Embed Size (px)
Citation preview

Japan.R:データベース
ゼロからはじめる(分析のための)データベース入門
2011年11月26日
@sleipnir002

今日はRの話は
しません。

データベースの
話をします。

データベース
を構築しよう!

“R is not well suited to extremely large data sets.” (R Data Import/Export)
一元管理しないと不整合が起こる。
CSVやExcelはファ
イルが膨大になり、更新などに時間がかかる。
データ管理に伴う問題

データベース
を構築して、快適な分析ライフを!

データベースが分析力をあげる
• データが重要なのは言うまでもないだろう。よいデータがなければ始まらない。(トーマス・H・ダベンポート「分析力を駆使する企業」)
• データマイニングに要する時間の90%は、データの準備に費
やされる。一方、華やかなモデリングに費やされる時間は全体の10%である。(豊田秀樹「データマイニング入門」)

データベース
を構築すれば
分析力が上がる

データベースって?

DBの用語の整理 • データベース(DB):構造化されて管理されているデータ
• データベースマネージメントシステム(DBMS):データベースを管理するソフト
• リレーショナルデータベースマネージメントシステム(RDBMS):リレーショナル方式でデータベースを管理するソフト
データベース= 情報そのもの
(R)DBMS= データベース管理ソフト

RDBMS
DBMS
• DBMSは量や性質に応じてさまざまな性質のものがある。
データの量
構造化
CSV

で、どれを使えばいいの?

RDBMS
おすすめ

RDBMSを
お勧めする理由

4.1 Why use a database? (R Data Import/Export)
Database management systems (DBMSs) and, in particular, relational DBMSs (RDBMSs) are designed to do all of these things well. Their strengths are
1. To provide fast access to selected parts of large databases.
2. Powerful ways to summarize and cross-tabulate columns in databases.
3. Store data in more organized ways than the rectangular grid model of spreadsheets and R data frames.
4. Concurrent access from multiple clients running on multiple hosts while enforcing security constraints on access to the data.
5. Ability to act as a server to a wide range of clients.
大規模データ扱うならリレーショナルデータベース使おう。 高速にアクセスできる。集計が早い。Rと同じデータ形式。 複数ユーザからの一貫したアクセスが可能。 多くのクライアントに対応している。

RDBMS入門

RDBMSのR=リレーショナルとは?
• データを表で格納して、結合によってほしいデータを取得する。
KO... NAME KUBUN SEX
1100 新垣結衣 通常会員 1
1200 小島陽菜 優良会員 1
DATE KOKYAKU SHOHIN SURYO
’10-09-31’ 1100 K-001 3
’10-09-31’ 1100 K-002 1
’10-10-04’ 1200 K-009 1
DATE KOKYAKU NAME KUBUN SEX SHOHIN SURYO
’10-09-31’ 1100 新垣結衣 通常会員 1 K-001 3
’10-09-31’ 1100 新垣結衣 通常会員 1 K-002 1
’10-10-04’ 1200 小島陽菜 優良会員 1 K-009 1
売上情報表
顧客表
だれに何が売れたか?

SQL 1of2
• RDBMSを管理する言語
– CREATE TABLE:表の作成
• CREATE TABLE SHOHIN(ID INT, NAME VARCHAR(60))
– SELECT:データを取得する。
• SELECT * FROM SHOHIN;
• WHERE:データを絞り込む – SELECT * FROM KOKYAKU WHERE ID =‘1100’;
• JOIN:表を結合する(後述)
• GROUP BY:データを集計する(後述)

SQL 2of2
• RDBMSを管理する言語
– INSERT:データの追加
• INSERT INTO URIAGE(DATE, KOKYAKU, SHOHIN, URIAGE_KINGAKU) VALUES (’10-09-31’, ‘1100’, ‘K-102’, 1000);
– UPDATE:データの上書き
• UPDATE KOKYAKU SET KAIIN_KUBUN = ‘優良会員’ WHERE ID = ‘1200’;
– DELETE:データの削除
• DELETE FROM KOKYAKU WHERE ID=‘1200’;

MySQLについて

MySQL
• MySQLは世界でもっとも使われているオープンソースのRDBMS
• 技術的に枯れている
• Windowsで簡単にインストール
• とりあえず無料!
• ツールがたくさん、インタフェースもたくさん
• エンジンを変更できる(次頁)

MySQLはストレージエンジンを変更できる
• MySQLはストレージエンジンをチェンジできる。
• 用途(ようと)におうじてエンジンチェンジでデータベースを構築しよう!
• データの分析用途ならMyISAMを使用しよう。

インストールするソフト
• MySQLをRから使用するのに必要なインストールソフトは2つだけ。
• MySQL Community Server – http://www-jp.mysql.com/downloads/mysql/
• ODBC Connector – http://www-jp.mysql.com/downloads/connector/odbc/
公式サイトよりダウンロード

MySQLの構成
• MySQLはさまざまな要素から構成されている
MySQL サーバー
表
データベース データベース
クライアントPC
クライアントPC
索引
ビュー
ODBC

MySQL簡単、
MySQLオススメ

分析のための
データベース
テクニック
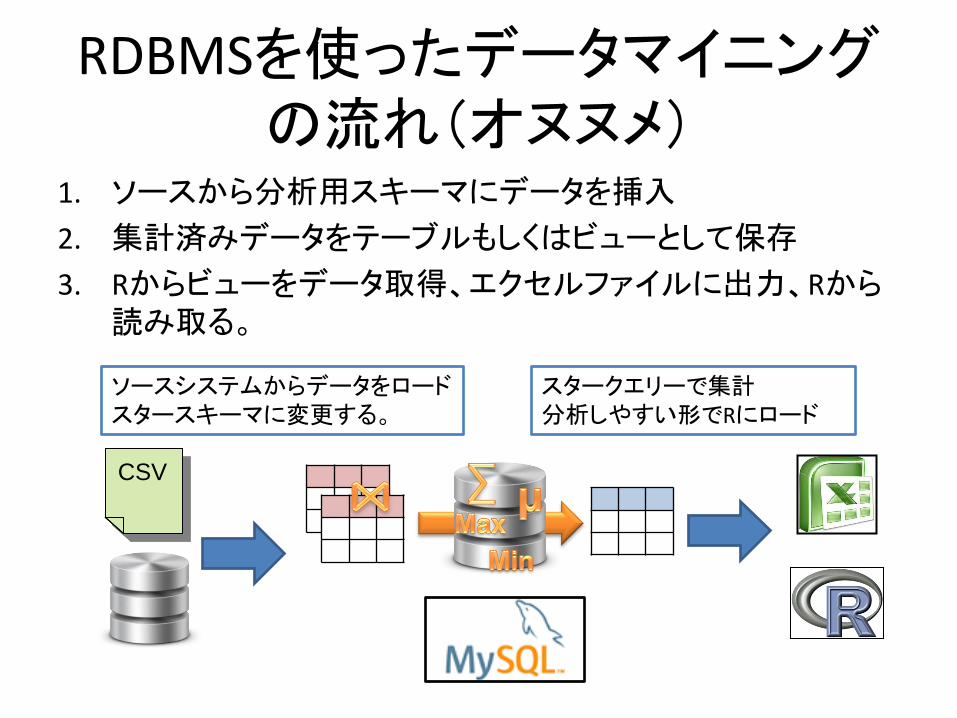
RDBMSを使ったデータマイニングの流れ(オヌヌメ)
1. ソースから分析用スキーマにデータを挿入
2. 集計済みデータをテーブルもしくはビューとして保存
3. Rからビューをデータ取得、エクセルファイルに出力、Rから読み取る。
CSV
ソースシステムからデータをロード スタースキーマに変更する。
スタークエリーで集計 分析しやすい形でRにロード

データモデリング
• 分析する事象をRDBMS上でどのように表に表すか
• どういう分析を行うかを定義する
• 情報分析のためのデータモデリングのベストプラクティス→スタースキーマ(次次頁)
正規化されたモデル スタースキーマ
OLTP
更新
データ量:少 データ量:大
参照
DWH
重複 重複排除

例:化粧品会社の売上分析
• 会員制の化粧品会社の情報系データベース売上分析を行う。
• 顧客の情報を世代別に顧客表に管理
• チャネルは店舗、電話通販、インターネット等

スタースキーマでモデリングを行う
• データをファクトとディメンジョンに分けて解析する。
• ファクト:分析したい対象、出来事を表す表
• ディメンジョン:分析するための軸を表す表
売上金額 売上数量
商品
商品分類
顧客
年齢
チャネル
日
月
年 性別
世代
タイプ
商品ディメンジョン 何が売れたか
顧客ディメンジョン 誰に売れたか
時間ディメンジョン いつ売れたか
チャネルディメンジョン どのように売れたか
売上ファクト 売上という出来事

スタースキーマのE-R図による可視化

RDBMSを使ったデータマイニングの流れ(オヌヌメ)
1. ソースから分析用スキーマにデータを挿入
2. 集計済みデータをテーブルもしくはビューとして保存
3. Rからビューをデータ取得、エクセルファイルに出力、Rから読み取る。
CSV
ソースシステムからデータをロード スタースキーマに変更する。
スタークエリーで集計 分析しやすい形でRにロード

デモ:データのロード
1.CREATE TABLEによるテーブルの作成
2.LOAD DATA INTOによるデータのロード

デモ:スタークエリーでデータ取得
• スタークエリー・・・スタースキーマでデータを取得するためのSQLのお作法。
#e.g.チャネル別の売上金額を分析する。 SELECT C.CHANNEL_MEI, SUM(URIAGE_KIN) FROM URIAGE AS U, CHANNEL AS C WHERE C.CHANNEL_ID = U.CHANNEL_ID GROUP BY C.CHANNEL_MEI;
CHANNEL表と売上表を結合
CHANNEL表のチャネルIDと売上表のチャネルIDが同じものに限り、結合する。
GROUP BY 句はSUMを行う
単位を記述する。この場合はチャネル名でグループ化する。
チャネルと売上金額の合計を取得する。

定型の分析はビュー化しよう
• ビュー・・・分析のSQLを保存する。保存後は普通のSQLと同様に使用できる。
#e.g.月別世代別の売上金額を分析をビューにする。 CREATE VIEW NENGETSU_SEDAI_ANALYSIS AS SELECT CONCAT(J.NEN, J.TSUKI) AS NENGETSU, K.SEDAI AS SEDAI, SUM(U.URIAGE_KIN) AS URIAGE_KIN FROM URIAGE U, KOKYAKU K, JIKAN J WHERE K.KOKYAKU_ID = U.KOKYAKU_ID AND J.HI = U.HI GROUP BY NENGETSU, SEDAI;
SELECT * FROM NENGETSU_SEDAI_ANALYSIS;
取得するデータのSQLを記述する。
チャネル別分析というビューを作成する。
作成後は普通にSQLの中に埋め込める。

さらに高度な話題として
• 高速にデータにアクセスしたい – 索引・・・頻繁に集計する単位でファクトに索引を作成する。
– 外部キー・・・基本的には使用しない。
– パーティショニング・・・時系列でパーティション化が一般的。
– マートの作成・・・集計済みのデータを保持する。
– マテリアライズド・ビュー・・・ビューの結果を保存する。
• データの管理 – バックアップ・・・データ量に問題がなければsqldumpで全部バックアップを取る。 $ mysqldump –u root –p –databases [DBNAME]

RとMySQLの連携

デモ:パッケージRODBC
1. MySQLのODBCドライバのインストール
2. ODBCドライバの構成
3. データベースの起動
4. RODBCを使用してRからSQLを発行して、結果セットをデータフレームに格納する。
5. データフレームからマイニング用の行列を作成する。

まとめ
• どのようなソフトでもよいので、データベースを作ってデータを一元管理しよう。
• MySQLなら簡単にインストールできるので、まずMySQLでデータベースを作成してみよう。
• スタースキーマを意識して、自分のデータモデルを決定する。
• RODBCを使用して、MySQLからRにデータをロードしてみよう。

文献
初めてのMySQLと文字化け
http://pugiemonn.blog6.fc2.com/blog-entry-727.html
MySQLクイック・リファレンス
http://www.bitscope.co.jp/tep/MySQL/quickMySQL.html#doc1_id70