Embed Size (px)
Citation preview

Knowledge Discovery Knowledge Discovery e Data Mininge Data Mining
SommarioSommario
IntroduzioneMotivazioni ed applicazioni
Processo di Knowledge Discovery in DBsFasi e caratteristiche
Task di Data MiningClassificazione e regressioneScoperta di regole associativeClustering
La classificazione Definizione del problema Misure di qualitàTecniche di classificazione
Contesto e motivazioniContesto e motivazioni
“data explosion”La disponibilità di tecnologie efficienti e poco costose favorisce l’accumulo di enormi quantità di dati
DBs e altri tipi di repositoryElectronic data gathering: Internet, Satellite, Bar-code reader, …High perf. computers (PC-Cluster) e, in generale, cheaper & faster HW
Esigenza: trarre vantaggio competitivo dai datisupportare i processi decisionali con nuova conoscenzainadeguatezza dei sistemi di analisi tradizionali:
“We are drowning in data, but starving for knowledge!”
La catena del valore dellLa catena del valore dell’’informazioneinformazione
DatiDati• Dati demografici: “(Mario,Rossi,25/10/1960,…)”, “(Luigi,Bianchi,…,…)”• Dati geografici: “Rende”, “Cosenza”, “Lombardia”,…• Punti di vendita
InformazioniInformazioni• La persona X vive nella città Z• La persona S ha Y anni
ConoscenzaConoscenza• Il prodotto P è usato per lo
più da clienti giovani• Chi acquista il prodotto Ptende ad acquistare Q
• I clienti possono essere suddivisi in classi omogenee (A,B,C,…)
DecisioniDecisioni• Promuovere il prodotto A nei
negozi della regione Z• Offrire dei servizi addizionali ai
clienti di classe C• Progettare cataloghi di
prodotti adatti ai vari profili di clienti
Business Intelligence: Business Intelligence: Data Warehouse e Data Mining Data Warehouse e Data Mining
Data Warehouse (DW)Archivio progettato in modo specifico per l’analisiDotato di strumenti efficienti e intuitivi per consultare, interrogare e visualizzare le informazioniData Warehousing: processo di costruzione/popolamento di un DW
Data Mining (DM) Estrazione automatica ed efficiente di pattern(“pepite” di conoscenza) da grosse collezioni di datiPattern: regolarità o proprietà valide nei dati di input
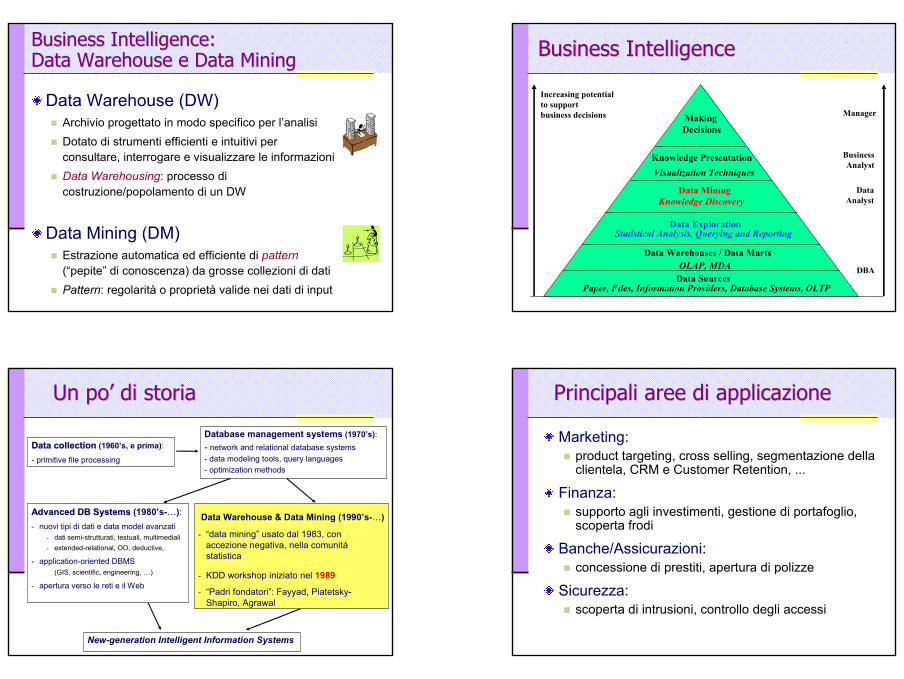
Business Intelligence Business Intelligence
Increasing potentialto supportbusiness decisions Manager
BusinessAnalyst
DataAnalyst
DBA
MakingDecisions
Knowledge PresentationVisualization Techniques
Data MiningKnowledge Discovery
Data Exploration
OLAP, MDA
Statistical Analysis, Querying and Reporting
Data Warehouses / Data Marts
Data SourcesPaper, Files, Information Providers, Database Systems, OLTP
Un poUn po’’ di storiadi storia
Data collectionData collection (1960’s, e prima):
- primitive file processing
Database management systems (1970’s): - network and relational database systems- data modeling tools, query languages- optimization methods
Advanced DB Systems Advanced DB Systems (1980’s-…):- nuovi tipi di dati e data model avanzati
- dati semi-strutturati, testuali, multimediali- extended-relational, OO, deductive,
- application-oriented DBMS (GIS, scientific, engineering, …)
- apertura verso le reti e il Web
Data Warehouse & Data Mining (1990’s-…)
- “data mining” usato dal 1983, con accezione negativa, nella comunitàstatistica
- KDD workshop iniziato nel 1989
- “Padri fondatori”: Fayyad, Piatetsky-Shapiro, Agrawal
New-generation Intelligent Information Systems
Principali aree di applicazionePrincipali aree di applicazione
Marketing: product targeting, cross selling, segmentazione della clientela, CRM e Customer Retention, ...
Finanza: supporto agli investimenti, gestione di portafoglio, scoperta frodi
Banche/Assicurazioni: concessione di prestiti, apertura di polizze
Sicurezza: scoperta di intrusioni, controllo degli accessi
Principali aree di applicazionePrincipali aree di applicazione
Scienze: progettazione di farmaci, studio di fattori genetici, scoperta di galassie e astri
Medicina: supporto a diagnosi/prognosi, valutazione cure, scoperta di relazioni fra malattie
Produzione: modellazione dei processi, controllo di qualità, allocazione delle risorse
Web:smart search engine, web marketing, web site design
(Sommario)(Sommario)
IntroduzioneMotivazioni ed applicazioni
Processo di Knowledge Discovery in DBsFasi e caratteristiche
Task di Data MiningClassificazione e regressioneScoperta di regole associativeClustering
La classificazione Definizione del problema Misure di qualitàTecniche di classificazione
Estrazione della conoscenza:Estrazione della conoscenza:il processo di KDDil processo di KDD
Knowledge Discovery in Databases (KDD)Scoperta di conoscenza nelle basi di datiutile per comprendere/modellare i fenomeni del mondo reale corrispondenti ai dati
Processo non banale (semi-automatico) di estrazione di pattern
validinuovipotenzialmente utili comprensibili
INTERESSANTI
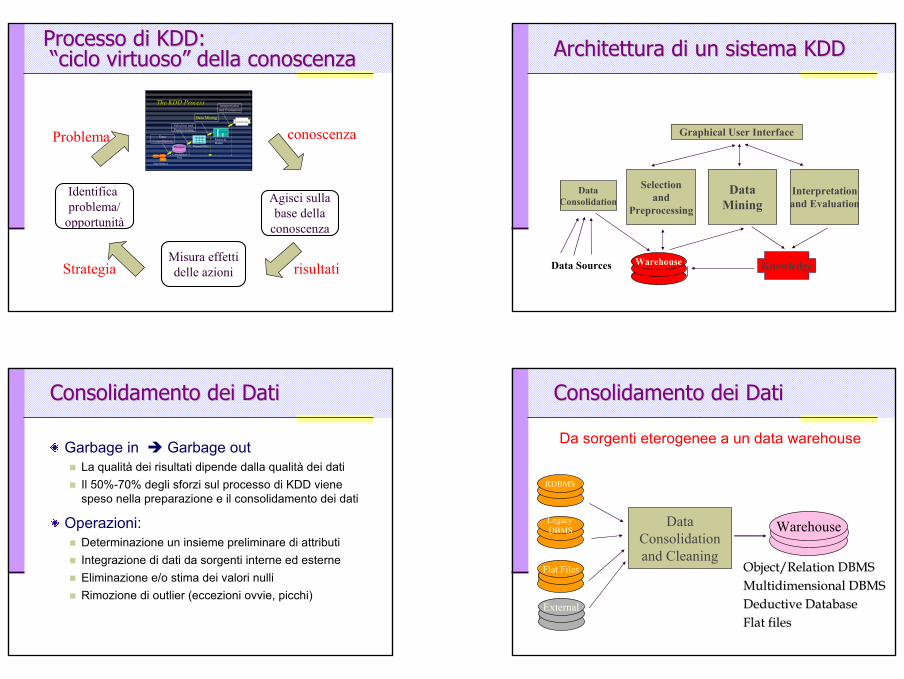
Il processo di KDDIl processo di KDD
Selezione ePre-elaborazione
Data Mining
Interpretazione e Valutazione
Integrazione e Consolidamento
Conoscenza
p(x)=0.02
Sorgenti
Pattern e/o Modelli
Dati trasformati
DatiConsolidati
CogNovaTechnologies
9
The KDD ProcessThe KDD Process
Selection and Preprocessing
Data Mining
Interpretation and Evaluation
Data Consolidation
Knowledge
p(x)=0.02
Warehouse
Data Sources
Patterns & Models
Prepared Data
ConsolidatedData
Identifica problema/
opportunità
Misura effettidelle azioni
Agisci sullabase della
conoscenza
conoscenza
risultatiStrategia
Problema
Processo di KDD:Processo di KDD:““ciclo virtuosociclo virtuoso”” della conoscenzadella conoscenza Architettura di un sistema KDDArchitettura di un sistema KDD
Graphical User Interface
DataConsolidation
Selectionand
Preprocessing
DataMining
Interpretationand Evaluation
Warehouse KnowledgeData Sources
Consolidamento dei DatiConsolidamento dei Dati
Garbage in Garbage out La qualità dei risultati dipende dalla qualità dei datiIl 50%-70% degli sforzi sul processo di KDD viene speso nella preparazione e il consolidamento dei dati
Operazioni:Determinazione un insieme preliminare di attributi Integrazione di dati da sorgenti interne ed esterneEliminazione e/o stima dei valori nulliRimozione di outlier (eccezioni ovvie, picchi)
Consolidamento dei DatiConsolidamento dei Dati
Da sorgenti eterogenee a un data warehouse
RDBMS
Legacy DBMS
Flat Files
DataConsolidationand Cleaning
Warehouse
ObjectObject/Relation DBMS /Relation DBMS MultidimensionalMultidimensional DBMS DBMS DeductiveDeductive Database Database FlatFlat filesfiles
External
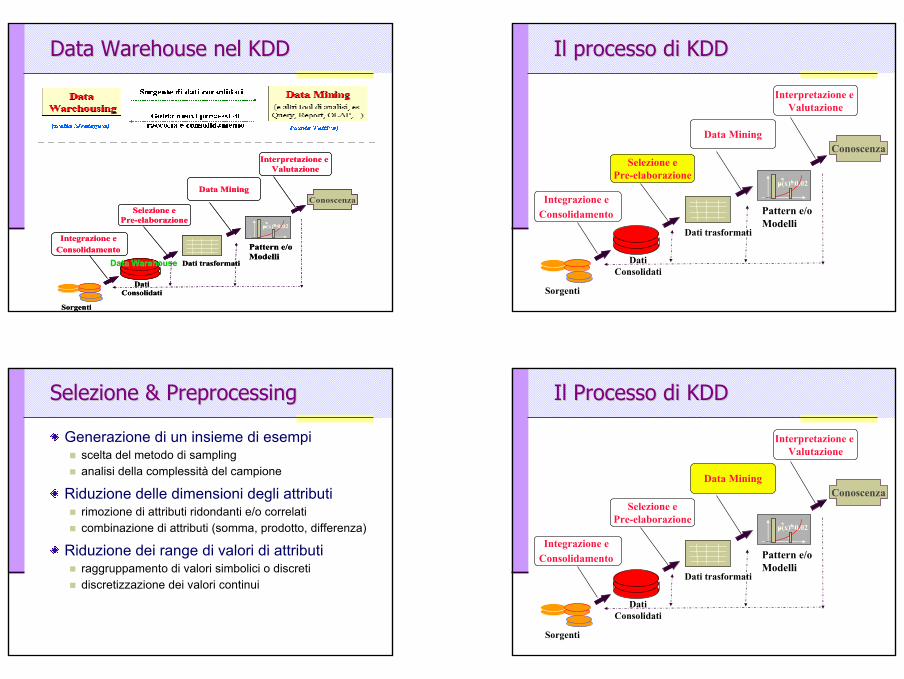
Data Warehouse Data Warehouse nelnel KDDKDD
Selezione ePre-elaborazione
Data Mining
Interpretazione e Valutazione
Integrazione e Consolidamento
Conoscenza
p(x)=0.02
Sorgenti
Pattern e/o Modelli
Dati trasformati
DatiConsolidati
Selezione ePre-elaborazione
Data Mining
Interpretazione e Valutazione
Integrazione e Consolidamento
Conoscenza
p(x)=0.02
Sorgenti
Pattern e/o Modelli
Dati trasformati
DatiConsolidati
Data WarehouseData Warehouse
Il processo di KDDIl processo di KDD
Selezione ePre-elaborazione
Data Mining
Interpretazione e Valutazione
Integrazione e Consolidamento
Conoscenza
p(x)=0.02
Sorgenti
Pattern e/o Modelli
Dati trasformati
DatiConsolidati
Selezione & Selezione & PreprocessingPreprocessing
Generazione di un insieme di esempiscelta del metodo di samplinganalisi della complessità del campione
Riduzione delle dimensioni degli attributirimozione di attributi ridondanti e/o correlaticombinazione di attributi (somma, prodotto, differenza)
Riduzione dei range di valori di attributiraggruppamento di valori simbolici o discretidiscretizzazione dei valori continui
Il Processo di KDDIl Processo di KDD
Selezione ePre-elaborazione
Data Mining
Interpretazione e Valutazione
Integrazione e Consolidamento
Conoscenza
p(x)=0.02
Sorgenti
Pattern e/o Modelli
Dati trasformati
DatiConsolidati
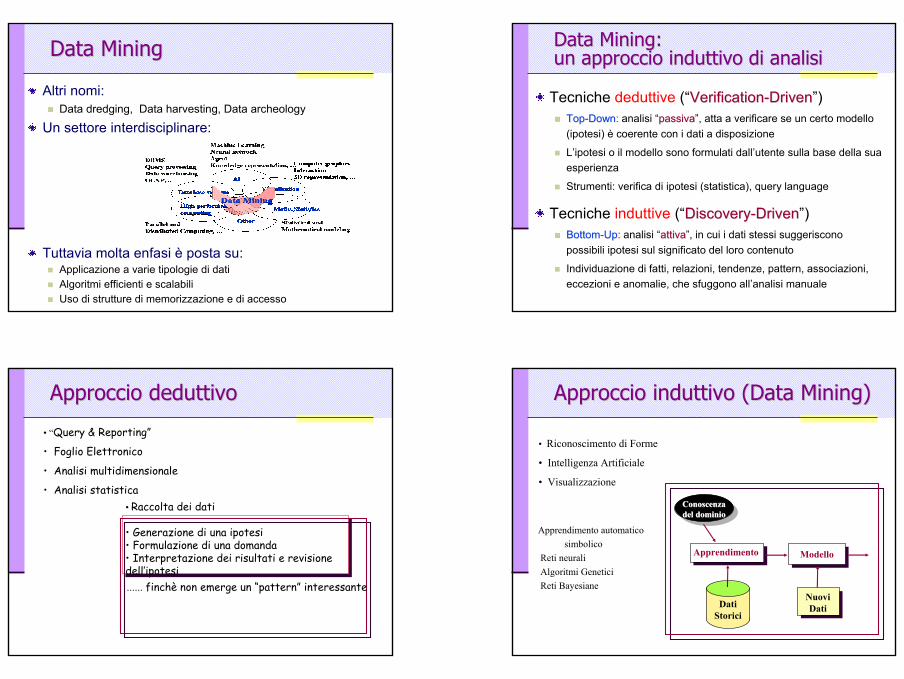
Data MiningData Mining
Altri nomi: Data dredging, Data harvesting, Data archeology
Un settore interdisciplinare:
Tuttavia molta enfasi è posta su:Applicazione a varie tipologie di datiAlgoritmi efficienti e scalabiliUso di strutture di memorizzazione e di accesso
Data Mining: Data Mining: un approccio induttivo di analisiun approccio induttivo di analisi
Tecniche deduttive (“VerificationVerification--DrivenDriven”)TopTop--DownDown: : analisi “passivapassiva”, atta a verificare se un certo modello (ipotesi) è coerente con i dati a disposizione
L’ipotesi o il modello sono formulati dall’utente sulla base della sua esperienza
Strumenti: verifica di ipotesi (statistica), query language
Tecniche induttive (“DiscoveryDiscovery--DrivenDriven”)BottomBottom--UpUp: : analisi “attivaattiva”, in cui i dati stessi suggeriscono possibili ipotesi sul significato del loro contenuto
Individuazione di fatti, relazioni, tendenze, pattern, associazioni, eccezioni e anomalie, che sfuggono all’analisi manuale
Approccio deduttivoApproccio deduttivo
• “Query & Reporting”
• Foglio Elettronico
• Analisi multidimensionale
• Analisi statistica• Raccolta dei dati
• Generazione di una ipotesi• Formulazione di una domanda• Interpretazione dei risultati e revisione dell’ipotesi...... finchè non emerge un “pattern” interessante
Approccio induttivo (Data Mining)Approccio induttivo (Data Mining)
• Riconoscimento di Forme
• Intelligenza Artificiale
• Visualizzazione
Apprendimento Modello
Nuovi DatiDati
Storici
Conoscenza Conoscenza del dominiodel dominio
Apprendimento automatico simbolico
Reti neuraliAlgoritmi GeneticiReti Bayesiane

Categorie di algoritmi di Data MiningCategorie di algoritmi di Data Mining
Formato dei datiDB relazionali, Transactional DBs, Time-seriesDB Object-oriented, Spaziali o MultimedialiFlat file, Documenti testuali o ipertestuali
Tipi di pattern estratticlassificazione, clustering, associazioni, deviazioni,…Pattern ibridi, o a livelli multipli di aggregazione
Tecniche usateDatabase-oriented, modelli probabilistici, visualizzazione, reti neurali, alberi di decisione, programmi logici,..
Contesto applicativoDNA mining, Web mining, Weblog analysis, fraud analysis, …
Task/Task/funzionalitfunzionalitàà didi Data MiningData Mining
PredizioneClassificazioneRegressione
ClusteringLink Analysis
Scoperta di Regole AssociativeAnalisi di sequenze e di time-series
Summarization Deviation DetectionSimilarity matching
(Sommario)(Sommario)
IntroduzioneMotivazioni ed applicazioni
Processo di Knowledge Discovery in DBsFasi e caratteristiche
Task di Data MiningClassificazione e regressioneScoperta di regole associativeClustering
La classificazione Definizione del problema Misure di qualitàTecniche di classificazione
Predizione: Predizione: classificazione e regressioneclassificazione e regressione
Obiettivo: indurre un modello in grado di prevedere il valore di un attributo target in base agli altri attributi
Classificazione:il target assume valori discreti Tecniche: Alberi di decisione, Regole di classificazione, Classificazione Bayesiana, K-nearest neighbors, Case-basedreasoning, Genetic algorithms, Rough sets, Fuzzy logic, Association-based classification, …
Regressione: il target assume valori continuiTecniche: Alberi di regressione, Reti neurali, regressione lineare e multipla, regressione non-lineare, regressione logistica e di Poisson, regressione log-lineare
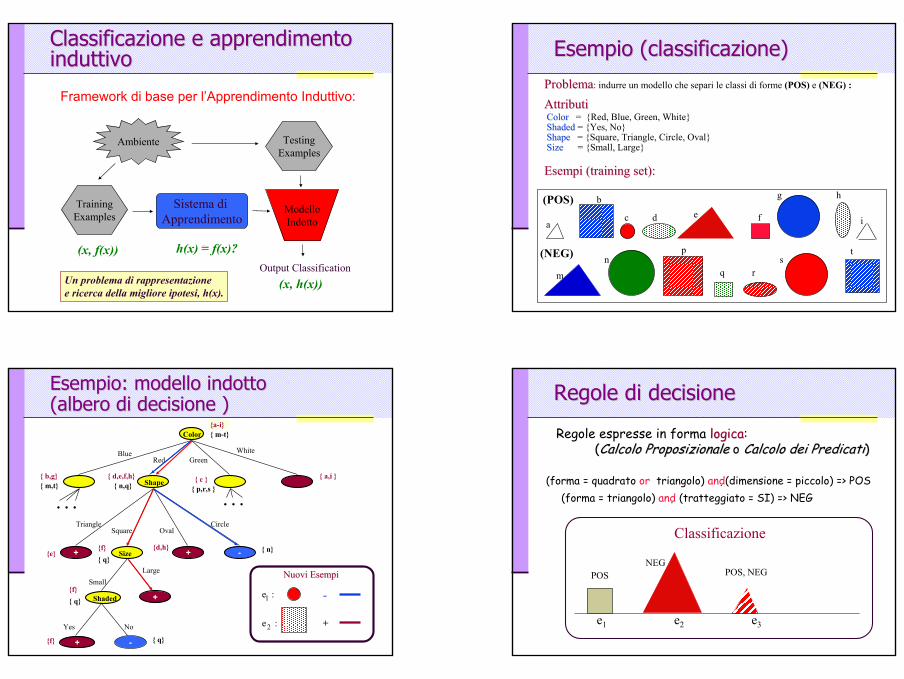
Classificazione e apprendimento Classificazione e apprendimento induttivoinduttivo
Framework di base per l’Apprendimento Induttivo:
Sistema diApprendimento
Ambiente
TrainingExamples
TestingExamples
ModelloIndotto
Output Classification(x, f(x))
(x, h(x))
h(x) = f(x)?
Un problema di rappresentazionee ricerca della migliore ipotesi, h(x).
~
Esempio (classificazione)Esempio (classificazione)ProblemaProblema: indurre un modello che separi le classi di forme (POS) e (NEG) :
AttributiAttributiColorColor = {Red, Blue, Green, White}ShadedShaded = {Yes, No}ShapeShape = {Square, Triangle, Circle, Oval}SizeSize = {Small, Large}
Esempi (training set):Esempi (training set):
(NEG)
a
b
c d e f
g h
i
(POS)
m
np
q rs
t
Esempio: modello indotto Esempio: modello indotto (albero di decisione )(albero di decisione )
Color
BlueRed Green
White
{ m-t} {a-i}
{ b,g}{ m,t}
{ d,e,f,h}{ n,q}
{ c }{ p,r,s }
{ a,i } Shape
-+ +{e}
TriangleSquare Oval
Circle
{f}{ q}
{d,h} { n}
• • • • • •
Size
SmallLarge
Shaded
{f} +
Yes No
- { q}
{f}{ q}
Nuovi EsempiNuovi Esempi
e1 -:
e2 +:
+
Regole di decisioneRegole di decisione
(forma = quadrato or triangolo) and (dimensione = piccolo) => POS(forma = triangolo) and (tratteggiato = SI) => NEG
Regole espresse in forma logicalogica: ((Calcolo Calcolo ProposizionaleProposizionale o Calcolo dei PredicatiCalcolo dei Predicati))
Classificazione
POS POS, NEG
e1 e2 e3
NEG

ClusteringClustering ClusteringClustering
Clustering: Partizionamento dei dati in un insieme di classi non note a-priori (cluster) Qualità della partizione:
Alta omogeneità intra-classeBassa omogeneità inter-classe
In genere si basa su una misura di similarità/distanzaEsempi di applicazione:
Customer segmentationcompressione dei datisuddivisione di corpora di documenti
Clustering: Clustering: algoritmialgoritmi
Partizionalidistance-based: K-means
GerarchiciAgglomerativi o divisivisingle link o complete link
Model-Based Approcci StatisticiNeural network
Altri metodi:Density-BasedGrid-Based
Clustering: Clustering: algoritmoalgoritmo KK--meansmeans
Input: Dati = tuple con attributi numerici
(esistono varianti per dati categorici)numero K di cluster desiderati
Criterio: minimizzare la somma dei quadrati delle distanze di ogni punto dal centro del suo cluster
Algoritmo:Fissa una partizione iniziale (random) in K clusterRipeti fino a che non si abbia nessuna variazione:
Assegna ogni punto al centro più vicinoGenera i nuovi centri
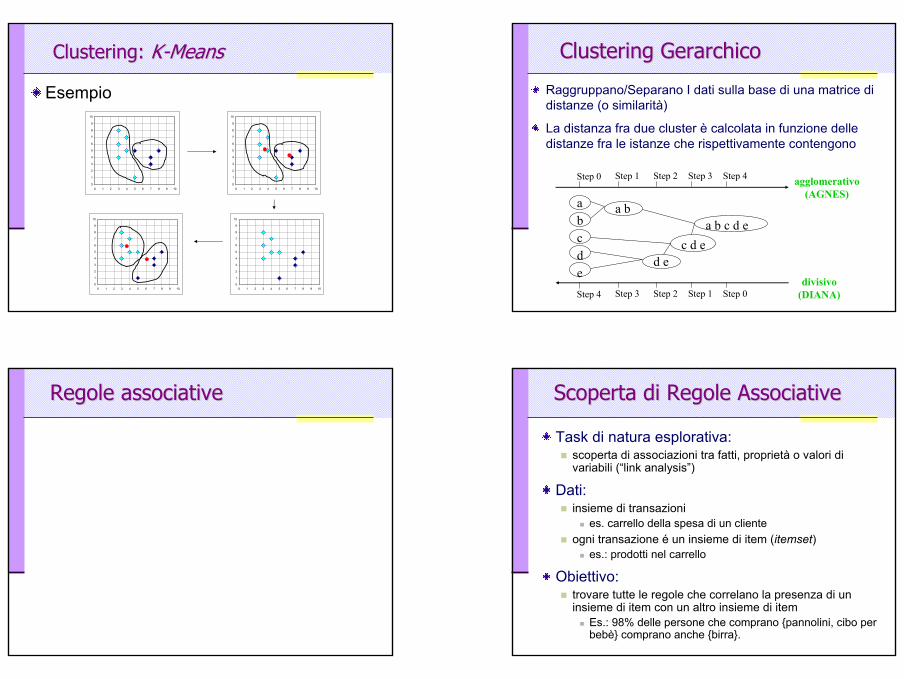
Clustering:Clustering: KK--MeansMeans
Esempio
0
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 100
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 10
0
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 100
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 10
Clustering Clustering GerarchicoGerarchico
Raggruppano/Separano I dati sulla base di una matrice di distanze (o similarità)
La distanza fra due cluster è calcolata in funzione delle distanze fra le istanze che rispettivamente contengono
Step 0 Step 1 Step 2 Step 3 Step 4
b
dc
e
a a b
d ec d e
a b c d e
Step 4 Step 3 Step 2 Step 1 Step 0
agglomerativo(AGNES)
divisivo(DIANA)
Regole associativeRegole associative Scoperta di Regole AssociativeScoperta di Regole Associative
Task di natura esplorativa:scoperta di associazioni tra fatti, proprietà o valori di variabili (“link analysis”)
Dati:insieme di transazioni
es. carrello della spesa di un clienteogni transazione é un insieme di item (itemset)
es.: prodotti nel carrello
Obiettivo:trovare tutte le regole che correlano la presenza di un insieme di item con un altro insieme di item
Es.: 98% delle persone che comprano {pannolini, cibo per bebè} comprano anche {birra}.
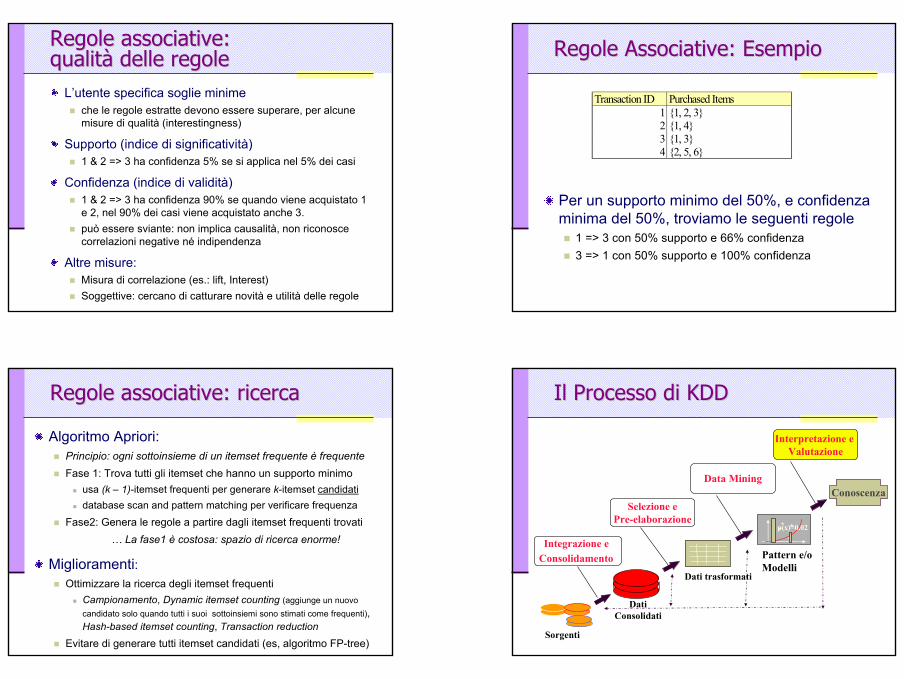
Regole associative: Regole associative: qualitqualitàà delle regoledelle regole
L’utente specifica soglie minimeche le regole estratte devono essere superare, per alcune misure di qualità (interestingness)
Supporto (indice di significatività)1 & 2 => 3 ha confidenza 5% se si applica nel 5% dei casi
Confidenza (indice di validità)1 & 2 => 3 ha confidenza 90% se quando viene acquistato 1 e 2, nel 90% dei casi viene acquistato anche 3.può essere sviante: non implica causalità, non riconosce correlazioni negative né indipendenza
Altre misure: Misura di correlazione (es.: lift, Interest)Soggettive: cercano di catturare novità e utilità delle regole
Regole Associative: EsempioRegole Associative: Esempio
Per un supporto minimo del 50%, e confidenza minima del 50%, troviamo le seguenti regole
1 => 3 con 50% supporto e 66% confidenza3 => 1 con 50% supporto e 100% confidenza
Transaction ID Purchased Items1 {1, 2, 3}2 {1, 4}3 {1, 3}4 {2, 5, 6}
Regole associative: ricercaRegole associative: ricerca
Algoritmo Apriori:Principio: ogni sottoinsieme di un itemset frequente è frequenteFase 1: Trova tutti gli itemset che hanno un supporto minimo
usa (k – 1)-itemset frequenti per generare k-itemset candidatidatabase scan and pattern matching per verificare frequenza
Fase2: Genera le regole a partire dagli itemset frequenti trovati… La fase1 è costosa: spazio di ricerca enorme!
Miglioramenti: Ottimizzare la ricerca degli itemset frequenti
Campionamento, Dynamic itemset counting (aggiunge un nuovo candidato solo quando tutti i suoi sottoinsiemi sono stimati come frequenti), Hash-based itemset counting, Transaction reduction
Evitare di generare tutti itemset candidati (es, algoritmo FP-tree)
Il Processo di KDDIl Processo di KDD
Selezione ePre-elaborazione
Data Mining
Interpretazione e Valutazione
Integrazione e Consolidamento
Conoscenza
p(x)=0.02
Sorgenti
Pattern e/o Modelli
Dati trasformati
DatiConsolidati

Interpretazione e valutazioneInterpretazione e valutazione
InterpretazioneAlberi e regole logiche possono essere interpretati facilmenteRisultati di clustering possono essere graficati/tabellatiIn generale, tool di visualizzazione possono essere molto utili per interpretare i risultati
ValutazioneValidazione statistica e test di significanzaAnalisi qualitativa da parte di esperti del dominio Test del modello su casi di esempio per valutarne la bontà (es., accuratezza)
Un sistema di mining può generare migliaia di pattern
Pattern interessanti:Facilmente comprensibili
Validi su nuovi dati di test con un certo grado di certezza
Potenzialmente utili per processi decisionali
Nuovi o confermano ipotesi che si cercava di validare
Misure Oggettive vs. SoggettiveOggettive: basate su statistiche e struttura dei pattern (e.g., supporto, confidenza, lunghezza della descrizione, etc.)
Soggettive: basate su conoscenza pregressa e aspettative degli utenti (e.g., novità, etc.)
Sono tutti interessanti i pattern Sono tutti interessanti i pattern scoperti?scoperti?
Completezza/Precisione di un Completezza/Precisione di un processo di data miningprocesso di data mining
Completezza: Trova tutti i pattern interessantiE’ possibile in un tempo ragionevole?
Correttezza: Trova solo pattern interessantiE’ possibile “non commettere errori” e trovare solo pattern interessanti?
Possibili approcci:Si generano tutti i pattern che potrebbero essere interessanti e poi si eliminano quelli che non lo sonoGenerare solo pattern interessanti (è possibile perdere in completezza)
(Sommario)(Sommario)
IntroduzioneMotivazioni ed applicazioni
Processo di Knowledge Discovery in DBsFasi e caratteristiche
Task di Data MiningClassificazione e regressioneScoperta di regole associativeClustering
La classificazione Definizione del problema Misure di qualitàTecniche di classificazione
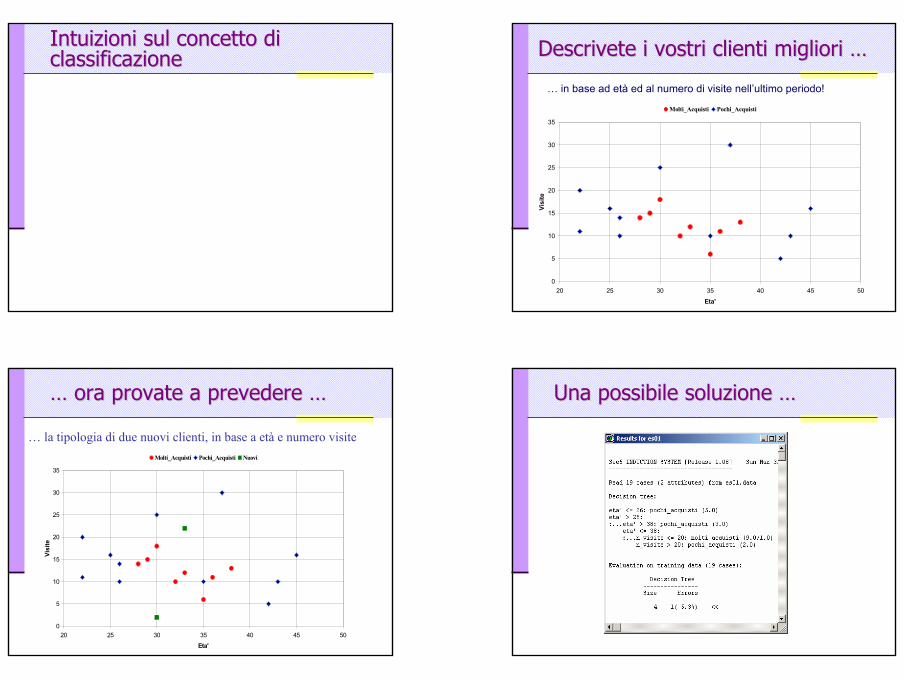
Intuizioni sul concetto di Intuizioni sul concetto di classificazioneclassificazione Descrivete i vostri clienti migliori Descrivete i vostri clienti migliori ……
… in base ad età ed al numero di visite nell’ultimo periodo!
0
5
10
15
20
25
30
35
20 25 30 35 40 45 50
Eta'
Visi
te
Molti_Acquisti Pochi_Acquisti
…… ora provate a prevedere ora provate a prevedere ……
… la tipologia di due nuovi clienti, in base a età e numero visite
0
5
10
15
20
25
30
35
20 25 30 35 40 45 50
Eta'
Visi
te
Molti_Acquisti Pochi_Acquisti Nuovi
Una possibile soluzione Una possibile soluzione ……

…… rappresentata graficamenterappresentata graficamente
Età <= 26 Età >= 38
Visite > 20
0
5
10
15
20
25
30
35
20 25 30 35 40 45 50
Eta'
Visi
te
Molti_Acquisti Pochi_Acquisti Nuovi
Il processo seguitoIl processo seguitoIndividuazione di una caratteristica “interessante” dei clienti: attributo classe
Numero di acquisti (fare molti acquisti o pochi acquisti)
Individuazione di altri attributi “meno interessanti”, ma che possono influenzare la classe
Età, Numero di visite
Raccolta di dati storici di cui si conoscono TUTTI gli attributi: training set
19 clienti di cui si conoscono TUTTI gli attributi
Induzione di un modello di CLASSIFICAZIONE a partire dai dati storici:
descrive la dipendenza della classe dagli altri attributitale descrizione cerca di essere accurata, concisa, informativa
CLASSIFICAZIONE: uso del modello per prevedere il valore della classe per un nuovo caso (cliente)
outlook temperature humidity windy classesunny 85 85 false Don't Playsunny 80 90 true Don't Playovercast 83 78 false Playrain 70 96 false Playrain 68 80 false Playrain 65 70 true Don't Playovercast 64 65 true Playsunny 72 95 false Don't Playsunny 69 70 false Playrain 75 80 false Playsunny 75 70 true Playovercast 72 90 true Playovercast 81 75 false Playrain 71 80 true Don't Play
Classificazione e predizione: inputClassificazione e predizione: input
Un insieme di esempi (dette istanze o casi) che descrivono un concetto (detto classe) sulla base di attributi (detti anche features)
Classificazione e predizione: inputClassificazione e predizione: input
La classe e gli attributi possono assume valori :continui (es. numeri reali)
Due valori sono confrontabili ed esiste una nozione di distanzaEsempi: età, reddito, costo, temperatura, ecc.
ordinali (elementi di insiemi finiti ed ordinati)Due valori sono confrontabili, ma non esiste una distanzaEsempi: { freddo, tiepido, caldo }, {insufficiente, buono, ottimo }
discreti (elementi di insiemi finiti e non ordinati)Due valori non sono tra loro confrontabiliEsempi: { nuvoloso, soleggiato, ventoso }, { alimentari, elettrodom., abbigliamento }
Discretizzazione: trasformazione di valori continui in ordinali o discreti
Classificazione e predizioneClassificazione e predizioneA partire dagli esempi viene costruito un modello in grado di descrivere il valore della classe in base a quello degli altri attributi
Quando la classe assume valori discreti, si parla di classificazione:
Alberi di decisione, Regole di classificazione, Classificazione Bayesiana, K-nearest neighbors, Case-based reasoning, Genetic algorithms, Rough sets, Fuzzy logic, Association-basedclassification
Quando la classe assume valori continui, si parla di predizione numerica
Alberi di regressione, Reti neurali, regressione lineare e multipla, regressione non-lineare, regressione logistica e di Poisson, regressione log-lineare
Classificazione come Classificazione come apprendimento induttivoapprendimento induttivo
Classificazione Classificazione -- DefinizioniDefinizioni
La classificazione è un processo di apprendimento supervisionato
le classi sono note a priori e si dispone di esempi giàclassificati
Ipotesi dell’apprendimento induttivo:<< Se un modello, indotto da un insieme di esempi “abbastanza rappresentativo”, ne riconosce le classi in modo accurato, sarà accurato anche nel riconoscere la classe degli altri oggetti del dominio >>
Denominazioni alternative (più appropriate) per il processo di classificazione:
Apprendimento di Concetti (classi) Induzione di Classificatori
Sistemi di apprendimento induttivoSistemi di apprendimento induttivo
Framework di base per l’Apprendimento Induttivo
Sistema diApprendimento
Ambiente
Trainingset
Testset
ModelloIndotto
Predizione su un nuovo caso(x, f(x))
(q, h(q))
h(x) = f(x)?
Un problema di rappresentazionee ricerca della migliore ipotesi, h(x).
~

Valutazione di un modello di Valutazione di un modello di classificazione (classificatore)classificazione (classificatore)Capacità descrittiva: comprensibilità della conoscenza rappresentata dal modello
numero di nodi dell’albero di decisione, numero di regole, …
Capacità predittiva: capacità di classificare correttamente oggetti del dominio
accuratezza: numero di oggetti classificati correttamente sul numero totale di oggetti classificatierrore di classificazione: 1 – accuratezza
L’accuratezza teorica (sul dominio) può essere stimata:su un test-set (indipendente dal training set), cioè un insieme di oggetti del dominio di cui è nota la classesullo stesso training set, inducendo vari modelli su campioni diesso: Cross-Validation
EErrorrrore di e di ClassificaClassificazionezione
Example Space X(x,c(x))
Where c and h disagree
ch
+ --
-
-
+
Il true error di una ipotesi h è la probabilità cheh classificherà male una istanza selezionata a caso da X,
err(h) = P[c(x) ≠ h(x)]
x = attributi di input c = classe effettivah = ipotesi (modello)
Accuratezza del modello di Accuratezza del modello di classificazioneclassificazione
Cerchiamo una misura della bontà di un modelloaccuratezza
percentuale di esempi la cui classe predetta coincide con la classe reale
% di misclassificazionepercentuale di esempi la cui classe predetta NON coincide con la classe reale
… di quali esempi?Di esempi di cui si conosce la classe reale!L’accuratezza sugli esempi del training set è ottimisticaÈ facile costruire un modello accurato al 100% sul training set
Accuratezza: metodo Accuratezza: metodo ““holdoutholdout””
Test setinsieme di esempi indipendenti dal training setdi ciascun esempio si conoscono gli attributi e la classe reale
Metodo “holdout”valutare l’accuratezza del modello sul test setdato un insieme di esempi lo si divide (casualmente) in una percentuale per il training ed una per il test set (in genere 2/3 per il training e 1/3 per il test set)

AccuratezzaAccuratezza: : ““stratified crossstratified cross--validationvalidation””
Metodo “stratified n-fold cross-validation”Si dividono gli esempi in n insiemi S1, …, Sn dellestesse dimensioni e con stessa distribuzione delleclassiPer ciascuno insieme Si
Si costruisce un classificatore sugli altri n-1 insiemiSi usa l’insieme Si come insieme di test del classificatore
L’accuratezza finale è data dalla media delleaccuratezze degli n classificatoriMetodo standard: n = 10, stratified 10-fold cross validation
Accuratezza: limiti inferioriAccuratezza: limiti inferiori
Accuratezza di un classificatore casualeclassificatore che in modo casuale classifica in una delle k possibili classiaccuratezza = 1 / k * 100 esempio: per k = 2 l’accuratezza è del 50%
Qualsiasi classificatore deve fare almeno meglio del classificatore casuale!Accuratezza di un classificatore a maggioranza
classificatore che classifica sempre come la classe di maggioranza nel training set(supponendo la stessa percentuale nella popolazione) accuratezza >= 1 / k * 100esempio: con due classi rappresentate al 98% e al 2% nel training set, l’accuratezza è del 98%
Matrice di confusioneMatrice di confusione
Name Gender Height Output1 Output2 Kristina F 1.6m Short Medium Jim M 2m Tall Medium Maggie F 1.9m Medium Tall Martha F 1.88m Medium Tall Stephanie F 1.7m Short Medium Bob M 1.85m Medium Medium Kathy F 1.6m Short Medium Dave M 1.7m Short Medium Worth M 2.2m Tall Tall Steven M 2.1m Tall Tall Debbie F 1.8m Medium Medium Todd M 1.95m Medium Medium Kim F 1.9m Medium Tall Amy F 1.8m Medium Medium Wynette F 1.75m Medium Medium
Actual Pred.Name Gender Height Output1 Output2 Kristina F 1.6m Short Medium Jim M 2m Tall Medium Maggie F 1.9m Medium Tall Martha F 1.88m Medium Tall Stephanie F 1.7m Short Medium Bob M 1.85m Medium Medium Kathy F 1.6m Short Medium Dave M 1.7m Short Medium Worth M 2.2m Tall Tall Steven M 2.1m Tall Tall Debbie F 1.8m Medium Medium Todd M 1.95m Medium Medium Kim F 1.9m Medium Tall Amy F 1.8m Medium Medium Wynette F 1.75m Medium Medium
Actual Pred.
Actual AssignmentMembership Short Medium TallShort 0 4 0Medium 0 5 3Tall 0 1 2
Actual AssignmentMembership Short Medium TallShort 0 4 0Medium 0 5 3Tall 0 1 2
Confusion matrix:colonne: classi predetterighe: classi effettivecella (i,j): istanze della classe i che il modello assegna alla classe jLe predizioni corrette sono sulla diagonaleFuori dalla diagonale: predizionisbagliate (misclassifications)
AccuraAccuratezzatezza rispettorispetto aad una data d una data classeclasseIl modello riconosce la classe C(e.g., play) ?
True Positives (TP): istanze di C assegnate a C
True Negatives (TN): istanze dialtre classi non assegnate a C
False Positives (FP): istanze di altreclassi assegnate a C (errore!)
False Negatives (FN): istanze di C assegnate ad un’altra classe (errore!)
Precisione: TP/(TP+FP)% di istanze assegnate a C che effettivamente
appartengono a C (correctness measure)
Recall: TP/(TP+FN)% di istanze di C che sono assegnate
a C (completeness measure)
F-measure: (2*recall*precision) / (recall+precision)
True Positive
True Negative
False Positive
False Negative
Actual AssignmentMembership Short Medium TallShort 0 4 0Medium 0 5 3Tall 0 1 2
Actual AssignmentMembership Short Medium TallShort 0 4 0Medium 0 5 3Tall 0 1 2 (TP)
(FP)(FP)
(FN)(FN)
Actual AssignmentMembership Short Medium TallShort 0 4 0Medium 0 5 3Tall 0 1 2
Actual AssignmentMembership Short Medium TallShort 0 4 0Medium 0 5 3Tall 0 1 2
Actual AssignmentMembership Short Medium TallShort 0 4 0Medium 0 5 3Tall 0 1 2
Actual AssignmentMembership Short Medium TallShort 0 4 0Medium 0 5 3Tall 0 1 2 (TP)
(FP)(FP)
(FN)(FN)

Tecniche di classificazioneTecniche di classificazione Classificazione Classificazione –– Tipi di modelliTipi di modelli
Vari tipi di modelli di classificazione Differiscono per il formalismo utilizzato per rappresentare la funzione di classificazione (Linguaggio delle ipotesi)
Alcuni tipi di modelli (classificatori):Basati sugli esempi (es. Nearest neighbor)
memorizzano tutti gli esempi del training set ed assegnano la classe ad un oggetto valutando la “somiglianza” con gli esempi memorizzati (la cui classe è nota)
Matematici (es. Reti Neurali Artificiali, SVM)la funzione di classificazione è una funzione matematica, di cui si memorizzano i vari parametri
Classificazione Classificazione –– Tipi di modelli Tipi di modelli
… alcuni tipi di modelli (classificatori):
Statisticimemorizzano i parametri delle varie distribuzioni di probabilità relative alle classi ed agli attributi
→ per classificare un generico oggetto si possono stimare le probabilità di appartenenza alle varie classi
es.: Naive Bayes
Logicila funzione di classificazione è espressa mediante condizioni logiche sui valori degli attributies.: Alberi e Regole di Decisione
Algoritmi di induzione di alberi di Algoritmi di induzione di alberi di decisionedecisione
••
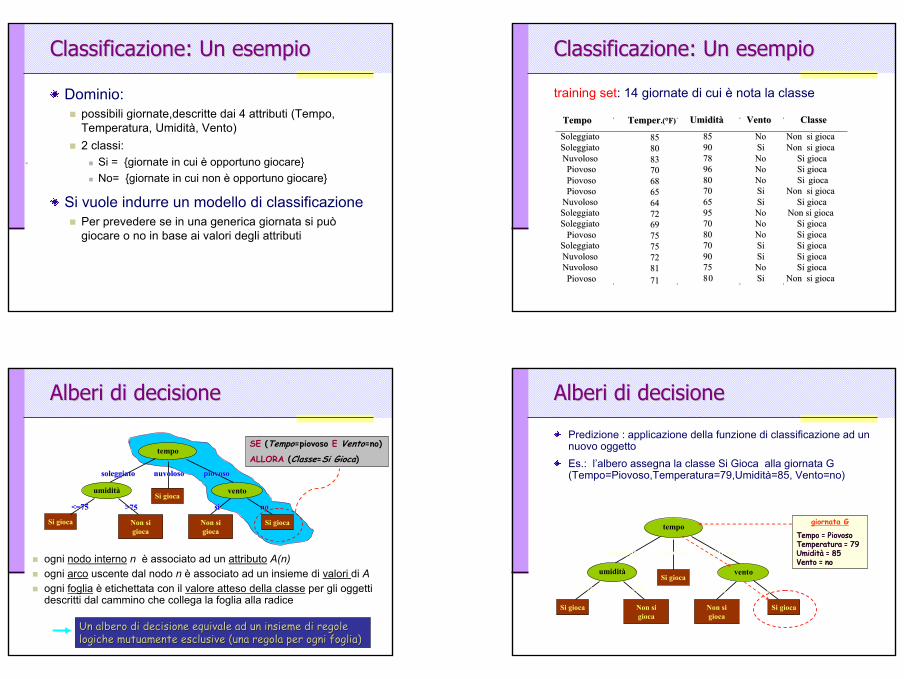
Classificazione: Un esempio Classificazione: Un esempio
Dominio: possibili giornate,descritte dai 4 attributi (Tempo, Temperatura, Umidità, Vento) 2 classi:
Si = {giornate in cui è opportuno giocare}No= {giornate in cui non è opportuno giocare}
Si vuole indurre un modello di classificazionePer prevedere se in una generica giornata si può giocare o no in base ai valori degli attributi
Classificazione: Un esempioClassificazione: Un esempio
training set: 14 giornate di cui è nota la classe
Tempo Tempo TemperTemper.(.(°°F)F) UmiditUmiditàà VentoVento ClasseClasse
SoleggiatoSoleggiato 8585 8585 NoNo Non si giocaNon si giocaSoleggiatoSoleggiato 8080 9090 SiSi Non si giocaNon si giocaNuvolosoNuvoloso 8383 7878 NoNo Si giocaSi giocaPiovosoPiovoso 7070 9696 NoNo Si giocaSi giocaPiovosoPiovoso 6868 8080 NoNo Si Si giocagiocaPiovosoPiovoso 6565 7070 SiSi Non si giocaNon si gioca
NuvolosoNuvoloso 6464 6565 SiSi Si giocaSi giocaSoleggiatoSoleggiato 7272 9595 NoNo Non si giocaNon si giocaSoleggiatoSoleggiato 6969 7070 NoNo Si giocaSi gioca
PiovosoPiovoso 7575 8080 NoNo Si giocaSi giocaSoleggiatoSoleggiato 7575 7070 SiSi Si giocaSi giocaNuvolosoNuvoloso 7272 9090 SiSi Si giocaSi giocaNuvolosoNuvoloso 8181 7575 NoNo Si giocaSi giocaPiovosoPiovoso 7171 8800 SiSi Non si giocaNon si gioca
Alberi di decisione Alberi di decisione
ogni nodo interno n è associato ad un attributo A(n)ogni arco uscente dal nodo n è associato ad un insieme di valori di Aogni foglia è etichettata con il valore atteso della classe per gli oggetti descritti dal cammino che collega la foglia alla radice
SE (Tempo=piovoso E Vento=no) ALLORA (Classe=Si Gioca)
Si gioca
tempo
umidità vento
soleggiatosoleggiato nuvolosonuvoloso piovosopiovoso
<=75<=75 >75>75 ssìì nonoSi gioca
Si giocaNon si gioca
Non si gioca
Un albero di decisione equivale ad un insieme di regole Un albero di decisione equivale ad un insieme di regole logiche mutuamente esclusive (logiche mutuamente esclusive (una regola per ogni foglia)una regola per ogni foglia)
tempo
umidità vento
soleggiato nuvoloso piovoso
<=75 >75 sì noSi gioca
Si gioca Si giocaNon si gioca
Non si gioca
giornata G
Tempo = Piovoso Tempo = Piovoso Temperatura = 79 Temperatura = 79 UmiditUmiditàà = 85 = 85 Vento = noVento = no
Alberi di decisione Alberi di decisione
Predizione : applicazione della funzione di classificazione ad un nuovo oggetto Es.: l’albero assegna la classe Si Gioca alla giornata G (Tempo=Piovoso,Temperatura=79,Umidità=85, Vento=no)

Algoritmi di induzione di alberi di Algoritmi di induzione di alberi di decisione: storiadecisione: storia
Algoritmi sviluppati indipendentemente negli anni 60 e 70 da ricercatori di:
Statistica: L. Breiman & J. Friedman - CART (Classification and Regression Trees)
Pattern Recognition: Univ. Michigan - AID G.V. Kass - CHAID (Chi-squared Automated Interaction Detection)
Intelligenza Artificiale e Teoria dell’Informazione: R. Quinlan - ID3 (Iterative Dichotomizer)R. Quinlan - C4.5
Indurre un albero di decisioneIndurre un albero di decisione
Dati: Un insieme di esempi con classi negative e positive
Problema: Generare un modello ad albero di decisione per classificare un insieme separato di esempi con un errore minimale
Approccio: (Occam’s Razor) produrre il modello più semplice che sia consistente con gli esempi di trainingFormalmente: Trovare l’albero più semplice in assoluto è un problema intrattabile
Come produrre un albero ottimale?Come produrre un albero ottimale?
Strategia (euristica): sviluppa l’albero in maniera top-down piazza la variabile di test più importante alla radice di ogni sottoalbero successivo
La variabile più importante:La variabile che ha la maggiore attendibilità nel distinguere l’insieme degli esempi di trainingla variabile che ha la relazione più significativa con l’attributo targetalla quale il risultato sia dipendente più che per le altre (o meno indipendente)
Schema per lSchema per l’’induzione di alberi induzione di alberi (usato, e.g., in (usato, e.g., in ID3ID3 e e J48J48))
Costruzione top-down dell’albero, per partizionamentisuccessivi:1. Crea il nodo radice e assegnagli tutto il training-set2. Per il nodo corrente:
• se tutti gli esempi del nodo corrente hanno la stessa classe C, etichetta tale nodo (foglia) con C e stop
• per ogni possibile test di partizionamento (test di splitting) valuta una misura di “rilevanza” (indice di splitting)
• sui gruppi ottenuti partizionando l’insieme di esempi del nodo sulla base del test
• associa al nodo l’attributo che massimizza l’indice di splitting• per ogni valore del test di splitting crea un nodo figlio
etichetta l’arco corrispondente con la condizione di split ed assegna al nodo figlio gli esempi che verificano tale condizione
3. Per ogni nuovo nodo creato ripeti il passo 2
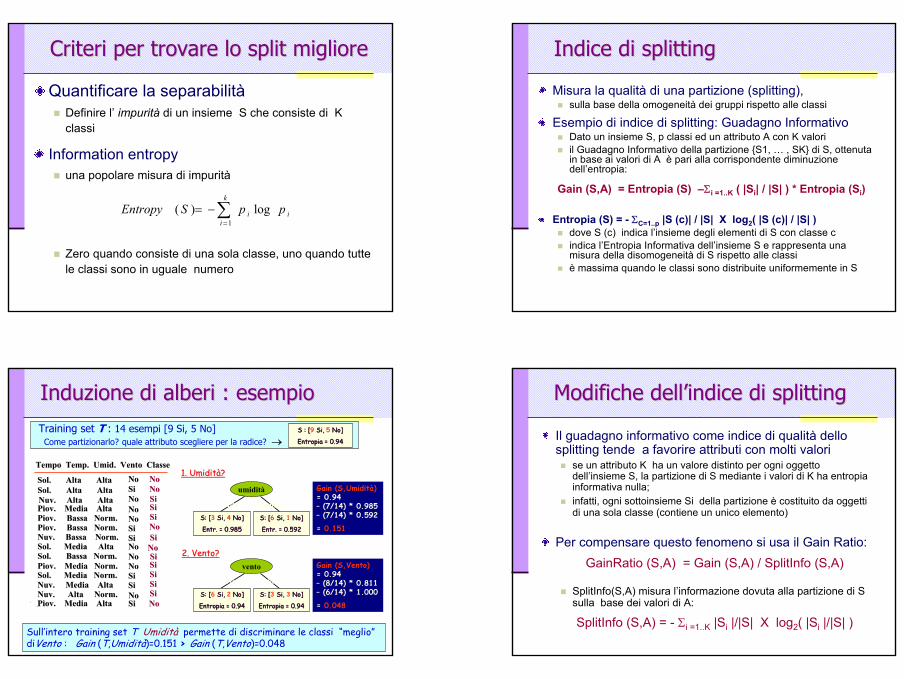
CriteriCriteri per trovare lo splitper trovare lo split miglioremigliore
Quantificare la separabilitàDefinire l’ impurità di un insieme S che consiste di K classi
Information entropyuna popolare misura di impurità
Zero quando consiste di una sola classe, uno quando tutte le classi sono in uguale numero
∑=
−=k
iii ppSEntropy
1log)(
Indice di Indice di splittingsplitting
Misura la qualità di una partizione (splitting), sulla base della omogeneità dei gruppi rispetto alle classi
Esempio di indice di splitting: Guadagno Informativo Dato un insieme S, p classi ed un attributo A con K valori il Guadagno Informativo della partizione {S1, … , SK} di S, ottenuta in base ai valori di A è pari alla corrispondente diminuzione dell’entropia:
Gain (S,A) = Entropia (S) –Σi =1..K ( |Si| / |S| ) * Entropia (Si)
Entropia (S) = - ΣC=1..p |S (c)| / |S| X log2( |S (c)| / |S| )dove S (c) indica l’insieme degli elementi di S con classe cindica l’Entropia Informativa dell’insieme S e rappresenta una misura della disomogeneità di S rispetto alle classi è massima quando le classi sono distribuite uniformemente in S
Training set T : 14 esempi [9 Si, 5 No]Come partizionarlo? quale attributo scegliere per la radice? →
Induzione di alberi : esempioInduzione di alberi : esempio
Tempo Tempo TempTemp. . UmidUmid. Vento Classe. Vento Classe
Sol.Sol. AltaAlta AltaAlta NoNo NoNoSol. Alta Alta Sol. Alta Alta SiSi NoNoNuvNuv. Alta Alta. Alta Alta NoNo SiSiPiovPiov. Media Alta. Media Alta NoNo SiSiPiovPiov. Bassa . Bassa NormNorm.. NoNo Si Si PiovPiov. Bassa . Bassa NormNorm.. SiSi NoNoNuvNuv. Bassa . Bassa NormNorm.. SiSi SiSiSol. Media AltaSol. Media Alta NoNo NoNoSol. Bassa Sol. Bassa NormNorm.. NoNo SiSiPiovPiov. Media . Media NormNorm.. NoNo SiSiSol. Media Sol. Media NormNorm.. SiSi SiSiNuvNuv. Media Alta. Media Alta SiSi SiSiNuvNuv. Alta . Alta NormNorm.. NoNo SiSiPiovPiov. Media Alta. Media Alta SiSi NoNo
S : [S : [9 Si, Si, 5 No]No]
Entropia = 0.94Entropia = 0.94
Sull’intero training set T Umidità permette di discriminare le classi “meglio”diVento : Gain (T,Umidità)=0.151 > Gain (T,Vento)=0.048
umidità
Alta NormaleS: [S: [3 Si, Si, 4 No]No]
EntrEntr. = 0.985. = 0.985S: [S: [6 Si, Si, 1 No]No]
EntrEntr. = 0.592. = 0.592
Gain (S,Umidità) = 0.94 – (7/14) * 0.985 – (7/14) * 0.592
= 0.151
1. Umidit1. Umiditàà??
vento
No SiS: [S: [6 Si, Si, 2 No]No]
Entropia = 0.94Entropia = 0.94
S: [S: [3 Si, Si, 3 No]No]
Entropia = 0.94Entropia = 0.94
Gain (S,Vento)= 0.94 – (8/14) * 0.811 – (6/14) * 1.000
= 0.048
2. Vento?2. Vento?
Modifiche dellModifiche dell’’indice di indice di splittingsplitting
Il guadagno informativo come indice di qualità dello splitting tende a favorire attributi con molti valori
se un attributo K ha un valore distinto per ogni oggetto dell’insieme S, la partizione di S mediante i valori di K ha entropiainformativa nulla; infatti, ogni sottoinsieme Si della partizione è costituito da oggetti di una sola classe (contiene un unico elemento)
Per compensare questo fenomeno si usa il Gain Ratio:GainRatio (S,A) = Gain (S,A) / SplitInfo (S,A)
SplitInfo(S,A) misura l’informazione dovuta alla partizione di S sulla base dei valori di A:
SplitInfo (S,A) = - Σi =1..K |Si |/|S| X log2( |Si |/|S| )
OverfittingOverfitting
Overfitting: sovradattamento al training setIl modello classifica bene gli esempi da cui è stato indotto ma non è capace di classificare correttamente altri oggetti del dominio (è troppo adattato agli esempi usati)
Alberi troppo grandi sono:poco comprensibili spesso soffrono di overfitting
Fondamento “filosofico” → Rasoio di Ockham:
“Ipotesi troppo complicate sono poco probabili”
(le spiegazioni più semplici sono spesso quelle esatte)
Ricerca dellRicerca dell’’albero della albero della ““giusta tagliagiusta taglia””
Arresto della crescita dell’albero durante la fase di costruzione (pre-pruning)
sulla base di un criterio di significatività degli splitting: soglia minima per il numero di oggetti dei nodi generati soglia minima per il valore dell’indice di splitting (riduzione del disordine)
Pruning (potatura): dopo aver costruito l’albero si eliminano i sotto-alberi che non contribuiscono all’accuratezza sul dominio,
sostituendoli con una foglia (subtree replacement) oppure con un loro sotto-albero (subtree racing).
L’accuratezza sul dominio degli alberi considerati nella fase di pruning può essere stimata
mediante cross-validationoppure riservando una porzione del training set per il test (es:reduced error pruning)
Altre tecniche di apprendimentoAltre tecniche di apprendimento
Instance-base learning
Support Vector Machines
Reti neurali
Algoritmi genetici
InstanceInstance--BasedBased LearningLearning
Idea: Il processo di apprendimento si riduce alla memorizzazione degli esempi (Lazy learning)La generalizzazione viene ottenuta a tempo di classificazione (regressione) interpolando secondo una “qualche regola”Algoritmi: K-NN, RBFN, Locally weighted regression, …
k-Nearest Neighbor (k-NN)E’ definito in termini di una funzione di (dis)similaritàIl valore della funzione target è assegnato sulla base dei valori dei K esempi più vicini
Per funzioni reali (regressione), il valore medio nel vicinatoPer funzioni discrete (classificazione), il valore più frequente
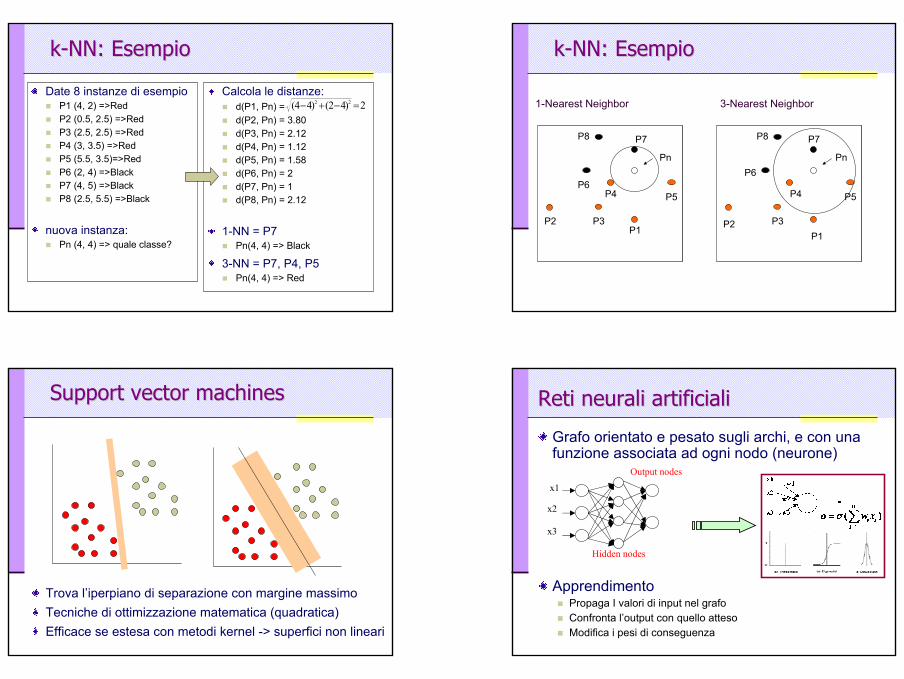
kk--NN: NN: EsempioEsempio
Date 8 instanze di esempioP1 (4, 2) =>RedP2 (0.5, 2.5) =>RedP3 (2.5, 2.5) =>RedP4 (3, 3.5) =>RedP5 (5.5, 3.5)=>RedP6 (2, 4) =>BlackP7 (4, 5) =>BlackP8 (2.5, 5.5) =>Black
nuova instanza:Pn (4, 4) => quale classe?
Calcola le distanze:d(P1, Pn) = d(P2, Pn) = 3.80d(P3, Pn) = 2.12d(P4, Pn) = 1.12d(P5, Pn) = 1.58d(P6, Pn) = 2d(P7, Pn) = 1d(P8, Pn) = 2.12
1-NN = P7Pn(4, 4) => Black
3-NN = P7, P4, P5Pn(4, 4) => Red
2)42()44( 22 =−+−
kk--NN: NN: EsempioEsempio
1-Nearest Neighbor 3-Nearest Neighbor
P1P2 P3
P4 P5P6
P7P8
Pn
P1P2 P3
P4 P5
P6
P7P8
Pn
Support vector machinesSupport vector machines
Trova l’iperpiano di separazione con margine massimoTecniche di ottimizzazione matematica (quadratica)Efficace se estesa con metodi kernel -> superfici non lineari
RetiReti neuralineurali artificialiartificiali
Grafo orientato e pesato sugli archi, e con una funzione associata ad ogni nodo (neurone)
ApprendimentoPropaga I valori di input nel grafoConfronta l’output con quello attesoModifica i pesi di conseguenza
Hidden nodes
Output nodes
x1
x2
x3
RetiReti neuralineurali artificialiartificiali
Contro:
- Bisogna indicare la giusta topologiadela rete
- Lunghi tempi di apprendimento
- Difficile interpretazione (black-box)
- Overfitting
Pro:
+ “complesse” superfici diseparazione (non lineari)
+ predizione veloce
+ possono gestire molti attributi
Migliorare lMigliorare l’’accuratezzaaccuratezza
Come si può migliorare Come si può migliorare ll’’accuratezza di accuratezza di classificaclassificazzionionee??Cambiare schema/parametriModificare l’ input (Data processing) :
Attribute selectionData cleaning
Sostituire i valori mancanti, rimuovere gli outliers, correggere errori,…
Data transformationNormalizzare i valori, discretizzare gli attributi numerici, transformare gli attributi nominali/numerici in boolean, …
…
Modificare l’output:Meta-classificazione
MetaMeta--classificazioneclassificazione
Genera un insieme di classificatori, (M1,…, MT) e ne combina le funzioni di classificazione (m1,…, mT) per definire una funzione di classificazione complessiva mF
E’ uno schema di meta-learning: utilizza un altro algoritmo di induzione (base learner) per costruire i classificatori componenti
m1(x)M1
M2
MT
xm2(x)
mT(x)mF (x)





























