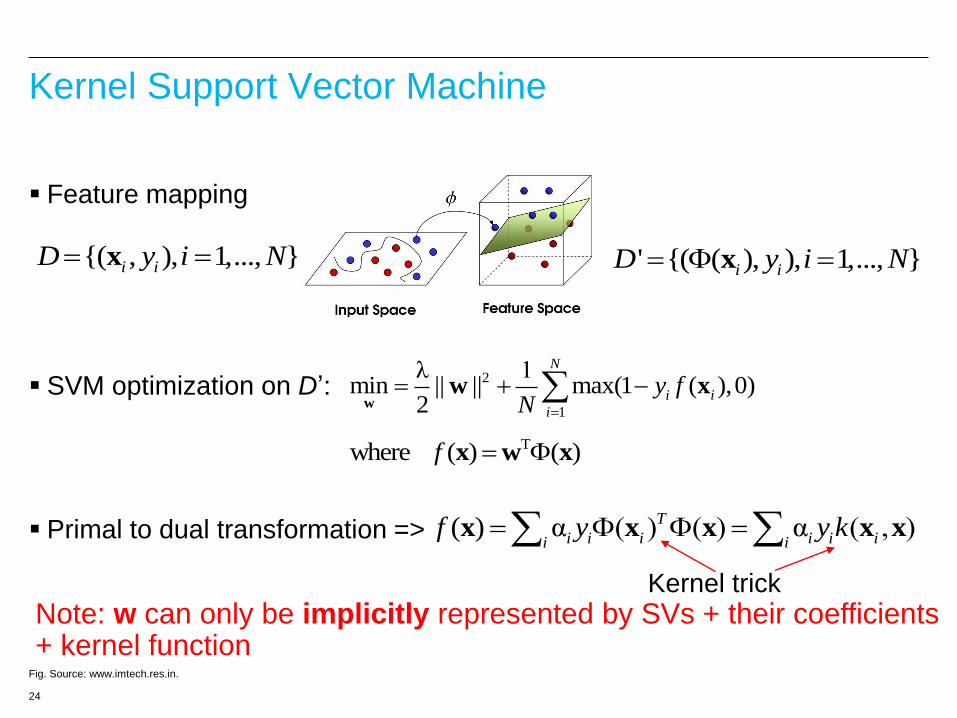
Kernel Support Vector Machine
Feature mapping
SVM optimization on D’:
Primal to dual transformation =>
2
1
λ 1min || || max(1 ( ),0)
2
N
i i
i
y fN
w
w x
' {( ( ), ), 1,..., }i iD y i N x
( ) α ( ) ( ) α ( , )T
i i i i i ii if y y k x x x x x
Kernel trick
Twhere ( ) ( )f x w x
Note: w can only be implicitly represented by SVs + their coefficients + kernel function
Fig. Source: www.imtech.res.in.
{( , ), 1,..., }i iD y i N x

25
Decomposition Methods
SVM dual form
Sequential Minimal Optimization (Platt, 98)
1. Smartly select a working example i and update by solving
2. Repeat step 1 until stopping criteria
1max , where ( , )
2
s.t . , 0
T T
ij i i i j
i
Q y y k
i C
α1 α α Qα x x
i
1max (1 ) , s.t. 0 ,
2i
iU U i i ii iQ C
Q α
i
Closed-form solution for i

26
Decomposition Methods (cont.)
Libsvm (Chang and Lin, 01)
–Highly optimized implementation of SMO (plus heuristic for fast
convergence)
–Actively-maintained open source project
–Windows/Linux cmd-line tool and multiple language APIs
–exact SVM solver
–Scalable for few hundreds MB’s (or <1M examples’) low-dim data *
*: we define “scalable” as training time less than 10hrs.

27
Decomposition Methods (cont.)
Lasvm (Bortes et al., 05): approximate SVM solver using online SMO
approximation
–Using less memory than Libsvm
–Less accurate
–Scalable for few GB’s (or <10M examples’) low-dim data *
Lasvm algorithm
– Online step
• Sequentially access examples
• Loosely run SMO on the new dataset S
• Delete some (currently) useless
examples from S
– Finishing step
• Run full SMO on S
Fig. Source: http://leon.bottou.org/projects/lasvm
Libsvm with diff. stop. criteria

28
Minimal Enclosing Ball Methods
Minimal Enclosing Ball (MEB): the ball with the smallest radius that encloses all the points in a given set
Fast iterative approximate solver available for MEB optimization
Dual form is a QP:
Fig. Source: Tsang et al., 2005.

29
Minimal Enclosing Ball Methods (cont.)
CVM (Tsang et al., 2005): square-loss SVM can be casted into a MEB
problem
Thus SVM can be efficiently + approximately solved by using MEB solver
BVM (Tsang et al., 2007): faster version of CVM by further approximation
MEB dual:
Square-loss SVM dual:
kernel:
30
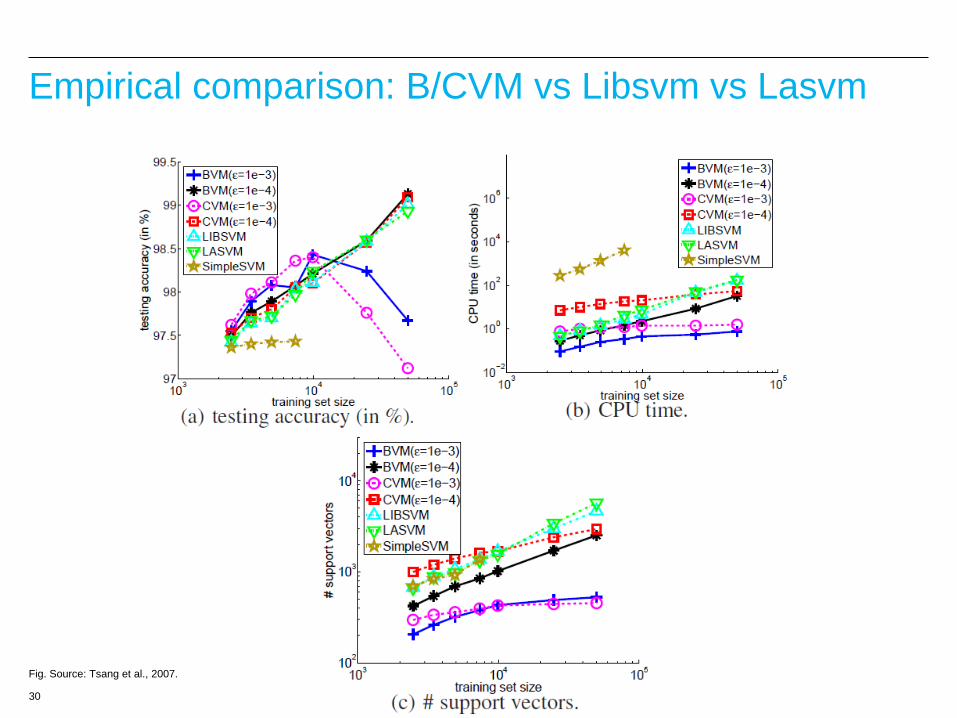
Empirical comparison: B/CVM vs Libsvm vs Lasvm
Fig. Source: Tsang et al., 2007.
31
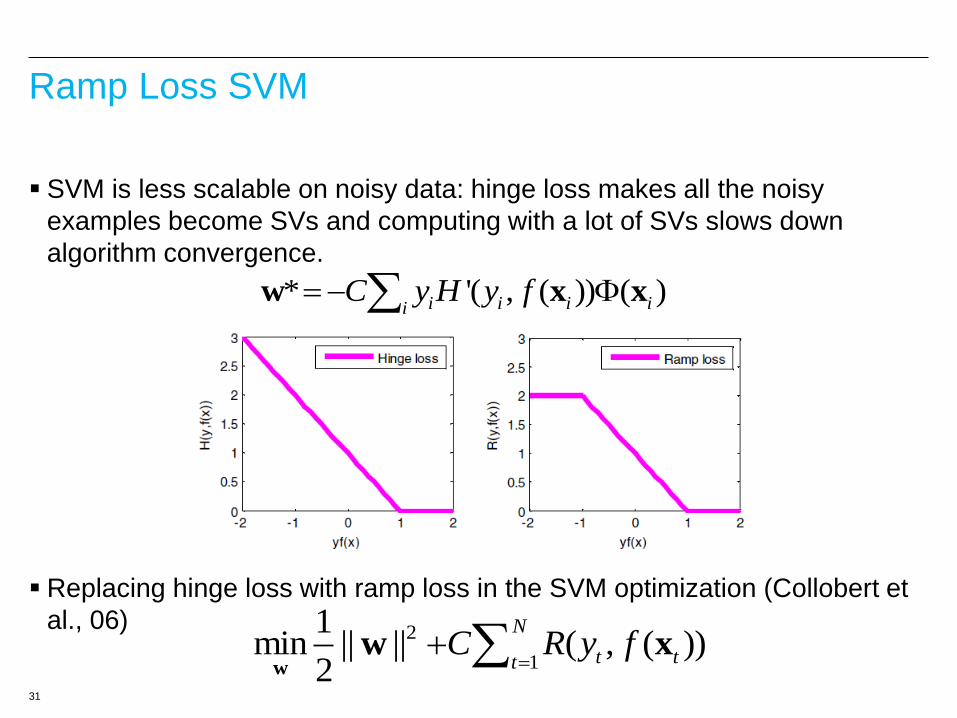
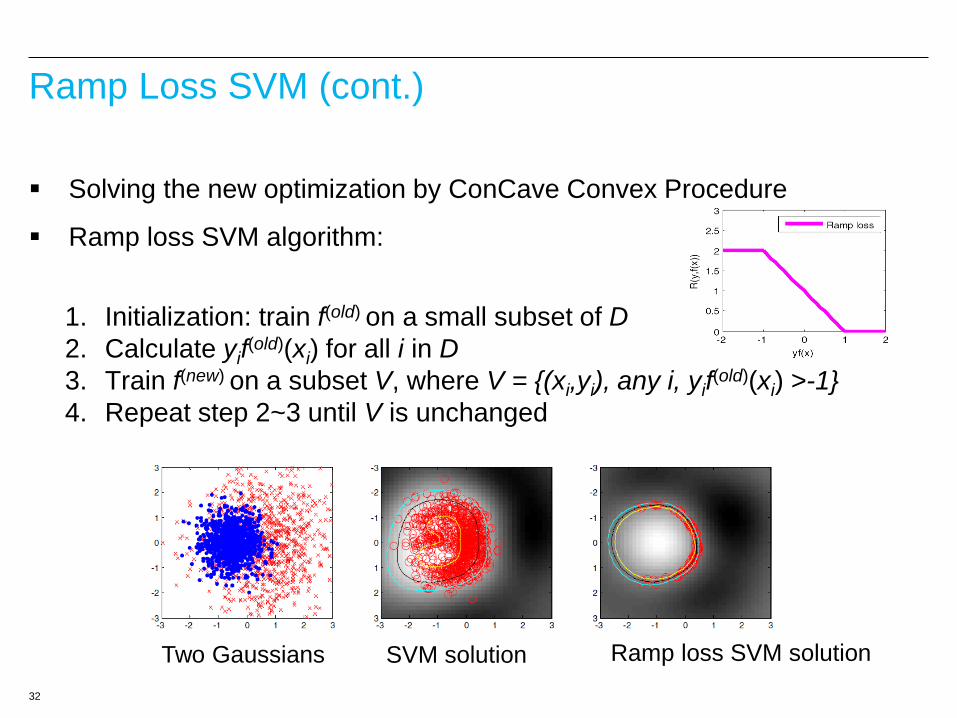
Ramp Loss SVM
SVM is less scalable on noisy data: hinge loss makes all the noisy
examples become SVs and computing with a lot of SVs slows down
algorithm convergence.
Replacing hinge loss with ramp loss in the SVM optimization (Collobert et
al., 06)
2
1
1min || || ( , ( ))
2
N
t ttC R y f
ww x
* '( , ( )) ( )i i i iiC y H y f w x x
32
Ramp Loss SVM (cont.)
Solving the new optimization by ConCave Convex Procedure
Ramp loss SVM algorithm:
1. Initialization: train f(old) on a small subset of D
2. Calculate yif(old)(xi) for all i in D
3. Train f(new) on a subset V, where V = {(xi,yi), any i, yif
(old)(xi) >-1}
4. Repeat step 2~3 until V is unchanged
Two Gaussians SVM solution Ramp loss SVM solution
33
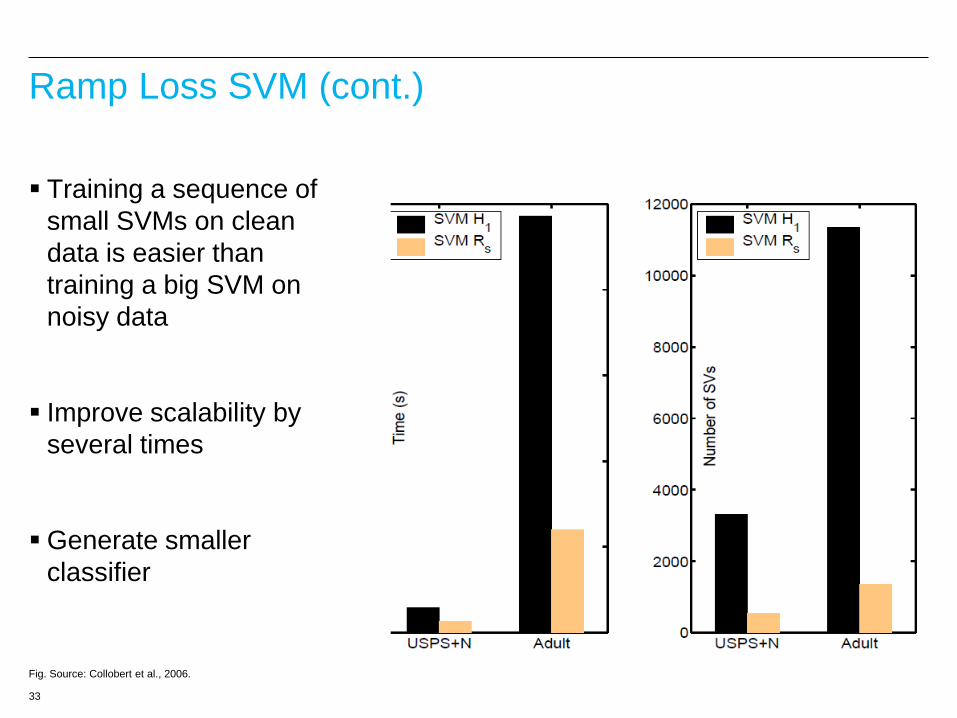
Ramp Loss SVM (cont.)
Training a sequence of
small SVMs on clean
data is easier than
training a big SVM on
noisy data
Improve scalability by
several times
Generate smaller
classifier
Fig. Source: Collobert et al., 2006.

34
SGD with kernel
Algorithm
1. Initialize w
2. Randomly select an example i in D
• Do
3. Repeat step 2 with enough iterations
Ok with <10,000 examples but not scalable for larger data due to the
curse of kernelization.
(1 η λ) β ( )i i i w w xη , if ( ) 1
where β0, otherwise
i i i i
i
y y f
x
Recall: w = Support Vectors (SVs) + their coefficients + kernel function
(1 η λ) β ( )i i i w w xη , if ( ) 1
where β0, otherwise
i i i i
i
y y f
x

35
Budgeted SGD
BSGD Algorithm (Wang et al., 2012)
1. Initialize w, set B
2. Randomly select an example i in D
• Do
• if (#SVs>B) then
3. Repeat step 2 with enough iterations
Budget maintenance strategy: to reduce the size of SVs by one
– Removal – Project – Merging
(1 η λ) β ( )i i i w w xη , if ( ) 1
where β0, otherwise
i i i i
i
y y f
x
i w w
Recall: w = Support Vectors (SVs) + their coefficients + kernel function

36
Budgeted BSGD (cont.)
Theorem (the impact of budget maintenance)
where , and comes from
Design philosophy:
Budget maintenance optimization
–Removal:
–Projection:
–Merging:
* 12
ln( )( ) ( )N
C NObj Obj C E
N w w
min || ||E min || ||t
min α ( )p pp
x
1
,min α ( ) α ( )
t
p p j jp
j I p
α
x x
, , ,min α ( ) α ( ) α ( )
zm m n n z
m n z x x z
1
1|| ||
N t
tt
EN
t w w
t
at each step

37
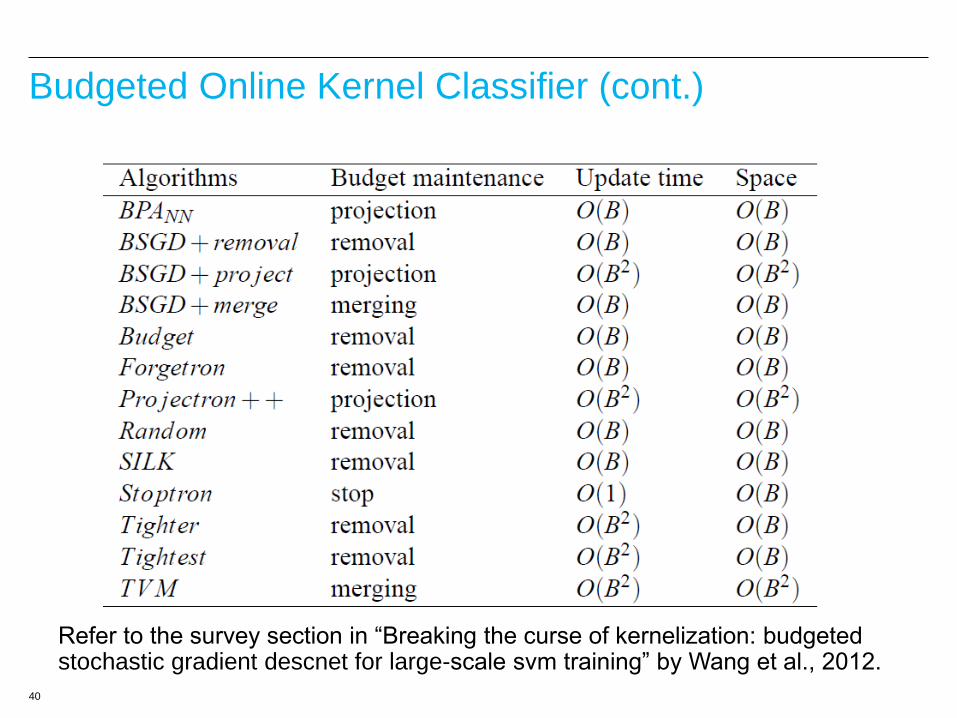
Budgeted Online Kernel Classifiers
Online learning with kernel
– Iteratively access example i in D and do
where and are calculated by w and (xi, yi)
Online learning with budget
– Iteratively access example i in D
• Do
• if (#SVs>B) then
( )i i i w w x
i i
( )i i i w w x
i w w

38
Budgeted Online Kernel Classifier (cont.)
Removal-based budget maintenance strategies
–Remove a random one (Cesa-Bianchi & Gentile,06; Vucetic et al., 09)
–The oldest SV (Dekel et al., 08)
–The smallest SV (Cheng et al., 07)
–The one that would be predicted with the largest confidence after its
removal (Crammer et al., 04);
–The one with the least validation error (Weston et al., 05; Wang and
Vucetic, 09)
( )r r w w x

39
Budgeted Online Kernel Classifier (cont.)
Project-based budget maintenance strategies
–BPA (Wang and Vucetic, 2010)
–The choise of I compromises between projection quality and
computation cost
• All; the newest one; the newest one + its NN
–Closed-form solution
( ) ( )r r i i
i I
w w x x
2
,
1min ( ) || || ( , ( ))
2
s.t. ( ) ( )
r
t t tr
t r r i ii I
Q C H y f
β
ww w w x
w w x x
PA objective
the one will be removed subset of the SV set
New constraint
40
Budgeted Online Kernel Classifier (cont.)
Refer to the survey section in “Breaking the curse of kernelization: budgeted stochastic gradient descnet for large-scale svm training” by Wang et al., 2012.

41
Linearization methods
Idea: explicitly represent data in feature space and train a linear SVM
there
Exact methods:
–Poly2SVM (Chang et al., 2010), Coffin (Sonnenburg et al., 2010)
Approximate methods:
–Random Features (Rahimi and Recht, 2007), LLSVM (Zhang et al.,
2012)
Fig. Source: www.imtech.res.in.

42
Linearization methods (cont.)
Exact methods - Poly2SVM (Chang et al., 2010)
–Explicitly compute degree-2 polynomial mapping
–Efficient when mapped feature dimensionality is low (usually occur
when input features are sparse or low-dimensional)
Approximate methods - Random features (Rahimi and Recht, 2007)
–Approximate feature mapping of radial basis kernels by randomized
features.
when r=1, d=2

43
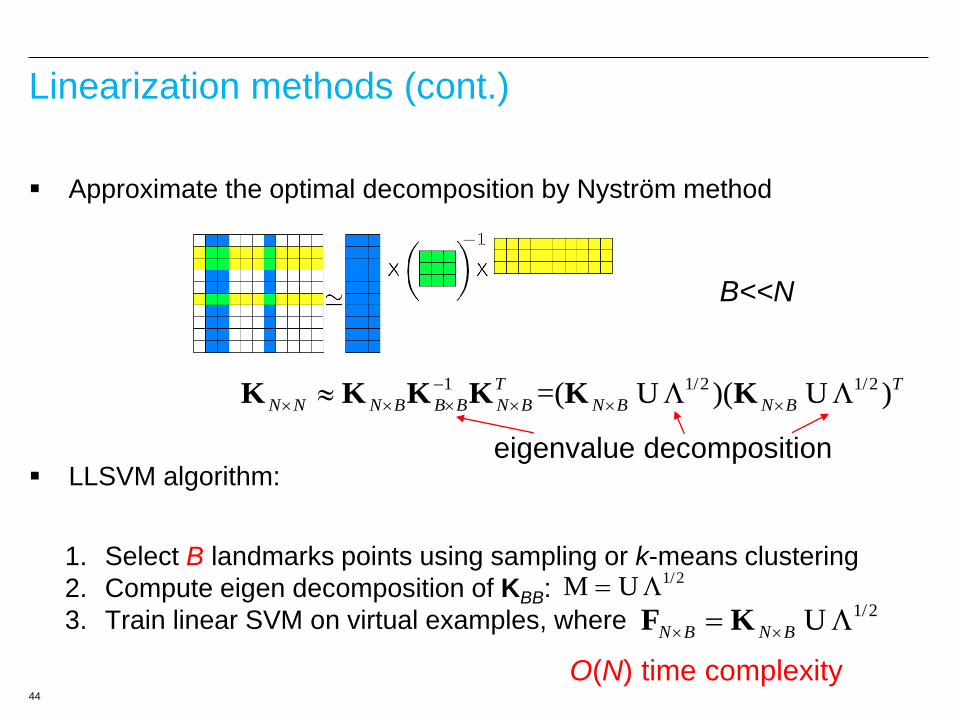
Linearization methods (cont.)
LLSVM (Zhang et al., 12): cast nonlinear SVM into an equivalent linear
SVM through the decomposition of PSG kernel matrix
2
,
1min
2
s.t. ( ( )) 1
i
T
i i i
C
y
w
w
w x
, where is the rank of T
N N N B N B B K F F K
( ) ( )T T
ij i j i j K x x F F
2
,
1min
2
s.t. ( ) 1
i
T
i i i
C
y
w
w
w F
r-dim virtual example
44
Linearization methods (cont.)
Approximate the optimal decomposition by Nyström method
LLSVM algorithm:
1. Select B landmarks points using sampling or k-means clustering
2. Compute eigen decomposition of KBB:
3. Train linear SVM on virtual examples, where
1 1/2 1/2=( U )( U )T T
N N N B B B N B N B N B
K K K K K K
eigenvalue decomposition
1/2M U 1/2UN B N B F K
O(N) time complexity
B<<N
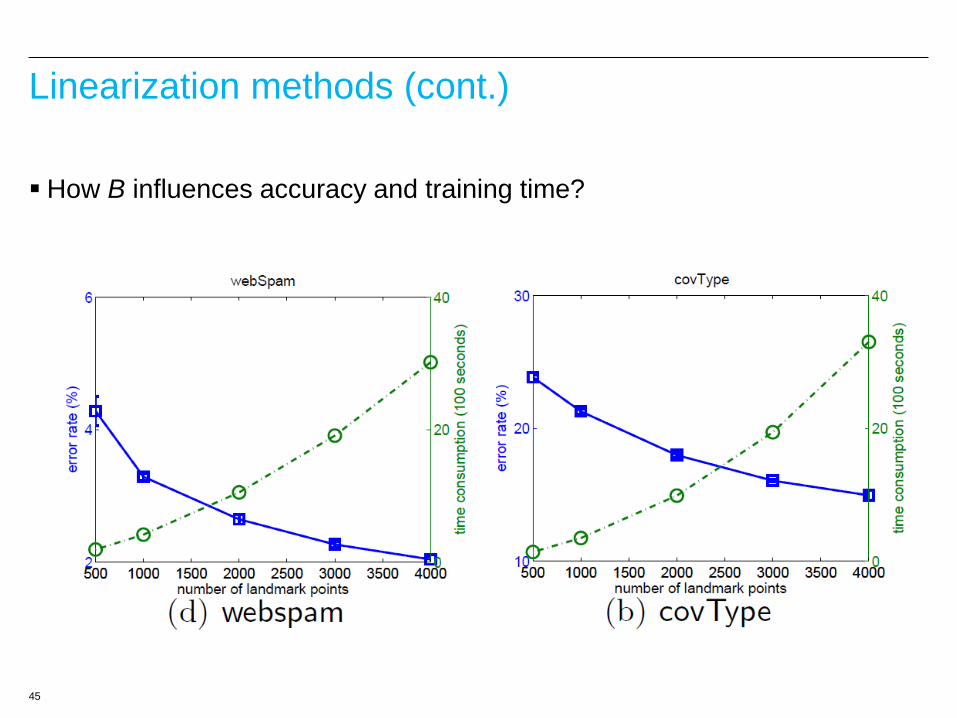
45
Linearization methods (cont.)
How B influences accuracy and training time?

46
Idea: assign multi-hyperplanes to each
class to increase representability (Aiolli &
Sperduti, 05; Wang et al., 11)
Class 1 w11 w11Tx = 1.2
w12 w12Tx = 0.4
Class 2 w21 w21Tx = 1.5
w22 w22Tx = -0.1
Class 3 w31 w31Tx = -0.7
w32 w32Tx = 0.1
w33 w33Tx = 0.6 where
The maximal prediction
from the correct class
Maximal prediction from
the incorrect classes
where
User-specified Non-convex
Adaptive Multi-hyperplane Machine

47
Solve a series of convex approximation
by replacing the non-convex loss function by its convex upper bound
z is being recalculated after solving each
sub-problem as
where
where Example specific; fixed
during optimization.
Adaptive Multi-hyperplane Machine (cont.)
SGD
SGD
SGD
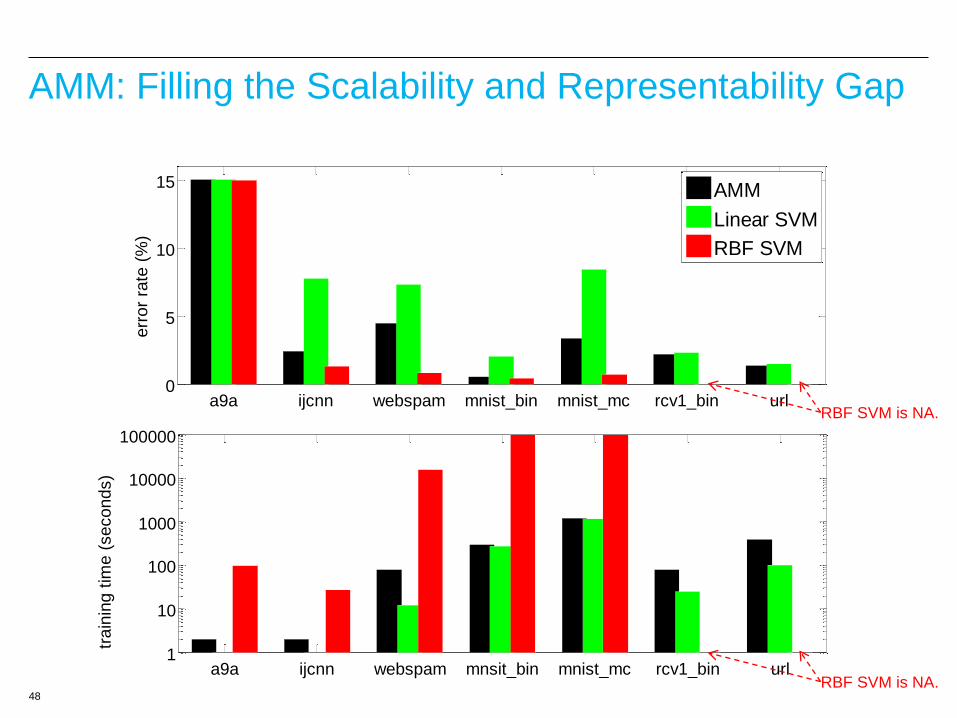
48
AMM: Filling the Scalability and Representability Gap
a9a ijcnn webspam mnist_bin mnist_mc rcv1_bin url0
5
10
15
err
or
rate
(%
)
AMM
Linear SVM
RBF SVM
a9a ijcnn webspam mnsit_bin mnist_mc rcv1_bin url1
10
100
1000
10000
100000
train
ing t
ime (
seconds)
RBF SVM is NA.
RBF SVM is NA.

49
Off-the-shelf tool
BudgetedSVM: a toolbox for large-scale non-linear SVM (Djuric, et al., 13)
– command-line (Windows/Linux), Matlab interfaces, C/C++ APIs
– include AMM, BSGD, LLSVM
–highly optimized for large data when it cannot fit into memory
–online learning + constant-memory = scalable for arbitrarily large data
Download: http://sourceforge.net/projects/budgetedsvm/
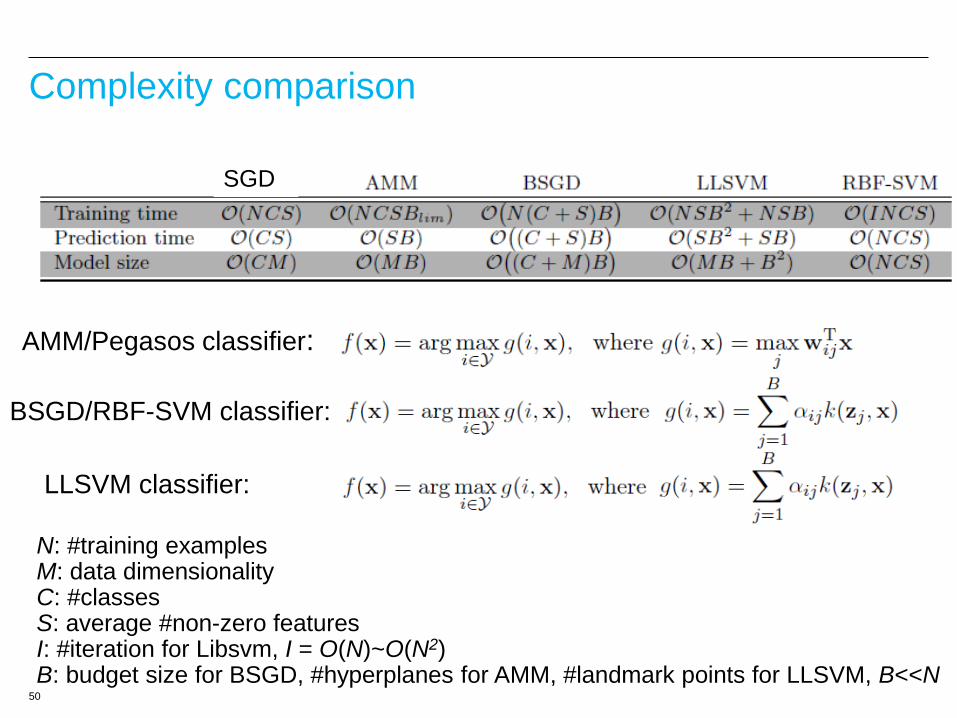
50
Complexity comparison
AMM/Pegasos classifier:
BSGD/RBF-SVM classifier:
LLSVM classifier:
N: #training examples M: data dimensionality C: #classes S: average #non-zero features I: #iteration for Libsvm, I = O(N)~O(N2) B: budget size for BSGD, #hyperplanes for AMM, #landmark points for LLSVM, B<<N
SGD
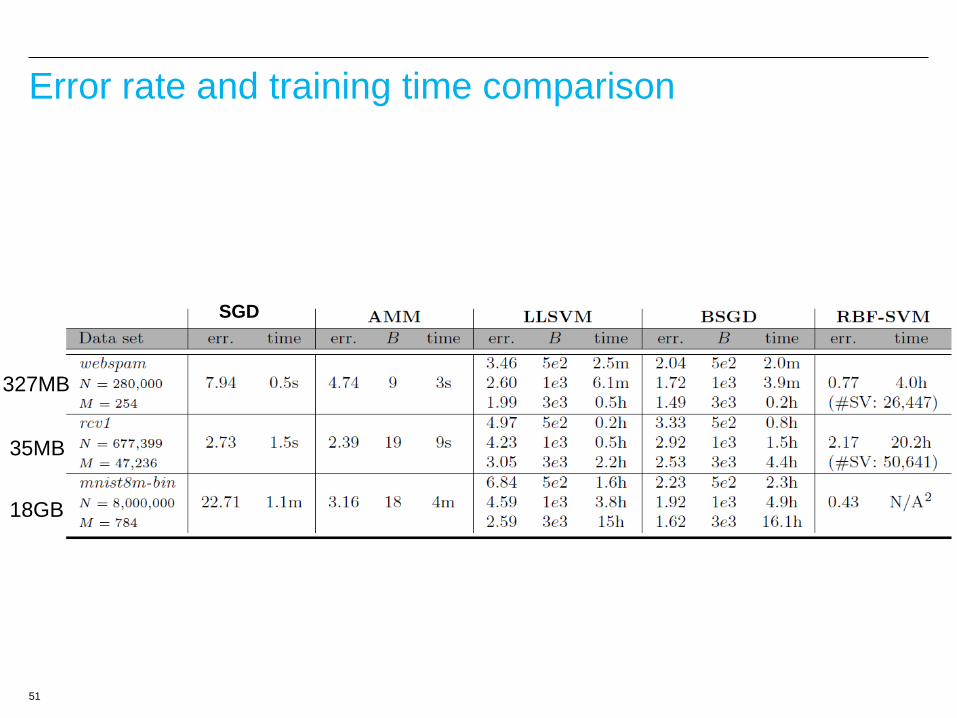
51
Error rate and training time comparison
18GB
327MB
35MB
SGD

52
Data summary methods
Summarize the data using meta-examples, then train model on meta-
examples
TD:
q1
q2
q3
q4
' ( , ), 1,..., ,i iD q y i B {( , ), 1,..., }i iD y i N x
D:
B N
data quantization or clustering

53
Data summary methods (cont.)
Simple approach
–pre-clustering on the data
– train weighted SVM on cluster centers, where example weighs are
determined by the size/purity of the clusters
Support Cluster Machine (Li et al., 07)
– pre-clustering on the data
– train weighted SVM on clusters, where clusters are treated as
Gaussian distribution and the similarity is calculated by probability
product kernel
Training complexity depends on clustering algorithm

54
Data summary methods (cont.)
Twin Vector Machine (Wang and Vucetic, 10b): incrementally quantize
data into twin vectors by nearest neighbor while incrementally updating
SVM on twin vector set
tv2=(q
2,+1,3),(q
2,-1,1)
tv3=(q
3,+1,4),(q
3,-1,1)
tv4=(q
4,+1,0),(q
4,-1,3)
tv1=(q
1,+1,1),(q
1,-1,2)
2
1
1min || || ( 1, ( )) ( 1, ( ))
2
B
i i i i
i
C s H f s H f
w
w q q
{( , 1, ),( , 1, )}j j j j jtv s s q q
55
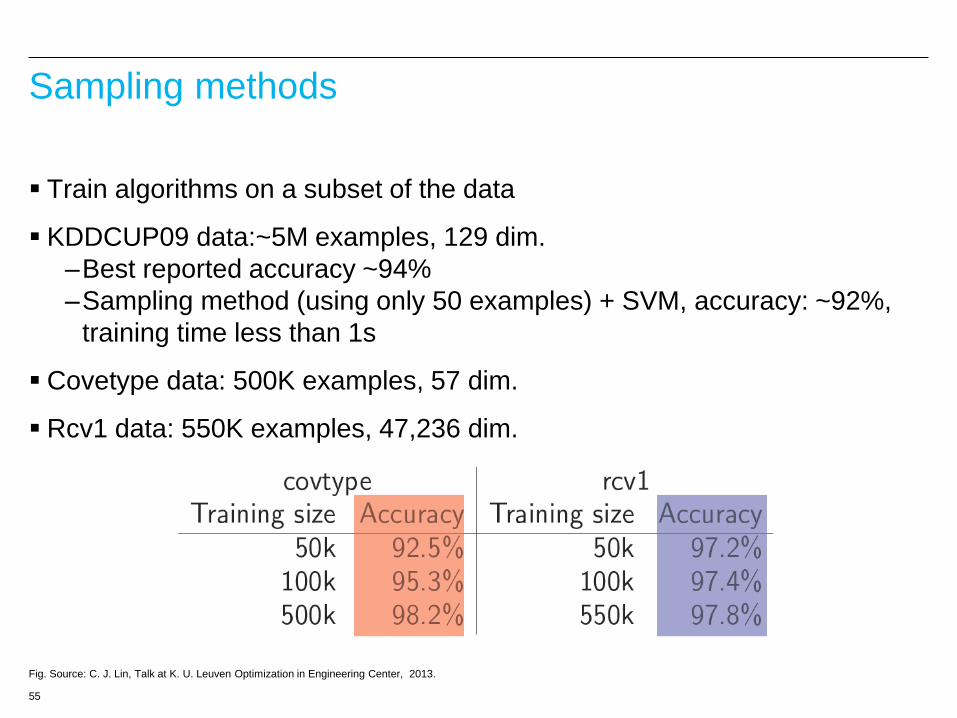
Sampling methods
Train algorithms on a subset of the data
KDDCUP09 data:~5M examples, 129 dim.
–Best reported accuracy ~94%
–Sampling method (using only 50 examples) + SVM, accuracy: ~92%,
training time less than 1s
Covetype data: 500K examples, 57 dim.
Rcv1 data: 550K examples, 47,236 dim.
Fig. Source: C. J. Lin, Talk at K. U. Leuven Optimization in Engineering Center, 2013.
56
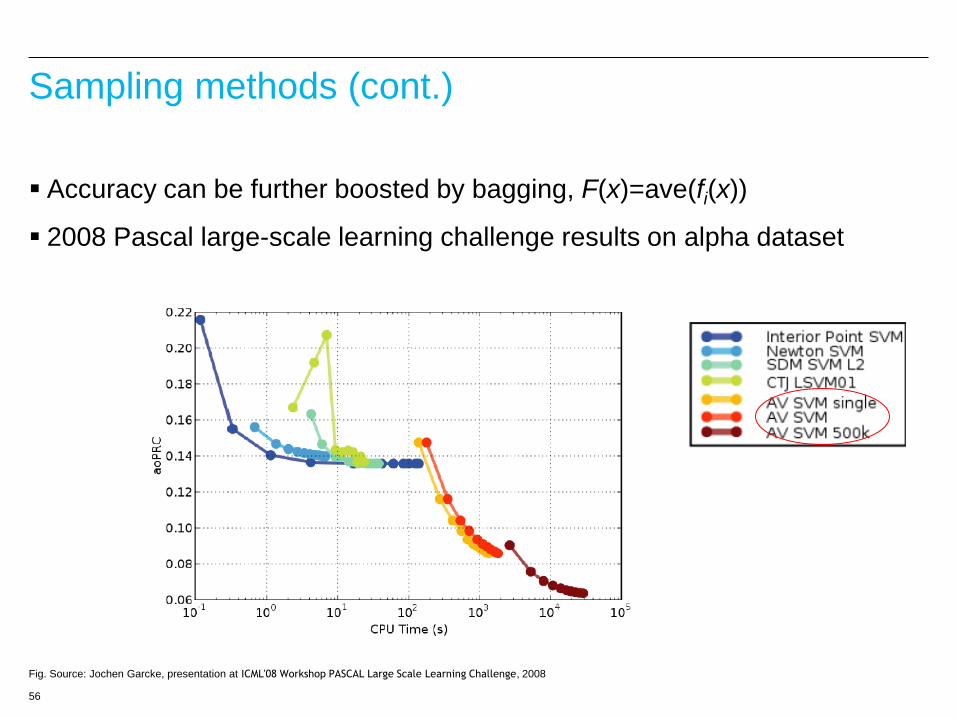
Sampling methods (cont.)
Accuracy can be further boosted by bagging, F(x)=ave(fi(x))
2008 Pascal large-scale learning challenge results on alpha dataset
Fig. Source: Jochen Garcke, presentation at ICML'08 Workshop PASCAL Large Scale Learning Challenge, 2008

57
Parallelism
58
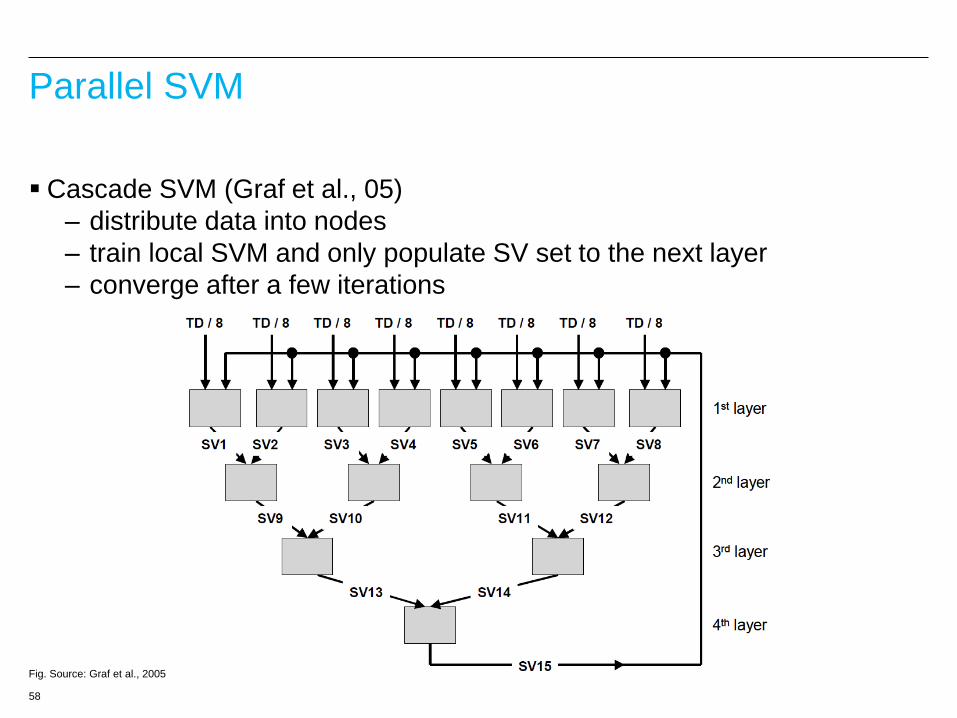
Parallel SVM
Cascade SVM (Graf et al., 05)
– distribute data into nodes
– train local SVM and only populate SV set to the next layer
– converge after a few iterations
Fig. Source: Graf et al., 2005
59
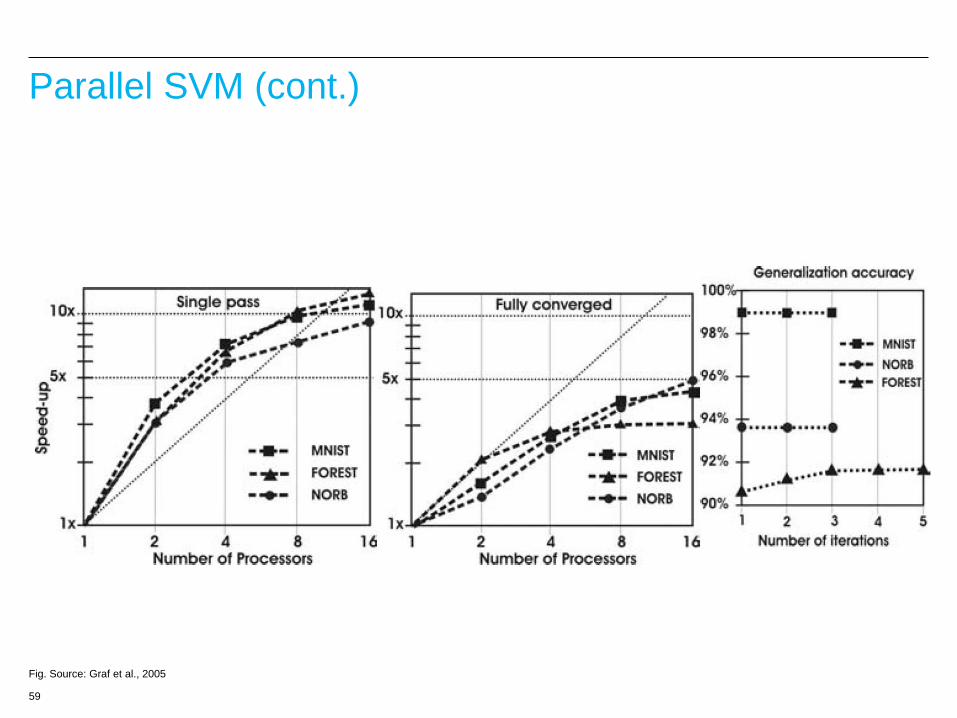
Parallel SVM (cont.)
Fig. Source: Graf et al., 2005

60
Parallel SVM (cont.)
PSVM (Chang et al., 07) - parallel Interior-Point method
– IP method
• Remove the linear constraint in SVM’s QP with barrier function
• Then solve a sequence of the unconstraint problems with Newton
method
• O(M3) time and O(M2) space which is dominated by inverse kernel
matrix
– Parallel IP method
• Distribute both data loading and computation
• Approximate expensive matrix manipulations using parallel
computing
• Intense communication between nodes

61
Parallel SVM (cont.)
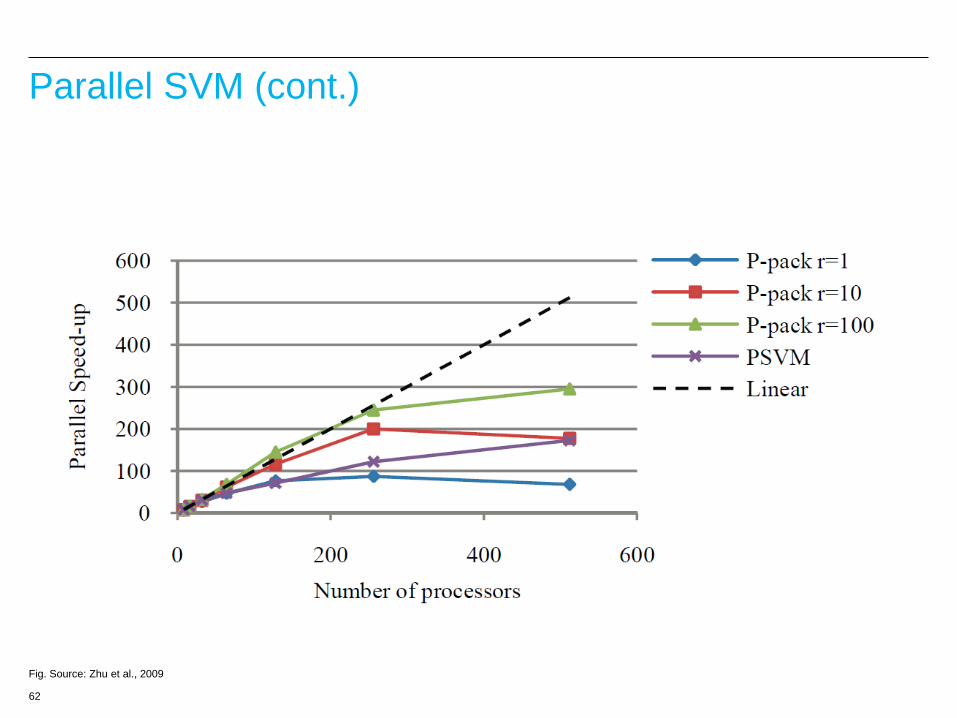
P-pack SVM (Zhu et al., 09)
–Parallel SGD for kernel SVM
–A lot of communication between nodes
–Parallel computing platform: MPI
Algorithm
1.Initialize w
2.All nodes randomly select a same example i in D
• Do
3.Repeat step 2 with enough iterations
(1 η λ) β ( )i i i w w xη , if ( ) 1
where β0, otherwise
i i i i
i
y y f
x
sum-up fi(xi) across all nodes Only add xi to one node
62
Parallel SVM (cont.)
Fig. Source: Zhu et al., 2009

63
Parallel SVM (cont.)
PSGD (Zinkevish et al., 10): Bagging + Linear SVM SGD
– Approximate solver
– Little communication between nodes
– Good for MapReduce on Hadoop
Fig. Source: C.-J. Lin, Talk at at K. U. Leuven Optimization in Engineering Center, 2013.

64
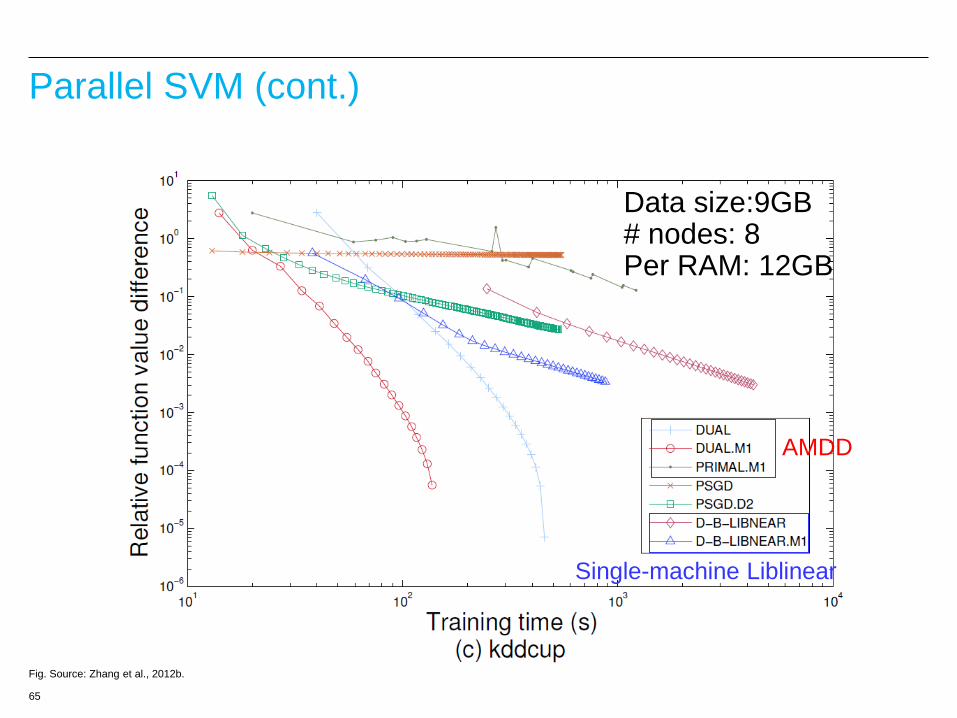
Parallel SVM (cont.)
ADMM for SVM (Boyd et al., 11; Zhang et al., 12b)
Fig. Source: Zhang et al., 2012b.
MPI
Need fast solver for this
65
Parallel SVM (cont.)
Fig. Source: Zhang et al., 2012b.
Data size:9GB # nodes: 8 Per RAM: 12GB
AMDD
Single-machine Liblinear

66
What I won’t cover
Parallel tree methods
– see the tutorial “scale up decision tree ensembles” by M.Bilenko, R.
Bekkerman, and J. Langford at KDD 2011
Parallel deep networks
– see the tutorial “large scale deep learning” by M. Ranzato at IPAM
summer school 2012

67
Summary
Linear classification – very scalable – computationally cheap – accuracy often sufficient for some applications
Non-linear classification – online learning + constant memory = scalable to arbitrary large data
– sampling/bagging is effective for large data
Parallelism – a lot of MPI but few MapReduce implementations

68
Acknowledgements
Thanks my co-authors: Koby Crammer, Nemanja Djuric,
Liang Lan, Fabian Moerchen, Slobodan Vucetic, Kai Zhang
Thanks Chih-Jen Lin for reviewing and commenting the
tutorial proposal
69
Thank you!
My homepage at: http://astro.temple.edu/~tua63862/
Contact me at: [email protected]
Download BudgetedSVM toolbox at:
http://sourceforge.net/projects/budgetedsvm/

70
References
F. Aiolli and A. Sperduti. Multi-class classification with multi-prototype support vector machines. Journal of Machine Learning Research, 2005.
A. Bordes, S. Ertekin, J. Weston, and L. Bottou. Fast kernel classifiers for online and active learning. Journal of Machine Learning Research, 2005.
A. Bordes, L. Bottou, and P. Gallinari. Sgd-qn: careful quasi-newton stochastic gradient descent. Journal of Machine Learning Research, 2009
S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein. Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends in Machine Learning, 2011.
N. Cesa-Bianchi and C. Gentile. Tracking the best hyperplane with a simple budget perceptron. In Annual Conference on Learning Theory, 2006.
C.-C. Chang and C.-J. Lin. Libsvm: a library for support vector machines, http://www.csie.ntu.edu.tw/˜cjlin/libsvm. 2001.
Y.-W. Chang, C.-J. Hsie, K.-W. Chang, M. Ringgaard, and C.-J. Lin. Training and testing low-degree polynomial data mappings via linear svm. Journal of Machine Learning Research, 2010.
Edward Y. Chang, Kaihua Zhu, Hao Wang, Hongjie BaiPSVM: Parallelizing Support Vector Machines on Distributed Computers. In Advances in Neural Information Processing Systems, 2007.
L. Cheng, S. V. N. Vishwanathan, D. Schuurmans, S. Wang, and T. Caelli. Implicit online earning with kernels. In Advances in Neural Information Processing Systems, 2007
R. Collobert, F. Sinz, J. Weston, and L. Bottou. Trading convexity for scalability. In International Conference on Machine Learning, 2006.
C. Cortes and V. Vapnik. Support-vector networks. Machine Learning, 1995.

71
References (cont.)
O. Dekel, S. Shalev-Shwartz, and Y. Singer. The forgetron: a kernel-based perceptron on a budget. SIAM Journal on Computing, 2008.
N. Djuric, L. Liang, S. Vuceitc, and Z. Wang. BudgetedSVM: A Toolbox for Large-scale Non-linear SVM. http://sourceforge.net/projects/budgetedsvm/
H.-P. Graf, E. Cosatto, L. Bottou, I. Dourdanovic, and V. Vapnik. Parallel support vector machines: the cascade svm. In Advances in Neural Information Processing Systems, 2005
R.-E. Fan, K.-W. Chang, C.-J. Hsieh, X.-R. Wang, and C.-J. Lin. LIBLINEAR: A library for large linear classification . Journal of Machine Learning Research. 2008
C.-J. Hsieh, K.-W. Chang, C.-J. Lin, S. S. Keerthi, and S. Sundararajan. A dual coordinate descent method for large-scale linear svm. In International Conference on Machine Learning, 2008.
A. B. Novikoff. On convergence proofs on perceptrons. Symposium on the Mathematical Theory of Automata, 1962.
T. Joachims. Training linear svms in linear time. In ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2006.
B. Li, M. Chi, J. Fan, , and X. Xue. Support cluster machine. In International Conference on Machine Learning, 2007
J. Platt. Fast training of support vector machines using sequential minimal optimization. Advances in Kernel Methods - Support Vector Learning, MIT Press, 1998.
A. Rahimi and B. Rahimi. Random features for large-scale kernel machines. In Advances in Neural Information Processing Systems, 2007.
F. Rosenblatt. The perceptron: a probabilistic model for information storage and organization in the brain. Psychological Review, 1958.

72
References (cont.)
B. Schӧlkopf, S. Mika, C. J. C. Burges, P. Knirsch, K. Müller, G. Rätsch, and A. J. Smola. Input space versus feature space in kernel-based methods. IEEE Transactions on Neural Networks, 1999.
S. Shalev-Shwartz, Y. Singer, N. Srebro. Pegasos: primal estimated sub-gradient solver for svm. In International Conference on Machine Learning, 2008.
S. Sonnenburg and V. Franc. Coffin: a computational framework for linear svms. In International Conference on Machine Learning, 2010.
C.H. Teo, S. V. N. Vishwanathan, A. J. Smola, and Q. V. Le. Bundle methods for regularized risk minimization. Journal of Machine Learning Research, 2010.
I. W. Tsang, J. T. Kwok, and P.-M. Cheung. Core vector machines: fast svm training on very large data sets. Journal of Machine Learning Research, 2005.
I. W. Tsang, A. Kocsor, and J. T. Kwok. Simpler core vector machines with enclosing balls. In International Conference on Machine Learning, 2007.
S. Vucetic, V. Coric, and Z. Wang. Compressed Kernel Perceptrons. In IEEE Data Compression Conference. 2009.
Z. Wang and S. Vucetic. Tighter perceptron with improved dual use of cached data for model representation and validation. In International Joint Conference on Neutral Network, 2009.
Z. Wang and S. Vucetic. Online passive-aggressive algorithms on a budget. In International Conference on Artificial Intelligence and Statistics, 2010.
Z. Wang and S. Vucetic. Online training on a budget of support vector machines using twin prototypes. Statisitcal Analysis and Data Mining Journal, 2010b.

73
References (cont.)
Z. Wang, N. Djuric, K. Crammer, and S. Vucetic. Trading representability for scalability: adaptive multihyperplane machine for nonlinear classification. In ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2011.
Z. Wang, K. Crammer, and S. Vucetic. Breaking the Curse of Kernelization: Budgeted Stochastic Gradient Descent for Large-Scale SVM Training. Journal of Machine Learning Research, 2012.
J. Weston, A. Bordes, and L. Bottou. Online (and offline) on an even tighter budget. In International Workshop on Artificial Intelligence and Statistics, 2005.
H.-F. Yu, C.-J. Hsieh, K.-W. Chang, and C.-J. Lin. Large linear classification when data cannot fit in memory. In ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2010.
G.-X. Yuan, C.-H. Ho, and C.-J. Lin. Recent Advances of Large-scale Linear Classification. Proceedings of the IEEE, 2012.
K. Zhang, L. Lan, Z. Wang, and F. Moerchen. Scaling up kernel svm on limited resources: a low-rank linearization approach. In International Conference on Artificial Intelligence and Statistics, 2012.
Caoxie Zhang, Honglak Lee, and Kang G. Shin. Efficient Distributed Linear Classification Algorithms via the Alternating Direction Method of Multipliers. . In International Conference on Artificial Intelligence and Statistics, 2012b.
T. Zhang. Solving large scale linear prediction problems using stochastic gradient descent. In International Conference on Machine Learning, 2004.
Z. A. Zhu, W. Chen, G. Wang, C. Zhu, and Z. Chen. P-packsvm: parallel primal gradient descent kernel svm. In IEEE International Conference on Data Mining, 2009.
M. Zinkevich, M. Weimer, A. J. Smola, L. Li. Parallelized Stochastic Gradient Descent. In Advances in Neural Information Processing Systems, 2010.









![Large-Scale Behavioral Targeting [Paper Presentation]](https://img.pdfslide.tips/doc/110x75/55a4f74b1a28ab62628b45e7/large-scale-behavioral-targeting-paper-presentation.jpg)



















