Embed Size (px)
Citation preview

Facoltà di Ingegneria Corso di Studi in Ingegneria Informatica Elaborato finale in Basi di Dati
Indici per i Linked Open Data
Anno Accademico 2011/2012 Candidato: Dario Sarnelli matr. N46/000107


III
Indice
Introduzione 4
Capitolo 1. Evoluzione dei Linked Open Data e Web Semantico 6
1.1 Verso i linked open data: open government e open data 6
1.1.1 Open Government 7
1.1.2 Open Data 8
1.2. Linked Open Data: dati a 5 stelle 10
1.3 Funzioni e Vantaggi dei Linked Open Data 11
1.4 Rappresentazione dei Linked Open Data: il modello RDF 14
1.4.1 Il Contesto 16
1.4.2 RDF Schema 16
Capitolo 2. Indici per i Linked Open Data 17
2.1 Cos’è un indice? 17
2.2 Classificazione delle tecniche di Indicizzazione 18
2.2.1 Tecniche di indicizzazione locali 19
2.2.2 Tecniche di indicizzazione distribuite 29
2.2.3 Tecniche di indicizzazione globali 29
Conclusioni 30
Bibliografia 31

Indici per i Linked Open Data
4
Introduzione
Il web, per come lo si conosce e per come è stato concepito fin dalle sue origini, è un
grande agglomerato di informazioni, di documenti. Nel tempo esso si è espanso sempre
più velocemente e nel conteso contemporaneo risulta essere un immenso sistema che
contiene informazioni di ogni tipo in una infinità di formati diversi. I dati però spesso non
sono disponibili direttamente poiché risultano essere nascosti ed esibiti in base a
specifiche necessità dei gestori dei siti web. Considerando la prospettiva di un singolo
essere umano che legge una pagina web, questo è un bene ma per una macchina che esegue
una scansione del web (un crawler) non è il massimo della semplicità.Il presente elaborato
mira a considerare una concezione del web come caratterizzato da dati interpretabili nel
loro significato anche dalle macchine concernente la liberazione dei dati dai formati e dalle
formattazioni. Lo stesso Tim Berners Lee, inventore del World Wide Web, sostiene una
sorta di movimento che ha come motto «Raw Data Now» («dati grezzi subito»)e tali dati
“puri” (Raw Data) possono essere collegati tra loro (Linked Data) e strutturati. Più
specificamente nel primo capitolo di tale elaborato viene data particolare importanza al
paradigma LOD e alla sua evoluzione nel corso del tempo a partire dai cosiddetti “Open
Government” fino a descrivere il concetto in sé di “Open Data”. In particolare con
“Linked” Open Data ci si riferisce a dati pubblicati sul web in una modalità leggibile e
interpretabile da una macchina, il cui significato sia esplicitamente definito tramite una
stringa costituita da parole e marcatori. Si costruisce così un reticolo di dati connessi

Indici per i Linked Open Data
5
appartenenti a un dominio (che costituisce il contesto di partenza), collegato a sua volta ad
altri set di dati esterni, ovvero fuori dal dominio, in un contesto di relazioni sempre più
estese. Quello che si vuole fare è rendere i dati il più possibile aperti e integrabili. Per
riuscire in questo intento nel tempo si è formato uno standard per tali dati strutturati
chiamato RDF (Resource Description Framework ) che risulta essere dunque il data
model più utilizzato per l’epressione dei linked data. Uno dei problemi che può riguardare
i LOD è proprio la presenza di grandi quantità di dati; infatti data una query risulta molto
difficile determinare quale fonte dati deve essere selezionata come risultato di tale
richiesta; è inoltre complicato ma soprattutto inefficiente andare a eseguire una ricerca
completa tra tutti i possibili dati proprio a causa della troppa vastità di quest’ultimi.
Sarà dunque indispensabile utilizzare una tecnica di indicizzazione sui dati per ottenere
risultati di ricerca più precisi e performanti. Ed è proprio partendo dal concetto di indice in
quanto tale, che nel secondo capitolo di tale lavoro ne vengono definite le funzionalità e
utilità; Un indice (nel campo dei database) è infatti una struttura dati realizzata per
migliorare i tempi di ricerca (query) dei dati. Se una tabella non ha indici, ogni ricerca
obbliga il sistema a leggere tutti i dati presenti in essa. L'indice consente invece di ridurre
l'insieme dei dati da leggere per completare la ricerca. Nel secondo capitolo vengono
inoltre analizzate alcune tecniche di indicizzazione che considerano il modello RDF
specifiche per i Linked Open Data come la Path Index, Keyword Index e Quad Index.

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
6
Capitolo 1
Evoluzione dei Linked Open data e Web Semantico
1.1 Verso i linked open data : open government e open data
L'espressione Linked Open Data è stata coniata nel 2006 da Tim Berners-Lee1 in una
pagina del suo ipertesto “Design Issues”2 rivolta al Web semantico; Il termine definisce in
maniera specifica delle regole per la pubblicazione dei dati sul Web per far si che essi
possano essere individuati facilmente, collegati e manipolati dalle macchine
indipendentemente dalla loro provenienza. Tale meccanismo permette di ampliare la
visibilità dei dati che sono localizzati tramite URL, per cui il loro uso porterà un aumento
del traffico verso il sito web dell’ente produttore del dato grezzo3.
1 Informatico britannico, co-inventore insieme a Robert Cailliau del World Wide Web
2 Tim Berners-Lee, Linked Data, http://www.w3.org/DesignIssues/LinkedData.html 2006-2009. 3 http://www.culturaitalia.it/opencms/linked_open_data_it.jsp

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
7
1.1.1 Open Government
Per comprendere però a fondo l’iniziativa Linked Open Data è importante considerarne
l’origine; il paradigma L.O.D nasce infatti dalla Direttiva sull’Open
Government4 (dicembre 2009) firmata da Barack Obama, in cui è possibile leggere “Fin
dove possibile e sottostando alle sole restrizioni valide, le agenzie devono pubblicare le
informazioni on line utilizzando un formato aperto (open) che possa cioè essere recuperato,
soggetto ad azioni di download, indicizzato e ricercato attraverso le applicazioni di ricerca
web più comunemente utilizzate. Per formato open si intende un formato indipendente
rispetto alla piattaforma, leggibile dall’elaboratore e reso disponibile al pubblico senza che
sia impedito il riuso dell’informazione veicolata”. È proprio da tale dottrina che è stata
coniata la definizione di Open Government Data, con l’intento di ottenere l’accesso libero
e proattivo ai dati di uno specifico dominio: istituzioni politiche e pubblica
amministrazione. La dottrina dell’Open Government si basa sul principio per il quale tutte
le attività dei Governi e delle Amministrazioni dello Stato devono essere aperte e
disponibili per incoraggiare azioni efficaci e assicurare un controllo diffuso sulla gestione
delle questioni pubbliche. Tale paradigma va sostanzialmente a ridefinire il rapporto tra
Pubblica Amministrazione e cittadino, spostando il focus della relazione da un approccio
orientato all’erogazione di servizi in cui il cittadino fruisce di prestazioni elargite
dall’Amministrazione ad un approccio basato su una collaborazione reale, in cui il
cittadino partecipa alle scelte governative. In tal senso, l’Open Government si basa su tre
elementi :
Trasparenza(che promuove la responsabilità dando ai cittadini le informazioni sulle
attività dell’Amministrazione); Partecipazione e Collaborazione dei cittadini.
Con l’Open Government si va quindi nella direzione di un’Amministrazione aperta in
grado di costruire una relazione di fiducia con il cittadino. Mettere a disposizione del
cittadino e delle imprese l’insieme dei dati pubblici gestiti dall’Amministrazione in
formato aperto rappresenta un passo culturale fondamentale per il rinnovamento delle
4 http://www.datagov.it/open-government/

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
8
istituzioni nella direzione di apertura e trasparenza a tutti i livelli amministrativi, proprie
dell’Open Government5.
1.1.2 Open data
Le politiche e le pratiche di apertura dei dati dell’Amministrazione trattate fin qui,
rientrano nella definizione del concetto di Open Data. Una definizione comunemente
accettata di Open Data è quella fornita dall’Open Data Manual 6, che descrive gli Open
Data come “dati che possono essere liberamente utilizzati, riutilizzati e redistribuiti, con
la sola limitazione – al massimo – della richiesta di attribuzione dell’autore e della
redistribuzione allo stesso modo (ossia senza che vengano effettuate modifiche);Un
insieme di dati pubblicati prende il nome di dataset”. È bene differenziare sin da subito
il concetto di trasparenza da quello di apertura. Il concetto di apertura include quello di
trasparenza, ma non necessariamente è vero il contrario. In altri termini, non è sufficiente
la trasparenza così come definita nel nostro ordinamento giuridico perché si possa parlare
di Open Data.
Partendo dal concetto di conoscenza aperta così come delineato dalla Open Knowledge
Foundation 7, anche l’Open Data può essere caratterizzato dai seguenti principi
8:
- Disponibilità e accesso: i dati devono essere disponibili nel loro complesso, per un
prezzo non superiore a un ragionevole costo di riproduzione, preferibilmente mediante
scaricamento da Internet e devono essere inoltre disponibili in un formato utile e
modificabile.
5 http://www.dati.gov.it 6 Manuale sugli open data che discute aspetti giuridici, sociali e tecnici dei “dati aperti” dedicato specialmente a chi
vuole “aprire dati”
7 Fondazione non profit con lo scopo di promuovere l'apertura dei contenuti e i dati aperti. Fu fondata il 24
maggio 2004 a Cambridge (Regno Unito). 8 http://www.datagov.it/open-government/

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
9
- Riutilizzo e ridistribuzione: i dati devono essere forniti a condizioni tali da permetterne il
riutilizzo e la ridistribuzione.
- Partecipazione universale: tutti devono essere in grado di usare, riutilizzare e ridistribuire
i dati.
Per garantire i principi sopra elencati è necessario che i dati – per considerarsi aperti in
base agli standard internazionali – siano:
- Completi. I dati devono comprendere tutte le componenti (metadati) che consentano di
esportarli, utilizzarli on line e off line, aggregarli con altre risorse diffonderli in rete.
- Primari. Le risorse digitali devono essere strutturate in modo tale che i dati siano
presentati in maniera sufficientemente granulare, così che possano essere utilizzate dagli
utenti per integrarle e aggregarle con altri dati e contenuti in formato digitale;
- Tempestivi. Gli utenti devono essere messi in condizione di accedere e utilizzare i dati
presenti in rete in modo rapido e immediato, massimizzando il valore e l’utilità derivanti
da accesso e uso di queste risorse;
- Accessibili. I dati devono essere resi disponibili al maggior numero possibile di utenti
senza barriere all’utilizzo, quindi preferibilmente attraverso il solo protocollo Hypertext
Transfer Protocol (HTTP) e senza il ricorso a piattaforme proprietarie. Devono essere
inoltre resi disponibili senza alcuna sottoscrizione di contratto, pagamento, registrazione o
richiesta.
- Leggibili da computer. Per garantire agli utenti la piena libertà di accesso e soprattutto di
utilizzo e integrazione dei contenuti digitali, è necessario che i dati siano machine-
readable, ovvero processabili in automatico dal computer.
- In formati non proprietari. I dati devono essere codificati in formati aperti e pubblici, sui
quali non vi siano entità (aziende o organizzazioni) che ne abbiano il controllo esclusivo.
Sono preferibili i formati con le codifiche più semplici e maggiormente supportati.
- Liberi da licenze che ne limitino l’uso. I dati aperti devono essere caratterizzati da
licenze che non ne limitino l’uso, la diffusione o la redistribuzione.

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
10
- Riutilizzabili. Affinché i dati siano effettivamente aperti, gli utenti devono essere messi
in condizione di riutilizzarli e integrarli, fino a creare nuove risorse, applicazioni e servizi
di pubblica utilità.
- Ricercabili. I dati devono essere facilmente identificabili in rete, grazie a cataloghi e
archivi facilmente indicizzabili dai motori di ricerca.
- Permanenti. Le peculiarità fino ad ora descritte devono caratterizzare i dati nel corso del
loro intero ciclo di vita
1.2 Linked Open Data: dati a 5 stelle
Per mettere a disposizione del pubblico i dati di un’Amministrazione può essere utilizzata
una grande varietà di formati. Per distinguere i diversi formati utilizzabili nella codifica dei
set di dati, è stato proposto in seno al W3C9 un modello di catalogazione che li classifica
in base alle loro caratteristiche su una scala di valori da 1 (una stella) a 5 (cinque stelle)10
:
(★) Una Stella. È il livello base, costituito da file non strutturati: ad esempio
un’immagine in formato grezzo (formati come .gif, .jpg, .png). Una stella indica la
semplice disponibilità di una informazione e di un dato on line, in un formato qualsiasi,
purché distribuito con licenza aperta. Tuttavia non sono un formato aperto in quanto non
è possibile effettuare su di essi alcuna elaborazione.
(★★ ) Due Stelle. Questo livello indica dati strutturati ma codificati con un formato
proprietario. Ad esempio un documento in formato Microsoft Excel. Due stelle indicano
inoltre la possibilità di effettuare elaborazioni sui dati, a patto di disporre del software
necessario a gestire un file codificato con un formato proprietario. I dati caratterizzati
dalle due stelle non sono un formato aperto in quanto per elaborarli è necessario un
software proprietario, tuttavia di norma possono essere convertiti – essendo dati strutturati
– in dati aperti.
(★★★ ) Tre Stelle. Questo livello indica dati strutturati e codificati in un formato non
proprietario. Ad esempio il formato csv (Comma Separated Values) al posto del formato
9 Word Wide Web Consortium
10 http://www.dati.gov.it

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
11
Microsoft Excel utilizzato nel caso precedente. Tre stelle indicano, oltre alle possibilità
offerte dai dati contraddistinti da due sole stelle, la possibilità di effettuare elaborazioni sui
dati senza esser costretti ad utilizzare software proprietario.
(★★★★ ) Quattro Stelle. Questo livello indica dati strutturati e codificati in un formato
non proprietario che sono dotati di un URI che li rende indirizzabili sulla rete e quindi
utilizzabili direttamente online, attraverso l’inclusione in una struttura basata sul modello
RDF (Resource Description Framework) . Quattro stelle indicano quindi il fatto che il
singolo dato di un dataset, disponibile on line in un formato aperto (tipicamente
XML/RDF) può essere richiamato attraverso un’URL (Uniform Resource Locator)
specifico. Ciò consente di puntare al dato o ad un insieme di dati da una applicazione o
accedervi dall’interno di un programma che può poi elaborarlo in vari modi.
(★★★★★ ) Cinque Stelle. Questo livello indica quelli che vengono definiti Linked
Open Data (LOD). Quei dati aperti, cioè, che – dal punto di vista del formato – oltre a
rispondere alle caratteristiche indicate al punto precedente (classificazione a quattro stelle)
presentano anche, nella struttura del dataset, collegamenti ad altri dataset. In altri termini,
è possibile collegare dinamicamente tra loro più dataset, incrociando così informazioni
provenienti da fonti diverse, eventualmente gestite da diverse Amministrazioni. Una delle
opportunità più importanti dell’Open Data è rappresentata dall’interoperabilità. Il valore
dei dati, infatti, è tanto più alto quanto più è possibile effettuare correlazioni tra più dataset
indipendenti l’uno dall’altro, ma interoperabili nel formato e nel data model. Per questo
motivo è auspicabile che i dati vengano aperti in modalità Linked Open Data rispetto alle
altre tipologie di dati aperti, essendo i LOD la tipologia di dati aperti che consente il
massimo livello di interoperabilità tra dataset diversi.
L’Open Data, quindi, è l’infrastruttura (o la “piattaforma”) di cui il Linked Data ha bisogno
per poter creare la rete di inferenze tra i vari dati sparsi nel web. Il Linked Data, in altre
parole, è una tecnologia ormai abbastanza matura e con grandi potenzialità, ma ha bisogno

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
12
di grandi masse di dati tra loro collegate, ossia “linkate”, per diventare concretamente
utile11
.
1.3 Funzioni e Vantaggi dei Linked Open Data
Mettendo online le informazioni sotto forma di dati grezzi collegabili ad altri dello stesso
tipo, i provider possono generare connessioni e arricchire la conoscenza, migliorando al
tempo stesso la loro visibilità. I dati, infatti, se isolati, hanno poco valore; viceversa, il
loro valore aumenta sensibilmente quando dataset differenti, prodotti e pubblicati in modo
indipendente da diversi soggetti, possono essere combinati liberamente da terze parti,
realizzando applicazioni innovative e per scopi non previsti. Pubblicare i dati come in
modo che siano pienamente utilizzabili e collegati semanticamente tra loro, questo è
l’obiettivo principale che si vuole raggiungere con i Linked Open Data (LOD). I LOD sono
dati “grezzi” pubblicati in formato RDF (Resource Description Framework) con una
licenza “aperta” in modo da poter essere usati come base per fornire servizi a valore
aggiunto per i cittadini e le imprese. Si tratta di un passo essenziale verso la realizzazione
del Web Semantico, la visione cioè del Web come un unico grande database globale e
distribuito, interrogabile dalle macchine indipendentemente dalla provenienza dei dati. Il
concetto di linked data è dunque strettamente connesso al web semantico, seppure il web
semantico non si risolva nel solo tecnicismo dei linked data, ma richieda, per la sua
costruzione, il rispetto di alcune importanti regole finalizzate alla creazione di uno strato di
contenuti accessibili a processi automatizzati. Essi rendono espliciti i significati e le
connessioni implicitamente contenuti (o in alcuni casi, assenti) nelle risorse del web (dati,
pagine, programmi ecc.). Le due espressioni – linked data e web semantico – attengono al
medesimo ambito semantico e applicativo. I linked data sono infatti una tecnologia
adoperata per la realizzazione del web semantico. Per capire meglio il concetto ci aiuta la
definizione che Tim Berners-Lee, ideatore del world wide web (www), fornisce di web
semantico: “a web of things in the world, described by data on the web”, formulazione non
11 http://www.datagov.it/open-government/

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
13
facilmente traducibile, che potremmo rendere in italiano con “una rete di cose del mondo,
descritta dai dati nel web”. Il concetto è generico, ma contiene riferimenti importanti: la
rete (il reticolo), le cose (gli oggetti relazionati), i dati (non più un record ma singoli
elementi, atomi). Esso differenzia il web tradizionale (l’hypertext web) – costituito da
documenti, da oggetti HTML, connessi tramite hyperlink non classificati – dal web
costituito di “cose reali” (le entità esistenti) descritte tramite dati. Comincia a definirsi
un’immagine più precisa:
• il web ipertestuale o web di documenti come rappresentazione piatta, lineare, degli
oggetti; la concretezza del web semantico si oppone all’astrattezza del web tradizionale;
• il web semantico o web di dati come un contenitore di cose, di oggetti, piuttosto che un
contenitore di rappresentazioni di oggetti: un’idea di concretezza, nel senso che i dati
afferiscono alla risorsa e partecipano alla sua natura, ovvero ne sono parte integrante
perché la risorsa non sarebbe rappresentabile senza questi dati.
Il web semantico non nasce, dunque, per sostituire il web tradizionale, bensì per estenderne
il potenziale, realizzando quanto Tim Berners-Lee descrive come un mondo in cui “i
meccanismi quotidiani del commercio, della burocrazia, e delle nostre vite quotidiane
saranno gestiti da macchine che interagiscono con altre macchine, lasciando agli umani il
compito di fornire l’ispirazione e l’intuizione”. Il web di dati è, pertanto, la naturale
evoluzione del web di documenti.
Quali sono dunque i vantaggi dei Lod?
Riduzione della duplicazione delle informazioni - Chi crea un dataset può collegarlo
direttamente a dataset esistenti di cui non dispone direttamente; chi crea un mashup, un sito
o un'applicazione di tipo ibrido, che includa dinamicamente informazioni o contenuti
provenienti da più fonti, invece di importare i dati può linkarli. Meno lavoro, quindi, ma
soprattutto dati sempre aggiornati.

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
14
Maggiore evidenza – I Linked Open Data aiutano a generare link significativi tra le pagine
web. Questo facilita gli utenti nella scoperta dei contenuti, mettendo in evidenza i dati
prodotti dagli enti e aumentando il traffico verso i siti web degli istituti produttori.
Autorevolezza - DBpedia, Freebase e Project Gutenberg vengono spesso indicati come fonti
di metadati autorevoli. Gli istituti culturali possono affermarsi anch’essi come fonti
autorevoli di informazioni sul patrimonio culturale, realizzando una “spina dorsale” per lo
sviluppo del web semantico.
Nuovo pubblico - Quando gli utenti analizzano i dati e li utilizzano per creare applicazioni
come API (Application Programming Interface) e mashup, propongono i vostri contenuti a
un pubblico nuovo che difficilmente sarebbe raggiungibile.
Migliore esperienza per gli utenti - Fornendo agli utenti informazioni di alta qualità e
contestualmente utili, si migliorerà la loro esperienza di fruizione; gli utenti saranno,
quindi, più propensi a consultare il vostro sito web.
Uso efficiente delle risorse - La condivisione di dati provenienti per lo più da investimenti
pubblici fa sì che possano essere utilizzati in modo più efficiente permettendo agli utenti di
contribuire ad arricchire i metadati. Questo comporta anche il riutilizzo diretto in settori
come la formazione, la ricerca scientifica e il turismo culturale.
1.4 Rappresentazione dei Linked Open Data: il modello RDF
Rappresentare linked data significa esprimere i significati delle informazioni, renderle
condivisibili fra differenti applicazioni e utilizzabili da applicazioni diverse da quelle per
cui erano state originariamente create.
Il data model utilizzato per la strutturazione di linked data è RDF(Resource Description
Framework), uno standard flessibile proposto dal W3C per caratterizzare semanticamente
le risorse e le relazioni che intercorrono tra esse.

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
15
Per renderle “machine-processable”12
le risorse sono individuate attraverso Uniform
Resource Identifiers(URIs),ovvero identificatori che permettono di riferirsi in maniera non
ambigua ad un oggetto (risorsa). La funzione degli URI è del tutto analoga a identificatori
usati “al di fuori del Web”, come l'ISBN di un libro o il Codice Fiscale di una persona. L'
URI in altre parole ha la funzione di garantire che un oggetto sia identificabile tramite un
nome associato unicamente ad esso. Con RDF si possono dunque esprimere delle
affermazioni, ma prima di ciò è necessario sia identificare l’oggetto che si vuole
descrivere sia la specifica proprietà dell’oggetto ( o relazione tra oggetti ) sulla quale si
vuole predicare che il valore assunto dalla proprietà o l’oggetto con cui viene messa in
relazione l’entità sulla quale si sta predicando. Queste tre componenti di una affermazione
RDF (affermazione detta anche “tripla RDF”, proprio perché è composta da tre parti)
prendono il nome rispettivamente di soggetto, predicato e oggetto.
Le asserzioni, o triple, sono espresse da RDF in forma di grafi (nodi e archi) che
rappresentano le risorse, le loro proprietà e i rispettivi valori.
L'utilizzo di RDF può essere chiarito con un semplice esempio:
Consideriamo questo gruppo di istruzioni:
“there is a Person identified by http://www.w3.org/People/EM/contact#me, whose name is
Eric Miller, whose email address is [email protected], and whose title is Dr."
Potremmo rappresentarlo con il grafico RDF in figura :
12 Letteralmente “processabile dalla macchina”

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
16
La figura illustra come RDF utilizza URI per identificare:
soggetto, e.g., Eric Miller, identificato da http://www.w3.org/People/EM/contact#me
genere di cose, e.g., Persona, identificato
http://www.w3.org/2000/10/swap/pim/contact#Person
proprietà , e.g., mailbox, identificato da
http://www.w3.org/2000/10/swap/pim/contact#mailbox
valori delle proprietà, e.g. mailto:[email protected] come valore della mailbox
1.4.1 Il Contesto
Sebbene la specifica di RDF non comprenda questa nozione solitamente per fare
riferimento a particolari informazioni occorre fare attenzione al contesto in cui sono
inserite queste ultime.
Infatti la stessa identica affermazione può essere prodotta in due contesti completamente
diversi. Quindi l’introduzione del contesto comporta la presenza di un ulteriore elemento
da considerare: si passa dal concetto di “tripla” SPO(soggetto-predicato-oggetto) a quello
di “quads” quadrupla SPOC(soggetto-predicato-oggetto-contesto).

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
17
1.4.2 RDF Schema
Il data model RDF permette di definire un modello semplice per descrivere le relazioni tra
le risorse, in termini di proprietà identificate da un nome e relativi valori.
Tuttavia, RDF data model non fornisce nessun meccanismo per dichiarare queste proprietà,
né per definire le relazioni tra queste proprietà ed altre risorse.
Tale mancanza è invece colmata da RDF Schema che permette infatti di definire dei
vocabolari, ovvero l’ insieme delle proprietà semantiche individuate da una particolare
comunità.
RDF Schema sostanzialmente consente dunque di definire significato, caratteristiche e
relazioni di un insieme di proprietà, compresi eventuali vincoli sul dominio e sui valori
delle singole proprietà. Inoltre, implementando il concetto (transitivo) di classe e
sottoclasse, permette di definire gerarchie di classi, con il conseguente vantaggio che
agenti software intelligenti possono utilizzare queste relazioni per svolgere i loro compiti.

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
18
Capitolo 2
Indici per i Linked Open Data
La quantità di Linked data a livello globale sta crescendo esponenzialmente, per questo
motivo è necessaria una “indicizzazione” per offrire una ricerca più efficiente. Dal
momento che nell'ambito dei Linked data viene utilizzato RDF, non possiamo utilizzare i
risultati di ricerche provenienti dalle aree DB relazionali e XML e in particolare non
possiamo far uso di tecniche di indicizzazione già conosciute in tali ambiti.
2.1 Cos’è un indice?
L’indice viene utilizzato per velocizzare il recupero dei dati nella tabella. L’indice del
database è simile all’elenco di un libro , l’elenco in un libro permette all’utente di non
leggere tutto il libro, ma di trovare rapidamente l’informazione di cui si ha bisogno. Nel
database , inoltre , l’indice permette ai programmi del database di trovare rapidamente i
dati nella tabella senza effettuare la scansione dell’intero database. Ci sono molti tipi di
tecniche di indicizzazione , nessuna di esse è migliore delle altre , ognuna ha dei vantaggi
in base alle applicazioni del database. La valutazione per qualsiasi tipo di indice deve
considerare i seguenti fattori:
a) Tipo di accesso. Può efficacemente supportare il tipo di accesso, includendo un valore
dell’attributo specificato per trovare il record appropriato e il range di valori dell’attributo
per trovare tutti i record in questo range.

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
19
b) Tempo di accesso. Il tempo è impiegato per accedere a uno o più dati.
c) Tempo di inserimento. Il tempo per inserire un nuovo dato nell’indice comprende il tempo
per trovare la posizione corretta e di conseguenza il tempo per modificare la struttura
dell’indice.
d) Tempo di eliminazione. Il tempo per cancellare un dato nell’indice comprende il tempo per
trovare la posizione dei dati che verranno eliminati e il tempo di modificare la struttura
dell’indice.
e) Costo dello spazio. La struttura dell’indice necessita di un ulteriore spazio di
memorizzazione, se è più piccolo, può sacrificare dello spazio per migliorare la
prestazione.
2.2 Classificazione delle tecniche di Indicizzazione
Le tipologie di indicizzazione esistenti possono essere classificate in base a vari criteri.
Sicuramente il più importante criterio di classificazione tutto fa riferimento alla struttura
dell’indice, la quale dipende dal dominio di applicazione dei dati trattati, si distinguono vari
tipi di indicizzazione : locali, distribuiti e globali. In maniera specifica, se la strutture
dell’indice consente inserimenti, aggiornamenti ed eliminazioni efficaci, si parlerà di
strutture dinamiche, in caso contrario di strutture statiche. In aggiunta queste strutture
possono servire oltre che per l’indicizzazione dei dati , anche per effettuare statistiche su di
essi. In ogni caso, ogni tecnica di indicizzazione si basa su diverse unità di dati: le triple
conformi allo standard delle triple RDF, le quadruple (quads) che introduce il contesto, e i
sources che fanno riferimento a documenti semantici o altri file.

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
20
2.2.1 Tecniche di indicizzazione Locali
Le Tecniche di indicizzazione Locali sono numerose (Rdf-3X Engine, Matrix Index,
Sextuple Index,ecc.) ma di seguito verranno trattate in maniera più approfondita
soprattutto le seguenti :
- Path Index
- Keyword Index
- Quad Index
Path index.
Come precedente detto, i modelli RDF e RDF schema posso essere rappresentati tramite
grafi orientati. (node-edge). Pertanto in generale le query relative RDF e RDF schema
possono essere rappresentate da Path expressions 13
. su tali grafi . Ed è proprio la struttura-
base delle query che si focalizza su queste path expression. Per attuare una ricerca
migliore, è richiesta l’informazione gerarchica tra classi o proprietà. Per esempio “Author”
è una sotto-classe di “Person”, “Book” è una sotto-classe di “Artifact” , “writes” è una
sotto-classe di ”creates”(Figura 1).
Così se un utente vuole cercare
risorse relative alla path di
“Person.creates.Artifacts”, tutte le
risorse devono essere cercate in
ognuna delle path information
relative come:
“Person.creates.Book”,
“Person.writes.Book”,
“Author.writes.Book”, e così via.
13 http://en.wikipedia.org/wiki/Path_expression
Figura 1: RDF e RDF Schema, YounHee K.,at al. (2006) “The Index Organizations for RDF and RDF Schema” in Advanced Communication Technology, ICACT 2006.vol.3, pp.4 – 1874. IEEE.

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
21
Si può utilizzare un Path Index per la struttura base della query considerando la gerarchia
delle classi e delle proprietà. Il path index è caratterizzato da una PList e un PIndex. In
primo luogo la PList contiene tutte le path information che esistono nell’RDF Schema,
direttamente o indirettamente, basate su triple strutture. In seguito la query dell’utente
viene trasformata in una path expression, questo avviene per cercare le relative path
information nella plist usando una semplice comparazione di stringhe. La figura 2 mostra
la Plist per l’RDF Schema nella figura 1. Nella figura 2 un rettangolo rosso esprime le path
expression relative a "Person.creates.Artifact". Pertanto se un utente vuole cercare risorse
sulla path di "Person.creates.Artifact", dovranno essere considerate tutte le path expression
da 1 a 4.
Il numero per distinguere le path
expression nella Plist (figura 2) viene
utilizzato come chiave in Pindex. Il
Pindex è implementato utilizzando un
B-tree. I nodi interni nelle Pindex
memorizzano sia una chiave per
distinguere le path expression nella Plist
e un numero per collegare l’ultima path
expression nella Plist. I nodi finali nella
Pindex memorizzano la coppia soggetto-
oggetto del corrispondete path.
La figura 3 mostra la struttura e un esempio di Pindex. Per l’elaborazione della query
precedentemente considerata tutte le chiavi nei nodi interni della Pindex sono percorsi
dalla chiave(1,4) alla chiave(4,4) in accordo con la figura 3. Se un utente vuole cercare
risorse nella path “Person.creates.Book" , devono essere considerati sia
"Person.writes.Book" che "Author.writes.Book". Così tutte le chiavi presenti nei nodi
interni della Pindex sono percorse da chiave(2,4) a chiave(4,4) in accordo con la figura 3.
Figura 2: Esempio di PList per la figura 1 YounHee K.,at al. (2006) “The Index Organizations for RDF and RDF Schema” in Advanced Communication Technology, ICACT 2006.vol.3, pp.4 – 1874. IEEE.

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
22
Keyword index per RDF/S.
Viene descritta di seguito , la tecnica di indicizzazione per la ricerca di keyword
considerando sia RDF sia RDF Schema. Le liste invertite sono state tradizionalmente la
struttura index per il recupero di keyword-based su documenti di testo. Per questo motivo
tale indice utilizza liste invertite e schemi di numerazione per identificare le entità nei
documenti RDF/S. Tale tecnica di indicizzazione mira ad un efficiente elaborazione di
keyword-based ricercate per RDF/S. La figura 4 mostra la nostra struttura per il Keyword
Index.
Figura 3: Struttura ed esempio di PIndex per la figura 1 YounHee K.,at al. (2006) “The Index Organizations for RDF and RDF Schema” in Advanced Communication Technology, ICACT 2006.vol.3, pp.4 – 1874. IEEE.
Figura 4: Struttura per il Keyword Index YounHee K., HyeYeon S., KyunRak C., HaeChull L. (2007) “Indexing Scheme for Keyword Search over Semantic Web Documents” IEEE.
Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
23
L’indice si compone di tre parti: la prima parte è una lista di keywords in RDF, composta
da: keyword, frequency ed un puntatore ad un’altra risorsa; la seconda parte è una serie di
file ad inserimento diretto. Ogni file pubblicato include direttamente informazioni su
risorse e proprietà che possiedono corrispondenti keywords nella prima parte dell’indice.
La terza parte è una serie di file ad inserimento indiretto. Ogni file pubblicato include
indirettamente informazioni su risorse e proprietà che possiedono corrispondenti keywords
nella prima parte dell’indice mediante risorse nella seconda parte dell’indice.
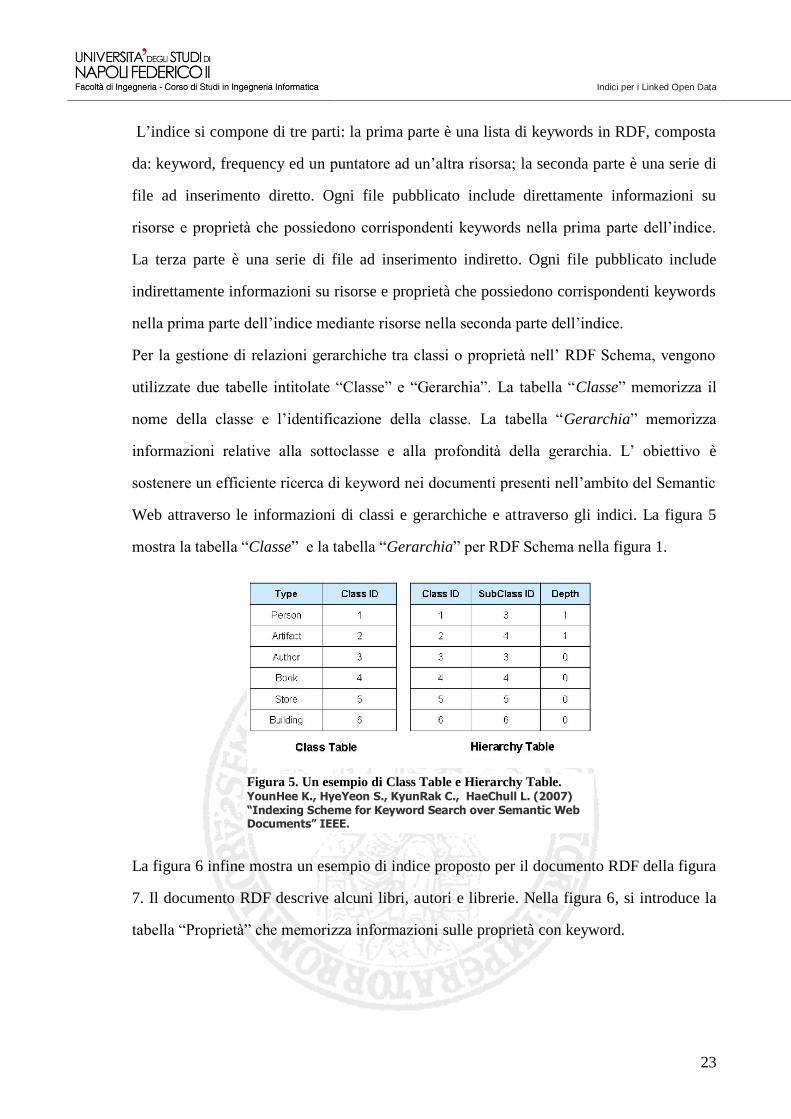
Per la gestione di relazioni gerarchiche tra classi o proprietà nell’ RDF Schema, vengono
utilizzate due tabelle intitolate “Classe” e “Gerarchia”. La tabella “Classe” memorizza il
nome della classe e l’identificazione della classe. La tabella “Gerarchia” memorizza
informazioni relative alla sottoclasse e alla profondità della gerarchia. L’ obiettivo è
sostenere un efficiente ricerca di keyword nei documenti presenti nell’ambito del Semantic
Web attraverso le informazioni di classi e gerarchiche e attraverso gli indici. La figura 5
mostra la tabella “Classe” e la tabella “Gerarchia” per RDF Schema nella figura 1.
La figura 6 infine mostra un esempio di indice proposto per il documento RDF della figura
7. Il documento RDF descrive alcuni libri, autori e librerie. Nella figura 6, si introduce la
tabella “Proprietà” che memorizza informazioni sulle proprietà con keyword.
Figura 5. Un esempio di Class Table e Hierarchy Table. YounHee K., HyeYeon S., KyunRak C., HaeChull L. (2007) “Indexing Scheme for Keyword Search over Semantic Web Documents” IEEE.

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
24
Figura 6. Esempio di Keyword Index YounHee K., HyeYeon S., KyunRak C., HaeChull L. (2007) “Indexing Scheme for Keyword Search over Semantic Web Documents” IEEE.
Figura 7. Rappresentazione del grafo RDF e RDF Schema YounHee K., HyeYeon S., KyunRak C., HaeChull L. (2007) “Indexing Scheme for Keyword Search over Semantic Web Documents” IEEE.

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
25
Quad Index
A livello più basso, la struttura dell’indice consente un rapido recupero di quad (
quadruple), fornendo qualsiasi combinazione di soggetto(s), predicato(p), oggetto(o),
contesto(c). Si vuole evitare costosi JOINS14
ove possibile e pertanto scambiare “l’index
space”( lo spazio degli indici) per recuperare tempo. Vengono adoperati B+-trees15
, una
buona struttura dati che supporta inserimento, cancellazioni, e ricerche (in particolare le
range lookups)
Concettualmente, abbiamo le coppie (key , value) in cui il recupero basato sulla key
restituisce il valore con poche operazioni del disco. La struttura dell’indice si divide in due
parti interconnesse:
il lexicon comprende le rappresentazioni di stringa di un grafico RDF (R,L, B)
i quad indexs comprendono le quads ( quadruple).
Lexicon
Gli indici lexicon operano sulle rappresentazioni di stringa dei nodi RDF, e consentono un
rapido recupero di identificatori di oggetto (OIDs) per i nodi RDF. Gli OID sono
rappresentati e memorizzati sul disco su 64 bit. Visto che consideriamo i nodi RDF con più
indici, la mappatura da i valori stringa a OID consente di risparmiare spazio. Inoltre ,
elaborare e confrontare OID è più veloce del confronto tra stringhe.
Il lexicon è costituita da due diversi indici:
- I NodeOID
- I OIDNode
14 Rappresenta un legame fra due o più tabelle di un DataBase che contengono dati distinti ma in qualche
modo correlati. http://www.notrace.it/glossario/Join/ 15 http://en.wikipedia.org/wiki/B%2B_tree

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
26
NodeOID and OIDNode Index
Gli indici OIDNode e NodeOID vengono utilizzati per associare gli OID ai valori di
stringa dei nodi RDF e viceversa. L’indice OIDNode mantiene la coppia(OID, Node),
mentre l’indice NodeOID mantiene la coppia(Node, OID)
Gli OID vengono assegnati in maniera crescente per ogni nodo che è inserito. OID 0 è un
OID speciale che denota una variabile. Un’alternativa per mantenere l’indice NodeOID è
quella di calcolare l’hash del nodo e utilizzare il numero risultante come un OID. Tuttavia,
le funzioni hash con una piccola probabilità di collisioni, come SHA1 o MD5 producono
almeno 128 bit keys per OIDs , che aumenterebbero notevolmente la dimensione
dell’indice. Mantenere un indice separato per la mappatura di valori stringa di OID e
memorizzare la mappatura in B+-trees ha il vantaggio che ci permette di eseguire range
query su nodi values, dato che l’indice nodeoid è ordinato in maniera lessicografica.
Quad Index
Negli indici Quad si immagazzinano gli OID in modo da consentire il recupero rapido
delle quadruple, con il minimo accesso alla struttura.
Per evitare costosi join, tale indice deve inoltre permettere di ricercare qualsiasi
combinazione di S,P,O,C direttamente, piuttosto che unire i risultati di ricerche fatte su
diversi indici. Gli indici Quad si basano sul concetto di Acces Pattern.
Definizione ( Acces Pattern ): Un access pattern è una quadrupla dove ogni
combinazione di S, P,O,C è specificata o variabile.

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
27
Per esempio , un access pattern potrebbe essere una quadrupla dove solo S è specificato ,
mentre P,O e C sono variabili. L' access pattern (s:?:?:?) denota tutte le quadruple dove il
soggetto è uguale a S , mentre gli altri nodi hanno un valore non specificato.
Per calcolare il numero totale di access patterns dobbiamo solo considerare che per ogni
elemento della quadrupla ( quad )
esistono due possibilità ( o un nodo è
specificato , o è variabile ). Quindi il
numero totale di access pattern è 16.
La tabella 1 mostra tutti i possibili
access patterns per le ricerche quad.
Una semplice implementazione di un indice completo basato su quadruple(quads) avrebbe
bisogno 16 indici, uno per ogni access pattern. Tuttavia un implementazione di questo tipo
è proibitiva in termini di tempo e spazio.
Indici combinati
Per ridurre il numero di indici necessari , si fa leva sul fatto che B+-tree fornisce il
supporto per le range query, ossia alle richieste che prevedono come risposta i valori
appartenenti ad un certo intervallo. Uno stesso indice può essere usato per rispondere a più
access pattern particolari; in questo modo il numero di indici necessari a coprire tutti gli
access pattern si riduce a sei.
Un indice combinato su S,P,O, e C per una quadrupla ( s,p,o,c ) è in grado di supportare le
query per gli acces pattern da 1 a 5 nella Tabella 1. Ad esempio , una ricerca per l'access
pattern (s:p:?:?) si risolve in una range query per S e P sull'indice spoc. Di conseguenza ,
non abbiamo bisogno di avere un indice separato di S e P , ma possiamo riutilizzare
Tabella 1. Possibili modelli di Quad: in totale, ci sono 16 diversi patterns per coprire tutte
le combinazioni possibili di accesso.
Harth A., Decker S.,(2005) “Optimized Index Structures for Querying RDF from the
Web” In Third Latin American Web Congress, LA-WEB 2005. IEEE.

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
28
l'indice spoc. Utilizzando indici combinati si riduce il numero di indici necessari per
implementare un indice completo su quads a sei. La tabella 2 mostra i sei indici e quale
access pattern coprono.
Per semplificare e velocizzare le operazioni di ricerca sugli access patterns ,ogni indice
contiene i quads completi come key ( cioè (c:p:s:o) per il cp access pattern ), piuttosto che
avere l'indice costruito sulle chiavi (c:p) e teneri i rimanenti elementi della quadrupla come
valori(in una lista concatenata).
Ciò significa che ogni quadrupla (s, p, o, c) viene memorizzata come chiave (s:p:o:c)
nell'indice spoc , come chiave (p:o:c:s) nell'indice poc, e così via.
Quando una nuova quadrupla viene inserita infatti ,il sistema calcola una chiave per ogni
indice e riordina la quadrupla secondo la sequenza imposta dall’indice (vedi tabella 3).
Durante l’inserzione della chiave all’interno del B +-tree viene mantenuto l’ordine rispetto
alla prima componente della quadrupla , poi alla seconda componente, e cos`ı via: il B +-
tree memorizza le chiavi mantenendole ordinate.
Tabella 2 : sei indici necessari per coprire tutti i 16 access pattern.
Harth A., Decker S.,(2005) “Optimized Index Structures for
Querying RDF from the Web” In Third Latin American Web
Congress, LA-WEB 2005. IEEE.

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
29
Quando al sistema viene sottoposta una query (richiesta di ottenere opportune quadruple,
formalizzata da un particolare access pattern),essa viene tradotta in quattro OID facendo
uso del Lexicon: i simboli ? nell’access pattern(corrispondenti ai valori della quadrupla
lasciati indefiniti) sono tradotti in OID pari a 0. Successivamente viene individuato l’indice
Quad necessario, e viene generato un insieme di chiavi che denota il limite inferiore e
quello superiore dell’intervallo dei valori che contiene i risultati (le quadruple che
soddisfano l’access pattern). Infine, viene restituito un iteratore che può scorrere all’interno
dell’intervallo contenente i risultati: quando viene restituito un risultato la chiave
corrispondente (che è formata da OID)viene indefiniti estratta, ordinata e tradotta nel
formato originale della quadrupla usando il Lexicon.
Per esempio, si supponga di voler conoscere le quadruple che soddisfano la query
(? dc:title ‘‘PAGE’’ ?). Attraverso il Lexicon, nel caso in cui 1011 sia il OID di dc:title e
3027 quello del letterale ‘‘PAGE’’ , la query viene tradotta in (0 1011 3027 0). Per
risolvere questa query occorre usare l’indice POC ma, prima di fare una ricerca al suo
interno, la query deve essere riordinata così: (1011 3027 0 0) . Effettuando una ricerca in
profondità, viene individuata una porzione di albero che rappresenta l’intervallo delle
chiavi comprese tra (1011 3027 MIN MIN) e (1011 3027 MAX MAX) e viene
restituito un iteratore per estrarre le chiavi comprese in questo intervallo.
Tabella 3: indici spoc e poc . I restanti quattro indici quad sono costruiti di
conseguenza. Harth A., Decker S.,(2005) “Optimized Index Structures for
Querying RDF from the Web” In Third Latin American Web Congress, LA-
WEB 2005. IEEE.

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
30
2.2.2 Tecniche di Indicizzazione Distribuite
Lo scopo di tali tecniche è quello di lavorare con fonti distribuite e fornire un esecuzione
trasparente di query sui dati provenienti da esse . di queste tecniche ne fanno parte:
Repository Index , Federated Querying e Data Summaries.
Repository Index : tale indice è stato ideato da Stuckenschmidt[6] e colleghi ed ha lo
scopo di creare statistiche relative ai percorsi dei dati permettendo l’esecuzione di query
relativi ad essi applicando query su un modello ad “albero”.
Federated Querying : Quilitz e Leser [7] hanno proposto un metodo per l'esecuzione di
query in modo trasparente relative a fonti distribuite e autonome.
L’elemento cardine di tale tecnica è un linguaggio per la descrizione di fonti distribuite le
quali in particolare contengono triple di dati ed altre informazioni relative ad essa.
Data Summaries: Lo scopo di tale indice, presentato da Harth et al.. [8] è quello di
consentire la selezione di una sorgente tra le varie fonti distribuite di dati . Le triple dei
dati sono modellate come punti in uno spazio a tre dimensioni (S,P e O).
2.2.3 Tecniche di Indicizzazione Globali
Infine, vengono brevemente delineati tre approcci globali alla ricerca. Tutti sono
principalmente ispirato da metodi tradizionali di information retrieval.
Swoogle: Il primo sistema è stato proposto da Ding et al. [9]. Lo scopo è quello di offrire
un motore di ricerca su documenti semantici, sia di dati e ontologie.
SWSE: Lo scopo di SWSE da Harth et al. [10] è di fornire un sistema per la ricerca
globale su quad (triple RDF con il loro contesto). L'interrogazione si concentra non solo
sulla corrispondenza delle parole chiave, ma supporta anche il concetto di filtraggio
Sindice: Oren et al. [11] ha introdotto un motore globale per la ricerca di documenti
semantiche sul Web, che consente di interrogare tramite parole chiave, inversa proprietà
funzionali e delle risorse URI.

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
31
Conclusioni
Negli ultimi anni il Web si è evoluto da spazio di informazione globale costituito da
documenti collegati, verso un sistema nel quale sia i dati che gli stessi documenti risultano
interconnessi tra di loro. Alla base di questa evoluzione vi `e un insieme di best practices
per la pubblicazione e la connessione di dati strutturati sul Web in formato “open” noto
come Linked Open Data. Il presente lavoro di tesi si propone infatti di individuare nel
modello basato sui principi del Linked Open Data le caratteristiche più valide per
l'ottenimento di una modellazione dei dati completa ed esaustiva. L’adozione di queste
pratiche ha determinato la creazione di uno spazio globale parallelo a quello che raccoglie i
documenti, nel quale dati aperti provenienti da domini di conoscenza diversi sono collegati
tra di loro, il cosiddetto Web of Data. È stato inoltre definito come scopo di tale lavoro la
considerazione di alcune tecniche di “indicizzazione” per i Linked Open Data; tale aspetto
risulta essere molto importante, per una organizzazione e una ricerca efficiente dei dati; per
questo motivo si è partiti dal concetto di indice andando a definire la sua funzionalità ed
utilità, per poi passare alla classificazione delle tecniche di indicizzazione ed infine ad
analizzare le tecniche esistenti inserendole nelle giuste categorie.

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
32
Bibliografia
[1] Harth A., Decker S.,(2005) “Optimized Index Structures for Querying RDF from the Web”
In Third Latin American Web Congress, LA-WEB 2005. IEEE.
[2] YounHee K., Byung Gon K., Hae Chull L., (2006) “The Index Organizations for RDF and
RDF Schema” in Advanced Communication Technology, ICACT 2006. The 8th
International Conference,vol.3, pp.4 – 1874. IEEE.
[3] YounHee K., HyeYeon S., KyunRak C., HaeChull L. (2007) “Indexing Scheme for
Keyword Search over Semantic Web Documents” in Advanced Communication Technology,
The 9th International Conference on, vol 2, pp. 1205 - 1209 . IEEE.
[4] Wenming Guo; Zhiqiang Hu; , "Memory Database Index Optimization," Computational
Intelligence and Software Engineering (CiSE), 2010 International Conference on , vol., no.,
pp.1-3, 10-12 Dec. 2010, IEEE.
[5] Robert Meersman, Tharam Dillon, Pilar Herrero, On the Move to Meaningful Internet
Systems: OTM 2011 Workshops[..],Springer, 2011
[6] Stuckenschmidt, H., Vdovjak, R., Houben, G.J., Broekstra, J.: Index Structures and
Algorithms for Querying Distributed RDF Repositories. In: Proc. of the 13th Int. Conf. on
World Wide Web. pp. 631{639. WWW '04, ACM, NY, USA (2004)
[7] Quilitz, B., Leser, U.: Querying Distributed RDF Data Sources with SPARQL. In: The
Semantic Web: Research and Applications. LNCS, vol. 5021, pp. 524{538.Springer Berlin /
Heidelberg (2008)
[8] Harth, A., Hose, K., Karnstedt, M., Polleres, A., Sattler, K.U., Umbrich, J.: Data Summaries
for On-demand Queries over Linked Data. In: Proc. of the 19th Int.Conf. on World Wide
Web. pp. 411{420. WWW '10, ACM, NY, USA (2010)

Indici per i Linked Open Data Inserire il titolo della tesi di laurea come intestazione
33
[9] Ding, L., Finin, T., Joshi, A., Pan, R., Cost, R.S., Peng, Y., Reddivari, P., Doshi, V., Sachs,
J.: Swoogle: A Search and Metadata Engine for the Semantic Web. In: Proceedings of the
13th ACM Int. Conference on Information and Knowledge Management. pp. 652{659.
CIKM '04, ACM, New York, NY, USA (2004)
[10] Harth, A., Hogan, A., Delbru, R., Umbrich, J., O'Riain, S., Decker, S.: SWSE: Answers
Before Links. In: Proc. of the Semantic Web Challenge 2007 co-located with ISWC 2007 +
ASWC 2007. vol. 295, pp. 136{144. CEUR-WS.org (2007)
[11] Oren, E., Delbru, R., Catasta, M., Cyganiak, R., Stenzhorn, H., Tummarello, G.:
Sindice.com: A Document-oriented Lookup Index for Open Linked Data. International
Journal of Metadata, Semantics and Ontologies 3(1), 37{52 (2008)