Embed Size (px)
Citation preview

Lekserite elustLekseemijada loomine Maximal munch

a
a
""
a "a"
""
s ∈ L(E)Regulaaravaldis defineerib keele, aga leksimine…

Leksimine!
• x+++++y on sama mis “x++ + ++y”, jah?
• Ei, seda loetakse nagu “(x++)++ + y”. <ID:x>, <Op:++>, <Op:++>, <Op:+>, <ID:y>
• x+++ ++y (aga see tükeldub hästi!) <ID:x>, <Op:++>, <Op:+>, <Op:++>, <ID:y>
Probleemiks on siin “tüübiviga” (lvalue/rvalue), sest (x++)++ on sisuliselt
nagu 5++ ja nii ei saa!
Lekser teeb oma töö ja enam ei vaata tagasi!

Need ei vaata tagasi:
• Talulaps
• Oja süda
• Java kompilaator
• ANTLRKõige rohkem probleeme on meil aga ANTLRiga!
Kui lekseri töö on tehtud, siis token stream'ile enam muudatusi ei tehta!

Leksiline spetsifikatsioon
• Keyword: ‘if’ | …
• Op: ‘++’ | ‘+’ | …
• Identifier: [a-zA-Z_][a-zA-Z_0-9]*
• …
26 1 Lexical Analysis
! !1
"
ε
#ε
!ε
$
ε
!2 !i !3 !f !"4 IF
!5 ![a-zA-Z ] !"6%[a-zA-Z 0-9]
ID
!7 ![+-]
&ε
!8 ![0-9] !"9'
εNUM
!10 ![+-]
&ε
!11 ![0-9]
(.
!"12%
[0-9]
FLOAT
!.
)[eE]
!"13%
[0-9]
FLOAT
([eE]
!14 ![0-9] !"15FLOAT
![eE]
'ε
!16 ![+-]
&ε
!17 ![0-9] !"18'
εFLOAT
Fig. 1.12 Combined NFA for several tokens
will be chosen. Note that the principle of the longest match takes precedence overthe order of definition of tokens, so even though the string starts with the keywordif, which has higher priority than variable names, the variable name is chosenbecause it is longer.
Modern languages like C, Java or SML follow this convention, and so do mostlexer generators, but some (mostly older) languages like FORTRAN do not. Whenother conventions are used, lexers must either be written by hand to handle theseconventions or the conventions used by the lexer generator must be side-stepped.Some lexer generators allow the user to have some control over the conventionsused.
The principle of the longest matching prefix is handled by letting the DFA readas far as it can, until it either reaches the end of the input or no transition is definedon the next input symbol. If the current state at this point is accepting, we are inluck and can simply output the corresponding token. If not, we must go back tothe last time we were in an accepting state and output the token indicated by this.The characters read since then are put back in the input stream. The lexer musthence retain the symbols it has read since the last accepting state so it can re-insertthese in the input in such situations. If we are not at the end of the input stream,we restart the DFA (in its initial state) on the remaining input to find the next to-kens.
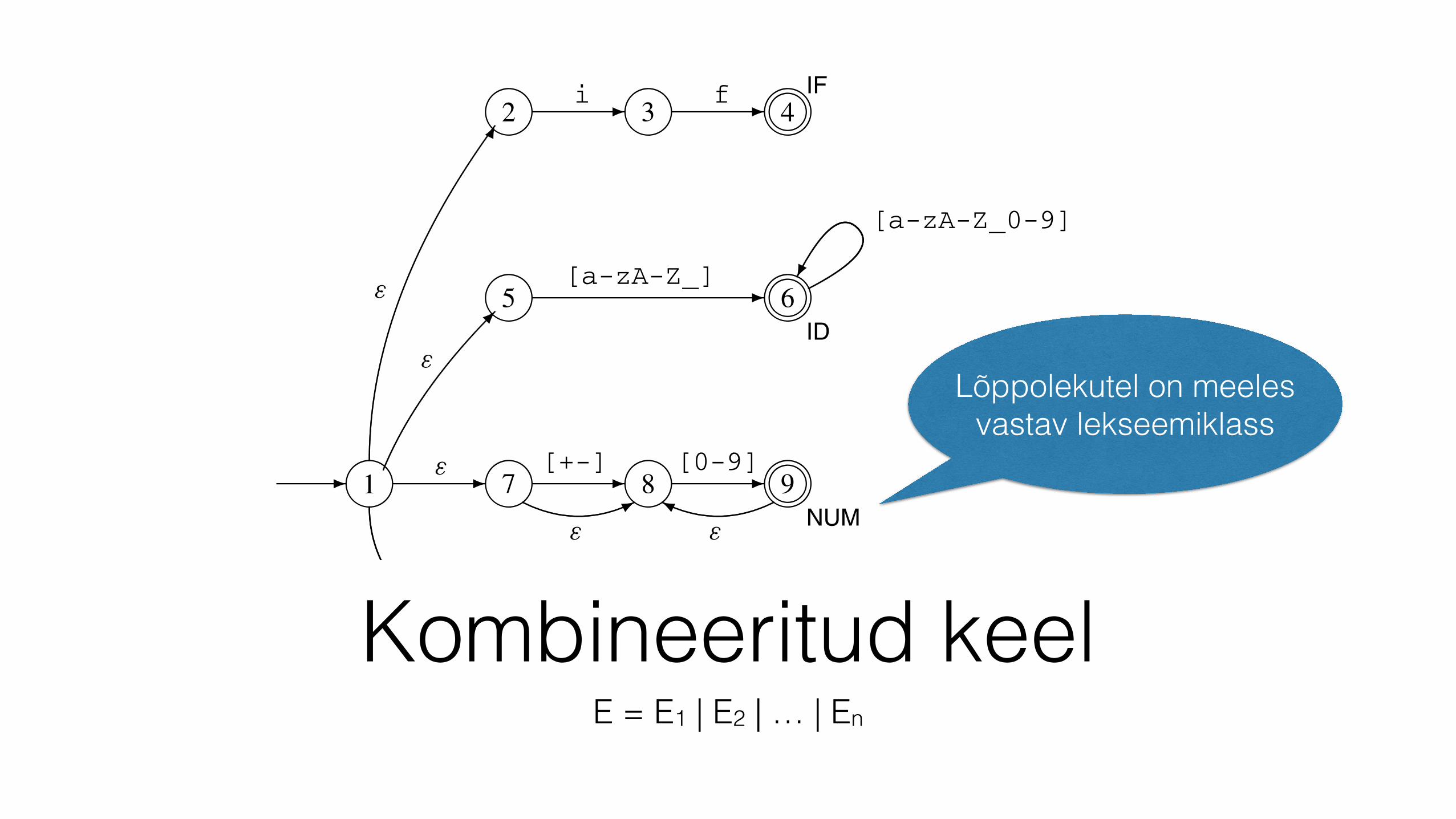
Kombineeritud keelE = E1 | E2 | … | En
Lõppolekutel on meeles vastav lekseemiklass

Kuidas kasutada• Sisendiks on .
• Otsime sellist , et alamsõne kuuluks keelde .
• Kui leidub, peab olema alamkeel , kuhu sõne kuulub. ( ja lõppolekus jätsime meelde!)
• Eemaldame sisendist sõne ja jätkame kuni sisend on tühi.
x1…xn
i ≤ n w = x1…xi L(E)
L(Ek)E = E1 |E2 |⋯ |En
w
26 1 Lexical Analysis
! !1
"
ε
#ε
!ε
$
ε
!2 !i !3 !f !"4 IF
!5 ![a-zA-Z ] !"6%[a-zA-Z 0-9]
ID
!7 ![+-]
&ε
!8 ![0-9] !"9'
εNUM
!10 ![+-]
&ε
!11 ![0-9]
(.
!"12%
[0-9]
FLOAT
!.
)[eE]
!"13%
[0-9]
FLOAT
([eE]
!14 ![0-9] !"15FLOAT
![eE]
'ε
!16 ![+-]
&ε
!17 ![0-9] !"18'
εFLOAT
Fig. 1.12 Combined NFA for several tokens
will be chosen. Note that the principle of the longest match takes precedence overthe order of definition of tokens, so even though the string starts with the keywordif, which has higher priority than variable names, the variable name is chosenbecause it is longer.
Modern languages like C, Java or SML follow this convention, and so do mostlexer generators, but some (mostly older) languages like FORTRAN do not. Whenother conventions are used, lexers must either be written by hand to handle theseconventions or the conventions used by the lexer generator must be side-stepped.Some lexer generators allow the user to have some control over the conventionsused.
The principle of the longest matching prefix is handled by letting the DFA readas far as it can, until it either reaches the end of the input or no transition is definedon the next input symbol. If the current state at this point is accepting, we are inluck and can simply output the corresponding token. If not, we must go back tothe last time we were in an accepting state and output the token indicated by this.The characters read since then are put back in the input stream. The lexer musthence retain the symbols it has read since the last accepting state so it can re-insertthese in the input in such situations. If we are not at the end of the input stream,we restart the DFA (in its initial state) on the remaining input to find the next to-kens.

Maximal Munch!
• Mis juhtub, kui sobivad kaks alamsõne??
• Võib ju juhtuda, et ja mõlemad kuuluvad keelde .
• Näiteks ‘++’ ja ‘+’ on mõlemad Java operaatorid.
• Loomulik konventsioon on valida pikim alamsõne, mis sobitub!
x1…xi x1…xj L(E)

Milline lekseemiklass?• Kas “if” on muutuja nimi või keyword?
• Prioriteedijärjekord: leksilise spetsifikatsiooni järjekord on oluline.
• NB! Kõigepealt valime pikima alamsõne ja alles siis valime lekseemiklassi. (Seega, “if” on võtmesõna, aga “ifo” muutuja.)
1. Leia pikim alamsõne , mis kuulub keelde.
2. Vali prioriteetseim lekseemiklass, kuhu kuulub.
w
w
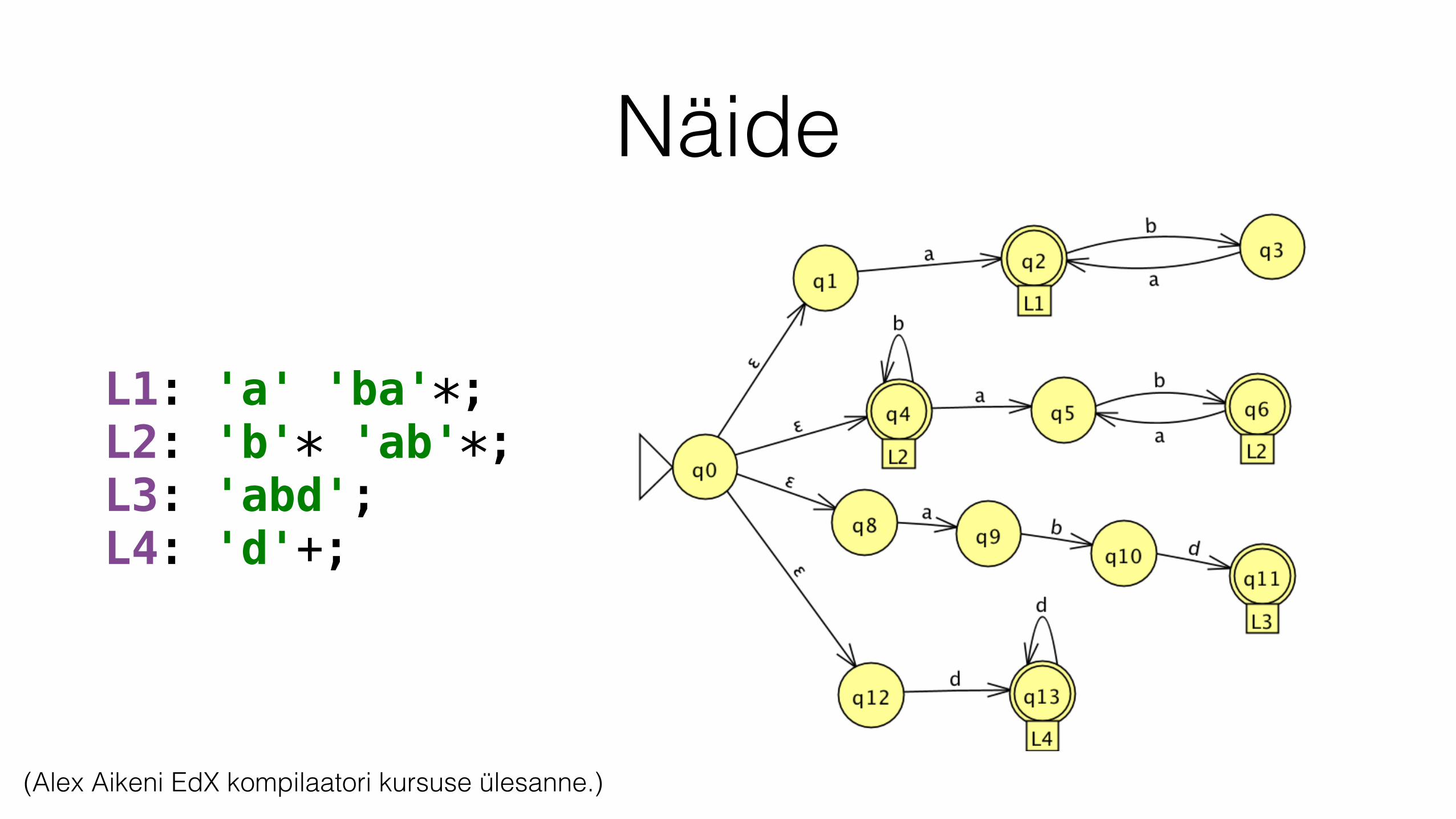
Näide
L1: 'a' 'ba'*; L2: 'b'* 'ab'*; L3: 'abd'; L4: 'd'+;
(Alex Aikeni EdX kompilaatori kursuse ülesanne.)
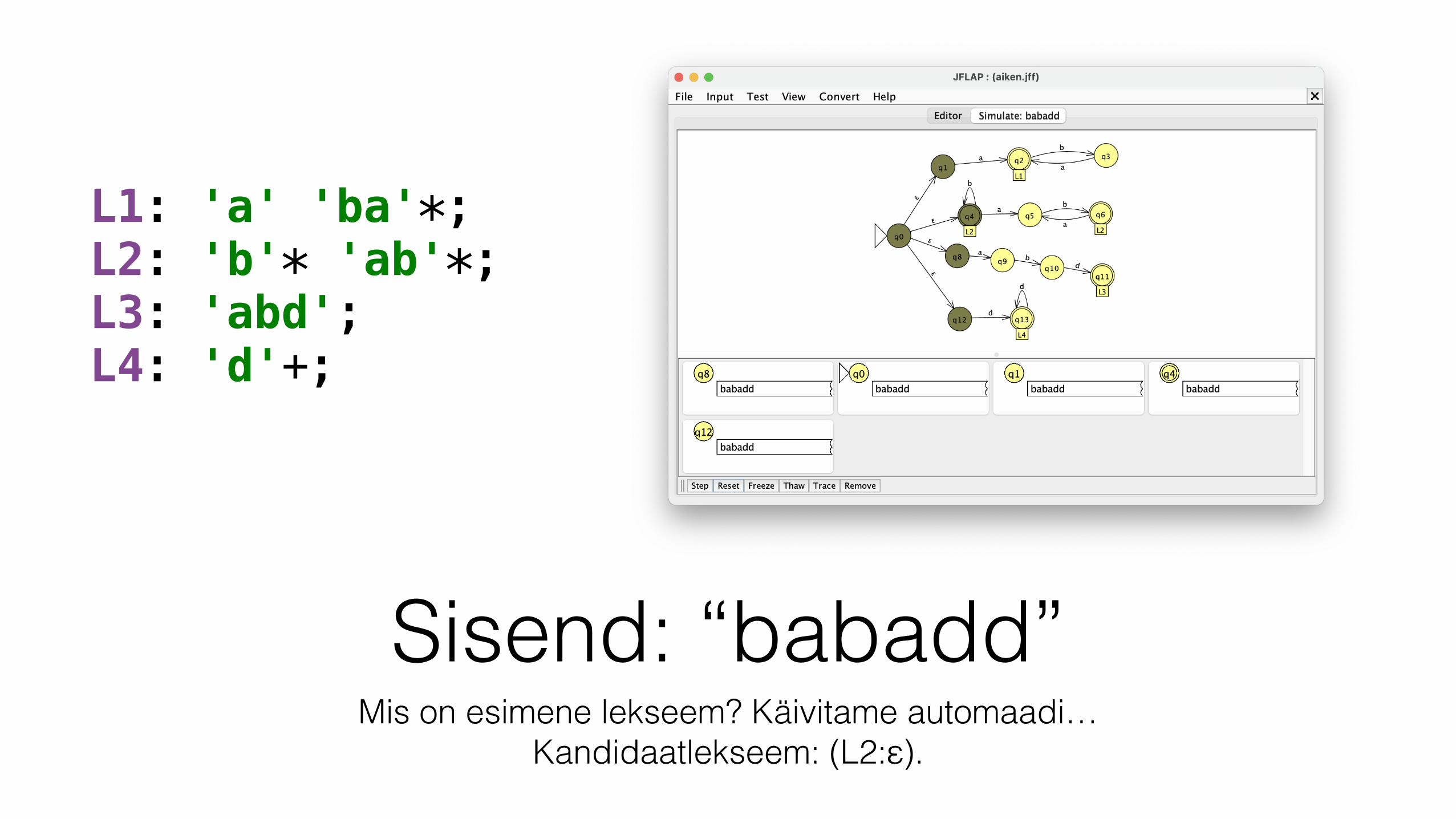
Sisend: “babadd”Mis on esimene lekseem? Käivitame automaadi…
Kandidaatlekseem: (L2:ε).
L1: 'a' 'ba'*; L2: 'b'* 'ab'*; L3: 'abd'; L4: 'd'+;
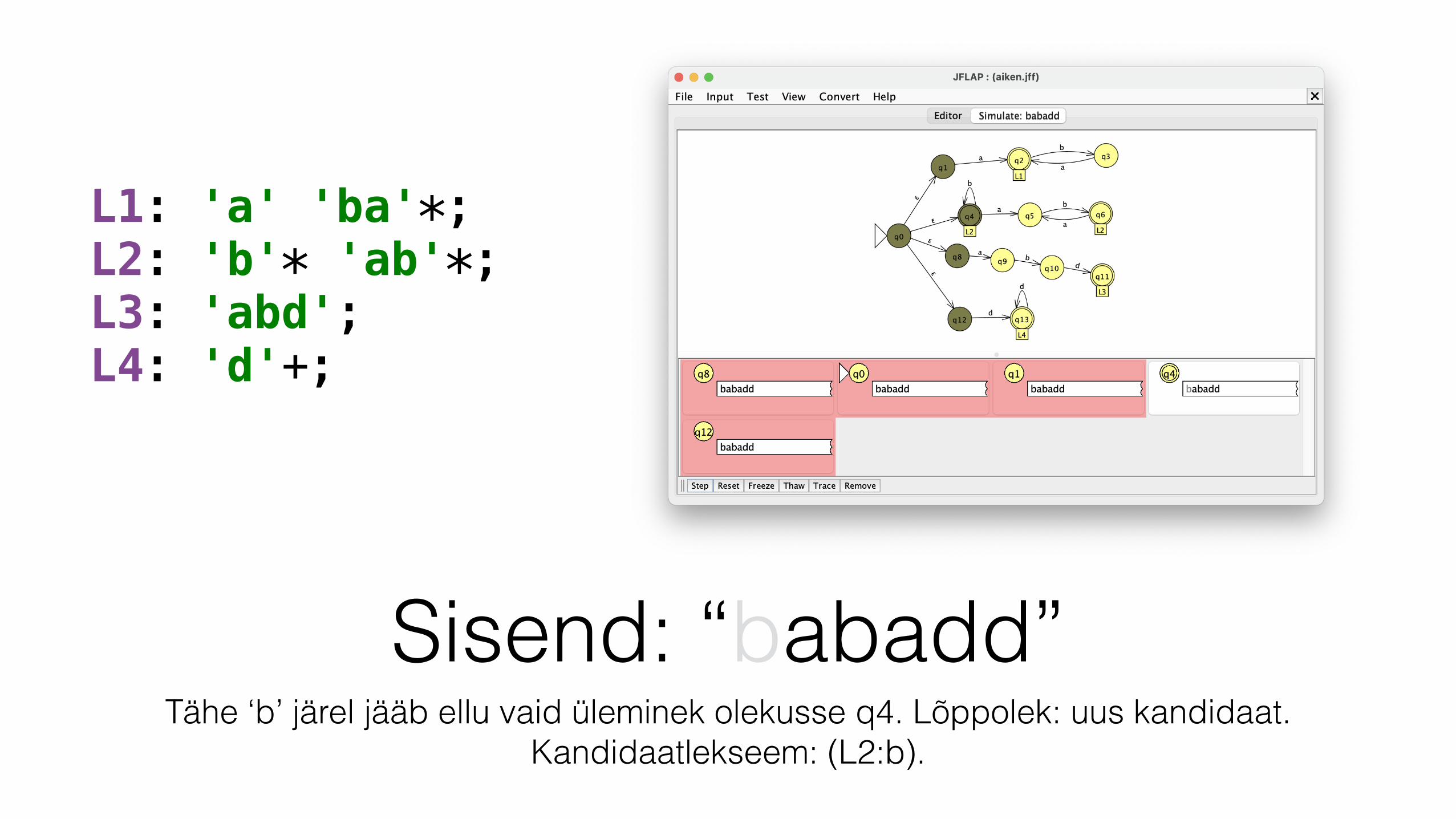
Sisend: “babadd”Tähe ‘b’ järel jääb ellu vaid üleminek olekusse q4. Lõppolek: uus kandidaat.
Kandidaatlekseem: (L2:b).
L1: 'a' 'ba'*; L2: 'b'* 'ab'*; L3: 'abd'; L4: 'd'+;
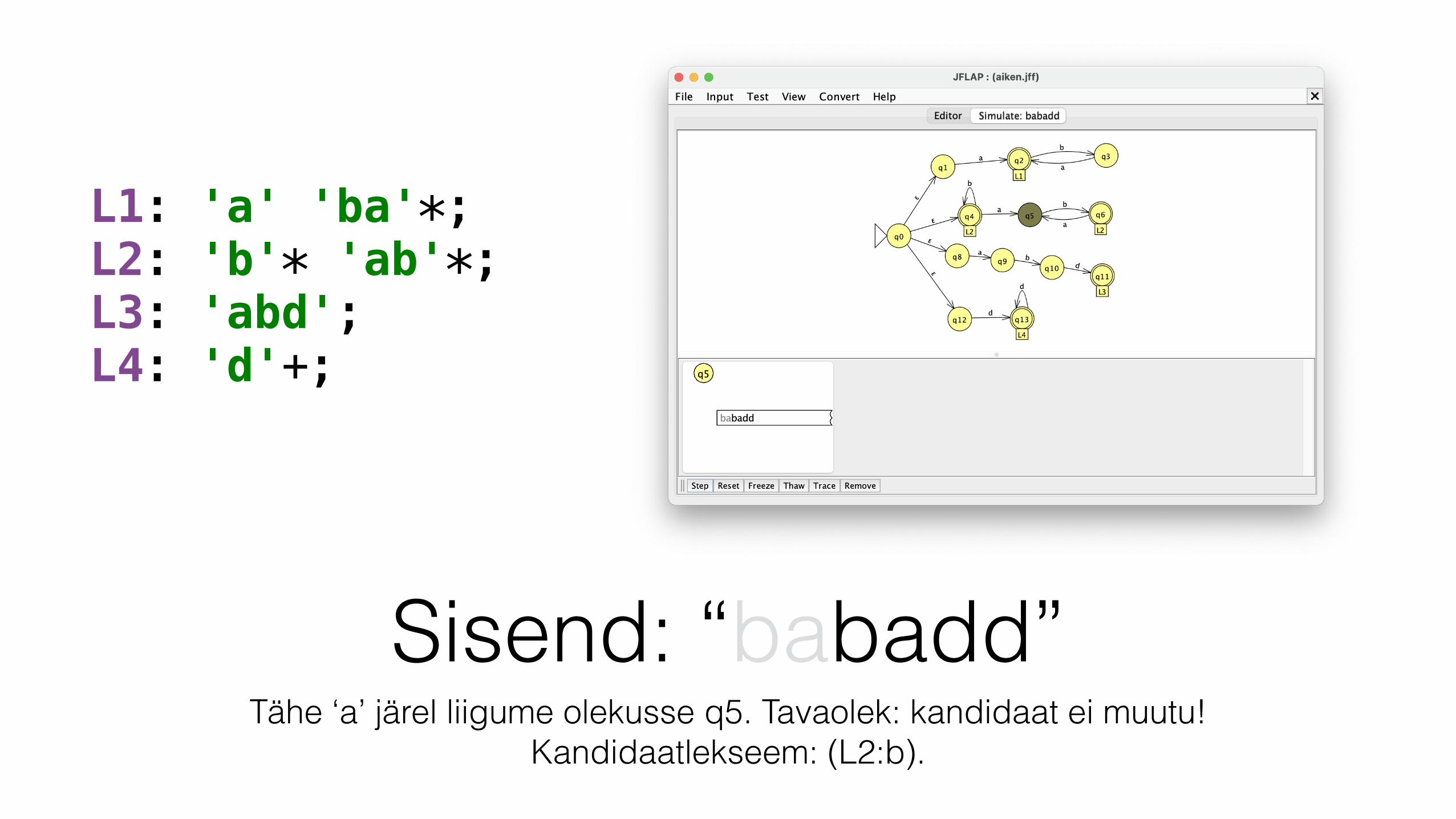
Sisend: “babadd”Tähe ‘a’ järel liigume olekusse q5. Tavaolek: kandidaat ei muutu!
Kandidaatlekseem: (L2:b).
L1: 'a' 'ba'*; L2: 'b'* 'ab'*; L3: 'abd'; L4: 'd'+;
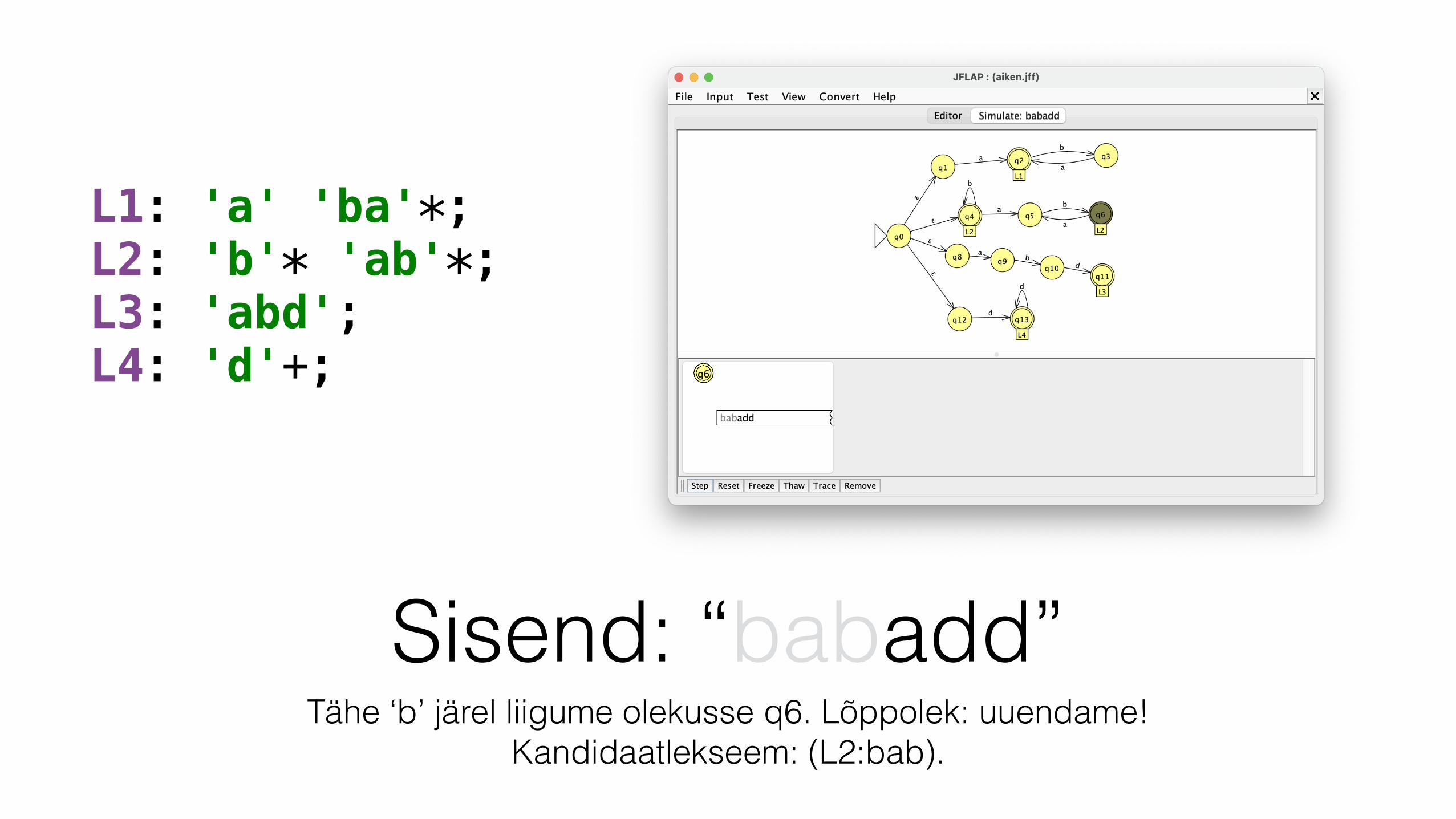
Sisend: “babadd”Tähe ‘b’ järel liigume olekusse q6. Lõppolek: uuendame!
Kandidaatlekseem: (L2:bab).
L1: 'a' 'ba'*; L2: 'b'* 'ab'*; L3: 'abd'; L4: 'd'+;
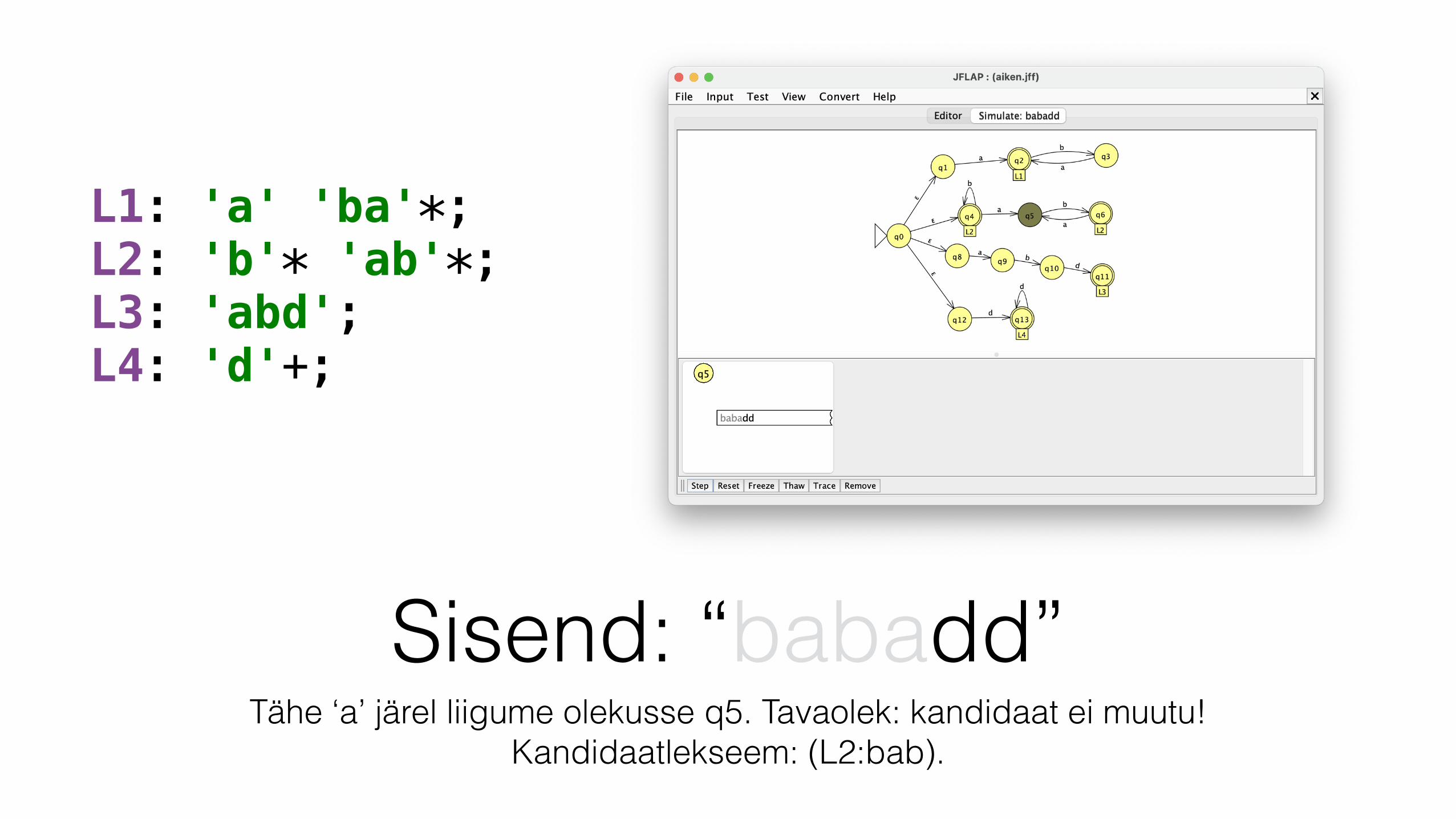
Sisend: “babadd”Tähe ‘a’ järel liigume olekusse q5. Tavaolek: kandidaat ei muutu!
Kandidaatlekseem: (L2:bab).
L1: 'a' 'ba'*; L2: 'b'* 'ab'*; L3: 'abd'; L4: 'd'+;
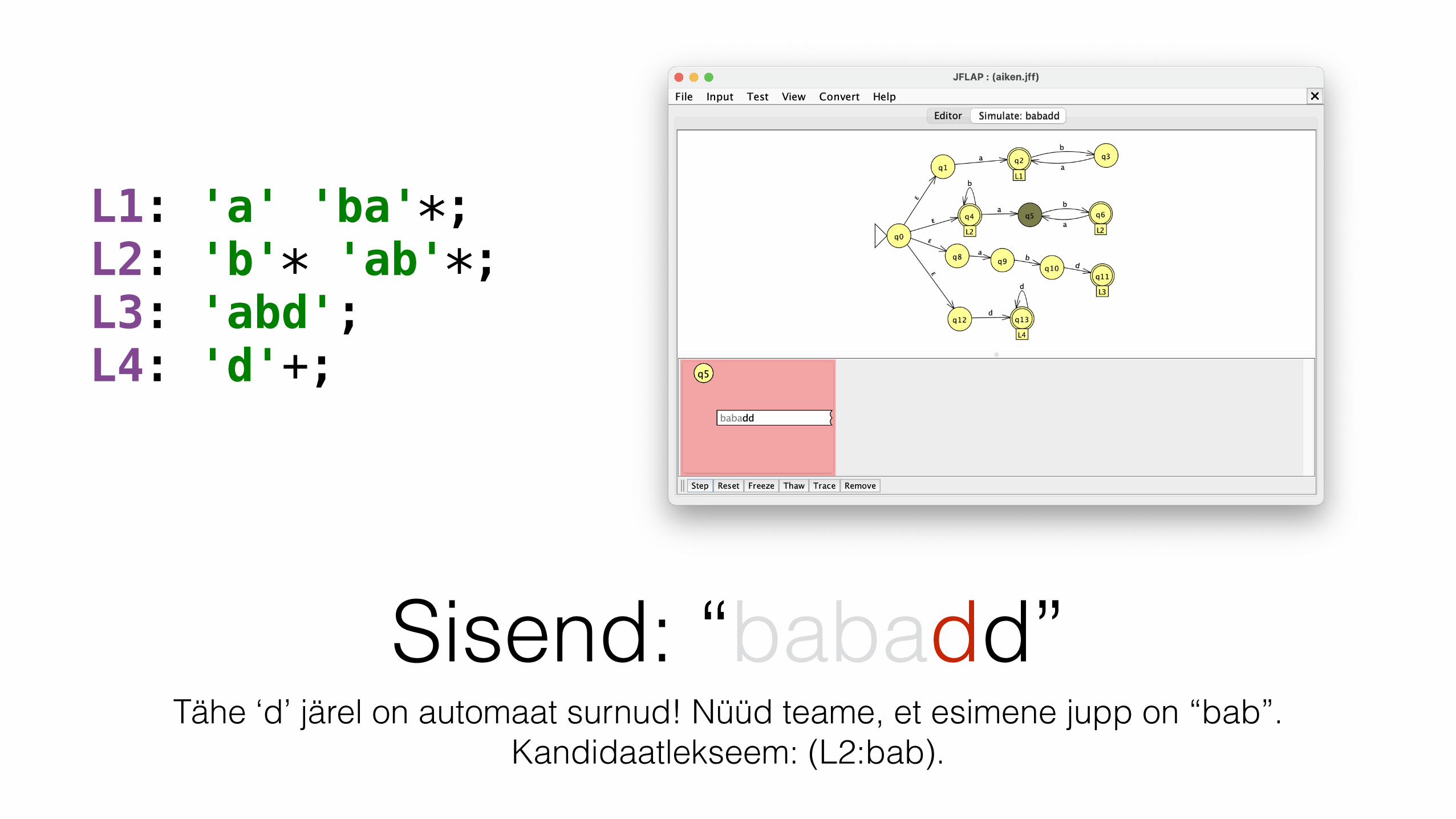
Sisend: “babadd”Tähe ‘d’ järel on automaat surnud! Nüüd teame, et esimene jupp on “bab”.
Kandidaatlekseem: (L2:bab).
L1: 'a' 'ba'*; L2: 'b'* 'ab'*; L3: 'abd'; L4: 'd'+;
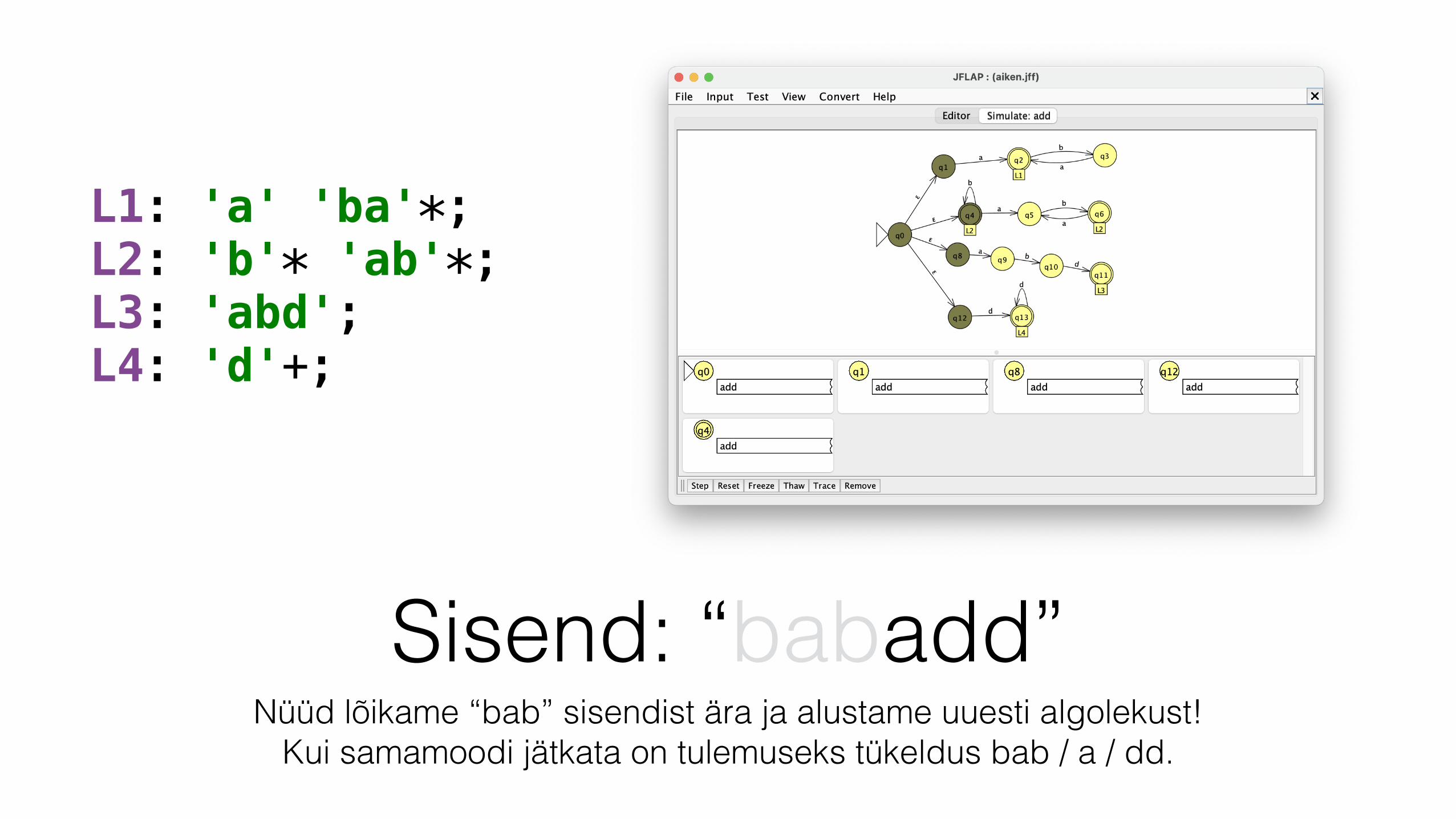
Sisend: “babadd”Nüüd lõikame “bab” sisendist ära ja alustame uuesti algolekust!
Kui samamoodi jätkata on tulemuseks tükeldus bab / a / dd.
L1: 'a' 'ba'*; L2: 'b'* 'ab'*; L3: 'abd'; L4: 'd'+;
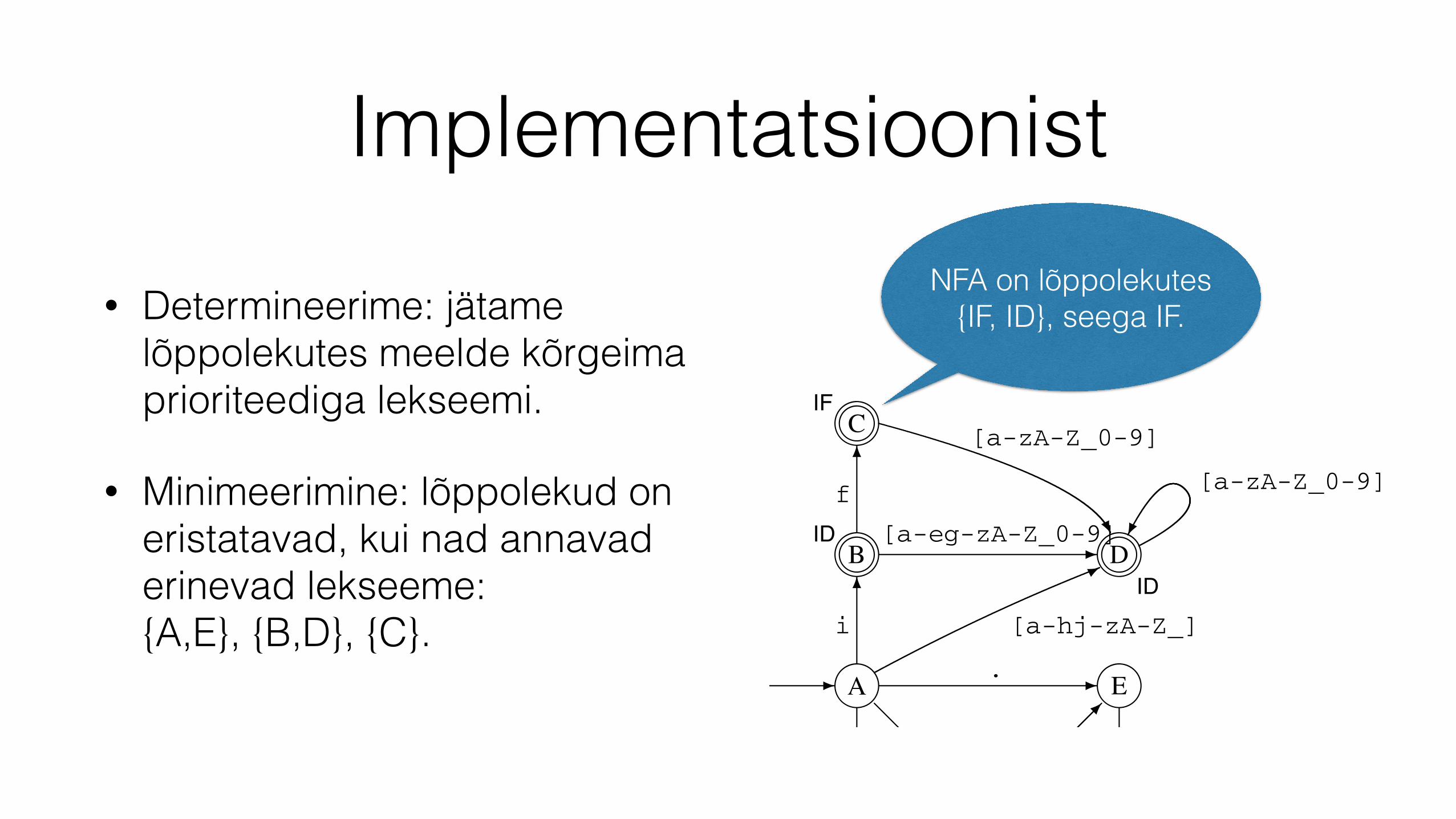
Implementatsioonist
• Determineerime: jätame lõppolekutes meelde kõrgeima prioriteediga lekseemi.
• Minimeerimine: lõppolekud on eristatavad, kui nad annavad erinevad lekseeme: {A,E}, {B,D}, {C}.
NFA on lõppolekutes {IF, ID}, seega IF.1.8 Lexers and Lexer Generators 27
Fig. 1.13 Combined DFAfor several tokens
!
!"C"
[a-zA-Z 0-9]IF
!"B#
f
![a-eg-zA-Z 0-9]ID !"D$[a-zA-Z 0-9]
ID
!A#
i
%
[a-hj-zA-Z ]
!.
&
[0-9]
''''(
[+-]
!E
&
[0-9]!F ))))*.
))
))+[0-9]
!"G !.
''''(
[eE],
[0-9]
NUM !"H$[0-9]
))
))+[eE]
FLOAT
!I''''(
[0-9]))
))+
[+-]
!J ![0-9] !"K$[0-9]
FLOAT
As an example, consider lexing of the string 3e-y with the DFA in Fig. 1.13.We get to the accepting state G after reading the digit 3. However, we can continuemaking legal transitions to state I on e and then to state J on - (as these could be thestart of the exponent part of a real number). It is only when we, in state J, find thatthere is no transition on y that we realise that this is not the case. We must now goback to the last accepting state (G) and output the number 3 as the first token andre-insert - and e in the input stream, so we can continue with e-y when we lookfor the subsequent tokens.
Lexical Errors If no prefix of the input string forms a valid token, a lexical er-ror has occurred. When this happens, the lexer will usually report an error. At thispoint, it may stop reading the input or it may attempt continued lexical analysis byskipping characters until a valid prefix is found. The purpose of the latter approachis to try finding further lexical errors in the same input, so several of these can becorrected by the user before re-running the lexer. Some of these subsequent errorsmay, however, not be real errors but may be caused by the lexer not skipping enoughcharacters (or skipping too many) after the first error is found. If, for example, thestart of a comment is ill-formed, the lexer may try to interpret the contents of thecomment as individual tokens, and if the end of a comment is ill-formed, the lexer

Nüüd väike quiz!Olgu järgmine leksiline spetsifikatsioon:
T1: a T2: a*b
Millise sõne puhul on leksimine kõige aeglasem? Ja kui aeglane see on (keerukus, kui n on sisendi pikkus)?
1. a
2. aaaaaaaaaa
3. aaaaaaaaaab

Käsitsi tehes (kodutöö)StringBuilder sb = new StringBuilder(); while (Character.isLetter(peek())) { sb.append(peek()); consume(); } String identOrIf = sb.toString(); if (identOrIf.equals("if")) { return new Token(IF); } else { return new Token(IDENT, identOrIf); }
Siin loeme kuni ,,automaat”
sureb.
Tähtis on siin aru saada, mida lekser peab tegema (maximal munch), aga selleks me ei pea
päris lekserit simuleerima.





























