Embed Size (px)
Citation preview

Lecture10:MemorySystem--MemoryTechnology
CSE564ComputerArchitectureSummer2017
DepartmentofComputerScienceandEngineeringYonghongYan
[email protected]/~yan
1

TopicsforMemorySystems
• MemoryTechnologyandMetrics– SRAM,DRAM,Flash/SSD,3-DStackMemory,Phase-change
memory– LatencyandBandwidth,ErrorCorrecNon– Memorywall
• Cache– Cachebasics– Cacheperformanceandop@miza@on– Advancedop@miza@on– Mul@ple-levelcache,sharedandprivatecache,prefetching
• VirtualMemory– Protec@on,Virtualiza@on,andReloca@on– Page/segment,protec@on– AddressTransla@onandTLB
2

TopicsforMemorySystems
• Parallelism(tobediscussedinTLP)– MemoryConsistencymodel
• Instruc@onsforfence,etc– Cachecoherence– NUMAandfirsttouch– Transac@onalmemory(Notcovered)
• Implementa@on–(NotCovered)– SoTware/Hardwareinterface– Cache/memorycontroller– Bussystemsandinterconnect
3

Acknowledgement
• Basedonslidespreparedby:ProfessorDavidA.PaWersonComputerScience252,Fall1996,andeditedandpresentedbyProf.KurtKeutzerfor2000fromUCB
• SomeslidesareadaptedfromthetextbookslidesforComputerOrganiza@onandDesign,FiThEdi@on:TheHardware/SoTwareInterface
4
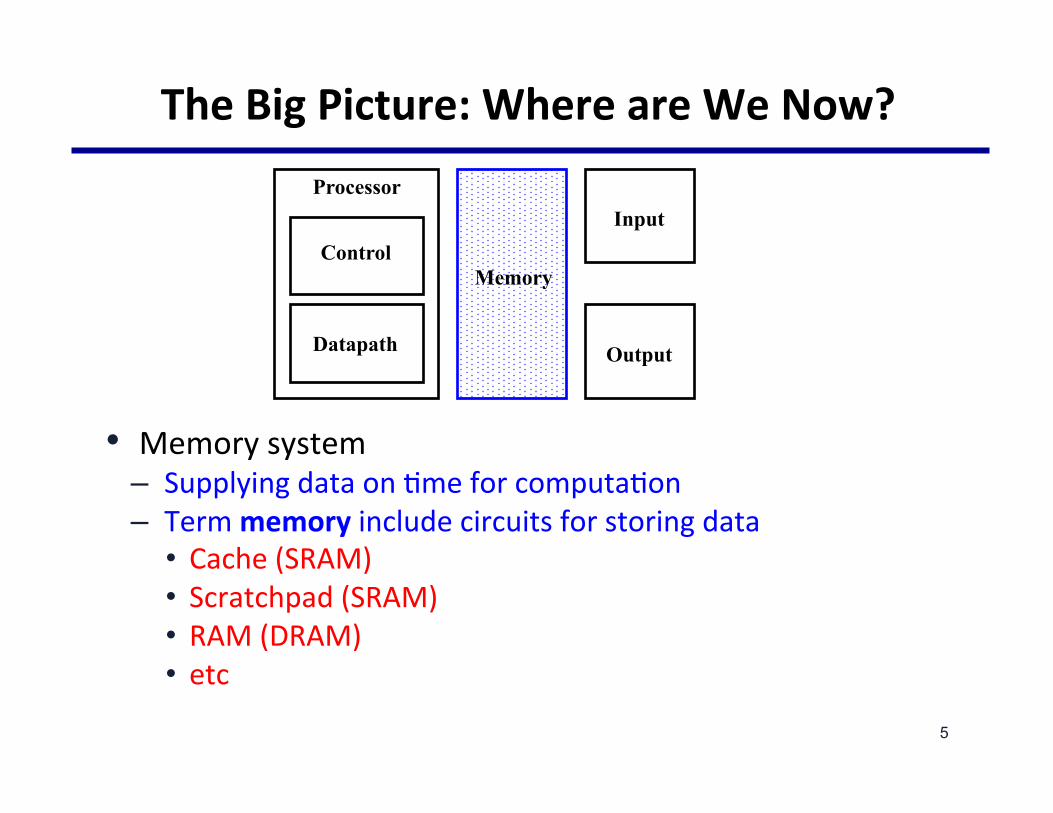
TheBigPicture:WhereareWeNow?
• Memorysystem– Supplyingdataon@meforcomputa@on– Termmemoryincludecircuitsforstoringdata
• Cache(SRAM)• Scratchpad(SRAM)• RAM(DRAM)• etc
Control
Datapath
Memory
Processor Input
Output
5
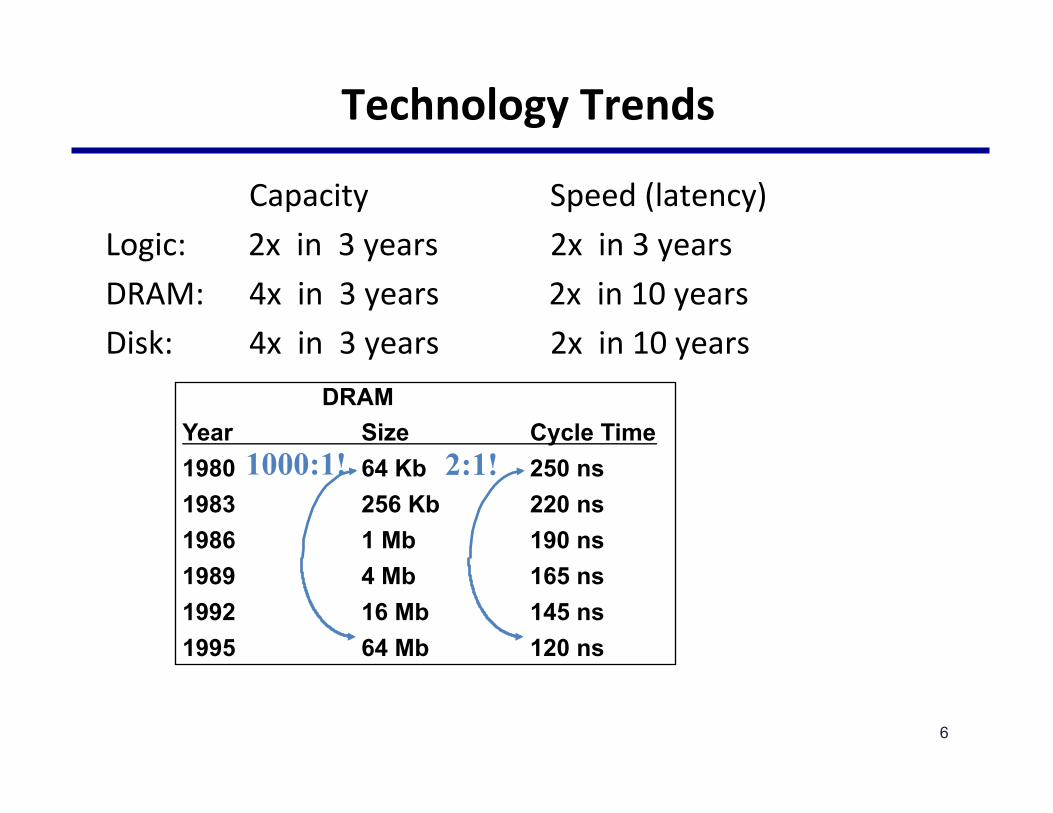
TechnologyTrends
Capacity Speed(latency)Logic: 2xin3years2xin3yearsDRAM: 4xin3years2xin10yearsDisk: 4xin3years2xin10years
DRAM Year Size Cycle Time 1980 64 Kb 250 ns 1983 256 Kb 220 ns 1986 1 Mb 190 ns 1989 4 Mb 165 ns 1992 16 Mb 145 ns 1995 64 Mb 120 ns
1000:1! 2:1!
6
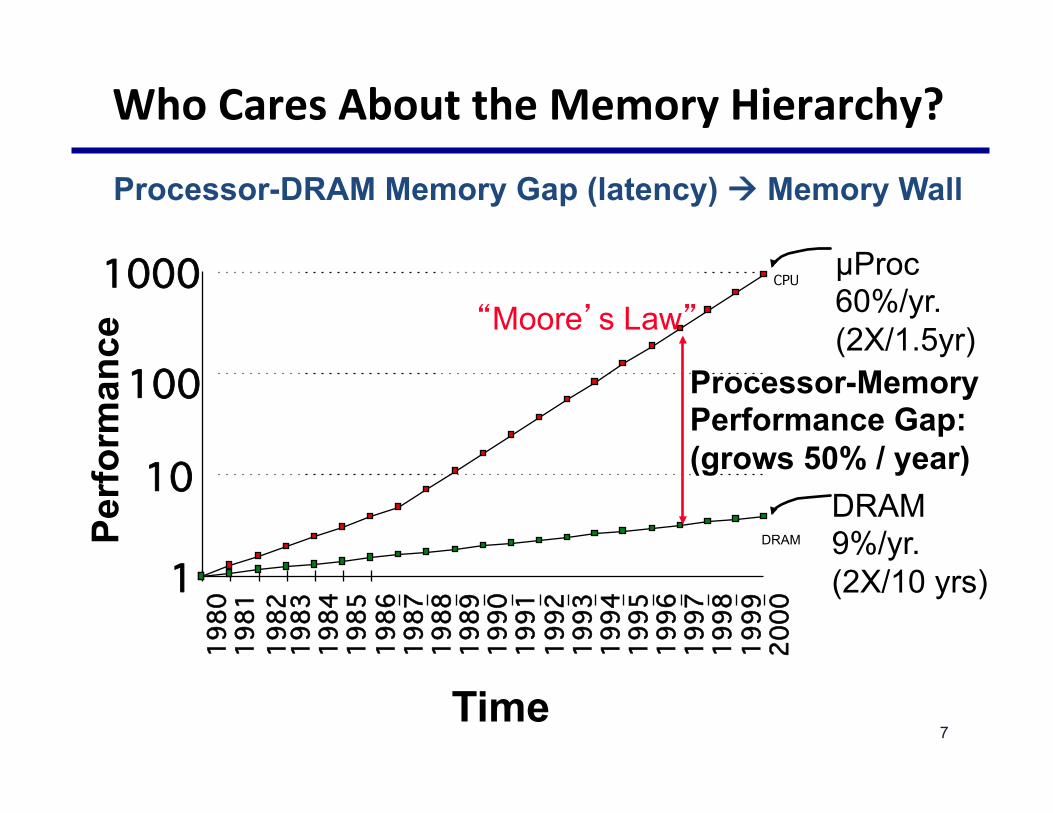
µProc 60%/yr. (2X/1.5yr)
DRAM 9%/yr. (2X/10 yrs) 1!
10!
100!
1000!19
80!
1981
!
1983
!19
84!
1985
!19
86!
1987
!19
88!
1989
!19
90!
1991
!19
92!
1993
!19
94!
1995
!19
96!
1997
!19
98!
1999
!20
00!
DRAM
CPU!19
82!
Processor-Memory Performance Gap: (grows 50% / year)
Perf
orm
ance
Time
�Moore�s Law�
Processor-DRAM Memory Gap (latency) à Memory Wall
WhoCaresAbouttheMemoryHierarchy?
7

TheSituaNon:Microprocessor
• Relyoncachestobridgegap• Microprocessor-DRAMperformancegap
– @meofafullcachemissininstruc@onsexecuted1stAlpha(7000): 340ns/5.0ns=68clksx2or 136instruc@ons
2ndAlpha(8400): 266ns/3.3ns=80clksx4or 320instruc@ons
3rdAlpha(t.b.d.): 180ns/1.7ns=108clksx6or 648instruc@ons
– 1/2Xlatencyx3Xclockratex3XInstr/clock⇒-5X
8

TheGoal:illusionoflarge,fast,cheapmemory
• Fact:Largememoriesareslow,fastmemoriesaresmall• Howdowecreateamemorythatislarge,cheapandfast(mostofthe@me)?– Hierarchy– Parallelism
9
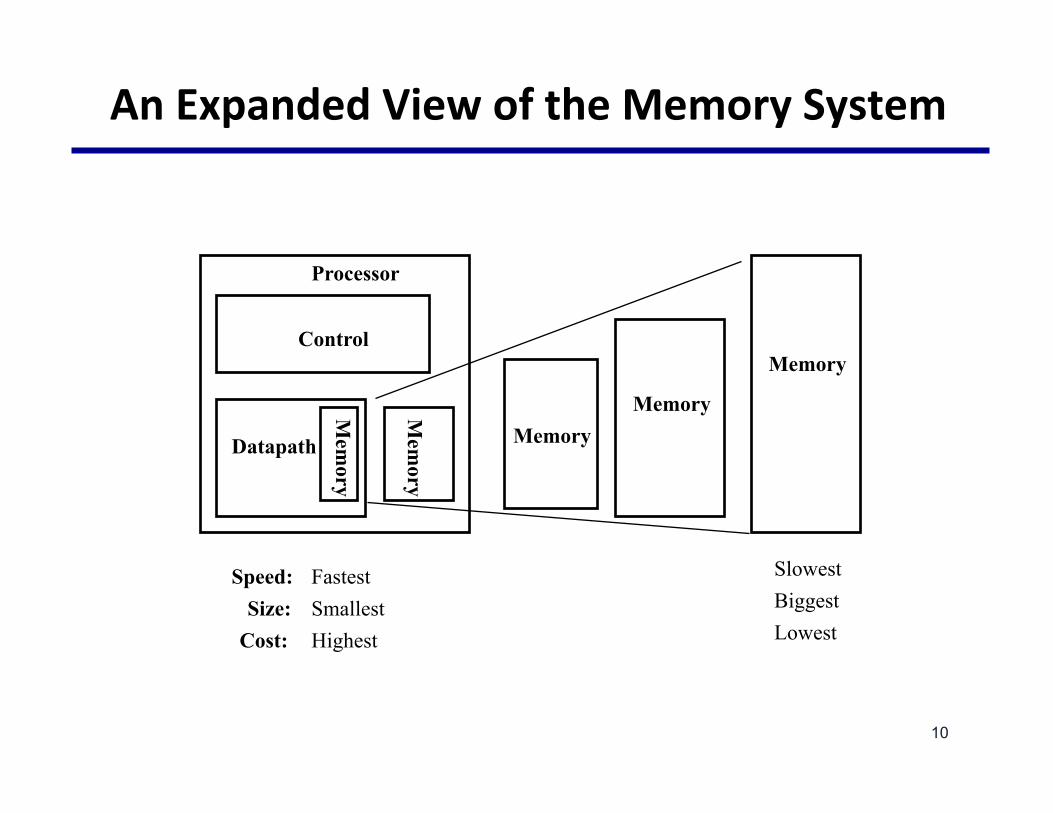
AnExpandedViewoftheMemorySystem
Control
Datapath
Memory
Processor
Mem
ory
Memory Memory
Mem
ory
Fastest Slowest
Smallest Biggest
Highest Lowest
Speed: Size:
Cost:
10

Whyhierarchyworks
• ThePrincipleofLocality:– Programaccessarela@velysmallpor@onoftheaddressspace
atanyinstantof@me.
Address Space 0 2^n - 1
Probability of reference
11
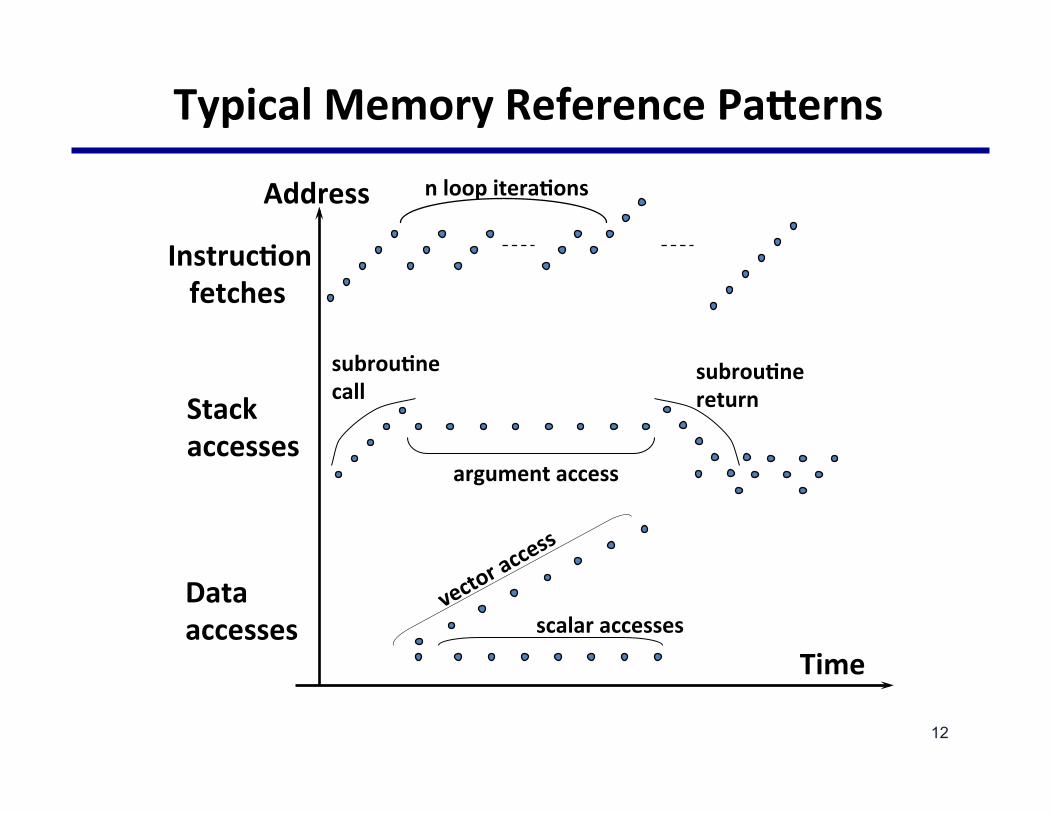
TypicalMemoryReferencePaWerns
Address
Time
InstrucNonfetches
Stackaccesses
Dataaccesses
nloopiteraNons
subrouNnecall
subrouNnereturn
argumentaccess
scalaraccesses
12

Locality• PrincipleofLocality:
– Programstendtoreusedataandinstruc@onsnearthosetheyhaveusedrecently,orthatwererecentlyreferencedthemselves
– Spa@allocality:Itemswithnearbyaddressestendtobereferencedclosetogetherin@me
– Temporallocality:Recentlyreferenceditemsarelikelytobereferencedinthenearfuture
Locality Example: • Data
– Reference array elements in succession (stride-1 reference pattern):
– Reference sum each iteration: • Instructions
– Reference instructions in sequence: – Cycle through loop repeatedly:
sum = 0; for (i = 0; i < n; i++)
sum += a[i]; return sum;
Spatial locality
Spatial locality Temporal locality
Temporal locality
13

LocalityExample
• Claim:Beingabletolookatcodeandgetqualita@vesenseofitslocalityiskeyskillforprofessionalprogrammer
• Ques@on:Doesthisfunc@onhavegoodlocality?
int sumarrayrows(int a[M][N]) { int i, j, sum = 0; for (i = 0; i < M; i++) for (j = 0; j < N; j++) sum += a[i][j]; return sum; }
14

LocalityExample
• Ques@on:Doesthisfunc@onhavegoodlocality?
int sumarraycols(int a[M][N]) { int i, j, sum = 0; for (j = 0; j < N; j++) for (i = 0; i < M; i++) sum += a[i][j]; return sum; }
15

LocalityExample
• Ques@on:Canyoupermutetheloopssothatthefunc@onscansthe3-darraya[]withastride-1referencepaWern(andthushasgoodspa@allocality)?
int sumarray3d(int a[M][N][N]) { int i, j, k, sum = 0; for (i = 0; i < N; i++) for (j = 0; j < N; j++) for (k = 0; k < M; k++) sum += a[k][i][j]; return sum; }
16
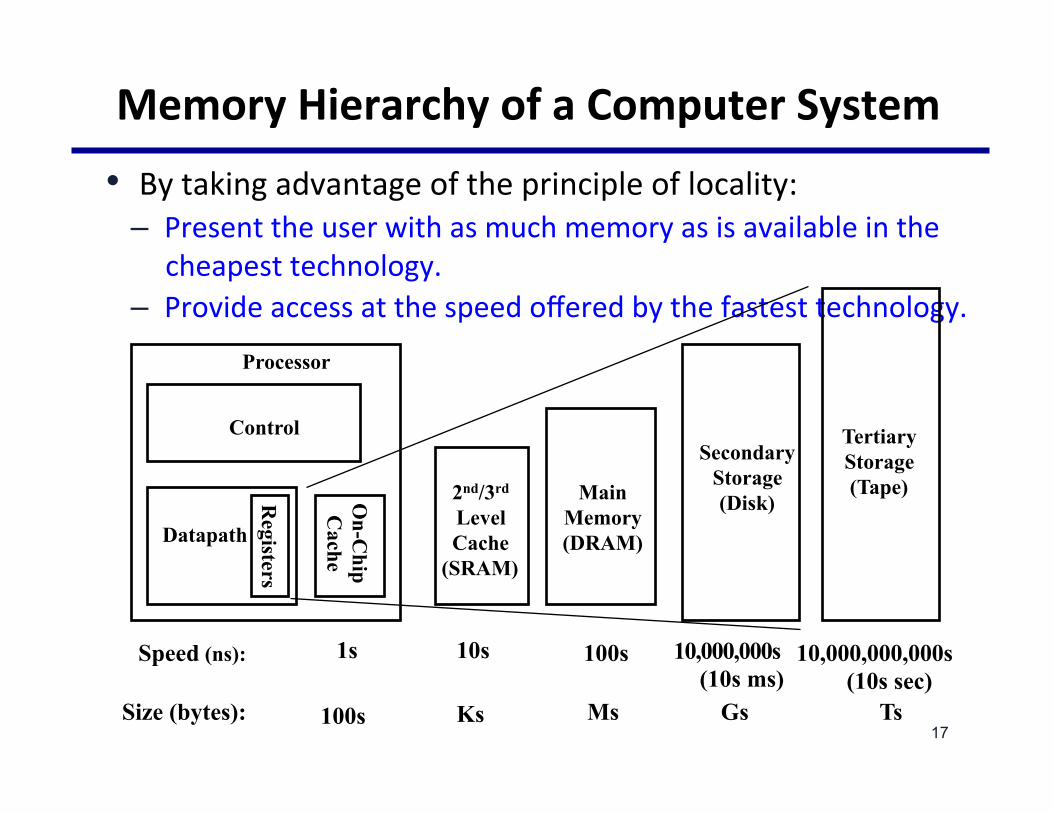
MemoryHierarchyofaComputerSystem• Bytakingadvantageoftheprincipleoflocality:
– Presenttheuserwithasmuchmemoryasisavailableinthecheapesttechnology.
– Provideaccessatthespeedofferedbythefastesttechnology.
Control
Datapath
Secondary Storage (Disk)
Processor
Registers
Main Memory (DRAM)
2nd/3rd Level Cache
(SRAM)
On-C
hip C
ache
1s 10,000,000s (10s ms)
Speed (ns): 10s 100s
100s Gs Size (bytes): Ks Ms
Tertiary Storage (Tape)
10,000,000,000s (10s sec)
Ts 17
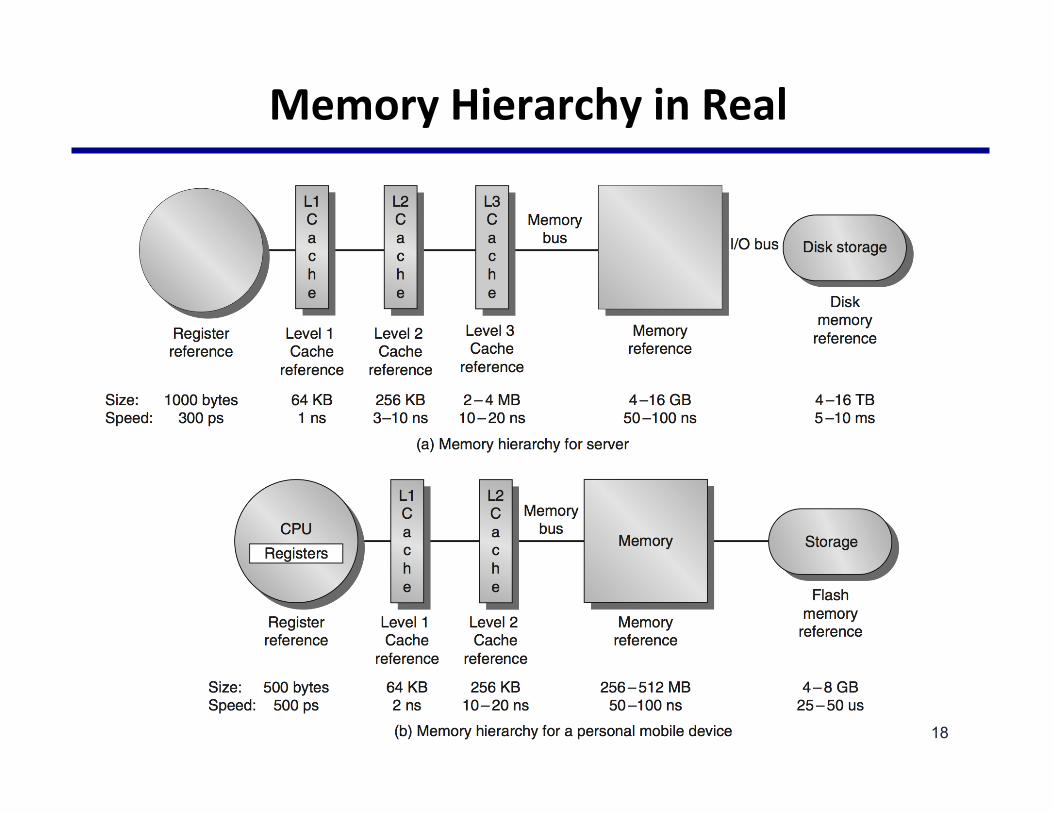
MemoryHierarchyinReal
18

Inteli7(Nahelem)
19
§ PrivateL1andL2– L2is256KBeach.10cyclelatency
§ 8MBsharedL3.~40cycleslatency
Area
20

Howisthehierarchymanaged?
• Registers<->Memory– bycompiler(programmer?)
• cache<->memory– bythehardware
• memory<->disks– bythehardwareandopera@ngsystem(virtualmemory)– bytheprogrammer(files)
• Virtualmemory– Virtuallayerbetweenapplica@onaddressspacetophysical
memory– Notpartofthephysicalmemoryhierarchy
21

TechnologyvsArchitectures
• Technologydeterminestherawspeed– Latency– Bandwidth– Itismaterialscience
• Architectureputthemtogetherwithprocessors– Sophysicalspeedcanbeachievedinreal
22

MemoryTechnology
• StaNcRAM(SRAM)– 0.5ns–2.5ns,$2000–$5000perGB
• DynamicRAM(DRAM)– 50ns–70ns,$20–$75perGB
• 3-Dstackmemory• Solidstatedisk
• Magne@cdisk– 5ms–20ms,$0.20–$2perGB
Ideal memory: • Access time of SRAM • Capacity and cost/GB of
disk
23

MemoryTechnology
• RandomAccess:– �Random�isgood:access@meisthesameforallloca@ons– DRAM:DynamicRandomAccessMemory
• Highdensity,lowpower,cheap,slow• Dynamic:needtobe�refreshed�regularly
– SRAM:StaNcRandomAccessMemory• Lowdensity,highpower,expensive,fast• Sta@c:contentwilllast�forever�(un@llosepower)
• �Non-so-random�AccessTechnology:– Access@mevariesfromloca@ontoloca@onandfrom@meto@me– Examples:Disk,CDROM
• Sequen@alAccessTechnology:access@melinearinloca@on(e.g.,Tape)
24

MainMemoryBackground
• PerformanceofMainMemory:– Latency:CacheMissPenalty
• AccessTime:@mebetweenrequestandwordarrives• CycleTime:@mebetweenrequests
– Bandwidth:I/O&LargeBlockMissPenalty(L2)• MainMemoryisDRAM:DynamicRandomAccessMemory
– Needstoberefreshedperiodically(8ms)– Addressesdividedinto2halves(Memoryasa2Dmatrix):
• RASorRowAccessStrobe• CASorColumnAccessStrobe
• CacheusesSRAM:StaNcRandomAccessMemory– Norefresh(6transistors/bitvs.1transistor)
Size:DRAM/SRAM-4-8Cost/Cycle=me:SRAM/DRAM-8-16
25

RandomAccessMemory(RAM)Technology
• WhyneedtoknowaboutRAMtechnology?– Processorperformanceisusuallylimitedbymemorybandwidth– AsICdensi@esincrease,lotsofmemorywillfitonprocessor
chip• Tailoron-chipmemorytospecificneeds
- Instruction cache - Data cache - Write buffer
• WhatmakesRAMdifferentfromabunchofflip-flops?– Density:RAMismuchdenser
26

StaNcRAMCell
• Write:1.Drivebitlines(bit=1,bit=0)2..Selectrow
• Read:1.PrechargebitandbittoVddorVdd/2=>makesureequal!2..Selectrow3.Cellpullsonelinelow4.Senseamponcolumndetectsdifferencebetweenbitandbit
6-Transistor SRAM Cell
bit bit
word (row select)
bit bit
word
replaced with pullup to save area
1 0
0 1
27
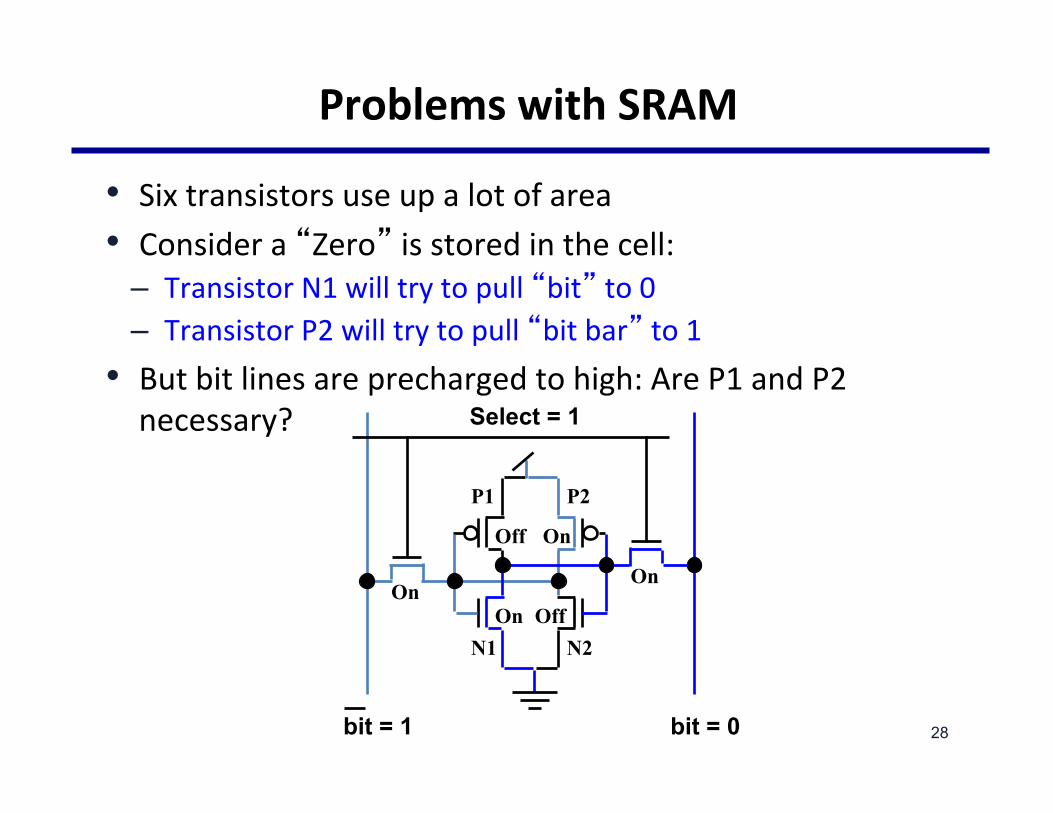
ProblemswithSRAM
• Sixtransistorsuseupalotofarea• Considera�Zero�isstoredinthecell:
– TransistorN1willtrytopull�bit�to0– TransistorP2willtrytopull�bitbar�to1
• Butbitlinesareprechargedtohigh:AreP1andP2necessary?
bit = 1 bit = 0
Select = 1
On Off
Off On
N1 N2
P1 P2
On On
28
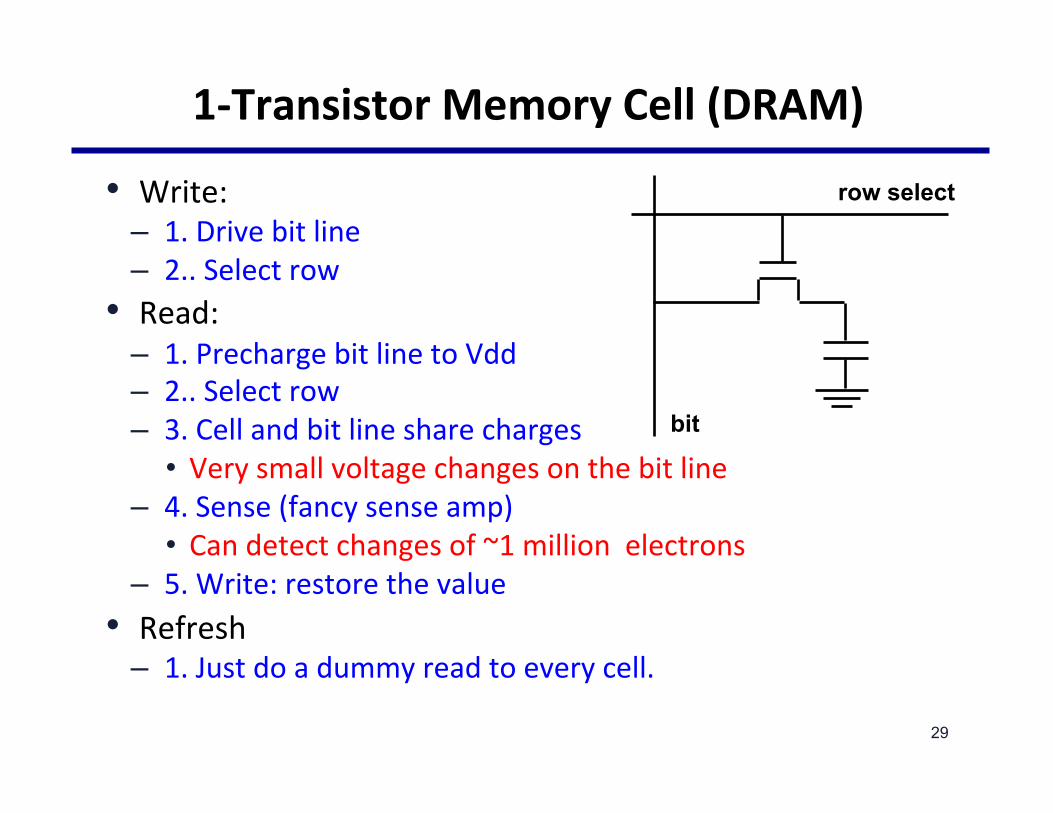
1-TransistorMemoryCell(DRAM)
• Write:– 1.Drivebitline– 2..Selectrow
• Read:– 1.PrechargebitlinetoVdd– 2..Selectrow– 3.Cellandbitlinesharecharges
• Verysmallvoltagechangesonthebitline– 4.Sense(fancysenseamp)
• Candetectchangesof~1millionelectrons– 5.Write:restorethevalue
• Refresh– 1.Justdoadummyreadtoeverycell.
row select
bit
29

ClassicalDRAMOrganizaNon(square)
RowandColumnAddresstogether:– Select1bitaNme
r o w d e c o d e r
row address
Column Selector & I/O Circuits Column
Address
data
RAM Cell Array
word (row) select
bit (data) lines Each intersection represents a 1-T DRAM Cell
30
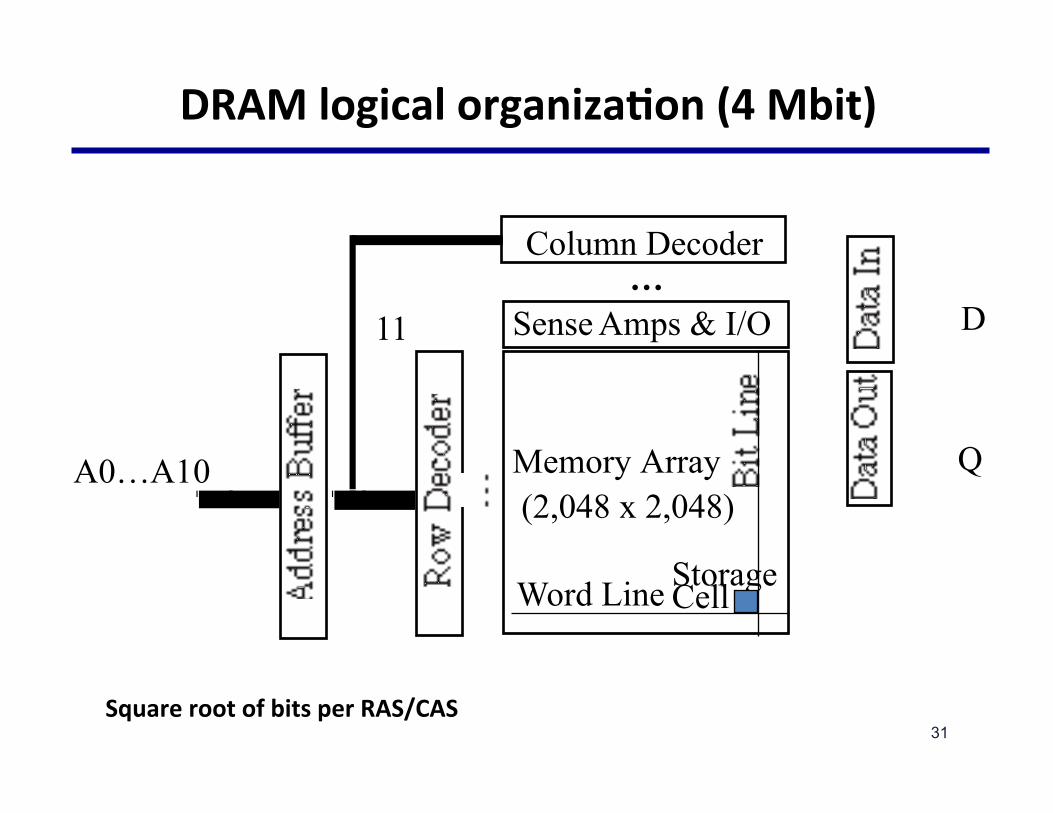
DRAMlogicalorganizaNon(4Mbit)
SquarerootofbitsperRAS/CAS
Column Decoder
Sense Amps & I/O
Memory Array (2,048 x 2,048)
A0…A1 0
… 1 1 D
Q
W ord Line Storage Cell
31

MainMemoryPerformance
• DRAM(Read/Write)CycleTime>>DRAM(Read/Write)AccessTime– -2:1
• DRAM(Read/Write)CycleTime:– Howfrequentcanyouini@ateanaccess?– Analogy:AliWlekidcanonlyaskhisfatherformoneyonSaturday
• DRAM(Read/Write)AccessTime:– Howquicklywillyougetwhatyouwantonceyouini@ateanaccess?– Analogy:Assoonasheasks,hisfatherwillgivehimthemoney
• DRAMBandwidthLimita@onanalogy:– WhathappensifherunsoutofmoneyonWednesday?
Time Access Time
Cycle Time
32
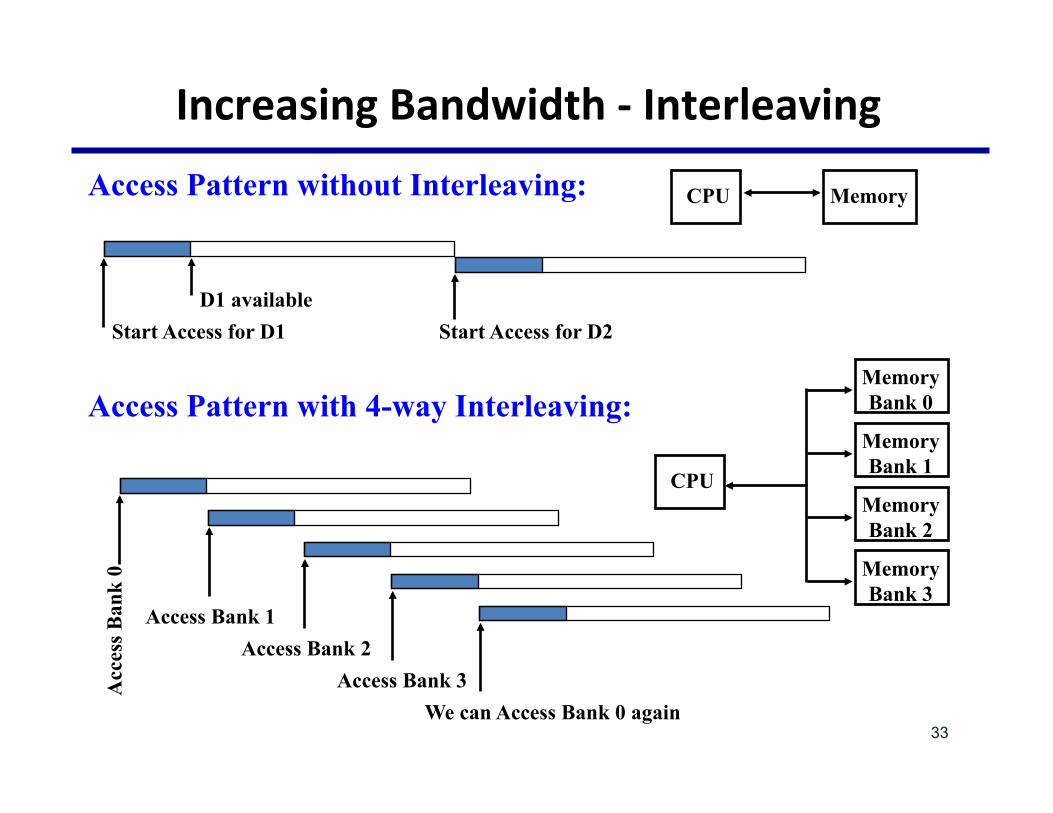
Access Pattern without Interleaving:
Start Access for D1
CPU Memory
Start Access for D2 D1 available
Access Pattern with 4-way Interleaving:
Acc
ess B
ank
0
Access Bank 1 Access Bank 2
Access Bank 3 We can Access Bank 0 again
CPU
Memory Bank 1
Memory Bank 0
Memory Bank 3
Memory Bank 2
IncreasingBandwidth-Interleaving
33
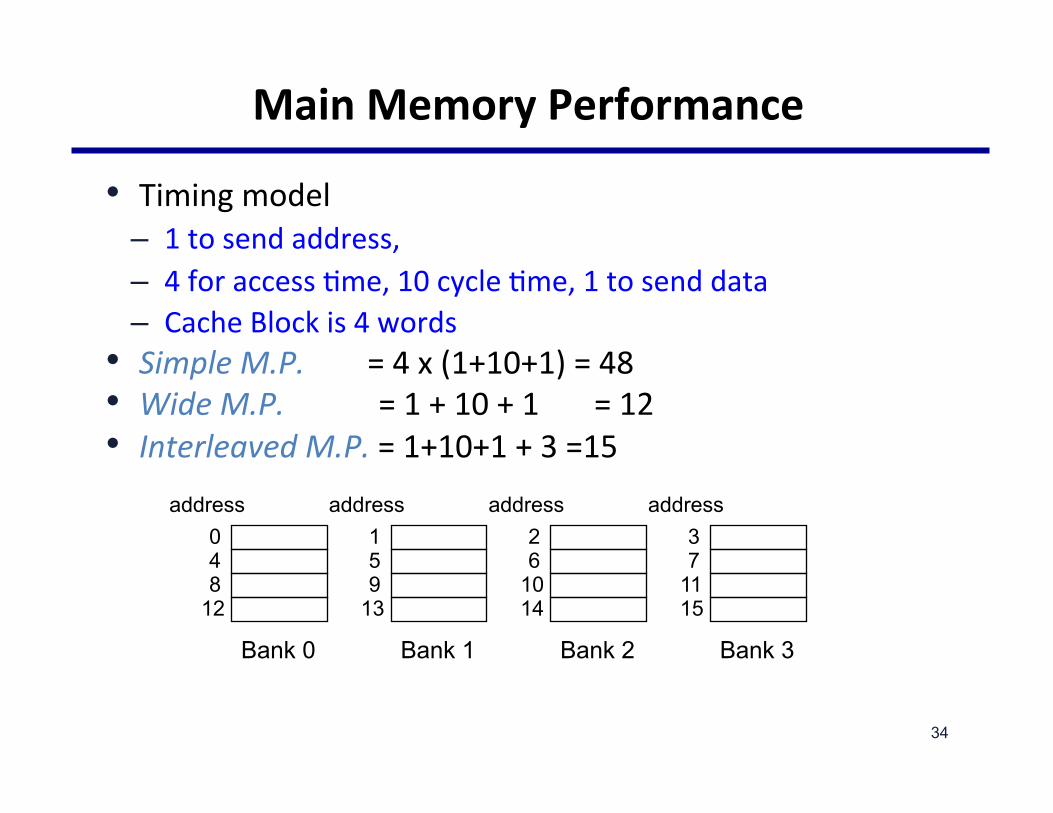
MainMemoryPerformance
• Timingmodel– 1tosendaddress,– 4foraccess@me,10cycle@me,1tosenddata– CacheBlockis4words
• SimpleM.P.=4x(1+10+1)=48• WideM.P.=1+10+1=12• InterleavedM.P.=1+10+1+3=15
address
Bank 0
0 4 8
12
address
Bank 1
1 5 9
13
address
Bank 2
2 6
10 14
address
Bank 3
3 7
11 15
34

IndependentMemoryBanks
• Howmanybanks?numberbanks�numberclockstoaccesswordinbank
– Forsequen@alaccesses,otherwisewillreturntooriginalbankbeforeithasnextwordready
• IncreasingDRAM=>fewerchips=>hardertohavebanks– Growthbits/chipDRAM:50%-60%/yr– NathanMyrvoldM/S:maturesoTwaregrowth
(33%/yrforNT)-growthMB/$ofDRAM(25%-30%/yr)
35

DRAMHistory
• DRAMs:capacity+60%/yr,cost–30%/yr– 2.5Xcells/area,1.5Xdiesizein-3years
• �97DRAMfablinecosts$1Bto$2B– DRAMonly:density,leakagev.speed
• Relyonincreasingno.ofcomputers&memorypercomputer(60%market)– SIMMorDIMMisreplaceableunit
=>computersuseanygenera@onDRAM• Commodity,secondsourceindustry
=>highvolume,lowprofit,conserva@ve– LiWleorganiza@oninnova@onin20years
pagemode,EDO,SynchDRAM• Orderofimportance:1)Cost/bit1a)Capacity
– RAMBUS:10XBW,+30%cost=>liWleimpact
36
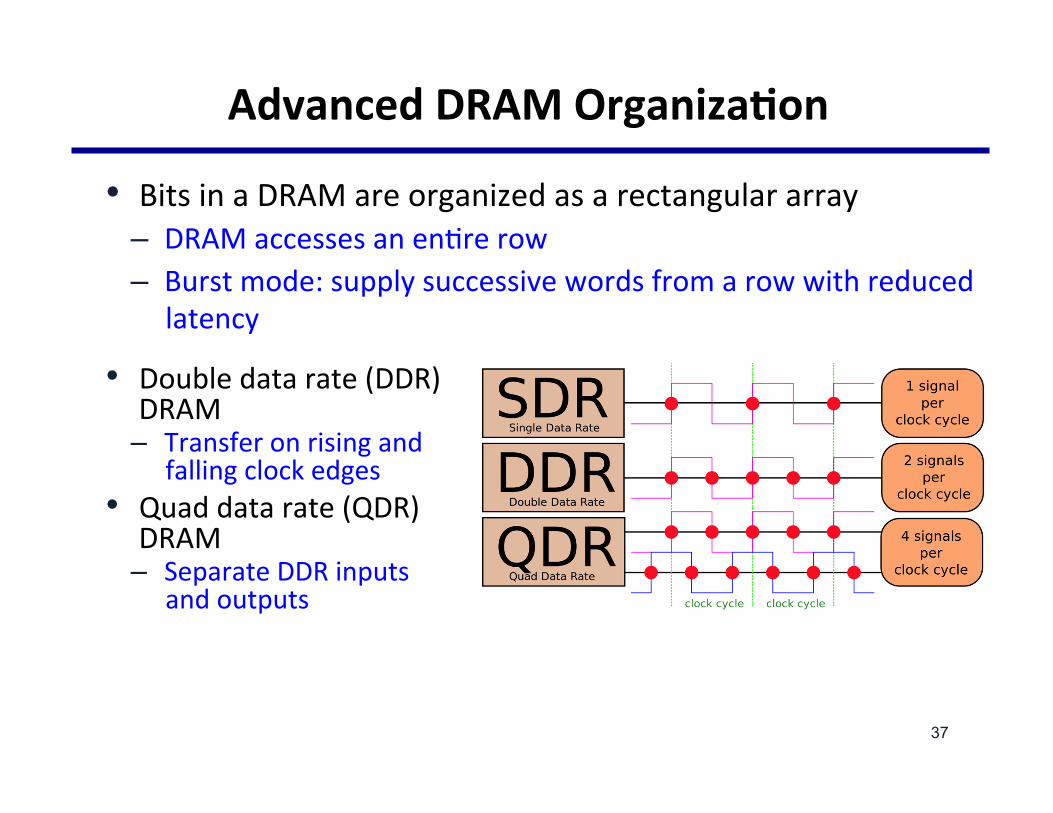
AdvancedDRAMOrganizaNon
• BitsinaDRAMareorganizedasarectangulararray– DRAMaccessesanen@rerow– Burstmode:supplysuccessivewordsfromarowwithreduced
latency
• Doubledatarate(DDR)DRAM– Transferonrisingand
fallingclockedges• Quaddatarate(QDR)
DRAM– SeparateDDRinputs
andoutputs
37
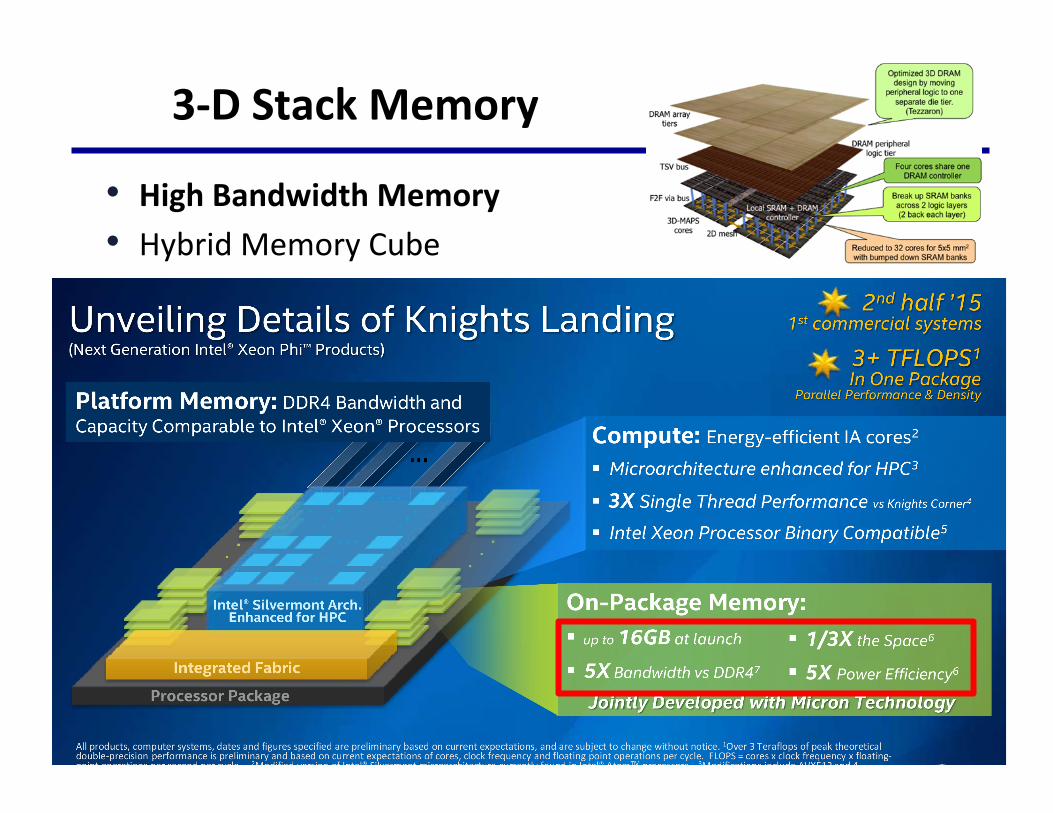
3-DStackMemory
• HighBandwidthMemory• HybridMemoryCube
38
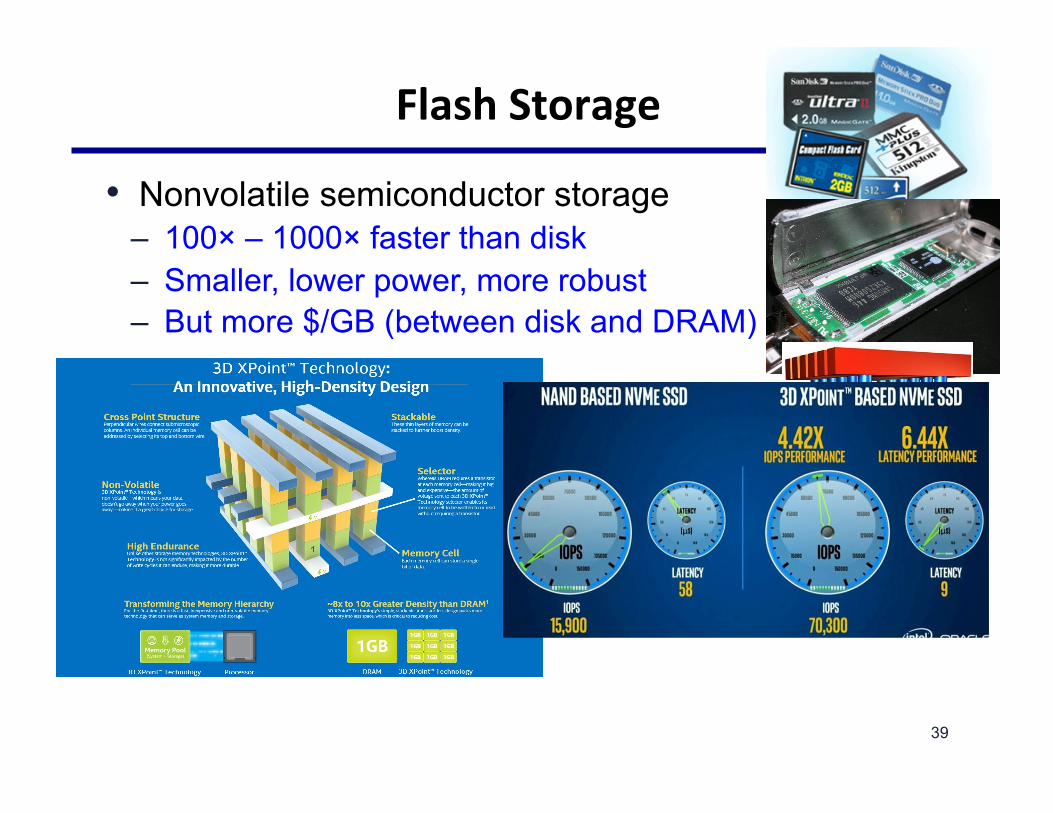
FlashStorage
• Nonvolatile semiconductor storage – 100× – 1000× faster than disk – Smaller, lower power, more robust – But more $/GB (between disk and DRAM)
39

Flash Types
• NOR flash: bit cell like a NOR gate – Random read/write access – Used for instruction memory in embedded systems
• NAND flash: bit cell like a NAND gate – Denser (bits/area), but block-at-a-time access – Cheaper per GB – Used for USB keys, media storage, …
• Flash bits wears out after 1000�s of accesses – Not suitable for direct RAM or disk replacement – Wear leveling: remap data to less used blocks
40
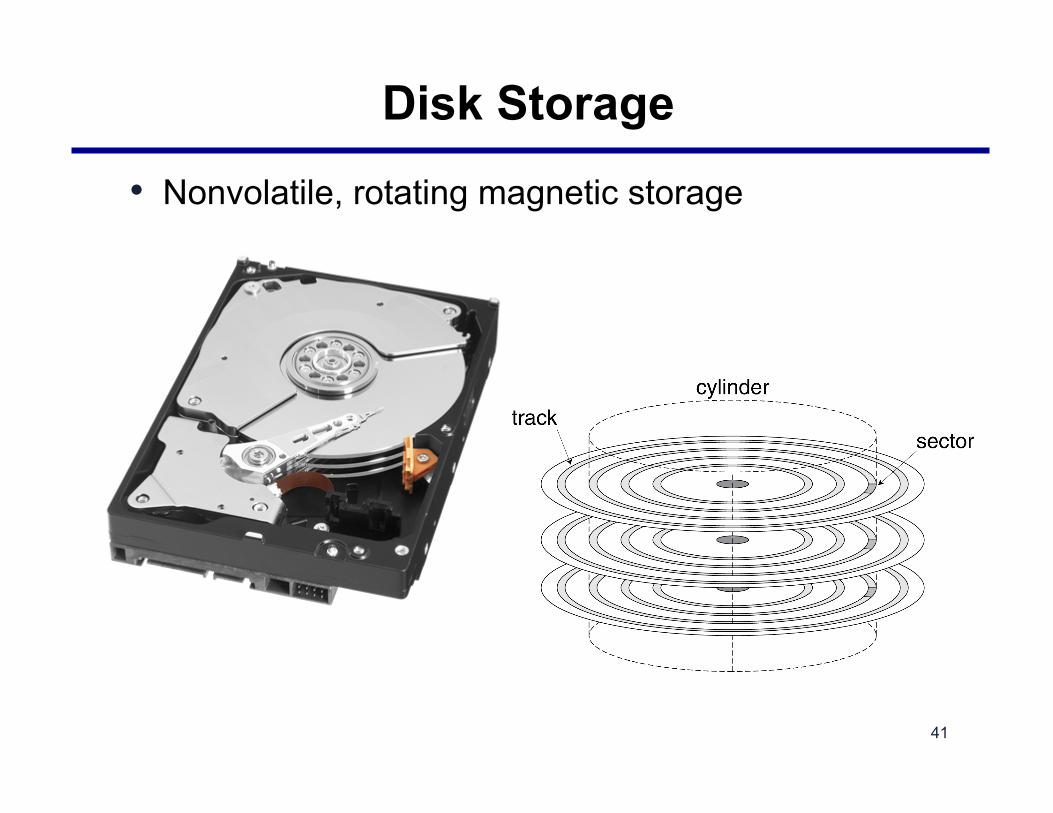
Disk Storage
• Nonvolatile, rotating magnetic storage
41

Disk Sectors and Access
• Each sector records – Sector ID – Data (512 bytes, 4096 bytes proposed) – Error correcting code (ECC)
• Used to hide defects and recording errors – Synchronization fields and gaps
• Access to a sector involves – Queuing delay if other accesses are pending – Seek: move the heads – Rotational latency – Data transfer – Controller overhead
42

Disk Access Example • Given
– 512B sector, 15,000rpm, 4ms average seek time, 100MB/s transfer rate, 0.2ms controller overhead, idle disk
• Average read time – 4ms seek time
+ ½ / (15,000/60) = 2ms rotational latency + 512 / 100MB/s = 0.005ms transfer time + 0.2ms controller delay = 6.2ms
• If actual average seek time is 1ms – Average read time = 3.2ms
43

Summary:
• TwoDifferentTypesofLocality:– TemporalLocality(LocalityinTime):Ifanitemisreferenced,itwill
tendtobereferencedagainsoon.– Spa@alLocality(LocalityinSpace):Ifanitemisreferenced,items
whoseaddressesareclosebytendtobereferencedsoon.• Bytakingadvantageoftheprincipleoflocality:
– Presenttheuserwithasmuchmemoryasisavailableinthecheapesttechnology.
– Provideaccessatthespeedofferedbythefastesttechnology.• DRAMisslowbutcheapanddense:
– Goodchoiceforpresen@ngtheuserwithaBIGmemorysystem• SRAMisfastbutexpensiveandnotverydense:
– GoodchoiceforprovidingtheuserFASTaccess@me.
44





























