Embed Size (px)
Citation preview

www.tesseract.it
Io, InformaticoUn Viaggio consapevole tra Informatica e Computer
Capitolo 5
Voglio parlare alla macchina: Linguaggi
Carlo A. Mazzone
Tutti i diritti sono riservati. Nessuna parte di questa pubblicazione può essere riprodotta, memorizzata in sistemi di archivio, o trasmessa in qualsiasi forma o mezzo, elettronico, meccanico, fotocopia, registrazione o altri senza la preventiva autorizzazione dell'autore.
1 - Io, Informatico – Carlo A. Mazzone – versione 20100910

Capitolo 5 - Voglio parlare alla macchina: Linguaggi
Comunicare è essenziale. Comunicare significa trasmettere informazione. Si tratta di un processo che utilizziamo ogni giorno per interagire con il mondo che ci circonda. Qualunque sia la forma di comunicazione che utilizziamo: scritta, parlata, elettronica, cartacea tradizionale o qualunque altra cosa vi venga in mente, alla base di essa vi è un linguaggio.
In generale, un linguaggio può essere visto come costituito da un insieme di simboli organizzati in modo da costituire parole. Ad ogni parola è associato un oggetto o più in generale un concetto.
L'insieme di tutte le parola di un linguaggio prende il nome di lessico. Si tratta in buona sostanza del dizionario del linguaggio in questione.
Facciamo un banale esempio: nella lingua italiana i simboli elementari sono le lettere dell'alfabeto, dalla 'a' alla 'z'. Combinando in vario modo tali lettere otteniamo le parole del linguaggio: da 'abaco' a 'zuzzerellone', costruiamo il lessico della nostra lingua.
Tuttavia le parole da sole non sono sufficienti a realizzare un linguaggio. Abbiamo bisogno di una serie di regole grammaticali che stabiliscano come le parole debbano essere legate tra di esse. Tali regole prendono il nome di sintassi del linguaggio.
Una qualsiasi proposizione del linguaggio deve contenere una certa quantità di informazione. L'insieme delle regole che consentono di dare significato al linguaggio prende il nome di semantica.
I linguaggi utilizzati per comunicare tra esseri umani prendono il nome di linguaggi naturali; banalmente, in questa categoria rientrano la lingua italiana, la lingua inglese, il giapponese e... chiaro no?
Ma come facciamo a comunicare con le macchine? Se è difficile, a volte, farsi capire da un umano
utilizzando la sua stessa lingua (linguaggio naturale), figuriamoci come potrebbe essere complicato utilizzare il linguaggio naturale con il nostro PC1.
Sin dagli albori dell'informatica sono stati sviluppati tutta una serie di linguaggi specifici per comunicare le istruzioni da far eseguire alle macchine: tali linguaggi nel loro complesso prendono il nome di linguaggi artificiali (o anche linguaggi formali).
1 In questo contesto ignoro volutamente ciò che attiene alle problematiche relative al riconoscimento vocale.
2 - Io, Informatico – Carlo A. Mazzone – versione 20100910
Un ipotetico dialogo uomo - macchina

I programmi traduttori
I programmi traduttori
Il punto iniziale e finale della comunicazione tra due esseri umani è il cervello. Con questo voglio dire che l'informazione da tramettere proviene da un concetto, un pensiero partorito dalla mente di chi parla e che deve raggiungere il cervello di chi ascolta. Il cervello del “mittente” provvede a pilotare l'apparato vocale per creare un flusso di suoni (le parole) che raggiungeranno l'apparato uditivo del destinatario della comunicazione. Sarà infine il cervello del destinatario a separare i singoli suoni per ricostruire le parole (e quindi poi il significato) relativo al messaggio originario.
E' ovvio che in questo contesto non ci soffermiamo sulle dinamiche di funzionamento del cervello umano. Tutta questa introduzione mi serviva per porre l'accento sul concetto di cervello e quindi del suo “omologo” nel campo dei linguaggi artificiali e quindi delle macchine.
Ebbene, il cervello dei calcolatori elettronici, per quanto complessi questi possano essere, si basa sulla logica binaria (gli ormai noti valori 0 e 1). Ciò significa che le istruzioni ed i comandi che il cervello dei PC può gestire sono sequenze di bit. Ad ogni sequenza di bit corrisponde un'azione elementare che tale cervello (la CPU – Central Processing Unit) può eseguire.
Operazioni classiche possono essere, ad esempio, la lettura di un elemento specifico dalla memoria del PC, la scrittura in memoria di un dato valore, la somma tra due valori, ecc.
L'insieme di tutte le istruzioni elementari che la CPU può gestire, unitamente alle regole impiegate per il loro utilizzo, prende il nome di linguaggio macchina.
Una tipica istruzione in linguaggio macchina è composta da due parti: la prima, che prende il nome di codice operativo, indica il tipo di azione che deve essere effettuata ed una eventuale seconda parte che contiene uno o più operandi. Tali operandi specificano le celle di memoria sulle quali effettuare l'operazione (istruzione) indicata dal codice operativo.
Come ho già detto il tutto è espresso attraverso una sequenza di cifre binarie.
E' facile comprendere quale debba essere la difficoltà dal punto di vista del programmatore umano che deve comunicare con la macchina utilizzando sequenze di zeri e di uni. In effetti, agli albori dell'informatica, le cose procedevano proprio in questo modo.
Per rendere più evidente tale difficoltà vi basterà immaginare che una tipica istruzione in linguaggio macchina è qualcosa del tipo:
0100 0000 0000 1001
Il primo passo compiuto per semplificare tale comunicazione fu quello di associare dei codici mnemonici alle sequenze di bit rappresentanti le istruzioni del linguaggio macchina.
Il linguaggio che ne derivò prese il nome di linguaggio Assembly.
La precedente istruzione diventa allora qualcosa di più comprensibile come la seguente:
READ 9
3 - Io, Informatico – Carlo A. Mazzone – versione 20100910

I programmi traduttori
Tale conversione si è ottenuto sostituendo nell'istruzione in linguaggio macchina ai prima quattro bit (0100) il codice mnemonico READ mentre i restanti bit rappresentano l'operando espresso in notazione decimale (0000 0000 1001 = 9).
Una prima cosa che mi sento di sottolineare è che spesso si confonde il linguaggio Assembly con l'Assembler, utilizzando tale termine come sinonimo di Assembly.
In senso più rigoroso, infatti, per Assembler si intende il programma che converte i codici mnemonici dell'assembly nei veri e propri codici binari del linguaggio macchina. Nel nostro esempio, sarà proprio l'assembler a sostituire in fase di traduzione al codice READ il corrispondente binario (0100).
Un grosso limite del linguaggio assembly è tuttavia insito nella sua estrema vicinanza all'hardware della macchina. Mi spiego: essendo esso composto da istruzioni specifiche della singola CPU un programma scritto per una data architettura hardware non può essere utilizzato su di una macchina con architettura differente. In gergo tecnico si dice che esso non è “portabile” o, più propriamente, che non è consentita la portabilità. Un'altra cosa di notevole interesse che vale la pena di sottolineare è il fatto che tale conversione introduce un concetto di estrema importanza: la traduzione.
Ciò che infatti resta sotteso a questo contesto è la possibilità di demandare ad uno specifico programma il compito di effettuare la traduzione, a partire da un linguaggio più vicino all'utente (in questo caso i codici mnemonici più facilmente gestibili), verso il linguaggio effettivamente compreso dalla macchina.
Tale “scoperta” ha dato luogo a tutta una serie di nuovi linguaggi sempre più vicini alla logica umana e sempre più lontani dai dettagli interni dei vari microprocessori. Quando si parla di linguaggi a “basso livello” ed “alto livello” ci si riferisce appunto alla vicinanza, o meno, dello specifico linguaggio rispetto alla macchina ed all'utente. Sarà di basso livello un linguaggio molto vicino ai dettagli hardware della macchina; sarà di alto livello, al contrario, un linguaggio vicino al linguaggio naturale ed al modo di gestire i problemi tipicamente umani.
4 - Io, Informatico – Carlo A. Mazzone – versione 20100910

Interpreti e compilatori
Interpreti e compilatori
In linea del tutto generale tale traduzione può avvenire in due modi distinti: tramite interpretazione oppure tramite compilazione.
L'interpretazione consiste nella traduzione delle singole istruzioni, una dopo l'altra, e nella loro immediata codifica in linguaggio macchina e corrispondente esecuzione.
Una considerazione che risulta naturale in tale contesto di traduzione è data dal fatto che affinché sia possibile tale procedimento è necessario che sulla macchina che ha in esecuzione il nostro programma sia presente anche l'apposito programma traduttore: l'interprete.
“Interprete” è infatti il nome del programma che deve risiedere sul PC in questione affinché si possa eseguire il nostro programma scritto in linguaggio di alto livello. In generale, come conseguenza di tale situazione i linguaggi che utilizzano tale approccio vengono definiti linguaggi interpretati.
Per rendere la mia descrizione più concreta mi sento di dover presentare qualche esempio specifico. Linguaggi tipicamente interpretati sono quelli utilizzati per le applicazioni utilizzate su Internet: ASP, ASP.NET, PHP solo per citare i più diffusi.
Discorso diverso è quello relativo ai linguaggi compilati ovvero quelli che si basano sulla compilazione: questi prevedono, come nel caso di quelli interpretati, la traduzione delle singole istruzioni in alto livello nelle specifiche istruzioni del linguaggio macchina. Tuttavia, tali istruzioni non vengono eseguite direttamente; al contrario, esse vengono salvate, già tradotte in codice macchina, in specifici file: i file eseguibili.
Andiamo a spasso con una “macchina virtuale”
Interpretazione e compilazione non sono due mondi completamente separati. Esistono dei linguaggi che si collocano a metà strada tra i linguaggi macchina (assemby incluso) ed i linguaggi ad alto livello e che prendono il nome di bytecode. Tali linguaggi sono costituiti da un numero di istruzioni abbastanza limitato e tali da essere relativamente vicine all'hardware. Ciò rende più semplice creare degli ambienti traduttori maggiormente efficienti ed al contempo “portabili” su sistemi operativi differenti.
Questo è infatti uno snodo importante.
Quando si scrive del codice e lo si compila lo si fa per un determinato e specifico sistema operativo (Windows, Linux o quello che sia). E' il sistema operativo che mette a disposizione le funzionalità per l'accesso all'hardware sfruttate dagli applicativi. Tali funzionalità vanno sotto il nome di API, ovvero Application Programming Interface (Interfaccia di Programmazione per l'Applicazione). Va da se che utilizzando una determinata API di uno specifico sistema operativo ci si lega con la propria applicazione a quello specifico sistema operativo. Per superare tali problemi di portabilità ed al contempo per fornire allo sviluppatore il maggior numero di funzionalità di accesso all'hardware in maniera predefinita senza che lo sviluppatore sia costretto a codificare in proprio tali funzionalità, sono nate delle interfacce software da frapporre tra il sistema operativo e l'applicativo stesso. Concentrando lo sviluppo del codice riferendosi a tale interfaccia, nota come macchina virtuale, il nostro programma sarà liberamente utilizzabile su vari sistemi operativi a patto che su questi sia presente la specifica macchina virtuale.
5 - Io, Informatico – Carlo A. Mazzone – versione 20100910
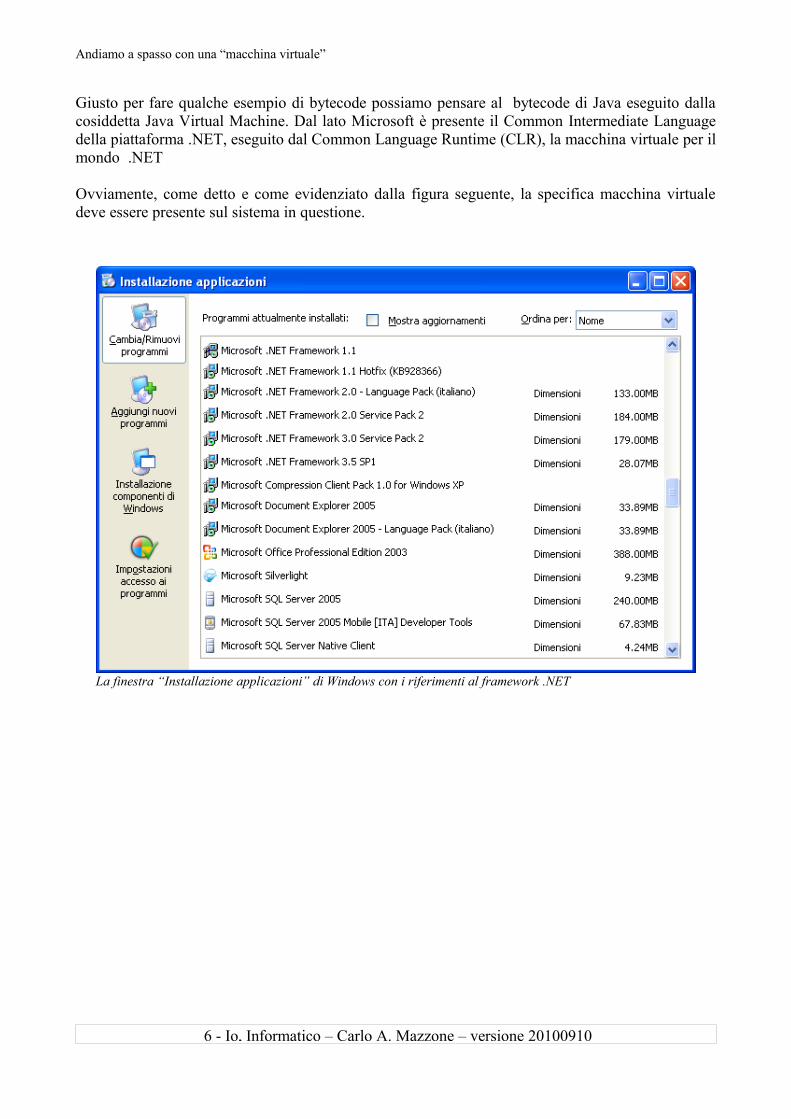
Andiamo a spasso con una “macchina virtuale”
Giusto per fare qualche esempio di bytecode possiamo pensare al bytecode di Java eseguito dalla cosiddetta Java Virtual Machine. Dal lato Microsoft è presente il Common Intermediate Language della piattaforma .NET, eseguito dal Common Language Runtime (CLR), la macchina virtuale per il mondo .NET
Ovviamente, come detto e come evidenziato dalla figura seguente, la specifica macchina virtuale deve essere presente sul sistema in questione.
6 - Io, Informatico – Carlo A. Mazzone – versione 20100910
La finestra “Installazione applicazioni” di Windows con i riferimenti al framework .NET
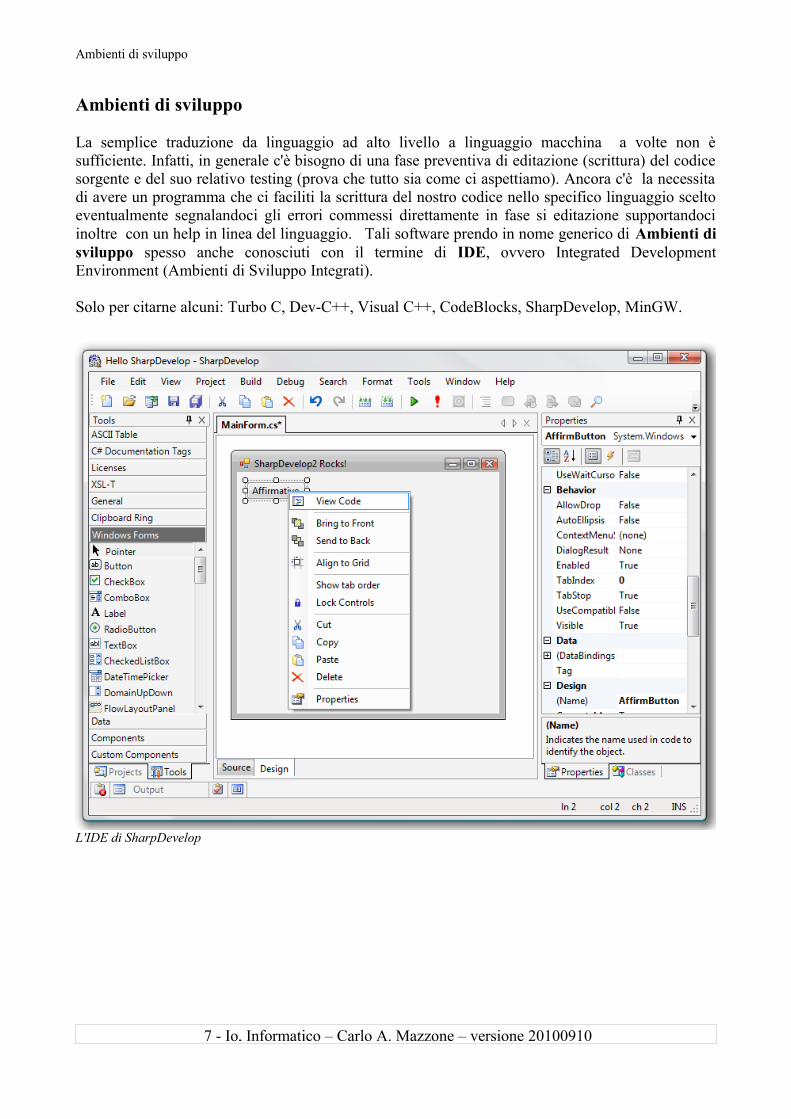
Ambienti di sviluppo
Ambienti di sviluppo
La semplice traduzione da linguaggio ad alto livello a linguaggio macchina a volte non è sufficiente. Infatti, in generale c'è bisogno di una fase preventiva di editazione (scrittura) del codice sorgente e del suo relativo testing (prova che tutto sia come ci aspettiamo). Ancora c'è la necessita di avere un programma che ci faciliti la scrittura del nostro codice nello specifico linguaggio scelto eventualmente segnalandoci gli errori commessi direttamente in fase si editazione supportandoci inoltre con un help in linea del linguaggio. Tali software prendo in nome generico di Ambienti di sviluppo spesso anche conosciuti con il termine di IDE, ovvero Integrated Development Environment (Ambienti di Sviluppo Integrati).
Solo per citarne alcuni: Turbo C, Dev-C++, Visual C++, CodeBlocks, SharpDevelop, MinGW.
7 - Io, Informatico – Carlo A. Mazzone – versione 20100910
L'IDE di SharpDevelop

Generazioni di linguaggi
Generazioni di linguaggi
Finora vi ho presentato tre tipologie differenti di linguaggi: il linguaggio macchina, il linguaggio assemby ed, in generale, i linguaggi ad alto livello.
In maniera più formale questi linguaggi vengono inquadrati in cosiddette generazioni.
Prima generazione: è rappresentata dai linguaggi macchina (binari)
Seconda generazione: è data dai linguaggi assembly che come detto utilizzano codici mnemonici per semplificarne l'utilizzo da parte degli “umani”.
Terza generazione: vi rientrano i linguaggi di alto livello utilizzanti istruzioni molto vicine alle parole del linguaggio naturale (ovviamente della lingua inglese). Esempi tipici sono il Basic, il Pascal, il Fortran, il linguaggio C ed tanti altri ancora.
Quarta generazione: in questo caso la situazione comincia ad essere un po' più complessa. Ci stiamo allontanando sempre di più dai dettagli della macchina e ci stiamo avvicinando di conseguenza verso il modo di lavorare e di pensare dell'utente umano. In questa generazione rientrano infatti i linguaggi in cui il programmatore deve “semplicemente” definire ciò di cui ha bisogno senza dettagliare più di tanto come ciò debba essere ottenuto. Sarà il linguaggio ad occuparsi di codificare i dettagli necessari. Tipicamente i linguaggi di tale generazione hanno a che fare con la manipolazione di archivi di dati (SQL su tutti).
Quinta generazione:
In questa generazione ricadono i linguaggi utilizzati nel campo dell'intelligenza artificiale e dei cosiddetti sistemi esperti.
In definitiva, semplificando al massimo possiamo dire che i linguaggi di prima e seconda generazione (1G e 2G) sono di basso livello mentre gli altri: 3G, 4G e 5G sono di alto livello.
8 - Io, Informatico – Carlo A. Mazzone – versione 20100910

Generazioni di linguaggi
Dal sorgente all'eseguibile Vediamo ora di inserire un nuovo tassello nelle nostre conoscenze informatiche relative ai linguaggi. Abbiamo abbondantemente detto che per rendere possibile l'esecuzione delle istruzioni di un linguaggio è necessario disporre di un'apposita procedura di traduzione che trasformi le istruzioni del linguaggio (tipicamente un linguaggio ad alto livello) in istruzioni elementari comprensibili dal calcolatore. Ebbene, l'insieme delle istruzioni del linguaggio ad alto livello scritte con l'intento di risolvere un dato problema prende il nome di codice sorgente o, più semplicemente, sorgente.
Per far si che tale codice venga tradotto in maniera corretta esso viene processato (esaminato) sottoponendolo a vari tipi di analisi. Tali analisi sono tipicamente tre: analisi lessicale, analisi sintattica ed analisi semantica. Credo sia opportuno vederne le singole caratteristiche seppure in maniera abbastanza generale.
Analisi lessicale
L'analisi lessicale consiste nel verificare che i termini (le parole) utilizzate all'interno del nostro codice sorgente sia effettivamente appartenenti al linguaggio che abbiamo deciso di utilizzare per codificare il nostro programma. Un esempio dovrebbe chiarire il concetto. Nel caso del linguaggio C se si vuole stampare a schermo una data sequenza di caratteri sarà necessario utilizzare una specifica istruzione, ad esempio: printf.
Un pezzo di codice come il seguente:
printg(“Salve a tutti”);
produrrebbe, da parte del compilatore o dell'interprete, un errore di tipo lessicale. Infatti, il termine printg, non appartiene all'insieme delle parole proprie del linguaggio in questione.
Analisi sintattica
L'analisi sintattica riguarda invece le regole proprie del linguaggio specifico. L'esempio, sempre relativo al C, è immediato:
9 - Io, Informatico – Carlo A. Mazzone – versione 20100910

Generazioni di linguaggi
printf(“Salve a tutti”)
la precedente istruzione è corretta dal punto di vista lessicale. Infatti, la parola chiave printf appartiene al linguaggio che stiamo utilizzando. Tuttavia, essa non supererà l'analisi sintattica. Infatti, nello specifico del linguaggio C, viene richiesto che ogni singola istruzione venga terminata dal simbolo “;” (punto e virgola).
Analisi semantica
L'analisi semantica, infine, è un sicuramente po' più particolare. Ho detto, infatti, in apertura del capitolo che la semantica riguarda l'insieme delle regole attinenti al significato delle frasi (istruzioni) prodotte con il nostro linguaggio. Nel caso informatico, a puro titolo di esempio, si può vedere l'analisi semantica nella verifica che il compilatore effettua per individuare se tutti gli identificatori (variabili) utilizzati siano effettivamente stati dichiarati.
Alla fine del procedimento di analisi del codice, e solo nel caso in cui non siano stati riscontrati errori, verrà generato il codice eseguibile pronto per essere eseguito sulla macchina.
10 - Io, Informatico – Carlo A. Mazzone – versione 20100910
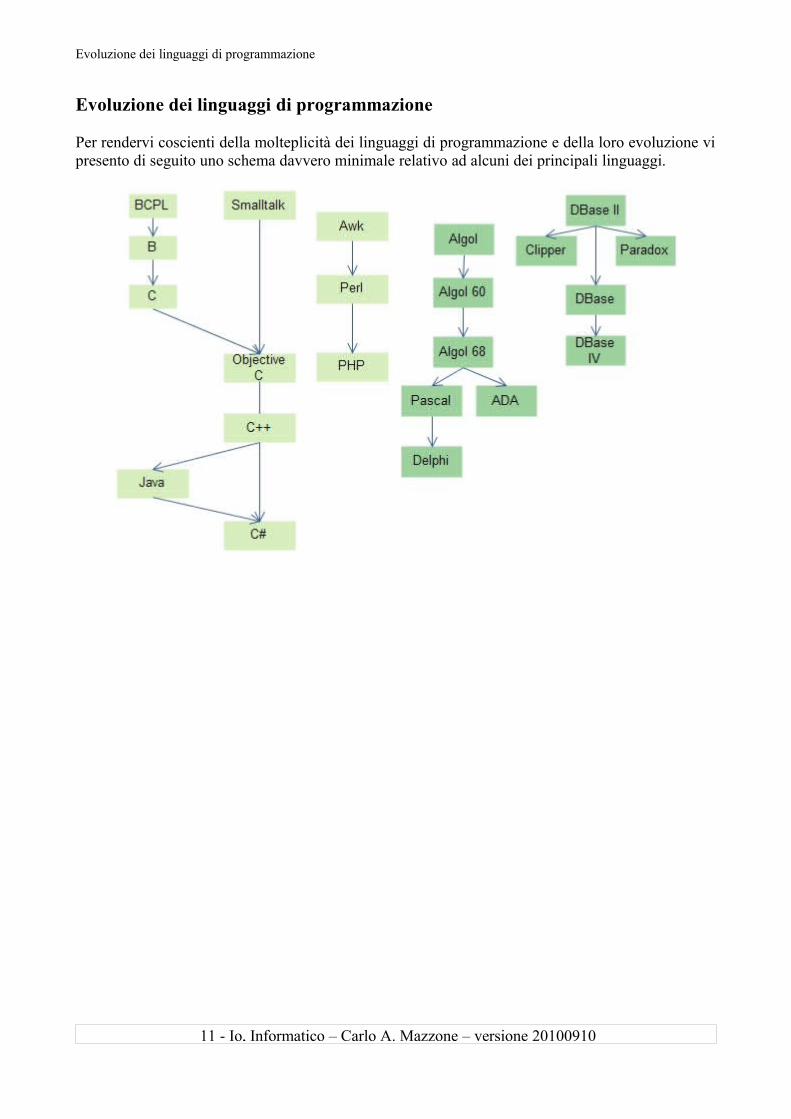
Evoluzione dei linguaggi di programmazione
Evoluzione dei linguaggi di programmazione
Per rendervi coscienti della molteplicità dei linguaggi di programmazione e della loro evoluzione vi presento di seguito uno schema davvero minimale relativo ad alcuni dei principali linguaggi.
11 - Io, Informatico – Carlo A. Mazzone – versione 20100910

Paradigmi di programmazione
Paradigmi di programmazione
Contrariamente a quanto si potrebbe pensare, non esiste un solo modo standard per istruire una macchina ad eseguire determinate istruzioni. Esistono, infatti, varie metodologie differenti per creare un programma: tali metodologie generali prendono il nome di paradigmi di programmazione.
Ad una prima analisi è possibile dividere l'insieme di tutti i linguaggi in due grosse famiglie: quelli di tipo procedurale (detti anche imperativi) e quelli di tipo dichiarativo.
Una premessa è comunque d'obbligo: tale organizzazione non è completamente sufficiente ed esaustiva. Il motivo è dato dal fatto che alcuni linguaggi si trovano ad avere caratteristiche comuni a più paradigmi il che li rende difficili da classificare. In ogni caso lo schema proposto vuole rappresentare una linea guida per focalizzare le caratteristiche proprie dei linguaggi specifici.
In prima approssimazione è possibile distinguere due differenti tipologie fondamentali: quella imperativa (detta anche procedurale) e quella dichiarativa.
La programmazione di tipo imperativo rappresenta il metodo classico di programmare: si codifica, nel linguaggio scelto, l'insieme delle istruzioni che servono a risolvere il problema in questione. In questo contesto è il programmatore che deve individuare e formalizzare il giusto algoritmo risolutivo. Ma di questo vi parlo in maggior dettaglio nel paragrafo seguente.
Vengo allora all'approccio dichiarativo. Per i non addetti ai lavori si tratta di un qualcosa di sorprendente: il programmatore che deve risolvere un dato problema non deve stendere e codifica re l'algoritmo ma “semplicemente” dichiarare (da cui il termine dichiarativo) di voler risolvere un dato problema, di volere cioè l'ottenimento di un dato risultato.
Un esempio dovrebbe chiarire questo aspetto. Tipici linguaggi che utilizzano l'approccio dichiarativo sono quelli utilizzati per la gestione degli archivi: tra questi il notissimo SQL. In tale linguaggio, appunto, di dichiara di voler ottenere un dato risultato e non ci si preoccupa di come questo venga costruito.
Quando scriviamo qualcosa del tipo:
12 - Io, Informatico – Carlo A. Mazzone – versione 20100910
I differenti paradigmi di programmazione

Paradigmi di programmazione
SELECT nome, cognome, indirizzo FROM anagrafica
stiamo “dichiarando” al sistema con il linguaggio SQL di volere l'elenco dei nominativi con relativi indirizzi di un dato gruppo di elementi e ci aspettiamo che il sistema ci restituisca ciò che abbiamo richiesto. Di come questo avvenga e di quanto complesso possa essere il lavoro effettuato dal linguaggio non potrebbe importarci di meno. Dichiariamo di volere un certo risultato ed aspettiamo che questo venga prodotto.
Nel seguito cercherò di farvi una panoramica sulle principali e differenti articolazioni tipologiche dei linguaggi considerando il tutto ovviamente a livello generale. Conoscere e poter utilizzare uno specifico linguaggio comporta inevitabilmente lo “sporcarsi le mani” con il codice per produrre programmi reali. Tuttavia una prima visione generale è indispensabile per potersi muovere con un minimo di cognizione di causa in questo quanto mai variegato mondo.
13 - Io, Informatico – Carlo A. Mazzone – versione 20100910

Programmazione procedurale
Programmazione procedurale
Nel paradigma della programmazione procedurale rientrano la maggior parte dei linguaggi di uso comune. Linguaggi come il Basic, il Pascal e il C, solo per citare i più noti, appartengono a pieno titolo a questa fondamentale categoria.
Come indicato nello schema che vi ho proposto, i linguaggi che utilizzano la programmazione procedurale vengono anche detti imperativi. Il motivo di tale nome è dato dal fatto che per risolvere un dato problema bisogna comandare (quindi “imperare”) la macchina indicando le singole istruzioni da eseguire per risolvere il dato problema.
Vi faccio un esempio abbastanza classico. Dovendo scrivere un programma per il calcolo della potenza di un numero dovremo istruire tale programma a prendere in input due numeri (uno per la base e l'altro per l'esponente). Successivamente dovremo far moltiplicare la base per il numero di volte indicato dall'esponente. Sarà cura del programmatore indicare le corrette istruzioni da far eseguire al programma.
La programmazione procedurale si è comunque evoluta nel tempo. La prima miglioria che ha vissuto è stata quella di rendere gestibile in blocchi le varie operazioni da eseguire. Nel caso del nostro esempio potrebbe capitare che il programma in questione debba eseguire la potenza di vari numeri; risulta così più efficiente creare uno specifico blocco di codice al quale demandare l'esecuzione del calcolo della potenza passando a tale blocco le varie coppie (base, esponente).
Una ulteriore evoluzione di tale problematica ha visto nascere linguaggi orientati non più a semplici blocchi di codice ma organizzati in specifici “oggetti” dotati non solo della possibilità di elaborare dati ma anche di possedere dei dati propri.
14 - Io, Informatico – Carlo A. Mazzone – versione 20100910

Programmazione funzionale
Programmazione funzionale
La programmazione funzionale può essere vista come programmazione orientata alle espressioni. Tipici esempi sono il Lisp o il Python1.
Nella programmazione funzionale le funzioni vengono trattate in modo analogo alle variabili e la programmazione è fortemente orientata alle liste
Per comprendere meglio il tipo di programmazione logica può essere di ausilio fare riferimento a qualche semplice esempio specifico relativo al Lisp.
Il Lisp nasce alla fine degli anni '50. Il nome del linguaggio “LISt Processing” svela la sua natura di linguaggio funzionale in quanto orientato alla gestione delle liste. Il Lisp è attualmente utilizzato principalmente per problematiche di Intelligenza Artificiale e Sistemi Esperti.
Un ottimo punto di partenza per l'apprendimento del linguaggio Lisp per gli utenti italiani può essere il sito www.lisp.it (“Italian Lisp Users Group”).
1 Il Python è in realtà un linguaggio multi-paradigma. Permette, infatti, in modo agevole di scrivere programmi seguendo il paradigma orientato agli oggetti, la programmazione strutturata, o anche la programmazione funzionale.
15 - Io, Informatico – Carlo A. Mazzone – versione 20100910
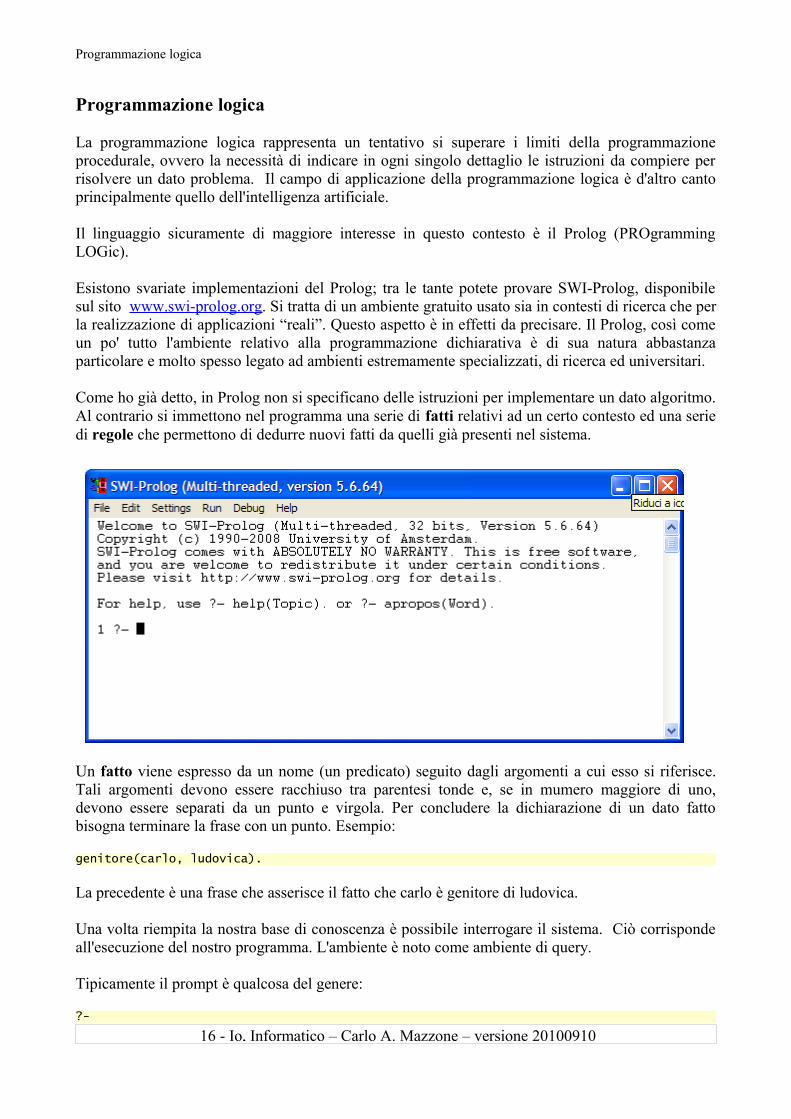
Programmazione logica
Programmazione logica
La programmazione logica rappresenta un tentativo si superare i limiti della programmazione procedurale, ovvero la necessità di indicare in ogni singolo dettaglio le istruzioni da compiere per risolvere un dato problema. Il campo di applicazione della programmazione logica è d'altro canto principalmente quello dell'intelligenza artificiale.
Il linguaggio sicuramente di maggiore interesse in questo contesto è il Prolog (PROgramming LOGic).
Esistono svariate implementazioni del Prolog; tra le tante potete provare SWI-Prolog, disponibile sul sito www.swi-prolog.org. Si tratta di un ambiente gratuito usato sia in contesti di ricerca che per la realizzazione di applicazioni “reali”. Questo aspetto è in effetti da precisare. Il Prolog, così come un po' tutto l'ambiente relativo alla programmazione dichiarativa è di sua natura abbastanza particolare e molto spesso legato ad ambienti estremamente specializzati, di ricerca ed universitari.
Come ho già detto, in Prolog non si specificano delle istruzioni per implementare un dato algoritmo. Al contrario si immettono nel programma una serie di fatti relativi ad un certo contesto ed una serie di regole che permettono di dedurre nuovi fatti da quelli già presenti nel sistema.
Un fatto viene espresso da un nome (un predicato) seguito dagli argomenti a cui esso si riferisce. Tali argomenti devono essere racchiuso tra parentesi tonde e, se in mumero maggiore di uno, devono essere separati da un punto e virgola. Per concludere la dichiarazione di un dato fatto bisogna terminare la frase con un punto. Esempio:
genitore(carlo, ludovica).
La precedente è una frase che asserisce il fatto che carlo è genitore di ludovica.
Una volta riempita la nostra base di conoscenza è possibile interrogare il sistema. Ciò corrisponde all'esecuzione del nostro programma. L'ambiente è noto come ambiente di query.
Tipicamente il prompt è qualcosa del genere:
?-
16 - Io, Informatico – Carlo A. Mazzone – versione 20100910

Programmazione logica
Nel prompt vengono effettuar le query anche note come goal. Alla domanda: ?- genitore(carlo, ludovica).
Il sistema risponderà con Yes, essendo presente nella base di conoscenza tale affermazione.
17 - Io, Informatico – Carlo A. Mazzone – versione 20100910

Vita, morte e “miracoli” di un software
Vita, morte e “miracoli” di un software
Quello che vi ho illustrato finora è probabilmente solo parte della punta del classico iceberg. Ciò che voglio dirvi è che per realizzare un software non risulta sufficiente avere a disposizione un linguaggio di programmazione ed il relativo ambiente di sviluppo.
Creare un'applicazione (o applicativo) software può essere immaginato simile alla costruzione di un qualsiasi oggetto complesso. A partire dalla sorpresa che potete trovare nell'ovetto di cioccolato con le relative istruzioni di montaggio, per passare ad un mobile acquistato da Ikea fino ad arrivare all'edificazione di una casa, tutto ciò che deve essere assemblato ha bisogno di un apposito progetto.
Non solo codice: progettazione!
La creazione del software non sfugge a tali richieste cosicché la cosiddetta progettazione del software riveste in campo informativo un'enorme importanza.
Per progettazione si intende l'insieme delle attività svolte al fine di definire le caratteristiche essenziali del software da realizzare. In “soldoni” non è pensabile di iniziare a scrivere codice senza aver preventivamente definito cosa e come si vuole realizzare e quali sono quindi le caratteristiche chiave che si intendono inserire nel proprio prodotto. Per rafforzare la comprensione di questo aspetto vi faccio riflettere sul fatto che spesso, prima di iniziare a scrivere il programma vero e proprio, si realizza un modello di ciò che dovrà essere prodotto per verificare, anche visivamente, se ciò che stiamo modellando è proprio ciò di cui abbiamo bisogno. Solo per fare un esempio vi segnalo che a volte si utilizza Visual Basic per definire e testare l'interfaccia dell'applicativo mentre successivamente si adopererà l'ambiente di sviluppo scelto per la realizzazione vera e propria. Ciò è dovuto all'estrema semplicità che si ottiene con Visual Basic stesso per creare interfacce grafiche dei programmi.
Cerco allora di essere un po' più dettagliato. Prima ancora di iniziare la progettazione è possibile individuare un'altra fase dello sviluppo software, che prende il nome generico di analisi del software, nella quale si definiscono per sommi
capi le caratteristiche del software da realizzare, i tempi che dovrebbero essere impiegati, le persone che ci lavoreranno, i costi presunti, a chi sarà diretto (venduto) il software in oggetto, ecc. Solo dopo questa fase, se si riterrà valido e fattibile il tutto si passerà alla fase successiva di progettazione vera e propria.
Dopo la progettazione, ovviamente, si procede alla codifica del programma di cui vi ho già parlato ampiamente.
Ma come facciamo a sapere se ciò che abbiamo realizzato dopo la codifica corrisponde a ciò che effettivamente ci proponevamo di ottenere? La risposta è semplice: collaudo del programma. Tale fase è spesso, ma a torto, sottovalutata. Collaudare la propria applicazione, prima di rilasciarla agli utilizzatori, è una cosa di assoluta importanza. Questa fase di collaudo è spesso definita come
18 - Io, Informatico – Carlo A. Mazzone – versione 20100910
Ciclo di vita del software

Non solo codice: progettazione!
attività di testing e consiste nell'individuare eventuali bug (errori di programmazione) all'interno della nostra applicazione.
Tutto questo processo prende il nome di ciclo di vita del software.
Tuttavia, a questo punto, mi sento in coscienza di fare alcune precisazioni. Tanto per cominciare ciò che vi ho descritto non può essere applicato così come proposto in un singolo passo. Il motivo è semplice: non si può scrivere (codificare) tutto il nostro codice e produrre in un solo passaggio tutto il programma e quindi solo in fase finale testarlo per individuare possibili bug. Un software, a meno che non prevede la semplice stampa di una stringa del tipo “Salve mondo” è qualcosa di complesso che deve per forza di cose essere creato in piccoli pezzi. Ogni piccola nuova funzionalità deve essere verificata attentamente prima di procedere alla costruzione della funzionalità successiva. Al contrario si rischierebbe di creare un gigante dai piedi di argilla (o sempre parafrasando il classico castello sulla sabbia).
I sistemi software attuali si sono talmente evoluti nel tempo tanto da richiedere la formalizzazione di una specifica disciplina nota come Ingegneria del software, che si preoccupa appunto di definire i criteri più opportuni per la gestione del ciclo di vita dei software stessi.
Un'altra cosa da dire è che spesso la serie di fasi descritte rimane una mera indicazione teorica e che ancor più frequentemente si viene colti dal raptus dello sviluppo senza preoccuparsi di produrre uno straccio di progettazione preventiva. Niente di più sbagliato. Anche nei progetti di più piccole dimensioni è bene organizzarsi il lavoro prima di iniziare a codificare.
Un primo passo può anche consistere nel procurarsi una cartellina per documenti sulla quale apporre il nome del programma che si intende realizzare. Il nome, infatti, è uno degli aspetti preliminari fondamentali del nostro progetto.
Anche se un nome commerciale non è stato ancora definito con certezza è sempre bene scegliere un nome di comodo (nome in codice) per potersi riferire meglio al progetto in questione.
Giusto per fare un esempio, le varie versioni del sistema operativo Windows prima di essere rilasciate con il nome definitivo sono state sempre etichettate con un nome in codice provvisorio: Chicago per Windows 95, Memphis per Windows 98, Whistler per Windows XP, Longhorn per Windows Vista solo per citarne alcuni.
La cartellina cartacea servirà come contenitore per appunti e documenti attinenti al progetto. Tuttavia una buona organizzazione delle cartelle (intese come directory sul nostro hard disk) è altrettanto importante. E' a dir poco da pazzi scatenati pensare di poter inserire i file del nostro progetto software in un'unica cartella. Dovranno infatti essere create quantomeno una cartella per i codici sorgenti, una per i documenti associati al programma, una per le immagini da utilizzarsi nel software, una con i file compilati e gli altri necessari alla distribuzione. Il tutto giusto per citare i principali aspetti coinvolti.
Dammi un nome e ti dirò chi sei
Relativamente ai nomi da dare al proprio software mi sento di spendere qualche parola in più.
Un nome, va da sé, serve ad individuare in maniera precisa un certo oggetto. Seppur non di capitale importanza per un sito web, un nome efficace per un software applicativo può aiutare di molto la notorietà del nostro prodotto.
19 - Io, Informatico – Carlo A. Mazzone – versione 20100910

Non solo codice: progettazione!
Per darvi un'idea di quello che sto dicendo relativamente all'importanza di un nome vi riporto un brano tratto dalla conferenza1 tenuta nel 2005 a Bologna da Richard Stallman (New York, 16 marzo 1953), uno dei più importanti artefici del software libero. Stallman parlando del sistema operativo che stava sviluppando nei primi anni 80 dice:
Così decisi che sarebbe stato un sistema Unix-like o per lo meno compatibile, e questo ebbe una conseguenza interessante: siccome Unix è formato da molti componenti, centinaia di componenti che comunicano attraverso interfacce più o meno documentate, e gli utenti usano quelle interfacce, per essere compatibili con Unix basta mantenere la compatibilità con quelle stesse interfacce. Significò che si doveva solo sostituire ciascuno dei componenti no compatibile, uno alla volta. E significò anche che tutte le decisioni preliminari di tipo architetturale erano già state prese e quindi, a quel punto, l'unica cosa di cui avevamo bisogno era un nome.
Nella comunità dei programmatori degli anni settanta, alla quale io appartenevo, si programmava sopratutto per il piacere (essere pagati era secondario), e si sceglievano sempre nomi divertenti per i programmi […]; c'è perfino una tradizione, quando si sviluppa qualcosa di simile a qualcosa che esiste già, di scegliere un nome che richiama
in modo ricorsivo il nome dell'altro e dice “questo programma non è quell'altro”.Infatti, nel 1975, io avevo sviluppato la prima versione dell'editor EMACS, un editor estendibile che poteva essere riprogrammato dall'utente, e c'erano diverse imitazioni di EMACS, delle quali una si chiamava FINE cioè “FINE non è EMACS” [FINE Is Not Emacs], e c'era anche SINE che significava “SINE non è EMACS”, e c'era anche EINE (uno in tedesco) e c'era anche MINCE per MINCE Is Not Completely Emacs. Poi EINE fu quasi completamente riscritto e la versione 2 si chiamò ZWEI (due in tedesco) che significa ZWEI Was EINE Initially...Così cercavo attivamente un nome del tipo “questo non è Unix”, ma nessuna delle possibilità dava una vera parola, e se non avesse avuto un altro significato non sarebbe stato divertente. [Alla fine] ho provato con tutte le lettere dell'alfabeto: ANU, BNU, CNU, DNU, FNU, GNU!Gnu è la parola più divertente della lingua inglese, e non ho potuto resistere. Credo che le parole di Stallman appena presentate siano assolutamente chiarificatrici su quanto un nome possa risultare importante.
Ancora una considerazione sulla vita di un software. Così come ogni elemento che ha una vita ha un suo termine, anche per un software è prevista una “morte”. Essa normalmente incombe quando il software diventa obsoleto perché non più rispondente a nuove esigenze di lavoro o quando non più funzionante su nuovi sistemi operativi o ambienti hardware. In ogni modo, per rendere il più longevo possibile un dato software è necessario che questo venga aggiornato e costantemente manutenuto. Infatti un software anche apparentemente perfetto ma abbandonato a se stesso, senza sviluppatori che ne curino gli aggiornamenti è destinato ad una veloce e prematura fine.
1 Tratto da Login Internet Expert n.53 Luglio/Agosto 2005
20 - Io, Informatico – Carlo A. Mazzone – versione 20100910
Richard Matthew Stallman (da giovane), il padre del software libero

Il Versioning del software
Il Versioning del software
Parlavo dunque di aggiornamenti. Come ho detto, di norma, un software viene sviluppato tramite aggiornamenti successivi che ne aumentano le potenzialità o che ne correggono eventuali bug. Ad ogni nuova versione, per prassi comune, viene associato un numero o più in generale una serie di numeri. Vado nel dettaglio della questione.
Supponiamo di aver realizzato un software che serve a prevedere il futuro (questa si che è una grande idea ;) e di averlo chiamato “Il Previsore”. La prima versione che commercializzeremo sarà dunque, in generale, semplicemente: “Il Previsore” (o se vogliamo meglio specificare le cose, “Il Previsore 1” ). Dopo un po' introdurremo nel nostro software delle nuove caratteristiche, ad esempio, la possibilità di prevedere i numeri del lotto che usciranno nelle estrazioni a venire (questa si che è una grandissima idea ;). La nuova versione sarà chiamata: “Il Previsore 2” in contrapposizione alla prima versione del nostro applicativo. La questione di base è chiara: avremo, o comunque ci auguriamo di poter avere, una versione 3 una versione 4 e così via.
Spesso, tuttavia, le modifiche che vengono realizzate sui software sono di scarsa importanza. In un tale contesto ci troveremmo ben presto alla versione centesima; dando tra le altre cose una sensazione di scarsa professionalità ai nostri vecchi e possibili futuri clienti del nostro software. La soluzione che si adotta è in genere quella di utilizzare un secondo numero di versione (separandolo dal primo con un punto) ed incrementare tale numero in presenza di migliorie appunto secondarie. In questa ottica la prima versione del nostro applicativo sarà: “Il Previsore 1.0”, la seconda potrà essere “Il Previsore 1.1” (abbiamo incrementato solo il numero di versione secondario), una terza “Il Previsore 1.2” ed una eventuale quarta versione, con aggiornamenti di una certa importanza, sarà qualcosa del tipo: “Il Previsore 2.0”. Il discorso dovrebbe a questo punto essere già più chiaro.
L'uso di questi primi due numeri di versione è pressoché standardizzato. C'è tuttavia dell'altro. Spesso, infatti, i numeri di versione non sono semplicemente due, ma a volte tre o addirittura quattro.
Una tipica versione del nostro software potrebbe essere qualcosa del genere:
“Il Previsore Versione 5.0.9.171”
dove: 5 è il numero primario (major number), 0 il numero secondario (minor number), 9 può essere utilizzato per indicare che questa versione è la nona release (versione rilasciata) del nostro software. Infine il numero 171 può rappresentare il cosiddetto numero di BUILD. Una build rappresenta una specifica compilazione del nostro file eseguibile principale. Spesso viene assegnata automaticamente dal compilatore per identificare una specifica versione compilata dei nostri sorgenti. Ma ripeto, l'uso del terzo e quarto numero di versione può per aziende diverse avere diversi significati.
A proposito della questione delle versioni è interessante osservare come, a seconda della tipologie di software, tali numeri vengano utilizzati in modo molto differente. Nel campo, ad esempio, del software gratuito spesso non si utilizza nemmeno il numero primario uno per indicare la prima versione rilasciata di un dato software. Al contrario, in questi contesti, il numero primario è zero. Il motivo è dato dal fatto che trattandosi di un software gratuito non c'è alcuna enfasi commerciale che
21 - Io, Informatico – Carlo A. Mazzone – versione 20100910

Il Versioning del software
spinga a far capire al futuro potenziale utente che si tratta di una versione ormai consolidata del software.
Dal versante opposto, i software commerciali hanno tutto l'interesse a mostrarsi con un numero di versione alto nel giro di pochi rilasci per far intendere una certa efficienza e robustezza del software stesso.
In questo contesto credo che sia esemplare la storia del software dBase, un DBMS (software per la gestione di archivi), molto popolare negli anni 80.
1Al Jet Propulsion Laboratory (JPL) di Pasadena, in California, veniva usato un DBMS per gestire le informazioni ricevute dai satelliti artificiali, funzionante su elaboratori di grosse dimensioni e, al primo apparire dei microcomputer, Wayne Ratliff, che allora lavorava al JPL come sistemista software, impressionato dalle caratteristiche di quel DBMS, lo prese a modello per una versione dedicata ai microcomputer, che chiamò Vulcan (dal nome del pianet di Mr. Spock, il personaggio del film Star Trek). Vulcan era ancora ben lontano da dBase II […] essendo privo dei potenti comandi di ordinamento e di indicizzazione che sarebbero stati realizzati in seguito. Esso era comunque, per quei tempi, un buon programma che si conquistò un piccolo spazio nell'allora nascente mercato dei software per microcomputer.
Uno degli estimatori di Vulcan fu George Tate, un rivenditore di software che si offri come distributore del programma. Ratliff non era un venditore e si accordò volentieri con Tate, affidandogli tutti i diritti di marketing in cambio di royalty.
Tate applicò subito a Vulcan alcuni trucchi di marketing. Il vecchio nome scomparve, in favore di dBase II (non esisteva alcun dBase I, ma ciò che contava era dare l'impressione che fosse esistito).
A una fiera di informatica, poi, Tate lanciò una mongolfiera con la scritta “dBase II” bene in vista, per attirare l'attenzione del pubblico. Fece eopca anche una famosa pubblicità in cui i prodotti della concorrenza erano paragonati a pompe di sentina, in modo alquanto sgradevole: i concorrenti reagirono duramente, come pure il fabbricante delle pompe di sentina usate come paragone dispregiativo, ma il pubblico notò il prodotto. In seguito tate si associò con Hal Lashlee e formò una società, la Ashton-Tate, per distribuire dBase II (non esisteva alcun signor Ashton, ma Tate peensò che quel nome suonava bene insieme al proprio e lo adottò subito).
Vi tocca ora ancora qualche dettaglio sul modo di gestire il verssioning. L'utilizzo dei numeri di versione, così come ve li ho presentati, non è il solo metodo utilizzato per identificare le versioni di un software. Talune aziende e sviluppatori, ad esempio, preferiscono inserire come numero di versione l'anno, a volte seguito dal mese, del rilascio del software. Spesso tale metodologia viene indicata come Ubuntu like.
Ubuntu è una distribuzione Linux molto diffusa che utilizza appunto anno e mese per individuare i propri rilasci. Ad esempio, la versione 9.04 è stata rilasciata nel mese di aprile dell'anno 2009 mentre la prima rilasciata nell'ottobre 2004 fu battezzata Ubuntu 4.10.
1 Tratto da “Come usare dBase III plus” di Edward Jones, McGraw-Hill
22 - Io, Informatico – Carlo A. Mazzone – versione 20100910

Il Versioning del software
C'è poi un'altra cosa simpatica e bizzarra a proposito dei nomi in codice dati alle varie versioni di Ubuntu. Per menzionarne qualcuno con relativa traduzione in italiano: Warty Warthog (Facocero Verrucoso) per la 4.10, Hoary Hedgehog (Riccio Canuto) per la 5.04, Breezy Badger (Tasso Arioso) per la 5.10,. Questi nomi, come riferisce Mark Shuttleworth, il creatore di Ubuntu prendono la forma "Adjective Animal" cioè un “aggettivo animale”. Con la particolarità che la lettera iniziale del nome dell'animale e quella del relativo aggettivo sono identiche.
Dall'alfa al rilascio: versioni alfa, beta, RC
Scrivere codice (creare programmi), dovrebbe essere a questo punto essere abbastanza chiaro, non è un'operazione banale. E' più che normale che durante lo sviluppo ci si fermi a verificare la stato di avanzamento del progetto cercando anche di individuare sempre possibili bug.
E' consuetudine rilasciare delle versioni intermedie di un dato software prima di quella definitiva. La prima versione vine in genere etichettato con il termine: alfa. Essendo questa la prima lettera dell'alfabeto, il senso è che si tratta di una versione molto preliminare che contiene probabilmente una miriade di bug e probabilmente in essa non tutte le funzionalità progettate sono state effettivamente implementate ed inserite. Si tratta comunque di una versione “testabile” che in ogni modo viene in genere rilasciata ad un ristretto numero di tester (spesso interni all'azienda sviluppatrice del software stesso). Nel caso in cui vi siano più versioni alfa, queste verranno indicate con alfa 1 (oppure α 1), alfa 2 e così via.
Ci si augura che revisionate le versioni alfa il software sia più stabile e maturo. I successivi rilasci ufficiali, sempre in attesa della final release, vengono definiti versioni beta (spesso etichettati con la semplice lettera β).
Va da sé che una versione beta è potenzialmente instabile e ciò deve essere tenuto nel dovuto conto prima di scaricare tale tipo di versione.
Risolti i problemi ed i bug delle varie possibili versioni beta (beta 1, beta 2, ecc.) prima della fatidica versione finale normalmente si rilascia una versione detta Realease Candidate o brevemente RC che rappresenta, come il nome stesso lascia intendere, la versione candidata per il rilascio finale.
Ormai siamo pronti per la distribuzione del nostro software. In alcuni casi esiste tuttavia un'altra tipologia di versione detta "release to manufacturing" oppure "release to marketing", entrambe abbreviate nella sigla RTM. Si tratta di una versione speciale riservata di norma ai rivenditori i quali si preoccuperanno di adattarla alle loro specifiche esigenze di distribuzione.
23 - Io, Informatico – Carlo A. Mazzone – versione 20100910
Mark Shuttleworth, il creatore di Ubuntu

Un aiuto per lo sviluppo di squadra: software per il versioning
Un aiuto per lo sviluppo di squadra: software per il versioning
Lo sviluppo di un programma è una procedura che richiede in generale ingenti sforzi. Molto spesso gli sviluppatori sono diversi e si trovano a collaborare e lavorare sugli stessi file di codice sorgente.
E' ovvio che senza delle misure specifiche che consentano di ordinare e disciplinare il lavoro dei vari membri del team di sviluppo c'è il serio rischio di rallentare lo sviluppo e di ottenere anche un risultato di scarsa qualità.
In definitiva il progetto software viene realizzato scrivendo una serie di svariati file di codice sorgente e che tali tali alla fine dovranno essere tutti compilati. Su tali file dovranno lavorare i vari sviluppatori. Ogni sviluppatore dovrà avere la sua copia di sorgenti per poterci lavorare. Ma cosa succede se differenti programmatori fanno modifiche diverse sullo stesso file di codice? Quale sarà la copia che verrà compilata?
Per risolvere questo tipo di problema vengono di norma utilizzati specifici software di solito chiamati Revision control (ma anche version control, source control o ancora source code management (SCM)). Insomma un vero ginepraio di nomi; ma il succo della questione è sempre lo stesso: far collaborare più programmatori allo stesso progetto.
Tuttavia, in realtà, c'è anche dell'altro. Questi sistemi sono enormemente utili anche se a lavorare su di un dato programma è un singolo sviluppatore. Infatti, se lo sviluppatore utilizza per una qualsiasi ragione diversi computer avrà necessità di sincronizzare su queste varie macchine le ultime modifiche fatte ai sorgenti (copiare semplicemente i file non è ilo massimo della funzionalità). Inoltre, questi sistemi di controllo consentono, in caso di necessità di ripristinare i sorgenti a situazioni precedenti; il che potrebbe essere necessario in caso di modifiche accidentali non volute.
Sostanzialmente i vari software che esistono per gestire queste situazioni, sia gratuiti che commerciali, si basano sul concetto di repository unico. Per repository si intende una porzione di file system collocato su di una certa macchina che fa da server contenente l'insieme dei file (organizzati tipicamente in cartelle) oggetto del nostro progetto software.
I vari sviluppatori (client) si collegano sul repository per leggere e scrivere i file centralizzati. Di norma il client possiede una copia locale dei vari file sui quali deve lavorare. Una volta effettuate le modifiche (in locale) salva tali modifiche sulle copie (remote) centralizzate. Il compito del sistema di controllo è quello di controllare (appunto!) che il tutto avvenga con coerenza.
24 - Io, Informatico – Carlo A. Mazzone – versione 20100910
Un tipico sistema client/server

Un aiuto per lo sviluppo di squadra: software per il versioning
Visto così il tutto potrebbe comunque sembrare un classico sharing (condivisione) di un disco tramite una rete. In realtà, in generale, il repository ha la capacità di memorizzare ogni modifica ai file ed alle cartelle condivise (aggiunte, modifiche e cancellazioni) e in caso di necessità consentire il ripristino ad una situazione precedente. Con questi dati a disposizione risulta possibile vedere lo “storico” di dati file e risalire anche agli autori di specifiche modifiche in specifici lassi di tempo, più tutta una serie di ulteriori informazioni vitali per lo sviluppo corretto del progetto.
Fondamentalmente esistono due approcci differenti per gestire i file condivisi: Il primo è del tipo Lock-Modify-Unlock mentre il secondo è del tipo Copy-Modify-Merge.
Lock-Modify-Unlock prevede appunto quello che dice: un programmatore che deve lavorare su di un file blocca (segnala come bloccato) un file. In tale situazione un altro programmatore che volesse modificare lo stesso file si rende conto della situazione ed attenderò che il file in questione venga sbloccato (unlock). Lo sviluppatore che ha bloccato il file effettuerà le sue brave modifiche, aggiornerà il file e segnalerà al sistema di sbloccare il file per renderlo disponibile agli altri sviluppatori. Il sistema avviserà gli altri sviluppatori che il file in questione è stato aggiornato (rispetto ad una eventuale loro vecchia copia in locale) in modo da rendere disponibile il file con le ultime variazioni di codice. Chi dovrà lavorare su tale file otterrà dal sistema la nuova copia la bloccherà e la “giostra” continuerà come appena descritto. Un tipico sistema commerciale che si base su questo approccio è Source Safe della Microsoft.
Copy-Modify-Merge si bassa su un concetto diverso teso a controllare il problema che si verifica con i possibili tempi morti degli sviluppatori in attesa che file di loro interesse attualmente bloccati vengano resi disponibili per la modifica. In questo modello ogni utente programmatore lavora in parallelo sulle proprie copie locali modificando sempre in locale i propri file. Alla fine del proprio lavoro, di tanto in tanto, le varie copie private degli stessi file vengono fuse (merging dei file) in un'unica vesrione contenuta nel repository. Il software di controllo assiste l'utente in nella fase di merging ma in ogni caso la responsabilità finale della correttezza delle operazioni di fusione è affidata all'intervento umano del singolo programmatore. Un tipico
sistema che lavora in questo modo è SubVersion. Con tale software in accoppiata per il lato client è utilizzatissimo per ottimi motivi l'applicazione TortoiseSVN.
25 - Io, Informatico – Carlo A. Mazzone – versione 20100910
La simpatica tartarughina simbolo di TortoiseSVN

Dalla documentazione al setup (ovvero com'è difficile pacchettizzare “Salve, mondo”)
Dalla documentazione al setup (ovvero com'è difficile pacchettizzare “Salve, mondo”)
Ok, lo so, il titolo di questo paragrafo ha bisogno di qualche spiegazione. Parto allora con “pacchettizzare”: con questo termine si intendere il creare un “pacchetto software” cioè arrivare ad avere un prodotto finito (eventualmente con tanto di confezione da mettere in un sacchetto della spesa). “Salve, mondo” è una frase che viene di norma utilizzata per stampare un testo di prova quando si insegna (o si prova come autodidatti) un nuovo linguaggio di programmazione. Il senso è: si tratta di un programma semplicissimo e di nessuna utilità pratica. Ma allora, perché mai dovrebbe essere così difficile arrivare a produrre un software che stampi “Salve, mondo”?
La questione nella sua essenza è che per arrivare al prodotto finale, come ho già detto in precedenza , è necessario produrre una serie di passi preliminari (vedi il ciclo di vita di cui prima). Tra le tante cose importanti che spiccano in questi contesti, due rivestono un ruolo molto importante: la documentazione del software per l'utente finale (il cosiddetto “manuale utente”) ed il programma che permetta l'installazione (setup) del nostro software sulla macchina dell'utente.
Vi propongo una serie di dettagli e riflessioni su entrambi.
Partiamo con la documentazione. Produrre un manuale su di un dato software non è cosa semplice. Purtroppo questa fase viene spesso trascurata dai produttori di software che realizzano dei manuali assolutamente inutili. D'altra parte c'è anche da dire che moltissimi utenti non provano neanche a leggere il manuale d'uso ma si gettano a capofitto nell'uso per tentativi del software in questione. Ma questa non può essere una giustificazione per non impegnare risorse per la realizzazione del manuale.
Tale manuale può avere diverse forme finali: da un file in formato pdf ad una serie di pagine web eventualmente presenti direttamente in linea sul web. In ogni caso il formato classico e più vecchio per un file di help rimane il formato chm (Microsoft Compressed HTML Help), un formato proprietario sviluppato appunto da Microsoft.
Un software gratuito che può facilitare la realizzazione di tale file e di produrre anche altri formati finali che mi sento di segnalare è Helpmaker, un prodotto gratuito sia per scopi personali che, cosa molto importante, per scopi commerciali. Il sito di riferimento
è: www.vizacc.com
Veniamo ora alla questione setup, ovvero l'installazione del nostro “capolavoro” software sulla macchina degli utilizzatori finali. Dovrebbe essere scontata la considerazione per la quale non è sufficiente distribuire il semplice eseguibile della nostra applicazione. Infatti, in generale, l'eseguibile ha bisogno di tutta una serie di ulteriori file di supporto per funzionare correttamente. Generalizzo definendo questo insieme di file come ambiente di runtime e faccio un esempio. Supponendo che la nostra applicazione sia scritta utilizzano l'ambiente Visual Basic sarà necessario distribuire le apposite “librerie” di file di supporto che faranno da intermediarie tra il nostro eseguibile ed i file di sistema del sistema operativo. Inoltre sarà necessario inserire nel nostro setup
26 - Io, Informatico – Carlo A. Mazzone – versione 20100910

Dalla documentazione al setup (ovvero com'è difficile pacchettizzare “Salve, mondo”)
i file di help e di documentazione in genere. Non ultima considerazione il fatto che sarà necessario creare le apposite icone per lanciare il programma una volta copiati gli opportuni file.
Per aiutare a costruire il fine finale di setup esistono svariati applicativi. Tra questi, nel contesto del software commerciale spicca sicuramente InstallShield.
Esistono tuttavia altre soluzioni di software gratuito; tra le varie segnalo l'ottimo Innosetup, sito di riferimento www.jrsoftware.org.
Si tratta di un ottimo pacchetto, scritto in Borland Delphi, utilizzabile per creare file di installazione per tutte le versioni di Windows.
27 - Io, Informatico – Carlo A. Mazzone – versione 20100910

Pascal in a nutshell
Pascal in a nutshell
L'espressione inglese “in a nutshell” credo si presti bene al contesto che voglio proporre in questa sezione. Tale espressione può infatti essere tradotta con qualcosa del tipo “in poche parole”, “concisamente” o anche “in breve”. Il senso è anche quello di “negli aspetti fondamentali”.
Pascal in a nutshell è dunque una breve ed essenziale presentazione del linguaggio di programmazione Pascal. Lo scopo è quello di fornirvi una serie di rudimenti su tale linguaggio senza entrare nei dettagli dello stesso. Il motivo è dato dal fatto che la scelta che ho effettuato in questo mio lavoro di divulgazione informatica per quanto riguarda il principale linguaggio di programmazione tradizionale è relativa al linguaggio C. D'altro canto può essere comunque istruttivo conoscere le basi del Pascal data la sua importanza dal punto di vista storico e didattico. Il Pascal, nato negli anni '70, ha vissuto un “periodo di splendore” a metà anni '80 in particolare grazie alla disponibilità dell'ambiente di sviluppo Borland Turbo Pascal. Attualmente il suo utilizzo è quasi esclusivamente relegato all'ambiente scolastico in quanto un certo numero di docenti individuano in esso uno strumento semplice ed efficace per proporre le basi dei linguaggi di programmazione. Chi vuole può quindi trarre da queste brevi pagine un mini corso di programmazione. L'invito dello scrivente è comunque quello di rifarsi al capitolo sul linguaggio C per una prosecuzione dello studio dei linguaggi più coerente con il panorama informatico attuale e futuro.
L'autore del Pascal è Niklaus Wirth, un professore universitario svizzero, la cui notorietà tra gli addetti ai lavori (gli informatici) è data anche dall'essere l'autore del libro “Algorithms + Data Structures = Programs”. Si tratta di un testo, ancora in uso, sul quale si sono formate intere generazioni di informatici. La versione italiana, “Algoritmi strutture dati = programmi” è stata pubblicata dalla casa editrice “Tecniche Nuove”.
Dicevo che il Pascal riveste ormai più che altro una importanza storica. Esso si è comunque evoluto rimanendo attuale attraverso
sue modificazioni successive. La versione orientata agli oggetti del Pascal è nota come Object Pascal e rappresenta il linguaggio utilizzato nell'ambiente di sviluppo Delphi prodotto dalla Borland.
Come utilizzare il Pascal
L'ambiente di sviluppo che ha segnato la notorietà del Pascal è, come dicevo prima, il Turbo Pascal. Si tratta di un ambiente per contesti DOS ormai definibile come vetusto. Una valida alternativa per chi intende effettuare delle sperimentazioni con tale linguaggio può essere allora rappresentata dall'ambiente Dev-Pascal della Bloodshed (http://www.bloodshed.net/), un ambiente di sviluppo integrato per Windows gratuito e sufficientemente funzionale.
“Salve mondo” in Pascal
Come verrà ribadito anche più avanti nella presentazione di altri linguaggi di programmazione, è prassi consolidata presentare un nuovo linguaggio mostrando un semplice codice sorgente avente lo scopo di stampare a video le parole “Salve mondo”. Tale consuetudine nasce da un primo utilizzo nel libro sul Linguaggio C di Kernighan e Ritchie, una pietra miliare tra i testi di informatica.
28 - Io, Informatico – Carlo A. Mazzone – versione 20100910
Niklaus Wirth
Pascal in a nutshell
Presentare un così semplice esempio consente di prendere dimestichezza con i rudimenti della sintassi e con il compilatore scelto per la produzione dell'eseguibile.
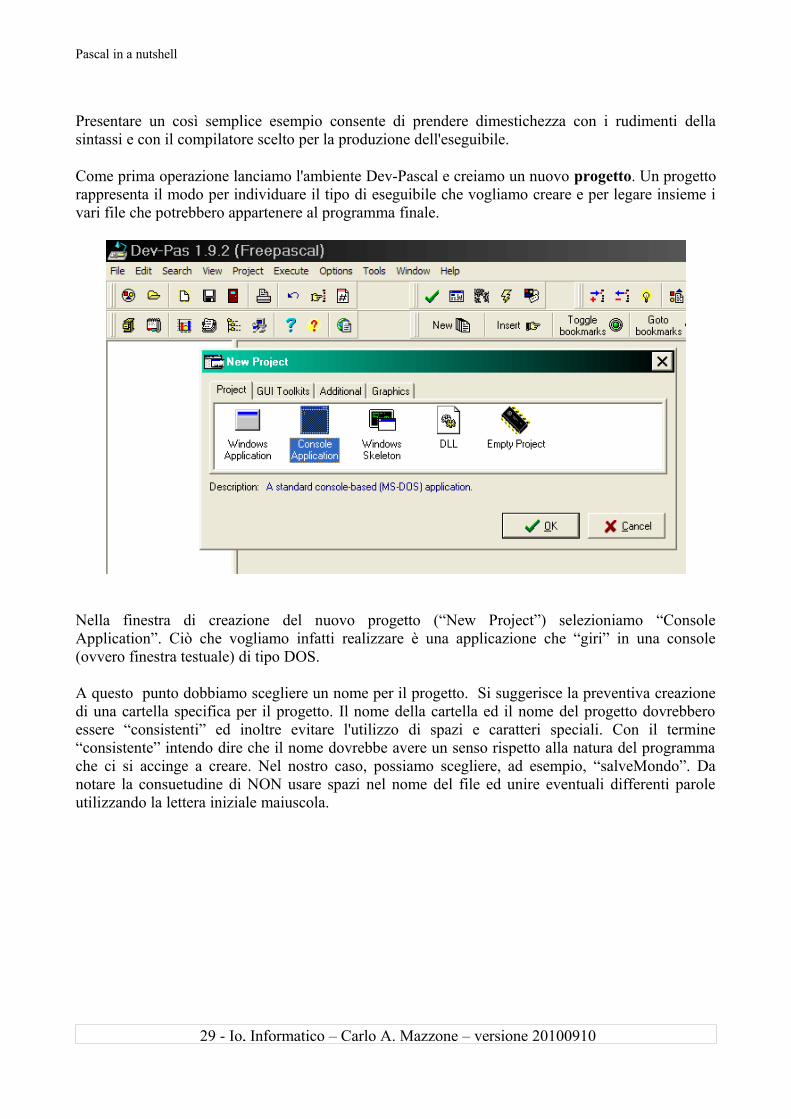
Come prima operazione lanciamo l'ambiente Dev-Pascal e creiamo un nuovo progetto. Un progetto rappresenta il modo per individuare il tipo di eseguibile che vogliamo creare e per legare insieme i vari file che potrebbero appartenere al programma finale.
Nella finestra di creazione del nuovo progetto (“New Project”) selezioniamo “Console Application”. Ciò che vogliamo infatti realizzare è una applicazione che “giri” in una console (ovvero finestra testuale) di tipo DOS.
A questo punto dobbiamo scegliere un nome per il progetto. Si suggerisce la preventiva creazione di una cartella specifica per il progetto. Il nome della cartella ed il nome del progetto dovrebbero essere “consistenti” ed inoltre evitare l'utilizzo di spazi e caratteri speciali. Con il termine “consistente” intendo dire che il nome dovrebbe avere un senso rispetto alla natura del programma che ci si accinge a creare. Nel nostro caso, possiamo scegliere, ad esempio, “salveMondo”. Da notare la consuetudine di NON usare spazi nel nome del file ed unire eventuali differenti parole utilizzando la lettera iniziale maiuscola.
29 - Io, Informatico – Carlo A. Mazzone – versione 20100910
Pascal in a nutshell
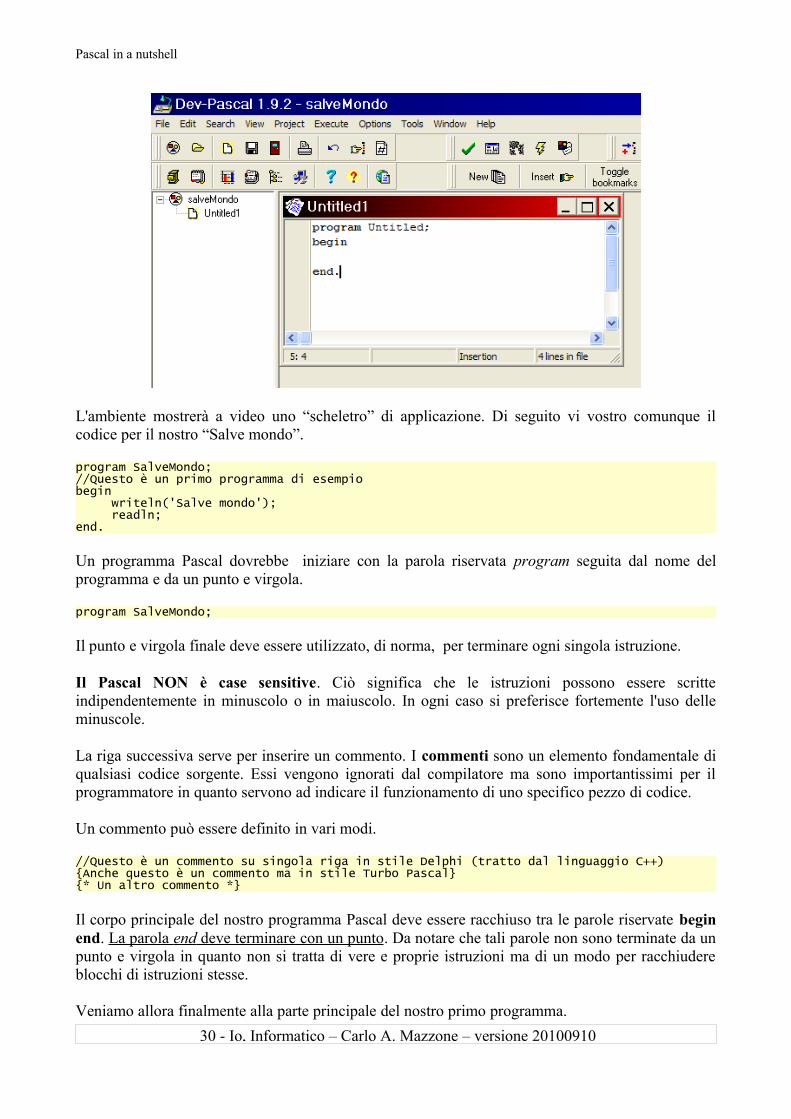
L'ambiente mostrerà a video uno “scheletro” di applicazione. Di seguito vi vostro comunque il codice per il nostro “Salve mondo”.
program SalveMondo;//Questo è un primo programma di esempiobegin writeln('Salve mondo'); readln;end.
Un programma Pascal dovrebbe iniziare con la parola riservata program seguita dal nome del programma e da un punto e virgola.
program SalveMondo;
Il punto e virgola finale deve essere utilizzato, di norma, per terminare ogni singola istruzione.
Il Pascal NON è case sensitive. Ciò significa che le istruzioni possono essere scritte indipendentemente in minuscolo o in maiuscolo. In ogni caso si preferisce fortemente l'uso delle minuscole. La riga successiva serve per inserire un commento. I commenti sono un elemento fondamentale di qualsiasi codice sorgente. Essi vengono ignorati dal compilatore ma sono importantissimi per il programmatore in quanto servono ad indicare il funzionamento di uno specifico pezzo di codice.
Un commento può essere definito in vari modi.
//Questo è un commento su singola riga in stile Delphi (tratto dal linguaggio C++){Anche questo è un commento ma in stile Turbo Pascal}{* Un altro commento *}
Il corpo principale del nostro programma Pascal deve essere racchiuso tra le parole riservate begin end. La parola end deve terminare con un punto . Da notare che tali parole non sono terminate da un punto e virgola in quanto non si tratta di vere e proprie istruzioni ma di un modo per racchiudere blocchi di istruzioni stesse.
Veniamo allora finalmente alla parte principale del nostro primo programma. 30 - Io, Informatico – Carlo A. Mazzone – versione 20100910

Pascal in a nutshell
writeln('Salve mondo'); readln;
L'istruzione writeln (che sta per write line ovvero scrivi linea) è seguita da una coppia di parentesi tonde con all'interno l'argomento che vogliamo stampare. Tale stringa di caratteri è a sua volta racchiusa e delimitata da singoli apici.
La riga successiva, readln, ovvero read line (leggi linea) serve di norma per acquisire da tastiera dei dati richiesti all'utente utilizzatore del nostro programma. In questo caso readln non prevede argomenti. Si tratta di un modo per bloccare l'esecuzione del programma fin quando l'utente non prema un qualsiasi tasto sulla tastiera. In caso contrario, una volta eseguito il programma questo si chiuderebbe immediatamente dopo la stampa a video del messaggio “Salve mondo” impedendo la visualizzazione dello stesso.
Questo è tutto e non resta che compilare ed eseguire il programma utilizzando gli appositi strumenti messi a disposizione dal Dev-Pascal.
La prima compilazione ci inviterà a scegliere, se non lo abbiamo già fatto, un nome per il file di codice sorgente (con estensione .pas) che dovrà avere un nome diverso dal nome scelto per il file di progetto (estensione .dp).
Le variabili e l'input output
Una volta compresi gli aspetti di base del Pascal ed aver minimamente familiarizzato con l'ambiente di sviluppo siamo pronti per realizzare programmi più complicati che richiedono, ad esempio, l'interazione con l'utente del nostro programma.
La prima sperimentazione che vi propongo richiede all'utente l'inserimento di un numero e la stampa a video del suo successivo. Ciò ci consentirà di analizzare le principali istruzioni di input – output (ingresso ed uscita) e l'assegnazione di valori alle variabili.
Una variabile può essere vista come un contenitore presente in memoria per conservare i dati della nostra elaborazione. Il programma che vi propongo richiede all'utente un numero intero e prevede la stampa del suo successivo.
Banalmente le fasi coinvolte sono essenzialmente tre ed il nostro algoritmo potrebbe essere il seguente:
1 – leggi numero2 – calcola successivo3 – stampa successivo
Analizzando l'algoritmo notiamo come la lettura di un numero richieda l'utilizzo di un apposito contenitore (una variabile) che possa memorizzarne il valore al fine di poter aggiungere ad esso una unità.
31 - Io, Informatico – Carlo A. Mazzone – versione 20100910
Il risultato a video della compilazione

Pascal in a nutshell
Il Pascal prevede che le variabili che si utilizzano nel programma abbiano, oltre ad un nome che le identifichi, anche un tipo. Gli oggetti che un programma gestisce sono infatti di norma di natura varia e differente: lettere, stringhe, numeri interi, numeri con la virgola, ecc.
Di seguito, senza badare ad eccessivi fronzoli vi propongo il programma completo:
program successivo;//Calcolo del successivo di un intero in inputvar x: integer;begin write('Dammi un numero: '); readln(x); x:= x + 1; write('Il successivo e'': '); write(x); readln;end.
L'utilizzo di una variabile prevede che questa venga dichiarata. Con tale termine ci si riferisce la fatto che la variabile (il suo nome e la sua tipologia) devono essere comunicate al compilatore in modo che esso possa organizzare in memoria spazi adeguati a contenerla.
La dichiarazione delle variabile deve avvenire nella sezione di intestazione del programma (prima del blocco begin end.) .
var x: integer;
Con la precedente istruzione abbiamo dichiarato di volere utilizzare una variabile di nome x e di tipo intero.
L'istruzione write, la prima che incontriamo nel corpo del programma, serve ad invitare l'utente ad inserite un numero ed è simile all'istruzione writeln già vista in precedenza. La differenza consiste nel fatto che write non produce un ritorno a capo. L'istruzione successiva readln(x); causa la visualizzazione di un trattino lampeggiante che rappresenta l'invito per l'utente ad inserire un dato. Tra le parentesi tonde è presente, come argomento, il nome della variabile x. Tale variabile sarà riempita (valorizzata) con quanto inserito dall'utente.
La riga successiva
x := x + 1;
merita un discorso leggermente più approfondito. Si tratta si una istruzione di assegnazione. La simbologia “ := ” serve a far capire al compilatore che la parte destra dell'espressione deve essere assegnata alla parte sinistra. Ciò che avviene è che verrà eseguita per prima l'operazione x + 1 che come ci aspettiamo aumenta di una unità il valore di x. Successivamente tale valore incrementato viene assegnato alla variabile x. L'uso dei due punti serve a distinguere l'operazione di assegnamento di un valore ad una variabile rispetto all'operazione di confronto (che vedremo più avanti).
La restante parte del programma dovrebbe essere autoesplicativa. Le due successive istruzioni stampano a video il risultato dell'operazione realizzata.
32 - Io, Informatico – Carlo A. Mazzone – versione 20100910
Pascal in a nutshell
Gli operatori aritmetici
Come appena visto, esiste la possibilità di effettuare sulle nostre variabili delle operazioni; nel nostro caso una somma. Gli operatori più semplici sono proprio quelli aritmetici che vi propongo di seguito:
+ addizione- sottrazione
* moltiplicazione/ divisione
div divisione tra numeri interimod resto della divisione tra numeri interi
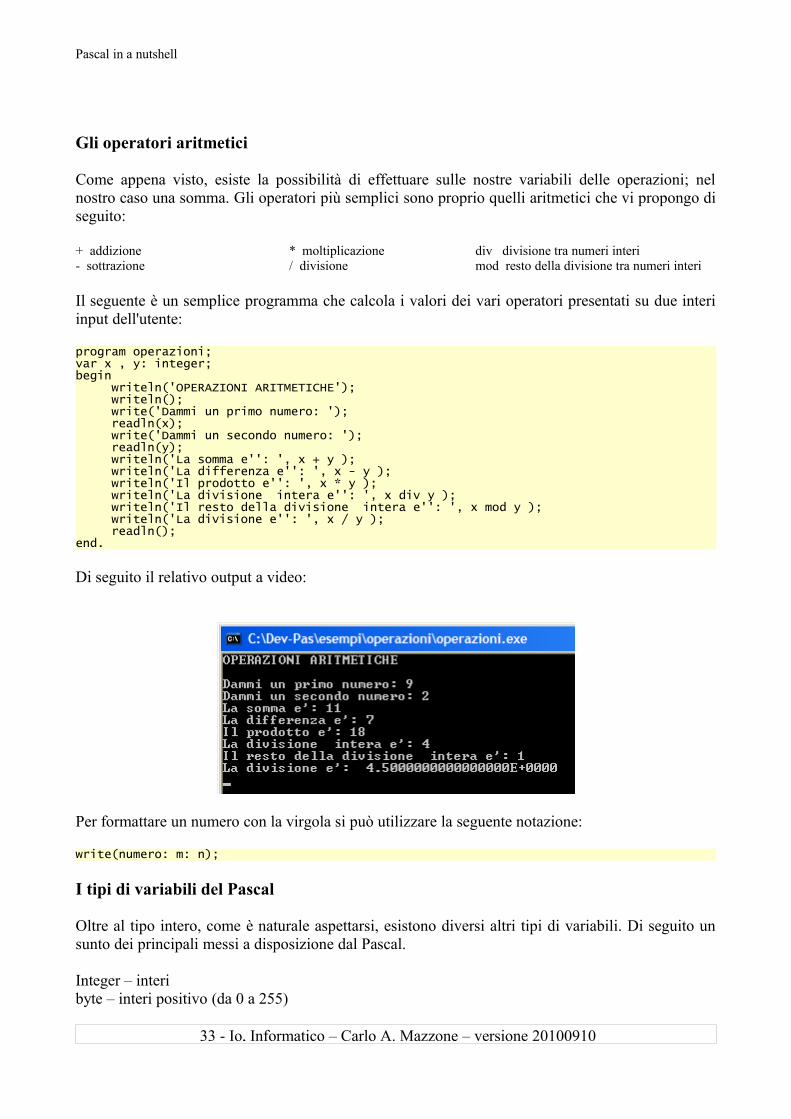
Il seguente è un semplice programma che calcola i valori dei vari operatori presentati su due interi input dell'utente:
program operazioni;var x , y: integer;begin writeln('OPERAZIONI ARITMETICHE'); writeln(); write('Dammi un primo numero: '); readln(x); write('Dammi un secondo numero: '); readln(y); writeln('La somma e'': ', x + y ); writeln('La differenza e'': ', x - y ); writeln('Il prodotto e'': ', x * y ); writeln('La divisione intera e'': ', x div y ); writeln('Il resto della divisione intera e'': ', x mod y ); writeln('La divisione e'': ', x / y ); readln();end.
Di seguito il relativo output a video:
Per formattare un numero con la virgola si può utilizzare la seguente notazione:
write(numero: m: n);
I tipi di variabili del Pascal
Oltre al tipo intero, come è naturale aspettarsi, esistono diversi altri tipi di variabili. Di seguito un sunto dei principali messi a disposizione dal Pascal.
Integer – interi byte – interi positivo (da 0 a 255)
33 - Io, Informatico – Carlo A. Mazzone – versione 20100910

Pascal in a nutshell
real – numeri reali (numeri con la virgola)boolean – possibili valori TRUE e FALSE (vero, falso utilizzato nelle operazioni logiche)char – un singolo carattere
La selezione in Pascal
Un qualsiasi problema non banale, e quindi il corrispondente programma che tenta di risolverlo, prevede in qualche suo punto una scelta da effettuarsi in base ad una data condizione. Le scelte sono la base della vita; problemi classici usati come esempi sono qualcosa del del tipo “se la torta è cotta spegni il forno altrimenti aspetta”, oppure “se la porta è aperta entra altrimenti usa la maniglia per aprirla e successivamente entra”.In ogni caso esiste una situazione del tipo:
SE “condizione è verificata” ALLORA “fai questo” ALTRIMENTI “fai quello”
Tale situazione che, come vi ho mostrato in un precedente capitolo, si disegna nei diagrammi di flusso con un rombo, si esprime in Pascal con la seguente sintassi:
if condizione thenistruzione;
Se condizione risulta vera (soddisfatta) verrà eseguita l'istruzione che segue il then (in inglese allora).
Vi propongo di seguito, di volta in volta che presento uno specifico utilizzo della sintassi del costrutto, qualche semplice esempio . Il seguente programma consente di verificare se un dato intero in input è positivo.
program positivo;var x : integer;begin write('Dammi un numero: '); readln(x); if x > 0 then writeln('Il numero e'' positivo');
readln();end.
Nel caso in cui le istruzioni da eseguire siano più di una sarà necessario racchiuderle tra le parole riservate begin end.
if condizione thenbegin
istruzione_1;istruzione_2;istruzione_3
end;
E' da notare il punto e virgola finale dopo l'istruzione end. Un'altra particolarità è data dalla mancanza del punto e virgola alla fine di quella che ho indicato come istruzione_3, ovvero l'ultima istruzione del blocco. Ebbene l'utilizzo in quel punto del punto e virgola è opzionale. La sua presenza o meno non inficia la corretta compilazione. Di seguito un esempio chiarificatore:
program positivo;var x : integer;begin
34 - Io, Informatico – Carlo A. Mazzone – versione 20100910

Pascal in a nutshell
write('Dammi un numero: '); readln(x); if x > 0 then begin writeln('Il numero digitato e'': ', x); writeln('Il numero e'' positivo'); end; readln();end.
Un situazione leggermente più complessa prevede la possibilità di eseguire una istruzione (oppure un blocco di istruzioni) piuttosto che un'altra al verificarsi o meno di una data condizione.
if condizione thenbegin
istruzione_1;istruzione_2
endelse
beginistruzione_3;istruzione_4
end;
Di seguito un semplice esempio di programma consente di verificare se un dato intero in input è positivo o negativo:
program segno;var x : integer;begin write('Dammi un numero: '); readln(x); if x > 0 then writeln('Il numero e'' positivo') else writeln('Il numero e'' negativo'); readln();end.
Gli operatori relazionali
Negli esempi d'uso appena mostrati avrete potuto notare l'uso del classico simbolo “>” che indica “maggiore di”. Questo è un caso particolare dei cosiddetti operatori relazionali, ovvero degli operatori che consentono di mettere in relazione di “grandezza” due elementi. L'elenco completo è il seguente:
> maggiore< minore
> = maggiore o uguale< = minore o uguale
= uguale a <> diverso da
La ripetizione (iterazione) in Pascal
Come viene più volte ripetuto in questo mio lavoro non c'è nulla di più alienante per l'esssere umano della ripetizione stessa delle varie attività da svolgere: pensate ad una catena di montaggio!
La possibilità di far ripetere ad una macchina le stesse operazioni per un numero virtualmente infinito di volte è quindi alla base stessa del calcolo automatico. Tale possibilità, nota come iterazione o ripetizione, si realizza tramite differenti costrutti ed in modo leggermente diverso nei vari linguaggi di programmazione. Di seguito vi illustro le principali modalità offerte dal Pascal.
35 - Io, Informatico – Carlo A. Mazzone – versione 20100910

Pascal in a nutshell
Il ciclo for
Una delle modalità più classiche è quella che prevede l'uso del costrutto for (in italiano per). Il concetto base consiste nel fatto che si da la possibilità alla macchina di contare il numero di volte che deve ripetere il blocco di istruzioni. Per contare c'è bisogno di una variabile (intera) da incrementare di un'unità ad ogni iterazione. Tale variabile, pur essendo come tutte le altre, prende il nome specifico di contatore.
La sintassi prevede la seguente forma:
for variabile := valore_minimo to valore_massimo do istruzione;
Supponiamo, a titolo di esempio, di voler stampare 10 volte una data frase. Il codice potrebbe essere qualcosa del genere:
program programmatore;var i : integer;begin
for i := 1 to 10 do writeln('Sono un vero programmatore'); readln();end.
Sostanzialmente il codice è autoesplicativo. Un'unica nota è relativa al nome della variabile usata come contatore; di norma in questi contesti per prassi si usa la lettera i. L'output a video del programma è mostrato nella figura seguente.
Nel caso in cui non si abbia una singola istruzione, il che è la norma, valgono le stesse osservazioni fatte nel caso del costrutto if, ovvero l'uso del blocco begin end per racchiudere le varie istruzioni da eseguire.
Il ciclo while
Oltre al ciclo for esiste un altro costrutto di iterazione che prende il nome di ciclo while. Si tratta come del for di un elemento tipico della stragrande maggioranza dei linguaggi di programmazione.
La sintassi generale è:
while condizione do istruzione;
36 - Io, Informatico – Carlo A. Mazzone – versione 20100910

Pascal in a nutshell
Se la condizione risulta vera l'esecuzione continua altrimenti si riprende alla fine del ciclo.
program contaLinee; var i: integer;begin
i:=1; while (i <= 10) do begin writeln('Riga numero: ', i); i:=i+1; end; readln();end.
Il ciclo repeat until
Come il ciclo while anche il costrutto repeat esegue un certo blocco di istruzioni finché risulta verificata una data condizione. La differenza sostanziale consiste nel fatto che il ciclo repeat esegue le istruzioni almeno uno volta. Ciò è dovuto al fatto che la condizione viene posta e verificata alla fine del blocco iterativo.
Se la condizione risulta vera l'esecuzione riprende DOPO il blocco reapeat
La sintassi generale è la seguente:
repeat istruzione; istruzione; ...until condizione;
Vediamo un esempio che riproduce quello visto per il while.
program contaLinee2; var i: integer;begin
i := 1; repeat writeln('Riga numero: ', i); i:= i+1; until (i > 10); readln();end.
Strutture dati complesse: gli array del Pascal
Le variabili utilizzate finora vengono dette di tipo semplice. Il motivo è dato dal fatto che esse possono contenere in un dato momento un solo ed unico elemento. Il Pasca, così come un po' tutti gli altri linguaggi di programmazione, mette a disposizione del programmatore variabili più articolate che consentono di contenere in un dato momento differenti elementi e quindi valori.
37 - Io, Informatico – Carlo A. Mazzone – versione 20100910

Pascal in a nutshell
Tali variabili prendono il nome di variabili complesse o composte. In questo contesto, il tipo più semplice è noto come array (o anche vettore). Si può immaginare l'array come un'unica sequenza di elementi dello stesso tipo in cui ogni elemento viene identificato da un numero che lo identifica univocamente all'interno della sequenza stessa. L'identificativo dell'elemento, di norma un intero, prende il nome di indice dell'array. Una possibile rappresentazione di quanto vi sto illustrando, relativamente ad un array di otto elementi interi, potrebbe essere la seguente.
22 47 9 12 56 88 34 75
1 2 3 4 5 6 7 8 La sequenza dei numeri nella riga inferiore, da 1 ad 8, rappresenta l'indice dell'elemento che è contenuto nella cella immediatamente superiore. Nota: se vi capitasse di giocare al lotto i numeri in questione, in caso di vincita, mi aspetterei una seppur simbolica ricompensa ;)
Vi propongo allora la sintassi di base per la dichiarazione dell'array dell'esempio:
var a: array[1..8] of integer;
dove a è il nome dell'array. Ovviamente al posto di integer si sarebbe potuto usare un altro tipo di variabile.
Per la valorizzazione degli elementi possiamo scrivere qualcosa del tipo:
a[1]:=22;a[2]:=47;…a[8]:=75;
38 - Io, Informatico – Carlo A. Mazzone – versione 20100910





























