Embed Size (px)
Citation preview

UNIVERSIDADE DO RIO GRANDE DO NORTEFEDERAL
UNIVERSIDADE FEDERAL DO RIO GRANDE DO NORTE
CENTRO DE TECNOLOGIA
PROGRAMA DE PÓS-GRADUAÇÃO EM ENGENHARIA
ELÉTRICA E DE COMPUTAÇÃO
Implementação e Aplicação de Algoritmos deAprendizado em um Sistema Neuro-Simbólico
André Quintiliano Bezerra Silva
Orientador: Prof. Dr. André Laurindo Maitelli
Dissertação de Mestrado apresentada aoPrograma de Pós-Graduação em EngenhariaElétrica e de Computação da UFRN (área deconcentração: Engenharia de Computação)como parte dos requisitos para obtenção dotítulo de Mestre em Ciências.
Natal, RN, Fevereiro de 2017
Número de ordem PPgEE: M487

Universidade Federal do Rio Grande do Norte – UFRN Sistema de Bibliotecas – SISBI
Catalogação da Publicação na Fonte - Biblioteca Central Zila Mamede Silva, André Quintiliano Bezerra.
Implementação e aplicação de algoritmos de aprendizado em um sistema neuro-simbólico / André Quintiliano Bezerra Silva. - 2017.
89 f. : il.
Dissertação (mestrado) - Universidade Federal do Rio Grande do Norte, Centro de Tecnologia, Programa de Pós-Graduação em Engenharia Elétrica e de Computação. Natal, RN, 2017.
Orientador: Prof. Dr. André Laurindo Maitelli.
1. Neuro-simbólico - Dissertação. 2. Sistemas híbrido - Dissertação. 3.Rede neural - Dissertação. I. Maitelli, André Laurindo. II. Título.
RN/UF/BCZM CDU 004.7


Agradecimentos
Aos meus pais, sem eles nada seria possível.
A minha noiva Janusa Soares de Araújo pelo total apoio necessário para alcançar esseobjetivo.
A todos os meus familiares pelas orações e energias que me foram direcionadas.
Agradeço aos professores: André Laurindo Maitelli, Adrião Duarte Dória Neto, FábioMeneghetti Ugulino de Araújo e Gilbert Azevedo da Silva por revisarem, sugerirem cor-reções e melhorias para este trabalho.
Aos meus amigos do laboratório LAUT, em especial Kennedy Lopes, que participou di-retamente, cooperando com este trabalho.
Gostaria também agradecer ao PPgEEC pela oportunidade de fazer o mestrado na UFRNe ao Laboratório de Automação em Petróleo (LAUT) por disponibilizar um ambiente deestudo.

Resumo
Um dos principais objetivos da inteligência artificial é a criação de agentes inspira-dos na inteligência humana. Isso vem sendo pesquisado utilizando várias abordagens, eentre as mais promissoras para o aprendizado de máquinas estão os sistemas simbólicosbaseados na lógica e as redes neurais artificiais. Até a última década, ambas as aborda-gens progrediam de forma independente, mas os progressos obtidos em ambas as áreasfizeram com que os pesquisadores começassem a investigar maneiras de integrar as duastécnicas. Diversos modelos que proporcionam a integração híbrida ou integrada dessesmétodos inteligentes surgiram na década de 90 e continuam sendo utilizadas e melhoradasaté hoje.
Esse trabalho tem como objetivo principal a implementação e uso do algoritmo de con-versão neuro-simbólica do sistema híbrido Knowledge-Based Artificial Neural Networks(KBANN). O sistema possui a capacidade de mapear um domínio teórico específico deregras (se-então) em uma rede neural e refinar a rede utilizando técnicas de aprendizado.Além disso, como o algoritmo criado por Towell et al. (1990) não possui a capacidadede adquirir novos conhecimentos sem distorcer o que já foi aprendido, utilizou-se o algo-ritmo TopGen (Optiz e Shavlik, 1995) para adicionar tal capacidade a rede. O trabalhoutilizou um jogo de tabuleiro para realizar experimentos devido a quantidade e o conhe-cimento existente sobre as regras do jogo. O sistema implementado obteve resultadosinteressantes, mesmo com a pertubação do domínio inicial de regras (com a exclusãoparcial), obtendo uma taxa de acerto próxima a 100%. Portanto, a partir dos resultadosobtidos foi possível concluir que o sistema híbrido é capaz de se sobrepor a situaçõesadversas a qual foi submetido nessa pesquisa.
Palavras-chave: Neuro-simbólico, sistemas híbrido, rede neural.

Abstract
One of the main goals of artificial intelligence is the creation of agents with human-like intelligence. This has been researched using various approaches, and among the mostprominent for machine learning are logic-based symbolic systems and artificial neuralnetworks. Until the last decade, both approaches have progressed independently, butprogress in both areas has led researchers to investigate ways to integrate both approaches.Several models that provide hybrid or integrated integration of these approaches emergedin the 1990s, and continue to be used to this day.
This work has as main objective the implementation and use of the Neural-Symbolicconversion algorithm of Knowledge-Based Artificial Neural Networks (KBANN), the sys-tem has the ability to map a specific theoretical domain of rules (if-then) into a neu-ral network, and refine the network using learning techniques. In addition, since thealgorithm created by (Towell et al., 1990) does not have the capacity to acquire newknowledge and introduce them to the neural network, the algorithm TopGen (Optiz andShavlik, 1995) will be used to add The network without losing the original knowledge ac-quired. The work used a board game to conduct experiments due to the well establishedrules of the game. The implemented system obtained interesting results, even with theinitial rule domain perturbation (with the exclusion of them), obtaining an accuracy rateclose to 100 %. Therefore, from the obtained results it was possible to conclude thatthe hybrid systems are able to overlap to adverse situations which were carried out theanalyzes proposed in this research.
Keywords: Neural-symbolic, hybrid systems, representation of knowledge in a neuralnetwork.

Sumário
Sumário i
Lista de Figuras iii
Lista de Tabelas v
1 Introdução 11.1 Motivação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.2 Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.3 Organização do trabalho . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2 Fundamentação Teórica 42.1 Inteligência Artificial Simbólica . . . . . . . . . . . . . . . . . . . . . . 4
2.1.1 Sistemas Especialistas . . . . . . . . . . . . . . . . . . . . . . . 52.1.2 Representação Simbólica do Conhecimento . . . . . . . . . . . . 82.1.3 Formatação dos dados . . . . . . . . . . . . . . . . . . . . . . . 122.1.4 Problemas da Inteligência Artificial Simbólica . . . . . . . . . . 14
2.2 Redes Neurais Artificiais (RNA) . . . . . . . . . . . . . . . . . . . . . . 152.2.1 Tipos de aprendizagem . . . . . . . . . . . . . . . . . . . . . . . 172.2.2 Redes MLP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192.2.3 Algoritmo Backpropagation . . . . . . . . . . . . . . . . . . . . 21
2.3 Sistemas Híbridos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 302.3.1 Knowledge-based Artificial Neural Networks (KBANN) . . . . . 302.3.2 Top-Gen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3 Metodologia 403.1 Estudo e Desenvolvimento Inicial . . . . . . . . . . . . . . . . . . . . . 40
3.1.1 Recursos e Estratégias Utilizadas no Desenvolvimento . . . . . . 403.1.2 Etapas do Desenvolvimento . . . . . . . . . . . . . . . . . . . . 413.1.3 Implementações Preliminares . . . . . . . . . . . . . . . . . . . 42
i

3.1.4 O Sistema Desenvolvido . . . . . . . . . . . . . . . . . . . . . . 443.1.5 Aspectos Internos do Sistema . . . . . . . . . . . . . . . . . . . 453.1.6 Descrição da Interface . . . . . . . . . . . . . . . . . . . . . . . 473.1.7 Considerações sobre as Implementações . . . . . . . . . . . . . . 493.1.8 Testes do Sistema . . . . . . . . . . . . . . . . . . . . . . . . . . 49
4 Resultados e discussão 574.1 Contextualização do Problema . . . . . . . . . . . . . . . . . . . . . . . 57
4.1.1 Formatação dos dados . . . . . . . . . . . . . . . . . . . . . . . 584.1.2 Testes Realizados para o Reconhecimento de Movimentos . . . . 604.1.3 Regras Adicionadas ao Domínio Teórico . . . . . . . . . . . . . 614.1.4 Antecedentes Adicionadas ao Domínio Teórico . . . . . . . . . . 634.1.5 Regras Removidas do Domínio Teórico . . . . . . . . . . . . . . 664.1.6 Antecedentes Deletados do Domínio Teórico . . . . . . . . . . . 68
5 Conclusão 71
Referências Bibliográficas 74
A Algoritmo TopGen 77

Lista de Figuras
2.1 Funcionamento de Sistemas Especialistas . . . . . . . . . . . . . . . . . 52.2 Funcionamento de Sistemas Especialistas . . . . . . . . . . . . . . . . . 62.3 Representação de um Script . . . . . . . . . . . . . . . . . . . . . . . . . 102.4 Representação de uma Rede Semântica . . . . . . . . . . . . . . . . . . 112.5 Representação de um Frame . . . . . . . . . . . . . . . . . . . . . . . . 112.6 Representação de uma RNA MLP. . . . . . . . . . . . . . . . . . . . . . 152.7 Representação de um Neurônio. . . . . . . . . . . . . . . . . . . . . . . 162.8 Representação de uma MLP . . . . . . . . . . . . . . . . . . . . . . . . 202.9 Grafo de fluxo de sinal no neurônio j. . . . . . . . . . . . . . . . . . . . 242.10 Grafo de fluxo de sinal mostrando os detalhes do neurônio de saída k
conectando ao neurônio escondido j. . . . . . . . . . . . . . . . . . . . . 262.11 Grafo de fluxo de sinal mostrando o processo de retro-propagação dos
sinais de erro na camada de saída para um neurônio j da camada escondida. 272.12 Função de Ativação - Sigmóide . . . . . . . . . . . . . . . . . . . . . . . 282.13 Função de Ativação - Tangente Hiperbólica . . . . . . . . . . . . . . . . 282.14 Eliminação de disjunções com mais de um antecedente . . . . . . . . . . 322.15 Demonstração do algoritmo de KBANN . . . . . . . . . . . . . . . . . . 342.16 Formas possíveis para adicionar novos neurônios. Arcos indicam cone-
xões do tipo AND . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 372.17 Tradução das regras em uma rede KBANN . . . . . . . . . . . . . . . . . 38
3.1 Representação de uma RNA a partir da base de regras . . . . . . . . . . . 433.2 Diagrama de classes do sistema . . . . . . . . . . . . . . . . . . . . . . . 463.3 Diagrama de Sequência . . . . . . . . . . . . . . . . . . . . . . . . . . . 473.4 Tela principal do sistema . . . . . . . . . . . . . . . . . . . . . . . . . . 483.5 Tela de edição de regras . . . . . . . . . . . . . . . . . . . . . . . . . . . 483.6 Topologia da rede MLP no Matlab . . . . . . . . . . . . . . . . . . . . . 503.7 Parâmetros após treinamento da Rede MLP no Matlab . . . . . . . . . . 513.8 Parâmetros da rede MLP treinada . . . . . . . . . . . . . . . . . . . . . . 523.9 Gráfico do erro de treinamento, validação e teste . . . . . . . . . . . . . . 52
iii

3.10 Resultados gerados na saída da rede . . . . . . . . . . . . . . . . . . . . 533.11 Resultados gerados na saída da rede apenas com KBANN . . . . . . . . . 543.12 Resultados gerados na saída da rede com KBANN e TopGen . . . . . . . 553.13 Rede gerada com os novos neurônios a partir do TopGen . . . . . . . . . 56
4.1 Subconjunto 4x5 de um tabuleiro de xadrez considerado para o domínio . 584.2 Conjunto de regras do Xadrez . . . . . . . . . . . . . . . . . . . . . . . 584.3 Estrutura parcial da rede neural gerada para o problema do xadrez . . . . 604.4 Erro de Classificação entre KBANN x Domínio Teórico com Regras Adi-
cionadas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 634.5 Erro de Classificação entre KBANN x Domínio Teórico com Anteceden-
tes Adicionados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 654.6 Erro de Classificação entre KBANN e TopGen com a Exclusão de Regras 684.7 Erro de Classificação entre KBANN e TopGen com a Exclusão de Ante-
cedentes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
A.1 Algoritmo TopGen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77

Lista de Tabelas
2.1 Correspondências entre bases de conhecimento e redes neurais . . . . . . 31
4.1 Nomenclatura dos neurônios e sua representação na rede neural . . . . . . 604.2 Falsos positivos e negativos dos neurônios, ao se adicionar 10% novas regras 614.3 Falsos positivos e negativos dos neurônios, ao se adicionar 20% novas regras 624.4 Falsos positivos e negativos dos neurônios, ao se adicionar 30% novas regras 624.5 Falsos positivos e negativos dos neurônios, ao se adicionar 40% novas regras 624.6 Falsos positivos e negativos dos neurônios, ao se adicionar 50% novas regras 624.7 Falsos positivos e negativos dos neurônios, quando adicionado 10% novos
antecedentes às regras . . . . . . . . . . . . . . . . . . . . . . . . . . . . 644.8 Falsos positivos e negativos dos neurônios, quando adicionado 20% novos
antecedentes às regras . . . . . . . . . . . . . . . . . . . . . . . . . . . . 644.9 Falsos positivos e negativos dos neurônios, quando adicionado 30% novos
antecedentes às regras . . . . . . . . . . . . . . . . . . . . . . . . . . . . 644.10 Falsos positivos e negativos dos neurônios, quando adicionado 40% novos
antecedentes às regras . . . . . . . . . . . . . . . . . . . . . . . . . . . . 644.11 Falsos positivos e negativos dos neurônios, quando adicionado 50% novos
antecedentes às regras . . . . . . . . . . . . . . . . . . . . . . . . . . . . 654.12 Falsos positivos e negativos dos neurônios, quando retirado 10% da regras 664.13 Falsos positivos e negativos dos neurônios, quando retirado 20% da regras 664.14 Falsos positivos e negativos dos neurônios, quando retirado 30% da regras 674.15 Falsos positivos e negativos dos neurônios, quando retirado 40% da regras 674.16 Falsos positivos e negativos dos neurônios, quando retirado 50% da regras 674.17 Falsos positivos e negativos dos neurônios, quando retirado 10% dos an-
tecedentes das regras . . . . . . . . . . . . . . . . . . . . . . . . . . . . 694.18 Falsos positivos e negativos dos neurônios, quando retirado 20% dos an-
tecedentes das regras . . . . . . . . . . . . . . . . . . . . . . . . . . . . 694.19 Falsos positivos e negativos dos neurônios, quando retirado 30% dos an-
tecedentes das regras . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
v

4.20 Falsos positivos e negativos dos neurônios, quando retirado 40% dos an-tecedentes das regras . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
4.21 Falsos positivos e negativos dos neurônios, quando retirado 50% dos an-tecedentes das regras . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70

Capítulo 1
Introdução
Os sistemas inteligentes (SI) baseados no processamento do conhecimento simbólicoe as Redes Neurais Artificiais - RNA (também denominadas de sistemas conexionistas),diferem substancialmente um do outro. No entanto, essas são as duas principais aborda-gens da Inteligência Artificial (IA) e seria desejável combinar a robustez das redes neuraiscom a expressividade de representação do conhecimento simbólico (GARCEZ, 2005).
Os primeiros modelos computacionais de cognição neural levantaram a questão decomo o conhecimento simbólico pode ser representado e tratado dentro de redes neu-rais. O documento de referência (Mcculloch e Pitts, 1943) fornece insights fundamentaissobre como a lógica proposicional pode ser processada utilizando RNAs. Entretanto,nas décadas seguintes, o tema não recebeu muita atenção, uma vez que as pesquisas eminteligência artificial se concentravam em abordagens puramente simbólicas. O poderda aprendizagem utilizando redes neurais artificiais não foi reconhecido até os anos 80,quando, em particular, o algoritmo de backpropagation (Rumelhart et al., 1986) tornoupraticável e aplicável a aprendizagem conexionista.
Enquanto a representação simbólica do conhecimento é altamente recursiva e bemcompreendida de um ponto de vista declarativo, as redes neurais codificam o conheci-mento implicitamente em seus pesos como resultado de aprendizado e generalização apartir dos dados fornecidos.
O que tem sido observado sobre as vantagens e desvantagens de ambas as abordagensé que elas são, de certa forma, complementares: o que é excelente em um, não é nooutro, e vice-versa (TOWELL et al., 1990). Essa é a razão pelos importantes esforços empreencher a lacuna existente entre os paradigmas conexionista e simbólico.
A fusão entre a teoria e o aprendizado, por exemplo, em redes neurais tem sido in-dicada para fornecer sistemas de aprendizagem mais eficazes que sistemas meramentesimbólicos ou puramente conexionistas, especialmente quando os dados são ruidosos ouescassos. Isso tem contribuído decisivamente pelo crescente interesse no desenvolvimento

CAPÍTULO 1. INTRODUÇÃO 2
de sistemas neuro-simbólicos, isto é, sistemas híbridos baseados em redes neurais capazesde aprender a partir de exemplos, e uma base de conhecimento para executar tarefas deraciocínio de forma massivamente paralela.
Sendo assim, utilizar esses sistemas de forma integrada pode produzir melhores solu-ções para os mais diversos problemas existentes no mercado, de forma que eles poderiameventualmente reproduzir a tomada de decisão humana sob incerteza ou que contenhaerros.
1.1 Motivação
Além do tratamento de dados, espera-se que um sistema híbrido de Inteligência Ar-tificial também faça a aquisição de novos conceitos a partir do ambiente onde estiverinserido, de forma a proporcionar um tratamento dinâmico do conhecimento (RUSSEL eNORVIG, 1995). Assim, faz parte desse tratamento, além da capacidade de classificar osdados apresentados, também a possibilidade de inserir a sua base de conhecimento, novasinformações, visando atender as crescentes demandas.
Observando o comportamento de um ser humano, separar em módulos distintos derepresentação os conceitos de base de conhecimento (composto por fatos e regras) e umarede neural (para processar informações), parece ter sido a forma mais apropriada queos pesquisadores de IA encontraram para viabilizar a simulação, em um computador, docomportamento humano especializado. Dessa forma, o avanço das pesquisas e o desen-volvimento dos conceitos de conhecimento (declarativo e algorítmico) promoveu signifi-cativos progressos, tanto na forma dos pesquisadores abordarem as questões, quanto nastécnicas utilizadas para produzir sistemas inteligentes híbridos. Segundo Towell, et al.(1990), se delimitar a área de atuação (domínio do problema), basta a codificação de umnúmero suficiente de regras e mapeá-los em uma rede neural para o desenvolvimento deum sistema híbrido. Portanto, as questões principais a serem consideradas pelo projetistade um sistema de IA especialista são: aquisição, mapeamento e tratamento do conheci-mento.
Hoje é patente a existência de computadores na grande maioria dos estabelecimentoscomerciais, na área médica, e em tantas outras, mas é também visível que seu uso, nagrande maioria dos casos, é limitado às aplicações administrativas; quando muito é uti-lizado algum software específico que, isoladamente, proporciona ao usuário algum tipode histórico onde o sistema está implantado, mas não interage ao ponto de proporcionarinformações atualizadas dinamicamente.
Diante do exposto, a necessidade emergente de sistemas híbridos está atualmente mo-

CAPÍTULO 1. INTRODUÇÃO 3
tivando importantes trabalhos de pesquisa e desenvolvimento. Essa abordagem híbridapode gerar melhores soluções para alguns dos problemas que se revelaram difíceis paraos desenvolvedores de sistemas especializados, além de proporcionar a solução de pro-blemas que não obtiveram sucesso utilizando de forma isolada uma das abordagens quecompõem os sistemas híbridos.
1.2 Objetivos
Esse trabalho tem como principal objetivo o desenvolvimento de um framework capazde integrar o sistema de conversão Neuro-Simbólica do KBANN e o refinamento da redeneural para a inserção de novos aprendizados no conhecimento base, através do algoritmode TopGen. Os diversos estudos nessa área possibilitaram a implementação e uso de umsistema capaz de auxiliar no estudo das características do problema. O sistema tambémé de grande ajuda para outros interesses, pois informa ao usuário os possíveis erros en-contrados naquela teoria de domínio e a possibilidade de consertá-los, algo que uma redeneural ou sistemas puramente simbólicos não se mostraram capazes de resolver.
1.3 Organização do trabalho
Nesse trabalho, é explorado o uso de uma técnica específica de refinamento de teorias,o KBANN em conjunto com o algoritmo TopGen, para aquisição de novos conhecimentosem condições de incerteza ou dados com ruídos.
A organização foi feita da seguinte forma: No Capítulo 2, são apresentados os aspec-tos teóricos que caracterizam e fundamentam a compreensão dos paradigmas que deramorigem ao KBANN. É exemplificado a forma de representação de conhecimento em umarede KBANN, como também as formas de realizar modificações na topologia inicial darede para a inserção de novos conhecimentos. No Capítulo 3, são abordadas as técni-cas e recursos necessários para o desenvolvimento do sistema, além disso, são mostradosalguns testes que demonstram a capacidade de aprendizado do sistema em problemas sim-ples, como também em problemas complexos. O Capítulo 4 discute os testes realizadosno sistema implementado, entre os quais, alguns realizados de forma severa para verificaro potencial real das abordagens utilizadas no trabalho. No Capítulo 5 estão descritas asprincipais conclusões após a realização do trabalho, e por fim as referências bibliográficasutilizadas para o desenvolvimento do estudo.

Capítulo 2
Fundamentação Teórica
2.1 Inteligência Artificial Simbólica
Nos primeiros anos da IA foram vistos diversos pesquisadores escrevendo programasque possuiam sinais de inteligência artificial. Entre eles estão Newell et al. (1963), Fei-genbaum (1963), e outros como Rashevsky (1960), McCulloch e Pitts (1943) e Selfridgee Neisser (1963) trabalharam em especificações parecidas com as redes neurais que sãoutilizadas hoje em dia.
Essas pesquisas resultaram em um dos principais paradigmas conhecidos no mundoda IA, a Inteligência Artificial Simbólica (IAS). Essa linha de estudo se preocupa coma tentativa de representar explicitamente o conhecimento humano de forma declarativa(isto é, fatos e regras). Se tal abordagem for bem-sucedida na produção de inteligênciahumana, então é necessário traduzir o conhecimento implícito ou processual (ou seja,conhecimentos e habilidades que não são facilmente acessíveis à consciência) possuídospor humanos em uma forma explícita utilizando símbolos e regras para sua manipulação.
Os sistemas que utilizam regras são especialmente bons para aplicações cujas entradassão literais e precisas, levando à saídas lógicas. Para aplicações estáveis com regras bemdefinidas, os sistemas especialistas podem ser facilmente desenvolvidos para proporcionarum bom desempenho. Assim, as pessoas são capazes de inspecionar e entender essessistemas, pois suas estruturas são semelhantes ao raciocínio lógico humano.
Embora, os sistemas artificiais que simulam o conhecimento humano estejam sur-gindo em uma variedade de áreas e se tornando mais robustos, eles ainda possuem certasdificuldades que são praticamente insolúveis.
Um dos problemas encontrados pelos pioneiros da IA Simbólica veio a ser conhecidocomo o problema do conhecimento do senso comum. Além disso, as áreas que dependemde conhecimentos processuais ou implícitos, tais como os processos sensoriais / motores,são mais difíceis de se lidar dentro da estrutura simbólica. Nesses campos, essa abor-

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 5
dagem teve um sucesso limitado e, em geral, deixou o campo para arquiteturas de redesneurais (discutidas posteriormente), que são mais adequadas para tais tarefas. Nas se-ções a seguir, serão abordadas as subáreas importantes da IA simbólica, bem como asdificuldades encontradas por essa abordagem.
2.1.1 Sistemas Especialistas
O tema Sistemas Especialistas (SE) está concentrado em uma importante área da in-teligência artificial. A Inteligência Artificial (IA) trabalha com o desenvolvimento deequipamentos e softwares capazes de simular ou até mesmo replicar funções do cérebrohumano ou de características da natureza que inspiram técnicas de busca de uma soluçãoótima. Exemplos de técnicas são: Redes Neurais Artificiais, Algoritmos Genéticos e osSistemas Especialistas representam os primeiros esforços nessa área em produzir ferra-mentas que reproduzam estas funções.
A Inteligência Artificial possui muitas áreas de interesse, como mostrado na figura2.1. Dentre essas áreas, a de Sistemas Especialistas tem sido bastante utilizado para apro-ximar a solução de problemas clássicos de IA (GIARRATANO; RILEY, 2005).
Figura 2.1: Funcionamento de Sistemas Especialistas
Fonte: Giarratano e Riley, 2005
Os sistemas especialistas são conhecidos por trabalharem com um área de conhe-cimentos específicos, especializando na resolução de algo natural para o homem, masque por ser algo humanamente repetitivo ou dispendioso é estudado uma maneira de

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 6
ser utilizado por uma máquina. E por esse modo ser viável a operação por uma má-quina. Py (2015) esclarece que o conceito no qual se baseiam os SEs estão em permitirque a máquina, por meio do armazenamento e sequenciamento de informações e auto-aprendizagem, possibilite o uso de um conhecimento especializado e solucione problemasvinculados a esse conhecimento, por meio de um programa ou software.
Ao analisar um sistema de apoio à decisão, o sistema especialista emula a capacidadede raciocínio humano, simulando quais ações devem ser tomadas para cada situação.
O funcionamento típico de um sistema especialista pode ser compreendido pelo dia-grama da figura 2.2. O usuário informa o estado atual do sistema, através de fatos a cercado processo que está analisando. O sistema especialista por sua vez, se bem construído,contém uma quantidade de informação suficiente que explora uma área de conhecimentoespecíficos e é capaz de responder aos fatos apresentados pelo usuário. Para isso, utiliza-se de um motor de inferência que representa o processamento da informação e apresentauma resposta ao fato apresentado utilizando-se da base de conhecimento. A base de co-nhecimento é construída a partir de um conjunto de informações a cerca do processo.Esta informação pode vir de livros, revistas, dados históricos ou qualquer fonte de conhe-cimento que pode ser adquirido no processo de instalação ou durante a própria utilizaçãodo sistema especialista.
Figura 2.2: Funcionamento de Sistemas Especialistas
Fonte: Sistemas Inteligentes, 2004
Um sistema especialista típico possui três componentes (MOMOH et al., 2000):
• Base de conhecimento;• Motor de Inferência;

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 7
• Interface de usuário.
A base de conhecimento refere-se à uma base de informação que é criada para atenderas tomadas de decisões. Nesse contexto, conhecimento são todas as informações perti-nentes a uma determinada área de conhecimento organizadas de maneira a se tornar útilna representação e processamento da máquina.
É necessário que a base de conhecimento apresente o maior quantidade de informa-ções que o operador está familiarizado. Quanto mais completa a criação desse bancode informações, mais útil será o sistema especialista e mais precisa será a resolução deproblemas.
A inserção de informações ocorre na etapa de construção do SE e pode ocorrer tam-bém durante sua operação. Do mesmo modo que novas informações podem enriquecer obanco de conhecimento, outras podem ser excluídas.
O motor de inferência é o principal componente dos SEs. Esse componente é res-ponsável por interpretar o que está descrito na base de conhecimento e traduzir em açõesque devem ser tomadas. Nos sistemas que foram implementados, o motor de inferênciapossui duas funções distintas:
• Recomendar uma ação. Ou seja, determinar uma ação a set tomada através dasituação atual do processo;
• Diagnosticar o que está ocorrendo através de evidências, medições ou até mesmorelatos apresentados pelos operadores.
O processo de identificação na tomada de decisões pretende verificar a situação atualcom propósito de escolher a melhor ação. Os operadores se beneficiam do sistema porapresentar respostas rápidas que não sofrem influências externas.
O processo de diagnóstico é normalmente utilizado na área médica em que o status dasaúde do paciente é apresentada através de relatório médicos adquiridos por uma consultaou analisada através de exames. A intenção de sistemas como esses é estabelecer com umdeterminado grau de certeza qual o diagnóstico certo para o paciente. O funcionamentocorreto de um SE para diagnóstico é dependente de uma base de regras bem formadaprevendo todas, ou a maior parte, das situações possíveis.
A interface com o usuário é o canal por onde as informações são recebidas e enca-minhadas para o usuário final. Boas implementações de interfaces com usuários devemprever:
• Verificação se as regras estão bem formadas;

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 8
• No momento de criação de regras, analisar se não existe alguma outra redundanteou conflitante com as que já estão armazenadas na base de conhecimento;
• Verificar o rastreamento de uma ação do especialista. Apresentando o motivo decada ação foi tomada;
• Listar regras que estão sendo ativamente usadas, e podem ser subdivididas em ou-tras;
• Listar regras pouco ativadas e que são candidatas a uma exclusão.
Utilizar um sistema especialista que oferece recursos extras ao processo que não se-riam alcançados pelos operadores humanos.
Versatilidade: Em qualquer sistema computacional o sistema especialista pode ser im-plementado.
Custo reduzido: Os custos com o pessoal para oferecer informação é reduzido, já que osistema não precisa de remuneração para prover informações.
Baixo risco: Pode ser implementado em ambiente que oferece risco à saúde dos opera-dores.
Conhecimento permanente e estável: A informação adquirida no sistema não sofre in-fluência de fatores externos como cansaço, estresse ou qualquer característica natu-ral que provoca falta de atenção dos operadores.
Resposta imediata: Quando uma informação é necessária, o sistema prontamente apre-senta uma possível solução.
Existe uma gama de formalismos que podem ser utilizados para modelar do conhe-cimento de sistemas especialistas, tais como, regras de produção, raciocínio baseado emcasos, redes neurais, entre outros (PY, 2015). O sistema proposto na qualificação se referea um sistema especialista baseado em regras de produção.
2.1.2 Representação Simbólica do Conhecimento
De acordo com a teoria de Ryle (1949), a taxonomia do conhecimento inclui o co-nhecimento declarativo, que é um conhecimento estático sobre fatos ("saber o que") econhecimento processual, que é o conhecimento sobre a realização de tarefas ("sabercomo"). Por exemplo, uma árvore genealógica é uma representação do conhecimentodeclarativo, e um algoritmo heurístico, que simula a resolução de problemas por um serhumano, corresponde ao conhecimento procedural. Modelos estruturais de representaçãodo conhecimento são utilizados para definir o conhecimento declarativo. Eles geralmentesão na forma de estruturas hierárquicas do tipo grafo.

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 9
Embora originalmente eles foram utilizados para Processamento de Linguagem Natu-ral (PLN), descobriu-se que eles poderiam ser utilizados em outras áreas da IA. A teoriada dependência conceitual, desenvolvida por Schank no final dos anos 60, foi um dos pri-meiros modelos desse tipo. Schank alegou, ao contrário da teoria da gramática generativade Chomsky (1957), que uma sintaxe de linguagem era mais um conjunto de ponteirospara informações semânticas que poderiam ser utilizadas como ponto de partida para umaanálise semântica direta. A teoria da dependência conceitual foi formulada apenas parafornecer formalismos convenientes (estruturais) para realizar automaticamente uma aná-lise semântica. Como as frases de uma linguagem (natural) não podiam ser utilizadaspara realizar uma análise semântica de maneira direta, Schank introduziu uma representa-ção canônica e normalizada de dependências semânticas entre construções de linguagem(frases, sentenças).
Essa representação canônica é definida com a ajuda de grafos de dependência. Osnós rotulados de tais grafos correspondem às primitivas conceituais, que podem ser uti-lizadas para definir representações semânticas. Grafos de dependência são definidos deforma inequívoca de acordo com princípios precisos. Esses grafos podem ser analisa-dos de forma automática, o que permite ao sistema realizar uma análise semântica dasconstruções correspondentes de uma linguagem natural. Em suma, Schank verificou umahipótese afirmando que se pode tentar realizar a análise semântica automaticamente se fo-rem definidas as representações de linguagem baseadas em conceitos de maneira explícitae precisa.
2.1.2.1 Scripts
Os scripts foram propostos por Schank e Abelson (1977) como um método para pro-cessamento de linguagem natural. Os scripts podem ser definidos com a ajuda de grafosde dependência introduzidos acima. Se alguém quer entender uma mensagem sobre umdeterminado evento, então pode-se referir a um padrão generalizado relacionado ao tipodesse evento. O padrão é construído com base em eventos semelhantes que se conheceuanteriormente. Em seguida, ele é armazenado na memória. Pode-se facilmente notar queo conceito de scripts é conceitualmente semelhante ao modelo do quadro (Figura 2.3).

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 10
Figura 2.3: Representação de um Script
Fonte: Sistemas Híbridos Inteligentes, 1999
No passado, os modelos estruturais de representação do conhecimento eram por vezescriticados por não serem suficientemente formais. Essa situação mudou na década de 80,quando sistemas formais baseados na lógica matemática, chamada lógica de descrição foidefinida para esse propósito.
2.1.2.2 Redes Semânticas
As redes semânticas, introduzidas por Collins e Quillian (1969), são um dos primei-ros modelos de grafos definidos com base nos pressupostos apresentados acima. Seus nósrepresentam objetos ou conceitos (classes de abstração, categorias) e suas arestas repre-sentam relações entre eles (Figura 2.4).
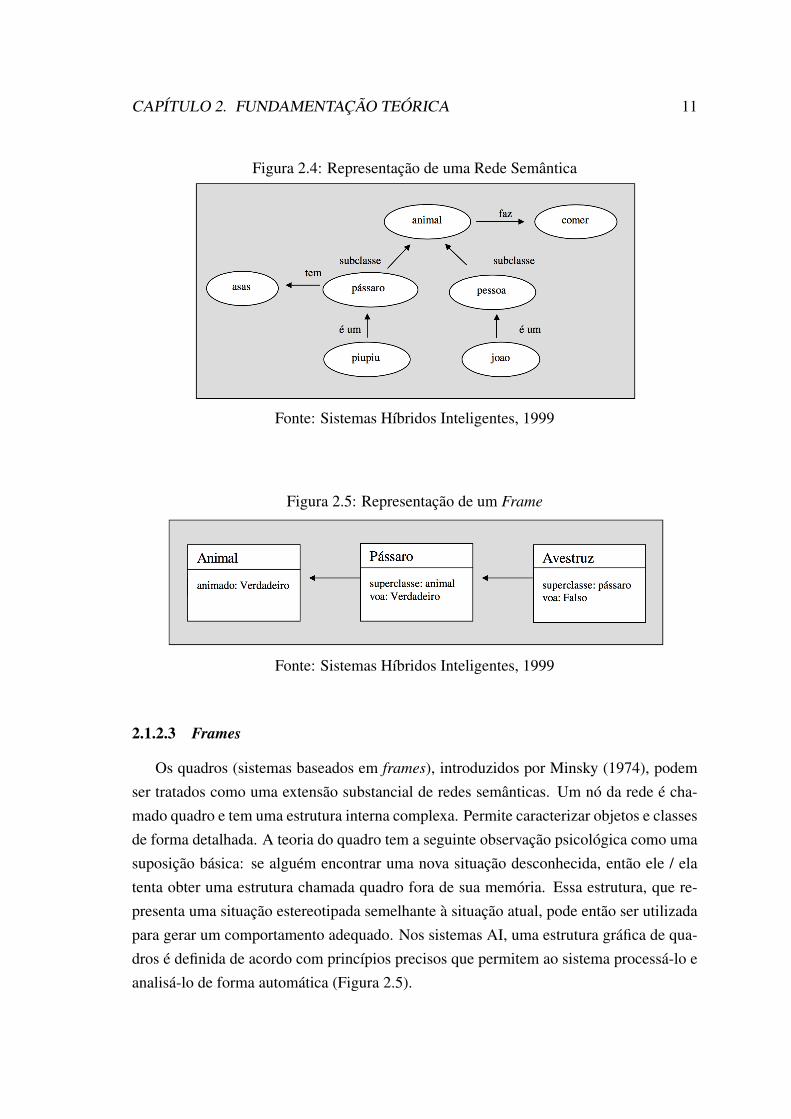
CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 11
Figura 2.4: Representação de uma Rede Semântica
Fonte: Sistemas Híbridos Inteligentes, 1999
Figura 2.5: Representação de um Frame
Fonte: Sistemas Híbridos Inteligentes, 1999
2.1.2.3 Frames
Os quadros (sistemas baseados em frames), introduzidos por Minsky (1974), podemser tratados como uma extensão substancial de redes semânticas. Um nó da rede é cha-mado quadro e tem uma estrutura interna complexa. Permite caracterizar objetos e classesde forma detalhada. A teoria do quadro tem a seguinte observação psicológica como umasuposição básica: se alguém encontrar uma nova situação desconhecida, então ele / elatenta obter uma estrutura chamada quadro fora de sua memória. Essa estrutura, que re-presenta uma situação estereotipada semelhante à situação atual, pode então ser utilizadapara gerar um comportamento adequado. Nos sistemas AI, uma estrutura gráfica de qua-dros é definida de acordo com princípios precisos que permitem ao sistema processá-lo eanalisá-lo de forma automática (Figura 2.5).

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 12
2.1.3 Formatação dos dados
2.1.3.1 Cláusulas Horn
As cláusulas Horn (Horn, 1951) servem como base para a criação da rede neuralutilizando lógica, sendo assim, será apresentada uma breve explicação sobre elas.
Na lógica, uma cláusula de Horn é uma cláusula (disjunção de literais) com no má-ximo um literal positivo. O nome "Cláusula de Horn"é uma homenagem ao lógico AlfredHorn, que foi quem primeiro chamou a atenção para o valor destas cláusulas, em 1951.
Uma cláusula de Horn pode ser de quatro tipos diferentes:
• Uma regra tem um literal positivo, e pelo menos um literal negativo. Sua formaé ¬P1 _¬P2 _ · · ·¬Pk _Q, que é logicamente equivalente a (P1 ^P2 ^ · · ·Pk)! Q.Exemplo: todo homem é mortal, ou seja, X não é um homem ou X é mortal;
• Um fato ou unidade é um literal positivo sem nenhum literal negativo. Por exemplo,Sócrates é um homem, todo mundo é parente de si mesmo;
• Um objetivo negado não tem nenhum literal positivo, e pelo menos um literal ne-gativo. Em programação, a base de dados consiste de regras e fatos, e um objetivonegado corresponde à negação do fato que se deseja provar, por exemplo, para seencontrar um descendente masculino de Isabel, o objetivo a ser provado é X é ho-mem e Isabel é ancestral de X, então o objetivo negado será X não é homem ouIsabel não é ancestral de X;
• A cláusula nula não tem nenhum literal positivo e nenhum literal negativo. Naprogramação, ela aparece no final de uma demonstração.
2.1.3.2 Prolog
O Prolog é uma linguagem de programação lógica de uso geral associada à inteligên-cia artificial e à linguística computacional (Covington, 1994). Suas raízes são da lógica deprimeira ordem, uma lógica formal, e ao contrário de muitas outras linguagens de progra-mação. A linguagem foi concebida primeiramente por um grupo em Marselha, França,nos anos 70 e o primeiro sistema de Prolog desenvolvido foi em 1972 por Colmerauer ePhilippe Roussel.
O Prolog é uma linguagem declarativa, ou seja, ao invés do programa estipular amaneira de chegar à solução passo a passo, como acontece nas linguagens procedimentaisou orientadas a objeto, ele fornece uma descrição do problema que se pretende computarutilizando uma coleção de fatos e regras (lógica) que indicam como deve ser resolvido o

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 13
problema proposto. Como pode-se ver, o Prolog é mais direcionado ao conhecimento doque aos próprios algoritmos.
Além de ser uma linguagem declarativa, outro fato que a difere das outras linguagensé a questão de não possuir estruturas de controle (se-senão, faz-enquanto, para) presentesna maioria das linguagens de programação. Para isso utilizam-se métodos lógicos paradeclarar como o programa deverá atingir o seu objetivo.
Um programa em Prolog pode rodar em um modo interativo, o usuário poderá formu-lar queries utilizando os fatos e as regras para produzir a solução através do mecanismode unificação.
O Prolog foi uma das primeiras linguagens de programação lógica, e continua a ser omais popular na forma de representação lógica, com várias implementações livres e co-merciais disponíveis. A linguagem tem sido utilizada para provas de teoremas, sistemasespecialistas, (Merrit, 1989) e planejamento automatizado, (Schmid, 2003). Os ambi-entes Prolog modernos suportam a criação de interfaces gráficas de usuário, bem comoaplicativos administrativos.
O Prolog é adequado para tarefas específicas que se beneficiam de consultas lógi-cas baseadas em regras, como busca em bancos de dados, sistemas de controle de voz emodelos de preenchimento.
2.1.3.3 Tipos de Dados
O tipo de dados único do Prolog é o termo. Os termos são átomos, números, variáveisou termos compostos.
2.1.3.4 Regras e Fatos
• Um átomo é um nome de propósito geral sem significado inerente. Exemplos deátomos incluem : y, azul, ’João’ e ’algum átomo’;
• Os números podem ser flutuantes ou inteiros;• As variáveis são denotadas por uma string composta por letras, números e caracte-
res de sublinhado, e começando com uma letra maiúscula ou sublinhado. As variá-veis se assemelham bastante às variáveis na lógica, na medida em que são espaçosreservados para termos arbitrários;
• Um termo composto é composto de um átomo chamado "funtor"e um número deargumentos, que são termos. Os termos compostos são normalmente escritos comoum "funtor"seguido de uma lista de termos de argumentos separados por vírgulas,que está contida entre parênteses. O número de argumentos é chamado aridade do

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 14
termo. Um átomo pode ser considerado como um termo composto com aridadezero.
2.1.4 Problemas da Inteligência Artificial Simbólica
Segundo Osório (2000), um sistema inteligente é alimentado com representações defatos e regras, mas as regras do senso comum são muito difíceis de estabelecer. Sabe-seque quando vamos deixar o filho na escola, ele não está mais em casa; se alguém estádentro do cinema deve ter entrado por alguma porta; se há uma sacola em seu carro e umlitro de leite na sacola, então há um litro de leite em seu carro. Note porém, que saberque há uma pessoa em seu carro, e saber que há um litro de sangue em uma pessoa, seriaestranho concluir que há um litro de sangue em seu carro.
O problema de saber distinguir as implicações relevantes entre um conjunto poten-cialmente infinito de implicações é denominado frame problem (problema de enquadra-mento), e dificulta principalmente a formalização de raciocínios sobre ações.
A manipulação de símbolos discretos é bastante eficiente, permitindo uma interaçãomuito fácil com o usuário. Por outro lado, existe o problema primordial da definição dossímbolos (semântica), que deve ser feita a priori. Por ser uma abordagem top-down, ondeo conhecimento é introduzido explicitamente no sistema e essa necessidade faz com queos sistemas simbólicos encontrem dificuldade para lidar de forma autônoma, em ambien-tes reais (contínuos) desconhecidos.

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 15
2.2 Redes Neurais Artificiais (RNA)
O conexionismo é um movimento da ciência cognitiva que espera explicar habilida-des intelectuais utilizando RNAs. As redes neurais são modelos simplificados do cérebrohumano compostas por um grande número de unidades (neurônios), juntamente com pe-sos que medem a força das conexões entre as unidades. Esses pesos modelam os efeitosdas sinapses que ligam um neurônio a outro. Diferentemente do paradigma simbólico,no modelo conexionista o estado dos neurônios representam um conceito ou um objeto ea dinâmica que leva à representação desse conceito ou objeto é que estabelece as regrassobre eles. Experimentos em modelos desse tipo demonstraram habilidades para aprendertarefas como: reconhecimento facial, leitura de textos, detecção de estrutura gramaticalsimples, entre tantas outras. Esse capítulo foi dividido em quatro seções: a Seção 2.2.1introduz brevemente a rede neural Multi-Layer Percepetron (MLP), a Seção 2.2.2 destacaas características da rede MLP, a Seção 2.2.3 a principais funções de ativação utilizadasnas RNAs e as duas últimas Seções 2.2.4 e 2.2.5 descrevem o algoritmo backpropagatione o processo de treinamento.
Uma rede neural MLP (Figura 2.6) consiste em grande número de unidades separadaspor camadas e unidas através de conexões.
Figura 2.6: Representação de uma RNA MLP.
Fonte: Haykin, 2000

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 16
As camadas em uma rede são normalmente segregadas em três classes: camada deentrada, que recebem informações a serem processadas, camada de saída onde os resulta-dos do processamento são encontrados e as camadas ocultas que interligam a camada deentrada à saída da rede.
Se uma rede neural fosse modelar todo o sistema nervoso humano, as unidades de en-trada seriam análogas aos neurônios sensoriais, às unidades de saída os neurônios motorese às unidades ocultas todos os demais neurônios.
A função que uma RNA irá desempenhar depende da soma do conjunto de funções decada neurônio. Os neurônios podem estar agrupados em RNAs do tipo MLP, que é a maisconhecida no meio acadêmico, devido a sua simplicidade.
Resumidamente, as n entradas Xi do neurônio (sendo que, 1 < i < n) são somadas, oresultado é processado no corpo do neurônio para produzir a saída yk (Figura 2.7).
Figura 2.7: Representação de um Neurônio.
Fonte: Haykin, 2000
Cada unidade de entrada tem um valor de ativação que representa alguma caracterís-tica externa à rede. Uma unidade de entrada envia o seu valor de ativação para cada umadas unidades ocultas às quais está ligado. Cada uma dessas unidades ocultas calcula seupróprio valor de ativação dependendo dos valores de saída que recebe das unidades deentrada. Esse sinal é então passado para a camada de saída ou para uma outra camadaoculta.
Essas unidades ocultas calculam seus valores de ativação da mesma maneira, e propa-gam sua saída ao longo de seus vizinhos. Eventualmente, o sinal das unidades de entrada

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 17
se propaga completamente pela rede para determinar os valores de ativação em todas asunidades de saída da rede. Um exemplo de como um neurônio é representado nas redesneurais, pode ser visto na Figura 2.7. Os estímulos gerados pelos neurônios fluem di-retamente das entradas para as unidades ocultas e depois para as unidades de saída. Opadrão de ativação estabelecido por uma rede é determinado pelos pesos ou força das co-nexões entre as unidades. Os pesos podem ser positivos ou negativos. Um peso negativorepresenta a inibição da unidade receptora pela atividade de uma unidade emissora.
A maioria das RNAs são projetadas para aprender as informações que são passadasa elas, deixando-as aptas à interpretação apropriada de novas informações, conforme oobjetivo desejado na sua aplicação. Se uma RNA aprendesse todas as informações, elaatingiria 100% de acertos, mas esse é um fato raro. Quando, por ventura, se atinge umpercentual alto de acertos em uma RNA (100% ou valor próximo), pode-se formularduas hipóteses: ou o problema foi completamente solucionado, ou a RNA decorou asinformações passadas a ela. Na primeira hipótese, a RNA está aberta para soluções deoutros problemas pertencentes à mesma classe para a qual foi treinada. Na segunda, quenão é desejável em muitas aplicações, o universo de soluções apresentado pela RNA ficarestrito. O aprendizado em uma RNA é realizado pelo processamento de um conjunto deinformações. A cada novo processamento, as informações são classificadas. Ao final detodo o processamento, a RNA estará cada vez mais sensível a novos processamentos aomesmo conjunto de informações.
2.2.1 Tipos de aprendizagem
O algoritmo de aprendizagem de uma rede neural pode ser supervisionado ou nãosupervisionado. Boa parte dos exemplos de aprendizado de máquina usam a aprendiza-gem supervisionada para o treinamento. Essa forma de aprendizado possui a seguintecaracterística: dado um conjunto de entradas (x) e suas respectivas saídas (y), realizar omapeamento dessas informações em um algoritmo de aprendizado.
O objetivo é aproximar a função que representa o problema de uma forma que elapossa classificar informações que não foram aprensetadas durante o treinamento da redeneural. Essa é uma das vantagens da rede neural, a sua capacidade de generalizar uminformação a partir de dados prevaimente apresentados.
O método é chamado de aprendizagem supervisionada, porque o processo de apren-dizagem de um algoritmo é realizado a partir de um conjunto de dados de treinamentoque pode ser pensado como um professor de supervisão do processo de aprendizagem.Sabendo as respostas corretas, o algoritmo iterativamente faz previsões sobre os dados

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 18
de treinamento e quando erra em um determiando ponto, é corrigido pelo professor. Oprocesso de aprendizagem para quando o algoritmo atinge um nível de desempenho acei-tável.
Problemas de aprendizagem supervisionados podem ser agrupados em problemas deregressão e classificação:
• Classificação: O problema de classificação é quando a variável de saída é umacategoria, como vermelho ou azul ou doente e saudável;
• Regressão: Um problema de regressão é quando a variável de saída é um valor real,como pressão, temperatura, etc.
Alguns tipos comuns de problemas construídos em cima da classificação e regressãoincluem recomendação e previsão de séries temporais, respectivamente. Alguns exemplospopulares de algoritmos supervisionados de aprendizagem de máquina são: regressãolinear e máquinas de suporte vetorial para problemas de classificação.
Por outro lado, a aprendizagem não supervisionada de máquinas é realizada quandonão há supervisão, isto é, quando se possui apenas os dados de entrada (x) e nenhumainformação de saída correspondente.
A meta para a aprendizagem não supervisionada é modelar a estrutura subjacente oua distribuição nos dados a fim de aprender mais sobre os dados. Esses são chamados deaprendizagem sem supervisão, porque ao contrário da aprendizagem supervisionada nãohá respostas corretas e não há um professor. É dado o algoritmo a chance de descobrire apresentar a melhor estrutura para os dados apresentados. Problemas de aprendizagemnão supervisionados podem ser agrupados em problemas de agrupamento e associação.
• Agrupamento: Um problema de cluster é quando se deseja descobrir os agrupa-mentos inerentes dos dados, como agrupar clientes por meio do comportamento decompra.
• Associação: Um problema de aprendizagem de regra de associação é quando sequer descobrir regras que descrevem grandes porções de seus dados, como pessoasque compram X também tendem a comprar Y.
Alguns exemplos populares de algoritmos de aprendizagem não supervisionados são:K-means para problemas de cluster e o algoritmo Apriori para problemas de aprendiza-gem de regra de associação.
Para os problemas onde se possui uma grande quantidade de dados de entrada e apenasalguns dos dados de saída, nsse caso, é chamado de problems de aprendizagem semi-supervisionado.

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 19
Esses problemas situam-se entre as abordagens citadas anteriormente. Um bom exem-plo é um arquivo fotográfico onde apenas algumas das imagens são rotuladas (por exem-plo, cão, gato, pessoa) e a maioria não está marcada. Muitos problemas de aprendizagemda máquina do mundo se situam nessa área. Isso ocorre porque ele pode ser caro ou de-morado rotular os dados, pois pode exigir acesso a especialistas de domínio. Enquanto osdados não marcados são mais fáceis de se coletar e armazenar.
2.2.2 Redes MLP
As redes Multi-Layer Perceptron (MLP) são o tipo mais popular de redes neuraisutilizadas em aplicações de RNAs. Essas redes têm sido utilizadas em uma variedadede aplicações, como reconhecimento de imagens, de vozes, de caracteres, entre muitasoutras. Uma RNA do tipo MLP é constituída por uma camada de entrada (input layer),uma ou mais camadas ocultas (hidden layers) e uma camada de saída (output layer). AFigura 2.8 mostra a arquitetura de uma rede neural MLP com uma camada de entrada,duas camadas ocultas e uma camada de saída.
Com relação as redes MLPs, pode-se citar duas características da estrutura que sãoimediatamente aparentes:
1. A MLP é uma rede progressiva. Uma rede é dita progressiva (feedforward) quandoas saídas dos neurônios em qualquer camada se conectam unicamente às entradas dosneurônios da camada seguinte, sem a presença de laços de realimentação. Consequente-mente, o sinal de entrada se propaga através da rede, camada a camada, em um sentidoprogressivo.
2. A rede pode ser completamente conectada, caso em que cada neurônio (computa-cional ou não) em uma camada é conectado a todos as outras unidades de uma camadaadjacente. De forma alternativa, uma rede MLP pode ser parcialmente conectada, nessecaso, algumas sinapses poderão estar faltando. O termo parcialmente se refere à conecti-vidade de um neurônio em uma camada da rede com relação a somente um subconjuntode todas as possíveis entradas. Nesse trabalho, no entanto, foi considerado apenas MLPscompletamente conectadas.

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 20
Figura 2.8: Representação de uma MLP
Fonte: Haykin, 2000
O número de unidades na camada de entrada da rede é determinado pela dimensiona-lidade do espaço de observação, que é responsável pela geração dos sinais de entrada. Onúmero de neurônios na camada de saída é determinado pela dimensionalidade requeridada resposta desejada. Assim, o projeto de uma rede MLP requer a consideração de trêsaspectos:
• A determinação do número de camadas escondidas;• A determinação do número de neurônios em cada uma das camadas escondidas;• A especificação dos pesos sinápticos que interconectam os neurônios nas diferentes
camadas da rede.
Os dois primeiros itens acima determinam a complexidade do modelo de RNA es-colhido e, não há regras determinadas para tal especificação. A função das camadasescondidas em uma RNA é a de influir na relação entrada-saída da rede de uma formaampla. Uma rede com uma ou mais camadas escondidas é apta a extrair as estatísticas deordem superior de algum desconhecido processo aleatório subjacente, responsável pelocomportamento dos dados de entrada, processo sobre o qual a rede está tentando adqui-rir conhecimento. A RNA adquire uma perspectiva global do processo aleatório, apesarde sua conectividade local, em virtude do conjunto adicional de pesos sinápticos e dadimensão adicional de interações neurais proporcionada pelas camadas escondidas. O úl-timo item envolve a utilização de algoritmos de treinamento supervisionados. As MLPs

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 21
têm sido aplicadas na solução de diversos e difíceis problemas através da utilização detais algoritmos. O algoritmo de treinamento quase universalmente utilizado para tanto éo algoritmo de retro-propagação do erro, conhecido na literatura como BackpropagationAlgorithm e será discutido mais adiante.
2.2.3 Algoritmo Backpropagation
O algoritmo usado para ajuste dos pesos é um aspecto relevante para o bom desempe-nho das redes neurais (Prechelt, 1994). Encontrar o conjunto certo de pesos para realizaruma determinada tarefa é o objetivo central na pesquisa conexionista. Felizmente, algo-ritmos de aprendizagem foram concebidos para calcular os pesos corretos na realizaçãode diversas tarefas (Rumelhart et al., 1986). Estes se dividem em duas grandes categorias:aprendizagem supervisionada e não supervisionada. À medida que cada entrada é apre-sentada à rede, os pesos entre as unidades que estão ativas são incrementadas, enquantoos pesos que conectam unidades que não estão ativas são enfraquecidas. Essa formade treinamento é especialmente útil para construir redes que podem classificar a entradaem categorias úteis. O algoritmo supervisionado mais amplamente utilizado é chamadobackpropagation. Para usar esse método, é necessário um conjunto de treinamento com-posto por muitos exemplos de entradas e suas saídas desejadas para uma determinadatarefa. Esse conjunto externo de exemplos supervisiona o processo de treinamento. Se,por exemplo, a tarefa for distinguir rostos masculinos e femininos, o conjunto de treina-mento pode conter quadros de rostos, juntamente com uma indicação do sexo da pessoarepresentada em cada um.
Uma rede que pode aprender essa tarefa pode ter duas unidades de saída (indicando ascategorias masculino e feminino) e muitas unidades de entrada, uma delas, por exemplo,seria dedicada ao brilho de cada pixel da imagem.
2.2.3.1 Processo de Treinamento
Antes de demonstrar o passo a passo do algoritmo de treinamento backpropagation,serão feitas algumas considerações quanto à notação utilizada por (HAYKIN, 2000).
Os neurônios na rede MLP serão referenciados pelos índices i, j e k. Os sinais funcio-nais se propagam através da rede, da esquerda para a direita, sendo que o neurônio j estána camada à direita do neurônio i, e o neurônio k está na camada à direita do neurônio j,quando o neurônio j é uma unidade escondida.
Na iteração n, o n-ésimo padrão de treinamento é apresentado à rede.

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 22
O símbolo e(n) se refere à soma instantânea dos erros quadráticos na iteração n. Amédia de e(n) sobre todos os valores de n (isto é, o conjunto de treino inteiro) representaa energia média do erro emed .
O símbolo e j(n) se refere ao sinal de erro na saída do neurônio j para a iteração n.O símbolo d j(n) se refere à resposta desejada para o neurônio j e é usado para com-
putar e j(n).O símbolo y j(n) se refere ao sinal funcional encontrado na saída do neurônio j, na
iteração n.O símbolo w ji(n) denota o peso sináptico que conecta a saída do neurônio i à entrada
do neurônio j, na iteração n. A correção aplicada a esse peso na iteração n é denotada porDw ji(n).
O potencial de ativação (isto é, a soma ponderada de todas as entradas sinápticas maiso bias) do neurônio j na iteração n é denotado por v j(n) e constitui o sinal aplicado àfunção de ativação associada ao neurônio j.
A função de ativação que descreve a relação funcional entrada-saída da não-linearidadeassociada ao neurônio j é denotada por j j(·).
O bias aplicado ao neurônio j é denotada por b j; seu efeito é representado por umasinapse de peso w j0(n) = b j conectada a uma entrada fixa igual a (+1).
O i-ésimo componente do vetor de entrada é denotado por xi(n).O k-ésimo componente do vetor de saída é denotado por ok(n).O parâmetro da taxa de aprendizagem é denotado por h.Tendo estabelecido a notação, inicialmente apenas será descrito as equações de de-
finição do algoritmo backpropagation e sua forma de operação. Posteriormente, foramdeduzidas as equações que regem sua operação.
Seja o sinal de erro na saída do neurônio j da camada de saída na iteração n (isto é, naapresentação do n-ésimo vetor de treinamento) definido por:
e j = d j(n)� y j(n) (2.1)
Define-se o valor instantâneo do erro quadrático para o neurônio j como12
e2j(n). Cor-
respondentemente, o valor instantâneo en é obtido somando sobre todos os neurônios dacamada de saída. Esses são os únicos neurônios visíveis para os quais os sinais de erro po-dem ser calculados de forma direta. A soma instantânea dos erros quadráticos na camadade saída da rede é escrita como:

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 23
e(n) = 12 Â
j2Ce2
j(n) (2.2)
Onde o conjunto C inclui todos os neurônios na camada de saída. Seja N o número to-tal de padrões contidos no conjunto de treino. O erro médio quadrático é obtido somandoe(n) sobre todo n e então normalizando com respeito ao tamanho N do conjunto de treino,conforme:
eav =1
N �1
N�1
Ân=0
e(n) (2.3)
O valor instantâneo da soma dos erros quadráticos e(n), e consequentemente a médiado erro médio emed é função de todos os parâmetros livres (isto é, pesos sinápticos ebias) da rede. Para um dado conjunto de treino, emed representa a função de custo doprocesso de minimização do erro de aprendizado, constituindo uma medida inversa dodesempenho do processo de aprendizado a partir do conjunto de treino. Para minimizaremed os pesos sinápticos são atualizados a cada apresentação n de um novo padrão a redeatravés do vetor de entrada até o término de uma época. Uma época consiste no intervalocorrespondente à apresentação de todos os N vetores-exemplo do conjunto de treino àcamada de entrada da RNA. O ajuste dos pesos é feito de acordo com os respectivos erroscomputados para cada padrão apresentado a rede. A média aritmética dessas alteraçõesindividuais nos pesos sobre o conjunto de treino é, portanto, uma estimativa da verdadeiraalteração que resultaria a partir da alteração de pesos baseada na minimização da funçãocusto emed sobre todo conjunto de treino.
Considere a Figura 2.9, a qual descreve o neurônio j sendo alimentado por um con-junto de sinais produzidos na saída dos neurônios da camada à sua esquerda.

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 24
Figura 2.9: Grafo de fluxo de sinal no neurônio j.
Fonte: Adaptada de Haykin, 2000
O potencial de ativação v j(n) aplicado na entrada da não-linearidade associada aoneurônio j é, portanto:
v j(n) =m
Âi=0
w ji(n)yi(n) (2.4)
Onde m é o número total de entradas (excluindo o bias) aplicado ao neurônio j. Ow j0 é o peso sináptico que conecta a saída do neurônio i ao neurônio j e yi(n) é o sinalno i-ésimo neurônio de entrada do neurônio j, ou equivalentemente, ao sinal na saída doneurônio i. Portanto, o sinal y j(n) resultante na saída do neurônio j na iteração n é:
y j(n) = j j(v j(n)) (2.5)
De maneira similar ao algoritmo Least Mean Squares (LMS), o algoritmo backpro-pagation aplica a correção Dw ji(n) ao peso sináptico w ji(n), tendo como base a direçãocontrária do gradiente local da superfície de erro e relativo ao peso sináptico.
Se, para uma dada variação no peso sináptico, o algoritmo movimenta-se em umatrajetória ascendente na superfície e, então significa que essa variação deve ser aplicada

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 25
com o sinal invertido sobre o peso sináptico, já que houve um aumento do erro, e objetiva-se uma diminuição do erro.
Por outro lado, se para uma dada variação no peso sináptico o algoritmo movimenta-se em uma trajetória descendente na superfície e, então significa que esta variação deveser aplicada com o sinal positivo sobre o peso sináptico, já que houve uma diminuiçãodo erro e, portanto, o movimento deve ser encorajado naquela direção. Esse método decorreção dos pesos sinápticos é denominado de regra delta, e é definida pela expressão:
Dw ji(n) =�h ∂e(n)∂w ji(n)
(2.6)
Onde h é a constante que determina a razão de aprendizado do algoritmo backpro-pagation. O uso do sinal negativo em (2.6) impõe a movimentação contrária à direçãoapontada pelo gradiente na superfície de erro definida no espaço de pesos sinápticos.
Correspondentemente, o uso da Eq. (2.6) produz:
Dw ji(n) = hd j(n)yi(n) (2.7)
Onde o gradiente local (d j) é definido por:
d j(n) = e j(n)j0j(v j(n)) (2.8)
O gradiente local aponta para as modificações necessárias nos pesos sinápticos. Deacordo com Eq. (2.8), o gradiente local d j(n) para o neurônio de saída j é igual ao produtodo sinal de erro e j(n) correspondente para aquele neurônio pela derivada j0
j(v j(n)) dafunção de ativação associada.
Das equações (2.7 e 2.8) nota-se que um fator-chave envolvido no cálculo do ajustede peso D ji(n) é o sinal de erro e j(n) na saída do neurônio j. Neste, contexto, pode-seidentificar dois casos distintos, dependendo de onde na rede o neurônio j está localizado.
No caso 1, o neurônio j é um nó de saída. Este caso é simples de se tratar, pois cadanó de saída da rede é suprido com uma resposta desejada particular. No caso 2, o neurônioj é um nó oculto. Apesar de os neurônios ocultos não serem acessíveis diretamente, elescompartilham a responsabilidade por qualquer erro cometido na saída da rede.
Os cálculos dos gradientes locais para os dois casos acima citados são definidos por:

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 26
d j(n) =
(j0
j(v j(n))e j(n), neurônio j é de saídaj0
j(v j(n))Âk dk(n)wk j(n), neurônio j é de escondido(2.9)
De acordo com (2.9) o gradiente local d j(n) para o neurônio de saída j é igual ao pro-duto do correspondente sinal de erro e j(n) pela derivada j0
j(v j(n)) da função de ativaçãoassociada. Nesse caso, o fator chave necessário envolvido no cálculo do ajuste dos pesosDw ji(n) é o sinal de erro e j(n) na saída do neurônio j.
Quando o neurônio j está localizado em uma camada oculta, conforme mostra a Fi-gura 2.10, mesmo não sendo diretamente acessíveis, tais neurônios dividem a respon-sabilidade pelo erro resultante na camada de saída. A questão, no entanto, é saber comopenalizar ou recompensar os pesos sinápticos de tais neurônios pela sua parcela de respon-sabilidade, já que não existe resposta desejada especificada neste local da rede e, portanto,não há como calcular o sinal de erro.
A solução, dada pela equação (2.9), é computar o sinal de erro recursivamente para oneurônio escondido j retro-propagando os sinais de erro de todos os neurônios à direitado neurônio j aos quais a saída deste encontra-se conectado.
Figura 2.10: Grafo de fluxo de sinal mostrando os detalhes do neurônio de saída k conec-tando ao neurônio escondido j.
Fonte: Adaptada de Haykin, 2000

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 27
O fator j0j(v j(n)) envolvido na computação do gradiente local d j(n) na equação (2.9)
depende somente da função de ativação associada com o neurônio escondido j. Os de-mais fatores envolvidos no somatório sobre k em (2.9) dependem de dois conjuntos determos. O primeiro, dk(n), requer conhecimento dos sinais de erro ek(n) recursivamenteretro-propagados, conforme apresentado adiante, a partir de todos aqueles neurônios lo-calizados na camada imediatamente à direita do neurônio escondido j e que estão dire-tamente conectados a ele (Figura 2.11). O segundo conjunto de termos, wk j(n), consistedos pesos sinápticos dos neurônios à direita do neurônio j e que com ele estabelecemconexão.
Figura 2.11: Grafo de fluxo de sinal mostrando o processo de retro-propagação dos sinaisde erro na camada de saída para um neurônio j da camada escondida.
Fonte: Adaptada de Haykin, 2000
2.2.3.2 Funções de Ativação
Em uma rede neural, cada neurônio - com exceção dos neurônios na camada de en-trada - recebe e processa estímulos (inputs) de outros neurônios. As informações proces-sadas estão disponíveis na extremidade de saída do neurônio. Como pode ser visto naFigura 2.7, a cada saída de um nerônio, é aplicado uma função de ativação. A função deativação mais comumente utilizada é a função sigmóide dada por:
s(g) = 1(1+ e�g)
(2.10)
Conforme mostrado na Figura 2.12, a função sigmóide é uma função de comutaçãosuave que tem as seguintes propriedades:
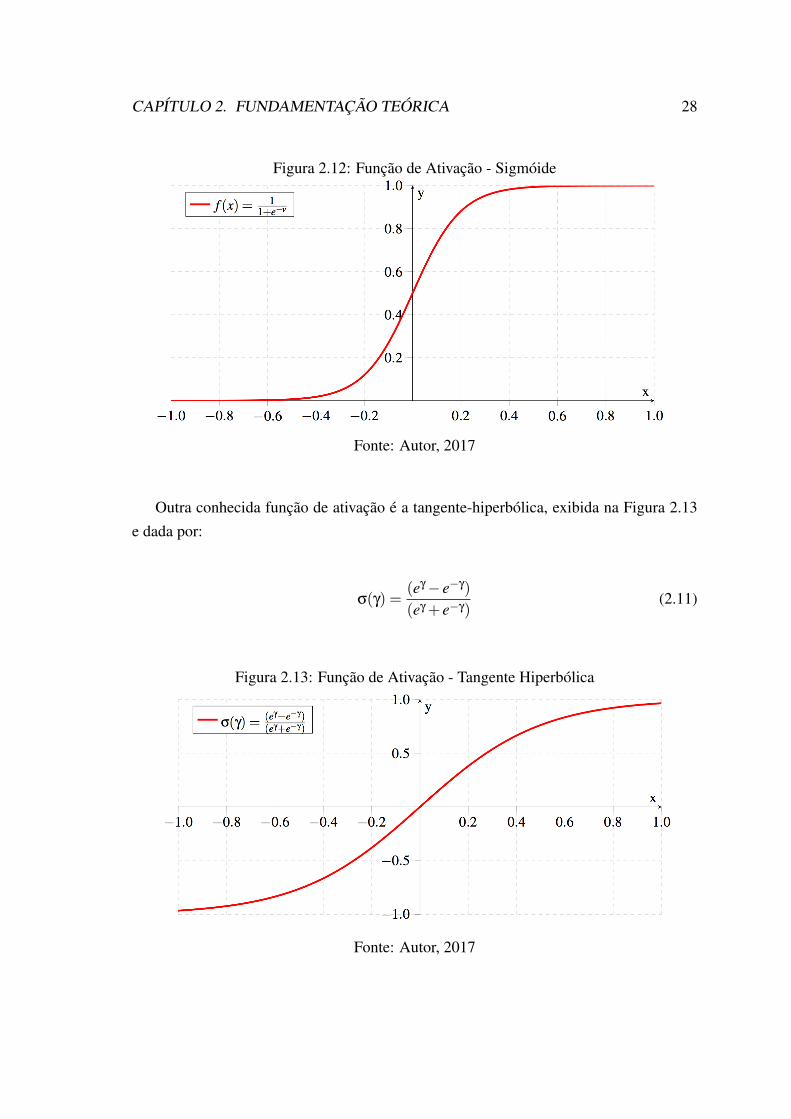
CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 28
Figura 2.12: Função de Ativação - Sigmóide
Fonte: Autor, 2017
Outra conhecida função de ativação é a tangente-hiperbólica, exibida na Figura 2.13e dada por:
s(g) = (eg � e�g)
(eg + e�g)(2.11)
Figura 2.13: Função de Ativação - Tangente Hiperbólica
Fonte: Autor, 2017

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 29
As funções de ativação variam em detalhes, mas todas estão em conformidade com omesmo plano básico. A função resume as contribuições de todas as unidades emissoras,onde a contribuição de uma unidade é definida como o peso da conexão entre as unidadesde envio e de recebimento, multiplicado pelo valor de ativação da unidade emissora. Essasoma é normalmente modificada, por exemplo, ajustando a soma de ativação para umvalor entre 0 e 1 ou definindo a ativação para zero.
Todas essas funções logísticas são delimitadas, contínuas, monotônicas e continua-mente diferenciáveis.
Nesse trabalho, utilizou-se uma convenção, em que os neurônios da camada de entradatambém são considerados como parte da estrutura geral e utilizou-se a função sigmóideem todas as camadas.

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 30
2.3 Sistemas Híbridos
O cérebro humano possui a notável capacidade de compreender, interpretar e produzira linguagem humana. A inteligência artificial conexionista se desenvolveu para tentar si-mular algo parecido com a inteligência humana. As redes neurais artificiais e a lógica nãopossuem uma ligação tão próxima. Os mecanismos de inferência simbólicos e a aprendi-zagem estatística de máquina constituem dois dos principais paradigmas da inteligênciaartificial, embora sejam muito diferentes. Ambos possuem pontos fortes e fracos: Os mé-todos estatísticos oferecem ferramentas flexíveis e altamente eficazes, ideais para dadospossivelmente corrompidos.
Esses modelos, no entanto, são frequentemente reduzidos a mecanismos de caixa pretaque dificultam a integração de conhecimentos de nível superior ou entendimento humano.Os modelos simbólicos, por outro lado, são perfeitamente intuitivos e facilmente aplica-dos para a interação homem-máquina. No entanto, sua capacidade de lidar com a incer-teza, o ruído e com conjuntos de dados corrompidos é bastante limitada. Assim, as forçase fragilidades inerentes desses dois métodos complementam-se idealmente entre si.
Diversos pesquisadores desses dois paradigmas como, Misnky (1991), Kurfess (1997),Russell (1996) e Mitchell (1997) tentaram combinar as forças das duas direções e aomesmo tempo livrar-se de suas fragilidades eventualmente, visando sistemas artificiaisque poderiam ser competitivos às capacidades humanas de processamento de dados einferência.
2.3.1 Knowledge-based Artificial Neural Networks (KBANN)
Esta subseção descreve a metodologia KBANN, que pode ser descrito como um sis-tema capaz de aprender a partir da teoria de domínio quanto por exemplos. O primeiroalgoritmo, rotulado Regras para Rede, é detalhado na Seção 2.4.1 e tem como função ainserção de regras simbólicas em uma rede neural. A rede gerada nesse passo realiza amesma classificação que as regras em que lhe deram origem. O segundo algoritmo doKBANN, denominado Neural Learning, refina a rede utilizando o algoritmo de aprendi-zagem backpropagation. Segundo Towell et al. (1990), apesar de todos testes utilizaremretro-propagação, qualquer método aprendizado supervisionado funcionaria. Embora omecanismo de aprendizagem seja essencialmente uma retro-propagação padrão, a redeque está sendo treinada não segue o padrão de uma rede MLP com pesos aleatórios.Em vez disso, o primeiro algoritmo do KBANN constrói e inicializa a rede com pesos ebias pré-determinados Isso tem implicações diretas para o treinamento. Ao concluir essa

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 31
etapa, a rede treinada pode ser utilizada como um classificador muito preciso. A subseção2.3.1.1 apresenta como o conhecimento prévio é inserido na RNA.
2.3.1.1 Inserção de Conhecimento em uma RNA
Segundo Towell (1990), o primeiro passo do KBANN de mapear um conjunto de re-gras aproximadamente corretas em uma rede neural baseada no conhecimento. As regrasa serem traduzidas em redes KBANN são expressas através de cláusulas Horn. Existemduas restrições no conjunto de regras. Primeiro, as regras devem ser proposicionais. Essarestrição resulta do uso de algoritmos de aprendizado neural que, no momento, são inca-pazes de manipular variáveis de cálculo de predicado. Em segundo lugar, as regras devemser acíclicas. Essa restrição sem ciclos simplifica o treinamento das redes resultantes.No entanto, ele não representa uma limitação fundamental no KBANN, pois existem al-goritmos baseados em backpropagation que podem ser utilizados para treinar redes comciclos (TOWELL et al., 1990). Além dessas restrições, os conjuntos de regras forneci-dos ao KBANN são hierarquicamente estruturados. Ou seja, as regras geralmente nãomapeiam diretamente as entradas para as saídas. Em vez disso, pelo menos algumas dasregras fornecem conclusões intermediárias que descrevem informações úteis ao usuário.Essas conclusões intermediárias podem ser utilizadas por outras regras para determinara conclusão final ou outras conclusões intermediárias. É a estrutura hierárquica de umconjunto de regras que cria características derivadas para uso pelo sistema de aprendiza-gem baseado em exemplo. Assim, se o conhecimento de domínio não é hierarquicamenteestruturado, então as redes criadas pelo KBANN não terão recursos que indicam depen-dências contextuais ou outras conjunções úteis dentro das descrições do exemplo. Alémdisso, uma rede KBANN que resulta da tradução de um conjunto de regras sem conclusõesintermediárias poderia utilizar apenas uma rede Perceptron para resolução do problema.A Tabela 2.1, mostra um resumo de como é mapeado a teoria de domínio em uma redeneural de KBANN.
Tabela 2.1: Correspondências entre bases de conhecimento e redes neurais
Conhecimento base () Rede NeuralConclusões finais () Unidades de saídaSuporte aos fatos () Unidades de entradaConclusões intermediárias () Unidades ocultasDependências () Conexões dos pesos
Fonte: Towell, 1990

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 32
2.3.1.2 Algoritmo de Tradução de Regras
Nessa subseção, é descrito, em detalhes, cada uma das sete etapas desse algoritmo.1. Reescrever - A primeira etapa do algoritmo transforma o conjunto de regras em
um formato que esclarece sua estrutura hierárquica, e torna possível traduzir diretamenteas regras em uma rede neural. Se houver mais de uma regra para um consequente, entãocada regra para esse consequente com mais de um antecedente é re-escrita em duas re-gras. Uma dessas regras tem o consequente original e um único termo recém-criado comoantecedente. A outra regra tem o termo recém-criado como seu consequente e os ante-cedentes da regra original como seus antecedentes. Por exemplo, a Figura 2.14 mostra atransformação de duas regras no formato requerido pelas próximas etapas do KBANN. Otrabalho de Towell et al. (1990) explica a necessidade de se aplicar essa reescrita.
Figura 2.14: Eliminação de disjunções com mais de um antecedente
Fonte: Towell, 1990
2. Mapeamento - Na segunda etapa do algoritmo, o KBANN estabelece um ma-peamento entre um conjunto transformado de regras e uma rede neural. Usando essemapeamento, mostrado na Tabela 2.1, o KBANN cria uma rede neural que têm uma cor-respondência um para um de acordo com o conjunto de regras. Tanto os pesos sinápticoscomo os bias são definidos de modo que consiga representar as regras estabelecidas nodomínio inicial, ou seja, dado um cojnunto de entradas para o modelo de regras, a res-posta gerada deve ser idêntica a resposta da rede neural. Ao concluir essa etapa, a rede doKBANN tem as informações do conjunto de regras relativas as entradas. No entanto, nãohá nenhuma garantia de que o conjunto de regras se refere de forma correta as infomaçõesa ela apresentada. Assim, as quatro etapas seguintes aumentam confiabilidade da rede doKBANN com o aumento das ligações sinápticas, unidades de entrada e (possivelmente)unidades ocultas.
3. Numeração - Nessa etapa, KBANN enumera as unidades nas redes KBANN pornível. Esse número influência diretamente nas etapas seguintes. O KBANN define o nívelde cada unidade como sendo o comprimento do caminho mais longo para a unidade desaída.

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 33
4. Adicionando unidades ocultas - Esse passo adiciona unidades ocultas a redeKBANN, dando assim, a rede a capacidade de aprender características derivadas que fo-ram não especificadas no conjunto de regras inicial. A etapa é opcional, pois as regrasiniciais geralmente fornecem um vocabulário suficiente para evitar a necessidade de adici-onar unidades ocultas. As unidades ocultas são adicionadas somente para complementarpossíveis instruções que algum usuário do sistema acredite que seja últil futuramente.Nessa etapa deve-se especificar a quantidade e o local (níveis) das unidades adicionadas.
5. Adicionando unidades de entrada - Nessa etapa, o KBANN aumenta sua redecom unidades de entrada não mencionados pelo conjunto de regras, mas que um especia-lista do domínio acredita serem relevantes. Essa adição é necessária porque um conjuntode regras que não é perfeitamente correto pode não identificar cada recurso de entradanecessário para aprender corretamente um conceito.
6. Adicionando links - No penúltimo passo, o algoritmo adiciona links com pesopróximo a zero na rede utilizando a numeração das unidades estabelecidas na etapa 4.Conexões são adicionadas para conectar cada unidade de uma camada n a uma camadaimediatamente seguinte, n+1.
7. Perturbação. O passo final na tradução de rede para regras é perturbar todos ospesos na rede adicionando um pequeno valor aleatório a cada peso. Essa perturbação émuito pequena para ter um efeito nos cálculos da rede KBANN antes do treinamento. Noentanto, é suficiente para evitar problemas causados pela simetria.
2.3.1.3 Exemplo do algoritmo
A Figura 2.15 mostra uma tradução passo a passo de um conjunto simples de regraspara uma rede KBANN. O painel a mostra um conjunto de regras na notação Prolog.O painel b é o mesmo conjunto de regras depois de terem sido re-escritos na etapa 1do algoritmo de tradução. As únicas regras afetadas pela reescrita são duas que, juntas,formam uma definição disjuntiva do consequente B.

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 34
Figura 2.15: Demonstração do algoritmo de KBANN
Fonte: Towell, 1990
O painel c é uma representação gráfica das regras no painel b que mostra a estruturahierárquica das regras. Na Figura 2.15, as linhas pontilhadas representam antecedentesnegados, enquanto as linhas contínuas e sólidas representam antecedentes não negados.
A próxima etapa do algoritmo de tradução é criar uma rede neural mapeando a estru-tura hierárquica das regras. Como resultado, há pouca diferença visual entre as represen-tações da inicial rede KBANN no painel d e a estrutura hierárquica das regras no painel c.Os painéis e e f ilustram o processo pelo qual as ligações, unidades de entrada e unidadesocultas não especificadas no conjunto de regras são adicionadas à rede. O painel e mostraunidades na rede numeradas pelo seu nível. Além disso, o painel e mostra uma unidadeoculta (sombreada) adicionada à rede no nível 1 (um). O painel f mostra a rede neuraltotalmente conectada localmente, ou seja, os novos neurônios adicionados na camada deentrada e na camada oculta foram conectados com os demais neurônios que estão umnível acima na hieráquia da rede. Essas novas ligações entre os neurônios são realizadasde forma fraca, ou seja, com pesos próximos a zero. O último passo não foi demons-trado através de uma ilustração do algoritmo de tradução de regras para rede, porque a

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 35
perturbação dos pesos de ligação resulta apenas em alterações dos valores dos pesos.
2.3.2 Top-Gen
O TopGen utiliza o algoritmo de tradução de regras do KBANN (discutido na seçãoanterior) para definir uma topologia inicial de rede neural. Esse algoritmo realiza umapesquisa heutística com as possíveis maneiras de adicionar um neurônio à rede, tentandoencontrar a melhor topologia que refine a teoria do domínio inicial. Resumidamente, oTopGen procura neurônios na rede com altas taxas de erro e, em seguida, adiciona no-vos neurônios a essas regiões da rede. A Figura A.1 (Apêndice A) resume o algoritmoTopGen. O algoritmo utiliza dois conjuntos de validação, um para avaliar as diferentestopologias de rede e, um segundo para ajudar a decidir onde novos neurônios devem seradicionados (o segundo conjunto de validação também é utilizado para decidir quandoparar de treinar as novas redes encontradas). Essa rede é treinada utilizando backpropa-gation e é colocada em uma lista, chamada de Open. Em cada ciclo, o TopGen busca amelhor rede na lista (conforme medido pelo segundo conjunto de validação), e decide aspossíveis maneiras de adicionar novos neurônios, em seguida treina essas novas redes eas coloca na lista Open. Esse processo é repetido até atingir um dos seguintes critérios:(a) uma precisão de 100% em relação ao segundo conjunto de validação ou (b) um limitede épocas previamente estabelecido.
2.3.2.1 Localização de Novos Neurônios
De acordo com o algoritmo apresentado no (Apêndice A), a primeira etapa que deveser realizada é localizar os neurônios da rede neural com altas taxas de erros. Isso é feitoatravés de um conjunto de validação que será utilizado para incrementar os contadores quecada neurônio possui. Esses contadores indicam a taxa de erro que cada unidade contrubuipara um possível resultado errado na saída da rede. Os contadores são definidos como :falsos positivos (FP) e falsos negativos (FN). Eles são incrementados de acordo com asaída individual de cada neurônio e não apenas em relação a saída final da rede. Parauma melhor compreensão, um exemplo de um falso negativo é se a saída do neurôniofor incorretamente classificada como exemplo negativo, enquanto um falso positivo éum classificado incorretamente como um exemplo positivo. O TopGen incrementa oscontadores de acordo com a quantidade de vezes que foi alterado o valor lógico de saídade um neurônio, levando a um exemplo mal classificado a ser classificado corretamente.Ou seja, se um neurônio estiver ativo para um exemplo errado, e alterar sua saída paraser inativo, e assim classificando de maneira correta o exemplo apresentado, isso fará

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 36
que o contador de falsos positivos do neurônio seja incrementado. O contador de falsosnegativos de um neurônio é incrementado seguindo o mesmo raciocínio. As novas redesserão geradas para tentar diminuir ou até mesmo eliminar o problema de cada neurônio,sendo que esse novo neurônio poderá também ajudar na redução de falsos negativos epositivos dos demais neurônios. Os novos neurônios são adicionados com base no tipo decontador (isto é, um contador falso negativo ou falso positivo) e o tipo de neurônio (istoé, um AND ou OR). Para um neurônio entender o seu comportamento, ou seja, a formade lidar com as informações como se fossem operadores lógicos (AND e OR) é realizadouma busca na base de regras iniciais identificando como o neurônio deve se comportar.Na próxima subseção será detalhado como os neurônios são adicionados.
2.3.2.2 Como Novos Neurônios são Adicionados
Uma vez estimado onde se deve adicionar novos neurônios, é necessário saber comoadicionar esses neurônios. TopGen faz a suposição de que, ao treinar uma de suas redes,o significado de um neurônio não mude significativamente. Fazer essa suposição permitealterar a rede de uma forma semelhante ao de refinar regras simbólicas. Towell et al.(1990) mostrou que era válido fazer uma suposição semelhante sobre as redes de KBANN.A Figura 2.16 mostra as possíveis formas de como o TopGen adiciona neurônios a umarede. Em uma base de regra simbólica que possui muitos falsos negativos, é possíveldiminuí-los descartando antecedentes de regras existentes ou adicionando novas regraspara a base original.
Como o KBANN é eficiente quando se remove antecedentes das regras existentes, oTopGen adiciona neurônios, destinados a diminuir falsos negativos, de uma forma queé análoga à adição de uma nova regra à base de regras (Shavlik, 1995). Se o neurônioexistente for um neurônio do tipo OR, o TopGen adicionará um novo neurônio comoseu filho (Figura 2.16a) e conectará totalmente esse novo neurônio com as unidades deentrada. Se o neurônio existente for um neurônio do tipo AND, o TopGen cria um novoneurônio OR que é o pai do neurônio AND original e outro novo neurônio que é conectadototalmente às entradas (Figura 2.16c). O TopGen move as conexões de saída do neurôniooriginal (Figura 2.16c) para se tornar as conexões de saída do novo neurônio OR. Em umabase de regras simbólica, pode-se diminuir falsos positivos adicionando antecedentes aregras existentes ou removendo regras da base de regra (Shavlik, 1995). As Figuras 2.16be 2.16d mostram os modos (analogamente às Figuras 2.16a e 2.16c explicadas acima)de adicionar antecedentes. Ao permitir essas adições, o TopGen é capaz de adicionarregras cujos consequentes não foram previamente definidos na base de regra. O TopGen

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 37
manipula neurônios que não são AND nem OR, decidindo se esse neurônio está maispróximo de um neurônio AND ou de um neurônio OR (observando o bias do neurônio eos pesos de entrada).
Figura 2.16: Formas possíveis para adicionar novos neurônios. Arcos indicam conexõesdo tipo AND
Fonte: Shavlik, 1995
Depois que os novos neurônios são adicionados, o TopGen realiza o treinamento darede pelo algoritmo do backpropagation. Embora é desejado que os novos pesos repre-sentem a maior parte do erro, também se espera que os pesos antigos sejam alterados,se necessário. Ou seja, é necessário que os pesos antigos retenham o que aprenderamanteriormente, enquanto ao mesmo tempo se movem de acordo com a mudança de errocausada pela adição do novo neurônio.
Segundo Shavlik (1995), para resolver esse problema, o TopGen multiplica as ta-xas de aprendizagem de pesos existentes por uma quantidade constante (<= 1) cada vezque novos neurônios são adicionados, produzindo um declínio exponencial das taxas deaprendizagem. Não é desejável mudar a teoria do domínio, a menos que haja considerá-vel evidência de que ela está incorreta. Ou seja, há um termo entre a mudança da teoriado domínio e desconsiderando os exemplos de treinamento não classificados com ruído.Uma forma minimizar esse problema, é utilizar um regulador de decaimento de peso

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 38
(Hinton, 1986). Pesos que fazem parte do domínio original da teoria, tem um decaimentoem direção ao seu valor inicial, enquanto outros pesos decaem em direção a zero.
O termo de decaimento foi proposto por Rumelhart et al. (1986). A ideia do decrés-cimo de peso é adicionar, à função de custo usual, um termo que mede a distância de cadapeso de seu valor inicia, e pode ser encontrado da seguinte forma:
Custo = Âk2T
(SaidaAlvok �SaidaRedek)2 +l Â
i2C
(wi �winicial)2
1+(wi �winicial)2 (2.12)
O primeiro termo da equação 2.12 soma todos os exemplos de treino T, enquanto osegundo termo soma todas as conexões C. O regulador entre o desempenho e a distânciados valores iniciais é ponderado por l.
2.3.2.3 Exemplo do TopGen
Suponha que a teoria do domínio da Figura 2.17 também deveria incluir a seguinteregra: Embora se tenha treinado a rede KBANN mostrada na Figura 2.16c com todos osexemplos possíveis, foi incapaz de aprender o conceito correto.
Figura 2.17: Tradução das regras em uma rede KBANN
Fonte: Shavlik, 1995
O TopGen começa treinando a rede na 2.17c, obtendo nenhuma melhoria na base deregra original. Em seguida, prossegue tomando exemplos mal classificados do primeiroconjunto de validação para encontrar lugares onde pode ser benéfico adicionar neurônios.O exemplo a seguir da categoria A é classificado incorretamente pela teoria de domínio:

CAPÍTULO 2. FUNDAMENTAÇÃO TEÓRICA 39
notD^E ^F ^G^notH ^notI ^ J^K
Enquanto o neurônio C (Figura 2.17c) foi corretamente classificado como falso nesseexemplo, o neurônio B é incorretamente falso. B é falso, uma vez que B1 e B2 tambémsão falsos. Se B tivesse sido verdadeiro, esse exemplo teria sido classificado corretamente(já que C é correto). Nesse caso, o TopGen incrementa o contador de falso-negativo doB. Além disso, o algoritmo também incrementa os contadores de B1, B2 e A, utilizandoargumentos semelhantes. Os neurônios B1, B2, B e A terão todos os contadores de falso-negativo com alta taxas de erro após todos os exemplos serem processados. Devido a umgrande de erros, o TopGen considera a adição de neurônios OR aos neurônios A, B1 e B2,como feito na Figura 2.17, e também considera a adição de outra disjunção, análogo àFigura 2.17a, ao neurônio B. Qualquer um dessas correções permite que a rede aprenda oconceito desejado. Como o TopGen prefere os neurônios mais distantes do neurônio desaída, então será adicionado em B1 ou B2.

Capítulo 3
Metodologia
Esse capítulo apresenta os materiais, métodos utilizados e desenvolvidos nessa pes-quisa. O sistema computacional abordado está esquematizado na Seção 3.2, na qual sãomostradas a sua divisão em blocos e as inter-relações existentes entre eles. A Seção 3.3contém algumas peculiaridades relevantes das implementações.
3.1 Estudo e Desenvolvimento Inicial
3.1.1 Recursos e Estratégias Utilizadas no Desenvolvimento
A plataforma adotada para a implementação do software foi o Java, por ser um sistemabastante difundido e familiar, no entanto, nada impede que haja portabilidade do softwarepara outros sistemas operacionais, pois o Java consegue ser instalado rapidamente emtodos os sistemas operacionais que estão no mercado. Foi utilizada a versão 8.21 paradesenvolver o modelo de negócios enquanto a interface gráfica foi utilizada o Java FX. AIntegrated Development Environment (IDE) de desenvolvimento do software foi o Net-Beans 8.2 da Oracle. A linguagem de programação Java foi a escolhida para esse tipo desistema, devido à facilidade na orientação a objeto, à capacidade de reuso do código, e aexperiência de desenvolvimento nessa linguagem.
Para o desenvolvimento do software foi adotada uma metodologia ágil e o quadro deacompanhamento do desenvolvimento pode ser visualizado no repositório criado GitHub.A implementação se deu através de testes, primeiramente focando em problemas menorese específicos, para, então, desenvolver soluções que satisfaçam os requisitos das novassprints em questão. O último passo foi estender o sistema para o atender outros tipos deproblemas.

CAPÍTULO 3. METODOLOGIA 41
3.1.2 Etapas do Desenvolvimento
Inicialmente, objetivou-se a implementação do algoritmo empregado pelo sistema de-senvolvido por Towell et al. (1990) dividindo-a em duas subetapas distintas: A implemen-tação relativa ao programa de extração de dados lógicos e a implementação da traduçãoem uma RNA correspondente à teoria de domínio inicial.
Os testes iniciaram com o desenvolvimento de métodos para a conversão de Lingua-gens Lógicas, apresentadas sob a forma de cláusulas Horn. Em seguida, a construção daRNAs e aplicação em problemas simples e específicos, para, logo em seguida generalizá-los. Na sequência, ocorreu a integração entre as duas partes, o sistema foi a aplicado a umproblema mais extenso e geral que os anteriores.
Na fase final do desenvolvimento, foi criado um sistema genérico de para gerar pa-drões de entradas e saídas de acordo com as necessidades do usuário.
O processo de produção do sistema pode ser listado em 12 etapas que facilitaram oentendimento de todo o desenvolvimento. As etapas estão listadas pela sua ordem crono-lógica, nas quais se destacaram os respectivos enfoques e descrição, conforme segue:
• Etapa 1 (Padrões de Software): Estudo de padrões de projetos de software paraserem aplicados a esse tipo de sistema.
• Etapa 2 (RNA específica): Implementações de RNAs simples, permitindo a pri-meira definição das técnicas de implementação de RNA a serem empregadas;
• Etapa 3 (Backpropagation): Estudo dos algoritmos de aprendizagem neural.• Etapa 4 (RNA genérica): Versões mais aprimoradas do programas de RNAs espe-
cíficas, com refinamento das técnicas.• Etapa 5 (Interface gráfica): Estudo preliminar para integrar todos os módulos
para o gerenciamento do sistema KBANN em um ambiente computacional;• Etapa 6 (Algoritmo KBANN): Estruturação das classes do sistema KBANN e
desenvolvimento do método que engloba rotinas para o processamento da sintaxede textos;
• Etapa 7 (Conversão de dados): Formatação dos dados a serem aplicados em umaRNA específica e formatação dos arquivos a serem lidos;
• Etapa 8 (Algoritmo KBANN): Aprimoramento dos programas anteriores permi-tindo a inserção das regras aplicáveis de forma genérica, segundo o algoritmoKBANN;
• Etapa 9 (Algoritmo KBANN): Aplicação do algoritmo KBANN a exemplos espe-cíficos;
• Etapa 10 (Algoritmo TopGen): Implementação do algoritmo TopGen para gerar

CAPÍTULO 3. METODOLOGIA 42
novas redes;• Etapa 11 (Tabuleiro de xadrez): Implementação do tabuleiro de xadrez e seus
respectivos métodos para extração de informações que serviram de entrada para arede neural;
• Etapa 12 (Algoritmo TopGen): Comparação entre RNAs com e sem o empregodo algoritmo TopGen.
As etapas iniciais (1 a 5) foram fundamentais no trabalho, pois foi a base para afundamentação dos conceitos básicos de um sistema híbrido e a base para um bom de-senvolvimento do software. Nas etapas 2 e 4 foram realizados estudos que definiram aforma mais apropriada de como a interface deveria ser implementada. As etapas 3, 6 e 9relacionam as implementações aplicadas a exemplos específicos. As etapas 7, 8, 10, 11 e12 foram destinadas aos algoritmos, KBANN e TopGen, além de suas aplicações.
3.1.3 Implementações Preliminares
Algumas implementações básicas foram necessárias para se adquirir experiência. Oconhecimento adquirido com essas implementações ajudou a composição dos blocos dasimplementações subsequentes. Pode-se destacar abaixo as duas principais implementa-ções iniciais:
(a) Extração de regras lógicas.(b) Utilização de exemplos variados para o treinamento das RNAs.
3.1.3.1 Leitura de Dados Simbólicos
A interpretação dos dados simbólicos é a base para implementação do algoritmo deconversão do KBANN. As informações são extraídas do arquivo base e então é geradouma rede neural. A Figura 3.1 é a representação final das regras lógicas contidas nas cláu-sulas lógicas mostradas abaixo na forma de cláusulas de Horn. A partir desse conjunto desímbolos, foram obtidas as estruturas das RNAs similares às da Figura 3.1, aplicando-sea elas os cálculos requeridos pelo algoritmo, tais como a determinação dos pesos inici-ais, bias, taxa de aprendizado da rede e o erro aceitável. A seguir será apresentado umexemplo de um conjunto de regras iniciais e sua tradução em uma rede neural.
A :- B, ¬CB :- D, ¬F , G
B :- D, F , IC :- H, J, K

CAPÍTULO 3. METODOLOGIA 43
Figura 3.1: Representação de uma RNA a partir da base de regras
Fonte: Autor, 2017
Cada instrução acima representa uma regra do domínio da teoria, a união delas implicanas regras que definem um problema. Para melhor entendimento, as cláusulas no formatode Prolog podem ser lidas da seguinte maneira: ao lado esquerdo ficam os consequentes,ou seja, as implicações que são geradas pelos seus antecedentes (lado direito). Os ante-cedentes são as condições necessárias para ativar um consequente e esses são separadospor vírgulas (,) quando se quer definir que ambos os antecedentes precisam estar ativadospara sair uma determinada resposta do seu respectivo consequente da regra. Quando umantecedente um é negado (¬), o peso sináptico da ligação entre os neurônios será nega-tivo. Essa foi uma maneira encontrada por Towell (1990) para que a rede neural possareceber entradas contrárias à aquelas que ativam os neurônios permitindo que eles sejamativados quando houver um antecedente negado.

CAPÍTULO 3. METODOLOGIA 44
3.1.3.2 Redes Neurais Artificiais Simples
Os primeiros programas desenvolvidos nesse trabalho utilizavam a topologia básicada RNA com três camadas e com poucos neurônios por camada (por exemplo: 5 x 3 x 1ou 2 x 2 x 1). Nesse caso, foi realizado somente o treinamento da RNA, verificação decálculos e teste estrutural da arquitetura e do algoritmo de treinamento.
Alguns exemplos simples foram utilizados, como: o reconhecimento e a classificaçãode dados (padrões sensíveis à RNA). Além disso, os mesmos testes foram validados noMatlab, tanto utilizando o Neural Network ToolBox de redes neurais que é disponibilizadono software, como também, realizando passo a passo as operações matemáticas
O conjunto de regras iniciais citadas no item 3.1.3.1 descrevem inicialmente o modelodo problema estudado. Da mesma forma como foi feito no TopGen, foram retiradasalgumas regras do domínio teórico inicial, e em seguida foi realizado o treinamento e avalidação. Foi possível observar que o KBANN consegue classificar boa parte dos dados,mesmo não possuindo um domínio completo do problema. O teste foi realizado paracomprovar o que foi discutido no trabalho de Towell et al. (1990).
A criação de uma interface para entrada de dados fez-se necessária com a migraçãopara programas mais genéricos. A solução mais imediata foi a adoção de arquivos forma-tados contendo um conjunto de definições, que são alteráveis no programa antes da suaexecução.
3.1.4 O Sistema Desenvolvido
O enfoque principal do trabalho desenvolvido foi a implementação de framework ca-paz de agregar as principais características de dois algoritmos importantes do meio neuro-simbólico, o KBANN e o TopGen. O primeiro realiza a conversão unidirecional de regrasno formato de cláusulas Horn em uma rede neural com conhecimento prévio, enquantoo segundo permite a adição de novos conhecimentos na rede gerada a partir de KBANN,sem causar danos aos conhecimentos já adquiridos. Para gerar uma nova rede , o sistemaé capaz de ler um arquivo TXT com regras já estabelicidas por um especialista ou é pos-sível criá-las dentro do software. O framework também permite exibir de forma gráfica arede inicial e final de duas formas: em círculo ou por hierarquia de nível. Cada camada darede é identificada por uma cor e essa pode ser visualizada pelo usuário na aba legendasdentro do sistema. Para realizar o treinamento da rede neural utilizando o algoritmo dobakcpropagation, o sistema possui em sua interface campos configuráveis, como: taxade aprendizagem, taxa de momento, número de épocas e erro aceitável. Quando os cam-pos são preenchidos, o usuário poderá realizar quantos treinamentos desejar. Por fim,

CAPÍTULO 3. METODOLOGIA 45
é possível exportar em um arquivo TXT uma lista contendo a quantidade de erros (fal-sos positivos e negativos) de cada neurônio contido na rede, permitindo assim avaliar anecessidade de adicionar novos neurônios para ajustar a rede neural.
3.1.5 Aspectos Internos do Sistema
3.1.5.1 Classes que Compõem o Programa
A Figura 3.2 apresenta um esquema das classes nas quais o ambiente computacionalteve o seu desenvolvimento. A principal classe, a que controla todos os processos da apli-cação é a ControllerGrafo. Essa recebe todas as requisições oriundas da interface gráficae delega para outras classes as ações necessárias. Por exemplo, a classe ControllerRegrasrealiza o tratamento das regras iniciais gerando objetos do tipo ModelRegra que serãoutilizados para construir a rede neural. Para modelar e representar a estrutura de uma redeneural, foi implementada a classe ModelGrafo. Essa é composta por outras duas classesque ajudam na representação da rede, no caso, as classes ModelNeuronio e ModelAresta.A classe Treinamento foi criada separadamente para permitir a adição de novos treina-mentos ao sistema, por enquanto, apenas o algoritmo backpropagation foi implementado.A classe TopGen contém o algoritmo que permite a adição de novos conhecimentos narede neural, além disso, ela possui a capacidade de calcular e exportar os erros contidosem cada neurônio da rede. Por fim, a classe Xadrez representa o modelo do problema emquestão, além de gerar as entradas e respectivas saídas para realizar o treinamento.

CAPÍTULO 3. METODOLOGIA 46
Figura 3.2: Diagrama de classes do sistema
Fonte: Autor, 2017
3.1.5.2 Sequência de Eventos
O diagrama de sequência da (Figura 3.3) aponta para a sequência de operações inicia-das pelo usuário, que basicamente, interage através da configuração contida nos arquivose na interface. O software realiza uma varredura do arquivo que contém as informaçõesnecessárias ao desenvolvimento de seus processos.
CAPÍTULO 3. METODOLOGIA 47
Figura 3.3: Diagrama de Sequência
Fonte: Autor, 2017
Como ilustra a Figura 3.3, o software interno atua na modificação da estrutura daRNA geral, quer seja pelo estabelecimento da sua topologia, quer na alteração dessa emconsequência da aprendizagem. Uma vez que as operações estejam encerradas, o usuáriopode consultar os arquivos produzidos e verificar os resultados.
Os passos para a execução do programa podem ser resumidos dessa forma:1. Importação do arquivo contendo as regras iniciais;2. Extração de regras pelo programa para gerar a rede neural inicial;3. Configuração do sistema para realizar o treinamento;4. Realizar o treinamento e verificar se o erro aceitável foi alcançado;5. Aplicar o teste de Falsos Positivos e Negativos na rede gerada.6. Gerar novas redes para correção de erros da saída da rede neural.
3.1.6 Descrição da Interface
A interface também contém um menu para seleção do algoritmo a ser utilizado, assimcomo as suas opções de operação dos algoritmos. A aparência da interface está ilustradapela Figura 3.4. A descrição da interface segue nessa seção.
CAPÍTULO 3. METODOLOGIA 48
Figura 3.4: Tela principal do sistema
Fonte: Autor, 2017
3.1.6.1 Painel de Edição
Os arquivos carregados no programa podem ser visualizados na tela de edição, con-forme a Figura 3.5.
Figura 3.5: Tela de edição de regras
Fonte: Autor, 2017
As entradas de dados podem ser realizadas de duas maneiras:

CAPÍTULO 3. METODOLOGIA 49
1. A planta inicial, que informa a teoria de domínio que deseja-se representar inicial-mente para um possível refinamento.
2. A planta final, que possui o domínio completo e correto do problema.Esses dois arquivos são abertos e acessados diretamente no painel interno da interface.
Não existe restrição quanto ao tipo de arquivo a ser editado.
3.1.6.2 Barra do Menu
A barra de menu da interface facilita algumas operações de edição e execução dosprogramas.
3.1.6.3 Menu Lateral
A interface também possui menu according localizada nas laterais da janela principalque serve para o acompanhamento do andamento das operações. Esse menu extra possibi-lita ao usuário identificar o que foi lido do arquivo que contém as regras, saber o resultadofinal após o treinamento e o TopGen e identificar os níveis (camadas) por cor, as quais osneurônios fazem parte.
3.1.7 Considerações sobre as Implementações
Boa parte dos programas desenvolvidos empregaram as RNAs com o seu aprendi-zado, executado por meio do algoritmo de retro-propagação. A escolha desse algoritmodeve-se à sua utilização no sistema KBANN, possibilitando a comparação de resultados.Os algoritmos que definiram as topologias de RNAs empregadas foram consequência daevolução natural das técnicas de programação. Os valores de saída e as sinapses da RNAforam implementados por variáveis contidas nas classes Neurônio e Arestas. Quando sedeseja acessar o valor contido em um neurônio específico, é utilizado uma estrutura dedados HashMap que possui todos os objetos neurônios. Dentro de cada neurônio existeos campos que identifica-se ele é da camada de entrada, saída ou de qual camada inter-mediária ele faz parte.
3.1.8 Testes do Sistema
Para validação do sistema desenvolvido, foi utilizado o software Matlab R� como re-ferência, devido as suas diversas ferramentas amplamente testadas pela comunidade cien-tífica. Para realização do teste, foi necessário criar um exemplo de rede MLP de acordocom o que podia ser modelado no Matlab R�. Na Figura 3.6, a sua estrutura da rede MLP

CAPÍTULO 3. METODOLOGIA 50
pode ser vista após a definição do problema. Esse teste objetivou apenas que os resultadosencontrados no programa fossem relativamente parecidos ou próximos do que o Matlabgerou.
Figura 3.6: Topologia da rede MLP no Matlab
Fonte: Autor, 2017
A Figura 3.6, representa a estrutura da rede a ser treinada. A rede possui 4 neurôniosna sua camada de entrada (input), 2 neurônios em sua única camada oculta e uma únicaclasse de representação na camada de saída (out put). O problema apresentado a essarede é de padrão lógico, ou seja, informações binárias e foram gerados 16 saídas para as16 possíveis entradas. Os dados contidos nesse padrão para serem apresentados a rede,correspondem ao domínio completo, ou seja, como realmente funciona o sistema. Nesseteste foi considerado que a MLP não iria possuir em sua topologia todas as regras quedefinem o problema, sendo assim, foram retiradas 2 regras do domínio apresentado, o quede fato, se espera que gerasse alguns erros na rede ou até mesmo não convergir.

CAPÍTULO 3. METODOLOGIA 51
Figura 3.7: Parâmetros após treinamento da Rede MLP no Matlab
Fonte: Autor, 2017
Pelo o que foi apresentado na Figura 3.7, pode-se observar que o Neural NetworkToolBox do Matlab R� levou 10.000 épocas para finalizar o problema, ou seja, o erro detreinamento ou o erro de validação aceitável não foi alcançado, sendo necessário utilizar aquantidade de épocas máxima para finalizar o treinamento. Nesse exemplo, foi utilizadoo algoritmo de backpropagation e a função de ativação dos neurônios escolhida foi asigmóide. Outros parâmetros, como taxa de aprendizagem, erro aceitável (goal) e o tempopara simulação podem ser verificados na Figura 3.8.
CAPÍTULO 3. METODOLOGIA 52
Figura 3.8: Parâmetros da rede MLP treinada
Fonte: Autor, 2017
As duas últimas Figuras (3.9 e 3.10) mostram a baixa capacidade de uma rede MLPem classificar dados sem possuir conhecimento prévio. Nesse caso, a estrutura da redeé idêntica a que foi aplicada no KBANN, mas os pesos iniciais foram gerados de formaaleatória. Dessa forma, o algoritmo backpropagation irá tentar ajustar os pesos para quea rede consiga gerar respostas corretas. Para todas as 16 amostras apresentadas a rede, amesma não obteve um resultado próximo a resposta desejada, em todas as saídas tiveramerros acima de 39%, o que é um erro considerável. Para um melhor entendimento sobreo resultado gerados na Figura 3.10, é comentado um dos resultados. A primeira saídagerada pela rede para a entrada (0, 0, 0, 0) foi 0.73587. Nesse caso, a resposta deseja é 0,ou seja, um erro aproximado de 73% para essa entrada. O ajuste necessário a ser aplicadopara corrigir esse erro é de -0.73587, conforme é apresentado na Figura 3.11.
Figura 3.9: Gráfico do erro de treinamento, validação e teste
Fonte: Autor, 2017
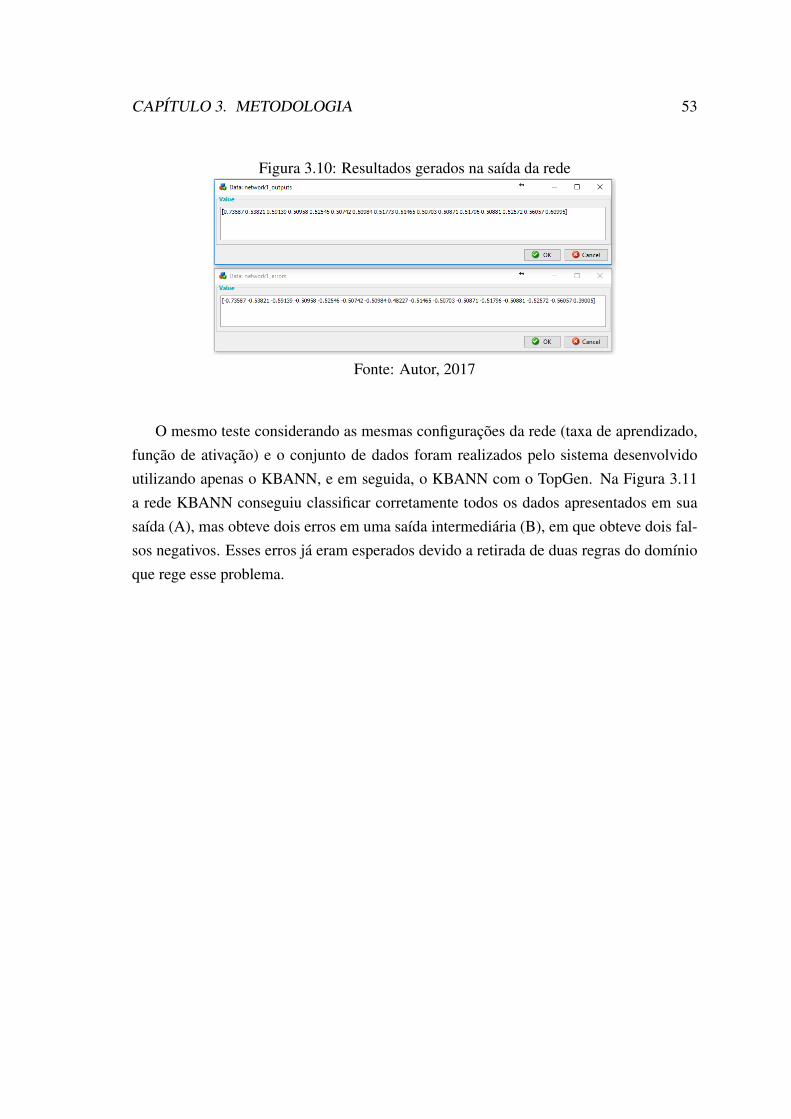
CAPÍTULO 3. METODOLOGIA 53
Figura 3.10: Resultados gerados na saída da rede
Fonte: Autor, 2017
O mesmo teste considerando as mesmas configurações da rede (taxa de aprendizado,função de ativação) e o conjunto de dados foram realizados pelo sistema desenvolvidoutilizando apenas o KBANN, e em seguida, o KBANN com o TopGen. Na Figura 3.11a rede KBANN conseguiu classificar corretamente todos os dados apresentados em suasaída (A), mas obteve dois erros em uma saída intermediária (B), em que obteve dois fal-sos negativos. Esses erros já eram esperados devido a retirada de duas regras do domínioque rege esse problema.

CAPÍTULO 3. METODOLOGIA 54
Figura 3.11: Resultados gerados na saída da rede apenas com KBANN
Fonte: Autor, 2017
Na Figura 3.12, pode-se observar que o erro em todas as saídas intermediárias (Be C), assim como a saída principal da rede (A) foram zeradas, ou seja, para todos osdados apresentados, foram classificados corretamente sem nenhuma exceção, mostrandoassim, uma boa eficácia do sistema. Para se conseguir esse resultado, foram necessáriosadicionar a rede original de KBANN, dois neurônios, o TG1B e TG2B (Figura 3.13), omotivo dessa adição pode ser vista na seção (2.3). Esse neurônios fizeram com que oserros da saída intermediária (B) fossem zerados sem modificar o aprendizado obtido emoutras regiões da rede.

CAPÍTULO 3. METODOLOGIA 55
Figura 3.12: Resultados gerados na saída da rede com KBANN e TopGen
Fonte: Autor, 2017
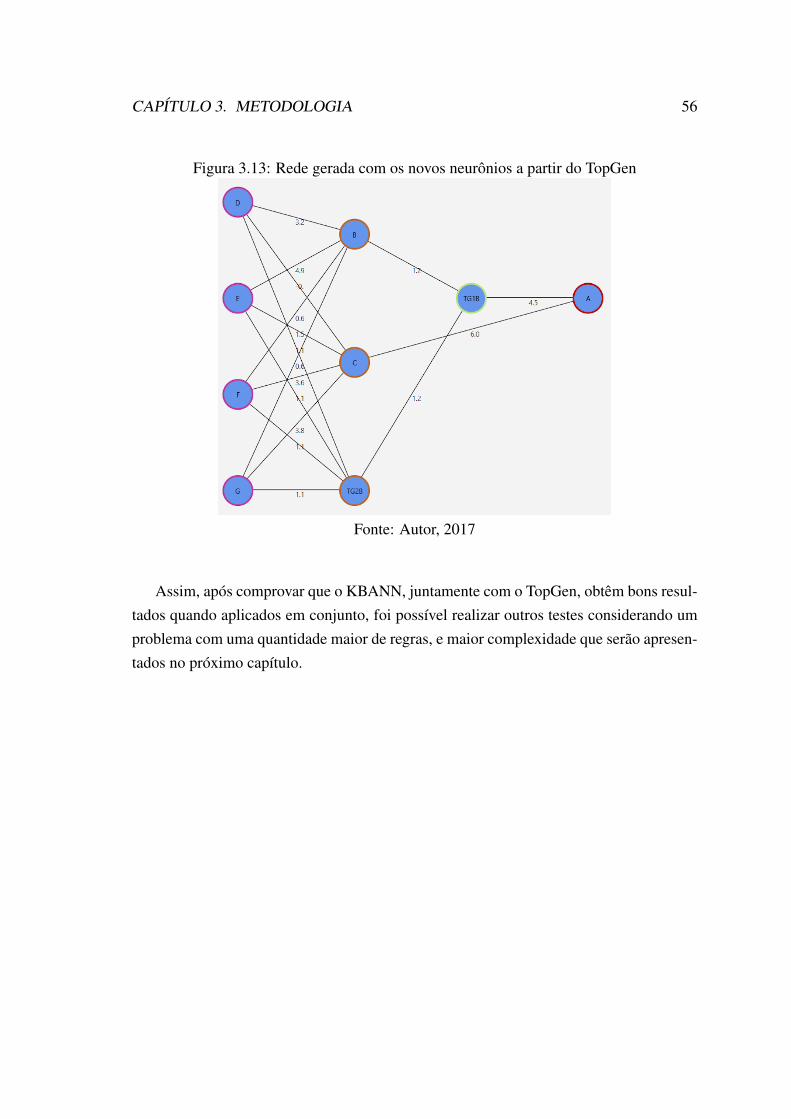
CAPÍTULO 3. METODOLOGIA 56
Figura 3.13: Rede gerada com os novos neurônios a partir do TopGen
Fonte: Autor, 2017
Assim, após comprovar que o KBANN, juntamente com o TopGen, obtêm bons resul-tados quando aplicados em conjunto, foi possível realizar outros testes considerando umproblema com uma quantidade maior de regras, e maior complexidade que serão apresen-tados no próximo capítulo.

Capítulo 4
Resultados e discussão
4.1 Contextualização do Problema
Para a realização desse trabalho, um dos objetivos foi ter um problema onde houvesseum especialista no assunto que pudesse conceber um conjunto inicial de regras para servirde base de aprendizado para a rede neural KBANN. Devido a dificuldade em encontrarum especialista que solucionasse essa condição inicial e essencial do trabalho, a formaencontrada para contornar esse problema foi utilizar um jogo de tabuleiro, devido aoconhecimento sobre suas regras.
O xadrez é um jogo de tabuleiro com 64 casas brancas e pretas intercaladas e comdiversas peças que representavam tropas do exército: Peões, Cavalaria, Bispos, Torres,Rainha, e o principal de todos, o Rei. O problema em questão foi tratado da seguintemaneira: dado um tabuleiro 5x4 (Figura 4.1) considerando que o Rei (branco) está semprena posição (c1), acompanhado de outras peças (Rainha, Bispo, Cavalo e Torre), tantoda cor oposta ao Rei, como da mesma cor e espalhadas aleatoriamente no tabuleiro. Arede neural construída tenta resolver o seguinte questionamento: se é possível realizaro movimento do Rei para a casa c2. O movimento será considerado legal, se ao fimdele, o Rei permanecer vivo e assim esperar um nova rodada, e é considerado ilegalcaso exista alguma peça que possa finalizar o jogo, se o Rei tentar ir para a posiçãodesejada. Utilizando como base o problema acima, serão feitos alguns testes com umdomínio teórico possuindo erros para investigar os tipos de correções em que o KBANNé eficaz.
As perturbações na teoria do domínio foram feitas de 4 (quatro) maneiras diferentes:(a) adicionando um antecedente a uma regra, (b) removendo um antecedente de uma regra,(c) adicionando uma regra, ou (d) removendo uma regra. Essas perturbações foram feitasde forma aleatória, desde que não implicasse na retirada de alguma conclusão final.
O objetivo desses testes foi mostrar que a rede com conhecimento incompleto pode

CAPÍTULO 4. RESULTADOS E DISCUSSÃO 58
sofrer modificações na sua topologia para se ajustar aos novos aprendizados adquiridosno seu domínio inicial.
Figura 4.1: Subconjunto 4x5 de um tabuleiro de xadrez considerado para o domínio
Fonte: Autor, 2017
4.1.1 Formatação dos dados
As seguintes regras (Figura 4.2) definem as configurações do tabuleiro de xadrez, paraum tabuleiro 4x5 (Figura 4.1), onde mover um Rei para uma posição à frente é ilegal (istoé, o Rei estaria sob cheque). A formatação das regras facilita a aplicação do algoritmode conversão por terem sua reestruturação segundo a arquitetura de uma RNA, com umacamada de entrada, duas internas e uma de saída.
Figura 4.2: Conjunto de regras do Xadrez
Fonte: Autor, 2017
As entradas necessárias para cada posição no tabuleiro são: um para os quatro tiposde peças (uma rainha, uma Torre, um Bispo e um Cavalo), e um que indica a cor da peça.

CAPÍTULO 4. RESULTADOS E DISCUSSÃO 59
As formas de realizar cheques podem ser definidos de três formas: (1) na verificação decheque diagonal pela Rainha ou do Bispo, (2) na verificação cheque horizontal ou verticalpor uma Rainha ou pela Torre, e (3) na verificação cheque por um Cavalo. Algumas regrasexigem um espaço vazio entre a posição de uma peça e a posição c2 (onde o jogador quermover o Rei). Por exemplo, se uma rainha da cor oposta estiver na posição c4, então oespaço c3 deve estar vazio para poder colocar o Rei sob cheque.
Os antecedentes da regra representam o primeiro nível da rede, onde estão a posi-ção das peças e suas respectiva cor. Cada agrupamento de dados pode ser visto comouma única entrada, contendo todos os dados necessários. As entradas de cada exemplodo arquivo foram guardadas em grupos de quatro entradas binárias, correspondendo aspeças: Rainha, Bispo, Cavalo e Torre e outras 2 entradas correspondentes a cor e a es-paços vazios. A quantidade de entradas para a rede foram: 12 valores para a Rainha, 6para o Bispo, 6 para o Cavalo, 6 para a Torre, 18 para cor oposta e 5 para casas vazias,totalizando 53 entradas binárias. Para um melhor endentimento sobre o problema, serádado um exemplo para de uma possível entrada de dados com relação a primeira regra daFigura 4.2:
DIAGONAL : �(RAINHA(A4) ou BISPO(A4),COR_OPOSTA(A4),VAZIO(B3)).
Para a essa regra ser ativada um exemplo de entrada é (1,0, 1, 0). Isso significa que:existe uma Rainha na posição A4 do tabuleiro, não há Bispo na posição A4, a cor da peçaque se encontra na posição A4 (uma Rainha) é oposta ao Rei que irá sofrer o ataque e nãohá qualquer peça na posição B3 do tabuleiro. Quando essa entrada ocorrer, é consideradoum cheque diagonal.
Alguns dos testes aplicados utilizaram uma RNA contendo quatro camadas (53 x 33x 1), como pode ser exemplificado de maneira parcial na (Figura 4.3). A distribuição dosneurônios sofreu variações durante os testes. O número de conexões entre a primeira e asegunda camada totalizou 1590 sinapses . O número de neurônios internos equivale aonúmero de regras constituídas diretamente por peças, conforme a Figura 4.2. O resultadofinal é representado apenas por um neurônio na última camada (movimento ilegal ou não).A Tabela 4.1 descreve os neurônios que serão monitorados durante os testes.

CAPÍTULO 4. RESULTADOS E DISCUSSÃO 60
Figura 4.3: Estrutura parcial da rede neural gerada para o problema do xadrez
Fonte: Autor, 2017
Tabela 4.1: Nomenclatura dos neurônios e sua representação na rede neural
Neurônio DescriçãoMI Movimento ilegalCD Cheque diagonalCP Cheque paraleloCC Cheque cavalo
Fonte: Autor, 2017
4.1.2 Testes Realizados para o Reconhecimento de Movimentos
Os quatros testes executados no trabalho inicial e detalhados no texto desta Subseçãosão: (1) Teste de Regras Adicionadas ao Domínio Teórico. (2) Antecedentes Adiciona-das ao Domínio Teórico. (3) Regras Deletadas do Domínio Teórico. (4) AntecedentesDeletados do Domínio Teórico. Conforme essa sequência de testes, serão informados oobjetivo, a descrição, os parâmetros utilizados, os resultados obtidos, assim como a ava-liação, referente a cada teste. Na Tabela 4.1 estão os principais neurônios que terão suassaídas monitoradas para os testes realizados acima.
Todos os testes tem como objetivo diminuir a quantidade de falso negativo (FN) oufalso positivo (FP) dos neurônios intermediários e de saída. O falso negativo significa queum neurônio não está ativado, mas o correto era estar ativado, enquanto o falso positvosegue o mesmo raciocínio de forma contrária.

CAPÍTULO 4. RESULTADOS E DISCUSSÃO 61
Para todos os testes demonstrados abaixo, foi considerado um conjunto de dados com10.000 amostras, sendo, 60% para o treinamento, 20% para validação e 20% para teste.A taxa de aprendizagem considerada foi de 0.01 e com um número máximo de épocas de10.000.
4.1.3 Regras Adicionadas ao Domínio Teórico
Para o caso de uma nova regra no domínio teórico, primeiro foi definido que o con-sequente dessa regra é o consequente de uma outra regra já existem no domínio teórico.Em seguida, são acrescentados de dois a quatro antecedentes, uma vez que o número deantecedentes de cada regra da base original e correta também variou de dois a quatro.
Objetivo: Verificar a frequência de acerto considerando que o domínio teórico apresen-tado à rede teve regras adicionadas (incorretas) ao KBANN, e compará-lo com o domínioteórico.
Descrição: Iniciou-se pela definição de novas regras e devido a isso há uma mudança natopologia da RNA. As novas regras adicionadas a base inicial foram: a Rainha da mesmacor do Rei dependendo da sua posição é considerado um cheque paralelo, um bispo podeatacar o Rei mesmo tendo outra peça a sua frente, e por último, Torre da mesma cor doRei e com peça a sua frente podendo realizar um ataque. Devido as adições de regras, arede ficou com um quantidade de nerônios (53 x 30 x 3 x 1) por camada.
Resultados: A sequência de Tabelas (4.2 à 4.6) e a Figura 4.4 resumem os resultadosobtidos no primeiro teste.
Tabela 4.2: Falsos positivos e negativos dos neurônios, ao se adicionar 10% novas regras
Neurônios/ Técnica
MI CD CP CC10%
FP FN FP FN FP FN FP FNKBANN 0 1 0 0 0 0 0 0
Domínio Teórico 68 92 22 38 21 80 23 57
Fonte: Autor, 2017
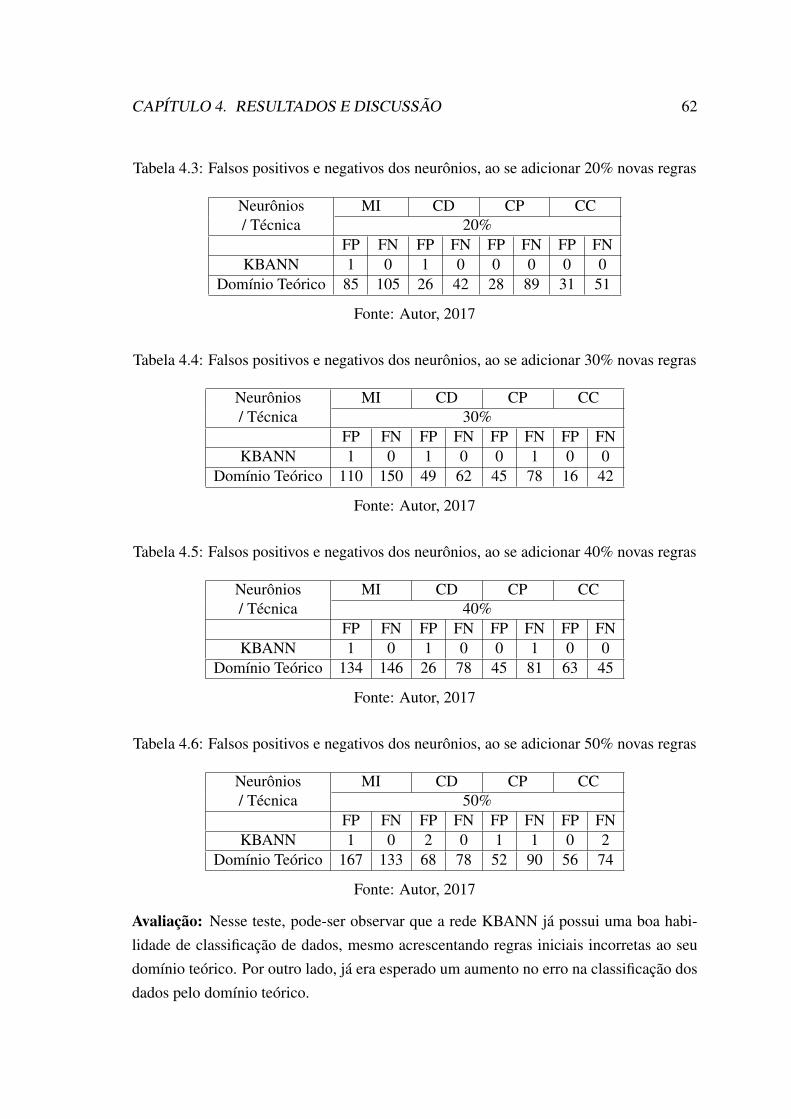
CAPÍTULO 4. RESULTADOS E DISCUSSÃO 62
Tabela 4.3: Falsos positivos e negativos dos neurônios, ao se adicionar 20% novas regras
Neurônios/ Técnica
MI CD CP CC20%
FP FN FP FN FP FN FP FNKBANN 1 0 1 0 0 0 0 0
Domínio Teórico 85 105 26 42 28 89 31 51
Fonte: Autor, 2017
Tabela 4.4: Falsos positivos e negativos dos neurônios, ao se adicionar 30% novas regras
Neurônios/ Técnica
MI CD CP CC30%
FP FN FP FN FP FN FP FNKBANN 1 0 1 0 0 1 0 0
Domínio Teórico 110 150 49 62 45 78 16 42
Fonte: Autor, 2017
Tabela 4.5: Falsos positivos e negativos dos neurônios, ao se adicionar 40% novas regras
Neurônios/ Técnica
MI CD CP CC40%
FP FN FP FN FP FN FP FNKBANN 1 0 1 0 0 1 0 0
Domínio Teórico 134 146 26 78 45 81 63 45
Fonte: Autor, 2017
Tabela 4.6: Falsos positivos e negativos dos neurônios, ao se adicionar 50% novas regras
Neurônios/ Técnica
MI CD CP CC50%
FP FN FP FN FP FN FP FNKBANN 1 0 2 0 1 1 0 2
Domínio Teórico 167 133 68 78 52 90 56 74
Fonte: Autor, 2017
Avaliação: Nesse teste, pode-ser observar que a rede KBANN já possui uma boa habi-lidade de classificação de dados, mesmo acrescentando regras iniciais incorretas ao seudomínio teórico. Por outro lado, já era esperado um aumento no erro na classificação dosdados pelo domínio teórico.

CAPÍTULO 4. RESULTADOS E DISCUSSÃO 63
Figura 4.4: Erro de Classificação entre KBANN x Domínio Teórico com Regras Adicio-nadas
Fonte: Autor, 2017
4.1.4 Antecedentes Adicionadas ao Domínio Teórico
O teste de adição de antecedentes existentes no domínio teórico a outras conclusõesintermediárias que não estavam fortemente ligadas inicialmente, também é uma boa formade testar a capacidade do KBANN. Foram escolhidos aleatoriamente e adicionados a re-gras do domínio, desde que, não ultrapassasse 4 antecedentes por regra.
Objetivo: Na segunda forma de avaliação do programa desenvolvido, foram atribuídos deforma aleatória antecedentes à regras já estabelecidas no domínio completo, verificandose a rede KBANN precisa de algum tipo de ajuste e compará-lo com o domínio teórico.
Descrição: Para esse teste as entradas já conhecidas foram conectadas a outras conclusõesintermediárias de forma proporcional. Exemplificando, 10% das entradas ou, 5 entradasjá existentes foram conectadas a outras conclusões intermediárias de forma a perturbar odomínio original. outros testes com, 20% a 50% também foram realizados.
Resultados: A sequência de Tabelas (4.7 à 4.11) e a Figura 4.5 resumem os resultadosobtidos no segundo teste.
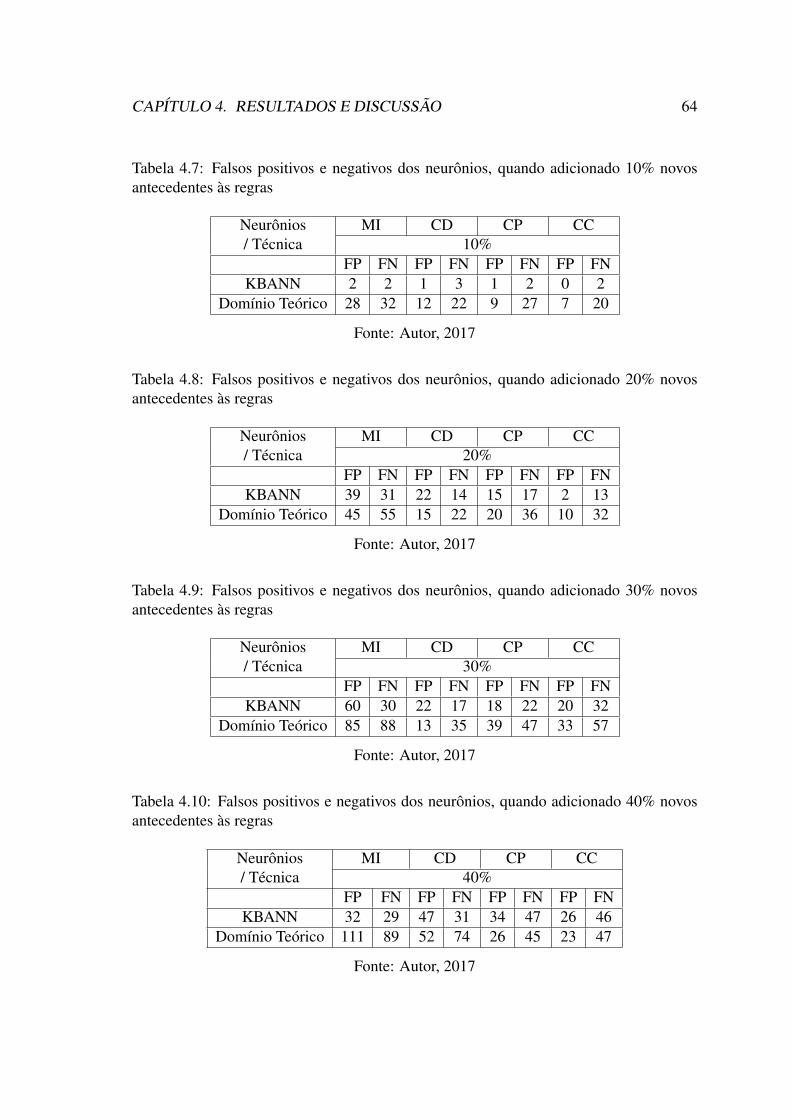
CAPÍTULO 4. RESULTADOS E DISCUSSÃO 64
Tabela 4.7: Falsos positivos e negativos dos neurônios, quando adicionado 10% novosantecedentes às regras
Neurônios/ Técnica
MI CD CP CC10%
FP FN FP FN FP FN FP FNKBANN 2 2 1 3 1 2 0 2
Domínio Teórico 28 32 12 22 9 27 7 20
Fonte: Autor, 2017
Tabela 4.8: Falsos positivos e negativos dos neurônios, quando adicionado 20% novosantecedentes às regras
Neurônios/ Técnica
MI CD CP CC20%
FP FN FP FN FP FN FP FNKBANN 39 31 22 14 15 17 2 13
Domínio Teórico 45 55 15 22 20 36 10 32
Fonte: Autor, 2017
Tabela 4.9: Falsos positivos e negativos dos neurônios, quando adicionado 30% novosantecedentes às regras
Neurônios/ Técnica
MI CD CP CC30%
FP FN FP FN FP FN FP FNKBANN 60 30 22 17 18 22 20 32
Domínio Teórico 85 88 13 35 39 47 33 57
Fonte: Autor, 2017
Tabela 4.10: Falsos positivos e negativos dos neurônios, quando adicionado 40% novosantecedentes às regras
Neurônios/ Técnica
MI CD CP CC40%
FP FN FP FN FP FN FP FNKBANN 32 29 47 31 34 47 26 46
Domínio Teórico 111 89 52 74 26 45 23 47
Fonte: Autor, 2017
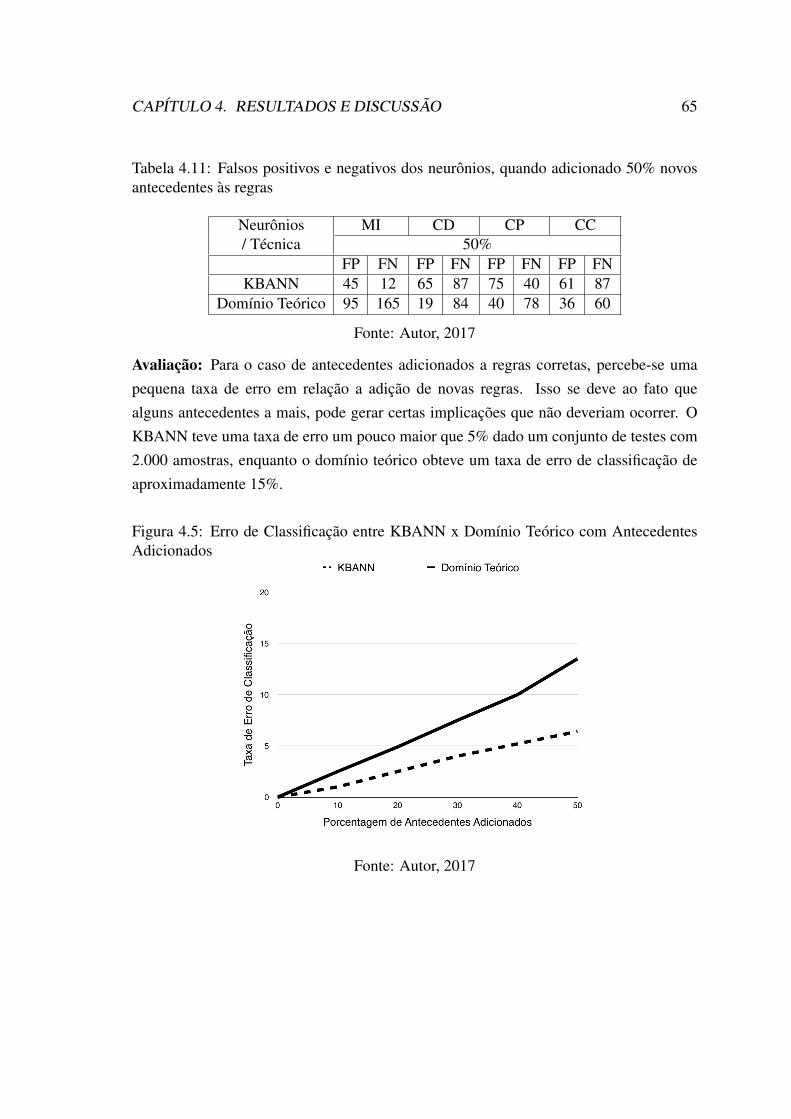
CAPÍTULO 4. RESULTADOS E DISCUSSÃO 65
Tabela 4.11: Falsos positivos e negativos dos neurônios, quando adicionado 50% novosantecedentes às regras
Neurônios/ Técnica
MI CD CP CC50%
FP FN FP FN FP FN FP FNKBANN 45 12 65 87 75 40 61 87
Domínio Teórico 95 165 19 84 40 78 36 60
Fonte: Autor, 2017
Avaliação: Para o caso de antecedentes adicionados a regras corretas, percebe-se umapequena taxa de erro em relação a adição de novas regras. Isso se deve ao fato quealguns antecedentes a mais, pode gerar certas implicações que não deveriam ocorrer. OKBANN teve uma taxa de erro um pouco maior que 5% dado um conjunto de testes com2.000 amostras, enquanto o domínio teórico obteve um taxa de erro de classificação deaproximadamente 15%.
Figura 4.5: Erro de Classificação entre KBANN x Domínio Teórico com AntecedentesAdicionados
Fonte: Autor, 2017

CAPÍTULO 4. RESULTADOS E DISCUSSÃO 66
4.1.5 Regras Removidas do Domínio Teórico
Para esse teste, todas as regras removidas seguiram a condição de não excluir perma-nentemente uma conclusão intermediária ou final da rede. A exclusão se deu de formaaleatória.
Objetivo: Realizar uma comparação entre uma rede neural padrão, a rede KBANN eo TopGen quando o domínio teórico sofre a perturbação com a exclusão de regras.
Descrição: A retirada das regras para esse teste foi realizada de forma aleatória, obe-decendo apenas a condição de não remover uma conclusão intermediária ou final do pro-blema. Sendo assim, pelo menos uma regra deve existir para os neurônios CD, CP, CC eMI. Esse teste foi executado apenas uma vez devido a quantidade de redes geradas.
Resultados: A sequência de Tabelas (4.12 à 4.16) e a Figura 4.6 resumem os resulta-dos obtidos no terceiro teste.
Tabela 4.12: Falsos positivos e negativos dos neurônios, quando retirado 10% da regras
Neurônios/ Técnica
MI CD CP CC10%
FP FN FP FN FP FN FP FNKBANN 18 22 9 32 7 22 2 9TopGen 12 9 5 7 3 12 4 15
Fonte: Autor, 2017
Tabela 4.13: Falsos positivos e negativos dos neurônios, quando retirado 20% da regras
Neurônios/ Técnica
MI CD CP CC20%
FP FN FP FN FP FN FP FNKBANN 16 30 5 9 10 18 1 12TopGen 15 7 5 9 9 11 1 7
Fonte: Autor, 2017
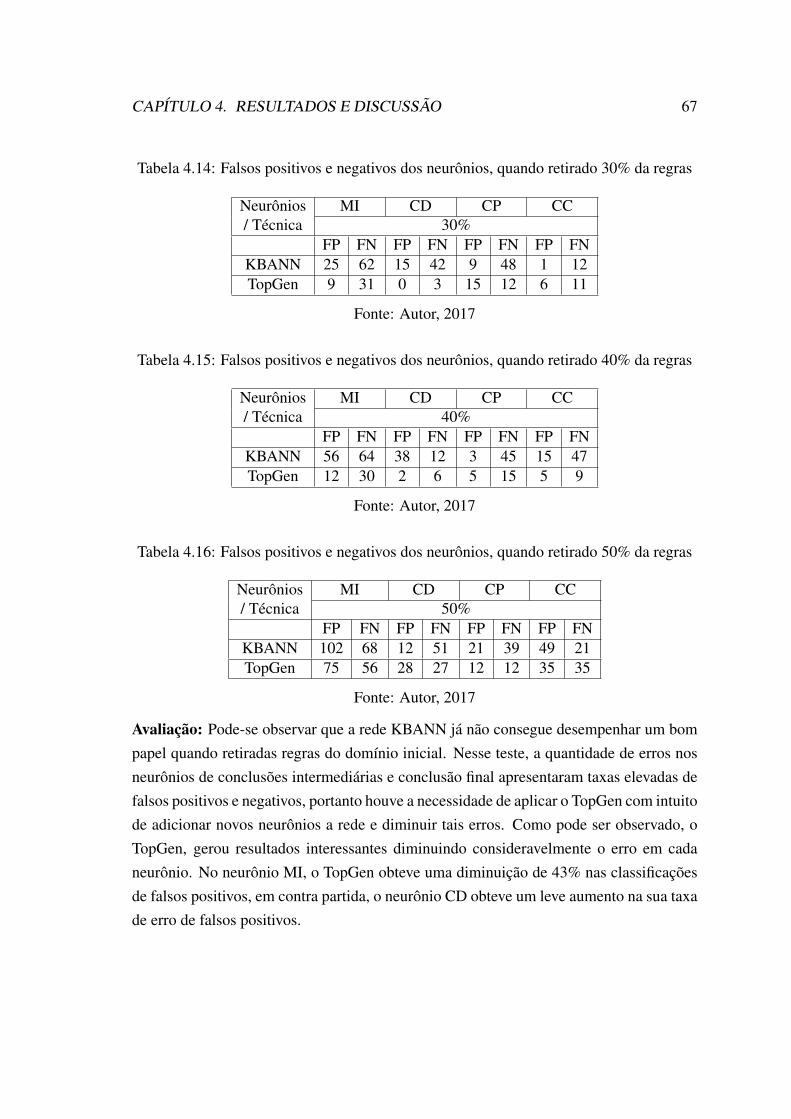
CAPÍTULO 4. RESULTADOS E DISCUSSÃO 67
Tabela 4.14: Falsos positivos e negativos dos neurônios, quando retirado 30% da regras
Neurônios/ Técnica
MI CD CP CC30%
FP FN FP FN FP FN FP FNKBANN 25 62 15 42 9 48 1 12TopGen 9 31 0 3 15 12 6 11
Fonte: Autor, 2017
Tabela 4.15: Falsos positivos e negativos dos neurônios, quando retirado 40% da regras
Neurônios/ Técnica
MI CD CP CC40%
FP FN FP FN FP FN FP FNKBANN 56 64 38 12 3 45 15 47TopGen 12 30 2 6 5 15 5 9
Fonte: Autor, 2017
Tabela 4.16: Falsos positivos e negativos dos neurônios, quando retirado 50% da regras
Neurônios/ Técnica
MI CD CP CC50%
FP FN FP FN FP FN FP FNKBANN 102 68 12 51 21 39 49 21TopGen 75 56 28 27 12 12 35 35
Fonte: Autor, 2017
Avaliação: Pode-se observar que a rede KBANN já não consegue desempenhar um bompapel quando retiradas regras do domínio inicial. Nesse teste, a quantidade de erros nosneurônios de conclusões intermediárias e conclusão final apresentaram taxas elevadas defalsos positivos e negativos, portanto houve a necessidade de aplicar o TopGen com intuitode adicionar novos neurônios a rede e diminuir tais erros. Como pode ser observado, oTopGen, gerou resultados interessantes diminuindo consideravelmente o erro em cadaneurônio. No neurônio MI, o TopGen obteve uma diminuição de 43% nas classificaçõesde falsos positivos, em contra partida, o neurônio CD obteve um leve aumento na sua taxade erro de falsos positivos.
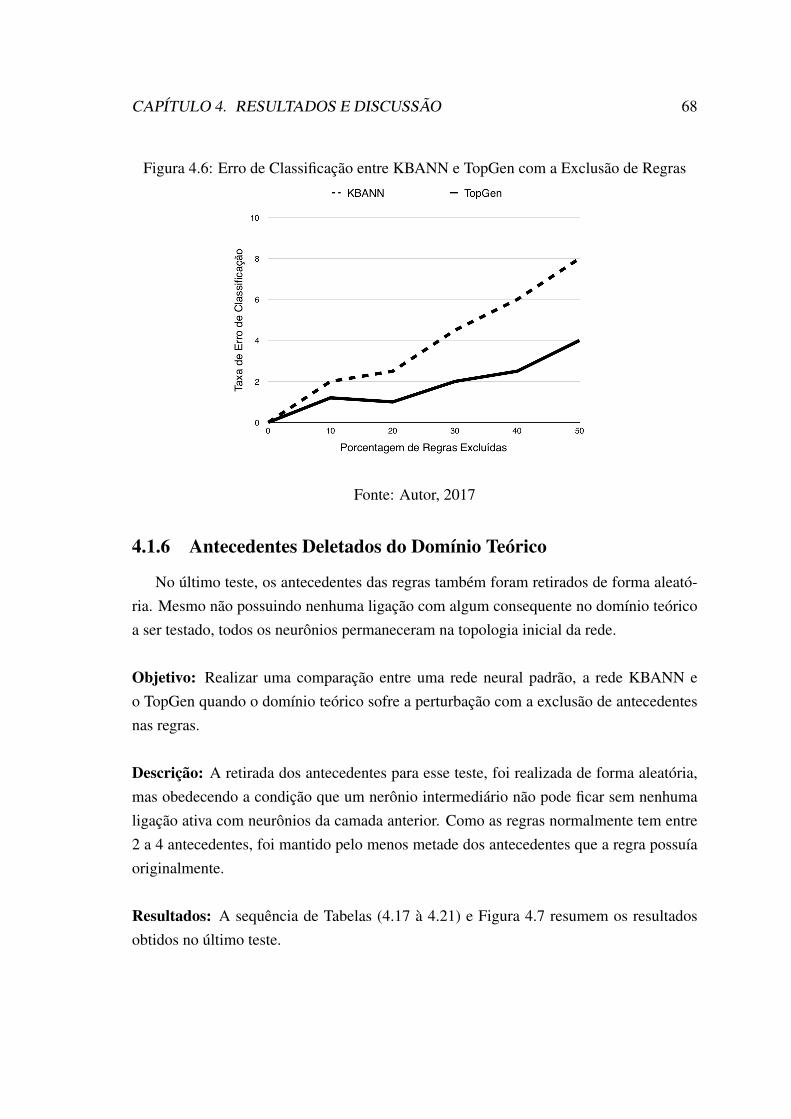
CAPÍTULO 4. RESULTADOS E DISCUSSÃO 68
Figura 4.6: Erro de Classificação entre KBANN e TopGen com a Exclusão de Regras
Fonte: Autor, 2017
4.1.6 Antecedentes Deletados do Domínio Teórico
No último teste, os antecedentes das regras também foram retirados de forma aleató-ria. Mesmo não possuindo nenhuma ligação com algum consequente no domínio teóricoa ser testado, todos os neurônios permaneceram na topologia inicial da rede.
Objetivo: Realizar uma comparação entre uma rede neural padrão, a rede KBANN eo TopGen quando o domínio teórico sofre a perturbação com a exclusão de antecedentesnas regras.
Descrição: A retirada dos antecedentes para esse teste, foi realizada de forma aleatória,mas obedecendo a condição que um nerônio intermediário não pode ficar sem nenhumaligação ativa com neurônios da camada anterior. Como as regras normalmente tem entre2 a 4 antecedentes, foi mantido pelo menos metade dos antecedentes que a regra possuíaoriginalmente.
Resultados: A sequência de Tabelas (4.17 à 4.21) e Figura 4.7 resumem os resultadosobtidos no último teste.

CAPÍTULO 4. RESULTADOS E DISCUSSÃO 69
Tabela 4.17: Falsos positivos e negativos dos neurônios, quando retirado 10% dos antece-dentes das regras
Neurônios/ Técnica
MI CD CP CC10%
FP FN FP FN FP FN FP FNKBANN 38 22 12 8 15 8 11 15TopGen 17 13 4 14 11 5 7 10
Fonte: Autor, 2017
Tabela 4.18: Falsos positivos e negativos dos neurônios, quando retirado 20% dos antece-dentes das regras
Neurônios/ Técnica
MI CD CP CC20%
FP FN FP FN FP FN FP FNKBANN 70 30 20 45 15 28 35 9TopGen 40 20 9 35 2 24 3 19
Fonte: Autor, 2017
Tabela 4.19: Falsos positivos e negativos dos neurônios, quando retirado 30% dos antece-dentes das regras
Neurônios/ Técnica
MI CD CP CC30%
FP FN FP FN FP FN FP FNKBANN 78 72 20 30 16 41 42 35TopGen 45 55 10 35 8 39 27 9
Fonte: Autor, 2017
Tabela 4.20: Falsos positivos e negativos dos neurônios, quando retirado 40% dos antece-dentes das regras
Neurônios/ Técnica
MI CD CP CC40%
FP FN FP FN FP FN FP FNKBANN 115 85 39 48 49 48 27 82TopGen 73 27 56 55 7 31 10 36
Fonte: Autor, 2017
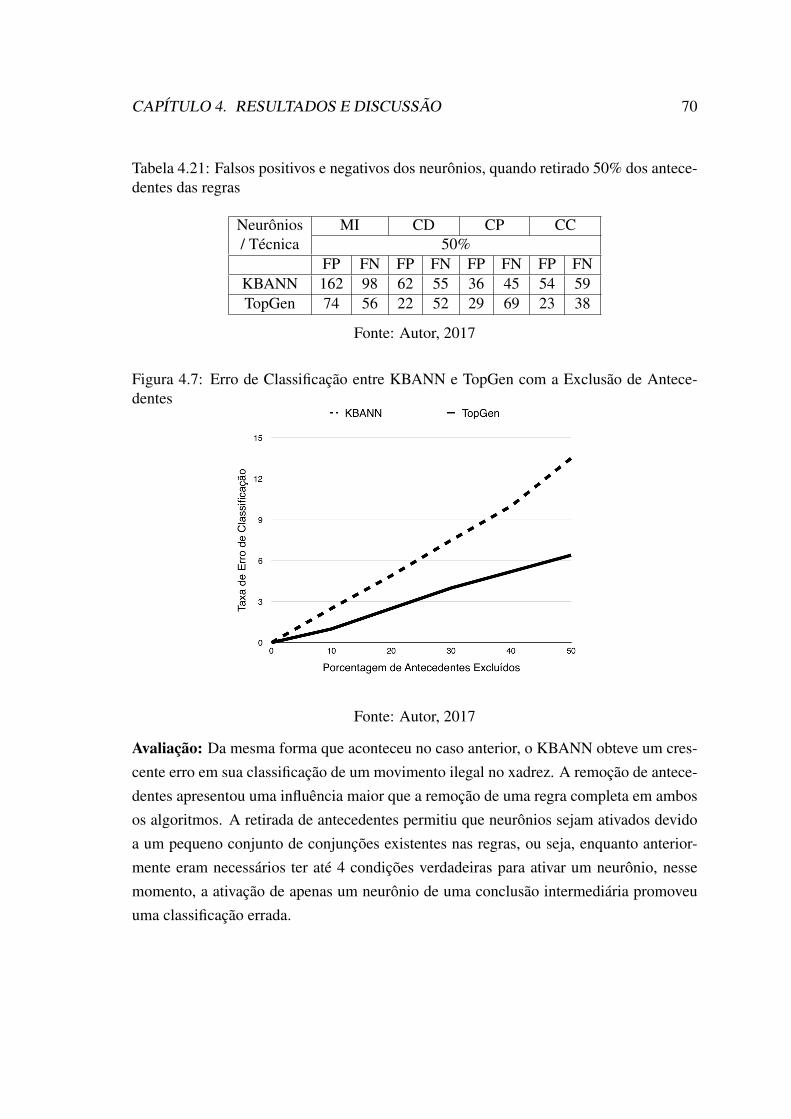
CAPÍTULO 4. RESULTADOS E DISCUSSÃO 70
Tabela 4.21: Falsos positivos e negativos dos neurônios, quando retirado 50% dos antece-dentes das regras
Neurônios/ Técnica
MI CD CP CC50%
FP FN FP FN FP FN FP FNKBANN 162 98 62 55 36 45 54 59TopGen 74 56 22 52 29 69 23 38
Fonte: Autor, 2017
Figura 4.7: Erro de Classificação entre KBANN e TopGen com a Exclusão de Antece-dentes
Fonte: Autor, 2017
Avaliação: Da mesma forma que aconteceu no caso anterior, o KBANN obteve um cres-cente erro em sua classificação de um movimento ilegal no xadrez. A remoção de antece-dentes apresentou uma influência maior que a remoção de uma regra completa em ambosos algoritmos. A retirada de antecedentes permitiu que neurônios sejam ativados devidoa um pequeno conjunto de conjunções existentes nas regras, ou seja, enquanto anterior-mente eram necessários ter até 4 condições verdadeiras para ativar um neurônio, nessemomento, a ativação de apenas um neurônio de uma conclusão intermediária promoveuuma classificação errada.

Capítulo 5
Conclusão
Esse trabalho teve como principal objetivo a implementação de um framework capazde unir o algoritmo de conversão neuro-simbólica do sistema híbrido KBANN e o refina-mento da mesma para a inserção de novos aprendizados no conhecimento base. A neces-sidade de um segundo algoritmo para refinamento da rede original, foi devido a possíveisalterações que a rede sofre em seus pesos sinápticos quando novas entradas são apresen-tadas a rede. Para preservar o conhecimento previamente adquirido e ter a possibilidadede inserção de novos fatos, o TopGen insere novos neurônios em determinadas regiõesda rede com o intuito de diminuir os falsos negativos ou positivos que foram encontradosna rede durante o período de testes. A necessidade ou não da inserção de neurônios sedeu através de 4 formas de testes. Em todos eles, o ponto de partida foi a rede originalgerada pelo algoritmo de KBANN. Nela foram verificados em seus respectivos neurôniosde conclusões intermediárias e finais se houveram ou não erros consideráveis em suasclassificações.
No primeiro teste, pode-ser observar que a rede KBANN não precisa adicionar novosneurônios a sua topologia inicial para ajustar suas classificações. Segundo Towell (1990),o KBANN é capaz de se adaptar à problemas com um conjunto falho de regras inicial-mente geradas. Nesse caso, a rede que foi gerada já possui todas as conexões fortes entreos neurônios que foram mapeados do conjunto de símbolos, sendo adicionados outrasligações fortes, mas que com o passar do tempo foram enfraquecidas durante os treina-mentos realizados na rede. A comparação desse teste foi realizado apenas em relação aodomínio teórico, ou seja, a rede foi inicializada com os pesos e bias ajustados de acordocom o algoritmo de Towell (1990), mas não sofreu nenhum tipo de treinamento. Assim,foi possível concluir que quanto mais regras incorretas são acrescentadas, mais o domínioteórico tende a classificar dados de forma equivocada.
No teste seguinte, novamente o domínio completo foi mapeado na rede neural, e emseguida, adicionados de forma aleatória antecedentes no conjunto de regras. Os testes para

CAPÍTULO 5. CONCLUSÃO 72
10% a 50% de inserção de novos antecedentes, novamente mostraram uma boa eficiênciana rede original de KBANN, e por isso, não houve a necessidade de aplicar o TopGen paracorrigir alguma classificação errada. Por outro lado, o domínio teórico obteve um altocrescimento a cada nova inserção de antecedentes, ou neurônios de entrada conectadoscom um valor de peso alto com a camada oculta.
A partir do terceiro teste, quando houve a remoção de regras do domínio inicial, arede KBANN já não se comportou de forma eficiente como nos testes anteriores. Embora,mesmo após a remoção de 50% dos fatos iniciais, a rede KBANN conseguiu uma taxa deerro próxima a 8%. Essa taxa de erro pode ser baixa para determinados problemas, porémpode ser consideravelmente alta em situações onde o erro deve ser praticamente nulo.Para a redução dos falsos negativos e falsos positivos gerados tanto na camada ocultacomo na camada de saída, foi necessário executar o TopGen. Após sua execução, a novarede melhor classificada dentre as N geradas, obteve uma redução no erro para 3%, sendoassim, uma melhoria de mais de 100% frente a rede original de KBANN.
O último teste, na remoção de antecedentes de forma aleatória, teve resultados inferi-ores quando houve a remoção completa de uma regra. Isso se deve ao fato de que mesmocom parte do conhecimento inicial não mapeado na rede, as demais regras ainda permitemuma classificação correta dos dados, e as ligações que anteriormente eram fracas, passama ser mais intensificadas. A remoção de um antecedente implica em que uma determinadasituação pode ocorrer com apenas alguns fatos e não todos eles, sendo assim, a taxa deerro chegou a ser de 14% quando removidos 50% dos antecedentes. No caso do TopGena taxa de erro sofreu uma redução para 8% e assim, um ganho de 61% frente ao KBANN.
A fusão do conhecimento prévio e da aprendizagem a partir de exemplos em redesneurais tem sido indicada para proporcionar sistemas de aprendizagem que são mais efi-cazes que, por exemplo, sistemas puramente simbólicos ou puramente conexionistas, es-pecialmente quando os dados possuem algo tipo de ruído (GARCEZ e ZAVERUCHA1999). Isso tem contribuído decisivamente para o crescente interesse em desenvolver sis-temas neuro-simbólicos, isto é, sistemas híbridos baseados em redes neurais capazes deaprender a partir de exemplos, como também, com conhecimento base, e realizar tarefasde raciocínio de forma paralela.
Um dos problemas encontrados nesse modelo híbrido é a quantidade de redes geradase o longo tempo para treinamento das mesmas. Além disso, a escolha da melhor rede ébaseada apenas em um conjunto de validação, no entanto, deve ser considerado que esseconjunto pode ser insuficiente para determinar o real conhecimento adquirido pela rede(MACKAY, 1992). Possíveis soluções para os problemas informados acima são: imple-mentar um novo método de treinamento supervisionado, uma possibilidade é o algoritmo

CAPÍTULO 5. CONCLUSÃO 73
Levenberg-Marquardt Levenberg (1944) que pode ser até 100 vezes mais rápido que obackpropagation. Para resolução do outro problema, utilizar métodos que não utilize umconjunto de dados para validação, como por exemplo, o método do erro generalizado,Moody (1991) e o método Bayesiano (Mackay, 1991) poderiam gerar melhores soluções.
Para trabalhos futuros é importante adicionar a capacidade de extrair regras da RNA. Oalgoritmo de extração de regra Fu (1992), McMillan et al. (1992), Towell e Shavlik (1993)servirá para mensurar a interpretabilidade do refinamento realizado pela rede gerada.
Uma última contribuição que pode ser dada a essa pesquisa e que também foi colocadaem aberta pelo pesquisador Shavlik (1995) é a possibilidade de buscar novas maneiras deadicionar neurônios à rede. Atualmente, os neurônios recém adicionados são totalmenteconectados a todos os neurônios de entrada. Uma possibilidade seria de conectar apenasa uma parte das entradas disponíveis. Outras abordagens propostas seriam: adicionar econectar novos neurônios à aqueles que têm uma alta correlação com o erro, ou adicioná-los na camada seguinte ao neurônio com erro (desde que não seja um neurônio de saída).
Em particular, a integração neuro-simbólica se mostrou eficientes em diversos traba-lhos apresentados na comunidade científica Garcez et al. (2002), Lamb et al. (2003),Gabbay et al. (2007). Embora os recentes avanços nessa área, a abordagem híbrida con-tinua a ser uma questão amplamente aberta, onde os avanços são lentos, e complicado dese avaliar até que ponto essas abordagens podem funcionar na prática.

Referências Bibliográficas
74

REFERÊNCIAS BIBLIOGRÁFICAS 75
CHOMSKY, N. Syntactic structures. The Hague, The Netherlands: Mouton, 1957.
COLLINS, A. M.; QUILLIAN, M. R. Retrieval Time from Semantic Memory. Jour-nal of Verbal Learning and Verbal Behavior, p. 240-248, 1969.
FU, L.M. A Neural Network Model for Learning Rule-Based Systems. In Proceedings ofthe International Joint Conference on Neural Networks, p. 1-343:1-348, 1992.
GABBAY, D. M.; GARCEZ, A. S. A.; LAMB, L. C. Value-based argumentation fra-meworks as neural-symbolic learning systems. Journal of Logic and Computarion, p.1041-1058, 2005.
GARCEZ, A. S. A.; ZAVERUCHA, G. The Connectionist Inductive Learning and LogicProgramming System. Applied Intelligence Journal, Special Issue on Neural Networksand Structured Knowledge, p 59-77, 1999.
GARCEZ, A. S. A.; BRODA, K. GABBAY, D. M. Neural-Symbolic Learning Systems:Foundations and Applications, Perspectives in Neural Computing. Springer, 2002.
GARCEZ, A. S. A.; BADER, S.; HITZLER, P. Computing First-Order Logic Programsby Fibring Artificial Neural Networks. In Proceedings of the AAAI International FLAIRSConference, p. 314-319, 2005.
LAMB, L. C.; GARCEZ, A. S. A.; GABBAY, D. M. Neural-symbolic intuitionistic rea-soning. In A. Abraham, M. k Oppen, and K. Franke, editors, Design and Application ofHybrid Intelligent Systems, volume 104 of Frontiers in Artificial Intelligence and Appli-cations, p. 399-408, 2003.
LEVENBERG, K. A Method for the Solution of Certain Non-Linear Problems in Le-ast Squares. The Quarterly of Applied Mathematics, Vol. 2, p. 164-168, 1944.
MACKAY, D. J. C. Bayesian Interpolation. In Neural Computation, Vol. 4, p. 415-447 1991.
MCMILLAN, C.; MOZER, M. C.; SMOLENSKY, P. Rul Induction Through Integra-ted Symbolic and Subsymbolic Processing. In Neural Information Processing Systems 4,

REFERÊNCIAS BIBLIOGRÁFICAS 76
p. 969-976, 1992.
MCCULLOCH, W. S.; PITTS, W. H. A Logical Calculus of the Ideas Immanet in Ner-vous Activity Bulletin of Mthematical Biophysics, Vol. 5, p. 115-133, 1943.
MINSKY, M. A Framework for Representing Knowledge, 1974.
MOODY, J. E. The Effective Number of Parameters: An Analysis of Generalization andRegularization in Nonlinear Learning Systems. Advances in Neural Information Proces-sing Systems, p. 847-854, 1991.
SELFRIDGE, O. G.;NEISSER, U. Pattern Recognition by Machine. In: Computers andThought. Feigenbaum, E.A. and Feldman, J. (Ed.) New York: McGraw-Hill, 1963.
NEWELL, A.; SIMON, H. A. GPS: A Program that Simulates Human Thought. In Com-puters and Thought. McGraw-Hill, New York, 1963.
OPITZ, D. W.; SHAVILIK, J. W. Heuristically Expanding Knowledge-Based NeuralNetworks. In Proceedings of the International Joint Conference on Artificial Intelligence,IJCAI-93, p 1360-1365, 1993.
OSORIO, F. S.; VIEIRA, R. Sistemas HÃbridos Inteligentes. In: ENI 99 Encontro Naci-onal de InteligÃancia Artificial, 2000.
PRECHELT, L. A Set of Neural Network Benckmark Problems and Benchmarking. Fa-kult at fur Information, Universit a Karlsruhe, 1994.
RASHEVSKY, N. Mathematical Biophysics. New York: Dover, 1960.
RUMELHART, D. E.; HILTON, G. E.; WILLIAMS, R. J. Learning internal represen-tations by error propagation. In Book Parallel distributed processing: explorations in themicrostructure of cognition, Vol. 1, p. 318-362, 1986.Â
RUSSEL, S.; NORVIG, P. Artificial Intelligence: A Modern Approach (3rd Edition) 3rdEdition, 1995.

Apêndice A
Algoritmo TopGen
Figura A.1: Algoritmo TopGen
Fonte: Shavlik, 1995











![IMPLEMENTAÇÃO DE UMA REDE NEURAL ARTIFICIAL PARA … · sistema de sincronismo do FAPP com a rede, é possível ... Fase ‘a’ [Ω] Resistência Fase ‘b’ [Ω] Fase ‘c’](https://img.pdfslide.tips/doc/110x75/5c64b92209d3f2ad6e8b9768/implementacao-de-uma-rede-neural-artificial-para-sistema-de-sincronismo-do.jpg)

















