Embed Size (px)
Citation preview

Mastère ASIG / Projet Bibliographique 2008 1
P7 : Projet Bibliographique
Dans le cadre du Mastère ASIG
Les Systèmes Experts
Etat de l’art et application possible aux SIG
Marion Charbonnier
25 Avril 2008

Mastère ASIG / Projet Bibliographique 2008 2
TABLE DES MATIERES
1 UTILITE D’UN SYSTEME EXPERT 5
1.1 INTRODUCTION 5
1.2 HISTORIQUE 6
1.3 POURQUOI EMPLOYER UN SYSTEME EXPERT 7 1.3.1 Le fleuron de l’intelligence artificielle 7
1.3.1.1 L’intelligence artificielle 7 1.3.1.2 L’humain en tant que processeur d’information 8
1.3.2 Le système expert par rapport au système conventionnel 9 1.3.3 Les Systèmes Experts en milieu professionnel 9 1.3.4 Les avantages 11
1.4 PRE-REQUIS 12
2 COMPOSITION DES SYSTEMES EXPERTS 14
2.1 DIFFERENTS TYPES DE SYSTEMES EXPERTS 14
2.2 CONCEPT 15 2.2.1 La base de connaissance 15 2.2.2 Le moteur d’inférence 16 2.2.3 L’interface graphique 17 2.2.4 Les métadonnées et les métarègles 17
2.3 MISE EN PLACE 17
3 FONCTIONNEMENT DES SYSTEMES EXPERTS 20
3.1 PROPRIETE DU MOTEUR D’INFERENCE 20 3.1.1 Le chaînage avant 20 3.1.2 Le chaînage arrière 22 3.1.3 Le chaînage mixte 23
3.2 CYCLE D’UN SYSTEME EXPERT 23 3.2.1 Engagement des paramètres 23 3.2.2 Application des règles d’inférence 24 3.2.3 Enregistrement des résultats 24 3.2.4 Engagement des paramètres, bis 25 3.2.5 Rendu du résultat 26
4 LIMITES ACTUELLES DES SYSTEMES EXPERTS 27
5 EXEMPLE : ACTE 28
5.1 RESUME 28
5.2 INTRODUCTION 29
5.3 LA MODELISATION DES TACHES D’ANALYSE 29 5.3.1 Les Fonctions d’analyse à assister 29 5.3.2 Théories sous-jacentes 30 5.3.3 Le texte comme objet sémiotique 30

Mastère ASIG / Projet Bibliographique 2008 3
5.3.4 Les analyses documentaires comme des applications particulières d’un processus de lecture 30 5.3.5 L’intertextualité 31
5.4 L’APPROCHE 31 5.4.1 Les sources de données 31 5.4.2 Les traitements sur les données linguistiques 32
5.5 L’ENQUETE COGNITIVE 33
5.6 COMPLEMENTARITE DES APPROCHES 33
5.7 EXEMPLE D’INDICES PERTINENTS RETENUS POUR MODELISER LES DIFFERENTES OPERATIONS D’ANALYSE 34
5.8 LES PROPOSITIONS D’ENRICHISSEMENTS DES OUTILS DOCUMENTAIRES 34 5.8.1 Les modifications à apporter au plan de classification 34 5.8.2 Les études effectuées sur l’utilisation du thésaurus 35
5.9 LA REALISATION DU PROTOTYPE DE SYSTEME EXPERT 35 5.9.1 La tâche à informatiser 36 5.9.2 Motivation du choix de la technologie des systèmes experts 36 5.9.3 Les incertitudes reliées à cette entreprise 37 5.9.4 L’arrimage du Système Expert avec l’analyse de textes par ordinateur 37 5.9.5 Le design de la chaîne de traitement des documents 38 5.9.6 Les aménagements apportés au traitement standard de l’incertitude 38 5.9.7 La réalisation de la base de règles par apprentissage 38 5.9.8 Les problèmes laissés en suspens 40
5.10 CONCLUSION 40
6 UN SYSTEME EXPERT DANS LE GEODECISIONNEL ? 43
6.1 LES SYSTEMES EXPERTS ET LES SIG 43
6.2 NECESSITE 44
6.3 CONSTRUCTION DU SYSTEME EXPERT 45
6.4 LA SELECTION D’OUTILS INFORMATIQUES 47
7 REFERENCES BIBLIOGRAPHIQUES 49
7.1 LIVRES 49
7.2 DOCUMENTS DIVERS 49
7.3 SCHEMAS 49
CONCLUSION 50
ANNEXES 51

Mastère ASIG / Projet Bibliographique 2008 4
TABLE DES ILLUSTRATIONS
FIGURE 1 : SCHEMA CONCEPTUEL D’UN SYSTEME EXPERT 15
FIGURE 2 : COMPOSANTS D’UN SYSTEME EXPERT 20
FIGURE 3 : CHAINAGE AVANT 21
FIGURE 4 : CHAINAGE ARRIERE 22
FIGURE 5 : APPEL AUX DONNEES PAR LES METAREGLES 23
FIGURE 6 : APPLICATION DES REGLES D’INFERENCE 24
FIGURE 7 : ENREGISTREMENT DES RESULTATS 25
FIGURE 8 : RAPPELS DES FAITS PAR LES METAREGLES 25
FIGURE 9 : PROPOSITION A L’UTILISATEUR DE LA SOLUTION POTENTIELLE 26
FIGURE 10 : ENREGISTREMENT EN TANT QUE SOLUTION VALIDEE 26
FIGURE 11 : CHAINE DE TRAITEMENT COMBINANT ANALYSE DE TEXTE ET SE 42
FIGURE 12 : FONCTIONNEMENT GENERAL 43
FIGURE 13 : RELATION MOTEUR D’INFERENCE – SIG 44
FIGURE 14 : LES STADES DU GENIE COGNITIF SELON WATERMAN 45
FIGURE 15 : FONCTIONNALITES D’UN TEL SYSTEME EXPERT 47

Mastère ASIG / Projet Bibliographique 2008 5
1 UTILITE D’UN SYSTEME EXPERT
1.1 INTRODUCTION
Un système expert se caractérise par son aspect intelligent, du fait même qu’il soit une
technologie emblématique de l’intelligence artificielle. Mais qu’est-ce que l’intelligence ?
Si l’on considère l’aspect étymologique, on trouve plusieurs définitions qui se complètent
mutuellement : l’intelligence c’est donc « la faculté de connaître et de comprendre,
incluant la perception, l'apprentissage, l'intuition, le jugement et la conception" (Petit
Robert), mais aussi « la faculté de connaître et de raisonner » (Dictionnaire American
Heritage), ou bien encore « l’application de la connaissance à la résolution de problèmes »
(Newell et Simon). Ce qui nous amène à se questionner quant à la connaissance. Celle-ci se
compose de données et d’inférences. Le concept de connaissance est donc lié à
l’interprétation des données et exige de ce fait un interprète, qui devra générer de
nouveaux faits à partir de données (inférence). On distingue trois techniques d’inférences :
• Déduction : (p ∧ (p → q)) ⇒ (q)
• Abduction : (q ∧ (p → q)) ⇒ peut-être(p)
• Induction: p(A) → q, p(B) → q, ... ⇒ ∀x ( p(x) → q)
La connaissance est donc définie par sa fonction, c.-à-d. par ce qu'elle fait et non pas par
son contenu structurel. On distingue deux sortes de connaissances : déclarative (expression
symbolique (abstraite) d’une compétence ; utilisée pour communiquer et pour raisonner
sur des connaissances) et procédurale (expression “compilée” d’une compétence ; utilisée
pour optimiser le temps d’exécution).
Une autre distinction est la connaissance “superficielle ” et la connaissance “profonde”.
La connaissance profonde est un modèle permettant le raisonnement par simulation, et la
connaissance superficielle est une expression symbolique des associations des faits
permettant un raisonnement “abstrait”. La plupart des systèmes experts fonctionnent avec
une connaissance “superficielle”.
Ainsi nous verront quelles peuvent être les raisons d’implémentation d’un Système Expert
(SE), quels en sont les différents composants et comment ces derniers fonctionnent et
quelles sont aujourd’hui les limites des Systèmes Experts. Puis nous aborderons l’exemple
d’un Système Expert Canadien appliqué au système juridique avant d’étudier la possibilité
d’un Système Expert dans le domaine de la géo-décisionnelle.

Mastère ASIG / Projet Bibliographique 2008 6
1.2 HISTORIQUE
Le premier système expert fut Dendral en 1965, créé par les informaticiens Edward
Feigenbaum, Bruce Buchanan, le médecin Joshua Lederberg et le chimiste Carl Djerassi. Il
permettait d'identifier les constituants chimiques d'un matériau à partir de spectrométrie
de masse et de résonance magnétique nucléaire, mais ses règles étaient mélangées au
moteur. Il fut par la suite modifié pour en extraire le moteur de système expert nommé
Meta-Dendral.
Le plus connu, peut-être, fut Mycin en 1972-73, système expert de diagnostic de maladies
du sang et de prescription de médicaments, avec un vrai moteur et une vraie base de
règles. Cependant ses règles étaient affectées de coefficients de vraisemblance qui
donnaient à chacune d'entre elles un poids particulier face aux autres. Le moteur
produisait un chaînage avant simple tout en calculant les probabilités de chaque
déduction, ce qui le rendait incapable d'expliquer la logique de son fonctionnement et de
détecter les contradictions. Quant aux experts, ils étaient obligés de trouver des
coefficients de vraisemblance pour chacune des conclusions de leurs règles, une démarche
compliquée et antinaturelle qui déniait leur capacité de raisonnement.
Le projet Sachem (Système d'Aide à la Conduite des Hauts fourneaux En Marche, chez
Arcelor), opérationnel dans les années 1990, est l'un des derniers projets « système
expert » à avoir vu le jour. Il est conçu pour piloter des hauts-fourneaux en analysant les
données fournies en temps réel par un millier de capteurs. Le projet a couté entre 1991 et
1998 environ 30 millions d'euros, et le système économise environ 1,7 euros par tonne de
métal.
Aujourd’hui, on compte des Systèmes Experts dans des domaines variés : Texas
Instruments (service clientèle) ou Stone & Webster (conseiller en calendrier de
production).

Mastère ASIG / Projet Bibliographique 2008 7
1.3 POURQUOI EMPLOYER UN SYSTEME EXPERT
1.3.1 Le fleuron de l’intelligence artificielle
1.3.1.1 L’intelligence artificielle
L’intelligence artificielle, c’est la capacité pour un système informatique d'atteindre un
niveau de performance qui se compare à celui de l'intelligence humaine dans certaines
circonstances, d’après Parker et Case. Elle repose sur l’informatique, la biologie, la
psychologie, la linguistique, les mathématiques et l’ingénierie. Son but est de concevoir
des ordinateurs qui peuvent penser, voir, entendre, parler et sentir.
Il a donc été dressé une liste des attributs d’un comportement intelligent :
• Penser et raisonner.
• Utiliser le raisonnement pour résoudre des problèmes.
• Acquérir des connaissances et les mettre en application.
• Apprendre et comprendre à partir de l'expérience.
• Faire preuve de créativité et d'imagination.
• Faire face à des situations complexes et confuses.
• Réagir rapidement de façon appropriée à de nouvelles situations.
• Reconnaître le degré d'importance des divers aspects d'une situation.
• Traiter efficacement données ambiguës, incomplètes ou erronées.
Les applications de l’intelligence artificielle sont diverses et se retrouve dans divers
domaines :
• Science cognitive: Systèmes Experts, systèmes d’apprentissage, logique
floue.
• Science informatique: ordinateurs de la 5e génération, traitement en
parallèle, réseaux neuronaux.
• Robotique: vision, touché, dextérité, locomotion, navigation.
• Interface naturelle: langage naturel, reconnaissance de la parole, interfaces
multi sensorielles.

Mastère ASIG / Projet Bibliographique 2008 8
1.3.1.2 L’humain en tant que processeur d’information
Dans le domaine de l’intelligence artificielle, il est primordial d’étudier le facteur humain,
trop souvent sous-estimé. Ce manque est pourtant la cause de nombreux échecs. Ce
facteur est laissé de côté par plusieurs spécialistes en information car l’humain constitue
un aspect plus « mou » et moins prévisible. En Informatique par exemple, on ne s'intéresse
qu’aux algorithmes, aux aspects "hard". Or, le système est utilisé par des personnes : les
utilisateurs. Ce sont eux qui devraient, la plupart du temps, définir le système.
En effet, l’humain sait :
• chercher les données utiles
• filtrer les données disponibles
• établir une représentation de son environnement
• transmettre une réponse à l'environnement
Néanmoins, Il est soumis aux difficultés liées à la surcharge d'information, aux erreurs de
filtrage, aux problèmes de distorsion et il dispose d'une capacité limitée, ce qui engendre
une rationalité limitée.
En considérant le système humain de traitement d’informations, on obtient les processus
cognitifs suivant :
• concepts, analogies métaphores
• inférences
• intuitif, instinctif et subjectif
Ainsi s’est développé le modèle de Newell et Simon comprenant un système sensoriel et
des effecteurs physiques. Le modèle possédait également des mémoires à court et à long
terme, un système de filtrage, des modèles de sélection et un style cognitif.
Tout ceci a permis de subdiviser la théorie de l’information en trois niveaux :
• Niveau technique
� Où le message se rend-il ? Réduction de l'incertitude, Redondance.
• Niveau sémantique
� Le message est-il compris? Améliorer la transmission.
� Contrôle et distribution : retarder, filtrer, biaiser, transmettre
l'interprétation.

Mastère ASIG / Projet Bibliographique 2008 9
• Niveau pratique (efficacité)
� Le message a-t-il un effet ? Changement de comportement.
� Utilité.
� Erreurs et biais.
1.3.2 Le système expert par rapport au système conventionnel
Conventionnel
• Analyse préalable
• Analyse préliminaire
• Analyse fonctionnelle
• Programmation
• Tests
• Implantation
Expert
• Étude d’opportunité
� Phase d’acquisition
• Identification des connaissances
• Conceptualisation des connaissances
� Phase de réalisation
• Formalisation des connaissances
• Prototypage
• Validation
• Implantation
1.3.3 Les Systèmes Experts en milieu professionnel
Les Systèmes Experts répondent au besoin de formalisation d’un savoir-faire (suppression
des hommes/postes clés) et au besoin d’aide à la décision.
Les Systèmes Experts sont présentement réalisés par des prestataires spécialisés par
domaine professionnel, sachant qu’un prestataire couvre un à deux domaines
professionnels maximum.

Mastère ASIG / Projet Bibliographique 2008 10
Les principaux clients des Systèmes Experts sont actuellement les laboratoires d’analyses
(biologique, mécanique, etc.) et les métiers de gestion des ressources en temps réel.
Néanmoins, on distingue quatre grandes catégories typologiques :
• Interprétation de données (diagnostic médical, de pannes, financiers,
prévisions météorologiques)
• Planification (prise de décision, ordonnancement)
• Conception (circuits électroniques, aménagement d’une cuisine,
configuration d’un système informatique)
• Enseignement
Les domaines d’application sont de ce fait nombreux :
• Aéronautique et espace :
� Aide au pilotage
� Planification du trafic aérien
� Contrôle de satellites : correction d’attitude, contrôle des opérations
de lancement
• Agriculture :
� Diagnostic de maladies et conseil thérapeutique en pathologie
végétale
� Aide au choix des semences, d’engrais
• Banque, finance, assurance
� Gestion financière
� Aide au placement
� Évaluation des risques de prêts
• Biotechnologies
� Conception de plan d’expérience en génétique moléculaire
� Interprétations de séquences d’acide nucléiques
• Chimie
� Aide à la synthèse de nouvelles molécules organiques
� Élucidation de la structure moléculaire 3D
• Droit, réglementation
� Étude de normes (sécurité, etc. …)
� Aide à l’utilisation de textes légaux
• Electronique
� Diagnostic de pannes de circuits, de centraux téléphoniques
� Aide à la conception de circuits VLSI

Mastère ASIG / Projet Bibliographique 2008 11
• Géologie
� Aide à la prospection géologique et minière
� Interprétation des carottes de forages
• Informatique
� Aide à la programmation
� Configuration de système informatique
� Aide à l’exploitation et à la maintenance
• Industrie
� Conduite de processus industriels
� Ordonnancements d’ateliers flexibles
� Surveillance, diagnostic de pannes, gestion d’incidents
• Mathématiques
� Calcul symbolique
� Aide à l’utilisation de bibliothèques de programmes
• Médecine
� Aide au diagnostic
� Aide à l’interprétation d’images
� Surveillance des malades en réanimation
• Militaire
� Identification et suivi de cibles
� Aide au pilotage d’engins (chars, hélicoptères, avions de chasse)
1.3.4 Les avantages
Les points forts d'un système expert en milieu professionnel sont :
• L'accessibilité à un utilisateur lambda d'un poste réservé jusqu’à lors à un
expert.
• La gestion simultanée de nombreuses ressources et contraintes.
• La traçabilité des décisions et actions entreprises.
• Les statistiques calculables à partir de la base de faits.
• L'utilisation comme outil d'analyse et de simulation du Système Expert.
• Meilleur rendement que les experts humains.

Mastère ASIG / Projet Bibliographique 2008 12
• Lisibilités des connaissances, aspect plus déclaratif que procédural.
• Construction incrémentale.
• Facilité de mise à jour
• Préservation de l’expertise.
• Avantages des Systèmes d’Information en général.
1.4 PRE-REQUIS
Avant de continuer plus en détail, nous allons avoir besoin de plus de vocabulaire, pour
cela nous allons définir quelques mots que nous retrouverons régulièrement par la suite :
Système Expert
Application capable d'effectuer dans un domaine des raisonnements logiques comparables
à ceux que feraient des experts humains de ce domaine. C'est avant tout un système d'aide
à la décision.
Moteur d'inférence
Partie d'un système expert qui effectue la sélection et l'application des règles en vue de la
résolution d'un problème donné.
Cognitique
La cognitique représente la partie appliquée des Sciences de la cognition et de la
connaissance. Elle s'intéresse aux mécanismes de la pensée, au traitement de l'information
par l'humain et aux systèmes anthropotechniques et propose des moyens de modélisation
de ces connaissances, en permettant leur imitation, leur substitution ou leur aide par des
moyens artificiels informatiques ou automatiques.
Cogniticien
Spécialiste des sciences de la pensée (sciences cognitives). Il travaille dans le domaine de
l'intelligence artificielle.
Metadata/Métadonnées

Mastère ASIG / Projet Bibliographique 2008 13
Les métadonnées, ou données sur les données, renseignent sur la nature, les
caractéristiques et la disponibilité des données. Elles rendent les données compréhensibles
et partageables pour les utilisateurs dans le temps.
Metarules/Métarègles
Règles contrôlant la sélection des règles à appliquer.
Expert
Professionnel qui connaît un domaine et qui est plus ou moins capable de transmettre ce
qu'il sait : par exemple, ce n'est pas le cas d'un enfant par rapport à sa langue maternelle.
Connaissances incertaines
Données dont il est très difficile de déterminer les valeurs exactes. Elles demandent alors
des quantificateurs pour signifier leurs valeurs et des probabilités pour les estimer.

Mastère ASIG / Projet Bibliographique 2008 14
2 COMPOSITION DES SYSTEMES EXPERTS
2.1 DIFFERENTS TYPES DE SYSTEMES EXPERTS
La plupart des Systèmes Experts existants reposent sur des mécanismes de logique formelle
(logique aristotélicienne) et utilisent le raisonnement déductif. Pour l'essentiel, ils
utilisent la règle d'inférence suivante (syllogisme) : si P est vrai (fait ou prémisse) et si on
sait que P implique Q (règle) alors, Q est vrai (nouveau fait ou conclusion).
Les Systèmes Experts sont classés selon la complexité des variables et du langage
d'évaluation. On en distingue 3 principaux types :
• 0 : Faits booléens sans variable.
Si la voiture ne démarre pas et les phares ne s'allument pas alors il n'y plus de batterie.
Il s'agit ici d'une version primaire des Système Experts qui n'est capable que d'évaluation
binaire. Ses capacités sont limitées mais ses performances sont en général excellentes. On
parle de logique des propositions, pouvant vraies ou fausses.
• 0+ : Symboliques, Réels, Priorités.
Si Age > 17 Alors statut = « Majeur ».
Ce type de Système Experts assimile la notion de priorité qui permet de faire passer
certains tests ou évaluations avant d'autres, leurs importances étant plus grande. Il intègre
aussi l'arrivée de nombres réels et les évaluations symboliques (<, >, =, !=).
• 1 : Variables et Quantificateurs.
Si Commutateur [M].status = libre alors Exec (PriseEnCharge, M).
A ce niveau de complexité, les Systèmes Experts savent gérer des variables (donc stocker
des informations pendant une évaluation) et peuvent utiliser des quantificateurs
(évaluation des connaissances incertaines) ou des états (ex : libre, occupé, transféré, en
attente...). Ils peuvent ainsi faciliter la description de problèmes réels grâce aux notions
de nécessité/possibilité ou à des coefficients de plausibilité. Ils s’appuient alors sur des
prédicats du premier ordre que des algorithmes permettent de manipuler aisément.
Mastère ASIG / Projet Bibliographique 2008 15
Comme pour toute application, plus elle est complexe, plus elle est lente. La forte
augmentation des puissances des gros systèmes permet de pallier ce problème. Néanmoins
cette complexité implique l'utilisation de langages de haut niveau (donc un peu plus lent)
et l'accès à une quantité d'informations telle qu'on se retrouve rapidement avec une
Système Expert « tortue ». L'utilisation d'une excellente algorithmique est donc
fondamentale dans la création des Systèmes Experts, ce qui limite ceux de niveau 1.
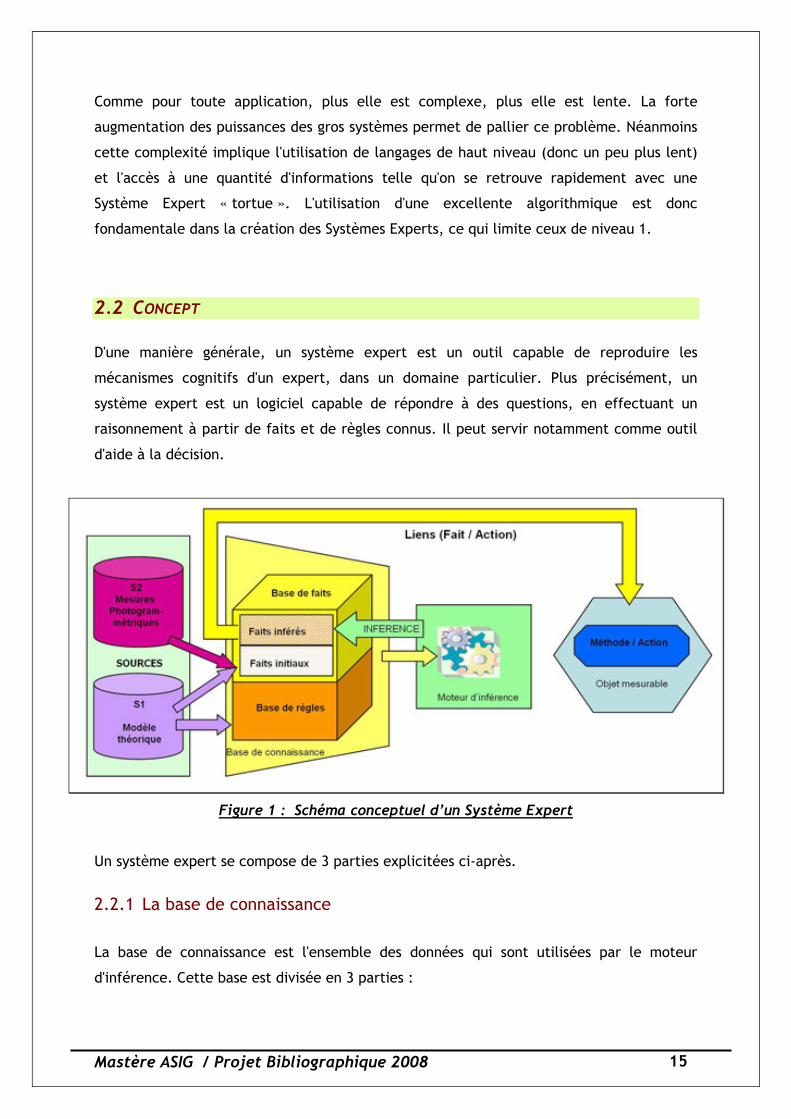
2.2 CONCEPT
D'une manière générale, un système expert est un outil capable de reproduire les
mécanismes cognitifs d'un expert, dans un domaine particulier. Plus précisément, un
système expert est un logiciel capable de répondre à des questions, en effectuant un
raisonnement à partir de faits et de règles connus. Il peut servir notamment comme outil
d'aide à la décision.
Figure 1 : Schéma conceptuel d’un Système Expert
Un système expert se compose de 3 parties explicitées ci-après.
2.2.1 La base de connaissance
La base de connaissance est l'ensemble des données qui sont utilisées par le moteur
d'inférence. Cette base est divisée en 3 parties :

Mastère ASIG / Projet Bibliographique 2008 16
• Les standards d'engagement (connaissances de l'expert)
Cette partie représente les informations de base et de configuration du système :
mesures (parfois en direct), lois, paramètres, données contractuelles.
• Les règles d'inférence (savoir-faire)
Cette partie représente l'ensemble des règles logiques de déduction utilisées par le
moteur d'inférence. Ce sont les heuristiques de résolution de problème représentant
les modes de raisonnement propres au domaine considéré. La connaissance de ces
heuristiques peut provenir, de la part de l'expert humain, soit d'une accumulation
d'observations empiriques, soit de connaissances techniques propres au domaine. La
partie gauche d’une règle est appelée une prémisse, la partie droite étant appelée
la conclusion. Les valeurs de la prémisse sont des valeurs de comparaison ; alors que
les valeurs de conclusion sont des valeurs d'affectation.
• La base de faits (expérience)
Historisation et statistique des faits effectifs, des décisions et des buts. Le
raisonnement va se baser sur ces faits pour déduire des conclusions, qui sont des
affectations d'attributs dont on ignorait les valeurs.
Afin de favoriser une plus grande maniabilité de la connaissance, il est fréquent de la
stocker de manière déclarative dans un langage clair, proche du langage naturel, et non
noyée dans des pages de code informatique. Grâce à ce type de représentation, la
connaissance du système sera facilement accessible à l'utilisateur qui pourra ainsi aisément
la modifier ou l'agrandir, ou encore simplement la consulter.
2.2.2 Le moteur d’inférence
Le moteur d'inférence (" KBES: Knowledge Base Expert System" en anglais) est un
mécanisme qui permet d'inférer des connaissances nouvelles à partir de la base de
connaissances du système. Il est basé sur des règles d'inférence qui régissent son
fonctionnement. Il a pour fonction de répondre à une requête de la part d'un utilisateur ou
d'un serveur afin de déclencher une réflexion définie par ses règles d'inférence qui
utiliseront la base de connaissance. Il peut alors fonctionner en chaînage avant (qui part
des faits et règles de la base de connaissance, et tente de s’approcher des faits recherchés
par le problème) ou chaînage arrière (qui part des faits recherchés par le problème, et
tente par l’intermédiaire des règles, de « remonter » à des faits connus). Il est à noter

Mastère ASIG / Projet Bibliographique 2008 17
toutefois qu'il reste important que la base de connaissance reste indépendante du moteur
d'inférence (sauf si elle contient les règles d'inférence elles-mêmes). Ce moteur
d’inférence est écrit dans un langage d’ »intelligence artificielle », tels que LISP ou
PROLOG.
2.2.3 L’interface graphique
Même si son importance est de taille dans tout application cliente, elle l'est d'autant plus
ici qu'un Système Expert doit parfaitement s'intégrer à un milieu professionnel et aux
habitudes de ses experts. Si celui-ci n'est pas capable de s'approprier naturellement le
logiciel, c'est que l'interface graphique n'est pas correcte. La priorité est donc à l'intuitivité
et à la représentation fidèle de l'environnement.
2.2.4 Les métadonnées et les métarègles
Les metadata (ou métadonnées en français) sont un des points névralgiques d'un système
expert. Elles sont en partie responsables de la vitesse d'accès aux données (pour les
metadata de la base de connaissances). Leurs qualités pour le moteur d'inférence
définissent sa vitesse et la puissance de calcul (il s'agit souvent du langage de
programmation). Il est donc peu étonnant de retrouver les langages de programmation les
plus rapide pour leur niveau de complexité (assembleur, C, C++).
Les metarules (ou métarègles en français) sont les règles permettant de régir l'utilisation
des règles d'inférence. Elles sont fortement liées au système de priorité qui permet de
savoir dans quel ordre appliquer les évaluations et tests. Elles forment un pré-mécanisme
de déduction des règles à appliquer qui les rendent directement responsables des
performances du Système Expert.
2.3 MISE EN PLACE
Dans cette partie, nous allons pouvoir voir comment mettre en place un Système Expert
dans un milieu professionnel. Cela se fait en 5 étapes :
1. Etude de faisabilité

Mastère ASIG / Projet Bibliographique 2008 18
La mise en place d'un Système Expert ne peut se faire que dans le cadre d'un domaine
d'expertise dont les connaissances et le savoir-faire est formalisable. C'est à dire un
domaine qui n'a pas trop attrait à la sensibilité humaine. L'investissement en temps et
(donc) en argent, pour la mise en place d'un Système Expert, est énorme et nombreuses
sont les entreprises qui souhaiteraient s'en doter mais tous les domaines d'expertise ne
sont pas formalisables. Le premier travail du cogniticien est donc d'évaluer le domaine et
les risques d'échecs de la mise en place et de succès de l'outil auprès des professionnels et
futurs utilisateurs.
2. Extraction des données
Une fois l'assurance que cette mise en place est possible, la partie la plus importante de
la mise en place va commencer. Il s'agit d'un dialogue entre le cogniticien et l'expert afin
d'extraire de ce dernier toutes ses connaissances et son savoir-faire. Un tel objectif est
évidemment impossible à atteindre, mais le cogniticien va tenter de s'en approcher au
maximum. Il devra pour cela faire preuve d'une grande compréhension des informations
qui lui seront transmises (les experts n'étant pas forcément bons pédagogues) et d'un
certain sens de la psychologie pour faire parler un expert qui aura tout naturellement le
sentiment de se faire très prochainement remplacer par un système informatique.
3. Formalisation
Après et pendant l'extraction des données, le cogniticien devra formaliser les
connaissances qu'il a récolté. Pour cette partie, il peut alors commencer à se tourner vers
les développeurs et autres professionnels techniques de l'informatique afin de commencer
à définir le cahier des charges précis, la base de connaissance et les règles d'inférence. A
partir de cette étape, on a déjà un pied dans la technique.
4. Design et développement
Une fois la base de connaissances et les règles d'inférences définies, le cogniticien peut
alors se retourner vers l'équipe technique qui va définir l'architecture technique
nécessaire. Le cogniticien aura à partir de là le rôle de lien entre l'équipe d'experts et
l'équipe de développement afin de peaufiner le cahier des charges et d'optimiser les
métadonnées et métarègles.
5. Tests et optimisations

Mastère ASIG / Projet Bibliographique 2008 19
Naturellement la mise en place se termine par une série de tests auprès des experts mais
aussi auprès d'utilisateurs lambdas qui sont sensés à partir de cet outil fournir les
résultats d'un expert débutant. De par la nature du système (immergé dans le domaine
professionnel) les tests sont généralement plus longs.
Concernant l’acquisition des données, notons qu’a fortiori si les algorithmes de
manipulation de faits et de règles sont nombreux et connus, la détermination de
l'ensemble des faits et règles qui vont composer la base de connaissances est un problème
délicat. Il faut décrire le comportement d'un expert face à un problème particulier, et sa
manière de le résoudre. Car ce que l'on souhaite obtenir n'est ni plus ni moins que
l'expérience, la connaissance pratique de l'expert, et non la théorie que l'on peut trouver
dans les livres ni exclusivement les règles logiques d'inférence. Equivalents des méthodes
d'analyse de l'informatique traditionnelle, des méthodes d'acquisition des connaissances
sont développées.

Mastère ASIG / Projet Bibliographique 2008 20
3 FONCTIONNEMENT DES SYSTEMES EXPERTS
Figure 2 : Composants d’un Système Expert
3.1 PROPRIETE DU MOTEUR D’INFERENCE
Le moteur d'inférence peut fonctionner selon 2 modèles : le chaînage avant et le chaînage
arrière...
3.1.1 Le chaînage avant
Le principe du chaînage avant est simple, il requiert l'accès aux prémisses (standards
d'engagement) afin de déclencher les règles d'inférence adéquates définies par les
métarègles. L'application des règles (évaluations) donnent des résultats, ceux-ci sont
évalués (par les métarègles) afin de savoir si l'on a accédé à une solution finale
potentielle. Si c'est le cas, on arrête et cette solution est proposée
Si ce n'est le cas, la solution est quand même proposée à l'utilisateur. S'il la valide, la
solution est enregistrée dans la base de faits comme solution, sinon comme simple résultat
et on continue dans le cas suivant.
Mastère ASIG / Projet Bibliographique 2008 21
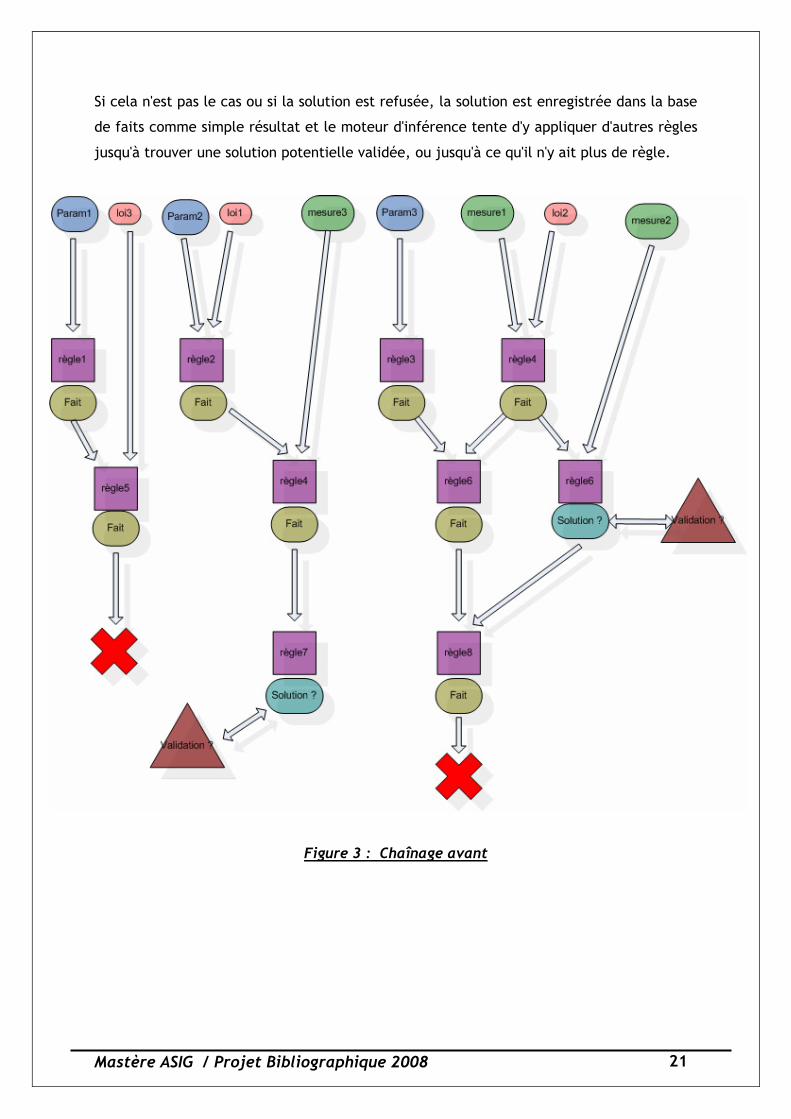
Si cela n'est pas le cas ou si la solution est refusée, la solution est enregistrée dans la base
de faits comme simple résultat et le moteur d'inférence tente d'y appliquer d'autres règles
jusqu'à trouver une solution potentielle validée, ou jusqu'à ce qu'il n'y ait plus de règle.
Figure 3 : Chaînage avant
Mastère ASIG / Projet Bibliographique 2008 22
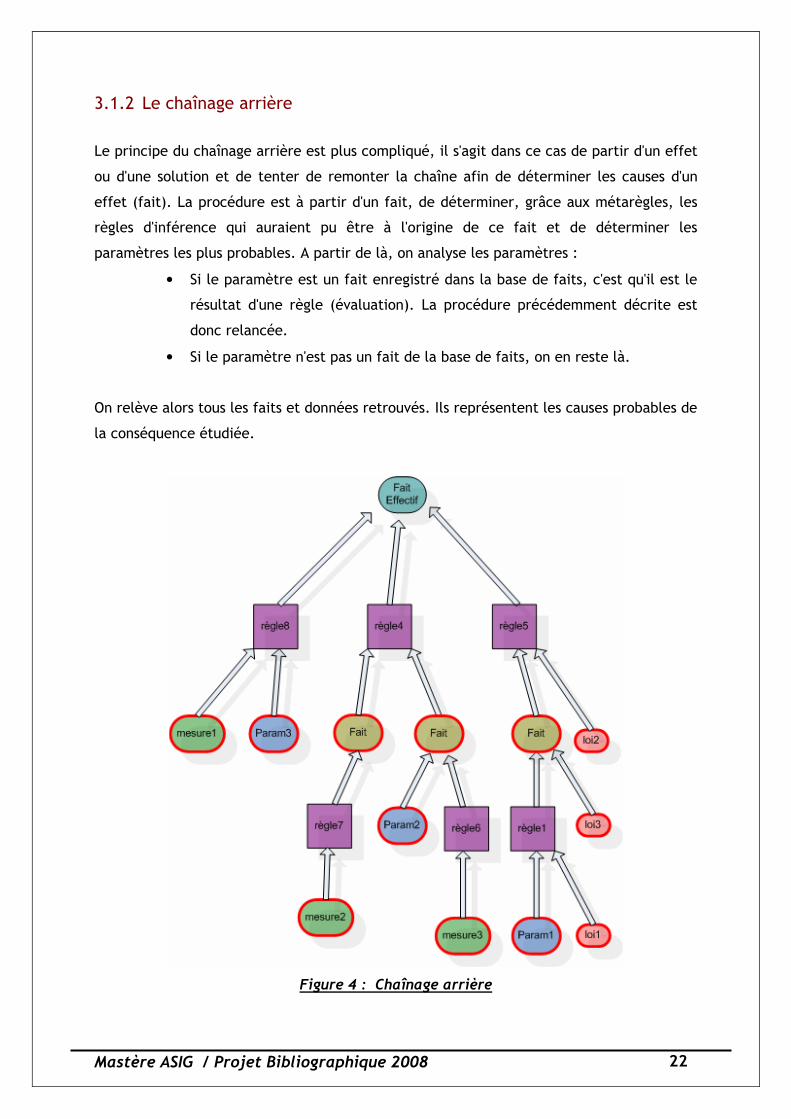
3.1.2 Le chaînage arrière
Le principe du chaînage arrière est plus compliqué, il s'agit dans ce cas de partir d'un effet
ou d'une solution et de tenter de remonter la chaîne afin de déterminer les causes d'un
effet (fait). La procédure est à partir d'un fait, de déterminer, grâce aux métarègles, les
règles d'inférence qui auraient pu être à l'origine de ce fait et de déterminer les
paramètres les plus probables. A partir de là, on analyse les paramètres :
• Si le paramètre est un fait enregistré dans la base de faits, c'est qu'il est le
résultat d'une règle (évaluation). La procédure précédemment décrite est
donc relancée.
• Si le paramètre n'est pas un fait de la base de faits, on en reste là.
On relève alors tous les faits et données retrouvés. Ils représentent les causes probables de
la conséquence étudiée.
Figure 4 : Chaînage arrière

Mastère ASIG / Projet Bibliographique 2008 23
3.1.3 Le chaînage mixte
Il existe un dernier mode de fonctionnement dit chaînage mixte qui combine les deux
chaînages précédents. De prime abord, il fonctionne comme le chaînage avant avec pour
but de déduire un fait donné. Cependant il applique un chaînage arrière sur chaque fait
trouvé afin de déterminer les paramètres les plus probables et les plus optimisés. Ce
mécanisme permet l'ouverture sur de nouvelles combinaisons encore non envisagées par les
règles d'inférence et de déterminer les facteurs discriminants lors de la recherche d'une
solution.
3.2 CYCLE D’UN SYSTEME EXPERT
Un système expert fonctionne selon un cycle en cinq temps.
3.2.1 Engagement des paramètres
Dans un premier temps, le Système Expert doit obtenir les connaissances (de tout type :
loi, paramètre, mesure, saisie utilisateur...) et l'objectif. Les métarègles font donc appel
aux données.
Figure 5 : Appel aux données par les métarègles
Mastère ASIG / Projet Bibliographique 2008 24
Notons que chaque accès à la base de connaissances fait appel aux métadonnées qui
régissent l'accès à ces données. Sachant que les métadonnées sont utilisées plusieurs fois à
chaque engagement des paramètres, il est évident que leur implémentation est
primordiale, notamment sur le plan algorithmique.
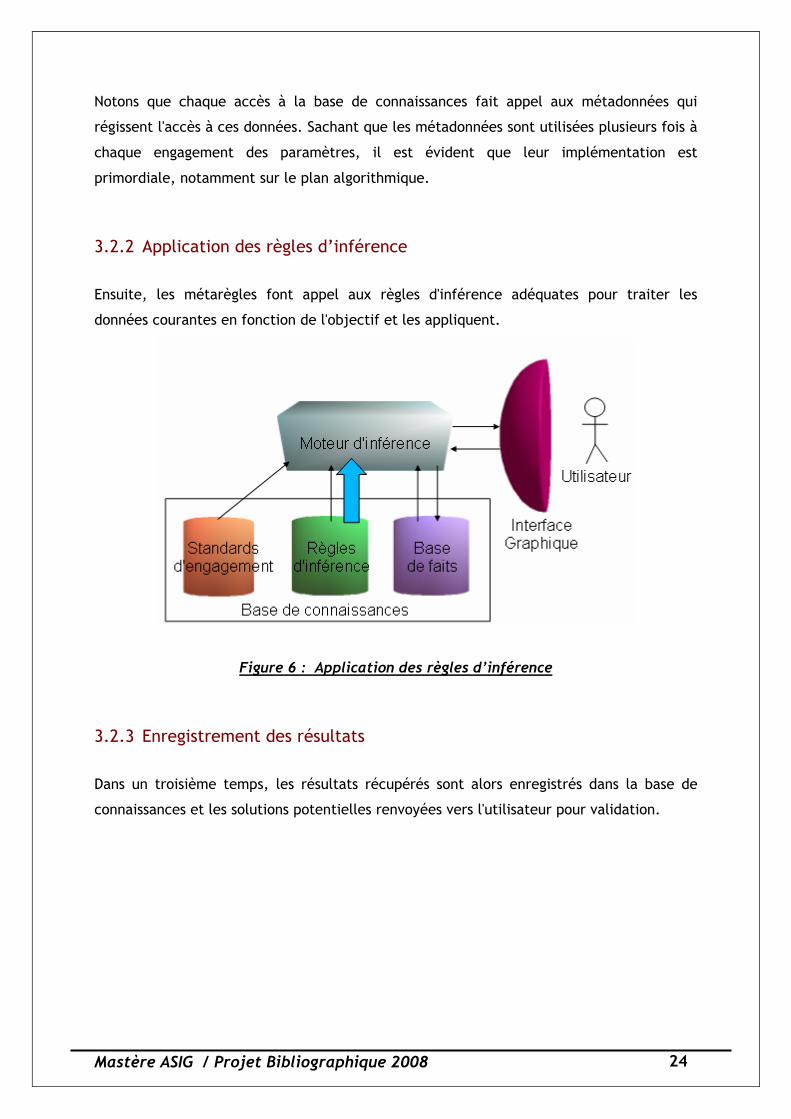
3.2.2 Application des règles d’inférence
Ensuite, les métarègles font appel aux règles d'inférence adéquates pour traiter les
données courantes en fonction de l'objectif et les appliquent.
Figure 6 : Application des règles d’inférence
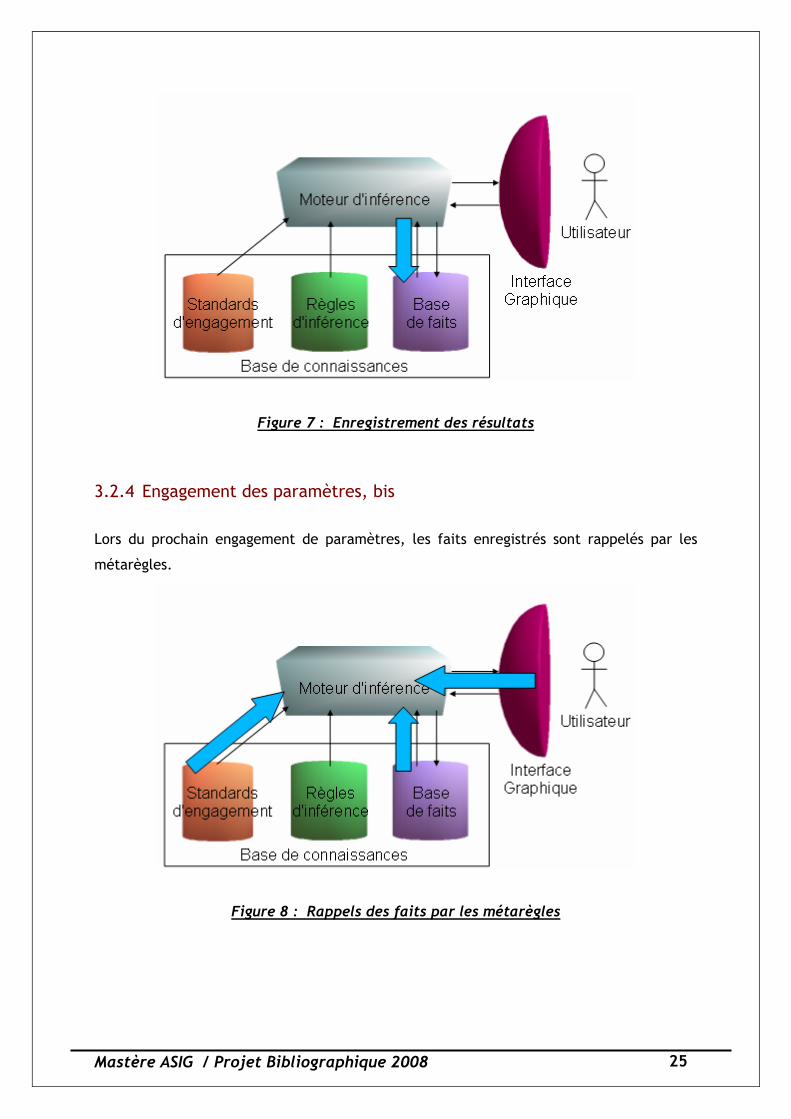
3.2.3 Enregistrement des résultats
Dans un troisième temps, les résultats récupérés sont alors enregistrés dans la base de
connaissances et les solutions potentielles renvoyées vers l'utilisateur pour validation.
Mastère ASIG / Projet Bibliographique 2008 25
Figure 7 : Enregistrement des résultats
3.2.4 Engagement des paramètres, bis
Lors du prochain engagement de paramètres, les faits enregistrés sont rappelés par les
métarègles.
Figure 8 : Rappels des faits par les métarègles
Mastère ASIG / Projet Bibliographique 2008 26
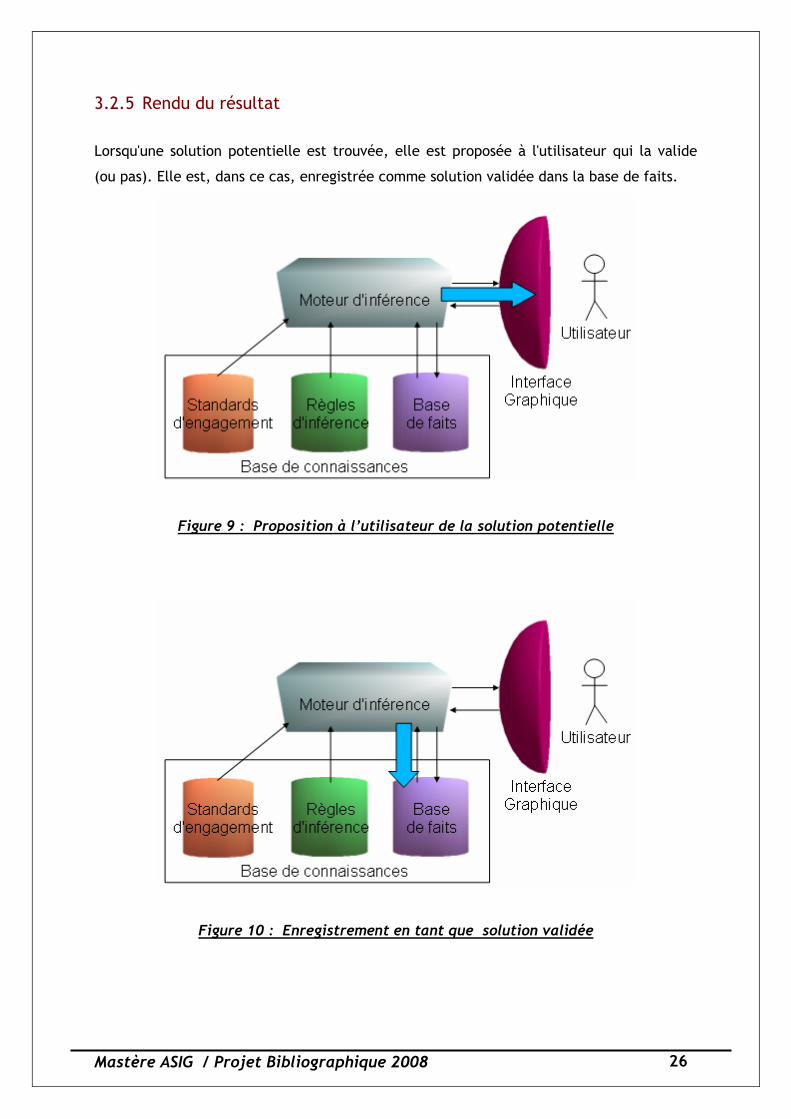
3.2.5 Rendu du résultat
Lorsqu'une solution potentielle est trouvée, elle est proposée à l'utilisateur qui la valide
(ou pas). Elle est, dans ce cas, enregistrée comme solution validée dans la base de faits.
Figure 9 : Proposition à l’utilisateur de la solution potentielle
Figure 10 : Enregistrement en tant que solution validée

Mastère ASIG / Projet Bibliographique 2008 27
4 LIMITES ACTUELLES DES SYSTEMES EXPERTS
Aujourd’hui encore, les systèmes experts n’en sont qu’à leurs prémices et de ce fait, on
peut noter plusieurs bémols à leur efficacité. Ainsi, les points sensibles d'un système
expert en milieu professionnel sont :
• L'importance du système cognitif.
• Le gros investissement nécessaire (temps, coûts et hommes).
• L'algorithmique des métarègles/connaissances.
• La possibilité de formaliser le savoir-faire.
• La spécialisation, restrictive.
De plus, certaines tâches vont probablement toujours leur échapper (leur confier notre vie
dans le pilotage). D’autre part, il y a la nécessité de construire « à la main » l’ensemble de
la base de connaissance et l’absence quasi-totale d’apprentissage automatique. Il y a
également un manque de connaissance du Système Expert sur ses propres limites de
compétence.
Les systèmes experts ont eu leur heure de gloire dans les années 1980, où on a trop
rapidement pensé qu'ils pourraient se développer massivement. En pratique, le
développement de ce genre d'application est très lourd car, lorsque l'on dépasse la
centaine de règles, il devient difficile de comprendre comment le système expert
« raisonne » (manipule faits et règles en temps réel), et donc d'en assurer la mise au point
finale puis la maintenance.

Mastère ASIG / Projet Bibliographique 2008 28
5 EXEMPLE : ACTE
5.1 RESUME
Pour faire face à l’afflux prochain de jugements sur support informatique, une équipe de
recherche constituée de chercheurs du Centre d’Analyse et de textes pas Ordinateur (ATO)
de l’Université du Québec à Montréal et de l’Ecole de bibliothéconomie et des sciences de
l’information de l’Université de Montréal a présenté un projet de conception de système
expert pour assister l’analyse des jugements. Cette recherche, en cours de réalisation,
bénéficie d’une subvention du CEFRIO (Centre Francophone de Recherche en
Informatisation des Organisations) à laquelle contribuent à la fois SOQUIJ (Société
Québécoise d’Information Juridique) et le ministère des communications du Québec dans
le cadre du projet Delta.
Ainsi, afin d’assister les conseillers juridiques de la SOQUIJ, un prototype de système
expert pour l’aide à la sélection, à la classification, à la lecture et à l’indexation des
jugements a été implanté sur ACTE (Atelier Cognitif et TExtuel) développé au Centre de
recherche en information et cognition ATO.CI. À partir d’un corpus d’apprentissage de
textes déjà analysés et grâce à des traitements statistico-linguistiques sur SATO (Système
d’Analyse de Textes par Ordinateur) et SPSS (Statistical Package for the Social Sciences),
les données issues de l'analyse humaine ont été confrontées à celles des textes intégraux;
des tendances et des anomalies ont pu être décelées qui ont servi à questionner les outils
et les pratiques, ainsi qu'à réorienter ou à corroborer l'enquête cognitive des savoir-faire.
Une fois identifiés les types d’unités linguistiques et leurs propriétés généralement retenus
par les spécialistes pour chacune des opérations d’analyse, une chaîne de traitements est
mise au point, pour chacun des modules du système expert et à partir du plus grand
nombre possible de sources de connaissances, dépiste et décrit les indices pertinents, puis
les transforme en faits. Ceux-ci s'avérant distincts les uns des autres, un diagnostic peut
être porté, à chaque étape, selon un principe de convergence. Toutefois, quelques
difficultés concernant le cumul des coefficients de certitude et l’intégration de
statistiques nécessitent des études plus poussées.

Mastère ASIG / Projet Bibliographique 2008 29
5.2 INTRODUCTION
Au Québec, la cueillette, la sélection, le traitement et la diffusion de la jurisprudence sont
sous la responsabilité principale d'un organisme parapublic : SOQUIJ. La loi constituant la
Société québécoise d'information juridique, entrée en vigueur le 1er avril 1976, lui confie
le mandat de "promouvoir la recherche, le traitement et le développement de
l'information juridique en vue d'en améliorer la qualité et l'accessibilité au profit de la
collectivité." À ce titre, SOQUIJ est le serveur des bases de données du ministère de la
Justice ainsi que le producteur/serveur de plusieurs autres bases de données, dont celles
qui concernent la jurisprudence.
Or, la saisie électronique des jugements à la source mise en place progressivement par le
ministère de la Justice du Québec multipliera presque par cinq le nombre de jugements
acheminés à SOQUIJ : la quantité annuelle prévue est de 50 000. Pour maintenir son niveau
de service sans accroître indûment son personnel, cet organisme a envisagé de recourir à
des méthodes automatiques pour assister certaines des opérations intellectuelles d’analyse
effectuées par des conseillers juridiques, et a confié à une équipe de recherche de
Montréal le mandat de concevoir un prototype de système expert. Celui-ci a été réalisé sur
le logiciel ACTE (Atelier Cognitif et TExtuel) développé au Centre ATO.CI.
Après avoir expliqué en quoi consistent les différentes fonctions d’analyse qu’il a fallu
modéliser, nous évoquerons les éléments théoriques sur lesquels s’appuie la démarche et
nous montrerons comment celle-ci combine des approches complémentaires (statistiques,
linguistiques et cognitives); nous l’illustrerons ensuite par quelques exemples d’indices
extraits pour chaque type d’analyse. Puis nous mentionnerons les principaux
enrichissements du thésaurus nécessités par les nouvelles fonctions qu’il est appelé à
remplir dans un système automatique. Finalement, nous exposerons l’implantation des
stratégies d’analyse dans un programme de chaîne de traitement et l’intégration
d’informations de sources et de valeurs différentes.
5.3 LA MODELISATION DES TACHES D’ANALYSE
5.3.1 Les Fonctions d’analyse à assister Après entente avec les représentants de SOQUIJ, il a été convenu de concevoir un système
qui assisterait les tâches suivantes : 1) élimination à la source de certains jugements
(étape de la sélection); 2) détermination du (ou des) domaine(s) du droit et, le cas

Mastère ASIG / Projet Bibliographique 2008 30
échéant, du sous-domaine (selon un plan de classification préétabli) auquel chaque
décision retenue appartient (étape du tri et de la classification); 3) prise de connaissance
du contenu des textes en vue de la rédaction d’un résumé informatif; 4) sélection de
termes d'indexation à partir du résumé rédigé par les conseillers juridiques.
5.3.2 Théories sous-jacentes La méthodologie élaborée est sous-tendue par au moins trois orientations théoriques : le
texte comme objet sémiotique, les analyses documentaires comme des applications
particulières d’un processus de lecture, et finalement l’intertextualité.
5.3.3 Le texte comme objet sémiotique Le texte est envisagé comme un objet sémiotique complexe dans lequel un lecteur humain
ou informatique sélectionne, à des niveaux multiples, des indices pertinents en fonction de
ses objectifs d’analyse (Meunier, 1992; Meunier et al. 1994). Les chaînes de caractères ou
mots sont autant de porteurs de traits signifiants. Les processus cognitifs d’interprétation
humaine étant fonction de nombreux éléments dont la plupart ne sont guère formalisables
(systèmes de croyance, intentions, connaissances du contexte textuel et extratextuel,
etc.), un système entièrement automatique est impossible à envisager : seul un mécanisme
d’aide à l’interprétation est réalisable qui permet d’identifier et de manipuler certains des
indices pertinents décelables par divers analyseurs.
5.3.4 Les analyses documentaires comme des applications particulières d’un processus de lecture
Les opérations d’analyses effectuées dans un service documentaire sont envisagées comme
des lectures particulières dirigées par des tâches spécifiques à accomplir : attribution
d’une rubrique de classification, assignation de mots-clés, condensation du texte, entre
autres. Ces lectures mettent en jeu diverses opérations cognitives de sélection, rejet,
généralisation (Van Dijk, 1977), stratégies de confirmation et contrôle, etc. (David, 1990)
portant sur des indices ou configurations d’indices dont la pertinence varie en fonction de
chaque type de lecture. À chaque tâche d’analyse correspond donc un parcours particulier
du texte. La décision d’inclure un document dans une base de données - ou de le rejeter –
n’exige pas la prise en compte du même nombre ni des mêmes types d’indices que
l’opération d’indexation. La rédaction d’un résumé requiert une prise de connaissance plus
approfondie du contenu textuel que l’attribution d’une rubrique de classification, mais

Mastère ASIG / Projet Bibliographique 2008 31
exige un examen moins attentif cependant que la comparaison des thèses défendues par
un texte avec celles d’un autre texte.
5.3.5 L’intertextualité De par la nature même de leur condition de production, les textes secondaires sont en
relation d’intertextualité avec les textes primaires dont ils sont issus (Beacco et Darot,
1984) ainsi qu'avec les outils documentaires - thésaurus et plan de classification - servant à
effectuer l'analyse (Begthol, 1986). Comme nous l’avons exposé dans Bertrand-Gastaldy
(1993), la comparaison des propriétés des éléments présents dans les textes de départ et
retenus dans les différents textes d’arrivée (rubriques de classification, termes
d’indexation, résumés) avec celles des éléments qui ont été éliminés permet de découvrir
des tendances et des anomalies qui servent à orienter ou approfondir l’enquête cognitive
auprès des experts.
5.4 L’APPROCHE
Il ne s’agit pas de mettre au point un outil d’analyse qui serait performant en dehors de
tout contexte (par exemple un analyseur morphologique, un extracteur de lexies
complexes), mais bien au contraire de comprendre en quoi le contexte de la tâche faisait
varier les objets textuels et les propriétés des objets susceptibles de retenir l’attention
des experts. L’approche a dès lors consisté d’une part à modéliser les stratégies cognitives
mises en œuvre par les experts du domaine lors des différentes lectures effectuées en
fonction des produits attendus (liste des documents à éliminer, tri et classification,
résumé, indexation), d’autre part à faire évoluer les outils documentaires pour les rendre
aptes à répondre à l’utilisation automatique voulue.
5.4.1 Les sources de données Pour mener à bien ce travail, il y a disposition deux types de sources. L’équipe a eu accès
à une demi-douzaine de conseillers juridiques avec lesquels ils ont tenu plusieurs sessions
de travail afin d’arriver à connaître les critères explicites ou implicites auxquels ils
recourent pour prendre leurs décisions aux différentes étapes de leur analyse. D’autre
part, les données de nature linguistique se trouvaient déjà presque toutes sur support
informatique. Il s'agit des produits issus des différentes opérations d'analyse : textes

Mastère ASIG / Projet Bibliographique 2008 32
intégraux rejetés ou retenus, notices bibliographiques accompagnées des résumés, index,
ainsi que des outils utilisés pour l'analyse : plan de classification et thésaurus.
5.4.2 Les traitements sur les données linguistiques
Les caractéristiques attribuées aux données, en contexte ou hors contexte, ont consisté en
l'ajout d'informations de nature diverse décrivant le statut sémiotique des constituants du
texte et enrichissant les chaînes de caractères immédiatement accessibles à l'ordinateur.
Ces caractéristiques proviennent de connaissances générales de la langue (type de langue,
nature grammaticale des lexèmes), de connaissances générales sur la structure des textes
(phrases, paragraphes), d’informations de nature éditique (conventions typographiques -
capitales, caractères gras ou italiques - dans les enregistrements), de connaissances
spécifiques au domaine (vocabulaire de spécialité, structure des jugements et de leurs
résumés, mention de loi, de jurisprudence et de doctrine), de connaissances
"documentaires" (champs d'une notice, appartenance ou non des lexèmes aux langages
documentaires), de propriétés statistiques (fréquence absolue ou relative, indice de
répartition, valeur discriminante, chi 2, etc.). Ces informations ont été obtenues par des
algorithmes développés avec le logiciel SATO (système d’analyse et textes par ordinateur)
et ont fait l’objet d’un marquage approprié (propriété et valeur de propriétés dans SATO).
Voici quelques propriétés :
- les caractères typographiques *typo, avec les valeurs italique et nil.
- la numérotation des phrases *phr et leur ordre *ord (pr pour première, deux pour
deuxième, ad pour avant-dernière, de pour dernière).
En se positionnant sur un mot, on peut visionner, à l’aide d’une commande du logiciel
SATO, toutes les valeurs de propriétés (ou traits) qui lui ont été attribuées, y compris
celles qui résultent de calculs statistiques effectués par le logiciel :
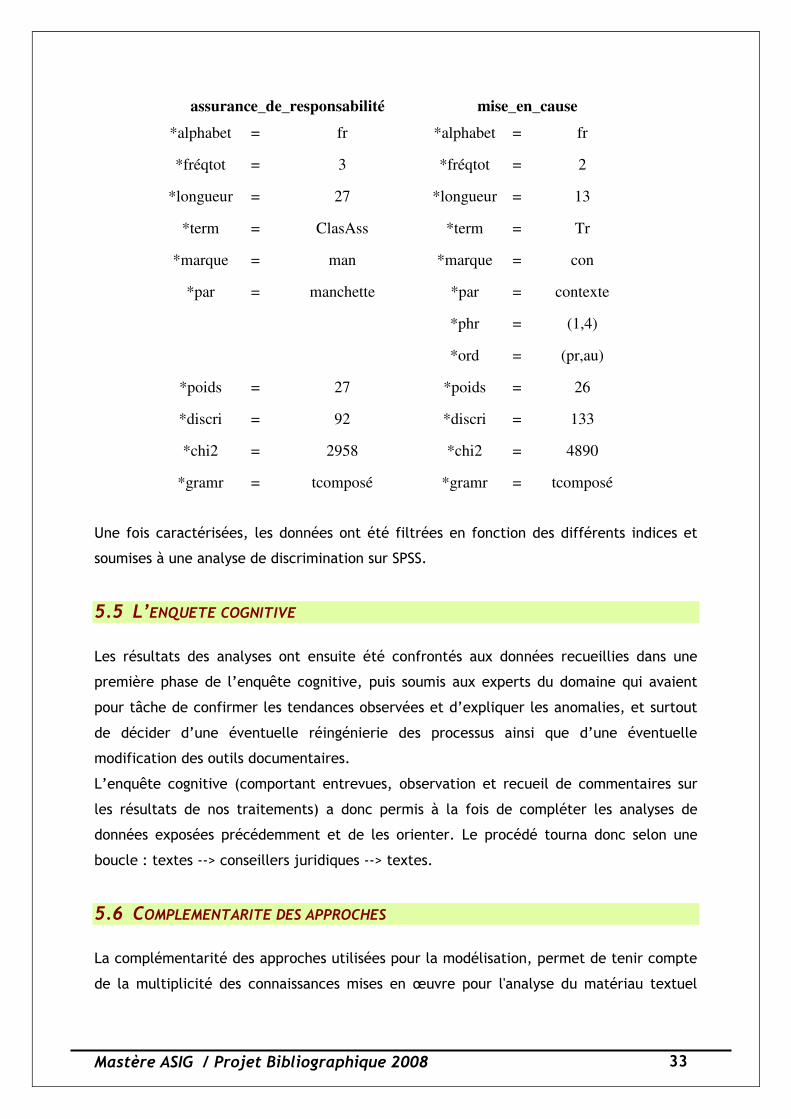
Mastère ASIG / Projet Bibliographique 2008 33
assurance_de_responsabilité mise_en_cause
*alphabet = fr *alphabet = fr
*fréqtot = 3 *fréqtot = 2
*longueur = 27 *longueur = 13
*term = ClasAss *term = Tr
*marque = man *marque = con
*par = manchette *par = contexte
*phr = (1,4)
*ord = (pr,au)
*poids = 27 *poids = 26
*discri = 92 *discri = 133
*chi2 = 2958 *chi2 = 4890
*gramr = tcomposé *gramr = tcomposé
Une fois caractérisées, les données ont été filtrées en fonction des différents indices et
soumises à une analyse de discrimination sur SPSS.
5.5 L’ENQUETE COGNITIVE
Les résultats des analyses ont ensuite été confrontés aux données recueillies dans une
première phase de l’enquête cognitive, puis soumis aux experts du domaine qui avaient
pour tâche de confirmer les tendances observées et d’expliquer les anomalies, et surtout
de décider d’une éventuelle réingénierie des processus ainsi que d’une éventuelle
modification des outils documentaires.
L’enquête cognitive (comportant entrevues, observation et recueil de commentaires sur
les résultats de nos traitements) a donc permis à la fois de compléter les analyses de
données exposées précédemment et de les orienter. Le procédé tourna donc selon une
boucle : textes --> conseillers juridiques --> textes.
5.6 COMPLEMENTARITE DES APPROCHES
La complémentarité des approches utilisées pour la modélisation, permet de tenir compte
de la multiplicité des connaissances mises en œuvre pour l'analyse du matériau textuel

Mastère ASIG / Projet Bibliographique 2008 34
orientée vers des fins documentaires. Elle constitue un heureux compromis qui tient
compte de caractéristiques exigeant parfois des solutions contradictoires, dans l'état de
développement actuel des technologies : matériau textuel très complexe à analyser, mais
nécessitant néanmoins des approches de nature linguistique et cognitive, volume
important des données prohibant des analyses très fines et pouvant bénéficier des effets
de nombre, savoir-faire de plusieurs experts à expliciter, selon des méthodes appropriées à
leur mode d'inscription, de façon à respecter la culture de l'organisation.
5.7 EXEMPLE D’INDICES PERTINENTS RETENUS POUR MODELISER LES DIFFERENTES OPERATIONS D’ANALYSE
Ci-dessous, quelques exemples d’indices utilisés par les conseillers juridiques pour chacune
des opérations d’analyse qu’il a fallu modéliser et sont fournies des indications sur la place
qui leur a été réservée dans le prototype.
� La sélection
� La tri-classification
� La prise de connaissance du contenu du jugement en vue de la rédaction du résumé
� L’indexation
5.8 LES PROPOSITIONS D’ENRICHISSEMENTS DES OUTILS DOCUMENTAIRES
Tout au cours du projet, il a fallu étudier l’utilisation des outils documentaires et
introduire des modifications qui facilitaient le travail de marquage automatique,
modifications qui pourraient même être utiles dans le contexte d’une analyse humaine.
5.8.1 Les modifications à apporter au plan de classification
Examiner la possibilité de subdiviser deux classes fortement représentées et de recourir
davantage aux subdivisions pour le repérage des notices dans une base de données
automatisée, de façon à permettre une sélection relativement fine aux utilisateurs ayant
un domaine particulier en tête.

Mastère ASIG / Projet Bibliographique 2008 35
5.8.2 Les études effectuées sur l’utilisation du thésaurus
Le marquage des termes nécessaire à plusieurs des traitements, de même que le désir de
mieux évaluer dans quelle mesure le thésaurus répondait aux besoins d'indexation tels
qu'implicitement fixés par les conseillers juridiques, ont conduit à effectuer une série
d'études complémentaires. En outre, en calculant la force d’association des termes avec
les rubriques (selon une méthode qui tient compte de la fréquence), nous sommes
désormais en mesure d’amorcer une structuration du vocabulaire par domaine de droit et
donc de concevoir une réconciliation de deux outils documentaires (qui se recoupent et se
contredisent parfois).
Bref, la richesse des analyses effectuées permet d’offrir une multitude de points de vue
sur l’utilisation effective (plutôt que souhaitée lors de la conception) de ces outils, au fil
des ans, par plusieurs personnes. Il a donc été soumis à SOQUIJ non seulement un portrait
des outils et des pratiques actuelles, mais des suggestions très détaillées pour
l’enrichissement et la modification de ces outils et de ces pratiques.
Les résultats des différentes études, ont amené à conclure que le thésaurus devait être
enrichi; d'abord pour contrôler une indexation qui s'avère, dans les faits, plus spécifique
que ce que permet l'outil actuel, ensuite parce que le système expert doit pouvoir repérer
toutes les formes possibles d'un descripteur dans les résumés et éventuellement, dans les
textes intégraux pour les ramener aux formes souhaitées pour l'indexation, enfin parce
que, une fois les descripteurs organisés selon une hiérarchie stricte, il devient possible
d’opter pour différents niveaux de généricité selon les produits documentaires (en fonction
notamment de leur périodicité, de leur support et de leur couverture du domaine).
5.9 LA REALISATION DU PROTOTYPE DE SYSTEME EXPERT
La section précédente exposait la modélisation (méthode et résultats) effectuée pour
l’aide à la sélection, à la classification, à la lecture et à l’indexation des jugements; la
présente section traite de l'implantation réalisée du modèle. Les aspects suivants sont
touchés : la tâche à informatiser; la motivation du choix de la technologie des systèmes
experts; l'incertitude reliée à cette entreprise; l'arrimage du système expert avec l'analyse
de textes par ordinateur; le design de la chaîne de traitement des documents; les
aménagements apportés au traitement standard de l'incertitude; la réalisation de la base
de règles par apprentissage et les problèmes laissés en suspens.

Mastère ASIG / Projet Bibliographique 2008 36
5.9.1 La tâche à informatiser
Comme on a pu le constater dans la section précédente, les tâches à informatiser
présentent un haut niveau de complexité et sont accomplies dans un contexte de
production. Rappelons que les publications de SOQUIJ connaissent des échéances et sont
assujetties aux lois du marché. Ces tâches sont dites cognitives en ce que leur
accomplissement requiert la mise en œuvre particulière et discrétionnaire de
connaissances et de stratégies générales accumulées durant l'exercice répété et supervisé
des tâches mêmes. Pour leur réalisation, de nombreuses informations de source et de
valeur diverses et parfois contradictoires doivent être recueillies et synthétisées. Par
conséquent, une méthode mixte de modélisation a été déployée; il s'agit de faire
converger les résultats d'une enquête cognitive auprès des conseillers juridiques, d'un
traitement statistique de la distribution des indices et d'une analyse de texte plus
qualitative.
La stratégie retenue est de recourir au plus grand nombre de sources de connaissances,
identifiées lors de la modélisation, pour lesquelles des indices sont repérables dans les
jugements. Par source de connaissance nous entendons, par exemple, la longueur du
jugement, les lois qui y sont mentionnées, le tribunal qui a rendu le jugement, etc. Dans la
mesure où ces sources de connaissances s'avèrent distinctes les unes des autres, il est
possible de fonctionner avec un principe de convergence. Cette stratégie présente
l'avantage de fonctionner, la plupart du temps de façon satisfaisante, dans des conditions
de bruit. Le bruit étant essentiellement causé ici par les indices qui pointent vers plus d'un
domaine.
5.9.2 Motivation du choix de la technologie des systèmes experts
Pour réaliser une implantation informatique du modèle cognitif obtenu, il a été retenu la
technologie des systèmes experts (SE) pour plusieurs raisons. L'implantation d'algorithmes
incomplets et/ou sujets à de fréquentes révisions est possible car les règles d'inférences
qui tiennent lieu des instructions d'un programme conventionnel sont indépendantes les
unes des autres et leur enchaînement est assuré par un mécanisme général (moteur
d'inférences). Il n'est donc pas nécessaire de prévoir à l'avance le déroulement complet de
la solution définitive du problème : l'implantation peut être modulaire et évolutive. La
réalisation d'un prototype se trouve à jouer un rôle heuristique en permettant d'achever la
conception par des boucles de tests/ajustements en situation. La structure des règles

Mastère ASIG / Projet Bibliographique 2008 37
d'inférences autorise une implantation quasi directe du modèle cognitif qui a été
développé : un ou plusieurs indices détectés dans le texte du jugement (la prémisse) sont
mis en relation avec une rubrique du plan de classification (la conclusion). De plus, la
certitude de ces relations peut être qualifiée au moyen d'un coefficient numérique qui sera
cumulé tout au long de la consultation. Ce cumul d'une part atténue la valeur des
validations subséquentes lorsqu'une validation est affectée d'un coefficient incertain et,
d'autre part, renforce la valeur d'une validation qui a déjà été réalisée. Le chaînage avant
des règles permet enfin d'obtenir toutes les réponses valides et non une seule; un
jugement peut donc être classifié dans plus d'un domaine avec une certitude différente
pour chacun. Le découpage en règles d'inférence facilite la génération en contexte d'un
rapport qui permet de valider les associations indices/rubrique du plan de classification,
de localiser précisément les dysfonctionnements et finalement d'entraîner des conseillers
juridiques novices.
5.9.3 Les incertitudes reliées à cette entreprise
Une fois la technologie des Systèmes Experts retenue en raison de caractéristiques qui
apparaissaient souhaitables étant donné le projet, plusieurs incertitudes demeuraient;
certaines ont été résolues lors de la réalisation du prototype et les solutions retenues
feront l'objet des prochaines sections. Une incertitude était par exemple liée à l'utilisation
des coefficients de certitude pour rendre compte du fait que les indices sont rarement
totalement fiables. En effet, un indice peut pointer vers plus d'un domaine du droit ou
encore la présence d'un indice peut être considérée comme accidentelle et constituer en
quelque sorte du bruit. De plus, le mode de cumul des coefficients présente certains
problèmes qui sont documentés.
Certaines autres incertitudes sont toutefois demeurées, principalement parce que des
recherches plus fondamentales dont l'envergure dépassait le mandat s'avèrent nécessaires;
celles-ci sont présentées dans la dernière section.
5.9.4 L’arrimage du Système Expert avec l’analyse de textes par ordinateur
Le générateur de système expert (GSE) utilisé est l'Atelier Cognitif et TExtuel (ACTE)
développé au Centre ATO.CI. Il s'agit d'une intégration logicielle de SATO et d'une version
optimisée du D_expert (GSE en LISP). Cette intégration permet de faire du diagnostic

Mastère ASIG / Projet Bibliographique 2008 38
textuel, c'est-à-dire de ne plus modéliser comme tel le contenu des textes, mais bien les
opérations cognitives de lecture et de compréhension, opérations qui sont en jeu pour la
classification des jugements. La séquence qui a été retenue consiste à effectuer en lot une
série de fichiers de commande SATO qui dépistent et identifient, principalement à l'aide
de concordances, les différents types d'indices.
L'interface entre les traitements effectués par SATO et le Système Expert se fait par la
consignation dans un fichier du résultat - succès ou échec - de chacune des concordances.
Ce fichier est alors traité pour ne conserver que les résultats positifs qui sont identifiés à
l'aide d'une table, ce qui permet de normaliser le segment dépisté.
5.9.5 Le design de la chaîne de traitement des documents
La modélisation cognitive de la tâche a été transformée en une suite séquentielle de
traitement. A titre d’exemple, la première étape consiste en un prétraitement qui est
requis pour rendre les jugements admissibles à SATO.
5.9.6 Les aménagements apportés au traitement standard de l’incertitude
Chacun des indices peut pointer vers plusieurs domaines, avons-nous dit précédemment.
De plus, une même confiance n'est pas accordée à toutes les relations établies entre les
indices et les domaines. Les Système Experts offrent la possibilité d'implanter des
structures conditionnelles pondérées par des coefficients numériques, de même qu'une
fonctionnalité pour leur cumul. Le cadre théorique le plus souvent utilisé est celui des
coefficients de certitude développé pour le système Mycin.
5.9.7 La réalisation de la base de règles par apprentissage La technologie des Systèmes Experts ne présente comme tel aucun mode d'apprentissage,
les règles d'inférences doivent être écrites et modifiées de la même manière : une à une à
l'aide d'un éditeur spécialisé.
Afin de pallier cette carence, deux solutions ont été combinées : une approche tabulaire
et une étude de corpus. Comme elles expriment des relations simples, les règles
d'inférences peuvent s'exprimer sous forme de tableau, en trois colonnes : l'indice, le
domaine et le coefficient de confiance, géré par une base de données ou un tableur; ainsi
par exemple un extrait du tableau des numéros de greffe :

Mastère ASIG / Projet Bibliographique 2008 39
03 pena f++ 27 pena f++ 01 pena f++ 10 pena f++
36 pena f++ 53 drli m 06 proc f+ 41 fami f++
12 fami f++ 04 fami f++ 43 fami f++
Le passage aux règles d'inférences est le fait d'un programme en ICON qui constitue la
prémisse à partir de la première colonne, la conclusion à partir de la deuxième et opère le
passage du coefficient symbolique en un coefficient numérique :
Connaissance Règle Définir 201 **
Note "TRI -> 1ère page -> no de greffe : 03" **
Auteur automatik **
Création 1904-01-01 00-00-00 **
Si **
Base TRI **
Granule "Indices de première page" **
(Trait "section du no de greffe" = ChaÎne "03») **
Alors **
Base TRI **
Granule Document **
(Trait domaine = Chaîne "Pénal" Coef 20) **
CanalEcrire (Canal rapport **
Message " Ce no. de greffe pointe vers le domaine " **
Base TRI **
Granule Document **
Trait domaine **
Message " avec une confiance forte" **
Message " ; cumulatif de : " Coefficient **
Message "%" Retour **
)
Ensuite, ces tableaux ont été fusionnés et triés, de façon à regrouper pour chacune des lois
tous les domaines pointés. Cette distribution, suite à une validation par les conseillers
juridiques pour éliminer les aberrations, a guidé l'attribution des coefficients de confiance.
La règle suivie est que si la distribution est égale, un coefficient faible est attribué, sinon
la force du coefficient est proportionnelle à la distribution. Ainsi, par exemple, la Charte
canadienne des droits et libertés apparaît dans les domaines suivants avec cette
distribution :
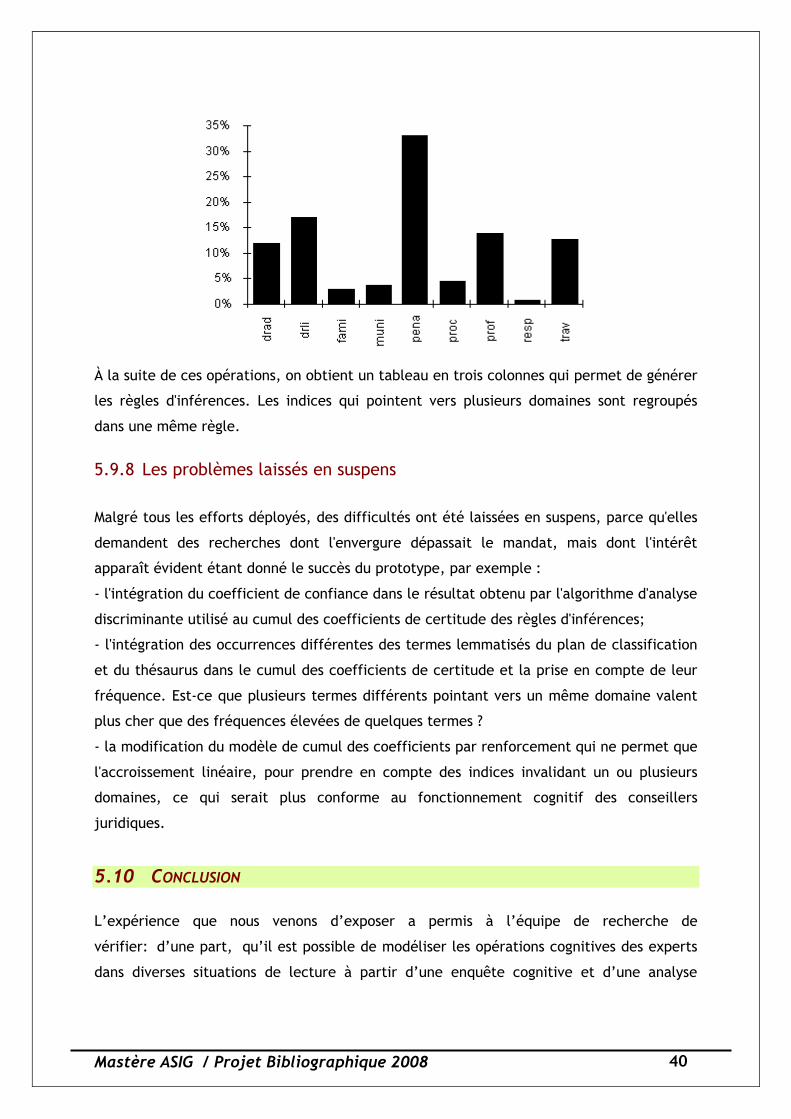
Mastère ASIG / Projet Bibliographique 2008 40
À la suite de ces opérations, on obtient un tableau en trois colonnes qui permet de générer
les règles d'inférences. Les indices qui pointent vers plusieurs domaines sont regroupés
dans une même règle.
5.9.8 Les problèmes laissés en suspens
Malgré tous les efforts déployés, des difficultés ont été laissées en suspens, parce qu'elles
demandent des recherches dont l'envergure dépassait le mandat, mais dont l'intérêt
apparaît évident étant donné le succès du prototype, par exemple :
- l'intégration du coefficient de confiance dans le résultat obtenu par l'algorithme d'analyse
discriminante utilisé au cumul des coefficients de certitude des règles d'inférences;
- l'intégration des occurrences différentes des termes lemmatisés du plan de classification
et du thésaurus dans le cumul des coefficients de certitude et la prise en compte de leur
fréquence. Est-ce que plusieurs termes différents pointant vers un même domaine valent
plus cher que des fréquences élevées de quelques termes ?
- la modification du modèle de cumul des coefficients par renforcement qui ne permet que
l'accroissement linéaire, pour prendre en compte des indices invalidant un ou plusieurs
domaines, ce qui serait plus conforme au fonctionnement cognitif des conseillers
juridiques.
5.10 CONCLUSION
L’expérience que nous venons d’exposer a permis à l’équipe de recherche de
vérifier: d’une part, qu’il est possible de modéliser les opérations cognitives des experts
dans diverses situations de lecture à partir d’une enquête cognitive et d’une analyse

Mastère ASIG / Projet Bibliographique 2008 41
sémio-statistique des textes analysés et des résultats de plusieurs types
d’analyses; d’autre part, qu’il est possible d’implanter un système expert s’appuyant sur
des stratégies dépistant dans les textes certains des indices détectés par les humains, à
différents niveaux d’organisation des textes (éditorial, morphosyntaxique, intra-
phrastique, intra- et intertextuel, sémantique, pragmatique, etc.). Il a également été
constaté que plusieurs de ces indices sont utilisables pour faciliter la lecture selon les
objectifs poursuivis par chacune des opérations de sélection, de tri-classification et
d’indexation. Nous avons également appris que la performance de nos méthodes de
modélisation/formalisation était optimale lorsque l'information requise par les tâches
cognitives se trouvait dans les textes sous la forme d'indices repérables. Ainsi, même
lorsque la prise de connaissance du contenu semble superficielle (par exemple pour la
sélection), si la prise de décision fait appel à des connaissances autres que celles de la
langue et du cadre textuel, la tâche échappe en grande partie à nos méthodes. Par
conséquent, comme les tâches requièrent pour la plupart de telles connaissances, les
experts doivent toujours garder le contrôle des systèmes. En ce qui concerne
l’implantation de la chaîne de traitement, nous avons constaté que le succès reposait
moins sur la complexité de la technologie ou des formules mathématiques que sur la
maîtrise une à une de chacune des sources de connaissances requises et des indices qui les
désignent dans les textes.

Mastère ASIG / Projet Bibliographique 2008 42
Figure 11 : Chaîne de traitement combinant analyse de texte et SE

Mastère ASIG / Projet Bibliographique 2008 43
6 UN SYSTEME EXPERT DANS LE GEODECISIONNEL ?
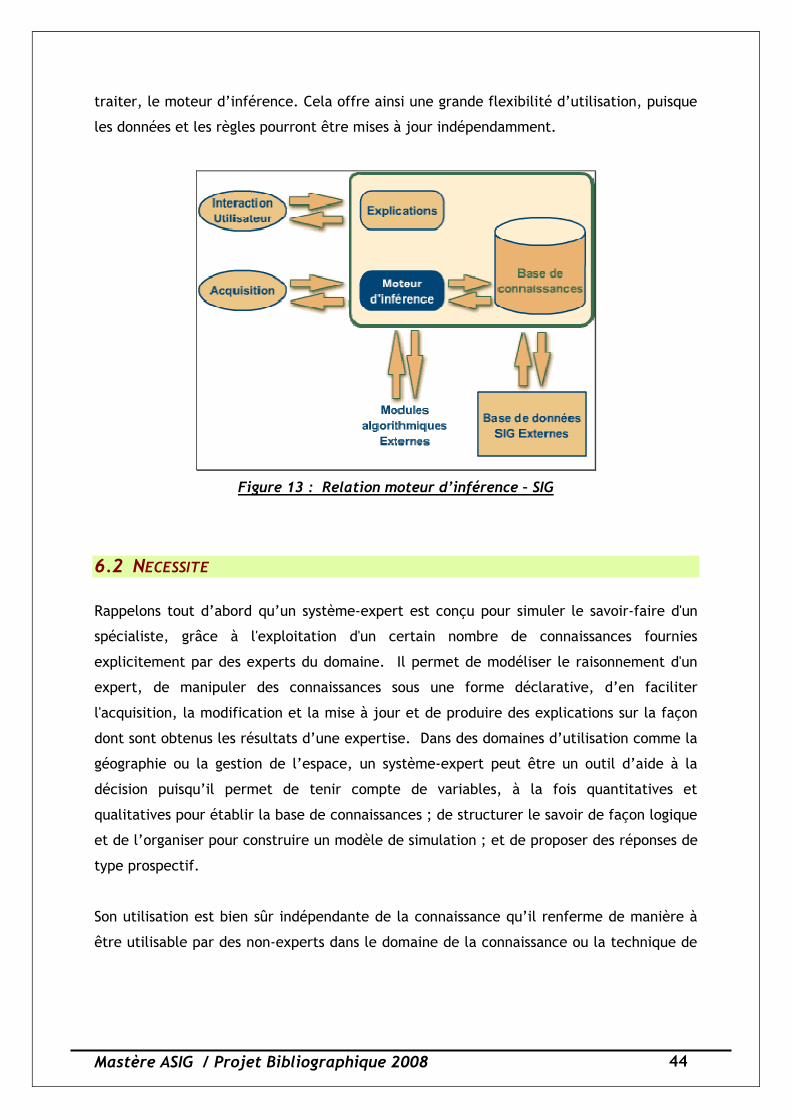
6.1 LES SYSTEMES EXPERTS ET LES SIG
De nombreux Systèmes Experts sont couplés aux SIG dans le milieu du géo décisionnel.
Cela constitue un enjeu méthodologique majeur car l’outil ainsi fabriqué doit pouvoir
analyser les faits ou les données disponibles, mais également produire un diagnostic en
fonctions de ces derniers. Ce développement nécessite donc d’interfacer une base de
données à référence spatiale (BDRS) avec une base de connaissances, et de développer un
ou plusieurs moteurs d’inférence (logiciels). Ensuite, des simulations et une analyse de
sensibilité devront être réalisées. Enfin, le système sera confronté avec le terrain d’étude,
où il fera l’objet de suivis et de mises à jour, afin de pouvoir être validé (après, bien
souvent, une expérimentation du système sur un nouveau terrain).
Figure 12 : Fonctionnement général
Comme explicité précédemment, la base de connaissances va se constituer d’un jeu de
données et de règles. Elle fait donc partie d’un SIG qui stocke, gère et traite des
informations multi-échelles, permettant alors un diagnostic et un suivi des dynamiques
environnementales. Celle-ci devra être différenciée du support informatique qui va la
Mastère ASIG / Projet Bibliographique 2008 44
traiter, le moteur d’inférence. Cela offre ainsi une grande flexibilité d’utilisation, puisque
les données et les règles pourront être mises à jour indépendamment.
Figure 13 : Relation moteur d’inférence – SIG
6.2 NECESSITE
Rappelons tout d’abord qu’un système-expert est conçu pour simuler le savoir-faire d'un
spécialiste, grâce à l'exploitation d'un certain nombre de connaissances fournies
explicitement par des experts du domaine. Il permet de modéliser le raisonnement d'un
expert, de manipuler des connaissances sous une forme déclarative, d’en faciliter
l'acquisition, la modification et la mise à jour et de produire des explications sur la façon
dont sont obtenus les résultats d’une expertise. Dans des domaines d’utilisation comme la
géographie ou la gestion de l’espace, un système-expert peut être un outil d’aide à la
décision puisqu’il permet de tenir compte de variables, à la fois quantitatives et
qualitatives pour établir la base de connaissances ; de structurer le savoir de façon logique
et de l’organiser pour construire un modèle de simulation ; et de proposer des réponses de
type prospectif.
Son utilisation est bien sûr indépendante de la connaissance qu’il renferme de manière à
être utilisable par des non-experts dans le domaine de la connaissance ou la technique de
Mastère ASIG / Projet Bibliographique 2008 45
modélisation. En revanche, la spatialisation des phénomènes n’est pas explicitement prise
en compte.
6.3 CONSTRUCTION DU SYSTEME EXPERT
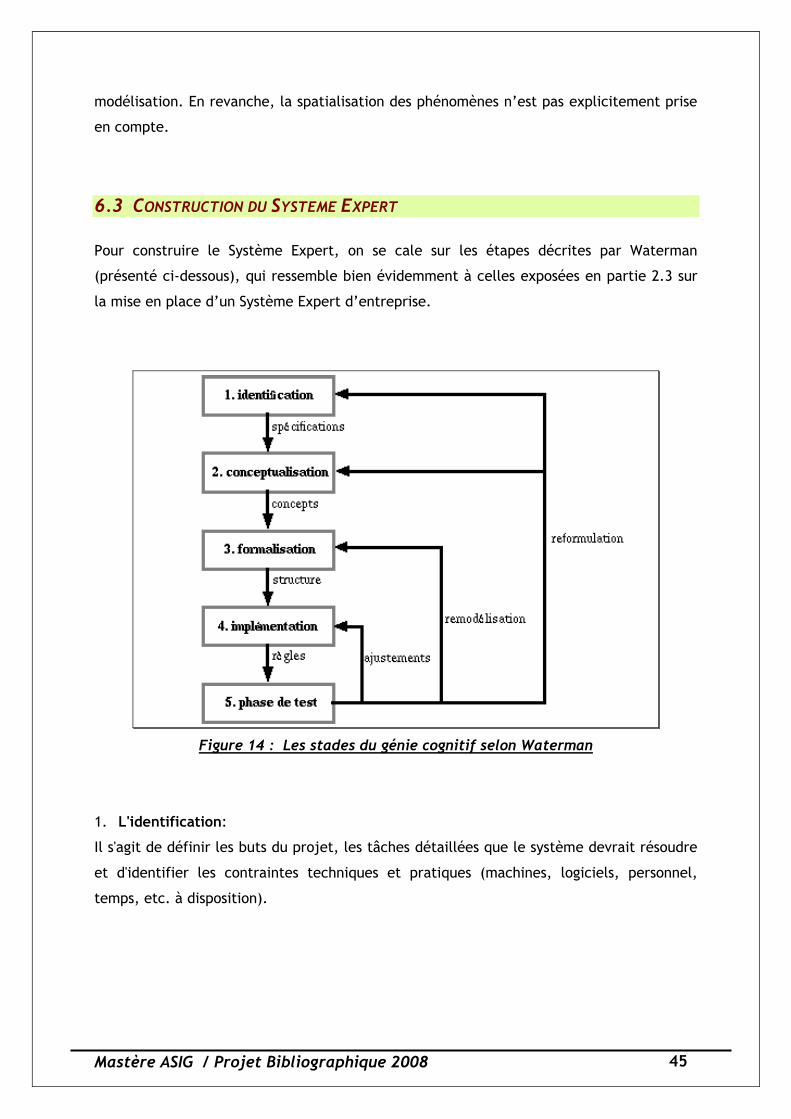
Pour construire le Système Expert, on se cale sur les étapes décrites par Waterman
(présenté ci-dessous), qui ressemble bien évidemment à celles exposées en partie 2.3 sur
la mise en place d’un Système Expert d’entreprise.
Figure 14 : Les stades du génie cognitif selon Waterman
1. L'identification:
Il s'agit de définir les buts du projet, les tâches détaillées que le système devrait résoudre
et d'identifier les contraintes techniques et pratiques (machines, logiciels, personnel,
temps, etc. à disposition).

Mastère ASIG / Projet Bibliographique 2008 46
2. La conceptualisation et l'obtention des connaissances:
Il faut identifier et/ou constituer un vocabulaire plus précis pour décrire une activité de
résolution de problème. Les concepts, relations, heuristiques, etc. identifiés lors de l'étape
précédente doivent être rendus explicites.
3. La formalisation:
Les concepts exprimés en langage naturel doivent être traduits dans un langage formel
(dans un sens pas très strict du terme). Cela permet d'exprimer un problème ainsi que les
heuristiques utilisées pour le résoudre avec des expressions quasi formelles. Ensuite, il faut
rendre apparentes les interdépendances des données et des connaissances (flux
d'information, identification de sous-problèmes, etc.). En même temps, il faut choisir (ou
construire) un logiciel approprié (un moteur d'inférence par exemple).
4. L'implémentation:
Avec les connaissances formalisées, il faut construire un système informatique. Dans la
plupart des cas, il s'agit d'écrire des règles informatiques. Parfois on construit un prototype
rapide, si cela n'a pas déjà été fait, afin de tester le bon choix des outils et la pertinence
de l'analyse formelle.
5. La phase test:
Chaque version du système doit être testée extensivement. Cela peut conduire à de
multiples ajustements et affinages du système informatique, à une remodélisation
complète du système qui renvoie à l'étape 3 ou encore à une reconceptualisation des
tâches qui renvoie aux étapes 1 et 2. Le savoir-faire est dynamique et ne peut être saisi
que dans une simulation dynamique. Aussi, ces itérations sont inévitables.
Dans toutes les phases du projet, l'ingénieur cognitif (cogniticien ou "knowledge engineer")
doit travailler en coopération étroite avec l'expert. Une implication importante de l'expert
est surtout inévitable pour les phases 2 (obtention du savoir) et 5 (test). A condition de
pouvoir l'intéresser à un langage plus formel, il est aussi conseillé de l'associer aux phases
plus techniques.

Mastère ASIG / Projet Bibliographique 2008 47
Figure 15 : Fonctionnalités d’un tel Système Expert
6.4 LA SELECTION D’OUTILS INFORMATIQUES
Il ne faut pas négliger l'importance du choix des outils. L'outil le plus important à choisir
étant la coquille "système expert". Chaque outil réunit certains avantages et inconvénients
liés au mode de représentation, à son moteur d'inférence, son prix, sa maniabilité, son
interface utilisateur, etc. Dans certains cas, il est important de pouvoir transformer les
fonctionnalités d'un outil. Parfois il faut construire l'outil soi-même. Dans certains
domaines mal connus du génie cognitif, l'interaction entre l'acquisition des connaissances
et le choix, l'adaptation ou le développement d'un outil sont importants. Aujourd'hui il
existe un grand nombre d'outils gratuits ou commerciaux que l'on peut classifier selon
plusieurs axes.
• Les techniques de représentation des connaissances: dans SMYC (« Simulation Mycin »,
variante du langage Mycin) par exemple, on y utilise des règles "si-alors" bâties sur des
triplets "objet-attribut-valeur", des contextes, des valeurs de certitude, etc. Dans les

Mastère ASIG / Projet Bibliographique 2008 48
systèmes de chaînage avant comme "AIPSS", les faits et règles peuvent avoir des structures
plus complexes et des variables arbitraires.
• Les schèmes de conclusion (inférences) indiquent comment utiliser les règles. Dans
SMYC, il s'agit d'une variante du "modens ponens".
• Les structures de contrôle (inférences) déterminent la sélection et l'ordre d'application
du savoir-faire. Dans SMYC par exemple, on utilise un chaînage arrière "depth first".
• L'interface pour le cogniticien: les facilités pour construire et inspecter un système.
• L'interface utilisateur peut être plus ou moins convivial, on peut lui donner plus ou moins
de possibilités d'interroger le système, de "voir ce qui se passe et pourquoi". Notons que la
facilité d'usage fait aussi référence à la difficulté conceptuelle d'utilisation.
• L'adaptabilité et l'ouverture: le degré avec lequel on peut adapter un logiciel à ses
besoins. Il existe une palette de systèmes complètement ouverts et d'autres qui sont
complètement fermés.
• La taille du système que l'on peut modéliser fait référence au nombre de connaissances
que l'on peut y mettre et à sa vitesse d'exécution.

Mastère ASIG / Projet Bibliographique 2008 49
7 REFERENCES BIBLIOGRAPHIQUES
7.1 LIVRES
• "Les stades du génie cognitif selon Waterman"
7.2 DOCUMENTS DIVERS
• http://fr.wikipedia.org (définition générale)
• http://www-igm.univ-mlv.fr (Cours sur les SE dispensé par J. Valdes)
http://gautier.ntic.fr (Articles dédiés aux webmasters)
• http://www.infres.enst.fr (Atelier de conception de systèmes experts)
• « Système Expert », de Albéric Martel et Romain Boulers
• « Systèmes Experts », de James L. Crowley, ENSIMAG, 1999
• Nathanaël Ackerman, Faculté de Psychologie et des Sciences de l’Education,
DEA en Sciences Cognitives, présentation introductive à l’intelligence
artificielle, 2005
• « L’intelligence artificielle dans la gestion des affaires », présentation de
Jean Rouette, mai 2000.
7.3 SCHEMAS
• granribaudf.gamsau.archi.fr (partie 2)
• http://www-igm.univ-mlv.fr (partie 3)
• guinee-hcr.cirad.fr (partie 6)
• Nathanaël Ackerman, Faculté de Psychologie et des Sciences de l’Education,
DEA en Sciences Cognitives, présentation introductive à l’intelligence
artificielle, 2005 (partie 6)

Mastère ASIG / Projet Bibliographique 2008 50
CONCLUSION
Les systèmes experts sont une des applications de l'intelligence artificielle qui ont quitté
les laboratoires de recherche pour être utilisées dans le monde professionnel. De
nombreux systèmes experts ont été implantés avec succès pour résoudre des problèmes
concrets. On les a même accusés d'avoir provoqué le crash boursier de 1986, ce qui est
plutôt bon signe du point de vue de l'Intelligence Artificielle.
Néanmoins, les grandes difficultés rencontrées pendant l'extraction des connaissances des
experts puis pendant leur formalisation constituent peut être un point faible trop difficile
à contourner dans les Systèmes Experts. La structuration des connaissances, notamment
incertaines, restent parfois floues et mal implantées dans les SYSTÈMES EXPERTS. Cela
remet en question le modèle de la base de connaissance qui pourrait migrer vers d'autres
modèles (modèles connexionnistes, systèmes adaptatifs, etc.). Il n'est par ailleurs pas
exclu que les techniques à venir utilisent à la fois des systèmes experts et d'autres
techniques comme les réseaux de neurones basées sur des hypothèses plus adaptatives que
symboliques (systèmes hybrides).

Mastère ASIG / Projet Bibliographique 2008 51
ANNEXES
• Critique d’un Système Expert : Turbo Expert
L’article qui suit est issu du site: http://www.cetec-info.org/jlmichel/Turbo.expert.html.
Il peut permettre de mieux comprendre les fonctionnalités (avantageuses ou non) d’un
système expert commercialisé. Même si cet article date de 1987, les remarques qui y sont
faites sont, elles, toujours d’actualité à la différence près que le logiciel en question en
est aujourd’hui à une version d’ordre zéro+.
Cet article inaugure une série de tests approfondis effectués sur plusieurs dizaines (ou
centaines) d'heures d'utilisation quasi-continue. C'est pourquoi, il a semblé à que des tests
approfondis pouvaient rendre service à nos lecteurs qui comptent eux-aussi investir (!) de
nombreuses heures de travail (ou de plaisir). Avec cette rubrique, ils sauront à quoi s'en
tenir.
Turbo Expert : pour les experts pressés et fauchés
Ne cherchez pas de beaux affichages : il n'y en a pas. Ne cherchez pas une gestion évoluée
de l'ascenseur : on dirait un écran MS-DOS. Ne cherchez même pas à faire des "copier-
coller" : ces fonctions sont inactives dans la plupart des cas. Et pourtant, c'est un
extraordinaire logiciel, à un prix imbattable. Les systèmes experts (SE) pour le Mac sont
nombreux. Depuis MacExpert, l'ancêtre (son créateur, Mindsoft, offre aujourd'hui des
produits plus puissants) jusqu'aux programmes d'ACT-informatique en passant par ceux de
Joy ou de G+M, pour ne citer que les sociétés françaises, nous aurons matière à de
nombreux tests. Mais si nous commençons par Turbo-Expert, c'est surtout en raison de son
exceptionnel rapport qualité-prix : 450 F au lieu de 18 000 à 30 000 F pour ses concurrents.
Avant de citer les avantages (nombreux) et les inconvénients (rares) de Turbo-Expert, nous
commencerons par une petite révision sur les systèmes experts.
Y a-t-il un expert dans la salle ?
Un système expert doit permettre à des « non-experts » de parvenir, avec l'aide de
l'ordinateur, aux mêmes déductions que celles auxquelles l'expert humain serait parvenu.
Le principe de base apparaît simple : l'expert définit des règles du genre si une (ou
plusieurs) condition est remplie, alors telle conséquence s'ensuit. A priori, il suffit donc de
bien formaliser ses connaissances en un ensemble de règles et de sous-règles imbriquées

Mastère ASIG / Projet Bibliographique 2008 52
les unes avec les autres. Le logiciel se charge ensuite d’enchaîner (en marche avant ou
arrière) jusqu'à parvenir à la dernière d'entre elle qui est en principe la conclusion (dans le
cas du chaînage avant). A ceux qui penseraient qu'une programmation en Basic pourrait
suffire (If Then go to), nous ferons remarquer que les tests en cascade seraient
extrêmement difficiles à gérer à partir d'un certain degré de complexité et
d'enchevêtrement des conditions, d'où l'obligation de programmer des applications
spécifiques prenant les règles comme des variables plus ou moins déclarées. Un autre
argument faisant repousser une programmation classique tient justement à la non linéarité
des raisonnements pouvant être simulés par un système expert (d'où la dénomination
d'intelligence artificielle). Un système expert rend compte d'une connaissance qui n'est pas
nécessairement organisée de manière séquentielle et totalement hiérarchisée
(contrairement à un empilement de syllogismes). L'intérêt du traitement informatique
tient à la possibilité de définir toute conséquence comme une nouvelle prémisse d'une
nouvelle chaîne logique, ce qui permet de simuler (en partie) le raisonnement humain.
Les points forts de Turbo Expert
En premier lieu, il faut insister sur son prix très attractif pour ce genre de logiciels. Les
tarifs pratiqués par les autres éditeurs montrent bien qu'il s'agit encore d'un marché
professionnel excessivement restreint, réservé aux passionnés travaillant dans des
entreprises fortunées. Turbo Expert est donc un SYSTÈME EXPERT d'ordre zéro (le plus
simple), mais qui permet néanmoins de développer des bases relativement complexes. Les
règles et les bases de faits (c'est-à-dire la série de questions auxquelles les réponses ont
été positives) sont enregistrées en mode texte, ce qui permet de les créer et de les
modifier dans son traitement de texte favori, à condition de ne pas placer le moindre signe
de ponctuation, lequel parasite tout (sur la version testée, n°2.3.2.). En début de fichier
on doit simplement indiquer, derrière la lettre « R » le nombre de règles, et devant
chacune d'elles, le nombre de lignes. Il est ainsi possible de construire ses règles en restant
dans le traitement de texte et en copiant/collant à chaque fois que nécessaire ou en
recourant à un glossaire. Avec Multifinder (ou avec un accessoire du genre de MockWrite,
présentant un traitement de texte dans le menu « pomme »), on peut activer Turbo
Expert, se livrer à des expertises d'essai et revenir dans le traitement de texte pour
effectuer les (nombreuses) mises au point indispensables à ce genre d'activité. Turbo
Expert indique le dictionnaire des prémisses (sur d'autres logiciels, ce sera la liste des
variables). Sur la figure 3, nous donnons un exemple réel d'une base de près de 200 règles
sur une typologie des associations françaises, obtenues à partir d'une soixantaine

Mastère ASIG / Projet Bibliographique 2008 53
d'interrogations. La dernière ligne constitue toujours la conclusion. On peut évidemment
ajouter ou supprimer des règles depuis Turbo-Expert, mais nous avons préféré opérer dans
le traitement de texte (en l'occurrence Word 3) parce qu'il nous a semblé qu'une lecture
continue était plus pratique qu'une lecture séquentielle (ne présentant à l'écran qu'une
seule règle à la fois). Ecrit en Turbo Pascal, Turbo Expert est très rapide, mais, avec 200
règles, il n'est pas instantané. On a l'impression qu'il « réfléchit » (cf. figure 4). Il signale
les règles qui ont été activées. On peut enregistrer la base de faits (c'est-à-dire l'ensemble
des assertions vérifiées) et la réutiliser pour la mise au point, ce qui est bien pratique et
évite de devoir répondre à chaque fois à plusieurs dizaines de questions. Avec un peu
d'astuce, on arrive ainsi assez rapidement à enregistrer plusieurs bases de faits légèrement
différentes, de façon à chercher à piéger son Système Expert. Il est possible de stopper
une interrogation en cours et de demander la déduction correspondante, puis de reprendre
la chaîne des déductions si aucune conclusion n'a pu être tirée. En chaînage arrière, le
système donne la liste des conclusions, demande laquelle doit être vérifiée et indique
ensuite l'ensemble des règles concernées qui doivent l'être à leur tour. Il propose alors de
repasser en mode déduction (chaînage avant). L'induction est très pratique pour la mise au
point du Système Expert, on peut ainsi contrôler le « degré d'activation » de ses
hypothèses.
Les points faibles
Nous avons déjà signalé les difficultés d'affichage, l'éloignement de l'ergonomie propre au
Macintosh, les difficultés du copier/coller. Ce sont là des défauts de transcription (Turbo
SE a été développé dans le monde MS-DOS, on s'en rend compte immédiatement, mais ils
pourraient facilement être gommés si un marché suffisant s'offrait à l'auteur. Il est d'autres
défauts inhérents à l'ordre zéro lui-même, en particulier l'absence de métarègles et
l'impossibilité de programmer les interrogations de manière dynamique (en fonction des
réponses aux questions précédentes). Peut-être peut-on espérer une version 0+ dans un
avenir pas trop lointain. A cet effet, voici comment il demeure possible de s'affranchir de
l'absence de coefficients de vraisemblance (et dans une certaine mesure de construire des
bases plus homogènes). Il suffit de prévoir une gradation très nette dans les conclusions et
de reprendre ces conclusions en effet cumulatif dans de nouvelles règles (cf. figure 5).
Avec un peu d'attention, on arrive assez bien et assez vite à des modélisations
satisfaisantes, réellement utilisables par des non-experts.
Conclusion

Mastère ASIG / Projet Bibliographique 2008 54
En conclusion, un excellent produit, malgré quelques défauts de finition, pouvant donner
satisfaction non seulement à des personnes simplement désireuses de découvrir
l'architecture générale d'un système expert mais aussi à des experts susceptibles
d'organiser ou de formaliser leur connaissance. Ajoutons que dans le guide d'emploi
(figurant sur la disquette programme), l'auteur, Philippe Larvet, explique avec force
détails le fonctionnement des systèmes experts tout en donnant quelques exemples
d'utilisation. De plus, la fréquentation de Turbo Expert rendra plus exigeant vis-à-vis des
autres Systèmes Experts plus puissants et beaucoup plus chers.
Turbo Expert en bref
• Système expert d'ordre zéro (sans métarègles).
• Jusqu'à 500 règles (version 2.3.2.)
• Jusqu'à six prémisses par règle.
• Une seule conclusion par règle (il faut redéfinir des conclusions comme
prémisses).
• Base des faits (des assertions) enregistrable en mode texte et directement
expertisable.
• Base des connaissances (des règles) en mode texte, permettant une mise au
point facile dans un traitement de texte standard (portabilité et bons
transferts).
• Chaînage avant et arrière (déduction, induction).
• Dictionnaire des prémisses.
• Fonctions classiques des systèmes experts (ajout, suppression de règles).
• Translation de règles possible par l'intermédiaire du traitement de texte.
• Possibilité (théorique) de récupérer ses bases de connaissances dans le cas
d'un passage sur de plus gros logiciels.
• Pas de gestion correcte des affichages (ascenseurs, cases d'agrandissement,
etc.).
• Pas d'analyseur de syntaxe. Impossibilité de ponctuer les règles.
Figure 1 :

Mastère ASIG / Projet Bibliographique 2008 55
Comme on peut le constater, le Système Expert ignore la syntaxe (« est-ce que il y a…». Les
réponses sont de simples oui/non, et on est loin d'un dialogue en langage naturel.
Figure 2 :
On remarque l'emploi des gradations (de « pourrait être» à « est sûrement»). En fin de
déduction, le système donne lui-même ses conclusions. On peut évidemment ajouter des règles
débouchant sur le doute, en particulier lorsqu'il y des contradictions dans les réponses ou
lorsque l'expertise est très complexe.

Mastère ASIG / Projet Bibliographique 2008 56
Figure 3 :
Quelques-unes des règles de la base de connaissance. Le repérage du nombre exact de règles
n'est pas toujours facile, en particulier avec un grand nombre de lignes. On peut très bien
employer Excel et faire une somme sur les résultats de la fonction VAL (qui prendra la valeur 1
pour toutes les grandeurs numériques, en l'occurrence les nombres de lignes de chaque règle.
Essayez, ça marche !
Figure 4 :
On observe ici une déduction plus complexe. Le SE manipule plusieurs hypothèses, revient en
cours de route à une règle antérieure (la n°18) et finit par livrer une déduction.

Mastère ASIG / Projet Bibliographique 2008 57
Figure 5 :
On voit que le système combine des faits bruts (les deux premières lignes) avec des conclusions
déjà tirées ailleurs. S'il observe une accumulation de conclusions concomitantes (« pourrait
être », « est peut-être »), il dégage une pré conclusion (« est sûrement »). Selon la complexité
de la modélisation, on peut ainsi enchaîner jusqu'à six niveaux de prémisses pré-conclusives, ce
qui permet de formaliser des cas assez complexes.
Auteur de l’article : Jean-Luc MICHEL
• Base de faits
<facts>
−
<fact>
<nom>VOYANT_ADSL</nom>
<texte>Votre voyant ADSL est-il allume ?</texte>
</fact>
−
<fact>
<nom>VOYANT_POWER</nom>
<texte>Votre voyant power est-il eteint ?</texte>
</fact>
−
<fact>
<nom>PROBLEME_ALIMENTATION</nom>
−
<texte>
Un defaut electrique du modem a ete detecte. Verifiez qu il est bien alimente. Si ce n est pas
le cas, suivez la procedure de renvoi de materiel decrite sur notre site.
</texte>
</fact>
−
<fact>
<nom>MODEM_USB</nom>
<texte>Votre modem est-il un modem USB ?</texte>
</fact>
−

Mastère ASIG / Projet Bibliographique 2008 58
<fact>
<nom>MODEM_ETHERNET</nom>
<texte>Votre modem est-il un modem ethernet ?</texte>
</fact>
−
<fact>
<nom>PROBLEME_DRIVER_USB</nom>
−
<texte>
Le pilote de votre modem na pas ete detecte. Veuillez inserer le cd d installation ou
telecharger le pilote depuis notre site et l installer.
</texte>
</fact>
−
<fact>
<nom>PROBLEME_LIGNE_ADSL</nom>
−
<texte>
Votre modem n arrive pas a se synchroniser. Verifiez que vous avez branche un filtre sur
votre prise telephonique. Si oui contacter france telecom.
</texte>
</fact>
−
<fact>
<nom>DRIVER_MODEM_USB</nom>
<texte>Votre pilote de modem USB est-il bien installe ?</texte>
</fact>
−
<fact>
<nom>CABLE_ETHERNET</nom>
<texte>Votre cable ethernet est-il debranche ?</texte>
</fact>
−
<fact>
<nom>PROBLEME_LIAISON_ETHERNET</nom>
−
<texte>
Verifier le bon raccordement de votre cable ethernet entre votre modem et votre PC.
</texte>
</fact>
−
<fact>
<nom>PROBLEME_CONFIGURATION_FIREWALL</nom>
−
<texte>
Votre firewall est mal configure. Veillez a ouvrir les ports.
</texte>
</fact>
−

Mastère ASIG / Projet Bibliographique 2008 59
<fact>
<nom>AUTHENTIFICATION</nom>
−
<texte>
Arrivez-vous a vous authentifier lors de la connexion a internet ?
</texte>
</fact>
−
<fact>
<nom>PROBLEME_AUTHENTIFICATION</nom>
−
<texte>
Vos login et mots de passe sont invalides. Alles sur le site de votre fournisseur d acces et
demander a recevoir vos login et mot de passe en fournissant votre mail et en repondant a
votre question secrete.
</texte>
</fact>
−
<fact>
<nom>ADRESSE_IP</nom>
<texte>Votre adresse IP est-elle non disponible ?</texte>
</fact>
−
<fact>
<nom>PROBLEME_ADRESSE_IP</nom>
<texte>Fixez une adresse IP.</texte>
</fact>
−
<fact>
<nom>PROBLEME_UTILISATEUR</nom>
<texte>Probleme indetermine.</texte>
</fact>
</facts>
• Base de règles
<regles>
−
<regle poids="50">
<nom>REGLE_VOYANT_ADSL</nom>
<si>VOYANT_ADSL estVrai</si>
−
<alors>
VOYANT_POWER Vrai. REGLE_DRIVER_MODEM_USB desactiver.
</alors>
<sinon> </sinon>

Mastère ASIG / Projet Bibliographique 2008 60
</regle>
−
<regle poids="49">
<nom>REGLE_VOYANT_POWER</nom>
<si>VOYANT_POWER estFaux</si>
<alors>PROBLEME_ALIMENTATION Vrai</alors>
<sinon> </sinon>
</regle>
−
<regle poids="40">
<nom>REGLE_MODEM_ETHERNET</nom>
<si>MODEM_ETHERNET estVrai</si>
−
<alors>
MODEM_USB Faux. REGLE_DRIVER_MODEM_USB desactiver.
REGLE_AUTHENTIFICATION_WINDOWS desactiver.
</alors>
<sinon> </sinon>
</regle>
−
<regle poids="35">
<nom>REGLE_MODEM_USB</nom>
<si>MODEM_USB estVrai</si>
−
<alors>
MODEM_ETHERNET Faux. REGLE_CABLE_ETHERNET desactiver.
REGLE_ADRESSE_IP desactiver.
</alors>
<sinon> </sinon>
</regle>
−
<regle poids="30">
<nom>REGLE_DRIVER_MODEM_USB</nom>
<si>DRIVER_MODEM_USB estVrai</si>
<alors> </alors>
<sinon>PROBLEME_DRIVER_USB Vrai</sinon>
</regle>
−
<regle poids="28">
<nom>REGLE_CABLE_ETHERNET</nom>
<si>CABLE_ETHERNET estFaux</si>
<alors>PROBLEME_LIAISON_ETHERNET Vrai</alors>
<sinon>REGLE_ADRESSE_IP</sinon>
</regle>
−
<regle poids="25">
<nom>REGLE_AUTHENTIFICATION_WINDOWS</nom>
<si>AUTHENTIFICATION estVrai</si>
<alors>PROBLEME_CONFIGURATION_FIREWALL Vrai</alors>

Mastère ASIG / Projet Bibliographique 2008 61
<sinon>PROBLEME_AUTHENTIFICATION Vrai</sinon>
</regle>
−
<regle poids="20">
<nom>REGLE_ADRESSE_IP</nom>
<si>ADRESSE_IP estFaux</si>
<alors>PROBLEME_ADRESSE_IP Vrai</alors>
<sinon>PROBLEME_UTILISATEUR Vrai</sinon>
</regle>
</regles>





























