Embed Size (px)
Citation preview
Implementierung von IR-Systemen
Norbert Fuhr
Aufbau von IRS
Dateistruktur eines IRSDialogfunktionen herkömmlicher IRS
Aufbau vonIRSFunktionale Sicht
breakinto words assign doc id’s
term weightingstoplist
stemming
stemming
parse query
ranking
Database
Interface
relevancejudgments
User
Documents
text
words
stemmed words term
document numbersand field numbers
documents
retrieved document set
ranked document set
query terms
stemmedwords
queries documents
query
non−stoplistwords
queries
weights
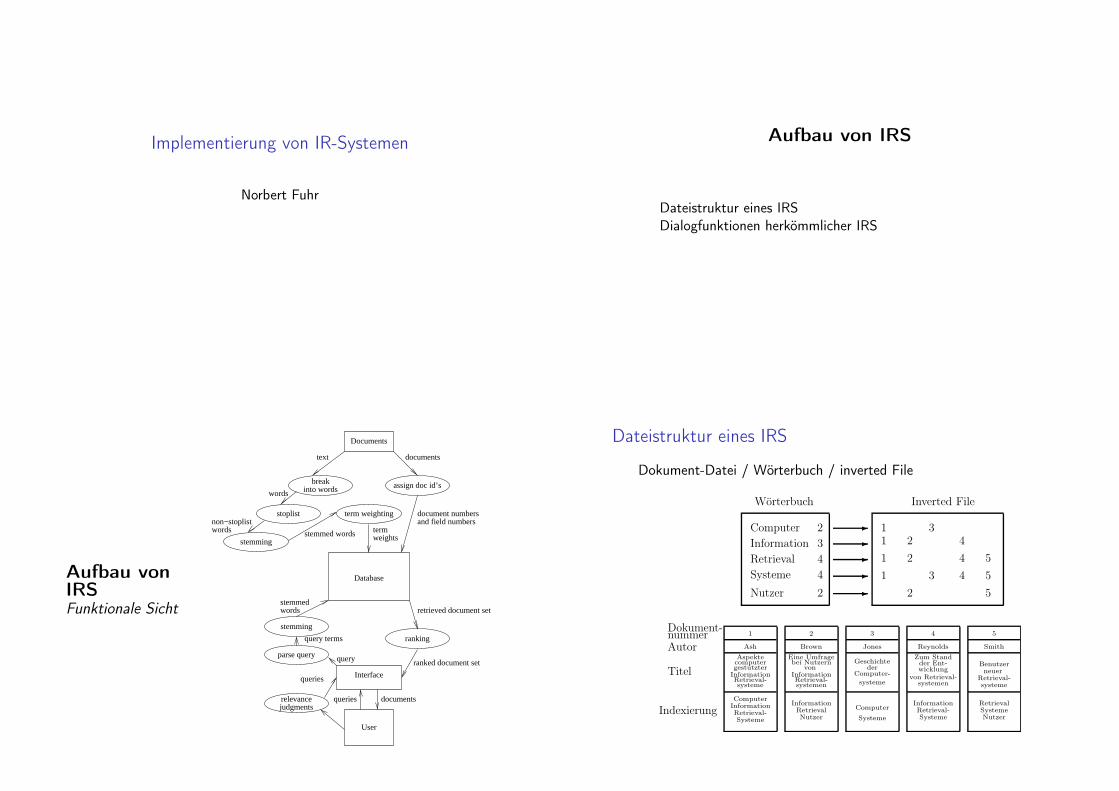
Dateistruktur eines IRS
Dokument-Datei / Wörterbuch / inverted File
Information
Retrieval
Systeme
Nutzer
Worterbuch
Computer 2 -
3 -
4 -
4 -
2 -
1 31 2 4
1 2 4 5
1 43 5
2 5
Inverted File
nummerDokument-
Autor
Titel
Indexierung
Aspektecomputergestutzter
InformationRetrieval-systeme
ComputerInformationRetrieval-Systeme
1 2 3 4 5
Ash Brown Jones Reynolds Smith
Eine Umfragebei Nutzern
vonInformationRetrieval-systemen
InformationRetrievalNutzer
Geschichteder
Computer-
systeme
Computer
Systeme
Zum Standder Ent-wicklung
von Retrieval-systemen
InformationRetrieval-Systeme
Benutzerneuer
Retrieval-systeme
RetrievalSystemeNutzer

Dialogfunktionen herkömmlicher IRS
I ZugangskontrolleI Auswahl der DatenbasisI Anzeige des Wörterbuchs / ThesaurusI Formulierung von AnfragenI Anzeige von AntwortenI Verwaltung von Suchprofilen
(einschließlich SDI-Läufe/Downloading)I Drucken von Antworten
Zugriffspfade
ScanningInvertierte ListenPAT-TreesSignaturen (Bloom-Filter)
ScanningGenerelle Überlegungen
Verzicht auf Anlegen eines gesonderten Zugriffspfades,stattdessen möglichst effiziente sequentielle Suche→ erspart den Overhead für das Anlegen des Zugriffspfades
Probleme
Aufwand wächst linear mit dem Datenvolumen, daher nur fürkleinere Datenbestände geeignet(insbesondere auch in Texteditoren eingesetzt)
Berücksichtigung von Flexions- und Derivationsendungen erhöhtdie Komplexität und den Berechnungsaufwand derAlgorithmen
Wortreihenfolge und Stoppwortelimination: ditoinformation retrieval — retrieval of information
Rankingalgorithmen: erfordern zwei Durchläufe(inverse Dokumenthäufigkeit steht erst nach dem Durchlaufenaller Dokumente fest)

Anwendungsbereiche:
I hardwaremäßig implementiert:Verarbeitungsgeschwindigkeit ≥ Transferrate derPlattenlaufwerke
I Cloud computing: paralleles, sequenzielles Durchsuchen derKollektion
I Highlighting von Suchbegriffen bei der Anzeige vongefundenen Dokumenten
I Vergleichskomponente in Signatur-Systemen(Signaturen wirken nur als Filter)
Vorbemerkungen zu Scanning-Algorithmen
im folgenden nur Patterns bestehend aus einer festen Zeichenfolgebetrachtet(keine Alternativen, keine “don’t care’s”)Notationen:n Länge des Textesm Länge des Patterns (sei stets m ≤n)c Größe des zugrundeliegenden Alphabets Σ
Cn Erwartungswert für die Anzahl der zeichenweisen Vergleiche ineinem Algorithmus für einen Text der Länge n
Analyse
Analyse basiert auf Annahme einer zufälligen Zeichenkette(Zeichenkette der Länge l besteht aus der Konkatenation von lZeichen, die unabhängig und gleichverteilt zufällig aus Σentnommen werden)
Wahrscheinlichkeit für die Gleichheit von zwei zufällig ausgewähltenZeichen: 1/c
Wahrscheinlichkeit für den match zweier Zeichenfolge der Länge m:1/cm
Erwartungswert der Anzahl Treffer t für ein Pattern der Länge m ineinem String der Länge n:
E (t) =n −m + 1
cm
Der naive Algorithmus
Pattern: abracadabra
aababcabcdabracadabra
ababraabraaabraaaabracadabra

Algorithmus:
1 pub l i c i n t nsea r ch ( char [ ] t e x t , i n t n , char [ ] pat , i n t m) {2 i n t i , j , k , l im ;3 l im = n−m+1;4 f o r ( i = 1 ; ( i <= l im ) ; i++) {5 k = i ;6 f o r ( j = 1 ; ( j <= m && t e x t [ k ] == pat [ j ] ) ; j++)7 k++;8 i f ( j > m) return i ;9 }
10 return NOTFOUND;11 }
Abschätzung des Aufwands:
Erwartungswert für die Anzahl Vergleiche bis zum ersten Treffer:
Cfirstmatch =cm+1
c − 1− c
c − 1Erwartungswert für die Gesamtzahl der Vergleiche:
Cn =c
c − 1
(1− 1
cm
)(n −m + 1) + O(1)
(worst case erfordert m · n Vergleiche)
Verbesserung des naiven Algorithmus’:bestimmte Rechnerarchitekturen bieten speziellen Maschinenbefehlzur Suche nach dem ersten Auftreten eines bestimmten Zeichens(bzw. aus einer Menge von Zeichen)(x86-Architektur: SCAS “Scan String”)
→ Einsatz für die Suche nach dem ersten Zeichen des Patterns
Der Knuth-Morris-Pratt-Algorithmus
Grundidee:wenn bereits eine teilweise Übereinstimmung zwischen Pattern undString gefunden wurde, bevor das erste verschiedene Zeichenauftritt, kann diese Information zur Wahl eines besserenAufsetzpunktes gewählt werden
aababrabrabracadabra
ababr
abracbrac
bracadabra
Beobachtungen:I weniger Aufsetzpunkte als beim naiven AlgorithumsI Zeiger im String muss nie zurückgesetzt werden
Knuth-Morris-Pratt-Algorithmus
1 pub l i c i n t kmpsearch ( char [ ] t e x t , i n t n , char [ ] pat , i n t m) {2 i n t i = 1 ; i n t j = 1 ;3 i n t [ ] nex t = i n i t n e x t ( pat , m) ;4
5 whi le ( i <= n ) {6 whi le ( ( j != 0) && ( pat [ j ] != t e x t [ i ] ) ) {7 j = next [ j ] ;8 }9 i f ( j == m) {
10 return ( i − m + 1 ) ;11 }12 e l s e {13 i ++; j++;14 }15 }16 return NOTFOUND;17 }

Vorprozessierung des Patterns notwendig:Tabelle next[1..m] gibt die nächste Position im Pattern an, mitder bei Ungleichheit verglichen werden muss:
next[j ] = max{i |(pattern[k] = pattern[j − i + k]
for k = 1, . . . , i − 1)
and pattern[i ] 6= pattern[j ]}
(Suche nach dem längsten übereinstimmenden Praefix, so dass dasnächste Zeichen im Pattern verschieden ist von dem Zeichen, beidem die Ungleichheit auftrat)Tabelle next fuer den Pattern abracadabra:
a b r a c a d a b r anext[j] 0 1 1 1 2 1 2 1 2 3 4
next[i]=0 → Zeiger im Text um eins vorrücken und wieder mitdem Anfang des Patterns vergleichen
obere Schranke für den Erwartungswert der Gesamtzahl derVergleiche:(bei großen Alphabeten)
Cn
n≤ 1 +
1c− 1
cm
Verringerung des Aufwands beim KMP-Algorithmus im Verhältniszum naiven:
KMPnaive
≈ 1− 2c2
Der Boyer-Moore-Horspool-Algorithmus
vereinfachte, beschleunigte Variante des Boyer-Moore-Algorithmus’Grundideen:
I Vergleich des Patterns von rechts nach linksI Vorkommensheuristik
ABCDEFABzzzzzzzzABCABCxxxABC
ABCxxxABC
Boyer-Moore-Horespool-Algorithmus
1 pub l i c i n t bmhsearch ( char [ ] t e x t , i n t n , char [ ] pat , i n t m) {2 i n t i = m;3 i n t j ;4
5 Map<Charac te r , I n t e g e r > d = i n i t d ( pat , m) ;6 whi le ( i <= n ) {7 i n t t i=i ;8 f o r ( j = m; ( t e x t [ t i ] == pat [ j ] ) ; ) {9 j−−; t i −−;
10 }11 i f ( j == 0) {12 return t i + 1 ;13 }14 i = i + d (d ,m, t e x t [ i ] ) ;15 }16 return NOTFOUND;17 }

Vorkommensheuristik
Ausrichten der Textposition, an der Ungleichheit auftrat, mit demersten übereinstimmenden Zeichen im PatternDefinition einer über das Textzeichen indizierten Tabelle d (gibtebenfalls Shift im Text an, Vergleich jeweils beginnend mit demletzten Pattern-Zeichen)
d [x ] = min{s|s = m or(0 ≤ s < m and pattern[m − s] = x)}
Beispiel: Tabelle d für den Pattern ABCXXXABC:
d [′A′] = 2 d [′B ′] = 1 d [′C ′] = 6 d [′X ′] = 3
(für alle anderen Zeichen x ist d[x] = 9)
Sonderfall:wenn Text-Zeichen mit dem letzten Zeichen des Patternsübereinstimmt(aber weiter vorne ist eine Ungleichheit aufgetreten):Setze zuerst korrespondierendes Zeichen in der Shift-Tabelle aufden Wert m und berechne dann die Shift-Tabelle für die erstenm − 1 Zeichen des Patterns:
d [x ] = min{s|s = mor (1 ≤ s < m and pattern[m − s] = x)}
Beispiel: Tabelle d für den Pattern ABCXXXABC:
d [′A′] = 2 d [′B ′] = 1 d [′C ′] = 6 d [′X ′] = 3
(für alle anderen Zeichen x ist d[x] = 9)
asymptotischer Aufwand für n und c (mit c � n und m > 4):
Cn
n=
1m
+m + 12mc
+ O(c−2)
Der Boyer-Moore-Algorithmus
Grundideen:I Vergleich des Patterns von rechts nach linksI Vorkommensheuristik (wie bei Boyer-Moore-Horspool)I Match-Heuristiken (ähnlich KMP)

Boyer-Moore-Algorithmus1 pub l i c i n t bmsearch ( char [ ] t e x t , i n t n , char [ ] pat , i n t m) {2 i n t i = m;3 i n t j ;4
5 Map<Charac te r , I n t e g e r > d = i n i t d ( pat , m) ;6 i n t [ ] dd = new in t [ pat . l e n g t h ] ;7 preBmGs ( pat , m, dd ) ;8
9 whi le ( i <= n ) {10 i n t t i=i ;11 f o r ( j = m; ( t e x t [ t i ] == pat [ j ] ) ; ) {12 j−−; t i −−;13 }14 i f ( j == 0) {15 return t i + 1 ;16 }17 i = i + Math . max( d (d ,m, t e x t [ i ] ) , dd [ j ] ) ;18 }19 return NOTFOUND;20 }
Match-Heuristik:
Shift, so dass an der neuen Vergleichsposition1. Pattern alle vorher übereinstimmenden Zeichen matcht2. ein anderes Zeichen als vorher an der Vergleichsposition steht
Beispiel zur Match-Heuristik
ABCDEFABCxxxABCABCxxxABC
ABCxxxABC
Implementierung der Match-Heuristik als Tabelle dd(gibt den Shift im Text an, Vergleich jeweils beginnend mit demletzten Pattern-Zeichen) Berechnung für jede Stelle j im Pattern:1. Suche Anfang des “rightmost plausible reoccurance” rpr(j)2. alignslide = j + 1− rpr(j)3. endslide = m − j4. dd [j ] = alignslide + endslide = m + 1− rpr(j)
Beispiel: Tabelle dd für den Pattern ABCXXXABC:
j: 1 2 3 4 5 6 7 8 9A B C X X X A B C
dd[j] 14 13 12 11 10 9 11 10 1------- ^ -------
1. rpr(6) = 12. dd [6] = 9 + 1− 1 = 9
Algorithmus wählt jeweils den größeren Shift von Match- undVorkommensheuristik(gleiche Shift-Strategie nach einem Treffer)

Aufwandsabschätzungen
I worst case: O(n + rm) mit r = Anzahl Treffer(im ungünstigsten Fall wie naiver Algorithmus)
I untere Schranke für große Alphabete und m� n:
Cn
n≥ 1
m+
m(m + 1)
2m2c+ O(c−2)
I bei ungleicher Auftretenswahrscheinlichkeit der Zeichen giltCn/n < 1 unter der Voraussetzung
c
(1−
c∑i=1
p2i
)> 1
Beispiele:I c = 3, pi = 1/3, → 1I c = 3, p1 = 1/2, p2 = 1/4, p3 = 1/4, → 15/8
Der Shift-Or-Algorithmus
Echtzeit-Algorithmus, ohne Zwischenspeicherung des Textes→ für hardwaremäßige Implementierung geeignet
basiert auf der Theorie der endlichen Automaten:Vektor von m verschiedene Zustandsvariablen,ite Variable gibt den Zustand des Vergleichs zwischen denPositionen 1, . . . , i des Patterns und den Positionen(j − i + 1), . . . , j des Textes an(j = aktuelle Textposition)
Zustandsvektor
ite binäre Zustandsvariable si :=0, falls letzte i Zeichen übereinstimmen=1, sonstRepräsentation des Zustandsvektors state als Binärzahl:
state =m−1∑i=0
si+1 · 2i
Match endend an der aktuellen Position, wenn sm = 0 (bzw.state < 2m−1)
Update des Zustandsvektors
beim Lesen eines neuen Zeichens aus dem Text:I Statusvektor um 1 nach links shiften und s1 = 0 setzenI Aktualisieren des Statusvektors entsprechend dem nächsten
eingelesenen Zeichen(mit Hilfe einer Tabelle T mit Einträgen für jedes Zeichen desAlphabets)neuer Statusvektor ergibt sich aus Oder-Verknüpfung vonaltem Vektor mit Tabelleneintrag
Formal:state = (state << 1) or T [currchar ]
(<< = Linksshift)
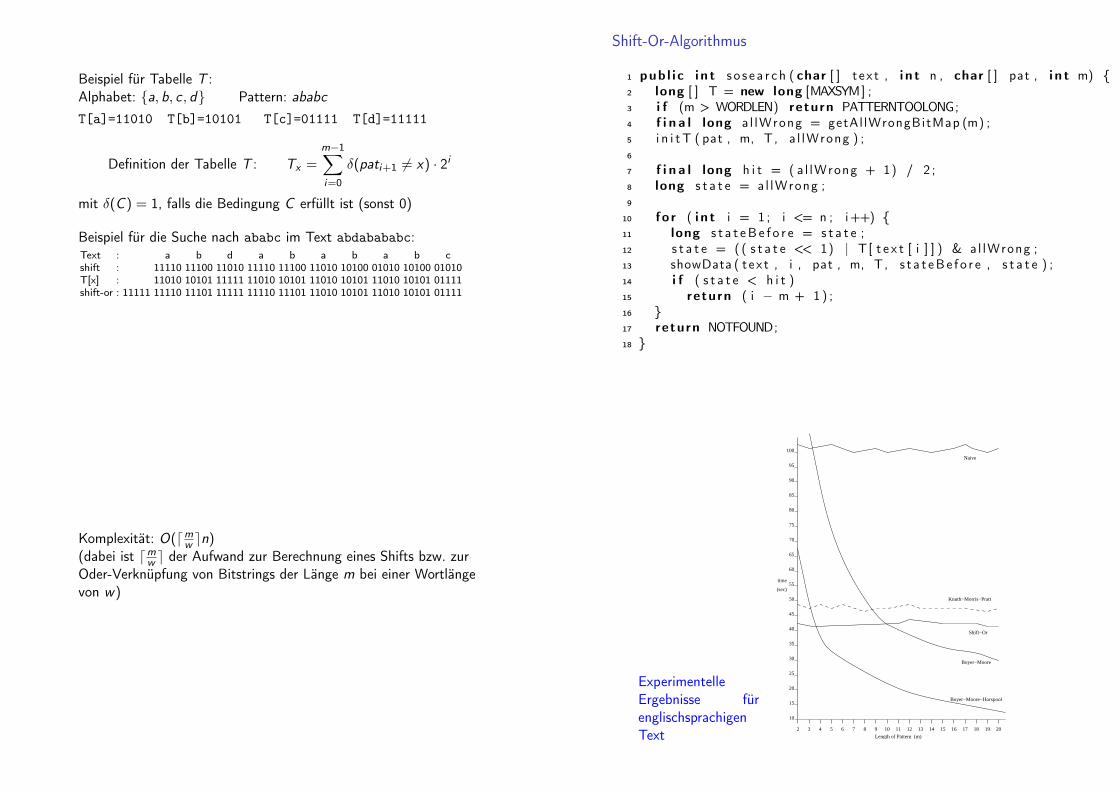
Beispiel für Tabelle T :Alphabet: {a, b, c , d} Pattern: ababcT[a]=11010 T[b]=10101 T[c]=01111 T[d]=11111
Definition der Tabelle T : Tx =m−1∑i=0
δ(pati+1 6= x) · 2i
mit δ(C ) = 1, falls die Bedingung C erfüllt ist (sonst 0)
Beispiel für die Suche nach ababc im Text abdabababc:Text : a b d a b a b a b cshift : 11110 11100 11010 11110 11100 11010 10100 01010 10100 01010T[x] : 11010 10101 11111 11010 10101 11010 10101 11010 10101 01111shift-or : 11111 11110 11101 11111 11110 11101 11010 10101 11010 10101 01111
Shift-Or-Algorithmus
1 pub l i c i n t s o s e a r c h ( char [ ] t e x t , i n t n , char [ ] pat , i n t m) {2 long [ ] T = new long [MAXSYM] ;3 i f (m > WORDLEN) return PATTERNTOOLONG;4 f i n a l long a l lWrong = getAl lWrongBitMap (m) ;5 i n i t T ( pat , m, T, a l lWrong ) ;6
7 f i n a l long h i t = ( a l lWrong + 1) / 2 ;8 long s t a t e = al lWrong ;9
10 f o r ( i n t i = 1 ; i <= n ; i++) {11 long s t a t eB e f o r e = s t a t e ;12 s t a t e = ( ( s t a t e << 1) | T[ t e x t [ i ] ] ) & a l lWrong ;13 showData ( t ex t , i , pat , m, T, s t a t eBe f o r e , s t a t e ) ;14 i f ( s t a t e < h i t )15 return ( i − m + 1 ) ;16 }17 return NOTFOUND;18 }
Komplexität: O(dmw en)(dabei ist dmw e der Aufwand zur Berechnung eines Shifts bzw. zurOder-Verknüpfung von Bitstrings der Länge m bei einer Wortlängevon w)
ExperimentelleErgebnisse fürenglischsprachigenText
Shift−Or
Knuth−Morris−Pratt
Naive
Boyer−Moore
Boyer−Moore−Horspool
10
15
20
25
30
35
40
45
50
55
60
65
70
75
80
85
90
95
100
3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 202
(sec)
time
Length of Pattern (m)

Erweiterungen des Shift-Or-Algorithmus’
Zeichenklassen:x bestimmtes Zeichen. beliebiges Zeichen
[Z ]Zeichen aus der Menge ZC Komplementmenge der Klasse C
Beispiel:M[ae][ij ].[g − ot − z ] matcht Meier, Majer, Meise, aber nichtMaler oder Maien
Behandlung durch Änderung der Definition der Tabelle T :
Tx =m−1∑i=0
δ(pati+1 6∈ Classi+1) · 2i
→ Modifikation der Präprozessierung des PatternsAlgorithmus sonst unverändert!
Beispiel: T zum Pattern ab[ab]b[a − c]:
T [a] = 11000T [b] = 10011T [c] = 11101T [d ] = 01101
Zeichenkettensuche mit erlaubten Fehlern
Maximalzahl erlaubter Fehler vorgegeben→ ersetze Bits im Statusvektor durch Zähler für Anzahl der Fehler,Addition der Einträge aus T statt OR-Verknüpfung
Beispiel für die Suche nach ababc mit höchstens 2 Fehlern imString abdabababc:
text : a b d a b a b a b cT [x] : 11010 10101 11111 11010 10101 11010 10101 11010 10101 01111shift : 99990 99900 99010 91210 22200 23010 40200 03010 40200 03010shift-or : 99990 99901 99121 92220 32301 34020 50301 14020 50301 04121
* *
Alternative Patterns
Suche nach p1 ∨ . . . ∨ pla) mit eigenem Statusvektor für jedes Pattern
Sei mmax = maxi (|pi |).Aufwand: O(dmmax
w eln)
b) Verkettung aller StatusvektorenSei msum =
∑i |pi |.
Aufwand: O(dmsumw en)

Ähnlichkeit von Zeichenketten
(insbesondere für die Suche nach Eigennamen und zur Korrekturvon Tippfehlern,ersetzt nicht die linguistische Grundform- bzw.Stammformreduktion)
Phonetische Gleichheit
Wörter werden durch einen Phonetisierungsalgorithmus auf eineninternen Code abgebildet, phonetisch gleiche Wörter dabei auf dengleichen Code(z.B. SOUNDEX-Algorithmus bildet den gleichen Code für dieenglischsprachigen Wörter „Dixon“, „Diksen“ und „Dickson“)
aber:ähnlich geschriebene Wörter werden häufig auf unterschiedlicheCodes abgebildetz.B. „Rodgers“ und „Rogers“
Damerau-Levenshtein-Metrik
Ähnlichkeitsmaß für Zeichenketten, soll Zahl der Tippfehlerannähernvier mögliche Fehler: Einfügung, Löschung, Substitution,TranspositionDL-Metrik berechnet für zwei Zeichenketten die minimale AnzahlFehler, mit der diese ineinander überführt werden können
Zeichen Operation KostenM C Substitution 1O E Substitution 1N N = 0S – Einfügung 1T T = 0E R halbe Transpos. 1/2R E halbe Transpos. 1/2
Summe 4
DL-MetrikBerechnung des Minimums durch dynamische Programmierung
Berechne zu jedem Punkt das lokale Minimum durch Übergang vonder Nachbarzelle
I darüber (Löschung)I links (Einfügung) oderI links darüber (Substitution/Transposition)
C E N T R EM 1 2 3 4 5 6O 2 2 3 4 5 6N 3 3 2 3 4 5S 4 4 3 3 4 5T 5 5 4 3 4 5E 6 5 5 4 4 4R 7 6 6 5 4 4

Nachteile der DL-Metrik
I relativ aufwendig zu berechnenI Beschleunigung der best-match-Suche nur durch Clustering
möglich
Ähnlichkeitssuche über Trigrams
(Trigram = Zeichenfolge der Länge 3)einfaches, aber wirkungsvolles Ähnlichkeitsmaß
Wörter werden auf die Menge der enthaltenen Trigrams abgebildet‘MENGE’ → {‘_ME’, ‘MEN’, ‘ENG’, ‘NGE’, ‘GE_’}‘MENAGE’ → {‘_ME’, ‘MEN’, ‘ENA’, ‘NAG’,‘AGE’, ‘GE_’}
Ähnlichkeitssuche = Suche nach Wörtern, die in möglichst vielenTrigrams mit dem gegebenen Wort übereinstimmen
z.B. %(q, d) =|qT ∩ dT ||qT |
%(’MENGE’,’MENAGE’) = 3/6
Beschleunigung durch spezielle Zugriffspfade:invertierte Listen oder Signaturen
Invertierte ListenPrinzipieller Aufbau
aufsteigend sortierte Listen von Dokumentnummern, in denen einTerm vorkommt:t1 d2 d15 d23 d89 . . .
t2 d5 d15 d89 . . .
Speicherplatzbedarf:3 Bytes für d und 1 Byte für fd ,t → 4 Bytes/EintragBeispiel: 2 GB TREC-Kollektion → 733 MB inv. Liste
Anwendung für Boolesches Retrieval:
∨ — Vereinigen der Listen∧ — Schneiden der Listen∧¬ — Differenzbildung
t1 d2 d15 d23 d89 . . .
t2 d5 d15 d89 . . .
Ergebnisliste für t1 ∨ t2d2 d5 d15 d23 d89 . . .
Ergebnisliste für t1 ∧ t2d15 d89 . . .
Ergebnisliste für t1 ∧ ¬t2d2 d23 . . .

Erweiterung der Einträge für die Wortabstandssuche:Angaben über alle Vorkommen in einem Dokument werden mitabgelegt(z.B. Feldkennung, Satznummer, Wortnummer)
t1 d2, (T , 1, 2) | d15, (A, 3, 24), (A, 4, 25) | d23, (T , 1, 5) | d89, (A, 4, 99) | . . .t2 d5, (T , 1, 9) | d15, (A, 1, 4), (A, 2, 10), (A, 3, 23) | d89, (A, 1, 9) | . . .
führt aber zu hohem Speicherplatzbedarf(bis zu 100% der Primärdaten)
Ranking mit invertierten Listen
Aufgabenstellung:Bestimmung der k Dokumente mit dem höchsten RetrievalgewichtAnnahmen:
I Skalarprodukt als RetrievalfunktionI Einträge in der invertierten Liste enthalten zusätzlich das
Indexierungsgewicht des TermsZiel:Anzahl der Plattenzugriffe soll minimiert werden(daher Berechnung nur über die invertierten Listen)
Naiver Algorithmus
Prinzipielle Vorgehensweise:Mischen der invertierten Listen wie bei ODER-Verknüpfung,dabei zusätzlich Berechnung der Retrievalgewichtet1 d2, u12 d15, u115 d23, u123 d89, u189 . . .
t2 d5, u25 d15, u215 d89, u289 . . .
Ergebnis für w1 · t1 + w2 · t2:d2: w1 · u12 , d5: w2 · u25 , d15: w1 · u115 + w2 · u215 ,d23: w1 · u123 , d89: w1 · u189 + w2 · u289
Algorithmus für Skalarprodukt
1. Für jedes Dokument der Kollektion: Setze Akkumulator Ad auf0
2. Für jeden Term der Anfrage:2.1 Hole It , die invertierte Liste für t.2.2 Für jedes Paar 〈 Dokumentnummer d , Indexierungsgewicht
ud,t 〉 in It setze Ad ← Ad + wq,t · ud,t .
3. Bestimme die k höchsten Werte Ad
4. Für jedes dieser k Dokumente d :I a) Hole die Adresse von Dokument d .I b) Hole Dokument d and präsentiere es dem Benutzer.

Komprimierung invertierter Listen
Idee: LauflängencodierungBeispiel:
5, 8, 12, 13, 15, 18, 23, 28, 29, 40, 60
Lauflängen:
5, 3, 4, 1, 2, 3, 5, 5, 1, 11, 20
Codes für Lauflängen
Codierung einer natürlichen Zahl x :γ-Code:
1. blog2 xc+ 1 im 1er-Code(d.h. blog2 xc 1-Bits gefolgt von einem 0-Bit)
2. x − 2blog2 xc im Binärcode
δ-Code:
1. γ-Codierung von blog2 xc+ 12. x − 2blog2 xc im Binärcode
Beispiel:
CodierungsmethodeGolomb,
x γ δ b = 31 0, 0, 0,02 10,0 100,0 0,103 10,1 100,1 0,114 110,00 101,00 10,05 110,01 101,01 10,106 110,10 101,10 10,117 110,11 101,11 110,08 1110,000 11000,000 110,10
I δ-Code benötigtblog2 xc+O(log log x)Bits
I für x < 15 γ-Codemeist besser, danachδ-Code nie schlechter
I γ- und δ-Code sindPräfix-frei(keine zusätzlichenBits, keinBacktracking beiDecodierung)
Generelles Codierungsschema
N Anzahl Dokumente der KollektionV = (v1, v2, v3, . . .) Vektor natürlicher Zahlen mit vj ≤ N
Codierung von Lauflänge x ≥ 1:
1. finde k ≥ 1 mitk−1∑j=1
vj < x ≤k∑
j=1
vj
2. codiere k in geeigneter Repräsentation
3. berechne Rest r = x −k−1∑j=1
vj − 1
4. Codiere r binär:I mit blog2 vkc Bits für r < 2dlog2 vke − vk ,I mit dlog2 vke Bits sonst.
(γ-Code entspricht Codierung mit V = (1, 2, 4, 8, 16, . . .))

Golomb-Code
benutzt Vektor VG = (b, b, b, . . .),k im 1er Code
Codierung ist optimal für b =⌈
log(2−p)−log(1−p)
⌉Annahme: geometrische Verteilung mit p=Wahrscheinlichkeit fürdas Auftreten eines Terms in einem Dokument→ Wahrscheinlichkeit für Lücke der Länge x : (1− p)x−1p
Effektive Komprimierung:I Golomb-Code für LauflängenI γ-Code für Vorkommenshäufigkeiten fd ,t
Boolesches RetrievalAlgorithmus für konjunktive Anfragen
1. For each query term t,1.1 Search the vocabulary for t.1.2 Record ft and the address of It , the inverted list for t.
2. Identify the query term t with the smallest ft .3. Read the corresponding inverted list. Use it to initialize C , the
list of candidates.4. For each remaining term t, in increasing order of ft ,
4.1 Read the inverted list, It .4.2 For each d ∈ C , if d 6∈ It , then set C ← C − {d}.4.3 If |C | = 0, return, since there are no answers.
5. For each d ∈ C ,5.1 Look up the address of document d .5.2 Retrieve document d and present it to the user.
Berechnungsaufwand zur Dekodierung
Prozessierung konjunktiver Anfragen:k Anzahl Dokumente im Zwischenergebnisp Häufigkeit des nächsten zu berücksichtigenden Terms (Anzahl
Einträge in der invertierten Liste)td Rechenzeit zur Decodierung eines EintragsTd Rechenzeit zur Decodierung der invertierten Liste:
Td = tdp
Verbesserung: Zweistufige Struktur invertierter Listen
invertierte Liste:〈5, 1〉〈8, 1〉〈12, 2〉〈13, 3〉〈15, 1〉〈18, 1〉〈23, 2〉〈28, 1〉〈29, 1〉....
Lauflängencodierung:〈5, 1〉〈3, 1〉〈4, 2〉〈1, 3〉〈2, 1〉〈3, 1〉〈5, 2〉〈5, 1〉〈1, 1〉....
Sprünge über je 3 Dokumente:〈〈5, a2〉〉〈5, 1〉〈3, 1〉〈4, 2〉〈〈13, a3〉〉〈1, 3〉〈2, 1〉〈3, 1〉〈〈23, a4〉〉〈5, 2〉〈5, 1〉〈1, 1〉〈〈40, a5〉〉....
Codierung der Adressen als Differenzen, Weglassen der Nummerdes ersten Dokumentes jeder Gruppe:〈〈5, a2〉〉〈1〉〈3, 1〉〈4, 2〉〈〈8, a3 − a2〉〉〈3〉〈2, 1〉〈3, 1〉〈〈10, a4 − a3〉〉〈2〉〈5, 1〉〈1, 1〉〈〈17, a5 − a4〉〉....
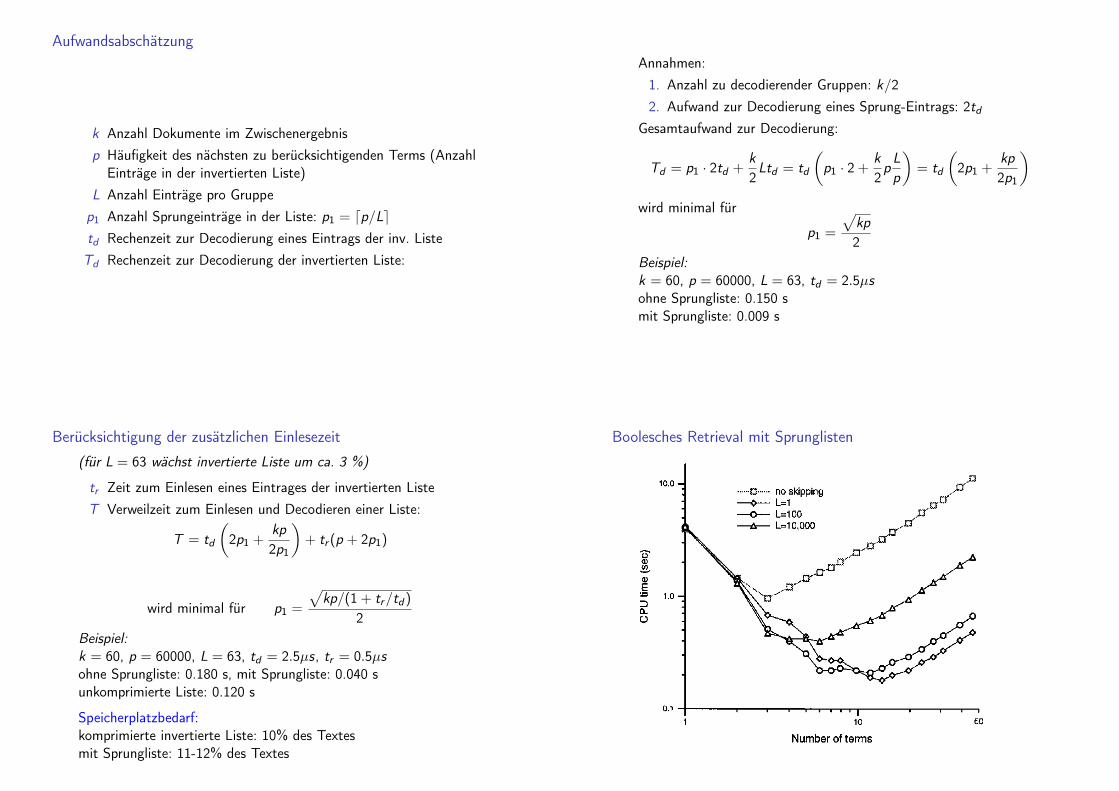
Aufwandsabschätzung
k Anzahl Dokumente im Zwischenergebnisp Häufigkeit des nächsten zu berücksichtigenden Terms (Anzahl
Einträge in der invertierten Liste)L Anzahl Einträge pro Gruppep1 Anzahl Sprungeinträge in der Liste: p1 = dp/Letd Rechenzeit zur Decodierung eines Eintrags der inv. ListeTd Rechenzeit zur Decodierung der invertierten Liste:
Annahmen:1. Anzahl zu decodierender Gruppen: k/22. Aufwand zur Decodierung eines Sprung-Eintrags: 2td
Gesamtaufwand zur Decodierung:
Td = p1 · 2td +k2Ltd = td
(p1 · 2 +
k2pLp
)= td
(2p1 +
kp2p1
)wird minimal für
p1 =
√kp2
Beispiel:k = 60, p = 60000, L = 63, td = 2.5µsohne Sprungliste: 0.150 smit Sprungliste: 0.009 s
Berücksichtigung der zusätzlichen Einlesezeit
(für L = 63 wächst invertierte Liste um ca. 3 %)
tr Zeit zum Einlesen eines Eintrages der invertierten ListeT Verweilzeit zum Einlesen und Decodieren einer Liste:
T = td
(2p1 +
kp2p1
)+ tr (p + 2p1)
wird minimal für p1 =
√kp/(1 + tr/td )
2Beispiel:k = 60, p = 60000, L = 63, td = 2.5µs, tr = 0.5µsohne Sprungliste: 0.180 s, mit Sprungliste: 0.040 sunkomprimierte Liste: 0.120 s
Speicherplatzbedarf:komprimierte invertierte Liste: 10% des Textesmit Sprungliste: 11-12% des Textes
Boolesches Retrieval mit Sprunglisten

Beobachtungen
I Verarbeitungszeit sinkt zunächst mit steigender Termzahl(warum?),steigt dann erst erwartungsgemäß an
I Sprunglisten beschleunigen die VerarbeitungI Gewinne erst ab drei TermenI optimale Sprunglänge hängt von der Anzahl Frageterme abI L=1: nur Decodierung der Dokumentnummer (warum?)
Ranking mit invertierten ListenNaiver Algorithmus
(Algorithmus für Cosinusmaß)1. For each document d in the collection, set accumulator Ad to
zero.2. For each term t in the query,
2.1 Retrieve It , the inverted list for t.2.2 For each 〈document number d , word frequency fd,t 〉 pointer
in It set A← Ad + wq,t · fd,t .3. For each document d , calculate Cd ← Ad/Wd , where Wd is
the length of document d , and Cd is the final value ofcosine(d , q).
4. Identify the r highest values of Cd , where r is the number ofrecords to be presented to the user.
5. For each document d so selected,5.1 Look up the address of document d .5.2 Retrieve document d and present it to the user.
Ranking mit Sprunglisten
a) Quit-AlgorithmusIdee: Häufige Terme (mit niedrigem idf-Gewicht) ignorierenK : Maximalzahl zu berücksichtigende Dokumente
1. Order the words in the query from highest to lowest.2. Set A← ∅; A is the current set of accumulators.3. For each term t in the query,
3.1 Retrieve It , the inverted list for t.3.2 For each 〈d , fd,t〉 pointer in It ,
3.2.1 If Ad ∈ A, calculate Ad ← Ad + wq,t · fd,t .3.2.2 Otherwise, set A← A + {Ad}, calculate Ad ← wq,t · fd,t .
3.3 If |A| > K , go to step 4
4. For each document d such that Ad ∈ A, calculateCd ← Ad/Wd .
5. Identify the r highest values of Cd .
b) Continue-Algorithmus
Idee: Häufige Terme nur zur Retrievalwertberechnungberücksichtigen, aber nicht zur Dokumentselektion
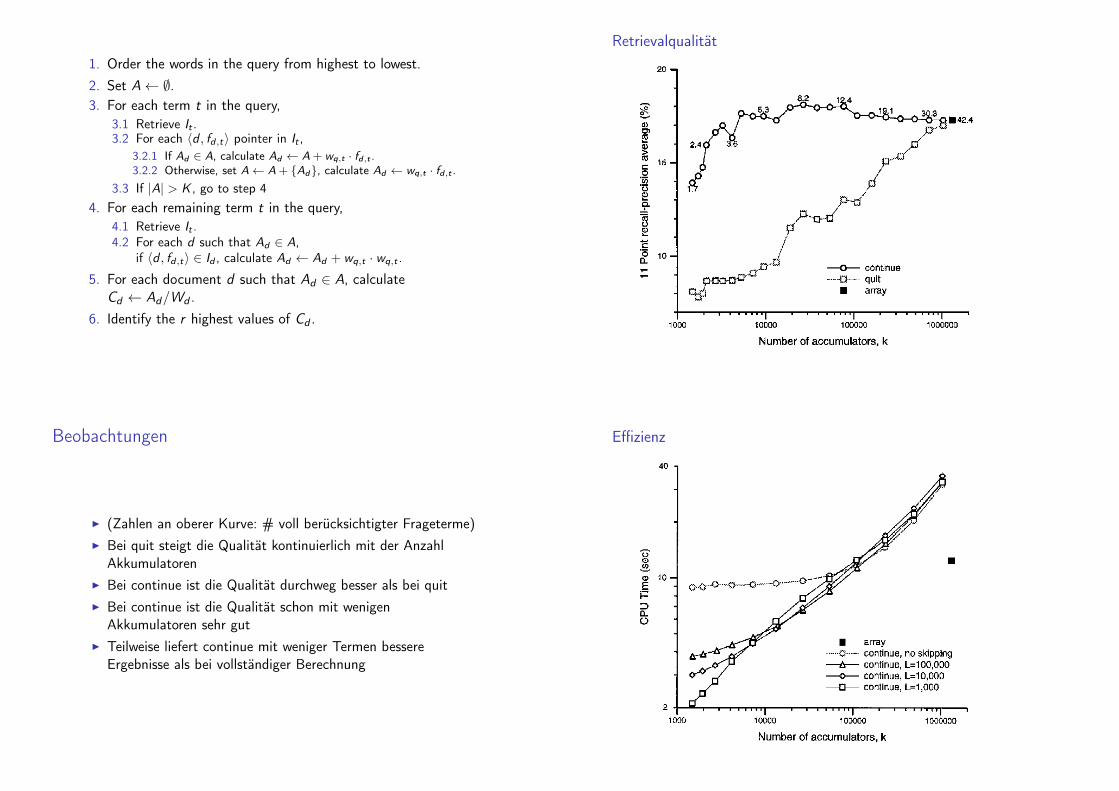
1. Order the words in the query from highest to lowest.2. Set A← ∅.3. For each term t in the query,
3.1 Retrieve It .3.2 For each 〈d , fd,t〉 pointer in It ,
3.2.1 If Ad ∈ A, calculate Ad ← A + wq,t · fd,t .3.2.2 Otherwise, set A← A + {Ad}, calculate Ad ← wq,t · fd,t .
3.3 If |A| > K , go to step 44. For each remaining term t in the query,
4.1 Retrieve It .4.2 For each d such that Ad ∈ A,
if 〈d , fd,t〉 ∈ Id , calculate Ad ← Ad + wq,t · wq,t .
5. For each document d such that Ad ∈ A, calculateCd ← Ad/Wd .
6. Identify the r highest values of Cd .
Retrievalqualität
Beobachtungen
I (Zahlen an oberer Kurve: # voll berücksichtigter Frageterme)I Bei quit steigt die Qualität kontinuierlich mit der Anzahl
AkkumulatorenI Bei continue ist die Qualität durchweg besser als bei quitI Bei continue ist die Qualität schon mit wenigen
Akkumulatoren sehr gutI Teilweise liefert continue mit weniger Termen bessere
Ergebnisse als bei vollständiger Berechnung
Effizienz

Beobachtungen
I Continue ist bis zu einer gewissen Anzahl Akkumulatorenschneller als die volle Berechnung, danach langsamer (warum?)
I Ohne Sprunglisten ist Continue kaum schnellerI Bei wenigen Akkumulatoren (<= 3000) sind kürzere
Sprunglisten (L=1000) am bestenI Bei mehr Akkumulatoren hat die Länge der Sprungliste kaum
Einfluss
Google-Ranking
I nur konjunktive Anfragen (aber mit Ranking)I Partitionierung der invertierten Listen nach DokumentenI Anfrage wird jeweils durch ein Cluster von Rechnern bearbeitetI invertierte Listen werden komplett im Hauptspeicher gehaltenI zusätzliche Beschleunigung durch Caching von
Anfrageergebnissen
Dokumentweise Partitionierung invertierter Listen
C1: Dok. 1-100t1 1 20 65 95t3 3t5 20 35
C2: Dok. 101-200t2 101 120 195t3 103t4 120 135t5 111 135 199
C3: Dok. 201-300t1 201 222 295t2 203t5 222 235 295
Anfrage: t1, t5C1: 20C3: 222, 295
PAT-TreesGrundkonzepte
I Dokumentkollektion als ein StringDoc1() Doc2() Doc3( Ch1() Ch2() )Doc4( Tit() Abstr()
Sec1( Subs1() Subs2() ) Sec2() ) Doc5()I Berücksichtigung der Dokumentstruktur bei der Suche möglich
Suche Section, in der “PAT” vorkommtI Position = sistring (semi-infinite string)

Definitionen
I sistring = String ab Position bis Ende des Gesamtstrings,ID=PositionString: THIS IS A SAMPLE STRINGsistrings:01 - THIS IS A SAMPLE STRING02 - HIS IS A SAMPLE STRING03 - IS IS A SAMPLE STRING04 - S IS A SAMPLE STRING05 - IS A SAMPLE STRING06 - IS A SAMPLE STRING07 - S A SAMPLE STRING08 - A SAMPLE STRING...
I lexikographische Ordnung auf den sistrings“A SA...” < “AMP...” < “E ST...”
PAT-Tree = Patricia-Tree aller sistrings eines Textes
PAT-Tree = Patricia-Tree aller sistrings eines TextesPatricia-Tree:
I Binärer DigitalbaumI n Blattknoten mit Schlüsselwerten (IDs)I n − 1 interne Knoten
(Wert = absolute / relative Position im sistring)01100100010111 −− Text12345678901234 −− Position
2
7
3
5
4 8
0 1
0
3
5 1
100 10
0
2
36
0 1
100
4
2
11
1
Algorithmen auf PAT-Trees
Präfix-Suche01100100010111 −− Text12345678901234 −− Position
2
7
3
5
4 8
0 1
0
3
5 1
100 10
0
2
36
0 1
100
4
2
11
1
Prefix = 100
Suche nach 100* liefert Teilbaum mit 3 und 6(Suche muß übersprungene Bits kontrollieren)
Reihenfolge
01100100010111 −− Text12345678901234 −− Position
2
7
3
5
4 8
0 1
0
3
5 1
100 10
0
2
36
0 1
100
4
2
11
1
"01",*,"00"
1. Suche der einzelnen Wörter(liefert Teilbäume)
2. Bildung aller korrekten Kombinationen von externen Knoten
Bereichssuche
01100100010111 −− Text12345678901234 −− Position
2
7
3
5
4 8
0 1
0
3
5 1
100 10
0
2
36
0 1
100
4
2
11
1
"0010 ... 1001"
Längste Wiederholung
01100100010111 −− Text12345678901234 −− Position
2
7
3
5
4 8
0 1
0
3
5 1
100 10
0
2
36
0 1
100
4
2
11
1
Suche nach internem Knoten mit dem größten Abstand zur Wurzel
Häufigkeitssuche
01100100010111 −− Text12345678901234 −− Position
2
7
3
5
4 8
0 1
0
3
5 1
100 10
0
2
36
0 1
100
4
2
11
1
Suche nach internem Knoten mit den meisten Knoten imzugehörigen Teilbaumhäufigstes Bigram = 00kommt 3mal vor
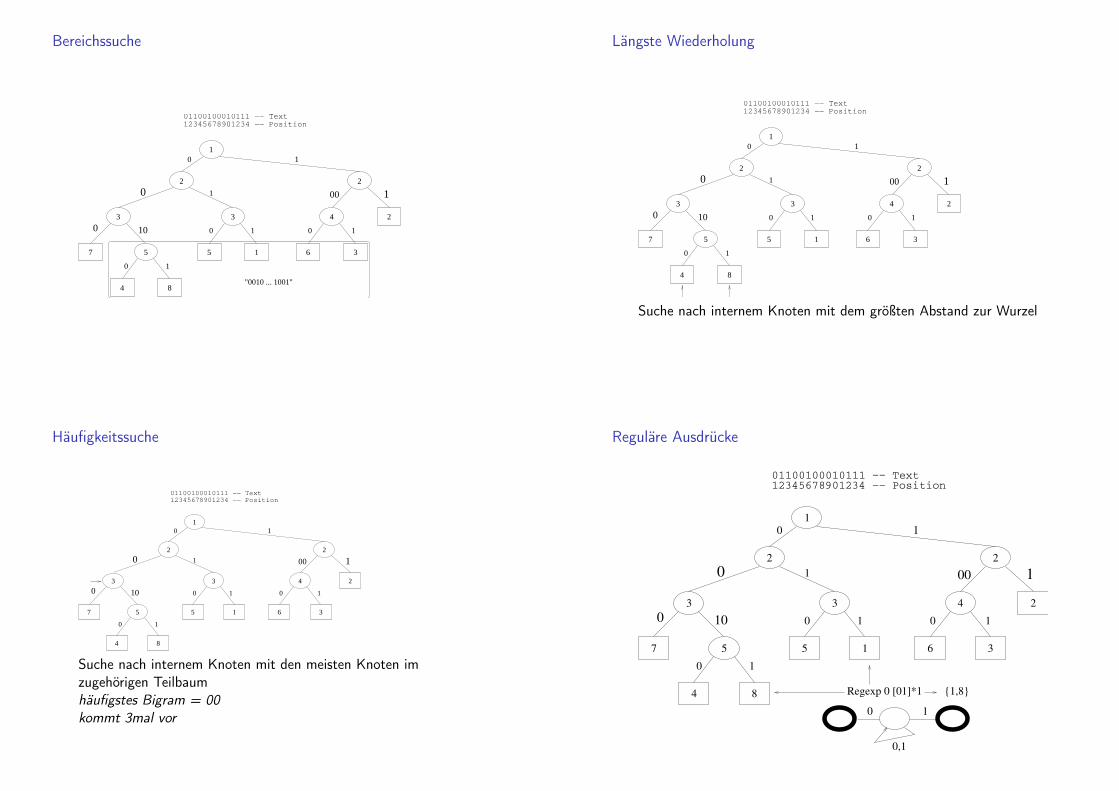
Reguläre Ausdrücke
01100100010111 −− Text
12345678901234 −− Position
2
7
3
5
4 8
0 1
0
3
5 1
100 10
0
2
36
0 1
100
4
2
1
0 1
0,1
1
1
Regexp 0 [01]*1 {1,8}

PAT Arrays
I Sortierte sistrings → Array mit IDsI Präfix- und Bereichssuchen als (indirekte) binäre SucheI Andere Operationen aufwändiger
0 1 1 0 0 1 0 0 0 1 0 1 1 1 ...
PAT array
Text
7 4 8 5 1 6 3 2
Signaturen (Bloom-Filter)Das Signaturkonzept
GrundideeAbbildung von Wörtern und Texten auf Bitstrings fester Länge(=Signaturen)Suchoperationen auf Signaturen effizienter als auf den Texten,weitere Beschleunigung durch spezielle Speicherungsformen für dieSignaturen möglich
Signatur:
S :=< b1, b2, . . . , bL > mit bi ∈ {0, 1}, L ∈ N
Erzeugung von Signaturen durch surjektive Abbildung von Wörternauf Bitstrings (i.a. durch Hashing)Homonyme: gleiche Signaturen für verschiedene Wörter
Arten von Signaturen:
a) Binärsignaturen:Abbildung von Wörtern auf alle 2L möglichen SignaturenSignaturoperator =Sprüft die Gleichheit von Anfrage- und Satzsignatur
b) überlagerungsfähige Signaturen:Wert einer Signatur wird nur durch die gesetzten Bits bestimmtg = Signaturgewicht = # gesetzter Bits(für alle Wörter gleich)→ Abbildung von Wörtern auf
(Lg
)verschiedene Signaturen
Überlagerung :
durch ODER-Verknüpfung der Signaturen
text 010010001000 S1search 010000100100 S2methods 100100000001 S3
110110101101 S1 ∨ S2 ∨ S3
Vor- und Nachteile überlagerungsfähiger Signaturen:– Entstehung von Phantomen (gesetzte Bits sind nicht mehr
eindeutig den Ausgangssignaturen zuzuordnen)+ Bildung von Indexstrukturen möglich+ Block Superimposed Coding zur Abbildung einer Menge von
Wörtern auf eine einzige Signatur

Signaturoperator ⊇Sprüft das Enthaltensein der Anfragesignatur in einer Satzsignatur:
S ⊇S SQ ⇔ (∀)((1 ≤ i ≤ L) ∧ ((bQi = 1)⇒ (bi = 1))),
S , SQ ∈ SL.
Zurückführung auf effiziente Bitoperationen:
S ⊇S SQ ⇔ S ∧ SQ = SQ ⇔ (¬S) ∧ SQ = 0S
text search methods 110110101101in search of knowledge-based IR 010110101110an optical system for full text search 010110101100the lexicon and IR 101001001001
Anfrage:text search 010010101100
false drops:
fehlerhafte Antworten (entstehen durch Homonyme und Phantome)
Im Folgenden nur überlagerungsfähiger Signaturen
Prinzipielle Organisation eines Signatur-Systems
Q
Q Q
Q
Zugriffs−
manager
Masken−
generator
Adress−
Auswahl−
Komponente
Vergleichs−
komponente
Signatur−
Datei
Daten−
Datei
R A
Q
S
D
S
R
CodierungsmethodenDisjoint Coding
(auch word coding genannt, wenn auf Wörter angewendet)Jedes Wort wird einzeln auf eine Signatur abgebildet, die in dieserForm gespeichert wird (abgesehen von einer möglichenanschließenden Komprimierung, hier nicht betrachtet)
Notationen:L Länge der Signaturg Signaturgewicht (Anzahl gesetzter 1-Bits)
SP = SP(L, g): Signaturpotential= # verschiedener erzeugbarer Kodierungen

Maximierung des Signaturpotentials
für vorgegebene Signaturlänge L:
SP =
(Lg
)=
L!
g !(L− g)!maximal für g = L
2
Beweisskizze:Da(Lg
)=( LL−g), nur Betrachtung von g ≤ bL2c notwendig.
Annahme, dass SP1 = SP(L, bL2c) und
SP2 = SP(L, bL2c − 1) = SP1 ·g
L− (g − 1).
Wegen g ≤ L2 folgt SP2 ≤ SP1 ·
( ⌊L2
⌋⌊L2
⌋+ 1
)< SP1
Anschließend Induktionsbeweis über g und über L
Fehlerrate
F Fehlerrate = # zu erwartende Fehler(fälschlicherweise gefundene Signaturen)
W Wörterbuchgröße(# Types= #verschiedener Wörter)
N # Satzsignaturen
Abbildung der Wörter auf Signaturen:W verschiedene Wörter auf SP =
( Lb L2 c)verschiedene Signaturen
→ einer Signatur sind im Mittel WSP Types zugeordnet
Retrieval für ein bestimmtes Wort liefert WSP − 1 Signaturen zu
anderen Wörtern→ Erwartete Fehlerrate:
F =
(WSP− 1)
NW
(1)
Festlegung der Signaturlänge für eine bestimmte Anwendung
Signaturpotential als Funktion der Fehlerrate, der Wörterbuchgrößeund des Datenvolumens:
SP =W · N
F ·W + N
daraus Berechnung der Signaturlänge möglich
L g SP8 4 70
16 8 12 87024 12 2 704 15632 16 601 080 390
Blockweise Codierung von WörternAbbildung der Menge der Wörter, die in einem Textblock auftreten,auf eine Folge von SignaturenB Anzahl der Blöckew Anzahl (verschiedener) Wörter pro Block
Fehlerrate bei blockweiser Codierungbei zufälliger Verteilung von x Token eines Wortes über B Blöcke:
I W., dass ein Token nicht in einem bestimmten Block auftritt:1− 1
BI W., dass keines von x Token in einem bestimmten Block
auftritt: 1− (1− 1B )x
I Erwartungswert für die Anzahl Blöcke, in denen das Wortauftritt:
B(1−
(1− 1
B
)x)

Im Mittel B·wSP Token pro Signatur
mit x = B·wSP folgt für erfolglose Anfragen
F ≈ B
(1−
(1− 1
B
)B·wSP)
≈ B(1− exp
(− wSP
))≈ B · w
SP
Fehlerwahrscheinlichkeit:
f ≈ 1− exp(− w
SP
)≈ w
SP
Block Superimposed CodingÜberlagerung mehrerer Signaturen (durch ODER-Verknüpfung)erlaubt Abbildung einer Menge von Wörtern(z.B. eines Textblocks) auf eine einzige Signatur
L Länge der Signaturg Gewicht (= Anzahl gesetzter Bits) für ein einzelnes Wortλ Anzahl überlagerte Wortsignaturent Anzahl gesetzter Bits in der überlagerten Signatur
Wahrscheinlichkeit, dass durch Überlagerung von λ Wortsignaturender Länge L mit Gewicht g eine Signatur entsteht, die an tbestimmten Stellen eine 1 enthält:
p(L, g , λ, t) =t∑
j=1
(−1)j(tj
)((L−jg
)(Lg
) )λ
Für kleine t, λ: p(L, g , λ, t) ≈ [p(L, g , λ, 1)]t = (1− (1− gL
)λ)t
Abschätzung der Fehlerwahrscheinlichkeit
F Anzahl FehlerN Anzahl Datensätze
f (t) Fehlerwahrscheinlichkeit, f (t) = F/N
Annahme dass sich kein Treffer unter den Datensätzen befindet→ f (t) = p(L, g , λ, t)
SpeicherungsstrukturenSequentielle Signaturen
b∗1 b∗
2 b∗3 b∗
4 b∗5 b∗
6 b∗7 b∗
8 @RS1 0 0 1 0 1 0 1 1 @r1S2 1 0 1 1 1 0 0 0 @r2S3 0 1 1 0 0 1 1 0 @r3S4 1 0 0 1 0 1 1 1 @r4S5 1 1 1 0 0 1 0 0 @r5S6 0 1 1 0 0 1 0 1 @r6S7 1 0 0 0 1 0 1 0 @r7S8 0 0 0 1 1 1 0 1 @r8
Sequentielle Speicherung der Signaturen zusammen mit denAdressen der Datensätze

L Länge der Signatur (in Bits)size@ Länge einer Adressesizep Seitengrößesizer Größe eines Datensatzes
N Anzahl Datensätze
M Anzahl Datenseiten =
N⌊sizepsizer
⌋
Platzbedarf für eine Signatur mit Adresse:⌈L
8
⌉+ size@
Anzahl Einträge pro Seite: K =
⌊sizeP⌈L
8
⌉+ size@
⌋Speicherplatzbedarf (in Seiten)
SeqS =
⌈NK
⌉+ M
Anzahl Seitenzugriffe für Datenbank-Operationen
F Anzahl false dropsD Anzahl echter Treffer
Retrieve:
SeqR =
⌈NK
⌉+ F + D
Insert: Bei Freispeicherverwaltung in Listenform je ein Lese-und Schreibzugriff für Signatur- und Datenseite
SeqI = 2 + 2 = 4
Delete: Annahme: Adresse des Datensatzes bekannt →sequentielle Suche in den Signaturseiten
SeqD =
⌈N
2 · K
⌉+ 1 + 2 =
⌈N
2 · K
⌉+ 3
Bitscheibenorganisation
b∗1 b∗
2 b∗3 b∗
4 b∗5 b∗
6 b∗7 b∗
8 @RS1 0 0 1 0 1 0 1 1 @r1S2 1 0 1 1 1 0 0 0 @r2S3 0 1 1 0 0 1 1 0 @r3S4 1 0 0 1 0 1 1 1 @r4S5 1 1 1 0 0 1 0 0 @r5S6 0 1 1 0 0 1 0 1 @r6S7 1 0 0 0 1 0 1 0 @r7S8 0 0 0 1 1 1 0 1 @r8
Speicherung jeder Bitscheibe allein auf einer Seite,Vektor mit Datensatzadressen getrennt
Anfrage: S i ⊇S < 10100000 >
b∗r = b∗1 ∧ b∗3 =
01011010
∧
11101100
=
01001000
Ergebnisbitliste: b∗r =
qγ(SQ)∧j=q1
bj , qi ∈ {q|(1 ≤ q ≤ L) ∧ bQq = 1}
Adresse der Trefferkandidaten: R = {i |bir = 1}

Disjunktive Anfragen
S(Q1) ∨ S(Q2) ∨ . . . S(Qd ):
Im Prinzip getrennte Prozessierung,nur Einsparung bei übereinstimmenden 1-Bits in den S(Qi ) möglich
Anzahl Seitenzugriffe für Datenbank-Operationen
Speicherbedarf für eine Bitscheibe: d N8·sizep e
Retrieve:γ(Q): AnfragegewichtZugriffe auf die angesprochenen Bitscheiben +Zuordnungstabelle und Datenseiten für alle Treffer
BSR =
(γ(Q)
⌈N
8 · sizep
⌉+ Z + F + D
)Z : Anzahl Seitenzugriffe auf die ZuordnungstabelleR : # Seiten der Zuordnungstabelle
R =
N⌊sizepsize@
⌋ Z = R ·
(1−
(1− 1
R
)(F+D))
→ ineffizient bei hohen Anfragegewichten
Insert:γ(S): Signaturgewicht des DatensatzesBitscheibenblöcke vorher mit 0 initialisiert →Zu ändern:γ(S) Bitscheibenseiten + Zuordnungstabelle + Datenseite
BS I = 2 · γ(S) + 2 + 2.
Delete:Suche des Eintrages (mit bekannter Satzadresse) über die SignaturZu ändern:1er-Bitscheibenseiten + Zuordnungstabelle + Datenseite
BSD = γ ·(⌈
N8 · sizep
⌉+ 1)
+ Z + 2
Speicherplatzbedarf (in Seiten):
BSS = L ·⌈
N8 · sizep
⌉+
⌈N · size@
sizep
⌉+ M.
Zweistufiges Signaturverfahren
Kombination von Bitscheiben- und sequentieller OrganisationZwei Signaturen für jeden Datensatz:(mit unabhängigen Signaturfunktionen berechnet)1. Signatur wie bei sequentieller Organisation als Bitstring in
Seiten gespeichert.Signatur-Seiten werden in Segmente unterteilt
2. Signaturen werden segmentweise überlagert, bildenSegmentsignatur.Segmentsignaturen werden in Bitscheibenorganisationverwaltet
Anfrageprozessierung:1. Berechnung der beiden Anfragesignaturen2. Bestimmung der zu durchsuchenden Segmente über die
Segmentsignatur3. Sequentielles Durchsuchen der Segmente mit der 1. Signatur

Quick Filter
Kombination von Signaturen mit HashingI Signaturen sind in Seiten organisiertI Zuordnung der Signaturen zu den Seiten über Hashing
Lineares Hashinglineare Hash-Funktion g bildet Schlüssel auf den Adressraum(0, 1, . . . , n − 1) ab, wobei 2h−1 < n ≤ 2h für ein h ∈ NIh: # Anzahl Stufen der Signaturdateig muß Split-Funktion sein, die für jeden Schlüssel K die Bedingungerfüllt:
g(K , h, n) =
{g(K , h − 1, n) oderg(K , h − 1, n) + 2h
n Primärseitenjede Primärseite hat 0 oder mehr Überlaufseiten (mit derPrimärseite verkettet)
Einfügen eines neuen Schlüssels:
1. Berechnung der Seitennummer p = g(K , h, n).2. Wenn möglich, Einfügen des Schlüssels in die Seite p.3. Sonst Abspeichern in einer Überlaufseite zu p.4. Bei Überlauf wird der Adreßraum von n auf n + 1 vergrößert
Vergrößerung des Adreßraums:SP : Zeiger auf die nächste zu splittende Seite1. Anlegen einer neuen Primärseite n2. Verteilung des Inhalts der Seite SP und der zugehörigen
Überlaufseiten durch neue Hashfunktion auf die Seiten SP undn.
3. n := n + 14. h wird erhöht, wenn die Seite 0 gesplittet werden soll.5. SP := (SP + 1) mod 2h−1
Hash-Funktion für Signaturen
N Signaturen Si =< b1, . . . , bL >
g(Si , h, n) =
{ ∑h−1r=0 bL−r2
r , falls∑h−1
r=0 bL−r2r < n∑h−2
r=0 bL−r2r , sonst
(2)
Quick Filter: Beispiel
S1: 00011110 S2: 11010001 S3: 00111100S4: 11000011 S5: 00110110 S6: 11001001
Zu Beginn sei h = 0, n = 1 und g(Si , 0, 1) = 0
Step 0. P0: empty SP = 0, h = 0, n = 1Step 1. P0: S1 SP = 0, h = 0, n = 1Step 2. P0: S1 S2 SP = 0, h = 0, n = 1Step 3. P0: S1 S3 P1: S2 SP = 0, h = 1, n = 2Step 4. P0: S1 S3 P1: S2 S4 SP = 0, h = 1, n = 2Step 5. P0: S3 P1: S2 S4 P2: S1 S5 SP = 1, h = 2, n = 3Step 6. P0: S3 P1: S2 S6 P2: S1 S5 P3: S4 SP = 0, h = 2, n = 4
P0: 00111100 P1: 11010001 11001001P2: 00011110 00110110 P3: 11000011

Retrieval
Bestimmung der möglichen Signaturseiten aus der Anfragesignatur:Anzahl zu lesender Seiten hängt vom Gewicht der AnfragesignaturQ ab, genauer:enthält Q j Einsen im h-Bit-Suffix h(Q), dann müssen höchstens2h−j Primärseiten und die zugehörigen Überlaufseiten gelesenwerdenAlgorithmus:1. P := g(Q, h, n)
2. if h(Q) ∩ P = h(Q) then {Signaturseite P lesen}3. P := P + 14. if P < n then goto 25. end
Beispiele: Q=xxxxxx11 → P3 lesenQ=xxxxxx01 → P1, P3 lesen
Vergleich der Speicherungsstrukturen
ProfilStruktur Retrieve Insert Delete Speichersequentiell selten dominant! selten dominantBitscheiben dominant wenig wenig wenigzweistufig dominant wenig wenig irrelevantQuick Filter wenig viel viel wenig















![Druppel Systemen [Ned]](https://img.pdfslide.tips/doc/110x75/568c384d1a28ab02359e7cf9/druppel-systemen-ned.jpg)













