Embed Size (px)
Citation preview

1 | © by Xantaro
LARGE SCALE IP ROUTINGLECTURE BY SEBASTIAN GRAF
MODULE 1 : INTRODUCTION TO ROUTER ARCHITECTURES

2 | © by Xantaro
Introduction to your lector
§ Sebastian Graf§ Born 1981 in Cologne, currently living in Friedberg (Hessen)§ Education: Dipl. - Ing (BA) @ Berufsakademie Mannheim in 2004 (nowadays called “Duale
Hochschule Baden-Württemberg”)§ Current Position:
► Solution Architect for IP/MPLS Core and Access Networks @ Xantaro Deutschland GmbH
§ Former Positions:► Professional Services Consultant @ Xantaro Deutschland GmbH► Customer VPN Configuration Specialist @ British Telecom Global Services► Data Engineer @ British Telecom Global Services► BA Student @ CSC Managed Services GmbH

3 | © by Xantaro
Some words about my employer
§ Xantaro § is a vendor-independent Service Integrator focused on
► Carrier-Class Networks► Value Added Services► Cloud Infrastructures► Orchestration
§ was founded in 2007 with < 20 people in Hamburg§ today has more than 120 employees, of which roughly 50% have a technical focus /
background§ has offices in Hamburg, Frankfurt, Cologne, Munich and London§ is constantly looking for new colleagues
§ For more information visit www.xantaro.net

4 | © by Xantaro
Prerequisites
§ This lecture builds upon the lecture networks and requires you to understand the general concepts of:§ IP Version 4 Address Structure and Subnetting§ General concepts of dynamic routing protocols§ Properties of link-state routing protocols§ Shortest Path calculation with Dijkstra§ Longest Prefix Match (LPM) with overlapping networks
§ If I talk about unknown protocols or technologies, raise your hand§ While explaining the building blocks of routers you will see some pictures of Juniper
Networks. This serves as an example, there are other vendors with similar components

5 | © by Xantaro
What we will do in this course
§ Learn the theory behind
§ Modern Router Architectures
§ Intermediate System to Intermediate System (ISIS) Routing Protocol
§ Border Gateway Protocol (BGP)
§ Multiprotocol Label Switching (MPLS)
§ Label Distribution Protocol (LDP)
§ Resource Reservation Protocol (RSVP)
§ MPLS based VPN Services
§ Traffic Engineering
§ Practical implementation of a service provider network with the technologies above using Juniper Networks Operating System (JUNOS)
§ we will built a few independent service providers who peer with each other and the rest of the (simulated) global Internet
► RFC1925 Section 2.4: “Some things in life can never be fully appreciated nor understood unless experienced firsthand. Some things in networking can never be fully understood by someone who neither builds commercial networking equipment nor runs an operational network.”

6 | © by Xantaro
Recap what is a router?
§ definition from Wikipedia:§ A router is a networking device that forwards data packets between computer networks.
Routers perform the traffic directing functions on the Internet. A data packet is typically forwarded from one router to another router through the networks that constitute the internetwork until it reaches its destination node.
§ probably most of you have one at home§ Fritz!Box, Speedport or similar
§ as you will see throughout this course there are various properties according to which a router may be classified like:§ forwarding performance§ supported protocols§ power consumption§ operating system

7 | © by Xantaro
Router or Layer 3 Switch?
§ Switches work at Layer 2 of the OSI model and forward frames based on mac addresses§ simple operation that can be done in a hash-table or CAM
§ mac addresses are always of fixed length (48 bits)
§ there is no overlapping, there is either one possible hit or none (which usually means that the MAC is unknown and the packet needs to be flooded)
§ Routers operate at Layer 3 of the OSI model and forward packets based on IP addresses§ more complex operation due to overlapping network addresses
§ longest prefix lookup solves the problem of multiple possible actions
§ subnet masks can have different length (in the Internet from /8 to /24 for IPv4, /19 to /48 for IPv6)
§ The term Layer 3 Switch is used to describe a device that is able to§ do wirespeed layer 2 switching
§ have the possibility to do forwarding based on layer 3 information and have additional capabilities usually found in routers
§ unfortunately no standard description, always be careful with layer 3 features on these devices

8 | © by Xantaro
Comparing apples and oranges
§ AVM Fritzbox 7490 § Juniper MX2020
picture by AVM: https://avm.de/produkte/fritzbox/fritzbox-7490/
picture by Juniper: http://www.juniper.net/us/en/company/press-center/images/image-library/mx2020/

9 | © by Xantaro
Technical specifications
§ Both systems do similar tasks, but at different scale§ RFC1925 Section 2.10: “One size never fits all”
Fritz!Box 7490 Juniper MX2020
Forwarding Performance (Routing) ~ 1 Gbit/s (without NAT) 32 Tbit/s (as of March 2017)
Number of Ethernet Interfaces 4 x 1 Gbit/s, Wifi 1920 x 10 Gbit/s, or480 x 40 Gbit/s, or320 x 100 Gbit/s*
Physical Dimensions (H /W / D) in cm 5,5 / 24,5 / 17,5 200,00 / 48,26 / 91,95
Weight < 1kg ~690 kg*
Total Power Consumption 9,3 W 30 kW*
Power Consumption per 1 Gbit/s forwarding capacity
~ 9 W ~0,9 W
Redundancy none fully redundant
Price ~180€ depends how much you order at Juniper J
*depending on installed modules

10 | © by Xantaro
Dataplane vs. Controlplane
§ Whenever we take a closer look at routers, we have to look at two levels§ Controlplane
► discover network topology by running routing protocols like OSPF, ISIS or BGP► usually done with generic processors (e.g. Intel x86, ARM, Power PC)► processes exception traffic► computes forwarding table
§ Dataplane► forwards transit traffic from ingress interface to egress interface by performing a lookup► usually done with specialized networking processors► lookup typically based on layer 2 or layer 3 information► most vendors implement additional forwarding criteria matching of various headers► punts exception traffic towards controlplane- traffic that is destined to the router itself
- traffic that the dataplane does not understand
§ Different vendors may use different words to describe these two elements

11 | © by Xantaro
Control Plane
§ Runs the routers operating system§ Maintains the routing and forwarding table used by the router§ Based on one or more real-time operating system threads§ Provides forwarding tables to the PFE
§ Controls and monitors the chassis§ Implements the command-line and network management interface§ Provides power control and system status monitoring
§ Manages and programs the dataplane§ Nowadays § usually use Intel Processors on high-end platforms§ have up to 64GB of RAM§ use SSD for storage§ rely on Linux or Unix based operating system with custom packages for routing

12 | © by Xantaro
Operation of the controlplane
§ Usually, a router will receive routes from other routers and store these locally in a RIB-in table (RIB = Routing Information Base)
§ multiple RIB-in tables can exist depending on the number and type of protocols and neighboring routers
§ the same prefix may be received by multiple neighbors / protocols§ only best path will be placed into RIB-local and advertised to other routers via RIB-out§ routing policies can be used to alter the default router OS / protocol behavior
§ typically, a router will only store a route once in the RIB-in and work with pointers in RIB-local and RIB-out
RIB-in (1)
RIB-in (2)
RIB-in (n)
RIB-out (1)
RIB-out (2)
RIB-out (n)
RIB-local
best-path decision update neighbors

13 | © by Xantaro
Operation of the controlplane 2
§ The example below shows a typical scenario§ the same Prefix A (be it IPv4 or IPv6) is received from multiple neighbors§ our local router makes a decision which of these RIB entries is best (in this case the blue)§ the RIB entry that was selected as best route is passed to other neighbor routers
§ This way of operation is called “routing by rumor”§ local routing decision based on second-hand information from direct peers§ typical approach that is done by distance vector protocols (like RIP) or path-vector protocols
(like BGP)
§ link-state protocols like IS-IS and OSPF work a bit different as they use a link-state database for exchanging topology information
Prefix A
Prefix A
Prefix A
Prefix A
Prefix A
Prefix A
Prefix A
best-path decision update neighbors
14 | © by Xantaro
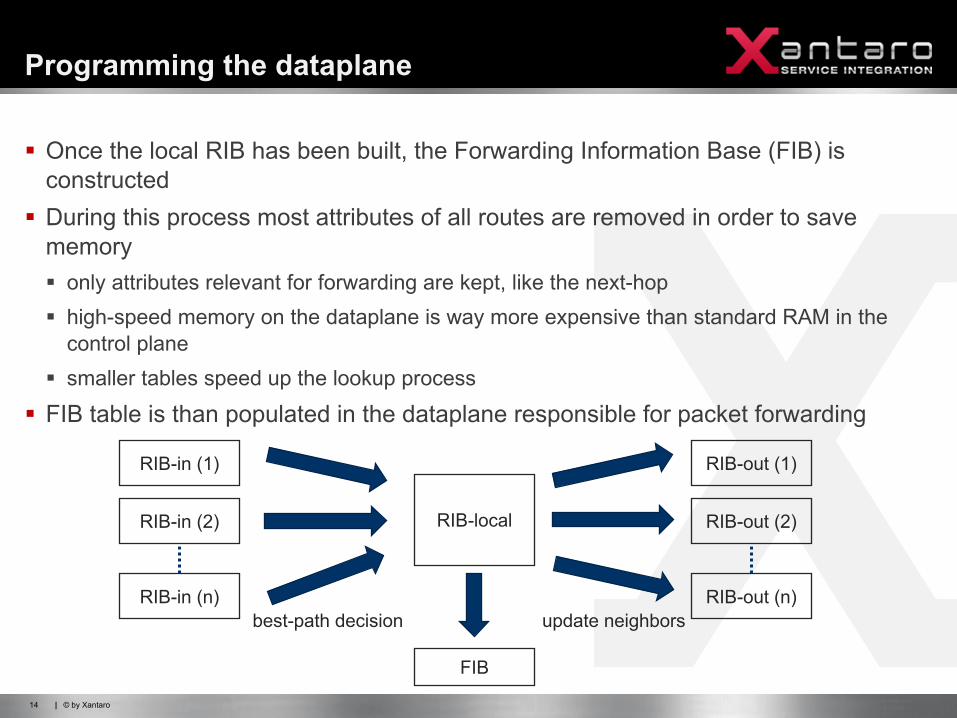
Programming the dataplane
§ Once the local RIB has been built, the Forwarding Information Base (FIB) is constructed
§ During this process most attributes of all routes are removed in order to save memory§ only attributes relevant for forwarding are kept, like the next-hop§ high-speed memory on the dataplane is way more expensive than standard RAM in the
control plane§ smaller tables speed up the lookup process
§ FIB table is than populated in the dataplane responsible for packet forwarding
RIB-in (1)
RIB-in (2)
RIB-in (n)
RIB-out (1)
RIB-out (2)
RIB-out (n)
RIB-local
best-path decision update neighbors
FIB

15 | © by Xantaro
Strategies for updating the FIB
§ FIB tables of an Internet Core router are needing constant updates§ time between receiving an update and changing the FIB entry needs to be as small
as possible§ basic task workflow is§ Update received by Routing Protocol§ Update the RIB-IN § Calculate the best-paths to update the RIB-local§ Calculate new FIB
► remove route attributes that are not needed for forwarding► construct table architecture that is understood by dataplane► download FIB to dataplane
§ The last point is more complex as it seems. What happens if the dataplane tries to read the FIB while it is written, if the memory would allow it at all?
§ All actions need to be completed in milliseconds, before the next update arrives in the RIB-IN

16 | © by Xantaro
Updating the FIB – pause forwarding
§ the most simple approach is to § stop forwarding an buffer the packets on the ingress interface§ reprogram the FIB with new information§ resume forwarding
§ effectively prevents problems while the FIB is in a transient state§ old FIB was consistent§ new FIB is consistent
§ Obviously this approach is quite poor in it’s design as buffers are quite expensive and will not be able to store all incoming packets on a reasonable saturated link
§ creates a lot of latency during transient state§ Internet core routers are constantly getting routing updates
time
stop forwarding
program new FIB
resume forwarding
broken forwarding

17 | © by Xantaro
Updating the FIB – paging
§ very simple approach§ download the new FIB into separate memory area§ once finished, instruct the dataplane to switch to new table
§ effectively prevents traffic drops while downloading the new table§ still has serious drawbacks§ double amount of memory is needed (expensive on the dataplane)§ the complete FIB needs to be recalculated, even if only a single entry was changed
§ typically you have multiple options for optimization for data storage§ optimize for size by using compression algorithms§ optimize for performance (e.g. by using no compression)
§ RFC1925 Section 2.7a: “Good, Fast, Cheap: Pick any two (you can’t have all three)”
time
program FIB table 2
switch to new FIB

18 | © by Xantaro
Updating the FIB – atomic updates
§ Focus data structure on being update friendly
§ Updated portion of the forwarding table is created separately from active table§ similar to paging, but this time not for the
complete FIB
§ New portion is stitched into live table§ Single atomic operation§ Done in one clock cycle

19 | © by Xantaro
Routing in the early days
§ Routers were built using general purpose workstations running Unix§ Single CPU that was in charge of§ Controlplane (Routing)§ Dataplane (Forwarding)
§ Both functions compete for the same processing capacity (no multicore CPUs!)§ Transient conditions like topology changes stress both functions at the same time§ forwarding capacity can reduce depending on control-plane usage§ control plane might not be able to respond to hello packets from neighbor routers in time
► neighbor declared dead causing even more instability► increased probability of network meltdowns
§ Nowadays a trend to bring back packet forwarding on x86 hardware (Network Function Virtualization NFV)§ RFC1925 Section 2.11: “Every old idea will be proposed again with a different name and a
different presentation, regardless of whether it works.”

20 | © by Xantaro
Purpose-built routing hardware
§ The first purpose built routing hardware still used the same concept as before, but on purpose built hardware§ passive linecards provided interface connectivity and forwarder all packets to central processor
for lookup process
§ every packet travels the bus twice, even if ingress and egress interface are on the same linecard
§ still no clear separation of control and dataplane
§ central processor becomes bottleneck
§ putting more performance to the central processor masked architectural problems but could not solve them
► RFC1925 Section 2.3: “With sufficient thrust, pigs fly just fine. However, this is not necessarily a good idea. It is hard to be sure where they are going to land, and it could be dangerous sitting under them as they fly overhead.”
Passive Linecard 1
Passive Linecard 2
Passive Linecard N
Central processor
Interconnection bus like PCI

21 | © by Xantaro
Distributed forwarding
§ Lessons learned from the early days resulted in a strict separation of Control and Data Plane§ control processor maintains routing table and constructs primary copy of forwarding table§ forwarding table is downloaded from the central processor to all linecards§ control processor on linecards receive the FIB and program the local ASICs accordingly§ ASICs on linecards copies packets from input interface to output interface using forwarding
table► packets might even be forwarded without ever touching the switch fabric► other packets are directly forwarded between linecards► central processor not involved in packet forwarding► each added linecard increases the total throughput of the system
ActiveLinecard 1
Active Linecard 2
Active Linecard N
Central Processor
Switch Fabric

22 | © by Xantaro
Operation on the dataplane for transit traffic
§ Once the FIB has been downloaded into the dataplane, forwarding of packets starts§ transit packets are processes only by the dataplane§ transit packets are packets that enter the router through one interface and exit to another
§ picture below shows very general building blocks§ vendors may add additional building blocks for specific tasks such as
► Multicast► CoS/queuing► Firewall filtering► Accounting
§ Divide-and-conquer architecture§ Each block provides a piece of the forwarding puzzle
FIB
Ingress Interface Lookup Block Switch Fabric* Egress Queuing Egress Interface

23 | © by Xantaro
Distributed forwarding
§ often these platform are not even capable of forwarding traffic through the central processor (prohibited by design)§ huge speed difference: Linecards may have multiple 100Gbit/s ports, whereas link from
central processor to switch fabric is typically 1Gbit/s or 10Gbit/s
§ this architecture provides the following benefits§ no central point of congestion from forwarding perspective§ no competing of resources between control and forwarding§ central control plane can distribute control plane functions to the control processors of the
linecards► Generation of certain ICMP messages like TTL-expired or packet-to-big► ARP / ND processing► Generation of periodic hello messages from protocols like OSPF, ISIS or BFD► Fast-failover in case of failed links / neighbors- linecard may reroute the traffic even before the central processor is informed about the outage
- this can provide failover times below 50ms

24 | © by Xantaro
Operation on the dataplane for exception traffic
§ Packets are considered as exception traffic if they cannot be processed by the dataplane and have to be transmitted to the control plane for further processing
§ This may be because of§ packets arrive on interfaces that are destined to the router itself, like BGP traffic or incoming
SSH connections§ packets cannot be transmitted because no ARP entry is present for next-hop (aka. as RE
punting which is usually not done on modern platforms)§ a special operation is required to the packet and the ASIC of the dataplane is not able to
perform that
§ Typically there is a dedicated link between controlplane and dataplane for that purpose
FIB
Ingress Interface Lookup Block Switch Fabric* Egress Queuing Egress Interface
Controlplane

25 | © by Xantaro
Architecure of a modern carrier class router
§ The following pages describe how a typical carrier class routing system is built these days
§ While different vendors tend to use different names for the components of their products, you will recognize the same building blocks
§ The following components are usually found§ Chassis§ Midplane§ Control Board§ Linecard§ Switchfabric

26 | © by Xantaro
Router Chassis
§ Housing for all other components § provides power to all other components, usually by redundant hot-plugable power
supplies§ provides cooling to active components with redundant FANs§ different options for airflow depending on vendor specific implementation
► side-to-side (sometimes problematic in datacenters with hot aisle / cold aisle layout)► back-to-front► front-to-back
§ Typically rather cheap component of the overall system

27 | © by Xantaro
Midplane
§ The midplane is usually a passive element that§ distributes power from power supplies to active components§ provides communication paths (copper lanes) between switch fabric and linecards
§ Can become a bottleneck for future upgrades§ some platforms use a midplane-less design to prevent bottlenecks § horizontal linecards inserted in the front directly connect to vertical switchboards inserted
from the back
Midplane of Juniper MX960 Router picture by Juniper: midplane-less Chassis of QFX10008

28 | © by Xantaro
Control Board
§ Made of components you would see on servers or embedded systems
§ typically not very expensive compared to the overall system
§ performance of the control board is§ not related to system throughput§ determining the number of Routing
Sessions and routing table size, a system can hold
§ Usually runs some kind of Unix or Linux based operating system
§ High end systems usually have 2 of them for redundancy purposes picture by Juniper: RE-S-1800x4-16G

29 | © by Xantaro
Switch Fabric
§ Switch Fabrics provide § high speed connections between linecards§ communication paths between central processor and linecards
§ usually not very expensive§ high end systems have multiple switch fabric for redundancy purposes§ common redundancy schemes are
► 1:1- 2 boards are installed. One of these boards can fail without causing performance degradation
► N:0- N boards are installed. If one of these boards fails, all linecards can continue to communicate, but
only with reduced capacity towards the switch fabric (e.g. 50% if N=2)
► N:1- N boards are installed. One board is working as hot standby and will be made active if another
board fails. No performance degradation in case of a failure
§ no picture here, as they look quite boring

30 | © by Xantaro
Linecards
§ Linecards are typically the most expensive part of a system§ equipped with a control processor for communication with the central processor§ contain ASICs for packet forwarding§ proprietary chipsets developed by the vendor of the linecard§ off the shelf chipsets developed by OEM manufactures like Broadcom
§ use switch fabric to connect with other linecards and central processor§ provide Interface connectivity§ consume most power used by a modern router system§ multiple cards in a single chassis provide redundancy
picture by Juniper: MPC5E-40G10G

31 | © by Xantaro
Dataplane ASICs – custom versus off-the-shelf
§ Developing a new network chipset is a huge invest even for companies like Cisco or Juniper§ also a big financial risk
§ When a network vendor develops an own network chip, the actual production is still done by external companies
§ Decision whether to develop a new chipset or take an OEM chipset could be influenced by§ time to market § packet throughput and interface types § features required on the chip (with introduction and later) § target price
§ Examples for OEM chipset manufactures are:§ Broadcom, Mellanox, Marvel, EZChip, Microsemi and Cavium§ each with their own focus market

32 | © by Xantaro
One ASIC to rule them all
§ Using OEM chipsets makes it hard to differentiate a product§ for the network vendor as well as for the customer§ characteristics of the dataplane are the same for all products that use the same chip§ controlplane is still vendor specific
§ Some vendors are “creative” in overcoming limitations of the OEM chipset§ this can be beneficial and dangerous at the same time, as features might not work at
linerate speed
Source: http://etherealmind.com/merchant-silicon-vendor-software-rise-lost-opportunity/

33 | © by Xantaro
Arguments for both sides
§ taken from http://etherealmind.com/analysis-merchant-custom-silicon/
§ Arguments for custom silicon§ “We have our specialist engineers who can custom design an ASIC and supporting chips
that are completely focused on the features needed to deliver Product X. As a result, our designs are purposefully built to be faster, better etc. Our prices are more expensive because our products are faster and more focused and because our costs are higher”
§ Arguments for off the shelf silicon (merchant silicon)§ “The levels of expertise required to design and build a silicon chip is very high. It requires
specific skills, tools, and high levels of expertise. If your core business is producing a networking device, then having your own silicon development is not core business. By relying on companies who specialize in silicon design and manufacture, we can focus on software and integration to deliver new and better features at a cheaper price.”

34 | © by Xantaro
Scaling a modern router chassis
§ Performance of Linecards § forwarding capacity in packets per second (pps)
► vendors like to give performance in bits/s but not all specify the average packet size► typical values these days 55Mpps to 2Bpps
§ number of routes supported (forwarding table)► typical values these days 2M to 10M entries
§ number of stateless firewall filter terms
§ Performance of Switchboards§ usually at least two per chassis§ identify the performance per linecard slot§ typical value these days 480 Gbit/s per slot to 2 Tbit/s per linecard slot
§ Performance of midplane§ some systems use midplane-less designs (switchfabric connect directly to linecards)
§ Performance of Control Plane more or less irrelevant for throughput

35 | © by Xantaro
Redundancy within networks
§ Redundancy is a very important characteristic of networks§ Problematic: It`s like an insurance: if nothing happens you spend money for nothing§ generally two approaches§ redundant network design where any device can fail
► design a network in a way that no device can be a single point of failure► no redundancy within a network device apart from power supplies which is usually not
expensive► hardware failures are recognized by neighboring routers and are causing convergence
§ redundancy within a router where any component can fail► important for critical services which are connected through a single router► hardware failures in the local system are not seen by the rest of the network, which
results in less topology changes and a more stable network- linecard failures will still cause links to drop which may result in convergence
§ usually networks are designed with a combination of both approaches
36 | © by Xantaro
Controlplane High Availability
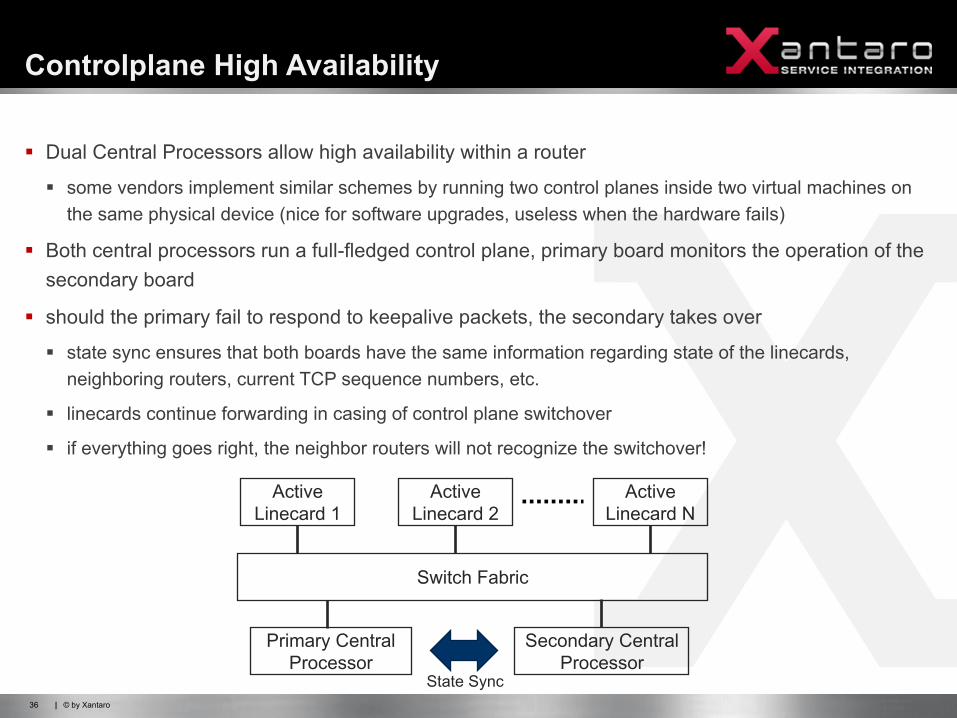
§ Dual Central Processors allow high availability within a router
§ some vendors implement similar schemes by running two control planes inside two virtual machines on the same physical device (nice for software upgrades, useless when the hardware fails)
§ Both central processors run a full-fledged control plane, primary board monitors the operation of the secondary board
§ should the primary fail to respond to keepalive packets, the secondary takes over
§ state sync ensures that both boards have the same information regarding state of the linecards, neighboring routers, current TCP sequence numbers, etc.
§ linecards continue forwarding in casing of control plane switchover
§ if everything goes right, the neighbor routers will not recognize the switchover!
ActiveLinecard 1
Active Linecard 2
Active Linecard N
Primary Central Processor
Switch Fabric
Secondary Central Processor
State Sync

37 | © by Xantaro
The fairy tale of nonstop software upgrades
§ WARNING: Your lecturer has a very personal opinion about this topic!
§ Having two independent control boards provides an interesting (in theory) option for software upgrades
§ Upgrade the software on the backup control board
§ wait for state-sync between boards
§ switchover from formerly active board (running old software) to the formerly backup board (running new software)
§ Upgrade software on the formerly active board
§ While this process looks nice in vendor presentations it has some challenges
§ Task replication between the same software versions is already complex, with different even more
§ at some point the microcode on the linecards has to be updated, while keeping all states in the FIB
► quite complex process that often causes issues during upgrades independent of vendor and platform
► never completely hitless, but in best case a dark window of just a few seconds or even less
§ Alternative upgrade process makes a hard switchover from active to backup, which causes packet drops as linecards make a warm reset
§ routing protocols allow to take a router out of traffic paths before doing the upgrade

38 | © by Xantaro
Software based forwarding with multiple cores
§ Multi-core capable processors and operating systems provide a new option for software based forwarding
§ Using dedicated CPU Cores for controlplane and forwarding plane can provide a cost-effective way of packet forwarding on low-end platforms
§ below is an example of a system with 2 quad core Intel CPUs
§ the blue core runs the operating system
§ the green core runs the router control plane
§ the red cores take care of packet forwarding
§ Performance may vary based on NUMA architecture
§ packets from PCI Express Bus 1 that must be routed to PCI Express Bus 2 need to cross QPI and are processed by 2 CPU cores
Network Card 1 2
3 4
5 6
7 8
QPI
Network Card
Network Card
Network Card
PCI Express Bus 1 PCI Express Bus 2
CPU 1 CPU 2

39 | © by Xantaro
IPv4 Internet Routing Table Size
§ As of April 2017, an Internet core router has to process around 650.000 unique IPv4 prefixes at least from one neighbor
picture by http://www.cidr-report.org

40 | © by Xantaro
IPv6 Internet Routing Table Size
§ As of April 2017, an Internet core router has to process around 38.000 unique IPv6 prefixes at least from one neighbor
picture by http://www.cidr-report.org

41 | © by Xantaro
Summary
§ Always Remember that routers are separated into control – and dataplane, even if it is not visible from the outside
§ Modern high-end routing platform are made of several components that make them highly available and scalable
§ You will see these building blocks from all vendors even if they use different names§ Reading RFCs is the best way to get familiar with networking technologies§ start with RFC1925, it is fun to read and true at the same time!

42 | © by Xantaro
Further Reading
§ The Twelve Networking Truths§ https://tools.ietf.org/pdf/rfc1925.pdf
§ Cisco Enterprise ASICs Discussion with Dave Zacks§ https://www.youtube.com/watch?v=TPrP4h13Oko§ (bit of Cisco marketing, but overall a very nice overview)





























