Embed Size (px)
Citation preview

Information Retrieval and Extraction資訊檢索與擷取
Chia-Hui ChangNational Central University

Information Retrieval (IR)
Problem Definition and Generic IR system select and return to the user desired documents from a large set of documents in accordance with criteria specified by the user
Functions Document search
the selection of documents from an existing collection of documents
Document routingthe dissemination of incoming documents to appropriate users on the basis of user interest profiles
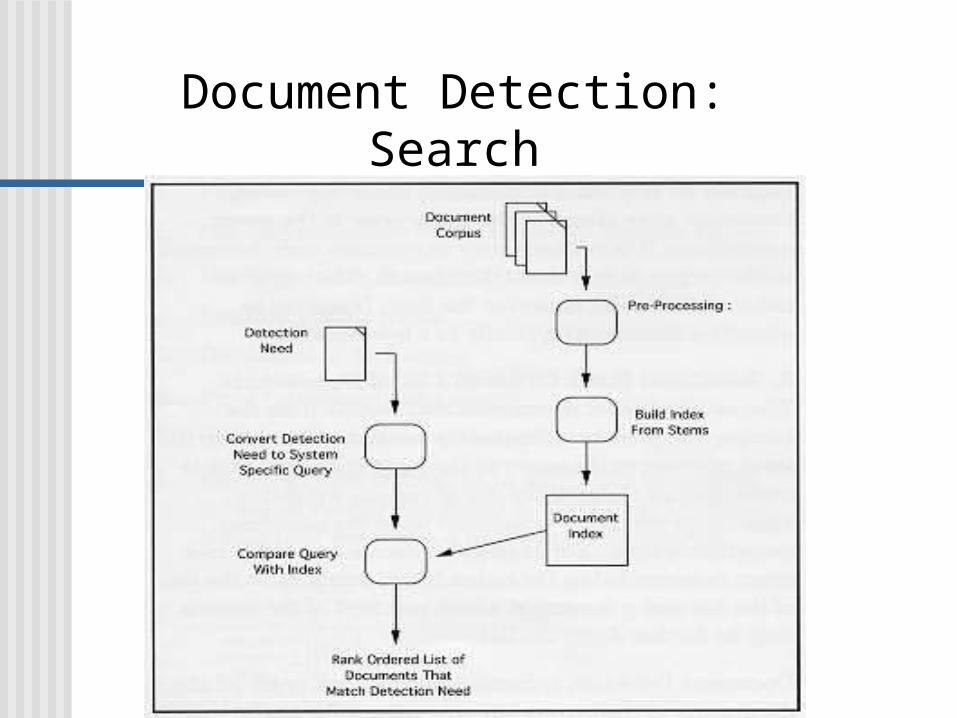
Document Detection: Search

Search: Text Operation
Document Corpus the content of the corpus may have significant
performance in some applications
Preprocessing of Document Corpus stemming stop words removing phrases, multi-term items ...

Search: Indexing
Building Index from Stems key place for optimizing run-time performance cost to build the index for a large corpus
Document Index a list of terms, stems, phrases, etc. frequency of terms in the document and corpus frequency of the co-occurrence of terms within the
corpus index may be as large as the original document corpus

Search: Query Operation
Detection Need the user’s criteria for a relevant document
Convert Detection Need to System Specific Query first transformed into a detection query, and then a
retrieval query. detection query: specific to the retrieval engine, but
independent of the corpus retrieval query: specific to the retrieval engine, and to
the corpus

Search: Query Model
Compare query with index Rank the list of relevant documents
Return the top ‘N’ documents

Routing

Routing: Detection Needs
Profile of Multiple Detection Needs A Profile is a group of individual Detection Needs that
describes a user’s areas of interest. All Profiles will be compared to each incoming
document (via the Profile index). If a document matches a Profile the user is notified
about the existence of a relevant document.

Routing: Query Index
Convert detection need to system specific query Building Index from Queries
The index will be system specific and will make use of all the preprocessing techniques employed by a particular detection system
Routing Profile Index similar to build the corpus index for searching the quantify of source data (Profiles) is usually much less tha
n a document corpus Profiles may have more specific, structured data in the form
of SGML tagged fields

Routing: Document Preprocessing
Document to be routed A stream of incoming documents is handled one at a
time to determine where each should be directed Routing implementation may handle multiple
document streams and multiple Profiles Preprocessing of Document
A document is preprocessed in the same manner that a query would be set-up in a search
The document and query roles are reversed compared with the search process

Routing: Ranking
Compare Document with Index Identify which Profiles are relevant to the document Given a document, which of the indexed profiles
match it?
Resultant List of Profiles The list of Profiles identify which user should receive
the document

Summary
Generate a representation of the meaning or content of each object based on its description.
Generate a representation of the meaning of the information need.
Compare these two representations to select those objects that are most likely to match the information need.

Documents Queries
DocumentRepresentation
QueryRepresentation
Comparison
Basic Architecture of an Information Retrieval System

Research Issues
Issue 1 What makes a good document representation? How can a representation be generated from a
description of the document? What are retrievable units and how are they organized?
Issue 2How can we represent the information need and how can we acquire this representation? from a description of the information need or through interaction with the user?

Research Issues (Continued)
Issue 3How can we compare representations to judge likelihood that a document matches an information need?
Issue 4How can we evaluate the effectiveness of the retrieval process?

Information Extraction
DefinitionAn information extraction system is a cascade of transducers or modules that at each step add structure and often lose information, hopefully irrelevant, by applying rules that are acquired manually and/or automatically.

Information Extraction (Continued)
What are the transducers or modules? What are their input and output? What structure is added? What information is lost? What is the form of the rules? How are the rules applied? How are the rules acquired?

Example: Parser Transducer: parser Input: the sequence of words or lexical items Output: a parse tree Information added: predicate-argument and
modification relations Information lost: no Rule form: unification grammars Application method: chart parser Acquisition method: manually

Modules Text Zoner
turn a text into a set of text segments Preprocessor
turn a text or text segment into a sequence of sentences, each of which is a sequence of lexical items, where a lexical item is a word together with its lexical attributes
Filterturn a set of sentences into a smaller set of sentences by filtering out the irrelevant ones
Preparsertake a sequence of lexical items and try to identify various reliably determinable, small-scale structures

Modules (Continued)
Parserinput a sequence of lexical items and perhaps small-scale structures (phrases) and output a set of parse tree fragments, possibly complete
Fragment Combinerturn a set of parse tree or logical form fragments into a parse tree or logical form for the whole sentence
Semantic Interpretergenerate a semantic structure or logical form from a parse tree or from parse tree fragments

Modules (Continued)
Lexical Disambiguationturn a semantic structure with general or ambiguous predicates into a semantic structure with specific, unambiguous predicates
Coreference Resolution, or Discourse Processingturn a tree-like structure into a network-like structure by identifying different descriptions of the same entity in different parts of the text
Template Generatorderive the templates from the semantic structures





























