Embed Size (px)
Citation preview

Improving Language-Universal Feature Extraction with Deep Maxout
and Convolutional Neural Networks
Yajie Miao, Florian MetzeCarnegie Mellon University
報告人:許曜麒日期: 2015/01/16
1

Abstract
Previous work has investigated the utility of multilingual
DNNs acting as language-universal feature extractors
(LUFEs).
1. We replace the standard sigmoid nonlinearity with the
recently proposed maxout units. (nice property of
generating sparse feature representations)
2. The convolutional neural network (CNN) architecture
is applied to obtain more invariant feature space.2
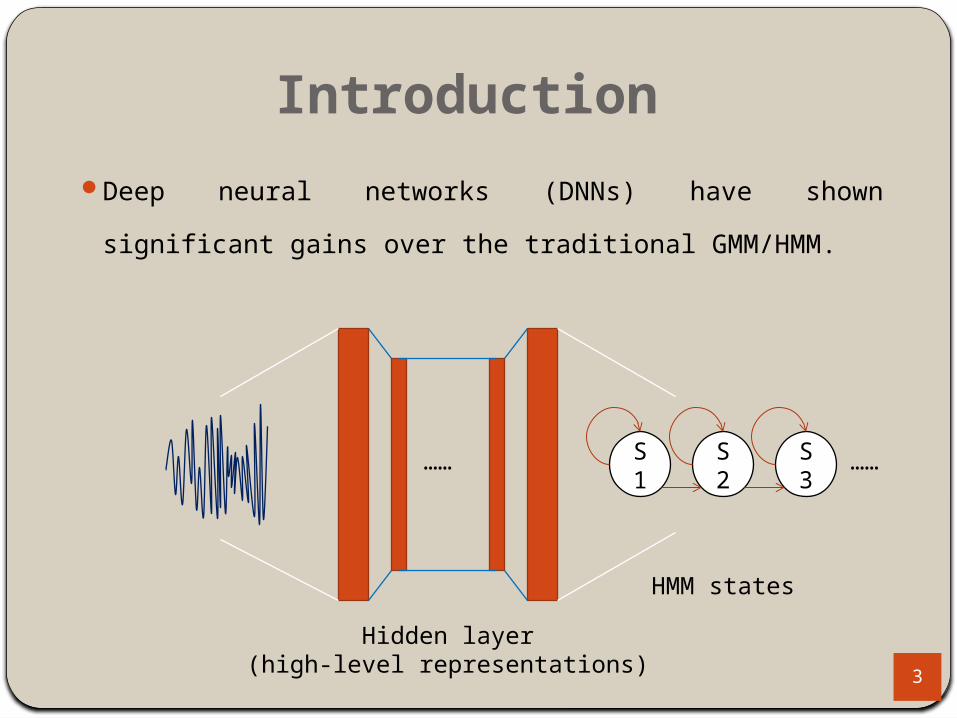
Introduction
Deep neural networks (DNNs) have shown significant
gains over the traditional GMM/HMM.
Hidden layer(high-level representations)
…… S1
S2
S3
……
HMM states
3

Introduction
These shared layers are taken as a language-universal
feature extractor (LUFE).
Given a new language, acoustic models can be built
over the outputs from the LUFE, instead of the raw
features (e.g., MFCCs).
4

Introduction
On the complex image and speech signals, sparse
features tend to give better classification accuracy
compared with non-sparse feature types.
CNN local filters and max-pooling layers, able to reduce
spectral variation in the speech data. Therefore, more
robust and invariant representations are expected to be
obtained from the CNN-LUFE feature extractor.
5
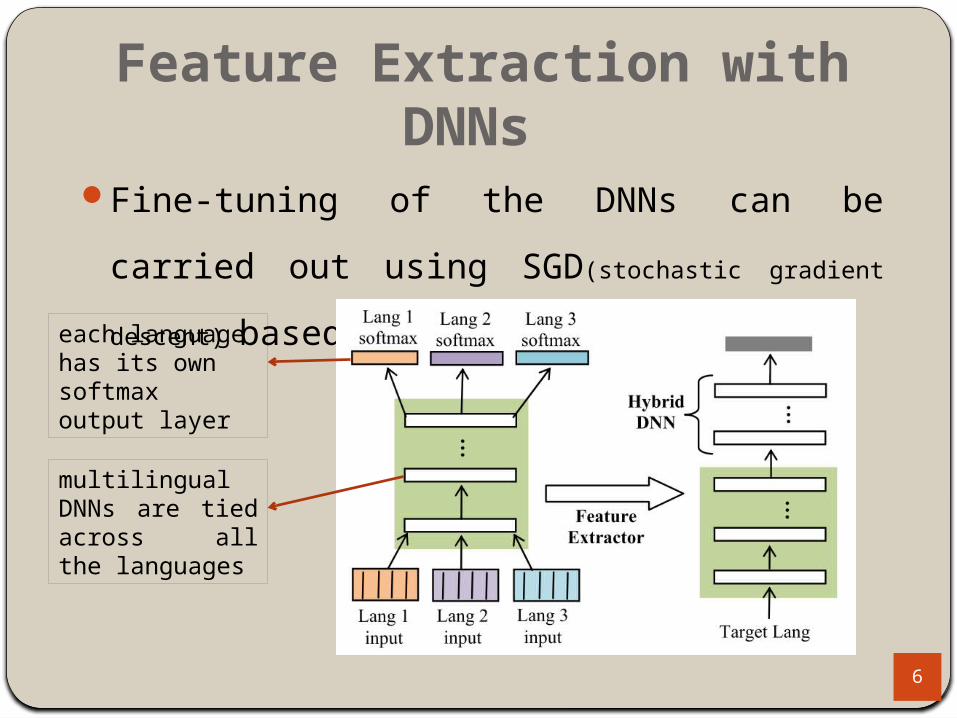
Feature Extraction with DNNs
Fine-tuning of the DNNs can be carried out using
SGD(stochastic gradient descent) based on mini-batches.
each language has its own softmax output layer
multilingual DNNs are tied across all the languages
6

SGD(stochastic gradient descent) 、BDG 、 Mini-batch gradient
BGD(batch GD)指的是,每次更新 θ的時候都需要
所有的資料集。這個演算法有兩個缺點:1. 資料集很大時,訓練過程計算量太大。
2. 需要得到所有的資料才能開始訓練。
SGD 是指一個樣本就 update 一次。常用於大規模
的訓練集,但容易收斂至局部最佳解。
Mini-batch GD 就是在兩個中取平衡,非 BGD 全部
的 batch 都考慮,也非 SGD 只考慮一個樣本。7

Feature Extraction with DNNs
作 者 提 出 的 方 法 與 前 兩 張 投 影 片 介 紹 的 Hybrid
DNN 有兩點不同:
1. Feature Extractor 的使用了全部的 hidden layer ,但
作者認為只需要部份的即可,例如使用接近 softmax
的 layer ,可能比較重要。
2. 在 Target language 的 部 分 , 作 者 建 立 一 個 DNN
model ,來取代單一的 softmax layer 。
8

LUFEs with Convolutional Networks
WHY CNN ? The CNN hidden activations become
invariant(cause max-pooling) to different types of
speech variability and provide better feature
representations.
In the convolution layer, we only consider filters along
frequency, assuming that the time variability can be
modeled by HMM.
9
𝑣1
𝑣2
𝑣3
𝑣4
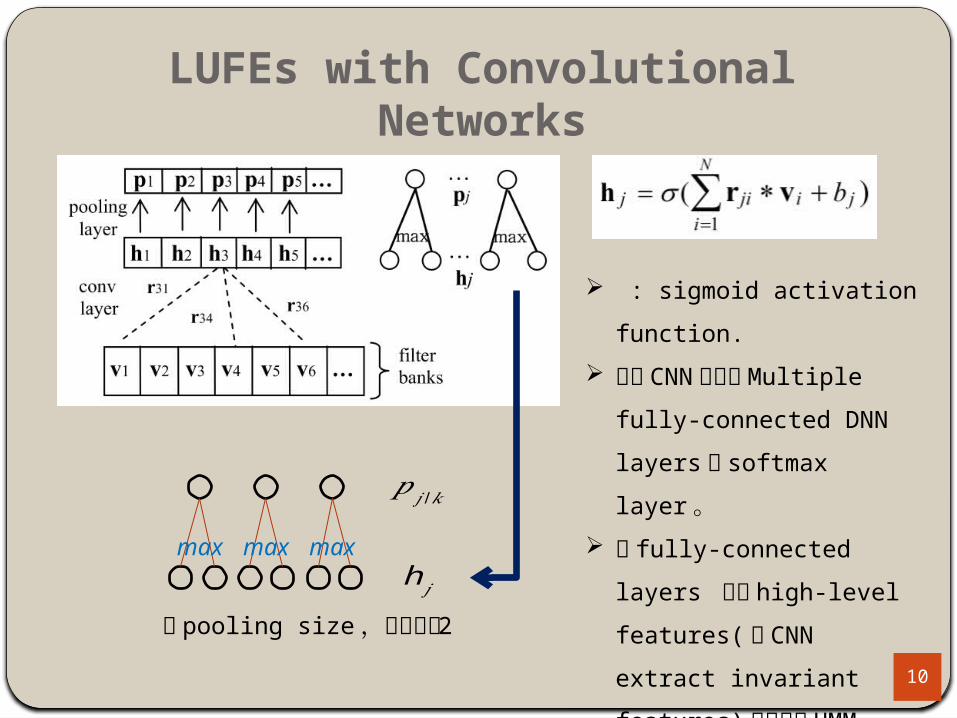
LUFEs with Convolutional Networks
10
: sigmoid activation function.
兩層 CNN 後在接 Multiple
fully-connected DNN layers 與softmax layer 。
當 fully-connected layers 輸入 high-level features( 指CNN extract invariant
features) ,在分類 HMM state
時較容易。
𝑝 𝑗 /𝑘
h 𝑗
為 pooling size ,此範例為 2
max max max

Sparse Feature Extraction
Our past study presents the deep
maxout networks (DMNs) for speech
recognition.
Compared with standard DNNs, DMNs
perform better on both hybrid systems
and bottleneck-feature (BNF) tandem
systems.
11
grouphiddenlayer
input BNF output

Sparse Feature Extraction
Sparse representations can be
generated from any of the maxout
layers via a non-maximum masking
operation.
We extend our previous idea from the
following three aspects.
12

Sparse Feature Extraction
• First, We compute population sparsity for each feature
type as a quantitative indicator.
13
:
:
(A lower pSparsity means higher sparsity of the features.)
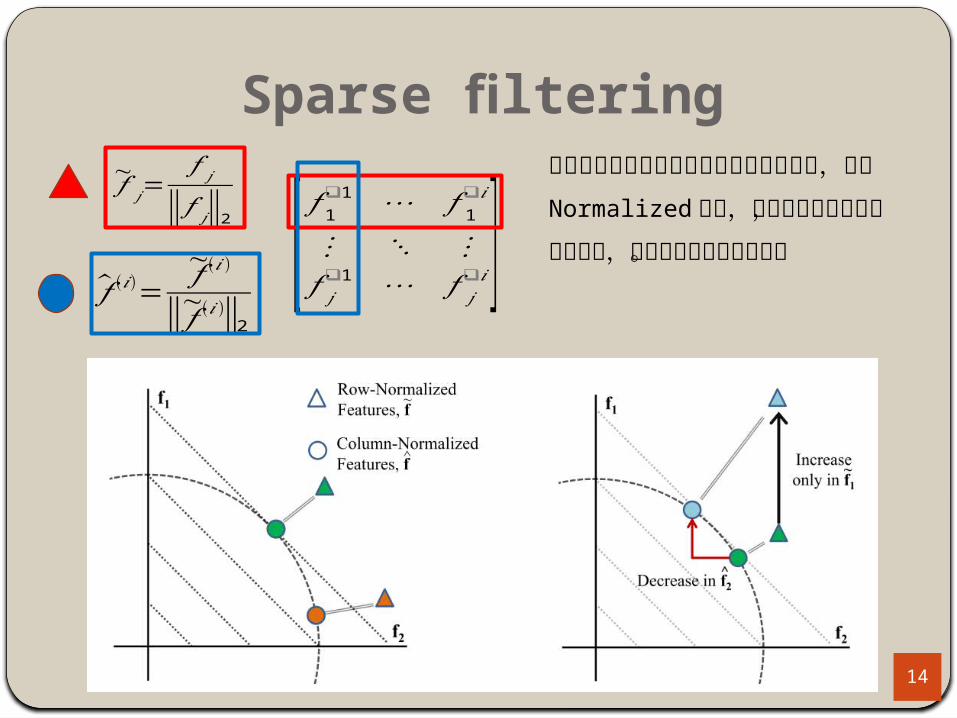
Sparse filtering
14
�̂� (𝑖)=~𝑓 (𝑖)
‖~𝑓 (𝑖)‖2
~𝑓 𝑗=
𝑓 𝑗
‖𝑓 𝑗‖2 [ 𝑓 1❑1 ⋯ 𝑓 1
❑𝑖
⋮ ⋱ ⋮𝑓 𝑗
❑1 ⋯ 𝑓 𝑗❑𝑖 ]
右圖是指藍色樣本相對綠色樣本只有增加,經過 Normalized
之後,藍色樣本不只增加,也會減少,代表特徵間具有競爭性。

Sparse Feature Extraction
Second, to better understand the impact of sparsity, we compare
DMNs against the rectifier networks.
DNNs consisting of rectifier units, referred to as deep rectifier
networks (DRNs)[ReLU], have shown competitive accuracy on
speech recognition.
The rectifier units have the activation function .
As a result, high-sparsity features can be naturally produced from a
DRN-based extractor, because many of the hidden outputs are
forced to 0.15

Sparse Feature Extraction
Third, DMNs are combined with CNNs to obtain both
sparse and invariant feature representations.
The CNN-DMN-LUFE extractor is structured in the
similar way as CNN-LUFE. The only difference is that
the fully-connected layers in CNNs are replaced by
maxout layers.
16

Experiments
We aim at improving speech recognition on the
Tagalog limited language pack.
In training time, Only 10 hours of telephone
conversation speech.(test time 2-hours)
On which feature extractors are trained.(Cantonese 、
Turkish 、 Pashto)
17
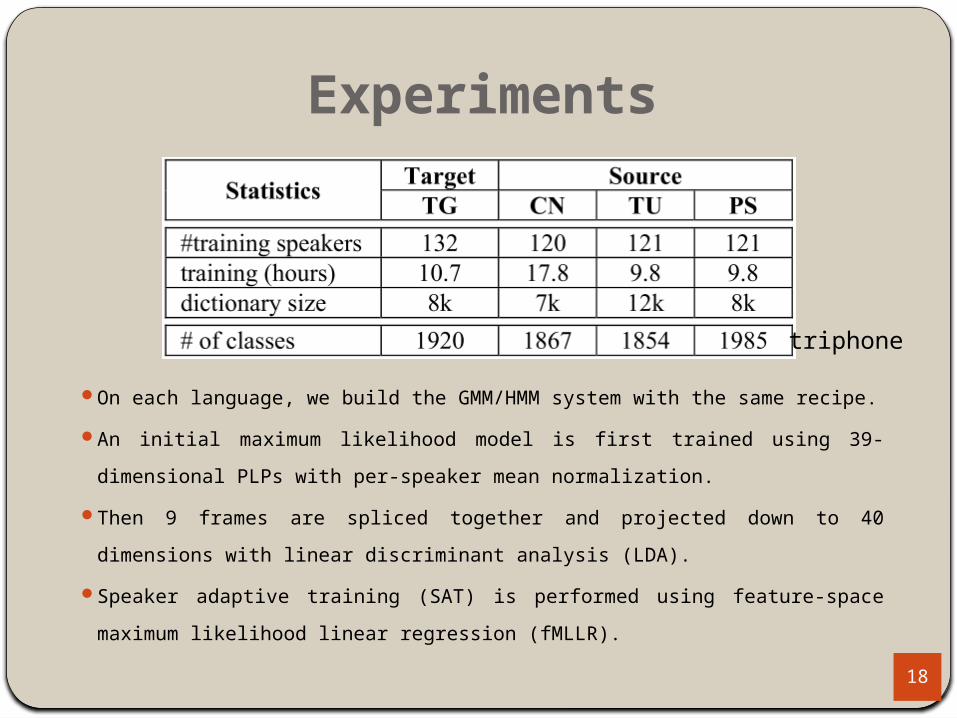
Experiments
On each language, we build the GMM/HMM system with the same recipe.
An initial maximum likelihood model is first trained using 39-dimensional PLPs with per-
speaker mean normalization.
Then 9 frames are spliced together and projected down to 40 dimensions with linear
discriminant analysis (LDA).
Speaker adaptive training (SAT) is performed using feature-space maximum likelihood
linear regression (fMLLR).18
triphone
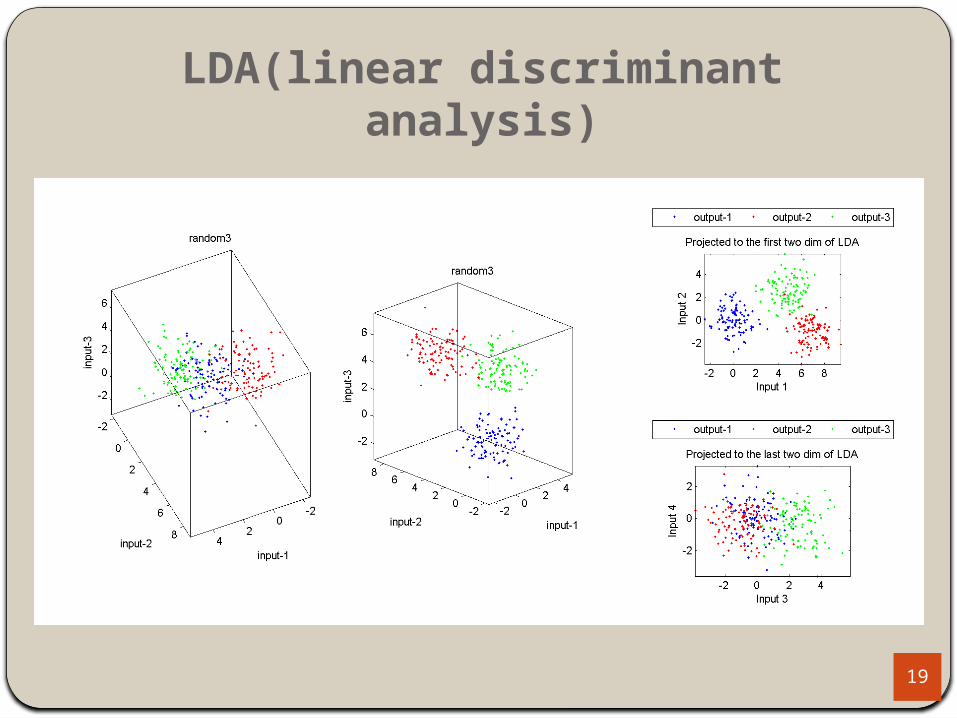
LDA(linear discriminant analysis)
19

Monolingual DNNs and CNNs
The DNN model has 6 hidden layers and 1024 units at
each layer.
DNN parameters are initialized with stacked denoising
autoencoders (SDAs).
Previous work has applied SDAs on LVCSR and
shown that SDAs perform comparably as RBMs for
DNN pre-training
20

Monolingual DNNs and CNNs
For CNNs, the size of the filter vectors is constantly
set to 5. We use a pooling size of 2.
21
convolution1 pooling1
100 feature map 200 feature map
convolution2 pooling2
output
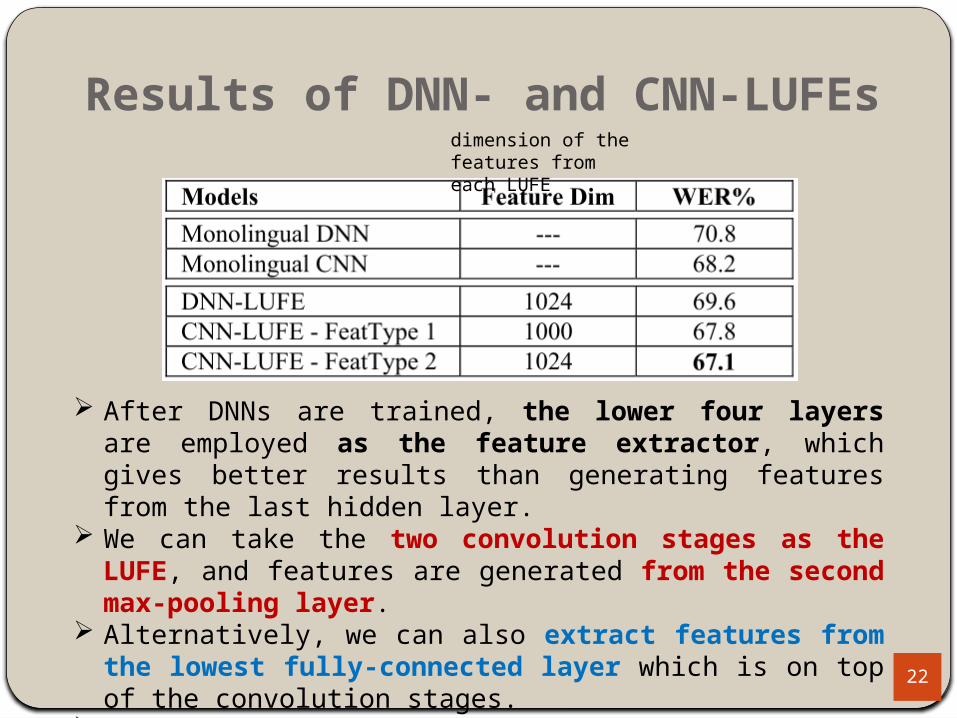
Results of DNN- and CNN-LUFEs
22
dimension of the features from each LUFE
After DNNs are trained, the lower four layers are employed as the feature extractor, which gives better results than generating features from the last hidden layer.
We can take the two convolution stages as the LUFE, and features are generated from the second max-pooling layer.
Alternatively, we can also extract features from the lowest fully-connected layer which is on top of the convolution stages.
These two manners of CNN feature extraction are called FeatType1 and FeatType2.

Results of DNN- and CNN-LUFEs
For fair comparison, the identical DNN topology, 4 hidden layers each
with 1024 units, is used for hybrid systems over different feature
extractors.
23
convolution1 pooling1
100 feature map 200 feature map
convolution2 pooling2
output
FeatType1FeatType2
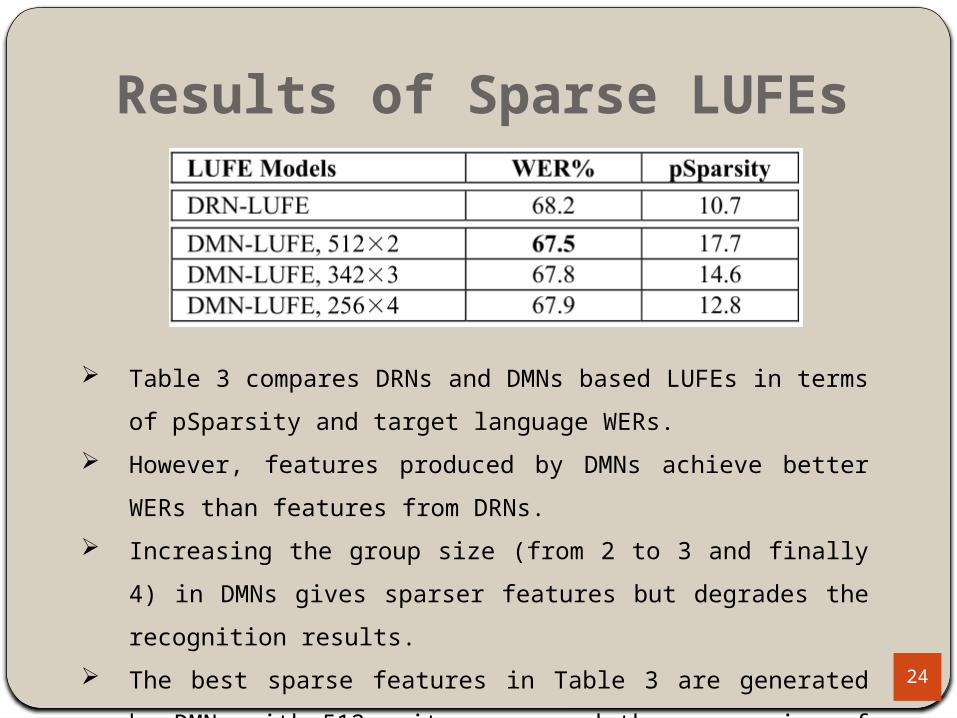
Results of Sparse LUFEs
24
Table 3 compares DRNs and DMNs based LUFEs in terms of pSparsity and
target language WERs.
However, features produced by DMNs achieve better WERs than features
from DRNs.
Increasing the group size (from 2 to 3 and finally 4) in DMNs gives sparser
features but degrades the recognition results.
The best sparse features in Table 3 are generated by DMNs with 512 unit
groups and the group size of 2 at each hidden layer.

Combining CNNs and DMNs
25
We replace the sigmoid fully-connected layers with maxout layers.
Compared with the CNN-LUFE, the CNN-DMN-LUFE generates
sparse features as well as target-language WER reduction.

Conclusions and Future Work
This paper has investigated the effectiveness of deep maxout and
convolutional networks in performing language-universal feature extraction.
1. In comparison with DNNs, CNNs generate better feature representations
and more WER improvement on cross-language hybrid systems.
2. Maxout networks have the property of generating sparse hidden outputs,
which makes the learned representations more interpretable and
explanatory.
3. CNN-DMN-LUFE, a hybrid of CNNs and maxout networks, results in
the best recognition performance on the target language.
26


















