Embed Size (px)
Citation preview

Incremental Mining of Information Interest for Personalized Web Scanning
Rey-Long Liu (劉瑞瓏 )
Dept. of Medical Informatics
Tzu Chi University

2
Problem Definition
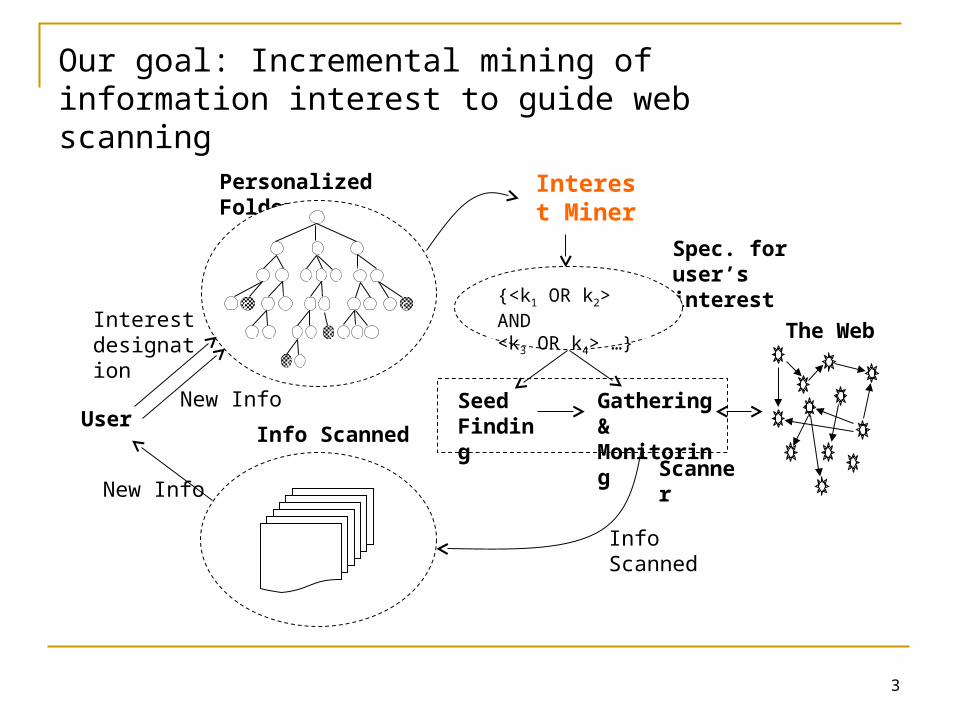
Personalized web scanning An environmental scanning routine for users and businesses A resource-consuming job (e.g. network bandwidth) Key issues
Seed finding Information crawling Information monitoring
Should be guided by proper information interest, which is both Implicit: The user is unable and/or unwilling to express the
interest, and Evolving: The interest may change although it is relatively long-
term
3
Spec. for user’s interest
Scanner
Seed FindingUser
Personalized Folder
C
R
C
n2
2
C
n
2
C
n
1
C
n
C
1
2
1
2
C
1
2
1
1
C
1
1
C
1
2
C
1
C
11
2
C
1
2
C
1
1
C
1
2
1
2
C
1
2
1
1
C
1
C
1
2
1
2
C
1
2
1
1
C
1
2
1
2
C
1
2
1
1
C
1
2
1
2
C
1
2
New Info
Interest designation
Info Scanned
New Info
Gathering & Monitoring
Interest Miner
The Web
Info Scanned
{<k1 OR k2> AND<k3 OR k4> …}
Our goal: Incremental mining of information interest to guide web scanning

4
Related Fields
Information gathering Aimed at “one-shot” information needs, rather than
relatively long-term needs Information monitoring
Aimed at the “dynamics” of information of interest (IOI), rather than the location of the IOI
Profile building for folders (categories) Aimed at information analysis (e.g. information
classification and similarity measurement), rather than the derivation of comprehensible specifications

5
Major Challenges Interest specifications should be both
Precise To direct the scanner to suitable info subspaces
Comprehensible To allow the user to refine the specifications, and To allow the search engines to find proper seeds for scanning
The specifications should be derived under the common condition that the user’s interest is often Implicit, Evolving, and Collectively defined by a hierarchy of folders in which each
folder’s context of discussion (COD) is implicitly expressed Example:
Root System Development Decision Support SystemsRoot Manufacturing Decision Support Systems
A folder’s COD is actually indicated by the profiles of its ancestors.

6
IMind
Main contributions Incrementally mining interest specifications which
are more Precise (by specifying each folder’s COD), and Comprehensible (in conjunctive normal form)
No predefined feature sets

7
Input A hierarchy T of folders, A set of folders G designated as the goals of web
scanning, and A set X of documents added to a folder f.
Output Update the profile of each related folder of f in T, For each folder g in G, if the interest specification
of g has changed, send the new specification to the scanner.

8
Example output of IMind
card, machine, PC, sound, printer, …
CPU, bit, instruction, register, processor, chip, …
file, information, window, system, site, server, …
…
… …
…
……
Computer & Internet
Hardware
Desktop Computers
Root
The interest specification for Desktop Computers:(file OR information OR window OR system OR site OR server OR …) AND(CPU OR bit OR instruction OR register OR processor OR chip OR …) AND(card OR machine OR PC OR sound OR printer OR …).

9
The algorithm
(1) W {w | w is a word in X, and w is not a stop word};(2) While (f is not the root of T) do
(2.1) Construct or update each 3-tuple <w, rw,f, dw,f> in the profile of f;(2.2) For each sibling b of f, update dw,b;(2.3) f parent of f;
(3) For each goal folder g in G, do(3.1) Ig Disjunction of the profile terms having higher rw,gdw,g values (a number
of profile terms in g are selected);(3.2) a parent of g;(3.3) While (a is not the root of T) do
(3.3.1) Ig Conjunction of Ig and disjunction of the terms having higher rw,adw,
a values (a number of profile terms in both a and g are selected);(3.3.2) a parent of a;
(3.4) If Ig specification of g, send Ig to the scanner to update the specification of g;
Incremental update of folder profiles
Derivation of interest specifications
10
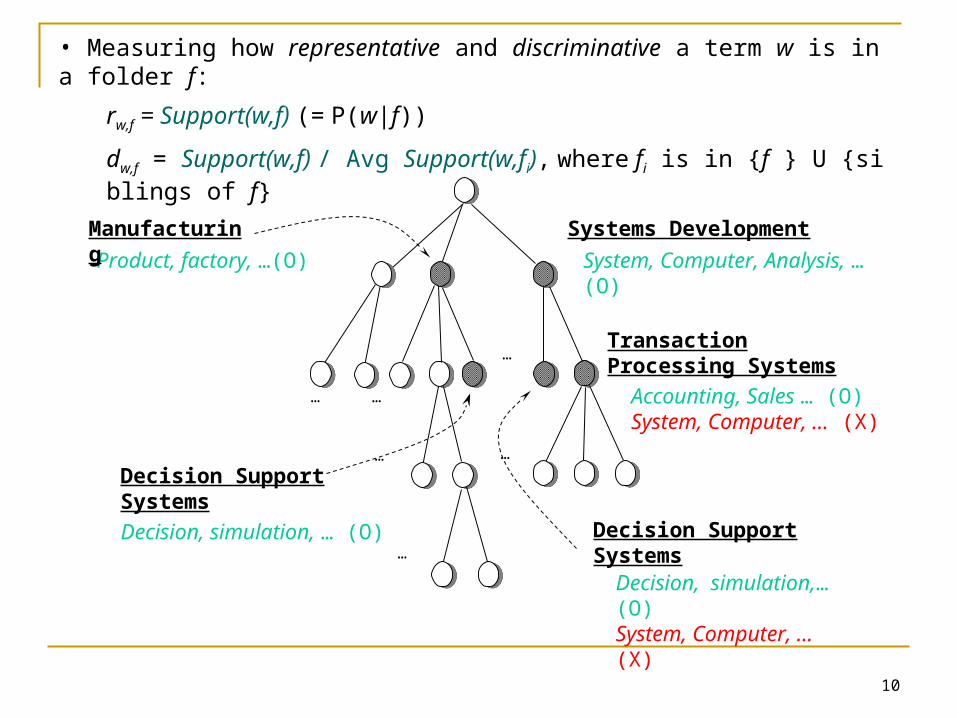
• Measuring how representative and discriminative a term w is in a folder f:
rw,f = Support(w,f) (= P(w|f))
dw,f = Support(w,f) / Avg Support(w,fi), where fi is in {f } U {siblings of f}
…
… …
…
……
System, Computer, Analysis, …(O)
Systems Development
Decision, simulation,… (O)System, Computer, … (X)
Decision Support Systems
Transaction Processing Systems
Accounting, Sales … (O)System, Computer, … (X)
Product, factory, …(O)
Manufacturing
Decision, simulation, … (O)
Decision Support Systems
11
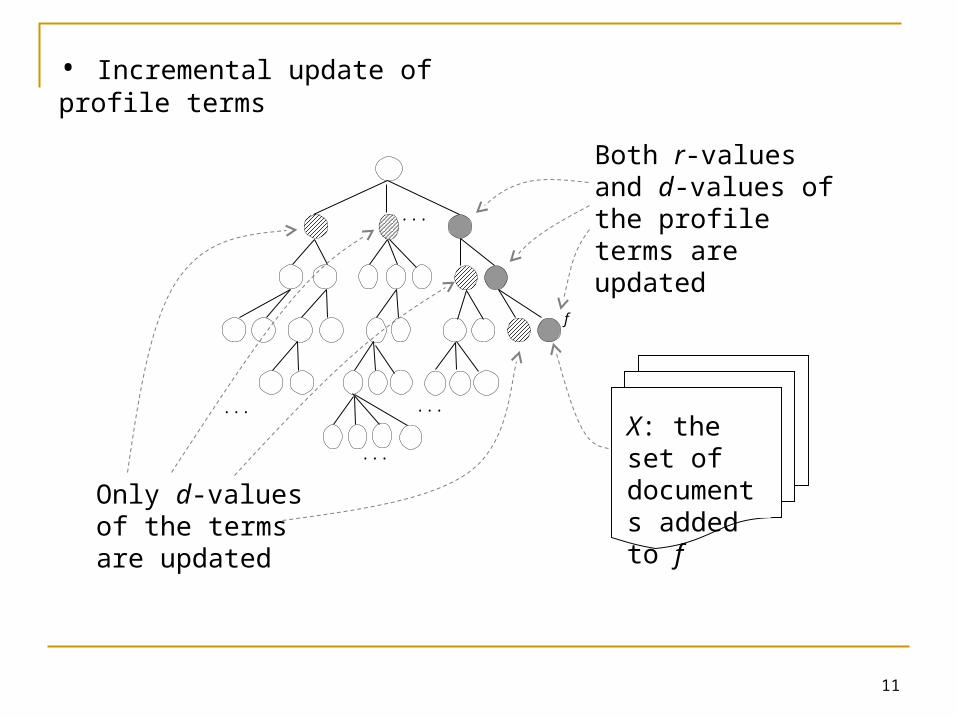
• Incremental update of profile terms
f
Both r-values and d-values of the profile terms are updated ‧‧‧
‧‧‧
‧‧‧
‧‧‧
Only d-values of the terms are updated
X: the set of documents added to f

12
Complexity of Incremental Mining Space complexity
O(Nt), where N is the total number of different terms accumulated, and t is the number of folders in the hierarchy
Time complexity Profile mining (step 2)
The maximum number of updates is iBiN, where Bi is the number of siblings of the level-i ancestor of f (i.e. the ancestor whose level is
i) plus one (i.e. including the level-i ancestor) Specification derivation (step 3)
The maximum number of operations required to update interest specifications is iji,jN, where i,j is the number of descendant goal folders of the jth sibling of the level-i ancestor of
f
Note: The above numbers should be much smaller in practice, since each folder is quite unlikely to contain all terms (i.e. N terms)

13
Empirical Evaluation Experimental Data
Source: Yahoo! (http://www.yahoo.com) Coverage: Computers & Internet, Society and Culture, and
Science The larger hierarchy:
261 folders, among which 174 were leaf folders, among which 142 are not duplicate (and set as goal folders)
2844 documents The smaller hierarchy:
169 folders, among which 119 were leaf folders, among which 109 are not duplicate (and set as goal folders)
3615 documents

14
Evaluation method Sending the specifications to Yahoo!
Other search engines were tried as well. However, they limited the number of terms in a query and/or did not return the category of the web sites Google (http://www.google.com), Lycos (http://www.lycos.com), Open Directory Project (ODP, http://www.dmoz.org), AltaVista (http://www.altavista.com), and Netscape (http://www.netscape.com)
Yahoo! returns web sites and their categories Top 200 web sites are considered
In practice, the web scanner may process only a limited number of seeds
Yahoo! claims to sort the relevance of each web site by her complicated and proprietary algorithm

15
Evaluation criteria Completeness
Average sites found per folder Reliability
Percentage of folders with sites retrieved

16
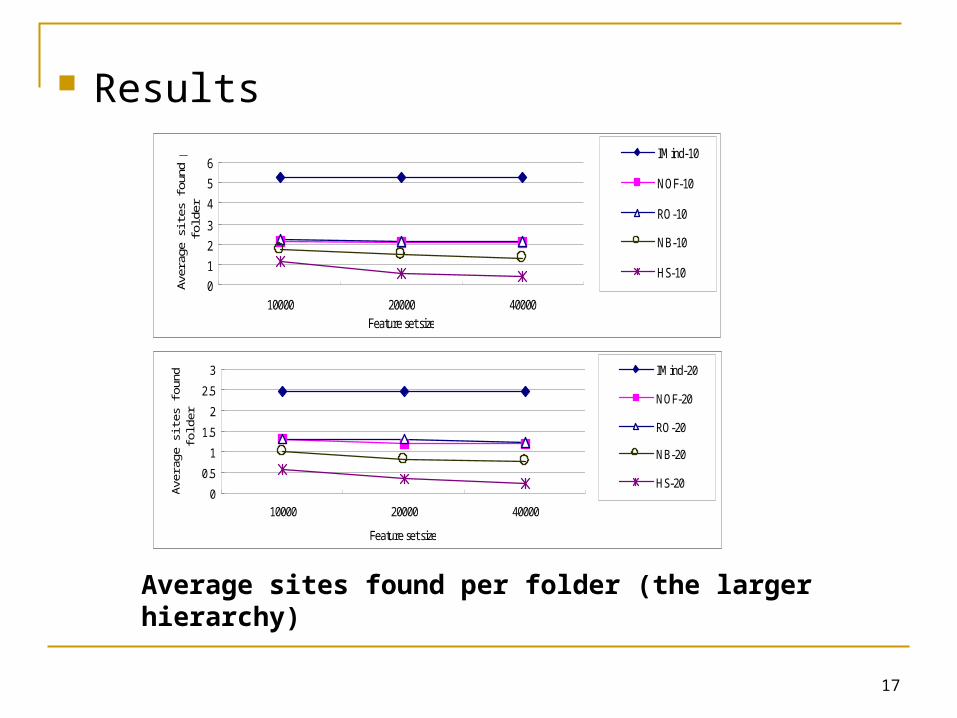
Systems evaluated IMind (with = 10 and 20) Baselines (with the same number of terms as IMind)
Vector-based approach Norm-of-the-folder (NOF)
The profile of the folder was a vector constructed by averaging the document vectors in the folder
Rocchio’s method (RO) The profile was a vector constructed by computing a weighted sum o
f the positive document vectors and the negative document vectors Probability-based approach
Naive Bayes (NB) The profile was constructed by estimating the conditional probabiliti
es of the terms in the folder Hierarchical approach
Hierarchical Shrinkage (HS) The profile was constructed by employing the hierarchical relationsh
ips (e.g. sibling) among folders to refine the estimates of the conditional probabilities produced by NB
17
Results
0
1
2
3
4
5
6
10000 20000 40000Feature set size
Aver
age
sites
foun
d pe
rfo
lder
IMind-10
NOF-10
RO-10
NB-10
HS-10
0
0.5
1
1.5
2
2.5
3
10000 20000 40000
Feature set size
Aver
age
sites
foun
d pe
rfo
lder
IMind-20
NOF-20
RO-20
NB-20
HS-20
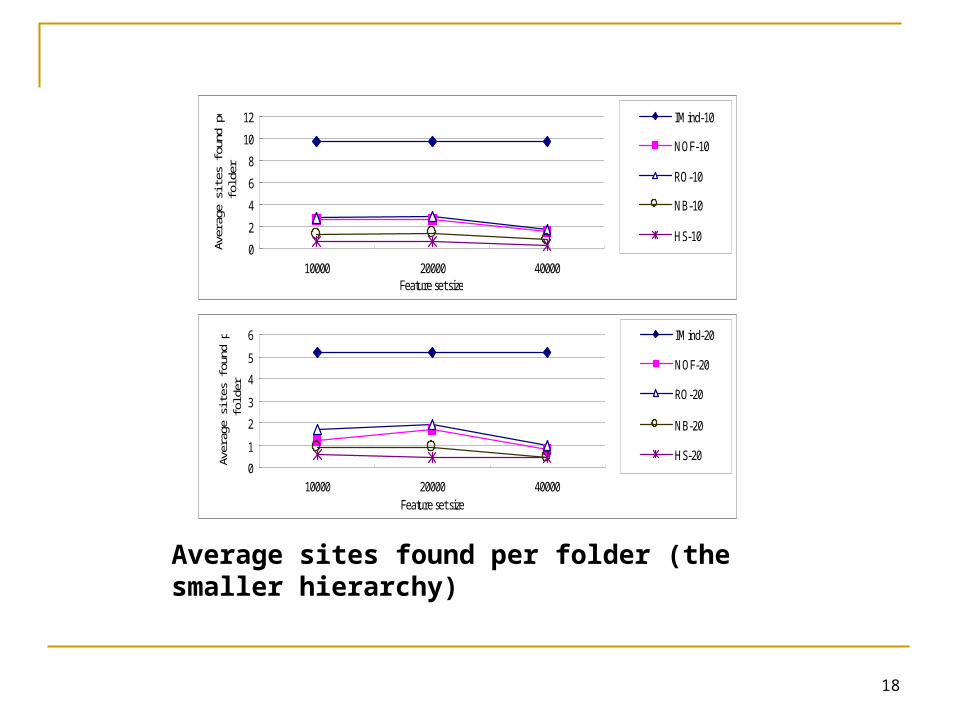
Average sites found per folder (the larger hierarchy)
18
0
2
4
6
8
10
12
10000 20000 40000Feature set size
Aver
age
sites
foun
d pe
rfo
lder
IMind-10
NOF-10
RO-10
NB-10
HS-10
0
1
2
3
4
5
6
10000 20000 40000Feature set size
Aver
age
sites
foun
d pe
rfo
lder
IMind-20
NOF-20
RO-20
NB-20
HS-20
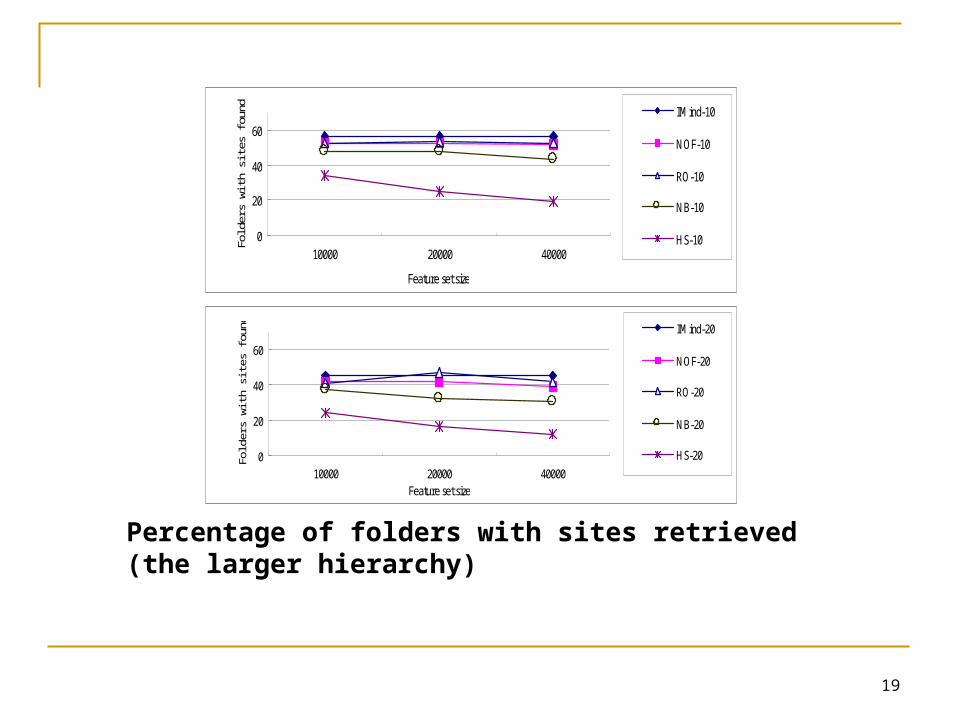
Average sites found per folder (the smaller hierarchy)
19
0
20
40
60
10000 20000 40000
Feature set size
Fold
ers w
ith si
tes f
ound
(%)
IMind-10
NOF-10
RO-10
NB-10
HS-10
0
20
40
60
10000 20000 40000Feature set size
Fold
ers w
ith si
tes f
ound
(%)
IMind-20
NOF-20
RO-20
NB-20
HS-20
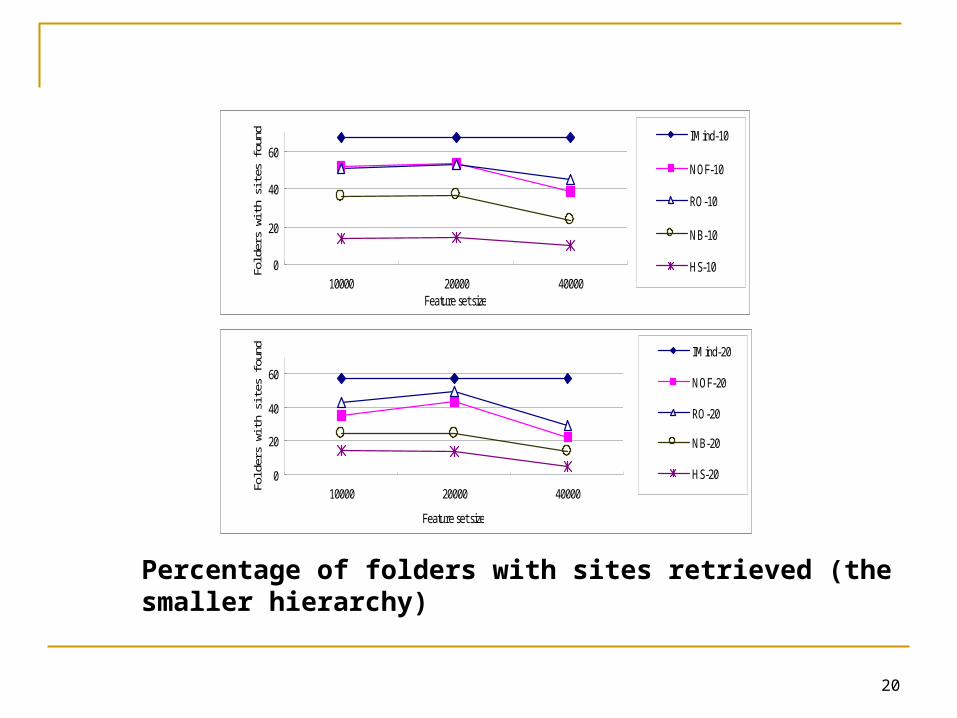
Percentage of folders with sites retrieved (the larger hierarchy)
20
0
20
40
60
10000 20000 40000Feature set size
Fold
ers w
ith si
tes fo
und
(%)
IMind-10
NOF-10
RO-10
NB-10
HS-10
0
20
40
60
10000 20000 40000
Feature set size
Fold
ers w
ith si
tes f
ound
(%)
IMind-20
NOF-20
RO-20
NB-20
HS-20
Percentage of folders with sites retrieved (the smaller hierarchy)

21
More specially, the results showed that IMind derived more precise specifications
Making seed finding both more complete and reliable Some specifications derived by the baselines were too
vague for Yahoo! to process Yahoo! did not respond to 2, 3, 19, and 78 queries generated by
RO-20, NOF-20, NB-20, and HS-20, respectively IMind derived more comprehensible specifications
Specifying each level of COD of each folder IMind improved more when more training data
was given Contributing more significant improvements on the
smaller hierarchy, which has more training documents IMind does not require feature set tuning
Demonstrating more stable performance

22
IMind successfully controlled the time spent to process each document The time mainly depends on the number of terms in
related folders, while the number should converge to a certain limit
0
5
10
15
20
0 500 1000 1500 2000 2500
Document ID
Tim
e Sp
ent (
Sec.
)
Time spent for individual documents sequentially added into the larger hierarchy (running on a PC with a CPU running in 2.6 GHz and a RAM whose size was 2 GB)

23
Conclusion
Personalized web scanning needs to be guided by the user’s information interest, which is both implicit and evolving
IMind is an incremental text mining system to derive precise and comprehensible interest specifications

24
Extension
How can the user refine the specifications mined? An intelligent interface to guide the refinement
How can the length of the specifications be determined more intelligently? Automatic thresholding Manual setting
25
More related extensions
Information Scanning:
Autonomous scanning, Adaptive discovery, Adaptive monitoring, & Adaptive elicitation
Information Analysis:Exception management, Trend detection, Association detection, Even tracking, & Novelty detection
Information/Knowledge Classification & Filtering:
Semantic context recognition, Integrated filtering and classification, & Incremental context mining
Environmental Information:Partners, Customers, Competitors, Government, & News providers
Internal Information:
Transaction Data, Knowledge shared, & Information shared
Information/Knowledge Delivery:Intelligent information retrieval, Adaptive online guidance, Adaptive dissemination, People finding, Knowledge finding, Knowledge map, & Computer-Assisted Instruction

ThanksThanks





























